- LINUX — это семейство операционных систем (ОС), работающих на основе одноименного ядра.
- Emacs — один из наиболее мощных и широко распространённых редакторов, используемых в мире Unix.
- Nginx — это программное обеспечение с открытым исходным кодом для создания легкого и мощного веб-сервера.
- TeX — это созданная американским математиком и программистом Дональдом Кнутом (Donald E. Knuth) система для верстки текстов с формулами.
Это многостраничный печатный вид этого раздела. Нажмите что бы печатать.
Справочники по автоматизации и программированию
Технические справочники по Linux, Latex, Nginx, Emacs и другие системы и языки программирования
- 1: Искусственный интеллект
- 1.1: Ollama
- 1.1.1: Настройка запросов к моделям через Ollama
- 1.1.2: Пример с curl и полным набором параметров
- 1.1.3: Пример из командной строки с ollama run
- 1.1.4: Alias для zsh с конфигурационным файлом YAML
- 1.1.5: Запуск модели из Ollama с конфигурационным файлом JSON
- 1.1.6: Запуск модели из Ollama с конфигурационным файлом JSON и контекстом
- 1.1.7: Запуск модели Ollama с конфигурационным файлом JSON из NODE.JS
- 1.1.8: Запуск модели Ollama на языке Go
- 1.1.9: Запуск модели Ollama на языке программирования Python
- 2: Язык программирования LUA
- 2.1: 2. Базовые концепции языка LUA
- 2.2: 3 – Язык Lua: Лексика и синтаксис
- 2.3: 4 – Интерфейс прикладного программирования (API)
- 2.4: Вспомогательная библиотека Lua
- 2.5: Руководство по языку Lua: Стандартные библиотеки
- 2.6: 7 – Lua как самостоятельное приложение
- 3: Authelia
- 3.1: Конфигурация Authelia
- 3.2: Методы Authelia
- 3.2.1: Секреты Authelia
- 3.2.2: Файлы конфигурации
- 3.2.3: Переменные Authelia
- 3.3: Однофакторная аутентификация
- 3.3.1: Однофакторная аутентификация
- 3.3.2: LDAP
- 3.3.3: Файлы конфигурации
- 3.4: Двухфакторная аутентификация
- 3.4.1: Мобильные устройства
- 3.4.2: Time-based One-Time Password
- 3.4.3: WebAuthn
- 3.5: Security
- 3.5.1: Контроль доступа
- 3.5.2: Регулирование
- 3.5.3: Password Policy
- 3.6: Проверка входа
- 3.6.1: Elevated Session
- 3.6.2: Reset password
- 3.7: Seccion
- 3.7.1: Конфигурация
- 3.7.2: Redis
- 3.8: Storage Хранилище данных
- 3.8.1: PostgreSQL
- 3.8.2: SQLite3
- 3.8.3: MySQL
- 3.9: Notifications (Уведомления)
- 3.9.1: SMTP
- 3.9.2: File system
- 3.10: Telemetry (телеметрия)
- 3.11: Определения
- 3.11.1: Network
- 3.11.2: User Attributes
- 3.12: Разное
- 3.12.1: Server в Authelia
- 3.12.2: Server Authz Endpoints
- 3.12.3: Server Endpoint Rate Limits
- 4: Bootstrap
- 4.1: Работа с цветами в Bootstrap
- 4.2: Mixins
- 4.3: Bootstrap Flexbox
- 4.4: Bootstrap Отступы
- 5: Описание настроек Docker
- 5.1: Шпаргалка по Docker и Docker Compose (CLI)
- 5.2: Справочник по созданию образов Docker
- 5.3: Очистка кеша при использовании Docker
- 6: Микроразметка для СЕО поиска
- 6.1: JSON-LD - микроразметка материалов для выдачи сниппетов в поиске Google
- 6.2: Документация RDF для универсальной микроразметки текстов для микропоиска
- 6.2.1: Обзор синтаксиса
- 6.2.2: Терминология RDF
- 6.2.3: Соответствие в RDF
- 6.2.4: Аттрибуты и синтаксис в RDF
- 6.2.5: Определение синтаксиса CURIE в RDF
- 7: Latex
- 7.1: Библиотека цветных блоков и рамок tcolorbox для Latex
- 7.1.1: Ключи к командам tcolorbox
- 7.1.2: Команды для Title
- 7.1.3: Команды для SubTitle
- 7.1.4: Команды для Part
- 7.1.5: Команды для Lower Part
- 7.1.6: Команды для Color и Font
- 7.1.7: Команды для выравнивания текста
- 7.1.8: Команды для управления размерами и отступами в боксах
- 7.1.9: Команды для управления параметрами углов в боксах
- 7.1.10: Команды для управления прозрачностью в боксах
- 7.1.11: Команды для управления высотой боксов
- 7.1.12: Команды для добавления различного контента в боксы
- 7.1.13: Команды для упрвления слоями в боксах
- 7.1.14: Команды для управления плавающими объектами боксов
- 7.1.15: Команды для встраивания объектов и боксов в боксы (embedding)
- 7.1.16: Управление ограничивающей рамкой (Bounding Box) в tcolorbox
- 7.1.17: Управление уровнями/слоями в пакете tcolorbox
- 7.1.18: Управление Capture mode в пакете tcolorbox
- 7.1.19: Управление характеристиками текста в пакете tcolorbox
- 7.1.20: Files - Работа с временными файлами в tcolorbox
- 7.1.21: cbox Specials - Специальные настройки для cbox и cboxmath
- 7.1.22: Counters, Labels, and References - Счётчики, метки и ссылки в tcolorbox
- 7.1.23: Even and Odd Pages - Разное оформление для чётных и нечётных страниц
- 7.1.24: Externalization - Интеграция с внешними файлами TikZ
- 7.1.25: Miscellaneous - Разные дополнительные возможности
- 7.2: Справочник основных пакетов LaTeX
- 7.3: Latex для авторов
- 7.3.1: Памятка по командам Latex 3
- 7.4: Пакеты для работы с таблицами в LaTeX
- 7.5: Описание пакетов fancyhdr и fancybox
- 7.6: TEX издательская система
- 7.6.1: TEX команды
- 7.6.2: TEX for the Impatient
- 7.6.3: TEX
- 7.6.4:
- 7.7: Графический пакет TIKZ для Latex
- 7.7.1: Дисплей для руководства пользователя
- 7.7.2: Foreach for Tex
- 7.7.3: Key Management
- 7.7.4: Примеры PIC в библиотеке TIKZ
- 7.7.5: Matrix в модуле TIKZ
- 7.7.6: PIC маленький рисунок
- 7.7.7: Node TIKZ
- 7.7.8: Path и его особенности
- 7.7.9: Вводные понятия в TIKZ
- 7.7.10: Диаграммы в Latex библиотека TIKZ
- 7.7.11: Примеры по Эвклиду
- 7.7.12: Сети PETRI
- 7.7.13: Графики в TIKZ для Latex
- 7.8: Пакет Xcolor и colortbl
- 7.9: Пакет longtable
- 7.10: Newfont
- 7.11: Pdfpages
- 7.12: Titleps
- 7.13: Titlesec
- 7.14: Пакет fontenc - Управление кодировками шрифтов в LaTeX
- 7.15: Пакет fontspec - Управление кодировками шрифтов в XeLaTeX
- 8: opensearch
- 8.1: Введение в Opensearch
- 8.1.1: Быстрый старт установки
- 8.1.2: Взаимодействие с OpenSearch
- 8.1.3: Загрузка данных в OpenSearch
- 8.1.4: Поиск данных в OpenSearch
- 8.1.5: Начало работы с безопасностью в OpenSearch
- 8.1.6: Основные концепции OpenSearch
- 8.2: Install and upgrade OpenSearch
- 8.2.1: Установка OpenSearch
- 8.2.1.1: Docker
- 8.2.1.2: Установка OpenSearch на Debian
- 8.2.2: Установка OpenSearch Dashboards
- 8.2.2.1: Запуск OpenSearch Dashboards с использованием Docker
- 8.2.2.2: Установка OpenSearch Dashboards (Debian)
- 8.2.2.3: Настройка TLS для OpenSearch Dashboards
- 8.2.3: configuring opensearch
- 8.2.3.1: Настройки доступности и восстановления
- 8.2.3.2: Конфигурация и системные настройки
- 8.2.3.3: Сетевые настройки
- 8.2.3.4: Настройки обнаружения и шлюза
- 8.2.3.5: Настройки безопасности
- 8.2.3.6: Настройки предохранителей
- 8.2.3.7: Настройка кластера
- 8.2.3.8: Настройка индекса
- 8.2.3.9: Настройки поиска
- 8.2.3.10: Настройки плагинов
- 8.2.3.11: Экспериментальные флаги функций
- 8.2.3.12: Logs
- 8.2.4: Сравнение ОС
- 8.2.5: Настройка OpenSearch Dashboards
- 8.2.6: Upgrading OpenSearch
- 8.2.6.1: Приложение по обновлениям
- 8.2.6.2: Постепенное обновление
- 8.2.6.3: Лаборатория последовательного обновления
- 8.2.7: Установка плагинов
- 8.2.7.1: Дополнительные плагины
- 8.2.7.2: mapper-size
- 8.2.7.3: ingest-attachment
- 8.2.8: Управление плагинами OpenSearch Dashboards
- 8.3: Query DSL - язык запросов OpenSearch
- 8.3.1: Контекст запроса и фильтра
- 8.3.2: Сравнение термовых и полнотекстовых запросов
- 8.3.3: Термино-уровневые запросы
- 8.3.3.1: exists
- 8.3.3.2: fuzzy
- 8.3.3.3: ids
- 8.3.3.4: prefix
- 8.3.3.5: range
- 8.3.3.6: regexp
- 8.3.3.7: term
- 8.3.3.8: terms
- 8.3.3.9: terms set
- 8.3.3.10: wildcard
- 8.3.4: full_text
- 8.3.4.1: match
- 8.3.4.2: match-bool-prefix
- 8.3.4.3: match-phrase
- 8.3.4.4: match-phrase-prefix
- 8.3.4.5: multi-match
- 8.3.4.6: query-string
- 8.3.4.7: simple-query-string
- 8.3.4.8: intervals query
- 8.3.5: compound queries
- 8.3.5.1: boolean query
- 8.3.5.2: boosting query
- 8.3.5.3: constant_score
- 8.3.5.4: disjunction_max
- 8.3.5.5: function_score
- 8.3.5.6: hibrid
- 8.3.6: geographic and xy query
- 8.3.6.1: Запрос по гео-ограничивающему прямоугольнику
- 8.3.6.2: Запрос по гео-расстоянию
- 8.3.6.3: Запрос по гео-многоугольнику
- 8.3.6.4: Запрос по гео-форме
- 8.3.6.5: xy запрос
- 8.3.7: Объединение запросов
- 8.3.7.1: Запрос has_child
- 8.3.7.2: Запрос has_parent
- 8.3.7.3: Вложенный запрос
- 8.3.7.4: Запрос по идентификатору родителя
- 8.3.8: Запросы Span
- 8.3.8.1: Запрос Span containing
- 8.3.8.2: Запрос Span field masking
- 8.3.8.3: Запрос Span first
- 8.3.8.4: Запрос Span multi-term
- 8.3.8.5: Запрос Span near
- 8.3.8.6: span_not
- 8.3.8.7: Запрос Span or
- 8.3.8.8: Запрос Span term
- 8.3.8.9: Запрос Span within
- 8.3.9: Запрос Match all
- 8.3.10: Специализированные запросы
- 8.3.10.1: distance_feature
- 8.3.10.2: k-NN
- 8.3.10.3: k-NN explain
- 8.3.10.4: neural
- 8.3.10.5: Нейронный разреженный запрос
- 8.3.10.6: Перколяция
- 8.3.10.7: script query
- 8.3.10.8: Запрос с оценкой скрипта
- 8.3.10.9: Запрос шаблона
- 8.3.10.10: Обертка
- 8.3.11: Minimum should match (Минимальное соответствие)
- 8.3.12: Синтаксис регулярных выражений
- 8.4: goclient
- 9: Визуализация графов библиотека Graphviz
- 10: Визуализация графиков и данных Chart.js
- 11: Emacs
- 11.1: LaTeX в Emacs
- 11.2: Yasnippet
- 11.3: Как настроить и работать с Go в Emacs?
- 11.4: Как настроить и работать с Python в Emacs?
- 11.5: Как настроить и работать с Magit?
- 12: GO
- 12.1: Полный гайд по установке и настройке Go для работы с базами данных (OpenSearch, PostgreSQL, SQLite)
- 12.2: Работа с JSON в Go
- 12.3: Работа с OpenSearch в Go для системы управления знаниями
- 12.4: Пакеты языка Go
- 12.4.1: Описание пакета html для GO
- 12.4.1.1: Описание пакета html/template в Go
- 12.4.1.1.1: Шпаргалка по html/template в Go
- 12.4.1.1.2: Подробное руководство по define, template и block в html/template
- 12.4.1.1.3: Шпаргалка по конвейерам и функциям в html/template (Go)
- 12.4.1.1.4: Функции экранирования HTML/JavaScript/URL пакета html/template языка Go
- 12.4.1.1.5: Типы экранирования HTML/JavaScript/URL пакета html/template языка Go
- 12.4.2: Пакет bufio встроенных функций Go
- 12.4.3: Пакет builtin встроенных функций Go
- 12.4.3.1: Функции builtin
- 12.4.3.2: Типы в пакете builtin
- 12.4.4: Описание пакета context языка программирования Go
- 12.4.4.1: Описание функций пакета Context
- 12.4.4.2: Описание типов пакета Context
- 12.4.5: Пакет bytes языка программирования Go
- 12.4.6: Описание пакета database языка программирования Go
- 12.4.6.1: Работа с пакетом database/sql в Go: ошибки и их обработка
- 12.4.6.2: Подробное описание функций пакета database/sql в Go
- 12.4.6.3: Контекст (context) в транзакциях database/sql
- 12.4.6.4: Описание типа database/sql DB
- 12.4.6.5: Описание типа database/sql ColumnType
- 12.4.6.6: Описание типа Conn database/sql
- 12.4.6.7: Описание типа DBStats database/sql
- 12.4.6.8: Описание типа Out database/sql
- 12.4.6.9: Описание типа Row database/sql
- 12.4.6.10: Описание типа Stmt database/sql
- 12.4.6.11: Описание типа Tx database/sql
- 12.4.7: Описание пакета flag языка программирования Go
- 12.4.7.1: Функции пакета flag
- 12.4.7.2: Типы пакета flag
- 12.4.8: Полный справочник по пакету fmt в Go
- 12.4.9: Описание пакета io языка программирования Go
- 12.4.9.1: Описание функций пакета io
- 12.4.9.2: Описание типов пакета io языка программирования GO
- 12.4.9.3: Пакет для работы с файловой системой io/fs
- 12.4.10: Пакет Sync для Go
- 12.4.10.1: Описание пакета sync/atomic
- 12.4.11: Пакет os языка программирования Go
- 12.4.11.1: Описание функций пакета os
- 12.4.11.2: Описание типов пакета os языка программирования Go
- 12.4.11.3: Описание функций и типов пакета os/exec языка программирования Go
- 12.4.11.4: Пакет os/user языка программирования Go
- 12.4.11.5: Пакет os/signal языка программирования Go
- 12.4.12: Описание пакета strconv
- 12.4.12.1: Описание функций пакета strconv
- 12.4.12.2: Тип NumError пакета strconv
- 12.4.13: Описание пакета error языка программирования Go
- 12.4.14: Описание пакета iter языка программирования Go
- 12.4.15: Пакет net встроенных функций и типов языка Go
- 12.4.15.1: Функции пакета net языка Go
- 12.4.15.2: Типы и методы пакета net языка Go
- 12.4.15.3: Пакет net/http встроенных функций и типов языка Go
- 12.4.15.3.1: Функции пакета net/http языка Go
- 12.4.15.3.2: Типы пакета net/http языка Go
- 12.4.15.4: Описание пакета для управления маршрутизацией github.com/julienschmidt/httprouter для GO
- 12.4.16: Пакет OAuth2 языка программирования Go
- 12.4.16.1: Пакет jwt (JSON Web Token)
- 12.4.16.2: Пакет jws (JSON Web Signature)
- 12.4.16.3: Пакет authhandler (Three-Legged OAuth 2.0)
- 12.4.16.4: Пакет clientcredentials OAuth 2.0 Client Credentials Flow
- 12.4.17: Описание пакета string языка программирования Go
- 12.4.17.1: Функции пакета string языка программирования Go
- 12.4.17.2: Описание типов пакета string языка программирования Go
- 12.4.18: Полное описание пакета log в Go
- 12.4.19: Описание пакета unsafe языка программирования Go
- 12.4.20: Пакет time языка программирования Go
- 12.4.21: SCS: Управление HTTP-сессиями для Go
- 12.5: Горутина (goroutine) в Go, Каналы (channels) в Go и Конвейеры (Pipelines) в Go.
- 12.6: Подключение к SQLite в Go: Полное руководство
- 12.7: Спецификация языка программирования Go
- 12.8: Спецификация по модулям языка программирования Go
- 12.9: Изучение языка Go
- 12.9.1: Alex Edwards Let's Go часть 1
- 12.9.2: Alex Edwards Let's Go часть 2
- 12.9.3: Alex Edwards Let's Go часть 3
- 12.9.4: Alex Edwards Let's Go часть 4
- 12.9.5: Alex Edwards Let's Go часть 5
- 12.10: Памятка по примерам GO
- 12.10.1: таблица с основными форматами Printf в Go
- 12.10.2: Closure
- 12.10.3: Создание модуля в GO
- 12.10.4: Создание тестов в GO
- 12.10.5: Работа с Workspace в Go: Полное руководство
- 12.10.6: массивы (arrays) и срезы (slices)
- 12.10.7: Назначение пакетов net и net/http
- 13: Linux
- 13.1: Шпаргалка по полезным командам Linux для работы с дисками и устройствами
- 13.2: Что такое PGP?
- 13.2.1: Структура хранения ключей
- 13.2.2: gpg-agent
- 13.2.3: dirmngr
- 13.2.4: gpg
- 13.2.4.1: Команды GPG
- 13.2.4.2: Опции PGP
- 13.2.4.3: Ввод и вывод
- 13.2.4.4: OpenGPG опции
- 13.2.4.5: Опции соответствия
- 13.2.4.6: Дополнительные опции
- 13.2.4.7: Config
- 13.2.5: gpgsm
- 13.2.6: scdaemon
- 13.2.7: user id
- 13.2.8: сравнение SSH и PGP
- 13.3: Инструкция по настройке клавиатуры для i2wm с xkb
- 13.4: JQ парсер JSON
- 13.5: Шпаргалка по основным командам nano
- 13.6: Шпаргалка по основным командам Vim
- 13.7: Пакет scrcpy для управления Android устройством через Linux
- 13.8: Yazi - Файловый менеджер
- 13.9: Установка Nextcloud AIO с Let's Encx
- 13.10: Подключение Android телефона к Linux
- 13.11: Установка виртуальных машин QEMU/KVM на рабочей станции или сервере
- 13.12: Шпаргалка по основным командам crone
- 13.13: Шпаргалка по работе с ядрами в Linux
- 13.14: Создание собственных уроков для GNU Typist
- 13.15: Find and Sed
- 13.16: Управление пакетами PACMAN
- 13.17: UGREP и все о нем
- 13.18: Find
- 13.19: ZSH
- 13.20: Строчный редактор SED
- 13.21: SSH на все случаи жизни
- 13.22: i3
- 13.23: Файловый менеджер ranger
- 14: Mailu
- 15: Nginx
- 16: Управление базами данных: основные команды
- 16.1: Справочный гайд по командам PostgreSQL
- 16.2: Справочный гайд по командам MySQL
- 16.3: Справочный гайд по командам SQLite
- 16.4: Полное руководство по MongoDB: от основ до работы с JSON
- 16.5: Полное руководство по OpenSearch: установка, настройка и использование
- 17: WireGuard
- 17.1: Обзор WireGuard
- 17.2: Установка WireGuard
- 17.3: Быстрый старт
- 17.4: wg-quick — руководство
- 17.5: wg — руководство
- 17.6: Компиляция из исходного кода
- 17.7: Протокол и криптография
- 17.8: Формальная верификация
- 17.9: Кроссплатформенная реализация
- 17.10: Маршрутизация и сетевые пространства имён
- 17.11: Встраивание в приложения
1 - Искусственный интеллект
Описание различных применений моделей искусственного интеллекта
1.1 - Ollama
Описание различных инструментов по использованию оболочки ollama на сервере и локальном компьютере
1.1.1 - Настройка запросов к моделям через Ollama
Построение различных запросов к моделям используя оболочку Ollama
Структура JSON модели для передачи на сервер OLLAMA
{
"model": "qwen3:4b",
"prompt": "Ваш запрос",
"stream": false,
"format": "json",
"options": {
"temperature": 0.8,
"top_p": 0.9,
"top_k": 40,
"num_predict": 512,
"stop": ["\n", "###"],
"repeat_penalty": 1.1,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"seed": 42,
"mirostat": 0,
"num_ctx": 2048,
"num_thread": 8
},
"template": "{{ .Prompt }}",
"context": [1, 2, 3]
}
Описание и назначение основных параметров для управления моделями в Ollama:
1. "model": "qwen3:4b"
- Что делает: Указывает, какую модель использовать
- Применение: Замените на нужную модель:
"llama3:8b","mistral:7b", etc - Пример:
"model": "llama3:8b"
2. "prompt": "Ваш запрос"
- Что делает: Текст запроса к модели
- Применение: Можно использовать многострочные промпты
- Пример:
"prompt": "Напиши рецепт пасты карбонара:\n"
3. "stream": false
- Что делает: Возвращать ответ потоком или целиком
- Применение:
false- весь ответ сразу (для скриптов)true- потоковая передача (для UI)
- Пример:
"stream": true
4. "format": "json"
- Что делает: Заставляет модель возвращать ответ в JSON формате
- Применение: Полезно для структурированных данных
- Пример:
"format": "json"+"prompt": "Верни JSON с именем и возрастом"
В Ollama параметр format поддерживает несколько значений:
Толкование
Поддерживаемые форматы
1. "format": "json"
- Описание: Заставляет модель возвращать ответ в валидном JSON формате
- Пример промпта:
"Верни JSON: {\\\"name\\\": \\\"John\\\", \\\"age\\\": 30}" - Пример вывода:
{"name": "John", "age": 30}
2. "format": "text" (по умолчанию)
- Описание: Обычный текстовый ответ без специального форматирования
- Пример промпта:
"Расскажи о космосе" - Пример вывода:
"Космос - это бескрайнее пространство..."
3. "format": "markdown"
- Описание: Ответ в формате Markdown
- Пример промпта:
"Напиши документацию в markdown" - Пример вывода:
# Заголовок - Список **Жирный текст**
4. "format": "html"
- Описание: Ответ в HTML формате
- Пример промпта:
"Создай HTML страницу" - Пример вывода:
<html><body><h1>Заголовок</h1></body></html>
5. "format": "xml"
- Описание: Ответ в XML формате
- Пример промпта:
"Верни данные в XML" - Пример вывода:
<data><name>John</name><age>30</age></data>
6. "format": "yaml"
- Описание: Ответ в YAML формате
- Пример промпта:
"Верни конфигурацию в YAML" - Пример вывода:
name: John age: 30
7. "format": "csv"
- Описание: Ответ в CSV формате
- Пример промпта:
"Верни данные в CSV" - Пример вывода:
name,age\nJohn,30\nJane,25
8. "format": "code"
- Описание: Для генерации кода (поддерживает подсветку синтаксиса)
- Пример промпта:
"Напиши функцию на Python" - Пример вывода:
def hello(): return "Hello World"
Практические примеры:
JSON запрос:
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Верни JSON с информацией о пользователе: имя, возраст, город",
"format": "json",
"stream": false
}'
Markdown запрос:
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Напиши руководство по Git в markdown",
"format": "markdown",
"stream": false
}'
HTML запрос:
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Создай простую HTML страницу с заголовком и параграфом",
"format": "html",
"stream": false
}'
Важные замечания:
- Не все модели одинаково хорошо поддерживают все форматы
- Формат - это указание модели, а не гарантия
- Лучше всего работают JSON и text
- Для сложных форматов лучше явно указывать в промпте
Комбинирование с промптом:
# Более надежный способ
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Верни ответ в формате JSON: {\"name\": \"string\", \"age\": number}",
"format": "json",
"stream": false
}'
Большинство моделей лучше всего работают с json и text форматами.
Параметры в options:
5. "temperature": 0.8
- Что делает: Контролирует случайность ответов (0.0-1.0)
- Применение:
0.1- детерминированные, повторяемые ответы0.8- креативные, разнообразные ответы1.0- максимальная случайность
- Пример:
"temperature": 0.3для фактологических ответов
6. "top_p": 0.9
- Что делает: nucleus sampling - учитывает только топ-N% вероятных слов
- Применение:
0.1- только самые вероятные слова0.9- более разнообразный выбор
- Пример:
"top_p": 0.7
7. "top_k": 40
- Что делает: Ограничивает выбор только топ-K слов
- Применение:
10- только 10 самых вероятных слов40- хороший баланс
- Пример:
"top_k": 20
Толкование
Подробное объяснение top_p и top_k
top_p (также known as nucleus sampling) - это алгоритм выборки, который ограничивает генерацию только теми словами, кумулятивная вероятность которых попадает в верхние P% распределения.
Как это работает:
- Сортировка вероятностей: Модель ранжирует все возможные следующие слова по вероятности
- Кумулятивная сумма: Складывает вероятности от самой высокой к самой низкой
- Выбор ядра: Берет только те слова, чья кумулятивная сумма ≤
top_p - Перераспределение вероятностей: Нормализует вероятности выбранных слов
Математическая формула:
Выбрать множество V таких что: ∑(p(x) для x в V) ≥ p
где p = значение top_p (0.0-1.0)
Практические примеры:
Пример 1: top_p = 0.3 (очень строгий)
Возможные слова:
- "кот" (p=0.25)
- "собака" (p=0.20)
- "птица" (p=0.15)
- "рыба" (p=0.10)
- ... остальные (сумма p=0.30)
Выбор: только "кот" (0.25 ≤ 0.3)
Пример 2: top_p = 0.6 (умеренный)
Выбор: "кот" + "собака" + "птица" (0.25+0.20+0.15=0.6)
Пример 3: top_p = 0.9 (либеральный)
Выбор: почти все вероятные слова кроме самых маловероятных
Сравнение с top_k:
| Параметр | Что делает | Преимущества | Недостатки |
|---|---|---|---|
top_p | Динамический выбор вероятностей | Автоматически адаптируется к распределению | Может быть непредсказуемым |
top_k | Фиксированное количество слов | Предсказуемость | Не учитывает распределение вероятностей |
Рекомендации по использованию:
Для точных ответов:
{
"top_p": 0.3,
"temperature": 0.1,
"top_k": 20
}
- Фактологические ответы
- Техническая документация
- Код генерация
Для творческих текстов:
{
"top_p": 0.9,
"temperature": 0.8,
"top_k": 60
}
- Поэзия
- Художественные тексты
- Креативные идеи
Для баланса:
{
"top_p": 0.7,
"temperature": 0.5,
"top_k": 40
}
- Диалоги
- Общие вопросы
- Аналитические тексты
Практические примеры запросов:
1. Строгий режим (top_p = 0.3)
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Столица Франции это",
"top_p": 0.3,
"temperature": 0.1,
"stream": false
}'
Результат: “Париж” (максимально точный ответ)
2. Творческий режим (top_p = 0.9)
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Опиши закат на море",
"top_p": 0.9,
"temperature": 0.8,
"stream": false
}'
Результат: Развернутое художественное описание
3. Комбинирование с другими параметрами
{
"top_p": 0.7,
"top_k": 50,
"temperature": 0.6,
"repeat_penalty": 1.1
}
Частые ошибки:
Слишком низкий top_p:
{"top_p": 0.1} # Может приводить к зацикливанию
Слишком высокий top_p:
{"top_p": 0.99} # Почти не фильтрует, может включать nonsense
Конфликт с temperature:
{"top_p": 0.3, "temperature": 0.9} # Противоречивые настройки
Золотые правила:
top_pиtemperatureдолжны быть согласованы- Низкий top_p + низкая temperature = точность
- Высокий top_p + высокая temperature = креативность
- Тестируйте разные значения для вашей задачи
Оптимальные значения для большинства задач: top_p: 0.7-0.9
8. "num_predict": 512
- Что делает: Максимальное количество генерируемых токенов
- Применение:
64- короткие ответы512- средние ответы2048- длинные тексты
- Пример:
"num_predict": 256
9. "stop": ["\n", "###"]
- Что делает: Символы/слова, при которых генерация останавливается
- Применение:
["\n"]- остановиться в конце строки["###", "Конец"]- кастомные стоп-слова
- Пример:
"stop": ["\n\n", "Ответ:"]
10. "repeat_penalty": 1.1
- Что делает: Штраф за повторения (>1.0 уменьшает повторения)
- Применение:
1.0- без штрафа1.2- сильный штраф за повторения
- Пример:
"repeat_penalty": 1.15
11. "presence_penalty": 0.0
- Что делает: Штраф за новые темы (положительные значения поощряют новизну)
- Применение:
-2.0до2.0
12. "frequency_penalty": 0.0
- Что делает: Штраф за частые слова
- Применение:
-2.0до2.0
13. "seed": 42
- Что делает: Seed для детерминированной генерации
- Применение: Одинаковый seed = одинаковые ответы
- Пример:
"seed": 12345
Толкование
Подробное объяснение SEED
Seed (сид) - это начальное значение для генератора псевдослучайных чисел. В контексте LLM это означает, что при одинаковых:
- Модели
- Промпте
- Параметрах
- И одинаковом seed
Вы получите идентичный результат каждый раз.
Как это работает технически:
- Инициализация:
seed = 42 - Детерминированность: Генератор случайных чисел начинает с одинаковой точки
- Воспроизводимость: Все “случайные” выборы становятся предсказуемыми
- Идентичный результат: Токен за токеном одинаковый вывод
Практические примеры:
Пример 1: Детерминированная генерация
# Первый запуск
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Напиши короткое стихотворение о весне",
"seed": 42,
"stream": false
}'
# Второй запуск (ТОЧНО такой же результат)
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Напиши короткое стихотворение о весне",
"seed": 42,
"stream": false
}'
Пример 2: Разные seed = разные результаты
# Seed 42
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Придумай название для кофе",
"seed": 42,
"stream": false
}'
# Результат: "Утренняя свежесть"
# Seed 43 (немного другой)
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Придумай название для кофе",
"seed": 43,
"stream": false
}'
# Результат: "Золотой эспрессо"
Ключевые особенности:
1. Полная детерминированность
{
"seed": 123,
"temperature": 0.1, // Должен быть низким!
"top_p": 0.3 // Должен быть низким!
}
- ✅ Работает с низкой temperature
- ✅ Работает с низким top_p
- ❌ Не работает с высокой temperature
2. Зависимость от всех параметров
# Изменится ЛЮБОЙ параметр → изменится результат
seed=42 + prompt="A" ≠ seed=42 + prompt="A "
3. Постоянство между запусками
# Сегодня
seed=42 → "Ответ А"
# Завтра
seed=42 → "Ответ А" (тот же самый)
# После перезагрузки
seed=42 → "Ответ А" (все равно тот же)
Практическое применение:
1. Тестирование и отладка
# Тестирование изменений промпта
seed=42 + prompt="Версия 1" → Результат А
seed=42 + prompt="Версия 2" → Результат Б
# Можно точно сравнить улучшения
2. Воспроизведение результатов
# Найден хороший результат → сохраняем seed
curl ... -d '{
"prompt": "Креативное название",
"seed": 78901, # ← ЗАПОМНИТЬ ЭТОТ SEED
"temperature": 0.3
}'
# Результат: "Небесный аромат" (сохраняем для производства)
3. A/B тестирование моделей
# Сравнение моделей на одинаковых данных
seed=42 + model="qwen3:4b" → Результат А
seed=42 + model="llama3:8b" → Результат Б
# Честное сравнение без случайности
4. Обучение и демонстрации
# Демо для клиента - всегда одинаковый результат
seed=12345 → "Ваш идеальный бизнес-план..."
Важные ограничения:
1. Temperature должен быть низким
{
"seed": 42,
"temperature": 0.9, // ❌ Высокая randomness
"top_p": 0.9 // ❌ Высокая randomness
}
// Результат НЕ будет детерминированным!
2. Оптимальные настройки для детерминированности
{
"seed": 42,
"temperature": 0.1, // ✅ Низкая случайность
"top_p": 0.3, // ✅ Строгая выборка
"top_k": 20, // ✅ Ограниченный выбор
"repeat_penalty": 1.1 // ✅ Предсказуемость
}
3. Зависит от версии модели
# Модель обновилась → результаты могут измениться
seed=42 + model=v1.0 → Результат А
seed=42 + model=v1.1 → Результат Б (может отличаться)
Практические примеры настроек:
Для детерминированного кода:
{
"seed": 12345,
"temperature": 0.1,
"top_p": 0.2,
"top_k": 10,
"prompt": "Напиши функцию на Python для сложения чисел"
}
Для воспроизводимых аналитических ответов:
{
"seed": 67890,
"temperature": 0.2,
"top_p": 0.4,
"prompt": "Проанализируй преимущества технологии блокчейн"
}
Для тестирования промптов:
{
"seed": 11111,
"temperature": 0.1,
"prompt": "Версия 1 промпта..."
}
// Меняем только промпт, сохраняем seed
Как выбрать хороший seed?
# Любое целое число
"seed": 42
"seed": 1234567890
"seed": 999888777
# Но лучше избегать:
"seed": 0 # Иногда особый случай
"seed": 1 # Слишком простой
"seed": 123456 # Нормально
Пример полного workflow:
- Экспериментируем без seed, находим хорошие параметры
- Фиксируем параметры и промпт
- Добавляем
"seed": 12345для воспроизводимости - Сохраняем конфигурацию для production
{
"model": "qwen3:4b",
"prompt": "Генерируй креативные названия для кофе",
"seed": 424242,
"temperature": 0.3,
"top_p": 0.6,
"top_k": 30,
"num_predict": 50
}
Seed - это мощный инструмент для обеспечения воспроизводимости и отладки LLM приложений!
14. "mirostat": 0
- Что делает: Алгоритм контроля перплексии (0, 1, 2)
- Применение:
0- выключено1или2- для контроля качества
Толкование
Подробное объяснение MIROSTAT
Mirostat - это алгоритм контроля качества текста, который динамически регулирует параметры генерации чтобы поддерживать заданный уровень перплексии (сложности/предсказуемости текста).
Как это работает:
Mirostat постоянно измеряет перплексию генерируемого текста и подстраивает параметры в реальном времени чтобы достичь целевого значения.
Аналогия:
Представьте круиз-контроль в автомобиле:
- Без mirostat: Вы сами управляете газом/тормозом
- С mirostat: Автоматически поддерживает заданную скорость
Режимы работы:
"mirostat": 0 - Выключено
{"mirostat": 0}
- Обычная генерация
- Без контроля качества
- По умолчанию
"mirostat": 1 - Mirostat 1.0
{
"mirostat": 1,
"mirostat_tau": 5.0,
"mirostat_eta": 0.1
}
- Более простой алгоритм
- Меньше вычислительных затрат
"mirostat": 2 - Mirostat 2.0
{
"mirostat": 2,
"mirostat_tau": 5.0,
"mirostat_eta": 0.1
}
- Улучшенная версия
- Более точный контроль
- Лучшее качество текста
Дополнительные параметры:
mirostat_tau - Целевая перплексия
{"mirostat_tau": 5.0}
- Низкие значения (2.0-4.0): Более предсказуемый, простой текст
- Средние значения (4.0-6.0): Баланс сложности и читаемости
- Высокие значения (6.0-8.0): Более сложный, креативный текст
mirostat_eta - Скорость обучения
{"mirostat_eta": 0.1}
- Низкие значения (0.01-0.1): Медленная адаптация, стабильность
- Высокие значения (0.1-0.3): Быстрая адаптация, агрессивные изменения
Практические примеры:
Пример 1: Техническая документация
{
"mirostat": 2,
"mirostat_tau": 3.0, // Низкая перплексия = простота
"mirostat_eta": 0.05,
"prompt": "Объясни концепцию API REST"
}
Результат: Четкий, структурированный текст без излишней сложности
Пример 2: Художественный текст
{
"mirostat": 2,
"mirostat_tau": 7.0, // Высокая перплексия = сложность
"mirostat_eta": 0.2,
"prompt": "Напиши поэтическое описание заката"
}
Результат: Богатый, образный язык с сложными конструкциями
Пример 3: Сбалансированный режим
{
"mirostat": 1,
"mirostat_tau": 5.0, // Баланс
"mirostat_eta": 0.1,
"prompt": "Напиши статью о искусственном интеллекте"
}
Сравнение с традиционными параметрами:
Без Mirostat:
{
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40
}
// Качество может "плавать" в течение генерации
С Mirostat:
{
"mirostat": 2,
"mirostat_tau": 5.0,
"mirostat_eta": 0.1
}
// Постоянное качество throughout текста
Преимущества Mirostat:
- Стабильное качество: Избегает деградации в длинных текстах
- Автоматическая адаптация: Не нужно manually настраивать temperature
- Контроль сложности: Точная настройка уровня сложности текста
- Воспроизводимость: Предсказуемые результаты
Недостатки:
- Вычислительная стоимость: Дополнительные расчеты
- Сложность настройки: Нужно понимать перплексию
- Не для всех задач: Иногда проще использовать temperature
Рекомендации по настройке:
Для разных задач:
| Задача | mirostat_tau | mirostat_eta |
|---|---|---|
| Техническая документация | 2.0-4.0 | 0.05-0.1 |
| Новостные статьи | 4.0-6.0 | 0.1-0.2 |
| Художественная литература | 6.0-8.0 | 0.2-0.3 |
| Научные тексты | 5.0-7.0 | 0.1-0.15 |
Примеры полных конфигураций:
Высокое качество, стабильность:
{
"mirostat": 2,
"mirostat_tau": 5.0,
"mirostat_eta": 0.1,
"temperature": 0.3,
"top_p": 0.8
}
Креативность с контролем:
{
"mirostat": 2,
"mirostat_tau": 7.0,
"mirostat_eta": 0.25,
"temperature": 0.7
}
Практический пример запроса:
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Напиши подробное руководство по использованию Docker",
"mirostat": 2,
"mirostat_tau": 4.0,
"mirostat_eta": 0.08,
"temperature": 0.2,
"stream": false
}' | jq -r '.response'
Когда использовать Mirostat:
✅ Длинные тексты (избегает деградации качества)
✅ Консистентность (техдокументация, руководства)
✅ Точный контроль сложности текста
✅ Автоматизация генерации контента
Когда НЕ использовать:
❌ Короткие ответы (излишне сложно)
❌ Максимальная скорость (дополнительные вычисления)
❌ Эксперименты (проще использовать temperature)
❌ Очень креативные задачи (может ограничивать)
Отладка Mirostat:
Если текст слишком простой:
{"mirostat_tau": 6.0} // Увеличить перплексию
Если текст слишком сложный:
{"mirostat_tau": 3.0} // Уменьшить перплексию
Если качество нестабильное:
{"mirostat_eta": 0.05} // Уменьшить скорость обучения
15. "num_ctx": 2048
- Что делает: Размер контекстного окна
- Применение: Зависит от модели
16. "num_thread": 8
- Что делает: Количество потоков для вычислений
- Применение: Обычно равно количеству ядер CPU
Дополнительные параметры:
17. "template": "{{ .Prompt }}"
- Что делает: Шаблон для форматирования промпта
- Применение:
"template": "Ответь как эксперт: {{ .Prompt }}\nОтвет:"
18. "context": [1, 2, 3]
- Что делает: Контекст предыдущего взаимодействия
- Применение: Для продолжения диалога
Толкование
Подробное объяснение CONTEXT
Context - это массив чисел, который представляет собой “память” предыдущего взаимодействия с моделью. Это позволяет продолжить диалог или текст точно с того места, где остановились.
Как это работает технически:
Контекст содержит эмбеддинги (векторные представления) предыдущего взаимодействия:
- Кодирование: Текст → числовой вектор
- Сохранение: Вектор сохраняется в
context - Восстановление: При следующем запросе вектор передается обратно
- Продолжение: Модель “помнит” предыдущий разговор
Практический пример workflow:
Шаг 1: Первый запрос
response=$(curl -s http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Расскажи о преимуществах Python",
"stream": false
}')
# Извлекаем ответ И контекст
answer=$(echo $response | jq -r '.response')
context=$(echo $response | jq '.context')
Шаг 2: Продолжение с контекстом
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "А какие недостатки?",
"context": '"$context"',
"stream": false
}'
Полный пример скрипта:
#!/bin/bash
# Первый запрос
echo "Шаг 1: Первый запрос"
response1=$(curl -s http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Расскажи о Python для начинающих",
"stream": false
}')
answer1=$(echo $response1 | jq -r '.response')
context=$(echo $response1 | jq '.context')
echo "Ответ: $answer1"
echo "Контекст сохранен"
# Второй запрос с контекстом
echo -e "\nШаг 2: Продолжение диалога"
response2=$(curl -s http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Какие книги посоветуешь для изучения?",
"context": '"$context"',
"stream": false
}')
answer2=$(echo $response2 | jq -r '.response')
echo "Ответ: $answer2"
Формат контекста:
Контекст возвращается и принимается как массив чисел:
{
"context": [123, 456, 789, 12, 34, 56, 78, 90, ...]
}
Практические применения:
1. Многошаговые диалоги
# Пользователь: Привет
# Модель: Привет! Как дела?
# Пользователь: Хорошо, расскажи о погоде
# Модель: Помнит предыдущие реплики
2. Продолжение длинных текстов
# Начало: "В далекой галактике..."
# Продолжение: "где мы остановились..."
3. Технические консультации
# Шаг 1: Обсуждение проблемы
# Шаг 2: Уточняющие вопросы
# Шаг 3: Решение с учетом всей истории
4. Написание кода по частям
# Сначала: архитектура проекта
# Затем: реализация конкретных функций
# В конце: тестирование
Преимущества использования context:
По сравнению с передачей всей истории в prompt:
# Без context (громоздко):
"prompt": "Предыдущий разговор: Привет - Привет! Как дела? - Хорошо. Текущий вопрос: Что нового?"
# С context (эффективно):
"prompt": "Что нового?",
"context": [123, 456, 789]
Экономия токенов:
- ❌ Без context: Каждый раз передается вся история
- ✅ С context: Передаются только компактные эмбеддинги
Сохраняется состояние:
- Переменные
- Контекст разговора
- Стиль и тон
- Технические детали
Ограничения и важные моменты:
1. Совместимость моделей
# Контекст от одной модели может не работать с другой
context от "qwen3:4b" ≠ context для "llama3:8b"
2. Временные ограничения
# Контекст может "устаревать" после долгого времени
# Или после обновления модели
3. Размер контекста
# Слишком длинный контекст может быть обрезан
# Зависит от ограничений модели
4. Не для всех задач
# Для совершенно новых тем лучше не использовать context
# Чтобы избежать влияния предыдущего разговора
Пример с обработкой ошибок:
#!/bin/bash
ask_question() {
local prompt="$1"
local context="$2"
local data='{
"model": "qwen3:4b",
"prompt": "'"$prompt"'",
"stream": false'
if [ -n "$context" ] && [ "$context" != "null" ]; then
data+=', "context": '"$context"
fi
data+='}'
curl -s http://localhost:11434/api/generate -d "$data"
}
# Диалог
response1=$(ask_question "Привет! Как тебя зовут?")
answer1=$(echo $response1 | jq -r '.response')
context1=$(echo $response1 | jq '.context')
echo "Модель: $answer1"
response2=$(ask_question "А чем ты занимаешься?" "$context1")
answer2=$(echo $response2 | jq -r '.response')
echo "Модель: $answer2"
Использование в API чата:
Для чат-интерфейсов лучше использовать /api/chat:
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:4b",
"messages": [
{"role": "user", "content": "Привет"},
{"role": "assistant", "content": "Привет! Как дела?"},
{"role": "user", "content": "Хорошо, а у тебя?"}
],
"stream": false
}'
Лучшие практики:
1. Сохраняйте контекст между запросами
# В приложении сохраняйте context в:
# - Базе данных
# - Файле
# - Памятии сессии
2. Очищайте контекст для новых тем
# Если тема полностью меняется:
context=null
3. Проверяйте валидность контекста
if [ "$context" != "null" ] && [ -n "$context" ]; then
# Используем контекст
else
# Новый разговор
fi
4. Ограничивайте длину диалога
# После N реплик начинайте новый контекст
# Чтобы избежать накопления ошибок
Продвинутое использование:
Сохранение контекста в файл:
# Сохраняем
echo $context > context.json
# Загружаем
context=$(cat context.json)
Многоуровневые диалоги:
# Разные контексты для разных тем
context_python=$(cat python_context.json)
context_js=$(cat js_context.json)
Воспроизведение диалогов:
# Для тестирования можно сохранить и воспроизвести
# exact диалог с одинаковым context
Пример для продакшена:
# Псевдокод для веб-приложения
sessions = {}
def handle_message(user_id, message):
if user_id not in sessions:
# Новый диалог
response = ollama.generate(prompt=message)
sessions[user_id] = {
'context': response['context'],
'history': [message, response['response']]
}
else:
# Продолжение диалога
response = ollama.generate(
prompt=message,
context=sessions[user_id]['context']
)
sessions[user_id]['context'] = response['context']
sessions[user_id]['history'].extend([message, response['response']])
return response['response']
Практические примеры настроек:
Для точных фактологических ответов:
{
"temperature": 0.1,
"top_p": 0.3,
"top_k": 20,
"repeat_penalty": 1.2
}
Для креативных текстов:
{
"temperature": 0.9,
"top_p": 0.95,
"top_k": 60,
"num_predict": 1024
}
Для детерминированных результатов:
{
"temperature": 0.1,
"seed": 42,
"top_p": 0.1
}
1.1.2 - Пример с curl и полным набором параметров
Полноценный пример запроса с curl и полным набором параметров с учетом контекста
#!/bin/bash
# Первый запрос - получаем контекст
echo "=== Первый запрос ==="
response1=$(curl -s http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "Расскажи о преимуществах языка Python",
"stream": false,
"format": "json",
"options": {
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"num_predict": 256,
"stop": ["\n", "###"],
"repeat_penalty": 1.1,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"seed": 42,
"mirostat": 2,
"mirostat_tau": 5.0,
"mirostat_eta": 0.1,
"num_ctx": 2048,
"num_thread": 8
},
"template": "Ответь как эксперт: {{ .Prompt }}\n\nОтвет:"
}')
# Извлекаем ответ и контекст
answer1=$(echo $response1 | jq -r '.response')
context=$(echo $response1 | jq '.context')
echo "Ответ: $answer1"
echo "Контекст получен"
# Второй запрос с контекстом
echo -e "\n=== Второй запрос с контекстом ==="
response2=$(curl -s http://localhost:11434/api/generate -d '{
"model": "qwen3:4b",
"prompt": "А какие у Python недостатки?",
"context": '"$context"',
"stream": false,
"format": "text",
"options": {
"temperature": 0.5,
"top_p": 0.8,
"top_k": 30,
"num_predict": 200,
"stop": ["\n\n"],
"repeat_penalty": 1.2,
"seed": 123
}
}')
answer2=$(echo $response2 | jq -r '.response')
echo "Ответ: $answer2"
1.1.3 - Пример из командной строки с ollama run
Полноценный пример запроса из командной строки и полным набором параметров с учетом контекста
# Создаем конфигурационный файл для первого запроса
cat > first_request.txt << 'EOF'
Расскажи о преимуществах языка Python для data science
EOF
# Первый запрос с полными параметрами через stdin
echo "=== Первый запрос ==="
response1=$(ollama run qwen3:4b --temperature 0.7 --top-p 0.9 --top-k 40 \
--num-predict 256 --seed 42 --mirostat 2 --mirostat-tau 5.0 --mirostat-eta 0.1 \
--repeat-penalty 1.1 --stop "\n" --stop "###" < first_request.txt)
echo "$response1"
# Сохраняем промпт для второго запроса
cat > second_request.txt << 'EOF'
А какие недостатки у Python для data science по сравнению с R?
EOF
# Второй запрос (Ollama run не поддерживает context напрямую,
# поэтому используем альтернативный подход)
echo -e "\n=== Второй запрос ==="
ollama run qwen3:4b --temperature 0.5 --top-p 0.8 --top-k 30 \
--num-predict 200 --seed 123 --repeat-penalty 1.2 < second_request.txt
1.1.4 - Alias для zsh с конфигурационным файлом YAML
Полноценный пример создания рабочего alias для командной оболочки zsh с запросом из командной строки и полным набором параметров с подключением внешнего файла настроек yaml
Установите дополнительные зависимости
# Для Ubuntu/Debian
sudo apt-get install yq jq
#Для Arch
sudo pacman -S yq jq
Добавить настройку в ~/.zshrc:
# Alias для работы с конфигурационным файлом
alias ollama-config='func() {
local config_file="$1"
local prompt="$2"
if [ ! -f "$config_file" ]; then
echo "Config file $config_file not found!"
return 1
fi
# Читаем конфигурацию из файла
local model=$(yq eval ".model" "$config_file")
local temperature=$(yq eval ".options.temperature" "$config_file")
local top_p=$(yq eval ".options.top_p" "$config_file")
local top_k=$(yq eval ".options.top_k" "$config_file")
local num_predict=$(yq eval ".options.num_predict" "$config_file")
local seed=$(yq eval ".options.seed" "$config_file")
# Выполняем запрос
ollama run "$model" --temperature "$temperature" --top-p "$top_p" \
--top-k "$top_k" --num-predict "$num_predict" --seed "$seed" "$prompt"
}; func'
# Alias для JSON конфигурации
alias ollama-json='func() {
local config_file="$1"
local prompt="$2"
if [ ! -f "$config_file" ]; then
echo "Config file $config_file not found!"
return 1
fi
# Используем jq для извлечения параметров
local model=$(jq -r ".model" "$config_file")
local temperature=$(jq -r ".options.temperature" "$config_file")
local top_p=$(jq -r ".options.top_p" "$config_file")
ollama run "$model" --temperature "$temperature" --top-p "$top_p" "$prompt"
}; func'
Конфигурационный файл ollama_config.yaml:
model: qwen3:4b
options:
temperature: 0.7
top_p: 0.9
top_k: 40
num_predict: 256
seed: 42
repeat_penalty: 1.1
mirostat: 2
mirostat_tau: 5.0
mirostat_eta: 0.1
format: text
Использование
# Установите yq для работы с YAML: brew install yq
ollama-config ollama_config.yaml "Расскажи о machine learning"
# Или с JSON конфигом
ollama-json config.json "Напиши код на Python"
1.1.5 - Запуск модели из Ollama с конфигурационным файлом JSON
Полноценный пример создания запроса из командной строки и полным набором параметров с подключением внешнего файла настроек JSON
Командная строка с передачей JSON файла
Создаем конфигурационный файл request_config.json:
{
"model": "qwen3:4b",
"prompt": "Объясни концепцию искусственного интеллекта",
"stream": false,
"format": "markdown",
"options": {
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"num_predict": 300,
"stop": ["\n", "##"],
"repeat_penalty": 1.1,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"seed": 424242,
"mirostat": 2,
"mirostat_tau": 5.0,
"mirostat_eta": 0.1,
"num_ctx": 2048,
"num_thread": 8
},
"template": "Ответь как эксперт по AI: {{ .Prompt }}\n\n"
}
Скрипт для обработки JSON конфига:
#!/bin/bash
process_ollama_config() {
local config_file="$1"
if [ ! -f "$config_file" ]; then
echo "Config file $config_file not found!"
return 1
fi
# Извлекаем параметры из JSON
local model=$(jq -r '.model' "$config_file")
local prompt=$(jq -r '.prompt' "$config_file")
local temperature=$(jq -r '.options.temperature' "$config_file")
local top_p=$(jq -r '.options.top_p' "$config_file")
local top_k=$(jq -r '.options.top_k' "$config_file")
local num_predict=$(jq -r '.options.num_predict' "$config_file")
local seed=$(jq -r '.options.seed' "$config_file")
local repeat_penalty=$(jq -r '.options.repeat_penalty' "$config_file")
# Строим команду ollama run
local command="ollama run '$model' --temperature $temperature --top-p $top_p --top-k $top_k --num-predict $num_predict --seed $seed --repeat-penalty $repeat_penalty"
# Добавляем stop слова если они есть
local stop_words=$(jq -r '.options.stop[]?' "$config_file" 2>/dev/null)
if [ -n "$stop_words" ]; then
while IFS= read -r word; do
command+=" --stop \"$word\""
done <<< "$stop_words"
fi
# Добавляем промпт
command+=" \"$prompt\""
echo "Выполняем команду: $command"
eval "$command"
}
# Использование
process_ollama_config "request_config.json"
Альтернативный вариант с прямым использованием curl:
#!/bin/bash
# Прямое использование JSON конфига с curl
curl -s http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d "$(cat request_config.json)" \
| jq -r '.response'
1.1.6 - Запуск модели из Ollama с конфигурационным файлом JSON и контекстом
Полноценный пример создания запроса из командной строки и полным набором параметров с подключением внешнего файла настроек JSON с контекстом
Продвинутый пример с контекстом и многошаговым диалогом
Создаем скрипт advanced_dialog.sh:
#!/bin/bash
CONFIG_FILE="dialog_config.json"
CONTEXT_FILE="context.json"
# Функция для отправки запроса
send_request() {
local prompt="$1"
local context="${2:-null}"
local request_data=$(jq --arg prompt "$prompt" --argjson context "$context" '
{
model: .model,
prompt: $prompt,
stream: false,
format: .format,
options: .options,
template: .template,
context: $context
}' "$CONFIG_FILE")
curl -s http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d "$request_data"
}
# Основной диалог
echo "🤖 Начинаем диалог с AI"
# Шаг 1
echo "👤: Расскажи о Python"
response1=$(send_request "Расскажи о Python")
answer1=$(echo $response1 | jq -r '.response')
context=$(echo $response1 | jq '.context')
echo "🤖: $answer1"
# Сохраняем контекст
echo "$context" > "$CONTEXT_FILE"
# Шаг 2 с контекстом
echo -e "\n👤: А какие у него недостатки?"
response2=$(send_request "А какие у него недостатки?" "$(cat $CONTEXT_FILE)")
answer2=$(echo $response2 | jq -r '.response')
echo "🤖: $answer2"
# Обновляем контекст
echo "$(echo $response2 | jq '.context')" > "$CONTEXT_FILE"
# Шаг 3
echo -e "\n👤: Что посоветуешь для изучения?"
response3=$(send_request "Что посоветуешь для изучения?" "$(cat $CONTEXT_FILE)")
answer3=$(echo $response3 | jq -r '.response')
echo "🤖: $answer3"
Конфигурационный файл dialog_config.json:
{
"model": "qwen3:4b",
"format": "text",
"template": "Ответь дружелюбно и подробно: {{ .Prompt }}\n\n",
"options": {
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"num_predict": 200,
"stop": ["\n\n", "###"],
"repeat_penalty": 1.1,
"seed": 12345,
"mirostat": 1,
"mirostat_tau": 5.0,
"mirostat_eta": 0.1
}
}
Запуск:
chmod +x advanced_dialog.sh
./advanced_dialog.sh
1.1.7 - Запуск модели Ollama с конфигурационным файлом JSON из NODE.JS
Полноценный пример создания запроса из NODE.JS с подключением внешнего файла настроек JSON
JavaScript/Node.js пример с полными параметрами
Установите зависимости:
npm init -y
npm install axios
ollama-client.js:
const axios = require('axios');
class OllamaClient {
constructor(baseURL = 'http://localhost:11434') {
this.baseURL = baseURL;
this.context = null;
}
/**
* Генерация текста с полным набором параметров
*/
async generate({
prompt,
model = 'qwen3:4b',
stream = false,
format = 'text',
temperature = 0.7,
top_p = 0.9,
top_k = 40,
num_predict = 256,
stop = ['\n', '###'],
repeat_penalty = 1.1,
presence_penalty = 0.0,
frequency_penalty = 0.0,
seed = null,
mirostat = 0,
mirostat_tau = 5.0,
mirostat_eta = 0.1,
num_ctx = 2048,
num_thread = 8,
template = null,
useContext = true
}) {
const payload = {
model,
prompt,
stream,
format,
options: {
temperature,
top_p,
top_k,
num_predict,
stop,
repeat_penalty,
presence_penalty,
frequency_penalty,
mirostat,
mirostat_tau,
mirostat_eta,
num_ctx,
num_thread
}
};
// Добавляем опциональные параметры
if (seed !== null) {
payload.options.seed = seed;
}
if (template) {
payload.template = template;
}
if (useContext && this.context) {
payload.context = this.context;
}
try {
const response = await axios.post(`${this.baseURL}/api/generate`, payload, {
timeout: 30000
});
// Сохраняем контекст для следующего запроса
if (useContext && response.data.context) {
this.context = response.data.context;
}
return response.data;
} catch (error) {
console.error('Ошибка запроса:', error.message);
return { error: error.message };
}
}
/**
* Чат-интерфейс с поддержкой истории
*/
async chat(messages, model = 'qwen3:4b', options = {}) {
try {
const response = await axios.post(`${this.baseURL}/api/chat`, {
model,
messages,
stream: false,
options
}, {
timeout: 30000
});
return response.data;
} catch (error) {
console.error('Ошибка чата:', error.message);
return { error: error.message };
}
}
/**
* Очистить контекст
*/
clearContext() {
this.context = null;
}
/**
* Сохранить контекст в файл
*/
async saveContext(filename) {
const fs = require('fs').promises;
try {
await fs.writeFile(filename, JSON.stringify(this.context, null, 2));
console.log(`Контекст сохранен в ${filename}`);
} catch (error) {
console.error('Ошибка сохранения контекста:', error.message);
}
}
/**
* Загрузить контекст из файла
*/
async loadContext(filename) {
const fs = require('fs').promises;
try {
const data = await fs.readFile(filename, 'utf8');
this.context = JSON.parse(data);
console.log(`Контекст загружен из ${filename}`);
} catch (error) {
console.error('Ошибка загрузки контекста:', error.message);
}
}
}
// Пример использования
async function main() {
const client = new OllamaClient();
// Пример 1: Простая генерация
console.log('=== Пример 1: Простая генерация ===');
const result1 = await client.generate({
prompt: 'Расскажи о JavaScript и его особенностях',
model: 'qwen3:4b',
temperature: 0.7,
top_p: 0.9,
num_predict: 200,
seed: 42,
format: 'text'
});
console.log('Ответ:', result1.response || result1.error);
// Пример 2: Продолжение с контекстом
console.log('\n=== Пример 2: Продолжение с контекстом ===');
const result2 = await client.generate({
prompt: 'А какие современные фреймворки используются?',
temperature: 0.5,
top_p: 0.8
});
console.log('Ответ:', result2.response || result2.error);
// Пример 3: Чат с историей
console.log('\n=== Пример 3: Чат-интерфейс ===');
const chatResult = await client.chat([
{ role: 'user', content: 'Привет! Расскажи о Node.js' },
{ role: 'assistant', content: 'Node.js - это JavaScript runtime...' },
{ role: 'user', content: 'Какие пакеты самые популярные?' }
], 'qwen3:4b', {
temperature: 0.6,
top_p: 0.85
});
console.log('Чат ответ:', chatResult.message?.content || chatResult.error);
// Пример 4: Сохранение и загрузка контекста
await client.saveContext('context.json');
client.clearContext();
await client.loadContext('context.json');
// Пример 5: Генерация кода с специфическими параметрами
console.log('\n=== Пример 5: Генерация кода ===');
const codeResult = await client.generate({
prompt: 'Напиши простой HTTP сервер на Node.js',
temperature: 0.3,
top_p: 0.7,
num_predict: 300,
seed: 12345,
format: 'code',
stop: ['```']
});
console.log('Сгенерированный код:');
console.log(codeResult.response || codeResult.error);
}
// Запуск примера
main().catch(console.error);
package.json для JavaScript:
{
"name": "ollama-client",
"version": "1.0.0",
"description": "Ollama client with full parameters support",
"main": "ollama-client.js",
"scripts": {
"start": "node ollama-client.js",
"dev": "node ollama-client.js"
},
"dependencies": {
"axios": "^1.6.0"
},
"keywords": ["ollama", "ai", "llm", "javascript"],
"author": "Your Name",
"license": "MIT"
}
1.1.8 - Запуск модели Ollama на языке Go
Полноценный пример создания запроса к модели ИИ на языке программирования Go
Go пример с полными параметрами
Установите зависимости:
go mod init ollama-client
go get github.com/valyala/fasthttp
main.go:
package main
import (
"encoding/json"
"fmt"
"log"
"strings"
"time"
"github.com/valyala/fasthttp"
)
type OllamaOptions struct {
Temperature float32 `json:"temperature"`
TopP float32 `json:"top_p"`
TopK int `json:"top_k"`
NumPredict int `json:"num_predict"`
Stop []string `json:"stop"`
RepeatPenalty float32 `json:"repeat_penalty"`
PresencePenalty float32 `json:"presence_penalty"`
FrequencyPenalty float32 `json:"frequency_penalty"`
Seed int64 `json:"seed,omitempty"`
Mirostat int `json:"mirostat"`
MirostatTau float32 `json:"mirostat_tau"`
MirostatEta float32 `json:"mirostat_eta"`
NumCtx int `json:"num_ctx"`
NumThread int `json:"num_thread"`
}
type OllamaRequest struct {
Model string `json:"model"`
Prompt string `json:"prompt"`
Stream bool `json:"stream"`
Format string `json:"format,omitempty"`
Options OllamaOptions `json:"options"`
Template string `json:"template,omitempty"`
Context []int `json:"context,omitempty"`
}
type OllamaResponse struct {
Model string `json:"model"`
Response string `json:"response"`
Context []int `json:"context,omitempty"`
Done bool `json:"done"`
Error string `json:"error,omitempty"`
}
type OllamaClient struct {
BaseURL string
Context []int
}
func NewOllamaClient(baseURL string) *OllamaClient {
if baseURL == "" {
baseURL = "http://localhost:11434"
}
return &OllamaClient{BaseURL: baseURL}
}
func (c *OllamaClient) Generate(prompt string, options OllamaOptions) (OllamaResponse, error) {
request := OllamaRequest{
Model: "qwen3:4b",
Prompt: prompt,
Stream: false,
Format: "text",
Options: options,
}
if len(c.Context) > 0 {
request.Context = c.Context
}
requestBody, err := json.Marshal(request)
if err != nil {
return OllamaResponse{}, err
}
req := fasthttp.AcquireRequest()
defer fasthttp.ReleaseRequest(req)
req.SetRequestURI(c.BaseURL + "/api/generate")
req.Header.SetMethod("POST")
req.Header.SetContentType("application/json")
req.SetBody(requestBody)
resp := fasthttp.AcquireResponse()
defer fasthttp.ReleaseResponse(resp)
client := &fasthttp.Client{
ReadTimeout: 30 * time.Second,
}
if err := client.Do(req, resp); err != nil {
return OllamaResponse{}, err
}
var response OllamaResponse
if err := json.Unmarshal(resp.Body(), &response); err != nil {
return OllamaResponse{}, err
}
// Сохраняем контекст для следующих запросов
if response.Context != nil {
c.Context = response.Context
}
return response, nil
}
func (c *OllamaClient) ClearContext() {
c.Context = nil
}
func main() {
client := NewOllamaClient("")
// Пример 1: Простая генерация
options1 := OllamaOptions{
Temperature: 0.7,
TopP: 0.9,
TopK: 40,
NumPredict: 200,
Stop: []string{"\n", "###"},
RepeatPenalty: 1.1,
Seed: 42,
Mirostat: 2,
MirostatTau: 5.0,
MirostatEta: 0.1,
}
fmt.Println("=== Пример 1: Простая генерация ===")
response1, err := client.Generate("Расскажи о Go языке программирования", options1)
if err != nil {
log.Fatal("Ошибка:", err)
}
fmt.Printf("Ответ: %s\n", response1.Response)
// Пример 2: Продолжение с контекстом
options2 := OllamaOptions{
Temperature: 0.5,
TopP: 0.8,
TopK: 30,
NumPredict: 150,
RepeatPenalty: 1.2,
}
fmt.Println("\n=== Пример 2: Продолжение с контекстом ===")
response2, err := client.Generate("Какие у него преимущества?", options2)
if err != nil {
log.Fatal("Ошибка:", err)
}
fmt.Printf("Ответ: %s\n", response2.Response)
// Пример 3: Генерация кода
options3 := OllamaOptions{
Temperature: 0.3,
TopP: 0.7,
NumPredict: 300,
Seed: 12345,
}
fmt.Println("\n=== Пример 3: Генерация кода ===")
response3, err := client.Generate("Напиши HTTP сервер на Go", options3)
if err != nil {
log.Fatal("Ошибка:", err)
}
fmt.Printf("Код: %s\n", response3.Response)
// Очищаем контекст
client.ClearContext()
fmt.Println("\nКонтекст очищен")
}
1.1.9 - Запуск модели Ollama на языке программирования Python
Полноценный пример создания запроса к модели ИИ на языке Python
Python пример с полными параметрами
Установите зависимости:
pip install requests python-dotenv
ollama_client.py:
import requests
import json
import os
from typing import Dict, Any, List, Optional
class OllamaClient:
def __init__(self, base_url: str = "http://localhost:11434"):
self.base_url = base_url
self.context = None
def generate(
self,
prompt: str,
model: str = "qwen3:4b",
stream: bool = False,
format: str = "text",
temperature: float = 0.7,
top_p: float = 0.9,
top_k: int = 40,
num_predict: int = 256,
stop: List[str] = None,
repeat_penalty: float = 1.1,
presence_penalty: float = 0.0,
frequency_penalty: float = 0.0,
seed: int = None,
mirostat: int = 0,
mirostat_tau: float = 5.0,
mirostat_eta: float = 0.1,
num_ctx: int = 2048,
num_thread: int = 8,
template: str = None,
use_context: bool = True
) -> Dict[str, Any]:
"""
Генерация текста с полным набором параметров
"""
if stop is None:
stop = ["\n", "###"]
payload = {
"model": model,
"prompt": prompt,
"stream": stream,
"format": format,
"options": {
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"num_predict": num_predict,
"stop": stop,
"repeat_penalty": repeat_penalty,
"presence_penalty": presence_penalty,
"frequency_penalty": frequency_penalty,
"mirostat": mirostat,
"mirostat_tau": mirostat_tau,
"mirostat_eta": mirostat_eta,
"num_ctx": num_ctx,
"num_thread": num_thread
}
}
# Добавляем опциональные параметры
if seed is not None:
payload["options"]["seed"] = seed
if template:
payload["template"] = template
if use_context and self.context:
payload["context"] = self.context
try:
response = requests.post(
f"{self.base_url}/api/generate",
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
# Сохраняем контекст для следующего запроса
if use_context and "context" in result:
self.context = result["context"]
return result
except requests.exceptions.RequestException as e:
print(f"Ошибка запроса: {e}")
return {"error": str(e)}
def chat(
self,
messages: List[Dict[str, str]],
model: str = "qwen3:4b",
**kwargs
) -> Dict[str, Any]:
"""
Чат-интерфейс с поддержкой истории сообщений
"""
payload = {
"model": model,
"messages": messages,
"stream": False,
"options": kwargs.get("options", {})
}
try:
response = requests.post(
f"{self.base_url}/api/chat",
json=payload,
timeout=30
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Ошибка чата: {e}")
return {"error": str(e)}
def clear_context(self):
"""Очистить контекст"""
self.context = None
# Пример использования
def main():
client = OllamaClient()
# Пример 1: Простая генерация
print("=== Пример 1: Простая генерация ===")
result1 = client.generate(
prompt="Расскажи о преимуществах Python для data science",
model="qwen3:4b",
temperature=0.7,
top_p=0.9,
num_predict=150,
seed=42,
format="text"
)
print("Ответ:", result1.get("response", "Ошибка"))
# Пример 2: Продолжение с контекстом
print("\n=== Пример 2: Продолжение с контекстом ===")
result2 = client.generate(
prompt="А какие недостатки у Python?",
temperature=0.5,
top_p=0.8
)
print("Ответ:", result2.get("response", "Ошибка"))
# Пример 3: Чат с историей
print("\n=== Пример 3: Чат-интерфейс ===")
chat_result = client.chat(
messages=[
{"role": "user", "content": "Привет! Как тебя зовут?"},
{"role": "assistant", "content": "Привет! Я помощник на основе AI."},
{"role": "user", "content": "Расскажи о машинном обучении"}
],
model="qwen3:4b",
options={
"temperature": 0.7,
"top_p": 0.9
}
)
print("Чат ответ:", chat_result.get("message", {}).get("content", "Ошибка"))
# Пример 4: Сброс контекста
client.clear_context()
print("\nКонтекст очищен")
if __name__ == "__main__":
main()
advanced_example.py - продвинутый пример:
import json
from ollama_client import OllamaClient
def advanced_example():
client = OllamaClient()
# Многошаговый диалог с сохранением контекста
steps = [
"Расскажи о языке программирования Go",
"Какие у него преимущества перед Python?",
"А недостатки какие?",
"Напиши простой HTTP сервер на Go"
]
for i, prompt in enumerate(steps, 1):
print(f"\n--- Шаг {i}: {prompt} ---")
result = client.generate(
prompt=prompt,
model="qwen3:4b",
temperature=0.7 if i > 1 else 0.5,
top_p=0.9,
num_predict=200 if i < 4 else 300,
seed=12345,
format="text" if i < 4 else "code"
)
if "response" in result:
print(f"Ответ: {result['response']}")
else:
print(f"Ошибка: {result.get('error', 'Неизвестная ошибка')}")
# Сохраняем контекст в файл
if client.context:
with open("context.json", "w") as f:
json.dump(client.context, f)
print("\nКонтекст сохранен в context.json")
if __name__ == "__main__":
advanced_example()
2 - Язык программирования LUA
Lua — это бесплатное программное обеспечение, распространяемое в исходном коде. Его можно использовать для любых целей, включая коммерческие, совершенно бесплатно.
Все версии доступны для загрузки. Эта документация пишется для текущей версии — Lua 5.4, а текущий релиз — Lua 5.4.8.
Lua
Lua — это бесплатное программное обеспечение, распространяемое в исходном коде. Его можно использовать для любых целей, включая коммерческие, совершенно бесплатно.
Все версии доступны для загрузки. Текущая версия — Lua 5.4, а текущий релиз — Lua 5.4.8.
Инструменты
Основной репозиторий модулей Lua — это LuaRocks. Также смотрите Awesome Lua. Предварительно скомпилированные библиотеки и исполняемые файлы Lua доступны на LuaBinaries. Вики lua-users содержит множество пользовательских дополнений для Lua.
Сборка
Lua реализован на чистом ANSI C и компилируется без изменений на всех платформах, где есть компилятор ANSI C. Lua также компилируется без проблем как C++.
Lua очень легко собрать и установить. В пакете есть подробные инструкции, но вот простой пример терминальной сессии, которая загружает текущий релиз Lua и собирает его на распространенных платформах:
curl -L -R -O https://www.lua.org/ftp/lua-5.4.8.tar.gz
tar zxf lua-5.4.8.tar.gz
cd lua-5.4.8
make all test
Введение
Lua — это мощный, эффективный, легковесный и встраиваемый язык сценариев. Он поддерживает процедурное программирование, объектно-ориентированное программирование, функциональное программирование, программирование на основе данных и описание данных.
Lua сочетает в себе простую процедурную синтаксис с мощными конструкциями описания данных, основанными на ассоциативных массивах и расширяемой семантике. Lua является динамически типизированным языком, работает путем интерпретации байт-кода с помощью виртуальной машины на основе регистров и имеет автоматическое управление памятью с помощью генерационного сборщика мусора, что делает его идеальным для конфигурации, сценариев и быстрого прототипирования.
Lua реализован как библиотека, написанная на чистом C, общепринятом подмножестве стандартного C и C++. Распределение Lua включает в себя хост-программу под названием lua, которая использует библиотеку Lua для предоставления полного, автономного интерпретатора Lua, как для интерактивного, так и для пакетного использования. Lua предназначен как мощный, легковесный, встраиваемый язык сценариев для любой программы, которая в этом нуждается, а также как мощный, но легковесный и эффективный автономный язык.
Как язык расширения, Lua не имеет понятия “главной” программы: он работает встраиваемым в хост-клиент, называемым программой встраивания или просто хостом. (Часто этот хост — это автономная программа lua.) Хост-программа может вызывать функции для выполнения фрагмента кода Lua, может записывать и считывать переменные Lua, а также может регистрировать функции C, которые будут вызываться кодом Lua. С помощью функций C Lua может быть расширен для работы с широким спектром различных областей, создавая таким образом настраиваемые языки программирования, которые разделяют синтаксическую основу.
Lua является бесплатным программным обеспечением и предоставляется, как обычно, без каких-либо гарантий, как указано в его лицензии. Реализация, описанная в этом руководстве, доступна на официальном сайте Lua, www.lua.org.
Как и любой другой справочный мануал, этот документ в некоторых местах может быть сухим. Для обсуждения решений, стоящих за дизайном Lua, смотрите технические статьи, доступные на сайте Lua. Для подробного введения в программирование на Lua смотрите книгу Роберто, “Программирование на Lua”.
2.1 - 2. Базовые концепции языка LUA
Этот раздел описывает основные концепции языка.
2.1 – Значения и типы
Lua — это динамически типизированный язык. Это означает, что переменные не имеют типов; только значения имеют типы. В языке отсутствуют определения типов. Все значения имеют свой собственный тип.
Все значения в Lua являются значениями первого класса. Это означает, что все значения могут храниться в переменных, передаваться в качестве аргументов другим функциям и возвращаться в качестве результатов.
В Lua есть восемь основных типов: nil, boolean, number, string, function, userdata, thread и table.
- Тип
nilимеет одно единственное значение —nil, основное свойство которого заключается в том, что оно отличается от любого другого значения; оно часто представляет отсутствие полезного значения. - Тип
booleanимеет два значения:falseиtrue. Оба nil и false делают условие ложным; их вместе называют ложными значениями. Любое другое значение делает условие истинным. Несмотря на свое название, false часто используется как альтернатива nil, с ключевым отличием в том, что false ведет себя как обычное значение в таблице, в то время как nil в таблице представляет отсутствующий ключ. - Тип
numberпредставляет как целые числа, так и вещественные (числа с плавающей запятой), используя два подтипа:integerиfloat. Стандартный Lua использует 64-битные целые числа и числа с двойной точностью (64 бита), но вы также можете скомпилировать Lua так, чтобы он использовал 32-битные целые числа и/или числа с одинарной точностью (32 бита). Опция с 32 битами как для целых чисел, так и для чисел с плавающей запятой особенно привлекательна для малых машин и встроенных систем. (Смотрите макрос LUA_32BITS в файле luaconf.h.)
Если не указано иное, любое переполнение при манипуляциях с целыми значениями оборачивается, согласно обычным правилам арифметики с дополнительным кодом. (Другими словами, фактический результат — это уникальное представимое целое число, которое равно математическому результату по модулю 2n, где n — это количество битов целого типа.)
Lua имеет явные правила о том, когда используется каждый подтип, но также автоматически выполняет преобразования между ними по мере необходимости (см. §3.4.3). Поэтому программист может в основном игнорировать разницу между целыми числами и числами с плавающей запятой или полностью контролировать представление каждого числа.
- Тип
stringпредставляет собой неизменяемые последовательности байтов. Lua является 8-битным чистым языком: строки могут содержать любое 8-битное значение, включая встроенные нули (’\0’). Lua также не зависит от кодировки; он не делает предположений о содержимом строки. Длина любой строки в Lua должна помещаться в целое число Lua.
Lua может вызывать (и манипулировать) функциями, написанными как на Lua, так и на C (см. §3.4.10). Обе они представлены типом function.
Тип userdata предоставляется для хранения произвольных данных C в переменных Lua. Значение
userdataпредставляет собой блок необработанной памяти. Существует два видаuserdata: полноеuserdata, которое является объектом с блоком памяти, управляемым Lua, и легкоеuserdata, которое просто представляет собой значение указателя C. Уuserdataнет предопределенных операций в Lua, кроме присваивания и теста идентичности. С помощью метатаблиц программист может определить операции для значений полногоuserdata(см. §2.4). Значенияuserdataне могут быть созданы или изменены в Lua, только через C API. Это гарантирует целостность данных, принадлежащих хост-программе и библиотекам C.Тип
threadпредставляет собой независимые потоки выполнения и используется для реализации корутин (см. §2.6). Потоки Lua не связаны с потоками операционной системы. Lua поддерживает корутины на всех системах, даже на тех, которые не поддерживают потоки нативно.Тип
tableреализует ассоциативные массивы, то есть массивы, которые могут иметь в качестве индексов не только числа, но и любое значение Lua, кроме nil и NaN. (Not a Number — это специальное значение с плавающей запятой, используемое стандартом IEEE 754 для представления неопределенных числовых результатов, таких как 0/0.) Таблицы могут быть гетерогенными; то есть они могут содержать значения всех типов (кроме nil). Любой ключ, связанный со значением nil, не считается частью таблицы. Напротив, любой ключ, который не является частью таблицы, имеет связанное значение nil.
Таблицы являются единственным механизмом структурирования данных в Lua; их можно использовать для представления обычных массивов, списков, символических таблиц, множеств, записей, графов, деревьев и т. д. Для представления записей Lua использует имя поля в качестве индекса. Язык поддерживает это представление, предоставляя a.name как синтаксический сахар для a[“name”]. В Lua есть несколько удобных способов создания таблиц (см. §3.4.9).
Как и индексы, значения полей таблицы могут быть любого типа. В частности, поскольку функции являются значениями первого класса, поля таблицы могут содержать функции. Таким образом, таблицы также могут содержать методы (см. §3.4.11).
Индексирование таблиц следует определению сырого равенства (raw equality) в языке. Выражения a[i] и a[j] обозначают один и тот же элемент таблицы тогда и только тогда, когда i и j сыро равны (то есть равны без учёта метаметодов).
В частности:
- Числа с плавающей точкой, имеющие целочисленные значения, считаются равными соответствующим целым числам (например,
1.0 == 1). - Чтобы избежать неоднозначностей, любое число с плавающей точкой, используемое в качестве ключа и равное целому числу, преобразуется в это целое число.
Пример:
Если написать a[2.0] = true, то фактически в таблицу будет вставлен ключ 2 (целое число), а не 2.0.
Ключевые моменты:
- Сырое равенство (
raw equality) — сравнение без метаметодов. - Целые и дробные числа —
1.0и1считаются одинаковыми ключами. - Автоматическое преобразование —
a[2.0]превращается вa[2].
Это важно учитывать при работе с таблицами, чтобы избежать неожиданного поведения.
Таблицы, функции, потоки и значения (полного) userdata являются объектами: переменные на самом деле не содержат эти значения, а только ссылки на них. Присваивание, передача параметров и возвращение функций всегда манипулируют ссылками на такие значения; эти операции не подразумевают никакого рода копирования.
Функция библиотеки type возвращает строку, описывающую тип данного значения (см. type).
2.2 – Окружения и глобальное окружение
Имена переменных, области их видимости, правила лексического скрытия (shadowing) и работа с окружениями _ENV в языке Lua.
Имя переменной ссылается на глобальную или локальную переменную в соответствии с объявлением, которое находится в контексте в данной точке кода. (Для целей данного обсуждения формальный параметр функции эквивалентен локальной переменной.)
Все чанки (блоки кода) начинаются с неявного объявления global *, которое объявляет все свободные имена как глобальные переменные; это вводное объявление становится недействительным (void) внутри области видимости любого другого объявления global, как показано в следующем примере:
X = 1 -- Ok, глобальная по умолчанию
do
global Y -- отменяет неявное начальное объявление
Y = 1 -- Ok, Y объявлена как глобальная
X = 1 -- ОШИБКА, X не объявлена
end
X = 2 -- Ok, снова глобальная по умолчанию
Таким образом, вне любого объявления global Lua работает по принципу “глобальные по умолчанию”. Внутри любого объявления global Lua работает без умолчания: все переменные должны быть объявлены.
Lua — это язык с лексической областью видимости. Область видимости объявления переменной начинается с первого оператора после объявления и длится до последнего не-пустого (non-void) оператора самого внутреннего блока, включающего это объявление. (Пустыми операторами считаются метки и пустые инструкции.)
Объявление скрывает (shadowing) любое другое объявление с тем же именем, находящееся в контексте в точке объявления. Внутри этой тени любое внешнее объявление для этого имени становится недействительным. Смотрите следующий пример:
global print, x
x = 10 -- глобальная переменная
do -- новый блок
local x = x -- новая 'x' со значением 10
print(x) --> 10
x = x+1
do -- еще один блок
local x = x+1 -- еще одна 'x'
print(x) --> 12
end
print(x) --> 11
end
print(x) --> 10 (глобальная)
Обратите внимание, что в объявлении вроде local x = x новая объявляемая x еще не находится в области видимости, поэтому x в правой части ссылается на внешнюю переменную.
Благодаря правилам лексической области видимости, локальные переменные могут свободно использоваться функциями, определенными внутри их области видимости. Локальная переменная, используемая внутренней функцией, называется upvalue (или внешней локальной переменной, или просто внешней переменной) внутри этой внутренней функции.
Обратите внимание, что каждое выполнение оператора local определяет новые локальные переменные. Рассмотрим следующий пример:
a = {}
local x = 20
for i = 1, 10 do
local y = 0
a[i] = function () y = y + 1; return x + y end
end
Цикл создает десять замыканий (то есть десять экземпляров анонимной функции). Каждое из этих замыканий использует свою отдельную переменную y, в то время как все они совместно используют одну и ту же x.
Как будет более подробно обсуждаться в §3.2 и §3.3.3, любая ссылка на глобальную переменную var синтаксически транслируется в _ENV.var. Более того, каждый чанк компилируется в области видимости внешней локальной переменной с именем _ENV (см. §3.3.2), поэтому само имя _ENV никогда не является свободным именем в чанке.
Несмотря на существование этой внешней переменной _ENV и трансляцию свободных имен, _ENV является обычным именем. В частности, вы можете определять новые переменные и параметры с этим именем. (Однако не следует определять _ENV как глобальную переменную, иначе _ENV.var транслировалось бы в _ENV._ENV.var и так далее, в бесконечном цикле.) Каждая ссылка на имя глобальной переменной использует ту _ENV, которая видна в данной точке программы.
Любая таблица, используемая в качестве значения _ENV, называется окружением (environment).
Lua поддерживает выделенное окружение, называемое глобальным окружением (global environment). Это значение хранится по специальному индексу в реестре C (см. §4.3). В Lua глобальная переменная _G инициализируется этим же значением. (_G никогда не используется внутри самого Lua, поэтому изменение ее значения повлияет только на ваш собственный код.)
Когда Lua загружает чанк, значением по умолчанию для его переменной _ENV является глобальное окружение (см. функцию load). Следовательно, по умолчанию глобальные переменные в коде Lua ссылаются на записи в глобальном окружении и, таким образом, ведут себя как обычные глобальные переменные. Более того, все стандартные библиотеки загружены в глобальное окружение, и некоторые функции там работают именно с этим окружением. Вы можете использовать load (или loadfile) для загрузки чанка с другим окружением. (В языке C для этого необходимо загрузить чанк, а затем изменить значение его первого upvalue; см. lua_setupvalue.)
2.3 – Обработка ошибок
Несколько операций в Lua могут вызывать ошибку. Ошибка прерывает нормальный поток выполнения программы, который может продолжиться, поймав ошибку.
Lua-код может явно вызвать ошибку, вызвав функцию error. (Эта функция никогда не возвращает значение.)
Чтобы поймать ошибки в Lua, вы можете выполнить защищенный вызов, используя pcall (или xpcall). Функция pcall вызывает заданную функцию в защищенном режиме. Любая ошибка во время выполнения функции останавливает ее выполнение, и управление немедленно возвращается в pcall, который возвращает код состояния.
Поскольку Lua является встроенным языком расширения, код Lua начинает выполняться по вызову из C-кода в хост-программе. (Когда вы используете Lua в автономном режиме, приложение lua является хост-программой.) Обычно этот вызов защищен; поэтому, когда происходит незащищенная ошибка во время компиляции или выполнения блока Lua, управление возвращается в хост, который может предпринять соответствующие меры, такие как вывод сообщения об ошибке.
Каждый раз, когда возникает ошибка, объект ошибки передается с информацией об ошибке. Сам Lua генерирует только ошибки, объект ошибки которых является строкой, но программы могут генерировать ошибки с любым значением в качестве объекта ошибки. Обработка таких объектов ошибок зависит от программы Lua или ее хоста. По историческим причинам объект ошибки часто называется сообщением об ошибке, даже если он не обязательно должен быть строкой.
Когда вы используете xpcall (или lua_pcall в C), вы можете передать обработчик сообщений, который будет вызван в случае ошибок. Эта функция вызывается с оригинальным объектом ошибки и возвращает новый объект ошибки. Она вызывается до того, как ошибка развернет стек, чтобы собрать больше информации об ошибке, например, проверяя стек и создавая трассировку стека. Этот обработчик сообщений также защищен защищенным вызовом; поэтому ошибка внутри обработчика сообщений снова вызовет обработчик сообщений. Если этот цикл продолжается слишком долго, Lua прерывает его и возвращает соответствующее сообщение. Обработчик сообщений вызывается только для обычных ошибок времени выполнения. Он не вызывается для ошибок выделения памяти и для ошибок при выполнении финализаторов или других обработчиков сообщений.
Lua также предлагает систему предупреждений (см. warn). В отличие от ошибок, предупреждения никоим образом не мешают выполнению программы. Обычно они просто генерируют сообщение для пользователя, хотя это поведение можно адаптировать из C (см. lua_setwarnf).
2.4 – Метатаблицы и метаметоды
Каждое значение в Lua может иметь метатаблицу. Эта метатаблица — это обычная таблица Lua, которая определяет поведение оригинального значения при определенных событиях. Вы можете изменить несколько аспектов поведения значения, установив конкретные поля в его метатаблице. Например, когда нечисловое значение является операндом сложения, Lua проверяет наличие функции в поле __add метатаблицы значения. Если она находит такую функцию, Lua вызывает ее для выполнения сложения.
Ключом для каждого события в метатаблице является строка с именем события, предшествующая двумя подчеркиваниями; соответствующее значение называется метазначением. Для большинства событий метазначение должно быть функцией, которая затем называется метаметодом. В предыдущем примере ключом является строка “__add”, а метаметодом — функция, выполняющая сложение. Если не указано иное, метаметодом может быть любое вызываемое значение, которое является либо функцией, либо значением с метаметодом __call.
Вы можете запросить метатаблицу любого значения, используя функцию getmetatable. Lua запрашивает метаметоды в метатаблицах, используя сырой доступ (см. rawget).
Вы можете заменить метатаблицу таблиц, используя функцию setmetatable. Вы не можете изменить метатаблицу других типов из кода Lua, кроме как с помощью библиотеки debug (§6.10).
Таблицы и полное userdata имеют индивидуальные метатаблицы, хотя несколько таблиц и userdata могут делить свои метатаблицы. Значения всех других типов делят одну единственную метатаблицу на тип; то есть, существует одна единственная метатаблица для всех чисел, одна для всех строк и т. д. По умолчанию значение не имеет метатаблицы, но библиотека строк устанавливает метатаблицу для типа строк (см. §6.4).
Подробный список операций, контролируемых метатаблицами, приведен ниже. Каждое событие идентифицируется своим соответствующим ключом. По соглашению, все ключи метатаблиц, используемые Lua, состоят из двух подчеркиваний, за которыми следуют строчные латинские буквы.
__add: операция сложения (+). Если любой операнд для сложения не является числом, Lua попытается вызвать метаметод. Он начинает с проверки первого операнда (даже если это число); если этот операнд не определяет метаметод для__add, то Lua проверит второй операнд. Если Lua находит метаметод, он вызывает этот метаметод с двумя операндами в качестве аргументов, и результат вызова (приведенный к одному значению) является результатом операции. В противном случае, если метаметод не найден, Lua вызывает ошибку.__sub: операция вычитания (-). Поведение аналогично операции сложения.__mul: операция умножения (*). Поведение аналогично операции сложения.__div: операция деления (/). Поведение аналогично операции сложения.__mod: операция взятия остатка (%) . Поведение аналогично операции сложения.__pow: операция возведения в степень (^). Поведение аналогично операции сложения.__unm: операция отрицания (унарный -). Поведение аналогично операции сложения.__idiv: операция целочисленного деления (//). Поведение аналогично операции сложения.__band: побитовая операция И (&). Поведение аналогично операции сложения, за исключением того, что Lua попытается вызвать метаметод, если любой операнд не является ни целым числом, ни числом с плавающей запятой, приводимым к целому (см. §3.4.3).__bor: побитовая операция ИЛИ (|). Поведение аналогично побитовой операции И.__bxor: побитовая операция исключающего ИЛИ (двойной ~). Поведение аналогично побитовой операции И.__bnot: побитовая операция НЕ (унарный ~). Поведение аналогично побитовой операции И.__shl: побитовый сдвиг влево («). Поведение аналогично побитовой операции И.__shr: побитовый сдвиг вправо (»). Поведение аналогично побитовой операции И.__concat: операция конкатенации (..). Поведение аналогично операции сложения, за исключением того, что Lua попытается вызвать метаметод, если любой операнд не является ни строкой, ни числом (которое всегда приводимо к строке).__len: операция длины (#). Если объект не является строкой, Lua попытается вызвать его метаметод. Если метаметод существует, Lua вызывает его с объектом в качестве аргумента, и результат вызова (всегда приведенный к одному значению) является результатом операции. Если метаметода нет, но объект является таблицей, то Lua использует операцию длины таблицы (см. §3.4.7). В противном случае Lua вызывает ошибку.__eq: операция равенства (==). Поведение аналогично операции сложения, за исключением того, что Lua попытается вызвать метаметод только тогда, когда сравниваемые значения являются либо обеими таблицами, либо обоими полными userdata и они не равны по примитивному сравнению. Результат вызова всегда преобразуется в логическое значение.__lt: операция “меньше чем” (<). Поведение аналогично операции сложения, за исключением того, что Lua попытается вызвать метаметод только тогда, когда сравниваемые значения не являются ни обоими числами, ни обеими строками. Более того, результат вызова всегда преобразуется в логическое значение.__le: операция “меньше или равно” (<=). Поведение аналогично операции “меньше чем”.__index: операция доступа по индексу table[key]. Это событие происходит, когда table не является таблицей или когда ключ отсутствует в таблице. Метазначение ищется в метатаблице таблицы. Метазначение для этого события может быть либо функцией, либо таблицей, либо любым значением с метазначением__index. Если это функция, она вызывается с таблицей и ключом в качестве аргументов, и результат вызова (приведенный к одному значению) является результатом операции. В противном случае окончательный результат — это результат индексации этого метазначения с ключом. Эта индексация является обычной, а не сырой, и, следовательно, может вызвать другой метаметод__index.__newindex: операция присваивания по индексу table[key] = value. Как и событие индексации, это событие происходит, когда table не является таблицей или когда ключ отсутствует в таблице. Метазначение ищется в метатаблице таблицы. Как и в случае с индексацией, метазначение для этого события может быть либо функцией, либо таблицей, либо любым значением с метазначением__newindex. Если это функция, она вызывается с таблицей, ключом и значением в качестве аргументов. В противном случае Lua повторяет присваивание индексации для этого метазначения с тем же ключом и значением. Это присваивание является обычным, а не сырым, и, следовательно, может вызвать другой метаметод__newindex.
Каждый раз, когда вызывается метазначение __newindex, Lua не выполняет примитивное присваивание. Если это необходимо, сам метаметод может вызвать rawset для выполнения присваивания.
__call: операция вызоваfunc(args). Это событие происходит, когда Lua пытается вызвать значение, не являющееся функцией (то есть func не является функцией). Метаметод ищется в func. Если он присутствует, метаметод вызывается с func в качестве первого аргумента, за которым следуют аргументы оригинального вызова (args). Все результаты вызова являются результатами операции. Это единственный метаметод, который позволяет возвращать несколько результатов.
2.5 – Сборка мусора
Lua осуществляет автоматическое управление памятью. Это означает, что вам не нужно беспокоиться о выделении памяти для новых объектов или ее освобождении, когда объекты больше не нужны. Lua управляет памятью автоматически, запуская сборщик мусора для сбора всех мертвых объектов. Вся память, используемая Lua, подлежит автоматическому управлению: строки, таблицы, пользовательские данные (userdata), функции, потоки, внутренние структуры и т.д.
Объект считается мертвым, как только сборщик может быть уверен, что к объекту больше не будет обращений при нормальном выполнении программы. («Нормальное выполнение» здесь исключает финализаторы, которые воскрешают мертвые объекты (см. §2.5.3), а также исключает некоторые операции с использованием библиотеки отладки.) Обратите внимание, что момент, когда сборщик может быть уверен в том, что объект мертв, может не совпадать с ожиданиями программиста. Единственными гарантиями являются то, что Lua не будет собирать объект, к которому все еще можно обратиться при нормальном выполнении программы, и что в конечном итоге он соберет объект, который недоступен из Lua. (Здесь «недоступен из Lua» означает, что ни переменная, ни другой живой объект не ссылаются на данный объект.) Поскольку Lua ничего не знает о коде C, он никогда не собирает объекты, доступные через реестр (см. §4.3), который включает глобальное окружение (см. §2.2) и главный поток.
Сборщик мусора (GC) в Lua может работать в двух режимах: инкрементальном и поколенческом (generational).
Режим GC по умолчанию с параметрами по умолчанию подходит для большинства случаев использования. Однако программы, которые тратят большую часть своего времени на выделение и освобождение памяти, могут выиграть от других настроек. Имейте в виду, что поведение GC непереносимо как между платформами, так и между разными версиями Lua; следовательно, оптимальные настройки также непереносимы.
Вы можете изменить режим и параметры GC, вызвав lua_gc в C или collectgarbage в Lua. Вы также можете использовать эти функции для прямого управления сборщиком, например, для его остановки или перезапуска.
2.5.1 – Инкрементальная сборка мусора
В инкрементальном режиме каждый цикл GC выполняет сборку с пометкой и очисткой (mark-and-sweep) небольшими шагами, чередующимися с выполнением программы. В этом режиме сборщик использует три числа для управления своими циклами сборки мусора: паузу сборщика мусора, множитель шага сборщика мусора и размер шага сборщика мусора.
Пауза сборщика мусора управляет тем, как долго сборщик ждет перед началом нового цикла. Сборщик начинает новый цикл, когда количество байтов достигает n% от общего количества после предыдущей сборки. Большие значения делают сборщик менее агрессивным. Значения, равные или меньшие 100, означают, что сборщик не будет ждать начала нового цикла. Значение 200 означает, что сборщик ждет, пока общее количество байтов удвоится, прежде чем начать новый цикл.
Размер шага сборщика мусора управляет размером каждого инкрементального шага, а именно тем, сколько байтов выделяет интерпретатор перед выполнением шага: Значение n означает, что интерпретатор выделит примерно n байтов между шагами.
Множитель шага сборщика мусора управляет тем, сколько работы выполняет каждый инкрементальный шаг. Значение n означает, что интерпретатор выполнит n% единиц работы на каждое выделенное слово. Единица работы примерно соответствует обходу одного слота или очистке одного объекта. Большие значения делают сборщик более агрессивным. Остерегайтесь слишком малых значений, так как они могут сделать сборщик слишком медленным, чтобы вообще когда-либо завершить цикл. В качестве особого случая, нулевое значение означает неограниченную работу, фактически создавая неинкрементальный сборщик, останавливающий весь мир (stop-the-world).
2.5.2 – Поколенческая сборка мусора
В поколенческом режиме сборщик выполняет частые малые сборки, которые обходят только недавно созданные объекты. Если после малой сборки количество байтов превышает лимит, сборщик переключается на большую сборку, которая обходит все объекты. Затем сборщик продолжает выполнять большие сборки до тех пор, пока не обнаружит, что программа генерирует достаточно мусора, чтобы оправдать возврат к малым сборкам.
Поколенческий режим использует три параметра: множитель малой сборки (minor multiplier), множитель перехода от малой к большой сборке (minor-major multiplier) и множитель перехода от большой к малой сборке (major-minor multiplier).
Множитель малой сборки управляет частотой малых сборок. Для множителя x новая малая сборка будет выполнена, когда количество байтов станет на x% больше, чем количество используемых байтов сразу после последней большой сборки. Например, при множителе 20 сборщик выполнит малую сборку, когда количество байтов станет на 20% больше, чем общее количество после последней большой сборки.
Множитель перехода от малой к большой сборке управляет переходом к большим сборкам. Для множителя x сборщик переключится на большую сборку, когда количество байтов от старых объектов станет на x% больше, чем общее количество после предыдущей большой сборки. Например, при множителе 100 сборщик выполнит большую сборку, когда количество старых байтов превысит удвоенное общее количество после предыдущей большой сборки. В качестве особого случая, значение 0 останавливает выполнение сборщиком больших сборок.
Множитель перехода от большой к малой сборке управляет возвратом к малым сборкам. Для множителя x сборщик вернется к малым сборкам после того, как большая сборка соберет не менее x% байтов, выделенных во время последнего цикла. В частности, при множителе 0 сборщик немедленно вернется к малым сборкам после выполнения одной большой сборки.
2.5.3 – Метаметоды сборки мусора
Вы можете установить метаметоды сборщика мусора для таблиц и, используя C API, для полных пользовательских данных (userdata) (см. §2.4). Эти метаметоды, называемые финализаторами, вызываются, когда сборщик мусора обнаруживает, что соответствующая таблица или userdata мертвы. Финализаторы позволяют вам координировать сборку мусора Lua с управлением внешними ресурсами, такими как закрытие файлов, сетевых соединений или соединений с базами данных, или освобождение вашей собственной памяти.
Чтобы объект (таблица или userdata) был финализирован при сборе, вы должны пометить его для финализации. Вы помечаете объект для финализации, когда устанавливаете его метатаблицу, и эта метатаблица имеет метаметод __gc. Обратите внимание, что если вы установите метатаблицу без поля __gc и позже создадите это поле в метатаблице, объект не будет помечен для финализации.
Когда помеченный объект становится мертвым, он не собирается сборщиком мусора немедленно. Вместо этого Lua помещает его в список. После сборки Lua проходит по этому списку. Для каждого объекта в списке он проверяет метаметод __gc объекта: Если он присутствует, Lua вызывает его, передавая объект в качестве единственного аргумента.
В конце каждого цикла сборки мусора финализаторы вызываются в порядке, обратном тому, в котором объекты были помечены для финализации, среди тех, что были собраны в этом цикле; то есть первым вызывается финализатор, связанный с объектом, помеченным последним в программе. Выполнение каждого финализатора может произойти в любой момент во время выполнения обычного кода.
Поскольку собираемый объект все еще должен использоваться финализатором, этот объект (и другие объекты, доступные только через него) должны быть воскрешены Lua. Обычно это воскрешение является временным, и память объекта освобождается в следующем цикле сборки мусора. Однако, если финализатор сохраняет объект в каком-либо глобальном месте (например, в глобальной переменной), то воскрешение становится постоянным. Более того, если финализатор снова помечает финализируемый объект для финализации, его финализатор будет вызван снова в следующем цикле, когда объект будет мертв. В любом случае память объекта освобождается только в том цикле GC, когда объект мертв и не помечен для финализации.
Когда вы закрываете состояние (см. lua_close), Lua вызывает финализаторы всех объектов, помеченных для финализации, следуя обратному порядку их пометки. Если какой-либо финализатор помечает объекты для сбора на этом этапе, эти пометки не имеют эффекта.
Финализаторы не могут прерываться (yield) и не могут запускать сборщик мусора. Поскольку они могут выполняться в непредсказуемые моменты времени, хорошей практикой является ограничение каждого финализатора минимумом, необходимым для надлежащего освобождения связанного с ним ресурса.
Любая ошибка во время выполнения финализатора генерирует предупреждение; ошибка не распространяется дальше.
2.5.4 – Слабые таблицы
Слабая таблица — это таблица, элементы которой являются слабыми ссылками. Слабая ссылка игнорируется сборщиком мусора. Другими словами, если единственными ссылками на объект являются слабые ссылки, то сборщик мусора соберет этот объект.
Слабая таблица может иметь слабые ключи, слабые значения или и то, и другое. Таблица со слабыми значениями позволяет собирать свои значения, но предотвращает сбор своих ключей. Таблица со слабыми и ключами, и значениями позволяет собирать как ключи, так и значения. В любом случае, если либо ключ, либо значение собраны, вся пара удаляется из таблицы. Слабость таблицы контролируется полем __mode ее метатаблицы. Это метазначение, если присутствует, должно быть одной из следующих строк: "k" для таблицы со слабыми ключами; "v" для таблицы со слабыми значениями; или "kv" для таблицы со слабыми и ключами, и значениями.
Таблица со слабыми ключами и сильными значениями также называется эфемеронной таблицей (ephemeron table). В эфемеронной таблице значение считается достижимым, только если достижим его ключ. В частности, если единственная ссылка на ключ исходит из его значения, пара удаляется.
Любое изменение слабости таблицы может вступить в силу только на следующем цикле сбора. В частности, если вы меняете слабость на более сильный режим, Lua все еще может собрать некоторые элементы из этой таблицы до того, как изменение вступит в силу.
Только объекты, имеющие явное построение, удаляются из слабых таблиц. Значения, такие как числа и легкие C-функции, не подлежат сборке мусора и, следовательно, не удаляются из слабых таблиц (если только не собраны связанные с ними значения). Хотя строки подлежат сборке мусора, они не имеют явного построения, и их равенство определяется по значению; они ведут себя скорее как значения, чем как объекты. Поэтому они не удаляются из слабых таблиц.
Воскрешенные объекты (то есть объекты, находящиеся в процессе финализации, и объекты, доступные только через финализируемые объекты) имеют особое поведение в слабых таблицах. Они удаляются из слабых значений перед запуском их финализаторов, но удаляются из слабых ключей только при следующей сборке после запуска финализаторов, когда такие объекты фактически освобождаются. Это поведение позволяет финализатору получать доступ к свойствам, связанным с объектом, через слабые таблицы.
Если слабая таблица находится среди воскрешенных объектов в цикле сборки, она может быть не очищена должным образом до следующего цикла.
2.6 – Сопрограммы
Lua поддерживает сопрограммы (coroutines), также называемые совместной многопоточностью. Сопрограмма в Lua представляет собой независимый поток выполнения. Однако, в отличие от потоков в многопоточных системах, сопрограмма приостанавливает свое выполнение только путем явного вызова функции прерывания (yield).
Вы создаете сопрограмму, вызывая coroutine.create. Ее единственным аргументом является функция, которая является главной функцией сопрограммы. Функция create только создает новую сопрограмму и возвращает дескриптор на нее (объект типа thread); она не запускает сопрограмму.
Вы выполняете сопрограмму, вызывая coroutine.resume. Когда вы впервые вызываете coroutine.resume, передавая в качестве первого аргумента поток, возвращенный coroutine.create, сопрограмма начинает свое выполнение с вызова своей главной функции. Дополнительные аргументы, переданные в coroutine.resume, передаются в качестве аргументов этой функции. После того как сопрограмма начинает работать, она выполняется до тех пор, пока не завершится или не прервется (yield).
Сопрограмма может завершить свое выполнение двумя способами: нормально, когда ее главная функция возвращает управление (явно или неявно, после последней инструкции); и аварийно, если происходит незащищенная ошибка. В случае нормального завершения coroutine.resume возвращает true плюс любые значения, возвращенные главной функцией сопрограммы. В случае ошибок coroutine.resume возвращает false плюс объект ошибки. В этом случае сопрограмма не разворачивает свой стек, так что после ошибки его можно проверить с помощью API отладки.
Сопрограмма прерывается (yield) вызовом coroutine.yield. Когда сопрограмма прерывается, соответствующий coroutine.resume возвращается немедленно, даже если прерывание происходит внутри вложенных вызовов функций (то есть не в главной функции, а в функции, прямо или косвенно вызванной главной функцией). В случае прерывания coroutine.resume также возвращает true плюс любые значения, переданные в coroutine.yield. В следующий раз, когда вы возобновите ту же сопрограмму, она продолжит свое выполнение с точки прерывания, при этом вызов coroutine.yield вернет любые дополнительные аргументы, переданные в coroutine.resume.
Как и coroutine.create, функция coroutine.wrap также создает сопрограмму, но вместо возврата самой сопрограммы она возвращает функцию, которая при вызове возобновляет сопрограмму. Любые аргументы, переданные этой функции, идут как дополнительные аргументы в coroutine.resume. coroutine.wrap возвращает все значения, возвращенные coroutine.resume, кроме первого (булева кода ошибки). В отличие от coroutine.resume, функция, созданная coroutine.wrap, распространяет любую ошибку вызывающей стороне. В этом случае функция также закрывает сопрограмму (см. coroutine.close).
В качестве примера того, как работают сопрограммы, рассмотрим следующий код:
function foo (a)
print("foo", a)
return coroutine.yield(2*a)
end
co = coroutine.create(function (a,b)
print("co-body", a, b)
local r = foo(a+1)
print("co-body", r)
local r, s = coroutine.yield(a+b, a-b)
print("co-body", r, s)
return b, "end"
end)
print("main", coroutine.resume(co, 1, 10))
print("main", coroutine.resume(co, "r"))
print("main", coroutine.resume(co, "x", "y"))
print("main", coroutine.resume(co, "x", "y"))
Когда вы запустите его, он выдаст следующий вывод:
co-body 1 10
foo 2
main true 4
co-body r
main true 11 -9
co-body x y
main true 10 end
main false cannot resume dead coroutine
Вы также можете создавать сопрограммы и управлять ими через C API: см. функции lua_newthread, lua_resume и lua_yield.
2.2 - 3 – Язык Lua: Лексика и синтаксис
Полное описание лексических соглашений, ключевых слов, литералов, переменных и операторов языка Lua.
Оглавление
3 – Язык
В этом разделе описываются лексика, синтаксис и семантика Lua. Другими словами, здесь описывается, какие лексемы допустимы, как их можно комбинировать и что означают их комбинации.
Языковые конструкции будут объясняться с использованием обычной расширенной формы Бэкуса-Наура (РБНФ), в которой {a} означает 0 или более a, а [a] означает необязательное a. Нетерминалы показаны как нетерминал, ключевые слова показаны как kword, а другие терминальные символы показаны как ‘=’. Полный синтаксис Lua можно найти в §9 в конце этого руководства.
3.1 – Лексические соглашения
Lua — это язык со свободной формой записи. Он игнорирует пробелы и комментарии между лексическими элементами (токенами), за исключением случаев, когда они выступают в роли разделителей между двумя токенами. В исходном коде Lua распознает как пробелы стандартные пробельные символы ASCII: пробел, перевод страницы, перевод строки, возврат каретки, горизонтальную табуляцию и вертикальную табуляцию.
Имена (также называемые идентификаторами) в Lua могут быть любой строкой, состоящей из латинских букв, арабско-индийских цифр и символов подчеркивания, не начинающейся с цифры и не являющейся зарезервированным словом. Идентификаторы используются для именования переменных, полей таблиц и меток.
Следующие ключевые слова зарезервированы и не могут использоваться в качестве имен:
and break do else elseif end
false for function global goto if
in local nil not or repeat
return then true until while
Lua — регистрозависимый язык: and — зарезервированное слово, но And и AND — два разных допустимых имени. В соответствии с соглашением, в программах следует избегать создания имен, начинающихся с подчеркивания, за которым следует одна или несколько заглавных букв (например, _VERSION).
Следующие строки обозначают другие токены:
+ - * / % ^ #
& ~ | << >> //
== ~= <= >= < > =
( ) { } [ ] ::
; : , . .. ...
Короткая литеральная строка может быть ограничена парными одинарными или двойными кавычками и может содержать следующие C-подобные escape-последовательности: \a (звонок), \b (забой), \f (перевод страницы), \n (перевод строки), \r (возврат каретки), \t (горизонтальная табуляция), \v (вертикальная табуляция), \\ (обратная косая черта), \" (кавычка [двойная]) и \' (апостроф [одинарная кавычка]). Обратная косая черта, за которой следует разрыв строки, приводит к появлению символа новой строки в строке. Escape-последовательность \z пропускает следующий за ней диапазон пробельных символов, включая разрывы строк; это особенно полезно для разбиения и отступа длинной литеральной строки на несколько строк без добавления символов новой строки и пробелов в содержимое строки. Короткая литеральная строка не может содержать неэкранированные разрывы строк или escape-последовательности, не образующие допустимую управляющую последовательность.
Мы можем указать любой байт в короткой литеральной строке, включая встроенные нули, по его числовому значению. Это можно сделать с помощью escape-последовательности \xXX, где XX — это последовательность ровно из двух шестнадцатеричных цифр, или с помощью escape-последовательности \ddd, где ddd — последовательность до трех десятичных цифр. (Обратите внимание, что если за десятичной escape-последовательностью должна следовать цифра, она должна быть выражена ровно тремя цифрами).
Кодировка UTF-8 символа Unicode может быть вставлена в литеральную строку с помощью escape-последовательности \u{XXX} (с обязательными фигурными скобками), где XXX — это последовательность из одной или более шестнадцатеричных цифр, представляющих кодовую точку символа. Эта кодовая точка может быть любым значением меньше 231. (Здесь Lua использует оригинальную спецификацию UTF-8, которая не ограничена допустимыми кодовыми точками Unicode).
Литеральные строки также могут быть определены с использованием длинного формата, заключенного в длинные скобки. Мы определяем открывающую длинную скобку уровня n как открывающую квадратную скобку, за которой следует n знаков равенства, а затем еще одна открывающая квадратная скобка. Так, открывающая длинная скобка уровня 0 записывается как [[, уровня 1 — как [=[, и так далее. Закрывающая длинная скобка определяется аналогично; например, закрывающая длинная скобка уровня 4 записывается как ]====]. Длинный литерал начинается с открывающей длинной скобки любого уровня и заканчивается на первой закрывающей длинной скобке того же уровня. Он может содержать любой текст, кроме закрывающей скобки того же уровня. Литералы в этой скобочной форме могут занимать несколько строк, не интерпретируют никакие escape-последовательности и игнорируют длинные скобки любых других уровней. Любой вид последовательности конца строки (возврат каретки, перевод строки, возврат каретки с последующим переводом строки или перевод строки с последующим возвратом каретки) преобразуется в простой перевод строки. Если за открывающей длинной скобкой сразу следует перевод строки, этот перевод строки не включается в строку.
В качестве примера, в системе, использующей ASCII (где ‘a’ кодируется как 97, перевод строки как 10, а ‘1’ как 49), следующие пять литеральных строк обозначают одну и ту же строку:
a = 'alo\n123"'
a = "alo\n123\""
a = '\97lo\10\04923"'
a = [[alo
123"]]
a = [==[
alo
123"]==]
Любой байт в литеральной строке, на который явно не повлияли предыдущие правила, представляет сам себя. Однако Lua открывает файлы для разбора в текстовом режиме, и файловые функции системы могут иметь проблемы с некоторыми управляющими символами. Поэтому безопаснее представлять двоичные данные в виде закавыченного литерала с явными escape-последовательностями для нетекстовых символов.
Числовая константа (или число) может быть записана с необязательной дробной частью и необязательным десятичным порядком, обозначаемым буквой ’e’ или ‘E’. Lua также принимает шестнадцатеричные константы, начинающиеся с 0x или 0X. Шестнадцатеричные константы также могут иметь необязательную дробную часть плюс необязательный двоичный порядок, обозначаемый буквой ‘p’ или ‘P’ и записываемый в десятичном виде. (Например, 0x1.fp10 обозначает 1984, то есть 0x1f / 16, умноженное на 210).
Числовая константа с десятичной точкой или порядком обозначает число с плавающей запятой (float); в противном случае, если ее значение помещается в целое число или она является шестнадцатеричной константой, она обозначает целое число (integer); в противном случае (то есть десятичное целое число, вызывающее переполнение) она обозначает float. Шестнадцатеричные числа без точки и порядка всегда обозначают целое значение; если значение переполняется, оно “сворачивается” (wrap around), чтобы соответствовать допустимому целому числу.
Примеры допустимых целочисленных констант:
3 345 0xff 0xBEBADA
Примеры допустимых констант с плавающей запятой:
3.0 3.1416 314.16e-2 0.31416E1 34e1
0x0.1E 0xA23p-4 0X1.921FB54442D18P+1
Комментарий начинается с двойного дефиса (--) в любом месте вне строки. Если текст сразу после -- не является открывающей длинной скобкой, комментарий является коротким комментарием, который длится до конца строки. В противном случае это длинный комментарий, который длится до соответствующей закрывающей длинной скобки.
3.2 – Переменные
Переменные — это места, хранящие значения. В Lua существует три вида переменных: глобальные переменные, локальные переменные и поля таблиц.
Одиночное имя может обозначать глобальную переменную или локальную переменную (или формальный параметр функции, который является особым видом локальной переменной) (см. §2.2):
var ::= Name
Name обозначает идентификаторы (см. §3.1).
Поскольку переменные имеют лексическую область видимости, локальные переменные могут свободно использоваться функциями, определенными внутри их области видимости (см. §2.2).
До первого присваивания переменной ее значение равно nil.
Квадратные скобки используются для индексации таблицы:
var ::= prefixexp ‘[’ exp ‘]’
Значение доступов к полям таблицы может быть изменено через метатаблицы (см. §2.4).
Синтаксис var.Name — это просто синтаксический сахар для var["Name"]:
var ::= prefixexp ‘.’ Name
Доступ к глобальной переменной x эквивалентен _ENV.x.
3.3 – Инструкции (Statements)
Lua поддерживает почти общепринятый набор инструкций, похожий на те, что есть в других обычных языках. Этот набор включает блоки, присваивания, управляющие структуры, вызовы функций и объявления переменных.
3.3.1 – Блоки
Блок — это список инструкций, которые выполняются последовательно:
block ::= {stat}
В Lua есть пустые инструкции, которые позволяют разделять инструкции точкой с запятой, начинать блок с точки с запятой или писать две точки с запятой подряд:
stat ::= ‘;’
Как вызовы функций, так и присваивания могут начинаться с открывающей скобки. Эта возможность приводит к неоднозначности в грамматике Lua. Рассмотрим следующий фрагмент:
a = b + c
(print or io.write)('done')
Грамматика может интерпретировать этот фрагмент двумя способами:
a = b + c(print or io.write)('done')
a = b + c; (print or io.write)('done')
Текущий парсер всегда интерпретирует такие конструкции первым способом, рассматривая открывающую скобку как начало аргументов вызова. Чтобы избежать этой неоднозначности, рекомендуется всегда предварять точкой с запятой инструкции, начинающиеся со скобки:
;(print or io.write)('done')
Блок может быть явно выделен для создания одиночной инструкции:
stat ::= do block end
Явные блоки полезны для управления областью видимости объявлений переменных. Явные блоки также иногда используются для добавления инструкции return в середине другого блока (см. §3.3.4).
3.3.2 – Чанки
Единица компиляции Lua называется чанком (chunk). Синтаксически чанк — это просто блок:
chunk ::= block
Lua обрабатывает чанк как тело анонимной функции с переменным числом аргументов (см. §3.4.11). Таким образом, чанки могут определять локальные переменные, получать аргументы и возвращать значения. Более того, такая анонимная функция компилируется как находящаяся в области видимости внешней локальной переменной с именем _ENV (см. §2.2). Результирующая функция всегда имеет _ENV в качестве своей единственной внешней переменной, даже если она не использует эту переменную.
Чанк может храниться в файле или в строке внутри программы-хоста. Чтобы выполнить чанк, Lua сначала загружает его, предварительно компилируя код чанка в инструкции для виртуальной машины, а затем Lua выполняет скомпилированный код с помощью интерпретатора виртуальной машины.
Чанки также могут быть предварительно скомпилированы в двоичную форму; подробности см. в программе luac и функции string.dump. Программы в исходной и скомпилированной формах взаимозаменяемы; Lua автоматически определяет тип файла и действует соответственно (см. load). Имейте в виду, что, в отличие от исходного кода, злонамеренно созданные двоичные чанки могут вызвать крах интерпретатора.
3.3.3 – Присваивание
Lua допускает множественное присваивание. Поэтому синтаксис присваивания определяет список переменных слева и список выражений справа. Элементы в обоих списках разделяются запятыми:
stat ::= varlist ‘=’ explist
varlist ::= var {‘,’ var}
explist ::= exp {‘,’ exp}
Выражения обсуждаются в §3.4.
Перед присваиванием список значений выравнивается по длине списка переменных (см. §3.4.12).
Если переменная одновременно присваивается и читается внутри множественного присваивания, Lua гарантирует, что все чтения получат значение переменной до присваивания. Таким образом, код
i = 3
i, a[i] = i+1, 20
устанавливает a[3] в 20, не затрагивая a[4], потому что i в a[i] вычисляется (в 3) до того, как ей присваивается 4. Аналогично, строка
x, y = y, x
обменивает значения x и y, а
x, y, z = y, z, x
циклически переставляет значения x, y и z.
Обратите внимание, что эта гарантия распространяется только на доступы, синтаксически находящиеся внутри инструкции присваивания. Если функция или метаметод, вызванные во время присваивания, изменяют значение переменной, Lua не дает никаких гарантий относительно порядка этого доступа.
Присваивание глобальному имени x = val эквивалентно присваиванию _ENV.x = val (см. §2.2).
Значение присваиваний полям таблиц и глобальным переменным (которые на самом деле тоже являются полями таблиц) может быть изменено через метатаблицы (см. §2.4).
3.3.4 – Управляющие структуры
Управляющие структуры if, while и repeat имеют обычный смысл и знакомый синтаксис:
stat ::= while exp do block end
stat ::= repeat block until exp
stat ::= if exp then block {elseif exp then block} [else block] end
В Lua также есть инструкция for в двух вариантах (см. §3.3.5).
Выражение-условие управляющей структуры может возвращать любое значение. И false, и nil проверяются как ложь. Все значения, отличные от nil и false, проверяются как истина. В частности, число 0 и пустая строка также проверяются как истина.
В цикле repeat–until внутренний блок не заканчивается на ключевом слове until, а только после условия. Таким образом, условие может ссылаться на локальные переменные, объявленные внутри блока цикла.
Инструкция goto передает управление программой на метку. По синтаксическим причинам метки в Lua также считаются инструкциями:
stat ::= goto Name
stat ::= label
label ::= ‘::’ Name ‘::’
Метка видна во всем блоке, где она определена, за исключением вложенных функций. goto может переходить на любую видимую метку, если при этом не происходит входа в область видимости объявления переменной. Метка не должна быть объявлена там, где видна предыдущая метка с тем же именем, даже если эта другая метка была объявлена в охватывающем блоке.
Инструкция break завершает выполнение цикла while, repeat или for, переходя к следующей инструкции после цикла:
stat ::= break
break завершает самый внутренний объемлющий цикл.
Инструкция return используется для возврата значений из функции или чанка (который обрабатывается как анонимная функция). Функции могут возвращать более одного значения, поэтому синтаксис инструкции return таков:
stat ::= return [explist] [‘;’]
Инструкция return может быть записана только как последняя инструкция блока. Если необходимо выполнить возврат в середине блока, можно использовать явный внутренний блок, как в идиоме do return end, потому что теперь return является последней инструкцией в своем (внутреннем) блоке.
3.3.5 – Инструкция For
Инструкция for имеет две формы: числовую и обобщенную.
Числовой цикл for
Числовой цикл for повторяет блок кода, пока управляющая переменная проходит через арифметическую прогрессию. Он имеет следующий синтаксис:
stat ::= for Name ‘=’ exp ‘,’ exp [‘,’ exp] do block end
Заданный идентификатор (Name) определяет управляющую переменную, которая является новой переменной только для чтения (const), локальной для тела цикла (block).
Цикл начинается с однократного вычисления трех управляющих выражений. Их значения называются соответственно начальным значением, пределом и шагом. Если шаг отсутствует, по умолчанию он равен 1.
Если и начальное значение, и шаг являются целыми числами, цикл выполняется с целыми числами; обратите внимание, что предел может не быть целым числом. В противном случае три значения преобразуются в числа с плавающей запятой, и цикл выполняется с плавающей запятой. В этом случае следует опасаться точности чисел с плавающей запятой.
После этой инициализации тело цикла повторяется, при этом значение управляющей переменной проходит через арифметическую прогрессию, начиная с начального значения, с разностью, заданной шагом. Отрицательный шаг создает убывающую последовательность; шаг, равный нулю, вызывает ошибку. Цикл продолжается, пока значение меньше или равно пределу (больше или равно для отрицательного шага). Если начальное значение уже больше предела (или меньше, если шаг отрицательный), тело не выполняется.
Для целочисленных циклов управляющая переменная никогда не “сворачивается” (wrap around); вместо этого цикл заканчивается в случае переполнения.
Обобщенный цикл for
Обобщенная инструкция for работает с функциями, называемыми итераторами. На каждой итерации функция-итератор вызывается для получения нового значения, останавливаясь, когда это новое значение равно nil. Обобщенный цикл for имеет следующий синтаксис:
stat ::= for namelist in explist do block end
namelist ::= Name {‘,’ Name}
Инструкция for, такая как
for var_1, ···, var_n in explist do body end
работает следующим образом.
Имена var_i объявляют переменные цикла, локальные для тела цикла. Первая из этих переменных является управляющей переменной, которая является переменной только для чтения (const).
Цикл начинается с вычисления explist для получения четырех значений: функции-итератора, состояния, начального значения для управляющей переменной и закрывающего значения.
Затем, на каждой итерации, Lua вызывает функцию-итератор с двумя аргументами: состоянием и управляющей переменной. Результаты этого вызова затем присваиваются переменным цикла в соответствии с правилами множественного присваивания (см. §3.3.3). Если управляющая переменная становится nil, цикл завершается. В противном случае выполняется тело, и цикл переходит к следующей итерации.
Закрывающее значение ведет себя как закрываемая переменная (to-be-closed variable) (см. §3.3.8), которая может использоваться для освобождения ресурсов при завершении цикла. В остальном оно не влияет на цикл.
3.3.6 – Вызовы функций как инструкции
Для обеспечения возможных побочных эффектов вызовы функций могут выполняться как инструкции:
stat ::= functioncall
В этом случае все возвращаемые значения отбрасываются. Вызовы функций объясняются в §3.4.10.
3.3.7 – Объявления переменных
Локальные и глобальные переменные могут быть объявлены в любом месте внутри блока. Объявление может включать инициализацию:
stat ::= local attnamelist [‘=’ explist]
stat ::= global attnamelist [‘=’ explist]
Если инициализация отсутствует, локальные переменные инициализируются значением nil; глобальные переменные остаются без изменений. В противном случае инициализация подвергается тому же выравниванию, что и множественное присваивание (см. §3.3.3). Более того, для глобальных переменных инициализация вызовет ошибку времени выполнения, если переменная уже определена, то есть имеет значение, отличное от nil.
Список имен может иметь префиксный атрибут (имя в угловых скобках), и каждое имя переменной может иметь постфиксный атрибут:
attnamelist ::= [attrib] Name [attrib] {‘,’ Name [attrib]}
attrib ::= ‘<’ Name ‘>’
Префиксный атрибут применяется ко всем именам в списке; постфиксный атрибут применяется к конкретному имени. Существует два возможных атрибута: const, который объявляет константу или переменную только для чтения, то есть переменную, которая не может использоваться в левой части присваивания, и close, который объявляет закрываемую переменную (to-be-closed variable) (см. §3.3.8). Только локальные переменные могут иметь атрибут close. Список переменных может содержать не более одной закрываемой переменной.
Lua предлагает также коллективное объявление для глобальных переменных:
stat ::= global [attrib] ‘*’
Эта специальная форма неявно объявляет как глобальные все имена, которые ранее не были объявлены явно. В частности, global<const> * неявно объявляет как глобальные только для чтения все имена, не объявленные ранее явно; см. следующий пример:
global X
global<const> *
print(math.pi) -- Ok, 'print' и 'math' только для чтения
X = 1 -- Ok, объявлена как для чтения-записи
Y = 1 -- Ошибка, Y только для чтения
Как отмечено в §2.2, все чанки начинаются с неявного объявления global *, но это вводное объявление становится недействительным внутри области видимости любого другого объявления global. Следовательно, программа, которая не использует объявления global или начинается с global *, имеет свободный доступ на чтение и запись к любой глобальной переменной; программа, которая начинается с global<const> *, имеет свободный доступ только для чтения к любой глобальной переменной; а программа, которая начинается с любого другого объявления global (например, global none), может ссылаться только на объявленные переменные.
Обратите внимание, что для глобальных переменных эффект любого объявления является чисто синтаксическим (за исключением необязательного присваивания):
global X <const>, _G
X = 1 -- ОШИБКА
_ENV.X = 1 -- Ok
_G.print(X) -- Ok
foo() -- 'foo' может свободно изменять любую глобальную переменную
Чанк также является блоком (см. §3.3.2), поэтому переменные могут быть объявлены в чанке вне любого явного блока.
Правила видимости для объявлений переменных объясняются в §2.2.
3.3.8 – Закрываемые переменные (To-be-closed Variables)
Закрываемая переменная ведет себя как константная локальная переменная, за исключением того, что ее значение закрывается всякий раз, когда переменная выходит из области видимости, включая нормальное завершение блока, выход из блока по break/goto/return или выход из-за ошибки.
Здесь закрыть значение означает вызвать его метаметод __close. При вызове метаметода само значение передается в качестве первого аргумента. Если произошла ошибка, объект ошибки, вызвавший выход, передается в качестве второго аргумента; в противном случае второй аргумент отсутствует.
Значение, присваиваемое закрываемой переменной, должно иметь метаметод __close или быть ложным значением. (nil и false игнорируются как закрываемые значения).
Если несколько закрываемых переменных выходят из области видимости при одном и том же событии, они закрываются в порядке, обратном порядку их объявления.
Если во время выполнения метода закрытия возникает ошибка, эта ошибка обрабатывается как ошибка в обычном коде, где была определена переменная. После ошибки остальные ожидающие методы закрытия все равно будут вызваны.
Если сопрограмма (coroutine) выполняет yield и никогда не возобновляется, некоторые переменные могут никогда не выйти из области видимости и, следовательно, никогда не будут закрыты. (Эти переменные — те, которые созданы внутри сопрограммы и находятся в области видимости в точке, где сопрограмма выполнила yield). Аналогично, если сопрограмма завершается с ошибкой, она не разворачивает свой стек, поэтому не закрывает никакие переменные. В обоих случаях вы можете либо использовать финализаторы, либо вызвать coroutine.close для закрытия переменных. Однако если сопрограмма была создана через coroutine.wrap, то соответствующая функция закроет сопрограмму в случае ошибок.
3.4 – Выражения
Базовыми выражениями в Lua являются следующие:
exp ::= prefixexp
exp ::= nil | false | true
exp ::= Numeral
exp ::= LiteralString
exp ::= functiondef
exp ::= tableconstructor
exp ::= ‘...’
exp ::= exp binop exp
exp ::= unop exp
prefixexp ::= var | functioncall | ‘(’ exp ‘)’
Числа и литеральные строки объясняются в §3.1; переменные — в §3.2; определения функций — в §3.4.11; вызовы функций — в §3.4.10; конструкторы таблиц — в §3.4.9. Выражения vararg, обозначаемые тремя точками ('...'), могут использоваться только непосредственно внутри вариадической функции; они объясняются в §3.4.11.
Бинарные операторы включают арифметические операторы (см. §3.4.1), побитовые операторы (см. §3.4.2), операторы отношения (см. §3.4.4), логические операторы (см. §3.4.5) и оператор конкатенации (см. §3.4.6). Унарные операторы включают унарный минус (см. §3.4.1), унарное побитовое НЕ (см. §3.4.2), унарное логическое not (см. §3.4.5) и унарный оператор длины (см. §3.4.7).
3.4.1 – Арифметические операторы
Lua поддерживает следующие арифметические операторы:
+: сложение-: вычитание*: умножение/: деление с плавающей запятой (float division)//: деление нацело вниз (floor division)%: остаток от деления (modulo)^: возведение в степень-: унарный минус
За исключением возведения в степень и деления с плавающей запятой, арифметические операторы работают следующим образом: Если оба операнда являются целыми числами, операция выполняется над целыми числами, и результат является целым числом. В противном случае, если оба операнда — числа, они преобразуются в числа с плавающей запятой, операция выполняется в соответствии с машинными правилами арифметики с плавающей запятой (обычно стандарт IEEE 754), и результатом является число с плавающей запятой. (Библиотека string приводит строки к числам в арифметических операциях; подробности см. в §3.4.3).
Возведение в степень и деление с плавающей запятой (/) всегда преобразуют свои операнды в числа с плавающей запятой, и результатом всегда является число с плавающей запятой. Возведение в степень использует функцию pow стандарта ISO C, поэтому оно работает и для нецелочисленных показателей.
Деление нацело вниз (//) — это деление, которое округляет частное в сторону минус бесконечности, в результате чего получается пол (floor) от деления операндов.
Остаток от деления (%) определяется как остаток от деления, которое округляет частное в сторону минус бесконечности (деление нацело вниз).
В случае переполнения в целочисленной арифметике все операции “сворачиваются” (wrap around).
3.4.2 – Побитовые операторы
Lua поддерживает следующие побитовые операторы:
&: побитовое И (AND)|: побитовое ИЛИ (OR)~: побитовое исключающее ИЛИ (XOR)>>: сдвиг вправо<<: сдвиг влево~: унарное побитовое НЕ (NOT)
Все побитовые операции преобразуют свои операнды в целые числа (см. §3.4.3), работают со всеми битами этих целых чисел и дают в результате целое число.
Как правый, так и левый сдвиги заполняют освобождающиеся биты нулями. Отрицательные сдвиги смещают в противоположном направлении; сдвиги с абсолютными значениями, равными или превышающими количество бит в целом числе, дают в результате ноль (поскольку все биты сдвигаются за пределы).
3.4.3 – Приведения и преобразования
Lua предоставляет некоторые автоматические преобразования между типами и представлениями во время выполнения. Побитовые операторы всегда преобразуют операнды с плавающей запятой в целые числа. Возведение в степень и деление с плавающей запятой всегда преобразуют целочисленные операнды в числа с плавающей запятой. Все другие арифметические операции, применяемые к смешанным числам (целым и с плавающей запятой), преобразуют целочисленный операнд в число с плавающей запятой. C API также преобразует целые числа в числа с плавающей запятой и наоборот по мере необходимости. Более того, конкатенация строк принимает числа в качестве аргументов, помимо строк.
При преобразовании из целого числа в число с плавающей запятой, если целое значение имеет точное представление в виде числа с плавающей запятой, то оно и является результатом. В противном случае преобразование дает ближайшее большее или ближайшее меньшее представимое значение. Такой вид преобразования никогда не завершается неудачей.
Преобразование из числа с плавающей запятой в целое проверяет, имеет ли число с плавающей запятой точное представление в виде целого числа (то есть число с плавающей запятой имеет целое значение и находится в диапазоне целочисленного представления). Если да, то это представление является результатом. В противном случае преобразование завершается неудачей.
В нескольких местах Lua приводит строки к числам, когда это необходимо. В частности, библиотека string устанавливает метаметоды, которые пытаются привести строки к числам во всех арифметических операциях. Если преобразование не удается, библиотека вызывает метаметод другого операнда (если он присутствует) или вызывает ошибку. Обратите внимание, что побитовые операторы не выполняют этого приведения.
Всегда рекомендуется не полагаться на неявные приведения строк к числам, поскольку они применяются не всегда; в частности, "1"==1 ложно, а "1"<1 вызывает ошибку (см. §3.4.4). Эти приведения существуют в основном для совместимости и могут быть удалены в будущих версиях языка.
Строка преобразуется в целое число или число с плавающей запятой в соответствии со своим синтаксисом и правилами лексера Lua. Строка также может иметь начальные и конечные пробелы и знак. Все преобразования строк в числа принимают как точку, так и текущий локальный разделитель целой и дробной части в качестве символа десятичной точки. (Однако лексер Lua принимает только точку). Если строка не является допустимым числом, преобразование завершается неудачей. При необходимости результат этого первого шага затем преобразуется в конкретный числовой подтип в соответствии с предыдущими правилами для преобразований между числами с плавающей запятой и целыми числами.
Преобразование чисел в строки использует неуказанный человекочитаемый формат. Для преобразования чисел в строки каким-либо определенным способом используйте функцию string.format.
3.4.4 – Операторы отношения
Lua поддерживает следующие операторы отношения:
==: равенство~=: неравенство<: меньше>: больше<=: меньше или равно>=: больше или равно
Эти операторы всегда дают результат false или true.
Равенство (==) сначала сравнивает типы своих операндов. Если типы различны, то результатом является false. В противном случае сравниваются значения операндов. Строки равны, если они имеют одинаковое байтовое содержимое. Числа равны, если они обозначают одно и то же математическое значение.
Таблицы, пользовательские данные (userdata) и потоки (threads) сравниваются по ссылке: два объекта считаются равными, только если это один и тот же объект. Каждый раз, когда вы создаете новый объект (таблицу, userdata или поток), этот новый объект отличается от любого ранее существовавшего объекта. Функция всегда равна самой себе. Функции с любым обнаруживаемым различием (разное поведение, разное определение) всегда различны. Функции, созданные в разное время, но без обнаруживаемых различий, могут быть классифицированы как равные или нет (в зависимости от деталей внутреннего кэширования).
Вы можете изменить способ сравнения таблиц и userdata в Lua, используя метаметод __eq (см. §2.4).
Сравнения на равенство не преобразуют строки в числа или наоборот. Таким образом, "0"==0 дает false, а t[0] и t["0"] обозначают разные записи в таблице.
Оператор ~= является точным отрицанием равенства (==).
Операторы порядка работают следующим образом. Если оба аргумента — числа, то они сравниваются в соответствии с их математическими значениями, независимо от их подтипов. В противном случае, если оба аргумента — строки, то их значения сравниваются в соответствии с текущей локалью. В противном случае Lua пытается вызвать метаметод __lt или __le (см. §2.4). Сравнение a > b транслируется в b < a, а a >= b транслируется в b <= a.
В соответствии со стандартом IEEE 754, специальное значение NaN не считается ни меньше, ни равным, ни больше какого-либо значения, включая само себя.
3.4.5 – Логические операторы
Логическими операторами в Lua являются and, or и not. Как и управляющие структуры (см. §3.3.4), все логические операторы считают false и nil ложью, а все остальное — истиной.
Оператор отрицания not всегда возвращает false или true. Оператор конъюнкции and возвращает свой первый аргумент, если это значение ложно (false или nil); в противном случае and возвращает свой второй аргумент. Оператор дизъюнкции or возвращает свой первый аргумент, если это значение отличается от nil и false; в противном случае or возвращает свой второй аргумент. И and, и or используют сокращенное вычисление (short-circuit evaluation); то есть второй операнд вычисляется, только если это необходимо. Вот несколько примеров:
10 or 20 --> 10
10 or error() --> 10
nil or "a" --> "a"
nil and 10 --> nil
false and error() --> false
false and nil --> false
false or nil --> nil
10 and 20 --> 20
3.4.6 – Конкатенация
Оператор конкатенации строк в Lua обозначается двумя точками ('..'). Если оба операнда являются строками или числами, то числа преобразуются в строки в неуказанном формате (см. §3.4.3). В противном случае вызывается метаметод __concat (см. §2.4).
3.4.7 – Оператор длины
Оператор длины обозначается унарным префиксным оператором #.
Длина строки — это количество ее байтов. (Это обычный смысл длины строки, когда каждый символ занимает один байт).
Оператор длины, примененный к таблице, возвращает границу (border) в этой таблице. Граница в таблице t — это любое неотрицательное целое число, которое удовлетворяет следующему условию:
(border == 0 or t[border] ~= nil) and
(t[border + 1] == nil or border == math.maxinteger)
Другими словами, граница — это любой положительный целочисленный индекс, присутствующий в таблице, за которым следует отсутствующий индекс, плюс два предельных случая: ноль, когда индекс 1 отсутствует; и максимальное значение для целого числа, когда этот индекс присутствует. Обратите внимание, что ключи, не являющиеся положительными целыми числами, не влияют на границы.
Таблица ровно с одной границей называется последовательностью (sequence). Например, таблица {10,20,30,40,50} является последовательностью, так как у нее только одна граница (5). Таблица {10,20,30,nil,50} имеет две границы (3 и 5) и, следовательно, не является последовательностью. (nil по индексу 4 называется дырой). Таблица {nil,20,30,nil,nil,60,nil} имеет три границы (0, 3 и 6), поэтому она тоже не является последовательностью. Таблица {} является последовательностью с границей 0.
Когда t — последовательность, #t возвращает ее единственную границу, что соответствует интуитивному понятию длины последовательности. Когда t не является последовательностью, #t может вернуть любую из ее границ. (Конкретная граница зависит от деталей внутреннего представления таблицы, которые, в свою очередь, могут зависеть от того, как таблица была заполнена, и от адресов памяти ее нечисловых ключей).
Вычисление длины таблицы имеет гарантированное наихудшее время O(log n), где n — наибольший целочисленный ключ в таблице.
Программа может изменить поведение оператора длины для любого значения, кроме строк, через метаметод __len (см. §2.4).
3.4.8 – Приоритет операторов
Приоритет операторов в Lua соответствует таблице ниже, от низшего к высшему:
or
and
< > <= >= ~= ==
|
~
&
<< >>
..
+ -
* / // %
унарные операторы (not # - ~)
^
Как обычно, вы можете использовать скобки для изменения приоритетов в выражении. Операторы конкатенации ('..') и возведения в степень ('^') правоассоциативны. Все остальные бинарные операторы левоассоциативны.
3.4.9 – Конструкторы таблиц
Конструкторы таблиц — это выражения, которые создают таблицы. Каждый раз, когда конструктор вычисляется, создается новая таблица. Конструктор можно использовать для создания пустой таблицы или для создания таблицы и инициализации некоторых ее полей. Общий синтаксис конструкторов таков:
tableconstructor ::= ‘{’ [fieldlist] ‘}’
fieldlist ::= field {fieldsep field} [fieldsep]
field ::= ‘[’ exp ‘]’ ‘=’ exp | Name ‘=’ exp | exp
fieldsep ::= ‘,’ | ‘;’
Каждое поле вида [exp1] = exp2 добавляет в новую таблицу запись с ключом exp1 и значением exp2. Поле вида name = exp эквивалентно ["name"] = exp. Поля вида exp эквивалентны [i] = exp, где i — последовательные целые числа, начиная с 1; поля в других форматах не влияют на этот подсчет. Например,
a = { [f(1)] = g; "x", "y"; x = 1, f(x), [30] = 23; 45 }
эквивалентно
do
local t = {}
t[f(1)] = g
t[1] = "x" -- 1-е exp
t[2] = "y" -- 2-е exp
t.x = 1 -- t["x"] = 1
t[3] = f(x) -- 3-е exp
t[30] = 23
t[4] = 45 -- 4-е exp
a = t
end
Порядок присваиваний в конструкторе не определен. (Этот порядок имел бы значение только при наличии повторяющихся ключей).
Если последнее поле в списке имеет вид exp и выражение является выражением с множественными результатами (multires expression), то все значения, возвращаемые этим выражением, последовательно входят в список (см. §3.4.12).
Список полей может иметь необязательный завершающий разделитель для удобства машинно-генерируемого кода.
3.4.10 – Вызовы функций
Вызов функции в Lua имеет следующий синтаксис:
functioncall ::= prefixexp args
При вызове функции сначала вычисляются prefixexp и args. Если значение prefixexp имеет тип function, то эта функция вызывается с заданными аргументами. В противном случае, если присутствует метаметод __call у prefixexp, он вызывается: его первым аргументом является значение prefixexp, за которым следуют исходные аргументы вызова (см. §2.4).
Форма
functioncall ::= prefixexp ‘:’ Name args
может использоваться для эмуляции методов. Вызов v:name(args) является синтаксическим сахаром для v.name(v, args), за исключением того, что v вычисляется только один раз.
Аргументы имеют следующий синтаксис:
args ::= ‘(’ [explist] ‘)’
args ::= tableconstructor
args ::= LiteralString
Все выражения-аргументы вычисляются перед вызовом. Вызов формы f{fields} является синтаксическим сахаром для f({fields}); то есть список аргументов — это единственная новая таблица. Вызов формы f'string' (или f"string", или f[[string]]) является синтаксическим сахаром для f('string'); то есть список аргументов — это единственная литеральная строка.
Вызов формы return functioncall, не находящийся в области видимости закрываемой переменной, называется хвостовым вызовом (tail call). Lua реализует правильные хвостовые вызовы (proper tail calls или proper tail recursion): при хвостовом вызове вызываемая функция повторно использует стековый фрейм вызывающей функции. Следовательно, нет ограничения на количество вложенных хвостовых вызовов, которые может выполнить программа. Однако хвостовой вызов стирает любую отладочную информацию о вызывающей функции. Обратите внимание, что хвостовой вызов происходит только при определенном синтаксисе, когда return имеет один-единственный вызов функции в качестве аргумента, и это происходит вне области видимости любой закрываемой переменной. Этот синтаксис заставляет вызывающую функцию возвращать в точности то, что возвращает вызываемая функция, без каких-либо промежуточных действий. Таким образом, ни один из следующих примеров не является хвостовым вызовом:
return (f(x)) -- результаты выравниваются до 1
return 2 * f(x) -- результат умножается на 2
return x, f(x) -- дополнительные результаты
f(x); return -- результаты отбрасываются
return x or f(x) -- результаты выравниваются до 1
3.4.11 – Определения функций
Синтаксис определения функции следующий:
functiondef ::= function funcbody
funcbody ::= ‘(’ [parlist] ‘)’ block end
Следующий синтаксический сахар упрощает определения функций:
stat ::= function funcname funcbody
stat ::= local function Name funcbody
stat ::= global function Name funcbody
funcname ::= Name {‘.’ Name} [‘:’ Name]
Инструкция
function f () body end
транслируется в
f = function () body end
Инструкция
function t.a.b.c.f () body end
транслируется в
t.a.b.c.f = function () body end
Инструкция
local function f () body end
транслируется в
local f; f = function () body end
а не в
local f = function () body end
(Это имеет значение только тогда, когда тело функции содержит рекурсивные ссылки на f). Аналогично, инструкция
global function f () body end
транслируется в
global f; global f = function () body end
Второе global делает присваивание инициализацией, которая вызовет ошибку, если эта глобальная переменная уже определена.
Синтаксис с двоеточием используется для эмуляции методов, добавляя неявный дополнительный параметр self в функцию. Таким образом, инструкция
function t.a.b.c:f (params) body end
является синтаксическим сахаром для
t.a.b.c.f = function (self, params) body end
Определение функции — это выполняемое выражение, значением которого является значение типа function. Когда Lua предкомпилирует чанк, все тела его функций также предкомпилируются, но они еще не создаются. Затем, когда Lua выполняет определение функции, функция инстанцируется (или замыкается). Этот экземпляр функции, или замыкание (closure), является окончательным значением выражения.
Результаты возвращаются с помощью инструкции return (см. §3.3.4). Если управление достигает конца функции без встречи инструкции return, то функция возвращается без результатов.
Существует системно-зависимое ограничение на количество значений, которые может вернуть функция. Гарантируется, что этот предел составляет не менее 1000.
Параметры
Параметры действуют как локальные переменные, которые инициализируются значениями аргументов:
parlist ::= namelist [‘,’ varargparam] | varargparam
varargparam ::= ‘...’ [Name]
Когда функция Lua вызывается, она выравнивает свой список аргументов по длине списка параметров (см. §3.4.12), если только функция не является вариадической, что указывается тремя точками ('...') в конце ее списка параметров. Вариадическая функция не выравнивает свой список аргументов; вместо этого она собирает все дополнительные аргументы и предоставляет их функции через vararg-таблицу. В этой таблице значения с индексами 1, 2 и т. д. являются дополнительными аргументами, а значение с индексом "n" — это количество дополнительных аргументов.
В качестве примера рассмотрим следующие определения:
function f(a, b) end
function g(a, b, ...) end
function r() return 1,2,3 end
Тогда мы имеем следующее отображение аргументов в параметры и в vararg-таблицу:
CALL PARAMETERS
f(3) a=3, b=nil
f(3, 4) a=3, b=4
f(3, 4, 5) a=3, b=4
f(r(), 10) a=1, b=10
f(r()) a=1, b=2
g(3) a=3, b=nil, va. table -> {n = 0}
g(3, 4) a=3, b=4, va. table -> {n = 0}
g(3, 4, 5, 8) a=3, b=4, va. table -> {5, 8, n = 2}
g(5, r()) a=5, b=1, va. table -> {2, 3, n = 2}
Vararg-таблица в вариадической функции может иметь необязательное имя, указанное после трех точек. Если оно присутствует, это имя обозначает локальную переменную только для чтения, которая ссылается на vararg-таблицу. Если у vararg-таблицы нет имени, доступ к ней можно получить только через vararg-выражение.
Vararg-выражение также записывается как три точки, и его значением является список значений в vararg-таблице от 1 до целочисленного значения по индексу "n". (Следовательно, если код не изменяет vararg-таблицу, этот список соответствует дополнительным аргументам в вызове функции). Этот список ведет себя как результаты функции с множественными результатами (см. §3.4.12).
В качестве оптимизации, если vararg-таблица удовлетворяет некоторым условиям, код не создает фактическую таблицу, а вместо этого транслирует индексные выражения и vararg-выражения в доступы к внутренним данным vararg. Условия следующие: если у vararg-таблицы есть имя, это имя не является upvalue во вложенной функции, и оно используется только как базовая таблица в синтаксических конструкциях t[exp] или t.id. Обратите внимание, что анонимная vararg-таблица всегда удовлетворяет этим условиям.
3.4.12 – Списки выражений, множественные результаты и выравнивание
Как вызовы функций, так и vararg-выражения могут давать множественные значения. Эти выражения называются выражениями с множественными результатами (multires expressions).
Когда выражение с множественными результатами используется как последний элемент списка выражений, все результаты выражения добавляются к списку значений, создаваемому списком выражений. Обратите внимание, что одиночное выражение в месте, где ожидается список выражений, является последним выражением в этом (одноэлементном) списке.
Вот места, где Lua ожидает список выражений:
- Инструкция
return, напримерreturn e1,e2,e3(см. §3.3.4). - Конструктор таблицы, например
{e1,e2,e3}(см. §3.4.9). - Аргументы вызова функции, например
foo(e1,e2,e3)(см. §3.4.10). - Множественное присваивание, например
a,b,c = e1,e2,e3(см. §3.3.3). - Объявление
localилиglobal, которое аналогично множественному присваиванию. - Начальные значения в обобщенном цикле
for, напримерfor k in e1,e2,e3 do ... end(см. §3.3.5).
В последних четырех случаях список значений из списка выражений должен быть выровнен до определенной длины: количество параметров при вызове невариадической функции (см. §3.4.11), количество переменных в множественном присваивании или объявлении и ровно четыре значения для обобщенного цикла for. Выравнивание следует этим правилам: если значений больше, чем нужно, лишние значения отбрасываются; если значений меньше, чем нужно, список дополняется значениями nil. Когда список выражений заканчивается выражением с множественными результатами, все результаты этого выражения входят в список значений до выравнивания.
Когда выражение с множественными результатами используется в списке выражений, не будучи последним элементом, или в месте, где синтаксис ожидает одиночное выражение, Lua выравнивает список результатов этого выражения до одного элемента. Как частный случай, синтаксис ожидает одиночное выражение внутри выражения в скобках; следовательно, добавление скобок вокруг выражения с множественными результатами заставляет его выдавать ровно один результат.
Нам редко нужно использовать vararg-выражение в месте, где синтаксис ожидает одиночное выражение. (Обычно проще добавить обычный параметр перед вариадической частью и использовать этот параметр). Когда такая необходимость возникает, мы рекомендуем присвоить vararg-выражение одиночной переменной и использовать эту переменную вместо него.
Вот несколько примеров использования выражений с множественными результатами. Во всех случаях, когда конструкции нужен “n-й результат”, а такого результата нет, используется nil.
print(x, f()) -- печатает x и все результаты из f().
print(x, (f())) -- печатает x и первый результат из f().
print(f(), x) -- печатает первый результат из f() и x.
print(1 + f()) -- печатает 1, сложенную с первым результатом из f().
local x = ... -- x получает первый vararg-аргумент.
x,y = ... -- x получает первый vararg-аргумент,
-- y получает второй vararg-аргумент.
x,y,z = w, f() -- x получает w, y получает первый результат из f(),
-- z получает второй результат из f().
x,y,z = f() -- x получает первый результат из f(),
-- y получает второй результат из f(),
-- z получает третий результат из f().
x,y,z = f(), g() -- x получает первый результат из f(),
-- y получает первый результат из g(),
-- z получает второй результат из g().
x,y,z = (f()) -- x получает первый результат из f(), y и z получают nil.
return f() -- возвращает все результаты из f().
return x, ... -- возвращает x и все полученные vararg-аргументы.
return x,y,f() -- возвращает x, y и все результаты из f().
{f()} -- создает список со всеми результатами из f().
{...} -- создает список со всеми vararg-аргументами.
{f(), 5} -- создает список с первым результатом из f() и 5.
2.3 - 4 – Интерфейс прикладного программирования (API)
Полное описание C API для Lua: стек, функции, типы, обработка ошибок и отладочный интерфейс.
Оглавление
4 – Интерфейс прикладного программирования
В этом разделе описывается C API для Lua, то есть набор функций C, доступных программе-хосту для взаимодействия с Lua. Все функции API и связанные с ними типы и константы объявлены в заголовочном файле lua.h.
Даже когда мы используем термин “функция”, любое средство в API может быть предоставлено в виде макроса. За исключением случаев, где указано иное, все такие макросы используют каждый из своих аргументов ровно один раз (кроме первого аргумента, который всегда является состоянием Lua), и поэтому не генерируют никаких скрытых побочных эффектов.
Как и в большинстве библиотек C, функции Lua API не проверяют свои аргументы на допустимость или согласованность. Однако вы можете изменить это поведение, скомпилировав Lua с определенным макросом LUA_USE_APICHECK.
Библиотека Lua полностью реентерабельна: у нее нет глобальных переменных. Она хранит всю необходимую информацию в динамической структуре, называемой состоянием Lua (Lua state).
Каждое состояние Lua имеет один или несколько потоков (threads), которые соответствуют независимым, кооперативным линиям выполнения. Тип lua_State (несмотря на свое имя) ссылается на поток. (Косвенно, через поток, он также ссылается на состояние Lua, связанное с потоком.)
Указатель на поток должен передаваться в качестве первого аргумента каждой функции в библиотеке, кроме lua_newstate, которая создает состояние Lua с нуля и возвращает указатель на главный поток в новом состоянии.
4.1 – Стек
Lua использует виртуальный стек для передачи значений в C и из C. Каждый элемент в этом стеке представляет значение Lua (nil, число, строка и т. д.). Функции в API могут обращаться к этому стеку через параметр состояния Lua, который они получают.
Всякий раз, когда Lua вызывает C, вызываемая функция получает новый стек, который независим от предыдущих стеков и от стеков функций C, которые все еще активны. Этот стек изначально содержит любые аргументы для функции C, и именно в нем функция C может хранить временные значения Lua и должна помещать свои результаты для возврата вызывающей стороне (см. lua_CFunction).
Для удобства большинство операций запроса в API не следуют строгой стековой дисциплине. Вместо этого они могут ссылаться на любой элемент в стеке, используя индекс: Положительный индекс представляет абсолютную позицию в стеке, начиная с 1 как дна стека; отрицательный индекс представляет смещение относительно вершины стека. Более конкретно, если в стеке n элементов, то индекс 1 представляет первый элемент (то есть элемент, который был помещен в стек первым), а индекс n представляет последний элемент; индекс -1 также представляет последний элемент (то есть элемент на вершине), а индекс -n представляет первый элемент.
4.1.1 – Размер стека
При взаимодействии с Lua API вы несете ответственность за обеспечение согласованности. В частности, вы отвечаете за контроль переполнения стека. При вызове любой функции API вы должны убедиться, что в стеке достаточно места для размещения результатов.
Из вышеуказанного правила есть одно исключение: когда вы вызываете функцию Lua без фиксированного количества результатов (см. lua_call), Lua гарантирует, что в стеке достаточно места для всех результатов. Однако она не гарантирует никакого дополнительного места. Поэтому перед тем, как помещать что-либо в стек после такого вызова, следует использовать lua_checkstack.
Всякий раз, когда Lua вызывает C, он гарантирует, что в стеке есть место как минимум для LUA_MINSTACK дополнительных элементов; то есть вы можете безопасно поместить в него до LUA_MINSTACK значений. LUA_MINSTACK определено как 20, так что обычно вам не нужно беспокоиться о пространстве стека, если только ваш код не содержит циклов, помещающих элементы в стек. При необходимости вы можете использовать функцию lua_checkstack, чтобы убедиться, что в стеке достаточно места для размещения новых элементов.
4.1.2 – Допустимые и приемлемые индексы
Любая функция в API, которая получает индексы стека, работает только с допустимыми индексами (valid indices) или приемлемыми индексами (acceptable indices).
Допустимый индекс — это индекс, который ссылается на позицию, хранящую изменяемое значение Lua. Он включает индексы стека между 1 и вершиной стека (1 ≤ abs(index) ≤ top) плюс псевдоиндексы, которые представляют некоторые позиции, доступные коду C, но не находящиеся в стеке. Псевдоиндексы используются для доступа к реестру (см. §4.3) и к upvalue функции C (см. §4.2).
Функции, которым не нужна конкретная изменяемая позиция, а только значение (например, функции запроса), могут вызываться с приемлемыми индексами. Приемлемый индекс может быть любым допустимым индексом, но также может быть любым положительным индексом после вершины стека в пределах пространства, выделенного для стека, то есть индексами вплоть до размера стека. (Обратите внимание, что 0 никогда не является приемлемым индексом.) Индексы к upvalue (см. §4.2), превышающие реальное количество upvalue в текущей функции C, также являются приемлемыми (но недопустимыми). За исключением случаев, когда указано иное, функции в API работают с приемлемыми индексами.
Приемлемые индексы служат для избежания дополнительных проверок вершины стека при запросе стека. Например, функция C может запросить свой третий аргумент без необходимости проверять, существует ли третий аргумент, то есть без необходимости проверять, является ли 3 допустимым индексом.
Для функций, которые могут вызываться с приемлемыми индексами, любой недопустимый индекс обрабатывается так, как если бы он содержал значение виртуального типа LUA_TNONE, которое ведет себя как значение nil.
4.1.3 – Указатели на строки
Несколько функций в API возвращают указатели (const char*) на строки Lua в стеке. (См. lua_pushfstring, lua_pushlstring, lua_pushstring и lua_tolstring. См. также luaL_checklstring, luaL_checkstring и luaL_tolstring во вспомогательной библиотеке.)
В общем случае сборщик мусора Lua может освобождать или перемещать память и, таким образом, делать недействительными указатели на строки, обрабатываемые состоянием Lua. Чтобы обеспечить безопасное использование этих указателей, API гарантирует, что любой указатель на строку в индексе стека действителен, пока строковое значение по этому индексу не удалено из стека. (Однако оно может быть перемещено на другой индекс). Когда индекс является псевдоиндексом (ссылающимся на upvalue), указатель действителен, пока активен соответствующий вызов и соответствующее upvalue не изменено.
Некоторые функции в отладочном интерфейсе также возвращают указатели на строки, а именно lua_getlocal, lua_getupvalue, lua_setlocal и lua_setupvalue. Для этих функций гарантируется, что указатель действителен, пока активна функция-вызыватель и данное замыкание (если оно было дано) находится в стеке.
За исключением этих гарантий, сборщик мусора может свободно делать недействительным любой указатель на внутренние строки.
4.2 – Замыкания C
При создании функции C с ней можно связать некоторые значения, создавая таким образом замыкание C (C closure) (см. lua_pushcclosure); эти значения называются upvalue и доступны функции при каждом ее вызове.
Всякий раз, когда вызывается функция C, ее upvalue располагаются по определенным псевдоиндексам. Эти псевдоиндексы создаются макросом lua_upvalueindex. Первое upvalue, связанное с функцией, находится по индексу lua_upvalueindex(1), и так далее. Любой доступ к lua_upvalueindex(n), где n больше количества upvalue текущей функции (но не больше 256, что на единицу больше максимального количества upvalue в замыкании), дает приемлемый, но недопустимый индекс.
Замыкание C также может изменять значения своих соответствующих upvalue.
4.3 – Реестр
Lua предоставляет реестр (registry) — предопределенную таблицу, которая может использоваться любым кодом C для хранения любых значений Lua, которые ему необходимо сохранить. Таблица реестра всегда доступна по псевдоиндексу LUA_REGISTRYINDEX. Любая библиотека C может хранить данные в этой таблице, но она должна позаботиться о выборе ключей, отличных от тех, что используются другими библиотеками, чтобы избежать коллизий. Обычно в качестве ключа следует использовать строку, содержащую имя вашей библиотеки, или легкий userdata с адресом объекта C в вашем коде, или любой объект Lua, созданный вашим кодом. Как и в случае с именами переменных, строковые ключи, начинающиеся с подчеркивания, за которым следуют заглавные буквы, зарезервированы для Lua.
Целочисленные ключи в реестре используются механизмом ссылок (см. luaL_ref) и имеют некоторые предопределенные значения. Поэтому целочисленные ключи в реестре не должны использоваться для других целей.
При создании нового состояния Lua его реестр содержит некоторые предопределенные значения. Эти предопределенные значения индексируются целочисленными ключами, определенными как константы в lua.h. Определены следующие константы:
LUA_RIDX_MAINTHREAD: По этому индексу в реестре находится главный поток состояния. (Главный поток — это тот, который создается вместе с состоянием).LUA_RIDX_GLOBALS: По этому индексу в реестре находится глобальное окружение.
4.4 – Обработка ошибок в C
Внутренне Lua использует средство C longjmp для обработки ошибок. (Lua будет использовать исключения, если вы компилируете его как C++; подробности ищите в исходном коде по LUAI_THROW). Когда Lua сталкивается с какой-либо ошибкой, такой как ошибка выделения памяти или ошибка типа, он возбуждает ошибку (raises an error); то есть выполняет длинный переход (long jump). Защищенное окружение использует setjmp для установки точки восстановления; любая ошибка переходит к самой последней активной точке восстановления.
Внутри функции C вы можете явно возбудить ошибку, вызвав lua_error.
Большинство функций в API могут возбуждать ошибки, например, из-за ошибки выделения памяти. Документация для каждой функции указывает, может ли она возбуждать ошибки.
Если ошибка происходит вне любого защищенного окружения, Lua вызывает функцию паники (panic function) (см. lua_atpanic), а затем вызывает abort, завершая таким образом хостовое приложение. Ваша функция паники может избежать этого завершения, никогда не возвращаясь (например, выполняя длинный переход к вашей собственной точке восстановления вне Lua).
Функция паники, как следует из ее названия, является механизмом “последней надежды”. Программы должны избегать ее. Как общее правило, когда функция C вызывается из Lua с состоянием Lua, она может делать с этим состоянием все, что угодно, так как оно уже должно быть защищено. Однако когда код C работает с другими состояниями Lua (например, аргумент-состояние Lua для функции, состояние Lua, сохраненное в реестре, или результат lua_newthread), он должен использовать их только в вызовах API, которые не могут возбуждать ошибки.
Функция паники работает так, как если бы она была обработчиком сообщений (см. §2.3); в частности, объект ошибки находится на вершине стека. Однако нет никаких гарантий относительно пространства стека. Чтобы поместить что-либо в стек, функция паники должна сначала проверить доступное пространство (см. §4.1.1).
4.4.1 – Коды состояния
Некоторые функции, сообщающие об ошибках в API, используют следующие коды состояния для указания различных видов ошибок или других условий:
LUA_OK(0): нет ошибок.LUA_ERRRUN: ошибка времени выполнения.LUA_ERRMEM: ошибка выделения памяти. Для таких ошибок Lua не вызывает обработчик сообщений.LUA_ERRERR: переполнение стека при выполнении обработчика сообщений из-за другого переполнения стека. Чаще всего эта ошибка является результатом какой-либо другой ошибки во время выполнения обработчика сообщений. Ошибка в обработчике сообщений вызовет обработчик снова, что снова сгенерирует ошибку, и так далее, пока этот цикл не исчерпает стек и не вызовет эту ошибку.LUA_ERRSYNTAX: синтаксическая ошибка во время предкомпиляции или ошибка формата в двоичном чанке.LUA_YIELD: поток (сопрограмма) выполняет yield.LUA_ERRFILE: ошибка, связанная с файлом; например, невозможно открыть или прочитать файл.
Эти константы определены в заголовочном файле lua.h.
4.5 – Обработка yield в C
Внутренне Lua использует средство C longjmp для выполнения yield в сопрограмме. Следовательно, если функция C foo вызывает функцию API, и эта функция API выполняет yield (прямо или косвенно, вызывая другую функцию, которая выполняет yield), Lua больше не может вернуться в foo, потому что longjmp удаляет ее фрейм из стека C.
Чтобы избежать подобной проблемы, Lua возбуждает ошибку всякий раз, когда пытается выполнить yield через вызов API, за исключением трех функций: lua_yieldk, lua_callk и lua_pcallk. Все эти функции получают функцию продолжения (continuation function) (в качестве параметра с именем k) для продолжения выполнения после yield.
Нам необходимо установить некоторую терминологию для объяснения продолжений. У нас есть функция C, вызванная из Lua, которую мы будем называть исходной функцией (original function). Эта исходная функция затем вызывает одну из этих трех функций в C API, которую мы будем называть вызываемой функцией (callee function), которая затем выполняет yield текущего потока. Это может произойти, когда вызываемая функция — lua_yieldk, или когда вызываемая функция — lua_callk либо lua_pcallk, и функция, вызываемая ими, выполняет yield.
Предположим, что выполняющийся поток делает yield во время выполнения вызываемой функции. После возобновления потока он в конечном итоге завершит выполнение вызываемой функции. Однако вызываемая функция не может вернуться в исходную функцию, потому что ее фрейм в стеке C был уничтожен при yield. Вместо этого Lua вызывает функцию продолжения, которая была передана в качестве аргумента вызываемой функции. Как следует из названия, функция продолжения должна продолжить задачу исходной функции.
В качестве иллюстрации рассмотрим следующую функцию:
int original_function (lua_State *L) {
... /* код 1 */
status = lua_pcall(L, n, m, h); /* вызывает Lua */
... /* код 2 */
}
Теперь мы хотим позволить коду Lua, выполняемому lua_pcall, делать yield. Во-первых, мы можем переписать нашу функцию следующим образом:
int k (lua_State *L, int status, lua_KContext ctx) {
... /* код 2 */
}
int original_function (lua_State *L) {
... /* код 1 */
return k(L, lua_pcall(L, n, m, h), ctx);
}
В приведенном выше коде новая функция k является функцией продолжения (с типом lua_KFunction), которая должна выполнять всю ту работу, которую исходная функция выполняла после вызова lua_pcall. Теперь мы должны сообщить Lua, что он должен вызвать k, если код Lua, выполняемый lua_pcall, будет прерван каким-либо образом (ошибки или yield), поэтому мы переписываем код следующим образом, заменяя lua_pcall на lua_pcallk:
int original_function (lua_State *L) {
... /* код 1 */
return k(L, lua_pcallk(L, n, m, h, ctx2, k), ctx1);
}
Обратите внимание на внешний явный вызов продолжения: Lua вызовет продолжение только при необходимости, то есть в случае ошибок или возобновления после yield. Если вызываемая функция возвращается нормально, ни разу не выполнив yield, lua_pcallk (и lua_callk) также вернется нормально. (Конечно, вместо вызова продолжения в этом случае вы можете выполнить эквивалентную работу непосредственно внутри исходной функции).
Помимо состояния Lua, функция продолжения имеет два других параметра: окончательный статус вызова и значение контекста (ctx), которое было изначально передано в lua_pcallk. Lua не использует это значение контекста; он только передает это значение от исходной функции к функции продолжения. Для lua_pcallk статус — это то же значение, которое было бы возвращено lua_pcallk, за исключением того, что это LUA_YIELD при выполнении после yield (вместо LUA_OK). Для lua_yieldk и lua_callk статус всегда LUA_YIELD, когда Lua вызывает продолжение. (Для этих двух функций Lua не будет вызывать продолжение в случае ошибок, потому что они не обрабатывают ошибки). Аналогично, при использовании lua_callk вы должны вызвать функцию продолжения с LUA_OK в качестве статуса. (Для lua_yieldk нет особого смысла вызывать функцию продолжения напрямую, потому что lua_yieldk обычно не возвращается).
Lua обрабатывает функцию продолжения так, как если бы она была исходной функцией. Функция продолжения получает тот же стек Lua от исходной функции, в том же состоянии, в котором он был бы, если бы вызываемая функция вернулась. (Например, после lua_callk функция и ее аргументы удаляются из стека и заменяются результатами вызова). Она также имеет те же upvalue. Все, что она возвращает, обрабатывается Lua так, как если бы это был возврат исходной функции.
4.6 – Функции и типы
Здесь мы перечисляем все функции и типы из C API в алфавитном порядке. Каждая функция имеет индикатор вида: [-o, +p, x]
Первое поле, o, — сколько элементов функция извлекает из стека. Второе поле, p, — сколько элементов функция помещает в стек. (Любая функция всегда помещает свои результаты после извлечения своих аргументов.) Поле вида x|y означает, что функция может поместить (или извлечь) x или y элементов, в зависимости от ситуации; знак вопроса '?' означает, что мы не можем узнать, сколько элементов функция извлекает/помещает, глядя только на ее аргументы. (Например, это может зависеть от того, что находится в стеке). Третье поле, x, сообщает, может ли функция возбуждать ошибки: '-' означает, что функция никогда не возбуждает ошибок; 'm' означает, что функция может возбуждать только ошибки нехватки памяти; 'v' означает, что функция может возбуждать ошибки, объясненные в тексте; 'e' означает, что функция может выполнять произвольный код Lua, либо напрямую, либо через метаметоды, и поэтому может возбуждать любые ошибки.
lua_absindex
[-0, +0, –]
int lua_absindex (lua_State *L, int idx);
Преобразует приемлемый индекс idx в эквивалентный абсолютный индекс (то есть такой, который не зависит от размера стека).
lua_Alloc
typedef void * (*lua_Alloc) (void *ud,
void *ptr,
size_t osize,
size_t nsize);
Тип функции распределения памяти, используемой состояниями Lua. Функция-аллокатор должна обеспечивать функциональность, аналогичную realloc, но не точно такую же. Ее аргументы: ud — непрозрачный указатель, переданный в lua_newstate; ptr — указатель на выделяемый/перераспределяемый/освобождаемый блок; osize — исходный размер блока или некоторый код о том, что выделяется; и nsize — новый размер блока.
Когда ptr не равен NULL, osize — это размер блока, на который указывает ptr, то есть размер, указанный при его выделении или перераспределении.
Когда ptr равен NULL, osize кодирует тип объекта, который Lua выделяет. osize равен LUA_TSTRING, LUA_TTABLE, LUA_TFUNCTION, LUA_TUSERDATA или LUA_TTHREAD, когда (и только когда) Lua создает новый объект этого типа. Когда osize имеет какое-либо другое значение, Lua выделяет память для чего-то другого.
Lua предполагает следующее поведение от функции-аллокатора:
Когда nsize равно нулю, аллокатор должен вести себя как free и затем возвращать NULL.
Когда nsize не равно нулю, аллокатор должен вести себя как realloc. В частности, аллокатор возвращает NULL тогда и только тогда, когда он не может выполнить запрос.
Вот простая реализация функции-аллокатора, соответствующая функции luaL_alloc из вспомогательной библиотеки.
void *luaL_alloc (void *ud, void *ptr, size_t osize,
size_t nsize) {
(void)ud; (void)osize; /* не используется */
if (nsize == 0) {
free(ptr);
return NULL;
}
else
return realloc(ptr, nsize);
}
Обратите внимание, что стандарт ISO C гарантирует, что free(NULL) не имеет эффекта, и что realloc(NULL,size) эквивалентно malloc(size).
lua_arith
[-(2|1), +1, e]
void lua_arith (lua_State *L, int op);
Выполняет арифметическую или побитовую операцию над двумя значениями (или одним, в случае отрицаний) на вершине стека, при этом значение на вершине является вторым операндом, извлекает эти значения и помещает результат операции в стек. Функция следует семантике соответствующего оператора Lua (то есть может вызывать метаметоды).
Значение op должно быть одной из следующих констант:
| Константа | Операция |
|---|---|
LUA_OPADD | сложение (+) |
LUA_OPSUB | вычитание (-) |
LUA_OPMUL | умножение (*) |
LUA_OPDIV | деление с плавающей запятой (/) |
LUA_OPIDIV | деление нацело вниз (//) |
LUA_OPMOD | остаток от деления (%) |
LUA_OPPOW | возведение в степень (^) |
LUA_OPUNM | унарный минус (унарный -) |
LUA_OPBNOT | побитовое НЕ (~) |
LUA_OPBAND | побитовое И (&) |
LUA_OPBOR | побитовое ИЛИ (|) |
LUA_OPBXOR | побитовое исключающее ИЛИ (~) |
LUA_OPSHL | сдвиг влево (<<) |
LUA_OPSHR | сдвиг вправо (>>) |
lua_atpanic
[-0, +0, –]
lua_CFunction lua_atpanic (lua_State *L, lua_CFunction panicf);
Устанавливает новую функцию паники и возвращает старую (см. §4.4).
lua_call
[-(nargs+1), +nresults, e]
void lua_call (lua_State *L, int nargs, int nresults);
Вызывает функцию. Как и обычные вызовы Lua, lua_call учитывает метаметод __call. Таким образом, здесь слово “функция” означает любое вызываемое значение.
Для выполнения вызова необходимо использовать следующий протокол: сначала функция, которую нужно вызвать, помещается в стек; затем аргументы вызова помещаются в прямом порядке, то есть первый аргумент помещается первым. Наконец, вы вызываете lua_call; nargs — это количество аргументов, которое вы поместили в стек. Когда функция возвращается, все аргументы и значение функции извлекаются, а результаты вызова помещаются в стек. Количество результатов выравнивается до nresults, если только nresults не равно LUA_MULTRET, что приводит к помещению всех результатов функции. В первом случае (явное количество результатов) вызывающая сторона должна убедиться, что в стеке достаточно места для возвращаемых значений. Во втором случае (все результаты) Lua заботится о том, чтобы возвращаемые значения поместились в пространство стека, но не гарантирует никакого дополнительного места в стеке. Результаты функции помещаются в стек в прямом порядке (первый результат помещается первым), так что после вызова последний результат находится на вершине стека.
Максимальное значение для nresults — 250.
Любая ошибка при вызове и выполнении функции распространяется вверх (с помощью longjmp).
Следующий пример показывает, как программа-хост может выполнить эквивалент этого кода Lua:
a = f("how", t.x, 14)
Вот это на C:
lua_getglobal(L, "f"); /* функция для вызова */
lua_pushliteral(L, "how"); /* 1-й аргумент */
lua_getglobal(L, "t"); /* таблица для индексации */
lua_getfield(L, -1, "x"); /* поместить результат t.x (2-й аргумент) */
lua_remove(L, -2); /* удалить 't' из стека */
lua_pushinteger(L, 14); /* 3-й аргумент */
lua_call(L, 3, 1); /* вызвать 'f' с 3 аргументами и 1 результатом */
lua_setglobal(L, "a"); /* установить глобальную 'a' */
Обратите внимание, что приведенный выше код сбалансирован: в конце стек возвращается к своей исходной конфигурации. Это считается хорошей практикой программирования.
lua_callk
[-(nargs + 1), +nresults, e]
void lua_callk (lua_State *L,
int nargs,
int nresults,
lua_KContext ctx,
lua_KFunction k);
Эта функция ведет себя точно так же, как lua_call, но позволяет вызываемой функции выполнять yield (см. §4.5).
lua_CFunction
typedef int (*lua_CFunction) (lua_State *L);
Тип для функций C.
Чтобы правильно взаимодействовать с Lua, функция C должна использовать следующий протокол, который определяет способ передачи параметров и результатов: функция C получает свои аргументы от Lua в своем стеке в прямом порядке (первый аргумент помещается первым). Таким образом, когда функция запускается, lua_gettop(L) возвращает количество аргументов, полученных функцией. Первый аргумент (если есть) находится по индексу 1, а последний аргумент — по индексу lua_gettop(L). Чтобы вернуть значения в Lua, функция C просто помещает их в стек в прямом порядке (первый результат помещается первым) и возвращает в C количество результатов. Любые другие значения в стеке ниже результатов будут корректно отброшены Lua. Как и функция Lua, функция C, вызванная из Lua, также может возвращать много результатов.
В качестве примера, следующая функция получает переменное количество числовых аргументов и возвращает их среднее значение и сумму:
static int foo (lua_State *L) {
int n = lua_gettop(L); /* количество аргументов */
lua_Number sum = 0.0;
int i;
for (i = 1; i <= n; i++) {
if (!lua_isnumber(L, i)) {
lua_pushliteral(L, "неверный аргумент");
lua_error(L);
}
sum += lua_tonumber(L, i);
}
lua_pushnumber(L, sum/n); /* первый результат */
lua_pushnumber(L, sum); /* второй результат */
return 2; /* количество результатов */
}
lua_checkstack
[-0, +0, –]
int lua_checkstack (lua_State *L, int n);
Гарантирует, что в стеке есть место как минимум для n дополнительных элементов, то есть что вы можете безопасно поместить в него до n значений. Возвращает false, если не может выполнить запрос, либо потому, что это привело бы к превышению фиксированного максимального размера стека (обычно не менее нескольких тысяч элементов), либо потому, что не может выделить память для дополнительного пространства. Эта функция никогда не уменьшает стек; если в стеке уже есть место для дополнительных элементов, он остается без изменений.
lua_close
[-0, +0, –]
void lua_close (lua_State *L);
Закрывает все активные закрываемые переменные (to-be-closed variables) в главном потоке, освобождает все объекты в данном состоянии Lua (вызывая соответствующие метаметоды сборки мусора, если таковые имеются) и освобождает всю динамическую память, используемую этим состоянием.
На некоторых платформах вам может не потребоваться вызывать эту функцию, потому что все ресурсы естественным образом освобождаются при завершении программы-хоста. С другой стороны, долго работающим программам, создающим несколько состояний, таким как демоны или веб-серверы, вероятно, потребуется закрывать состояния, как только они становятся ненужными.
lua_closeslot
[-0, +0, e]
void lua_closeslot (lua_State *L, int index);
Закрывает закрываемый слот (to-be-closed slot) по заданному индексу и устанавливает его значение в nil. Индекс должен быть последним индексом, ранее отмеченным для закрытия (см. lua_toclose), который все еще активен (то есть еще не закрыт).
Метаметод __close не может выполнять yield при вызове через эту функцию.
lua_closethread
[-0, +?, –]
int lua_closethread (lua_State *L, lua_State *from);
Сбрасывает поток, очищая его стек вызовов и закрывая все ожидающие закрываемые переменные. Параметр from представляет сопрограмму, которая сбрасывает L. Если такой сопрограммы нет, этот параметр может быть NULL.
Если L не равен from, вызов возвращает код состояния: LUA_OK при отсутствии ошибок в потоке (либо исходная ошибка, остановившая поток, либо ошибки в методах закрытия), или статус ошибки в противном случае. В случае ошибки объект ошибки помещается на вершину стека.
Если L равен from, это соответствует потоку, закрывающему сам себя. В этом случае вызов не возвращается; вместо этого возвращается resume, который (пере)запустил поток. Поток должен выполняться внутри resume.
lua_compare
[-0, +0, e]
int lua_compare (lua_State *L, int index1, int index2, int op);
Сравнивает два значения Lua. Возвращает 1, если значение по индексу index1 удовлетворяет условию op при сравнении со значением по индексу index2, следуя семантике соответствующего оператора Lua (то есть может вызывать метаметоды). В противном случае возвращает 0. Также возвращает 0, если какой-либо из индексов недействителен.
Значение op должно быть одной из следующих констант:
LUA_OPEQ: сравнение на равенство (==)LUA_OPLT: сравнение на меньше (<)LUA_OPLE: сравнение на меньше или равно (<=)
lua_concat
[-n, +1, e]
void lua_concat (lua_State *L, int n);
Конкатенирует n значений на вершине стека, извлекает их и оставляет результат на вершине. Если n равно 1, результатом является единственное значение в стеке (то есть функция ничего не делает); если n равно 0, результатом является пустая строка. Конкатенация выполняется в соответствии с обычной семантикой Lua (см. §3.4.6).
lua_copy
[-0, +0, –]
void lua_copy (lua_State *L, int fromidx, int toidx);
Копирует элемент по индексу fromidx в допустимый индекс toidx, заменяя значение в этой позиции. Значения в других позициях не затрагиваются.
lua_createtable
[-0, +1, m]
void lua_createtable (lua_State *L, int nseq, int nrec);
Создает новую пустую таблицу и помещает ее в стек. Параметр nseq — это подсказка о том, сколько элементов таблица будет иметь в качестве последовательности; параметр nrec — подсказка о том, сколько других элементов будет иметь таблица. Lua может использовать эти подсказки для предварительного выделения памяти для новой таблицы. Это предварительное выделение может помочь производительности, когда вы заранее знаете, сколько элементов будет в таблице. В противном случае следует использовать функцию lua_newtable.
lua_dump
[-0, +0, –]
int lua_dump (lua_State *L,
lua_Writer writer,
void *data,
int strip);
Дамп функции в виде двоичного чанка. Получает функцию Lua на вершине стека и создает двоичный чанк, который, будучи загруженным снова, дает функцию, эквивалентную дампнутой. По мере создания частей чанка lua_dump вызывает функцию writer (см. lua_Writer) с заданными data для их записи.
Функция lua_dump полностью сохраняет стек Lua при вызовах функции-писателя, за исключением того, что она может поместить некоторые значения для внутреннего использования перед первым вызовом и восстанавливает размер стека до исходного после последнего вызова.
Если strip истинно, двоичное представление может не включать всю отладочную информацию о функции для экономии места.
Возвращаемое значение — это код ошибки, возвращенный последним вызовом writer; 0 означает отсутствие ошибок.
lua_error
[-1, +0, v]
int lua_error (lua_State *L);
Возбуждает ошибку Lua, используя значение на вершине стека в качестве объекта ошибки. Эта функция выполняет длинный переход и, следовательно, никогда не возвращается (см. luaL_error).
lua_gc
[-0, +0, –]
int lua_gc (lua_State *L, int what, ...);
Управляет сборщиком мусора.
Эта функция выполняет несколько задач в зависимости от значения параметра what. Для опций, требующих дополнительных аргументов, они перечислены после опции.
LUA_GCCOLLECT: Выполняет полный цикл сборки мусора.LUA_GCSTOP: Останавливает сборщик мусора.LUA_GCRESTART: Перезапускает сборщик мусора.LUA_GCCOUNT: Возвращает текущий объем памяти (в Кбайтах), используемый Lua.LUA_GCCOUNTB: Возвращает остаток от деления текущего объема памяти в байтах, используемого Lua, на 1024.LUA_GCSTEP(size_t n): Выполняет шаг сборки мусора.LUA_GCISRUNNING: Возвращает булево значение, указывающее, работает ли сборщик (т.е. не остановлен).LUA_GCINC: Переключает сборщик в инкрементальный режим. Возвращает предыдущий режим (LUA_GCGENилиLUA_GCINC).LUA_GCGEN: Переключает сборщик в поколенческий режим. Возвращает предыдущий режим (LUA_GCGENилиLUA_GCINC).LUA_GCPARAM(int param, int val): Изменяет и/или возвращает значение параметра сборщика. Еслиvalравно -1, вызов только возвращает текущее значение. Аргументparamдолжен иметь одно из следующих значений:LUA_GCPMINORMUL: Множитель minor.LUA_GCPMAJORMINOR: Множитель major-minor.LUA_GCPMINORMAJOR: Множитель minor-major.LUA_GCPPAUSE: Пауза сборщика мусора.LUA_GCPSTEPMUL: Множитель шага.LUA_GCPSTEPSIZE: Размер шага.
Для получения более подробной информации об этих опциях см. collectgarbage.
Эта функция не должна вызываться финализатором.
lua_getallocf
[-0, +0, –]
lua_Alloc lua_getallocf (lua_State *L, void **ud);
Возвращает функцию-аллокатор памяти для данного состояния. Если ud не NULL, Lua сохраняет в *ud непрозрачный указатель, переданный при установке функции-аллокатора.
lua_getfield
[-0, +1, e]
int lua_getfield (lua_State *L, int index, const char *k);
Помещает в стек значение t[k], где t — это значение по заданному индексу. Как и в Lua, эта функция может вызвать метаметод для события “index” (см. §2.4).
Возвращает тип помещенного значения.
lua_getextraspace
[-0, +0, –]
void *lua_getextraspace (lua_State *L);
Возвращает указатель на область сырой памяти, связанную с данным состоянием Lua. Приложение может использовать эту область для любых целей; Lua не использует ее ни для чего.
Каждый новый поток имеет эту область, инициализированную копией области главного потока.
По умолчанию эта область имеет размер указателя на void, но вы можете перекомпилировать Lua с другим размером для этой области. (См. LUA_EXTRASPACE в luaconf.h).
lua_getglobal
[-0, +1, e]
int lua_getglobal (lua_State *L, const char *name);
Помещает в стек значение глобальной переменной name. Возвращает тип этого значения.
lua_geti
[-0, +1, e]
int lua_geti (lua_State *L, int index, lua_Integer i);
Помещает в стек значение t[i], где t — это значение по заданному индексу. Как и в Lua, эта функция может вызвать метаметод для события “index” (см. §2.4).
Возвращает тип помещенного значения.
lua_getmetatable
[-0, +(0|1), –]
int lua_getmetatable (lua_State *L, int index);
Если значение по заданному индексу имеет метатаблицу, функция помещает эту метатаблицу в стек и возвращает 1. В противном случае функция возвращает 0 и ничего не помещает в стек.
lua_gettable
[-1, +1, e]
int lua_gettable (lua_State *L, int index);
Помещает в стек значение t[k], где t — это значение по заданному индексу, а k — значение на вершине стека.
Эта функция извлекает ключ из стека, помещая результирующее значение на его место. Как и в Lua, эта функция может вызвать метаметод для события “index” (см. §2.4).
Возвращает тип помещенного значения.
lua_gettop
[-0, +0, –]
int lua_gettop (lua_State *L);
Возвращает индекс верхнего элемента в стеке. Поскольку индексы начинаются с 1, этот результат равен количеству элементов в стеке; в частности, 0 означает пустой стек.
lua_getiuservalue
[-0, +1, –]
int lua_getiuservalue (lua_State *L, int index, int n);
Помещает в стек n-е пользовательское значение (user value), связанное с полным userdata по заданному индексу, и возвращает тип помещенного значения.
Если userdata не имеет такого значения, помещает nil и возвращает LUA_TNONE.
lua_insert
[-1, +1, –]
void lua_insert (lua_State *L, int index);
Перемещает верхний элемент в заданный допустимый индекс, сдвигая вверх элементы над этим индексом для освобождения места. Эта функция не может вызываться с псевдоиндексом, поскольку псевдоиндекс не является фактической позицией в стеке.
lua_Integer
typedef ... lua_Integer;
Тип целых чисел в Lua.
По умолчанию этот тип — long long (обычно 64-битное целое число в дополнительном коде), но его можно изменить на long или int (обычно 32-битное целое число в дополнительном коде). (См. LUA_INT_TYPE в luaconf.h).
Lua также определяет константы LUA_MININTEGER и LUA_MAXINTEGER с минимальным и максимальным значениями, которые помещаются в этот тип.
lua_isboolean
[-0, +0, –]
int lua_isboolean (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является булевым, и 0 в противном случае.
lua_iscfunction
[-0, +0, –]
int lua_iscfunction (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является функцией C, и 0 в противном случае.
lua_isfunction
[-0, +0, –]
int lua_isfunction (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является функцией (либо C, либо Lua), и 0 в противном случае.
lua_isinteger
[-0, +0, –]
int lua_isinteger (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является целым числом (то есть значение является числом и представлено как целое), и 0 в противном случае.
lua_islightuserdata
[-0, +0, –]
int lua_islightuserdata (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является легким userdata, и 0 в противном случае.
lua_isnil
[-0, +0, –]
int lua_isnil (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу равно nil, и 0 в противном случае.
lua_isnone
[-0, +0, –]
int lua_isnone (lua_State *L, int index);
Возвращает 1, если заданный индекс недействителен, и 0 в противном случае.
lua_isnoneornil
[-0, +0, –]
int lua_isnoneornil (lua_State *L, int index);
Возвращает 1, если заданный индекс недействителен или если значение по этому индексу равно nil, и 0 в противном случае.
lua_isnumber
[-0, +0, –]
int lua_isnumber (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является числом или строкой, преобразуемой в число, и 0 в противном случае.
lua_isstring
[-0, +0, –]
int lua_isstring (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является строкой или числом (которое всегда можно преобразовать в строку), и 0 в противном случае.
lua_istable
[-0, +0, –]
int lua_istable (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является таблицей, и 0 в противном случае.
lua_isthread
[-0, +0, –]
int lua_isthread (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является потоком, и 0 в противном случае.
lua_isuserdata
[-0, +0, –]
int lua_isuserdata (lua_State *L, int index);
Возвращает 1, если значение по заданному индексу является userdata (полным или легким), и 0 в противном случае.
lua_isyieldable
[-0, +0, –]
int lua_isyieldable (lua_State *L);
Возвращает 1, если данная сопрограмма может выполнить yield, и 0 в противном случае.
lua_KContext
typedef ... lua_KContext;
Тип для контекстов функций продолжения. Должен быть числовым типом. Этот тип определен как intptr_t, когда intptr_t доступен, чтобы он мог хранить и указатели. В противном случае он определен как ptrdiff_t.
lua_KFunction
typedef int (*lua_KFunction) (lua_State *L, int status, lua_KContext ctx);
Тип для функций продолжения (см. §4.5).
lua_len
[-0, +1, e]
void lua_len (lua_State *L, int index);
Возвращает длину значения по заданному индексу. Эквивалентно оператору # в Lua (см. §3.4.7) и может вызвать метаметод для события “length” (см. §2.4). Результат помещается в стек.
lua_load
[-0, +1, –]
int lua_load (lua_State *L,
lua_Reader reader,
void *data,
const char *chunkname,
const char *mode);
Загружает чанк Lua без его выполнения. Если ошибок нет, lua_load помещает скомпилированный чанк как функцию Lua на вершину стека. В противном случае она помещает сообщение об ошибке.
Функция lua_load использует предоставленную пользователем функцию-читатель (reader) для чтения чанка (см. lua_Reader). Аргумент data — это непрозрачное значение, передаваемое в функцию-читатель.
Аргумент chunkname дает имя чанку, которое используется для сообщений об ошибках и в отладочной информации (см. §4.7).
lua_load автоматически определяет, является ли чанк текстовым или двоичным, и загружает его соответствующим образом (см. программу luac). Строка mode работает как в функции load, с тем дополнением, что значение NULL эквивалентно строке "bt". Более того, она может содержать 'B' вместо 'b', что означает фиксированный буфер (fixed buffer) с двоичным дампом.
Фиксированный буфер означает, что адрес, возвращаемый функцией-читателем, будет содержать чанк до тех пор, пока все, созданное чанком, не будет собрано сборщиком мусора; таким образом, Lua может избежать копирования некоторых частей чанка во внутренние структуры. (В общем случае фиксированный буфер будет сохранять свое содержимое до конца программы, например, при чанке в ПЗУ). Более того, для фиксированного буфера функция-читатель должна вернуть весь чанк при первом чтении. (В качестве примера, luaL_loadbufferx делает это, что означает, что вы можете использовать ее для загрузки фиксированных буферов).
Функция lua_load полностью сохраняет стек Lua при вызовах функции-читателя, за исключением того, что она может поместить некоторые значения для внутреннего использования перед первым вызовом и восстанавливает размер стека до исходного размера плюс один (для помещенного результата) после последнего вызова.
lua_load может возвращать LUA_OK, LUA_ERRSYNTAX или LUA_ERRMEM. Функция также может возвращать другие значения, соответствующие ошибкам, возбужденным функцией чтения (см. §4.4.1).
Если результирующая функция имеет upvalue, ее первое upvalue устанавливается в значение глобального окружения, хранящееся по индексу LUA_RIDX_GLOBALS в реестре (см. §4.3). При загрузке главных чанков этим upvalue будет переменная _ENV (см. §2.2). Остальные upvalue инициализируются значением nil.
lua_newstate
[-0, +0, –]
lua_State *lua_newstate (lua_Alloc f, void *ud,
unsigned int seed);
Создает новое независимое состояние и возвращает его главный поток. Возвращает NULL, если не может создать состояние (из-за нехватки памяти). Аргумент f — это функция-аллокатор; Lua будет выполнять все выделение памяти для этого состояния через эту функцию (см. lua_Alloc). Второй аргумент, ud, — непрозрачный указатель, который Lua передает аллокатору при каждом вызове. Третий аргумент, seed, — это начальное значение для хеширования строк.
lua_newtable
[-0, +1, m]
void lua_newtable (lua_State *L);
Создает новую пустую таблицу и помещает ее в стек. Эквивалентно lua_createtable(L,0,0).
lua_newthread
[-0, +1, m]
lua_State *lua_newthread (lua_State *L);
Создает новый поток, помещает его в стек и возвращает указатель на lua_State, представляющий этот новый поток. Новый поток, возвращаемый этой функцией, разделяет с исходным потоком его глобальное окружение, но имеет независимый стек выполнения.
Потоки подлежат сборке мусора, как и любой объект Lua.
lua_newuserdatauv
[-0, +1, m]
void *lua_newuserdatauv (lua_State *L, size_t size, int nuvalue);
Эта функция создает и помещает в стек новый полный userdata с nuvalue связанными значениями Lua, называемыми пользовательскими значениями (user values), плюс связанный блок сырой памяти размером size байт. (Пользовательские значения можно устанавливать и читать с помощью функций lua_setiuservalue и lua_getiuservalue).
Функция возвращает адрес блока памяти. Lua гарантирует, что этот адрес действителен, пока соответствующий userdata жив (см. §2.5). Более того, если userdata помечен для финализации (см. §2.5.3), его адрес действителен по крайней мере до вызова его финализатора.
lua_next
[-1, +(2|0), v]
int lua_next (lua_State *L, int index);
Извлекает ключ из стека и помещает пару ключ-значение из таблицы по заданному индексу — “следующую” пару после данного ключа. Если в таблице больше нет элементов, lua_next возвращает 0 и ничего не помещает.
Типичный обход таблицы выглядит так:
/* таблица находится в стеке по индексу 't' */
lua_pushnil(L); /* первый ключ */
while (lua_next(L, t) != 0) {
/* используем 'key' (по индексу -2) и 'value' (по индексу -1) */
printf("%s - %s\n",
lua_typename(L, lua_type(L, -2)),
lua_typename(L, lua_type(L, -1)));
/* удаляем 'value'; сохраняем 'key' для следующей итерации */
lua_pop(L, 1);
}
При обходе таблицы избегайте вызова lua_tolstring непосредственно для ключа, если вы не уверены, что ключ действительно является строкой. Напомним, что lua_tolstring может изменить значение по заданному индексу; это собьет следующий вызов lua_next.
Эта функция может возбудить ошибку, если данный ключ не равен nil и не присутствует в таблице. См. функцию next для предостережений относительно модификации таблицы во время ее обхода.
lua_Number
typedef ... lua_Number;
Тип чисел с плавающей запятой в Lua.
По умолчанию этот тип — double, но его можно изменить на float или long double. (См. LUA_FLOAT_TYPE в luaconf.h).
lua_numbertointeger
int lua_numbertointeger (lua_Number n, lua_Integer *p);
Пытается преобразовать число Lua с плавающей запятой в целое число Lua; число n должно иметь целое значение. Если это значение находится в диапазоне целых чисел Lua, оно преобразуется в целое и присваивается *p. Макрос возвращает булево значение, указывающее, было ли преобразование успешным. (Обратите внимание, что эту проверку диапазона трудно выполнить корректно без этого макроса из-за округления).
Этот макрос может вычислять свои аргументы более одного раза.
lua_numbertocstring
[-0, +0, –]
unsigned lua_numbertocstring (lua_State *L, int idx,
char *buff);
Преобразует число по приемлемому индексу idx в строку и помещает результат в buff. Буфер должен иметь размер не менее LUA_N2SBUFFSZ байт. Преобразование следует неуказанному формату (см. §3.4.3). Функция возвращает количество байт, записанных в буфер (включая завершающий ноль), или ноль, если значение по idx не является числом.
lua_pcall
[-(nargs + 1), +(nresults|1), –]
int lua_pcall (lua_State *L, int nargs, int nresults, int msgh);
Вызывает функцию (или вызываемый объект) в защищенном режиме.
И nargs, и nresults имеют то же значение, что и в lua_call. Если во время вызова нет ошибок, lua_pcall ведет себя точно так же, как lua_call. Однако, если возникает какая-либо ошибка, lua_pcall перехватывает ее, помещает в стек единственное значение (объект ошибки) и возвращает код ошибки. Как и lua_call, lua_pcall всегда удаляет функцию и ее аргументы из стека.
Если msgh равно 0, то объект ошибки, возвращаемый в стеке, является в точности исходным объектом ошибки. В противном случае msgh — это индекс в стеке обработчика сообщений. (Этот индекс не может быть псевдоиндексом). В случае ошибок времени выполнения этот обработчик будет вызван с объектом ошибки, и его возвращаемое значение будет объектом, возвращенным в стеке функцией lua_pcall.
Обычно обработчик сообщений используется для добавления дополнительной отладочной информации к объекту ошибки, такой как трассировка стека. Такую информацию невозможно собрать после возврата lua_pcall, поскольку к тому времени стек уже свернут.
Функция lua_pcall возвращает один из следующих кодов состояния: LUA_OK, LUA_ERRRUN, LUA_ERRMEM или LUA_ERRERR.
lua_pcallk
[-(nargs + 1), +(nresults|1), –]
int lua_pcallk (lua_State *L,
int nargs,
int nresults,
int msgh,
lua_KContext ctx,
lua_KFunction k);
Эта функция ведет себя точно так же, как lua_pcall, за исключением того, что она позволяет вызываемой функции выполнять yield (см. §4.5).
lua_pop
[-n, +0, e]
void lua_pop (lua_State *L, int n);
Извлекает n элементов из стека. Реализован как макрос над lua_settop.
lua_pushboolean
[-0, +1, –]
void lua_pushboolean (lua_State *L, int b);
Помещает булево значение со значением b в стек.
lua_pushcclosure
[-n, +1, m]
void lua_pushcclosure (lua_State *L, lua_CFunction fn, int n);
Помещает новое замыкание C в стек. Эта функция получает указатель на функцию C и помещает в стек значение Lua типа function, которое при вызове вызывает соответствующую функцию C. Параметр n сообщает, сколько upvalue будет у этой функции (см. §4.2).
Любая функция, вызываемая из Lua, должна следовать правильному протоколу для получения параметров и возврата результатов (см. lua_CFunction).
При создании функции C с ней можно связать некоторые значения, так называемые upvalue; эти upvalue затем доступны функции при каждом ее вызове. Эта связь называется замыканием C (см. §4.2). Чтобы создать замыкание C, сначала начальные значения для его upvalue должны быть помещены в стек. (Если upvalue несколько, первое значение помещается первым). Затем вызывается lua_pushcclosure для создания и помещения функции C в стек, при этом аргумент n сообщает, сколько значений будет связано с функцией. lua_pushcclosure также извлекает эти значения из стека.
Максимальное значение для n — 255.
Когда n равно нулю, эта функция создает легкую функцию C (light C function), которая является просто указателем на функцию C. В этом случае она никогда не вызывает ошибку памяти.
lua_pushcfunction
[-0, +1, –]
void lua_pushcfunction (lua_State *L, lua_CFunction f);
Помещает функцию C в стек. Эта функция эквивалентна lua_pushcclosure без upvalue.
lua_pushexternalstring
[-0, +1, m]
const char *lua_pushexternalstring (lua_State *L,
const char *s, size_t len, lua_Alloc falloc, void *ud);
Создает внешнюю строку (external string), то есть строку, использующую память, не управляемую Lua. Указатель s указывает на внешний буфер, содержащий содержимое строки, а len — это длина строки. Строка должна иметь ноль в конце, то есть должно выполняться условие s[len] == '\0'. Как и для любой строки в Lua, длина должна помещаться в целое число Lua.
Если falloc отличается от NULL, эта функция будет вызвана Lua, когда внешний буфер больше не нужен. Содержимое буфера не должно изменяться до этого вызова. Функция будет вызвана с заданным ud, строкой s в качестве блока, длиной плюс один (для учета завершающего нуля) в качестве старого размера и 0 в качестве нового размера.
Даже при использовании внешнего буфера Lua все равно должен выделить заголовок для строки. В случае ошибки выделения памяти Lua вызовет falloc перед возбуждением ошибки.
Функция возвращает указатель на строку (то есть s).
lua_pushfstring
[-0, +1, v]
const char *lua_pushfstring (lua_State *L, const char *fmt, ...);
Помещает в стек форматированную строку и возвращает указатель на эту строку (см. §4.1.3). Результат — это копия fmt, в которой каждый спецификатор преобразования заменен строковым представлением соответствующего дополнительного аргумента. Спецификатор преобразования (и соответствующий ему дополнительный аргумент) может быть: '%%' (вставляет символ '%'), '%s' (вставляет строку с завершающим нулем, без ограничений по размеру), '%f' (вставляет lua_Number), '%I' (вставляет lua_Integer), '%p' (вставляет указатель void*), '%d' (вставляет int), '%c' (вставляет int как однобайтовый символ) и '%U' (вставляет unsigned long как последовательность байт UTF-8).
Каждое вхождение '%' в строке fmt должно образовывать допустимый спецификатор преобразования.
Помимо ошибок выделения памяти, эта функция может возбудить ошибку, если результирующая строка слишком велика.
lua_pushglobaltable
[-0, +1, –]
void lua_pushglobaltable (lua_State *L);
Помещает глобальное окружение в стек.
lua_pushinteger
[-0, +1, –]
void lua_pushinteger (lua_State *L, lua_Integer n);
Помещает целое число со значением n в стек.
lua_pushlightuserdata
[-0, +1, –]
void lua_pushlightuserdata (lua_State *L, void *p);
Помещает легкий userdata в стек.
Userdata представляют значения C в Lua. Легкий userdata представляет указатель, void*. Это значение (как число): вы его не создаете, у него нет индивидуальной метатаблицы, и оно не собирается сборщиком мусора (поскольку никогда не создавалось). Легкий userdata равен “любому” легкому userdata с тем же адресом C.
lua_pushliteral
[-0, +1, v]
const char *lua_pushliteral (lua_State *L, const char *s);
Этот макрос эквивалентен lua_pushstring, но должен использоваться только тогда, когда s является литеральной строкой. (Lua может оптимизировать этот случай).
lua_pushlstring
[-0, +1, v]
const char *lua_pushlstring (lua_State *L, const char *s, size_t len);
Помещает строку, на которую указывает s, размером len, в стек. Lua создаст или повторно использует внутреннюю копию данной строки, так что память по адресу s может быть освобождена или повторно использована сразу после возврата функции. Строка может содержать любые двоичные данные, включая встроенные нули.
Возвращает указатель на внутреннюю копию строки (см. §4.1.3).
Помимо ошибок выделения памяти, эта функция может возбудить ошибку, если строка слишком велика.
lua_pushnil
[-0, +1, –]
void lua_pushnil (lua_State *L);
Помещает значение nil в стек.
lua_pushnumber
[-0, +1, –]
void lua_pushnumber (lua_State *L, lua_Number n);
Помещает число с плавающей запятой со значением n в стек.
lua_pushstring
[-0, +1, m]
const char *lua_pushstring (lua_State *L, const char *s);
Помещает строку с завершающим нулем, на которую указывает s, в стек. Lua создаст или повторно использует внутреннюю копию данной строки, так что память по адресу s может быть освобождена или повторно использована сразу после возврата функции.
Возвращает указатель на внутреннюю копию строки (см. §4.1.3).
Если s равен NULL, помещает nil и возвращает NULL.
lua_pushthread
[-0, +1, –]
int lua_pushthread (lua_State *L);
Помещает поток, представленный L, в стек. Возвращает 1, если этот поток является главным потоком своего состояния.
lua_pushvalue
[-0, +1, –]
void lua_pushvalue (lua_State *L, int index);
Помещает копию элемента по заданному индексу в стек.
lua_pushvfstring
[-0, +1, –]
const char *lua_pushvfstring (lua_State *L,
const char *fmt,
va_list argp);
Эквивалентно lua_pushfstring, за исключением того, что получает va_list вместо переменного количества аргументов и не возбуждает ошибок. Вместо этого в случае ошибок помещает сообщение об ошибке и возвращает NULL.
lua_rawequal
[-0, +0, –]
int lua_rawequal (lua_State *L, int index1, int index2);
Возвращает 1, если два значения по индексам index1 и index2 примитивно равны (то есть равны без вызова метаметода __eq). В противном случае возвращает 0. Также возвращает 0, если какой-либо из индексов недействителен.
lua_rawget
[-1, +1, –]
int lua_rawget (lua_State *L, int index);
Аналогично lua_gettable, но выполняет сырой доступ (т.е. без метаметодов). Значение по индексу index должно быть таблицей.
lua_rawgeti
[-0, +1, –]
int lua_rawgeti (lua_State *L, int index, lua_Integer n);
Помещает в стек значение t[n], где t — таблица по заданному индексу. Доступ сырой, то есть не использует метазначение __index.
Возвращает тип помещенного значения.
lua_rawgetp
[-0, +1, –]
int lua_rawgetp (lua_State *L, int index, const void *p);
Помещает в стек значение t[k], где t — таблица по заданному индексу, а k — указатель p, представленный как легкий userdata. Доступ сырой, то есть не использует метазначение __index.
Возвращает тип помещенного значения.
lua_rawlen
[-0, +0, –]
lua_Unsigned lua_rawlen (lua_State *L, int index);
Возвращает сырую “длину” значения по заданному индексу: для строк это длина строки; для таблиц это результат оператора длины (#) без метаметодов; для userdata это размер блока памяти, выделенного для userdata. Для других значений этот вызов возвращает 0.
lua_rawset
[-2, +0, m]
void lua_rawset (lua_State *L, int index);
Аналогично lua_settable, но выполняет сырое присваивание (т.е. без метаметодов). Значение по индексу index должно быть таблицей.
lua_rawseti
[-1, +0, m]
void lua_rawseti (lua_State *L, int index, lua_Integer i);
Выполняет эквивалент t[i] = v, где t — таблица по заданному индексу, а v — значение на вершине стека.
Эта функция извлекает значение из стека. Присваивание сырое, то есть не использует метазначение __newindex.
lua_rawsetp
[-1, +0, m]
void lua_rawsetp (lua_State *L, int index, const void *p);
Выполняет эквивалент t[p] = v, где t — таблица по заданному индексу, p закодировано как легкий userdata, а v — значение на вершине стека.
Эта функция извлекает значение из стека. Присваивание сырое, то есть не использует метазначение __newindex.
lua_Reader
typedef const char * (*lua_Reader) (lua_State *L,
void *data,
size_t *size);
Функция-читатель, используемая lua_load. Каждый раз, когда lua_load нуждается в очередной части чанка, она вызывает читатель, передавая его параметр data. Читатель должен вернуть указатель на блок памяти с новым куском чанка и установить size в размер блока. Блок должен существовать до тех пор, пока функция-читатель не будет вызвана снова. Чтобы сигнализировать о конце чанка, читатель должен вернуть NULL или установить size в ноль. Функция-читатель может возвращать куски любого размера больше нуля.
lua_register
[-0, +0, e]
void lua_register (lua_State *L, const char *name, lua_CFunction f);
Устанавливает функцию C f как новое значение глобальной переменной name. Определено как макрос:
#define lua_register(L,n,f) \
(lua_pushcfunction(L, f), lua_setglobal(L, n))
lua_remove
[-1, +0, –]
void lua_remove (lua_State *L, int index);
Удаляет элемент по заданному допустимому индексу, сдвигая вниз элементы над этим индексом для заполнения промежутка. Эта функция не может вызываться с псевдоиндексом, поскольку псевдоиндекс не является фактической позицией в стеке.
lua_replace
[-1, +0, –]
void lua_replace (lua_State *L, int index);
Перемещает верхний элемент в заданный допустимый индекс без сдвига каких-либо элементов (таким образом, заменяя значение по этому заданному индексу), а затем извлекает верхний элемент.
lua_resume
[-?, +?, –]
int lua_resume (lua_State *L, lua_State *from, int nargs,
int *nresults);
Запускает и возобновляет сопрограмму в заданном потоке L.
Чтобы запустить сопрограмму, вы помещаете главную функцию и все аргументы в пустой стек потока, затем вызываете lua_resume, где nargs — количество аргументов. Функция возвращается, когда сопрограмма приостанавливается, завершает свое выполнение или возбуждает незащищенную ошибку. Когда она возвращается без ошибок, *nresults обновляется, и вершина стека содержит *nresults значений, переданных в lua_yield или возвращенных функцией тела. lua_resume возвращает LUA_YIELD, если сопрограмма выполняет yield, LUA_OK, если сопрограмма завершает выполнение без ошибок, или код ошибки в случае ошибок (см. §4.4.1). В случае ошибок объект ошибки помещается на вершину стека. (В этом случае nresults не обновляется, так как его значение должно было бы быть 1 для единственного объекта ошибки).
Чтобы возобновить приостановленную сопрограмму, вы удаляете *nresults значений, возвращенных yield, из ее стека, помещаете значения, которые будут переданы как результаты из yield, а затем вызываете lua_resume.
Параметр from представляет сопрограмму, которая возобновляет L. Если такой сопрограммы нет, этот параметр может быть NULL.
lua_rotate
[-0, +0, –]
void lua_rotate (lua_State *L, int idx, int n);
Вращает элементы стека между допустимым индексом idx и вершиной стека. Элементы вращаются на n позиций в направлении вершины для положительного n или на -n позиций в направлении дна для отрицательного n. Абсолютное значение n не должно превышать размер вращаемого среза. Эта функция не может вызываться с псевдоиндексом, поскольку псевдоиндекс не является фактической позицией в стеке.
lua_setallocf
[-0, +0, –]
void lua_setallocf (lua_State *L, lua_Alloc f, void *ud);
Изменяет функцию-аллокатор данного состояния на f с пользовательскими данными ud.
lua_setfield
[-1, +0, e]
void lua_setfield (lua_State *L, int index, const char *k);
Выполняет эквивалент t[k] = v, где t — значение по заданному индексу, а v — значение на вершине стека.
Эта функция извлекает значение из стека. Как и в Lua, эта функция может вызвать метаметод для события “newindex” (см. §2.4).
lua_setglobal
[-1, +0, e]
void lua_setglobal (lua_State *L, const char *name);
Извлекает значение из стека и устанавливает его как новое значение глобальной переменной name.
lua_seti
[-1, +0, e]
void lua_seti (lua_State *L, int index, lua_Integer n);
Выполняет эквивалент t[n] = v, где t — значение по заданному индексу, а v — значение на вершине стека.
Эта функция извлекает значение из стека. Как и в Lua, эта функция может вызвать метаметод для события “newindex” (см. §2.4).
lua_setiuservalue
[-1, +0, –]
int lua_setiuservalue (lua_State *L, int index, int n);
Извлекает значение из стека и устанавливает его как новое n-е пользовательское значение, связанное с полным userdata по заданному индексу. Возвращает 0, если userdata не имеет такого значения.
lua_setmetatable
[-1, +0, –]
int lua_setmetatable (lua_State *L, int index);
Извлекает таблицу или nil из стека и устанавливает это значение как новую метатаблицу для значения по заданному индексу. (nil означает отсутствие метатаблицы).
(По историческим причинам эта функция возвращает int, который теперь всегда равен 1).
lua_settable
[-2, +0, e]
void lua_settable (lua_State *L, int index);
Выполняет эквивалент t[k] = v, где t — значение по заданному индексу, v — значение на вершине стека, а k — значение непосредственно под вершиной.
Эта функция извлекает и ключ, и значение из стека. Как и в Lua, эта функция может вызвать метаметод для события “newindex” (см. §2.4).
lua_settop
[-?, +?, e]
void lua_settop (lua_State *L, int index);
Принимает любой приемлемый индекс стека или 0 и устанавливает вершину стека в этот индекс. Если новая вершина больше старой, то новые элементы заполняются значением nil. Если index равен 0, то все элементы стека удаляются.
Эта функция может выполнять произвольный код при удалении из стека индекса, помеченного как закрываемый (to-be-closed).
lua_setwarnf
[-0, +0, –]
void lua_setwarnf (lua_State *L, lua_WarnFunction f, void *ud);
Устанавливает функцию предупреждения, используемую Lua для выдачи предупреждений (см. lua_WarnFunction). Параметр ud устанавливает значение ud, передаваемое в функцию предупреждения.
lua_State
typedef struct lua_State lua_State;
Непрозрачная структура, которая указывает на поток и косвенно (через поток) на все состояние интерпретатора Lua. Библиотека Lua полностью реентерабельна: у нее нет глобальных переменных. Вся информация о состоянии доступна через эту структуру.
Указатель на эту структуру должен передаваться в качестве первого аргумента каждой функции в библиотеке, кроме lua_newstate, которая создает состояние Lua с нуля.
lua_status
[-0, +0, –]
int lua_status (lua_State *L);
Возвращает статус потока L.
Статус может быть LUA_OK для нормального потока, кодом ошибки, если поток завершил выполнение lua_resume с ошибкой, или LUA_YIELD, если поток приостановлен.
Вы можете вызывать функции только в потоках со статусом LUA_OK. Вы можете возобновлять потоки со статусом LUA_OK (для запуска новой сопрограммы) или LUA_YIELD (для возобновления сопрограммы).
lua_stringtonumber
[-0, +1, –]
size_t lua_stringtonumber (lua_State *L, const char *s);
Преобразует строку с завершающим нулем s в число, помещает это число в стек и возвращает общий размер строки, то есть ее длину плюс один. Преобразование может дать целое число или число с плавающей запятой в соответствии с лексическими соглашениями Lua (см. §3.1). Строка может иметь начальные и конечные пробелы и знак. Если строка не является допустимым числом, возвращает 0 и ничего не помещает. (Обратите внимание, что результат можно использовать как булево значение, true, если преобразование успешно).
lua_toboolean
[-0, +0, –]
int lua_toboolean (lua_State *L, int index);
Преобразует значение Lua по заданному индексу в булево значение C (0 или 1). Как и все проверки в Lua, lua_toboolean возвращает true для любого значения Lua, отличного от false и nil; в противном случае возвращает false. (Если вы хотите принимать только фактические булевы значения, используйте lua_isboolean для проверки типа значения).
lua_tocfunction
[-0, +0, –]
lua_CFunction lua_tocfunction (lua_State *L, int index);
Преобразует значение по заданному индексу в функцию C. Это значение должно быть функцией C; в противном случае возвращает NULL.
lua_toclose
[-0, +0, v]
void lua_toclose (lua_State *L, int index);
Помечает заданный индекс в стеке как закрываемый слот (to-be-closed slot) (см. §3.3.8). Как и закрываемая переменная в Lua, значение в этом слоте стека будет закрыто, когда оно выйдет из области видимости. Здесь, в контексте функции C, “выйти из области видимости” означает, что выполняющаяся функция возвращается в Lua, или происходит ошибка, или слот удаляется из стека через lua_settop или lua_pop, или происходит вызов lua_closeslot. Слот, помеченный как закрываемый, не должен удаляться из стека никакой другой функцией API, кроме lua_settop или lua_pop, если только он предварительно не деактивирован вызовом lua_closeslot.
Эта функция возбуждает ошибку, если значение в заданном слоте не имеет метаметода __close и не является ложным значением.
Эту функцию не следует вызывать для индекса, который равен или находится ниже активного закрываемого слота.
Обратите внимание, что как в случае ошибок, так и при обычном возврате, к моменту выполнения метаметода __close стек C уже свернут, так что любые автоматические переменные C, объявленные в вызывающей функции (например, буфер), будут вне области видимости.
lua_tointeger
[-0, +0, –]
lua_Integer lua_tointeger (lua_State *L, int index);
Эквивалентно lua_tointegerx с isnum, равным NULL.
lua_tointegerx
[-0, +0, –]
lua_Integer lua_tointegerx (lua_State *L, int index, int *isnum);
Преобразует значение Lua по заданному индексу в знаковый целочисленный тип lua_Integer. Значение Lua должно быть целым числом, или числом, или строкой, преобразуемой в целое число (см. §3.4.3); в противном случае lua_tointegerx возвращает 0.
Если isnum не NULL, по его ссылке присваивается булево значение, указывающее, успешно ли выполнена операция.
lua_tolstring
[-0, +0, m]
const char *lua_tolstring (lua_State *L, int index, size_t *len);
Преобразует значение Lua по заданному индексу в строку C. Значение Lua должно быть строкой или числом; в противном случае функция возвращает NULL. Если значение — число, то lua_tolstring также изменяет фактическое значение в стеке на строку. (Это изменение сбивает lua_next, когда lua_tolstring применяется к ключам во время обхода таблицы).
Если len не NULL, функция устанавливает *len в длину строки. Возвращаемая строка C всегда имеет ноль ('\0') после своего последнего символа, но может содержать другие нули в своем теле.
Указатель, возвращаемый lua_tolstring, может быть признан недействительным сборщиком мусора, если соответствующее значение Lua удалено из стека (см. §4.1.3).
Эта функция может вызывать ошибки памяти только при преобразовании числа в строку (поскольку в этом случае она может создать новую строку).
lua_tonumber
[-0, +0, –]
lua_Number lua_tonumber (lua_State *L, int index);
Эквивалентно lua_tonumberx с isnum, равным NULL.
lua_tonumberx
[-0, +0, –]
lua_Number lua_tonumberx (lua_State *L, int index, int *isnum);
Преобразует значение Lua по заданному индексу в тип C lua_Number (см. lua_Number). Значение Lua должно быть числом или строкой, преобразуемой в число (см. §3.4.3); в противном случае lua_tonumberx возвращает 0.
Если isnum не NULL, по его ссылке присваивается булево значение, указывающее, успешно ли выполнена операция.
lua_topointer
[-0, +0, –]
const void *lua_topointer (lua_State *L, int index);
Преобразует значение по заданному индексу в обобщенный указатель C (void*). Значение может быть userdata, таблицей, потоком, строкой или функцией; в противном случае lua_topointer возвращает NULL. Разные объекты будут давать разные указатели. Нет способа преобразовать указатель обратно в исходное значение.
Обычно эта функция используется только для хеширования и отладочной информации.
lua_tostring
[-0, +0, m]
const char *lua_tostring (lua_State *L, int index);
Эквивалентно lua_tolstring с len, равным NULL.
lua_tothread
[-0, +0, –]
lua_State *lua_tothread (lua_State *L, int index);
Преобразует значение по заданному индексу в поток Lua (представленный как lua_State*). Это значение должно быть потоком; в противном случае функция возвращает NULL.
lua_touserdata
[-0, +0, –]
void *lua_touserdata (lua_State *L, int index);
Если значение по заданному индексу является полным userdata, возвращает адрес его блока памяти. Если значение — легкий userdata, возвращает его значение (указатель). В противном случае возвращает NULL.
lua_type
[-0, +0, –]
int lua_type (lua_State *L, int index);
Возвращает тип значения в заданном допустимом индексе или LUA_TNONE для недопустимого, но приемлемого индекса. Типы, возвращаемые lua_type, кодируются следующими константами, определенными в lua.h: LUA_TNIL, LUA_TNUMBER, LUA_TBOOLEAN, LUA_TSTRING, LUA_TTABLE, LUA_TFUNCTION, LUA_TUSERDATA, LUA_TTHREAD и LUA_TLIGHTUSERDATA.
lua_typename
[-0, +0, –]
const char *lua_typename (lua_State *L, int tp);
Возвращает имя типа, закодированного значением tp, которое должно быть одним из значений, возвращаемых lua_type.
lua_Unsigned
typedef ... lua_Unsigned;
Беззнаковая версия lua_Integer.
lua_upvalueindex
[-0, +0, –]
int lua_upvalueindex (int i);
Возвращает псевдоиндекс, представляющий i-е upvalue выполняющейся функции (см. §4.2). i должно быть в диапазоне [1,256].
lua_version
[-0, +0, –]
lua_Number lua_version (lua_State *L);
Возвращает номер версии данного ядра.
lua_WarnFunction
typedef void (*lua_WarnFunction) (void *ud, const char *msg, int tocont);
Тип функций предупреждения, вызываемых Lua для выдачи предупреждений. Первый параметр — непрозрачный указатель, установленный lua_setwarnf. Второй параметр — сообщение предупреждения. Третий параметр — булево значение, указывающее, будет ли сообщение продолжено сообщением в следующем вызове.
См. warn для получения дополнительной информации о предупреждениях.
lua_warning
[-0, +0, –]
void lua_warning (lua_State *L, const char *msg, int tocont);
Выдает предупреждение с заданным сообщением. Сообщение в вызове с tocont равным true должно быть продолжено в другом вызове этой функции.
См. warn для получения дополнительной информации о предупреждениях.
lua_Writer
typedef int (*lua_Writer) (lua_State *L,
const void* p,
size_t sz,
void* ud);
Тип функции-писателя, используемой lua_dump. Каждый раз, когда lua_dump создает очередную часть чанка, она вызывает писатель, передавая буфер для записи (p), его размер (sz) и параметр ud, переданный в lua_dump.
После того как lua_dump запишет свою последнюю часть, она сигнализирует об этом, вызывая функцию-писатель еще один раз с буфером NULL (и размером 0).
Писатель возвращает код ошибки: 0 означает отсутствие ошибок; любое другое значение означает ошибку и останавливает lua_dump от дальнейших вызовов писателя.
lua_xmove
[-?, +?, –]
void lua_xmove (lua_State *from, lua_State *to, int n);
Обменивает значения между разными потоками одного и того же состояния.
Эта функция извлекает n значений из стека from и помещает их в стек to.
lua_yield
[-?, +?, v]
int lua_yield (lua_State *L, int nresults);
Эта функция эквивалентна lua_yieldk, но не имеет продолжения (см. §4.5). Следовательно, когда поток возобновляется, он продолжает функцию, которая вызвала функцию, вызывающую lua_yield. Во избежание неожиданностей эту функцию следует вызывать только в хвостовом вызове.
lua_yieldk
[-?, +?, v]
int lua_yieldk (lua_State *L,
int nresults,
lua_KContext ctx,
lua_KFunction k);
Выполняет yield сопрограммы (потока).
Когда функция C вызывает lua_yieldk, выполняющаяся сопрограмма приостанавливает свое выполнение, и вызов lua_resume, запустивший эту сопрограмму, возвращается. Параметр nresults — это количество значений из стека, которые будут переданы как результаты в lua_resume.
Когда сопрограмма возобновляется снова, Lua вызывает заданную функцию продолжения k для продолжения выполнения функции C, которая выполнила yield (см. §4.5). Эта функция продолжения получает тот же стек, что и предыдущая функция, с удаленными n результатами и замененными аргументами, переданными в lua_resume. Более того, функция продолжения получает значение ctx, которое было передано в lua_yieldk.
Обычно эта функция не возвращается; когда сопрограмма в конечном итоге возобновляется, она продолжает выполнение функции продолжения. Однако есть один особый случай: когда эта функция вызывается изнутри хука строки или счетчика (см. §4.7). В этом случае lua_yieldk должна вызываться без продолжения (вероятно, в форме lua_yield) и без результатов, а хук должен возвращаться немедленно после вызова. Lua выполнит yield, и, когда сопрограмма снова возобновится, она продолжит нормальное выполнение функции (Lua), которая вызвала хук.
Эта функция может возбудить ошибку, если она вызывается из потока с ожидающим вызовом C без функции продолжения (то, что называется границей C-вызова), или если она вызывается из потока, который не выполняется внутри resume (обычно главный поток).
4.7 – Отладочный интерфейс
Lua не имеет встроенных средств отладки. Вместо этого он предлагает специальный интерфейс посредством функций и хуков. Этот интерфейс позволяет создавать различные виды отладчиков, профайлеров и других инструментов, которым нужна “внутренняя информация” от интерпретатора.
lua_Debug
typedef struct lua_Debug {
int event;
const char *name; /* (n) */
const char *namewhat; /* (n) */
const char *what; /* (S) */
const char *source; /* (S) */
size_t srclen; /* (S) */
int currentline; /* (l) */
int linedefined; /* (S) */
int lastlinedefined; /* (S) */
unsigned char nups; /* (u) количество upvalue */
unsigned char nparams; /* (u) количество параметров */
char isvararg; /* (u) */
unsigned char extraargs; /* (t) количество дополнительных аргументов */
char istailcall; /* (t) */
int ftransfer; /* (r) индекс первого передаваемого значения */
int ntransfer; /* (r) количество передаваемых значений */
char short_src[LUA_IDSIZE]; /* (S) */
/* приватная часть */
другие поля
} lua_Debug;
Структура, используемая для переноса различных фрагментов информации о функции или записи активации. lua_getstack заполняет только приватную часть этой структуры для последующего использования. Чтобы заполнить другие поля lua_Debug полезной информацией, необходимо вызвать lua_getinfo с соответствующим параметром. (В частности, чтобы получить поле, необходимо добавить букву в скобках в комментарии к полю в параметр what функции lua_getinfo.)
Поля lua_Debug имеют следующее значение:
source: источник чанка, создавшего функцию. Еслиsourceначинается с'@', это означает, что функция была определена в файле, имя которого следует за'@'. Еслиsourceначинается с'=', остальная часть его содержимого описывает источник способом, зависящим от пользователя. В противном случае функция была определена в строке, гдеsourceи есть эта строка.srclen: Длина строкиsource.short_src: “печатная” версияsourceдля использования в сообщениях об ошибках.linedefined: номер строки, с которой начинается определение функции.lastlinedefined: номер строки, на которой заканчивается определение функции.what: строка"Lua", если функция Lua,"C", если функция C,"main", если это главная часть чанка.currentline: текущая строка, в которой выполняется данная функция. Когда информация о строке недоступна,currentlineустанавливается в -1.name: подходящее имя для данной функции. Поскольку функции в Lua являются значениями первого класса, у них нет фиксированного имени: некоторые функции могут быть значением нескольких глобальных переменных, в то время как другие могут храниться только в поле таблицы. Функцияlua_getinfoпроверяет, как была вызвана функция, чтобы найти подходящее имя. Если она не может найти имя, тоnameустанавливается вNULL.namewhat: объясняет полеname. Значениеnamewhatможет быть"global","local","upvalue","field",""(пустая строка) плюс некоторые другие варианты, в зависимости от того, как была вызвана функция. (Lua использует пустую строку, когда ни один другой вариант не подходит).istailcall:true, если этот вызов функции был сделан через хвостовой вызов. В этом случае вызыватель этого уровня отсутствует в стеке.extraargs: Количество дополнительных аргументов, добавленных при вызове функций через метаметоды__call. (Каждое метазначение__callдобавляет один дополнительный аргумент — вызываемый объект, но может быть цепочка метазначений__call).nups: количество upvalue функции.nparams: количество параметров функции (всегда 0 для функций C).isvararg:true, если функция вариадическая (всегдаtrueдля функций C).ftransfer: индекс в стеке первого “передаваемого” значения, то есть параметров при вызове или возвращаемых значений при возврате. (Остальные значения находятся в последовательных индексах). Используя этот индекс, вы можете получать и изменять эти значения черезlua_getlocalиlua_setlocal. Это поле имеет значение только во время хука вызова, обозначая первый параметр, или хука возврата, обозначая первое возвращаемое значение. (Для хуков вызова это значение всегда равно 1).ntransfer: Количество передаваемых значений (см. предыдущий пункт). (Для вызовов функций Lua это значение всегда равноnparams).
lua_gethook
[-0, +0, –]
lua_Hook lua_gethook (lua_State *L);
Возвращает текущую функцию хука.
lua_gethookcount
[-0, +0, –]
int lua_gethookcount (lua_State *L);
Возвращает текущий счетчик хука.
lua_gethookmask
[-0, +0, –]
int lua_gethookmask (lua_State *L);
Возвращает текущую маску хука.
lua_getinfo
[-(0|1), +(0|1|2), m]
int lua_getinfo (lua_State *L, const char *what, lua_Debug *ar);
Получает информацию о конкретной функции или вызове функции.
Чтобы получить информацию о вызове функции, параметр ar должен быть действительной записью активации, которая была заполнена предыдущим вызовом lua_getstack или передана в качестве аргумента хуку (см. lua_Hook).
Чтобы получить информацию о функции, вы помещаете ее в стек и начинаете строку what с символа '>'. (В этом случае lua_getinfo извлекает функцию с вершины стека). Например, чтобы узнать, в какой строке была определена функция f, можно написать следующий код:
lua_Debug ar;
lua_getglobal(L, "f"); /* получить глобальную 'f' */
lua_getinfo(L, ">S", &ar);
printf("%d\n", ar.linedefined);
Каждый символ в строке what выбирает некоторые поля структуры ar для заполнения или значение для помещения в стек. (Эти символы также задокументированы в объявлении структуры lua_Debug, в скобках в комментариях после каждого поля).
'f': помещает в стек функцию, которая выполняется на данном уровне;'l': заполняет полеcurrentline;'n': заполняет поляnameиnamewhat;'r': заполняет поляftransferиntransfer;'S': заполняет поляsource,short_src,linedefined,lastlinedefinedиwhat;'t': заполняет поляistailcallиextraargs;'u': заполняет поляnups,nparamsиisvararg;'L': помещает в стек таблицу, индексами которой являются строки в функции с некоторым ассоциированным кодом, то есть строки, в которых можно поставить точку останова. (Строки без кода включают пустые строки и комментарии). Если эта опция дана вместе с опцией'f', ее таблица помещается после функции. Это единственная опция, которая может вызвать ошибку памяти.
Эта функция возвращает 0, чтобы сигнализировать о недопустимой опции в what; даже в этом случае допустимые опции обрабатываются корректно.
lua_getlocal
[-0, +(0|1), –]
const char *lua_getlocal (lua_State *L, const lua_Debug *ar, int n);
Получает информацию о локальной переменной или временном значении заданной записи активации или заданной функции.
В первом случае параметр ar должен быть действительной записью активации, которая была заполнена предыдущим вызовом lua_getstack или передана в качестве аргумента хуку (см. lua_Hook). Индекс n выбирает, какую локальную переменную инспектировать; подробности об индексах и именах переменных см. в debug.getlocal.
lua_getlocal помещает значение переменной в стек и возвращает ее имя.
Во втором случае ar должен быть NULL, а инспектируемая функция должна находиться на вершине стека. В этом случае видны только параметры функций Lua (поскольку нет информации о том, какие переменные активны), и значения в стек не помещаются.
Возвращает NULL (и ничего не помещает), когда индекс больше количества активных локальных переменных.
lua_getstack
[-0, +0, –]
int lua_getstack (lua_State *L, int level, lua_Debug *ar);
Получает информацию о стеке времени выполнения интерпретатора.
Эта функция заполняет части структуры lua_Debug идентификацией записи активации функции, выполняющейся на заданном уровне. Уровень 0 — это текущая выполняющаяся функция, тогда как уровень n+1 — это функция, которая вызвала уровень n (за исключением хвостовых вызовов, которые не учитываются в стеке). При вызове с уровнем, превышающим глубину стека, lua_getstack возвращает 0; в противном случае возвращает 1.
lua_getupvalue
[-0, +(0|1), –]
const char *lua_getupvalue (lua_State *L, int funcindex, int n);
Получает информацию об n-м upvalue замыкания по индексу funcindex. Помещает значение upvalue в стек и возвращает его имя. Возвращает NULL (и ничего не помещает), когда индекс n больше количества upvalue.
Дополнительную информацию об upvalue см. в debug.getupvalue.
lua_Hook
typedef void (*lua_Hook) (lua_State *L, lua_Debug *ar);
Тип для отладочных функций хука.
Всякий раз, когда вызывается хук, его аргумент ar имеет поле event, установленное в конкретное событие, которое вызвало хук. Lua идентифицирует эти события следующими константами: LUA_HOOKCALL, LUA_HOOKRET, LUA_HOOKTAILCALL, LUA_HOOKLINE и LUA_HOOKCOUNT. Более того, для событий строки также устанавливается поле currentline. Чтобы получить значение любого другого поля в ar, хук должен вызвать lua_getinfo.
Для событий вызова event может быть LUA_HOOKCALL (обычное значение) или LUA_HOOKTAILCALL (для хвостового вызова); в этом случае не будет соответствующего события возврата.
Пока Lua выполняет хук, он отключает другие вызовы хуков. Следовательно, если хук вызывает обратно в Lua для выполнения функции или чанка, это выполнение происходит без каких-либо вызовов хуков.
Функции хуков не могут иметь продолжений, то есть они не могут вызывать lua_yieldk, lua_pcallk или lua_callk с не-null k.
Функции хуков могут выполнять yield при следующих условиях: Только события счетчика и строки могут выполнять yield; чтобы выполнить yield, функция хука должна завершить свое выполнение вызовом lua_yield с nresults, равным нулю (то есть без значений).
lua_sethook
[-0, +0, –]
void lua_sethook (lua_State *L, lua_Hook f, int mask, int count);
Устанавливает отладочную функцию хука.
Аргумент f — функция хука. mask указывает, на каких событиях будет вызываться хук: она формируется побитовым ИЛИ констант LUA_MASKCALL, LUA_MASKRET, LUA_MASKLINE и LUA_MASKCOUNT. Аргумент count имеет значение только тогда, когда маска включает LUA_MASKCOUNT. Для каждого события хук вызывается, как описано ниже:
- Хук вызова: вызывается, когда интерпретатор вызывает функцию. Хук вызывается сразу после того, как Lua входит в новую функцию.
- Хук возврата: вызывается, когда интерпретатор возвращается из функции. Хук вызывается непосредственно перед тем, как Lua покидает функцию.
- Хук строки: вызывается, когда интерпретатор собирается начать выполнение новой строки кода или когда он перепрыгивает назад в коде (даже на ту же строку). Это событие происходит только во время выполнения Lua функции Lua.
- Хук счетчика: вызывается после того, как интерпретатор выполняет каждые
countинструкций. Это событие происходит только во время выполнения Lua функции Lua.
Хуки отключаются установкой mask в ноль.
lua_setlocal
[-(0|1), +0, –]
const char *lua_setlocal (lua_State *L, const lua_Debug *ar, int n);
Устанавливает значение локальной переменной заданной записи активации. Присваивает значение на вершине стека переменной и возвращает ее имя. Также извлекает значение из стека.
Возвращает NULL (и ничего не извлекает), когда индекс больше количества активных локальных переменных.
Параметры ar и n такие же, как в функции lua_getlocal.
lua_setupvalue
[-(0|1), +0, –]
const char *lua_setupvalue (lua_State *L, int funcindex, int n);
Устанавливает значение upvalue замыкания. Присваивает значение на вершине стека upvalue и возвращает его имя. Также извлекает значение из стека.
Возвращает NULL (и ничего не извлекает), когда индекс n больше количества upvalue.
Параметры funcindex и n такие же, как в функции lua_getupvalue.
lua_upvalueid
[-0, +0, –]
void *lua_upvalueid (lua_State *L, int funcindex, int n);
Возвращает уникальный идентификатор для upvalue с номером n из замыкания по индексу funcindex.
Эти уникальные идентификаторы позволяют программе проверять, разделяют ли разные замыкания upvalue. Замыкания Lua, которые разделяют upvalue (то есть обращаются к одной и той же внешней локальной переменной), будут возвращать идентичные идентификаторы для этих индексов upvalue.
Параметры funcindex и n такие же, как в функции lua_getupvalue, но n не может быть больше количества upvalue.
lua_upvaluejoin
[-0, +0, –]
void lua_upvaluejoin (lua_State *L, int funcindex1, int n1,
int funcindex2, int n2);
Делает так, чтобы n1-е upvalue замыкания Lua по индексу funcindex1 ссылалось на n2-е upvalue замыкания Lua по индексу funcindex2.
2.4 - Вспомогательная библиотека Lua
Полное описание функций и типов вспомогательной библиотеки Lua (lauxlib)
Оглавление
- Введение
- Функции и типы
- luaL_addchar
- luaL_addgsub
- luaL_addlstring
- luaL_addsize
- luaL_addstring
- luaL_addvalue
- luaL_argcheck
- luaL_argerror
- luaL_argexpected
- luaL_Buffer
- luaL_buffaddr
- luaL_buffinit
- luaL_bufflen
- luaL_buffinitsize
- luaL_buffsub
- luaL_callmeta
- luaL_checkany
- luaL_checkinteger
- luaL_checklstring
- luaL_checknumber
- luaL_checkoption
- luaL_checkstack
- luaL_checkstring
- luaL_checktype
- luaL_checkudata
- luaL_checkversion
- luaL_dofile
- luaL_dostring
- luaL_error
- luaL_execresult
- luaL_fileresult
- luaL_getmetafield
- luaL_getmetatable
- luaL_getsubtable
- luaL_gsub
- luaL_len
- luaL_loadbuffer
- luaL_loadbufferx
- luaL_loadfile
- luaL_loadfilex
- luaL_loadstring
- luaL_makeseed
- luaL_newlib
- luaL_newlibtable
- luaL_newmetatable
- luaL_newstate
- luaL_opt
- luaL_optinteger
- luaL_optlstring
- luaL_optnumber
- luaL_optstring
- luaL_prepbuffer
- luaL_prepbuffsize
- luaL_pushfail
- luaL_pushresult
- luaL_pushresultsize
- luaL_ref
- luaL_Reg
- luaL_requiref
- luaL_setfuncs
- luaL_setmetatable
- luaL_alloc
- luaL_Stream
- luaL_testudata
- luaL_tolstring
- luaL_traceback
- luaL_typeerror
- luaL_typename
- luaL_unref
- luaL_where
Введение
Вспомогательная библиотека предоставляет несколько удобных функций для взаимодействия C с Lua. В то время как базовый API предоставляет примитивные функции для всех взаимодействий между C и Lua, вспомогательная библиотека предоставляет функции более высокого уровня для некоторых распространенных задач.
Все функции и типы из вспомогательной библиотеки определены в заголовочном файле lauxlib.h и имеют префикс luaL_.
Все функции вспомогательной библиотеки построены поверх базового API, поэтому они не предоставляют ничего, что нельзя было бы сделать с помощью этого API. Тем не менее, использование вспомогательной библиотеки обеспечивает большую согласованность вашего кода.
Некоторые функции во вспомогательной библиотеке используют внутри себя несколько дополнительных слотов стека. Когда функция вспомогательной библиотеки использует менее пяти слотов, она не проверяет размер стека; она просто предполагает, что слотов достаточно.
Некоторые функции вспомогательной библиотеки используются для проверки аргументов функций C. Поскольку сообщение об ошибке форматируется для аргументов (например, "bad argument #1"), вы не должны использовать эти функции для других значений стека.
Функции, называемые luaL_check*, всегда вызывают ошибку, если проверка не пройдена.
Функции и типы
Здесь мы перечисляем все функции и типы из вспомогательной библиотеки в алфавитном порядке.
luaL_addchar
[-?, +?, m]
void luaL_addchar (luaL_Buffer *B, char c);
Добавляет байт c в буфер B (см. luaL_Buffer).
luaL_addgsub
[-?, +?, m]
const void luaL_addgsub (luaL_Buffer *B, const char *s,
const char *p, const char *r);
Добавляет копию строки s в буфер B (см. luaL_Buffer), заменяя любое вхождение строки p строкой r.
luaL_addlstring
[-?, +?, m]
void luaL_addlstring (luaL_Buffer *B, const char *s, size_t l);
Добавляет строку, на которую указывает s, длиной l в буфер B (см. luaL_Buffer). Строка может содержать встроенные нули.
luaL_addsize
[-?, +?, –]
void luaL_addsize (luaL_Buffer *B, size_t n);
Добавляет в буфер B строку длиной n, предварительно скопированную в область буфера (см. luaL_prepbuffer).
luaL_addstring
[-?, +?, m]
void luaL_addstring (luaL_Buffer *B, const char *s);
Добавляет строку с завершающим нулем, на которую указывает s, в буфер B (см. luaL_Buffer).
luaL_addvalue
[-?, +?, m]
void luaL_addvalue (luaL_Buffer *B);
Добавляет значение на вершине стека в буфер B (см. luaL_Buffer). Выталкивает значение.
Это единственная функция строковых буферов, которую можно (и нужно) вызывать с дополнительным элементом в стеке, который является значением, добавляемым в буфер.
luaL_argcheck
[-0, +0, v]
void luaL_argcheck (lua_State *L,
int cond,
int arg,
const char *extramsg);
Проверяет, является ли cond истиной. Если нет, вызывает ошибку со стандартным сообщением (см. luaL_argerror).
luaL_argerror
[-0, +0, v]
int luaL_argerror (lua_State *L, int arg, const char *extramsg);
Вызывает ошибку, сообщающую о проблеме с аргументом arg функции C, которая ее вызвала, используя стандартное сообщение, которое включает extramsg в качестве комментария:
bad argument #arg to 'funcname' (extramsg)
Эта функция никогда не возвращается.
luaL_argexpected
[-0, +0, v]
void luaL_argexpected (lua_State *L,
int cond,
int arg,
const char *tname);
Проверяет, является ли cond истиной. Если нет, вызывает ошибку о типе аргумента arg со стандартным сообщением (см. luaL_typeerror).
luaL_Buffer
typedef struct luaL_Buffer luaL_Buffer;
Тип для строкового буфера.
Строковый буфер позволяет коду C строить строки Lua по частям. Шаблон его использования следующий:
- Сначала объявите переменную
bтипаluaL_Buffer. - Затем инициализируйте ее вызовом
luaL_buffinit(L, &b). - Затем добавляйте фрагменты строки в буфер, вызывая любую из функций
luaL_add*. - Завершите вызовом
luaL_pushresult(&b). Этот вызов оставляет итоговую строку на вершине стека.
Если вы заранее знаете максимальный размер результирующей строки, вы можете использовать буфер следующим образом:
- Сначала объявите переменную
bтипаluaL_Buffer. - Затем инициализируйте ее и предварительно выделите пространство размером
szвызовомluaL_buffinitsize(L, &b, sz). - Затем создайте строку в этом пространстве.
- Завершите вызовом
luaL_pushresultsize(&b, sz), гдеsz— общий размер результирующей строки, скопированной в это пространство (который может быть меньше или равен предварительно выделенному размеру).
Во время своей нормальной работы строковый буфер использует переменное количество слотов стека. Поэтому при использовании буфера вы не можете предполагать, что знаете, где находится вершина стека. Вы можете использовать стек между последовательными вызовами операций с буфером, если это использование сбалансировано; то есть, когда вы вызываете операцию с буфером, стек находится на том же уровне, на котором он был сразу после предыдущей операции с буфером. (Единственным исключением из этого правила является luaL_addvalue.) После вызова luaL_pushresult стек возвращается на уровень, на котором он был при инициализации буфера, плюс итоговая строка на его вершине.
luaL_buffaddr
[-0, +0, –]
char *luaL_buffaddr (luaL_Buffer *B);
Возвращает адрес текущего содержимого буфера B (см. luaL_Buffer). Обратите внимание, что любое добавление в буфер может сделать этот адрес недействительным.
luaL_buffinit
[-0, +?, –]
void luaL_buffinit (lua_State *L, luaL_Buffer *B);
Инициализирует буфер B (см. luaL_Buffer). Эта функция не выделяет никакого пространства; буфер должен быть объявлен как переменная.
luaL_bufflen
[-0, +0, –]
size_t luaL_bufflen (luaL_Buffer *B);
Возвращает длину текущего содержимого буфера B (см. luaL_Buffer).
luaL_buffinitsize
[-?, +?, m]
char *luaL_buffinitsize (lua_State *L, luaL_Buffer *B, size_t sz);
Эквивалент последовательности luaL_buffinit, luaL_prepbuffsize.
luaL_buffsub
[-?, +?, –]
void luaL_buffsub (luaL_Buffer *B, int n);
Удаляет n байт из буфера B (см. luaL_Buffer). Буфер должен иметь как минимум столько байт.
luaL_callmeta
[-0, +(0|1), e]
int luaL_callmeta (lua_State *L, int obj, const char *e);
Вызывает метаметод.
Если объект по индексу obj имеет метатаблицу и эта метатаблица имеет поле e, эта функция вызывает это поле, передавая объект в качестве единственного аргумента. В этом случае функция возвращает true и помещает в стек значение, возвращенное вызовом. Если метатаблицы нет или нет метаметода, функция возвращает false, не помещая никакого значения в стек.
luaL_checkany
[-0, +0, v]
void luaL_checkany (lua_State *L, int arg);
Проверяет, есть ли у функции аргумент любого типа (включая nil) в позиции arg.
luaL_checkinteger
[-0, +0, v]
lua_Integer luaL_checkinteger (lua_State *L, int arg);
Проверяет, является ли аргумент функции arg целым числом (или может быть преобразован в целое число), и возвращает это целое число.
luaL_checklstring
[-0, +0, v]
const char *luaL_checklstring (lua_State *L, int arg, size_t *l);
Проверяет, является ли аргумент функции arg строкой, и возвращает эту строку; если l не NULL, заполняет его ссылку длиной строки.
Эта функция использует lua_tolstring для получения результата, поэтому здесь применяются все преобразования и предостережения этой функции.
luaL_checknumber
[-0, +0, v]
lua_Number luaL_checknumber (lua_State *L, int arg);
Проверяет, является ли аргумент функции arg числом, и возвращает это число, преобразованное в lua_Number.
luaL_checkoption
[-0, +0, v]
int luaL_checkoption (lua_State *L,
int arg,
const char *def,
const char *const lst[]);
Проверяет, является ли аргумент функции arg строкой, и ищет эту строку в массиве lst (который должен заканчиваться NULL). Возвращает индекс в массиве, где была найдена строка. Вызывает ошибку, если аргумент не является строкой или если строка не может быть найдена.
Если def не NULL, функция использует def как значение по умолчанию, когда аргумент arg отсутствует или когда этот аргумент равен nil.
Это полезная функция для сопоставления строк с перечислениями C. (Обычное соглашение в библиотеках Lua — использовать строки вместо чисел для выбора опций.)
luaL_checkstack
[-0, +0, v]
void luaL_checkstack (lua_State *L, int sz, const char *msg);
Увеличивает размер стека до top + sz элементов, вызывая ошибку, если стек не может вырасти до этого размера. msg — дополнительный текст для сообщения об ошибке (или NULL для отсутствия дополнительного текста).
luaL_checkstring
[-0, +0, v]
const char *luaL_checkstring (lua_State *L, int arg);
Проверяет, является ли аргумент функции arg строкой, и возвращает эту строку.
Эта функция использует lua_tolstring для получения результата, поэтому здесь применяются все преобразования и предостережения этой функции.
luaL_checktype
[-0, +0, v]
void luaL_checktype (lua_State *L, int arg, int t);
Проверяет, имеет ли аргумент функции arg тип t. См. lua_type для кодировки типов для t.
luaL_checkudata
[-0, +0, v]
void *luaL_checkudata (lua_State *L, int arg, const char *tname);
Проверяет, является ли аргумент функции arg пользовательскими данными типа tname (см. luaL_newmetatable), и возвращает адрес блока памяти пользовательских данных (см. lua_touserdata).
luaL_checkversion
[-0, +0, v]
void luaL_checkversion (lua_State *L);
Проверяет, используют ли код, выполняющий вызов, и вызываемая библиотека Lua одну и ту же версию Lua и одни и те же числовые типы.
luaL_dofile
[-0, +?, m]
int luaL_dofile (lua_State *L, const char *filename);
Загружает и выполняет указанный файл. Определен как следующий макрос:
(luaL_loadfile(L, filename) || lua_pcall(L, 0, LUA_MULTRET, 0))
Возвращает 0 (LUA_OK), если ошибок нет, или 1 в случае ошибок. (За исключением ошибок нехватки памяти, которые вызываются.)
luaL_dostring
[-0, +?, –]
int luaL_dostring (lua_State *L, const char *str);
Загружает и выполняет указанную строку. Определен как следующий макрос:
(luaL_loadstring(L, str) || lua_pcall(L, 0, LUA_MULTRET, 0))
Возвращает 0 (LUA_OK), если ошибок нет, или 1 в случае ошибок.
luaL_error
[-0, +0, v]
int luaL_error (lua_State *L, const char *fmt, ...);
Вызывает ошибку. Формат сообщения об ошибке задается fmt плюс любые дополнительные аргументы, следуя тем же правилам, что и lua_pushfstring. Она также добавляет в начало сообщения имя файла и номер строки, где произошла ошибка, если эта информация доступна.
Эта функция никогда не возвращается, но идиоматично использовать ее в функциях C как return luaL_error(args).
luaL_execresult
[-0, +3, m]
int luaL_execresult (lua_State *L, int stat);
Эта функция создает возвращаемые значения для функций, связанных с процессами, в стандартной библиотеке (os.execute и io.close).
luaL_fileresult
[-0, +(1|3), m]
int luaL_fileresult (lua_State *L, int stat, const char *fname);
Эта функция создает возвращаемые значения для функций, связанных с файлами, в стандартной библиотеке (io.open, os.rename, file:seek и т.д.).
luaL_getmetafield
[-0, +(0|1), m]
int luaL_getmetafield (lua_State *L, int obj, const char *e);
Помещает в стек поле e из метатаблицы объекта по индексу obj и возвращает тип помещенного значения. Если объект не имеет метатаблицы или если метатаблица не имеет этого поля, ничего не помещает и возвращает LUA_TNIL.
luaL_getmetatable
[-0, +1, m]
int luaL_getmetatable (lua_State *L, const char *tname);
Помещает в стек метатаблицу, связанную с именем tname в реестре (см. luaL_newmetatable), или nil, если с этим именем не связано метатаблицы. Возвращает тип помещенного значения.
luaL_getsubtable
[-0, +1, e]
int luaL_getsubtable (lua_State *L, int idx, const char *fname);
Обеспечивает, что значение t[fname], где t — значение по индексу idx, является таблицей, и помещает эту таблицу в стек. Возвращает true, если находит там существующую таблицу, и false, если создает новую таблицу.
luaL_gsub
[-0, +1, m]
const char *luaL_gsub (lua_State *L,
const char *s,
const char *p,
const char *r);
Создает копию строки s, заменяя любое вхождение строки p строкой r. Помещает результирующую строку в стек и возвращает ее.
luaL_len
[-0, +0, e]
lua_Integer luaL_len (lua_State *L, int index);
Возвращает “длину” значения по указанному индексу в виде числа; это эквивалентно оператору # в Lua (см. §3.4.7). Вызывает ошибку, если результат операции не является целым числом. (Этот случай может произойти только через метаметоды.)
luaL_loadbuffer
[-0, +1, –]
int luaL_loadbuffer (lua_State *L,
const char *buff,
size_t sz,
const char *name);
Эквивалент luaL_loadbufferx с mode, равным NULL.
luaL_loadbufferx
[-0, +1, –]
int luaL_loadbufferx (lua_State *L,
const char *buff,
size_t sz,
const char *name,
const char *mode);
Загружает буфер как чанк Lua. Эта функция использует lua_load для загрузки чанка в буфере, на который указывает buff, размером sz.
Эта функция возвращает те же результаты, что и lua_load. name — имя чанка, используемое для отладочной информации и сообщений об ошибках. Строка mode работает так же, как в функции lua_load. В частности, эта функция поддерживает режим 'B' для фиксированных буферов.
luaL_loadfile
[-0, +1, m]
int luaL_loadfile (lua_State *L, const char *filename);
Эквивалент luaL_loadfilex с mode, равным NULL.
luaL_loadfilex
[-0, +1, m]
int luaL_loadfilex (lua_State *L, const char *filename,
const char *mode);
Загружает файл как чанк Lua. Эта функция использует lua_load для загрузки чанка в файле с именем filename. Если filename равен NULL, то загружает из стандартного ввода. Первая строка в файле игнорируется, если она начинается с #.
Строка mode работает так же, как в функции lua_load.
Эта функция возвращает те же результаты, что и lua_load, или LUA_ERRFILE для ошибок, связанных с файлом.
Как и lua_load, эта функция только загружает чанк; она не выполняет его.
luaL_loadstring
[-0, +1, –]
int luaL_loadstring (lua_State *L, const char *s);
Загружает строку как чанк Lua. Эта функция использует lua_load для загрузки чанка в строке с завершающим нулем s.
Эта функция возвращает те же результаты, что и lua_load.
Также как и lua_load, эта функция только загружает чанк; она не выполняет его.
luaL_makeseed
[-0, +0, –]
unsigned int luaL_makeseed (lua_State *L);
Возвращает значение со слабой попыткой случайности. Параметр L может быть NULL, если состояние Lua недоступно.
luaL_newlib
[-0, +1, m]
void luaL_newlib (lua_State *L, const luaL_Reg l[]);
Создает новую таблицу и регистрирует в ней функции из списка l.
Реализована как следующий макрос:
(luaL_newlibtable(L,l), luaL_setfuncs(L,l,0))
Массив l должен быть фактическим массивом, а не указателем на него.
luaL_newlibtable
[-0, +1, m]
void luaL_newlibtable (lua_State *L, const luaL_Reg l[]);
Создает новую таблицу с размером, оптимизированным для хранения всех записей в массиве l (но фактически не сохраняет их). Предназначена для использования в сочетании с luaL_setfuncs (см. luaL_newlib).
Реализована как макрос. Массив l должен быть фактическим массивом, а не указателем на него.
luaL_newmetatable
[-0, +1, m]
int luaL_newmetatable (lua_State *L, const char *tname);
Если в реестре уже есть ключ tname, возвращает 0. В противном случае создает новую таблицу для использования в качестве метатаблицы для пользовательских данных, добавляет в эту новую таблицу пару __name = tname, добавляет в реестр пару [tname] = new table и возвращает 1.
В обоих случаях функция помещает в стек итоговое значение, связанное с tname в реестре.
luaL_newstate
[-0, +0, –]
lua_State *luaL_newstate (void);
Создает новое состояние Lua. Вызывает lua_newstate с luaL_alloc в качестве функции распределения памяти и результатом luaL_makeseed(NULL) в качестве seed, а затем устанавливает функцию предупреждения и функцию паники (см. §4.4), которые выводят сообщения в стандартный вывод ошибок.
Возвращает новое состояние или NULL в случае ошибки выделения памяти.
luaL_opt
[-0, +0, –]
T luaL_opt (L, func, arg, dflt);
Этот макрос определяется следующим образом:
(lua_isnoneornil(L,(arg)) ? (dflt) : func(L,(arg)))
Словами: если аргумент arg равен nil или отсутствует, макрос возвращает значение по умолчанию dflt. В противном случае он возвращает результат вызова func с состоянием L и индексом аргумента arg в качестве аргументов. Обратите внимание, что он вычисляет выражение dflt только при необходимости.
luaL_optinteger
[-0, +0, v]
lua_Integer luaL_optinteger (lua_State *L,
int arg,
lua_Integer d);
Если аргумент функции arg является целым числом (или может быть преобразован в целое число), возвращает это целое число. Если этот аргумент отсутствует или равен nil, возвращает d. В противном случае вызывает ошибку.
luaL_optlstring
[-0, +0, v]
const char *luaL_optlstring (lua_State *L,
int arg,
const char *d,
size_t *l);
Если аргумент функции arg является строкой, возвращает эту строку. Если этот аргумент отсутствует или равен nil, возвращает d. В противном случае вызывает ошибку.
Если l не NULL, заполняет его ссылку длиной результата. Если результат NULL (возможно только при возврате d и d == NULL), его длина считается нулевой.
Эта функция использует lua_tolstring для получения результата, поэтому здесь применяются все преобразования и предостережения этой функции.
luaL_optnumber
[-0, +0, v]
lua_Number luaL_optnumber (lua_State *L, int arg, lua_Number d);
Если аргумент функции arg является числом, возвращает это число как lua_Number. Если этот аргумент отсутствует или равен nil, возвращает d. В противном случае вызывает ошибку.
luaL_optstring
[-0, +0, v]
const char *luaL_optstring (lua_State *L,
int arg,
const char *d);
Если аргумент функции arg является строкой, возвращает эту строку. Если этот аргумент отсутствует или равен nil, возвращает d. В противном случае вызывает ошибку.
luaL_prepbuffer
[-?, +?, m]
char *luaL_prepbuffer (luaL_Buffer *B);
Эквивалент luaL_prepbuffsize с предопределенным размером LUAL_BUFFERSIZE.
luaL_prepbuffsize
[-?, +?, m]
char *luaL_prepbuffsize (luaL_Buffer *B, size_t sz);
Возвращает адрес пространства размером sz, куда вы можете скопировать строку для добавления в буфер B (см. luaL_Buffer). После копирования строки в это пространство вы должны вызвать luaL_addsize с размером строки, чтобы фактически добавить ее в буфер.
luaL_pushfail
[-0, +1, –]
void luaL_pushfail (lua_State *L);
Помещает значение fail в стек (см. §6).
luaL_pushresult
[-?, +1, m]
void luaL_pushresult (luaL_Buffer *B);
Завершает использование буфера B, оставляя итоговую строку на вершине стека.
luaL_pushresultsize
[-?, +1, m]
void luaL_pushresultsize (luaL_Buffer *B, size_t sz);
Эквивалент последовательности luaL_addsize, luaL_pushresult.
luaL_ref
[-1, +0, m]
int luaL_ref (lua_State *L, int t);
Создает и возвращает ссылку в таблице по индексу t для объекта на вершине стека (и выталкивает объект).
Система ссылок использует целочисленные ключи таблицы. Ссылка — это уникальный целочисленный ключ; luaL_ref обеспечивает уникальность возвращаемых ключей. Запись 1 зарезервирована для внутреннего использования. Перед первым использованием luaL_ref целочисленные ключи таблицы должны образовывать правильную последовательность (без пропусков), а значение в записи 1 должно быть false: nil, если последовательность пуста, false в противном случае. Вы не должны вручную устанавливать целочисленные ключи в таблице после первого использования luaL_ref.
Вы можете получить объект, на который ссылается ссылка r, вызвав lua_rawgeti(L, t, r) или lua_geti(L, t, r). Функция luaL_unref освобождает ссылку.
Если объект на вершине стека равен nil, luaL_ref возвращает константу LUA_REFNIL. Гарантируется, что константа LUA_NOREF отличается от любой ссылки, возвращаемой luaL_ref.
luaL_Reg
typedef struct luaL_Reg {
const char *name;
lua_CFunction func;
} luaL_Reg;
Тип для массивов функций, регистрируемых luaL_setfuncs. name — имя функции, func — указатель на функцию. Любой массив luaL_Reg должен заканчиваться сигнальной записью, в которой и name, и func равны NULL.
luaL_requiref
[-0, +1, e]
void luaL_requiref (lua_State *L, const char *modname,
lua_CFunction openf, int glb);
Если package.loaded[modname] не является true, вызывает функцию openf со строкой modname в качестве аргумента и устанавливает результат вызова в package.loaded[modname], как если бы эта функция была вызвана через require.
Если glb равно true, также сохраняет модуль в глобальную переменную modname.
Оставляет копию модуля в стеке.
luaL_setfuncs
[-nup, +0, m]
void luaL_setfuncs (lua_State *L, const luaL_Reg *l, int nup);
Регистрирует все функции в массиве l (см. luaL_Reg) в таблице на вершине стека (ниже необязательных upvalues, см. далее).
Когда nup не равен нулю, все функции создаются с nup upvalues, инициализированными копиями nup значений, предварительно помещенных в стек поверх таблицы библиотеки. Эти значения выталкиваются из стека после регистрации.
Функция со значением NULL представляет заполнитель, который заполняется значением false.
luaL_setmetatable
[-0, +0, –]
void luaL_setmetatable (lua_State *L, const char *tname);
Устанавливает метатаблицу объекта на вершине стека как метатаблицу, связанную с именем tname в реестре (см. luaL_newmetatable).
luaL_alloc
void *luaL_alloc (void *ud, void *ptr, size_t osize, size_t nsize);
Стандартная функция распределения памяти для Lua (см. lua_Alloc), построенная поверх функций C realloc и free.
luaL_Stream
typedef struct luaL_Stream {
FILE *f;
lua_CFunction closef;
} luaL_Stream;
Стандартное представление файловых дескрипторов, используемое стандартной библиотекой ввода-вывода.
Файловый дескриптор реализован как полные пользовательские данные с метатаблицей, называемой LUA_FILEHANDLE (где LUA_FILEHANDLE — это макрос с фактическим именем метатаблицы). Метатаблица создается библиотекой ввода-вывода (см. luaL_newmetatable).
Эти пользовательские данные должны начинаться со структуры luaL_Stream; они могут содержать другие данные после этой начальной структуры. Поле f указывает на соответствующий поток C или равно NULL, чтобы указать на не полностью созданный дескриптор. Поле closef указывает на функцию Lua, которая будет вызвана для закрытия потока при закрытии или сборке дескриптора; эта функция получает файловый дескриптор в качестве единственного аргумента и должна возвращать либо true в случае успеха, либо false плюс сообщение об ошибке в случае ошибки. Как только Lua вызывает это поле, он изменяет значение поля на NULL, чтобы сигнализировать о том, что дескриптор закрыт.
luaL_testudata
[-0, +0, m]
void *luaL_testudata (lua_State *L, int arg, const char *tname);
Эта функция работает как luaL_checkudata, за исключением того, что при неудачной проверке она возвращает NULL вместо вызова ошибки.
luaL_tolstring
[-0, +1, e]
const char *luaL_tolstring (lua_State *L, int idx, size_t *len);
Преобразует любое значение Lua по указанному индексу в строку C в разумном формате. Результирующая строка помещается в стек и также возвращается функцией (см. §4.1.3). Если len не NULL, функция также устанавливает *len в длину строки.
Если значение имеет метатаблицу с полем __tostring, то luaL_tolstring вызывает соответствующий метаметод со значением в качестве аргумента и использует результат вызова в качестве своего результата.
luaL_traceback
[-0, +1, m]
void luaL_traceback (lua_State *L, lua_State *L1, const char *msg,
int level);
Создает и помещает в стек трассировку стека L1. Если msg не NULL, он добавляется в начало трассировки. Параметр level указывает, с какого уровня начинать трассировку.
luaL_typeerror
[-0, +0, v]
int luaL_typeerror (lua_State *L, int arg, const char *tname);
Вызывает ошибку типа для аргумента arg функции C, которая ее вызвала, используя стандартное сообщение; tname — это “имя” ожидаемого типа. Эта функция никогда не возвращается.
luaL_typename
[-0, +0, –]
const char *luaL_typename (lua_State *L, int index);
Возвращает имя типа значения по указанному индексу.
luaL_unref
[-0, +0, –]
void luaL_unref (lua_State *L, int t, int ref);
Освобождает ссылку (см. luaL_ref). Целое число ref должно быть либо LUA_NOREF, либо LUA_REFNIL, либо ссылкой, ранее возвращенной luaL_ref и еще не освобожденной. Если ref равен LUA_NOREF или LUA_REFNIL, эта функция ничего не делает. В противном случае запись удаляется из таблицы, чтобы объект, на который ссылались, мог быть собран, а ссылка ref могла быть снова использована luaL_ref.
luaL_where
[-0, +1, m]
void luaL_where (lua_State *L, int lvl);
Помещает в стек строку, идентифицирующую текущую позицию управления на уровне lvl в стеке вызовов. Обычно эта строка имеет следующий формат:
chunkname:currentline:
Уровень 0 — выполняющаяся функция, уровень 1 — функция, вызвавшая выполняющуюся функцию, и т.д.
Эта функция используется для построения префикса для сообщений об ошибках.
2.5 - Руководство по языку Lua: Стандартные библиотеки
Полное описание стандартных библиотек Lua, включая базовые функции, работу со строками, таблицами, математику, ввод/вывод, ОС и отладку
Оглавление
- Загрузка библиотек в коде C
- Базовые функции
- Управление сопрограммами
- Модули
- Манипуляции со строками
- Поддержка UTF-8
- Манипуляции с таблицами
- Математические функции
- Средства ввода и вывода
- Средства операционной системы
- Библиотека отладки
6 – Стандартные библиотеки
Стандартные библиотеки Lua предоставляют полезные функции, реализованные на C через C API. Некоторые из этих функций предоставляют основные службы для языка (например, type и getmetatable); другие предоставляют доступ к внешним службам (например, ввод/вывод); а третьи могли бы быть реализованы на самом Lua, но по разным причинам заслуживают реализации на C (например, table.sort).
Все библиотеки реализованы через официальный C API и предоставляются как отдельные модули C. Если не указано иное, эти библиотечные функции не корректируют количество своих аргументов в соответствии с ожидаемыми параметрами. Например, функцию, задокументированную как foo(arg), не следует вызывать без аргумента.
Обозначение fail означает ложное значение, представляющее некую неудачу. (В настоящее время fail эквивалентно nil, но это может измениться в будущих версиях. Рекомендуется всегда проверять успешность этих функций с помощью (not status), а не (status == nil).)
В настоящее время Lua имеет следующие стандартные библиотеки:
- базовая библиотека (§6.2);
- библиотека сопрограмм (§6.3);
- библиотека пакетов (§6.4);
- манипуляции со строками (§6.5);
- базовая поддержка UTF-8 (§6.6);
- манипуляции с таблицами (§6.7);
- математические функции (§6.8) (sin, log и т.д.);
- ввод и вывод (§6.9);
- средства операционной системы (§6.10);
- средства отладки (§6.11).
За исключением базовой библиотеки и библиотеки пакетов, каждая библиотека предоставляет все свои функции как поля глобальной таблицы или как методы своих объектов.
6.1 – Загрузка библиотек в коде C
Главная программа на C должна явно загрузить стандартные библиотеки в состояние, если она хочет, чтобы ее скрипты могли их использовать. Для этого главная программа может вызвать функцию luaL_openlibs. В качестве альтернативы, главная программа может выбрать, какие библиотеки открывать, используя luaL_openselectedlibs. Обе функции объявлены в заголовочном файле lualib.h.
Автономный интерпретатор lua (см. §7) уже открывает все стандартные библиотеки.
luaL_openlibs
[-0, +0, e]
void luaL_openlibs (lua_State *L);
Открывает все стандартные библиотеки Lua в данном состоянии.
luaL_openselectedlibs
[-0, +0, e]
void luaL_openselectedlibs (lua_State *L, int load, int preload);
Открывает (загружает) и предзагружает выбранные стандартные библиотеки в состояние L. (Предзагрузить означает добавить загрузчик библиотеки в таблицу package.preload, чтобы библиотеку можно было затребовать (require) позже в программе. Имейте в виду, что сам require предоставляется библиотекой пакетов. Если программа не загружает эту библиотеку, она не сможет ничего затребовать.)
Целое число load выбирает, какие библиотеки загружать; целое число preload выбирает, какие из незагруженных библиотек предзагружать. Оба являются масками, сформированными побитовым ИЛИ следующих констант:
LUA_GLIBK: базовая библиотека.LUA_LOADLIBK: библиотека пакетов.LUA_COLIBK: библиотека сопрограмм.LUA_STRLIBK: библиотека строк.LUA_UTF8LIBK: библиотека UTF-8.LUA_TABLIBK: библиотека таблиц.LUA_MATHLIBK: математическая библиотека.LUA_IOLIBK: библиотека ввода/вывода.LUA_OSLIBK: библиотека операционной системы.LUA_DBLIBK: библиотека отладки.
6.2 – Базовые функции
Базовая библиотека предоставляет ядро функций для Lua. Если вы не включаете эту библиотеку в свое приложение, вам следует тщательно проверить, нужно ли вам предоставлять реализации для некоторых ее средств.
assert (v [, message])
Вызывает ошибку, если значение ее аргумента v ложно (т.е. nil или false); в противном случае возвращает все свои аргументы. В случае ошибки message является объектом ошибки; при отсутствии по умолчанию используется "assertion failed!"
collectgarbage ([opt [, arg]])
Эта функция является универсальным интерфейсом к сборщику мусора. Она выполняет различные функции в зависимости от своего первого аргумента, opt:
"collect": Выполняет полный цикл сборки мусора. Это опция по умолчанию."stop": Останавливает автоматическое выполнение сборщика мусора. Сборщик будет запускаться только при явном вызове, до вызова для его перезапуска."restart": Перезапускает автоматическое выполнение сборщика мусора."count": Возвращает общий объем памяти, используемый Lua, в Кбайтах. Значение имеет дробную часть, так что умножение его на 1024 дает точное количество байтов, используемых Lua."step": Выполняет шаг сборки мусора. За этой опцией может следовать дополнительный аргумент, целое число с размером шага.Если размер — положительное
n, сборщик действует так, как будто было выделеноnновых байтов. Если размер равен нулю, сборщик выполняет базовый шаг. В инкрементальном режиме базовый шаг соответствует текущему размеру шага. В поколенческом режиме базовый шаг выполняет полную малую сборку или инкрементальный шаг, если сборщик его запланировал.В инкрементальном режиме функция возвращает
true, если шаг завершил цикл сборки. В поколенческом режиме функция возвращаетtrue, если шаг завершил большую сборку."isrunning": Возвращает булево значение, указывающее, запущен ли сборщик (т.е. не остановлен)."incremental": Изменяет режим сборщика на инкрементальный и возвращает предыдущий режим."generational": Изменяет режим сборщика на поколенческий и возвращает предыдущий режим."param": Изменяет и/или извлекает значения параметра сборщика. За этой опцией должны следовать один или два дополнительных аргумента: имя изменяемого или извлекаемого параметра (строка) и необязательное новое значение для этого параметра, целое число в диапазоне[0,100000]. Первый аргумент должен иметь одно из следующих значений:"minormul": Множитель малой сборки."majorminor": Множитель перехода от большой к малой сборке."minormajor": Множитель перехода от малой к большой сборке."pause": Пауза сборщика мусора."stepmul": Множитель шага."stepsize": Размер шага.
Вызов всегда возвращает предыдущее значение параметра. Если вызов не передает новое значение, значение остается неизменным.
Lua хранит эти значения в сжатом формате, поэтому значение, возвращаемое как предыдущее, может не точно совпадать с последним установленным значением.
См. §2.5 для более подробной информации о сборке мусора и некоторых из этих опций.
Эту функцию не следует вызывать из финализатора.
dofile ([filename])
Открывает указанный файл и выполняет его содержимое как чанк Lua, возвращая все значения, возвращенные чанком. При вызове без аргументов dofile выполняет содержимое стандартного ввода (stdin). В случае ошибок dofile передает ошибку своему вызывающему коду. (То есть dofile не работает в защищенном режиме.)
error (message [, level])
Вызывает ошибку (см. §2.3) с message в качестве объекта ошибки. Эта функция никогда не возвращает управление.
Обычно error добавляет некоторую информацию о позиции ошибки в начало сообщения, если сообщение является строкой. Аргумент level указывает, как получить позицию ошибки. При уровне 1 (по умолчанию) позиция ошибки — это место вызова функции error. Уровень 2 указывает на ошибку в месте вызова функции, которая вызвала error; и так далее. Передача уровня 0 предотвращает добавление информации о позиции ошибки в сообщение.
_G
Глобальная переменная (не функция), которая содержит глобальное окружение (см. §2.2). Сама Lua не использует эту переменную; изменение ее значения не влияет ни на какое окружение, и наоборот.
getmetatable (object)
Если object не имеет метатаблицы, возвращает nil. В противном случае, если метатаблица объекта имеет поле __metatable, возвращает связанное с ним значение. В противном случае возвращает метатаблицу данного объекта.
ipairs (t)
Возвращает три значения (функцию-итератор, значение t и 0), так что конструкция
for i,v in ipairs(t) do body end
будет итерироваться по парам ключ-значение (1,t[1]), (2,t[2]), …, до первого отсутствующего индекса.
load (chunk [, chunkname [, mode [, env]]])
Загружает чанк.
Если chunk — строка, то чанк является этой строкой. Если chunk — функция, load вызывает ее повторно для получения частей чанка. Каждый вызов chunk должен возвращать строку, которая конкатенируется с предыдущими результатами. Возврат пустой строки, nil или отсутствие возврата сигнализирует о конце чанка.
Если синтаксических ошибок нет, load возвращает скомпилированный чанк как функцию; в противном случае возвращает fail плюс сообщение об ошибке.
Когда вы загружаете главный чанк, результирующая функция всегда будет иметь ровно одно верхнее значение (upvalue) — переменную _ENV (см. §2.2). Однако, когда вы загружаете бинарный чанк, созданный из функции (см. string.dump), результирующая функция может иметь произвольное количество верхних значений, и нет гарантии, что ее первым верхним значением будет переменная _ENV. (Неглавная функция может даже не иметь верхнего значения _ENV.)
Независимо от этого, если результирующая функция имеет какие-либо верхние значения, ее первое верхнее значение устанавливается в значение env, если этот параметр указан, или в значение глобального окружения. Другие верхние значения инициализируются как nil. Все верхние значения являются новыми, то есть они не разделяются ни с какой другой функцией.
chunkname используется как имя чанка для сообщений об ошибках и отладочной информации (см. §4.7). При отсутствии по умолчанию используется chunk, если chunk — строка, или "=(load)" в противном случае.
Строка mode определяет, может ли чанк быть текстовым или бинарным (то есть предварительно скомпилированным чанком). Это может быть строка "b" (только бинарные чанки), "t" (только текстовые чанки) или "bt" (и бинарные, и текстовые). По умолчанию "bt".
Lua не проверяет целостность бинарных чанков. Злонамеренно созданные бинарные чанки могут привести к краху интерпретатора. Вы можете использовать параметр mode, чтобы предотвратить загрузку бинарных чанков.
loadfile ([filename [, mode [, env]]])
Аналогична load, но получает чанк из файла filename или из стандартного ввода, если имя файла не указано.
next (table [, index])
Позволяет программе обойти все поля таблицы. Ее первый аргумент — таблица, а второй аргумент — индекс в этой таблице. Вызов next возвращает следующий индекс таблицы и связанное с ним значение. При вызове с nil в качестве второго аргумента next возвращает начальный индекс и связанное с ним значение. При вызове с последним индексом или с nil в пустой таблице next возвращает nil. Если второй аргумент отсутствует, он интерпретируется как nil. В частности, вы можете использовать next(t) для проверки, пуста ли таблица.
Порядок перечисления индексов не определен, даже для числовых индексов. (Для обхода таблицы в числовом порядке используйте числовой for.)
Не следует присваивать значение несуществующему полю таблицы во время ее обхода. Однако вы можете изменять существующие поля. В частности, вы можете устанавливать существующие поля в nil.
pairs (t)
Если t имеет метаметод __pairs, вызывает его с t в качестве аргумента и возвращает первые четыре результата вызова.
В противном случае возвращает функцию next, таблицу t и два значения nil, так что конструкция
for k,v in pairs(t) do body end
будет итерироваться по всем парам ключ-значение таблицы t.
См. предостережения о модификации таблицы во время ее обхода в описании функции next.
pcall (f [, arg1, ···])
Вызывает функцию f с заданными аргументами в защищенном режиме. Это означает, что любая ошибка внутри f не распространяется дальше; вместо этого pcall перехватывает ошибку и возвращает код состояния. Ее первый результат — код состояния (булево значение), который равен true, если вызов завершился успешно без ошибок. В таком случае pcall также возвращает все результаты вызова после этого первого результата. В случае любой ошибки pcall возвращает false плюс объект ошибки. Обратите внимание, что ошибки, перехваченные pcall, не вызывают обработчик сообщений.
print (···)
Получает любое количество аргументов и выводит их значения в stdout, преобразуя каждый аргумент в строку по тем же правилам, что и tostring.
Функция print не предназначена для форматированного вывода, а только как быстрый способ показать значение, например, для отладки. Для полного контроля над выводом используйте string.format и io.write.
rawequal (v1, v2)
Проверяет, равен ли v1 v2, без вызова метаметода __eq. Возвращает булево значение.
rawget (table, index)
Получает реальное значение table[index], не используя метазначение __index. table должна быть таблицей; index может быть любым значением.
rawlen (v)
Возвращает длину объекта v, который должен быть таблицей или строкой, без вызова метаметода __len. Возвращает целое число.
rawset (table, index, value)
Устанавливает реальное значение table[index] в value, не используя метазначение __newindex. table должна быть таблицей, index — любым значением, отличным от nil и NaN, а value — любым значением Lua.
Эта функция возвращает table.
select (index, ···)
Если index — число, возвращает все аргументы после аргумента с номером index; отрицательное число индексирует с конца (-1 — последний аргумент). В противном случае index должен быть строкой "#", и select возвращает общее количество полученных дополнительных аргументов.
setmetatable (table, metatable)
Устанавливает метатаблицу для данной таблицы. Если metatable равно nil, удаляет метатаблицу данной таблицы. Если исходная метатаблица имеет поле __metatable, вызывает ошибку.
Эта функция возвращает table.
Чтобы изменить метатаблицу других типов из кода Lua, вы должны использовать библиотеку отладки (§6.11).
tonumber (e [, base])
При вызове без base tonumber пытается преобразовать свой аргумент в число. Если аргумент уже является числом или строкой, преобразуемой в число, tonumber возвращает это число; в противном случае возвращает fail.
Преобразование строк может давать целые числа или числа с плавающей точкой в соответствии с лексическими соглашениями Lua (см. §3.1). Строка может иметь начальные и конечные пробелы и знак.
При вызове с base аргумент e должен быть строкой, интерпретируемой как целое число в этой системе счисления. base может быть любым целым числом от 2 до 36 включительно. В системах счисления больше 10 буква ‘A’ (в верхнем или нижнем регистре) представляет 10, ‘B’ представляет 11 и так далее, ‘Z’ представляет 35. Если строка e не является допустимым числом в заданной системе счисления, функция возвращает fail.
tostring (v)
Получает значение любого типа и преобразует его в строку в удобочитаемом формате.
Если метатаблица v имеет поле __tostring, tostring вызывает соответствующее значение с v в качестве аргумента и использует результат вызова в качестве своего результата. В противном случае, если метатаблица v имеет поле __name со строковым значением, tostring может использовать эту строку в своем конечном результате.
Для полного контроля над тем, как преобразуются числа, используйте string.format.
type (v)
Возвращает тип своего единственного аргумента, закодированный в виде строки. Возможные результаты этой функции: "nil" (строка, а не значение nil), "number", "string", "boolean", "table", "function", "thread" и "userdata".
_VERSION
Глобальная переменная (не функция), которая содержит строку с текущей версией Lua. Текущее значение этой переменной — "Lua 5.5".
warn (msg1, ···)
Выдает предупреждение с сообщением, составленным путем конкатенации всех ее аргументов (которые должны быть строками).
По соглашению, однокомпонентное сообщение, начинающееся с ‘@’, предназначено быть управляющим сообщением, то есть сообщением для самой системы предупреждений. В частности, стандартная функция предупреждения в Lua распознает управляющие сообщения "@off" (для остановки выдачи предупреждений) и "@on" (для (пере)запуска выдачи); неизвестные управляющие сообщения игнорируются.
xpcall (f, msgh [, arg1, ···])
Эта функция аналогична pcall, за исключением того, что она устанавливает новый обработчик сообщений msgh.
6.3 – Управление сопрограммами
Эта библиотека включает операции для управления сопрограммами, которые находятся внутри таблицы coroutine. См. §2.6 для общего описания сопрограмм.
coroutine.close ([co])
Закрывает сопрограмму co, то есть закрывает все ее ожидающие закрытия переменные и переводит сопрограмму в мертвое состояние. По умолчанию co — это выполняющаяся сопрограмма.
Данная сопрограмма должна быть мертвой, приостановленной или выполняющейся. Для выполняющейся сопрограммы эта функция не возвращает управление. Вместо этого возвращается resume, который (пере)запустил сопрограмму.
Для других сопрограмм, в случае ошибки (либо исходной ошибки, остановившей сопрограмму, либо ошибок в методах закрытия), эта функция возвращает false плюс объект ошибки; в противном случае она возвращает true.
coroutine.create (f)
Создает новую сопрограмму с телом f. f должна быть функцией. Возвращает эту новую сопрограмму, объект типа "thread".
coroutine.isyieldable ([co])
Возвращает true, если сопрограмма co может прерваться (yield). По умолчанию co — это выполняющаяся сопрограмма.
Сопрограмма может прерываться, если она не является главным потоком и не находится внутри непрерываемой C-функции.
coroutine.resume (co [, val1, ···])
Запускает или продолжает выполнение сопрограммы co. При первом возобновлении сопрограммы она начинает выполнение своего тела. Значения val1, … передаются в качестве аргументов функции тела. Если сопрограмма прервалась, resume перезапускает ее; значения val1, … передаются как результаты из yield.
Если сопрограмма выполняется без ошибок, resume возвращает true плюс любые значения, переданные в yield (когда сопрограмма прерывается), или любые значения, возвращенные функцией тела (когда сопрограмма завершается). Если произошла ошибка, resume возвращает false плюс сообщение об ошибке.
coroutine.running ()
Возвращает выполняющуюся сопрограмму и булево значение, true, если выполняющаяся сопрограмма является главной.
coroutine.status (co)
Возвращает статус сопрограммы co в виде строки: "running", если сопрограмма выполняется (то есть это та, которая вызвала status); "suspended", если сопрограмма приостановлена в вызове yield или если она еще не начала выполняться; "normal", если сопрограмма активна, но не выполняется (то есть она возобновила другую сопрограмму); и "dead", если сопрограмма завершила свою функцию тела или остановилась с ошибкой.
coroutine.wrap (f)
Создает новую сопрограмму с телом f; f должна быть функцией. Возвращает функцию, которая возобновляет сопрограмму при каждом вызове. Любые аргументы, переданные этой функции, ведут себя как дополнительные аргументы для resume. Функция возвращает те же значения, что и resume, за исключением первого булева. В случае ошибки функция закрывает сопрограмму и распространяет ошибку.
coroutine.yield (···)
Приостанавливает выполнение вызывающей сопрограммы. Любые аргументы для yield передаются как дополнительные результаты в resume.
6.4 – Модули
Библиотека пакетов предоставляет базовые средства для загрузки модулей в Lua. Она экспортирует одну функцию непосредственно в глобальное окружение: require. Все остальное экспортируется в таблице package.
require (modname)
Загружает данный модуль. Функция начинает с проверки таблицы package.loaded, чтобы определить, загружен ли уже modname. Если да, то require возвращает значение, хранящееся в package.loaded[modname]. (Отсутствие второго результата в этом случае сигнализирует, что этому вызову не пришлось загружать модуль.) В противном случае она пытается найти загрузчик для модуля.
Чтобы найти загрузчик, require руководствуется таблицей package.searchers. Каждый элемент в этой таблице является функцией поиска, которая ищет модуль определенным способом. Изменяя эту таблицу, мы можем изменить способ поиска модуля функцией require. Следующее объяснение основано на конфигурации по умолчанию для package.searchers.
Сначала require запрашивает package.preload[modname]. Если там есть значение, это значение (которое должно быть функцией) является загрузчиком. В противном случае require ищет Lua-загрузчик, используя путь, хранящийся в package.path. Если это также не удается, она ищет C-загрузчик, используя путь, хранящийся в package.cpath. Если и это не удается, она пробует универсальный загрузчик (см. package.searchers).
Как только загрузчик найден, require вызывает загрузчик с двумя аргументами: modname и дополнительным значением, данными загрузчика, также возвращенными функцией поиска. Данные загрузчика могут быть любым значением, полезным для модуля; для стандартных функций поиска они указывают, где был найден загрузчик. (Например, если загрузчик был получен из файла, это дополнительное значение — путь к файлу.) Если загрузчик возвращает любое значение, отличное от nil, require присваивает возвращенное значение package.loaded[modname]. Если загрузчик не возвращает значение, отличное от nil, и не присвоил никакого значения package.loaded[modname], то require присваивает true этой записи. В любом случае require возвращает конечное значение package.loaded[modname]. Помимо этого значения, require также возвращает вторым результатом данные загрузчика, возвращенные функцией поиска, которые указывают, как require нашла модуль.
Если возникает какая-либо ошибка при загрузке или выполнении модуля, или если не удается найти ни одного загрузчика для модуля, require вызывает ошибку.
package.config
Строка, описывающая некоторые конфигурации времени компиляции для пакетов. Эта строка представляет собой последовательность строк:
- Первая строка — это строка-разделитель каталогов. По умолчанию
'\'для Windows и'/'для всех других систем. - Вторая строка — это символ, разделяющий шаблоны в пути. По умолчанию
';'. - Третья строка — это строка, обозначающая точки подстановки в шаблоне. По умолчанию
'?'. - Четвертая строка — это строка, которая в пути в Windows заменяется на каталог исполняемого файла. По умолчанию
'!'. - Пятая строка — это метка для игнорирования всего текста после нее при построении имени функции
luaopen_. По умолчанию'-'.
package.cpath
Строка с путем, используемым require для поиска C-загрузчика.
Lua инициализирует C-путь package.cpath так же, как и Lua-путь package.path, используя переменную окружения LUA_CPATH_5_5, или переменную окружения LUA_CPATH, или путь по умолчанию, определенный в luaconf.h.
package.loaded
Таблица, используемая require для контроля того, какие модули уже загружены. Когда вы запрашиваете модуль modname и package.loaded[modname] не равно false, require просто возвращает значение, хранящееся там.
Эта переменная является лишь ссылкой на реальную таблицу; присваивания этой переменной не изменяют таблицу, используемую require. Реальная таблица хранится в реестре C (см. §4.3), индексируемая ключом LUA_LOADED_TABLE (строкой).
package.loadlib (libname, funcname)
Динамически связывает главную программу с C-библиотекой libname.
Если funcname равно "*", то она только связывается с библиотекой, делая символы, экспортируемые библиотекой, доступными для других динамически связанных библиотек. В противном случае она ищет функцию funcname внутри библиотеки и возвращает эту функцию как C-функцию. Таким образом, funcname должна соответствовать прототипу lua_CFunction (см. lua_CFunction).
Это функция низкого уровня. Она полностью обходит систему пакетов и модулей. В отличие от require, она не выполняет поиск по путям и не добавляет автоматически расширения. libname должно быть полным именем файла C-библиотеки, включая при необходимости путь и расширение. funcname должно быть точным именем, экспортируемым C-библиотекой (которое может зависеть от используемого C-компилятора и компоновщика).
Эта функциональность не поддерживается стандартом ISO C. Поэтому loadlib доступна только на некоторых платформах: Linux, Windows, Mac OS X, Solaris, BSD, а также других Unix-системах, поддерживающих стандарт dlfcn.
Эта функция по своей сути небезопасна, так как позволяет Lua вызывать любую функцию в любой читаемой динамической библиотеке в системе. (Lua вызывает любую функцию, предполагая, что функция имеет правильный прототип и соблюдает правильный протокол (см. lua_CFunction). Поэтому вызов произвольной функции в произвольной динамической библиотеке чаще всего приводит к нарушению доступа.)
package.path
Строка с путем, используемым require для поиска Lua-загрузчика.
При запуске Lua инициализирует эту переменную значением переменной окружения LUA_PATH_5_5 или переменной окружения LUA_PATH, или путем по умолчанию, определенным в luaconf.h, если эти переменные окружения не определены. ";;" в значении переменной окружения заменяется путем по умолчанию.
package.preload
Таблица для хранения загрузчиков для конкретных модулей (см. require).
Эта переменная является лишь ссылкой на реальную таблицу; присваивания этой переменной не изменяют таблицу, используемую require. Реальная таблица хранится в реестре C (см. §4.3), индексируемая ключом LUA_PRELOAD_TABLE (строкой).
package.searchers
Таблица, используемая require для управления поиском модулей.
Каждая запись в этой таблице является функцией поиска. При поиске модуля require вызывает каждую из этих функций поиска в порядке возрастания, передавая имя модуля (аргумент, переданный в require) в качестве единственного аргумента. Если функция поиска находит модуль, она возвращает другую функцию — загрузчик модуля, плюс дополнительное значение — данные загрузчика, которые будут переданы этому загрузчику и возвращены вторым результатом из require. Если она не может найти модуль, она возвращает строку с объяснением причины (или nil, если ей нечего сказать).
Lua инициализирует эту таблицу четырьмя функциями поиска.
Первая функция поиска просто ищет загрузчик в таблице package.preload.
Вторая функция поиска ищет загрузчик как Lua-библиотеку, используя путь, хранящийся в package.path. Поиск выполняется, как описано в функции package.searchpath.
Третья функция поиска ищет загрузчик как C-библиотеку, используя путь, заданный переменной package.cpath. Поиск также выполняется, как описано в функции package.searchpath. Например, если C-путь — это строка
"./?.so;./?.dll;/usr/local/?/init.so"
функция поиска для модуля foo попытается открыть файлы ./foo.so, ./foo.dll и /usr/local/foo/init.so в этом порядке. Найдя C-библиотеку, эта функция поиска сначала использует средство динамической загрузки для связывания приложения с библиотекой. Затем она пытается найти C-функцию внутри библиотеки, которая будет использоваться в качестве загрузчика. Имя этой C-функции — это строка "luaopen_", конкатенированная с копией имени модуля, где каждая точка заменена на подчеркивание. Более того, если имя модуля содержит дефис, его суффикс после (и включая) первого дефиса удаляется. Например, если имя модуля a.b.c-v2.1, имя функции будет luaopen_a_b_c.
Четвертая функция поиска пробует универсальный загрузчик. Она ищет в C-пути библиотеку для корневого имени заданного модуля. Например, при запросе a.b.c она будет искать C-библиотеку для a. Если она найдена, она ищет в ней функцию открытия для подмодуля; в нашем примере это будет luaopen_a_b_c. С помощью этого средства пакет может упаковать несколько C-подмодулей в одну библиотеку, при этом каждый подмодуль сохраняет свою оригинальную функцию открытия.
Все функции поиска, кроме первой (предзагрузки), возвращают в качестве дополнительного значения путь к файлу, где был найден модуль, как возвращено package.searchpath. Первая функция поиска всегда возвращает строку ":preload:".
Функции поиска не должны вызывать ошибок и не должны иметь побочных эффектов в Lua. (Они могут иметь побочные эффекты в C, например, связывая приложение с библиотекой.)
package.searchpath (name, path [, sep [, rep]])
Ищет заданное name в заданном path.
Путь — это строка, содержащая последовательность шаблонов, разделенных точкой с запятой. Для каждого шаблона функция заменяет каждый вопросительный знак (если есть) в шаблоне копией name, в которой все вхождения sep (по умолчанию точка) заменены на rep (по умолчанию системный разделитель каталогов), а затем пытается открыть полученное имя файла.
Например, если путь — строка
"./?.lua;./?.lc;/usr/local/?/init.lua"
поиск имени foo.a попытается открыть файлы ./foo/a.lua, ./foo/a.lc и /usr/local/foo/a/init.lua в этом порядке.
Возвращает результирующее имя первого файла, который удается открыть в режиме чтения (после закрытия файла), или fail плюс сообщение об ошибке, если ни один не подошел. (Это сообщение об ошибке перечисляет все имена файлов, которые пытались открыть.)
6.5 – Манипуляции со строками
Эта библиотека предоставляет общие функции для работы со строками, такие как поиск и извлечение подстрок, а также сопоставление с образцом. При индексации строки в Lua первый символ находится в позиции 1 (а не 0, как в C). Индексы могут быть отрицательными и интерпретируются как индексация с конца строки. Таким образом, последний символ находится в позиции -1, и так далее.
Библиотека строк предоставляет все свои функции внутри таблицы string. Она также устанавливает метатаблицу для строк, где поле __index указывает на таблицу string. Поэтому вы можете использовать строковые функции в объектно-ориентированном стиле. Например, string.byte(s,i) можно записать как s:byte(i).
Библиотека строк предполагает однобайтовые кодировки символов.
string.byte (s [, i [, j]])
Возвращает внутренние числовые коды символов s[i], s[i+1], …, s[j]. Значение по умолчанию для i — 1; значение по умолчанию для j — i. Эти индексы корректируются по тем же правилам, что и для функции string.sub.
Числовые коды не обязательно переносимы между платформами.
string.char (···)
Получает ноль или более целых чисел. Возвращает строку длиной, равной количеству аргументов, в которой каждый символ имеет внутренний числовой код, равный соответствующему аргументу.
Числовые коды не обязательно переносимы между платформами.
string.dump (function [, strip])
Возвращает строку, содержащую бинарное представление (бинарный чанк) заданной функции, так что последующая load этой строки вернет копию функции (но с новыми верхними значениями). Если strip — истинное значение, бинарное представление может не включать всю отладочную информацию о функции для экономии места.
У функций с верхними значениями сохраняется только их количество. При (пере)загрузке эти верхние значения получают новые экземпляры. (Подробности о том, как эти верхние значения инициализируются, см. в описании функции load. Вы можете использовать библиотеку отладки для сериализации и перезагрузки верхних значений функции способом, адекватным вашим потребностям.)
string.find (s, pattern [, init [, plain]])
Ищет первое совпадение с pattern (см. §6.5.1) в строке s. Если находит совпадение, find возвращает индексы s, где это вхождение начинается и заканчивается; в противном случае возвращает fail. Третий, необязательный числовой аргумент init указывает, с какой позиции начинать поиск; его значение по умолчанию 1, и оно может быть отрицательным. Значение true в качестве четвертого, необязательного аргумента plain отключает средства сопоставления с образцом, так что функция выполняет простой “поиск подстроки”, при этом ни один символ в pattern не считается магическим.
Если в образце есть захваты, то при успешном совпадении захваченные значения также возвращаются после двух индексов.
string.format (formatstring, ···)
Возвращает отформатированную версию своего переменного числа аргументов в соответствии с описанием, данным в первом аргументе, который должен быть строкой. Строка формата следует тем же правилам, что и функция ISO C sprintf. Допустимые спецификаторы преобразования: A, a, c, d, E, e, f, G, g, i, o, p, s, u, X, x и '%', а также не-C спецификатор q. Допустимые флаги: '-', '+', '#', '0' и ' ' (пробел). Как ширина, так и точность, если указаны, ограничены двумя цифрами.
Спецификатор q форматирует булевы значения, nil, числа и строки таким образом, что результат является допустимой константой в исходном коде Lua. Булевы значения и nil записываются очевидным образом (true, false, nil). Числа с плавающей точкой записываются в шестнадцатеричном виде для сохранения полной точности. Строка записывается в двойных кавычках с использованием escape-последовательностей, где это необходимо, чтобы гарантировать, что она может быть безопасно прочитана обратно интерпретатором Lua. Например, вызов
string.format('%q', 'a string with "quotes" and \n new line')
может произвести строку:
"a string with \"quotes\" and \
new line"
Этот спецификатор не поддерживает модификаторы (флаги, ширину, точность).
Спецификаторы преобразования A, a, E, e, f, G и g ожидают число в качестве аргумента. Спецификаторы c, d, i, o, u, X и x ожидают целое число. Когда Lua скомпилирован с компилятором C89, спецификаторы A и a (шестнадцатеричные числа с плавающей точкой) не поддерживают модификаторы.
Спецификатор s ожидает строку; если его аргумент не является строкой, он преобразуется в нее по тем же правилам, что и tostring. Если спецификатор имеет какой-либо модификатор, соответствующий строковый аргумент не должен содержать встроенных нулей.
Спецификатор p форматирует указатель, возвращенный lua_topointer. Это дает уникальный строковый идентификатор для таблиц, пользовательских данных, потоков, строк и функций. Для других значений (числа, nil, булевы значения) этот спецификатор дает строку, представляющую указатель NULL.
string.gmatch (s, pattern [, init])
Возвращает функцию-итератор, которая при каждом вызове возвращает следующие захваты из pattern (см. §6.5.1) по строке s. Если pattern не указывает захватов, то при каждом вызове выдается все совпадение целиком. Третий, необязательный числовой аргумент init указывает, с какой позиции начинать поиск; его значение по умолчанию 1, и оно может быть отрицательным.
В качестве примера, следующий цикл будет итерироваться по всем словам из строки s, печатая по одному в строке:
s = "hello world from Lua"
for w in string.gmatch(s, "%a+") do
print(w)
end
Следующий пример собирает все пары key=value из заданной строки в таблицу:
t = {}
s = "from=world, to=Lua"
for k, v in string.gmatch(s, "(%w+)=(%w+)") do
t[k] = v
end
Для этой функции символ '^' в начале образца не работает как якорь, так как это предотвратило бы итерацию.
string.gsub (s, pattern, repl [, n])
Возвращает копию s, в которой все (или первые n, если указано) вхождения pattern (см. §6.5.1) были заменены строкой замены, указанной в repl, которая может быть строкой, таблицей или функцией. gsub также возвращает вторым значением общее количество произошедших совпадений. Имя gsub происходит от Global SUBstitution.
Если repl — строка, то ее значение используется для замены. Символ % работает как escape-символ: любая последовательность в repl вида %d, где d от 1 до 9, обозначает значение d-й захваченной подстроки; последовательность %0 обозначает все совпадение целиком; последовательность %% обозначает одиночный %.
Если repl — таблица, то к таблице выполняется запрос для каждого совпадения, используя первый захват в качестве ключа.
Если repl — функция, то эта функция вызывается каждый раз при совпадении, при этом все захваченные подстроки передаются в качестве аргументов по порядку.
В любом случае, если образец не указывает захватов, он ведет себя так, как будто весь образец находится внутри захвата.
Если значение, возвращенное запросом к таблице или вызовом функции, является строкой или числом, оно используется в качестве строки замены; в противном случае, если оно false или nil, замены не происходит (то есть исходное совпадение сохраняется в строке).
Вот несколько примеров:
x = string.gsub("hello world", "(%w+)", "%1 %1")
-- x="hello hello world world"
x = string.gsub("hello world", "%w+", "%0 %0", 1)
-- x="hello hello world"
x = string.gsub("hello world from Lua", "(%w+)%s*(%w+)", "%2 %1")
-- x="world hello Lua from"
x = string.gsub("home = $HOME, user = $USER", "%$(%w+)", os.getenv)
-- x="home = /home/roberto, user = roberto"
x = string.gsub("4+5 = $return 4+5$", "%$(.-)%$", function (s)
return load(s)()
end)
-- x="4+5 = 9"
local t = {name="lua", version="5.5"}
x = string.gsub("$name-$version.tar.gz", "%$(%w+)", t)
-- x="lua-5.5.tar.gz"
string.len (s)
Получает строку и возвращает ее длину. Пустая строка "" имеет длину 0. Встроенные нули считаются, поэтому "a\000bc\000" имеет длину 5.
string.lower (s)
Получает строку и возвращает копию этой строки, в которой все заглавные буквы заменены на строчные. Все остальные символы остаются без изменений. Определение того, что является заглавной буквой, зависит от текущей локали.
string.match (s, pattern [, init])
Ищет первое совпадение с образцом (см. §6.5.1) в строке s. Если находит, match возвращает захваты из образца; в противном случае возвращает fail. Если образец не указывает захватов, возвращается все совпадение целиком. Третий, необязательный числовой аргумент init указывает, с какой позиции начинать поиск; его значение по умолчанию 1, и оно может быть отрицательным.
string.pack (fmt, v1, v2, ···)
Возвращает бинарную строку, содержащую значения v1, v2 и т.д., сериализованные в бинарной форме (упакованные) в соответствии со строкой формата fmt (см. §6.5.2).
string.packsize (fmt)
Возвращает длину строки, получаемой в результате string.pack с заданным форматом. Строка формата не может иметь опции переменной длины 's' или 'z' (см. §6.5.2).
string.rep (s, n [, sep])
Возвращает строку, которая является конкатенацией n копий строки s, разделенных строкой sep. Значение по умолчанию для sep — пустая строка (то есть без разделителя). Возвращает пустую строку, если n не положительно.
(Обратите внимание, что очень легко исчерпать память вашей машины одним вызовом этой функции.)
string.reverse (s)
Возвращает строку, которая является перевернутой строкой s.
string.sub (s, i [, j])
Возвращает подстроку s, которая начинается с i и продолжается до j; i и j могут быть отрицательными. Если j отсутствует, предполагается, что оно равно -1 (что соответствует длине строки). В частности, вызов string.sub(s,1,j) возвращает префикс s длиной j, а string.sub(s,-i) (для положительного i) возвращает суффикс s длиной i.
Если после преобразования отрицательных индексов i меньше 1, оно корректируется до 1. Если j больше длины строки, оно корректируется до этой длины. Если после этих коррекций i больше j, функция возвращает пустую строку.
string.unpack (fmt, s [, pos])
Возвращает значения, упакованные в строке s (см. string.pack) в соответствии со строкой формата fmt (см. §6.5.2). Необязательный параметр pos указывает, с какой позиции начинать чтение в s (по умолчанию 1). После прочитанных значений эта функция также возвращает индекс первого непрочитанного байта в s.
string.upper (s)
Получает строку и возвращает копию этой строки, в которой все строчные буквы заменены на заглавные. Все остальные символы остаются без изменений. Определение того, что является строчной буквой, зависит от текущей локали.
6.5.1 – Образцы (Patterns)
Образцы в Lua описываются обычными строками, которые интерпретируются как образцы функциями сопоставления с образцом string.find, string.gmatch, string.gsub и string.match. В этом разделе описывается синтаксис и значение (то есть что они сопоставляют) этих строк.
Класс символов:
Класс символов используется для представления набора символов. Следующие комбинации допустимы при описании класса символов:
x: (гдеxне является одним из магических символов^$()%.[]*+-?) представляет сам символx..: (точка) представляет все символы.%a: представляет все буквы.%c: представляет все управляющие символы.%d: представляет все цифры.%g: представляет все печатные символы, кроме пробела.%l: представляет все строчные буквы.%p: представляет все знаки пунктуации.%s: представляет все пробельные символы.%u: представляет все заглавные буквы.%w: представляет все буквенно-цифровые символы.%x: представляет все шестнадцатеричные цифры.%x: (гдеx— любой небуквенно-цифровой символ) представляет сам символx. Это стандартный способ экранирования магических символов. Любой небуквенно-цифровой символ (включая все знаки пунктуации, даже немагические) может быть предварен'%', чтобы представить самого себя в образце.[set]: представляет класс, который является объединением всех символов вset. Диапазон символов может быть указан путем разделения конечных символов диапазона в порядке возрастания с помощью'-'. Все классы%x, описанные выше, также могут использоваться как компоненты вset. Все остальные символы вsetпредставляют сами себя. Например,[%w_](или[_%w]) представляет все буквенно-цифровые символы плюс подчеркивание,[0-7]представляет восьмеричные цифры, а[0-7%l%-]представляет восьмеричные цифры плюс строчные буквы плюс символ'-'.Вы можете поместить закрывающую квадратную скобку в набор, расположив ее как первый символ в наборе. Вы можете поместить дефис в набор, расположив его как первый или последний символ в наборе. (Вы также можете использовать экранирование для обоих случаев.)
Взаимодействие между диапазонами и классами не определено. Поэтому образцы типа
[%a-z]или[a-%%]не имеют смысла.[^set]: представляет дополнение кset, гдеsetинтерпретируется как выше.
Для всех классов, представленных одиночными буквами (%a, %c и т.д.), соответствующая заглавная буква представляет дополнение класса. Например, %S представляет все непробельные символы.
Определения буквы, пробела и других групп символов зависят от текущей локали. В частности, класс [a-z] может быть не эквивалентен %l.
Элемент образца:
Элементом образца может быть
- одиночный класс символов, который соответствует любому одиночному символу в классе;
- одиночный класс символов, за которым следует
'*', что соответствует последовательностям из нуля или более символов в классе. Эти элементы повторения всегда будут соответствовать самой длинной возможной последовательности; - одиночный класс символов, за которым следует
'+', что соответствует последовательностям из одного или более символов в классе. Эти элементы повторения всегда будут соответствовать самой длинной возможной последовательности; - одиночный класс символов, за которым следует
'-', что также соответствует последовательностям из нуля или более символов в классе. В отличие от'*', эти элементы повторения всегда будут соответствовать самой короткой возможной последовательности; - одиночный класс символов, за которым следует
'?', что соответствует нулю или одному вхождению символа в классе. Всегда соответствует одному вхождению, если это возможно; %n, дляnот 1 до 9; такой элемент соответствует подстроке, равнойn-й захваченной строке (см. ниже);%bxy, гдеxиy— два различных символа; такой элемент соответствует строкам, которые начинаются сx, заканчиваются наyи гдеxиyсбалансированы. Это означает, что если читать строку слева направо, считая+1дляxи-1дляy, конечныйy— это первыйy, где счетчик достигает 0. Например, элемент%b()соответствует выражениям со сбалансированными круглыми скобками.%f[set], образец границы; такой элемент соответствует пустой строке в любой позиции, такой что следующий символ принадлежитset, а предыдущий символ не принадлежитset. Наборsetинтерпретируется, как описано ранее. Начало и конец строки обрабатываются так, как если бы они были символом'\0'.
Образец:
Образец — это последовательность элементов образца. Символ '^' в начале образца привязывает совпадение к началу строки. Символ '$' в конце образца привязывает совпадение к концу строки. В других позициях '^' и '$' не имеют специального значения и представляют сами себя.
Захваты:
Образец может содержать подобразцы, заключенные в круглые скобки; они описывают захваты. Когда совпадение успешно, подстроки строки, соответствующие захватам, сохраняются (захватываются) для будущего использования. Захваты нумеруются в соответствии с их левыми скобками. Например, в образце "(a*(.)%w(%s*))" часть строки, соответствующая "a*(.)%w(%s*)", сохраняется как первый захват и, следовательно, имеет номер 1; символ, соответствующий ".", захватывается с номером 2, а часть, соответствующая "%s*", имеет номер 3.
В качестве особого случая, захват () захватывает текущую позицию в строке (число). Например, если применить образец "()aa()" к строке "flaaap", будет два захвата: 3 и 5.
Множественные совпадения:
Функция string.gsub и итератор string.gmatch ищут множественные вхождения заданного образца в строке. Для этих функций новое совпадение считается допустимым, только если оно заканчивается хотя бы на один байт позже конца предыдущего совпадения. Другими словами, автомат образцов никогда не принимает пустую строку в качестве совпадения сразу после другого совпадения. В качестве примера рассмотрим результаты следующего кода:
> string.gsub("abc", "()a*()", print);
--> 1 2
--> 3 3
--> 4 4
Второй и третий результаты получаются, когда Lua сопоставляет пустую строку после 'b' и еще одну после 'c'. Lua не сопоставляет пустую строку после 'a', потому что она закончилась бы в той же позиции, что и предыдущее совпадение.
6.5.2 – Строки формата для Pack и Unpack
Первым аргументом для string.pack, string.packsize и string.unpack является строка формата, которая описывает структуру создаваемой или читаемой структуры.
Строка формата — это последовательность опций преобразования. Опции преобразования следующие:
<: устанавливает little-endian (порядок байтов от младшего к старшему)>: устанавливает big-endian (порядок байтов от старшего к младшему)=: устанавливает native-endian (родной порядок байтов)![n]: устанавливает максимальное выравнивание вn(по умолчанию родное выравнивание)b: знаковый байт (char)B: беззнаковый байт (unsigned char)h: знаковыйshort(родного размера)H: беззнаковыйshort(родного размера)l: знаковыйlong(родного размера)L: беззнаковыйlong(родного размера)j:lua_IntegerJ:lua_UnsignedT:size_t(родного размера)i[n]: знаковыйintразмеромnбайт (по умолчанию родной размер)I[n]: беззнаковыйintразмеромnбайт (по умолчанию родной размер)f:float(родного размера)d:double(родного размера)n:lua_Numbercn: строка фиксированного размера длинойnбайтz: строка, завершающаяся нулемs[n]: строка, предваренная своей длиной, закодированной как беззнаковое целое размеромnбайт (по умолчаниюsize_t)x: один байт заполненияXop: пустой элемент, который выравнивает в соответствии с опциейop(которая в остальном игнорируется)' ': (пробел) игнорируется
(Запись "[n]" означает необязательное целое число.) За исключением заполнения, пробелов и конфигураций (опции "xX <=>!"), каждая опция соответствует аргументу в string.pack или результату в string.unpack.
Для опций "!n", "sn", "in" и "In" n может быть любым целым числом от 1 до 16. Все целочисленные опции проверяют переполнение; string.pack проверяет, помещается ли данное значение в заданный размер; string.unpack проверяет, помещается ли прочитанное значение в целое число Lua. Для беззнаковых опций целые числа Lua также рассматриваются как беззнаковые.
Любая строка формата начинается так, как если бы перед ней стояло "!1=", то есть с максимальным выравниванием 1 (без выравнивания) и родным порядком байтов.
Родной порядок байтов предполагает, что вся система имеет либо big-endian, либо little-endian порядок. Функции упаковки не будут корректно эмулировать поведение форматов со смешанным порядком байтов.
Выравнивание работает следующим образом: Для каждой опции формат дополняется до тех пор, пока данные не начнутся со смещением, кратным минимуму между размером опции и максимальным выравниванием; этот минимум должен быть степенью двойки. Опции "c" и "z" не выравниваются; опция "s" следует выравниванию своего начального целого.
Все заполнение заполняется нулями в string.pack и игнорируется в string.unpack.
6.6 – Поддержка UTF-8
Эта библиотека предоставляет базовую поддержку кодировки UTF-8. Она предоставляет все свои функции внутри таблицы utf8. Эта библиотека не предоставляет никакой поддержки Unicode, кроме обработки кодировки. Любая операция, требующая знания смысла символа, например, классификация символов, выходит за рамки ее возможностей.
Если не указано иное, все функции, ожидающие позицию в байтах в качестве параметра, предполагают, что данная позиция является либо началом байтовой последовательности, либо длиной строки плюс один. Как и в библиотеке строк, отрицательные индексы отсчитываются от конца строки.
Функции, создающие байтовые последовательности, принимают все значения вплоть до 0x7FFFFFFF, как определено в оригинальной спецификации UTF-8; это подразумевает байтовые последовательности длиной до шести байт.
Функции, интерпретирующие байтовые последовательности, принимают только допустимые последовательности (правильно сформированные и не избыточные). По умолчанию они принимают только байтовые последовательности, дающие допустимые кодовые точки Unicode, отвергая значения больше 10FFFF и суррогаты. Булев аргумент lax, если доступен, отменяет эти проверки, так что принимаются все значения вплоть до 0x7FFFFFFF. (Неправильно сформированные и избыточные последовательности по-прежнему отвергаются.)
utf8.char (···)
Получает ноль или более целых чисел, преобразует каждое в соответствующую ему байтовую последовательность UTF-8 и возвращает строку с конкатенацией всех этих последовательностей.
utf8.charpattern
Образец (строка, а не функция) "[\0-\x7F\xC2-\xFD][\x80-\xBF]*" (см. §6.5.1), который соответствует ровно одной байтовой последовательности UTF-8, при условии, что строка является допустимой строкой UTF-8.
utf8.codes (s [, lax])
Возвращает значения таким образом, что конструкция
for p, c in utf8.codes(s) do body end
будет итерироваться по всем символам UTF-8 в строке s, где p — позиция (в байтах), а c — кодовая точка каждого символа. Вызывает ошибку, если встречает недопустимую байтовую последовательность.
utf8.codepoint (s [, i [, j [, lax]]])
Возвращает кодовые точки (как целые числа) из всех символов в s, которые начинаются между байтовыми позициями i и j (обе включительно). Значение по умолчанию для i — 1, а для j — i. Вызывает ошибку, если встречает недопустимую байтовую последовательность.
utf8.len (s [, i [, j [, lax]]])
Возвращает количество символов UTF-8 в строке s, которые начинаются между позициями i и j (обе включительно). Значение по умолчанию для i — 1, а для j — -1. Если находит недопустимую байтовую последовательность, возвращает fail плюс позицию первого недопустимого байта.
utf8.offset (s, n [, i])
Возвращает позицию n-го символа s (начиная с байтовой позиции i) в виде двух целых чисел: индекс (в байтах), где начинается его кодировка, и индекс (в байтах), где она заканчивается.
Если указанный символ находится сразу после конца s, функция ведет себя так, как если бы там был '\0'. Если указанный символ не находится ни в строке, ни сразу после ее конца, функция возвращает fail.
Отрицательное n получает символы до позиции i. По умолчанию i равно 1, когда n неотрицательно, и #s + 1 в противном случае, так что utf8.offset(s,-n) получает смещение n-го символа с конца строки.
В качестве особого случая, когда n равно 0, функция возвращает начало и конец кодировки символа, который содержит i-й байт s.
Эта функция предполагает, что s является допустимой строкой UTF-8.
6.7 – Манипуляции с таблицами
Эта библиотека предоставляет общие функции для манипуляции таблицами. Она предоставляет все свои функции внутри таблицы table.
Помните, что всякий раз, когда операция требует длины таблицы, применяются все предостережения относительно оператора длины (см. §3.4.7). Все функции игнорируют нечисловые ключи в таблицах, переданных в качестве аргументов.
table.concat (list [, sep [, i [, j]]])
Для списка, где все элементы являются строками или числами, возвращает строку list[i]..sep..list[i+1] ... sep..list[j]. Значение по умолчанию для sep — пустая строка, для i — 1, для j — #list. Если i больше j, возвращает пустую строку.
table.create (nseq [, nrec])
Создает новую пустую таблицу, предварительно выделяя память. Это предварительное выделение может помочь производительности и сэкономить память, если вы заранее знаете, сколько элементов будет в таблице.
Параметр nseq — это подсказка о том, сколько элементов будет в таблице в виде последовательности. Необязательный параметр nrec — это подсказка о том, сколько других элементов будет в таблице; по умолчанию ноль.
table.insert (list, [pos,] value)
Вставляет элемент value в позицию pos в списке list, сдвигая вверх элементы list[pos], list[pos+1], ..., list[#list]. Значение по умолчанию для pos — #list+1, так что вызов table.insert(t,x) вставляет x в конец списка t.
table.move (a1, f, e, t [,a2])
Перемещает элементы из таблицы a1 в таблицу a2, выполняя эквивалент следующего множественного присваивания: a2[t],... = a1[f],...,a1[e]. По умолчанию a2 равна a1. Диапазон назначения может перекрываться с диапазоном источника. Количество перемещаемых элементов должно помещаться в целое число Lua. Если f больше e, ничего не перемещается.
Возвращает таблицу назначения a2.
table.pack (···)
Возвращает новую таблицу со всеми аргументами, сохраненными под ключами 1, 2 и т.д., и с полем "n", содержащим общее количество аргументов. Обратите внимание, что результирующая таблица может не быть последовательностью, если некоторые аргументы равны nil.
table.remove (list [, pos])
Удаляет из списка list элемент в позиции pos, возвращая значение удаленного элемента. Когда pos — целое число между 1 и #list, она сдвигает вниз элементы list[pos+1], list[pos+2], ..., list[#list] и стирает элемент list[#list]; Индекс pos также может быть 0, когда #list равно 0, или #list + 1.
Значение по умолчанию для pos — #list, так что вызов table.remove(l) удаляет последний элемент списка l.
table.sort (list [, comp])
Сортирует элементы списка в заданном порядке, на месте, от list[1] до list[#list]. Если указана comp, она должна быть функцией, которая получает два элемента списка и возвращает true, если первый элемент должен стоять перед вторым в конечном порядке, так что после сортировки i <= j влечет not comp(list[j],list[i]). Если comp не указана, используется стандартный оператор Lua <.
Функция comp должна определять непротиворечивый порядок; более формально, функция должна определять строгий слабый порядок. (Слабый порядок похож на полный порядок, но он может приравнивать разные элементы для целей сравнения.)
Алгоритм сортировки не является стабильным: Различные элементы, считающиеся равными при заданном порядке, могут изменить свое относительное положение в результате сортировки.
table.unpack (list [, i [, j]])
Возвращает элементы из данного списка. Эта функция эквивалентна
return list[i], list[i+1], ..., list[j]
По умолчанию i равно 1, а j равно #list.
6.8 – Математические функции
Эта библиотека предоставляет базовые математические функции. Она предоставляет все свои функции и константы внутри таблицы math. Функции с аннотацией “integer/float” дают целочисленные результаты для целочисленных аргументов и результаты с плавающей точкой для нецелочисленных аргументов. Функции округления math.ceil, math.floor и math.modf возвращают целое число, если результат помещается в диапазон целых чисел, или число с плавающей точкой в противном случае.
math.abs (x)
Возвращает максимальное значение между x и -x. (integer/float)
math.acos (x)
Возвращает арккосинус x (в радианах).
math.asin (x)
Возвращает арксинус x (в радианах).
math.atan (y [, x])
Возвращает арктангенс y/x (в радианах), используя знаки обоих аргументов для определения квадранта результата. Также корректно обрабатывает случай, когда x равен нулю.
Значение по умолчанию для x — 1, так что вызов math.atan(y) возвращает арктангенс y.
math.ceil (x)
Возвращает наименьшее целое значение, большее или равное x.
math.cos (x)
Возвращает косинус x (предполагается, что x в радианах).
math.deg (x)
Преобразует угол x из радиан в градусы.
math.exp (x)
Возвращает значение ex (где e — основание натуральных логарифмов).
math.floor (x)
Возвращает наибольшее целое значение, меньшее или равное x.
math.fmod (x, y)
Возвращает остаток от деления x на y, который округляет частное в сторону нуля. (integer/float)
math.frexp (x)
Возвращает два числа m и e такие, что x = m * 2^e, где e — целое число. Когда x равен нулю, NaN, +inf или -inf, m равен x; в противном случае абсолютное значение m находится в диапазоне [0.5, 1).
math.huge
Значение с плавающей точкой HUGE_VAL, значение, большее любого другого числового значения.
math.ldexp (m, e)
Возвращает m * 2^e, где e — целое число.
math.log (x [, base])
Возвращает логарифм x по заданному основанию base. По умолчанию base равно e (так что функция возвращает натуральный логарифм x).
math.max (x, ···)
Возвращает аргумент с максимальным значением в соответствии с оператором Lua <.
math.maxinteger
Целое число с максимальным значением для целого числа.
math.min (x, ···)
Возвращает аргумент с минимальным значением в соответствии с оператором Lua <.
math.mininteger
Целое число с минимальным значением для целого числа.
math.modf (x)
Возвращает целую часть x и дробную часть x. Ее второй результат всегда является числом с плавающей точкой.
math.pi
Значение π.
math.rad (x)
Преобразует угол x из градусов в радианы.
math.random ([m [, n]])
При вызове без аргументов возвращает псевдослучайное число с плавающей точкой с равномерным распределением в диапазоне [0, 1). При вызове с двумя целыми числами m и n, math.random возвращает псевдослучайное целое число с равномерным распределением в диапазоне [m, n]. Вызов math.random(n) для положительного n эквивалентен math.random(1,n). Вызов math.random(0) производит целое число, в котором все биты (псевдо)случайны.
Эта функция использует алгоритм xoshiro256** для получения псевдослучайных 64-битных целых чисел, которые являются результатами вызовов с аргументом 0. Другие результаты (диапазоны и числа с плавающей точкой) несмещенно извлекаются из этих целых чисел.
Lua инициализирует свой генератор псевдослучайных чисел эквивалентом вызова math.randomseed без аргументов, так что math.random должен генерировать разные последовательности результатов при каждом запуске программы.
math.randomseed ([x [, y]])
При вызове хотя бы с одним аргументом целочисленные параметры x и y объединяются в зерно (seed), которое используется для реинициализации генератора псевдослучайных чисел; одинаковые зерна производят одинаковые последовательности чисел. По умолчанию y равно нулю.
При вызове без аргументов Lua генерирует зерно со слабой попыткой случайности.
Эта функция возвращает два компонента зерна, которые были фактически использованы, так что их повторная установка повторяет последовательность.
Чтобы обеспечить требуемый уровень случайности начального состояния (или, наоборот, иметь детерминированную последовательность, например, при отладке программы), следует вызывать math.randomseed с явными аргументами.
math.sin (x)
Возвращает синус x (предполагается, что x в радианах).
math.sqrt (x)
Возвращает квадратный корень из x. (Вы также можете использовать выражение x^0.5 для вычисления этого значения.)
math.tan (x)
Возвращает тангенс x (предполагается, что x в радианах).
math.tointeger (x)
Если значение x может быть преобразовано в целое число, возвращает это целое число. В противном случае возвращает fail.
math.type (x)
Возвращает "integer", если x — целое число, "float", если это число с плавающей точкой, или fail, если x не является числом.
math.ult (m, n)
Возвращает булево значение, true, если и только если целое число m меньше целого числа n при их сравнении как беззнаковых целых чисел.
6.9 – Средства ввода и вывода
Библиотека ввода/вывода предоставляет два разных стиля для манипуляции файлами. Первый использует неявные файловые дескрипторы; то есть существуют операции для установки файла ввода по умолчанию и файла вывода по умолчанию, и все операции ввода/вывода выполняются с этими файлами по умолчанию. Второй стиль использует явные файловые дескрипторы.
При использовании неявных файловых дескрипторов все операции предоставляются таблицей io. При использовании явных файловых дескрипторов операция io.open возвращает файловый дескриптор, а затем все операции предоставляются как методы файлового дескриптора.
Метатаблица для файловых дескрипторов предоставляет метаметоды __gc и __close, которые пытаются закрыть файл при вызове.
Таблица io также предоставляет три предопределенных файловых дескриптора с их обычными значениями из C: io.stdin, io.stdout и io.stderr. Библиотека ввода/вывода никогда не закрывает эти файлы.
Если не указано иное, все функции ввода/вывода возвращают fail при неудаче плюс сообщение об ошибке в качестве второго результата и системно-зависимый код ошибки в качестве третьего результата, и некоторое значение, отличное от false, при успехе. На не-POSIX системах вычисление сообщения об ошибке и кода ошибки в случае ошибок может быть не потокобезопасным, поскольку они полагаются на глобальную переменную C errno.
io.close ([file])
Эквивалент file:close(). Без файла закрывает файл вывода по умолчанию.
io.flush ()
Эквивалент io.output():flush().
io.input ([file])
При вызове с именем файла открывает указанный файл (в текстовом режиме) и устанавливает его дескриптор как файл ввода по умолчанию. При вызове с файловым дескриптором просто устанавливает этот файловый дескриптор как файл ввода по умолчанию. При вызове без аргументов возвращает текущий файл ввода по умолчанию.
В случае ошибок эта функция вызывает ошибку вместо возврата кода ошибки.
io.lines ([filename, ···])
Открывает указанный файл в режиме чтения и возвращает функцию-итератор, которая работает как file:lines(...) для открытого файла. Когда функция-итератор не может прочитать ни одного значения, она автоматически закрывает файл. Помимо функции-итератора, io.lines возвращает три других значения: два значения nil в качестве заполнителей и созданный файловый дескриптор. Таким образом, при использовании в общем цикле for файл закрывается, даже если цикл прерывается ошибкой или break.
Вызов io.lines() (без имени файла) эквивалентен io.input():lines("l"); то есть он итерируется по строкам файла ввода по умолчанию. В этом случае итератор не закрывает файл по окончании цикла.
В случае ошибок при открытии файла эта функция вызывает ошибку вместо возврата кода ошибки.
io.open (filename [, mode])
Эта функция открывает файл в режиме, указанном в строке mode. В случае успеха возвращает новый файловый дескриптор.
Строка режима может быть любой из следующих:
"r": режим чтения (по умолчанию);"w": режим записи;"a": режим добавления;"r+": режим обновления, все предыдущие данные сохраняются;"w+": режим обновления, все предыдущие данные стираются;"a+": режим добавления с обновлением, предыдущие данные сохраняются, запись разрешена только в конец файла.
Строка режима может также иметь 'b' в конце, что необходимо в некоторых системах для открытия файла в бинарном режиме.
io.output ([file])
Аналогично io.input, но работает с файлом вывода по умолчанию.
io.popen (prog [, mode])
Эта функция является системно-зависимой и доступна не на всех платформах.
Запускает программу prog в отдельном процессе и возвращает файловый дескриптор, который можно использовать для чтения данных из этой программы (если mode равен "r", по умолчанию) или для записи данных в эту программу (если mode равен "w").
io.read (···)
Эквивалент io.input():read(...).
io.tmpfile ()
В случае успеха возвращает дескриптор для временного файла. Этот файл открывается в режиме обновления и автоматически удаляется по завершении программы.
io.type (obj)
Проверяет, является ли obj допустимым файловым дескриптором. Возвращает строку "file", если obj — открытый файловый дескриптор, "closed file", если obj — закрытый файловый дескриптор, или fail, если obj не является файловым дескриптором.
io.write (···)
Эквивалент io.output():write(...).
file:close ()
Закрывает file. Обратите внимание, что файлы автоматически закрываются, когда их дескрипторы собираются сборщиком мусора, но это происходит через непредсказуемый промежуток времени.
При закрытии файлового дескриптора, созданного с помощью io.popen, file:close возвращает те же значения, что и os.execute.
file:flush ()
Сохраняет все записанные данные в файл.
file:lines (···)
Возвращает функцию-итератор, которая при каждом вызове читает файл в соответствии с заданными форматами. Если формат не указан, по умолчанию используется "l". В качестве примера, конструкция
for c in file:lines(1) do body end
будет итерироваться по всем символам файла, начиная с текущей позиции. В отличие от io.lines, эта функция не закрывает файл по окончании цикла.
file:read (···)
Читает файл file в соответствии с заданными форматами, которые указывают, что читать. Для каждого формата функция возвращает строку или число с прочитанными символами, или fail, если не может прочитать данные с указанным форматом. (В этом последнем случае функция не читает последующие форматы.) При вызове без аргументов используется формат по умолчанию, который читает следующую строку (см. ниже).
Доступные форматы:
"n": читает число и возвращает его как число с плавающей точкой или целое число, следуя лексическим соглашениям Lua. (Число может иметь начальные пробелы и знак.) Этот формат всегда читает самую длинную входную последовательность, которая является допустимым префиксом для числа; если этот префикс не образует допустимого числа (например, пустая строка,"0x"или"3.4e-") или он слишком длинный (более 200 символов), он отбрасывается, и формат возвращаетfail."a": читает весь файл, начиная с текущей позиции. В конце файла возвращает пустую строку; этот формат никогда не завершается неудачей."l": читает следующую строку, пропуская конец строки, возвращаетfailв конце файла. Это формат по умолчанию."L": читает следующую строку, сохраняя символ конца строки (если он есть), возвращаетfailв конце файла.- число: читает строку длиной до этого количества байтов, возвращает
failв конце файла. Если число равно нулю, ничего не читает и возвращает пустую строку илиfailв конце файла.
Форматы "l" и "L" следует использовать только для текстовых файлов.
file:seek ([whence [, offset]])
Устанавливает и получает позицию в файле, измеряемую от начала файла, в позицию, заданную как offset плюс база, указанная строкой whence, следующим образом:
"set": база — позиция 0 (начало файла);"cur": база — текущая позиция;"end": база — конец файла;
В случае успеха seek возвращает конечную позицию в файле, измеренную в байтах от начала файла. Если seek терпит неудачу, он возвращает fail плюс строку с описанием ошибки.
Значение по умолчанию для whence — "cur", а для offset — 0. Поэтому вызов file:seek() возвращает текущую позицию в файле, не изменяя ее; вызов file:seek("set") устанавливает позицию в начало файла (и возвращает 0); а вызов file:seek("end") устанавливает позицию в конец файла и возвращает его размер.
file:setvbuf (mode [, size])
Устанавливает режим буферизации для файла. Доступны три режима:
"no": без буферизации."full": полная буферизация."line": построчная буферизация.
Для последних двух случаев size является подсказкой для размера буфера в байтах. По умолчанию используется подходящий размер.
Конкретное поведение каждого режима непереносимо; для получения дополнительной информации проверьте базовую функцию ISO C setvbuf на вашей платформе.
file:write (···)
Записывает значение каждого из своих аргументов в файл. Аргументы должны быть строками или числами.
В случае успеха эта функция возвращает file. В противном случае возвращает четыре значения: fail, сообщение об ошибке, код ошибки и количество байтов, которое удалось записать.
6.10 – Средства операционной системы
Эта библиотека реализована через таблицу os.
os.clock ()
Возвращает приблизительное количество секунд процессорного времени, использованного программой, как возвращается базовой функцией ISO C clock.
os.date ([format [, time]])
Возвращает строку или таблицу, содержащую дату и время, отформатированные в соответствии с заданной строкой format.
Если аргумент time присутствует, это время, которое должно быть отформатировано (см. описание этого значения в функции os.time). В противном случае date форматирует текущее время.
Если format начинается с '!', то дата форматируется во Всемирном координированном времени (UTC). После этого необязательного символа, если format — строка "*t", то date возвращает таблицу со следующими полями: year, month (1–12), day (1–31), hour (0–23), min (0–59), sec (0–61, из-за високосных секунд), wday (день недели, 1–7, воскресенье — 1), yday (день года, 1–366) и isdst (флаг летнего времени, булево значение). Это последнее поле может отсутствовать, если информация недоступна.
Если format не "*t", то date возвращает дату как строку, отформатированную по тем же правилам, что и функция ISO C strftime.
Если format отсутствует, по умолчанию используется "%c", что дает удобочитаемое представление даты и времени с использованием текущей локали.
На не-POSIX системах эта функция может быть не потокобезопасной из-за зависимости от функций C gmtime и localtime.
os.difftime (t2, t1)
Возвращает разницу в секундах между временем t1 и временем t2 (где времена являются значениями, возвращенными os.time). В POSIX, Windows и некоторых других системах это значение точно равно t2-t1.
os.execute ([command])
Эта функция эквивалентна функции ISO C system. Она передает command для выполнения оболочке операционной системы. Ее первый результат — true, если команда завершилась успешно, или fail в противном случае. После этого первого результата функция возвращает строку и число следующим образом:
"exit": команда завершилась нормально; следующее число — это статус выхода команды."signal": команда была завершена сигналом; следующее число — это сигнал, завершивший команду.
При вызове без команды os.execute возвращает булево значение, которое равно true, если оболочка доступна.
os.exit ([code [, close]])
Вызывает функцию ISO C exit для завершения главной программы. Если code равно true, возвращаемый статус — EXIT_SUCCESS; если code равно false, возвращаемый статус — EXIT_FAILURE; если code — число, возвращаемый статус — это число. Значение по умолчанию для code — true.
Если необязательный второй аргумент close равен true, функция закрывает состояние Lua перед выходом (см. lua_close).
os.getenv (varname)
Возвращает значение переменной окружения процесса varname или fail, если переменная не определена.
os.remove (filename)
Удаляет файл (или пустой каталог в POSIX-системах) с заданным именем. Если эта функция терпит неудачу, она возвращает fail плюс строку с описанием ошибки и код ошибки. В противном случае возвращает true.
os.rename (oldname, newname)
Переименовывает файл или каталог с именем oldname в newname. Если эта функция терпит неудачу, она возвращает fail плюс строку с описанием ошибки и код ошибки. В противном случае возвращает true.
os.setlocale (locale [, category])
Устанавливает текущую локаль программы. locale — это системно-зависимая строка, указывающая локаль; category — необязательная строка, описывающая, какую категорию изменить: "all", "collate", "ctype", "monetary", "numeric" или "time"; категория по умолчанию — "all". Функция возвращает имя новой локали или fail, если запрос не может быть выполнен.
Если locale — пустая строка, текущая локаль устанавливается в определенную реализацией родную локаль. Если locale — строка "C", текущая локаль устанавливается в стандартную локаль C.
При вызове с nil в качестве первого аргумента эта функция только возвращает имя текущей локали для заданной категории.
Эта функция может быть не потокобезопасной из-за зависимости от функции C setlocale.
os.time ([table])
Возвращает текущее местное время при вызове без аргументов или время, представляющее местные дату и время, заданные данной таблицей. Эта таблица должна иметь поля year, month и day и может иметь поля hour (по умолчанию 12), min (по умолчанию 0), sec (по умолчанию 0) и isdst (по умолчанию nil). Другие поля игнорируются. Описание этих полей см. в функции os.date.
При вызове функции значения в этих полях не обязаны находиться внутри своих допустимых диапазонов. Например, если sec равно -10, это означает 10 секунд до времени, указанного другими полями; если hour равно 1000, это означает 1000 часов после времени, указанного другими полями.
Возвращаемое значение — это число, значение которого зависит от вашей системы. В POSIX, Windows и некоторых других системах это число отсчитывает количество секунд с некоторого заданного начального момента времени (“эпохи”). В других системах значение не определено, и число, возвращаемое time, может использоваться только в качестве аргумента для os.date и os.difftime.
При вызове с таблицей os.time также нормализует все поля, задокументированные в функции os.date, так что они представляют то же самое время, что и до вызова, но со значениями внутри допустимых диапазонов.
os.tmpname ()
Возвращает строку с именем файла, которое можно использовать для временного файла. Файл должен быть явно открыт перед использованием и явно удален, когда больше не нужен.
В POSIX-системах эта функция также создает файл с этим именем, чтобы избежать рисков безопасности. (Кто-то другой может создать файл с неправильными разрешениями за время между получением имени и созданием файла.) Вам все равно нужно открыть файл для его использования и удалить его (даже если вы его не используете).
По возможности лучше использовать io.tmpfile, которая автоматически удаляет файл по завершении программы.
6.11 – Библиотека отладки
Эта библиотека предоставляет функциональность отладочного интерфейса (§4.7) программам Lua. Следует проявлять осторожность при использовании этой библиотеки. Некоторые из ее функций нарушают базовые предположения о коде Lua (например, что к локальным переменным функции нельзя получить доступ извне; что метатаблицы пользовательских данных не могут быть изменены кодом Lua; что программы Lua не падают) и, следовательно, могут скомпрометировать в остальном безопасный код. Более того, некоторые функции в этой библиотеке могут быть медленными.
Все функции в этой библиотеке предоставляются внутри таблицы debug. Все функции, работающие с потоком, имеют необязательный первый аргумент — поток, с которым нужно работать. По умолчанию всегда используется текущий поток.
debug.debug ()
Входит в интерактивный режим с пользователем, выполняя каждую строку, которую вводит пользователь. Используя простые команды и другие средства отладки, пользователь может проверять глобальные и локальные переменные, изменять их значения, вычислять выражения и т.д. Строка, содержащая только слово cont, завершает эту функцию, так что вызывающий код продолжает свое выполнение.
Обратите внимание, что команды для debug.debug лексически не вложены ни в какую функцию и поэтому не имеют прямого доступа к локальным переменным.
debug.gethook ([thread])
Возвращает текущие настройки перехватчика (hook) для потока в виде трех значений: текущая функция перехватчика, текущая маска перехватчика и текущий счетчик перехватчика, как установлено функцией debug.sethook.
Возвращает fail, если активного перехватчика нет.
debug.getinfo ([thread,] f [, what])
Возвращает таблицу с информацией о функции. Вы можете передать функцию напрямую или передать число в качестве значения f, что означает функцию, выполняющуюся на уровне f стека вызовов данного потока: уровень 0 — текущая функция (сама getinfo); уровень 1 — функция, вызвавшая getinfo (за исключением хвостовых вызовов, которые не учитываются в стеке); и так далее. Если f — число, превышающее количество активных функций, getinfo возвращает fail.
Возвращаемая таблица может содержать все поля, возвращаемые lua_getinfo, при этом строка what описывает, какие поля следует заполнить. По умолчанию для what запрашивается вся доступная информация, кроме таблицы допустимых строк. Опция 'f' добавляет поле с именем func с самой функцией. Опция 'L' добавляет поле с именем activelines с таблицей допустимых строк, при условии, что функция является Lua-функцией. Если у функции нет отладочной информации, таблица пуста.
Например, выражение debug.getinfo(1,"n").name возвращает имя для текущей функции, если подходящее имя может быть найдено, а выражение debug.getinfo(print) возвращает таблицу со всей доступной информацией о функции print.
debug.getlocal ([thread,] f, local)
Эта функция возвращает имя и значение локальной переменной с индексом local функции на уровне f стека. Эта функция получает доступ не только к явным локальным переменным, но также к параметрам и временным значениям.
Первый параметр или локальная переменная имеет индекс 1, и так далее, в порядке их объявления в коде, при этом учитываются только переменные, активные в текущей области видимости функции. Константы времени компиляции могут не появляться в этом списке, если они были оптимизированы компилятором. Отрицательные индексы относятся к аргументам vararg; -1 — это первый аргумент vararg. Эти отрицательные индексы доступны только тогда, когда таблица vararg была оптимизирована; в противном случае аргументы vararg доступны в таблице vararg.
Функция возвращает fail, если нет переменной с заданным индексом, и вызывает ошибку при вызове с уровнем вне диапазона. (Вы можете вызвать debug.getinfo, чтобы проверить, допустим ли уровень.)
Имена переменных, начинающиеся с '(' (открывающая скобка), представляют переменные без известных имен (внутренние переменные, такие как переменные управления циклом, и переменные из чанков, сохраненных без отладочной информации).
Параметр f также может быть функцией. В этом случае getlocal возвращает только имена параметров функции.
debug.getmetatable (value)
Возвращает метатаблицу данного значения или nil, если у него нет метатаблицы.
debug.getregistry ()
Возвращает таблицу реестра (см. §4.3).
debug.getupvalue (f, up)
Эта функция возвращает имя и значение верхнего значения (upvalue) с индексом up функции f. Функция возвращает fail, если нет верхнего значения с заданным индексом.
(Для Lua-функций верхние значения — это внешние локальные переменные, которые использует функция и которые, следовательно, включены в ее замыкание.)
Для C-функций эта функция использует пустую строку "" в качестве имени для всех верхних значений.
Имя переменной '?' (вопросительный знак) представляет переменные без известных имен (переменные из чанков, сохраненных без отладочной информации).
debug.getuservalue (u, n)
Возвращает n-е пользовательское значение, связанное с пользовательскими данными u, плюс булево значение, false, если пользовательские данные не имеют этого значения.
debug.sethook ([thread,] hook, mask [, count])
Устанавливает заданную функцию в качестве отладочного перехватчика (hook). Строка mask и число count описывают, когда будет вызываться перехватчик. Строка mask может иметь любую комбинацию следующих символов с заданным значением:
'c': перехватчик вызывается каждый раз, когда Lua вызывает функцию;'r': перехватчик вызывается каждый раз, когда Lua возвращается из функции;'l': перехватчик вызывается каждый раз, когда Lua переходит на новую строку кода.
Более того, при count, отличном от нуля, перехватчик вызывается также после каждых count инструкций.
При вызове без аргументов debug.sethook отключает перехватчик.
При вызове перехватчика его первым параметром является строка, описывающая событие, вызвавшее его срабатывание: "call", "tail call", "return", "line" и "count". Для событий "line" перехватчик также получает номер новой строки в качестве второго параметра. Внутри перехватчика вы можете вызвать getinfo с уровнем 2, чтобы получить больше информации о выполняющейся функции. (Уровень 0 — это функция getinfo, а уровень 1 — функция перехватчика.)
debug.setlocal ([thread,] level, local, value)
Эта функция присваивает значение value локальной переменной с индексом local функции на уровне level стека. Функция возвращает fail, если нет локальной переменной с заданным индексом, и вызывает ошибку при вызове с уровнем вне диапазона. (Вы можете вызвать getinfo, чтобы проверить, допустим ли уровень.) В противном случае возвращает имя локальной переменной.
См. debug.getlocal для получения дополнительной информации об индексах и именах переменных.
debug.setmetatable (value, table)
Устанавливает метатаблицу для данного значения в заданную таблицу (которая может быть nil). Возвращает value.
debug.setupvalue (f, up, value)
Эта функция присваивает значение value верхнему значению (upvalue) с индексом up функции f. Функция возвращает fail, если нет верхнего значения с заданным индексом. В противном случае возвращает имя верхнего значения.
См. debug.getupvalue для получения дополнительной информации о верхних значениях.
debug.setuservalue (udata, value, n)
Устанавливает данное значение в качестве n-го пользовательского значения, связанного с данными udata. udata должны быть полными пользовательскими данными (full userdata).
Возвращает udata или fail, если пользовательские данные не имеют этого значения.
debug.traceback ([thread,] [message [, level]])
Если message присутствует, но не является ни строкой, ни nil, эта функция возвращает message без дальнейшей обработки. В противном случае она возвращает строку с трассировкой стека вызовов. Необязательная строка message добавляется в начало трассировки. Необязательный номер level указывает, с какого уровня начинать трассировку (по умолчанию 1, функция, вызывающая traceback).
debug.upvalueid (f, n)
Возвращает уникальный идентификатор (как легкие пользовательские данные — light userdata) для верхнего значения с номером n из данной функции.
Эти уникальные идентификаторы позволяют программе проверять, разделяют ли разные замыкания верхние значения. Замыкания Lua, которые разделяют верхнее значение (то есть обращаются к одной и той же внешней локальной переменной), вернут идентичные идентификаторы для этих индексов верхних значений.
debug.upvaluejoin (f1, n1, f2, n2)
Делает так, что n1-е верхнее значение Lua-замыкания f1 ссылается на n2-е верхнее значение Lua-замыкания f2.
2.6 - 7 – Lua как самостоятельное приложение
Использование интерпретатора Lua из командной строки, аргументы, интерактивный режим и переменные окружения.
Оглавление
7 – Lua как самостоятельное приложение
Хотя Lua был разработан как язык расширения для встраивания в хост-программу на C, он также часто используется как самостоятельный язык. Интерпретатор для Lua как самостоятельного языка, называемый просто lua, поставляется со стандартным дистрибутивом. Автономный интерпретатор включает все стандартные библиотеки. Его использование:
lua [options] [script [args]]
Опции следующие:
-e stat: выполнить строкуstat;-i: войти в интерактивный режим после выполнения скрипта;-l mod: выполнитьrequire "mod"и присвоить результат глобальной переменнойmod;-l g=mod: выполнитьrequire "mod"и присвоить результат глобальной переменнойg;-v: вывести информацию о версии;-E: игнорировать переменные окружения;-W: включить предупреждения;--: прекратить обработку опций;-: выполнить стандартный ввод (stdin) как файл и прекратить обработку опций.
После обработки своих опций lua запускает указанный скрипт. При вызове без аргументов lua ведет себя как lua -v -i, если стандартный ввод (stdin) является терминалом, и как lua - в противном случае.
При вызове без опции -E интерпретатор проверяет переменную окружения LUA_INIT_5_5 (или LUA_INIT, если версионированное имя не определено) перед выполнением любого аргумента. Если содержимое переменной имеет формат @filename, то lua выполняет этот файл. В противном случае lua выполняет саму строку.
При вызове с опцией -E Lua не проверяет никакие переменные окружения. В частности, значения package.path и package.cpath устанавливаются с путями по умолчанию, определенными в luaconf.h. Чтобы сигнализировать библиотекам, что эта опция включена, автономный интерпретатор устанавливает поле "LUA_NOENV" в реестре в истинное значение. Другие библиотеки могут проверять это поле с той же целью.
Опции -e, -l и -W обрабатываются в порядке их появления. Например, вызов вида
$ lua -e 'a=1' -llib1 script.lua
сначала установит a в 1, затем выполнит require для библиотеки lib1 и, наконец, запустит файл script.lua без аргументов. (Здесь $ — приглашение командной оболочки. Ваше приглашение может отличаться).
Перед выполнением любого кода lua собирает все аргументы командной строки в глобальную таблицу arg. Имя скрипта помещается в индекс 0, первый аргумент после имени скрипта — в индекс 1, и так далее. Любые аргументы перед именем скрипта (то есть имя интерпретатора плюс его опции) помещаются в отрицательные индексы. Например, в вызове
$ lua -la b.lua t1 t2
таблица выглядит так:
arg = { [-2] = "lua", [-1] = "-la",
[0] = "b.lua",
[1] = "t1", [2] = "t2" }
Если в вызове нет скрипта, имя интерпретатора помещается в индекс 0, за ним следуют остальные аргументы. Например, вызов
$ lua -e "print(arg[1])"
выведет "-e". Если есть скрипт, скрипт вызывается с аргументами arg[1], ···, arg[#arg]. Как и все чанки в Lua, скрипт компилируется как вариадическая функция.
В интерактивном режиме Lua многократно выводит приглашение и ожидает строку. После чтения строки Lua сначала пытается интерпретировать строку как выражение. Если это удается, он выводит его значение. В противном случае он интерпретирует строку как чанк. Если вы вводите незавершенный чанк, интерпретатор ожидает его завершения, выдавая другое приглашение.
Обратите внимание, что, поскольку каждая полная строка читается как новый чанк, локальные переменные не переживают строки. Чтобы избежать путаницы, интерпретатор выдает предупреждение, если строка начинается с зарезервированного слова local:
> x = 20 -- глобальная 'x'
> local x = 10; print(x)
--> warning: locals do not survive across lines in interactive mode
--> 10
> print(x) -- снова глобальная 'x'
--> 20
> do -- незавершенный чанк
>> local x = 10; print(x) -- '>>' приглашение для завершения строки
>> print(x)
>> end -- чанк завершен
--> 10
--> 10
Если глобальная переменная _PROMPT содержит строку, то ее значение используется в качестве приглашения. Аналогично, если глобальная переменная _PROMPT2 содержит строку, ее значение используется в качестве вторичного приглашения (выдаваемого во время незавершенных инструкций).
В случае незащищенных ошибок в скрипте интерпретатор сообщает об ошибке в стандартный поток ошибок. Если объект ошибки не является строкой, но имеет метаметод __tostring, интерпретатор вызывает этот метаметод для создания итогового сообщения. В противном случае интерпретатор преобразует объект ошибки в строку и добавляет к нему трассировку стека. Когда предупреждения включены, они просто выводятся в стандартный вывод ошибок.
При нормальном завершении интерпретатор закрывает свое главное состояние Lua (см. lua_close). Скрипт может избежать этого шага, вызвав os.exit для завершения.
Чтобы позволить использовать Lua в качестве интерпретатора скриптов в системах Unix, Lua пропускает первую строку файла чанка, если она начинается с #. Поэтому Lua-скрипты можно сделать исполняемыми программами, используя chmod +x и форму #!, как в
#!/usr/local/bin/lua
Конечно, расположение интерпретатора Lua на вашей машине может отличаться. Если lua находится в вашем PATH, то
#!/usr/bin/env lua
является более переносимым решением.
8 – Несовместимости с предыдущей версией
Здесь мы перечисляем несовместимости, с которыми вы можете столкнуться при переходе программы с Lua 5.4 на Lua 5.5.
Вы можете избежать некоторых несовместимостей, скомпилировав Lua с соответствующими опциями (см. файл luaconf.h). Однако все эти опции совместимости будут удалены в будущем. Чаще всего проблемы совместимости возникают именно при удалении этих опций. Поэтому, когда у вас есть возможность, старайтесь тестировать свой код с версией Lua, скомпилированной со всеми отключенными опциями совместимости. Это облегчит переходы на более новые версии Lua.
Версии Lua всегда могут изменять C API способами, которые не подразумевают изменений в исходном коде программы, например, числовые значения констант или реализацию функций в виде макросов. Поэтому никогда не следует предполагать, что двоичные файлы совместимы между разными версиями Lua. Всегда перекомпилируйте клиентов Lua API при использовании новой версии.
Аналогично, версии Lua всегда могут изменять внутреннее представление предварительно скомпилированных чанков; предкомпилированные чанки несовместимы между разными версиями Lua.
Стандартные пути в официальном дистрибутиве могут меняться между версиями.
8.1 – Несовместимости в языке
- Слово
globalявляется зарезервированным словом. Не используйте его как обычное имя. - Управляющая переменная в циклах
forдоступна только для чтения. Если вам нужно ее изменить, объявите локальную переменную с тем же именем в теле цикла. - Цепочка метаметодов
__callможет содержать не более 15 объектов. - При ошибке
nilв качестве объекта ошибки заменяется строковым сообщением.
8.2 – Несовместимости в библиотеках
- Параметры сборки мусора не устанавливаются опциями
"incremental"и"generational"; вместо этого для этой цели есть новая опция"param". Более того, были внесены некоторые изменения в сами параметры.
8.3 – Несовместимости в API
- В
lua_callи связанных функциях максимальное значение для количества требуемых результатов (nresults) составляет 250. Если вам действительно нужно большее значение, используйтеLUA_MULTRET, а затем настройте размер стека. Ранее этот предел не был указан. lua_newstateимеет третий параметр — начальное значение для хеширования строк.- Функция
lua_resetthreadустарела; она эквивалентнаlua_closethreadсfrom, равнымNULL. - Функция
lua_setcstacklimitустарела. Вызовы к ней можно просто удалить. - Функция
lua_dumpизменила способ сохранения стека при вызовах функции-писателя. (Это не было указано в предыдущих версиях). Кроме того, она вызывает функцию-писатель один дополнительный раз, чтобы сигнализировать о конце дампа. - Параметры сборки мусора не устанавливаются опциями
LUA_GCINCиLUA_GCGEN; вместо этого для этой цели есть новая опцияLUA_GCPARAM. Более того, были внесены некоторые изменения в сами параметры. - Функция
lua_pushvfstringтеперь сообщает об ошибках, а не возбуждает их.
9 – Полный синтаксис Lua
Здесь представлен полный синтаксис Lua в расширенной БНФ. Как обычно в расширенной БНФ, {A} означает 0 или более A, а [A] означает необязательное A. (Приоритеты операторов см. в §3.4.8; описание терминалов Name, Numeral и LiteralString см. в §3.1).
chunk ::= block
block ::= {stat} [retstat]
stat ::= ‘;’ |
varlist ‘=’ explist |
functioncall |
label |
break |
goto Name |
do block end |
while exp do block end |
repeat block until exp |
if exp then block {elseif exp then block} [else block] end |
for Name ‘=’ exp ‘,’ exp [‘,’ exp] do block end |
for namelist in explist do block end |
function funcname funcbody |
local function Name funcbody |
global function Name funcbody |
local attnamelist [‘=’ explist] |
global attnamelist |
global [attrib] ‘*’
attnamelist ::= [attrib] Name [attrib] {‘,’ Name [attrib]}
attrib ::= ‘<’ Name ‘>’
retstat ::= return [explist] [‘;’]
label ::= ‘::’ Name ‘::’
funcname ::= Name {‘.’ Name} [‘:’ Name]
varlist ::= var {‘,’ var}
var ::= Name | prefixexp ‘[’ exp ‘]’ | prefixexp ‘.’ Name
namelist ::= Name {‘,’ Name}
explist ::= exp {‘,’ exp}
exp ::= nil | false | true | Numeral | LiteralString | ‘...’ | functiondef |
prefixexp | tableconstructor | exp binop exp | unop exp
prefixexp ::= var | functioncall | ‘(’ exp ‘)’
functioncall ::= prefixexp args | prefixexp ‘:’ Name args
args ::= ‘(’ [explist] ‘)’ | tableconstructor | LiteralString
functiondef ::= function funcbody
funcbody ::= ‘(’ [parlist] ‘)’ block end
parlist ::= namelist [‘,’ varargparam] | varargparam
varargparam ::= ‘...’ [Name]
tableconstructor ::= ‘{’ [fieldlist] ‘}’
fieldlist ::= field {fieldsep field} [fieldsep]
field ::= ‘[’ exp ‘]’ ‘=’ exp | Name ‘=’ exp | exp
fieldsep ::= ‘,’ | ‘;’
binop ::= ‘+’ | ‘-’ | ‘*’ | ‘/’ | ‘//’ | ‘^’ | ‘%’ |
‘&’ | ‘~’ | ‘|’ | ‘>>’ | ‘<<’ | ‘..’ |
‘<’ | ‘<=’ | ‘>’ | ‘>=’ | ‘==’ | ‘~=’ |
and | or
unop ::= ‘-’ | not | ‘#’ | ‘~’
3 - Authelia
Описание настройки Authelia. Интсрумент для аутентификации пользователей на сайте.
Структура Authelia
Базовая схема взаимодействия Authelia с сервисами
---
config:
theme: redux
---
flowchart LR
A["Пользователь"] -- Запрос --> B["Reverse Proxy Nginx/Traefik"]
B -- Проверка аутентификации --> C["Authelia"]
C -- Данные пользователей --> D["Хранилище: PostgreSQL/MySQL"]
C -- 2FA/SMS --> E["Провайдер: Twilio/Email"]
C -- Разрешить/Запретить --> B
B -- Доступ разрешен --> F["Защищенный сервис"]
B:::Aqua
C:::Rose
F:::Peach
classDef Aqua stroke-width:1px, stroke-dasharray:none, stroke:#46EDC8, fill:#DEFFF8, color:#378E7A
classDef Rose stroke-width:2px, stroke-dasharray:none, stroke:#FF5978, fill:#FFDFE5, color:#8E2236
classDef Peach stroke-width:1px, stroke-dasharray:none, stroke:#FBB35A, fill:#FFEFDB, color:#8F632D
style D fill:#FFD600
style E fill:#C8E6C9Детализированная архитектура Authelia
graph TD
subgraph Authelia
A[Frontend] -->|API| B[Backend]
B --> C[Аутентификация]
B --> D[Авторизация]
B --> E[2FA]
C -->|LDAP/OIDC| F[Identity Provider]
D -->|ACL| G[Политики доступа]
E -->|TOTP/SMS| H[Провайдеры 2FA]
end
I[Reverse Proxy] -->|Запросы| B
B -->|Сессии| J[Redis]
F -->|Пользователи| K[PostgreSQL]3.1 - Конфигурация Authelia
Конфигурация оформляется в виде файла
config.template.yml который располагается в каждой секции сайта.Файл конфигурации Authelia
Конфигурация оформляется в виде файла config.template.yml который располагается в каждой секции сайта.
docker run authelia/authelia:latest authelia config validate --config /config/configuration.yml
Смотреть файл конфигурации
# yamllint disable rule:comments-indentation
---
###############################################################################
## Authelia Configuration ##
###############################################################################
##
## Notes:
##
## - the default location of this file is assumed to be configuration.yml unless otherwise noted
## - when using docker the container expects this by default to be at /config/configuration.yml
## - the default location where this file is loaded from can be overridden with the X_AUTHELIA_CONFIG environment var
## - the comments in this configuration file are helpful but users should consult the official documentation on the
## website at https://www.authelia.com/ or https://www.authelia.com/configuration/prologue/introduction/
## - this configuration file template is not automatically updated
##
## Certificates directory specifies where Authelia will load trusted certificates (public portion) from in addition to
## the system certificates store.
## They should be in base64 format, and have one of the following extensions: *.cer, *.crt, *.pem.
# certificates_directory: '/config/certificates/'
## The theme to display: light, dark, grey, auto.
# theme: 'light'
## Set the default 2FA method for new users and for when a user has a preferred method configured that has been
## disabled. This setting must be a method that is enabled.
## Options are totp, webauthn, mobile_push.
# default_2fa_method: ''
##
## Server Configuration
##
# server:
## The address for the Main server to listen on in the address common syntax.
## Formats:
## - [<scheme>://]<hostname>[:<port>][/<path>]
## - [<scheme>://][hostname]:<port>[/<path>]
## Square brackets indicate optional portions of the format. Scheme must be 'tcp', 'tcp4', 'tcp6', 'unix', or 'fd'.
## The default scheme is 'unix' if the address is an absolute path otherwise it's 'tcp'. The default port is '9091'.
## If the path is specified this configures the router to handle both the `/` path and the configured path.
# address: 'tcp://:9091/'
## Set the path on disk to Authelia assets.
## Useful to allow overriding of specific static assets.
# asset_path: '/config/assets/'
## Disables writing the health check vars to /app/.healthcheck.env which makes healthcheck.sh return exit code 0.
## This is disabled by default if either /app/.healthcheck.env or /app/healthcheck.sh do not exist.
# disable_healthcheck: false
## Authelia by default doesn't accept TLS communication on the server port. This section overrides this behaviour.
# tls:
## The path to the DER base64/PEM format private key.
# key: ''
## The path to the DER base64/PEM format public certificate.
# certificate: ''
## The list of certificates for client authentication.
# client_certificates: []
## Server headers configuration/customization.
# headers:
## The CSP Template. Read the docs.
# csp_template: ''
## Server Buffers configuration.
# buffers:
## Buffers usually should be configured to be the same value.
## Explanation at https://www.authelia.com/c/server#buffer-sizes
## Read buffer size adjusts the server's max incoming request size in bytes.
## Write buffer size does the same for outgoing responses.
## Read buffer.
# read: 4096
## Write buffer.
# write: 4096
## Server Timeouts configuration.
# timeouts:
## Read timeout in the duration common syntax.
# read: '6 seconds'
## Write timeout in the duration common syntax.
# write: '6 seconds'
## Idle timeout in the duration common syntax.
# idle: '30 seconds'
## Server Endpoints configuration.
## This section is considered advanced and it SHOULD NOT be configured unless you've read the relevant documentation.
# endpoints:
## Enables the pprof endpoint.
# enable_pprof: false
## Enables the expvars endpoint.
# enable_expvars: false
## Configure the authz endpoints.
# authz:
# forward-auth:
# implementation: 'ForwardAuth'
# authn_strategies: []
# ext-authz:
# implementation: 'ExtAuthz'
# authn_strategies: []
# auth-request:
# implementation: 'AuthRequest'
# authn_strategies: []
# legacy:
# implementation: 'Legacy'
# authn_strategies: []
##
## Log Configuration
##
# log:
## Level of verbosity for logs: info, debug, trace.
# level: 'debug'
## Format the logs are written as: json, text.
# format: 'json'
## File path where the logs will be written. If not set logs are written to stdout.
# file_path: '/config/authelia.log'
## Whether to also log to stdout when a log_file_path is defined.
# keep_stdout: false
##
## Telemetry Configuration
##
# telemetry:
##
## Metrics Configuration
##
# metrics:
## Enable Metrics.
# enabled: false
## The address for the Metrics server to listen on in the address common syntax.
## Formats:
## - [<scheme>://]<hostname>[:<port>][/<path>]
## - [<scheme>://][hostname]:<port>[/<path>]
## Square brackets indicate optional portions of the format. Scheme must be 'tcp', 'tcp4', 'tcp6', 'unix', or 'fd'.
## The default scheme is 'unix' if the address is an absolute path otherwise it's 'tcp'. The default port is '9959'.
## If the path is not specified it defaults to `/metrics`.
# address: 'tcp://:9959/metrics'
## Metrics Server Buffers configuration.
# buffers:
## Read buffer.
# read: 4096
## Write buffer.
# write: 4096
## Metrics Server Timeouts configuration.
# timeouts:
## Read timeout in the duration common syntax.
# read: '6 seconds'
## Write timeout in the duration common syntax.
# write: '6 seconds'
## Idle timeout in the duration common syntax.
# idle: '30 seconds'
##
## TOTP Configuration
##
## Parameters used for TOTP generation.
# totp:
## Disable TOTP.
# disable: false
## The issuer name displayed in the Authenticator application of your choice.
# issuer: 'authelia.com'
## The TOTP algorithm to use.
## It is CRITICAL you read the documentation before changing this option:
## https://www.authelia.com/c/totp#algorithm
# algorithm: 'SHA1'
## The number of digits a user has to input. Must either be 6 or 8.
## Changing this option only affects newly generated TOTP configurations.
## It is CRITICAL you read the documentation before changing this option:
## https://www.authelia.com/c/totp#digits
# digits: 6
## The period in seconds a Time-based One-Time Password is valid for.
## Changing this option only affects newly generated TOTP configurations.
# period: 30
## The skew controls number of Time-based One-Time Passwords either side of the current one that are valid.
## Warning: before changing skew read the docs link below.
# skew: 1
## See: https://www.authelia.com/c/totp#input-validation to read
## the documentation.
## The size of the generated shared secrets. Default is 32 and is sufficient in most use cases, minimum is 20.
# secret_size: 32
## The allowed algorithms for a user to pick from.
# allowed_algorithms:
# - 'SHA1'
## The allowed digits for a user to pick from.
# allowed_digits:
# - 6
## The allowed periods for a user to pick from.
# allowed_periods:
# - 30
## Disable the reuse security policy which prevents replays of one-time password code values.
# disable_reuse_security_policy: false
##
## WebAuthn Configuration
##
## Parameters used for WebAuthn.
# webauthn:
## Disable WebAuthn.
# disable: false
## Enables logins via a Passkey.
# enable_passkey_login: false
## The display name the browser should show the user for when using WebAuthn to login/register.
# display_name: 'Authelia'
## Conveyance preference controls if we collect the attestation statement including the AAGUID from the device.
## Options are none, indirect, direct.
# attestation_conveyance_preference: 'indirect'
## The interaction timeout for WebAuthn dialogues in the duration common syntax.
# timeout: '60 seconds'
## Authenticator Filtering.
# filtering:
## Prohibits registering Authenticators that claim they can export their credentials in some way.
# prohibit_backup_eligibility: false
## Permitted AAGUID's. If configured specifically only allows the listed AAGUID's.
# permitted_aaguids: []
## Prohibited AAGUID's. If configured prohibits the use of specific AAGUID's.
# prohibited_aaguids: []
## Selection Criteria controls the preferences for registration.
# selection_criteria:
## The attachment preference. Either 'cross-platform' for dedicated authenticators, or 'platform' for embedded
## authenticators.
# attachment: 'cross-platform'
## The discoverability preference. Options are 'discouraged', 'preferred', and 'required'.
# discoverability: 'discouraged'
## User verification controls if the user must make a gesture or action to confirm they are present.
## Options are required, preferred, discouraged.
# user_verification: 'preferred'
## Metadata Service validation via MDS3.
# metadata:
## Enable the metadata fetch behaviour.
# enabled: false
## Enable Validation of the Trust Anchor. This generally should be enabled if you're using the metadata. It
## ensures the attestation certificate presented by the authenticator is valid against the MDS3 certificate that
## issued the attestation certificate.
# validate_trust_anchor: true
## Enable Validation of the Entry. This ensures that the MDS3 actually contains the metadata entry. If not enabled
## attestation certificates which are not formally registered will be skipped. This may potentially exclude some
## virtual authenticators.
# validate_entry: true
## Enabling this allows attestation certificates with a zero AAGUID to pass validation. This is important if you do
## use non-conformant authenticators like Apple ID.
# validate_entry_permit_zero_aaguid: false
## Enable Validation of the Authenticator Status.
# validate_status: true
## List of statuses which are considered permitted when validating an authenticator's metadata. Generally it is
## recommended that this is not configured as any other status the authenticator's metadata has will result in an
## error. This option is ineffectual if validate_status is false.
# validate_status_permitted: ~
## List of statuses that should be prohibited when validating an authenticator's metadata. Generally it is
## recommended that this is not configured as there are safe defaults. This option is ineffectual if validate_status
## is false, or validate_status_permitted has values.
# validate_status_prohibited: ~
##
## Duo Push API Configuration
##
## Parameters used to contact the Duo API. Those are generated when you protect an application of type
## "Partner Auth API" in the management panel.
# duo_api:
# disable: false
# hostname: 'api-123456789.example.com'
# integration_key: 'ABCDEF'
## Secret can also be set using a secret: https://www.authelia.com/c/secrets
# secret_key: '1234567890abcdefghifjkl'
# enable_self_enrollment: false
##
## Identity Validation Configuration
##
## This configuration tunes the identity validation flows.
identity_validation:
## Reset Password flow. Adjusts how the reset password flow operates.
reset_password:
## Maximum allowed time before the JWT is generated and when the user uses it in the duration common syntax.
# jwt_lifespan: '5 minutes'
## The algorithm used for the Reset Password JWT.
# jwt_algorithm: 'HS256'
## The secret key used to sign and verify the JWT.
jwt_secret: 'a_very_important_secret'
## Elevated Session flows. Adjusts the flow which require elevated sessions for example managing credentials, adding,
## removing, etc.
# elevated_session:
## Maximum allowed lifetime after the One-Time Code is generated that it is considered valid.
# code_lifespan: '5 minutes'
## Maximum allowed lifetime after the user uses the One-Time Code and the user must perform the validation again in
## the duration common syntax.
# elevation_lifespan: '10 minutes'
## Number of characters the one-time password contains.
# characters: 8
## In addition to the One-Time Code requires the user performs a second factor authentication.
# require_second_factor: false
## Skips the elevation requirement and entry of the One-Time Code if the user has performed second factor
## authentication.
# skip_second_factor: false
##
## NTP Configuration
##
## This is used to validate the servers time is accurate enough to validate TOTP.
# ntp:
## The address of the NTP server to connect to in the address common syntax.
## Format: [<scheme>://]<hostname>[:<port>].
## Square brackets indicate optional portions of the format. Scheme must be 'udp', 'udp4', or 'udp6'.
## The default scheme is 'udp'. The default port is '123'.
# address: 'udp://time.cloudflare.com:123'
## NTP version.
# version: 4
## Maximum allowed time offset between the host and the NTP server in the duration common syntax.
# max_desync: '3 seconds'
## Disables the NTP check on startup entirely. This means Authelia will not contact a remote service at all if you
## set this to true, and can operate in a truly offline mode.
# disable_startup_check: false
## The default of false will prevent startup only if we can contact the NTP server and the time is out of sync with
## the NTP server more than the configured max_desync. If you set this to true, an error will be logged but startup
## will continue regardless of results.
# disable_failure: false
##
## Definitions
##
## The definitions are used in other areas as reference points to reduce duplication.
##
# definitions:
## The user attribute definitions.
# user_attributes:
## The name of the definition.
# definition_name:
## The common expression language expression for this definition.
# expression: ''
## The network definitions.
# network:
## The name of the definition followed by the list of CIDR network addresses in this definition.
# internal:
# - '10.10.0.0/16'
# - '172.16.0.0/12'
# - '192.168.2.0/24'
# VPN:
# - '10.9.0.0/16'
##
## Authentication Backend Provider Configuration
##
## Used for verifying user passwords and retrieve information such as email address and groups users belong to.
##
## The available providers are: `file`, `ldap`. You must use only one of these providers.
# authentication_backend:
## Password Change Options.
# password_change:
## Disable both the HTML element and the API for password change functionality.
# disable: false
## Password Reset Options.
# password_reset:
## Disable both the HTML element and the API for reset password functionality.
# disable: false
## External reset password url that redirects the user to an external reset portal. This disables the internal reset
## functionality.
# custom_url: ''
## The amount of time to wait before we refresh data from the authentication backend in the duration common syntax.
## To disable this feature set it to 'disable', this will slightly reduce security because for Authelia, users will
## always belong to groups they belonged to at the time of login even if they have been removed from them in LDAP.
## To force update on every request you can set this to '0' or 'always', this will increase processor demand.
## See the below documentation for more information.
## Refresh Interval docs: https://www.authelia.com/c/1fa#refresh-interval
# refresh_interval: '5 minutes'
##
## LDAP (Authentication Provider)
##
## This is the recommended Authentication Provider in production
## because it allows Authelia to offload the stateful operations
## onto the LDAP service.
# ldap:
## The address of the directory server to connect to in the address common syntax.
## Format: [<scheme>://]<hostname>[:<port>].
## Square brackets indicate optional portions of the format. Scheme must be 'ldap', 'ldaps', or 'ldapi`.
## The default scheme is 'ldapi' if the address is an absolute path otherwise it's 'ldaps'.
## The default port is '636', unless the scheme is 'ldap' in which case it's '389'.
# address: 'ldaps://127.0.0.1:636'
## The LDAP implementation, this affects elements like the attribute utilised for resetting a password.
## Acceptable options are as follows:
## - 'activedirectory' - for Microsoft Active Directory.
## - 'freeipa' - for FreeIPA.
## - 'lldap' - for lldap.
## - 'custom' - for custom specifications of attributes and filters.
## This currently defaults to 'custom' to maintain existing behaviour.
##
## Depending on the option here certain other values in this section have a default value, notably all of the
## attribute mappings have a default value that this config overrides, you can read more about these default values
## at https://www.authelia.com/c/ldap#defaults
# implementation: 'custom'
## The dial timeout for LDAP in the duration common syntax.
# timeout: '20 seconds'
## Use StartTLS with the LDAP connection.
# start_tls: false
## TLS configuration.
# tls:
## The server subject name to check the servers certificate against during the validation process.
## This option is not required if the certificate has a SAN which matches the address options hostname.
# server_name: 'ldap.example.com'
## Skip verifying the server certificate entirely. In preference to setting this we strongly recommend you add the
## certificate or the certificate of the authority signing the certificate to the certificates directory which is
## defined by the `certificates_directory` option at the top of the configuration.
## It's important to note the public key should be added to the directory, not the private key.
## This option is strongly discouraged but may be useful in some self-signed situations where validation is not
## important to the administrator.
# skip_verify: false
## Minimum TLS version for the connection.
# minimum_version: 'TLS1.2'
## Maximum TLS version for the connection.
# maximum_version: 'TLS1.3'
## The certificate chain used with the private_key if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
## The private key used with the certificate_chain if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# private_key: |
# -----BEGIN PRIVATE KEY-----
# ...
# -----END PRIVATE KEY-----
## Connection Pooling configuration.
# pooling:
## Enable Pooling.
# enable: false
## Pool count.
# count: 5
## Retries to obtain a connection during the timeout.
# retries: 2
## Timeout before the attempt to obtain a connection fails.
# timeout: '10 seconds'
## The distinguished name of the container searched for objects in the directory information tree.
## See also: additional_users_dn, additional_groups_dn.
# base_dn: 'dc=example,dc=com'
## The additional_users_dn is prefixed to base_dn and delimited by a comma when searching for users.
## i.e. with this set to OU=Users and base_dn set to DC=a,DC=com; OU=Users,DC=a,DC=com is searched for users.
# additional_users_dn: 'ou=users'
## The users filter used in search queries to find the user profile based on input filled in login form.
## Various placeholders are available in the user filter which you can read about in the documentation which can
## be found at: https://www.authelia.com/c/ldap#users-filter-replacements
##
## Recommended settings are as follows:
## - Microsoft Active Directory: (&({username_attribute}={input})(objectCategory=person)(objectClass=user))
## - OpenLDAP:
## - (&({username_attribute}={input})(objectClass=person))
## - (&({username_attribute}={input})(objectClass=inetOrgPerson))
##
## To allow sign in both with username and email, one can use a filter like
## (&(|({username_attribute}={input})({mail_attribute}={input}))(objectClass=person))
# users_filter: '(&({username_attribute}={input})(objectClass=person))'
## The additional_groups_dn is prefixed to base_dn and delimited by a comma when searching for groups.
## i.e. with this set to OU=Groups and base_dn set to DC=a,DC=com; OU=Groups,DC=a,DC=com is searched for groups.
# additional_groups_dn: 'ou=groups'
## The groups filter used in search queries to find the groups based on relevant authenticated user.
## Various placeholders are available in the groups filter which you can read about in the documentation which can
## be found at: https://www.authelia.com/c/ldap#groups-filter-replacements
##
## If your groups use the `groupOfUniqueNames` structure use this instead:
## (&(uniqueMember={dn})(objectClass=groupOfUniqueNames))
# groups_filter: '(&(member={dn})(objectClass=groupOfNames))'
## The group search mode to use. Options are 'filter' or 'memberof'. It's essential to read the docs if you wish to
## use 'memberof'. Also 'filter' is the best choice for most use cases.
# group_search_mode: 'filter'
## Follow referrals returned by the server.
## This is especially useful for environments where read-only servers exist. Only implemented for write operations.
# permit_referrals: false
## The username and password of the admin user.
# user: 'cn=admin,dc=example,dc=com'
## Password can also be set using a secret: https://www.authelia.com/c/secrets
# password: 'password'
## The attributes for users and objects from the directory server.
# attributes:
## The distinguished name attribute if your directory server supports it. Users should read the docs before
## configuring. Only used for the 'memberof' group search mode.
# distinguished_name: ''
## The attribute holding the username of the user. This attribute is used to populate the username in the session
## information. For your information, Microsoft Active Directory usually uses 'sAMAccountName' and OpenLDAP
## usually uses 'uid'. Beware that this attribute holds the unique identifiers for the users binding the user and
## the configuration stored in database; therefore only single value attributes are allowed and the value must
## never be changed once attributed to a user otherwise it would break the configuration for that user.
## Technically non-unique attributes like 'mail' can also be used but we don't recommend using them, we instead
## advise to use a filter to perform alternative lookups and the attributes mentioned above
## (sAMAccountName and uid) to follow https://datatracker.ietf.org/doc/html/rfc2307.
# username: 'uid'
## The attribute holding the display name of the user. This will be used to greet an authenticated user.
# display_name: 'displayName'
## The attribute holding the mail address of the user. If multiple email addresses are defined for a user, only
## the first one returned by the directory server is used.
# mail: 'mail'
## The attribute which provides distinguished names of groups an object is a member of.
## Only used for the 'memberof' group search mode.
# member_of: 'memberOf'
## The attribute holding the name of the group.
# group_name: 'cn'
##
## File (Authentication Provider)
##
## With this backend, the users database is stored in a file which is updated when users reset their passwords.
## Therefore, this backend is meant to be used in a dev environment and not in production since it prevents Authelia
## to be scaled to more than one instance. The options under 'password' have sane defaults, and as it has security
## implications it is highly recommended you leave the default values. Before considering changing these settings
## please read the docs page below:
## https://www.authelia.com/r/passwords#tuning
##
## Important: Kubernetes (or HA) users must read https://www.authelia.com/t/statelessness
##
# file:
# path: '/config/users_database.yml'
# watch: false
# search:
# email: false
# case_insensitive: false
# password:
# algorithm: 'argon2'
# argon2:
# variant: 'argon2id'
# iterations: 3
# memory: 65536
# parallelism: 4
# key_length: 32
# salt_length: 16
# scrypt:
# variant: 'scrypt'
# iterations: 16
# block_size: 8
# parallelism: 1
# key_length: 32
# salt_length: 16
# pbkdf2:
# variant: 'sha512'
# iterations: 310000
# salt_length: 16
# sha2crypt:
# variant: 'sha512'
# iterations: 50000
# salt_length: 16
# bcrypt:
# variant: 'standard'
# cost: 12
##
## Password Policy Configuration.
##
# password_policy:
## The standard policy allows you to tune individual settings manually.
# standard:
# enabled: false
## Require a minimum length for passwords.
# min_length: 8
## Require a maximum length for passwords.
# max_length: 0
## Require uppercase characters.
# require_uppercase: true
## Require lowercase characters.
# require_lowercase: true
## Require numeric characters.
# require_number: true
## Require special characters.
# require_special: true
## zxcvbn is a well known and used password strength algorithm. It does not have tunable settings.
# zxcvbn:
# enabled: false
## Configures the minimum score allowed.
# min_score: 3
##
## Privacy Policy Configuration
##
## Parameters used for displaying the privacy policy link and drawer.
# privacy_policy:
## Enables the display of the privacy policy using the policy_url.
# enabled: false
## Enables the display of the privacy policy drawer which requires users accept the privacy policy
## on a per-browser basis.
# require_user_acceptance: false
## The URL of the privacy policy document. Must be an absolute URL and must have the 'https://' scheme.
## If the privacy policy enabled option is true, this MUST be provided.
# policy_url: ''
##
## Access Control Configuration
##
## Access control is a list of rules defining the authorizations applied for one resource to users or group of users.
##
## If 'access_control' is not defined, ACL rules are disabled and the 'deny' rule is applied, i.e., access is denied
## to everyone. Otherwise restrictions follow the rules defined.
##
## Note: One can use the wildcard * to match any subdomain.
## It must stand at the beginning of the pattern. (example: *.example.com)
##
## Note: You must put patterns containing wildcards between simple quotes for the YAML to be syntactically correct.
##
## Definition: A 'rule' is an object with the following keys: 'domain', 'subject', 'policy' and 'resources'.
##
## - 'domain' defines which domain or set of domains the rule applies to.
##
## - 'subject' defines the subject to apply authorizations to. This parameter is optional and matching any user if not
## provided. If provided, the parameter represents either a user or a group. It should be of the form
## 'user:<username>' or 'group:<groupname>'.
##
## - 'policy' is the policy to apply to resources. It must be either 'bypass', 'one_factor', 'two_factor' or 'deny'.
##
## - 'resources' is a list of regular expressions that matches a set of resources to apply the policy to. This parameter
## is optional and matches any resource if not provided.
##
## Note: the order of the rules is important. The first policy matching (domain, resource, subject) applies.
# access_control:
## Default policy can either be 'bypass', 'one_factor', 'two_factor' or 'deny'. It is the policy applied to any
## resource if there is no policy to be applied to the user.
# default_policy: 'deny'
# rules:
## Rules applied to everyone
# - domain: 'public.example.com'
# policy: 'bypass'
## Domain Regex examples. Generally we recommend just using a standard domain.
# - domain_regex: '^(?P<User>\w+)\.example\.com$'
# policy: 'one_factor'
# - domain_regex: '^(?P<Group>\w+)\.example\.com$'
# policy: 'one_factor'
# - domain_regex:
# - '^appgroup-.*\.example\.com$'
# - '^appgroup2-.*\.example\.com$'
# policy: 'one_factor'
# - domain_regex: '^.*\.example\.com$'
# policy: 'two_factor'
# - domain: 'secure.example.com'
# policy: 'one_factor'
## Network based rule, if not provided any network matches.
# networks:
# - 'internal'
# - 'VPN'
# - '192.168.1.0/24'
# - '10.0.0.1'
# - domain:
# - 'secure.example.com'
# - 'private.example.com'
# policy: 'two_factor'
# - domain: 'singlefactor.example.com'
# policy: 'one_factor'
## Rules applied to 'admins' group
# - domain: 'mx2.mail.example.com'
# subject: 'group:admins'
# policy: 'deny'
# - domain: '*.example.com'
# subject:
# - 'group:admins'
# - 'group:moderators'
# policy: 'two_factor'
## Rules applied to 'dev' group
# - domain: 'dev.example.com'
# resources:
# - '^/groups/dev/.*$'
# subject: 'group:dev'
# policy: 'two_factor'
## Rules applied to user 'john'
# - domain: 'dev.example.com'
# resources:
# - '^/users/john/.*$'
# subject: 'user:john'
# policy: 'two_factor'
## Rules applied to user 'harry'
# - domain: 'dev.example.com'
# resources:
# - '^/users/harry/.*$'
# subject: 'user:harry'
# policy: 'two_factor'
## Rules applied to user 'bob'
# - domain: '*.mail.example.com'
# subject: 'user:bob'
# policy: 'two_factor'
# - domain: 'dev.example.com'
# resources:
# - '^/users/bob/.*$'
# subject: 'user:bob'
# policy: 'two_factor'
##
## Session Provider Configuration
##
## The session cookies identify the user once logged in.
## The available providers are: `memory`, `redis`. Memory is the provider unless redis is defined.
session:
## The secret to encrypt the session data. This is only used with Redis / Redis Sentinel.
## Secret can also be set using a secret: https://www.authelia.com/c/secrets
secret: 'insecure_session_secret'
## Cookies configures the list of allowed cookie domains for sessions to be created on.
## Undefined values will default to the values below.
# cookies:
# -
## The name of the session cookie.
# name: 'authelia_session'
## The domain to protect.
## Note: the Authelia portal must also be in that domain.
# domain: 'example.com'
## Required. The fully qualified URI of the portal to redirect users to on proxies that support redirections.
## Rules:
## - MUST use the secure scheme 'https://'
## - The above 'domain' option MUST either:
## - Match the host portion of this URI.
## - Match the suffix of the host portion when prefixed with '.'.
# authelia_url: 'https://auth.example.com'
## Optional. The fully qualified URI used as the redirection location if the portal is accessed directly. Not
## configuring this option disables the automatic redirection behaviour.
##
## Note: this parameter is optional. If not provided, user won't be redirected upon successful authentication
## unless they were redirected to Authelia by the proxy.
##
## Rules:
## - MUST use the secure scheme 'https://'
## - MUST not match the 'authelia_url' option.
## - The above 'domain' option MUST either:
## - Match the host portion of this URI.
## - Match the suffix of the host portion when prefixed with '.'.
# default_redirection_url: 'https://www.example.com'
## Sets the Cookie SameSite value. Possible options are none, lax, or strict.
## Please read https://www.authelia.com/c/session#same_site
# same_site: 'lax'
## The value for inactivity, expiration, and remember_me are in seconds or the duration common syntax.
## All three of these values affect the cookie/session validity period. Longer periods are considered less secure
## because a stolen cookie will last longer giving attackers more time to spy or attack.
## The inactivity time before the session is reset. If expiration is set to 1h, and this is set to 5m, if the user
## does not select the remember me option their session will get destroyed after 1h, or after 5m since the last
## time Authelia detected user activity.
# inactivity: '5 minutes'
## The time before the session cookie expires and the session is destroyed if remember me IS NOT selected by the
## user.
# expiration: '1 hour'
## The time before the cookie expires and the session is destroyed if remember me IS selected by the user. Setting
## this value to -1 disables remember me for this session cookie domain. If allowed and the user uses the remember
## me checkbox this overrides the expiration option and disables the inactivity option.
# remember_me: '1 month'
## Cookie Session Domain default 'name' value.
# name: 'authelia_session'
## Cookie Session Domain default 'same_site' value.
# same_site: 'lax'
## Cookie Session Domain default 'inactivity' value.
# inactivity: '5m'
## Cookie Session Domain default 'expiration' value.
# expiration: '1h'
## Cookie Session Domain default 'remember_me' value.
# remember_me: '1M'
##
## Redis Provider
##
## Important: Kubernetes (or HA) users must read https://www.authelia.com/t/statelessness
##
# redis:
# host: '127.0.0.1'
# port: 6379
## Use a unix socket instead
# host: '/var/run/redis/redis.sock'
## The connection timeout in the duration common syntax.
# timeout: '5 seconds'
## The maximum number of retries on a failed command. Set it to 0 to disable retries.
# max_retries: 3
## Username used for redis authentication. This is optional and a new feature in redis 6.0.
# username: 'authelia'
## Password can also be set using a secret: https://www.authelia.com/c/secrets
# password: 'authelia'
## This is the Redis DB Index https://redis.io/commands/select (sometimes referred to as database number, DB, etc).
# database_index: 0
## The maximum number of concurrent active connections to Redis.
# maximum_active_connections: 8
## The target number of idle connections to have open ready for work. Useful when opening connections is slow.
# minimum_idle_connections: 0
## The Redis TLS configuration. If defined will require a TLS connection to the Redis instance(s).
# tls:
## The server subject name to check the servers certificate against during the validation process.
## This option is not required if the certificate has a SAN which matches the host option.
# server_name: 'myredis.example.com'
## Skip verifying the server certificate entirely. In preference to setting this we strongly recommend you add the
## certificate or the certificate of the authority signing the certificate to the certificates directory which is
## defined by the `certificates_directory` option at the top of the configuration.
## It's important to note the public key should be added to the directory, not the private key.
## This option is strongly discouraged but may be useful in some self-signed situations where validation is not
## important to the administrator.
# skip_verify: false
## Minimum TLS version for the connection.
# minimum_version: 'TLS1.2'
## Maximum TLS version for the connection.
# maximum_version: 'TLS1.3'
## The certificate chain used with the private_key if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
## The private key used with the certificate_chain if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# private_key: |
# -----BEGIN PRIVATE KEY-----
# ...
# -----END PRIVATE KEY-----
## The Redis HA configuration options.
## This provides specific options to Redis Sentinel, sentinel_name must be defined (Master Name).
# high_availability:
## Sentinel Name / Master Name.
# sentinel_name: 'mysentinel'
## Specific username for Redis Sentinel. The node username and password is configured above.
# sentinel_username: 'sentinel_specific_user'
## Specific password for Redis Sentinel. The node username and password is configured above.
# sentinel_password: 'sentinel_specific_pass'
## The additional nodes to pre-seed the redis provider with (for sentinel).
## If the host in the above section is defined, it will be combined with this list to connect to sentinel.
## For high availability to be used you must have either defined; the host above or at least one node below.
# nodes:
# - host: 'sentinel-node1'
# port: 6379
# - host: 'sentinel-node2'
# port: 6379
## Choose the host with the lowest latency.
# route_by_latency: false
## Choose the host randomly.
# route_randomly: false
##
## Regulation Configuration
##
## This mechanism prevents attackers from brute forcing the first factor. It bans the user if too many attempts are made
## in a short period of time.
# regulation:
## Regulation Mode.
# modes:
# - 'user'
## The number of failed login attempts before user is banned. Set it to 0 to disable regulation.
# max_retries: 3
## The time range during which the user can attempt login before being banned in the duration common syntax. The user
## is banned if the authentication failed 'max_retries' times in a 'find_time' seconds window.
# find_time: '2 minutes'
## The length of time before a banned user can login again in the duration common syntax.
# ban_time: '5 minutes'
##
## Storage Provider Configuration
##
## The available providers are: `local`, `mysql`, `postgres`. You must use one and only one of these providers.
# storage:
## The encryption key that is used to encrypt sensitive information in the database. Must be a string with a minimum
## length of 20. Please see the docs if you configure this with an undesirable key and need to change it, you MUST use
## the CLI to change this in the database if you want to change it from a previously configured value.
# encryption_key: 'you_must_generate_a_random_string_of_more_than_twenty_chars_and_configure_this'
##
## Local (Storage Provider)
##
## This stores the data in a SQLite3 Database.
## This is only recommended for lightweight non-stateful installations.
##
## Important: Kubernetes (or HA) users must read https://www.authelia.com/t/statelessness
##
# local:
## Path to the SQLite3 Database.
# path: '/config/db.sqlite3'
##
## MySQL / MariaDB (Storage Provider)
##
# mysql:
## The address of the MySQL server to connect to in the address common syntax.
## Format: [<scheme>://]<hostname>[:<port>].
## Square brackets indicate optional portions of the format. Scheme must be 'tcp', 'tcp4', 'tcp6', or 'unix`.
## The default scheme is 'unix' if the address is an absolute path otherwise it's 'tcp'. The default port is '3306'.
# address: 'tcp://127.0.0.1:3306'
## The database name to use.
# database: 'authelia'
## The username used for SQL authentication.
# username: 'authelia'
## The password used for SQL authentication.
## Can also be set using a secret: https://www.authelia.com/c/secrets
# password: 'mypassword'
## The connection timeout in the duration common syntax.
# timeout: '5 seconds'
## MySQL TLS settings. Configuring this requires TLS.
# tls:
## The server subject name to check the servers certificate against during the validation process.
## This option is not required if the certificate has a SAN which matches the address options hostname.
# server_name: 'mysql.example.com'
## Skip verifying the server certificate entirely. In preference to setting this we strongly recommend you add the
## certificate or the certificate of the authority signing the certificate to the certificates directory which is
## defined by the `certificates_directory` option at the top of the configuration.
## It's important to note the public key should be added to the directory, not the private key.
## This option is strongly discouraged but may be useful in some self-signed situations where validation is not
## important to the administrator.
# skip_verify: false
## Minimum TLS version for the connection.
# minimum_version: 'TLS1.2'
## Maximum TLS version for the connection.
# maximum_version: 'TLS1.3'
## The certificate chain used with the private_key if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
## The private key used with the certificate_chain if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# private_key: |
# -----BEGIN PRIVATE KEY-----
# ...
# -----END PRIVATE KEY-----
##
## PostgreSQL (Storage Provider)
##
# postgres:
## The address of the PostgreSQL server to connect to in the address common syntax.
## Format: [<scheme>://]<hostname>[:<port>].
## Square brackets indicate optional portions of the format. Scheme must be 'tcp', 'tcp4', 'tcp6', or 'unix`.
## The default scheme is 'unix' if the address is an absolute path otherwise it's 'tcp'. The default port is '5432'.
# address: 'tcp://127.0.0.1:5432'
## List of additional server instance configurations to fallback to when the primary instance is not available.
# servers:
# -
## The Address of this individual instance.
# address: 'tcp://127.0.0.1:5432'
## The TLS configuration for this individual instance.
# tls:
# server_name: 'postgres.example.com'
# skip_verify: false
# minimum_version: 'TLS1.2'
# maximum_version: 'TLS1.3'
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# private_key: |
# -----BEGIN PRIVATE KEY-----
# ...
# -----END PRIVATE KEY-----
## The database name to use.
# database: 'authelia'
## The schema name to use.
# schema: 'public'
## The username used for SQL authentication.
# username: 'authelia'
## The password used for SQL authentication.
## Can also be set using a secret: https://www.authelia.com/c/secrets
# password: 'mypassword'
## The connection timeout in the duration common syntax.
# timeout: '5 seconds'
## PostgreSQL TLS settings. Configuring this requires TLS.
# tls:
## The server subject name to check the servers certificate against during the validation process.
## This option is not required if the certificate has a SAN which matches the address options hostname.
# server_name: 'postgres.example.com'
## Skip verifying the server certificate entirely. In preference to setting this we strongly recommend you add the
## certificate or the certificate of the authority signing the certificate to the certificates directory which is
## defined by the `certificates_directory` option at the top of the configuration.
## It's important to note the public key should be added to the directory, not the private key.
## This option is strongly discouraged but may be useful in some self-signed situations where validation is not
## important to the administrator.
# skip_verify: false
## Minimum TLS version for the connection.
# minimum_version: 'TLS1.2'
## Maximum TLS version for the connection.
# maximum_version: 'TLS1.3'
## The certificate chain used with the private_key if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
## The private key used with the certificate_chain if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# private_key: |
# -----BEGIN PRIVATE KEY-----
# ...
# -----END PRIVATE KEY-----
##
## Notification Provider
##
## Notifications are sent to users when they require a password reset, a WebAuthn registration or a TOTP registration.
## The available providers are: filesystem, smtp. You must use only one of these providers.
# notifier:
## You can disable the notifier startup check by setting this to true.
# disable_startup_check: false
##
## File System (Notification Provider)
##
## Important: Kubernetes (or HA) users must read https://www.authelia.com/t/statelessness
##
# filesystem:
# filename: '/config/notification.txt'
##
## SMTP (Notification Provider)
##
## Use a SMTP server for sending notifications. Authelia uses the PLAIN or LOGIN methods to authenticate.
## [Security] By default Authelia will:
## - force all SMTP connections over TLS including unauthenticated connections
## - use the disable_require_tls boolean value to disable this requirement
## (only works for unauthenticated connections)
## - validate the SMTP server x509 certificate during the TLS handshake against the hosts trusted certificates
## (configure in tls section)
# smtp:
## The address of the SMTP server to connect to in the address common syntax.
# address: 'smtp://127.0.0.1:25'
## The connection timeout in the duration common syntax.
# timeout: '5 seconds'
## The username used for SMTP authentication.
# username: 'test'
## The password used for SMTP authentication.
## Can also be set using a secret: https://www.authelia.com/c/secrets
# password: 'password'
## The sender is used to is used for the MAIL FROM command and the FROM header.
## If this is not defined and the username is an email, we use the username as this value. This can either be just
## an email address or the RFC5322 'Name <email address>' format.
# sender: 'Authelia <admin@example.com>'
## HELO/EHLO Identifier. Some SMTP Servers may reject the default of localhost.
# identifier: 'localhost'
## Subject configuration of the emails sent. {title} is replaced by the text from the notifier.
# subject: '[Authelia] {title}'
## This address is used during the startup check to verify the email configuration is correct.
## It's not important what it is except if your email server only allows local delivery.
# startup_check_address: 'test@authelia.com'
## By default we require some form of TLS. This disables this check though is not advised.
# disable_require_tls: false
## Disables sending HTML formatted emails.
# disable_html_emails: false
# tls:
## The server subject name to check the servers certificate against during the validation process.
## This option is not required if the certificate has a SAN which matches the address options hostname.
# server_name: 'smtp.example.com'
## Skip verifying the server certificate entirely. In preference to setting this we strongly recommend you add the
## certificate or the certificate of the authority signing the certificate to the certificates directory which is
## defined by the `certificates_directory` option at the top of the configuration.
## It's important to note the public key should be added to the directory, not the private key.
## This option is strongly discouraged but may be useful in some self-signed situations where validation is not
## important to the administrator.
# skip_verify: false
## Minimum TLS version for the connection.
# minimum_version: 'TLS1.2'
## Maximum TLS version for the connection.
# maximum_version: 'TLS1.3'
## The certificate chain used with the private_key if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
## The private key used with the certificate_chain if the server requests TLS Client Authentication
## i.e. Mutual TLS.
# private_key: |
# -----BEGIN PRIVATE KEY-----
# ...
# -----END PRIVATE KEY-----
##
## Identity Providers
##
# identity_providers:
##
## OpenID Connect (Identity Provider)
##
## It's recommended you read the documentation before configuration of this section.
## See: https://www.authelia.com/c/oidc/provider
# oidc:
## The hmac_secret is used to sign OAuth2 tokens (authorization code, access tokens and refresh tokens).
## HMAC Secret can also be set using a secret: https://www.authelia.com/c/secrets
# hmac_secret: 'this_is_a_secret_abc123abc123abc'
## The JWK's issuer option configures multiple JSON Web Keys. It's required that at least one of the JWK's
## configured has the RS256 algorithm. For RSA keys (RS or PS) the minimum is a 2048 bit key.
# jwks:
# -
## Key ID embedded into the JWT header for key matching. Must be an alphanumeric string with 7 or less characters.
## This value is automatically generated if not provided. It's recommended to not configure this.
# key_id: 'example'
## The key algorithm used with this key.
# algorithm: 'RS256'
## The key use expected with this key. Currently only 'sig' is supported.
# use: 'sig'
## Required Private Key in PEM DER form.
# key: |
# -----BEGIN PRIVATE KEY-----
# ...
# -----END PRIVATE KEY-----
## Optional matching certificate chain in PEM DER form that matches the key. All certificates within the chain
## must be valid and current, and from top to bottom each certificate must be signed by the subsequent one.
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
## Enables additional debug messages.
# enable_client_debug_messages: false
## SECURITY NOTICE: It's not recommended changing this option and values below 8 are strongly discouraged.
# minimum_parameter_entropy: 8
## SECURITY NOTICE: It's not recommended changing this option, and highly discouraged to have it set to 'never'
## for security reasons.
# enforce_pkce: 'public_clients_only'
## SECURITY NOTICE: It's not recommended changing this option. We encourage you to read the documentation and fully
## understanding it before enabling this option.
# enable_jwt_access_token_stateless_introspection: false
## The signing algorithm used for signing the discovery and metadata responses. An issuer JWK with a matching
## algorithm must be available when configured. Most clients completely ignore this and it has a performance cost.
# discovery_signed_response_alg: 'none'
## The signing key id used for signing the discovery and metadata responses. An issuer JWK with a matching key id
## must be available when configured. Most clients completely ignore this and it has a performance cost.
# discovery_signed_response_key_id: ''
## Authorization Policies which can be utilized by clients. The 'policy_name' is an arbitrary value that you pick
## which is utilized as the value for the 'authorization_policy' on the client.
# authorization_policies:
# policy_name:
# default_policy: 'two_factor'
# rules:
# - policy: 'one_factor'
# subject: 'group:services'
# networks:
# - '192.168.1.0/24'
## The lifespans configure the expiration for these token types in the duration common syntax. In addition to this
## syntax the lifespans can be customized per-client.
# lifespans:
## Configures the default/fallback lifespan for given token types. This behaviour applies to all clients and all
## grant types but you can override this behaviour using the custom lifespans.
# access_token: '1 hour'
# authorize_code: '1 minute'
# id_token: '1 hour'
# refresh_token: '90 minutes'
## Cross-Origin Resource Sharing (CORS) settings.
# cors:
## List of endpoints in addition to the metadata endpoints to permit cross-origin requests on.
# endpoints:
# - 'authorization'
# - 'pushed-authorization-request'
# - 'token'
# - 'revocation'
# - 'introspection'
# - 'userinfo'
## List of allowed origins.
## Any origin with https is permitted unless this option is configured or the
## allowed_origins_from_client_redirect_uris option is enabled.
# allowed_origins:
# - 'https://example.com'
## Automatically adds the origin portion of all redirect URI's on all clients to the list of allowed_origins,
## provided they have the scheme http or https and do not have the hostname of localhost.
# allowed_origins_from_client_redirect_uris: false
## Clients is a list of registered clients and their configuration.
## It's recommended you read the documentation before configuration of a registered client.
## See: https://www.authelia.com/c/oidc/registered-clients
# clients:
# -
## The Client ID is the OAuth 2.0 and OpenID Connect 1.0 Client ID which is used to link an application to a
## configuration.
# client_id: 'myapp'
## The description to show to users when they end up on the consent screen. Defaults to the ID above.
# client_name: 'My Application'
## The client secret is a shared secret between Authelia and the consumer of this client.
# yamllint disable-line rule:line-length
# client_secret: '$pbkdf2-sha512$310000$c8p78n7pUMln0jzvd4aK4Q$JNRBzwAo0ek5qKn50cFzzvE9RXV88h1wJn5KGiHrD0YKtZaR/nCb2CJPOsKaPK0hjf.9yHxzQGZziziccp6Yng' # The digest of 'insecure_secret'.
## Sector Identifiers are occasionally used to generate pairwise subject identifiers. In most cases this is not
## necessary. It is critical to read the documentation for more information.
# sector_identifier_uri: 'https://example.com/sector.json'
## Sets the client to public. This should typically not be set, please see the documentation for usage.
# public: false
## Redirect URI's specifies a list of valid case-sensitive callbacks for this client.
# redirect_uris:
# - 'https://oidc.example.com:8080/oauth2/callback'
## Request URI's specifies a list of valid case-sensitive TLS-secured URIs for this client for use as
## URIs to fetch Request Objects.
# request_uris:
# - 'https://oidc.example.com:8080/oidc/request-object.jwk'
## Audience this client is allowed to request.
# audience: []
## Scopes this client is allowed to request.
# scopes:
# - 'openid'
# - 'groups'
# - 'email'
# - 'profile'
## Grant Types configures which grants this client can obtain.
## It's not recommended to define this unless you know what you're doing.
# grant_types:
# - 'authorization_code'
## Response Types configures which responses this client can be sent.
## It's not recommended to define this unless you know what you're doing.
# response_types:
# - 'code'
## Response Modes configures which response modes this client supports.
# response_modes:
# - 'form_post'
# - 'query'
## The policy to require for this client; one_factor or two_factor. Can also be the key names for the
## authorization policies section.
# authorization_policy: 'two_factor'
## The custom lifespan name to use for this client. This must be configured independent of the client before
## utilization. Custom lifespans are reusable similar to authorization policies.
# lifespan: ''
## The consent mode controls how consent is obtained.
# consent_mode: 'auto'
## This value controls the duration a consent on this client remains remembered when the consent mode is
## configured as 'auto' or 'pre-configured' in the duration common syntax.
# pre_configured_consent_duration: '1 week'
## Requires the use of Pushed Authorization Requests for this client when set to true.
# require_pushed_authorization_requests: false
## Enforces the use of PKCE for this client when set to true.
# require_pkce: false
## Enforces the use of PKCE for this client when configured, and enforces the specified challenge method.
## Options are 'plain' and 'S256'.
# pkce_challenge_method: 'S256'
## The signing algorithm used for signing the authorization responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#authorization_signed_response_alg
# authorization_signed_response_alg: 'none'
## The signing key id used for signing the authorization responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#authorization_signed_response_key_id
# authorization_signed_response_key_id: ''
## The content encryption algorithm used for encrypting the authorization responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#authorization_encrypted_response_alg
# authorization_encrypted_response_alg: 'none'
## The encryption algorithm used for encrypting the authorization responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#authorization_encrypted_response_enc
# authorization_encrypted_response_enc: 'A128CBC-HS256'
## The content encryption key id used for encrypting the authorization responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#authorization_encrypted_response_key_id
# authorization_encrypted_response_key_id: ''
## The signing algorithm used for signing the ID Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#id_token_signed_response_alg
# id_token_signed_response_alg: 'RS256'
## The signing key id used for signing the ID Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#id_token_signed_response_key_id
# id_token_signed_response_key_id: ''
## The content encryption algorithm used for encrypting the ID Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#id_token_encrypted_response_alg
# id_token_encrypted_response_alg: 'none'
## The encryption algorithm used for encrypting the ID Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#id_token_encrypted_response_enc
# id_token_encrypted_response_enc: 'A128CBC-HS256'
## The content encryption key id used for encrypting the ID Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#authorization_encrypted_response_key_id
# id_token_encrypted_response_key_id: ''
## The signing algorithm used for signing the Access Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#access_token_signed_response_alg
# access_token_signed_response_alg: 'none'
## The signing key id used for signing the Access Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#access_token_signed_response_key_id
# access_token_signed_response_key_id: ''
## The content encryption algorithm used for encrypting the Access Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#access_token_encrypted_response_alg
# access_token_encrypted_response_alg: 'none'
## The encryption algorithm used for encrypting the Access Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#access_token_encrypted_response_enc
# access_token_encrypted_response_enc: 'A128CBC-HS256'
## The content encryption key id used for encrypting the Access Tokens in Access Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#access_token_encrypted_response_key_id
# access_token_encrypted_response_key_id: ''
## The signing algorithm used for signing the User Info Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#userinfo_signed_response_alg
# userinfo_signed_response_alg: 'none'
## The signing key id used for signing the User Info Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#userinfo_signed_response_key_id
# userinfo_signed_response_key_id: ''
## The content encryption algorithm used for encrypting the User Info Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#userinfo_encrypted_response_alg
# userinfo_encrypted_response_alg: 'none'
## The encryption algorithm used for encrypting the User Info Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#userinfo_encrypted_response_enc
# userinfo_encrypted_response_enc: 'A128CBC-HS256'
## The content encryption key id used for encrypting the User Info Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#userinfo_encrypted_response_key_id
# userinfo_encrypted_response_key_id: ''
## The signing algorithm used for signing the Introspection Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#introspection_signed_response_alg
# introspection_signed_response_alg: 'none'
## The signing key id used for Introspection responses. An issuer JWK with a matching key id must be available
## when configured.
# introspection_signed_response_key_id: ''
## The content encryption algorithm used for encrypting the Introspection Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#introspection_encrypted_response_alg
# introspection_encrypted_response_alg: 'none'
## The encryption algorithm used for encrypting the Introspection Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#introspection_encrypted_response_enc
# introspection_encrypted_response_enc: 'A128CBC-HS256'
## The content encryption key id used for encrypting the Introspection Request responses.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#introspection_encrypted_response_key_id
# introspection_encrypted_response_key_id: ''
## The signature algorithm which must be used for request objects.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#request_object_signing_alg
# request_object_signing_alg: 'RS256'
## The content encryption algorithm which must be used for request objects.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#request_object_encryption_alg
# request_object_encryption_alg: ''
## The encryption algorithm which must be used for request objects.
## Please read the documentation before adjusting this option.
## See: https://www.authelia.com/c/oidc/registered-clients#request_object_encryption_enc
# request_object_encryption_enc: ''
## The permitted client authentication method for the Token Endpoint for this client.
## For confidential client types this value defaults to 'client_secret_basic' and for the public client types it
## defaults to 'none' per the specifications.
# token_endpoint_auth_method: 'client_secret_basic'
## The permitted client authentication signing algorithm for the Token Endpoint for this client when using
## the 'client_secret_jwt' or 'private_key_jwt' token_endpoint_auth_method.
# token_endpoint_auth_signing_alg: 'RS256'
## The permitted client authentication method for the Revocation Endpoint for this client.
## For confidential client types this value defaults to 'client_secret_basic' and for the public client types it
## defaults to 'none' per the specifications.
# revocation_endpoint_auth_method: 'client_secret_basic'
## The permitted client authentication signing algorithm for the Revocation Endpoint for this client when using
## the 'client_secret_jwt' or 'private_key_jwt' revocation_endpoint_auth_method.
# revocation_endpoint_auth_signing_alg: 'RS256'
## The permitted client authentication method for the Introspection Endpoint for this client.
## For confidential client types this value defaults to 'client_secret_basic' and for the public client types it
## defaults to 'none' per the specifications.
# introspection_endpoint_auth_method: 'client_secret_basic'
## The permitted client authentication signing algorithm for the Introspection Endpoint for this client when
## using the 'client_secret_jwt' or 'private_key_jwt' introspection_endpoint_auth_method.
# introspection_endpoint_auth_signing_alg: 'RS256'
## The permitted client authentication method for the Pushed Authorization Request Endpoint for this client.
## For confidential client types this value defaults to 'client_secret_basic' and for the public client types it
## defaults to 'none' per the specifications.
# pushed_authorization_request_endpoint_auth_method: 'client_secret_basic'
## The permitted client authentication signing algorithm for the Pushed Authorization Request Endpoint for this
## client when using the 'client_secret_jwt' or 'private_key_jwt'
## pushed_authorization_request_endpoint_auth_method.
# pushed_authorization_request_endpoint_auth_signing_alg: 'RS256'
## Trusted public keys configuration for request object signing for things such as 'private_key_jwt'.
## URL of the HTTPS endpoint which serves the keys. Please note the 'jwks_uri' and the 'jwks' option below
## are mutually exclusive.
# jwks_uri: 'https://app.example.com/jwks.json'
## Trusted public keys configuration for request object signing for things such as 'private_key_jwt'.
## List of JWKs known and registered with this client. It's recommended to use the 'jwks_uri' option if
## available due to key rotation. Please note the 'jwks' and the 'jwks_uri' option above are mutually exclusive.
# jwks:
# -
## Key ID used to match the JWT's to an individual identifier. This option is required if configured.
# key_id: 'example'
## The key algorithm expected with this key.
# algorithm: 'RS256'
## The key use expected with this key. Currently only 'sig' is supported.
# use: 'sig'
## Required Public Key in PEM DER form.
# key: |
# -----BEGIN RSA PUBLIC KEY-----
# ...
# -----END RSA PUBLIC KEY-----
## The matching certificate chain in PEM DER form that matches the key if available.
# certificate_chain: |
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
# -----BEGIN CERTIFICATE-----
# ...
# -----END CERTIFICATE-----
...
Синтаксис
Ключи
policies: # словарь ключа
arbitrary_name: # значение ключа для последующего использования в блоке usage_example
enable: true
usage_example:
- name: 'example'
policy: 'arbitrary_name' # использование ключа policy
Время
| Unit | Short Unit | Human Readable Long Unit |
|---|---|---|
| Years | y | year, years |
| Months | M | month, months |
| Weeks | w | week, weeks |
| Days | d | day, days |
| Hours | h | hour, hours |
| Minutes | m | minute, minutes |
| Seconds | s | second, seconds |
| Milliseconds | ms | millisecond, milliseconds |
В настройках указываются значения в коротком или длинном формате
| Desired Value | Configuration Examples (Short) | Configuration Examples (Long) |
|---|---|---|
| 1 hour and 30 minutes | 90m or 1h30m or 5400 or 5400s | 1 hour and 30 minutes |
| 1 day | 1d or 24h or 86400 or 86400s | 1 day |
| 10 hours | 10h or 600m or 9h60m or 36000 | 10 hours |
Адрес
Строковая переменная
Параметры
| Parameter | Listeners | Connectors | Purpose |
|---|---|---|---|
| umask | Да | Нет | Устанавливает umask перед созданием сокета и восстанавливает его после создания. Значение должно быть восьмеричным числом с 3 или 4 цифрами. |
| path | Да | Нет | Устанавливает переменную path для настройки подпути, специально для unix-сокета, но технически работает и для TCP. Обратите внимание, что это должна быть только буквенно-цифровая часть без префикса в виде прямой косой черты. |
Формат
Квадратные скобки обозначают необязательные разделы, а угловые скобки - обязательные разделы.
Hostname
Имя хоста
Следующий формат представляет собой формат имени хоста. В большинстве случаев он подходит как для слушателя, так и для коннектора. В этом формате, согласно обозначениям, схема и порт являются необязательными. Если они не указаны, то используются по умолчанию.
[<scheme>://]<hostname>[:<port>][/<path>]
Файл дескриптор
fd://<file descriptor number>
fd://<file descriptor number>?umask=0022
fd://<file descriptor number>?path=auth
fd://<file descriptor number>?umask=0022&path=auth
Unix domain socket
unix://<path>
unix://<path>?umask=0022
unix://<path>?path=auth
unix://<path>?umask=0022&path=auth
В большинстве случаев он подходит как для слушателя, так и для коннектора.
Формат Unix Domain Socket также принимает строку запроса.
Примеры
0.0.0.0
tcp://0.0.0.0
tcp://0.0.0.0/subpath
tcp://0.0.0.0:9091
tcp://0.0.0.0:9091/subpath
tcp://:9091
tcp://:9091/subpath
0.0.0.0:9091
udp://0.0.0.0:123
udp://:123
unix:///var/lib/authelia.sock
Scheme
Вся схема не является обязательной, но если в строке присутствует разделитель узла схемы ://, то схема должна присутствовать.
| Scheme | Listeners | Connectors | Default Port | Notes |
|---|---|---|---|---|
| tcp | Yes | Yes | N/A | Standard TCP Socket which allows IPv4 and/or IPv6 addresses |
| tcp4 | Yes | Yes | N/A | Standard TCP Socket which allows only IPv4 addresses |
| tcp6 | Yes | Yes | N/A | Standard TCP Socket which allows only IPv6 addresses |
| udp | Yes | Yes | N/A | Standard UDP Socket which allows IPv4 and/or IPv6 addresses |
| udp4 | Yes | Yes | N/A | Standard UDP Socket which allows only IPv4 addresses |
| udp6 | Yes | Yes | N/A | Standard UDP Socket which allows only IPv6 addresses |
| unix | Yes | Yes | N/A | Standard Unix Domain Socket which allows only absolute paths |
| ldap | No | Yes | 389 | Remote LDAP connection via a TCP socket using StartTLS if available |
| ldaps | No | Yes | 636 | Remote LDAP connection via a TLS socket |
| ldapi | No | Yes | N/A | LDAP connection via Unix Domain Socket |
| smtp | No | Yes | 25 | Remote SMTP connection via a TCP socket using StartTLS if available |
| submission | No | Yes | 587 | Remote SMTP Submission connection via a TCP socket using StartTLS if available |
| submissions | No | Yes | 465 | Remote SMTP Submission connection via a TLS socket |
hostname
Имя хоста требуется, если схема является одной из схем tcp или udp и не указан порт. Это может быть любой локально адресуемый IP или имя хоста, которое разрешается в локально адресуемый IP.
При указании IPv6 он должен быть заключен в квадратные скобки. Например, для IPv6-адреса ::1 со схемой tcp и портом 80 правильным адресом будет tcp://[::1]:80.
Регулярные выражения
domain_regex: '^(admin|secure)\.example\.com$'
Network
Мы поддерживаем сетевой синтаксис, который разворачивает строки в сетевой диапазон. Формат строк использует стандартную нотацию CIDR и предполагает наличие одного хоста (адаптированного как /32 для IPv4 и /128 для IPv6), если суффикс CIDR отсутствует.
| Example | CIDR | Range |
|---|---|---|
| 192.168.0.1 | 192.168.0.1/32 | 192.168.0.1 |
| 192.168.1.0/24 | 192.168.1.0/24 | 192.168.1.0 - 192.168.1.255 |
| 192.168.2.1/24 | 192.168.2.0/24 | 192.168.2.0 - 192.168.2.255 |
| 2001:db8:3333:4444:5555:6666:7777:8888 | 2001:db8:3333:4444:5555:6666:7777:8888/128 | 2001:db8:3333:4444:5555:6666:7777:8888 |
| 2001:db8:3333:4400::/56 | 2001:db8:3333:4400::/56 | 2001:0db8:3333:4400:0000:0000:0000:0000 - 2001:0db8:3333:44ff:ffff:ffff:ffff:ffff |
| 2001:db8:3333:4444:5555:6666:7777:8888/56 | 2001:db8:3333:4400::/56 | 2001:0db8:3333:4400:0000:0000:0000:0000 - 2001:0db8:3333:44ff:ffff:ffff:ffff:ffff |
Структуры
Ниже представлены общие структуры данных, используемые в конфигурации, к которым предъявляются особые требования, используемые в различных областях.
TLS
В различных разделах конфигурации используется единый раздел конфигурации под названием tls, в котором настраиваются параметры TLS-сокета и TLS-проверки. В этом разделе описаны общие части этой структуры. По умолчанию Authelia использует системный сертификат доверия для проверки сертификата TLS, но вы можете дополнить его с помощью глобальной опции certificates_directory, а также полностью отключить проверку сертификата TLS с помощью опции skip_verify.
tls:
server_name: 'example.com'
skip_verify: false
minimum_version: 'TLS1.2'
maximum_version: 'TLS1.3'
certificate_chain: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
private_key: |
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY-----
server_name
Ключ server_name переопределяет имя, проверяемое по сертификату в процессе проверки. Полезно, если вам требуется IP-адрес узла внутренней службы, но вы хотите проверить конкретное имя сервера сертификатов.
skip_verify
Ключ skip_verify полностью исключает проверку сертификата внутреннего сервиса. Это не рекомендуется, вместо этого следует настроить параметр server_name и глобальный параметр certificates directory.
minimum_version - maximum_version
Устанавливает минимальную версию TLS, которую Authelia будет использовать при выполнении сопряжений TLS. Возможные значения: TLS1.3, TLS1.2, TLS1.1, TLS1.0, SSL3.0.
certificate_chain
Цепочка/набор сертификатов, которые будут использоваться вместе с private_key для выполнения взаимной TLS-аутентификации с сервером.
Значение должно представлять собой один или несколько сертификатов, закодированных в формате PEM с кодировкой DER base64 (RFC4648). Если предоставлено более одного сертификата, то каждый сертификат должен быть подписан следующим сертификатом, если он предоставлен, в порядке сверху вниз.
private_key
Закрытый ключ, который будет использоваться с цепочкой_сертификатов для взаимной аутентификации TLS. Материал открытого ключа, связанного с закрытым ключем, должен совпадать с закрытым ключом первого сертификата в цепочке_сертификатов.
Значение должно представлять собой один закрытый ключ, закодированный в формате PEM DER base64 (RFC4648), и должно быть закодировано в соответствии со спецификациями PKCS#8, PKCS#1 или SECG1.
Server Buffers
Различные разделы конфигурации используют единый раздел конфигурации под названием buffers, который настраивает буферы HTTP-сервера. В частности, секции сервера и телеметрии метрик. В этом разделе описаны общие части этой структуры.
buffers:
read: 4096
write: 4096
read
Настройка максимального размера запроса. Значение по умолчанию 4096 обычно достаточно для большинства случаев использования.
write
Настройка максимального размера ответа. Значение по умолчанию 4096 обычно достаточно для большинства случаев использования.
Server Timeouts
В различных разделах конфигурации используется единый раздел конфигурации под названием timeouts, в котором настраиваются таймауты HTTP-сервера. В частности, в секциях телеметрии сервера и метрик.
timeouts:
read: '6s'
write: '6s'
idle: '30s'
read write
Настройка таймаута чтения и записи сервера.
idle
Настройка таймаута простоя сервера.
3.2 - Методы Authelia
Методы
Authelia имеет несколько способов настройки. Порядок приоритета следующий:
- Секреты
- Переменные окружения
- Файлы (в порядке их указания)
3.2.1 - Секреты Authelia
Для настройки Authelia требуется несколько секретов и паролей.
Для настройки Authelia требуется несколько секретов и паролей. Даже если они могут быть заданы в конфигурационном файле или стандартных переменных окружения, рекомендуется использовать этот метод настройки, описанный ниже.
Filters
Помимо описанных ниже методов, файлы конфигурации можно передавать через фильтры шаблонов. Эти фильтры можно использовать для вставки или изменения содержимого файла. В частности, функция fileContent может быть использована для получения содержимого файла, а nindent - для добавления новой строки и отступа содержимого этого файла.
authentication_backend:
ldap:
address: 'ldap://{{ env "SERVICES_SERVER" }}'
tls:
private_key: |
{{- fileContent "./test_resources/example_filter_rsa_private_key" | nindent 8 }}
{{ и }} ограничители шаблона
вставляем содержимое файла в ключ private_key с отступом 8 пробелов
Layers
Важно
Хотя этот метод является третьим уровнем многоуровневой модели конфигурации, как описано во введении, этот уровень особенный, так как Authelia не запустится, если вы определите секрет, как и любой другой метод конфигурации.Security
Этот метод немного улучшает безопасность других методов, поскольку позволяет легко разделить конфигурацию логически безопасным способом.
Environment variables
Секретное значение может быть загружено Authelia, если ключ конфигурации заканчивается одним из следующих слов: key, secret, password, token или certificate_chain.
Если вы возьмете ожидаемую переменную окружения для конфигурационного параметра с суффиксом _FILE в конце. Значение этих переменных окружения должно быть путем к файлу, который может быть прочитан процессом Authelia, если это не так, Authelia не сможет загрузиться. Authelia автоматически удалит новые строки в конце содержимого файлов.
Например, пароль LDAP может быть определен в конфигурации по пути authentication_backend.ldap.password, поэтому в качестве альтернативы этот пароль может быть задан с помощью переменной окружения под названием
AUTHELIA_AUTHENTICATION_BACKEND_LDAP_PASSWORD_FILE
Список переменных
| Configuration Key | Environment Variable |
|---|---|
| authentication_backend.ldap.password | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_PASSWORD_FILE |
| authentication_backend.ldap.tls.certificate_chain | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_TLS_CERTIFICATE_CHAIN_FILE |
| authentication_backend.ldap.tls.private_key | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_TLS_PRIVATE_KEY_FILE |
| duo_api.integration_key | AUTHELIA_DUO_API_INTEGRATION_KEY_FILE |
| duo_api.secret_key | AUTHELIA_DUO_API_SECRET_KEY_FILE |
| identity_providers.oidc.hmac_secret | AUTHELIA_IDENTITY_PROVIDERS_OIDC_HMAC_SECRET_FILE |
| identity_validation.reset_password.jwt_secret | AUTHELIA_IDENTITY_VALIDATION_RESET_PASSWORD_JWT_SECRET_FILE |
| notifier.smtp.password | AUTHELIA_NOTIFIER_SMTP_PASSWORD_FILE |
| notifier.smtp.tls.certificate_chain | AUTHELIA_NOTIFIER_SMTP_TLS_CERTIFICATE_CHAIN_FILE |
| notifier.smtp.tls.private_key | AUTHELIA_NOTIFIER_SMTP_TLS_PRIVATE_KEY_FILE |
| session.redis.high_availability.sentinel_password | AUTHELIA_SESSION_REDIS_HIGH_AVAILABILITY_SENTINEL_PASSWORD_FILE |
| session.redis.password | AUTHELIA_SESSION_REDIS_PASSWORD_FILE |
| session.redis.tls.certificate_chain | AUTHELIA_SESSION_REDIS_TLS_CERTIFICATE_CHAIN_FILE |
| session.redis.tls.private_key | AUTHELIA_SESSION_REDIS_TLS_PRIVATE_KEY_FILE |
| session.secret | AUTHELIA_SESSION_SECRET_FILE |
| storage.encryption_key | AUTHELIA_STORAGE_ENCRYPTION_KEY_FILE |
| storage.mysql.password | AUTHELIA_STORAGE_MYSQL_PASSWORD_FILE |
| storage.mysql.tls.certificate_chain | AUTHELIA_STORAGE_MYSQL_TLS_CERTIFICATE_CHAIN_FILE |
| storage.mysql.tls.private_key | AUTHELIA_STORAGE_MYSQL_TLS_PRIVATE_KEY_FILE |
| storage.postgres.password | AUTHELIA_STORAGE_POSTGRES_PASSWORD_FILE |
| storage.postgres.tls.certificate_chain | AUTHELIA_STORAGE_POSTGRES_TLS_CERTIFICATE_CHAIN_FILE |
| storage.postgres.tls.private_key | AUTHELIA_STORAGE_POSTGRES_TLS_PRIVATE_KEY_FILE |
Секреты в конфигурационном файле
Хранение секретов
Если по каким-то причинам вы решили хранить секреты в конфигурационном файле, настоятельно рекомендуется убедиться, что права доступа к конфигурационному файлу установлены соответствующим образом, чтобы другие пользователи или процессы не могли получить доступ к этому файлу. Обычно для UNIX подходят следующие разрешения: 0600.Секреты, открытые в переменной окружения
Во всех версиях 4.30.0+ вы можете задать секреты с помощью переменных окружения без суффикса _FILE, установив значение, которое вы хотите задать в конфигурации, однако мы настоятельно рекомендуем не использовать эту возможность и вместо этого использовать файловые секреты, описанные выше.
3.2.2 - Файлы конфигурации
Параметры конфигурации могут быть определены либо через аргумент, либо через переменную окружения, но не через оба параметра одновременно.
Поведение при загрузке и обнаружение
Существует несколько опций, которые влияют на загрузку файлов:
| Name | Argument | Environment Variable | Описание и назначение переменных |
|---|---|---|---|
| Files/Directories | --config, -c | X_AUTHELIA_CONFIG | Список путей к файлам или каталогам (без рекурсии) для загрузки файлов конфигурации |
| Filters | --config.experimental.filters | X_AUTHELIA_CONFIG_FILTERS | Список фильтров, применяемых к каждому файлу из опций «Файлы» или «Каталоги». |
Параметры конфигурации могут быть определены либо через аргумент, либо через переменную окружения, но не через оба параметра одновременно. Если указаны оба параметра, приоритет имеет аргумент, а переменная окружения игнорируется. Обычно рекомендуется использовать переменную окружения, если вы используете контейнер, так как это позволит вам легче выполнять другие команды из контекста контейнера.
Запуск контейнера с файлом конфигурации
docker run authelia/authelia:latest authelia --config configuration.yml
docker run -d authelia/authelia:latest authelia --config configuration.yml --config config-acl.yml --config config-other.yml
docker run -d authelia/authelia:latest authelia --config configuration.yml,config-acl.yml,config-other.yml
По умолчанию контейнер ищет файл конфигурации по адресу /config/configuration.yml
docker run -d --volume /path/to/config:/config authelia:authelia:latest authelia --config=/config/configuration.yml --config=/config/configuration.acl.yml
Docker Compose
services:
authelia:
container_name: 'authelia'
image: 'authelia/authelia:latest'
command:
- 'authelia'
- '--config=/config/configuration.yml'
- '--config=/config/configuration.acl.yml'
Kubernetes
пример файла deployment.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: authelia
namespace: authelia
labels:
app.kubernetes.io/instance: authelia
app.kubernetes.io/name: authelia
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/instance: authelia
app.kubernetes.io/name: authelia
template:
metadata:
labels:
app.kubernetes.io/instance: authelia
app.kubernetes.io/name: authelia
spec:
enableServiceLinks: false
containers:
- name: authelia
image: docker.io/authelia/authelia:latest
command:
- authelia
args:
- '--config=/configuration.yml'
- '--config=/configuration.acl.yml'
Файлы фильтров
Существуют файловые фильтры, которые позволяют изменять все конфигурационные файлы после их чтения из файловой системы, но до разбора их содержимого. Если эти фильтры не указаны явно, они НЕ подпадают под действие нашей стандартной политики версионирования.
Наступит момент, когда:
Имя аргумента CLI изменится (мы рекомендуем использовать переменную окружения, которая этого не сделает)
Фильтры настраиваются как список имен фильтров с помощью аргумента CLI –config.experimental.filters и переменной окружения X_AUTHELIA_CONFIG_FILTERS. Мы рекомендуем использовать переменную окружения, так как это гарантирует, что команды, выполняемые из контейнера, используют одни и те же фильтры, и, скорее всего, это постоянное значение, в то время как аргумент может меняться. Если используется и аргумент CLI, и переменная окружения, то переменная окружения полностью игнорируется.
Фильтры могут использоваться самостоятельно, в комбинации или вообще не использоваться. Фильтры обрабатываются в порядке их определения. Вы можете просмотреть вывод YAML-файлов при обработке с помощью фильтров, используя команду authelia config template.
docker run -d authelia/authelia:latest authelia --config /config/configuration.yml --config.experimental.filters template
docker run -d -e X_AUTHELIA_CONFIG_FILTERS=template -e X_AUTHELIA_CONFIG=/config/configuration.yml authelia/authelia:latest authelia
Используются функции шаблонизатора GO
3.2.3 - Переменные Authelia
Переменные окружения должны иметь префикс
AUTHELIA_. Все переменные окружения, начинающиеся с этого префикса, должны быть предназначены для конфигурации. Любые переменные окружения, имеющие этот префикс и не предназначенные для конфигурации, скорее всего, приведут к ошибке или, что еще хуже, к неправильной конфигурации.Синтаксис переменных
Переменные окружения должны иметь префикс AUTHELIA_. Все переменные окружения, начинающиеся с этого префикса, должны быть предназначены для конфигурации. Любые переменные окружения, имеющие этот префикс и не предназначенные для конфигурации, скорее всего, приведут к ошибке или, что еще хуже, к неправильной конфигурации.
Mapping
Параметры конфигурации сопоставляются по их имени. Уровни отступа / подклавиши заменяются символами подчеркивания.
log:
level: 'info'
server:
buffers:
read: 4096
или
AUTHELIA_LOG_LEVEL=info
AUTHELIA_SERVER_BUFFERS_READ=4096
Список переменных
| Configuration Key | Environment Variable |
|---|---|
| access_control.default_policy | AUTHELIA_ACCESS_CONTROL_DEFAULT_POLICY |
| authentication_backend.file.password.algorithm | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_ALGORITHM |
| authentication_backend.file.password.argon2.iterations | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_ARGON2_ITERATIONS |
| authentication_backend.file.password.argon2.key_length | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_ARGON2_KEY_LENGTH |
| authentication_backend.file.password.argon2.memory | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_ARGON2_MEMORY |
| authentication_backend.file.password.argon2.parallelism | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_ARGON2_PARALLELISM |
| authentication_backend.file.password.argon2.salt_length | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_ARGON2_SALT_LENGTH |
| authentication_backend.file.password.argon2.variant | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_ARGON2_VARIANT |
| authentication_backend.file.password.bcrypt.cost | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_BCRYPT_COST |
| authentication_backend.file.password.bcrypt.variant | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_BCRYPT_VARIANT |
| authentication_backend.file.password.pbkdf2.iterations | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_PBKDF2_ITERATIONS |
| authentication_backend.file.password.pbkdf2.salt_length | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_PBKDF2_SALT_LENGTH |
| authentication_backend.file.password.pbkdf2.variant | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_PBKDF2_VARIANT |
| authentication_backend.file.password.scrypt.block_size | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SCRYPT_BLOCK_SIZE |
| authentication_backend.file.password.scrypt.iterations | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SCRYPT_ITERATIONS |
| authentication_backend.file.password.scrypt.key_length | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SCRYPT_KEY_LENGTH |
| authentication_backend.file.password.scrypt.parallelism | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SCRYPT_PARALLELISM |
| authentication_backend.file.password.scrypt.salt_length | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SCRYPT_SALT_LENGTH |
| authentication_backend.file.password.scrypt.variant | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SCRYPT_VARIANT |
| authentication_backend.file.password.sha2crypt.iterations | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SHA2CRYPT_ITERATIONS |
| authentication_backend.file.password.sha2crypt.salt_length | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SHA2CRYPT_SALT_LENGTH |
| authentication_backend.file.password.sha2crypt.variant | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PASSWORD_SHA2CRYPT_VARIANT |
| authentication_backend.file.path | AUTHELIA_AUTHENTICATION_BACKEND_FILE_PATH |
| authentication_backend.file.search.case_insensitive | AUTHELIA_AUTHENTICATION_BACKEND_FILE_SEARCH_CASE_INSENSITIVE |
| authentication_backend.file.search.email | AUTHELIA_AUTHENTICATION_BACKEND_FILE_SEARCH_EMAIL |
| authentication_backend.file.watch | AUTHELIA_AUTHENTICATION_BACKEND_FILE_WATCH |
| authentication_backend.ldap.additional_groups_dn | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ADDITIONAL_GROUPS_DN |
| authentication_backend.ldap.additional_users_dn | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ADDITIONAL_USERS_DN |
| authentication_backend.ldap.address | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ADDRESS |
| authentication_backend.ldap.attributes.birthdate | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_BIRTHDATE |
| authentication_backend.ldap.attributes.country | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_COUNTRY |
| authentication_backend.ldap.attributes.display_name | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_DISPLAY_NAME |
| authentication_backend.ldap.attributes.distinguished_name | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_DISTINGUISHED_NAME |
| authentication_backend.ldap.attributes.family_name | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_FAMILY_NAME |
| authentication_backend.ldap.attributes.gender | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_GENDER |
| authentication_backend.ldap.attributes.given_name | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_GIVEN_NAME |
| authentication_backend.ldap.attributes.group_name | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_GROUP_NAME |
| authentication_backend.ldap.attributes.locale | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_LOCALE |
| authentication_backend.ldap.attributes.locality | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_LOCALITY |
| authentication_backend.ldap.attributes.mail | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_MAIL |
| authentication_backend.ldap.attributes.member_of | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_MEMBER_OF |
| authentication_backend.ldap.attributes.middle_name | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_MIDDLE_NAME |
| authentication_backend.ldap.attributes.nickname | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_NICKNAME |
| authentication_backend.ldap.attributes.phone_extension | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_PHONE_EXTENSION |
| authentication_backend.ldap.attributes.phone_number | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_PHONE_NUMBER |
| authentication_backend.ldap.attributes.picture | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_PICTURE |
| authentication_backend.ldap.attributes.postal_code | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_POSTAL_CODE |
| authentication_backend.ldap.attributes.profile | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_PROFILE |
| authentication_backend.ldap.attributes.region | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_REGION |
| authentication_backend.ldap.attributes.street_address | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_STREET_ADDRESS |
| authentication_backend.ldap.attributes.username | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_USERNAME |
| authentication_backend.ldap.attributes.website | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_WEBSITE |
| authentication_backend.ldap.attributes.zoneinfo | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_ATTRIBUTES_ZONEINFO |
| authentication_backend.ldap.base_dn | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_BASE_DN |
| authentication_backend.ldap.group_search_mode | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_GROUP_SEARCH_MODE |
| authentication_backend.ldap.groups_filter | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_GROUPS_FILTER |
| authentication_backend.ldap.implementation | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_IMPLEMENTATION |
| authentication_backend.ldap.permit_feature_detection_failure | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_PERMIT_FEATURE_DETECTION_FAILURE |
| authentication_backend.ldap.permit_referrals | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_PERMIT_REFERRALS |
| authentication_backend.ldap.permit_unauthenticated_bind | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_PERMIT_UNAUTHENTICATED_BIND |
| authentication_backend.ldap.pooling.count | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_POOLING_COUNT |
| authentication_backend.ldap.pooling.enable | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_POOLING_ENABLE |
| authentication_backend.ldap.pooling.retries | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_POOLING_RETRIES |
| authentication_backend.ldap.pooling.timeout | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_POOLING_TIMEOUT |
| authentication_backend.ldap.start_tls | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_START_TLS |
| authentication_backend.ldap.timeout | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_TIMEOUT |
| authentication_backend.ldap.tls.maximum_version | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_TLS_MAXIMUM_VERSION |
| authentication_backend.ldap.tls.minimum_version | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_TLS_MINIMUM_VERSION |
| authentication_backend.ldap.tls.server_name | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_TLS_SERVER_NAME |
| authentication_backend.ldap.tls.skip_verify | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_TLS_SKIP_VERIFY |
| authentication_backend.ldap.user | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_USER |
| authentication_backend.ldap.users_filter | AUTHELIA_AUTHENTICATION_BACKEND_LDAP_USERS_FILTER |
| authentication_backend.password_change.disable | AUTHELIA_AUTHENTICATION_BACKEND_PASSWORD_CHANGE_DISABLE |
| authentication_backend.password_reset.custom_url | AUTHELIA_AUTHENTICATION_BACKEND_PASSWORD_RESET_CUSTOM_URL |
| authentication_backend.password_reset.disable | AUTHELIA_AUTHENTICATION_BACKEND_PASSWORD_RESET_DISABLE |
| authentication_backend.refresh_interval | AUTHELIA_AUTHENTICATION_BACKEND_REFRESH_INTERVAL |
Identuty
| Configuration Key | Environment Variable |
|---|---|
| certificates_directory | AUTHELIA_CERTIFICATES_DIRECTORY |
| default_2fa_method | AUTHELIA_DEFAULT_2FA_METHOD |
| duo_api.disable | AUTHELIA_DUO_API_DISABLE |
| duo_api.enable_self_enrollment | AUTHELIA_DUO_API_ENABLE_SELF_ENROLLMENT |
| duo_api.hostname | AUTHELIA_DUO_API_HOSTNAME |
| identity_providers.oidc | AUTHELIA_IDENTITY_PROVIDERS_OIDC |
| identity_providers.oidc.cors.allowed_origins_from_client_redirect_uris | AUTHELIA_IDENTITY_PROVIDERS_OIDC_CORS_ALLOWED_ORIGINS_FROM_CLIENT_REDIRECT_URIS |
| identity_providers.oidc.cors.endpoints | AUTHELIA_IDENTITY_PROVIDERS_OIDC_CORS_ENDPOINTS |
| identity_providers.oidc.discovery_signed_response_alg | AUTHELIA_IDENTITY_PROVIDERS_OIDC_DISCOVERY_SIGNED_RESPONSE_ALG |
| identity_providers.oidc.discovery_signed_response_key_id | AUTHELIA_IDENTITY_PROVIDERS_OIDC_DISCOVERY_SIGNED_RESPONSE_KEY_ID |
| identity_providers.oidc.enable_client_debug_messages | AUTHELIA_IDENTITY_PROVIDERS_OIDC_ENABLE_CLIENT_DEBUG_MESSAGES |
| identity_providers.oidc.enable_jwt_access_token_stateless_introspection | AUTHELIA_IDENTITY_PROVIDERS_OIDC_ENABLE_JWT_ACCESS_TOKEN_STATELESS_INTROSPECTION |
| identity_providers.oidc.enable_pkce_plain_challenge | AUTHELIA_IDENTITY_PROVIDERS_OIDC_ENABLE_PKCE_PLAIN_CHALLENGE |
| identity_providers.oidc.enforce_pkce | AUTHELIA_IDENTITY_PROVIDERS_OIDC_ENFORCE_PKCE |
| identity_providers.oidc.lifespans.access_token | AUTHELIA_IDENTITY_PROVIDERS_OIDC_LIFESPANS_ACCESS_TOKEN |
| identity_providers.oidc.lifespans.authorize_code | AUTHELIA_IDENTITY_PROVIDERS_OIDC_LIFESPANS_AUTHORIZE_CODE |
| identity_providers.oidc.lifespans.device_code | AUTHELIA_IDENTITY_PROVIDERS_OIDC_LIFESPANS_DEVICE_CODE |
| identity_providers.oidc.lifespans.id_token | AUTHELIA_IDENTITY_PROVIDERS_OIDC_LIFESPANS_ID_TOKEN |
| identity_providers.oidc.lifespans.jwt_secured_authorization | AUTHELIA_IDENTITY_PROVIDERS_OIDC_LIFESPANS_JWT_SECURED_AUTHORIZATION |
| identity_providers.oidc.lifespans.refresh_token | AUTHELIA_IDENTITY_PROVIDERS_OIDC_LIFESPANS_REFRESH_TOKEN |
| identity_providers.oidc.minimum_parameter_entropy | AUTHELIA_IDENTITY_PROVIDERS_OIDC_MINIMUM_PARAMETER_ENTROPY |
| identity_providers.oidc.require_pushed_authorization_requests | AUTHELIA_IDENTITY_PROVIDERS_OIDC_REQUIRE_PUSHED_AUTHORIZATION_REQUESTS |
| identity_validation.elevated_session.characters | AUTHELIA_IDENTITY_VALIDATION_ELEVATED_SESSION_CHARACTERS |
| identity_validation.elevated_session.code_lifespan | AUTHELIA_IDENTITY_VALIDATION_ELEVATED_SESSION_CODE_LIFESPAN |
| identity_validation.elevated_session.elevation_lifespan | AUTHELIA_IDENTITY_VALIDATION_ELEVATED_SESSION_ELEVATION_LIFESPAN |
| identity_validation.elevated_session.require_second_factor | AUTHELIA_IDENTITY_VALIDATION_ELEVATED_SESSION_REQUIRE_SECOND_FACTOR |
| identity_validation.elevated_session.skip_second_factor | AUTHELIA_IDENTITY_VALIDATION_ELEVATED_SESSION_SKIP_SECOND_FACTOR |
| identity_validation.reset_password.jwt_algorithm | AUTHELIA_IDENTITY_VALIDATION_RESET_PASSWORD_JWT_ALGORITHM |
| identity_validation.reset_password.jwt_lifespan | AUTHELIA_IDENTITY_VALIDATION_RESET_PASSWORD_JWT_LIFESPAN |
log
| Configuration Key | Environment Variable |
|---|---|
| log.file_path | AUTHELIA_LOG_FILE_PATH |
| log.format | AUTHELIA_LOG_FORMAT |
| log.keep_stdout | AUTHELIA_LOG_KEEP_STDOUT |
| log.level | AUTHELIA_LOG_LEVEL |
| notifier.disable_startup_check | AUTHELIA_NOTIFIER_DISABLE_STARTUP_CHECK |
| notifier.filesystem.filename | AUTHELIA_NOTIFIER_FILESYSTEM_FILENAME |
| notifier.smtp.address | AUTHELIA_NOTIFIER_SMTP_ADDRESS |
| notifier.smtp.disable_html_emails | AUTHELIA_NOTIFIER_SMTP_DISABLE_HTML_EMAILS |
| notifier.smtp.disable_require_tls | AUTHELIA_NOTIFIER_SMTP_DISABLE_REQUIRE_TLS |
| notifier.smtp.disable_starttls | AUTHELIA_NOTIFIER_SMTP_DISABLE_STARTTLS |
| notifier.smtp.identifier | AUTHELIA_NOTIFIER_SMTP_IDENTIFIER |
| notifier.smtp.sender | AUTHELIA_NOTIFIER_SMTP_SENDER |
| notifier.smtp.startup_check_address | AUTHELIA_NOTIFIER_SMTP_STARTUP_CHECK_ADDRESS |
| notifier.smtp.subject | AUTHELIA_NOTIFIER_SMTP_SUBJECT |
| notifier.smtp.timeout | AUTHELIA_NOTIFIER_SMTP_TIMEOUT |
| notifier.smtp.tls.maximum_version | AUTHELIA_NOTIFIER_SMTP_TLS_MAXIMUM_VERSION |
| notifier.smtp.tls.minimum_version | AUTHELIA_NOTIFIER_SMTP_TLS_MINIMUM_VERSION |
| notifier.smtp.tls.server_name | AUTHELIA_NOTIFIER_SMTP_TLS_SERVER_NAME |
| notifier.smtp.tls.skip_verify | AUTHELIA_NOTIFIER_SMTP_TLS_SKIP_VERIFY |
| notifier.smtp.username | AUTHELIA_NOTIFIER_SMTP_USERNAME |
| notifier.template_path | AUTHELIA_NOTIFIER_TEMPLATE_PATH |
| ntp.address | AUTHELIA_NTP_ADDRESS |
| ntp.disable_failure | AUTHELIA_NTP_DISABLE_FAILURE |
| ntp.disable_startup_check | AUTHELIA_NTP_DISABLE_STARTUP_CHECK |
| ntp.max_desync | AUTHELIA_NTP_MAX_DESYNC |
| ntp.version | AUTHELIA_NTP_VERSION |
| password_policy.standard.enabled | AUTHELIA_PASSWORD_POLICY_STANDARD_ENABLED |
| password_policy.standard.max_length | AUTHELIA_PASSWORD_POLICY_STANDARD_MAX_LENGTH |
| password_policy.standard.min_length | AUTHELIA_PASSWORD_POLICY_STANDARD_MIN_LENGTH |
| password_policy.standard.require_lowercase | AUTHELIA_PASSWORD_POLICY_STANDARD_REQUIRE_LOWERCASE |
| password_policy.standard.require_number | AUTHELIA_PASSWORD_POLICY_STANDARD_REQUIRE_NUMBER |
| password_policy.standard.require_special | AUTHELIA_PASSWORD_POLICY_STANDARD_REQUIRE_SPECIAL |
| password_policy.standard.require_uppercase | AUTHELIA_PASSWORD_POLICY_STANDARD_REQUIRE_UPPERCASE |
| password_policy.zxcvbn.enabled | AUTHELIA_PASSWORD_POLICY_ZXCVBN_ENABLED |
| password_policy.zxcvbn.min_score | AUTHELIA_PASSWORD_POLICY_ZXCVBN_MIN_SCORE |
privacy
| Configuration Key | Environment Variable |
|---|---|
| privacy_policy.enabled | AUTHELIA_PRIVACY_POLICY_ENABLED |
| privacy_policy.policy_url | AUTHELIA_PRIVACY_POLICY_POLICY_URL |
| privacy_policy.require_user_acceptance | AUTHELIA_PRIVACY_POLICY_REQUIRE_USER_ACCEPTANCE |
| regulation.ban_time | AUTHELIA_REGULATION_BAN_TIME |
| regulation.find_time | AUTHELIA_REGULATION_FIND_TIME |
| regulation.max_retries | AUTHELIA_REGULATION_MAX_RETRIES |
| regulation.modes | AUTHELIA_REGULATION_MODES |
| server.address | AUTHELIA_SERVER_ADDRESS |
| server.asset_path | AUTHELIA_SERVER_ASSET_PATH |
| server.buffers.read | AUTHELIA_SERVER_BUFFERS_READ |
| server.buffers.write | AUTHELIA_SERVER_BUFFERS_WRITE |
| server.disable_healthcheck | AUTHELIA_SERVER_DISABLE_HEALTHCHECK |
| server.endpoints.enable_expvars | AUTHELIA_SERVER_ENDPOINTS_ENABLE_EXPVARS |
| server.endpoints.enable_pprof | AUTHELIA_SERVER_ENDPOINTS_ENABLE_PPROF |
| server.endpoints.rate_limits.reset_password_finish.enable | AUTHELIA_SERVER_ENDPOINTS_RATE_LIMITS_RESET_PASSWORD_FINISH_ENABLE |
| server.endpoints.rate_limits.reset_password_start.enable | AUTHELIA_SERVER_ENDPOINTS_RATE_LIMITS_RESET_PASSWORD_START_ENABLE |
| server.endpoints.rate_limits.second_factor_duo.enable | AUTHELIA_SERVER_ENDPOINTS_RATE_LIMITS_SECOND_FACTOR_DUO_ENABLE |
| server.endpoints.rate_limits.second_factor_totp.enable | AUTHELIA_SERVER_ENDPOINTS_RATE_LIMITS_SECOND_FACTOR_TOTP_ENABLE |
| server.endpoints.rate_limits.session_elevation_finish.enable | AUTHELIA_SERVER_ENDPOINTS_RATE_LIMITS_SESSION_ELEVATION_FINISH_ENABLE |
| server.endpoints.rate_limits.session_elevation_start.enable | AUTHELIA_SERVER_ENDPOINTS_RATE_LIMITS_SESSION_ELEVATION_START_ENABLE |
| server.headers.csp_template | AUTHELIA_SERVER_HEADERS_CSP_TEMPLATE |
| server.timeouts.idle | AUTHELIA_SERVER_TIMEOUTS_IDLE |
| server.timeouts.read | AUTHELIA_SERVER_TIMEOUTS_READ |
| server.timeouts.write | AUTHELIA_SERVER_TIMEOUTS_WRITE |
| server.tls.certificate | AUTHELIA_SERVER_TLS_CERTIFICATE |
| server.tls.client_certificates | AUTHELIA_SERVER_TLS_CLIENT_CERTIFICATES |
| server.tls.key | AUTHELIA_SERVER_TLS_KEY |
| session | AUTHELIA_SESSION |
| session.expiration | AUTHELIA_SESSION_EXPIRATION |
| session.inactivity | AUTHELIA_SESSION_INACTIVITY |
| session.name | AUTHELIA_SESSION_NAME |
| session.redis.database_index | AUTHELIA_SESSION_REDIS_DATABASE_INDEX |
| session.redis.high_availability.route_by_latency | AUTHELIA_SESSION_REDIS_HIGH_AVAILABILITY_ROUTE_BY_LATENCY |
| session.redis.high_availability.route_randomly | AUTHELIA_SESSION_REDIS_HIGH_AVAILABILITY_ROUTE_RANDOMLY |
| session.redis.high_availability.sentinel_name | AUTHELIA_SESSION_REDIS_HIGH_AVAILABILITY_SENTINEL_NAME |
| session.redis.high_availability.sentinel_username | AUTHELIA_SESSION_REDIS_HIGH_AVAILABILITY_SENTINEL_USERNAME |
| session.redis.host | AUTHELIA_SESSION_REDIS_HOST |
| session.redis.max_retries | AUTHELIA_SESSION_REDIS_MAX_RETRIES |
| session.redis.maximum_active_connections | AUTHELIA_SESSION_REDIS_MAXIMUM_ACTIVE_CONNECTIONS |
| session.redis.minimum_idle_connections | AUTHELIA_SESSION_REDIS_MINIMUM_IDLE_CONNECTIONS |
| session.redis.port | AUTHELIA_SESSION_REDIS_PORT |
| session.redis.timeout | AUTHELIA_SESSION_REDIS_TIMEOUT |
| session.redis.tls.maximum_version | AUTHELIA_SESSION_REDIS_TLS_MAXIMUM_VERSION |
| session.redis.tls.minimum_version | AUTHELIA_SESSION_REDIS_TLS_MINIMUM_VERSION |
| session.redis.tls.server_name | AUTHELIA_SESSION_REDIS_TLS_SERVER_NAME |
| session.redis.tls.skip_verify | AUTHELIA_SESSION_REDIS_TLS_SKIP_VERIFY |
| session.redis.username | AUTHELIA_SESSION_REDIS_USERNAME |
| session.remember_me | AUTHELIA_SESSION_REMEMBER_ME |
| session.same_site | AUTHELIA_SESSION_SAME_SITE |
storage
| Configuration Key | Environment Variable |
|---|---|
| storage.local.path | AUTHELIA_STORAGE_LOCAL_PATH |
| storage.mysql.address | AUTHELIA_STORAGE_MYSQL_ADDRESS |
| storage.mysql.database | AUTHELIA_STORAGE_MYSQL_DATABASE |
| storage.mysql.timeout | AUTHELIA_STORAGE_MYSQL_TIMEOUT |
| storage.mysql.tls.maximum_version | AUTHELIA_STORAGE_MYSQL_TLS_MAXIMUM_VERSION |
| storage.mysql.tls.minimum_version | AUTHELIA_STORAGE_MYSQL_TLS_MINIMUM_VERSION |
| storage.mysql.tls.server_name | AUTHELIA_STORAGE_MYSQL_TLS_SERVER_NAME |
| storage.mysql.tls.skip_verify | AUTHELIA_STORAGE_MYSQL_TLS_SKIP_VERIFY |
| storage.mysql.username | AUTHELIA_STORAGE_MYSQL_USERNAME |
| storage.postgres.address | AUTHELIA_STORAGE_POSTGRES_ADDRESS |
| storage.postgres.database | AUTHELIA_STORAGE_POSTGRES_DATABASE |
| storage.postgres.schema | AUTHELIA_STORAGE_POSTGRES_SCHEMA |
| storage.postgres.timeout | AUTHELIA_STORAGE_POSTGRES_TIMEOUT |
| storage.postgres.tls.maximum_version | AUTHELIA_STORAGE_POSTGRES_TLS_MAXIMUM_VERSION |
| storage.postgres.tls.minimum_version | AUTHELIA_STORAGE_POSTGRES_TLS_MINIMUM_VERSION |
| storage.postgres.tls.server_name | AUTHELIA_STORAGE_POSTGRES_TLS_SERVER_NAME |
| storage.postgres.tls.skip_verify | AUTHELIA_STORAGE_POSTGRES_TLS_SKIP_VERIFY |
| storage.postgres.username | AUTHELIA_STORAGE_POSTGRES_USERNAME |
| telemetry.metrics.address | AUTHELIA_TELEMETRY_METRICS_ADDRESS |
| telemetry.metrics.buffers.read | AUTHELIA_TELEMETRY_METRICS_BUFFERS_READ |
| telemetry.metrics.buffers.write | AUTHELIA_TELEMETRY_METRICS_BUFFERS_WRITE |
| telemetry.metrics.enabled | AUTHELIA_TELEMETRY_METRICS_ENABLED |
| telemetry.metrics.timeouts.idle | AUTHELIA_TELEMETRY_METRICS_TIMEOUTS_IDLE |
| telemetry.metrics.timeouts.read | AUTHELIA_TELEMETRY_METRICS_TIMEOUTS_READ |
| telemetry.metrics.timeouts.write | AUTHELIA_TELEMETRY_METRICS_TIMEOUTS_WRITE |
| theme | AUTHELIA_THEME |
| totp.algorithm | AUTHELIA_TOTP_ALGORITHM |
| totp.allowed_algorithms | AUTHELIA_TOTP_ALLOWED_ALGORITHMS |
| totp.allowed_digits | AUTHELIA_TOTP_ALLOWED_DIGITS |
| totp.allowed_periods | AUTHELIA_TOTP_ALLOWED_PERIODS |
| totp.digits | AUTHELIA_TOTP_DIGITS |
| totp.disable | AUTHELIA_TOTP_DISABLE |
| totp.disable_reuse_security_policy | AUTHELIA_TOTP_DISABLE_REUSE_SECURITY_POLICY |
| totp.issuer | AUTHELIA_TOTP_ISSUER |
| totp.period | AUTHELIA_TOTP_PERIOD |
| totp.secret_size | AUTHELIA_TOTP_SECRET_SIZE |
| totp.skew | AUTHELIA_TOTP_SKEW |
| webauthn.attestation_conveyance_preference | AUTHELIA_WEBAUTHN_ATTESTATION_CONVEYANCE_PREFERENCE |
| webauthn.disable | AUTHELIA_WEBAUTHN_DISABLE |
| webauthn.display_name | AUTHELIA_WEBAUTHN_DISPLAY_NAME |
| webauthn.enable_passkey_login | AUTHELIA_WEBAUTHN_ENABLE_PASSKEY_LOGIN |
| webauthn.experimental_enable_passkey_upgrade | AUTHELIA_WEBAUTHN_EXPERIMENTAL_ENABLE_PASSKEY_UPGRADE |
| webauthn.experimental_enable_passkey_uv_two_factors | AUTHELIA_WEBAUTHN_EXPERIMENTAL_ENABLE_PASSKEY_UV_TWO_FACTORS |
| webauthn.filtering.prohibit_backup_eligibility | AUTHELIA_WEBAUTHN_FILTERING_PROHIBIT_BACKUP_ELIGIBILITY |
| webauthn.metadata.enabled | AUTHELIA_WEBAUTHN_METADATA_ENABLED |
| webauthn.metadata.validate_entry | AUTHELIA_WEBAUTHN_METADATA_VALIDATE_ENTRY |
| webauthn.metadata.validate_entry_permit_zero_aaguid | AUTHELIA_WEBAUTHN_METADATA_VALIDATE_ENTRY_PERMIT_ZERO_AAGUID |
| webauthn.metadata.validate_status | AUTHELIA_WEBAUTHN_METADATA_VALIDATE_STATUS |
| webauthn.metadata.validate_status_permitted | AUTHELIA_WEBAUTHN_METADATA_VALIDATE_STATUS_PERMITTED |
| webauthn.metadata.validate_status_prohibited | AUTHELIA_WEBAUTHN_METADATA_VALIDATE_STATUS_PROHIBITED |
| webauthn.metadata.validate_trust_anchor | AUTHELIA_WEBAUTHN_METADATA_VALIDATE_TRUST_ANCHOR |
| webauthn.selection_criteria.attachment | AUTHELIA_WEBAUTHN_SELECTION_CRITERIA_ATTACHMENT |
| webauthn.selection_criteria.discoverability | AUTHELIA_WEBAUTHN_SELECTION_CRITERIA_DISCOVERABILITY |
| webauthn.selection_criteria.user_verification | AUTHELIA_WEBAUTHN_SELECTION_CRITERIA_USER_VERIFICATION |
| webauthn.timeout | AUTHELIA_WEBAUTHN_TIMEOUT |
3.3 - Однофакторная аутентификация
Существует два способа интеграции Authelia с бэкэндом аутентификации:
- LDAP: пользователи хранятся на удаленных серверах, таких как OpenLDAP, OpenDJ, FreeIPA или Microsoft Active Directory.
- Файл: пользователи хранятся в YAML-файле с хэшированной версией пароля.
3.3.1 - Однофакторная аутентификация
Конфигурация аутентификации
authentication_backend:
refresh_interval: '5m'
password_reset:
disable: false
custom_url: ''
password_change:
disable: false
refresh_interval
Этот параметр управляет интервалом, через который обновляются данные из бэкэнда. В порядке важности обновляются такие данные, как группы, адрес электронной почты и отображаемое имя. Это особенно полезно для файлового провайдера, когда часы включены или вообще включены в LDAP-провайдере.
В дополнение к значениям длительности этот параметр принимает значения always и disable; при этом always будет всегда обновлять это значение, а disable - никогда не обновлять профиль.
password_reset
disable
Этот параметр определяет, могут ли пользователи сбрасывать свой пароль через веб-фронтенд или нет.
custom_url
Пользовательский URL-адрес сброса пароля. Он заменяет встроенную функцию сброса пароля и отключает конечные точки, если он настроен на что-либо, кроме “ничего” или пустой строки.
password_change
disable
Этот параметр определяет, могут ли пользователи изменять свой пароль через веб-фронтенд или нет.
file
Поставщик аутентификации файлов.
ldap
Поставщик аутентификации LDAP.
3.3.2 - LDAP
Этот раздел предназначен для примера конфигурации, чтобы помочь пользователям получить примерное представление о контекстном расположении этого раздела конфигурации.
Настройка LDAP
configuration.yml
authentication_backend:
ldap:
address: 'ldap://127.0.0.1'
implementation: 'custom'
timeout: '5s'
start_tls: false
tls:
server_name: 'ldap.rabrain.ru'
skip_verify: false
minimum_version: 'TLS1.2'
maximum_version: 'TLS1.3'
certificate_chain: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
private_key: |
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY-----
pooling:
enable: false
count: 5
retries: 2
timeout: '10 seconds'
base_dn: 'DC=rabrain,DC=ru'
additional_users_dn: 'OU=users'
users_filter: '(&({username_attribute}={input})(objectClass=person))'
additional_groups_dn: 'OU=groups'
groups_filter: '(&(member={dn})(objectClass=groupOfNames))'
group_search_mode: 'filter'
permit_referrals: false
permit_unauthenticated_bind: false
permit_feature_detection_failure: false
user: 'CN=admin,DC=rabrain,DC=ru'
password: 'password'
attributes:
distinguished_name: 'distinguishedName'
username: 'uid'
display_name: 'displayName'
family_name: 'sn'
given_name: 'givenName'
middle_name: 'middleName'
nickname: ''
gender: ''
birthdate: ''
website: 'wWWHomePage'
profile: ''
picture: ''
zoneinfo: ''
locale: ''
phone_number: 'telephoneNumber'
phone_extension: ''
street_address: 'streetAddress'
locality: 'l'
region: 'st'
postal_code: 'postalCode'
country: 'c'
mail: 'mail'
member_of: 'memberOf'
group_name: 'cn'
extra:
extra_example:
name: ''
multi_valued: false
value_type: 'string'
Описание настроек
address
URL-адрес LDAP, состоящий из схемы, имени хоста и порта. Формат - [<схема>://]<имя хоста>[:<порт>]. По умолчанию используется схема ldapi, если путь абсолютный, иначе - ldaps, а допустимыми схемами являются ldap, ldaps или ldapi (сокет домена unix).
Если схема ldapi, то за ней должен следовать абсолютный путь к существующему сокету домена unix, для доступа к которому у пользователя/группы, от имени которой запущен процесс Authelia, есть соответствующие разрешения. Например, если сокет расположен по адресу /var/run/slapd.sock, то адрес должен быть ldapi:///var/run/slapd.sock.
authentication_backend:
ldap:
address: 'ldaps://dc1.rabrain.ru'
или
authentication_backend:
ldap:
address: 'ldap://[fd00:1111:2222:3333::1]'
implementation
Настраивает реализацию LDAP, используемую Authelia.
timeout
Тайм-аут для набора номера при подключении к LDAP.
start_tls
Включает использование процесса LDAP StartTLS, который не часто используется. Настраивать его следует только в том случае, если вы знаете, что он вам нужен. Первоначальное соединение будет осуществляться через обычный текст, и Authelia попытается обновить его с помощью LDAP-сервера. URL-адреса LDAPS немного более безопасны.
tls
Если эта опция определена, она управляет параметрами проверки TLS-соединений для LDAP-сервера.
По умолчанию Authelia использует системный сертификат доверия для проверки TLS-сертификатов TLS-соединений, а глобальная опция certificates_directory может быть использована для дополнения этого параметра.
pooling
enable
Включает функцию объединения соединений.
count
Количество открытых соединений, которые должны быть доступны в пуле в любой момент времени.
retries
Количество попыток получить свободное соединение, предпринятых в течение периода таймаута. Это эффективно разбивает таймаут на части.
timeout
Время, в течение которого мы ждем, пока соединение освободится в пуле, прежде чем сдаться и выдать ошибку.
base_dn
Устанавливает базовый контейнер отличительных имен для всех LDAP-запросов. Если ваш LDAP-домен rabrain.ru, то обычно это DC=rabrain,DC=ru, однако вы можете настроить его более точно, например, чтобы включить только объекты внутри OU authelia: OU=authelia,DC=rabrain,DC=ru. К этому приставке добавляется additional_users_dn для поиска пользователей и additional_groups_dn для поиска групп.
users_filter
Фильтр LDAP, позволяющий сузить круг пользователей. Это важно установить правильно, чтобы исключить пользователей с ограниченными возможностями.
additional_groups_dn
Аналогично additional_users_dn, но применяется к групповому поиску.
groups_filter
Аналогичен фильтру users_filter, но применяется к поиску по группам. Чтобы включить в поиск группы, в которых участник не является непосредственным членом, но является членом другой группы, которая является членом этих групп (т. е. рекурсивные группы)
(&(member:1.2.840.113556.1.4.1941:={dn})(objectClass=group)(objectCategory=group))
permit_referrals
Разрешает следовать за рефералами. Это полезно, если в вашей архитектуре есть серверы, доступные только для чтения, и поэтому требуется, чтобы при выполнении операций записи ссылки выполнялись.
user
Отличительное имя пользователя в паре с паролем для привязки к операциям поиска и смены пароля.
password
Пароль, связанный с пользователем, используемый для привязки к LDAP-серверу для операций поиска и смены пароля.
attributes
Следующие параметры настраивают сопоставление атрибутов сервера каталогов.
distinguished_name
Атрибут сервера каталогов, содержащий отличительное имя, в основном используется для выполнения фильтрованного поиска. Существует четкое различие между реальным отличительным именем и атрибутом отличительного имени, все каталоги имеют отличительные имена для объектов, но не все имеют атрибут, представляющий это имя, по которому можно осуществлять поиск.
Единственная известная поддержка на данный момент - это Active Directory.
user name
Атрибут сервера каталогов, который сопоставляется с именем пользователя в Authelia. Он должен содержать заполнитель {username_attribute}.
display_name
Атрибут сервера каталогов для извлечения, который отображается в веб-интерфейсе для пользователя при входе в систему.
family_name given_name middle_name nickname
Атрибут сервера каталогов, содержащий фамилию, имя, ник, пользователя.
extra
Дополнительные атрибуты для загрузки с сервера каталогов. Эти дополнительные атрибуты могут использоваться в других областях Authelia, таких как OpenID Connect 1.0.
Ключ представляет собой имя атрибута бэкэнда и по умолчанию является именем атрибута в Authelia.
В приведенном ниже примере мы загружаем атрибут сервера каталогов exampleServerAttribute в атрибут Authelia example_authelia_attribute, рассматривая его как однозначный атрибут, имеющий базовый тип integer.
authentication_backend:
ldap:
attributes:
extra:
exampleServerAttribute:
name: 'example_authelia_attribute'
multi_valued: false
value_type: 'integer'
Refresh Interval
Рекомендуется использовать интервал обновления по умолчанию или настроить его на достаточно низкое значение, чтобы обновлять группы пользователей и их статус (удалены, отключены и т. д.) для адекватной защиты вашей среды.
3.3.3 - Файлы конфигурации
Этот раздел предназначен для примера конфигурации, чтобы помочь пользователям получить примерное представление о контекстном расположении этого раздела конфигурации, но не для объяснения опций.
Файл конфигурации configuration.yml
authentication_backend:
file:
path: '/config/users.yml'
watch: false
search:
email: false
case_insensitive: false
extra_attributes:
extra_example:
multi_valued: false
value_type: 'string'
password:
algorithm: 'argon2'
argon2:
variant: 'argon2id'
iterations: 3
memory: 65536
parallelism: 4
key_length: 32
salt_length: 16
scrypt:
variant: 'scrypt'
iterations: 16
block_size: 8
parallelism: 1
key_length: 32
salt_length: 16
pbkdf2:
variant: 'sha512'
iterations: 310000
salt_length: 16
sha2crypt:
variant: 'sha512'
iterations: 50000
salt_length: 16
bcrypt:
variant: 'standard'
cost: 12
Опции
path
Путь к файлу со списком сведений о пользователе. Поддерживаются типы файлов: YAML-файл
watch
Позволяет перезагрузить базу данных, наблюдая за ее изменениями.
search
Функциональные возможности поиска по имени пользователя.
Позволяет пользователям входить в систему, используя свой адрес электронной почты. Если эта функция включена, два пользователя не должны иметь одинаковые адреса электронной почты, а их имена пользователей не должны быть адресами электронной почты.
extra_attributes
Дополнительные атрибуты для загрузки с сервера каталогов.
Ключ представляет собой имя атрибута бэкэнда. База данных будет проверена с учетом конфигурации multi_valued и value_type.
В приведенном ниже примере мы загружаем атрибут сервера каталогов example_file_attribute в атрибут Authelia example_file_attribute, рассматривая его как однозначный атрибут, имеющий базовый тип integer.
authentication_backend:
file:
extra_attributes:
example_file_attribute:
multi_valued: false
value_type: 'integer'
Password Options
algorithm
Управляет алгоритмом хэширования, используемым для хэширования новых паролей. Значение должно быть одним из:
argon2 для алгоритма Argon2
scrypt для алгоритма Scrypt
pbkdf2 для алгоритма PBKDF2
sha2crypt для алгоритма SHA2Crypt
bcrypt для алгоритма Bcrypt.
argon2
Реализация алгоритма Argon2. Это один из единственных алгоритмов, который был разработан исключительно для хеширования паролей, и впоследствии является одним из лучших алгоритмов для обеспечения безопасности на сегодняшний день.
scrypt
Реализация алгоритма Scrypt.
pbkdf2
Реализация алгоритма PBKDF2.
sha2crypt
Реализация алгоритма SHA2 Crypt.
bcrypt
Реализация алгоритма Bcrypt.
3.4 - Двухфакторная аутентификация
Одноразовый пароль
Authelia поддерживает настройку одноразовых паролей, основанных на времени.
Ключ безопасности
Authelia поддерживает настройку ключей безопасности WebAuthn.
Mobile Push
Authelia поддерживает настройку Duo для предоставления мобильного push-сервиса.
3.4.1 - Мобильные устройства
Authelia поддерживает мобильные push-уведомления, основанные на Duo.
Файл конфигурации configuration.yml
duo_api:
disable: false
hostname: 'api-123456789.rabrain.ru'
integration_key: 'ABCDEF'
secret_key: '1234567890abcdefghifjkl'
enable_self_enrollment: false
Опции
Disable
Отключает Duo. Если имена хостов, integration_key и secret_key являются пустыми строками или не определены, это значение автоматически становится истинным.
hostname
Имя хоста API Duo. Он указывается на панели управления Duo.
integration_key
Не секретный ключ интеграции Duo. Аналогичен идентификатору клиента. Он указывается на панели управления Duo.
secret_key
Секретный ключ Duo, используемый для проверки подлинности вашего приложения. Он предоставляется на панели управления Duo.
enable_self_enrollment
Позволяет самостоятельно регистрировать устройства Duo на портале Authelia.
3.4.2 - Time-based One-Time Password
Метод OTP, который использует Authelia, - это алгоритм одноразовых паролей на основе времени (TOTP) RFC6238, который является расширением алгоритма одноразовых паролей на основе HMAC (HOTP) RFC4226.
Файл конфигурации configuration.yml
totp:
disable: false
issuer: 'authelia.com'
algorithm: 'sha1'
digits: 6
period: 30
skew: 1
secret_size: 32
allowed_algorithms:
- 'SHA1'
allowed_digits:
- 6
allowed_periods:
- 30
disable_reuse_security_policy: false
Опции
Disable
Это отключает одноразовый пароль (TOTP), если установлено значение true.
issuer
Приложения, генерирующие одноразовые пароли, основанные на времени, обычно отображают эмитента, чтобы отличить приложения, зарегистрированные пользователем.
Authelia позволяет настраивать эмитента, чтобы отличить запись, созданную Authelia, от других.
algorithm
Алгоритм, используемый для ключа TOTP.
Возможные значения:
- sha1
- sha256
- sha512
Изменение этого значения влияет только на вновь зарегистрированные ключи TOTP.
digits
Количество цифр, которые пользователь должен ввести для аутентификации. Обычно не рекомендуется изменять этот параметр, поскольку многие TOTP-приложения не поддерживают ничего, кроме 6. Хуже того, некоторые TOTP-приложения позволяют добавить ключ, но не используют правильное количество цифр, указанное в ключе.
Правильные значения - 6 или 8.
period
Период времени в секундах между поворотами клавиш или временной элемент TOTP.
Рекомендуется держать это значение равным 30, минимальное значение - 15.
skew
Количество временных одноразовых паролей по обе стороны от текущего действующего временного одноразового пароля, которые также должны считаться действительными. Значение по умолчанию 1 приводит к 3 действительным одноразовым паролям на основе времени. При значении 2 их будет 5.
secret_size
Длина в байтах генерируемых общих секретов. Минимальное значение - 20 (или 160 бит), а по умолчанию - 32 (или 256 бит).
allowed_algorithms
Аналогичен алгоритму с теми же ограничениями, за исключением того, что эта опция позволяет пользователям выбирать из этого списка. Этот список всегда будет содержать значение, заданное в опции алгоритма.
disable_reuse_security_policy
Отключает политику, которая предотвращает повторное использование кодов одноразовых паролей, основанных на времени. Это дополнительная мера безопасности, которая предотвращает повторное воспроизведение кодов. Это касается только тех кодов, которые используются в течение срока действия более одного раза.
Регистрация
Когда пользователи впервые регистрируют свое устройство TOTP, текущий эмитент, алгоритм и период используются для генерации ссылки TOTP и QR-кода. Эти значения сохраняются в базе данных для последующих проверок.
Входная валидация
Параметры конфигурации периода и перекоса влияют друг на друга. По умолчанию период равен 30, а перекос - 1.
3.4.3 - WebAuthn
WebAuthn (Web Authentication) — это стандарт аутентификации, позволяющий входить на сайты без паролей, используя биометрию (отпечаток пальца, Face ID) или аппаратные ключи безопасности (YubiKey, Titan Key).
Файл конфигурации configuration.yml
webauthn:
disable: false
enable_passkey_login: false
display_name: 'Authelia'
attestation_conveyance_preference: 'indirect'
timeout: '60 seconds'
filtering:
permitted_aaguids: []
prohibited_aaguids: []
prohibit_backup_eligibility: false
selection_criteria:
attachment: ''
discoverability: 'preferred'
user_verification: 'preferred'
metadata:
enabled: false
validate_trust_anchor: true
validate_entry: true
validate_entry_permit_zero_aaguid: false
validate_status: true
validate_status_permitted: []
validate_status_prohibited:
- 'REVOKED'
- 'USER_KEY_PHYSICAL_COMPROMISE'
- 'USER_KEY_REMOTE_COMPROMISE'
- 'USER_VERIFICATION_BYPASS'
- 'ATTESTATION_KEY_COMPROMISE'
Опции
Disable
Это отключает WebAuthn, если установлено значение true.
enable_passkey_login
Позволяет входить в систему с помощью Passkey вместо имени пользователя и пароля. Такой вход считается только однофакторным. По умолчанию пользователю будет предложено ввести пароль, если запрос требует многофакторной аутентификации.
display_name
Устанавливает отображаемое имя, которое отправляется клиенту для отображения. Отдельные браузеры и, возможно, отдельные операционные системы сами решают, отображать ли эту информацию и каким образом.
Дополнительную информацию см. в документации W3C WebAuthn.
timeout
Это настраивает запрошенное время ожидания для взаимодействия с WebAuthn.
filtering
В этом разделе настраиваются различные параметры фильтрации при регистрации.
selection_criteria
Параметры критериев выбора задают предпочтения для выбора подходящего аутентификатора.
metadata
Настраивает службу метаданных, которая используется для проверки подлинности аутентификаторов.
3.5 - Security
Security в Authelia относится к механизмам защиты, которые обеспечивают безопасную аутентификацию и авторизацию пользователей. Authelia — это менеджер аутентификации и авторизации с открытым исходным кодом, который можно интегрировать с обратными прокси (Nginx, Traefik) для защиты веб-приложений
3.5.1 - Контроль доступа
Описание организация контроля доступа в Authelia
Файл конфигурации configuration.yml
access_control:
default_policy: 'deny'
rules:
- domain: 'private.rabrain.ru'
domain_regex: '^(\d+\-)?priv-img\.rabrain\.ru$'
policy: 'one_factor'
networks:
- 'internal'
- '1.1.1.1'
subject:
- ['user:adam']
- ['user:fred']
- ['group:admins']
methods:
- 'GET'
- 'HEAD'
resources:
- '^/api.*'
query:
- - operator: 'present'
key: 'secure'
- operator: 'absent'
key: 'insecure'
- - operator: 'pattern'
key: 'token'
value: '^(abc123|zyx789)$'
- operator: 'not pattern'
key: 'random'
value: '^(1|2)$'
Опции
default_policy
Политика по умолчанию определяет политику, применяемую, если к информации, известной о запросе, не применяется ни один раздел правил. По соображениям безопасности рекомендуется настраивать это значение на отказ. Сайты, которые вы не хотите защищать с помощью Authelia, не должны быть настроены в вашем обратном прокси на выполнение аутентификации с помощью Authelia по соображениям производительности.
rules
Правила имеют множество параметров настройки. Правило совпадает, если все критерии правила соответствуют запросу, за исключением политики, которая применяется к запросу.
Правило определяет две основные вещи:
- политика, применяемая при совпадении всех критериев
- критерии соответствия запроса, представленного обратному прокси
Критерии разбиты на несколько частей:
- domain: домен или список доменов, на которые направлен запрос.
- domain_regex: regex-форма домена.
- resources: шаблон или список шаблонов, которым должен соответствовать путь.
- subject: пользователь или группа пользователей, для которых нужно определить политику.
- networks: сетевые адреса, диапазоны (нотация CIDR) или группы, из которых исходит запрос.
- methods: http-методы, используемые в запросе.
Правило выполняется, если все критерии правила совпадают. Правила оцениваются в последовательном порядке в соответствии с концепцией 1 сопоставления правил.
domain
Требуется: Этот критерий и/или критерий domain_regex являются обязательными.
Этот критерий соответствует имени домена и имеет два способа настройки: в виде одной строки или в виде списка строк. Если это список строк, правило будет соответствовать любому из доменов в списке, совпадающему с доменом запроса. При использовании в сочетании с domain_regex правило будет соответствовать критериям domain или domain_regex.
access_control:
rules:
- domain: '*.rabrain.ru'
policy: 'bypass'
- domain:
- '*.rabrain.ru'
policy: 'bypass'
access_control:
rules:
- domain: ['apple.rabrain.ru', 'banana.rabrain.ru']
policy: 'bypass'
- domain:
- 'apple.rabrain.ru'
- 'banana.rabrain.ru'
policy: 'bypass'
access_control:
rules:
- domain: 'apple.rabrain.ru'
domain_regex: '^(pub|img)-data\.rabrain\.ru$'
policy: bypass
domain_regex
Требуется: Этот критерий и/или критерий домена являются обязательными.
Этот критерий соответствует имени домена и имеет два способа настройки: в виде одной строки или в виде списка строк. Если это список строк, правило будет соответствовать, когда любой из доменов в списке совпадает с доменом запроса. При использовании в сочетании с domain правило будет соответствовать либо критерию domain, либо критерию domain_regex.
access_control:
rules:
- domain_regex:
- '^user-(?P<User>\w+)\.rabrain\.ru$'
- '^group-(?P<Group>\w+)\.rabrain\.ru$'
policy: 'one_factor'
access_control:
rules:
- domain: 'protected.rabrain.ru'
- domain_regex: '^(img|data)-private\.rabrain\.ru'
policy: 'one_factor'
policy
Конкретная политика, которую следует применить к выбранному правилу. Это не критерии для совпадения, это действие, которое нужно предпринять при совпадении.
subject
Этот критерий соответствует идентифицирующим характеристикам субъекта. В настоящее время это либо пользователь, либо группы, к которым он принадлежит. Это позволяет эффективно контролировать, к чему именно имеет доступ каждый пользователь, или требовать двухфакторной аутентификации для определенных пользователей. Субъекты должны быть снабжены следующими префиксами, чтобы соответствовать определенной части субъекта.
| Тип subject | Префикс | Описание |
|---|---|---|
| User | user: | Сопоставляет имя пользователя. |
| Group | group: | Определяет, есть ли у пользователя группа с таким именем. |
| OAuth 2.0 Client | oauth2:client: | Определяет, был ли запрос авторизован с помощью токена, выданного клиентом с указанным идентификатором, использующим тип гранта client_credentials. |
access_control:
rules:
- domain: 'rabrain.ru'
policy: 'two_factor'
subject:
- 'user:john'
- ['group:admin', 'group:app-name']
- 'group:super-admin'
- domain: 'rabrain.ru'
policy: 'two_factor'
subject:
- ['user:john']
- ['group:admin', 'group:app-name']
- ['group:super-admin']
access_control:
rules:
- domain: 'rabrain.ru'
policy: 'one_factor'
subject: 'group:super-admin'
- domain: 'rabrain.ru'
policy: 'one_factor'
subject:
- 'group:super-admin'
- domain: 'rabrain.ru'
policy: 'one_factor'
subject:
- ['group:super-admin']
methods
Этот критерий соответствует методу запроса HTTP. В первую очередь это полезно при попытке обойти аутентификацию для определенных типов запросов, когда эти запросы могут помешать основной или публичной работе сайта. Например, если вам нужно сделать предварительный CORS-запрос, вы можете применить политику обхода к OPTIONS-запросам.
Важно отметить, что Authelia не может сохранять данные запроса при перенаправлении пользователя.
| RFC | Methods | Additional Documentation |
|---|---|---|
| RFC7231 | GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, TRACE | MDN |
| RFC5789 | PATCH | MDN |
| RFC4918 | PROPFIND, PROPPATCH, MKCOL, COPY, MOVE, LOCK, UNLOCK |
access_control:
rules:
- domain: 'rabrain.ru'
policy: 'bypass'
methods:
- 'OPTIONS'
Обход OPTIONS-запросов к домену rabrain.ru.
networks
Эти критерии состоят из списка значений, которые могут быть IP-адресом, диапазоном сетевых адресов в нотации CIDR или именованным определением сети. Он сопоставляет первый адрес в заголовке X-Forwarded-For, или, если их нет, он возвращается к IP-адресу TCP-источника пакета. По этой причине важно правильно настроить прокси-сервер для точного соответствия запросов этим критериям. Примечание: вы можете комбинировать CIDR-сети с правилами псевдонимов по своему усмотрению.
Основное применение этого критерия - настройка требований безопасности ресурса в зависимости от местоположения пользователя. Теоретически вы можете рассматривать конкретную сеть как один из факторов, участвующих в аутентификации, можете запрещать конкретные сети и т. д.
Например, если у вас есть приложение, открытое как в локальных, так и во внешних сетях, вы можете различать эти запросы и применять к каждому из них разные политики. Либо отказывая в доступе, когда пользователь находится во внешних сетях, и разрешая доступ определенным внешним клиентам, а также внутренним клиентам, либо требуя меньших привилегий, когда пользователь находится в локальных сетях.
definitions:
network:
internal:
- '10.0.0.0/8'
- '172.16.0.0/12'
- '192.168.0.0/18'
access_control:
default_policy: 'two_factor'
rules:
- domain: 'secure.rabrain.ru'
policy: 'one_factor'
networks:
- '10.0.0.0/8'
- '172.16.0.0/12'
- '192.168.0.0/18'
- '112.134.145.167/32'
- domain: 'secure.rabrain.ru'
policy: 'one_factor'
networks:
- 'internal'
- '112.134.145.167/32'
- domain: 'secure.rabrain.ru'
policy: 'two_factor'
resources
Этот критерий соответствует пути и запросу запроса с помощью регулярных выражений. Правило выражается в виде списка строк. Если любое из регулярных выражений в списке соответствует запросу, оно считается совпавшим. Полезный инструмент для отладки этих регулярных выражений называется Regex 101 (убедитесь, что вы выбрали опцию Golang).
access_control:
rules:
- domain: 'app.rabrain.ru'
policy: 'bypass'
resources:
- '^/api([/?].*)?$'
query
Критерии запроса - это расширенный критерий, который позволяет настраивать правила, сопоставляющие определенные ключи аргументов запроса с различными правилами. Для базовых нужд рекомендуется использовать правила ресурсов.
Формат этого правила уникален тем, что представляет собой список списков. Логика, лежащая в основе этого формата, позволяет использовать логику ИЛИ и И. Первый уровень списка определяет логику ИЛИ, а второй уровень - логику И. Кроме того, каждый уровень этих списков не обязательно должен быть явно определен.
key
Ключ аргумента запроса для проверки.
value
Значение, по которому будет выполняться проверка. Оно необходимо, если оператор отсутствует или присутствует. Рекомендуется, чтобы это значение всегда заключалось в кавычки, как показано в примерах.
operator
Оператор правила для этого правила.
access_control:
rules:
- domain: 'app.rabrain.ru'
policy: 'bypass'
query:
- - operator: 'present'
key: 'secure'
- operator: 'absent'
key: 'insecure'
- - operator: 'pattern'
key: 'token'
value: '^(abc123|zyx789)$'
- operator: 'not pattern'
key: 'random'
value: '^(1|2)$'
Policies
Политика первого подходящего правила в списке определяет политику, применяемую к запросу, если ни одно правило не соответствует запросу, применяется политика по умолчанию (default_policy).
deny
Это политика, применяемая по умолчанию, и именно ее мы рекомендуем использовать по умолчанию для всех установок. Ее действие заключается в том, чтобы буквально запретить пользователю доступ к ресурсу. Кроме того, вы можете использовать эту политику для условного запрета доступа в нужных ситуациях. В качестве примера можно привести запрет доступа к API, в который не встроен механизм аутентификации.
bypass
Эта политика пропускает все проверки подлинности и позволяет любому пользователю использовать ресурс. Эта политика недоступна с правилом, включающим ограничение по субъекту, поскольку минимальный уровень аутентификации, необходимый для получения информации о субъекте, - one_factor.
one_factor
Эта политика требует, чтобы пользователь как минимум успешно выполнил 1FA (имя пользователя и пароль). Это означает, что если пользователь выполнил 2FA, ему будет разрешен доступ к ресурсу.
two_factor
Эта политика требует от пользователя успешного выполнения 2FA. В настоящее время это самый высокий уровень политики аутентификации.
Сопоставление правил
Есть две важные концепции, которые необходимо понимать, когда речь идет о сопоставлении правил.
С помощью команды authelia access-control check-policy можно легко определить, соответствует ли раздел правил управления доступом заданному запросу и почему он не соответствует.
Концепция сопоставления правил 1: последовательный порядок
Правила сопоставляются в последовательном порядке. Первая запись в списке, в которой совпадают все критерии, является правилом, которое применяется. Некоторые критерии правил дополнительно допускают список критериев, когда один из этих критериев в списке соответствует запросу, этот критерий считается подходящим для данного конкретного правила.
Например, следующее правило будет считать запросы на rabrain.ru или любой поддомен rabrain.ru соответствующими, если они имеют путь /api или если они начинаются с /api/. Это означает, что второе правило для app.rabrain.ru не будет рассматриваться, если запрос будет направлен на https://app.rabrain.ru/api, потому что первое правило совпадает с этим запросом.
- domain:
- 'rabrain.ru'
- '*.rabrain.ru'
policy: 'bypass'
resources:
- '^/api$'
- '^/api/'
- domain:
- 'app.rabrain.ru'
policy: 'two_factor'
Концепция соответствия правил 2: Критерии субъекта требуют аутентификации
Правила, содержащие элементы, зависящие от субъекта, требуют аутентификации для определения их соответствия. Поэтому такие правила не должны использоваться с политикой обхода. Критериями, которые содержат элементы, зависящие от субъекта, являются:
- Сам критерий субъекта
- Критерий domain_regex, когда он содержит именованные группы Regex.
Кроме того, если в правиле есть критерий темы, но все остальные критерии совпадают, пользователь будет немедленно перенаправлен на аутентификацию, если ни одно из предыдущих правил не соответствует запросу в соответствии с концепцией 1 соответствия правил. Это означает, что если у вас есть два одинаковых правила, одно из которых имеет зависимый от темы критерий, а другое является правилом обхода, то правило обхода должно быть первым.
Именованные группы регексов
Некоторые критерии допускают совпадение с именованными группами regex. Эти группы мы принимаем: User и Group
Именованные группы regex представлены синтаксисом (?P
definitions:
network:
internal:
- '10.10.0.0/16'
- '192.168.2.0/24'
vpn: '10.9.0.0/16'
access_control:
default_policy: 'deny'
rules:
- domain: 'public.rabrain.ru'
policy: 'bypass'
- domain: '*.rabrain.ru'
policy: 'bypass'
methods:
- 'OPTIONS'
- domain: 'secure.rabrain.ru'
policy: 'one_factor'
networks:
- 'internal'
- 'vpn'
- '192.168.1.0/24'
- '10.0.0.1'
- domain:
- 'secure.rabrain.ru'
- 'private.rabrain.ru'
policy: 'two_factor'
- domain: 'singlefactor.rabrain.ru'
policy: 'one_factor'
- domain: 'mx2.mail.rabrain.ru'
subject: 'group:admins'
policy: 'deny'
- domain: '*.rabrain.ru'
subject:
- 'group:admins'
- 'group:moderators'
policy: 'two_factor'
- domain: 'dev.rabrain.ru'
resources:
- '^/groups/dev/.*$'
subject: 'group:dev'
policy: 'two_factor'
- domain: 'dev.rabrain.ru'
resources:
- '^/users/john/.*$'
subject:
- ['group:dev', 'user:john']
- 'group:admins'
policy: 'two_factor'
3.5.2 - Регулирование
Authelia может временно запретить учетные записи, когда происходит слишком много попыток аутентификации на конечной точке имени пользователя / пароля. Это помогает предотвратить атаки методом грубой силы.
Конфигурация регулирования
regulation:
modes:
- 'user'
- 'ip'
max_retries: 3
find_time: '2m'
ban_time: '5m'
Опции
modes
Режимы для регулирования. В таблице ниже описан каждый вариант. Рекомендуемый режим - ip. Следует отметить, что независимо от настроенных в данный момент режимов запрета, если в базе данных существуют запреты, пользователю или IP будет отказано в доступе.
| Режим | Описание |
|---|---|
| user | Учетная запись пользователя является объектом любых автоматических запретов |
| ip | Удаленный ip является объектом любых автоматических запретов |
max_retries
Количество неудачных попыток входа в систему, после которых пользователь может быть забанен. Установка этого параметра в 0 полностью отключает регулирование.
find_time
Период времени, анализируемый на предмет неудачных попыток. Например, если вы установили max_retries в 3, а find_time в 2m, это означает, что у пользователя должно быть 3 неудачных входа в систему за 2 минуты.
ban_time
Период времени, на который пользователь будет заблокирован после выполнения настроек max_retries и find_time. По истечении этого срока пользователь сможет снова войти в систему.
3.5.3 - Password Policy
Политика паролей
Конфигурация регулирования
password_policy:
standard:
enabled: false
min_length: 8
max_length: 0
require_uppercase: false
require_lowercase: false
require_number: false
require_special: false
zxcvbn:
enabled: false
min_score: 3
Опции
standard
В этом разделе можно включить стандартные политики безопасности.
enabled
Включает стандартную политику паролей.
min_length
Определяет минимально допустимую длину пароля.
max_length
Определяет максимально допустимую длину пароля.
require_uppercase
Указывает, что в пароле должна быть указана хотя бы одна буква UPPERCASE.
require_lowercase
Указывает, что в пароле должна быть указана хотя бы одна строчная буква.
require_number
Указывает, что в пароле должна быть указана хотя бы одна цифра.
require_special
Указывает, что в пароле должен быть указан хотя бы один специальный символ.
zxcvbn
Эта политика паролей включает расширенный учет надежности паролей с помощью zxcvbn.
Обратите внимание, что данная политика паролей не ограничивает вход пользователя, а лишь предоставляет ему информацию о том, насколько надежным является его пароль.
enabled
Включает политику паролей zxcvbn.
min_score
Настраивает минимальный балл zxcvbn, допустимый для новых паролей. В системе баллов zxcvbn существует 5 уровней (взято с github.com/dropbox/zxcvbn):
- оценка 0: слишком угадываемый: рискованный пароль (угадываний < 10^3)
- оценка 1: очень угадываемый: защита от дросселированных онлайн-атак (угадываний < 10^6)
- оценка 2: несколько угадываемый: защита от недросселированных онлайн-атак. (угадываний < 10^8)
- оценка 3: надежно не угадывается: умеренная защита от сценария медленного хэширования в автономном режиме. (угадываний < 10^10)
- оценка 4: очень неугадываемо: сильная защита от сценария медленного хэширования в автономном режиме. (guesses >= 10^10)
Мы не допускаем оценку 0, если вы установите значение min_score равным 0, вместо него будет использоваться значение по умолчанию.
3.6 - Проверка входа
Как выполняется проверка личности при входе в систему
Конфигурация
identity_validation:
elevated_session: {}
reset_password: {}
Методы проверки защищают две области:
Elevated Session, которая не позволяет вошедшему в систему пользователю выполнять привилегированные действия без предварительного подтверждения своей личности.
Reset Password — Сброс пароля, который не позволяет анонимному пользователю выполнить сброс пароля для пользователя без предварительного подтверждения его личности.
3.6.1 - Elevated Session
Elevated Session (Повышенная сессия) — это механизм безопасности в Authelia, который требует дополнительной проверки личности пользователя при выполнении критически важных действий, связанных с безопасностью аккаунта.
Elevated Session (Повышенная сессия) — это механизм безопасности в Authelia, который требует дополнительной проверки личности пользователя при выполнении критически важных действий, связанных с безопасностью аккаунта. Это предотвращает несанкционированные изменения, даже если злоумышленник получил доступ к сессии пользователя.
Как это работает?
Пользователь пытается выполнить важное действие, например:
- Смена пароля
- Настройка 2FA (TOTP, WebAuthn)
- Изменение email или других персональных данных
- Доступ к критическим разделам
Authelia запрашивает повторную аутентификацию:
- Ввод пароля
- Подтверждение через 2FA (если включено)
- Проверка биометрии (для WebAuthn)
Создается “повышенная сессия” на ограниченное время (по умолчанию — 5 минут), в течение которой пользователь может выполнять защищенные действия.
Конфигурация
identity_validation:
elevated_session:
code_lifespan: '5 minutes'
elevation_lifespan: '10 minutes'
characters: 8
require_second_factor: false
skip_second_factor: false
Опции
code_lifespan
Срок действия случайно сгенерированного одноразового кода, после которого он считается недействительным
elevation_lifespan
Время жизни возвышения после первоначальной проверки одноразового кода до истечения срока его действия.
characters
Количество символов в случайном одноразовом коде. Максимальное значение на данный момент составляет 20, но мы рекомендуем держать его в диапазоне от 8 до 12. Уменьшать значение ниже 8 крайне не рекомендуется.
require_second_factor
Требуется аутентификация по второму фактору для всех защищенных действий в дополнение к повышенному сеансу, если пользователь настроил метод аутентификации по второму фактору.
skip_second_factor
Пропускает требование повышенной сессии, если пользователь выполнил аутентификацию по второму фактору. Можно комбинировать с параметром require_second_factor, чтобы всегда (и только) требовать аутентификацию по второму фактору.
3.6.2 - Reset password
Функция Reset Password в Authelia предназначена для безопасного восстановления доступа к аккаунту, если пользователь забыл пароль.
Основное назначение
- Позволяет пользователям самостоятельно сбросить пароль без вмешательства администратора.
- Альтернатива ручному сбросу через базу данных или LDAP.
- Интегрируется с email-уведомлениями для подтверждения личности.
Как это работает?
- Пользователь нажимает “Забыли пароль?” на странице входа.
- Authelia отправляет письмо с уникальной ссылкой для сброса (JWT-токен с ограниченным сроком действия).
- При переходе по ссылке открывается форма ввода нового пароля.
- После подтверждения пароль изменяется в выбранном бэкенде (LDAP, MySQL, PostgreSQL и т.д.).
Конфигурация
identity_validation:
reset_password:
jwt_secret: ''
jwt_lifespan: '5 minutes'
jwt_algorithm: 'HS256'
Опции
jwt_secret
Секрет, используемый алгоритмом HMAC для подписи JWT. Это значение должно представлять собой произвольную случайную строку с печатаемыми символами ASCII.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов.
jwt_lifespan
Время жизни JSON Web Token после его первоначальной генерации, по истечении которого он считается недействительным.
jwt_algorithm
Алгоритм JSON Web Token, используемый для подписи JWT. Должен быть HS256, HS384 или HS512.
3.7 - Seccion
Режим Session в Authelia отвечает за управление сессионными куками, которые используются для авторизации пользователей на защищенных ресурсах.
Основная задача
Режим Session контролирует:
- Создание и валидацию сессионных кук после успешной аутентификации.
- Домены, для которых Authelia может выдавать авторизационные куки.
- Параметры безопасности кук (время жизни, HTTPS-only, SameSite и др.).
3.7.1 - Конфигурация
Конфигурация
session:
secret: 'insecure_session_secret'
name: 'authelia_session'
same_site: 'lax'
inactivity: '5m'
expiration: '1h'
remember_me: '1M'
cookies:
- domain: 'rabrain.ru'
authelia_url: 'https://auth.rabrain.ru'
default_redirection_url: 'https://www.rabrain.ru'
name: 'authelia_session'
same_site: 'lax'
inactivity: '5m'
expiration: '1h'
remember_me: '1d'
Конфигурация
session:
secret: 'insecure_session_secret'
name: 'authelia_session'
same_site: 'lax'
inactivity: '5m'
expiration: '1h'
remember_me: '1M'
cookies:
- domain: 'rabrain.ru'
authelia_url: 'https://auth.rabrain.ru'
default_redirection_url: 'https://www.rabrain.ru'
name: 'authelia_session'
same_site: 'lax'
inactivity: '5m'
expiration: '1h'
remember_me: '1d'
Провайдеры
В настоящее время существует два провайдера для хранения сессий (три, если считать Redis Sentinel отдельным провайдером):
- Memory (по умолчанию, с состоянием, без дополнительной настройки)
- Redis (без состояния).
- Redis Sentinel (без статических данных, высокая доступность).
Kubernetes
Kubernetes или High Availability
Важно отметить, что при выборе провайдера не рекомендуется использовать провайдеров с функцией stateless в сценариях High Availability, таких как Kubernetes. Рядом с каждым провайдером есть примечание, указывающее, является ли он государственным или нестационарным, рекомендуется использовать нестационарные провайдеры.
Опции
name
Значение имени по умолчанию для всех конфигураций cookies.
same_site
Значение same_site по умолчанию для всех конфигураций cookies.
inactivity
Значение бездействия по умолчанию для всех конфигураций cookies.
expiration
Значение срока действия по умолчанию для всех конфигураций cookies.
remember_me
Значение remember_me по умолчанию для всех конфигураций cookies.
cookies
Список определенных доменов cookie, которые Authelia настроена обрабатывать. Домены, не настроенные должным образом, будут автоматически отклоняться Authelia. Список позволяет администраторам определить несколько конфигураций доменов cookie сеанса с индивидуальными настройками.
domain
Домен, для защиты которого назначается сессионный cookie. Он должен совпадать с доменом, на котором обслуживается Authelia, или корнем домена, и, следовательно, если настроен authelia_url, должен иметь возможность читать и записывать куки для этого домена.
Например, если Authelia доступна по URL https://auth.rabrain.ru, домен должен быть либо auth.rabrain.ru, либо rabrain.ru.
Значение не должно совпадать с доменом из списка публичных суффиксов, поскольку браузеры не разрешают веб-сайтам записывать файлы cookie для таких доменов. Это касается большинства служб динамического DNS, таких как duckdns.org. Вы должны использовать свой домен вместо duckdns.org для этого значения, например example.duckdns.org.
Следовательно, если у вас есть example.duckdns.org и example-auth.duckdns.org, вы не сможете обмениваться файлами cookie между этими доменами.
authelia_url
Это обязательный URL, который является корневым URL вашей установки Authelia для этого домена cookie, который может быть использован для создания соответствующего URL перенаправления, когда требуется аутентификация. Этот URL должен:
- Уметь читать и записывать файлы cookie для настроенного домена.
- Использовать схему https://.
- Включать путь, если это необходимо (например, https://rabrain.ru/authelia, а не https://rabrain.ru, если вы используете опцию адреса сервера в authelia для указания подпути и если портал Authelia недоступен с https://rabrain.ru).
Соответствующий параметр запроса или заголовок для соответствующего прокси может отменить это поведение.
default_redirection_url
Это совершенно необязательный URL, который используется в качестве места перенаправления при прямом посещении Authelia. Эта опция отменяет глобальную опцию default_redirection_url.
name
Значение по умолчанию: Этот параметр принимает значение по умолчанию из настройки имени, приведенной выше.
Имя куки сеанса. По умолчанию устанавливается значение имени в основном разделе конфигурации сеанса.
same_site
Значение по умолчанию: Этот параметр принимает значение по умолчанию из настройки same_site, указанной выше.
Устанавливает значение cookies SameSite. До появления этого параметра по умолчанию было установлено значение None. Новое значение по умолчанию - Lax. Эта опция задается в нижнем регистре. Поэтому, например, если вы хотите установить значение Strict, то в конфигурации оно должно быть строгим.
Подробно о куках SameSite можно прочитать в MDN. Короче говоря, установка SameSite в значение Lax является наиболее предпочтительным вариантом для Authelia. None не рекомендуется, если только вы не знаете, что делаете, и не доверяете всем защищенным приложениям. Strict не будет работать во многих случаях, и мы не тестировали его в этом состоянии, но в любом случае он доступен как опция.
inactivity
Значение по умолчанию: Этот параметр принимает значение по умолчанию из настройки бездействия, приведенной выше.
Период времени, в течение которого пользователь может быть неактивен, пока сессия не будет уничтожена. Пригодится, если вам нужны длительные таймеры сеансов, но вы не хотите, чтобы неиспользуемые устройства были уязвимы.
expiration
Значение по умолчанию: Этот параметр принимает значение по умолчанию из настройки истечения срока действия, указанной выше.
Период времени до истечения срока действия cookie и уничтожения сессии. Это значение переопределяется параметром remember_me, если установлен флажок remember me.
remember_me
Значение по умолчанию: Этот параметр принимает значение по умолчанию из настройки remember_me, указанной выше.
Период времени до истечения срока действия куки и уничтожения сессии, когда установлен флажок remember me. Установка значения -1 полностью отключает эту функцию для данного домена сессионных cookie.
3.7.2 - Redis
Redis в Authelia решает ключевую проблему — делает систему статус-независимой (stateless) и обеспечивает высокую доступность (HA).
Проблема стандартного режима (In-Memory)
По умолчанию Authelia хранит сессии в оперативной памяти (in-memory). Это приводит к:
- Потере сессий при перезагрузке Authelia.
- Невозможности масштабирования (если запущено несколько экземпляров Authelia, сессии не синхронизируются).
- Риску отказа — при падении сервера все пользователи разлогиниваются.
Как Redis решает эти проблемы?
| Проблема | Решение через Redis |
|---|---|
| Потеря сессий при перезагрузке | Сессии хранятся на внешнем сервере и сохраняются после рестарта |
| Несколько экземпляров Authelia | Все ноды читают/пишут сессии в единое хранилище |
| Высокая нагрузка | Redis оптимизирован для частых операций чтения/записи |
Конфигурация
session:
redis:
host: '127.0.0.1'
port: 6379
timeout: '5s'
max_retries: 0
username: 'authelia'
password: 'authelia'
database_index: 0
maximum_active_connections: 8
minimum_idle_connections: 0
tls:
server_name: 'myredis.rabrain.ru'
skip_verify: false
minimum_version: 'TLS1.2'
maximum_version: 'TLS1.3'
certificate_chain: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
private_key: |
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY-----
high_availability:
sentinel_name: 'mysentinel'
# If `sentinel_username` is supplied, Authelia will connect using ACL-based
# authentication. Otherwise, it will use traditional `requirepass` auth.
sentinel_username: 'sentinel_user'
sentinel_password: 'sentinel_specific_pass'
nodes:
- host: 'sentinel-node1'
port: 26379
- host: 'sentinel-node2'
port: 26379
route_by_latency: false
route_randomly: false
Опции
host
Хост redis или путь к сокету unix. Если используется буквенный адрес IPv6, он должен быть заключен в квадратные скобки и взят в кавычки:
host: '[fd00:1111:2222:3333::1]'
timeout
Таймаут соединения с Redis.
max_retries
Максимальное количество повторных попыток при неудачной команде. Установка этого параметра в 0 полностью отключает повторные попытки.
port
Порт, на котором прослушивается Redis.
username
Имя пользователя для аутентификации в redis. Поддерживается только в redis 6.0+, и в настоящее время redis предлагает обратную совместимость с аутентификацией только по паролю. Вероятно, вам не нужно задавать это значение, если вы не проходили через процесс настройки ACL redis.
password
Пароль для аутентификации в Redis.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов, и пароль пользователя был изменен на это значение.
database_index
Номер индекса базы данных redis, то же значение, что и в команде redis SELECT.
maximum_active_connections
Максимальное количество соединений, открытых к redis в одно и то же время.
minimum_idle_connections
Минимальное количество соединений redis, которые следует держать открытыми, пока они не превышают максимальное количество активных соединений. Это полезно, если возникают большие задержки при установлении соединений.
tls
Если определено, включает соединение через TLS-сокет и дополнительно управляет параметрами проверки TLS-соединения для сервера redis.
По умолчанию Authelia использует системный сертификат доверия для проверки TLS-соединений, а глобальная опция certificates_directory может быть использована для дополнения этого параметра.
high_availability
При определении этой сессии включается соединение с redis sentinel. Возможно, в будущем мы добавим кластер redis.
sentinel_name
Имя ведущего сервера redis sentinel. Оно задается в конфигурации redis sentinel, это не имя хоста. Для конфигурации высокой доступности оно должно быть определено в данный момент.
sentinel_username
Имя пользователя для подключения к Redis Sentinel. Если оно указано, оно будет использоваться вместе с паролем sentinel_password для аутентификации на основе ACL для Redis Sentinel. Если указан только пароль, соединение с Redis Sentinel будет аутентифицировано с помощью традиционной аутентификации requirepass.
sentinel_password
Пароль для подключения к Redis Sentinel. Если указан с именем sentinel_username, Authelia настраивает аутентификацию на Redis Sentinel с помощью аутентификации на основе ACL. В противном случае используется аутентификация по requirepass.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов, и пароль пользователя был изменен на это значение.
nodes
Список узлов redis sentinel для балансировки нагрузки. Этот список добавляется к хосту в разделе redis выше. Необходимо определить либо хост redis, либо один сентинел-узел redis. Хост redis должен быть узлом redis sentinel, а не обычным узлом. Отдельные узлы redis определяются с помощью команд redis sentinel.
- host: redis-sentinel-0
port: 26379
host
Хост этого узла redis sentinel.
port
Порт этого узла redis sentinel.
route_by_latency
Приоритет отдается узлам redis sentinel с низкой задержкой, если установлено значение true.
route_randomly
Случайным образом выбирает узлы redis sentinel, если установлено значение true.
3.8 - Storage Хранилище данных
Storage (хранилище) в Authelia — это централизованное место для хранения критически важных данных, необходимых для работы системы.
Какие данные хранятся?
| Тип данных | Примеры | Важность |
|---|---|---|
| Настройки пользователей | Выбранная тема, язык интерфейса | Низкая |
| 2FA-данные | TOTP-секреты, ключи WebAuthn | Высокая |
| Журналы аутентификации | Входы, попытки сброса пароля | Средняя |
| OAuth2-данные | Токены, authorization codes | Высокая |
| Сессии (если не используется Redis) | Активные сеансы пользователей | Высокая |
Поддерживаемые хранилища
Authelia работает с такими базами данных:
| Хранилище | Когда выбирать | Особенности |
|---|---|---|
| PostgreSQL | Production-среда | Высокая производительность, поддержка сложных запросов |
| MySQL/MariaDB | Уже есть инфраструктура MySQL | Совместимость с большинством хостингов |
| SQLite | Тестирование/разработка | Не требует сервера, но не для продакшена |
| Redis (только для сессий) | Высоконагруженные системы | Только key-value, без SQL |
Конфигурация
storage:
encryption_key: 'a_very_important_secret'
local: {}
mysql: {}
postgres: {}
Опции
encryption_key
Ключ шифрования, используемый для шифрования данных в базе данных. Мы шифруем данные, создавая контрольную сумму sha256 из указанного значения, и используем ее для шифрования данных с помощью 256-битного алгоритма AES-GCM.
Минимальная длина этого ключа - 20 символов.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов.
3.8.1 - PostgreSQL
PostgreSQL в Authelia выполняет роль основного хранилища данных, обеспечивая безопасное сохранение критически важной информации.
Какие данные хранятся в PostgreSQL?
| Тип данных | Примеры | Важность |
|---|---|---|
| Учетные данные 2FA | TOTP-секреты, ключи WebAuthn | 🔥 Высокая |
| Журналы аутентификации | Входы, попытки сброса пароля | 🔍 Средняя |
| Настройки пользователей | Язык, тема интерфейса | 📌 Низкая |
| OAuth2-токены | Access/refresh tokens | 🔥 Высокая |
| Данные сессий (если не используется Redis) | Активные сеансы | ⚡ Высокая |
Почему именно PostgreSQL?
Преимущества перед другими СУБД
| Критерий | PostgreSQL | MySQL/SQLite | Redis |
|---|---|---|---|
| Поддержка сложных запросов | ✅ Да | ❌ Ограничена | ❌ Нет |
| Надежность транзакций | ✅ ACID | ✅ ACID | ❌ Key-Value |
| Производительность | ⚡ Высокая | ⚡ Средняя | ⚡ Максимальная |
| Масштабируемость | ✅ Горизонтальная | ✅ Вертикальная | ✅ Кластеры |
| Безопасность | 🔒 Row-Level Security | 🔒 Базовые права | 🔒 Нет |
Пример конфигурации
Добавьте в configuration.yml:
storage:
encryption_key: 'a_very_important_secret'
postgres:
address: 'tcp://127.0.0.1:5432'
servers: []
database: 'authelia'
schema: 'public'
username: 'authelia'
password: 'mypassword'
timeout: '5s'
tls:
server_name: 'postgres.rabrain.ru'
skip_verify: false
minimum_version: 'TLS1.2'
maximum_version: 'TLS1.3'
certificate_chain: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
private_key: |
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY-----
Ключевые сценарии использования
Хранение секретов 2FA
- TOTP: Секретные ключи (totp_secrets таблица)
- WebAuthn: Публичные ключи устройств (webauthn_credentials)
-- Пример данных в PostgreSQL:
SELECT * FROM totp_secrets WHERE username = 'user@example.com';
Аудит безопасности
- Логи входов (authentication_logs)
- Попытки сброса пароля (identity_verification)
Масштабируемость
- Поддержка репликации для отказоустойчивости
- Возможность распределенной установки с несколькими нодами Authelia
Опции
encryption_key
Ключ шифрования, используемый для шифрования данных в базе данных. Мы шифруем данные, создавая контрольную сумму sha256 из указанного значения, и используем ее для шифрования данных с помощью 256-битного алгоритма AES-GCM.
Минимальная длина этого ключа - 20 символов.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов.
address
Настраивает адрес для сервера PostgreSQL. Сам адрес является коннектором, а схема должна быть либо схемой unix, либо одной из схем tcp.
storage:
postgres:
address: 'tcp://127.0.0.1:5432'
storage:
postgres:
address: 'tcp://[fd00:1111:2222:3333::1]:5432'
storage:
postgres:
address: 'unix:///var/run/postgres.sock'
servers
Здесь указывается список дополнительных резервных экземпляров PostgreSQL, которые будут использоваться в случае возникновения проблем с основным экземпляром, настроенным с помощью опций address и tls.
У каждого экземпляра сервера есть опции address и tls, которые имеют одинаковые требования и влияние, а также одинаковый синтаксис конфигурации. Это означает, что все остальные настройки, включая базу данных, схему, имя пользователя и пароль, должны быть такими же, как у основного экземпляра, и полностью реплицироваться.
storage:
postgres:
address: 'tcp://postgres1:5432'
tls:
server_name: 'postgres1.local'
servers:
- address: 'tcp://postgres2:5432'
tls:
server_name: 'postgres2.local'
- address: 'tcp://postgres3:5432'
tls:
server_name: 'postgres3.local'
database
Имя базы данных на сервере баз данных, к которой назначенный пользователь имеет доступ для работы с Authelia.
schema
Имя схемы базы данных, используемой на сервере базы данных, к которому назначенный пользователь имеет доступ для Authelia. По умолчанию это публичная схема.
username
Имя пользователя в паре с паролем, используемые для подключения к базе данных.
password
Пароль, связанный с именем пользователя, используемым для подключения к базе данных.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов, и пароль пользователя был изменен на это значение.
timeout
Таймаут соединения SQL.
tls
Если этот параметр определен, он включает соединение через сокет TLS и дополнительно управляет параметрами проверки TLS-соединения для сервера PostgreSQL.
По умолчанию Authelia использует системный сертификат доверия для проверки TLS-соединений, а глобальная опция certificates_directory может быть использована для дополнения этого параметра.
3.8.2 - SQLite3
Если у вас нет SQL-сервера, вы можете использовать SQLite. Однако учтите, что при такой настройке вы не сможете запустить несколько экземпляров Authelia, поскольку база данных будет находиться в локальном файле.
Использование этого провайдера хранилища делает Authelia доступной для состояния. В сценариях высокой доступности важно использовать один из других провайдеров, и мы настоятельно рекомендуем использовать его в производственных средах, но это потребует от вас установки внешней базы данных, например PostgreSQL.
Пример конфигурации
Добавьте в configuration.yml:
storage:
encryption_key: 'a_very_important_secret'
local:
path: '/config/db.sqlite3'
Опции
encryption_key
Ключ шифрования, используемый для шифрования данных в базе данных. Мы шифруем данные, создавая контрольную сумму sha256 из указанного значения, и используем ее для шифрования данных с помощью 256-битного алгоритма AES-GCM.
Минимальная длина этого ключа - 20 символов.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов.
path
Путь, по которому будет храниться файл базы данных SQLite3. Он будет создан, если файл не существует.
3.8.3 - MySQL
MySQL в Authelia выполняет роль основного хранилища данных, обеспечивая безопасное сохранение критически важной информации.
Сравнение с PostgreSQL?
Преимущества перед другими СУБД
| Критерий | PostgreSQL | MySQL/SQLite | Redis |
|---|---|---|---|
| Поддержка сложных запросов | ✅ Да | ❌ Ограничена | ❌ Нет |
| Надежность транзакций | ✅ ACID | ✅ ACID | ❌ Key-Value |
| Производительность | ⚡ Высокая | ⚡ Средняя | ⚡ Максимальная |
| Масштабируемость | ✅ Горизонтальная | ✅ Вертикальная | ✅ Кластеры |
| Безопасность | 🔒 Row-Level Security | 🔒 Базовые права | 🔒 Нет |
Пример конфигурации
Добавьте в configuration.yml:
storage:
encryption_key: 'a_very_important_secret'
mysql:
address: 'tcp://127.0.0.1:3306'
database: 'authelia'
username: 'authelia'
password: 'mypassword'
timeout: '5s'
tls:
server_name: 'mysql.rabrain.ru'
skip_verify: false
minimum_version: 'TLS1.2'
maximum_version: 'TLS1.3'
certificate_chain: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
private_key: |
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY-----
Опции
encryption_key
Ключ шифрования, используемый для шифрования данных в базе данных. Мы шифруем данные, создавая контрольную сумму sha256 из указанного значения, и используем ее для шифрования данных с помощью 256-битного алгоритма AES-GCM.
Минимальная длина этого ключа - 20 символов.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов.
address
Настраивает адрес для сервера PostgreSQL. Сам адрес является коннектором, а схема должна быть либо схемой unix, либо одной из схем tcp.
storage:
mysql:
address: 'tcp://127.0.0.1:3306'
storage:
mysql:
address: 'tcp://[fd00:1111:2222:3333::1]:3306'
storage:
mysql:
address: 'unix:///var/run/mysqld.sock'
database
Имя базы данных на сервере баз данных, к которой назначенный пользователь имеет доступ для работы с Authelia.
username
Имя пользователя в паре с паролем, используемые для подключения к базе данных.
password
Пароль, связанный с именем пользователя, используемым для подключения к базе данных.
Настоятельно рекомендуется, чтобы это была случайная буквенно-цифровая строка из 64 или более символов, и пароль пользователя был изменен на это значение.
timeout
Таймаут соединения SQL.
tls
Если этот параметр определен, он включает соединение через сокет TLS и дополнительно управляет параметрами проверки TLS-соединения для сервера MySQL.
По умолчанию Authelia использует системный сертификат доверия для проверки TLS-соединений, а глобальная опция certificates_directory может быть использована для дополнения этого параметра.
3.9 - Notifications (Уведомления)
Функция Notifications (Уведомления) в Authelia отвечает за отправку сообщений пользователям для подтверждения их личности и критически важных действий. Это ключевой компонент безопасности, обеспечивающий защиту от несанкционированного доступа.
Основные цели
- Верификация пользователя: Подтверждение email/телефона при регистрации или сбросе пароля.
- Безопасность: Уведомления о подозрительных действиях (например, вход с нового устройства).
- Восстановление доступа: Отправка временных кодов для сброса пароля или 2FA.
Типы уведомлений
| Тип уведомления | Когда отправляется | Метод отправки |
|---|---|---|
| Сброс пароля | При запросе восстановления пароля | Email/SMS |
| Подтверждение 2FA | При добавлении нового устройства | Email/Push |
| Подозрительный вход | При входе с нового IP/устройства | Email/SMS |
| Identity Verification | Для подтверждения личности | Email/SMS |
Конфигурация
notifier:
disable_startup_check: false
template_path: ''
filesystem: {}
smtp: {}
Опции
disable_startup_check
В уведомлении предусмотрена проверка запуска, которая проверяет правильность конфигурации указанного провайдера и возможность отправки писем. Эту проверку можно отключить с помощью опции disable_startup_check.
template_path
Этот параметр позволяет администратору указать путь к каталогу, в котором будут находиться пользовательские шаблоны уведомлений.
3.9.1 - SMTP
SMTP (Simple Mail Transfer Protocol) в Authelia используется для отправки email-уведомлений пользователям.
Назначение SMTP
Верификации пользователей
- Отправка ссылок для сброса пароля
- Подтверждение email при регистрации
- Коды для двухфакторной аутентификации (2FA)
Безопасности
- Уведомления о подозрительных действиях (например, вход с нового устройства)
- Предупреждения о попытках взлома
Работоспособности функций
- Без SMTP не будут работать:
- Сброс пароля (/reset-password)
- Регистрация новых пользователей
- Уведомления безопасности
Конфигурация
notifier:
disable_startup_check: false
smtp:
address: 'smtp://127.0.0.1:25'
timeout: '5s'
username: 'test'
password: 'password'
sender: "Authelia <admin@rabrain.ru>"
identifier: 'localhost'
subject: "[Authelia] {title}"
startup_check_address: 'test@rabrain.ru'
disable_require_tls: false
disable_starttls: false
disable_html_emails: false
tls:
server_name: 'smtp.rabrain.ru'
skip_verify: false
minimum_version: 'TLS1.2'
maximum_version: 'TLS1.3'
certificate_chain: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
private_key: |
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY-----
Опции
address
Настройка адреса для SMTP-сервера. Сам адрес является коннектором, а схема должна быть smtp, submission или submissions. Единственное различие между этими схемами заключается в портах по умолчанию, а для отправки требуется транспорт TLS в соответствии с мерами безопасности портов SMTP, в то время как отправка и smtp используют стандартный транспорт TCP и обычно применяют StartTLS.
notifier:
smtp:
address: 'smtp://127.0.0.1:25'
notifier:
smtp:
address: 'submissions://[fd00:1111:2222:3333::1]:465'
timeout
Таймаут соединения SMTP.
username
Имя пользователя, отправляемое для аутентификации на SMTP-сервере. В паре с паролем.
password
Пароль в паре с именем пользователя, отправляемый для аутентификации на SMTP-сервере.
sender
Адрес отправителя используется для создания SMTP-команды MAIL FROM и добавления заголовка FROM. Этот адрес должен быть в формате RFC5322. Это означает, что он должен иметь один из двух форматов:
- jsmith@domain.com
- John Smith jsmith@domain.com
Команда MAIL FROM, отправляемая SMTP-серверам, не будет включать часть имени, она задается только в FROM в соответствии со спецификациями.
identifier
Имя, которое нужно отправить SMTP-серверу в качестве идентификатора с помощью команды HELO/EHLO. Некоторые SMTP-провайдеры, такие как Google Mail, отклоняют сообщение, если это localhost.
subject
Это тема, которую Authelia будет использовать в электронном письме. В настоящее время она имеет единственный заполнитель {title}, который должен быть включен во все электронные письма, поскольку это внутренний дескриптор содержимого письма.
startup_check_address
При запуске Authelia проверяет действительность SMTP-сервера, одна из проверок требует, чтобы мы спросили SMTP-сервер, может ли он отправить письмо от нас на определенный адрес, и это тот самый адрес. На самом деле никаких писем при этом не отправляется. Можно оставить все как есть, но вы можете настроить это, если у вас возникнут проблемы или вы захотите.
disable_require_tls
В целях безопасности настройки по умолчанию для Authelia требуют, чтобы SMTP-соединение было зашифровано с помощью TLS. Дополнительные сведения см. в разделе Безопасность. Эта опция отключает данную меру (не рекомендуется).
disable_starttls
Некоторые SMTP-серверы игнорируют спецификации SMTP и утверждают, что поддерживают STARTTLS, хотя на самом деле это не так. По соображениям безопасности Authelia отказывается отправлять сообщения на такие серверы. Данная опция отключает эту меру и включается на ВАШ собственный страх и риск.
disable_html_emails
Эта настройка полностью отключает HTML-форматирование писем и отправляет только текстовые сообщения. По умолчанию Authelia отправляет смешанные письма, содержащие как HTML, так и текст, поэтому эта опция редко бывает необходима.
tls
Если эта опция определена, она управляет параметрами проверки TLS-соединения для SMTP-сервера.
По умолчанию Authelia использует системное доверие к сертификатам для проверки TLS-соединений, а глобальная опция certificates_directory может быть использована для дополнения этого параметра.
Using Gmail
notifier:
smtp:
address: 'submission://smtp.gmail.com:587'
username: 'myaccount@gmail.com'
# Password can also be set using a secret: https://www.authelia.com/configuration/methods/secrets/
password: 'yourapppassword'
sender: 'admin@rabrain.ru'
3.9.2 - File system
Режим File System (файловая система) в разделе уведомлений (notifications) Authelia — это тестовый метод, который записывает уведомления (например, письма для сброса пароля) в файлы вместо реальной отправки.
Для чего используется?
- Тестирование шаблонов писем: Проверка внешнего вида email без настройки SMTP.
- Отладка логики уведомлений: Анализ содержимого сообщений (токены, ссылки).
- Локальная разработка: Когда нет доступа к SMTP-серверу.
Конфигурация
notifier:
disable_startup_check: false
filesystem:
filename: '/config/notification.txt'
Опции
filename
Файл, в который нужно добавить текст письма. Если он не существует, он будет создан.
3.10 - Telemetry (телеметрия)
Telemetry (телеметрия) в Authelia — это система сбора метрик производительности и состояния системы для мониторинга работы сервера аутентификации. Она помогает администраторам выявлять проблемы и оптимизировать работу Authelia.
Какие данные собираются?
Authelia хранит метрики только в оперативной памяти (не отправляет их автоматически наружу).
Примеры данных:
| Метрика | Описание | Пример значения |
|---|---|---|
| authelia_requests_total | Общее количество запросов | 1523 |
| authelia_2fa_attempts | Попыток 2FA (успешные/неудачные) | success: 120, failed: 5 |
| authelia_session_duration | Длительность сессий пользователей | avg: 5m |
| authelia_storage_queries | Запросы к базе данных | postgres: 42/s |
Как это работает?
- Данные собираются в реальном времени (например, при каждом входе пользователя).
- Хранятся в памяти до перезагрузки Authelia.
- Доступны для выгрузки через Prometheus или ручной запрос.
Конфигурация
telemetry:
metrics:
enabled: false
address: 'tcp://:9959/metrics'
buffers:
read: 4096
write: 4096
timeouts:
read: '6s'
write: '6s'
idle: '30s'
Опции
enabled
Определяет, включен ли Prometheus HTTP Metrics Exporter.
address
Настраивает адрес слушателя для HTTP-сервера Prometheus Metrics Exporter. Адрес сам по себе является слушателем, а схема должна быть либо схемой unix, либо одной из схем tcp.
buffers
Настройка буферов сервера.
timeouts
Настройка тайм-аутов сервера.
3.11 - Определения
Раздел определений управляет несколькими определениями, которые могут быть повторно использованы в других областях конфигурации вместо того, чтобы повторять значения в других местах.
3.11.1 - Network
Раздел Network в конфигурации Authelia отвечает за сетевые параметры сервера, определяя, как Authelia взаимодействует с клиентами, прокси-серверами и другими компонентами системы. Это критически важные настройки для безопасности и производительности.
Основные функции Network-настроек
| Настройка | За что отвечает | Пример значения |
|---|---|---|
| Прослушивание интерфейсов | На каких IP и портах доступен сервер | 0.0.0.0:9091 |
| Ограничение доверенных прокси | Какие IP могут передавать заголовки аутентификации | 192.168.1.0/24 |
| Таймауты | Защита от DDoS и медленных соединений | read: 10s |
| TLS/SSL | Шифрование соединений | Сертификаты Let’s Encrypt |
Конфигурация
definitions:
network:
network_name:
- '192.168.1.0/24'
- '192.168.2.20'
- '2001:db8::/32'
- '2001:db8:1234:5678::1'
Эти определения используются в качестве сетей управления доступом и сетей политики авторизации OpenID Connect 1.0.
Опции
key
Ключ - это имя политики. В приведенном выше примере ключом является network_name, и это значение должно использоваться в других областях конфигурации для ссылки на нее.
value
Значения, представляющие CIDR-нотацию IP-адресов, к которым применяется данное определение. В примере значение представляет собой список, содержащий 192.168.1.0/24, 192.168.2.20, 2001:db8::/32 и 2001:db8:1234:5678::1.
Нотация CIDR (например, 192.168.1.0/24) представляет собой диапазон IP-адресов. Число после косой черты указывает, сколько бит используется для сетевой части. Например, /24 означает, что первые 24 бита фиксированы, а последние 8 бит могут изменяться (что дает 256 возможных адресов). Один IP-адрес, например 192.168.2.20, может быть записан как есть или с /32.
3.11.2 - User Attributes
Раздел Атрибуты пользователя позволяет определить пользовательские атрибуты для пользователей с помощью языка Common Expression Language (CEL). Эти атрибуты могут быть использованы в текущий момент времени для Усовершенствования утверждений OpenID Connect 1.0 с динамическими значениями
Конфигурация
definitions:
user_attributes:
# Boolean attribute example
is_admin:
expression: '"admin" in groups'
# String attribute example
department:
expression: 'groups[0]'
# Number attribute example
access_level:
expression: '"admin" in groups ? 10 : 5'
Опции
В этом разделе описаны отдельные параметры конфигурации. В настоящее время эти определения атрибутов используются в провайдере OpenID Connect 1.0.
Имя ключа - это имя результирующего атрибута. Важно отметить, что это имя атрибута не должно конфликтовать с дополнительными атрибутами, определенными в бэкенде аутентификации, или с общими атрибутами, которые мы определили.
В приведенном выше примере добавлены следующие атрибуты:
- is_admin
- department
- access_level
expression
Выражение Common Expression Language для этого атрибута.
3.12 - Разное
Раздел в который вошло все остальное, которое не вошло в тематические разделы.
Конфигурация
certificates_directory: '/config/certs/'
default_redirection_url: 'https://home.example.com:8080/'
theme: 'light'
Опции
certificates_directory
По умолчанию Authelia использует системное хранилище сертификатов для проверки сертификатов TLS, но вы можете расширить его с помощью этой опции, которая формирует основу для доверия к TLS-соединениям в Authelia. В большинстве случаев, если не во всех TLS-соединениях, TLS-сертификат сервера проверяется с помощью этого расширенного хранилища доверия сертификатов.
Эта опция задает путь к каталогу, который может содержать один или несколько сертификатов, закодированных в формате X.509 PEM. Сами сертификаты должны иметь расширение .pem, .crt или .cer.
Эти сертификаты могут быть либо открытым ключом ЦС, который доверяет данному сертификату и любому подписанному им сертификату, либо отдельным сертификатом листа.
default_redirection_url
URL перенаправления по умолчанию - это URL, на который перенаправляются пользователи, когда Authelia не может определить целевой URL, на который направлялся пользователь.
В обычном процессе аутентификации пользователь пытается зайти на веб-сайт, и его перенаправляют на портал для входа в систему, чтобы пройти аутентификацию. Поскольку пользователь изначально нацелился на веб-сайт, портал знает, куда он направлялся, и может перенаправить его после процесса аутентификации. Однако, когда пользователь посещает портал регистрации напрямую, портал считает, что целевой веб-сайт - это портал. В этом случае, если настроен URL-адрес перенаправления по умолчанию, пользователь будет перенаправлен на этот URL-адрес. Если он не задан, пользователь не будет перенаправлен после аутентификации.
default_2fa_method
Устанавливает метод второго фактора по умолчанию для пользователей. Это должно быть пустое значение или один из включенных методов. Для новых пользователей по умолчанию будет выбран этот метод. Кроме того, если для пользователя был выбран метод webauthn, а у него был выбран метод totp, и метод totp был отключен в конфигурации, метод пользователя будет автоматически обновлен до метода webauthn.
Варианты:
- totp
- webauthn
- mobile_push
theme
В настоящее время для Authelia доступно 3 темы:
- light (по умолчанию)
- darck
- gray
Чтобы включить автоматическое переключение между темами, вы можете установить для темы значение auto. Тема будет установлена на темную или светлую в зависимости от системных предпочтений пользователя, которые определяются с помощью медиа-запросов.
3.12.1 - Server в Authelia
Раздел Server в конфигурации Authelia определяет параметры работы сервера, включая сетевые настройки, безопасность и управление ресурсами. Это основа для развертывания Authelia в production-среде.
Ключевые функции настроек Server
| Настройка | Описание | Важность |
|---|---|---|
| address | Интерфейс и порт прослушивания | 🔥 Критично |
| tls | Настройки HTTPS (сертификаты) | 🔥 Критично |
| headers | Безопасность HTTP-заголовков | 🔐 Высокая |
| buffers | Оптимизация производительности | ⚡ Средняя |
| timeouts | Защита от DDoS/подвешенных сессий | 🛡️ Высокая |
| endpoints | Управление служебными API | 🔧 Опционально |
Конфигурация
server:
address: 'tcp://:9091/'
disable_healthcheck: false
tls:
key: ''
certificate: ''
client_certificates: []
headers:
csp_template: ''
buffers:
read: 4096
write: 4096
timeouts:
read: '6s'
write: '6s'
idle: '30s'
endpoints:
enable_pprof: false
enable_expvars: false
authz: {} ## See the dedicated "Server Authz Endpoints" configuration guide.
rate_limits: {} ## See the dedicated "Server Endpoint Rate Limits" configuration guide.
Детальный разбор параметров
Базовые настройки (address, disable_healthcheck)
server:
address: 'tcp://0.0.0.0:9091' # Слушать все интерфейсы на порту 9091
disable_healthcheck: false # Включить эндпоинт /healthcheck
Зачем:
- address: Определяет, откуда можно подключиться к Authelia.
- healthcheck: Нужен для мониторинга работы (Kubernetes, Docker Swarm).
Настройки TLS (HTTPS)
tls:
key: /etc/ssl/private/key.pem # Приватный ключ
certificate: /etc/ssl/certs/cert.pem # Сертификат
client_certificates: [] # mTLS (опционально)
Зачем:
- Без TLS пароли и сессии передаются в открытом виде.
- Важно: В production всегда используйте TLS (например, с Let’s Encrypt).
Безопасность заголовков (headers)
headers:
csp_template: "default-src 'self'" # Content Security Policy
Зачем:
- Защита от XSS-атак через CSP.
- Рекомендуемый шаблон для strict-режима:
csp_template: "default-src 'none'; script-src 'self'; style-src 'self'; font-src 'self'; img-src 'self' data:; connect-src 'self'"
Оптимизация (buffers, timeouts)
buffers:
read: 4096 # Размер буфера чтения (байт)
write: 4096 # Размер буфера записи
timeouts:
read: '6s' # Таймаут чтения запроса
write: '6s' # Таймаут отправки ответа
idle: '30s' # Таймаут неактивного соединения
####Зачем:
- buffers: Баланс между потреблением RAM и производительностью.
- timeouts: Защита от Slowloris-атак и “подвешенных” сессий.
Служебные эндпоинты (endpoints)
endpoints:
enable_pprof: false # Отключить debug-эндпоинты (/debug/pprof)
enable_expvars: false # Отключить метрики runtime (/debug/vars)
authz: {} # Настройки авторизации для API
rate_limits: {} # Лимиты запросов к API
Зачем:
- pprof/expvars: Полезны для отладки, но опасны в production.
- rate_limits: Защита API от брутфорса.
Пример production-конфигурации
server:
address: 'tcp://127.0.0.1:9091' # Только локальный доступ + Nginx/Traefik
tls:
certificate: /etc/letsencrypt/live/example.com/fullchain.pem
key: /etc/letsencrypt/live/example.com/privkey.pem
headers:
csp_template: "default-src 'self'; script-src 'none'"
timeouts:
read: '10s'
write: '15s'
idle: '1m'
Частые ошибки и решения
| Проблема | Решение |
|---|---|
| Authelia не запускается на порту | Проверьте address и отсутствие конфликта портов (netstat -tulpn) |
| Ошибки HTTPS (ERR_SSL_PROTOCOL_ERROR) | Убедитесь, что сертификаты не повреждены и имеют права 400 |
| Медленные ответы | Увеличьте buffers (например, до 8192) |
| Атаки на /debug/pprof | Всегда enable_pprof: false в production |
Интеграция с обратным прокси (Nginx/Traefik)
Для максимальной безопасности:
Настройте Authelia на 127.0.0.1:
address: 'tcp://127.0.0.1:9091'
В Nginx добавьте проксирование:
location /authelia {
proxy_pass http://127.0.0.1:9091;
proxy_set_header X-Real-IP $remote_addr;
}
Проверка конфигурации
authelia validate-config --config /etc/authelia/configuration.yml
Ожидаемый вывод:
Configuration parsed and validated successfully!
3.12.2 - Server Authz Endpoints
В Authelia параметр Server Authz Endpoints (или server.authz.endpoints) в конфигурации отвечает за настройку авторизационных (authorization) эндпоинтов, которые определяют, какие HTTP-запросы могут быть обработаны и какие политики применяются к ним.
Назначение Server Authz Endpoints
Этот раздел конфигурации позволяет контролировать:
- Какие HTTP-методы разрешены (GET, POST, PUT, DELETE и т. д.).
- Какие URL-пути защищены (например, /api, /admin).
- Какие политики применяются (например, one_factor, two_factor, bypass, deny).
Конфигурация
server:
endpoints:
authz:
forward-auth:
implementation: 'ForwardAuth'
authn_strategies:
- name: 'HeaderAuthorization'
schemes:
- 'Basic'
scheme_basic_cache_lifespan: 0
- name: 'CookieSession'
ext-authz:
implementation: 'ExtAuthz'
authn_strategies:
- name: 'HeaderAuthorization'
schemes:
- 'Basic'
scheme_basic_cache_lifespan: 0
- name: 'CookieSession'
auth-request:
implementation: 'AuthRequest'
authn_strategies:
- name: 'HeaderAuthorization'
schemes:
- 'Basic'
scheme_basic_cache_lifespan: 0
- name: 'CookieSession'
legacy:
implementation: 'Legacy'
Опции
name
Первый уровень под директивой authz - это имя конечной точки. В примере это имена forward-auth, ext-authz, auth-request и legacy.
Имя коррелирует с путем к конечной точке. Все конечные точки начинаются с /api/authz/ и заканчиваются именем. В примере конечная точка forward-auth имеет полный путь /api/authz/forward-auth.
Допустимыми символами для имени являются буквенно-цифровые символы, а также -, _ и /. Они ДОЛЖНЫ начинаться и заканчиваться буквенно-цифровым символом.
implementation
Базовая реализация для конечной точки. Допустимые значения с учетом регистра: ForwardAuth, ExtAuthz, AuthRequest и Legacy.
authn_strategies
Список стратегий аутентификации и параметров их конфигурации. Эти стратегии расположены по порядку, и используется первая из них, оказавшаяся успешной. В случае отказа, кроме отсутствия в запросе информации, достаточной для выполнения стратегии, аутентификация немедленно прекращается, в противном случае выполняется попытка использования следующей стратегии из списка.
name
Имя стратегии. Допустимые значения с учетом регистра: CookieSession, HeaderAuthorization, HeaderProxyAuthorization, HeaderAuthRequestProxyAuthorization и HeaderLegacy.
schemes
Список схем, разрешенных для этой конечной точки. Варианты: Basic и Bearer. Эта опция применима только к стратегиям HeaderAuthorization, HeaderProxyAuthorization и HeaderAuthRequestProxyAuthorization и недоступна для устаревшей конечной точки, которая использует только Basic.
scheme_basic_cache_lifespan
Время жизни для кэширования комбинаций имени пользователя и пароля при использовании схемы Basic. Эта опция позволяет использовать кэширование, которое по умолчанию полностью отключено. Эта опция должна использоваться только при настройке схемы Basic, и, как и все новые опции, не может использоваться при реализации Legacy.
3.12.3 - Server Endpoint Rate Limits
Authelia накладывает ограничения скорости по умолчанию на определенные конечные точки, что позволяет предотвратить потребление клиентами или злоумышленниками слишком большого количества ресурсов или использование брутфорса для потенциального нарушения безопасности.
Конфигурация
server:
endpoints:
rate_limits:
reset_password_start:
enable: true
buckets:
- period: '10 minutes'
requests: 5
- period: '15 minutes'
requests: 10
- period: '30 minutes'
requests: 15
reset_password_finish:
enable: true
buckets:
- period: '1 minute'
requests: 10
- period: '2 minutes'
requests: 15
second_factor_totp:
enable: true
buckets:
- period: '1 minute'
requests: 30
- period: '2 minutes'
requests: 40
- period: '10 minutes'
requests: 50
second_factor_duo:
enable: true
buckets:
- period: '1 minute'
requests: 10
- period: '2 minutes'
requests: 15
session_elevation_start:
enable: true
buckets:
- period: '5 minutes'
requests: 3
- period: '10 minutes'
requests: 5
- period: '1 hour'
requests: 15
session_elevation_finish:
enable: true
buckets:
- period: '10 minutes'
requests: 3
- period: '20 minutes'
requests: 5
- period: '1 hour'
requests: 15
Опции
enable
Включает заданную конфигурацию ограничения скорости. По умолчанию они включены.
buckets
Список отдельных buckets, которые необходимо рассмотреть для каждого запроса.
period
Настраивает период времени, на который распространяется действие токенизированного bucket.
requests
Настраивает количество запросов, к которым применяется токенизированный бакет.
reset_password_start
Настраивает ограничитель скорости, который применяется к конечной точке, инициализирующей поток сброса пароля.
reset_password_finish
Настраивает ограничитель скорости, который применяется к конечным точкам, потребляющим токены для потока сброса пароля.
second_factor_totp
Настраивает ограничитель скорости, который применяется к представлениям кода конечной точки TOTP для потока второго фактора.
second_factor_duo
Настраивает ограничитель скорости, применяемый к конечной точке Duo / Mobile Push, которая инициализирует поток авторизации приложения для потока второго фактора.
session_elevation_start
Настраивает ограничитель скорости, применяемый к конечной точке Elevated Session, которая инициализирует генерацию кода и уведомление для потока elevated session.
session_elevation_finish
Настраивает ограничитель скорости, применяемый к конечной точке Elevated Session, которая потребляет код для потока повышенной сессии.
4 - Bootstrap
Описание Bootstrap
Официальная документация Bootstrap
https://getbootstrap.com/docs/5.3/getting-started/introduction/
Шпаргалка по Bootstrap
4.1 - Работа с цветами в Bootstrap
Описание Bootstrap
Названия цветов в HUGO
.text-primary
.text-primary-emphasis
.text-secondary
.text-secondary-emphasis
.text-success
.text-success-emphasis
.text-danger
.text-danger-emphasis
.text-warning
.text-warning-emphasis
.text-info
.text-info-emphasis
.text-light
.text-light-emphasis
.text-dark
.text-dark-emphasis
.text-body
.text-body-emphasis
.text-body-secondary
.text-body-tertiary
.text-black
.text-white
.text-black-50
.text-white-50
<p class="text-primary">.text-primary</p>
<p class="text-primary-emphasis">.text-primary-emphasis</p>
<p class="text-secondary">.text-secondary</p>
<p class="text-secondary-emphasis">.text-secondary-emphasis</p>
<p class="text-success">.text-success</p>
<p class="text-success-emphasis">.text-success-emphasis</p>
<p class="text-danger">.text-danger</p>
<p class="text-danger-emphasis">.text-danger-emphasis</p>
<p class="text-warning bg-dark">.text-warning</p>
<p class="text-warning-emphasis">.text-warning-emphasis</p>
<p class="text-info bg-dark">.text-info</p>
<p class="text-info-emphasis">.text-info-emphasis</p>
<p class="text-light bg-dark">.text-light</p>
<p class="text-light-emphasis">.text-light-emphasis</p>
<p class="text-dark bg-white">.text-dark</p>
<p class="text-dark-emphasis">.text-dark-emphasis</p>
<p class="text-body">.text-body</p>
<p class="text-body-emphasis">.text-body-emphasis</p>
<p class="text-body-secondary">.text-body-secondary</p>
<p class="text-body-tertiary">.text-body-tertiary</p>
<p class="text-black bg-white">.text-black</p>
<p class="text-white bg-dark">.text-white</p>
<p class="text-black-50 bg-white">.text-black-50</p>
<p class="text-white-50 bg-dark">.text-white-50</p>
$blue: #0d6efd;
$indigo: #6610f2;
$purple: #6f42c1;
$pink: #d63384;
$red: #dc3545;
$orange: #fd7e14;
$yellow: #ffc107;
$green: #198754;
$teal: #20c997;
$cyan: #0dcaf0;
$primary: $blue;
$secondary: $gray-600;
$success: $green;
$info: $cyan;
$warning: $yellow;
$danger: $red;
$light: $gray-100;
$dark: $gray-900;
$white: #fff;
$gray-100: #f8f9fa;
$gray-200: #e9ecef;
$gray-300: #dee2e6;
$gray-400: #ced4da;
$gray-500: #adb5bd;
$gray-600: #6c757d;
$gray-700: #495057;
$gray-800: #343a40;
$gray-900: #212529;
$black: #000;
background
.bg-primary
.bg-primary-subtle
.bg-secondary
.bg-secondary-subtle
.bg-success
.bg-success-subtle
.bg-danger
.bg-danger-subtle
.bg-warning
.bg-warning-subtle
.bg-info
.bg-info-subtle
.bg-light
.bg-light-subtle
.bg-dark
.bg-dark-subtle
.bg-body-secondary
.bg-body-tertiary
.bg-body
.bg-black
.bg-white
.bg-transparent
<div class="p-3 mb-2 bg-primary text-white">.bg-primary</div>
<div class="p-3 mb-2 bg-primary-subtle text-primary-emphasis">.bg-primary-subtle</div>
<div class="p-3 mb-2 bg-secondary text-white">.bg-secondary</div>
<div class="p-3 mb-2 bg-secondary-subtle text-secondary-emphasis">.bg-secondary-subtle</div>
<div class="p-3 mb-2 bg-success text-white">.bg-success</div>
<div class="p-3 mb-2 bg-success-subtle text-success-emphasis">.bg-success-subtle</div>
<div class="p-3 mb-2 bg-danger text-white">.bg-danger</div>
<div class="p-3 mb-2 bg-danger-subtle text-danger-emphasis">.bg-danger-subtle</div>
<div class="p-3 mb-2 bg-warning text-dark">.bg-warning</div>
<div class="p-3 mb-2 bg-warning-subtle text-warning-emphasis">.bg-warning-subtle</div>
<div class="p-3 mb-2 bg-info text-dark">.bg-info</div>
<div class="p-3 mb-2 bg-info-subtle text-info-emphasis">.bg-info-subtle</div>
<div class="p-3 mb-2 bg-light text-dark">.bg-light</div>
<div class="p-3 mb-2 bg-light-subtle text-light-emphasis">.bg-light-subtle</div>
<div class="p-3 mb-2 bg-dark text-white">.bg-dark</div>
<div class="p-3 mb-2 bg-dark-subtle text-dark-emphasis">.bg-dark-subtle</div>
<div class="p-3 mb-2 bg-body-secondary">.bg-body-secondary</div>
<div class="p-3 mb-2 bg-body-tertiary">.bg-body-tertiary</div>
<div class="p-3 mb-2 bg-body text-body">.bg-body</div>
<div class="p-3 mb-2 bg-black text-white">.bg-black</div>
<div class="p-3 mb-2 bg-white text-dark">.bg-white</div>
<div class="p-3 mb-2 bg-transparent text-body">.bg-transparent</div>
Прозрачность
This is default success background
This is 75% opacity success background
This is 50% opacity success background
This is 25% opacity success background
This is 10% opacity success background
<div class="bg-success p-2 text-white">This is default success background</div>
<div class="bg-success p-2 text-white bg-opacity-75">This is 75% opacity success background</div>
<div class="bg-success p-2 text-dark bg-opacity-50">This is 50% opacity success background</div>
<div class="bg-success p-2 text-dark bg-opacity-25">This is 25% opacity success background</div>
<div class="bg-success p-2 text-dark bg-opacity-10">This is 10% opacity success background</div>
4.2 - Mixins
Mixins в Bootstrap что это и как использовать
Mixins в Bootstrap: что это и как использовать
Mixins (примеси) — это функции в Sass (SCSS), которые позволяют повторно использовать куски кода в CSS. В Bootstrap они используются для генерации готовых стилей (например, сетки, кнопок, утилит) без дублирования кода.
1. Зачем нужны Mixins?
- Уменьшают повторение кода — один миксин может генерировать множество вариантов стилей.
- Делают код модульным — можно кастомизировать Bootstrap, не правя исходные файлы.
- Упрощают создание адаптивных стилей — например, для сетки или отступов.
2. Примеры миксинов в Bootstrap
Bootstrap предоставляет десятки миксинов. Вот основные категории:
① Grid Mixins (Сетка)
// Пример: Создание кастомной колонки
@include make-col(6); // Колонка на 50% ширины (6/12)
② Flexbox Mixins
// Пример: Flex-контейнер с центрированием
.my-component {
@include d-flex();
@include justify-content(center);
}
③ Spacing Mixins (Отступы)
// Пример: Добавление margin-top
.element {
@include margin-top(1rem);
}
④ Breakpoint Mixins (Адаптивность)
// Пример: Стили только для экранов ≥768px
@include media-breakpoint-up(md) {
.card { width: 50%; }
}
⑤ Button Mixins (Кнопки)
// Пример: Создание кастомной кнопки
.my-btn {
@include button-variant(
$background: #ff5722,
$border: #ff5722,
$hover-background: darken(#ff5722, 10%)
);
}
3. Как использовать миксины?
Шаг 1: Подключите Bootstrap SCSS
Убедитесь, что в вашем проекте есть исходные файлы Bootstrap (SCSS), а не только скомпилированный CSS.
Шаг 2: Создайте свой SCSS-файл
Например, custom.scss:
// Импорт Bootstrap
@import "bootstrap/scss/bootstrap";
// Ваши кастомные стили с миксинами
.my-custom-grid {
@include make-col-ready();
@include make-col(4); // Колонка на 33.3%
}
@include media-breakpoint-down(sm) {
.my-custom-grid {
@include make-col(12); // На мобильных — 100%
}
}
Шаг 3: Скомпилируйте SCSS
Используйте Sass-компилятор (например, через npm):
sass custom.scss custom.css
4. Популярные миксины Bootstrap
| Миксин | Описание | Пример |
|---|---|---|
make-container() | Создает контейнер | @include make-container(); |
make-col() | Генерирует колонку | @include make-col(6); |
border-radius() | Скругление углов | @include border-radius(0.5rem); |
transition() | Анимация перехода | @include transition(all 0.3s); |
box-shadow() | Тень | @include box-shadow(0 0 10px rgba(0,0,0,0.1)); |
5. Зачем это нужно?
- Кастомизация Bootstrap — если вам нужно что-то уникальное, но на основе логики Bootstrap.
- Оптимизация CSS — миксины помогают избежать дублирования кода.
- Адаптивность — легко создавать breakpoint-зависимые стили.
6. Где найти все миксины?
- Официальная документация
- Исходные файлы Bootstrap:
node_modules/bootstrap/scss/mixins/
Итог
Mixins в Bootstrap — это мощный инструмент для тех, кто работает с Sass. Они позволяют:
✅ Гибко настраивать компоненты.
✅ Создавать адаптивные стили.
✅ Держать код чистым и модульным.
Пример использования:
// Кастомная кнопка
.my-btn {
@include button-variant(
$background: #17a2b8,
$border: #17a2b8,
$hover-background: darken(#17a2b8, 10%)
);
@include border-radius(2rem);
}
4.3 - Bootstrap Flexbox
Bootstrap 5 Flexbox Управление Полная Таблица
Bootstrap 5 Flexbox Управление: Полная Таблица
Таблица с основными классами Bootstrap 5 для работы с Flexbox:
1. Основные Flex-контейнеры
| Класс | Описание | Пример |
|---|---|---|
.d-flex | Включает Flexbox | <div class="d-flex"> |
.d-inline-flex | Строчный Flex-контейнер | <span class="d-inline-flex"> |
.d-sm-flex | Адаптивный Flex (на экранах ≥576px) | <div class="d-sm-flex"> |
2. Направление осей (Flex Direction)
| Класс | Описание | CSS-аналог |
|---|---|---|
.flex-row | Горизонтальное (слева направо) | flex-direction: row |
.flex-row-reverse | Горизонтальное (справа налево) | flex-direction: row-reverse |
.flex-column | Вертикальное (сверху вниз) | flex-direction: column |
.flex-column-reverse | Вертикальное (снизу вверх) | flex-direction: column-reverse |
Пример:
<div class="d-flex flex-row"> <!-- По умолчанию -->
<div>1</div><div>2</div>
</div>
3. Выравнивание по главной оси (Justify Content)
| Класс | Описание | CSS-аналог |
|---|---|---|
.justify-content-start | В начале оси | justify-content: flex-start |
.justify-content-end | В конце оси | justify-content: flex-end |
.justify-content-center | По центру | justify-content: center |
.justify-content-between | Равные промежутки между | justify-content: space-between |
.justify-content-around | Равные отступы вокруг | justify-content: space-around |
.justify-content-evenly | Полное равномерное распределение | justify-content: space-evenly |
Пример:
<div class="d-flex justify-content-between">
<div>Лево</div><div>Право</div>
</div>
4. Выравнивание по поперечной оси (Align Items)
| Класс | Описание | CSS-аналог |
|---|---|---|
.align-items-start | В начале оси | align-items: flex-start |
.align-items-end | В конце оси | align-items: flex-end |
.align-items-center | По центру | align-items: center |
.align-items-baseline | По базовой линии | align-items: baseline |
.align-items-stretch | Растянуть (по умолчанию) | align-items: stretch |
Пример:
<div class="d-flex align-items-center" style="height: 100px;">
<div>По центру высоты</div>
</div>
5. Управление отдельными элементами (Align Self)
| Класс | Описание | CSS-аналог |
|---|---|---|
.align-self-start | Элемент в начале | align-self: flex-start |
.align-self-end | Элемент в конце | align-self: flex-end |
.align-self-center | Элемент по центру | align-self: center |
.align-self-stretch | Растянуть элемент | align-self: stretch |
Пример:
<div class="d-flex">
<div class="align-self-end">Прижат к низу</div>
</div>
6. Перенос элементов (Flex Wrap)
| Класс | Описание | CSS-аналог |
|---|---|---|
.flex-nowrap | Без переноса (по умолчанию) | flex-wrap: nowrap |
.flex-wrap | С переносом | flex-wrap: wrap |
.flex-wrap-reverse | Перенос в обратном порядке | flex-wrap: wrap-reverse |
Пример:
<div class="d-flex flex-wrap">
<div class="w-25">1</div><div class="w-25">2</div>...
</div>
7. Управление порядком (Order)
| Класс | Описание |
|---|---|
.order-0 – .order-5 | Приоритет от 0 (высокий) до 5 (низкий) |
.order-first | Первым (аналог order: -1) |
.order-last | Последним (аналог order: 6) |
Пример:
<div class="d-flex">
<div class="order-2">Второй</div>
<div class="order-1">Первый</div>
</div>
8. Автоматические отступы (Flex Fill)
| Класс | Описание |
|---|---|
.flex-fill | Элемент растягивается, заполняя пространство |
.flex-grow-1 | Аналог flex-grow: 1 |
Пример:
<div class="d-flex">
<div class="flex-fill">Занимает всё место</div>
</div>
9. Адаптивные классы
Все классы работают с breakpoints:
.flex-sm-row,.justify-content-md-center,.align-items-lg-endи т.д.
Пример:
<div class="d-flex flex-column flex-md-row">
<!-- На мобильных — вертикально, на десктопе — горизонтально -->
</div>
Итог
Bootstrap 5 предоставляет полный контроль над Flexbox через простые классы. Для сложных макетов комбинируйте их с Grid.
Совет: Используйте .gap-* для отступов между элементами:
<div class="d-flex gap-3">
<div>Элемент 1</div>
<div>Элемент 2</div>
</div>
4.4 - Bootstrap Отступы
Bootstrap 5 Горизонтальные и вертикальные отступы - Gutters — Полная таблица
Bootstrap 5: Горизонтальные и вертикальные отступы (Gutters) — Полная таблица
Bootstrap 5 предоставляет удобные классы для управления отступами между блоками (margin и padding).
Вот полная таблица с примерами для горизонтальных и вертикальных отступов.
1. Классы для отступов (Spacing Utilities)
Bootstrap использует систему {property}{sides}-{size}, где:
property:m— margin (внешний отступ).p— padding (внутренний отступ).
sides:t— top (верх).b— bottom (низ).s— start (лево для LTR, право для RTL).e— end (право для LTR, лево для RTL).x— горизонтальные (левый + правый).y— вертикальные (верхний + нижний).- (пусто) — все стороны.
size:0— 0px.1— 0.25rem (4px).2— 0.5rem (8px).3— 1rem (16px).4— 1.5rem (24px).5— 3rem (48px).auto— автоматический отступ.
2. Горизонтальные отступы (между колонками и блоками)
| Класс | Описание | Пример |
|---|---|---|
.gap-1 – .gap-5 | Отступ между flex-элементами (margin) | <div class="d-flex gap-3"> |
.gx-1 – .gx-5 | Горизонтальный padding (левый + правый) | <div class="row gx-3"> |
.mx-1 – .mx-5 | Горизонтальный margin (левый + правый) | <div class="mx-auto"> |
.ms-1 – .ms-5 | Отступ слева (margin-start) | <div class="ms-3"> |
.me-1 – .me-5 | Отступ справа (margin-end) | <div class="me-2"> |
.px-1 – .px-5 | Горизонтальный padding (левый + правый) | <div class="px-4"> |
Пример:
<div class="d-flex gap-3"> <!-- Отступы между flex-элементами -->
<div>Блок 1</div>
<div>Блок 2</div>
</div>
<div class="row gx-4"> <!-- Горизонтальные отступы в гриде -->
<div class="col">Колонка 1</div>
<div class="col">Колонка 2</div>
</div>
3. Вертикальные отступы (между строками и блоками)
| Класс | Описание | Пример |
|---|---|---|
.gy-1 – .gy-5 | Вертикальный padding (верх + низ) | <div class="row gy-3"> |
.my-1 – .my-5 | Вертикальный margin (верх + низ) | <div class="my-4"> |
.mt-1 – .mt-5 | Отступ сверху (margin-top) | <div class="mt-2"> |
.mb-1 – .mb-5 | Отступ снизу (margin-bottom) | <div class="mb-3"> |
.py-1 – .py-5 | Вертикальный padding (верх + низ) | <div class="py-5"> |
Пример:
<div class="row gy-4"> <!-- Вертикальные отступы в гриде -->
<div class="col-12">Строка 1</div>
<div class="col-12">Строка 2</div>
</div>
<div class="my-5"> <!-- Большой вертикальный margin -->
<p>Контент с отступами сверху и снизу</p>
</div>
4. Автоматические и специальные отступы
| Класс | Описание | Пример |
|---|---|---|
.m-auto | Автоматический margin (центрирование) | <div class="mx-auto"> |
.p-auto | Автоматический padding (редко используется) | <div class="p-auto"> |
.m-n1 – m-n5 | Отрицательный margin | <div class="m-n3"> |
Пример:
<div class="mx-auto" style="width: 200px;"> <!-- Центрирование -->
Этот блок будет по центру
</div>
5. Адаптивные отступы
Все классы поддерживают адаптивность через breakpoints:
sm(≥576px),md(≥768px),lg(≥992px),xl(≥1200px),xxl(≥1400px).
Пример:
<div class="mx-3 mx-md-5"> <!-- На мобильных mx-3, на десктопе mx-5 -->
Адаптивный отступ
</div>
Итог
✅ Горизонтальные отступы → .gap-*, .gx-*, .mx-*, .ms-*, .me-*.
✅ Вертикальные отступы → .gy-*, .my-*, .mt-*, .mb-*.
✅ Центрирование → .mx-auto.
✅ Адаптивность → .mx-sm-3, .gy-lg-4.
Совет: Для сеток (row/col) лучше использовать .gx-* и .gy-*, а для flex-контейнеров — .gap-*.
5 - Описание настроек Docker
5.1 - Шпаргалка по Docker и Docker Compose (CLI)
Основные команды Docker и Docker Compose из командной строки
Основные команды Docker
| Команда | Описание |
|---|---|
docker ps | Список работающих контейнеров |
docker ps -a | Список всех контейнеров (включая остановленные) |
docker images | Список образов |
docker pull <image> | Скачать образ (например, docker pull nginx) |
docker run <image> | Запустить контейнер из образа |
docker run -d <image> | Запуск в фоновом режиме (detached) |
docker run -p 8080:80 <image> | Проброс портов (хост:контейнер) |
docker run -v /path:/path <image> | Подключение тома (volume) |
docker stop <container> | Остановить контейнер |
docker start <container> | Запустить остановленный контейнер |
docker restart <container> | Перезапустить контейнер |
docker rm <container> | Удалить контейнер |
docker rmi <image> | Удалить образ |
docker exec -it <container> bash | Войти в контейнер (интерактивный терминал) |
docker logs <container> | Просмотр логов контейнера |
docker build -t <name> . | Собрать образ из Dockerfile |
docker system prune | Очистка неиспользуемых данных (кэш, остановленные контейнеры) |
docker network ls | Список сетей |
Docker Compose (управление мультиконтейнерными приложениями)
| Команда | Описание |
|---|---|
docker-compose up | Запуск сервисов из docker-compose.yml |
docker-compose up -d | Запуск в фоновом режиме |
docker-compose down | Остановка и удаление контейнеров |
docker-compose ps | Список запущенных сервисов |
docker-compose logs | Просмотр логов |
docker-compose logs <service> | Логи конкретного сервиса |
docker-compose build | Пересобрать образы |
docker-compose exec <service> bash | Войти в контейнер сервиса |
docker-compose restart | Перезапуск сервисов |
docker-compose pull | Обновить образы из docker-compose.yml |
Полезные флаги
-d→ Запуск в фоне (detached)-p 80:80→ Проброс портов-v /data:/app→ Подключение volume--name my_container→ Задать имя контейнеру--rm→ Автоудаление контейнера после остановки-e VAR=value→ Передача переменных окружения
Примеры
- Запуск Nginx с пробросом порта
docker run -d -p 8080:80 --name my_nginx nginx - Сборка и запуск через Docker Compose
docker-compose up -d --build - Остановка всех контейнеров
docker stop $(docker ps -aq)
docker --help и docker-compose --help для справки по командам.
5.2 - Справочник по созданию образов Docker
Полный справочник по Dockerfile и сборке образов
В этом руководстве рассмотрим:
- Синтаксис Dockerfile
- Основные директивы
- Оптимизация сборки
- Команды для работы с образами
1. Структура Dockerfile
Файл Dockerfile — это инструкция для сборки Docker-образа.
Пример минимального Dockerfile
# Базовый образ
FROM ubuntu:22.04
# Установка зависимостей
RUN apt-get update && apt-get install -y curl
# Копирование файлов в образ
COPY ./app /app
# Рабочая директория
WORKDIR /app
# Команда запуска контейнера
CMD ["python", "app.py"]
2. Основные директивы
| Директива | Описание | Пример |
|---|---|---|
FROM | Базовый образ | FROM python:3.9 |
RUN | Выполнить команду при сборке | RUN apt-get update |
COPY | Копировать файлы в образ | COPY ./src /app |
ADD | Аналог COPY, но с распаковкой архивов и поддержкой URL | ADD https://example.com/file.tar.gz /tmp |
WORKDIR | Установить рабочую директорию | WORKDIR /app |
ENV | Установить переменную окружения | ENV NODE_ENV=production |
ARG | Переменная, используемая только при сборке | ARG VERSION=1.0 |
EXPOSE | Объявить порт (не пробрасывает его!) | EXPOSE 80 |
CMD | Команда по умолчанию при запуске | CMD ["npm", "start"] |
ENTRYPOINT | Основная команда контейнера | ENTRYPOINT ["/app/start.sh"] |
VOLUME | Создать точку монтирования | VOLUME /data |
USER | Задать пользователя | USER nobody |
HEALTHCHECK | Проверка здоровья контейнера | HEALTHCHECK --interval=30s CMD curl -f http://localhost/health |
3. Оптимизация сборки
Многоступенчатая сборка (Multi-stage Build)
Уменьшает размер финального образа.
# 1. Этап сборки
FROM node:18 AS builder
WORKDIR /app
COPY . .
RUN npm install && npm run build
# 2. Финальный образ
FROM nginx:alpine
COPY --from=builder /app/dist /usr/share/nginx/html
Кэширование слоев
COPYиADDинвалидируют кэш, если файлы меняются.RUNкэшируется, если команда не менялась.
Совет: Меняющиеся команды (apt-get update) размещайте в начале.
4. Сборка и управление образами
Сборка образа
docker build -t myapp:latest .
-t— задать имя и тег (name:tag).— путь кDockerfile
Сборка с аргументами
ARG VERSION=1.0
ENV APP_VERSION=$VERSION
docker build --build-arg VERSION=2.0 -t myapp:2.0 .
Просмотр истории образа
docker history myapp:latest
Экспорт/импорт образа
docker save myapp:latest > myapp.tar
docker load < myapp.tar
5. Продвинутые техники
.dockerignore
Исключает файлы из копирования (аналог .gitignore):
node_modules/
*.log
.git/
Динамический CMD/ENTRYPOINT
ENTRYPOINT ["/app/start.sh"]
CMD ["--port=8080"]
Запуск с переопределением:
docker run myapp --port=3000
Health Check
HEALTHCHECK --interval=5s --timeout=3s \
CMD curl -f http://localhost/ || exit 1
6. Примеры для разных языков
Python (FastAPI)
FROM python:3.9
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "app:app", "--host", "0.0.0.0"]
Node.js
FROM node:18
WORKDIR /app
COPY package*.json ./
RUN npm ci --production
COPY . .
CMD ["npm", "start"]
Go
FROM golang:1.20 AS builder
WORKDIR /app
COPY . .
RUN go build -o /app/main .
FROM alpine:latest
COPY --from=builder /app/main /main
CMD ["/main"]
7. Полезные команды
| Команда | Описание |
|---|---|
docker buildx build --platform linux/amd64,linux/arm64 -t myapp:multiarch . | Сборка мультиархитектурного образа |
docker scan myapp:latest | Проверка на уязвимости (Snyk) |
docker image prune -a | Удалить неиспользуемые образы |
Итог:
- Используйте многоступенчатую сборку для оптимизации.
- Минимизируйте количество слоев (объединяйте
RUN). - Применяйте
.dockerignore, чтобы ускорить сборку. - Для продакшена указывайте конкретные версии (
python:3.9, а неpython:latest).
5.3 - Очистка кеша при использовании Docker
Для очистки кэша Docker можно использовать несколько команд, в зависимости от того, что именно нужно удалить
Очистка кэша Docker на сервере
Для очистки кэша Docker можно использовать несколько команд, в зависимости от того, что именно нужно удалить:
1. Очистка неиспользуемых (висячих) образов, контейнеров, сетей и volumes
docker system prune
- Удалит:
- Остановленные контейнеры
- Сети, не используемые ни одним контейнером
- Висячие (dangling) образы (те, у которых нет тегов)
- Висячие билд-кэш
2. Агрессивная очистка (включая неиспользуемые образы)
docker system prune -a
- Удалит все неиспользуемые образы, а не только dangling.
3. Удаление всех остановленных контейнеров
docker container prune
4. Удаление всех неиспользуемых образам
docker image prune -a
5. Удаление кэша сборки (build cache)
docker builder prune
6. Удаление всех volumes, не привязанных к контейнерам
docker volume prune
7. Полная очистка (осторожно!)
Если нужно полностью очистить Docker (все контейнеры, образы, volumes, сети):
docker system prune -a --volumes
⚠️ Будьте осторожны! Эта команда удалит всё, что не используется в данный момент.
Дополнительные полезные команды:
- Просмотр занимаемого места:
docker system df - Удаление конкретного образа:
docker rmi <image_id> - Удаление всех образов (очень опасно!):
docker rmi $(docker images -q)
Вывод
Лучший вариант для периодической очистки — docker system prune.
Если нужно освободить максимум места — docker system prune -a --volumes.
🚀 После очистки можно проверить свободное место:
df -h
6 - Микроразметка для СЕО поиска
Подборка материалов и переводов статей для объяснения механизмов, как выполняют поиск данных поисковые машины Google, Yandex и другие.
Микроразметка для поисковых систем: Google, Яндекс и другие
В современном цифровом мире важно не только создавать качественный контент, но и помогать поисковым системам правильно его интерпретировать. Микроразметка (Schema.org) — это мощный инструмент, который позволяет структурировать данные на сайте, улучшая их отображение в поисковой выдаче. С помощью микроразметки можно выделять рейтинги, цены, события, товары и многое другое, делая сниппеты более информативными и привлекательными для пользователей.
В этом разделе собраны подробные руководства по работе с микроразметкой для разных поисковых систем, включая Google, Яндекс и другие. Вы узнаете, какие форматы поддерживаются, как проверять разметку и какие ошибки стоит избегать.
6.1 - JSON-LD - микроразметка материалов для выдачи сниппетов в поиске Google
Перевод статьи с ресурса moz.com для начинающих и знакомящихся с микроразметкой JSON-LD
Оригинал статьи находится здесь
Руководство по JSON-LD для начинающих
Что такое JSON-LD?
JSON-LD расшифровывается как JavaScript Object Notation for Linked Data, что представляет собой многомерные массивы (представьте себе: список пар атрибут-значение).
Это формат реализации для структурирования данных, аналогичный Microdata и RDFa. Обычно, в контексте SEO, JSON-LD реализуется с использованием словаря Schema.org, совместной инициативы Google, Bing, Yahoo! и Yandex, созданной в 2011 году для создания единого словаря структурированных данных для веба. (Тем не менее, Bing и другие поисковые системы официально не заявили о своей поддержке реализаций JSON-LD для Schema.org.)
JSON-LD считается более простым в реализации, благодаря возможности просто вставить разметку в HTML-документ, в отличие от необходимости оборачивать разметку вокруг HTML-элементов (как это делается с Microdata).
Что делает JSON-LD?
JSON-LD аннотирует элементы на веб-странице, придавая данным структуру. Это позволяет поисковым системам лучше понимать содержимое, устранять неоднозначности и устанавливать связи между сущностями. В результате формируется более упорядоченная и понятная структура данных, что способствует созданию лучше организованного интернета в целом.
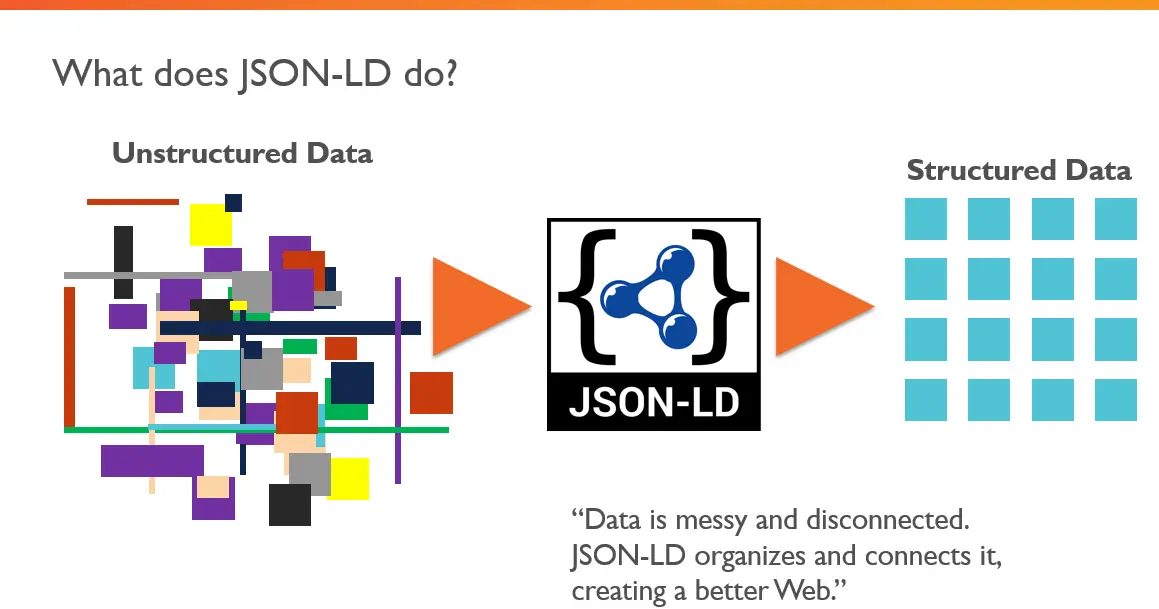
JSON-LD преобразует неструктурированные данные в структурированные
Рисунок 1 — Концептуальная визуализация работы JSON-LD: обработка неструктурированного контента в интернете, его аннотирование и структурирование для получения организованного результата.
Таким образом, JSON-LD помогает поисковым системам, таким как Google и Яндекс, точнее интерпретировать информацию на сайте, что может улучшить отображение страницы в результатах поиска (например, с помощью расширенных сниппетов).
Где в HTML-коде страницы должен располагаться JSON-LD?
Google рекомендует размещать JSON-LD в разделе <head> HTML-документа. Однако допустимо также добавлять его и внутри <body>. Кроме того, Google способен обрабатывать динамически сгенерированные JSON-LD теги в DOM (объектной модели документа).
Коротко:
- Лучше:
<head> - Но можно:
<body> - Динамические теги (например, загружаемые через JavaScript) тоже работают.
Это означает, что поисковые системы смогут распознать разметку независимо от её расположения в HTML, если она корректно сформирована.
Разбираем JSON-LD
Неизменяемые теги (Не нужно запоминать — просто копируйте и вставляйте)
<script type="application/ld+json">
{
...
}
</script>
Когда вы видите JSON-LD, первое, что должно бросаться в глаза — это тег <script>. Атрибут type="application/ld+json" сообщает браузеру: «Эй, здесь JavaScript, содержащий JSON-LD».
💡 Профессиональный совет
- Всегда закрывайте теги сразу после открытия.
Как соль и перец идут вместе, так и открывающие фигурные скобки{требуют закрывающих}. - Важно: Если ваш JSON-LD не заключён в фигурные скобки
{}, он не будет обработан. (Держите его «завёрнутым» в скобки!)
Таким образом, правильная структура JSON-LD гарантирует, что поисковые системы смогут корректно прочитать и использовать вашу разметку.
"@context": “http://schema.org”
Второй обязательный элемент в JSON-LD разметке — это @context со значением http://schema.org.
Этот параметр сообщает браузеру: «Эй, вот словарь, на который я ссылаюсь — ты можешь найти его по адресу http://schema.org».
Преимущество для SEO-специалиста:
Мы получаем доступ ко всем типам элементов (item types) и их свойствам (item properties), которые определены в Schema.org.
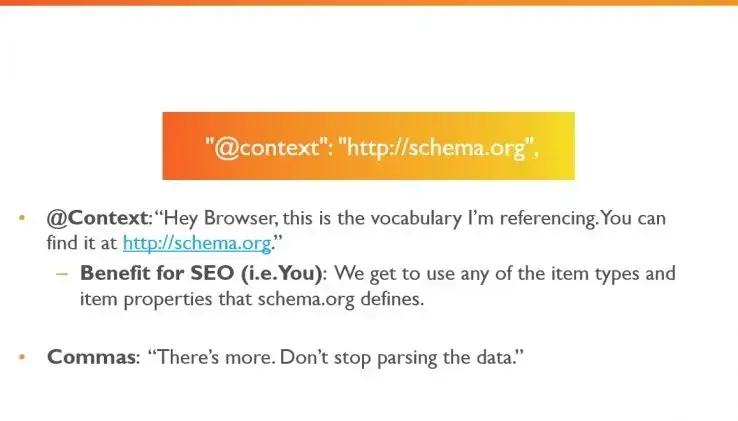 📌 Пример структуры:
📌 Пример структуры:
{
"@context": "http://schema.org",
"@type": "Article",
"headline": "Пример статьи",
"author": {
"@type": "Person",
"name": "Иван Петров"
}
}
🔍 Обратите внимание:
- Видите эту запятую после
"http://schema.org"? Она говорит парсеру: «Данные продолжаются, не останавливайся».
💡 Профессиональный совет
- Следите за запятыми (и всегда проверяйте разметку в Google’s Structured Data Testing Tool).
- Пропущенная запятая = невалидная разметка. Даже опытные разработчики часто ошибаются в этом месте.
JSON-LD строго требует правильного синтаксиса, поэтому всегда проверяйте свою разметку перед публикацией!
"@type": “…”
Третий ключевой элемент JSON-LD разметки — это указание @type. После двоеточия здесь начинается аннотация данных. Параметр @type определяет тип размеченной сущности. Полный список всех доступных типов можно найти в официальной документации: https://schema.org/docs/full.html.
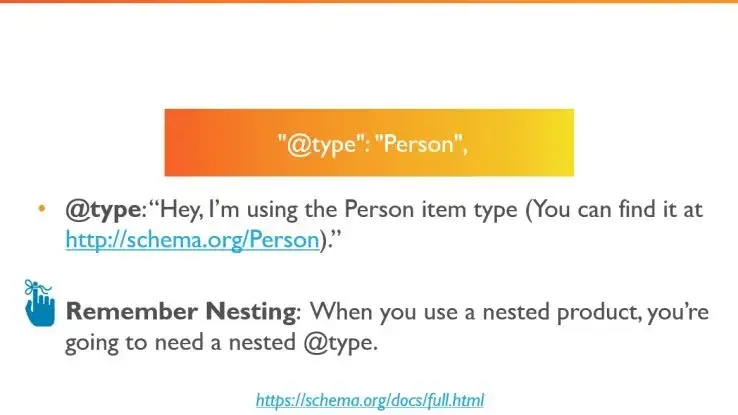
Как это работает?
В примере ниже:
{
"@context": "http://schema.org",
"@type": "Person",
"name": "Иван Иванов"
}
@type сообщает: «Эй, здесь используется тип Person (его описание можно найти по адресу http://schema.org/Person)».
Если ввести эту ссылку в браузер, откроется документация Schema.org с:
- Техническими спецификациями этого типа
- Списком допустимых свойств (
item properties) - Часто — примерами использования
Вложенные @type
При использовании вложенных структур потребуется указывать @type для каждого уровня. Это особенно важно в разметке:
- Товаров (
Product) - Хлебных крошек (
BreadcrumbList) - Организаций с сотрудниками (
Organization→Employee)
Пример вложенности:
{
"@context": "http://schema.org",
"@type": "Product",
"brand": {
"@type": "Brand",
"name": "Nike"
}
}
💡 Профессиональный совет:
- Всегда проверяйте допустимые свойства для вашего
@typeна Schema.org. Например, дляPersonобязательным может бытьname, а дляProduct—offers. - Используйте инструмент проверки структурированных данных Google, чтобы убедиться в отсутствии ошибок.
@type или его неверное указание сделает разметку бесполезной для поисковых систем!Пары “атрибут-значение”
Следующий шаг — аннотирование информации о выбранном типе сущности (@type). Допустимые свойства для каждого типа можно найти на соответствующей странице Schema.org.
Синтаксис JSON-LD для свойств
Каждое свойство в разметке состоит из двух элементов:
Свойство (Item Property)
- Должно быть взято из словаря Schema.org.
- Обязательно заключайте в двойные прямые кавычки (
" ").
🔹 Важно: Использование фигурных (“ ”) или одинарных (' ') кавычек приведёт к ошибке валидации! - Должно принадлежать к разрешённым свойствам для выбранного
@type(указаны в документации Schema.org).
Значение (Value)
- Сюда вписывается конкретное значение свойства.
- Правила форматирования:
- Текстовые строки и URL: всегда в двойных кавычках (
"пример"). - Числа (целые, дробные): можно без кавычек (
42), но допустимо и с ними ("42"— тогда тип данных будет строковым). - Несколько значений: используйте квадратные скобки (
["значение1", "значение2"]).
- Текстовые строки и URL: всегда в двойных кавычках (
Примеры
✅ Корректно:
{
"@type": "Book",
"name": "Война и мир",
"isbn": "978-5-699-12014-7", // Строка в кавычках
"price": 599.99, // Число без кавычек
"author": ["Лев Толстой", "Иван Тургенев"] // Массив значений
}
❌ Ошибки:
- Фигурные кавычки:
“Война и мир”→ невалидно. - Пропущенные кавычки:
name: Война и мир→ синтаксическая ошибка. - Неразрешённое свойство:
"pageCount": 1225(если@typeне поддерживает это свойство).
💡 Профессиональный совет:
- Всегда сверяйтесь со списком свойств для вашего
@type. - Для сложных случаев (например, товары с вариантами) используйте вложенные структуры и массивы.
- Проверяйте разметку в Google Rich Results Test — он покажет не только ошибки, но и потенциальные улучшения.
Запомните:
Правильный синтаксис — это не педантичность, а необходимость. Поисковые системы обрабатывают только безупречно оформленные данные!
Квадратные скобки [ ] в JSON-LD
Квадратные скобки используются, когда у свойства есть несколько значений.
Примеры использования:
Несколько значений одного свойства
Например, если у человека два имени:"givenName": ["Джейсон", "Деруло"]Здесь скобки говорят: «У этого свойства несколько значений — у Джейсона Деруло два имени».
Ссылки на соцсети (sameAs)
Часто применяется для перечисления профилей в соцсетях:"sameAs": [ "https://facebook.com/jasonderulo", "https://twitter.com/jasonderulo", "https://instagram.com/jasonderulo" ]
Важные правила:
Запятая после последнего элемента не ставится
"sameAs": [ "https://facebook.com/jasonderulo", // запятая "https://twitter.com/jasonderulo" // НЕТ запятой в конце ]Отсутствие запятой означает конец списка.
Не путать с фигурными скобками
{}
Квадратные скобки — только для перечисления однотипных значений, а фигурные — для вложенных объектов (например, адреса или организации).
💡 Профессиональный совет:
- Используйте квадратные скобки для:
- Списков (например, авторов книги).
- Альтернативных URL (например,
sameAsдля соцсетей). - Любых свойств, допускающих множественные значения по Schema.org.
- Всегда проверяйте, поддерживает ли выбранный
@typeмножественные значения для конкретного свойства.
Пример корректной и некорректной разметки:
✅ Правильно:
"author": ["Лев Толстой", "Фёдор Достоевский"]
❌ Неправильно:
"author": ["Лев Толстой", "Фёдор Достоевский",]
→ Лишняя запятая после последнего элемента.
Для проверки используйте Google’s Structured Data Testing Tool.
Вложенность (Nesting) в JSON-LD
Вложенность означает организацию данных слоями, где одни объекты содержат другие объекты. Это можно сравнить с матрешкой, где большая кукла содержит внутри меньшую — так же и данные могут быть структурированы иерархически.
Зачем нужна вложенность?
Некоторые свойства относятся только к определенным типам сущностей. Например, в разметке события (Event):
nameможет означать название события,- но внутри могут быть вложены свойства
performer(исполнитель) иvenue(место проведения), у которых тоже есть своиname.
Без вложенности поисковые системы не поймут, к чему относится каждое свойство.
Как правильно вкладывать данные в JSON-LD
Начните с основного типа (
@type)
Например,Event.Укажите свойство, требующее вложенности
Например,performerилиoffers.Откройте фигурные скобки
{ }для нового объекта
Внутри укажите:@type(тип вложенной сущности, напримерPersonилиOffer),- его свойства и значения.
Закройте вложенный объект
- Не ставьте запятую перед закрывающей скобкой
}. - Запятая после
}нужна, только если дальше идут другие свойства.
- Не ставьте запятую перед закрывающей скобкой
Пример вложенности
Разметка музыкального события:
{
"@context": "http://schema.org",
"@type": "MusicEvent",
"name": "Концерт Jason Aldean",
"performer": { // ← Начало вложенного объекта
"@type": "MusicGroup",
"name": "Jason Aldean",
"sameAs": "https://www.jasonaldean.com"
}, // ← Запятая, потому что дальше есть еще свойства
"location": {
"@type": "Place",
"name": "Мэдисон-Сквер-Гарден",
"address": "Нью-Йорк, США"
} // ← Нет запятой, это последнее свойство
}
Чек-лист по вложенности
✅ Используйте свойства, допустимые для родительского @type (см. Schema.org).
✅ Значение вложенного объекта заключайте в { }.
✅ Указывайте @type для вложенной сущности.
✅ Добавляйте обязательные свойства для вложенного типа (например, price для Offer).
❌ Не ставьте запятую перед } (это вызовет ошибку).
✅ Запятая после }, если дальше идут другие свойства.
Где чаще всего встречается вложенность?
- Товары (
Product):- Цена и условия предложения вкладываются в
offers(@type: Offer). - Отзывы — в
review(@type: Review).
- Цена и условия предложения вкладываются в
- Организации (
Organization):- Адрес (
@type: PostalAddress), - контакты, учредители.
- Адрес (
- Рецепты (
Recipe):- Ингредиенты, инструкции, питательная ценность.
💡 Профессиональный совет:
- Делайте отступы для вложенных объектов — так код легче читать.
- Проверяйте обязательные свойства для вложенных типов на Schema.org.
- Тестируйте разметку в Google Rich Results Test.
Ошибка → Пропущенный @type во вложенном объекте или лишние/недостающие запятые сделают разметку нерабочей!
Пример ошибки:
❌ Неправильно:
"performer": {
"name": "Jason Aldean" // ← Нет @type!
}
✅ Исправлено:
"performer": {
"@type": "MusicGroup",
"name": "Jason Aldean"
}
Распространённые ошибки в JSON-LD разметке
Если ваша разметка не проходит валидацию в Google’s Structured Data Testing Tool, проверьте этот список типичных проблем.
1. Синтаксические ошибки
Кавычки: прямые vs. фигурные
- ✅ Правильно:
""(прямые двойные кавычки). - ❌ Ошибка:
“”(фигурные кавычки, которые могут появиться при копировании из Word/Excel).
Запятые
- Пропущенная запятая между свойствами → разметка не валидируется.
- Лишняя запятая после последнего элемента в объекте или массиве → ошибка.
- Как найти: В инструменте тестирования ищите красный крестик (
✗) слева — он часто указывает на проблему с запятой.
Пример:
// ❌ Ошибка (лишняя запятая)
"author": {
"@type": "Person",
"name": "Иван Иванов", // ← Запятая не нужна, это последнее свойство
}
// ✅ Исправлено
"author": {
"@type": "Person",
"name": "Иван Иванов"
}
2. Ошибки словаря Schema.org
- Использование свойств, недопустимых для данного
@type.
Пример: Свойствоauthorне поддерживается для@type: Product. - Пропуск обязательных свойств.
Пример: ДляOfferобязательно указаниеpriceиpriceCurrency.
Решение:
- Всегда сверяйтесь с документацией Schema.org для вашего
@type. - Проверяйте разметку в тестере Google.
3. Нарушение правил Google
- Размеченные данные должны быть видны на странице.
Пример: Если в JSON-LD указан рейтинг 5.0, а на странице его нет — это нарушение. - Запрещены манипулятивные практики.
Пример: Добавление ложных отзывов или несвязанных сущностей для обхода алгоритмов.
Что делать:
- Ознакомьтесь с Google’s Structured Data Policies.
- Убедитесь, что контент в разметке соответствует содержимому страницы.
4. Проблемы при копировании из Microsoft Office
- Word/Excel автоматически заменяют кавычки на фигурные (
“”). - Добавляют невидимые символы форматирования.
Решение:
- Используйте HTML-редактор (например, VS Code, Sublime Text).
- Вставляйте текст через «Вставить как обычный текст» (Ctrl+Shift+V).
Итоговый чек-лист
- Кавычки: Только прямые (
""). - Запятые: Ни лишних, ни пропущенных.
- Словарь: Только разрешённые свойства для
@type. - Контент: Разметка = содержимое страницы.
- Проверка: Всегда тестируйте в Google Rich Results Test.
💡 Совет: Для сложных типов (например, Product с Review) используйте пошаговую проверку — сначала базовые свойства, затем вложенные объекты.
Ошибка → Даже одна пропущенная кавычка или запятая может привести к тому, что Google проигнорирует всю разметку!
Процесс добавления JSON-LD на сайт
Создание JSON-LD разметки зависит от вашего уровня знакомства с синтаксисом JSON-LD и словарем Schema.org. Ниже приведен пошаговый процесс для новичков, который поможет вам разобраться в основах и создать эффективную разметку.
1. Определите цель разметки
📌 Вопросы, которые нужно задать себе:
- Что вы хотите разметить?
Убедитесь, что выбранный вами контент можно аннотировать с помощью Schema.org. Некоторые вещи могут казаться логичными, но не иметь подходящего типа в словаре. - Зачем вам это нужно?
Определите, есть ли практическая польза (например, улучшение сниппетов в поиске) или вы просто экспериментируете. Разметка должна помогать поисковым системам лучше понимать ключевую информацию на странице.
2. Изучите документацию и примеры
- Проверьте, поддерживает ли Google ваш тип разметки.
Откройте официальную документацию Google и найдите примеры. - Не изобретайте велосипед!
Используйте готовые примеры от Google или Schema.org, адаптируя их под свои нужды.
3. Откройте страницу типа данных на Schema.org
- Перейдите на Schema.org и найдите нужный
@type(например,Product,Article). - Ознакомьтесь с:
- Описанием типа,
- Обязательными и рекомендуемыми свойствами,
- Примерами использования.
4. Скопируйте “неизменяемые” элементы
Начните с базовой структуры:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "ТипДанных"
}
</script>
- Не забывайте, что тег
<script>обязателен!
5. Определите свойства и их значения
- Выпишите свойства, которые хотите добавить (например, для
Product:name,description,image). - Пока не думайте о синтаксисе — просто составьте список.
6. Добавьте синтаксис JSON-LD и вложенности
- Заполните свойства, соблюдая правила:
- Кавычки: только
"". - Запятые: между свойствами, но не после последнего.
- Кавычки: только
- Для вложенных объектов (например,
offersвProduct) используйте фигурные скобки{}и указывайте@type.
Пример для товара:
{
"@context": "http://schema.org",
"@type": "Product",
"name": "Смартфон XYZ",
"image": "https://example.com/image.jpg",
"offers": {
"@type": "Offer",
"price": "299.99",
"priceCurrency": "USD"
}
}
7. Протестируйте разметку
- Используйте Google’s Structured Data Testing Tool.
- Убедитесь, что:
- Нет ошибок (красных крестиков),
- Все свойства распознаются.
8. Добавьте разметку на сайт
- Способ 1: Вставьте код в
<head>страницы. - Способ 2: Для динамического контента согласуйте с разработчиками (например, генерация через CMS).
- Дополнительно: Используйте
itemIDиitemRefдля сложных структур (подробнее в статье Moz).
9. Делитесь опытом!
У вас есть вопросы или интересные кейсы по JSON-LD? Делитесь в комментариях!
Итог:
- Планируйте → Изучайте → Копируйте → Тестируйте → Внедряйте.
- Избегайте типичных ошибок: неправильные кавычки, запятые, нарушение правил Google.
- Используйте инструменты валидации на каждом этапе.
Теперь вы готовы создавать SEO-оптимизированную разметку!
6.2 - Документация RDF для универсальной микроразметки текстов для микропоиска
Синтаксис и правила обработки для встраивания RDF через атрибуты Рекомендация W3C от 17 марта 2015 года
RDFa Core 1.1 — Третье издание
Синтаксис и правила обработки для встраивания RDF через атрибуты
Рекомендация W3C от 17 марта 2015 года
Актуальная версия:
http://www.w3.org/TR/2015/REC-rdfa-core-20150317/
Последняя опубликованная версия:
http://www.w3.org/TR/rdfa-core/
Отчёт о внедрении:
http://www.w3.org/2010/02/rdfa/wiki/CR-ImplementationReport
Предыдущая версия:
http://www.w3.org/TR/2014/PER-rdfa-core-20141216/
Предыдущая рекомендация:
http://www.w3.org/TR/2013/REC-rdfa-core-20130822/
Редакторы:
- Бен Адида, Creative Commons, ben@adida.net
- Марк Бирбек, webBackplane, mark.birbeck@webBackplane.com
- Шейн МакКаррон, Applied Testing and Technology, Inc., shane@aptest.com
- Иван Герман, W3C, ivan@w3.org
Английская версия данной спецификации является единственной нормативной. Неофициальные переводы могут быть доступны.
Авторские права: © 2007–2015 W3C® (MIT, ERCIM, Кейо, Бэйхан). Применяются правила W3C об ответственности, товарных знаках и использовании документов.
Аннотация
Современный Интернет в основном состоит из огромного количества документов, созданных с использованием HTML. Эти документы содержат значительный объём структурированных данных, которые в большинстве случаев недоступны для инструментов и приложений. Если издатели смогут выражать эти данные более полно, а инструменты — считывать их, откроются новые возможности для пользователей: структурированные данные можно будет передавать между приложениями и веб-сайтами, а браузеры смогут улучшить пользовательский опыт. Например:
- событие на веб-странице можно будет напрямую импортировать в настольный календарь;
- лицензию на документ можно будет автоматически определить, чтобы информировать пользователей об их правах;
- информацию о создателе фотографии, настройках камеры, разрешении, местоположении и теме можно будет публиковать так же легко, как и саму фотографию, что позволит осуществлять структурированный поиск и обмен.
RDFa Core — это спецификация атрибутов для выражения структурированных данных в любом языке разметки. Встроенные данные, уже доступные в языке разметки (например, HTML), часто можно повторно использовать в RDFa, что избавляет издателей от необходимости дублировать информацию в содержимом документа.
Абстрактное представление данных основано на RDF (RDF11-PRIMER), что позволяет издателям создавать собственные словари, расширять чужие и развивать свою терминологию с максимальной совместимостью. Выраженная структура тесно связана с данными, поэтому визуализированную информацию можно копировать вместе с её структурой.
Правила интерпретации данных универсальны и не требуют отдельных инструкций для разных форматов. Это позволяет авторам и издателям данных определять собственные форматы без необходимости обновлять ПО, регистрировать их в централизованном органе или опасаться конфликтов между разными форматами.
RDFa разделяет некоторые цели с микроформатами (MICROFORMATS). Однако если микроформаты задают и синтаксис для встраивания структурированных данных в HTML, и конкретный словарь терминов для каждого микроформата, то RDFa определяет только синтаксис, полагаясь на независимые спецификации терминов (часто называемых словарями или таксономиями). RDFa позволяет свободно комбинировать термины из разных словарей и разработан так, что язык можно анализировать без знания конкретного используемого словаря.
Этот документ представляет собой детальное описание синтаксиса RDFa, предназначенное для:
- Разработчиков процессоров RDFa, которым необходимо точное описание правил разбора.
- Тех, кто хочет интегрировать RDFa в новый язык разметки.
- Организаций, желающих рекомендовать использование RDFa и создать руководства для пользователей.
- Всем, кто знаком с RDF и хочет понять, как работает процессор RDFa «под капотом».
Для тех, кто ищет введение в RDFa и практические примеры, рекомендуется ознакомиться с RDFA-PRIMER.
Как читать этот документ
Если вы не знакомы ни с RDFa, ни с RDF и просто хотите добавить RDFa в свои документы, то вам может быть полезнее ознакомиться с RDFa Primer, который даёт более простое введение.
Если вы уже знакомы с RDFa и хотите изучить правила обработки (например, для создания собственного процессора RDFa), то наиболее интересным для вас будет раздел «Модель обработки». В нём содержится обзор каждого этапа обработки, а затем более детальные подразделы с описанием отдельных правил.
Если вы не знакомы с RDFa, но знаете RDF, то перед изучением модели обработки полезно прочитать раздел «Обзор синтаксиса», где приведены примеры разметки с использованием RDFa. Примеры помогут легче понять правила обработки.
Если вы не знакомы с RDF, то перед активной работой с RDFa рекомендуется ознакомиться с разделом «Терминология RDF». Хотя RDFa разработан так, чтобы быть простым для авторов (и для его использования не обязательно глубоко разбираться в RDF), разработчикам приложений, обрабатывающих RDFa, понимание RDF необходимо. В интернете есть множество материалов по RDF, а также растущее число инструментов, поддерживающих RDFa. В этом документе содержится лишь минимальный необходимый контекст по RDF, чтобы прояснить цели RDFa.
Примечание
RDFa — это способ выражения отношений в стиле RDF с помощью простых атрибутов в существующих языках разметки, таких как HTML.
- RDF полностью интернационализирован и допускает использование Internationalized Resource Identifiers (IRI). В этой спецификации повсеместно используется термин IRI.
- Даже если вы не знакомы с термином IRI, вы, вероятно, встречали URI или URL. IRI — это расширение URI, позволяющее использовать символы за пределами ASCII.
- RDF поддерживает такие символы, как и RDFa. В этой спецификации сознательно используется термин IRI, чтобы подчеркнуть эту возможность.
Важное уточнение
Хотя в данной спецификации упоминаются исключительно IRI, язык-хост (Host Language) может ограничивать синтаксис своих атрибутов подмножеством IRI (например, атрибут @href в HTML5).
Однако, независимо от ограничений валидации в языке-хозяине, процессор RDFa способен обрабатывать полный диапазон IRI.
Статус данного документа
Данный раздел описывает статус документа на момент его публикации. Другие документы могут заменять текущую версию. Актуальный список публикаций W3C и последнюю редакцию данного технического отчёта можно найти в индексе технических отчётов W3C по адресу: http://www.w3.org/TR/.
Редакционные изменения
Настоящая версия представляет собой редакционную правку Рекомендации, опубликованной 22 августа 2013 года. Указанный документ являлся пересмотренной версией спецификации RDFa Syntax 1.0 [RDFA-SYNTAX]. Между текущей версией и версией 1.0 существует ряд существенных различий, включая:
- Удаление специальных правил для XHTML - теперь они определены в отдельном документе XHTML+RDFa [XHTML-RDFA].
- Расширение типов данных некоторых атрибутов RDFa для поддержки Terms (терминов), CURIES и Absolute IRIs.
- Разрешение языкам-хостам определять коллекции терминов по умолчанию, префиксные отображения и словарь по умолчанию.
- Возможность определения словаря по умолчанию для использования с неопределёнными терминами.
- Требование к регистронезависимому сравнению терминов.
- Расширенное поведение атрибута @property, которое во многих случаях может заменять атрибут @rel.
- Изменённая обработка @typeof для лучшего соответствия практическому использованию.
Более подробный список изменений доступен в разделе Changes (Изменения).
Тестирование
Доступен тестовый набор, который не является исчерпывающим, но может быть полезен как пример использования RDFa.
Участие и отзывы
Документ опубликован Рабочей группой RDFa в качестве Рекомендации. Все замечания и предложения можно направлять по адресу: public-rdfa@w3.org (подписка, архивы). Отзывы приветствуются.
С отчётом о внедрении рабочей группы можно ознакомиться здесь.
Статус рекомендации
Документ был рассмотрен членами W3C, разработчиками программного обеспечения, другими группами W3C и заинтересованными сторонами. Директор W3C утвердил его в качестве официальной Рекомендации. Это стабильный документ, который может использоваться в качестве справочного материала или цитироваться в других документах. Роль W3C заключается в привлечении внимания к спецификации и содействии её широкому внедрению, что способствует улучшению функциональности и совместимости веба.
Патентная политика
Документ разработан группой, действующей в соответствии с Патентной политикой W3C от 5 февраля 2004 года. W3C ведёт публичный список патентных заявлений, связанных с результатами работы группы. На этой странице также содержатся инструкции по подаче патентных заявлений. Лица, располагающие информацией о патентах, которые могут содержать существенные пункты (Essential Claims), обязаны раскрыть эту информацию в соответствии с разделом 6 Патентной политики W3C.
Процесс W3C
Документ регулируется Процессом W3C от 14 октября 2005 года.
1. Мотивация
(Данный раздел не является нормативным)
Проблемы RDF/XML
Спецификация RDF/XML [RDF-SYNTAX-GRAMMAR] обеспечивает достаточную гибкость для представления всех абстрактных концепций RDF. Однако у неё есть ряд недостатков:
Сложность валидации
- Документы, содержащие RDF/XML, крайне сложно (или невозможно) проверять с помощью XML-схем (XML Schemas) или DTD.
- Это затрудняет интеграцию RDF/XML в другие языки разметки.
- Новые языки схем, такие как RELAX NG [RELAXNG-SCHEMA], поддерживают валидацию произвольного RDF/XML, но их широкое внедрение займёт время.
Дублирование данных
- Даже если добавить RDF/XML напрямую в XML-диалект (например, XHTML), возникнет дублирование между визуальным содержимым и структурированными данными RDF.
- Идеальным решением было бы дополнять документ RDF-разметкой без повторения существующих данных.
- Пример: если имя автора указано в тексте (например, в подписи к новости), его не нужно дублировать в RDF — разметка должна позволять интерпретировать существующие данные как часть RDF-структуры.
Преимущества интеграции структуры и содержимого
Контекстная структуризация
- Совмещение визуальных и структурированных данных упрощает передачу информации между приложениями (включая не-веб-системы).
- Пример: пользователи могут получать дополнительную информацию о данных (например, через контекстное меню по клику).
Удобство для издателей
- Организациям, публикующим много контента (например, СМИ), проще встраивать семантические данные напрямую в разметку, чем поддерживать их отдельно.
Ограничения «жёстко заданных» атрибутов
- В традиционных языках разметки (например, XHTML 1.1 [XHTML11] или HTML [HTML401]) используются атрибуты с фиксированной семантикой, такие как
@citeдля указания источника цитаты. - Однако такие атрибуты:
- Требуют от процессоров RDFa знания каждого специфичного атрибута.
- Усложняют создание универсальных инструментов извлечения метаданных.
Решение через RDFa
Гибкость вместо «жёсткой» разметки
- RDFa предлагает универсальный набор атрибутов и правил разбора, позволяющий использовать свойства из любых RDF-словарей.
- В большинстве случаев значения этих свойств уже присутствуют в документе.
Снижение нагрузки на разработчиков языков
- RDFa устраняет необходимость предугадывать все возможные требования пользователей к структуре.
- Дизайнеры языков могут легко интегрировать RDFa, обеспечивая извлечение семантических данных любыми совместимыми процессорами.
Ключевые тезисы
- RDFa избегает дублирования данных, используя существующую разметку.
- Позволяет добавлять произвольные семантические свойства без привязки к конкретному словарю.
- Упрощает создание единого стандарта для извлечения метаданных из любых документов.
6.2.1 - Обзор синтаксиса
Следующие примеры помогут новичкам быстро понять принципы работы RDFa.
Для более глубокого изучения рекомендуется ознакомиться с RDFa Primer.
Сокращённые IRIs (CURIEs)
В RDF принято сокращать термины словарей с помощью префиксов и ссылок. Этот механизм подробно описан в разделе Compact URI Expressions. В примерах ниже используются следующие предопределённые префиксы словарей:
Примечание о локальных идентификаторах
В некоторых примерах используются IRI с фрагментными идентификаторами (например, about="#me"), которые ссылаются на сущности внутри текущего документа. Этот подход:
- Широко применяется в RDF/XML [RDF-SYNTAX-GRAMMAR] и других сериализациях RDF.
- Позволяет легко создавать новые IRIs для объектов, описываемых через RDFa, значительно расширяя выразительные возможности.
Точная семантика таких IRIs в RDF-графах определена в разделе 7 RDF-SYNTAX-GRAMMAR.
Важно
Для корректной интерпретации фрагментных идентификаторов регистрации MIME-типов языков разметки, поддерживающих RDFa, должны ссылаться на эту спецификацию (прямо или косвенно).2.1 Атрибуты RDFa
RDFa использует ряд распространённых атрибутов, а также вводит несколько новых. Атрибуты, уже существующие в популярных языках разметки (например, HTML), сохраняют своё исходное значение, хотя в некоторых случаях их синтаксис был немного модифицирован. Например, в (X)HTML нет чёткого способа добавлять новые значения для атрибута @rel; RDFa явно решает эту проблему, разрешая использовать IRI в качестве значений. Также вводятся понятия терминов и “компактных выражений URI” (CURIEs), которые позволяют кратко выражать полные значения IRI. Полный список атрибутов RDFa и их синтаксис приведён в разделе “Атрибуты и синтаксис”.
2.2 Примеры
В (X)HTML авторы могут включать метаданные и отношения, касающиеся текущего документа, используя элементы meta и link (в этих примерах используется XHTML+RDFa [XHTML-RDFA]). Например, автор страницы вместе со ссылками на предыдущую и следующую страницы могут быть выражены следующим образом:
Пример 1
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Страница 7</title>
<meta name="author" content="Марк Бирбек" />
<link rel="prev" href="page6.html" />
<link rel="next" href="page8.html" />
</head>
<body>...</body>
</html>
RDFa использует эту концепцию, расширяя её возможностью работы с различными словарями через полные IRI:
Пример 2
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Моя домашняя страница</title>
<meta property="http://purl.org/dc/terms/creator" content="Марк Бирбек" />
<link rel="http://xmlns.com/foaf/0.1/topic" href="http://www.example.com/#us" />
</head>
<body>...</body>
</html>
Поскольку использование полных IRI, как в примере выше, может быть громоздким, RDFa также разрешает использовать компактные выражения URI (CURIEs), позволяя авторам применять сокращения для ссылок на термины из различных словарей:
Пример 3
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="foaf: http://xmlns.com/foaf/0.1/
dc: http://purl.org/dc/terms/"
>
<head>
<title>Моя домашняя страница</title>
<meta property="dc:creator" content="Марк Бирбек" />
<link rel="foaf:topic" href="http://www.example.com/#us" />
</head>
<body>...</body>
</html>
RDFa поддерживает использование @rel и @rev на любых элементах. Это становится ещё полезнее с добавлением поддержки различных словарей:
Пример 4
Этот документ распространяется по лицензии
<a prefix="cc: http://creativecommons.org/ns#"
rel="cc:license"
href="http://creativecommons.org/licenses/by-nc-nd/3.0/"
>Creative Commons By-NC-ND License</a>.
RDFa позволяет повторно использовать не только IRI в документе для предоставления метаданных, но и встроенный текст при использовании с @property:
Пример 5
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="dc: http://purl.org/dc/terms/"
>
<head><title>Моя домашняя страница</title></head>
<body>
<h1 property="dc:title">Моя домашняя страница</h1>
<p>Последнее изменение: 16 сентября 2015</p>
</body>
</html>
Когда отображаемый текст отличается от фактического значения, можно указать точное значение с помощью атрибута @content. Также можно явно указать тип данных через @datatype:
Пример 6
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="xsd: http://www.w3.org/2001/XMLSchema#
dc: http://purl.org/dc/terms/"
>
<head><title>Моя домашняя страница</title></head>
<body>
<h1 property="dc:title">Моя домашняя страница</h1>
<p>Последнее изменение:
<span property="dc:modified"
content="2015-09-16T16:00:00-05:00"
datatype="xsd:dateTime">16 сентября 2015</span>.
</p>
</body>
</html>
RDFa позволяет описывать метаданные не только для текущего документа, но и для других ресурсов:
Пример 7
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="bibo: http://purl.org/ontology/bibo/
dc: http://purl.org/dc/terms/"
>
<head>
<title>Книги Марко Пьера Уайта</title>
</head>
<body>
Я считаю, что книга Уайта
«<span about="urn:ISBN:0091808189"
property="dc:title">Кухня столовой</span>»
стоит того, чтобы её приобрести: хотя рецепты сложные,
автор объясняет их очень доступно. Вам также может понравиться
<span about="urn:ISBN:1596913614"
property="dc:description">автобиография Уайта</span>.
</body>
</html>
Для группировки свойств, относящихся к одному объекту, используется атрибут @typeof:
Пример 8
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="bibo: http://purl.org/ontology/bibo/
dc: http://purl.org/dc/terms/"
>
<head>
<title>Книги Марко Пьера Уайта</title>
</head>
<body>
Я считаю, что книга Уайта
«<span about="urn:ISBN:0091808189" typeof="bibo:Book"
property="dc:title">Кухня столовой</span>»
стоит того, чтобы её приобрести. Также рекомендую
<span about="urn:ISBN:1596913614"
typeof="bibo:Book"
property="dc:description"
>автобиографию Уайта</span>.
</body>
</html>
Для небольших фрагментов разметки иногда удобнее использовать полные IRI:
Пример 9
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Книги Марко Пьера Уайта</title>
</head>
<body>
Книга Уайта
«<span about="urn:ISBN:0091808189"
typeof="http://purl.org/ontology/bibo/Book"
property="http://purl.org/dc/terms/title"
>Кухня столовой</span>»
написана очень доступно. Также обратите внимание на
<span about="urn:ISBN:1596913614"
typeof="http://purl.org/ontology/bibo/Book"
property="http://purl.org/dc/terms/description"
>его автобиографию</span>.
</body>
</html>
Атрибут @vocab позволяет определить словарь по умолчанию для элементов:
Пример 10
<div vocab="http://xmlns.com/foaf/0.1/" about="#me">
Меня зовут <span property="name">Иван Иванов</span>, а мой блог —
<a rel="homepage" href="http://example.org/blog/">«Понимая семантику»</a>.
</div>
Приведённый выше пример (Пример 10) сгенерирует следующие триплеты в формате Turtle:
Пример 11
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<#me> foaf:name "John Doe" ;
foaf:homepage <http://example.org/blog/> .
В простых случаях атрибут @property может использоваться вместо @rel. Фактически, когда элемент не содержит атрибутов @rel, @datatype или @content, но имеет, например, атрибут @href, эффект от @property аналогичен @rel.
Тот же пример можно переписать следующим образом:
Пример 12
<div vocab="http://xmlns.com/foaf/0.1/" about="#me">
Меня зовут <span property="name">Иван Иванов</span>, а мой блог —
<a property="homepage" href="http://example.org/blog/">«Понимая семантику»</a>.
</div>
Особенности обработки:
- Когда используется только @property с элементом, содержащим @href, система интерпретирует это как отношение (аналогично @rel)
- Такой подход упрощает разметку в случаях, когда не требуется явное указание типа связи
Это демонстрирует гибкость RDFa в интерпретации различных вариантов разметки как семантически эквивалентных структур.
6.2.2 - Терминология RDF
Обзор терминологии RDF в различных примерах
3. Терминология RDF
Введение
Предыдущий раздел иллюстрировал типичную разметку RDFa. Хотя для создания RDFa-разметки глубокое понимание RDF не обязательно, разработчикам систем, обрабатывающих RDF-вывод, необходимо разбираться в концепциях RDF. Далее представлены базовые понятия. Для углублённого изучения обратитесь к:
3.1 Утверждения (Statements)
Структурированные данные в RDFa представляют собой коллекцию утверждений — минимальных единиц информации, оформленных по определённым правилам для упрощения обработки. Даже сложные метаданные можно обрабатывать, разбивая их на такие утверждения.
Пример неструктурированных данных:
Альберт родился 14 марта 1879 года в Германской империи. Его фото доступно
по адресу http://en.wikipedia.org/wiki/Image:Albert_Einstein_Head.jpg.
Для машины этот текст неинтерпретируем. В формате утверждений та же информация выглядит так:
Альберт родился 14 марта 1879 года
Альберт родился в Германской империи
Альберт имеет фото http://en.wikipedia.org/...
3.2 Триплеты (Triples)
RDF формализует утверждения как триплеты — структуры из трёх компонентов:
Субъект (Subject)
- Объект, о котором делается утверждение.
- В примерах: «Альберт».
Предикат (Predicate)
- Свойство субъекта.
- В примерах: «родился», «имеет фото».
Объект (Object)
- Значение свойства.
- В примерах: дата, место, URL фото.
Пример триплетов в RDF:
<Albert> <wasBornOn> "March 14, 1879" .
<Albert> <wasBornIn> <German_Empire> .
<Albert> <hasPhoto> <http://.../Albert_Einstein_Head.jpg> .
Особенности:
- RDFa поддерживает интернационализированные символы (Unicode) во всех компонентах триплета.
- Субъекты и предикаты обычно выражаются IRI, объекты — IRI или литералы (строки/числа).
3.3 Ссылки на IRI
Разбиение сложной информации на управляемые части помогает уточнить данные, но не исключает неоднозначности. Например, о каком именно “Альберте” идёт речь? Если другая система содержит дополнительные факты об “Альберте”, как определить, что они относятся к тому же человеку? Как сопоставить предикаты “родился в” и “место рождения” из разных систем? RDF решает эти проблемы, заменяя расплывчатые термины на ссылки IRI.
Уникальные идентификаторы
Хотя IRI чаще всего используются для идентификации веб-страниц, в RDF они служат уникальными идентификаторами концепций. Например, вместо неоднозначной строки “Альберт” можно использовать IRI из DBPedia:
Пример 15
<http://dbpedia.org/resource/Albert_Einstein>
имеет имя
"Альберт Эйнштейн".
<http://dbpedia.org/resource/Albert_Einstein>
родился
"14 марта 1879".
<http://dbpedia.org/resource/Albert_Einstein>
родился в
<http://dbpedia.org/resource/German_Empire>.
<http://dbpedia.org/resource/Albert_Einstein>
имеет фотографию
<http://.../Albert_Einstein_Head.jpg>.
Идентификация объектов
IRI также используются для однозначного определения объектов (третья часть триплета). Фотография уже имеет IRI, но можно аналогично идентифицировать и “Германскую империю”. Строковые значения (литералы) выделяются кавычками:
Пример 16
<http://dbpedia.org/resource/Albert_Einstein>
<http://xmlns.com/foaf/0.1/name>
"Альберт Эйнштейн".
<http://dbpedia.org/resource/Albert_Einstein>
<http://dbpedia.org/property/dateOfBirth>
"14 марта 1879".
Унификация предикатов
IRI устраняют неоднозначность предикатов, объединяя синонимы (“место рождения”, “birthplace”, “Lieu de naissance”) под одним идентификатором:
Пример 17
<http://dbpedia.org/resource/Albert_Einstein>
<http://dbpedia.org/property/birthPlace>
<http://dbpedia.org/resource/German_Empire>.
Ключевые преимущества:
- Устранение неоднозначностей — IRI точно идентифицируют сущности
- Межсистемная совместимость — разные источники могут ссылаться на одни и те же концепции
- Поддержка многоязычия — один IRI может представлять понятие на любом языке
Особенности реализации:
- Литералы (строки, числа) всегда заключаются в кавычки
- Веб-адреса (URL) и другие IRI обрамляются угловыми скобками
- Использование общепринятых словарей (FOAF, DBpedia) улучшает связанность данных
3.4 Простые литералы (Plain Literals)
Хотя для субъектов и предикатов всегда используются IRI-идентификаторы, объект в триплете может быть как IRI, так и литералом. В примерах имя Эйнштейна представлено простым литералом — строкой без указания типа или языка:
Пример 18
<http://dbpedia.org/resource/Albert_Einstein>
<http://xmlns.com/foaf/0.1/name> "Альберт Эйнштейн".
Литералы с указанием языка
Для текстов на естественных языках используется тег языка. Например, название Германской империи на разных языках:
Пример 19
<http://dbpedia.org/resource/German_Empire>
rdfs:label "German Empire"@en;
rdfs:label "Deutsches Kaiserreich"@de;
rdfs:label "Германская империя"@ru.
3.5 Типизированные литералы (Typed Literals)
Для специальных значений (даты, числа и т.д.) в RDF предусмотрен механизм указания типа литерала. Типизированный литерал формируется путём добавления IRI типа данных после литерала с использованием символов ^^. Обычно используются типы данных из спецификации XML Schema:
Пример 20
<http://dbpedia.org/resource/Albert_Einstein>
<http://dbpedia.org/property/dateOfBirth>
"1879-03-14"^^<http://www.w3.org/2001/XMLSchema#date>.
Ключевые особенности:
Строковые литералы
- Простые текстовые значения без дополнительной информации
- Могут включать указание языка (
@"ru")
Типизированные значения
- Числа:
"42"^^xsd:integer - Даты:
"2023-05-15"^^xsd:date - Логические значения:
"true"^^xsd:boolean
- Числа:
Стандартные типы данных
- Используются XSD-типы (
xsd:string,xsd:dateTimeи др.) - Позволяют однозначно интерпретировать значения
- Используются XSD-типы (
Практическое применение:
# Числовое значение
<http://example.org/product/123>
ex:weight "2.5"^^xsd:decimal.
# Дата и время
ex:event ex:startTime "2023-05-15T19:00:00"^^xsd:dateTime.
# Булево значение
ex:user ex:isActive "true"^^xsd:boolean.
3.6 Turtle (Синтаксис Turtle)
RDF не имеет единого обязательного формата представления триплетов, поскольку ключевыми концепциями являются сами триплеты и использование IRI, а не конкретный синтаксис. Однако существует несколько способов выражения триплетов, включая RDF/XML, Turtle и, конечно, RDFa. В документации часто используется синтаксис Turtle благодаря его компактности.
Пример с префиксами:
@prefix dbp: <http://dbpedia.org/property/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<http://dbpedia.org/resource/Albert_Einstein>
foaf:name "Альберт Эйнштейн" .
<http://dbpedia.org/resource/Albert_Einstein>
dbp:birthPlace <http://dbpedia.org/resource/German_Empire> .
Расширенный пример:
@prefix dbr: <http://dbpedia.org/resource/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
dbr:Albert_Einstein
foaf:name "Альберт Эйнштейн";
dbp:dateOfBirth "1879-03-14"^^xsd:date;
foaf:depiction <http://example.org/einstein.jpg> .
Специальные обозначения:
<>- обозначает текущий обрабатываемый документ- Префиксы используются только для удобства записи, в итоговых триплетах всегда полные IRI
3.7 Графы
Совокупность триплетов называется графом. Все триплеты, генерируемые согласно этой спецификации, содержатся в выходном графе, создаваемом процессором RDFa.
3.8 Компактные выражения URI (CURIEs)
Для сокращённой записи IRI в разметке RDFa использует механизм CURIEs. Подробное описание - в разделе “Обработка CURIE и IRI”.
Важно: CURIEs используются только в разметке и примерах, в итоговых триплетах всегда присутствуют полные IRI.
3.9 Фрагменты разметки и RDFa
При переносе фрагментов разметки между документами (например, через копирование или инструменты) следует учитывать:
- Обработка изолированных фрагментов вне контекста полного документа не определена
- Разработчикам инструментов следует предусматривать передачу необходимого контекста
- Авторам фрагментов нужно учитывать их поведение в составе полного документа
3.10 Описание RDFa в терминах RDF
Краткое соответствие между RDFa и RDF:
| Компонент RDF | Эквивалент в RDFa |
|---|---|
| Субъект | @about |
| Предикат | @property, @rel, @rev |
| Объект (IRI) | @resource, @href, @src |
| Объект (литерал) | @content или содержимое элемента |
| Тип данных | @datatype |
| Язык | @xml:lang или аналоги |
Пример соответствия:
<div about="#albert"
property="foaf:name"
content="Альберт Эйнштейн"
datatype="xsd:string">
Генерируемый триплет:
<http://example.org/doc#albert>
<http://xmlns.com/foaf/0.1/name>
"Альберт Эйнштейн"^^xsd:string .
6.2.3 - Соответствие в RDF
Помимо разделов, помеченных как ненормативные, все рекомендации по разработке, диаграммы, примеры и примечания в этой спецификации не являются нормативными. Все остальное в этой спецификации является нормативным.
Ключевые слова MAY (может), MUST (должен), MUST NOT (не должен), RECOMMENDED (рекомендуется), SHOULD (следует) и SHOULD NOT (не следует) должны интерпретироваться в соответствии с [RFC2119].
4.1 Соответствие процессора RDFa
В данной спецификации термин выходной граф означает все триплеты, утвержденные документом в соответствии с разделом Модель обработки. Соответствующий требованиям процессор RDFa ДОЛЖЕН предоставить потребляющему приложению единый RDF-граф, содержащий все возможные триплеты, сгенерированные с использованием правил из раздела Модель обработки. Термин граф процессора используется для обозначения всех информационных, предупреждающих и ошибочных триплетов, которые МОГУТ быть сгенерированы процессором RDFa для отчета о своем состоянии. Выходной граф и граф процессора являются отдельными графами, и процессор RDFa НЕ ДОЛЖЕН хранить их в одном графе. Однако процессоры могут разрешать одновременное получение обоих графов; подробности см. в разделе 7.6.1.
Соответствующий требованиям процессор RDFa МОЖЕТ предоставлять дополнительные триплеты, сгенерированные с использованием правил, не описанных здесь, но эти триплеты НЕ ДОЛЖНЫ включаться в выходной граф. (Будут ли эти дополнительные триплеты доступны в одном или нескольких дополнительных RDF-графах, зависит от реализации и здесь не определяется.)
Соответствующий требованиям процессор RDFa ДОЛЖЕН сохранять пробельные символы как в простых литералах, так и в XML-литералах. Однако может случиться так, что архитектура, в которой работает процессор, изменила пробельные символы в документе до того, как он попал в процессор RDFa (например, процессоры [XMLSCHEMA11-1] могут «нормализовать» пробелы в значениях атрибутов — см. раздел 3.1.4). Чтобы обеспечить максимальную согласованность между средами обработки, авторам СЛЕДУЕТ удалять все избыточные пробелы в своих простых и XML-литералах.
Соответствующий требованиям процессор RDFa ДОЛЖЕН анализировать медиатип документа, который он обрабатывает, чтобы определить его язык-хост. Если процессор RDFa не может определить медиатип или не поддерживает его, он ДОЛЖЕН обрабатывать документ так, как если бы его медиатип был application/xml. См. Соответствие документов XML+RDFa. Язык-хост МОЖЕТ определять дополнительные механизмы объявления.
Примечание
Соответствующий требованиям процессор RDFa МОЖЕТ использовать дополнительные механизмы (например,DOCTYPE, расширение файла, корневой элемент, переопределяемый пользовательский параметр) для определения языка-хоста, если медиатип недоступен. Эти механизмы не регламентируются.4.2 Соответствие языка-хоста RDFa
Языки-хосты, включающие RDFa, должны соответствовать следующим требованиям:
- Все функции, требуемые в данной спецификации, ДОЛЖНЫ быть включены в язык-хост.
- Обязательные атрибуты, определенные в данной спецификации, ДОЛЖНЫ быть включены в модель содержимого языка-хоста.
Примечание
Во избежание сомнений, нет требования, чтобы атрибуты, такие как@href и @src, использовались в соответствующем языке-хостe. Также нет требования, чтобы все обязательные атрибуты были включены в модель содержимого всех элементов. Рабочая группа рекомендует разработчикам языков-хостов обеспечивать включение обязательных атрибутов в модель содержимого элементов, которые часто используются в языке.- Если язык-хост использует пространства имен XML [XML-NAMES], атрибуты из этой спецификации СЛЕДУЕТ определять «без пространства имен» (например, когда атрибуты используются на элементах в пространстве имен языка-хоста, они могут применяться без префикса:
<myml:myElement property="license">). Если язык-хост не использует атрибуты «без пространства имен», они ДОЛЖНЫ ссылаться на пространство имен XHTML (http://www.w3.org/1999/xhtml). - Если язык-хост имеет собственное определение для любого атрибута, описанного в данной спецификации, это определение ДОЛЖНО обеспечивать возможность обработки, требуемой данной спецификацией, когда атрибут используется в соответствии с ее требованиями.
- Язык-хост МОЖЕТ определять начальный контекст (например, IRI-отображения и/или определение терминов или IRI словаря по умолчанию). Такой начальный контекст СЛЕДУЕТ определять с использованием соглашений, описанных в Начальные контексты RDFa.
4.3 Соответствие документов XML+RDFa
Данная спецификация не определяет самостоятельный тип документа. Атрибуты здесь предназначены для интеграции в другие языки-хосты (например, HTML+RDFa или XHTML+RDFa). Однако данная спецификация определяет правила обработки для общих XML-документов — то есть документов, доставляемых с медиатипами text/xml или application/xml. Такие документы должны соответствовать всем следующим критериям:
- Документ ДОЛЖЕН быть корректно сформированным, как определено в [XML10-4e].
- Документ СЛЕДУЕТ использовать атрибуты, определенные в данной спецификации, «без пространства имен» (например,
<myml:myElement property="license">).
Примечание
Возможно, что XML-грамматика будет иметь собственные атрибуты, конфликтующие с атрибутами из этой спецификации. Это может привести к тому, что процессор RDFa сгенерирует неожиданные триплеты.- Существуют термины по умолчанию (например,
describedby,license,role), определенные вhttp://www.w3.org/2011/rdfa-context/rdfa-1.1. - Существуют префиксные отображения по умолчанию (например,
dc), определенные вhttp://www.w3.org/2011/rdfa-context/rdfa-1.1. - Нет IRI словаря по умолчанию.
- База может быть установлена с помощью атрибута
@xml:base, как определено в [XML10-4e]. - Текущий язык может быть установлен с помощью атрибута
@xml:lang.
6.2.4 - Аттрибуты и синтаксис в RDF
Данная спецификация определяет ряд атрибутов и способ интерпретации их значений при генерации RDF-триплетов. В этом разделе описываются атрибуты и синтаксис их значений.
Атрибуты:
aboutSafeCURIEorCURIEorIRI— указывает, о чем именно представлены данные («субъект» в терминологии RDF).contentCDATA-строка — предоставляет машиночитаемое содержимое для литерала («литеральный объект» в терминологии RDF).datatypeTERMorCURIEorAbsIRI— определяет тип данных литерала.href(опциональный)
Традиционно навигационный IRI — выражает связанный ресурс отношения («ресурсный объект» в терминологии RDF).inlist
Атрибут, указывающий, что объект, связанный с атрибутамиrelилиpropertyна том же элементе, должен быть добавлен в список для данного предиката. Значение этого атрибута ДОЛЖНО игнорироваться. Наличие атрибута приводит к созданию списка, если он ещё не существует.prefix
Список пар «префикс : IRI», разделенных пробелами, в формате:NCName ':' ' '+ xsd:anyURIproperty
СписокTERMorCURIEorAbsIRI, разделенных пробелами, — выражает отношения между субъектом и либо ресурсным объектом (если указан), либо текстовым литералом («предикат»).rel
СписокTERMorCURIEorAbsIRI, разделенных пробелами, — выражает отношения между двумя ресурсами («предикаты» в терминологии RDF).resourceSafeCURIEorCURIEorIRI— выражает связанный ресурс отношения, не предназначенный для навигации (например, не «кликабельная» ссылка) («объект»).rev
СписокTERMorCURIEorAbsIRI, разделенных пробелами, — выражает обратные отношения между двумя ресурсами («предикаты»).src(опциональный)
IRI — выражает связанный ресурс отношения, когда ресурс встроен («ресурсный объект»).typeof
СписокTERMorCURIEorAbsIRI, разделенных пробелами, — указывает RDF-тип(ы), связываемые с субъектом.vocab
IRI — определяет отображение, используемое при ссылке на термин в значении атрибута. См. Общее использование терминов в атрибутах и раздел Расширение словаря.
Примечание
Во всех случаях возможно использование этих атрибутов без значения (например, @datatype="") или со значением, которое после обработки по правилам CURIE и IRI становится пустым (например, @datatype="[noprefix:foobar]").
5.1 Роли атрибутов
Атрибуты RDFa выполняют разные роли в семантически насыщенном документе. Вкратце:
- Синтаксические атрибуты:
@prefix,@vocab. - Атрибуты субъекта:
@about. - Атрибуты предиката:
@property,@rel,@rev. - Атрибуты ресурса:
@resource,@href,@src. - Атрибуты литерала:
@datatype,@content,@xml:langили@lang. - Макроатрибуты:
@typeof,@inlist.
5.2 Пробелы в значениях атрибутов
Многие атрибуты принимают список токенов, разделенных пробелами. В данной спецификации пробел определяется как:
whitespace ::= (#x20 | #x9 | #xD | #xA)+
Если атрибут принимает список токенов, разделенных пробелами, процессор RDFa ДОЛЖЕН игнорировать любые ведущие или завершающие пробелы.
Примечание
Это определение согласуется с определением из [XML10].6.2.5 - Определение синтаксиса CURIE в RDF
Ключевым компонентом RDF является IRI, но такие идентификаторы обычно длинные и неудобные. Поэтому RDFa поддерживает механизм сокращения IRI, называемый компактными URI-выражениями (CURIE).
6. Определение синтаксиса CURIE
Примечание
Рабочая группа в настоящее время анализирует приведённые ниже правила формирования CURIE с учётом недавних замечаний от RDF Working Group и участников RDFa Working Group. Возможны незначительные изменения в правилах в ближайшем будущем, которые могут оказаться обратно несовместимыми. Однако любые такие несовместимости будут ограничены крайними случаями.
Основные положения
Ключевым компонентом RDF является IRI, но такие идентификаторы обычно длинные и неудобные. Поэтому RDFa поддерживает механизм сокращения IRI, называемый компактными URI-выражениями (CURIE).
При раскрытии CURIE ДОЛЖЕН получаться синтаксически корректный IRI ([RFC3987]). Подробнее см. Обработка CURIE и IRI. Лексическое пространство CURIE определяется правилом curie, приведённым ниже. Пространство значений — это множество IRI.
CURIE состоит из двух компонентов: префикса и ссылки. Префикс отделяется от ссылки двоеточием (:). В общем случае префикс можно опустить, создав CURIE, использующий отображение префикса по умолчанию. В RDFa отображение префикса по умолчанию — http://www.w3.org/1999/xhtml/vocab#. Также можно опустить и префикс, и двоеточие, создав CURIE, содержащий только ссылку, использующую отображение без префикса. Данная спецификация НЕ определяет отображение без префикса. Языки-хосты RDFa НЕ ДОЛЖНЫ определять отображение без префикса.
Примечание
Префикс по умолчанию в RDFa не следует путать с пространством имён по умолчанию, определённым в [XML-NAMES]. Процессор RDFa НЕ ДОЛЖЕН обрабатывать объявление пространства имён по умолчанию в XML-NAMES так, как если бы оно устанавливало префикс по умолчанию.
Общий синтаксис CURIE
Синтаксис CURIE можно описать следующим образом:
prefix ::= NCName
reference ::= ( ipath-absolute / ipath-rootless / ipath-empty )
[ "?" iquery ] [ "#" ifragment ] (как определено в [[!RFC3987]])
curie ::= [ [ prefix ] ':' ] reference
safe_curie ::= '[' [ [ prefix ] ':' ] reference ']'
Примечание
Правилоsafe_curie не является обязательным, даже в ситуациях, когда значение атрибута может быть CURIE или IRI: IRI, использующий схему, не соответствующую текущим отображениям, нельзя спутать с CURIE. Концепция safe_curie сохранена для обратной совместимости.Примечание
Можно определить отображение префикса CURIE таким образом, что оно «перекроет» определённую схему IRI. Например, документ может сопоставить префиксmailto с http://www.example.com/addresses/. Тогда атрибут @resource со значением mailto:user@example.com может создать триплет с объектом http://www.example.com/addresses/user@example.com. Более того, возможно (хотя и маловероятно), что в будущем появятся схемы, конфликтующие с отображениями префиксов в документе (например, предлагаемая схема widget [WIDGETS-URI]). В обоих случаях такое «перекрытие» не изменит способ обработки IRI другими потребителями, но может привести к неверной интерпретации CURIE автора документа. Рабочая группа считает этот риск минимальным.Контекст обработки CURIE
При обычной обработке CURIE требуется следующая контекстная информация:
- Набор отображений префиксов в IRI.
- Отображение для префикса по умолчанию (например,
:p). - Отображение для случая без префикса (например,
p). - Отображение для префикса
_, который используется для генерации уникальных идентификаторов (например,_:p).
В RDFa эти значения определяются следующим образом:
- Набор отображений префиксов в IRI предоставляется текущими активными объявлениями префиксов элемента во время разбора.
- Отображение для префикса по умолчанию — текущее отображение префикса по умолчанию.
- Отображение для случая без префикса НЕ определено.
- Отображение для префикса
_не указано явно, но, поскольку он используется для генерации blank nodes, его реализация должна быть совместима с определением RDF и правилами из Ссылки на Blank Nodes. Документ НЕ ДОЛЖЕН определять отображение для префикса_. Соответствующий требованиям процессор RDFa ДОЛЖЕН игнорировать любые определения отображений для префикса_.
Правила преобразования CURIE в IRI
CURIE представляет собой полный IRI. Правила его определения:
- Если CURIE состоит из пустого префикса и ссылки, IRI получается путём конкатенации текущего отображения префикса по умолчанию и ссылки. Если отображение префикса по умолчанию отсутствует, CURIE считается невалидным и ДОЛЖЕН игнорироваться.
- Если CURIE состоит из непустого префикса и ссылки, и для префикса существует активное отображение (сравнение без учёта регистра), то IRI создаётся путём конкатенации этого отображения и ссылки.
- Если для префикса нет активного отображения, значение не является валидным CURIE.
Примечание
См. Общее использование терминов в атрибутах для случаев, когда элементы без двоеточия могут интерпретироваться процессорами RDFa в некоторых типах данных.6.1 Почему CURIE, а не QNames?
(Этот раздел является не нормативным.)
Во многих случаях разработчики языков пытались использовать QNames в качестве механизма расширения [XMLSCHEMA11-2]. QNames действительно позволяют управлять коллекцией имён независимо и могут сопоставлять имена с ресурсами. Однако QNames в большинстве случаев не подходят, потому что:
- Использование QName в качестве идентификаторов в значениях атрибутов и содержимом элементов проблематично, как обсуждается в [QNAMES].
- Синтаксис QNames избыточно строг и не позволяет выразить все возможные IRI.
Пример проблемы: попытка определить коллекцию имён для книг. В QName часть после двоеточия должна быть валидным именем элемента, что делает следующий пример недопустимым:
isbn:0321154991
Это невалидный QName, потому что 0321154991 не является допустимым именем элемента. Однако в данном случае нам и не нужно определять валидное имя элемента — цель использования QName заключалась в ссылке на элемент в частной области видимости (ISBN). Более того, мы хотим, чтобы имена в этой области видимости сопоставлялись с IRI, раскрывающим смысл ISBN. Как видно, определение QNames противоречит этому (довольно распространённому) сценарию.
Данная спецификация решает проблему, вводя CURIE. Синтаксически CURIE являются надмножеством QNames.
Важно
Эта спецификация предназначена для разработчиков языков, а не авторов документов. Любой разработчик языка, рассматривающий использование QNames для представления IRI или уникальных токенов, должен вместо этого рассмотреть CURIE:
- CURIE изначально разработаны для использования в значениях атрибутов. QNames предназначены для однозначного именования элементов и атрибутов.
- CURIE раскрываются в IRI, и любой IRI может быть представлен таким образом. QNames обрабатываются как пары значений, но даже если их объединить в строку, можно представить только подмножество IRI.
- CURIE можно использовать в не-XML грамматиках и даже в XML-языках, не поддерживающих XML Namespaces. QNames ограничены XML-приложениями с поддержкой XML Namespaces.
7 - Latex
«TeX» — это созданная американским математиком и программистом Дональдом Кнутом (Donald E. Knuth) система для верстки текстов с формулами.
«TeX» — это созданная американским математиком и программистом Дональдом Кнутом (Donald E. Knuth) система для верстки текстов с формулами.
Сам по себе TEX представляет собой специализированный язык программирования (Кнут не только придумал язык, но и написал для него транслятор, причем таким образом, что он работает совершенно одинаково на самых разных компьютерах), на котором пишутся издательские системы, используемые на практике.
Точнее говоря, каждая издательская система на базе TEX’а представляет собой пакет макроопределений (макропакет) этого языка.
«LaTeX») — это созданная Лесли Лэмпортом (Leslie Lamport) издательская система на базе TEX’а.
7.1 - Библиотека цветных блоков и рамок tcolorbox для Latex
Этот пакет предоставляет окружение для цветных и обрамленных текстовых блоков с заголовком.
Официальное описание пакета по адресу: https://ctan.org/pkg/tcolorbox
tcolorbox – Цветные рамки для примеров и теорем в LaTeX и т. д.
Этот пакет предоставляет среду для цветных текстовых рамок с заголовком. По желанию, такая рамка может быть разделена на верхнюю и нижнюю части; таким образом, пакет может быть использован для настройки примеров LaTeX, где одна часть рамки отображает исходный код, а другая часть показывает результат. Другой распространенный случай использования – настройка теорем. Пакет поддерживает сохранение и повторное использование исходного кода и частей текста.
Пакет зависит от пакетов pgf, verbatim, environ и etoolbox.
Пример обложки документации
\documentclass[a4paper]{article}
\usepackage{tikz}
\usepackage[all]{tcolorbox}
\usepackage{incgraph}
\usepackage{lipsum}
\usepackage{accsupp}
\begin{document}
\begin{inctext}
\begin{tikzpicture}
\definecolorseries{boxcol}{rgb}{last}{blue}{red}
\resetcolorseries[28]{boxcol}
\coordinate (A) at (0,0); \coordinate (B) at (21,29.7);
\path[use as bounding box] (A) rectangle coordinate (C) (B);
\node[transform shape,xslant=0.7,rotate=-10,xshift=0cm] at (C) {%
\BeginAccSupp{method=plain,ActualText={}}%
\begin{tcbraster}[raster columns=4,title=tcolorbox,
fonttitle=\small\bfseries,raster width=50cm]
\foreach \b in {1,...,28} {\begin{tcolorbox}[enhanced,
watermark text=\thetcbrasternum,
colframe=boxcol!30!white,
colback=boxcol!25!white!30!white,
colbacktitle=boxcol!!+!50!black!30!white,
colupper=black!30!white]\lipsum[2]\end{tcolorbox}}
\end{tcbraster}%
\EndAccSupp{}%
};
\node at (C) {%
\begin{tcbitemize}[title=tcolorbox ,fonttitle=\small\bfseries,
enhanced jigsaw,opacityback=0.5,opacitybacktitle=0.75,
halign=center,valign=center,arc=5mm,
raster width=16cm,raster column skip=8mm,raster halign=center,
raster force size=false,
raster row 1/.style={height=6cm},
raster row 2/.style={width=6cm,height=4cm},
raster column 1/.style={flushright title,
frame style={left color=yellow!50!black,right color=green!50!black},
title style={left color=yellow!50!blue,right color=blue!50!green!50!black},
interior style={left color=yellow!70,right color=green!70},
underlay={\draw[line width=6mm,line cap=round,black!60]
([shift={(0.4,-0.15)}]frame.north east)
--([shift={(0.4,0.15)}]frame.south east); }},
raster column 2/.style={
frame style={left color=green!50!black,right color=yellow!50!black},
title style={left color=blue!50!green!50!black,right color=yellow!50!blue},
interior style={left color=green!70,right color=yellow!70}}]
\tcbitem[fontupper=\Huge\bfseries,sharp corners=east,
underlay={\draw[line width=6mm,line cap=round,black!60]
([shift={(0.4,0.30)}]frame.north east)-- coordinate(A) +(0,0.2);
\draw[line width=1mm,line cap=round,black!60](A) -- +(30:1.5cm);
\draw[line width=1mm,line cap=round,black!60](A) -- +(150:1.5cm);}]
tcolorbox
\tcbitem[fontupper=\large\bfseries,sharp corners=west]
Manual for
\tcbitem[sharp corners=northeast]
\tcbitem[sharp corners=northwest] Thomas F.~Sturm
\end{tcbitemize}%
};
\end{tikzpicture}
\end{inctext}
\end{document}
Установка пакета
\usepackage{tcolorbox}
Пакет принимает ключи опций в синтаксисе “ключ-значение”. В качестве альтернативы вы можете использовать эти ключи позже в преамбуле с помощью команды \tcbuselibrary.
\tcbuselibrary{⟨key list⟩}
Вот перевод на русский язык с примерами, обернутыми в latex:
Следующие ключи используются внутри \tcbuselibrary соответственно \usepackage без ключа:
tree path
/tcb/library/./tcb/library/skins (LIB skins)
Загружает пакетtikzfill.image→ CTAN и предоставляет дополнительные стили (skins) для внешнего вида цветных коробок;\tcbuselibrary{skins}/tcb/library/vignette (LIB vignette)
Предоставляет код для более орнаментального оформления;\tcbuselibrary{vignette}/tcb/library/raster (LIB raster)
Предоставляет дополнительные макросы и опции для наборки нескольких коробок, расположенных в виде растровой сетки;\tcbuselibrary{raster}/tcb/library/listings (LIB listings)
Загружает пакетlistings→ CTAN и предоставляет дополнительные макросы для наборки листингов\tcbuselibrary{listings}/tcb/library/listingsutf8 (LIB listingsutf8)
Загружает пакетыlistings→ CTAN иlistingsutf8для поддержки UTF-8.\tcbuselibrary{listingsutf8}/tcb/library/minted (LIB minted)
Загружает пакетminted→ CTAN для наборки листингов с помощью инструмента Pygments;\tcbuselibrary{minted}/tcb/library/theorems (LIB theorems)
Предоставляет дополнительные макросы для наборки теорем\tcbuselibrary{theorems}/tcb/library/breakable (LIB breakable)
Предоставляет поддержку автоматического разбиения коробок с одной страницы на другую;\tcbuselibrary{breakable}/tcb/library/magazine (LIB magazine)
Предоставляет поддержку для хранения частей разбитых коробок для последующего использования или в измененном порядке;\tcbuselibrary{magazine}/tcb/library/poster (LIB poster)
Предоставляет поддержку для создания постеров;\tcbuselibrary{poster}/tcb/library/fitting (LIB fitting)
Предоставляет поддержку адаптации размера шрифта содержимого коробки к размерам коробки;\tcbuselibrary{fitting}/tcb/library/hooks (LIB hooks)
Расширяет несколько опций до “hookable” ключей;\tcbuselibrary{hooks}/tcb/library/xparse (LIB xparse)
Загружает пакетxparse→ CTAN и считается устаревшей библиотекой, сохраненной для совместимости;\tcbuselibrary{xparse}/tcb/library/external (LIB external)
Предоставляет поддержку экстернализации для фрагментов документов, которые могут быть самостоятельными;\tcbuselibrary{external}/tcb/library/documentation (LIB documentation)
Предоставляет дополнительные макросы для наборки документации LATEX
Основные параметры рамок tcolorbox
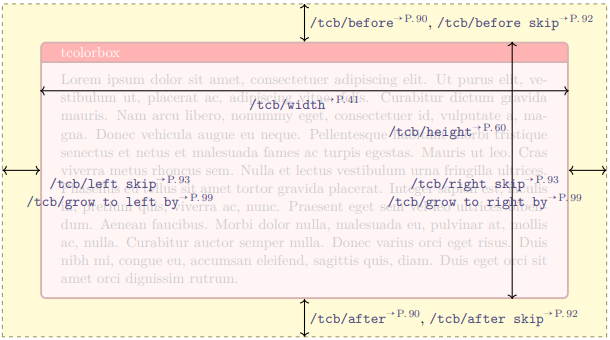
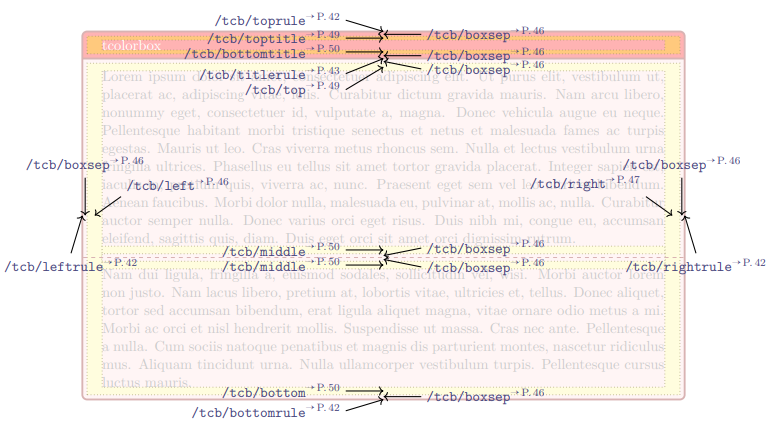
Создание рамок
Команды tcolorbox и \tcbox
\begin{tcolorbox}
This is a \textbf{tcolorbox}.
\end{tcolorbox}
\begin{tcolorbox}[colback=red!5!white,colframe=red!75!black,title=My nice heading]
This is another \textbf{tcolorbox}.
\tcblower %разделитель бокса
Here, you see the lower part of the box.
\end{tcolorbox}

\tcblower
Используется внутри tcolorbox для разделения верхней части коробки от необязательной нижней части коробки. Верхняя и нижняя части рассматриваются как отдельные функциональные единицы. Если вы хотите просто провести линию, используйте \tcbline.
Пример использования:
\begin{tcolorbox}
Верхняя часть коробки.
\tcblower
Нижняя часть коробки.
\end{tcolorbox}
\tcbset{⟨options⟩}
Устанавливает параметры для всех последующих tcolorbox внутри текущей группы TEX. По умолчанию это не применяется к вложенным коробкам.
Например, цвета коробок могут быть определены для всего документа следующим образом:
\tcbset{colback=red!5!white, colframe=red!75!black}
После этого все последующие tcolorbox будут использовать указанные цвета фона и рамки.
\tcbsetforeverylayer{⟨options⟩}
Устанавливает параметры для всех последующих tcolorbox внутри текущей группы TEX. В отличие от \tcbset, это также применяется к вложенным коробкам. Технически, параметры ⟨options⟩ добавляются к значениям по умолчанию для каждой tcolorbox, которые применяются с помощью /tcb/reset
Не следует использовать этот макрос, если вы не уверены, что хотите применять ⟨options⟩ также для коробок в коробках (в коробках в коробках и т.д.).
Пример использования:
\tcbset{colback=green!10!white}
\tcbsetforeverylayer{colframe=red!75!black}
В этом примере все последующие tcolorbox будут иметь зеленый фон и красную рамку, включая вложенные коробки.
\tcbox[⟨options⟩]{⟨box content⟩}
Создает цветную коробку, которая подгоняется по ширине к заданному содержимому ⟨box content⟩. В принципе, большинство ⟨options⟩ для tcolorbox могут быть использованы для \tcbox с некоторыми ограничениями. \tcbox не может иметь нижнюю часть и не может быть разбита.
Пример использования:
\tcbox[colback=blue!10!white, colframe=blue!75!black]{Это содержимое цветной коробки.}
В этом примере создается цветная коробка с заданным фоном и рамкой, подгоняющаяся по ширине к тексту внутри.
\tcboxverb[⟨options⟩]{⟨verbatim box content⟩}
Создает цветную коробку на основе \tcbox, которая подгоняется по ширине к заданному содержимому ⟨verbatim box content⟩. Основная \tcbox стилизована с помощью /tcb/verbatim плюс заданные ⟨options⟩. Разница с \tcbox заключается в том, что ⟨verbatim box content⟩ интерпретируется как текст без форматирования. Поэтому \tcboxverb действует аналогично \verb.
Пример использования:
\tcboxverb[colback=yellow!10!white, colframe=yellow!75!black]{\texttt{Это содержимое в verbatim-формате.}}
В этом примере создается цветная коробка с заданным фоном и рамкой, подгоняющаяся по ширине к тексту, который интерпретируется без форматирования.
Создание окружений и команд tcolorbox
\newtcolorbox[⟨init options⟩]{⟨name⟩}[⟨number⟩][⟨default⟩]{⟨options⟩}
Создает новое окружение ⟨name⟩ на основе tcolorbox. В принципе, \newtcolorbox работает как \newenvironment. Это означает, что новое окружение ⟨name⟩ может принимать ⟨number⟩ аргументов, где ⟨default⟩ — это значение по умолчанию для необязательного первого аргумента. Параметры ⟨options⟩ передаются основной tcolorbox. Обратите внимание, что /tcb/savedelimiter автоматически устанавливается на заданное ⟨name⟩. Параметры ⟨init options⟩ позволяют настроить автоматическую нумерацию.
Пример использования:
\newtcolorbox[auto numbered]{mybox}[2][default value]{colback=blue!5!white, colframe=blue!75!black, title=Заголовок}
В этом примере создается новое окружение mybox, которое может принимать два аргумента, где первый аргумент имеет значение по умолчанию “default value”. Параметры для tcolorbox задают цвет фона, цвет рамки и заголовок.
\newtcolorbox{mybox}{colback=red!5!white,
colframe=red!75!black}
\begin{mybox}
This is my own box.
\end{mybox}

\newtcolorbox{mybox}[1]{colback=red!5!white,
colframe=red!75!black,fonttitle=\bfseries,
title={#1}}
\begin{mybox}{Hello there}
This is my own box with a mandatory title.
\end{mybox}

\newtcolorbox{mybox}[2][]{colback=red!5!white,
colframe=red!75!black,fonttitle=\bfseries,
colbacktitle=red!85!black,enhanced,
attach boxed title to top center={yshift=-2mm},
title={#2},#1}
\begin{mybox}[colback=yellow]{Hello there}
This is my own box with a mandatory title
and options.
\end{mybox}

\newtcolorbox[auto counter,number within=section]{pabox}[2][]{%
colback=red!5!white,colframe=red!75!black,fonttitle=\bfseries,
title=Examp.~\thetcbcounter: #2,#1}
\begin{pabox}[colback=yellow]{Hello there}
This is my own box with a mandatory
numbered title and options.
\end{pabox}

\renewtcolorbox[⟨init options⟩]{⟨name⟩}[⟨number⟩][⟨default⟩]{⟨options⟩}
Работает аналогично \newtcolorbox, но основан на \renewenvironment вместо \newenvironment. Существующее окружение переопределяется.
Пример использования:
\renewtcolorbox[auto numbered]{mybox}[2][default value]{colback=green!5!white, colframe=green!75!black, title=Обновленный заголовок}
В этом примере существующее окружение mybox переопределяется с новыми параметрами, включая цвет фона, цвет рамки и заголовок. Теперь это окружение будет использовать новые настройки при каждом вызове.
\NewTColorBox[⟨init options⟩]{⟨name⟩}{⟨specification⟩}{⟨options⟩}
Создает новое окружение ⟨name⟩ на основе tcolorbox. В принципе, \NewTColorBox работает как \NewDocumentEnvironment. Это означает, что новое окружение ⟨name⟩ создается с заданным аргументом LATEX3 ⟨specification⟩. Если окружение с именем ⟨name⟩ уже было определено, будет выдана ошибка. Параметры ⟨options⟩ передаются основной tcolorbox. Обратите внимание, что /tcb/savedelimiter автоматически устанавливается на заданное ⟨name⟩. Параметры ⟨init options⟩ позволяют настроить автоматическую нумерацию.
Пример использования:
% counter из предыдущего примера pabox продолжается в этом стиле
\NewTColorBox[use counter from=pabox]{mybox}{ O{red} m d"" !O{} }
{enhanced,colframe=#1!75!black,colback=#1!5!white,
fonttitle=\bfseries,title={\thetcbcounter~#2},
IfValueT={#3}{watermark text={#3}},#4}
\begin{mybox}{My title}
This is a tcolorbox.
\end{mybox}
\begin{mybox}[blue]{My title}
This is a tcolorbox.
\end{mybox}
\begin{mybox}[green]{My title}"My Watermark"
This is a tcolorbox.
\end{mybox}
\begin{mybox}[yellow]{My title}[colbacktitle=yellow!50!white,coltitle=black]
This is a tcolorbox.
\end{mybox}
\begin{mybox}[purple]{My title}"All together"[coltitle=yellow]
This is a tcolorbox.
\end{mybox}

В этом примере создается новое окружение mynewbox с заданной спецификацией и параметрами, включая цвет фона, цвет рамки и заголовок. Если окружение с именем mynewbox уже существует, будет выдана ошибка.
\RenewTColorBox[⟨init options⟩]{⟨name⟩}{⟨specification⟩}{⟨options⟩}
Работает аналогично \NewTColorBox , но основан на \RenewDocumentEnvironment вместо \NewDocumentEnvironment. Существующее окружение переопределяется.
Пример использования:
\RenewTColorBox[auto numbered]{mybox}{m}{colback=red!10!white, colframe=red!75!black, title=Обновленный заголовок}
В этом примере существующее окружение mybox переопределяется с новыми параметрами.
\ProvideTColorBox[⟨init options⟩]{⟨name⟩}{⟨specification⟩}{⟨options⟩}
Работает аналогично \NewTColorBox, но основан на \ProvideDocumentEnvironment вместо \NewDocumentEnvironment. Окружение ⟨name⟩ создается только в том случае, если оно еще не определено.
Пример использования:
\ProvideTColorBox[auto numbered]{mybox}{m}{colback=green!10!white, colframe=green!75!black, title=Предоставленный заголовок}
В этом примере окружение mybox будет создано только если оно еще не существует.
\DeclareTColorBox[⟨init options⟩]{⟨name⟩}{⟨specification⟩}{⟨options⟩}
Работает аналогично \NewTColorBox, но основан на \DeclareDocumentEnvironment вместо \NewDocumentEnvironment. Новое окружение всегда создается, независимо от того, существует ли уже окружение с тем же именем.
Пример использования:
\DeclareTColorBox[auto numbered]{mybox}{m}{colback=blue!10!white, colframe=blue!75!black, title=Объявленный заголовок}
В этом примере окружение mybox будет создано, даже если оно уже существует, что может привести к ошибке.
\NewTotalTColorBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Создает новую команду \⟨name⟩ на основе tcolorbox. В отличие от \NewTColorBox, также указывается ⟨content⟩ для tcolorbox. В принципе, \NewTotalTColorBox работает как \NewDocumentCommand. Это означает, что новая команда \⟨name⟩ создается с заданным аргументом LATEX3 ⟨specification⟩. Если \⟨name⟩ уже было определено, будет выдана ошибка. Параметры ⟨options⟩ передаются основной tcolorbox, которая заполняется указанным ⟨content⟩. Обратите внимание, что /tcb/savedelimiter автоматически устанавливается на заданное \⟨name⟩. Также обратите внимание, что /tcb/saveto, /tcb/savelowerto и /tcb/redirectlowerto не могут использоваться с \NewTotalTColorBox и аналогичными командами. Параметры ⟨init options⟩ позволяют настроить автоматическую нумерацию.
Пример использования:
\NewTotalTColorBox{\diabox}{ O{} v m }
{ bicolor,nobeforeafter,equal height group=diabox,width=5.7cm,
fonttitle=\bfseries\ttfamily,adjusted title={#2},center title,
colframe=blue!20!black,leftupper=0mm,rightupper=0mm,colback=black!75!white,#1}
{ \tikz\path[fill zoom image={#2}] (0,0) rectangle (\linewidth,4cm);%
\tcblower#3}
\diabox{blueshade.png}{Created with |GIMP|.\\\url{http://www.gimp.org}}
\diabox{goldshade.png}{Created with |GIMP|.\\\url{http://www.gimp.org}}
В этом примере создается новая команда mytotalbox, которая принимает содержимое и параметры, включая цвет фона и цвет рамки. Если команда с именем mytotalbox уже существует, будет выдана ошибка.
\RenewTotalTColorBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Работает аналогично \NewTotalTColorBox, но основан на \RenewDocumentCommand вместо \NewDocumentCommand. Существующая команда переопределяется.
Пример использования:
\RenewTotalTColorBox[auto numbered]{mytotalbox}{m}{colback=purple!10!white, colframe=purple!75!black}{Обновленное содержимое команды.}
В этом примере существующая команда mytotalbox переопределяется с новыми параметрами и содержимым.
\ProvideTotalTColorBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Работает аналогично \NewTotalTColorBox, но основан на \ProvideDocumentCommand вместо \NewDocumentCommand. Команда \⟨name⟩ создается только в том случае, если она еще не определена.
Пример использования:
\ProvideTotalTColorBox[auto numbered]{mytotalbox}{m}{colback=teal!10!white, colframe=teal!75!black}{Предоставленное содержимое команды.}
В этом примере команда mytotalbox будет создана только если она еще не существует.
\DeclareTotalTColorBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Работает аналогично \NewTotalTColorBox, но основан на \DeclareDocumentCommand вместо \NewDocumentCommand. Новая команда всегда создается, независимо от того, существует ли уже команда с тем же именем.
Пример использования:
\DeclareTotalTColorBox[auto numbered]{mytotalbox}{m}{colback=cyan!10!white, colframe=cyan!75!black}{Объявленное содержимое команды.}
В этом примере команда mytotalbox будет создана, даже если она уже существует, что может привести к ошибке.
Создание команд на основе \tcbox
\newtcbox[⟨init options⟩]{\⟨name⟩}[⟨number⟩][⟨default⟩]{⟨options⟩}
Создает новый макрос \⟨name⟩ на основе \tcbox. В принципе, \newtcbox работает как \newcommand. Новый макрос \⟨name⟩ может принимать ⟨number⟩+1 аргументов (до 10), где ⟨default⟩ — это значение по умолчанию для необязательного первого аргумента. В дополнение к аргументам ⟨number⟩ есть автоматический последний (обязательный) аргумент \⟨name⟩, который принимает содержимое коробки. Параметры ⟨options⟩ передаются основной tcbox. Параметры ⟨init options⟩ позволяют настроить автоматическую нумерацию.
Пример использования:
\newtcbox{\mybox}[1][red]{on line,
arc=0pt,outer arc=0pt,colback=#1!10!white,colframe=#1!50!black,
boxsep=0pt,left=1pt,right=1pt,top=2pt,bottom=2pt,
boxrule=0pt,bottomrule=1pt,toprule=1pt}
\newtcbox{\xmybox}[1][red]{on line,
arc=7pt,colback=#1!10!white,colframe=#1!50!black,
before upper={\rule[-3pt]{0pt}{10pt}},boxrule=1pt,
boxsep=0pt,left=6pt,right=6pt,top=2pt,bottom=2pt}
The \mybox[green]{quick} brown \mybox{fox} \mybox[blue]{jumps} over the \mybox[green]{lazy} \mybox{dog}.\par
The \xmybox[green]{quick} brown \xmybox{fox} \xmybox[blue]{jumps} over the \xmybox[green]{lazy} \xmybox{dog}.
В этом примере создается новый макрос mytcbox, который может принимать два аргумента, где первый аргумент имеет значение по умолчанию “default value”. Параметры для tcbox задают цвет фона и цвет рамки.
\renewtcbox[⟨init options⟩]{\⟨name⟩}[⟨number⟩][⟨default⟩]{⟨options⟩}
Работает аналогично \newtcbox, но основан на \renewcommand вместо \newcommand. Существующий макрос переопределяется.
Пример использования:
\renewtcbox[auto numbered]{mytcbox}[2][default value]{colback=blue!10!white, colframe=blue!75!black}
В этом примере существующий макрос mytcbox переопределяется с новыми параметрами и значением по умолчанию для первого аргумента.
\NewTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}
Создает новую команду \⟨name⟩ на основе \tcbox. В принципе, \NewTCBox работает как \NewDocumentCommand. Это означает, что новая команда \⟨name⟩ создается с заданным аргументом LATEX3 ⟨specification⟩. В дополнение к аргументу ⟨specification⟩ есть автоматический последний (обязательный) аргумент \⟨name⟩, который принимает содержимое коробки. Таким образом, \⟨name⟩ может иметь до 10 аргументов в сумме. Если \⟨name⟩ уже было определено, будет выдана ошибка. Параметры ⟨options⟩ передаются основной \tcbox. Обратите внимание, что /tcb/savedelimiter автоматически устанавливается на заданное \⟨name⟩. Параметры ⟨init options⟩ позволяют настроить автоматическую нумерацию.
Пример использования:
\NewTCBox[auto numbered]{mynewtcbox}{m}{colback=green!10!white, colframe=green!75!black}
В этом примере создается новая команда mynewtcbox, которая принимает спецификацию и параметры, включая цвет фона и цвет рамки. Если команда с именем mynewtcbox уже существует, будет выдана ошибка.
\RenewTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}
Работает аналогично \NewTCBox, но основан на \RenewDocumentCommand вместо \NewDocumentCommand. Существующая команда переопределяется.
Пример использования:
\RenewTCBox[auto numbered]{mytcbox}{m}{colback=red!10!white, colframe=red!75!black}
В этом примере существующая команда mytcbox переопределяется с новыми параметрами.
\ProvideTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}
Работает аналогично \NewTCBox, но основан на \ProvideDocumentCommand вместо \NewDocumentCommand. Команда \⟨name⟩ создается только в том случае, если она еще не определена.
Пример использования:
\ProvideTCBox[auto numbered]{mytcbox}{m}{colback=green!10!white, colframe=green!75!black}
В этом примере команда mytcbox будет создана только если она еще не существует.
\DeclareTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}
Работает аналогично \NewTCBox, но основан на \DeclareDocumentCommand вместо \NewDocumentCommand. Новая команда всегда создается, независимо от того, существует ли уже команда с тем же именем.
Пример использования:
\DeclareTCBox[auto numbered]{mytcbox}{m}{colback=blue!10!white, colframe=blue!75!black}
В этом примере команда mytcbox будет создана, даже если она уже существует, что может привести к ошибке.
\NewTotalTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Создает новую команду \⟨name⟩ на основе \tcbox. В отличие от \NewTCBox, также указывается ⟨content⟩ для tcbox. В принципе, \NewTotalTCBox работает как \NewDocumentCommand. Это означает, что новая команда \⟨name⟩ создается с заданным аргументом LATEX3 ⟨specification⟩. Если \⟨name⟩ уже было определено, будет выдана ошибка. Параметры ⟨options⟩ передаются основной \tcbox, которая заполняется указанным ⟨content⟩. Обратите внимание, что /tcb/savedelimiter автоматически устанавливается на заданное \⟨name⟩. Параметры ⟨init options⟩ позволяют настроить автоматическую нумерацию.
Пример использования:
\NewTotalTCBox[auto numbered]{mytotaltcbox}{m}{colback=yellow!10!white, colframe=yellow!75!black}{Это содержимое новой команды.}
В этом примере создается новая команда mytotaltcbox, которая принимает спецификацию и параметры, включая цвет фона и цвет рамки, а также содержимое коробки. Если команда с именем mytotaltcbox уже существует, будет выдана ошибка.
\NewTotalTCBox{\myverb}{ O{red} v !O{} }
{ fontupper=\ttfamily,nobeforeafter,tcbox raise base,arc=0pt,outer arc=0pt,
top=0pt,bottom=0pt,left=0mm,right=0mm,
leftrule=0pt,rightrule=0pt,toprule=0.3mm,bottomrule=0.3mm,boxsep=0.5mm,
colback=#1!10!white,colframe=#1!50!black,#3}{#2}
To set a word \textbf{bold} in \myverb{\LaTeX}, use
\myverb[green]{\textbf{bold}}. Alternatively, write
\myverb[yellow]{{\bfseries bold}}.
In \myverb[blue]{\LaTeX}[enhanced,fuzzy halo], other font settings are
done in the same way, e.\,g. \myverb{\textit}, \myverb{\itshape}\\
or \myverb[brown]{\texttt}, \myverb[brown]{\ttfamily}.

% \usepackage{listings} or \tcbuselibrary{listings}
\NewTotalTCBox{\commandbox}{ s v }
{verbatim,colupper=white,colback=black!75!white,colframe=black}
{\IfBooleanT{#1}{\textcolor{red}{\ttfamily\bfseries > }}%
\lstinline[language=command.com,keywordstyle=\color{blue!35!white}\bfseries]^#2^}
\commandbox*{cd "My Documents"} changes to directory \commandbox{My Documents}.
\commandbox*{dir /A} lists the directory content.
\commandbox*{copy example.txt d:\target} copies \commandbox{example.txt} to
\commandbox{d:\target}.

\RenewTotalTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Работает аналогично \NewTotalTCBox, но основан на \RenewDocumentCommand вместо \NewDocumentCommand. Существующая команда переопределяется.
Пример использования:
\RenewTotalTCBox[auto numbered]{mytotaltcbox}{m}{colback=purple!10!white, colframe=purple!75!black}{Обновленное содержимое команды.}
В этом примере существующая команда mytotaltcbox переопределяется с новыми параметрами и содержимым.
\ProvideTotalTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Работает аналогично \NewTotalTCBox, но основан на \ProvideDocumentCommand вместо \NewDocumentCommand. Команда \⟨name⟩ создается только в том случае, если она еще не определена.
Пример использования:
\ProvideTotalTCBox[auto numbered]{mytotaltcbox}{m}{colback=teal!10!white, colframe=teal!75!black}{Предоставленное содержимое команды.}
В этом примере команда mytotaltcbox будет создана только если она еще не существует.
\DeclareTotalTCBox[⟨init options⟩]{\⟨name⟩}{⟨specification⟩}{⟨options⟩}{⟨content⟩}
Работает аналогично \NewTotalTCBox, но основан на \DeclareDocumentCommand вместо \NewDocumentCommand. Новая команда всегда создается, независимо от того, существует ли уже команда с тем же именем.
Пример использования:
\DeclareTotalTCBox[auto numbered]{mytotaltcbox}{m}{colback=cyan!10!white, colframe=cyan!75!black}{Объявленное содержимое команды.}
В этом примере команда mytotaltcbox будет создана, даже если она уже существует, что может привести к ошибке.
Переопределение других сред (обертывание с помощью tcolorbox)
\tcolorboxenvironment{⟨name⟩}{⟨options⟩}
Существующая среда ⟨name⟩ переопределяется, чтобы быть обернутой внутри tcolorbox с заданными ⟨options⟩.
% tcbuselibrary{skins}
\newenvironment{myitemize}{%
\begin{itemize}}{\end{itemize}}
\tcolorboxenvironment{myitemize}{blanker,
before skip=6pt,after skip=6pt,
borderline west={3mm}{0pt}{red}}
Some text.
\begin{myitemize}
\item Alpha
\item Beta
\item Gamma
\end{myitemize}
More text.

7.1.1 - Ключи к командам tcolorbox
Полный список ключей для настройки боксов в tcolorbox
Ключи для TCB
| Ключ | Синтаксис | Назначение |
|---|---|---|
/tcb/ | Префикс для ключей | Обозначение пространства имен tcolorbox. |
add to height | add to height=<length> | Добавляет фиксированную высоту к общему размеру бокса. |
add to list | add to list=<text> | Регистрирует бокс в списке (например, для оглавления). |
add to natural height | add to natural height=<length> | Увеличивает “естественную” высоту бокса (без учета boxsep и boxrule). |
add to width | add to width=<length> | Добавляет фиксированную ширину к общему размеру бокса. |
adjust text | adjust text=<options> | Настраивает параметры текста (например, hyphenation). |
adjusted title | adjusted title=<text> | Заголовок с динамическим форматированием (например, для нумерации). |
adjusted title after break | adjusted title after break=<text> | Заголовок после разрыва многостраничного бокса. |
after | after={<code>} | Код TikZ/LaTeX, выполняемый после рисования бокса. |
after app | after app={<code>} | Код, выполняемый после добавления бокса в приложении. |
after doc body | after doc body={<code>} | Код, вставляемый после основного содержимого документа. |
after doc body command | after doc body command=<command> | Команда LaTeX, выполняемая после тела документа. |
after doc body environment | after doc body env=<env> | Окружение LaTeX, добавляемое после тела документа. |
after doc body key | after doc body key=<key> | Ключ TikZ, применяемый после тела документа. |
after doc body path | after doc body path=<path> | Путь TikZ, рисуемый после тела документа. |
after float | after float={<code>} | Код, выполняемый после плавающего бокса (float). |
after float app | after float app={<code>} | Аналог after float для приложений. |
after float pre | after float pre={<code>} | Код перед плавающим боксом (для приложений). |
after lower | after lower={<code>} | Код, выполняемый после нижней части (lower part) бокса. |
after lower app | after lower app={<code>} | Аналог after lower для приложений. |
after lower pre | after lower pre={<code>} | Код перед нижней частью (для приложений). |
after lower* | after lower*={<code>} | Код после нижней части (без группировки в {}). |
after pre | after pre={<code>} | Код перед завершением бокса (для приложений). |
after skip | after skip=<length> | Вертикальный отступ после бокса. |
after skip balanced | after skip balanced=<length> | Сбалансированный отступ (учитывает разрывы страниц). |
after title | after title={<code>} | Код, выполняемый после заголовка. |
after title app | after title app={<code>} | Аналог after title для приложений. |
after title pre | after title pre={<code>} | Код перед заголовком (для приложений). |
after title* | after title*={<code>} | Код после заголовка (без группировки в {}). |
after upper | after upper={<code>} | Код, выполняемый после верхней части (upper part) бокса. |
after upper app | after upper app={<code>} | Аналог after upper для приложений. |
after upper pre | after upper pre={<code>} | Код перед верхней частью (для приложений). |
after upper* | after upper*={<code>} | Код после верхней части (без группировки в {}). |
alert | alert | Стиль для выделенных боксов (например, в Beamer). |
alt | alt=<text> | Альтернативный текст (для PDF-тегов или подписей). |
ams align | ams align | Включает окружение align из amsmath в основной части. |
ams align lower | ams align lower | Аналог ams align для нижней части. |
ams align upper | ams align upper | Аналог ams align для верхней части. |
ams align* | ams align* | Версия align* (без нумерации). |
ams equation | ams equation | Включает окружение equation из amsmath. |
ams equation lower | ams equation lower | Аналог ams equation для нижней части. |
ams equation upper | ams equation upper | Аналог ams equation для верхней части. |
ams gather | ams gather | Включает окружение gather из amsmath. |
ams nodisplayskip | ams nodisplayskip | Убирает отступы вокруг формул amsmath. |
arc | arc=<length> | Радиус скругления углов. |
arc is angular | arc is angular | Делает скругление углов “острым” (стиль TikZ). |
arc is curved | arc is curved | Делает скругление плавным (по умолчанию). |
at begin tikz | at begin tikz={<code>} | Код TikZ, выполняемый в начале рисования. |
attach boxed title to bottom | attach boxed title to bottom | Размещает заголовок внизу бокса. |
attach boxed title to top | attach boxed title to top | Размещает заголовок вверху бокса (по умолчанию). |
attach title | attach title | Включает прикрепленный заголовок. |
auto outer arc | auto outer arc | Автонастройка внешних дуг для сложных рамок. |
autoparskip | autoparskip | Автоматически регулирует parskip внутри бокса. |
baseline | baseline=<length> | Выравнивание бокса по базовой линии текста. |
beamer | beamer | Стиль для презентаций Beamer. |
beamer alerted | beamer alerted | Стиль для “alerted” боксов в Beamer. |
beamer hidden | beamer hidden | Стиль для скрытых боксов в Beamer. |
bean arc | bean arc | Альтернативный стиль скругления углов (“бобовый”). |
before | before={<code>} | Код, выполняемый перед рисованием бокса. |
before skip | before skip=<length> | Вертикальный отступ перед боксом. |
bicolor | bicolor | Двухцветный стиль (разные цвета для верхней/нижней частей). |
blank | blank | Пустой стиль (без рамок и фона). |
blanker | blanker | Еще более минималистичный стиль, чем blank. |
blankest | blankest | Максимально упрощенный стиль (только текст). |
blend before title | blend before title | Смешивает фон перед заголовком с основным фоном. |
bookmark | bookmark=<text> | Добавляет закладку PDF для бокса. |
borderline | borderline={<options>} | Рисует дополнительные границы (например, тени). |
bottomrule | bottomrule=<length> | Толщина нижней границы. |
bottomrule at break | bottomrule at break=<length> | Толщина нижней границы на разрыве страницы. |
box align | box align=<baseline/top/bottom> | Выравнивание содержимого внутри бокса. |
boxed title size | boxed title size=<options> | Размеры рамки заголовка. |
boxrule | boxrule=<length> | Толщина основной рамки. |
boxsep | boxsep=<length> | Внутренний отступ содержимого от границ. |
colback | colback=<color> | Цвет фона основной части. |
colbacklower | colbacklower=<color> | Цвет фона нижней части (для bicolor). |
colbacktitle | colbacktitle=<color> | Цвет фона заголовка. |
colframe | colframe=<color> | Цвет рамки бокса. |
collower | collower=<color> | Цвет текста в нижней части бокса. |
color color | color color=<name> | Настройка цвета (внутренний ключ для управления цветами). |
color command | color command=<cmd> | Команда для применения цвета. |
color counter | color counter=<ctr> | Счетчик для генерации цветов. |
color definition | color definition={<code>} | Определение нового цвета. |
color environment | color environment=<env> | Окружение для применения цвета. |
color fade | color fade={<options>} | Градиентная заливка фона. |
color hyperlink | color hyperlink={<options>} | Цвет гиперссылок внутри бокса. |
color key | color key=<key> | Ключ для доступа к цвету. |
color length | color length=<len> | Длина цветового перехода. |
color option | color option={<opt>} | Опции цвета. |
color path | color path={<path>} | Путь TikZ для градиента. |
color value | color value=<val> | Значение цвета (например, red!50). |
coltext | coltext=<color> | Цвет основного текста. |
coltitle | coltitle=<color> | Цвет текста заголовка. |
colupper | colupper=<color> | Цвет текста в верхней части бокса. |
comment | comment={<text>} | Добавляет комментарий внутри бокса. |
comment above listing | comment above listing={<text>} | Комментарий над листингом кода. |
comment above* listing | comment above* listing={<text>} | Комментарий над листингом (без форматирования). |
comment and listing | comment and listing={<text>} | Комбинация комментария и листинга. |
comment only | comment only={<text>} | Только комментарий (без листинга). |
comment outside listing | comment outside listing={<text>} | Комментарий вне листинга (например, сбоку). |
comment side listing | comment side listing={<text>} | Комментарий сбоку от листинга. |
comment style | comment style={<style>} | Стиль оформления комментариев. |
compilable listing | compilable listing | Листинг, который можно компилировать. |
compress page | compress page | Сжимает страницу для экономии места. |
ctan formatter | ctan formatter={<code>} | Форматирование для CTAN-документации. |
default minted options | default minted options={<opt>} | Опции по умолчанию для пакета minted. |
description color | description color=<color> | Цвет текста в описании. |
description delimiters | description delimiters={<left><right>} | Разделители для описаний (например, скобки). |
description delimiters none | description delimiters none | Убирает разделители описаний. |
description delimiters parenthesis | description delimiters parenthesis | Использует круглые скобки для описаний. |
description font | description font={<font>} | Шрифт для описаний. |
description formatter | description formatter={<code>} | Функция форматирования описаний. |
detach title | detach title | Отделяет заголовок от основного бокса. |
do not store to box array | do not store to box array | Запрещает сохранение бокса в массив. |
doc description | doc description={<text>} | Описание для документации. |
doc head | doc head={<text>} | Заголовок раздела документации. |
doc head command | doc head command={<cmd>} | Команда для заголовка документации. |
doc head environment | doc head environment={<env>} | Окружение для заголовка документации. |
doc head key | doc head key={<key>} | Ключ для заголовка документации. |
doc head path | doc head path={<path>} | Путь TikZ для заголовка документации. |
doc index | doc index={<text>} | Индекс для документации. |
doc into index | doc into index={<text>} | Добавляет запись в индекс документации. |
doc key prefix | doc key prefix={<prefix>} | Префикс для ключей документации. |
doc keypath | doc keypath={<path>} | Путь к ключу документации. |
doc label | doc label={<label>} | Метка для перекрестных ссылок. |
doc left | doc left={<text>} | Текст слева в документации. |
doc left indent | doc left indent={<len>} | Отступ слева в документации. |
doc marginnote | doc marginnote={<text>} | Заметка на полях документации. |
doc name | doc name={<name>} | Имя элемента документации. |
doc new | doc new | Пометка нового элемента в документации. |
doc new and updated | doc new and updated | Пометка нового и обновленного элемента. |
doc no index | doc no index | Исключает элемент из индекса. |
doc parameter | doc parameter={<param>} | Параметр для документации. |
doc raster | doc raster={<options>} | Сетка (raster) для документации. |
doc right | doc right={<text>} | Текст справа в документации. |
doc right indent | doc right indent={<len>} | Отступ справа в документации. |
doc sort index | doc sort index={<key>} | Ключ сортировки индекса. |
doc updated | doc updated | Пометка обновленного элемента. |
docexample | docexample={<code>} | Пример кода для документации. |
documentation listing options | documentation listing options={<opt>} | Опции листинга в документации. |
documentation listing style | documentation listing style={<style>} | Стиль листинга в документации. |
documentation minted language | documentation minted language={<lang>} | Язык для minted в документации. |
documentation minted options | documentation minted options={<opt>} | Опции minted для документации. |
documentation minted style | documentation minted style={<style>} | Стиль minted для документации. |
draft | draft | Черновой режим (упрощенное отображение). |
draftmode | draftmode | Режим черновика с дополнительными опциями. |
drop fuzzy midday shadow | drop fuzzy midday shadow={<opt>} | Размытая тень с эффектом “полдень”. |
drop fuzzy shadow | drop fuzzy shadow={<opt>} | Размытая тень вокруг бокса. |
drop large lifted shadow | drop large lifted shadow={<opt>} | Большая “приподнятая” тень. |
drop lifted shadow | drop lifted shadow={<opt>} | Эффект приподнятого бокса с тенью. |
drop midday shadow | drop midday shadow={<opt>} | Тень с акцентом на верхнюю границу. |
drop shadow | drop shadow={<opt>} | Стандартная тень. |
empty | empty | Полностью пустой бокс (без содержимого). |
enforce breakable | enforce breakable | Принудительно разрешает разрыв бокса. |
english language | english language | Устанавливает английский язык для текста. |
enhanced | enhanced | Включает улучшенный режим рисования (с TikZ). |
enhanced jigsaw | enhanced jigsaw | Режим “пазла” с закругленными углами. |
enlarge bottom at break by | enlarge bottom at break by=<len> | Увеличивает нижний отступ при разрыве. |
enlarge bottom by | enlarge bottom by=<len> | Увеличивает нижний отступ. |
enlarge left by | enlarge left by=<len> | Увеличивает левый отступ. |
enlarge right by | enlarge right by=<len> | Увеличивает правый отступ. |
enlarge top at break by | enlarge top at break by=<len> | Увеличивает верхний отступ при разрыве. |
enlarge top by | enlarge top by=<len> | Увеличивает верхний отступ. |
enlargepage | enlargepage | Расширяет страницу для размещения бокса. |
enlargepage flexible | enlargepage flexible | Гибкое расширение страницы. |
environment lower | environment lower={<env>} | Окружение для нижней части бокса. |
environment lower app | environment lower app={<env>} | Окружение для нижней части (для приложений). |
environment lower args | environment lower args={<args>} | Аргументы для окружения нижней части. |
environment lower args app | environment lower args app={<args>} | Аргументы окружения нижней части для приложений |
environment lower args pre | environment lower args pre={<args>} | Аргументы окружения нижней части (предварительные) |
environment lower pre | environment lower pre={<env>} | Окружение нижней части (предварительное) |
environment title | environment title={<env>} | Окружение для заголовка |
environment title app | environment title app={<env>} | Окружение заголовка для приложений |
environment title args | environment title args={<args>} | Аргументы окружения заголовка |
environment title args app | environment title args app={<args>} | Аргументы окружения заголовка для приложений |
environment title args pre | environment title args pre={<args>} | Аргументы окружения заголовка (предварительные) |
environment title pre | environment title pre={<env>} | Окружение заголовка (предварительное) |
environment upper | environment upper={<env>} | Окружение верхней части |
environment upper app | environment upper app={<env>} | Окружение верхней части для приложений |
environment upper args | environment upper args={<args>} | Аргументы окружения верхней части |
environment upper args app | environment upper args app={<args>} | Аргументы окружения верхней части для приложений |
environment upper args pre | environment upper args pre={<args>} | Аргументы окружения верхней части (предварительные) |
environment upper pre | environment upper pre={<env>} | Окружение верхней части (предварительное) |
equal height group | equal height group=<name> | Группа боксов с одинаковой высотой |
every box | every box={<options>} | Стиль для всех боксов |
every box on higher layers | every box on higher layers={<options>} | Стиль для боксов на верхних слоях |
every box on layer n | every box on layer n={<options>} | Стиль для боксов на конкретном слое |
every float | every float={<options>} | Стиль для плавающих боксов |
every listing line | every listing line={<options>} | Стиль для каждой строки листинга |
every listing line* | every listing line*={<options>} | Альтернативный стиль строк листинга |
extend freelance | extend freelance={<options>} | Расширение freelance-стиля |
extend freelancefirst | extend freelancefirst={<options>} | Расширение для первого freelance-бокса |
extend freelancelast | extend freelancelast={<options>} | Расширение для последнего freelance-бокса |
extend freelancemiddle | extend freelancemiddle={<options>} | Расширение для средних freelance-боксов |
external | external={<options>} | Внешнее содержимое бокса |
externalize example | externalize example | Внешний пример (без форсирования) |
externalize example! | externalize example! | Внешний пример (с форсированием) |
externalize listing | externalize listing | Внешний листинг (без форсирования) |
externalize listing! | externalize listing! | Внешний листинг (с форсированием) |
extras | extras={<options>} | Дополнительные стили |
extras broken | extras broken={<options>} | Стили для разорванного бокса |
extras broken pre | extras broken pre={<options>} | Предварительные стили для разорванного бокса |
extras first | extras first={<options>} | Стили для первой части |
extras first and middle | extras first and middle={<options>} | Стили для первой и средней частей |
extras first and middle pre | extras first and middle pre={<options>} | Предварительные стили для первой и средней частей |
extras first pre | extras first pre={<options>} | Предварительные стили для первой части |
extras last | extras last={<options>} | Стили для последней части |
extras last pre | extras last pre={<options>} | Предварительные стили для последней части |
extras middle | extras middle={<options>} | Стили для средней части |
extras middle and last | extras middle and last={<options>} | Стили для средней и последней частей |
extras middle and last pre | extras middle and last pre={<options>} | Предварительные стили для средней и последней частей |
extras middle pre | extras middle pre={<options>} | Предварительные стили для средней части |
extras pre | extras pre={<options>} | Предварительные дополнительные стили |
extras title after break | extras title after break={<options>} | Стили заголовка после разрыва |
extras unbroken | extras unbroken={<options>} | Стили для неразорванного бокса |
extras unbroken and first | extras unbroken and first={<options>} | Стили для неразорванного и первого бокса |
extras unbroken and first pre | extras unbroken and first pre={<options>} | Предварительные стили для неразорванного и первого бокса |
extras unbroken and last | extras unbroken and last={<options>} | Стили для неразорванного и последнего бокса |
extras unbroken and last pre | extras unbroken and last pre={<options>} | Предварительные стили для неразорванного и последнего бокса |
extras unbroken pre | extras unbroken pre={<options>} | Предварительные стили для неразорванного бокса |
extrude bottom by | extrude bottom by=<length> | Выступ снизу бокса |
extrude by | extrude by=<length> | Выступ со всех сторон |
extrude left by | extrude left by=<length> | Выступ слева |
extrude right by | extrude right by=<length> | Выступ справа |
extrude top by | extrude top by=<length> | Выступ сверху |
fill downwards | fill downwards | Заполнение содержимого сверху вниз |
finish | finish={<options>} | Завершающие стили |
finish broken | finish broken={<options>} | Завершающие стили для разорванного бокса |
finish broken pre | finish broken pre={<options>} | Предварительные завершающие стили для разорванного бокса |
finish fading vignette | finish fading vignette={<options>} | Завершение fading vignette-эффекта |
finish first | finish first={<options>} | Завершающие стили для первой части |
finish first and middle | finish first and middle={<options>} | Завершающие стили для первой и средней частей |
finish first and middle pre | finish first and middle pre={<options>} | Предварительные завершающие стили для первой и средней частей |
finish first pre | finish first pre={<options>} | Предварительные завершающие стили для первой части |
finish last | finish last={<options>} | Завершающие стили для последней части |
finish last pre | finish last pre={<options>} | Предварительные завершающие стили для последней части |
finish middle | finish middle={<options>} | Завершающие стили для средней части |
finish middle and last | finish middle and last={<options>} | Завершающие стили для средней и последней частей |
finish middle and last pre | finish middle and last pre={<options>} | Предварительные завершающие стили для средней и последней частей |
finish middle pre | finish middle pre={<options>} | Предварительные завершающие стили для средней части |
finish pre | finish pre={<options>} | Предварительные завершающие стили |
finish raised fading vignette | finish raised fading vignette={<options>} | Завершение raised fading vignette-эффекта |
finish unbroken | finish unbroken={<options>} | Завершающие стили для неразорванного бокса |
finish unbroken and first | finish unbroken and first={<options>} | Завершающие стили для неразорванного и первого бокса |
finish unbroken and first pre | finish unbroken and first pre={<options>} | Предварительные завершающие стили для неразорванного и первого бокса |
finish unbroken and last | finish unbroken and last={<options>} | Завершающие стили для неразорванного и последнего бокса |
finish unbroken and last pre | finish unbroken and last pre={<options>} | Предварительные завершающие стили для неразорванного и последнего бокса |
finish unbroken pre | finish unbroken pre={<options>} | Предварительные завершающие стили для неразорванного бокса |
finish vignette | finish vignette={<options>} | Завершение vignette-эффекта |
fit | fit={<options>} | Подгонка размера содержимого |
fit algorithm | fit algorithm=<name> | Алгоритм подгонки |
fit basedim | fit basedim=<length> | Базовый размер для подгонки |
fit fontsize macros | fit fontsize macros={<names>} | Макросы размера шрифта для подгонки |
fit height from | fit height from={<code>} | Вычисление высоты из кода |
fit height plus | fit height plus={<length>} | Дополнительная высота при подгонке |
fit maxfontdiff | fit maxfontdiff=<value> | Максимальная разница шрифтов |
fit maxfontdiffgap | fit maxfontdiffgap=<value> | Максимальный промежуток разницы шрифтов |
fit maxstep | fit maxstep=<value> | Максимальное количество шагов |
fit maxwidthdiff | fit maxwidthdiff=<value> | Максимальная разница ширины |
fit maxwidthdiffgap | fit maxwidthdiffgap=<value> | Максимальный промежуток разницы ширины |
fit skip | fit skip={<options>} | Пропуск элементов при подгонке |
fit to | fit to={<dimensions>} | Подгонка к указанным размерам |
fit to height | fit to height={<height>} | Подгонка по высоте |
fit warning | fit warning={<options>} | Предупреждения при подгонке |
fit width from | fit width from={<code>} | Вычисление ширины из кода |
fit width plus | fit width plus={<length>} | Дополнительная ширина при подгонке |
flip title | flip title | Переворот заголовка |
float | float | Плавающий бокс |
float* | float* | Альтернативный плавающий бокс |
floatplacement | floatplacement={<placement>} | Позиционирование плавающего бокса |
flush left | flush left | Выравнивание по левому краю |
flush right | flush right | Выравнивание по правому краю |
flushleft lower | flushleft lower | Выравнивание нижней части по левому краю |
flushleft title | flushleft title | Выравнивание заголовка по левому краю |
flushleft upper | flushleft upper | Выравнивание верхней части по левому краю |
flushright lower | flushright lower | Выравнивание нижней части по правому краю |
flushright title | flushright title | Выравнивание заголовка по правому краю |
flushright upper | flushright upper | Выравнивание верхней части по правому краю |
fontlower | fontlower={<font>} | Шрифт нижней части |
fonttitle | fonttitle={<font>} | Шрифт заголовка |
fontupper | fontupper={<font>} | Шрифт верхней части |
force nobeforeafter | force nobeforeafter | Принудительное отключение before/after |
frame code | frame code={<code>} | Пользовательский код рамки |
frame code app | frame code app={<code>} | Код рамки для приложений |
frame code pre | frame code pre={<code>} | Предварительный код рамки |
frame empty | frame empty | Пустая рамка |
frame engine | frame engine=<name> | Движок отрисовки рамки |
frame hidden | frame hidden | Скрытая рамка |
frame style | frame style={<style>} | Стиль рамки |
frame style image | frame style image={<image>} | Стиль рамки с изображением |
frame style tile | frame style tile={<options>} | Стиль рамки с плиткой |
freelance | freelance={<options>} | Freelance-стиль |
freeze extension | freeze extension={<ext>} | Расширение для замороженных файлов |
freeze file | freeze file={<name>} | Имя замороженного файла |
freeze jpg | freeze jpg | Заморозка в JPG |
freeze none | freeze none | Без заморозки |
freeze pdf | freeze pdf | Заморозка в PDF |
freeze png | freeze png | Заморозка в PNG |
fuzzy halo | fuzzy halo={<options>} | Размытое гало |
fuzzy shadow | fuzzy shadow={<options>} | Размытая тень |
geometry nodes | geometry nodes={<names>} | Геометрические узлы |
graphics directory | graphics directory={<path>} | Директория с графикой |
graphics options | graphics options={<options>} | Опции графики |
graphics orientation | graphics orientation={<angle>} | Ориентация графики |
graphics pages | graphics pages={<range>} | Страницы графики |
grow sidewards by | grow sidewards by={<length>} | Рост вбок |
grow to left by | grow to left by={<length>} | Рост влево |
grow to right by | grow to right by={<length>} | Рост вправо |
halign | halign=<alignment> | Горизонтальное выравнивание |
halign code | halign code={<code>} | Код горизонтального выравнивания |
halign lower | halign lower=<alignment> | Выравнивание нижней части |
halign lower code | halign lower code={<code>} | Код выравнивания нижней части |
halign title | halign title=<alignment> | Выравнивание заголовка |
halign title code | halign title code={<code>} | Код выравнивания заголовка |
halign upper | halign upper=<alignment> | Выравнивание верхней части |
halign upper code | halign upper code={<code>} | Код выравнивания верхней части |
halo | halo={<options>} | Эффект гало |
hbox | hbox | Горизонтальная коробка |
hbox boxed title | hbox boxed title | Горизонтальная коробка заголовка |
height | height={<length>} | Фиксированная высота |
height fill | height fill | Заполнение высоты |
height fixed for | height fixed for={<name>} | Фиксированная высота для группы |
height from | height from={<code>} | Высота из кода |
height plus | height plus={<length>} | Дополнительная высота |
hide | hide | Скрытый бокс |
highlight math | highlight math | Подсветка математики |
highlight math style | highlight math style={<style>} | Стиль подсветки математики |
hyperlink | hyperlink={<name>} | Гиперссылка |
hyperlink interior | hyperlink interior={<name>} | Гиперссылка на внутреннюю часть |
hyperlink node | hyperlink node={<name>} | Гиперссылка на узел |
hyperlink title | hyperlink title={<name>} | Гиперссылка на заголовок |
hyperref | hyperref={<options>} | Настройки hyperref |
hyperref interior | hyperref interior={<options>} | Hyperref для внутренней части |
hyperref node | hyperref node={<options>} | Hyperref для узла |
hyperref title | hyperref title={<options>} | Hyperref для заголовка |
hypertarget | hypertarget={<name>} | Цель гиперссылки |
hyperurl | hyperurl={<url>} | Гиперссылка-URL |
hyperurl interior | hyperurl interior={<url>} | URL для внутренней части |
hyperurl node | hyperurl node={<url>} | URL для узла |
hyperurl title | hyperurl title={<url>} | URL для заголовка |
hyperurl* | hyperurl*={<url>} | Альтернативный гиперurl |
hyperurl* interior | hyperurl* interior={<url>} | Альтернативный URL для внутренней части |
hyperurl* node | hyperurl* node={<url>} | Альтернативный URL для узла |
hyperurl* title | hyperurl* title={<url>} | Альтернативный URL для заголовка |
hyphenationfix | hyphenationfix | Исправление переносов |
if odd page | if odd page={<code>} | Условие для нечетной страницы |
if odd page or oneside | if odd page or oneside={<code>} | Условие для нечетной/односторонней страницы |
if odd page or oneside* | if odd page or oneside*={<code>} | Альтернативное условие |
if odd page* | if odd page*={<code>} | Альтернативное условие нечетной страницы |
IfBlankF | IfBlankF={<arg>}{<code>} | Условный код если аргумент пуст (ложь) |
IfBlankT | IfBlankT={<arg>}{<code>} | Условный код если аргумент пуст (истина) |
IfBlankTF | IfBlankTF={<arg>}{<if>}{<else>} | Полное условие для пустого аргумента |
IfBooleanF | IfBooleanF={<arg>}{<code>} | Условие для булева значения (ложь) |
IfBooleanT | IfBooleanT={<arg>}{<code>} | Условие для булева значения (истина) |
IfBooleanTF | IfBooleanTF={<arg>}{<if>}{<else>} | Полное булево условие |
IfEmptyF | IfEmptyF={<arg>}{<code>} | Условие для пустого значения (ложь) |
IfEmptyT | IfEmptyT={<arg>}{<code>} | Условие для пустого значения (истина) |
IfEmptyTF | IfEmptyTF={<arg>}{<if>}{<else>} | Полное условие для пустого значения |
IfNoValueF | IfNoValueF={<arg>}{<code>} | Условие если нет значения (ложь) |
IfNoValueT | IfNoValueT={<arg>}{<code>} | Условие если нет значения (истина) |
IfNoValueTF | IfNoValueTF={<arg>}{<if>}{<else>} | Полное условие для отсутствия значения |
IfValueF | IfValueF={<arg>}{<code>} | Условие если есть значение (ложь) |
IfValueT | IfValueT={<arg>}{<code>} | Условие если есть значение (истина) |
IfValueTF | IfValueTF={<arg>}{<if>}{<else>} | Полное условие для наличия значения |
ignore nobreak | ignore nobreak | Игнорирование запрета разрыва |
image comment | image comment={<text>} | Комментарий к изображению |
index | index={<entry>} | Запись в индекс |
index actual | index actual={<options>} | Фактические настройки индекса |
index annotate | index annotate={<options>} | Аннотации индекса |
index colorize | index colorize={<options>} | Раскрашивание индекса |
index command | index command={<cmd>} | Команда индекса |
index command name | index command name={<name>} | Имя команды индекса |
index default settings | index default settings | Настройки индекса по умолчанию |
index format | index format={<format>} | Формат индекса |
index gather all | index gather all | Сбор всех элементов в индекс |
index gather colors | index gather colors | Сбор цветов в индекс |
index gather commands | index gather commands | Сбор команд в индекс |
index gather counters | index gather counters | Сбор счетчиков в индекс |
index gather environments | index gather environments | Сбор окружений в индекс |
index gather keys | index gather keys | Сбор ключей в индекс |
index gather lengths | index gather lengths | Сбор длин в индекс |
index gather none | index gather none | Отключение сбора в индекс |
index gather paths | index gather paths | Сбор путей в индекс |
index gather values | index gather values | Сбор значений в индекс |
index german settings | index german settings | Немецкие настройки индекса |
index key formatter | index key formatter={<formatter>} | Форматирование ключей индекса |
index keys formatter | index keys formatter={<formatter>} | Форматирование нескольких ключей |
index level | index level={<level>} | Уровень индекса |
index quote | index quote={<text>} | Цитата в индексе |
index* | index*={<entry>} | Альтернативная запись в индекс |
inherit height | inherit height | Наследование высоты |
interior code | interior code={<code>} | Пользовательский код внутренней части |
interior code app | interior code app={<code>} | Код внутренней части для приложений |
interior code pre | interior code pre={<code>} | Предварительный код внутренней части |
interior empty | interior empty | Пустая внутренняя часть |
interior engine | interior engine={<name>} | Движок внутренней части |
interior hidden | interior hidden | Скрытая внутренняя часть |
interior style | interior style={<style>} | Стиль внутренней части |
interior style image | interior style image={<image>} | Стиль внутренней части с изображением |
interior style tile | interior style tile={<options>} | Стиль внутренней части с плиткой |
interior titled code | interior titled code={<code>} | Код внутренней части с заголовком |
interior titled code app | interior titled code app={<code>} | Код внутренней части с заголовком для приложений |
interior titled code pre | interior titled code pre={<code>} | Предварительный код внутренней части с заголовком |
interior titled empty | interior titled empty | Пустая внутренняя часть с заголовком |
interior titled engine | interior titled engine=<name> | Движок для внутренней части с заголовком |
invisible | invisible | Делает бокс полностью невидимым (но сохраняет содержимое) |
keywords bold | keywords bold | Выделение ключевых слов жирным шрифтом в документации |
label | label=<text> | Метка для перекрестных ссылок |
label is label | label is label | Использовать стандартные метки LaTeX |
label is zlabel | label is zlabel | Использовать zref-метки |
label separator | label separator=<text> | Разделитель между меткой и текстом |
label type | label type=<type> | Тип метки (например, ’tcb@label') |
left | left=<length> | Отступ слева для основного содержимого |
left skip | left skip=<length> | Горизонтальный отступ слева |
left* | left*=<length> | Альтернативный отступ слева |
lefthand ratio | lefthand ratio=<value> | Соотношение для левой части (в split боксах) |
lefthand width | lefthand width=<length> | Ширина левой части (в split боксах) |
leftlower | leftlower=<length> | Отступ слева для нижней части |
leftright skip | leftright skip=<length> | Одновременный отступ слева и справа |
leftrule | leftrule=<length> | Толщина левой границы |
lefttitle | lefttitle=<length> | Отступ слева для заголовка |
leftupper | leftupper=<length> | Отступ слева для верхней части |
lifted shadow | lifted shadow={<options>} | Эффект “приподнятой” тени |
lines before break | lines before break=<number> | Минимальное количество строк перед разрывом |
list entry | list entry=<text> | Запись для списка (оглавления) |
list text | list text=<text> | Текст для списка |
listing above comment | listing above comment={<text>} | Листинг с комментарием сверху |
listing above text | listing above text={<text>} | Листинг с текстом сверху |
listing and comment | listing and comment={<text>} | Комбинация листинга и комментария |
listing engine | listing engine=<name> | Движок для обработки листингов |
listing file | listing file={<filename>} | Файл с кодом для листинга |
listing inputencoding | listing inputencoding=<encoding> | Кодировка входного файла листинга |
listing only | listing only | Только листинг (без дополнительного текста) |
listing options | listing options={<options>} | Опции для листинга |
listing remove caption | listing remove caption | Удаление подписи у листинга |
listing side comment | listing side comment={<text>} | Листинг с боковым комментарием |
listing side text | listing side text={<text>} | Листинг с боковым текстом |
listing style | listing style={<style>} | Стиль оформления листинга |
listing utf8 | listing utf8 | Использование UTF-8 для листинга |
lower separated | lower separated | Разделение нижней части визуальной линией |
lowerbox | lowerbox | Обработка нижней части как бокса |
marker | marker={<options>} | Маркеры для оформления |
math | math | Математический режим в основном содержимом |
math lower | math lower | Математический режим в нижней части |
math upper | math upper | Математический режим в верхней части |
middle | middle=<length> | Вертикальное выравнивание по середине |
minipage | minipage | Обработка содержимого как minipage |
minipage boxed title | minipage boxed title | Заголовок как minipage |
minted language | minted language={<lang>} | Язык для пакета minted |
minted options | minted options={<options>} | Опции для minted |
minted style | minted style={<style>} | Стиль для minted |
move upwards | move upwards=<length> | Сдвиг содержимого вверх |
nameref | nameref | Использование nameref для ссылок |
natural height | natural height | Естественная высота содержимого |
no borderline | no borderline | Удаление дополнительных границ |
no boxed title style | no boxed title style | Отключение стиля для заголовка в рамке |
no extras | no extras | Отключение дополнительных стилей |
no finish | no finish | Отключение завершающих стилей |
no label type | no label type | Отключение специального типа метки |
no listing options | no listing options | Отключение опций листинга |
no overlay | no overlay | Отключение наложений |
no shadow | no shadow | Отключение теней |
no underlay | no underlay | Отключение подложек |
no watermark | no watermark | Отключение водяных знаков |
nobeforeafter | nobeforeafter | Отключение отступов before/after |
nofloat | nofloat | Запрет плавающего размещения |
noparskip | noparskip | Отключение parskip |
notitle | notitle | Отключение заголовка |
octogon arc | octogon arc | Восьмиугольная форма углов |
on line | on line | Размещение в строке текста |
only | only={<options>} | Условное отображение содержимого |
opacityback | opacityback=<value> | Прозрачность фона |
opacitybacktitle | opacitybacktitle=<value> | Прозрачность фона заголовка |
opacityframe | opacityframe=<value> | Прозрачность рамки |
opacitytext | opacitytext=<value> | Прозрачность текста |
outer arc | outer arc | Скругление внешних углов |
overlay | overlay={<code>} | Наложение TikZ-кода |
oversize | oversize | Разрешение содержимому выходить за границы |
pad at break | pad at break=<length> | Заполнение при разрыве |
page ref formatter | page ref formatter={<code>} | Форматирование ссылок на страницы |
parbox | parbox | Обработка содержимого как parbox |
parskip | parskip | Использование parskip между абзацами |
phantom | phantom | Невидимый бокс, занимающий место |
process code | process code={<code>} | Обработка кода перед вставкой |
raster columns | raster columns=<number> | Количество колонок в сетке |
raster equal height | raster equal height | Выравнивание высоты элементов сетки |
raster rows | raster rows=<number> | Количество строк в сетке |
record | record | Запись параметров бокса |
right | right=<length> | Отступ справа для основного содержимого |
right skip | right skip=<length> | Горизонтальный отступ справа |
rightrule | rightrule=<length> | Толщина правой границы |
rotate | rotate=<angle> | Вращение бокса |
rounded corners | rounded corners=<length> | Скругление углов |
run pdflatex | run pdflatex | Запуск pdflatex для обработки содержимого |
savedelimiter | savedelimiter={<text>} | Сохранение разделителя |
saveto | saveto={<filename>} | Сохранение содержимого в файл |
scale | scale=<factor> | Масштабирование содержимого |
segmentation at break | segmentation at break | Разделитель при разрыве |
segmentation code | segmentation code={<code>} | Пользовательский код разделителя |
segmentation style | segmentation style={<style>} | Стиль линии-разделителя между верхней и нижней частями |
separator sign | separator sign={<char>} | Символ-разделитель в описаниях |
separator sign colon | separator sign colon | Использование двоеточия как разделителя |
separator sign dash | separator sign dash | Использование тире как разделителя |
separator sign none | separator sign none | Отсутствие разделителя |
set alt | set alt={<text>} | Установка альтернативного текста |
set temporal | set temporal={<text>} | Временная установка значения |
shadow | shadow={<options>} | Настройка тени вокруг бокса |
sharp corners | sharp corners | Острые углы (без скругления) |
sharpish corners | sharpish corners | Слегка скругленные углы |
shield externalize | shield externalize | Защита от externalize |
short title | short title={<text>} | Краткий вариант заголовка |
show bounding box | show bounding box | Отображение ограничивающей рамки |
shrink break goal | shrink break goal={<length>} | Целевое значение сжатия при разрыве |
shrink tight | shrink tight | Плотное сжатие содержимого |
sidebyside | sidebyside | Размещение содержимого бок о бок |
sidebyside align | sidebyside align={<option>} | Выравнивание side-by-side содержимого |
sidebyside gap | sidebyside gap={<length>} | Зазор между side-by-side элементами |
sidebyside switch | sidebyside switch | Переключение порядка side-by-side |
size | size={<option>} | Размер бокса (normal, small, etc.) |
skin | skin={<name>} | Скин для оформления бокса |
skin first | skin first={<name>} | Скин для первого бокса в группе |
skin last | skin last={<name>} | Скин для последнего бокса в группе |
skin middle | skin middle={<name>} | Скин для средних боксов в группе |
smart shadow arc | smart shadow arc | Умное скругление теней |
space | space={<length>} | Вертикальный промежуток |
space to | space to={<length>} | Гибкий вертикальный промежуток |
space to lower | space to lower={<length>} | Промежуток до нижней части |
space to upper | space to upper={<length>} | Промежуток до верхней части |
spartan | spartan | Минималистичный стиль оформления |
split | split={<options>} | Разделение бокса на части |
spread | spread | Равномерное распределение пространства |
spread downwards | spread downwards | Распределение вниз |
spread inwards | spread inwards | Распределение внутрь |
spread outwards | spread outwards | Распределение наружу |
spread upwards | spread upwards | Распределение вверх |
square | square | Квадратная форма бокса |
squeezed title | squeezed title | Сжатый заголовок |
standard | standard | Стандартный стиль оформления |
standard jigsaw | standard jigsaw | Стандартный стиль с “пазлами” |
step | step={<counter>} | Шаг нумерации |
step and label | step and label | Автоматическая нумерация и метка |
store to box array | store to box array={<name>} | Сохранение в массив боксов |
subtitle style | subtitle style={<style>} | Стиль подзаголовка |
tabularx | tabularx | Использование tabularx внутри |
tcbimage comment | tcbimage comment={<text>} | Комментарий к изображению |
tcbox raise | tcbox raise={<length>} | Поднятие бокса |
tempfile | tempfile | Использование временного файла |
temporal | temporal={<text>} | Временное значение |
terminator sign | terminator sign={<char>} | Конечный символ в описаниях |
text above listing | text above listing={<text>} | Текст над листингом |
text and listing | text and listing | Комбинация текста и листинга |
text fill | text fill | Заполнение текстом |
text height | text height={<length>} | Высота текстовой области |
text width | text width={<length>} | Ширина текстовой области |
theorem | theorem | Стиль для теорем |
theorem label supplement | theorem label supplement={<text>} | Дополнение к метке теоремы |
theorem style | theorem style={<name>} | Стиль оформления теоремы |
tikz | tikz={<options>} | Опции TikZ |
tikz lower | tikz lower={<options>} | TikZ для нижней части |
tikz upper | tikz upper={<options>} | TikZ для верхней части |
tikznode | tikznode | Обработка как TikZ-узел |
tile | tile | Плиточное оформление фона |
title | title={<text>} | Заголовок бокса |
title after break | title after break={<text>} | Заголовок после разрыва |
title style | title style={<style>} | Стиль заголовка |
titlerule | titlerule={<length>} | Линия под заголовком |
toggle enlargement | toggle enlargement | Переключение увеличения |
toggle left and right | toggle left and right | Переключение левого/правого |
top | top={<length>} | Отступ сверху |
toprule | toprule={<length>} | Верхняя граница |
unbreakable | unbreakable | Запрет разрыва бокса |
underlay | underlay={<code>} | Подложка (TikZ-код под содержимым) |
underlay boxed title | underlay boxed title={<code>} | Подложка для заголовка |
underlay first | underlay first={<code>} | Подложка для первой части |
underlay last | underlay last={<code>} | Подложка для последней части |
underlay middle | underlay middle={<code>} | Подложка для средней части |
underlay vignette | underlay vignette={<options>} | Виньетка в качестве подложки |
upperbox | upperbox | Обработка верхней части как бокса |
use alt | use alt | Использование альтернативного текста |
use color stack | use color stack | Использование стека цветов |
valign | valign={<option>} | Вертикальное выравнивание |
varwidth upper | varwidth upper | Переменная ширина верхней части |
verbatim | verbatim | Режим verbatim |
visible | visible | Видимый бокс (антоним invisible) |
watermark graphics | watermark graphics={<file>} | Водяной знак из изображения |
watermark opacity | watermark opacity={<value>} | Прозрачность водяного знака |
watermark text | watermark text={<text>} | Текстовый водяной знак |
watermark tikz | watermark tikz={<code>} | Водяной знак TikZ |
width | width={<length>} | Ширина бокса |
Основные ключи оформления заголовка (/tcb/boxtitle/)
| Ключ | Синтаксис | Назначение |
|---|---|---|
xshift | xshift=<length> | Горизонтальное смещение заголовка |
yshift | yshift=<length> | Вертикальное смещение заголовка |
yshift* | yshift*=<length> | Альтернативное вертикальное смещение |
yshifttext | yshifttext=<length> | Смещение текста заголовка |
Ключи документации (/tcb/doclang/)
| Ключ | Синтаксис | Назначение |
|---|---|---|
color | color={<name>} | Цвет для документации |
commands | commands={<list>} | Список команд |
counter | counter={<name>} | Счетчик для документации |
environment | environment={<name>} | Окружение для документации |
index | index={<options>} | Настройки индекса |
key | key={<name>} | Ключ документации |
length | length={<name>} | Длина для документации |
new | new | Пометка нового элемента |
path | path={<name>} | Путь для документации |
updated | updated | Пометка обновленного элемента |
value | value={<val>} | Значение для документации |
Ключи внешнего контента (/tcb/external/)
| Ключ | Синтаксис | Назначение |
|---|---|---|
- | - | Стандартный режим externalize |
! | ! | Форсированный режим externalize |
compiler | compiler={<name>} | Компилятор для внешних файлов |
environment | environment={<name>} | Окружение для внешнего контента |
externalize | externalize | Активация externalize |
name | name={<base>} | Базовое имя для файлов |
preamble | preamble={<code>} | Преамбула для внешних файлов |
prefix | prefix={<text>} | Префикс для имен файлов |
runner | runner={<command>} | Команда для запуска |
safety | safety={<options>} | Настройки безопасности |
Библиотеки (/tcb/library/)
| Ключ | Назначение |
|---|---|
all | Все библиотеки |
breakable | Поддержка разрывов |
documentation | Документационные стили |
external | Внешний контент |
fitting | Автоподгонка размеров |
listings | Поддержка листингов |
minted | Интеграция с Minted |
raster | Сеточная компоновка |
skins | Дополнительные скины |
theorems | Стили для теорем |
Ключи постеров (/tcb/poster/)
| Ключ | Синтаксис | Назначение |
|---|---|---|
colspacing | colspacing=<length> | Расстояние между колонками |
columns | columns=<number> | Количество колонок |
height | height=<length> | Высота постера |
rowspacing | rowspacing=<length> | Расстояние между строками |
showframe | showframe | Показать рамки |
width | width=<length> | Ширина постера |
Ключи виньетирования (/tcb/vig/)
| Ключ | Синтаксис | Назначение |
|---|---|---|
base color | base color={<color>} | Базовый цвет виньетки |
east size | east size=<length> | Размер восточной части |
fade in | fade in={<options>} | Эффект плавного появления |
lower left corner | lower left corner={<coord>} | Левый нижний угол |
size | size={<length>} | Общий размер |
upper right corner | upper right corner={<coord>} | Правый верхний угол |
Интеграция с TikZ (/tikz/)
| Ключ | Синтаксис | Назначение |
|---|---|---|
tcb fill frame | tcb fill frame={<color>} | Заливка рамки |
tcb fill interior | tcb fill interior={<color>} | Заливка внутренней части |
tcb fill title | tcb fill title={<color>} | Заливка заголовка |
Особенности:
- Группы ключей организованы по функциональности (заголовки, документация, внешний контент и т.д.)
- Виньетки (/tcb/vig/) предоставляют сложные эффекты затемнения/осветления углов
- Постеры (/tcb/poster/) позволяют создавать сложные сеточные компоновки
- Интеграция с TikZ дает полный контроль над графическими элементами
Каждая группа ключей решает специфические задачи, от базового позиционирования до сложных эффектов оформления.
7.1.2 - Команды для Title
Управляет параметрами заголовка в боксах
| Команда | Полный синтаксис | Описание и назначение |
|---|---|---|
title | /tcb/title=⟨text⟩ | Создает заголовок с указанным текстом. |
notitle | /tcb/notitle | Удаляет строку заголовка, если установлено. |
adjusted title | /tcb/adjusted title=⟨text⟩ | Создает заголовок с автоматической подгонкой высоты под текст (полезно для выравнивания высоты боксов в группе). |
adjust text | /tcb/adjust text=⟨text⟩ | Устанавливает эталонный текст для подгонки высоты в adjusted title. |
squeezed title | /tcb/squeezed title=⟨text⟩ | Создает заголовок, сжимая текст, если он не помещается в доступное пространство. |
squeezed title* | /tcb/squeezed title*=⟨text⟩ | Комбинация adjusted title и squeezed title (подгонка высоты и сжатие текста). |
titlebox | /tcb/titlebox=⟨mode⟩ | Управляет отображением заголовка (visible — стандартное отображение, invisible — скрывает текст, оставляя пустое место). |
detach title | /tcb/detach title | Отделяет заголовок от стандартной позиции, сохраняя его в \tcbtitletext и \tcbtitle. |
attach title | /tcb/attach title | Возвращает заголовок в стандартную позицию (отменяет detach title). |
attach title to upper | /tcb/attach title to upper=⟨text⟩ | Прикрепляет заголовок к началу верхней части содержимого бокса (с дополнительным текстом между заголовком и содержимым). |
\tcbset{colback=White,arc=0mm,width=(\linewidth-4pt)/4,
equal height group=AT,before=,after=\hfill,fonttitle=\bfseries}
The following titles are not adjusted:\\
\foreach \n in {xxx,ggg,AAA,\"Agypten}
{\begin{tcolorbox}[title=\n,colframe=red!75!black]
Some content.\end{tcolorbox}}
Now, we try again with adjusted titles:\\
\foreach \n in {xxx,ggg,AAA,\"Agypten}
{\begin{tcolorbox}[adjusted title=\n,colframe=blue!75!black]
Some content.\end{tcolorbox}}
7.1.3 - Команды для SubTitle
Управляет параметрами подзаголовка в боксах
Таблица команд для управления Subtitle в пакете tcolorbox
| Команда | Полный синтаксис | Описание и назначение |
|---|---|---|
\tcbsubtitle | \tcbsubtitle[⟨options⟩]{⟨text⟩} | Добавляет подзаголовок внутри tcolorbox. Наследует стили родительского бокса, но может быть дополнительно настроен через ⟨options⟩. |
subtitle style | /tcb/subtitle style=⟨options⟩ | Задает стиль для всех подзаголовков (\tcbsubtitle) внутри бокса. Позволяет централизованно настроить оформление. |
Примеры использования
1. Базовый подзаголовок
\begin{tcolorbox}[title=Основной заголовок, colback=blue!5!white, colframe=blue!75!black]
Основное содержимое.
\tcbsubtitle{Первый подзаголовок}
Текст под первым подзаголовком.
\tcbsubtitle{Второй подзаголовок}
Текст под вторым подзаголовком.
\end{tcolorbox}
2. Настройка стиля подзаголовков
\begin{tcolorbox}[
title=Пример с subtitle style,
colback=green!5!white,
colframe=green!75!black,
subtitle style={
colback=yellow!20!white,
colframe=red!50!black,
fontupper=\bfseries,
boxrule=1pt
}
]
Основной текст.
\tcbsubtitle{Настроенный подзаголовок}
Текст с кастомным оформлением.
\end{tcolorbox}
3. Локальная переопределение через ⟨options⟩
\begin{tcolorbox}[title=Локальные настройки, colback=purple!5!white]
\tcbsubtitle[colback=orange!30!white, before skip=10pt]{Особый подзаголовок}
Текст с увеличенным отступом сверху и оранжевым фоном.
\end{tcolorbox}
7.1.4 - Команды для Part
Управляет параметрами разделенных частей в боксах
Таблица команд для управления частями (Upper/Lower Part) в пакете tcolorbox
| Команда | Полный синтаксис | Описание и назначение |
|---|---|---|
upperbox | /tcb/upperbox=⟨mode⟩ | Управляет отображением верхней части бокса. Допустимые значения: visible (стандартное отображение), invisible (скрывает содержимое). |
lowerbox | /tcb/lowerbox=⟨mode⟩ | Управляет отображением нижней части (после \tcblower). Аналогично upperbox. |
visible | /tcb/visible | Сокращение для upperbox=visible, lowerbox=visible, titlebox=visible. |
invisible | /tcb/invisible | Сокращение для upperbox=invisible, lowerbox=invisible, titlebox=invisible. |
saveto | /tcb/saveto=⟨file name⟩ | Сохраняет весь контент бокса (включая нижнюю часть, если есть) в указанный файл. Несовместимо с savelowerto/redirectlowerto. |
savelowerto | /tcb/savelowerto=⟨file name⟩ | Сохраняет только нижнюю часть (после \tcblower) в файл. |
redirectlowerto | /tcb/redirectlowerto=⟨file name⟩ | Перенаправляет нижнюю часть в файл (без отображения в документе). |
Примеры использования
1. Управление видимостью частей
\begin{tcolorbox}[upperbox=invisible, colback=white]
Этот текст не виден (верхняя часть скрыта).
\end{tcolorbox}
\begin{tcolorbox}[lowerbox=invisible, colback=white]
Виден только верх.
\tcblower
Нижняя часть скрыта.
\end{tcolorbox}
Результат:
- Первый бокс: пустое пространство (верх скрыт).
- Второй бокс: отображается только текст до
\tcblower.
2. Сокращенные команды visible/invisible
\begin{tcolorbox}[invisible, title=Скрытый бокс]
Весь контент (включая заголовок) не виден.
\tcblower
Нижняя часть тоже скрыта.
\end{tcolorbox}
Результат: Пустое место (все части скрыты).
3. Сохранение контента в файл
\begin{tcolorbox}[saveto=mybox.tex, title=Сохраненный бокс]
Верхняя часть.
\tcblower
Нижняя часть.
\end{tcolorbox}
Загружаем сохраненное:
\input{mybox.tex}
Результат:
- В документе отображается оригинальный бокс.
- Содержимое сохранено в
mybox.texи может быть повторно загружено через\input.
4. Работа с нижней частью
\begin{tcolorbox}[savelowerto=lower.tex]
Верхняя часть (отображается).
\tcblower
Нижняя часть (сохраняется в файл).
\end{tcolorbox}
Результат:
- В документе видна только верхняя часть.
- Нижняя часть сохранена в
lower.tex.
Важные нюансы:
Разделение частей:
- Верхняя часть обязательна, нижняя — опциональна (активируется
\tcblower). - Без
\tcblowerвесь контент считается верхней частью.
- Верхняя часть обязательна, нижняя — опциональна (активируется
Совместимость:
savetoнельзя использовать сsavelowertoилиredirectlowerto.
Применение:
invisibleполезен для скрытия контента (например, при сохранении в файл без отображения).savelowertoудобен для извлечения доп. материалов (решений задач, примечаний).
7.1.5 - Команды для Lower Part
Управляет параметрами нижней части lower part в боксах
Таблица команд для управления нижней частью (Lower Part) в пакете tcolorbox
| Команда | Полный синтаксис | Описание и назначение |
|---|---|---|
lowerbox | /tcb/lowerbox=⟨mode⟩ | Управляет отображением нижней части. Допустимые значения: visible (стандартное отображение), invisible (скрывает содержимое, оставляя пустое место), ignored (полностью игнорирует нижнюю часть). |
savelowerto | /tcb/savelowerto=⟨file name⟩ | Сохраняет содержимое нижней части в указанный файл для последующего использования. Несовместимо с saveto. |
redirectlowerto | /tcb/redirectlowerto=⟨file name⟩ | Комбинация savelowerto и lowerbox=ignored. Сохраняет нижнюю часть в файл, но не отображает её в документе. Полезно для работы с счётчиками. |
lower separated | `/tcb/lower separated=true | false(по умолчаниюtrue`) |
savedelimiter | /tcb/savedelimiter=⟨name⟩ | Используется при создании новых окружений на основе tcolorbox для корректной работы с savelowerto или redirectlowerto. ⟨name⟩ должно совпадать с именем нового окружения. |
Примеры использования
1. Управление видимостью нижней части
\begin{tcolorbox}[lowerbox=invisible, colback=white]
Верхняя часть (видна).
\tcblower
Нижняя часть (скрыта, но место остаётся).
\end{tcolorbox}
\begin{tcolorbox}[lowerbox=ignored, colback=white]
Верхняя часть (видна).
\tcblower
Нижняя часть (полностью игнорируется).
\end{tcolorbox}
Результат:
- Первый бокс: нижняя часть скрыта, но занимает место.
- Второй бокс: нижняя часть отсутствует.
2. Сохранение нижней части в файл
\begin{tcolorbox}[savelowerto=lower_content.tex, lowerbox=invisible]
Верхняя часть.
\tcblower
Нижняя часть (сохранена в файл).
\end{tcolorbox}
Загружаем сохранённое:
\input{lower_content.tex}
Результат:
- В документе отображается только верхняя часть.
- Нижняя часть сохранена в
lower_content.texи может быть загружена через\input.
3. Перенаправление нижней части без отображения
\setcounter{enumi}{1}
Значение счётчика: \theenumi
\begin{tcolorbox}[redirectlowerto=counter_example.tex]
Верхняя часть.
\tcblower
Нижняя часть. \stepcounter{enumi} Новое значение: \theenumi.
\end{tcolorbox}
Загружаем:
\input{counter_example.tex}
Результат:
- В документе: отображается только верхняя часть, счётчик не изменён.
- В файле
counter_example.tex: сохранён текст нижней части с обновлённым счётчиком.
4. Визуальное разделение частей
\begin{tcolorbox}[title=Разделённые части, lower separated=true]
Верхняя часть.
\tcblower
Нижняя часть (визуально отделена).
\end{tcolorbox}
\begin{tcolorbox}[title=Неразделённые части, lower separated=false]
Верхняя часть.
\tcblower
Нижняя часть (без разделения).
\end{tcolorbox}
Результат:
- Первый бокс: части разделены линией (зависит от стиля).
- Второй бокс: части сливаются.
5. Создание пользовательского окружения с сохранением
\newtcolorbox{mybox}[1]{%
savelowerto=#1, lowerbox=ignored,
colback=blue!5!white, colframe=blue!75!black,
title=Мой бокс
}
\begin{mybox}{saved_part.tex}
Верхняя часть.
\tcblower
Сохранённая нижняя часть.
\end{mybox}
Используем сохранённое:
\input{saved_part.tex}
Результат:
- В документе: только верхняя часть с заголовком “Мой бокс”.
- В файле
saved_part.tex: сохранена нижняя часть.
Ключевые особенности:
Гибкость:
lowerbox=ignoredполностью исключает нижнюю часть из обработки, что полезно для оптимизации.redirectlowertoпозволяет сохранять контент без побочных эффектов (например, изменения счётчиков).
Совместимость:
savelowertoиredirectlowertoнельзя использовать вместе сsaveto.
Дизайн:
- Разделение частей (
lower separated) можно настроить для разных стилей (например,beamerилиraster).
- Разделение частей (
7.1.6 - Команды для Color и Font
Управляет параметрами цвета и шрифтов текста и заголовков в боксах
Таблица управления цветами и шрифтами в tcolorbox
Основные параметры цвета
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
colframe | /tcb/colframe=⟨color⟩ | Цвет рамки бокса. По умолчанию: black!75!white. | colframe=red |
colback | /tcb/colback=⟨color⟩ | Цвет фона содержимого бокса. По умолчанию: black!5!white. | colback=blue!10 |
colbacktitle | /tcb/colbacktitle=⟨color⟩ | Цвет фона заголовка. По умолчанию: black!50!white. | colbacktitle=green!20 |
colupper | /tcb/colupper=⟨color⟩ | Цвет текста верхней части. По умолчанию: black. | colupper=red!50 |
collower | /tcb/collower=⟨color⟩ | Цвет текста нижней части. По умолчанию: black. | collower=blue!50 |
coltext | /tcb/coltext=⟨color⟩ | Устанавливает одинаковый цвет текста для верхней и нижней части. | coltext=purple |
coltitle | /tcb/coltitle=⟨color⟩ | Цвет текста заголовка. По умолчанию: white. | coltitle=yellow |
Управление отображением заголовка
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
title filled | `/tcb/title filled=true | false` | Включает/отключает заливку фона заголовка. По умолчанию: false. |
Параметры шрифтов
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
fontupper | /tcb/fontupper=⟨text⟩ | Устанавливает шрифт для верхней части. | fontupper=\bfseries |
fontlower | /tcb/fontlower=⟨text⟩ | Устанавливает шрифт для нижней части. | fontlower=\itshape |
fonttitle | /tcb/fonttitle=⟨text⟩ | Устанавливает шрифт для заголовка. | fonttitle=\sffamily |
Примеры использования
1. Настройка цветов
\begin{tcolorbox}[colframe=red, colback=yellow!10, colbacktitle=blue!20, coltitle=white, title=Цветной бокс]
Это пример цветного tcolorbox.
\tcblower
Нижняя часть с другим цветом текста.
\end{tcolorbox}
2. Управление шрифтами
\begin{tcolorbox}[fonttitle=\sffamily\bfseries\large, fontupper=\itshape, fontlower=\bfseries, title=Шрифты]
Верхняя часть курсивом.
\tcblower
Нижняя часть жирным.
\end{tcolorbox}
3. Комбинированный пример
\begin{tcolorbox}[
colframe=green!50!black,
colback=green!10,
colbacktitle=green!40,
coltitle=white,
fonttitle=\bfseries,
title filled=true,
title=Комбинированный пример,
fontupper=\small,
collower=red
]
Верхняя часть мелким шрифтом.
\tcblower
Нижняя часть красным цветом.
\end{tcolorbox}
Особенности:
- Все цветовые параметры поддерживают стандартные цветовые модели LaTeX (например,
red!50!white). - Для шрифтов можно использовать любые стандартные команды изменения шрифта (
\bfseries,\itshapeи т.д.). - Параметр
title filledавтоматически активируется при установкеcolbacktitleили других связанных с заголовком параметров. coltextудобен для установки единого цвета текста во всем боксе, тогда какcolupperиcollowerпозволяют дифференцировать части.
7.1.7 - Команды для выравнивания текста
Управляет параметрами выравнивания текста в боксах
Таблица управления выравниванием текста в tcolorbox
Горизонтальное выравнивание
| Параметр | Синтаксис | Допустимые значения | Описание | Пример |
|---|---|---|---|---|
halign / halign upper | /tcb/halign=⟨alignment⟩ | justify, left, flush left, right, flush right, center, flush center | Выравнивание верхней части (или всего содержимого, если нет нижней части) | halign=flush center |
halign lower | /tcb/halign lower=⟨alignment⟩ | те же, что для halign | Выравнивание нижней части | halign lower=right |
halign title | /tcb/halign title=⟨alignment⟩ | те же, что для halign | Выравнивание заголовка | halign title=center |
halign code / halign upper code | /tcb/halign code={⟨code⟩} | произвольный LaTeX-код | Произвольное выравнивание верхней части | halign code={\raggedright} |
halign lower code | /tcb/halign lower code={⟨code⟩} | произвольный LaTeX-код | Произвольное выравнивание нижней части | halign lower code={\centering} |
halign title code | /tcb/halign title code={⟨code⟩} | произвольный LaTeX-код | Произвольное выравнивание заголовка | halign title code={\raggedleft} |
Вертикальное выравнивание
| Параметр | Синтаксис | Допустимые значения | Описание | Пример |
|---|---|---|---|---|
valign / valign upper | /tcb/valign=⟨alignment⟩ | top, center, bottom, scale, scale* | Вертикальное выравнивание верхней части | valign=center |
valign lower | /tcb/valign lower=⟨alignment⟩ | те же, что для valign | Вертикальное выравнивание нижней части | valign lower=bottom |
valign scale limit | /tcb/valign scale limit=⟨real⟩ | число (по умолчанию 1.1) | Максимальный коэффициент масштабирования для scale* | valign scale limit=1.5 |
Сокращённые команды
| Команда | Эквивалент | Описание |
|---|---|---|
flushleft upper | halign=flush left | Выравнивание верхней части по левому краю |
center upper | halign=flush center | Выравнивание верхней части по центру |
flushright upper | halign=flush right | Выравнивание верхней части по правому краю |
flushleft lower | halign lower=flush left | Выравнивание нижней части по левому краю |
center lower | halign lower=flush center | Выравнивание нижней части по центру |
flushright lower | halign lower=flush right | Выравнивание нижней части по правому краю |
flushleft title | halign title=flush left | Выравнивание заголовка по левому краю |
center title | halign title=flush center | Выравнивание заголовка по центру |
flushright title | halign title=flush right | Выравнивание заголовка по правому краю |
Примеры использования
1. Горизонтальное выравнивание
\begin{tcolorbox}[halign=flush left, title=Пример выравнивания]
Текст, выровненный по левому краю.
\tcblower
Нижняя часть с выравниванием по правому краю.
\end{tcolorbox}
2. Вертикальное выравнивание
\begin{tcolorbox}[valign=center, height=4cm]
Текст, выровненный по центру по вертикали.
\end{tcolorbox}
3. Выравнивание заголовка
\begin{tcolorbox}[halign title=center, title=Центрированный заголовок]
Содержимое бокса.
\end{tcolorbox}
Особенности:
Разница между
flushи не-flushверсиями:flushверсии используют стандартные LaTeX-команды (\raggedright,\centering,\raggedleft)- Не-
flushверсии реализованы через TikZ и могут давать более сбалансированное расположение с переносами
Вертикальное выравнивание имеет смысл только при явно заданной высоте бокса
Параметры
scaleиscale*масштабируют текст по вертикали, что может быть полезно для точного заполнения пространства
7.1.8 - Команды для управления размерами и отступами в боксах
Управляет параметрами размеров боксов и рамок в боксах
Управление геометрией в tcolorbox
4.7.1 Ширина (Width)
| Команда | Синтаксис | Описание | Пример |
|---|---|---|---|
width | /tcb/width=⟨length⟩ | Устанавливает общую ширину бокса | width=\linewidth/2 |
text width | /tcb/text width=⟨length⟩ | Устанавливает ширину текста в верхней части | text width=4cm |
add to width | /tcb/add to width=⟨length⟩ | Добавляет значение к текущей ширине бокса | add to width=1cm |
4.7.2 Границы (Rules)
| Команда | Синтаксис | Описание | Пример |
|---|---|---|---|
toprule | /tcb/toprule=⟨length⟩ | Толщина верхней границы | toprule=3mm |
bottomrule | /tcb/bottomrule=⟨length⟩ | Толщина нижней границы | bottomrule=3mm |
leftrule | /tcb/leftrule=⟨length⟩ | Толщина левой границы | leftrule=3mm |
rightrule | /tcb/rightrule=⟨length⟩ | Толщина правой границы | rightrule=3mm |
titlerule | /tcb/titlerule=⟨length⟩ | Толщина линии под заголовком | titlerule=3mm |
boxrule | /tcb/boxrule=⟨length⟩ | Устанавливает толщину всех границ | boxrule=3mm |
4.7.3 Скругления (Arcs)
| Команда | Синтаксис | Описание | Пример |
|---|---|---|---|
arc | /tcb/arc=⟨length⟩ | Радиус скругления углов | arc=3mm |
circular arc | /tcb/circular arc | Делает бокс круглым (при равных ширине и высоте) | circular arc |
bean arc | /tcb/bean arc | Автоматический радиус скругления | bean arc |
octogon arc | /tcb/octogon arc | Создает восьмиугольник | octogon arc |
arc is angular | /tcb/arc is angular | Заменяет скругления на углы | arc is angular |
arc is curved | /tcb/arc is curved | Восстанавливает скругления (по умолчанию) | arc is curved |
outer arc | /tcb/outer arc=⟨length⟩ | Внешний радиус скругления | outer arc=1mm |
auto outer arc | /tcb/auto outer arc | Автоматический внешний радиус | auto outer arc |
4.7.4 Отступы (Spacing)
| Команда | Синтаксис | Описание | Пример |
|---|---|---|---|
boxsep | /tcb/boxsep=⟨length⟩ | Общий внутренний отступ | boxsep=5mm |
left | /tcb/left=⟨length⟩ | Левый отступ для всех частей | left=0mm |
left* | /tcb/left*=⟨length⟩ | Левый отступ от границы | left*=0mm |
lefttitle | /tcb/lefttitle=⟨length⟩ | Левый отступ заголовка | lefttitle=3cm |
leftupper | /tcb/leftupper=⟨length⟩ | Левый отступ верхней части | leftupper=3cm |
leftlower | /tcb/leftlower=⟨length⟩ | Левый отступ нижней части | leftlower=3cm |
right | /tcb/right=⟨length⟩ | Правый отступ для всех частей | right=2cm |
right* | /tcb/right*=⟨length⟩ | Правый отступ от границы | right*=0mm |
righttitle | /tcb/righttitle=⟨length⟩ | Правый отступ заголовка | righttitle=2cm |
rightupper | /tcb/rightupper=⟨length⟩ | Правый отступ верхней части | rightupper=2cm |
rightlower | /tcb/rightlower=⟨length⟩ | Правый отступ нижней части | rightlower=2cm |
top | /tcb/top=⟨length⟩ | Верхний отступ | top=0mm |
toptitle | /tcb/toptitle=⟨length⟩ | Верхний отступ заголовка | toptitle=3mm |
bottom | /tcb/bottom=⟨length⟩ | Нижний отступ | bottom=0mm |
bottomtitle | /tcb/bottomtitle=⟨length⟩ | Нижний отступ заголовка | bottomtitle=3mm |
middle | /tcb/middle=⟨length⟩ | Отступ между частями | middle=0mm |
4.7.5 Размеры (Size Shortcuts)
| Команда | Синтаксис | Описание | Пример |
|---|---|---|---|
size | /tcb/size=⟨name⟩ | Предустановленные размеры: normal, title, small, fbox, tight, minimal | size=small |
oversize | /tcb/oversize=⟨length⟩ | Расширяет ширину за пределы страницы | oversize |
4.7.6 Переключение сторон (Toggle Left and Right)
| Команда | Синтаксис | Описание | Пример |
|---|---|---|---|
toggle left and right | /tcb/toggle left and right=⟨toggle preset⟩ | Переключает левую и правую стороны (none, forced, evenpage) | toggle left and right=evenpage |
Примеры использования
Настройка ширины
\begin{tcolorbox}[width=0.5\linewidth, text width=4cm]
Бокс с ограниченной шириной текста
\end{tcolorbox}
Границы и скругления
\begin{tcolorbox}[
boxrule=2mm,
arc=5mm,
arc is angular,
toprule=3mm,
bottomrule=1mm
]
Бокс с нестандартными границами
\end{tcolorbox}
Отступы
\begin{tcolorbox}[
boxsep=2mm,
left=1cm,
right*=0mm,
toptitle=5mm
]
Бокс с кастомными отступами
\end{tcolorbox}
Размеры
\begin{tcolorbox}[size=small, oversize]
Компактный бокс, расширенный за поля
\end{tcolorbox}
Переключение сторон
\begin{tcolorbox}[
toggle left and right=evenpage,
leftrule=1cm,
rightrule=1mm
]
Бокс с переключением границ на четных страницах
\end{tcolorbox}
7.1.9 - Команды для управления параметрами углов в боксах
Управляет параметрами углов в боксах
Управление углами (Corners) в tcolorbox
Основные команды для работы с углами
| Команда | Синтаксис | Допустимые значения | Описание | Пример |
|---|---|---|---|---|
sharp corners | /tcb/sharp corners=⟨position⟩ | northwest, northeast, southwest, southeast, north, south, east, west, downhill, uphill, all | Делает указанные углы острыми | sharp corners=northwest |
rounded corners | /tcb/rounded corners=⟨position⟩ | Те же, что для sharp corners | Делает указанные углы скругленными (по умолчанию) | rounded corners=all |
sharpish corners | /tcb/sharpish corners | - | Делает углы визуально острыми (технически остаются скругленными) | sharpish corners |
Особенности работы с углами:
- По умолчанию все углы скруглены (
rounded corners=all) sharpish corners- это компромиссный вариант, когда углы выглядят острыми, но технически остаются скругленными (влияет на тени и границы)- Можно комбинировать разные типы углов в одном боксе
Примеры использования
1. Острые углы
\begin{tcolorbox}[
colback=white,
colframe=blue,
sharp corners=northwest, % только северо-западный угол острый
title=Бокс с острым углом
]
Содержимое бокса
\end{tcolorbox}
2. Полностью острый бокс
\begin{tcolorbox}[
colback=white,
colframe=red,
sharp corners, % все углы острые
title=Полностью острый бокс
]
Содержимое бокса
\end{tcolorbox}
3. Комбинирование углов
\begin{tcolorbox}[
colback=white,
colframe=green,
sharp corners=north, % верхние углы острые
rounded corners=south, % нижние углы скругленные
title=Комбинированный бокс
]
Содержимое бокса
\end{tcolorbox}
4. Sharpish corners
\begin{tcolorbox}[
colback=white,
colframe=purple,
sharpish corners, # углы выглядят острыми
title=Бокс с sharpish corners
]
Содержимое бокса
\end{tcolorbox}
Визуальные различия:
Обычные скругленные углы (
rounded corners):- Плавные изгибы
- Тени и границы полностью повторяют форму
Sharpish corners:
- Углы выглядят почти острыми
- Тени и границы слегка скруглены
Полностью острые углы (
sharp corners):- Четкие прямые углы
- Тени и границы имеют острые края
Советы по использованию:
- Для большинства случаев достаточно
sharp cornersилиrounded corners - Используйте
sharpish corners, если нужен компромисс между внешним видом и поведением теней - Можно точечно менять отдельные углы для создания уникальных дизайнов
- Настройки углов влияют на:
- Основную рамку бокса
- Границы (
borderline) - Тени (
shadow)
7.1.10 - Команды для управления прозрачностью в боксах
Управляет параметрами прозрачности в боксах
Таблица управления прозрачностью в tcolorbox
Основные параметры прозрачности
| Параметр | Синтаксис | Описание | Диапазон значений | Пример |
|---|---|---|---|---|
opacityframe | /tcb/opacityframe=⟨fraction⟩ | Прозрачность рамки | 0.0 (полная прозрачность) - 1.0 (непрозрачный) | opacityframe=0.5 |
opacityback | /tcb/opacityback=⟨fraction⟩ | Прозрачность фона содержимого | 0.0-1.0 | opacityback=0.3 |
opacitybacktitle | /tcb/opacitybacktitle=⟨fraction⟩ | Прозрачность фона заголовка | 0.0-1.0 | opacitybacktitle=0.7 |
opacityfill | /tcb/opacityfill=⟨fraction⟩ | Прозрачность заливки (рамка + фон + заголовок) | 0.0-1.0 | opacityfill=0.6 |
opacityupper | /tcb/opacityupper=⟨fraction⟩ | Прозрачность текста верхней части | 0.0-1.0 | opacityupper=0.4 |
opacitylower | /tcb/opacitylower=⟨fraction⟩ | Прозрачность текста нижней части | 0.0-1.0 | opacitylower=0.8 |
opacitytext | /tcb/opacitytext=⟨fraction⟩ | Прозрачность всего текста (верх + низ) | 0.0-1.0 | opacitytext=0.5 |
opacitytitle | /tcb/opacitytitle=⟨fraction⟩ | Прозрачность текста заголовка | 0.0-1.0 | opacitytitle=0.9 |
Примеры использования
1. Полупрозрачная рамка и фон
\begin{tcolorbox}[
colframe=blue,
colback=white,
opacityframe=0.3,
opacityback=0.7,
title=Пример прозрачности
]
Этот бокс имеет полупрозрачную рамку и фон
\end{tcolorbox}
2. Прозрачный заголовок
\begin{tcolorbox}[
colframe=red,
colbacktitle=yellow,
opacitybacktitle=0.5,
opacitytitle=0.8,
title=Прозрачный заголовок
]
Текст содержимого
\end{tcolorbox}
3. Разная прозрачность частей
\begin{tcolorbox}[
opacityupper=0.9,
opacitylower=0.5,
opacityframe=0.6,
opacityback=0.8
]
Верхний текст более непрозрачный
\tcblower
Нижний текст более прозрачный
\end{tcolorbox}
4. Комплексный пример с jigsaw-скином
\begin{tcolorbox}[
enhanced jigsaw,
colframe=green!75!black,
colback=green!10!white,
opacityframe=0.4,
opacityback=0.6,
opacitybacktitle=0.8,
opacitytitle=1.0,
title=Сложный пример
]
Бокс с различными настройками прозрачности
\end{tcolorbox}
Особенности работы с прозрачностью:
Визуальные эффекты:
- Значение 0.0 делает элемент полностью невидимым
- Значение 1.0 - полностью непрозрачным
- Промежуточные значения создают эффект просвечивания
Рекомендации:
- Для лучшего визуального восприятия используйте значения в диапазоне 0.3-0.8
- Прозрачность особенно эффектна при наложении элементов или использовании фоновых изображений
- В сочетании с jigsaw-скинами можно создавать интересные дизайнерские решения
Технические ограничения:
- Прозрачность может по-разному отображаться в различных PDF-ридерах
- При печати эффекты прозрачности могут не сохраняться в зависимости от принтера
Комбинации:
- Можно комбинировать несколько параметров прозрачности для одного бокса
- Эффекты прозрачности суммируются при наложении элементов
Эти параметры позволяют создавать сложные визуальные эффекты и гибко управлять внешним видом элементов tcolorbox.
7.1.11 - Команды для управления высотой боксов
Управляет параметрами высоты боксов
Управление высотой в tcolorbox
Основные параметры высоты
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
natural height | /tcb/natural height | Естественная высота по содержимому | natural height |
height | /tcb/height=⟨length⟩ | Фиксированная высота бокса | height=3cm |
height plus | /tcb/height plus=⟨length⟩ | Максимальное увеличение высоты | height plus=1cm |
height from | /tcb/height from=⟨min⟩ to ⟨max⟩ | Диапазон высот | height from=2cm to 5cm |
text height | /tcb/text height=⟨length⟩ | Высота текстовой области | text height=4cm |
add to height | /tcb/add to height=⟨length⟩ | Добавление к текущей высоте | add to height=0.5cm |
add to natural height | /tcb/add to natural height=⟨length⟩ | Добавление к естественной высоте | add to natural height=1cm |
height fill | /tcb/height fill=true|false|maximum | Заполнение оставшегося пространства | height fill=true |
inherit height | /tcb/inherit height=⟨fraction⟩ | Наследование высоты от родителя | inherit height=0.8 |
square | /tcb/square | Квадратный бокс (высота=ширине) | square |
Распределение пространства
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
space | /tcb/space=⟨fraction⟩ | Распределение пространства (0-1) | space=0.3 |
space to upper | /tcb/space to upper | Все пространство в верхнюю часть | space to upper |
space to lower | /tcb/space to lower | Все пространство в нижнюю часть | space to lower |
space to both | /tcb/space to both | Равное распределение | space to both |
space to | /tcb/space to=⟨macro⟩ | Сохранение пространства в макрос | space to=\myspace |
split | /tcb/split=⟨fraction⟩ | Позиция разделителя (0-1) | split=0.7 |
Группы высот
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
equal height group | /tcb/equal height group=⟨id⟩ | Группа с одинаковой высотой | equal height group=A |
minimum for equal height group | /tcb/minimum for equal height group=⟨id⟩:⟨length⟩ | Минимальная высота группы | minimum for equal height group=A:3cm |
minimum for current equal height group | /tcb/minimum for current equal height group=⟨length⟩ | Минимальная высота текущей группы | minimum for current equal height group=2cm |
use height from group | /tcb/use height from group=⟨id⟩ | Использование высоты группы | use height from group=A |
\tcbheightfromgroup | \tcbheightfromgroup{⟨macro⟩}{⟨id⟩} | Получение высоты группы | \tcbheightfromgroup{\myheight}{A} |
Примеры использования
1. Фиксированная высота
\begin{tcolorbox}[height=4cm, valign=center]
Бокс с фиксированной высотой 4cm
\end{tcolorbox}
2. Автоматическое выравнивание высоты
\begin{tcolorbox}[equal height group=A]
Первый бокс
\end{tcolorbox}
\begin{tcolorbox}[equal height group=A]
Второй бокс с большим количеством текста, который делает высоту больше
\end{tcolorbox}
3. Заполнение пространства
\begin{tcolorbox}[height fill]
Бокс заполнит все доступное вертикальное пространство
\end{tcolorbox}
4. Квадратный бокс
\begin{tcolorbox}[width=3cm, square]
Квадратный бокс 3x3cm
\end{tcolorbox}
5. Наследование высоты
\begin{tcolorbox}[height=5cm]
\begin{tcolorbox}[inherit height=0.5]
Бокс с половиной высоты родителя
\end{tcolorbox}
\end{tcolorbox}
Особенности работы с высотой:
- Для работы некоторых параметров (
height fill) требуется библиотекаbreakable - Параметры групп высот требуют двойной компиляции
natural height- это высота по умолчанию, рассчитываемая автоматически- При использовании
equal height groupвсе боксы в группе получают высоту самого высокого бокса height plusпозволяет задать максимально возможное увеличение высоты при необходимости
7.1.12 - Команды для добавления различного контента в боксы
Управляет добавлением различного контента в боксы
Управление содержимым бокса в tcolorbox
Добавление контента в различные части бокса
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
before title | /tcb/before title=⟨code⟩ | Код перед заголовком (с \ignorespaces) | before title={\textbf{Важно:}~} |
before title* | /tcb/before title*=⟨code⟩ | Код перед заголовком (без \ignorespaces) | before title*={\textbf{Важно:}} |
after title | /tcb/after title=⟨code⟩ | Код после заголовка (с \unskip) | after title={\hfill\small[подпись]} |
after title* | /tcb/after title*=⟨code⟩ | Код после заголовка (без \unskip) | after title*={\quad[подпись]} |
before upper | /tcb/before upper=⟨code⟩ | Код перед верхней частью (с \ignorespaces) | before upper={\begin{quote}} |
before upper* | /tcb/before upper*=⟨code⟩ | Код перед верхней частью (без \ignorespaces) | before upper*=\begin{tabular} |
after upper | /tcb/after upper=⟨code⟩ | Код после верхней части (с \unskip) | after upper={\end{quote}} |
after upper* | /tcb/after upper*=⟨code⟩ | Код после верхней части (без \unskip) | after upper*=\end{tabular} |
before lower | /tcb/before lower=⟨code⟩ | Код перед нижней частью (с \ignorespaces) | before lower={\textbf{Примечание:}} |
before lower* | /tcb/before lower*=⟨code⟩ | Код перед нижней частью (без \ignorespaces) | before lower*=\begin{itemize} |
after lower | /tcb/after lower=⟨code⟩ | Код после нижней части (с \unskip) | after lower={\hfill\footnotesize*} |
after lower* | /tcb/after lower*=⟨code⟩ | Код после нижней части (без \unskip) | after lower*=\end{itemize} |
Специальные окружения для контента
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
text fill | /tcb/text fill | Включает minipage для вертикального выравнивания | text fill |
tabulars | /tcb/tabulars=⟨preamble⟩ | Окружает контент tabular* | tabulars={lcr} |
tabulars* | /tcb/tabulars*={⟨code⟩}{⟨preamble⟩} | Tabular* с дополнительным кодом | tabulars*={\small}{lcr} |
tabularx | /tcb/tabularx=⟨preamble⟩ | Окружает контент tabularx | `tabularx={X |
tabularx* | /tcb/tabularx*={⟨code⟩}{⟨preamble⟩} | Tabularx с дополнительным кодом | `tabularx*={\footnotesize}{X |
tikz upper | /tcb/tikz upper=⟨options⟩ | Окружает верхнюю часть tikzpicture | tikz upper={scale=0.5} |
tikz lower | /tcb/tikz lower=⟨options⟩ | Окружает нижнюю часть tikzpicture | tikz lower={rotate=30} |
tikznode upper | /tcb/tikznode upper=⟨options⟩ | Помещает контент в TikZ node | tikznode upper={draw} |
tikznode lower | /tcb/tikznode lower=⟨options⟩ | Помещает нижнюю часть в TikZ node | tikznode lower={fill=yellow} |
tikznode | /tcb/tikznode=⟨options⟩ | Применяет tikznode к обеим частям | tikznode={shape=circle} |
varwidth upper | /tcb/varwidth upper=⟨length⟩ | Окружает varwidth окружением | varwidth upper=5cm |
environment upper | /tcb/environment upper=⟨name⟩ | Окружает верхнюю часть указанным окружением | environment upper=itemize |
environment upper args | /tcb/environment upper args={⟨name⟩}{⟨code⟩} | Окружение с дополнительными параметрами | environment upper args={tabular}{{cc}} |
environment lower | /tcb/environment lower=⟨name⟩ | Окружает нижнюю часть указанным окружением | environment lower=enumerate |
environment lower args | /tcb/environment lower args={⟨name⟩}{⟨code⟩} | Окружение с дополнительными параметрами | environment lower args={tabular}{{lr}} |
environment title | /tcb/environment title=⟨name⟩ | Окружает заголовок указанным окружением | environment title=center |
environment title args | /tcb/environment title args={⟨name⟩}{⟨code⟩} | Окружение с дополнительными параметрами | environment title args={flushright}{} |
Примеры использования
1. Добавление текста вокруг содержимого
\begin{tcolorbox}[
before title={\textbf{Внимание:}~},
after title={\hfill\footnotesize[источник]},
before upper={\textit{Начало текста:}\par},
after upper={\par\hfill\textit{окончание}}
]
Заголовок
\tcblower
Основное содержимое бокса
\end{tcolorbox}
2. Использование окружений
\begin{tcolorbox}[
environment upper=itemize,
environment lower args={tabular}{{ll}}
\item Первый пункт
\item Второй пункт
\tcblower
A & B \\
C & D
\end{tcolorbox}
3. Таблицы в боксе
\begin{tcolorbox}[
tabulars={|l|c|r|},
title=Таблица в боксе
]
Левый & Центр & Правый \\
A & B & C
\end{tcolorbox}
4. TikZ рисунки
\begin{tcolorbox}[
tikz upper={scale=0.8},
title=TikZ рисунок
]
\draw (0,0) circle (1cm);
\fill (0,0) circle (2pt);
\end{tcolorbox}
Особенности работы:
- Параметры с
*(например,before upper*) не добавляют автоматические пробелы (\ignorespaces/\unskip) - Для работы
tabulars/tabularxтребуются соответствующие пакеты text fillполезен для вертикального выравнивания с\vfill- TikZ-окружения позволяют легко встраивать графику
- Окружения
environmentне работают с другими tcolorbox-окружениями
7.1.13 - Команды для упрвления слоями в боксах
Управляет слоями в боксах, наложение друг на друга и т.д.
Управление наложениями (Overlays) в tcolorbox
Основные параметры наложений
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
overlay | /tcb/overlay=⟨graphical code⟩ | Графическое наложение для всех состояний бокса | overlay={\draw[red] (frame.south west) rectangle (frame.north east);} |
no overlay | /tcb/no overlay | Отключает все наложения | no overlay |
overlay broken | /tcb/overlay broken=⟨graphical code⟩ | Наложение только для разорванных боксов | overlay broken={\draw[dashed] (frame.south west) -- (frame.north east);} |
overlay unbroken | /tcb/overlay unbroken=⟨graphical code⟩ | Наложение только для целых боксов | overlay unbroken={\fill[yellow] (frame.center) circle (5mm);} |
overlay first | /tcb/overlay first=⟨graphical code⟩ | Наложение для первой части разорванного бокса | overlay first={\node at (frame.center) {First};} |
overlay middle | /tcb/overlay middle=⟨graphical code⟩ | Наложение для средних частей разорванного бокса | overlay middle={\node at (frame.center) {Middle};} |
overlay last | /tcb/overlay last=⟨graphical code⟩ | Наложение для последней части разорванного бокса | overlay last={\node at (frame.center) {Last};} |
Комбинированные параметры
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
overlay unbroken and first | /tcb/overlay unbroken and first=⟨graphical code⟩ | Комбинация unbroken и first | overlay unbroken and first={\draw[blue] (frame.south west) -- (frame.north east);} |
overlay middle and last | /tcb/overlay middle and last=⟨graphical code⟩ | Комбинация middle и last | overlay middle and last={\draw[green] (frame.south west) -- (frame.north east);} |
overlay unbroken and last | /tcb/overlay unbroken and last=⟨graphical code⟩ | Комбинация unbroken и last | overlay unbroken and last={\draw[red] (frame.south west) -- (frame.north east);} |
overlay first and middle | /tcb/overlay first and middle=⟨graphical code⟩ | Комбинация first и middle | overlay first and middle={\draw[yellow] (frame.south west) -- (frame.north east);} |
Примеры использования
1. Простое наложение
\begin{tcolorbox}[
enhanced,
overlay={\draw[red, line width=2pt] (frame.south west) rectangle (frame.north east);},
title=Пример с наложением
]
Содержимое бокса с красной рамкой
\end{tcolorbox}
2. Наложение для разорванных боксов
\begin{tcolorbox}[
breakable,
overlay first={\node[rotate=45] at (frame.center) {Начало};},
overlay middle={\node[rotate=45] at (frame.center) {Продолжение};},
overlay last={\node[rotate=45] at (frame.center) {Конец};},
title=Разорванный бокс
]
Много текста, который будет разорван на несколько частей...
\end{tcolorbox}
3. Комбинированное наложение
\begin{tcolorbox}[
enhanced,
overlay unbroken and first={\fill[yellow!50] (frame.north west) rectangle ([xshift=2cm]frame.north east);},
title=Комбинированный пример
]
Содержимое бокса с желтой полосой вверху для unbroken/first состояний
\end{tcolorbox}
4. Водяной знак
\begin{tcolorbox}[
enhanced,
overlay={\node[rotate=45,scale=10,text=gray!20] at (frame.center) {ЧЕРНОВИК};},
title=Документ с водяным знаком
]
Текст документа с полупрозрачным водяным знаком
\end{tcolorbox}
Особенности работы с наложениями:
- Для сложных наложений рекомендуется использовать
enhancedрежим из библиотекиskins - Наложения применяются после рисования рамки и фона, но перед отображением текста
- Для позиционирования элементов можно использовать узлы геометрии (
frame.north west,title.southи т.д.) - При работе с разорванными боксами (
breakable) можно задавать разные наложения для разных частей - Наложения могут содержать любые допустимые TikZ-команды
Советы:
- Используйте
overlayдля элементов, которые должны отображаться всегда - Для разорванных боксов применяйте
overlay first/middle/lastдля разных частей - Комбинированные параметры (
unbroken and firstи т.д.) помогают избежать дублирования кода - Для сложных графических элементов создавайте стили с наложениями и переиспользуйте их
7.1.14 - Команды для управления плавающими объектами боксов
Управляет плавающими боксами на странице
Управление плавающими объектами (Floating Objects) в tcolorbox
Основные параметры плавающих объектов
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
floatplacement | /tcb/floatplacement=⟨values⟩ | Устанавливает параметры размещения по умолчанию | floatplacement=tbp |
float | /tcb/float=⟨values⟩ | Превращает бокс в плавающий объект | float=ht |
float* | /tcb/float*=⟨values⟩ | Плавающий объект на всю ширину страницы | float*=b, width=\textwidth |
nofloat | /tcb/nofloat | Отключает плавающее поведение | nofloat |
every float | /tcb/every float={⟨code⟩} | Код, выполняемый перед каждым плавающим объектом | every float=\centering |
before float | /tcb/before float={⟨code⟩} | Код перед началом float-окружения | before float=\small |
after float | /tcb/after float={⟨code⟩} | Код после окончания float-окружения | after float=\vspace{1cm} |
Примеры использования
1. Базовый плавающий бокс
\begin{tcolorbox}[
float=htb,
title=Пример плавающего бокса,
colback=blue!5!white,
colframe=blue!75!black
]
Этот бокс будет автоматически размещен в подходящем месте документа
(обычно вверху страницы, если возможно).
\end{tcolorbox}
2. Плавающий бокс на всю ширину
\begin{tcolorbox}[
float*=t,
width=\textwidth,
title=Широкий плавающий бокс,
colback=green!5!white,
colframe=green!75!black
]
Этот бокс занимает всю ширину страницы и будет размещен вверху.
\end{tcolorbox}
3. Центрирование плавающих объектов
\begin{tcolorbox}[
float,
every float=\centering,
title=Центрированный плавающий бокс,
colback=red!5!white,
colframe=red!75!black
]
Этот плавающий бокс будет центрирован на странице.
\end{tcolorbox}
4. Плавающий бокс с дополнительным кодом
\begin{tcolorbox}[
float,
before float={\small Начало float-окружения},
after float={\vspace{5mm} Конец float-окружения},
title=Бокс с дополнительным кодом,
colback=yellow!5!white,
colframe=yellow!75!black
]
Этот плавающий бокс имеет дополнительный код до и после.
\end{tcolorbox}
Особенности работы с плавающими объектами:
Параметры размещения (для
floatиfloat*):h- здесь (если возможно)t- вверху страницыb- внизу страницыp- на отдельной странице!- принудительное размещение
Различия между
floatиfloat*:floatработает как стандартное плавающее окружениеfloat*предназначен для:- Двухколоночных документов
- Использования с пакетами multicol/paracol
- Широких боксов (требует
width=\textwidth)
Отключение плавающего поведения:
- Используйте
nofloatдля возврата к обычному поведению
- Используйте
Особые случаи:
- Для разрываемых боксов (
breakable)every floatвыполняется перед каждой частью before floatиafter floatпозволяют вставить код до/после float-окружения
- Для разрываемых боксов (
Советы по использованию:
- Для изображений и широких таблиц лучше использовать
float* - Комбинация
every float=\centeringполезна для центрирования содержимого - При использовании в двухколоночном режиме не забывайте указывать
width=\textwidth - Для точного контроля размещения используйте комбинации параметров (например,
float=!bдля принудительного размещения внизу)
7.1.15 - Команды для встраивания объектов и боксов в боксы (embedding)
Управляет встраиванием объектов в боксы
Управление встраиванием (Embedding) в tcolorbox
Основные параметры встраивания
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
before | /tcb/before=⟨code⟩ | Код, выполняемый перед боксом | before={\par\medskip} |
after | /tcb/after=⟨code⟩ | Код, выполняемый после бокса | after={\par\medskip} |
nobeforeafter | /tcb/nobeforeafter | Отключает пробелы до/после бокса | nobeforeafter |
force nobeforeafter | /tcb/force nobeforeafter | Принудительно отключает пробелы | force nobeforeafter |
Вертикальные отступы
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
before skip balanced | /tcb/before skip balanced=⟨glue⟩ | Вертикальный отступ с учетом базовой линии | before skip balanced=1cm |
after skip balanced | /tcb/after skip balanced=⟨glue⟩ | Вертикальный отступ после с базовой линией | after skip balanced=1cm |
beforeafter skip balanced | /tcb/beforeafter skip balanced=⟨glue⟩ | Отступы до/после с базовой линией | beforeafter skip balanced=0.5cm |
before skip | /tcb/before skip=⟨glue⟩ | Простой вертикальный отступ перед | before skip=10pt |
after skip | /tcb/after skip=⟨glue⟩ | Простой вертикальный отступ после | after skip=10pt |
beforeafter skip | /tcb/beforeafter skip=⟨glue⟩ | Простые отступы до/после | beforeafter skip=10pt |
Горизонтальные отступы
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
left skip | /tcb/left skip=⟨length⟩ | Горизонтальный отступ слева | left skip=1cm |
right skip | /tcb/right skip=⟨length⟩ | Горизонтальный отступ справа | right skip=1cm |
leftright skip | /tcb/leftright skip=⟨length⟩ | Отступы слева и справа | leftright skip=1cm |
Выравнивание и позиционирование
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
baseline | /tcb/baseline=⟨length⟩ | Установка базовой линии | baseline=3mm |
box align | /tcb/box align=⟨alignment⟩ | Выравнивание бокса (bottom, top, center, base) | box align=top |
Особые параметры
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
ignore nobreak | `/tcb/ignore nobreak=true | false` | Игнорировать запрет разрыва после заголовка |
before nobreak | /tcb/before nobreak=⟨code⟩ | Код перед боксом при запрете разрыва | before nobreak={\noindent} |
parfillskip restore | `/tcb/parfillskip restore=true | false` | Восстанавливать значение \parfillskip |
Примеры использования
1. Базовые вертикальные отступы
\begin{tcolorbox}[
before skip balanced=1cm,
after skip balanced=0.5cm,
colframe=blue
]
Бокс с кастомными отступами
\end{tcolorbox}
2. Горизонтальное позиционирование
\begin{tcolorbox}[
left skip=2cm,
right skip=1cm,
colframe=red
]
Бокс со смещением по горизонтали
\end{tcolorbox}
3. Выравнивание по базовой линии
Текст \begin{tcolorbox}[nobeforeafter, box align=base, colframe=green]
Выровнено по базовой линии
\end{tcolorbox} продолжение текста
4. Интеграция в поток текста
\begin{tcolorbox}[
nobeforeafter,
box align=base,
colback=yellow,
colframe=orange
]
Встроенный в текст бокс
\end{tcolorbox} продолжение текста.
Особенности работы:
- Параметры
*balancedучитывают базовую линию текста для более точного выравнивания nobeforeafterполностью убирает бокс из отдельного абзаца- Для точного контроля вертикального положения используйте комбинацию
baselineиbox align - Параметры с
skipизменяют bounding box, что может влиять на общий макет
Советы:
- Для встраивания в текст используйте
nobeforeafter+box align=base - Для сложных макетов предпочтительнее
*balancedверсии отступов - При работе с разрываемыми боксами учитывайте поведение
ignore nobreak - Для восстановления стандартного поведения
\parfillskipиспользуйтеparfillskip restore
7.1.16 - Управление ограничивающей рамкой (Bounding Box) в tcolorbox
Управление ограничивающей рамкой (Bounding Box) в tcolorbox в различных вариациях
Управление ограничивающей рамкой (Bounding Box) в tcolorbox
Смещение границ ограничивающей рамки
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
enlarge top initially by | /tcb/enlarge top initially by=⟨length⟩ | Расширение верхней границы (только для первого бокса) | enlarge top initially by=5mm |
enlarge bottom finally by | /tcb/enlarge bottom finally by=⟨length⟩ | Расширение нижней границы (только для последнего бокса) | enlarge bottom finally by=5mm |
enlarge top at break by | /tcb/enlarge top at break by=⟨length⟩ | Расширение верхней границы для разорванных частей | enlarge top at break by=3mm |
enlarge bottom at break by | /tcb/enlarge bottom at break by=⟨length⟩ | Расширение нижней границы для разорванных частей | enlarge bottom at break by=3mm |
enlarge top by | /tcb/enlarge top by=⟨length⟩ | Расширение верхней границы для всех случаев | enlarge top by=5mm |
enlarge bottom by | /tcb/enlarge bottom by=⟨length⟩ | Расширение нижней границы для всех случаев | enlarge bottom by=5mm |
enlarge left by | /tcb/enlarge left by=⟨length⟩ | Расширение левой границы | enlarge left by=2cm |
enlarge right by | /tcb/enlarge right by=⟨length⟩ | Расширение правой границы | enlarge right by=2cm |
enlarge by | /tcb/enlarge by=⟨length⟩ | Расширение всех границ | enlarge by=5mm |
Выравнивание бокса
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
grow to left by | /tcb/grow to left by=⟨length⟩ | Увеличение ширины влево | grow to left by=2cm |
grow to right by | /tcb/grow to right by=⟨length⟩ | Увеличение ширины вправо | grow to right by=2cm |
grow sidewards by | /tcb/grow sidewards by=⟨length⟩ | Увеличение ширины в обе стороны | grow sidewards by=2cm |
flush left | /tcb/flush left | Выравнивание влево | flush left |
flush right | /tcb/flush right | Выравнивание вправо | flush right |
center | /tcb/center | Центрирование | center |
Переключение расширений
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
toggle enlargement | /tcb/toggle enlargement=⟨toggle preset⟩ | Переключение расширений (none, forced, evenpage) | toggle enlargement=evenpage |
Растягивание до границ страницы
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
spread inwards | /tcb/spread inwards=⟨length⟩ | Растягивание к внутреннему краю страницы | spread inwards=5mm |
spread outwards | /tcb/spread outwards=⟨length⟩ | Растягивание к внешнему краю страницы | spread outwards=5mm |
move upwards | /tcb/move upwards=⟨length⟩ | Перемещение к верхнему краю (с новой страницы) | move upwards=5mm |
move upwards* | /tcb/move upwards*=⟨length⟩ | Перемещение к верхнему краю (без новой страницы) | move upwards*=5mm |
fill downwards | /tcb/fill downwards=⟨length⟩ | Заполнение до нижнего края | fill downwards=5mm |
spread upwards | /tcb/spread upwards=⟨length⟩ | Комбинация: вверх + внутрь + наружу | spread upwards=5mm |
spread upwards* | /tcb/spread upwards*=⟨length⟩ | То же без новой страницы | spread upwards*=5mm |
spread sidewards | /tcb/spread sidewards=⟨length⟩ | Растягивание в стороны | spread sidewards=5mm |
spread | /tcb/spread=⟨length⟩ | Заполнение всей страницы | spread=5mm |
spread downwards | /tcb/spread downwards=⟨length⟩ | Комбинация: вниз + внутрь + наружу | spread downwards=5mm |
Выступание бокса
| Параметр | Синтаксис | Описание | Пример |
|---|---|---|---|
shrink tight | /tcb/shrink tight | Плотное облегание содержимого | shrink tight |
extrude left by | /tcb/extrude left by=⟨length⟩ | Выступание влево | extrude left by=1cm |
extrude right by | /tcb/extrude right by=⟨length⟩ | Выступание вправо | extrude right by=1cm |
extrude top by | /tcb/extrude top by=⟨length⟩ | Выступание вверх | extrude top by=1cm |
extrude bottom by | /tcb/extrude bottom by=⟨length⟩ | Выступание вниз | extrude bottom by=1cm |
extrude by | /tcb/extrude by=⟨length⟩ | Выступание во все стороны | extrude by=5mm |
Примеры использования
1. Расширение границ
\begin{tcolorbox}[
enlarge left by=2cm,
enlarge top by=5mm,
enhanced,
show bounding box
]
Бокс с расширенными границами
\end{tcolorbox}
2. Растягивание до краев страницы
\begin{tcolorbox}[
spread sidewards,
spread upwards,
height=3cm,
colframe=blue,
sharp corners=north
]
Бокс, растянутый до краев страницы
\end{tcolorbox}
3. Выступающие элементы
Текст \tcbox[shrink tight, extrude right by=5mm]{с выступающим} элементом
Особенности работы:
- Параметры с
*не создают новую страницу - Для визуализации bounding box используйте
show bounding box - Комбинированные параметры (
spreadи др.) экономят время настройки - Выступающие элементы (
extrude) не изменяют bounding box
7.1.17 - Управление уровнями/слоями в пакете tcolorbox
Управление слоями в tcolorbox
1. Основные команды для управления слоями
| Команда / Стиль | Синтаксис | Описание |
|---|---|---|
every box | \tcbset{every box/.style={...}} | Стиль, применяемый ко всем tcolorbox (по умолчанию пуст). |
every box on layer n | \tcbset{every box on layer 1/.style={...}} | Стиль для конкретного слоя (1-4 по умолчанию). |
every box on higher layers | \tcbset{every box on higher layers/.style={...}} | Стиль для слоёв выше управляемых (по умолчанию reset,every box). |
\tcbsetmanagedlayers | \tcbsetmanagedlayers{<число>} | Устанавливает максимальный номер управляемого слоя (только в преамбуле). |
2. Примеры использования
Пример 1: Настройка стилей для всех слоёв
\usepackage{tcolorbox}
\tcbset{
every box/.style={enhanced, colframe=blue}, % Базовый стиль
every box on layer 2/.style={colback=yellow}, % Стиль для второго слоя
every box on higher layers/.style={colframe=red} % Стиль для вложенных
}
\begin{tcolorbox}[title=Layer 1]
Внешний блок.
\begin{tcolorbox}[title=Layer 2]
Вложенный блок (жёлтый фон).
\begin{tcolorbox}[title=Layer 3]
Ещё глубже (красная рамка).
\end{tcolorbox}
\end{tcolorbox}
\end{tcolorbox}
Пример 2: Сброс стилей (reset)
\tcbset{
every box/.style={fonttitle=\bfseries},
every box on layer 2/.style={reset, colback=green} % Сброс стилей перед применением
}
\begin{tcolorbox}[title=Layer 1]
Заголовок жирный.
\begin{tcolorbox}[title=Layer 2]
Заголовок НЕ жирный (сброшен), фон зелёный.
\end{tcolorbox}
\end{tcolorbox}
Пример 3: Увеличение числа управляемых слоёв
\usepackage{tcolorbox}
\tcbsetmanagedlayers{5} % В преамбуле
\tcbset{
every box on layer 5/.style={colframe=purple}
}
\begin{tcolorbox}[title=Layer 1]
\begin{tcolorbox}[title=Layer 2]
\begin{tcolorbox}[title=Layer 3]
\begin{tcolorbox}[title=Layer 4]
\begin{tcolorbox}[title=Layer 5]
Фиолетовая рамка (5-й слой).
\end{tcolorbox}
\end{tcolorbox}
\end{tcolorbox}
\end{tcolorbox}
\end{tcolorbox}
3. Важные примечания
- Команда
\tcbsetmanagedlayersработает только в преамбуле. - По умолчанию для вложенных блоков применяется
reset, что сбрасывает стили родительского блока. - Для глобального применения стиля используйте
\tcbsetforeverylayer{...}.
7.1.18 - Управление Capture mode в пакете tcolorbox
Capture Mode определяет, как содержимое tcolorbox обрабатывается и отображается.
Capture Mode в tcolorbox
Capture Mode определяет, как содержимое tcolorbox обрабатывается и отображается.
Доступные режимы:
minipage(по умолчанию дляtcolorbox)hbox(по умолчанию для\tcbox)fitbox(требует библиотекуfitting)
1. Основные команды и стили
| Команда / Опция | Синтаксис | Описание |
|---|---|---|
capture=<mode> | \begin{tcolorbox}[capture=minipage] ... \end{tcolorbox} | Устанавливает режим обработки содержимого (minipage, hbox, fitbox). |
hbox (стиль) | \begin{tcolorbox}[hbox] ... \end{tcolorbox} | Короткая запись для capture=hbox. |
minipage (стиль) | \begin{tcolorbox}[minipage] ... \end{tcolorbox} | Короткая запись для capture=minipage. |
fitbox (стиль) | \begin{tcolorbox}[fitbox] ... \end{tcolorbox} | Короткая запись для capture=fitbox (требует \tcbuselibrary{fitting}). |
2. Примеры использования
2.1. Режим minipage (по умолчанию)
\begin{tcolorbox}[
capture=minipage, % можно опустить (стоит по умолчанию)
colframe=blue,
colback=white,
title=Minipage Mode
]
Этот блок ведёт себя как `minipage`.
Можно разбивать на части (`breakable`), добавлять верхнюю и нижнюю части.
\end{tcolorbox}
Особенности:
- Поддерживает
breakable(разрыв на страницах). - Можно использовать
upperиlowerчасти.
2.2. Режим hbox (как \tcbox)
\begin{tcolorbox}[
hbox, % короткая запись для capture=hbox
colframe=red,
colback=white,
title=HBox Mode
]
Этот блок ведёт себя как `\hbox` (аналогично `\tcbox`).
\end{tcolorbox}
Особенности:
- Нельзя разбивать (
breakableне работает). - Размер подстраивается под содержимое.
2.3. Режим fitbox (требует fitting)
\usepackage{tcolorbox}
\tcbuselibrary{fitting} % обязательно подключить
\begin{tcolorbox}[
fitbox, % короткая запись для capture=fitbox
height=2cm,
width=6cm,
colframe=green,
colback=white,
title=FitBox Mode
]
Содержимое масштабируется под размер блока.
\end{tcolorbox}
Особенности:
- Размер содержимого подгоняется под заданные размеры блока.
- Полезно для создания блоков фиксированного размера.
3. Сравнение режимов
| Режим | Разрыв (breakable) | Размер | Использование |
|---|---|---|---|
minipage | Да | Под содержимое | Основные блоки с текстом |
hbox | Нет | Под содержимое | Компактные блоки (\tcbox) |
fitbox | Нет | Фиксированный | Блоки с жёсткими размерами |
4. Полный пример с разными режимами
\documentclass{article}
\usepackage{tcolorbox}
\tcbuselibrary{fitting} % для fitbox
\begin{document}
\begin{tcolorbox}[
minipage, % или capture=minipage
colframe=blue,
title=Minipage Mode,
breakable % можно разрывать
]
Этот блок ведёт себя как `minipage`.
Можно разбивать на страницы и использовать `lower` и `upper` части.
\end{tcolorbox}
\begin{tcolorbox}[
hbox,
colframe=red,
title=HBox Mode
]
Это компактный блок (`\hbox`).
\end{tcolorbox}
\begin{tcolorbox}[
fitbox,
width=5cm,
height=3cm,
colframe=green,
title=FitBox Mode
]
Содержимое подгоняется под размер блока.
\end{tcolorbox}
\end{document}
Результат:
- Первый блок (
minipage) может быть разорван на страницы. - Второй блок (
hbox) компактный, без разрывов. - Третий блок (
fitbox) имеет фиксированный размер.
7.1.19 - Управление характеристиками текста в пакете tcolorbox
Настройки оформления текста внутри tcolorbox позволяют управлять поведением абзацев, переносом слов и другими текстовыми характеристиками.
Text Characteristics в tcolorbox
Настройки оформления текста внутри tcolorbox позволяют управлять поведением абзацев, переносом слов и другими текстовыми характеристиками.
1. Основные команды и стили
| Опция | Синтаксис | Описание | Значение по умолчанию |
|---|---|---|---|
parbox | parbox=true / parbox=false | Определяет, будет ли текст обрабатываться как в minipage/parbox (влияет на форматирование абзацев). | true |
hyphenationfix | hyphenationfix=true / hyphenationfix=false | Включает исправление проблем с переносом длинных слов в узких блоках. | false |
2. Примеры использования
2.1. Опция parbox
Включает/отключает режим parbox (аналогично minipage).
Пример с parbox=true (по умолчанию)
\begin{tcolorbox}[
parbox=true, % можно не указывать (стоит по умолчанию)
width=0.45\linewidth,
colframe=blue,
title=parbox=true (стандартное поведение)
]
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
\end{tcolorbox}
Особенности:
- Абзацы форматируются как в
minipage. - Подходит для большинства случаев.
Пример с parbox=false
\begin{tcolorbox}[
parbox=false,
width=0.45\linewidth,
colframe=red,
title=parbox=false (обычный текст)
]
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
\end{tcolorbox}
Особенности:
- Текст ведёт себя как в основном документе (не как в
minipage). - Может вызывать неожиданные эффекты в сложных блоках.
2.2. Опция hyphenationfix
Исправляет проблемы с переносом длинных слов в узких блоках.
Пример без hyphenationfix (по умолчанию)
\begin{tcolorbox}[
width=3cm,
colframe=green,
title=Без hyphenationfix
]
Rechnungsadjunktentochter.\par
Statthaltereikonzipist.
\end{tcolorbox}
Проблема:
- Длинные слова не переносятся.
Пример с hyphenationfix=true
\begin{tcolorbox}[
hyphenationfix=true,
width=3cm,
colframe=green,
title=С hyphenationfix
]
Rechnungsadjunktentochter.\par
Statthaltereikonzipist.
\end{tcolorbox}
Результат:
- Длинные слова корректно переносятся.
3. Важные замечания
- Не используйте
parbox=falseиhyphenationfixвместе — они предназначены для разных типов блоков и могут конфликтовать. parbox=false— экспериментальная опция, применяйте её только при необходимости.hyphenationfixполезен в узких блоках, гдеpdflatexне справляется с переносом.
4. Полный пример
\documentclass{article}
\usepackage[utf8]{inputenc}
\usepackage{tcolorbox}
\usepackage{lipsum} % для демонстрации текста
\begin{document}
\begin{tcolorbox}[
parbox=true,
width=0.45\linewidth,
colframe=blue,
title=parbox=true (стандартное поведение)
]
\lipsum[1][1-3] % Первые три предложения из lipsum
\end{tcolorbox}
\hfill
\begin{tcolorbox}[
parbox=false,
width=0.45\linewidth,
colframe=red,
title=parbox=false (обычный текст)
]
\lipsum[1][1-3]
\end{tcolorbox}
\vspace{1cm}
\begin{tcolorbox}[
width=3cm,
colframe=green,
title=Без hyphenationfix
]
Rechnungsadjunktentochter.\par
Statthaltereikonzipist.
\end{tcolorbox}
\hfill
\begin{tcolorbox}[
hyphenationfix=true,
width=3cm,
colframe=green,
title=С hyphenationfix
]
Rechnungsadjunktentochter.\par
Statthaltereikonzipist.
\end{tcolorbox}
\end{document}
Результат:
- Первые два блока показывают разницу между
parbox=trueиparbox=false. - Вторые два блока демонстрируют работу
hyphenationfix.
Вывод
parbox=true— стандартное поведение (рекомендуется).parbox=false— экспериментальная опция (используйте осторожно).hyphenationfix=true— решает проблемы с переносом длинных слов.
Если нужно что-то уточнить или добавить, дайте знать!
7.1.20 - Files - Работа с временными файлами в tcolorbox
В этом разделе рассматривается управление временными файлами, которые используются при работе с tcbwritetemp и cbusetemp.
Files - Работа с временными файлами в tcolorbox
В этом разделе рассматривается управление временными файлами, которые используются при работе с tcbwritetemp и \tcbusetemp.
1. Основные команды и параметры
| Опция / Команда | Синтаксис | Описание |
|---|---|---|
tempfile | tempfile=<имя_файла> | Устанавливает имя временного файла (по умолчанию: \jobname.tcbtemp). |
\tcbwritetemp | \tcbwritetemp{<содержимое>} | Записывает содержимое во временный файл. |
\tcbusetemp | \tcbusetemp | Вставляет содержимое временного файла в документ. |
2. Примеры использования
2.1. Изменение имени временного файла
\documentclass{article}
\usepackage{tcolorbox}
\begin{document}
\tcbset{tempfile=mytempfile.tmp} % меняем имя временного файла
\begin{tcolorbox}[title=Пример с временным файлом]
Содержимое блока будет записано в \texttt{mytempfile.tmp} вместо \texttt{\jobname.tcbtemp}.
\end{tcolorbox}
\end{document}
Результат:
Временный файл будет называться mytempfile.tmp вместо стандартного <имя_документа>.tcbtemp.
2.2. Запись и использование временного файла
\documentclass{article}
\usepackage{tcolorbox}
\begin{document}
% Записываем текст во временный файл
\tcbwritetemp{Этот текст будет сохранён во временный файл.}
% Вставляем содержимое временного файла в документ
\begin{tcolorbox}[title=Содержимое временного файла]
\tcbusetemp
\end{tcolorbox}
\end{document}
Результат:
В блоке tcolorbox отобразится текст, записанный через \tcbwritetemp.
3. Важные замечания
Имя файла по умолчанию
Если не указатьtempfile, будет использоваться<имя_документа>.tcbtemp(например,document.tcbtemp).Автоматическое управление
\tcbwritetempавтоматически записывает содержимое в указанный временный файл.\tcbusetempавтоматически вставляет его в документ.
Очистка временных файлов
LaTeX не удаляет временные файлы автоматически - их нужно удалять вручную или с помощью скриптов сборки.
4. Полный пример
\documentclass{article}
\usepackage{tcolorbox}
\begin{document}
% Устанавливаем кастомное имя файла
\tcbset{tempfile=my_custom_tempfile.tmp}
% Пишем текст во временный файл
\tcbwritetemp{
Этот текст был записан во временный файл \texttt{my\_custom\_tempfile.tmp}.
}
% Вставляем содержимое файла в бокс
\begin{tcolorbox}[
colframe=blue,
colback=white,
title=Пример работы с временными файлами,
fonttitle=\bfseries
]
Содержимое временного файла:\\
\tcbusetemp
\end{tcolorbox}
\end{document}
Результат:
- Создаётся временный файл
my_custom_tempfile.tmp - Его содержимое вставляется в цветную рамку
Вывод
Опция tempfile позволяет:
- Контролировать имена временных файлов
- Избегать конфликтов при использовании нескольких документов
- Организовать сложные схемы работы с содержимым
Команды \tcbwritetemp и \tcbusetemp предоставляют удобный способ:
- Сохранения промежуточного содержимого
- Повторного использования текста в документе
Для сложных документов рекомендуется явно указывать tempfile, чтобы избежать неожиданных перезаписей.
7.1.21 - cbox Specials - Специальные настройки для cbox и cboxmath
В этом разделе рассматриваются специальные параметры, которые работают только с командами cbox и cboxmath.
\tcbox Specials - Специальные настройки для \tcbox и \tcboxmath
В этом разделе рассматриваются специальные параметры, которые работают только с командами \tcbox и \tcboxmath.
1. Основные команды и параметры
1.1. Вертикальное выравнивание
| Опция / Стиль | Синтаксис | Описание |
|---|---|---|
tcbox raise | tcbox raise=<длина> | Поднимает \tcbox на указанную высоту (например, 5mm). |
tcbox raise base | tcbox raise base | Выравнивает \tcbox по базовой линии текста. |
on line | on line | Комбинация tcbox raise base + nobeforeafter (аналог \fbox). |
Пример:
\tcbset{colframe=blue!50!black, colback=white}
Test\tcbox[tcbox raise base]{Выровнено по базовой линии} и \tcbox[tcbox raise=2mm]{Приподнято на 2mm}.
1.2. Стиль verbatim
| Опция / Стиль | Синтаксис | Описание |
|---|---|---|
verbatim | verbatim | Уменьшает размеры \tcbox и включает nobeforeafter + tcbox raise base. |
Пример:
\DeclareTotalTCBox{\myverb}{ v }{verbatim, colframe=red!75!black}{#1}
Команда \myverb{\textbf} выделяет текст.
1.3. Управление шириной (tcbox width)
| Режим | Описание |
|---|---|
auto | Ширина определяется содержимым (по умолчанию). |
auto limited | Ширина как у содержимого, но не больше заданной (width). |
forced center | Фиксированная ширина (width), текст по центру (может выходить за границы). |
forced left | Фиксированная ширина, текст по левому краю. |
forced right | Фиксированная ширина, текст по правому краю. |
minimum center | Минимальная ширина (width), может увеличиваться. |
minimum left | Минимальная ширина, текст по левому краю. |
minimum right | Минимальная ширина, текст по правому краю. |
Пример:
\tcbset{width=3cm, colframe=blue!75!black}
\tcbox[tcbox width=auto]{auto} \\
\tcbox[tcbox width=forced center]{forced center} \\
\tcbox[tcbox width=minimum left]{minimum left}
2. Примеры использования
2.1. Выравнивание по базовой линии
Обычный текст \tcbox[tcbox raise base, colframe=green]{Выровнено} и \tcbox[colframe=red]{Не выровнено}.
Результат:
Первая рамка выровнена с текстом, вторая — смещена вниз.
2.2. Режимы ширины
\tcbset{width=4cm, colframe=blue!50!black}
\begin{itemize}
\item \tcbox[tcbox width=auto]{auto} — ширина по содержимому
\item \tcbox[tcbox width=forced center]{forced center} — фиксированная ширина
\item \tcbox[tcbox width=minimum right]{minimum right} — минимальная ширина
\end{itemize}
2.3. Verbatim-боксы
\DeclareTotalTCBox{\code}{ v }{verbatim, colframe=black}{#1}
Используйте \code{\textbackslash LaTeX} для красивого набора.
3. Полный пример
\documentclass{article}
\usepackage{tcolorbox}
\begin{document}
\section{Выравнивание}
Обычный текст \tcbox[on line, colframe=blue]{on line} и \tcbox[tcbox raise=3mm, colframe=red]{raise=3mm}.
\section{Управление шириной}
\tcbset{width=5cm, colframe=green!70!black}
\begin{tabular}{ll}
\textbf{Режим} & \textbf{Пример} \\
auto & \tcbox[tcbox width=auto]{Короткий текст} \\
forced center & \tcbox[tcbox width=forced center]{Очень длинный текст, который не помещается} \\
minimum left & \tcbox[tcbox width=minimum left]{Адаптивная ширина} \\
\end{tabular}
\section{Verbatim}
\DeclareTotalTCBox{\cmd}{ v }{verbatim, colframe=black}{#1}
Команда \cmd{\textbf} делает текст жирным.
\end{document}
4. Важные замечания
tcbox raiseработает только с\tcboxи\tcboxmath.verbatimстиль уменьшает отступы — используйте для коротких команд.forcedрежимы могут обрезать текст — применяйте осторожно.
Вывод
- Для встроенных в текст рамок используйте
on lineилиtcbox raise base. - Для управления шириной выбирайте подходящий
tcbox widthрежим. - Для оформления команд удобен
verbatimстиль.
Эти настройки дают полный контроль над встроенными цветными рамками в LaTeX!
7.1.22 - Counters, Labels, and References - Счётчики, метки и ссылки в tcolorbox
В этом разделе рассматриваются механизмы работы с нумерацией, перекрёстными ссылками и гиперссылками в рамках tcolorbox.
Counters, Labels, and References - Счётчики, метки и ссылки в tcolorbox
В этом разделе рассматриваются механизмы работы с нумерацией, перекрёстными ссылками и гиперссылками в рамках tcolorbox.
1. Основные команды и параметры
1.1. Основные опции для работы с метками
| Опция | Синтаксис | Описание |
|---|---|---|
phantom | phantom={\refstepcounter{mycounter}} | Выполняет код без видимого вывода (для счётчиков и меток) |
nophantom | nophantom | Отключает ранее заданный phantom код |
label | label=mylabel | Устанавливает метку для ссылок через \ref |
phantomlabel | phantomlabel=mylabel | Аналог label для ненумерованных боксов |
step | step=mycounter | Увеличивает счётчик (\refstepcounter) |
step and label | step and label={mycounter}{mylabel} | Комбинация step + label |
Пример базового использования:
\begin{tcolorbox}[
label=mybox,
title=Пример с меткой
]
Содержимое бокса. Ссылка: \ref{mybox}.
\end{tcolorbox}
1.2. Типы ссылок
| Опция | Синтаксис | Описание |
|---|---|---|
label is label | label is label | Использует стандартные \label/\ref (по умолчанию) |
label is zlabel | label is zlabel | Использует \zlabel из пакета zref |
label type | label type=theorem | Задаёт тип ссылки для cleveref/zref-clever |
no label type | no label type | Сбрасывает тип ссылки |
Пример с cleveref:
\usepackage{cleveref}
\begin{tcolorbox}[
label=mytheorem,
label type=theorem,
title=Теорема
]
Содержимое. Ссылка: \cref{mytheorem}.
\end{tcolorbox}
1.3. Дополнительные возможности
| Опция | Синтаксис | Описание |
|---|---|---|
nameref | nameref=Моё название | Текст для \nameref |
short title | short title=Краткое название | Устанавливает nameref и list entry |
hypertarget | hypertarget=mytarget | Создаёт якорь для гиперссылок |
bookmark | bookmark=Название | Добавляет закладку PDF |
index | index=Термин | Добавляет запись в индекс |
2. Примеры использования
2.1. Автоматическая нумерация
\newtcolorbox[auto counter]{mybox}[1][]{
colback=white,
title=Блок \thetcbcounter,
#1
}
\begin{mybox}[label=box1]
Первый блок. Ссылка: \ref{box1}.
\end{mybox}
2.2. Работа с гиперссылками
\usepackage{hyperref}
\begin{tcolorbox}[
hypertarget=target1,
title=Кликабельный блок
]
\hyperlink{target2}{Перейти к другому блоку}.
\end{tcolorbox}
\begin{tcolorbox}[
hypertarget=target2,
title=Целевой блок
]
Этот блок будет целью ссылки.
\end{tcolorbox}
2.3. Индексирование и закладки
\usepackage{imakeidx,bookmark}
\makeindex
\begin{tcolorbox}[
bookmark=Важная теорема,
index=Теоремы,
title=Теорема Пифагора
]
$a^2 + b^2 = c^2$
\end{tcolorbox}
3. Полный пример
\documentclass{article}
\usepackage{tcolorbox}
\usepackage{hyperref,cleveref,bookmark,imakeidx}
\makeindex
\newtcolorbox[auto counter]{theorem}[2][]{
colback=green!5,
title=Теорема \thetcbcounter: #2,
label type=theorem,
#1
}
\begin{document}
\section{Примеры}
\begin{theorem}[label=pyth]{Пифагора}
$a^2 + b^2 = c^2$
\end{theorem}
Ссылка на \cref{pyth}.
\begin{tcolorbox}[
bookmark=Демонстрация,
index=Примеры,
hypertarget=demo,
title=Демо-блок
]
Этот блок имеет:
\begin{itemize}
\item Закладку PDF
\item Запись в индексе
\item Якорь для ссылок
\end{itemize}
\end{tcolorbox}
\printindex
\end{document}
4. Важные замечания
- Для работы
zlabelтребуется пакетzref phantomкод выполняется в группе - используйте\globalдля глобальных изменений- Опции
bookmarkиindexтребуют соответствующих пакетов
Вывод
- Используйте
labelиphantomдля перекрёстных ссылок label typeулучшает работу сcleverefhypertargetиbookmarkдобавляют интерактивности PDFindexинтегрирует боксы в предметный указатель
7.1.23 - Even and Odd Pages - Разное оформление для чётных и нечётных страниц
В этом разделе рассматриваются механизмы для различного оформления tcolorbox на чётных и нечётных страницах документа.
Even and Odd Pages - Разное оформление для чётных и нечётных страниц
В этом разделе рассматриваются механизмы для различного оформления tcolorbox на чётных и нечётных страницах документа.
1. Основные команды и параметры
1.1. Основные опции
| Опция/Команда | Синтаксис | Описание |
|---|---|---|
check odd page | check odd page=true/false | Включает точную проверку чётности страницы (требует 2-х компиляций) |
if odd page | if odd page={нечётные}{чётные} | Разные стили для чётных/нечётных страниц |
if odd page or oneside | if odd page or oneside={нечётные}{чётные} | Для односторонней печати всегда применяет “нечётные” стили |
if odd page* | if odd page*={нечётные}{чётные} | Аналог if odd page для breakable-боксов (требует библиотеку breakable) |
\tcbifoddpage | \tcbifoddpage{нечётный код}{чётный код} | Условный оператор в коде |
\thetcolorboxnumber | \thetcolorboxnumber | Уникальный номер бокса (внутри бокса) |
\thetcolorboxpage | \thetcolorboxpage | Номер страницы бокса (требует check odd page=true) |
2. Примеры использования
2.1. Разные цвета для чётных/нечётных страниц
\begin{tcolorbox}[
if odd page={colback=yellow!30}{colback=blue!30},
title=Блок на \tcbifoddpage{нечётной}{чётной} странице
]
Этот блок будет жёлтым на нечётных и синим на чётных страницах.
Текущая страница: \thetcolorboxpage.
\end{tcolorbox}
2.2. Для breakable-боксов (с разрывом)
\usepackage{tcolorbox}
\tcbuselibrary{breakable}
\begin{tcolorbox}[
breakable,
if odd page*={colback=red!20}{colback=green!20},
title=Разрываемый блок
]
Длинный текст, который может занимать несколько страниц...
Каждая часть будет окрашена в зависимости от чётности страницы.
\end{tcolorbox}
2.3. Использование в водяных знаках
\begin{tcolorbox}[
enhanced,
check odd page,
watermark text={\tcbifoddpage{НЕЧЁТНАЯ}{ЧЁТНАЯ}},
title=Пример с водяным знаком
]
Содержимое блока. Водяной знак покажет чётность страницы.
\end{tcolorbox}
3. Важные особенности
Точность проверки:
- Для точного определения чётности страницы требуется:
- Установить
check odd page=true - Двойная компиляция документа
- Установить
- Без этой опции проверка может работать некорректно для первого блока на странице
- Для точного определения чётности страницы требуется:
Разрываемые боксы:
- Для breakable-боксов используйте
if odd page*вместоif odd page - Либо упакуйте
if odd pageвextras:
- Для breakable-боксов используйте
\begin{tcolorbox}[
breakable,
check odd page,
extras={if odd page={colback=yellow}{colback=blue}}
]
...
\end{tcolorbox}
- Односторонняя печать:
- Для документов с
onesideиспользуйтеif odd page or oneside - В этом случае всегда будут применяться “нечётные” стили
- Для документов с
4. Полный пример
\documentclass[twoside]{article}
\usepackage{tcolorbox}
\tcbuselibrary{breakable}
\usepackage{lipsum}
\newtcolorbox{smartbox}[1][]{
check odd page,
if odd page*={colback=yellow!10}{colback=blue!10},
colframe=black,
title=Блок на странице \thetcolorboxpage,
#1
}
\begin{document}
\section{Разное оформление для чётных/нечётных страниц}
\begin{smartbox}
Этот блок автоматически меняет цвет в зависимости от страницы.
\begin{itemize}
\item Номер бокса: \thetcolorboxnumber
\item Номер страницы: \thetcolorboxpage
\end{itemize}
\end{smartbox}
\begin{smartbox}[breakable]
\lipsum[1-4]
Длинное содержимое, которое может переноситься на несколько страниц.
Каждая часть будет окрашена соответствующим образом.
\end{smartbox}
\end{document}
5. Вывод
Для разного оформления на чётных/нечётных страницах:
- Используйте
if odd pageдля обычных боксов - Используйте
if odd page*для breakable-боксов - Для точности добавьте
check odd page=true
- Используйте
Специальные команды:
\tcbifoddpage- условный оператор в коде\thetcolorboxnumber- уникальный номер бокса\thetcolorboxpage- точный номер страницы
Для односторонней печати используйте варианты с
or oneside.
7.1.24 - Externalization - Интеграция с внешними файлами TikZ
В этом разделе рассматривается взаимодействие tcolorbox с системой внешних файлов (externalization) пакета TikZ.
Externalization - Интеграция с внешними файлами TikZ
В этом разделе рассматривается взаимодействие tcolorbox с системой внешних файлов (externalization) пакета TikZ.
1. Основные команды и параметры
| Опция/Команда | Синтаксис | Описание |
|---|---|---|
shield externalize | shield externalize=true/false | Защищает tcolorbox от внешнего экспорта (по умолчанию false) |
external | external=имя_файла | Устанавливает имя файла для экспорта TikZ-рисунков внутри бокса |
remake | remake=true/false | Форсирует пересоздание внешнего файла для TikZ-рисунка |
2. Примеры использования
2.1. Базовое использование
\documentclass{article}
\usepackage{tcolorbox}
\usetikzlibrary{external}
\tikzexternalize % Включаем систему внешних файлов
\begin{document}
\begin{tcolorbox}[
shield externalize, % Защищаем сам бокс от экспорта
title=Защищённый бокс
]
Этот tcolorbox не будет экспортирован как внешний файл.
\begin{tikzpicture}
\draw (0,0) circle (1cm); % Этот рисунок БУДЕТ экспортирован
\end{tikzpicture}
\end{tcolorbox}
\end{document}
2.2. Управление экспортом отдельных рисунков
\begin{tcolorbox}[
external=myplot, % Устанавливаем имя файла для экспорта
remake=true, % Форсируем пересоздание
title=Бокс с управляемым экспортом
]
\begin{tikzpicture}
\draw[red] (0,0) rectangle (2,2); % Экспортируется в myplot.pdf
\end{tikzpicture}
\end{tcolorbox}
3. Важные особенности
Автоматическое отключение в TikZ-окружении:
- Внутри
tikzpictureопцияshield externalizeавтоматически отключается - Не используйте
\tikzexternaldisableперед tcolorbox в этом случае
- Внутри
Рекомендуемые паттерны использования:
\tikzexternalenable % Рисунки для экспорта \tikzexternaldisable % Обычные tcolorboxТребования:
- Для работы необходимо подключить библиотеку TikZ:
\usetikzlibrary{external} \tikzexternalize
- Для работы необходимо подключить библиотеку TikZ:
Ограничения:
- Рисунки, созданные через
tikz upperи аналогичные опции, не экспортируются - Для сложных документов может потребоваться несколько компиляций
- Рисунки, созданные через
4. Полный пример
\documentclass{article}
\usepackage{tcolorbox}
\usetikzlibrary{external}
\tikzexternalize % Активируем систему внешних файлов
\tcbset{shield externalize} % Глобально защищаем все tcolorbox
\begin{document}
\section{Пример интеграции с внешними файлами}
\begin{tcolorbox}[title=Обычный защищённый бокс]
Этот блок не будет экспортирован как внешний файл.
\end{tcolorbox}
\begin{tcolorbox}[
external=mycircle,
title=Бокс с экспортируемым рисунком
]
\begin{tikzpicture}
\draw[blue, thick] (0,0) circle (1.5cm);
\node at (0,0) {Экспортируется};
\end{tikzpicture}
\end{tcolorbox}
\tikzexternaldisable % Временно отключаем экспорт
\begin{tcolorbox}[title=Временный незащищённый бокс]
Этот блок создан при отключённом экспорте.
\end{tcolorbox}
\tikzexternalenable % Возобновляем экспорт
\end{document}
5. Вывод
Защита боксов:
- Используйте
shield externalizeдля предотвращения экспорта tcolorbox - Устанавливайте глобально через
\tcbset, если не нужен экспорт
- Используйте
Управление экспортом:
- Для экспорта отдельных рисунков используйте
external=имя_файла - Для принудительного обновления -
remake=true
- Для экспорта отдельных рисунков используйте
Лучшие практики:
- Чётко разделяйте код, требующий экспорта и не требующий
- Используйте
\tikzexternalenable/disableдля группировки экспортируемых элементов
Эти механизмы позволяют эффективно комбинировать tcolorbox с системой внешних файлов TikZ, оптимизируя процесс сборки сложных документов.
7.1.25 - Miscellaneous - Разные дополнительные возможности
В этом разделе рассматриваются различные дополнительные функции tcolorbox, которые не вошли в предыдущие категории.
4.24 Miscellaneous - Разные дополнительные возможности
В этом разделе рассматриваются различные дополнительные функции tcolorbox, которые не вошли в предыдущие категории.
1. Основные команды и параметры
1.1. Сброс настроек
| Опция | Синтаксис | Описание |
|---|---|---|
reset | reset | Сбрасывает все настройки tcolorbox к значениям по умолчанию |
Пример:
\begin{tcolorbox}[reset, title=Блок со сброшенными настройками]
Этот блок игнорирует все предыдущие \tcbset{}
\end{tcolorbox}
1.2. Условные операторы
| Опция | Синтаксис | Описание |
|---|---|---|
IfBlankTF | IfBlankTF={текст}{опции если пусто}{опции если не пусто} | Проверяет на пустоту (пробелы считаются пустотой) |
IfEmptyTF | IfEmptyTF={текст}{опции если пусто}{опции если не пусто} | Проверяет на полную пустоту |
IfNoValueTF | IfNoValueTF={аргумент}{опции если нет значения}{опции если есть} | Для обработки необязательных аргументов |
IfValueTF | IfValueTF={аргумент}{опции если есть значение}{опции если нет} | Обратная версия IfNoValueTF |
IfBooleanTF | IfBooleanTF={аргумент}{опции если true}{опции если false} | Для булевых значений |
Пример с IfValueTF:
\DeclareTColorBox{mybox}{o}{%
IfValueTF={#1}{title=#1}{title=Без названия},
colframe=blue
}
\begin{mybox}
Блок без названия
\end{mybox}
\begin{mybox}[Мой заголовок]
Блок с названием
\end{mybox}
1.3. Специальные режимы
| Опция | Синтаксис | Описание |
|---|---|---|
void | void | Полностью удаляет бокс (как комментарий) |
nirvana | nirvana | Обрабатывает содержимое, но не отображает бокс |
Пример:
Текст до
\begin{tcolorbox}[void]
Этот блок полностью исчезнет
\end{tcolorbox}
Текст после
2. Примеры использования
2.1. Условное форматирование
\newtcolorbox{smartbox}[1][]{
IfBlankTF={#1}{colback=red!10}{colback=green!10},
title=Умный бокс
}
\begin{smartbox}[]
Будет красным (аргумент пуст)
\end{smartbox}
\begin{smartbox}[X]
Будет зелёным (аргумент не пуст)
\end{smartbox}
2.2. Обработка необязательных аргументов
\DeclareTColorBox{mybox}{o}{
IfNoValueTF={#1}{title=Стандартный}{title=#1},
colframe=black
}
\begin{mybox}
Стандартный заголовок
\end{mybox}
\begin{mybox}[Кастомный]
Специальный заголовок
\end{mybox}
2.3. Временное отключение боксов
Текст до
\begin{tcolorbox}[nirvana]
Этот блок обработается, но не будет виден
\begin{tcolorbox}
Вложенный блок (будет виден)
\end{tcolorbox}
\end{tcolorbox}
Текст после
3. Важные особенности
reset:- Не сбрасывает
capture,shield externalizeи настройки raster - Автоматически применяется для вложенных боксов (начиная с v2.40)
- Не сбрасывает
Условные операторы:
- Основаны на функциях
expl3иxparse - Полезны для создания гибких шаблонов боксов
- Основаны на функциях
voidvsnirvana:voidполностью удаляет бокс (как если бы его закомментировали)nirvanaобрабатывает содержимое (счётчики и пр.), но не отображает
Ограничения:
voidнельзя использовать для вложенных боксов с одинаковыми именамиvoidне работает с\tcolorboxenvironment
4. Полный пример
\documentclass{article}
\usepackage{tcolorbox}
\usepackage{xcolor}
% Бокс с условным форматированием
\newtcolorbox{condbox}[1][]{
IfBlankTF={#1}{colback=gray!20}{colback=#1!20},
title=Условный бокс
}
\begin{document}
\section{Примеры разных возможностей}
\begin{condbox}[]
Стандартный серый фон (аргумент пуст)
\end{condbox}
\begin{condbox}[red]
Красный фон (аргумент указан)
\end{condbox}
% Пример с void
Текст до \begin{tcolorbox}[void]Невидимый блок\end{tcolorbox} текст после
% Пример с nirvana
Текст до \begin{tcolorbox}[nirvana]
Невидимый но обработанный блок
\begin{tcolorbox}[colback=yellow]
Вложенный видимый блок
\end{tcolorbox}
\end{tcolorbox} текст после
\end{document}
5. Вывод
- Для сброса настроек используйте
reset - Для условного форматирования применяйте:
IfBlankTF/IfEmptyTF- проверка на пустотуIfNoValueTF/IfValueTF- работа с аргументамиIfBooleanTF- для булевых флагов
- Для скрытия блоков:
void- полное удалениеnirvana- скрытие с обработкой содержимого
7.2 - Справочник основных пакетов LaTeX
Справочник основных пакетов LaTeX, которые я использую, с кратким описанием их назначения и ключевых команд:
1. Кодировка и языки
fontenc
Назначение: Выбор кодировки шрифтов.
T1– для западноевропейских языков.T2A– для кириллицы (русский текст).
Пример:
\usepackage[T1,T2A]{fontenc}
inputenc
Назначение: Указывает кодировку исходного файла.
utf8x– поддержка UTF-8.
Пример:
\usepackage[utf8x]{inputenc}
babel
Назначение: Поддержка многоязычных документов (переносы, автоимена разделов).
russian– активирует русскую локализацию.english– резервный язык.
Пример:
\usepackage[english, russian]{babel}
2. Разметка страницы
geometry
Назначение: Настройка полей и размеров страницы.
Основные параметры:
tmargin,bmargin,lmargin,rmargin– отступы.headsep,headheight– расстояние до верхнего колонтитула.
Пример:
\usepackage{geometry}
\geometry{tmargin=25mm, bmargin=20mm, lmargin=20mm, rmargin=20mm}
fancyhdr
Назначение: Настройка колонтитулов.
\pagestyle{fancy}– активирует стиль.\lhead,\chead,\rhead– левый/центральный/правый верхний колонтитул.\lfoot,\cfoot,\rfoot– нижний колонтитул.
Пример:
\usepackage{fancyhdr}
\pagestyle{fancy}
\lhead{Левый заголовок}
\rfoot{Страница \thepage}
3. Математика
amsmath, amsthm, amssymb
Назначение: Расширенная математическая вёрстка.
amsmath– улучшенные уравнения (align,gather).amssymb– дополнительные символы (\mathbb,\mathcal).amsthm– теоремы (\newtheorem).
Пример:
\begin{align}
a &= b + c \\
E &= mc^2
\end{align}
wasysym
Назначение: Дополнительные символы (например, \diameter для диаметра).
4. Графика и таблицы
graphicx
Назначение: Вставка изображений.
\includegraphics[width=5cm]{image.png}– вставка с масштабированием.
Пример:
\usepackage{graphicx}
\graphicspath{{images/}} % путь к изображениям
float
Назначение: Улучшенное управление позиционированием плавающих объектов (рисунков, таблиц).
subcaption
Назначение: Подписи к нескольким изображениям в одной фигуре.
Пример:
\begin{figure}
\begin{subfigure}{0.5\textwidth}
\includegraphics{img1.png}
\caption{Первое изображение}
\end{subfigure}
\begin{subfigure}{0.5\textwidth}
\includegraphics{img2.png}
\caption{Второе изображение}
\end{subfigure}
\caption{Два изображения}
\end{figure}
multirow, colortbl, hhline
Назначение: Сложные таблицы.
\multirow– объединение строк.\colortbl– цветные ячейки.\hhline– двойные линии.
Пример:
\begin{tabular}{|c|c|}
\hline
\multirow{2}{*}{Объединённые строки} & Текст \\ \cline{2-2}
& Ещё текст \\ \hline
\end{tabular}
5. Гиперссылки и оглавление
hyperref
Назначение: Интерактивные ссылки в PDF.
\href{url}{текст}– гиперссылка.\autoref{label}– автоматические подписи (“Рисунок 1”).
Пример:
\usepackage{hyperref}
\hypersetup{colorlinks=true, linkcolor=blue}
varioref
Назначение: Умные ссылки (“на стр. 5”).
imakeidx
Назначение: Создание индекса.
\makeindex– активация.\index{ключ}– добавление записи.
Пример:
\usepackage{imakeidx}
\makeindex
...
\printindex
6. Текст и форматирование
ulem
Назначение: Дополнительное оформление текста.
\sout{текст}– зачёркивание.\uline{текст}– подчёркивание.
indentfirst
Назначение: Автоматический отступ у первого абзаца.
multicol
Назначение: Многоколоночная вёрстка.
Пример:
\begin{multicols}{2}
Текст в две колонки...
\end{multicols}
7. Разное
tikz
Назначение: Создание векторной графики прямо в LaTeX.
Пример:
\begin{tikzpicture}
\draw (0,0) -- (1,1);
\end{tikzpicture}
xcolor
Назначение: Работа с цветами.
\textcolor{red}{текст}– цвет текста.
7.3 - Latex для авторов
LATEX для авторов актуальная версия
Введение
LaTeX 2ε был выпущен в 1994 году и добавил ряд новых концепций, которые на тот момент были актуальны. Эти концепции описаны в документе usrguide-historic, который в значительной степени остался неизменным. С тех пор команда LaTeX работала над рядом идей, в первую очередь над языком программирования для LaTeX (expl3), а затем над рядом инструментов для авторов документов, которые основываются на этом языке. Здесь мы описываем стабильные и широко используемые концепции, которые стали результатом этой работы. Эти «новые» идеи были перенесены из пакетов разработки в ядро LaTeX 2ε. Таким образом, они теперь доступны всем пользователям LaTeX и имеют такую же стабильность, как и любая другая часть ядра. Тот факт, что «за кулисами» они построены на основе expl3, полезен для команды разработчиков, но не имеет прямого значения для пользователей.
2 Создание команд и окружений документа
2.1 Обзор
Создание команд и окружений документа с использованием инструментария LaTeX3 основано на идее, что общий набор описаний может быть использован для охвата почти всех типов аргументов, используемых в реальных документах. Таким образом, парсинг сводится к простому описанию того, какие аргументы принимает команда: это описание обеспечивает «связь» между синтаксисом документа и реализацией команды.
Сначала мы опишем типы аргументов, затем перейдем к объяснению того, как их можно использовать для создания как команд документа, так и окружений. Затем будут описаны различные более специализированные функции, которые позволяют еще более богатое применение простого интерфейса.
Детали, приведенные здесь, предназначены для помощи пользователям в создании команд документа в общем. Более технические детали, подходящие для программистов TeX, включены в раздел interface3.
2.2 Описание типов аргументов
Для того чтобы каждый аргумент можно было определить независимо, парсеру необходимо знать не только количество аргументов для функции, но и природу каждого из них. Это достигается путем построения спецификации аргумента, которая определяет количество аргументов, тип каждого аргумента и любую дополнительную информацию, необходимую парсеру для чтения пользовательского ввода и правильной передачи его во внутренние функции.
Основная форма спецификатора аргумента — это список букв, где каждая буква определяет тип аргумента. Как будет описано ниже, некоторые типы требуют дополнительной информации, такой как значения по умолчанию. Типы аргументов можно разделить на две категории: те, которые определяют обязательные аргументы (возможно, вызывая ошибку, если они не найдены), и те, которые определяют необязательные аргументы.
Обязательные типы
m
Стандартный обязательный аргумент, который может быть либо единственным токеном, либо несколькими токенами, заключенными в фигурные скобки {}. Независимо от ввода, аргумент будет передан во внутренний код без внешних скобок. Это спецификатор типа для обычного аргумента TeX.r
Указывается как r⟨token1⟩⟨token2⟩, это обозначает «обязательный» аргумент с разделителями, где разделителями являются ⟨token1⟩ и ⟨token2⟩. Если открывающий разделитель ⟨token1⟩ отсутствует, будет вставлен маркер по умолчанию -NoValue- после соответствующей ошибки.R
Указывается как R⟨token1⟩⟨token2⟩{⟨default⟩}, это «обязательный» аргумент с разделителями, как и r, но он имеет определяемое пользователем значение по умолчанию ⟨default⟩ вместо -NoValue-.v
Читает аргумент «дословно» между следующим символом и его следующим вхождением, аналогично аргументу команды LaTeX 2ε \verb. Таким образом, аргумент типа v читается между двумя одинаковыми символами, которые не могут быть %, , #, {, } или ␣. Дословный аргумент также может быть заключен в фигурные скобки { и }. Команда с дословным аргументом вызовет ошибку, если она появится внутри аргумента другой команды.b
Подходит только в спецификации аргумента окружения, обозначает тело окружения, между \begin{⟨environment⟩} и \end{⟨environment⟩}. См. раздел 2.11 для подробностей.
Типы, которые определяют необязательные аргументы, следующие:
o
Стандартный необязательный аргумент LaTeX, заключенный в квадратные скобки, который будет предоставлять специальный маркер -NoValue-, если не указан (как будет описано позже).d
Указывается как d⟨token1⟩⟨token2⟩, необязательный аргумент, который ограничен ⟨token1⟩ и ⟨token2⟩. Как и в случае с o, если значение не указано, возвращается специальный маркер -NoValue-.O
Указывается как O{⟨default⟩}, аналогично o, но возвращает ⟨default⟩, если значение не указано.D
Указывается как D⟨token1⟩⟨token2⟩{⟨default⟩}, аналогично d, но возвращает ⟨default⟩, если значение не указано. Внутренне типы o, d и O являются сокращениями для соответствующим образом сконструированного аргумента типа D.s
Необязательная звезда(*), которая приведет к значению \BooleanTrue, если звезда присутствует, и \BooleanFalse в противном случае (как будет описано позже).t
Необязательный ⟨token⟩, который приведет к значению \BooleanTrue, если ⟨token⟩ присутствует, и \BooleanFalse в противном случае. Указывается как t⟨token⟩.e
Указывается как e{⟨tokens⟩}, набор необязательных украшений, каждое из которых требует значения. Если украшение отсутствует, возвращается -NoValue-. Каждое украшение дает один аргумент, упорядоченный в соответствии со списком ⟨tokens⟩ в спецификации аргумента. Все ⟨tokens⟩ должны быть различными.E
Аналогично e, но возвращает одно или несколько ⟨defaults⟩, если значения не указаны: E{⟨tokens⟩}{⟨defaults⟩}. См. раздел 2.7 для получения дополнительных деталей.
2.3 Модификация описаний аргументов
В дополнение к типам аргументов, обсужденным выше, описание аргументов также придает специальное значение трем другим символам.
Во-первых, + используется для того, чтобы сделать аргумент длинным (принимать параграфные токены). В отличие от \newcommand, это применяется на основе каждого отдельного аргумента. Таким образом, модификация примера на «s o o +m O{default}» означает, что обязательный аргумент теперь является \long, в то время как необязательные аргументы таковыми не являются.
Во-вторых, ! используется для управления тем, разрешены ли пробелы перед необязательными аргументами. Здесь есть некоторые тонкости, так как сам TeX имеет ограничения на то, где пробелы могут быть «обнаружены»: более подробная информация приведена в разделе 2.6.
В-третьих, = используется для объявления того, что следующий аргумент должен интерпретироваться как серия ключевых значений (keyvals). См. раздел 2.9 для получения дополнительных деталей.
Наконец, символ > используется для объявления так называемых «процессоров аргументов», которые могут быть использованы для модификации содержимого аргумента перед его передачей в определение макроса. Использование процессоров аргументов является несколько продвинутой темой (или, по крайней мере, менее часто используемой функцией) и рассматривается в разделе 2.10.
Вот перевод раздела 2.4 “Создание команд и окружений документа”:
2.4 Создание команд и окружений документа
\NewDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\RenewDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\ProvideDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\DeclareDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
Эта группа команд используется для создания команды ⟨cmd⟩. Спецификация аргумента для функции задается с помощью ⟨arg spec⟩, а команда использует ⟨code⟩, где #1, #2 и т. д. заменяются на аргументы, найденные парсером.
Пример:
\NewDocumentCommand\chapter{s o m} {
\IfBooleanTF{#1}
{\typesetstarchapter{#3}}
{\typesetnormalchapter{#2}{#3}}
}
Это способ определения команды \chapter, которая будет вести себя аналогично текущей команде LaTeX 2ε (за исключением того, что она будет принимать необязательный аргумент, даже когда был распарсен символ *). Команда \typesetnormalchapter может проверить свой первый аргумент на наличие значения -NoValue-, чтобы определить, присутствует ли необязательный аргумент. (См. раздел 2.8 для деталей о \IfBooleanTF и проверке на -NoValue-.)
Разница между версиями \New…, \Renew…, \Provide… и \Declare… заключается в поведении, если ⟨cmd⟩ уже определена.
- \NewDocumentCommand выдаст ошибку, если ⟨cmd⟩ уже была определена.
- \RenewDocumentCommand выдаст ошибку, если ⟨cmd⟩ ранее не была определена.
- \ProvideDocumentCommand создаст новое определение для ⟨cmd⟩ только в том случае, если оно еще не было дано.
- \DeclareDocumentCommand всегда создаст новое определение, независимо от существующей ⟨cmd⟩ с тем же именем. Это следует использовать с осторожностью.
Если ⟨cmd⟩ не может быть предоставлена как единый токен, но требует «конструирования», вы можете использовать \ExpandArgs, как объясняется в разделе 4, который также дает пример, в котором это необходимо.
\NewDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
\RenewDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
\ProvideDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
\DeclareDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
Эти команды работают так же, как \NewDocumentCommand и т. д., но создают окружения (\begin{⟨env⟩} … \end{⟨env⟩}). Как ⟨beg-code⟩, так и ⟨end-code⟩ могут получать доступ к аргументам, как определено в ⟨arg spec⟩. Аргументы будут переданы после \begin{⟨env⟩}. Все пробелы в начале и в конце {⟨env⟩} удаляются перед определением, таким образом:
\NewDocumentEnvironment{foo}
и
\NewDocumentEnvironment{ foo }
оба создают одно и то же окружение «foo».
2.5 Необязательные аргументы
В отличие от команд, созданных с помощью \newcommand в LaTeX 2ε, необязательные аргументы, созданные с помощью \NewDocumentCommand, могут безопасно вкладываться. Таким образом, например, после
\NewDocumentCommand\foo{om}{I grabbed ‘#1’ and ‘#2’}
\NewDocumentCommand\baz{o}{#1-#1}
использование команды как
\foo[\baz[stuff]]{more stuff}
выведет
I grabbed ‘stuff-stuff’ and ‘more stuff’
Это особенно полезно, когда команда с необязательным аргументом помещается внутри необязательного аргумента второй команды.
Когда необязательный аргумент следует за обязательным аргументом с тем же разделителем, парсер выдает предупреждение, поскольку необязательный аргумент не может быть опущен пользователем, тем самым фактически становясь обязательным. Это может касаться аргументов типов o, d, O, D, s, t, e и E, за которыми следуют обязательные аргументы типа r или R.
Значение по умолчанию для аргументов O, D и E может быть результатом захвата другого аргумента. Таким образом, например,
\NewDocumentCommand\foo{O{#2} m}
будет использовать обязательный аргумент в качестве значения по умолчанию для ведущего необязательного аргумента.
2.6 Пробелы и необязательные аргументы
TeX найдет первый аргумент после имени функции независимо от любых промежуточных пробелов. Это верно как для обязательных, так и для необязательных аргументов. Таким образом, \foo[arg] и \foo␣[arg] эквивалентны. Пробелы также игнорируются при сборе аргументов до последнего обязательного аргумента, который должен существовать. Поэтому после
\NewDocumentCommand\foo{m o m}{ ... }
ввод пользователя \foo{arg1}[arg2]{arg3} и \foo{arg1}␣[arg2]␣{arg3} будут парситься одинаково.
Поведение необязательных аргументов после любых обязательных аргументов можно настроить. Стандартные настройки позволят пробелы здесь, и таким образом, с
\NewDocumentCommand\foobar{m o}{ ... }
как \foobar{arg1}[arg2], так и \foobar{arg1}␣[arg2] найдут необязательный аргумент. Это можно изменить, добавив модификатор ! в спецификацию аргументов:
\NewDocumentCommand\foobar{m !o}{ ... }
где \foobar{arg1}␣[arg2] не найдет необязательный аргумент.
Существует одна тонкость, связанная с различием в обработке TeX «управляющих символов», когда имя команды состоит из одного символа, например, ‘\’. Пробелы здесь не игнорируются TeX, и, таким образом, возможно, чтобы необязательный аргумент следовал непосредственно за такой командой. Наиболее распространенный пример — использование \ в окружениях amsmath, которое в терминах здесь будет определено как
\NewDocumentCommand\\{!s !o}{ ... }
Также стоит отметить, что при использовании необязательных аргументов в последней позиции TeX обязательно будет заглядывать вперед для открытия токена аргумента. Это означает, что значение \inputlineno будет «сдвинуто на один», если такой завершающий необязательный аргумент отсутствует и команда заканчивает строку; оно будет на единицу больше, чем номер строки, содержащей последний обязательный аргумент.
2.7 «Украшения»
Аргумент типа E позволяет задавать одно значение по умолчанию для каждого тестового токена. Это достигается путем указания списка значений по умолчанию для каждой записи в списке, например:
E{^_}{{UP}{DOWN}}
Если список значений по умолчанию короче списка тестовых токенов, будет возвращен специальный маркер -NoValue- (как и для аргумента типа e). Таким образом, например:
E{^_}{{UP}}
имеет значение по умолчанию UP для тестового символа ^, но вернет маркер -NoValue- в качестве значения по умолчанию для _. Это позволяет смешивать явные значения по умолчанию с проверкой на отсутствие значений.
2.8 Проверка специальных значений
Необязательные аргументы используют специальные переменные для возврата информации о природе полученного аргумента.
\IfNoValueTF {⟨arg⟩} {⟨true code⟩} {⟨false code⟩}
\IfNoValueT {⟨arg⟩} {⟨true code⟩}
\IfNoValueF {⟨arg⟩} {⟨false code⟩}
Команды \IfNoValue(TF) используются для проверки, является ли ⟨argument⟩ (#1, #2 и т. д.) специальным маркером -NoValue-. Например:
\NewDocumentCommand\foo{o m} {
\IfNoValueTF {#1}
{\DoSomethingJustWithMandatoryArgument{#2}}
{\DoSomethingWithBothArguments{#1}{#2}}
}
будет использовать другую внутреннюю функцию, если необязательный аргумент задан, чем если он отсутствует.
Обратите внимание, что доступны три теста, в зависимости от того, какие ветви результата требуются: \IfNoValueTF, \IfNoValueT и \IfNoValueF. Поскольку тесты \IfNoValue(TF) являются расширяемыми, возможно проверять эти значения позже, например, в момент верстки или в контексте расширения.
Важно отметить, что -NoValue- сконструирован таким образом, что он не будет соответствовать простому текстовому вводу -NoValue-, т.е.
\IfNoValueTF{-NoValue-}
будет логически ложным. Когда два необязательных аргумента следуют друг за другом (синтаксис, который мы обычно не рекомендуем), может иметь смысл позволить пользователям команды указывать только второй аргумент, предоставив пустой первый аргумент. Вместо того чтобы отдельно проверять на пустоту и на -NoValue-, лучше использовать тип аргумента O с пустым значением по умолчанию, а затем проверять на пустоту, используя условие \IfBlankTF (описанное ниже).
\IfValueTF {⟨arg⟩} {⟨true code⟩} {⟨false code⟩}
\IfValueT {⟨arg⟩} {⟨true code⟩}
\IfValueF {⟨arg⟩} {⟨false code⟩}
Обратная форма тестов \IfNoValue(TF) также доступна как \IfValue(TF). Контекст определит, какая логическая форма имеет наибольший смысл для данного сценария кода.
\IfBlankTF {⟨arg⟩} {⟨true code⟩} {⟨false code⟩}
\IfBlankT {⟨arg⟩} {⟨true code⟩}
\IfBlankF {⟨arg⟩} {⟨false code⟩}
Команда \IfNoValueTF выбирает ⟨true code⟩, если необязательный аргумент вообще не использовался (и возвращает специальный маркер -NoValue-), но не если ему было дано пустое значение. В отличие от этого, \IfBlankTF возвращает true, если его аргумент либо действительно пуст, либо содержит один или несколько обычных пробелов. Например:
\NewDocumentCommand\foo{m!o}{\par #1:
\IfNoValueTF{#2}
{No optional}%
{%
\IfBlankTF{#2}
{Blanks in or empty}%
{Real content in}%
}%
\space argument!}
\foo{1}[bar] \foo{2}[ ] \foo{3}[] \foo{4}[\space] \foo{5}[x]
результирует в следующем выводе:
1: Real content in argument!
2: Blanks in or empty argument!
3: Blanks in or empty argument!
4: Real content in argument!
5: No optional argument! [x]
Обратите внимание, что \space в (4) считается реальным содержимым — потому что это команда, а не символ «пробел» — даже если это приводит к созданию пробела. Вы также можете наблюдать в (5) эффект спецификатора !, предотвращающего последнюю \foo от интерпретации [x] как своего необязательного аргумента.
\BooleanFalse
\BooleanTrue
Флаги истинности и ложности, устанавливаемые при поиске необязательного символа (с использованием s или t⟨char⟩), имеют имена, которые доступны вне блоков кода.
\IfBooleanTF {⟨arg⟩} {⟨true code⟩} {⟨false code⟩}
\IfBooleanT {⟨arg⟩} {⟨true code⟩}
\IfBooleanF {⟨arg⟩} {⟨false code⟩}
Эти команды используются для проверки, является ли ⟨argument⟩ (#1, #2 и т. д.) равным \BooleanTrue или \BooleanFalse. Например:
\NewDocumentCommand\foo{sm} {
\IfBooleanTF {#1}
{\DoSomethingWithStar{#2}}
{\DoSomethingWithoutStar{#2}}
}
Этот код проверяет наличие звезды в качестве первого аргумента, а затем выбирает действие на основе этой информации.
2.9 Автоматическое преобразование в формат ключ-значение
Некоторые команды документа имеют долгую историю принятия необязательного аргумента в виде «свободного текста», например, \caption и команды секционирования \section и т.д. Введение более сложных (keyval) опций для этих команд требует метода интерпретации необязательного аргумента как свободного текста или как серии ключевых значений. Это должно происходить во время захвата аргумента, так как необходимо аккуратно обрабатывать фигурные скобки для получения правильного результата.
Модификатор = доступен для того, чтобы позволить ltcmd правильно реализовать этот процесс. Модификатор гарантирует, что аргумент будет передан в дальнейший код как серия ключевых значений. Для этого = должен быть за ним, за которым следует аргумент, содержащий имя ключа по умолчанию. Это используется как ключ в паре ключ-значение, если «сырой» аргумент не имеет правильной формы для интерпретации как набора ключевых значений.
Пример с \caption
Рассмотрим \caption в качестве примера с демонстрационной реализацией:
\DeclareDocumentCommand \caption {s ={short-text} +O{#3} +m} {%
\showtokens{Grabbed arguments:^^J(#2)^^Jand^^J(#3)}%
}
Имя ключа по умолчанию — short-text. Когда команда \caption используется, если необязательный аргумент является свободным текстом, например:
\caption[Некоторый короткий текст]{Длинный и более детализированный текст для демонстрационных целей}
то вывод будет:
Grabbed arguments: (short-text={Некоторый короткий текст}) and (Длинный и более детализированный текст для демонстрационных целей)
С другой стороны, если заголовок задан с аргументом в формате ключ-значение:
\caption[label = cap:demo]{Длинный и более детализированный текст для демонстрационных целей}
то это будет учтено:
Grabbed arguments: (label = cap:demo) and (Длинный и более детализированный текст для демонстрационных целей)
Интерпретация в формате ключ-значение
Интерпретация как ключ-значение определяется наличием символов = в аргументе. Символы в режиме встроенной математики (включенные в $...$ или \(...\)) игнорируются. Аргумент можно заставить быть прочитанным как ключ-значение, включив пустую запись в начале:
\caption[=,Это теперь ключ-значение]%
\caption[Это не $=$ ключ-значение]%
Эта пустая запись не передается в основной код, поэтому не приведет к проблемам с парсерами ключ-значение, которые не допускают пустое имя ключа. Любые знаки = в текстовом режиме необходимо обрамлять фигурными скобками, чтобы избежать неправильной интерпретации: это, вероятно, наиболее удобно обрабатывать, обрамляя весь аргумент:
\caption[{Не = ключ-значение!}]%
что будет правильно передано как:
Grabbed arguments: (short-text = {Не = ключ-значение!})
2.10 Процессоры аргументов
Процессоры аргументов применяются к аргументу после его захвата основной системой, но перед передачей в ⟨код⟩. Таким образом, процессор аргументов может использоваться для нормализации ввода на ранней стадии, позволяя внутренним функциям быть полностью независимыми от формы ввода. Процессоры применяются к пользовательскому вводу и к значениям по умолчанию для необязательных аргументов, но не к специальному маркеру -NoValue-.
Каждый процессор аргументов указывается синтаксисом >{⟨процессор⟩} в спецификации аргумента. Процессоры применяются справа налево, так что >{\ProcessorB} >{\ProcessorA} m применит \ProcessorA, а затем \ProcessorB к токенам, захваченным аргументом m.
\SplitArgument {⟨number⟩} {⟨token(s)⟩}
Этот процессор разделяет аргумент, заданный при каждом вхождении ⟨tokens⟩, до максимума ⟨number⟩ токенов (тем самым деля ввод на ⟨number⟩ + 1 частей). Ошибка будет выдана, если в вводе присутствует слишком много ⟨токенов⟩. Обработанный ввод помещается внутри ⟨number⟩ + 1 наборов фигурных скобок для дальнейшего использования. Если в аргументе меньше, чем ⟨number⟩, то в конце обработанного аргумента добавляются маркеры -NoValue-.
\NewDocumentCommand \foo {>{\SplitArgument{2}{;}} m} {\InternalFunctionOfThreeArguments#1}
Если для разделения используется только один символ ⟨токен⟩, любой символ с кодом категории 13 (активный) совпадающий с ⟨токеном⟩ будет заменен до того, как произойдет разделение. Пробелы обрезаются в начале и в конце каждого элемента, который разбирается.
Тип аргумента E несколько особенный, потому что с одним E в объявлении команды вы можете получить несколько аргументов в команде (по одному формальному аргументу на каждый токен украшения). Поэтому, когда процессор аргументов применяется к аргументу типа e/E, все аргументы проходят через этот процессор перед тем, как быть переданными в ⟨код⟩. Например, эта команда:
\NewDocumentCommand \foo { >{\TrimSpaces} e{_^} } { [#1](#2) }
применяет \TrimSpaces к обоим аргументам.
\SplitList {⟨токены⟩}
Этот процессор разделяет аргумент, заданный при каждом вхождении ⟨токенов⟩, где количество элементов не фиксировано. Каждый элемент затем оборачивается в фигурные скобки внутри #1. Результат заключается в том, что обработанный аргумент может быть дополнительно обработан с использованием функции отображения (см. ниже).
\NewDocumentCommand \foo {>{\SplitList{;}} m} {\MappingFunction#1}
Если для разделения используется только один символ ⟨токен⟩, он учтет возможность того, что ⟨токен⟩ был активирован (код категории 13) и будет разделять по таким токенам. Пробелы обрезаются в начале и в конце каждого элемента, который разбирается. Точно один набор фигурных скобок будет удален, если весь элемент окружен ими, т.е. следующие вводы и выводы приводят к результату (каждый отдельный элемент как группа фигурных скобок):
a ==> {a}
{a} ==> {a}
{a}b ==> {{a}b}
a,b ==> {a}{b}
{a},b ==> {a}{b}
a,{b} ==> {a}{b}
a,{b}c ==> {a}{{b}c}
\ProcessList {⟨список⟩} {⟨токены⟩}
Чтобы поддержать \SplitList, доступна функция \ProcessList, которая применяет ⟨токены⟩ ко всем элементам в ⟨списке⟩. ⟨Токены⟩ могут содержать произвольные данные, которые ожидают один аргумент после них: элемент списка. Например:
\NewDocumentCommand \foo {>{\SplitList{;}} m}
{\ProcessList{#1}{\SomeDocumentCommand}}
или
\NewDocumentCommand \foo {>{\SplitList{;}} m}
{\ProcessList{#1}{Abc \SomeDocumentCommand}}
\ReverseBoolean
Этот процессор изменяет логику \BooleanTrue и \BooleanFalse, так что пример из предыдущего раздела будет выглядеть следующим образом:
\NewDocumentCommand\foo{>{\ReverseBoolean} s m} {%
\IfBooleanTF#1%
{\DoSomethingWithoutStar{#2}}%
{\DoSomethingWithStar{#2}}%
}
\TrimSpaces
Удаляет любые ведущие и завершающие пробелы (токены с кодом символа 32 и кодом категории 10) на концах аргумента. Таким образом, например, объявление функции:
\NewDocumentCommand\foo {>{\TrimSpaces} m}
{\showtokens{#1}}
и использование ее в документе как:
\foo{␣hello␣world␣}
покажет «hello␣world» в терминале, при этом пробелы в начале и в конце будут удалены. \TrimSpaces удалит множественные пробелы с концов ввода в случаях, когда они были включены так, что стандартное преобразование TEX, которое сводит множественные пробелы к одному, не применяется.
2.11 Тело окружения
Хотя окружения \begin{⟨окружение⟩} ... \end{⟨окружение⟩} обычно используются в случаях, когда код, реализующий ⟨окружение⟩, не нуждается в доступе к содержимому окружения (его «телу»), иногда полезно иметь тело в качестве стандартного аргумента. Это достигается путем завершения спецификации аргумента с помощью b, который является специальным типом аргумента для этой ситуации. Например:
\NewDocumentEnvironment{twice} {O{\ttfamily} +b} {#2#1#2} {}
\begin{twice}[\itshape]
Hello world!
\end{twice}
выводит «Hello world!Hello world!».
Префикс + используется для разрешения нескольких абзацев в теле окружения. Процессоры аргументов также могут применяться к аргументам типа b. По умолчанию пробелы обрезаются в начале и в конце тела: в приведенном примере в противном случае будут пробелы, исходящие из концов строк после [\itshape] и world!. Добавление префикса ! перед b подавляет обрезку пробелов.
Когда b используется в спецификации аргумента, последний аргумент объявления окружения (например, \NewDocumentEnvironment), который состоит из ⟨кода завершения⟩ для вставки в \end{⟨окружение⟩}, является избыточным, так как можно просто поместить этот код в конец ⟨кода начала⟩. Тем не менее, этот (пустой) ⟨код завершения⟩ должен быть предоставлен.
Окружения, использующие эту функцию, могут быть вложенными.
2.12 Полностью расширяемые команды документа
Команды документа, созданные с помощью \NewDocumentCommand и т.д., обычно создаются так, чтобы они не расширялись неожиданно. Это достигается с использованием возможностей движка, поэтому это более мощно, чем механизм \protect в LATEX 2ε. Существуют очень редкие случаи, когда может быть полезно создать функции с использованием захватчика, который работает только на расширении. Это накладывает ряд ограничений на природу аргументов, принимаемых функцией, и на код, который она реализует. Эта возможность должна использоваться только в случае необходимости.
Команды для создания полностью расширяемых команд
\NewExpandableDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\RenewExpandableDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\ProvideExpandableDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\DeclareExpandableDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
Эта группа команд используется для создания команды документа уровня ⟨cmd⟩, которая будет захватывать свои аргументы в полностью расширяемом режиме. Спецификация аргументов для функции задается с помощью ⟨arg spec⟩, а ⟨cmd⟩ будет выполнять ⟨code⟩. В общем, ⟨code⟩ также будет полностью расширяемым, хотя возможно, что это не так (например, функция для использования в таблице может расширяться так, что \omit будет первым нерасширяемым не-пробельным токеном).
Ограничения при парсинге аргументов
Парсинг аргументов с помощью чистого расширения накладывает ряд ограничений как на типы аргументов, которые могут быть прочитаны, так и на доступную проверку ошибок:
- Последний аргумент (если таковой имеется) должен быть одним из обязательных типов
m,rилиR. - Аргумент типа «вербатим»
vнедоступен. - Процессоры аргументов (с использованием
>) недоступны. - Невозможно различить, например,
\foo[и\foo{[}: в обоих случаях[будет интерпретироваться как начало необязательного аргумента. В результате проверка на необязательные аргументы менее надежна, чем в стандартной версии.
2.13 Команды в начале ячеек таблицы
Создание команд, которые используются в начале ячеек таблицы, накладывает некоторые ограничения на основную реализацию. Стандартные окружения LATEX для таблиц (такие как tabular и т.д.) используют механизм, который требует, чтобы любая команда, оборачивающая \multicolumn или подобные команды, была «расширяемой». Это не относится к командам, созданным с помощью \NewDocumentCommand и т.д., которые, как описано в разделе 2.12, используют функцию движка, предотвращающую такое «расширение».
Поэтому, чтобы создать такие обертки для использования в начале ячеек таблицы, необходимо использовать \NewExpandableDocumentCommand. Например:
\NewExpandableDocumentCommand\MyMultiCol{m}{\multicolumn{3}{c}{#1}}
\begin{tabular}{lcr}
a & b & c \\
\MyMultiCol{stuff} \\
\end{tabular}
В этом примере команда \MyMultiCol позволяет использовать \multicolumn в ячейках таблицы, обеспечивая необходимую расширяемость.
2.14 Использование аргументов типа verbatim
Как описано выше, аргумент типа v можно рассматривать как аналог команды \verb. Прежде чем рассмотреть, что это именно означает, важно выделить некоторые ключевые различия. Прежде всего, захват аргумента, подобного verbatim, отделен от его наборки: последнее будет рассмотрено в следующем разделе.
При захвате аргумента типа v LATEX сначала использует команду ядра \dospecials, чтобы отключить «специальный» характер символов. Затем он делает как пробелы, так и табуляции «активными», чтобы им можно было задать пользовательское определение. Все остальные символы захватываются как есть: это означает, что если какие-либо символы были сделаны «специальными» и не перечислены в \dospecials, возникнет ошибка (см. ниже).
Символы, которые захватываются как аргумент, — это все те, что находятся между двумя одинаковыми символами: в отличие от \verb, символы \,, {, } и % не могут использоваться в качестве разделителей. Если любой из захваченных токенов имеет «специальное» значение, будет выдана ошибка.
Для аргумента типа +v, который позволяет переносить строки внутри аргумента, символы новой строки преобразуются в команды \obeyedline. Стандартное определение \obeyedline — это простая команда \par, что позволяет захваченным токенам использоваться непосредственно в наборе. Локальное переопределение \obeyedline может быть использовано для достижения других результатов. Например, чтобы сохранить пустые строки при наборе, можно использовать:
\renewcommand*\obeyedline{\mbox{}\par}
Дополнительная информация о использовании этих аргументов в наборе представлена в следующем подразделе.
Некоторые дополнительные детали, которые могут быть полезны для тех, кто имеет больше знаний о TEX: не беспокойтесь, если это не имеет смысла для вас! Пробелы и табуляции хранятся как активные символы. В 8-битных движках не-ASCII символы являются «активными», в то время как все символы ASCII, кроме букв a–zA–Z, являются «другими». В Юникодных движках не-ASCII кодовые точки будут либо буквами, либо «другими», в зависимости от стандартных настроек LATEX, основанных на данных Юникода. Для сравнений на основе токенов, вероятно, активные пробелы и табуляции должны быть заменены: это можно удобно сделать с помощью расширения.
2.15 Набор материала, подобного verbatim
В отличие от \verb, аргумент типа (+)v касается только захвата аргумента, а не его набора. Таким образом, функции, которые пользователи часто ассоциируют с «verbatim», не активируются автоматически, например, выбор моноширинного шрифта. Материал, захваченный аргументом типа v, не подавляет автоматически лигатуры: с современными движками TEX это в значительной степени можно сделать без манипуляций с токенами, которые использует \verb. (В \verb лигатуры подавляются путем активации символов и вставки нулевой ширины керна перед самим символом.)
Команда \verb также выбирает моноширинный шрифт: это не является внутренним для verbatim-материала, поэтому его нужно настраивать, например, с помощью \ttfamily. Аналогично, окружение verbatim настраивает значение \par, подходящее для переноса строк.
2.16 Окружения verbatim
В некоторых случаях, когда вы захватываете тело окружения, вы захотите, чтобы содержимое обрабатывалось как verbatim. Это доступно с использованием спецификации аргумента c. Как и спецификация b, это должно быть последним. Таким образом, например:
\NewDocumentEnvironment{MyVerbatim}{!O{\ttfamily} c} {\begin{center} #1 #2\end{center}} {}
\begin{MyVerbatim}[\ttfamily\itshape]
% Some code is shown here
$y = mx + c$
\end{MyVerbatim}
будет выводить содержимое verbatim, таким образом:
␣␣%␣Some␣code␣is␣shown␣here
␣␣$y␣=␣mx␣+␣c$
Поскольку захват всего содержимого verbatim приведет к отсутствию токенов \par, новые строки всегда разрешены: здесь нет необходимости в модификаторе +. Как и в спецификации v, новые строки хранятся как \obeyedline. Аналогично спецификации b, по умолчанию новые строки обрезаются в начале и в конце тела. Добавление префикса ! перед c подавляет эту обрезку.
Сбор тела происходит построчно: содержимое собирается до конца строки в исходном коде, затем проверяется перед хранением. Это означает, что строка, завершающая окружение (содержащая в приведенном выше примере \end{MyVerbatim}), не может содержать текст после конца окружения. Текст перед концом окружения обрабатывается нормально, но обратите внимание, что если здесь есть текст, то не добавляется завершающий \obeyedline. Кроме необязательных аргументов, текст не допускается на открывающей строке окружения.
Специальная обработка применяется к аргументам с спецификацией o, O, d или D, которые идут сразу перед спецификацией c. Это означает, что когда необязательный аргумент отсутствует, первый символ следующей строки будет прочитан с правильно примененным кодом категории verbatim. Проблемы могут возникнуть, если несколько необязательных аргументов используются перед спецификацией c: это будет работать надежно только в тех случаях, когда необязательные токены являются «другими» символами.
По техническим причинам мы рекомендуем не игнорировать пробелы при поиске необязательного аргумента перед спецификацией c: это можно сделать, добавив модификатор !, как показано в примере. Однако это оставлено на усмотрение пользователя.
2.17 Производительность
Для команд документа, где спецификация аргументов полностью состоит из записей m или +m (или полностью пуста), внутренняя структура, создаваемая с помощью \NewDocumentCommand, по сути, так же эффективна, как и предоставляемая \newcommand(*). Таким образом, команды документа могут заменять конструкции, возникающие из \newcommand и т.д., без необходимости беспокоиться о производительности. Следует отметить, что \newcommand(*) производит расширяемые результаты, поэтому прямой заменой является \NewExpandableDocumentCommand; однако в большинстве случаев лучше использовать \NewDocumentCommand, чтобы обеспечить более надежные структуры.
2.18 Подробности о разделителях аргументов
В обычных (нерасширяемых) командах делимитированные типы ищут начальный разделитель, заглядывая вперед (с использованием функций \peek_... из expl3), ища токен-разделитель. Токен должен иметь то же значение и «форму», что и токен, определенный как разделитель. Существует три возможных случая разделителей: символы, управляющие последовательности и активные символы. Для всех практических целей этого описания активные символы будут вести себя точно так же, как управляющие последовательности.
2.18.1 Символьные токены
Символьный токен характеризуется своим кодом символа, а его значение — кодом категории (\catcode). Когда команда определяется, значение символьного токена фиксируется в определении команды и не может изменяться. Команда правильно увидит разделитель аргумента, если открывающий разделитель имеет те же коды символа и категории, что и в момент определения. Например:
\NewDocumentCommand { \foobar } { D<>{default} } {(#1)}
\foobar <hello> \par
\char_set_catcode_letter:N <
\foobar <hello>
вывод будет:
(hello)
(default)<hello>
так как открывающий разделитель < изменил свое значение между двумя вызовами \foobar, поэтому второй вызов не видит < как допустимый разделитель. Команды предполагают, что если был найден допустимый открывающий разделитель, то также будет соответствующий закрывающий разделитель. Если его нет (либо из-за пропуска, либо из-за изменения значения), возникает ошибка низкого уровня TEX, и вызов команды прерывается.
2.18.2 Токены управляющих последовательностей
Токен управляющей последовательности (или управляющего символа) характеризуется своим именем, а его значение — это его определение. Токен не может иметь два разных значения одновременно. Когда управляющая последовательность определяется как разделитель в команде, она будет обнаружена как разделитель всякий раз, когда имя управляющей последовательности встречается в документе, независимо от ее текущего определения. Например:
\cs_set:Npn \x { abc }
\NewDocumentCommand { \foobar } { D\x\y{default} } {(#1)}
\foobar \x hello\y \par
\cs_set:Npn \x { def }
\foobar \x hello\y
вывод будет:
(hello)
(hello)
при этом оба вызова команды видят разделитель \x.
2.19 Создание новых процессоров аргументов
\ProcessedArgument
Процессоры аргументов позволяют манипулировать захваченным аргументом перед его передачей в основной код. Новые реализации процессоров могут быть созданы в виде функций, которые принимают один завершающий аргумент и оставляют свой результат в переменной \ProcessedArgument.
Например, \ReverseBoolean определяется следующим образом:
\ExplSyntaxOn
\cs_new_protected:Npn \ReverseBoolean #1 {
\bool_if:NTF #1 {
\tl_set:Nn \ProcessedArgument { \c_false_bool }
} {
\tl_set:Nn \ProcessedArgument { \c_true_bool }
}
}
\ExplSyntaxOff
Примечание: Код написан на языке expl3, поэтому нам не нужно беспокоиться о том, что пробелы могут попасть в определение.
3 Копирование и отображение (робустных) команд и окружений
Если вы хотите (слегка) изменить существующую команду, вам может понадобиться сохранить текущее определение под новым именем, а затем использовать его в новом определении. Если существующая команда является робустной, то старый трюк с использованием низкоуровневой команды \let не сработает, потому что он копирует только верхнее определение, но не ту часть, которая фактически выполняет работу. Поскольку большинство команд LATEX в настоящее время являются робустными, LATEX предлагает некоторые высокоуровневые объявления для этого.
Однако, пожалуйста, обратите внимание, что обычно лучше использовать доступные хуки (например, хуки для общих команд или окружений), вместо того чтобы копировать текущее определение и тем самым замораживать его; смотрите документацию по управлению хуками lthooks-doc.pdf для получения подробной информации.
\NewCommandCopy {⟨cmd⟩} {⟨existing-cmd⟩}
\RenewCommandCopy {⟨cmd⟩} {⟨existing-cmd⟩}
\DeclareCommandCopy {⟨cmd⟩} {⟨existing-cmd⟩}
Эти команды копируют определение ⟨existing-cmd⟩ в ⟨cmd⟩. После этого ⟨existing-cmd⟩ может быть переопределен, и ⟨cmd⟩ все еще будет работать! Это позволяет вам предоставить новое определение для ⟨existing-cmd⟩, которое использует ⟨cmd⟩ (т.е. его старое определение). Например, после
\NewCommandCopy\LaTeXorig\LaTeX
\RenewDocumentCommand\LaTeX{}{\textcolor{blue}{\LaTeXorig}}
все логотипы LATEX, сгенерированные с помощью \LaTeX, будут отображаться синим цветом (при условии, что у вас загружен пакет цвета).
Различия между \New... и \Renew... такие же, как и в других случаях: вы получите ошибку в зависимости от того, существует ли уже ⟨cmd⟩, или в случае \Declare... оно будет скопировано независимо от этого. Обратите внимание, что нет объявления \Provide..., потому что это было бы ограниченной ценностью.
Если ⟨cmd⟩ или ⟨existing-cmd⟩ не могут быть предоставлены как единый токен, а требуют “конструирования”, вы можете использовать \ExpandArgs, как объясняется в разделе 4.
\ShowCommand {⟨cmd⟩}
Эта команда отображает значение ⟨cmd⟩ в терминале и затем останавливается (так же, как и примитивная \show). Разница в том, что она правильно показывает значение более сложных команд, например, в случае робустных команд она отображает не только верхнее определение, но и фактический код нагрузки, а в случае команд, объявленных с помощью \NewDocumentCommand и т.д., она также предоставляет подробную информацию о сигнатуре аргументов.
\NewEnvironmentCopy {⟨env⟩} {⟨existing-env⟩}
\RenewEnvironmentCopy {⟨env⟩} {⟨existing-env⟩}
\DeclareEnvironmentCopy {⟨env⟩} {⟨existing-env⟩}
Эти команды копируют определение окружения ⟨existing-env⟩ в ⟨env⟩ (как начальный, так и конечный код), т.е. это просто применение \NewCommandCopy дважды к внутренним командам, которые определяют окружение, т.е. \⟨env⟩ и \end⟨env⟩. Различия между \New..., \Renew... и \Declare... являются обычными.
\ShowEnvironment {⟨env⟩}
Эта команда отображает значение начального и конечного кода для окружения ⟨env⟩.
4 Предварительное построение имен команд (или иное расширение аргументов)
При объявлении новых команд с помощью \NewDocumentCommand, \NewCommandCopy или аналогичных команд иногда необходимо “построить” имя команды. В качестве общего механизма L3 программный уровень предлагает \exp_args:N... для этой цели, но нет механизма для этого, если \ExplSyntaxOn не активен (и смешивание команд программного и пользовательского уровней не является хорошим подходом). Поэтому мы предлагаем механизм для доступа к этой возможности с использованием именования в стиле CamelCase.
\UseName {⟨string⟩}
\ExpandArgs {⟨spec⟩} {⟨cmd⟩} {⟨arg1⟩} . . .
\UseName преобразует ⟨string⟩ непосредственно в имя команды и затем выполняет его: это эквивалентно давно существующей внутренней команде LATEX 2ε \@nameuse или эквиваленту L3 программирования \use:c. \ExpandArgs принимает ⟨spec⟩, который описывает, как расширять ⟨arguments⟩, выполняет эти операции, а затем выполняет ⟨cmd⟩. ⟨spec⟩ использует описания, предлагаемые L3 программным уровнем, и соответствующая функция \exp_args:N... должна существовать. Общие случаи будут иметь ⟨spec⟩ в виде c, cc или Nc: см. ниже.
В качестве примера, следующее объявление предоставляет метод для генерации команд редактирования:
\NewDocumentCommand\newcopyedit{mO{red}} {
\newcounter{todo#1}%
\ExpandArgs{c}\NewDocumentCommand{#1}{s m} {
\stepcounter{todo#1}%
\IfBooleanTF {##1} {
\todo[color=#2!10]{\UseName{thetodo#1}: ##2}%
} {
\todo[inline,color=#2!10]{\UseName{thetodo#1}: ##2}%
}%
}%
}
С учетом этого объявления вы можете написать \newcopyedit{note}[blue], что определит команду \note и соответствующий счетчик для вас.
Второй пример — это копирование команды по строковому имени с использованием \NewCommandCopy: здесь нам может понадобиться построить оба имени команд.
\NewDocumentCommand\savebyname{m} {
\ExpandArgs{cc}\NewCommandCopy{saved#1}{#1}
}
В ⟨spec⟩ каждая c обозначает один аргумент, который преобразуется в команду. n представляет собой “нормальный” аргумент, который не изменяется, а N обозначает “нормальный” аргумент, который также остается неизменным, но состоит только из одного токена (и обычно не заключен в фигурные скобки). Таким образом, чтобы построить команду из строки только для второго аргумента \NewCommandCopy, вы бы написали:
\ExpandArgs{Nc}\NewCommandCopy\mysectionctr{c@section}
Существует несколько других одиночных букв, поддерживаемых в L3 программном уровне, которые могут быть использованы в ⟨spec⟩ для манипуляции аргументами другими способами. Если вас это интересует, ознакомьтесь с разделом “Расширение аргументов” в документации L3 программного уровня в файле interface3.pdf.
5 Расширяемые вычисления с плавающей точкой (и другие)
Программный уровень LATEX3, который является частью формата, предлагает богатый интерфейс для манипуляции переменными и значениями с плавающей точкой. Чтобы позволить (более простым) приложениям использовать это на уровне документа или в пакетах, которые иначе не используют L3 программный уровень, предоставляется несколько интерфейсных команд.
\fpeval {⟨floating point expression⟩}
Расширяемая команда \fpeval принимает в качестве аргумента выражение с плавающей точкой и производит результат, используя обычные правила математики. Поскольку эта команда является расширяемой, ее можно использовать там, где TEX требует числа, например, в низкоуровневой операции \edef, чтобы получить чисто числовой результат.
Кратко, выражения с плавающей точкой могут включать:
- Основные арифметические операции: сложение
x + y, вычитаниеx - y, умножениеx * y, делениеx / y, квадратный кореньsqrt xи скобки. - Операторы сравнения:
x < y,x <= y,x > y,x != yи т.д. Отношениеx ? yистинно, если один или оба операнда являются NaN или являются кортежем, если только они не равны кортежам. Каждое ⟨отношение⟩ может быть любой (непустой) комбинацией<,=,>, и?, плюс необязательный ведущий!(который отрицает ⟨отношение⟩), с ограничением, что отрицательное ⟨отношение⟩ не может начинаться с?. - Булева логика: знак
sign x, отрицание! x, конъюнкцияx && y, дизъюнкцияx || y, тернарный операторx ? y : z. - Экспоненты:
exp x,ln x,xˆy. - Целочисленный факториал:
fact x. - Тригонометрия:
sin x,cos x,tan x,cot x,sec x,csc x, ожидая, что их аргументы будут в радианах, иsind x,cosd x,tand x,cotd x,secd x,cscd x, ожидая, что их аргументы будут в градусах. - Обратные тригонометрические функции:
asin x,acos x,atan x,acot x,asec x,acsc x, дающие результат в радианах, иasind x,acosd x,atand x,acotd x,asecd x,acscd x, дающие результат в градусах. - Экстремумы:
max(x1, x2, ...),min(x1, x2, ...),abs(x). - Функции округления, управляемые двумя необязательными значениями,
n(количество знаков, по умолчанию 0) иt(поведение при равенстве, по умолчанию NaN):trunc(x, n)округляет к нулю,floor(x, n)округляет к −∞,ceil(x, n)округляет к +∞,round(x, n, t)округляет к ближайшему значению, при равенстве округляя к четному значению по умолчанию, к нулю, еслиt = 0, к +∞, еслиt > 0, и к −∞, еслиt < 0.
- Случайные числа:
rand(),randint(m, n). - Константы:
pi,deg(один градус в радианах). - Размерности, автоматически выраженные в пунктах, например,
pcравен 12. - Автоматическое преобразование (нет необходимости в
\number) целочисленных, размерных и пропускных переменных в числа с плавающей точкой, выражая размерности в пунктах и игнорируя компоненты растяжения и сжатия пропусков. - Кортежи:
(x1, ..., xn), которые могут быть сложены, умножены или разделены на число с плавающей точкой, а также могут быть вложенными. Пример использования может быть следующим:
\LaTeX{} может теперь вычислить: $ \frac{\sin (3.5)}{2} + 2\cdot 10^{-3} = \fpeval{sin(3.5)/2 + 2e-3} $.
Это приводит к следующему результату:
LATEX может теперь вычислить: sin(3.5) / 2 + 2 · 10−3 = −0.1733916138448099.
\inteval {⟨integer expression⟩}
Расширяемая команда \inteval принимает в качестве аргумента целочисленное выражение и производит результат, используя обычные правила математики с некоторыми ограничениями, см. ниже. Признаваемые операции: +, -, * и /, а также скобки. Поскольку эта команда является расширяемой, ее можно использовать там, где TEX требует числа, например, в низкоуровневой операции \edef, чтобы получить чисто числовой результат.
Это, по сути, тонкая оболочка для примитивной команды \numexpr, и поэтому имеет некоторые синтаксические ограничения. Эти ограничения следующие:
/обозначает деление, округленное до ближайшего целого числа, при этом при равенстве округление происходит от нуля;- возникает ошибка, и общее выражение оценивается в ноль, когда абсолютное значение любого промежуточного результата превышает (2^{31} - 1), за исключением случаев операций масштабирования (ab/c), для которых (ab) может быть произвольно большим;
- скобки не могут появляться после унарных
+или-, а именно, размещение+(или-(в начале выражения или после+,-,*,/или(приводит к ошибке.
Пример использования может быть следующим:
\LaTeX{} может теперь вычислить: Сумма чисел равна $\inteval{1 + 2 + 3}$.
Это приводит к результату:
LATEX может теперь вычислить: Сумма чисел равна 6.
\dimeval {⟨dimen expression⟩}
\skipeval {⟨skip expression⟩}
Эти команды аналогичны \inteval, но вычисляют длину (dimen) или значение резинки (skip). Обе команды являются тонкими оболочками вокруг соответствующих примитивов движка, что делает их быстрыми, но, следовательно, они имеют те же синтаксические особенности, как обсуждалось выше. Тем не менее, на практике они обычно достаточно эффективны. Например:
\NewDocumentCommand\calculateheight{m}{%
\setlength\textheight{\dimeval{\topskip+\baselineskip*\inteval{#1-1}}}
}
Эта команда устанавливает \textheight на соответствующее значение, если страница должна содержать определенное количество строк текста. Таким образом, после вызова \calculateheight{40} значение будет установлено на 478.0pt, учитывая значения \topskip (10.0pt) и \baselineskip (12.0pt) в текущем документе.
6 Расширяемый эквивалент \input
\expandableinput {⟨filename⟩}
Определение \input в LATEX не может быть использовано в местах, где TEX выполняет расширение: классический пример — в начале ячейки таблицы. Существует несколько причин для этого: ключевыми являются то, что \input фиксирует, какие файлы были прочитаны, и предоставляет хуки до и после чтения файла.
Чтобы поддержать необходимость выполнения ввода файла в контекстах расширения, доступна команда \expandableinput: она пропускает запись имени файла и не применяет никакие хуки для файлов, но в остальном ведет себя как \input. В частности, она по-прежнему использует \input@path при выполнении поиска файла.
7 Изменение регистра
\MakeUppercase [⟨keyvals⟩] {⟨text⟩}
\MakeLowercase [⟨keyvals⟩] {⟨text⟩}
\MakeTitlecase [⟨keyvals⟩] {⟨text⟩}
TEX предоставляет две примитивные команды \uppercase и \lowercase для изменения регистра текста. Однако у них есть ряд ограничений: они изменяют регистр только явных символов, не учитывают окружающий контекст, не поддерживают ввод UTF-8 с 8-битными движками и т.д. Чтобы преодолеть эту проблему, LATEX предоставляет команды \MakeUppercase, \MakeLowercase и \MakeTitlecase: они предлагают значительное улучшение по сравнению с примитивами TEX. Эти команды являются робустными (\protected) и могут использоваться в движущихся аргументах.
Изменение регистра в общем смысле хорошо понимается в разговорной речи. Заглавный регистр здесь следует определению, данному Консорциумом Unicode: первый символ входных данных будет преобразован в (широком смысле) заглавный регистр, а остальные символы — в строчный. Полный диапазон ввода Unicode UTF-8 может быть поддержан.
\MakeUppercase{hello WORLD ßüé} % HELLO WORLD SSÜÉ
\MakeLowercase{hello WORLD ßüé} % hello world ßüé
\MakeTitlecase{hello WORLD ßüé} % Hello WORLD ßüé
Команды изменения регистра принимают необязательный аргумент, который можно использовать для настройки вывода. Этот необязательный аргумент принимает ключ locale, также доступный под псевдонимом lang, который можно использовать для указания идентификатора языка в формате BCP-47. Это затем применяется для выбора языковых особенностей при изменении регистра.
Для заглавного регистра также могут использоваться ключевые слова: это выбор между first или all. Стандартная настройка — first, что означает, что только самый первый “буквенный” символ будет (широком смысле) преобразован в заглавный регистр. Альтернатива, all, означает, что входные данные делятся по каждому пробелу, и для каждого полученного слова первый символ будет преобразован в заглавный регистр. Например:
\MakeTitlecase[words=first]{some words} % Some words
\MakeTitlecase[words=all]{some words} % Some Words
Входные данные, переданные этим командам, “расширяются” перед применением изменения регистра. Это означает, что любые команды внутри входных данных, которые преобразуются в чистый текст, будут изменены по регистру. Математическое содержимое автоматически исключается, как и аргументы команд \label, \ref, \cite, \begin и \end. Дополнительные исключения могут быть добавлены с помощью команды \AddToNoCaseChangeList. Входные данные могут быть исключены из изменения регистра с помощью команды \NoCaseChange.
\MakeUppercase{Some text $y = mx + c$} % SOME TEXT y = mx + c
\MakeUppercase{\NoCaseChange{iPhone}} % iPhone
Чтобы позволить использовать робустные команды внутри изменения регистра и получить ожидаемый вывод, доступны две дополнительные управляющие команды. \CaseSwitch позволяет пользователю указать результат для четырех возможных случаев:
- Без изменения регистра
- Преобразование в заглавный регистр
- Преобразование в строчный регистр
- Заглавный регистр (применяется только к началу входных данных)
Команда \DeclareCaseChangeEquivalent предоставляет способ заменить команду альтернативной версией, когда она встречается внутри ситуации изменения регистра. Существуют три команды для настройки изменения регистра кодовых точек:
\DeclareLowercaseMapping [⟨locale⟩] {⟨codepoint⟩} {⟨output⟩}
\DeclareTitlecaseMapping [⟨locale⟩] {⟨codepoint⟩} {⟨output⟩}
\DeclareUppercaseMapping [⟨locale⟩] {⟨codepoint⟩} {⟨output⟩}
Все три принимают ⟨codepoint⟩ (в виде целочисленного выражения) и приводят к тому, что
8 Поддержка решения проблем
\listfiles [⟨options⟩]
Если эта команда помещена в преамбулу, то в конце выполнения документа на терминале (и в лог-файле) будет отображен список прочитанных файлов (в результате обработки документа). При возможности также будет предоставлено краткое описание. Эти описания, надеемся, будут включать описания, даты и номера версий для файлов пакетов и классов.
Иногда может случиться так, что в файл пакета или класса (или, скорее, в его копию) были внесены локальные изменения. Чтобы позволить идентифицировать такие случаи, \listfiles принимает необязательный аргумент, который позволяет настроить выводимую информацию с использованием подхода ключ-значение:
hashes— добавляет MD5-хеш для каждого файла в выводимую информацию.sizes— добавляет размер файла для каждого файла в выводимую информацию.
Обратите внимание, что так как Windows и Unix используют разные окончания строк (LF против LF CR), хеши и размеры файлов из двух систем не будут одинаковыми. Поэтому следует сравнивать эти значения между операционными системами одного типа.
Предупреждение: эта команда будет перечислять только файлы, которые были прочитаны с использованием команд LATEX, таких как \input{⟨file⟩} или \include{⟨file⟩}. Если файл был прочитан с использованием примитивного синтаксиса TEX \input file (без фигурных скобок вокруг имени файла), то он не будет перечислен; несоблюдение формата LATEX с фигурными скобками может вызвать более серьезные проблемы, возможно, приведя к перезаписи важных файлов, поэтому всегда используйте фигурные скобки.
7.3.1 - Памятка по командам Latex 3
Краткий справочник по командам LAtex 3 для создания собственных команд и окружения
Краткая таблица с основными типами аргументов и их описанием:
| Ключ | Краткое описание |
|------|----------------------------------------------------------------------------------|
| **m** | Обычный обязательный аргумент (один токен или `{...}`). |
| **r** | Обязательный аргумент с разделителями (формат: `r⟨t1⟩⟨t2⟩`). |
| **R** | Как `r`, но с значением по умолчанию (формат: `R⟨t1⟩⟨t2⟩{⟨default⟩}`). |
| **v** | Дословный аргумент (аналог `\verb` в LaTeX). |
| **b** | Тело окружения (только для `\begin{...}...\end{...}`). |
| **o** | Необязательный аргумент в `[...]`, возвращает `-NoValue-` если отсутствует. |
| **d** | Необязательный аргумент с разделителями (формат: `d⟨t1⟩⟨t2⟩`). |
| **O** | Как `o`, но с значением по умолчанию (формат: `O{⟨default⟩}`). |
| **D** | Как `d`, но с значением по умолчанию (формат: `D⟨t1⟩⟨t2⟩{⟨default⟩}`). |
| **s** | Необязательная звезда (`*`), возвращает `\BooleanTrue`/`\BooleanFalse`. |
| **t** | Необязательный токен (формат: `t⟨token⟩`), возвращает `\BooleanTrue`/`False`. |
| **e** | Необязательные "украшения" (формат: `e{⟨tokens⟩}`), возвращает `-NoValue-`. |
| **E** | Как `e`, но с значениями по умолчанию (формат: `E{⟨tokens⟩}{⟨defaults⟩}`). |
| **+** | Модификатор: делает аргумент "длинным" (параграфным). |
| **!** | Модификатор: управляет пробелами перед необязательными аргументами. |
| **=** | Модификатор: аргумент интерпретируется как ключ-значение (keyvals). |
| **>** | Модификатор: применяет "процессор аргументов" для преобразования ввода. |
Создание команд документа
\NewDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\RenewDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\ProvideDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
\DeclareDocumentCommand {⟨cmd⟩} {⟨arg spec⟩} {⟨code⟩}
Эта группа команд используется для создания команды ⟨cmd⟩. Спецификация аргумента для функции задается с помощью ⟨arg spec⟩, а команда использует ⟨code⟩, где #1, #2 и т. д. заменяются на аргументы, найденные парсером.
Пример:
\NewDocumentCommand\chapter{s o m} {
\IfBooleanTF{#1}
{\typesetstarchapter{#3}}
{\typesetnormalchapter{#2}{#3}}
}
Создание окружений документа
\NewDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
\RenewDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
\ProvideDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
\DeclareDocumentEnvironment {⟨env⟩} {⟨arg spec⟩} {⟨beg-code⟩} {⟨end-code⟩}
Эти команды работают так же, как \NewDocumentCommand и т. д., но создают окружения (\begin{⟨env⟩} … \end{⟨env⟩}). Как ⟨beg-code⟩, так и ⟨end-code⟩ могут получать доступ к аргументам, как определено в ⟨arg spec⟩. Аргументы будут переданы после \begin{⟨env⟩}. Все пробелы в начале и в конце {⟨env⟩} удаляются перед определением, таким образом:
Проверка специальных значений
\IfNoValueTF {⟨arg⟩} {⟨true code⟩} {⟨false code⟩}
\IfNoValueT {⟨arg⟩} {⟨true code⟩}
\IfNoValueF {⟨arg⟩} {⟨false code⟩}
Команды \IfNoValue(TF) используются для проверки, является ли ⟨argument⟩ (#1, #2 и т. д.) специальным маркером -NoValue-. Например:
\NewDocumentCommand\foo{o m} {
\IfNoValueTF {#1}
{\DoSomethingJustWithMandatoryArgument{#2}}
{\DoSomethingWithBothArguments{#1}{#2}}
}
\IfValueTF {⟨arg⟩} {⟨true code⟩} {⟨false code⟩}
\IfValueT {⟨arg⟩} {⟨true code⟩}
\IfValueF {⟨arg⟩} {⟨false code⟩}
Обратная форма тестов \IfNoValue(TF) также доступна как \IfValue(TF). Контекст определит, какая логическая форма имеет наибольший смысл для данного сценария кода.
\IfBlankTF {⟨arg⟩} {⟨true code⟩} {⟨false code⟩}
\IfBlankT {⟨arg⟩} {⟨true code⟩}
\IfBlankF {⟨arg⟩} {⟨false code⟩}
Таблица описывающая команды проверки специальных значений:
| Команда | Краткое описание |
|-----------------------------|----------------------------------------------------------------------------------|
| `\BooleanFalse` | Логическое значение "ложь" (используется с аргументами `s`/`t`). |
| `\BooleanTrue` | Логическое значение "истина" (используется с аргументами `s`/`t`). |
| `\IfBooleanTF{arg}{true}{false}` | Проверяет, является ли `arg` булевым значением (`\BooleanTrue`/`\BooleanFalse`). |
| `\IfBooleanT{arg}{true}` | Выполняет `true` код, если `arg` равно `\BooleanTrue`. |
| `\IfBooleanF{arg}{false}` | Выполняет `false` код, если `arg` равно `\BooleanFalse`. |
| `\IfNoValueTF{arg}{true}{false}` | Проверяет, равен ли `arg` маркеру `-NoValue-`. |
| `\IfNoValueT{arg}{true}` | Выполняет `true` код, если `arg` равен `-NoValue-`. |
| `\IfNoValueF{arg}{false}` | Выполняет `false` код, если `arg` **не** равен `-NoValue-`. |
| `\IfValueTF{arg}{true}{false}` | Обратная логика: `true` если `arg` **имеет** значение. |
| `\IfValueT{arg}{true}` | Выполняет `true` код, если `arg` **имеет** значение. |
| `\IfValueF{arg}{false}` | Выполняет `false` код, если `arg` **не имеет** значения. |
| `\IfBlankTF{arg}{true}{false}` | Проверяет, является ли `arg` пустым или содержит только пробелы. |
| `\IfBlankT{arg}{true}` | Выполняет `true` код, если `arg` пустой/пробельный. |
| `\IfBlankF{arg}{false}` | Выполняет `false` код, если `arg` **не** пустой. |
Пример использования:
\NewDocumentCommand\foo{o m}{
\IfNoValueTF{#1}
{Команда без опции: #2}
{Команда с опцией [#1] и аргументом #2}
}
Таблица с описанием процессоров аргументов и примерами их использования:
| Процессор | Описание | Пример использования |
|--------------------------------|--------------------------------------------------------------------------|--------------------------------------------------------------------------------------|
| **`\SplitArgument{n}{sep}`** | Разделяет аргумент по `sep` на `n+1` частей, оборачивая в `{}`. | `\NewDocumentCommand\foo{>{\SplitArgument{2}{;}}m}{#1}` → `\foo{a;b;c}` → `{a}{b}{c}` |
| **`\SplitList{sep}`** | Разделяет аргумент по `sep` на неограниченное число частей. | `\NewDocumentCommand\foo{>{\SplitList{,}}m}{\ProcessList{#1}{\textbf}}` → `\foo{a,b}` → **a** **b** |
| **`\ProcessList{list}{cmd}`** | Применяет `cmd` к каждому элементу `list` (используется с `\SplitList`). | `\ProcessList{{a}{b}}{\textbf}` → **a****b** |
| **`\ReverseBoolean`** | Инвертирует булевы значения (`\BooleanTrue` ↔ `\BooleanFalse`). | `\NewDocumentCommand\foo{>{\ReverseBoolean}s}{Star: \IfBooleanT{#1}{YES}}` → `\foo*` выведет "Star: NO" |
| **`\TrimSpaces`** | Удаляет пробелы в начале/конце аргумента. | `\NewDocumentCommand\foo{>{\TrimSpaces}m}{[#1]}` → `\foo{ text }` → `[text]` |
| **Комбинация процессоров** | Процессоры применяются справа налево. | `>{\TrimSpaces} >{\SplitList{,}} m` → сначала разделит запятыми, затем обрежет пробелы. |
Примеры использования
Разделение аргументов с обработкой:
\NewDocumentCommand\formatlist{>{\SplitList{,}}m}{ \ProcessList{#1}{\textbf} } \formatlist{a, b, c} % → **a** **b** **c**Обработка ключевых значений:
\NewDocumentCommand\setoptions{>{\TrimSpaces}m}{ \keys_set:nn {my-module} {#1} } \setoptions{ key1 = value1 , key2 = value2 }Инверсия логики звездочки:
\NewDocumentCommand\checkstar{>{\ReverseBoolean}s}{ \IfBooleanT{#1}{Звезды НЕТ} \IfBooleanF{#1}{Звезда ЕСТЬ} } \checkstar* % Выведет "Звезда ЕСТЬ"Многоэтапная обработка:
\NewDocumentCommand\process{>{\TrimSpaces} >{\SplitList{;}} m}{ \ProcessList{#1}{\SomeCommand} } \process{ a; b; c } % → обработает как `{a}{b}{c}`
7.4 - Пакеты для работы с таблицами в LaTeX
Команды и примеры построения таблиц
Пакет longtable
Назначение
Пакет longtable позволяет создавать таблицы, которые могут разбиваться на несколько страниц. Это особенно полезно для длинных таблиц, которые не помещаются на одной странице.
Основные возможности
- Автоматический разрыв таблицы на страницы
- Повторение заголовков на каждой странице
- Настройка оформления разрывов
Пример использования
\usepackage{longtable}
% Настройка отступов в таблицах
\renewcommand{\tabcolsep}{0.05cm} % Горизонтальный отступ между колонками
\renewcommand{\arraystretch}{1.7} % Вертикальное растяжение строк
\begin{center}
% Настройка цветов таблицы
\rowcolors{2}{gray!10}{white} % Чередование цветов строк (начиная со 2-й)
\arrayrulecolor{gray!20} % Цвет линий таблицы
% Начало длинной таблицы (может переноситься на несколько страниц)
% Формат колонок: B{2} - жирная шириной 2cm, L{8} и L{5} - обычные шириной 8cm и 5cm
\begin{longtable}{B{2}|L{8}|L{5}}
%%% ЗАГОЛОВОК НА ПЕРВОЙ СТРАНИЦЕ %%%
\caption[Технические характеристики]{Основные характеристики \label{tab:tech-character}}\\
\rowcolor{black!90} % Цвет фона заголовка
% Названия колонок (белый текст на темном фоне)
\multicolumn{1}{c}{\color{white}{№}} &
\multicolumn{1}{c}{\color{white}{Характеристика}} &
\multicolumn{1}{c}{\color{white}{Значение}} \\
\endfirsthead % Конец заголовка для первой страницы
%%% ЗАГОЛОВОК НА СЛЕДУЮЩИХ СТРАНИЦАХ %%%
\caption[]{Продолжение таблицы}\\
\rowcolor{black!90}
\multicolumn{1}{c}{№} &
\multicolumn{1}{c}{Характеристика} &
\multicolumn{1}{c}{Значение} \\
\endhead % Конец заголовка для последующих страниц
%%% ТЕЛО ТАБЛИЦЫ %%%
1 & Вес: & 80кг \\
2 & Габаритные размеры: & 730мм * 530мм * 850мм \\
3 & Напряжение управляющего питания (низковольтное): & 9-30 Вольт \\
\end{longtable}
\end{center}
Пояснение ключевых команд:
Настройка внешнего вида таблицы:
\tabcolsep- расстояние между колонками\arraystretch- коэффициент растяжения строк по вертикали\rowcolors- чередование цветов строк\arrayrulecolor- цвет линий таблицы
Структура таблицы:
\begin{longtable}{формат_колонок}- начало длинной таблицы- Формат колонок:
B{2}|L{8}|L{5}- три колонки с заданной шириной и выравниванием
Заголовки:
\caption- название таблицы (в квадратных скобках - для списка таблиц)\endfirsthead- заголовок только для первой страницы\endhead- заголовок для последующих страниц
Форматирование содержимого:
\rowcolor- цвет фона строки\multicolumn- объединение ячеек по горизонтали\color- цвет текста
Специальные символы:
\diameter- символ диаметра (из пакета wasysym)
Этот пример создает профессионально оформленную таблицу с:
- автоматическим переносом на несколько страниц
- повторяющимися заголовками
- чередованием цветов строк
- настраиваемыми отступами и выравниванием
Пользовательские типы колонок
\newcolumntype{C}[1]{>{\columncolor{white}\ttfamily\centering\arraybackslash}p{#1cm}}
\newcolumntype{R}[1]{>{\columncolor{white}\ttfamily\raggedleft\arraybackslash}p{#1cm}}
\newcolumntype{L}[1]{>{\columncolor{white}\ttfamily\raggedright\arraybackslash}p{#1cm}}
\newcolumntype{B}[1]{>{\columncolor{white}\ttfamily\bfseries\raggedright\arraybackslash}p{#1cm}}
Эти определения создают новые типы колонок:
C- центрированное содержимоеR- выравнивание по правому краюL- выравнивание по левому краюB- полужирное содержимое с выравниванием по левому краю
Пакет tabbing
Назначение
Среда tabbing предоставляет простой способ создания таблиц с выравниванием по табуляции. Полезен для простых таблиц без рамок.
Пример использования
\begin{tabbing}
Первая колонка \= Вторая колонка \= Третья колонка \kill
Заголовок 1 \> Заголовок 2 \> Заголовок 3 \\
Данные 1 \> Данные 2 \> Данные 3 \\
Выровнено \> по \> табуляторам \\
\end{tabbing}
Основные команды
\=- установка табулятора\>- переход к следующему табулятору\kill- строка используется для установки табуляторов, но не печатается
Пакет array
Назначение
Пакет array расширяет возможности работы с таблицами, предоставляя дополнительные функции для форматирования колонок и строк.
Основные возможности
- Дополнительные спецификаторы колонок
- Улучшенное выравнивание
- Возможность вставки команд перед/после элементов
Примеры использования
- Математическое выравнивание:
\begin{tabular}{>{$}l<{$} >{\centering\arraybackslash}m{2cm}}
\alpha & Буква альфа \\
\beta & Буква бета \\
\end{tabular}
- Условное форматирование:
\begin{tabular}{|>{\ifnum\value{rownum}=1 \bfseries\fi}l|l|}
\hline
Строка 1 & Данные 1 \\
Строка 2 & Данные 2 \\
\hline
\end{tabular}
- Использование пользовательских колонок:
\newcolumntype{M}[1]{>{\centering\arraybackslash}m{#1}}
\begin{tabular}{|M{2cm}|M{3cm}|}
Центрированная & колонка \\
ячейка & с заданной шириной \\
\end{tabular}
Полезные команды
\extrarowheight- добавление дополнительного пространства в строках\newcolumntype- определение новых типов колонок\multicolumn- объединение колонок (также доступно без array)
Эти пакеты предоставляют мощные инструменты для создания профессионально оформленных таблиц в LaTeX, от простых до самых сложных.
7.5 - Описание пакетов fancyhdr и fancybox
подробное описание пакетов
fancyhdr и fancybox, включая ваши настройки и дополнительные примеры.Пакеты fancyhdr и fancybox
Назначение: Оформление колонтитулов (fancyhdr) и декоративных рамок (fancybox).
1. fancyhdr
Основные возможности
- Настройка верхних (
head) и нижних (foot) колонтитулов. - Разные стили для чётных/нечётных страниц (
twoside). - Автоматическая подстановка номеров страниц, названий разделов.
Команды и параметры
Инициализация
\usepackage[twoside,headings]{fancyhdr} % twoside — разные колонтитулы для чётных/нечётных страниц
\pagestyle{fancy} % Активирует стиль fancy
\fancyhf{} % Очистка текущих настроек
Настройка колонтитулов
\fancyhead[позиция]{содержимое}– верхний колонтитул.\fancyfoot[позиция]{содержимое}– нижний колонтитул.
Позиции:
L– слева,C– центр,R– справа.E– чётная страница,O– нечётная.- Комбинации:
LE,RO,CEи т.д.
Пример:
\fancyhead[LE,RO]{\leftmark} % Название раздела (для чётных и нечётных)
\fancyfoot[C]{\thepage} % Номер страницы по центру
Ваш пример с tikz для фона
\AddEverypageHook{
\begin{tikzpicture}[remember picture,overlay]
\fill[black!90] (current page.north west) rectangle ($(current page.north east)+(0,-22mm)$);
\fill[black!90] (current page.south west) rectangle ($(current page.south east)+(0,15mm)$);
\end{tikzpicture}
}
\fancyhead[LE,RO]{\raisebox{1.2em}{\color{white}{\Large\leftmark}}}
\fancyfoot[LE,RO]{\color{white}{\textbf{\thepage}}}
Удаление разделительных линий
\renewcommand{\headrulewidth}{0pt} % Убирает линию под верхним колонтитулом
\renewcommand{\footrulewidth}{0pt} % Убирает линию над нижним колонтитулом
2. fancybox
Назначение: Создание декоративных рамок вокруг текста.
Основные команды
\shadowbox{текст}– рамка с тенью.\doublebox{текст}– двойная рамка.\ovalbox{текст}– овальная рамка.
Пример:
\usepackage{fancybox}
...
\shadowbox{\parbox{10cm}{Это текст в рамке с тенью.}}
\doublebox{\parbox{10cm}{Это текст в двойной рамке.}}
Кастомизация
\setlength{\shadowrule}{1pt} % Толщина тени
\setlength{\shadowsize}{4pt} % Размер тени
Примеры использования
1. Разные колонтитулы для глав и страниц
\fancyhead[LE]{\color{white}Глава \thechapter}
\fancyhead[RO]{\color{white}\nouppercase{\rightmark}}
\fancyfoot[CO,CE]{\color{white}\thepage}
2. Логотип и номер страницы
\fancyhead[L]{\includegraphics[width=2cm]{logo}}
\fancyfoot[R]{\thepage}
3. Рамки для выделения текста
\ovalbox{
\begin{minipage}{0.9\linewidth}
Важное замечание: этот текст выделен овальной рамкой.
\end{minipage}
}
Заключение
fancyhdrидеален для сложных колонтитулов с графикой и динамическим содержимым.fancyboxполезен для визуального выделения блоков текста.
7.6 - TEX издательская система
Старая как мир компьютерная система для верстки и оформления документов.
Я от части пожалел, что сначала изучил Latex, а потом взялся за TeX.
Обзор пакета TeX для программирования электронных документов.
Установка TeX
https://tug.org/texlive/doc/texlive-ru/texlive-ru.html
Установите Tex Live для полного удовлетворения своих запросов в издательской системе TeX и LaTeX.
На этой странице полная инструкция по установке https://tug.org/texlive/acquire-netinstall.html
или набрать в командной строке:
sudo pacman -S texlive
#manjaro
или
pkg install texlive
#freebsd
7.6.1 - TEX команды
Самые полезные для меня команды TEX
Минисправочник по TEX для практической работы в сегодняшней реальности
Символы
Специальные символы
- \# pound sign #
- \$ dollar sign $
- \% percent sign %
- \& ampersand &
- \_ underscore _
- \lq left quote ‘
- \rq right quote ’
- \lbrack left bracket [
- \rbrack right bracket ]
- \dag dagger symbol †
- \ddag double dagger symbol ‡
- \copyright copyright symbol c©
- \P paragraph symbol ¶
- \S section symbol §
Произвольные символы
{\char65} {\char `A} {\char `\A}
Акценты
| наименование | Tex input | Tex output | Compose |
|---|---|---|---|
| grave | \`o | ò | cmp+` o |
| acute | \’o | ó | cmp+’ o |
| circumflex | \^o | ô | cmp+^ o |
| umlaut/dieresis/tr ́emat | \“o | ö | cmp+” o |
| tilde | \~o | õ | cmp+~ o |
| macron | \=o | ő | cmp+= o |
| dot | \.o | ȯ | cmp+. o |
Продолжение для символов требующих пробела
| наименование | Tex input | Tex output | Compose |
|---|---|---|---|
| cedilla | \c o | ǫ | cmp+, o |
| underdot | \d o | ọ | cmp+! o |
| underbar | \b o | o᤻ | o C-x 8 RET 193b |
| h ́acˇek | \v o | ǒ | cmp+v o |
| breve | \u o | ŏ | cmp+u o |
| tie | \t oo | o͡o | o C-x 8 RET 0361 o |
| Hungarian umlaut | \H o | ő | cmp+= o |
| ơ | cmp++ o | ||
| ° | cmp+o o | ||
| § | cmp+s o | ||
| ø | cmp+? o |
или команда \accent94 или номер в таблице шрифта
Встроенные шрифты
| имя | описание |
|---|---|
| \fivebf | use 5-point bold font |
| \fivei | use 5-point math italic font |
| \fiverm | use 5-point roman font |
| \fivesy | use 5-point math symbol font |
| \sevenbf | use 7-point bold font |
| \seveni | use 7-point math italic font |
| \sevenrm | use 7-point roman font |
| \sevensy | use 7-point math symbol font |
| \tenbf | use 10-point bold text font |
| \tenex | use 10-point math extension font |
| \teni | use 10-point math italic font |
| \tenrm | use 10-point roman text font |
| \tensl | use 10-point slanted roman font |
| \tensy | use 10-point math symbol font |
| \tenit | use 10-point italic font |
| \tentt | use 10-point typewriter font |
\nullfont — отменить шрифты (пусто)
В Tex по умолчанию доступны 16 шрифтов
| Наименование | команда |
|---|---|
| Roman | \rm |
| Boldface | \bf |
| Italic | \it |
| Slanted | \sl |
| Typewriter | \tt |
| Math symbol5 | \cal |
Верхний и нижний регистр
\lccode 〈charcode〉 [ 〈number〉 table entry ]\uccode 〈charcode〉 [ 〈number〉 table entry ]
\char\uccode`s \char\lccode`a \char\lccode`M — выдаст Sam
Строка в верхний или нижний регистр
\lowercase { 〈token list〉 }
\uppercase { 〈token list〉 }
Пробелы
\— вставит пробел после команды~— неразрывный пробел\/— курсивный пробел\obeyspaces— не сжимает пробелы, а сохраняет их как есть- \spacefactor [ 〈number〉 parameter ] — 1000 норма, <1000 больше сжимается между словами, >1000 больше растягивается.
- \spaceskip [ 〈glue〉 parameter ] — применяет клей при SF < 2000
- \xspaceskip [ 〈glue〉 parameter ] — применяет клей для SF > 2000
- \sfcode 〈charcode〉 [ 〈number〉 table entry ] — устанавливает spacefactor для отдельного символа (для . он 3000)
Выравнивание строк
\centerline 〈argument〉\leftline 〈argument〉\rightline 〈argument〉\line{}— выровняет по левому и правому краю\llap{}— печатает влево от курсора\rlap{}— печатает вправо от курсора
\noindent
\llap{off left }
\line{\vrule $\Leftarrow$ left margin of examples\hfil right margin of examples $\Rightarrow$\vrule}
\rlap{ off right}
Параграф
\par— новый абзац\parskip=\parindent=\endgraf— синоним\par\parfillskip [ 〈glue〉 parameter ]— \parfillskip = 0pt plus 1fil по умолчанию, определяет последнюю строку в абзаце.\indent— Если TEX находится в вертикальном режиме, как это происходит после окончания абзаца, эта команда вставляет межабзацную связку \parskip, переводит TEX в горизонтальный режим, начинает абзац и делает отступ в этом абзаце на \parindent. Если TEX уже находится в горизонтальном режиме, эта команда просто создает пробел шириной \parindent. Два \indent подряд создают два отступа.\noindent— запрещает отступ в начале абзаца\textindent 〈argument〉— используется для печатания сносок и пунктов списков\everypar [ 〈token list〉 parameter ]— назначает команды для выполнения перед началом нового абзаца
\everypar = {$\Longrightarrow$\enspace}
Now pay attention!\par I said,
"Pay attention!".\par
I'll say it again! Pay attention!
на выходе получим:
⇒ Now pay attention!
⇒ I said, “Pay attention!”.
⇒ I’ll say it again! Pay attention!
\hsize— ширина печатной области
\leftline{\raggedright\vtop{\hsize = 2.5in Here is some text that we put into a paragraph that is an inch and a half wide.}\qquad \vtop{\hsize = 1.5in Here is some more text that we put into another paragraph that is an inch and a half wide.}}
шикарный пример как печатать в 2 колонки без мути в Latex
\narrower— сужает абзац слева и справа на\parindent\leftskip [ 〈glue〉 parameter ]— отступ слева\rightskip [ 〈glue〉 parameter ]— отступ справа\raggedright— убирает выравнивание справа\ttraggedright— тоже для мониширинного текста\hang— Эта команда устанавливает отступ во второй и последующих строках абзаца на \parindent, отступ абзаца\hangafter [ 〈number〉 parameter ]— определяет, какие строки имеют отступ: Если n < 0, первые −n строк абзаца будут иметь отступ. Если n ≥ 0, все строки абзаца, кроме первых n, будут иметь отступ.\hangindent [ 〈dimen〉 parameter ]— определяет величину отступа и то, находится ли он слева или справа: Если x ≥ 0, строки будут иметь отступ x слева. Если x < 0, строки будут иметь отступ -x справа.\prevgraf [ 〈number〉 parameter ]— количество строк в абзаце\vadjust { 〈vertical mode material〉 }— Эта команда вставляет указанный 〈материал вертикального режима〉 сразу после выходной строки, содержащей позицию, в которой встречается команда. Вы можете использовать его, например, чтобы вызвать выброс страницы или вставить дополнительное пространство после определенной строки.
Полезная штука для вставки указателей и линий:
Some of these words are \vadjust{\kern8pt\hrule} to be found above the line and others are to be found below it.
Выдаст линиюпод строкой:
Some of these words are to be found above the line and others are to be found
below it.
\parshape n i1l1 i2l2 . . . inln
Это магия TEX для абзацев
Эта команда определяет форму первых n строк абзаца, следующего абзаца, если вы находитесь в вертикальном режиме, и текущего абзаца, если вы находитесь в горизонтальном режиме. «i» — это отступ слева и справа, а «l» — это длина строки, n — это количество строк, на которые будет выполнено воздействие.
Line breaks
\break— просто прервет строку\nobreak\allowbreak— для математики полезен\penalty 〈number〉— штраф 10000 или -10000 управляет разрывом строк\obeylines— концу строки присваивает значение конец абзаца (полезно для стихов и программного кода)\slash— поставит /, но$\backslash$работает в математической моде\pretolerance [ 〈number〉 parameter ]— (по умолчанию 100)\tolerance [ 〈number〉 parameter ]— (200) это как штрафы \penalty определяют плохость для абзацев, чтобы их разрывать на странице.\emergencystretch [ 〈dimen〉 parameter ]— Если TEX не может набрать абзац, не превысив \tolerance, он попытается еще раз, добавив \emergencystretch к растягиванию каждой строки.\looseness [ 〈number〉 parameter ]— Этот параметр дает вам возможность изменить общее количество строк в абзаце по сравнению с оптимальным.\linepenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф, который TEX начисляет за каждый перенос строки при разбиении абзаца на строки.\adjdemerits [ 〈number〉 parameter ]— Этот параметр определяет дополнительные недостатки, которые TEX прикрепляет к точке останова между двумя соседними строками, которые «визуально несовместимы».\exhyphenpenalty [ 〈number〉 parameter ]— Увеличение этого параметра препятствует тому, чтобы TEX заканчивал строку явным дефисом. Обычный TEX устанавливает \exhyphenpenalty равным 50.\hyphenpenalty [ 〈number〉 parameter ]— Увеличение этого параметра препятствует использованию в TEX переноса слов. Обычный TEX устанавливает \hyphenpenalty равным 50.\doublehyphendemerits [ 〈number〉 parameter ]— Увеличение значения этого параметра препятствует TEXу расставлять переносы в двух строках подряд.\finalhyphendemerits [ 〈number〉 parameter ]— Увеличение значения этого параметра препятствует тому, чтобы TEX заканчивал предпоследнюю строку дефисом.
Переносы слов Hyphenation
\-— расставить в тех местах слов, где допускается перенос.\discretionary { 〈pre-break text〉 } { 〈post-break text〉 } { 〈no-break text〉 }— Эта команда определяет «дискреционный разрыв», а именно место, где TEX может разорвать строку. Он также сообщает TEXу, какой текст поместить по обе стороны от разрыва.
% Accounts for German usage: ‘flicken’, but ‘flik% ken’: German
"fli\discretionary{k-}{k}{ck}en"
\hyphenation { 〈word〉 . . . 〈word〉 }— TEX хранит словарь исключений из своих правил расстановки переносов. В каждой словарной статье указано, как следует писать через дефис то или иное слово.
\hyphenation{Gry-phon my-co-phagy}
\hyphenation{man-u-script man-u-scripts piz-za}
\uchyph [ 〈number〉 parameter ]— разрешает перенос в верхнем регистре\language [ 〈number〉 parameter ]— устанавливает язык для переносов в абзаце\setlanguage 〈number〉— установит текущий язык\lefthyphenmin [ 〈number〉 parameter ] \righthyphenmin [ 〈number〉 parameter ]— левое и правое количество слогов при переносе\hyphenchar 〈font〉 [ 〈number〉 parameter ]— установит символ переноса
\hyphenchar\tenrm = ‘% Set hyphenation for tenrm font to ‘-’.
\hyphenchar\tentt = -1 % Don’t hyphenate words in font tentt.% нет переноса
Секции и заголовки
- `\beginsection 〈argument〉 \par` --- заголовок секции
- `\item 〈argument〉 \itemitem 〈argument〉` --- отступ для списков
- `\proclaim 〈argument〉. 〈general text〉 \par` --- теоремы
\proclaim Theorem 1.
What I say is not to be believed.
\proclaim Corollary 1. Theorem 1 is false.\par
Команды для создания страниц
Межстрочный клей
\baselineskip [ 〈glue〉 parameter ]— расстояние от базовой линии одного блока до другой\lineskiplimit [ 〈dimen〉 parameter ]— минимальное значение межстрочного клея\lineskip [ 〈glue〉 parameter ]— расстояние между низом верхнего блока и верхом нижнего блока\prevdepth [ 〈dimen〉 parameter ]— глубина блока\normalbaselineskip [ 〈glue〉 parameter ]— хранит значение baselineskip\normallineskiplimit [ 〈dimen〉 parameter ]— хранит значение lineskiplimit\normallineskip [ 〈glue〉 parameter ]— хранит значение lineskip\normalbaselines— устанавливает значатения, хранящиеся в параметрах normal…\offinterlineskip— отключает вставку межстрочного клея\nointerlineskip— Эта команда сообщает TEXу не вставлять межстрочный клей перед следующей строкой. На последующие строки это не влияет.\openup 〈dimen〉— Эта команда увеличивает \baselineskip на 〈dimen〉.
Разрыв страниц
\break—\nobreak—\allowbreak—\penalty 〈number〉—\goodbreak— Эта команда завершает абзац, а также указывает TEXу, что это подходящее место для разрыва страницы.\smallbreak \medbreak \bigbreak—\eject \supereject— Эти команды вызывают разрыв страницы в текущей позиции и завершают текущий абзац. Если нет vfill будет пытаться сам растянуть страницу.\filbreak— Эта команда обеспечивает своего рода условный разрыв страницы. Он сообщает TEXу разбить страницу, но не в том случае, если текст до более позднего \filbreak также помещается на той же странице.\raggedbottom \normalbottom— сообщает TEXу, что нужно разрешить некоторую вариативность нижних полей на разных страницах.
Параметры разрыва страницы
\interlinepenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф за разрыв страницы между строками абзаца.\clubpenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф за разрыв страницы сразу после первой строки абзаца.\widowpenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф за разрыв страницы непосредственно перед последней строкой абзаца.\displaywidowpenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф за разрыв страницы непосредственно перед последней строкой частичного абзаца, который непосредственно предшествует математическому отображению.\predisplaypenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф за разрыв страницы непосредственно перед математическим отображением. Обычный TEX устанавливает \predisplaypenalty равным 10000.\postdisplaypenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф за разрыв страницы сразу после математического отображения.\brokenpenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф за разрыв страницы сразу после строки, которая заканчивается произвольным элементом (обычно дефисом).\insertpenalties [ 〈number〉 parameter ]— Этот параметр содержит сумму определенных штрафов, которые накапливает TEX при размещении вставок на текущей странице.\floatingpenalty [ 〈number〉 parameter ]— Этот параметр определяет штраф, который TEX добавляет к \insertpenalties, когда построитель страниц добавляет вставку на текущую страницу и обнаруживает, что предыдущая вставка того же типа на этой странице была разделена, оставив ее часть для последующих страниц.\pagegoal [ 〈dimen〉 parameter ]— Этот параметр определяет желаемую высоту текущей страницы. TEX устанавливает \pagegoal в текущее значение \vsize, когда он впервые помещает блок или вставку на текущую страницу.\pagetotal [ 〈dimen〉 parameter ]— Этот параметр определяет накопленную естественную высоту текущей страницы. TEX обновляет \pagetotal по мере добавления элементов в основной вертикальный список.\pagedepth [ 〈dimen〉 parameter ]— Этот параметр определяет глубину текущей страницы.\pageshrink [ 〈dimen〉 parameter ]— Этот параметр определяет степень сжатия накопленного клея на текущей странице.\pagestretch [ 〈dimen〉 parameter ] \pagefilstretch [ 〈dimen〉 parameter ] \pagefillstretch [ 〈dimen〉 parameter ] \pagefilllstretch [ 〈dimen〉 parameter ]— Эти четыре параметра вместе определяют степень растяжения клея на текущей странице. n0 + n1fil + n2fill + n3filll
Макет страницы
\hsize [ 〈dimen〉 parameter ]— горизонтальный размер текста\vsize [ 〈dimen〉 parameter ]— вертикальный размер текста\hoffset [ 〈dimen〉 parameter ] \voffset [ 〈dimen〉 parameter ]— отступ слева и сверху\topskip [ 〈glue〉 parameter ]— TEX вставляет клей вверху каждой страницы, чтобы гарантировать, что базовая линия первого блока на странице всегда находится на одинаковом расстоянии d от верха страницы.\parskip [ 〈glue〉 parameter ]— Этот параметр определяет «пропуск абзаца», то есть вертикальную склейку, которую TEX вставляет в начало абзаца.\maxdepth [ 〈dimen〉 parameter ]— Этот параметр определяет максимальную глубину нижнего поля на странице.
Номер страницы
\pageno [ 〈number〉 parameter ]— Этот параметр содержит номер текущей страницы в виде целого числа. Номер страницы обычно является отрицательным для страниц титульной страницы, которые нумеруются маленькими римскими цифрами, а не арабскими цифрами.
\pageno = 30 % Number the next page as 30. Don’t look for this explanation on page \number\pageno.
\advancepageno— Эта команда добавляет 1 к номеру страницы n в \pageno, если n ≥ 0, и вычитает из него 1, если n < 0.\nopagenumbers— создает пустой нижний колонтитул\folio— Эта команда создает номер текущей страницы, значением которого является число n, содержащееся в \pageno. Если n ≥ 0, TEX выдает n как десятичное число, а если n < 0, TEX выдает −n в виде строчных римских цифр.
Header и Footer
\headline [ 〈token list〉 parameter ]— заголовок\footline [ 〈token list〉 parameter ]— подвал
Метки Marks
\mark { 〈text〉 }— Эта команда заставляет TEX добавлять метку, содержащую 〈текст метки〉, к любому списку, который он в данный момент создает.\firstmark \botmark \topmark— Эти команды расширяются до текста метки в элементе, созданном предыдущей командой \mark.\splitfirstmark \splitbotmark— Эти команды расширяются до текста метки, сгенерированного более ранней командой \mark, которая создала элемент в списке элементов vbox V .
Сноски footnotes
\footnote 〈argument1 〉 〈argument2 〉—
To quote the mathematician P\’olya is a ploy.\footnote *{This is an example of an anagram, but not a strict one.}
\vfootnote 〈argument1 〉 〈argument2 〉— \footnote, и \vfootnote вставляют знак ссылки перед самой сноской, но \vfootnote не вставляет знак ссылки в текст.
Вставки
\topinsert 〈vertical mode material〉 \endinsert— пытается разместить материал вверху текущей страницы.\midinsert 〈vertical mode material〉 \endinsert— пытается поместить материал в текущую позицию.\pageinsert 〈vertical mode material〉 \endinsert— помещает материал отдельно на следующую страницу.\insert 〈number〉 { 〈vertical mode material〉 }— Эта примитивная команда обеспечивает базовый механизм создания вставок, но она почти никогда не используется за пределами определения макроса. Необходимо три элемента для insert- \box n — это место, где TEX накапливает материал для вставок с кодом n. Когда TEX разбивает страницу, он помещает в \box n столько вставочного материала, сколько поместится на странице. Ваша процедура вывода должна затем переместить этот материал на реальную страницу. Вы можете использовать \ifvoid (стр. 238), чтобы проверить, есть ли какой-либо материал в \box n. Если не весь материал помещается, TEX сохраняет остатки для следующей страницы.
- \count n — коэффициент увеличения f. Когда TEX вычисляет вертикальное пространство, занимаемое на странице вставкой n материала, он умножает вертикальную протяженность этого материала на f/1000. Таким образом, вы обычно устанавливаете f равным 500 для вставки двух столбцов и 0 для примечания на полях.
- \dimen n определяет максимальное количество вставок n материала, которые TEX поместит на одну страницу.
- \skip n указывает дополнительное пространство, которое TEX выделяет на странице, если страница содержит какой-либо материал вставки n. Это место дополнительное пространство, занимаемое самой вставкой.
Изменение процедуры вывода
\output [ 〈token list〉 parameter ]— Этот параметр содержит текущую процедуру вывода, т. е. список токенов, который TEX расширяет, когда находит разрыв страницы.\plainoutput— Эта команда вызывает обычную процедуру вывода TEXа.\shipout 〈box〉— Эта команда инструктирует TEX отправить 〈box〉 в файл .dvi.\deadcycles [ 〈number〉 parameter ]— Этот параметр содержит количество раз, когда TEX инициировал процедуру вывода с момента последнего выполнения команды \shipout.\maxdeadcycles [ 〈number〉 parameter ]— Если значение \deadcycles превышает значение \maxdeadcycles, TEX предполагает, что процедура вывода зациклилась.\outputpenalty [ 〈number〉 parameter ]— TEX устанавливает этот параметр, когда разрывает страницу.\holdinginserts [ 〈number〉 parameter ]— Если этот параметр больше 0, когда TEX обрабатывает разрыв страницы, TEX воздержится от обработки вставок.
Разрыв вертикальных списков
\vsplit 〈number〉 to 〈dimen〉— Эта команда заставляет TEX разделить блок с номером 〈number〉, который мы назовем B2, на две части.\splitmaxdepth [ 〈dimen〉 parameter ]— Этот параметр определяет максимально допустимую глубину поля, полученного в результате \vsplit.\splittopskip [ 〈glue〉 parameter ]— Этот параметр определяет клей, который TEX вставляет в верхнюю часть блока, полученного в результате \vsplit.
Горизонтальная и вертикальная мода
\thinspace— Эта команда создает положительный керн, ширина которого составляет одну шестую em, т.е. она заставляет TEX смещать свою позицию вправо на эту величину. Полезно при использовании одиночных и двойных ковычек.\negthinspace— Эта команда создает отрицательный керн, ширина которого составляет одну шестую em, т. е. заставляет TEX смещать свою позицию влево на эту величину.\enspace— Эта команда создает керн, ширина которого равна 1em.\enskip \quad \qquad— Каждая из этих команд создает шарик горизонтального клея, который не может ни растягиваться, ни сжиматься. 1/2em, 1em, 2em.\smallskip \medskip \bigskip— вертикальный отступ.\smallskipamount [ 〈glue〉 parameter ]— Эти параметры определяют количество клея, производимого командами \smallskip, \medskip и \bigskip.\medskipamount [ 〈glue〉 parameter ]\bigskipamount [ 〈glue〉 parameter ]
Вертикальные и горизонтальные отступы (клей)
\hskip 〈dimen1 〉 plus 〈dimen2 〉 minus 〈dimen3 〉— горизонтальная\vskip 〈dimen1 〉 plus 〈dimen2 〉 minus 〈dimen3 〉— вертикальная
\hbox to 2in{one\hskip 0pt plus .5in two}
\hglue 〈glue〉— Команда \hglue создает горизонтальное склеивание, которое не исчезает при разрыве строки\vglue 〈glue〉— команда \vglue создает вертикальную склейку, которая не исчезает при разрыве страницы.\topglue 〈glue〉— Эта команда заставляет пространство от верха страницы до верха первого поля на странице быть склеенным.\kern 〈dimen〉— В горизонтальном режиме TEX перемещает свое положение вправо (при положительном керне) или влево (при отрицательном керне). В вертикальном режиме TEX перемещает свою позицию вниз по странице (при положительном керне) или вверх (при отрицательном керне).
\centerline{$\Downarrow$}\kern 3pt % a vertical kern
\centerline{$\Longrightarrow$\kern 6pt % a horizontal kern
{\bf Heed my warning!}\kern 6pt % another horizontal kern
$\Longleftarrow$}
\kern 3pt % another vertical kern
\centerline{$\Uparrow$}
\hfil \hfill— Эти команды создают бесконечно растягиваемый горизонтальный и вертикальный клей, который подавляет любое конечное растяжение, которое может присутствовать.\vfil \vfill\hss \vss— Эти команды создают горизонтальный и вертикальный клей, который одновременно бесконечно растягивается и бесконечно сжимается.\hfilneg \vfilneg— Эти команды отменяют эффект предыдущего \hfil или \vfil. В то время как \hfil и \vfil производят бесконечно растягиваемый позитивный клей, \hfilneg и \vfilneg производят бесконечно растягиваемый негативный клей.
Управление Box-ами
\hbox { 〈horizontal mode material〉 }
\hbox to 〈dimen〉 { 〈horizontal mode material〉 }
\hbox spread 〈dimen〉 { 〈horizontal mode material〉 }
Эта команда создает hbox (горизонтальный прямоугольник), содержащий 〈материал горизонтального режима〉.
\vtop 〈vertical mode material〉
\vtop to 〈dimen〉 { 〈vertical mode material〉 }
\vtop spread 〈dimen〉 { 〈vertical mode material〉 }
\vbox { 〈vertical mode material〉 }
\vbox to 〈dimen〉 { 〈vertical mode material〉 }
\vbox spread 〈dimen〉 { 〈vertical mode material〉 }
Эти команды создают vbox (вертикальный блок), содержащий 〈материал вертикального режима〉.
\boxmaxdepth [ 〈dimen〉 parameter ]— Этот параметр содержит размер D. TEX не будет создавать блок, глубина которого превышает D.\underbar 〈argument〉— Эта команда помещает 〈аргумент〉 в hbox и подчеркивает его, не обращая внимания на все, что выступает за базовую линию блока.\everyhbox [ 〈token list〉 parameter ]— Эти параметры содержат списки токенов, которые TEX расширяет в начале каждого создаваемого им hbox или vbox.\everyvbox [ 〈token list〉 parameter ]
Создание box-ов для многократного использования
\setbox 〈register〉 = 〈box〉— команда устанавливают содержимое регистра, номер которого равен 〈register〉.\box 〈register〉— команда выводит содержимое регистра
\setbox0 = \hbox{mushroom}
\setbox1 = \vbox{\copy0\box0\box0}
\box1 %выведет box1 и забудет его содержимое
\copy 〈register〉— копирует содержимое box n не стирая его содержимого\unhbox 〈register〉— Эти команды создают список, содержащийся в регистре ящика 〈register〉, и делают этот регистр ящика недействительным.\unvbox 〈register〉— эти команды освобождают память и очищают box с выбранным номером\unhcopy 〈register〉 \unvcopy 〈register〉— Эти команды создают список, содержащийся в блочном регистре 〈register〉, и оставляют содержимое регистра нетронутым.
Смещение Box-ов
\moveleft 〈dimen〉 〈box〉 \moveright 〈dimen〉 〈box〉— сдвинуть влево, сдвинуть вправо\lower 〈dimen〉 〈box〉 \raise 〈dimen〉 〈box〉— сдвинуть вниз, сдвинуть вниз.
Размеры Box-ов
\ht 〈register〉 [ 〈dimen〉 parameter ]— высота\dp 〈register〉 [ 〈dimen〉 parameter ]— глубина\wd 〈register〉 [ 〈dimen〉 parameter ]— ширина
Эти команды хранят размеры box-ов
\setbox0 = \vtop{\hbox{a}\hbox{beige}\hbox{bunny}}%
The box has width \the\wd0, height \the\ht0, and depth \the\dp0.
Struts и фантомы
\strut— Эта команда создает блок, ширина которого равна нулю, а высота (8,5 пт) и глубина (3,5 пт) соответствуют более или менее типичной строке текста в cmr10, простом шрифте TEX по умолчанию.\mathstrut— Эта команда создает фантомную формулу, ширина которой равна нулю, а высота и глубина такие же, как у левой круглой скобки.\phantom 〈argument〉— Эта команда создает пустое поле того же размера и размещения, что и 〈аргумент〉, если бы он был набран.\hphantom 〈argument〉—hphantom создает блок той же ширины, что и 〈аргумент〉, но с нулевой высотой и глубиной.\vphantom 〈argument〉— vphantom создает блок той же высоты и глубины, что и 〈аргумент〉, но нулевой ширины.\smash 〈argument〉— Эта команда вводит 〈аргумент〉, но заставляет высоту и глубину содержащего его поля равняться нулю.\null— Эта команда создает пустой hbox.\setbox0 = \null
Неправильные поля (ошибки формирования документа)
\overfullrule [ 〈dimen〉 parameter ]— Этот параметр определяет ширину правила, которое TEX добавляет к переполненному hbox. Plain TEX устанавливает значение 5pt.\hbadness [ 〈number〉 parameter ] \vbadness [ 〈number〉 parameter ]— Эти параметры определяют пороговые значения горизонтальной и вертикальной неисправности для сообщения о недостаточном или переполненном ящиках.\badness— Эта команда возвращает числовое значение дефектности блока (горизонтального или вертикального), созданного TEX в последний раз.\hfuzz [ 〈dimen〉 parameter ] \vfuzz [ 〈dimen〉 parameter ]— Эти параметры определяют величину, на которую ящик может превысить свой естественный размер, прежде чем TEX сочтет его переполненным.
\hfuzz = .5in \hbox to 2in{This box is longer than two inches.}
Получение последнего элемента из списка
- \lastkern
- \lastskip
- \lastpenalty
- \lastbox
Эти управляющие последовательности возвращают значение последнего элемента в текущем списке. Это не настоящие команды, поскольку они могут появляться только как часть аргумента.
Эти управляющие последовательности наиболее полезны после вызовов макросов, в которые могли быть вставлены объекты указанных типов.
- \unkern
- \unskip
- \unpenalty
Если последний элемент в текущем списке имеет тип керн, клей или пенальти соответственно, эти команды удаляют его из этого списка. Если элемент не того типа, эти команды не имеют никакого эффекта.
Rules and leaders
\hrule
\hrule height 〈dimen〉 width 〈dimen〉 depth 〈dimen〉
\vrule
\vrule width 〈dimen〉 height 〈dimen〉 depth 〈dimen〉
Команда \hrule создает горизонтальную линию; команда \vrule создает вертикальное линию.
По умолчанию \hrule будет расширено по горизонтали до границ самого внутреннего поля или выравнивания. Высота 0,4 пт; Глубина 0pt.
Leaders
\leaders 〈box or rule〉 〈skip command〉
\cleaders 〈box or rule〉 〈skip command〉
\xleaders 〈box or rule〉 〈skip command〉
заполняют горизонтальное или вертикальное пространство копиями узора
〈box or rule〉— указывает шаблон〈skip command— указывает команду для заполнения, т.е. пространство
\def\pattern{\hbox to 15pt{\hfil.\hfil}}
\line{Down the Rabbit-Hole {\leaders\pattern\hfil} 1}
\line{The Pool of Tears {\leaders\pattern\hfil} 9}
\line{A Caucus-Race and a Long Tale {\cleaders\pattern \hfil} 19}
\line{Pig and Pepper {\xleaders\pattern\hfil} 27}
\dotfill \hrulefill— Эти команды соответственно заполняют окружающее горизонтальное пространство рядом точек на базовой линии и горизонтальной линией на базовой линии.
\hbox to 3in{Start {\dotfill} Finish}
\hbox to 3in{Swedish {\hrulefill} Finnish}
\leftarrowfill \rightarrowfill— Эти команды заполняют окружающее горизонтальное пространство стрелками, указывающими влево или вправо.
\hbox to 3in{\vrule \rightarrowfill \ 3 in \leftarrowfill\vrule}
Выравнивание
+ 〈text〉 & 〈text〉 & · · · \cr
\+ 〈text〉 & 〈text〉 & · · · \cr\tabalign— Эти команды начинаются с одной строки с выравниванием по вкладкам.
\cleartabs % обнуляет установки предыдущих settabs
\+ {\bf if }$a[i] < a[i+1]$ &{\bf then}&\cr
\+&&$a[i] := a[i+1]$;\cr
\+&&{\it found }$:=$ {\bf true};\cr
\+&{\bf else}\cr
\+&&{\it found }$:=$ {\bf false};\cr
\+&{\bf end if};\cr
\settabs 〈number〉 \columns— задает одинаковый размер колонкам\settabs \+ 〈sample line〉 \cr— задает шаблон с образцом\cleartabs— очищает предыдущие settabs
Общие выравнивания
\halign { 〈preamble〉 \cr 〈row〉 \cr . . . 〈row〉 \cr }
\halign to 〈dimen〉{ 〈preamble〉 \cr 〈row〉 \cr . . . 〈row〉 \cr }
\halign spread 〈dimen〉{ 〈preamble〉 \cr 〈row〉 \cr . . . 〈row〉 \cr }
Эта команда создает горизонтальное выравнивание, состоящее из последовательности строк, где каждая строка, в свою очередь, содержит последовательность записей столбцов. TEX регулирует ширину записей столбца, чтобы разместить самую широкую запись в каждом столбце.
\valign { 〈preamble〉\cr 〈column〉\cr . . . 〈column〉\cr }
\valign to 〈dimen〉{ 〈preamble〉\cr 〈column〉\cr . . . 〈column〉\cr }
\valign spread 〈dimen〉{ 〈preamble〉\cr 〈column〉\cr . . . 〈column〉\cr }
делает вертикальную таблицу
\ialign— Эта команда ведет себя так же, как \halign, за исключением того, что она сначала устанавливает клей \tabskip равным нулю, а \everycr — пустым.\cr— Эта команда завершает преамбулу горизонтального или вертикального выравнивания.\endline— Эта команда является синонимом команды \cr.\crcr— Эта команда ведет себя так же, как \cr, за исключением того, что TEX игнорирует ее, если она идет сразу после \cr или \noalign.\omit— Эта команда сообщает TEX игнорировать шаблон при горизонтальном или вертикальном выравнивании\span— Значение этой команды зависит от того, появляется ли она в преамбуле или в записи выравнивания. Помещение \span перед токеном в преамбуле приводит к немедленному расширению этого токена в соответствии с обычными правилами расширения макросов TEXа. Размещение \span вместо «&» между двумя записями столбца или строки приводит к объединению этих столбцов или строк.\multispan 〈number〉— Эта команда сообщает TEX, что следующие столбцы 〈number〉 в строке с горизонтальным выравниванием или строки 〈number〉 в столбце с вертикальным выравниванием должны быть объединены в один столбец или строку.\noalign { 〈vertical mode material〉 } \noalign { 〈horizontal mode material〉 }— Чаще всего \noalign используется для добавления дополнительного пробела после строки или столбца.\tabskip [ 〈glue〉 parameter ]— Этот параметр определяет количество горизонтального или вертикального клея, который TEX накладывает между столбцами горизонтального выравнивания или между строками вертикального выравнивания.\hidewidth— Эта команда сообщает TEX игнорировать ширину следующей записи столбца при горизонтальном выравнивании.\everycr [ 〈token list〉 parameter ]— TEX расширяет 〈список токенов〉 всякий раз, когда он выполняет \cr — в конце каждой преамбулы. Т.е. выполняет список команд после \cr.
Математическая мода
Скобки
\lbrace { \{
} \rbrace } \}
[ \lbrack
] \rbrack
〈 \langle
〉 \rangle
Стрелки
← \leftarrow
← \gets
⇐ \Leftarrow
→ \rightarrow
→ \to
⇒ \Rightarrow
↔ \leftrightarrow
⇔ \Leftrightarrow
←− \longleftarrow
⇐= \Longleftarrow
−→ \longrightarrow
=⇒ \Longrightarrow
←→ \longleftrightarrow
⇐⇒ \Longleftrightarrow
⇐⇒ \iff
←↩ \hookleftarrow
↪→ \hookrightarrow
↽ \leftharpoondown
⇁ \rightharpoondown
↼ \leftharpoonup
⇀ \rightharpoonup
⇀↽ \rightleftharpoons
7→ \mapsto
7−→ \longmapsto
↓ \downarrow
⇓ \Downarrow
↑ \uparrow
⇑ \Uparrow
l \updownarrow
m \Updownarrow
↗ \nearrow
↘ \searrow
↖ \nwarrow
↙ \swarrow
Основные команды
Шрифты
\font
\font 〈control sequence〉 = 〈fontname〉
\font 〈control sequence〉 = 〈fontname〉 scaled 〈number〉
\font 〈control sequence〉 = 〈fontname〉 at 〈dimen〉
Это заставляет TEX загружать файл метрик шрифта (файл .tfm) для 〈fontname〉.
Если ни масштабированный 〈number〉, ни 〈dimen〉 отсутствуют, шрифт используется в его дизайнерском размере — размере, в котором он обычно выглядит лучше всего. В противном случае загружается увеличенная версия шрифта.
Scaled — 〈number〉, шрифт увеличивается в 〈number〉/1000.
Если присутствует 〈dimen〉, шрифт масштабируется до 〈dimen〉
\font\tentt = cmtt10
\font\bigttfont = cmtt10 scaled \magstep2
\font\eleventtfont = cmtt10 at 11pt
\fontdimen 〈number〉 〈font〉 [ 〈dimen〉 parameter ]— изменяет различные параметры шрифта
| номер | значение |
|---|---|
| 1 | slant per point |
| 2 | interword space |
| 3 | interword stretch |
| 4 | interword shrink |
| 5 | x-height (size of 1ex) |
| 6 | quad width (size of 1em) |
| 7 | extra space |
Here’s a line printed normally.\par
\dimen0=\fontdimen2\font %сохранить значение пробела в dimen0
\fontdimen2\font=3\fontdimen2\font % увеличить пробел в 3 раза
\noindent Here’s a really spaced-out line.
\fontdimen2\font=\dimen0 %восстановить первоначальные значения
\magnification = 〈number〉— масштабирование\mag [ 〈number〉 parameter ]— лучше использовать первое\magstep 〈number〉— Эта команда расширяется до коэффициента увеличения, необходимого для увеличения всего документа (кроме истинных размеров) на 1,2r, где r — значение 〈number〉. 〈число〉 должно быть от 0 до 5.\magstephalf— маштабирование в полразмера
Конвертирование информации в токене
\number 〈number〉— Эта команда создает представление числа в виде последовательности токенов символов.
\number 24 \quad \count13 = -10000 \number\count13
выдаст: 24 -10000
\romannumeral 〈number〉— Эта команда создает представление числа римскими цифрами в виде последовательности токенов символов.\time [ 〈number〉 parameter ]— TEX устанавливает этот параметр равным количеству минут, прошедших с полуночи (текущего дня).\day [ 〈number〉 parameter ]— TEX устанавливает этот параметр на текущий день месяца. Это число от 1 до 31.\month [ 〈number〉 parameter ]— TEX устанавливает для этого параметра текущий месяц. Это число от 1 до 12.\year [ 〈number〉 parameter ]— TEX устанавливает для этого параметра текущий год\fmtname \fmtversion— Эти команды создают имя и номер версии формата TEX, например, обычного TEX или LATEX, который вы используете.\jobname— Эта команда создает базовое имя файла, с которым был вызван TEX.
Значение переменных
\meaning 〈token〉— Эта команда определяет значение 〈токена〉.
[{\tt \meaning\eject}] [\meaning\tenrm] [\meaning Y]
вернет:
[macro:->\par \break ] [select font cmr10] [the letter Y]
\string 〈control sequence〉— Эта команда создает символы, составляющие имя control sequence\escapechar [ 〈number〉 parameter ]— Этот параметр определяет код ASCII символа, который TEX использует для представления escape-символа\fontname 〈font〉— Эта команда создает имя файла для 〈font〉. Имя файла — это 〈имя шрифта〉, которое использовалось для определения 〈font〉.
\font\myfive=cmr5
[\fontname\myfive]
вернет [cmr5]
Grouping
\begingroup \endgroup— Эти две команды начинают и завершают группу.\global— Эта команда делает следующее определение или назначение глобальным\globaldefs [ 〈number〉 parameter ]— тоже, что\global\def\aftergroup 〈token〉— Когда TEX встречает эту команду во время ввода, он сохраняет 〈токен〉. После окончания текущей группы он вставляет 〈token〉 обратно во входные данные и расширяет их.\afterassignment 〈token〉— Когда TEX встречает эту команду, он сохраняет 〈token〉 в специальном месте. После следующего выполнения присваивания он вставляет 〈token〉 во входные данные и расширяет их.
Macros
\def 〈control sequence〉 〈parameter text〉 { 〈replacement text〉 }— Эта команда определяет 〈последовательность управления〉 как макрос с указанным 〈текстом параметра〉 и 〈текстом замены〉.\edef 〈control sequence〉 〈parameter text〉 { 〈replacement text〉 }— Эта команда определяет макрос таким же общим способом, как и \def. Разница в том, что TEX немедленно расширяет 〈текст замены〉 \edef (но при этом ничего не выполняя).
Вы можете запретить расширение управляющей последовательности, которая в противном случае была бы расширена, используя \noexpand или можете отложить раскрытие управляющей последовательности, используя команду \expandafter.
Команды \write, \message, \errmessage, \wlog и \csname расширяют свои списки токенов, используя те же правила, которые \edef использует для расширения замещающего текста.
\gdef 〈control sequence〉 〈parameter text〉 { 〈replacement text〉 }— эквивалентно\global\def.\xdef 〈control sequence〉 〈parameter text〉 { 〈replacement text〉 }— эквивалентно\global\edef\long— Эта команда используется как префикс к определению макроса. Он сообщает TEX, что аргументы макроса могут включать токены \par
\long\def\aa#1{\par\hrule\smallskip#1\par\smallskip\hrule}
\aa{This is the first line.\par
This is the second line.} % without \long, TeX would complain
\outer— Эта команда используется как префикс к определению макроса. Он сообщает TEX, что макрос является внешним (стр. 83) и не может использоваться в определенных контекстах.
\outer\def\chapterhead#1{%
\eject\topglue 2in \centerline{\bf #1}\bigskip}
% Using \chapterhead in a forbidden context causes an
% error message.
\chardef 〈control sequence〉=〈charcode〉— Эта команда определяет 〈последовательность управления〉 как 〈символьный код〉. Хотя \chardef чаще всего используется для определения символов, его также можно использовать для присвоения имени числу в диапазоне 0–255, даже если вы не используете это число в качестве кода символа.
\chardef\percent = ‘\%
21\percent, {\it 19\percent}
% Get the percent character in roman and in italic
выдаст: 21%, 19%
\mathchardef 〈control sequence〉=〈mathcode〉— определит математический символ\let 〈control sequence〉 = 〈token〉— определит синоним команды\futurelet 〈control sequence〉 〈token1 〉 〈token2 〉—\csname 〈token list〉 \endcsname— Эта команда создает управляющую последовательность из 〈списка токенов〉. Он обеспечивает способ синтеза управляющих последовательностей, в том числе тех, которые вы обычно не можете написать. 〈список токенов〉 сам может включать в себя управляющие последовательности; он расширяется так же, как заменяющий текст определения \edef
\def\capTe{Te} This book purports to be about \csname\capTe X\endcsname.
\expandafter 〈token1 〉 〈token2 〉— Эта команда сообщает TEXу расширить 〈token1〉 в соответствии со своими правилами расширения макросов после расширения 〈token2〉 на один уровень.
\def\aa{xyz}
\tt % Use this font so ‘\’ prints that way.
[\string\aa] [\expandafter\string\aa] [\expandafter\string\csname TeX\endcsname]
%выводит: [\aa] [xyz] [\TeX]
\noexpand 〈token〉— Эта команда сообщает TEX о подавлении расширения 〈token〉, если 〈token〉 является управляющей последовательностью, которую можно расширить.\the 〈token〉— Эта команда обычно расширяется до списка токенов символов, представляющих 〈токен〉. Это могут быть регистры, переменные и т.д.\parindent \deadcycles \count0 \catcode \fontdimen3\sevenbf \hyphenchar \skewchar \skewchar\teni \lastpenalty, \lastskip, \lastkern \chardef \mathchardef
Кроме того, \the может расширяться до несимвольных токенов в следующих двух случаях:
- \the 〈font〉, который расширяется до последней определенной управляющей последовательности, которая выбирает тот же шрифт, что и управляющая последовательность 〈font〉
- \the 〈переменная токена〉, которая расширяется до копии значения переменной, например, \the \everypar
Сравнения Conditional
\if 〈token1 〉 〈token2 〉— Эта команда проверяет, имеют ли 〈token1 〉 и 〈token2 〉 одинаковый код символа, независимо от кодов их категорий.\ifcat 〈token1 〉 〈token2 〉— Эта команда проверяет, имеют ли 〈token1〉 и 〈token2〉 одинаковый код категории.\ifx 〈token1 〉 〈token2 〉— Эта команда проверяет, совпадают ли 〈token1〉 и 〈token2〉. В отличие от \if и \ifcat, \ifx не расширяет токены, следующие за \ifx, поэтому 〈token1 〉 и 〈token2 〉 — это два токена сразу после \ifx.\ifnum 〈number1 〉 〈relation〉 〈number2 〉— Эта команда проверяет, удовлетворяют ли 〈номер1〉 и 〈номер2〉 〈отношению〉, которое должно быть либо «<», «=» или «>».\ifodd 〈number〉— Эта команда проверяет, является ли 〈число〉 нечетным.\ifdim 〈dimen1 〉 〈relation〉 〈dimen2 〉— Эта команда проверяет, удовлетворяют ли 〈dimen1 〉 и 〈dimen2 〉 〈отношению〉, которое должно быть либо «<», «=» или «>».\ifhmode \ifvmode \ifmmode \ifinner— определяет в какой моде находится Tex\ifhbox 〈register〉 \ifvbox 〈register〉 \ifvoid 〈register〉— Эти команды проверяют содержимое ящика-регистра с номером 〈register〉.\ifeof 〈number〉— Эта команда проверяет входной поток на конец файла.\ifcase 〈number〉〈case0 text〉 \or 〈case1 text〉 \or . . . \or 〈casen text〉 \else 〈otherwise text〉 \fi— Эта команда представляет тест с пронумерованными несколькими случаями. Если 〈number〉 имеет значение k, TEX расширит 〈casek text〉, если он существует, и 〈иначе text〉, если его нет.\iftrue \iffalse— Эти команды эквивалентны тестам, которые всегда верны или всегда ложны.\else— Эта команда представляет «ложную» альтернативу условной проверки.\fi— Эта команда завершает текст условной проверки.\newif \if〈test name〉— Эта команда называет три управляющих последовательности именами \alphatrue, \alphafalse и \ifalpha, где alpha — это 〈имя теста〉
Циклы и повторы
\loop α \ifΩ β \repeat— Эти команды предоставляют конструкцию цикла для TEXа. Здесь α и β — произвольные последовательности команд, а \ifΩ — любой из условных тестов. \repeat заменяет \fi, соответствующий тесту, поэтому вам не нужно явно писать \fi для завершения теста.
\count255 = 6
\loop
\number\count255\
\ifnum\count255 > 0
\advance\count255 by -1
\repeat
Пустота
\relax— Эта команда сообщает TEXу ничего не делать.\empty— Эта команда вообще не требует токенов. Он отличается от \relax тем, что исчезает после раскрытия макроса.
Регистры
\count 〈register〉 = 〈number〉
\dimen 〈register〉 = 〈dimen〉
\skip 〈register〉 = 〈glue〉
\muskip 〈register〉 = 〈muglue〉
\toks 〈register〉 = 〈token variable〉
\toks 〈register〉 = { 〈token list〉 }
%Регистру \toks можно назначить либо переменную токена (регистр или параметр),
%либо список токенов. Когда вы назначаете список токенов регистру токенов,
%токены в списке токенов не расширяются.
\count 〈register〉
\dimen 〈register〉
\skip 〈register〉
\muskip 〈register〉
\toks 〈register>
Первые шесть команд, перечисленных здесь, присваивают что-то регистру. Остальные пять управляющих последовательностей не являются настоящими командами, поскольку могут появляться только как часть аргумента. Они возвращают содержимое указанного регистра. Хотя вы не можете использовать эти управляющие последовательности сами по себе в качестве текстовых команд, вы можете использовать \the для преобразования их в текст и набора их значений.
\newcount— Резервирование регистров\maxdimen— Эта последовательность управления дает 〈размер〉, который является наибольшим размером, приемлемым для TEX
Операции над регистрами: \advance, \multiply, \divide, \setbox, \box.
Объявление регистров
\newcount %каждый резервирует регистр указанного типа.
\newdimen
\newskip
\newmuskip
\newtoks
\newbox
\newread %зарезервируйте входной поток и выходной поток соответственно.
\newwrite
\newfam %резервирует семейство математических шрифтов.
\newinsert %резервирует тип вставки.
\newlanguage %резервирует набор шаблонов расстановки переносов.
\countdef 〈control sequence〉 = 〈register〉
\dimendef 〈control sequence〉 = 〈register〉
\skipdef 〈control sequence〉 = 〈register〉
\muskipdef 〈control sequence〉 = 〈register〉
\toksdef 〈control sequence〉 = 〈register〉
Эти команды определяют 〈последовательность управления〉 для ссылки на регистр указанной категории, номер которого равен 〈register〉.
Операции над регистрами
\advance 〈count register〉 by 〈number〉
\advance 〈dimen register〉 by 〈dimen〉
\advance 〈skip register〉 by 〈glue〉
\advance 〈muskip register〉 by 〈muglue〉
Эта команда добавляет совместимое количество в регистр.
\multiply 〈register〉 by 〈number〉
\divide 〈register〉 by 〈number〉
Эти команды умножают и делят значение в 〈register〉 на 〈number〉 (которое может быть отрицательным).
Завершение работы
\bye— заканчивается документ\end— Эта команда сообщает TEX создать последнюю страницу и завершить задание. Однако он не заполняет страницу, поэтому обычно лучше использовать \bye, а не \end.
Input и Output
Input
\input 〈filename〉— Эта команда сообщает TEX прочитать входные данные из файла 〈имя файла〉. Когда этот файл исчерпан, TEX возвращается к чтению из предыдущего источника ввода.\endinput— Эта команда сообщает TEXу прекратить чтение ввода из текущего файла, когда он в следующий раз достигнет конца строки.\inputlineno— Эта команда возвращает число (не строку), задающее номер текущей строки, определенный как номер, который будет отображаться в сообщении об ошибке, если ошибка произойдет в этот момент.\openin 〈number〉 = 〈filename〉— Эта команда сообщает TEXу открыть файл с именем 〈имя файла〉 и сделать его доступным для чтения через входной поток, обозначенный 〈number〉 . Number от 0 до 15. Чтение из файла выполняется командой\read. Номера потоков определяются с помощью команды\newread.\closein 〈number〉— Эта команда сообщает TEXу закрыть входной поток с номером 〈number〉, т. е. прекратить связь между входным потоком и его файлом.\read 〈number〉 to 〈control sequence〉— Эта команда сообщает TEX прочитать строку из файла, связанного с входным потоком, обозначенным 〈номером〉, и назначить токены в этой строке 〈управляющей последовательности〉.
Output
\openout 〈number〉 = 〈filename〉— Эта команда сообщает TEXу открыть файл с именем 〈имя файла〉 и сделать его доступным для записи через выходной поток, обозначенный 〈номер〉. 〈число〉 должно быть от 0 до 15.\closeout 〈number〉— Эта команда сообщает TEXу закрыть выходной поток с номером 〈number〉.\write 〈number〉 { 〈token list〉 }— Эта команда сообщает TEX записать 〈список токенов〉 в файл, связанный с выходным потоком, обозначенным 〈номер〉.\immediate— Эта команда должна предшествовать командам \openout, \closeout или \write. Он сообщает TEXу выполнить указанную операцию с файлом без задержки.\special { 〈token list〉 }— Эта команда сообщает TEX записать 〈список токенов〉 непосредственно в файл .dvi при следующей отправке страницы.\newlinechar [ 〈number〉 parameter ]— Этот параметр содержит символ, обозначающий новую строку на выходе. Когда TEX встречает этот символ при чтении аргумента команды \write, \message или \errmessage, он начинает новую строку.
Интерпретация входных символов
\catcode 〈charcode〉 [ 〈number〉 table entry ]— Эта запись таблицы содержит код категории символа, код ASCII которого равен 〈charcode〉.\active— Эта команда содержит код категории для активного символа, а именно цифру 13.\mathcode 〈charcode〉 [ 〈number〉 table entry ]— Эта запись таблицы содержит математический код символа, ASCII-код которого равен 〈charcode〉\delcode 〈charcode〉 [ 〈number〉 table entry ]— Эта запись таблицы определяет код-разделитель для входного символа, код ASCII которого равен 〈charcode〉.\endlinechar [ 〈number〉 parameter ]— Этот параметр содержит код символа, который TEX добавляет в конец каждой входной строки.\ignorespaces— Эта команда сообщает TEXу читать и расширять токены, пока не найдет тот, который не является токеном пространства, игнорируя любые токены пространства, которые он находит на своем пути.
Отладка кода Tex’s
\show 〈token〉 \showthe 〈argument〉 \showbox 〈number〉 \showlists— Эти команды записывают информацию в журнал вашего запуска TEXа\tracingonline [ 〈number〉 parameter ]— Если этот параметр больше нуля, TEX будет отображать результаты трассировки (включая \showbox и \showlists) на вашем терминале в дополнение к записи их в файл журнала.\message { 〈token list〉 } \errmessage { 〈token list〉 }— Эти команды отображают сообщение, заданное 〈списком токенов〉, на вашем терминале, а также записывают его в журнал. Все макросы в сообщении раскрываются, но команды не выполняются.\wlog { 〈token list〉 }— Эта команда записывает 〈список токенов〉 в файл журнала.\errhelp [ 〈token list〉 parameter ]— Этот параметр содержит список токенов, который TEX отображает, когда вы запрашиваете помощь в ответ на команду \errmessage.\newhelp 〈control sequence〉 { 〈help text〉 }— Эта команда назначает справочное сообщение, заданное 〈текстом помощи〉, 〈последовательности управления〉.
Инициализация TEX
\dump— Эта команда, которая не должна появляться внутри группы, сбрасывает содержимое памяти TEXа в файл формата (стр. 65). Используя virtex, специальную «чистую» форму TEXа, вы можете затем перезагрузить файл формата на высокой скорости и продолжить работу в том же состоянии, в котором находился TEX на момент создания дампа. \dump также завершает выполнение. Поскольку \dump можно использовать только в initex, а не в рабочих формах TEXа, он полезен только тем, кто устанавливает TEX.\everyjob [ 〈token list〉 parameter ]— Этот параметр содержит список токенов, который TEX расширяет в начале каждого задания. Поскольку назначение \everyjob не может повлиять на текущий запуск (к тому времени, когда вы выполните назначение, будет уже слишком поздно), оно полезно только для людей, которые подготавливают файлы форматирования.
7.6.2 - TEX for the Impatient
Обзор документации TEX по книге TEX for the Impatient
Это не полный конспект. Это дополнение к предыдущим знаниям. Поэтому, только отличия от другой статьи.
Некоторые команды
\null
Ставится после большой буквы,чтобы Tex мог понять, что точку нужно воспринимать не как после большой буквы.
Двойные кавычки
Поставить две одинарные, а чтобы разделить одинарную от двойной между ними поставить команду ’text’\thinspace"
Объявление \def
\def\xmpheader#1/#2{% Now here’s the title.
\leftline{\xmplbx Example #1:\quad\xmplbxti #2}%
\vglue .5\baselineskip % skip an extra half line
}
Какие особенности?
при объявлении между параметрами указывается разделитель,которым будут отделяться параметры, это может быть пробел или как у меня #1/#2. Сложные данные передаются просто в группе {}.
Но определению \def я еще посвящу отдельную главу.
Управляем отступами
- \parindent = 0pt — отступ первой строки
- \noindent — подавить отступ
- \parskip = 6pt — отступ между абзацев
- \par — новый абзац
- \smallskip — маленький разрыв абзацев
- \medskip
- \bigskip
- \narrower — отступ слева и справа на ширину \parindent
- \vskip 1pc — вертикальный отступ
- \leftskip .5in — отступ слева
- \rightskip .5in — отступ справа
- \baselineskip = 7pt — межстрочный интервал
- \raggedright — отключить выравнивание по правому краю
- \leftline{} — строку выравнивает по левому краю
- \rightline{}
- \centerline{}
Определение символов
\chardef \\ = `\\ — определили \\ как backslash
\char `\^ — выводит символ по его коду
Акценты и диакритические знаки
\`
\'
\"
\^
...
через backslash ставим знак и дальше нужную букву.
Дроби
Макрос дробилка. На вход две цифири через слеш.
\def\frac#1/#2{\leavevmode
\kern.1em \raise .5ex \hbox{\the\scriptfont0 #1}%
\kern-.1em $/$%
\kern-.15em \lower .25ex \hbox{\the\scriptfont0 #2}%
}%
`\kern` --- сдвигает символ вправо или влево
`\raise` --- сдвигает вверх
`\lower` --- сдвигает вниз
`\leavevmode` --- переключается из вертикальной моды
Определение измеряемых величин \newdimen
Нужно для правильной разметки пространства
\newdimen\descindent
\descindent = 8pc
llap начинает печатать влево от текущей позиции курсора
rlap — делает тоже, но вправо. Позицию курсора при этом не меняет.
\llap{\hbox to \descindent{\bf Queen of Hearts\hfil}}%
замечательный прием:
- создать hbox длиной \descindent и поместить текст, выровненный по левому краю с помощью \hfil
\hbox \vbox
У этих замечательных box-ов есть переменные:
- to — которая задает размер
- spread — которая задает отступ текста, это установка для \hfil и \vfil
\hbox spread 8pt{\hfil\vbox spread 8pt{\vfil
\leaders заполняет окна символами
Для различных строк с подчеркиванием или точками, а также любые пространства для заполнения однообразным элементом
\line{\hfil\hbox to 3in{\leaders\hbox{ * }\hfil}\hfil}
Заполнит 3in звездочками и выровняет их по центру
У него есть 2 брата: \cleaders и \xleaders — которые заполняют не выравнивая элементы заполнения относительно разных строк.
\proclaim теорема
Печатает первое предложение выделенным жирным, а остальной абзац курсивом.
\footline \headline
footer и header
Таблицы
{\xmpheader 8/{A ruled table}% see p. 21
\bigskip \offinterlineskip % So the vertical rules are connected.
% \tablerule constructs a thin rule across the table.
\def\tablerule{\noalign{\hrule}}
% \tableskip creates 9pt of space between entries.
\def\tableskip{\omit&height 9pt&&&\omit\cr}
% & separates templates for each column. TeX substitutes
% the text of the entries for #. We must have a strut
% present in every row of the table; otherwise, the boxes
% won’t butt together properly, and the rules won’t join.
\halign{\tabskip = .7em plus 1em % glue between columns
% Use \vtop for whole paragraphs in the first column.
% Typeset the lines ragged right, without hyphenation.
\vtop{\hsize=6pc\pretolerance = 10000\hbadness = 10000
\normalbaselines\noindent\it#\strut}%
&\vrule #&#\hfil &\vrule #% the rules and middle column
% Use \vtop for whole paragraphs in the last column.
&\vtop{\hsize=11pc \parindent=0pt \normalbaselineskip=12pt
\normalbaselines \rightskip=3pt plus2em #}\cr
- \offinterlineskip — не дает масштабироваться вертикальным отступам в таблице
- \def\tablerule{\noalign{\hrule}} — для правильного отображения горизонтальных линий
- \def\tableskip{\omit&height 9pt&&&\omit\cr} — расстояние между строками в таблице
- \halign — определяет параметры колонок таблицы
- \vtop — выравнивает вертикальный бокс по верху
- \pretolerance = 10000\hbadness = 10000 — не показывает ошибки
- \vrule — рисует вертикальные линии
- \omit — отменяет действие шаблона в ячейке или строке и заменяет его обычным #
- \vtop{\hsize=11pc \parindent=0pt \normalbaselineskip=12pt \normalbaselines \rightskip=3pt plus2em #}\cr — чтобы задать в ячейке многострочный текст, а ячейку размером 11pc
Формулы математика
Очень большой раздел и пока им не интересуюсь
- eqno — выведет номер формулы справа
- leqno — выведет номер формулы слева
Концепция TEX
Активный символ \active
Это символ, которому будет назначено действие в TEX
- Символ нужно определить в \catcode назначить ему категорию 13 (\active)
- Определить действия через \def \let \chardef
Если символ не будет \active до определения, назначить ему команду не удастся
Например: \catcode ‘~ = \active \def~{\penalty10000\ }
alignment — выравнивание
Выравнивание TAB
- \settabs
- \+
- &
- \cr
{\hsize = 1.7 in \settabs 2 \columns
\+cattle&herd\cr
\+fish&school\cr
\+lions&pride\cr}
Выравнивание \haling
выравнивание с учетом настроек преамбулы
\halign{\hfil#\hfil &\hfil#\hfil &\hfil#\hfil \cr
- \tabskip =2pc — клей между колонками
- \noalign — вертикально выровнять строки
- \strut — увеличивает отступ между строк
- \valign — вертикальное выравнивание (это таблица на боку)
{\hsize=0.6in \parindent=0pt
\valign{#\strut&#\strut&#\strut\cr
one&two&three\cr
four&five&six\cr
seven&eight&nine\cr
ten&eleven\cr}}
Анатомия TEX
Текс расширяет макросы слева направо, но команда \expandafter может изменить порядокраскрытия макросов
Блоки в TEX
- reference point
- height
- width
- depth
- baseline
Коды категорий символов
| Code | Назначение |
|---|---|
| 0 | \ |
| 1 | { |
| 2 | } |
| 3 | $ |
| 4 | & |
| 5 | ^^M= |
| 6 | # |
| 7 | ^ и ^^K |
| 8 | _ и ^^A |
| 9 | ^^@ (ignored) |
| 10 | пробел ^^I |
| 11 | a..z A..Z |
| 12 | другие символы |
| 13 | ~ и ^^L активный |
| 14 | % |
| 15 | ^^? ошибка |
Символы
Категория 11 и 12
команда (напечатать символ) \char `h тоже самое, что \char104 напечатает h
Классы символов
Используется в математической моде и влияет на выделение места для каждого символа
Команды TEX
Все, что должен выполнить TEX:
- активный символ
- последовательность управляющих символов
- сам символ
Сравнение
\ifα〈true text〉\else〈false text〉\fi или \ifα〈true text〉\fi
проверка выполняется до расширения макросов
Управляющая последовательность
Обычно начинаетяс с \ и имя последовательности, определенное в \def
Заканчивается, когда TEX видит небукву. Или когда заканчивается управляющий символ.
Управляющий символ
состоит из \ и символа
Разделители — delimeters
обычно скобки в математической моде
dimention
| код | значение |
|---|---|
| pt | point (72.27 points = 1 inch) |
| pc | pica (1 pica = 12 points) |
| bp | big point (72 big points = 1 inch) |
| in | inch |
| cm | centimeter (2.54 centimeters = 1 inch) |
| mm | millimeter (10 millimeters = 1 centimeter) |
| dd | didˆot point (1157 didˆot points = 1238 points) |
| cc | cicero (1 cicero = 12 didoˆt points) |
| sp | scaled point (65536 scaled points = 1 point) |
| em | ширина M |
| ex | высота x |
бесконечность: fil, fill, filll
Множитель перед размерами f/1000
\kern 8 true pt — сделает неизменным размер при масштабировании
Шрифты
\font\имя=шрифт в системе
\font\twelvebf=cmbx12
Глобальное определение \globaldefs
распространяется на весь документ
или сокращенный вариант: \gdef или \xdef вместо \global\def и \global\edef
Клей \hskip
есть вертикальный и горизонтальный
\hskip 6pt plus 2pt minus 3pt — клей может растягиваться и сжиматься
у клея есть свойства stretch — plus и shrink — minus
Межстрочный клей
определяет расстояние между строк и определяется параметрами:
\baselineskip, \lineskip, \lineskiplimit
item
текст с отступом
выравнивание
\leftskip, \rightskip, \raggedright — установит размеры горизонтального бокса
kern
смещает символы горизонтально
leaders
заполнит пространство символами (нужно для оглавления)
Метка MARK
\topmark, \firstmark, \botmark размещаются на странице и используются командой \mark
\def\section#1{\medskip{\bf#1}\smallskip\mark{#1}} % #1 is the name of the section
Определение section устанавливает метку с именем секции
Числа
- 52 — десятичное число
- ‘14 — восьмеричное число
- “FF — шестнадцатиричное число
- `с или `\с — ASCII последовательность, но лучше второй вариант, хотя они идентичны. Со вторым вариантом можно использовать `\\, `\%, `\^^M
Но нежелательно при использовании команды \edef и \write
78 +078 "4E '116 `N `\N — это один и тот же код
число печатается командой \number78 или \romannumeral78 — получим 78lxxviii
box255
в этот box помещается готовая страница
готовый box255 отправляется командой \shipout в файл .dvi
Разрыв страницы
В Tex разрывом страницы управляет штраф:
\penalty 10000 = \nobreak
\penalty -10000 = \break
Размер страницы
- \voffset — отступ сверху
- \hoffset — отступ слева
- hsize — ширина текста
- vsize — высота текста
Регистры
| тип | контент |
|---|---|
| box | a box |
| count | a number |
| dimen | a dimension |
| muskip | muglue |
| skip | glue |
| toks | a token list |
Все регистры имеют нумерацию от 0 до 255
Вызов регистра \box0 или \box100, \skip0 или \skip20
setbox3 = \hbox{text} — присвоит значение регистру box3
count255 = -1 — присвоит -1
для резервирования регистров используются команды:
- \newbox,
- \newcount,
- \newdimen,
- \newmuskip,
- \newskip,
- \newtoks
Просмотреть содержимое регистра можно с помощью команды \showthe\dimen0
\whatsit
действия для TeX когда, что-то пошло не так
- команды \openout, \closeout, \write — откладывает запись в выходной файл до следующей команды
- \special — вставить текс в выходной файл
- при смене языка поместит информацию
7.6.3 - TEX
Документация TEX, в объеме,которуюя использую для своих задач
TEX это база, на которой строятся все прекрасные вещи из Latex и Tikz
Введение
% A small font and close interline spacing make this work
\smallskip\font\sixrm=cmr6 \sixrm \baselineskip=7pt
\dimen0=\fontdimen3\font \dimen2=\fontdimen4\font
\fontdimen3\font=1.8pt \fontdimen4\font=.9pt
\noindent \hfuzz=.1pt
\parshape 30 0pt 120pt 1pt 118pt 2pt 116pt 4pt 112pt 6pt
108pt 9pt 102pt 12pt 96pt 15pt 90pt 19pt 84pt 23pt 77pt
27pt 68pt 30.5pt 60pt 35pt 52pt 39pt 45pt 43pt 36pt 48pt
27pt 51.5pt 21pt 53pt 16.75pt 53pt 16.75pt 53pt 16.75pt 53pt
16.75pt 53pt 16.75pt 53pt 16.75pt 53pt 16.75pt 53pt 16.75pt
53pt 14.6pt 48pt 24pt 45pt 30.67pt 36.5pt 51pt 23pt 76.3pt
The wines of France and California may be the best known,
but they are not the only fine wines. Spanish wines are
often underestimated, and quite old ones may be available at
reasonable prices. For Spanish wines the vintage is not so
critical, but the climate of the Bordeaux region varies
greatly from year to year. Some vintages are not as good as
others, so these years ought to be s\kern -.1pt p\kern -.1pt
e\kern -.1pt c\hfil ially n\kern .1pt o\kern .1pt
t\kern .1pt e\kern .1pt d\hfil: 1962, 1964, 1966. 1958,
1959, 1960, 1961, 1964, 1966 are also good California
vintages. Good luck finding them!
\fontdimen3\font=\dimen0 \fontdimen4\font=\dimen2

Изучаю книгу A Gentle Introduction to TEX
Первый шаг Создать файл.
Я это делаю в своем любимом Emacs
Here is my first \TeX\ sentence.
\bye
и сохранил с именем test.tex
Второй шаг выполнить tex
tex test.tex
Получилось два файла на выходе: test.dvi и test.log
В test.log
This is TeX, Version 3.141592653 (TeX Live 2024) (preloaded format=tex 2024.10.2) 5 JAN 2025 20:03
**test.tex
(./test.tex [1] )
Output written on test.dvi (1 page, 292 bytes).
А файл dvi вполне себе просматривается emacs, в том виде, как и должно быть.
Специальные символы в Tex
| символ | назначение | как вывести в tex |
|---|---|---|
| \ | спец символ и инструкции | $\backslash$ |
| { | открывает группу | ${$ |
| } | закрывает группу | $}$ |
| % | комментарии | % |
| & | разграничение колонок в таблице | & |
| ~ | неразрываемый пробел | ~{} |
| $ | начало и окончание математической моды | $ |
| ^ | надстрочник | ^{} |
| _ | подстрочник | _{} |
| # | определение заменяемого символа | # |
Набор текста с акцентом
Акцент — это надстрочники и подстрочники над и под буквами
Акцент за которым следует буква
| наименование | Tex input | Tex output | Compose |
|---|---|---|---|
| grave | \`o | ò | cmp+` o |
| acute | \’o | ó | cmp+’ o |
| circumflex | \^o | ô | cmp+^ o |
| umlaut/dieresis/tr ́emat | \“o | ö | cmp+” o |
| tilde | \~o | õ | cmp+~ o |
| macron | \=o | ő | cmp+= o |
| dot | \.o | ȯ | cmp+. o |
Продолжение для символов требующих пробела
| наименование | Tex input | Tex output | Compose |
|---|---|---|---|
| cedilla | \c o | ǫ | cmp+, o |
| underdot | \d o | ọ | cmp+! o |
| underbar | \b o | o᤻ | o C-x 8 RET 193b |
| h ́acˇek | \v o | ǒ | cmp+v o |
| breve | \u o | ŏ | cmp+u o |
| tie | \t oo | o͡o | o C-x 8 RET 0361 o |
| Hungarian umlaut | \H o | ő | cmp+= o |
| ơ | cmp++ o | ||
| ° | cmp+o o | ||
| § | cmp+s o | ||
| ø | cmp+? o |
По этой ссылке весь unicode а в Emacs C-x 8 RET в помощь. ⤖ https://www.compart.com/en/unicode/
Но и это еще не всё!
В UNICODE есть прекрасные имена тысячам символов https://www.compart.com/en/unicode/html
Это нужно при оформлении HTML документации просто пишем имя через &Rarrtl и получаем результат.
Можно создать собственную комбинацию клавиш
Создайте пустой ~/.XCompose и включите в него содержимое стандартного файла, используя директиву include “%L”, например:
# ~/.XCompose
include "%L"
<Multi_key> <g> <a> : "α"
<Multi_key> <g> <b> : "β"
<Multi_key> <g> <g> : "γ"
Определение шрифта
В Tex по умолчанию доступны 16 шрифтов
| Наименование | команда |
|---|---|
| Roman | \rm |
| Boldface | \bf |
| Italic | \it |
| Slanted | \sl |
| Typewriter | \tt |
| Math symbol5 | \cal |
Масштабирование шрифта
используем команду \magstep 0...5 или \magstephalf
\font\bigrm = cmr10 scaled \magstep 5 %объявим свой шрифт crm10 и смасштабируем 5 magstep
\font\bigbigrm = cmr14 scaled \magstep 3
Имена стандартных шрифтов TEX
| CMBSY10 | CMBXSL10 | CMBXTI10 | CMBX10 | CMBX12 | CMBX5 |
|---|---|---|---|---|---|
| CMBX6 | CMBX7 | CMBX8 | CMBX9 | CMB10 | CMCSC10 |
| CMDUNH10 | CMEX10 | CMFF10 | CMFIB8 | CMFI10 | CMITT10 |
| CMMIB10 | CMMI10 | CMMI12 | CMMI5 | CMMI6 | CMMI7 |
| CMMI8 | CMMI9 | CMR10 | CMR12 | CMR17 | CMR5 |
| CMR6 | CMR7 | CMR8 | CMR9 | CMSLTT10 | CMSL10 |
| CMSL12 | CMSL8 | CMSL9 | CMSSBX10 | CMSSDC10 | CMSSI10 |
| CMSSI12 | CMSSI17 | CMSSI8 | CMSSI9 | CMSSQI8 | CMSSQ8 |
| CMSS10 | CMSS12 | CMSS17 | CMSS8 | CMSS9 | CMSY10 |
| CMSY5 | CMSY6 | CMSY7 | CMSY8 | CMSY9 | CMTCSC10 |
| CMTEX10 | CMTEX8 | CMTEX9 | CMTI10 | CMTI12 | CMTI7 |
| CMTI8 | CMTI9 | CMTT10 | CMTT12 | CMTT8 | CMTT9 |
| CMU10 | CMVTT10 |
- CM — Computer Modern
- B — Bold
- R — roman
- I — italic
- CSC — small caps
- SL — наклонный
- SS — sans serif
- SY — symbols
- TT — моноширинный
Форма выводимого текста
Tex понимает различные единицы измерения:
- in
- cm
- pt
- pc
и другие
- ex — высота маленькой x
- em — ширина большой M
Форма страницы
Три части:
- header
- body
- footer
| наименование | команда | значение |
|---|---|---|
| ширина | \hsize | 6.5in |
| высота | \vsize | 8.9in |
| горизонтальный отступ | \hoffset | 0 |
| вертикальный отступ | \voffset | 0 |
\vfill \eject — оборвет страницу и начнет новую
\hsize = 4in — определяет горизонтальный размер текста в текущем абзаце
0.75\hsize установит размер \hsize 0.75 от последнего значения
\vsize — задает вертикальный размер страницы
\hoffset \voffset — задают смещение текста относительно левого верхнего угла страницы. По умолчанию они равны 1in.
Команды \hsize и \vsize нужно давать в начале абзаца
Команды \hoffset \voffset действуют на всю страницу где они находятся и последняя переустановит всех предыдущих на этой странице
Для \hoffset и \voffset нет пределов страницы. Спокойно выведет текст за его пределами
\magnification = \magstep 3
Ставится в самом начале документа до начала первого символа и увеличивает весь документ, вместе с \hsize и \vsize
чтобы сохранить неизменными \hsize и \vsize используем true
\hsize = 5 true in
Форма параграфа
На размер абзаца влияет \hsize
Tex всегда читает весь абзац целиком и применяет последние настройки.
| функция | команда | значение |
|---|---|---|
| ширина | \hsize | 6.5in |
| отступ первой линии | \parindent | 20pt |
| расстояние между линиями | \baselineskip | 12pt |
| расстояние между абзацами | \parskip | 0pt |
команда \noindent убирает первый отступ линии, тоже,что и \parindent= 0pt
\rightskip \leftskip
это команды margin отступов слева и справа от обзаца
\narrower — изменяет оба значения сразу значением равным \parindent
\hangindent=2.5 in \hangafter=2
первую строку заполняет полностью на всю ширину, а следующую с отступом. Если положительное, то слева, если отрицательное, то справа.
\hangafter указывает после какой строки начинать отступ.
По умолчанию равно 1. Если поставлю 0, то отступ начнется с первой строки. Если отрицательное, то первые строки будут с отступом, а следующие на полную ширину.
еще есть команда \hang — которая сделает отступ абзаца на длину \parindent
\parshape
Создает абзацы любой формы
\item
Начинает абзац с отступом \parindent и вначале указывает значение, которое в {}
Команда \itemitem сделает двойной отступ
\parskip = 0pt \parindent = 30 pt \noindent
Answer all the following questions:
\item{(1)} What is question 1?
\item{(2)} What is question 2?
\item{(3)} What is question 3?
\itemitem{(3a)} What is question 3a?
\itemitem{(3b)} What is question 3b?
\parskip
расстояние между параграфами
и его друг \vskip 1 in — задают интервал между абзацами (у него нет знака равно)
\vglue 1 in — вставляет 1 in куда угодно, даже в начале страницы.
\topinsert \vskip -2 in \centerline{Figure 1} \endinsert
Эта команда поставит на текущей странице все, что находится между командами \topinsert и \endinsert
Я умышленно поставил \vskip -2 in и весь текстстраницы улетел вверх.
\smallskip, \medskip, \bigskip
Для смещений между абзацами. Действует только на текущий абзац.
Форма строки
\hfill \break — разорвет строку
\hfill — заполнит пространство
\line{} — выведет строку
\liftline{} \rightline{} \centerline{} выравнивает строку
\hfil — заполняет пространство для выравнивания
\raggedrigth — обрыв правого выравнивания
\hskip 1 in — горизонтальный отступ
Сноски
\footnote{}{}
в первой части {} могут быть знаки \dag, \ddag, \S, \P или номер ссылки в формате Tex {${}^{21}$} но сейчас работает {$^{21}$}
в Latex немного измененный формат \footnote{}
header и footer
определяется командами
\headline{} — header
\footline{} — footer
аналогично как при заполнении \line{}
\headline={\hfil \tenrm Page \the\pageno}
\tenrm — это шрифт roman 10pt
\the\pageno — номер страницы
\folio — тоже номер страницы, но выводит римские буквы когда \pageno отрицательный
\pageno=-1 может быть любого значения
Четные и нечетные заголовки
\headline={\ifodd \pageno {...}\else {...}\fi}
Переполнение или недобор в боксах
При переполнении или недоборе в строках появляется slug — слизень █ который показывает проблему в этой строке.
vbox hbox
Так Tex делит на блоки всю страницу и заполняет ее
vbox — вертикальные блоки абзацев
hbox — горизонтальные блоки строк
\hbadness
Это параметр плохости строки — по умолчанию 1000
Накапливается от количества пробелов, вставленных в строку для ее выравнивания.
Увеличения параметра до 10000 подавляет все сообщения о плохости блока.
\tolerance
Это параметр устанавливает на сколько строка может превышать допустимый размер
По умолчанию = 200. 10000 также стирает все предупреждения.
\hfuzz
Параметр, который определяет, на сколько может выступать переполнение строки \hfuzz = 0.1 pt
\overfullrule
это толщина слизняка slug, появляющегося на полях.
Если установить его 0pt то маркеры будут незаметны
\hyphenation{data-base}
установка переносов для лучшего форматирования боксов
\vbadness
параметры для вертикального наполнения текста на странице
Группы
При наборе текст можно упаковать в группы {}
При выходе из группы, все настройки возвращаются к тем, которые были до входа в группу.
{ \hsize = 4 in \parindent = 0 pt \leftskip = 1 in will produce a paragraph that is four ... (this is an easy mistake to make). \par }
Математичесский режим
Третий режим Tex математический. Задается $…$ в строке и $$…$$ для многострочного блока.
Теоремы — это тоже почти математика.
\proclaim — макрос,который выделит первое предложение до точки. А оставшуюся часть абзаца выдаст как описание теоремы.
\proclaim Theorem 1 (H.~G.~Wells). In the country of the blind, the one-eyed man is king.
Матрицы
Это мне всегда больше нравилось.
$$\pmatrix{
a & b & c & d \cr
b & a & c+d & c-d \cr
0 & 0 & a+b & a-b \cr
0 & 0 & ab & cd \cr
}.$$
создаст матрицу с круглыми скобками
\hfill — выравнивают значения в матрице
\matrix
удаляет разделители круглые скобки и их можно задать явно с помощью команд: \left и \right
$$ \left |
\matrix{
a & b & c & d \cr
b & a & c+d & c-d \cr
0 & 0 & a+b & a-b \cr
0 & 0 & ab & cd \cr
}
\right | $$
типы скобок: (){}[]||
еще можно значения замещать многоточием: \cdots, \vdots, \ddots
Выравнивание по знаку =
$$\eqalign{
a+b &= c+d \cr
x &= w + y + z \cr
m + n + o + p &= q \cr
}$$
Можно нумеровать уравнения тоже через знак &
$$\eqalignno{
a+b &= c+d & (1) \cr
x &= w + y + z \cr
m + n + o + p &= q & * \cr
}$$
Таблицы и tabbing
\settabs — команда создать tabbing
\settabs 4 \columns %установить 4 равных столбца
\+ British Columbia & Alberta & Saskatchewan & Manitoba \cr
\+ Ontario & Quebec & New Brunswick & Nova Scotia \cr
\+ & Prince Edward Island & Newfoundland \cr
+ — начало строки
\cr — завершение строки
\hfil, \hfill выравнивают текст в ячейках
\settabs \+ \hskip 1 in & \hskip 2 in & \hskip 1.5 in & \cr — это более жизненный пример таблицы с установленными значениями ширины столбцов
или так: \settabs \+ ---------- & ------------------ & ----------------------- & \cr
черточки не выводятся, так же как и любой текст
\hrule — начертит линию под строкой
+\strut — сделает отступ вокруг строки
$$\vbox{
\settabs \+ ----------------&-----&----\cr
\+Plums&\hfill \$1&.22\hfill \cr
\+Coffee&\hfill 1&.78\hfill \cr
\+Granola&\hfill 1&.98\hfill \cr
\+Mushrooms&\hfill &.63\hfill \cr
\+Kiwi fruit&\hfill& .39\hfill \cr
\+Orange juice&\hfill 1&.09\hfill \cr
\+Tuna&\hfill 1&.29\hfill \cr
\+Zucchini&\hfill 0&.64\hfill \cr
\+Grapes&\hfill 1&.69\hfill \cr
\+Smoked beef&\hfill &.75\hfill \cr
\+Broccoli&\hfill\underbar{\ \ 1}&\underbar{.09}\hfill \cr
\+Total&\hfill \$12&.55\hfill \cr
}$$
Горизонтальное выравнивание и шаблон \halign
\halign{шаблон} \cr
\halign{\hskip 2 in $#$& \hfil \quad # \hfil & \qquad $#$ & \hfil \quad # \hfil \cr
вместо # будет подставлено значение из строки
\halign{\hskip 2 in $#$& \hfil \quad # \hfil & \qquad $#$ & \hfil \quad # \hfil \cr \alpha & alpha & \beta & beta \cr
\gamma & gamma & \delta & delta \cr
\epsilon & epsilon & \zeta & zeta \cr
}
\hrule — горизонтальная линия
\vrule — вертикальная линия
\offinterlineskip — позволяет зафиксировать раздвижение строк в таблице
\moveright 2 in
\vbox{\offinterlineskip
\halign{\strut \vrule \quad $#$\quad &\vrule \hfil \quad #\quad \hfil &\vrule \quad $#$\quad &\vrule \hfil \quad #\quad \hfil \vrule \cr
\noalign{\hrule}
\alpha & alpha & \beta & beta \cr
\noalign{\hrule} \gamma & gamma & \delta & delta \cr
\noalign{\hrule} \epsilon & epsilon & \zeta & zeta \cr
\noalign{\hrule}
}}
финальный вариант. \moveright сдвинет box на два In вправо
но для этого также исправно работают \centrline, а также \rightline и \leftline
Создание своих макросов
\def\name{}
name — только буквы или одна не буква
Задать переменные #1
\def\name#1#2{#1...#2}
Задать синоним команде \let
\let \newname = \oldname
работать будут оба имени
Протокол ошибок Tex
обязательно в конце ввода поставить \bye
! Undefined control sequence. %название ошибки
l.1 \line{ The left side \hfli %успешно прочитанная строка
the right side} % продолжение строки после ошибки
? %что делать?
варианты ответа:
| Ответ | буква | результат |
|---|---|---|
| help | h | причина указана на терминале |
| insert | i | показать следующую строку |
| exit | x | завершить tex |
| scroll | s | прокрутить ошибки |
| run | r | продолжить работу |
| quiet | q | подавляет вывод в терминал |
| carry on | продолжить лучше как можно |
Большие файлы
\input filename
добавит маленькие файлы в большой
Линии rule
\hrule \vrule — имеют параметры width height depth
\vrule height 0 pt depth 0.4 pt width 3 in
Boxes
\vbox и \hbox — основные кирпичи в tex.
Вкладывая их друг в друга можно получить любой результат.
Задать размер \hbox to 5cm{}
у \vbox есть брат \vtop — будет выравнивать по верхнему краю boxes
\vbox{ \hrule
\hbox{\vrule{} The text to be boxed \vrule}
\hrule }
А это будет текст в рамочке, а с ключевым слово \strut — оно будет с отступами
Перемещение box по странице
\moveright \moveleft — переместит вертикальный бокс
\raise \lower — переместит горизонтальный бокс
Линии в боксе
\hbox to 5 in{Getting Started\hrulefill 1} и еще есть \dotfill — полезно для оглавления
7.6.4 -
7.7 - Графический пакет TIKZ для Latex
Дружелюбный функционал для полной графики в Latex. Картинки, иконки, графики и пр.
Дружелюбный функционал для полной графики в Latex. Картинки, иконки, графики и пр. Очень мощный пакет в котором можно нарисовать все.
Обзор пакета Tikz для рисования графики в Latex.
Установка пакета
\usepackage{tikz}
Использование пакета
Окружение {tikzpicture} или команды \tikzpicture и \endtikzpicture
Использование дополнительных библиотек
\documentclass{article} % say
\usepackage{tikz}
\usetikzlibrary{arrows.meta,decorations.pathmorphing,backgrounds,positioning,fit,petri}
\begin{document}
\begin{tikzpicture}
\draw (0,0) -- (1,1);
\end{tikzpicture}
\end{document}
7.7.1 - Дисплей для руководства пользователя
Практическая задача в LATEX по созданию настраиваемого дисплея при описании руководства пользователя
Примеры использования поисковых запросов POSIX
Практический пример построения средствами LATEX TIKZ графических элементов в документации
Постановка задачи
Для описания инструкции по эксплуатации прибора необходимо описывать интерфейс внутренней программы с меню и другими изображениями на 7-ми строчном дисплее.
Дисплей имеет 22 знака в ширину и 7 строк.
Необходимо создать однострочную команду в Latex для удобного заполнения параметров дисплея и вывода графического изображения в любое место на странице документации.
Команда должна обеспечивать сохранение размеров и цветовой гаммы дисплея на всех страницах документации однообразными.
- Дисплей должен отражать текстовые строки заглавными и строчными буквами латинского алфавита.
- На дисплее должны отображаться арабские цифры
- Графические элементы применяемые на дисплее:
- аккумулятор
- антенна
- уровень сигнала
- замок
- линия под статусной строкой
- линия середины экрана
- Типы строк дисплея:
- строка с текстом выровненным по левому краю до 22 символов
- строка подсвеченная прямоугольником с инвертированным цветом символов
- строка с текстом выровненным по середине экрана
- строка с текстом в две колонки
- строка без текста
- Типы строк статусной строки
- режим 1 с аккумулятором и антенной
- режим 2 с аккумулятором
- режим 3 текст
- Отдельный режим отображения средней линии на дисплее
- Режим вывода картинки в правой части дисплея
- Обозначение подсвеченных информационных кнопок в нижней части дисплея
- Информационный режим дисплея
Решение задачи
- Использование издательской системы Latex
- Загрузка специального графического пакета TIKZ
- Настройка графических примитивов с помощью библиотеки TIKZ для использования в строках
- Программирование Tex для создания простых команд для указания в строках дисплея выводимой информации
- Создание библиотеки с возможностью многократного использования дисплея в различных документах
Описание решения
\definecolor{disp}{HTML}{000041} % цвет дисплея
\definecolor{textdisp}{HTML}{f0ffff} %цвет текста дисплея
\tikzset{%настройки стиля шрифта для вывода символов на терминал дисплея
terminal/.style = {text=textdisp,inner sep=0pt, anchor=west,font=\fontfamily{cmtt}\fontsize{10}{10}\selectfont}}
Создание графических элементов
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%Аккумулятор
%%%%%%%%%%%%%
\tikzset{
accum/.pic={[font=\ttfamily]
\path (.5,.35) coordinate(acbl) ++(1,0) coordinate(acbr)
++(0,.6) coordinate(actr) ++(-1,0) coordinate(actl);
\draw[pic actions,thick] (acbl) -- (acbr) -- ($(acbr)!.2!(actr)$)-- ++(1pt,0) |- ($(acbr)!.8!(actr)$) -- (actr) -- (actl) -- cycle;
\fill[pic actions] (acbl) rectangle ($(actl)!#1!(actr)$);
}
}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%Антенна
%%%%%%%%%%%%%
\tikzset{
antena/.pic={
\path
(0,.35) coordinate(anbot) ++(0,.6) coordinate(antop)
+(-.3,0) coordinate(antl) +(.3,0) coordinate(antr);
\draw[pic actions,thick] (anbot) -- (antop)
($(anbot)!.5!(antop)$)--(antl)
($(anbot)!.5!(antop)$)--(antr);
\path[pic actions] (anbot) ++(.4,.3) node[terminal]{100\%};
}
}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%Уровень сигнала
%%%%%%%%%%%%%
\tikzset{
lsignal/.pic={
\coordinate (a) at (.35,.35);
\draw[pic actions,thick] (a) foreach \x in {1,...,#1} {+(.\x,0) -- +(.\x,.\x)};
}
}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%замок LOCK
%%%%%%%%%%%
\tikzset{
lockc/.pic={
\path (0,.15) coordinate (bl) +(.4,0) coordinate (br) +(.4,.3) coordinate (tr) +(0,.3) coordinate (tl);
\draw[pic actions,thick,fill] (bl) rectangle (tr);
\draw[thick,out=90,in=90,distance=.3em] (tl) to (tr);
}
}
Настройка типов строк
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%активная строка
%%%%%%%%%%%%%
\tikzset{
araw/.pic={%отображает строку подсвеченной как активную без текста
\path
(.4,.2) coordinate(arbl) ++(11.6,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-11.6,0) coordinate(artl);
\fill[white!95,opacity=.7] (arbl) rectangle (artr);
},
arawp/.pic={%выводит текст без подсветки
\path
(0.4,.2) coordinate(arbl) ++(11.6,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-11.6,0) coordinate(artl);
\node[terminal,text width=5.6em] at ($(arbl)!.5!(artl)$) {#1};%обычная строка
},
arawa/.pic={%выводит текст в активной строке
\path
(0.4,.2) coordinate(arbl) ++(11.6,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-11.6,0) coordinate(artl);
\node[terminal,text width=5.6em,text=disp] at ($(arbl)!.5!(artl)$) {#1} [fill=white!95,opacity=.7] (arbl) rectangle (artr);%обычная строка
},
lbut/.pic={%выводит текст в левой функциональной кнопке в нижнем ряду
\path
(.4,.2) coordinate(arbl) ++(5.7,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-5.7,0) coordinate(artl);
\node[terminal,text=disp,anchor=center] at ($(arbl)!.5!(artr)$) {#1} [fill=white!95,opacity=.7] (arbl) rectangle (artr) ;
},
rbut/.pic={%выводит текст в правой функциональной кнопке в нижнем ряду
\path
(6.3,.2) coordinate(arbl) ++(5.7,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-5.7,0) coordinate(artl);
\node[terminal,text=disp,anchor=center] at ($(arbl)!.5!(artr)$) {#1} [fill=white!95,opacity=.7] (arbl) rectangle (artr) ;
},
rawc/.pic={%строка через весь дисплей с выделенной активностью и текстом по центру
\path
(.4,.2) coordinate(arbl) ++(11.6,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-11.6,0) coordinate(artl);
\node[terminal,text=disp,anchor=center] at ($(arbl)!.5!(artr)$) {#1} [fill=white!95,opacity=.7] (arbl) rectangle (artr);
}
}
Оформление контура дисплея
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%Дисплей маленького экрана
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\tikzset{
display/.pic={%рамка для дисплея
\path[terminal] (0,.2) coordinate (dtl) ++(12.4,0) coordinate (dtr) ++(0,-7.2) coordinate (dbr) ++(-12.4,0) coordinate (dbl);
\draw[thick,gray!20,fill=disp,rounded corners] (dbl) rectangle (dtr);
}
}
Создание стилей строки статуса для различных режимов
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%Строка состояния пульта
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\tikzset{
pultmain/.pic={% режим 1 с произвольным текстом, часами и аккумулятором заголовок дисплея пульт на вход отправим text
\path
(0.4,.2) coordinate(arbl) ++(11.6,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-11.6,0) coordinate(artl);
\path ($(arbl)!.5!(artl)$) node[terminal] {#1} +(4,0) node[terminal] {08:20:46};
\pic[textdisp] at (10.4,0) {accum=.4};
\draw[textdisp,thick] (arbl.south west)--(arbr.south east);
},
pultfree/.pic={%заголовок дисплея пульт на вход отправим свободную строку
\path
(0.4,.2) coordinate(arbl) ++(11.6,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-11.6,0) coordinate(artl);
\node[terminal,text width=10.5em] at ($(arbl)!.5!(artl)$) {#1};%обычная строка
\pic[textdisp] at (10.4,0) {accum=.4};%\fill[red](arbl.south west)circle (1pt);
\draw[textdisp,thick] (arbl.south west)--(arbr.south east);
},
priemfree/.pic={%заголовок дисплея приемника на вход отправим свободную строку
\path
(0.4,.2) coordinate(arbl) ++(11.6,0) coordinate(arbr)
++(0,.9) coordinate(artr) ++(-11.6,0) coordinate(artl);
\pic[textdisp]{accum=.5};\pic[textdisp] at (9.4,0) {antena};
\draw[textdisp,thick] (arbl.south west)--(arbr.south east);
},
rawg/.pic={\node[terminal,text width=5.6em] {#1};%обычная строка
},
rawa/.pic={\pic{arow} node[terminal,text width=5.6em,text=disp] {#1};%активная строка
}
}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%шаблон дисплея создаем команду \dispm с 8-ю входными параметрами
\def\dispm#1#2#3#4#5#6#7#8{
\begin{tikzpicture}[x=10pt,y=10pt,node distance=10pt]%установить масштаб отображения
\pic{display};%вывести фон дисплея
\pic at (0,-1) {#1};%строка состояния
\pic at (0,-2) {#2};%вторая строка
\pic at (0,-3) {#3};%третья строка
\pic at (0,-4) {#4};%четвертая строка
\pic at (0,-5) {#5};%пятая строка
\pic at (0,-6) {#6};%шестая строка
\path (0,-7) pic{lbut=#7} pic{rbut=#8};%седьмая строка с кнопками состояния
\draw[textdisp,thick] (6.2,-.9) -- (6.2,-5.9);%линия по центру экрана вертикальная
\end{tikzpicture}
}
% \dispm
% {}%1-я строка значения входного параметра (pultmain=text priemfree, pultfree=TEXT)
% {}%2-я строка (arawa=TEXT - активная строка, )
% {}%3-я строка (arawp=TEXT - пассивная строка,)
% {}%4-я строка (rawc=TEXT - активная строка с текстом по центру)
% {}%5-я строка
% {}%6-я строка
% {}{}%нижние кнопки в 7-й строке
%
Пример
\dispm
{pultmain=ARM}%1-я строка (pultmain=ARM, pultmain=DISARM, priemfree, pultfree=TEXT)
{arawa=TEXT}%2-я строка (arawa=TEXT - активная строка, )
{arawp=TEXT}%3-я строка (arawp=TEXT - пассивная строка,)
{}%4-я строка (rawc=TEXT - активная строка с текстом по центру)
{}%5-я строка
{rawc=TEXT}%6-я строка
{MENU}{SERVICE}%нижние кнопки в 7-й строке
7.7.2 - Foreach for Tex
Пакет pgffor для использования функции FOREACH в TEX
Циклы в Tex и Latex
Установка
\usepackage{pgffor} % LATEX
\input pgffor.tex % plain TEX
\usemodule[pgffor] % ConTEXt
Отдельный пакет для самостоятельного использования в документах Tex и Latex
По умолчанию сам загружает пакет \tikz
Он определяет две новые команды: \foreach и \breakforeach.
Синтаксис
\foreach 〈variables〉 [〈options〉] in 〈list〉 〈commands〉
Простой пример
\def\mylist{1,2,3,0}
\foreach \x in \mylist {[\x]}
Выдаст: [1][2][3][0]
Вложенные циклы
\begin{tikzpicture}
\foreach \x in {0,1,2,3}
\foreach \y in {0,1,2,3}
{
\draw (\x,\y) circle (0.2cm);
\fill (\x,\y) circle (0.1cm);
}
\end{tikzpicture}
Списки через многоточие
\foreach \x in {a,b,9,8,...,1,2,2.125,...,2.5} {\x, }
выдаст:
a, b, 9, 8, 7, 6, 5, 4, 3, 2, 1, 2, 2.125, 2.25, 2.375, 2.5,
\foreach \x in {2^1,2^...,2^7} {$\x$, } yields 21, 22, 23, 24, 25, 26, 27,
\foreach \x in {0\pi,0.5\pi,...\pi,3\pi} {$\x$, } yields 0π, 0.5π, 1π, 1.5π, 2π, 2.5π, 3π,
\foreach \x in {A_1,..._1,H_1} {$\x$, } yields A1, B1, C1, D1, E1, F1, G1, H1,
Координаты для TIKZ
\tikz \foreach \position in {(0,0), (1,1), (2,0), (3,1)}
\draw \position rectangle +(.25,.5);
Несколько переменных в цикле
\begin{tikzpicture}
\foreach \x/\xtext in {0,...,3,2.72 / e}
\draw (\x,0) node{$\xtext$};
\end{tikzpicture}
задан паттерн для получения переменных \x второе значение через / — \xtext
Отсутствие значений для второго параметра замещается первым значением.
Пробовал другие разделители, но стабильно работает только
/\begin{tikzpicture} % Let's draw circles at interesting points:
\foreach \x / \y / \r in {0 / 0 / 2mm, 1 / 1 / 3mm, 2 / 0 / 1mm}
\draw (\x,\y) circle (\r);
% Same effect
\foreach \center/\r in {{(0,0)/2mm}, {(1,1)/3mm}, {(2,0)/1mm}} \draw[yshift=2.5cm] \center circle (\r);
\end{tikzpicture}
Угловые координаты
\begin{tikzpicture}[line cap=round,line width=3pt]
\filldraw [fill=yellow!80!black] (0,0) circle (2cm);
\foreach \angle / \label in
{0/3, 30/2, 60/1, 90/12, 120/11, 150/10, 180/9, 210/8, 240/7, 270/6, 300/5, 330/4}
{
\draw[line width=1pt] (\angle:1.8cm) -- (\angle:2cm);
\draw (\angle:1.4cm) node{\textsf{\label}};
}
\foreach \angle in {0,90,180,270}
\draw[line width=2pt] (\angle:1.6cm) -- (\angle:2cm);
\draw (0,0) -- (120:0.8cm); % hour
\draw (0,0) -- (90:1cm); % minute
\end{tikzpicture}%

Параметры настройки оператора foreach
Описанные ниже ключи можно использовать в аргументе 〈options〉 команды \foreach. Все они имеют путь /pgf/foreach/, однако путь устанавливается автоматически при анализе 〈options〉, поэтому его не нужно указывать явно.
/pgf/foreach/var=〈variable〉— Этот ключ обеспечивает альтернативный способ указания переменных: \foreach [var=\x,var=\y] аналогичен \foreach \x/\y./pgf/foreach/evaluate=〈variable〉 as 〈macro〉 using 〈formula〉— Этот ключ позволяет оценивать переменную с помощью математического механизма.\foreach \x [evaluate=\x] in {2^0,2^...,2^8}{$\x$, }вернет 1.0, 2.0, 4.0, 8.0, 16.0, 32.0, 64.0, 128.0, 256.0,
as
или \foreach \x [evaluate=\x as \xeval] in {2^0,2^...,2^8}{$\x=\xeval$, } значение будет помещено в \xeval
using
указывает формулу для вычисления
\tikz\foreach \x [evaluate=\x as \shade using \x*10] in {0,1,...,10} \node [fill=red!\shade!yellow, minimum size=0.65cm] at (\x,0) {\x};
/pgf/foreach/remember=〈variable〉 as 〈macro〉 (initially 〈value〉)— Этот ключ позволяет запомнить значение элемента, хранящееся в 〈variable〉, во время следующей итерации, сохраненное в 〈macro〉.
\foreach \x [remember=\x as \lastx (initially A)] in {B,...,H}{$\overrightarrow{\lastx\x}$, }
/pgf/foreach/count=〈macro〉 from 〈value〉— считает номер итерации
\tikz[x=0.75cm,y=0.75cm]
\foreach \x [count=\xi] in {a,...,e}
\foreach \y [count=\yi] in {\x,...,e}
\node [draw, top color=white, bottom color=blue!50, minimum size=0.666cm]
at (\xi,-\yi) {$\mathstrut\x\y$};
/pgf/foreach/parse={〈boolean〉}— Если для этого ключа установлено значение true, верхняя граница цикла будет передана в \pgfmathparse./pgf/foreach/expand list={〈boolean〉}— Если для этого ключа установлено значение true, содержимое списка полностью раскрывается с помощью \edef перед дальнейшей обработкой.
\breakforeach
Если эта команда задана внутри команды \foreach, дальнейшее выполнение 〈команд〉 происходить не будет. Однако текущее выполнение 〈команд〉 продолжается в обычном режиме, поэтому, вероятно, лучше использовать эту команду только в конце команды \foreach.
7.7.3 - Key Management
Key Management из пакета pgfkeys, может использоваться самостоятельно или в составе пакета TIKZ, управляет ключами пользователя
Ключи пользователя для управления различными состояниями в LATEX
Введение
В основном этот раздел описываю, так как его активно используют библиотеки TIKZ.
А в общем этот вопрос вполне удовлетворяет знание TEX и его внутренней кухни по созданию макросов и переменных.
Подключение пакета
\usepackage{pgfkeys}
Отличия pgfkeys от xkeyval
- pgfkeys организует дерево ключей
- pgfkeys не влияет на состояние стека
- pgfkeys медленнее keyval
- pgfkeys поддерживает стили (полезно для TIKZ)
- pgfkeys поддерживает множественные аргументы
- pgfkeys поддерживает обработчики обратного вызова и ошибок
Краткое описание механизма Key Management
Организован по принципу файловой системы Unix, корень и как дерево ветвление всех элементов
Можно указать полный путь к ключу или сокращенное наименование и путь будет подставлен автоматически.
Основная команда \pgfkeys берет пару ключ и значение.
Для каждого
\pgfkeys{/my key=hallo,/your keys/main key=something\strange,
key name without path=something else}
Сначала установим код для ключа: стр.1 и затем выполним его с переданным параметром стр.2
\pgfkeys{/my key/.code=The value is '#1'.}
\pgfkeys{/my key=hi!}
В качестве параметров может быть несколько значений (ключевое слово /.code 2 args=)
\pgfkeys{/my key/.code 2 args=The values are '#1' and '#2'.}
\pgfkeys{/my key={a1}{a2}}
Может быть значение по умолчанию: \pgfkeys{/my key/.default=hello}
Можно указать обязательное значение /.value required или запрещенное значение /.value forbidden, т.е. не нужно вводить значение.
Ключ /.cd - изменит путь. Т.е. после этого ключа, все остальные будут выполнять команды с новым путем.
\pgfkeys{/tikz/.cd,line width=1cm,line cap=round}
т.е. все остальные команды будут начинаться с /tikz/
Ключи могут вызывать выполнение других ключей.
\pgfkeys{/a/.code=(a:#1)}
\pgfkeys{/b/.code=(b:#1)}
\pgfkeys{/my style/.style={/a=foo,/b=bar,/a=#1}}
\pgfkeys{/my style=wow}
получим (a:foo)(b:bar)(a:wow)
Еще пример с созданием стиля tikz
\pgfkeys{/tikz/.style=/tikz/.cd}
\pgfkeys{tikz,line width=1cm,draw=red}
Описание синтаксиса pgfkeys
Если ключ начинается с / — это ключ с полным путем, если без слеша, то это не полный путь.
\pgfkeyssetvalue{⟨full key⟩}{⟨token text⟩}
Эта команда сохраняет token text в full key
Это не может быть частичным ключом.
\pgfkeyssetvalue{/my family/my key}{Hello, world!}%установить ключ
\pgfkeysvalueof{/my family/my key}%вывести ключ
\pgfkeyssetevalue{⟨full key⟩}{⟨token text⟩} — это тоже, но \edef версия
\pgfkeyslet{⟨full key⟩}{⟨macro⟩}
\def\helloworld{Hello, world!}
\pgfkeyslet{/my family/my key}{\helloworld}
\pgfkeysvalueof{/my family/my key}
позволяет устанавливать для ключа значение макроса, в нашем случае будет подставлено значение \helloworld
Недопустимо,чтобы ключ совпадал с \relax — relax это пустышка
\pgfkeysgetvalue{⟨full key⟩}{⟨macro⟩}
Извлекает токены из ключа
Если ключ не установлен то токен будет равен \relax
\pgfkeysvalueof{⟨full key⟩}
Возвращает значение ключа и вставляет его в текст
\pgfkeysifdefined{⟨full key⟩}{⟨if⟩}{⟨else⟩}
\pgfkeyssetvalue{/my family/my key}{Hello, world!}
\pgfkeysifdefined{/my family/my key}{yes}{no}
проверяет, если ключ был определен, то выведет значение if, если не определен, то else
\pgfkeys
Главная команда для установки ключей
Ключи могут выполнять следующие действия:
- выполняет команду,хранящуюся в key с аргументом value
- сохраняет значение value в ключе key
- если имя ключа известный обработчик,тогда обработчик все сделает
- если ключ неизвестный, то вызовется обработчик неизвестных ключей
Синтаксис команд
\pgfkeys{key=value,key,key={val1}{val2}}
Возможно указать:
- key=value,
- key,
- key={val1}{val2}
или просто значение в {} если оно содержит запятые или спецсимволы
\pgfqkeys{⟨default path⟩}{⟨key list⟩}
Эта команда имеет тот же эффект,что и \pgfkeys{⟨default path⟩/.cd,⟨key list⟩}
\pgfkeysalso{⟨key list⟩}
в этой команде путь не изменяется
\pgfqkeysalso{⟨default path⟩}{⟨key list⟩}
вызывает с изменением пути
Команда привязанная к 1 символу
Если в командной строке \pgfkeys встретится строка, обернутая в этот символ, то она будет передана в макрос этого символа как параметр
Наверно это удобно.
Так работают во всех nodes кавычки " которые заменяются текстом \label={}
Для этого нужно:
- Установить
/handlers/first char syntax=〈true or false〉вtrue - Привязать к волшебному слову
the character <символ>макрос, который будет выполняться - Объявить привязанный макрос
\pgfkeys{
/handlers/first char syntax=true,
/handlers/first char syntax/the character "/.initial=\myquotemacro,
/handlers/first char syntax/the character </.initial=\mypointedmacro,
}
\def\myquotemacro#1{Quoted: #1. }
\def\mypointedmacro#1{Pointed: #1. }
\ttfamily \pgfkeys{"foo", <bar>}
Дальше все параметры в "" будут переданы в макрос myquotemacro, а в <> в макрос mypointedmacro
Значение по умолчанию 〈key〉/.@def
- если не нужно вводить значения, то можно указать
key=\pgfkeysnovalue - проверяется наличие ключа:
〈key〉/.@def - если ключ есть, то он замещается в токене
Для установки по умолчанию значения используем команду: \pgfkeys{/my key/.default=hello}
Команды выполняемые в ключах 〈key〉/.@cmd
Во всем макросах в \pgf параметры должны заканчиваться значением \pgfeov
т.е. что сделает на самом деле пакет \pgf
\usepackage {shortvrb} \MakeShortVerb {\|}
\def\mystore#1+#2\pgfeov{\def\a{#1}\def\b{#2}}
\pgfkeyslet{/my key/.@cmd}{\mystore}
\pgfkeys{/my key=hello+world}
получим:
|\a| is `\a', |\b| is `\b'.
т.е.
\a is ‘hello’, \b is ‘world’.
Что предлагает пакет взамен
\pgfkeysdef{〈key〉}{〈code〉}— Эта команда временно определяет TEX-макрос со списком аргументов #1\pgfeov, а затем позволяет 〈key〉/.@cmd быть равным этому макросу.\pgfkeysedef{〈key〉}{〈code〉}— аналогично, но работает, какedef\pgfkeysdefnargs{〈key〉}{〈argument count〉}{〈code〉}— Эта команда работает аналогично \pgfkeysdef, но позволяет вам указать произвольное «счетчик аргументов» от 0 до 9 (включительно).
\usepackage {shortvrb} \MakeShortVerb {\|}
\pgfkeysdefnargs{/my key}{2}{\def\a{#1}\def\b{#2}}
\pgfkeys{/my key= {hello} {world}}
|\a| is `\a', |\b| is `\b'
\pgfkeysedefnargs{〈key〉}{〈argument count〉}{〈code〉}— аналогично, ноedef\pgfkeysdefargs{〈key〉}{〈argument pattern〉}{〈code〉}— Эта команда работает аналогично \pgfkeysdefnargs, но позволяет вам предоставить произвольный «шаблон аргумента», а не просто несколько аргументов.\pgfkeysdefargs{/my key}{#1+#2}{\def\a{#1}\def\b{#2}}\pgfkeysedefargs{〈key〉}{〈argument pattern〉}{〈code〉}— это егоedefверсия
Хранение значений в ключах
Если у ключа не определен key/.@cmd, то он будет просто хранить значение которое может быть задано командой \pgfkeyssetvalue
Обработчики ключей
Обработчики — это дополнительная возможность выполнять некие действия над ключами сверх того, что предоставляется стандартной библиотекой.
\pgfkeysdef{/handlers/.my code}{\pgfkeysdef{\pgfkeyscurrentpath}{#1}}
Путь ключа, хранится в макросе
\pgfkeyscurrentpathИмя ключа, хранится в макросе
\pgfkeyscurrentnameобработчик должен начинаться с
./handler config=all|only existing|full or existing— Изменяет исходную конфигурацию использования обработчиков ключей./handler config/only existing/add exception={〈key handler name〉}— Позволяет добавлять исключения к существующей функции /handler config=only.
Обработка ключей, которые неизвестны
Для некоторых ключей не определен ни сам ключ, ни его подраздел .@cmd, ни обработчик. В этом случае проверяется, существует ли ключ 〈текущий путь〉/.unknown/.@cmd.
Т.к. он существует, то будет выполнена какая-то странная вещь, как он ее поймет.
Пути поиска и обрабатываемые ключи
Обработчики ключей
Теперь мы опишем, какие обработчики клавиш определены по умолчанию.
Обработчик пути
Key handler 〈key〉/.cd— Этот обработчик устанавливает путь по умолчанию 〈key〉. Обратите внимание, что путь по умолчанию сбрасывается в начале каждого вызова \pgfkeys и становится равным/.
\pgfkeys{/tikz/.cd,...}
Key handler 〈key〉/.is family— Этот обработчик настраивает такие вещи, что при выполнении 〈key〉 текущий путь устанавливается на 〈key〉.
\pgfkeys{/tikz/.is family}
\pgfkeys{tikz,line width=1cm}
Установка по умолчанию
Key handler 〈key〉/.default=〈value〉— Устанавливает значение по умолчанию 〈key〉 в 〈value〉. Это означает, что всякий раз, когда при вызове \pgfkeys не указывается значение, вместо него будет использоваться это 〈значение〉.\pgfkeys{/width/.default=1cm}Key handler 〈key〉/.value required— Этот обработчик вызывает выдачу ключа /errors/value сообщения об ошибке всякий раз, когда 〈key〉 используется без значения.\pgfkeys{/width/.value required}Т.е. требует обязательно указать значение.Key handler 〈key〉/.value forbidden— не будет выдавать сообщение об ошибке, если указано будет значение ключа
Определение кода ключа
Key handler 〈key〉/.code=〈code〉— Этот обработчик выполняет \pgfkeysdef с параметрами 〈key〉 и 〈code〉.Key handler 〈key〉/.ecode=〈code〉— выполнит команду \pgfkeysedefKey handler 〈key〉/.code 2 args=〈code〉— с двумя аргументамиKey handler 〈key〉/.ecode 2 args=〈code〉— с двумя аргументами edefKey handler 〈key〉/.code n args={〈argument count〉}{〈code〉}— с n аргументамиKey handler 〈key〉/.ecode n args={〈argument count〉}{〈code〉}— с n аргументами edefKey handler 〈key〉/.code args={〈argument pattern〉}{〈code〉}— с произвольным паттерном аргументовKey handler 〈key〉/.ecode args={〈argument pattern〉}{〈code〉}— с произвольным паттерном аргументов edefKey handler 〈key〉/.add code={〈prefix code〉}{〈append code〉}— Этот обработчик добавляет код к существующему ключу. 〈код префикса〉 добавляется к коду, хранящемуся в 〈key〉/.@cmd, в начале, 〈код добавления〉 добавляется к этому коду в конце.
\pgfkeys{/par indent/.code={\parindent=#1}}
\newdimen\myparindent
\pgfkeys{/par indent/.add code={}{\myparindent=#1}}
...
\pgfkeys{/par indent=1cm} % This will set both \p
Key handler 〈key〉/.prefix code=〈prefix code〉— Этот обработчик является ярлыком для 〈key〉/.add code={〈prefix code〉}{}. То есть этот обработчик добавляет 〈префиксный код〉 в начало кода, хранящегося в 〈key〉/.@cmd.Key handler 〈key〉/.append code=〈append code〉— Этот обработчик является ярлыком для 〈key〉/.add code={}{〈append code〉}.
Определение стиля
Key handler 〈key〉/.style=〈key list〉— Этот обработчик настраивает ситуацию таким образом, что всякий раз, когда 〈ключ〉=〈значение〉 встречается в списке ключей, вместо этого обрабатывается 〈список ключей〉, в котором каждое вхождение #1 заменено на 〈значение〉. Как всегда, если 〈значение〉 не указано, используется значение по умолчанию, если оно определено, или специальное значение \pgfkeysnovalue.
\pgfkeys{/par indent/.code={\parindent=#1}}
\pgfkeys{/no indent/.style={/par indent=0pt}}
\pgfkeys{/normal indent/.style={/par indent=2em}}
\pgfkeys{/no indent}
...
\pgfkeys{/normal indent}
Key handler 〈key〉/.estyle=〈key list〉— определяет стиль черезedefKey handler 〈key〉/.style 2 args=〈key list〉— с двумя аргументамиKey handler 〈key〉/.estyle 2 args=〈key list〉— с двумя аргументами edefKey handler 〈key〉/.style n args={〈argument count〉}〈key list〉— n аргументовKey handler 〈key〉/.add style={〈prefix key list〉}{〈append key list〉}— добавить значение к стилюKey handler 〈key〉/.style args={〈argument pattern〉}{〈key list〉}— стиль с произвольным паттерномKey handler 〈key〉/.estyle args={〈argument pattern〉}{〈code〉}— стиль с произвольным паттерном edefKey handler 〈key〉/.prefix style=〈prefix key list〉— prefix style добавитьKey handler 〈key〉/.append style=〈append key list〉— добавить стиль в конец
Определение ключей значений, макросов, if и выбора
Для некоторых клавиш код, который должен по ним выполняться, достаточно «специализирован».
Key handler 〈key〉/.initial=〈value〉— Этот обработчик устанавливает значение 〈key〉 в 〈value〉. Обратите внимание, что никакие подразделы не задействованы. После использования этого обработчика, согласно правилам, регулирующим ключи, вы можете впоследствии изменить значение 〈key〉, просто написав 〈key〉=〈value〉. Таким образом, этот обработчик используется для установки начального значения ключа.Key handler 〈key〉/.get=〈macro〉— выведет содержимое ключа и поместит в\macroKey handler 〈key〉/.add={〈prefix value〉}{〈append value〉}— добавит к ключуKey handler 〈key〉/.prefix={〈prefix value〉}— добавит префиксKey handler 〈key〉/.append={〈append value〉}— добавит суффиксKey handler 〈key〉/.link=〈another key〉— сделает ссылку на другой ключKey handler 〈key〉/.store in=〈macro〉— это прямой аналог\def\macro{#1}
\pgfkeys{/text/.store in=\mytext}
\def\a{world} \pgfkeys{/text=Hello \a!}
\def\a{Gruffalo}
\mytext
выведет:
Hello Gruffalo!
Key handler 〈key〉/.estore in=〈macro〉— тоже, только edefKey handler 〈key〉/.is if=〈TEX-if name〉— имитация if Tex
\newif\iftheworldisflat
\pgfkeys{/flat world/.is if=theworldisflat}
\pgfkeys{/flat world=false}
\iftheworldisflat
Flat \else Round?
\fi
Key handler 〈key〉/.is choice— Этот обработчик настраивает ситуацию так, что запись 〈key〉=〈value〉 приведет к выполнению подраздела 〈key〉/〈value〉. Таким образом, каждый из возможных вариантов должен быть задан подразделом 〈key〉.
\pgfkeys{/line cap/.is choice}
\pgfkeys{/line cap/round/.code={\pgfsetroundcap}}
\pgfkeys{/line cap/butt/.code={\pgfsetbuttcap}}
\pgfkeys{/line cap/rect/.code={\pgfsetrectcap}}
\pgfkeys{/line cap/rectangle/.style={/line cap=rect}}
...
\draw [/line cap=butt] ...
Расширенные и множественные значения
Key handler 〈key〉/.expand once=〈value〉— Этот обработчик расширяет 〈value〉 один раз (точнее, он выполняет команду \expandafter для первого токена 〈value〉), а затем обрабатывает полученный 〈result〉, как если бы вы написали 〈key〉=〈result〉.Key handler 〈key〉/.expand twice=〈value〉— дважды расширяет значениеKey handler 〈key〉/.expanded=〈value〉— Этот обработчик полностью расширит 〈value〉 (с помощью \edef) перед обработкой 〈key〉=〈result〉.Key handler 〈key〉/.evaluated=〈value〉— Этот обработчик оценит 〈value〉 как математическое выражение с помощью \pgfmathparse и присвоит 〈key〉=\pgfmathresult.Key handler 〈key〉/.list=〈comma-separated list of values〉— Этот обработчик вызывает многократное использование ключа, а именно один раз для каждого элемента списка значений. Что-то вроде foreach
Обработчик с пересылкой значений
Key handler 〈key〉/.forward to=〈another key〉— Этот обработчик заставляет 〈key〉 «пересылать» свой аргумент 〈другому ключу〉. При использовании 〈key〉 сначала будет выполнен ее обычный код. Затем значение (дополнительно) передается «другому ключу».
\pgfkeys{
/a/.code=(a:#1),
/b/.code=(b:#1),
/b/.forward to=/a,
/c/.forward to=/a
}
\pgfkeys{/b=1} \pgfkeys{/c=2}
выведет
(b:1)(a:1) (a:2)
Key handler 〈key〉/.search also={〈path list〉}— Стиль, который устанавливает обработчик /.unknown в 〈key〉. Этот обработчик /.unknown затем будет искать неизвестные ключи по каждому пути, указанному в {〈списке путей〉}.
Обработчики для тестирования ключей
Key handler 〈key〉/.try=〈value〉— Этот обработчик вызывает то же самое, как если бы вместо этого было написано 〈key〉=〈value〉. Однако если ни 〈key〉/.@cmd, ни сам ключ не определены, обработчики вызываться не будут. Вместо этого выполнение ключа просто останавливается. Таким образом, этот обработчик «пытается» использовать ключ, но никаких дальнейших действий не предпринимается, если ключ не определен.Key handler 〈key〉/.retry=〈value〉— Этот обработчик работает так же, как /.try, только он ничего не будет делать, если \ifpgfkeyssuccess имеет значение false. Таким образом, этот обработчик попытается установить ключ только в том случае, если «последняя попытка не удалась».Key handler 〈key〉/.lastretry=〈value〉— Этот обработчик работает как /.retry, только он будет вызывать обычные обработчики для неизвестных ключей, если \ifpgfkeyssuccess имеет значение false.
Обработчики для проверки ключей
Key handler 〈key〉/.show value— Этот обработчик выполняет команду \show для значения, хранящегося в 〈key〉. Это полезно в основном для отладки.Key handler 〈key〉/.show code— Этот обработчик выполняет команду \show для кода, хранящегося в 〈key〉/.@cmd. Это полезно в основном для отладки.
Обработка ошибок
В определенных ситуациях могут возникнуть ошибки, например, при использовании неопределенного ключа. В таких ситуациях выполняются ключи ошибок. Они должны хранить макрос, который получает два аргумента: первый — это ключ-нарушитель (возможно, только после раскрытия макроса), второй — значение, которое было передано в качестве параметра (также возможно, только после раскрытия макроса).
Ключевая фильтрация
Обычно вызов \pgfkeys устанавливает все ключи, указанные в списке аргументов. Обычно именно этого ожидают пользователи. Однако реализации различных пакетов или pgf-библиотек могут нуждаться в большем контроле над процедурой установки ключей: библиотека A может захотеть установить свои параметры напрямую и передать все оставшиеся в библиотеку B.
Установить библиотеку фильтрации
\usepgfkeyslibrary{filtered} % LATEX and plain TEX
\usepgfkeyslibrary[filtered] % ConTEXt
7.7.4 - Примеры PIC в библиотеке TIKZ
Живой пример использования мощи TIKZ на примерах с маленькими картинками PIC
Примеры использования поисковых запросов POSIX
Живой пример для создания настраиваемых картинок при описании документации
Постановка задачи
Необходимо разработать динамичную картинку,которой на вход подается массив адресов и они размещаются в структурированной матрице с цифровым обозначением выходов на устройстве.
Немного запутанно, но суть в том, что у устройства есть адреса на каждом выходе, и эти адреса изменяются, а картинок несколько.
Было принято решение не рисовать в редакторе картинки, а запрограммировать в LATEX и на вход просто подавать массив с адресами и номерами выходов.
- рисуем матрицу с адресами
- адрес состоит из двух частей, разделенных :
- первая часть 4 разряда
- вторая часть 5 разрядов
- матрица может располагаться горизонтально и вертикально
- в вертикальном положении над каждым адресом необходимо указать номер порта в черном кружке и схематичное изображение в виде скобки с кружком
- в горизонтальном положении слева от адреса расположить номер порта в черном кружке
Решение
- Создать стили для вертикальных и горизонтальных адресов
- Создать шаблон для номера выходного порта (цифра в черном кружке)
- Создать шаблон для имитации скрепки с красной точкой
- Создать шаблон для формирования горизонтального адреса
- Создать шаблон для формирования вертикального адреса
- Создать матрицу из 5-ти горизонтальных адресов в одной строке с номерами выходных портов в черных кружках
- Создать матрицу из 5-ти вертикальных адресов в одной колонке с номерами выходных портов в черных кружках и скрепкой с красной точкой
Код с описанием
\tikzset{vad/.style={node distance=0pt,inner sep=2pt,rotate=90,draw}}%настройка стиля для вертикальных адресов
\tikzset{had/.style={node distance=0pt,inner sep=2pt,rotate=0,draw}}%настройка стиля для горизонтальных адресов
\tikzset{
orr/.pic={%рисуем маленький красный кружок на белом фоне
\fill[white] (0,-0.3mm) ellipse (.6mm and 1mm);
\fill[red] (0,0) ellipse (.4mm and .6mm);},
piro/.pic={%рисуем скобку и внизу скобки помещаем красный кружок orr
\draw[thick,orange,rounded corners] (-.7ex,1cm) -- (-.7ex,.3cm) -- (0,0) pic{orr} -- (.7ex,.3cm) -- (.7ex,1cm);},
pics/ntt/.style={%рисуем черный кружок с переменной номер внутри кружка
code={\node [circle,fill=black,minimum size=1em,inner sep=0pt,text=white] {#1};}},
sp/.pic={\path (0,0)--(.2,0);}%это хитрый pic пробел. Чтобы не разъезжались строки.
}
\def\haddr#1#2{%строим горизонтальный адрес в формате 4:5
\coordinate(a0)at(0,.12);
\foreach \z [count=\x,evaluate=\x as \y using \x-1] in {#1}{
\node(a\x)[had,right=of a\y] {\z};
};
\node(s0)[had,draw=none,right=of a4] {:};
\foreach \z [count=\x,evaluate=\x as \y using \x-1] in {#2}{
\node(s\x)[had,right=of s\y] {\z};
};
}
\def\vaddr#1#2{%строим вертикальный адрес в формате 4:5
\coordinate(a0)at(0,0);
\foreach \z [count=\x,evaluate=\x as \y using \x-1] in {#1}{
\node(a\x)[vad,right=of a\y] {\z};
};
\node(s0)[vad,draw=none,right=of a4] {:};
\foreach \z [count=\x,evaluate=\x as \y using \x-1] in {#2}{
\node(s\x)[vad,right=of s\y] {\z};
};
}
%рисуем горизонтальную матрицу из пяти адресов
%в первой колонке черный кружок с номером \pic{ntt=1}
%во второй колонке пробел \pic{sp}, чтобы отделить
%в третьей колонке горизонтальный адрес \haddr...
\begin{tikzpicture}
\matrix[matrix of nodes,row sep={0ex}]{
\pic{ntt=1};&\pic{sp};&\haddr{0,0,0,1}{0,0,0,1,2}\\
\pic{ntt=2};& &\haddr{0,0,0,1}{0,0,0,1,3}\\
\pic{ntt=3};& &\haddr{0,0,0,1}{0,0,0,1,4}\\
\pic{ntt=4};& &\haddr{0,0,0,1}{0,0,0,1,5}\\
\pic{ntt=5};& &\haddr{0,0,0,1}{0,0,0,1,6}\\};
\end{tikzpicture}
%рисуем вертикальную матрицу из пяти адресов
%в первой строке черные кружки с номерами \pic{ntt=1}
%во второй строке скобки, \pic{piro}
%в третьей строке вертикальный адрес \vaddr...
\begin{tikzpicture}
\matrix[matrix of nodes,column sep={0ex}]{
\pic{ntt=1};&\pic{ntt=2};&\pic{ntt=3};&\pic{ntt=4};&\pic{ntt=5};\\
\pic{piro};&\pic{piro};&\pic{piro};&\pic{piro};&\pic{piro};\\
\vaddr{0,0,0,1}{0,0,0,1,2}&
\vaddr{0,0,0,1}{0,0,0,1,2}&
\vaddr{0,0,0,1}{0,0,0,1,2}&
\vaddr{0,0,0,1}{0,0,0,1,2}&
\vaddr{0,0,0,1}{0,0,0,1,2}\\};
\end{tikzpicture}
7.7.5 - Matrix в модуле TIKZ
Матрицы в графическом мобуле TIKZ
Очень полезная вещь для рисования различных экранчиков и описаний к ним. Все по полочкам и все промаркировано.
Введение в MATRIX
при объявлении node просто указать, что это будет matrix
\node [matrix,fill=red!20,draw=blue,very thick]
а дальше как в обычной таблице или array
\draw (0,0) circle (4mm); & \node[rotate=10] {Hello}; \\
\draw (0.2,0) circle (2mm); & \fill[red] (0,0) circle (3mm); \\
};
вот и всё.
every matrix
определяет стиль matrix
every outer matrix
это настраивает внешний node в котором объявлен matrix
\matrix
специальная команда без node
аналог \path node[matrix]
Выравнивание matrix
column sep=⟨spacing list⟩
расстояние между колонками
column sep={1cm,between origins} — расстояние будет мерить не по краям, а по центрам
row sep=⟨spacing list⟩
расстояние между строк
Задавать можно целиком на matrix, так и на отдельную ячейку
\draw (0,0) circle (2mm); \\[1cm,between origins] — можно так
\node {8}; &[2mm] \node{1}; &[-1mm] \node {6}; \\ — а можно и так
&[between borders] \node (c) {6}; — а можно и так
параметры ячейки (размеры)
every cell={⟨row⟩}{⟨column⟩} задает параметры каждой ячейки
cells=⟨options⟩
это стиль ячейки cell/.append style=⟨options⟩
nodes=⟨options⟩
это тоже стиль для ячеек matrix node/.append style=⟨options⟩
\begin{tikzpicture}
\matrix [nodes={fill=blue!20,minimum size=5mm}]
{
\node {8}; & \node{1}; & \node {6}; \\
\node {3}; & \node{5}; & \node {7}; \\
\node {4}; & \node{9}; & \node {2}; \\
};
\end{tikzpicture}
стили колонок и строк
- /tikz/column ⟨number⟩ —
column 2/.style={green!50!black} - /tikz/every odd column — стиль для нечетной колонки
- /tikz/every even column — стиль для четной колонки
- /tikz/row ⟨number⟩ —
row 3/.style={green!50!black} - /tikz/every odd row — стиль для нечетной строки
- /tikz/every even row — стиль для четной строки
- /tikz/row ⟨row number⟩ column ⟨column number⟩ — стиль для строки и колонки
\begin{tikzpicture}
[row 1/.style={red},
column 2/.style={green!50!black},
row 3 column 3/.style={blue}]
\matrix
{
\node {8}; & \node{1}; & \node {6}; \\
\node {3}; & \node{5}; & \node {7}; \\
\node {4}; & \node{9}; & \node {2}; \\
};
\end{tikzpicture}
Выравнивание в ячейках и колонках
\begin{tikzpicture}
[column 1/.style={anchor=base west},%выравнивает слева
column 2/.style={anchor=base east},%выравнивает справа
column 3/.style={anchor=base}]% выравнивает по центру
\matrix
{
\node {123}; & \node{456}; & \node {789}; \\
\node {12}; & \node{45}; & \node {78}; \\
\node {1}; & \node{4}; & \node {7}; \\
};
\end{tikzpicture}
Большая таблица
\usetikzlibrary {matrix,fit}
\begin{tikzpicture}[
font=\sffamily,
head color/.style args={#1/#2}{
row 1 column #1/.append style={nodes={fill=#2}}},
% swap order of row and column styles
matrix/inner style order={
every cell,
row, even odd row,
column, even odd column,
cell
}
]
\matrix [
matrix of nodes, nodes in empty cells,
nodes={text width=2cm, align=center,
minimum height=1.5em, anchor=center},
% add striped row style
every even row/.style={nodes={fill=olive!50}},
% modify the feature column and header row
column 1/.style= {nodes={fill=olive, inner ysep=0}},
row 1/.style= {nodes={text depth=0.2ex, text=white}},
row 1 column 1/.style={nodes={fill=none, draw=none}},
head color/.list={2/orange,3/teal,4/cyan,5/magenta} % specify header colors
] (m)
{
& Basic & Standard & Professional & Enterprise \\
Feature A & $\bullet$ & $\bullet$ & $\bullet$ & $\bullet$ \\
Feature B & $\bullet$ & $\bullet$ & $\bullet$ & $\bullet$ \\
Feature C & & & & $\bullet$ \\
Feature D & & $\bullet$ & $\bullet$ & $\bullet$ \\
Feature E & & & $\bullet$ & $\bullet$ \\
};
% Add emphasis on selection by the use of "fit" library
\node[fit={(m-1-4.north west) (m-6-4.south east)},
ultra thick, inner sep=0pt, rounded corners=1mm,
draw=cyan, label={[cyan,align=center]270:Popular\\Choice!}]{};
\end{tikzpicture}
внутренние стили назначаются в определенной очередности.
Очередность задается параметром:
inner style order
\tikzset{
matrix/inner style order={
every cell,
column,
even odd column,
row,
even odd row,
cell,
},
}
- inner style/every cell
- inner style/column
- inner style/even odd column
- inner style/row
- inner style/even odd row
- inner style/cell
- inner style order
Настройки по умолчанию
Для многих матриц нужно делать однообразные настройки
node{ какой-то текст и };
поэтому определим три макроса:
- /tikz/execute at begin cell=⟨code⟩ — перед текстом
- /tikz/execute at end cell=⟨code⟩ — послетекста
- /tikz/execute at empty cell=⟨code⟩ — если пусто
\begin{tikzpicture}
[matrix of nodes/.style={
execute at begin cell=\node\bgroup,
execute at end cell=\egroup;%
}]
\matrix [matrix of nodes]
{
8 & 1 & 6 \\
3 & 5 & 7 \\
4 & 9 & 2 \\
};
\end{tikzpicture}
В итоге можем теперь писать только текст и разделять его &
или так
\begin{tikzpicture}
[matrix of nodes/.style={
execute at begin cell=\node\bgroup,
execute at end cell=\egroup;,%
execute at empty cell=\node{--};%
}]
\matrix [matrix of nodes]
{
8 & 1 & \\
3 & & 7 \\
& & 2 \\
};
\end{tikzpicture}
По этому поводу есть целая библиотека matrix
https://tikz.dev/library-matrix
Якоря Matrix
matrix anchor=⟨anchor⟩
этот параметр применяется только к самой матрице, но не применяется к ячейкам
т.е. все north, south, east, west
\matrix [matrix anchor=west] at (0,0) поместит левую сторону матрицы в координату (0,0)
отличается от параметра [anchor=west] — который выравнивает в ячейках по левому краю
anchor=⟨anchor or node.anchor⟩
относится только к ячейке
если ячейке дали имя, то можно обращаться к ее якорям node.anchor
\begin{tikzpicture}
\draw[help lines] (0,0) grid (3,2);
\matrix[matrix anchor=inner node.south,anchor=base,row sep=3mm] at (1,1)
{
\node {a}; & \node {b}; & \node {c}; & \node {d}; \\
\node {a}; & \node(inner node) {b}; & \node {c}; & \node {d}; \\
\node {a}; & \node {b}; & \node {c}; & \node {d}; \\
};
\draw (inner node.south) circle (1pt);
\end{tikzpicture}

кратко по примеру выше:
- во второй строчке node дали имя
inner node - в опциях matrix дали команду
[matrix anchor=inner node.south, ... at (1,1), т.е. сказали, что точку юга этой ноды поместить в координату (1,1) anchor=base— колонки выравнивать по центру
Замена & как разделителя колонок
ampersand replacement=⟨macro name or empty⟩
для некоторых процедур это нужно,чтобы не было конфликта с другими библиотеками. Если матрицу закручивать по контуру, то придется поменять разделитель на другое.
\matrix [ampersand replacement=\&]
Matrix Library
без нее эта тема не закончена
\usetikzlibrary{matrix}
matrix of nodes
это матрица в которой каждая ячейка это node
\usetikzlibrary {matrix}
\begin{tikzpicture}
\matrix (magic) [matrix of nodes]
{
8 & 1 & 6 \\
3 & 5 & 7 \\
4 & 9 & 2 \\
};
\draw[thick,red,->] (magic-1-1) |- (magic-2-3);
\end{tikzpicture}
мы такую уже делали сами, но она объявлена в библиотеке, нужно просто сослаться в заголовке
добавить свои опции вариант 1
указать колонку и строку в заголовке и назначить свой стиль
\begin{tikzpicture}[row 2 column 3/.style=red]
\matrix [matrix of nodes]
добавить опции непосредственно ячейке вариант 2
\usetikzlibrary {matrix}
\begin{tikzpicture}
\matrix [matrix of nodes]
{
8 & 1 & 6 \\
3 & 5 & |[red]| 7 \\
4 & 9 & 2 \\
};
\end{tikzpicture}
для этого нужно поместить между вертикальных линий все данные |[red] (seven)|, как здесь передаем цвет и имя ноды
у & есть необязательный аргумент [3mm] — это расстояние между колонками
8 &[1cm] 1 &[3mm] |[red]| 6 \\
вариант 3 — указать полный список параметров
3 & 5 & \node[red]{7}; \draw(0,0) circle(10pt);\\
matrix of math nodes
все ячейки становятся заключены в $
nodes in empty cells=⟨true or false⟩
обязывает отображать пустые ячейки
\usetikzlibrary {matrix}
\begin{tikzpicture}
\matrix [matrix of math nodes,nodes={circle,draw},nodes in empty cells]
{
a_8 & & a_6 \\
a_3 & & a_7 \\
a_4 & a_9 & \\
};
\end{tikzpicture}
Символы конца строк и переноса строк в узлах
обычно это \\
чтобы в ячейке переносить по строкам, нужно поместить текст в {}
\usetikzlibrary {matrix}
\begin{tikzpicture}
\matrix [matrix of nodes,nodes={text width=16mm,draw}]
{
row 1 & {upper line \\ lower line} \\
row 2 & hmm \\
};
\end{tikzpicture}
Разделители в матрицах
- left delimiter=⟨delimiter⟩
- right delimiter=⟨delimiter⟩
- every delimiter
- every left delimiter
- every right delimiter
- above delimiter
- every above delimiter
- below delimiter=⟨delimiter⟩
- every below delimiter
\usetikzlibrary {matrix}
\begin{tikzpicture}
\matrix [matrix of math nodes,%
left delimiter=\|,right delimiter=\rmoustache,%
above delimiter=(,below delimiter=\}]
{
a_8 & a_1 & a_6 \\
a_3 & a_5 & a_7 \\
a_4 & a_9 & a_2 \\
};
\end{tikzpicture}
7.7.6 - PIC маленький рисунок
PIC это маленькие рисунки в TIKZ которые можно встраивать в большие и делать свои библиотеки
Какие-то маленькие вещи наверно буду делать, но пока обходился обычными node
Синтаксис PIC
\path … pic ⟨foreach statements⟩ [⟨options⟩] (⟨prefix⟩) at(⟨coordinate⟩) :⟨animation attribute⟩={⟨options⟩} {⟨pic type⟩} …;
- PIC можно объявить в
\tikzsetв преамбуле - можно написать прямо в path в опции code
\tikzset{
seagull/.pic={
% Code for a "seagull". Do you see it?...
\draw (-3mm,0) to [bend left] (0,0) to [bend left] (3mm,0);
}
}
Вообще PIC это упрощенная запись вставки кода в path.
во втором случае напишем через pic type =:
\tikz {
\path (0,0) pic [pic type = seagull]
(1,0) pic {seagull};
}
- Или в третьем случае через
pics/code={}:
\tikz \pic [pics/code={\draw (-3mm,0) to[bend left] (0,0)
to[bend left] (3mm,0);}]
{}; % no pic type specified
но в последнем варианте, pic не будет, а будет чистый code, который и делает сам pic
pic action
позволяет в опцияхк команде pic передать дополнительные параметры.
\tikzset{
my pic/.pic = {
\path [pic actions] (0,0) circle[radius=3mm];
\draw (-3mm,-3mm) rectangle (3mm,3mm);
}
}
\tikz \pic {my pic}; \space
\tikz \pic [red] {my pic}; \space
\tikz \pic [draw] {my pic}; \space
\tikz \pic [draw=red] {my pic}; \space
\tikz \pic [draw, shading=ball] {my pic}; \space
\tikz \pic [fill=red!50] {my pic};
behind path и in front of path
также как и node позволяет рисовать за основным рисунком или перед ним
foreground code=⟨code⟩ и background code=⟨code⟩
можно указать индекс слоя
foreach
принимает параметры от foreach
\tikz \pic foreach \x in {1,2,3} at (\x,0) {seagull};
every pic
настраиваем стили для pic
\begin{tikzpicture}[every pic/.style={scale=2,transform shape}]
\pic foreach \x in {1,2,3} at (\x,0) {seagull};
\end{tikzpicture}
prefix name
я не уверен,что буду этим пользоваться, но можно добавлять префиксы к именам точек pic
pic text
будет работать как label в nodes
или его аналог в библиотеке quotes
pic [draw, "$\alpha$"] {angle};
every pic quotes — для настройки кавычек
глобальный стиль для pic
\tikzset{
pics/my circle/.style = {
background code = { \fill circle [radius=#1]; }
}
}
\tikz [fill=blue!30]
\draw (0,0) pic {my circle=2mm} -- (1,1) pic {my circle=5mm};
7.7.7 - Node TIKZ
Nodes и Edges, киты TIKZ в которых можно все писать и компоновать
NODES размещает текст в указанных координатах, рисунки, графику, повторяет контуры и пр. Встраивается в path или coordinate.
Синтаксис NODE
\path … node ⟨foreach statements⟩ [⟨options⟩] (⟨name⟩) at(⟨coordinate⟩) :⟨animation attribute⟩={⟨options⟩} {⟨node contents⟩} …;
node contents
это тоже, что и в фигурных скобках.
\tikz {
\path (0,0) node [red] {A}
(1,0) node [blue] {B}
(2,0) node [green, node contents=C]
(3,0) node [node contents=D] ;
}
at
Node размещается в последней координате path, а at указывает конкретно куда поместить node.
\node at (0,0) {сюда}
behind path
нарисует сзади текущего рисунка.
\tikz \fill [fill=blue!50, draw=blue, very thick] (0,0) node [behind path, fill=red!50] {first node}
in front of path
тоже, что и выше, только нарисует спереди текущего рисунка
name
задает имя node, полезно для якорей и координат
можно задать alias и есть еще режим also, позволяет под этим же именем node разместить другой текст
coordinate
\path … coordinate[⟨options⟩](⟨name⟩)at(⟨coordinate⟩) …;
специальный синтаксис для легковесных node
это будет просто точка и все якоря будут иметь одно и тоже значение.
\coordinate — простая запись
\path[shape=coordinate]
(0,0) coordinate(b1)
(1,0) coordinate(b2)
(1,1) coordinate(b3)
(0,1) coordinate(b4);
OPTIONS
Опции для node отличаются от назначений path, поэтому для node нужно давать свои назначения в опциях.
Для рисования вокруг node используем библиотеку \usetikzlibrary {shapes.geometric}
https://tikz.dev/library-shapes
в ней много разных shapes, которые можно указывать в options
По умолчанию без библиотек в node можно применять 3 вида shapes:
- rectangle
- circle
- coordinate
Анимации в пакете TIKZ работают только для экспорта в svg. Если вы занимаетесь документами в PDF. Можно расслабиться и не заниматься этой темой.
foreach
в node можно вставлять несколько foreach
\tikz \node foreach \x in {1,...,4} foreach \y in {1,2,3}
[draw] at (\x,\y) {\x,\y};

every node
устанавливает стиль для каждой ноды
\begin{tikzpicture}[every node/.style={draw}]
или
\begin{tikzpicture}
[every rectangle node/.style={draw},
every circle node/.style={draw,double}]
\draw (0,0) node[rectangle] {A} -- (1,1) node[circle] {B};
\end{tikzpicture}
для каждой прямоугольной node или для каждой круглой node
execute at begin node (end node)
\begin{tikzpicture}
[execute at begin node={A},
execute at end node={D}]
\node[execute at begin node={B}] {C};
\end{tikzpicture}
На выходе даст ABCD
name prefix=⟨text⟩
Используется в scope и добавляет префикс к имени node
\tikz {
\begin{scope}[name prefix = top-]
\node (A) at (0,1) {A};
\node (B) at (1,1) {B};
\draw (A) -- (B);
\end{scope}
\begin{scope}[name prefix = bottom-]
\node (A) at (0,0) {A};
\node (B) at (1,0) {B};
\draw (A) -- (B);
\end{scope}
\draw [red] (top-A) -- (bottom-B);
}
ее брат name suffix=⟨text⟩ добавит суффикс в конце имени
inner sep=⟨dimension⟩
внутренний отступ от текста к рамке
inner xsep=⟨dimension⟩
margin по x
inner ysep=⟨dimension⟩
margin по y
outer sep=⟨dimension or “auto”⟩
эффект этой опции позволит сместить все якоря вовне
outer sep=auto
outer xsep=⟨dimension⟩
outer ysep=⟨dimension⟩
minimum height=⟨dimension⟩
минимальная высота node
если текст не вместится,то node расширится
minimum width=⟨dimension⟩
минимальная ширина node
minimum size=⟨dimension⟩
для квадратных и круглых форм
shape aspect=⟨aspect ratio⟩
пропорции сжатия
shape border uses incircle=⟨boolean⟩
проверяет,чтобы внутрь фигуры вписывалась окружность
shape border rotate=⟨angle⟩
поворачивает контур фигуры, но не поворачивает текст
\nodepart[⟨options⟩]{⟨part name⟩}
это node состоящая из нескольких частей
\usetikzlibrary {shapes.multipart}
\begin{tikzpicture}
\node [circle split,draw,double,fill=red!20]
{
% No \nodepart has been used, yet. So, the following is put in the
% ``text'' node part by default.
$q_1$
\nodepart{lower} % Ok, end ``text'' part, start ``output'' part
$00$
}; % output part ended.
\end{tikzpicture}

для ее использования нужно применить circle split и в \nodeparts указать аргументы {text,lower}.
для нее же можно настроить стиль:
every ⟨part name⟩ node part
\usetikzlibrary {shapes.multipart}
\tikz [every lower node part/.style={red}]
\node [circle split,draw] {$q_1$ \nodepart{lower} $00$};
NODE TEXT
text=color
задает цвет текста
node font=⟨font commands⟩
\draw[node font=\itshape] — задает шрифт в node
или font=⟨font commands⟩ если задать внутри node
\begin{tikzpicture}
\node [font=\itshape] {italic};
\end{tikzpicture}
align
- center
- left
- right
- align=flush left
- align=flush right — выравнивает без переноса слов
- align=fkush center
- align=justify
- align=none
\tikz[align=center] \node[draw] {This is a\\demonstration.};
text width=⟨dimension⟩
задает ширину текстового поля в node
text height=⟨dimension⟩
высоту текстового блока
text depth=⟨dimension⟩
глубина текста
badness warnings for centered text=⟨true or false⟩
система координат NODE
south тоже есть
anchor=⟨anchor name⟩
anchor= — по умолчанию это центр node, но можно задать любую координату и относительно ее будет идти привязка
относительные надписи
- above=⟨offset⟩
- below=⟨offset⟩
- left=⟨offset⟩
- right=⟨offset⟩
- above left
- above right
- below left
- below right
- centered
\tikz \fill (0,0) circle (2pt) node[above=2pt] {above};
библиотека positioning
\usetikzlibrary{positioning}
дает все тоже самое,но можно еще вычислять расстояния
\node at (1,1) [above=2pt+3pt,draw]
плюс у нее есть команда of
\usetikzlibrary {positioning}
\begin{tikzpicture}[every node/.style=draw]
\draw[help lines] (0,0) grid (2,2);
\node (somenode) at (1,1) {some node};
\node [above=5mm of somenode.north east] {\tiny 5mm of somenode.north east};
\node [above=1cm of somenode.north] {\tiny 1cm of somenode.north};
\end{tikzpicture}
of укажет относительно чего смещение
on grig
смещает node по сетке, а не относительно бордюра node
\usetikzlibrary {positioning}
\begin{tikzpicture}[every node/.style=draw]
\draw[help lines] (0,0) grid (2,3);
% Not gridded
\node (a1) at (0,0) {not gridded};
\node (b1) [above=1cm of a1] {fooy};
\node (c1) [above=1cm of b1] {a};
% gridded
\node (a2) at (2,0) {gridded};
\node (b2) [on grid,above=1cm of a2] {fooy};
\node (c2) [on grid,above=1cm of b2] {a};
\end{tikzpicture}
смещает без on grid относительно бордюра node
с on grid смещает четко по сетке grid
node distance=⟨shifting part⟩
\begin{tikzpicture}[every node/.style=draw,node distance=5mm]
теперь все смещения будут на 5мм
Очень показательно как работает этот ключ
\usetikzlibrary {positioning}
\begin{tikzpicture}[every node/.style={draw,node distance=0mm}]
\draw[help lines] (0,0) grid (2,3);
% Not gridded
\node (a1) at (0,0) {not gridded};
\node (b1) [above=of a1] {fooy};
\node (c1) [above=of b1] {a};
% gridded
\node (a2) at (2,0) {gridded};
\node (b2) [on grid,above=of a2] {fooy};
\node (c2) [on grid,above=of b2] {a};
\end{tikzpicture}
node distance=0mm — показало смещение для on grid по центрам, а без grid от бордюра.
еще есть вариант [node distance=1 and 1]
К вышеперечисленной серии команд в библиотеке еще есть
- base left=⟨specification⟩
- base right
- mid left
- mid right
библиотека matrix и graphdrawing
о них отдельно
лучше позиционируют большие массивы node
fitting node
т.е. подгонка координат
\usetikzlibrary {fit,shapes.geometric}
\begin{tikzpicture}[level distance=8mm]
\node (root) {root}
child { node (a) {a} }
child { node (b) {b}
child { node (d) {d} }
child { node (e) {e} } }
child { node (c) {c} };
\node[draw=red,inner sep=0pt,thick,ellipse,fit=(root) (b) (d) (e)] {};
\node[draw=blue,inner sep=0pt,thick,ellipse,fit=(b) (c) (e)] {};
\end{tikzpicture}
библиотека fit и опция fit позволяет охватить место,чтобы в него могли войти нужные данные
Transformations
transform shape
\tikz[scale=3] \node[transform shape] {X};
т.е. я сначала сказал, что нужно сделать scale=3, а потом команда transform shape выполнит это действие и я получу гигантскую X.
причем сказать можно в path или draw, а команда выполнится в node
\usepgfmodule {nonlineartransformations}\usetikzlibrary {curvilinear}
модули и библиотеки для трансформаций
transform shape nonlinear=⟨true or false⟩
будет рисовать по криволинейным траекториям подробнее https://tikz.dev/tikz-shapes
pos
указывает явно координату, где разместить node в path
\tikz \draw (0,0) -- (3,1)
node[pos=0]{0} node[pos=0.5]{1/2} node[pos=0.9]{9/10};
pos получает значение от 0 до 1 по длине пути
auto=⟨direction⟩
направление может быть left или right в зависимости от этого будет выбираться якорь в node для соединения
swap
если установлена опция auto то будет делать наоборот, для left будет искать right якорь
' — апостроф отработает как swap
sloped
будет писать текст вдоль кривой
можно добавить [allow upside down] или [rotate=180]
node[midway,sloped,below] {$y$};
allow upside down=⟨boolean⟩
перевернет надпись вверх ногами
midway имена точек в пути
- midway — напишет посередине линии
- near start — pos=0.25.
- near end — pos=0.75.
- very near start — pos=0.125.
- very near end — pos=0.875.
- at start — pos=0.
- at end — pos=1
label
это такая надпись в надписи
\usetikzlibrary {positioning}
\tikz [circle] {
\node [draw] (s) [label=below:$s$] {ф};
\node [draw] (a) [right=of s] {} edge (s);
\node [draw] (b) [right=of a] {} edge (a);
\node [draw] (t) [right=of b, label=$t$] {} edge (b);
}
направление метки словами left, right, below, above или градусы и двоеточие:
label=[⟨options⟩]⟨angle⟩:⟨text⟩ или \node [draw] (s) [label=100:$s$] {ф};
\tikz
\node [circle, draw,
label=default,
label=60:$60^\circ$,
label=below:$-90^\circ$,
label=3:$3^\circ$,
label=2:$2^\circ$,
label={[below]180:$180^\circ$},
label={[centered]135:$135^\circ$}] {my circle};
label distance=⟨distance⟩
установит дистанцию для label от меток
every label
настроит стиль для label
PIN
булавка — похожа на label, но с булавкой)
pin distance=⟨distance⟩
расстояние до текста в булавке
every pin
стиль булавки
pin position=⟨angle⟩
аналогично label position
every pin edge
настроит вид edge для pin
pin={[pin edge={blue,thick}]right:X},
Кавычки
Нужна библиотека \usetikzlibrary{quotes}
\usetikzlibrary {quotes}
\begin{tikzpicture}
\matrix [row sep=5mm] {
\node [draw, "label"] {A}; \\
\node [draw, "label" left] {B}; \\
\node [draw, "label" centered] {C}; \\
\node [draw, "label" color=red] {D}; \\
\node [draw, "label" {red,draw,thick}] {E}; \\
};
\end{tikzpicture}
текст в кавычках становится обычным label
quotes mean label
\usetikzlibrary {quotes}
\tikz
\node ["90:$90^\circ$", "left:$180^\circ$", circle, draw] {circle};
every label quotes
задать стиль
quotes mean pin
Connecting Nodes
Соединение Nodes
\begin{tikzpicture}
\path (0,0) node (x) {Hello World!}
(3,1) node[circle,draw](y) {$\int_1^2 x \mathrm d x$};
\draw[->,blue] (x) -- (y);
\draw[->,red] (x) -| node[near start,below] {label} (y);
\draw[->,orange] (x) .. controls +(up:1cm) and +(left:1cm) .. node[above,sloped] {label} (y);
\end{tikzpicture}
При соединении nodes стрелки будут проходить от границы node
EDGES
это ребро, которое будет добавлено после того, как будет нарисован основной путь.
\path … edge[⟨options⟩] ⟨nodes⟩ (⟨coordinate⟩) …;
\begin{tikzpicture}
\node foreach \name/\angle in {a/0,b/90,c/180,d/270}
(\name) at (\angle:1) {$\name$};
\path[->] (b) edge (a)
edge (c)
edge [-,dotted] (d)
(c) edge (a)
edge (d)
(d) edge (a);
\end{tikzpicture}
edge — это просто ребра между координатами.
Внутри edge можно вставлять node
every edge
назначить стиль для всех edge
quotes
для edge в библиотеке quotes также работает текст в кавычках, как label
\usetikzlibrary {quotes}
\tikz \draw (0,0) edge ["left", ->] (2,0);
every edge quotes
Стиль quotes
swap
к тексту с кавычками добавить '
расстояние между label и edge
определяется параметром inner sep=
\usetikzlibrary {quotes}
\tikz [tight/.style={inner sep=1pt}, loose/.style={inner sep=.7em}]
\draw (0,0) edge ["left" tight,
"right"' loose,
"start" near start] (4,0);
Ссылка на узлы за пределами текущего изображения
Это означает,что можно ссылаться из одной картинки в другую картинку на странице.
remember picture=⟨boolean⟩
этот параметр нужно назначить картинкам, которые будут друг на друга ссылаться
\tikzset{every picture/.append style={remember picture}}
этот стиль для всех картинок сразу.
overlay
эту опцию необходимо указать в свойствах path, которые будут ссылаться на другие изображения.
Да, я это видел и я это сделал. Все соединились стрелочками.
\tikz[remember picture] \node[circle,fill=red!50] (n1) {}; — это кружок в любом месте текста.
\tikz[remember picture] \node[fill=blue!50] (n2) {}; — это квадратик, в другом месте.
\begin{tikzpicture}[remember picture,overlay]
\draw[->,very thick] (n1) -- (n2);
\end{tikzpicture}
а это линия,которая соединит кружок с квадратиком

все так и произошло.
\begin{tikzpicture}[remember picture]
\node (c) [circle,draw] {Big circle};
\draw [overlay,->,very thick,red,opacity=.5]
(c) to[bend left] (n1) (n1) -| (n2);
\end{tikzpicture}
Это красная линия с еще более сложным маршрутом.
Абсолютные координаты страницы
на каждой странице присутствует node — current page и у нее есть полный набор ancher: west,east,north,south,center…
для размещения в любом месте страницы нужно в свойствах указать:
\begin{tikzpicture}[remember picture,overlay]
Поздний код
\path … node also[⟨late options⟩](⟨name⟩) …; — добавляет опции к узлу позже.
Обязательно нужно указать имя node и не должно быть указано текста. Только опции.
\begin{tikzpicture}
\node [draw,circle] (a) {Hello};
\node also [label=above:world] (a);
\end{tikzpicture}
\tikzlastnode
этот макрос подобен командам append after command и prefix after command
late options=⟨options⟩
это еще один аналог node also
\begin{tikzpicture}
\node [draw,circle] (a) {Hello};
\path [late options={name=a, label=above:world}];
\end{tikzpicture}
7.7.8 - Path и его особенности
Разбираю документацию TIKZ и некоторые свои добавления по PATH
PATH — это ключевой инструмент для рисования в TIKZ
Вступление с моими открытиями
\begin{tikzpicture}
\begin{scope}%делаю специальнуюзону видимости для CLIP
\fill[black!20](-6,0) circle (1.6);%немного фона вокруг кружка
\clip (-6,0) circle (1.5cm);%клипаю будущий рисунок
\node (p) at (-6,0) {\includegraphics[width=3.5cm]{lamp}%вставляю рисунок
\rule{15pt}{0pt}};%так я придумал делать отступ от рисунка невидимой rule
\end{scope}
\gridnum %это просто разметка координат в моем нехитром исполнении, покажу позже
\node[text width=12cm,anchor=north west] at (p.north east) {Для проведения теста, подайте рабочее напряжение на вход ...};%это собственно текстовый блок, который выровнялся по правому верхнему углу рисунка и левому верхнему углу текста
%anchor=north west] at (p.north east) - это магия
\end{tikzpicture}
Grid
Grid сделал, чтобы удобно было рисовать и не разу не пожалел.
Кидаешь рисунок в координату и дальше расставляешь свои фичи.
%%%%%%%%%%%%%%%%%%%%%%%%% GRID
\def\gridnum {
\draw[help lines] (-8,-8) grid +(16,16);
\node foreach \x in {-8,-7,...,8} at (\x,8.5) {\x};
\node foreach \y in {-8,-7,...,8} at (8.5,\y) {\y};
\node foreach \x in {-8,-7,...,8} at (\x,-8.5) {\x};
\node foreach \y in {-8,-7,...,8} at (-8.5,\y) {\y};
\draw[red] (0,-8.5) -- (0,8.5);
\draw[red] (-8.5,0) -- (8.5,0);
}
Кружки со стрелками
\tikzset{
num/.style={draw,shape=circle,fill=black,text=white,minimum size=2em,font=\bf,general shadow={fill=gray,shadow scale=1.1}},%определяет стиль кружка для отметки на рисунках
numtext/.style={draw,shape=circle,fill=black!85,text=white,minimum size=1em,font=\bf,general shadow={fill=gray,shadow scale=1.1}},%определяет стиль кружка для отметки в тексте
arrow num/.style={line width=.1em, gray,arrows = {-Stealth[line width=0.3pt, fill=gray, length=10pt,open,fill=gray,white,quick]}},%определяет стиль стрелки для отметки на рисунках
}
А это сами кружки
\def\numar#1#2#3{
\node [num] (l#1) at (#2) {#1};
\coordinate (t#1) at (#3);
\draw[line width=.15em, white] (l#1) -- ($(l#1)!.95!(t#1)$);
\draw[arrow num] (l#1) -- (t#1);
%рисует черный кружок с цифрой #1 кружок в координате #2, а стрелочку в координату #3
}
А это результат все вместе:
\begin{tikzpicture}
\begin{scope}%это клипнутый рисунок
\fill[black!20](-6,0) circle (1.6);
\clip (-6,0) circle (1.5cm);
\node (p) at (-6,0) {\includegraphics[width=3.5cm]{lamp}\rule{15pt}{0pt}};
\end{scope}
\gridnum % это мой грид
\numar{2}{0,-4}{-2.2,-1.8};%это кружок с 2 и со стрелкой
\numar{2}{0,-4}{2.2,-1.8};%из двойки вторая стрелка
\node at (-4,0){\num{1}};%это кружок без стрелки
\node at ( 4,0){\num{1}};
\end{tikzpicture}
Path
Это путь от одной точки к другой и т.д. На пути могут быть draw, fill, clip, node сколько угодно раз.
Мощная примудрость, позволит на многое открыть глаза в TIKZ
\begin{tikzpicture}
\gridnum
\begin{scope}[scale=2] %сделал, чтобы видно лучше было
\draw[thick,red]
(0,0) coordinate (a) %назначаем координате имя (a)
-- coordinate (ab) %а это пока рисуем от (a) к (b) запоминаем середину и называем ее (ab)
(1,.5) coordinate (b) %назначаем координате имя (b)
.. coordinate (bc) controls +(up:1.5cm) and +(left:0cm) .. %а это пока рисуем от (b) к (c) запоминаем середину и называем ее (bc)
%но считает серидину сложно с учетом контрольных точек
(3,1) coordinate (c) %назначаем координате имя (c)
(0,1) -- (2,1) -- %просто рисуем замкнутый треугольник и
coordinate (x) (1,2) -- cycle;%x - будет точно серединой между двух вершин
\draw (a) node[below] {start part 1} %ничего интересного, просто подписать точки
(ab) node[below right] {straight segment}
(b) node[right] {end first segment}
(c) node[right] {end part 1}
(x) node[above right] {part 2 (closed)};
\fill[red](a) circle (1pt); %а это просто эти точки разукрасить
\fill[blue](b) circle (1pt);
\fill[green](ab) circle (1pt);
\fill[yellow](bc) circle (1pt);
\fill[magenta](c) circle (1pt);
\fill[orange](x) circle (1pt);
\end{scope}
\end{tikzpicture}
[rounded corners] [sharp corners]
круглые и угловатые соединения линий
rounded corners=4pt — по умолчанию, или можно поменять
\tikz \draw (0,0) -- (1,1) [rounded corners] -- (2,0) -- (3,1) [sharp corners] -- (3,0) -- (2,1);
это группировка scope для назначения стиля
\tikz \draw (0,0) -- (1,1) {[rounded corners] -- (2,0) -- (3,1)} -- (3,0) -- (2,1);
name=
задает имя пути, полезно при пересечениях
every path
задает стиль всем значениям path
\begin{tikzpicture}
[fill=yellow!80!black, % only sets the color
every path/.style={draw}] % all paths are drawn
\fill (0,0) rectangle +(1,1); %все будут с конуром
\shade (2,0) rectangle +(1,1);%и градиент тоже
\end{tikzpicture}

insert path
по пути основного пути вставит любой другой путь))))
\tikz [c/.style={insert path={circle[radius=2pt]}}] \draw (0,0) -- (1,1) [c] -- (3,2) [c];
append after command=
и его брат prefix after command=〈path〉
\tikz \draw node [append after command={(foo)--(1,1) (foo)--(2,1) (foo)--(3,1)},draw] (foo){foo};
Т.е. пока рисую draw, включаю node и обвожу ее [draw], а в параметрах command задаю лучики, сколько угодно.
cycle & current subpath start
cycle — замыкает контур
current subpath start — возвращается в исходную координату, но контур не замыкает
\useasboundingbox (0,2.5); % увеличивает отступ в картинке
– |- -| .. controls ..
тип линии которую нужно провести
-- — прямая
|- — вертикально, потом горизонтально или cycle
.. controls .. — контрольная точка 1 или 2
circle
begin{tikzpicture}
\draw (1,0) circle [radius=1.5];
\fill (1,0) circle [x radius=1cm, y radius=5mm, rotate=30];
\end{tikzpicture}
ellipse
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\draw (1,1) ellipse [x radius=1cm,y radius=.5cm];
\end{tikzpicture}
arc
/tikz/start angle=〈degrees〉
/tikz/end angle=〈degrees〉
/tikz/delta angle=〈degrees〉
grid
\tikz[rotate=30] \draw[step=1mm] (0,0) grid (2,2);
/tikz/step=〈number or dimension or coordinate〉
/tikz/xstep=〈dimension or number〉
/tikz/ystep=〈dimension or number〉
/tikz/help lines
parabola
\path ... parabola[〈options〉]bend〈bend coordinate〉〈coordinate or cycle〉 ...;
/tikz/bend=〈coordinate〉
/tikz/bend pos=〈fraction〉
/tikz/parabola height=〈dimension〉
/tikz/bend at start
/tikz/bend at end
sin & cos
\path ... sin〈coordinate or cycle〉 ...;
svg
\path ... svg[〈options〉]{〈path data〉} ...;
\usetikzlibrary {svg.path}
\begin{tikzpicture}
\filldraw [fill=red!20] (0,1) svg[scale=2] {h 10 v 10 h -10} node [above left] {upper left} -- cycle;
\draw svg {M 0 0 L 20 20 h 10 a 10 10 0 0 0 -20 0};
\end{tikzpicture}
И кульминация!!!
\usetikzlibrary {svg.path}
\begin{tikzpicture}
\draw[fill=red] svg[rotate=180,scale=1pt] {m 0,0 c -7.1455,-3.0005 -14.1485,-6.184 -6.261,-17.3275 l 0.7006,-8.7994 -2.2838,-2.151 c 6.7935,-23.5259 19.2799,-46.8506 29.895,-65.918 11.1032,-15.0145 24.2647,-28.7189 28.7623,-47.9367 l 11.9841,-34.99407 c -0.1546,-13.35578 -2.0371,-27.40362 3.835,-38.34918 l 6.2318,-9.82699 c 1.5939,-28.91141 13.1608,-53.72504 12.7031,-82.211751 11.2272,-29.04903 17.5024,-22.60743 25.1668,-26.1256 4.524,-1.40654 8.693,-3.38055 10.0668,-9.827 l 4.554,2.1571 c -3.5888,-15.13669 -2.1459,-27.75767 1.9176,-39.06851 1.3477,-6.40097 7.8536,-8.21675 14.8602,-9.58722 8.592,-2.16346 14.2134,1.61359 20.3733,4.31421 3.564,5.54462 6.8227,11.17624 5.9921,17.97645 -0.088,2.44508 -1.4805,0.80239 -1.7797,2.90917 -0.6305,4.43879 2.7321,11.60579 -0.8615,12.55824 -4.4315,1.17434 -0.8057,12.46002 -5.2394,13.07901 -11.4427,1.59752 -8.2461,7.35191 -11.8607,9.9434 -2.2929,3.4139 -3.7804,7.09455 0.088,11.12472 7.8121,8.29041 7.5135,18.05557 8.6284,27.563671 5.5774,16.1437 10.1453,32.62388 26.8446,45.06055 8.8021,6.70563 14.713,14.56771 20.3734,22.53013 l 11.0253,11.26537 c 9.1625,0.81664 11.8325,3.66246 10.7858,7.6699 5.2654,7.69444 0.9194,8.78118 -3.835,9.58721 l -19.4145,0.23948 c -6.3528,-2.57118 -8.2777,-6.80263 -9.5872,-11.26507 -4.7804,-8.04729 -11.2793,-15.52136 -19.8938,-22.29065 -18.0192,-7.5638 -23.762,-19.73159 -32.1176,-30.91936 l -1.6779,37.15119 c 1.1413,7.46498 1.8943,15.70567 2.3969,24.44775 6.3573,7.86785 13.5455,15.45832 14.381,25.16679 l 14.6207,50.57336 c 5.1154,14.4625 1.2032,22.1542 -0.9588,31.1588 l -16.0588,44.3416 c -4.5409,19.7879 5.1463,25.3556 -1.6827,26.5005 1.2122,4.1548 5.7941,11.5294 10.791,15.6839 l 16.538,5.5128 c 5.8814,5.4882 4.5425,8.71988 0.2395,11.02528 -10.2823,0.03 -20.4991,0.7699 -31.3983,-5.99208 -24.5966,2.299 -20.5907,-1.8606 -27.3242,-3.5952 -6.3237,-9.1034 0.046,-19.8628 2.075,-24.194 l -6.8033,2.9522 c 2.2535,-29.9275 11.2296,-63.866 17.911,-84.9381 l 4.0747,-4.3145 c -2.5708,-2.0158 -5.4922,-2.5127 -6.2318,-12.4634 -4.9405,-15.5883 -14.1539,-28.3278 -22.7699,-41.4653 -16.0976,16.02 -27.5888,36.6464 -36.6716,59.6813 -3.0305,7.3616 -8.3362,10.1725 -13.1827,13.9017 -11.4324,16.4468 -20.5631,46.1767 -29.4813,66.3954 l -3.5952,-1.2016 c -2.918,8.9664 1.9352,10.8095 6.4716,12.9432 l 8.6284,4.7935 c 5.8839,5.6301 4.5728,8.9879 -1.6778,10.7858 -9.743,4.25658 -18.0911,2.2347 -26.6049,0.9588 -3.7097,-3.4521 -7.4534,-6.8618 -13.6619,-7.1907 z};
\end{tikzpicture}

plot
- –plot[〈local options〉]coordinates{〈coordinate 1〉〈coordinate 2〉…〈coordinate n〉}
- –plot[〈local options〉]file{〈filename〉} 342
- –plot[〈local options〉]〈coordinate expression〉
- –plot[〈local options〉]function{〈gnuplot formula〉}
строит график по координатам
\tikz \draw plot coordinates {(0,0) (1,1) (2,0) (3,1) (2,1) (10:2cm)};
to path
(a) to (b) примерно тоже, что (a) – (b), но есть нюансы.
После to я могу передать дополнительные настройки для этого участка пути:
(a) to [out=135,in=45] (b) выйдет из точки (a) под углом 135, а войдет под 45.
или еще 3 замечательных макроса:
\tikztostart, \tikztotarget, и \tikztonodes — запоминают координаты без зацикливания пути: т.е. в режиме current subpath start
\begin{tikzpicture}[to path={
.. controls +(1,0) and +(1,0) .. (\tikztotarget) \tikztonodes}]
\node (a) at (0,0) {a};
\node (b) at (2,1) {b};
\node (c) at (1,2) {c};
\draw (a) to node {x} (b)
(a) to (c);
\end{tikzpicture}
Этот вариант я припас для вертикального написания шрифта
\begin{tikzpicture}
\draw (0,0) to node [sloped,above] {x} (3,2);
\draw (0,0) to[out=90,in=180] node [sloped,above] {x} (3,2);
\draw (0,0) to node[sloped,above] {0001000:000200} (0,5);
\end{tikzpicture}

edge
EDGE умеет делать:
edge node={node [sloped,above] {x}}нодыedge label=xставит меткиedge label=x, edge label'=yставит зеркальные метки
every to
Назначаем стили для всех to
\tikz[every to/.style={bend left}] \draw (0,0) to (3,2); назначает стиль для to
execute at begin to=⟨code⟩ (no default)
и ее брат execute at end to=⟨code⟩ выполняют код до и после начала рисования
FOREACH
Для него посвящу отдельную статью но в кратце:
\tikz \draw (0,0) foreach \x in {1,...,3} { -- (\x,1) -- (\x,0) };
Это цикл по списку.
LET IN
Сначала не хотел разбираться, но потом стало так интересно, а выяснилось, что еще и полезно.
\path … let⟨assignment⟩ ,⟨assignment⟩,⟨assignment⟩… in …;
В let … in можем использовать переменные
- \n1 или \n5 — суть номер регистра, где можно вычислить что нибудь и потом в разделе IN подставить
- \p1,\x1,\y1 — работает с координатами и тоже запоминает в своих регистрах
- \p{name} — тоже, что и \p1,\p3 … только под любым именем.
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\draw let \p{foo} = (1,1), \p2 = (2,0) in
(0,0) -- (\p2) -- (\p{foo});
\end{tikzpicture}
xshift yshift
оказалась полезная штука для смещения SCOPE и рисовать все в координатах с (0,0)
\pgfextra{⟨code⟩}
сначала хотел выбросить, но появилось время, почитал и тоже понравилось
\newdimen\mydim %назначаем переменную для измерения
\begin{tikzpicture}
\mydim=1cm% присваиваем первое значение
\draw (0pt,\mydim) \pgfextra{\mydim=2cm} -- (0pt,\mydim); изменяем значение и получаем новый результат
\end{tikzpicture}
я думаю использовать при настройке типовых рисунков для передачи им параметров
SOFT USE PATH
это такие ячейки памяти с сохранеными PATH, которые потом можно применять безограничений
\usetikzlibrary {intersections}
\begin{tikzpicture}
\path[save path=\pathA,name path=A] (0,1) to [bend left] (1,0);%запоминаю путь pathA
\path[save path=\pathB,name path=B]%запоминаю путь pathB
(0,0) .. controls (.33,.1) and (.66,.9) .. (1,1);
\fill[name intersections={of=A and B}] (intersection-1) circle (1pt);%нахожу пересечения пути (причем пути даже не наприсовал)
\draw[blue][use path=\pathA];%а теперь достаю путь и рисую
\draw[red] [use path=\pathB];
\end{tikzpicture}
действия с path
Это наверно аксиомы с которыми работает path
\draw — аналогично \path[draw]. рисует
\fill — аналогично \path[fill]. заполняет цветом
\filldraw — \path[fill,draw]. рисует и заполняет
\pattern — \path[pattern]. заполняет маленькими path из библиотеки pattern
\shade — \path[shade]. градиент
\shadedraw — \path[shade,draw]. рисует и заполняет градиентом
\clip — \path[clip]. клипит
\useasboundingbox — \path[use as bounding box] связывает до и после
опции
color=— покрасит в цветомline width=— толщина линииline cap=— round, rect, butt — завершение линииline join=— тип соединения линии round, bevel, mitermiter limit=— определяет остроту угла соединенияdash pattern— чередуются on 2pt off 3pt on 4pt off 4pt и получаем свой пунктирdash phase=— первоначальный сдвиг паттернаdash=— совмещает pattern и phase \draw [dash=on 20pt off 10pt phase 10pt]dash expand offрастягивает на сколько может dash, т.е. линия будет нужной длины и без разрывов
\usetikzlibrary {decorations}
\begin{tikzpicture}[|-|, dash pattern=on 4pt off 2pt]
\draw [dash expand off] (0pt,30pt) -- (26pt,30pt);
\draw [dash expand off] (0pt,20pt) -- (24pt,20pt);
\draw [dash expand off] (0pt,10pt) -- (22pt,10pt);
\draw [dash expand off] (0pt, 0pt) -- (20pt, 0pt);
\begin{scope}[xshift=2cm]
\draw (0pt,30pt) -- (26pt,30pt);
\draw (0pt,20pt) -- (24pt,20pt);
\draw (0pt,10pt) -- (22pt,10pt);
\draw (0pt, 0pt) -- (20pt, 0pt);
\end{scope}
\end{tikzpicture}
solid— сплошная прямая- dotted
- densely dotted
- loosely dotted
- dashed
- densely dashed
- loosely dashed
- dash dot
- densely dash dot
- loosely dash dot
- dash dot dot
- densely dash dot dot
- loosely dash dot dot
draw opacity
работает для всего и draw и fill и svg
double
double=<color>— нарисует двойную линию и закрасит цветомdouble distance=⟨dimension⟩— расстояние между линиямиdouble distance between line centers=⟨dimension⟩— расстояние между центрами линийdouble equal sign distance— удвоит расстояние знака
\Huge $==>\implies$\tikz[baseline,double equal sign distance]
\draw[double,thick,-{Implies[]}](0,0.55ex) --++(3ex,0);

рисуем стрелу
\usetikzlibrary {arrows.meta,bending} — это нам пригодится
\usetikzlibrary {arrows.meta,bending}
\tikz \draw[tips, -{Latex[open,length=10pt,bend]}] (0,0) to[bend left] (1,0);
pattern
\usetikzlibrary {patterns}
\begin{tikzpicture}
\draw[pattern=dots] (0,0) circle (1cm);
\draw[pattern=fivepointed stars] (0,0) rectangle (3,1);
\end{tikzpicture}
в библиотеке их много и лучше смотреть библиотеку https://tikz.dev/library-patterns#section-library-patterns
- pattern color — покрасит в нужный цвет
nonzero rule
исключит из пересечения фигур
\begin{tikzpicture}
\filldraw[fill=yellow!80!black]
% Clockwise rectangle
(0,0) -- (0,1) -- (1,1) -- (1,0) -- cycle
% Counter-clockwise rectangle
(0.25,0.25) -- (0.75,0.25) -- (0.75,0.75) -- (0.25,0.75) -- cycle;
\draw[->] (0,1) -- (.4,1);
\draw[->] (0.75,0.75) -- (0.3,.75);
\draw[->] (0.5,0.5) -- +(0,1) node[above] {crossings: $-1+1 = 0$};
\begin{scope}[yshift=-3cm]
\filldraw[fill=yellow!80!black]
% Clockwise rectangle
(0,0) -- (0,1) -- (1,1) -- (1,0) -- cycle
% Clockwise rectangle
(0.25,0.25) -- (0.25,0.75) -- (0.75,0.75) -- (0.75,0.25) -- cycle;
\draw[->] (0,1) -- (.4,1);
\draw[->] (0.25,0.75) -- (0.4,.75);
\draw[->] (0.5,0.5) -- +(0,1) node[above] {crossings: $1+1 = 2$};
\end{scope}
\end{tikzpicture}
сразу не понял, но если внутри рисунок против шерсти,то вырезает пустоту. Смотрим на стрелочки внутреннего квадрата.
even odd rule
просто вырежет внутренний паттерн
pattern picture
Идея данной функции, добавить внутрь объекта другой объект, ограниченный первым.
причем родительский объект будет иметь имя box с метками по сторонам света.
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\filldraw [fill=blue!10,draw=blue,thick] (1.5,1) circle (1)% нарисую круг
[path picture={
\node at (path picture bounding box.center) {%вставлю в круг надпись в центр круга
This is a long text.
};}
];
\end{tikzpicture}
также path picture может быть \draw, \fill, \node, \pattern
Shade
Градиент
у него есть настройки
\tikz \shadedraw [shading=axis] (0,0) rectangle (1,1);
\tikz \shadedraw [shading=radial] (0,0) rectangle (1,1);
\tikz \shadedraw [shading=ball,ball color=red] (0,0) circle (.5cm);
\tikz \shadedraw [shading=ball,ball color=blue] (0,0) circle (.5cm);
\tikz \shadedraw [shading=ball,ball color=green] (0,0) circle (.5cm);

bilinear interpolation
это красивые градиентные заливки объектов по 4-м углам
\usepgflibrary {shadings}
\tikz
\shade[upper left=red,upper right=green,
lower left=blue,lower right=yellow]
(0,0) rectangle (3,2);
\tikz \shade[shading=color wheel] (0,0) circle (1.5);
\tikz \shade[shading=color wheel] [even odd rule]
(0,0) circle (1.5)
(0,0) circle (1);
- color wheel
- color wheel black center
- color wheel white center
- inner color= % радиальная заливка
- outer color= %радиальная заливка

use as bounding box
графически привязывает блоки слева и справа Наверно будет удобно для создания различных перекрестных указателей или еще чего-нибудь, где важно, чтобы блоки склеились в единое целое
У них есть подпараметры:
- trim left=⟨dimension or coordinate or default⟩
- trim right=⟨dimension or coordinate or default⟩
- trim lowlevel=true|false
clip
вырезает все на скорую руку
лучше использовать внутри рисунков с применением группировки scope
\begin{tikzpicture}
\draw (0,0) -- ( 0:1cm);
\draw (0,0) -- (10:1cm);
\draw (0,0) -- (20:1cm);
\draw (0,0) -- (30:1cm);
\begin{scope}[fill=red]
\fill[clip] (0.2,0.2) rectangle (0.5,0.5);
\draw (0,0) -- (40:1cm);
\draw (0,0) -- (50:1cm);
\draw (0,0) -- (60:1cm);
\end{scope}
\draw (0,0) -- (70:1cm);
\draw (0,0) -- (80:1cm);
\draw (0,0) -- (90:1cm);
\end{tikzpicture}
preaction
Я раньше использовал подобное для рисование стрелок с подложкой белого фона.
Оказалось, что все уже придумано до нас))
\begin{tikzpicture}
\draw[help lines] (0,0) grid (3,2);
\draw
[preaction={draw,line width=4mm,blue}]%нарисует по координатам draw прямоугольник с толщиной линии 4mm
[line width=2mm,red] (0,0) rectangle (2,2);%нарисует сверху по этим же координатам линию 2mm
\end{tikzpicture}
удобно для выделения контраста и рисования теней
\begin{tikzpicture}
\draw[help lines] (0,0) grid (3,2);
\draw
[preaction={fill=black,opacity=.5,
transform canvas={xshift=1mm,yshift=-1mm}}]
[fill=red] (0,0) rectangle (1,2)
(1,2) circle (5mm);
\end{tikzpicture}
preaction — может быть несколько штук в одном объекте
postaction=⟨options⟩
Это друг preaction, только делает после того как нарисовал основной рисунок
decorations
\usetikzlibrary {decorations.pathmorphing,shadows}
\begin{tikzpicture}
\node [circular drop shadow={shadow scale=1.05},minimum size=3.13cm,
decorate, decoration=zigzag,
fill=blue!20,draw,thick,circle] {Hello!};
\end{tikzpicture}
Целая библиотека различных декораций и линий для рисования объектов.

7.7.9 - Вводные понятия в TIKZ
Базовые понятия TIKZ и описание системы координат. Без этого урока разбираться в TIKZ бессмысленно
Уроки TIKZ чтобы научиться делать все в одном стиле
Подключение TIKZ в документ.
Лично для себя установка! Много раз пробовал сделать, что нибудь в графическом редакторе и потом перенести в latex, но каждый раз нарывался на многочисленные переделки графики. Вывод! Все что больше 1-2х страниц, делай в LATEX и графику в TIKZ. В итоге сэкономишь.
Для подключения TIKZ нужно в преамбуле добавить:
\usepackage{tikz} %подключить пакет
\usetikzlibrary {angles,calc,quotes} %подключить нужные библиотеки
Библиотеки по ходу буду тоже описывать, те, которые мне точно понравились и нужны. Но их очень много.
Чтобы вставить в текст объект TIKZ нужно использовать окружение
\begin{tikzpicture}
...
\end{tikzpicture}
или
\tikz ...
Координаты в TIKZ
Обычные координаты
(X, Y) — разделитель запятая.
Измеряем либо в стандартных единицах TeX (cm, pt). По умолчанию PGF использует сантиметр: X -> вправо, Y -> вверх.
(30:1cm) — полярные координаты. Т.е. от текущей точки на 1см 30 градусов.
Для трехмерных объектов (1,1,1)
Якорные координаты
У каждого объекта есть свои якорные координаты,связанные со сторонами света:
например: first node.north
- north
- south
- east
- west
И их возможные комбинации: node.north west
Относительные координаты
Нужно перед указанием координат поставить ++ и указать относительное смещение ++(1cm,0pt) — вправо на 1см.
Но для этого нужно знать, где сейчас находится курсор.
Как выяснил, команда \node не изменяет текущую координату.
Если использовать один + перед координатами, то перемещение произойдет, но текущая координата не сменится.
(1,0) +(1,0) +(0,1) даст три точки (1,0), (2,0), (1,1).
Специальный синтаксис для PATH
PATH — водит пером по бумаге, но не оставляет следов, если его не попросить специально.
-- — прямая линия
-| — горизонтально + вертикально
|- — вертикально + горизонтально
cycle — вернуться в точку старта
PATH может:
- draw — рисовать линию
- fill — заполнять пространство
- shade — градиент
- clip — вырезать
Так же доступны комбинации с ними.
\path (0,0) rectangle (2ex,1ex); % ничего визуального не произойдет
\path[draw] (0,0) rectangle (2ex,1ex); % появится рамка
\path[fill=black] (0,0) rectangle (2ex,1ex); % появится черный прямоугольник
Для этих случаев есть сокращенные команды:
\path[draw]=\draw\path[fill]=\fill\path[fill,draw]=\filldraw\path[shade]=\shade\path[shade,draw]=\shadedraw\path[clip]=\clip\path[clip,draw]=\draw[clip]
Вставка текста
Текст добавляем с помощью команды \node прямо в синтаксис \path
\tikz \draw (1,1) node {text} -- (2,2);
У node могут быть:
(name) или [name=имя] [другие опции] {текст}
опции node:
- rectangle
- fill
- circle
- draw
- ellipse
и т.д. это то, что будет нарисовано вокруг текста.
Рисуем деревья
Это такая умная \node с поднодиками.
\begin{tikzpicture}
\node {root}
child {node {left}}
child {node {right}
child {node {child}}
child {node {child}}
};
\end{tikzpicture}
Подключаем библиотеку со стрелочками и оформим стили.
FORK — это вилка, которой будем соединять вниз (down),также можно написать up, left, right и от этой стороны будет выходить стрелка.
\usetikzlibrary {arrows.meta,trees}
\begin{tikzpicture}
[edge from parent fork down, sibling distance=15mm, level distance=15mm,
every node/.style={fill=red!30,rounded corners},
edge from parent/.style={red,-{Circle[open]},thick,draw}]
\node {root}
child {node {left}}
child {node {right}
child {node {child}}
child {node {child}}
};
\end{tikzpicture}
И еще с шариками, а grow — покажет куда расти дереву (up,down,left,right или north,south,east,west). Anchor — это куда прицепляться parent и child.
sibling — ширина плечика на одном уровне, level — это расстояние между уровнями.
every node/.style — назначает стиль глобально для всех node без указания класса.
edge — это собственно само ребро или соединение
ball — это еще одна разновидность фигуры, шарик называется.
\begin{tikzpicture}
[parent anchor=east,child anchor=west,grow=east,
sibling distance=15mm, level distance=15mm,
every node/.style={ball color=red,circle,text=white},
edge from parent/.style={draw,dashed,thick,red}]
\node {root}
child {node {left}}
child {node {right}
child {node {child}}
child {node {child}}
};
\end{tikzpicture}
Графы
Нужна своя библиотека graphs
\usetikzlibrary {graphs}
\tikz \graph [grow down, branch left] {
root -> {
left,
2,3 ->{
5,6,7,8 ->{
11,12,13},
9},
right -> {
child,
child} }
};
Тема с графом тоже интересна.
grow — куда растем, указать сторону
branch — в какую сторону ветви раскидать
\usetikzlibrary {graphs.standard}
\tikz \graph [clockwise] { subgraph K_n [n=9] };
Уж очень он мне понравился. Библиотеку обязательно отдельно всю опишу.
SCOPE
Это внутреннее окружение для группировки настроек.
Это фактически зона видимости.
\begin{tikzpicture}
\begin{scope}[color=red]
\draw (0mm,10mm) -- (10mm,10mm);
\draw (0mm, 8mm) -- (10mm, 8mm);
\draw (0mm, 6mm) -- (10mm, 6mm);
\end{scope}
\begin{scope}[color=green]
\draw (0mm, 4mm) -- (10mm, 4mm);
\draw (0mm, 2mm) -- (10mm, 2mm);
\draw[color=blue] (0mm, 0mm) -- (10mm, 0mm);
\end{scope}
\end{tikzpicture}

Еще SCOPE умеет
/tikz/name=⟨scope name⟩ /tikz/every scope /tikz/execute at begin scope=⟨code⟩ /tikz/execute at end scope=⟨code⟩
И у нее есть даже библиотека \usetikzlibrary{scopes}
Когда библиотека загружена, то можно просто указать фигурные скобки, без begin/end
А еще становится доступной команда \scoped ⟨animations spec⟩[⟨options⟩]⟨path command⟩
\usetikzlibrary {scopes}
\begin{tikzpicture}
{ [ultra thick]
{ [red]
\draw (0mm,10mm) -- (10mm,10mm);
\draw (0mm,8mm) -- (10mm,8mm);
}
\draw (0mm,6mm) -- (10mm,6mm);
}
{ [green]
\draw (0mm,4mm) -- (10mm,4mm);
\draw (0mm,2mm) -- (10mm,2mm);
\draw[blue] (0mm,0mm) -- (10mm,0mm);
}
\end{tikzpicture}
\usetikzlibrary {backgrounds}
\begin{tikzpicture}
\node [fill=white] at (1,1) {Hello world};
\scoped [on background layer]
\draw (0,0) grid (3,2);
\end{tikzpicture}
Опции
\tikzset
— установит в переменную любую команду для применения в окружении \begin{tikzpicture}
baseline
— еще можно задать с помощью координаты, тоже поймет.
\tikz[baseline=0pt]\draw(0,0)circle(.5ex); — установит смещение от базовой линии. По умолчанию строго по центру.
А вот так перечеркнем слово
\usetikzlibrary {shapes.misc}
Hello
\tikz[baseline=(X.base)]
\node [cross out,draw] (X) {world.};

Назначение своего стиля
my style/.style={draw=red,fill=red!20}
Использование стилей
\begin{tikzpicture}[help lines/.style={blue!50,very thin}]
\draw (0,0) grid +(2,2);
\draw[help lines] (2,0) grid +(2,2);
\end{tikzpicture}
Чтобы добавить настройки к существующему стилю /.append style вместо style
Стили с переменными
\begin{tikzpicture}[outline/.style={draw=#1,thick,fill=#1!50}]
\node [outline=red] at (0,1) {red};
\node [outline=blue] at (0,0) {blue};
\end{tikzpicture}
или задать значение по умолчанию
\begin{tikzpicture}[outline/.style={draw=#1,thick,fill=#1!50},
outline/.default=black]
\node [outline] at (0,1) {default};
\node [outline=blue] at (0,0) {blue};
\end{tikzpicture}
/tikz/execute at begin picture=⟨code⟩
Выполнит код до того как начал рисовать картину
/tikz/execute at end picture=⟨code⟩
Выполнит код после того как нарисовал картину
\usetikzlibrary {backgrounds}
\begin{tikzpicture}[execute at end picture=%
{
\begin{pgfonlayer}{background}
\path[fill=yellow,rounded corners]
(current bounding box.south west) rectangle
(current bounding box.north east);
\end{pgfonlayer}
}]
\node at (0,0) {X};
\node at (2,1) {Y};
\end{tikzpicture}

Нарисовал X и Y, а потом подрисовал фон желтого цвета.
Установка глобального стиля /tikz/every picture
В преамбуле напишем \tikzset{every picture/.style=semithick}
или если несколько значений, то \tikzset{every picture/.style={line width=1pt}}
Библиотека \usetikzlibrary{babel}
Для работы со шрифтами,рекомендуется всегда загружать эту библиотеку.
Specifying Coordinates
Или поговорим о координатах.
([⟨options⟩]⟨coordinate specification⟩)
Три вида координат:
- декартовы
- полярные
- сферические
Явное указание координат и неявное указание.
Декартова система координат CANVAS
Ключевое слово CANVAS
/tikz/cs/x=⟨dimension⟩
/tikz/cs/y=⟨dimension⟩
Система координат XYZ
Все тоже, только xyz
\begin{tikzpicture}[->]
\draw (0,0) -- (xyz cs:x=1);
\draw (0,0) -- (xyz cs:y=1);
\draw (0,0) -- (xyz cs:z=1);
\end{tikzpicture}
Система координат canvas polar
/tikz/cs/angle=⟨градусы⟩ — Угол координаты. Угол всегда должен быть указан в градусах.
/tikz/cs/radius=⟨размер) — Расстояние от текущей точки
/tikz/cs/x radius=⟨размер⟩ /tikz/cs/y radius=⟨размер⟩
\tikz \draw (0cm,0cm) -- (30:1cm) -- (60:1cm) -- (90:1cm)
-- (120:1cm) -- (150:1cm) -- (180:1cm);
Специальные слова для указания угла
up, down, left, right, north, south, west, east, north east, north west, south east, south west
Система координат XYZ POLAR
\begin{tikzpicture}[x=1.5cm,y=1cm]%масштаб системы координат
\draw[help lines] (0cm,0cm) grid (3cm,2cm);
\draw (0,0) -- (xyz polar cs:angle=0,radius=1);
\draw (0,0) -- (xyz polar cs:angle=30,radius=1);
\draw (0,0) -- (xyz polar cs:angle=60,radius=1);
\draw (0,0) -- (xyz polar cs:angle=90,radius=1);
\draw (xyz polar cs:angle=0,radius=2)
-- (xyz polar cs:angle=30,radius=2)
-- (xyz polar cs:angle=60,radius=2)
-- (xyz polar cs:angle=90,radius=2);
\end{tikzpicture}
\begin{tikzpicture}[x={(-1cm,0cm)},y={(0cm,-1cm)}] %переворачиваю систему координат
\draw[help lines] (0cm,0cm) grid (3cm,2cm);%рисую сетку
\fill (canvas cs:x=1cm,y=0cm) node[right] {X} circle (2pt);%точка в абсолютных координатах без изменений (черная)
\fill (canvas cs:x=0cm,y=1cm) node[left] {Y} circle (2pt);%точка в абсолютных координатах без изменений (черная)
\fill [color=red] (1,0) node[left]{X'} circle (2pt);%точка в относительных координатах перевернутая (красная)
\fill [color=red] (0,1) node[right]{Y'} circle (2pt);%точка в относительных координатах перевернутая (красная)
\draw [color=red] (0,0) -- (30:1) -- (60:1) -- (90:1)
-- (120:1) -- (150:1) -- (180:1);%рисунок в относительных координатах красный
\end{tikzpicture}
Для указания координат и смещений NODE указываем ключевые слова : left, right, below, above и их комбинации.
Барицентрические системы координат
barycentric — это координаты по сторонам света north, south, east, west и их комбинации
\begin{tikzpicture}
\coordinate (content) at (90:3cm);
\coordinate (structure) at (210:3cm);
\coordinate (form) at (-30:3cm);
\node [above] at (content) {content oriented};
\node [below left] at (structure) {structure oriented};
\node [below right] at (form) {form oriented};
\draw [thick,gray] (content.south) -- (structure.north east) -- (form.north west) -- cycle;
\small
\node at (barycentric cs:content=0.5,structure=0.1 ,form=1) {PostScript};
\node at (barycentric cs:content=1 ,structure=0 ,form=0.4) {DVI};
\node at (barycentric cs:content=0.5,structure=0.5 ,form=1) {PDF};
\node at (barycentric cs:content=0 ,structure=0.25,form=1) {CSS};
\node at (barycentric cs:content=0.5,structure=1 ,form=0) {XML};
\node at (barycentric cs:content=0.5,structure=1 ,form=0.4) {HTML};
\node at (barycentric cs:content=1 ,structure=0.2 ,form=0.8) {\TeX};
\node at (barycentric cs:content=1 ,structure=0.6 ,form=0.8) {\LaTeX};
\node at (barycentric cs:content=0.8,structure=0.8 ,form=1) {Word};
\node at (barycentric cs:content=1 ,structure=0.05,form=0.05) {ASCII};
\end{tikzpicture}
Для понимания процесса barycentric, каждая координата тянет к себе с определенной силой. Если я поставлю с одинаковой силой, то будет ровно посередине, относительно всех точек.
\node at (barycentric cs:content=1,structure=1 ,form=1) {PostScript}; как на рисунке ниже
Node координатная система
/tikz/cs/name=⟨node name⟩
/tikz/anchor=⟨anchor⟩
\usetikzlibrary {arrows.meta}
\begin{tikzpicture}[node font=\ttfamily]
\node (shape) at (0,2) [draw] {class Shape};
\node (rect) at (-2,0) [draw] {class Rectangle};
\node (circle) at (2,0) [draw] {class Circle};
\node (ellipse) at (6,0) [draw] {class Ellipse};
\draw [color=red](node cs:name=circle,anchor=north) |- (0,1);
\draw [blue] (node cs:name=ellipse,anchor=north) |- (0,1);
\draw [arrows = -{Triangle[open, angle=60:3mm]}]
(node cs:name=rect,anchor=north)
|- (0,1) -| (node cs:name=shape,anchor=south);
\end{tikzpicture}
\usetikzlibrary {arrows.meta} — библиотека для красивых стрелочек
\begin{tikzpicture}[node font=\ttfamily] — назначаем шрифт
Присвоим имена каждой ноде
\node (shape) at (0,2) [draw] {class Shape};
\node (rect) at (-2,0) [draw] {class Rectangle};
\node (circle) at (2,0) [draw] {class Circle};
\node (ellipse) at (6,0) [draw] {class Ellipse};
Нарисуем первую линию красного цвета
\draw [color=red](node cs:name=circle,anchor=north) |- (0,1);
Нарисуем вторую линию синего цвета
\draw [blue] (node cs:name=ellipse,anchor=north) |- (0,1);
Нарисуем стрелку черногго цвета
\draw [arrows = -{Triangle[open, angle=60:3mm]}]
(node cs:name=rect,anchor=north)
|- (0,1) -| (node cs:name=shape,anchor=south);
А эта штука соединяет между собой две ноды по бордюру самым коротким путем: (node cs:name=a) -- (node cs:name=b), т.е. все, что в круглых скобках — это координаты.
\usetikzlibrary {shapes.geometric}
\begin{tikzpicture}
\path (0,0) node(a) [ellipse,rotate=10,draw] {An ellipse}
(3,-1) node(b) [circle,draw] {A circle};
\draw[thick] (node cs:name=a) -- (node cs:name=b);
\end{tikzpicture}
А это легкая замена rectangle, чтобы не пересекалось
\tikz \draw (0,0) node(x) [draw] {Text}
% rectangle (1,1)
(node cs:name=x) -- +(0,1) -- +(1,1) -- +(1,0) -- (node cs:name=x)
(node cs:name=x) -- +(1,1)
(node cs:name=x) -- +(1,.5)
(node cs:name=x) -- +(.5,1)
;
Для те, кто в танке, чтобы не забыть: +(координаты) — не изменяет точку отсчета и указывает относительную координату; ++(координаты) — изменяет точку отсчета и указывает относительные координаты; (координаты) — изменяет точку отсчета и указывает абсолютные координаты.
\begin{tikzpicture}
\draw[blue!20] (0,0) grid +(2,2);
\draw (0,0) node(x) [draw] {Text}
(node cs:name=x) -- ++(0,1) -- ++(1,1) -- +(1,0) -- (node cs:name=x);
\end{tikzpicture}
\usetikzlibrary {shapes.geometric}
\begin{tikzpicture}[fill=blue!20]
\draw[help lines] (-1,-2) grid (6,3);
\path (0,0) node(a) [ellipse,rotate=10,draw,fill] {An ellipse}
(3,-1) node(b) [circle,draw,fill] {A circle}
(2,2) node(c) [rectangle,rotate=20,draw,fill] {A rectangle}
(5,2) node(d) [rectangle,rotate=-30,draw,fill] {Another rectangle};
\draw[thick] (a.south) -- (b) -- (c) -- (d);
\draw[thick,red,->] (a) |- +(1,3) -| (c) |- (b);
\draw[thick,blue,<->] (b) .. controls +(right:2cm) and +(down:1cm) .. (d);
\end{tikzpicture}
Что здесь примечательного?
- Все ноды рисуются в один присест, просто перечисляем через слово
nodeи вначале подставляем координаты. - Линии рисуем отдельными командами через
\draw
Координатная система TANGENT
Работает только с загруженной библиотекой CALC
Нарисует по касательной от точки (a):
- tangent — система координат
- cs: — сами координаты
- node=c — фигура
- point={(a)} — точка, от которой пойдет касательная
- solution=1 — номер решения, если их несколько
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw[help lines] (0,0) grid (3,2);
\coordinate (a) at (3,2);
\node [circle,draw] (c) at (1,1) [minimum size=40pt] {$c$};
\draw[red] (a) -- (tangent cs:node=c,point={(a)},solution=1) --
(c.center) -- (tangent cs:node=c,point={(a)},solution=2) -- cycle;
\end{tikzpicture}
Создание собственной системы координат
Требует отдельного изучения, если вдруг понадобится
Ключевое слово \tikzdeclarecoordinatesystem{⟨name⟩}{⟨code⟩}
Или создать alias существующей системекоординат
\tikzaliascoordinatesystem{⟨new name⟩}{⟨old name⟩}
https://tikz.dev/tikz-coordinates#sec-13.2.5
Координаты точек пересечения
Библиотека \usetikzlibrary{intersections}
/tikz/name path=⟨name⟩ — задать имя path для поиска пересечения
/tikz/name path global=⟨name⟩ — задает имя path глобально,будет доступно за пределами окружения SCOPE в рисунке
/tikz/name intersections={⟨options⟩} — поиск точек пересечения путей path
Если несколько точек пересечения им будут заданы координаты intersections-1 и intersections-2 и т.д. сколько получится.
\usetikzlibrary {intersections}
\begin{tikzpicture}[every node/.style={opacity=1, black, above left}]%стиль node подписи в лево вверх
\draw [help lines] grid (3,2);%нарисуем grid
\draw [name path=ellipse] (2,0.5) ellipse (0.75cm and 1cm);%нарисуем элипс и имя path=ellipse
\draw [name path=rectangle, rotate=10] (0.5,0.5) rectangle +(2,1);%нарисуем прямоугольник и имя path=rectangle
\fill [red, opacity=0.5, name intersections={of=ellipse and rectangle}]% найдем точки пересечения двух path
%name intersections --- это команда для поиска пересечений
%of= --- задает path для поиска пересечений
(intersection-1) circle (2pt) node {1}%нарисовать точку в пересечении 1
(intersection-2) circle (2pt) node {2};%нарисовать точку в пересечении 2
\end{tikzpicture}
Ключи intersections
of=
name intersections={of=ellipse and rectangle} — задает имена path для поиска пересечений
name=
выдаст имена точек пересечения, какие заданы в name
\fill [red, opacity=0.5, name intersections={of=ellipse and rectangle,name=insec}]
(insec-1) circle (2pt) node {1}
(insec-2) circle (2pt) node {2};
total=⟨macro⟩
Создает список всех точек пересечения и сохраняет его в макросе tex по номерам 1,2,3 и т.д.
[name intersections={of=curve 1 and curve 2, name=i, total=\t}] — сохранит в макросе \t
by={a,b}
присвоит каждой точке свое имя a и b
\fill [name intersections={of=curve 1 and curve 2, by={a,b}}]
(a) circle (2pt)
(b) circle (2pt);
Еще можно использовать нотацию ... подставит имена автоматически
[name intersections={
of=curve 1 and curve 2,
by={[label=center:a],[label=center:...],[label=center:i]}}]
Относительные и инкрементальные координаты
Это мои любимые + и ++
Дают одинаковый вариант:
++ изменяет текущую координату и премещается относительно
+ не изменяет текущую координату и перемещается относительно
\begin{tikzpicture}
\draw (0,0) -- ++(1,0) -- ++(0,1) -- ++(-1,0) -- cycle;
\draw (2,0) -- ++(1,0) -- ++(0,1) -- ++(-1,0) -- cycle;
\draw (1.5,1.5) -- ++(1,0) -- ++(0,1) -- ++(-1,0) -- cycle;
\end{tikzpicture}
\begin{tikzpicture}
\draw (0,0) -- +(1,0) -- +(1,1) -- +(0,1) -- cycle;
\draw (2,0) -- +(1,0) -- +(1,1) -- +(0,1) -- cycle;
\draw (1.5,1.5) -- +(1,0) -- +(1,1) -- +(0,1) -- cycle;
\end{tikzpicture}
Ключевое слово TURN
\tikz \draw (0,0) -- (1,1) -- ([turn]-45:1cm) -- ([turn]-30:1cm);
Поворачивает ось координат по касательной к последней точке.
\begin{tikzpicture} [delta angle=-180, radius=1cm]
\draw [help lines] (0,0) grid (10,5);
\draw (0,3) arc [start angle=-180] -- ([turn]60:1cm)
arc [start angle=-180] -- ([turn]60:1cm)
arc [start angle=180] -- ([turn]60:1cm);
\end{tikzpicture}
До меня дошло, когда нарисовал сетку координат
[delta angle=-180, radius=1cm] — параметры дуги: ее угол и радиус, минус говорит, что рисуем по часовой стрелке
[start angle=-180] — собственно стартовый угол дуги, относительно системы координат — здесь -180 и +180 роли не играет, но -90 и +90 развернут дугу в разные стороны.
– ([turn]60:1cm) — эта штука нарисует отрезок из последней точки но в системе координат именно последней точки. Т.е. 60 градусов она развернет относительно мысленного продолжения arc по касательной.
[current point is local]
Укажет, что внутри фигурных скобок была относительная координата и после выхода из скобок, система координат будет как была до нее.
\begin{tikzpicture}
\draw (0,0) -- ++(1,0) -- ++(0,1) -- ++(-1,0);
\draw[red] (2,0) -- ++(1,0)
{ [current point is local] -- ++(0,1) } -- ++(-1,0);
\end{tikzpicture}
Вычисляемые координаты
Вся мощь библиотеки CALC в расчете координат
($(a) + 1/3*(1cm,0)$) — вот так берем и изменяем координаты. Не забываем поставить эту конструкцию в $.
([⟨options⟩]$⟨coordinate computation⟩$)
— синтаксис
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\fill [red] ($2*(1,1)$) circle (2pt);
\fill [green] (${1+1}*(1,.5)$) circle (2pt);
\fill [blue] ($cos(0)*sin(90)*(1,1)$) circle (2pt);
\fill [black] (${3*(4-3)}*(1,0.5)$) circle (2pt);
\end{tikzpicture}
Это возможные операции над координатами. Координаты всегда имеют структуру (x,y) и умножение будет происходить над x и y по отдельности.
⟨coordinate⟩!⟨number⟩!⟨angle⟩:⟨second coordinate⟩
(1,2)!.75!(3,4) — это значит, что координата будет на .75 между точками (1,2) и (3,4)
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\draw (1,0) -- (3,2);
\foreach \i in {0,0.2,0.5,0.9,1}
\node at ($(1,0)!\i!(3,2)$) {\i};
\end{tikzpicture}
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,3);
\coordinate (a) at (1,0);
\coordinate (b) at (3,2);
\draw[->] (a) -- (b);
\coordinate (c) at ($ (a)!1! 10:(b) $); % от точки (a) длина !1! --- такая же как (ab) и повернуть на 10 градусов.
\draw[->,red] (a) -- (c);
\fill ($ (a)!.5! 10:(b) $) circle (2pt); % а здесь точку нарисуем
\end{tikzpicture}
Змея для примера
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (4,4);
\foreach \i in {0,0.125,...,2}
\fill ($(2,2) !\i! \i*180:(3,2)$) circle (2pt);
\end{tikzpicture}
Модифаеры могут быть по нескольку штук дляг за другом
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\draw (0,0) -- (3,2);
\draw[red] ($(0,0)!.3!(3,2)$) -- (3,0);
\fill[red] ($(0,0)!.3!(3,2)!.7!(3,0)$) circle (2pt); %как здесь. Нашли точку на одной прямой и о нее ищем на другой.
\end{tikzpicture}
⟨coordinate⟩!⟨dimension⟩!⟨angle⟩:⟨second coordinate⟩
т.е. эта штука вычислит все в миллиметрах и расставит метки по прямой
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\draw (1,0) -- (3,2);
\foreach \i in {0cm,1cm,15mm}
\node at ($(1,0)!\i!(3,2)$) {\i};
\end{tikzpicture}
А эта будет ставить измерения
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\coordinate (a) at (1,0);
\coordinate (b) at (3,1);
\draw (a) -- (b);%нарисуем прямую ab
\coordinate (c) at ($ (a)!.25!(b) $);%найдем точку c
\coordinate (d) at ($ (c)!1cm!90:(b) $);%найдем точку d 90град от cb
\draw [<->] (c) -- (d) node [sloped,midway,above] {1cm};% начертим стрелочки и напишем 1 cm
\end{tikzpicture}
⟨coordinate⟩!⟨projection coordinate⟩!⟨angle⟩:⟨second coordinate⟩
модификаторы проекции
Нарисуем треугольник и опустим перпендикуляры от вершин на противоположные стороны
между !()! укажем вершину в скобках
\usetikzlibrary {calc}
\begin{tikzpicture}
\draw [help lines] (0,0) grid (3,2);
\coordinate (a) at (0,1);
\coordinate (b) at (3,2);
\coordinate (c) at (2.5,0);
\draw (a) -- (b) -- (c) -- cycle;
\draw[red] (a) -- ($(b)!(a)!(c)$);%от a на сторону bc
\draw[orange] (b) -- ($(a)!(b)!(c)$);%от b на сторону ac
\draw[blue] (c) -- ($(a)!(c)!(b)$);%от c на сторону ab
\end{tikzpicture}
Перпендикуляры
Основные команды это:
- /tikz/cs/horizontal line through={(⟨coordinate⟩)}
- /tikz/cs/vertical line through={(⟨coordinate⟩)}
задают вертикальную и горизонтальные линии, но в основном используется синтаксис:
(⟨p⟩ |- ⟨q⟩) или (⟨q⟩ -| ⟨p⟩).
Для примера: (2,1 |- 3,4) и (3,4 -| 2,1) дадут точку (2,4)
\begin{tikzpicture}
\path (30:1cm) node(p1) {$p_1$} (75:1cm) node(p2) {$p_2$};
\draw (-0.2,0) -- (1.2,0) node(xline)[right] {$q_1$};
\draw (2,-0.2) -- (2,1.2) node(yline)[above] {$q_2$};
\draw[->] (p1) -- (p1 |- xline);
\draw[->] (p2) -- (p2 |- xline);
\draw[->] (p1) -- (p1 -| yline);
\draw[->] (p2) -- (p2 -| yline);
\end{tikzpicture}

или такой
\usetikzlibrary {calc}
\begin{tikzpicture}
\node (A) at (0,1) {A};
\node (B) at (1,1.5) {B};
\node (C) at (2,0) {C};
\node (D) at (2.5,-2) {D};
\draw (A) -- (B) node [midway] {x};
\draw (C) -- (D) node [midway] {x};
\node at ({$(A)!.5!(B)$} -| {$(C)!.5!(D)$}) {X};
\end{tikzpicture}
от одной средней точки возьмем координату X от другой Y и напишем метку X.

7.7.10 - Диаграммы в Latex библиотека TIKZ
Возможности библиотеки TIKZ для рисования графиков в Latex
Возможности библиотеки TIKZ для рисования графиков в Latex. Обзор учебника из документации.
Рисование графиков в Latex. Добро пожаловать в систематизацию процессов.
Библиотеки для работы с диаграммами
\usetikzlibrary {
positioning,% нативные позиции node
shapes.misc, % настройка внешнего вида фигур, углы и т.д.
graphs, % работает с диаграммами и графами
calc, % считает координаты
arrows.meta % рисует наконечники стрел
}
Стилизация узлов диаграммы
Простой прямоугольник (Не-Терминал)
\usetikzlibrary {positioning}
\begin{tikzpicture}[
nonterminal/.style={
% The shape:
rectangle,
% The size:
minimum size=6mm,
% The border:
very thick,
draw=red!50!black!50, % 50% red and 50% black,
% and that mixed with 50% white
% The filling:
top color=white, % a shading that is white at the top...
bottom color=red!50!black!20, % and something else at the bottom
% Font
font=\itshape
}]
\node [nonterminal] {unsigned integer};
\end{tikzpicture}
В стиле определил:
- rectangle
- minimum size
- border — красночерного цвета толстый бордюр
- filling — градиент top и bottom
- font
Для рисования просто пишу NODE и все готово 
Стиль терминалов с круглыми углами
\usetikzlibrary {positioning}
\begin{tikzpicture}[node distance=5mm,
terminal/.style={
% The shape:
rectangle,minimum size=6mm,rounded corners=3mm,
% The rest
very thick,draw=black!50,
top color=white,bottom color=black!20,
font=\ttfamily}]
\node (dot) [terminal] {.};
\node (digit) [terminal,right=of dot] {digit};
\node (E) [terminal,right=of digit] {E};
\end{tikzpicture}
Как приятно писать что-то, когда ты понимаешь, что ты это понимаешь)))
В стиле определено:
- node distance — это значит,что расстояние между
nodeбудет, то, которое задано. - terminal — название стиля
- rectangle — форма
- minimum size
- rounded corners — радиус закругления углов (закругляет у любой фигуры \node, \fill, \path)
- very thick — толщина обводки
- top, bottom — градиент заливки
- font
Односимвольный терминал станет кругом, а многосимвольный — прямоугольником с закругленными углами.

Использование библиотеки shapes.misc
Только немного изменится настройка в описании стиля
[node distance=5mm,
terminal/.style={
% The shape:
rounded rectangle,
minimum size=6mm,
% The rest
very thick,draw=black!50,
top color=white,bottom color=black!20,
font=\ttfamily}]
убрали rounded corners а поставили rounded rectangle — собственно и все. Но разметка слегка отъехала. На рисунке можно увидеть небольшую разницу.
Выравнивание текста в терминалах
Просто добавляем в стиль высоту и глубину строки [text height=1.5ex,text depth=.25ex]
Полезная библиотека позиционирования
\usetikzlibrary {positioning,shapes.misc}
\begin{tikzpicture}[node distance=5mm and 5mm]
\node (ui1) [nonterminal] {unsigned integer};
\node (dot) [terminal,right=of ui1] {.};
\node (digit) [terminal,right=of dot] {digit};
\node (E) [terminal,right=of digit] {E};
\node (plus) [terminal,above right=of E] {+};
\node (minus) [terminal,below right=of E] {-};
\node (ui2) [nonterminal,below right=of plus] {unsigned integer};
\end{tikzpicture}
основные команды:
- right=of
- left=of
- above=of
- below=of
- above right=of
- и т.д.
На маленьких node при работе с библиотекой позиционирования, может не хватать смещения, добавим в ручную: xshift=5mm
Или использовать матрицы. Но это позже.
Перенесем настройки стилей в преамбулу документа
\tikzset {terminal/.style={
% The shape:
rectangle,minimum size=6mm,rounded corners=3mm,
% The rest
very thick,draw=black!50,
top color=white,bottom color=black!20,
font=\ttfamily}}
\tikzset {nonterminal/.style={
% The shape:
rectangle,
% The size:
minimum size=6mm,
% The border:
very thick,
draw=red!50!black!50, % 50% red and 50% black,
% and that mixed with 50% white
% The filling:
top color=white, % a shading that is white at the top...
bottom color=red!50!black!20, % and something else at the bottom
% Font
font=\itshape
}}
Теперь будет действовать глобально на всех.
Рисуем стрелки
\usetikzlibrary {calc,positioning,shapes.misc}
\begin{tikzpicture}[node distance=5mm and 5mm,
skip loop/.style={to path={-- ++(0,#1) -| (\tikztotarget)}}]
\node (dot) [terminal] {.};
\node (digit) [terminal,right=of dot] {digit};
\node (E) [terminal,right=of digit] {E};
\path (dot) edge[->] (digit) % simple edges
(digit) edge[->] (E)
($ (digit.east)!.5!(E.west) $)
edge[->,skip loop=-5mm] ($ (digit.west)!.5!(dot.east) $);
\end{tikzpicture}
Разберем кривую стрелку
($ (digit.east)!.5!(E.west) $)
edge[->,skip loop=-5mm] ($ (digit.west)!.5!(dot.east) $);
т.е. от середины между метками (digit.east)!.5!(E.west) до середины между метками (digit.west)!.5!(dot.east) рисуем кривулину типа skip loop

Пока все довольны.
Но разобрать по частям стиль skip loop очень хочется: skip loop/.style={to path={-- ++(0,#1) -| (\tikztotarget)}}
- первая часть понятна: от текущей точке рисуем линию вертикально на заданный параметр
#1, а потом -|— рисует горизонтально, а потом вертикально к цели, это один из родственников--— рисует прямую;|-— рисует вертикально и горизонтально и..— рисует кривую- возвращаемся к поставленной цели
(\tikztotarget)вообще таких макросов три (\tikztostart, \tikztotarget, and \tikztonodes;)
Матрицы
\usetikzlibrary {shapes.misc}
\begin{tikzpicture}
\matrix[row sep=1mm,column sep=5mm] {
% First row:
& & & & \node [terminal] {+}; & \\
% Second row:
\node [nonterminal] {unsigned integer}; &
\node [terminal] {.}; &
\node [terminal] {digit}; &
\node [terminal] {E}; &
&
\node [nonterminal] {unsigned integer}; \\
% Third row:
& & & & \node [terminal] {-}; & \\
};
\end{tikzpicture}
Пока \matrix представляет собой что-то вроде таблицы, со своими дополнениями.
- row sep — расстояние между строками
- column sep — расстояние между столбцами
Дальше обычная tabular.

Промежуточная задача с узлами привязки
\usetikzlibrary {shapes.misc}
\begin{tikzpicture}[point/.style={circle,inner sep=0pt,minimum size=2pt,fill=red},
skip loop/.style={to path={-- ++(0,#1) -| (\tikztotarget)}}]
\matrix[row sep=1mm,column sep=2mm] {
% First row:
& & & & & & & & & & & \node (plus) [terminal] {+};\\
% Second row:
\node (p1) [point] {}; & \node (ui1) [nonterminal] {unsigned integer}; &
\node (p2) [point] {}; & \node (dot) [terminal] {.}; &
\node (p3) [point] {}; & \node (digit) [terminal] {digit}; &
\node (p4) [point] {}; & \node (p5) [point] {}; &
\node (p6) [point] {}; & \node (e) [terminal] {E}; &
\node (p7) [point] {}; & &
\node (p8) [point] {}; & \node (ui2) [nonterminal] {unsigned integer}; &
\node (p9) [point] {}; & \node (p10) [point] {};\\
% Third row:
& & & & & & & & & & & \node (minus)[terminal] {-};\\
};
\path (p4) edge [->,skip loop=-5mm] (p3)
(p2) edge [->,skip loop=5mm] (p6);
\end{tikzpicture}
- Описываем стиль
[point/.style={circle,inner sep=0pt,minimum size=2pt,fill=red}] - Расставляем точки в матрице и даем им имена:
\node (p1) [point] {}; - Соединяем точки
edge—(p4) edge [->,skip loop=-5mm] (p3)
Частично задача решена. Вторым этапом убираем видимость точек и результат готов.
Команда GRAPH (библиотека graphs)
Это еще одна мощная команда, которая должна со всем этим хозяйством управиться.
\begin{tikzpicture}[skip loop/.style={to path={-- ++(0,#1) -| (\tikztotarget)}},
point/.style={circle,inner sep=0pt,minimum size=2pt,fill=red},
hv path/.style={to path={-| (\tikztotarget)}},
vh path/.style={to path={|- (\tikztotarget)}}]
\matrix[row sep=1mm,column sep=2mm] {
% First row:
& & & & & & & & & & & \node (plus) [terminal] {+};\\
% Second row:
\node (p1) [point] {}; & \node (ui1) [nonterminal] {unsigned integer}; &
\node (p2) [point] {}; & \node (dot) [terminal] {.}; &
\node (p3) [point] {}; & \node (digit) [terminal] {digit}; &
\node (p4) [point] {}; & \node (p5) [point] {}; &
\node (p6) [point] {}; & \node (e) [terminal] {E}; &
\node (p7) [point] {}; & &
\node (p8) [point] {}; & \node (ui2) [nonterminal] {unsigned integer}; &
\node (p9) [point] {}; & \node (p10) [point] {};\\
% Third row:
& & & & & & & & & & & \node (minus)[terminal] {-};\\
};
\graph {
(p1) -> (ui1) -- (p2) -> (dot) -- (p3) -> (digit) -- (p4)
-- (p5) -- (p6) -> (e) -- (p7) -- (p8) -> (ui2) -- (p9) -> (p10);
(p4) ->[skip loop=-5mm] (p3);
(p2) ->[skip loop=5mm] (p5);
(p6) ->[skip loop=-11mm] (p9);
(p7) ->[vh path] (plus) -> [hv path] (p8);
(p7) ->[vh path] (minus) -> [hv path] (p8);
};
\end{tikzpicture}

Завершаем оформление и добавляем стрелочки
Библиотека arrows.meta: и вариант работы p7 ->[vh path] { plus, minus } -> [hv path] p8; библиотеки graphs по раздвоению стрелок. Просто перечисляем узлы в фигурных скобках.
Итоговый вариант:
\begin{tikzpicture}[skip loop/.style={to path={-- ++(0,#1) -| (\tikztotarget)}},
point/.style={circle,inner sep=0pt,minimum size=2pt,fill=red},
>={Stealth[round]},thick,black!50,text=black,
every new ->/.style={shorten >=1pt},
graphs/every graph/.style={edges=rounded corners},
hv path/.style={to path={-| (\tikztotarget)}},
vh path/.style={to path={|- (\tikztotarget)}}]
\matrix[column sep=4mm] {
% First row:
& & & & & & & & & & & \node (plus) [terminal] {+};\\
% Second row:
\node (p1) [point] {}; & \node (ui1) [nonterminal] {unsigned integer}; &
\node (p2) [point] {}; & \node (dot) [terminal] {.}; &
\node (p3) [point] {}; & \node (digit) [terminal] {digit}; &
\node (p4) [point] {}; & \node (p5) [point] {}; &
\node (p6) [point] {}; & \node (e) [terminal] {E}; &
\node (p7) [point] {}; & &
\node (p8) [point] {}; & \node (ui2) [nonterminal] {unsigned integer}; &
\node (p9) [point] {}; & \node (p10) [point] {};\\
% Third row:
& & & & & & & & & & & \node (minus)[terminal] {-};\\
};
\graph [use existing nodes] {
p1 -> ui1 -- p2 -> dot -- p3 -> digit -- p4 -- p5 -- p6 -> e -- p7 -- p8 -> ui2 -- p9 -> p10;
p4 ->[skip loop=-5mm] p3;
p2 ->[skip loop=5mm] p5;
p6 ->[skip loop=-11mm] p9;
p7 ->[vh path] { plus, minus } -> [hv path] p8;
};
\end{tikzpicture}

Более серьезное погужение в GRAPHs
\tikz \graph [grow right=2cm] { unsigned integer -> d -> digit -> E };
выдаст сразу: 
Добавим стилей:
\tikz \graph [grow right sep] {
unsigned integer[nonterminal] -> "."[terminal] -> digit[terminal] -> E[terminal]
};

Добавим + и -:
\usetikzlibrary {graphs,shapes.misc}
\tikz \graph [grow right sep] {
unsigned integer [nonterminal] ->
"." [terminal] ->
digit [terminal] ->
E [terminal] ->
{
"+" [terminal],
"" [coordinate],
"-" [terminal]
} ->
ui2/unsigned integer [nonterminal]
};
Окончательный вариант через Graphs
\usetikzlibrary {arrows.meta,graphs,shapes.misc}
\tikz [>={Stealth[round]}, black!50, text=black, thick,
every new ->/.style = {shorten >=1pt},
graphs/every graph/.style = {edges=rounded corners},
skip loop/.style = {to path={-- ++(0,#1) -| (\tikztotarget)}},
hv path/.style = {to path={-| (\tikztotarget)}},
vh path/.style = {to path={|- (\tikztotarget)}},
nonterminal/.style = {
rectangle, minimum size=6mm, very thick, draw=red!50!black!50, top color=white,
bottom color=red!50!black!20, font=\itshape, text height=1.5ex,text depth=.25ex},
terminal/.style = {
rounded rectangle, minimum size=6mm, very thick, draw=black!50, top color=white,
bottom color=black!20, font=\ttfamily, text height=1.5ex, text depth=.25ex},
shape = coordinate
]
\graph [grow right sep, branch down=7mm, simple] {
/ -> unsigned integer[nonterminal] -- p1 -> "." [terminal] -- p2 -> digit[terminal] --
p3 -- p4 -- p5 -> E[terminal] -- q1 ->[vh path]
{[nodes={yshift=7mm}]
"+"[terminal], q2, "-"[terminal]
} -> [hv path]
q3 -- /unsigned integer [nonterminal] -- p6 -> /;
p1 ->[skip loop=5mm] p4;
p3 ->[skip loop=-5mm] p2;
p5 ->[skip loop=-11mm] p6;
q1 -- q2 -- q3; % make these edges plain
};

Особенности кода:
- использовании групп, при делении веток, группы заключаем в
{} - анонимные координаты обозначаются
/ simpe— свойство graph — которое определяем, что между 2-мя узлами может быть только 1edge.graphs/every graph/.style = {edges=rounded corners}— закругленные уголки у стрелок>={Stealth[round]}, black!50, text=black, thick,— стиль стрелок
7.7.11 - Примеры по Эвклиду
Продолжаем осваивать библиотеку TIKZ и изучаем новые команды
Вторая часть учебного курса по TIKZ. Сеть PETRI.
Установка необходимых библиотек для работы
\documentclass{article} % say
% For LaTeX:
\usepackage{tikz}
\usetikzlibrary{calc,intersections,through,backgrounds}
\begin{tikzpicture}
\coordinate [label=left:\textcolor{blue}{$A$}] (A) at (0,0);
\coordinate [label=right:\textcolor{blue}{$B$}] (B) at (1.25,0.25);
\draw[blue] (A) -- (B);
\end{tikzpicture}
Уже много полезного из первого примера, команда \coordinate
Мощь библиотеки calc
\begin{tikzpicture}
\coordinate [label=left:\textcolor{blue}{$A$}] (A) at ($ (0,0) + .1*(rand,rand) $);
\coordinate [label=right:\textcolor{red}{$B$}] (B) at ($ (1.25,0.25) + .1*(rand,rand) $);
\draw[blue] (A) -- (B);
\end{tikzpicture}
Все вычисления происходят между двух символов $.
Особенность оператора rand, что он каждый раз будет вычисляться одинаково. Т.е. не такой он уж и случайное число.
Оператор let и команда veclen
\usetikzlibrary {calc}
\begin{tikzpicture}
\coordinate [label=left:$A$] (A) at (0,0);
\coordinate [label=right:$B$] (B) at (1.25,0.25);
\draw (A) -- (B);
\draw (A) let
\p1 = ($ (B) - (A) $)
in
circle ({veclen(\x1,\y1)});
\end{tikzpicture}
\p1 = ($ (B) - (A) $)вычислит длину вектора и запишет в переменную1p— это команда записать точку (коорд.x, коорд.y)veclen(\x1,\y1)— соответственно передать коордитатыxиyиз переменной1и вычислить их длину для радиуса.n— похожа наp, но записывает число.
т.е. let определил p1 и передал in в circle
\usetikzlibrary {calc}
\begin{tikzpicture}
\coordinate [label=left:$A$] (A) at (0,0);
\coordinate [label=right:$B$] (B) at (1.25,0.25);
\draw (A) -- (B);
\draw let \p1 = ($ (B) - (A) $),
\n2 = {veclen(\x1,\y1)}
in
(A) circle (\n2)
(B) circle (\n2);
\end{tikzpicture}
в этом примере, как раз вычисленный радиус, записали в переменную 2. Вместо цифры в этих переменных можно использовать длинные имена в скобках n{ragius} и также их использовать circle (\n{radius})
Библиотека THROUGH
Библиотека THROUGH содержит разные методы создания различных фигур через заданные точки.
Создадим окружность через точку B относительно A, находящейся в центре координат. Т.е. точку A он всегда будет считать центром.
\usetikzlibrary {through}
\begin{tikzpicture}
\coordinate [label=left:$A$] (A) at (0,0);
\coordinate [label=right:$B$] (B) at (1.25,0.25);
\draw (A) -- (B);
\node [draw,circle through=(B),label=left:$D$] at (A) {};
\end{tikzpicture}
Библиотека INTERSECTION
Библиотека INTERSECTION вычисляет пересечения различных линий.
\usetikzlibrary {intersections,through}
\begin{tikzpicture}
\coordinate [label=left:$A$] (A) at (0,0);
\coordinate [label=right:$B$] (B) at (1.25,0.25);
\draw (A) -- (B);
\node (D) [name path=D,draw,circle through=(B),label=left:$D$] at (A) {}; %нода D и путь D это разные объекты, можно называть по разному
\node (E) [name path=E,draw,circle through=(A),label=right:$E$] at (B) {};
% Name the coordinates, but do not draw anything:
\path [name intersections={of=D and E}];
\coordinate [label=above:$C$] (C) at (intersection-1);
\draw [red] (A) -- (C);
\draw [red] (B) -- (C);
\end{tikzpicture}
\node (D) [name path=D,draw,circle through=(B),label=left:$D$]задаем имя\pathгде проходит окружность.\path [name intersections={of=D and E}];— определяем пересечение двух путей D и E и у них образуются точки пересечения как(intersection-1)и(intersection-2).\coordinate [label=above:$C$] (C) at (intersection-1);— определим точку C с координатами пересечения.
но есть еще у name intersections команда by, которая все это решит автоматически: \path [name intersections={of=D and E, by={[label=above:$C$]C, [label=below:$C'$]C'}}]; т.е. поставит точки и метки в них.
Потом просто проведем линию и дадим ей тоже имя \path — \draw [name path=C--C',red] (C) -- (C'); имя будет C--C'.
Новый intersection получит точку F
\path [name intersections={of=A--B and C--C',by=F}];
\begin{tikzpicture}
\coordinate [label=left:$A$] (A) at (0,0);
\coordinate [label=right:$B$] (B) at (1.25,0.25);
\draw [name path=A--B] (A) -- (B);
\node (D) [name path=D,draw,circle through=(B),label=left:$D$] at (A) {};
\node (E) [name path=E,draw,circle through=(A),label=right:$E$] at (B) {};
\path [name intersections={of=D and E, by={[label=above:$C$]C, [label=below:$C'$]C'}}];
\draw [name path=C--C',red] (C) -- (C');
\path [name intersections={of=A--B and C--C',by=F}];
\node [fill=red,inner sep=2pt,label=-45:$F$] at (F) {};
\end{tikzpicture}
это полная картина, где из нового inner sep=2pt — это толщина точки пересечения, а на самом деле просто размер node в виде точки
если бы я написал \node [fill=red,circle, inner sep=2pt,label=-45:$F$] at (F) {}; то получилось бы:
Разукрашки и определение макросов
\begin{tikzpicture}[
thick,% толстые линии
help lines/.style={thin,draw=black!50}]%вспомогательные линии
\def\A{\textcolor{input}{$A$}} % макросы ABCDE со стилями меток
\def\B{\textcolor{input}{$B$}}
\def\C{\textcolor{output}{$C$}}
\def\D{$D$}
\def\E{$E$}
\colorlet{input}{blue!80!black} % input и output цвета, которые подставятся в макросы
\colorlet{output}{red!70!black}
\colorlet{triangle}{orange}
Наарисуем треугольник
\draw [output] (A) -- (C) -- (B);
Поставим в вершинах точки
\foreach \point in {A,B,C}
\fill [black,opacity=.5] (\point) circle (2pt);
Закрасим треугольник
\begin{pgfonlayer}{background}
\fill[triangle!80] (A) -- (C) -- (B) -- cycle;
\end{pgfonlayer}
Итоговый код
\usetikzlibrary {backgrounds,calc,intersections,through}
\begin{tikzpicture}[thick,help lines/.style={thin,draw=black!50}]
\def\A{\textcolor{input}{$A$}} \def\B{\textcolor{input}{$B$}}
\def\C{\textcolor{output}{$C$}} \def\D{$D$}
\def\E{$E$}
\colorlet{input}{blue!80!black} \colorlet{output}{red!70!black}
\colorlet{triangle}{orange}
\coordinate [label=left:\A] (A) at ($ (0,0) + .1*(rand,rand) $);
\coordinate [label=right:\B] (B) at ($ (1.25,0.25) + .1*(rand,rand) $);
\draw [input] (A) -- (B);
\node [name path=D,help lines,draw,label=left:\D] (D) at (A) [circle through=(B)] {};
\node [name path=E,help lines,draw,label=right:\E] (E) at (B) [circle through=(A)] {};
\path [name intersections={of=D and E,by={[label=above:\C]C}}];
\draw [output] (A) -- (C) -- (B);
\foreach \point in {A,B,C}
\fill [black,opacity=.5] (\point) circle (2pt);
\begin{pgfonlayer}{background}
\fill[triangle!80] (A) -- (C) -- (B) -- cycle;
\end{pgfonlayer}
\node [below right, text width=10cm,align=justify] at (4,3) {
\small\textbf{Proposition I}\par
\emph{To construct an \textcolor{triangle}{equilateral triangle}
on a given \textcolor{input}{finite straight line}.}
\par\vskip1em
Let \A\B\ be the given \textcolor{input}{finite straight line}. \dots
};
\end{tikzpicture}

Мой первый прямоугольник с почти умными координатами
\begin{tikzpicture}
\coordinate (NW) at (0,5); \coordinate (nw) at ($ (NW) + (1,-1) $);
\coordinate (NE) at (7,5); \coordinate (ne) at ($ (NE) + (-1,-1) $);
\coordinate (SE) at (7,0); \coordinate (se) at ($ (SE) + (-1,1) $);
\coordinate (SW) at (0,0); \coordinate (sw) at ($ (SW) + (1,1) $);
\draw[black!10] (NW) -- (NE) -- (SE) -- (SW) -- cycle;
\draw[black!30, thick, fill=black!25] ($ (NW) + (1,-1) $) -- (ne) -- (se) -- (sw) -- cycle;
\fill[black!25] (nw) -- (ne) -- (se) -- (sw) -- cycle;
\end{tikzpicture}

Немного неказист, но многообещающь.
Дальше он будет понемногу обрастать,пока не превратится в то,что я задумал.
Продолжение сериала по Эвклиду.
Найдем точку между координатами
($ (A)!.5!(B) $)
Это будет ровно посередине между A и B.
\usetikzlibrary {calc}
\begin{tikzpicture}
\coordinate [label=left:$A$] (A) at (0,0);
\coordinate [label=right:$B$] (B) at (1.25,0.25);
\draw (A) -- (B);
\node [fill=red,inner sep=1pt,label=below:$X$] (X) at ($ (A)!.5!(B) $) {};
\end{tikzpicture}
Это для убедительности: 
Или за пределами точек и даже сложные вычисления:
\coordinate [label=above:$D$] (D) at ($ (A) ! .5 ! (B) ! {sin(60)*2} ! 90:(B) $) {};
И еще пример, чисто как памятка, потому-что очень сложные вычисления, мне точно не нужны.
\draw (D) -- ($ (D) ! 2.5 ! (A) $) coordinate [label=below:$E$] (E); — начертит прямую и установит новую точку E
7.7.12 - Сети PETRI
Сети петри для ознакомления с возможностями
NODE и настройки своих стилей.Вторая часть учебного курса по TIKZ. Сеть PETRI.
Установка необходимых библиотек для работы
\documentclass{article} % say
\usepackage{tikz}
\usetikzlibrary{arrows.meta,decorations.pathmorphing,backgrounds,positioning,fit,petri}
\begin{document}
\begin{tikzpicture}
\draw (0,0) -- (1,1);
\end{tikzpicture}
\end{document}
Сети петри для ознакомления с возможностями
NODE и настройки своих стилей.Просто нарисуем в системе координат 5 node
\begin{tikzpicture}
\path ( 0,2) node [shape=circle,draw] {}
( 0,1) node [shape=circle,draw] {}
( 0,0) node [shape=circle,draw] {}
( 1,1) node [shape=rectangle,draw] {}
(-1,1) node [shape=rectangle,draw] {};
\end{tikzpicture}
Но, выяснилось, что вариант выше не очень умен по своей сути. \path задает координату откуда начинается какое-то действие, в нашем случае размещаем node, а можно draw, но node с параметром draw обернет текст рамкой.
Синтаксис at т.е. поместить в…
\begin{tikzpicture}
\path node at ( 0,2) [shape=circle,draw] {}
node at ( 0,1) [shape=circle,draw] {}
node at ( 0,0) [shape=circle,draw] {}
node at ( 1,1) [shape=rectangle,draw] {}
node at (-1,1) [shape=rectangle,draw] {};
\end{tikzpicture}
Получаем тотже эффект, но говорят умнее.
Дальше больше:
Говорят библиотеки TIKZ shape понимают по умолчанию, если они стандартные. Опускаем их.
\begin{tikzpicture}
\path node at ( 0,2) [circle,draw] {}
node at ( 0,1) [circle,draw] {}
node at ( 0,0) [circle,draw] {}
node at ( 1,1) [rectangle,draw] {}
node at (-1,1) [rectangle,draw] {};
\end{tikzpicture}
Прикручиваем стили
\begin{tikzpicture}[thick]
\path node at ( 0,2) [circle,draw=blue,fill=red] {}
node at ( 0,1) [circle,draw=blue,fill=yellow] {}
node at ( 0,0) [circle,draw=blue,fill=green] {}
node at ( 1,1) [rectangle,draw=black!50,fill=black!20] {}
node at (-1,1) [rectangle,draw=black!50,fill=black!20] {};
\end{tikzpicture}
 Причем
Причем [draw=blue] — рисует такого цвета обводку, а fill — заполняет пространство
А теперь сделаем стиль универсальным на блок
\begin{tikzpicture}
[place/.style={circle,draw=blue!50,fill=blue!20,thick},
transition/.style={rectangle,draw=black!50,fill=black!20,thick}]
\node at ( 0,2) [place] {};
\node at ( 0,1) [place] {};
\node at ( 0,0) [place] {};
\node at ( 1,1) [transition] {};
\node at (-1,1) [transition] {};
\end{tikzpicture}
просто один будет называться place а второй transition и теперь название этихстилей ставим в описании node.
И еще одно нововведение: команда \path node - тоже самое, что \node
Размеры SHAPE
Можно задать переменную inner sep=2mm в блоке — и это сделает отступ вокруг текста 2mm. Или:
[place/.style={circle,draw=blue!50,fill=blue!20,thick,
inner sep=0pt,minimum size=6mm},
т.е прямо в стиль и это даст эффект, что размер будет не меньше 4мм, пока в него влезает текст.
Имена SHAPEs
Очень пригодятся имена SHAPEs для того,чтобы иметь привязки и потом на них ссылаться.
\begin{tikzpicture}
\node (waiting 1) at ( 0,2) [place] {};
\node (critical 1) at ( 0,1) [place] {};
\node (semaphore) at ( 0,0) [place] {};
\node (leave critical) at ( 1,1) [transition] {};
\node (enter critical) at (-1,1) [transition] {};
\end{tikzpicture}
имена будут в круглых скобочках, причем порядок написания не имеет значения. Это все определения одного \path
Нативное размещение SHAPEs
Вместо указания координат, можно указывать влево, вправо, ниже, выше. Такого ума можно набраться в библиотеке: \usetikzlibrary {positioning}
\usetikzlibrary {positioning}
\begin{tikzpicture}
\node[place] (waiting) {};
\node[place] (critical) [below=of waiting] {}; % ниже waitinig
\node[place] (semaphore) [below=of critical] {}; % ниже critical
\node[transition] (leave critical) [right=of critical] {}; % справа от critical
\node[transition] (enter critical) [left=of critical] {}; % слева от critical
\end{tikzpicture}
Объекты размещаются по координатной сетке.
Метки объектов по сторонам света
Все объекты TIKZ получают метки по сторонам света:
- north
- south
- west
- east
- north east
- north west
- south east
- south west
\node [red,above] at (semaphore.north) {$s\le 3$};
\end{tikzpicture}
напишет node красного цвета red над above северной меткой объекта semaphore.
но в библиотеке есть вариант с label, который сделает тоже самое.
\node[place] (semaphore) [below=of critical,
label=above:$s\le3$] {};
Памятка, как label работает:
\tikz
\node [circle,draw,label=60:$60^\circ$,label=below:$-90^\circ$] {my circle};
И немного подольем красочки: label={[red]below:$-90^\circ$} и будет метка красная, но чтобы небыло конфлика поставим все это дело в {}.
Коннекторы это просто
\draw [->] (enter critical.east) -- (critical.west);
\draw [->] (waiting.west) .. controls +(left:5mm) and +(up:5mm)
.. (enter critical.north);
т.е. \draw [в какую сторону стрелу] (координата откуда) -- (координата куда);
Краткий комментарий к .. CONTROLS ..
Это вставка вместо оператора рисования - -, которая позволяет поставить несколько контрольных точек относительно некоторого центра вращения и сказать куда они сдвигаются и насколько:
\draw[->](waiting.west) ..controls +(left:15mm) and +(up:15mm) .. (enter critical.north);
Умность библиотеки tirz
Можно не указывать стороны света в метках, от сделает это автоматически
\draw [->] (enter critical) -- (critical);
\draw [->] (waiting) .. controls +(left:5mm) and +(up:5mm)
.. (enter critical);
будет тоже самое.
Совершенствуем стрелочки до предела (to [in out])
Замечательный оператор to, который укажет под каким углом выйти и под каким углом войти стрелке.
Схема такая же, только вместо наших - - и .. controls .. появляется еще один оператор to [out=,in=]
in=220 — выглядит еще причудлевее.
\draw[->](waiting) to [out=0, in=180] (leave critical)
Команда bend right left
изгиб кривой.
\draw[->](leave critical) to [bend left=150] (semaphore)
но лучше загибать bend left=45, правда лучше.
Теперь еще один элемент EDGE
край - ребро, как угодно, но эта штука действует как внутри \path так и самостоятельно. Т.е. можно задавать свои особые наконечники и цвета для edge.
\node[transition] (enter critical) [left=of critical] {}
edge [->] (critical)
edge [<-,bend left=45] (waiting)
edge [->,bend right=45] (semaphore);
буквально: там где нарисовал node от неё начинаю рисовать edges.
- не завершая
nodeточкой с запятой пишемedge - [здесь команды куда стрела, как гнуть]
- (куда соединяем)
- теперь текущая точка опять в пункте
node - продолжаем рисовать дальше от той же точки
Обязательно, прежде чем рисовать EDGE - NODE должны быть уже известны.
Вот такой казус может получиться:
\begin{tikzpicture}
\node (c) at (0,0) {};
\node (n) at (0,1) {}
edge [bend right=45] (w);
\node (s) at (0,-1) {}
edge [bend right=45] (e);
\node (w) at (-1,0) {}
edge [bend right=45] (s);
\node (e) at (1,0) {}
edge [->,bend right=45] (n);
\end{tikzpicture}
Но если рисовать по задумке:
\begin{tikzpicture}
\node (c) at (0,0) {};
\node (n) at (0,1) {};
\node (w) at (-1,0) {}
edge [bend left=45] (n);
\node (s) at (0,-1) {}
edge [bend left=45] (w);
\node (e) at (1,0) {}
edge [bend left=45] (s)
edge [bend right=45] (n);
\end{tikzpicture}
то получим ->
И все это упакуем в стили
[bend angle=45,
pre/.style={<-,shorten <=1pt,>={Stealth[round]},semithick},
post/.style={->,shorten >=1pt,>={Stealth[round]},semithick}]
вот такая штука позволит дальше в коде писать просто:
edge [pre] (critical) и edge [post,bend right] (waiting) и TIKZ все поймет.
Метки на линиях
\begin{tikzpicture}[auto,bend right]
\node (a) at (0:1) {$0^\circ$};
\node (b) at (120:1) {$120^\circ$};
\node (c) at (240:1) {$240^\circ$};
\draw (a) to node {1} node [swap] {1'} (b)
(b) to node {2} node [swap] {2'} (c)
(c) to node {3} node [swap] {3'} (a);
\end{tikzpicture}
- NODE — нарисовали метки в узлах через оператор
at, т.е. поместить в … конкретную точку - DRAW — рисует через оператор
to, т.е. от одной точки к другой, а на пути его рисования мы размещаем другие NODE и говорим с какой стороны их рисовать относительно линии. - SWAP — это нарисовать зеркально
- на пути DRAW, NODEs может быть сколько угодно, главное их всех разместить правильно, а то все в одну точку вляпаются.
Декоративные линии (\usetikzlibrary {decorations.pathmorphing})
Собственно любую линию можно нарисовать, просто отдельно нужно изучить особенности этой библиотеки.
\usetikzlibrary {decorations.pathmorphing}
\begin{tikzpicture}
\draw [->,decorate,
decoration={snake,amplitude=.4mm,segment length=2mm,post length=1mm}]
(0,0) -- (3,0);
\end{tikzpicture}
получится вот такая кривулина: 
Чтобы мне небыло страшно, классы pre и post для стрелок уже определены в стандартной библиотеке.
И продолжая тему кривулины или любой другой линии, если мне нужно разместить текст, то делаю в разрыве DRAW вставку NODE:
node [above,text width=3cm,align=center,midway]
{
replacement of the \textcolor{red}{capacity} by
\textcolor{red}{two places}
}
- above — выше над линией
- text width=3cm — ширина текста 3см
- align-center — текст выравнять по центру
- midway — в центре линии (у него еще есть братья:
- near start — pos=0.25.
- near end — pos=0.75.
- very near start — pos=0.125.
- very near end — pos=0.875.
- at start — pos=0.
- at end — pos=1
BACKGROUND или слои и фон под картинкой
Нам поможет библиотека fit и background
fit — дает координаты всех узлов
background — размещает на разных слоях рисунки
Еще нам понадобятся знания об окружении SCOPE — это просто окружение чего-то, такие своеобразные скобки, в которых будут действовать правила, которые мы установим, а за пределами SCOPE все возвращается в исходные установки.
\begin{tikzpicture}[ultra thick]
\begin{scope}[red]
\draw (0mm,10mm) -- (10mm,10mm);
\draw (0mm,8mm) -- (10mm,8mm);
\end{scope}
\draw (0mm,6mm) -- (10mm,6mm);
\begin{scope}[green]
\draw (0mm,4mm) -- (10mm,4mm);
\draw (0mm,2mm) -- (10mm,2mm);
\draw[blue] (0mm,0mm) -- (10mm,0mm);
\end{scope}
\end{tikzpicture}
этот пример на линиях все показал

а про background мы просто добавим в конце такой код:
\begin{scope}[on background layer]
\node [fill=black!30,fit=(waiting) (critical) (semaphore)
(leave critical) (enter critical)] {};
\end{scope}
on background layer— на каком слое разместить, т.е. под рисунком\node— рисуем nodefill— заполняем ее цветомfit— перечисляем все внутренние node по которым определяем координаты
Настройки стандартных библиотек для рисования сетей PETRI
\begin{tikzpicture}
[node distance=1.3cm,on grid,>={Stealth[round]},bend angle=45,auto,
every place/.style= {minimum size=6mm,thick,draw=blue!75,fill=blue!20},
every transition/.style={thick,draw=black!75,fill=black!20},
red place/.style= {place,draw=red!75,fill=red!20},
every label/.style= {red}]
т.е. там уже все определено, поэтому нарисуем все, что уже пытались с использованием библиотеки:
\usetikzlibrary {arrows.meta,petri,positioning}
\node [place,tokens=1] (w1) {};
\node [place] (c1) [below=of w1] {};
\node [place] (s) [below=of c1,label=above:$s\le 3$] {};
\node [place] (c2) [below=of s] {};
\node [place,tokens=1] (w2) [below=of c2] {};
\node [transition] (e1) [left=of c1] {}
edge [pre,bend left] (w1)
edge [post,bend right] (s)
edge [post] (c1);
\node [transition] (e2) [left=of c2] {}
edge [pre,bend right] (w2)
edge [post,bend left] (s)
edge [post] (c2);
\node [transition] (l1) [right=of c1] {}
edge [pre] (c1)
edge [pre,bend left] (s)
edge [post,bend right] node[swap] {2} (w1);
\node [transition] (l2) [right=of c2] {}
edge [pre] (c2)
edge [pre,bend right] (s)
edge [post,bend left] node {2} (w2);
а это ее более кудрявый друг:
\usetikzlibrary {arrows.meta,petri,positioning}
\begin{scope}[xshift=6cm]
\node [place,tokens=1] (w1') {};
\node [place] (c1') [below=of w1'] {};
\node [red place] (s1') [below=of c1',xshift=-5mm]
[label=left:$s$] {};
\node [red place,tokens=3] (s2') [below=of c1',xshift=5mm]
[label=right:$\bar s$] {};
\node [place] (c2') [below=of s1',xshift=5mm] {};
\node [place,tokens=1] (w2') [below=of c2'] {};
\node [transition] (e1') [left=of c1'] {}
edge [pre,bend left] (w1')
edge [post] (s1')
edge [pre] (s2')
edge [post] (c1');
\node [transition] (e2') [left=of c2'] {}
edge [pre,bend right] (w2')
edge [post] (s1')
edge [pre] (s2')
edge [post] (c2');
\node [transition] (l1') [right=of c1'] {}
edge [pre] (c1')
edge [pre] (s1')
edge [post] (s2')
edge [post,bend right] node[swap] {2} (w1');
\node [transition] (l2') [right=of c2'] {}
edge [pre] (c2')
edge [pre] (s1')
edge [post] (s2')
edge [post,bend left] node {2} (w2');
\end{scope}
и на финише фон:
\begin{scope}[on background layer]
\node (r1) [fill=black!10,rounded corners,fit=(w1)(w2)(e1)(e2)(l1)(l2)] {};
\node (r2) [fill=black!10,rounded corners,fit=(w1')(w2')(e1')(e2')(l1')(l2')] {};
\end{scope}
\draw [shorten >=1mm,->,thick,decorate,
decoration={snake,amplitude=.4mm,segment length=2mm,
pre=moveto,pre length=1mm,post length=2mm}]
(r1) -- (r2) node [above=1mm,midway,text width=3cm,align=center]
{replacement of the \textcolor{red}{capacity} by \textcolor{red}{two places}};
\end{tikzpicture}
получим такую красоту:
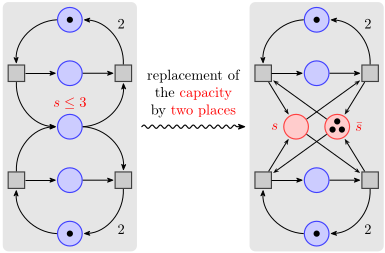
7.7.13 - Графики в TIKZ для Latex
Дружелюбный функционал для полной графики в Latex. Картинки, иконки, графики и пр.
Дружелюбный функционал для полной графики в Latex. Картинки, иконки, графики и пр. Очень мощный пакет в котором можно нарисовать все.
Обзор пакета Tikz для рисования графики в Latex.
Установка пакета
\usepackage{tikz}
Использование пакета
Окружение {tikzpicture} или команды \tikzpicture и \endtikzpicture

\documentclass{article} % say
\usepackage{tikz}
\begin{document}
We are working on
\begin{tikzpicture}
\draw (-1.5,0) -- (1.5,0);
\draw (0,-1.5) -- (0,1.5);
\end{tikzpicture}.
\end{document}
Нарисует точки в координатах и проведет через них кривую
\begin{tikzpicture}
\filldraw [gray] (0,0) circle [radius=2pt]
(1,1) circle [radius=2pt]
(2,1) circle [radius=2pt]
(2,0) circle [radius=2pt];
\draw (0,0) .. controls (1,1) and (2,1) .. (2,0);
\end{tikzpicture}
Цвет
filldraw [gray] — зальет фигуру серым цветом
Кривые
.. controls — укажет контрольные точки для кривой Безье.
Окружность
circle [radius=10pt] — нарисует окружность
нарисуем эллипс
\tikz \draw (0,0) ellipse [x radius=20pt, y radius=10pt];
Поворот рисунка
\draw[rotate=30] — развернет рисунок на 30гр.
нарисуем квадраты
\draw (0,0) rectangle (0.5,0.5);
\draw (-0.5,-0.5) rectangle (-1,-1);
Нарисуем сетку
\tikz \draw[step=2pt] (0,0) grid (10pt,10pt);
нарисует сетку козявочку 
\begin{tikzpicture}
\draw[step=.5cm,gray,very thin] (-1.4,-1.4) grid (1.4,1.4);
\draw (-1.5,0) -- (1.5,0);
\draw (0,-1.5) -- (0,1.5);
\draw (0,0) circle [radius=1cm];
\end{tikzpicture}
в draw — определим шаг, цвет и толщину линий
Установим настройку стилей по умолчанию
Глобально в переменной Ra grid
\tikzset{Ra grid/.style={help lines,color=blue!50}}
или локально в переменной Karl's grid
\begin{tikzpicture}
[Karl's grid/.style ={help lines,color=#1!50},
Karl's grid/.default=blue]
\draw[Karl's grid] (0,0) grid (1.5,2);
\draw[Karl's grid=red] (2,0) grid (3.5,2);
\end{tikzpicture}
Толщина линий
- ultra thin
- very thin
- thin
- semithick
- thick
- very thick
- ultra thick
\draw[ultra thin] (-1.5,1.1) -- (1.5,1.1);
\draw[very thin] (-1.5,1.6) -- (1.5,1.6);
\draw[thin] (-1.5,2.1) -- (1.5,2.1);
\draw[semithick] (-1.5,2.6) -- (1.5,2.6);
\draw[very thick] (-1.5,3.1) -- (1.5,3.1);
\draw[ultra thick] (-1.5,3.6) -- (1.5,3.6);

\begin{tikzpicture}[line width=5pt] — любая толщина
Стиль линии
- loosely dashed,
- densely dashed,
- loosely dotted,
- densely dotted
\draw[loosely dashed, ultra thick] (-1.5,-3.6) -- (1.5,-3.6);
\draw[densely dashed, ultra thick] (-1.5,-3.1) -- (1.5,-3.1);
\draw[loosely dotted, ultra thick] (-1.5,-2.6) -- (1.5,-2.6);
\draw[densely dotted, ultra thick] (-1.5,-2.1) -- (1.5,-2.1);

dash pattern — можно определить сложный паттерн
Нарисуем дугу
arc[start angle=10, end angle=80, radius=10pt]
Элипсоидная дуга
\tikz \draw (0,0)
arc [start angle=0, end angle=315,
x radius=1.75cm, y radius=1cm];
Масштабирование
\begin{tikzpicture}[scale=3]
\draw[step=.5cm,gray,very thin] (-1.4,-1.4) grid (1.4,1.4);
\draw (-1.5,0) -- (1.5,0);
\draw (0,-1.5) -- (0,1.5);
\draw (0,0) circle [radius=1cm];
\draw (3mm,0mm) arc [start angle=0, end angle=30, radius=3mm];
\end{tikzpicture}
после определения окружения, ставим [scale=3]
Клиппинг
или обрезание рисунка
\clip (-0.1,-0.2) rectangle (1.1,0.75);
две точки на рисунке для обрезки прямоугольником, обрезать можно любой фигурой
\begin{tikzpicture}[scale=3]
\clip (-0.1,-0.2) rectangle (1.1,0.75);
\draw[step=.5cm,gray,very thin] (-1.4,-1.4) grid (1.4,1.4);
\draw (-1.5,0) -- (1.5,0);
\draw (0,-1.5) -- (0,1.5);
\draw (0,0) circle [radius=1cm];
\draw (3mm,0mm) arc [start angle=0, end angle=30, radius=3mm];
\end{tikzpicture}
Основные команды рисования
\path[draw, clip] или \path[clip] или \path[draw] — братья по смыслу и к ним же \draw[clip]
Параболы, синусы и изгибы
% чертит параболу в квадрате
\tikz \draw (0,0) rectangle (1,1) (0,0) parabola (1,1);
% чертит параболу и изгиб, по дороге поменяем размерность координат x и y
\tikz \draw[x=1pt,y=1pt] (0,0) parabola bend (4,16) (6,12);
A sine \tikz \draw[x=1ex,y=1ex] (0,0) sin (1.57,1); curve.
Нарисует прямо в тексте кривулину. A sine (-tikz- diagram) curve.
А вот эта штука покажет, что такое sin и cos на самом деле:
\tikz \draw[x=3.57ex,y=1ex] (0,0) sin (4,1) cos (6,-14) sin (8,12)
да,именно так — sin поднимаемся, cos — опускаемся
Закрасить пространство
\fill[green!20!white] (0,0) -- (3mm,0mm)
arc [start angle=0, end angle=30, radius=3mm] -- (0,0);
% или сразу рисуем и красим
\filldraw[fill=green!20!white, draw=green!50!black] (0,0) -- (3mm,0mm)
arc [start angle=0, end angle=30, radius=3mm] -- cycle;
Замыкание контуров
\begin{tikzpicture}[line width=5pt]
\draw (0,0) -- (1,0) -- (1,1) -- (0,0);
\draw (2,0) -- (3,0) -- (3,1) -- cycle;
\useasboundingbox (0,1.5); % make bounding box higher
\end{tikzpicture}
cycle — плавно замкнет контур, похожа на последнюю команду -- (0,0) но работает лучше
Градиент
Команды shade и shadedraw
\begin{tikzpicture}[rounded corners,ultra thick]
\shade[top color=yellow,bottom color=black] (0,0) rectangle +(2,1);
\shade[left color=yellow,right color=black] (3,0) rectangle +(2,1);
\shadedraw[inner color=yellow,outer color=black,draw=yellow] (6,0) rectangle +(2,1);
\shade[ball color=green] (9,.5) circle (.5cm);
\end{tikzpicture}

Координаты точек
(x,y) — с указанием размерности или по умолчанию в см.
(30:1cm) — полярные координаты 30 градусов и 1 см.
Относительные перемещения
+(x,y) — переместиться относительно последней точки на x и y
++(x,y) — переместить указатель, но ничего не чертить, чертит только команда --.
\begin{tikzpicture}[scale=3]
\clip (-0.1,-0.2) rectangle (1.1,0.75);
\draw[step=.5cm,gray,very thin] (-1.4,-1.4) grid (1.4,1.4);
\draw (-1.5,0) -- (1.5,0);
\draw (0,-1.5) -- (0,1.5);
\draw (0,0) circle [radius=1cm];
\filldraw[fill=green!20,draw=green!50!black] (0,0) -- (3mm,0mm)
arc [start angle=0, end angle=30, radius=3mm] -- cycle;
\draw[red,very thick] (30:1cm) -- +(0,-0.5);
\draw[blue,very thick] (30:1cm) ++(0,-0.5) -- (0,0);
\end{tikzpicture}
Определяем свои команды
\begin{tikzpicture}
\def\rectanglepath{-- ++(1cm,0cm) -- ++(0cm,1cm) -- ++(-1cm,0cm) -- cycle}
\draw (0,0) \rectanglepath;
\draw (1.5,0) \rectanglepath;
\end{tikzpicture}
нарисует два квадратика
или идентично:
\tikz \draw (0,0) rectangle +(1,1) (1.5,0) rectangle +(1,1);
1,{tan(30)}) — так тоже умеет. Любую функцию для расчета координат.
Координаты по пересекающимся линиям
\path [name path=upward line] (1,0) -- (1,1);
\path [name path=sloped line] (0,0) -- (30:1.5cm);
% Рисуем невидимые пути. \path без атрибутов, просто перемещает указатель
% (добавить библиотеку `\usetikzlibrary{intersections}' после загрузки tikz)
\draw [name intersections={of=upward line and sloped line, by=x}] % нашли точку пересечения и назвали ее x
[very thick,orange] (1,0) -- (x); % нарисовали линию от (1,0) до точки пересечения
Стрелки
\draw[->] (-1.5,0) -- (1.5,0);
\draw[->] (0,-1.5) -- (0,1.5);
->, <-, <->, <<-, ->>
или использовать специальную библиотеку Documentation arrow
\usetikzlibrary {arrows.meta}
\begin{tikzpicture}[>=Stealth]
Облать видимости
\begin{tikzpicture}[ultra thick]
\draw (0,0) -- (0,1);
\begin{scope}[thin]
\draw (1,0) -- (1,1);
\draw (2,0) -- (2,1);
\end{scope}
\draw (3,0) -- (3,1);
\end{tikzpicture}
Окружение {scope}
Преобразования
xshift=2pt — смещает все точки на 2pt по x
\begin{tikzpicture}[even odd rule,rounded corners=2pt,x=10pt,y=10pt]
\filldraw[fill=yellow!80!black] (0,0) rectangle (1,1)
[xshift=5pt,yshift=5pt] (0,0) rectangle (1,1)
[rotate=30] (-1,-1) rectangle (2,2);
\end{tikzpicture}
Самое интересное во всем этом процессе, что когда ты пишешь эти строки и видишь, как все это происходит по настоящему в твоем Latex документе — приходишь в восторг!
xshift и yshift смещают по осям, shift={(1,0)} смещает в точку shift={+(0,0)} или относительную точку.
rotate или rotate around вращают объект относительно точки
scale, xscale, yscale — масштабирует xscale=-1 схлопывает фигуру
xslant, yslant — наклоняет
cm — опция для произвольных преобразований по матрице
Повторения и циклы
Можно использовать независимый пакет для \foreach или он автоматически подключен в Tikz
Синтаксис команды:
\foreach ⟨variable⟩ in {⟨list of values⟩} ⟨commands⟩
Пример:
\foreach \x in {1,2,3} {$x =\x$, }
x=1, x=2, x=3,
\begin{tikzpicture}[scale=3]
\clip (-0.1,-0.2) rectangle (1.1,1.51);
\draw[step=.5cm,gray,very thin] (-1.4,-1.4) grid (1.4,1.4);
\filldraw[fill=green!20,draw=green!50!black] (0,0) -- (3mm,0mm)
arc [start angle=0, end angle=30, radius=3mm] -- cycle;
\draw[->] (-1.5,0) -- (1.5,0);
\draw[->] (0,-1.5) -- (0,1.5);
\draw (0,0) circle [radius=1cm];
\foreach \x in {-1cm,-0.5cm,0.5cm,1cm}
\draw [red](\x,-1pt) -- (\x,1pt);
\foreach \y in {-1cm,-0.5cm,0.5cm,1cm}
\draw [blue](-1pt,\y) -- (1pt,\y);
\end{tikzpicture}
Поставил меточки на осях координат
\tikz \foreach \x in {1,...,10}
\draw (\x,0) circle (0.4cm);
еще вариант для диапазона значений: цикл в цикле
\begin{tikzpicture}
\foreach \x in {1,2,...,5,7,8,...,12}
\foreach \y in {1,...,5}
{
\draw (\x,\y) +(-.5,-.5) rectangle ++(.5,.5);
\draw (\x,\y) node{\x,\y};
}
\end{tikzpicture}
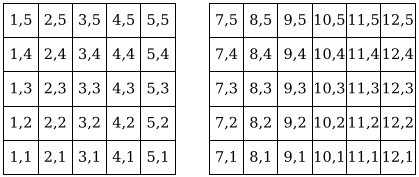
Nodes
\begin{tikzpicture}
\draw (0,0) rectangle (2,2);
\draw (0.5,0.5) node [fill=yellow!80!black]
{Text at \texttt{node 1}}
-- (1.5,1.5) node {Text at \texttt{node 2}};
\end{tikzpicture}
любой текст или все что нам нужно можно вставить в Node и поместить в нужную точку координат рисунка
Фон можно закрасить [fill=white]
Якоря по сторонам света
На всех рисунках есть якоря со сторонами света:
- north
- south
- east
- west
и их комбинации anchor=south west и т.д.
above rigth тоже, что south west
below=1pt — можно задавать смещение
\usetikzlibrary {intersections}
\begin{tikzpicture}[scale=3]
\clip (-2,-0.2) rectangle (2,0.8);
\draw[step=.5cm,gray,very thin] (-1.4,-1.4) grid (1.4,1.4);
\filldraw[fill=green!20,draw=green!50!black] (0,0) -- (3mm,0mm)
arc [start angle=0, end angle=30, radius=3mm] -- cycle;
\draw[->] (-1.5,0) -- (1.5,0) coordinate (x axis);
\draw[->] (0,-1.5) -- (0,1.5) coordinate (y axis);
\draw (0,0) circle [radius=1cm];
\draw[very thick,red]
(30:1cm) -- node[left=1pt,fill=white] {$\sin \alpha$} (30:1cm |- x axis);
\draw[very thick,blue]
(30:1cm |- x axis) -- node[below=2pt,fill=white] {$\cos \alpha$} (0,0);
\path [name path=upward line] (1,0) -- (1,1);
\path [name path=sloped line] (0,0) -- (30:1.5cm);
\draw [name intersections={of=upward line and sloped line, by=t}]
[very thick,orange] (1,0) -- node [right=1pt,fill=white]
{$\displaystyle \tan \alpha \color{black}=
\frac{{\color{red}\sin \alpha}}{\color{blue}\cos \alpha}$} (t);
\draw (0,0) -- (t);
\foreach \x/\xtext in {-1, -0.5/-\frac{1}{2}, 1}
\draw (\x cm,1pt) -- (\x cm,-1pt) node[anchor=north,fill=red!20] {$\xtext$};
\foreach \y/\ytext in {-1, -0.5/-\frac{1}{2}, 0.5/\frac{1}{2}, 1}
\draw (1pt,\y cm) -- (-1pt,\y cm) node[anchor=east,fill=red!20] {$\ytext$};
\end{tikzpicture}
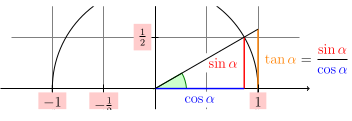
Текст по контуру
\begin{tikzpicture}
\draw (0,0) .. controls (6,1) and (9,1) ..
node[near start,sloped,above] {near start}
node {midway}
node[very near end,sloped,below] {very near end} (12,0);
\end{tikzpicture}
Полностью пример
\begin{tikzpicture}
[scale=3,line cap=round,
% Styles
axes/.style=,
important line/.style={very thick},
information text/.style={rounded corners,fill=red!10,inner sep=1ex}]
% Colors
\colorlet{anglecolor}{green!50!black}
\colorlet{sincolor}{red}
\colorlet{tancolor}{orange!80!black}
\colorlet{coscolor}{blue}
% The graphic
\draw[help lines,step=0.5cm] (-1.4,-1.4) grid (1.4,1.4);
\draw (0,0) circle [radius=1cm];
\begin{scope}[axes]
\draw[->] (-1.5,0) -- (1.5,0) node[right] {$x$} coordinate(x axis);
\draw[->] (0,-1.5) -- (0,1.5) node[above] {$y$} coordinate(y axis);
\foreach \x/\xtext in {-1, -.5/-\frac{1}{2}, 1}
\draw[xshift=\x cm] (0pt,1pt) -- (0pt,-1pt) node[below,fill=white] {$\xtext$};
\foreach \y/\ytext in {-1, -.5/-\frac{1}{2}, .5/\frac{1}{2}, 1}
\draw[yshift=\y cm] (1pt,0pt) -- (-1pt,0pt) node[left,fill=white] {$\ytext$};
\end{scope}
\filldraw[fill=green!20,draw=anglecolor] (0,0) -- (3mm,0pt)
arc [start angle=0, end angle=30, radius=3mm];
\draw (15:2mm) node[anglecolor] {$\alpha$};
\draw[important line,sincolor]
(30:1cm) -- node[left=1pt,fill=white] {$\sin \alpha$} (30:1cm |- x axis);
\draw[important line,coscolor]
(30:1cm |- x axis) -- node[below=2pt,fill=white] {$\cos \alpha$} (0,0);
\path [name path=upward line] (1,0) -- (1,1);
\path [name path=sloped line] (0,0) -- (30:1.5cm);
\draw [name intersections={of=upward line and sloped line, by=t}]
[very thick,orange] (1,0) -- node [right=1pt,fill=white]
{$\displaystyle \tan \alpha \color{black}=
\frac{{\color{red}\sin \alpha}}{\color{blue}\cos \alpha}$} (t);
\draw (0,0) -- (t);
\draw[xshift=1.85cm]
node[right,text width=6cm,information text]
{
The {\color{anglecolor} angle $\alpha$} is $30^\circ$ in the
example ($\pi/6$ in radians). The {\color{sincolor}sine of
$\alpha$}, which is the height of the red line, is
\[
{\color{sincolor} \sin \alpha} = 1/2.
\]
By the Theorem of Pythagoras ...
};
\end{tikzpicture}
Для node задали ширину текста text width=6cm
Макросы
\usetikzlibrary {angles,quotes}
\begin{tikzpicture}[scale=3]
\coordinate (A) at (1,0);
\coordinate (B) at (0,0);
\coordinate (C) at (30:1cm);
\draw (A) -- (B) -- (C)
pic [draw=green!50!black, fill=green!20, angle radius=9mm,
"$\alpha$"] {angle = A--B--C};
\end{tikzpicture}
Команда pic создает макрос для последующего использования кода.
7.8 - Пакет Xcolor и colortbl
Обзор документации пакетов Xcolor и colortbl
Пакет xcolor и colortbl - управление цветами в LaTeX
Установка и базовое использование
\usepackage{xcolor} % Основной пакет для работы с цветами
\usepackage[table]{xcolor} % Альтернативный вариант с загрузкой colortbl
% или
\usepackage{colortbl} % Пакет для цветных таблиц
Цветовые модели
Пакет поддерживает несколько цветовых моделей:
| Модель | Компоненты | Диапазон значений |
|---|---|---|
rgb | red, green, blue | [0, 1] для каждого |
cmyk | cyan, magenta, yellow, black | [0, 1] для каждого |
gray | оттенки серого | [0, 1] |
HTML | RRGGBB | 000000 до FFFFFF |
RGB | Red, Green, Blue | 0-255 для каждого |
Предопределенные цвета
Базовые цвета:
red, green, blue, cyan, magenta, yellow, black, white, gray, darkgray, lightgray
Дополнительные цвета:
brown, lime, olive, orange, pink, purple, teal, violet
Расширенные палитры:
\usepackage[dvipsnames]{xcolor} % 68 CMYK цветов
\usepackage[svgnames]{xcolor} % 151 RGB цвет
\usepackage[x11names]{xcolor} % 317 RGB цветов
Основные команды
Определение цветов
\definecolor{myred}{rgb}{1,0,0} % Чистый красный
\definecolor{mygray}{gray}{0.5} % Серый 50%
\definecolor{myblue}{HTML}{1F77B4} % Синий в HEX
Изменение существующих цветов
\colorlet{lightblue}{blue!20} % Светло-синий (20% от blue)
\colorlet{darkred}{red!80!black} % Темно-красный
Использование цветов
\textcolor{red}{Красный текст} % Цвет текста
\colorbox{yellow}{Желтый фон} % Фон текста
\fcolorbox{blue}{white}{Рамка} % Рамка и фон
Работа с таблицами (colortbl)
\begin{tabular}{|>{\columncolor{yellow!20}}c|c|}
\hline
\rowcolor{blue!10}
Заголовок 1 & Заголовок 2 \\
\hline
Ячейка 1 & \cellcolor{green!20}Ячейка 2 \\
\hline
\end{tabular}
Смешивание цветов
\color{red!50!blue} % Фиолетовый (50% красного + 50% синего)
\color{green!40!white!60} % Светло-зеленый
Прозрачность (требует pdfTeX или LuaTeX)
\textcolor{red!50}{Полупрозрачный текст}
Примеры использования
Цветной текст с рамкой:
\fcolorbox{black}{yellow!30}{
\textcolor{blue!80!black}{
Важное сообщение!
}
}
Градиентный фон:
\colorlet{startcolor}{red!20}
\colorlet{endcolor}{red!60}
\colorlet{middlecolor}{red!40}
\begin{tabular}{|p{3cm}|}
\arrayrulecolor{white}
\hline
\rowcolor{startcolor} Строка 1 \\
\rowcolor{middlecolor} Строка 2 \\
\rowcolor{endcolor} Строка 3 \\
\hline
\end{tabular}
Цветные математические формулы:
\[
\textcolor{blue}{E} = \textcolor{red}{m}\textcolor{green}{c^2}
\]
\[
\colorbox{yellow!20}{
\color{blue}
\int_a^b f(x)dx
}
\]
Советы
- Для документов, которые будут печататься, используйте CMYK цвета
- Для веб-документов лучше подходят RGB/HTML цвета
- Используйте мягкие цвета (!20-!40) для фонов
- Сохраняйте контраст между текстом и фоном
- Для сложных таблиц используйте
\rowcolorsизxcolor
\rowcolors{1}{blue!10}{white} % Чередование цветов строк
\begin{tabular}{cc}
A & B \\
C & D \\
E & F \\
\end{tabular}
Этот пакет предоставляет полный контроль над цветами в вашем LaTeX документе, от простого окрашивания текста до сложного оформления таблиц и математических формул.
7.9 - Пакет longtable
Применение longtable с тонкими настройками в Latex
Пакет Longtable
Размещение пакета
https://ctan.org/pkg/longtable
Официальная документация
https://mirror.macomnet.net/pub/CTAN/macros/latex/required/tools/longtable.pdf
Установка
\usepackage{longtable} %собственно сам пакет для работы с таблицами
\usepackage{xcolor} %чтобы работать с цветами
\usepackage{colortbl} %чтобы работать с цветными таблицами
Особенности
Полная приемственность от tabular и tabularx, поэтому можно только им и пользоваться.
Очень понадобятся первоначальные настройки для формата таблицы
\newcolumntype{C}[1]{>{\columncolor{white}\ttfamily\centering\arraybackslash}p{#1cm}}
\newcolumntype{R}[1]{>{\columncolor{white}\ttfamily\raggedleft\arraybackslash}p{#1cm}}
\newcolumntype{L}[1]{>{\columncolor{white}\ttfamily\raggedright\arraybackslash}p{#1cm}}
\newcolumntype{B}[1]{>{\columncolor{white}\ttfamily\bfseries\raggedright\arraybackslash}p{#1cm}}
\renewcommand{\tabcolsep}{0.05cm}
\renewcommand{\arraystretch}{1.7}
\newcolumntype похожа на \newcommand но только для настройки таблиц. Работает со всеми пакетами расширяющие стандартый пакет таблиц: xtab, xtabular, tabularx и longtable.
https://ctan.org/pkg/tabularx https://mirror.truenetwork.ru/CTAN/macros/latex/required/tools/tabularx.pdf
оттуда и возьмем описание команд:
\arraybackslash
\raggedright, \raggedleft, \centering — после этих команд изменяется поведение команды \\ и \\*, вот, чтобы этого не произошло и применяем команду \arraybackslash.
>{\raggedright\arraybackslash}X
\newcolumntype
определяет новые параметры колонки и назначает их переменной Y или какую напишем, но только из одной буквы. Мне алфавита хватало всегда.
\newcolumntype{Y}{>{\small\raggedright\arraybackslash}X}
после знака {> пишем любые команды для определения шрифта, цвета, выравнивания и т.д. Обычно это удобно связывать с шириной колонки и передавать значение через переменную в p{#1}.
Количество переменных может быть любое, главное в них самому не запутаться.
После определения новых типов колонок их можно использовать в заголовке описания таблицы наравне с lcrpm
\tabularxcolumn
Изменяет тип колонки X
\newcommand{\tabularxcolumn}[1]{p{#1}} — соответствует \parbox[t] — и определено по умолчанию
\renewcommand{\tabularxcolumn}[1]{>{\small}m{#1}} — соответствует \parbox[m] — контент выравнивается по центру и типа так я могу переопределить, но у меня ничего не получилось, зато мои настройки \newcolumn работают шикарно.
ширина колонки
Умный Latex по умолчанию всегда пытается создать одинаковые колонки с размером \hsize, но мы можем переопределить пропорционально ширину каждой колонки. Первая будет половина от стандартной ширины, а вторая в 3 раза больше.
{>{\hsize=.5\hsize\linewidth=\hsize}X >{\hsize=1.5\hsize\linewidth=\hsize}X}
Дальше tabularx упрощает работы со сносками. Но я на этом пакете заканчиваю и перехожу к longtable.
Сделал себе мастер таблицу и закатал в yasnippet
# -*- mode: snippet -*-
# name: longtable
# key: longtable
# --
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%LONGTABLE
\begin{center}
\rowcolors{2}{gray!10}{white} \\arrayrulecolor{gray!20} %раскрасим в два цвета строки
\begin{longtable}{c|c} %описание таблицы
%%%%%%%%%%%%%%% заголовок на первой странице
\caption[Название таблицы короткое]{Название таблицы длинное\label{tab:}}\\\
\rowcolor{blue!40} %раскрасим заголовок таблицы
\multicolumn{1}{c}{Наименование} % название первой колонки
& \multicolumn{1}{c}{Описание} % название второй колонки
% при большем количестве колонок последнюю строчку повторить столько же раз
% готовый раздел скопировать в раздел Заголовок на второй странице
\endfirsthead % конец заголовка
%%%%%%%%%%%%%%%%% конец заголовка на первой странице
%%%%%%%%%%%%%%% Заголовок на второй странице
\caption{продолжение таблицы на следующей странице}\\\
\rowcolor{blue!40}
\multicolumn{1}{c}{Наименование}
& \multicolumn{1}{c}{Описание}
\endhead %конец заголовка
%%%%%%%%%%%%%%%%% конец заголовка на второй странице
%%%%%%%%%%%%%%%%%%%%% BODY TABLE
Первый & Второй\\\\
Третий & Четвертый\\\\
%%%%%%%%%%%%%%%%%%%%%
\end{longtable}
\end{center}

Команды для высоты строк и отступов между колонками
\renewcommand{\tabcolsep}{0.05cm}
\renewcommand{\arraystretch}{1.7}
- первая определит отступ между колонками
- вторая высоту строк в таблице
[i18n] info
Собственно мне всего перечисленного хватало практически на 90% всех таблиц.
Длина таблицы на странице
По умолчанию длина таблицы 20 строк, но можно изменить с помощью команты
\setcounter{LTchunksize}{10}
и будет 10!
Изменить нумерацию таблиц
\renewcommand\LTcaptype{⟨counter ⟩}
Header & Footer
- У таблицы могут быть первый Header и после его описания нужно поставить
\endfirsthead - После определения заголовков на 2-й и следующих таблицах поставить
\endhead. - Если таблица на одной странице, то пункт 2 не нужен.
\endfootтакже заканчивает описание последней строки таблицы на странице\endlastfootописывает последнюю строку таблицы
\сaption
\caption{...} команда эквивалентна \multicolumn{n}{c}{\parbox{\LTcapwidth}{…}}
она просто объединяет все колонки и пишется как полноценная строка таблицы.
\caption[Опциональное имя, используется в списке таблиц]{Полноценное имя таблицы\label{long}}.
\multicolumn
объединяет колонки \multicolumn{numcols}{cols}{text}
- количество объединяемых колонок
- формат колонок
lcrmp - Собственно текст в этой ячейке с применением всех возможных комманд и боксов, а также
\multirowдля объединения строк. Но для нее нужно подключить пакет\usepackage{multirow}
\kill
делаем строку для определения ширины столбцов и вместо \\ ставим \kill. Строка не будет отображаться в таблице, но ширину настроит.
Выравнивание таблицы на странице
LTleft и LTright
\setlength\LTleft\parindent
\setlength\LTright\fill
устанавливаем отступ для всей таблицы слева и справа, но один параметр нужно сотавлять тягучим \fill
\setlength\LTleft{0pt}
\setlength\LTright{0pt}
\begin{longtable}{@{\extracolsep{...}}...}
\extracolsep — делает резиновым столбец.
Сводная таблица
Параметры
| \LTleft | Glue to the left of the table. | (\fill) |
|---|---|---|
| \LTright | Glue to the right of the table. | (\fill) |
| \LTpre | Glue before the table. | (\bigskipamount) |
| \LTpost | Glue after the table. | (\bigskipamount) |
| \LTcapwidth | The width of a parbox containing the caption. | (4in) |
| \LTchunksize | The number of rows per chunk. | (20) |
Optional arguments to \begin{longtable}
| none | Position as specified by \LTleft and \LTright. |
|---|---|
| [c] | Centre the table. |
| [l] | Place the table flush left. |
| [r] | Place the table flush right. |
Commands to end table rows
| \ | Specifies the end of a row |
|---|---|
| \\[⟨dim⟩] | Ends row, then adds vertical space (as in the tabular environment). |
| \\* | The same as \ but disallows a page break after the row. |
| \tabularnewline | Alternative to \\ for use in the scope of \raggedright and similar commands that redefine \\. |
| \kill | Row is ‘killed’, but is used in calculating widths. |
| \endhead | Specifies rows to appear at the top of every page. |
| \endfirsthead | Specifies rows to appear at the top of the first page. |
| \endfoot | Specifies rows to appear at the bottom of every page. |
| \endlastfoot | Specifies rows to appear at the bottom of the last page. |
Longtable caption commands
| \caption{⟨caption⟩} | Caption ‘Table ?: ⟨caption⟩’, and a ‘⟨caption⟩’ entry in the list of tables. |
|---|---|
| \caption[⟨lot⟩]{⟨caption⟩} | Caption ‘Table ?: ⟨caption⟩’, and a ‘⟨lot⟩’ entry in the list of tables. |
| \caption[]{⟨caption⟩} | Caption ‘Table ?: ⟨caption⟩’, but no entry in the list of tables. |
| \caption*{⟨caption⟩} | Caption ‘⟨caption⟩’, but no entry in the list of tables. |
Commands available at the start of a row
| \pagebreak | Force a page break. |
|---|---|
| \pagebreak[⟨val ⟩] | A ‘hint’ between 0 and 4 of the desirability of a break. |
| \nopagebreak | Prohibit a page break. |
| \nopagebreak[⟨val ⟩] | A ‘hint’ between 0 and 4 of the undesirability of a break. |
| \newpage | Force a page break. |
Footnote commands available inside longtable
| \footnote | Footnotes, but may not be used in the table head & foot. |
|---|---|
| \footnotemark | Footnotemark, may be used in the table head & foot. |
| \footnotetext | Footnote text, use in the table body. |
Setlongtables
| \setlongtables | Obsolete command. Does nothing now. |
|---|
Multirow замолвите слово
Объединяет строки в таблице
Подключить через команду
\usepackage{multirow}
\multirow[〈vpos 〉]{〈nrows 〉}[〈bigstruts 〉]{〈width 〉}[〈vmove 〉]{〈text 〉}
- vpos —
tcbвыравнивает текст в общей ячейке по [t] [c] [b] (необязательный параметр) - nrows — количество строк
- bigstruts — это распорки или больше похоже на заполнение текста (я не использовал)
- width — ширина ячейки с текстом. Обычно (*), но если используем \multirow то не все колонки могут быть заполнены текстом
- vmove — это как \raisebox — поднимает текст вверх или вниз. Удобная штука. Можно отрицательные и положительные значения.
- text — собственно сам текст
\multicolumn{2}{c}{\multirow{3}{*}{Multi-multi}} — с multirow использовать только в таком порядке, а не наоборот.
[i18n] note
В этом пакете еще есть утилиты для работы с большими скобками на объединенные строки.
7.10 - Newfont
Моя история подключения различных шрифтов в Latex
Удивительное путешествие в мир создания интегрированных шрифтов в Latex
История началась с французской компании, которая попросила меня написать несколько документаций на свои изделия.
Так как я сначала подумал,что отделаюсь легким испугом, то первую работу сделал в XARA. Замечательный редактор, но когда в моем документе перевалило за 50 страниц, я понял, что ошибся с выбором инструмента.
Потом было несколько документов по 4-8 страниц. Что не составило проблем сделать в XARA.
Но когда дело дошло до очередного 80-ти страничного документа, я решил просто сделать в Latex.
Эта компания использовала свои фирменные шрифты, поэтому шрифты скачал в интернет, подключил модуль \usepackage{fontspec} и вуаля!!!
\setmainfont{AllRoundGothic-Book}[
BoldFont = AllRoundGothic-Bold ,
ItalicFont = AllRoundGothic-BookOblique ]
\setsansfont{AllRoundGothic-XLig}
\setmonofont{Calibri}[
Extension = .ttf ,
BoldFont = Calibri_bold] % задаёт \sffamily, шрифт без засечек
Настроил цвета через пакет \usepackage{xcolor}
%%%%%%%%% COLOR %%%%%%%%%%%%%%%5
\definecolor{BleuProfond}{RGB}{7,29,73}%#071D49
\definecolor{BleuLBA}{RGB}{65,182,230}
\definecolor{GrisA}{RGB}{37,40,42}
\definecolor{GrisC}{RGB}{178,180,178}
Подключил нужные раскладки и настроил свои fontfamily
\newfontfamily\boldfont{AllRoundGothic-Bold}
\newfontfamily\demifont{AllRoundGothic-Demi}
\newfontfamily\demifontwhite{AllRoundGothic-Demi}[Color = white]
\newfontfamily\mediumfont{AllRoundGothic-Medium}
\newfontfamily\boldfontbleu{AllRoundGothic-Bold}[Color = BleuProfond]
\newfontfamily\boldfontlba{AllRoundGothic-Bold}[Color = BleuLBA]
\newfontfamily\boldfontwhite{AllRoundGothic-Bold}[Color = white]
\newfontfamily\lc[Scale=MatchLowercase]{AllRoundGothic-Demi}[Color = BleuProfond]
\newfontfamily\uc[Scale=MatchUppercase]{AllRoundGothic-Demi}
\newfontfamily\ac[Scale=MatchAveragecase]{AllRoundGothic-Demi}
\newfontfamily\numamco{Calibri}
Собственно все!
Дальше рутина по созданию стиля страницы. Очень приятный XELATEX с которым мы достаточно быстро справились с поставленной задачей (убрал только привычный мне %\usepackage{hyperref}), потому-что на него странно ругался компилятор. (вычислил эксперементально).
Но все мои познания подключения шрифтов начались тогда, когда заказчик попросил сделать оглавление кликабельное с возможностью переходить по ссылкам на страницы.
И ВОТ ЗДЕСЬ НАЧАЛОСЬ!
Оказывается не XELATEX не LUALATEX при всей своей красоте поддержки TrueType шрифтов напрямую, отказываются работать с \usepackage[xetex]{hyperref} даже в таком варианте.
Копирую шрифты в папку проекта
Есть варианты создать свою структуру и прописать настройки к ней, но в этом варианте я ограничиваюсь настройкой в рабочей директории.
Подключать буду три шрифта:
- AllRoundGothic-Bold.ttf
- AllRoundGothic-Book.ttf
- AllRoundGothic-Demi.ttf
Подготовительные мероприятия
Нахожу в Latex (T1-WGL4.enc) на Manjaro он спрятался в /opt/texlive/2024/texmf-dist/fonts/enc/ttf2pk/base
Его тоже копирую в рабочуюдиректорию, чтобы ничего не потерялось. Для кирилических шрифтов копируем T2A.enc, он находится по соседству: /opt/texlive/2024/texmf-dist/fonts/enc/t2.
Теперь все готово для подключения.
Создаю TeX Font Metrics (tfm)
Файлы с расширением tfm хранят необработанные шрифты, а файлы vpl виртуальные шрифты.
ttf2tfm AllRoundGothic-Demi.ttf -q -T T1-WGL4.enc -v ecAllRoundGothic-Demi.vpl recAllRoundGothic-Demi.tfm >> ttfonts.map
ttf2tfm AllRoundGothic-Bold.ttf -q -T T1-WGL4.enc -v ecAllRoundGothic-Bold.vpl recAllRoundGothic-Bold.tfm >> ttfonts.map
ttf2tfm AllRoundGothic-Book.ttf -q -T T1-WGL4.enc -v ecAllRoundGothic-Book.vpl recAllRoundGothic-Dook.tfm >> ttfonts.map
Можно посмотреть в ttfont.map, должно получиться что-то вроде:
recAllRoundGothic-Bold AllRoundGothic-Bold.ttf Encoding=T1-WGL4.enc
recAllRoundGothic-Book AllRoundGothic-Book.ttf Encoding=T1-WGL4.enc
recAllRoundGothic-Demi AllRoundGothic-Demi.ttf Encoding=T1-WGL4.enc
Чтобы создать наклонные версии обычного и жирного шрифта, команду следует расширить следующим образом:
ttf2tfm AllRoundGothic-Book.ttf -q -T T1-WGL4.enc -s .167 -v ecAllRoundGothic-Book.vpl recAllRoundGothic-Dook.tfm >> ttfonts.map
Но я так не делал, потому-что было не нужно.
Создаю Virtual Fonts (vf)
vptovf ecAllRoundGothic-Demi.vpl ecAllRoundGothic-Demi.vf ecAllRoundGothic-Demi.tfm
vptovf ecAllRoundGothic-Bold.vpl ecAllRoundGothic-Bold.vf ecAllRoundGothic-Bold.tfm
vptovf ecAllRoundGothic-Book.vpl ecAllRoundGothic-Book.vf ecAllRoundGothic-Book.tfm
Но если бы я создавал какой-нибудь times, то нужно было создавать по всем законам толстые, наклонные и т.д.
vptovf ectimes.vpl ectimes.vf ectimes.tfm
vptovf ectimesi.vpl ectimesi.vf ectimesi.tfm
vptovf ectimesbd.vpl ectimesbd.vf ectimesbd.tfm
vptovf ectimesbi.vpl ectimesbi.vf ectimesbi.tfm
vptovf ectimeso.vpl ectimeso.vf ectimeso.tfm
vptovf ectimesbdo.vpl ectimesbdo.vf ectimesbdo.tfm
Что имеем по итогу?
-rw-r--r-- 1 edge edge 555 ноя 12 16:31 ecAllRoundGothic-Bold.log
-rw-r--r-- 1 edge edge 1792 ноя 12 16:26 ecAllRoundGothic-Bold.tfm
-rw-r--r-- 1 edge edge 1784 ноя 12 16:26 ecAllRoundGothic-Bold.vf
-rw-r--r-- 1 edge edge 22500 ноя 12 16:19 ecAllRoundGothic-Bold.vpl
-rw-r--r-- 1 edge edge 1780 ноя 12 16:26 ecAllRoundGothic-Book.tfm
-rw-r--r-- 1 edge edge 1784 ноя 12 16:26 ecAllRoundGothic-Book.vf
-rw-r--r-- 1 edge edge 22365 ноя 12 16:20 ecAllRoundGothic-Book.vpl
-rw-r--r-- 1 edge edge 1788 ноя 12 16:25 ecAllRoundGothic-Demi.tfm
-rw-r--r-- 1 edge edge 1784 ноя 12 16:25 ecAllRoundGothic-Demi.vf
-rw-r--r-- 1 edge edge 22434 ноя 12 16:21 ecAllRoundGothic-Demi.vpl
del *.vpl они нам больше не нужны. Из них создали *.vf
Дальше размещаем по структурам каталогов Latex для постоянного использования или ничего не делаем, а все храним в рабочей папке. И все будет работать.
Вместо заключения
В latex вставляем такие простые вещи:
\font\myfont=ecAllRoundGothic-Bold
\font\mybigfont=ecAllRoundGothic-Bold at 36pt
\font\bookfont=ecAllRoundGothic-Book
\font\demifont=ecAllRoundGothic-Demi
\myfont Hello, I am being typeset in AllRoundGothic
\mybigfont Me too...
или назначаем по умолчанию, как описывал раньше.
Но, получаем:

Для постоянного использования шрифта
Создаем файл .fd я этого не делал, но из образца записываю. Там подключали times.
\ProvidesFile{t1tnr.fd}[Put your description of font here]
\DeclareFontFamily{T1}{tnr}{}
\DeclareFontShape{T1}{tnr}{b}{n}{<->ectimesbd}{}
\DeclareFontShape{T1}{tnr}{b}{sl}{<-> ectimesbdo}{}
\DeclareFontShape{T1}{tnr}{b}{it}{<-> ectimesbi}{}
\DeclareFontShape{T1}{tnr}{m}{n}{<-> ectimes}{}
\DeclareFontShape{T1}{tnr}{m}{sl}{<-> ectimeso}{}
\DeclareFontShape{T1}{tnr}{m}{it}{<-> ectimesi}{}
\DeclareFontShape{T1}{tnr}{bx}{n}{<->ssub * tnr/b/n}{}
\DeclareFontShape{T1}{tnr}{bx}{sl}{<->ssub * tnr/b/sl}{}
\DeclareFontShape{T1}{tnr}{bx}{it}{<->ssub * tnr/b/it}{}
\endinput
Затем использование в документе будет выглядеть:
documentclass{article}
\begin{document}
\usefont{T1}{tnr}{m}{sl}
Hello, I am being typeset in Times New Roman Slanted
\end{document}
Или прописать прямо в преамбуле
\documentclass{article}
\renewcommand{\encodingdefault}{T1}
\renewcommand{\rmdefault}{tnr}
\begin{document}
Hello, I am being typeset in \textsl{Times New Roman Slanted}
\end{document}
Проверяем:
pdftex story
This is pdfTeX, Version 3.141592653-2.6-1.40.26 (TeX Live 2024) (preloaded format=pdftex)
restricted \write18 enabled.
entering extended mode
(/opt/texlive/2024/texmf-dist/tex/plain/knuth-lib/story.tex [1{/opt/texlive/202
4/texmf-var/fonts/map/pdftex/updmap/pdftex.map}])
*\bye
Подключение шрифтов Adobe (afm)
Создаем afm шрифты
ttf2afm -e T1-WGL4.enc -o rectimes.afm times.ttf
ttf2afm -e T1-WGL4.enc -o rectimesi.afm timesi.ttf
ttf2afm -e T1-WGL4.enc -o rectimesbd.afm timesbd.ttf
ttf2afm -e T1-WGL4.enc -o rectimesbi.afm timesbi.ttf
Создаем tfm и map
afm2tfm rectimes.afm -T T1-WGL4.enc rectimes.tfm >>winfonts.map
afm2tfm rectimesi.afm -T T1-WGL4.enc rectimesi.tfm >>winfonts.map
afm2tfm rectimesbd.afm -T T1-WGL4.enc rectimesbd.tfm >>winfonts.map
afm2tfm rectimesbi.afm -T T1-WGL4.enc rectimesbi.tfm >>winfonts.map
afm2tfm rectimes.afm -T T1-WGL4.enc -s .167 rectimeso.tfm >>winfonts.map
afm2tfm rectimesbd.afm -T T1-WGL4.enc -s .167 rectimesbdo.tfm >>winfonts.map
Редактируем map файл
rectimes TimesNewRomanPSMT " T1Encoding ReEncodeFont " <times.ttf T1-WGL4.enc
rectimesi TimesNewRomanPS-ItalicMT " T1Encoding ReEncodeFont " <timesi.ttf T1-WGL4.enc
rectimesbd TimesNewRomanPS-BoldMT " T1Encoding ReEncodeFont " <timesbd.ttf T1-WGL4.enc
rectimesbi TimesNewRomanPS-BoldItalicMT " T1Encoding ReEncodeFont " <timesbi.ttf T1-WGL4.enc
rectimeso TimesNewRomanPSMT " .167 SlantFont T1Encoding ReEncodeFont " <times.ttf T1-WGL4.enc
rectimesbdo TimesNewRomanPS-BoldMT " .167 SlantFont T1Encoding ReEncodeFont " <timesbd.ttf T1-WGL4.enc
Далее можно разложить по правильным директориям или оставить в рабочей дирректории.
У Latex есть много своих встроенных шрифтов
Подключаем
\usepackage{DejaVuSans}
\renewcommand*\familydefault{\sfdefault}
и пользуемся без геммороя.
7.11 - Pdfpages
Вдруг понадобилось вставить титульную страницу, сделанную на XARA. Пришлось подключить пакет pdfpages
Подключение пакета
Для установки пакета в преамбуле документа пишем:
\usepackage[⟨options ⟩]{pdfpages}
Родная документация
https://mirror.macomnet.net/pub/CTAN/macros/latex/contrib/pdfpages/pdfpages.pdf
Сам пакет на SPAN
Опции при подключении
⟨option⟩
- final: режим по умолчанию, вставляет страницы в документ
- draft: не вставляет страницу, но вставляет ссылку в боксе
- demo: вставляет пустую страницу
- nodemo: отключает демо
Вставка документа
\includepdf[⟨key=val ⟩]{⟨filename⟩}
Вставляет файл где укажешь.
Key=val могут быть различными.
Если нужно вставить избранные страницы, используем ключ page
pages={3,5,6,8})
pages={4-9}
pages={3,{},8-11,15}
nup — укладывает логические страницы на лист (что-то вроде микространиц) nup=⟨xnup⟩x⟨ynup⟩
landscape=false — по умолчанию, но можно развернуть, если нужно
и еще куча всяких опций для какого-то боловства. Мне пока хватает этого.
7.12 - Titleps
Оформление стилей страниц, заголовков и оглавления. Продвинутый пакет. Оставляю его для настроек различных стилей документов.
Совместно с TITLESEC бомбическая штука по настройке стилей страниц. Обзор документации.
Пакет TITLEPS
Установка пакета
Для установки пакета в преамбуле документа пишем:
\usepackage[pagestyles]{titlesec}
Страница репозитория
Документация
https://mirror.truenetwork.ru/CTAN/macros/latex/contrib/titlesec/titleps.pdf
Определение стиля страницы
\newpagestyle{⟨name⟩}[⟨global-style⟩]{⟨commands⟩}
\renewpagestyle{⟨name⟩}[⟨global-style⟩]{⟨commands⟩}
Они их почему-то называют верхние и нижние команды.
Установка для HEADER и FOOTER
\sethead[⟨even-left⟩][⟨even-center⟩][⟨even-right⟩] {⟨odd-left⟩}{⟨odd-center⟩}{⟨odd-right⟩}
\setfoot[⟨even-left⟩][⟨even-center⟩][⟨even-right⟩] {⟨odd-left⟩}{⟨odd-center⟩}{⟨odd-right⟩}
А теперь по-порядку.
Все
Первая группа комманд
– \thechapter, \thesection, \thesubsection. . . --- печатают номера заголовков
– \chaptertitle, \sectiontitle, \subsectiontitle. . . --- печатают наименования заголовков
– (только для titlesec) \ifthechapter{⟨true⟩}{⟨false⟩}, \ifthesection{⟨true⟩}{⟨false⟩}, \ifthesubsection{⟨true⟩}{⟨false⟩}. . . --- проверяют где сейчас находится страница
– любые другие команды
Вторая группа комманд
относится ко всему, что есть на странице: - \thepage - другие не включенные в первую группу
Установка MARKSов
\settitlemarks{⟨level-name⟩,⟨sublevel-name⟩,⟨subsublevel-name⟩...}
\settitlemarks*{⟨level-name⟩,⟨sublevel-name⟩,⟨subsublevel-name⟩...}
Устанавливает, какие команды ...title должны быть определены и когда выдаются метки; допускается любое количество уровней (1, 2, 3…). Например, \settitlemarks{chapter,section}
Установка RULES
\headrule
\footrule
\setheadrule{⟨length⟩}
\setfootrule{⟨length⟩}
линии будут проведены под или над калантитулом
Установка отступов RULES
\makeheadrule
\makefootrule
\renewcommand{\makeheadrule}{\rule[-.3\baselineskip]{\linewidth}{⟨dim⟩}}
Этот пример из документации создаст две линнии в HEADER
\renewcommand{\makeheadrule}{%
\makebox[0pt][l]{\rule[.7\baselineskip]{\linewidth}{0.8pt}}%
\color[named]{Red}%
\rule[-.3\baselineskip]{\linewidth}{0.4pt}}
\markboth and \markleft
В документации целая дискуссия по поводу не нужности \markboth и что достаточно \markleft.
Пока не вдаюсь в подробности, но в пакете есть функция \setmarkboth{⟨code-to-use⟩}, чтобы переопределить markboth.
Headline/footline ширина
\widenhead[⟨even-left⟩][⟨even-right⟩]{⟨odd-left⟩}{⟨odd-right⟩}
\widenhead*{⟨even-right/odd-left⟩}{⟨even-left/odd-right⟩}
Этот параметр соответственно добавляет ширину header и footer-ов.
\widenhead*{0pt}{6pc}
тоже самое
\widenhead[6pc][0pt]{0pt}{6pc}
nopatches — это опция в преамбуле пакета для самостоятельной тонкой настройки с помощью \sectionmark.
Marks
Марксы можно получить 4 способами:
- top marks
- first marks
- botttom marks
- next top marks
7.13 - Titlesec
Оформление стилей страниц, заголовков и оглавления. Продвинутый пакет. Оставляю его для настроек различных стилей документов.
Обзор документации.
Пакет TITLESEC
Подключение пакета
Для установки пакета в преамбуле документа пишем:
\usepackage[explicit]{titlesec}
Родная документация
https://mirror.macomnet.net/pub/CTAN/macros/latex/contrib/titlesec/titlesec.pdf
Сам пакет на SPAN
команда explicit мне будет нужна, чтобы в настройках заголовков указывать {#1} для подстановки в нужное место.
В пакете есть так называемые простые настройки и продвинутые.
Простые настройки
Что можно изменять в формате
Для настройки формата заголовка используем три параметра:
- Тип шрифта
rm sf tt md bf up it sl scпо умолчанию в заголовках стоит\bf. - Размер шрифта
big medium small tiny - Выравнивание заголовка
raggedleft center raggedright compact— задает более компактный вид и уменьшает пробелыuppercase— выведет все буквы заглавными (говорят не всегда работает)
Основные команды в простом режиме
titlelabel
\titlelabel{⟨label-format ⟩}
Эта команда изменяет формат метки заголовка
\titlelabel{\thetitle\quad}
т.е можно настроить буквенный вывод, изменить длину пробела, поставить точку и т.д.
titleformat
\titleformat*{⟨command ⟩}{⟨format⟩}
Собственно сам формат заголовка.
command — это \section, \subsection и т.д.
format — соответственно, все, что было сказано выше. Размер шрифта, семейство шрифта и выравнивание.
\titleformat*{\section}{\Large\sf}
Собственно для простой настройки и все!!!
Продвинутые настройки
titleformat
\titleformat{⟨command ⟩}[⟨shape⟩]{⟨format⟩}{⟨label ⟩}{⟨sep⟩}{⟨before-code⟩}[⟨after-code⟩]
command:
это:
- \part,
- \chapter,
- \section,
- \subsection,
- \subsubsection,
- \paragraph,
- \subparagraph.
shape:
это:
- hang — значение по умолчанию (висящая метка)
- block — заголовок помещает в блок. Можно добавлять рисунки и прочее.
- display — помещает метку в отдельный абзац.
\titleformat{\section}[display]
{\fontsize{120}{20}\boldfont}
{\vbox{\hfil\thesection}\hfil}{0em}
{\LARGE\uppercase{#1}}
\titlespacing{\section} {0pc}{20.5ex plus .1ex minus .2ex}{30.5ex minus .1ex}[0pc]

Вот так получится.
- runin — в документации пишут, что как стандартный параграф, но особо не заметил разницы. Наверно бесполезная вещь.
\titleformat{\subsection}[runin]
{\fontsize{44}{10}\boldfont}
{\thesection}{0.5em}
{\LARGE\uppercase{#1}}
\titlespacing{\section} {0pc}{20.5ex plus .1ex minus .2ex}{30.5ex minus .1ex}[0pc]

Использую пакет fontspec для большей красоты настроек. fontsize оттуда.
- leftmargin — тяжело понять, лучше увидеть. Все выравнивает по левому краю.
\titleformat{\subsection}[leftmargin]
{\boldfont}
{\thesection}{1.5em}
{\Large\uppercase{#1}}
\titlespacing{\subsection} {-15pc}{2.5ex plus .1ex minus .2ex}{3.5ex minus .1ex}[5pc]
...
\subsection{Subsection test two line}

И еще одна интересная заметка для заголовка: если я меняю первый параметр в \titlespacing на 3pc то получится:

- rightmargin — как leftmargin, но только вправо. Но у меня результата не получилось. Все улетает за пределы страницы.
titlespasing изменил третий параметр в отрицательную величину, и добился результата.
- drop/wrap — реально оборачивает текст вокруг заголовка
\titleformat{\subsection}[wrap]
{\Large\boldfont}
{\thesection}{1.5em}
{\uppercase{#1}}
\titlespacing{\subsection}{2pc}{4.5ex plus .1ex minus .2ex}{8.5ex plus .2ex minus .1ex}[2pc]
но нужно правильно настроить 3-й параметр в \titlespacing я для своего заголовка поставил 8.5ex, в общем подбираем экспериментально.
Но получилось:

\titlespacing{\subsection}{12pc}{8.5ex plus .1ex minus .2ex}{8.5ex plus .2ex minus .1ex}[6pc]
поменял настройки на 12pc и заголовок стал выглядеть приятнее,
 для сравнения если я поставлю
для сравнения если я поставлю drop то будет перенос строк по другому режиму: см. ниже:

- frame — также переносит метку в отдельный параграф как display, но еще рисует рамку
format
Все что угодно из латекса. Ставится перед заголовком и действует на метку и заголовок. Цвет, шрифт, размер и пр.
\titleformat{\section}[display]
{\color{red}\fontsize{120}{20}\boldfont}
{\vbox{\hfil\thesection}\hfil}{0em}
{\LARGE\uppercase{#1}}
label
метка раздела. Чтобы все работало корректно лучше ставить, если предусмотрено стилем. Т.к., когда будет применяться команда заголовка со *, то номер подавится автоматически.
\thesection
\thesubsection
\thesubsubsection
...
sep
отступ от метки. Тоже нельзя оставлять пустым. 0pt но поставь.
before-code
самая звездная штука. В нее можно поставить вообще все и в качестве аргумента вляпать #1 как текст заголовка.
\titleformat{\section}
{\LARGE\boldfontwhite}
{}{.5em}
{\colorbox{BleuLBA}{\parbox{21cm}{\rule[-5pt]{0pt}{21pt}\hspace{1.5cm}\thesection\, \uppercase{#1}}}}
это я сделал для французов в синей рамочке белыми буквами. Но тут есть одна ошибка. Надеюсь с ней разобраться. Это номер заголовка.

after-code
тоже самое, что и before, только код ставит после заголовка. Любой!
chaptertitlename
изменяет название главы по умолчанию
\renewcommand{\chaptertitlename}{Новое название главы}
titlespacing
\titlespacing*{⟨command ⟩}{⟨left⟩}{⟨before-sep⟩}{⟨after-sep⟩}[⟨right-sep⟩]
Нужная команда для настроек пространства заголовка
Версия со звездочкой убирает отступ абзаца, следующего за заголовком, за исключением случаев удаления, переноса и запуска, где эта возможность не имеет смысла.
command
команда заголовка \section и т.д.
left
обязательный параметр, может быть положительный и отрицательный делает отступ заголовка влево и вправо.
Помогает при настройке с параметром drop и wrap.
before-sep
буквально вертикаьный отступ перед заголовком
after-sep
двигает текст после заголовка вертикально и горизонтально. Важен при настройке текста с обтеканием.
right-sep
необязательный параметр для установки отступа справа для установок с hang, block и display. Помогает залезать в правое поле. Это \beforetitleunit и \aftertitleunit тонкие настройки клея в заголовках. Я не использую.
А теперь я добился того, ради чего затевал этот конспект. Я настроил заголовок без ошибок:
%%%%%%%%%%%%%%% SECTION %%%%%%%%%%%%%5000
\titleformat{\section} [hang]
{\LARGE\boldfontwhite}
{\llap{\colorbox{BleuLBA}{\parbox{2cm}{\rule[-5pt]{0pt}{21pt}\filleft\thesection}}}}{0em}
{\colorbox{BleuLBA}{\parbox{21cm}{\rule[-5pt]{0pt}{21pt}\filright \uppercase{#1}}}}
\titlespacing{\section} {0pc}{2.5ex plus .1ex minus .2ex}{3.5ex minus .1ex}[0pc]
Результат смотрим ниже:

Дополнительные команды выравнивания
\filright \filcenter \filleft \fillast \filinner \filouter
в принципе благодаря им очень хорошо настроил и решил свою задачу выше.
Они заполняют пространство перед или после заголовкаа, в зависимости от названия.
\wordsep — пространство между слов в заголовке
indentafter noindentafter — обходит настройки отступов страницы
rigidchapters rubberchapters — регулирует пространство между титулом главы и текстом.
bottomtitles nobottomtitles nobottomtitles*
Устанавливаем минимальное пространство внизу страницы, чтобы заголовок не переносился на новую страницу.
\renewcommand{\bottomtitlespace}{⟨length ⟩}
aftersep largestsep
По умолчанию, когда есть два последовательных заголовка, между ними используется пространство ⟨after-sep⟩ от первого. Иногда это нежелательное поведение, особенно когда пространство ⟨before-sep⟩ намного больше, чем пространство ⟨after-sep⟩ (в противном случае предпочтительнее выглядит значение по умолчанию).
pageatnewline — этот странный параметр насильно разрывает заголовок на разные страницы, хотя по умолчанию команды \\ \\* подавлены.
\nostruts nostruts — подавляет умничество latex при изменении высоты пространства в заголовках.
RULES
Добавляет линии под заголовками и не только.
\titleline[⟨align⟩]{⟨horizontal material ⟩}
\titlerule[⟨height ⟩]
\titlerule*[⟨width ⟩]{⟨text ⟩}
Можно добавить прямо в текст и получить результат для одного заголовка:
\section{Title first}
\label{sec:title-first}
\titlerule[.8pt]%
\vspace{1pt}%
\titlerule
или можно эту же конструкцию добавить в настройки \titleformat.

calcwidth — изменяет формат переноса строк для режима wrap
PAGE STYLES
\assignpagestyle{⟨command ⟩}{⟨pagestyle⟩}
...
\assignpagestyle{\chapter}{empty}
любой главе или странице можно назначить стиль по умолчанию.
Breaks
\sectionbreak \subsectionbreak \subsubsectionbreak \paragraphbreak \subparagraphbreak \⟨section⟩break
\newcommand{\sectionbreak}{\clearpage}
или
\newcommand{\sectionbreak}{%
\addpenalty{-300}%
\vspace*{0pt}}
эта утилита настраивает автоматический разрыв страниц при достижения заданных параметров в разделах.
\chaptertolists — изменяет отступы перед заголовками
\newcommand{\chaptertolists}{}
а этот будет пустой
Команды в преамбуле
explicit
позволяет указывать в titleformat #1 как место для текста заголовка
\titleformat{\section}
{..}
{\thesection}{..}{#1.}
newparttoc oldparttoc
используется если \part была переопределена, помогает настроить TOC
clearempty
Изменяет поведение \cleardoublepage, чтобы на пустых страницах использовался стиль пустой страницы.
toctitles
Изменяет поведение необязательного аргумента в заголовках разделов, так что он устанавливает только заголовки в квадратных скобках, а не записи оглавления, которые будут основаны на полном заголовке.
newlinetospace
Заменяет каждое вхождение символов \ или \* в заголовках на пробел в заголовках и записях оглавления.
Расширенные настройки
⟨key⟩=⟨value⟩, ⟨key⟩=⟨value⟩, ⟨key⟩, ⟨key⟩,...
Первый аргумент как \titleformat, так и \titlespaceing имеет расширенный синтаксис, который позволяет устанавливать разные форматы в зависимости от контекста.
name=Допустимые значения: \chapter, \section и т. д.page=Допустимые значения: odd или even.numberlessБесполезный ключ. В этом нет необходимости, если вы не хотите установить разные нумерованные (без этого ключа) и ненумерованные (с безномерными) варианты.
\titleformat{name=\section,page=even}[leftmargin]
{\filleft\scshape}{\thesection}{.5em}{}
\titleformat{name=\section,page=odd}[rightmargin]
{\filright\scshape}{\thesection}{.5em}{}
Создание новыхуровней заголовков
\titleclass{⟨name ⟩}{⟨class ⟩} \titleclass{⟨name⟩}{⟨class⟩}[⟨super-level-cmd ⟩]
Существует три класса:
page— это часть книги, на одной странице,top— это \chapter, который начинает страницу и помещает заголовок вверху,straightпредназначен для заголовков в середине текста.
В первом случае \titleclass{\part}{straight} заменяется просто класс.
Во втором случае, можно создать новые подуровни:
\titleclass{\subchapter}{straight}[\chapter] %новый класс
\newcounter{subchapter} %новый счетчик
\renewcommand{\thesubchapter}{\Alph{subchapter}} %буквенный счетчик
уровни секций изменяются автоматически
Глава 0 – уровень \section — 1 уровень и т.д.
loadonly
Обнулит все настройки уровней и позволит создавать свои уровни с нуля.
\titleclass
\titleclass{⟨name ⟩}[⟨start-level-num ⟩]{⟨class ⟩}
добавляет высшего уровня заголовок (0) или (-1) и дальше создаем сои новые уровни.
FootNotes
В заголовки можно добавлять ссылки footnotes, но чтобы они не показывались в оглавлении нужно в преамбулу добавить:
\usepackage[stable]{footmisc}
Номер заголовка в BOX
Полезная вещь. Особенно когда колдуешь с отступами за пределы печатаемой области или работаешь с цветами.
\titleformat{\section}
{..}
{\makebox[2em]{\thesection}}{..}{..}
или
\titleformat{\section} [hang]
{\LARGE\boldfontwhite}
{\llap{\colorbox{BleuLBA}{\parbox{2cm}{\rule[-5pt]{0pt}{21pt}\filleft\thesection}}}}{0em}
{\colorbox{BleuLBA}{\parbox{21cm}{\rule[-5pt]{0pt}{21pt}\filright \uppercase{#1}}}}
Подавляет нумерацию заголовков
\setcounter{secnumdepth}{0}
или
\newenvironment{exercises}
{\setcounter{secnumdepth}{0}}
{\setcounter{secnumdepth}{2}}
или
\newenvironment{exercises}
{\setcounter{secnumdepth}{0}%
\addtocontents{toc}{\protect\setcounter{tocdepth}{0}\ignorespaces}}
{\setcounter{secnumdepth}{2}%
\addtocontents{toc}{\protect\setcounter{tocdepth}{2}\ignorespaces}}
Как пометить заголовки со сзвездочкой
\newcommand{\secmark}{}
\newenvironment{advanced}
{\renewcommand{\secmark}{*}}
{}
\titleformat{\section} {..}
{\thesection\secmark\quad}{..}{..}
В документе пишим
\begin{advanced}
\section{...} ...
\end{advanced}
Этот раздел будет со звездочкой.
Крутой код по настройке стилей страниц
\documentclass[14pt,a4paper,twoside]{extbook}
\usepackage[utf8]{inputenc} %
\usepackage[T1]{fontenc}
\usepackage{lmodern} %
\usepackage[pagestyles]{titlesec}
\usepackage[x11names]{xcolor} %
\usepackage{theorem}
\newtheorem{worked example}{Worked Example}[chapter]
\newtheorem{solution}{SOLUTION}[chapter]
%\usepackage{anyfontsize}
\usepackage{amsfonts}
\usepackage{textcomp}
\usepackage{enumerate}
\setlength\headheight{21pt}
\newcommand{\hsp}{\hspace{20pt}}
\newcommand{\ntl}{\newline \newline}
\titleformat{\chapter}[hang]{\fontsize{50}{60}\bfseries\color[rgb]{0,0.5,0.75}}{\thechapter\hsp\fontsize{90}{60}\selectfont\textcolor{black}{|}\hsp}{0pt}{\thispagestyle{empty}\Huge\bfseries}
\titleformat{\section}{\large\bfseries}{}{0pt}{\textcolor[rgb]{0,0.5,0.75}{Topic \thesection} \ }[{\titlerule[0.8pt]}]
\usepackage{blindtext}
\newpagestyle{mine}{%
\setlength\fboxsep{10pt}
\sethead[\bfseries\llap{\colorbox{SteelBlue3}{\parbox{\dimexpr\marginparsep + \marginparwidth\relax}{\hspace{20pt}\color{white}\thepage\vphantom{|}}}}%
\colorbox{SlateGray2!40}{\parbox{\dimexpr\linewidth-2\fboxsep}{~\thechapter~|\hspace{0.75em}\chaptertitle}}][][]%
{}{}{\bfseries\colorbox{SlateGray2!40}{\parbox{\dimexpr\linewidth-2\fboxsep}{\thesection~|\hspace{0.75em}\sectiontitle}}%
\rlap{\colorbox{SteelBlue3}{\parbox{\dimexpr\marginparsep + \marginparwidth\relax}{\hspace{20pt}\color{white}\thepage\vphantom{|}}}}}
\setfoot{}{}{}
}
\pagestyle{mine}
\begin{document}
\chapter{{NUMBER}}%\textcolor{black}
\section{BIDMAS.}
\blindtext[10]
\end{document}
Выдает шикарную вещь:

7.14 - Пакет fontenc - Управление кодировками шрифтов в LaTeX
Загрузка шрифтов в Latex. Package titlesec
Пакет fontenc - Управление кодировками шрифтов в LaTeX
Введение
Пакет fontenc является критически важным для правильного отображения текста в LaTeX-документах, особенно при работе с не-ASCII символами (кириллицей, диакритическими знаками и др.).
Установка и базовое использование
\usepackage[<кодировки>]{fontenc}
Основные кодировки
Для латинских алфавитов:
T1- Расширенная латинская кодировка (поддержка акцентов, лигатур)OT1- Базовая кодировка TeX (устаревшая)
Для кириллицы:
T2A- Основная кириллическая кодировкаT2B- Альтернативная кириллическая кодировкаT2C- Дополнительная кириллическая кодировка
Примеры комбинаций:
\usepackage[T1,T2A]{fontenc} % Латинские и кириллические символы
\usepackage[T1]{fontenc} % Только латинские символы
Полный список поддерживаемых кодировок
| Кодировка | Описание |
|---|---|
| OT1 | Базовая кодировка TeX |
| T1 | Расширенная латинская |
| T2A | Основная кириллица |
| T2B | Альтернативная кириллица |
| T2C | Дополнительная кириллица |
| LY1 | Улучшенная кодировка для LaTeX |
| … | Другие специализированные кодировки |
Команды пакета
Основные команды:
\fontencoding{<кодировка>}- Переключает текущую кодировку шрифта\selectfont- Применяет изменения кодировки
Пример использования команд:
{\fontencoding{T1}\selectfont Текст в T1 кодировке}
{\fontencoding{T2A}\selectfont Текст в T2A кодировке}
Практические примеры
Пример 1: Базовое использование
\usepackage[T1,T2A]{fontenc}
\usepackage[utf8]{inputenc}
\usepackage[english,russian]{babel}
\begin{document}
Латинские символы: Café, naïve
Кириллические символы: Пример русского текста
\end{document}
Пример 2: Смешение кодировок в документе
{\fontencoding{T1}\selectfont
This text uses T1 encoding for proper hyphenation of words like "naïve".}
{\fontencoding{T2A}\selectfont
Этот текст использует кодировку T2A для корректного отображения кириллицы.}
Пример 3: Определение нового кодированного шрифта
\DeclareFontFamily{T2A}{cmr}{}
\DeclareFontShape{T2A}{cmr}{m}{n}{<-> ecrm1000}{}
Проблемы и решения
Проблема 1: Неправильное отображение кириллицы
Решение:
\usepackage[T2A]{fontenc}
\usepackage[utf8]{inputenc}
\usepackage[russian]{babel}
Проблема 2: Разрывы слов с диакритическими знаками
Решение:
\usepackage[T1]{fontenc} % Для правильного разрыва слов типа "naïve"
Проблема 3: Конфликты кодировок
Решение: Явное указание кодировок:
\usepackage[T1,T2A]{fontenc}
Совместимость с другими пакетами
С inputenc:
\usepackage[T1,T2A]{fontenc}
\usepackage[utf8]{inputenc} % Рекомендуется всегда использовать utf8
С babel:
\usepackage[T1,T2A]{fontenc}
\usepackage[english,russian]{babel}
С современными шрифтовыми пакетами (fontspec):
\usepackage{fontspec} % Для XeLaTeX/LuaLaTeX
% fontenc не нужен при использовании fontspec
Расширенные возможности
Определение собственных кодировок:
\DeclareFontEncoding{XYZ}{}{}
\DeclareErrorFont{XYZ}{cmr}{m}{n}{10}
Настройка подстановок шрифтов:
\DeclareFontSubstitution{T2A}{cmr}{m}{n}
Рекомендации
- Для документов с кириллицей всегда используйте:
\usepackage[T2A]{fontenc} - Для документов с европейскими языками:
\usepackage[T1]{fontenc} - Для многоязычных документов:
\usepackage[T1,T2A]{fontenc} - При использовании XeLaTeX/LuaLaTeX вместо
fontencиспользуйтеfontspec
Заключение
Пакет fontenc обеспечивает критически важную функциональность для правильного отображения текста в различных языках. Правильная настройка кодировок шрифтов предотвращает множество проблем с отображением символов и переносом слов.
7.15 - Пакет fontspec - Управление кодировками шрифтов в XeLaTeX
Полное руководство по пакету fontspec для XeLaTeX и LuaLaTeX
Введение в fontspec
Пакет fontspec предоставляет мощную систему выбора и настройки шрифтов для движков XeTeX и LuaTeX. Он заменяет традиционный подход с использованием fontenc и inputenc, предлагая прямую работу со шрифтами системы через Unicode.
Основные возможности
- Доступ к любым системным шрифтам (OTF, TTF)
- Полная поддержка Unicode
- Гибкое управление начертаниями шрифтов
- Настройка параметров шрифтов
- Работа с OpenType-функциями
Установка и загрузка
\usepackage{fontspec} % В преамбуле документа
Основные команды
1. Установка основного шрифта
\setmainfont{<название шрифта>}[<опции>]
Пример:
\setmainfont{TeX Gyre Termes}[
Path = /usr/local/texlive/texmf-local/fonts/opentype/,
Extension = .otf,
UprightFont = *-regular,
BoldFont = *-bold,
ItalicFont = *-italic,
BoldItalicFont = *-bolditalic
]
2. Установка моноширинного шрифта
\setmonofont{<название шрифта>}[<опции>]
3. Установка шрифта без засечек
\setsansfont{<название шрифта>}[<опции>]
4. Временное изменение шрифта
\newfontfamily\<команда>{<название шрифта>}[<опции>]
Пример:
\newfontfamily\cyrillicfont{PT Serif}
\newfontfamily\cyrillicfontsf{PT Sans}
\newfontfamily\cyrillicfonttt{PT Mono}
Основные опции шрифтов
Пути и файлы
| Опция | Описание |
|---|---|
Path | Путь к файлам шрифтов |
Extension | Расширение файлов |
UprightFont | Обычное начертание |
BoldFont | Полужирное начертание |
ItalicFont | Курсивное начертание |
BoldItalicFont | Полужирный курсив |
Характеристики шрифта
| Опция | Описание |
|---|---|
Ligatures | Управление лигатурами |
Numbers | Стиль цифр |
Scale | Масштабирование |
Color | Цвет шрифта |
WordSpace | Межсловные пробелы |
OpenType-функции
| Опция | Описание |
|---|---|
Renderer | Рендерер (Basic/Node) |
Script | Скрипт (Cyrillic, Latin и др.) |
Language | Язык |
FeatureFile | Файл с OpenType-фичами |
Примеры конфигураций
Базовая настройка для русского/английского
\usepackage{polyglossia}
\setmainlanguage{russian}
\setotherlanguage{english}
\setmainfont{PT Serif}[
Ligatures=TeX,
Extension=.ttf,
UprightFont=*-Regular,
BoldFont=*-Bold,
ItalicFont=*-Italic,
BoldItalicFont=*-BoldItalic
]
\setsansfont{PT Sans}[
Ligatures=TeX,
Extension=.ttf,
UprightFont=*-Regular,
BoldFont=*-Bold,
ItalicFont=*-Italic,
BoldItalicFont=*-BoldItalic
]
\setmonofont{PT Mono}[
Scale=0.9,
Extension=.ttf,
UprightFont=*-Regular
]
Использование разных шрифтов для разных языков
\usepackage{polyglossia}
\setdefaultlanguage{russian}
\setotherlanguage{english}
\defaultfontfeatures{Ligatures=TeX}
\setmainfont{EB Garamond}[
Language=English,
Script=Latin
]
\newfontfamily\cyrillicfont{PT Serif}[
Language=Russian,
Script=Cyrillic
]
OpenType-фичи
Включение дополнительных возможностей
\setmainfont{Some Font}[
RawFeature={
+ss01; % Альтернативные глифы
+onum; % Старостильные цифры
+frac; % Дроби
+c2sc; % Капитель из прописных
}
]
Доступные OpenType-фичи
+liga- стандартные лигатуры+dlig- декоративные лигатуры+tnum- табличные цифры+pnum- пропорциональные цифры+smcp- капитель из строчных+c2sc- капитель из прописных+frac- дроби+ss01-+ss20- альтернативные наборы глифов
Работа с математическими шрифтами
\usepackage{unicode-math} % Должен загружаться после fontspec
\setmathfont{TeX Gyre Termes Math}
\setmathfont{XITS Math}[range={\mathcal,\mathbfcal}]
\setmathfont{STIX Two Math}[range={\mathscr}]
Продвинутые техники
Динамическое изменение шрифтов
\newfontfamily\headfont{Helvetica Neue}[Scale=1.2]
\newcommand{\heading}[1]{{\headfont\Large #1}}
Использование символов за пределами Unicode BMP
\newfontface\emojifont{Segoe UI Emoji}[Renderer=Harfbuzz]
\newcommand{\showemoji}[1]{{\emojifont #1}}
Вертикальное выравнивание
\newfontfamily\vertfont{SomeFont}[Vertical=RotatedGlyphs]
Решение проблем
Шрифт не находится
\setmainfont{Arial}[
Path=/Users/username/Library/Fonts/,
Extension=.ttf
]
Конфликты кодировок
\usepackage{fontspec}
% Не загружать fontenc или inputenc!
Проблемы с переносами
\usepackage{polyglossia}
\setmainlanguage{russian}
\setmainfont{Some Font}[Language=Russian]
Заключение
Пакет fontspec предоставляет:
- Полный доступ к системным шрифтам
- Гибкую систему настройки шрифтов
- Поддержку современных OpenType-возможностей
- Удобную работу с многоязычными документами
- Интеграцию с математическими шрифтами через
unicode-math
Для максимальной эффективности используйте fontspec в сочетании с:
polyglossiaдля языковой поддержкиunicode-mathдля математических шрифтовmicrotypeдля улучшенной типографики
8 - opensearch
OpenSearch — это распределённая поисковая и аналитическая система, основанная на Apache Lucene. После добавления данных в OpenSearch вы можете выполнять полнотекстовый поиск с полным набором ожидаемых функций: поиск по полям, поиск по нескольким индексам, усиление полей, ранжирование результатов по релевантности, сортировка по полям и агрегация результатов.
Неудивительно, что разработчики часто используют поисковые системы, такие как OpenSearch, в качестве бэкенда для поисковых приложений — например, для Википедии или интернет-магазинов. Он обеспечивает отличную производительность и может масштабироваться в зависимости от потребностей приложения.
Ещё один популярный, но менее очевидный сценарий использования — анализ логов. В этом случае логи приложения загружаются в OpenSearch, а мощные функции поиска и визуализации помогают выявлять проблемы. Например, неисправный веб-сервер может выдавать ошибку 500 в 0,5% случаев, что сложно заметить без графика в реальном времени, отображающего все HTTP-статусы за последние четыре часа. С помощью OpenSearch Dashboards можно создавать такие визуализации на основе данных из OpenSearch.
Компоненты
OpenSearch — это не только поисковый движок. В его состав также входят:
- OpenSearch Dashboards — интерфейс для визуализации данных OpenSearch.
- Data Prepper — серверный сборщик данных, способный фильтровать, обогащать, преобразовывать, нормализовать и агрегировать данные для последующего анализа и визуализации.
- Клиенты — языковые API, позволяющие взаимодействовать с OpenSearch на популярных языках программирования.
Сценарии использования
OpenSearch поддерживает множество сценариев, например:
- Наблюдаемость (Observability) — визуализация событий на основе данных с помощью Piped Processing Language (PPL) для исследования, обнаружения и запросов к данным в OpenSearch.
- Поиск — выбор оптимального метода поиска для вашего приложения: от стандартного лексического поиска до диалогового поиска на базе машинного обучения (ML).
- Машинное обучение — интеграция ML-моделей в приложения на OpenSearch.
- Анализ безопасности — расследование, обнаружение, анализ и реагирование на угрозы, которые могут повлиять на успех организации и её онлайн-операции.
Следующие шаги
- Ознакомьтесь с [Введением в OpenSearch](Introduction to OpenSearch), чтобы изучить основные концепции OpenSearch.
8.1 - Введение в Opensearch
OpenSearch — это распределённая поисковая и аналитическая система, которая поддерживает различные сценарии использования: от реализации поисковой строки на веб-сайте до анализа данных безопасности для выявления угроз.
Введение в OpenSearch
Термин распределённая означает, что OpenSearch можно запускать на нескольких компьютерах. Поиск и аналитика подразумевают, что после загрузки данных в OpenSearch их можно искать и анализировать. Независимо от типа данных, их можно хранить и исследовать с помощью OpenSearch.
Документ
Документ — это единица хранения информации (текстовой или структурированной). В OpenSearch документы хранятся в формате JSON.
Документ можно представить несколькими способами:
- В базе данных студентов документ может представлять одного учащегося.
- При поиске информации OpenSearch возвращает документы, соответствующие запросу.
- Документ аналогичен строке в традиционной реляционной базе данных.
Например, в школьной базе данных документ может представлять студента и содержать следующие данные:
| ID | Имя | GPA | Год выпуска |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
Вот как этот документ выглядит в формате JSON:
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
Вы узнаете, как назначаются идентификаторы документов, в разделе Индексация документов.
Индекс
Индекс — это коллекция документов.
Индекс можно рассматривать несколькими способами:
- В базе данных студентов индекс представляет всех учащихся в базе.
- При поиске информации запрос выполняется к данным внутри индекса.
- Индекс соответствует таблице в традиционной реляционной базе данных.
Например, в школьной базе данных индекс может содержать всех студентов школы:
| ID | Имя | GPA | Год выпуска |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
| 2 | Jonathan Powers | 3.85 | 2025 |
| 3 | Jane Doe | 3.52 | 2024 |
| … | … | … | … |
Кластеры и узлы
OpenSearch разработан как распределённая поисковая система, что означает возможность работы на одном или нескольких узлах — серверах, хранящих данные и обрабатывающих поисковые запросы. Кластер OpenSearch — это совокупность таких узлов.
Вы можете запустить OpenSearch локально на ноутбуке (системные требования минимальны), но также можно масштабировать кластер до сотен мощных серверов в дата-центре.
В одноузловом кластере (например, развёрнутом на ноутбуке) одна машина выполняет все задачи:
- управляет состоянием кластера,
- индексирует данные и обрабатывает поисковые запросы,
- выполняет предварительную обработку данных перед индексацией.
Однако по мере роста кластера обязанности можно распределить:
- Узлы с быстрыми дисками и большим объёмом ОЗУ подходят для индексации и поиска.
- Узлы с мощными CPU, но малым дисковым пространством, могут управлять состоянием кластера.
В каждом кластере выбирается главный узел (cluster manager node), который координирует операции на уровне кластера (например, создание индекса). Узлы взаимодействуют между собой: если запрос направлен к одному узлу, он может запрашивать данные у других узлов, агрегировать их ответы и возвращать итоговый результат.
Подробнее о других типах узлов см. в разделе Формирование кластера.
Шарды (Shards)
OpenSearch разделяет индексы на шарды. Каждый шард хранит подмножество всех документов индекса, как показано на следующей диаграмме:
Шарды используются для равномерного распределения данных между узлами кластера. Например:
- Индекс размером 400 ГБ может быть слишком большим для обработки на одном узле
- Если разделить его на 10 шардов по 40 ГБ каждый, OpenSearch сможет распределить их между 10 узлами
- Каждый шард будет обрабатываться независимо
Рассмотрим кластер с двумя индексами:
- Индекс 1 разделён на 2 шарда
- Индекс 2 разделён на 4 шарда
Эти шарды распределены между двумя узлами, как показано на схеме:
Хотя каждый шард является частью индекса OpenSearch, технически он представляет собой полноценный индекс Lucene. Это важно учитывать, потому что:
- Каждый экземпляр Lucene - это отдельный процесс
- Каждый процесс потребляет ресурсы CPU и памяти
- Слишком большое количество шардов может перегрузить кластер
Рекомендации по работе с шардами:
- Не стоит разделять индекс на чрезмерное количество шардов
- Например, деление индекса 400 ГБ на 1000 шардов создаст ненужную нагрузку
- Оптимальный размер шарда - от 10 до 50 ГБ
Первичные и реплицированные шарды
В OpenSearch шарды могут быть двух типов:
- Первичные (primary) - оригинальные шарды
- Реплики (replica) - копии шардов
По умолчанию OpenSearch создаёт по одной реплике для каждого первичного шарда. Таким образом:
- Если индекс разделён на 10 шардов, будет создано 10 реплик
- В примере из предыдущего раздела (2 индекса):
- Индекс 1: 2 шарда + 2 реплики
- Индекс 2: 4 шарда + 4 реплики
Функции реплик:
- Резервное копирование на случай сбоя узла
- Реплики размещаются на разных узлах от первичных шардов
- Ускорение обработки поисковых запросов
- Для нагрузок с интенсивным поиском можно создать несколько реплик
Инвертированный индекс
OpenSearch использует структуру данных под названием инвертированный индекс, которая:
- Сопоставляет слова с документами, где они встречаются
- Пример для двух документов:
- Документ 1: “Красота в глазах смотрящего”
- Документ 2: “Красавица и чудовище”
Инвертированный индекс будет выглядеть так:
| Слово | Документы |
|---|---|
| красота | 1 |
| в | 1 |
| глазах | 1 |
| смотрящего | 1 |
| красавица | 2 |
| и | 2 |
| чудовище | 2 |
Дополнительно OpenSearch хранит:
- Позиции слов в документах
- Это позволяет выполнять поиск по фразам
Релевантность
При поиске OpenSearch:
- Сопоставляет слова запроса с документами
- Присваивает каждому документу оценку релевантности
Факторы оценки:
- Частота термина (TF):
- Чем чаще слово встречается в документе, тем выше оценка
- Обратная частота документа (IDF):
- Редкие слова имеют больший вес (например, “аксолотль” vs “синий”)
- Нормализация по длине:
- Более короткие документы получают преимущество
OpenSearch использует алгоритм BM25 для расчёта релевантности и сортировки результатов.
Следующие шаги
Узнайте, как быстро установить OpenSearch, в разделе Быстрый старт установки.
8.1.1 - Быстрый старт установки
Для быстрого запуска OpenSearch и OpenSearch Dashboards используйте контейнеры Docker.
Для быстрого запуска OpenSearch и OpenSearch Dashboards используйте контейнеры Docker. Полное руководство по установке доступно в разделе Установка и обновление OpenSearch.
Предварительные требования:
- Установите Docker и Docker Compose на локальную машину
Запуск кластера
Настройка системы
Перед запуском рекомендуется:- Отключить подкачку памяти для повышения производительности:
sudo swapoff -a - Увеличить максимальное количество memory maps:Добавьте строку:
sudo vi /etc/sysctl.confПримените изменения:vm.max_map_count=262144sudo sysctl -p
- Отключить подкачку памяти для повышения производительности:
Получение файла конфигурации
Загрузите образецdocker-compose.yml:- Через cURL:
curl -O https://raw.githubusercontent.com/opensearch-project/documentation-website/3.1/assets/examples/docker-compose.yml - Через wget:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/3.1/assets/examples/docker-compose.yml
- Через cURL:
Запуск кластера
Перейдите в директорию с файлом и выполните:docker compose up -dПроверьте статус контейнеров:
docker compose psОжидаемый вывод:
NAME COMMAND SERVICE STATUS PORTS opensearch-dashboards "./opensearch-dashbo…" opensearch-dashboards running 0.0.0.0:5601->5601/tcp opensearch-node1 "./opensearch-docker…" opensearch-node1 running 0.0.0.0:9200->9200/tcp, 9300/tcp, 0.0.0.0:9600->9600/tcp, 9650/tcp opensearch-node2 "./opensearch-docker…" opensearch-node2 running 9200/tcp, 9300/tcp, 9600/tcp, 9650/tcpПроверка работы
Выполните тестовый запрос к API:curl https://localhost:9200 -ku admin:ВАШ_ПАРОЛЬУспешный ответ:
{ "name": "opensearch-node1", "cluster_name": "opensearch-cluster", "version": { "distribution": "opensearch", "number": "2.6.0" }, "tagline": "The OpenSearch Project: https://opensearch.org/" }Доступ к Dashboards
Откройте в браузере:http://localhost:5601/
Логин:admin
Пароль: указан вOPENSEARCH_INITIAL_ADMIN_PASSWORDфайла docker-compose.yml
Примечания:
- Для безопасности отключается проверка хоста (
-k) при использовании демо-сертификатов - Все команды предполагают работу в Linux-окружении
- Пароль администратора задаётся при первом запуске
Распространённые проблемы
Рассмотрите эти типичные проблемы и способы их решения, если контейнеры не запускаются или завершаются неожиданно.
Необходимость прав sudo для Docker команд
Проблема:
Требуется использовать sudo для выполнения Docker команд.
Решение:
Добавьте пользователя в группу docker:
sudo usermod -aG docker $USER
Подробнее: Post-installation steps for Linux
Ошибка: “-bash: docker-compose: command not found”
Ситуация:
При использовании Docker Desktop.
Решение:
Используйте команду без дефиса:
docker compose
См. документацию Docker Compose
Ошибка: “docker: ‘compose’ is not a docker command”
Ситуация:
При использовании Docker Engine.
Решение:
Установите Docker Compose отдельно и используйте команду с дефисом:
docker-compose
Ошибка: “max virtual memory areas vm.max_map_count [65530] is too low”
Симптомы:
В логах сервиса появляется сообщение:
opensearch-node1 | ERROR: [1] bootstrap checks failed
opensearch-node1 | [1]: max virtual memory areas vm.max_map_count [65530] is too low...
Решение:
Увеличьте значение vm.max_map_count (см. раздел “Важные системные настройки”):
sudo sysctl -w vm.max_map_count=262144
Альтернативные способы установки
Помимо Docker, OpenSearch можно установить:
- На различные дистрибутивы Linux
- На Windows
Полные руководства: Установка и обновление OpenSearch
Дальнейшее изучение
После успешного развёртывания кластера рекомендуется изучить:
Следующие шаги
Ознакомьтесь с разделом Взаимодействие с OpenSearch, чтобы узнать как отправлять запросы в систему.
8.1.2 - Взаимодействие с OpenSearch
Вы можете работать с OpenSearch через REST API или используя клиентские библиотеки для различных языков программирования.
На этой странице рассматривается REST API. Список доступных клиентов для языков программирования вы найдёте в разделе Клиенты.
REST API OpenSearch
REST API предоставляет гибкий способ взаимодействия с кластерами OpenSearch. Через API вы можете:
- Изменять настройки OpenSearch
- Управлять индексами
- Проверять состояние кластера
- Получать статистику
- И многое другое
Для отправки запросов можно использовать:
- Командную строку (cURL)
- Консоль Dev Tools в OpenSearch Dashboards
- Любой язык программирования с поддержкой HTTP-запросов
Отправка запросов через терминал
Формат запросов зависит от использования плагина безопасности.
Без плагина безопасности:
curl -X GET "http://localhost:9200/_cluster/health"
С плагином безопасности (требуются учётные данные):
curl -X GET "https://localhost:9200/_cluster/health" -ku admin:ВАШ_ПАРОЛЬ
По умолчанию:
- Логин:
admin - Пароль: задаётся в параметре
OPENSEARCH_INITIAL_ADMIN_PASSWORDфайла docker-compose.yml
Форматирование ответа:
Для удобочитаемого JSON добавьте параметр pretty:
curl -X GET "https://localhost:9200/_cluster/health?pretty"
Запросы с телом:
Укажите заголовок Content-Type и передайте данные через параметр -d:
curl -X GET "https://localhost:9200/students/_search?pretty" \
-H 'Content-Type: application/json' \
-d '{
"query": {
"match_all": {}
}
}'
Отправка запросов через Dev Tools
Консоль Dev Tools в OpenSearch Dashboards использует упрощённый синтаксис:
- Откройте Dashboards:
https://localhost:5601/ - Перейдите: Management > Dev Tools
- Введите запрос (например):
GET _cluster/health - Отправьте запрос:
- Клик по иконке ▶
- Ctrl+Enter (Cmd+Enter на Mac)
В документации OpenSearch запросы чаще всего приводятся в формате Dev Tools.
Дополнительно:
Индексация документов
Для добавления JSON-документа в индекс OpenSearch (индексации документа) отправьте HTTP-запрос со следующим форматом:
PUT https://<хост>:<порт>/<имя-индекса>/_doc/<идентификатор-документа>
Пример индексации документа о студенте:
PUT /students/_doc/1
{
"name": "Иван Иванов",
"gpa": 4.5,
"grad_year": 2023
}
После выполнения запроса:
- OpenSearch создаст индекс
students(если не существует) - Сохранит документ с указанным ID (
1) - Если ID не указан - сгенерирует его автоматически
Динамическое маппинг
OpenSearch автоматически определяет типы полей на основе JSON-структуры документа.
Просмотр схемы полей:
GET /students/_mapping
Пример ответа:
{
"students": {
"mappings": {
"properties": {
"gpa": {"type": "float"},
"grad_year": {"type": "long"},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
Особенности типов:
- Числовые значения:
float,long - Текстовые поля:
- Основное поле (
text): для полнотекстового поиска (с анализом) - Подполе (
keyword): для точного поиска по терминам
- Основное поле (
Важно: Для изменения типов (например, преобразования grad_year в дату) требуется пересоздание индекса с явным указанием маппинга.
Поиск документов
Базовый запрос (возвращает все документы):
GET /students/_search
{
"query": {
"match_all": {}
}
}
Пример ответа:
{
"took": 12,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 1,
"_source": {
"name": "Иван Иванов",
"gpa": 4.5,
"grad_year": 2023
}
}
]
}
}
Ключевые элементы ответа:
took: время выполнения (мс)hits.total: количество найденных документовhits.hits: массив результатов_score: релевантность документа
Дополнительные материалы:
Обновление документов
В OpenSearch документы неизменяемы, но их можно обновить, полностью заменив содержимое или изменив отдельные поля.
Полное обновление (переиндексация)
Используйте Index Document API для полного обновления:
PUT /students/_doc/1
{
"name": "Иван Иванов",
"gpa": 4.7, // Обновлённое значение
"grad_year": 2023,
"address": "ул. Ленина, 123" // Новое поле
}
Частичное обновление
Используйте Update Document API для изменения отдельных полей:
POST /students/_update/1/
{
"doc": {
"gpa": 4.7,
"address": "ул. Ленина, 123"
}
}
Удаление данных
Удаление документа
DELETE /students/_doc/1
Удаление индекса
DELETE /students
Настройка индексов
Маппинги и параметры
Индексы настраиваются через:
- Маппинги - определяют типы полей
- Параметры - настройки индекса (количество шардов и т.д.)
Пример создания индекса с явными настройками:
PUT /students
{
"settings": {
"index.number_of_shards": 1
},
"mappings": {
"properties": {
"name": {"type": "text"},
"grad_year": {"type": "date"}
}
}
}
Проверка маппинга:
GET /students/_mapping
Важно:
- Типы полей нельзя изменить после создания
- Для изменения требуется пересоздание индекса
Дополнительные материалы
Следующие шаги
Ознакомьтесь с разделом Загрузка данных в OpenSearch для изучения способов импорта данных.
8.1.3 - Загрузка данных в OpenSearch
Добавление отдельных документов. Массовая загрузка документов. Использование Data Prepper.
Существует несколько способов импорта данных:
Добавление отдельных документов
См. раздел Индексация документовМассовая загрузка документов
См. раздел Пакетная индексацияИспользование Data Prepper
Серверного сборщика данных OpenSearch для обработки перед анализомДругие инструменты
См. Инструменты OpenSearch
Пакетная индексация
Для массовой загрузки используйте Bulk API:
POST _bulk
{ "create": { "_index": "students", "_id": "2" } }
{ "name": "Алексей Петров", "gpa": 4.2, "grad_year": 2025 }
{ "create": { "_index": "students", "_id": "3" } }
{ "name": "Мария Смирнова", "gpa": 4.8, "grad_year": 2024 }
Работа с тестовыми данными
OpenSearch предоставляет демонстрационный набор данных электронной коммерции.
Шаги для создания тестового индекса:
Скачайте файлы:
# Маппинг полей curl -O https://raw.githubusercontent.com/.../ecommerce-field_mappings.json # Данные для загрузки curl -O https://raw.githubusercontent.com/.../ecommerce.ndjsonПримените схему полей:
curl -H "Content-Type: application/json" -X PUT "https://localhost:9200/ecommerce" \ -ku admin:ПАРОЛЬ --data-binary "@ecommerce-field_mappings.json"Загрузите данные:
curl -H "Content-Type: application/x-ndjson" -X POST "https://localhost:9200/ecommerce/_bulk" \ -ku admin:ПАРОЛЬ --data-binary "@ecommerce.ndjson"
Пример поиска:
GET ecommerce/_search
{
"query": {
"match": {
"customer_first_name": "Светлана"
}
}
}
Визуализация данных
Инструкции по работе с визуализациями см. в руководстве по OpenSearch Dashboards.
Дополнительные материалы
Следующие шаги
Изучите раздел Поиск по данным для получения информации о возможностях поиска.
8.1.4 - Поиск данных в OpenSearch
OpenSearch предлагает несколько методов поиска: Query DSL, Query string, SQL, PPL, DQL
OpenSearch предлагает несколько методов поиска:
- Query DSL - основной язык запросов для сложных поисковых сценариев
- Query string - упрощённый синтаксис для параметров запроса
- SQL - традиционный язык запросов для реляционных данных
- PPL (Piped Processing Language) - язык для задач observability
- DQL (Dashboards Query Language) - текстовый язык фильтрации в Dashboards
Подготовка данных
Перед началом загрузим тестовые данные о студентах:
POST _bulk
{ "create": { "_index": "students", "_id": "1" } }
{ "name": "Иван Петров", "gpa": 4.5, "grad_year": 2023}
{ "create": { "_index": "students", "_id": "2" } }
{ "name": "Алексей Смирнов", "gpa": 4.2, "grad_year": 2025 }
{ "create": { "_index": "students", "_id": "3" } }
{ "name": "Мария Иванова", "gpa": 4.8, "grad_year": 2024 }
Базовые запросы
Получение всех документов:
GET /students/_search
Эквивалентно:
GET /students/_search
{
"query": { "match_all": {} }
}
Структура ответа:
took- время выполнения (мс)timed_out- флаг превышения таймаута_shards- статистика по шардамhits- результаты поиска:total- общее количество совпаденийmax_score- максимальная релевантностьhits- массив документов с оценкой релевантности
Query string поиск
Пример поиска по имени:
GET /students/_search?q=name:john
вернет ответ:
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "John Doe",
"grade": 12,
"gpa": 3.89,
"grad_year": 2022,
"future_plans": "John plans to be a computer science major"
}
}
]
}
}
Полнотекстовый поиск (Query DSL)
Поиск с анализом текста:
GET /students/_search
{
"query": {
"match": {
"name": "иван" # Найдёт "Иван Петров" и "Мария Иванова"
}
}
}
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "Иван Петров",
"gpa": 3.89,
"grad_year": 2022
}
}
]
}
}
Поиск по ключевым словам
Точное совпадение (без анализа):
GET /students/_search
{
"query": {
"match": {
"name.keyword": "john doe" # Только полное совпадение
}
}
}
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
}
]
}
}
Фильтры
Точное значение:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "grad_year": 2023 }}
]
}
}
}
Диапазон значений:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "range": { "gpa": { "gt": 4.0 }}}
]
}
}
}
Составные запросы
Комбинация условий:
GET students/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "иван" } },
{ "range": { "gpa": { "gte": 4.0 } } },
{ "term": { "grad_year": 2023 }}
]
}
}
}
Расширенные возможности
OpenSearch поддерживает современные методы поиска:
- k-NN (поиск ближайших соседей)
- Семантический поиск
- Мультимодальный поиск
- Гибридный поиск
Дополнительные материалы
8.1.5 - Начало работы с безопасностью в OpenSearch
Демонстрационная конфигурация безопасности и настройка демонстрационной конфигурации
Демонстрационная конфигурация безопасности
Наиболее простой способ начать работу с безопасностью OpenSearch - использовать демонстрационную конфигурацию. OpenSearch включает полезные скрипты, в том числе:
install_demo_configuration.sh(для Linux/macOS)install_demo_configuration.bat(для Windows)
Расположение скрипта:plugins/opensearch-security/tools/
Действия скрипта:
- Создает демонстрационные сертификаты для TLS-шифрования на транспортном и REST-уровнях
- Настраивает тестовых пользователей, роли и привязки ролей
- Конфигурирует плагин безопасности для использования внутренней базы данных аутентификации
- Обновляет
opensearch.ymlбазовой конфигурацией для запуска кластера
Важно! Демонстрационные сертификаты и пароли по умолчанию не должны использоваться в production. Перед развертыванием в продакшене их необходимо заменить на собственные.
Настройка демонстрационной конфигурации
Перед запуском скрипта:
- Установите переменную окружения с надежным паролем администратора:
export OPENSEARCH_INITIAL_ADMIN_PASSWORD=<ваш_надежный_пароль> - Проверьте надежность пароля с помощью инструмента Zxcvbn
Запуск скрипта:
./plugins/opensearch-security/tools/install_demo_configuration.sh
Проверка конфигурации:
curl -k -XGET -u admin:<пароль> https://<ip-opensearch>:9200
Ожидаемый ответ:
{
"name": "smoketestnode",
"cluster_name": "opensearch",
"version": {
"distribution": "opensearch",
"number": "2.13.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
Настройка OpenSearch Dashboards
Добавьте в opensearch_dashboards.yml следующую конфигурацию:
opensearch.hosts: [https://localhost:9200]
opensearch.ssl.verificationMode: none
opensearch.username: kibanaserver
opensearch.password: kibanaserver
opensearch.requestHeadersWhitelist: [authorization, securitytenant]
opensearch_security.multitenancy.enabled: true
opensearch_security.multitenancy.tenants.preferred: [Private, Global]
opensearch_security.readonly_mode.roles: [kibana_read_only]
opensearch_security.cookie.secure: false # Отключено для HTTP
Запуск Dashboards:
yarn start --no-base-path
После запуска в логах появятся строки:
[info][listening] Server running at http://localhost:5601
[info][server][OpenSearchDashboards][http] http server running at http://localhost:5601
Доступ через браузер: http://localhost:5601
Логин: admin
Пароль: значение из OPENSEARCH_INITIAL_ADMIN_PASSWORD
Управление пользователями и ролями
1. Добавление пользователей
Способы:
- Редактирование
internal_users.yml - Использование API
- Через интерфейс OpenSearch Dashboards
Пример добавления пользователя в internal_users.yml:
test-user:
hash: "$2y$12$CkxFoTAJKsZaWv/m8VoZ6ePG3DBeBTAvoo4xA2P21VCS9w2RYumsG"
backend_roles:
- "test-backend-role"
- "kibanauser"
description: "Тестовый пользователь"
Генерация хеша пароля:
./plugins/opensearch-security/tools/hash.sh
Введите пароль (например, secretpassword), скопируйте полученный хеш.
2. Создание ролей
Формат roles.yml:
<имя_роли>:
cluster_permissions:
- <разрешение_кластера>
index_permissions:
- index_patterns:
- <шаблон_индекса>
allowed_actions:
- <разрешения_индекса>
Пример роли для доступа к индексу:
human_resources:
index_permissions:
- index_patterns:
- "humanresources"
allowed_actions:
- "READ"
3. Привязка пользователей к ролям
Формат roles_mapping.yml:
<имя_роли>:
users:
- <имя_пользователя>
backend_roles:
- <имя_роли>
Пример привязки:
human_resources:
backend_roles:
- "test-backend-role"
kibana_user:
backend_roles:
- "kibanauser"
Применение изменений конфигурации
После изменения файлов необходимо загрузить конфигурацию в security index:
./plugins/opensearch-security/tools/securityadmin.sh \
-cd "config/opensearch-security" \
-icl \
-key "../kirk-key.pem" \
-cert "../kirk.pem" \
-cacert "../root-ca.pem" \
-nhnv
Дальнейшие шаги
- Ознакомьтесь с Рекомендациями по безопасности OpenSearch
- Изучите Обзор конфигурации безопасности для кастомизации под ваши задачи
Примечания:
- Все команды предполагают выполнение из корневой директории OpenSearch
- Для production-окружений обязательно замените демонстрационные сертификаты
- Регулярно обновляйте пароли администраторов
8.1.6 - Основные концепции OpenSearch
Полное руководство по OpenSearch: документы, индексы, шарды, узлы кластера, текстовый анализ и жизненный цикл данных. Узнайте, как работают индексация, поиск и агрегация в распределенной поисковой системе.
Базовые понятия
Документ
Базовая единица информации в OpenSearch, хранимая в формате JSON. Представляет собой структурированные данные в виде пар “ключ-значение”.
Индекс
Коллекция логически связанных документов. Аналог таблицы в реляционных БД.
JSON (JavaScript Object Notation)
Текстовый формат для хранения данных, использующий структуру ключ-значение. Основной формат представления данных в OpenSearch.
Маппинг
Схема индекса, определяющая:
- Типы полей документов
- Способы индексации и хранения
- Параметры анализа текста
Архитектура кластера
Узел (Node)
Отдельный сервер, являющийся частью кластера OpenSearch.
Кластер
Совокупность узлов, работающих как единая система.
Управляющий узел (Cluster Manager)
Специальный узел, координирующий кластерные операции:
- Создание/удаление индексов
- Балансировка нагрузки
- Мониторинг состояния узлов
Шард (Shard)
Часть индекса, содержащая подмножество его данных. Индексы разделяются на шарды для:
- Горизонтального масштабирования
- Распределения нагрузки
Типы шардов:
- Первичный (Primary) - основной шард с данными
- Реплика (Replica) - копия первичного шарда для:
- Отказоустойчивости
- Повышения производительности поиска
Структуры данных и хранение
Doc Values
Оптимизированная on-disk структура для:
- Сортировки
- Агрегации
- Доступа к значениям полей
Инвертированный индекс
Структура данных, отображающая термины на документы, которые их содержат. Основа полнотекстового поиска.
Lucene
Библиотека поиска, лежащая в основе OpenSearch. Отвечает за:
- Индексацию
- Хранение
- Поиск данных
Сегмент (Segment)
Неизменяемая единица хранения данных внутри шарда. Особенности:
- Создается при операции refresh
- Объединяется в процессе merge
- Оптимизирован для быстрого поиска
Операции с данными
Ингestion
Процесс добавления данных в OpenSearch. Включает:
- Прием данных
- Парсинг
- Подготовку к индексации
Индексация
Процесс организации данных для эффективного поиска:
- Анализ текста
- Построение инвертированного индекса
- Хранение документов
Пакетная индексация
Массовая загрузка документов через Bulk API:
- Высокая производительность
- Минимизация сетевых издержек
- Атомарность операций
Анализ текста
Текстовый анализ
Процесс преобразования неструктурированного текста в последовательность терминов для индексации.
Компоненты анализатора:
Character Filter
Обрабатывает сырой текст:- Удаление/замена символов
- HTML-разметка
Tokenizer
Разбивает текст на токены (слова) с метаданными:- Позиция
- Длина
- Смещение
Token Filter
Модифицирует токены:- Приведение к нижнему регистру
- Удаление стоп-слов
- Добавление синонимов
- Стемминг
Типы анализаторов:
Analyzer
Полный конвейер обработки (character filter → tokenizer → token filter)Normalizer
Только character filter (без токенизации)
Стемминг
Приведение слов к базовой форме (например: “running” → “run”)
Поиск и запросы
Типы запросов:
- Query DSL - основной язык сложных запросов
- Query String - упрощенный синтаксис для URL
- DQL - язык фильтрации в Dashboards
- PPL - язык для observability с pipe-синтаксисом
Контексты выполнения:
Query Context
Оценивает релевантность (как хорошо документ соответствует запросу)Filter Context
Проверяет точное соответствие (да/нет) без расчета релевантности
Типы поиска:
Полнотекстовый
С учетом морфологии и вариаций словПо ключевым словам
Точное совпадение (без анализа)
Агрегации
Механизм анализа и суммирования данных:
- Метрики (avg, sum)
- Бакетизация (histogram, date_histogram)
- Вложенные агрегации
Жизненный цикл обновлений
Транзакционный лог (translog)
- Операция записывается в translog
- Гарантия durability через fsync
- Подтверждение клиенту
In-memory буфер
- Данные добавляются в буфер Lucene
- Еще не видны для поиска
Refresh
- Сброс буфера в сегменты
- Данные становятся видимыми для поиска
- Без гарантии durability
Flush
- Запись сегментов на диск (fsync)
- Очистка translog
- Гарантия сохранности данных
Merge
- Объединение мелких сегментов
- Оптимизация:
- Уменьшение количества файлов
- Освобождение места
- Улучшение производительности
Критические операции
Translog
Журнал операций для гарантии сохранности данных. Особенности:
- Записывается синхронно перед подтверждением
- Ограничен по размеру
- Очищается после flush
Refresh
Периодическая операция (по умолчанию каждые 1с):
- Делает данные доступными для поиска
- Создает новые сегменты
- Не гарантирует сохранность при сбое
Flush
Операция записи на диск:
- Обеспечивает durability
- Выполняется автоматически при:
- Достижении лимита translog
- Плановом обслуживании
Merge
Фоновая оптимизация:
- Управляется политикой слияния
- Регулирует:
- Частоту слияний
- Максимальный размер сегментов
- Параллелизм операций
8.2 - Install and upgrade OpenSearch
OpenSearch и OpenSearch Dashboards доступны на любом совместимом хосте, который поддерживает Docker
OpenSearch и OpenSearch Dashboards доступны на любом совместимом хосте, который поддерживает Docker (таких как Linux, MacOS или Windows). Кроме того, вы можете установить оба продукта на различных дистрибутивах Linux и на Windows.
Скачайте OpenSearch для вашей предпочтительной платформы, а затем выберите один из следующих руководств по установке.
| OpenSearch | OpenSearch Dashboards |
|---|---|
| Docker | Docker |
| Helm | Helm |
| Tarball | Tarball |
| RPM | RPM |
| Debian | Debian |
| Ansible playbook | |
| Windows | Windows |
После установки OpenSearch ознакомьтесь с его настройкой для вашего развертывания.
Для получения дополнительной информации об обновлении вашего кластера OpenSearch смотрите руководство по обновлению.
Для информации об инструментах обновления смотрите инструменты обновления, миграции и сравнения OpenSearch.
Для установки плагинов смотрите раздел Установка плагинов.
8.2.1 - Установка OpenSearch
В этом разделе представлена информация о том, как установить OpenSearch на вашем хосте, включая порты, которые необходимо открыть, и важные настройки, которые нужно сконфигурировать на вашем хосте.
Рекомендации по файловой системе
Избегайте использования сетевой файловой системы для хранения узлов в рабочем процессе в производственной среде. Использование сетевой файловой системы для хранения узлов может вызвать проблемы с производительностью в вашем кластере из-за таких факторов, как условия сети (например, задержка или ограниченная пропускная способность) или скорости чтения/записи. Вам следует использовать твердотельные накопители (SSD), установленные на хосте, для хранения узлов, где это возможно.
Совместимость с Java
Распределение OpenSearch для Linux поставляется с совместимой версией JDK Adoptium Java в каталоге jdk. Чтобы узнать версию JDK, выполните команду ./jdk/bin/java -version. Например, архив OpenSearch 1.0.0 поставляется с Java 15.0.1+9 (не LTS), OpenSearch 1.3.0 поставляется с Java 11.0.14.1+1 (LTS), а OpenSearch 2.0.0 поставляется с Java 17.0.2+8 (LTS). OpenSearch тестируется со всеми совместимыми версиями Java.
| Версия OpenSearch | Совместимые версии Java | Встроенная версия Java |
|---|---|---|
| 1.0–1.2.x | 11, 15 | 15.0.1+9 |
| 1.3.x | 8, 11, 14 | 11.0.25+9 |
| 2.0.0–2.11.x | 11, 17 | 17.0.2+8 |
| 2.12.0+ | 11, 17, 21 | 21.0.5+11 |
Чтобы использовать другую установку Java, установите переменную окружения OPENSEARCH_JAVA_HOME или JAVA_HOME на расположение установки Java. Например:
export OPENSEARCH_JAVA_HOME=/path/to/opensearch-3.1.0/jdk
Сетевые требования
Следующие порты необходимо открыть для компонентов OpenSearch.
| Номер порта | Компонент OpenSearch |
|---|---|
| 443 | OpenSearch Dashboards в AWS OpenSearch Service с шифрованием в пути (TLS) |
| 5601 | OpenSearch Dashboards |
| 9200 | OpenSearch REST API |
| 9300 | Внутреннее взаимодействие узлов и транспорт, поиск по кластерам |
| 9600 | Анализатор производительности |
Важные настройки
Для рабочих нагрузок в производственной среде убедитесь, что настройка Linux vm.max_map_count установлена как минимум на 262144. Даже если вы используете образ Docker, установите это значение на хост-машине. Чтобы проверить текущее значение, выполните следующую команду:
cat /proc/sys/vm/max_map_count
Чтобы увеличить значение, добавьте следующую строку в файл /etc/sysctl.conf:
vm.max_map_count=262144
Затем выполните команду sudo sysctl -p, чтобы перезагрузить настройки.
Для рабочих нагрузок Windows вы можете установить vm.max_map_count, выполнив следующие команды:
wsl -d docker-desktop
sysctl -w vm.max_map_count=262144
Пример файла docker-compose.yml
Файл docker-compose.yml также содержит несколько ключевых настроек:
bootstrap.memory_lock: true
Эта настройка отключает свопинг (вместе с memlock). Свопинг может значительно снизить производительность и стабильность, поэтому вы должны убедиться, что он отключен на производственных кластерах.
Включение настройки bootstrap.memory_lock заставит JVM зарезервировать всю необходимую память. Руководство по настройке сборки мусора Java SE Hotspot VM документирует резервирование 1 гигабайта (ГБ) нативной памяти для метаданных классов по умолчанию. В сочетании с кучей Java это может привести к ошибке из-за нехватки нативной памяти на ВМ с меньшим объемом памяти, чем эти требования. Чтобы предотвратить ошибки, ограничьте размер резервируемой памяти с помощью -XX:CompressedClassSpaceSize или -XX:MaxMetaspaceSize и установите размер кучи Java, чтобы убедиться, что у вас достаточно системной памяти.
OPENSEARCH_JAVA_OPTS: -Xms512m -Xmx512m
Эта настройка устанавливает размер кучи Java (рекомендуем использовать половину системной ОЗУ).
OpenSearch по умолчанию использует -Xms1g -Xmx1g для выделения памяти кучи, что имеет приоритет над конфигурациями, указанными с использованием процентной нотации (-XX:MinRAMPercentage, -XX:MaxRAMPercentage). Например, если вы установите OPENSEARCH_JAVA_OPTS=-XX:MinRAMPercentage=30 -XX:MaxRAMPercentage=70, предустановленные значения -Xms1g -Xmx1g переопределят эти настройки. При использовании OPENSEARCH_JAVA_OPTS для определения выделения памяти убедитесь, что вы используете нотацию -Xms и -Xmx.
nofile: 65536
Эта настройка устанавливает лимит в 65536 открытых файлов для пользователя OpenSearch.
port: 9600
Эта настройка позволяет вам получить доступ к Анализатору производительности на порту 9600.
Не объявляйте одни и те же параметры JVM в нескольких местах, так как это может привести к непредсказуемому поведению или сбою запуска службы OpenSearch. Если вы объявляете параметры JVM с помощью переменной окружения, такой как OPENSEARCH_JAVA_OPTS=-Xms3g -Xmx3g, то вам следует закомментировать любые ссылки на этот параметр JVM в config/jvm.options. Напротив, если вы определяете параметры JVM в config/jvm.options, то не следует определять эти параметры JVM с помощью переменных окружения.
Важные системные свойства
OpenSearch имеет ряд системных свойств, перечисленных в следующей таблице, которые вы можете указать в файле config/jvm.options или в переменной OPENSEARCH_JAVA_OPTS, используя нотацию аргументов командной строки -D.
| Свойство | Описание |
|---|---|
opensearch.xcontent.string.length.max=<value> | По умолчанию OpenSearch не накладывает ограничений на максимальную длину строковых полей JSON/YAML/CBOR/Smile. Чтобы защитить ваш кластер от потенциальных атак типа “отказ в обслуживании” (DDoS) или проблем с памятью, вы можете установить это свойство на разумный предел (максимум 2,147,483,647), например, -Dopensearch.xcontent.string.length.max=5000000. |
| `opensearch.xcontent.fast_double_writer=[true | false]` |
opensearch.xcontent.name.length.max=<value> | По умолчанию OpenSearch не накладывает ограничений на максимальную длину имен полей JSON/YAML/CBOR/Smile. Чтобы защитить ваш кластер от потенциальных DDoS или проблем с памятью, вы можете установить это свойство на разумный предел (максимум 2,147,483,647), например, -Dopensearch.xcontent.name.length.max=50000. |
opensearch.xcontent.depth.max=<value> | По умолчанию OpenSearch не накладывает ограничений на максимальную глубину вложенности для документов JSON/YAML/CBOR/Smile. Чтобы защитить ваш кластер от потенциальных DDoS или проблем с памятью, вы можете установить это свойство на разумный предел (максимум 2,147,483,647), например, -Dopensearch.xcontent.depth.max=1000. |
opensearch.xcontent.codepoint.max=<value> | По умолчанию OpenSearch накладывает ограничение в 52428800 на максимальный размер YAML-документов (в кодовых точках). Чтобы защитить ваш кластер от потенциальных DDoS или проблем с памятью, вы можете изменить это свойство на разумный предел (максимум 2,147,483,647). Например, -Dopensearch.xcontent.codepoint.max=5000000. |
8.2.1.1 - Docker
Docker значительно упрощает процесс настройки и управления вашими кластерами OpenSearch.
Docker значительно упрощает процесс настройки и управления вашими кластерами OpenSearch. Вы можете загружать официальные образы из Docker Hub или Amazon Elastic Container Registry (Amazon ECR) и быстро развернуть кластер, используя Docker Compose и любой из примеров файлов Docker Compose, включенных в этот гид. Опытные пользователи OpenSearch могут дополнительно настроить свое развертывание, создав собственный файл Docker Compose.
Контейнеры Docker являются портативными и будут работать на любом совместимом хосте, который поддерживает Docker (таких как Linux, MacOS или Windows). Портативность контейнера Docker предлагает гибкость по сравнению с другими методами установки, такими как RPM или ручная установка из Tarball, которые требуют дополнительной конфигурации после загрузки и распаковки.
Этот гид предполагает, что вы уверенно работаете с интерфейсом командной строки (CLI) Linux. Вы должны понимать, как вводить команды, перемещаться между директориями и редактировать текстовые файлы. Для получения помощи по Docker или Docker Compose обратитесь к официальной документации на их веб-сайтах.
Установка Docker и Docker Compose
Посетите страницу Get Docker для получения рекомендаций по установке и настройке Docker для вашей среды. Если вы устанавливаете Docker Engine с помощью CLI, то по умолчанию Docker не будет иметь никаких ограничений на доступные ресурсы хоста. В зависимости от вашей среды вы можете настроить ограничения ресурсов в Docker. См. раздел Runtime options with Memory, CPUs, and GPUs для получения информации.
Пользователи Docker Desktop должны установить использование памяти хоста на минимум 4 ГБ, открыв Docker Desktop и выбрав Settings → Resources.
Docker Compose — это утилита, которая позволяет пользователям запускать несколько контейнеров с одной командой. Вы передаете файл Docker Compose при его вызове. Docker Compose читает эти настройки и запускает запрашиваемые контейнеры. Docker Compose устанавливается автоматически с Docker Desktop, но пользователи, работающие в командной строке, должны установить Docker Compose вручную. Вы можете найти информацию о установке Docker Compose на официальной странице Docker Compose GitHub.
Если вам нужно установить Docker Compose вручную и ваш хост поддерживает Python, вы можете использовать pip для автоматической установки пакета Docker Compose.
Настройка важных параметров хоста
Перед установкой OpenSearch с использованием Docker настройте следующие параметры. Это самые важные настройки, которые могут повлиять на производительность ваших сервисов, но для дополнительной информации смотрите раздел о важных системных настройках.
Настройки для Linux
Для среды Linux выполните следующие команды:
Отключите производительность памяти с помощью свопинга для улучшения производительности:
sudo swapoff -aУвеличьте количество доступных для OpenSearch карт памяти:
# Отредактируйте файл конфигурации sysctl sudo vi /etc/sysctl.conf # Добавьте строку для определения желаемого значения # или измените значение, если ключ существует, # а затем сохраните изменения. vm.max_map_count=262144 # Перезагрузите параметры ядра с помощью sysctl sudo sysctl -p # Проверьте, что изменение было применено, проверив значение cat /proc/sys/vm/max_map_count
Настройки для Windows
Для рабочих нагрузок Windows, использующих WSL через Docker Desktop, выполните следующие команды в терминале, чтобы установить vm.max_map_count:
wsl -d docker-desktop
sysctl -w vm.max_map_count=262144
Запуск OpenSearch в контейнере Docker
Официальные образы OpenSearch размещены на Docker Hub и Amazon ECR. Если вы хотите просмотреть образы, вы можете загружать их по отдельности, используя команду docker pull, как в следующих примерах.
Docker Hub:
docker pull opensearchproject/opensearch:3
docker pull opensearchproject/opensearch-dashboards:3
Amazon ECR:
docker pull public.ecr.aws/opensearchproject/opensearch:3
docker pull public.ecr.aws/opensearchproject/opensearch-dashboards:3
Чтобы загрузить конкретную версию OpenSearch или OpenSearch Dashboards, отличную от последней доступной версии, измените тег образа, где он упоминается (либо в командной строке, либо в файле Docker Compose). Например, opensearchproject/opensearch:3.1.0 загрузит версию OpenSearch 3.1.0. Чтобы загрузить последнюю версию, используйте opensearchproject/opensearch:latest. Обратитесь к официальным репозиториям образов для доступных версий.
Перед тем как продолжить, вы должны убедиться, что Docker работает корректно, развернув OpenSearch в одном контейнере.
Запуск OpenSearch в контейнере Docker
- Выполните следующую команду:
# Эта команда сопоставляет порты 9200 и 9600, устанавливает тип обнаружения на "single-node" и запрашивает самый новый образ OpenSearch
docker run -d -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" opensearchproject/opensearch:latest
Для OpenSearch версии 2.12 или выше установите новый пользовательский пароль администратора перед установкой, используя следующую команду:
docker run -d -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" -e "OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password>" opensearchproject/opensearch:latest
- Отправьте запрос на порт 9200. Имя пользователя и пароль по умолчанию —
admin.
curl https://localhost:9200 -ku admin:<custom-admin-password>
Вы должны получить ответ, который выглядит следующим образом:
{
"name" : "a937e018cee5",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "GLAjAG6bTeWErFUy_d-CLw",
"version" : {
"distribution" : "opensearch",
"number" : "<version>",
"build_type" : "<build-type>",
"build_hash" : "<build-hash>",
"build_date" : "<build-date>",
"build_snapshot" : false,
"lucene_version" : "<lucene-version>",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
- Перед остановкой работающего контейнера отобразите список всех работающих контейнеров и скопируйте идентификатор контейнера для узла OpenSearch, который вы тестируете. В следующем примере идентификатор контейнера —
a937e018cee5:
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a937e018cee5 opensearchproject/opensearch:latest "./opensearch-docker…" 19 minutes ago Up 19 minutes 0.0.0.0:9200->9200/tcp, 9300/tcp, 0.0.0.0:9600->9600/tcp, 9650/tcp wonderful_boyd
- Остановите работающий контейнер, передав идентификатор контейнера в команду
docker stop.
docker stop <containerId>
Помните, что команда
docker container lsне отображает остановленные контейнеры. Если вы хотите просмотреть остановленные контейнеры, используйте командуdocker container ls -a. Вы можете удалить ненужные контейнеры вручную с помощью командыdocker container rm <containerId_1> <containerId_2> <containerId_3> [...](укажите все идентификаторы контейнеров, которые вы хотите остановить, разделенные пробелами), или, если вы хотите удалить все остановленные контейнеры, вы можете использовать более короткую командуdocker container prune.
Развертывание кластера OpenSearch с использованием Docker Compose
Хотя технически возможно создать кластер OpenSearch, создавая контейнеры по одной команде за раз, гораздо проще определить вашу среду в YAML-файле и позволить Docker Compose управлять кластером. В следующем разделе содержатся примеры YAML-файлов, которые вы можете использовать для запуска предопределенного кластера с OpenSearch и OpenSearch Dashboards. Эти примеры полезны для тестирования и разработки, но не подходят для производственной среды. Если у вас нет опыта работы с Docker Compose, вам может быть полезно ознакомиться со спецификацией Docker Compose для получения рекомендаций по синтаксису и форматированию перед внесением изменений в структуры словарей в примерах.
Файл YAML, который определяет среду, называется файлом Docker Compose. По умолчанию команды docker-compose сначала проверяют вашу текущую директорию на наличие файла, который соответствует любому из следующих имен:
docker-compose.ymldocker-compose.yamlcompose.ymlcompose.yaml
Если ни один из этих файлов не существует в вашей текущей директории, команда docker-compose завершится с ошибкой.
Вы можете указать пользовательское местоположение и имя файла при вызове docker-compose с помощью флага -f:
# Используйте относительный или абсолютный путь к файлу.
docker compose -f /path/to/your-file.yml up
Если вы впервые запускаете кластер OpenSearch с использованием Docker Compose, используйте следующий пример файла docker-compose.yml. Сохраните его в домашнем каталоге вашего хоста и назовите его docker-compose.yml. Этот файл создает кластер, который содержит три контейнера: два контейнера, работающих с сервисом OpenSearch, и один контейнер, работающий с OpenSearch Dashboards. Эти контейнеры общаются через мостовую сеть под названием opensearch-net и используют два тома, по одному для каждого узла OpenSearch. Поскольку этот файл явно не отключает демонстрационную конфигурацию безопасности, устанавливаются самоподписанные TLS-сертификаты, и создаются внутренние пользователи с именами и паролями по умолчанию.
Установка пользовательского пароля администратора
Начиная с OpenSearch 2.12, для настройки демонстрационной конфигурации безопасности требуется пользовательский пароль администратора. Выполните одно из следующих действий:
Перед запуском
docker-compose.ymlустановите новый пользовательский пароль администратора, используя следующую команду:export OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password>Создайте файл
.envв той же папке, что и ваш файлdocker-compose.yml, с переменнойOPENSEARCH_INITIAL_ADMIN_PASSWORDи значением надежного пароля.
Требования к паролям
OpenSearch по умолчанию обеспечивает высокую безопасность паролей, используя библиотеку оценки прочности паролей zxcvbn, разработанную компанией Dropbox.
Эта библиотека оценивает пароли на основе энтропии, а не жестких правил сложности, используя следующие рекомендации:
Сосредоточьтесь на энтропии, а не только на правилах: Вместо того чтобы просто добавлять цифры или специальные символы, придавайте приоритет общей непредсказуемости. Длинные пароли, состоящие из случайных слов или символов, обеспечивают более высокую энтропию, что делает их более безопасными, чем короткие пароли, соответствующие традиционным правилам сложности.
Избегайте общих шаблонов и слов из словаря: Библиотека zxcvbn обнаруживает распространенные шаблоны и слова из словаря, что помогает предотвратить использование легко угадываемых паролей.
Следуя этим рекомендациям, вы сможете создать более надежные пароли, которые обеспечат лучшую защиту ваших учетных записей и данных в OpenSearch.
Sample docker-compose.yml
services:
opensearch-node1: # This is also the hostname of the container within the Docker network (i.e. https://opensearch-node1/)
image: opensearchproject/opensearch:latest # Specifying the latest available image - modify if you want a specific version
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster # Name the cluster
- node.name=opensearch-node1 # Name the node that will run in this container
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligible to serve as cluster manager
- bootstrap.memory_lock=true # Disable JVM heap memory swapping
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Set min and max JVM heap sizes to at least 50% of system RAM
- OPENSEARCH_INITIAL_ADMIN_PASSWORD=${OPENSEARCH_INITIAL_ADMIN_PASSWORD} # Sets the demo admin user password when using demo configuration, required for OpenSearch 2.12 and later
ulimits:
memlock:
soft: -1 # Set memlock to unlimited (no soft or hard limit)
hard: -1
nofile:
soft: 65536 # Maximum number of open files for the opensearch user - set to at least 65536
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data # Creates volume called opensearch-data1 and mounts it to the container
ports:
- 9200:9200 # REST API
- 9600:9600 # Performance Analyzer
networks:
- opensearch-net # All of the containers will join the same Docker bridge network
opensearch-node2:
image: opensearchproject/opensearch:latest # This should be the same image used for opensearch-node1 to avoid issues
container_name: opensearch-node2
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node2
- discovery.seed_hosts=opensearch-node1,opensearch-node2
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- OPENSEARCH_INITIAL_ADMIN_PASSWORD=${OPENSEARCH_INITIAL_ADMIN_PASSWORD}
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch-data2:/usr/share/opensearch/data
networks:
- opensearch-net
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest # Make sure the version of opensearch-dashboards matches the version of opensearch installed on other nodes
container_name: opensearch-dashboards
ports:
- 5601:5601 # Map host port 5601 to container port 5601
expose:
- "5601" # Expose port 5601 for web access to OpenSearch Dashboards
environment:
OPENSEARCH_HOSTS: '["https://opensearch-node1:9200","https://opensearch-node2:9200"]' # Define the OpenSearch nodes that OpenSearch Dashboards will query
networks:
- opensearch-net
volumes:
opensearch-data1:
opensearch-data2:
networks:
opensearch-net:
Если вы переопределяете настройки opensearch_dashboards.yml, используя переменные окружения в вашем файле Compose, используйте все заглавные буквы и заменяйте точки на подчеркивания. Например, для opensearch.hosts используйте OPENSEARCH_HOSTS.
Это поведение отличается от переопределения настроек opensearch.yml, где преобразование заключается только в изменении оператора присваивания. Например, discovery.type: single-node в opensearch.yml определяется как discovery.type=single-node в docker-compose.yml.
Запуск и управление контейнерами OpenSearch с использованием Docker Compose
Создайте и запустите контейнеры в фоновом режиме из домашнего каталога вашего хоста (содержащего
docker-compose.yml):docker compose up -dПроверьте, что сервисные контейнеры запустились корректно:
docker compose psЕсли контейнер не удалось запустить, вы можете просмотреть логи сервиса:
# Если вы не укажете имя сервиса, docker compose покажет логи всех узлов docker compose logs <serviceName>Проверьте доступ к OpenSearch Dashboards, подключившись к http://localhost:5601 из браузера. Для OpenSearch версии 2.12 и выше вы должны использовать ваш настроенный логин и пароль. Для более ранних версий логин и пароль по умолчанию —
admin. Мы не рекомендуем использовать эту конфигурацию на хостах, доступных из публичного интернета, пока вы не настроите конфигурацию безопасности вашего развертывания.Помните, что
localhostне может быть доступен удаленно. Если вы развертываете эти контейнеры на удаленном хосте, вам нужно установить сетевое соединение и заменитьlocalhostна IP-адрес или DNS-запись, соответствующую хосту.Остановите работающие контейнеры в вашем кластере:
docker compose down
Команда
docker compose downостановит работающие контейнеры, но не удалит Docker-тома, которые существуют на хосте. Если вам не важны содержимое этих томов, используйте опцию-v, чтобы удалить все тома, например:docker compose down -v
Настройка OpenSearch
В отличие от RPM-распределения OpenSearch, которое требует значительного объема конфигурации после установки, запуск кластеров OpenSearch с помощью Docker позволяет вам определить среду еще до создания контейнеров. Это возможно как при использовании Docker, так и при использовании Docker Compose.
Пример команды Docker
Рассмотрим следующую команду:
docker run \
-p 9200:9200 -p 9600:9600 \
-e "discovery.type=single-node" \
-v /path/to/custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml \
opensearchproject/opensearch:latest
Разберем каждую часть команды:
- Сопоставляет порты 9200 и 9600 (HOST_PORT:CONTAINER_PORT).
- Устанавливает
discovery.typeвsingle-node, чтобы проверки загрузки не завершились неудачей для этого развертывания с одним узлом. - Использует флаг
-v, чтобы передать локальный файл с именемcustom-opensearch.ymlв контейнер, заменяя файлopensearch.yml, включенный в образ. - Запрашивает образ
opensearchproject/opensearch:latestиз Docker Hub. - Запускает контейнер.
Если вы сравните эту команду с примером файла docker-compose.yml, вы можете заметить некоторые общие настройки, такие как сопоставление портов и ссылка на образ. Однако эта команда только развертывает один контейнер, работающий с OpenSearch, и не создает контейнер для OpenSearch Dashboards. Более того, если вы хотите использовать пользовательские TLS-сертификаты, пользователей или роли, или определить дополнительные тома и сети, то эта “однострочная” команда быстро становится непрактичной. Вот где полезность Docker Compose становится очевидной.
Использование Docker Compose
Когда вы строите свой кластер OpenSearch с помощью Docker Compose, вам может быть проще передавать пользовательские файлы конфигурации с вашего хоста в контейнер, вместо того чтобы перечислять каждую отдельную настройку в docker-compose.yml. Аналогично тому, как в примере команды docker run был смонтирован том с хоста в контейнер с помощью флага -v, файлы Compose могут указывать тома для монтирования как подопцию для соответствующей службы. Следующий сокращенный YAML-файл демонстрирует, как смонтировать файл или директорию в контейнер:
services:
opensearch-node1:
volumes:
- opensearch-data1:/usr/share/opensearch/data
- ./custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml
opensearch-node2:
volumes:
- opensearch-data2:/usr/share/opensearch/data
- ./custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml
opensearch-dashboards:
volumes:
- ./custom-opensearch_dashboards.yml:/usr/share/opensearch-dashboards/config/opensearch_dashboards.yml
Обратите внимание, что в этом примере каждый узел OpenSearch использует один и тот же файл конфигурации, что упрощает управление настройками. Для получения более подробной информации о использовании томов и синтаксисе обратитесь к официальной документации Docker по томам.
Пример файла Docker Compose для разработки
Если вы хотите создать свой собственный файл compose на основе примера, ознакомьтесь с следующим образцом файла docker-compose.yml. Этот образец создает два узла OpenSearch и один узел OpenSearch Dashboards с отключенным плагином безопасности. Вы можете использовать этот образец в качестве отправной точки, просматривая Настройка основных параметров безопасности.
services:
opensearch-node1:
image: opensearchproject/opensearch:latest
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster # Название кластера
- node.name=opensearch-node1 # Название узла, который будет работать в этом контейнере
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Узлы, которые будут использоваться для обнаружения кластера
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Узлы, которые могут служить менеджерами кластера
- bootstrap.memory_lock=true # Отключить свопинг памяти кучи JVM
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Установить минимальный и максимальный размеры кучи JVM не менее 50% от системной оперативной памяти
- "DISABLE_INSTALL_DEMO_CONFIG=true" # Предотвращает выполнение встроенного демо-скрипта, который устанавливает демо-сертификаты и конфигурации безопасности в OpenSearch
- "DISABLE_SECURITY_PLUGIN=true" # Отключает плагин безопасности
ulimits:
memlock:
soft: -1 # Установить memlock на неограниченное (без мягкого или жесткого ограничения)
hard: -1
nofile:
soft: 65536 # Максимальное количество открытых файлов для пользователя opensearch - установить не менее 65536
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data # Создает том с именем opensearch-data1 и монтирует его в контейнер
ports:
- 9200:9200 # REST API
- 9600:9600 # Анализатор производительности
networks:
- opensearch-net # Все контейнеры будут присоединены к одной и той же сети Docker bridge
opensearch-node2:
image: opensearchproject/opensearch:latest
container_name: opensearch-node2
environment:
- cluster.name=opensearch-cluster # Название кластера
- node.name=opensearch-node2 # Название узла, который будет работать в этом контейнере
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Узлы, которые будут использоваться для обнаружения кластера
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Узлы, которые могут служить менеджерами кластера
- bootstrap.memory_lock=true # Отключить свопинг памяти кучи JVM
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Установить минимальный и максимальный размеры кучи JVM не менее 50% от системной оперативной памяти
- "DISABLE_INSTALL_DEMO_CONFIG=true" # Предотвращает выполнение встроенного демо-скрипта, который устанавливает демо-сертификаты и конфигурации безопасности в OpenSearch
- "DISABLE_SECURITY_PLUGIN=true" # Отключает плагин безопасности
ulimits:
memlock:
soft: -1 # Установить memlock на неограниченное (без мягкого или жесткого ограничения)
hard: -1
nofile:
soft: 65536 # Максимальное количество открытых файлов для пользователя opensearch - установить не менее 65536
hard: 65536
volumes:
- opensearch-data2:/usr/share/opensearch/data # Создает том с именем opensearch-data2 и монтирует его в контейнер
networks:
- opensearch-net # Все контейнеры будут присоединены к одной и той же сети Docker bridge
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
ports:
- 5601:5601 # Привязка порта хоста 5601 к порту контейнера 5601
expose:
- "5601" # Открыть порт 5601 для веб-доступа к OpenSearch Dashboards
environment:
- 'OPENSEARCH_HOSTS=["http://opensearch-node1:9200","http://opensearch-node2:9200"]' # Указать узлы OpenSearch для Dashboards
- "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true" # Отключает плагин безопасности в OpenSearch Dashboards
networks:
- opensearch-net
volumes:
opensearch-data1: {} # Создает том opensearch-data1
opensearch-data2: {} # Создает том opensearch-data2
networks:
opensearch-net: {} # Создает сеть opensearch-net
Настройка основных параметров безопасности
Перед тем как сделать ваш кластер OpenSearch доступным для внешних хостов, рекомендуется ознакомиться с конфигурацией безопасности развертывания. Вы можете вспомнить из первого примера файла docker-compose.yml, что, если не отключить плагин безопасности, установив DISABLE_SECURITY_PLUGIN=true, встроенный скрипт применит стандартную демо-конфигурацию безопасности к узлам в кластере. Поскольку эта конфигурация используется для демонстрационных целей, стандартные имена пользователей и пароли известны. Поэтому мы рекомендуем создать собственные файлы конфигурации безопасности и использовать тома для передачи этих файлов в контейнеры. Для получения конкретных рекомендаций по настройке безопасности OpenSearch смотрите Конфигурация безопасности.
Чтобы использовать свои собственные сертификаты в конфигурации, добавьте все необходимые сертификаты в раздел томов файла compose:
volumes:
- ./root-ca.pem:/usr/share/opensearch/config/root-ca.pem
- ./admin.pem:/usr/share/opensearch/config/admin.pem
- ./admin-key.pem:/usr/share/opensearch/config/admin-key.pem
- ./node1.pem:/usr/share/opensearch/config/node1.pem
- ./node1-key.pem:/usr/share/opensearch/config/node1-key.pem
Когда вы добавляете сертификаты TLS к узлам OpenSearch с помощью томов Docker Compose, вы также должны включить пользовательский файл opensearch.yml, который определяет эти сертификаты. Например:
volumes:
- ./root-ca.pem:/usr/share/opensearch/config/root-ca.pem
- ./admin.pem:/usr/share/opensearch/config/admin.pem
- ./admin-key.pem:/usr/share/opensearch/config/admin-key.pem
- ./node1.pem:/usr/share/opensearch/config/node1.pem
- ./node1-key.pem:/usr/share/opensearch/config/node1-key.pem
- ./custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml
Помните, что сертификаты, которые вы указываете в файле compose, должны совпадать с сертификатами, определенными в вашем пользовательском файле opensearch.yml. Вам следует заменить корневые, администраторские и узловые сертификаты на свои собственные. Для получения дополнительной информации смотрите Настройка сертификатов TLS.
Пример конфигурации в вашем пользовательском файле opensearch.yml может выглядеть следующим образом, добавляя сертификаты TLS и отличительное имя (DN) сертификата администратора, определяя несколько разрешений и включая подробное аудиторское логирование:
plugins.security.ssl.transport.pemcert_filepath: node1.pem
plugins.security.ssl.transport.pemkey_filepath: node1-key.pem
plugins.security.ssl.transport.pemtrustedcas_filepath: root-ca.pem
plugins.security.ssl.transport.enforce_hostname_verification: false
plugins.security.ssl.http.enabled: true
plugins.security.ssl.http.pemcert_filepath: node1.pem
plugins.security.ssl.http.pemkey_filepath: node1-key.pem
plugins.security.ssl.http.pemtrustedcas_filepath: root-ca.pem
plugins.security.allow_default_init_securityindex: true
plugins.security.authcz.admin_dn:
- CN=A,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA
plugins.security.nodes_dn:
- 'CN=N,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA'
plugins.security.audit.type: internal_opensearch
plugins.security.enable_snapshot_restore_privilege: true
plugins.security.check_snapshot_restore_write_privileges: true
plugins.security.restapi.roles_enabled: ["all_access", "security_rest_api_access"]
cluster.routing.allocation.disk.threshold_enabled: false
opendistro_security.audit.config.disabled_rest_categories: NONE
opendistro_security.audit.config.disabled_transport_categories: NONE
Полный список настроек
Для получения полного списка настроек смотрите Безопасность.
Используйте тот же процесс для указания конфигурации Backend в файле /usr/share/opensearch/config/opensearch-security/config.yml, а также для создания новых внутренних пользователей, ролей, сопоставлений, групп действий и арендаторов в соответствующих YAML-файлах.
После замены сертификатов и создания собственных внутренних пользователей, ролей, сопоставлений, групп действий и арендаторов, используйте Docker Compose для запуска кластера:
docker compose up -d
Работа с плагинами
Чтобы использовать образ OpenSearch с пользовательским плагином, вам сначала нужно создать Dockerfile. Ознакомьтесь с официальной документацией Docker для получения информации о создании Dockerfile.
FROM opensearchproject/opensearch:latest
RUN /usr/share/opensearch/bin/opensearch-plugin install --batch <pluginId>
Затем выполните следующие команды:
# Создание образа из Dockerfile
docker build --tag=opensearch-custom-plugin .
# Запуск контейнера из пользовательского образа
docker run -p 9200:9200 -p 9600:9600 -v /usr/share/opensearch/data opensearch-custom-plugin
В качестве альтернативы, вы можете удалить плагин из образа перед его развертыванием. Этот пример Dockerfile удаляет плагин безопасности:
FROM opensearchproject/opensearch:latest
RUN /usr/share/opensearch/bin/opensearch-plugin remove opensearch-security
Вы также можете использовать Dockerfile для передачи своих собственных сертификатов для использования с плагином безопасности:
FROM opensearchproject/opensearch:latest
COPY --chown=opensearch:opensearch opensearch.yml /usr/share/opensearch/config/
COPY --chown=opensearch:opensearch my-key-file.pem /usr/share/opensearch/config/
COPY --chown=opensearch:opensearch my-certificate-chain.pem /usr/share/opensearch/config/
COPY --chown=opensearch:opensearch my-root-cas.pem /usr/share/opensearch/config/
8.2.1.2 - Установка OpenSearch на Debian
Установка OpenSearch с использованием менеджера пакетов Advanced Packaging Tool (APT)
Установка OpenSearch с использованием менеджера пакетов Advanced Packaging Tool (APT) значительно упрощает процесс по сравнению с методом Tarball. Несколько технических аспектов, таких как путь установки, расположение конфигурационных файлов и создание службы, управляемой systemd, обрабатываются автоматически менеджером пакетов.
В общем, установка OpenSearch из дистрибутива Debian может быть разбита на несколько шагов:
- Скачать и установить OpenSearch.
- Установить вручную из Debian-пакета или из APT-репозитория.
- (Необязательно) Протестировать OpenSearch.
- Подтвердите, что OpenSearch может работать, прежде чем применять какую-либо пользовательскую конфигурацию.
- Это можно сделать без какой-либо безопасности (без пароля, без сертификатов) или с демо-конфигурацией безопасности, которая может быть применена с помощью упакованного скрипта.
- Настроить OpenSearch для вашей среды.
- Примените основные настройки к OpenSearch и начните использовать его в вашей среде.
Дистрибутив Debian предоставляет все необходимое для запуска OpenSearch внутри дистрибутивов Linux на базе Debian, таких как Ubuntu.
Этот гид предполагает, что вы уверенно работаете с интерфейсом командной строки (CLI) Linux. Вы должны понимать, как вводить команды, перемещаться между директориями и редактировать текстовые файлы. Некоторые примеры команд ссылаются на текстовый редактор vi, но вы можете использовать любой доступный текстовый редактор.
Шаг 1: Скачивание и установка OpenSearch
Установка OpenSearch из пакета
Скачайте Debian-пакет для желаемой версии непосредственно с страницы загрузок OpenSearch. Debian-пакет можно скачать как для архитектуры x64, так и для arm64.
Из командной строки установите пакет с помощью dpkg:
Для новых установок OpenSearch 2.12 и более поздних версий необходимо определить пользовательский пароль администратора для настройки демо-конфигурации безопасности. Используйте одну из следующих команд для определения пользовательского пароля администратора:
# x64
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> dpkg -i opensearch-3.1.0-linux-x64.deb
# arm64
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> dpkg -i opensearch-3.1.0-linux-arm64.deb
Используйте следующую команду для версий OpenSearch 2.11 и более ранних:
# x64
sudo dpkg -i opensearch-3.1.0-linux-x64.deb
# arm64
sudo dpkg -i opensearch-3.1.0-linux-arm64.deb
После успешной установки включите OpenSearch как службу:
sudo systemctl enable opensearch
Запустите службу OpenSearch:
sudo systemctl start opensearch
Проверьте, что OpenSearch запустился корректно:
sudo systemctl status opensearch
Проверка отпечатка
Debian-пакет не подписан. Если вы хотите проверить отпечаток, проект OpenSearch предоставляет файл .sig, а также пакет .deb для использования с GNU Privacy Guard (GPG).
Скачайте желаемый Debian-пакет:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch/3.1.0/opensearch-3.1.0-linux-x64.deb
Скачайте соответствующий файл подписи:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch/3.1.0/opensearch-3.1.0-linux-x64.deb.sig
Скачайте и импортируйте GPG-ключ:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | gpg --import -
Проверьте подпись:
gpg --verify opensearch-3.1.0-linux-x64.deb.sig opensearch-3.1.0-linux-x64.deb
Установка OpenSearch из APT-репозитория
APT, основной инструмент управления пакетами для операционных систем на базе Debian, позволяет загружать и устанавливать Debian-пакет из APT-репозитория.
- Установите необходимые пакеты:
sudo apt-get update && sudo apt-get -y install lsb-release ca-certificates curl gnupg2
- Импортируйте публичный GPG-ключ. Этот ключ используется для проверки подписи APT-репозитория:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | sudo gpg --dearmor --batch --yes -o /usr/share/keyrings/opensearch-release-keyring
- Создайте APT-репозиторий для OpenSearch:
echo "deb [signed-by=/usr/share/keyrings/opensearch-release-keyring] https://artifacts.opensearch.org/releases/bundle/opensearch/3.x/apt stable main" | sudo tee /etc/apt/sources.list.d/opensearch-3.x.list
- Проверьте, что репозиторий был успешно создан:
sudo apt-get update
- С добавленной информацией о репозитории перечислите все доступные версии OpenSearch:
sudo apt list -a opensearch
- Выбор версии OpenSearch для установки
- Если не указано иное, будет установлена последняя доступная версия OpenSearch.
# Для новых установок OpenSearch 2.12 и более поздних версий необходимо определить пользовательский пароль администратора для настройки демо-конфигурации безопасности.
# Используйте одну из следующих команд для определения пользовательского пароля:
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> apt-get install opensearch
# Для версий OpenSearch 2.11 и более ранних используйте следующую команду:
sudo apt-get install opensearch
- Установка конкретной версии OpenSearch
# Чтобы установить конкретную версию OpenSearch, укажите версию вручную, используя `opensearch=<version>`:
# Для новых установок OpenSearch 2.12 и более поздних версий:
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> apt-get install opensearch=3.1.0
# Для версий OpenSearch 2.11 и более ранних:
sudo apt-get install opensearch=3.1.0
- Во время установки установщик предоставит вам отпечаток GPG-ключа. Убедитесь, что информация совпадает с указанной ниже:
Fingerprint: c5b7 4989 65ef d1c2 924b a9d5 39d3 1987 9310 d3fc
- Проверьте, что отпечаток ключа соответствует ожидаемому значению, чтобы гарантировать целостность и подлинность пакета.
sudo systemctl enable opensearch
- Запуск OpenSearch
Чтобы запустить OpenSearch, выполните следующую команду:
sudo systemctl start opensearch
- Проверка статуса OpenSearch
После запуска проверьте, что OpenSearch запустился корректно, с помощью следующей команды:
sudo systemctl status opensearch
Шаг 2: (Необязательно) Тестирование OpenSearch
Перед тем как продолжить с любой конфигурацией, рекомендуется протестировать вашу установку OpenSearch. В противном случае может быть сложно определить, связаны ли будущие проблемы с установочными ошибками или с пользовательскими настройками, которые вы применили после установки.
Когда OpenSearch установлен с использованием Debian-пакета, некоторые демо-настройки безопасности автоматически применяются. Это включает в себя самоподписанные TLS-сертификаты и несколько пользователей и ролей. Если вы хотите настроить их самостоятельно, смотрите раздел Настройка OpenSearch в вашей среде.
Узел OpenSearch в своей стандартной конфигурации (с демо-сертификатами и пользователями с стандартными паролями) не подходит для производственной среды. Если вы планируете использовать узел в производственной среде, вам следует, как минимум, заменить демо TLS-сертификаты на ваши собственные и обновить список внутренних пользователей и паролей. Смотрите Конфигурация безопасности для получения дополнительной информации, чтобы убедиться, что ваши узлы настроены в соответствии с вашими требованиями безопасности.
Отправка запросов на сервер
Отправьте запросы на сервер, чтобы проверить, что OpenSearch работает. Обратите внимание на использование флага --insecure, который необходим, поскольку TLS-сертификаты самоподписаны.
Отправьте запрос на порт 9200:
curl -X GET https://localhost:9200 -u 'admin:<custom-admin-password>' --insecure
Ожидаемый ответ
Вы должны получить ответ, который выглядит примерно так:
{
"name": "hostname",
"cluster_name": "opensearch",
"cluster_uuid": "QqgpHCbnSRKcPAizqjvoOw",
"version": {
"distribution": "opensearch",
"number": <version>,
"build_type": <build-type>,
"build_hash": <build-hash>,
"build_date": <build-date>,
"build_snapshot": false,
"lucene_version": <lucene-version>,
"minimum_wire_compatibility_version": "7.10.0",
"minimum_index_compatibility_version": "7.0.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
Запрос к конечной точке плагинов
Запросите конечную точку плагинов:
curl -X GET https://localhost:9200/_cat/plugins?v -u 'admin:<custom-admin-password>' --insecure
Этот запрос вернет список установленных плагинов, что также подтвердит, что OpenSearch работает корректно.
Ожидаемый ответ для запроса к конечной точке плагинов
| Name | Component | Version |
|---|---|---|
| hostname | opensearch-alerting | 3.1.0 |
| hostname | opensearch-anomaly-detection | 3.1.0 |
| hostname | opensearch-asynchronous-search | 3.1.0 |
| hostname | opensearch-cross-cluster-replication | 3.1.0 |
| hostname | opensearch-geospatial | 3.1.0 |
| hostname | opensearch-index-management | 3.1.0 |
| hostname | opensearch-job-scheduler | 3.1.0 |
| hostname | opensearch-knn | 3.1.0 |
| hostname | opensearch-ml | 3.1.0 |
| hostname | opensearch-neural-search | 3.1.0 |
| hostname | opensearch-notifications | 3.1.0 |
| hostname | opensearch-notifications-core | 3.1.0 |
| hostname | opensearch-observability | 3.1.0 |
| hostname | opensearch-performance-analyzer | 3.1.0 |
| hostname | opensearch-reports-scheduler | 3.1.0 |
| hostname | opensearch-security | 3.1.0 |
| hostname | opensearch-security-analytics | 3.1.0 |
| hostname | opensearch-sql | 3.1.0 |
Шаг 3: Настройка OpenSearch в вашей среде
Пользователи, не имеющие предварительного опыта работы с OpenSearch, могут захотеть получить список рекомендуемых настроек для начала работы с сервисом. По умолчанию OpenSearch не привязан к сетевому интерфейсу и не может быть доступен внешними хостами. Кроме того, настройки безопасности заполняются стандартными именами пользователей и паролями. Следующие рекомендации позволят пользователю привязать OpenSearch к сетевому интерфейсу, создать и подписать TLS-сертификаты, а также настроить базовую аутентификацию.
Рекомендуемые настройки
Следующие настройки позволят вам:
- Привязать OpenSearch к IP-адресу или сетевому интерфейсу на хосте.
- Установить начальные и максимальные размеры кучи JVM.
- Определить переменную окружения, указывающую на встроенный JDK.
- Настроить собственные TLS-сертификаты — сторонний центр сертификации (CA) не требуется.
- Создать администратора с пользовательским паролем.
Если вы запускали демо-скрипт безопасности, вам нужно будет вручную перенастроить настройки, которые были изменены. Обратитесь к Конфигурации безопасности для получения рекомендаций перед продолжением.
Перед внесением каких-либо изменений в конфигурационные файлы всегда полезно сохранить резервную копию. Резервный файл можно использовать для устранения любых проблем, вызванных неправильной конфигурацией.
- Открытие файла
opensearch.yml
Откройте файл opensearch.yml:
sudo vi /etc/opensearch/opensearch.yml
- Добавление следующих строк
Добавьте следующие строки в файл:
# Привязать OpenSearch к правильному сетевому интерфейсу. Используйте 0.0.0.0
# для включения всех доступных интерфейсов или укажите IP-адрес,
# назначенный конкретному интерфейсу.
network.host: 0.0.0.0
# Если вы еще не настроили кластер, установите
# discovery.type в single-node, иначе проверки загрузки
# не пройдут, когда вы попытаетесь запустить службу.
discovery.type: single-node
# Если вы ранее отключили плагин безопасности в opensearch.yml,
# обязательно включите его снова. В противном случае вы можете пропустить эту настройку.
plugins.security.disabled: false
Сохраните изменения и закройте файл
Укажите начальные и максимальные размеры кучи JVM
- Откройте файл
jvm.options:
vi /etc/opensearch/jvm.options
Измените значения для начального и максимального размеров кучи. В качестве отправной точки вы должны установить эти значения на половину доступной системной памяти. Для выделенных хостов это значение можно увеличить в зависимости от ваших рабочих требований.
Например, если у хост-машины 8 ГБ памяти, вы можете установить начальные и максимальные размеры кучи на 4 ГБ:
-Xms4g
-Xmx4g
- Сохраните изменения и закройте файл.
Настройка TLS
Сертификаты TLS обеспечивают дополнительную безопасность для вашего кластера, позволяя клиентам подтверждать личность хостов и шифровать трафик между клиентом и хостом. Для получения дополнительной информации обратитесь к разделам “Настройка сертификатов TLS” и “Генерация сертификатов”, которые включены в документацию по плагину безопасности. Для работы в среде разработки обычно достаточно самоподписанных сертификатов. Этот раздел проведет вас через основные шаги, необходимые для генерации собственных сертификатов TLS и их применения к вашему хосту OpenSearch.
- Перейдите в директорию, где будут храниться сертификаты
cd /etc/opensearch
- Удалите демонстрационные сертификаты
sudo rm -f *pem
- Сгенерируйте корневой сертификат
Это то, что вы будете использовать для подписания других сертификатов.
# Создайте закрытый ключ для корневого сертификата
sudo openssl genrsa -out root-ca-key.pem 2048
# Используйте закрытый ключ для создания самоподписанного корневого сертификата. Обязательно
# замените аргументы, переданные в -subj, чтобы они отражали ваш конкретный хост.
sudo openssl req -new -x509 -sha256 -key root-ca-key.pem -subj "/C=CA/ST=ONTARIO/L=TORONTO/O=ORG/OU=UNIT/CN=ROOT" -out root-ca.pem -days 730
- Создайте сертификат администратора
Этот сертификат используется для получения повышенных прав для выполнения административных задач, связанных с плагином безопасности.
# Создайте закрытый ключ для сертификата администратора
sudo openssl genrsa -out admin-key-temp.pem 2048
# Преобразуйте закрытый ключ в PKCS#8
sudo openssl pkcs8 -inform PEM -outform PEM -in admin-key-temp.pem -topk8 -nocrypt -v1 PBE-SHA1-3DES -out admin-key.pem
# Создайте запрос на подпись сертификата (CSR). Общим именем (CN) "A" можно пользоваться, так как этот сертификат
# используется для аутентификации повышенного доступа и не привязан к хосту.
sudo openssl req -new -key admin-key.pem -subj "/C=CA/ST=ONTARIO/L=TORONTO/O=ORG/OU=UNIT/CN=A" -out admin.csr
# Подпишите сертификат администратора с помощью корневого сертификата и закрытого ключа, которые вы создали ранее.
sudo openssl x509 -req -in admin.csr -CA root-ca.pem -CAkey root-ca-key.pem -CAcreateserial -sha256 -out admin.pem -days 730
- Создайте закрытый ключ для сертификата узла
sudo openssl genrsa -out node1-key-temp.pem 2048
# Преобразуйте закрытый ключ в PKCS#8
sudo openssl pkcs8 -inform PEM -outform PEM -in node1-key-temp.pem -topk8 -nocrypt -v1 PBE-SHA1-3DES -out node1-key.pem
# Создайте CSR и замените аргументы, переданные в -subj, чтобы они отражали ваш конкретный хост
# Обратите внимание, что CN должен соответствовать DNS A записи для хоста — не используйте имя хоста.
sudo openssl req -new -key node1-key.pem -subj "/C=CA/ST=ONTARIO/L=TORONTO/O=ORG/OU=UNIT/CN=node1.dns.a-record" -out node1.csr
# Создайте файл расширений, который определяет SAN DNS имя для хоста
# Этот файл должен соответствовать DNS A записи хоста.
sudo sh -c 'echo subjectAltName=DNS:node1.dns.a-record > node1.ext'
# Подпишите сертификат узла с помощью корневого сертификата и закрытого ключа, которые вы создали ранее
sudo openssl x509 -req -in node1.csr -CA root-ca.pem -CAkey root-ca-key.pem -CAcreateserial -sha256 -out node1.pem -days 730 -extfile node1.ext
- Удалите временные файлы, которые больше не нужны
sudo rm -f *temp.pem *csr *ext
- Убедитесь, что оставшиеся сертификаты принадлежат пользователю opensearch
sudo chown opensearch:opensearch admin-key.pem admin.pem node1-key.pem node1.pem root-ca-key.pem root-ca.pem root-ca.srl
- Добавьте эти сертификаты в
opensearch.yml
Как описано в разделе “Генерация сертификатов”. Продвинутые пользователи также могут выбрать добавление настроек с помощью скрипта.
#! /bin/bash
# Before running this script, make sure to replace the CN in the
# node's distinguished name with a real DNS A record.
echo "plugins.security.ssl.transport.pemcert_filepath: /etc/opensearch/node1.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.transport.pemkey_filepath: /etc/opensearch/node1-key.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.transport.pemtrustedcas_filepath: /etc/opensearch/root-ca.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.enabled: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.pemcert_filepath: /etc/opensearch/node1.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.pemkey_filepath: /etc/opensearch/node1-key.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.pemtrustedcas_filepath: /etc/opensearch/root-ca.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.allow_default_init_securityindex: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.authcz.admin_dn:" | sudo tee -a /etc/opensearch/opensearch.yml
echo " - 'CN=A,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA'" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.nodes_dn:" | sudo tee -a /etc/opensearch/opensearch.yml
echo " - 'CN=node1.dns.a-record,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA'" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.audit.type: internal_opensearch" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.enable_snapshot_restore_privilege: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.check_snapshot_restore_write_privileges: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.restapi.roles_enabled: [\"all_access\", \"security_rest_api_access\"]" | sudo tee -a /etc/opensearch/opensearch.yml
- (Необязательно) Добавление доверия к самоподписанному корневому сертификату
# Скопируйте корневой сертификат в правильную директорию
sudo cp /etc/opensearch/root-ca.pem /etc/pki/ca-trust/source/anchors/
# Добавьте доверие
sudo update-ca-trust
Настройка пользователя
Пользователи определяются и аутентифицируются OpenSearch различными способами. Один из методов, который не требует дополнительной инфраструктуры на стороне сервера, — это ручная настройка пользователей в файле internal_users.yml. В следующих шагах объясняется, как добавить нового внутреннего пользователя и как заменить пароль по умолчанию для администратора с помощью скрипта.
- Перейдите в директорию инструментов плагина безопасности
cd /usr/share/opensearch/plugins/opensearch-security/tools
- Запустите
hash.shдля генерации нового пароля
- Этот скрипт завершится с ошибкой, если путь к JDK не был определен.
# Пример вывода, если JDK не найден...
$ ./hash.sh
**************************************************************************
** Этот инструмент будет устаревшим в следующем крупном релизе OpenSearch **
** https://github.com/opensearch-project/security/issues/1755 **
**************************************************************************
which: no java in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/user/.local/bin:/home/user/bin)
WARNING: nor OPENSEARCH_JAVA_HOME nor JAVA_HOME is set, will use
./hash.sh: line 35: java: command not found
- Объявите переменную окружения при вызове скрипта, чтобы избежать проблем
OPENSEARCH_JAVA_HOME=/usr/share/opensearch/jdk ./hash.sh
- Введите желаемый пароль на запросе и запомните хэш, который будет выведен
- Откройте файл
internal_users.yml
sudo vi /etc/opensearch/opensearch-security/internal_users.yml
- Добавьте нового внутреннего пользователя и замените хэш внутри
internal_users.ymlна вывод, предоставленныйhash.shна шаге 2
Файл должен выглядеть примерно так:
---
# This is the internal user database
# The hash value is a bcrypt hash and can be generated with plugin/tools/hash.sh
_meta:
type: "internalusers"
config_version: 2
# Define your internal users here
admin:
hash: "$2y$1EXAMPLEQqwS8TUcoEXAMPLEeZ3lEHvkEXAMPLERqjyh1icEXAMPLE."
reserved: true
backend_roles:
- "admin"
description: "Admin user"
user1:
hash: "$2y$12$zoHpvTCRjjQr6h0PEaabueCaGam3/LDvT6rZZGDGMusD7oehQjw/O"
reserved: false
backend_roles: []
description: "New internal user"
# Other users
...
Применение изменений
Теперь, когда сертификаты TLS установлены, а демонстрационные пользователи были удалены или им были назначены новые пароли, последний шаг — применить изменения конфигурации. Этот последний шаг конфигурации требует вызова securityadmin.sh, пока OpenSearch работает на хосте.
Убедитесь, что OpenSearch запущен
OpenSearch должен быть запущен, чтобы securityadmin.sh мог применить изменения. Если вы внесли изменения в opensearch.yml, перезапустите OpenSearch:
sudo systemctl restart opensearch
Откройте отдельную сессию терминала на хосте и перейдите в директорию, содержащую securityadmin.sh
# Перейдите в правильную директорию
cd /usr/share/opensearch/plugins/opensearch-security/tools
Вызовите скрипт
Смотрите раздел “Применение изменений с помощью securityadmin.sh” для определения аргументов, которые вы должны передать.
# Вы можете опустить переменную окружения, если вы объявили ее в вашем $PATH.
OPENSEARCH_JAVA_HOME=/usr/share/opensearch/jdk ./securityadmin.sh -cd /etc/opensearch/opensearch-security/ -cacert /etc/opensearch/root-ca.pem -cert /etc/opensearch/admin.pem -key /etc/opensearch/admin-key.pem -icl -nhnv
Параметры скрипта:
-cd: указывает директорию конфигурации.-cacert: указывает путь к корневому сертификату.-cert: указывает путь к сертификату администратора.-key: указывает путь к закрытому ключу администратора.-icl: включает режим конфигурации.-nhnv: отключает проверку хоста и не выводит информацию о версии.
Проверка работы сервиса
OpenSearch теперь работает на вашем хосте с пользовательскими сертификатами TLS и безопасным пользователем для базовой аутентификации. Вы можете проверить внешнюю доступность, отправив API-запрос к вашему узлу OpenSearch с другого хоста.
Во время предыдущего теста вы направляли запросы на localhost. Теперь, когда сертификаты TLS были применены и новые сертификаты ссылаются на фактическую DNS-запись вашего хоста, запросы к localhost не пройдут проверку CN, и сертификат будет считаться недействительным. Вместо этого запросы должны быть отправлены на адрес, который вы указали при генерации сертификата.
Перед отправкой запросов вы должны добавить доверие к корневому сертификату на вашем клиенте. Если вы не добавите доверие, вам нужно будет использовать опцию
-k, чтобы cURL игнорировал проверку CN и корневого сертификата.
$ curl https://your.host.address:9200 -u admin:yournewpassword -k
{
"name":"hostname",
"cluster_name":"opensearch",
"cluster_uuid":"QqgpHCbnSRKcPAizqjvoOw",
"version":{
"distribution":"opensearch",
"number":<version>,
"build_type":<build-type>,
"build_hash":<build-hash>,
"build_date":<build-date>,
"build_snapshot":false,
"lucene_version":<lucene-version>,
"minimum_wire_compatibility_version":"7.10.0",
"minimum_index_compatibility_version":"7.0.0"
},
"tagline":"The OpenSearch Project: https://opensearch.org/"
}
Обновление до новой версии
Экземпляры OpenSearch, установленные с помощью dpkg или apt-get, можно легко обновить до более новой версии.
Ручное обновление с помощью DPKG
Скачайте Debian-пакет для желаемой версии обновления непосредственно со страницы загрузок OpenSearch Project.
Перейдите в директорию, содержащую дистрибутив, и выполните следующую команду:
sudo dpkg -i opensearch-3.1.0-linux-x64.deb
Обновление с помощью APT-GET
Чтобы обновить до последней версии OpenSearch с помощью apt-get, выполните:
sudo apt-get upgrade opensearch
Вы также можете обновить до конкретной версии OpenSearch:
sudo apt-get upgrade opensearch=<version>
Автоматическая перезагрузка сервиса после обновления пакета (2.13.0+)
Чтобы автоматически перезапустить OpenSearch после обновления пакета, включите opensearch.service через systemd:
sudo systemctl enable opensearch.service
8.2.2 - Установка OpenSearch Dashboards
OpenSearch Dashboards предоставляет полностью интегрированное решение для визуального изучения, обнаружения и запроса ваших данных наблюдаемости.
OpenSearch Dashboards предоставляет полностью интегрированное решение для визуального изучения, обнаружения и запроса ваших данных наблюдаемости. Вы можете установить OpenSearch Dashboards с помощью одного из следующих вариантов:
- Docker
- Tarball
- RPM
- Debian
- Helm
- Windows
Совместимость с браузерами
OpenSearch Dashboards поддерживает следующие веб-браузеры:
- Chrome
- Firefox
- Safari
- Edge (Chromium)
Другие браузеры на основе Chromium также могут работать. Internet Explorer и Microsoft Edge Legacy не поддерживаются.
Совместимость с Node.js
OpenSearch Dashboards требует бинарный файл среды выполнения Node.js для работы. Один из них включен в дистрибутивные пакеты, доступные на странице загрузок OpenSearch.
OpenSearch Dashboards версии 2.8.0 и новее могут использовать версии Node.js 14, 16 и 18. Дистрибутивные пакеты для OpenSearch Dashboards версии 2.10.0 и новее включают Node.js 18 и 14 (для обратной совместимости).
Чтобы использовать бинарный файл среды выполнения Node.js, отличный от включенных в дистрибутивные пакеты, выполните следующие шаги:
Скачайте и установите Node.js; совместимые версии: >=14.20.1 <19.
Установите путь установки в переменные окружения NODE_HOME или NODE_OSD_HOME.
На UNIX, если Node.js установлен в /usr/local/nodejs, а бинарный файл среды выполнения находится по пути /usr/local/nodejs/bin/node:
export NODE_HOME=/usr/local/nodejsЕсли Node.js установлен с помощью NVM, а бинарный файл среды выполнения находится по пути /Users/user/.nvm/versions/node/v18.19.0/bin/node:
export NODE_HOME=/Users/user/.nvm/versions/node/v18.19.0 # или, если NODE_HOME используется для чего-то другого: export NODE_OSD_HOME=/Users/user/.nvm/versions/node/v18.19.0На Windows, если Node.js установлен в C:\Program Files\nodejs, а бинарный файл среды выполнения находится по пути C:\Program Files\nodejs\node.exe:
set "NODE_HOME=C:\Program Files\nodejs" # или с использованием PowerShell: $Env:NODE_HOME = 'C:\Program Files\nodejs'
Ознакомьтесь с документацией вашей операционной системы, чтобы внести постоянные изменения в переменные окружения.
Скрипт запуска OpenSearch Dashboards, bin/opensearch-dashboards, ищет бинарный файл среды выполнения Node.js, используя NODE_OSD_HOME, затем NODE_HOME, прежде чем использовать бинарные файлы, включенные в дистрибутивные пакеты. Если подходящий бинарный файл среды выполнения Node.js не найден, скрипт запуска попытается найти его в системном PATH, прежде чем завершить работу с ошибкой.
Конфигурация
Чтобы узнать, как настроить TLS для OpenSearch Dashboards, смотрите раздел Настройка TLS.
8.2.2.1 - Запуск OpenSearch Dashboards с использованием Docker
“Вы можете запустить OpenSearch Dashboards с помощью команды docker run после создания сети Docker и запуска OpenSearch, но процесс подключения OpenSearch Dashboards к OpenSearch значительно проще с использованием файла Docker Compose.”
Выполните команду для загрузки образа OpenSearch Dashboards:
docker pull opensearchproject/opensearch-dashboards:2Создайте файл
docker-compose.yml, соответствующий вашей среде. Пример файла, который включает OpenSearch Dashboards, доступен на странице установки OpenSearch Docker.Так же, как и для
opensearch.yml, вы можете передать пользовательский файлopensearch_dashboards.ymlв контейнер в файле Docker Compose.Запустите команду:
docker compose upПодождите, пока контейнеры запустятся. Затем ознакомьтесь с документацией OpenSearch Dashboards.
Когда закончите, выполните команду:
docker compose down
8.2.2.2 - Установка OpenSearch Dashboards (Debian)
Установка OpenSearch Dashboards с использованием менеджера пакетов Advanced Packaging Tool (APT)
Установка OpenSearch Dashboards с использованием менеджера пакетов Advanced Packaging Tool (APT) значительно упрощает процесс по сравнению с методом Tarball. Например, менеджер пакетов обрабатывает несколько технических аспектов, таких как путь установки, расположение конфигурационных файлов и создание службы, управляемой systemd.
Перед установкой OpenSearch Dashboards необходимо настроить кластер OpenSearch. Обратитесь к руководству по установке OpenSearch для Debian для получения инструкций.
Данное руководство предполагает, что вы уверенно работаете с интерфейсом командной строки (CLI) Linux. Вы должны понимать, как вводить команды, перемещаться между директориями и редактировать текстовые файлы. Некоторые примеры команд ссылаются на текстовый редактор vi, но вы можете использовать любой доступный текстовый редактор.
Установка OpenSearch Dashboards из пакета
Скачайте пакет Debian для нужной версии непосредственно с страницы загрузок OpenSearch. Пакет Debian доступен для архитектур x64 и arm64.
Установите пакет с помощью
dpkgиз командной строки:Для x64:
sudo dpkg -i opensearch-dashboards-3.1.0-linux-x64.debДля arm64:
sudo dpkg -i opensearch-dashboards-3.1.0-linux-arm64.deb
После завершения установки перезагрузите конфигурацию менеджера systemd:
sudo systemctl daemon-reloadВключите OpenSearch как службу:
sudo systemctl enable opensearch-dashboardsЗапустите службу OpenSearch:
sudo systemctl start opensearch-dashboardsПроверьте, что OpenSearch запустился корректно:
sudo systemctl status opensearch-dashboards
Проверка подписи
Пакет Debian не подписан. Если вы хотите проверить подпись, проект OpenSearch предоставляет файл .sig, а также .deb пакет для использования с GNU Privacy Guard (GPG).
Скачайте нужный пакет Debian:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/3.1.0/opensearch-dashboards-3.1.0-linux-x64.debСкачайте соответствующий файл подписи:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/3.1.0/opensearch-dashboards-3.1.0-linux-x64.deb.sigСкачайте и импортируйте GPG-ключ:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | gpg --import -Проверьте подпись:
gpg --verify opensearch-dashboards-3.1.0-linux-x64.deb.sig opensearch-dashboards-3.1.0-linux-x64.deb
Установка OpenSearch Dashboards из репозитория APT
APT, основной инструмент управления пакетами для операционных систем на базе Debian, позволяет загружать и устанавливать пакет Debian из репозитория APT.
Установите необходимые пакеты:
sudo apt-get update && sudo apt-get -y install lsb-release ca-certificates curl gnupg2Импортируйте публичный GPG-ключ. Этот ключ используется для проверки подписи репозитория APT:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | sudo gpg --dearmor --batch --yes -o /usr/share/keyrings/opensearch-release-keyringСоздайте репозиторий APT для OpenSearch:
echo "deb [signed-by=/usr/share/keyrings/opensearch-release-keyring] https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/3.x/apt stable main" | sudo tee /etc/apt/sources.list.d/opensearch-dashboards-3.x.listПроверьте, что репозиторий был успешно создан:
sudo apt-get updateС добавленной информацией о репозитории, перечислите все доступные версии OpenSearch:
sudo apt list -a opensearch-dashboardsВыберите версию OpenSearch, которую хотите установить:
Если не указано иное, будет установлена последняя доступная версия OpenSearch:
sudo apt-get install opensearch-dashboardsЧтобы установить конкретную версию OpenSearch Dashboards, укажите номер версии после имени пакета:
# Укажите версию вручную с помощью opensearch=<version> sudo apt-get install opensearch-dashboards=3.1.0
После завершения установки включите OpenSearch:
sudo systemctl enable opensearch-dashboardsЗапустите OpenSearch:
sudo systemctl start opensearch-dashboardsПроверьте, что OpenSearch запустился корректно:
sudo systemctl status opensearch-dashboards
Изучение OpenSearch Dashboards
По умолчанию OpenSearch Dashboards, как и OpenSearch, связывается с localhost при первоначальной установке. В результате OpenSearch Dashboards недоступен с удаленного хоста, если конфигурация не обновлена.
Откройте файл
opensearch_dashboards.yml:sudo vi /etc/opensearch-dashboards/opensearch_dashboards.ymlУкажите сетевой интерфейс, к которому должен связываться OpenSearch Dashboards:
# Используйте 0.0.0.0, чтобы связаться с любым доступным интерфейсом. server.host: 0.0.0.0Сохраните изменения и выйдите из редактора.
Перезапустите OpenSearch Dashboards, чтобы применить изменения конфигурации:
sudo systemctl restart opensearch-dashboardsВ веб-браузере перейдите к OpenSearch Dashboards. Порт по умолчанию — 5601.
Войдите с использованием имени пользователя
adminи пароляadmin. (Для OpenSearch 2.12 и новее пароль должен быть пользовательским паролем администратора.)Посетите раздел “Начало работы с OpenSearch Dashboards”, чтобы узнать больше.
Обновление до новой версии
Экземпляры OpenSearch Dashboards, установленные с помощью dpkg или apt-get, можно легко обновить до новой версии.
Ручное обновление с помощью DPKG
Скачайте пакет Debian для желаемой версии обновления непосредственно со страницы загрузок проекта OpenSearch.
Перейдите в директорию, содержащую дистрибутив, и выполните следующую команду:
sudo dpkg -i opensearch-dashboards-3.1.0-linux-x64.deb
Обновление с помощью APT-GET
Чтобы обновить до последней версии OpenSearch Dashboards с помощью apt-get, выполните следующую команду:
sudo apt-get upgrade opensearch-dashboards
Вы также можете обновить до конкретной версии OpenSearch Dashboards, указав номер версии:
sudo apt-get upgrade opensearch-dashboards=<version>
Автоматический перезапуск службы после обновления пакета (2.13.0+)
Чтобы автоматически перезапустить OpenSearch Dashboards после обновления пакета, включите службу opensearch-dashboards.service через systemd:
sudo systemctl enable opensearch-dashboards.service
8.2.2.3 - Настройка TLS для OpenSearch Dashboards
По умолчанию, для упрощения тестирования и начала работы, OpenSearch Dashboards работает по протоколу HTTP. Чтобы включить TLS для HTTPS, обновите следующие настройки в файле opensearch_dashboards.yml.
| Настройка | Описание |
|---|---|
server.ssl.enabled | Включает SSL-соединение между сервером OpenSearch Dashboards и веб-браузером пользователя. Установите значение true для HTTPS или false для HTTP. |
server.ssl.supportedProtocols | Указывает массив поддерживаемых протоколов TLS. Возможные значения: TLSv1, TLSv1.1, TLSv1.2, TLSv1.3. По умолчанию: ['TLSv1.1', 'TLSv1.2', 'TLSv1.3']. |
server.ssl.cipherSuites | Указывает массив шифров TLS. Необязательная настройка. |
server.ssl.certificate | Если server.ssl.enabled установлено в true, указывает полный путь к действительному сертификату сервера Privacy Enhanced Mail (PEM) для OpenSearch Dashboards. Вы можете сгенерировать свой сертификат или получить его у центра сертификации (CA). |
server.ssl.key | Если server.ssl.enabled установлено в true, указывает полный путь к ключу для вашего серверного сертификата, например, /usr/share/opensearch-dashboards-1.0.0/config/my-client-cert-key.pem. Вы можете сгенерировать свой сертификат или получить его у CA. |
server.ssl.keyPassphrase | Устанавливает пароль для ключа. Удалите эту настройку, если у ключа нет пароля. Необязательная настройка. |
server.ssl.keystore.path | Использует файл JKS (Java KeyStore) или PKCS12/PFX (Public-Key Cryptography Standards) вместо сертификата и ключа PEM. |
server.ssl.keystore.password | Устанавливает пароль для хранилища ключей. Обязательная настройка. |
server.ssl.clientAuthentication | Указывает режим аутентификации клиента TLS. Может быть одним из следующих: none, optional или required. Если установлено в required, ваш веб-браузер должен отправить действительный клиентский сертификат, подписанный CA, настроенным в server.ssl.certificateAuthorities. По умолчанию: none. |
server.ssl.certificateAuthorities | Указывает полный путь к одному или нескольким сертификатам CA в массиве, которые выдают сертификат, используемый для аутентификации клиента. Обязательная настройка, если server.ssl.clientAuthentication установлено в optional или required. |
server.ssl.truststore.path | Использует файл JKS или PKCS12/PFX trust store вместо сертификатов CA PEM. |
server.ssl.truststore.password | Устанавливает пароль для trust store. Обязательная настройка. |
opensearch.ssl.verificationMode | Устанавливает связь между OpenSearch и OpenSearch Dashboards. Допустимые значения: full, certificate или none. Рекомендуется использовать full, если TLS включен, что включает проверку имени хоста. certificate проверяет сертификат, но не имя хоста. none не выполняет никаких проверок (подходит для HTTP). По умолчанию: full. |
opensearch.ssl.certificateAuthorities | Если opensearch.ssl.verificationMode установлено в full или certificate, указывает полный путь к одному или нескольким сертификатам CA в массиве, которые составляют доверенную цепочку для кластера OpenSearch. Например, вам может потребоваться включить корневой CA и промежуточный CA, если вы использовали промежуточный CA для выдачи ваших сертификатов администратора, клиента и узла. |
opensearch.ssl.truststore.path | Использует файл trust store JKS или PKCS12/PFX вместо сертификатов CA PEM. |
opensearch.ssl.truststore.password | Устанавливает пароль для trust store. Обязательная настройка. |
opensearch.ssl.alwaysPresentCertificate | Отправляет клиентский сертификат в кластер OpenSearch, если установлено значение true, что необходимо, когда mTLS включен в OpenSearch. По умолчанию: false. |
opensearch.ssl.certificate | Если opensearch.ssl.alwaysPresentCertificate установлено в true, указывает полный путь к действительному клиентскому сертификату для кластера OpenSearch. Вы можете сгенерировать свой сертификат или получить его у CA. |
opensearch.ssl.key | Если opensearch.ssl.alwaysPresentCertificate установлено в true, указывает полный путь к ключу для клиентского сертификата. Вы можете сгенерировать свой сертификат или получить его у CA. |
opensearch.ssl.keyPassphrase | Устанавливает пароль для ключа. Удалите эту настройку, если у ключа нет пароля. Необязательная настройка. |
opensearch.ssl.keystore.path | Использует файл хранилища ключей JKS или PKCS12/PFX вместо сертификата и ключа PEM. |
opensearch.ssl.keystore.password | Устанавливает пароль для хранилища ключей. Обязательная настройка. |
opensearch_security.cookie.secure | Если TLS включен для OpenSearch Dashboards, измените эту настройку на true. Для HTTP установите значение false. |
Пример конфигурации opensearch_dashboards.yml
Следующая конфигурация opensearch_dashboards.yml показывает, как OpenSearch и OpenSearch Dashboards могут работать на одной машине с демонстрационной конфигурацией:
server.host: '0.0.0.0'
server.ssl.enabled: true
server.ssl.certificate: /usr/share/opensearch-dashboards/config/client-cert.pem
server.ssl.key: /usr/share/opensearch-dashboards/config/client-cert-key.pem
opensearch.hosts: ["https://localhost:9200"]
opensearch.ssl.verificationMode: full
opensearch.ssl.certificateAuthorities: [ "/usr/share/opensearch-dashboards/config/root-ca.pem", "/usr/share/opensearch-dashboards/config/intermediate-ca.pem" ]
opensearch.username: "kibanaserver"
opensearch.password: "kibanaserver"
opensearch.requestHeadersAllowlist: [ authorization,securitytenant ]
opensearch_security.multitenancy.enabled: true
opensearch_security.multitenancy.tenants.preferred: ["Private", "Global"]
opensearch_security.readonly_mode.roles: ["kibana_read_only"]
opensearch_security.cookie.secure: true
Если вы используете опцию установки через Docker, вы можете передать пользовательский файл opensearch_dashboards.yml в контейнер. Чтобы узнать больше, посетите страницу установки Docker.
После включения этих настроек и запуска приложения вы можете подключиться к OpenSearch Dashboards по адресу https://localhost:5601. Возможно, вам потребуется подтвердить предупреждение браузера, если ваши сертификаты самоподписанные. Чтобы избежать такого предупреждения (или полной несовместимости с браузером), рекомендуется использовать сертификаты от доверенного центра сертификации (CA).
8.2.3 - configuring opensearch
Существует два типа настроек OpenSearch: динамические и статические.
Динамические настройки
Динамические настройки индекса — это настройки, которые вы можете обновлять в любое время. Вы можете настраивать динамические параметры OpenSearch через API настроек кластера. Для получения подробной информации смотрите раздел Обновление настроек кластера с помощью API.
При возможности используйте API настроек кластера; файл opensearch.yml локален для каждого узла, в то время как API применяет настройки ко всем узлам в кластере.
Статические настройки
Некоторые операции являются статическими и требуют изменения конфигурационного файла opensearch.yml и перезапуска кластера. В общем, эти настройки относятся к сетевым параметрам, формированию кластера и локальной файловой системе. Чтобы узнать больше, смотрите раздел Формирование кластера.
Указание настроек в виде переменных окружения
Вы можете указывать переменные окружения следующими способами:
Аргументы при запуске
Вы можете указать переменные окружения в качестве аргументов, используя -E при запуске OpenSearch:
./opensearch -Ecluster.name=opensearch-cluster -Enode.name=opensearch-node1 -Ehttp.host=0.0.0.0 -Ediscovery.type=single-node
Непосредственно в среде оболочки
Вы можете настроить переменные окружения непосредственно в среде оболочки перед запуском OpenSearch, как показано в следующем примере:
export OPENSEARCH_JAVA_OPTS="-Xms2g -Xmx2g"
export OPENSEARCH_PATH_CONF="/etc/opensearch"
./opensearch
Файл службы systemd
При запуске OpenSearch как службы, управляемой systemd, вы можете указать переменные окружения в файле службы, как показано в следующем примере:
# /etc/systemd/system/opensearch.service.d/override.conf
[Service]
Environment="OPENSEARCH_JAVA_OPTS=-Xms2g -Xmx2g"
Environment="OPENSEARCH_PATH_CONF=/etc/opensearch"
После создания или изменения файла перезагрузите конфигурацию systemd и перезапустите службу с помощью следующих команд:
sudo systemctl daemon-reload
sudo systemctl restart opensearch
Переменные окружения Docker
При запуске OpenSearch в Docker вы можете указать переменные окружения, используя опцию -e с командой docker run, как показано в следующей команде:
docker run -e "OPENSEARCH_JAVA_OPTS=-Xms2g -Xmx2g" -e "OPENSEARCH_PATH_CONF=/usr/share/opensearch/config" opensearchproject/opensearch:latest
Обновление настроек кластера с помощью API
Первый шаг в изменении настройки — это просмотр текущих настроек, отправив следующий запрос:
GET _cluster/settings?include_defaults=true
Для более краткого резюме нестандартных настроек отправьте следующий запрос:
GET _cluster/settings
В API настроек кластера существуют три категории настроек: постоянные, временные и стандартные. Постоянные настройки сохраняются после перезапуска кластера. После перезапуска OpenSearch очищает временные настройки.
Если вы указываете одну и ту же настройку в нескольких местах, OpenSearch использует следующий порядок приоритета:
- Временные настройки
- Постоянные настройки
- Настройки из
opensearch.yml - Стандартные настройки
Чтобы изменить настройку, используйте API настроек кластера и укажите новое значение как постоянное или временное. Этот пример показывает форму плоских настроек:
PUT _cluster/settings
{
"persistent" : {
"action.auto_create_index" : false
}
}
Вы также можете использовать расширенную форму, которая позволяет вам копировать и вставлять из ответа GET и изменять существующие значения:
PUT _cluster/settings
{
"persistent": {
"action": {
"auto_create_index": false
}
}
}
Конфигурационный файл
Вы можете найти файл opensearch.yml по следующему пути:
- Для Docker:
/usr/share/opensearch/config/opensearch.yml - Для большинства дистрибутивов Linux:
/etc/opensearch/opensearch.yml
Вы можете отредактировать переменную OPENSEARCH_PATH_CONF=/etc/opensearch, чтобы изменить расположение каталога конфигурации. Эта переменная берется из /etc/default/opensearch (для Debian-пакета) и /etc/sysconfig/opensearch (для RPM-пакета).
Если вы установите свою пользовательскую переменную OPENSEARCH_PATH_CONF, имейте в виду, что другие стандартные переменные окружения не будут загружены.
В файле opensearch.yml вы не помечаете настройки как постоянные или временные, и настройки используют плоскую форму:
cluster.name: my-application
action.auto_create_index: true
compatibility.override_main_response_version: true
Демонстрационная конфигурация включает в себя ряд настроек для плагина безопасности, которые вы должны изменить перед использованием OpenSearch для производственной нагрузки. Чтобы узнать больше, смотрите раздел Безопасность.
(Необязательно) Конфигурация заголовков CORS
Если вы работаете над клиентским приложением, которое взаимодействует с кластером OpenSearch на другом домене, вы можете настроить заголовки в opensearch.yml, чтобы разрешить разработку локального приложения на той же машине. Используйте механизм Cross Origin Resource Sharing (CORS), чтобы ваше приложение могло делать вызовы к API OpenSearch, работающему локально. Добавьте следующие строки в ваш файл custom-opensearch.yml (обратите внимание, что символ “-” должен быть первым символом в каждой строке):
- http.host: 0.0.0.0
- http.port: 9200
- http.cors.allow-origin: "http://localhost"
- http.cors.enabled: true
- http.cors.allow-headers: X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
- http.cors.allow-credentials: true
8.2.3.1 - Настройки доступности и восстановления
Настройки доступности и восстановления включают настройки для следующих компонентов
- Снимки
- Ограничение задач менеджера кластера
- Хранение с удаленной поддержкой
- Обратное давление при поиске
- Обратное давление при индексации шардов
- Репликация сегментов
- Репликация между кластерами
Чтобы узнать больше о статических и динамических настройках, см. Настройка OpenSearch.
Настройки снимков
OpenSearch поддерживает следующие настройки снимков:
- snapshot.max_concurrent_operations (Динамическое, целое число): Максимальное количество одновременных операций снимков. По умолчанию 1000.
Настройки снимков, связанные с безопасностью
Для настроек снимков, связанных с безопасностью, см. Настройки безопасности.
Настройки файловой системы
Для получения информации о настройках файловой системы см. Общая файловая система.
Настройки Amazon S3
Для получения информации о настройках репозитория Amazon S3 см. Amazon S3.
Настройки ограничения задач менеджера кластера
Для получения информации о настройках ограничения задач менеджера кластера см. Установка пределов ограничения.
Настройки хранения с удаленной поддержкой
OpenSearch поддерживает следующие настройки хранения с удаленной поддержкой на уровне кластера:
cluster.remote_store.translog.buffer_interval (Динамическое, единица времени): Значение по умолчанию для интервала буфера транзакционного лога, используемого при выполнении периодических обновлений транзакционного лога. Эта настройка эффективна только в том случае, если настройка индекса
index.remote_store.translog.buffer_intervalотсутствует.remote_store.moving_average_window_size (Динамическое, целое число): Размер окна скользящего среднего, используемый для расчета значений скользящей статистики, доступных через API статистики удаленного хранилища. По умолчанию 20. Минимально допустимое значение - 5.
Для получения дополнительной информации о настройках хранения с удаленной поддержкой см. Хранение с удаленной поддержкой и Настройка хранения с удаленной поддержкой.
Для получения информации о настройках обратного давления сегментов см. Настройки обратного давления сегментов.
Настройки обратного давления при поиске
Обратное давление при поиске - это механизм, используемый для выявления ресурсоемких запросов на поиск и их отмены, когда узел испытывает нагрузку. Для получения дополнительной информации см. Настройки обратного давления при поиске.
Настройки обратного давления при индексации шардов
Обратное давление при индексации шардов - это механизм умного отклонения на уровне шардов, который динамически отклоняет запросы на индексацию, когда ваш кластер испытывает нагрузку. Для получения дополнительной информации см. Настройки обратного давления при индексации шардов.
Настройки репликации сегментов
Для получения информации о настройках репликации сегментов см. Репликация сегментов.
Для получения информации о настройках обратного давления репликации сегментов см. Обратное давление репликации сегментов.
Настройки репликации между кластерами
Для получения информации о настройках репликации между кластерами см. Настройки репликации.
8.2.3.2 - Конфигурация и системные настройки
Обзор настрек Opensearch
Для получения обзора создания кластера OpenSearch и примеров настроек конфигурации см. раздел Создание кластера. Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
OpenSearch поддерживает следующие системные настройки:
cluster.name (Статическая, строка): Имя кластера.
node.name (Статическая, строка): Описательное имя для узла.
node.roles (Статическая, список): Определяет одну или несколько ролей для узла OpenSearch. Допустимые значения:
cluster_manager,data,ingest,search,ml,remote_cluster_clientиcoordinating_only.path.data (Статическая, строка): Путь к директории, где хранятся ваши данные. Разделяйте несколько местоположений запятыми.
path.logs (Статическая, строка): Путь к файлам журналов.
bootstrap.memory_lock (Статическая, логическое): Блокирует память при запуске. Рекомендуется установить размер кучи примерно на половину доступной памяти в системе и убедиться, что владелец процесса имеет право использовать этот лимит. OpenSearch работает неэффективно, когда система использует свопинг памяти.
8.2.3.3 - Сетевые настройки
OpenSearch использует настройки HTTP для конфигурации связи с внешними клиентами через REST API и транспортные настройки для внутренней связи между узлами в OpenSearch.
Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
OpenSearch поддерживает следующие общие сетевые настройки:
network.host (Статическая, список): Привязывает узел OpenSearch к адресу. Используйте
0.0.0.0, чтобы включить все доступные сетевые интерфейсы, или укажите IP-адрес, назначенный конкретному интерфейсу. Настройкаnetwork.hostявляется комбинациейnetwork.bind_hostиnetwork.publish_host, если они имеют одинаковое значение. Альтернативойnetwork.hostявляется отдельная настройкаnetwork.bind_hostиnetwork.publish_hostпо мере необходимости. См. раздел Расширенные сетевые настройки.http.port (Статическая, одно значение или диапазон): Привязывает узел OpenSearch к пользовательскому порту или диапазону портов для HTTP-связи. Вы можете указать адрес или диапазон адресов. По умолчанию — 9200-9300.
transport.port (Статическая, одно значение или диапазон): Привязывает узел OpenSearch к пользовательскому порту для связи между узлами. Вы можете указать адрес или диапазон адресов. По умолчанию — 9300-9400.
Расширенные сетевые настройки
OpenSearch поддерживает следующие расширенные сетевые настройки:
network.bind_host (Статическая, список): Привязывает узел OpenSearch к адресу или адресам для входящих соединений. По умолчанию — значение из
network.host.network.publish_host (Статическая, список): Указывает адрес или адреса, которые узел OpenSearch публикует для других узлов в кластере, чтобы они могли подключиться к нему.
Расширенные HTTP-настройки
OpenSearch поддерживает следующие расширенные сетевые настройки для HTTP-связи:
http.host (Статическая, список): Устанавливает адрес узла OpenSearch для HTTP-связи. Настройка
http.hostявляется комбинациейhttp.bind_hostиhttp.publish_host, если они имеют одинаковое значение. Альтернативойhttp.hostявляется отдельная настройкаhttp.bind_hostиhttp.publish_hostпо мере необходимости.http.bind_host (Статическая, список): Указывает адрес или адреса, к которым узел OpenSearch привязывается для прослушивания входящих HTTP-соединений.
http.publish_host (Статическая, список): Указывает адрес или адреса, которые узел OpenSearch публикует для других узлов для HTTP-связи.
http.compression (Статическая, логическое): Включает поддержку сжатия с использованием
Accept-Encoding, когда это применимо. Когда включен HTTPS, по умолчанию — false, в противном случае — true. Отключение сжатия для HTTPS помогает снизить потенциальные риски безопасности, такие как атаки BREACH. Чтобы включить сжатие для HTTPS-трафика, явно установитеhttp.compressionв true.http.max_header_size (Статическая, строка): Максимальный общий размер всех HTTP-заголовков, разрешенный в запросе. По умолчанию — 16KB.
Расширенные транспортные настройки
OpenSearch поддерживает следующие расширенные сетевые настройки для транспортной связи:
transport.host (Статическая, список): Устанавливает адрес узла OpenSearch для транспортной связи. Настройка
transport.hostявляется комбинациейtransport.bind_hostиtransport.publish_host, если они имеют одинаковое значение. Альтернативойtransport.hostявляется отдельная настройкаtransport.bind_hostиtransport.publish_hostпо мере необходимости.transport.bind_host (Статическая, список): Указывает адрес или адреса, к которым узел OpenSearch привязывается для прослушивания входящих транспортных соединений.
transport.publish_host (Статическая, список): Указывает адрес или адреса, которые узел OpenSearch публикует для других узлов для транспортной связи.OpenSearch использует настройки HTTP для конфигурации связи с внешними клиентами через REST API и транспортные настройки для внутренней связи между узлами в OpenSearch.
Выбор транспорта
По умолчанию OpenSearch использует транспорт, предоставляемый модулем transport-netty4, который использует движок Netty 4 как для внутренней TCP-связи между узлами в кластере, так и для внешней HTTP-связи с клиентами. Эта связь полностью асинхронна и неблокирующая. В следующей таблице перечислены другие доступные плагины транспорта, которые могут использоваться взаимозаменяемо.
| Плагин | Описание |
|---|---|
| transport-reactor-netty4 | HTTP-транспорт OpenSearch на основе Project Reactor и Netty 4 (экспериментальный) |
Установка
./bin/opensearch-plugin install transport-reactor-netty4
Конфигурация (с использованием opensearch.yml)
http.type: reactor-netty4
http.type: reactor-netty4-secure
8.2.3.4 - Настройки обнаружения и шлюза
Следующие настройки относятся к процессу обнаружения и локальному шлюзу.
Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
Настройки обнаружения
Процесс обнаружения используется при формировании кластера. Он включает в себя обнаружение узлов и выбор узла-менеджера кластера. OpenSearch поддерживает следующие настройки обнаружения:
discovery.seed_hosts (Статическая, список): Список хостов, которые выполняют обнаружение при запуске узла. По умолчанию список хостов:
["127.0.0.1", "[::1]"].discovery.seed_providers (Статическая, список): Указывает типы провайдеров начальных хостов, которые будут использоваться для получения адресов начальных узлов с целью запуска процесса обнаружения.
discovery.type (Статическая, строка): По умолчанию OpenSearch формирует кластер с несколькими узлами. Установите
discovery.typeвsingle-node, чтобы сформировать кластер с одним узлом.cluster.initial_cluster_manager_nodes (Статическая, список): Список узлов, имеющих право быть узлами-менеджерами кластера, используемых для начальной загрузки кластера.
Настройки шлюза
Локальный шлюз хранит состояние кластера и данные шардов, которые используются при перезапуске кластера. OpenSearch поддерживает следующие настройки локального шлюза:
gateway.recover_after_nodes (Статическая, целое число): После полного перезапуска кластера количество узлов, которые должны присоединиться к кластеру, прежде чем может начаться восстановление.
gateway.recover_after_data_nodes (Статическая, целое число): После полного перезапуска кластера количество узлов данных, которые должны присоединиться к кластеру, прежде чем может начаться восстановление.
gateway.expected_data_nodes (Статическая, целое число): Ожидаемое количество узлов данных, которые должны существовать в кластере. После того как ожидаемое количество узлов присоединится к кластеру, может начаться восстановление локальных шардов.
gateway.recover_after_time (Статическая, значение времени): Количество времени, которое нужно подождать перед началом восстановления, если количество узлов данных меньше ожидаемого количества узлов данных.
8.2.3.5 - Настройки безопасности
Плагин безопасности предоставляет ряд файлов конфигурации YAML, которые используются для хранения необходимых настроек, определяющих, как плагин безопасности управляет пользователями, ролями и активностью внутри кластера.
Для полного списка файлов конфигурации плагина безопасности см. раздел Изменение файлов YAML.
Следующие разделы описывают настройки, связанные с безопасностью, в файле opensearch.yml. Вы можете найти opensearch.yml в <OPENSEARCH_HOME>/config/opensearch.yml. Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
Общие настройки
Плагин безопасности поддерживает следующие общие настройки:
plugins.security.nodes_dn (Статическая): Указывает список отличительных имен (DN), обозначающих другие узлы в кластере. Эта настройка поддерживает подстановочные знаки и регулярные выражения. Список DN также считывается из индекса безопасности, помимо конфигурации YAML, когда
plugins.security.nodes_dn_dynamic_config_enabledустановлено в true. Если эта настройка не настроена правильно, кластер не сможет сформироваться, так как узлы не смогут доверять друг другу, что приведет к следующей ошибке: “Аутентификация транспортного клиента больше не поддерживается”.plugins.security.nodes_dn_dynamic_config_enabled (Статическая): Актуально для сценариев использования кросс-кластера, где необходимо управлять разрешенными узлами DN без необходимости перезапускать узлы каждый раз, когда настраивается новый удаленный кросс-кластер. Установка
nodes_dn_dynamic_config_enabledв true включает доступные для супер-администратора API для отличительных имен, которые предоставляют средства для динамического обновления или получения узлов DN. Эта настройка имеет эффект только еслиplugins.security.cert.intercluster_request_evaluator_classне установлено. По умолчанию — false.plugins.security.authcz.admin_dn (Статическая): Определяет DN сертификатов, к которым должны быть назначены административные привилегии. Обязательно.
plugins.security.roles_mapping_resolution (Статическая): Определяет, как бэкенд-ролям сопоставляются роли безопасности. Поддерживаются следующие значения:
- MAPPING_ONLY (По умолчанию): Сопоставления должны быть явно настроены в
roles_mapping.yml. - BACKENDROLES_ONLY: Бэкенд-роли сопоставляются с ролями безопасности напрямую. Настройки в
roles_mapping.ymlне имеют эффекта. - BOTH: Бэкенд-роли сопоставляются с ролями безопасности как напрямую, так и через
roles_mapping.yml.
- MAPPING_ONLY (По умолчанию): Сопоставления должны быть явно настроены в
plugins.security.dls.mode (Статическая): Устанавливает режим оценки безопасности на уровне документа (DLS). По умолчанию — адаптивный. См. раздел Как установить режим оценки DLS.
plugins.security.compliance.salt (Статическая): Соль, используемая при генерации хеш-значения для маскирования полей. Должна содержать не менее 32 символов. Разрешены только ASCII-символы. Необязательно.
plugins.security.compliance.immutable_indices (Статическая): Документы в индексах, помеченных как неизменяемые, следуют парадигме “запись один раз, чтение много раз”. Документы, созданные в этих индексах, не могут быть изменены и, следовательно, являются неизменяемыми.
config.dynamic.http.anonymous_auth_enabled (Статическая): Включает анонимную аутентификацию. Это приведет к тому, что все HTTP-аутентификаторы не будут вызывать запросы на аутентификацию. По умолчанию — false.
http.detailed_errors.enabled (Статическая): Включает подробное сообщение об ошибке для REST-вызовов, выполненных против кластера OpenSearch. Если установлено в true, предоставляет
root_causeвместе с кодом ошибки. По умолчанию — true.
Настройки API управления REST
Плагин безопасности поддерживает следующие настройки API управления REST:
plugins.security.restapi.roles_enabled (Статическая): Включает доступ к API управления REST на основе ролей для указанных ролей. Роли разделяются запятой. По умолчанию — пустой список (ни одна роль не имеет доступа к API управления REST). См. раздел Контроль доступа для API.
plugins.security.restapi.endpoints_disabled.
. (Статическая): Отключает конкретные конечные точки и их HTTP-методы для ролей. Значения для этой настройки составляют массив HTTP-методов. Например:plugins.security.restapi.endpoints_disabled.all_access.ACTIONGROUPS: ["PUT","POST","DELETE"]. По умолчанию все конечные точки и методы разрешены. Существующие конечные точки включают ACTIONGROUPS, CACHE, CONFIG, ROLES, ROLESMAPPING, INTERNALUSERS, SYSTEMINFO, PERMISSIONSINFO и LICENSE. См. раздел Контроль доступа для API.plugins.security.restapi.password_validation_regex (Статическая): Указывает регулярное выражение для задания критериев для пароля при входе. Для получения дополнительной информации см. раздел Настройки пароля.
plugins.security.restapi.password_validation_error_message (Статическая): Указывает сообщение об ошибке, которое отображается, когда пароль не проходит проверку. Эта настройка используется вместе с
plugins.security.restapi.password_validation_regex.plugins.security.restapi.password_min_length (Статическая): Устанавливает минимальное количество символов для длины пароля при использовании оценщика силы пароля на основе баллов. По умолчанию — 8. Это также является минимальным значением. Для получения дополнительной информации см. раздел Настройки пароля.
plugins.security.restapi.password_score_based_validation_strength (Статическая): Устанавливает порог для определения, является ли пароль сильным или слабым. Допустимые значения: fair, good, strong и very_strong. Эта настройка используется вместе с
plugins.security.restapi.password_min_length.plugins.security.unsupported.restapi.allow_securityconfig_modification (Статическая): Включает использование методов PUT и PATCH для API конфигурации.
Расширенные настройки
Плагин безопасности поддерживает следующие расширенные настройки:
plugins.security.authcz.impersonation_dn (Статическая): Включает подмену на уровне транспортного слоя. Это позволяет DN выдавать себя за других пользователей. См. раздел Подмена пользователей.
plugins.security.authcz.rest_impersonation_user (Статическая): Включает подмену на уровне REST. Это позволяет пользователям выдавать себя за других пользователей. См. раздел Подмена пользователей.
plugins.security.allow_default_init_securityindex (Статическая): При установке в true OpenSearch Security автоматически инициализирует индекс конфигурации с файлами из директории
/config, если индекс не существует.Это будет использовать известные стандартные пароли. Используйте только в частной сети/окружении.
plugins.security.allow_unsafe_democertificates (Статическая): При установке в true OpenSearch запускается с демонстрационными сертификатами. Эти сертификаты выданы только для демонстрационных целей.
Эти сертификаты хорошо известны и, следовательно, небезопасны для использования в производственной среде. Используйте только в частной сети/окружении.
plugins.security.system_indices.permission.enabled (Статическая): Включает функцию разрешений для системных индексов. При установке в true функция включена, и пользователи с разрешением на изменение ролей могут создавать роли, которые включают разрешения, предоставляющие доступ к системным индексам. При установке в false разрешение отключено, и только администраторы с административным сертификатом могут вносить изменения в системные индексы. По умолчанию разрешение установлено в false в новом кластере.
Настройки уровня эксперта
Настройки уровня эксперта должны настраиваться и развертываться только администратором, который полностью понимает данную функцию. Неправильное понимание функции может привести к рискам безопасности, неправильной работе плагина безопасности или потере данных.
Плагин безопасности поддерживает следующие настройки уровня эксперта:
plugins.security.config_index_name (Статическая): Имя индекса, в котором .opendistro_security хранит свою конфигурацию.
plugins.security.cert.oid (Статическая): Определяет идентификатор объекта (OID) сертификатов узлов сервера.
plugins.security.cert.intercluster_request_evaluator_class (Статическая): Указывает реализацию
org.opensearch.security.transport.InterClusterRequestEvaluator, которая используется для оценки межкластерных запросов. Экземплярыorg.opensearch.security.transport.InterClusterRequestEvaluatorдолжны реализовывать конструктор с одним аргументом, принимающим объектorg.opensearch.common.settings.Settings.plugins.security.enable_snapshot_restore_privilege (Статическая): При установке в false эта настройка отключает восстановление снимков для обычных пользователей. В этом случае принимаются только запросы на восстановление снимков, подписанные административным TLS-сертификатом. При установке в true (по умолчанию) обычные пользователи могут восстанавливать снимки, если у них есть привилегии
cluster:admin/snapshot/restore,indices:admin/createиindices:data/write/index.Снимок можно восстановить только в том случае, если он не содержит глобального состояния и не восстанавливает индекс .opendistro_security.
plugins.security.check_snapshot_restore_write_privileges (Статическая): При установке в false дополнительные проверки индекса пропускаются. При установке по умолчанию в true попытки восстановить снимки оцениваются на наличие привилегий
indices:admin/createиindices:data/write/index.plugins.security.cache.ttl_minutes (Статическая): Определяет, как долго кэш аутентификации будет действителен. Кэш аутентификации помогает ускорить аутентификацию, временно храня объекты пользователей, возвращаемые из бэкенда, чтобы плагин безопасности не требовал повторных запросов к ним. Установите значение в минутах. По умолчанию — 60. Отключите кэширование, установив значение в 0.
plugins.security.disabled (Статическая): Отключает OpenSearch Security.
Отключение этого плагина может подвергнуть вашу конфигурацию (включая пароли) публичному доступу.
plugins.security.protected_indices.enabled (Статическая): Если установлено в true, включает защищенные индексы. Защищенные индексы более безопасны, чем обычные индексы. Эти индексы требуют роли для доступа, как и любой другой традиционный индекс, и требуют дополнительной роли для видимости. Эта настройка используется вместе с настройками
plugins.security.protected_indices.rolesиplugins.security.protected_indices.indices.plugins.security.protected_indices.roles (Статическая): Указывает список ролей, к которым пользователь должен быть сопоставлен для доступа к защищенным индексам.
plugins.security.protected_indices.indices (Статическая): Указывает список индексов, которые следует пометить как защищенные. Эти индексы будут видны только пользователям, сопоставленным с ролями, указанными в
plugins.security.protected_indices.roles. После выполнения этого требования пользователю все равно потребуется быть сопоставленным с традиционной ролью, используемой для предоставления разрешения на доступ к индексу.plugins.security.system_indices.enabled (Статическая): Если установлено в true, включает системные индексы. Системные индексы аналогичны индексу безопасности, за исключением того, что их содержимое не зашифровано. Индексы, настроенные как системные индексы, могут быть доступны либо супер-администратором, либо пользователем с ролью, включающей разрешение на системный индекс. Для получения дополнительной информации о системных индексах см. раздел Системные индексы.
plugins.security.system_indices.indices (Статическая): Список индексов, которые будут использоваться как системные индексы. Эта настройка контролируется настройкой
plugins.security.system_indices.enabled.plugins.security.allow_default_init_securityindex (Статическая): При установке в true устанавливает плагин безопасности в его стандартные настройки безопасности, если попытка создать индекс безопасности завершается неудачей при запуске OpenSearch. Стандартные настройки безопасности хранятся в YAML-файлах, находящихся в директории
opensearch-project/security/config. По умолчанию — false.plugins.security.cert.intercluster_request_evaluator_class (Статическая): Класс, который будет использоваться для оценки межкластерной связи.
plugins.security.enable_snapshot_restore_privilege (Статическая): Включает предоставление привилегии восстановления снимков. Необязательно. По умолчанию — true.
plugins.security.check_snapshot_restore_write_privileges (Статическая): Обеспечивает оценку привилегий записи при создании снимков. По умолчанию — true.
Если вы измените любое из следующих свойств хеширования паролей, вам необходимо повторно хешировать все внутренние пароли для обеспечения совместимости и безопасности.
plugins.security.password.hashing.algorithm (Статическая): Указывает алгоритм хеширования паролей, который следует использовать. Поддерживаются следующие значения:
- BCrypt (По умолчанию)
- PBKDF2
- Argon2
plugins.security.password.hashing.bcrypt.rounds (Статическая): Указывает количество раундов, используемых для хеширования паролей с помощью BCrypt. Допустимые значения находятся в диапазоне от 4 до 31, включая. По умолчанию — 12.
plugins.security.password.hashing.bcrypt.minor (Статическая): Указывает минорную версию алгоритма BCrypt, используемую для хеширования паролей. Поддерживаются следующие значения:
- A
- B
- Y (По умолчанию)
plugins.security.password.hashing.pbkdf2.function (Статическая): Указывает псевдослучайную функцию, применяемую к паролю. Поддерживаются следующие значения:
- SHA1
- SHA224
- SHA256 (По умолчанию)
- SHA384
- SHA512
plugins.security.password.hashing.pbkdf2.iterations (Статическая): Указывает количество раз, которое псевдослучайная функция применяется к паролю. По умолчанию — 600,000.
plugins.security.password.hashing.pbkdf2.length (Статическая): Указывает желаемую длину окончательного производного ключа. По умолчанию — 256.
plugins.security.password.hashing.argon2.iterations (Статическая): Указывает количество проходов по памяти, которые выполняет алгоритм. Увеличение этого значения увеличивает время вычислений на ЦП и улучшает устойчивость к атакам грубой силы. По умолчанию — 3.
plugins.security.password.hashing.argon2.memory (Статическая): Указывает количество памяти (в кибибайтах), используемой во время хеширования. По умолчанию — 65536 (64 МиБ).
plugins.security.password.hashing.argon2.parallelism (Статическая): Указывает количество параллельных потоков, используемых для вычислений. По умолчанию — 1.
plugins.security.password.hashing.argon2.length (Статическая): Указывает длину (в байтах) результирующего хеш-выхода. По умолчанию — 32.
plugins.security.password.hashing.argon2.type (Статическая): Указывает, какой вариант Argon2 использовать. Поддерживаются следующие значения:
- Argon2i
- Argon2d
- Argon2id (по умолчанию)
plugins.security.password.hashing.argon2.version (Статическая): Указывает, какую версию Argon2 использовать. Поддерживаются следующие значения:
- 16
- 19 (по умолчанию)
Настройки журнала аудита
Плагин безопасности поддерживает следующие настройки журнала аудита:
plugins.security.audit.enable_rest (Динамическая): Включает или отключает ведение журнала REST-запросов. По умолчанию установлено в true (включено).
plugins.security.audit.enable_transport (Динамическая): Включает или отключает ведение журнала запросов на уровне транспорта. По умолчанию установлено в false (выключено).
plugins.security.audit.resolve_bulk_requests (Динамическая): Включает или отключает ведение журнала пакетных запросов. При включении все подзапросы в пакетных запросах также записываются в журнал. По умолчанию установлено в false (выключено).
plugins.security.audit.config.disabled_categories (Динамическая): Отключает указанные категории событий.
plugins.security.audit.ignore_requests (Динамическая): Исключает указанные запросы из ведения журнала. Поддерживает подстановочные знаки и регулярные выражения, содержащие действия или пути REST-запросов.
plugins.security.audit.threadpool.size (Статическая): Определяет количество потоков в пуле потоков, используемом для ведения журнала событий. По умолчанию установлено в 10. Установка этого значения в 0 отключает пул потоков, что означает, что плагин ведет журнал событий синхронно.
plugins.security.audit.threadpool.max_queue_len (Статическая): Устанавливает максимальную длину очереди на поток. По умолчанию установлено в 100000.
plugins.security.audit.ignore_users (Динамическая): Массив пользователей. Запросы аудита от пользователей в списке не будут записываться в журнал.
plugins.security.audit.type (Статическая): Назначение событий журнала аудита. Допустимые значения: internal_opensearch, external_opensearch, debug и webhook.
plugins.security.audit.config.http_endpoints (Статическая): Список конечных точек для localhost.
plugins.security.audit.config.index (Статическая): Индекс журнала аудита. По умолчанию установлен auditlog6. Индекс может быть статическим или индексом, который включает дату, чтобы он вращался ежедневно, например, “‘auditlog6-‘YYYY.MM.dd”. В любом случае убедитесь, что индекс защищен должным образом.
plugins.security.audit.config.type (Статическая): Укажите тип журнала аудита как auditlog.
plugins.security.audit.config.username (Статическая): Имя пользователя для конфигурации журнала аудита.
plugins.security.audit.config.password (Статическая): Пароль для конфигурации журнала аудита.
plugins.security.audit.config.enable_ssl (Статическая): Включает или отключает SSL для ведения журнала аудита.
plugins.security.audit.config.verify_hostnames (Статическая): Включает или отключает проверку имени хоста для SSL/TLS сертификатов. По умолчанию установлено в true (включено).
plugins.security.audit.config.enable_ssl_client_auth (Статическая): Включает или отключает аутентификацию клиента SSL/TLS. По умолчанию установлено в false (выключено).
plugins.security.audit.config.cert_alias (Статическая): Псевдоним для сертификата, используемого для доступа к журналу аудита.
plugins.security.audit.config.pemkey_filepath (Статическая): Относительный путь к файлу ключа Privacy Enhanced Mail (PEM), используемого для ведения журнала аудита.
plugins.security.audit.config.pemkey_content (Статическая): Содержимое PEM-ключа, закодированное в base64, используемого для ведения журнала аудита. Это альтернатива …config.pemkey_filepath.
plugins.security.audit.config.pemkey_password (Статическая): Пароль для частного ключа в формате PEM, используемого клиентом.
plugins.security.audit.config.pemcert_filepath (Статическая): Относительный путь к файлу PEM-сертификата, используемого для ведения журнала аудита.
plugins.security.audit.config.pemcert_content (Статическая): Содержимое PEM-сертификата, закодированное в base64, используемого для ведения журнала аудита. Это альтернатива указанию пути к файлу с помощью …config.pemcert_filepath.
plugins.security.audit.config.pemtrustedcas_filepath (Статическая): Относительный путь к файлу доверенного корневого центра сертификации.
plugins.security.audit.config.pemtrustedcas_content (Статическая): Содержимое корневого центра сертификации, закодированное в base64. Это альтернатива …config.pemtrustedcas_filepath.
plugins.security.audit.config.webhook.url (Статическая): URL вебхука.
plugins.security.audit.config.webhook.format (Статическая): Формат, используемый для вебхука. Допустимые значения: URL_PARAMETER_GET, URL_PARAMETER_POST, TEXT, JSON и SLACK.
plugins.security.audit.config.webhook.ssl.verify (Статическая): Включает или отключает проверку любых SSL/TLS сертификатов, отправленных с любым запросом вебхука. По умолчанию установлено в true (включено).
plugins.security.audit.config.webhook.ssl.pemtrustedcas_filepath (Статическая): Относительный путь к файлу доверенного центра сертификации, против которого проверяются запросы вебхука.
plugins.security.audit.config.webhook.ssl.pemtrustedcas_content (Статическая): Содержимое центра сертификации, используемого для проверки запросов вебхука, закодированное в base64. Это альтернатива …config.pemtrustedcas_filepath.
plugins.security.audit.config.log4j.logger_name (Статическая): Пользовательское имя для логгера Log4j.
plugins.security.audit.config.log4j.level (Статическая): Устанавливает уровень журнала по умолчанию для логгера Log4j. Допустимые значения: OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE и ALL. По умолчанию установлено в INFO.
opendistro_security.audit.config.disabled_rest_categories (Динамическая): Список категорий REST, которые будут игнорироваться логгером. Допустимые значения: AUTHENTICATED и GRANTED_PRIVILEGES.
opendistro_security.audit.config.disabled_transport_categories (Динамическая): Список категорий на транспортном уровне, которые будут игнорироваться логгером. Допустимые значения: AUTHENTICATED и GRANTED_PRIVILEGES.
Настройки проверки имени хоста и DNS
Плагин безопасности поддерживает следующие настройки проверки имени хоста и DNS:
plugins.security.ssl.transport.enforce_hostname_verification (Статическая): Указывает, следует ли проверять имена хостов на транспортном уровне. Необязательно. По умолчанию установлено в true.
plugins.security.ssl.transport.resolve_hostname (Статическая): Указывает, следует ли разрешать имена хостов через DNS на транспортном уровне. Необязательно. По умолчанию установлено в true. Работает только если включена проверка имени хоста.
Для получения дополнительной информации см. раздел Проверка имени хоста и разрешение DNS.
Настройки аутентификации клиента
Плагин безопасности поддерживает следующую настройку аутентификации клиента:
- plugins.security.ssl.http.clientauth_mode (Статическая): Режим аутентификации клиента TLS, который следует использовать. Допустимые значения: OPTIONAL (по умолчанию), REQUIRE и NONE. Необязательно.
Для получения дополнительной информации см. раздел Аутентификация клиента.
Настройки включенных шифров и протоколов
Плагин безопасности поддерживает следующие настройки включенных шифров и протоколов. Каждая настройка должна быть выражена в массиве:
plugins.security.ssl.http.enabled_ciphers (Статическая): Включенные шифры TLS для REST-уровня. Поддерживается только формат Java.
plugins.security.ssl.http.enabled_protocols (Статическая): Включенные протоколы TLS для REST-уровня. Поддерживается только формат Java.
plugins.security.ssl.transport.enabled_ciphers (Статическая): Включенные шифры TLS для транспортного уровня. Поддерживается только формат Java.
plugins.security.ssl.transport.enabled_protocols (Статическая): Включенные протоколы TLS для транспортного уровня. Поддерживается только формат Java.
Для получения дополнительной информации см. раздел Включенные шифры и протоколы.
Файлы хранилища ключей и доверенных сертификатов — настройки TLS на транспортном уровне
Плагин безопасности поддерживает следующие настройки хранилища ключей и доверенных сертификатов для транспортного уровня TLS:
plugins.security.ssl.transport.keystore_type (Статическая): Тип файла хранилища ключей. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
plugins.security.ssl.transport.keystore_filepath (Статическая): Путь к файлу хранилища ключей, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.transport.keystore_alias (Статическая): Имя псевдонима хранилища ключей. Необязательно. По умолчанию используется первый псевдоним.
plugins.security.ssl.transport.keystore_password (Статическая): Пароль для хранилища ключей. По умолчанию установлено в changeit.
plugins.security.ssl.transport.truststore_type (Статическая): Тип файла доверенного хранилища. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
plugins.security.ssl.transport.truststore_filepath (Статическая): Путь к файлу доверенного хранилища, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.transport.truststore_alias (Статическая): Имя псевдонима доверенного хранилища. Необязательно. По умолчанию используются все сертификаты.
plugins.security.ssl.transport.truststore_password (Статическая): Пароль для доверенного хранилища. По умолчанию установлено в changeit.
Для получения дополнительной информации о файлах хранилища ключей и доверенных сертификатов см. раздел TLS на транспортном уровне.
Файлы хранилища ключей и доверенных сертификатов — настройки TLS на уровне REST
Плагин безопасности поддерживает следующие настройки хранилища ключей и доверенных сертификатов для уровня REST TLS:
plugins.security.ssl.http.enabled (Статическая): Указывает, следует ли включить TLS на уровне REST. Если включено, разрешен только HTTPS. Необязательно. По умолчанию установлено в false.
plugins.security.ssl.http.keystore_type (Статическая): Тип файла хранилища ключей. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
plugins.security.ssl.http.keystore_filepath (Статическая): Путь к файлу хранилища ключей, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.http.keystore_alias (Статическая): Имя псевдонима хранилища ключей. Необязательно. По умолчанию используется первый псевдоним.
plugins.security.ssl.http.keystore_password (Статическая): Пароль для хранилища ключей. По умолчанию установлено в changeit.
plugins.security.ssl.http.truststore_type (Статическая): Тип файла доверенного хранилища. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
plugins.security.ssl.http.truststore_filepath (Статическая): Путь к файлу доверенного хранилища, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.http.truststore_alias (Статическая): Имя псевдонима доверенного хранилища. Необязательно. По умолчанию используются все сертификаты.
plugins.security.ssl.http.truststore_password (Статическая): Пароль для доверенного хранилища. По умолчанию установлено в changeit.
Для получения дополнительной информации см. раздел TLS на уровне REST.
X.509 PEM-сертификаты и ключи PKCS #8 — настройки TLS на транспортном уровне
Плагин безопасности поддерживает следующие настройки TLS на транспортном уровне, связанные с X.509 PEM-сертификатами и ключами PKCS #8:
plugins.security.ssl.transport.pemkey_filepath (Статическая): Путь к файлу ключа сертификата (PKCS #8), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.transport.pemkey_password (Статическая): Пароль для ключа. Укажите эту настройку, если у ключа есть пароль. Необязательно.
plugins.security.ssl.transport.pemcert_filepath (Статическая): Путь к цепочке сертификатов узла X.509 (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.transport.pemtrustedcas_filepath (Статическая): Путь к корневым центрам сертификации (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
Для получения дополнительной информации см. раздел TLS на транспортном уровне.
X.509 PEM-сертификаты и ключи PKCS #8 — настройки TLS на уровне REST
Плагин безопасности поддерживает следующие настройки TLS на уровне REST, связанные с X.509 PEM-сертификатами и ключами PKCS #8:
plugins.security.ssl.http.enabled (Статическая): Указывает, следует ли включить TLS на уровне REST. Если включено, разрешен только HTTPS. Необязательно. По умолчанию установлено в false.
plugins.security.ssl.http.pemkey_filepath (Статическая): Путь к файлу ключа сертификата (PKCS #8), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.http.pemkey_password (Статическая): Пароль для ключа. Укажите эту настройку, если у ключа есть пароль. Необязательно.
plugins.security.ssl.http.pemcert_filepath (Статическая): Путь к цепочке сертификатов узла X.509 (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
plugins.security.ssl.http.pemtrustedcas_filepath (Статическая): Путь к корневым центрам сертификации (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
Для получения дополнительной информации см. раздел TLS на уровне REST.
Настройки безопасности на транспортном уровне
Плагин безопасности поддерживает следующие настройки безопасности на транспортном уровне:
plugins.security.ssl.transport.enabled (Статическая): Указывает, следует ли включить TLS на уровне REST.
plugins.security.ssl.transport.client.pemkey_password (Статическая): Пароль для частного ключа в формате PEM, используемого клиентом на транспортном уровне.
plugins.security.ssl.transport.keystore_keypassword (Статическая): Пароль для ключа внутри хранилища ключей.
plugins.security.ssl.transport.server.keystore_keypassword (Статическая): Пароль для ключа внутри хранилища ключей сервера.
plugins.security.ssl.transport.server.keystore_alias (Статическая): Имя псевдонима для хранилища ключей сервера.
plugins.security.ssl.transport.client.keystore_alias (Статическая): Имя псевдонима для хранилища ключей клиента.
plugins.security.ssl.transport.server.truststore_alias (Статическая): Имя псевдонима для доверенного хранилища сервера.
plugins.security.ssl.transport.client.truststore_alias (Статическая): Имя псевдонима для доверенного хранилища клиента.
plugins.security.ssl.client.external_context_id (Статическая): Предоставляет клиенту на транспортном уровне идентификатор для использования внешнего SSL-контекста.
plugins.security.ssl.transport.principal_extractor_class (Статическая): Указывает класс, реализующий извлечение, чтобы использовать пользовательскую часть сертификата в качестве основного.
plugins.security.ssl.http.crl.file_path (Статическая): Путь к файлу списка отозванных сертификатов (CRL).
plugins.security.ssl.http.crl.validate (Статическая): Включает проверку списка отозванных сертификатов (CRL). По умолчанию установлено в false (выключено).
plugins.security.ssl.http.crl.prefer_crlfile_over_ocsp (Статическая): Указывает, следует ли предпочитать запись сертификата CRL перед записью протокола статуса сертификата в режиме онлайн (OCSP), если сертификат содержит обе записи. Необязательно. По умолчанию установлено в false.
plugins.security.ssl.http.crl.check_only_end_entities (Статическая): Если установлено в true, проверяются только конечные сертификаты. По умолчанию установлено в true.
plugins.security.ssl.http.crl.disable_ocsp (Статическая): Отключает OCSP. По умолчанию установлено в false (OCSP включен).
plugins.security.ssl.http.crl.disable_crldp (Статическая): Отключает конечные точки CRL в сертификатах. По умолчанию установлено в false (конечные точки CRL включены).
plugins.security.ssl.allow_client_initiated_renegotiation (Статическая): Включает или отключает повторнуюNegotiation, инициированную клиентом. По умолчанию установлено в false (повторнаяNegotiation, инициированная клиентом, не разрешена).
Примеры настроек плагина безопасности
# Common configuration settings
plugins.security.nodes_dn:
- "CN=*.example.com, OU=SSL, O=Test, L=Test, C=DE"
- "CN=node.other.com, OU=SSL, O=Test, L=Test, C=DE"
- "CN=node.example.com, OU=SSL\\, Inc., L=Test, C=DE" # escape additional comma with `\\`
plugins.security.authcz.admin_dn:
- CN=kirk,OU=client,O=client,L=test, C=de
plugins.security.roles_mapping_resolution: MAPPING_ONLY
plugins.security.ssl.transport.pemcert_filepath: esnode.pem
plugins.security.ssl.transport.pemkey_filepath: esnode-key.pem
plugins.security.ssl.transport.pemtrustedcas_filepath: root-ca.pem
plugins.security.ssl.transport.enforce_hostname_verification: false
plugins.security.ssl.http.enabled: true
plugins.security.ssl.http.pemcert_filepath: esnode.pem
plugins.security.ssl.http.pemkey_filepath: esnode-key.pem
plugins.security.ssl.http.pemtrustedcas_filepath: root-ca.pem
plugins.security.allow_unsafe_democertificates: true
plugins.security.allow_default_init_securityindex: true
plugins.security.nodes_dn_dynamic_config_enabled: false
plugins.security.cert.intercluster_request_evaluator_class: # need example value for this.
plugins.security.audit.type: internal_opensearch
plugins.security.enable_snapshot_restore_privilege: true
plugins.security.check_snapshot_restore_write_privileges: true
plugins.security.cache.ttl_minutes: 60
plugins.security.restapi.roles_enabled: ["all_access", "security_rest_api_access"]
plugins.security.system_indices.enabled: true
plugins.security.system_indices.indices: [".opendistro-alerting-config", ".opendistro-alerting-alert*", ".opendistro-anomaly-results*", ".opendistro-anomaly-detector*", ".opendistro-anomaly-checkpoints", ".opendistro-anomaly-detection-state", ".opendistro-reports-*", ".opendistro-notifications-*", ".opendistro-notebooks", ".opendistro-asynchronous-search-response*"]
node.max_local_storage_nodes: 3
plugins.security.restapi.password_validation_regex: '(?=.*[A-Z])(?=.*[^a-zA-Z\d])(?=.*[0-9])(?=.*[a-z]).{8,}'
plugins.security.restapi.password_validation_error_message: "Password must be minimum 8 characters long and must contain at least one uppercase letter, one lowercase letter, one digit, and one special character."
plugins.security.allow_default_init_securityindex: true
plugins.security.cache.ttl_minutes: 60
#
# REST Management API configuration settings
plugins.security.restapi.roles_enabled: ["all_access","xyz_role"]
plugins.security.restapi.endpoints_disabled.all_access.ACTIONGROUPS: ["PUT","POST","DELETE"] # Alternative example: plugins.security.restapi.endpoints_disabled.xyz_role.LICENSE: ["DELETE"] #
# Audit log configuration settings
plugins.security.audit.enable_rest: true
plugins.security.audit.enable_transport: false
plugins.security.audit.resolve_bulk_requests: false
plugins.security.audit.config.disabled_categories: ["AUTHENTICATED","GRANTED_PRIVILEGES"]
plugins.security.audit.ignore_requests: ["indices:data/read/*","*_bulk"]
plugins.security.audit.threadpool.size: 10
plugins.security.audit.threadpool.max_queue_len: 100000
plugins.security.audit.ignore_users: ['kibanaserver','some*user','/also.*regex possible/']
plugins.security.audit.type: internal_opensearch
#
# external_opensearch settings
plugins.security.audit.config.http_endpoints: ['localhost:9200','localhost:9201','localhost:9202']
plugins.security.audit.config.index: "'auditlog6-'2023.06.15"
plugins.security.audit.config.type: auditlog
plugins.security.audit.config.username: auditloguser
plugins.security.audit.config.password: auditlogpassword
plugins.security.audit.config.enable_ssl: false
plugins.security.audit.config.verify_hostnames: false
plugins.security.audit.config.enable_ssl_client_auth: false
plugins.security.audit.config.cert_alias: mycert
plugins.security.audit.config.pemkey_filepath: key.pem
plugins.security.audit.config.pemkey_content: <...pem base 64 content>
plugins.security.audit.config.pemkey_password: secret
plugins.security.audit.config.pemcert_filepath: cert.pem
plugins.security.audit.config.pemcert_content: <...pem base 64 content>
plugins.security.audit.config.pemtrustedcas_filepath: ca.pem
plugins.security.audit.config.pemtrustedcas_content: <...pem base 64 content>
#
# Webhook settings
plugins.security.audit.config.webhook.url: "http://mywebhook/endpoint"
plugins.security.audit.config.webhook.format: JSON
plugins.security.audit.config.webhook.ssl.verify: false
plugins.security.audit.config.webhook.ssl.pemtrustedcas_filepath: ca.pem
plugins.security.audit.config.webhook.ssl.pemtrustedcas_content: <...pem base 64 content>
#
# log4j settings
plugins.security.audit.config.log4j.logger_name: auditlogger
plugins.security.audit.config.log4j.level: INFO
#
# Advanced configuration settings
plugins.security.authcz.impersonation_dn:
"CN=spock,OU=client,O=client,L=Test,C=DE":
- worf
"cn=webuser,ou=IT,ou=IT,dc=company,dc=com":
- user2
- user1
plugins.security.authcz.rest_impersonation_user:
"picard":
- worf
"john":
- steve
- martin
plugins.security.allow_default_init_securityindex: false
plugins.security.allow_unsafe_democertificates: false
plugins.security.cache.ttl_minutes: 60
plugins.security.restapi.password_validation_regex: '(?=.*[A-Z])(?=.*[^a-zA-Z\d])(?=.*[0-9])(?=.*[a-z]).{8,}'
plugins.security.restapi.password_validation_error_message: "A password must be at least 8 characters long and contain at least one uppercase letter, one lowercase letter, one digit, and one special character."
plugins.security.restapi.password_min_length: 8
plugins.security.restapi.password_score_based_validation_strength: very_strong
#
# Advanced SSL settings - use only if you understand SSL ins and outs
plugins.security.ssl.transport.client.pemkey_password: superSecurePassword1
plugins.security.ssl.transport.keystore_keypassword: superSecurePassword2
plugins.security.ssl.transport.server.keystore_keypassword: superSecurePassword3
plugins.security.ssl.http.keystore_keypassword: superSecurePassword4
plugins.security.ssl.http.clientauth_mode: REQUIRE
plugins.security.ssl.transport.enabled: true
plugins.security.ssl.transport.server.keystore_alias: my_alias
plugins.security.ssl.transport.client.keystore_alias: my_other_alias
plugins.security.ssl.transport.server.truststore_alias: trustore_alias_1
plugins.security.ssl.transport.client.truststore_alias: trustore_alias_2
plugins.security.ssl.client.external_context_id: my_context_id
plugins.security.ssl.transport.principal_extractor_class: org.opensearch.security.ssl.ExampleExtractor
plugins.security.ssl.http.crl.file_path: ssl/crl/revoked.crl
plugins.security.ssl.http.crl.validate: true
plugins.security.ssl.http.crl.prefer_crlfile_over_ocsp: true
plugins.security.ssl.http.crl.check_only_end_entitites: false
plugins.security.ssl.http.crl.disable_ocsp: true
plugins.security.ssl.http.crl.disable_crldp: true
plugins.security.ssl.allow_client_initiated_renegotiation: true
#
# Expert settings - use only if you understand their use completely: accidental values can potentially cause security risks or failures to OpenSearch Security.
plugins.security.config_index_name: .opendistro_security
plugins.security.cert.oid: '1.2.3.4.5.5'
plugins.security.cert.intercluster_request_evaluator_class: org.opensearch.security.transport.DefaultInterClusterRequestEvaluator
plugins.security.enable_snapshot_restore_privilege: true
plugins.security.check_snapshot_restore_write_privileges: true
plugins.security.cache.ttl_minutes: 60
plugins.security.disabled: false
plugins.security.protected_indices.enabled: true
plugins.security.protected_indices.roles: ['all_access']
plugins.security.protected_indices.indices: []
plugins.security.system_indices.enabled: true
plugins.security.system_indices.indices: ['.opendistro-alerting-config', '.opendistro-ism-*', '.opendistro-reports-*', '.opensearch-notifications-*', '.opensearch-notebooks', '.opensearch-observability', '.opendistro-asynchronous-search-response*', '.replication-metadata-store']
8.2.3.6 - Настройки предохранителей
Предохранители предотвращают возникновение ошибки Java OutOfMemoryError в OpenSearch.
Родительский предохранитель указывает общее доступное количество памяти для всех дочерних предохранителей. Дочерние предохранители указывают общее доступное количество памяти для себя.
Для получения дополнительной информации о статических и динамических настройках см. раздел Конфигурация OpenSearch.
Настройки родительского предохранителя
OpenSearch поддерживает следующие настройки родительского предохранителя:
indices.breaker.total.use_real_memory (Статическая, логическая): Если установлено в true, родительский предохранитель учитывает фактическое использование памяти. В противном случае родительский предохранитель учитывает количество памяти, зарезервированной дочерними предохранителями. По умолчанию установлено в true.
indices.breaker.total.limit (Динамическая, процент): Указывает начальный лимит памяти для родительского предохранителя. Если indices.breaker.total.use_real_memory установлено в true, по умолчанию составляет 95% кучи JVM. Если indices.breaker.total.use_real_memory установлено в false, по умолчанию составляет 70% кучи JVM.
Настройки предохранителя данных полей
Предохранитель данных полей ограничивает объем памяти кучи, необходимый для загрузки поля в кэш данных полей. OpenSearch поддерживает следующие настройки предохранителя данных полей:
indices.breaker.fielddata.limit (Динамическая, процент): Указывает лимит памяти для предохранителя данных полей. По умолчанию составляет 40% кучи JVM.
indices.breaker.fielddata.overhead (Динамическая, дробное число): Константа, на которую умножаются оценки данных полей для определения окончательной оценки. По умолчанию составляет 1.03.
Настройки предохранителя запросов
Предохранитель запросов ограничивает объем памяти, необходимый для построения структур данных, необходимых для запроса (например, при вычислении агрегатов). OpenSearch поддерживает следующие настройки предохранителя запросов:
indices.breaker.request.limit (Динамическая, процент): Указывает лимит памяти для предохранителя запросов. По умолчанию составляет 60% кучи JVM.
indices.breaker.request.overhead (Динамическая, дробное число): Константа, на которую умножаются оценки запросов для определения окончательной оценки. По умолчанию составляет 1.
Настройки предохранителя текущих запросов
Предохранитель текущих запросов ограничивает использование памяти для всех текущих входящих запросов на транспортном и HTTP-уровне. Использование памяти для запроса основано на длине содержимого запроса и включает память, необходимую для необработанного запроса и структурированного объекта, представляющего запрос. OpenSearch поддерживает следующие настройки предохранителя текущих запросов:
network.breaker.inflight_requests.limit (Динамическая, процент): Указывает лимит памяти для предохранителя текущих запросов. По умолчанию составляет 100% кучи JVM (таким образом, лимит использования памяти для текущего запроса определяется лимитом памяти родительского предохранителя).
network.breaker.inflight_requests.overhead (Динамическая, дробное число): Константа, на которую умножаются оценки текущих запросов для определения окончательной оценки. По умолчанию составляет 2.
Настройки предохранителя компиляции скриптов
Предохранитель компиляции скриптов ограничивает количество компиляций встроенных скриптов в течение временного интервала. OpenSearch поддерживает следующую настройку предохранителя компиляции скриптов:
- script.max_compilations_rate (Динамическая, ставка): Максимальное количество уникальных динамических скриптов, скомпилированных в течение временного интервала для данного контекста. По умолчанию составляет 150 каждые 5 минут (150/5m).
Настройки предохранителя регулярных выражений
Предохранитель регулярных выражений включает или отключает регулярные выражения и ограничивает их сложность. OpenSearch поддерживает следующие настройки предохранителя регулярных выражений:
script.painless.regex.enabled (Статическая, строка): Включает регулярные выражения в скриптах Painless. Допустимые значения:
- limited: Включает регулярные выражения и ограничивает их сложность с помощью настройки script.painless.regex.limit-factor.
- true: Включает регулярные выражения. Отключает предохранитель регулярных выражений и не ограничивает сложность регулярных выражений.
- false: Отключает регулярные выражения. Если скрипт Painless содержит регулярное выражение, возвращает ошибку.
По умолчанию установлено в limited.
script.painless.regex.limit-factor (Статическая, целое число): Применяется только если script.painless.regex.enabled установлено в limited. Ограничивает количество символов, которые может содержать регулярное выражение в скрипте Painless. Лимит символов рассчитывается путем умножения количества символов во входных данных скрипта на script.painless.regex.limit-factor. По умолчанию составляет 6 (таким образом, если входные данные содержат 5 символов, максимальное количество символов в регулярном выражении составляет 5 · 6 = 30).
8.2.3.7 - Настройка кластера
Следующие настройки относятся к кластеру OpenSearch.
Чтобы узнать больше о статических и динамических настройках, смотрите раздел Настройка OpenSearch.
Настройки маршрутизации и распределения на уровне кластера
OpenSearch поддерживает следующие настройки маршрутизации на уровне кластера и распределения шардов:
cluster.routing.allocation.enable (Динамическая, строка)
Включает или отключает распределение для определенных типов шардов.
Допустимые значения:
- all – Разрешает распределение шардов для всех типов шардов.
- primaries – Разрешает распределение шардов только для первичных шардов.
- new_primaries – Разрешает распределение шардов только для первичных шардов новых индексов.
- none – Распределение шардов не разрешено для любых индексов.
По умолчанию установлено значение all.
cluster.routing.allocation.node_concurrent_incoming_recoveries (Динамическая, целое число)
Настраивает, сколько параллельных входящих восстановлений шардов разрешено на узле. По умолчанию установлено значение 2.
cluster.routing.allocation.node_concurrent_outgoing_recoveries (Динамическая, целое число)
Настраивает, сколько параллельных исходящих восстановлений шардов разрешено на узле. По умолчанию установлено значение 2.
cluster.routing.allocation.node_concurrent_recoveries (Динамическая, строка)
Используется для установки значений cluster.routing.allocation.node_concurrent_incoming_recoveries и cluster.routing.allocation.node_concurrent_outgoing_recoveries на одно и то же значение.
cluster.routing.allocation.node_initial_primaries_recoveries (Динамическая, целое число)
Устанавливает количество восстановлений для нераспределенных первичных шардов после перезапуска узла. По умолчанию установлено значение 4.
cluster.routing.allocation.same_shard.host (Динамическая, логическое)
При установке в true предотвращает распределение нескольких копий шарда на разные узлы на одном хосте. По умолчанию установлено значение false.
cluster.routing.rebalance.enable (Динамическая, строка)
Включает или отключает перераспределение для определенных типов шардов.
Допустимые значения:
- all – Разрешает балансировку шардов для всех типов шардов.
- primaries – Разрешает балансировку шардов только для первичных шардов.
- replicas – Разрешает балансировку шардов только для реплик.
- none – Балансировка шардов не разрешена для любых индексов.
По умолчанию установлено значение all.
cluster.routing.allocation.allow_rebalance (Динамическая, строка)
Указывает, когда разрешено перераспределение шардов.
Допустимые значения:
- always – Всегда разрешать перераспределение.
- indices_primaries_active – Разрешать перераспределение только когда все первичные шары в кластере распределены.
- indices_all_active – Разрешать перераспределение только когда все шары в кластере распределены.
По умолчанию установлено значение indices_all_active.
cluster.routing.allocation.cluster_concurrent_rebalance (Динамическая, целое число)
Позволяет контролировать, сколько параллельных перераспределений шардов разрешено в кластере. По умолчанию установлено значение 2.
cluster.routing.allocation.balance.shard (Динамическая, число с плавающей точкой)
Определяет весовой коэффициент для общего количества шардов, распределенных на узел. По умолчанию установлено значение 0.45.
cluster.routing.allocation.balance.index (Динамическая, число с плавающей точкой)
Определяет весовой коэффициент для количества шардов на индекс, распределенных на узел. По умолчанию установлено значение 0.55.
cluster.routing.allocation.balance.threshold (Динамическая, число с плавающей точкой)
Минимальное значение оптимизации операций, которые должны быть выполнены. По умолчанию установлено значение 1.0.
cluster.routing.allocation.balance.prefer_primary (Динамическая, логическое)
При установке в true OpenSearch пытается равномерно распределить первичные шары между узлами кластера. Включение этой настройки не всегда гарантирует равное количество первичных шардов на каждом узле, особенно в случае сбоя. Изменение этой настройки на false после установки в true не вызывает перераспределение первичных шардов. По умолчанию установлено значение false.
cluster.routing.allocation.rebalance.primary.enable (Динамическая, логическое)
При установке в true OpenSearch пытается перераспределить первичные шары между узлами кластера. При включении кластер пытается поддерживать количество первичных шардов на каждом узле, с максимальным буфером, определенным настройкой cluster.routing.allocation.rebalance.primary.buffer. Изменение этой настройки на false после установки в true не вызывает перераспределение первичных шардов. По умолчанию установлено значение false.
cluster.routing.allocation.rebalance.primary.buffer (Динамическая, число с плавающей точкой)
Определяет максимальный допустимый буфер первичных шардов между узлами, когда включена настройка cluster.routing.allocation.rebalance.primary.enable. По умолчанию установлено значение 0.1.
cluster.routing.allocation.disk.threshold_enabled (Динамическая, логическое)
При установке в false отключает решение о распределении по диску. Это также удалит любые существующие блокировки индекса index.blocks.read_only_allow_delete, когда отключено. По умолчанию установлено значение true.
Настройки водяных знаков дискового пространства
cluster.routing.allocation.disk.watermark.low (Динамическая, строка)
Контролирует низкий водяной знак для использования дискового пространства. При установке в процентном соотношении OpenSearch не будет распределять шары на узлы с указанным процентом использования диска. Это также можно указать в виде дробного значения, например, 0.85. Наконец, это можно установить в байтовом значении, например, 400mb. Эта настройка не влияет на первичные шары новых индексов, но предотвратит распределение их реплик. По умолчанию установлено значение 85%.
cluster.routing.allocation.disk.watermark.high (Динамическая, строка)
Контролирует высокий водяной знак. OpenSearch попытается переместить шары с узла, использование диска на котором превышает установленный процент. Это также можно указать в виде дробного значения, например, 0.85. Наконец, это можно установить в байтовом значении, например, 400mb. Эта настройка влияет на распределение всех шардов. По умолчанию установлено значение 90%.
cluster.routing.allocation.disk.watermark.flood_stage (Динамическая, строка)
Контролирует водяной знак на уровне затопления. Это последний шаг для предотвращения исчерпания дискового пространства на узлах. OpenSearch применяет блокировку индекса только для чтения (index.blocks.read_only_allow_delete) ко всем индексам, на которых есть один или несколько шардов, распределенных на узле, и хотя бы один диск превышает уровень затопления. Блокировка индекса снимается, как только использование диска падает ниже высокого водяного знака. Это также можно указать в виде дробного значения, например, 0.85. Наконец, это можно установить в байтовом значении, например, 400mb. По умолчанию установлено значение 95%.
cluster.info.update.interval (Динамическая, единица времени)
Устанавливает, как часто OpenSearch должен проверять использование диска для каждого узла в кластере. По умолчанию установлено значение 30s.
Настройки распределения шардов по атрибутам
cluster.routing.allocation.include. (Динамическая, перечисление)
Распределяет шары на узел, атрибут которого содержит хотя бы одно из включенных значений, разделенных запятыми.
cluster.routing.allocation.require. (Динамическая, перечисление)
Распределяет шары только на узел, атрибут которого содержит все включенные значения, разделенные запятыми.
cluster.routing.allocation.exclude. (Динамическая, перечисление)
Не распределяет шары на узел, атрибут которого содержит любое из включенных значений, разделенных запятыми. Настройки распределения кластера поддерживают следующие встроенные атрибуты.
Допустимые значения:
- _name – Совпадение узлов по имени узла.
- _host_ip – Совпадение узлов по IP-адресу хоста.
- _publish_ip – Совпадение узлов по публикуемому IP-адресу.
- _ip – Совпадение по _host_ip или _publish_ip.
- _host – Совпадение узлов по имени хоста.
- _id – Совпадение узлов по идентификатору узла.
- _tier – Совпадение узлов по роли уровня данных.
Настройки перемещения шардов
cluster.routing.allocation.shard_movement_strategy (Динамическая, перечисление)
Определяет порядок, в котором шары перемещаются с исходящих узлов на входящие.
Эта настройка поддерживает следующие стратегии:
- PRIMARY_FIRST – Первичные шары перемещаются первыми, перед репликами. Эта приоритизация может помочь предотвратить переход состояния здоровья кластера в красный, если узлы, на которые перемещаются шары, выйдут из строя в процессе.
- REPLICA_FIRST – Репликационные шары перемещаются первыми, перед первичными. Эта приоритизация может помочь предотвратить переход состояния здоровья кластера в красный при выполнении перемещения шардов в кластере OpenSearch с смешанными версиями и включенной репликацией сегментов. В этой ситуации первичные шары, перемещенные на узлы OpenSearch более новой версии, могут попытаться скопировать файлы сегментов на репликационные шары более старой версии OpenSearch, что приведет к сбою шардов. Перемещение репликационных шардов первыми может помочь избежать этого в кластерах с несколькими версиями.
- NO_PREFERENCE – Поведение по умолчанию, при котором порядок перемещения шардов не имеет значения.
cluster.routing.search_replica.strict (Динамическая, логическое)
Контролирует, как маршрутизируются поисковые запросы, когда для индекса существуют репликационные шары, например, когда index.number_of_search_replicas больше 0. Эта настройка применяется только в случае, если для индекса настроены поисковые реплики. При установке в true все поисковые запросы для таких индексов маршрутизируются только на репликационные шары. Если репликационные шары не назначены, запросы завершаются неудачей. При установке в false, если репликационные шары не назначены, запросы возвращаются к любому доступному шару. По умолчанию установлено значение true.
cluster.allocator.gateway.batch_size (Динамическая, целое число)
Ограничивает количество шардов, отправляемых на узлы данных в одной партии для получения метаданных любых нераспределенных шардов. По умолчанию установлено значение 2000.
cluster.allocator.existing_shards_allocator.batch_enabled (Статическая, логическая)
Включает пакетное распределение нераспределенных шардов, которые уже существуют на диске, вместо распределения одного шара за раз. Это снижает нагрузку на память и транспорт, получая метаданные любых нераспределенных шардов в пакетном вызове. По умолчанию установлено значение false.
cluster.routing.allocation.total_shards_per_node (Динамическая, целое число)
Максимальное общее количество первичных и репликационных шардов, которые могут быть распределены на один узел. По умолчанию установлено значение -1 (без ограничений). Помогает равномерно распределять шары по узлам, ограничивая общее количество шардов на узел. Используйте с осторожностью, так как шары могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
cluster.routing.allocation.total_primary_shards_per_node (Динамическая, целое число)
Максимальное количество первичных шардов, которые могут быть распределены на один узел. Эта настройка применима только для кластеров с удаленной поддержкой. По умолчанию установлено значение -1 (без ограничений). Помогает равномерно распределять первичные шары по узлам, ограничивая количество первичных шардов на узел. Используйте с осторожностью, так как первичные шары могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
Настройки шардов, блокировок и задач на уровне кластера
OpenSearch поддерживает следующие настройки шардов, блокировок и задач на уровне кластера:
action.search.shard_count.limit (Целое число)
Ограничивает максимальное количество шардов, которые могут быть задействованы во время поиска. Запросы, превышающие этот лимит, будут отклонены.
cluster.blocks.read_only (Логическое)
Устанавливает весь кластер в режим только для чтения. По умолчанию установлено значение false.
cluster.blocks.read_only_allow_delete (Логическое)
Похоже на cluster.blocks.read_only, но позволяет удалять индексы.
cluster.max_shards_per_node (Целое число)
Ограничивает общее количество первичных и репликационных шардов для кластера. Лимит рассчитывается следующим образом: cluster.max_shards_per_node умножается на количество не замороженных узлов данных. Шары для закрытых индексов не учитываются в этом лимите. По умолчанию установлено значение 1000.
cluster.persistent_tasks.allocation.enable (Строка)
Включает или отключает распределение для постоянных задач.
Допустимые значения:
- all – Разрешает назначение постоянных задач на узлы.
- none – Распределение для постоянных задач не разрешено. Это не влияет на уже работающие постоянные задачи.
По умолчанию установлено значение all.
cluster.persistent_tasks.allocation.recheck_interval (Единица времени)
Менеджер кластера автоматически проверяет, нужно ли назначать постоянные задачи, когда состояние кластера изменяется значительным образом. Существуют и другие факторы, такие как использование памяти, которые повлияют на то, будут ли постоянные задачи назначены на узлы, но не вызывают изменения состояния кластера. Эта настройка определяет, как часто выполняются проверки назначения в ответ на эти факторы. По умолчанию установлено значение 30 секунд, при этом минимальное значение составляет 10 секунд.
Настройки медленных логов на уровне кластера
Для получения дополнительной информации смотрите раздел Медленные логи запросов поиска.
cluster.search.request.slowlog.threshold.warn (Единица времени)
Устанавливает порог WARN для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.threshold.info (Единица времени)
Устанавливает порог INFO для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.threshold.debug (Единица времени)
Устанавливает порог DEBUG для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.threshold.trace (Единица времени)
Устанавливает порог TRACE для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.level (Строка)
Устанавливает минимальный уровень медленного лога для записи: WARN, INFO, DEBUG и TRACE. По умолчанию установлено значение TRACE.
Настройки индекса на уровне кластера
Для получения информации о настройках индекса на уровне индекса смотрите раздел Настройки индекса на уровне кластера.
Настройки координации на уровне кластера
OpenSearch поддерживает следующие настройки координации на уровне кластера. Все настройки в этом списке являются динамическими:
cluster.fault_detection.leader_check.timeout (Единица времени)
Количество времени, в течение которого узел ждет ответа от избранного менеджера кластера во время проверки лидера, прежде чем считать проверку неудачной. Допустимые значения от 1ms до 60s, включая. По умолчанию установлено значение 10s. Изменение этой настройки на значение, отличное от значения по умолчанию, может привести к нестабильности кластера.
cluster.fault_detection.follower_check.timeout (Единица времени)
Количество времени, в течение которого избранный менеджер кластера ждет ответа во время проверки последователя, прежде чем считать проверку неудачной. Допустимые значения от 1ms до 60s, включая. По умолчанию установлено значение 10s. Изменение этой настройки на значение, отличное от значения по умолчанию, может привести к нестабильности кластера.
cluster.fault_detection.follower_check.interval (Единица времени)
Количество времени, в течение которого избранный менеджер кластера ждет между отправкой проверок последователей другим узлам в кластере. Допустимые значения 100ms и выше. По умолчанию установлено значение 1000ms. Изменение этой настройки на значение, отличное от значения по умолчанию, может привести к нестабильности кластера.
cluster.follower_lag.timeout (Единица времени)
Количество времени, в течение которого избранный менеджер кластера ждет получения подтверждений обновлений состояния кластера от отстающих узлов. По умолчанию установлено значение 90s. Если узел не успешно применяет обновление состояния кластера в течение этого времени, он считается неудавшимся и удаляется из кластера.
cluster.publish.timeout (Единица времени)
Количество времени, в течение которого менеджер кластера ждет, пока каждое обновление состояния кластера будет полностью опубликовано на всех узлах, если только discovery.type не установлен на single-node. По умолчанию установлено значение 30s.
Настройки пределов ответов CAT на уровне кластера
OpenSearch поддерживает следующие настройки пределов ответов CAT API на уровне кластера, все из которых являются динамическими:
cat.indices.response.limit.number_of_indices (Целое число)
Устанавливает предел на количество индексов, возвращаемых API CAT Indices. Значение по умолчанию -1 (без ограничений). Если количество индексов в ответе превышает этот предел, API возвращает ошибку 429. Чтобы избежать этого, вы можете указать фильтр по шаблону индекса в вашем запросе (например, _cat/indices/<index-pattern>).
cat.shards.response.limit.number_of_shards (Целое число)
Устанавливает предел на количество шардов, возвращаемых API CAT Shards. Значение по умолчанию -1 (без ограничений). Если количество шардов в ответе превышает этот предел, API возвращает ошибку 429. Чтобы избежать этого, вы можете указать фильтр по шаблону индекса в вашем запросе (например, _cat/shards/<index-pattern>).
cat.segments.response.limit.number_of_indices (Целое число)
Устанавливает предел на количество индексов, возвращаемых API CAT Segments. Значение по умолчанию -1 (без ограничений). Если количество индексов в ответе превышает этот предел, API возвращает ошибку 429. Чтобы избежать этого, вы можете указать фильтр по шаблону индекса в вашем запросе (например, _cat/segments/<index-pattern>).
8.2.3.8 - Настройка индекса
Настройки индекса могут быть двух типов: настройки уровня кластера, которые влияют на все индексы в кластере, и настройки уровня индекса, которые влияют на отдельные индексы.
Чтобы узнать больше о статических и динамических настройках, смотрите Конфигурирование OpenSearch.
Настройки индекса уровня кластера
Существует два типа настроек кластера:
- Статические настройки индекса уровня кластера — это настройки, которые нельзя обновить, пока кластер работает. Чтобы обновить статическую настройку, необходимо остановить кластер, обновить настройку, а затем перезапустить кластер.
- Динамические настройки индекса уровня кластера — это настройки, которые можно обновлять в любое время.
Статические настройки индекса уровня кластера
OpenSearch поддерживает следующие статические настройки индекса уровня кластера:
indices.cache.cleanup_interval(Единица времени): Запланирует периодическую фоновую задачу, которая очищает истекшие записи из кэша с указанным интервалом. По умолчанию 1m (1 минута). Для получения дополнительной информации смотрите Кэш запросов индекса.indices.requests.cache.size(Строка): Размер кэша в процентах от размера кучи (например, чтобы использовать 1% кучи, укажите 1%). По умолчанию 1%. Для получения дополнительной информации смотрите Кэш запросов индекса.
Динамические настройки индекса уровня кластера
OpenSearch поддерживает следующие динамические настройки индекса уровня кластера:
action.auto_create_index(Булевый): Автоматически создает индекс, если индекс еще не существует. Также применяет любые конфигурации шаблонов индексов. По умолчанию true.indices.recovery.max_concurrent_file_chunks(Целое число): Количество частей файлов, отправляемых параллельно для каждой операции восстановления. По умолчанию 2.indices.recovery.max_concurrent_operations(Целое число): Количество операций, отправляемых параллельно для каждого восстановления. По умолчанию 1.indices.recovery.max_concurrent_remote_store_streams(Целое число): Количество потоков к удаленному репозиторию, которые могут быть открыты параллельно при восстановлении индекса из удаленного хранилища. По умолчанию 20.indices.replication.max_bytes_per_sec(Строка): Ограничивает общий входящий и исходящий трафик репликации для каждого узла. Если значение не указано в конфигурации, используется настройкаindices.recovery.max_bytes_per_sec, по умолчанию равная 40 МБ. Если вы установите значение трафика репликации меньше или равным 0 МБ, ограничение скорости будет отключено, что приведет к передаче данных репликации с максимальной возможной скоростью.indices.fielddata.cache.size(Строка): Максимальный размер кэша данных полей. Может быть указан как абсолютное значение (например, 8 ГБ) или процент от кучи узла (например, 50%). Это значение статическое, поэтому его необходимо указать в файлеopensearch.yml. Если вы не укажете эту настройку, максимальный размер будет неограниченным. Это значение должно быть меньше, чемindices.breaker.fielddata.limit. Для получения дополнительной информации смотрите Систему защиты от переполнения кэша данных полей.indices.query.bool.max_clause_count(Целое число): Определяет максимальное произведение полей и терминов, которые могут быть запрошены одновременно. До версии OpenSearch 2.16 для применения этой статической настройки требовалась перезагрузка кластера. Теперь она динамическая, существующие пулы потоков поиска могут использовать старое статическое значение, что может привести к исключениям TooManyClauses. Новые пулы потоков используют обновленное значение. По умолчанию 1024.cluster.remote_store.index.path.type(Строка): Стратегия пути для данных, хранящихся в удаленном хранилище. Эта настройка эффективна только для кластеров с включенным удаленным хранилищем. Эта настройка поддерживает следующие значения:fixed: Хранит данные в структуре пути<repository_base_path>/<index_uuid>/<shard_id>/.hashed_prefix: Хранит данные в структуре путиhash(<shard-data-identifier>)/<repository_base_path>/<index_uuid>/<shard_id>/.hashed_infix: Хранит данные в структуре пути<repository_base_path>/hash(<shard-data-identifier>)/<index_uuid>/<shard_id>/.shard-data-identifierхарактеризуетсяindex_uuid,shard_id, типом данных (translog, segments) и типом данных (data, metadata, lock_files). По умолчаниюfixed.
cluster.remote_store.index.path.hash_algorithm(Строка): Хеш-функция, используемая для получения хеш-значения, когдаcluster.remote_store.index.path.typeустановлено наhashed_prefixилиhashed_infix. Эта настройка эффективна только для кластеров с включенным удаленным хранилищем. Эта настройка поддерживает следующие значения:fnv_1a_base64: Использует хеш-функцию FNV1a и генерирует безопасное для URL 20-битное хеш-значение в формате base64.fnv_1a_composite_1: Использует хеш-функцию FNV1a и генерирует пользовательское закодированное хеш-значение, которое хорошо масштабируется с большинством опций удаленного хранилища. Функция FNV1a генерирует 64-битное значение. Пользовательское кодирование использует 6 старших бит для создания безопасного для URL символа base64 и следующие 14 бит для создания двоичной строки. По умолчаниюfnv_1a_composite_1.
cluster.remote_store.translog.transfer_timeout(Единица времени): Управляет значением таймаута при загрузке файлов translog и контрольных точек во время синхронизации с удаленным хранилищем. Эта настройка применяется только для кластеров с включенным удаленным хранилищем. По умолчанию 30 секунд.cluster.remote_store.index.segment_metadata.retention.max_count(Целое число): Управляет минимальным количеством файлов метаданных, которые необходимо сохранить в репозитории сегментов на удаленном хранилище. Значение ниже 1 отключает удаление устаревших файлов метаданных сегментов. По умолчанию 10.cluster.remote_store.segment.transfer_timeout(Единица времени): Управляет максимальным временем ожидания обновления всех новых сегментов после обновления в удаленное хранилище. Если загрузка не завершится в течение указанного времени, будет выброшено исключение SegmentUploadFailedException. По умолчанию 30 минут. Минимальное ограничение составляет 10 минут.cluster.remote_store.translog.path.prefix(Строка): Управляет фиксированным префиксом пути для данных translog на кластере с включенным удаленным хранилищем. Эта настройка применяется только в том случае, если настройкаcluster.remote_store.index.path.typeустановлена наHASHED_PREFIXилиHASHED_INFIX. По умолчанию пустая строка, “”.cluster.remote_store.segments.path.prefix(Строка): Управляет фиксированным префиксом пути для данных сегментов на кластере с включенным удаленным хранилищем. Эта настройка применяется только в том случае, если настройкаcluster.remote_store.index.path.typeустановлена наHASHED_PREFIXилиHASHED_INFIX. По умолчанию пустая строка, “”.cluster.snapshot.shard.path.prefix(Строка): Управляет фиксированным префиксом пути для блобов уровня сегмента снимка. Эта настройка применяется только в том случае, если настройкаrepository.shard_path_typeустановлена наHASHED_PREFIXилиHASHED_INFIX. По умолчанию пустая строка, “”.cluster.default_number_of_replicas(Целое число): Управляет значением по умолчанию для количества реплик индексов в кластере. Настройка уровня индексаindex.number_of_replicasпо умолчанию принимает это значение, если не настроена. По умолчанию 1.cluster.thread_pool.<fixed-threadpool>.size(Целое число): Управляет размерами как фиксированных, так и изменяемых очередей пулов потоков. Переопределяет значения по умолчанию, указанные вopensearch.yml.cluster.thread_pool.<scaling-threadpool>.max(Целое число): Устанавливает максимальный размер пула потоков с изменяемым размером. Переопределяет значение по умолчанию, указанное вopensearch.yml.cluster.thread_pool.<scaling-threadpool>.core(Целое число): Указывает базовый размер пула потоков с изменяемым размером. Переопределяет значение по умолчанию, указанное вopensearch.yml.
Прежде чем настраивать параметры пула потоков динамически, обратите внимание, что это настройки для экспертов, которые могут потенциально дестабилизировать ваш кластер. Изменение настроек пула потоков применяет один и тот же размер пула потоков ко всем узлам, поэтому это не рекомендуется для кластеров с различным оборудованием для одних и тех же ролей. Аналогично, избегайте настройки пулов потоков, которые используются как узлами данных, так и узлами управления кластером. После внесения этих изменений рекомендуется следить за вашим кластером, чтобы убедиться, что он остается стабильным и работает как ожидается.
Настройки индекса уровня индекса
Вы можете указать настройки индекса при создании индекса. Существует два типа настроек индекса:
Статические настройки индекса уровня индекса — это настройки, которые нельзя обновить, пока индекс открыт. Чтобы обновить статическую настройку, необходимо закрыть индекс, обновить настройку, а затем снова открыть индекс.
Динамические настройки индекса уровня индекса — это настройки, которые можно обновлять в любое время.
Указание настройки при создании индекса
При создании индекса вы можете указать его статические или динамические настройки следующим образом:
PUT /testindex
{
"settings": {
"index.number_of_shards": 1,
"index.number_of_replicas": 2
}
}
Статические настройки индекса уровня индекса
OpenSearch поддерживает следующие статические настройки индекса уровня индекса:
index.number_of_shards(Целое число): Количество первичных шардов в индексе. По умолчанию 1.index.number_of_routing_shards(Целое число): Количество шардов маршрутизации, используемых для разделения индекса.index.shard.check_on_startup(Булевый): Указывает, следует ли проверять шардов индекса на наличие повреждений. Доступные опции:false(не проверять на повреждения),checksum(проверять на физические повреждения),true(проверять как на физические, так и на логические повреждения). По умолчаниюfalse.
index.codec(Строка): Определяет, как сжимаются и хранятся на диске сохраненные поля индекса. Эта настройка влияет на размер шардов индекса и производительность операций индексации.Допустимые значения:
defaultbest_compressionzstd(OpenSearch 2.9 и позже)zstd_no_dict(OpenSearch 2.9 и позже)qat_lz4(OpenSearch 2.14 и позже, на поддерживаемых системах)qat_deflate(OpenSearch 2.14 и позже, на поддерживаемых системах)
Для
zstd,zstd_no_dict,qat_lz4иqat_deflateвы можете указать уровень сжатия в настройкеindex.codec.compression_level. Для получения дополнительной информации смотрите Настройки кодека индекса. Опционально. По умолчаниюdefault.index.codec.compression_level(Целое число): Настройка уровня сжатия обеспечивает компромисс между коэффициентом сжатия и скоростью. Более высокий уровень сжатия приводит к более высокому коэффициенту сжатия (меньший размер хранения), но замедляет скорость сжатия и распаковки, что приводит к увеличению задержек при индексации и поиске. Эта настройка может быть указана только еслиindex.codecустановлен наzstdиzstd_no_dictв OpenSearch 2.9 и позже илиqat_lz4иqat_deflateв OpenSearch 2.14 и позже. Допустимые значения — целые числа в диапазоне [1, 6]. Для получения дополнительной информации смотрите Настройки кодека индекса. Опционально. По умолчанию 3.index.codec.qatmode(Строка): Режим аппаратного ускорения, используемый для кодеков сжатияqat_lz4иqat_deflate. Допустимые значения:autoиhardware. Для получения дополнительной информации смотрите Настройки кодека индекса. Опционально. По умолчаниюauto.index.routing_partition_size(Целое число): Количество шардов, к которым может быть направлено значение пользовательской маршрутизации. Маршрутизация помогает несбалансированному кластеру, перемещая значения к подмножеству шардов, а не к одному шару. Чтобы включить маршрутизацию, установите это значение больше 1, но меньшеindex.number_of_shards. По умолчанию 1.index.soft_deletes.retention_lease.period(Единица времени): Максимальное время хранения истории операций шара. По умолчанию 12 часов.index.load_fixed_bitset_filters_eagerly(Булевый): Указывает, должен ли OpenSearch предварительно загружать кэшированные фильтры. Доступные опции:trueиfalse. По умолчаниюtrue.index.hidden(Булевый): Указывает, должен ли индекс быть скрытым. Скрытые индексы не возвращаются в результате запросов, содержащих подстановочные знаки. Доступные опции:trueиfalse. По умолчаниюfalse.index.merge.policy(Строка): Эта настройка управляет политикой слияния для сегментов Lucene. Доступные опции:tieredиlog_byte_size. По умолчаниюtiered, но для временных данных, таких как журналы событий, рекомендуется использовать политику слиянияlog_byte_size, которая может улучшить производительность запросов при выполнении диапазонных запросов по полю@timestamp. Рекомендуется не изменять политику слияния существующего индекса. Вместо этого настройте эту опцию при создании нового индекса.index.merge_on_flush.enabled(Булевый): Эта настройка управляет функцией слияния при обновлении Apache Lucene, которая направлена на уменьшение количества сегментов путем выполнения слияний при обновлении (или, в терминах OpenSearch, при сбросе). По умолчаниюtrue.index.merge_on_flush.max_full_flush_merge_wait_time(Единица времени): Эта настройка устанавливает время ожидания для слияний, когдаindex.merge_on_flush.enabledвключен. По умолчанию 10 секунд.index.merge_on_flush.policy(Строка): Эта настройка управляет тем, какая политика слияния должна использоваться, когдаindex.merge_on_flush.enabledвключен. По умолчаниюdefault.index.check_pending_flush.enabled(Булевый): Эта настройка управляет параметромcheckPendingFlushOnUpdateиндексации Apache Lucene, который указывает, должен ли поток индексации проверять наличие ожидающих сбросов при обновлении, чтобы сбросить буферы индексации на диск. По умолчаниюtrue.index.use_compound_file(Булевый): Эта настройка управляет параметрамиuseCompoundFileиндексации Apache Lucene, которые указывают, будут ли новые файлы сегментов упакованы в составной файл. По умолчаниюtrue.index.append_only.enabled(Булевый): Установите значениеtrue, чтобы предотвратить любые обновления документов в индексе. По умолчаниюfalse.
Обновление статической настройки индекса
Вы можете обновить статическую настройку индекса только для закрытого индекса. Следующий пример демонстрирует обновление настройки кодека индекса.
Сначала закройте индекс:
POST /testindex/_close
Затем обновите настройки, отправив запрос к конечной точке _settings:
PUT /testindex/_settings
{
"index": {
"codec": "zstd_no_dict",
"codec.compression_level": 3
}
}
Наконец, снова откройте индекс, чтобы включить операции чтения и записи:
POST /testindex/_open
Для получения дополнительной информации об обновлении настроек, включая поддерживаемые параметры запроса, смотрите Обновление настроек.
Динамические настройки индекса уровня индекса
OpenSearch поддерживает следующие динамические настройки индекса уровня индекса:
index.number_of_replicas(Целое число): Количество реплик, которые должен иметь каждый первичный шард. Например, если у вас 4 первичных шарда и вы установитеindex.number_of_replicasна 3, индекс будет иметь 12 реплик. Если не установлено, по умолчанию используется значениеcluster.default_number_of_replicas(по умолчанию 1).index.number_of_search_replicas(Целое число): Количество поисковых реплик, которые должен иметь каждый первичный шард. Например, если у вас 4 первичных шарда и вы установитеindex.number_of_search_replicasна 3, индекс будет иметь 12 поисковых реплик. По умолчанию 0.index.auto_expand_replicas(Строка): Указывает, должен ли кластер автоматически добавлять реплики на основе количества узлов данных. Укажите нижнюю и верхнюю границы (например, 0–9) илиallдля верхней границы. Например, если у вас 5 узлов данных и вы установитеindex.auto_expand_replicasна 0–3, кластер не добавит еще одну реплику. Однако, если вы установите это значение на 0-all и добавите 2 узла, всего 7, кластер расширится до 6 реплик. По умолчанию отключено.index.auto_expand_search_replicas(Строка): Управляет тем, автоматически ли кластер регулирует количество поисковых реплик на основе количества доступных узлов поиска. Укажите значение в виде диапазона с нижней и верхней границей, например, 0-3 или 0-all. Если вы не укажете значение, эта функция отключена.Например, если у вас 5 узлов данных и вы установите
index.auto_expand_search_replicasна 0-3, индекс может иметь до 3 поисковых реплик, и кластер не добавит еще одну поисковую реплику. Однако, если вы установитеindex.auto_expand_search_replicasна 0-all и добавите 2 узла, всего 7, кластер расширится до 7 поисковых реплик. Эта настройка по умолчанию отключена.index.search.idle.after(Единица времени): Время, в течение которого шард должен ждать запроса поиска или получения, прежде чем перейти в состояние ожидания. По умолчанию 30 секунд.index.search.default_pipeline(Строка): Имя поискового конвейера, который используется, если при поиске индекса не установлен явный конвейер. Если установлен конвейер по умолчанию и он не существует, запросы к индексу завершатся неудачей. Используйте имя конвейера_none, чтобы указать отсутствие конвейера поиска по умолчанию. Для получения дополнительной информации смотрите Конвейер поиска по умолчанию.index.refresh_interval(Единица времени): Как часто индекс должен обновляться, что публикует его последние изменения и делает их доступными для поиска. Может быть установлено на -1 для отключения обновления. По умолчанию 1 секунда.index.max_result_window(Целое число): Максимальное значениеfrom + sizeдля запросов к индексу.from— это начальный индекс для поиска, аsize— количество результатов для возврата. По умолчанию 10000.index.max_inner_result_window(Целое число): Максимальное значениеfrom + size, которое указывает количество возвращаемых вложенных результатов поиска и наиболее релевантных документов, агрегированных во время запроса.from— это начальный индекс для поиска, аsize— количество верхних результатов для возврата. По умолчанию 100.index.max_rescore_window(Целое число): Максимальное значениеwindow_sizeдля запросов пересчета к индексу. Запросы пересчета изменяют порядок документов индекса и возвращают новый балл, который может быть более точным. По умолчанию такое же, какindex.max_inner_result_window, или 10000 по умолчанию.index.max_docvalue_fields_search(Целое число): Максимальное количествоdocvalue_fields, разрешенных в запросе. По умолчанию 100.index.max_script_fields(Целое число): Максимальное количествоscript_fields, разрешенных в запросе. По умолчанию 32.index.max_ngram_diff(Целое число): Максимальная разница между значениямиmin_gramиmax_gramдляNGramTokenizerиNGramTokenFilter. По умолчанию 1.index.max_shingle_diff(Целое число): Максимальная разница междуmax_shingle_sizeиmin_shingle_size, которая подается в фильтр токеновshingle. По умолчанию 3.index.max_refresh_listeners(Целое число): Максимальное количество слушателей обновления, которые может иметь каждый шард.index.analyze.max_token_count(Целое число): Максимальное количество токенов, которые могут быть возвращены из операции API_analyze. По умолчанию 10000.index.highlight.max_analyzed_offset(Целое число): Количество символов, которые может анализировать запрос на выделение. По умолчанию 1000000.index.max_terms_count(Целое число): Максимальное количество терминов, которые может принять запрос терминов. По умолчанию 65536.index.max_regex_length(Целое число): Максимальная длина символов регулярного выражения, которое может быть в запросеregexp. По умолчанию 1000.index.query.default_field(Список): Поле или список полей, которые OpenSearch использует в запросах, если поле не указано в параметрах.index.query.max_nested_depth(Целое число): Максимальное количество уровней вложенности для вложенных запросов. По умолчанию 20. Минимум 1 (один вложенный запрос).index.requests.cache.enable(Булевый): Включает или отключает кэш запросов индекса. По умолчаниюtrue. Для получения дополнительной информации смотрите Кэш запросов индекса.index.routing.allocation.enable(Строка): Указывает параметры для распределения шардов индекса. Доступные опции:all(разрешить распределение для всех шардов),primaries(разрешить распределение только для первичных шардов),new_primaries(разрешить распределение только для новых первичных шардов),none(не разрешать распределение). По умолчаниюall.
index.routing.rebalance.enable(Строка): Включает перераспределение шардов для индекса. Доступные опции:all(разрешить перераспределение для всех шардов),primaries(разрешить перераспределение только для первичных шардов),replicas(разрешить перераспределение только для реплик),none(не разрешать перераспределение). По умолчаниюall.
index.gc_deletes(Единица времени): Время хранения номера версии удаленного документа. По умолчанию 60 секунд.index.default_pipeline(Строка): Конвейер узла обработки по умолчанию для индекса. Если установлен конвейер по умолчанию и он не существует, запросы к индексу завершатся неудачей. Имя конвейера_noneуказывает на то, что у индекса нет конвейера обработки.index.final_pipeline(Строка): Конечный конвейер узла обработки для индекса. Если установлен конечный конвейер и он не существует, запросы к индексу завершатся неудачей. Имя конвейера_noneуказывает на то, что у индекса нет конвейера обработки.index.optimize_doc_id_lookup.fuzzy_set.enabled(Булевый): Эта настройка управляет тем, следует ли включатьfuzzy_setдля оптимизации поиска идентификаторов документов в индексах или запросах, используя дополнительную структуру данных, в данном случае структуру данных Bloom filter. Включение этой настройки улучшает производительность операцийupsertи поиска, которые зависят от идентификаторов документов, создавая новую структуру данных (Bloom filter). Bloom filter позволяет обрабатывать отрицательные случаи (то есть идентификаторы, отсутствующие в существующем индексе) с помощью более быстрых обращений вне кучи. Обратите внимание, что создание Bloom filter требует дополнительного использования кучи во время индексации. По умолчаниюfalse.index.optimize_doc_id_lookup.fuzzy_set.false_positive_probability(Число с плавающей точкой)
Устанавливает вероятность ложного срабатывания для базового fuzzy_set (то есть, фильтра Блума). Более низкая вероятность ложного срабатывания обеспечивает более высокую пропускную способность для операций upsert и get, но приводит к увеличению использования памяти и хранилища. Допустимые значения находятся в диапазоне от 0.01 до 0.50. По умолчанию установлено значение 0.20.
index.routing.allocation.total_shards_per_node(Целое число)
Максимальное общее количество первичных и репликационных шардов из одного индекса, которые могут быть распределены на один узел. По умолчанию установлено значение -1 (без ограничений). Помогает контролировать распределение шардов по узлам для каждого индекса, ограничивая количество шардов на узел. Используйте с осторожностью, так как шары из этого индекса могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
index.routing.allocation.total_primary_shards_per_node(Целое число)
Максимальное количество первичных шардов из одного индекса, которые могут быть распределены на один узел. Эта настройка применима только для кластеров с удаленной поддержкой. По умолчанию установлено значение -1 (без ограничений). Помогает контролировать распределение первичных шардов по узлам для каждого индекса, ограничивая количество первичных шардов на узел. Используйте с осторожностью, так как первичные шары из этого индекса могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
Обновление динамической настройки индекса
Вы можете обновить динамическую настройку индекса в любое время через API. Например, чтобы обновить интервал обновления, используйте следующий запрос:
PUT /testindex/_settings
{
"index": {
"refresh_interval": "2s"
}
}
Для получения дополнительной информации об обновлении настроек, включая поддерживаемые параметры запроса, смотрите раздел Обновление настроек.
8.2.3.9 - Настройки поиска
OpenSearch поддерживает следующие настройки поиска
search.max_buckets (Динамическое, целое число): Максимальное количество агрегатных бакетов, разрешенных в одном ответе. По умолчанию 65535.
search.phase_took_enabled (Динамическое, логическое): Включает возврат значений времени на уровне фаз в ответах на поиск. По умолчанию false.
search.allow_expensive_queries (Динамическое, логическое): Разрешает или запрещает дорогостоящие запросы. Для получения дополнительной информации см. Дорогостоящие запросы.
search.default_allow_partial_results (Динамическое, логическое): Настройка на уровне кластера, которая позволяет возвращать частичные результаты поиска, если запрос превышает время ожидания или если шард не отвечает. Если запрос на поиск содержит параметр
allow_partial_search_results, этот параметр имеет приоритет над данной настройкой. По умолчанию true.search.cancel_after_time_interval (Динамическое, единица времени): Настройка на уровне кластера, которая устанавливает значение по умолчанию для таймаута всех запросов на поиск на уровне координирующего узла. После достижения указанного времени запрос останавливается, и все связанные задачи отменяются. По умолчанию -1 (без таймаута).
search.default_search_timeout (Динамическое, единица времени): Настройка на уровне кластера, которая указывает максимальное время, в течение которого запрос на поиск может выполняться, прежде чем он будет отменен на уровне шарда. Если интервал таймаута указан в запросе на поиск, этот интервал имеет приоритет над настроенной настройкой. По умолчанию -1.
search.default_keep_alive (Динамическое, единица времени): Указывает значение по умолчанию для поддержания активности для запросов с прокруткой и точкой во времени (PIT). Поскольку запрос может попадать на шард несколько раз (например, во время фаз запроса и извлечения), OpenSearch открывает контекст запроса, который существует на протяжении всего времени запроса, чтобы обеспечить согласованность состояния шарда для каждого отдельного запроса к шард. В стандартном поиске, как только фаза извлечения завершается, контекст запроса закрывается. Для запроса с прокруткой или PIT OpenSearch сохраняет контекст запроса открытым до явного закрытия (или до достижения времени поддержания активности). Фоновый поток периодически проверяет все открытые контексты прокрутки и PIT и удаляет те, которые превысили свой таймаут поддержания активности. Настройка
search.keep_alive_intervalуказывает, как часто контексты проверяются на истечение срока. Настройкаsearch.default_keep_aliveявляется значением по умолчанию для истечения срока. Запрос с прокруткой или PIT может явно указать время поддержания активности, которое имеет приоритет над этой настройкой. По умолчанию 5m.search.keep_alive_interval (Статическое, единица времени): Определяет интервал, с которым OpenSearch проверяет контексты запросов, которые превысили свой лимит поддержания активности. По умолчанию 1m.
search.max_keep_alive (Динамическое, единица времени): Указывает максимальное значение поддержания активности. Настройка
max_keep_aliveиспользуется в качестве меры безопасности по отношению к другим настройкам поддержания активности (например,default_keep_alive) и настройкам поддержания активности на уровне запроса (для контекстов прокрутки и PIT). Если запрос превышает значениеmax_keep_aliveв любом из случаев, операция завершится неудачей. По умолчанию 24h.search.low_level_cancellation (Динамическое, логическое): Включает механизм низкоуровневой отмены запросов. Классический механизм таймаута Lucene проверяет время только во время сбора результатов поиска. Однако дорогостоящий запрос, такой как запрос с подстановочными знаками или префиксами, может занять много времени для расширения перед началом сбора результатов. В этом случае запрос может выполняться в течение времени, превышающего значение таймаута. Механизм низкоуровневой отмены решает эту проблему, устанавливая таймаут не только во время сбора результатов поиска, но и во время фазы расширения запроса или перед выполнением любой операции Lucene. По умолчанию true.
search.max_open_scroll_context (Динамическое, целое число): Настройка на уровне узла, которая указывает максимальное количество открытых контекстов прокрутки для узла. По умолчанию 500.
search.request_stats_enabled (Динамическое, логическое): Включает сбор статистики времени фаз на уровне узла с точки зрения координирующего узла. Статистика на уровне запроса отслеживает, сколько времени (всего) запросы на поиск проводят в каждой из различных фаз поиска. Вы можете получить эти счетчики, используя API статистики узлов. По умолчанию false.
search.highlight.term_vector_multi_value (Статическое, логическое): Указывает на необходимость выделять фрагменты по значениям многозначного поля. По умолчанию true.
search.max_aggregation_rewrite_filters (Динамическое, целое число): Определяет максимальное количество фильтров переписывания, разрешенных во время агрегации. Установите это значение в 0, чтобы отключить оптимизацию переписывания фильтров для агрегаций. Это экспериментальная функция и может измениться или быть удалена в будущих версиях.
search.dynamic_pruning.cardinality_aggregation.max_allowed_cardinality (Динамическое, целое число): Определяет порог для применения динамической обрезки в агрегации по кардинальности. Если кардинальность поля превышает этот порог, агрегация возвращается к методу по умолчанию. Это экспериментальная функция и может измениться или быть удалена в будущих версиях.
search.keyword_index_or_doc_values_enabled (Динамическое, логическое): Определяет, использовать ли индекс или значения документа при выполнении запросов
multi_termна полях ключевых слов. Значение по умолчанию - false.
Настройки точки во времени (PIT)
Для получения информации о настройках PIT см. Настройки PIT.
Чтобы узнать больше о статических и динамических настройках, см. Настройка OpenSearch.
8.2.3.10 - Настройки плагинов
Следующие настройки относятся к плагинам OpenSearch.
Настройки плагина оповещений
Для получения информации о настройках оповещений см. Настройки оповещений.
Настройки плагина обнаружения аномалий
Для получения информации о настройках обнаружения аномалий см. Настройки обнаружения аномалий.
Настройки плагина асинхронного поиска
Для получения информации о настройках асинхронного поиска см. Настройки асинхронного поиска.
Настройки плагина репликации между кластерами
Для получения информации о настройках репликации между кластерами см. Настройки репликации.
Настройки плагина Flow Framework
Для получения информации о настройках автоматического рабочего процесса см. Настройки рабочего процесса.
Настройки плагина геопространственных данных
Для получения информации о настройках процессора IP2Geo плагина геопространственных данных см. Настройки кластера.
Настройки плагина управления индексами
Для получения информации о настройках управления состоянием индекса (ISM) см. Настройки ISM.
Настройки сворачивания индексов
Для получения информации о настройках сворачивания индексов см. Настройки сворачивания индексов.
Настройки плагина планировщика задач
Для получения информации о настройках плагина планировщика задач см. Настройки кластера планировщика задач.
Настройки плагина k-NN
Для получения информации о настройках k-NN см. Настройки k-NN.
Настройки плагина ML Commons
Для получения информации о настройках машинного обучения см. Настройки кластера ML Commons.
Настройки плагина нейронного поиска
Плагин Security Analytics поддерживает следующие настройки:
- plugins.neural_search.hybrid_search_disabled (Динамическое, логическое): Отключает гибридный поиск. По умолчанию false.
Настройки плагина уведомлений
Плагин уведомлений поддерживает следующие настройки. Все настройки в этом списке являются динамическими:
opensearch.notifications.core.allowed_config_types (Список): Разрешенные типы конфигурации плагина уведомлений. Используйте API
GET /_plugins/_notifications/features, чтобы получить значение этой настройки. Типы конфигурации включают slack, chime, microsoft_teams, webhook, email, sns, ses_account, smtp_account и email_group.opensearch.notifications.core.email.minimum_header_length (Целое число): Минимальная длина заголовка электронной почты. Используется для проверки общей длины сообщения электронной почты. По умолчанию 160.
opensearch.notifications.core.email.size_limit (Целое число): Лимит размера электронной почты. Используется для проверки общей длины сообщения электронной почты. По умолчанию 10000000.
opensearch.notifications.core.http.connection_timeout (Целое число): Таймаут подключения внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 5000.
opensearch.notifications.core.http.host_deny_list (Список): Список запрещенных хостов. HTTP-клиент не отправляет уведомления на URL вебхуков из этого списка.
opensearch.notifications.core.http.max_connection_per_route (Целое число): Максимальное количество HTTP-соединений на маршрут внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 20.
opensearch.notifications.core.http.max_connections (Целое число): Максимальное количество HTTP-соединений внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 60.
opensearch.notifications.core.http.socket_timeout (Целое число): Конфигурация таймаута сокета внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 50000.
opensearch.notifications.core.tooltip_support (Логическое): Включает поддержку подсказок для плагина уведомлений. Используйте API
GET /_plugins/_notifications/features, чтобы получить значение этой настройки. По умолчанию true.opensearch.notifications.general.filter_by_backend_roles (Логическое): Включает фильтрацию по ролям бэкенда (контроль доступа на основе ролей для каналов уведомлений). По умолчанию false.
Настройки плагина Query Insights
Для получения информации о настройках плагина Query Insights см. Функции и настройки Query Insights.
Настройки плагина безопасности
Для получения информации о настройках плагина безопасности см. Настройки безопасности.
Настройки плагина Security Analytics
Для получения информации о настройках аналитики безопасности см. Настройки Security Analytics.
Настройки плагина SQL
Для получения информации о настройках, связанных с SQL и PPL, см. Настройки SQL.
8.2.3.11 - Экспериментальные флаги функций
Релизы OpenSearch могут содержать экспериментальные функции, которые вы можете включать или отключать по мере необходимости. Существует несколько способов включения флагов функций в зависимости от типа установки.
Включение в opensearch.yml
Если вы запускаете кластер OpenSearch и хотите включить флаги функций в конфигурационном файле, добавьте следующую строку в opensearch.yml:
opensearch.experimental.feature.<feature_name>.enabled: true
Включение в контейнерах Docker
Если вы используете Docker, добавьте следующую строку в docker-compose.yml в разделе opensearch-node > environment:
OPENSEARCH_JAVA_OPTS="-Dopensearch.experimental.feature.<feature_name>.enabled=true"
Включение в установке tarball
Чтобы включить флаги функций в установке tarball, укажите новый параметр JVM либо в config/jvm.options, либо в OPENSEARCH_JAVA_OPTS.
Вариант 1: Изменение jvm.options
Добавьте следующие строки в config/jvm.options перед запуском процесса OpenSearch, чтобы включить функцию и ее зависимости:
-Dopensearch.experimental.feature.<feature_name>.enabled=true
Затем запустите OpenSearch:
./bin/opensearch
Вариант 2: Включение с помощью переменной окружения
В качестве альтернативы прямому изменению config/jvm.options, вы можете определить свойства, используя переменную окружения. Это можно сделать с помощью одной команды при запуске OpenSearch или определив переменную с помощью export.
Чтобы добавить флаги функций в строке при запуске OpenSearch, выполните следующую команду:
OPENSEARCH_JAVA_OPTS="-Dopensearch.experimental.feature.<feature_name>.enabled=true" ./opensearch-3.1.0/bin/opensearch
Если вы хотите определить переменную окружения отдельно перед запуском OpenSearch, выполните следующие команды:
export OPENSEARCH_JAVA_OPTS="-Dopensearch.experimental.feature.<feature_name>.enabled=true"
./bin/opensearch
Включение для разработки OpenSearch
Чтобы включить флаги функций для разработки, вы должны добавить правильные свойства в run.gradle перед сборкой OpenSearch. См. Руководство для разработчиков для получения информации о том, как использовать Gradle для сборки OpenSearch.
Добавьте следующие свойства в run.gradle, чтобы включить функцию:
testClusters {
runTask {
testDistribution = 'archive'
if (numZones > 1) numberOfZones = numZones
if (numNodes > 1) numberOfNodes = numNodes
systemProperty 'opensearch.experimental.feature.<feature_name>.enabled', 'true'
}
}
8.2.3.12 - Logs
Логи OpenSearch содержат ценную информацию для мониторинга операций кластера и устранения неполадок. Местоположение логов зависит от типа установки:
- В Docker OpenSearch записывает большинство логов в консоль и сохраняет оставшиеся в
opensearch/logs/. Установка tarball также используетopensearch/logs/. - В большинстве установок на Linux OpenSearch записывает логи в
/var/log/opensearch/.
Логи доступны в формате .log (обычный текст) и .json. Права доступа к логам OpenSearch по умолчанию составляют -rw-r--r--, что означает, что любой пользователь на узле может их читать. Вы можете изменить это поведение для каждого типа логов в log4j2.properties, используя опцию filePermissions. Например, вы можете добавить appender.rolling.filePermissions = rw-r-----, чтобы изменить права доступа для JSON-сервера логов. Для получения подробной информации см. документацию Log4j 2.
Логи приложений
Для своих логов приложений OpenSearch использует Apache Log4j 2 и его встроенные уровни логирования (от наименее до наиболее серьезных). В следующей таблице описаны настройки логирования.
| Настройка | Тип данных | Описание |
|---|---|---|
logger.org.opensearch.discovery | Строка | Логгеры принимают встроенные уровни логирования Log4j2: OFF, FATAL, ERROR, WARN, INFO, DEBUG и TRACE. По умолчанию INFO. |
Вместо изменения уровня логирования по умолчанию (logger.level), вы можете изменить уровень логирования для отдельных модулей OpenSearch:
PUT /_cluster/settings
{
"persistent" : {
"logger.org.opensearch.index.reindex" : "DEBUG"
}
}
Самый простой способ идентифицировать модули — не по логам, которые сокращают путь (например, o.o.i.r), а по исходному коду OpenSearch.
После этого изменения OpenSearch будет генерировать гораздо более подробные логи во время операций повторной индексации:
[2019-10-18T16:52:51,184][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: starting
[2019-10-18T16:52:51,186][DEBUG][o.o.i.r.TransportReindexAction] [node1] executing initial scroll against [some-index]
[2019-10-18T16:52:51,291][DEBUG][o.o.i.r.TransportReindexAction] [node1] scroll returned [3] documents with a scroll id of [DXF1Z==]
[2019-10-18T16:52:51,292][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: got scroll response with [3] hits
[2019-10-18T16:52:51,294][DEBUG][o.o.i.r.WorkerBulkByScrollTaskState] [node1] [1626]: preparing bulk request for [0s]
[2019-10-18T16:52:51,297][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: preparing bulk request
[2019-10-18T16:52:51,299][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: sending [3] entry, [222b] bulk request
[2019-10-18T16:52:51,310][INFO ][o.e.c.m.MetaDataMappingService] [node1] [some-new-index/R-j3adc6QTmEAEb-eAie9g] create_mapping [_doc]
[2019-10-18T16:52:51,383][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: got scroll response with [0] hits
[2019-10-18T16:52:51,384][DEBUG][o.o.i.r.WorkerBulkByScrollTaskState] [node1] [1626]: preparing bulk request for [0s]
[2019-10-18T16:52:51,385][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: preparing bulk request
[2019-10-18T16:52:51,386][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: finishing without any catastrophic failures
[2019-10-18T16:52:51,395][DEBUG][o.o.i.r.TransportReindexAction] [node1] Freed [1] contexts
Уровни DEBUG и TRACE являются чрезвычайно подробными. Если вы включаете один из них для устранения проблемы, отключите его после завершения.
Существуют и другие способы изменения уровней логирования:
- Добавление строк в
opensearch.yml
logger.org.opensearch.index.reindex: debug
Изменение opensearch.yml имеет смысл, если вы хотите повторно использовать свою конфигурацию логирования для нескольких кластеров или отлаживать проблемы запуска с одним узлом.
- Изменение
log4j2.properties
# Определите новый логгер с уникальным ID для повторной индексации
logger.reindex.name = org.opensearch.index.reindex
# Установите уровень логирования для этого ID
logger.reindex.level = debug
Этот подход является чрезвычайно гибким, но требует знакомства с синтаксисом файла свойств Log4j 2. В общем, другие варианты предлагают более простую конфигурацию.
Если вы изучите файл log4j2.properties по умолчанию в каталоге конфигурации, вы увидите несколько специфичных для OpenSearch переменных:
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %m%n
appender.rolling_old.fileName = ${sys:opensearch.logs.base_path}${sys:file.separator}${sys:opensearch.logs.cluster_name}.log
${sys:opensearch.logs.base_path}— это каталог для логов (например,/var/log/opensearch/).${sys:opensearch.logs.cluster_name}— это имя кластера.${sys:opensearch.logs.node_name}— это имя узла.[%node_name]— это имя узла.
Медленные логи запросов поиска
Новая функция в версии 2.12, OpenSearch предлагает медленные логи на уровне запросов для поиска. Эти логи основываются на пороговых значениях, чтобы определить, что квалифицируется как “медленно”. Все запросы, которые превышают порог, записываются в логи.
Медленные логи запросов поиска включаются динамически через API настроек кластера. В отличие от медленных логов шардов, пороги медленных логов запросов поиска настраиваются для общего времени выполнения запроса. По умолчанию логи отключены (все пороги установлены на -1).
PUT /_cluster/settings
{
"persistent" : {
"cluster.search.request.slowlog.level" : "TRACE",
"cluster.search.request.slowlog.threshold.warn": "10s",
"cluster.search.request.slowlog.threshold.info": "5s",
"cluster.search.request.slowlog.threshold.debug": "2s",
"cluster.search.request.slowlog.threshold.trace": "10ms"
}
}
Строка из opensearch_index_search_slowlog.log может выглядеть следующим образом:
[2023-10-30T15:47:42,630][TRACE][c.s.r.slowlog] [runTask-0] took[80.8ms], took_millis[80], phase_took_millis[{expand=0, query=39, fetch=22}], total_hits[4 hits], search_type[QUERY_THEN_FETCH], shards[{total: 10, successful: 10, skipped: 0, failed: 0}], source[{"query":{"match_all":{"boost":1.0}}}], id[]
Медленные логи запросов поиска могут занимать значительное место на диске и влиять на производительность, если вы установите низкие пороговые значения. Рассмотрите возможность временного включения их для устранения неполадок или настройки производительности. Чтобы отключить медленные логи запросов поиска, верните все пороги к -1.
Медленные логи шардов
OpenSearch имеет два типа медленных логов шардов, которые помогают выявлять проблемы с производительностью: медленный лог поиска и медленный лог индексации.
Эти логи основываются на пороговых значениях, чтобы определить, что квалифицируется как “медленный” поиск или “медленная” операция индексации. Например, вы можете решить, что запрос считается медленным, если его выполнение занимает более 15 секунд. В отличие от логов приложений, которые настраиваются для модулей, медленные логи настраиваются для индексов. По умолчанию оба лога отключены (все пороги установлены на -1).
В отличие от медленных логов запросов поиска, пороги медленных логов шардов настраиваются для времени выполнения отдельных шардов.
GET <some-index>/_settings?include_defaults=true
{
"indexing": {
"slowlog": {
"reformat": "true",
"threshold": {
"index": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
}
},
"source": "1000",
"level": "TRACE"
}
},
"search": {
"slowlog": {
"level": "TRACE",
"threshold": {
"fetch": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
},
"query": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
}
}
}
}
}
Чтобы включить эти логи, увеличьте один или несколько порогов:
PUT <some-index>/_settings
{
"indexing": {
"slowlog": {
"threshold": {
"index": {
"warn": "15s",
"trace": "750ms",
"debug": "3s",
"info": "10s"
}
},
"source": "500",
"level": "INFO"
}
}
}
Пример настройки медленных логов индексации
В этом примере OpenSearch записывает операции индексации, которые занимают 15 секунд или дольше, на уровне WARN, а операции, которые занимают от 10 до 14.x секунд, на уровне INFO. Если вы установите порог в 0 секунд, OpenSearch будет записывать все операции, что может быть полезно для проверки, действительно ли медленные логи включены.
- reformat указывает, следует ли записывать поле _source документа в одной строке (true) или позволить ему занимать несколько строк (false).
- source — это количество символов поля _source документа, которые нужно записать.
- level — это минимальный уровень логирования, который следует включить.
Строка из opensearch_index_indexing_slowlog.log может выглядеть следующим образом:
node1 | [2019-10-24T19:48:51,012][WARN][i.i.s.index] [node1] [some-index/i86iF5kyTyy-PS8zrdDeAA] took[3.4ms], took_millis[3], type[_doc], id[1], routing[], source[{"title":"Your Name", "Director":"Makoto Shinkai"}]
Медленные логи шардов могут занимать значительное место на диске и влиять на производительность, если вы установите низкие пороговые значения. Рассмотрите возможность временного включения их для устранения неполадок или настройки производительности. Чтобы отключить медленные логи шардов, верните все пороги к -1.
Журналы задач
OpenSearch может записывать время ЦП и использование памяти для N самых затратных по памяти поисковых задач, когда включены потребители ресурсов задач. По умолчанию потребители ресурсов задач будут записывать 10 самых затратных поисковых задач с интервалом в 60 секунд. Эти значения можно настроить в файле opensearch.yml.
Запись задач включается динамически через API настроек кластера:
PUT _cluster/settings
{
"persistent" : {
"task_resource_consumers.enabled" : "true"
}
}
Включение потребителей ресурсов задач может повлиять на задержку поиска.
После включения журналы будут записываться в файлы logs/opensearch_task_detailslog.json и logs/opensearch_task_detailslog.log.
Чтобы настроить интервал записи и количество записываемых поисковых задач, добавьте следующие строки в opensearch.yml:
# Количество затратных поисковых задач для записи
cluster.task.consumers.top_n.size: 100
# Интервал записи
cluster.task.consumers.top_n.frequency: 30s
Журналы устаревания
Журналы устаревания фиксируют, когда клиенты делают устаревшие вызовы API к вашему кластеру. Эти журналы могут помочь вам выявить и исправить проблемы до обновления до новой основной версии. По умолчанию OpenSearch записывает устаревшие вызовы API на уровне WARN, что хорошо подходит для почти всех случаев использования. При необходимости настройте logger.deprecation.level, используя _cluster/settings, opensearch.yml или log4j2.properties.
8.2.4 - Сравнение ОС
Совместимость OpenSearch и OpenSearch Dashboards
Совместимость OpenSearch и OpenSearch Dashboards
OpenSearch и OpenSearch Dashboards совместимы с Red Hat Enterprise Linux (RHEL) и дистрибутивами Linux на базе Debian, которые используют systemd, такими как Amazon Linux и Ubuntu Long-Term Support (LTS). Хотя OpenSearch и OpenSearch Dashboards должны работать на большинстве дистрибутивов Linux, мы тестируем только подмножество из них.
Поддерживаемые операционные системы
Следующая таблица перечисляет версии операционных систем, которые мы в настоящее время тестируем:
| ОС | Версия |
|---|---|
| Rocky Linux | 8 |
| Alma Linux | 8 |
| Amazon Linux | 2/2023 |
| Ubuntu | 24.04 |
| Windows Server | 2019 |
Журнал изменений
Следующая таблица перечисляет изменения, внесенные в совместимость операционных систем.
| Дата | Проблема | PR | Подробности |
|---|---|---|---|
| 2025-02-06 | opensearch-build Issue 5270 | PR 9165 | Удаление Ubuntu 20.04 |
| 2024-07-23 | opensearch-build Issue 4379 | PR 7821 | Удаление CentOS7 |
| 2024-03-08 | opensearch-build Issue 4573 | PR 6637 | Удаление CentOS8, добавление Almalinux8/Rockylinux8 и удаление Ubuntu 16.04/18.04, так как мы в настоящее время тестируем только на 20.04 |
| 2023-06-06 | documentation-website Issue 4217 | PR 4218 | Создание матрицы поддержки |
8.2.5 - Настройка OpenSearch Dashboards
OpenSearch Dashboards использует файл конфигурации opensearch_dashboards.yml
OpenSearch Dashboards использует файл конфигурации opensearch_dashboards.yml для чтения настроек при запуске кластера. Вы можете найти opensearch_dashboards.yml по следующему пути: /usr/share/opensearch-dashboards/config/opensearch_dashboards.yml (Docker) или /etc/opensearch-dashboards/opensearch_dashboards.yml (большинство дистрибутивов Linux) на каждом узле.
Для получения информации о настройках OpenSearch Dashboards ознакомьтесь с образцом файла opensearch_dashboards.yml.
8.2.6 - Upgrading OpenSearch
OpenSearch использует семантическое версионирование, что означает, что разрушающие изменения вводятся только между основными версиями.
Проект OpenSearch регулярно выпускает обновления, которые включают новые функции, улучшения и исправления ошибок. OpenSearch использует семантическое версионирование, что означает, что разрушающие изменения вводятся только между основными версиями. Чтобы узнать о предстоящих функциях и исправлениях, ознакомьтесь с дорожной картой проекта OpenSearch на GitHub. Чтобы просмотреть список предыдущих релизов или узнать больше о том, как OpenSearch использует версионирование, смотрите раздел “График релизов и политика обслуживания”.
Мы понимаем, что пользователи заинтересованы в обновлении OpenSearch, чтобы воспользоваться последними функциями, и мы будем продолжать расширять эти документы по обновлению и миграции, чтобы охватить дополнительные темы, такие как обновление OpenSearch Dashboards и сохранение пользовательских конфигураций, например, для плагинов.
Если вы хотите, чтобы был добавлен конкретный процесс или хотите внести свой вклад, создайте задачу на GitHub. Ознакомьтесь с Руководством для участников, чтобы узнать, как вы можете помочь.
Учет рабочих процессов
Потратьте время на планирование процесса перед внесением каких-либо изменений в ваш кластер. Например, рассмотрите следующие вопросы:
- Сколько времени займет процесс обновления?
- Если ваш кластер используется в производственной среде, насколько критично время простоя?
- У вас есть инфраструктура для развертывания нового кластера в тестовой или разработческой среде перед его переводом в эксплуатацию, или вам нужно обновить производственные узлы напрямую?
Ответы на такие вопросы помогут вам определить, какой путь обновления будет наиболее подходящим для вашей среды.
Минимально вы должны:
- Ознакомиться с разрушающими изменениями.
- Ознакомиться с матрицами совместимости инструментов OpenSearch.
- Ознакомиться с совместимостью плагинов.
- Создать резервные копии файлов конфигурации.
- Создать снимок.
Остановить любую несущественную индексацию перед началом процедуры обновления, чтобы устранить ненужные требования к ресурсам кластера во время выполнения обновления.
Ознакомление с разрушающими изменениями
Важно определить, как новая версия OpenSearch будет интегрироваться с вашей средой. Ознакомьтесь с разделом “Разрушающие изменения” перед началом любых процедур обновления, чтобы определить, нужно ли вам вносить изменения в ваш рабочий процесс. Например, компоненты, находящиеся выше или ниже по потоку, могут потребовать модификации для совместимости с изменением API (см. мета-проблему #2589).
Ознакомление с матрицами совместимости инструментов OpenSearch
Если ваш кластер OpenSearch взаимодействует с другими службами в вашей среде, такими как Logstash или Beats, вам следует проверить матрицы совместимости инструментов OpenSearch, чтобы определить, нужно ли обновлять другие компоненты.
Ознакомление с совместимостью плагинов
Проверьте плагины, которые вы используете, чтобы определить их совместимость с целевой версией OpenSearch. Официальные плагины проекта OpenSearch можно найти в репозитории проекта OpenSearch на GitHub. Если вы используете сторонние плагины, вам следует ознакомиться с документацией для этих плагинов, чтобы определить, совместимы ли они.
Перейдите в раздел “Доступные плагины”, чтобы увидеть справочную таблицу, которая подчеркивает совместимость версий для встроенных плагинов OpenSearch.
Основные, второстепенные и патч-версии плагинов должны соответствовать основным, второстепенным и патч-версиям OpenSearch для обеспечения совместимости. Например, версии плагинов 2.3.0.x работают только с OpenSearch 2.3.0.
Резервное копирование файлов конфигурации
Снизьте риск потери данных, создав резервные копии любых важных файлов перед началом обновления. Обычно эти файлы будут находиться в одной из двух директорий:
opensearch/configopensearch-dashboards/config
Некоторые примеры включают opensearch.yml, opensearch_dashboards.yml, файлы конфигурации плагинов и сертификаты TLS. Как только вы определите, какие файлы хотите сохранить, скопируйте их на удаленное хранилище для безопасности.
Если вы используете функции безопасности, обязательно ознакомьтесь с разделом “Предостережение” для получения информации о резервном копировании и восстановлении ваших настроек безопасности.
Создание снимка
Рекомендуется создать резервную копию состояния вашего кластера и индексов с помощью снимков. Снимки, сделанные перед обновлением, могут быть использованы в качестве точек восстановления, если вам нужно будет откатить кластер к его оригинальной версии.
Вы можете дополнительно снизить риск потери данных, храня ваши снимки на внешнем хранилище, таком как смонтированная файловая система сети (NFS) или облачное хранилище, как указано в следующей таблице.
| Местоположение репозитория снимков | Требуемый плагин OpenSearch |
|---|---|
| Amazon Simple Storage Service (Amazon S3) | repository-s3 |
| Google Cloud Storage (GCS) | repository-gcs |
| Apache Hadoop Distributed File System (HDFS) | repository-hdfs |
| Microsoft Azure Blob Storage | repository-azure |
Методы обновления
Выберите подходящий метод для обновления вашего кластера до новой версии OpenSearch в зависимости от ваших требований:
- Постепенное обновление (rolling upgrade) обновляет узлы по одному без остановки кластера.
- Обновление с перезапуском кластера (cluster restart upgrade) обновляет службы, пока кластер остановлен.
Обновления, охватывающие более одной основной версии OpenSearch, потребуют дополнительных усилий из-за необходимости повторной индексации. Для получения дополнительной информации обратитесь к API повторной индексации. См. таблицу совместимости индексов, включенную позже в этом руководстве, для помощи в планировании миграции данных.
Постепенное обновление
Постепенное обновление — отличный вариант, если вы хотите сохранить работоспособность вашего кластера на протяжении всего процесса. Данные могут продолжать поступать, анализироваться и запрашиваться, пока узлы поочередно останавливаются, обновляются и перезапускаются. Вариация постепенного обновления, называемая “замена узла” (node replacement), следует точно такому же процессу, за исключением того, что хосты и контейнеры не повторно используются для нового узла. Вы можете выполнить замену узла, если также обновляете базовые хосты.
Узлы OpenSearch не могут присоединиться к кластеру, если менеджер кластера работает на более новой версии OpenSearch, чем узел, запрашивающий членство. Чтобы избежать этой проблемы, обновляйте узлы, имеющие право на управление кластером, последними.
Смотрите раздел “Постепенное обновление” для получения дополнительной информации о процессе.
Обновление с перезапуском кластера
Администраторы OpenSearch могут выбрать выполнение обновления с перезапуском кластера по нескольким причинам, например, если администратор не хочет проводить обслуживание работающего кластера или если кластер мигрируется в другую среду.
В отличие от постепенного обновления, при котором только один узел отключен в любой момент времени, обновление с перезапуском кластера требует остановки OpenSearch и OpenSearch Dashboards на всех узлах кластера перед продолжением. После остановки узлов устанавливается новая версия OpenSearch. Затем OpenSearch запускается, и кластер загружается на новую версию.
Совместимость
Узлы OpenSearch совместимы с другими узлами OpenSearch, работающими на любой другой минорной версии в рамках одного основного релиза. Например, версия 1.1.0 совместима с 1.3.7, поскольку они являются частью одной основной версии (1.x). Кроме того, узлы OpenSearch и индексы обратно совместимы с предыдущей основной версией. Это означает, что, например, индекс, созданный узлом OpenSearch, работающим на любой версии 1.x, может быть восстановлен из снимка в кластер OpenSearch, работающий на любой версии 2.x.
Узлы OpenSearch 1.x совместимы с узлами, работающими на Elasticsearch 7.x, но продолжительность работы смешанной версии не должна превышать период обновления кластера.
Совместимость индексов определяется версией Apache Lucene, которая создала индекс. Если индекс был создан кластером OpenSearch, работающим на версии 1.0.0, то этот индекс может использоваться любым другим кластером OpenSearch, работающим до последнего релиза 1.x или 2.x. См. таблицу совместимости индексов для версий Lucene, работающих в OpenSearch 1.0.0 и более поздних версиях, а также в Elasticsearch 6.8 и более поздних версиях.
Если ваш путь обновления охватывает более одной основной версии и вы хотите сохранить существующие индексы, вы можете использовать API повторной индексации (Reindex API), чтобы сделать ваши индексы совместимыми с целевой версией OpenSearch перед обновлением. Например, если ваш кластер в настоящее время работает на Elasticsearch 6.8 и вы хотите обновиться до OpenSearch 2.x, вам сначала нужно обновиться до OpenSearch 1.x, заново создать ваши индексы с помощью API повторной индексации и, наконец, обновиться до 2.x. Одной из альтернатив повторной индексации является повторное извлечение данных из источника, например, воспроизведение потока данных или извлечение данных из базы данных.
Справочная таблица совместимости индексов
Если вы планируете сохранить старые индексы после обновления версии OpenSearch, вам может потребоваться повторная индексация или повторное извлечение данных. Обратитесь к следующей таблице для версий Lucene в недавних релизах OpenSearch и Elasticsearch.
| Версия Lucene | Версия OpenSearch | Версия Elasticsearch |
|---|---|---|
| 9.10.0 | 2.14.0 | |
| 2.13.0 | 8.13 | |
| 9.9.2 | 2.12.0 | — |
| 9.7.0 | 2.11.1 | |
| 2.9.0 | 8.9.0 | |
| 9.6.0 | 2.8.0 | 8.8.0 |
| 9.5.0 | 2.7.0 | |
| 2.6.0 | 8.7.0 | |
| 9.4.2 | 2.5.0 | |
| 2.4.1 | 8.6 | |
| 9.4.1 | 2.4.0 | — |
| 9.4.0 | — | 8.5 |
| 9.3.0 | 2.3.0 | |
| 2.2.x | 8.4 | |
| 9.2.0 | 2.1.0 | 8.3 |
| 9.1.0 | 2.0.x | 8.2 |
| 9.0.0 | — | 8.1 |
| 8.0 | ||
| 8.11.1 | — | 7.17 |
| 8.10.1 | 1.3.x | |
| 1.2.x | 7.16 | |
| 8.9.0 | 1.1.0 | 7.15 |
| 7.14 | ||
| 8.8.2 | 1.0.0 | 7.13 |
| 8.8.0 | — | 7.12 |
| 8.7.0 | — | 7.11 |
| 7.10 | ||
| 8.6.2 | — | 7.9 |
| 8.5.1 | — | 7.8 |
| 7.7 | ||
| 8.4.0 | — | 7.6 |
| 8.3.0 | — | 7.5 |
| 8.2.0 | — | 7.4 |
| 8.1.0 | — | 7.3 |
| 8.0.0 | — | 7.2 |
| 7.1 | ||
| 7.7.3 | — | 6.8 |
Тире (—) указывает на то, что нет версии продукта, содержащей указанную версию Apache Lucene.
8.2.6.1 - Приложение по обновлениям
Используйте приложение по обновлениям, чтобы найти дополнительную вспомогательную документацию, такую как лабораторные работы, которые включают примеры API-запросов и конфигурационных файлов для дополнения соответствующей документации по процессам.
Конкретные процедуры, изложенные в разделе приложения, могут быть использованы различными способами:
- Новые пользователи OpenSearch могут использовать шаги и примеры ресурсов, которые мы предоставляем, чтобы узнать о конфигурации и использовании OpenSearch и OpenSearch Dashboards.
- Системные администраторы, работающие с кластерами OpenSearch, могут использовать предоставленные примеры для симуляции обслуживания кластера в тестовой среде перед применением любых изменений к рабочей нагрузке в производственной среде.
Если вы хотите запросить конкретную тему, пожалуйста, оставьте комментарий по вопросу #2830 в проекте OpenSearch на GitHub.
Конкретные команды, включенные в это приложение, служат примерами взаимодействия с API OpenSearch и основным хостом, чтобы продемонстрировать шаги, описанные в связанных документах по процессу обновления. Цель состоит не в том, чтобы быть чрезмерно предписывающим, а в том, чтобы добавить контекст для пользователей, которые новы в OpenSearch и хотят увидеть практические примеры.
8.2.6.2 - Постепенное обновление
Постепенные обновления, иногда называемые обновлениями замены узлов, могут выполняться на работающих кластерах с практически нулевым временем простоя.
Постепенные обновления, иногда называемые “обновлениями замены узлов”, могут выполняться на работающих кластерах с практически нулевым временем простоя. Узлы поочередно останавливаются и обновляются на месте. В качестве альтернативы узлы могут быть остановлены и заменены, один за другим, хостами, работающими на новой версии. В процессе вы можете продолжать индексировать и запрашивать данные в вашем кластере.
Этот документ служит общим обзором процедуры постепенного обновления, не зависящим от платформы. Для конкретных примеров команд, скриптов и файлов конфигурации смотрите Приложение.
Подготовка к обновлению
Ознакомьтесь с разделом “Обновление OpenSearch” для получения рекомендаций по резервному копированию ваших файлов конфигурации и созданию снимка состояния кластера и индексов перед внесением каких-либо изменений в ваш кластер OpenSearch.
Важно: Узлы OpenSearch не могут быть понижены. Если вам нужно отменить обновление, вам потребуется выполнить новую установку OpenSearch и восстановить кластер из снимка. Сделайте снимок и сохраните его в удаленном репозитории перед началом процедуры обновления.
Выполнение обновления
- Проверьте состояние вашего кластера OpenSearch перед началом. Вам следует решить любые проблемы с индексами или распределением шардов перед обновлением, чтобы гарантировать сохранность ваших данных. Статус “green” указывает на то, что все первичные и реплика-шарды распределены. См. раздел “Состояние кластера” для получения дополнительной информации. Следующая команда запрашивает конечную точку API _cluster/health:
GET "/_cluster/health?pretty"
Ответ должен выглядеть примерно так:
{
"cluster_name": "opensearch-dev-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 4,
"number_of_data_nodes": 4,
"active_primary_shards": 1,
"active_shards": 4,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
- Отключите репликацию шардов, чтобы предотвратить создание реплик шардов, пока узлы отключаются. Это остановит перемещение сегментов индекса Lucene на узлах в вашем кластере. Вы можете отключить репликацию шардов, запросив конечную точку API _cluster/settings:
PUT "/_cluster/settings?pretty"
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}
Ответ должен выглядеть примерно так:
{
"acknowledged": true,
"persistent": {
"cluster": {
"routing": {
"allocation": {
"enable": "primaries"
}
}
}
},
"transient": {}
}
- Выполните операцию сброса на кластере, чтобы зафиксировать записи журнала транзакций в индексе Lucene:
POST "/_flush?pretty"
Ответ должен выглядеть примерно так:
{
"_shards": {
"total": 4,
"successful": 4,
"failed": 0
}
}
Ознакомьтесь с вашим кластером и определите первый узел для обновления. Узлы, имеющие право на управление кластером, должны обновляться последними, поскольку узлы OpenSearch могут присоединиться к кластеру с управляющими узлами, работающими на более старой версии, но не могут присоединиться к кластеру, в котором все управляющие узлы работают на более новой версии.
Запросите конечную точку
_cat/nodes, чтобы определить, какой узел был повышен до управляющего узла кластера. Следующая команда включает дополнительные параметры запроса, которые запрашивают только имя, версию, роль узла и заголовки master. Обратите внимание, что версии OpenSearch 1.x используют термин “master”, который был устаревшим и заменен на “cluster_manager” в OpenSearch 2.x и более поздних версиях.
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-01 7.10.2 dimr -
os-node-04 7.10.2 dimr -
os-node-03 7.10.2 dimr -
os-node-02 7.10.2 dimr *
Остановите узел, который вы обновляете. Не удаляйте объем, связанный с контейнером, когда вы удаляете контейнер. Новый контейнер OpenSearch будет использовать существующий объем. Удаление объема приведет к потере данных.
Подтвердите, что связанный узел был исключен из кластера, запросив конечную точку API
_cat/nodes:
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-02 7.10.2 dimr *
os-node-04 7.10.2 dimr -
os-node-03 7.10.2 dimr -
Узел os-node-01 больше не отображается, потому что контейнер был остановлен и удален.
Разверните новый контейнер, работающий на желаемой версии OpenSearch и подключенный к тому же объему, что и удаленный контейнер.
Запросите конечную точку
_cat/nodesпосле того, как OpenSearch запустится на новом узле, чтобы подтвердить, что он присоединился к кластеру:
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-02 7.10.2 dimr *
os-node-04 7.10.2 dimr -
os-node-01 7.10.2 dimr -
os-node-03 7.10.2 dimr -
В примере вывода новый узел OpenSearch сообщает о работающей версии 7.10.2 в кластер. Это результат compatibility.override_main_response_version, который используется при подключении к кластеру с устаревшими клиентами, проверяющими версию. Вы можете вручную подтвердить версию узла, вызвав конечную точку API /_nodes, как в следующей команде. Замените <nodeName> на имя вашего узла. См. раздел “API узлов”, чтобы узнать больше.
GET "/_nodes/<nodeName>?pretty=true" | jq -r '.nodes | .[] | "\(.name) v\(.version)"'
Подтвердите, что ответ выглядит примерно так:
os-node-01 v1.3.7
- Включите репликацию шардов снова:
PUT "/_cluster/settings?pretty"
{
"persistent": {
"cluster.routing.allocation.enable": "all"
}
}
Ответ должен выглядеть примерно так:
{
"acknowledged": true,
"persistent": {
"cluster": {
"routing": {
"allocation": {
"enable": "all"
}
}
}
},
"transient": {}
}
- Подтвердите, что кластер здоров:
GET "/_cluster/health?pretty"
Ответ должен выглядеть примерно так:
{
"cluster_name": "opensearch-dev-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 4,
"number_of_data_nodes": 4,
"discovered_master": true,
"active_primary_shards": 1,
"active_shards": 4,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
- Повторите шаги 2–11 для каждого узла в вашем кластере. Не забудьте обновить узел управляющего кластера последним. После замены последнего узла запросите конечную точку
_cat/nodes, чтобы подтвердить, что все узлы присоединились к кластеру. Кластер теперь загружен на новую версию OpenSearch. Вы можете проверить версию кластера, запросив конечную точку API_cat/nodes:
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-04 1.3.7 dimr -
os-node-02 1.3.7 dimr *
os-node-01 1.3.7 dimr -
os-node-03 1.3.7 dimr -
Обновление завершено, и вы можете начать пользоваться последними функциями и исправлениями!
Пошаговая перезагрузка
Пошаговая перезагрузка следует той же пошаговой процедуре, что и пошаговое обновление, за исключением обновления самих узлов. Во время пошаговой перезагрузки узлы перезагружаются по одному — обычно для применения изменений конфигурации, обновления сертификатов или выполнения системного обслуживания — без нарушения доступности кластера.
Чтобы выполнить пошаговую перезагрузку, следуйте шагам, описанным в разделе “Пошаговое обновление”, исключая шаги, связанные с обновлением бинарного файла OpenSearch или образа контейнера:
Проверьте состояние кластера Убедитесь, что статус кластера зеленый и все шардов назначены. (Шаг 1 пошагового обновления)
Отключите перераспределение шардов Предотвратите попытки OpenSearch перераспределить шардов, пока узлы находятся в оффлайне. (Шаг 2 пошагового обновления)
Сбросьте журналы транзакций Зафиксируйте недавние операции в Lucene, чтобы сократить время восстановления. (Шаг 3 пошагового обновления)
Просмотрите и определите следующий узел для перезагрузки Убедитесь, что вы перезагрузите текущий узел-менеджер кластера последним. (Шаг 4 пошагового обновления)
Проверьте, какой узел является текущим менеджером кластера Используйте API _cat/nodes, чтобы определить, какой узел является текущим активным менеджером кластера. (Шаг 5 пошагового обновления)
Остановите узел Корректно завершите работу узла. Не удаляйте связанный объем данных. (Шаг 6 пошагового обновления)
Подтвердите, что узел покинул кластер Используйте _cat/nodes, чтобы убедиться, что он больше не указан в списке. (Шаг 7 пошагового обновления)
Перезагрузите узел Запустите тот же узел (тот же бинарный файл/версия/конфигурация) и дайте ему повторно присоединиться к кластеру. (Шаг 8 пошагового обновления — без обновления бинарного файла)
Проверьте, что перезагруженный узел повторно присоединился Проверьте _cat/nodes, чтобы подтвердить, что узел присутствует и работает корректно. (Шаг 9 пошагового обновления)
Включите перераспределение шардов Восстановите полную возможность перемещения шардов. (Шаг 10 пошагового обновления)
Подтвердите, что состояние кластера зеленое Проверьте стабильность перед перезагрузкой следующего узла. (Шаг 11 пошагового обновления)
Повторите процесс для всех остальных узлов Перезагрузите каждый узел по одному. Если узел подходит для роли менеджера кластера, перезагрузите его последним. (Шаг 12 пошагового обновления — снова без шага обновления)
Сохраняя кворум и перезагружая узлы последовательно, пошаговые перезагрузки обеспечивают нулевое время простоя и полную непрерывность данных.
8.2.6.3 - Лаборатория последовательного обновления
Вы можете следовать этим шагам на своем совместимом хосте, чтобы воссоздать то же состояние кластера, которое использовался в проекте OpenSearch для тестирования пошаговых обновлений.
Это упражнение полезно, если вы хотите протестировать процесс обновления в среде разработки.
Шаги, использованные в этой лаборатории, были проверены на произвольно выбранном экземпляре Amazon Elastic Compute Cloud (Amazon EC2) t2.large с использованием ядра Amazon Linux 2 версии Linux 5.10.162-141.675.amzn2.x86_64 и Docker версии 20.10.17, сборка 100c701. Экземпляр был предоставлен с прикрепленным корневым томом Amazon EBS объемом 20 GiB gp2. Эти спецификации включены для информационных целей и не представляют собой аппаратные требования для OpenSearch или OpenSearch Dashboards.
Ссылки в этой процедуре на путь $HOME на хост-машине представлены символом тильда (“~”), чтобы сделать инструкции более переносимыми. Если вы предпочитаете указывать абсолютный путь, измените пути томов, определенные в upgrade-demo-cluster.sh, и используемые в соответствующих командах в этом документе, чтобы отразить вашу среду.
Настройка окружения
Следуя шагам в этом документе, вы определите несколько ресурсов Docker, включая контейнеры, тома и выделенную сеть Docker, с помощью предоставленного нами скрипта. Вы можете очистить свою среду с помощью следующей команды, если хотите перезапустить процесс:
docker container stop $(docker container ls -aqf name=os-); \
docker container rm $(docker container ls -aqf name=os-); \
docker volume rm -f $(docker volume ls -q | egrep 'data-0|repo-0'); \
docker network rm opensearch-dev-net
Эта команда удаляет контейнеры с именами, соответствующими регулярному выражению os-, тома данных, соответствующие data-0 и repo-0*, а также сеть Docker с именем opensearch-dev-net. Если у вас есть другие ресурсы Docker, работающие на вашем хосте, вам следует просмотреть и изменить команду, чтобы избежать случайного удаления других ресурсов. Эта команда не отменяет изменения конфигурации хоста, такие как поведение обмена памяти.
После выбора хоста вы можете начать лабораторию:
Установите соответствующую версию Docker Engine для вашего дистрибутива Linux и архитектуры системы.
Настройте важные системные параметры на вашем хосте:
- Отключите обмен и пейджинг памяти на хосте для повышения производительности:
sudo swapoff -a - Увеличьте количество доступных для OpenSearch карт памяти. Откройте файл конфигурации sysctl для редактирования. Эта команда использует текстовый редактор vim, но вы можете использовать любой доступный текстовый редактор:
sudo vim /etc/sysctl.conf - Добавьте следующую строку в
/etc/sysctl.conf:vm.max_map_count=262144 - Сохраните и выйдите. Если вы используете текстовые редакторы vi или vim, сохраните и выйдите, переключившись в командный режим и введя
:wq!илиZZ. - Примените изменение конфигурации:
sudo sysctl -p
- Отключите обмен и пейджинг памяти на хосте для повышения производительности:
Создайте новую директорию с именем
deployв вашем домашнем каталоге, затем перейдите в нее. Вы будете использовать~/deployдля путей в скрипте развертывания, конфигурационных файлах и TLS-сертификатах:mkdir ~/deploy && cd ~/deployСкачайте
upgrade-demo-cluster.shиз репозитория документации проекта OpenSearch:wget https://raw.githubusercontent.com/opensearch-project/documentation-website/main/assets/examples/upgrade-demo-cluster.shЗапустите скрипт без каких-либо изменений, чтобы развернуть четыре контейнера, работающих с OpenSearch, и один контейнер, работающий с OpenSearch Dashboards, с пользовательскими самоподписанными TLS-сертификатами и заранее определенным набором внутренних пользователей:
sh upgrade-demo-cluster.sh
- Проверьте, что контейнеры были успешно запущены:
docker container ls
Пример ответа
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6e5218c8397d opensearchproject/opensearch-dashboards:1.3.7 "./opensearch-dashbo…" 24 seconds ago Up 22 seconds 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp os-dashboards-01
cb5188308b21 opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 25 seconds ago Up 24 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9204->9200/tcp, :::9204->9200/tcp, 0.0.0.0:9604->9600/tcp, :::9604->9600/tcp os-node-04
71b682aa6671 opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 26 seconds ago Up 25 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9203->9200/tcp, :::9203->9200/tcp, 0.0.0.0:9603->9600/tcp, :::9603->9600/tcp os-node-03
f894054a9378 opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 27 seconds ago Up 26 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9202->9200/tcp, :::9202->9200/tcp, 0.0.0.0:9602->9600/tcp, :::9602->9600/tcp os-node-02
2e9c91c959cd opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 28 seconds ago Up 27 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9201->9200/tcp, :::9201->9200/tcp, 0.0.0.0:9601->9600/tcp, :::9601->9600/tcp os-node-01
- Время, необходимое OpenSearch для инициализации кластера, варьируется в зависимости от производительности хоста. Вы можете следить за журналами контейнеров, чтобы увидеть, что делает OpenSearch в процессе загрузки:
- Введите следующую команду, чтобы отобразить журналы для контейнера os-node-01 в терминальном окне:
docker logs -f os-node-01
- Вы увидите запись в журнале, похожую на следующий пример, когда узел будет готов:
Пример
[INFO ][o.o.s.c.ConfigurationRepository] [os-node-01] Node 'os-node-01' initialized
- Нажмите
Ctrl+C, чтобы остановить просмотр журналов контейнера и вернуться к командной строке.
- Используйте cURL для запроса к OpenSearch REST API. В следующей команде os-node-01 запрашивается, отправляя запрос на порт 9201 хоста, который сопоставлен с портом 9200 на контейнере:
curl -s "https://localhost:9201" -ku admin:<custom-admin-password>
Пример ответа
{
"name" : "os-node-01",
"cluster_name" : "opensearch-dev-cluster",
"cluster_uuid" : "g1MMknuDRuuD9IaaNt56KA",
"version" : {
"distribution" : "opensearch",
"number" : "1.3.7",
"build_type" : "tar",
"build_hash" : "db18a0d5a08b669fb900c00d81462e221f4438ee",
"build_date" : "2022-12-07T22:59:20.186520Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
Совет: Используйте опцию
-sсcurl, чтобы скрыть индикатор прогресса и сообщения об ошибках.
Добавление данных и настройка безопасности OpenSearch
Теперь, когда кластер OpenSearch работает, пришло время добавить данные и настроить некоторые параметры безопасности OpenSearch. Данные, которые вы добавите, и настройки, которые вы сконфигурируете, будут проверены снова после завершения обновления версии.
Этот раздел можно разбить на две части:
- Индексация данных с помощью REST API
- Добавление данных с использованием OpenSearch Dashboards
Индексация данных с помощью REST API
- Скачайте файл с образцом сопоставления полей:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/main/assets/examples/ecommerce-field_mappings.json
- Затем скачайте объемные данные, которые вы будете загружать в этот индекс:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/main/assets/examples/ecommerce.ndjson
- Используйте API создания индекса, чтобы создать индекс, используя сопоставления, определенные в
ecommerce-field_mappings.json:
curl -H "Content-Type: application/json" \
-X PUT "https://localhost:9201/ecommerce?pretty" \
--data-binary "@ecommerce-field_mappings.json" \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "ecommerce"
}
- Используйте Bulk API, чтобы добавить данные в новый индекс
ecommerceизecommerce.ndjson:
curl -H "Content-Type: application/x-ndjson" \
-X PUT "https://localhost:9201/ecommerce/_bulk?pretty" \
--data-binary "@ecommerce.ndjson" \
-ku admin:<custom-admin-password>
Пример ответа (усеченный)
{
"took": 123,
"errors": false,
"items": [
{
"index": {
"_index": "ecommerce",
"_id": "1",
"_version": 1,
"result": "created",
"status": 201,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
},
...
]
}
5. Запрос поиска также может подтвердить, что данные были успешно проиндексированы. Следующий запрос возвращает количество документов, в которых ключевое слово `customer_first_name` равно `Sonya`:
```bash
curl -H 'Content-Type: application/json' \
-X GET "https://localhost:9201/ecommerce/_search?pretty=true&filter_path=hits.total" \
-d'{"query":{"match":{"customer_first_name":"Sonya"}}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"hits" : {
"total" : {
"value" : 106,
"relation" : "eq"
}
}
}
Добавление данных с использованием OpenSearch Dashboards
Откройте веб-браузер и перейдите на порт 5601 вашего Docker-хоста (например, https://HOST_ADDRESS:5601). Если OpenSearch Dashboards работает и у вас есть сетевой доступ к хосту из вашего клиентского браузера, вы будете перенаправлены на страницу входа.
- Если веб-браузер выдает ошибку из-за того, что TLS-сертификаты самоподписанные, вам может потребоваться обойти проверки сертификатов в вашем браузере. Обратитесь к документации браузера для получения информации о том, как обойти проверки сертификатов. Общее имя (CN) для каждого сертификата генерируется в соответствии с именами контейнеров и узлов для внутрикластерной связи, поэтому подключение к хосту из браузера все равно приведет к предупреждению “недействительное CN”.
Введите имя пользователя по умолчанию (admin) и пароль (admin).
На главной странице OpenSearch Dashboards выберите Добавить образцы данных.
В разделе Образцы веб-журналов выберите Добавить данные.
- (Необязательно) Выберите Просмотреть данные, чтобы просмотреть [Логи] панель веб-трафика.
Выберите кнопку меню, чтобы открыть панель навигации, затем перейдите в Безопасность > Внутренние пользователи.
Выберите Создать внутреннего пользователя.
Укажите имя пользователя и пароль.
В поле Роль в бэкенде введите
admin.Выберите Создать.
Резервное копирование важных файлов
Всегда создавайте резервные копии перед внесением изменений в ваш кластер, особенно если кластер работает в производственной среде.
В этом разделе вы будете:
- Регистрировать репозиторий снимков.
- Создавать снимок.
- Резервировать настройки безопасности.
Регистрация репозитория снимков
Зарегистрируйте репозиторий, используя том, который был смонтирован с помощью upgrade-demo-cluster.sh:
curl -H 'Content-Type: application/json' \
-X PUT "https://localhost:9201/_snapshot/snapshot-repo?pretty" \
-d '{"type":"fs","settings":{"location":"/usr/share/opensearch/snapshots"}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true
}
Необязательно: Выполните дополнительную проверку, чтобы убедиться, что репозиторий был успешно создан:
curl -H 'Content-Type: application/json' \
-X POST "https://localhost:9201/_snapshot/snapshot-repo/_verify?timeout=0s&master_timeout=50s&pretty" \
-ku admin:<custom-admin-password>
Пример ответа
{
"nodes" : {
"UODBXfAlRnueJ67grDxqgw" : {
"name" : "os-node-03"
},
"14I_OyBQQXio8nmk0xsVcQ" : {
"name" : "os-node-04"
},
"tQp3knPRRUqHvFNKpuD2vQ" : {
"name" : "os-node-02"
},
"rPe8D6ssRgO5twIP00wbCQ" : {
"name" : "os-node-01"
}
}
}
Создание снимка
Снимки — это резервные копии индексов и состояния кластера. См. раздел Снимки, чтобы узнать больше.
Создайте снимок, который включает все индексы и состояние кластера:
curl -H 'Content-Type: application/json' \
-X PUT "https://localhost:9201/_snapshot/snapshot-repo/cluster-snapshot-v137?wait_for_completion=true&pretty" \
-ku admin:<custom-admin-password>
Пример ответа
{
"snapshot" : {
"snapshot" : "cluster-snapshot-v137",
"uuid" : "-IYB8QNPShGOTnTtMjBjNg",
"version_id" : 135248527,
"version" : "1.3.7",
"indices" : [
"opensearch_dashboards_sample_data_logs",
".opendistro_security",
"security-auditlog-2023.02.27",
".kibana_1",
".kibana_92668751_admin_1",
"ecommerce",
"security-auditlog-2023.03.06",
"security-auditlog-2023.02.28",
"security-auditlog-2023.03.07"
],
"data_streams" : [ ],
"include_global_state" : true,
"state" : "SUCCESS",
"start_time" : "2023-03-07T18:33:00.656Z",
"start_time_in_millis" : 1678213980656,
"end_time" : "2023-03-07T18:33:01.471Z",
"end_time_in_millis" : 1678213981471,
"duration_in_millis" : 815,
"failures" : [ ],
"shards" : {
"total" : 9,
"failed" : 0,
"successful" : 9
}
}
}
Резервное копирование настроек безопасности
Администраторы кластера могут изменять настройки безопасности OpenSearch, используя любой из следующих методов:
- Изменение YAML-файлов и запуск
securityadmin.sh - Выполнение REST API запросов с использованием сертификата администратора
- Внесение изменений с помощью OpenSearch Dashboards
Независимо от выбранного метода, OpenSearch Security записывает вашу конфигурацию в специальный системный индекс, называемый .opendistro_security. Этот системный индекс сохраняется в процессе обновления и также сохраняется в созданном вами снимке. Однако восстановление системных индексов требует повышенного доступа, предоставленного сертификатом администратора. Чтобы узнать больше, смотрите разделы Системные индексы и Настройка TLS-сертификатов.
Вы также можете экспортировать настройки безопасности OpenSearch в виде YAML-файлов, запустив securityadmin.sh с опцией -backup на любом из ваших узлов OpenSearch. Эти YAML-файлы могут быть использованы для повторной инициализации индекса .opendistro_security с вашей существующей конфигурацией. Следующие шаги помогут вам сгенерировать эти резервные файлы и скопировать их на ваш хост для хранения:
Откройте интерактивную сессию псевдо-TTY с
os-node-01:docker exec -it os-node-01 bashСоздайте директорию с именем
backupsи перейдите в нее:mkdir /usr/share/opensearch/backups && cd /usr/share/opensearch/backupsИспользуйте
securityadmin.sh, чтобы создать резервные копии ваших настроек безопасности OpenSearch в/usr/share/opensearch/backups/:/usr/share/opensearch/plugins/opensearch-security/tools/securityadmin.sh \ -backup /usr/share/opensearch/backups \ -icl \ -nhnv \ -cacert /usr/share/opensearch/config/root-ca.pem \ -cert /usr/share/opensearch/config/admin.pem \ -key /usr/share/opensearch/config/admin-key.pem
Пример ответа
Security Admin v7
Will connect to localhost:9300 ... done
Connected as CN=A,OU=DOCS,O=OPENSEARCH,L=PORTLAND,ST=OREGON,C=US
OpenSearch Version: 1.3.7
OpenSearch Security Version: 1.3.7.0
Contacting opensearch cluster 'opensearch' and wait for YELLOW clusterstate ...
Clustername: opensearch-dev-cluster
Clusterstate: GREEN
Number of nodes: 4
Number of data nodes: 4
.opendistro_security index already exists, so we do not need to create one.
Will retrieve '/config' into /usr/share/opensearch/backups/config.yml
SUCC: Configuration for 'config' stored in /usr/share/opensearch/backups/config.yml
Will retrieve '/roles' into /usr/share/opensearch/backups/roles.yml
SUCC: Configuration for 'roles' stored in /usr/share/opensearch/backups/roles.yml
Will retrieve '/rolesmapping' into /usr/share/opensearch/backups/roles_mapping.yml
SUCC: Configuration for 'rolesmapping' stored in /usr/share/opensearch/backups/roles_mapping.yml
Will retrieve '/internalusers' into /usr/share/opensearch/backups/internal_users.yml
SUCC: Configuration for 'internalusers' stored in /usr/share/opensearch/backups/internal_users.yml
Will retrieve '/actiongroups' into /usr/share/opensearch/backups/action_groups.yml
SUCC: Configuration for 'actiongroups' stored in /usr/share/opensearch/backups/action_groups.yml
Will retrieve '/tenants' into /usr/share/opensearch/backups/tenants.yml
SUCC: Configuration for 'tenants' stored in /usr/share/opensearch/backups/tenants.yml
Will retrieve '/nodesdn' into /usr/share/opensearch/backups/nodes_dn.yml
SUCC: Configuration for 'nodesdn' stored in /usr/share/opensearch/backups/nodes_dn.yml
Will retrieve '/whitelist' into /usr/share/opensearch/backups/whitelist.yml
SUCC: Configuration for 'whitelist' stored in /usr/share/opensearch/backups/whitelist.yml
Will retrieve '/audit' into /usr/share/opensearch/backups/audit.yml
SUCC: Configuration for 'audit' stored in /usr/share/opensearch/backups/audit.yml
Необязательно: Создайте резервную директорию для TLS-сертификатов и сохраните копии сертификатов. Повторите это для каждого узла, если вы используете уникальные TLS-сертификаты: Создайте директорию для сертификатов и скопируйте сертификаты в нее:
mkdir /usr/share/opensearch/backups/certs && cp /usr/share/opensearch/config/*pem /usr/share/opensearch/backups/certs/Завершите сессию псевдо-TTY:
exitСкопируйте файлы на ваш хост:
docker cp os-node-01:/usr/share/opensearch/backups ~/deploy/
Выполнение обновления
Теперь, когда кластер настроен и вы сделали резервные копии важных файлов и настроек, пришло время начать обновление версии.
Некоторые шаги, включенные в этот раздел, такие как отключение репликации шардов и сброс журнала транзакций, не повлияют на производительность вашего кластера. Эти шаги включены в качестве лучших практик и могут значительно улучшить производительность кластера в ситуациях, когда клиенты продолжают взаимодействовать с кластером OpenSearch на протяжении всего обновления, например, запрашивая существующие данные или индексируя документы.
- Отключите репликацию шардов, чтобы остановить перемещение сегментов индекса Lucene внутри вашего кластера:
curl -H 'Content-type: application/json' \
-X PUT "https://localhost:9201/_cluster/settings?pretty" \
-d'{"persistent":{"cluster.routing.allocation.enable":"primaries"}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true,
"persistent" : {
"cluster" : {
"routing" : {
"allocation" : {
"enable" : "primaries"
}
}
}
},
"transient" : { }
}
- Выполните операцию сброса на кластере, чтобы зафиксировать записи журнала транзакций в индексе Lucene:
curl -X POST "https://localhost:9201/_flush?pretty" -ku admin:<custom-admin-password>
Пример ответа
{
"_shards" : {
"total" : 20,
"successful" : 20,
"failed" : 0
}
}
- Вы можете обновлять узлы в любом порядке, так как все узлы в этом демонстрационном кластере являются подходящими менеджерами кластера. Следующая команда остановит и удалит контейнер
os-node-01, не удаляя смонтированный том данных:
docker stop os-node-01 && docker container rm os-node-01
- Запустите новый контейнер с именем
os-node-01с образомopensearchproject/opensearch:2.5.0и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9201:9200 -p 9601:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-01:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-01.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-01.pem:/usr/share/opensearch/config/os-node-01.pem \
-v ~/deploy/os-node-01-key.pem:/usr/share/opensearch/config/os-node-01-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.11 \
--name os-node-01 \
opensearchproject/opensearch:2.5.0
Пример ответа
d26d0cb2e1e93e9c01bb00f19307525ef89c3c3e306d75913860e6542f729ea4
- Опционально: Запросите кластер, чтобы определить, какой узел выполняет функции менеджера кластера. Вы можете выполнить эту команду в любое время в процессе, чтобы увидеть, когда будет избран новый менеджер кластера:
curl -s "https://localhost:9201/_cat/nodes?v&h=name,version,node.role,master" \
-ku admin:<custom-admin-password> | column -t
Пример ответа
name version node.role master
os-node-01 2.5.0 dimr -
os-node-04 1.3.7 dimr *
os-node-02 1.3.7 dimr -
os-node-03 1.3.7 dimr -
- Опционально: Запросите кластер, чтобы увидеть, как изменяется распределение шардов по мере удаления и замены узлов. Вы можете выполнить эту команду в любое время в процессе, чтобы увидеть, как изменяются статусы шардов:
curl -s "https://localhost:9201/_cat/shards" \
-ku admin:<custom-admin-password>
Пример ответа
security-auditlog-2023.03.06 0 p STARTED 53 214.5kb 172.20.0.13 os-node-03
security-auditlog-2023.03.06 0 r UNASSIGNED
.kibana_1 0 p STARTED 3 14.5kb 172.20.0.12 os-node-02
.kibana_1 0 r STARTED 3 14.5kb 172.20.0.13 os-node-03
ecommerce 0 p STARTED 4675 3.9mb 172.20.0.12 os-node-02
ecommerce 0 r STARTED 4675 3.9mb 172.20.0.14 os-node-04
security-auditlog-2023.03.07 0 p STARTED 37 175.7kb 172.20.0.14 os-node-04
security-auditlog-2023.03.07 0 r UNASSIGNED
.opendistro_security 0 p STARTED 10 67.9kb 172.20.0.12 os-node-02
.opendistro_security 0 r STARTED 10 67.9kb 172.20.0.13 os-node-03
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.14 os-node-04
.opendistro_security 0 r UNASSIGNED
security-auditlog-2023.02.27 0 p STARTED 4 80.5kb 172.20.0.12 os-node-02
security-auditlog-2023.02.27 0 r UNASSIGNED
security-auditlog-2023.02.28 0 p STARTED 6 104.1kb 172.20.0.14 os-node-04
security-auditlog-2023.02.28 0 r UNASSIGNED
opensearch_dashboards_sample_data_logs 0 p STARTED 14074 9.1mb 172.20.0.12 os-node-02
opensearch_dashboards_sample_data_logs 0 r STARTED 14074 8.9mb 172.20.0.13 os-node-03
.kibana_92668751_admin_1 0 r STARTED 33 37.3kb 172.20.0.13 os-node-03
.kibana_92668751_admin_1 0 p STARTED 33 37.3kb 172.20.0.14 os-node-04
- Остановите os-node-02:
docker stop os-node-02 && docker container rm os-node-02
- Запустите новый контейнер с именем os-node-02 с образом opensearchproject/opensearch:2.5.0 и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9202:9200 -p 9602:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-02:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-02.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-02.pem:/usr/share/opensearch/config/os-node-02.pem \
-v ~/deploy/os-node-02-key.pem:/usr/share/opensearch/config/os-node-02-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.12 \
--name os-node-02 \
opensearchproject/opensearch:2.5.0
Пример ответа
7b802865bd6eb420a106406a54fc388ed8e5e04f6cbd908c2a214ea5ce72ac00
- Остановите os-node-03:
docker stop os-node-03 && docker container rm os-node-03
- Запустите новый контейнер с именем os-node-03 с образом opensearchproject/opensearch:2.5.0 и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9203:9200 -p 9603:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-03:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-03.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-03.pem:/usr/share/opensearch/config/os-node-03.pem \
-v ~/deploy/os-node-03-key.pem:/usr/share/opensearch/config/os-node-03-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.13 \
--name os-node-03 \
opensearchproject/opensearch:2.5.0
Пример ответа
d7f11726841a89eb88ff57a8cbecab392399f661a5205f0c81b60a995fc6c99d
- Остановите os-node-04:
docker stop os-node-04 && docker container rm os-node-04
- Запустите новый контейнер с именем os-node-04 с образом opensearchproject/opensearch:2.5.0 и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9204:9200 -p 9604:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-04:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-04.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-04.pem:/usr/share/opensearch/config/os-node-04.pem \
-v ~/deploy/os-node-04-key.pem:/usr/share/opensearch/config/os-node-04-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.14 \
--name os-node-04 \
opensearchproject/opensearch:2.5.0
Пример ответа
26f8286ab11e6f8dcdf6a83c95f265172f9557578a1b292af84c6f5ef8738e1d
- Подтвердите, что ваш кластер работает на новой версии:
curl -s "https://localhost:9201/_cat/nodes?v&h=name,version,node.role,master" \
-ku admin:<custom-admin-password> | column -t
Пример ответа
name version node.role master
os-node-01 2.5.0 dimr *
os-node-02 2.5.0 dimr -
os-node-04 2.5.0 dimr -
os-node-03 2.5.0 dimr -
- Последний компонент, который вы должны обновить, это узел OpenSearch Dashboards. Сначала остановите и удалите старый контейнер:
docker stop os-dashboards-01 && docker rm os-dashboards-01
- Создайте новый контейнер, работающий на целевой версии OpenSearch Dashboards:
docker run -d \
-p 5601:5601 --expose 5601 \
-v ~/deploy/opensearch_dashboards.yml:/usr/share/opensearch-dashboards/config/opensearch_dashboards.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch-dashboards/config/root-ca.pem \
-v ~/deploy/os-dashboards-01.pem:/usr/share/opensearch-dashboards/config/os-dashboards-01.pem \
-v ~/deploy/os-dashboards-01-key.pem:/usr/share/opensearch-dashboards/config/os-dashboards-01-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.10 \
--name os-dashboards-01 \
opensearchproject/opensearch-dashboards:2.5.0
Пример ответа
310de7a24cf599ca0b39b241db07fa8865592ebe15b6f5fda26ad19d8e1c1e09
- Убедитесь, что контейнер OpenSearch Dashboards запустился правильно. Команда, подобная следующей, может быть использована для подтверждения того, что запросы к
https://HOST_ADDRESS:5601перенаправляются (HTTP статус код 302) на/app/login?:
curl https://localhost:5601 -kI
Пример ответа
HTTP/1.1 302 Found
location: /app/login?
osd-name: opensearch-dashboards-dev
cache-control: private, no-cache, no-store, must-revalidate
set-cookie: security_authentication=; Max-Age=0; Expires=Thu, 01 Jan 1970 00:00:00 GMT; Secure; HttpOnly; Path=/
content-length: 0
Date: Wed, 08 Mar 2023 15:36:53 GMT
Connection: keep-alive
Keep-Alive: timeout=120
- Включите распределение реплик шардов:
curl -H 'Content-type: application/json' \
-X PUT "https://localhost:9201/_cluster/settings?pretty" \
-d'{"persistent":{"cluster.routing.allocation.enable":"all"}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true,
"persistent" : {
"cluster" : {
"routing" : {
"allocation" : {
"enable" : "all"
}
}
}
},
"transient" : { }
}
Проверка обновления
Вы успешно развернули защищенный кластер OpenSearch, проиндексировали данные, создали панель управления, заполненную образцами данных, создали нового внутреннего пользователя, сделали резервную копию важных файлов и обновили кластер с версии 1.3.7 до 2.5.0. Прежде чем продолжить исследовать и экспериментировать с OpenSearch и OpenSearch Dashboards, вам следует проверить результаты обновления.
Для этого кластера шаги по проверке после обновления могут включать в себя проверку следующего:
- Запущенная версия
- Здоровье и распределение шардов
- Согласованность данных
Проверка текущей запущенной версии ваших узлов OpenSearch:
curl -s "https://localhost:9201/_cat/nodes?v&h=name,version,node.role,master" \
-ku admin:<custom-admin-password> | column -t
Пример ответа
name version node.role master
os-node-01 2.5.0 dimr *
os-node-02 2.5.0 dimr -
os-node-04 2.5.0 dimr -
os-node-03 2.5.0 dimr -
Проверка текущей запущенной версии OpenSearch Dashboards:
Вариант 1: Проверьте версию OpenSearch Dashboards через веб-интерфейс.
- Откройте веб-браузер и перейдите на порт 5601 вашего Docker-хоста (например,
https://HOST_ADDRESS:5601). - Войдите с использованием имени пользователя по умолчанию (admin) и пароля по умолчанию (admin).
- Нажмите кнопку “Справка” в правом верхнем углу. Версия отображается в всплывающем окне.
- Снова нажмите кнопку “Справка”, чтобы закрыть всплывающее окно.
Вариант 2: Проверьте версию OpenSearch Dashboards, проверив файл manifest.yml.
- Из командной строки откройте интерактивную сессию псевдо-TTY с контейнером OpenSearch Dashboards:
docker exec -it os-dashboards-01 bash
- Проверьте файл manifest.yml на наличие версии:
head -n 5 manifest.yml
Пример ответа
---
schema-version: '1.1'
build:
name: OpenSearch Dashboards
version: 2.5.0
Завершите сессию псевдо-TTY:
exit
Проверка состояния кластера и распределения шардов
Запросите API-эндпоинт состояния кластера, чтобы увидеть информацию о здоровье вашего кластера. Вы должны увидеть статус “green”, что указывает на то, что все первичные и репликатные шарды распределены:
curl -s "https://localhost:9201/_cluster/health?pretty" -ku admin:<custom-admin-password>
Пример ответа
{
"cluster_name" : "opensearch-dev-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 4,
"number_of_data_nodes" : 4,
"discovered_master" : true,
"discovered_cluster_manager" : true,
"active_primary_shards" : 16,
"active_shards" : 36,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Запросите API-эндпоинт CAT shards, чтобы увидеть, как шардов распределены после обновления кластера:
curl -s "https://localhost:9201/_cat/shards" -ku admin:<custom-admin-password>
Пример ответа
security-auditlog-2023.02.27 0 r STARTED 4 80.5kb 172.20.0.13 os-node-03
security-auditlog-2023.02.27 0 p STARTED 4 80.5kb 172.20.0.11 os-node-01
security-auditlog-2023.03.08 0 p STARTED 30 95.2kb 172.20.0.13 os-node-03
security-auditlog-2023.03.08 0 r STARTED 30 123.8kb 172.20.0.11 os-node-01
ecommerce 0 p STARTED 4675 3.9mb 172.20.0.12 os-node-02
ecommerce 0 r STARTED 4675 3.9mb 172.20.0.13 os-node-03
.kibana_1 0 p STARTED 3 5.9kb 172.20.0.12 os-node-02
.kibana_1 0 r STARTED 3 5.9kb 172.20.0.11 os-node-01
.kibana_92668751_admin_1 0 p STARTED 33 37.3kb 172.20.0.13 os-node-03
.kibana_92668751_admin_1 0 r STARTED 33 37.3kb 172.20.0.11 os-node-01
opensearch_dashboards_sample_data_logs 0 p STARTED 14074 9.1mb 172.20.0.12 os-node-02
opensearch_dashboards_sample_data_logs 0 r STARTED 14074 9.1mb 172.20.0.14 os-node-04
security-auditlog-2023.02.28 0 p STARTED 6 26.2kb 172.20.0.11 os-node-01
security-auditlog-2023.02.28 0 r STARTED 6 26.2kb 172.20.0.14 os-node-04
.opendistro-reports-definitions 0 p STARTED 0 208b 172.20.0.12 os-node-02
.opendistro-reports-definitions 0 r STARTED 0 208b 172.20.0.13 os-node-03
.opendistro-reports-definitions 0 r STARTED 0 208b 172.20.0.14 os-node-04
security-auditlog-2023.03.06 0 r STARTED 53 174.6kb 172.20.0.12 os-node-02
security-auditlog-2023.03.06 0 p STARTED 53 174.6kb 172.20.0.14 os-node-04
.kibana_101107607_newuser_1 0 r STARTED 1 5.1kb 172.20.0.13 os-node-03
.kibana_101107607_newuser_1 0 p STARTED 1 5.1kb 172.20.0.11 os-node-01
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.12 os-node-02
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.13 os-node-03
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.11 os-node-01
.opendistro_security 0 p STARTED 10 64.5kb 172.20.0.14 os-node-04
.kibana_-152937574_admintenant_1 0 r STARTED 1 5.1kb 172.20.0.12 os-node-02
.kibana_-152937574_admintenant_1 0 p STARTED 1 5.1kb 172.20.0.14 os-node-04
security-auditlog-2023.03.07 0 r STARTED 37 175.7kb 172.20.0.12 os-node-02
security-auditlog-2023.03.07 0 p STARTED 37 175.7kb 172.20.0.14 os-node-04
.kibana_92668751_admin_2 0 p STARTED 34 38.6kb 172.20.0.13 os-node-03
.kibana_92668751_admin_2 0 r STARTED 34 38.6kb 172.20.0.11 os-node-01
.kibana_2 0 p STARTED 3 6kb 172.20.0.13 os-node-03
.kibana_2 0 r STARTED 3 6kb 172.20.0.14 os-node-04
.opendistro-reports-instances 0 r STARTED 0 208b 172.20.0.12 os-node-02
.opendistro-reports-instances 0 r STARTED 0 208b 172.20.0.11 os-node-01
.opendistro-reports-instances 0 p STARTED 0 208b 172.20.0.14 os-node-04
Проверка согласованности данных
Вам нужно снова запросить индекс ecommerce, чтобы подтвердить, что образцы данных все еще присутствуют:
- Сравните ответ на этот запрос с ответом, который вы получили на последнем шаге индексации данных с помощью REST API:
curl -H 'Content-Type: application/json' \
-X GET "https://localhost:9201/ecommerce/_search?pretty=true&filter_path=hits.total" \
-d'{"query":{"match":{"customer_first_name":"Sonya"}}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"hits" : {
"total" : {
"value" : 106,
"relation" : "eq"
}
}
}
- Откройте веб-браузер и перейдите на порт 5601 вашего Docker-хоста (например,
https://HOST_ADDRESS:5601). - Введите имя пользователя по умолчанию (admin) и пароль (admin).
- На главной странице OpenSearch Dashboards выберите кнопку Меню в верхнем левом углу веб-интерфейса, чтобы открыть панель навигации.
- Выберите “Панель управления”.
- Выберите
[Logs] Web Traffic, чтобы открыть панель управления, созданную при добавлении образцов данных ранее в процессе. - Когда вы закончите просмотр панели управления, выберите кнопку Профиль. Выберите “Выйти”, чтобы войти как другой пользователь.
- Введите имя пользователя и пароль, которые вы создали перед обновлением, затем выберите “Войти”.
8.2.7 - Установка плагинов
OpenSearch включает в себя ряд плагинов, которые добавляют функции и возможности к основной платформе.
Доступные вам плагины зависят от того, как был установлен OpenSearch и какие плагины были добавлены или удалены впоследствии. Например, минимальная дистрибуция OpenSearch включает только основные функции, такие как индексация и поиск. Использование минимальной дистрибуции OpenSearch полезно, когда вы работаете в тестовой среде, имеете собственные плагины или планируете интегрировать OpenSearch с другими сервисами.
Стандартная дистрибуция OpenSearch включает гораздо больше плагинов, предлагающих значительно больше функциональности. Вы можете выбрать добавление дополнительных плагинов или удалить любые плагины, которые вам не нужны.
Для получения списка доступных плагинов смотрите Доступные плагины.
Для корректной работы плагина с OpenSearch он может запрашивать определенные разрешения в процессе установки. Ознакомьтесь с запрашиваемыми разрешениями и действуйте соответственно. Важно понимать функциональность плагина перед его установкой. При выборе плагина, предоставленного сообществом, убедитесь, что источник надежен и заслуживает доверия.
Управление плагинами
Для управления плагинами в OpenSearch вы можете использовать инструмент командной строки под названием opensearch-plugin. Этот инструмент позволяет выполнять следующие действия:
- Список установленных плагинов.
- Установка плагинов.
- Удаление установленного плагина.
Вы можете вывести текст справки, передав -h или --help. В зависимости от конфигурации вашего хоста, вам также может потребоваться запускать команду с привилегиями sudo.
Если вы запускаете OpenSearch в контейнере Docker, плагины должны быть установлены, удалены и настроены путем изменения образа Docker. Для получения дополнительной информации смотрите Работа с плагинами.
Список
Используйте list, чтобы увидеть список плагинов, которые уже были установлены.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin list
ПРИМЕР
$ ./opensearch-plugin list
opensearch-alerting
opensearch-anomaly-detection
opensearch-asynchronous-search
opensearch-cross-cluster-replication
opensearch-geospatial
opensearch-index-management
opensearch-job-scheduler
opensearch-knn
opensearch-ml
opensearch-notifications
opensearch-notifications-core
opensearch-observability
opensearch-performance-analyzer
opensearch-reports-scheduler
opensearch-security
opensearch-sql
Список (с помощью CAT API)
Вы также можете перечислить установленные плагины, используя CAT API.
ИСПОЛЬЗОВАНИЕ
GET _cat/plugins
ПРИМЕР ОТВЕТА
opensearch-node1 opensearch-alerting 2.0.1.0
opensearch-node1 opensearch-anomaly-detection 2.0.1.0
opensearch-node1 opensearch-asynchronous-search 2.0.1.0
opensearch-node1 opensearch-cross-cluster-replication 2.0.1.0
opensearch-node1 opensearch-index-management 2.0.1.0
opensearch-node1 opensearch-job-scheduler 2.0.1.0
opensearch-node1 opensearch-knn 2.0.1.0
opensearch-node1 opensearch-ml 2.0.1.0
opensearch-node1 opensearch-notifications 2.0.1.0
opensearch-node1 opensearch-notifications-core 2.0.1.0
Установка
Существует три способа установки плагинов с помощью инструмента opensearch-plugin:
- Установить плагин по имени.
- Установить плагин из zip-файла.
- Установить плагин, используя координаты Maven.
Установка плагина по имени
Вы можете установить плагины, которые еще не предустановлены в вашей установке, используя имя плагина. Для получения списка плагинов, которые могут не быть предустановленными, смотрите Дополнительные плагины.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <plugin-name>
ПРИМЕР
$ sudo ./opensearch-plugin install analysis-icu
-> Установка analysis-icu
-> Загрузка analysis-icu из opensearch
[=================================================] 100%
-> Установлен analysis-icu с именем папки analysis-icu
Установка плагина из zip-файла
Вы можете установить удаленные zip-файлы, заменив <zip-file> на URL размещенного файла. Инструмент поддерживает загрузку только по протоколам HTTP/HTTPS. Для локальных zip-файлов замените <zip-file> на file:, за которым следует абсолютный или относительный путь к zip-файлу плагина, как показано во втором примере ниже.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <zip-file>
Пример
# Zip file is hosted on a remote server - in this case, Maven central repository.
$ sudo ./opensearch-plugin install https://repo1.maven.org/maven2/org/opensearch/plugin/opensearch-anomaly-detection/2.2.0.0/opensearch-anomaly-detection-2.2.0.0.zip
-> Installing https://repo1.maven.org/maven2/org/opensearch/plugin/opensearch-anomaly-detection/2.2.0.0/opensearch-anomaly-detection-2.2.0.0.zip
-> Downloading https://repo1.maven.org/maven2/org/opensearch/plugin/opensearch-anomaly-detection/2.2.0.0/opensearch-anomaly-detection-2.2.0.0.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessClassInPackage.sun.misc
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.net.SocketPermission * connect,resolve
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] registerMBean
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] unregisterMBean
* javax.management.MBeanServerPermission createMBeanServer
* javax.management.MBeanTrustPermission register
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed opensearch-anomaly-detection with folder name opensearch-anomaly-detection
# Zip file in a local directory.
$ sudo ./opensearch-plugin install file:/home/user/opensearch-anomaly-detection-2.2.0.0.zip
-> Installing file:/home/user/opensearch-anomaly-detection-2.2.0.0.zip
-> Downloading file:/home/user/opensearch-anomaly-detection-2.2.0.0.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessClassInPackage.sun.misc
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.net.SocketPermission * connect,resolve
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] registerMBean
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] unregisterMBean
* javax.management.MBeanServerPermission createMBeanServer
* javax.management.MBeanTrustPermission register
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed opensearch-anomaly-detection with folder name opensearch-anomaly-detection
Установка плагина, используя координаты Maven
Инструмент opensearch-plugin install также позволяет вам указывать координаты Maven для доступных артефактов и версий, размещенных на Maven Central. Инструмент анализирует предоставленные вами координаты Maven и формирует URL. В результате хост должен иметь возможность напрямую подключаться к сайту Maven Central. Установка плагина завершится неудачей, если вы передадите координаты прокси-серверу или локальному репозиторию.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <groupId>:<artifactId>:<version>
ПРИМЕР
$ sudo ./opensearch-plugin install org.opensearch.plugin:opensearch-anomaly-detection:2.2.0.0
-> Installing org.opensearch.plugin:opensearch-anomaly-detection:2.2.0.0
-> Downloading org.opensearch.plugin:opensearch-anomaly-detection:2.2.0.0 from maven central
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessClassInPackage.sun.misc
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.net.SocketPermission * connect,resolve
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] registerMBean
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] unregisterMBean
* javax.management.MBeanServerPermission createMBeanServer
* javax.management.MBeanTrustPermission register
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed opensearch-anomaly-detection with folder name opensearch-anomaly-detection
Перезапустите узел OpenSearch после установки плагина.
Установка нескольких плагинов
Несколько плагинов можно установить за одну команду.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <plugin-name> <plugin-name> ... <plugin-name>
ПРИМЕР
$ sudo ./opensearch-plugin install analysis-nori repository-s3
Удаление
Вы можете удалить плагин, который уже был установлен, с помощью опции remove.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin remove <plugin-name>
ПРИМЕР
$ sudo ./opensearch-plugin remove opensearch-anomaly-detection
-> Удаление [opensearch-anomaly-detection]...
После удаления плагина перезапустите узел OpenSearch.
Пакетный режим
При установке плагина, который требует дополнительных привилегий, не включенных по умолчанию, плагин запросит у вас подтверждение необходимых привилегий. Чтобы предоставить все запрашиваемые привилегии, используйте пакетный режим, чтобы пропустить запрос на подтверждение.
Чтобы принудительно включить пакетный режим при установке плагинов, добавьте опцию -b или --batch:
bin/opensearch-plugin install --batch <plugin-name>
Доступные плагины
OpenSearch предоставляет несколько встроенных плагинов, которые доступны для немедленного использования со всеми дистрибуциями OpenSearch, за исключением минимальной дистрибуции. Дополнительные плагины доступны, но их необходимо установить отдельно, используя один из вариантов установки.
Встроенные плагины
Следующие плагины входят во все дистрибуции OpenSearch, за исключением минимальной дистрибуции. Если вы используете минимальную дистрибуцию, вы можете добавить эти плагины, используя один из методов установки.
| Название плагина | Репозиторий | Самая ранняя доступная версия |
|---|---|---|
| Alerting | opensearch-alerting | 1.0.0 |
| Anomaly Detection | opensearch-anomaly-detection | 1.0.0 |
| Asynchronous Search | opensearch-asynchronous-search | 1.0.0 |
| Cross Cluster Replication | opensearch-cross-cluster-replication | 1.1.0 |
| Custom Codecs | opensearch-custom-codecs | 2.10.0 |
| Flow Framework | flow-framework | 2.12.0 |
| Notebooks | opensearch-notebooks | 1.0.0 до 1.1.0 |
| Notifications | notifications | 2.0.0 |
| Reports Scheduler | opensearch-reports-scheduler | 1.0.0 |
| Geospatial | opensearch-geospatial | 2.2.0 |
| Index Management | opensearch-index-management | 1.0.0 |
| Job Scheduler | opensearch-job-scheduler | 1.0.0 |
| k-NN | opensearch-knn | 1.0.0 |
| Learning to Rank | opensearch-ltr | 2.19.0 |
| ML Commons | opensearch-ml | 1.3.0 |
| Skills | opensearch-skills | 2.12.0 |
| Neural Search | neural-search | 2.4.0 |
| Observability | opensearch-observability | 1.2.0 |
| Performance Analyzer | opensearch-performance-analyzer | 1.0.0 |
| Security | opensearch-security | 1.0.0 |
| Security Analytics | opensearch-security-analytics | 2.4.0 |
| SQL | opensearch-sql | 1.0.0 |
| Learning to Rank Base | opensearch-learning-to-rank-base | 2.19.0 |
| Remote Metadata SDK | opensearch-remote-metadata-sdk | 2.19.0 |
| Query Insights | query-insights | 2.16.0 |
| System Templates | opensearch-system-templates | 2.17.0 |
| User Behavior Insights | ubi | 3.0.0 |
| Search Relevance | search-relevance | 3.1.0 |
Примечания:
- Dashboard Notebooks были объединены с плагином Observability с выходом OpenSearch 1.2.0.
- Performance Analyzer недоступен на Windows.
СКАЧИВАНИЕ ВСТРОЕННЫХ ПЛАГИНОВ ДЛЯ ОФЛАЙН-УСТАНОВКИ
Каждый встроенный плагин можно скачать и установить оффлайн из zip-файла.
URL для соответствующего плагина можно найти в файле manifest.yml, который расположен в корневом каталоге извлеченного пакета.
Основные плагины
Основной (или нативный) плагин в OpenSearch — это плагин, который находится в репозитории основного движка OpenSearch. Эти плагины тесно интегрированы с движком OpenSearch, версионируются вместе с основными релизами и по умолчанию не включены в стандартную дистрибуцию OpenSearch.
СКАЧИВАНИЕ ОСНОВНЫХ ПЛАГИНОВ ДЛЯ ОФЛАЙН-УСТАНОВКИ
Каждый из основных плагинов в этом списке можно скачать и установить оффлайн из zip-файла, используя официальный шаблон URL репозитория плагинов:
https://artifacts.opensearch.org/releases/plugins/<plugin-name>/<version>/<plugin-name>-<version>.zip
Где <plugin-name> соответствует имени встроенного плагина (например, analysis-icu). <version> должен соответствовать версии дистрибуции OpenSearch (например, 2.19.1).
Например, используйте следующий URL для скачивания дистрибуции встроенного плагина analysis-icu для версии OpenSearch 2.19.1:
https://artifacts.opensearch.org/releases/plugins/analysis-icu/2.19.1/analysis-icu-2.19.1.zip
Дополнительные плагины
Существует множество других плагинов, доступных помимо тех, что предоставлены в стандартной дистрибуции. Эти дополнительные плагины были разработаны разработчиками OpenSearch или членами сообщества OpenSearch. Для получения списка дополнительных плагинов, которые вы можете установить, смотрите Дополнительные плагины.
Совместимость плагинов
Вы можете указать совместимость плагина с определенной версией OpenSearch в файле plugin-descriptor.properties. Например, плагин с следующим свойством совместим только с OpenSearch 2.3.0:
opensearch.version=2.3.0
В качестве альтернативы вы можете указать диапазон совместимых версий OpenSearch, установив свойство dependencies в файле plugin-descriptor.properties в одну из следующих нотаций:
dependencies={ opensearch: "2.3.0" }: Плагин совместим только с версией OpenSearch 2.3.0.dependencies={ opensearch: "=2.3.0" }: Плагин совместим только с версией OpenSearch 2.3.0.dependencies={ opensearch: "~2.3.0" }: Плагин совместим со всеми версиями от 2.3.0 до следующей минорной версии, в данном примере — 2.4.0 (исключительно).dependencies={ opensearch: "^2.3.0" }: Плагин совместим со всеми версиями от 2.3.0 до следующей мажорной версии, в данном примере — 3.0.0 (исключительно).
Вы можете указать только одно из свойств opensearch.version или dependencies.
Связанные ссылки
8.2.7.1 - Дополнительные плагины
Существует множество других плагинов, доступных помимо тех, что предоставлены в стандартной дистрибуции OpenSearch.
Эти дополнительные плагины были разработаны разработчиками OpenSearch или членами сообщества OpenSearch. Хотя невозможно предоставить исчерпывающий список (поскольку многие плагины не поддерживаются в репозитории OpenSearch на GitHub), ниже приведены некоторые из плагинов, доступных в каталоге OpenSearch/plugins на GitHub, которые можно установить с помощью одного из вариантов установки, например, используя команду bin/opensearch-plugin install <plugin-name>.
| Название плагина | Самая ранняя доступная версия |
|---|---|
| analysis-icu | 1.0.0 |
| analysis-kuromoji | 1.0.0 |
| analysis-nori | 1.0.0 |
| analysis-phonenumber | 2.18.0 |
| analysis-phonetic | 1.0.0 |
| analysis-smartcn | 1.0.0 |
| analysis-stempel | 1.0.0 |
| analysis-ukrainian | 1.0.0 |
| discovery-azure-classic | 1.0.0 |
| discovery-ec2 | 1.0.0 |
| discovery-gce | 1.0.0 |
| ingest-attachment | 1.0.0 |
| ingestion-kafka | 3.0.0 |
| ingestion-kinesis | 3.0.0 |
| mapper-annotated-text | 1.0.0 |
| mapper-murmur3 | 1.0.0 |
| mapper-size | 1.0.0 |
| query-insights | 2.12.0 |
| repository-azure | 1.0.0 |
| repository-gcs | 1.0.0 |
| repository-hdfs | 1.0.0 |
| repository-s3 | 1.0.0 |
| store-smb | 1.0.0 |
| transport-grpc | 3.0.0 |
8.2.7.2 - mapper-size
Плагин mapper-size позволяет использовать поле _size в индексах OpenSearch. Поле _size хранит размер каждого документа в байтах.
Установка плагина
Вы можете установить плагин mapper-size, используя следующую команду:
./bin/opensearch-plugin install mapper-size
Примеры
После запуска кластера вы можете создать индекс с включенным отображением размера, индексировать документ и выполнять поиск по документам, как показано в следующих примерах.
Создание индекса с включенным отображением размера
curl -XPUT example-index -H "Content-Type: application/json" -d '{
"mappings": {
"_size": {
"enabled": true
},
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}'
Индексация документа
curl -XPOST example-index/_doc -H "Content-Type: application/json" -d '{
"name": "John Doe",
"age": 30
}'
Запрос к индексу
curl -XGET example-index/_search -H "Content-Type: application/json" -d '{
"query": {
"match_all": {}
},
"stored_fields": ["_size", "_source"]
}'
Результаты запроса
В следующем примере поле _size включено в результаты запроса и показывает размер индексированного документа в байтах:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "example_index",
"_id": "Pctw0I8BLto8I5f_NLKK",
"_score": 1.0,
"_size": 37,
"_source": {
"name": "John Doe",
"age": 30
}
}
]
}
}
8.2.7.3 - ingest-attachment
Плагин ingest-attachment позволяет OpenSearch извлекать содержимое и другую информацию из файлов с использованием библиотеки извлечения текста Apache Tika.
Поддерживаемые форматы документов включают PPT, PDF, RTF, ODF и многие другие (см. Поддерживаемые форматы документов Tika).
Входное поле должно быть закодировано в формате base64.
Установка плагина
Установите плагин ingest-attachment, используя следующую команду:
./bin/opensearch-plugin install ingest-attachment
Опции процессора вложений
| Название | Обязательный | Значение по умолчанию | Описание |
|---|---|---|---|
| field | Да | Имя поля, в котором будет храниться извлеченное содержимое. |
Пример использования плагина ingest-attachment
Следующие шаги покажут вам, как начать работу с плагином ingest-attachment.
Шаг 1: Создайте индекс для хранения ваших вложений
Следующая команда создает индекс для хранения ваших вложений:
PUT /example-attachment-index
{
"mappings": {
"properties": {}
}
}
Шаг 2: Создайте конвейер
Следующая команда создает конвейер, содержащий процессор вложений:
PUT _ingest/pipeline/attachment
{
"description" : "Извлечение информации о вложениях",
"processors" : [
{
"attachment" : {
"field" : "data"
}
}
]
}
Шаг 3: Сохраните вложение
Преобразуйте вложение в строку base64, чтобы передать его как данные. В этом примере команда base64 преобразует файл lorem.rtf:
base64 lorem.rtf
В качестве альтернативы вы можете использовать Node.js для чтения файла в формате base64, как показано в следующих командах:
import * as fs from "node:fs/promises";
import path from "node:path";
const filePath = path.join(import.meta.dirname, "lorem.rtf");
const base64File = await fs.readFile(filePath, { encoding: "base64" });
console.log(base64File);
Файл .rtf содержит следующий текст в формате base64:
Lorem ipsum dolor sit amet: e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=.
Теперь вы можете сохранить вложение, используя следующую команду:
PUT example-attachment-index/_doc/lorem_rtf?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0="
}
Результаты запроса
После обработки вложения вы можете выполнять поиск по данным, используя поисковые запросы, как показано в следующем примере:
POST example-attachment-index/_search
{
"query": {
"match": {
"attachment.content": "ipsum"
}
}
}
OpenSearch ответит следующим образом:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.1724279,
"hits": [
{
"_index": "example-attachment-index",
"_id": "lorem_rtf",
"_score": 1.1724279,
"_source": {
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"attachment": {
"content_type": "application/rtf",
"language": "pt",
"content": "Lorem ipsum dolor sit amet",
"content_length": 28
}
}
}
]
}
}
Извлеченная информация
Следующие поля могут быть извлечены с помощью плагина:
- content
- language
- date
- title
- author
- keywords
- content_type
- content_length
Чтобы извлечь только подмножество этих полей, определите их в свойствах процессора конвейера, как показано в следующем примере:
PUT _ingest/pipeline/attachment
{
"description" : "Извлечение информации о вложениях",
"processors" : [
{
"attachment" : {
"field" : "data",
"properties": ["content", "title", "author"]
}
}
]
}
Ограничение извлекаемого содержимого
Чтобы предотвратить извлечение слишком большого количества символов и перегрузку памяти узла, значение по умолчанию составляет 100_000. Вы можете изменить это значение, используя настройку indexed_chars. Например, вы можете использовать -1 для неограниченного количества символов, но необходимо убедиться, что у вас достаточно памяти HEAP на узле OpenSearch для извлечения содержимого больших документов.
Вы также можете определить этот лимит для каждого документа, используя поле запроса indexed_chars_field. Если документ содержит indexed_chars_field, оно перезапишет настройку indexed_chars, как показано в следующем примере:
PUT _ingest/pipeline/attachment
{
"description" : "Извлечение информации о вложениях",
"processors" : [
{
"attachment" : {
"field" : "data",
"indexed_chars" : 10,
"indexed_chars_field" : "max_chars"
}
}
]
}
С настроенным конвейером вложений вы можете извлечь 10 символов по умолчанию, не указывая max_chars в запросе, как показано в следующем примере:
PUT example-attachment-index/_doc/lorem_rtf?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0="
}
В качестве альтернативы вы можете изменить max_chars для каждого документа, чтобы извлечь до 15 символов, как показано в следующем примере:
PUT example-attachment-index/_doc/lorem_rtf?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"max_chars": 15
}
8.2.8 - Управление плагинами OpenSearch Dashboards
OpenSearch Dashboards предоставляет инструмент командной строки под названием opensearch-dashboards-plugin для управления плагинами.
OpenSearch Dashboards предоставляет инструмент командной строки под названием opensearch-dashboards-plugin для управления плагинами. Этот инструмент позволяет вам:
- Список установленных плагинов.
- Установить плагины.
- Удалить установленный плагин.
Совместимость плагинов
Основные, второстепенные и патч-версии плагинов должны соответствовать основным, второстепенным и патч-версиям OpenSearch для обеспечения совместимости. Например, версии плагинов 2.3.0.x работают только с OpenSearch 2.3.0.
Предварительные требования
- Совместимый кластер OpenSearch
- Соответствующие плагины OpenSearch, установленные на этом кластере
- Соответствующая версия OpenSearch Dashboards (например, OpenSearch Dashboards 2.3.0 работает с OpenSearch 2.3.0)
Доступные плагины
Следующая таблица перечисляет доступные плагины OpenSearch Dashboards.
| Название плагина | Репозиторий | Самая ранняя доступная версия |
|---|---|---|
| Alerting Dashboards | alerting-dashboards-plugin | 1.0.0 |
| Anomaly Detection Dashboards | anomaly-detection-dashboards-plugin | 1.0.0 |
| Custom Import Maps Dashboards | dashboards-maps | 2.2.0 |
| Search Relevance Dashboards | dashboards-search-relevance | 2.4.0 |
| Index Management Dashboards | index-management-dashboards-plugin | 1.0.0 |
| Notebooks Dashboards | dashboards-notebooks | 1.0.0 |
| Notifications Dashboards | dashboards-notifications | 2.0.0 |
| Observability Dashboards | dashboards-observability | 2.0.0 |
| Query Insights Dashboards | query-insights-dashboards | 2.19.0 |
| Query Workbench Dashboards | query-workbench | 1.0.0 |
| Reports Dashboards | dashboards-reporting | 1.0.0 |
| Security Analytics Dashboards | security-analytics-dashboards-plugin | 2.4.0 |
| Security Dashboards | security-dashboards-plugin | 1.0.0 |
Вот переведенная документация на русский язык с сохранением оформления Markdown для Hugo Docsy:
Установка
Перейдите в домашний каталог OpenSearch Dashboards (например, /usr/share/opensearch-dashboards) и выполните команду установки для каждого плагина.
Просмотр списка установленных плагинов
Чтобы просмотреть список установленных плагинов из командной строки, используйте следующую команду:
sudo bin/opensearch-dashboards-plugin list
Удаление плагинов
Чтобы удалить плагин, выполните команду:
sudo bin/opensearch-dashboards-plugin remove <plugin-name>
Затем удалите все связанные записи из opensearch_dashboards.yml.
Для некоторых плагинов также необходимо удалить пакет “оптимизации”. Вот пример команды для плагина Anomaly Detection:
sudo rm /usr/share/opensearch-dashboards/optimize/bundles/opensearch-anomaly-detection-opensearch-dashboards.*
После этого перезапустите OpenSearch Dashboards. После удаления любого плагина OpenSearch Dashboards выполняет операцию оптимизации при следующем запуске. Эта операция занимает несколько минут, даже на быстрых машинах, поэтому наберитесь терпения.
Обновление плагинов
OpenSearch Dashboards не обновляет плагины. Вместо этого вам нужно удалить старую версию и ее оптимизированный пакет, переустановить их и перезапустить OpenSearch Dashboards:
Удалите старую версию:
sudo bin/opensearch-dashboards-plugin remove <plugin-name>Удалите оптимизированный пакет:
sudo rm /usr/share/opensearch-dashboards/optimize/bundles/<bundle-name>Переустановите новую версию:
sudo bin/opensearch-dashboards-plugin install <plugin-name>Перезапустите OpenSearch Dashboards.
Например, чтобы удалить и переустановить плагин Anomaly Detection:
sudo bin/opensearch-dashboards-plugin remove anomalyDetectionDashboards
sudo rm /usr/share/opensearch-dashboards/optimize/bundles/opensearch-anomaly-detection-opensearch-dashboards.*
sudo bin/opensearch-dashboards-plugin install <AD OpenSearch Dashboards plugin artifact URL>
8.3 - Query DSL - язык запросов OpenSearch
OpenSearch предоставляет мощный язык запросов (Query Domain-Specific Language), основанный на JSON-синтаксисе. Этот язык позволяет выполнять гибкий и точный поиск по данным.
Введение в Query DSL
OpenSearch предоставляет мощный язык запросов (Query Domain-Specific Language), основанный на JSON-синтаксисе. Этот язык позволяет выполнять гибкий и точный поиск по данным.
Базовый пример запроса:
GET testindex/_search
{
"query": {
"match_all": {}
}
Этот запрос возвращает все документы в указанном индексе.
Типы запросов
Запросы делятся на две основные категории:
1. Листовые запросы (Leaf queries)
Особенности:
- Выполняют поиск по конкретным полям
- Могут использоваться самостоятельно
- Не содержат других запросов
Основные типы:
1.1 Полнотекстовые запросы:
- Анализируют текст запроса
- Применяют тот же анализатор, что и при индексации
- Примеры:
match,match_phrase,multi_match
1.2 Термино-уровневые запросы:
- Ищут точные значения без анализа текста
- Не учитывают релевантность
- Примеры:
term,terms,range,exists
1.3 Геопространственные запросы:
- Работают с географическими данными
- Примеры:
geo_distance,geo_bounding_box
1.4 Запросы соединений:
- Для работы с вложенными документами
- Примеры:
nested,has_child,has_parent
1.5 Позиционные запросы (Span queries):
- Точный поиск с учетом позиции терминов
- Часто используются для юридических документов
1.6 Специализированные запросы:
more_like_this- поиск похожих документовscript- запросы с использованием скриптовpercolate- обратный поиск
2. Составные запросы (Compound queries)
Особенности:
- Объединяют несколько запросов
- Модифицируют поведение дочерних запросов
- Управляют логикой выполнения
Основные типы:
bool- булева комбинация запросовdis_max- поиск по нескольким полямconstant_score- задает фиксированную релевантностьfunction_score- кастомные алгоритмы релевантности
Особенности обработки специальных символов
Проблема: Стандартный анализатор некорректно обрабатывает Unicode-символы (например, дефис), что может привести к:
- Неожиданным результатам поиска
- Проблемам контроля доступа
Пример проблемы:
{
"match": {
"user.id": "User-1"
}
}
Анализатор может интерпретировать “User-1” как два отдельных термина.
Решение:
- Использовать
keywordтип поля для точного совпадения - Настроить кастомный анализатор
Ресурсоемкие запросы
Типы затратных запросов:
- Нечеткий поиск (
fuzzy) - Поиск по префиксу (
prefix) - Диапазонные запросы по текстовым полям
- Регулярные выражения (
regexp) - Wildcard-запросы
- Сложные
query_stringзапросы
Защита от ресурсоемких запросов:
PUT _cluster/settings
{
"persistent": {
"search.allow_expensive_queries": false
}
}
Мониторинг: Для отслеживания медленных запросов используйте shard slow logs.
Рекомендации по использованию
- Для точного соответствия используйте
keywordтип полей - Избегайте специальных символов в текстовых полях
- Мониторьте ресурсоемкие запросы
- Для сложной логики комбинируйте запросы через
bool - Используйте
explainдля анализа работы запросов
8.3.1 - Контекст запроса и фильтра
Запросы состоят из условий (query clauses), которые могут выполняться в Контексте фильтра - проверяет соответствие документа условию Да/Нет и Контексте запроса - оценивает степень соответствия документа условию с расчетом релевантности
Основные концепции
Запросы состоят из условий (query clauses), которые могут выполняться в:
- Контексте фильтра - проверяет соответствие документа условию (“Да/Нет”)
- Контексте запроса - оценивает степень соответствия документа условию с расчетом релевантности
Оценка релевантности (_score)
Релевантность измеряется числовым значением в поле _score:
"hits" : [
{
"_index" : "shakespeare",
"_id" : "32437",
"_score" : 18.781435,
"_source" : {
"type" : "line",
"line_id" : 32438,
"play_name" : "Hamlet",
"speech_number" : 3,
"line_number" : "1.1.3",
"speaker" : "BERNARDO",
"text_entry" : "Long live the king!"
}
},
...
Чем выше значение _score, тем более релевантен документ. Разные типы запросов используют различные алгоритмы расчета релевантности, но все учитывают тип контекста выполнения условия.
Контекст фильтра
Характеристики:
- Возвращает только факт соответствия (бинарный результат)
- Не вычисляет оценку релевантности
- Оптимален для точных значений
- Результаты кэшируются для повышения производительности
Пример использования:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "honors": true }},
{ "range": { "graduation_year": { "gte": 2020, "lte": 2022 }}}
]
}
}
}
Этот запрос ищет студентов:
- С отличием (
honors: true) - Выпустившихся в 2020-2022 годах
Контекст запроса
Характеристики:
- Оценивает степень соответствия документа
- Возвращает численную оценку релевантности
- Используется для полнотекстового поиска
- Поддерживает анализ текста (морфологию, синонимы)
Пример использования:
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "long live king"
}
}
}
Этот запрос:
- Ищет вариации фразы “long live king”
- Учитывает словоформы и синонимы
- Сортирует результаты по релевантности
Особенности вычисления _score
- Используется 24-битная точность (числа с плавающей запятой)
- При превышении точности может происходить потеря данных
- Разные типы запросов используют различные алгоритмы расчета
Рекомендации по применению:
- Для точных значений (ID, даты, категории) используйте контекст фильтра
- Для текстового поиска применяйте контекст запроса
- Комбинируйте оба подхода в сложных запросах через
boolзапрос
8.3.2 - Сравнение термовых и полнотекстовых запросов
Термовые (term-level) и полнотекстовые (full-text) запросы используются для поиска по тексту, но имеют принципиальные отличия
Основные различия
Термовые (term-level) и полнотекстовые (full-text) запросы используются для поиска по тексту, но имеют принципиальные отличия:
| Характеристика | Термовые запросы | Полнотекстовые запросы |
|---|---|---|
| Описание | Определяют, какие документы соответствуют запросу | Оценивают, насколько хорошо документы соответствуют запросу |
| Анализатор | Поисковый терм не анализируется | Используется тот же анализатор, что и при индексации поля |
| Релевантность | Не сортируют результаты по релевантности | Рассчитывают оценку релевантности и сортируют результаты |
| Использование | Точные значения (числа, даты, теги) | Текстовые поля с учетом морфологии и вариантов слов |
OpenSearch использует алгоритм ранжирования BM25 для расчета оценок релевантности.
Когда использовать каждый тип запроса?
Пример 1: Поиск фразы
Рассмотрим поиск фразы “To be, or not to be” в произведениях Шекспира.
Термовый запрос:
GET shakespeare/_search
{
"query": {
"term": {
"text_entry": "To be, or not to be"
}
}
}
Результат:
{
"took": 3,
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"hits": []
}
}
Запрос не нашел совпадений, так как ищет точную неизмененную фразу.
Полнотекстовый запрос:
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "To be, or not to be"
}
}
}
Результат (сокращенный):
{
"took": 19,
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"hits": [
{
"_score": 17.419369,
"_source": {
"text_entry": "To be, or not to be: that is the question:"
}
},
{
"_score": 14.883024,
"_source": {
"text_entry": "Not like a corse; or if, not to be buried,"
}
}
]
}
}
Полнотекстовый запрос нашел релевантные результаты, проанализировав фразу.
Пример 2: Поиск точного термина
Для поиска точного значения “HAMLET” в поле speaker эффективнее термовый запрос:
GET shakespeare/_search
{
"query": {
"term": {
"speaker": "HAMLET"
}
}
}
Результат (сокращенный):
{
"took": 5,
"hits": {
"total": {
"value": 1582,
"relation": "eq"
},
"hits": [
{
"_score": 4.2540946,
"_source": {
"speaker": "HAMLET",
"text_entry": "[Aside] A little more than kin..."
}
},
{
"_score": 4.2540946,
"_source": {
"speaker": "HAMLET",
"text_entry": "Not so, my lord..."
}
}
]
}
}
Важно: Поиск по “Hamlet” не даст результатов, так как поле speaker является keyword и хранится в исходном регистре.
Рекомендации по выбору типа запроса
Используйте термовые запросы для:
- Точных значений (ID, коды, категории)
- Полям типа keyword
- Когда не нужна сортировка по релевантности
Используйте полнотекстовые запросы для:
- Текстового поиска с анализом
- Когда важна оценка релевантности
- Поиска по словоформам и синонимам
Для полей text:
Всегда используйте полнотекстовые запросы, так как их значения анализируются при индексации.Для полей keyword:
Используйте термовые запросы для точного соответствия.
8.3.3 - Термино-уровневые запросы
Ищут точные значения без анализа текста. Не учитывают релевантность
Общее описание
Термино-уровневые запросы (term-level queries) выполняют поиск по индексу для нахождения документов, содержащих точное соответствие указанному термину. В отличие от полнотекстовых запросов, результаты термино-уровневых запросов не сортируются по оценке релевантности.
Ключевые особенности:
- Работают только с точными значениями
- Не анализируют поисковый термин
- Оптимальны для поиска по полям типа
keyword - Не подходят для анализа текстовых полей (используйте полнотекстовые запросы)
Типы термино-уровневых запросов
В таблице представлены все виды термино-уровневых запросов:
| Тип запроса | Описание |
|---|---|
term | Поиск документов, содержащих точное соответствие указанному термину в заданном поле |
terms | Поиск документов, содержащих один или несколько указанных терминов в заданном поле |
terms_set | Поиск документов, соответствующих минимальному количеству указанных терминов |
ids | Поиск документов по их идентификаторам |
range | Поиск документов, значения поля которых попадают в указанный диапазон |
prefix | Поиск документов, содержащих термины с указанным префиксом |
exists | Поиск документов, имеющих любое проиндексированное значение в указанном поле |
fuzzy | Поиск документов, содержащих термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна (количество односимвольных изменений для преобразования одного термина в другой) |
wildcard | Поиск документов, содержащих термины, соответствующие шаблону с подстановочными символами |
regexp | Поиск документов, содержащих термины, соответствующие регулярному выражению |
Практические рекомендации
Для полей
keywordвсегда используйте термино-уровневые запросы:GET products/_search { "query": { "term": { "product_code": "ABC-123" } } }Избегайте использования термино-уровневых запросов для полей типа
text, так как они проходят анализ при индексации.Для сложных условий комбинируйте несколько термино-уровневых запросов через
bool:GET logs/_search { "query": { "bool": { "must": [ { "term": { "status": "error" } }, { "range": { "timestamp": { "gte": "2023-01-01" }}} ] } } }Для нечеткого поиска используйте
fuzzyс указанием максимального расстояния:GET contacts/_search { "query": { "fuzzy": { "last_name": { "value": "Smith", "fuzziness": 2 } } } }
Все технические термины сохранены в оригинальном написании (term, fuzzy, wildcard и т.д.) для соответствия международной практике, с добавлением пояснений на русском языке для лучшего понимания.
8.3.3.1 - exists
Поиск документов, имеющих любое проиндексированное значение в указанном поле
Запрос exists
Назначение
Запрос exists используется для поиска документов, содержащих указанное поле.
Когда поле считается отсутствующим?
Индексированное значение будет отсутствовать для поля документа в следующих случаях:
- В маппинге поля указано
"index": false - Значение поля в исходном JSON равно
nullили[](пустой массив) - Длина значения поля превышает параметр
ignore_aboveв маппинге - Значение поля имеет некорректный формат и в маппинге определен
ignore_malformed
Когда поле считается существующим?
Индексированное значение будет присутствовать для поля документа в следующих случаях:
- Значение является массивом, содержащим как
null, так и не-null элементы (например,["один", null]) - Значение представляет собой пустую строку (
""или"-") - Значение является кастомным
null_value, определенным в маппинге поля
Пример использования
Добавление тестовых документов:
PUT testindex/_doc/1
{
"title": "Ветер крепчает"
}
PUT testindex/_doc/2
{
"title": "Унесенные ветром",
"description": "Американский эпический исторический фильм 1939 года"
}
Поиск документов с полем description:
GET testindex/_search
{
"query": {
"exists": {
"field": "description"
}
}
}
Результат выполнения:
{
"took": 3,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "testindex",
"_id": "2",
"_source": {
"title": "Унесенные ветром",
"description": "Американский эпический исторический фильм 1939 года"
}
}
]
}
}
Поиск документов с отсутствующими полями
Для поиска документов без определенного поля используйте комбинацию must_not и exists:
GET testindex/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "description"
}
}
}
}
}
Результат выполнения:
{
"took": 19,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "testindex",
"_id": "1",
"_source": {
"title": "Ветер крепчает"
}
}
]
}
}
Параметры запроса
Запрос принимает следующие параметры:
| Параметр | Тип данных | Описание |
|---|---|---|
field | Строка | Обязательное поле. Имя поля, которое должно существовать в документе. |
boost | Число с плавающей точкой | Определяет вес поля при расчете релевантности. Значения >1 увеличивают вес, значения между 0 и 1 уменьшают вес. По умолчанию: 1.0. |
Пример с параметром boost:
GET testindex/_search
{
"query": {
"exists": {
"field": "description",
"boost": 2.0
}
}
}
Особенности работы
- Запрос
existsпроверяет именно наличие индексированного значения поля, а не его наличие в исходном документе. - Для проверки отсутствия поля всегда используйте комбинацию
bool+must_not+exists. - Запрос можно комбинировать с другими типами запросов в составе
boolзапроса.
8.3.3.2 - fuzzy
Поиск документов, содержащих термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна
Нечеткий поиск (Fuzzy query)
Основные понятия
Нечеткий запрос (fuzzy query) ищет документы, содержащие термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна. Это расстояние измеряет количество односимвольных изменений, необходимых для преобразования одного термина в другой:
- Замены: кот → бот
- Вставки: кот → коты
- Удаления: кот → от
- Транспозиции: кот → кто
Принцип работы
- Запрос генерирует все возможные варианты поискового термина, попадающие в заданное расстояние редактирования
- Количество вариантов ограничивается параметром
max_expansions - Поиск выполняется по всем сгенерированным вариантам
Примеры запросов
Базовый пример с поиском ошибочного написания “HALET” вместо “HAMLET”:
GET shakespeare/_search
{
"query": {
"fuzzy": {
"speaker": {
"value": "HALET"
}
}
}
}
Примечание: Используется автоматическое определение расстояния (AUTO)
Расширенный пример с настройкой параметров:
GET shakespeare/_search
{
"query": {
"fuzzy": {
"speaker": {
"value": "HALET",
"fuzziness": "2",
"max_expansions": 40,
"prefix_length": 0,
"transpositions": true,
"rewrite": "constant_score"
}
}
}
}
Параметры запроса
Синтаксис запроса:
GET _search
{
"query": {
"fuzzy": {
"<поле>": {
"value": "образец",
...
}
}
}
}
Доступные параметры:
| Параметр | Тип данных | Описание |
|---|---|---|
value | Строка | Обязательный. Искомый термин |
boost | Число с плавающей точкой | Влияет на вес поля при расчете релевантности (>1 - увеличивает, 0-1 - уменьшает). По умолчанию: 1.0 |
fuzziness | AUTO, 0 или положительное число | Максимальное расстояние редактирования. AUTO - автоматический расчет на основе длины термина |
max_expansions | Положительное целое | Максимальное количество вариантов термина для поиска. По умолчанию: 50 |
prefix_length | Неотрицательное целое | Количество начальных символов, не учитываемых при нечетком сравнении. По умолчанию: 0 |
rewrite | Строка | Стратегия перезаписи запроса. Допустимые значения: constant_score, scoring_boolean и др. По умолчанию: constant_score |
transpositions | Логическое | Разрешать перестановки соседних символов (ab→ba). По умолчанию: true |
Особенности производительности
- Большие значения
max_expansions(особенно сprefix_length=0) могут снизить производительность из-за генерации множества вариантов - При
search.allow_expensive_queries=falseнечеткие запросы не выполняются - Для длинных слов рекомендуется использовать
prefix_length>0
Практические рекомендации
- Для исправления опечаток используйте
fuzziness=1илиfuzziness=2 - Для профессиональных терминов уменьшайте
max_expansions - Для ускорения поиска увеличивайте
prefix_length - Для точных полей отключайте транспозиции (
transpositions=false)
8.3.3.3 - ids
Поиск документов по их идентификаторам
Запрос IDs (поиск по идентификаторам)
Назначение
Запрос ids позволяет находить документы по их уникальным идентификаторам в поле _id.
Синтаксис запроса
GET shakespeare/_search
{
"query": {
"ids": {
"values": [
"34229",
"91296"
]
}
}
}
Параметры запроса
| Параметр | Тип данных | Описание | Обязательный | По умолчанию |
|---|---|---|---|---|
values | Массив строк | Список идентификаторов документов для поиска | Да | - |
boost | Число с плавающей точкой | Коэффициент усиления релевантности. Значения >1 увеличивают вес, 0-1 уменьшают вес | Нет | 1.0 |
Особенности работы
Тип идентификаторов:
Идентификаторы всегда передаются как строки, даже если в системе они числовые.Производительность:
Запрос оптимален для выборки небольшого количества документов по известным ID.Использование с boost:
Пример с изменением релевантности:GET shakespeare/_search { "query": { "ids": { "values": ["34229", "91296"], "boost": 2.0 } } }Ограничения:
- Не поддерживает шаблоны или диапазоны ID
- Для поиска по >1000 ID рекомендуется использовать
termsзапрос
Ответ системы:
Возвращает только те документы, чьи ID присутствуют в индексе (несуществующие ID игнорируются без ошибки)
Альтернативные подходы
Для сложных сценариев поиска по ID можно использовать:
GET _search
{
"query": {
"terms": {
"_id": ["34229", "91296"]
}
}
}
8.3.3.4 - prefix
Поиск документов, содержащих термины с указанным префиксом
Запрос prefix (поиск по префиксу)
Назначение
Запрос prefix выполняет поиск терминов, начинающихся с указанной приставки (префикса). Используется для:
- Автодополнения
- Поиска по начальным символам
- Классификации данных с общими префиксами
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"prefix": {
"speaker": "KING H"
}
}
}
Этот запрос ищет документы, где поле speaker содержит термины, начинающиеся на “KING H”.
Расширенный синтаксис с параметрами
GET shakespeare/_search
{
"query": {
"prefix": {
"speaker": {
"value": "KING H",
"boost": 1.5,
"case_insensitive": true,
"rewrite": "scoring_boolean"
}
}
}
}
Параметры запроса
| Параметр | Тип данных | Описание | По умолчанию |
|---|---|---|---|
value | Строка | Обязательный. Искомый префикс | - |
boost | Число с плавающей точкой | Коэффициент усиления релевантности (>1 - увеличивает, 0-1 - уменьшает) | 1.0 |
case_insensitive | Логический | Регистронезависимый поиск. Если true, игнорирует регистр символов | false |
rewrite | Строка | Метод перезаписи запроса. Допустимые значения: constant_score, scoring_boolean и др. | constant_score |
Особенности работы
Производительность:
- При включенной настройке
index_prefixesв маппинге поля запрос выполняется оптимально - При
search.allow_expensive_queries=falseзапросыprefixне выполняются (кроме случаев сindex_prefixes)
- При включенной настройке
Регистр символов:
- По умолчанию поиск чувствителен к регистру
- Для регистронезависимого поиска используйте
"case_insensitive": true
Примеры использования:
// Поиск продуктов с кодом, начинающимся на "A12" GET products/_search { "query": { "prefix": { "product_code": "A12" } } } // Поиск городов, названия которых начинаются на "сан" GET cities/_search { "query": { "prefix": { "name": { "value": "сан", "case_insensitive": true } } } }Рекомендации:
- Для полей с длинными значениями установите
index_prefixesв маппинге - Избегайте очень коротких префиксов (1-2 символа) на больших индексах
- Для сложных сценариев автодополнения рассмотрите
completionsuggester
- Для полей с длинными значениями установите
8.3.3.5 - range
Поиск документов, значения поля которых попадают в указанный диапазон
Запрос range (диапазонный запрос)
Основные возможности
Запрос range позволяет выполнять поиск документов, значения полей которых попадают в указанный диапазон.
Синтаксис базового запроса
GET shakespeare/_search
{
"query": {
"range": {
"line_id": {
"gte": 10,
"lte": 20
}
}
}
}
Этот запрос находит документы, где значение поля line_id находится в диапазоне от 10 до 20 включительно.
Операторы сравнения
Параметр поля в запросе range принимает следующие операторы:
| Оператор | Описание |
|---|---|
gte | Больше или равно |
gt | Строго больше |
lte | Меньше или равно |
lt | Строго меньше |
Работа с датами
Пример поиска по датам:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "2019/01/01",
"lte": "2019/12/31"
}
}
}
}
Этот запрос находит все товары, добавленные в 2019 году.
Указание формата даты:
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "01/01/2022",
"lte": "31/12/2022",
"format":"dd/MM/yyyy"
}
}
}
}
Параметр format позволяет указать формат даты, отличный от формата, заданного в маппинге поля.
Особенности обработки дат
Автозаполнение отсутствующих компонентов даты: OpenSearch заполняет отсутствующие компоненты даты следующими значениями:
- MONTH_OF_YEAR: 01
- DAY_OF_MONTH: 01
- HOUR_OF_DAY: 23
- MINUTE_OF_HOUR: 59
- SECOND_OF_MINUTE: 59
- NANO_OF_SECOND: 999_999_999
Пример:
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2022",
"lte": "2022-12-31"
}
}
}
}
В этом случае начальная дата будет интерпретирована как 2022-01-01T23:59:59.999999999Z.
Относительные даты
Использование математики дат:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "2019/01/01||-1y-1d"
}
}
}
}
Здесь 2019/01/01 - это опорная дата, от которой вычитается 1 год и 1 день.
Округление дат:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "now-1y/M"
}
}
}
}
Ключевое слово now ссылается на текущую дату и время, /M означает округление по месяцам.
Правила округления относительных дат
| Параметр | Правило округления | Пример для 2022-05-18||/M |
|———-|—————————————-|—————————–|
| gt | Округляет вверх | 2022-06-01T00:00:00.000 |
| gte | Округляет вниз | 2022-05-01T00:00:00.000 |
| lt | Округляет вниз до последней миллисекунды | 2022-04-30T23:59:59.999 |
| lte | Округляет вверх до последней миллисекунды | 2022-05-31T23:59:59.999 |
Часовые пояса
По умолчанию даты считаются в UTC. Можно указать часовой пояс параметром time_zone:
GET /products/_search
{
"query": {
"range": {
"created": {
"time_zone": "-04:00",
"gte": "2022-04-17T06:00:00"
}
}
}
}
Значение 2022-04-17T06:00:00-04:00 будет преобразовано в 2022-04-17T10:00:00 UTC.
Дополнительные параметры
Синтаксис с параметрами:
GET _search
{
"query": {
"range": {
"<поле>": {
"gt": 10,
...
}
}
}
}
Доступные параметры:
| Параметр | Тип данных | Описание |
|---|---|---|
format | Строка | Формат даты для этого запроса. По умолчанию используется формат, заданный в маппинге поля. |
relation | Строка | Определяет способ сопоставления значений для полей диапазона. Допустимые значения: - INTERSECTS (по умолчанию): Находит документы, чей диапазон пересекается с запросом- CONTAINS: Находит документы, чей диапазон полностью содержит запрос- WITHIN: Находит документы, чей диапазон полностью внутри запроса |
boost | Число с плавающей точкой | Коэффициент усиления релевантности (>1 - увеличивает, 0-1 - уменьшает). По умолчанию: 1.0. |
time_zone | Строка | Часовой пояс для преобразования дат в UTC. Допустимы смещения UTC (например, -04:00) или идентификаторы IANA (например, America/New_York). |
Важно: При search.allow_expensive_queries=false диапазонные запросы по текстовым и ключевым полям не выполняются.
8.3.3.6 - regexp
Поиск документов, содержащих термины, соответствующие регулярному выражению
Запрос regexp (поиск по регулярным выражениям)
Назначение
Запрос regexp позволяет выполнять поиск терминов, соответствующих указанному регулярному выражению. Подробнее о синтаксисе регулярных выражений см. в документации по синтаксису регулярных выражений.
Базовый пример
GET shakespeare/_search
{
"query": {
"regexp": {
"play_name": "[a-zA-Z]amlet"
}
}
}
Этот запрос ищет любые термины в поле play_name, которые начинаются с любой буквы (верхнего или нижнего регистра), за которой следует “amlet”.
Ключевые особенности
Область применения:
Регулярные выражения применяются к отдельным терминам (токенам) в поле, а не ко всему полю целиком.Ограничения:
- Максимальная длина регулярного выражения по умолчанию: 1,000 символов (настраивается через
index.max_regex_length) - Используется синтаксис Lucene, который отличается от стандартных реализаций
- Максимальная длина регулярного выражения по умолчанию: 1,000 символов (настраивается через
Производительность:
- Избегайте шаблонов с
.*или.*?+без префикса/суффикса - Ресурсоемкие операции, требуют
search.allow_expensive_queries=true - Для частых запросов рекомендуется тестировать влияние на кластер
- Избегайте шаблонов с
Оптимизация:
Тип поляwildcardспециально оптимизирован для эффективных запросов с регулярными выражениями.
Расширенный синтаксис с параметрами
GET _search
{
"query": {
"regexp": {
"<поле>": {
"value": "[Ss]ample",
"boost": 1.5,
"case_insensitive": true,
"flags": "INTERSECTION|COMPLEMENT",
"max_determinized_states": 20000,
"rewrite": "constant_score"
}
}
}
}
Параметры запроса
| Параметр | Тип данных | Описание | По умолчанию |
|---|---|---|---|
value | Строка | Обязательный. Регулярное выражение для поиска | - |
boost | Число с плавающей точкой | Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) | 1.0 |
case_insensitive | Логический | Регистронезависимый поиск | false |
flags | Строка | Дополнительные операторы Lucene (INTERSECTION, COMPLEMENT и др.) | - |
max_determinized_states | Целое число | Максимальное число состояний автомата (защита от перегрузки) | 10000 |
rewrite | Строка | Метод перезаписи запроса (constant_score, scoring_boolean и др.) | constant_score |
Рекомендации по использованию
Тестирование:
Всегда проверяйте регулярные выражения на тестовых данных перед использованием в production.Производительность:
// Неэффективно: { "regexp": { "text": ".*pattern.*" } } // Оптимально: { "regexp": { "text": "prefix.*suffix" } }Альтернативы:
Для сложных сценариев рассмотрите:- Использование
wildcardтипа поля - Применение
match_phraseдля текстовых фраз - Использование
keywordполей для точного соответствия
- Использование
Безопасность:
Ограничивайтеmax_determinized_statesдля предотвращения DoS-атак через сложные регулярные выражения.
Примечание: При search.allow_expensive_queries=false запросы regexp не выполняются.
8.3.3.7 - term
Поиск документов, содержащих точное соответствие указанному термину в заданном поле
Запрос term (поиск точного термина)
Назначение
Запрос term выполняет поиск точного соответствия указанному термину в поле. Основные характеристики:
- Ищет неизмененное значение без анализа текста
- Чувствителен к регистру по умолчанию
- Оптимален для полей типа
keyword, дат и чисел
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"term": {
"line_id": {
"value": "61809"
}
}
}
}
Этот запрос ищет строку с точным значением line_id = "61809".
Важные особенности
Отличие от match запросов:
termне анализирует поисковый термин- Не подходит для текстовых полей (
text), так как они анализируются при индексации - Для текстовых полей используйте
matchзапросы
Регистронезависимый поиск (начиная с OpenSearch 2.x):
GET shakespeare/_search
{
"query": {
"term": {
"speaker": {
"value": "HAMLET",
"case_insensitive": true
}
}
}
}
Внимание! В версиях OpenSearch 2.x и ранее регистронезависимый поиск может значительно снижать производительность. Рекомендуется:
- Использовать lowercase фильтр при индексации
- Применять термины в нижнем регистре в запросах
Пример ответа
{
"hits": {
"total": {
"value": 1582,
"relation": "eq"
},
"hits": [
{
"_index": "shakespeare",
"_id": "32700",
"_score": 2,
"_source": {
"speaker": "HAMLET",
"text_entry": "[Aside] A little more than kin..."
}
}
]
}
}
Параметры запроса
Синтаксис с параметрами:
GET _search
{
"query": {
"term": {
"<поле>": {
"value": "образец",
...
}
}
}
}
| Параметр | Тип данных | Описание | По умолчанию |
|---|---|---|---|
value | Строка | Обязательный. Точное значение для поиска (учитывает регистр и пробелы) | - |
boost | Число с плавающей точкой | Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) | 1.0 |
_name | Строка | Имя запроса для тегирования (опционально) | - |
case_insensitive | Логический | Регистронезависимый поиск (только для OpenSearch 2.x+) | false |
Практические рекомендации
Для текстовых полей всегда используйте
matchвместоterm:// Неправильно (для text полей): { "term": { "description": "quick brown fox" } } // Правильно: { "match": { "description": "quick brown fox" } }Для точных значений (ID, коды, категории):
GET products/_search { "query": { "term": { "product_code": "ABC-123" } } }Комбинируйте с другими запросами:
GET logs/_search { "query": { "bool": { "must": [ { "term": { "status": "error" } }, { "range": { "timestamp": { "gte": "2023-01-01" }}} ] } } }Производительность:
- Для частых запросов добавьте индекс на поле
- Избегайте
case_insensitiveв favor lowercase анализаторов
8.3.3.8 - terms
Поиск документов, содержащих один или несколько указанных терминов в заданном поле
Terms Query (Поиск по нескольким значениям)
Основное назначение
Запрос terms позволяет искать документы, содержащие одно или несколько указанных значений в заданном поле. Документ возвращается в результатах, если значение его поля точно соответствует хотя бы одному термину из списка.
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"terms": {
"line_id": [
"61809",
"61810"
]
}
}
}
Ключевые особенности
Лимит терминов:
По умолчанию максимальное количество терминов в запросе - 65,536. Настраивается через параметрindex.max_terms_count.Производительность:
Для оптимизации производительности с длинными списками терминов рекомендуется:- Передавать термины в отсортированном порядке (по возрастанию UTF-8 byte values)
- Использовать механизм Terms Lookup для больших наборов терминов
Подсветка результатов:
Возможность подсветки результатов зависит от:- Типа highlighter’а
- Количества терминов в запросе
Параметры запроса
| Параметр | Тип данных | Описание | По умолчанию |
|---|---|---|---|
<field> | String | Поле для поиска (точное соответствие хотя бы одному термину) | - |
boost | Float | Вес поля в расчете релевантности (>1 - увеличивает, 0-1 - уменьшает) | 1.0 |
_name | String | Имя запроса для тегирования | - |
value_type | String | Тип значений для фильтрации (default или bitmap) | default |
Terms Lookup (Поиск терминов из другого документа)
Общие принципы
Механизм Terms Lookup позволяет:
- Извлекать значения полей из указанного документа
- Использовать эти значения как условия поиска
- Работать с большими наборами терминов
Требования:
- Поле
_sourceдолжно быть включено (включено по умолчанию) - Для уменьшения сетевого трафика рекомендуется использовать индекс с:
- Одним первичным шардом
- Полными репликами на всех узлах данных
Пример использования
- Создаем индекс студентов:
PUT students
{
"mappings": {
"properties": {
"student_id": { "type": "keyword" }
}
}
}
- Добавляем данные студентов:
PUT students/_doc/1
{
"name": "Jane Doe",
"student_id" : "111"
}
PUT students/_doc/2
{
"name": "Mary Major",
"student_id" : "222"
}
PUT students/_doc/3
{
"name": "John Doe",
"student_id" : "333"
}
- Создаем индекс классов с информацией о зачисленных студентах:
PUT classes/_doc/101
{
"name": "CS101",
"enrolled" : ["111" , "222"]
}
- Поиск студентов, зачисленных на CS101:
GET students/_search
{
"query": {
"terms": {
"student_id": {
"index": "classes",
"id": "101",
"path": "enrolled"
}
}
}
}
- Результат содержит соответствующих студентов:
{
"took": 13,
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_source": {
"name": "Jane Doe",
"student_id": "111"
}
},
{
"_index": "students",
"_id": "2",
"_source": {
"name": "Mary Major",
"student_id": "222"
}
}
]
}
}
Работа с вложенными полями
- Добавляем документ с вложенной структурой:
PUT classes/_doc/102
{
"name": "CS102",
"enrolled_students" : {
"id_list" : ["111" , "333"]
}
}
- Поиск с указанием пути к вложенному полю:
GET students/_search
{
"query": {
"terms": {
"student_id": {
"index": "classes",
"id": "102",
"path": "enrolled_students.id_list"
}
}
}
}
- Результат поиска:
{
"took": 18,
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_source": {
"name": "Jane Doe",
"student_id": "111"
}
},
{
"_index": "students",
"_id": "3",
"_source": {
"name": "John Doe",
"student_id": "333"
}
}
]
}
}
Параметры Terms Lookup
| Параметр | Тип данных | Описание | Обязательность |
|---|---|---|---|
index | String | Индекс, из которого извлекаются значения | Обязательно |
id | String | ID документа-источника | Обязательно |
path | String | Путь к полю (для вложенных полей - точечная нотация) | Обязательно |
routing | String | Кастомное значение маршрутизации документа | Опционально* |
store | Boolean | Использовать stored fields вместо _source | Опционально |
*Обязателен, если при индексации использовалось кастомное routing
Важные замечания
- Для полей типа
textиспользуйтеmatchвместоterms - При работе с большими наборами терминов (>10,000) рассмотрите возможность использования Bitmap Filtering
- Убедитесь, что поле
_sourceвключено для документов-источников
Bitmap Filtering (Фильтрация с использованием битовых карт)
Введение
Начиная с версии 2.17, OpenSearch предлагает механизм bitmap filtering для эффективной фильтрации по большому количеству терминов (10,000+). Этот подход решает проблему высокой нагрузки на сеть и память при работе с обычными terms-запросами.
Основные концепции
Проблема:
Обычные terms-запросы становятся неэффективными при большом количестве терминов из-за:- Высокого сетевого трафика
- Чрезмерного потребления памяти
Решение:
Использование roaring bitmap для кодирования условий фильтрации:- Эффективное сжатие данных
- Быстрые битовые операции
- Оптимизированное использование памяти
Пример реализации
1. Подготовка индексов
Индекс продуктов:
PUT /products
{
"mappings": {
"properties": {
"product_id": { "type": "integer" }
}
}
}
Добавление продуктов:
PUT /products/_doc/1
{
"name": "Product 1",
"product_id" : 111
}
PUT /products/_doc/2
{
"name": "Product 2",
"product_id" : 222
}
PUT /products/_doc/3
{
"name": "Product 3",
"product_id" : 333
}
Индекс клиентов с bitmap-полем:
PUT /customers
{
"mappings": {
"properties": {
"customer_filter": {
"type": "binary",
"store": true
}
}
}
}
2. Генерация bitmap
Пример кода на Python с использованием PyRoaringBitMap:
from pyroaring import BitMap
import base64
bm = BitMap([111, 222, 333]) # ID продуктов клиента
encoded = base64.b64encode(BitMap.serialize(bm))
encoded_bm_str = encoded.decode('utf-8')
print(f"Encoded Bitmap: {encoded_bm_str}")
3. Индексация bitmap
POST customers/_doc/customer123
{
"customer_filter": "OjAAAAEAAAAAAAIAEAAAAG8A3gBNAQ=="
}
Использование bitmap в запросах
Вариант 1: Lookup из документа
POST /products/_search
{
"query": {
"terms": {
"product_id": {
"index": "customers",
"id": "customer123",
"path": "customer_filter",
"store": true
},
"value_type": "bitmap"
}
}
}
Вариант 2: Прямая передача bitmap
POST /products/_search
{
"query": {
"terms": {
"product_id": [
"OjAAAAEAAAAAAAIAEAAAAG8A3gBNAQ=="
],
"value_type": "bitmap"
}
}
}
Ключевые параметры
| Параметр | Тип данных | Описание | Обязательность |
|---|---|---|---|
value_type | String | Должно быть bitmap для активации этого режима | Обязательно |
store | Boolean | true для поиска в stored field вместо _source | Опционально |
index | String | Индекс-источник bitmap (для lookup) | Для lookup |
id | String | ID документа с bitmap | Для lookup |
path | String | Поле с bitmap данными | Для lookup |
Преимущества подхода
Эффективность:
- Снижение сетевого трафика до 10 раз
- Уменьшение использования памяти на 50-90%
Гибкость:
- Поддержка динамического обновления фильтров
- Возможность комбинирования условий
Производительность:
- Быстрое выполнение даже для 100,000+ терминов
- Оптимизированные битовые операции на уровне ядра
Рекомендации
- Используйте для сложных фильтров с >10,000 значений
- Регулярно обновляйте bitmap при изменении данных
- Тестируйте производительность для вашего конкретного сценария
- Рассмотрите использование сжатых форматов bitmap для экономии места
8.3.3.9 - terms set
Поиск документов, соответствующих минимальному количеству указанных терминов
Terms Set Query (Запрос с условием минимального соответствия терминов)
Основное назначение
Запрос terms_set позволяет искать документы, которые соответствуют минимальному количеству точных терминов в указанном поле. В отличие от обычного terms запроса, terms_set требует явного указания минимального количества совпадений, которое может быть задано либо через поле индекса, либо через скрипт.
Основные характеристики
- Ищет точные соответствия терминов (без анализа текста)
- Требует указания минимального количества совпадающих терминов
- Поддерживает два способа определения минимального количества:
- Через поле документа (
minimum_should_match_field) - Через скрипт (
minimum_should_match_script)
- Через поле документа (
- Оптимален для работы с полями типа
keyword
Пример использования
1. Подготовка индекса
PUT students
{
"mappings": {
"properties": {
"name": { "type": "keyword" },
"classes": { "type": "keyword" },
"min_required": { "type": "integer" }
}
}
}
2. Индексация документов
PUT students/_doc/1
{
"name": "Mary Major",
"classes": [ "CS101", "CS102", "MATH101" ],
"min_required": 2
}
PUT students/_doc/2
{
"name": "John Doe",
"classes": [ "CS101", "MATH101", "ENG101" ],
"min_required": 2
}
3. Поиск с использованием поля для минимального соответствия
GET students/_search
{
"query": {
"terms_set": {
"classes": {
"terms": [ "CS101", "CS102", "MATH101" ],
"minimum_should_match_field": "min_required"
}
}
}
}
4. Поиск с использованием скрипта для минимального соответствия
GET students/_search
{
"query": {
"terms_set": {
"classes": {
"terms": [ "CS101", "CS102", "MATH101" ],
"minimum_should_match_script": {
"source": "Math.min(params.num_terms, doc['min_required'].value)"
}
}
}
}
}
Параметры запроса
Базовый синтаксис:
GET _search
{
"query": {
"terms_set": {
"<поле>": {
"terms": [ "term1", "term2" ],
...
}
}
}
}
| Параметр | Тип данных | Описание | Обязательность |
|---|---|---|---|
terms | Массив строк | Термины для поиска (точное соответствие) | Обязательно |
minimum_should_match_field | Строка | Поле, содержащее минимальное количество совпадений | Один из двух |
minimum_should_match_script | Строка | Скрипт, возвращающий минимальное количество совпадений | Один из двух |
boost | Число с плавающей точкой | Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) | Опционально |
Особенности работы
Механизм подсчета:
Документ считается соответствующим, если количество совпадающих терминов из массиваterms≥ указанного минимума.Определение минимума:
- Через поле: значение берется из указанного поля документа
- Через скрипт: вычисляется динамически для каждого документа
Производительность:
- Использование поля
minimum_should_match_fieldобычно более эффективно - Скрипты обеспечивают гибкость, но могут снижать производительность
- Использование поля
Рекомендации по использованию
- Для статических условий используйте
minimum_should_match_field - Для сложной логики применяйте
minimum_should_match_script - Всегда индексируйте поля, используемые для определения минимума
- Для текстовых полей предварительно применяйте нормализацию
- Тестируйте производительность на реалистичных объемах данных
Примеры скриптов
- Фиксированное значение:
"minimum_should_match_script": {
"source": "2"
}
- Динамическое вычисление:
"minimum_should_match_script": {
"source": "doc['min_required'].value * params.factor",
"params": {
"factor": 1.5
}
}
- Ограничение сверху:
"minimum_should_match_script": {
"source": "Math.min(5, doc['min_required'].value)"
}
8.3.3.10 - wildcard
Поиск документов, содержащих термины, соответствующие шаблону с подстановочными символами
Wildcard Query (Поиск с подстановочными символами)
Основное назначение
Запрос wildcard позволяет выполнять поиск терминов по шаблону с использованием подстановочных символов. Особенно полезен для:
- Поиска по частичным совпадениям
- Нечеткого поиска с известной структурой
- Работы с кодами, артикулами и другими структурированными данными
Поддерживаемые операторы
| Оператор | Описание | Пример |
|---|---|---|
* | Соответствует нулю или более символов | H*Y найдет “HAPPY”, “HALLEY” |
? | Соответствует любому одному символу | H?Y найдет “HAY”, но не “HAPPY” |
case_insensitive | Флаг регистронезависимости | true/false (по умолчанию false) |
Примеры запросов
1. Чувствительный к регистру поиск:
GET shakespeare/_search
{
"query": {
"wildcard": {
"speaker": {
"value": "H*Y",
"case_insensitive": false
}
}
}
}
2. Использование разных операторов:
H*Y- найдет любые значения, начинающиеся на H и заканчивающиеся на YH?Y- найдет только 3-символьные значения типа “HMY”
Параметры запроса
Базовый синтаксис:
GET _search
{
"query": {
"wildcard": {
"<поле>": {
"value": "шаб*лон",
...
}
}
}
}
| Параметр | Тип данных | Описание | По умолчанию |
|---|---|---|---|
value | String | Шаблон для поиска с подстановочными символами | Обязательный |
boost | Float | Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) | 1.0 |
case_insensitive | Boolean | Регистронезависимый поиск | false |
rewrite | String | Метод перезаписи запроса (constant_score, scoring_boolean и др.) | constant_score |
Критические особенности производительности
Предупреждение:
Wildcard-запросы могут быть медленными, так как требуют перебора множества терминов.Золотое правило:
Избегайте размещения подстановочных символов в начале шаблона (например,*pattern), так как это:- Крайне ресурсоемко
- Может привести к таймаутам
- Создает нагрузку на кластер
Оптимизация:
Для частых wildcard-запросов используйте специальныйwildcardтип поля, который:- Создает оптимизированный индекс
- Обеспечивает высокую производительность
- Поддерживает сложные шаблоны
Практические рекомендации
Для префиксного поиска используйте
prefixзапрос вместоH*:{ "query": { "prefix": { "field": "H" } } }Для сложных шаблонов рассмотрите:
- Использование
wildcardтипа поля - Применение
regexpзапросов для более сложных паттернов
- Использование
При работе с большими индексами:
- Ограничивайте время выполнения через
timeout - Используйте
search.allow_expensive_queriesдля контроля
- Ограничивайте время выполнения через
Пример безопасного шаблона:
{ "query": { "wildcard": { "product_code": { "value": "ABC-202?-*", "case_insensitive": true } } } }Такой шаблон найдет коды типа “ABC-2023-XXX” и безопасен для выполнения.
Важные ограничения
- При
search.allow_expensive_queries=falsewildcard-запросы не выполняются - Максимальная длина шаблона ограничена параметром
index.max_regex_length(по умолчанию 1000 символов) - Не поддерживает стандартные regex-конструкции (используйте
regexpзапрос для сложных выражений)
8.3.4 - full_text
Анализируют текст запроса, применяют тот же анализатор, что и при индексации. match, match_phrase, multi_match
Полнотекстовые запросы
Эта страница перечисляет все типы полнотекстовых запросов и общие параметры. Существует множество необязательных полей, которые вы можете использовать для создания тонких поисковых поведений, поэтому мы рекомендуем протестировать некоторые базовые типы запросов на представительных индексах и проверить вывод, прежде чем выполнять более сложные или комплексные поиски с несколькими параметрами.
OpenSearch использует библиотеку поиска Apache Lucene, которая предоставляет высокоэффективные структуры данных и алгоритмы для загрузки, индексации, поиска и агрегации данных.
Чтобы узнать больше о классах запросов поиска, смотрите JavaDocs по запросам Lucene.
Типы полнотекстовых запросов, показанные в этом разделе, используют стандартный анализатор, который автоматически анализирует текст при отправке запроса.
В следующей таблице перечислены все типы полнотекстовых запросов.
| Тип запроса | Описание |
|---|---|
| intervals | Позволяет точно контролировать близость и порядок совпадающих терминов. |
| match | Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости. |
| match_bool_prefix | Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс. |
| match_phrase | Похож на запрос match, но соответствует целой фразе с настраиваемым слопом. |
| match_phrase_prefix | Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс. |
| multi_match | Похож на запрос match, но используется для нескольких полей. |
| query_string | Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса. |
| simple_query_string | Более простая, менее строгая версия запроса query_string. |
8.3.4.1 - match
Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости.
Запрос Match
Используйте запрос match для полнотекстового поиска по конкретному полю документа. Если вы выполняете запрос match по текстовому полю, он анализирует предоставленную строку поиска и возвращает документы, которые соответствуют любым терминам этой строки. Если вы выполняете запрос match по полю с точным значением, он возвращает документы, которые соответствуют этому точному значению. Предпочтительный способ поиска по полям с точными значениями — использовать фильтр, поскольку, в отличие от запроса, фильтр кэшируется.
Пример
Следующий пример показывает базовый запрос match для слова “wind” в заголовке:
GET _search
{
"query": {
"match": {
"title": "wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match": {
"title": {
"query": "wind",
"analyzer": "stop"
}
}
}
}
Примеры
В следующих примерах вы будете использовать индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "Let the wind rise"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
PUT testindex/_doc/3
{
"title": "Rise is gone"
}
Оператор
Если запрос match выполняется по текстовому полю, текст анализируется с помощью анализатора, указанного в параметре analyzer. Затем полученные токены объединяются в логический запрос с использованием оператора, указанного в параметре operator. Оператор по умолчанию — OR, поэтому запрос “wind rise” преобразуется в “wind OR rise”. В этом примере этот запрос возвращает документы 1–3, поскольку каждый документ содержит термин, соответствующий запросу. Чтобы указать оператор AND, используйте следующий запрос:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "and"
}
}
}
}
Запрос формируется как “wind AND rise” и возвращает документ 1 как совпадающий документ.
Минимальное количество совпадений
Вы можете контролировать минимальное количество терминов, которые документ должен совпадать, чтобы быть возвращенным в результатах, указав параметр minimum_should_match:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "or",
"minimum_should_match": 2
}
}
}
}
Теперь документы должны совпадать с обоими терминами, поэтому возвращается только документ 1 (это эквивалентно оператору AND).
Анализатор
Поскольку в этом примере вы не указали анализатор, используется анализатор по умолчанию — стандартный анализатор. Стандартный анализатор не выполняет стемминг, поэтому если вы выполните запрос “the wind rises”, вы не получите результатов, поскольку токен “rises” не совпадает с токеном “rise”. Чтобы изменить анализатор поиска, укажите его в поле analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "the wind rises",
"operator": "and",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токены “wind” и “rise”. Последний токен совпадает с документом 1, который возвращается в результатах.
Пустой запрос
В некоторых случаях анализатор может удалить все токены из запроса. Например, английский анализатор удаляет стоп-слова, поэтому в запросе “and OR or” все токены удаляются. Чтобы проверить поведение анализатора, вы можете использовать API анализа:
GET testindex/_analyze
{
"analyzer": "english",
"text": "and OR or"
}
Как и ожидалось, запрос не производит токенов:
{
"tokens": []
}
Вы можете задать поведение для пустого запроса с помощью параметра zero_terms_query. Установка zero_terms_query в значение all возвращает все документы в индексе, а установка в none не возвращает ни одного документа:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "and OR or",
"analyzer": "english",
"zero_terms_query": "all"
}
}
}
}
Неопределенность (Fuzziness)
Чтобы учесть опечатки, вы можете указать уровень нечеткости для вашего запроса в одном из следующих форматов:
- Целое число, которое указывает максимальное допустимое расстояние по Дамерау-Левенштейну для этого редактирования.
- AUTO:
- Строки длиной 0–2 символа должны совпадать точно.
- Строки длиной 3–5 символов допускают 1 редактирование.
- Строки длиной более 5 символов допускают 2 редактирования.
Установка нечеткости на значение по умолчанию AUTO работает лучше всего в большинстве случаев:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO"
}
}
}
}
Токен “wnid” совпадает с “wind”, и запрос возвращает документы 1 и 2.
Длина префикса
Опечатки редко встречаются в начале слов. Таким образом, вы можете указать минимальную длину, которую должен иметь совпадающий префикс, чтобы документ был возвращен в результатах. Например, вы можете изменить предыдущий запрос, добавив параметр prefix_length:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"prefix_length": 2
}
}
}
}
Предыдущий запрос не возвращает результатов. Если вы измените prefix_length на 1, документы 1 и 2 будут возвращены, поскольку первая буква токена “wnid” не ошибочна.
Транспозиции
В предыдущем примере слово “wnid” содержало транспозицию (буквы “i” и “n” были поменяны местами). По умолчанию транспозиции допускаются в нечетком совпадении, но вы можете запретить их, установив fuzzy_transpositions в false:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"fuzzy_transpositions": false
}
}
}
}
Теперь запрос не возвращает результатов.
Синонимы
Если вы используете фильтр synonym_graph и параметр auto_generate_synonyms_phrase_query установлен в true (по умолчанию), OpenSearch разбивает запрос на термины, а затем объединяет термины для генерации фразового запроса для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average”.
Чтобы сопоставить многословные синонимы с союзами, установите auto_generate_synonyms_phrase_query в false:
GET /testindex/_search
{
"query": {
"match": {
"text": {
"query": "good ba",
"auto_generate_synonyms_phrase_query": false
}
}
}
}
Сформированный запрос будет “ba” OR (“batting” AND “average”).
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр | Тип данных | Описание |
|---|---|---|
| query | String | Строка запроса, используемая для поиска. Обязательный параметр. |
| auto_generate_synonyms_phrase_query | Boolean | Указывает, следует ли автоматически создавать фразовый запрос match для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average” (если этот параметр true) или “ba” OR (“batting” AND “average”) (если этот параметр false). По умолчанию true. |
| analyzer | String | Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| boost | Floating-point | Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| enable_position_increments | Boolean | Если true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fuzziness | String | Количество редактирований символов (вставок, удалений, замен или транспозиций), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite | String | Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions | Boolean | Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| lenient | Boolean | Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_expansions | Positive integer | Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match | Positive or negative integer, positive or negative percentage, combination | Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator | String | Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения: - OR: строка интерпретируется как “или” - AND: строка интерпретируется как “и”. По умолчанию используется OR. |
| prefix_length | Non-negative integer | Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
| zero_terms_query | String | В некоторых случаях анализатор удаляет все термины из строки запроса. Например, стоп-анализатор удаляет все термины из строки “an”, но оставляет “this”. В таких случаях zero_terms_query указывает, следует ли не совпадать ни с одним документом (none) или совпадать со всеми документами (all). Допустимые значения: none и all. По умолчанию none. |
8.3.4.2 - match-bool-prefix
Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс.
Запрос Match Boolean Prefix
Запрос match_bool_prefix анализирует предоставленную строку поиска и создает логический запрос из терминов строки. Он использует каждый термин, кроме последнего, как целое слово для совпадения. Последний термин используется как префикс. Запрос match_bool_prefix возвращает документы, которые содержат либо термины целых слов, либо термины, начинающиеся с префиксного термина, в любом порядке.
Пример
Следующий пример показывает базовый запрос match_bool_prefix:
GET _search
{
"query": {
"match_bool_prefix": {
"title": "the wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "the wind",
"analyzer": "stop"
}
}
}
}
Пример документов
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
Следующий запрос match_bool_prefix ищет целое слово “rises” и слова, начинающиеся с “wi”, в любом порядке:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"should": [
{ "term": { "title": "rises" }},
{ "prefix": { "title": "wi" }}
]
}
}
}
Ответ содержит оба документа:
Ответ
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.73617,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1.73617,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1,
"_source": {
"title": "Gone with the wind"
}
}
]
}
}
Запросы match_bool_prefix и match_phrase_prefix
Запрос match_bool_prefix сопоставляет термины в любой позиции, в то время как запрос match_phrase_prefix сопоставляет термины как целую фразу. Чтобы проиллюстрировать разницу, снова рассмотрим запрос match_bool_prefix из предыдущего раздела:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Оба документа “The wind rises” и “Gone with the wind” соответствуют поисковым терминам, поэтому запрос возвращает оба документа.
Теперь выполните запрос match_phrase_prefix по тому же индексу:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "rises wi"
}
}
}
Ответ не возвращает документов, потому что ни один из документов не содержит фразу “rises wi” в указанном порядке.
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "rise the wi",
"analyzer": "stop"
}
}
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match_bool_prefix": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр | Тип данных | Описание |
|---|---|---|
| query | String | Текст, число, логическое значение или дата, используемые для поиска. Обязательный параметр. |
| analyzer | String | Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| fuzziness | AUTO, 0 или положительное целое число | Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. По умолчанию используется значение AUTO, которое выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite | String | Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions | Boolean | Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| max_expansions | Положительное целое число | Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match | Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация | Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator | String | Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения: OR и AND. По умолчанию используется OR. |
| prefix_length | Ненегативное целое число | Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
Параметры fuzziness, fuzzy_transpositions, fuzzy_rewrite, max_expansions и prefix_length могут применяться к подзапросам term, созданным для всех терминов, кроме последнего. Они не оказывают никакого влияния на префиксный запрос, созданный для последнего термина.
8.3.4.3 - match-phrase
Похож на запрос match, но соответствует целой фразе с настраиваемым слопом.
Запрос match_phrase
Используйте запрос match_phrase, чтобы находить документы, содержащие точную фразу в указанном порядке. Вы можете добавить гибкость к фразовому соответствию, указав параметр slop.
Запрос match_phrase создает фразовый запрос, который соответствует последовательности терминов.
Пример базового запроса match_phrase:
GET _search
{
"query": {
"match_phrase": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase ищет фразу “wind rises”, где слово “ветер” следует за словом “поднимается”:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": "wind rises"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "The wind rises"
}
}
]
}
}
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": {
"query": "ветра",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токен “ветер”. Оба документа соответствуют этому токену и возвращаются в результатах:
Slop
Если вы укажете параметр slop, запрос допускает перестановку поисковых терминов. Параметр slop указывает количество других слов, разрешенных между словами в фразе запроса. Например, в следующем запросе текст поиска переставлен по сравнению с текстом документа:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер поднимается",
"slop": 3
}
}
}
}
Запрос все равно возвращает соответствующий документ:
Пустой запрос
Для информации о возможном пустом запросе смотрите соответствующий раздел запроса match.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр | Тип данных | Описание |
|---|---|---|
| query | Строка | Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer | Строка | Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для поля по умолчанию на этапе индексации. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
| slop | 0 (по умолчанию) или положительное целое число | Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
| zero_terms_query | Строка | В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки “an”, кроме “but”. В таких случаях zero_terms_query указывает, следует ли не находить ни одного документа (none) или находить все документы (all). Допустимые значения: none и all. По умолчанию используется none. |
8.3.4.4 - match-phrase-prefix
Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс.
Запрос match_phrase_prefix
Используйте запрос match_phrase_prefix, чтобы указать фразу для поиска в заданном порядке. Документы, содержащие указанную вами фразу, будут возвращены. Последний неполный термин в фразе интерпретируется как префикс, поэтому любые документы, содержащие фразы, начинающиеся с указанной фразы и префикса последнего термина, будут возвращены.
Запрос аналогичен match_phrase, но создает префиксный запрос из последнего термина в строке запроса.
Для различий между запросами match_phrase_prefix и match_bool_prefix смотрите раздел о запросах match_bool_prefix и match_phrase_prefix.
Пример базового запроса match_phrase_prefix:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "Ветер поднимается"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase_prefix ищет полное слово “ветер”, за которым следует слово, начинающееся на “под”:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "ветер под"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "Ветер поднимается"
}
}
]
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase_prefix": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр | Тип данных | Описание |
|---|---|---|
| query | Строка | Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer | Строка | Анализатор, используемый для токенизации текста строки запроса. |
| max_expansions | Положительное целое число | Максимальное количество терминов, на которые может расширяться запрос. Неопределенные запросы “расширяются” на количество совпадающих терминов, находящихся на расстоянии, указанном в параметре fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию значение равно 50. |
| slop | 0 (по умолчанию) или положительное целое число | Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
8.3.4.5 - multi-match
Похож на запрос match, но используется для нескольких полей.
Многофункциональные запросы (Multi-match queries)
Операция multi-match функционирует аналогично операции match. Вы можете использовать запрос multi_match для поиска по нескольким полям.
Символ ^ “увеличивает” вес определенных полей. Увеличения — это множители, которые придают больший вес совпадениям в одном поле по сравнению с совпадениями в других полях. В следующем примере совпадение для “ветер” в поле title влияет на _score в четыре раза больше, чем совпадение в поле plot:
GET _search
{
"query": {
"multi_match": {
"query": "ветер",
"fields": ["title^4", "plot"]
}
}
}
В результате фильмы, такие как “Ветер поднимается” и “Ушедший с ветром”, находятся в верхней части результатов поиска, а фильмы, такие как “Ураган”, которые, предположительно, содержат “ветер” в своих аннотациях, находятся внизу.
Вы можете использовать подстановочные знаки в имени поля. Например, следующий запрос будет искать поле speaker и все поля, начинающиеся с play_, например, play_name или play_title:
GET _search
{
"query": {
"multi_match": {
"query": "гамлет",
"fields": ["speaker", "play_*"]
}
}
}
Если вы не укажете параметр fields, запрос multi_match будет искать в полях, указанных в настройке index.query.default_field, которая по умолчанию равна *. Поведение по умолчанию заключается в извлечении всех полей в отображении, которые подходят для запросов на уровне терминов, фильтрации метаданных и комбинировании всех извлеченных полей для построения запроса.
Максимальное количество клауз в запросе определяется настройкой indices.query.bool.max_clause_count, которая по умолчанию равна 1,024.
Типы многофункциональных запросов
OpenSearch поддерживает следующие типы многофункциональных запросов, которые различаются по способу внутреннего выполнения запроса:
- best_fields (по умолчанию): Возвращает документы, которые соответствуют любому полю. Использует
_scoreлучшего совпадающего поля. - most_fields: Возвращает документы, которые соответствуют любому полю. Использует комбинированный балл каждого совпадающего поля.
- cross_fields: Обрабатывает все поля так, как если бы они были одним полем. Обрабатывает поля с одинаковым анализатором и сопоставляет слова в любом поле.
- phrase: Выполняет запрос
match_phraseдля каждого поля. Использует_scoreлучшего совпадающего поля. - phrase_prefix: Выполняет запрос
match_phrase_prefixдля каждого поля. Использует_scoreлучшего совпадающего поля. - bool_prefix: Выполняет запрос
match_bool_prefixдля каждого поля. Использует комбинированный балл каждого совпадающего поля.
Лучшие поля (Best fields)
Если вы ищете два слова, которые определяют концепцию, вы хотите, чтобы результаты, в которых два слова находятся рядом друг с другом, имели более высокий балл.
Например, рассмотрим индекс, содержащий следующие научные статьи:
PUT /articles/_doc/1
{
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
PUT /articles/_doc/2
{
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
Вы можете искать статьи, содержащие “северные огни” в заголовке или описании:
GET articles/_search
{
"query": {
"multi_match" : {
"query": "северные огни",
"type": "best_fields",
"fields": [ "title", "description" ],
"tie_breaker": 0.3
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с запросом match для каждого поля:
Запрос multi_match позволяет искать по нескольким полям. Он работает аналогично запросу match, но с возможностью указания нескольких полей для поиска.
Пример запроса dis_max
GET /articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "северные огни" }},
{ "match": { "description": "северные огни" }}
],
"tie_breaker": 0.3
}
}
}
Результаты содержат оба документа, но документ 1 имеет более высокий балл, потому что оба слова находятся в поле description:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.6322521,
"_source": {
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
}
]
}
}
Запрос best_fields использует балл лучшего совпадающего поля. Если вы укажете tie_breaker, балл рассчитывается по следующему алгоритму:
- Возьмите балл лучшего совпадающего поля.
- Добавьте (tie_breaker * _score) для всех других совпадающих полей.
Запрос most_fields
Используйте запрос most_fields для нескольких полей, которые содержат один и тот же текст, анализируемый разными способами. Например, оригинальное поле может содержать текст, проанализированный с помощью стандартного анализатора, а другое поле может содержать тот же текст, проанализированный с помощью английского анализатора, который выполняет стемминг:
PUT /articles
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Рассмотрим следующие два документа, которые индексируются в индексе articles:
PUT /articles/_doc/1
{
"title": "Гренки с маслом"
}
PUT /articles/_doc/2
{
"title": "Масло на тосте"
}
Стандартный анализатор анализирует заголовок “Гренки с маслом” в [гренки, масло], а заголовок “Масло на тосте” в [масло, на, тосте]. С другой стороны, английский анализатор производит один и тот же список токенов [масло, тост] для обоих заголовков из-за стемминга.
Вы можете использовать запрос most_fields, чтобы вернуть как можно больше документов:
GET /articles/_search
{
"query": {
"multi_match": {
"query": "гренки с маслом",
"fields": [
"title",
"title.english"
],
"type": "most_fields"
}
}
}
Предыдущий запрос выполняется как следующий булев запрос:
GET articles/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "гренки с маслом" }},
{ "match": { "title.english": "гренки с маслом" }}
]
}
}
}
Расчет релевантности
Чтобы рассчитать релевантность, баллы документа для всех клауз совпадений складываются, а затем результат делится на количество клауз совпадений.
Включение поля title.english позволяет получить второй документ, который соответствует стеммированным токенам:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.4418206,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 1.4418206,
"_source": {
"title": "Гренки с маслом"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.09304003,
"_source": {
"title": "Масло на тосте"
}
}
]
}
}
Поскольку оба поля title и title.english совпадают для первого документа, он имеет более высокий балл релевантности.
Оператор и минимальное количество совпадений
Запросы best_fields и most_fields генерируют запрос match на основе полей (по одному для каждого поля). Таким образом, параметры minimum_should_match и operator применяются к каждому полю, что обычно не является желаемым поведением.
Например, рассмотрим индекс customers со следующими документами:
PUT customers/_doc/1
{
"first_name": "John",
"last_name": "Doe"
}
PUT customers/_doc/2
{
"first_name": "Jane",
"last_name": "Doe"
}
Если вы ищете “John Doe” в индексе customers, вы можете составить следующий запрос:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Цель оператора and в этом запросе — найти документ, который соответствует “John” и “Doe”. Однако запрос не возвращает никаких результатов. Вы можете узнать, как выполняется запрос, запустив API валидации:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос пытается сопоставить как “John”, так и “Doe” с полем first_name или last_name:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "((+first_name:john +first_name:doe) | (+last_name:john +last_name:doe))"
}
]
}
Поскольку ни одно из полей не содержит оба слова, результаты не возвращаются.
Лучшей альтернативой для поиска по полям является использование запроса cross_fields. В отличие от ориентированных на поля запросов best_fields и most_fields, запрос cross_fields ориентирован на термины.
Запрос cross_fields
Используйте запрос cross_fields, чтобы искать данные по нескольким полям. Например, если индекс содержит данные о клиентах, имя и фамилия клиента находятся в разных полях. Тем не менее, когда вы ищете “John Doe”, вы хотите получить документы, в которых “John” находится в поле first_name, а “Doe” — в поле last_name.
Запрос most_fields не работает в этом случае по следующим причинам:
- Параметры
operatorиminimum_should_matchприменяются на уровне полей, а не на уровне терминов. - Частоты терминов в полях
first_nameиlast_nameмогут привести к неожиданным результатам. Например, если чье-то имя — “Doe”, документ с этим именем будет считаться лучшим совпадением, поскольку это имя не появится в других документах.
Запрос cross_fields анализирует строку запроса на отдельные термины и затем ищет каждый из терминов в любом из полей, как если бы они были одним полем.
Пример запроса cross_fields для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Ответ содержит единственный документ, в котором присутствуют как “John”, так и “Doe”:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.8754687,
"hits": [
{
"_index": "customers",
"_id": "1",
"_score": 0.8754687,
"_source": {
"first_name": "John",
"last_name": "Doe"
}
}
]
}
}
Вы можете использовать операцию API валидации, чтобы получить представление о том, как выполняется предыдущий запрос:
GET /customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос ищет все термины хотя бы в одном поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "+blended(terms:[last_name:john, first_name:john]) +blended(terms:[last_name:doe, first_name:doe])"
}
]
}
Таким образом, смешивание частот терминов для всех полей решает проблему различия частот терминов, корректируя различия.
Запрос cross_fields обычно полезен только для коротких строковых полей с коэффициентом 1. В других случаях балл не дает значимого смешивания статистики терминов из-за того, как коэффициенты, частоты терминов и нормализация длины влияют на балл.
Параметр fuzziness не поддерживается для запросов cross_fields.
Анализ
Запрос cross_fields работает как термоцентричный запрос для полей с одинаковым анализатором. Поля с одинаковым анализатором группируются вместе, и эти группы комбинируются с помощью булевого запроса.
Например, рассмотрим индекс, в котором поля first_name и last_name анализируются с использованием стандартного анализатора, а их подполе .edge анализируется с помощью анализатора edge n-gram:
Пример
Вы индексируете один документ в индексе customers:
PUT /customers/_doc/1
{
"first": "John",
"last": "Doe"
}
Вы можете использовать запрос cross_fields для поиска по полям для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Чтобы увидеть, как выполняется запрос, вы можете использовать API валидации:
GET /customers/_validate/query?explain
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Ответ показывает, что поля last_name и first_name сгруппированы вместе и рассматриваются как одно поле. Аналогично, поля last_name.edge и first_name.edge также сгруппированы и рассматриваются как одно поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "(blended(terms:[last_name:john, first_name:john]) | (blended(terms:[last_name.edge:Jo, first_name.edge:Jo]) blended(terms:[last_name.edge:Joh, first_name.edge:Joh]) blended(terms:[last_name.edge:John, first_name.edge:John])))"
}
]
}
Использование параметров operator или minimum_should_match с несколькими группами полей, как описано выше, может привести к проблемам. Чтобы избежать этого, вы можете переписать предыдущий запрос как два подзапроса cross_fields, объединенных с помощью булевого запроса, и применить minimum_should_match к одному из подзапросов:
GET /customers/_search
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name",
"last_name"
],
"minimum_should_match": "1"
}
},
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name.edge",
"last_name.edge"
]
}
}
]
}
}
}
Чтобы создать одну группу для всех полей, укажите анализатор в вашем запросе:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"analyzer": "standard",
"fields": ["first_name", "last_name", "*.edge"]
}
}
}
Запуск API валидации для предыдущего запроса показывает, как выполняется запрос:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "blended(terms:[last_name.edge:john, last_name:john, first_name:john, first_name.edge:john]) blended(terms:[last_name.edge:doe, last_name:doe, first_name:doe, first_name.edge:doe])"
}
]
}
Фразовый запрос
Фразовый запрос ведет себя аналогично запросу best_fields, но использует запрос match_phrase вместо match.
Следующий пример демонстрирует фразовый запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern lights",
"type": "phrase",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase": { "title": "northern lights" }},
{ "match_phrase": { "description": "northern lights" }}
]
}
}
}
Поскольку по умолчанию фразовый запрос совпадает с текстом только тогда, когда термины появляются в одном и том же порядке, в результатах возвращается только документ 1:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Aurora borealis",
"description": "Northern lights, or aurora borealis, explained"
}
}
]
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса. Например, следующий запрос принимает текст как совпадение, если между словами “fluorescent” и “therapy” находится до двух слов:
GET articles/_search
{
"query": {
"multi_match": {
"query": "fluorescent therapy",
"type": "phrase",
"fields": ["title", "description"],
"slop": 2
}
}
}
Ответ
В этом случае ответ содержит документ 2:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.7003825,
"hits": [
{
"_index": "articles",
"_id": "2",
"_score": 0.7003825,
"_source": {
"title": "Sun deprivation in the Northern countries",
"description": "Using fluorescent lights for therapy"
}
}
]
}
}
Для значений slop, меньших чем 2, документы не возвращаются.
Параметр fuzziness не поддерживается для фразовых запросов.
Фразовый префиксный запрос
Фразовый префиксный запрос ведет себя аналогично фразовому запросу, но использует запрос match_phrase_prefix вместо match_phrase.
Следующий пример демонстрирует фразовый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern light",
"type": "phrase_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase_prefix": { "title": "northern light" }},
{ "match_phrase_prefix": { "description": "northern light" }}
]
}
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса.
Параметр fuzziness не поддерживается для фразовых префиксных запросов.
Булевый префиксный запрос
Булевый префиксный запрос оценивает документы аналогично запросу most_fields, но использует запрос match_bool_prefix вместо match.
Следующий пример демонстрирует булевый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "li northern",
"type": "bool_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_bool_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_bool_prefix": { "title": "li northern" }},
{ "match_bool_prefix": { "description": "li northern" }}
]
}
}
}
Параметры fuzziness, prefix_length, max_expansions, fuzzy_rewrite и fuzzy_transpositions поддерживаются для терминов, которые используются для построения термовых запросов, но они не оказывают влияния на префиксный запрос, построенный из конечного термина.
Параметры
Запрос принимает следующие параметры. Все параметры, кроме query, являются необязательными.
query (Строка): Строка запроса, используемая для поиска. Обязательный параметр.
auto_generate_synonyms_phrase_query (Булев): Указывает, следует ли автоматически создавать фразу запроса для многословных синонимов. Например, если вы укажете
ba, batting averageкак синонимы и выполните поиск поba, OpenSearch будет искатьbaИЛИ “batting average” (если этот параметр установлен в true) илиbaИЛИ (batting И average) (если этот параметр установлен в false). По умолчанию true.analyzer (Строка): Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля
default_fieldна этапе индексации. Если анализатор не указан дляdefault_field, используется стандартный анализатор для индекса.boost (Число с плавающей запятой): Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1.
fields (Массив строк): Список полей, в которых следует выполнять поиск. Если вы не укажете параметр
fields, запросmulti_matchбудет искать в полях, указанных в настройкеindex.query.default_field, которая по умолчанию равна *.fuzziness (Строка): Количество изменений символов (вставка, удаление, замена), необходимых для преобразования одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между
winedиwindравно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев.fuzzy_rewrite (Строка): Определяет, как OpenSearch переписывает запрос. Допустимые значения:
constant_score,scoring_boolean,constant_score_boolean,top_terms_N,top_terms_boost_Nиtop_terms_blended_freqs_N. Если параметрfuzzinessне равен 0, запрос использует метод переписыванияfuzzy_rewriteпо умолчаниюtop_terms_blended_freqs_${max_expansions}. По умолчаниюconstant_score.fuzzy_transpositions (Булев): Установка
fuzzy_transpositionsв true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметреfuzziness. Например, расстояние междуwindиwnidравно 1, еслиfuzzy_transpositionsравно true (перестановка “n” и “i”) и 2, если false (удаление “n”, вставка “n”). По умолчанию является хорошим выбором для большинства случаев.lenient (Булев): Установка
lenientв true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false.max_expansions (Положительное целое число): Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа соответствующих терминов, которые находятся в пределах указанного расстояния в параметре
fuzziness. По умолчанию 50.minimum_should_match (Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация): Если строка запроса содержит несколько поисковых терминов и вы используете оператор
or, количество терминов, которые должны соответствовать, чтобы документ считался совпадением. Например, еслиminimum_should_matchравно 2,wind often risingне соответствуетThe Wind Rises. Еслиminimum_should_matchравно 1, совпадает. Для подробностей см. Minimum should match.operator (Строка): Если строка запроса содержит несколько поисковых терминов, нужно ли, чтобы все термины соответствовали (AND) или только один термин должен соответствовать (OR), чтобы документ считался совпадением. Допустимые значения:
- OR: Строка интерпретируется как “или”.
- AND: Строка интерпретируется как “и”. По умолчанию используется OR.
prefix_length (Неотрицательное целое число): Количество начальных символов, которые не учитываются при вычислении
fuzziness. По умолчанию 0.slop (0 по умолчанию или положительное целое число): Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Из документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова друг на друга), поэтому для разрешения перестановок фраз значение slop должно быть не менее двух. Значение ноль требует точного совпадения.” Поддерживается для типов запросов
phraseиphrase_prefix.tie_breaker (Число с плавающей запятой): Фактор между 0 и 1.0, который используется для придания большего веса документам, соответствующим нескольким условиям запроса. Для получения дополнительной информации см. параметр
tie_breaker.type (Строка): Тип запроса
multi-match. Допустимые значения:best_fields,most_fields,cross_fields,phrase,phrase_prefix,bool_prefix. По умолчанию используетсяbest_fields.zero_terms_query (Строка): В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки, кроме “this”. В таких случаях
zero_terms_queryуказывает, следует ли не соответствовать ни одному документу (none) или всем документам (all). Допустимые значения:noneиall. По умолчанию используетсяnone.
Параметр fuzziness не поддерживается для запросов типов
phrase,phrase_prefixиcross_fields.
Параметр slop поддерживается только для запросов типов
phraseиphrase_prefix.
Параметр tie_breaker:
Каждый запрос на уровне терминов с объединением вычисляет оценку документа как наилучшую оценку, возвращенную любым полем в группе. Оценки от всех объединенных запросов складываются, чтобы получить окончательную оценку. Вы можете изменить способ вычисления оценки, используя параметр tie_breaker. Параметр tie_breaker принимает следующие значения:
0.0 (по умолчанию для запросов типов
best_fields,cross_fields,phraseиphrase_prefix): Берется единственная наилучшая оценка, возвращенная любым полем в группе.1.0 (по умолчанию для запросов типов
most_fieldsиbool_prefix): Складываются оценки для всех полей в группе.Число с плавающей запятой в диапазоне (0, 1): Берется единственная наилучшая оценка наилучшего соответствующего поля и добавляется (tie_breaker * _score) для всех других соответствующих полей.
8.3.4.6 - query-string
Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса.
Запрос типа query_string
Запрос типа query_string разбирает строку запроса на основе синтаксиса строки запроса. Он позволяет создавать мощные, но лаконичные запросы, которые могут включать подстановочные знаки и осуществлять поиск по нескольким полям.
Поиски с использованием запросов типа query_string не возвращают вложенные документы. Для поиска по вложенным полям используйте вложенный запрос.
Запрос типа query_string имеет строгий синтаксис и возвращает ошибку в случае недопустимого синтаксиса. Поэтому он не подходит для приложений с текстовыми полями поиска. Для менее строгой альтернативы рассмотрите использование запроса simple_query_string. Если вам не нужна поддержка синтаксиса запроса, используйте запрос match.
Синтаксис строки запроса
Синтаксис строки запроса основан на синтаксисе запросов Apache Lucene.
Вы можете использовать синтаксис строки запроса в следующих случаях:
В запросе типа
query_string, например:GET _search { "query": { "query_string": { "query": "the wind AND (rises OR rising)" } } }В приложениях OpenSearch Dashboards Discover или Dashboard, если вы отключите DQL, как показано на следующем изображении. Использование синтаксиса строки запроса в OpenSearch Dashboards Discover.
DQL и язык запросов
query_string(Lucene) являются двумя вариантами языка для строк поиска в Discover и Dashboards. Для сравнения этих языковых опций смотрите раздел о строках поиска Discover и Dashboard.
Если вы выполняете поиск с использованием параметров запроса HTTP, например:
GET _search?q=wind
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises термины — это wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова сопоставляются в порядке их появления (например, "wind rises"). Операторы (такие как OR, AND и NOT) определяют логическую связь, используемую для интерпретации текста в строке запроса.
Примеры в этом разделе используют индекс, содержащий следующую схему и документы:
PUT /testindex
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
PUT /testindex/_doc/1
{
"title": "The wind rises"
}
PUT /testindex/_doc/2
{
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
PUT /testindex/_doc/3
{
"title": "Windy city"
}
PUT /testindex/_doc/4
{
"article title": "Wind turbines"
}
Зарезервированные символы
Следующий список содержит зарезервированные символы для запроса типа query_string:
+, -, =, &&, ||, >, <, !, (, ), {, }, [, ], ^, ", ~, *, ?, :, \, /
Экранируйте зарезервированные символы с помощью обратной косой черты (). При отправке JSON-запроса используйте двойную обратную косую черту (\) для экранирования зарезервированных символов (поскольку символ обратной косой черты сам по себе является зарезервированным, вы должны экранировать его с помощью другой обратной косой черты).
Например, чтобы выполнить поиск по выражению 2*3, укажите строку запроса: 2\\*3:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: 2\\*3"
}
}
}
Знаки > и < не могут быть экранированы. Они интерпретируются как запрос диапазона.
Пробелы и пустые запросы
Символы пробела не считаются операторами. Если строка запроса пуста или содержит только символы пробела, запрос не возвращает результатов.
Имена полей
Укажите имя поля перед двоеточием. В следующей таблице приведены примеры запросов с именами полей.
| Запрос в запросе типа query_string | Запрос в Discover | Критерий для соответствия документа | Соответствующие документы из индекса testindex |
|---|---|---|---|
| title: wind | title: wind | Поле title содержит слово wind. | 1, 2 |
| title: (wind OR windy) | title: (wind OR windy) | Поле title содержит слово wind или слово windy. | 1, 2, 3 |
| title: "wind rises" | title: “wind rises” | Поле title содержит фразу wind rises. Экранируйте кавычки с помощью обратной косой черты. | 1 |
| article\ title: wind | article\ title: wind | Поле article title содержит слово wind. Экранируйте пробел с помощью обратной косой черты. | 4 |
| title.\*: rise | title.*: rise | Каждое поле, начинающееся с title. (в этом примере, title.english) содержит слово rise. Экранируйте символ подстановки с помощью обратной косой черты. | 1 |
| exists: description | exists: description | Поле description существует. | 2 |
Подстановочные выражения
Вы можете указывать подстановочные выражения, используя специальные символы: ? заменяет один символ, а * заменяет ноль или более символов.
Пример
Следующий запрос ищет заголовок, содержащий слово “gone”, и описание, которое содержит слово, начинающееся с “hist”:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: gone AND description: hist*"
}
}
}
Запросы с подстановочными знаками могут использовать значительное количество памяти, что может ухудшить производительность. Подстановочные знаки в начале слова (например, *cal) являются наиболее затратными, поскольку сопоставление документов с такими подстановочными знаками требует проверки всех терминов в индексе. Чтобы отключить ведущие подстановочные знаки, установите параметр allow_leading_wildcard в значение false.
Для повышения эффективности чистые подстановочные знаки, такие как *, переписываются как запросы на существование. Таким образом, запрос description: * будет соответствовать документам, содержащим пустое значение в поле описания, но не будет соответствовать документам, в которых поле описания отсутствует или имеет значение null.
Если вы установите analyze_wildcard в значение true, OpenSearch будет анализировать запросы, которые заканчиваются на * (например, hist*). В результате OpenSearch создаст логический запрос, состоящий из полученных токенов, принимая точные совпадения для первых n-1 токенов и префиксное совпадение для последнего токена.
Регулярные выражения
Чтобы указать шаблоны регулярных выражений в строке запроса, окружите их косыми чертами (/), например, title: /w[a-z]nd/.
Параметр allow_leading_wildcard не применяется к регулярным выражениям. Например, строка запроса, такая как /.*d/, будет проверять все термины в индексе.
Нечеткий поиск
Вы можете выполнять нечеткие запросы, используя оператор ~, например, title: rise~.
Запрос ищет документы, содержащие термины, похожие на искомый термин в пределах максимального допустимого расстояния редактирования. Расстояние редактирования определяется как расстояние Дамерау-Левенштейна, которое измеряет количество изменений одного символа (вставок, удалений, замен или перестановок), необходимых для преобразования одного термина в другой.
По умолчанию расстояние редактирования равно 2, что должно охватывать 80% опечаток. Чтобы изменить значение по умолчанию для расстояния редактирования, укажите новое расстояние редактирования после оператора ~. Например, чтобы установить расстояние редактирования равным 1, используйте запрос title: rise~1.
Не смешивайте нечеткие и подстановочные операторы. Если вы укажете как нечеткий, так и подстановочный операторы, один из операторов не будет применен. Например, если вы можете выполнить поиск по wnid*~1, подстановочный оператор * будет применен, но нечеткий оператор ~1 не будет применен.
Запросы на близость
Запрос на близость не требует, чтобы искомая фраза была в указанном порядке. Он позволяет словам в фразе находиться в другом порядке или разделяться другими словами. Запрос на близость указывает максимальное расстояние редактирования между словами в фразе. Например, следующий запрос позволяет расстояние редактирования равное 4 при сопоставлении слов в указанной фразе:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: \"wind gone\"~4"
}
}
}
Когда OpenSearch сопоставляет документы, чем ближе слова в документе к порядку слов, указанному в запросе (тем меньше расстояние редактирования), тем выше оценка релевантности документа.
Диапазоны
Чтобы указать диапазон для числового, строкового или датированного поля, используйте квадратные скобки ([min TO max]) для включающего диапазона и фигурные скобки ({min TO max}) для исключающего диапазона. Вы также можете комбинировать квадратные и фигурные скобки, чтобы включить или исключить нижнюю и верхнюю границы (например, {min TO max]).
Даты для диапазона дат должны быть предоставлены в формате, который вы использовали при сопоставлении поля, содержащего дату. Для получения дополнительной информации о поддерживаемых форматах дат смотрите раздел Форматы.
Следующая таблица предоставляет примеры синтаксиса диапазонов.
| Тип данных | Запрос | Строка запроса |
|---|---|---|
| Числовой | Документы, у которых номера счетов от 1 до 15, включительно. | account_number: [1 TO 15] или account_number: (>=1 AND <=15) или account_number: (+>=1 +<=15) |
| Документы, у которых номера счетов 15 и больше. | account_number: [15 TO *] или account_number: >=15 (обратите внимание, что после знака >= нет пробела) | |
| Строковой | Документы, где фамилия от Bates, включительно, до Duke, исключительно. | lastname: [Bates TO Duke} или lastname: (>=Bates AND <Duke) |
| Документы, где фамилия предшествует Bates в алфавитном порядке. | lastname: {* TO Bates} или lastname: <Bates (обратите внимание, что после знака < нет пробела) | |
| Дата | Документы, где дата выпуска между 21.03.2023 и 25.09.2023, включительно. | release_date: [03/21/2023 TO 09/25/2023] |
В качестве альтернативы указанию диапазона в строке запроса вы можете использовать запрос диапазона, который предоставляет более надежный синтаксис.
Увеличение релевантности
Используйте оператор увеличения (^) для увеличения оценки релевантности документов на заданный множитель. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию используется 1.
Следующая таблица предоставляет примеры увеличения релевантности.
| Тип | Описание | Строка запроса |
|---|---|---|
| Увеличение слова | Найти все адреса, содержащие слово street, и увеличить вес тех, которые содержат слово Madison. | address: Madison^2 street |
| Увеличение фразы | Найти документы с заголовком, содержащим фразу wind rises, увеличив вес на 2. | title: \"wind rises\"^2 |
| Найти документы с заголовком, содержащим слова wind rises, и увеличить вес документов, содержащих фразу wind rises, на 2. | title: (wind rises)^2 |
Логические операторы
Когда вы указываете поисковые термины в запросе, по умолчанию запрос возвращает документы, содержащие хотя бы один из указанных терминов. Вы можете использовать параметр default_operator, чтобы задать оператор для всех терминов. Таким образом, если вы установите default_operator в значение AND, все термины будут обязательными, в то время как если вы установите его в значение OR, все термины будут необязательными.
Операторы + и -
Если вы хотите более детально контролировать обязательные и необязательные термины, вы можете использовать операторы + и -. Оператор + делает следующий за ним термин обязательным, в то время как оператор - исключает следующий за ним термин.
Например, в строке запроса title: (gone +wind -turbines) указывается, что термин gone является необязательным, термин wind должен присутствовать, а термин turbines не должен присутствовать в заголовке соответствующих документов:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone +wind -turbines)"
}
}
}
Запрос возвращает два соответствующих документа:
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "wind"
}
},
"should": {
"match": {
"title": "gone"
}
},
"must_not": {
"match": {
"title": "turbines"
}
}
}
}
}
Обычные логические операторы
В качестве альтернативы вы можете использовать следующие логические операторы: AND, &&, OR, ||, NOT, !. Однако эти операторы не следуют правилам приоритета, поэтому вы должны использовать скобки, чтобы указать приоритет при использовании нескольких логических операторов. Например, строку запроса title: (gone +wind -turbines) можно переписать следующим образом, используя логические операторы:
title: ((gone AND wind) OR wind) AND NOT turbines
Запустите следующий запрос, содержащий переписанную строку запроса:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: ((gone AND wind) OR wind) AND NOT turbines"
}
}
}
Запрос возвращает те же результаты, что и запрос, использующий операторы + и -. Однако обратите внимание, что оценки релевантности соответствующих документов могут отличаться от предыдущих результатов:
{
"_index": "testindex",
"_id": "2",
"_score": 1.6166971,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Группировка
Группируйте несколько условий или терминов в подзапросы, используя скобки. Например, следующий запрос ищет документы, содержащие слова “gone” или “rises”, которые обязательно должны содержать слово “wind” в заголовке:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone OR rises) AND wind"
}
}
}
Результаты содержат два соответствующих документа:
{
"_index": "testindex",
"_id": "1",
"_score": 1.5046883,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
}
Вы также можете использовать группировку для увеличения веса результатов подзапросов или для указания конкретного поля, например: title:(gone AND wind) description:(historical film)^2.
Поиск по нескольким полям
Чтобы выполнить поиск по нескольким полям, используйте параметр fields. Когда вы указываете параметр fields, запрос переписывается в формате field_1: query OR field_2: query ....
Например, следующий запрос ищет термины “ветер” или “фильм” в полях заголовка и описания:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title", "description" ],
"query": "ветер AND фильм"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields:
GET testindex/_search
{
"query": {
"query_string": {
"query": "(title:ветер OR description:ветер) AND (title:фильм OR description:фильм)"
}
}
}
Поиск по нескольким подполям поля
Чтобы выполнить поиск по всем внутренним полям, вы можете использовать подстановочный знак. Например, чтобы искать по всем подполям в поле address, используйте следующий запрос:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields" : ["address.*"],
"query" : "Нью AND (Йорк OR Джерси)"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields (обратите внимание, что * экранируется с помощью \\):
GET /testindex/_search
{
"query": {
"query_string" : {
"query": "address.\\*: Нью AND (Йорк OR Джерси)"
}
}
}
Увеличение веса (Boosting)
Подзапросы, которые генерируются для каждого поискового термина, комбинируются с помощью запроса dis_max с параметром tie_breaker. Чтобы увеличить вес отдельных полей, используйте оператор ^. Например, следующий запрос увеличивает вес поля заголовка в 2 раза:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title^2", "description" ],
"query": "ветер AND фильм"
}
}
}
Чтобы увеличить вес всех подполей поля, укажите оператор увеличения после подстановочного знака:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields": ["work_address", "address.*^2"],
"query": "Нью AND (Йорк OR Джерси)"
}
}
}
Параметры для поиска по нескольким полям
При выполнении поиска по нескольким полям вы можете передать дополнительный необязательный параметр type в запрос query_string.
| Параметр | Тип данных | Описание |
|---|---|---|
| type | String | Определяет, как OpenSearch выполняет запрос и оценивает результаты. Допустимые значения: best_fields, bool_prefix, most_fields, cross_fields, phrase и phrase_prefix. Значение по умолчанию — best_fields. Для описания допустимых значений см. раздел о типах многоцелевых запросов. |
Описание допустимых значений для параметра type
- best_fields: Использует наилучшие поля для оценки результатов. Это значение по умолчанию.
- bool_prefix: Позволяет использовать префиксы для логических операторов, что позволяет более гибко формировать запросы.
- most_fields: Оценивает результаты, используя все поля, что может быть полезно для более широкого поиска.
- cross_fields: Объединяет все поля в один общий запрос, что позволяет искать по всем полям одновременно.
- phrase: Ищет точные фразы в указанных полях.
- phrase_prefix: Позволяет искать фразы с префиксами, что может быть полезно для автозаполнения.
Эти параметры позволяют более точно настраивать поведение поиска в OpenSearch в зависимости от ваших потребностей.
Синонимы в запросе query_string
Запрос query_string поддерживает расширение синонимов с несколькими терминами с помощью фильтра токенов synonym_graph. Если вы используете фильтр synonym_graph, OpenSearch создает запрос на совпадение фразы для каждого синонима.
Параметр auto_generate_synonyms_phrase_query указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. По умолчанию auto_generate_synonyms_phrase_query установлен в true, поэтому, если вы укажете “ml” и “machine learning” как синонимы и выполните поиск по “ml”, OpenSearch будет искать ml OR "machine learning".
В качестве альтернативы вы можете сопоставлять многословные синонимы, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в false, OpenSearch будет искать ml OR (machine AND learning).
Пример запроса с отключенной авто-генерацией фраз
Следующий запрос ищет текст “ml models” и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Минимальное количество совпадений
Запрос query_string разбивает запрос вокруг каждого оператора и создает булев запрос для всего ввода. Параметр minimum_should_match указывает минимальное количество терминов, которые документ должен соответствовать, чтобы быть возвращенным в результатах поиска. Например, следующий запрос указывает, что поле description должно соответствовать как минимум двум терминам для каждого результата поиска:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"description"
],
"query": "historical epic film",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (description:historical description:epic description:film)~2.
Эти функции позволяют более гибко настраивать поиск и управлять тем, как обрабатываются синонимы и минимальные условия для совпадений.
Минимальное количество совпадений с несколькими полями
Если вы указываете несколько полей в запросе query_string, OpenSearch создает запрос dis_max для указанных полей. Если вы не указываете оператор для терминов запроса, весь текст запроса рассматривается как одно условие. OpenSearch строит запрос для каждого поля, используя это одно условие. В конечном булевом запросе содержится одно условие, соответствующее запросу dis_max для всех полей, поэтому параметр minimum_should_match не применяется.
Пример без явных операторов
В следующем запросе “historical epic heroic” рассматривается как одно условие:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical title:epic title:heroic) | (description:historical description:epic description:heroic)).
Пример с явными операторами
Если вы добавите явные операторы (AND или OR) к терминам запроса, каждый термин будет рассматриваться как отдельное условие, к которому можно применить параметр minimum_should_match. Например, в следующем запросе “historical”, “epic” и “heroic” считаются отдельными условиями:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical OR epic OR heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Запрос соответствует как минимум двум из трех условий. Каждое условие представляет собой запрос dis_max по полям title и description для каждого термина.
Использование параметра type
В качестве альтернативы, чтобы гарантировать применение minimum_should_match, вы можете установить параметр type в значение cross_fields. Это указывает на то, что поля с одинаковым анализатором должны быть сгруппированы вместе при анализе входного текста:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"type": "cross_fields",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Однако, если вы используете разные анализаторы, вам необходимо использовать явные операторы в запросе, чтобы гарантировать применение параметра minimum_should_match к каждому термину.
Параметры запроса query_string
Следующая таблица перечисляет параметры, поддерживаемые запросом query_string. Все параметры, кроме query, являются необязательными.
| Параметр | Тип данных | Описание |
|---|---|---|
| query | String | Текст, который может содержать выражения в синтаксисе строки запроса для поиска. Обязательный параметр. |
| allow_leading_wildcard | Boolean | Указывает, разрешены ли символы * и ? в качестве первых символов поискового термина. По умолчанию true. |
| analyze_wildcard | Boolean | Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию false. |
| analyzer | String | Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Дополнительную информацию о index.query.default_field см. в разделе о динамических настройках уровня индекса. |
| auto_generate_synonyms_phrase_query | Boolean | Указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. Например, если вы укажете “ba” и “batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать ba OR "batting average" (если этот параметр установлен в true) или ba OR (batting AND average) (если установлен в false). По умолчанию true. |
| boost | Floating-point | Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| default_field | String | Поле, в котором следует выполнять поиск, если поле не указано в строке запроса. Поддерживает подстановочные знаки. По умолчанию используется значение, указанное в настройках индекса index.query.default_field. По умолчанию index.query.default_field равно *, что означает извлечение всех полей, подходящих для термового запроса, и фильтрацию метаданных. Извлеченные поля объединяются в запрос, если префикс не указан. Подходящие поля не включают вложенные документы. Поиск по всем подходящим полям может быть ресурсоемкой операцией. Настройка indices.query.bool.max_clause_count определяет максимальное значение для произведения количества полей и количества терминов, которые могут быть запрошены одновременно. Значение по умолчанию для indices.query.bool.max_clause_count равно 1,024. |
| default_operator | String | Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины соответствовали (AND) или достаточно, чтобы соответствовал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения: - OR: строка интерпретируется как “или” - AND: строка интерпретируется как “и”. По умолчанию OR. |
| enable_position_increments | Boolean | Когда установлено в true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fields | String array | Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется значение, указанное в настройках индекса index.query.default_field, которое по умолчанию равно ["*"]. |
| fuzziness | String | Количество изменений символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, что является хорошим выбором для большинства случаев. |
| fuzzy_max_expansions | Positive integer | Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| fuzzy_transpositions | Boolean | Установка fuzzy_transpositions в true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false. По умолчанию — хороший выбор для большинства случаев. |
| lenient | Boolean | Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_determinized_states | Positive integer | Максимальное количество “состояний” (меры сложности), которые Lucene может создать для строк запросов, содержащих регулярные выражения (например, "query": "/wind.+?/"). Более крупные числа позволяют выполнять запросы, использующие больше памяти. По умолчанию 10,000. |
| minimum_should_match | Positive or negative integer, positive or negative percentage, combination | Если строка запроса содержит несколько поисковых терминов и вы используете оператор OR, количество терминов, которые должны соответствовать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не соответствует “The Wind Rises”. Если minimum_should_match равно 1, он соответствует. |
| phrase_slop | Integer | Максимальное количество слов, которые могут находиться между совпадающими словами. Если phrase_slop равно 2, максимальное количество двух слов разрешено между совпадающими словами в фразе. Переставленные слова имеют слоп 2. По умолчанию 0 (точное совпадение фразы, где совпадающие слова должны находиться рядом друг с другом). |
| quote_analyzer | String | Анализатор, используемый для токенизации текста в кавычках в строке запроса. Переопределяет параметр analyzer для текста в кавычках. По умолчанию используется search_quote_analyzer, указанный для default_field. |
| quote_field_suffix | String | Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неточных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово “lightly” в поле title.exact. Это второе поле может использовать другой тип (например, keyword вместо text) или другой анализатор. |
| rewrite | String | Определяет, как OpenSearch переписывает и оценивает многословные запросы. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. По умолчанию используется constant_score. |
| time_zone | String | Указывает количество часов для смещения желаемого часового пояса от UTC. Необходимо указать номер смещения часового пояса, если строка запроса содержит диапазон дат. Например, установите time_zone": "-08:00" для запроса с диапазоном дат, таким как "query": "wind rises release_date[2012-01-01 TO 2014-01-01]". Формат часового пояса по умолчанию для указания количества смещения часов — UTC. |
Дополнительные сведения
Запросы строки запроса могут быть внутренне преобразованы в префиксные запросы. Если параметр search.allow_expensive_queries установлен в false, префиксные запросы не выполняются. Если index_prefixes включен, настройка search.allow_expensive_queries игнорируется, и создается и выполняется оптимизированный запрос.
8.3.4.7 - simple-query-string
Более простая, менее строгая версия запроса query_string.
Простой запрос с использованием simple_query_string
Используйте тип simple_query_string, чтобы указать несколько аргументов, разделенных регулярными выражениями, непосредственно в строке запроса. Простой запрос имеет менее строгий синтаксис, чем обычный запрос, поскольку отбрасывает любые недопустимые части строки и не возвращает ошибки за недопустимый синтаксис.
Этот запрос выполняет нечеткий поиск по полю title:
GET _search
{
"query": {
"simple_query_string": {
"query": "\"rises wind the\"~4 | *ising~2",
"fields": ["title"]
}
}
}
Синтаксис простого запроса
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises терминами являются wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова совпадают в порядке их появления (например, "wind rises"). Операторы, такие как +, | и -, определяют логическую связь, используемую для интерпретации текста в строке запроса.
Операторы
Синтаксис простого запроса поддерживает следующие операторы:
| Оператор | Описание |
|---|---|
+ | Действует как оператор AND. |
| ` | ` |
* | Когда используется в конце термина, обозначает префиксный запрос. |
" | Обрамляет несколько терминов в фразу (например, "wind rises"). |
(, ) | Обрамляет клаузу для приоритета (например, `wind + (rises |
~n | Когда используется после термина (например, wind~3), устанавливает нечеткость. Когда используется после фразы, устанавливает слоп. |
- | Отрицает термин. |
Все вышеперечисленные операторы являются зарезервированными символами. Чтобы ссылаться на них как на обычные символы, необходимо экранировать их с помощью обратной косой черты. При отправке JSON-запроса используйте \\, чтобы экранировать зарезервированные символы (поскольку символ обратной косой черты сам по себе является зарезервированным, его необходимо экранировать еще одной обратной косой чертой).
Оператор по умолчанию
Оператор по умолчанию — OR (если вы не установите default_operator в AND). Оператор по умолчанию определяет общее поведение запроса. Например, рассмотрим индекс, содержащий следующие документы:
PUT /customers/_doc/1
{
"first_name":"Amber",
"last_name":"Duke",
"address":"880 Holmes Lane"
}
PUT /customers/_doc/2
{
"first_name":"Hattie",
"last_name":"Bond",
"address":"671 Bristol Street"
}
PUT /customers/_doc/3
{
"first_name":"Nanette",
"last_name":"Bates",
"address":"789 Madison St"
}
PUT /customers/_doc/4
{
"first_name":"Dale",
"last_name":"Amber",
"address":"467 Hutchinson Court"
}
Следующий запрос пытается найти документы, в которых адрес содержит слова street или st и не содержит слово madison:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st -madison"
}
}
}
Однако результаты включают не только ожидаемый документ, но и все четыре документа:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
},
{
"_index": "customers",
"_id": "3",
"_score": 1.2039728,
"_source": {
"first_name": "Nanette",
"last_name": "Bates",
"address": "789 Madison St"
}
},
{
"_index": "customers",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "Amber",
"last_name": "Duke",
"address": "880 Holmes Lane"
}
},
{
"_index": "customers",
"_id": "4",
"_score": 1,
"_source": {
"first_name": "Dale",
"last_name": "Amber",
"address": "467 Hutchinson Court"
}
}
]
}
}
Поскольку оператор по умолчанию — OR, этот запрос включает документы, которые содержат слова street или st (документы 2 и 3), а также документы, которые не содержат слово madison (документы 1 и 4).
Чтобы правильно выразить намерение запроса, предшествуйте -madison знаком +:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st +-madison"
}
}
}
Альтернативный подход
Или укажите AND в качестве оператора по умолчанию и используйте дизъюнкцию для слов street и st:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "st|street -madison",
"default_operator": "AND"
}
}
}
Предыдущий запрос возвращает документ 2:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
}
]
}
}
Таким образом, использование правильного оператора и синтаксиса позволяет точно формулировать запросы и получать ожидаемые результаты.
Ограничение операторов
Чтобы ограничить поддерживаемые операторы для парсера простого запроса, включите операторы, которые вы хотите поддерживать, разделенные символом |, в параметр flags. Например, следующий запрос включает только операторы OR, AND и FUZZY:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "bristol | madison +stre~2",
"flags": "OR|AND|FUZZY"
}
}
}
Доступные флаги операторов
Следующая таблица перечисляет все доступные флаги операторов:
| Флаг | Описание |
|---|---|
ALL (по умолчанию) | Включает все операторы. |
AND | Включает оператор + (AND). |
ESCAPE | Включает \ как символ экранирования. |
FUZZY | Включает оператор ~n после слова, где n — целое число, обозначающее допустимое расстояние редактирования для совпадения. |
NEAR | Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и SLOP. |
NONE | Отключает все операторы. |
NOT | Включает оператор - (NOT). |
OR | Включает оператор ` |
PHRASE | Включает кавычки " для поиска фраз. |
PRECEDENCE | Включает операторы ( и ) (скобки) для приоритета операторов. |
PREFIX | Включает оператор * (префикс). |
SLOP | Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и NEAR. |
WHITESPACE | Включает пробелы как символы, по которым текст разбивается. |
Эти флаги позволяют гибко настраивать поведение парсера простого запроса в зависимости от ваших потребностей.
Шаблоны с подстановочными знаками
Вы можете указывать шаблоны с подстановочными знаками, используя специальный символ *, который заменяет ноль или более символов. Например, следующий запрос ищет во всех полях, которые заканчиваются на name:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber Bond",
"fields": [ "*name" ]
}
}
}
Увеличение значимости
Используйте оператор увеличения значимости (^) для увеличения оценки релевантности поля с помощью множителя. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. Значение по умолчанию — 1.
Например, следующий запрос ищет в полях first_name и last_name и увеличивает значимость совпадений из поля first_name в 2 раза:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber",
"fields": [ "first_name^2", "last_name" ]
}
}
}
Мультипозиционные токены
Для мультипозиционных токенов простой запрос создает запрос на совпадение фразы. Таким образом, если вы укажете ml, machine learning как синонимы и выполните поиск по ml, OpenSearch будет искать ml ИЛИ "machine learning".
В качестве альтернативы вы можете сопоставить мультипозиционные токены, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в значение false, OpenSearch будет искать ml ИЛИ (machine И learning).
Например, следующий запрос ищет текст ml models и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"simple_query_string": {
"fields": ["title"],
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Параметры
Следующая таблица перечисляет параметры верхнего уровня, которые поддерживает запрос simple_query_string. Все параметры, кроме query, являются необязательными.
| Параметр | Тип данных | Описание |
|---|---|---|
query | Строка | Текст, который может содержать выражения в синтаксисе простого запроса для использования в поиске. Обязательный параметр. |
analyze_wildcard | Логический | Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию — false. |
analyzer | Строка | Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
auto_generate_synonyms_phrase_query | Логический | Указывает, следует ли автоматически создавать запросы на совпадение фразы для многословных синонимов. По умолчанию — true. |
default_operator | Строка | Если строка запроса содержит несколько поисковых терминов, указывает, должны ли совпадать все термины (AND) или только один термин (OR) для того, чтобы документ считался совпадением. Допустимые значения: - OR: строка интерпретируется как OR- AND: строка интерпретируется как ANDПо умолчанию — OR. |
fields | Массив строк | Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется настройка index.query.default_field, которая по умолчанию равна ["*"]. Максимальное количество полей, которые могут быть одновременно исследованы, определяется параметром indices.query.bool.max_clause_count, который по умолчанию равен 1,024. |
flags | Строка | Строка, разделенная символом ` |
fuzzy_max_expansions | Положительное целое число | Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах указанного расстояния нечеткости. Затем OpenSearch пытается сопоставить эти термины. По умолчанию — 50. |
fuzzy_transpositions | Логический | Установка fuzzy_transpositions в значение true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в опции нечеткости. Например, расстояние между wind и wnid равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, rewind и wnid имеют одинаковое расстояние (2) от wind, несмотря на более человеческое мнение, что wnid является очевидной опечаткой. Значение по умолчанию является хорошим выбором для большинства случаев использования. |
fuzzy_prefix_length | Целое число | Количество начальных символов, которые остаются неизменными для нечеткого сопоставления. По умолчанию — 0. |
lenient | Логический | Установка lenient в значение true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию — false. |
minimum_should_match | Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация | Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадением. Например, если minimum_should_match равно 2, wind often rising не совпадает с The Wind Rises. Если minimum_should_match равно 1, совпадение происходит. Для получения подробной информации смотрите раздел “Минимальное количество совпадений”. |
quote_field_suffix | Строка | Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неполных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово lightly в поле title.exact. Это второе поле может использовать другой тип (например, keyword, а не text) или другой анализатор. |
8.3.4.8 - intervals query
Позволяет точно контролировать близость и порядок совпадающих терминов.
Запрос интервалов
Запрос интервалов сопоставляет документы на основе близости и порядка совпадающих терминов. Он применяет набор правил сопоставления к терминам, содержащимся в указанном поле. Запрос генерирует последовательности минимальных интервалов, охватывающих термины в тексте. Вы можете комбинировать интервалы и фильтровать их по родительским источникам.
Рассмотрим индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "пары ключ-значение эффективно хранятся в хэш-таблице"
}
PUT /testindex/_doc/2
{
"title": "хранить пары ключ-значение в хэш-карте"
}
Например, следующий запрос ищет документы, содержащие фразу “пары ключ-значение” (без промежутков между терминами), за которой следует либо “хэш-таблица”, либо “хэш-карта”:
GET /testindex/_search
{
"query": {
"intervals": {
"title": {
"all_of": {
"ordered": true,
"intervals": [
{
"match": {
"query": "пары ключ-значение",
"max_gaps": 0,
"ordered": true
}
},
{
"any_of": {
"intervals": [
{
"match": {
"query": "хэш-таблица"
}
},
{
"match": {
"query": "хэш-карта"
}
}
]
}
}
]
}
}
}
}
}
Запрос возвращает оба документа.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"intervals": {
"<field>": {
...
}
}
}
}
Поле <field> принимает следующие объекты правил, которые используются для сопоставления документов на основе терминов, порядка и близости.
| Правило | Описание |
|---|---|
| match | Сопоставляет анализируемый текст. |
| prefix | Сопоставляет термины, которые начинаются с заданного набора символов. |
| wildcard | Сопоставляет термины, используя шаблон с подстановочными знаками. |
| fuzzy | Сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. |
| all_of | Объединяет несколько правил с использованием конъюнкции (AND). |
| any_of | Объединяет несколько правил с использованием дизъюнкции (OR). |
Правило match
Правило match сопоставляет анализируемый текст. В следующей таблице перечислены все параметры, которые поддерживает правило match.
| Параметр | Обязательный/Необязательный | Тип данных | Описание |
|---|---|---|---|
| query | Обязательный | Строка | Текст, по которому нужно выполнить поиск. |
| analyzer | Необязательный | Строка | Анализатор, используемый для анализа текста запроса. По умолчанию используется анализатор, указанный для <field>. |
| filter | Необязательный | Объект правила фильтра интервалов | Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps | Необязательный | Целое число | Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered | Необязательный | Логическое | Указывает, должны ли совпадающие термины появляться в указанном порядке. По умолчанию false. |
| use_field | Необязательный | Строка | Указывает, что следует искать в этом поле вместо верхнего уровня. Термины анализируются с использованием анализатора поиска, указанного для этого поля. Указав use_field, вы можете искать по нескольким полям, как если бы они были одним и тем же полем. Например, если вы индексируете один и тот же текст в полях с корнями и без корней, вы можете искать корневые токены, которые находятся рядом с некорневыми. |
Правило prefix
Правило prefix сопоставляет термины, которые начинаются с заданного набора символов (префикс). Префикс может расширяться для сопоставления максимум 128 терминов. Если префикс соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило prefix.
| Параметр | Обязательный/Необязательный | Тип данных | Описание |
|---|---|---|---|
| prefix | Обязательный | Строка | Префикс, используемый для сопоставления терминов. |
| analyzer | Необязательный | Строка | Анализатор, используемый для нормализации префикса. По умолчанию используется анализатор, указанный для <field>. |
| use_field | Необязательный | Строка | Указывает, что следует искать в этом поле вместо верхнего уровня. Префикс нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило wildcard
Правило wildcard сопоставляет термины, используя шаблон с подстановочными знаками. Шаблон с подстановочными знаками может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило wildcard.
| Параметр | Обязательный/Необязательный | Тип данных | Описание |
|---|---|---|---|
| pattern | Обязательный | Строка | Шаблон с подстановочными знаками, используемый для сопоставления терминов. Укажите ? для сопоставления любого одного символа или * для сопоставления нуля или более символов. |
| analyzer | Необязательный | Строка | Анализатор, используемый для нормализации шаблона. По умолчанию используется анализатор, указанный для <field>. |
| use_field | Необязательный | Строка | Указывает, что следует искать в этом поле вместо верхнего уровня. Шаблон нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Указание шаблонов, начинающихся с * или ?, может ухудшить производительность поиска, так как увеличивает количество итераций, необходимых для сопоставления терминов.
Правило fuzzy
Правило fuzzy сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. Шаблон fuzzy может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило fuzzy.
| Параметр | Обязательный/Необязательный | Тип данных | Описание |
|---|---|---|---|
| term | Обязательный | Строка | Термин для сопоставления. |
| analyzer | Необязательный | Строка | Анализатор, используемый для нормализации термина. По умолчанию используется анализатор, указанный для <field>. |
| fuzziness | Необязательный | Строка | Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова на другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение на основе длины каждого термина и является хорошим выбором для большинства случаев использования. |
| transpositions | Необязательный | Логическое | Установка transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если transpositions равно true (обмен “n” и “i”), и 2, если false (удаление “n”, вставка “n”). Если transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” является очевидной опечаткой. По умолчанию является хорошим выбором для большинства случаев использования. |
| prefix_length | Необязательный | Целое число | Количество начальных символов, оставляемых неизменными для нечеткого сопоставления. По умолчанию 0. |
| use_field | Необязательный | Строка | Указывает, что следует искать в этом поле вместо верхнего уровня. Термин нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило all_of
Правило all_of объединяет несколько правил с использованием конъюнкции (AND). В следующей таблице перечислены все параметры, которые поддерживает правило all_of.
| Параметр | Обязательный/Необязательный | Тип данных | Описание |
|---|---|---|---|
| intervals | Обязательный | Массив объектов правил | Массив правил для объединения. Документ должен соответствовать всем правилам, чтобы быть возвращенным в результатах. |
| filter | Необязательный | Объект правила фильтра интервалов | Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps | Необязательный | Целое число | Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered | Необязательный | Логическое | Если true, интервалы, сгенерированные правилами, должны появляться в указанном порядке. По умолчанию false. |
Правило any_of
Правило any_of объединяет несколько правил с использованием дизъюнкции (OR). В следующей таблице перечислены все параметры, которые поддерживает правило any_of.
| Параметр | Обязательный/Необязательный | Тип данных | Описание |
|---|---|---|---|
| intervals | Обязательный | Массив объектов правил | Массив правил для объединения. Документ должен соответствовать хотя бы одному правилу, чтобы быть возвращенным в результатах. |
| filter | Необязательный | Объект правила фильтра интервалов | Правило, используемое для фильтрации возвращаемых интервалов. |
Правило filter
Правило filter используется для ограничения результатов. В следующей таблице перечислены все параметры, которые поддерживает правило filter.
| Параметр | Обязательный/Необязательный | Тип данных | Описание |
|---|---|---|---|
| after | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, которые следуют за интервалом, указанным в правиле фильтра. |
| before | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, которые находятся перед интервалом, указанным в правиле фильтра. |
| contained_by | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, содержащихся в интервале, указанном в правиле фильтра. |
| containing | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, которые содержат интервал, указанный в правиле фильтра. |
| not_contained_by | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, которые не содержатся в интервале, указанном в правиле фильтра. |
| not_containing | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, которые не содержат интервал, указанный в правиле фильтра. |
| not_overlapping | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, которые не перекрываются с интервалом, указанным в правиле фильтра. |
| overlapping | Необязательный | Объект запроса | Запрос, используемый для возврата интервалов, которые перекрываются с интервалом, указанным в правиле фильтра. |
| script | Необязательный | Объект скрипта | Скрипт, используемый для сопоставления документов. Этот скрипт должен возвращать true или false. |
Пример: Фильтры
Следующий запрос ищет документы, содержащие слова “пары” и “хэш”, которые находятся в пределах пяти позиций друг от друга и не содержат слово “эффективно” между ними:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "пары хэш",
"max_gaps" : 5,
"filter" : {
"not_containing" : {
"match" : {
"query" : "эффективно"
}
}
}
}
}
}
}
}
Ответ содержит только документ 2.
Ответ
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.25,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.25,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Пример: Скриптовые фильтры
В качестве альтернативы вы можете написать свой собственный скриптовый фильтр для включения в запрос интервалов, используя следующие переменные:
interval.start: Позиция (номер термина), где начинается интервал.interval.end: Позиция (номер термина), где заканчивается интервал.interval.gap: Количество слов между терминами.
Например, следующий запрос ищет слова “карта” и “хэш”, которые находятся рядом друг с другом в указанном интервале. Термины нумеруются, начиная с 0, поэтому в тексте “хранить пары ключ-значение в хэш-карте” слово “хранить” находится на позиции 0, “пары” на позиции 1 и так далее. Указанный интервал должен начинаться после “а” и заканчиваться перед концом строки:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "карта хэш",
"filter" : {
"script" : {
"source" : "interval.start > 5 && interval.end < 8 && interval.gaps == 0"
}
}
}
}
}
}
}
Ответ
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.5,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.5,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Минимизация интервалов
Чтобы гарантировать, что запросы выполняются за линейное время, запрос интервалов минимизирует интервалы. Например, рассмотрим документ, содержащий текст “a b c d c”. Вы можете использовать следующий запрос для поиска “d”, который содержится между “a” и “c”:
POST /testindex/_search
{
"query": {
"intervals" : {
"my_text" : {
"match" : {
"query" : "d",
"filter" : {
"contained_by" : {
"match" : {
"query" : "a c"
}
}
}
}
}
}
}
}
Запрос не возвращает результатов, потому что он сопоставляет первые два термина “a” и “c” и не находит “d” между этими терминами.
8.3.5 - compound queries
Объединяют несколько запросов. Модифицируют поведение дочерних запросов. Управляют логикой выполнения
Составные запросы
Составные запросы служат обертками для нескольких листовых или составных клауз, чтобы либо объединить их результаты, либо изменить их поведение.
В следующей таблице перечислены все типы составных запросов.
| Тип запроса | Описание |
|---|---|
| bool (логический) | Объединяет несколько клауз запросов с помощью логики AND/OR. |
| boosting | Изменяет релевантность документов, не удаляя их из результатов поиска. Возвращает документы, которые соответствуют положительному запросу, но понижает релевантность документов в результатах, которые соответствуют отрицательному запросу. |
| constant_score | Оборачивает запрос или фильтр и присваивает постоянный балл всем совпадающим документам. Этот балл равен значению boost. |
| dis_max (максимум дизъюнкции) | Возвращает документы, которые соответствуют одному или нескольким клаузам запроса. Если документ соответствует нескольким клаузам запроса, ему присваивается более высокий балл релевантности. Балл релевантности рассчитывается с использованием наивысшего балла из любых совпадающих клауз и, при необходимости, баллов из других совпадающих клауз, умноженных на значение tiebreaker. |
| function_score | Пересчитывает балл релевантности документов, которые возвращаются запросом, с использованием функции, которую вы определяете. |
| hybrid | Объединяет баллы релевантности из нескольких запросов в один балл для данного документа. |
8.3.5.1 - boolean query
Объединяет несколько клауз запросов с помощью логики AND/OR.
Булевый запрос
Булевый (bool) запрос может комбинировать несколько клауз в один расширенный запрос. Клаузи объединяются с помощью булевой логики для поиска соответствующих документов, возвращаемых в результатах.
Используйте следующие клаузи в булевом запросе:
| Клауз | Поведение |
|---|---|
| must | Логический оператор “и”. Результаты должны соответствовать всем запросам в этой клаузе. |
| must_not | Логический оператор “не”. Все совпадения исключаются из результатов. Если must_not содержит несколько клауз, возвращаются только документы, которые не соответствуют ни одной из этих клауз. Например, “must_not”:[{clause_A}, {clause_B}] эквивалентно NOT(A OR B). |
| should | Логический оператор “или”. Результаты должны соответствовать хотя бы одному из запросов. Чем больше клауз should совпадает, тем выше оценка релевантности документа. Вы можете установить минимальное количество запросов, которые должны совпадать, с помощью параметра minimum_should_match. Если запрос содержит клаузу must или filter, значение по умолчанию для minimum_should_match равно 0. В противном случае значение по умолчанию равно 1. |
| filter | Логический оператор “и”, который применяется в первую очередь для уменьшения вашего набора данных перед применением запросов. Запрос внутри клаузи filter является бинарным: да или нет. Если документ соответствует запросу, он возвращается в результатах; в противном случае он не возвращается. Результаты фильтрующего запроса обычно кэшируются для более быстрого возврата. Используйте фильтрующий запрос для фильтрации результатов на основе точных совпадений, диапазонов, дат или чисел. |
Булевый запрос имеет следующую структуру:
GET _search
{
"query": {
"bool": {
"must": [
{}
],
"must_not": [
{}
],
"should": [
{}
],
"filter": {}
}
}
}
Например, предположим, что у вас есть полные произведения Шекспира, индексированные в кластере OpenSearch. Вы хотите построить один запрос, который соответствует следующим требованиям:
- Поле text_entry должно содержать слово “love” и должно содержать либо “life”, либо “grace”.
- Поле speaker не должно содержать “ROMEO”.
- Отфильтровать эти результаты по пьесе “Ромео и Джульетта”, не влияя на оценку релевантности.
Эти требования могут быть объединены в следующий запрос:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": "love"
}
}
],
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": "ROMEO"
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 4,
"successful": 4,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.356054,
"hits": [
{
"_index": "shakespeare",
"_id": "88020",
"_score": 11.356054,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Если вы хотите определить, какие из этих клауз фактически вызвали совпадение результатов, назовите каждый запрос с помощью параметра _name. Чтобы добавить параметр _name, измените имя поля в запросе сопоставления на объект:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": {
"query": "love",
"_name": "love-must"
}
}
}
],
"should": [
{
"match": {
"text_entry": {
"query": "life",
"_name": "life-should"
}
}
},
{
"match": {
"text_entry": {
"query": "grace",
"_name": "grace-should"
}
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": {
"query": "ROMEO",
"_name": "ROMEO-must-not"
}
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
OpenSearch возвращает массив matched_queries, который перечисляет запросы, соответствующие этим результатам:
"matched_queries": [
"love-must",
"life-should"
]
Если вы удалите запросы, не входящие в этот список, вы все равно увидите точно такой же результат. Изучая, какая клаузa should совпала, вы можете лучше понять оценку релевантности результатов.
Вы также можете строить сложные булевы выражения, вложив булевы запросы. Например, используйте следующий запрос, чтобы найти поле text_entry, которое соответствует (love ИЛИ hate) И (life ИЛИ grace) в пьесе “Ромео и Джульетта”:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"text_entry": "love"
}
},
{
"match": {
"text_entry": "hate"
}
}
]
}
},
{
"bool": {
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
]
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.37006,
"hits": [
{
"_index": "shakespeare",
"_type": "doc",
"_id": "88020",
"_score": 11.37006,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Таким образом, вы можете использовать вложенные булевы запросы для создания более сложных логических выражений, что позволяет более точно настраивать поиск и получать релевантные результаты в OpenSearch.
8.3.5.2 - boosting query
Изменяет релевантность документов, не удаляя их из результатов поиска. Возвращает документы, которые соответствуют положительному запросу, но понижает релевантность документов в результатах, которые соответствуют отрицательному запросу.
Запрос с бустингом
Если вы ищете слово “pitcher” (питчер), ваши результаты могут относиться как к бейсбольным игрокам, так и к контейнерам для жидкостей. Для поиска в контексте бейсбола вы можете полностью исключить результаты, содержащие слова “glass” (стекло) или “water” (вода), используя клаузу must_not. Однако, если вы хотите сохранить эти результаты, но понизить их релевантность, вы можете сделать это с помощью запросов с бустингом.
Запрос с бустингом возвращает документы, которые соответствуют положительному запросу. Среди этих документов те, которые также соответствуют отрицательному запросу, получают более низкую оценку релевантности (их оценка релевантности умножается на отрицательный коэффициент бустинга).
Пример
Рассмотрим индекс с двумя документами, которые вы индексируете следующим образом:
PUT testindex/_doc/1
{
"article_name": "The greatest pitcher in baseball history"
}
PUT testindex/_doc/2
{
"article_name": "The making of a glass pitcher"
}
Используйте следующий запрос match, чтобы искать документы, содержащие слово “pitcher”:
GET testindex/_search
{
"query": {
"match": {
"article_name": "pitcher"
}
}
}
Оба возвращенных документа имеют одинаковую оценку релевантности:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.18232156,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Теперь используйте следующий запрос с бустингом, чтобы искать документы, содержащие слово “pitcher”, но понизить оценку документов, содержащих слова “glass”, “crystal” или “water”:
GET testindex/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"article_name": "pitcher"
}
},
"negative": {
"match": {
"article_name": "glass crystal water"
}
},
"negative_boost": 0.1
}
}
}
Оба документа все еще возвращаются, но документ со словом “glass” имеет оценку релевантности, которая в 10 раз ниже, чем в предыдущем случае:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.018232157,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами с бустингом.
| Параметр | Описание |
|---|---|
| positive | Запрос, которому документ должен соответствовать, чтобы быть возвращенным в результатах. Обязательный параметр. |
| negative | Если документ в результатах соответствует этому запросу, его оценка релевантности уменьшается путем умножения его исходной оценки релевантности (полученной от положительного запроса) на параметр negative_boost. Обязательный параметр. |
| negative_boost | Плавающий коэффициент в диапазоне от 0 до 1.0, на который умножается исходная оценка релевантности для уменьшения релевантности документов, соответствующих отрицательному запросу. Обязательный параметр. |
8.3.5.3 - constant_score
Оборачивает запрос или фильтр и присваивает постоянный балл всем совпадающим документам. Этот балл равен значению boost.
Запрос constant_score
Если вам нужно вернуть документы, содержащие определенное слово, независимо от того, сколько раз это слово встречается, вы можете использовать запрос constant_score. Запрос constant_score оборачивает фильтрующий запрос и присваивает всем документам в результатах релевантный балл, равный значению параметра boost. Таким образом, все возвращенные документы имеют равный релевантный балл, и частота термина/обратная документная частота (TF/IDF) не учитываются. Фильтрующие запросы не вычисляют релевантные баллы. Кроме того, OpenSearch кэширует часто используемые фильтрующие запросы для повышения производительности.
Пример
Используйте следующий запрос, чтобы вернуть документы, содержащие слово “Hamlet” в индексе shakespeare:
GET shakespeare/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"text_entry": "Hamlet"
}
},
"boost": 1.2
}
}
}
Все документы в результатах получают релевантный балл 1.2.
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 96,
"relation": "eq"
},
"max_score": 1.2,
"hits": [
{
"_index": "shakespeare",
"_id": "32535",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32536,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.97",
"speaker": "HORATIO",
"text_entry": "Dared to the combat; in which our valiant Hamlet--"
}
},
{
"_index": "shakespeare",
"_id": "32546",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32547,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.108",
"speaker": "HORATIO",
"text_entry": "His fell to Hamlet. Now, sir, young Fortinbras,"
}
},
{
"_index": "shakespeare",
"_id": "32625",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32626,
"play_name": "Hamlet",
"speech_number": 59,
"line_number": "1.1.184",
"speaker": "HORATIO",
"text_entry": "Unto young Hamlet; for, upon my life,"
}
},
{
"_index": "shakespeare",
"_id": "32633",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32634,
"play_name": "Hamlet",
"speech_number": 60,
"line_number": "",
"speaker": "MARCELLUS",
"text_entry": "Enter KING CLAUDIUS, QUEEN GERTRUDE, HAMLET, POLONIUS, LAERTES, VOLTIMAND, CORNELIUS, Lords, and Attendants"
}
},
{
"_index": "shakespeare",
"_id": "32634",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32635,
"play_name": "Hamlet",
"speech_number": 1,
"line_number": "1.2.1",
"speaker": "KING CLAUDIUS",
"text_entry": "Though yet of Hamlet our dear brothers death"
}
},
{
"_index": "shakespeare",
"_id": "32699",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32700,
"play_name": "Hamlet",
"speech_number": 8,
"line_number": "1.2.65",
"speaker": "KING CLAUDIUS",
"text_entry": "But now, my cousin Hamlet, and my son,--"
}
},
{
"_index": "shakespeare",
"_id": "32703",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32704,
"play_name": "Hamlet",
"speech_number": 12,
"line_number": "1.2.69",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Good Hamlet, cast thy nighted colour off,"
}
},
{
"_index": "shakespeare",
"_id": "32723",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32724,
"play_name": "Hamlet",
"speech_number": 16,
"line_number": "1.2.89",
"speaker": "KING CLAUDIUS",
"text_entry": "Tis sweet and commendable in your nature, Hamlet,"
}
},
{
"_index": "shakespeare",
"_id": "32754",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32755,
"play_name": "Hamlet",
"speech_number": 17,
"line_number": "1.2.120",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Let not thy mother lose her prayers, Hamlet:"
}
},
{
"_index": "shakespeare",
"_id": "32759",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32760,
"play_name": "Hamlet",
"speech_number": 19,
"line_number": "1.2.125",
"speaker": "KING CLAUDIUS",
"text_entry": "This gentle and unforced accord of Hamlet"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами constant_score.
| Параметр | Описание |
|---|---|
| filter | Фильтрующий запрос, которому должен соответствовать документ, чтобы быть возвращенным в результатах. Обязательный. |
| boost | Числовое значение с плавающей запятой, которое присваивается как релевантный балл всем возвращенным документам. Необязательный. По умолчанию 1.0. |
8.3.5.4 - disjunction_max
Возвращает документы, которые соответствуют одному или нескольким клаузам запроса. Если документ соответствует нескольким клаузам запроса, ему присваивается более высокий балл релевантности.
Запрос disjunction max (dis_max)
Запрос disjunction max (dis_max) возвращает любой документ, который соответствует одному или нескольким условиям запроса. Для документов, которые соответствуют нескольким условиям запроса, релевантный балл устанавливается на основе наивысшего релевантного балла из всех соответствующих условий запроса.
Когда релевантные баллы возвращаемых документов идентичны, вы можете использовать параметр tie_breaker, чтобы придать больше веса документам, которые соответствуют нескольким условиям запроса.
Пример
Рассмотрим индекс с двумя документами, которые вы индексируете следующим образом:
PUT testindex1/_doc/1
{
"title": " The Top 10 Shakespeare Poems",
"description": "Top 10 sonnets of England's national poet and the Bard of Avon"
}
PUT testindex1/_doc/2
{
"title": "Sonnets of the 16th Century",
"body": "The poems written by various 16-th century poets"
}
Используйте запрос dis_max, чтобы искать документы, содержащие слова “Shakespeare poems”:
GET testindex1/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Shakespeare poems" }},
{ "match": { "body": "Shakespeare poems" }}
]
}
}
}
Ответ содержит оба документа:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1.3862942,
"_source": {
"title": " The Top 10 Shakespeare Poems",
"description": "Top 10 sonnets of England's national poet and the Bard of Avon"
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 0.2876821,
"_source": {
"title": "Sonnets of the 16th Century",
"body": "The poems written by various 16-th century poets"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами dis_max.
| Параметр | Описание |
|---|---|
| queries | Массив одного или нескольких условий запроса, которые используются для сопоставления документов. Документ должен соответствовать хотя бы одному условию запроса, чтобы быть возвращенным в результатах. Если документ соответствует нескольким условиям запроса, релевантный балл устанавливается на основе наивысшего релевантного балла из всех соответствующих условий запроса. Обязательный. |
| tie_breaker | Числовой коэффициент с плавающей запятой от 0 до 1.0, который используется для придания большего веса документам, соответствующим нескольким условиям запроса. В этом случае релевантный балл документа рассчитывается с использованием следующего алгоритма: берется наивысший релевантный балл из всех соответствующих условий запроса, умножаются баллы всех других соответствующих условий на значение tie_breaker, и затем баллы складываются, нормализуя их. Необязательный. По умолчанию 0 (что означает, что учитывается только наивысший балл). |
8.3.5.5 - function_score
Пересчитывает балл релевантности документов, которые возвращаются запросом, с использованием функции, которую вы определяете.
Запрос function score
Используйте запрос function_score, если вам нужно изменить релевантные баллы документов, возвращаемых в результатах. Запрос function_score определяет запрос и одну или несколько функций, которые могут быть применены ко всем результатам или подмножествам результатов для перерасчета их релевантных баллов.
Использование одной функции оценки
Самый простой пример запроса function_score использует одну функцию для перерасчета балла. Следующий запрос использует функцию weight, чтобы удвоить все релевантные баллы. Эта функция применяется ко всем документам в результатах, поскольку в запросе function_score не указаны параметры запроса:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
Применение функции оценки к подмножеству документов
Чтобы применить функцию оценки к подмножеству документов, укажите запрос внутри функции:
GET shakespeare/_search
{
"query": {
"function_score": {
"query": {
"match": {
"play_name": "Hamlet"
}
},
"weight": "2"
}
}
}
Поддерживаемые функции
Тип запроса function_score поддерживает следующие функции:
Встроенные:
- weight: Умножает балл документа на предопределенный коэффициент увеличения.
- random_score: Предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями.
- field_value_factor: Использует значение указанного поля документа для перерасчета балла.
- Функции затухания (gauss, exp и linear): Перерасчитывают балл с использованием заданной функции затухания.
Пользовательские:
- script_score: Использует скрипт для оценки документов.
Функция weight
Когда вы используете функцию weight, оригинальный релевантный балл умножается на значение с плавающей запятой weight:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
В отличие от значения boost, функция weight не нормализуется.
Функция random_score
Функция random_score предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями. Балл представляет собой число с плавающей запятой в диапазоне [0, 1). По умолчанию функция random_score использует внутренние идентификаторы документов Lucene в качестве значений семени, что делает случайные значения невоспроизводимыми, поскольку документы могут быть перенумерованы после слияний. Чтобы добиться согласованности в генерации случайных значений, вы можете предоставить параметры seed и field. Поле должно быть полем, для которого включены данные поля (обычно это числовое поле). Балл рассчитывается с использованием семени, значений данных поля для указанного поля и соли, рассчитанной с использованием имени индекса и идентификатора шардов. Поскольку имя индекса и идентификатор шардов одинаковы для документов, находящихся в одном шард, документы с одинаковыми значениями полей будут получать одинаковый балл. Чтобы обеспечить разные баллы для всех документов в одном шарде, используйте поле, которое имеет уникальные значения для всех документов. Одним из вариантов является использование поля _seq_no. Однако, если вы выберете это поле, баллы могут измениться, если документ будет обновлен из-за соответствующего обновления _seq_no.
Следующий запрос использует функцию random_score с семенем и полем:
GET shakespeare/_search
{
"query": {
"function_score": {
"random_score": {
"seed": 12345,
"field": "some_numeric_field"
}
}
}
}
Функция field_value_factor
Функция field_value_factor перерасчитывает балл, используя значение указанного поля документа. Если поле является многозначным, используется только его первое значение для расчетов, остальные значения не учитываются.
Функция field_value_factor поддерживает следующие параметры:
field: Поле, которое будет использоваться в расчетах баллов.
factor: Необязательный коэффициент, на который умножается значение поля. По умолчанию 1.
modifier: Один из модификаторов, который будет применен к значению поля.
Поддерживаемые модификаторы
Следующая таблица перечисляет все поддерживаемые модификаторы.
| Модификатор | Формула | Описание |
|---|---|---|
| log | [\log v] | Возьмите десятичный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать log1p или log2p вместо log. |
| log1p | [\log(1+v)] | Возьмите десятичный логарифм суммы 1 и значения. |
| log2p | [\log(2+v)] | Возьмите десятичный логарифм суммы 2 и значения. |
| ln | [\ln v] | Возьмите натуральный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать ln1p или ln2p вместо ln. |
| ln1p | [\ln(1+v)] | Возьмите натуральный логарифм суммы 1 и значения. |
| ln2p | [\ln(2+v)] | Возьмите натуральный логарифм суммы 2 и значения. |
| reciprocal | [\frac{1}{v}] | Возьмите обратное значение. |
| square | [v^2] | Возведите значение в квадрат. |
| sqrt | [\sqrt{v}] | Возьмите квадратный корень из значения. Взятие квадратного корня из отрицательного числа является недопустимой операцией и приведет к ошибке. Убедитесь, что значение неотрицательно. |
| none | N/A | Не применять никакой модификатор. |
- missing: Значение, которое будет использоваться, если поле отсутствует в документе. Коэффициент и модификатор применяются к этому значению вместо отсутствующего значения поля.
Пример
Например, следующий запрос использует функцию field_value_factor, чтобы придать больше веса полю views:
GET blogs/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
}
}
}
}
Предыдущий запрос рассчитывает релевантный балл, используя следующую формулу: [ score = original \ score \cdot log(1+1.5 \cdot views) ]
Функция script_score
Используя функцию script_score, вы можете написать пользовательский скрипт для оценки документов, при этом опционально включая значения полей в документе. Оригинальный релевантный балл доступен в переменной _score.
Рассчитанный балл не может быть отрицательным. Отрицательный балл приведет к ошибке. Баллы документов имеют положительные 32-битные значения с плавающей запятой. Балл с большей точностью преобразуется в ближайшее 32-битное число с плавающей запятой.
Пример
Например, следующий запрос использует функцию script_score для расчета балла на основе оригинального балла и количества просмотров и лайков для блога. Чтобы уменьшить вес количества просмотров и лайков, эта формула берет логарифм суммы просмотров и лайков. Чтобы сделать логарифм допустимым, даже если количество просмотров и лайков равно 0, к их сумме добавляется 1:
GET blogs/_search
{
"query": {
"function_score": {
"query": {"match": {"name": "opensearch"}},
"script_score": {
"script": "_score * Math.log(1 + doc['likes'].value + doc['views'].value)"
}
}
}
}
Скрипты компилируются и кэшируются для повышения производительности. Таким образом, предпочтительно повторно использовать один и тот же скрипт и передавать любые параметры, которые необходимы скрипту:
GET blogs/_search
{
"query": {
"function_score": {
"query": {
"match": { "name": "opensearch" }
},
"script_score": {
"script": {
"params": {
"add": 1
},
"source": "_score * Math.log(params.add + doc['likes'].value + doc['views'].value)"
}
}
}
}
}
Функции Decay (затухания)
Для многих приложений необходимо сортировать результаты на основе близости или недавности. Вы можете сделать это с помощью функций затухания. Функции затухания вычисляют балл документа, используя одну из трех кривых затухания: гауссову, экспоненциальную или линейную.
Функции decay (затухания) работают только с числовыми, датированными и геопунктовыми полями.
Функции затухания вычисляют баллы на основе начала, масштаба, смещения и затухания, как показано на следующем рисунке.
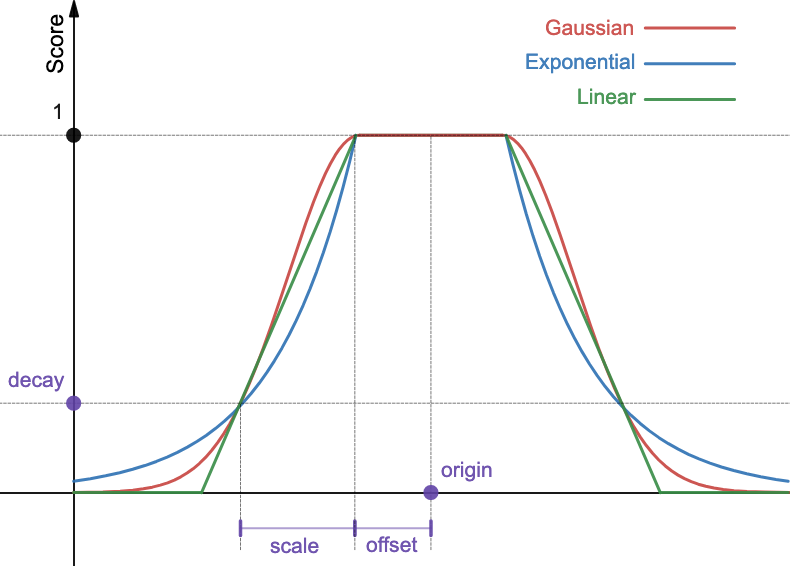
Примеры: Геопунктовые поля
Предположим, вы ищете отель рядом с вашим офисом. Вы создаете индекс отелей, который сопоставляет поле location как геопункт:
PUT hotels
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Вы индексируете два документа, которые соответствуют ближайшим отелям:
PUT hotels/_doc/1
{
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74.00
}
}
PUT hotels/_doc/2
{
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74.00
}
}
Начало определяет точку, от которой рассчитывается расстояние (местоположение офиса). Смещение указывает расстояние от начала, в пределах которого документам присваивается полный балл 1. Вы можете присвоить отелям, находящимся в пределах 200 футов от офиса, одинаковый наивысший балл. Масштаб определяет скорость затухания графика, а затухание определяет балл, который следует присвоить документу на расстоянии масштаб + смещение от начала. Как только вы выходите за пределы радиуса 200 футов, вы можете решить, что если вам нужно пройти еще 300 футов, чтобы добраться до отеля (масштаб = 300 футов), вы присвоите ему четверть оригинального балла (затухание = 0.25).
Вы создаете следующий запрос с началом в точке (74.00, 40.71):
GET hotels/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"location": {
"origin": "40.71,74.00",
"offset": "200ft",
"scale": "300ft",
"decay": 0.25
}
}
}
]
}
}
}
Ответ содержит оба отеля. Отель в пределах 200 футов от офиса имеет балл 1, а отель за пределами радиуса 500 футов имеет балл 0.20, что меньше параметра затухания 0.25.
{
"took": 854,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "hotels",
"_id": "1",
"_score": 1,
"_source": {
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74
}
}
},
{
"_index": "hotels",
"_id": "2",
"_score": 0.20099315,
"_source": {
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры, поддерживаемые функциями gauss, exp и linear.
| Параметр | Описание |
|---|---|
| origin | Точка, от которой рассчитывается расстояние. Должна быть указана как число для числовых полей, дата для полей даты или геопункт для геопунктовых полей. Обязательна для геопунктовых и числовых полей. Необязательна для полей даты (по умолчанию используется текущее время). Для полей даты поддерживается математическое вычисление дат (например, now-2d). |
| offset | Определяет расстояние от начала, в пределах которого документам присваивается балл 1. Необязательный. По умолчанию 0. |
| scale | Документам на расстоянии scale + offset от начала присваивается балл decay. Обязательный. Для числовых полей scale может быть любым числом. Для полей даты scale может быть определен как число с единицами (5h, 1d). Если единицы не указаны, scale по умолчанию равен миллисекундам. Для геопунктовых полей scale может быть определен как число с единицами (1mi, 5km). Если единицы не указаны, scale по умолчанию равен метрам. |
| decay | Определяет балл документа на расстоянии scale + offset от начала. Необязательный. По умолчанию 0.5. |
Для полей, отсутствующих в документе, функции затухания возвращают балл 1.
Пример: Числовые поля
Следующий запрос использует экспоненциальную функцию затухания, чтобы приоритизировать блоги по количеству комментариев:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"comments_count": {
"origin": 10,
"scale": 5,
"decay": 0.5
}
}
}
]
}
}
}
Первые два блога в результатах имеют балл 1, потому что один находится в начале (20), а другой на расстоянии 16, что находится в пределах смещения (диапазон, в пределах которого документы получают полный балл, рассчитывается как 20 - 5 и составляет [15, 25]). Третий блог находится на расстоянии scale + offset от начала (20 - (5 + 10) = 15), поэтому ему присваивается стандартный балл затухания (0.5):
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "1",
"_score": 1,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 1,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "3",
"_score": 0.5,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0.4352753,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Пример: Поля даты
Следующий запрос использует гауссову функцию затухания, чтобы приоритизировать блоги, опубликованные около 24 апреля 2002 года:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d",
"decay": 0.25
}
}
}
]
}
}
}
В результатах первый блог был опубликован в течение одного дня после 24 апреля 2022 года, поэтому он имеет наивысший балл 1. Второй блог был опубликован 17 апреля 2022 года, что находится в пределах смещения + масштаба (1 день + 6 дней), и поэтому имеет балл, равный затуханию (0.25). Третий блог был опубликован более чем через 7 дней после 24 апреля 2022 года, поэтому у него более низкий балл. Последний блог имеет балл 0, потому что он был опубликован много лет назад:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 1,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 0.25,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 0.15154076,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Многозначные поля
Если поле, которое вы указываете для расчета затухания, содержит несколько значений, вы можете использовать параметр multi_value_mode. Этот параметр указывает одну из следующих функций для определения значения поля, которое будет использоваться для расчетов:
- min: (по умолчанию) Минимальное расстояние от начала.
- max: Максимальное расстояние от начала.
- avg: Среднее расстояние от начала.
- sum: Сумма всех расстояний от начала.
Пример
Например, вы индексируете документ с массивом расстояний:
PUT testindex/_doc/1
{
"distances": [1, 2, 3, 4, 5]
}
Следующий запрос использует максимальное расстояние многозначного поля distances для расчета затухания:
GET testindex/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"distances": {
"origin": "6",
"offset": "5",
"scale": "1"
},
"multi_value_mode": "max"
}
}
]
}
}
}
Документ получает балл 1, потому что максимальное расстояние от начала (1) находится в пределах смещения от начала:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1,
"_source": {
"distances": [
1,
2,
3,
4,
5
]
}
}
]
}
}
Расчет кривой затухания
Следующие формулы определяют вычисление оценки для различных функций затухания (обозначает значение поля документа).
Гауссовская функция затухания
[ \text{score} = \exp \left(-\frac {(\max(0, \lvert v - \text{origin} \rvert - \text{offset}))^2} {2\sigma^2} \right), ] где (\sigma) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[ \sigma^2 = - \frac {\text{scale}^2} {2 \ln(\text{decay})} ]
Экспоненциальная функция затухания
[ \text{score} = \exp (\lambda \cdot \max(0, \lvert v - \text{origin} \rvert - \text{offset})), ]
где (\lambda) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат: [ \lambda = \frac {\ln(\text{decay})} {\text{scale}} ]
Линейная функция затухания
[ \text{score} = \max \left(\frac {s - \max(0, \lvert v - \text{origin} \rvert - \text{offset})} {s} \right), ]
где (s) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[ s = \frac {\text{scale}} {1 - \text{decay}} ]
Использование нескольких функций оценки
Вы можете указать несколько функций оценки в запросе функции оценки, перечислив их в массиве functions.
Комбинирование оценок от нескольких функций
Разные функции могут использовать разные масштабы для оценки. Например, функция random_score предоставляет оценку в диапазоне от 0 до 1, но field_value_factor не имеет конкретного масштаба для оценки. Кроме того, вы можете захотеть по-разному взвешивать оценки, полученные от различных функций. Чтобы скорректировать оценки для разных функций, вы можете указать параметр weight для каждой функции. Оценка, полученная от каждой функции, затем умножается на вес, чтобы получить окончательную оценку для этой функции. Параметр weight должен быть указан в массиве functions, чтобы отличать его от функции веса.
Оценки, полученные от каждой функции, комбинируются с помощью параметра score_mode, который принимает одно из следующих значений:
multiply: (по умолчанию) Оценки умножаются.
sum: Оценки складываются.
avg: Оценки усредняются. Если указан вес, это средневзвешенное. Например, если первая функция с весом
w1возвращает оценкуs1, а вторая функция с весомw2возвращает оценкуs2, среднее значение рассчитывается как:[ \text{average} = \frac{w1 \cdot s1 + w2 \cdot s2}{w1 + w2} ]
first: Берется оценка от первой функции, которая имеет соответствующий фильтр.
max: Берется максимальная оценка.
min: Берется минимальная оценка.
Указание верхнего предела для оценки
Вы можете указать верхний предел для функции оценки в параметре max_boost. Значение по умолчанию для верхнего предела — это максимальная величина для значения с плавающей запятой: ((2 - 2^{-23}) \cdot 2^{127}).
Комбинирование оценки для всех функций с оценкой запроса
Вы можете указать, как оценка, вычисленная с использованием всех функций, комбинируется с оценкой запроса, в параметре boost_mode, который принимает одно из следующих значений:
- multiply: (по умолчанию) Умножает оценку запроса на оценку функции.
- replace: Игнорирует оценку запроса и использует оценку функции.
- sum: Складывает оценку запроса и оценку функции.
- avg: Усредняет оценку запроса и оценку функции.
- max: Берет большее значение между оценкой запроса и оценкой функции.
- min: Берет меньшее значение между оценкой запроса и оценкой функции.
Фильтрация документов, которые не соответствуют порогу
Изменение оценки релевантности не изменяет список соответствующих документов. Чтобы исключить некоторые документы, которые не соответствуют порогу, укажите значение порога в параметре min_score. Все документы, возвращенные запросом, затем оцениваются и фильтруются с использованием значения порога.
Пример
Следующий запрос ищет блоги, которые содержат слова “OpenSearch Data Prepper”, предпочитая посты, опубликованные около 24 апреля 2022 года. Кроме того, учитывается количество просмотров и лайков. Наконец, пороговое значение установлено на уровне 10:
GET blogs/_search
{
"query": {
"function_score": {
"boost": "5",
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d"
}
},
"weight": 1
},
{
"gauss": {
"likes": {
"origin": 200,
"scale": 200
}
},
"weight": 4
},
{
"gauss": {
"views": {
"origin": 1000,
"scale": 800
}
},
"weight": 2
}
],
"query": {
"match": {
"name": "opensearch data prepper"
}
},
"max_boost": 10,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 10
}
}
}
Результаты содержат три соответствующих блога:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 31.191923,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 31.191923,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 13.907352,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 11.150461,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
}
]
}
}
Именованные функции
При определении функции вы можете указать ее имя, используя параметр _name на верхнем уровне. Это имя полезно для отладки и понимания процесса оценки. После указания имя функции включается в объяснение расчета оценки, когда это возможно (это относится к функциям, фильтрам и запросам). Вы можете идентифицировать функцию по ее _name в ответе.
Пример
Следующий запрос устанавливает explain в значение true для целей отладки, чтобы получить объяснение оценки в ответе. Каждая функция содержит параметр _name, чтобы вы могли однозначно идентифицировать функцию:
GET blogs/_search
{
"explain": true,
"size": 1,
"query": {
"function_score": {
"functions": [
{
"_name": "likes_function",
"script_score": {
"script": {
"lang": "painless",
"source": "return doc['likes'].value * 2;"
}
},
"weight": 0.6
},
{
"_name": "views_function",
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
},
"weight": 0.3
},
{
"_name": "comments_function",
"gauss": {
"comments": {
"origin": 1000,
"scale": 800
}
},
"weight": 0.1
}
]
}
}
}
Ответ объясняет процесс оценки. Для каждой функции объяснение содержит name функции в своем описании:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 6.1600614,
"hits": [
{
"_shard": "[blogs][0]",
"_node": "_yndTaZHQWimcDgAfOfRtQ",
"_index": "blogs",
"_id": "1",
"_score": 6.1600614,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
},
"_explanation": {
"value": 6.1600614,
"description": "function score, product of:",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
},
{
"value": 6.1600614,
"description": "min of:",
"details": [
{
"value": 6.1600614,
"description": "function score, score mode [multiply]",
"details": [
{
"value": 180,
"description": "product of:",
"details": [
{
"value": 300,
"description": "script score function(_name: likes_function), computed with script:\"Script{type=inline, lang='painless', idOrCode='return doc['likes'].value * 2;', options={}, params={}}\"",
"details": [
{
"value": 1,
"description": "_score: ",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
}
]
}
]
},
{
"value": 0.6,
"description": "weight",
"details": []
}
]
},
{
"value": 0.9766541,
"description": "product of:",
"details": [
{
"value": 3.2555137,
"description": "field value function(_name: views_function): log1p(doc['views'].value?:1.0 * factor=1.5)",
"details": []
},
{
"value": 0.3,
"description": "weight",
"details": []
}
]
},
{
"value": 0.035040613,
"description": "product of:",
"details": [
{
"value": 0.35040614,
"description": "Function for field comments:",
"details": [
{
"value": 0.35040614,
"description": "exp(-0.5*pow(MIN[Math.max(Math.abs(16.0(=doc value) - 1000.0(=origin))) - 0.0(=offset), 0)],2.0)/461662.4130844683, _name: comments_function)",
"details": []
}
]
},
{
"value": 0.1,
"description": "weight",
"details": []
}
]
}
]
},
{
"value": 3.4028235e+38,
"description": "maxBoost",
"details": []
}
]
}
]
}
}
]
}
}
8.3.5.6 - hibrid
Объединяет баллы релевантности из нескольких запросов в один балл для данного документа.
Гибридный запрос
Вы можете использовать гибридный запрос для комбинирования оценок релевантности из нескольких запросов в одну оценку для данного документа. Гибридный запрос содержит список из одного или нескольких запросов и независимо вычисляет оценки документов на уровне шардов для каждого подзапроса. Переписывание подзапросов выполняется на уровне координирующего узла, чтобы избежать дублирования вычислений.
Пример
Узнайте, как использовать гибридный запрос, следуя шагам в разделе Гибридный поиск.
Для получения более полного примера следуйте разделу Начало работы с семантическим и гибридным поиском.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые гибридными запросами.
| Параметр | Описание |
|---|---|
queries | Массив из одного или нескольких условий запроса, которые используются для поиска документов. Документ должен соответствовать хотя бы одному условию запроса, чтобы быть возвращенным в результатах. Оценки релевантности документов из всех условий запроса комбинируются в одну оценку с помощью поискового конвейера. Максимальное количество условий запроса — 5. Обязательно. |
filter | Фильтр, который применяется ко всем подзапросам гибридного запроса. |
Отключение гибридных запросов
По умолчанию гибридные запросы включены. Чтобы отключить гибридные запросы в вашем кластере, установите параметр plugins.neural_search.hybrid_search_disabled в значение true в файле opensearch.yml.
8.3.6 - geographic and xy query
Географические и xy-запросы позволяют искать поля, содержащие точки и фигуры на карте или в координатной плоскости.
Географические и xy-запросы
Географические и xy-запросы позволяют искать поля, содержащие точки и фигуры на карте или в координатной плоскости. Географические запросы работают с геопространственными данными, в то время как xy-запросы работают с двумерными координатными данными. Из всех географических запросов запрос geoshape очень похож на xy-запрос, но первый ищет географические поля, в то время как второй ищет декартовы поля.
xy-запросы
xy-запросы ищут документы, содержащие геометрии в декартовой системе координат. Эти геометрии могут быть указаны в полях xy_point, которые поддерживают точки, и в полях xy_shape, которые поддерживают точки, линии, круги и многоугольники.
xy-запросы возвращают документы, которые содержат:
- xy-формы и xy-точки, имеющие одно из четырех пространственных отношений к предоставленной форме: INTERSECTS (пересекает), DISJOINT (разъединены), WITHIN (внутри) или CONTAINS (содержит).
- xy-точки, которые пересекают предоставленную форму.
Географические запросы
Географические запросы ищут документы, содержащие геопространственные геометрии. Эти геометрии могут быть указаны в полях geo_point, которые поддерживают точки на карте, и в полях geo_shape, которые поддерживают точки, линии, круги и многоугольники.
OpenSearch предоставляет следующие типы географических запросов:
- Запросы по гео-ограничивающему прямоугольнику (Geo-bounding box queries): возвращают документы с значениями поля geopoint, которые находятся в пределах ограничивающего прямоугольника.
- Запросы по гео-расстоянию (Geodistance queries): возвращают документы с геоточками, которые находятся на заданном расстоянии от предоставленной геоточки.
- Запросы по гео-многоугольнику (Geopolygon queries): возвращают документы, содержащие геоточки, которые находятся внутри многоугольника.
- Запросы по гео-форме (Geoshape queries): возвращают документы, которые содержат:
- Геоформы и геоточки, имеющие одно из четырех пространственных отношений к предоставленной форме: INTERSECTS (пересекает), DISJOINT (разъединены), WITHIN (внутри) или CONTAINS (содержит).
- Геоточки, которые пересекают предоставленную форму.
8.3.6.1 - Запрос по гео-ограничивающему прямоугольнику
Запрос по гео-ограничивающему прямоугольнику возвращает документы, чьи геоточки находятся в пределах ограничивающего прямоугольника, указанного в запросе.
Чтобы искать документы, содержащие поля geopoint, используйте запрос по гео-ограничивающему прямоугольнику. Запрос по гео-ограничивающему прямоугольнику возвращает документы, чьи геоточки находятся в пределах ограничивающего прямоугольника, указанного в запросе. Документ с несколькими геоточками соответствует запросу, если хотя бы одна геоточка находится в пределах ограничивающего прямоугольника.
Пример
Вы можете использовать запрос по гео-ограничивающему прямоугольнику для поиска документов, содержащих геоточки.
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте три геоточки как объекты с широтой и долготой:
PUT testindex1/_doc/1
{
"point": {
"lat": 74.00,
"lon": 40.71
}
}
PUT testindex1/_doc/2
{
"point": {
"lat": 72.64,
"lon": 22.62
}
}
PUT testindex1/_doc/3
{
"point": {
"lat": 75.00,
"lon": 28.00
}
}
Ищите все документы и фильтруйте документы, чьи точки находятся внутри прямоугольника, определенного в запросе:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": {
"lat": 75,
"lon": 28
},
"bottom_right": {
"lat": 73,
"lon": 41
}
}
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "testindex1",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"point" : {
"lat" : 74.0,
"lon" : 40.71
}
}
}
]
}
}
Предыдущий ответ не включает документ с геоточкой “lat”: 75.00, “lon”: 28.00 из-за ограниченной точности геоточки.
Точность
Координаты геоточек всегда округляются вниз во время индексации. Во время выполнения запроса верхние границы ограничивающего прямоугольника округляются вниз, а нижние границы округляются вверх. Поэтому документы с геоточками, которые находятся на нижних и левых границах ограничивающего прямоугольника, могут не быть включены в результаты из-за ошибки округления. С другой стороны, геоточки, находящиеся на верхних и правых границах ограничивающего прямоугольника, могут быть включены в результаты, даже если они находятся за пределами границ. Ошибка округления составляет менее 4.20 × 10^−8 градусов для широты и менее 8.39 × 10^−8 градусов для долготы (примерно 1 см).
Указание ограничивающего прямоугольника
Вы можете указать ограничивающий прямоугольник, предоставив любую из следующих комбинаций координат его вершин:
- top_left и bottom_right
- top_right и bottom_left
- top, left, bottom и right
Следующий пример показывает, как указать ограничивающий прямоугольник, используя координаты top, left, bottom и right:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top": 75,
"left": 28,
"bottom": 73,
"right": 41
}
}
}
}
}
}
Параметры
Запросы по гео-ограничивающему прямоугольнику принимают следующие параметры:
| Параметр | Тип данных | Описание |
|---|---|---|
| _name | String | Имя фильтра. Необязательный параметр. |
| validation_method | String | Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). По умолчанию - STRICT. |
| type | String | Указывает, как выполнять фильтр. Допустимые значения: indexed (индексировать фильтр) и memory (выполнять фильтр в памяти). По умолчанию - memory. |
| ignore_unmapped | Boolean | Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы с неотображаемым полем. Если установлено в false, при неотображаемом поле возникает исключение. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты вершин ограничивающего прямоугольника в любом формате, который принимает тип поля geopoint.
Использование геохеша для указания ограничивающего прямоугольника
Если вы используете геохеш для указания ограничивающего прямоугольника, геохеш рассматривается как прямоугольник. Верхний левый угол ограничивающего прямоугольника соответствует верхнему левому углу геохеша top_left, а нижний правый угол ограничивающего прямоугольника соответствует нижнему правому углу геохеша bottom_right.
Следующий пример показывает, как использовать геохеш для указания того же ограничивающего прямоугольника, что и в предыдущих примерах:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": "ut7ftjkfxm34",
"bottom_right": "uuvpkcprc4rc"
}
}
}
}
}
}
Чтобы указать ограничивающий прямоугольник, который охватывает всю область геохеша, укажите этот геохеш как параметры top_left и bottom_right ограничивающего прямоугольника:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": "ut",
"bottom_right": "ut"
}
}
}
}
}
}
8.3.6.2 - Запрос по гео-расстоянию
Запрос по гео-расстоянию возвращает документы с геоточками, которые находятся в пределах заданного расстояния от предоставленной геоточки.
Документ с несколькими геоточками соответствует запросу, если хотя бы одна геоточка соответствует запросу.
Поле, в котором хранятся геоточки, должно быть правильно настроено в индексе как тип geo_point
Пример
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте геоточку, указав ее широту и долготу:
PUT testindex1/_doc/1
{
"point": {
"lat": 74.00,
"lon": 40.71
}
}
Ищите документы, чьи объекты точки находятся в пределах заданного расстояния от указанной точки:
GET /testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "50mi",
"point": {
"lat": 73.5,
"lon": 40.5
}
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"point": {
"lat": 74,
"lon": 40.71
}
}
}
]
}
}
Параметры
Запросы по гео-расстоянию принимают следующие параметры:
| Параметр | Тип данных | Описание |
|---|---|---|
| _name | String | Имя фильтра. Необязательный параметр. |
| distance | String | Расстояние, в пределах которого следует сопоставить точки. Это расстояние является радиусом круга, центрированного на указанной точке. Для поддерживаемых единиц расстояния см. раздел “Единицы расстояния”. Обязательный параметр. |
| distance_type | String | Указывает, как рассчитывать расстояние. Допустимые значения: arc (дуга) или plane (плоскость, быстрее, но менее точно для больших расстояний или точек, близких к полюсам). Необязательный параметр. По умолчанию - arc. |
| validation_method | String | Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). Необязательный параметр. По умолчанию - STRICT. |
| ignore_unmapped | Boolean | Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы, содержащие неотображаемое поле. Если установлено в false, при неотображаемом поле возникает исключение. Необязательный параметр. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты геоточки при индексации документа и поиске документов в любом формате, который принимает тип поля geopoint.
8.3.6.3 - Запрос по гео-многоугольнику
Запрос по гео-многоугольнику возвращает документы, содержащие геоточки, которые находятся внутри указанного многоугольника.
Запрос по гео-многоугольнику возвращает документы, содержащие геоточки, которые находятся внутри указанного многоугольника. Документ, содержащий несколько геоточек, соответствует запросу, если хотя бы одна геоточка соответствует запросу.
Многоугольник задается списком вершин в координатной форме. В отличие от указания многоугольника для поля geoshape, многоугольник не обязательно должен быть замкнутым (не нужно указывать первую и последнюю точки одновременно). Хотя точки не обязательно должны следовать в порядке часовой или против часовой стрелки, рекомендуется перечислять их в одном из этих порядков. Это обеспечит правильное определение многоугольника.
Иск searched document field must be mapped as geo_point.
Пример
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT /testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте геоточку, указав ее широту и долготу:
PUT testindex1/_doc/1
{
"point": {
"lat": 73.71,
"lon": 41.32
}
}
Ищите документы, чьи объекты точки находятся внутри указанного гео-многоугольника:
GET /testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 74.0060, "lon": 40.7128 }
]
}
}
}
}
}
}
Многоугольник, указанный в предыдущем запросе, представляет собой четырехугольник. Соответствующий документ находится внутри этого четырехугольника. Координаты вершин четырехугольника указаны в формате (широта, долгота).
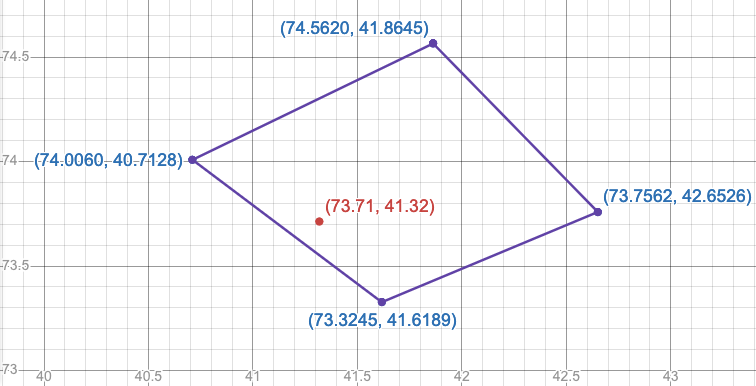 Ответ содержит соответствующий документ:
Ответ содержит соответствующий документ:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"point": {
"lat": 73.71,
"lon": 41.32
}
}
}
]
}
}
В предыдущем запросе вы указали вершины многоугольника в порядке часовой стрелки:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 74.0060, "lon": 40.7128 }
]
}
}
Альтернативно, вы можете указать вершины в порядке против часовой стрелки:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 74.0060, "lon": 40.7128 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 73.7562, "lon": 42.6526 }
]
}
}
Ответ на запрос будет содержать тот же соответствующий документ.
Однако, если вы укажете вершины в следующем порядке:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 74.0060, "lon": 40.7128 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 }
]
}
}
Ответ не вернет никаких результатов.
Параметры
Запросы по гео-многоугольнику принимают следующие параметры:
| Параметр | Тип данных | Описание |
|---|---|---|
| _name | String | Имя фильтра. Необязательный параметр. |
| validation_method | String | Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). Необязательный параметр. По умолчанию - STRICT. |
| ignore_unmapped | Boolean | Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы, содержащие неотображаемое поле. Если установлено в false, при неотображаемом поле возникает исключение. Необязательный параметр. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты геоточки при индексации документа и поиске документов в любом формате, который принимает тип поля geopoint.
8.3.6.4 - Запрос по гео-форме
Вы можете фильтровать документы, используя гео-форму, определенную в запросе, или использовать заранее индексированную гео-форму.
Используйте запрос по гео-форме для поиска документов, которые содержат поля geopoint или geoshape. Вы можете фильтровать документы, используя гео-форму, определенную в запросе, или использовать заранее индексированную гео-форму.
Иск searched document field must be mapped as geo_point или geo_shape.
Пространственные отношения
Когда вы предоставляете гео-форму для запроса по гео-форме, поля geopoint и geoshape в документах сопоставляются с использованием следующих пространственных отношений к предоставленной форме:
| Отношение | Описание | Поддерживаемый тип географического поля |
|---|---|---|
| INTERSECTS | (По умолчанию) Соответствует документам, чьи geopoint или geoshape пересекаются с формой, предоставленной в запросе. | geo_point, geo_shape |
| DISJOINT | Соответствует документам, чьи geoshape не пересекаются с формой, предоставленной в запросе. | geo_shape |
| WITHIN | Соответствует документам, чьи geoshape полностью находятся внутри формы, предоставленной в запросе. | geo_shape |
| CONTAINS | Соответствует документам, чьи geoshape полностью содержат форму, предоставленную в запросе. | geo_shape |
Определение формы в запросе по гео-форме
Вы можете определить форму для фильтрации документов в запросе по гео-форме, предоставив новое определение формы во время запроса или сославшись на имя формы, заранее индексированной в другом индексе.
Использование нового определения формы
Чтобы предоставить новую форму для запроса по гео-форме, определите ее в поле geo_shape. Вы должны определить гео-форму в формате GeoJSON.
Следующий пример иллюстрирует поиск документов, содержащих гео-формы, которые соответствуют гео-форме, определенной во время запроса.
Шаг 1: Создание индекса
Сначала создайте индекс и сопоставьте поле location как geo_shape:
PUT /testindex
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
Шаг 2: Индексация документов
Индексуйте один документ, содержащий точку, и другой, содержащий многоугольник:
PUT testindex/_doc/1
{
"location": {
"type": "point",
"coordinates": [ 73.0515, 41.5582 ]
}
}
PUT testindex/_doc/2
{
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
Шаг 3: Выполнение запроса по гео-форме
Наконец, определите гео-форму для фильтрации документов. Следующие разделы иллюстрируют предоставление различных гео-форм в запросе. Для получения дополнительной информации о различных форматах гео-форм см. раздел “Тип поля гео-формы”.
Конверт
Конверт — это ограничивающий прямоугольник в формате [[minLon, maxLat], [maxLon, minLat]]. Ищите документы, содержащие поля geoshape, которые пересекаются с предоставленным конвертом:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
71.0589,
42.3601
],
[
74.006,
40.7128
]
]
},
"relation": "WITHIN"
}
}
}
}
Ответ содержит оба документа:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0,
"_source": {
"location": {
"type": "point",
"coordinates": [
73.0515,
41.5582
]
}
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0,
"_source": {
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
}
]
}
}
Точка
Ищите документы, чьи поля geoshape содержат предоставленную точку:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "point",
"coordinates": [
72.8000,
41.6300
]
},
"relation": "CONTAINS"
}
}
}
}
Linestring
Поиск документов, геошейпы которых не пересекаются с предоставленным линией:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "linestring",
"coordinates": [[74.0060, 40.7128], [71.0589, 42.3601]]
},
"relation": "DISJOINT"
}
}
}
}
Запросы геошейпа с линией не поддерживают отношение WITHIN.
Полигон
В формате GeoJSON необходимо перечислить вершины полигона в порядке обхода против часовой стрелки и замкнуть полигон, чтобы первая и последняя вершины совпадали.
Поиск документов, геошейпы которых находятся внутри предоставленного полигона:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "polygon",
"coordinates": [
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]
]
},
"relation": "WITHIN"
}
}
}
}
Мультипоинт
Поиск документов, геошейпы которых не пересекаются с предоставленными точками:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multipoint",
"coordinates": [
[74.0060, 40.7128],
[71.0589, 42.3601]
]
},
"relation": "DISJOINT"
}
}
}
}
Мультилиния
Поиск документов, геошейпы которых не пересекаются с предоставленными линиями:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multilinestring",
"coordinates": [
[[74.0060, 40.7128], [71.0589, 42.3601]],
[[73.7562, 42.6526], [72.6734, 41.7658]]
]
},
"relation": "disjoint"
}
}
}
}
Запросы геошейпа с мультилинией не поддерживают отношение WITHIN.
Мультиполигоны
Поиск документов, геошейпы которых находятся внутри предоставленного мультиполигона:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multipolygon",
"coordinates": [
[
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
],
[
[73.0515, 41.5582],
[72.6506, 41.5623],
[72.6734, 41.7658],
[73.0515, 41.5582]
]
],
[
[
[73.9146, 40.8252],
[73.8871, 41.0389],
[73.6853, 40.9747],
[73.9146, 40.8252]
]
]
]
},
"relation": "WITHIN"
}
}
}
}
Коллекция геометрий
Поиск документов, геошейпы которых находятся внутри предоставленных полигонов:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "geometrycollection",
"geometries": [
{
"type": "polygon",
"coordinates": [[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]]
},
{
"type": "polygon",
"coordinates": [[
[73.0515, 41.5582],
[72.6506, 41.5623],
[72.6734, 41.7658],
[73.0515, 41.5582]
]]
}
]
},
"relation": "WITHIN"
}
}
}
}
Запросы геошейпа, содержащие в коллекции геометрий линию или мультилинии, не поддерживают отношение WITHIN.
Использование прединдексированного определения формы
При построении запроса геошейпа вы также можете ссылаться на имя формы, прединдексированной в другом индексе. С помощью этого метода вы можете определить геошейп во время индексации и ссылаться на него по имени во время поиска.
Вы можете определить прединдексированный геошейп в формате GeoJSON или Well-Known Text (WKT). Для получения дополнительной информации о различных форматах геошейпа см. тип поля Geoshape.
Объект indexed_shape поддерживает следующие параметры:
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
| id | Обязательный | Идентификатор документа, содержащего прединдексированную форму. |
| index | Необязательный | Имя индекса, содержащего прединдексированную форму. По умолчанию - shapes. |
| path | Необязательный | Имя поля, содержащего прединдексированную форму в виде пути. По умолчанию - shape. |
| routing | Необязательный | Маршрутизация документа, содержащего прединдексированную форму. |
Следующий пример иллюстрирует, как ссылаться на имя формы, прединдексированной в другом индексе. В этом примере индекс pre-indexed-shapes содержит форму, определяющую границы, а индекс testindex содержит формы, которые проверяются на соответствие этим границам.
Сначала создайте индекс pre-indexed-shapes и задайте поле boundaries для этого индекса как geo_shape:
PUT /pre-indexed-shapes
{
"mappings": {
"properties": {
"boundaries": {
"type": "geo_shape",
"orientation": "left"
}
}
}
}
Для получения дополнительной информации о том, как задать другую ориентацию вершин для полигонов, см. Полигон.
Индексируйте полигон, указывая границы поиска, в индекс pre-indexed-shapes. Идентификатор полигона - search_triangle. В этом примере вы индексируете полигон в формате WKT:
PUT /pre-indexed-shapes/_doc/search_triangle
{
"boundaries":
"POLYGON ((74.0060 40.7128, 71.0589 42.3601, 73.7562 42.6526, 74.0060 40.7128))"
}
Если вы еще не сделали этого, индексируйте один документ, содержащий точку, и другой документ, содержащий полигон, в индекс testindex:
PUT /testindex/_doc/1
{
"location": {
"type": "point",
"coordinates": [ 73.0515, 41.5582 ]
}
}
PUT /testindex/_doc/2
{
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
Поиск документов, геошейпы которых находятся внутри search_triangle:
GET /testindex/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_shape": {
"location": {
"indexed_shape": {
"index": "pre-indexed-shapes",
"id": "search_triangle",
"path": "boundaries"
},
"relation": "WITHIN"
}
}
}
}
}
}
Ответ содержит оба документа.
Запрос геоточек
Вы также можете использовать запрос геошейпа для поиска документов, содержащих геоточки.
Запросы геошейпа по полям геоточек поддерживают только пространственное отношение по умолчанию INTERSECTS, поэтому вам не нужно указывать параметр отношения.
Запросы геошейпа по полям геоточек не поддерживают следующие геошейпы:
- Точки
- Линии
- Мультипоинты
- Мультилинии
- Коллекции геометрий, содержащие один из вышеперечисленных типов геошейпа
Создайте отображение, где location является geo_point:
PUT /testindex1
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Индексируйте две точки в индекс. В этом примере вы предоставите координаты геоточек в виде строк:
PUT /testindex1/_doc/1
{
"location": "41.5623, 72.6506"
}
PUT /testindex1/_doc/2
{
"location": "76.0254, 39.2467"
}
Для получения информации о предоставлении координат геоточек в различных форматах см. Форматы.
Поиск геоточек, которые пересекаются с предоставленным полигоном:
GET /testindex1/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "polygon",
"coordinates": [
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]
]
}
}
}
}
}
Ответ на запрос
Ответ возвращает документ 1:
{
"took": 21,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0,
"_source": {
"location": "41.5623, 72.6506"
}
}
]
}
}
Обратите внимание, что при индексации геоточек вы указали их координаты в формате “широта, долгота”. Когда вы ищете соответствующие документы, массив координат находится в формате [долгота, широта]. Таким образом, документ 1 возвращается в результатах, но документ 2 - нет.
Параметры
Запросы геошейпа принимают следующие параметры:
| Параметр | Тип данных | Описание |
|---|---|---|
| ignore_unmapped | Boolean | Указывает, следует ли игнорировать неразмеченное поле. Если установлено в true, то запрос не возвращает документы, содержащие неразмеченное поле. Если установлено в false, то при отсутствии поля выбрасывается исключение. Необязательный. По умолчанию - false. |
8.3.6.5 - xy запрос
Для поиска документов, содержащих поля xy point или xy shape, используйте xy запрос.
Пространственные отношения
Когда вы предоставляете xy форму в xy запросе, поля xy в документах сопоставляются с использованием следующих пространственных отношений к предоставленной форме.
| Отношение | Описание | Поддерживаемый тип поля xy |
|---|---|---|
| INTERSECTS | (По умолчанию) Сопоставляет документы, чьи xy point или xy shape пересекают форму, предоставленную в запросе. | xy_point, xy_shape |
| DISJOINT | Сопоставляет документы, чьи xy shape не пересекаются с формой, предоставленной в запросе. | xy_shape |
| WITHIN | Сопоставляет документы, чьи xy shape полностью находятся внутри формы, предоставленной в запросе. | xy_shape |
| CONTAINS | Сопоставляет документы, чьи xy shape полностью содержат форму, предоставленную в запросе. | xy_shape |
Следующие примеры иллюстрируют поиск документов, содержащих xy формы. Чтобы узнать, как искать документы, содержащие xy точки, смотрите раздел “Запросы xy точек”.
Определение формы в xy запросе
Вы можете определить форму в xy запросе, предоставив новое определение формы во время запроса или сославшись на имя формы, предварительно индексированной в другом индексе.
Использование нового определения формы
Чтобы предоставить новую форму в xy запросе, определите ее в поле xy_shape.
Следующий пример иллюстрирует, как искать документы, содержащие xy формы, которые соответствуют xy форме, определенной во время запроса.
Сначала создайте индекс и сопоставьте поле геометрии как xy_shape:
PUT testindex
{
"mappings": {
"properties": {
"geometry": {
"type": "xy_shape"
}
}
}
}
Индексируйте документ с точкой и документ с многоугольником:
PUT testindex/_doc/1
{
"geometry": {
"type": "point",
"coordinates": [0.5, 3.0]
}
}
PUT testindex/_doc/2
{
"geometry" : {
"type" : "polygon",
"coordinates" : [
[[2.5, 6.0],
[0.5, 4.5],
[1.5, 2.0],
[3.5, 3.5],
[2.5, 6.0]]
]
}
}
Определите оболочку — ограничивающий прямоугольник в формате [[minX, maxY], [maxX, minY]]. Ищите документы с xy точками или формами, которые пересекают эту оболочку:
GET testindex/_search
{
"query": {
"xy_shape": {
"geometry": {
"shape": {
"type": "envelope",
"coordinates": [ [ 0.0, 6.0], [ 4.0, 2.0] ]
},
"relation": "WITHIN"
}
}
}
}
Следующее изображение иллюстрирует пример. И точка, и многоугольник находятся внутри ограничивающей оболочки.
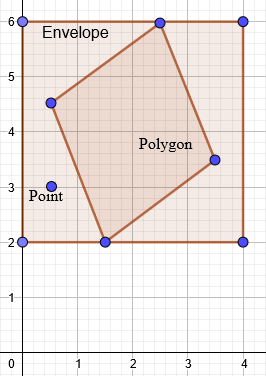
Использование предварительно индексированного определения формы
При построении xy запроса вы также можете ссылаться на имя формы, предварительно индексированной в другом индексе. Используя этот метод, вы можете определить xy форму во время индексации и ссылаться на нее по имени, предоставляя следующие параметры в объекте indexed_shape.
| Параметр | Описание |
|---|---|
| index | Имя индекса, содержащего предварительно индексированную форму. |
| id | Идентификатор документа, содержащего предварительно индексированную форму. |
| path | Имя поля, содержащего предварительно индексированную форму, в виде пути. |
Следующий пример иллюстрирует ссылку на имя формы, предварительно индексированной в другом индексе. В этом примере индекс pre-indexed-shapes содержит форму, определяющую границы, а индекс testindex содержит формы, местоположения которых проверяются относительно этих границ.
Сначала создайте индекс pre-indexed-shapes и сопоставьте поле геометрии для этого индекса как xy_shape:
PUT pre-indexed-shapes
{
"mappings": {
"properties": {
"geometry": {
"type": "xy_shape"
}
}
}
}
Индексируйте оболочку, которая определяет границы, и назовите ее rectangle:
PUT pre-indexed-shapes/_doc/rectangle
{
"geometry": {
"type": "envelope",
"coordinates" : [ [ 0.0, 6.0], [ 4.0, 2.0] ]
}
}
Индексируйте документ с точкой и документ с многоугольником в индекс testindex:
PUT testindex/_doc/1
{
"geometry": {
"type": "point",
"coordinates": [0.5, 3.0]
}
}
PUT testindex/_doc/2
{
"geometry" : {
"type" : "polygon",
"coordinates" : [
[[2.5, 6.0],
[0.5, 4.5],
[1.5, 2.0],
[3.5, 3.5],
[2.5, 6.0]]
]
}
}
Теперь выполните поиск документов с формами, которые пересекают rectangle в индексе testindex, используя фильтр:
GET testindex/_search
{
"query": {
"bool": {
"filter": {
"xy_shape": {
"geometry": {
"indexed_shape": {
"index": "pre-indexed-shapes",
"id": "rectangle",
"path": "geometry"
}
}
}
}
}
}
}
Этот запрос вернет документы из индекса testindex, которые пересекают предварительно индексированную форму rectangle, определенную в индексе pre-indexed-shapes.
Запрос xy точек
Вы также можете использовать xy запрос для поиска документов, содержащих xy точки.
Создание сопоставления с типом xy_point
Сначала создайте сопоставление с полем типа xy_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "xy_point"
}
}
}
}
Индексация трех точек
Индексируйте три точки:
PUT testindex1/_doc/1
{
"point": "1.0, 1.0"
}
PUT testindex1/_doc/2
{
"point": "2.0, 0.0"
}
PUT testindex1/_doc/3
{
"point": "-2.0, 2.0"
}
Поиск точек в круге
Теперь выполните поиск точек, которые находятся внутри круга с центром в (0, 0) и радиусом 2:
GET testindex1/_search
{
"query": {
"xy_shape": {
"point": {
"shape": {
"type": "circle",
"coordinates": [0.0, 0.0],
"radius": 2
}
}
}
}
}
Форма xy point поддерживает только пространственное отношение по умолчанию INTERSECTS, поэтому вам не нужно указывать параметр отношения.
Результаты запроса
Следующее изображение иллюстрирует пример. Точки 1 и 2 находятся внутри круга, а точка 3 находится вне круга.
Ответ на запрос возвращает документы 1 и 2, которые находятся внутри заданного круга:
{
"took" : 575,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "testindex1",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"point" : "1.0, 1.0"
}
},
{
"_index" : "testindex1",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"point" : "2.0, 0.0"
}
}
]
}
}
Объяснение результатов
- Документ 1: Содержит точку с координатами (1.0, 1.0), которая находится внутри круга.
- Документ 2: Содержит точку с координатами (2.0, 0.0), которая также находится внутри круга.
Обе точки соответствуют критериям поиска, так как они находятся в пределах радиуса 2 от центра (0, 0). Точка 3, с координатами (-2.0, 2.0), не была возвращена, так как она находится вне круга.
8.3.7 - Объединение запросов
OpenSearch предоставляет следующие запросы, которые выполняют операции объединения и оптимизированы для масштабирования на нескольких узлах:
OpenSearch является распределенной системой, в которой данные распределены по нескольким узлам. Поэтому выполнение операции JOIN, аналогичной SQL, в OpenSearch требует значительных ресурсов. В качестве альтернативы OpenSearch предоставляет следующие запросы, которые выполняют операции объединения и оптимизированы для масштабирования на нескольких узлах:
Запросы для поиска вложенных полей
- Вложенные запросы (nested queries): Действуют как обертки для других запросов, чтобы искать вложенные поля. Объекты вложенных полей ищутся так, как будто они индексированы как отдельные документы.
Запросы для поиска документов, связанных через тип поля объединения
Эти запросы устанавливают родительско-дочерние отношения между документами в одном индексе:
- has_child запросы: Ищут родительские документы, дочерние документы которых соответствуют запросу.
- has_parent запросы: Ищут дочерние документы, родительские документы которых соответствуют запросу.
- parent_id запросы: Ищут дочерние документы, которые связаны с конкретным родительским документом.
Настройка выполнения запросов
Если параметр search.allow_expensive_queries установлен в значение false, то объединяющие запросы не будут выполняться.
8.3.7.1 - Запрос has_child
Запрос has_child возвращает родительские документы, дочерние документы которых соответствуют определенному запросу.
Запрос has_child возвращает родительские документы, дочерние документы которых соответствуют определенному запросу. Вы можете установить родительско-дочерние отношения между документами в одном индексе, используя тип поля join.
Запрос has_child медленнее, чем другие запросы, из-за операции соединения, которую он выполняет. Производительность снижается по мере увеличения количества соответствующих дочерних документов, указывающих на разные родительские документы. Каждый запрос has_child в вашем поиске может значительно повлиять на производительность запроса. Если вы придаете приоритет скорости, избегайте использования этого запроса или ограничьте его использование насколько возможно.
Пример
Перед тем как вы сможете выполнить запрос has_child, ваш индекс должен содержать поле join для установления родительско-дочерних отношений. Запрос на отображение индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
В этом примере вы настроите индекс, который содержит документы, представляющие продукты и их бренды.
Сначала создайте индекс и установите родительско-дочерние отношения между брендом и продуктом:
PUT testindex1
{
"mappings": {
"properties": {
"product_to_brand": {
"type": "join",
"relations": {
"brand": "product"
}
}
}
}
}
Индексуйте два родительских (брендовых) документа:
PUT testindex1/_doc/1
{
"name": "Luxury brand",
"product_to_brand" : "brand"
}
PUT testindex1/_doc/2
{
"name": "Economy brand",
"product_to_brand" : "brand"
}
Индексуйте три дочерних (продуктовых) документа:
PUT testindex1/_doc/3?routing=1
{
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
PUT testindex1/_doc/4?routing=2
{
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
PUT testindex1/_doc/5?routing=2
{
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
Чтобы найти родителя дочернего документа, используйте запрос has_child. Следующий запрос возвращает родительские документы (бренды), которые производят часы:
GET testindex1/_search
{
"query" : {
"has_child": {
"type":"product",
"query": {
"match" : {
"name": "watch"
}
}
}
}
}
Ответ возвращает оба бренда:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 1,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
Извлечение внутренних результатов (inner hits)
Чтобы вернуть дочерние документы, которые соответствуют запросу, укажите параметр inner_hits:
GET testindex1/_search
{
"query" : {
"has_child": {
"type":"product",
"query": {
"match" : {
"name": "watch"
}
},
"inner_hits": {}
}
}
}
Ответ содержит дочерние документы в поле inner_hits:
{
"took": 52,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
},
"inner_hits": {
"product": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.53899646,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 0.53899646,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
}
]
}
}
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 1,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
},
"inner_hits": {
"product": {
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.53899646,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 0.53899646,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 0.53899646,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
}
}
]
}
}
Для получения дополнительной информации о извлечении внутренних результатов, смотрите раздел “Внутренние результаты” (Inner hits).
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами has_child.
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
| type | Обязательный | Указывает имя дочерней связи, как определено в отображении поля join. |
| query | Обязательный | Запрос, который будет выполнен на дочерних документах. Если дочерний документ соответствует запросу, возвращается родительский документ. |
| ignore_unmapped | Необязательный | Указывает, следует ли игнорировать неотображаемые поля типов и не возвращать документы вместо того, чтобы вызывать ошибку. Этот параметр можно указать при запросе нескольких индексов, некоторые из которых могут не содержать поле типа. По умолчанию false. |
| max_children | Необязательный | Максимальное количество соответствующих дочерних документов для родительского документа. Если превышено, родительский документ исключается из результатов поиска. |
| min_children | Необязательный | Минимальное количество соответствующих дочерних документов, необходимых для включения родительского документа в результаты. Если не достигнуто, родитель исключается. По умолчанию 1. |
| score_mode | Необязательный | Определяет, как оценки соответствующих дочерних документов влияют на оценку родительского документа. Допустимые значения: |
| - none: Игнорирует оценки релевантности дочерних документов и присваивает родительскому документу оценку 0. | ||
| - avg: Использует среднюю оценку релевантности всех соответствующих дочерних документов. | ||
| - max: Присваивает наивысшую оценку релевантности из соответствующих дочерних документов родителю. | ||
| - min: Присваивает наименьшую оценку релевантности из соответствующих дочерних документов родителю. | ||
| - sum: Суммирует оценки релевантности всех соответствующих дочерних документов. | ||
| По умолчанию none. | ||
| inner_hits | Необязательный | Если указан, возвращает внутренние результаты (дочерние документы), которые соответствуют запросу. |
Ограничения сортировки
Запрос has_child не поддерживает сортировку результатов с использованием стандартных опций сортировки. Если вам необходимо отсортировать родительские документы по полям их дочерних документов, вы можете использовать запрос function_score и сортировать по оценке родительского документа.
В приведенном выше примере вы можете отсортировать родительские документы (бренды) на основе поля sales_count их дочерних продуктов. Этот запрос умножает оценку на поле sales_count дочерних документов и присваивает наивысшую оценку релевантности из соответствующих дочерних документов родителю:
GET testindex1/_search
{
"query": {
"has_child": {
"type": "product",
"query": {
"function_score": {
"script_score": {
"script": "_score * doc['sales_count'].value"
}
}
},
"score_mode": "max"
}
}
}
Ответ содержит бренды, отсортированные по наивысшему значению sales_count дочерних документов:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 300,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 300,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
},
{
"_index": "testindex1",
"_id": "1",
"_score": 150,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
}
}
]
}
}
8.3.7.2 - Запрос has_parent
Запрос has_parent возвращает дочерние документы, родительские документы которых соответствуют определенному запросу.
Запрос has_parent возвращает дочерние документы, родительские документы которых соответствуют определенному запросу. Вы можете установить родительско-дочерние отношения между документами в одном индексе, используя тип поля join.
Запрос has_parent медленнее, чем другие запросы, из-за операции соединения, которую он выполняет. Производительность снижается по мере увеличения количества соответствующих родительских документов. Каждый запрос has_parent в вашем поиске может значительно повлиять на производительность запроса. Если вы придаете приоритет скорости, избегайте использования этого запроса или ограничьте его использование насколько возможно.
Пример
Перед тем как вы сможете выполнить запрос has_parent, ваш индекс должен содержать поле join для установления родительско-дочерних отношений. Запрос на отображение индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
Для этого примера сначала настройте индекс, который содержит документы, представляющие продукты и их бренды, как описано в примере запроса has_child.
Чтобы найти дочерний документ родителя, используйте запрос has_parent. Следующий запрос возвращает дочерние документы (продукты), произведенные брендом, соответствующим запросу “economy”:
GET testindex1/_search
{
"query" : {
"has_parent": {
"parent_type":"brand",
"query": {
"match" : {
"name": "economy"
}
}
}
}
}
Ответ возвращает все продукты, произведенные брендом:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
Извлечение внутренних результатов (inner hits)
Чтобы вернуть родительские документы, которые соответствуют запросу, укажите параметр inner_hits:
GET testindex1/_search
{
"query" : {
"has_parent": {
"parent_type":"brand",
"query": {
"match" : {
"name": "economy"
}
},
"inner_hits": {}
}
}
}
Ответ содержит родительские документы в поле inner_hits:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
},
"inner_hits": {
"brand": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 1.3862942,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
},
"inner_hits": {
"brand": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 1.3862942,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
}
}
]
}
}
Для получения дополнительной информации о извлечении внутренних результатов, смотрите раздел “Внутренние результаты” (Inner hits).
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами has_parent.
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
| parent_type | Обязательный | Указывает имя родительской связи, как определено в отображении поля join. |
| query | Обязательный | Запрос, который будет выполнен на родительских документах. Если родительский документ соответствует запросу, возвращается дочерний документ. |
| ignore_unmapped | Необязательный | Указывает, следует ли игнорировать неотображаемые поля типа parent_type и не возвращать документы вместо того, чтобы вызывать ошибку. Этот параметр можно указать при запросе нескольких индексов, некоторые из которых могут не содержать поле parent_type. По умолчанию false. |
| score | Необязательный | Указывает, учитывается ли оценка релевантности соответствующего родительского документа в дочерних документах. Если false, то оценка релевантности родительского документа игнорируется, и каждому дочернему документу присваивается оценка релевантности, равная коэффициенту увеличения запроса, который по умолчанию равен 1. Если true, то оценка релевантности соответствующего родительского документа агрегируется в оценки релевантности его дочерних документов. По умолчанию false. |
| inner_hits | Необязательный | Если указан, возвращает внутренние результаты (родительские документы), которые соответствуют запросу. |
Ограничения сортировки
Запрос has_parent не поддерживает сортировку результатов с использованием стандартных опций сортировки. Если вам необходимо отсортировать дочерние документы по полям их родительских документов, вы можете использовать запрос function_score и сортировать по оценке дочернего документа.
Для предыдущего примера сначала добавьте поле customer_satisfaction, по которому вы будете сортировать дочерние документы, принадлежащие родительским (брендовым) документам:
PUT testindex1/_doc/1
{
"name": "Luxury watch brand",
"product_to_brand" : "brand",
"customer_satisfaction": 4.5
}
PUT testindex1/_doc/2
{
"name": "Economy watch brand",
"product_to_brand" : "brand",
"customer_satisfaction": 3.9
}
Теперь вы можете сортировать дочерние документы (продукты) на основе поля customer_satisfaction их родительских брендов. Этот запрос умножает оценку на поле customer_satisfaction родительских документов:
GET testindex1/_search
{
"query": {
"has_parent": {
"parent_type": "brand",
"score": true,
"query": {
"function_score": {
"script_score": {
"script": "_score * doc['customer_satisfaction'].value"
}
}
}
}
}
}
Ответ содержит продукты, отсортированные по наивысшему значению customer_satisfaction родительских документов:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 4.5,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 4.5,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
},
{
"_index": "testindex1",
"_id": "4",
"_score": 3.9,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 3.9,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
8.3.7.3 - Вложенный запрос
Вложенный запрос служит оберткой для других запросов, позволяя искать во вложенных полях.
Вложенный запрос служит оберткой для других запросов, позволяя искать во вложенных полях. Объекты вложенных полей ищутся так, как будто они индексированы как отдельные документы. Если объект соответствует запросу, вложенный запрос возвращает родительский документ на корневом уровне.
Пример
Перед тем как выполнить вложенный запрос, ваш индекс должен содержать вложенное поле.
Чтобы настроить пример индекса, содержащего вложенные поля, отправьте следующий запрос:
PUT /testindex
{
"mappings": {
"properties": {
"patient": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
}
}
Далее, индексируйте документ в пример индекса:
PUT /testindex/_doc/1
{
"patient": {
"name": "John Doe",
"age": 56
}
}
Чтобы выполнить поиск по вложенному полю пациента, оберните ваш запрос во вложенный запрос и укажите путь к вложенному полю:
GET /testindex/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"match": {
"patient.name": "John"
}
}
}
}
}
Запрос возвращает соответствующий документ:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.2876821,
"_source": {
"patient": {
"name": "John Doe",
"age": 56
}
}
}
]
}
}
Получение внутренних результатов
Чтобы вернуть внутренние результаты, соответствующие запросу, укажите параметр inner_hits:
GET /testindex/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"match": {
"patient.name": "John"
}
},
"inner_hits": {}
}
}
}
Ответ содержит дополнительное поле inner_hits. Поле _nested идентифицирует конкретный внутренний объект, из которого произошел внутренний результат. Оно содержит вложенный результат и смещение относительно его положения в _source. Из-за сортировки и оценки положение объектов результатов во inner_hits часто отличается от их исходного местоположения во вложенном объекте.
По умолчанию _source объектов результатов внутри inner_hits возвращается относительно поля _nested. В этом примере _source внутри inner_hits содержит поля name и age, в отличие от верхнего уровня _source, который содержит весь объект пациента:
{
"took": 38,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.2876821,
"_source": {
"patient": {
"name": "John Doe",
"age": 56
}
},
"inner_hits": {
"patient": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_nested": {
"field": "patient",
"offset": 0
},
"_score": 0.2876821,
"_source": {
"name": "John Doe",
"age": 56
}
}
]
}
}
}
}
]
}
}
Многоуровневые вложенные запросы
Вы можете искать документы, которые содержат вложенные объекты внутри других вложенных объектов, используя многоуровневые вложенные запросы. В этом примере вы будете запрашивать несколько уровней вложенных полей, указывая вложенный запрос для каждого уровня иерархии.
Создание индекса с многоуровневыми вложенными полями
Сначала создайте индекс с многоуровневыми вложенными полями:
PUT /patients
{
"mappings": {
"properties": {
"patient": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"contacts": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"relationship": {
"type": "text"
},
"phone": {
"type": "keyword"
}
}
}
}
}
}
}
}
Индексация документа
Далее, индексируйте документ в пример индекса:
PUT /patients/_doc/1
{
"patient": {
"name": "John Doe",
"contacts": [
{
"name": "Jane Doe",
"relationship": "mother",
"phone": "5551111"
},
{
"name": "Joe Doe",
"relationship": "father",
"phone": "5552222"
}
]
}
}
Поиск по вложенному полю пациента
Чтобы выполнить поиск по вложенному полю пациента, используйте многоуровневый вложенный запрос. Следующий запрос ищет пациентов, чья контактная информация включает человека по имени Джейн с отношением “мать”:
GET /patients/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"nested": {
"path": "patient.contacts",
"query": {
"bool": {
"must": [
{ "match": { "patient.contacts.relationship": "mother" } },
{ "match": { "patient.contacts.name": "Jane" } }
]
}
}
}
}
}
}
}
Результаты запроса
Запрос возвращает пациента, у которого есть контактная запись, соответствующая этим данным:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "patients",
"_id": "1",
"_score": 1.3862942,
"_source": {
"patient": {
"name": "John Doe",
"contacts": [
{
"name": "Jane Doe",
"relationship": "mother",
"phone": "5551111"
},
{
"name": "Joe Doe",
"relationship": "father",
"phone": "5552222"
}
]
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые вложенными запросами.
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
| path | Обязательный | Указывает путь к вложенному объекту, который вы хотите искать. |
| query | Обязательный | Запрос, который будет выполнен на вложенных объектах в указанном пути. Если вложенный объект соответствует запросу, возвращается корневой родительский документ. Вы можете искать вложенные поля, используя нотацию с точками, например, nested_object.subfield. Поддерживается многоуровневое вложение, которое автоматически определяется. Таким образом, внутренний вложенный запрос внутри другого вложенного запроса автоматически соответствует правильному уровню вложенности, а не корню. |
| ignore_unmapped | Необязательный | Указывает, следует ли игнорировать неразмеченные поля пути и не возвращать документы вместо того, чтобы вызывать ошибку. Вы можете указать этот параметр при запросе нескольких индексов, некоторые из которых могут не содержать поле пути. По умолчанию значение - false. |
| score_mode | Необязательный | Определяет, как оценки соответствующих внутренних документов влияют на оценку родительского документа. Допустимые значения: - avg: Использует среднюю релевантность всех соответствующих внутренних документов. - max: Присваивает наивысшую релевантность из соответствующих внутренних документов родителю. - min: Присваивает наименьшую релевантность из соответствующих внутренних документов родителю. - sum: Суммирует релевантности всех соответствующих внутренних документов. - none: Игнорирует релевантности внутренних документов и присваивает оценку 0 родительскому документу. По умолчанию - avg. |
| inner_hits | Необязательный | Если указан, возвращает внутренние результаты, которые соответствуют запросу. |
8.3.7.4 - Запрос по идентификатору родителя
апрос parent_id возвращает дочерние документы, у которых родительский документ имеет указанный идентификатор.
Запрос parent_id возвращает дочерние документы, у которых родительский документ имеет указанный идентификатор. Вы можете установить отношения родитель/дочерний между документами в одном индексе, используя тип поля join.
Пример
Перед тем как выполнить запрос parent_id, ваш индекс должен содержать поле join, чтобы установить отношения родитель/дочерний. Запрос на создание индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
Для этого примера сначала настройте индекс, который содержит документы, представляющие продукты и их бренды, как описано в примере запроса has_child.
Чтобы искать дочерние документы конкретного родительского документа, используйте запрос parent_id. Следующий запрос возвращает дочерние документы (продукты), у которых родительский документ имеет идентификатор 1:
GET testindex1/_search
{
"query": {
"parent_id": {
"type": "product",
"id": "1"
}
}
}
Ответ возвращает дочерний продукт:
{
"took": 57,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.87546873,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 0.87546873,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами parent_id.
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
| type | Обязательный | Указывает имя дочерней связи, как определено в сопоставлении поля join. |
| id | Обязательный | Идентификатор родительского документа. Запрос возвращает дочерние документы, связанные с этим родительским документом. |
| ignore_unmapped | Необязательный | Указывает, следует ли игнорировать неразмеченные поля типа и не возвращать документы вместо того, чтобы вызывать ошибку. Вы можете указать этот параметр при запросе нескольких индексов, некоторые из которых могут не содержать поле типа. По умолчанию значение - false. |
8.3.8 - Запросы Span
Запросы Span являются низкоуровневыми, специфическими запросами, которые предоставляют контроль над порядком и близостью указанных терминов запроса.
Вы можете использовать запросы Span для выполнения точных позиционных поисков. Запросы Span являются низкоуровневыми, специфическими запросами, которые предоставляют контроль над порядком и близостью указанных терминов запроса. Они в основном используются для поиска юридических документов и патентов.
Запросы Span включают следующие типы запросов:
Span containing
Возвращает более крупные диапазоны, которые содержат меньшие диапазоны внутри них. Полезно для поиска конкретных терминов или фраз в более широком контексте. Противоположность запросу span_within.
Span field masking
Позволяет запросам Span работать с различными полями, заставляя одно поле выглядеть как другое. Особенно полезно, когда один и тот же текст индексируется с использованием различных анализаторов.
Span first
Совпадает с терминами или фразами, которые появляются в пределах указанного количества позиций от начала поля. Полезно для поиска контента в начале текста.
Span multi-term
Позволяет многотерминным запросам (таким как префиксные, с подстановочными знаками или нечеткие) работать в рамках запросов Span. Позволяет использовать более гибкие шаблоны соответствия в поисках Span.
Span near
Находит термины или фразы, которые появляются на указанном расстоянии друг от друга. Вы можете требовать, чтобы совпадения появлялись в определенном порядке и контролировать, сколько слов может находиться между ними.
Span not
Исключает совпадения, которые пересекаются с другим запросом Span. Полезно для поиска терминов, когда они не появляются в конкретных фразах или контекстах.
Span or
Совпадает с документами, которые удовлетворяют любому из предоставленных запросов Span. Объединяет несколько шаблонов Span с логикой OR.
Span term
Основной строительный блок для запросов Span. Совпадает с одним термином, сохраняя информацию о позиции для использования в других запросах Span.
Span within
Возвращает меньшие диапазоны, которые заключены в более крупные диапазоны. Противоположность запросу span_containing.
Настройка
Чтобы попробовать примеры в этом разделе, выполните следующие шаги для настройки примера индекса.
Шаг 1: Создание индекса
Сначала создайте индекс для веб-сайта электронной коммерции по продаже одежды. Поле описания использует стандартный анализатор по умолчанию, в то время как подполе description.stemmed применяет английский анализатор для включения стемминга:
PUT /clothing
{
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "standard",
"fields": {
"stemmed": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Шаг 2: Индексация данных
Индексиуйте образцы документов в индекс:
POST /clothing/_doc/1
{
"description": "Рубашка с длинными рукавами и формальным воротником с пуговицами."
}
POST /clothing/_doc/2
{
"description": "Красивое длинное платье из красного шелка, идеально подходит для формальных мероприятий."
}
POST /clothing/_doc/3
{
"description": "Рубашка с короткими рукавами и воротником на пуговицах, можно носить как в повседневном, так и в формальном стиле."
}
POST /clothing/_doc/4
{
"description": "Комплект из двух шелковых платьев-рубашек миди с длинными рукавами черного цвета."
}
8.3.8.1 - Запрос Span containing
Запрос span_containing находит совпадения, где более крупный текстовый шаблон (например, фраза или набор слов) содержит меньший текстовый шаблон в своих границах.
Рассматривайте это как поиск слова или фразы, но только когда они появляются в определенном более широком контексте.
Например, вы можете использовать запрос span_containing для выполнения следующих поисков:
- Найти слово “quick”, но только когда оно появляется в предложениях, которые упоминают как лисиц, так и поведение.
- Убедиться, что определенные термины появляются в контексте других терминов — не просто где-то в документе.
- Искать конкретные слова, которые появляются в рамках более значимых фраз.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет вхождения слова “red”, которые появляются в более крупном диапазоне, содержащем слова “silk” и “dress” (не обязательно в этом порядке) в пределах 5 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_containing": {
"little": {
"span_term": {
"description": "red"
}
},
"big": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "silk"
}
},
{
"span_term": {
"description": "dress"
}
}
],
"slop": 5,
"in_order": false
}
}
}
}
}
Запрос соответствует документу 1, потому что:
- Он находит диапазон, в котором “silk” и “dress” появляются на расстоянии не более 5 слов друг от друга ("…dress in red silk…"). Термины “silk” и “dress” находятся на расстоянии 2 слов друг от друга (между ними 2 слова).
- Внутри этого более крупного диапазона он находит термин “red”.
Ответ
Оба параметра little и big могут содержать любой тип запроса span, что позволяет создавать сложные вложенные запросы span при необходимости.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_containing. Все параметры обязательны.
| Параметр | Тип данных | Описание |
|---|---|---|
| little | Объект | Запрос span, который должен быть содержим внутри большого диапазона. Это определяет диапазон, который вы ищете в более широком контексте. |
| big | Объект | Содержащий запрос span, который определяет границы, в пределах которых должен появиться маленький диапазон. Это устанавливает контекст для вашего поиска. |
8.3.8.2 - Запрос Span field masking
Запрос field_masking_span позволяет запросам Span соответствовать различным полям, “маскируя” истинное поле запроса.
Это особенно полезно при работе с многопольными индексами (один и тот же контент индексируется с использованием различных анализаторов) или когда вам нужно выполнять запросы Span, такие как span_near или span_or, по различным полям (что обычно не разрешено).
Например, вы можете использовать запрос field_masking_span для:
- Совпадения терминов между сырым полем и его стеммированной версией.
- Объединения запросов Span по различным полям в одной операции Span.
- Работы с одним и тем же контентом, индексированным с использованием различных анализаторов.
При использовании маскирования поля релевантность рассчитывается с использованием характеристик (норм) маскированного поля, а не фактического поля, по которому выполняется поиск. Это означает, что если маскированное поле имеет другие свойства (например, длину или значения увеличения), чем поле, по которому выполняется поиск, вы можете получить неожиданные результаты оценки.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “long” рядом с вариациями слова “sleeve” в стеммированном поле:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "long"
}
},
{
"field_masking_span": {
"query": {
"span_term": {
"description.stemmed": "sleev"
}
},
"field": "description"
}
}
],
"slop": 1,
"in_order": true
}
}
}
Запрос соответствует документам 1 и 4:
- Термин “long” появляется в поле описания в обоих документах.
- Документ 1 содержит слово “sleeved”, а документ 4 содержит слово “sleeves”.
- Запрос field_masking_span делает так, что совпадение стеммированного поля выглядит так, как будто оно находится в сыром поле.
- Термины появляются на расстоянии 1 позиции друг от друга в указанном порядке (“long” должен появляться перед “sleeve”).
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.7444251,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 0.7444251,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.4291246,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами field_masking_span. Все параметры обязательны.
| Параметр | Тип данных | Описание |
|---|---|---|
| query | Объект | Запрос span, который будет выполнен на фактическом поле. |
| field | Строка | Имя поля, используемое для маскирования запроса. Другие запросы span будут рассматривать этот запрос так, как будто он выполняется на этом поле. |
8.3.8.3 - Запрос Span first
Запрос span_first соответствует диапазонам, которые начинаются в начале поля и заканчиваются в пределах указанного количества позиций.
Этот запрос полезен, когда вы хотите найти термины или фразы, которые появляются в начале документа.
Например, вы можете использовать запрос span_first для выполнения следующих поисков:
- Найти документы, в которых определенные термины появляются в первых нескольких словах поля.
- Убедиться, что определенные фразы встречаются в начале текста или рядом с ним.
- Совпадать с шаблонами только тогда, когда они появляются в пределах указанного расстояния от начала.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет стеммированное слово “dress”, которое появляется в первых 4 позициях поля описания:
GET /clothing/_search
{
"query": {
"span_first": {
"match": {
"span_term": {
"description.stemmed": "dress"
}
},
"end": 4
}
}
}
Запрос соответствует документам 1 и 2:
- Документы 1 и 2 содержат слово “dress” на третьей позиции (“Long-sleeved dress…” и “Beautiful long dress”). Индексация слов начинается с 0, поэтому слово “dress” находится на позиции 2.
- Позиция слова “dress” должна быть меньше 4, как указано в параметре end.
Ответ
Параметр match может содержать любой тип запроса span, что позволяет сопоставлять более сложные шаблоны в начале полей.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_first. Все параметры обязательны.
| Параметр | Тип данных | Описание |
|---|---|---|
| match | Объект | Запрос span для соответствия. Это определяет шаблон, который вы ищете в начале поля. |
| end | Целое число | Максимальная конечная позиция (исключительно), разрешенная для совпадения запроса span. Например, end: 4 соответствует терминам на позициях 0–3. |
8.3.8.4 - Запрос Span multi-term
Запрос span_multi позволяет обернуть многотерминный запрос (например, с подстановочными знаками, нечеткий, префиксный, диапазонный или регулярное выражение) в запрос Span.
Это позволяет использовать более гибкие запросы соответствия внутри других запросов Span.
Например, вы можете использовать запрос span_multi для:
- Поиска слов с общими префиксами рядом с другими терминами.
- Совпадения нечетких вариаций слов в пределах диапазонов.
- Использования регулярных выражений в запросах Span.
Запросы span_multi могут потенциально соответствовать многим терминам. Чтобы избежать чрезмерного использования памяти, вы можете:
- Установить параметр rewrite для многотерминного запроса.
- Использовать метод переписывания top_terms_*.
- Рассмотреть возможность включения опции index_prefixes для текстового поля, если вы используете span_multi только для префиксного запроса. Это автоматически переписывает любой префиксный запрос на поле в однотерминный запрос, который соответствует индексированному префиксу.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Запрос span_multi использует следующую синтаксис для обертывания префиксного запроса:
"span_multi": {
"match": {
"prefix": {
"description": {
"value": "flutter"
}
}
}
}
Следующий запрос ищет слова, начинающиеся с “dress”, рядом с любой формой “sleeve” в пределах 5 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_multi": {
"match": {
"prefix": {
"description": {
"value": "dress"
}
}
}
}
},
{
"field_masking_span": {
"query": {
"span_term": {
"description.stemmed": "sleev"
}
},
"field": "description"
}
}
],
"slop": 5,
"in_order": false
}
}
}
Запрос соответствует документам 1 (“Long-sleeved dress…”) и 4 ("…dresses with long fluttered sleeves…"), потому что “dress” и “long” встречаются в пределах максимального расстояния в обоих документах.
Ответ
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.7590723,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 1.7590723,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.84792376,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_multi. Все параметры обязательны.
| Параметр | Тип данных | Описание |
|---|---|---|
| match | Объект | Многотерминный запрос для обертывания (может быть префиксным, с подстановочными знаками, нечетким, диапазонным или регулярным выражением). |
8.3.8.5 - Запрос Span near
Запрос span_near соответствует диапазонам, которые находятся близко друг к другу.
Вы можете указать, насколько далеко могут находиться диапазоны и нужно ли, чтобы они появлялись в определенном порядке.
Например, вы можете использовать запрос span_near для:
- Поиска терминов, которые появляются на определенном расстоянии друг от друга.
- Совпадения фраз, в которых слова появляются в определенном порядке.
- Поиска связанных концепций, которые находятся близко друг к другу в тексте.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет любые формы слова “sleeve” и “long”, которые появляются рядом друг с другом в любом порядке:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_term": {
"description.stemmed": "sleev"
}
},
{
"span_term": {
"description.stemmed": "long"
}
}
],
"slop": 1,
"in_order": false
}
}
}
Запрос соответствует документам 1 (“Long-sleeved…”) и 2 ("…long fluttered sleeves…"). В документе 1 слова находятся рядом друг с другом, в то время как в документе 2 они находятся в пределах указанного расстояния slop равного 1 (между ними 1 слово).
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.36496973,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 0.36496973,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.25312424,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Запрос span_near позволяет находить термины и фразы, которые имеют определенные отношения по близости и порядку, что делает его полезным для анализа текстов и поиска связанных понятий.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_near.
| Параметр | Тип данных | Описание |
|---|---|---|
| clauses | Массив | Массив запросов span, которые определяют термины или фразы для соответствия. Все указанные термины должны появляться в пределах заданного расстояния slop. Обязательный параметр. |
| slop | Целое число | Максимальное количество промежуточных несоответствующих позиций между диапазонами. Обязательный параметр. |
| in_order | Логический | Указывает, должны ли диапазоны появляться в том же порядке, что и в массиве clauses. Необязательный параметр. По умолчанию false. |
8.3.8.6 - span_not
Запрос Span not
Запрос span_not исключает диапазоны, которые пересекаются с другим запросом span. Вы также можете указать расстояние до или после исключенных диапазонов, в пределах которого совпадения не могут происходить.
Например, вы можете использовать запрос span_not для:
- Поиска терминов, кроме тех случаев, когда они появляются в определенных фразах.
- Совпадения диапазонов, если они не находятся рядом с определенными терминами.
- Исключения совпадений, которые происходят в пределах определенного расстояния от других шаблонов.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “dress”, но не когда оно появляется в фразе “dress shirt”:
GET /clothing/_search
{
"query": {
"span_not": {
"include": {
"span_term": {
"description": "dress"
}
},
"exclude": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "dress"
}
},
{
"span_term": {
"description": "shirt"
}
}
],
"slop": 0,
"in_order": true
}
}
}
}
}
Запрос соответствует документу 2, потому что он содержит слово “dress” (“Beautiful long dress…”). Документ 1 не соответствует, потому что он содержит фразу “dress shirt”, которая исключена. Документы 3 и 4 не соответствуют, потому что они содержат вариации слова “dress” (“dressed” и “dresses”), а запрос ищет в сыром поле.
Ответ
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_not.
| Параметр | Тип данных | Описание |
|---|---|---|
| include | Объект | Запрос span, совпадения которого вы хотите найти. Обязательный параметр. |
| exclude | Объект | Запрос span, совпадения которого должны быть исключены. Обязательный параметр. |
| pre | Целое число | Указывает, что исключенный диапазон не может появляться в пределах указанного количества позиций токенов перед включенным диапазоном. Необязательный параметр. По умолчанию 0. |
| post | Целое число | Указывает, что исключенный диапазон не может появляться в пределах указанного количества позиций токенов после включенного диапазона. Необязательный параметр. По умолчанию 0. |
| dist | Целое число | Эквивалентно установке как pre, так и post на одно и то же значение. Необязательный параметр. |
8.3.8.7 - Запрос Span or
Запрос span_or объединяет несколько запросов span и соответствует объединению их диапазонов.
Совпадение происходит, если хотя бы один из содержащихся запросов span соответствует.
Например, вы можете использовать запрос span_or для:
- Поиска диапазонов, соответствующих любому из нескольких шаблонов.
- Объединения различных шаблонов span в качестве альтернатив.
- Совпадения нескольких вариаций span в одном запросе.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет либо “formal collar”, либо “button collar”, которые появляются в пределах 2 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_or": {
"clauses": [
{
"span_near": {
"clauses": [
{
"span_term": {
"description": "formal"
}
},
{
"span_term": {
"description": "collar"
}
}
],
"slop": 0,
"in_order": true
}
},
{
"span_near": {
"clauses": [
{
"span_term": {
"description": "button"
}
},
{
"span_term": {
"description": "collar"
}
}
],
"slop": 2,
"in_order": true
}
}
]
}
}
}
Запрос соответствует документам 1 ("…formal collar…") и 3 ("…button-down collar…") в пределах указанного расстояния slop.
Ответ
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.170027,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 2.170027,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "3",
"_score": 1.2509141,
"_source": {
"description": "Short-sleeved shirt with a button-down collar, can be dressed up or down."
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_or.
| Параметр | Тип данных | Описание |
|---|---|---|
| clauses | Массив | Массив запросов span для соответствия. Запрос соответствует, если любой из этих запросов span совпадает. Должен содержать как минимум один запрос span. Обязательный параметр. |
8.3.8.8 - Запрос Span term
Запрос span_term является самым базовым запросом span, который соответствует диапазонам, содержащим один термин.
Он служит строительным блоком для более сложных запросов span.
Например, вы можете использовать запрос span_term для:
- Поиска точных совпадений термина, которые могут быть использованы в других запросах span.
- Совпадения конкретных слов с сохранением информации о позиции.
- Создания базовых диапазонов, которые могут быть объединены с другими запросами span.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет точный термин “formal”:
GET /clothing/_search
{
"query": {
"span_term": {
"description": "formal"
}
}
}
В качестве альтернативы вы можете указать искомый термин в параметре value:
GET /clothing/_search
{
"query": {
"span_term": {
"description": {
"value": "formal"
}
}
}
}
Вы также можете указать значение boost, чтобы увеличить оценку документа:
GET /clothing/_search
{
"query": {
"span_term": {
"description": {
"value": "formal",
"boost": 2
}
}
}
}
Запрос соответствует документам 1 и 2, потому что они содержат точный термин “formal”. Информация о позиции сохраняется для использования в других запросах span.
Ответ
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.498922,
"hits": [
{
"_index": "clothing",
"_id": "2",
"_score": 1.498922,
"_source": {
"description": "Beautiful long dress in red silk, perfect for formal events."
}
},
{
"_index": "clothing",
"_id": "1",
"_score": 1.4466847,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_term.
| Параметр | Тип данных | Описание |
|---|---|---|
| Строка или объект | Имя поля, в котором нужно выполнить поиск. |
8.3.8.9 - Запрос Span within
Запрос span_within соответствует диапазонам, которые заключены в другой запрос span.
Это противоположность запросу span_containing: span_containing возвращает более крупные диапазоны, содержащие меньшие, в то время как span_within возвращает меньшие диапазоны, заключенные в более крупные.
Например, вы можете использовать запрос span_within для:
- Поиска более коротких фраз, которые появляются внутри более длинных фраз.
- Совпадения терминов, которые встречаются в определенных контекстах.
- Идентификации меньших шаблонов, заключенных в более крупные шаблоны.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “dress”, когда оно появляется внутри диапазона, содержащего “shirt” и “long”:
GET /clothing/_search
{
"query": {
"span_within": {
"little": {
"span_term": {
"description": "dress"
}
},
"big": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "shirt"
}
},
{
"span_term": {
"description": "long"
}
}
],
"slop": 2,
"in_order": false
}
}
}
}
}
Запрос соответствует документу 1, потому что:
- Слово “dress” появляется внутри более крупного диапазона (“Long-sleeved dress shirt…”).
- Более крупный диапазон содержит “shirt” и “long” в пределах 2 слов друг от друга (между ними 2 слова).
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.4677674,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 1.4677674,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_within. Все параметры обязательны.
| Параметр | Тип данных | Описание |
|---|---|---|
| little | Объект | Запрос span, который должен быть содержим внутри большого диапазона. Это определяет диапазон, который вы ищете в более широком контексте. |
| big | Объект | Содержащий запрос span, который определяет границы, в пределах которых должен появиться маленький диапазон. Это устанавливает контекст для вашего поиска. |
8.3.9 - Запрос Match all
Запрос match_all возвращает все документы. Этот запрос может быть полезен для тестирования больших наборов документов, если вам нужно вернуть весь набор.
GET _search
{
"query": {
"match_all": {}
}
}
Запрос match_all имеет аналог match_none, который редко бывает полезен:
GET _search
{
"query": {
"match_none": {}
}
}
Параметры
Оба запроса match_all и match_none принимают следующие параметры. Все параметры являются необязательными.
| Параметр | Тип данных | Описание |
|---|---|---|
| boost | Число с плавающей запятой | Значение с плавающей запятой, которое указывает на вес этого поля в отношении оценки релевантности. Значения выше 1.0 увеличивают релевантность поля. Значения от 0.0 до 1.0 уменьшают релевантность поля. По умолчанию 1.0. |
| _name | Строка | Имя запроса для тегирования запроса. Необязательный параметр. |
8.3.10 - Специализированные запросы
OpenSearch поддерживает следующие специализированные запросы: distance_feature, more_like_this и др.
distance_feature: Вычисляет оценки документов на основе динамически рассчитанного расстояния между исходной точкой и полями даты, date_nanos или geo_point документа. Этот запрос может пропускать неконкурентные результаты.
more_like_this: Находит документы, похожие на предоставленный текст, документ или коллекцию документов.
knn: Используется для поиска сырых векторов во время векторного поиска.
neural: Используется для поиска по тексту или изображению в векторном поиске.
neural_sparse: Используется для поиска по векторным полям в разреженном нейронном поиске.
percolate: Находит запросы (сохраненные в виде документов), которые соответствуют предоставленному документу.
rank_feature: Вычисляет оценки на основе значений числовых признаков. Этот запрос может пропускать неконкурентные результаты.
script: Использует скрипт в качестве фильтра.
script_score: Вычисляет пользовательскую оценку для соответствующих документов с использованием скрипта.
wrapper: Принимает другие запросы в виде строк JSON или YAML.
8.3.10.1 - distance_feature
distance_feature для увеличения релевантности документов, которые ближе к определенной дате или географической точке.
Используйте запрос distance_feature для увеличения релевантности документов, которые ближе к определенной дате или географической точке. Это может помочь вам приоритизировать более свежий или близкий контент в результатах поиска. Например, вы можете присвоить больший вес продуктам, произведенным более недавно, или повысить рейтинг товаров, находящихся ближе к указанному пользователем местоположению.
Вы можете применять этот запрос к полям, содержащим данные о дате или местоположении. Он часто используется в условии should запроса bool для улучшения оценки релевантности без фильтрации результатов.
Настройка индекса
Перед использованием запроса distance_feature убедитесь, что ваш индекс содержит хотя бы один из следующих типов полей:
- date
- date_nanos
- geo_point
В этом примере вы настроите поля opening_date и coordinates, которые можно использовать для выполнения запросов distance_feature:
PUT /stores
{
"mappings": {
"properties": {
"opening_date": {
"type": "date"
},
"coordinates": {
"type": "geo_point"
}
}
}
}
Добавьте пример документов в индекс:
PUT /stores/_doc/1
{
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [74.00, 40.70]
}
PUT /stores/_doc/2
{
"store_name": "Fresh Foods",
"opening_date": "2025-04-01",
"coordinates": [73.98, 40.75]
}
PUT /stores/_doc/3
{
"store_name": "City Organics",
"opening_date": "2021-04-20",
"coordinates": [74.02, 40.68]
}
Пример: Увеличение оценок на основе свежести
Следующий запрос ищет документы с store_name, соответствующим слову “market”, и увеличивает оценки недавно открытых магазинов:
GET /stores/_search
{
"query": {
"bool": {
"must": {
"match": {
"store_name": "market"
}
},
"should": {
"distance_feature": {
"field": "opening_date",
"origin": "2025-04-07",
"pivot": "10d"
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.2372394,
"hits": [
{
"_index": "stores",
"_id": "1",
"_score": 1.2372394,
"_source": {
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [
74,
40.7
]
}
}
]
}
}
Пример: Увеличение оценок на основе географической близости
Следующий запрос ищет документы с store_name, соответствующим слову “market”, и увеличивает результаты, находящиеся ближе к заданной исходной точке:
GET /stores/_search
{
"query": {
"bool": {
"must": {
"match": {
"store_name": "market"
}
},
"should": {
"distance_feature": {
"field": "coordinates",
"origin": [74.00, 40.71],
"pivot": "500m"
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.2910118,
"hits": [
{
"_index": "stores",
"_id": "1",
"_score": 1.2910118,
"_source": {
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [
74,
40.7
]
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами distance_feature.
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
| field | Обязательный | Имя поля, используемого для расчета расстояний. Должно быть полем типа date, date_nanos или geo_point с параметрами index: true (по умолчанию) и doc_values: true (по умолчанию). |
| origin | Обязательный | Точка отсчета, используемая для расчета расстояний. Используйте дату или математическое выражение даты (например, now-1h) для полей даты или геопункт для полей geo_point. |
| pivot | Обязательный | Расстояние от исходной точки, при котором оценки получают половину значения увеличения. Используйте единицу времени (например, 10d) для полей даты или единицу расстояния (например, 1km) для географических полей. Для получения дополнительной информации см. раздел “Единицы”. |
| boost | Необязательный | Множитель для оценки релевантности соответствующих документов. Должен быть неотрицательным числом с плавающей запятой. По умолчанию 1.0. |
Как рассчитываются оценки
Запрос distance_feature вычисляет оценку релевантности документа, используя следующую формулу: [ \text{score} = \text{boost} \cdot \frac {\text{pivot}} {\text{pivot} + \text{distance}} ]
где distance — это абсолютная разница между origin и значением поля.
Пропуск неконкурентных результатов
В отличие от других запросов, модифицирующих оценки, таких как запрос function_score, запрос distance_feature оптимизирован для эффективного пропуска неконкурентных результатов, когда отслеживание общего количества результатов (track_total_hits) отключено. Это позволяет улучшить производительность запросов, особенно при работе с большими объемами данных, так как система может сосредоточиться только на наиболее релевантных результатах.
8.3.10.2 - k-NN
Используйте запрос k-NN для выполнения поиска ближайших соседей по векторным полям.
Поля тела запроса
Укажите векторное поле в запросе k-NN и задайте дополнительные поля запроса в объекте векторного поля:
"knn": {
"<vector_field>": {
"vector": [<vector_values>],
"k": <k_value>,
...
}
}
Верхний уровень vector_field указывает на векторное поле, по которому будет выполняться запрос поиска. Следующая таблица перечисляет все поддерживаемые поля запроса.
| Поле | Тип данных | Обязательный/Необязательный | Описание |
|---|---|---|---|
| vector | Массив чисел с плавающей запятой или байтов | Обязательный | Вектор запроса, используемый для векторного поиска. Тип данных элементов вектора должен соответствовать типу данных векторов, индексированных в поле knn_vector. |
| k | Целое число | Необязательный | Количество ближайших соседей для возврата. Допустимые значения находятся в диапазоне [1, 10,000]. Обязательно, если не указаны max_distance или min_score. |
| max_distance | Число с плавающей запятой | Необязательный | Максимальный порог расстояния для результатов поиска. Можно указать только одно из k, max_distance или min_score. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| min_score | Число с плавающей запятой | Необязательный | Минимальный порог оценки для результатов поиска. Можно указать только одно из k, max_distance или min_score. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| filter | Объект | Необязательный | Фильтр, который применяется к поиску k-NN. Для получения дополнительной информации см. раздел “Векторный поиск с фильтрами”. Важно: фильтр можно использовать только с движками faiss или lucene. |
| method_parameters | Объект | Необязательный | Дополнительные параметры для тонкой настройки поиска: - ef_search (Целое число): количество векторов для проверки (для метода hnsw) - nprobes (Целое число): количество корзин для проверки (для метода ivf). Для получения дополнительной информации см. раздел “Указание параметров метода в запросе”. |
| rescore | Объект или логическое значение | Необязательный | Параметры для настройки функциональности повторной оценки: - oversample_factor (Число с плавающей запятой): контролирует, сколько кандидатных векторов извлекается перед повторной оценкой. Допустимые значения находятся в диапазоне [1.0, 100.0]. По умолчанию false для полей с режимом in_memory (без повторной оценки) и включено (с динамическими значениями) для полей с режимом on_disk. В режиме on_disk значение по умолчанию для oversample_factor определяется уровнем сжатия. Для получения дополнительной информации см. таблицу уровня сжатия. Чтобы явно включить повторную оценку с значением по умолчанию для oversample_factor равным 1.0, установите rescore в true. Для получения дополнительной информации см. раздел “Повторная оценка результатов”. |
| expand_nested_docs | Логическое значение | Необязательный | Если true, извлекает оценки для всех документов вложенных полей в каждом родительском документе. Используется с вложенными запросами. Для получения дополнительной информации см. раздел “Векторный поиск с вложенными полями”. |
Пример запроса
Запрос для выполнения поиска ближайших соседей:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [1.5, 2.5],
"k": 3
}
}
}
}
Пример запроса: Вложенные поля
Запрос для выполнения поиска ближайших соседей во вложенных полях:
GET /my-vector-index/_search
{
"_source": false,
"query": {
"nested": {
"path": "nested_field",
"query": {
"knn": {
"nested_field.my_vector": {
"vector": [1, 1, 1],
"k": 2,
"expand_nested_docs": true
}
}
},
"inner_hits": {
"_source": false,
"fields": ["nested_field.color"]
},
"score_mode": "max"
}
}
}
Пример запроса: Радиальный поиск с max_distance
Следующий пример демонстрирует радиальный поиск с использованием max_distance:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [
7.1,
8.3
],
"max_distance": 2
}
}
}
}
Пример запроса: Радиальный поиск с min_score
Следующий пример демонстрирует радиальный поиск с использованием min_score:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [7.1, 8.3],
"min_score": 0.95
}
}
}
}
Указание параметров метода в запросе
Начиная с версии 2.16, вы можете предоставлять параметры метода в запросе поиска:
GET /my-vector-index/_search
{
"size": 2,
"query": {
"knn": {
"target-field": {
"vector": [2, 3, 5, 6],
"k": 2,
"method_parameters": {
"ef_search": 100
}
}
}
}
}
Эти параметры зависят от комбинации движка и метода, использованных для создания индекса. Следующие разделы предоставляют информацию о поддерживаемых параметрах метода.
ef_search
Вы можете указать параметр ef_search при поиске в индексе, созданном с использованием метода hnsw. Параметр ef_search указывает количество векторов, которые необходимо проверить для нахождения k ближайших соседей. Более высокие значения ef_search улучшают полноту поиска за счет увеличения задержки поиска. Значение должно быть положительным.
Следующая таблица предоставляет информацию о параметре ef_search для поддерживаемых движков.
| Движок | Поддержка радиального запроса | Примечания |
|---|---|---|
| nmslib (устаревший) | Нет | Если ef_search присутствует в запросе, он переопределяет настройку index.knn.algo_param.ef_search индекса. |
| faiss | Да | Если ef_search присутствует в запросе, он переопределяет настройку index.knn.algo_param.ef_search индекса. |
| lucene | Нет | При создании поискового запроса необходимо указать k. Если вы укажете и k, и ef_search, то будет передано большее значение. Если ef_search больше k, вы можете указать параметр size, чтобы ограничить окончательное количество результатов до k. |
nprobes
Вы можете указать параметр nprobes при поиске в индексе, созданном с использованием метода ivf. Параметр nprobes указывает количество корзин, которые необходимо проверить для нахождения k ближайших соседей. Более высокие значения nprobes улучшают полноту поиска за счет увеличения задержки поиска. Значение должно быть положительным.
Следующая таблица предоставляет информацию о параметре nprobes для поддерживаемых движков.
| Движок | Примечания |
|---|---|
| faiss | Если nprobes присутствует в запросе, он переопределяет значение, указанное при создании индекса. |
Повторная оценка результатов
Вы можете тонко настроить поиск, предоставив параметры ef_search и oversample_factor.
Параметр oversample_factor контролирует фактор, на который поиск увеличивает количество кандидатных векторов перед их ранжированием. Использование более высокого значения oversample_factor означает, что больше кандидатов будет рассмотрено перед ранжированием, что улучшает точность, но также увеличивает время поиска. При выборе значения oversample_factor учитывайте компромисс между точностью и эффективностью. Например, установка oversample_factor на 2.0 удвоит количество кандидатов, рассматриваемых на этапе ранжирования, что может помочь достичь лучших результатов.
Следующий запрос указывает параметры ef_search и oversample_factor:
GET /my-vector-index/_search
{
"size": 2,
"query": {
"knn": {
"my_vector_field": {
"vector": [1.5, 5.5, 1.5, 5.5, 1.5, 5.5, 1.5, 5.5],
"k": 10,
"method_parameters": {
"ef_search": 10
},
"rescore": {
"oversample_factor": 10.0
}
}
}
}
}
8.3.10.3 - k-NN explain
При включении этот параметр предоставляет подробную информацию о процессе оценки для каждого результата поиска.
Запрос k-NN: Параметр explain
С версии 3.0 вы можете использовать параметр explain, чтобы понять, как рассчитываются, нормализуются и комбинируются оценки в запросах k-NN. При включении этот параметр предоставляет подробную информацию о процессе оценки для каждого результата поиска. Это включает в себя раскрытие используемых техник нормализации оценок, способы комбинирования различных оценок и расчеты для индивидуальных подзапросов. Этот всесторонний анализ упрощает понимание и оптимизацию результатов ваших запросов k-NN. Для получения дополнительной информации о параметре explain смотрите раздел API объяснения.
Обратите внимание, что использование параметра explain является ресурсоемкой операцией как по времени, так и по ресурсам. Для производственных кластеров рекомендуется использовать его экономно, в основном для устранения неполадок.
Использование параметра explain
Вы можете указать параметр explain в URL при выполнении полного запроса k-NN для движка Faiss, используя следующий синтаксис:
GET <index>/_search?explain=true
POST <index>/_search?explain=true
Для поиска k-NN с использованием движка Lucene параметр explain не возвращает подробное объяснение, как это делает движок Faiss.
Поддерживаемые типы запросов с параметром explain для движка Faiss:
- Приблизительный поиск k-NN
- Приблизительный поиск k-NN с точным поиском
- Поиск на диске
- Поиск k-NN с эффективной фильтрацией
- Радиальный поиск
- Поиск k-NN с термовым запросом
Для поиска k-NN с вложенными полями параметр explain не возвращает подробное объяснение, как это происходит с другими запросами.
Примеры использования параметра explain
Вы можете указать параметр explain как параметр запроса:
GET my-knn-index/_search?explain=true
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3, 5, 7],
"k": 2
}
}
}
}
Или вы можете указать параметр explain в теле запроса:
GET my-knn-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3, 5, 7],
"k": 2
}
}
},
"explain": true
}
Пример: Приблизительный поиск k-NN
{
"took": 216038,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 88.4,
"hits": [
{
"_shard": "[my-knn-index-1][0]",
"_node": "VHcyav6OTsmXdpsttX2Yug",
"_index": "my-knn-index-1",
"_id": "5",
"_score": 88.4,
"_source": {
"my_vector1": [
2.5,
3.5,
5.5,
7.4
],
"price": 8.9
},
"_explanation": {
"value": 88.4,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 88.4,
"description": "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details": [
{
"value": -87.4,
"description": "rawScore, returned from FAISS library",
"details": []
}
]
}
]
}
},
{
"_shard": "[my-knn-index-1][0]",
"_node": "VHcyav6OTsmXdpsttX2Yug",
"_index": "my-knn-index-1",
"_id": "2",
"_score": 84.7,
"_source": {
"my_vector1": [
2.5,
3.5,
5.6,
6.7
],
"price": 5.5
},
"_explanation": {
"value": 84.7,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 84.7,
"description": "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details": [
{
"value": -83.7,
"description": "rawScore, returned from FAISS library",
"details": []
}
]
}
]
}
}
]
}
}
Пример: Приблизительный поиск k-NN с точным поиском
{
"took": 87,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 84.7,
"hits": [
{
"_shard": "[my-knn-index-1][0]",
"_node": "MQVux8dZRWeznuEYKhMq0Q",
"_index": "my-knn-index-1",
"_id": "7",
"_score": 84.7,
"_source": {
"my_vector2": [
2.5,
3.5,
5.6,
6.7
],
"price": 5.5
},
"_explanation": {
"value": 84.7,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 84.7,
"description": "the type of knn search executed at leaf was Exact with spaceType = INNER_PRODUCT, vectorDataType = FLOAT, queryVector = [2.0, 3.0, 5.0, 6.0]",
"details": []
}
]
}
},
{
"_shard": "[my-knn-index-1][0]",
"_node": "MQVux8dZRWeznuEYKhMq0Q",
"_index": "my-knn-index-1",
"_id": "8",
"_score": 82.2,
"_source": {
"my_vector2": [
4.5,
5.5,
6.7,
3.7
],
"price": 4.4
},
"_explanation": {
"value": 82.2,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 82.2,
"description": "the type of knn search executed at leaf was Exact with spaceType = INNER_PRODUCT, vectorDataType = FLOAT, queryVector = [2.0, 3.0, 5.0, 6.0]",
"details": []
}
]
}
}
]
}
Пример: Поиск на диске
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 381.0,
"hits" : [
{
"_shard" : "[my-vector-index][0]",
"_node" : "pLaiqZftTX-MVSKdQSu7ow",
"_index" : "my-vector-index",
"_id" : "9",
"_score" : 381.0,
"_source" : {
"my_vector_field" : [
9.5,
9.5,
9.5,
9.5,
9.5,
9.5,
9.5,
9.5
],
"price" : 8.9
},
"_explanation" : {
"value" : 381.0,
"description" : "the type of knn search executed was Disk-based and the first pass k was 100 with vector dimension of 8, over sampling factor of 5.0, shard level rescoring enabled",
"details" : [
{
"value" : 381.0,
"description" : "the type of knn search executed at leaf was Approximate-NN with spaceType = HAMMING, vectorDataType = FLOAT, queryVector = [1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5]",
"details" : [ ]
}
]
}
}
]
}
}
Пример: поиск k-NN с эффективной фильтрацией
{
"took" : 51,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.8620689,
"hits" : [
{
"_shard" : "[products-shirts][0]",
"_node" : "9epk8WoFT8yvnUI0tAaJgQ",
"_index" : "products-shirts",
"_id" : "8",
"_score" : 0.8620689,
"_source" : {
"item_vector" : [
2.4,
4.0,
3.0
],
"size" : "small",
"rating" : 8
},
"_explanation" : {
"value" : 0.8620689,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 0.8620689,
"description" : "the type of knn search executed at leaf was Exact since filteredIds = 2 is less than or equal to K = 10 with spaceType = L2, vectorDataType = FLOAT, queryVector = [2.0, 4.0, 3.0]",
"details" : [ ]
}
]
}
},
{
"_shard" : "[products-shirts][0]",
"_node" : "9epk8WoFT8yvnUI0tAaJgQ",
"_index" : "products-shirts",
"_id" : "6",
"_score" : 0.029691212,
"_source" : {
"item_vector" : [
6.4,
3.4,
6.6
],
"size" : "small",
"rating" : 9
},
"_explanation" : {
"value" : 0.029691212,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 0.029691212,
"description" : "the type of knn search executed at leaf was Exact since filteredIds = 2 is less than or equal to K = 10 with spaceType = L2, vectorDataType = FLOAT, queryVector = [2.0, 4.0, 3.0]",
"details" : [ ]
}
]
}
}
]
}
}
Пример: Радиальный поиск
GET my-knn-index/_search?explain=true
{
"query": {
"knn": {
"my_vector": {
"vector": [7.1, 8.3],
"max_distance": 2
}
}
}
}
Ответ:
{
"took" : 376529,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.98039204,
"hits" : [
{
"_shard" : "[knn-index-test][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "knn-index-test",
"_id" : "1",
"_score" : 0.98039204,
"_source" : {
"my_vector" : [
7.0,
8.2
],
"price" : 4.4
},
"_explanation" : {
"value" : 0.98039204,
"description" : "the type of knn search executed was Radial with the radius of 2.0",
"details" : [
{
"value" : 0.98039204,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = l2 where score is computed as `1 / (1 + rawScore)` from:",
"details" : [
{
"value" : 0.020000057,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
},
{
"_shard" : "[knn-index-test][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "knn-index-test",
"_id" : "3",
"_score" : 0.9615384,
"_source" : {
"my_vector" : [
7.3,
8.3
],
"price" : 19.1
},
"_explanation" : {
"value" : 0.9615384,
"description" : "the type of knn search executed was Radial with the radius of 2.0",
"details" : [
{
"value" : 0.9615384,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = l2 where score is computed as `1 / (1 + rawScore)` from:",
"details" : [
{
"value" : 0.040000115,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
}
]
}
}
Пример: поиск k-NN с запросом по термину
GET my-knn-index/_search?explain=true
{
"query": {
"bool": {
"should": [
{
"knn": {
"my_vector2": { // vector field name
"vector": [2, 3, 5, 6],
"k": 2
}
}
},
{
"term": {
"price": "4.4"
}
}
]
}
}
}
Ответ:
{
"took" : 51,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 84.7,
"hits" : [
{
"_shard" : "[my-knn-index-1][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "my-knn-index-1",
"_id" : "7",
"_score" : 84.7,
"_source" : {
"my_vector2" : [
2.5,
3.5,
5.6,
6.7
],
"price" : 5.5
},
"_explanation" : {
"value" : 84.7,
"description" : "sum of:",
"details" : [
{
"value" : 84.7,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 84.7,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details" : [
{
"value" : -83.7,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
]
}
},
{
"_shard" : "[my-knn-index-1][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "my-knn-index-1",
"_id" : "8",
"_score" : 83.2,
"_source" : {
"my_vector2" : [
4.5,
5.5,
6.7,
3.7
],
"price" : 4.4
},
"_explanation" : {
"value" : 83.2,
"description" : "sum of:",
"details" : [
{
"value" : 82.2,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 82.2,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details" : [
{
"value" : -81.2,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
},
{
"value" : 1.0,
"description" : "price:[1082969293 TO 1082969293]",
"details" : [ ]
}
]
}
}
]
}
}
Поля ответа
Ответ содержит следующие поля:
- explanation: Объект объяснения, который включает следующие поля:
- value: Содержит результат расчета.
- description: Объясняет, какой тип расчета был выполнен. Для нормализации оценок информация в поле описания включает используемую технику нормализации или комбинации и соответствующую оценку.
- details: Показывает любые подрасчеты, выполненные в процессе.
8.3.10.4 - neural
Используйте запрос neural для поиска по векторным полям с помощью текста или изображения в векторном поиске.
Поля тела запроса
Включите следующие поля запроса в neural query:
"neural": {
"<vector_field>": {
"query_text": "<query_text>",
"query_image": "<image_binary>",
"model_id": "<model_id>",
"k": 100
}
}
Верхний уровень vector_field указывает на векторное или семантическое поле, по которому будет выполняться запрос поиска. Следующая таблица перечисляет другие поля запроса neural.
| Поле | Тип данных | Обязательный/Необязательный | Описание |
|---|---|---|---|
| query_text | Строка | Необязательный | Текст запроса, из которого будут генерироваться векторные эмбеддинги. Необходимо указать хотя бы одно из полей query_text или query_image. |
| query_image | Строка | Необязательный | Строка, закодированная в base-64, соответствующая изображению запроса, из которого будут генерироваться векторные эмбеддинги. Необходимо указать хотя бы одно из полей query_text или query_image. |
| model_id | Строка | Необязательный, если целевое поле является семантическим. Обязательно, если целевое поле является полем knn_vector и значение по умолчанию для модели не установлено. | Идентификатор модели, которая будет использоваться для генерации векторных эмбеддингов из текста запроса. Модель должна быть развернута в OpenSearch перед использованием в нейронном поиске. Не может быть указана вместе с semantic_field_search_analyzer. |
| k | Целое число | Необязательный | Количество результатов, возвращаемых при поиске k-NN. Можно указать только одну переменную: k, min_score или max_distance. Если переменная не указана, по умолчанию используется k со значением 10. |
| min_score | Число с плавающей запятой | Необязательный | Минимальный порог оценки для результатов поиска. Можно указать только одну переменную: k, min_score или max_distance. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| max_distance | Число с плавающей запятой | Необязательный | Максимальный порог расстояния для результатов поиска. Можно указать только одну переменную: k, min_score или max_distance. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| filter | Объект | Необязательный | Запрос, который можно использовать для уменьшения количества рассматриваемых документов. Для получения дополнительной информации о использовании фильтров см. раздел “Векторный поиск с фильтрами”. |
| method_parameters | Объект | Необязательный | Дополнительные параметры для тонкой настройки поиска: - ef_search (Целое число): количество векторов для проверки (для метода hnsw) - nprobes (Целое число): количество корзин для проверки (для метода ivf). Для получения дополнительной информации см. раздел “Указание параметров метода в запросе”. |
| rescore | Объект или логическое значение | Необязательный | Параметры для настройки функциональности повторной оценки: - oversample_factor (Число с плавающей запятой): контролирует, сколько кандидатных векторов извлекается перед повторной оценкой. Допустимые значения находятся в диапазоне [1.0, 100.0]. По умолчанию false для полей с режимом in_memory (без повторной оценки) и включено (с динамическими значениями) для полей с режимом on_disk. В режиме on_disk значение по умолчанию для oversample_factor определяется уровнем сжатия. Для получения дополнительной информации см. таблицу уровня сжатия. Чтобы явно включить повторную оценку с значением по умолчанию для oversample_factor равным 1.0, установите rescore в true. Для получения дополнительной информации см. раздел “Повторная оценка результатов”. |
expand_nested_docs | Логическое | Необязательное | Если установлено в true, извлекает оценки для всех документов вложенных полей в каждом родительском документе. Используется с вложенными запросами. |
semantic_field_search_analyzer | Строка | Необязательное | Указывает анализатор для токенизации query_text при использовании модели разреженного кодирования. Допустимые значения: standard, bert-uncased и mbert-uncased. Не может использоваться вместе с model_id. |
query_tokens | Карта токенов (строка) к весу (число с плавающей точкой) | Необязательное | Сырой разреженный вектор в виде токенов и их весов. Используется в качестве альтернативы query_text для прямого ввода вектора. Необходимо указать либо query_text, либо query_tokens. |
Пример запроса
Следующий пример демонстрирует поиск с значением k равным 100 и фильтром, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"k": 100,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий запрос поиска включает минимальный порог оценки min_score для k-NN радиального поиска, равный 0.95, и фильтр, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"min_score": 0.95,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий запрос поиска включает максимальное расстояние max_distance, равное 10, и фильтр, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"max_distance": 10,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий пример демонстрирует поиск по семантическому полю с использованием плотной модели. Семантическое поле хранит информацию о модели в своей конфигурации. Нейронный запрос автоматически извлекает model_id из конфигурации семантического поля в индексе и переписывает запрос для нацеливания на соответствующее поле эмбеддинга:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage": {
"query_text": "Hi world",
"k": 100
}
}
}
}
Следующий пример демонстрирует поиск по семантическому полю с использованием модели разреженного кодирования. Этот поиск использует разреженные эмбеддинги:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage": {
"query_tokens": {
"worlds": 0.57605183
}
}
}
}
}
Для получения дополнительной информации смотрите тип семантического поля.
8.3.10.5 - Нейронный разреженный запрос
Используйте нейронный разреженный запрос для поиска по векторному полю в нейронном разреженном поиске.
Вы можете выполнить запрос следующими способами:
- Предоставьте разреженные векторные эмбеддинги для сопоставления. Для получения дополнительной информации смотрите раздел “Нейронный разреженный поиск с использованием сырых векторов”:
"neural_sparse": {
"<vector_field>": {
"query_tokens": {
"<token>": <weight>,
...
}
}
}
- Предоставьте текст для токенизации и использования для сопоставления. Для токенизации текста вы можете использовать следующие компоненты:
- Встроенный анализатор DL модели:
"neural_sparse": {
"<vector_field>": {
"query_text": "<input text>",
"analyzer": "bert-uncased"
}
}
- Модель токенизатора:
"neural_sparse": {
"<vector_field>": {
"query_text": "<input text>",
"model_id": "<model ID>"
}
}
Для получения дополнительной информации смотрите раздел “Автоматическая генерация разреженных векторных эмбеддингов”.
Поля тела запроса
Верхний уровень vector_field указывает на векторное поле, по которому будет выполняться запрос поиска. Необходимо указать либо query_text, либо query_tokens для определения входных данных. Следующие поля могут быть использованы для настройки запроса:
| Поле | Тип данных | Обязательное/Необязательное | Описание |
|---|---|---|---|
query_text | Строка | Необязательное | Текст запроса, который будет преобразован в разреженные векторные эмбеддинги. Необходимо указать либо query_text, либо query_tokens. |
analyzer | Строка | Необязательное | Используется с query_text. Указывает встроенный анализатор DL модели для токенизации текста запроса. Допустимые значения: bert-uncased и mbert-uncased. По умолчанию используется bert-uncased. Не может использоваться одновременно с model_id. |
model_id | Строка | Необязательное | Используется с query_text. Идентификатор модели разреженного кодирования (для режима би-кодировщика) или токенизатора (для режима только документа), используемый для генерации векторных эмбеддингов из текста запроса. Модель/токенизатор должна быть развернута в OpenSearch перед использованием в нейронном разреженном поиске. Не может использоваться одновременно с analyzer. |
query_tokens | Карта токенов (строка) к весу (число с плавающей точкой) | Необязательное | Сырой разреженный вектор в виде токенов и их весов. Используется в качестве альтернативы query_text для прямого ввода вектора. Необходимо указать либо query_text, либо query_tokens. |
max_token_score | Число с плавающей точкой | Необязательное (устарело) | Этот параметр устарел с версии OpenSearch 2.12. Он поддерживается только для обратной совместимости и больше не влияет на функциональность. Параметр все еще может быть указан в запросах, но его значение не имеет значения. Ранее использовался как теоретическая верхняя граница оценки для всех токенов в словаре. |
Примеры запросов
Поиск с использованием текста, токенизированного анализатором
Чтобы выполнить поиск, используя текст, токенизированный анализатором, укажите анализатор в запросе. Анализатор должен быть совместим с моделью, которую вы использовали для анализа текста во время загрузки:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world",
"analyzer": "bert-uncased"
}
}
}
}
Для получения дополнительной информации смотрите раздел “Анализаторы DL модели”.
Поиск с использованием текста без указания анализатора
Если вы не укажете анализатор, будет использован анализатор по умолчанию bert-uncased:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world"
}
}
}
}
Поиск с использованием текста, токенизированного моделью токенизатора
Чтобы выполнить поиск, используя текст, токенизированный моделью токенизатора, укажите идентификатор модели в запросе:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world",
"model_id": "aP2Q8ooBpBj3wT4HVS8a"
}
}
}
}
Поиск с использованием разреженного вектора
Чтобы выполнить поиск, используя разреженный вектор, укажите разреженный вектор в параметре query_tokens:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_tokens": {
"hi": 4.338913,
"planets": 2.7755864,
"planet": 5.0969057,
"mars": 1.7405145,
"earth": 2.6087382,
"hello": 3.3210192
}
}
}
}
}
8.3.10.6 - Перколяция
Используйте запрос перколяции для поиска сохраненных запросов, которые соответствуют данному документу.
Используйте запрос перколяции для поиска сохраненных запросов, которые соответствуют данному документу. Эта операция является противоположностью обычного поиска: вместо того чтобы находить документы, соответствующие запросу, вы находите запросы, соответствующие документу. Запросы перколяции часто используются для оповещений, уведомлений и обратных поисковых случаев.
Основные моменты
- Вы можете перколировать документ, предоставленный в строке, или извлечь существующий документ из индекса.
- Документ и сохраненные запросы должны использовать одни и те же имена и типы полей.
- Вы можете комбинировать перколяцию с фильтрацией и оценкой, чтобы создать сложные системы соответствия.
- Запросы перколяции считаются дорогими запросами и будут выполняться только если настройка кластера
search.allow_expensive_queriesустановлена вtrue(по умолчанию). Если эта настройка установлена вfalse, запросы перколяции будут отклонены.
Примеры использования
Запросы перколяции полезны в различных сценариях реального времени. Некоторые распространенные случаи использования включают:
Уведомления для электронной коммерции: Пользователи могут зарегистрировать интерес к продуктам, например, “Уведомите меня, когда новые ноутбуки Apple будут в наличии”. Когда новые документы о продуктах индексируются, система находит всех пользователей с соответствующими сохраненными запросами и отправляет уведомления.
Уведомления о вакансиях: Соискатели сохраняют запросы на основе предпочтительных должностей или местоположений, и новые вакансии сопоставляются с этими запросами для триггера уведомлений.
Системы безопасности и оповещения: Перколируйте входящие данные журналов или событий по сохраненным правилам или паттернам аномалий.
Фильтрация новостей: Сопоставляйте входящие статьи с сохраненными профилями тем, чтобы классифицировать или доставлять релевантный контент.
Как работает перколяция
Сохраненные запросы хранятся в специальном типе поля перколятора. Документы сравниваются со всеми сохраненными запросами. Каждый соответствующий запрос возвращается с его _id. Если включено выделение, также возвращаются совпадающие текстовые фрагменты. Если отправляется несколько документов, поле _percolator_document_slot отображает соответствующий документ.
Пример запроса перколяции
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Новый ноутбук Apple",
"price": 1500,
"availability": "в наличии"
}
}
}
}
В этом примере запрос перколяции ищет сохраненные запросы, которые соответствуют документу о новом ноутбуке Apple.
Пример использования перколяции
Следующие примеры демонстрируют, как сохранять запросы перколяции и тестировать документы против них, используя различные методы.
Создание индекса для хранения сохраненных запросов
Сначала создайте индекс и настройте его маппинги с типом поля перколятора для хранения сохраненных запросов:
PUT /my_percolator_index
{
"mappings": {
"properties": {
"query": {
"type": "percolator"
},
"title": {
"type": "text"
}
}
}
}
Добавление запроса, соответствующего “apple” в поле title
Добавьте запрос, который соответствует слову “apple” в поле заголовка:
POST /my_percolator_index/_doc/1
{
"query": {
"match": {
"title": "apple"
}
}
}
Добавление запроса, соответствующего “banana” в поле title
Добавьте запрос, который соответствует слову “banana” в поле заголовка:
POST /my_percolator_index/_doc/2
{
"query": {
"match": {
"title": "banana"
}
}
}
Перколяция встроенного документа
Проверьте встроенный документ против сохраненных запросов:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Fresh Apple Harvest"
}
}
}
}
Ответ
Ответ предоставляет сохраненный запрос перколяции, который ищет документы, содержащие слово “apple” в поле заголовка, идентифицированный по _id: 1:
{
...
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
}
}
]
}
}
Перколяция с несколькими документами
Чтобы протестировать несколько документов в одном запросе, используйте следующий запрос:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Banana flavoured ice-cream" },
{ "title": "Apple pie recipe" },
{ "title": "Banana bread instructions" },
{ "title": "Cherry tart" }
]
}
}
}
Ответ
Поле _percolator_document_slot помогает вам идентифицировать каждый документ (по индексу), соответствующий каждому сохраненному запросу:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.54726034,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.54726034,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
0,
2
]
}
}
]
}
}
Перколяция существующего индексированного документа
Вы можете ссылаться на существующий документ, уже хранящийся в другом индексе, чтобы проверить соответствие запросов перколяции.
Создание отдельного индекса для ваших документов
Создайте индекс для хранения документов:
PUT /products
{
"mappings": {
"properties": {
"title": {
"type": "text"
}
}
}
}
Добавление документа
Добавьте документ:
POST /products/_doc/1
{
"title": "Banana Smoothie Special"
}
Проверка соответствия сохраненных запросов индексированному документу
Проверьте, соответствуют ли сохраненные запросы индексированному документу:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"index": "products",
"id": "1"
}
}
}
Вы должны предоставить как индекс, так и идентификатор при использовании сохраненного документа.
Перколяция пакетов (несколько документов)
Вы можете проверить несколько документов в одном запросе:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Apple event coming soon" },
{ "title": "Banana farms expand" },
{ "title": "Cherry season starts" }
]
}
}
}
Ответ
Каждое совпадение указывает на соответствующий документ в поле _percolator_document_slot:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.46484798,
"hits": [
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.46484798,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.41211313,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
}
}
]
}
}
Многоуровневая перколяция с использованием именованного запроса
Вы можете перколировать разные документы внутри именованного запроса:
GET /my_percolator_index/_search
{
"query": {
"bool": {
"should": [
{
"percolate": {
"field": "query",
"document": {
"title": "Apple pie recipe"
},
"name": "apple_doc"
}
},
{
"percolate": {
"field": "query",
"document": {
"title": "Banana bread instructions"
},
"name": "banana_doc"
}
}
]
}
}
}
Ответ
Параметр name добавляется к полю _percolator_document_slot, чтобы предоставить соответствующий запрос:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot_apple_doc": [
0
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot_banana_doc": [
0
]
}
}
]
}
}
Этот подход позволяет вам настраивать более индивидуальную логику запросов для отдельных документов. В следующем примере поле title запрашивается в первом документе, а поле description запрашивается во втором документе. Также предоставляется параметр boost:
GET /my_percolator_index/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"filter": {
"percolate": {
"field": "query",
"document": {
"title": "Apple pie recipe"
},
"name": "apple_doc"
}
},
"boost": 1.0
}
},
{
"constant_score": {
"filter": {
"percolate": {
"field": "query",
"document": {
"description": "Banana bread with honey"
},
"name": "banana_doc"
}
},
"boost": 3.0
}
}
]
}
}
}
Сравнение пакетной перколяции и именованной перколяции
Обе методы — пакетная перколяция (с использованием документов) и именованная перколяция (с использованием bool и name) — могут использоваться для перколяции нескольких документов, но они различаются по тому, как результаты маркируются, интерпретируются и контролируются. Они предоставляют функционально схожие результаты, но с важными структурными различиями, описанными в следующей таблице.
| Характеристика | Пакетная (документы) | Именованная (bool + percolate + name) |
|---|---|---|
| Формат ввода | Один клауз перколяции, массив документов | Несколько клауз перколяции, по одному на документ |
| Прослеживаемость по документу | По индексу слота (0, 1, …) | По имени (apple_doc, banana_doc) |
| Поле ответа для слота совпадения | _percolator_document_slot: [0] | _percolator_document_slot_<name>: [0] |
| Префикс выделения | 0_title, 1_title | apple_doc_title, banana_doc_title |
| Индивидуальный контроль по документу | Не поддерживается | Можно настроить каждую клаузу |
| Поддержка увеличений и фильтров | Нет | Да (по каждой клаузе) |
| Производительность | Лучше для больших партий | Немного медленнее при большом количестве клауз |
| Случай использования | Массовое соответствие, большие потоки событий | Прослеживание по документам, тестирование, индивидуальный контроль |
Подсветка совпадений
Запросы перколяции обрабатывают подсветку иначе, чем обычные запросы:
- В обычном запросе документ хранится в индексе, и поисковый запрос используется для подсветки совпадающих терминов.
- В запросе перколяции роли меняются: сохраненные запросы (в индексе перколятора) используются для подсветки документа.
Это означает, что документ, предоставленный в поле document или documents, является целью для подсветки, и запросы перколяции определяют, какие разделы будут подсвечены.
Подсветка одного документа
Этот пример использует ранее определенные запросы в my_percolator_index. Используйте следующий запрос для подсветки совпадений в поле заголовка:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Apple banana smoothie"
}
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
Ответ
Совпадения подсвечиваются в зависимости от соответствующего запроса:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"title": [
"<em>Apple</em> banana smoothie"
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"title": [
"Apple <em>banana</em> smoothie"
]
}
}
]
}
}
Подсветка нескольких документов
При перколяции нескольких документов с использованием массива documents каждому документу присваивается индекс слота. Ключи подсветки принимают следующую форму, где <slot> — это индекс документа в вашем массиве documents:
"<slot>_<fieldname>": [ ... ]
Используйте следующую команду для перколяции двух документов с подсветкой:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Apple pie recipe" },
{ "title": "Banana smoothie ideas" }
]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
Ответ
Ответ содержит поля подсветки с префиксами, соответствующими слотам документов, такими как 0_title и 1_title:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.31506687,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"0_title": [
"<em>Apple</em> pie recipe"
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
},
"highlight": {
"1_title": [
"<em>Banana</em> smoothie ideas"
]
}
}
]
}
}
Параметры запроса перколяции
Запрос перколяции поддерживает следующие параметры:
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
field | Обязательный | Поле, содержащее сохраненные запросы перколяции. |
document | Необязательный | Один встроенный документ для сопоставления с сохраненными запросами. |
documents | Необязательный | Массив нескольких встроенных документов для сопоставления с сохраненными запросами. |
index | Необязательный | Индекс, содержащий документ, с которым вы хотите сопоставить. |
id | Необязательный | Идентификатор документа для извлечения из индекса. |
routing | Необязательный | Значение маршрутизации, используемое при извлечении документа. |
preference | Необязательный | Предпочтение для маршрутизации шардов при извлечении документа. |
name | Необязательный | Имя, присвоенное клаузе перколяции. Полезно при использовании нескольких клауз перколяции в запросе bool. |
8.3.10.7 - script query
Этот запрос возвращает документы, для которых скрипт оценивается как истинный, что позволяет использовать сложную логику фильтрации, которую нельзя выразить с помощью стандартных запросов.
Используйте запрос скрипта для фильтрации документов на основе пользовательского условия, написанного на языке скриптов Painless. Этот запрос возвращает документы, для которых скрипт оценивается как истинный, что позволяет использовать сложную логику фильтрации, которую нельзя выразить с помощью стандартных запросов.
Запрос скрипта является вычислительно затратным и должен использоваться с осторожностью. Используйте его только при необходимости и убедитесь, что параметр search.allow_expensive_queries включен (по умолчанию установлен в true). Для получения дополнительной информации смотрите раздел “Дорогие запросы”.
Пример
Создайте индекс с именем products со следующими настройками:
PUT /products
{
"mappings": {
"properties": {
"title": { "type": "text" },
"price": { "type": "float" },
"rating": { "type": "float" }
}
}
}
Индексируйте пример документов, используя следующий запрос:
POST /products/_bulk
{ "index": { "_id": 1 } }
{ "title": "Беспроводные наушники", "price": 99.99, "rating": 4.5 }
{ "index": { "_id": 2 } }
{ "title": "Bluetooth колонка", "price": 79.99, "rating": 4.8 }
{ "index": { "_id": 3 } }
{ "title": "Наушники с шумоподавлением", "price": 199.99, "rating": 4.7 }
Базовый запрос скрипта
Верните продукты с рейтингом выше 4.6:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['rating'].value > 4.6"
}
}
}
}
Возвращенные результаты будут включать только документы с рейтингом выше 4.6:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
},
{
"_index": "products",
"_id": "3",
"_score": 1,
"_source": {
"title": "Наушники с шумоподавлением",
"price": 199.99,
"rating": 4.7
}
}
]
}
}
Параметры
Запрос скрипта принимает следующие параметры верхнего уровня.
| Параметр | Обязательный/Необязательный | Описание |
|---|---|---|
script.source | Обязательный | Код скрипта, который оценивается как истинный или ложный. |
script.params | Необязательный | Пользовательские параметры, на которые ссылается скрипт. |
Использование параметров скрипта
Вы можете использовать params для безопасной передачи значений, используя кэширование компиляции скриптов:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['price'].value < params.max_price",
"params": {
"max_price": 100
}
}
}
}
}
Возвращенные результаты будут включать только документы с ценой менее 100:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "1",
"_score": 1,
"_source": {
"title": "Беспроводные наушники",
"price": 99.99,
"rating": 4.5
}
},
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
}
]
}
}
Объединение нескольких условий
Используйте следующий запрос для поиска продуктов с рейтингом выше 4.5 и ценой ниже 100:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['rating'].value > 4.5 && doc['price'].value < 100"
}
}
}
}
Только документы, соответствующие требованиям, будут возвращены:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
}
]
}
}
8.3.10.8 - Запрос с оценкой скрипта
Используйте запрос script_score, чтобы настроить расчет оценки, используя скрипт.
Используйте запрос script_score, чтобы настроить расчет оценки, используя скрипт. Для вычислительно затратной функции оценки вы можете использовать запрос script_score, чтобы вычислить оценку только для возвращенных документов, которые были отфильтрованы.
Пример
Например, следующий запрос создает индекс, содержащий один документ:
PUT testindex1/_doc/1
{
"name": "John Doe",
"multiplier": 0.5
}
Вы можете использовать запрос match, чтобы вернуть все документы, содержащие “John” в поле имени:
GET testindex1/_search
{
"query": {
"match": {
"name": "John"
}
}
}
В ответе документ 1 имеет оценку 0.2876821:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "John Doe",
"multiplier": 0.5
}
}
]
}
}
Теперь давайте изменим оценку документа, используя скрипт, который вычисляет оценку как значение поля _score, умноженное на значение поля multiplier. В следующем запросе вы можете получить текущую релевантность документа в переменной _score, а значение множителя как doc['multiplier'].value:
GET testindex1/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "John"
}
},
"script": {
"source": "_score * doc['multiplier'].value"
}
}
}
}
В ответе оценка для документа 1 составляет половину от первоначальной оценки:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.14384104,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0.14384104,
"_source": {
"name": "John Doe",
"multiplier": 0.5
}
}
]
}
}
Параметры
Запрос script_score поддерживает следующие параметры верхнего уровня.
| Параметр | Тип данных | Описание |
|---|---|---|
query | Объект | Запрос, используемый для поиска. Обязательный. |
script | Объект | Скрипт, используемый для вычисления оценки документов, возвращаемых запросом. Обязательный. |
min_score | Число с плавающей запятой | Исключает документы с оценкой ниже min_score из результатов. Необязательный. |
boost | Число с плавающей запятой | Увеличивает оценки документов на заданный множитель. Значения меньше 1.0 уменьшают релевантность, а значения больше 1.0 увеличивают релевантность. По умолчанию 1.0. |
Оценки релевантности, вычисленные запросом script_score, не могут быть отрицательными.
Настройка вычисления оценки с помощью встроенных функций
Чтобы настроить вычисление оценки, вы можете использовать одну из встроенных функций Painless. Для каждой функции OpenSearch предоставляет один или несколько методов Painless, которые вы можете использовать в контексте оценки скрипта. Вы можете вызывать методы Painless, перечисленные в следующих разделах, напрямую, без использования имени класса или имени экземпляра.
Сатурация
Функция сатурации вычисляет сатурацию как score = value / (value + pivot), где value — это значение поля, а pivot выбирается так, чтобы оценка была больше 0.5, если value больше pivot, и меньше 0.5, если value меньше pivot. Оценка находится в диапазоне (0, 1). Чтобы применить функцию сатурации, вызовите следующий метод Painless:
double saturation(double <field-value>, double <pivot>)
ПРИМЕР
Следующий пример запроса ищет текст “neural search” в индексе статей. Он комбинирует оригинальную оценку релевантности документа с значением article_rank, которое сначала преобразуется с помощью функции сатурации:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "_score + saturation(doc['article_rank'].value, 11)"
}
}
}
}
Сигмоид
Аналогично функции сатурации, функция сигмоид вычисляет оценку как score = value^exp / (value^exp + pivot^exp), где value — это значение поля, exp — это коэффициент масштабирования степени, а pivot выбирается так, чтобы оценка была больше 0.5, если value больше pivot, и меньше 0.5, если value меньше pivot. Чтобы применить функцию сигмоид, вызовите следующий метод Painless:
double sigmoid(double <field-value>, double <pivot>, double <exp>)
Пример
Следующий пример запроса ищет текст “neural search” в индексе статей. Он комбинирует оригинальную оценку релевантности документа со значением article_rank, которое сначала преобразуется с помощью функции сигмоид:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "_score + sigmoid(doc['article_rank'].value, 11, 2)"
}
}
}
}
Случайная оценка
Функция случайной оценки генерирует равномерно распределенные случайные оценки в диапазоне [0, 1). Чтобы узнать, как работает эта функция, смотрите раздел “Функция случайной оценки”. Чтобы применить функцию случайной оценки, вызовите один из следующих методов Painless:
double randomScore(int <seed>): Использует внутренние идентификаторы документов Lucene в качестве значений семени.
double randomScore(int <seed>, String <field-name>)
Пример
Следующий запрос использует функцию random_score с семенем и полем:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "randomScore(20, '_seq_no')"
}
}
}
}
Функции затухания
С помощью функций затухания вы можете оценивать результаты на основе близости или недавности. Чтобы узнать больше, смотрите раздел “Функции затухания”. Вы можете вычислять оценки, используя экспоненциальную, гауссову или линейную кривую затухания. Чтобы применить функцию затухания, вызовите один из следующих методов Painless в зависимости от типа поля:
Числовые поля:
double decayNumericGauss(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
double decayNumericExp(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
double decayNumericLinear(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
Геопоинтовые поля:
double decayGeoGauss(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
double decayGeoExp(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
double decayGeoLinear(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
Поля даты:
double decayDateGauss(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
double decayDateExp(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
double decayDateLinear(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
Пример: Числовые поля
Следующий запрос использует функцию экспоненциального затухания на числовом поле:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": {
"article_name": "neural search"
}
},
"script": {
"source": "decayNumericExp(params.origin, params.scale, params.offset, params.decay, doc['article_rank'].value)",
"params": {
"origin": 50,
"scale": 20,
"offset": 30,
"decay": 0.5
}
}
}
}
}
Пример: Геопоинтовые поля
Следующий запрос использует функцию гауссового затухания на геопоинтовом поле:
GET hotels/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "hotel"
}
},
"script": {
"source": "decayGeoGauss(params.origin, params.scale, params.offset, params.decay, doc['location'].value)",
"params": {
"origin": "40.71,74.00",
"scale": "300ft",
"offset": "200ft",
"decay": 0.25
}
}
}
}
}
Пример: Поля даты
Следующий запрос использует функцию линейного затухания на поле даты:
GET blogs/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "opensearch"
}
},
"script": {
"source": "decayDateLinear(params.origin, params.scale, params.offset, params.decay, doc['date_posted'].value)",
"params": {
"origin": "2022-04-24",
"scale": "6d",
"offset": "1d",
"decay": 0.25
}
}
}
}
}
Функции частоты термина
Функции частоты термина предоставляют статистику на уровне термина в источнике скрипта оценки. Вы можете использовать эту статистику для реализации пользовательских алгоритмов извлечения информации и ранжирования, таких как умножение или сложение оценки по популярности во время запроса. Чтобы применить функцию частоты термина, вызовите один из следующих методов Painless:
int termFreq(String <field-name>, String <term>): Извлекает частоту термина в поле для конкретного термина.long totalTermFreq(String <field-name>, String <term>): Извлекает общую частоту термина в поле для конкретного термина.long sumTotalTermFreq(String <field-name>): Извлекает сумму общих частот термина в поле.
Пример
Следующий запрос вычисляет оценку как общую частоту термина для каждого поля в списке полей, умноженную на значение множителя:
GET /demo_index_v1/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"script_score": {
"script": {
"source": """
for (int x = 0; x < params.fields.length; x++) {
String field = params.fields[x];
if (field != null) {
return params.multiplier * totalTermFreq(field, params.term);
}
}
return params.default_value;
""",
"params": {
"fields": ["title", "description"],
"term": "ai",
"multiplier": 2,
"default_value": 1
}
}
}
}
}
}
8.3.10.9 - Запрос шаблона
Используйте запрос шаблона для создания поисковых запросов, которые содержат переменные-заполнители.
Используйте запрос шаблона для создания поисковых запросов, которые содержат переменные-заполнители. Заполнители указываются с помощью синтаксиса “${variable_name}” (обратите внимание, что переменные должны быть заключены в кавычки). Когда вы отправляете поисковый запрос, эти заполнители остаются неразрешенными до тех пор, пока они не будут обработаны процессорами запросов поиска. Этот подход особенно полезен, когда ваш начальный поисковый запрос содержит данные, которые необходимо преобразовать или сгенерировать во время выполнения.
Например, вы можете использовать запрос шаблона при работе с процессором запросов поиска ml_inference, который преобразует текстовый ввод в векторные эмбеддинги во время процесса поиска. Процессор заменит заполнители сгенерированными значениями перед выполнением окончательного запроса.
Для полного примера смотрите раздел “Переписывание запросов с использованием запросов шаблонов”.
Пример
Следующий пример показывает запрос шаблона k-NN с заполнителем “vector”: “${text_embedding}”. Заполнитель “${text_embedding}” будет заменен эмбеддингами, сгенерированными процессором запросов ml_inference из текстового поля ввода:
GET /template-knn-index/_search?search_pipeline=my_knn_pipeline
{
"query": {
"template": {
"knn": {
"text_embedding": {
"vector": "${text_embedding}", // Заполнитель для векторного поля
"k": 2
}
}
}
},
"ext": {
"ml_inference": {
"text": "sneakers" // Входной текст для процессора ml_inference
}
}
}
Конфигурация процессора запросов поиска
Чтобы использовать запрос шаблона с процессором запросов поиска, вам необходимо настроить конвейер поиска. Следующая конфигурация является примером для процессора запросов ml_inference. input_map сопоставляет поля документа с входами модели. В этом примере поле источника ext.ml_inference.text в документе сопоставляется с полем inputText — ожидаемым входным полем для модели. output_map сопоставляет выходы модели с полями документа. В этом примере поле выходного эмбеддинга из модели сопоставляется с полем назначения text_embedding в вашем документе:
PUT /_search/pipeline/my_knn_pipeline
{
"request_processors": [
{
"ml_inference": {
"model_id": "Sz-wFZQBUpPSu0bsJTBG",
"input_map": [
{
"inputText": "ext.ml_inference.text" // Сопоставить входной текст из запроса
}
],
"output_map": [
{
"text_embedding": "embedding" // Сопоставить выходные данные с заполнителем
}
]
}
}
]
}
После выполнения процессора запросов ml_inference запрос поиска переписывается. Поле вектора содержит эмбеддинги, сгенерированные процессором, а поле text_embedding содержит выходные данные процессора:
GET /template-knn-1/_search
{
"query": {
"template": {
"knn": {
"text_embedding": {
"vector": [0.6328125, 0.26953125, ...],
"k": 2
}
}
}
},
"ext": {
"ml_inference": {
"text": "sneakers",
"text_embedding": [0.6328125, 0.26953125, ...]
}
}
}
Ограничения
Запросы шаблона требуют как минимум одного процессора запросов поиска для разрешения заполнителей. Процессоры запросов поиска должны быть настроены для генерации переменных, ожидаемых в конвейере.
8.3.10.10 - Обертка
Запрос обертки позволяет отправлять полный запрос в формате JSON, закодированном в Base64.
Запрос обертки позволяет отправлять полный запрос в формате JSON, закодированном в Base64. Это полезно, когда запрос необходимо встроить в контексты, которые поддерживают только строковые значения.
Используйте этот запрос только в тех случаях, когда необходимо управлять системными ограничениями. Для читаемости и удобства обслуживания лучше использовать стандартные запросы на основе JSON, когда это возможно.
Пример
Создайте индекс с именем products со следующими настройками:
PUT /products
{
"mappings": {
"properties": {
"title": { "type": "text" }
}
}
}
Индексируйте пример документов:
POST /products/_bulk
{ "index": { "_id": 1 } }
{ "title": "Беспроводные наушники с шумоподавлением" }
{ "index": { "_id": 2 } }
{ "title": "Bluetooth колонка" }
{ "index": { "_id": 3 } }
{ "title": "Наушники накладного типа с глубоким басом" }
Закодируйте следующий запрос в формате Base64:
echo -n '{ "match": { "title": "headphones" } }' | base64
Выполните закодированный запрос:
POST /products/_search
{
"query": {
"wrapper": {
"query": "eyAibWF0Y2giOiB7ICJ0aXRsZSI6ICJoZWFkcGhvbmVzIiB9IH0="
}
}
}
Ответ
Ответ содержит два соответствующих документа:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.20098841,
"hits": [
{
"_index": "products",
"_id": "1",
"_score": 0.20098841,
"_source": {
"title": "Беспроводные наушники с шумоподавлением"
}
},
{
"_index": "products",
"_id": "3",
"_score": 0.18459359,
"_source": {
"title": "Наушники накладного типа с глубоким басом"
}
}
]
}
}
8.3.11 - Minimum should match (Минимальное соответствие)
Параметр minimum_should_match может использоваться для полнотекстового поиска и указывает минимальное количество терминов, с которыми документ должен соответствовать, чтобы быть возвращенным в результатах поиска.
Пример
Следующий пример требует, чтобы документ соответствовал как минимум двум из трех поисковых терминов, чтобы быть возвращенным в качестве результата поиска:
GET /shakespeare/_search
{
"query": {
"match": {
"text_entry": {
"query": "prince king star",
"minimum_should_match": "2"
}
}
}
}
В этом примере запрос имеет три необязательных условия, которые объединены с помощью оператора OR, поэтому документ должен соответствовать либо “prince” и “king”, либо “prince” и “star”, либо “king” и “star”.
Допустимые значения
Вы можете указать параметр minimum_should_match как одно из следующих значений.
| Тип значения | Пример | Описание |
|---|---|---|
| Ненегативное целое число | 2 | Документ должен соответствовать этому количеству необязательных условий. |
| Отрицательное целое число | -1 | Документ должен соответствовать общему количеству необязательных условий минус это число. |
| Ненегативный процент | 70% | Документ должен соответствовать этому проценту от общего количества необязательных условий. Количество условий округляется вниз до ближайшего целого числа. |
| Отрицательный процент | -30% | Документ может не соответствовать этому проценту от общего количества необязательных условий. Количество условий, которые документ может не соответствовать, округляется вниз до ближайшего целого числа. |
| Комбинация | 2<75% | Выражение в формате n<p%. Если количество необязательных условий меньше или равно n, документ должен соответствовать всем необязательным условиям. Если количество необязательных условий больше n, то документ должен соответствовать p процентам необязательных условий. |
| Множественные комбинации | 3<-1 5<50% | Более одной комбинации, разделенной пробелом. Каждое условие применяется к количеству необязательных условий, которое больше числа слева от знака <. В этом примере, если есть три или меньше необязательных условий, документ должен соответствовать всем им. Если есть четыре или пять необязательных условий, документ должен соответствовать всем, кроме одного из них. Если есть 6 или более необязательных условий, документ должен соответствовать 50% из них. |
Пусть n будет количеством необязательных условий, с которыми документ должен соответствовать. Когда n рассчитывается как процент, если n меньше 1, то используется 1. Если n больше количества необязательных условий, используется количество необязательных условий.
Использование параметра в булевых запросах
Булевый запрос перечисляет необязательные условия в разделе should и обязательные условия в разделе must. Опционально он может содержать раздел filter для фильтрации результатов.
Пример индекса
Рассмотрим пример индекса, содержащего следующие пять документов:
PUT testindex/_doc/1
{
"text": "one OpenSearch"
}
PUT testindex/_doc/2
{
"text": "one two OpenSearch"
}
PUT testindex/_doc/3
{
"text": "one two three OpenSearch"
}
PUT testindex/_doc/4
{
"text": "one two three four OpenSearch"
}
PUT testindex/_doc/5
{
"text": "OpenSearch"
}
Пример запроса
Следующий запрос содержит четыре необязательных условия:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
],
"minimum_should_match": "80%"
}
}
}
Поскольку minimum_should_match указан как 80%, количество необязательных условий для соответствия рассчитывается как 4 · 0.8 = 3.2 и затем округляется вниз до 3. Поэтому результаты содержат документы, которые соответствуют как минимум трем условиям:
{
"took": 40,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.5744598,
"_source": {
"text": "one two three OpenSearch"
}
}
]
}
}
Указание minimum_should_match как -20%
Следующий запрос устанавливает minimum_should_match как -20%:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
],
"minimum_should_match": "-20%"
}
}
}
Количество необязательных условий, которые документ может не соответствовать, рассчитывается как 4 · 0.2 = 0.8 и округляется вниз до 0. Таким образом, результаты содержат только один документ, который соответствует всем необязательным условиям:
{
"took": 41,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
}
]
}
}
Обратите внимание, что указание положительного процента (80%) и отрицательного процента (-20%) не привело к одинаковому количеству необязательных условий, с которыми документ должен соответствовать, поскольку в обоих случаях результат округляется вниз. Если бы количество необязательных условий, например, было 5, то как 80%, так и -20% привели бы к одинаковому количеству необязательных условий, с которыми документ должен соответствовать (4).
Значение по умолчанию для minimum_should_match
Если запрос содержит условие must или filter, значение по умолчанию для minimum_should_match равно 0. Например, следующий запрос ищет документы, которые соответствуют “OpenSearch” и не имеют необязательных условий в разделе should:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
]
}
}
}
Этот запрос возвращает все пять документов в индексе:
{
"took": 34,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.5744598,
"_source": {
"text": "one two three OpenSearch"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.91368985,
"_source": {
"text": "one two OpenSearch"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.4338556,
"_source": {
"text": "one OpenSearch"
}
},
{
"_index": "testindex",
"_id": "5",
"_score": 0.11964063,
"_source": {
"text": "OpenSearch"
}
}
]
}
}
Таким образом, поскольку значение minimum_should_match по умолчанию равно 0, все документы, соответствующие обязательному условию, будут возвращены, независимо от соответствия необязательным условиям.
Исключение условия must
Если вы опустите условие must, то запрос будет искать документы, которые соответствуют хотя бы одному из необязательных условий в разделе should:
GET testindex/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
]
}
}
}
Результаты содержат только четыре документа, которые соответствуют как минимум одному из необязательных условий:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2.426633,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.426633,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.4978898,
"_source": {
"text": "one two three OpenSearch"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.8266785,
"_source": {
"text": "one two OpenSearch"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3331056,
"_source": {
"text": "one OpenSearch"
}
}
]
}
}
Таким образом, без условия must запрос возвращает документы, которые соответствуют хотя бы одному из указанных необязательных условий, что приводит к меньшему количеству результатов по сравнению с запросом, содержащим обязательные условия.
8.3.12 - Синтаксис регулярных выражений
Регулярное выражение (regex) — это способ определения шаблонов поиска с использованием специальных символов и операторов.
Регулярное выражение (regex) — это способ определения шаблонов поиска с использованием специальных символов и операторов. Эти шаблоны позволяют вам сопоставлять последовательности символов в строках.
В OpenSearch вы можете использовать регулярные выражения в следующих типах запросов:
regexpquery_string
OpenSearch использует движок регулярных выражений Apache Lucene, который имеет свой собственный синтаксис и ограничения. Он не использует регулярные выражения, совместимые с Perl (PCRE), поэтому некоторые знакомые функции регулярных выражений могут вести себя иначе или не поддерживаться.
Выбор между запросами regexp и query_string
Оба запроса regexp и query_string поддерживают регулярные выражения, но они ведут себя по-разному и служат для разных случаев использования.
| Особенность | Запрос regexp | Запрос query_string |
|---|---|---|
| Сопоставление шаблонов | Шаблон regex должен соответствовать всему значению поля | Шаблон regex может соответствовать любой части поля |
| Поддержка флагов | Флаги включают необязательные операторы regex | Флаги не поддерживаются |
| Тип запроса | Запрос на уровне термина (не оценивается) | Полнотекстовый запрос (оценивается и разбирается) |
| Лучший случай использования | Строгое сопоставление шаблонов для полей типа keyword или exact | Поиск в анализируемых полях с использованием гибкой строки запроса, поддерживающей шаблоны regex |
| Сложная композиция запросов | Ограничена шаблонами regex | Поддерживает AND, OR, подстановочные знаки, поля, увеличение и другие функции. См. Запрос query_string. |
Зарезервированные символы
Движок регулярных выражений Lucene поддерживает все символы Unicode. Однако следующие символы рассматриваются как специальные операторы:
. ? + * | { } [ ] ( ) " \
В зависимости от включенных флагов, которые указывают необязательные операторы, следующие символы также могут быть зарезервированы:
@ & ~ < >
Чтобы сопоставить эти символы буквально, либо экранируйте их с помощью обратной косой черты (), либо оберните всю строку в двойные кавычки:
\&: Сопоставляет литерал &\\: Сопоставляет литерал обратной косой черты ()"hello@world": Сопоставляет полную строку hello@world
Стандартные операторы регулярных выражений
Lucene поддерживает основной набор операторов регулярных выражений:
. – Сопоставляет любой одиночный символ. Пример:
f.nсоответствует f, за которым следует любой символ, а затем n (например, fan или fin).? – Сопоставляет ноль или один из предыдущих символов. Пример:
colou?rсоответствует color и colour.+ – Сопоставляет один или более из предыдущих символов. Пример:
go+соответствует g, за которым следует один или более o (go, goo, gooo и так далее).* – Сопоставляет ноль или более из предыдущих символов. Пример:
lo*seсоответствует l, за которым следует ноль или более o, а затем se (lse, lose, loose, loooose и так далее).{min,max} – Сопоставляет конкретный диапазон повторений. Если max опущен, нет верхнего предела на количество сопоставляемых символов. Пример:
x{3}соответствует ровно 3 x (xxx);x{2,4}соответствует от 2 до 4 x (xx, xxx или xxxx);x{3,}соответствует 3 или более x (xxx, xxxx, xxxxx и так далее).| – Действует как логическое ИЛИ. Пример:
apple|orangeсоответствует apple или orange.( ) – Группирует символы в подпаттерн. Пример:
ab(cd)?соответствует ab и abcd.[ ] – Сопоставляет один символ из набора или диапазона. Пример:
[aeiou]соответствует любой гласной.- – Когда предоставляется внутри скобок, указывает диапазон, если не экранирован или является первым символом внутри скобок. Пример:
[a-z]соответствует любой строчной букве;[-az]соответствует -, a или z;[a\\-z]соответствует a, -, или z.^ – Когда предоставляется внутри скобок, действует как логическое НЕ, отрицая диапазон символов или любой символ в наборе. Пример:
[^az]соответствует любому символу, кроме a или z;[^a-z]соответствует любому символу, кроме строчных букв;[^-az]соответствует любому символу, кроме -, a и z;[^a\\-z]соответствует любому символу, кроме a, -, и z.
Необязательные операторы
Вы можете включить дополнительные операторы регулярных выражений, используя параметр flags. Разделяйте несколько флагов с помощью |.
Следующие флаги доступны:
ALL (по умолчанию) – Включает все необязательные операторы.
COMPLEMENT – Включает
~, который отрицает следующее выражение. Пример:d~efсоответствует dgf, dxf, но не def.INTERSECTION – Включает
&как логический оператор И. Пример:ab.+&.+cdсоответствует строкам, содержащим ab в начале и cd в конце.INTERVAL – Включает синтаксис
<min-max>для сопоставления числовых диапазонов. Пример:id<10-12>соответствует id10, id11 и id12.ANYSTRING – Включает
@для сопоставления любой строки. Вы можете комбинировать это с~и&для исключений. Пример:@&.*error.*&.*[0-9]{3}.*соответствует строкам, содержащим как слово “error”, так и последовательность из трех цифр.
Неподдерживаемые функции
Движок Lucene не поддерживает следующие часто используемые якоря регулярных выражений:
- ^ – Начало строки
- $ – Конец строки
Вместо этого ваш шаблон должен соответствовать всей строке, чтобы произвести совпадение.
Пример использования регулярных выражений
Чтобы попробовать регулярные выражения, индексируйте следующие документы в индекс logs:
PUT /logs/_doc/1
{
"message": "error404"
}
PUT /logs/_doc/2
{
"message": "error500"
}
PUT /logs/_doc/3
{
"message": "error1a"
}
Пример: Базовый запрос с использованием регулярных выражений
Следующий запрос regexp возвращает документы, в которых полное значение поля message соответствует шаблону “error”, за которым следует одна или более цифр. Значение не соответствует, если оно содержит шаблон только как подстроку:
GET /logs/_search
{
"query": {
"regexp": {
"message": {
"value": "error[0-9]+"
}
}
}
}
Этот запрос соответствует error404 и error500:
{
"took": 28,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Пример: Использование необязательных операторов
Следующий запрос соответствует документам, в которых поле message точно соответствует строке, начинающейся с “error”, за которой следует число от 400 до 500, включительно. Флаг INTERVAL позволяет использовать синтаксис <min-max> для числовых диапазонов:
GET /logs/_search
{
"query": {
"regexp": {
"message": {
"value": "error<400-500>",
"flags": "INTERVAL"
}
}
}
}
Этот запрос также соответствует error404 и error500:
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Пример: Использование ANYSTRING
Когда флаг ANYSTRING включен, оператор @ соответствует всей строке. Это полезно в сочетании с пересечением (&), поскольку позволяет вам строить запросы, которые соответствуют полным строкам при определенных условиях.
Следующий запрос соответствует сообщениям, которые содержат как слово “error”, так и последовательность из трех цифр. Используйте ANYSTRING, чтобы утверждать, что все поле должно соответствовать пересечению обоих шаблонов:
GET /logs/_search
{
"query": {
"regexp": {
"message.keyword": {
"value": "@&.*error.*&.*[0-9]{3}.*",
"flags": "ANYSTRING|INTERSECTION"
}
}
}
}
Этот запрос соответствует error404 и error500:
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Обратите внимание, что этот запрос также будет соответствовать xerror500, error500x и errorxx500.
8.4 - goclient
Клиент OpenSearch Go позволяет подключить ваше приложение Go к данным в кластере OpenSearch.
Клиент Go
В этом руководстве по началу работы описано, как подключиться к OpenSearch, индексировать документы и выполнять запросы. Полную документацию по API клиента и дополнительные примеры см. в документации по API клиента Go.
Исходный код клиента см. в репозитории opensearch-go.
Настройка
Если вы начинаете новый проект, создайте новый модуль, выполнив следующую команду:
go mod init <mymodulename>
Чтобы добавить клиент Go в свой проект, импортируйте его как любой другой модуль:
go get github.com/opensearch-project/opensearch-go
9 - Визуализация графов библиотека Graphviz
Graphviz — это программное обеспечение с открытым исходным кодом для визуализации графов.
📊 Что такое Graphviz?
Graphviz — это программное обеспечение с открытым исходным кодом для визуализации графов. Визуализация графов — это способ представления структурной информации в виде диаграмм абстрактных графов и сетей. Она имеет важные приложения в таких областях, как сетевое взаимодействие, биоинформатика, программная инженерия, проектирование баз данных и веб-дизайн, машинное обучение и в визуальных интерфейсах для других технических областей.
Полное описание библиотеки
Редактор графов
Редактор визуальный графов
🌐 Кластеры
Graphviz поддерживает концепцию кластеров, что позволяет группировать узлы в логические группы, улучшая визуальное представление и понимание структуры графа.
🎨 Особенности
Программы компоновки Graphviz принимают описания графов на простом текстовом языке и создают диаграммы в полезных форматах, таких как изображения и SVG для веб-страниц; PDF или Postscript для включения в другие документы; или отображение в интерактивном браузере графов.
Graphviz имеет множество полезных функций для конкретных диаграмм, таких как опции для цветов, шрифтов, табличных компоновок узлов, стилей линий, гиперссылок и пользовательских форм.
📊 Визуализация графов
Визуализация графов — это способ представления структурной информации в виде диаграмм абстрактных графов и сетей. Автоматическая отрисовка графов имеет множество важных приложений в области программной инженерии, проектирования баз данных и веб-дизайна, сетевого взаимодействия и в визуальных интерфейсах для многих других областей.
🌐 Graphviz
Graphviz — это программное обеспечение с открытым исходным кодом для визуализации графов. Оно включает несколько основных программ для компоновки графов. Посмотрите Галерею для примеров компоновок. Также имеются веб- и интерактивные графические интерфейсы, а также вспомогательные инструменты, библиотеки и языковые привязки.
Издание Graphviz для Mac OS X, разработанное Гленом Лоу, получило две награды Apple Design Awards в 2004 году.
Программы компоновки Graphviz принимают описания графов на простом текстовом языке и создают диаграммы в нескольких полезных форматах, таких как изображения и SVG для веб-страниц, Postscript для включения в PDF или другие документы; или отображение в интерактивном браузере графов. (Graphviz также поддерживает GXL, диалект XML.)
🎨 Особенности Graphviz
Graphviz имеет множество полезных функций для конкретных диаграмм, таких как опции для цветов, шрифтов, табличных компоновок узлов, стилей линий, гиперссылок и пользовательских форм.
На практике графы обычно генерируются из внешних источников данных, но их также можно создавать и редактировать вручную, как в виде сырых текстовых файлов, так и в графическом редакторе. (Graphviz не предназначен для замены Visio, поэтому, вероятно, будет разочаровывающим пытаться использовать его таким образом.)
🖥️ Просмотрщики
- Любой веб-браузер может открывать SVG или PDF, сгенерированные Graphviz.
- gvedit — это простой просмотрщик и редактор в Graphviz, написанный на Qt.
- Mac OS X Graphviz.app (переиздание скоро).
- Веб-песочницы редакторов Graphviz, такие как визуальный редактор Graphviz и Graphviz Online.
🔧 Фильтры
gvpr — это универсальный редактор потоков графов, в духе awk и sed (или подумайте о Perl, если вы не знакомы с ними).
📚 Примеры приложений
- Документация программного обеспечения: красивые диаграммы, автоматически сгенерированные с помощью doxygen и dot.
- WWW Graph Server: для веб-приложения Graphviz смотрите Webdot.
- Canviz — библиотека Javascript для HTML5 canvas.
10 - Визуализация графиков и данных Chart.js
Среди множества библиотек для построения графиков для разработчиков JavaScript, Chart.js в настоящее время является самой популярной, согласно звёздам на GitHub (~60,000) и загрузкам npm (~2,400,000 в неделю).
Chart.js была создана и анонсирована в 2013 году, но с тех пор прошла долгий путь. Это программное обеспечение с открытым исходным кодом, лицензированное по очень либеральной лицензии MIT, и поддерживается активным сообществом.
🎨 Особенности
Chart.js предоставляет набор часто используемых типов графиков, плагинов и опций настройки. В дополнение к разумному набору встроенных типов графиков, вы можете использовать дополнительные типы графиков, поддерживаемые сообществом. Более того, возможно комбинировать несколько типов графиков в смешанный график (по сути, объединяя несколько типов графиков в одном на одном холсте).
Chart.js имеет высокую степень настройки с помощью пользовательских плагинов для создания аннотаций, функций масштабирования или перетаскивания, чтобы назвать лишь некоторые.
⚙️ Настройки по умолчанию
Chart.js поставляется с хорошей конфигурацией по умолчанию, что делает его очень простым в использовании и позволяет быстро создать приложение, готовое к производству. Скорее всего, вы получите очень привлекательный график, даже если не укажете никаких опций. Например, в Chart.js анимации включены по умолчанию, так что вы можете мгновенно привлечь внимание к истории, которую рассказываете с помощью данных.
🔗 Интеграции
Chart.js поставляется с встроенными типами TypeScript и совместим со всеми популярными фреймворками JavaScript, включая React, Vue, Svelte и Angular. Вы можете использовать Chart.js напрямую или воспользоваться хорошо поддерживаемыми обертками, которые позволяют более естественно интегрироваться с вашими предпочтительными фреймворками.
👩💻 Опыт разработчика
Chart.js имеет очень подробную документацию (да, вы её читаете), справочник API и примеры. Поддерживающие и члены сообщества активно участвуют в обсуждениях на Discord, GitHub Discussions и Stack Overflow, где более 11,000 вопросов помечены тегом chart.js.
🎨 Рендеринг на Canvas
Chart.js рендерит элементы графиков на HTML5 canvas, в отличие от нескольких других библиотек для построения графиков, основанных на D3.js, которые рендерят в формате SVG. Рендеринг на canvas делает Chart.js очень производительным, особенно для больших наборов данных и сложных визуализаций, которые в противном случае потребовали бы тысячи узлов SVG в дереве DOM. В то же время рендеринг на canvas не позволяет использовать CSS-стили, поэтому вам придется использовать встроенные опции для этого или создать пользовательский плагин или тип графика, чтобы отобразить всё по вашему вкусу.
⚡ Производительность
Chart.js очень хорошо подходит для больших наборов данных. Такие наборы данных могут быть эффективно загружены с использованием внутреннего формата, так что вы можете пропустить парсинг и нормализацию данных. В качестве альтернативы можно настроить уменьшение данных, чтобы отобрать выборку из набора данных и уменьшить его размер перед рендерингом.
В конечном итоге рендеринг на canvas, который использует Chart.js, снижает нагрузку на ваше дерево DOM по сравнению с рендерингом SVG. Также поддержка tree-shaking позволяет включать минимальные части кода Chart.js в ваш пакет, уменьшая размер пакета и время загрузки страницы.
🌍 Сообщество
Chart.js активно разрабатывается и поддерживается сообществом. С незначительными релизами примерно раз в два месяца и основными релизами с разрушающими изменениями каждые несколько лет, Chart.js сохраняет баланс между добавлением новых функций и тем, чтобы это не стало обременительным для пользователей.
11 - Emacs
Emacs — один из наиболее мощных и широко распространённых редакторов, используемых в мире Unix. По популярности он соперничает с редактором vi и его клонами.
EMACS
Emacs — один из наиболее мощных и широко распространённых редакторов, используемых в мире Unix. По популярности он соперничает с редактором vi и его клонами.
- текстовым редактором;
- программой для чтения почты и новостей Usenet;
- интегрированной средой разработки (IDE);
- операционной системой;
- всем, чем угодно.
11.1 - LaTeX в Emacs
Полное руководство по настройке LaTeX в Emacs
Установка и базовая настройка
1. Установка необходимых пакетов
Добавьте в ваш .emacs или init.el:
(use-package tex
:ensure auctex
:mode ("\\.tex\\'" . latex-mode)
:config
(setq TeX-auto-save t
TeX-parse-self t
TeX-save-query nil
TeX-PDF-mode t))
(use-package company-auctex
:ensure t
:after (company tex))
(use-package reftex
:ensure t
:config
(add-hook 'LaTeX-mode-hook 'turn-on-reftex))
2. Системные зависимости
Убедитесь, что установлены:
- TeX-дистрибутив (TeX Live или MiKTeX)
latexmk(для автоматической сборки)chktex(для проверки стиля)
Основные горячие клавиши
Общие команды
| Комбинация | Описание |
|---|---|
C-c C-c | Компиляция документа |
C-c C-v | Просмотр PDF |
C-c C-e | Добавить окружение |
C-c C-s | Добавить section-like команду |
C-c C-m | Добавить макрос |
C-c C-k | Удалить макрос/окружение |
C-c C-w | Проверить орфографию |
Навигация
| Комбинация | Описание |
|---|---|
C-c = | Показать структуру документа |
C-c [ | Перейти к следующей метке |
C-c ] | Перейти к предыдущей метке |
C-c & | Перейти к месту ссылки |
RefTeX (ссылки и библиография)
| Комбинация | Описание |
|---|---|
C-c ( | Вставить ссылку |
C-c ) | Создать метку |
C-c [ | Вставить ссылку на библиографию |
C-c ] | Вставить citation |
C-c / | Поиск по меткам |
Настройка рабочего процесса
1. Конфигурация компилятора
(setq TeX-engine 'xetex) ;; Использовать XeLaTeX
(setq TeX-view-program-selection '((output-pdf "PDF Viewer")))
(setq TeX-view-program-list '(("PDF Viewer" "evince %o")))
2. Автоматическая сборка
(setq TeX-command-default "latexmk")
(setq TeX-command-extra-options "-pdf -shell-escape -synctex=1")
3. Проверка стиля
(add-hook 'LaTeX-mode-hook
(lambda ()
(flycheck-mode)
(setq flycheck-latex-checker 'chktex)))
Продвинутые настройки
1. Интеллектуальное завершение кода
(use-package company-auctex
:ensure t
:config
(company-auctex-init))
2. Подсветка синтаксиса
(use-package latex-preview-pane
:ensure t
:config
(latex-preview-pane-enable))
3. Шаблоны документов
(use-package yasnippet
:ensure t
:config
(yas-global-mode 1))
(use-package yasnippet-snippets
:ensure t)
Рабочий процесс с LaTeX-документом
- Создайте новый файл
.texили откройте существующий - Начните вводить
\documentclass- сработает автодополнение - Используйте
C-c C-eдля добавления окружений - Для вставки ссылок:
- Создайте метку:
C-c ) - Вставьте ссылку:
C-c (
- Создайте метку:
- Для компиляции:
C-c C-c(выберите команду, обычноlatexmk) - Для просмотра PDF:
C-c C-v
Интеграция с другими инструментами
1. Работа с библиографией (BibTeX)
(setq reftex-plug-into-AUCTeX t)
Команды:
C-c [- вставить ссылку на библиографиюC-c C-m bib RET- вставить новый элемент библиографии
2. Просмотр ошибок
Используйте M-x flycheck-list-errors для просмотра списка ошибок.
3. Синхронизация с PDF
(setq TeX-source-correlate-mode t
TeX-source-correlate-start-server t)
Для перехода из Emacs в PDF и обратно:
- В Emacs:
C-c C-g - В PDF-просмотрщике: Ctrl+клик
Полезные советы
- Для многофайловых проектов используйте
\includeи\input - Настройте шаблоны для часто используемых документов
- Используйте
yasnippetдля быстрой вставки структурных элементов - Для математических формул используйте
C-c C-mи выберите нужный символ
Решение проблем
1. Компиляция не работает
Проверьте:
- Установлен ли
latexmk:latexmk --version - Правильно ли указан путь к TeX-дистрибутиву
2. Нет автодополнения
Убедитесь, что:
- Пакет
company-auctexустановлен и загружен - Включен режим
company-mode
3. PDF не синхронизируется с исходником
Проверьте настройки:
(setq TeX-source-correlate-mode t)
Альтернативные пакеты
- AUCTeX - основной пакет для работы с LaTeX
- cdlatex - быстрый ввод математических выражений
- prettify-symbols-mode - отображение символов (например, \alpha как α)
- lsp-latex - Language Server Protocol для LaTeX (требуется texlab)
11.2 - Yasnippet
Документация и настройки Yasnippet
Yasnippet
Установка Yasnippet
Загрузил через M-x list-packages [RET] yasnippet
Поместил в init.el
(setq yas-snippet-dirs
'("~/.emacs.d/snippets" ;; personal snippets
"/path/to/some/collection/" ;; foo-mode and bar-mode snippet collection
"/path/to/yasnippet/yasmate/snippets" ;; the yasmate collection
))
(yas-global-mode 1) ;; or M-x yas-reload-all if you've started YASnippet already.
Команда M-x yas-reload-all перегружает все сниппеты и появляется меню в Emacs
Загрузил стандартную коллекцию сниппетов
M-x list-packages [RET] yasnippet-snippets
Использование снипетов
Все очень просто.
- Набираем ключ сниппета и нажимаем
<TAB>и сниппет загружается - Снипету можно назначить свою клавишу вызова на функцию
yas-expand
;; Bind `SPC' to `yas-expand' when snippet expansion available (it
;; will still call `self-insert-command' otherwise).
(define-key yas-minor-mode-map (kbd "SPC") yas-maybe-expand)
;; Bind `C-c y' to `yas-expand' ONLY.
(define-key yas-minor-mode-map (kbd "C-c y") #'yas-expand)
Автоматическое развертывание сниппетов
;; Function that tries to autoexpand YaSnippets
;; The double quoting is NOT a typo!
(defun my/yas-try-expanding-auto-snippets ()
(when (bound-and-true-p 'yas-minor-mode)
(let ((yas-buffer-local-condition ''(require-snippet-condition . auto)))
(yas-expand))))
;; Try after every insertion
(add-hook 'post-self-insert-hook #'my/yas-try-expanding-auto-snippets)
Добавим в описание сниппета переменную # condition: (and (texmathp) 'auto)
чтобы он стал авторасширяющимся.
Создание своих сниппетов
На примере сниппетов для markdown
в коллекции хранится как markdown-mode, это нужно знать, чтобы потом объяснить куда складывать yasnippet-у
- Выделяю текст для сниппета
{{ alert warning }}
{{ /alert }}
- и нажимаю
C-c & C-n, это серьезно так сложно и не забыть&.
Откроется окно:
# -*- mode: snippet -*-
# name: alert warning
# condition: (and (texmathp) 'auto)
# key: alert
# --
{{ alert warning }}
$0
{{ /alert }}
пишу значение
name,conditionиkey. Где должен оказаться курсор ставлю$0Нажимаю
C-c C-cдля сохранения сниппета. При сохранении на запрос:Choose or enter a table (yas guesses markdown-mode):указать markdown-mode [RET][yas] Loaded for markdown-mode. Also save snippet buffer? (y or n)указатьyFile to save snippet in: ~/.emacs.d/snippets/markdown-mode/alert.5имя файла нужно обязательно исправить, чтобы при использовании сниппета была возможность выбора значений. У меня это уже 5-й alert с разными значениями, поэтому имя далalert.5если сниппет будет один, то имя может быть как ключ.
Фишки сниппетов
Обход полей при вводе снипета задаются переменными
$1, $2, ... и заканчиваем $0 переход между ними идет [TAB]Чтобы сделать подсказку с заменой пишем
${1:подсказка} — когда начнем ввод, подсказка удалится
Зеркалить значения
Очень полезная функция для программирования Latex и Org-mode
\begin{${1:enumerate}}
$0
\end{$1}
Вводим значение в begin, оно автоматически дублируется в end.
Собрать в группу в меню
- В преамбуле каждого сниппета указать
# group: имя группыу всех одинаковое. - Создать директорию с названием группы
- Поместить в директорию пустой файл с именем
.yas-make-groups
Добавить в сниппет дату
Просто вставляем функцию, как и любую функцию LISP
`(format-time-string "%Y-%m-%d")`
11.3 - Как настроить и работать с Go в Emacs?
Полное руководство по настройке Go и работе с проектами в Emacs
Настройка Emacs для работы с Go включает установку необходимых пакетов и настройку среды разработки. Вот пошаговая инструкция:
1. Установите go-mode (основной режим для Go)
Добавьте в ваш ~/.emacs или ~/.emacs.d/init.el:
(require 'package)
(add-to-list 'package-archives '("melpa" . "https://melpa.org/packages/") t)
(package-initialize)
;; Установка go-mode (если не установлен)
(unless (package-installed-p 'go-mode)
(package-refresh-contents)
(package-install 'go-mode))
2. Установите lsp-mode (Language Server Protocol)
Для автодополнения, навигации и рефакторинга:
(unless (package-installed-p 'lsp-mode)
(package-install 'lsp-mode))
(require 'lsp-mode)
(add-hook 'go-mode-hook #'lsp-deferred) ;; Автоматический запуск LSP для Go
3. Установите lsp-ui (дополнения для LSP)
(unless (package-installed-p 'lsp-ui)
(package-install 'lsp-ui))
(require 'lsp-ui)
(setq lsp-ui-doc-enable t) ;; Включить документацию при наведении
(setq lsp-ui-sideline-enable t) ;; Показывать информацию на полях
4. Установите company (автодополнение)
(unless (package-installed-p 'company)
(package-install 'company))
(require 'company)
(add-hook 'go-mode-hook 'company-mode)
(setq company-minimum-prefix-length 1)
(setq company-idle-delay 0.1)
5. Установите flycheck (проверка синтаксиса)
(unless (package-installed-p 'flycheck)
(package-install 'flycheck))
(require 'flycheck)
(add-hook 'go-mode-hook 'flycheck-mode)
6. Настройка gofmt (форматирование кода)
Добавьте в go-mode-hook:
(add-hook 'go-mode-hook
(lambda ()
(add-hook 'before-save-hook 'gofmt-before-save nil t)))
7. Установите goimports (автоматическое добавление импортов)
Убедитесь, что goimports установлен:
go install golang.org/x/tools/cmd/goimports@latest
Затем настройте в Emacs:
(setq gofmt-command "goimports")
8. Дополнительные улучшения (опционально)
dap-mode(отладка):(unless (package-installed-p 'dap-mode) (package-install 'dap-mode)) (require 'dap-go) ;; Поддержка Goyasnippet(шаблоны кода):(unless (package-installed-p 'yasnippet) (package-install 'yasnippet)) (yas-global-mode 1)
9. Проверьте настройки
Перезапустите Emacs и откройте .go файл. Должны работать:
- Автодополнение (
company) - Проверка ошибок (
flycheck) - Форматирование при сохранении (
gofmt/goimports) - Навигация по коду (
lsp-mode)
Если LSP не работает, убедитесь, что у вас установлен Go Language Server (gopls):
go install golang.org/x/tools/gopls@latest
Готово! Теперь Emacs настроен для комфортной работы с Go. 🚀
11.4 - Как настроить и работать с Python в Emacs?
Полное руководство по настройке Elpy и работе с Python-проектами в Emacs
Установка и базовая настройка
1. Установка необходимых пакетов
Добавьте в ваш .emacs или init.el:
;; Активация Elpy
(use-package elpy
:ensure t
:init
(elpy-enable))
;; Дополнительные зависимости
(use-package flycheck
:ensure t)
(use-package py-autopep8
:ensure t)
2. Установка системных зависимостей
Выполните в терминале:
pip install jedi flake8 autopep8 black
Основные горячие клавиши
| Комбинация | Описание |
|---|---|
C-c C-c | Выполнить текущий буфер |
C-c C-z | Открыть Python shell |
C-c C-r | Выполнить выделенный регион |
C-c C-f | Форматировать код (autopep8) |
C-c C-d | Показать документацию |
M-. | Перейти к определению |
M-, | Вернуться назад |
C-c C-t | Запустить тест |
C-c C-e | Открыть список ошибок (flycheck) |
Настройка окружения
1. Работа с виртуальными окружениями
;; Настройка работы с virtualenv
(setq elpy-rpc-virtualenv-path 'current) ;; Использовать текущее virtualenv
Для активации virtualenv в Emacs:
M-x pyvenv-activate- Выберите путь к virtualenv
2. Настройка интерпретатора
(setq python-shell-interpreter "python3"
python-shell-interpreter-args "-i")
Рабочий процесс с Python-проектом
1. Создание нового проекта
M-x elpy-config- проверьте, что все зависимости установленыC-x f- откройте или создайте новый .py файлM-x elpy-project-root- установите корень проекта
2. Структура проекта
Elpy автоматически создает:
.projectile- файл для projectilesetup.py- если создаете пакет
Рекомендуемая структура:
project_root/
├── .git/
├── src/
│ ├── __init__.py
│ ├── module1.py
│ └── module2.py
├── tests/
├── requirements.txt
└── setup.py
3. Написание кода
- Автодополнение работает автоматически после
import - Для принудительного обновления:
M-x elpy-rpc-restart - Используйте
M-x elpy-company-backendдля управления бекендами автодополнения
4. Рефакторинг
;; Настройка рефакторинга
(use-package srefactor
:ensure t
:config
(define-key python-mode-map (kbd "M-RET") 'srefactor-refactor-at-point))
Доступные операции:
- Переименование переменной
- Извлечение метода
- Изменение сигнатуры функции
5. Отладка
- Установите
pip install epc - Добавьте в конфигурацию:
(use-package realgud
:ensure t)
Основные команды:
M-x realgud:pdb- запуск отладчикаC-c C-b- установить точку остановаn- следующая строкаs- шаг внутрь функцииc- продолжить выполнение
Интеграция с другими инструментами
1. Jupyter Notebook
(use-package ein
:ensure t)
Использование:
M-x ein:notebooklist-open- Выберите или создайте notebook
C-c C-c- выполнить ячейку
2. Тестирование
;; Настройка pytest
(setq elpy-test-runner 'elpy-test-pytest-runner)
Команды:
C-c C-t t- запустить тестC-c C-t m- запустить тесты модуляC-c C-t p- запустить все тесты проекта
3. Форматирование кода
;; Настройка black
(setq elpy-formatter 'black)
Используйте C-c C-f для форматирования текущего буфера.
Продвинутые настройки
1. Настройка flycheck
(setq flycheck-python-flake8-executable "flake8"
flycheck-python-pylint-executable "pylint"
flycheck-checker-error-threshold 1000
flycheck-python-mypy-executable "mypy")
2. Интерактивная разработка
;; Настройка интерактивного Python
(setq python-shell-interpreter "ipython"
python-shell-interpreter-args "-i --simple-prompt")
3. Работа с документацией
(use-package eldoc
:config
(setq eldoc-idle-delay 0.4))
Решение проблем
1. Elpy не загружается
Проверьте:
M-x elpy-config- все ли зависимости установленыM-x elpy-rpc-restart- перезапустите RPC сервер
2. Нет автодополнения
- Убедитесь, что установлен jedi:
pip install -U jedi - Проверьте
M-x elpy-company-backend
3. Медленная работа
(setq elpy-rpc-timeout 10
elpy-rpc-large-buffer-size 102400)
Заключение
Elpy предоставляет полноценную среду разработки для Python в Emacs. После настройки вы получаете:
- Интеллектуальное автодополнение
- Интегрированную отладку
- Поддержку тестирования
- Инструменты рефакторинга
- Интерактивную разработку
Для максимальной эффективности рекомендуется использовать в сочетании с:
magitдля контроля версийprojectileдля навигации по проектуlsp-modeдля дополнительных возможностей анализа кода
11.5 - Как настроить и работать с Magit?
Полное руководство по работе с Magit в Emacs
Сводная таблица горячих клавиш Magit
Основные команды
| Комбинация | Действие |
|---|---|
C-x g | Открыть Magit status |
s | Stage изменения |
u | Unstage изменения |
c | Commit |
C | Extended commit |
P | Push |
F | Pull |
b | Branch |
m | Merge |
l | Log |
t | Tag |
z | Stash |
k | Discard изменения |
Навигация
| Комбинация | Действие |
|---|---|
TAB | Развернуть/свернуть секцию |
n | Следующий элемент |
p | Предыдущий элемент |
M-n | Следующая секция |
M-p | Предыдущая секция |
Статус репозитория
| Комбинация | Действие |
|---|---|
g | Обновить статус |
= | Diff |
E | Ediff |
Установка Magit
- Установите через package.el:
(use-package magit
:ensure t)
- Или через MELPA:
M-x package-install RET magit RET
Основной рабочий процесс
1. Открытие Magit status
Основная точка входа - окно статуса:
C-x g
2. Просмотр изменений
В окне статуса:
- Неотслеживаемые файлы (Untracked)
- Измененные файлы (Unstaged changes)
- Подготовленные к коммиту изменения (Staged changes)
Используйте TAB для разворачивания секций.
3. Подготовка изменений (Stage)
- Наведите курсор на файл и нажмите
sдля stage - Для stage конкретных изменений внутри файла:
- Откройте diff (
=на файле) - Перейдите к нужному блоку изменений
- Нажмите
s
- Откройте diff (
4. Создание коммита
После stage изменений:
- Нажмите
cдля начала коммита - Затем:
c- обычный коммитC- extended commit (с дополнительными опциями)
Введите сообщение коммита и завершите C-c C-c.
5. Работа с ветками
b b- переключение между веткамиb c- создание новой веткиb n- переименование веткиb d- удаление ветки
6. Синхронизация с удаленным репозиторием
P p- push текущей веткиF u- pull с rebaseF p- обычный pull
Продвинутые возможности
1. Интерактивный rebase
- Откройте log (
l l) - Выберите коммит, с которого начать rebase
- Нажмите
r iдля интерактивного rebase - Используйте команды:
p- pick (оставить коммит)r- reword (изменить сообщение)e- edit (изменить коммит)s- squash (объединить с предыдущим)f- fixup (как squash, но отбросить сообщение)
2. Работа с stash
z s- создать stashz a- применить stashz p- pop stash (применить и удалить)z d- удалить stash
3. Разрешение конфликтов
При возникновении конфликтов:
- Откройте файл с конфликтами
- Используйте
M-x magit-ediff-resolveдля интерактивного разрешения - После разрешения всех конфликтов сделайте
git add(sв Magit)
Кастомизация Magit
Настройка в .emacs
(setq magit-display-buffer-function #'magit-display-buffer-fullframe-status-v1)
;; Автозавершение при вводе сообщений коммита
(add-hook 'git-commit-mode-hook 'git-commit-turn-on-flyspell)
Полезные расширения
magit-todos- просмотр TODO в кодеmagit-gitflow- поддержка git-flowforge- интеграция с GitHub/GitLab
Советы и рекомендации
- Используйте
M-x magit-file-deleteдля удаления файлов через Magit - Для частичного stage используйте
sвнутри diff M-x magit-blame-modeдля просмотра аннотаций к строкамM-x magit-submoduleдля работы с подмодулями- Для сложных операций используйте команды через
M-x magit-*
Решение проблем
Magit работает медленно
Добавьте в конфигурацию:
(setq magit-refresh-status-buffer nil)
Проблемы с аутентификацией
Настройте:
(setq magit-git-executable "/path/to/git")
(setq magit-credential-cache-daemon-socket "~/.git-credential-cache/socket")
Magit предоставляет мощный интерфейс для работы с Git, сочетающий удобство использования с полнотой функционала. Освоение его горячих клавиш значительно ускорит ваш рабочий процесс.
Команды Magit
C-x g для отображения информации о текущем репозитории Git
s / u добавить файл в индекс или убрать из индекса.C-SPC — поставить метку на файле C-n C-p отметить список файлов из отменить,потом s или u для включения или исключения.c откроет меню для COMMIT и другие варианты, нажимаю еще раз c, ввожу комментарий commit и нажимаю C-c для выполнения commit.
Список команд
Key Binding
TAB magit-section-toggle
RET magit-visit-thing
C-w magit-copy-section-value
SPC magit-diff-show-or-scroll-up
! magit-run
$ magit-process-buffer
% magit-worktree
+ magit-diff-more-context
- magit-diff-less-context
0 magit-diff-default-context
1 magit-section-show-level-1
2 magit-section-show-level-2
3 magit-section-show-level-3
4 magit-section-show-level-4
5 .. 9 digit-argument
: magit-git-command
< beginning-of-buffer
> magit-sparse-checkout
? magit-dispatch
A magit-cherry-pick
B magit-bisect
C magit-clone
D magit-diff-refresh
E magit-ediff
F magit-pull
G magit-refresh-all
H magit-describe-section
I magit-init
J magit-display-repository-buffer
K magit-file-untrack
L magit-log-refresh
M magit-remote
O magit-subtree
P magit-push
Q magit-git-command
R magit-file-rename
S magit-stage-modified
T magit-notes
U magit-unstage-all
V magit-revert
W magit-patch
X magit-reset
Y magit-cherry
Z magit-worktree
^ magit-section-up
a magit-cherry-apply
b magit-branch
c magit-commit
d magit-diff
e magit-ediff-dwim
f magit-fetch
g magit-refresh
h magit-dispatch
i magit-gitignore
j magit-status-jump
k magit-delete-thing
l magit-log
m magit-merge
n magit-section-forward
o magit-submodule
p magit-section-backward
q magit-mode-bury-buffer
r magit-rebase
s magit-stage-file
t magit-tag
u magit-unstage-file
v magit-revert-no-commit
w magit-am
x magit-reset-quickly
y magit-show-refs
z magit-stash
DEL magit-diff-show-or-scroll-down
S-SPC magit-diff-show-or-scroll-down
C-<return> magit-visit-thing
C-<tab> magit-section-cycle
M-<tab> magit-section-cycle-diffs
<backtab> magit-section-cycle-global
<remap> <dired-jump> magit-dired-jump
<remap> <back-to-indentation> magit-back-to-indentation
<remap> <evil-next-line> evil-next-visual-line
<remap> <evil-previous-line> evil-previous-visual-line
<remap> <next-line> magit-next-line
<remap> <previous-line> magit-previous-line
C-c C-c magit-dispatch
C-c C-e magit-edit-thing
C-c C-o magit-browse-thing
C-c C-w magit-copy-thing
C-M-i magit-dired-jump
M-w magit-copy-buffer-revision
C-c TAB magit-section-cycle
M-1 magit-section-show-level-1-all
M-2 magit-section-show-level-2-all
M-3 magit-section-show-level-3-all
M-4 magit-section-show-level-4-all
M-n magit-section-forward-sibling
M-p magit-section-backward-sibling
<left-fringe> <mouse-1> magit-mouse-toggle-section
<left-fringe> <mouse-2> magit-mouse-toggle-section
12 - GO
Язык Go может использоваться для создания любых продуктов, будь то консольные программы или сложные многопоточный приложения.
Go (или Golang)
представляет собой компилируемый многопоточный язык программирования, который имеет открытый исходный код. Его часто используют в веб-сервисах и клиент-серверных приложениях. К концу 2021 года Go вошёл в список самых востребованных языков.
12.1 - Полный гайд по установке и настройке Go для работы с базами данных (OpenSearch, PostgreSQL, SQLite)
Полный гайд по установке и настройке Go для работы с базами данных (OpenSearch, PostgreSQL, SQLite) на локальном компьютере
1. Установка Go на локальный компьютер
Linux (Ubuntu/Debian)
# Удаление старых версий (если есть)
sudo rm -rf /usr/local/go
# Скачивание и установка
wget https://go.dev/dl/go1.21.4.linux-amd64.tar.gz
sudo tar -C /usr/local -xzf go1.21.4.linux-amd64.tar.gz
# Добавление в PATH
echo 'export PATH=$PATH:/usr/local/go/bin' >> ~/.bashrc
source ~/.bashrc
# Проверка
go version
2. Настройка рабочего окружения
Создайте рабочую директорию:
mkdir -p ~/go/src/myproject cd ~/go/src/myprojectИнициализация модуля:
go mod init myprojectУстановка зависимостей (драйверы для баз данных):
go get github.com/opensearch-project/opensearch-go go get github.com/lib/pq go get github.com/mattn/go-sqlite3
3. Подключение к базам данных
OpenSearch
package main
import (
"context"
"crypto/tls"
"fmt"
"log"
"net/http"
"github.com/opensearch-project/opensearch-go"
)
func main() {
client, err := opensearch.NewClient(opensearch.Config{
Addresses: []string{"https://localhost:9200"},
Username: "admin",
Password: "admin",
Transport: &http.Transport{
TLSClientConfig: &tls.Config{InsecureSkipVerify: true},
},
})
if err != nil {
log.Fatal(err)
}
// Проверка подключения
res, err := client.Ping()
if err != nil {
log.Fatal(err)
}
fmt.Println("Connected to OpenSearch:", res.Status())
}
PostgreSQL
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/lib/pq"
)
func main() {
connStr := "user=postgres password=1234 dbname=test sslmode=disable"
db, err := sql.Open("postgres", connStr)
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Проверка подключения
err = db.Ping()
if err != nil {
log.Fatal(err)
}
fmt.Println("Connected to PostgreSQL")
}
SQLite
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/mattn/go-sqlite3"
)
func main() {
db, err := sql.Open("sqlite3", "./test.db")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Проверка подключения
err = db.Ping()
if err != nil {
log.Fatal(err)
}
fmt.Println("Connected to SQLite")
}
4. Пример CRUD-операций
PostgreSQL (создание таблицы и вставка данных)
func main() {
db, err := sql.Open("postgres", "user=postgres password=1234 dbname=test sslmode=disable")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Создание таблицы
_, err = db.Exec(`
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT,
email TEXT UNIQUE
)
`)
if err != nil {
log.Fatal(err)
}
// Вставка данных
_, err = db.Exec("INSERT INTO users (name, email) VALUES ($1, $2)", "Alice", "alice@example.com")
if err != nil {
log.Fatal(err)
}
fmt.Println("Data inserted")
}
SQLite (выборка данных)
func main() {
db, err := sql.Open("sqlite3", "./test.db")
if err != nil {
log.Fatal(err)
}
defer db.Close()
rows, err := db.Query("SELECT id, name FROM users")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
for rows.Next() {
var id int
var name string
err = rows.Scan(&id, &name)
if err != nil {
log.Fatal(err)
}
fmt.Printf("ID: %d, Name: %s\n", id, name)
}
}
5. Управление зависимостями
Инициализация модуля (если еще не сделано):
go mod init myprojectДобавление новых зависимостей:
go get github.com/new/packageОбновление зависимостей:
go mod tidy
6. Сборка и запуск приложения
Запуск в development-режиме:
go run main.goСборка бинарного файла:
go build -o appЗапуск собранного приложения:
./app
7. Дополнительные инструменты
Установка утилит для разработки
go install golang.org/x/tools/cmd/godoc@latest # Документация
go install github.com/go-delve/delve/cmd/dlv@latest # Отладчик
Настройка IDE (VS Code)
- Установите расширение Go от Microsoft
- Нажмите
Ctrl+Shift+P→Go: Install/Update Tools - Выберите все инструменты и нажмите OK
8. Решение частых проблем
Ошибка: “sql: unknown driver”
Убедитесь, что импортирован драйвер с _ перед пакетом:
import _ "github.com/lib/pq"
Ошибка подключения к OpenSearch
Проверьте:
- Работает ли сервер OpenSearch (
curl -X GET https://localhost:9200 -u 'admin:admin' --insecure) - Правильно ли указаны логин/пароль
Ошибка cgo при работе с SQLite
На Linux установите:
sudo apt install gcc
Теперь можем работать:
- Работать с OpenSearch, PostgreSQL и SQLite из Go-приложений
- Выполнять CRUD-операции
- Собирать и запускать приложения
Официальные справочники:
12.2 - Работа с JSON в Go
Полное руководство по работе с JSON в Go: файлы, API и базы данных
1. Основы работы с JSON в Go
Структуры для маршалинга/анмаршалинга
type User struct {
ID int `json:"id"`
Name string `json:"name"`
Email string `json:"email"`
Roles []string `json:"roles"`
IsActive bool `json:"is_active"`
}
Преобразование структур в JSON
user := User{
ID: 1,
Name: "Alice",
Email: "alice@example.com",
Roles: []string{"admin", "user"},
IsActive: true,
}
jsonData, err := json.Marshal(user)
if err != nil {
log.Fatal(err)
}
fmt.Println(string(jsonData))
// Output: {"id":1,"name":"Alice","email":"alice@example.com","roles":["admin","user"],"is_active":true}
Чтение JSON в структуру
var decodedUser User
err = json.Unmarshal(jsonData, &decodedUser)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%+v\n", decodedUser)
2. Работа с JSON-файлами
Запись JSON в файл
func writeJSON(filename string, data interface{}) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close()
encoder := json.NewEncoder(file)
encoder.SetIndent("", " ") // Форматирование с отступами
return encoder.Encode(data)
}
// Использование
err := writeJSON("user.json", user)
Чтение JSON из файла
func readJSON(filename string, target interface{}) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
return json.NewDecoder(file).Decode(target)
}
// Использование
var userFromFile User
err := readJSON("user.json", &userFromFile)
3. Обработка директорий с JSON-файлами
Чтение всех JSON-файлов в директории
func readAllJSONFiles(dirPath string) ([]User, error) {
var users []User
files, err := os.ReadDir(dirPath)
if err != nil {
return nil, err
}
for _, file := range files {
if !strings.HasSuffix(file.Name(), ".json") {
continue
}
var user User
err := readJSON(filepath.Join(dirPath, file.Name()), &user)
if err != nil {
return nil, err
}
users = append(users, user)
}
return users, nil
}
Пример: Сохранение множества файлов
users := []User{
{ID: 1, Name: "Alice"},
{ID: 2, Name: "Bob"},
}
for _, user := range users {
filename := fmt.Sprintf("user_%d.json", user.ID)
err := writeJSON(filename, user)
if err != nil {
log.Printf("Error saving %s: %v", filename, err)
}
}
4. Взаимодействие с API
Отправка JSON через HTTP POST
func sendUserToAPI(url string, user User) (*http.Response, error) {
jsonData, err := json.Marshal(user)
if err != nil {
return nil, err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonData))
if err != nil {
return nil, err
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer token123")
client := &http.Client{}
return client.Do(req)
}
// Использование
resp, err := sendUserToAPI("https://api.example.com/users", user)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
Чтение JSON-ответа от API
func getUsersFromAPI(url string) ([]User, error) {
resp, err := http.Get(url)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, fmt.Errorf("API returned status: %s", resp.Status)
}
var users []User
err = json.NewDecoder(resp.Body).Decode(&users)
return users, err
}
5. Продвинутые техники
Кастомный парсинг дат в JSON
type CustomTime time.Time
func (ct *CustomTime) UnmarshalJSON(b []byte) error {
s := strings.Trim(string(b), `"`)
t, err := time.Parse("2006-01-02", s)
if err != nil {
return err
}
*ct = CustomTime(t)
return nil
}
type Event struct {
Name string `json:"name"`
Date CustomTime `json:"date"`
}
Обработка динамических JSON-структур
var data map[string]interface{}
err := json.Unmarshal(jsonData, &data)
if err != nil {
log.Fatal(err)
}
if name, ok := data["name"].(string); ok {
fmt.Println("Name:", name)
}
6. Полный пример: CRUD с JSON-файлами
package main
import (
"encoding/json"
"fmt"
"log"
"os"
"path/filepath"
)
type User struct {
ID int `json:"id"`
Name string `json:"name"`
Email string `json:"email"`
}
const storageDir = "data/users"
func init() {
os.MkdirAll(storageDir, 0755)
}
func saveUser(user User) error {
filename := filepath.Join(storageDir, fmt.Sprintf("%d.json", user.ID))
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close()
encoder := json.NewEncoder(file)
encoder.SetIndent("", " ")
return encoder.Encode(user)
}
func getUser(id int) (User, error) {
var user User
filename := filepath.Join(storageDir, fmt.Sprintf("%d.json", id))
file, err := os.Open(filename)
if err != nil {
return user, err
}
defer file.Close()
err = json.NewDecoder(file).Decode(&user)
return user, err
}
func main() {
user := User{ID: 1, Name: "Alice", Email: "alice@example.com"}
// Create
if err := saveUser(user); err != nil {
log.Fatal(err)
}
// Read
savedUser, err := getUser(1)
if err != nil {
log.Fatal(err)
}
fmt.Printf("User: %+v\n", savedUser)
}
7. Оптимизация работы с большими JSON
Стриминг при записи
func writeLargeJSON(filename string, data []User) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close()
encoder := json.NewEncoder(file)
for _, item := range data {
if err := encoder.Encode(item); err != nil {
return err
}
}
return nil
}
Построчное чтение больших файлов
func readLargeJSON(filename string) ([]User, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close()
var users []User
decoder := json.NewDecoder(file)
for decoder.More() {
var user User
if err := decoder.Decode(&user); err != nil {
return nil, err
}
users = append(users, user)
}
return users, nil
}
8. Безопасность и валидация
Валидация JSON-схемы
import "github.com/xeipuuv/gojsonschema"
func validateJSON(schemaPath string, jsonData []byte) error {
schemaLoader := gojsonschema.NewReferenceLoader("file://" + schemaPath)
documentLoader := gojsonschema.NewBytesLoader(jsonData)
result, err := gojsonschema.Validate(schemaLoader, documentLoader)
if err != nil {
return err
}
if !result.Valid() {
return fmt.Errorf("validation errors: %v", result.Errors())
}
return nil
}
Защита от переполнения при парсинге
decoder := json.NewDecoder(file)
decoder.DisallowUnknownFields() // Запрет неизвестных полей
Полезные материалы:
- JSON Schema для сложной валидации
- Альтернативные JSON-парсеры: json-iterator
- Бинарные JSON-альтернативы: Protocol Buffers, MessagePack
12.3 - Работа с OpenSearch в Go для системы управления знаниями
В этом руководстве я покажу, как реализовать систему знаний с таксономиями в OpenSearch с использованием Go, включая сложные запросы и построение дерева знаний.
Подготовка структуры данных
Сначала определим структуру документа для нашей базы знаний:
type KnowledgeDocument struct {
ID string `json:"id"`
Title string `json:"title"`
Content string `json:"content"`
Category string `json:"category"`
Tags []string `json:"tags"`
Benefits []string `json:"benefits"`
Locations []string `json:"locations"`
LevelUser string `json:"level_user"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
RelatedDocs []string `json:"related_docs"`
Solutions []struct {
Description string `json:"description"`
Steps []string `json:"steps"`
} `json:"solutions"`
}
Настройка клиента OpenSearch в Go
package main
import (
"context"
"crypto/tls"
"fmt"
"log"
"net/http"
"strings"
"time"
"github.com/opensearch-project/opensearch-go"
"github.com/opensearch-project/opensearch-go/opensearchapi"
)
func getOpenSearchClient() *opensearch.Client {
cfg := opensearch.Config{
Addresses: []string{"https://localhost:9200"},
Username: "admin",
Password: "admin",
Transport: &http.Transport{
TLSClientConfig: &tls.Config{InsecureSkipVerify: true},
},
}
client, err := opensearch.NewClient(cfg)
if err != nil {
log.Fatalf("Error creating the client: %s", err)
}
return client
}
Создание индекса с маппингом
func createKnowledgeIndex(client *opensearch.Client) error {
mapping := `
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "stemmer"]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "custom_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"content": {
"type": "text",
"analyzer": "custom_analyzer"
},
"category": {
"type": "keyword"
},
"tags": {
"type": "keyword"
},
"benefits": {
"type": "keyword"
},
"locations": {
"type": "keyword"
},
"level_user": {
"type": "keyword"
},
"created_at": {
"type": "date"
},
"updated_at": {
"type": "date"
},
"related_docs": {
"type": "keyword"
},
"solutions": {
"type": "nested",
"properties": {
"description": {
"type": "text",
"analyzer": "custom_analyzer"
},
"steps": {
"type": "text",
"analyzer": "custom_analyzer"
}
}
}
}
}
}`
req := opensearchapi.IndicesCreateRequest{
Index: "knowledge_base",
Body: strings.NewReader(mapping),
}
res, err := req.Do(context.Background(), client)
if err != nil {
return fmt.Errorf("error creating index: %w", err)
}
defer res.Body.Close()
if res.IsError() {
return fmt.Errorf("error response: %s", res.String())
}
return nil
}
Добавление документа в базу знаний
func addDocument(client *opensearch.Client, doc KnowledgeDocument) error {
docBytes, err := json.Marshal(doc)
if err != nil {
return fmt.Errorf("error marshaling document: %w", err)
}
req := opensearchapi.IndexRequest{
Index: "knowledge_base",
Body: strings.NewReader(string(docBytes)),
DocumentID: doc.ID,
Refresh: "true",
}
res, err := req.Do(context.Background(), client)
if err != nil {
return fmt.Errorf("error indexing document: %w", err)
}
defer res.Body.Close()
if res.IsError() {
return fmt.Errorf("error response: %s", res.String())
}
return nil
}
Пример сложного поиска по таксономиям
func searchDocuments(client *opensearch.Client, query string, filters map[string]interface{}) ([]KnowledgeDocument, error) {
var buf bytes.Buffer
searchQuery := map[string]interface{}{
"query": map[string]interface{}{
"bool": map[string]interface{}{
"must": []map[string]interface{}{
{
"multi_match": map[string]interface{}{
"query": query,
"fields": []string{"title^3", "content", "solutions.description", "solutions.steps"},
},
},
},
"filter": []map[string]interface{}{},
},
},
"size": 10,
}
// Добавляем фильтры по таксономиям
for field, value := range filters {
filter := map[string]interface{}{
"term": map[string]interface{}{
field: value,
},
}
searchQuery["query"].(map[string]interface{})["bool"].(map[string]interface{})["filter"] = append(
searchQuery["query"].(map[string]interface{})["bool"].(map[string]interface{})["filter"].([]map[string]interface{}),
filter,
)
}
if err := json.NewEncoder(&buf).Encode(searchQuery); err != nil {
return nil, fmt.Errorf("error encoding query: %w", err)
}
res, err := client.Search(
client.Search.WithContext(context.Background()),
client.Search.WithIndex("knowledge_base"),
client.Search.WithBody(&buf),
client.Search.WithTrackTotalHits(true),
)
if err != nil {
return nil, fmt.Errorf("error executing search: %w", err)
}
defer res.Body.Close()
if res.IsError() {
return nil, fmt.Errorf("error response: %s", res.String())
}
var result struct {
Hits struct {
Hits []struct {
Source KnowledgeDocument `json:"_source"`
} `json:"hits"`
} `json:"hits"`
}
if err := json.NewDecoder(res.Body).Decode(&result); err != nil {
return nil, fmt.Errorf("error parsing the response body: %w", err)
}
var docs []KnowledgeDocument
for _, hit := range result.Hits.Hits {
docs = append(docs, hit.Source)
}
return docs, nil
}
Решение сложных запросов (например, проблема с принтером)
func troubleshootPrinterIssue(client *opensearch.Client, problemDescription string) ([]KnowledgeDocument, error) {
var buf bytes.Buffer
query := map[string]interface{}{
"query": map[string]interface{}{
"bool": map[string]interface{}{
"must": []map[string]interface{}{
{
"match": map[string]interface{}{
"category": "printer",
},
},
{
"multi_match": map[string]interface{}{
"query": problemDescription,
"fields": []string{"title^3", "content", "solutions.description", "solutions.steps"},
},
},
},
"should": []map[string]interface{}{
{
"match": map[string]interface{}{
"tags": "streaks",
},
},
{
"match": map[string]interface{}{
"tags": "cartridge",
},
},
{
"match": map[string]interface{}{
"tags": "printing_quality",
},
},
},
"minimum_should_match": 1,
},
},
"size": 5,
}
if err := json.NewEncoder(&buf).Encode(query); err != nil {
return nil, fmt.Errorf("error encoding query: %w", err)
}
res, err := client.Search(
client.Search.WithContext(context.Background()),
client.Search.WithIndex("knowledge_base"),
client.Search.WithBody(&buf),
client.Search.WithTrackTotalHits(true),
)
if err != nil {
return nil, fmt.Errorf("error executing search: %w", err)
}
defer res.Body.Close()
if res.IsError() {
return nil, fmt.Errorf("error response: %s", res.String())
}
var result struct {
Hits struct {
Hits []struct {
Source KnowledgeDocument `json:"_source"`
} `json:"hits"`
} `json:"hits"`
}
if err := json.NewDecoder(res.Body).Decode(&result); err != nil {
return nil, fmt.Errorf("error parsing the response body: %w", err)
}
var docs []KnowledgeDocument
for _, hit := range result.Hits.Hits {
docs = append(docs, hit.Source)
}
return docs, nil
}
Построение дерева знаний
func buildKnowledgeTree(client *opensearch.Client, rootCategory string, depth int) (map[string]interface{}, error) {
var buf bytes.Buffer
query := map[string]interface{}{
"size": 0,
"query": map[string]interface{}{
"term": map[string]interface{}{
"category.keyword": rootCategory,
},
},
"aggs": map[string]interface{}{
"subcategories": map[string]interface{}{
"terms": map[string]interface{}{
"field": "category.keyword",
"size": 10,
},
"aggs": map[string]interface{}{
"related_tags": map[string]interface{}{
"terms": map[string]interface{}{
"field": "tags.keyword",
"size": 5,
},
},
"top_documents": map[string]interface{}{
"top_hits": map[string]interface{}{
"size": 3,
"_source": map[string]interface{}{
"includes": []string{"title", "id"},
},
},
},
},
},
},
}
if err := json.NewEncoder(&buf).Encode(query); err != nil {
return nil, fmt.Errorf("error encoding query: %w", err)
}
res, err := client.Search(
client.Search.WithContext(context.Background()),
client.Search.WithIndex("knowledge_base"),
client.Search.WithBody(&buf),
)
if err != nil {
return nil, fmt.Errorf("error executing search: %w", err)
}
defer res.Body.Close()
if res.IsError() {
return nil, fmt.Errorf("error response: %s", res.String())
}
var result struct {
Aggregations struct {
Subcategories struct {
Buckets []struct {
Key string `json:"key"`
DocCount int `json:"doc_count"`
RelatedTags struct {
Buckets []struct {
Key string `json:"key"`
} `json:"buckets"`
} `json:"related_tags"`
TopDocuments struct {
Hits struct {
Hits []struct {
Source struct {
Title string `json:"title"`
ID string `json:"id"`
} `json:"_source"`
} `json:"hits"`
} `json:"hits"`
} `json:"top_documents"`
} `json:"buckets"`
} `json:"subcategories"`
} `json:"aggregations"`
}
if err := json.NewDecoder(res.Body).Decode(&result); err != nil {
return nil, fmt.Errorf("error parsing the response body: %w", err)
}
tree := make(map[string]interface{})
tree["category"] = rootCategory
var subcategories []map[string]interface{}
for _, bucket := range result.Aggregations.Subcategories.Buckets {
subcategory := map[string]interface{}{
"name": bucket.Key,
"count": bucket.DocCount,
"popularTags": []string{},
"documents": []map[string]string{},
}
for _, tag := range bucket.RelatedTags.Buckets {
subcategory["popularTags"] = append(subcategory["popularTags"].([]string), tag.Key)
}
for _, doc := range bucket.TopDocuments.Hits.Hits {
subcategory["documents"] = append(subcategory["documents"].([]map[string]string), map[string]string{
"title": doc.Source.Title,
"id": doc.Source.ID,
})
}
subcategories = append(subcategories, subcategory)
}
tree["subcategories"] = subcategories
return tree, nil
}
Пример использования
func main() {
client := getOpenSearchClient()
// Создаем индекс (один раз)
if err := createKnowledgeIndex(client); err != nil {
log.Fatalf("Error creating index: %v", err)
}
// Добавляем документ о проблемах с принтером
doc := KnowledgeDocument{
ID: "printer_streaks_1",
Title: "Принтер печатает с полосами",
Content: "Если принтер печатает с полосами, даже с новым картриджем, возможные причины...",
Category: "printer",
Tags: []string{"streaks", "printing_quality", "cartridge"},
Benefits: []string{"troubleshooting", "repair"},
Locations: []string{"office", "home"},
LevelUser: "beginner",
Solutions: []struct {
Description string `json:"description"`
Steps []string `json:"steps"`
}{
{
Description: "Очистка печатающей головки",
Steps: []string{
"Зайти в настройки принтера",
"Найти раздел обслуживания",
"Выбрать опцию очистки печатающей головки",
},
},
{
Description: "Проверка выравнивания картриджей",
Steps: []string{
"Заменить картридж",
"Запустить процедуру выравнивания",
},
},
},
}
if err := addDocument(client, doc); err != nil {
log.Fatalf("Error adding document: %v", err)
}
// Поиск решения проблемы
solutions, err := troubleshootPrinterIssue(client, "сломался принтер, печатает с полосой, картридж новый")
if err != nil {
log.Fatalf("Error searching: %v", err)
}
fmt.Println("Найдены решения:")
for _, sol := range solutions {
fmt.Printf("- %s\n", sol.Title)
for _, solution := range sol.Solutions {
fmt.Printf(" %s\n", solution.Description)
for i, step := range solution.Steps {
fmt.Printf(" %d. %s\n", i+1, step)
}
}
}
// Построение дерева знаний
tree, err := buildKnowledgeTree(client, "printer", 2)
if err != nil {
log.Fatalf("Error building knowledge tree: %v", err)
}
fmt.Println("\nДерево знаний:")
fmt.Printf("Категория: %s\n", tree["category"])
for _, subcat := range tree["subcategories"].([]map[string]interface{}) {
fmt.Printf(" Подкатегория: %s (%d документов)\n", subcat["name"], subcat["count"])
fmt.Printf(" Популярные теги: %v\n", subcat["popularTags"])
}
}
12.4 - Пакеты языка Go
Пакеты и библиотеки языка программирования Go на русском языке
12.4.1 - Описание пакета html для GO
Пакеты и функции для работы с html в GO
Пакет html предоставляет функции для экранирования и отмены экранирования HTML-текста.
func EscapeString
func EscapeString(s string) string
EscapeString экранирует специальные символы, такие как “<”, превращаясь в “<”. Он экранирует только пять таких символов: <, >, &, ’ и “. UnescapeString(EscapeString(s)) == s всегда выполняется, но обратное не всегда верно.
Пример
package main
import (
"fmt"
"html"
)
func main() {
const s = `"Fran & Freddie's Diner" <tasty@example.com>`
fmt.Println(html.EscapeString(s))
}
Output:
`"Fran & Freddie's Diner" <tasty@example.com>`
func UnescapeString
func UnescapeString(s string) string
UnescapeString отменяет экранирование таких сущностей, как “<”, чтобы они стали “<”. Он отменяет экранирование большего диапазона сущностей, чем EscapeString. Например, “á” отменяет экранирование на “á”, как и “á” и “á”. UnescapeString(EscapeString(s)) == s всегда выполняется, но обратное не всегда верно.
Пример
package main
import (
"fmt"
"html"
)
func main() {
const s = `"Fran & Freddie's Diner" <tasty@example.com>`
fmt.Println(html.UnescapeString(s))
}
Output:
"Fran & Freddie's Diner" <tasty@example.com>
12.4.1.1 - Описание пакета html/template в Go
Пакет html/template - шаблоны HTML с защитой от инъекций
Пакет html/template реализует шаблоны, управляемые данными, для генерации HTML-вывода, защищённого от внедрения кода. Он предоставляет тот же интерфейс, что и text/template, и должен использоваться вместо него, когда выводом является HTML.
Данная документация фокусируется на функциях безопасности пакета. Информацию о программировании самих шаблонов см. в документации text/template.
Введение
Этот пакет оборачивает text/template, позволяя использовать его API шаблонов для безопасного разбора и выполнения HTML-шаблонов.
Пример:
tmpl, err := template.New("name").Parse(...)
// Проверка ошибок опущена
err = tmpl.Execute(out, data)
Если операция успешна, tmpl будет защищён от инъекций. В противном случае err будет содержать ошибку, как описано в ErrorCode.
HTML-шаблоны обрабатывают значения данных как обычный текст, который должен быть закодирован для безопасного встраивания в HTML-документ. Экранирование является контекстно-зависимым, поэтому действия могут появляться в JavaScript, CSS и URI-контекстах.
Модель безопасности, используемая этим пакетом, предполагает, что авторы шаблонов являются доверенными, а параметр данных Execute - нет. Более подробная информация приведена ниже.
import "text/template"
...
t, err := template.New("foo").Parse(`{{define "T"}}Hello, {{.}}!{{end}}`)
err = t.ExecuteTemplate(out, "T", "<script>alert('you have been pwned')</script>")
Вывод
Hello, <script>alert('you have been pwned')</script>!
но контекстное автоэкранирование в html/шаблоне
import "html/template"
...
t, err := template.New("foo").Parse(`{{define "T"}}Hello, {{.}}!{{end}}`)
err = t.ExecuteTemplate(out, "T", "<script>alert('you have been pwned')</script>")
создает безопасный, экранированный HTML-вывод
Hello, <script>alert('you have been pwned')</script>!
Контексты
Этот пакет понимает HTML, CSS, JavaScript и URI. Он добавляет функции очистки к каждому простому конвейеру действий, поэтому, рассмотрим пример
<a href="/search?q={{.}}">{{.}}</a>
Во время разбора каждый {{.}} перезаписывается для добавления экранирующих функций по мере необходимости. В этом случае это становится
<a href="/search?q={{. | urlescaper | attrescaper}}">{{. | htmlescaper}}</a>
где urlescaper, attrescaper и htmlescaper — псевдонимы для внутренних функций экранирования.
Для этих внутренних функций экранирования, если конвейер действий оценивает значение интерфейса nil, он обрабатывается так, как будто это пустая строка.
Namespaced и data-атрибуты
Атрибуты с пространством имен обрабатываются так, как будто у них нет пространства имен. Рассмотрим пример:
<a my:href="{{.}}"></a>
Во время анализа атрибут будет обработан так, как если бы это был просто “href”. Таким образом, во время анализа шаблон становится:
<a my:href="{{. | urlescaper | attrescaper}}"></a>
Аналогично атрибутам с пространствами имен, атрибуты с префиксом “data-” обрабатываются так, как если бы у них не было префикса “data-”. Рассмотрим пример:
<a data-href="{{.}}"></a>
Во время анализа это становится
<a data-href="{{. | urlescaper | attrescaper}}"></a>
Если атрибут имеет как пространство имен, так и префикс “data-”, то при определении контекста будет удалено только пространство имен. Например:
<a my:data-href="{{.}}"></a>
Это обрабатывается так, как если бы “my:data-href” было просто “data-href”, а не “href”, как было бы, если бы префикс “data-” тоже игнорировался. Таким образом, во время анализа это становится просто
<a my:data-href="{{. | attrescaper}}"></a>
В качестве особого случая атрибуты с пространством имен “xmlns” всегда рассматриваются как содержащие URL-адреса. Например:
<a xmlns:title="{{.}}"></a>
<a xmlns:href="{{.}}"></a>
<a xmlns:onclick="{{.}}"></a>
Во время анализа они становятся:
<a xmlns:title="{{. | urlescaper | attrescaper}}"></a>
<a xmlns:href="{{. | urlescaper | attrescaper}}"></a>
<a xmlns:onclick="{{. | urlescaper | attrescaper}}"></a>
Ошибки
Подробности см. в документации ErrorCode.
Более полная картина
Остальную часть этого комментария к пакету можно пропустить при первом чтении; он включает детали, необходимые для понимания экранирования контекстов и сообщений об ошибках. Большинству пользователей не нужно понимать эти детали.
Контексты
Предположив, что {{.}} — это O'Reilly: How are <i>you</i>?, в таблице ниже показано, как выглядит {{.}} при использовании в контексте слева.
Context {{.}} After
{{.}} O'Reilly: How are <i>you</i>?
<a title='{{.}}'> O'Reilly: How are you?
<a href="/{{.}}"> O'Reilly: How are %3ci%3eyou%3c/i%3e?
<a href="?q={{.}}"> O'Reilly%3a%20How%20are%3ci%3e...%3f
<a onx='f("{{.}}")'> O\x27Reilly: How are \x3ci\x3eyou...?
<a onx='f({{.}})'> "O\x27Reilly: How are \x3ci\x3eyou...?"
<a onx='pattern = /{{.}}/;'> O\x27Reilly: How are \x3ci\x3eyou...\x3f
При использовании в небезопасном контексте значение может быть отфильтровано:
Context {{.}} After
<a href="{{.}}"> #ZgotmplZ
поскольку “O’Reilly:” не является разрешенным протоколом, как “http:”.
Если {{.}} — это безобидное слово left, то оно может появляться более широко,
Context {{.}} After
{{.}} left
<a title='{{.}}'> left
<a href='{{.}}'> left
<a href='/{{.}}'> left
<a href='?dir={{.}}'> left
<a style="border-{{.}}: 4px"> left
<a style="align: {{.}}"> left
<a style="background: '{{.}}'> left
<a style="background: url('{{.}}')> left
<style>p.{{.}} {color:red}</style> left
Нестроковые значения могут использоваться в контекстах JavaScript. Если {{.}} — это
struct{A,B string}{ "foo", "bar" }
в экранированном шаблоне
<script>var pair = {{.}};</script>
то вывод шаблона будет
<script>var pair = {"A": "foo", "B": "bar"};</script>
Ознакомьтесь с пакетом json, чтобы понять, как нестроковый контент маршалируется для встраивания в контексты JavaScript.
Типизированные строки
По умолчанию этот пакет предполагает, что все конвейеры производят простую текстовую строку. Он добавляет этапы экранирования конвейера, необходимые для корректного и безопасного встраивания этой простой текстовой строки в соответствующий контекст.
Если значение данных не является обычным текстом, вы можете убедиться, что оно не экранировано слишком сильно, пометив его разными типами.
Типы HTML, JS, URL и другие из content.go могут содержать безопасный контент, который освобожден от экранирования.
Например шаблон:
Hello, {{.}}!
может быть вызван с помощью
tmpl.Execute(out, template.HTML(`<b>World</b>`))
вывод
Hello, <b>World</b>!
вместо
Hello, <b>World<b>!
который был бы получен, если бы {{.}} был обычной строкой.
Модель безопасности
Определение “безопасности”, используемое в этом пакете, основано на спецификации.
Данный пакет исходит из следующих допущений:
- Авторы шаблонов считаются доверенными
- Данные, передаваемые в
Execute, — ненадёжные
При этом обеспечиваются следующие свойства безопасности при работе с ненадёжными данными:
1. Сохранение структуры (Structure Preservation Property)
Если автор шаблона пишет HTML-тег на безопасном языке шаблонов, браузер всегда будет интерпретировать соответствующую часть вывода именно как тег — независимо от значений ненадёжных данных. То же самое относится к другим структурам, таким как границы атрибутов, строки JavaScript и CSS.
2. Контроль исполнения кода (Code Effect Property)
В результате вставки вывода шаблона на страницу должен выполняться только код, явно указанный автором шаблона. При этом весь код, указанный автором, должен выполняться корректно.
3. Принцип наименьшего удивления (Least Surprise Property)
Разработчик (или ревьюер кода), знакомый с HTML, CSS и JavaScript и знающий о контекстном автоэкранировании, должен быть способен, увидев
{{.}}, однозначно определить, какое экранирование будет применено.
Поддержка шаблонных литералов ES6
Ранее шаблонные литералы ECMAScript 6 (${...}) были отключены по умолчанию, и их можно было включить через переменную окружения GODEBUG=jstmpllitinterp=1.
Сейчас шаблонные литералы поддерживаются по умолчанию, а настройка jstmpllitinterp больше не имеет эффекта.
Пример
package main
import (
"html/template"
"log"
"os"
)
func main() {
const tpl = `
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>{{.Title}}</title>
</head>
<body>
{{range .Items}}<div>{{ . }}</div>{{else}}<div><strong>no rows</strong></div>{{end}}
</body>
</html>`
check := func(err error) {
if err != nil {
log.Fatal(err)
}
}
t, err := template.New("webpage").Parse(tpl)
check(err)
data := struct {
Title string
Items []string
}{
Title: "My page",
Items: []string{
"My photos",
"My blog",
},
}
err = t.Execute(os.Stdout, data)
check(err)
noItems := struct {
Title string
Items []string
}{
Title: "My another page",
Items: []string{},
}
err = t.Execute(os.Stdout, noItems)
check(err)
}
Output:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>My page</title>
</head>
<body>
<div>My photos</div><div>My blog</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>My another page</title>
</head>
<body>
<div><strong>no rows</strong></div>
</body>
</html>Пример Autoescaping
package main
import (
"html/template"
"log"
"os"
)
func main() {
check := func(err error) {
if err != nil {
log.Fatal(err)
}
}
t, err := template.New("foo").Parse(`{{define "T"}}Hello, {{.}}!{{end}}`)
check(err)
err = t.ExecuteTemplate(os.Stdout, "T", "<script>alert('you have been pwned')</script>")
check(err)
}
Output:
Hello, <script>alert('you have been pwned')</script>!
Пример Escape
package main
import (
"fmt"
"html/template"
"os"
)
func main() {
const s = `"Fran & Freddie's Diner" <tasty@example.com>`
v := []any{`"Fran & Freddie's Diner"`, ' ', `<tasty@example.com>`}
fmt.Println(template.HTMLEscapeString(s))
template.HTMLEscape(os.Stdout, []byte(s))
fmt.Fprintln(os.Stdout, "")
fmt.Println(template.HTMLEscaper(v...))
fmt.Println(template.JSEscapeString(s))
template.JSEscape(os.Stdout, []byte(s))
fmt.Fprintln(os.Stdout, "")
fmt.Println(template.JSEscaper(v...))
fmt.Println(template.URLQueryEscaper(v...))
}
Output:
"Fran & Freddie's Diner" <tasty@example.com>
"Fran & Freddie's Diner" <tasty@example.com>
"Fran & Freddie's Diner"32<tasty@example.com>
\"Fran \u0026 Freddie\'s Diner\" \u003Ctasty@example.com\u003E
\"Fran \u0026 Freddie\'s Diner\" \u003Ctasty@example.com\u003E
\"Fran \u0026 Freddie\'s Diner\"32\u003Ctasty@example.com\u003E
%22Fran+%26+Freddie%27s+Diner%2232%3Ctasty%40example.com%3E
12.4.1.1.1 - Шпаргалка по html/template в Go
html/template - это пакет Go для безопасного создания HTML-выхода с автоматическим экранированием.
Инициализация шаблона
import "html/template"
// Создание нового шаблона
tmpl := template.New("templateName")
// Парсинг шаблона из строки
tmpl, err := template.New("test").Parse(`<h1>{{.Title}}</h1>`)
// Парсинг шаблона из файла
tmpl, err := template.ParseFiles("template.html")
// Парсинг нескольких файлов
tmpl, err := template.ParseGlob("templates/*.html")
Основные конструкции в шаблоне
1. Вывод значения
<!-- Простой вывод -->
<p>{{.UserName}}</p>
<!-- Вывод с экранированием HTML -->
<p>{{.UserComment}}</p>
<!-- Вывод без экранирования (осторожно!) -->
<p>{{.SafeHTML | html}}</p>
2. Условия
{{if .User}}
<p>Welcome, {{.User}}!</p>
{{else}}
<p>Please log in.</p>
{{end}}
{{if eq .Role "admin"}}
<p>Admin dashboard</p>
{{end}}
3. Циклы
<ul>
{{range .Items}}
<li>{{.}}</li>
{{end}}
</ul>
<!-- С индексом -->
<ul>
{{range $index, $item := .Items}}
<li>Item #{{$index}}: {{$item}}</li>
{{end}}
</ul>
<!-- Если слайс пуст -->
{{range .Items}}
{{.}}
{{else}}
<p>No items found</p>
{{end}}
4. Определение переменных
{{$name := .UserName}}
{{$count := len .Items}}
<p>Hello, {{$name}}. You have {{$count}} items.</p>
5. Функции и конвейеры
<!-- Вызов встроенных функций -->
<p>{{printf "Hello, %s" .Name}}</p>
<p>{{len .Items}} items</p>
<p>{{index .Items 0}}</p>
<!-- Конвейер -->
<p>{{.Title | upper | truncate 50}}</p>
6. Вложенные шаблоны
// Определение в коде
tmpl := template.Must(template.New("base").Parse(`
{{define "content"}}Default content{{end}}
<html>
<body>
{{template "content" .}}
</body>
</html>
`))
// Переопределение в другом шаблоне
tmpl2 := template.Must(tmpl.Parse(`{{define "content"}}New content{{end}}`))
<!-- В шаблоне -->
{{template "header" .}}
<!-- С передачей других данных -->
{{template "footer" .FooterData}}
7. Пользовательские функции
funcMap := template.FuncMap{
"upper": strings.ToUpper,
"add": func(a, b int) int { return a + b },
}
tmpl := template.New("test").Funcs(funcMap)
tmpl, err := tmpl.Parse(`{{upper .Name}} {{add 1 2}}`)
Пример полного шаблона
<!DOCTYPE html>
<html>
<head>
<title>{{.Title}} - My Site</title>
</head>
<body>
<header>
{{if .User}}
<p>Welcome, {{.User.Name}} ({{.User.Email}})</p>
{{else}}
<a href="/login">Login</a>
{{end}}
</header>
<nav>
<ul>
{{range .Menu}}
<li><a href="{{.URL}}">{{.Title}}</a></li>
{{end}}
</ul>
</nav>
<main>
{{template "content" .}}
</main>
<footer>
<p>© {{.CurrentYear}} My Company</p>
</footer>
</body>
</html>
Выполнение шаблона
// В память
err := tmpl.Execute(os.Stdout, data)
// В строку
var buf bytes.Buffer
err := tmpl.Execute(&buf, data)
result := buf.String()
// Конкретный шаблон из набора
err := tmpl.ExecuteTemplate(os.Stdout, "templateName", data)
Обработка ошибок
tmpl := template.Must(template.New("").Parse("...")) // паника при ошибке
if err := tmpl.Execute(w, data); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
}
Безопасность
- Автоматическое экранирование HTML/JS/CSS
- Для отключения экранирования используйте типы
template.HTML,template.JS,template.CSS:
type Data struct {
SafeContent template.HTML
}
data := Data{SafeContent: template.HTML("<b>Safe HTML</b>")}
12.4.1.1.2 - Подробное руководство по define, template и block в html/template
В пакете html/template есть три основные директивы для работы с повторно используемыми частями шаблонов: define, template, block
Основные концепции
В пакете html/template есть три основные директивы для работы с повторно используемыми частями шаблонов:
{{define "name"}}...{{end}}- определяет именованный шаблон{{template "name"}}- вставляет именованный шаблон{{block "name"}}...{{end}}- комбинация define+template с возможностью переопределения
1. Директива define
Где описывать:
- В любом месте шаблона (но обычно в начале или конце файла)
- В отдельных файлах, которые потом объединяются
Пример определения:
{{define "header"}}
<header>
<h1>{{.Title}}</h1>
<nav>
<a href="/">Home</a>
<a href="/about">About</a>
</nav>
</header>
{{end}}
{{define "footer"}}
<footer>
<p>Copyright © {{.Year}} My Company</p>
</footer>
{{end}}
2. Директива template
Где применять:
- В любом месте основного шаблона
- Можно передавать данные (по умолчанию - текущий контекст)
Пример использования:
<!DOCTYPE html>
<html>
<head>
<title>{{.Title}}</title>
</head>
<body>
{{template "header" .}} <!-- Передаем текущий контекст -->
<main>
{{.Content}}
</main>
{{template "footer" .}} <!-- Передаем текущий контекст -->
</body>
</html>
Передача другого контекста:
{{template "user_profile" .UserData}}
3. Директива block
Особенности:
- Комбинация
define+template - Можно переопределять в дочерних шаблонах
- Если не переопределен - используется содержимое по умолчанию
Пример:
<!-- base.html -->
<!DOCTYPE html>
<html>
<head>
{{block "head" .}}
<title>{{.Title}} - Default</title>
{{end}}
</head>
<body>
{{block "content" .}}
<p>Default content</p>
{{end}}
</body>
</html>
Переопределение в дочернем шаблоне:
<!-- home.html -->
{{define "content"}}
<h1>Welcome!</h1>
<p>This is the home page.</p>
{{end}}
{{template "base.html" .}}
Практические схемы организации
1. Многофайловая структура
templates/
├── base.html # Основной каркас
├── header.html # Шапка сайта
├── footer.html # Подвал
├── home.html # Главная страница
└── about.html # Страница "О нас"
base.html:
<!DOCTYPE html>
<html>
<head>
{{template "head" .}}
</head>
<body>
{{template "header" .}}
{{block "content" .}}{{end}}
{{template "footer" .}}
</body>
</html>
home.html:
{{define "content"}}
<h1>Welcome</h1>
<p>Home page content</p>
{{end}}
{{template "base.html" .}}
2. Наследование шаблонов
// Загрузка шаблонов
templates := template.Must(template.ParseFiles(
"base.html",
"header.html",
"footer.html",
"home.html",
))
// Исполнение конкретного шаблона
err := templates.ExecuteTemplate(w, "home.html", data)
3. Вложенные блоки
<!-- base.html -->
{{define "layout"}}
<div class="container">
{{block "sidebar" .}}
<!-- Default sidebar -->
<div class="sidebar">Default sidebar</div>
{{end}}
<div class="content">
{{template "content" .}}
</div>
</div>
{{end}}
<!-- profile.html -->
{{define "sidebar"}}
<div class="profile-sidebar">
<img src="{{.User.Avatar}}">
<h3>{{.User.Name}}</h3>
</div>
{{end}}
{{define "content"}}
<div class="profile-content">
<!-- Контент профиля -->
</div>
{{end}}
{{template "layout" .}}
Особенности работы
- Порядок загрузки: шаблоны, на которые есть ссылки, должны быть загружены до их использования
- Контекст данных: по умолчанию передается текущий контекст, но можно передать другой
- Рекурсия: шаблоны могут вызывать сами себя (но осторожно с бесконечной рекурсией)
- Переопределение: последний загруженный шаблон с тем же именем переопределяет предыдущий
Пример с пользовательскими функциями
func main() {
funcMap := template.FuncMap{
"formatDate": func(t time.Time) string {
return t.Format("2006-01-02")
},
}
tmpl := template.Must(
template.New("base").Funcs(funcMap).ParseFiles("base.html", "home.html"),
)
err := tmpl.ExecuteTemplate(os.Stdout, "home.html", data)
}
<!-- В шаблоне: -->
<p>Created: {{.CreatedAt | formatDate}}</p>
Лучшие практики
- Разделяйте шаблоны на логические компоненты
- Используйте
blockдля переопределяемых секций - Основной каркас выносите в
base.html - Называйте шаблоны осмысленно (не “template1”, а “user_profile”)
- Документируйте назначение шаблонов в комментариях
12.4.1.1.3 - Шпаргалка по конвейерам и функциям в html/template (Go)
Конвейеры позволяют последовательно применять функции к данным в шаблонах.
Синтаксис:
{{value | function1 | function2 | ...}}
Примеры:
<!-- Простой конвейер -->
<p>{{.Name | upper}}</p>
<!-- Множественные функции -->
<p>{{.Title | trim | lower | trunc 50}}</p>
<!-- С аргументами -->
<p>{{.Date | format "2006-01-02"}}</p>
<!-- Вложенные конвейеры -->
<p>{{.Description | trunc 100 | html}}</p>
Встроенные функции
1. Строковые функции
{{"hello" | title}} <!-- Hello -->
{{"HELLO" | lower}} <!-- hello -->
{{"hello" | upper}} <!-- HELLO -->
{{" hello " | trim}} <!-- hello -->
{{"hello" | repeat 3}} <!-- hellohellohello -->
2. HTML-функции
{{"<script>" | html}} <!-- Экранирование HTML -->
{{"<b>safe</b>" | html}} <!-- <b>safe</b> -->
{{"<b>safe</b>" | safeHTML}} <!-- <b>safe</b> (без экранирования) -->
3. Функции для коллекций
{{len .Items}} <!-- Длина массива/слайса/мапы -->
{{index .Users 0}} <!-- Первый элемент -->
{{index .Map "key"}} <!-- Значение по ключу -->
{{slice .List 1 3}} <!-- Подслайс -->
4. Логические функции
{{if eq .A .B}}...{{end}} <!-- Равно -->
{{if ne .A .B}}...{{end}} <!-- Не равно -->
{{if lt .A .B}}...{{end}} <!-- Меньше -->
{{if le .A .B}}...{{end}} <!-- Меньше или равно -->
{{if gt .A .B}}...{{end}} <!-- Больше -->
{{if ge .A .B}}...{{end}} <!-- Больше или равно -->
{{if and .A .B}}...{{end}} <!-- Логическое И -->
{{if or .A .B}}...{{end}} <!-- Логическое ИЛИ -->
{{if not .A}}...{{end}} <!-- Логическое НЕ -->
5. Математические функции
{{add 1 2}} <!-- 3 -->
{{sub 5 2}} <!-- 3 -->
{{mul 3 4}} <!-- 12 -->
{{div 10 2}} <!-- 5 -->
{{mod 10 3}} <!-- 1 -->
6. Функции форматирования
{{printf "%s - %d" .Name .Age}} <!-- Форматированная строка -->
{{.Price | printf "$%.2f"}} <!-- Форматирование числа -->
{{.Date | date "2006-01-02"}} <!-- Форматирование даты -->
Пользовательские функции
Регистрация функций:
funcMap := template.FuncMap{
"upper": strings.ToUpper,
"trunc": func(s string, max int) string {
if len(s) > max {
return s[:max] + "..."
}
return s
},
"add": func(a, b int) int { return a + b },
"contains": strings.Contains,
"now": time.Now,
}
tmpl := template.New("").Funcs(funcMap)
Использование в шаблоне:
{{.Title | trunc 50 | upper}}
{{add .Value 10}}
{{if contains .Description "important"}}Important!{{end}}
{{now | date "2006-01-02"}}
Примеры сложных конвейеров
1. Обработка текста
{{.UserComment | trim | trunc 200 | html}}
2. Форматирование данных
{{.CreatedAt | date "02.01.2006" | printf "Created: %s"}}
3. Работа с коллекциями
{{range .Items | sortBy "Name" | limit 10}}
{{.Name | upper}}
{{end}}
4. Условные конвейеры
{{if .Price | gt 100}}
<p class="expensive">{{.Price | printf "$%.2f"}}</p>
{{else}}
<p>{{.Price | printf "$%.2f"}}</p>
{{end}}
Полезные комбинации
Безопасный вывод HTML:
{{.UserContent | sanitizeHTML | safeHTML}}
Форматирование денежных значений:
{{.Amount | div 100 | printf "$%.2f"}}
Сортировка и фильтрация:
{{range .Products | filter "category" "electronics" | sortBy "price"}}
{{.Name}} - {{.Price | printf "$%.2f"}}
{{end}}
Ограничения
- Функции должны возвращать только одно значение (и опционально ошибку)
- Невозможно передавать функции как аргументы
- Нет поддержки сложных операций с каналами
- Автоматическое экранирование применяется к конечному результату
Лучшие практики
- Выносите сложную логику в Go-код, а не в шаблоны
- Используйте конвейеры для читаемости, но не переусердствуйте
- Документируйте пользовательские функции
- Тестируйте шаблоны с разными входными данными
- Избегайте побочных эффектов в функциях
12.4.1.1.4 - Функции экранирования HTML/JavaScript/URL пакета html/template языка Go
Описание функций пакета html/template языка Go в соответствии с официальной документацией
HTMLEscape
func HTMLEscape(w io.Writer, b []byte)
HTMLEscape записывает в w экранированный HTML-эквивалент текстовых данных b.
HTMLEscapeString
func HTMLEscapeString(s string) string
HTMLEscapeString возвращает экранированный HTML-эквивалент текстовых данных s.
HTMLEscaper
func HTMLEscaper(args ...any) string
HTMLEscaper возвращает экранированный HTML-эквивалент текстового представления своих аргументов.
IsTrue
func IsTrue(val any) (truth, ok bool)
IsTrue определяет, является ли значение “истинным” (не нулевым для своего типа) и имеет ли оно вообще смысл как булево значение. Это определение истинности используется в условных операциях типа if.
JSEscape
func JSEscape(w io.Writer, b []byte)
JSEscape записывает в w экранированный JavaScript-эквивалент текстовых данных b.
JSEscapeString
func JSEscapeString(s string) string
JSEscapeString возвращает экранированный JavaScript-эквивалент текстовых данных s.
JSEscaper
func JSEscaper(args ...any) string
JSEscaper возвращает экранированный JavaScript-эквивалент текстового представления своих аргументов.
URLQueryEscaper
func URLQueryEscaper(args ...any) string
URLQueryEscaper возвращает экранированное значение текстового представления аргументов в форме, пригодной для вставки в URL-запрос.
12.4.1.1.5 - Типы экранирования HTML/JavaScript/URL пакета html/template языка Go
Описание типов и функций пакета html/template языка Go в соответствии с официальной документацией
type CSS
type CSS string
CSS инкапсулирует заранее проверенное содержимое, соответствующее:
- Производству CSS3 таблиц стилей (напр.
p { color: purple }) - Производству CSS3 правил (напр.
a[href=~"https:"].foo#bar) - Производству CSS3 деклараций (напр.
color: red; margin: 2px) - Производству CSS3 значений (напр.
rgba(0, 0, 255, 127))
Внимание: Использование этого типа представляет угрозу безопасности - содержимое должно поступать из доверенного источника, так как включается в вывод шаблона без изменений.
type Error
type Error struct {
ErrorCode ErrorCode // Тип ошибки
Node parse.Node // Узел, вызвавший проблему (если известен)
Name string // Имя шаблона с ошибкой
Line int // Номер строки в исходнике шаблона
Description string // Человекочитаемое описание
}
Описывает проблему, возникшую при экранировании шаблона.
Коды ошибок (ErrorCode)
const (
OK ErrorCode = iota // Нет ошибки
// Неоднозначный контекст в URL
ErrAmbigContext
// Некорректный HTML (незакрытые теги/атрибуты)
ErrBadHTML
// Ветки if/range заканчиваются в разных контекстах
ErrBranchEnd
// Шаблон заканчивается в нетекстовом контексте
ErrEndContext
// Отсутствует указанный шаблон
ErrNoSuchTemplate
// Невозможно вычислить контекст вывода
ErrOutputContext
// Незавершённый набор символов в regexp JS
ErrPartialCharset
// Незавершённая escape-последовательность
ErrPartialEscape
// Повторный вход в range с изменением контекста
ErrRangeLoopReentry
// Неоднозначная интерпретация '/' (деление или regexp)
ErrSlashAmbig
// Использование запрещённых экранировщиков
ErrPredefinedEscaper
// Устаревшая ошибка для JS template literals
ErrJSTemplate
)
Особое значение ZgotmplZ
Пример:
<img src="{{.X}}">
где {{.X}} вычисляется в javascript:...
Результат:
<img src="#ZgotmplZ">
Объяснение:
“ZgotmplZ” - специальное значение, указывающее, что небезопасное содержимое достигло CSS или URL контекста во время выполнения. Для доверенных источников используйте типы содержимого для отключения фильтрации: URL(javascript:…).
type FuncMap
type FuncMap = template.FuncMap
FuncMap - это псевдоним для типа template.FuncMap из пакета text/template, представляющий карту функций для использования в шаблонах.
type HTML
type HTML string
HTML инкапсулирует безопасный фрагмент HTML-документа. Не следует использовать для:
- HTML из ненадёжных источников
- HTML с незакрытыми тегами или комментариями
Внимание: Содержимое должно поступать из доверенного источника, так как включается в вывод шаблона без изменений.
type HTMLAttr
type HTMLAttr string
HTMLAttr инкапсулирует безопасный HTML-атрибут, например dir="ltr".
Внимание: Как и с HTML, содержимое должно быть доверенным, так как включается без экранирования.
type JS
type JS string
JS инкапсулирует безопасное выражение EcmaScript5, например (x + y * z()).
Особенности:
- Авторы шаблонов должны обеспечивать правильный порядок операций
- Не должно быть неоднозначности между выражениями и инструкциями
Внимание: Не безопасно использовать для непроверенного JSON. Для JSON лучше использовать json.Unmarshal.
type JSStr
type JSStr string
JSStr инкапсулирует безопасную строку для JavaScript, которая будет заключена в кавычки.
Требования:
- Допустимые символы или escape-последовательности
- Запрещены переносы строк внутри escape-последовательностей
Пример:
JSStr("foo\\nbar") // допустимо
JSStr("foo\\\nbar") // недопустимо
type Srcset
type Srcset string
Srcset инкапсулирует безопасный атрибут srcset для тегов <img> (спецификация HTML5).
type Template
type Template struct {
Tree *parse.Tree // Абстрактное синтаксическое дерево шаблона
// ... скрытые поля
}
Template - это специализированная версия text/template, которая генерирует безопасные фрагменты HTML-документов.
Ключевые особенности:
- Расширяет базовый функционал text/template
- Автоматически применяет контекстно-зависимое экранирование
- Гарантирует безопасность вывода при правильном использовании
Все типы безопасного контента (HTML, JS и др.) требуют, чтобы их содержимое поступало из доверенных источников, так как они включаются в вывод без дополнительного экранирования.
Пример Block
package main
import (
"html/template"
"log"
"os"
"strings"
)
func main() {
const (
master = `Names:{{block "list" .}}{{"\n"}}{{range .}}{{println "-" .}}{{end}}{{end}}`
overlay = `{{define "list"}} {{join . ", "}}{{end}} `
)
var (
funcs = template.FuncMap{"join": strings.Join}
guardians = []string{"Gamora", "Groot", "Nebula", "Rocket", "Star-Lord"}
)
masterTmpl, err := template.New("master").Funcs(funcs).Parse(master)
if err != nil {
log.Fatal(err)
}
overlayTmpl, err := template.Must(masterTmpl.Clone()).Parse(overlay)
if err != nil {
log.Fatal(err)
}
if err := masterTmpl.Execute(os.Stdout, guardians); err != nil {
log.Fatal(err)
}
if err := overlayTmpl.Execute(os.Stdout, guardians); err != nil {
log.Fatal(err)
}
}
Output:
Names:
- Gamora
- Groot
- Nebula
- Rocket
- Star-Lord
Names: Gamora, Groot, Nebula, Rocket, Star-LordПример Glob
Здесь мы демонстрируем загрузку набора шаблонов из каталога.
package main
import (
"io"
"log"
"os"
"path/filepath"
"text/template"
)
// templateFile defines the contents of a template to be stored in a file, for testing.
type templateFile struct {
name string
contents string
}
func createTestDir(files []templateFile) string {
dir, err := os.MkdirTemp("", "template")
if err != nil {
log.Fatal(err)
}
for _, file := range files {
f, err := os.Create(filepath.Join(dir, file.name))
if err != nil {
log.Fatal(err)
}
defer f.Close()
_, err = io.WriteString(f, file.contents)
if err != nil {
log.Fatal(err)
}
}
return dir
}
func main() {
// Here we create a temporary directory and populate it with our sample
// template definition files; usually the template files would already
// exist in some location known to the program.
dir := createTestDir([]templateFile{
// T0.tmpl is a plain template file that just invokes T1.
{"T0.tmpl", `T0 invokes T1: ({{template "T1"}})`},
// T1.tmpl defines a template, T1 that invokes T2.
{"T1.tmpl", `{{define "T1"}}T1 invokes T2: ({{template "T2"}}){{end}}`},
// T2.tmpl defines a template T2.
{"T2.tmpl", `{{define "T2"}}This is T2{{end}}`},
})
// Clean up after the test; another quirk of running as an example.
defer os.RemoveAll(dir)
// pattern is the glob pattern used to find all the template files.
pattern := filepath.Join(dir, "*.tmpl")
// Here starts the example proper.
// T0.tmpl is the first name matched, so it becomes the starting template,
// the value returned by ParseGlob.
tmpl := template.Must(template.ParseGlob(pattern))
err := tmpl.Execute(os.Stdout, nil)
if err != nil {
log.Fatalf("template execution: %s", err)
}
}
Output:
T0 invokes T1: (T1 invokes T2: (This is T2))
Пример Helpers
Этот пример демонстрирует один из способов поделиться некоторыми шаблонами и использовать их в разных контекстах. В этом варианте мы вручную добавляем несколько шаблонов драйверов в существующий пакет шаблонов.
package main
import (
"io"
"log"
"os"
"path/filepath"
"text/template"
)
// templateFile defines the contents of a template to be stored in a file, for testing.
type templateFile struct {
name string
contents string
}
func createTestDir(files []templateFile) string {
dir, err := os.MkdirTemp("", "template")
if err != nil {
log.Fatal(err)
}
for _, file := range files {
f, err := os.Create(filepath.Join(dir, file.name))
if err != nil {
log.Fatal(err)
}
defer f.Close()
_, err = io.WriteString(f, file.contents)
if err != nil {
log.Fatal(err)
}
}
return dir
}
func main() {
// Here we create a temporary directory and populate it with our sample
// template definition files; usually the template files would already
// exist in some location known to the program.
dir := createTestDir([]templateFile{
// T1.tmpl defines a template, T1 that invokes T2.
{"T1.tmpl", `{{define "T1"}}T1 invokes T2: ({{template "T2"}}){{end}}`},
// T2.tmpl defines a template T2.
{"T2.tmpl", `{{define "T2"}}This is T2{{end}}`},
})
// Clean up after the test; another quirk of running as an example.
defer os.RemoveAll(dir)
// pattern is the glob pattern used to find all the template files.
pattern := filepath.Join(dir, "*.tmpl")
// Here starts the example proper.
// Load the helpers.
templates := template.Must(template.ParseGlob(pattern))
// Add one driver template to the bunch; we do this with an explicit template definition.
_, err := templates.Parse("{{define `driver1`}}Driver 1 calls T1: ({{template `T1`}})\n{{end}}")
if err != nil {
log.Fatal("parsing driver1: ", err)
}
// Add another driver template.
_, err = templates.Parse("{{define `driver2`}}Driver 2 calls T2: ({{template `T2`}})\n{{end}}")
if err != nil {
log.Fatal("parsing driver2: ", err)
}
// We load all the templates before execution. This package does not require
// that behavior but html/template's escaping does, so it's a good habit.
err = templates.ExecuteTemplate(os.Stdout, "driver1", nil)
if err != nil {
log.Fatalf("driver1 execution: %s", err)
}
err = templates.ExecuteTemplate(os.Stdout, "driver2", nil)
if err != nil {
log.Fatalf("driver2 execution: %s", err)
}
}
Output:
Driver 1 calls T1: (T1 invokes T2: (This is T2))
Driver 2 calls T2: (This is T2)
Пример Parsefiles
Здесь мы демонстрируем загрузку набора шаблонов из файлов в разных каталогах.
package main
import (
"io"
"log"
"os"
"path/filepath"
"text/template"
)
// templateFile defines the contents of a template to be stored in a file, for testing.
type templateFile struct {
name string
contents string
}
func createTestDir(files []templateFile) string {
dir, err := os.MkdirTemp("", "template")
if err != nil {
log.Fatal(err)
}
for _, file := range files {
f, err := os.Create(filepath.Join(dir, file.name))
if err != nil {
log.Fatal(err)
}
defer f.Close()
_, err = io.WriteString(f, file.contents)
if err != nil {
log.Fatal(err)
}
}
return dir
}
func main() {
// Here we create different temporary directories and populate them with our sample
// template definition files; usually the template files would already
// exist in some location known to the program.
dir1 := createTestDir([]templateFile{
// T1.tmpl is a plain template file that just invokes T2.
{"T1.tmpl", `T1 invokes T2: ({{template "T2"}})`},
})
dir2 := createTestDir([]templateFile{
// T2.tmpl defines a template T2.
{"T2.tmpl", `{{define "T2"}}This is T2{{end}}`},
})
// Clean up after the test; another quirk of running as an example.
defer func(dirs ...string) {
for _, dir := range dirs {
os.RemoveAll(dir)
}
}(dir1, dir2)
// Here starts the example proper.
// Let's just parse only dir1/T0 and dir2/T2
paths := []string{
filepath.Join(dir1, "T1.tmpl"),
filepath.Join(dir2, "T2.tmpl"),
}
tmpl := template.Must(template.ParseFiles(paths...))
err := tmpl.Execute(os.Stdout, nil)
if err != nil {
log.Fatalf("template execution: %s", err)
}
}
Output:
T1 invokes T2: (This is T2)Пример Share
В этом примере показано, как использовать одну группу шаблонов драйверов с различными наборами вспомогательных шаблонов.
package main
import (
"io"
"log"
"os"
"path/filepath"
"text/template"
)
// templateFile defines the contents of a template to be stored in a file, for testing.
type templateFile struct {
name string
contents string
}
func createTestDir(files []templateFile) string {
dir, err := os.MkdirTemp("", "template")
if err != nil {
log.Fatal(err)
}
for _, file := range files {
f, err := os.Create(filepath.Join(dir, file.name))
if err != nil {
log.Fatal(err)
}
defer f.Close()
_, err = io.WriteString(f, file.contents)
if err != nil {
log.Fatal(err)
}
}
return dir
}
func main() {
// Here we create a temporary directory and populate it with our sample
// template definition files; usually the template files would already
// exist in some location known to the program.
dir := createTestDir([]templateFile{
// T0.tmpl is a plain template file that just invokes T1.
{"T0.tmpl", "T0 ({{.}} version) invokes T1: ({{template `T1`}})\n"},
// T1.tmpl defines a template, T1 that invokes T2. Note T2 is not defined
{"T1.tmpl", `{{define "T1"}}T1 invokes T2: ({{template "T2"}}){{end}}`},
})
// Clean up after the test; another quirk of running as an example.
defer os.RemoveAll(dir)
// pattern is the glob pattern used to find all the template files.
pattern := filepath.Join(dir, "*.tmpl")
// Here starts the example proper.
// Load the drivers.
drivers := template.Must(template.ParseGlob(pattern))
// We must define an implementation of the T2 template. First we clone
// the drivers, then add a definition of T2 to the template name space.
// 1. Clone the helper set to create a new name space from which to run them.
first, err := drivers.Clone()
if err != nil {
log.Fatal("cloning helpers: ", err)
}
// 2. Define T2, version A, and parse it.
_, err = first.Parse("{{define `T2`}}T2, version A{{end}}")
if err != nil {
log.Fatal("parsing T2: ", err)
}
// Now repeat the whole thing, using a different version of T2.
// 1. Clone the drivers.
second, err := drivers.Clone()
if err != nil {
log.Fatal("cloning drivers: ", err)
}
// 2. Define T2, version B, and parse it.
_, err = second.Parse("{{define `T2`}}T2, version B{{end}}")
if err != nil {
log.Fatal("parsing T2: ", err)
}
// Execute the templates in the reverse order to verify the
// first is unaffected by the second.
err = second.ExecuteTemplate(os.Stdout, "T0.tmpl", "second")
if err != nil {
log.Fatalf("second execution: %s", err)
}
err = first.ExecuteTemplate(os.Stdout, "T0.tmpl", "first")
if err != nil {
log.Fatalf("first: execution: %s", err)
}
}
Output:
T0 (second version) invokes T1: (T1 invokes T2: (T2, version B))
T0 (first version) invokes T1: (T1 invokes T2: (T2, version A))
func Must
func Must(t *Template, err error) *Template
Must - вспомогательная функция, которая оборачивает вызов функции, возвращающей (*Template, error), и вызывает панику, если ошибка не равна nil. Предназначена для инициализации переменных:
Пример:
var t = template.Must(template.New("name").Parse("html"))
func New
func New(name string) *Template
New создает новый HTML-шаблон с указанным именем.
func ParseFS (добавлена в Go 1.16)
func ParseFS(fs fs.FS, patterns ...string) (*Template, error)
ParseFS аналогична ParseFiles и ParseGlob, но читает из файловой системы fs вместо файловой системы хоста. Принимает список glob-шаблонов (большинство имен файлов работают как glob-шаблоны, соответствующие только самим себе).
func ParseFiles
func ParseFiles(filenames ...string) (*Template, error)
ParseFiles создает новый шаблон и парсит определения шаблонов из указанных файлов. Имя возвращаемого шаблона будет соответствовать базовому имени первого файла. Должен быть указан хотя бы один файл.
Особенности:
- При парсинге нескольких файлов с одинаковыми именами будет использован последний указанный файл
- Например,
ParseFiles("a/foo", "b/foo")сохранит “b/foo” как шаблон “foo”, а “a/foo” будет недоступен
func ParseGlob
func ParseGlob(pattern string) (*Template, error)
ParseGlob создает новый шаблон и парсит определения шаблонов из файлов, соответствующих указанному шаблону (согласно семантике filepath.Match). Шаблон должен соответствовать хотя бы одному файлу.
Эквивалентно вызову ParseFiles со списком файлов, соответствующих шаблону. Как и в ParseFiles, при дублировании имен используется последний файл.
func (*Template) AddParseTree
func (t *Template) AddParseTree(name string, tree *parse.Tree) (*Template, error)
AddParseTree создает новый шаблон с указанным именем и деревом разбора, ассоциируя его с t.
Возвращает ошибку, если t или любой ассоциированный шаблон уже были выполнены.
func (*Template) Clone
func (t *Template) Clone() (*Template, error)
Clone создает копию шаблона, включая все ассоциированные шаблоны. Последующие вызовы Parse в копии будут добавлять шаблоны только в копию.
Возвращает ошибку, если t уже был выполнен.
func (*Template) DefinedTemplates (добавлена в Go 1.6)
func (t *Template) DefinedTemplates() string
DefinedTemplates возвращает строку с перечислением определенных шаблонов с префиксом “; defined templates are: “. Если шаблонов нет, возвращает пустую строку. Используется для генерации сообщений об ошибках.
func (*Template) Delims
func (t *Template) Delims(left, right string) *Template
Delims устанавливает разделители действий для последующих вызовов Parse, ParseFiles или ParseGlob. Вложенные определения шаблонов наследуют эти настройки. Пустые разделители соответствуют значениям по умолчанию: {{ и }}.
Возвращает сам шаблон, позволяя объединять вызовы в цепочку.
Пример
package main
import (
"html/template"
"log"
"os"
)
func main() {
const text = "<<.Greeting>> {{.Name}}"
data := struct {
Greeting string
Name string
}{
Greeting: "Hello",
Name: "Joe",
}
t := template.Must(template.New("tpl").Delims("<<", ">>").Parse(text))
err := t.Execute(os.Stdout, data)
if err != nil {
log.Fatal(err)
}
}
Output:
Hello {{.Name}}func (*Template) Execute
func (t *Template) Execute(wr io.Writer, data any) error
Применяет разобранный шаблон к указанным данным, записывая результат в wr. В случае ошибки выполнение прерывается, но частичные результаты могут быть уже записаны. Шаблон можно выполнять параллельно, но при использовании общего Writer вывод может перемешиваться.
func (*Template) ExecuteTemplate
func (t *Template) ExecuteTemplate(wr io.Writer, name string, data any) error
Применяет шаблон с указанным именем, ассоциированный с t, к данным и записывает результат в wr. Поведение при ошибках и параллельном выполнении аналогично Execute.
Отличие Execute от ExecuteTemplate
Отличие между Execute и ExecuteTemplate
Основное различие между этими методами заключается в том, какой шаблон они выполняют:
Execute- выполняет основной (корневой) шаблонExecuteTemplate- выполняет указанный именованный шаблон (включая ассоциированные шаблоны)
Пример использования:
package main
import (
"os"
"text/template"
)
func main() {
// Создаем шаблон с именем "base"
tmpl := template.Must(template.New("base").Parse(`
{{define "header"}}<h1>Заголовок</h1>{{end}}
{{define "content"}}<p>Основное содержимое</p>{{end}}
<!DOCTYPE html>
<html>
<head><title>Пример</title></head>
<body>
{{template "header"}}
{{template "content"}}
</body>
</html>
`))
// 1. Execute - выполнит основной шаблон "base"
err := tmpl.Execute(os.Stdout, nil)
if err != nil {
panic(err)
}
// 2. ExecuteTemplate - можно выполнить любой из определенных шаблонов
err = tmpl.ExecuteTemplate(os.Stdout, "header", nil)
if err != nil {
panic(err)
}
}
Ключевые отличия:
| Характеристика | Execute | ExecuteTemplate |
|---|---|---|
| Какой шаблон выполняется | Только основной (корневой) | Любой именованный (включая основной) |
| Использование | Когда нужно выполнить весь шаблон | Когда нужна часть шаблона |
| Производительность | Чуть быстрее | Чуть медленнее (поиск по имени) |
| Гибкость | Меньше | Больше (доступ ко всем шаблонам) |
Когда использовать:
Execute- для рендеринга всего шаблона целикомExecuteTemplate- когда нужно:- выполнить часть шаблона
- переиспользовать компоненты в разных контекстах
- отладить отдельный блок шаблона
func (*Template) Funcs
func (t *Template) Funcs(funcMap FuncMap) *Template
Добавляет функции из переданной мапы в функциональную мапу шаблона. Должен вызываться до парсинга шаблона. Вызывает панику, если значение в мапе не является функцией с подходящим типом возвращаемого значения. Возвращает сам шаблон для цепочки вызовов.
func (*Template) Lookup
func (t *Template) Lookup(name string) *Template
Возвращает шаблон с указанным именем, ассоциированный с t, или nil если такого шаблона нет.
func (*Template) Name
func (t *Template) Name() string
Возвращает имя шаблона.
func (*Template) New
func (t *Template) New(name string) *Template
Создает новый HTML-шаблон с указанным именем, ассоциированный с текущим и имеющий те же разделители. Позволяет использовать вызовы шаблонов через {{template}}. Если шаблон с таким именем уже существует, он будет заменен.
func (*Template) Option
func (t *Template) Option(opt ...string) *Template
Устанавливает опции шаблона в формате строк “ключ=значение” или простых строк. Вызывает панику при неизвестной или неверной опции.
Поддерживаемые опции:
missingkey=defaultилиmissingkey=invalid- поведение по умолчанию (продолжать выполнение)missingkey=zero- возвращать нулевое значение для отсутствующего ключаmissingkey=error- прерывать выполнение с ошибкой
func (*Template) Parse
func (t *Template) Parse(text string) (*Template, error)
Разбирает текст как тело шаблона для t. Определения именованных шаблонов ({{define}}/{{block}}) становятся ассоциированными шаблонами. Шаблоны можно переопределять до первого вызова Execute. Пустые определения (только пробелы/комментарии) не заменяют существующие шаблоны.
func (*Template) ParseFS
func (t *Template) ParseFS(fs fs.FS, patterns ...string) (*Template, error)
ParseFS аналогична Template.ParseFiles и Template.ParseGlob, но читает из абстрактной файловой системы fs вместо файловой системы хоста. Принимает список glob-шаблонов (большинство имен файлов работают как glob-шаблоны, соответствующие только самим себе).
func (*Template) ParseFiles
func (t *Template) ParseFiles(filenames ...string) (*Template, error)
ParseFiles парсит указанные файлы и ассоциирует полученные шаблоны с t. При ошибке парсинг останавливается и возвращается nil, иначе возвращается t. Должен быть указан хотя бы один файл.
Особенности:
- При парсинге нескольких файлов с одинаковыми именами используется последний указанный файл
- Возвращает ошибку, если t или любой ассоциированный шаблон уже были выполнены
func (*Template) ParseGlob
func (t *Template) ParseGlob(pattern string) (*Template, error)
ParseGlob парсит шаблоны из файлов, соответствующих указанному шаблону (согласно семантике filepath.Match), и ассоциирует их с t. Эквивалентно вызову t.ParseFiles со списком файлов, соответствующих шаблону.
Особенности:
- Как и в ParseFiles, при дублировании имен используется последний файл
- Возвращает ошибку, если t или любой ассоциированный шаблон уже были выполнены
func (*Template) Templates
func (t *Template) Templates() []*Template
Templates возвращает срез всех шаблонов, ассоциированных с t, включая сам t.
type URL
type URL string
URL инкапсулирует безопасный URL или подстроку URL (согласно RFC 3986). URL типа javascript:checkThatFormNotEditedBeforeLeavingPage() из доверенного источника может быть использован, но по умолчанию динамические javascript: URL фильтруются как частый вектор атак.
Внимание: Использование этого типа представляет угрозу безопасности - содержимое должно поступать из доверенного источника, так как включается в вывод шаблона без изменений.
12.4.2 - Пакет bufio встроенных функций Go
Пакет bufio реализует буферизованный ввод-вывод. Он оборачивает объект io.Reader или io.Writer, создавая другой объект (Reader или Writer), который также реализует интерфейс, но обеспечивает буферизацию и некоторую помощь для текстового ввода-вывода.
Объяснение bufio
Пакет bufio предоставляет буферизованный ввод/вывод, что делает работу с потоками данных более эффективной. Он особенно полезен для:
- Чтения больших файлов по частям
- Обработки текстовых данных построчно
- Разбивки входных данных на слова, символы и другие логические единицы
Почему использовать bufio?
- Эффективность: Буферизация уменьшает количество системных вызовов
- Удобство: Готовые функции для распространенных задач (чтение строк, слов)
- Гибкость: Можно создавать собственные функции разделения
- Производительность: Особенно заметна при работе с большими файлами
Пример комплексного использования:
file, _ := os.Open("data.txt")
defer file.Close()
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanWords) // Разбиваем по словам
wordCount := 0
for scanner.Scan() {
wordCount++
}
fmt.Printf("Файл содержит %d слов", wordCount)
Пакет bufio - это мощный инструмент для эффективной обработки текстовых и бинарных данных в Go, который стоит использовать вместо базовых операций ввода-вывода, когда важны производительность и удобство работы.
Константы
const (
// maxscantokensize - максимальный размер, используемый для буфера токена
// Если пользователь не предоставит явный буфер с [scanner.buffer].
// фактический максимальный размер токена может быть меньше в качестве буфера
// может потребоваться включить, например, новую линию.
Maxscantokensize = 64 * 1024
)
Переменные
var (
ErrinValidunReadByte = errors.new ("Bufio: недействительное использование UnReadByte")
Errinvalidunreadrune = errors.new ("bufio: недействительное использование Undeardrune")
Errbufferfull = errors.new ("bufio: buffer full")
Errnegativecount = errors.new ("bufio: отрицательный счет")
)
var (
Errtoolong = errors.new ("bufio.scanner: токен слишком длинный")
Errnegativeadvance = errors.new ("bufio.scanner: splitfunc возвращает отрицательное значение сдвига") ")
ErradvancetOfar = errors.new ("bufio.scanner: splitfunc возвращает сдвиг, превышающий входные данные")
ErrbadReadCount = errors.new ("bufio.scanner: read возвращается невозможное количество")
)
Ошибки возвращаемые Scanner.
var errfinaltoken = errors.new ("Окончательный токен")
ErrFinalToken — это специальное контрольное значение ошибки. Оно предназначено для возврата функцией Split, чтобы указать, что сканирование должно быть остановлено без ошибки. Если токен, передаваемый с этой ошибкой, не равен nil, то этот токен является последним токеном.
Это значение полезно для досрочного прекращения обработки или когда необходимо передать последний пустой токен (который отличается от токена nil). Такое же поведение можно достичь с помощью пользовательского значения ошибки, но использование этого значения более удобно. Пример использования этого значения см. в примере emptyFinalToken.
Функции
func ScanBytes
func ScanBytes(data []byte, atEOF bool) (advance int, token []byte, err error)
ScanBytes — это функция разделения для сканера, которая возвращает каждый байт в виде токена.
Назначение: Чтение входных данных побайтово.
Пример:
scanner := bufio.NewScanner(strings.NewReader("Go"))
scanner.Split(bufio.ScanBytes)
for scanner.Scan() {
fmt.Printf("%q ", scanner.Bytes())
}
// Вывод: 'G' 'o'
Когда использовать:
- Когда нужно обрабатывать каждый байт данных
- Для низкоуровневой обработки бинарных данных
func ScanLines
func ScanLines(data []byte, atEOF bool) (advance int, token []byte, err error)
ScanLines — это функция разделения для сканера, которая возвращает каждую строку текста без конечного маркера конца строки. Возвращаемая строка может быть пустой. Маркер конца строки — это один необязательный возврат каретки, за которым следует один обязательный символ новой строки. В нотации регулярных выражений это \r?\n. Последняя непустая строка ввода будет возвращена, даже если в ней нет символа новой строки.
Назначение: Чтение входных данных построчно (по умолчанию в Scanner).
Пример:
scanner := bufio.NewScanner(strings.NewReader("line1\nline2\n"))
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
// Вывод:
// line1
// line2
Когда использовать:
- Для обработки логов
- Чтения конфигурационных файлов
- Обработки любого текста, организованного по строкам
func ScanRunes
func ScanRunes(data []byte, atEOF bool) (advance int, token []byte, err error)
ScanRunes — это функция разделения для сканера, которая возвращает каждую руну, закодированную в UTF-8, в виде токена. Последовательность возвращаемых рун эквивалентна последовательности из цикла range над входом в виде строки, что означает, что ошибочные кодировки UTF-8 переводятся в U+FFFD = “\xef\xbf\xbd”. Из-за интерфейса Scan это делает невозможным для клиента отличить правильно закодированные руны-замены от ошибок кодирования.
Назначение: Чтение входных данных посимвольно (с поддержкой UTF-8).
Пример:
scanner := bufio.NewScanner(strings.NewReader("Привет"))
scanner.Split(bufio.ScanRunes)
for scanner.Scan() {
fmt.Printf("%q ", scanner.Text())
}
// Вывод: 'П' 'р' 'и' 'в' 'е' 'т'
Когда использовать:
- Для обработки Unicode-текстов
- Когда нужно работать с отдельными символами (рунами)
- Для анализа текста на уровне символов
func ScanWords
func ScanWords(data []byte, atEOF bool) (advance int, token []byte, err error)
ScanWords — это функция разделения для Scanner, которая возвращает каждое слово текста, разделенное пробелом, с удалением окружающих пробелов. Она никогда не возвращает пустую строку. Определение пробела устанавливается unicode.IsSpace.
Назначение: Чтение входных данных по словам.
Пример:
scanner := bufio.NewScanner(strings.NewReader("Hello world!"))
scanner.Split(bufio.ScanWords)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
// Вывод:
// Hello
// world!
Когда использовать:
- Для анализа текста по словам
- При обработке естественного языка
- Для подсчета слов в тексте
Типы
type ReadWriter
type ReadWriter struct {
*Reader
*Writer
}
ReadWriter хранит указатели на Reader и Writer. Он реализует io.ReadWriter.
func NewReadWriter
func NewReadWriter(r *Reader, w *Writer) *ReadWriter
NewReadWriter выделяет новый ReadWriter, который отправляет данные в R и W.
type Reader
type Reader struct {
// contains filtered or unexported fields
}
Reader реализует буферизацию для объекта io.Reader. Новый Reader создается вызовом NewReader или NewReaderSize; в качестве альтернативы можно использовать нулевое значение Reader после вызова [Reset] для него.
Объяснение отличий Scanner, Reader и Writer
Сравнение Scanner, Reader и Writer в пакете bufio
Основные различия
1. Reader (буферизованное чтение)
Что делает:
- Читает данные порциями в буфер
- Предоставляет низкоуровневые методы (
Read,ReadByte,ReadLineи др.) - Требует ручного управления процессом чтения
Когда использовать:
reader := bufio.NewReader(file)
// Чтение точного количества байт
buf := make([]byte, 1024)
n, err := reader.Read(buf)
// Чтение до разделителя
line, err := reader.ReadString('\n')
Лучше использовать когда:
- Нужен точный контроль над процессом чтения
- Требуется чтение данных фиксированного размера
- Работа с бинарными данными
- Когда нужно несколько раз переиспользовать один и тот же буфер
2. Scanner (высокоуровневое сканирование)
Что делает:
- Автоматически разбивает входные данные на токены
- Предоставляет простой итерационный интерфейс
- Имеет встроенные функции для разделения на строки, слова, руны
Когда использовать:
scanner := bufio.NewScanner(file)
for scanner.Scan() {
fmt.Println(scanner.Text()) // автоматическое чтение строк
}
Лучше использовать когда:
- Обработка текстовых данных построчно
- Нужно разделять входные данные по сложным правилам
- Работа с текстовыми форматами (логи, CSV и т.д.)
- Когда важна простота кода
3. Writer (буферизованная запись)
Что делает:
- Накапливает данные в буфере перед записью
- Предоставляет методы для эффективной записи (
Write,WriteString,WriteByte)
Когда использовать:
writer := bufio.NewWriter(file)
writer.WriteString("Hello, ")
writer.WriteString("World!\n")
writer.Flush() // запись из буфера в файл
Сравнительная таблица
| Характеристика | Reader | Scanner | Writer |
|---|---|---|---|
| Уровень абстракции | Низкий | Высокий | Средний |
| Управление буфером | Ручное | Автоматическое | Полуавтоматическое |
| Чтение строк | ReadString(’\n') | Scan() + Text() | - |
| Производительность | Очень высокая | Высокая | Высокая |
| Удобство использования | Среднее | Очень высокое | Высокое |
| Лучший случай использования | Бинарные данные, сети | Текстовые файлы, логи | Запись в файлы, сети |
Практические рекомендации
Используйте
Scannerкогда:- Обрабатываете текстовые файлы построчно
- Нужно разделять данные по словам/символам
- Хотите простой и читаемый код
// Подсчет слов в файле scanner := bufio.NewScanner(file) scanner.Split(bufio.ScanWords) count := 0 for scanner.Scan() { count++ }Используйте
Readerкогда:- Работаете с бинарными данными
- Нужно читать данные точными порциями
- Требуется низкоуровневый контроль
// Чтение заголовка файла reader := bufio.NewReader(file) header := make([]byte, 16) _, err := reader.Read(header)Используйте
Writerкогда:- Нужно эффективно записывать много небольших фрагментов
- Важна производительность при записи
// Буферизованная запись writer := bufio.NewWriter(file) for i := 0; i < 1000; i++ { writer.WriteString(fmt.Sprintf("Line %d\n", i)) } writer.Flush()
Производительность
- Для больших файлов
Readerобычно быстрееScanner - Для текстовой обработки
Scannerудобнее и часто достаточно быстр Writerдает значительный прирост производительности при множественных мелких записях
Заключение
Выбор между Scanner, Reader и Writer зависит от конкретной задачи:
- Простота и удобство →
Scanner - Контроль и производительность →
Reader/Writer - Текстовые данные →
Scanner - Бинарные данные →
Reader - Эффективная запись →
Writer
func NewReader
func NewReader(rd io.Reader) *Reader
NewReader возвращает новый объект Reader, буфер которого имеет размер по умолчанию.
func NewReaderSize
func NewReaderSize(rd io.Reader, size int) *Reader
NewReaderSize возвращает новый Reader, буфер которого имеет как минимум указанный размер. Если аргумент io.Reader уже является Reader с достаточно большим размером, то возвращается базовый Reader.
func (*Reader) Buffered
func (b *Reader) Buffered() int
Buffered возвращает количество байтов, которые можно прочитать из текущего буфера.
func (*Reader) Discard
added in go1.5
func (b *Reader) Discard(n int) (discarded int, err error)
Discard пропускает следующие n байтов и возвращает количество пропущенных байтов.
Если Discard пропускает меньше n байтов, он также возвращает ошибку. Если 0 <= n <= b.Buffered(), Discard гарантированно выполнится успешно без чтения из базового io.Reader.
func (*Reader) Peek
func (b *Reader) Peek(n int) ([]byte, error)
Peek возвращает следующие n байтов, не продвигая считывающее устройство. Байты перестают быть действительными при следующем вызове чтения. При необходимости Peek прочитает больше байтов в буфер, чтобы сделать доступными n байтов. Если Peek возвращает меньше n байтов, он также возвращает ошибку, объясняющую, почему чтение является коротким. Ошибка ErrBufferFull возникает, если n больше размера буфера b.
Вызов Peek предотвращает выполнение вызова Reader.UnreadByte или Reader.UnreadRune до следующей операции чтения.
func (*Reader) Read
func (b *Reader) Read(p []byte) (n int, err error)
Read считывает данные в p. Он возвращает количество байтов, прочитанных в p. Байты берутся максимум из одного Read в базовом Reader, поэтому n может быть меньше len(p). Чтобы прочитать ровно len(p) байтов, используйте io.ReadFull(b, p). Если базовый Reader может возвращать ненулевое значение с io.EOF, то этот метод Read также может это делать; см. документацию io.Reader.
func (*Reader) ReadByte
func (b *Reader) ReadByte() (byte, error)
ReadByte считывает и возвращает один байт. Если байт недоступен, возвращает ошибку.
func (*Reader) ReadBytes
func (b *Reader) ReadBytes(delim byte) ([]byte, error)
ReadBytes читает входные данные до первого появления разделителя delim, возвращая фрагмент, содержащий данные до разделителя включительно. Если ReadBytes обнаруживает ошибку до нахождения разделителя, он возвращает данные, прочитанные до ошибки, и саму ошибку (часто io.EOF). ReadBytes возвращает err != nil, если и только если возвращаемые данные не заканчиваются на delim. Для простых задач может быть более удобно использовать Scanner.
func (*Reader) ReadLine
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error)
ReadLine — это низкоуровневая примитивная функция чтения строк. Большинству вызывающих функций следует использовать Reader.ReadBytes(’\n’) или Reader.ReadString(’\n’) вместо нее, либо использовать Scanner.
ReadLine пытается вернуть одну строку, не включая байты конца строки. Если строка была слишком длинной для буфера, то устанавливается isPrefix и возвращается начало строки. Остальная часть строки будет возвращена при последующих вызовах. isPrefix будет false при возвращении последнего фрагмента строки. Возвращаемый буфер действителен только до следующего вызова ReadLine. ReadLine либо возвращает строку, отличную от nil, либо возвращает ошибку, но никогда и то, и другое одновременно.
Текст, возвращаемый из ReadLine, не включает конец строки («\r\n» или «\n»). Если ввод заканчивается без конечного конца строки, никаких указаний или ошибок не выдается. Вызов Reader.UnreadByte после ReadLine всегда отменяет чтение последнего прочитанного байта (возможно, символа, принадлежащего концу строки), даже если этот байт не является частью строки, возвращаемой ReadLine.
func (*Reader) ReadRune
func (b *Reader) ReadRune() (r rune, size int, err error)
ReadRune считывает один символ Unicode, закодированный в UTF-8, и возвращает руну и ее размер в байтах. Если закодированная руна недействительна, она потребляет один байт и возвращает unicode.ReplacementChar (U+FFFD) с размером 1.
func (*Reader) ReadSlice
func (b *Reader) ReadSlice(delim byte) (line []byte, err error)
ReadSlice читает до первого появления разделителя в входных данных, возвращая фрагмент, указывающий на байты в буфере. Байты перестают быть действительными при следующем чтении. Если ReadSlice встречает ошибку до нахождения разделителя, он возвращает все данные в буфере и саму ошибку (часто io.EOF). ReadSlice завершается с ошибкой ErrBufferFull, если буфер заполняется без delim. Поскольку данные, возвращаемые из ReadSlice, будут перезаписаны следующей операцией ввода-вывода, большинство клиентов должны использовать Reader.ReadBytes или ReadString вместо этого. ReadSlice возвращает err != nil, если и только если строка не заканчивается на delim.
func (*Reader) ReadString
func (b *Reader) ReadString(delim byte) (string, error)
ReadString читает входные данные до первого появления delim, возвращая строку, содержащую данные до разделителя включительно. Если ReadString встречает ошибку до нахождения разделителя, он возвращает данные, прочитанные до ошибки, и саму ошибку (часто io.EOF). ReadString возвращает err != nil тогда и только тогда, когда возвращаемые данные не заканчиваются на delim. Для простых задач может быть более удобно использовать Scanner.
func (*Reader) Reset
func (b *Reader) Reset(r io.Reader)
Reset удаляет все данные из буфера, сбрасывает все состояния и переключает буферизованный считыватель на чтение из r. Вызов Reset с нулевым значением Reader инициализирует внутренний буфер до размера по умолчанию. Вызов b.Reset(b) (то есть сброс Reader на себя) ничего не делает.
func (*Reader) Size
func (b *Reader) Size() int
Size возвращает размер базового буфера в байтах.
func (*Reader) UnreadByte
func (b *Reader) UnreadByte() error
UnreadByte отменяет чтение последнего байта. Отменить чтение можно только последнего прочитанного байта.
UnreadByte возвращает ошибку, если последний вызов метода Reader не был операцией чтения. В частности, методы Reader.Peek, Reader.Discard и Reader.WriteTo не считаются операциями чтения.
func (*Reader) UnreadRune
func (b *Reader) UnreadRune() error
UnreadRune снимает отметку о прочтении с последней руны. Если последний вызов метода Reader не был Reader.ReadRune, Reader.UnreadRune возвращает ошибку. (В этом отношении он более строг, чем Reader.UnreadByte, который снимает отметку о прочтении с последнего байта любой операции чтения.)
func (*Reader) WriteTo
func (b *Reader) WriteTo(w io.Writer) (n int64, err error)
WriteTo реализует io.WriterTo. Это может привести к нескольким вызовам метода Reader.Read базового Reader. Если базовый Reader поддерживает метод Reader.WriteTo, то вызывается базовый Reader.WriteTo без буферизации.
type Scanner
type Scanner struct {
// contains filtered or unexported fields
}
Scanner предоставляет удобный интерфейс для чтения данных, таких как файл текста, разбитый на строки с разделителями новой строки. Последовательные вызовы метода Scanner.Scan будут проходить по «токену» файла, пропуская байты между токенами. Спецификация токена определяется функцией разбиения типа SplitFunc; функция разбиения по умолчанию разбивает входные данные на строки с удалением символов окончания строки. Функции Scanner.Split определены в этом пакете для сканирования файла на строки, байты, руны с кодировкой UTF-8 и слова, разделенные пробелами. Клиент может вместо этого предоставить собственную функцию разделения.
Сканирование останавливается без возможности восстановления при EOF, первой ошибке ввода-вывода или токене, который слишком велик, чтобы поместиться в Scanner.Buffer. Когда сканирование останавливается, читатель может продвинуться произвольно далеко за последний токен. Программы, которым требуется больший контроль над обработкой ошибок или большими токенами, или которые должны выполнять последовательное сканирование на читателе, должны использовать bufio.Reader.
Объяснение Scanner
Тип Scanner из пакета bufio в Go
Scanner предоставляет удобный интерфейс для чтения и разбора текстовых данных. Это один из самых полезных инструментов для обработки текста в Go.
Основные возможности
- Чтение данных по частям (строкам, словам, символам и т.д.)
- Гибкое разделение входных данных (можно использовать готовые или свои функции)
- Эффективная буферизация (работает быстро даже с большими файлами)
Создание Scanner
scanner := bufio.NewScanner(reader)
где reader - это любой объект, реализующий интерфейс io.Reader (файл, строка, сетевое соединение и т.д.)
Основные методы
1. Scan() bool
Продвигает сканер к следующему токену. Возвращает false, когда сканирование завершено.
for scanner.Scan() {
// Обработка текущего токена
}
2. Text() string
Возвращает текущий токен как строку.
scanner := bufio.NewScanner(strings.NewReader("Hello\nWorld"))
for scanner.Scan() {
fmt.Println(scanner.Text())
}
// Вывод:
// Hello
// World
3. Bytes() []byte
Возвращает текущий токен как срез байтов.
scanner := bufio.NewScanner(strings.NewReader("Hello"))
scanner.Scan()
fmt.Printf("%q", scanner.Bytes()) // Вывод: "Hello"
4. Err() error
Возвращает первую ошибку, возникшую при сканировании.
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
5. Split(splitFunc SplitFunc)
Устанавливает функцию разделения. По умолчанию используется ScanLines.
scanner := bufio.NewScanner(strings.NewReader("Hello World"))
scanner.Split(bufio.ScanWords) // Разделять по словам
Стандартные функции разделения
ScanLines (по умолчанию)
scanner := bufio.NewScanner(strings.NewReader("line1\nline2\nline3"))
for scanner.Scan() {
fmt.Println(scanner.Text())
}
ScanWords
scanner := bufio.NewScanner(strings.NewReader("word1 word2 word3"))
scanner.Split(bufio.ScanWords)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
ScanRunes
scanner := bufio.NewScanner(strings.NewReader("Привет"))
scanner.Split(bufio.ScanRunes)
for scanner.Scan() {
fmt.Printf("%q ", scanner.Text())
}
// Вывод: 'П' 'р' 'и' 'в' 'е' 'т'
ScanBytes
scanner := bufio.NewScanner(strings.NewReader("Go"))
scanner.Split(bufio.ScanBytes)
for scanner.Scan() {
fmt.Printf("%q ", scanner.Bytes())
}
// Вывод: 'G' 'o'
Пользовательская функция разделения
Вы можете создать свою функцию разделения:
func atComma(data []byte, atEOF bool) (advance int, token []byte, err error) {
for i := 0; i < len(data); i++ {
if data[i] == ',' {
return i + 1, data[:i], nil
}
}
return 0, data, bufio.ErrFinalToken
}
func main() {
scanner := bufio.NewScanner(strings.NewReader("a,b,c,d"))
scanner.Split(atComma)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
}
// Вывод:
// a
// b
// c
// d
Полезные советы
Ограничение размера буфера:
scanner := bufio.NewScanner(reader) buf := make([]byte, 0, 64*1024) scanner.Buffer(buf, 1024*1024) // Максимальный размер токена 1MBОбработка больших строк:
scanner := bufio.NewScanner(file) scanner.Buffer(make([]byte, 100), bufio.MaxScanTokenSize)Подсчет строк в файле:
file, _ := os.Open("data.txt") defer file.Close() scanner := bufio.NewScanner(file) lineCount := 0 for scanner.Scan() { lineCount++ }
Scanner идеально подходит для:
- Обработки логов
- Чтения конфигурационных файлов
- Анализа текстовых данных
- Разбора CSV и других текстовых форматов
Главное преимущество - это простота использования и эффективность при работе с большими объемами данных.
Пример пользовательский
Используйте сканер с настраиваемой функцией разделения (созданный с помощью ScanWords) для проверки 32-разрядного десятичного ввода.
package main
import (
"bufio"
"fmt"
"strconv"
"strings"
)
func main() {
// An artificial input source.
const input = "1234 5678 1234567901234567890"
scanner := bufio.NewScanner(strings.NewReader(input))
// Create a custom split function by wrapping the existing ScanWords function.
split := func(data []byte, atEOF bool) (advance int, token []byte, err error) {
advance, token, err = bufio.ScanWords(data, atEOF)
if err == nil && token != nil {
_, err = strconv.ParseInt(string(token), 10, 32)
}
return
}
// Set the split function for the scanning operation.
scanner.Split(split)
// Validate the input
for scanner.Scan() {
fmt.Printf("%s\n", scanner.Text())
}
if err := scanner.Err(); err != nil {
fmt.Printf("Invalid input: %s", err)
}
}
Output:
1234
5678
Invalid input: strconv.ParseInt: parsing "1234567901234567890": value out of rangeПример EarlyStop
Используйте сканер с настраиваемой функцией разделения для разбора списка, разделенного запятыми, с пустым конечным значением, но останавливающимся на токене «STOP».
package main
import (
"bufio"
"bytes"
"fmt"
"os"
"strings"
)
func main() {
onComma := func(data []byte, atEOF bool) (advance int, token []byte, err error) {
i := bytes.IndexByte(data, ',')
if i == -1 {
if !atEOF {
return 0, nil, nil
}
// If we have reached the end, return the last token.
return 0, data, bufio.ErrFinalToken
}
// If the token is "STOP", stop the scanning and ignore the rest.
if string(data[:i]) == "STOP" {
return i + 1, nil, bufio.ErrFinalToken
}
// Otherwise, return the token before the comma.
return i + 1, data[:i], nil
}
const input = "1,2,STOP,4,"
scanner := bufio.NewScanner(strings.NewReader(input))
scanner.Split(onComma)
for scanner.Scan() {
fmt.Printf("Got a token %q\n", scanner.Text())
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading input:", err)
}
}
Output:
Got a token "1"
Got a token "2"Пример EmptyFinalToken
Используйте сканер с настраиваемой функцией разделения для разбора списка, разделенного запятыми, с пустым конечным значением.
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
func main() {
// Comma-separated list; last entry is empty.
const input = "1,2,3,4,"
scanner := bufio.NewScanner(strings.NewReader(input))
// Define a split function that separates on commas.
onComma := func(data []byte, atEOF bool) (advance int, token []byte, err error) {
for i := 0; i < len(data); i++ {
if data[i] == ',' {
return i + 1, data[:i], nil
}
}
if !atEOF {
return 0, nil, nil
}
// There is one final token to be delivered, which may be the empty string.
// Returning bufio.ErrFinalToken here tells Scan there are no more tokens after this
// but does not trigger an error to be returned from Scan itself.
return 0, data, bufio.ErrFinalToken
}
scanner.Split(onComma)
// Scan.
for scanner.Scan() {
fmt.Printf("%q ", scanner.Text())
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading input:", err)
}
}
Output:
"1" "2" "3" "4" ""Пример Lines
Самый простой способ использования сканера — чтение стандартного ввода в виде набора строк.
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
scanner := bufio.NewScanner(os.Stdin)
for scanner.Scan() {
fmt.Println(scanner.Text()) // Println will add back the final '\n'
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading standard input:", err)
}
}
Пример Words
Используйте сканер для реализации простой утилиты подсчета слов, сканируя входные данные как последовательность токенов, разделенных пробелами.
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
func main() {
// An artificial input source.
const input = "Now is the winter of our discontent,\nMade glorious summer by this sun of York.\n"
scanner := bufio.NewScanner(strings.NewReader(input))
// Set the split function for the scanning operation.
scanner.Split(bufio.ScanWords)
// Count the words.
count := 0
for scanner.Scan() {
count++
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading input:", err)
}
fmt.Printf("%d\n", count)
}
Output:
15func NewScanner
func NewScanner(r io.Reader) *Scanner
NewScanner возвращает новый сканер для чтения из r. По умолчанию функция разделения — ScanLines.
func (*Scanner) Buffer
func (s *Scanner) Buffer(buf []byte, max int)
Buffer устанавливает начальный буфер, который будет использоваться при сканировании, и максимальный размер буфера, который может быть выделен во время сканирования. Максимальный размер токена должен быть меньше большего из max и cap(buf). Если max <= cap(buf), Scanner.Scan будет использовать только этот буфер и не будет выделять дополнительную память.
По умолчанию Scanner.Scan использует внутренний буфер и устанавливает максимальный размер токена равным MaxScanTokenSize.
Buffer вызывает панику, если его вызвать после начала сканирования.
func (*Scanner) Bytes
func (s *Scanner) Bytes() []byte
Bytes возвращает самый последний токен, сгенерированный вызовом Scanner.Scan. Базовый массив может указывать на данные, которые будут перезаписаны последующим вызовом Scan. Он не выполняет выделение памяти.
Пример
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
func main() {
scanner := bufio.NewScanner(strings.NewReader("gopher"))
for scanner.Scan() {
fmt.Println(len(scanner.Bytes()) == 6)
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "shouldn't see an error scanning a string")
}
}
Output:
truefunc (*Scanner) Err
func (s *Scanner) Err() error
Err возвращает первую ошибку, не являющуюся EOF, которая была обнаружена Scanner.
func (*Scanner) Scan
func (s *Scanner) Scan() bool
Scan перемещает Scanner к следующему токену, который затем будет доступен через метод Scanner.Bytes или Scanner.Text. Он возвращает false, когда больше нет токенов, либо по достижении конца ввода, либо из-за ошибки. После того, как Scan возвращает false, метод Scanner.Err вернет любую ошибку, которая произошла во время сканирования, за исключением того, что если это было io.EOF, Scanner.Err вернет nil. Scan вызывает панику, если функция split возвращает слишком много пустых токенов, не продвигая ввод. Это обычный режим ошибки для сканеров.
func (*Scanner) Split
func (s *Scanner) Split(split SplitFunc)
Split устанавливает функцию разделения для сканера. Функция разделения по умолчанию — ScanLines.
Split вызывает панику, если его вызывают после начала сканирования.
func (*Scanner) Text
добавлено в go1.1
func (s *Scanner) Text() string
Text возвращает последний токен, сгенерированный вызовом Scanner.Scan, в виде вновь выделенной строки, содержащей его байты.
type SplitFunc
type SplitFunc func(data []byte, atEOF bool) (advance int, token []byte, err error)
SplitFunc — это сигнатура функции разделения, используемой для токенизации входных данных. Аргументами являются начальная подстрока оставшихся необработанных данных и флаг atEOF, который сообщает, есть ли у Reader еще данные для передачи. Возвращаемые значения — это количество байтов для продвижения входных данных и следующий токен для возврата пользователю, если таковой имеется, плюс ошибка, если таковая имеется.
Сканирование останавливается, если функция возвращает ошибку, и в этом случае часть ввода может быть отброшена. Если эта ошибка — ErrFinalToken, сканирование останавливается без ошибки. Токен, отличный от nil, доставленный с ErrFinalToken, будет последним токеном, а токен nil с ErrFinalToken немедленно останавливает сканирование.
В противном случае сканер продвигает ввод. Если токен не равен nil, сканер возвращает его пользователю. Если токен равен nil, сканер считывает больше данных и продолжает сканирование; если данных больше нет (если atEOF было true), сканер возвращается. Если данные еще не содержат полный токен, например, если при сканировании строк в них нет символа новой строки, SplitFunc может вернуть (0, nil, nil), чтобы сигнализировать сканеру о необходимости считывать больше данных в срез и повторить попытку с более длинным срезом, начиная с той же точки во входных данных.
Функция никогда не вызывается с пустым фрагментом данных, если atEOF не равно true. Однако, если atEOF равно true, данные могут быть непустыми и, как всегда, содержать необработанный текст.
Объяснение SplitFunc
Тип SplitFunc в пакете bufio
SplitFunc - это специальный тип функции, который определяет как сканер (Scanner) должен разделять входные данные на токены. Это ключевой механизм, обеспечивающий гибкость работы с текстовыми данными.
Для чего нужен SplitFunc?
Определение логики разделения данных:
- Где заканчивается один токен и начинается следующий
- Как обрабатывать неполные данные
- Как реагировать на ошибки
Поддержка различных форматов данных:
- Стандартные (строки, слова, символы)
- Пользовательские (CSV, логи, специфичные форматы)
Обработка сложных случаев:
- Данные, поступающие частями
- Нестандартные разделители
- Составные токены
Как работает SplitFunc
Функция принимает:
data []byte- буфер с данными для анализаatEOF bool- флаг, указывающий, что это конец данных
Возвращает:
advance int- на сколько байт продвинуться в буфереtoken []byte- выделенный токен (может быть nil)err error- ошибка, если возникла
Примеры использования
1. Стандартные функции разделения
// Чтение по строкам (по умолчанию)
scanner.Split(bufio.ScanLines)
// Чтение по словам
scanner.Split(bufio.ScanWords)
// Чтение по символам (рунам)
scanner.Split(bufio.ScanRunes)
// Чтение по байтам
scanner.Split(bufio.ScanBytes)
2. Пользовательская функция разделения
Пример разделения по запятым:
func splitByComma(data []byte, atEOF bool) (advance int, token []byte, err error) {
// Ищем запятую в данных
for i := 0; i < len(data); i++ {
if data[i] == ',' {
// Возвращаем позицию после запятой и токен
return i + 1, data[:i], nil
}
}
// Если достигнут конец данных и есть что возвращать
if atEOF && len(data) > 0 {
return len(data), data, nil
}
// Запрашиваем больше данных
return 0, nil, nil
}
// Использование
scanner.Split(splitByComma)
3. Сложный пример - чтение CSV
func csvSplit(data []byte, atEOF bool) (advance int, token []byte, err error) {
if len(data) == 0 {
return 0, nil, nil
}
// Пропускаем кавычки, если есть
inQuotes := false
if data[0] == '"' {
inQuotes = true
data = data[1:]
}
for i := 0; i < len(data); i++ {
switch {
case inQuotes && data[i] == '"' && i+1 < len(data) && data[i+1] == '"':
i++ // пропускаем двойные кавычки
case inQuotes && data[i] == '"':
// Закрывающая кавычка
return i + 2, data[:i], nil
case !inQuotes && data[i] == ',':
// Разделитель полей
return i + 1, data[:i], nil
case !inQuotes && (data[i] == '\r' || data[i] == '\n'):
// Конец строки
return i + 1, data[:i], nil
}
}
if atEOF {
return len(data), data, nil
}
return 0, nil, nil
}
Когда создавать свой SplitFunc?
Нестандартные форматы данных:
- Специфичные логи
- Двоичные протоколы
- Сложные разделители
Оптимизация обработки:
- Когда стандартные функции неэффективны
- Для обработки очень больших файлов
Специальная логика:
- Пропуск комментариев
- Обработка escape-последовательностей
- Валидация данных на лету
Особенности работы
Инкрементная обработка:
- Функция может вызываться много раз для одного токена
- Нужно корректно обрабатывать частичные данные
Управление буфером:
- Можно ограничивать максимальный размер токена
- Важно правильно указывать позицию продвижения
Обработка ошибок:
- Можно возвращать специальные ошибки
bufio.ErrFinalToken- маркер последнего токена
SplitFunc - это мощный механизм, который делает Scanner чрезвычайно гибким инструментом для обработки текстовых данных в Go.
type Writer
type Writer struct {
// contains filtered or unexported fields
}
Writer реализует буферизацию для объекта io.Writer. Если при записи в Writer происходит ошибка, дальнейшая запись данных не будет приниматься, а все последующие операции записи и Writer.Flush будут возвращать ошибку. После записи всех данных клиент должен вызвать метод Writer.Flush, чтобы гарантировать, что все данные были переданы в базовый io.Writer.
Пример
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
w := bufio.NewWriter(os.Stdout)
fmt.Fprint(w, "Hello, ")
fmt.Fprint(w, "world!")
w.Flush() // Don't forget to flush!
}
Output:
Hello, world!func NewWriter
func NewWriter(w io.Writer) *Writer
NewWriter возвращает новый Writer, буфер которого имеет размер по умолчанию. Если аргумент io.Writer уже является Writer с достаточно большим размером буфера, он возвращает базовый Writer.
func NewWriterSize
func NewWriterSize(w io.Writer, size int) *Writer
NewWriterSize возвращает новый Writer, буфер которого имеет как минимум указанный размер. Если аргумент io.Writer уже является Writer с достаточно большим размером, он возвращает базовый Writer.
func (*Writer) Available
func (b *Writer) Available() int
Available возвращает количество неиспользуемых байтов в буфере.
func (*Writer) AvailableBuffer
func (b *Writer) AvailableBuffer() []byte
AvailableBuffer возвращает пустой буфер с емкостью b.Available(). Этот буфер предназначен для добавления и передачи в следующий вызов Writer.Write. Буфер действителен только до следующей операции записи в b.
Пример
package main
import (
"bufio"
"os"
"strconv"
)
func main() {
w := bufio.NewWriter(os.Stdout)
for _, i := range []int64{1, 2, 3, 4} {
b := w.AvailableBuffer()
b = strconv.AppendInt(b, i, 10)
b = append(b, ' ')
w.Write(b)
}
w.Flush()
}
Output:
1 2 3 4func (*Writer) Buffered
func (b *Writer) Buffered() int
Buffered возвращает количество байтов, которые были записаны в текущий буфер.
func (*Writer) Flush
func (b *Writer) Flush() error
Flush записывает все буферизованные данные в базовый io.Writer.
func (*Writer) ReadFrom
func (b *Writer) ReadFrom(r io.Reader) (n int64, err error)
ReadFrom реализует io.ReaderFrom. Если базовый writer поддерживает метод ReadFrom, то вызывается базовый ReadFrom. Если есть буферизованные данные и базовый ReadFrom, то буфер заполняется и записывается перед вызовом ReadFrom.
Пример
package main
import (
"bufio"
"bytes"
"fmt"
"strings"
)
func main() {
var buf bytes.Buffer
writer := bufio.NewWriter(&buf)
data := "Hello, world!\nThis is a ReadFrom example."
reader := strings.NewReader(data)
n, err := writer.ReadFrom(reader)
if err != nil {
fmt.Println("ReadFrom Error:", err)
return
}
if err = writer.Flush(); err != nil {
fmt.Println("Flush Error:", err)
return
}
fmt.Println("Bytes written:", n)
fmt.Println("Buffer contents:", buf.String())
}
Output:
Bytes written: 41
Buffer contents: Hello, world!
This is a ReadFrom example.func (*Writer) Reset
func (b *Writer) Reset(w io.Writer)
Reset удаляет все невыгруженные данные из буфера, очищает все ошибки и сбрасывает b, чтобы записать его вывод в w. Вызов Reset с нулевым значением Writer инициализирует внутренний буфер до размера по умолчанию. Вызов w.Reset(w) (то есть сброс Writer к самому себе) ничего не делает.
func (*Writer) Size
added in go1.10
func (b *Writer) Size() int
Size возвращает размер базового буфера в байтах.
func (*Writer) Write
func (b *Writer) Write(p []byte) (nn int, err error)
Write записывает содержимое p в буфер. Он возвращает количество записанных байтов. Если nn < len(p), он также возвращает ошибку, объясняющую, почему запись не завершена.
func (*Writer) WriteByte
func (b *Writer) WriteByte(c byte) error
WriteByte записывает один байт.
func (*Writer) WriteRune
func (b *Writer) WriteRune(r rune) (size int, err error)
WriteRune записывает одну кодовую точку Unicode, возвращая количество записанных байтов и любую ошибку.
func (*Writer) WriteString
func (b *Writer) WriteString(s string) (int, error)
WriteString записывает строку. Он возвращает количество записанных байтов. Если количество меньше len(s), он также возвращает ошибку с объяснением, почему запись не завершена.
12.4.3 - Пакет builtin встроенных функций Go
Пакет builtin содержит документацию по заранее объявленным идентификаторам языка Go.
Элементы, задокументированные здесь, на самом деле не входят в пакет builtin, но их описание здесь позволяет godoc представить документацию для специальных идентификаторов языка.
Константы
const (
true = 0 == 0 // Untyped bool.
false = 0 != 0 // Untyped bool.
)
true и false - это два нетипизированных булевых значения.
const iota = 0 // Untyped int.
iota - это заранее объявленный идентификатор, представляющий нетипизированный целочисленный порядковый номер текущей спецификации const в объявлении const (обычно в круглых скобках). Он имеет нулевую индексацию.
Переменные ¶
var nil Type // Тип должен быть указателем, каналом, func, интерфейсом, map или slice-типом
nil - это заранее объявленный идентификатор, представляющий нулевое значение для указателя, канала, func, интерфейса, map или slice-типа.
12.4.3.1 - Функции builtin
Описание функций builtin
func append
func append(slice []Type, elems ...Type) []Type
Встроенная функция append добавляет элементы в конец слайса. Если он имеет достаточную емкость, целевой слайс переразбивается, чтобы вместить новые элементы. Если нет, выделяется новый базовый массив. Append возвращает обновленный слайс. Поэтому необходимо сохранить результат append, часто в переменной, содержащей сам слайс:
slice = append(slice, elem1, elem2)
slice = append(slice, anotherSlice...)
В качестве особого случая допустимо добавлять строку к байтовому слайсу, например:
slice = append([]byte(«hello »), «world»...)
func cap
func cap(v Type) int
Встроенная функция cap возвращает емкость v в зависимости от его типа:
- Массив: количество элементов в v (то же, что len(v)).
- Указатель на массив: количество элементов в *v (то же, что len(v)).
- Срез: максимальная длина, которую может достичь срез при повторном разрезании; если v равно nil, cap(v) равно нулю.
- Канал: емкость буфера канала в единицах элементов; если v равно nil, cap(v) равно нулю.
Для некоторых аргументов, таких как простое массивное выражение, результатом может быть константа. Подробности см. в разделе «Длина и емкость» спецификации языка Go.
func clear
func clear[T ~[]Type | ~map[Type]Type1](t T)
Встроенная функция clear очищает карты и фрагменты.
- Для карт clear удаляет все записи, в результате чего карта становится пустой.
- Для слайсов clear устанавливает все элементы до длины слайса в нулевое значение соответствующего типа элемента.
Если тип аргумента является типовым параметром, набор типов типового параметра должен содержать только типы карт или слайсов, и clear выполняет операцию, подразумеваемую типовым аргументом. Если t равно nil, clear не выполняет никаких действий.
func close
func close(c chan<- Type)
Встроенная функция close закрывает канал, который должен быть либо двунаправленным, либо только для отправки. Она должна выполняться только отправителем, никогда не получателем, и приводит к закрытию канала после получения последнего отправленного значения. После получения последнего значения из закрытого канала c любое получение из c будет выполняться без блокировки, возвращая нулевое значение для элемента канала. Форма
x, ok := <-c
также установит ok в false для закрытого и пустого канала.
func complex
func complex(r, i FloatType) ComplexType
Встроенная функция complex создает комплексное значение из двух значений с плавающей запятой. Действительная и мнимая части должны быть одинакового размера, либо float32, либо float64 (или приравниваемы к ним), и возвращаемое значение будет соответствующим комплексным типом (complex64 для float32, complex128 для float64).
func copy
func copy(dst, src []Type) int
Встроенная функция copy копирует элементы из исходного слайса в целевой слайс. (В качестве особого случая она также копирует байты из строки в слайс байтов.) Исходный и целевой слайсы могут пересекаться. Copy возвращает количество скопированных элементов, которое будет минимальным из len(src) и len(dst).
func delete
func delete(m map[Type]Type1, key Type)
Встроенная функция delete удаляет элемент с указанным ключом (m[key]) из карты. Если m равно nil или такого элемента нет, delete не выполняет никаких действий.
func imag
func imag(c ComplexType) FloatType
Встроенная функция imag возвращает мнимую часть комплексного числа c. Возвращаемое значение будет иметь тип с плавающей запятой, соответствующий типу c.
func len
func len(v Type) int
Встроенная функция len возвращает длину v в соответствии с его типом:
- Массив: количество элементов в v.
- Указатель на массив: количество элементов в *v (даже если v равен nil).
- Срез или карта: количество элементов в v; если v равен nil, len(v) равен нулю.
- Строка: количество байтов в v.
- Канал: количество элементов в очереди (непрочитанных) в буфере канала; если v равно nil, len(v) равно нулю.
Для некоторых аргументов, таких как строковый литерал или простое массивное выражение, результатом может быть константа. Подробности см. в разделе «Длина и емкость» спецификации языка Go.
func make
func make(t Type, size ...IntegerType) Type
Встроенная функция make выделяет и инициализирует объект типа slice, map или chan (только). Как и в случае с new, первый аргумент является типом, а не значением. В отличие от new, тип возвращаемого значения make совпадает с типом его аргумента, а не является указателем на него. Спецификация результата зависит от типа:
- Срез: размер определяет длину. Емкость среза равна его длине. Можно указать второй целочисленный аргумент, чтобы задать другую емкость; она не должна быть меньше длины. Например, make([]int, 0, 10) выделяет базовый массив размером 10 и возвращает срез длиной 0 и емкостью 10, который поддерживается этим базовым массивом.
- Карта: выделяется пустая карта с достаточным пространством для хранения указанного количества элементов. Размер может быть опущен, в этом случае выделяется небольшой начальный размер.
- Канал: буфер канала инициализируется с указанной емкостью буфера. Если размер равен нулю или опущен, канал не имеет буфера.
func max
func max[T cmp.Ordered](x T, y ...T) T
Встроенная функция max возвращает наибольшее значение из фиксированного числа аргументов типов cmp.Ordered. Должно быть как минимум один аргумент. Если T является типом с плавающей запятой и любой из аргументов является NaN, max вернет NaN.
func min
func min[T cmp.Ordered](x T, y ...T) T
Встроенная функция min возвращает наименьшее значение из фиксированного числа аргументов типов cmp.Ordered. Должно быть как минимум один аргумент. Если T является типом с плавающей запятой и любой из аргументов является NaN, min вернет NaN.
func new
func new(Type) *Type
Встроенная функция new выделяет память. Первый аргумент — это тип, а не значение, и возвращаемое значение — это указатель на вновь выделенное нулевое значение этого типа.
func panic
func panic(v any)
Встроенная функция panic останавливает нормальное выполнение текущего goroutine.
Когда функция F вызывает panic, нормальное выполнение F немедленно останавливается. Все функции, выполнение которых было отложено F, выполняются обычным образом, а затем F возвращается к своему вызывающему. Для вызывающего G вызов F ведет себя как вызов panic, прекращая выполнение G и запуская все отложенные функции. Это продолжается до тех пор, пока все функции в выполняющемся goroutine не остановятся в обратном порядке. В этот момент программа завершается с ненулевым кодом выхода. Эта последовательность завершения называется паникой и может контролироваться встроенной функцией recover.
Начиная с Go 1.21, вызов panic с нулевым значением интерфейса или нетипизированным nil вызывает ошибку выполнения (другой вид паники). Настройка GODEBUG panicnil=1 отключает ошибку выполнения.
func print
func print(args ...Type)
Встроенная функция print форматирует свои аргументы способом, специфичным для реализации, и записывает результат в стандартный поток ошибок. Print полезна для начальной загрузки и отладки; ее сохранение в языке не гарантируется.
func println
func println(args ...Type)
Встроенная функция println форматирует свои аргументы способом, специфичным для реализации, и записывает результат в стандартный поток ошибок. Между аргументами всегда добавляются пробелы и добавляется новая строка. Println полезна для начальной настройки и отладки; ее сохранение в языке не гарантируется.
func real
func real(c ComplexType) FloatType
Встроенная функция real возвращает действительную часть комплексного числа c. Возвращаемое значение будет иметь тип с плавающей запятой, соответствующий типу c.
func recover
func recover() any
Встроенная функция recover позволяет программе управлять поведением goroutine, входящего в состояние паники.
Вызов recover внутри отложенной функции (но не в любой функции, вызываемой ею) останавливает последовательность паники, восстанавливая нормальное выполнение и извлекая значение ошибки, переданное вызову panic.
Если recover вызывается вне отложенной функции, он не останавливает последовательность паники. В этом случае, или когда goroutine не входит в состояние паники, recover возвращает nil.
До Go 1.21 recover также возвращала nil, если panic вызывалась с аргументом nil. Подробности см. в разделе [panic].
Пример
Функция recover() используется для перехвата паники (panic) и восстановления нормального выполнения программы. Вот несколько практических примеров:
Пример 1: Базовое использование recover
package main
import "fmt"
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered from panic:", r)
}
}()
fmt.Println("Start")
panic("something went wrong")
fmt.Println("This won't be executed")
}
Вывод:
Start
Recovered from panic: something went wrong
Пример 2: Восстановление после деления на ноль
package main
import "fmt"
func safeDivide(a, b int) (result int) {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered:", r)
result = 0 // устанавливаем значение по умолчанию
}
}()
return a / b // может вызвать панику при b = 0
}
func main() {
fmt.Println(safeDivide(10, 2)) // 5
fmt.Println(safeDivide(10, 0)) // 0 (после восстановления)
fmt.Println("Program continues")
}
Пример 3: Разные типы паники
package main
import "fmt"
func handlePanic() {
if r := recover(); r != nil {
switch v := r.(type) {
case string:
fmt.Println("String panic:", v)
case error:
fmt.Println("Error panic:", v)
default:
fmt.Printf("Unknown panic: %v (%T)\n", v, v)
}
}
}
func main() {
defer handlePanic()
// Можно раскомментировать любой вариант:
panic("string panic")
// panic(fmt.Errorf("error panic"))
// panic(42)
}
Пример 4: recover в горутинах
package main
import (
"fmt"
"time"
)
func worker(id int) {
defer func() {
if r := recover(); r != nil {
fmt.Printf("Worker %d recovered: %v\n", id, r)
}
}()
if id == 2 {
panic(fmt.Sprintf("panic in worker %d", id))
}
fmt.Printf("Worker %d working\n", id)
}
func main() {
for i := 1; i <= 3; i++ {
go worker(i)
}
time.Sleep(time.Second) // Даем время горутинам завершиться
}
Пример 5: Вложенные recover
package main
import "fmt"
func inner() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Inner recovered:", r)
}
}()
panic("inner panic")
}
func outer() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Outer recovered:", r)
}
}()
inner()
fmt.Println("This won't be executed")
}
func main() {
outer()
fmt.Println("Program continues")
}
Важные замечания:
recover()работает только внутри defer-функций- Каждый вызов
recover()обрабатывает только одну панику - После восстановления выполнение продолжается после блока defer
- В Go 1.21+
recover()возвращает nil только если паники не было - Не злоупотребляйте recover - используйте только для действительно неожиданных ошибок
12.4.3.2 - Типы в пакете builtin
Описание типов из пакета builtin
type ComplexType
type ComplexType complex64
ComplexType используется здесь исключительно в целях документирования. Он заменяет любой из типов complex: complex64 или complex128.
type FloatType
type FloatType float32
FloatType используется здесь исключительно в целях документирования. Он заменяет любой из типов float: float32 или float64.
type IntegerType
type IntegerType int
IntegerType используется здесь только в целях документирования. Он заменяет любой тип целого числа: int, uint, int8 и т. д.
type Type
type Type int
Type используется здесь только в целях документирования. Он заменяет любой тип Go, но представляет один и тот же тип для любого вызова функции.
type Type1
type Type1 int
Type1 используется здесь только в целях документирования. Он является заменителем для любого типа Go, но представляет один и тот же тип для любого вызова функции.
type any
type any = interface{}
any является псевдонимом для interface{} и во всех отношениях эквивалентен interface{}.
type bool
type bool bool
bool — это набор булевых значений true и false.
type byte
type byte = uint8
byte — это псевдоним для uint8 и во всех отношениях эквивалентен uint8. По соглашению он используется для отличия значений byte от 8-битных целых чисел без знака.
type comparable
type comparable interface{ comparable }
comparable — это интерфейс, который реализуется всеми сопоставимыми типами (булевыми значениями, числами, строками, указателями, каналами, массивами сопоставимых типов, структурами, все поля которых являются сопоставимыми типами). Интерфейс comparable может использоваться только в качестве ограничения параметра типа, а не в качестве типа переменной.
Подробнее
Интерфейс comparable - это специальный встроенный интерфейс в Go, который представляет все типы, поддерживающие операции сравнения == и !=. Он используется исключительно как ограничение (constraint) для параметров типа в дженериках.
Особенности comparable:
- Неявная реализация - все сопоставимые типы автоматически удовлетворяют этому интерфейсу
- Ограниченное использование - может применяться только как ограничение типа в дженериках
- Строгая типизация - гарантирует, что типы можно сравнивать между собой
Пример 1: Простая функция сравнения
package main
import "fmt"
// Equal проверяет равенство двух значений comparable типа
func Equal[T comparable](a, b T) bool {
return a == b
}
func main() {
fmt.Println(Equal(1, 1)) // true
fmt.Println(Equal("a", "b")) // false
fmt.Println(Equal(true, false)) // false
}
Пример 2: Проверка наличия элемента в слайсе
func Contains[T comparable](slice []T, item T) bool {
for _, v := range slice {
if v == item {
return true
}
}
return false
}
func main() {
nums := []int{1, 2, 3}
fmt.Println(Contains(nums, 2)) // true
fmt.Println(Contains(nums, 5)) // false
strs := []string{"a", "b", "c"}
fmt.Println(Contains(strs, "b")) // true
}
Пример 3: Уникальные элементы в слайсе
func Unique[T comparable](slice []T) []T {
seen := make(map[T]bool)
result := []T{}
for _, v := range slice {
if !seen[v] {
seen[v] = true
result = append(result, v)
}
}
return result
}
func main() {
dupes := []int{1, 2, 2, 3, 4, 4, 5}
fmt.Println(Unique(dupes)) // [1 2 3 4 5]
}
Какие типы являются comparable:
- Базовые типы:
bool,int,float64,stringи т.д. - Указатели (
*T) - Каналы (
chan T) - Массивы, если их элементы comparable (
[3]int,[2]string) - Структуры, если все их поля comparable
Какие типы НЕ являются comparable:
- Слайсы (
[]T) - Мапы (
map[K]V) - Функции
- Структуры, содержащие несопоставимые поля
Пример 4: Ошибка при использовании несопоставимого типа
func main() {
// Ошибка: slice does not satisfy comparable
fmt.Println(Equal([]int{1}, []int{1}))
// Ошибка: map does not satisfy comparable
fmt.Println(Equal(map[int]int{}, map[int]int{}))
}
Практическое применение:
- Создание универсальных контейнеров
- Реализация алгоритмов для разных типов
- Написание тестовых утилит
- Создание библиотечных функций
type complex128
type complex128 complex128
complex128 — это набор всех комплексных чисел с вещественными и мнимыми частями float64.
type complex64
type complex64 complex64
complex64 — это набор всех комплексных чисел с вещественными и мнимыми частями типа float32.
type error
type error интерфейс {
Error() string
}
Встроенный интерфейсный тип error — это стандартный интерфейс для представления условия ошибки, причем значение nil означает отсутствие ошибки.
type float32
type float32 float32
float32 — это набор всех 32-разрядных чисел с плавающей запятой IEEE 754.
type float64
type float64 float64
float64 — это набор всех 64-разрядных чисел с плавающей запятой IEEE 754.
type int
type int int
int — это тип целых чисел с знаком, размер которого составляет не менее 32 бит. Однако это отдельный тип, а не псевдоним, например, int32.
type int16
type int16 int16
int16 — это набор всех 16-разрядных целых чисел со знаком. Диапазон: от -32768 до 32767.
type int32
type int32 int32
int32 — это набор всех 32-разрядных целых чисел со знаком. Диапазон: от -2147483648 до 2147483647.
type int64
type int64 int64
int64 — это набор всех 64-разрядных целых чисел со знаком. Диапазон: от -9223372036854775808 до 9223372036854775807.
type int8
type int8 int8
int8 — это набор всех 8-битных целых чисел со знаком. Диапазон: от -128 до 127.
type rune
type rune = int32
rune — это псевдоним для int32 и во всех отношениях эквивалентен int32. По соглашению он используется для отличия значений символов от целочисленных значений.
type string
type string string
string — это набор всех строк из 8-битных байтов, которые по соглашению, но не обязательно, представляют текст, закодированный в UTF-8. Строка может быть пустой, но не может быть nil. Значения типа string являются неизменяемыми.
type uint
type uint uint
uint — это тип целого числа без знака, размер которого составляет не менее 32 бит. Однако это отдельный тип, а не псевдоним, например, для uint32.
type uint16
type uint16 uint16
uint16 — это набор всех 16-битных целых чисел без знака. Диапазон: от 0 до 65535.
type uint32
type uint32 uint32
uint32 — это набор всех 32-битных целых чисел без знака. Диапазон: от 0 до 4294967295.
type uint64
type uint64 uint64
uint64 — это набор всех 64-разрядных целых чисел без знака. Диапазон: от 0 до 18446744073709551615.
type uint8
type uint8 uint8
uint8 — это набор всех 8-разрядных целых чисел без знака. Диапазон: от 0 до 255.
type uintptr
type uintptr uintptr
uintptr — это целочисленный тип, который достаточно велик, чтобы содержать битовую матрицу любого указателя.
12.4.4 - Описание пакета context языка программирования Go
Пакет Context определяет тип Context, который передает сроки, сигналы отмены и другие значения в рамках запроса через границы API и между процессами.
Входящие запросы к серверу должны создавать Context, а исходящие вызовы к серверам должны принимать Context. Цепочка вызовов функций между ними должна передавать Context, при необходимости заменяя его производным Context, созданным с помощью WithCancel, WithDeadline, WithTimeout или WithValue.
Контекст может быть отменен, чтобы указать, что работа, выполняемая от его имени, должна быть остановлена. Контекст с крайним сроком отменяется после истечения крайнего срока. Когда контекст отменяется, все производные от него контексты также отменяются.
Функции WithCancel, WithDeadline и WithTimeout принимают контекст (родительский) и возвращают производный контекст (дочерний) и CancelFunc. Прямой вызов CancelFunc отменяет дочерний контекст и его дочерние контексты, удаляет ссылку родительского контекста на дочерний и останавливает все связанные таймеры. Невыполнение вызова CancelFunc приводит к утечке дочернего контекста и его дочерних контекстов до тех пор, пока не будет отменен родительский контекст. Инструмент go vet проверяет, что CancelFuncs используются на всех путях управления потоком.
Функции WithCancelCause, WithDeadlineCause и WithTimeoutCause возвращают CancelCauseFunc, который принимает ошибку и записывает ее как причину отмены. Вызов Cause на отмененном контексте или любом из его дочерних элементов извлекает причину. Если причина не указана, Cause(ctx) возвращает то же значение, что и ctx.Err().
Программы, использующие контексты, должны следовать этим правилам, чтобы обеспечить согласованность интерфейсов между пакетами и позволить инструментам статического анализа проверять распространение контекста:
Не храните контексты внутри типа struct; вместо этого явно передавайте контекст каждой функции, которой он нужен. Это подробнее обсуждается в разделе «https://go.dev/blog/context-and-structs». Контекст должен быть первым параметром, обычно называемым ctx:
func DoSomething(ctx context.Context, arg Arg) error {
// ... использовать ctx ...
}
Не передавайте nil Context, даже если функция это допускает. Передайте context.TODO, если не уверены, какой Context использовать.
Используйте значения контекста только для данных в рамках запроса, которые проходят через процессы и API, а не для передачи опциональных параметров функциям.
Один и тот же Context может передаваться функциям, выполняющимся в разных goroutines; Context безопасен для одновременного использования несколькими goroutines.
См. https://go.dev/blog/context для примера кода сервера, использующего Context.
Переменные пакета
var Canceled = errors.New(«context canceled»)
Canceled — это ошибка, возвращаемая [Context.Err], когда контекст отменяется по какой-либо причине, кроме истечения срока.
var DeadlineExceeded error = deadlineExceededError{}
DeadlineExceeded — это ошибка, возвращаемая [Context.Err], когда контекст отменяется из-за истечения срока.
12.4.4.1 - Описание функций пакета Context
Описание функций пакета Context: AfterFunc, Cause, WithCancel, WithCancelCause, WithDeadline, WithDeadlineCause, WithTimeout, WithTimeoutCause
func AfterFunc
func AfterFunc(ctx Context, f func()) (stop func() bool)
AfterFunc организует вызов f в собственной горутине после отмены ctx. Если ctx уже отменен, AfterFunc вызывает f сразу в своей собственной горутине.
Несколько вызовов AfterFunc на одном контексте работают независимо; один не заменяет другой.
Вызов возвращаемой функции stop прекращает ассоциацию ctx с f. Он возвращает true, если вызов остановил запуск f. Если stop возвращает false, то либо контекст отменен и f была запущена в своей собственной goroutine, либо f уже была остановлена. Функция stop не ждет завершения f перед возвратом. Если вызывающей стороне необходимо знать, завершено ли выполнение f, она должна явно согласовать это с f.
Если у ctx есть метод “AfterFunc(func()) func() bool”, AfterFunc будет использовать его для планирования вызова.
Пример (Cond)
В этом примере AfterFunc используется для определения функции, которая ожидает синхронизацию с Cond, прекращая ожидание при отмене контекста.
package main
import (
"context"
"fmt"
"sync"
"time"
)
func main() {
waitOnCond := func(ctx context.Context, cond *sync.Cond, conditionMet func() bool) error {
// Создаем канал для отмены AfterFunc
done := make(chan struct{})
defer close(done)
// Настраиваем функцию отмены по таймауту контекста
stopf := context.AfterFunc(ctx, func() {
cond.L.Lock()
defer cond.L.Unlock()
select {
case <-done:
// Уже завершились, не нужно broadcast
return
default:
// Пробуждаем все ожидающие горутины
cond.Broadcast()
}
})
defer stopf()
// Ожидаем выполнения условия
for !conditionMet() {
// Проверяем контекст перед ожиданием
if ctx.Err() != nil {
return ctx.Err()
}
cond.Wait()
// Проверяем контекст после пробуждения
if ctx.Err() != nil {
return ctx.Err()
}
}
return nil
}
cond := sync.NewCond(&sync.Mutex{})
var wg sync.WaitGroup
start := time.Now()
for i := 0; i < 4; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Millisecond)
defer cancel()
cond.L.Lock()
defer cond.L.Unlock()
err := waitOnCond(ctx, cond, func() bool { return false })
fmt.Printf("Goroutine %d finished after %v with error: %v\n",
id, time.Since(start), err)
}(i)
}
wg.Wait()
fmt.Println("All goroutines completed")
}
Пример Connection
В этом примере используется AfterFunc для определения функции, которая считывает данные из net.Conn, останавливая считывание при отмене контекста.
package main
import (
"context"
"fmt"
"net"
"time"
)
func readFromConn(ctx context.Context, conn net.Conn, b []byte) (n int, err error) {
stopc := make(chan struct{})
defer close(stopc) // Гарантируем закрытие канала
// Устанавливаем функцию отмены чтения при отмене контекста
stop := context.AfterFunc(ctx, func() {
conn.SetReadDeadline(time.Now()) // Прерываем текущее чтение
close(stopc)
})
defer func() {
if !stop() {
// Если AfterFunc был запущен, сбрасываем дедлайн
<-stopc
conn.SetReadDeadline(time.Time{})
}
}()
n, err = conn.Read(b)
if ctx.Err() != nil {
return 0, ctx.Err() // Возвращаем ошибку контекста если он отменен
}
return n, err
}
func main() {
// Создаем тестовый сервер
listener, err := net.Listen("tcp", "localhost:0")
if err != nil {
fmt.Println("Failed to create listener:", err)
return
}
defer listener.Close()
// Устанавливаем соединение
conn, err := net.Dial(listener.Addr().Network(), listener.Addr().String())
if err != nil {
fmt.Println("Failed to dial:", err)
return
}
defer conn.Close()
// Создаем контекст с таймаутом
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Millisecond)
defer cancel()
// Читаем данные
b := make([]byte, 1024)
_, err = readFromConn(ctx, conn, b)
// Проверяем тип ошибки
switch {
case err == nil:
fmt.Println("Read completed successfully")
case ctx.Err() != nil:
fmt.Println("Operation canceled:", ctx.Err())
default:
fmt.Println("Read error:", err)
}
}
Дополнительные рекомендации:
Таймауты соединения:
conn.SetDeadline(time.Now().Add(30 * time.Second))Буферизация:
bufReader := bufio.NewReader(conn) n, err = bufReader.Read(b)Повторные попытки:
for retries := 0; retries < 3; retries++ { n, err = readFromConn(ctx, conn, b) if err == nil || !isTemporary(err) { break } }Логирование:
log.Printf("Read %d bytes, error: %v", n, err)
Пример Merge
В этом примере AfterFunc используется для определения функции, которая объединяет сигналы отмены двух Контекстов.
package main
import (
"context"
"errors"
"fmt"
"sync"
)
func main() {
// mergeCancel возвращает контекст, который отменяется при отмене любого из исходных контекстов
mergeCancel := func(ctx1, ctx2 context.Context) (context.Context, context.CancelFunc) {
mergedCtx, cancel := context.WithCancelCause(ctx1)
var once sync.Once
// Отслеживаем отмену первого контекста
go func() {
select {
case <-ctx1.Done():
once.Do(func() {
cancel(context.Cause(ctx1))
})
case <-ctx2.Done():
once.Do(func() {
cancel(context.Cause(ctx2))
})
case <-mergedCtx.Done():
// Уже отменен другим путем
}
}()
return mergedCtx, func() {
once.Do(func() {
cancel(context.Canceled)
})
}
}
// Создаем два контекста с возможностью отмены
ctx1, cancel1 := context.WithCancelCause(context.Background())
defer cancel1(errors.New("ctx1 canceled"))
ctx2, cancel2 := context.WithCancelCause(context.Background())
// Объединяем контексты
mergedCtx, mergedCancel := mergeCancel(ctx1, ctx2)
defer mergedCancel()
// Отменяем второй контекст
cancel2(errors.New("ctx2 canceled"))
// Ждем отмены объединенного контекста
<-mergedCtx.Done()
// Выводим причину отмены
fmt.Println("Merged context canceled because:", context.Cause(mergedCtx))
}
Ключевые моменты:
Потокобезопасность:
var once sync.Once once.Do(func() { cancel(context.Cause(ctx)) })Полное отслеживание контекстов:
select { case <-ctx1.Done(): case <-ctx2.Done(): case <-mergedCtx.Done(): }Четкая причина отмены:
fmt.Println("Merged context canceled because:", context.Cause(mergedCtx))Гарантированная очистка:
defer mergedCancel()
func Cause
func Cause(c Context) error
Cause возвращает не нулевую ошибку, объясняющую, почему c был отменен. Первая отмена c или одного из его родителей устанавливает причину. Если эта отмена произошла через вызов CancelCauseFunc(err), то Cause возвращает err. В противном случае Cause(c) возвращает то же значение, что и c.Err(). Cause возвращает nil, если c еще не был отменен.
func WithCancel
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
WithCancel возвращает производный контекст, который указывает на родительский контекст, но имеет новый канал Done. Канал Done возвращенного контекста закрывается при вызове возвращенной функции отмены или при закрытии канала Done родительского контекста, в зависимости от того, что произойдет раньше.
Отмена этого контекста освобождает связанные с ним ресурсы, поэтому код должен вызывать отмену, как только операции, выполняемые в этом контексте, завершатся.
Пример
Этот пример демонстрирует использование отменяемого контекста для предотвращения утечки данных из горутины. К концу выполнения функции примера горутина, запущенная gen, вернется без утечки.
package main
import (
"context"
"fmt"
"sync"
)
func main() {
// gen генерирует целые числа в отдельной горутине и
// отправляет их в возвращаемый канал.
// Вызывающая сторона должна отменить контекст после
// завершения потребления чисел, чтобы избежать утечки горутины.
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
defer close(dst) // Закрываем канал при завершении
n := 1
for {
select {
case <-ctx.Done():
return
case dst <- n:
n++
}
}
}()
// Горутина для безопасного завершения
go func() {
wg.Wait()
}()
return dst
}
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // Отменяем контекст при завершении
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
break
}
}
// Дополнительная отмена контекста (хотя defer уже сделает это)
cancel()
}
func WithCancelCause
func WithCancelCause(parent Context) (ctx Context, cancel CancelCauseFunc)
WithCancelCause ведет себя как WithCancel, но возвращает CancelCauseFunc вместо CancelFunc. Вызов cancel с no-nil ошибкой (причина) записывает эту ошибку в ctx; затем ее можно получить с помощью Cause(ctx). Вызов cancel с nil устанавливает причину в Canceled.
Пример использования:
ctx, cancel := context.WithCancelCause(parent)
cancel(myError)
ctx.Err() // возвращает context.Canceled
context.Cause(ctx) // возвращает myError
func WithDeadline
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
WithDeadline возвращает производный контекст, который указывает на родительский контекст, но имеет срок, скорректированный так, чтобы он не был позднее d. Если срок родительского контекста уже раньше d, WithDeadline(parent, d) семантически эквивалентен parent. Возвращаемый канал [Context.Done] закрывается по истечении срока, при вызове возвращаемой функции cancel или при закрытии канала Done родительского контекста, в зависимости от того, что произойдет раньше.
Отмена этого контекста освобождает связанные с ним ресурсы, поэтому код должен вызывать отмену, как только операции, выполняемые в этом контексте, завершатся.
Пример
В этом примере контекст с произвольным сроком передается блокирующей функции, чтобы сообщить ей, что она должна прекратить свою работу, как только до нее доберется.
package main
import (
"context"
"fmt"
"time"
)
func main() {
shortDuration := 50 * time.Millisecond // Явное указание времени таймаута
d := time.Now().Add(shortDuration)
// Создаем контекст с дедлайном
ctx, cancel := context.WithDeadline(context.Background(), d)
defer cancel() // Важно вызывать cancel для освобождения ресурсов
neverReady := make(chan struct{}) // Канал, который никогда не будет готов
select {
case <-neverReady:
fmt.Println("ready") // Эта ветка никогда не выполнится
case <-ctx.Done():
// Проверяем причину завершения контекста
switch ctx.Err() {
case context.DeadlineExceeded:
fmt.Println("context deadline exceeded")
case context.Canceled:
fmt.Println("context canceled")
default:
fmt.Println("context done for unknown reason")
}
}
}
func WithDeadlineCause
func WithDeadlineCause(parent Context, d time.Time, cause error) (Context, CancelFunc)
WithDeadlineCause ведет себя как WithDeadline, но также устанавливает причину возвращаемого контекста при превышении срока. Возвращаемая CancelFunc не устанавливает причину.
func WithTimeout
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
WithTimeout возвращает WithDeadline(parent, time.Now().Add(timeout)).
Отмена этого контекста освобождает связанные с ним ресурсы, поэтому код должен вызывать отмену, как только операции, выполняемые в этом контексте, завершатся:
func slowOperationWithTimeout(ctx context.Context) (Result, error) {
ctx, cancel := context.WithTimeout(ctx, 100*time.Millisecond)
defer cancel() // освобождает ресурсы, если slowOperation завершается до истечения времени ожидания
return slowOperation(ctx)
}
Пример
В этом примере контекст передается с таймаутом, чтобы сообщить блокирующей функции, что она должна завершить свою работу по истечении таймаута.
package main
import (
"context"
"fmt"
"time"
)
func main() {
shortDuration := 100 * time.Millisecond // Явное указание времени таймаута
// Создаем контекст с таймаутом
ctx, cancel := context.WithTimeout(context.Background(), shortDuration)
defer cancel() // Всегда вызываем cancel для освобождения ресурсов
neverReady := make(chan struct{}) // Создаем канал, который никогда не закроется
select {
case <-neverReady:
fmt.Println("ready") // Эта ветка никогда не выполнится
case <-ctx.Done():
// Проверяем причину завершения контекста
switch err := ctx.Err(); err {
case context.DeadlineExceeded:
fmt.Println("context deadline exceeded")
case context.Canceled:
fmt.Println("context canceled")
default:
fmt.Printf("context done: %v\n", err)
}
}
}
func WithTimeoutCause
func WithTimeoutCause(parent Context, timeout time.Duration, cause error) (Context, CancelFunc)
WithTimeoutCause ведет себя как WithTimeout, но также устанавливает причину возвращаемого Context при истечении таймаута. Возвращаемый CancelFunc не устанавливает причину.
12.4.4.2 - Описание типов пакета Context
Описание типов пакета Context
type CancelCauseFunc
type CancelCauseFunc func(cause error)
CancelCauseFunc ведет себя как CancelFunc, но дополнительно устанавливает причину отмены. Эту причину можно получить, вызвав Cause на отмененном Context или на любом из его производных Context.
Если контекст уже был отменен, CancelCauseFunc не устанавливает причину. Например, если childContext является производным от parentContext:
- если parentContext отменен с причиной cause1 до того, как childContext отменен с причиной cause2, то Cause(parentContext) == Cause(childContext) == cause1
- если childContext отменен с причиной cause2 до того, как parentContext отменен с причиной cause1, то Cause(parentContext) == cause1 и Cause(childContext) == cause2
type CancelFunc
type CancelFunc func()
CancelFunc сообщает операции о необходимости прекратить работу. CancelFunc не ждет, пока работа будет остановлена. CancelFunc может вызываться несколькими goroutines одновременно. После первого вызова последующие вызовы CancelFunc ничего не делают.
type Context
type Context interface {
// Deadline возвращает время, когда работа, выполняемая от имени этого
// контекста должна быть отменена. Deadline возвращает ok==false, если
// срок не установлен. Последовательные вызовы Deadline возвращают
// одинаковые результаты.
Deadline() (deadline time.Time, ok bool)
// Done возвращает канал, который закрывается, когда работа, выполняемая
// от имени этого контекста, должна быть отменена. Done может возвращать
// nil, если этот контекст никогда не может быть отменен. Последовательные
// вызовы Done возвращают одинаковое значение.
// Закрытие канала Done может происходить асинхронно,
// после возврата функции cancel.
//
// WithCancel организует закрытие Done при вызове cancel;
// WithDeadline организует закрытие Done по истечении срока;
// WithTimeout организует закрытие Done по истечении таймаута
//.
//
// Done предоставляется для использования в операторах select:
//
// // Stream генерирует значения с помощью DoSomething и отправляет их в out,
// // пока DoSomething не вернет ошибку или ctx.Done не будет закрыт.
// func Stream(ctx context.Context, out chan<- Value) error {
// for {
// v, err := DoSomething(ctx)
// if err != nil {
// return err
// }
// select {
// case <-ctx.Done():
// return ctx.Err()
// case out <- v:
// }
// }
// }
//
// См. https://blog.golang.org/pipelines для получения дополнительных примеров
// использования канала Done для отмены.
Done() <-chan struct{}
// Если Done еще не закрыт, Err возвращает nil.
// Если Done закрыт, Err возвращает no-nil ошибку, объясняющую причину:
// DeadlineExceeded, если срок контекста истек, или Canceled, если контекст
// был отменен по какой-либо другой причине.
// После того, как Err возвращает ошибку, отличную от nil, последующие вызовы
// Err возвращают ту же ошибку.
Err() error
// Value возвращает значение, связанное с этим контекстом для ключа, или nil,
// если с ключом не связано никакое значение. Последовательные вызовы Value с
// одним и тем же ключом возвращают один и тот же результат.
//
// Используйте значения контекста только для данных в рамках запроса, которые
// проходят через процессы и границы API, а не для передачи опциональных
// параметров в функции.
//
// Ключ идентифицирует конкретное значение в контексте. Функции, которые хотят
// сохранить значения в контексте, обычно выделяют ключ в глобальной
// переменной, а затем используют этот ключ в качестве аргумента для
// context.WithValue и Context.Value. Ключ может быть любого типа, который
// поддерживает равенство;
// пакеты должны определять ключи как неэкспортируемый тип, чтобы избежать коллизий.
//
// Пакеты, которые определяют ключ контекста, должны предоставлять типобезопасные
// аксессоры для значений, хранящихся с использованием этого ключа:
//
// // Пользователь пакета определяет тип User, который хранится в контекстах.
// пакет user
//
// import «context»
//
// // User — это тип значения, хранящегося в Contexts.
// type User struct {...}
//
// // key — это неэкспортируемый тип для ключей, определенных в этом пакете.
// // Это предотвращает конфликты с ключами, определенными в других пакетах.
// type key int
//
// // userKey — ключ для значений user.User в Contexts. Он
// // не экспортируется; клиенты используют user.NewContext и user.FromContext
// // вместо прямого использования этого ключа.
// var userKey key
//
// // NewContext возвращает новый Context, который несет значение u.
// func NewContext(ctx context.Context, u *User) context.Context {
// return context.WithValue(ctx, userKey, u)
// }
//
// // FromContext возвращает значение User, хранящееся в ctx, если оно есть.
// func FromContext(ctx context.Context) (*User, bool) {
// u, ok := ctx.Value(userKey).(*User)
// return u, ok
// }
Value(key any) any
}
Context несет в себе срок, сигнал отмены и другие значения через границы API.
Методы контекста могут вызываться несколькими goroutines одновременно.
func Background
func Background() Context
Background возвращает непустой Context, не равный nil. Он никогда не отменяется, не имеет значений и не имеет срока действия. Обычно он используется главной функцией, инициализацией и тестами, а также в качестве Context верхнего уровня для входящих запросов.
func TODO
func TODO() Context
TODO возвращает непустой Context, не равный nil. Код должен использовать context.TODO, когда неясно, какой Context использовать, или он еще не доступен (потому что окружающая функция еще не была расширена для приема параметра Context).
func WithValue
func WithValue(parent Context, key, val any) Context
WithValue возвращает производный контекст, который указывает на родительский Context. В производном контексте значение, связанное с ключом, является val.
Используйте контекстные значения только для данных в рамках запроса, которые проходят через процессы и API, а не для передачи опциональных параметров функциям.
Предоставленный ключ должен быть сопоставимым и не должен быть типом string или любым другим встроенным типом, чтобы избежать конфликтов между пакетами, использующими контекст. Пользователи WithValue должны определять свои собственные типы для ключей. Чтобы избежать выделения памяти при присвоении interface {}, ключи контекста часто имеют конкретный тип struct {}. В качестве альтернативы статический тип экспортированных переменных ключей контекста должен быть указателем или интерфейсом.
Пример
Этот пример демонстрирует, как можно передать значение в контекст, а также как получить его, если оно существует.
package main
import (
"context"
"fmt"
)
func main() {
// Определяем пользовательский тип для ключей контекста
type favContextKey string
// Функция для поиска значения в контексте
lookupValue := func(ctx context.Context, k favContextKey) {
if v := ctx.Value(k); v != nil {
fmt.Printf("Found value for key '%s': %v\n", k, v)
return
}
fmt.Printf("Key '%s' not found in context\n", k)
}
// Создаем ключ и контекст со значением
languageKey := favContextKey("language")
ctx := context.WithValue(context.Background(), languageKey, "Go")
// Ищем существующее значение
lookupValue(ctx, languageKey)
// Ищем несуществующее значение
colorKey := favContextKey("color")
lookupValue(ctx, colorKey)
// Дополнительная проверка с другим типом (демонстрация безопасности)
otherKey := "otherKey" // обычная строка, не favContextKey
lookupValue(ctx, favContextKey(otherKey)) // конвертируем в правильный тип
}
Дополнительные рекомендации:
- Для production-кода:
// Лучше выносить ключи в package-level константы
const (
LanguageKey favContextKey = "language"
ColorKey favContextKey = "color"
)
- Добавить проверку типа значения:
if v, ok := ctx.Value(k).(string); ok {
fmt.Printf("Found string value: %s\n", v)
}
- Для сложных данных использовать указатели:
type configKey struct{}
ctx = context.WithValue(ctx, configKey{}, &MyConfig{...})
func WithoutCancel
func WithoutCancel(parent Context) Context
WithoutCancel возвращает производный контекст, который указывает на родительский контекст и не отменяется при отмене родительского контекста. Возвращаемый контекст не возвращает Deadline или Err, а его канал Done равен nil. Вызов Cause на возвращаемом контексте возвращает nil.
12.4.5 - Пакет bytes языка программирования Go
Пакет bytes реализует функции для работы с байтовыми фрагментами. Он аналогичен средствам пакета strings.
Константы
const MinRead = 512
MinRead — минимальный размер фрагмента, передаваемый вызову Buffer.Read из Buffer.ReadFrom. Если буфер содержит не менее MinRead байт сверх того, что требуется для хранения содержимого r, Buffer.ReadFrom не будет увеличивать базовый буфер.
Переменные
var ErrTooLarge = errors.New("bytes.Buffer: too large")
ErrTooLarge передается в panic, если не удается выделить память для хранения данных в буфере.
Функции
func Clone
func Clone(b []byte) []byte
Clone возвращает копию b[:len(b)]. Результат может иметь дополнительный неиспользованный объем. Clone(nil) возвращает nil.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
b := []byte("abc")
clone := bytes.Clone(b)
fmt.Printf("%s\n", clone)
clone[0] = 'd'
fmt.Printf("%s\n", b)
fmt.Printf("%s\n", clone)
}
Output:
abc
abc
dbcfunc Compare
func Compare(a, b []byte) int
Compare возвращает целое число, сравнивая два лексикографических фрагмента байтов. Результат будет равен 0, если a == b, -1, если a < b, и +1, если a > b. Аргумент nil эквивалентен пустому фрагменту.
Пример
package main
import (
"bytes"
)
func main() {
// Interpret Compare's result by comparing it to zero.
var a, b []byte
if bytes.Compare(a, b) < 0 {
// a less b
}
if bytes.Compare(a, b) <= 0 {
// a less or equal b
}
if bytes.Compare(a, b) > 0 {
// a greater b
}
if bytes.Compare(a, b) >= 0 {
// a greater or equal b
}
// Prefer Equal to Compare for equality comparisons.
if bytes.Equal(a, b) {
// a equal b
}
if !bytes.Equal(a, b) {
// a not equal b
}
}
Пример Поиск
package main
import (
"bytes"
"slices"
)
func main() {
// Binary search to find a matching byte slice.
var needle []byte
var haystack [][]byte // Assume sorted
_, found := slices.BinarySearchFunc(haystack, needle, bytes.Compare)
if found {
// Found it!
}
}
func Contains
func Contains(b, subslice []byte) bool
Contains сообщает, находится ли подфрагмент в пределах b.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.Contains([]byte("seafood"), []byte("foo")))
fmt.Println(bytes.Contains([]byte("seafood"), []byte("bar")))
fmt.Println(bytes.Contains([]byte("seafood"), []byte("")))
fmt.Println(bytes.Contains([]byte(""), []byte("")))
}
Output:
true
false
true
truefunc ContainsAny
func ContainsAny(b []байт, chars string) bool
ContainsAny сообщает, находится ли какая-либо из кодовых точек в кодировке UTF-8 в chars в пределах b.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.ContainsAny([]byte("I like seafood."), "fÄo!"))
fmt.Println(bytes.ContainsAny([]byte("I like seafood."), "去是伟大的."))
fmt.Println(bytes.ContainsAny([]byte("I like seafood."), ""))
fmt.Println(bytes.ContainsAny([]byte(""), ""))
}
Output:
true
true
false
falsefunc ContainsFunc
func ContainsFunc(b []byte, f func(rune) bool) bool
ContainsFunc сообщает, удовлетворяет ли f(r) любая из кодовых точек r в кодировке UTF-8 в пределах b.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
f := func(r rune) bool {
return r >= 'a' && r <= 'z'
}
fmt.Println(bytes.ContainsFunc([]byte("HELLO"), f))
fmt.Println(bytes.ContainsFunc([]byte("World"), f))
}
Output:
false
truefunc ContainsRune
func ContainsRune(b []byte, r rune) bool
ContainsRune сообщает, содержится ли руна в UTF-8-кодированном байтовом фрагменте b.
func Count
func Count(s, sep []byte) int
Count подсчитывает количество непересекающихся экземпляров sep в s. Если sep - пустой фрагмент, Count возвращает 1 + количество кодовых точек в s, закодированных в UTF-8.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.Count([]byte("cheese"), []byte("e")))
fmt.Println(bytes.Count([]byte("five"), []byte(""))) // before & after each rune
}
Output:
3
5func Cut
func Cut(s, sep []byte) (before, after []byte, found bool)
Cut разрезает s вокруг первого экземпляра sep, возвращая текст до и после sep. Результат found сообщает, появляется ли sep в s. Если sep не появляется в s, cut возвращает s, nil, false.
Cut возвращает фрагменты исходного фрагмента s, а не его копии.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
show := func(s, sep string) {
before, after, found := bytes.Cut([]byte(s), []byte(sep))
fmt.Printf("Cut(%q, %q) = %q, %q, %v\n", s, sep, before, after, found)
}
show("Gopher", "Go")
show("Gopher", "ph")
show("Gopher", "er")
show("Gopher", "Badger")
}
Output:
Cut("Gopher", "Go") = "", "pher", true
Cut("Gopher", "ph") = "Go", "er", true
Cut("Gopher", "er") = "Goph", "", true
Cut("Gopher", "Badger") = "Gopher", "", falsefunc CutPrefix
func CutPrefix(s, prefix []byte) (after []byte, found bool)
CutPrefix возвращает s без предоставленного ведущего префиксного байтового фрагмента и сообщает, найден ли префикс. Если s не начинается с префикса, CutPrefix возвращает s, false. Если префикс - это пустой байтовый фрагмент, CutPrefix возвращает s, true.
CutPrefix возвращает фрагменты исходного фрагмента s, а не его копии.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
show := func(s, sep string) {
after, found := bytes.CutPrefix([]byte(s), []byte(sep))
fmt.Printf("CutPrefix(%q, %q) = %q, %v\n", s, sep, after, found)
}
show("Gopher", "Go")
show("Gopher", "ph")
}
Output:
CutPrefix("Gopher", "Go") = "pher", true
CutPrefix("Gopher", "ph") = "Gopher", falsefunc CutSuffix
func CutSuffix(s, suffix []byte) (before []byte, found bool)
CutSuffix возвращает s без предоставленного завершающего суффикса байтового фрагмента и сообщает, найден ли суффикс. Если s не заканчивается суффиксом, CutSuffix возвращает s, false. Если суффикс - пустой байтовый фрагмент, CutSuffix возвращает s, true.
CutSuffix возвращает фрагменты исходного фрагмента s, а не его копии.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
show := func(s, sep string) {
before, found := bytes.CutSuffix([]byte(s), []byte(sep))
fmt.Printf("CutSuffix(%q, %q) = %q, %v\n", s, sep, before, found)
}
show("Gopher", "Go")
show("Gopher", "er")
}
Output:
CutSuffix("Gopher", "Go") = "Gopher", false
CutSuffix("Gopher", "er") = "Goph", truefunc Equal
func Equal(a, b []byte) bool
Equal сообщает, имеют ли a и b одинаковую длину и содержат ли они одинаковые байты. Аргумент nil эквивалентен пустому фрагменту.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.Equal([]byte("Go"), []byte("Go")))
fmt.Println(bytes.Equal([]byte("Go"), []byte("C++")))
}
Output:
true
falsefunc EqualFold
func EqualFold(s, t []byte) bool
EqualFold сообщает, равны ли s и t, интерпретируемые как строки UTF-8, при простом преобразовании регистра Юникода, которое является более общей формой нечувствительности к регистру.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.EqualFold([]byte("Go"), []byte("go")))
}Output:
truefunc Fields
func Fields(s []byte) [][]byte
Fields интерпретирует s как последовательность кодовых точек, закодированных в UTF-8. Он разделяет срез s вокруг каждого экземпляра одного или нескольких последовательных пробельных символов, как определено в unicode.IsSpace, возвращая срез подсрезов s или пустой срез, если s содержит только пробельные символы.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("Fields are: %q", bytes.Fields([]byte(" foo bar baz ")))
}Output:
Fields are: ["foo" "bar" "baz"]func FieldsFunc
func FieldsFunc(s []byte, f func(rune) bool) [][]byte
FieldsFunc интерпретирует s как последовательность кодовых точек, закодированных в UTF-8. Он разбивает срез s на каждом проходе кодовых точек c, удовлетворяющих f(c), и возвращает срез подсрезов s. Если все кодовые точки в s удовлетворяют f(c) или len(s) == 0, возвращается пустой срез.
FieldsFunc не дает никаких гарантий относительно порядка вызова f(c) и предполагает, что f всегда возвращает одно и то же значение для данного c.
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
f := func(c rune) bool {
return !unicode.IsLetter(c) && !unicode.IsNumber(c)
}
fmt.Printf("Fields are: %q", bytes.FieldsFunc([]byte(" foo1;bar2,baz3..."), f))
}
Output:
Fields are: ["foo1" "bar2" "baz3"]func FieldsFuncSeq
func FieldsFuncSeq(s []byte, f func(rune) bool) iter.Seq[[]byte]
FieldsFuncSeq возвращает итератор над подфрагментами s, разбитыми по последовательностям кодовых точек Unicode, удовлетворяющих f(c). Итератор возвращает те же подфрагменты, которые были бы возвращены FieldsFunc(s), но без создания нового фрагмента, содержащего подфрагменты.
func FieldsSeq
func FieldsSeq(s []byte) iter.Seq[[]byte]
FieldsSeq возвращает итератор по подсрезам s, разделённым пробельными символами (как определено в unicode.IsSpace). Итератор возвращает те же подсрезы, что и функция Fields(s), но без создания нового среза.
func HasPrefix
func HasPrefix(s, prefix []byte) bool
HasPrefix проверяет, начинается ли байтовый срез s с prefix.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.HasPrefix([]byte("Gopher"), []byte("Go")))
fmt.Println(bytes.HasPrefix([]byte("Gopher"), []byte("C")))
fmt.Println(bytes.HasPrefix([]byte("Gopher"), []byte("")))
Output:
true
false
truefunc HasSuffix
func HasSuffix(s, suffix []byte) bool
HasSuffix проверяет, заканчивается ли байтовый срез s на suffix.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.HasSuffix([]byte("Amigo"), []byte("go")))
fmt.Println(bytes.HasSuffix([]byte("Amigo"), []byte("O")))
fmt.Println(bytes.HasSuffix([]byte("Amigo"), []byte("Ami")))
fmt.Println(bytes.HasSuffix([]byte("Amigo"), []byte("")))
}
Output:
true
false
false
truefunc Index
func Index(s, sep []byte) int
Index возвращает индекс первого вхождения sep в s или -1, если sep отсутствует в s.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.Index([]byte("chicken"), []byte("ken")))
fmt.Println(bytes.Index([]byte("chicken"), []byte("dmr")))
}Output:
4
-1func IndexAny
func IndexAny(s []byte, chars string) int
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.IndexAny([]byte("chicken"), "aeiouy"))
fmt.Println(bytes.IndexAny([]byte("crwth"), "aeiouy"))
}
Output:
2
-1IndexAny интерпретирует s как последовательность UTF-8 кодовых точек. Возвращает байтовый индекс первого вхождения любого символа из chars в s. Возвращает -1, если chars пуст или нет совпадений.
func IndexByte
func IndexByte(b []byte, c byte) int
IndexByte возвращает индекс первого вхождения байта c в b или -1, если c отсутствует в b.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.IndexByte([]byte("chicken"), byte('k')))
fmt.Println(bytes.IndexByte([]byte("chicken"), byte('g')))
}Output:
4
-1func IndexFunc
func IndexFunc(s []byte, f func(r rune) bool) int
IndexFunc интерпретирует s как последовательность UTF-8 кодовых точек. Возвращает байтовый индекс первой кодовой точки, удовлетворяющей условию f(c), или -1, если таких нет.
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
f := func(c rune) bool {
return unicode.Is(unicode.Han, c)
}
fmt.Println(bytes.IndexFunc([]byte("Hello, 世界"), f))
fmt.Println(bytes.IndexFunc([]byte("Hello, world"), f))
}
Output:
7
-1func IndexRune
func IndexRune(s []byte, r rune) int
IndexRune интерпретирует s как последовательность UTF-8 кодовых точек. Возвращает байтовый индекс первого вхождения руны r. Если r — utf8.RuneError, возвращает первый индекс невалидной UTF-8 последовательности.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.IndexRune([]byte("chicken"), 'k'))
fmt.Println(bytes.IndexRune([]byte("chicken"), 'd'))
}Output:
4
-1func Join
func Join(s [][]byte, sep []byte) []byte
Join объединяет элементы среза s в новый байтовый срез, разделяя их sep.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
s := [][]byte{[]byte("foo"), []byte("bar"), []byte("baz")}
fmt.Printf("%s", bytes.Join(s, []byte(", ")))
}
Output:
foo, bar, bazfunc LastIndex
func LastIndex(s, sep []byte) int
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.Index([]byte("go gopher"), []byte("go")))
fmt.Println(bytes.LastIndex([]byte("go gopher"), []byte("go")))
fmt.Println(bytes.LastIndex([]byte("go gopher"), []byte("rodent")))
}
Output:
0
3
-1LastIndex возвращает индекс последнего экземпляра sep в s или -1, если sep отсутствует в s.
func LastIndexAny
func LastIndexAny(s []byte, chars string) int
LastIndexAny интерпретирует s как последовательность кодовых точек Unicode в кодировке UTF-8. Возвращает индекс байта последнего вхождения в s любой из кодовых точек Unicode в chars. Возвращает -1, если chars пуст или если нет общей кодовой точки.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.LastIndexAny([]byte("go gopher"), "MüQp"))
fmt.Println(bytes.LastIndexAny([]byte("go 地鼠"), "地大"))
fmt.Println(bytes.LastIndexAny([]byte("go gopher"), "z,!."))
}
Output:
5
3
-1func LastIndexByte
func LastIndexByte(s []byte, c byte) int
LastIndexByte возвращает индекс последнего экземпляра c в s или -1, если c отсутствует в s.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.LastIndexByte([]byte("go gopher"), byte('g')))
fmt.Println(bytes.LastIndexByte([]byte("go gopher"), byte('r')))
fmt.Println(bytes.LastIndexByte([]byte("go gopher"), byte('z')))
}Output:
3
8
-1func LastIndexFunc
func LastIndexFunc(s []byte, f func(r rune) bool) int
LastIndexFunc интерпретирует s как последовательность кодовых точек, закодированных в UTF-8. Он возвращает индекс байта в s последней кодовой точки Unicode, удовлетворяющей f(c), или -1, если таковой нет.
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
fmt.Println(bytes.LastIndexFunc([]byte("go gopher!"), unicode.IsLetter))
fmt.Println(bytes.LastIndexFunc([]byte("go gopher!"), unicode.IsPunct))
fmt.Println(bytes.LastIndexFunc([]byte("go gopher!"), unicode.IsNumber))
}Output:
8
9
-1func Lines
func Lines(s []byte) iter.Seq[[]byte]
Lines возвращает итератор по строкам, завершающимся символом новой строки, в байтовом срезе s. Строки, возвращаемые итератором, включают в себя завершающие символы новой строки. Если s пустой, итератор не возвращает никаких строк. Если s не заканчивается символом новой строки, последняя возвращаемая строка не будет заканчиваться символом новой строки. Возвращает итератор однократного использования.
func Map
func Map(mapping func(r rune) rune, s []byte) []byte
Map возвращает копию байтового среза s со всеми символами, измененными в соответствии с функцией отображения. Если отображение возвращает отрицательное значение, символ удаляется из байтового среза без замены. Символы в s и выводе интерпретируются как кодовые точки, закодированные в UTF-8.
Пример
import (
"bytes"
"fmt"
)
func main() {
rot13 := func(r rune) rune {
switch {
case r >= 'A' && r <= 'Z':
return 'A' + (r-'A'+13)%26
case r >= 'a' && r <= 'z':
return 'a' + (r-'a'+13)%26
}
return r
}
fmt.Printf("%s\n", bytes.Map(rot13, []byte("'Twas brillig and the slithy gopher...")))
}Output:
'Gjnf oevyyvt naq gur fyvgul tbcure...func Repeat
func Repeat(b []byte, count int) []byte
Repeat возвращает новый байтовый срез, состоящий из count копий b.
Он вызывает панику, если count отрицательно или если результат (len(b) * count) переполняется.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("ba%s", bytes.Repeat([]byte("na"), 2))
}
Output:
bananafunc Replace
func Replace(s, old, new []byte, n int) []byte
Replace возвращает копию фрагмента s с первыми n непересекающимися экземплярами old, замененными на new. Если old пуст, то он совпадает в начале фрагмента и после каждой последовательности UTF-8, что позволяет получить до k+1 замен для k-рангового фрагмента. Если n < 0, то количество замен не ограничено.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%s\n", bytes.Replace([]byte("oink oink oink"), []byte("k"), []byte("ky"), 2))
fmt.Printf("%s\n", bytes.Replace([]byte("oink oink oink"), []byte("oink"), []byte("moo"), -1))
}Output:
oinky oinky oink
moo moo moofunc ReplaceAll
func ReplaceAll(s, old, new []byte) []byte
ReplaceAll возвращает копию фрагмента s со всеми непересекающимися экземплярами old, замененными на new. Если old пуст, то совпадение происходит в начале фрагмента и после каждой последовательности UTF-8, что позволяет получить до k+1 замен для фрагмента длиной в k строк.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%s\n", bytes.ReplaceAll([]byte("oink oink oink"), []byte("oink"), []byte("moo")))
}
Output:
moo moo moofunc Runes
func Runes(s []byte) []rune
Runes интерпретирует s как последовательность кодовых точек в кодировке UTF-8. Она возвращает фрагмент рун (кодовых точек Юникода), эквивалентный s.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
rs := bytes.Runes([]byte("go gopher"))
for _, r := range rs {
fmt.Printf("%#U\n", r)
}
}
Output:
U+0067 'g'
U+006F 'o'
U+0020 ' '
U+0067 'g'
U+006F 'o'
U+0070 'p'
U+0068 'h'
U+0065 'e'
U+0072 'r'func Split
func Split(s, sep []byte) [][]byte
Split разбивает s на все подфрагменты, разделенные sep, и возвращает фрагмент подфрагментов между этими разделителями. Если sep пуст, Split разделяет после каждой последовательности UTF-8. Это эквивалентно SplitN с числом -1.
Для разбиения вокруг первого экземпляра разделителя смотрите Cut.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%q\n", bytes.Split([]byte("a,b,c"), []byte(",")))
fmt.Printf("%q\n", bytes.Split([]byte("a man a plan a canal panama"), []byte("a ")))
fmt.Printf("%q\n", bytes.Split([]byte(" xyz "), []byte("")))
fmt.Printf("%q\n", bytes.Split([]byte(""), []byte("Bernardo O'Higgins")))
}
Output:
["a" "b" "c"]
["" "man " "plan " "canal panama"]
[" " "x" "y" "z" " "]
[""]func SplitAfter
func SplitAfter(s, sep []byte) [][]byte
SplitAfter разбивает s на все подфрагменты после каждого экземпляра sep и возвращает фрагмент этих подфрагментов. Если sep пуст, SplitAfter разбивает после каждой последовательности UTF-8. Это эквивалентно SplitAfterN с количеством -1.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%q\n", bytes.SplitAfter([]byte("a,b,c"), []byte(",")))
}
Output:
["a," "b," "c"]func SplitAfterN
func SplitAfterN(s, sep []byte, n int) [][]byte
SplitAfterN разбивает s на подфрагменты после каждого экземпляра sep и возвращает фрагмент этих подфрагментов. Если sep пуст, SplitAfterN разбивает после каждой последовательности UTF-8. Параметр count определяет количество возвращаемых подфрагментов:
- n > 0: не более n подфрагментов; последний подфрагмент будет нерасщепленным остатком;
- n == 0: результат равен nil (нулевые подмножества);
- n < 0: все поддоли.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%q\n", bytes.SplitAfterN([]byte("a,b,c"), []byte(","), 2))
}
Output:
["a," "b,c"]func SplitAfterSeq
func SplitAfterSeq(s, sep []byte) iter.Seq[[]byte]
SplitAfterSeq возвращает итератор по подфрагментам s, разделенным после каждого экземпляра sep. Итератор дает те же подфрагменты, которые были бы возвращены SplitAfter(s, sep), но без построения нового фрагмента, содержащего подфрагменты. Возвращается одноразовый итератор.
func SplitN
func SplitN(s, sep []байт, n int) [][]байт
SplitN разбивает s на подфрагменты, разделенные sep, и возвращает фрагмент подфрагментов между этими разделителями. Если sep пуст, SplitN разбивает после каждой последовательности UTF-8. Параметр count определяет количество возвращаемых подфрагментов:
- n > 0: не более n подфрагментов; последний подфрагмент будет нерасщепленным остатком;
- n == 0: результат равен nil (нулевые подмножества);
- n < 0: все подфрагменты.
Для разбиения вокруг первого экземпляра разделителя смотрите Cut.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%q\n", bytes.SplitN([]byte("a,b,c"), []byte(","), 2))
z := bytes.SplitN([]byte("a,b,c"), []byte(","), 0)
fmt.Printf("%q (nil = %v)\n", z, z == nil)
}Output:
["a" "b,c"]
[] (nil = true)func SplitSeq
func SplitSeq(s, sep []byte) iter.Seq[[]byte]
SplitSeq возвращает итератор по всем подфрагментам s, разделенным sep. Итератор дает те же подфрагменты, которые были бы возвращены функцией Split(s, sep), но без построения нового фрагмента, содержащего эти подфрагменты. Возвращается одноразовый итератор.
func Title (устарело)
func ToLower
func ToLower(s []byte) []byte
ToLower возвращает копию байтового фрагмента s со всеми буквами Юникода, переведенными в нижний регистр.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%s", bytes.ToLower([]byte("Gopher")))
}
Output:
gopherfunc ToLowerSpecial
func ToLowerSpecial(c unicode.SpecialCase, s []byte) []byte
ToLowerSpecial обрабатывает s как байт в кодировке UTF-8 и возвращает копию со всеми буквами Юникода, переведенными в нижний регистр, отдавая приоритет правилам специального регистра.
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
str := []byte("AHOJ VÝVOJÁRİ GOLANG")
totitle := bytes.ToLowerSpecial(unicode.AzeriCase, str)
fmt.Println("Original : " + string(str))
fmt.Println("ToLower : " + string(totitle))
}Output:
Original : AHOJ VÝVOJÁRİ GOLANG
ToLower : ahoj vývojári golangfunc ToTitle
func ToTitle(s []byte) []byte
ToTitle обрабатывает s как байт в кодировке UTF-8 и возвращает его копию со всеми буквами Юникода, отображенными в регистр заголовка.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%s\n", bytes.ToTitle([]byte("loud noises")))
fmt.Printf("%s\n", bytes.ToTitle([]byte("брат")))
}
Output:
LOUD NOISES
БРАТfunc ToTitleSpecial
func ToTitleSpecial(c unicode.SpecialCase, s []byte) []byte
ToTitleSpecial обрабатывает s как байты в кодировке UTF-8 и возвращает копию со всеми буквами Юникода, отображенными в их заглавный регистр, отдавая приоритет правилам специального регистра.
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
str := []byte("ahoj vývojári golang")
totitle := bytes.ToTitleSpecial(unicode.AzeriCase, str)
fmt.Println("Original : " + string(str))
fmt.Println("ToTitle : " + string(totitle))
}Output:
Original : ahoj vývojári golang
ToTitle : AHOJ VÝVOJÁRİ GOLANGfunc ToUpper
func ToUpper(s []byte) []byte
ToUpper возвращает копию байтового фрагмента s со всеми буквами Юникода, переведенными в верхний регистр.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%s", bytes.ToUpper([]byte("Gopher")))
}Output:
GOPHERfunc ToUpperSpecial
func ToUpperSpecial(c unicode.SpecialCase, s []byte) []byte
ToUpperSpecial обрабатывает s как байт в кодировке UTF-8 и возвращает копию со всеми буквами Юникода, переведенными в верхний регистр, отдавая приоритет правилам специального регистра.
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
str := []byte("ahoj vývojári golang")
totitle := bytes.ToUpperSpecial(unicode.AzeriCase, str)
fmt.Println("Original : " + string(str))
fmt.Println("ToUpper : " + string(totitle))
}
Output:
Original : ahoj vývojári golang
ToUpper : AHOJ VÝVOJÁRİ GOLANGfunc ToValidUTF8
func ToValidUTF8(s, replacement []byte) []byte
ToValidUTF8 обрабатывает s как байты в кодировке UTF-8 и возвращает копию, в которой каждый ряд байтов, представляющих недопустимый UTF-8, заменен байтами в replacement, которая может быть пустой.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%s\n", bytes.ToValidUTF8([]byte("abc"), []byte("\uFFFD")))
fmt.Printf("%s\n", bytes.ToValidUTF8([]byte("a\xffb\xC0\xAFc\xff"), []byte("")))
fmt.Printf("%s\n", bytes.ToValidUTF8([]byte("\xed\xa0\x80"), []byte("abc")))
}Output:
abc
abc
abcfunc Trim
func Trim(s []байт, cutset string) []байт
Trim возвращает подфрагмент s, отсекая все ведущие и последующие кодовые точки в кодировке UTF-8, содержащиеся в cutset.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("[%q]", bytes.Trim([]byte(" !!! Achtung! Achtung! !!! "), "! "))
}Output:
["Achtung! Achtung"]func TrimFunc
func TrimFunc(s []byte, f func(r rune) bool) []byte
TrimFunc возвращает подфрагмент s, отсекая все ведущие и последующие точки кода c в кодировке UTF-8, которые удовлетворяют f(c).
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
fmt.Println(string(bytes.TrimFunc([]byte("go-gopher!"), unicode.IsLetter)))
fmt.Println(string(bytes.TrimFunc([]byte("\"go-gopher!\""), unicode.IsLetter)))
fmt.Println(string(bytes.TrimFunc([]byte("go-gopher!"), unicode.IsPunct)))
fmt.Println(string(bytes.TrimFunc([]byte("1234go-gopher!567"), unicode.IsNumber)))
}
Output:
-gopher!
"go-gopher!"
go-gopher
go-gopher!func TrimLeft
func TrimLeft(s []байт, cutset string) []байт
TrimLeft возвращает подфрагмент s, отсекая все ведущие точки кода в кодировке UTF-8, содержащиеся в cutset.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Print(string(bytes.TrimLeft([]byte("453gopher8257"), "0123456789")))
}
Output:
gopher8257func TrimLeftFunc
func TrimLeftFunc(s []байт, f func(r rune) bool) []байт
TrimLeftFunc рассматривает s как байт в кодировке UTF-8 и возвращает подфрагмент s, отрезая все ведущие кодовые точки c в кодировке UTF-8, которые удовлетворяют f(c).
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
fmt.Println(string(bytes.TrimLeftFunc([]byte("go-gopher"), unicode.IsLetter)))
fmt.Println(string(bytes.TrimLeftFunc([]byte("go-gopher!"), unicode.IsPunct)))
fmt.Println(string(bytes.TrimLeftFunc([]byte("1234go-gopher!567"), unicode.IsNumber)))
}Output:
-gopher
go-gopher!
go-gopher!567func TrimPrefix
func TrimPrefix(s, prefix []byte) []byte
TrimPrefix возвращает s без предоставленной ведущей строки префикса. Если s не начинается с префикса, s возвращается без изменений.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
var b = []byte("Goodbye,, world!")
b = bytes.TrimPrefix(b, []byte("Goodbye,"))
b = bytes.TrimPrefix(b, []byte("See ya,"))
fmt.Printf("Hello%s", b)
}Output:
Hello, world!func TrimRight
func TrimRight(s []байт, cutset string) []байт
TrimRight возвращает подфрагмент s, отрезая все кодовые точки в кодировке UTF-8, которые содержатся в cutset.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Print(string(bytes.TrimRight([]byte("453gopher8257"), "0123456789")))
}
Output:
453gopherfunc TrimRightFunc
func TrimRightFunc(s []byte, f func(r rune) bool) []byte
TrimRightFunc возвращает подфрагмент s, отсекая все кодовые точки c, которые удовлетворяют f(c).
Пример
package main
import (
"bytes"
"fmt"
"unicode"
)
func main() {
fmt.Println(string(bytes.TrimRightFunc([]byte("go-gopher"), unicode.IsLetter)))
fmt.Println(string(bytes.TrimRightFunc([]byte("go-gopher!"), unicode.IsPunct)))
fmt.Println(string(bytes.TrimRightFunc([]byte("1234go-gopher!567"), unicode.IsNumber)))
}
Output:
go-
go-gopher
1234go-gopher!func TrimSpace
func TrimSpace(s []byte) []byte
TrimSpace возвращает подфрагмент s, отсекая все ведущие и последующие белые пробелы, как определено Unicode.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Printf("%s", bytes.TrimSpace([]byte(" \t\n a lone gopher \n\t\r\n")))
}
Output:
a lone gopherfunc TrimSuffix
func TrimSuffix(s, suffix []byte) []byte
TrimSuffix возвращает s без предоставленной строки суффикса. Если s не заканчивается суффиксом, s возвращается без изменений.
Пример
package main
import (
"bytes"
"os"
)
func main() {
var b = []byte("Hello, goodbye, etc!")
b = bytes.TrimSuffix(b, []byte("goodbye, etc!"))
b = bytes.TrimSuffix(b, []byte("gopher"))
b = append(b, bytes.TrimSuffix([]byte("world!"), []byte("x!"))...)
os.Stdout.Write(b)
}
Output:
Hello, world!Типы
type Buffer
type Buffer struct {
// содержит отфильтрованные или неэкспонированные поля
}
Буфер - это буфер переменного размера из байтов с методами Buffer.Read и Buffer.Write. Нулевое значение для Buffer - это пустой буфер, готовый к использованию.
Пример
package main
import (
"bytes"
"fmt"
"os"
)
func main() {
var b bytes.Buffer // A Buffer needs no initialization.
b.Write([]byte("Hello "))
fmt.Fprintf(&b, "world!")
b.WriteTo(os.Stdout)
}
Output:
Hello world!Пример Reader
package main
import (
"bytes"
"encoding/base64"
"io"
"os"
)
func main() {
// A Buffer can turn a string or a []byte into an io.Reader.
buf := bytes.NewBufferString("R29waGVycyBydWxlIQ==")
dec := base64.NewDecoder(base64.StdEncoding, buf)
io.Copy(os.Stdout, dec)
}
Output:
Gophers rule!func NewBuffer
func NewBuffer(buf []byte) *Buffer
NewBuffer создает и инициализирует новый буфер, используя buf в качестве его начального содержимого. Новый буфер получает право собственности на buf, и вызывающая сторона не должна использовать buf после этого вызова. NewBuffer предназначен для подготовки буфера к чтению существующих данных. Он также может быть использован для установки начального размера внутреннего буфера для записи. Для этого buf должен иметь желаемый объем, но длину, равную нулю.
В большинстве случаев для инициализации буфера достаточно использовать new(Buffer) (или просто объявить переменную Buffer).
func NewBufferString
func NewBufferString(s string) *Buffer
NewBufferString создает и инициализирует новый буфер, используя строку s в качестве его начального содержимого. Он предназначен для подготовки буфера к чтению существующей строки.
В большинстве случаев для инициализации буфера достаточно использовать new(Buffer) (или просто объявить переменную Buffer).
func (*Buffer) Available
func (b *Buffer) Available() int
Available возвращает количество неиспользованных байт в буфере.
func (*Buffer) AvailableBuffer
func (b *Buffer) AvailableBuffer() []byte
AvailableBuffer возвращает пустой буфер с емкостью b.Available(). Этот буфер предназначен для
Пример
package main
import (
"bytes"
"os"
"strconv"
)
func main() {
var buf bytes.Buffer
for i := 0; i < 4; i++ {
b := buf.AvailableBuffer()
b = strconv.AppendInt(b, int64(i), 10)
b = append(b, ' ')
buf.Write(b)
}
os.Stdout.Write(buf.Bytes())
}
Output:
0 1 2 3func (*Buffer) Bytes
func (b *Buffer) Bytes() []byte
Bytes возвращает фрагмент длины b.Len(), содержащий непрочитанную часть буфера. Этот фрагмент действителен для использования только до следующего изменения буфера (то есть только до следующего вызова метода типа Buffer.Read, Buffer.Write, Buffer.Reset или Buffer.Truncate). Слайс псевдоним содержимого буфера, по крайней мере, до следующей модификации буфера, поэтому немедленные изменения в слайсе повлияют на результат последующих чтений.
Пример
package main
import (
"bytes"
"os"
)
func main() {
buf := bytes.Buffer{}
buf.Write([]byte{'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'})
os.Stdout.Write(buf.Bytes())
}
Output:
hello worldfunc (*Buffer) Cap
func (b *Buffer) Cap() int
Cap возвращает емкость базового байтового среза буфера, то есть общее пространство, выделенное для данных буфера.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
buf1 := bytes.NewBuffer(make([]byte, 10))
buf2 := bytes.NewBuffer(make([]byte, 0, 10))
fmt.Println(buf1.Cap())
fmt.Println(buf2.Cap())
}Output:
10
10func (*Buffer) Grow
func (b *Buffer) Grow(n int)
Grow увеличивает емкость буфера, если необходимо, чтобы гарантировать место для еще n байт. После Grow(n) в буфер может быть записано не менее n байт без дополнительного выделения. Если n отрицательно, Grow паникует. Если буфер не может вырасти, то произойдет паника с ошибкой ErrTooLarge.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
var b bytes.Buffer
b.Grow(64)
bb := b.Bytes()
b.Write([]byte("64 bytes or fewer"))
fmt.Printf("%q", bb[:b.Len()])
}
Output:
"64 bytes or fewer"func (*Buffer) Len
func (b *Buffer) Len() int
Len возвращает количество байт непрочитанной части буфера; b.Len() == len(b.Bytes()).
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
var b bytes.Buffer
b.Grow(64)
b.Write([]byte("abcde"))
fmt.Printf("%d", b.Len())
}Output:
5func (*Buffer) Next
func (b *Buffer) Next(n int) []byte
Next возвращает фрагмент, содержащий следующие n байт из буфера, продвигая буфер так, как если бы байты были возвращены функцией Buffer.Read. Если в буфере меньше n байт, Next возвращает весь буфер. Фрагмент действителен только до следующего вызова метода чтения или записи.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
var b bytes.Buffer
b.Grow(64)
b.Write([]byte("abcde"))
fmt.Printf("%s\n", b.Next(2))
fmt.Printf("%s\n", b.Next(2))
fmt.Printf("%s", b.Next(2))
}
Output:
ab
cd
efunc (*Buffer) Read
func (b *Buffer) Read(p []byte) (n int, err error)
Read считывает следующие len(p) байт из буфера или пока буфер не будет исчерпан. Возвращаемое значение n - количество прочитанных байт. Если в буфере нет данных для возврата, err будет io.EOF (если только len(p) не равно нулю); в противном случае это будет nil.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
var b bytes.Buffer
b.Grow(64)
b.Write([]byte("abcde"))
rdbuf := make([]byte, 1)
n, err := b.Read(rdbuf)
if err != nil {
panic(err)
}
fmt.Println(n)
fmt.Println(b.String())
fmt.Println(string(rdbuf))
}Output:
1
bcde
afunc (*Buffer) ReadByte
func (b *Buffer) ReadByte() (byte, error)
ReadByte считывает и возвращает следующий байт из буфера. Если ни один байт не доступен, возвращается ошибка io.EOF.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
var b bytes.Buffer
b.Grow(64)
b.Write([]byte("abcde"))
c, err := b.ReadByte()
if err != nil {
panic(err)
}
fmt.Println(c)
fmt.Println(b.String())
}
Output:
97
bcdefunc (*Buffer) ReadBytes
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error)
ReadBytes читает до первого появления delim во входных данных, возвращая фрагмент, содержащий данные до разделителя включительно. Если ReadBytes встречает ошибку до нахождения разделителя, он возвращает данные, прочитанные до ошибки, и саму ошибку (часто io.EOF). ReadBytes возвращает err != nil тогда и только тогда, когда возвращаемые данные не заканчиваются на delim.
func (*Buffer) ReadFrom
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error)
ReadFrom читает данные из r до EOF и добавляет их в буфер, увеличивая буфер по мере необходимости. Возвращаемое значение n - это количество прочитанных байт. Также возвращается любая ошибка, кроме io.EOF, возникшая во время чтения. Если буфер становится слишком большим, ReadFrom паникует с сообщением ErrTooLarge.
func (*Buffer) ReadRune
func (b *Buffer) ReadRune() (r rune, size int, err error)
ReadRune считывает и возвращает следующую кодовую точку Юникода в кодировке UTF-8 из буфера. Если байтов нет, возвращается ошибка io.EOF. Если байты имеют ошибочную кодировку UTF-8, то считывается один байт и возвращается U+FFFD, 1.
func (*Buffer) ReadString
func (b *Buffer) ReadString(delim byte) (line string, err error)
ReadString читает до первого появления delim во входных данных, возвращая строку, содержащую данные до разделителя включительно. Если ReadString встречает ошибку до нахождения разделителя, она возвращает данные, считанные до ошибки, и саму ошибку (часто io.EOF). ReadString возвращает err != nil тогда и только тогда, когда возвращаемые данные не заканчиваются разделителем.
func (*Buffer) Reset
func (b *Buffer) Сброс()
Сброс приводит к тому, что буфер становится пустым, но сохраняет базовое хранилище для использования в будущих записях. Сброс - это то же самое, что и Buffer.Truncate(0).
func (*Buffer) String
func (b *Buffer) String() string
String возвращает содержимое непрочитанной части буфера в виде строки. Если буфер является нулевым указателем, возвращается «
Для более эффективного создания строк см. тип strings.Builder.
func (*Buffer) Truncate
func (b *Buffer) Truncate(n int)
Truncate удаляет из буфера все непрочитанные байты, кроме первых n, но продолжает использовать выделенную память. Если n отрицательно или больше длины буфера, происходит паника.
func (*Buffer) UnreadByte
func (b *Buffer) UnreadByte() error
UnreadByte считывает последний байт, возвращенный последней успешной операцией чтения, которая прочитала хотя бы один байт. Если с момента последнего чтения произошла запись, если последнее чтение вернуло ошибку или если при чтении было прочитано ноль байт, UnreadByte возвращает ошибку.
func (*Buffer) UnreadRune
func (b *Buffer) UnreadRune() error
UnreadRune считывает последнюю руну, возвращенную Buffer.ReadRune. Если последняя операция чтения или записи в буфер не была успешной Buffer.ReadRune, UnreadRune возвращает ошибку. (В этом отношении она строже, чем Buffer.UnreadByte, которая отменяет чтение последнего байта из любой операции чтения).
func (*Buffer) Write
func (b *Buffer) Write(p []byte) (n int, err error)
Write добавляет содержимое p в буфер, увеличивая буфер по мере необходимости. Возвращаемое значение n - длина p; err всегда равно nil. Если буфер становится слишком большим, Write паникует с сообщением ErrTooLarge.
func (*Buffer) WriteByte
func (b *Buffer) WriteByte(c byte) error
WriteByte добавляет байт c в буфер, увеличивая буфер по мере необходимости. Возвращаемая ошибка всегда равна nil, но она включается, чтобы соответствовать WriteByte от bufio.Writer. Если буфер становится слишком большим, WriteByte паникует с сообщением ErrTooLarge.
func (*Buffer) WriteRune
func (b *Buffer) WriteRune(r rune) (n int, err error)
WriteRune добавляет кодировку UTF-8 кодовой точки Юникода r к буферу, возвращая его длину и ошибку, которая всегда равна nil, но включается для соответствия WriteRune от bufio.Writer. Буфер увеличивается по мере необходимости; если он становится слишком большим, WriteRune паникует с сообщением ErrTooLarge.
func (*Buffer) WriteString
func (b *Buffer) WriteString(s string) (n int, err error)
WriteString добавляет содержимое s в буфер, увеличивая буфер по мере необходимости. Возвращаемое значение n - длина s; err всегда равно nil. Если буфер становится слишком большим, WriteString паникует с сообщением ErrTooLarge.
func (*Buffer) WriteTo
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error)
WriteTo записывает данные в w до тех пор, пока буфер не будет исчерпан или не произойдет ошибка. Возвращаемое значение n - это количество записанных байт; оно всегда помещается в int, но для соответствия интерфейсу io.WriterTo оно равно int64. Также возвращается любая ошибка, возникшая во время записи.
type Reader
type Reader struct {
// содержит отфильтрованные или неотфильтрованные поля
}
Reader реализует интерфейсы io.Reader, io.ReaderAt, io.WriterTo, io.Seeker, io.ByteScanner и io.RuneScanner, читая из байтового фрагмента. В отличие от буфера, Reader доступен только для чтения и поддерживает поиск. Нулевое значение для Reader работает как Reader пустого фрагмента.
func NewReader
func NewReader(b []byte) *Reader
NewReader возвращает новый Reader, читающий из b.
func (*Reader) Len
func (r *Reader) Len() int
Len возвращает количество байт непрочитанной части фрагмента.
Пример
package main
import (
"bytes"
"fmt"
)
func main() {
fmt.Println(bytes.NewReader([]byte("Hi!")).Len())
fmt.Println(bytes.NewReader([]byte("こんにちは!")).Len())
}Output:
3
16func (*Reader) Read
func (r *Reader) Read(b []byte) (n int, err error)
Read реализует интерфейс io.Reader.
func (*Reader) ReadAt
func (r *Reader) ReadAt(b []byte, off int64) (n int, err error)
ReadAt реализует интерфейс io.ReaderAt.
func (*Reader) ReadByte
func (r *Reader) ReadByte() (byte, error)
ReadByte реализует интерфейс io.ByteReader.
func (*Reader) ReadRune
func (r *Reader) ReadRune() (ch rune, size int, err error)
ReadRune реализует интерфейс io.RuneReader.
func (*Reader) Reset
func (r *Reader) Reset(b []byte)
Сброс переводит ридер в режим чтения из b.
func (*Reader) Seek
func (r *Reader) Seek(offset int64, whence int) (int64, error)
Seek реализует интерфейс io.Seeker.
func (*Reader) Size
func (r *Reader) Size() int64
Size возвращает исходную длину базового байтового фрагмента. Size - это количество байт, доступных для чтения через Reader.ReadAt. На результат не влияют никакие вызовы методов, кроме Reader.Reset.
func (*Reader) UnreadByte
func (r *Reader) UnreadByte() error
UnreadByte дополняет Reader.ReadByte в реализации интерфейса io.ByteScanner.
func (*Reader) UnreadRune
func (r *Reader) UnreadRune() error
UnreadRune дополняет Reader.ReadRune в реализации интерфейса io.RuneScanner.
func (*Reader) WriteTo
func (r *Reader) WriteTo(w io.Writer) (n int64, err error)
WriteTo реализует интерфейс io.WriterTo.
12.4.6 - Описание пакета database языка программирования Go
Пакет для работы с базами данных
Пакет sql предоставляет общий интерфейс для баз данных SQL (или SQL-подобных).
Пакет sql должен использоваться вместе с драйвером базы данных. Список драйверов см. на сайте https://golang.org/s/sqldrivers.
Драйверы, не поддерживающие отмену контекста, вернут результат только после завершения запроса.
Примеры использования приведены на вики-странице https://golang.org/s/sqlwiki.
Пакет driver определяет интерфейсы, которые должны быть реализованы драйверами баз данных, используемыми пакетом sql.
Большая часть кода должна использовать пакет database/sql.
Подробная документация по драйверам: https://pkg.go.dev/database/sql/driver
12.4.6.1 - Работа с пакетом database/sql в Go: ошибки и их обработка
Переменные в пакете database/sql с примерами
Пакет database/sql в Go предоставляет универсальный интерфейс для работы с SQL-базами данных. Рассмотрим основные ошибки, которые могут возникнуть при работе с этим пакетом, и как их правильно обрабатывать.
Основные ошибки пакета database/sql
1. ErrConnDone - соединение уже закрыто
var ErrConnDone = errors.New("sql: connection is already closed")
Эта ошибка возникает, когда вы пытаетесь выполнить операцию на соединении, которое уже было возвращено в пул соединений.
Пример:
db, err := sql.Open("mysql", "user:password@/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
conn, err := db.Conn(context.Background())
if err != nil {
log.Fatal(err)
}
// Возвращаем соединение в пул
conn.Close()
// Пытаемся использовать закрытое соединение
err = conn.PingContext(context.Background())
if errors.Is(err, sql.ErrConnDone) {
fmt.Println("Ошибка: соединение уже закрыто")
}
2. ErrNoRows - нет строк в результате
var ErrNoRows = errors.New("sql: no rows in result set")
Эта ошибка возвращается методом Scan, когда QueryRow не находит ни одной строки.
Правильная обработка:
var name string
err := db.QueryRow("SELECT name FROM users WHERE id = ?", 123).Scan(&name)
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
fmt.Println("Пользователь не найден")
} else {
log.Fatal(err)
}
} else {
fmt.Printf("Имя пользователя: %s\n", name)
}
3. ErrTxDone - транзакция уже завершена
var ErrTxDone = errors.New("sql: transaction has already been committed or rolled back")
Эта ошибка возникает при попытке выполнить операцию в уже завершенной транзакции.
Пример:
tx, err := db.Begin()
if err != nil {
log.Fatal(err)
}
// Фиксируем транзакцию
err = tx.Commit()
if err != nil {
log.Fatal(err)
}
// Пытаемся выполнить запрос в завершенной транзакции
_, err = tx.Exec("INSERT INTO users(name) VALUES (?)", "Alice")
if errors.Is(err, sql.ErrTxDone) {
fmt.Println("Ошибка: транзакция уже завершена")
}
Советы по работе с database/sql
- Всегда проверяйте ошибки после операций с базой данных.
- Используйте
errors.Isдля проверки конкретных ошибок пакета database/sql. - Закрывайте ресурсы (соединения, транзакции, результаты запросов) с помощью defer.
- Используйте контексты для управления таймаутами и отменой операций.
Полный пример работы с базой данных:
package main
import (
"context"
"database/sql"
"errors"
"fmt"
"log"
_ "github.com/go-sql-driver/mysql"
)
type User struct {
ID int
Name string
}
func main() {
db, err := sql.Open("mysql", "user:password@/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Проверка соединения
err = db.Ping()
if err != nil {
log.Fatal(err)
}
// Пример запроса с обработкой ErrNoRows
user, err := getUser(db, 123)
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
fmt.Println("Пользователь не найден")
} else {
log.Fatal(err)
}
} else {
fmt.Printf("Найден пользователь: %+v\n", user)
}
// Пример транзакции
err = transferMoney(db, 1, 2, 100)
if err != nil {
log.Fatal(err)
}
}
func getUser(db *sql.DB, id int) (*User, error) {
var user User
err := db.QueryRow("SELECT id, name FROM users WHERE id = ?", id).Scan(&user.ID, &user.Name)
if err != nil {
return nil, err
}
return &user, nil
}
func transferMoney(db *sql.DB, from, to, amount int) error {
tx, err := db.Begin()
if err != nil {
return err
}
defer func() {
if err != nil {
tx.Rollback()
return
}
err = tx.Commit()
}()
// Списание денег
_, err = tx.Exec("UPDATE accounts SET balance = balance - ? WHERE id = ?", amount, from)
if err != nil {
return err
}
// Зачисление денег
_, err = tx.Exec("UPDATE accounts SET balance = balance + ? WHERE id = ?", amount, to)
if err != nil {
return err
}
return nil
}
12.4.6.2 - Подробное описание функций пакета database/sql в Go
Пакет database/sql предоставляет универсальный интерфейс для работы с SQL-базами данных. Рассмотрим основные функции этого пакета с примерами использования.
Основные функции управления драйверами
func Drivers() []string
Эта функция возвращает отсортированный список имен зарегистрированных драйверов баз данных.
Пример использования:
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/go-sql-driver/mysql" // регистрируем MySQL драйвер
_ "github.com/lib/pq" // регистрируем PostgreSQL драйвер
)
func main() {
// Получаем список зарегистрированных драйверов
drivers := sql.Drivers()
fmt.Println("Зарегистрированные драйверы:")
for _, driver := range drivers {
fmt.Println("-", driver)
}
// Выведет что-то вроде:
// Зарегистрированные драйверы:
// - mysql
// - postgres
}
func Register(name string, driver driver.Driver)
Эта функция регистрирует драйвер базы данных под указанным именем. Если попытаться зарегистрировать два драйвера с одинаковым именем или передать nil, функция вызовет panic.
Обычно драйверы регистрируют себя автоматически при импорте с пустым идентификатором _, как в примере выше. Но можно регистрировать драйверы и вручную:
package main
import (
"database/sql"
"database/sql/driver"
"fmt"
)
// Простой mock-драйвер для примера
type mockDriver struct{}
func (d *mockDriver) Open(name string) (driver.Conn, error) {
fmt.Println("Mock driver открывает соединение с:", name)
return nil, nil
}
func main() {
// Регистрируем наш mock-драйвер
sql.Register("mock", &mockDriver{})
// Теперь можем его использовать
db, err := sql.Open("mock", "test-connection")
if err != nil {
fmt.Println("Ошибка:", err)
return
}
defer db.Close()
// Проверяем, что драйвер зарегистрирован
fmt.Println("Зарегистрированные драйверы:", sql.Drivers())
}
Основные функции для работы с БД
func Open(driverName, dataSourceName string) (*DB, error)
Открывает новое соединение с базой данных. На самом деле не устанавливает соединение сразу, а только готовит объект DB.
Пример:
db, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
func (*DB) Ping() error и func (*DB) PingContext(ctx context.Context) error
Проверяет, что соединение с БД живо и доступно.
Пример:
err = db.Ping()
if err != nil {
log.Fatal("Не удалось подключиться к БД:", err)
}
fmt.Println("Успешное подключение к БД!")
Функции выполнения запросов
func (*DB) Exec(query string, args ...interface{}) (Result, error)
func (*DB) ExecContext(ctx context.Context, query string, args ...interface{}) (Result, error)
Выполняет запрос без возврата строк (INSERT, UPDATE, DELETE).
Пример:
result, err := db.Exec(
"INSERT INTO users(name, age) VALUES (?, ?)",
"Alice",
30,
)
if err != nil {
log.Fatal(err)
}
lastID, err := result.LastInsertId()
rowsAffected, err := result.RowsAffected()
func (*DB) Query(query string, args ...interface{}) (*Rows, error)
func (*DB) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error)
Выполняет запрос, возвращающий строки (SELECT).
Пример:
rows, err := db.Query("SELECT id, name, age FROM users WHERE age > ?", 25)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
for rows.Next() {
var id int
var name string
var age int
err = rows.Scan(&id, &name, &age)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%d: %s, %d\n", id, name, age)
}
if err = rows.Err(); err != nil {
log.Fatal(err)
}
func (*DB) QueryRow(query string, args ...interface{}) *Row
func (*DB) QueryRowContext(ctx context.Context, query string, args ...interface{}) *Row
Выполняет запрос, который должен вернуть не более одной строки.
Пример:
var name string
var age int
err := db.QueryRow("SELECT name, age FROM users WHERE id = ?", 1).Scan(&name, &age)
if err != nil {
if err == sql.ErrNoRows {
fmt.Println("Пользователь не найден")
} else {
log.Fatal(err)
}
} else {
fmt.Printf("Имя: %s, Возраст: %d\n", name, age)
}
Функции для работы с транзакциями
func (*DB) Begin() (*Tx, error)
func (*DB) BeginTx(ctx context.Context, opts *TxOptions) (*Tx, error)
Начинает новую транзакцию.
Пример:
tx, err := db.Begin()
if err != nil {
log.Fatal(err)
}
// Откатываем транзакцию в случае ошибки
defer func() {
if err != nil {
tx.Rollback()
}
}()
_, err = tx.Exec("UPDATE accounts SET balance = balance - 100 WHERE id = 1")
if err != nil {
return err
}
_, err = tx.Exec("UPDATE accounts SET balance = balance + 100 WHERE id = 2")
if err != nil {
return err
}
// Если все успешно - коммитим
err = tx.Commit()
if err != nil {
return err
}
Работа с соединениями
func (*DB) Conn(ctx context.Context) (*Conn, error)
Получает одно соединение из пула для выполнения нескольких операций в одном контексте.
Пример:
conn, err := db.Conn(context.Background())
if err != nil {
log.Fatal(err)
}
defer conn.Close()
// Выполняем несколько операций в одном соединении
var count int
err = conn.QueryRowContext(context.Background(), "SELECT COUNT(*) FROM users").Scan(&count)
if err != nil {
log.Fatal(err)
}
_, err = conn.ExecContext(context.Background(), "UPDATE stats SET user_count = ?", count)
if err != nil {
log.Fatal(err)
}
Заключение
Пакет database/sql предоставляет все необходимые функции для работы с SQL-базами данных в Go. Основные принципы:
- Всегда проверяйте ошибки
- Закрывайте ресурсы (Rows, Tx, Conn) с помощью defer
- Используйте контексты для управления таймаутами
- Для разных типов запросов используйте соответствующие методы (Exec, Query, QueryRow)
Правильное использование этих функций позволит вам создавать надежные и эффективные приложения, работающие с базами данных.
12.4.6.3 - Контекст (context) в транзакциях database/sql
Контекст (context.Context) - это механизм в Go для управления временем жизни операций, отмены и передачи значений между вызовами функций. В работе с базой данных через database/sql контекст играет ключевую роль.
Основные цели использования контекста в транзакциях
- Отмена операций - можно прервать долгий запрос
- Таймауты - установка максимального времени выполнения
- Распространение значений - передача метаданных через цепочку вызовов
Методы с поддержкой контекста
В database/sql большинство операций имеют две версии:
- Обычная (
Begin,Exec,Queryи т.д.) - С контекстом (
BeginTx,ExecContext,QueryContextи т.д.)
Пример использования контекста с таймаутом
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
// Начинаем транзакцию с таймаутом
tx, err := db.BeginTx(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer tx.Rollback() // Безопасный откат при ошибках
// Выполняем запрос в транзакции
_, err = tx.ExecContext(ctx, "UPDATE accounts SET balance = balance - 100 WHERE id = 1")
if err != nil {
// Если контекст истек, получим context.DeadlineExceeded
log.Printf("Update failed: %v", err)
return
}
// Коммитим транзакцию
err = tx.Commit()
if err != nil {
log.Printf("Commit failed: %v", err)
}
Особенности работы контекста в транзакциях
- Каскадная отмена - отмена контекста прерывает все операции в транзакции
- Изоляция транзакций - контекст не влияет на другие транзакции
- Ресурсы - отмена не освобождает соединение автоматически
Практические сценарии использования
- HTTP-обработчики - привязка к времени жизни запроса:
func handler(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
tx, err := db.BeginTx(ctx, nil)
// ...
}
- Долгие отчеты - возможность отмены:
ctx, cancel := context.WithCancel(context.Background())
go func() {
time.Sleep(10*time.Second)
cancel() // Принудительная отмена через 10 сек
}()
rows, err := db.QueryContext(ctx, "SELECT * FROM big_table")
- Распределенные транзакции - передача идентификаторов:
ctx := context.WithValue(context.Background(), "txID", generateID())
tx, _ := db.BeginTx(ctx, nil)
Важные нюансы
- Всегда проверяйте ошибки на
context.Canceledиcontext.DeadlineExceeded - Освобождайте ресурсы с помощью
deferдаже при отмене контекста - Не передавайте один контекст в несколько независимых транзакций
Использование контекста делает ваши транзакции более управляемыми и устойчивыми к долгим операциям.
12.4.6.4 - Описание типа database/sql DB
DB - это хэндл базы данных, представляющий пул из нуля или более базовых соединений. Он безопасен для одновременного использования несколькими горутинами.
type DB struct {
// содержит отфильтрованные или неэкспонированные поля
}
Пакет sql создает и освобождает соединения автоматически; он также поддерживает свободный пул незадействованных соединений. Если в базе данных есть понятие состояния каждого соединения, то такое состояние можно надежно наблюдать в рамках транзакции (Tx) или соединения (Conn). После вызова DB.Begin возвращаемая Tx привязывается к одному соединению. После вызова Tx.Commit или Tx.Rollback для транзакции, соединение этой транзакции возвращается в пул незанятых соединений DB. Размер пула можно контролировать с помощью DB.SetMaxIdleConns.
func Open
func Open(driverName, dataSourceName string) (*DB, error)
Open открывает базу данных, указанную именем драйвера базы данных и именем источника данных, обычно состоящим как минимум из имени базы данных и информации о подключении.
Большинство пользователей открывают базу данных с помощью специфической для драйвера вспомогательной функции подключения, которая возвращает *DB. Драйверы баз данных не включены в стандартную библиотеку Go. Список драйверов сторонних разработчиков см. на https://golang.org/s/sqldrivers.
Open может просто проверить свои аргументы, не создавая соединения с базой данных. Чтобы убедиться, что имя источника данных действительно, вызовите DB.Ping.
Возвращаемая БД безопасна для одновременного использования несколькими горутинами и поддерживает собственный пул незанятых соединений. Таким образом, функцию Open следует вызывать только один раз. Редко возникает необходимость закрывать БД.
func OpenDB
func OpenDB(c driver.Connector) *DB
OpenDB открывает базу данных с помощью driver.Connector, позволяя драйверам обходить строковое имя источника данных.
Большинство пользователей открывают базу данных с помощью специфической для драйвера функции-помощника подключения, которая возвращает *DB. Драйверы баз данных не включены в стандартную библиотеку Go.
OpenDB может просто проверить свои аргументы, не создавая соединения с базой данных. Чтобы убедиться, что имя источника данных действительно, вызовите DB.Ping.
Возвращаемая БД безопасна для одновременного использования несколькими горутинами и поддерживает свой собственный пул незанятых соединений. Таким образом, функция OpenDB должна быть вызвана только один раз. Редко возникает необходимость закрывать БД.
func (*DB) Close
func (db *DB) Close() error
Close закрывает базу данных и предотвращает запуск новых запросов. Затем Close ожидает завершения всех запросов, которые начали обрабатываться на сервере.
Закрывать БД приходится редко, так как хэндл БД должен быть долгоживущим и использоваться совместно многими горутинами.
db, err := sql.Open("mysql", dsn)
if err != nil {
log.Fatal(err)
}
defer db.Close() // Всегда закрывайте соединение
func (*DB) Ping
func (db *DB) Ping() error
Ping проверяет, что соединение с базой данных еще живо, и при необходимости устанавливает соединение.
Внутри Ping использует context.Background; чтобы указать контекст, используйте DB.PingContext.
err = db.Ping()
if err != nil {
log.Fatal("Connection failed:", err)
}
func (*DB) PingContext
func (db *DB) PingContext(ctx context.Context) error
PingContext проверяет, что соединение с базой данных еще живо, и при необходимости устанавливает соединение.
Пример
package main
import (
"context"
"database/sql"
"log"
"time"
)
var (
ctx context.Context
db *sql.DB
)
func main() {
ctx, cancel := context.WithTimeout(ctx, 1*time.Second)
defer cancel()
status := "up"
if err := db.PingContext(ctx); err != nil {
status = "down"
}
log.Println(status)
}
func (*DB) Begin
func (db *DB) Begin() (*Tx, error)
Begin начинает транзакцию. Уровень изоляции по умолчанию зависит от драйвера.
Begin внутренне использует context.Background; чтобы указать контекст, используйте DB.BeginTx.
func (*DB) BeginTx
func (db *DB) BeginTx(ctx context.Context, opts *TxOptions) (*Tx, error)
BeginTx начинает транзакцию.
Предоставленный контекст используется до тех пор, пока транзакция не будет зафиксирована или откачена. Если контекст будет отменен, пакет sql откатит транзакцию. Tx.Commit вернет ошибку, если контекст, предоставленный BeginTx, будет отменен.
Предоставленный параметр TxOptions является необязательным и может быть равен nil, если следует использовать значения по умолчанию. Если используется уровень изоляции не по умолчанию, который драйвер не поддерживает, будет возвращена ошибка.
Пример
import (
"context"
"database/sql"
"log"
)
var (
ctx context.Context
db *sql.DB
)
func main() {
tx, err := db.BeginTx(ctx, &sql.TxOptions{Isolation: sql.LevelSerializable})
if err != nil {
log.Fatal(err)
}
id := 37
_, execErr := tx.Exec(`UPDATE users SET status = ? WHERE id = ?`, "paid", id)
if execErr != nil {
_ = tx.Rollback()
log.Fatal(execErr)
}
if err := tx.Commit(); err != nil {
log.Fatal(err)
}
}
func (*DB) Conn
func (db *DB) Conn(ctx context.Context) (*Conn, error)
Conn возвращает одно соединение, либо открывая новое соединение, либо возвращая существующее соединение из пула соединений. Conn будет блокироваться до тех пор, пока не будет возвращено соединение или не будет отменен ctx. Запросы, выполняемые по одному и тому же Conn, будут выполняться в одной и той же сессии базы данных.
Каждый Conn должен быть возвращен в пул баз данных после использования вызовом Conn.Close.
Подробнее о Conn
Работа с соединениями (Conn) в database/sql
Соединение (Conn) представляет собой одиночное подключение к базе данных, которое можно использовать как в уже открытом пуле соединений (DB), так и для прямого управления подключением.
Основные концепции
Отличие от
DB:DB- это пул соединений (управляет множеством подключений)Conn- одно конкретное соединение
Когда использовать:
- Когда нужно выполнить несколько операций в рамках одного соединения
- Для работы с сессионными переменными
- Для транзакций, требующих изоляции от других операций
Примеры использования
1. Получение соединения из пула
package main
import (
"context"
"database/sql"
"fmt"
"log"
_ "github.com/go-sql-driver/mysql"
)
func main() {
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Получаем отдельное соединение из пула
conn, err := db.Conn(context.Background())
if err != nil {
log.Fatal(err)
}
defer conn.Close() // Важно возвращать соединение в пул
// Используем соединение
var result int
err = conn.QueryRowContext(context.Background(), "SELECT 1 + 1").Scan(&result)
if err != nil {
log.Fatal(err)
}
fmt.Println("Result:", result)
}
2. Использование сессионных переменных
// Устанавливаем переменную сессии и используем её в запросе
err = conn.ExecContext(context.Background(), "SET @user_id = 123").Scan(&result)
if err != nil {
log.Fatal(err)
}
var userID int
err = conn.QueryRowContext(context.Background(), "SELECT @user_id").Scan(&userID)
fmt.Println("User ID:", userID) // Выведет: User ID: 123
3. Транзакции в отдельном соединении
// Начинаем транзакцию в этом соединении
tx, err := conn.BeginTx(context.Background(), &sql.TxOptions{Isolation: sql.LevelSerializable})
if err != nil {
log.Fatal(err)
}
// Выполняем операции в транзакции
_, err = tx.Exec("UPDATE accounts SET balance = balance - 100 WHERE id = 1")
_, err = tx.Exec("UPDATE accounts SET balance = balance + 100 WHERE id = 2")
if err != nil {
tx.Rollback()
log.Fatal(err)
} else {
tx.Commit()
}
4. Прямое подключение (без пула)
Для прямого подключения без пула можно использовать драйвер напрямую, но это не рекомендуется:
package main
import (
"database/sql"
"database/sql/driver"
"fmt"
"log"
)
func main() {
// Получаем драйвер по имени
driver := sql.Driver(new(mysql.MySQLDriver))
// Создаем прямое соединение (не рекомендуется для production)
conn, err := driver.Open("user:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatal(err)
}
defer conn.Close() // Закрываем соединение
// Преобразуем в тип Conn (если нужно)
if sqlConn, ok := conn.(driver.Conn); ok {
// Работаем с соединением...
}
}
Когда использовать Conn вместо DB?
- Сессионные переменные: Когда нужно сохранить состояние между запросами
- Временные таблицы: Которые видны только в текущем соединении
- LOCK TABLES: Когда нужно заблокировать таблицы на время сессии
- Точный контроль: Когда важно, чтобы несколько операций использовали одно соединение
Важные замечания
- Всегда закрывайте
Connс помощьюdefer conn.Close() - Не держите соединения долго - возвращайте их в пул
- Для большинства случаев достаточно стандартного
DB Connдороже в создании, чем операции черезDB
Пример комплексного использования:
func complexOperation(db *sql.DB) error {
// Получаем соединение
conn, err := db.Conn(context.Background())
if err != nil {
return err
}
defer conn.Close()
// Настраиваем сессию
if _, err := conn.ExecContext(context.Background(), "SET @start_time = NOW()"); err != nil {
return err
}
// Выполняем транзакцию
tx, err := conn.BeginTx(context.Background(), nil)
if err != nil {
return err
}
// Бизнес-логика...
if _, err := tx.Exec("INSERT INTO orders (...) VALUES (...)"); err != nil {
tx.Rollback()
return err
}
// Получаем время выполнения
var startTime string
conn.QueryRowContext(context.Background(), "SELECT @start_time").Scan(&startTime)
fmt.Println("Operation started at:", startTime)
return tx.Commit()
}
Используйте Conn осознанно, только когда действительно нужно контролировать конкретное соединение. В большинстве случаев достаточно стандартного DB.
func (*DB) Driver
func (db *DB) Driver() driver.Driver
Driver возвращает базовый драйвер базы данных.
func (*DB) Exec
func (db *DB) Exec(query string, args ...any) (Result, error)
Exec выполняет запрос, не возвращая ни одной строки. В качестве args используются любые параметры-заполнители в запросе.
Exec использует внутренний контекст context.Background; чтобы указать контекст, используйте DB.ExecContext.
context.Background
func Background() ContextBackground возвращает ненулевой, пустой Context. Он никогда не отменяется, не имеет значений и сроков. Обычно используется главной функцией, инициализацией и тестами, а также в качестве контекста верхнего уровня для входящих запросов.
func (*DB) ExecContext
func (db *DB) ExecContext(ctx context.Context, query string, args ...any) (Result, error)
ExecContext выполняет запрос, не возвращая ни одной строки. В качестве args используются любые параметры-заполнители в запросе.
func (*DB) Prepare
func (db *DB) Prepare(query string) (*Stmt, error)
Prepare создает подготовленный отчет для последующих запросов или выполнения. Из полученного отчета можно одновременно выполнять несколько запросов или операций. Вызывающая сторона должна вызвать метод *Stmt.Close оператора, когда он больше не нужен.
Prepare внутренне использует context.Background; чтобы указать контекст, используйте DB.PrepareContext.
Пример
import (
"context"
"database/sql"
"log"
)
var db *sql.DB
func main() {
projects := []struct {
mascot string
release int
}{
{"tux", 1991},
{"duke", 1996},
{"gopher", 2009},
{"moby dock", 2013},
}
stmt, err := db.Prepare("INSERT INTO projects(id, mascot, release, category) VALUES( ?, ?, ?, ? )")
if err != nil {
log.Fatal(err)
}
defer stmt.Close() // Prepared statements take up server resources and should be closed after use.
for id, project := range projects {
if _, err := stmt.Exec(id+1, project.mascot, project.release, "open source"); err != nil {
log.Fatal(err)
}
}
}
func (*DB) PrepareContext
func (db *DB) PrepareContext(ctx context.Context, query string) (*Stmt, error)
PrepareContext создает подготовленный запрос для последующих запросов или выполнений. Из полученного отчета можно одновременно выполнять несколько запросов или операций. Вызывающая сторона должна вызвать метод *Stmt.Close оператора, когда он больше не нужен.
Предоставленный контекст используется для подготовки утверждения, а не для его выполнения.
func (*DB) Query
func (db *DB) Query(query string, args ...any) (*Rows, error)
Query выполняет запрос, возвращающий строки, обычно SELECT. В качестве args используются любые параметры-заполнители в запросе.
Query внутренне использует context.Background; чтобы указать контекст, используйте DB.QueryContext.
Пример
package main
import (
"context"
"database/sql"
"log"
_ "github.com/lib/pq" // или другой драйвер БД
)
var db *sql.DB
func main() {
// Инициализация подключения к БД
var err error
db, err = sql.Open("postgres", "user=postgres dbname=test sslmode=disable") // замените на свои параметры
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// Проверка соединения
if err := db.Ping(); err != nil {
log.Fatal("Failed to ping database:", err)
}
age := 27
q := `
-- Создаем временную таблицу
CREATE TEMP TABLE uid (id bigint) ON COMMIT DROP;
-- Заполняем временную таблицу
INSERT INTO uid
SELECT id FROM users WHERE age < $1;
-- Первый набор результатов
SELECT
users.id, name
FROM
users
JOIN uid ON users.id = uid.id;
-- Второй набор результатов
SELECT
ur.user_id, ur.role_id
FROM
user_roles AS ur
JOIN uid ON uid.id = ur.user_id;
`
// Используем контекст для запроса
ctx := context.Background()
rows, err := db.QueryContext(ctx, q, age)
if err != nil {
log.Fatal("Query failed:", err)
}
defer rows.Close()
// Обрабатываем первый набор результатов
log.Println("Processing users:")
for rows.Next() {
var (
id int64
name string
)
if err := rows.Scan(&id, &name); err != nil {
log.Fatal("Failed to scan user row:", err)
}
log.Printf("id %d name is %s\n", id, name)
}
// Переходим ко второму набору результатов
if !rows.NextResultSet() {
if err := rows.Err(); err != nil {
log.Fatal("Failed to get next result set:", err)
}
log.Fatal("Expected more result sets, but none available")
}
// Обрабатываем второй набор результатов
roleMap := map[int64]string{
1: "user",
2: "admin",
3: "gopher",
}
log.Println("\nProcessing roles:")
for rows.Next() {
var (
userID int64
roleID int64
)
if err := rows.Scan(&userID, &roleID); err != nil {
log.Fatal("Failed to scan role row:", err)
}
roleName, ok := roleMap[roleID]
if !ok {
roleName = "unknown"
}
log.Printf("user %d has role %s\n", userID, roleName)
}
if err := rows.Err(); err != nil {
log.Fatal("Rows error:", err)
}
}
func (*DB) QueryContext
func (db *DB) QueryContext(ctx context.Context, query string, args ...any) (*Rows, error)
QueryContext выполняет запрос, возвращающий строки, обычно SELECT. В качестве args используются любые параметры-заполнители запроса.
Пример
package main
import (
"context"
"database/sql"
"fmt"
"log"
"strings"
_ "github.com/go-sql-driver/mysql" // или другой драйвер БД
)
func main() {
// 1. Инициализация подключения к БД
var err error
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// 2. Проверка соединения
ctx := context.Background()
if err := db.PingContext(ctx); err != nil {
log.Fatal("Failed to ping database:", err)
}
// 3. Выполнение запроса
age := 27
rows, err := db.QueryContext(ctx, "SELECT name FROM users WHERE age=?", age)
if err != nil {
log.Fatal("Query failed:", err)
}
defer rows.Close()
// 4. Обработка результатов
names := make([]string, 0)
for rows.Next() {
var name string
if err := rows.Scan(&name); err != nil {
log.Printf("Scan error (skipping row): %v", err) // Не прерываем выполнение
continue
}
names = append(names, name)
}
// 5. Проверка ошибок после итерации
if err := rows.Err(); err != nil {
log.Fatal("Rows error:", err)
}
// 6. Проверка ошибок закрытия (более аккуратная обработка)
if err := rows.Close(); err != nil {
log.Printf("Warning: error closing rows: %v", err) // Не фатальная ошибка
}
// 7. Вывод результатов
if len(names) > 0 {
fmt.Printf("%s are %d years old\n", strings.Join(names, ", "), age)
} else {
fmt.Printf("No users found at age %d\n", age)
}
}
func (*DB) QueryRow
func (db *DB) QueryRow(query string, args ...any) *Row
QueryRow выполняет запрос, который, как ожидается, вернет не более одной строки. QueryRow всегда возвращает значение, не являющееся нулем. Ошибки откладываются до вызова метода Row’s Scan. Если запрос не выбрал ни одной строки, то *Row.Scan вернет ErrNoRows. В противном случае *Row.Scan сканирует первую выбранную строку и отбрасывает остальные.
QueryRow внутренне использует context.Background;
func (*DB) QueryRowContext
func (db *DB) QueryRowContext(ctx context.Context, query string, args ...any) *Row
QueryRowContext выполняет запрос, который, как ожидается, вернет не более одной строки. QueryRowContext всегда возвращает значение non-nil. Ошибки откладываются до вызова метода Row’s Scan. Если запрос не выбрал ни одной строки, то *Row.Scan вернет ErrNoRows. В противном случае *Row.Scan сканирует первую выбранную строку и отбрасывает остальные.
Пример
package main
import (
"context"
"database/sql"
"log"
"time"
_ "github.com/go-sql-driver/mysql" // Импорт драйвера БД
)
func main() {
// Инициализация подключения к БД
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatalf("Failed to connect to database: %v", err)
}
defer db.Close()
// Проверка соединения
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
if err := db.PingContext(ctx); err != nil {
log.Fatalf("Failed to ping database: %v", err)
}
// Выполнение запроса
id := 123
var username string
var created time.Time
// Используем контекст с таймаутом для запроса
queryCtx, queryCancel := context.WithTimeout(context.Background(), 3*time.Second)
defer queryCancel()
err = db.QueryRowContext(queryCtx,
"SELECT username, created_at FROM users WHERE id=?",
id,
).Scan(&username, &created)
switch {
case err == sql.ErrNoRows:
log.Printf("No user found with id %d", id)
case err != nil:
log.Printf("Query error: %v", err) // Не используем Fatalf чтобы не прерывать программу
default:
log.Printf(
"Username: %q, Account created on: %s",
username,
created.Format("2006-01-02 15:04:05"),
)
}
}
func (*DB) SetConnMaxIdleTime
func (db *DB) SetConnMaxIdleTime(d time.Duration)
SetConnMaxIdleTime устанавливает максимальное время, в течение которого соединение может простаивать.
Просроченные соединения могут быть лениво закрыты перед повторным использованием.
Если d <= 0, соединения не закрываются из-за времени простоя соединения.
func (*DB) SetConnMaxLifetime
func (db *DB) SetConnMaxLifetime(d time.Duration)
SetConnMaxLifetime устанавливает максимальное количество времени, в течение которого соединение может быть использовано повторно.
Просроченные соединения могут быть лениво закрыты перед повторным использованием.
Если d <= 0, соединения не закрываются из-за возраста соединения.
func (*DB) SetMaxIdleConns
func (db *DB) SetMaxIdleConns(n int)
SetMaxIdleConns устанавливает максимальное количество соединений в пуле незадействованных соединений.
Если MaxOpenConns больше 0, но меньше нового MaxIdleConns, то новый MaxIdleConns будет уменьшен, чтобы соответствовать лимиту MaxOpenConns.
Если n <= 0, простаивающие соединения не сохраняются.
По умолчанию максимальное количество незадействованных соединений в настоящее время равно 2. Это может измениться в будущем выпуске.
func (*DB) SetMaxOpenConns
func (db *DB) SetMaxOpenConns(n int)
SetMaxOpenConns устанавливает максимальное количество открытых соединений с базой данных.
Если MaxIdleConns больше 0, а новое значение MaxOpenConns меньше MaxIdleConns, то MaxIdleConns будет уменьшено, чтобы соответствовать новому ограничению MaxOpenConns.
Если n <= 0, то количество открытых соединений не ограничено. По умолчанию 0 (неограниченно).
func (*DB) Stats
func (db *DB) Stats() DBStats
Stats возвращает статистику базы данных.
12.4.6.5 - Описание типа database/sql ColumnType
ColumnType тип для управлени структурой базы данных
type ColumnType struct {
// содержит отфильтрованные или неэкспортированные поля
}
ColumnType содержит имя и тип колонки.
func (*ColumnType) DatabaseTypeName
func (ci *ColumnType) DatabaseTypeName() string
DatabaseTypeName возвращает системное имя базы данных типа столбца. Если возвращается пустая строка, значит, имя типа драйвером не поддерживается. Список типов данных драйвера см. в документации к драйверу.
Спецификаторы ColumnType.Length не учитываются. Общие имена типов включают “VARCHAR”, “TEXT”, “NVARCHAR”, “DECIMAL”, “BOOL”, “INT” и “BIGINT”.
func (*ColumnType) DecimalSize
func (ci *ColumnType) DecimalSize() (precision, scale int64, ok bool)
DecimalSize возвращает масштаб и точность десятичного типа. Если они не применяются или не поддерживаются, ok равно false.
func (*ColumnType) Length
func (ci *ColumnType) Length() (length int64, ok bool)
Length возвращает длину типа столбца для типов столбцов переменной длины, таких как текстовые и бинарные типы полей. Если длина типа не ограничена, то значение будет math.MaxInt64 (все ограничения базы данных будут действовать). Если тип столбца не переменной длины, например int, или если он не поддерживается драйвером, ok будет false.
func (*ColumnType) Name
func (ci *ColumnType) Name() string
Name возвращает имя или псевдоним колонки.
func (*ColumnType) Nullable
func (ci *ColumnType) Nullable() (nullable, ok bool)
Nullable сообщает, может ли столбец быть нулевым. Если драйвер не поддерживает это свойство, ok будет равно false.
func (*ColumnType) ScanType
func (ci *ColumnType) ScanType() reflect.Type
ScanType возвращает тип Go, подходящий для сканирования с помощью Rows.Scan. Если драйвер не поддерживает это свойство, ScanType вернет тип пустого интерфейса.
package main
import (
"context"
"database/sql"
"fmt"
"log"
"time"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// Подключение к базе данных
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/testdb")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Проверка соединения
if err := db.Ping(); err != nil {
log.Fatal(err)
}
// Выполнение запроса
rows, err := db.QueryContext(context.Background(),
"SELECT id, username, created_at, balance, is_active FROM users LIMIT 1")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
// Получение информации о столбцах
columnTypes, err := rows.ColumnTypes()
if err != nil {
log.Fatal(err)
}
// Анализ метаданных каждого столбца
for i, ct := range columnTypes {
fmt.Printf("\n--- Столбец %d: %s ---\n", i+1, ct.Name())
// Тип данных в БД
databaseType := ct.DatabaseTypeName()
fmt.Printf("Тип в БД: %s\n", databaseType)
// Nullable
nullable, ok := ct.Nullable()
if ok {
fmt.Printf("Может быть NULL: %v\n", nullable)
} else {
fmt.Println("Информация о NULL недоступна")
}
// Длина/размер
length, ok := ct.Length()
if ok {
fmt.Printf("Длина: %d\n", length)
}
// Точность и масштаб (для чисел)
precision, scale, ok := ct.DecimalSize()
if ok {
fmt.Printf("Точность: %d, Масштаб: %d\n", precision, scale)
}
// Тип сканирования в Go
scanType := ct.ScanType()
fmt.Printf("Тип в Go: %v\n", scanType)
}
// Пример использования информации о типах для динамического сканирования
var (
id int64
username string
createdAt time.Time
balance float64
isActive bool
)
if rows.Next() {
err = rows.Scan(&id, &username, &createdAt, &balance, &isActive)
if err != nil {
log.Fatal(err)
}
fmt.Printf("\nРеальные значения: %d, %s, %v, %.2f, %t\n",
id, username, createdAt, balance, isActive)
}
}
12.4.6.6 - Описание типа Conn database/sql
Conn представляет собой одно соединение с базой данных, а не пул соединений с базой данных.
type Conn struct {
// содержит отфильтрованные или неэкспонированные поля
}
Conn представляет собой одно соединение с базой данных, а не пул соединений с базой данных. Предпочтительнее запускать запросы из БД, если нет особой необходимости в постоянном соединении с одной базой данных.
Conn должен вызвать Conn.Close, чтобы вернуть соединение в пул баз данных, и может делать это одновременно с выполняющимся запросом.
После вызова Conn.Close все операции над соединением завершаются с ошибкой ErrConnDone.
func (*Conn) BeginTx
func (c *Conn) BeginTx(ctx context.Context, opts *TxOptions) (*Tx, error)
BeginTx начинает транзакцию.
Предоставленный контекст используется до тех пор, пока транзакция не будет зафиксирована или откачена. Если контекст будет отменен, пакет sql откатит транзакцию. Tx.Commit вернет ошибку, если контекст, предоставленный BeginTx, будет отменен.
Предоставленный параметр TxOptions является необязательным и может быть равен nil, если следует использовать значения по умолчанию. Если используется уровень изоляции не по умолчанию, который драйвер не поддерживает, будет возвращена ошибка.
func (*Conn) Close
func (c *Conn) Close() error
Close возвращает соединение в пул соединений. Все операции после Close возвращаются с ошибкой ErrConnDone. Close безопасно вызывать одновременно с другими операциями, и он будет блокироваться до тех пор, пока все остальные операции не завершатся. Может оказаться полезным сначала отменить любой используемый контекст, а затем вызвать Close непосредственно после него.
func (*Conn) ExecContext
func (c *Conn) ExecContext(ctx context.Context, query string, args ...any) (Result, error)
ExecContext выполняет запрос, не возвращая никаких строк. В качестве args используются любые параметры-заполнители в запросе.
Пример
package main
import (
"context"
"database/sql"
"log"
"os"
_ "github.com/go-sql-driver/mysql" // Импорт драйвера БД
)
func main() {
// 1. Инициализация подключения к БД
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// 2. Проверка соединения
ctx := context.Background()
if err := db.PingContext(ctx); err != nil {
log.Fatal("Failed to ping database:", err)
}
// 3. Получение выделенного соединения
conn, err := db.Conn(ctx)
if err != nil {
log.Fatal("Failed to get connection:", err)
}
defer func() {
if err := conn.Close(); err != nil {
log.Printf("Warning: error closing connection: %v", err)
}
}()
// 4. Выполнение транзакции
id := 41
tx, err := conn.BeginTx(ctx, nil)
if err != nil {
log.Fatal("Failed to begin transaction:", err)
}
// 5. Выполнение UPDATE в транзакции
result, err := tx.ExecContext(ctx,
`UPDATE balances SET balance = balance + 10 WHERE user_id = ?`,
id,
)
if err != nil {
tx.Rollback()
log.Fatal("Failed to update balance:", err)
}
// 6. Проверка количества измененных строк
rows, err := result.RowsAffected()
if err != nil {
tx.Rollback()
log.Fatal("Failed to get rows affected:", err)
}
if rows != 1 {
tx.Rollback()
log.Printf("Expected single row affected, got %d rows affected", rows)
os.Exit(1) // Более мягкое завершение чем log.Fatal
}
// 7. Фиксация транзакции
if err := tx.Commit(); err != nil {
log.Fatal("Failed to commit transaction:", err)
}
log.Println("Balance updated successfully")
}
func (*Conn) PingContext
func (c *Conn) PingContext(ctx context.Context) error
PingContext проверяет, что соединение с базой данных все еще живо.
func (*Conn) PrepareContext
func (c *Conn) PrepareContext(ctx context.Context, query string) (*Stmt, error)
PrepareContext создает подготовленный запрос для последующих запросов или выполнений. Несколько запросов или выполнений могут быть запущены одновременно из полученного утверждения. Вызывающая сторона должна вызвать метод *Stmt.Close оператора, когда он больше не нужен.
Предоставленный контекст используется для подготовки утверждения, а не для его выполнения.
func (*Conn) QueryContext
func (c *Conn) QueryContext(ctx context.Context, query string, args ...any) (*Rows, error)
QueryContext выполняет запрос, возвращающий строки, обычно SELECT. В args указываются любые параметры-заполнители запроса.
func (*Conn) QueryRowContext
func (c *Conn) QueryRowContext(ctx context.Context, query string, args ...any) *Row
QueryRowContext выполняет запрос, который, как ожидается, вернет не более одной строки. QueryRowContext всегда возвращает значение non-nil. Ошибки откладываются до вызова метода *Row.Scan. Если запрос не выбрал ни одной строки, то *Row.Scan вернет ErrNoRows. В противном случае *Row.Scan сканирует первую выбранную строку и отбрасывает остальные.
func (*Conn) Raw
func (c *Conn) Raw(f func(driverConn any) error) (err error)
Raw выполняет f, раскрывая базовое соединение драйвера на время выполнения f. DriverConn не должен использоваться вне f.
После того как f вернется и err не будет driver.ErrBadConn, Conn будет продолжать использоваться до вызова Conn.Close.
Разбираем метод Raw() для работы с низкоуровневыми соединениями
Метод Raw() в database/sql позволяет получить прямое доступ к драйвер-специфичному соединению, минуя абстракции пакета database/sql. Это нужно для использования специфичных функций драйвера, которые не доступны через стандартный API.
Что такое f в этом контексте?
f - это ваша функция-колбэк, которая получает доступ к нативному соединению драйвера. Она должна иметь сигнатуру:
func(driverConn any) error
Зачем это нужно?
- Использование специфичных функций драйвера (например, PostgreSQL-специфичные команды)
- Оптимизация производительности для критичных участков кода
- Работа с нестандартными возможностями БД
Простой пример (PostgreSQL)
package main
import (
"context"
"database/sql"
"fmt"
"log"
_ "github.com/lib/pq"
)
func main() {
db, err := sql.Open("postgres", "user=postgres dbname=test sslmode=disable")
if err != nil {
log.Fatal(err)
}
defer db.Close()
conn, err := db.Conn(context.Background())
if err != nil {
log.Fatal(err)
}
defer conn.Close()
// Используем Raw для доступа к нативному соединению PostgreSQL
err = conn.Raw(func(driverConn interface{}) error {
// Приводим к типу, который ожидаем (для PostgreSQL)
pgConn, ok := driverConn.(driver.Conn) // Здесь нужен ваш тип соединения
if !ok {
return fmt.Errorf("unexpected driver connection type")
}
// Пример: выполняем LISTEN для PostgreSQL-нотификаций
// Это специфичная функция PostgreSQL, недоступная через стандартный API
_, err := pgConn.(*pq.Conn).Exec("LISTEN channel_name")
return err
})
if err != nil {
log.Fatal(err)
}
}
Более практичный пример (MySQL)
package main
import (
"context"
"database/sql"
"log"
_ "github.com/go-sql-driver/mysql"
)
func main() {
db, err := sql.Open("mysql", "user:password@/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
conn, err := db.Conn(context.Background())
if err != nil {
log.Fatal(err)
}
defer conn.Close()
// Получаем низкоуровневое соединение MySQL
err = conn.Raw(func(driverConn interface{}) error {
// Приводим к ожидаемому типу соединения MySQL
mysqlConn, ok := driverConn.(*mysql.Conn) // Требуется import драйвера
if !ok {
return fmt.Errorf("expected mysql.Conn, got %T", driverConn)
}
// Используем специфичные методы MySQL
fmt.Println("Server version:", mysqlConn.GetServerVersion())
fmt.Println("Connection ID:", mysqlConn.GetConnectionID())
// Можно выполнить специфичные команды
return mysqlConn.Ping()
})
if err != nil {
log.Fatal(err)
}
}
Важные предупреждения:
Тип соединения зависит от драйвера:
- PostgreSQL:
*pq.Conn - MySQL:
*mysql.Conn - SQLite: зависит от используемого драйвера
- PostgreSQL:
Безопасность:
- Не сохраняйте соединение вне функции
f - Все ошибки должны быть обработаны
- Не сохраняйте соединение вне функции
Совместимость:
- Код становится зависимым от конкретного драйвера
- Может сломаться при смене драйвера
Когда стоит использовать Raw()?
- Когда вам нужен доступ к специфичным функциям СУБД
- Для оптимизации критических участков
- При работе с нестандартными возможностями (нотификации, специфичные команды)
В большинстве случаев стандартного API database/sql достаточно, и Raw() не понадобится.
12.4.6.7 - Описание типа DBStats database/sql
DBStats DBStats содержит статистику базы данных. В этом разделе представлены другие типы: IsolationLevel, NamedArg, Null, NullBool
type DBStats
type DBStats struct {
MaxOpenConnections int // Максимальное количество открытых соединений с базой данных.
// Состояние пула
OpenConnections int // Количество установленных соединений, как используемых, так и простаивающих.
InUse int // Количество соединений, используемых в данный момент.
Idle int // Количество простаивающих соединений.
// Счетчики
WaitCount int64 // Общее количество ожидающих соединений.
WaitDuration time.Duration // Общее время, заблокированное в ожидании нового соединения.
MaxIdleClosed int64 // Общее количество соединений, закрытых из-за SetMaxIdleConns.
MaxIdleTimeClosed int64 // Общее количество соединений, закрытых из-за SetConnMaxIdleTime.
MaxLifetimeClosed int64 // Общее количество соединений, закрытых из-за SetConnMaxLifetime.
}
DBStats содержит статистику базы данных.
type IsolationLevel
type IsolationLevel int
IsolationLevel - это уровень изоляции транзакции, используемый в TxOptions.
const (
LevelDefault IsolationLevel = iota
LevelReadUncommitted
LevelReadCommitted
LevelWriteCommitted
LevelRepeatableRead
LevelSnapshot
LevelSerializable
LevelLinearizable
)
Различные уровни изоляции, которые драйверы могут поддерживать в DB.BeginTx. Если драйвер не поддерживает заданный уровень изоляции, может быть возвращена ошибка.
См. https://en.wikipedia.org/wiki/Isolation_(database_systems)#Isolation_levels.
func (IsolationLevel) String
func (i IsolationLevel) String() string
String возвращает имя уровня изоляции транзакции.
type NamedArg
type NamedArg struct {
// Name - имя параметра-заместителя.
//
// Если пусто, то будет использоваться
// порядковая позиция в списке аргументов.
//
// Имя не должно содержать префикса символа.
Name string
// Value - это значение параметра.
// Ему могут быть присвоены те же типы значений, что и аргументам запроса
//.
Value any
// содержит отфильтрованные или неэкспонированные поля
}
NamedArg - это именованный аргумент. Значения NamedArg могут использоваться в качестве аргументов DB.Query или DB.Exec и связываться с соответствующим именованным параметром в операторе SQL.
Для более краткого способа создания значений NamedArg см. функцию Named.
func Named
func Named(name string, value any) NamedArg
Named предоставляет более лаконичный способ создания значений NamedArg.
Пример
db.ExecContext(ctx, `
delete from Invoice
where
TimeCreated < @end
and TimeCreated >= @start;`,
sql.Named("start", startTime),
sql.Named("end", endTime),
)
type Null
type Null[T any] struct {
V T
Valid bool
}
Null представляет значение, которое может быть нулевым. Null реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования:
var s Null[string]
err := db.QueryRow("SELECT name FROM foo WHERE id=?", id).Scan(&s)
...
if s.Valid {
// используем s.V
} else {
// NULL значение
}
T должен быть одним из типов, принимаемых driver.Value.
func (*Null[T]) Scan
func (n *Null[T]) Scan(value any) error
func (Null[T]) Value
func (n Null[T]) Value() (driver.Value, error)
type NullBool ¶
type NullBool struct {
Bool bool
Valid bool // Valid is true if Bool is not NULL
}
NullBool представляет bool, который может быть нулевым. NullBool реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования, аналогично NullString.
func (*NullBool) Scan
func (n *NullBool) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullBool) Value
func (n NullBool) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
type NullByte
type NullByte struct {
Byte byte
Valid bool // Valid is true if Byte is not NULL
}
NullByte представляет байт, который может быть нулевым. NullByte реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования, аналогично NullString.
func (*NullByte) Scan
func (n *NullByte) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullByte) Value
func (n NullByte) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
type NullFloat64 ¶
type NullFloat64 struct {
Float64 float64
Valid bool // Valid is true if Float64 is not NULL
}
NullFloat64 представляет float64, который может быть нулевым. NullFloat64 реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования, аналогично NullString.
func (*NullFloat64) Scan ¶
func (n *NullFloat64) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullFloat64) Value ¶
func (n NullFloat64) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
type NullInt16
type NullInt16 struct {
Int16 int16
Valid bool // Valid is true if Int16 is not NULL
}
NullInt16 представляет int16, который может быть нулевым. NullInt16 реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования, аналогично NullString.
func (*NullInt16) Scan
func (n *NullInt16) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullInt16) Value
func (n NullInt16) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
type NullInt32
type NullInt32 struct {
Int32 int32
Valid bool // Valid is true if Int32 is not NULL
}
NullInt32 представляет int32, который может быть нулевым. NullInt32 реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования, аналогично NullString.
func (*NullInt32) Scan
func (n *NullInt32) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullInt32) Value
func (n NullInt32) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
type NullInt64
type NullInt64 struct {
Int64 int64
Valid bool // Valid is true if Int64 is not NULL
}
NullInt64 представляет int64, который может быть нулевым. NullInt64 реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования, аналогично NullString.
func (*NullInt64) Scan
func (n *NullInt64) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullInt64) Value
func (n NullInt64) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
type NullString
type NullString struct {
String string
Valid bool // Valid is true if String is not NULL
}
NullString представляет строку, которая может быть нулевой. NullString реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования:
var s NullString
err := db.QueryRow("SELECT name FROM foo WHERE id=?", id).Scan(&s)
...
if s.Valid {
// использовать s.String
} else {
// NULL значение
}
func (*NullString) Scan
func (ns *NullString) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullString) Value
func (ns NullString) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
type NullTime
type NullTime struct {
Time.Time
Valid bool // Valid is true if Time is not NULL
}
NullTime представляет время time.Time, которое может быть нулевым. NullTime реализует интерфейс Scanner, поэтому его можно использовать в качестве места сканирования, аналогично NullString.
func (*NullTime) Scan
func (n *NullTime) Scan(value any) error
Scan реализует интерфейс Scanner.
func (NullTime) Value
func (n NullTime) Value() (driver.Value, error)
Value реализует интерфейс driver.Valuer.
Практическое использование Null-типов в Go
Null-типы (NullString, NullInt64, NullTime и др.) нужны для работы с NULL-значениями из базы данных. Разберём на реальных примерах.
Интерфейсы
- Scanner - позволяет сканировать (читать) значение из БД
- driver.Valuer - позволяет преобразовывать значение для записи в БД
Полный пример с NullString и NullTime
Пример
package main
import (
"database/sql"
"log"
"time"
_ "github.com/go-sql-driver/mysql"
)
type UserProfile struct {
ID int64
Name sql.NullString
Bio sql.NullString
DeletedAt sql.NullTime
}
func main() {
db, err := sql.Open("mysql", "user:password@/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// 1. Запись данных с NULL-значениями
profile := UserProfile{
Name: sql.NullString{String: "Иван Иванов", Valid: true},
Bio: sql.NullString{}, // NULL
DeletedAt: sql.NullTime{Time: time.Now(), Valid: false}, // Будет записан как NULL
}
_, err = db.Exec(
"INSERT INTO users (name, bio, deleted_at) VALUES (?, ?, ?)",
profile.Name,
profile.Bio,
profile.DeletedAt,
)
if err != nil {
log.Fatal(err)
}
// 2. Чтение данных с возможными NULL-значениями
var user UserProfile
err = db.QueryRow(`
SELECT id, name, bio, deleted_at
FROM users
WHERE id = ?
`, 1).Scan(
&user.ID,
&user.Name,
&user.Bio,
&user.DeletedAt,
)
if err != nil {
log.Fatal(err)
}
// 3. Обработка NULL-значений
log.Println("ID:", user.ID)
if user.Name.Valid {
log.Println("Name:", user.Name.String)
} else {
log.Println("Name not set")
}
if user.Bio.Valid {
log.Println("Bio:", user.Bio.String)
} else {
log.Println("Bio not set")
}
if user.DeletedAt.Valid {
log.Println("Deleted at:", user.DeletedAt.Time)
} else {
log.Println("Not deleted")
}
}
Как работают Null-типы?
1. Scan (чтение из БД)
Пример
func (ns *NullString) Scan(value interface{}) error {
if value == nil {
ns.String, ns.Valid = "", false
return nil
}
ns.Valid = true
return convertAssign(&ns.String, value)
}
2. Value (запись в БД)
Пример
func (ns NullString) Value() (driver.Value, error) {
if !ns.Valid {
return nil, nil
}
return ns.String, nil
}
Пример с пользовательским Null-типом
Создадим свой NullStatus для enum-поля:
Пример
type NullStatus struct {
Status string
Valid bool
}
func (ns *NullStatus) Scan(value interface{}) error {
if value == nil {
ns.Status, ns.Valid = "", false
return nil
}
ns.Valid = true
switch v := value.(type) {
case []byte:
ns.Status = string(v)
case string:
ns.Status = v
default:
return fmt.Errorf("unsupported type: %T", value)
}
return nil
}
func (ns NullStatus) Value() (driver.Value, error) {
if !ns.Valid {
return nil, nil
}
return ns.Status, nil
}
Когда использовать Null-типы?
- Когда поле в БД может быть NULL
- Когда нужно отличать “нулевое значение” от “неустановленного”
- При работе с опциональными полями
Альтернативы
В новых версиях Go можно использовать указатели:
Пример
var name *string
err := db.QueryRow("SELECT name FROM users WHERE id = 1").Scan(&name)
if name != nil {
// есть значение
}
Но Null-типы предоставляют более удобный интерфейс и явный флаг Valid.
12.4.6.8 - Описание типа Out database/sql
Out может использоваться для извлечения параметров OUTPUT из хранимых процедур. В этом разделе представлены другие типы: RawBytes, Result
type Out
type Out struct {
// Dest — указатель на значение, которое будет установлено в качестве результата
// параметра OUTPUT хранящейся процедуры.
Dest any
// In — является ли параметр параметром INOUT. Если да, то входное значение для хранящейся
// процедуры — это разыменованное значение указателя Dest, которое затем заменяется
// выходным значением.
In bool
// содержит отфильтрованные или неэкспортированные поля
}
Out может использоваться для извлечения параметров OUTPUT из хранимых процедур.
Не все драйверы и базы данных поддерживают параметры OUTPUT.
Пример использования:
var outArg string
_, err := db.ExecContext(ctx, «ProcName», sql.Named(«Arg1», sql.Out{Dest: &outArg}))
type RawBytes
type RawBytes []byte
RawBytes — это байтовый срез, который содержит ссылку на память, принадлежащую самой базе данных. После выполнения Rows.Scan в RawBytes срез остается действительным только до следующего вызова Rows.Next, Rows.Scan или Rows.Close.
RawBytes - это специальный тип в пакете database/sql, определённый как []byte, который используется для сканирования данных из базы данных без копирования памяти. Это может быть полезно для оптимизации производительности при работе с большими бинарными данными.
Основные принципы работы с RawBytes
- Временное владение памятью: RawBytes содержит ссылку на память, управляемую драйвером БД, а не на копию данных.
- Ограниченное время жизни: Данные в RawBytes действительны только до следующего вызова методов:
Next()Scan()Close()
- Небезопасность: Если сохранить RawBytes и попытаться использовать после вышеуказанных вызовов, это приведёт к неопределённому поведению.
Пример 1: Базовое сканирование
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
db, err := sql.Open("mysql", "user:password@/dbname")
if err != nil {
panic(err)
}
defer db.Close()
rows, err := db.Query("SELECT blob_column FROM my_table WHERE id = ?", 1)
if err != nil {
panic(err)
}
defer rows.Close()
for rows.Next() {
var raw sql.RawBytes
if err := rows.Scan(&raw); err != nil {
panic(err)
}
// Используем raw сразу, пока он действителен
fmt.Printf("Data: %s\n", raw)
// Если нужно сохранить данные, нужно сделать копию:
dataCopy := make([]byte, len(raw))
copy(dataCopy, raw)
// Теперь dataCopy можно использовать после rows.Next()
}
}
Пример 2: Сканирование нескольких столбцов
func scanMultipleColumns(db *sql.DB) error {
rows, err := db.Query("SELECT id, name, data FROM documents")
if err != nil {
return err
}
defer rows.Close()
for rows.Next() {
var id int
var name string
var data sql.RawBytes
if err := rows.Scan(&id, &name, &data); err != nil {
return err
}
fmt.Printf("ID: %d, Name: %s, Data length: %d\n", id, name, len(data))
// Обработка данных должна быть здесь
processData(data)
}
return rows.Err()
}
func processData(data []byte) {
// Обработка данных
}
Пример 3: Опасное использование (неправильное)
func incorrectUsage(db *sql.DB) {
rows, err := db.Query("SELECT data FROM large_blobs")
if err != nil {
panic(err)
}
defer rows.Close()
var allData [][]byte
for rows.Next() {
var raw sql.RawBytes
if err := rows.Scan(&raw); err != nil {
panic(err)
}
// ОШИБКА: сохраняем RawBytes, который станет недействительным
allData = append(allData, raw)
}
// Здесь allData содержит недействительные данные!
for _, data := range allData {
fmt.Println(data) // Может привести к панике или неверным данным
}
}
Когда использовать RawBytes
- Для больших бинарных данных, когда копирование нежелательно
- Для временной обработки данных, которые не нужно сохранять
- Когда производительность критична, и вы готовы следить за временем жизни данных
Альтернативы
Если нужно сохранить данные:
var raw sql.RawBytes
var data []byte
rows.Scan(&raw)
data = make([]byte, len(raw))
copy(data, raw)
// Теперь data можно использовать в любом месте
type Result ¶
type Result интерфейс {
// LastInsertId возвращает целое число, сгенерированное базой данных
// в ответ на команду. Обычно это будет из
// столбца «автоинкремент» при вставке новой строки. Не все
// базы данных поддерживают эту функцию, и синтаксис таких
// операторов варьируется.
LastInsertId() (int64, error)
// RowsAffected возвращает количество строк, затронутых
// обновлением, вставкой или удалением. Не все базы данных или драйверы баз данных
// драйвер базы данных может поддерживать эту функцию.
RowsAffected() (int64, error)
}
Результат обобщает выполненную команду SQL.
12.4.6.9 - Описание типа Row database/sql
Row — результат вызова DB.QueryRow для выбора одной строки. В этом разделе представлены другие типы: Rows, Scanner
type Row
type Row struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Row — результат вызова DB.QueryRow для выбора одной строки.
func (*Row) Err
func (r *Row) Err() error
Err предоставляет способ для обертывающих пакетов проверять ошибки запроса без вызова Row.Scan. Err возвращает ошибку, если таковая имела место при выполнении запроса. Если эта ошибка не равна nil, она также будет возвращена из Row.Scan.
func (*Row) Scan
func (r *Row) Scan(dest ...any) error
Scan копирует столбцы из соответствующей строки в значения, на которые указывает dest. Подробности см. в документации по Rows.Scan. Если запросу соответствует более одной строки, Scan использует первую строку и отбрасывает остальные. Если ни одна строка не соответствует запросу, Scan возвращает ErrNoRows.
type Rows
type Rows struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Rows — это результат запроса. Его курсор начинается перед первой строкой набора результатов. Используйте Rows.Next для перехода от строки к строке.
Пример
package main
import (
"context"
"database/sql"
"log"
"strings"
)
// Глобальные переменные лучше инициализировать
var (
ctx = context.Background() // Инициализация контекста
db *sql.DB
)
func main() {
// На практике db должен быть инициализирован перед использованием
// Например:
// var err error
// db, err = sql.Open("driver-name", "datasource")
// if err != nil {
// log.Fatal(err)
// }
// defer db.Close()
age := 27
// Добавляем проверку, что db не nil
if db == nil {
log.Fatal("database connection is not initialized")
}
// Используем QueryContext вместо Query для явного указания контекста
rows, err := db.QueryContext(ctx, "SELECT name FROM users WHERE age=?", age)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
names := make([]string, 0)
for rows.Next() {
var name string
if err := rows.Scan(&name); err != nil {
log.Fatal(err)
}
names = append(names, name)
}
// Проверяем ошибки после итерации
if err := rows.Err(); err != nil {
log.Fatal(err)
}
// Добавляем проверку на пустой результат
if len(names) == 0 {
log.Printf("No users found with age %d", age)
return
}
log.Printf("%s are %d years old", strings.Join(names, ", "), age)
}
func (*Rows) Close
func (rs *Rows) Close() error
Close закрывает Rows, предотвращая дальнейшее перечисление. Если Rows.Next вызывается и возвращает false, а дальнейших наборов результатов нет, Rows закрывается автоматически, и достаточно проверить результат Rows.Err. Close является идемпотентным и не влияет на результат Rows.Err.
func (*Rows) ColumnTypes
func (rs *Rows) ColumnTypes() ([]*ColumnType, error)
ColumnTypes возвращает информацию о столбцах, такую как тип столбца, длина и возможность принятия нулевого значения. Некоторая информация может быть недоступна из некоторых драйверов.
func (*Rows) Columns
func (rs *Rows) Columns() ([]string, error)
Columns возвращает имена столбцов. Columns возвращает ошибку, если строки закрыты.
func (*Rows) Err
func (rs *Rows) Err() error
Err возвращает ошибку, если таковая возникла во время итерации. Err может быть вызван после явного или неявного Rows.Close.
func (*Rows) Next
func (rs *Rows) Next() bool
Next подготавливает следующую строку результата для чтения с помощью метода Rows.Scan. Он возвращает true в случае успеха или false, если следующей строки результата нет или при ее подготовке произошла ошибка. Для различения этих двух случаев следует обратиться к Rows.Err.
Каждому вызову Rows.Scan, даже первому, должен предшествовать вызов Rows.Next.
Функция Rows.Next() используется для итерации по строкам результата SQL-запроса.
Пример
Базовый пример использования Rows.Next()
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// Подключение к базе данных
db, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Выполнение запроса
rows, err := db.Query("SELECT id, name, email FROM users WHERE active = ?", true)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
// Итерация по строкам результата
for rows.Next() {
var id int
var name, email string
// Сканирование значений из текущей строки
if err := rows.Scan(&id, &name, &email); err != nil {
log.Fatal(err)
}
fmt.Printf("ID: %d, Name: %s, Email: %s\n", id, name, email)
}
// Проверка ошибок после итерации
if err := rows.Err(); err != nil {
log.Fatal(err)
}
}
Почему используется цикл for?
Цикл for rows.Next() выполняет итерации по всем строкам результата запроса:
Количество итераций равно количеству строк, возвращенных запросом.
Механизм работы:
- При первом вызове
rows.Next()перемещает курсор к первой строке результата - При последующих вызовах перемещает курсор к следующей строке
- Когда строки заканчиваются, возвращает
falseи цикл завершается
- При первом вызове
Важно: Каждый вызов
rows.Scan()должен быть предварен вызовомrows.Next()
Детализированный пример с обработкой ошибок
func getActiveUsers(db *sql.DB) ([]User, error) {
rows, err := db.Query("SELECT id, name, email FROM users WHERE active = ?", true)
if err != nil {
return nil, fmt.Errorf("query failed: %v", err)
}
defer rows.Close()
var users []User
for rows.Next() {
var u User
if err := rows.Scan(&u.ID, &u.Name, &u.Email); err != nil {
// Можно продолжить обработку других строк или прервать
return nil, fmt.Errorf("scan failed: %v", err)
}
users = append(users, u)
}
// Проверяем ошибки, которые могли возникнуть во время итерации
if err := rows.Err(); err != nil {
return nil, fmt.Errorf("rows iteration failed: %v", err)
}
return users, nil
}
type User struct {
ID int
Name string
Email string
}
Что происходит внутри цикла?
Первая итерация:
rows.Next()перемещает курсор к первой строке (если она есть)- Возвращает
true, если строка доступна - Выполняется
rows.Scan()
Последующие итерации:
rows.Next()перемещает курсор к следующей строке- Цикл продолжается, пока есть строки
Завершение:
- Когда строки заканчиваются,
rows.Next()возвращаетfalse - Цикл прерывается
- Проверяется
rows.Err()на наличие ошибок
- Когда строки заканчиваются,
Важные нюансы:
- Всегда вызывайте
defer rows.Close()для освобождения ресурсов - Проверяйте
rows.Err()после цикла для выявления ошибок итерации - Не используйте
rows.Next()без последующегоrows.Scan() - Для пустых результатов цикл не выполнится ни разу
Альтернативный пример с обработкой пустого результата
func printUserCount(db *sql.DB) {
rows, err := db.Query("SELECT COUNT(*) FROM users")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
// rows.Next() вернет true, даже если только одна строка
if rows.Next() {
var count int
if err := rows.Scan(&count); err != nil {
log.Fatal(err)
}
fmt.Printf("Total users: %d\n", count)
}
if err := rows.Err(); err != nil {
log.Fatal(err)
}
}
Этот пример показывает, что даже для запросов, возвращающих одну строку (как COUNT), необходимо использовать rows.Next() перед rows.Scan().
func (*Rows) NextResultSet
func (rs *Rows) NextResultSet() bool
NextResultSet подготавливает следующий набор результатов для чтения. Он сообщает, есть ли дальнейшие наборы результатов, или false, если дальнейших наборов результатов нет или если произошла ошибка при переходе к ним. Для различения этих двух случаев следует обратиться к методу Rows.Err.
После вызова NextResultSet перед сканированием всегда следует вызывать метод Rows.Next. Если есть дальнейшие наборы результатов, они могут не содержать строк в наборе результатов.
Функция NextResultSet() используется, когда запрос к базе данных возвращает несколько наборов результатов (например, при выполнении хранимых процедур или пакетных запросов).
Пример
Пример с несколькими наборами результатов
package main
import (
"context"
"database/sql"
"fmt"
"log"
_ "github.com/go-sql-driver/mysql" // Импорт драйвера MySQL
)
func main() {
// Инициализация подключения к базе данных
db, err := sql.Open("mysql", "user:password@tcp(127.0.0.1:3306)/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Запрос, возвращающий несколько наборов результатов
// (например, хранимая процедура с несколькими SELECT)
query := `
SELECT id, name FROM users WHERE active = 1;
SELECT id, title FROM products WHERE price > 100;
SELECT COUNT(*) FROM orders WHERE status = 'completed';
`
// Выполнение запроса
rows, err := db.QueryContext(context.Background(), query)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
// Обработка первого набора результатов (пользователи)
fmt.Println("=== Active Users ===")
for rows.Next() {
var id int
var name string
if err := rows.Scan(&id, &name); err != nil {
log.Fatal(err)
}
fmt.Printf("ID: %d, Name: %s\n", id, name)
}
if err := rows.Err(); err != nil {
log.Fatal(err)
}
// Переход к следующему набору результатов (продукты)
if rows.NextResultSet() {
fmt.Println("\n=== Expensive Products ===")
for rows.Next() {
var id int
var title string
if err := rows.Scan(&id, &title); err != nil {
log.Fatal(err)
}
fmt.Printf("ID: %d, Title: %s\n", id, title)
}
if err := rows.Err(); err != nil {
log.Fatal(err)
}
}
// Переход к следующему набору результатов (количество заказов)
if rows.NextResultSet() {
fmt.Println("\n=== Completed Orders Count ===")
for rows.Next() {
var count int
if err := rows.Scan(&count); err != nil {
log.Fatal(err)
}
fmt.Printf("Completed orders: %d\n", count)
}
if err := rows.Err(); err != nil {
log.Fatal(err)
}
}
// Проверяем, есть ли еще наборы результатов
if rows.NextResultSet() {
fmt.Println("\nThere are more result sets available")
} else {
fmt.Println("\nNo more result sets")
}
}
Ключевые моменты работы с NextResultSet():
Порядок обработки: Всегда сначала обрабатывайте текущий набор результатов с помощью
Next()иScan(), прежде чем переходить к следующему.Проверка наличия результатов:
NextResultSet()возвращаетtrue, если есть следующий набор результатов, даже если он пустой.Обработка ошибок: После
NextResultSet()всегда проверяйтеrows.Err()на наличие ошибок.Пустые наборы: Набор результатов может не содержать строк - это нормально, просто
Next()вернетfalseсразу.
Альтернативный пример с хранимой процедурой
func callMultiResultStoredProcedure(db *sql.DB) error {
// Вызов хранимой процедуры, возвращающей несколько наборов результатов
rows, err := db.Query("CALL get_report_data()")
if err != nil {
return err
}
defer rows.Close()
// Обработка всех наборов результатов
resultSetIndex := 0
for {
// Обработка текущего набора результатов
for rows.Next() {
// В зависимости от набора результатов используем разную логику сканирования
switch resultSetIndex {
case 0:
var id int
var name string
if err := rows.Scan(&id, &name); err != nil {
return err
}
fmt.Printf("User: %d - %s\n", id, name)
case 1:
var product string
var price float64
if err := rows.Scan(&product, &price); err != nil {
return err
}
fmt.Printf("Product: %s - $%.2f\n", product, price)
// Можно добавить дополнительные case для других наборов
}
}
if err := rows.Err(); err != nil {
return err
}
// Переход к следующему набору результатов
if !rows.NextResultSet() {
break
}
resultSetIndex++
}
return nil
}
Важные предупреждения:
- Не все драйверы баз данных поддерживают несколько наборов результатов.
- Всегда проверяйте
rows.Err()послеNextResultSet(). - После перехода к новому набору результатов обязательно вызывайте
rows.Next()перед сканированием. - Структура данных в каждом наборе результатов может отличаться.
func (*Rows) Scan
func (rs *Rows) Scan(dest ...any) error
Scan копирует столбцы в текущей строке в значения, на которые указывает dest. Количество значений в dest должно совпадать с количеством столбцов в Rows.
Scan преобразует столбцы, прочитанные из базы данных, в следующие общие типы Go и специальные типы, предоставляемые пакетом sql:
*string
*[]byte
*int, *int8, *int16, *int32, *int64
*uint, *uint8, *uint16, *uint32, *uint64
*bool
*float32, *float64
*interface{}
*RawBytes
*Rows (cursor value)
любой тип, реализующий Scanner (см. документацию по Scanner)
В самом простом случае, если тип значения из исходного столбца является целым, bool или строковым типом T, а dest имеет тип *T, Scan просто присваивает значение через указатель.
Scan также преобразует строковые и числовые типы, если при этом не теряется информация. В то время как Scan преобразует все числа, сканированные из числовых столбцов базы данных, в *string, сканирование в числовые типы проверяется на переполнение. Например, float64 со значением 300 или строка со значением «300» могут быть отсканированы в uint16, но не в uint8, хотя float64(255) или «255» могут быть отсканированы в uint8. Исключением является то, что при сканировании некоторых чисел float64 в строки может произойти потеря информации при преобразовании в строку. В общем случае, сканируйте столбцы с плавающей запятой в *float64.
Если аргумент dest имеет тип *[]byte, Scan сохраняет в этом аргументе копию соответствующих данных. Копия принадлежит вызывающему и может быть изменена и храниться неограниченное время. Копирование можно избежать, используя вместо этого аргумент типа *RawBytes; ограничения на его использование см. в документации по RawBytes.
Если аргумент имеет тип *interface{}, Scan копирует значение, предоставленное базовым драйвером, без преобразования. При сканировании из исходного значения типа []byte в *interface{} создается копия среза, и вызывающая сторона владеет результатом.
Исходные значения типа time.Time могут быть отсканированы в значения типа *time.Time, *interface{}, *string или *[]byte. При преобразовании в два последних используется time.RFC3339Nano.
Источниковые значения типа bool могут быть просканированы в типы *bool, *interface{}, *string, *[]byte или *RawBytes.
Для сканирования в *bool источником могут быть true, false, 1, 0 или строковые входы, которые можно проанализировать с помощью strconv.ParseBool.
Scan также может преобразовать курсор, возвращенный из запроса, такого как «select cursor(select * from my_table) from dual», в значение *Rows, которое само по себе может быть просканировано. Родительский запрос select закроет любой курсор *Rows, если родительский *Rows закрыт.
Если любой из первых аргументов, реализующих Scanner, возвращает ошибку, эта ошибка будет обернута в возвращаемую ошибку.
type Scanner
type Scanner interface {
// Scan назначает значение из драйвера базы данных.
//
// Значение src будет одного из следующих типов:
//
// int64
// float64
// bool
// []byte
// string
// time.Time
// nil - для значений NULL
//
// Если значение не может быть сохранено
// без потери информации.
//
// Типы ссылок, такие как []byte, действительны только до следующего вызова Scan
// и не должны сохраняться. Их базовая память принадлежит драйверу.
// Если сохранение необходимо, скопируйте их значения перед следующим вызовом Scan.
Scan(src any) error
}
Scanner — интерфейс, используемый Rows.Scan.
12.4.6.10 - Описание типа Stmt database/sql
Stmt — это подготовленное выражение. Stmt безопасно для одновременного использования несколькими goroutines.
type Stmt
type Stmt struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Stmt — это подготовленное выражение. Stmt безопасно для одновременного использования несколькими goroutines.
Если Stmt подготовлен на Tx или Conn, он будет навсегда привязан к одному базовому соединению. Если Tx или Conn закрывается, Stmt станет непригодным для использования, и все операции будут возвращать ошибку. Если Stmt подготовлен на DB, он будет оставаться пригодным для использования в течение всего срока жизни DB. Когда Stmt необходимо выполнить на новом базовом соединении, он автоматически подготовится на новом соединении.
Пример
package main
import (
"context"
"database/sql"
"log"
_ "github.com/go-sql-driver/mysql" // Добавляем импорт драйвера
)
func main() {
// Инициализируем контекст
ctx := context.Background()
// Инициализируем соединение с базой данных (в реальном коде)
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Проверяем соединение
if err := db.PingContext(ctx); err != nil {
log.Fatal(err)
}
// Создаем подготовленное выражение
stmt, err := db.PrepareContext(ctx, "SELECT username FROM users WHERE id = ?")
if err != nil {
log.Fatal(err)
}
defer stmt.Close()
// Выполняем запрос с параметром
id := 43
var username string
err = stmt.QueryRowContext(ctx, id).Scan(&username)
switch {
case err == sql.ErrNoRows:
log.Printf("no user with id %d", id) // Используем Printf вместо Fatalf чтобы не завершать программу
case err != nil:
log.Fatal(err)
default:
log.Printf("username is %s\n", username)
}
}
func (*Stmt) Close
func (s *Stmt) Close() error
Close закрывает оператор.
func (*Stmt) Exec
func (s *Stmt) Exec(args ...any) (Result, error)
Exec выполняет подготовленный оператор с заданными аргументами и возвращает Result, обобщающий результат оператора.
Exec использует context.Background внутренне; чтобы указать контекст, используйте Stmt.ExecContext.
func (*Stmt) ExecContext
func (s *Stmt) ExecContext(ctx context.Context, args ...any) (Result, error)
ExecContext выполняет подготовленное выражение с заданными аргументами и возвращает Result, обобщающий результат выражения.
func (*Stmt) Query
func (s *Stmt) Query(args ...any) (*Rows, error)
Query выполняет подготовленный запрос с заданными аргументами и возвращает результаты запроса в виде *Rows.
Query использует context.Background внутренне; для указания контекста используйте Stmt.QueryContext.
func (*Stmt) QueryContext ¶
func (s *Stmt) QueryContext(ctx context.Context, args ...any) (*Rows, error)
QueryContext выполняет подготовленное запросное выражение с заданными аргументами и возвращает результаты запроса в виде *Rows.
func (*Stmt) QueryRow
func (s *Stmt) QueryRow(args ...any) *Row
QueryRow выполняет подготовленный запрос с заданными аргументами. Если во время выполнения запроса происходит ошибка, она будет возвращена вызовом Scan на возвращенном *Row, который всегда не равен nil. Если запрос не выбирает никаких строк, *Row.Scan вернет ErrNoRows. В противном случае *Row.Scan сканирует первую выбранную строку и отбрасывает остальные.
Пример использования:
var name string
err := nameByUseridStmt.QueryRow(id).Scan(&name)
QueryRow использует context.Background внутренне; для указания контекста используйте Stmt.QueryRowContext.
func (*Stmt) QueryRowContext
func (s *Stmt) QueryRowContext(ctx context.Context, args ...any) *Row
QueryRowContext выполняет подготовленный запрос с заданными аргументами. Если во время выполнения запроса происходит ошибка, она будет возвращена вызовом Scan на возвращенном *Row, который всегда не равен nil. Если запрос не выбирает никаких строк, *Row.Scan вернет ErrNoRows. В противном случае *Row.Scan сканирует первую выбранную строку и отбрасывает остальные.
Пример
package main
import (
"context"
"database/sql"
"log"
_ "github.com/go-sql-driver/mysql" // Не забудьте импортировать драйвер
)
func main() {
// 1. Инициализация контекста
ctx := context.Background()
// 2. Инициализация подключения к БД (пример для MySQL)
db, err := sql.Open("mysql", "username:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// 3. Проверка соединения
if err := db.PingContext(ctx); err != nil {
log.Fatal("Failed to ping database:", err)
}
// 4. Создание подготовленного выражения
stmt, err := db.PrepareContext(ctx, "SELECT username FROM users WHERE id = ?")
if err != nil {
log.Fatal("Failed to prepare statement:", err)
}
defer stmt.Close()
// 5. Выполнение запроса
id := 43
var username string
err = stmt.QueryRowContext(ctx, id).Scan(&username)
// 6. Обработка результатов
switch {
case err == sql.ErrNoRows:
log.Printf("User with id %d not found", id) // Не фатальная ошибка
case err != nil:
log.Fatal("Query failed:", err)
default:
log.Printf("Found user: %s (ID: %d)", username, id)
}
}
12.4.6.11 - Описание типа Tx database/sql
Tx — это незавершенная транзакция базы данных.
type Tx
type Tx struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Tx — это незавершенная транзакция базы данных.
Транзакция должна заканчиваться вызовом Tx.Commit или Tx.Rollback.
После вызова Tx.Commit или Tx.Rollback все операции по транзакции завершаются с ошибкой ErrTxDone.
Инструкции, подготовленные для транзакции вызовом методов Tx.Prepare или Tx.Stmt транзакции, закрываются вызовом Tx.Commit или Tx.Rollback.
func (*Tx) Commit
func (tx *Tx) Commit() error
Commit фиксирует транзакцию.
func (*Tx) Exec
func (tx *Tx) Exec(query string, args ...any) (Result, error)
Exec выполняет запрос, который не возвращает строки. Например: INSERT и UPDATE.
Exec использует context.Background внутренне; для указания контекста используйте Tx.ExecContext.
func (*Tx) ExecContext
func (tx *Tx) ExecContext(ctx context.Context, query string, args ...any) (Result, error)
ExecContext выполняет запрос, который не возвращает строки. Например: INSERT и UPDATE.
Пример
package main
import (
"context"
"database/sql"
"log"
_ "github.com/go-sql-driver/mysql" // Импорт драйвера БД
)
func main() {
// Инициализация подключения к БД
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/dbname")
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// Проверка соединения
ctx := context.Background()
if err := db.PingContext(ctx); err != nil {
log.Fatal("Database connection failed:", err)
}
// Начало транзакции
tx, err := db.BeginTx(ctx, &sql.TxOptions{Isolation: sql.LevelSerializable})
if err != nil {
log.Fatal("Failed to begin transaction:", err)
}
// Выполнение операций в транзакции
id := 37
_, execErr := tx.ExecContext(ctx, "UPDATE users SET status = ? WHERE id = ?", "paid", id)
if execErr != nil {
// Попытка отката при ошибке
if rollbackErr := tx.Rollback(); rollbackErr != nil {
log.Printf("UPDATE failed: %v, rollback also failed: %v", execErr, rollbackErr)
} else {
log.Printf("UPDATE failed, transaction rolled back: %v", execErr)
}
return
}
// Фиксация транзакции
if err := tx.Commit(); err != nil {
log.Fatal("Failed to commit transaction:", err)
}
log.Println("Transaction completed successfully")
}
func (*Tx) Prepare
func (tx *Tx) Prepare(query string) (*Stmt, error)
Prepare создает подготовленное выражение для использования в транзакции.
Возвращаемое выражение работает в рамках транзакции и будет закрыто после фиксации или отката транзакции.
Чтобы использовать существующее подготовленное выражение в этой транзакции, см. Tx.Stmt.
Prepare использует context.Background внутренне; чтобы указать контекст, используйте Tx.PrepareContext.
Пример
package main
import (
"context"
"database/sql"
"log"
_ "github.com/go-sql-driver/mysql" // Импорт драйвера БД
)
func main() {
// Инициализация подключения к БД
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/dbname?parseTime=true")
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// Проверка соединения
if err := db.Ping(); err != nil {
log.Fatal("Database connection failed:", err)
}
projects := []struct {
mascot string
release int
}{
{"tux", 1991},
{"duke", 1996},
{"gopher", 2009},
{"moby dock", 2013},
}
// Начало транзакции
ctx := context.Background()
tx, err := db.BeginTx(ctx, nil)
if err != nil {
log.Fatal("Failed to begin transaction:", err)
}
// Откат в случае ошибки (игнорируется если был Commit)
defer func() {
if err := tx.Rollback(); err != nil && err != sql.ErrTxDone {
log.Printf("Warning: rollback failed: %v", err)
}
}()
// Подготовка выражения
stmt, err := tx.PrepareContext(ctx, "INSERT INTO projects(id, mascot, release, category) VALUES(?, ?, ?, ?)")
if err != nil {
log.Fatal("Failed to prepare statement:", err)
}
defer stmt.Close()
// Вставка данных
for id, project := range projects {
if _, err := stmt.ExecContext(ctx, id+1, project.mascot, project.release, "open source"); err != nil {
log.Fatal("Failed to insert project:", err)
}
}
// Фиксация транзакции
if err := tx.Commit(); err != nil {
log.Fatal("Failed to commit transaction:", err)
}
log.Println("Successfully inserted", len(projects), "projects")
}
Дополнительные рекомендации:
Параметры подключения:
db.SetMaxOpenConns(25) db.SetMaxIdleConns(25) db.SetConnMaxLifetime(5*time.Minute)Пакетная вставка: Для большого количества данных рассмотрите возможность:
// Начало пакетной вставки values := make([]interface{}, 0, len(projects)*4) query := "INSERT INTO projects(id, mascot, release, category) VALUES" for id, project := range projects { if id > 0 { query += "," } query += "(?, ?, ?, ?)" values = append(values, id+1, project.mascot, project.release, "open source") } if _, err := tx.ExecContext(ctx, query, values...); err != nil { log.Fatal(err) }Таймауты:
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second) defer cancel()Валидация данных: Добавьте проверку данных перед вставкой:
if project.release < 1990 || project.release > time.Now().Year() { log.Printf("Invalid release year for %s: %d", project.mascot, project.release) continue }
func (*Tx) PrepareContext
func (tx *Tx) PrepareContext(ctx context.Context, query string) (*Stmt, error)
PrepareContext создает подготовленное выражение для использования в транзакции.
Возвращенное выражение работает в рамках транзакции и будет закрыто после фиксации или отката транзакции.
Чтобы использовать существующее подготовленное выражение в этой транзакции, см. Tx.Stmt.
Предоставленный контекст будет использоваться для подготовки контекста, а не для выполнения возвращаемого оператора. Возвращаемый оператор будет выполняться в контексте транзакции.
func (*Tx) Query
func (tx *Tx) Query(query string, args ...any) (*Rows, error)
Query выполняет запрос, который возвращает строки, обычно SELECT.
Query использует context.Background внутренне; чтобы указать контекст, используйте Tx.QueryContext.
func (*Tx) QueryContext
func (tx *Tx) QueryContext(ctx context.Context, query string, args ...any) (*Rows, error)
QueryContext выполняет запрос, который возвращает строки, обычно SELECT.
func (*Tx) QueryRow
func (tx *Tx) QueryRow(query string, args ...any) *Row
QueryRow выполняет запрос, который должен вернуть не более одной строки. QueryRow всегда возвращает значение, отличное от nil. Ошибки откладываются до вызова метода Scan Row. Если запрос не выбирает ни одной строки, *Row.Scan вернет ErrNoRows. В противном случае *Row.Scan сканирует первую выбранную строку и отбрасывает остальные.
QueryRow использует context.Background внутренне; для указания контекста используйте Tx.QueryRowContext.
func (*Tx) QueryRowContext
func (tx *Tx) QueryRowContext(ctx context.Context, query string, args ...any) *Row
QueryRowContext выполняет запрос, который должен вернуть не более одной строки. QueryRowContext всегда возвращает значение, отличное от nil. Ошибки откладываются до вызова метода Scan Row. Если запрос не выбирает ни одной строки, *Row.Scan вернет ErrNoRows. В противном случае *Row.Scan сканирует первую выбранную строку и отбрасывает остальные.
func (*Tx) Rollback
func (tx *Tx) Rollback() error
Rollback прерывает транзакцию.
Пример
код транзакции для обновления водителей и заказов
package main
import (
"context"
"database/sql"
"log"
_ "github.com/lib/pq" // Импорт драйвера PostgreSQL
)
func main() {
// Инициализация подключения к БД
connStr := "user=postgres dbname=mydb sslmode=disable"
db, err := sql.Open("postgres", connStr)
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// Проверка соединения
if err := db.Ping(); err != nil {
log.Fatal("Database connection failed:", err)
}
// Создаем контекст с таймаутом
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// Начало транзакции
tx, err := db.BeginTx(ctx, &sql.TxOptions{Isolation: sql.LevelSerializable})
if err != nil {
log.Fatal("Failed to begin transaction:", err)
}
// Гарантированный откат при ошибках
defer func() {
if err := tx.Rollback(); err != nil && err != sql.ErrTxDone {
log.Printf("Warning: rollback error: %v", err)
}
}()
id := 53
// 1. Обновление статуса водителя
_, err = tx.ExecContext(ctx, "UPDATE drivers SET status = $1 WHERE id = $2", "assigned", id)
if err != nil {
log.Printf("Failed to update driver status: %v", err)
return
}
// 2. Назначение водителя на заказы
_, err = tx.ExecContext(ctx, "UPDATE pickups SET driver_id = $1 WHERE driver_id IS NULL", id)
if err != nil {
log.Printf("Failed to assign driver to pickups: %v", err)
return
}
// Фиксация транзакции
if err := tx.Commit(); err != nil {
log.Fatal("Failed to commit transaction:", err)
}
log.Printf("Successfully assigned driver %d and updated pickup orders", id)
}
Дополнительные улучшения:
Безопасность UPDATE:
// Ограничиваем обновление только незанятыми заказами "UPDATE pickups SET driver_id = $1 WHERE driver_id IS NULL"Проверка результата:
res, err := tx.ExecContext(...) if rowsAffected, _ := res.RowsAffected(); rowsAffected == 0 { log.Printf("Warning: no rows were updated") }Повторные попытки:
maxRetries := 3 for i := 0; i < maxRetries; i++ { // ... выполнение транзакции ... if err == nil { break } if shouldRetry(err) { continue } break }Connection Pool:
db.SetMaxOpenConns(25) db.SetMaxIdleConns(25) db.SetConnMaxLifetime(5*time.Minute)
func (*Tx) Stmt
func (tx *Tx) Stmt(stmt *Stmt) *Stmt
Stmt возвращает подготовленное заявление, специфичное для транзакции, из существующего заявления.
Пример:
updateMoney, err := db.Prepare(«UPDATE balance SET money=money+? WHERE id=?»)
...
tx, err := db.Begin()...
res, err := tx.Stmt(updateMoney).Exec(123.45, 98293203)
Возвращенное выражение работает в рамках транзакции и будет закрыто после фиксации или отката транзакции.
Stmt использует context.Background внутри всегда; для указания контекста используйте Tx.StmtContext.
func (*Tx) StmtContext
func (tx *Tx) StmtContext(ctx context.Context, stmt *Stmt) *Stmt
StmtContext возвращает подготовленное выражение, специфичное для транзакции, из существующего выражения.
Пример:
updateMoney, err := db.Prepare(«UPDATE balance SET money=money+? WHERE id=?») … tx, err := db.Begin()…
res, err := tx.StmtContext(ctx, updateMoney).Exec(123.45, 98293203) Предоставленный контекст используется для подготовки оператора, а не для его выполнения.
Возвращенный оператор работает в рамках транзакции и будет закрыт после фиксации или отката транзакции.
type TxOptions
type TxOptions struct {
// Isolation — уровень изоляции транзакции.
// Если равен нулю, используется уровень по умолчанию драйвера или базы данных.
Isolation IsolationLevel
ReadOnly bool
}
TxOptions содержит параметры транзакции, которые будут использоваться в DB.BeginTx.
12.4.7 - Описание пакета flag языка программирования Go
Пакет flag реализует разбор флагов командной строки.
Использование
Определите флаги с помощью flag.String, Bool, Int и т. д.
Это объявляет целочисленный флаг -n, хранящийся в указателе nFlag, с типом *int:
import «flag»
var nFlag = flag.Int("n", 1234, "сообщение справки для флага n")
При желании можно привязать флаг к переменной с помощью функций Var().
var flagvar int
func init() {
flag.IntVar(&flagvar, "flagname", 1234, "сообщение справки для flagname")
}
Или можно создать пользовательские флаги, которые удовлетворяют интерфейсу Value (с указателями-приемниками), и связать их с разбором флагов с помощью
flag.Var(&flagVal, "name", "сообщение справки для flagname")
Для таких флагов значением по умолчанию является просто начальное значение переменной.
После определения всех флагов вызовите
flag.Parse()
чтобы проанализировать командную строку в определенные флаги.
Затем флаги можно использовать напрямую. Если вы используете сами флаги, все они являются указателями; если вы связываете их с переменными, они являются значениями.
fmt.Println(«ip имеет значение », *ip)
fmt.Println(«flagvar имеет значение », flagvar)
После разбора аргументы, следующие за флагами, доступны как срез flag.Args или по отдельности как flag.Arg(i). Аргументы индексируются от 0 до flag.NArg-1.
Синтаксис флагов командной строки ¶
Допускаются следующие формы:
-flag
--flag // также допускаются двойные тире
-flag=x
-flag x // только небулевые флаги
Можно использовать один или два тире; они эквивалентны. Последняя форма не допускается для булевых флагов, поскольку значение команды
cmd -x *
где * — подстановочный знак оболочки Unix, изменится, если есть файл с именем 0, false и т. д. Для отключения булевого флага необходимо использовать форму -flag=false.
Разбор флагов прекращается непосредственно перед первым аргументом, не являющимся флагом («-» является аргументом, не являющимся флагом), или после терминатора «–».
- Целочисленные флаги принимают значения
1234,0664,0x1234и могут быть отрицательными. - Булевы флаги могут быть:
1, 0, t, f, T, F, true, false, TRUE, FALSE, True, False
Флаги продолжительности принимают любой ввод, допустимый для time.ParseDuration.
Набор флагов командной строки по умолчанию управляется функциями верхнего уровня. Тип FlagSet позволяет определять независимые наборы флагов, например для реализации подкоманд в интерфейсе командной строки. Методы FlagSet аналогичны функциям верхнего уровня для набора флагов командной строки.
Пример
package main
import (
"errors"
"flag"
"fmt"
"os"
"strings"
"time"
)
// Пример 1: Флаг строки с именем "species" и значением по умолчанию "gopher"
var species = flag.String("species", "gopher", "the species we are studying")
// Пример 2: Два флага (длинный и короткий) с общей переменной
var gopherType string
func init() {
const (
defaultGopher = "pocket"
usage = "the variety of gopher"
)
flag.StringVar(&gopherType, "gopher_type", defaultGopher, usage)
flag.StringVar(&gopherType, "g", defaultGopher, usage+" (shorthand)")
}
// Пример 3: Пользовательский тип флага - срез интервалов времени
type interval []time.Duration
// String реализует интерфейс flag.Value
func (i *interval) String() string {
if len(*i) == 0 {
return ""
}
var b strings.Builder
for idx, d := range *i {
if idx > 0 {
b.WriteString(", ")
}
b.WriteString(d.String())
}
return b.String()
}
// Set реализует интерфейс flag.Value
func (i *interval) Set(value string) error {
// Разрешаем множественные установки флага для накопления значений
for _, dt := range strings.Split(value, ",") {
duration, err := time.ParseDuration(strings.TrimSpace(dt))
if err != nil {
return fmt.Errorf("invalid duration %q: %v", dt, err)
}
*i = append(*i, duration)
}
return nil
}
var intervalFlag interval
func init() {
flag.Var(&intervalFlag, "deltaT", "comma-separated list of intervals to use between events")
}
func main() {
// Парсим флаги
flag.Parse()
// Выводим значения флагов
fmt.Println("Species:", *species)
fmt.Println("Gopher type:", gopherType)
fmt.Println("Intervals:", intervalFlag.String())
// Пример использования
if len(intervalFlag) == 0 {
fmt.Println("No intervals specified. Use -deltaT flag")
os.Exit(1)
}
// Демонстрация работы с интервалами
for i, d := range intervalFlag {
fmt.Printf("Event %d will happen after %v\n", i+1, d)
time.Sleep(d) // В реальном коде здесь была бы полезная работа
}
}
Как использовать:
- Сборка:
go build -o app
- Примеры запуска:
# Простой запуск
./app -species=rabbit -gopher_type=arctic -deltaT=1s,2s,3s
# Использование короткого флага
./app -g=arctic -deltaT=500ms,1s
# Просмотр помощи
./app -help
Переменные
var ErrHelp = errors.New("flag: help requested")
ErrHelp - это ошибка, возвращаемая при вызове флага -help или -h, но такой флаг не определен.
var Usage = func() {
fmt.Fprintf(CommandLine.Output(), "Usage of %s:\n", os.Args[0])
PrintDefaults()
}
Usage печатает сообщение об использовании всех определенных флагов командной строки в выходной файл CommandLine, который по умолчанию является os.Stderr.
Функция вызывается при возникновении ошибки во время разбора флагов.
Функция - это переменная, которая может быть изменена для указания на пользовательскую функцию. По умолчанию она печатает простой заголовок и вызывает PrintDefaults; подробности о формате вывода и о том, как им управлять, см. в документации к PrintDefaults.
Пользовательские функции могут выбрать выход из программы; по умолчанию выход происходит в любом случае, поскольку стратегия обработки ошибок в командной строке установлена на ExitOnError.
12.4.7.1 - Функции пакета flag
Основные функции пакета flag
func Arg
func Arg(i int) string
Arg возвращает i-й аргумент командной строки. Arg(0) — это первый аргумент, оставшийся после обработки флагов. Arg возвращает пустую строку, если запрошенный элемент не существует.
func Args
func Args() []string
Args возвращает аргументы командной строки, не являющиеся флагами.
func Bool
func Bool(name string, value bool, usage string) *bool
Bool определяет флаг bool с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной bool, в которой хранится значение флага.
func BoolFunc
добавлено в go1.21.0
func BoolFunc(name, usage string, fn func(string) error)
BoolFunc определяет флаг с указанным именем и строкой использования без требования значений. Каждый раз, когда флаг встречается, вызывается fn со значением флага. Если fn возвращает ошибку, отличную от nil, она будет рассматриваться как ошибка разбора значения флага.
Пример
package main
import (
"flag"
"fmt"
"os"
)
func main() {
// Создаем новый набор флагов
fs := flag.NewFlagSet("ExampleBoolFunc", flag.ContinueOnError)
fs.SetOutput(os.Stdout) // Выводим ошибки в stdout
// Регистрируем BoolFunc флаг
fs.BoolFunc("log", "logs a dummy message (default: false)", func(s string) error {
if s == "" {
// Без значения - просто флаг присутствует
fmt.Println("dummy message: flag is set")
return nil
}
// С значением - выводим его
fmt.Printf("dummy message: %s\n", s)
return nil
})
// Пример 1: Флаг без значения
fmt.Println("\nCase 1: -log (no value)")
if err := fs.Parse([]string{"-log"}); err != nil {
fmt.Println("Error:", err)
}
// Пример 2: Флаг с произвольным значением
fmt.Println("\nCase 2: -log=0")
if err := fs.Parse([]string{"-log=0"}); err != nil {
fmt.Println("Error:", err)
}
// Пример 3: Неизвестный флаг
fmt.Println("\nCase 3: -unknown")
if err := fs.Parse([]string{"-unknown"}); err != nil {
fmt.Println("Error:", err)
}
// Пример 4: Вывод помощи
fmt.Println("\nCase 4: -help")
fs.PrintDefaults()
}
Запуск программы:
go run main.go -log -log=hello
Результат:
Case 1: -log (no value)
dummy message: flag is set
Case 2: -log=0
dummy message: 0
Case 3: -unknown
Error: flag provided but not defined: -unknown
Case 4: -help
-log
logs a dummy message (default: false)
func BoolVar
func BoolVar(p *bool, name string, value bool, usage string)
BoolVar определяет флаг bool с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную bool, в которой будет храниться значение флага.
func Duration
func Duration(name string, value time.Duration, usage string) *time.Duration
Duration определяет флаг time.Duration с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной time.Duration, в которой хранится значение флага. Флаг принимает значение, допустимое для time.ParseDuration.
func DurationVar
func DurationVar(p *time.Duration, name string, value time.Duration, usage string)
DurationVar определяет флаг time.Duration с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную time.Duration, в которой хранится значение флага. Флаг принимает значение, допустимое для time.ParseDuration.
func Float64
func Float64(name string, value float64, usage string) *float64
Float64 определяет флаг float64 с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной float64, в которой хранится значение флага.
func Float64Var
func Float64Var(p *float64, name string, value float64, usage string)
Float64Var определяет флаг float64 с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную float64, в которой хранится значение флага.
func Float64Var
func Float64Var(p *float64, name string, value float64, usage string)
Float64Var определяет флаг float64 с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную float64, в которой будет храниться значение флага.
func Func
func Func(name, usage string, fn func(string) error)
Func определяет флаг с указанным именем и строкой использования. Каждый раз, когда флаг встречается, вызывается функция fn со значением флага. Если fn возвращает ошибку, отличную от nil, это будет расценено как ошибка разбора значения флага.
Пример
package main
import (
"errors"
"flag"
"fmt"
"net"
"os"
)
func main() {
// Создаем новый набор флагов
fs := flag.NewFlagSet("ExampleFunc", flag.ContinueOnError)
fs.SetOutput(os.Stdout)
// Переменная для хранения IP
var ip net.IP
// Регистрируем функцию-парсер для IP
fs.Func("ip", "`IP address` to parse (e.g. 192.168.1.1 or ::1)", func(s string) error {
parsedIP := net.ParseIP(s)
if parsedIP == nil {
return fmt.Errorf("invalid IP address format: %q", s)
}
ip = parsedIP
return nil
})
// Тест 1: Валидный IPv4 адрес
fmt.Println("Test case 1: Valid IPv4 address")
if err := fs.Parse([]string{"-ip", "127.0.0.1"}); err != nil {
fmt.Printf("Error: %v\n", err)
} else {
fmt.Printf("Parsed IP: %v\n", ip)
fmt.Printf("Is loopback: %t\n\n", ip.IsLoopback())
}
// Тест 2: Невалидный IP адрес
fmt.Println("Test case 2: Invalid IP address")
if err := fs.Parse([]string{"-ip", "256.0.0.1"}); err != nil {
fmt.Printf("Error: %v\n\n", err)
} else {
fmt.Printf("Parsed IP: %v\n", ip)
}
// Тест 3: Валидный IPv6 адрес
fmt.Println("Test case 3: Valid IPv6 address")
if err := fs.Parse([]string{"-ip", "::1"}); err != nil {
fmt.Printf("Error: %v\n", err)
} else {
fmt.Printf("Parsed IP: %v\n", ip)
fmt.Printf("Is loopback: %t\n\n", ip.IsLoopback())
}
// Вывод справки
fmt.Println("Help message:")
fs.PrintDefaults()
}
Вывод программы:
Test case 1: Valid IPv4 address
Parsed IP: 127.0.0.1
Is loopback: true
Test case 2: Invalid IP address
Error: invalid IP address format: "256.0.0.1"
Test case 3: Valid IPv6 address
Parsed IP: ::1
Is loopback: true
Help message:
-ip IP address
`IP address` to parse (e.g. 192.168.1.1 or ::1)
func Int
func Int(name string, value int, usage string) *int
Int определяет флаг int с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной int, в которой хранится значение флага.
func Int64
func Int64(name string, value int64, usage string) *int64
Int64 определяет флаг int64 с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной int64, в которой хранится значение флага.
func Int64Var
func Int64Var(p *int64, name string, value int64, usage string)
Int64Var определяет флаг int64 с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную int64, в которой хранится значение флага.
func IntVar
func IntVar(p *int, name string, value int, usage string)
IntVar определяет флаг int с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную int, в которой будет храниться значение флага.
func NArg
func NArg() int
NArg — количество аргументов, оставшихся после обработки флагов.
func NFlag
func NFlag() int
NFlag возвращает количество установленных флагов командной строки.
func Parse
func Parse()
Parse анализирует флаги командной строки из os.Args[1:]. Должен вызываться после определения всех флагов и до доступа к флагам из программы.
func Parsed
func Parsed() bool
Parsed сообщает, были ли проанализированы флаги командной строки.
func PrintDefaults
func PrintDefaults()
PrintDefaults выводит в стандартный поток ошибок (если не настроено иначе) сообщение об использовании, показывающее настройки по умолчанию всех определенных флагов командной строки. Для флага x с целочисленным значением вывод по умолчанию имеет вид
-x int
usage-message-for-x (default 7)
Сообщение об использовании будет отображаться в отдельной строке для всех флагов, кроме флагов типа bool с однобайтовым именем.
Для флагов типа bool тип опускается, и если имя флага состоит из одного байта, сообщение об использовании отображается в той же строке.
Значение по умолчанию в скобках опускается, если значение по умолчанию для типа равно нулю.
Указанный тип, в данном случае int, можно изменить, поместив имя в обратные кавычки в строке использования флага; первый такой элемент в сообщении принимается за имя параметра, которое будет отображаться в сообщении, а обратные кавычки удаляются из сообщения при отображении. Например, при задании
flag.String("I", "", "search `directory` for include files")
вывод будет следующим
-I directory
search directory for include files.
Чтобы изменить место назначения для сообщений флага, вызовите CommandLine.SetOutput.
func Set
func Set(name, value string) error
Set устанавливает значение флага командной строки с указанным именем.
func String
func String(name string, value string, usage string) *string
String определяет строковый флаг с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес строковой переменной, в которой хранится значение флага.
func StringVar
func StringVar(p *string, name string, value string, usage string)
StringVar определяет строковый флаг с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на строковую переменную, в которой хранится значение флага.
func TextVar
func TextVar(p encoding.TextUnmarshaler, name string, value encoding.TextMarshaler, usage string)
TextVar определяет флаг с указанным именем, значением по умолчанию и строкой использования. Аргумент p должен быть указателем на переменную, которая будет хранить значение флага, и p должен реализовывать encoding.TextUnmarshaler. Если флаг используется, его значение будет передано методу UnmarshalText p. Тип значения по умолчанию должен быть таким же, как тип p.
Пример
package main
import (
"flag"
"fmt"
"net"
"os"
)
func main() {
// Создаем новый набор флагов
fs := flag.NewFlagSet("ExampleTextVar", flag.ContinueOnError)
fs.SetOutput(os.Stdout)
// Переменная для хранения IP с значением по умолчанию
var ip net.IP = net.IPv4(192, 168, 0, 100)
// Регистрируем TextVar флаг для парсинга IP
fs.TextVar(&ip, "ip", ip, "`IP address` to parse (e.g. 192.168.1.1 or ::1)")
// Тест 1: Валидный IPv4 адрес
fmt.Println("Test case 1: Valid IPv4 address (127.0.0.1)")
if err := fs.Parse([]string{"-ip", "127.0.0.1"}); err != nil {
fmt.Printf("Error: %v\n", err)
} else {
fmt.Printf("Parsed IP: %v\n", ip)
fmt.Printf("Is loopback: %t\n\n", ip.IsLoopback())
}
// Тест 2: Невалидный IP адрес
fmt.Println("Test case 2: Invalid IP address (256.0.0.1)")
ip = nil // Сбрасываем предыдущее значение
if err := fs.Parse([]string{"-ip", "256.0.0.1"}); err != nil {
fmt.Printf("Error: %v\n\n", err)
} else {
fmt.Printf("Parsed IP: %v\n\n", ip)
}
// Тест 3: Вывод справки
fmt.Println("Test case 3: Help message")
fs.PrintDefaults()
}
Вывод программы:
Test case 1: Valid IPv4 address (127.0.0.1)
Parsed IP: 127.0.0.1
Is loopback: true
Test case 2: Invalid IP address (256.0.0.1)
Error: invalid IP address: 256.0.0.1
Test case 3: Help message
-ip IP address
`IP address` to parse (e.g. 192.168.1.1 or ::1) (default 192.168.0.100)
func Uint
func Uint(name string, value uint, usage string) *uint
Uint определяет флаг uint с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной uint, которая хранит значение флага.
func Uint64
func Uint64(name string, value uint64, usage string) *uint64
Uint64 определяет флаг uint64 с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной uint64, в которой хранится значение флага.
func Uint64Var
func Uint64Var(p *uint64, name string, value uint64, usage string)
Uint64Var определяет флаг uint64 с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную uint64, в которой будет храниться значение флага.
func UintVar
func UintVar(p *uint, name string, value uint, usage string)
UintVar определяет флаг uint с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную uint, в которой будет храниться значение флага.
func UnquoteUsage
func UnquoteUsage(flag *Flag) (name string, usage string)
UnquoteUsage извлекает имя в обратных кавычках из строки использования для флага и возвращает его и использование без кавычек. При заданном “a `name` to show” возвращает (“name”, “a name to show”). Если обратные кавычки отсутствуют, имя является обоснованным предположением о типе значения флага или пустой строкой, если флаг является булевым.
func Var
func Var(value Value, name string, usage string)
Var определяет флаг с указанным именем и строкой использования. Тип и значение флага представлены первым аргументом типа Value, который обычно содержит пользовательскую реализацию Value. Например, вызывающий может создать флаг, который преобразует строку, разделенную запятыми, в набор строк, предоставив набору методы Value; в частности, Set разложит строку, разделенную запятыми, на набор.
Пример
Пример использования flag.Var() с пользовательским типом
package main
import (
"errors"
"flag"
"fmt"
"strings"
)
// StringSet - пользовательский тип для множества строк
type StringSet map[string]struct{}
// String реализует интерфейс flag.Value
func (s StringSet) String() string {
return strings.Join(s.ToSlice(), ",")
}
// Set реализует интерфейс flag.Value
func (s StringSet) Set(value string) error {
if len(s) > 0 {
return errors.New("StringSet already set")
}
for _, item := range strings.Split(value, ",") {
item = strings.TrimSpace(item)
if item != "" {
s[item] = struct{}{}
}
}
return nil
}
// ToSlice преобразует StringSet в срез строк
func (s StringSet) ToSlice() []string {
result := make([]string, 0, len(s))
for k := range s {
result = append(result, k)
}
return result
}
func main() {
// Инициализируем наш StringSet
var tags StringSet = make(map[string]struct{})
// Регистрируем флаг через flag.Var
flag.Var(&tags, "tags", "comma-separated list of tags")
// Парсим аргументы командной строки
flag.Parse()
// Выводим результат
fmt.Println("Tags count:", len(tags))
fmt.Println("Tags list:", tags.ToSlice())
// Примеры запуска:
// go run main.go -tags=go,programming,example
// go run main.go -tags="rust, systems programming"
}
Ключевые компоненты:
Пользовательский тип
StringSet:- Реализует интерфейс
flag.Valueс методамиString()иSet() - Хранит уникальные строки как ключи map
- Реализует интерфейс
Метод
Set():- Разбивает строку по запятым
- Игнорирует пустые элементы
- Возвращает ошибку при повторной установке
Метод
String():- Формирует строку из элементов через запятую
- Используется для вывода значения по умолчанию
Дополнительный метод
ToSlice():- Удобное преобразование в срез строк
Как это работает:
При вызове
flag.Var()пакет flag получает:- Указатель на наш StringSet
- Имя флага (“tags”)
- Описание для справки
При парсинге аргументов:
- Для флага
-tags=go,programmingвызываетсяSet("go,programming") - Наш метод разбивает строку и заполняет map
- Для флага
При выводе справки:
- Вызывается
String()для показа текущего значения
- Вызывается
func Visit
func Visit(fn func(*Flag))
Visit посещает флаги командной строки в лексикографическом порядке, вызывая fn для каждого из них. Он посещает только те флаги, которые были установлены.
func VisitAll
func VisitAll(fn func(*Flag))
VisitAll посещает флаги командной строки в лексикографическом порядке, вызывая fn для каждого из них. Он посещает все флаги, даже те, которые не были установлены.
12.4.7.2 - Типы пакета flag
Типы и их функции, включенные в пакет flag
type ErrorHandling
type ErrorHandling int
ErrorHandling определяет, как будет вести себя FlagSet.Parse в случае неудачи разбора.
const (
ContinueOnError ErrorHandling = iota // Возвращаем описательную ошибку.
ExitOnError // Вызов os.Exit(2) или для -h/-help Exit(0).
PanicOnError // Вызываем панику с описанием ошибки.
)
Эти константы заставляют FlagSet.Parse вести себя так, как описано в случае неудачи разбора.
type Flag
type Flag struct {
Name string // имя в командной строке
Usage string // справочное сообщение
Value Value // значение по умолчанию
DefValue string // значение по умолчанию (в виде текста); для сообщения об использовании
}
Флаг представляет состояние флага.
func Lookup
func Lookup(name string) *Flag
Lookup возвращает структуру Flag именованного флага командной строки, возвращая nil, если таковой не существует.
type FlagSet
type FlagSet struct {
// Usage - это функция, вызываемая при возникновении ошибки во время разбора флагов.
// Поле представляет собой функцию (не метод), которая может быть изменена для указания на
// пользовательский обработчик ошибок. То, что произойдет после вызова Usage, зависит
// от настройки ErrorHandling; для командной строки по умолчанию
// установлено значение ExitOnError, которое завершает работу программы после вызова Usage.
Usage func()
// содержит отфильтрованные или неэкспонированные поля
}
FlagSet представляет собой набор определенных флагов. Нулевое значение FlagSet не имеет имени и имеет обработку ошибки ContinueOnError.
Имена флагов должны быть уникальными в пределах FlagSet. Попытка определить флаг, имя которого уже используется, приведет к панике.
Пример
package main
import (
"flag"
"fmt"
"os"
"time"
)
func main() {
if len(os.Args) < 2 {
printUsage()
os.Exit(1)
}
switch os.Args[1] {
case "start":
start(os.Args[2:])
case "stop":
stop(os.Args[2:])
case "help", "-h", "--help":
printUsage()
default:
fmt.Printf("error: unknown command %q\n", os.Args[1])
printUsage()
os.Exit(1)
}
}
func start(args []string) {
fs := flag.NewFlagSet("start", flag.ExitOnError)
addr := fs.String("addr", ":8080", "address to listen on")
logLevel := fs.String("log-level", "info", "log level (debug, info, warn, error)")
if err := fs.Parse(args); err != nil {
fs.Usage()
os.Exit(1)
}
fmt.Printf("Starting server on %s with log level %s\n", *addr, *logLevel)
// Здесь была бы реальная логика запуска сервера
}
func stop(args []string) {
fs := flag.NewFlagSet("stop", flag.ExitOnError)
timeout := fs.Duration("timeout", 5*time.Second, "stop timeout duration")
force := fs.Bool("force", false, "force shutdown")
if err := fs.Parse(args); err != nil {
fs.Usage()
os.Exit(1)
}
fmt.Printf("Stopping server (timeout=%v, force=%t)\n", *timeout, *force)
// Здесь была бы реальная логика остановки сервера
}
func printUsage() {
fmt.Println("Usage:")
fmt.Println(" httpd start [-addr :port] [-log-level level]")
fmt.Println(" httpd stop [-timeout duration] [-force]")
fmt.Println(" httpd help")
fmt.Println("\nFlags:")
fmt.Println(" -h, --help Show this help message")
}
Как использовать:
- Запуск сервера:
./httpd start -addr :9999 -log-level debug
- Остановка сервера:
./httpd stop -timeout 10s -force
- Просмотр справки:
./httpd help
# или
./httpd -h
var CommandLine *FlagSet
CommandLine - это набор флагов командной строки по умолчанию, взятый из os.Args. Функции верхнего уровня, такие как BoolVar, Arg и так далее, являются обертками для методов CommandLine.
func NewFlagSet
func NewFlagSet(name string, errorHandling ErrorHandling) *FlagSet
NewFlagSet возвращает новый пустой набор флагов с указанным именем и свойством обработки ошибок. Если имя не пустое, оно будет выведено в сообщении об использовании по умолчанию и в сообщениях об ошибках.
Пример
Объяснение flag.NewFlagSet с примерами
Функция flag.NewFlagSet создает новый независимый набор флагов, что особенно полезно для реализации:
- Подкоманд в CLI-приложениях (например,
git commit,docker run) - Изолированных групп флагов
- Повторного использования флагов в разных контекстах
Параметры:
name- имя набора флагов (используется в сообщениях об ошибках и справке)errorHandling- стратегия обработки ошибок:flag.ContinueOnError- продолжить выполнение после ошибкиflag.ExitOnError- вызватьos.Exit(2)при ошибкеflag.PanicOnError- вызватьpanicпри ошибке
Пример 1: Базовое использование
package main
import (
"flag"
"fmt"
)
func main() {
// Создаем новый набор флагов
fs := flag.NewFlagSet("example", flag.ExitOnError)
// Добавляем флаги
verbose := fs.Bool("verbose", false, "enable verbose output")
port := fs.Int("port", 8080, "port to listen on")
// Парсим аргументы
fs.Parse([]string{"-verbose", "-port", "9090"})
// Используем значения
fmt.Printf("Verbose: %v, Port: %d\n", *verbose, *port)
}
Пример 2: Подкоманды (как в git/docker)
package main
import (
"flag"
"fmt"
"os"
)
func main() {
if len(os.Args) < 2 {
fmt.Println("Expected 'greet' or 'time' subcommands")
os.Exit(1)
}
switch os.Args[1] {
case "greet":
// Набор флагов для команды greet
greetCmd := flag.NewFlagSet("greet", flag.ExitOnError)
name := greetCmd.String("name", "World", "name to greet")
greetCmd.Parse(os.Args[2:])
fmt.Printf("Hello, %s!\n", *name)
case "time":
// Набор флагов для команды time
timeCmd := flag.NewFlagSet("time", flag.ExitOnError)
format := timeCmd.String("format", "15:04:05", "time format")
timeCmd.Parse(os.Args[2:])
fmt.Println("Current time:", time.Now().Format(*format))
default:
fmt.Printf("Unknown command %q\n", os.Args[1])
os.Exit(1)
}
}
Пример 3: Разные стратегии обработки ошибок
package main
import (
"flag"
"fmt"
)
func main() {
// ContinueOnError - продолжить после ошибки
fs1 := flag.NewFlagSet("continue", flag.ContinueOnError)
fs1.Int("port", 0, "port number")
err := fs1.Parse([]string{"-port", "invalid"})
fmt.Println("ContinueOnError:", err)
// ExitOnError - выход при ошибке
fs2 := flag.NewFlagSet("exit", flag.ExitOnError)
fs2.Int("port", 0, "port number")
// В реальном коде это вызвало бы os.Exit(2)
fmt.Print("ExitOnError: ")
fs2.Parse([]string{"-port", "invalid"})
}
Рекомендации по использованию:
- Для CLI-приложений используйте
flag.ExitOnError - Для библиотек лучше
flag.ContinueOnError - Имя набора флагов помогает пользователю понять контекст ошибки
- Можно создавать несколько независимых наборов флагов в одной программе
func (*FlagSet) Arg
func (f *FlagSet) Arg(i int) string
Arg возвращает i-й аргумент. Arg(0) — это первый оставшийся аргумент после обработки флагов. Arg возвращает пустую строку, если запрошенный элемент не существует.
func (*FlagSet) Args
func (f *FlagSet) Args() []string
Args возвращает аргументы, не являющиеся флагами.
func (*FlagSet) Bool
func (f *FlagSet) Bool(name string, value bool, usage string) *bool
Bool определяет флаг bool с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной bool, в которой хранится значение флага.
func (*FlagSet) BoolFunc
func (f *FlagSet) BoolFunc(name, usage string, fn func(string) error)
BoolFunc определяет флаг с указанным именем и строкой использования без требования значений. Каждый раз, когда флаг встречается, вызывается fn со значением флага. Если fn возвращает ошибку, отличную от nil, она будет рассматриваться как ошибка разбора значения флага.
func (*FlagSet) BoolVar
func (f *FlagSet) BoolVar(p *bool, name string, value bool, usage string)
BoolVar определяет флаг bool с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную bool, в которой будет храниться значение флага.
func (*FlagSet) Duration
func (f *FlagSet) Duration(name string, value time.Duration, usage string) *time.Duration
Duration определяет флаг time.Duration с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной time.Duration, в которой хранится значение флага. Флаг принимает значение, допустимое для time.ParseDuration.
Пример
Объяснение flag.Duration с примерами
Метод Duration создает флаг для работы с временными интервалами (тип time.Duration). Это особенно полезно для параметров, которые представляют временные значения (таймауты, интервалы и т.д.).
Основные параметры:
name- имя флага (например, “timeout”)value- значение по умолчанию (например, 5*time.Second)usage- описание флага для справки
Пример 1: Простое использование
package main
import (
"flag"
"fmt"
"time"
)
func main() {
// Создаем флаг с продолжительностью
timeout := flag.Duration("timeout", 3*time.Second, "operation timeout duration")
// Парсим аргументы командной строки
flag.Parse()
// Используем значение
fmt.Printf("Waiting for %v before timeout...\n", *timeout)
time.Sleep(*timeout)
fmt.Println("Timeout reached!")
}
Использование:
go run main.go -timeout=2s
# или
go run main.go -timeout=500ms
Пример 2: В составе FlagSet (подкоманды)
package main
import (
"flag"
"fmt"
"time"
)
func main() {
serverCmd := flag.NewFlagSet("server", flag.ExitOnError)
// Флаги для команды server
port := serverCmd.Int("port", 8080, "port to listen on")
readTimeout := serverCmd.Duration("read-timeout", 5*time.Second, "read timeout")
writeTimeout := serverCmd.Duration("write-timeout", 10*time.Second, "write timeout")
serverCmd.Parse([]string{"-port=9000", "-read-timeout=2s", "-write-timeout=5s"})
fmt.Printf("Server config:\n")
fmt.Printf(" Port: %d\n", *port)
fmt.Printf(" Read Timeout: %v\n", *readTimeout)
fmt.Printf(" Write Timeout: %v\n", *writeTimeout)
}
Пример 3: Поддержка разных форматов времени
Флаг Duration автоматически поддерживает все форматы, которые понимает time.ParseDuration:
package main
import (
"flag"
"fmt"
)
func main() {
interval := flag.Duration("interval", 1*time.Minute, "check interval")
flag.Parse()
fmt.Printf("Checking every %v\n", *interval)
fmt.Printf("In nanoseconds: %d\n", interval.Nanoseconds())
}
Допустимые форматы:
- “300ms” - миллисекунды
- “1.5h” - часы с дробной частью
- “2h45m” - комбинированный формат
- “1d” - дни (расширение Go, означает 24h)
Типичные сценарии использования:
- Таймауты операций:
timeout := flag.Duration("timeout", 30*time.Second, "operation timeout")
- Интервалы повторения:
interval := flag.Duration("interval", 1*time.Hour, "check interval")
- Временные ограничения:
ttl := flag.Duration("ttl", 24*time.Hour, "time to live")
func (*FlagSet) DurationVar
func (f *FlagSet) DurationVar(p *time.Duration, name string, value time.Duration, usage string)
DurationVar определяет флаг time.Duration с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную time.Duration, в которой хранится значение флага. Флаг принимает значение, допустимое для time.ParseDuration.
func (*FlagSet) ErrorHandling
func (f *FlagSet) ErrorHandling() ErrorHandling
ErrorHandling возвращает поведение обработки ошибок набора флагов.
Пример
Объяснение ErrorHandling() с примерами
Метод ErrorHandling() возвращает текущую стратегию обработки ошибок для набора флагов (FlagSet). Это полезно, когда нужно проверить или изменить поведение обработки ошибок во время выполнения.
Возможные значения:
flag.ContinueOnError- продолжить выполнение после ошибкиflag.ExitOnError- вызватьos.Exit(2)при ошибкеflag.PanicOnError- вызватьpanicпри ошибке
Пример 1: Проверка текущей стратегии
package main
import (
"flag"
"fmt"
)
func main() {
// Создаем набор флагов с разными стратегиями
fs1 := flag.NewFlagSet("server", flag.ContinueOnError)
fs2 := flag.NewFlagSet("client", flag.ExitOnError)
// Проверяем стратегии обработки ошибок
fmt.Println("Server error handling:", fs1.ErrorHandling())
fmt.Println("Client error handling:", fs2.ErrorHandling())
}
Вывод:
Server error handling: 1 // ContinueOnError
Client error handling: 2 // ExitOnError
Пример 2: Динамическое изменение поведения
package main
import (
"flag"
"fmt"
"os"
)
func main() {
fs := flag.NewFlagSet("app", flag.ContinueOnError)
fs.Int("port", 8080, "port number")
// Для демонстрации - имитируем ошибку
args := []string{"-port", "invalid"}
// Парсим с текущей стратегией (ContinueOnError)
err := fs.Parse(args)
fmt.Printf("With ContinueOnError: error=%v, port=%d\n", err, fs.Lookup("port").Value)
// Меняем стратегию на ExitOnError
fs.Init(fs.Name(), flag.ExitOnError)
fmt.Println("New error handling:", fs.ErrorHandling())
// При новой стратегии парсинг вызовет os.Exit(2)
fmt.Print("With ExitOnError: ")
fs.Parse(args) // В реальности здесь будет выход
}
Пример 3: Использование в кастомной обработке ошибок
package main
import (
"flag"
"fmt"
"os"
)
func main() {
fs := flag.NewFlagSet("config", flag.ContinueOnError)
fs.String("config", "", "config file path")
fs.Duration("timeout", 5*time.Second, "operation timeout")
err := fs.Parse(os.Args[1:])
switch fs.ErrorHandling() {
case flag.ContinueOnError:
if err != nil {
fmt.Printf("Configuration error: %v\n", err)
// Продолжаем работу с значениями по умолчанию
}
case flag.ExitOnError:
// Обработка уже выполнена flag.Parse
case flag.PanicOnError:
// panic уже вызван
}
// Основная логика приложения
fmt.Println("Using config:", fs.Lookup("config").Value)
}
Основные сценарии использования:
- Библиотеки - когда нужно передать управление ошибкой вызывающему коду
- Тестирование - проверка поведения при разных стратегиях
- Гибкие CLI-утилиты - изменение поведения в зависимости от режима работы
Советы:
- Для приложений обычно используют
ExitOnError - Для библиотек лучше
ContinueOnError PanicOnErrorредко используется на практике
func (*FlagSet) Float64
func (f *FlagSet) Float64(name string, value float64, usage string) *float64
Float64 определяет флаг float64 с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной float64, в которой хранится значение флага.
func (*FlagSet) Float64Var
func (f *FlagSet) Float64Var(p *float64, name string, value float64, usage string)
Float64Var определяет флаг float64 с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную float64, в которой хранится значение флага.
func (*FlagSet) Func
func (f *FlagSet) Func(name, usage string, fn func(string) error)
Func определяет флаг с указанным именем и строкой использования. Каждый раз, когда флаг встречается, вызывается fn со значением флага. Если fn возвращает ошибку, отличную от nil, она будет рассматриваться как ошибка разбора значения флага.
func (*FlagSet) Init
func (f *FlagSet) Init(name string, errorHandling ErrorHandling)
Init устанавливает имя и свойство обработки ошибок для набора флагов. По умолчанию нулевой FlagSet использует пустое имя и политику обработки ошибок ContinueOnError.
func (*FlagSet) Int
func (f *FlagSet) Int(name string, value int, usage string) *int
Int определяет флаг int с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной int, в которой хранится значение флага.
func (*FlagSet) Int64
func (f *FlagSet) Int64(name string, value int64, usage string) *int64
Int64 определяет флаг int64 с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной int64, в которой хранится значение флага.
func (*FlagSet) Int64Var
func (f *FlagSet) Int64Var(p *int64, name string, value int64, usage string)
Int64Var определяет флаг int64 с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную int64, в которой хранится значение флага.
func (*FlagSet) IntVar
func (f *FlagSet) IntVar(p *int, name string, value int, usage string)
IntVar определяет флаг int с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную int, в которой будет храниться значение флага.
func (*FlagSet) Lookup
func (f *FlagSet) Lookup(name string) *Flag
Lookup возвращает структуру Flag с указанным именем флага, возвращая nil, если такой флаг не существует.
func (*FlagSet) NArg
func (f *FlagSet) NArg() int
NArg — количество аргументов, оставшихся после обработки флагов.
func (*FlagSet) NFlag
func (f *FlagSet) NFlag() int
NFlag возвращает количество установленных флагов.
func (*FlagSet) Name
func (f *FlagSet) Name() string
Name возвращает имя набора флагов.
func (*FlagSet) Output
func (f *FlagSet) Output() io.Writer
Output возвращает место назначения для сообщений об использовании и ошибках. os.Stderr возвращается, если выход не был установлен или был установлен в nil.
func (*FlagSet) Parse
func (f *FlagSet) Parse(arguments []string) error
Parse анализирует определения флагов из списка аргументов, который не должен включать имя команды. Должен вызываться после того, как все флаги в FlagSet определены, и до того, как программа получит доступ к флагам. Возвращаемое значение будет ErrHelp, если -help или -h были установлены, но не определены.
func (*FlagSet) Parsed
func (f *FlagSet) Parsed() bool
Parsed сообщает, был ли вызван f.Parse.
func (*FlagSet) PrintDefaults
func (f *FlagSet) PrintDefaults()
PrintDefaults выводит в стандартный поток ошибок (если не настроено иначе) значения по умолчанию всех определенных флагов командной строки в наборе. Дополнительную информацию см. в документации по глобальной функции PrintDefaults.
func (*FlagSet) Set
func (f *FlagSet) Set(name, value string) error
Set устанавливает значение флага с указанным именем.
func (*FlagSet) SetOutput
func (f *FlagSet) SetOutput(output io.Writer)
SetOutput устанавливает место назначения для сообщений об использовании и ошибках. Если output равно nil, используется os.Stderr.
func (*FlagSet) String
func (f *FlagSet) String(name string, value string, usage string) *string
String определяет строковый флаг с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес строковой переменной, в которой хранится значение флага.
func (*FlagSet) StringVar
func (f *FlagSet) StringVar(p *string, name string, value string, usage string)
StringVar определяет строковый флаг с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на строковую переменную, в которой будет храниться значение флага.
func (*FlagSet) TextVar
func (f *FlagSet) TextVar(p encoding.TextUnmarshaler, name string, value encoding.TextMarshaler, usage string)
TextVar определяет флаг с указанным именем, значением по умолчанию и строкой использования. Аргумент p должен быть указателем на переменную, которая будет хранить значение флага, и p должен реализовывать encoding.TextUnmarshaler. Если флаг используется, его значение будет передано методу UnmarshalText p. Тип значения по умолчанию должен быть таким же, как тип p.
func (*FlagSet) Uint
func (f *FlagSet) Uint(name string, value uint, usage string) *uint
Uint определяет флаг uint с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной uint, которая хранит значение флага.
func (*FlagSet) Uint64
func (f *FlagSet) Uint64(name string, value uint64, usage string) *uint64
Uint64 определяет флаг uint64 с указанным именем, значением по умолчанию и строкой использования. Возвращаемое значение — адрес переменной uint64, в которой хранится значение флага.
func (*FlagSet) Uint64Var
func (f *FlagSet) Uint64Var(p *uint64, name string, value uint64, usage string)
Uint64Var определяет флаг uint64 с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную uint64, в которой хранится значение флага.
func (*FlagSet) UintVar
func (f *FlagSet) UintVar(p *uint, name string, value uint, usage string)
UintVar определяет флаг uint с указанным именем, значением по умолчанию и строкой использования. Аргумент p указывает на переменную uint, в которой будет храниться значение флага.
func (*FlagSet) Var
func (f *FlagSet) Var(value Value, name string, usage string)
Var определяет флаг с указанным именем и строкой использования. Тип и значение флага представлены первым аргументом типа Value, который обычно содержит пользовательскую реализацию Value. Например, вызывающая сторона может создать флаг, который преобразует строку, разделенную запятыми, в набор строк, предоставив набору методы Value; в частности, Set разложит строку, разделенную запятыми, на набор.
func (*FlagSet) Visit
func (f *FlagSet) Visit(fn func(*Flag))
Visit посещает флаги в лексикографическом порядке, вызывая fn для каждого из них. Он посещает только те флаги, которые были установлены.
func (*FlagSet) VisitAll
func (f *FlagSet) VisitAll(fn func(*Flag))
VisitAll посещает флаги в лексикографическом порядке, вызывая fn для каждого из них. Он посещает все флаги, даже те, которые не были установлены.
type Getter
type Getter interface {
Value
Get() any
}
Getter — это интерфейс, который позволяет извлекать содержимое Value. Он оборачивает интерфейс Value, а не является его частью, поскольку появился после Go 1 и его правил совместимости. Все типы Value, предоставляемые этим пакетом, удовлетворяют интерфейсу Getter, за исключением типа, используемого Func.
Пример
Объяснение интерфейса Getter в пакете flag
Интерфейс Getter в пакете flag предоставляет способ получения значения флага в виде interface{} (тип any). Это расширение базового интерфейса Value, добавленное для обеспечения большей гибкости при работе с флагами.
Структура интерфейса:
type Getter interface {
Value
Get() any
}
Где:
Value- стандартный интерфейс для работы с флагами (требует методовString()иSet())Get() any- метод, возвращающий текущее значение флага в виде пустого интерфейса
Пример 1: Проверка значения флага
package main
import (
"flag"
"fmt"
"time"
)
func main() {
// Создаем несколько флагов разных типов
flag.Int("port", 8080, "server port")
flag.Duration("timeout", 5*time.Second, "operation timeout")
flag.String("name", "default", "service name")
flag.Parse()
// Получаем значения через Getter
printFlagValue("port")
printFlagValue("timeout")
printFlagValue("name")
}
func printFlagValue(name string) {
if f := flag.Lookup(name); f != nil {
if getter, ok := f.Value.(flag.Getter); ok {
fmt.Printf("%s: %v (%T)\n", name, getter.Get(), getter.Get())
} else {
fmt.Printf("%s: does not implement Getter\n", name)
}
} else {
fmt.Printf("%s: flag not found\n", name)
}
}
Пример 2: Кастомный тип с Getter
package main
import (
"flag"
"fmt"
"strings"
)
type StringSlice []string
func (s *StringSlice) String() string {
return strings.Join(*s, ",")
}
func (s *StringSlice) Set(value string) error {
*s = append(*s, value)
return nil
}
func (s *StringSlice) Get() any {
return []string(*s)
}
func main() {
var hosts StringSlice
flag.Var(&hosts, "host", "target host (can be specified multiple times)")
flag.Parse()
if g, ok := flag.Lookup("host").Value.(flag.Getter); ok {
fmt.Printf("Hosts: %v\n", g.Get())
}
}
Пример 3: Использование с разными типами флагов
package main
import (
"flag"
"fmt"
"reflect"
)
func main() {
// Разные типы флагов
intFlag := flag.Int("num", 42, "an integer")
boolFlag := flag.Bool("verbose", false, "verbose output")
stringFlag := flag.String("msg", "hello", "a message")
flag.Parse()
// Проверяем реализацию Getter для каждого флага
flags := []string{"num", "verbose", "msg"}
for _, name := range flags {
f := flag.Lookup(name)
if getter, ok := f.Value.(flag.Getter); ok {
val := getter.Get()
fmt.Printf("%s: %v (type: %v)\n", name, val, reflect.TypeOf(val))
}
}
}
Когда использовать Getter:
- Когда нужно работать с флагами разных типов единообразно
- Для создания обобщенных функций обработки флагов
- При реализации кастомных типов флагов с возможностью извлечения значения
Важные замечания:
- Почти все стандартные типы флагов реализуют
Getter - Исключение - флаги, созданные через
flag.Func() - Для проверки реализации используйте type assertion:
if getter, ok := flag.Value.(flag.Getter); ok { value := getter.Get() // ... }
Этот интерфейс особенно полезен при создании сложных CLI-приложений, где требуется гибкая работа с флагами разных типов.
type Value
type Value интерфейс {
String() string
Set(string) error
}
Value — это интерфейс к динамическому значению, хранящемуся в флаге. (Значение по умолчанию представлено в виде строки.)
Если Value имеет метод IsBoolFlag() bool, возвращающий true, парсер командной строки делает -name эквивалентным -name=true, а не использует следующий аргумент командной строки.
Set вызывается один раз, в порядке командной строки, для каждого присутствующего флага. Пакет flag может вызывать метод String с нулевым значением приемника, таким как указатель nil.
Пример
package main
import (
"flag"
"fmt"
"net/url"
)
// URLValue - кастомный тип для парсинга URL в флагах
type URLValue struct {
URL *url.URL // Хранит указатель на разобранный URL
}
// String реализует интерфейс flag.Value
func (v URLValue) String() string {
if v.URL != nil {
return v.URL.String()
}
return ""
}
// Set реализует интерфейс flag.Value
func (v *URLValue) Set(s string) error {
u, err := url.Parse(s)
if err != nil {
return fmt.Errorf("failed to parse URL: %w", err)
}
*v.URL = *u // Копируем разобранный URL
return nil
}
// Get реализует интерфейс flag.Getter
func (v URLValue) Get() any {
return v.URL
}
// Глобальная переменная для хранения разобранного URL
var targetURL = &url.URL{}
func main() {
// Создаем новый набор флагов
fs := flag.NewFlagSet("URLParser", flag.ExitOnError)
// Регистрируем наш кастомный флаг
fs.Var(&URLValue{targetURL}, "url", "URL to parse (e.g. 'https://example.com/path')")
// Парсим аргументы (в реальном приложении используйте os.Args[1:])
err := fs.Parse([]string{"-url", "https://golang.org/pkg/flag/"})
if err != nil {
fmt.Printf("Error parsing flags: %v\n", err)
return
}
// Выводим разобранные компоненты URL
fmt.Printf("Parsed URL components:\n")
fmt.Printf("{scheme: %q, host: %q, path: %q}\n",
targetURL.Scheme,
targetURL.Host,
targetURL.Path)
}
Комментарии по коду:
Интерфейс Value:
String()используется для вывода текущего значенияSet()парсит строку и сохраняет значение
Интерфейс Getter:
- Позволяет получить значение как
interface{} - Полезно для обобщенной обработки флагов
- Позволяет получить значение как
Особенности реализации:
- Используем указатель на
url.URLдля модификации - Метод
Set()должен быть с pointer receiver - Всегда проверяем ошибки парсинга URL
- Используем указатель на
Использование в реальных приложениях:
// Вместо fs.Parse([]string{...}) используйте: fs.Parse(os.Args[1:])Дополнительные улучшения:
- Можно добавить валидацию URL (например, требовать HTTPS)
- Можно добавить метод
IsSet()для проверки установки значения
Пример запуска:
go run main.go -url "https://example.com/api/v1?param=value"
Вывод:
Parsed URL components:
{scheme: "https", host: "example.com", path: "/api/v1"}
Этот код теперь представляет собой надежную реализацию кастомного флага для работы с URL в Go-приложениях.
12.4.8 - Полный справочник по пакету fmt в Go
Полное описание пакета fmt в Go с примерами применения и разными потоками вывода
Пакет fmt (format) — один из самых часто используемых в Go. Он предоставляет функции для форматированного ввода/вывода, аналогичные printf и scanf в C.
1. Основные функции вывода
1.1. Вывод в стандартный поток (stdout)
fmt.Print("Hello, ", "World!") // Без перевода строки
fmt.Println("Hello, World!") // С переводом строки
fmt.Printf("Name: %s, Age: %d\n", "Alice", 25) // Форматированный вывод
1.2. Вывод в строку (Sprint, Sprintf, Sprintln)
s1 := fmt.Sprint("Hello, ", "World!") // => "Hello, World!"
s2 := fmt.Sprintf("Name: %s, Age: %d", "Bob", 30) // => "Name: Bob, Age: 30"
s3 := fmt.Sprintln("Line with newline") // => "Line with newline\n"
1.3. Вывод в файл или io.Writer (Fprint, Fprintf, Fprintln)
file, _ := os.Create("output.txt")
fmt.Fprint(file, "Hello, file!") // Запись в файл
fmt.Fprintf(file, "Value: %v", 42) // Форматированная запись
fmt.Fprintln(file, "End of line") // Запись с переводом строки
2. Форматирование вывода (Printf, Sprintf, Fprintf)
2.1. Основные спецификаторы
| Спецификатор | Описание | Пример (%v) | Вывод (42) |
|---|---|---|---|
%v | Универсальный формат | %v | 42 |
%+v | С полями структур | %+v | {X:42} |
%#v | Go-синтаксис | %#v | 42 (int) |
%T | Тип переменной | %T | int |
%% | Символ % | %% | % |
2.2. Форматирование разных типов данных
// Целые числа
fmt.Printf("%d %b %o %x %X\n", 42, 42, 42, 42, 42) // 42 101010 52 2a 2A
// Вещественные числа
fmt.Printf("%f %.2f %e %g\n", 3.1415, 3.1415, 3.1415, 3.1415) // 3.141500 3.14 3.141500e+00 3.1415
// Строки и символы
fmt.Printf("%s %q %c\n", "Go", "Go", 'G') // Go "Go" G
// Логические значения
fmt.Printf("%t\n", true) // true
2.3. Ширина и точность
// Ширина поля (выравнивание)
fmt.Printf("|%5d|%-5d|\n", 42, 42) // | 42|42 |
// Точность для float
fmt.Printf("%.2f\n", 3.141592) // 3.14
// Комбинация ширины и точности
fmt.Printf("%10.2f\n", 3.141592) // " 3.14"
2.4. Позиционные аргументы
fmt.Printf("%[2]d %[1]d\n", 10, 20) // 20 10
3. Ввод данных (Scan, Scanf, Scanln)
3.1. Чтение из стандартного ввода (stdin)
var name string
var age int
fmt.Print("Enter name and age: ")
fmt.Scan(&name, &age) // Читает до пробела/перевода строки
fmt.Printf("Hello, %s (%d)\n", name, age)
3.2. Форматированный ввод (Scanf)
var a, b int
fmt.Scanf("%d,%d", &a, &b) // Ввод "10,20" → a=10, b=20
3.3. Чтение строки (Scanln)
var input string
fmt.Scanln(&input) // Читает до перевода строки
3.4. Чтение из строки (Sscan, Sscanf, Sscanln)
var x, y int
fmt.Sscanf("10 20", "%d %d", &x, &y) // x=10, y=20
3.5. Чтение из файла (Fscan, Fscanf, Fscanln)
file, _ := os.Open("input.txt")
var value int
fmt.Fscanf(file, "%d", &value) // Чтение числа из файла
4. Дополнительные функции
4.1. Форматирование ошибок (Errorf)
err := fmt.Errorf("invalid value: %d", 42) // Создает error
4.2. Вывод в io.Writer с форматированием (Fprintf)
var buf bytes.Buffer
fmt.Fprintf(&buf, "Value: %d", 42) // Запись в буфер
4.3. Сканирование из io.Reader (Fscanf)
reader := strings.NewReader("100")
var num int
fmt.Fscanf(reader, "%d", &num) // num = 100
5. Полезные примеры
5.1. Вывод таблицы
fmt.Printf("|%-10s|%10s|\n", "Name", "Age")
fmt.Printf("|%-10s|%10d|\n", "Alice", 25)
fmt.Printf("|%-10s|%10d|\n", "Bob", 30)
Вывод:
|Name | Age|
|Alice | 25|
|Bob | 30|
5.2. Чтение нескольких значений
var a, b int
fmt.Print("Enter two numbers: ")
fmt.Scan(&a, &b)
fmt.Println("Sum:", a+b)
5.3. Форматирование JSON
data := map[string]interface{}{"name": "Alice", "age": 25}
jsonStr := fmt.Sprintf("%+v", data) // {"age":25, "name":"Alice"}
Дополнительный раздел: Форматирование различных типов данных в Go
1. Форматирование базовых типов (Printf, Sprintf, Fprintf)
1.1. Целые числа (int, int32, int64, uint)
num := 42
fmt.Printf("Десятичное: %d\n", num) // 42
fmt.Printf("Двоичное: %b\n", num) // 101010
fmt.Printf("Восьмеричное: %o\n", num) // 52
fmt.Printf("Шестнадцатеричное (нижний регистр): %x\n", num) // 2a
fmt.Printf("Шестнадцатеричное (верхний регистр): %X\n", num) // 2A
fmt.Printf("С ведущими нулями: %05d\n", num) // 00042
1.2. Вещественные числа (float32, float64)
pi := 3.1415926535
fmt.Printf("По умолчанию: %f\n", pi) // 3.141593
fmt.Printf("С точностью 2 знака: %.2f\n", pi) // 3.14
fmt.Printf("Экспоненциальная запись: %e\n", pi) // 3.141593e+00
fmt.Printf("Автовыбор формата: %g\n", pi) // 3.1415926535
fmt.Printf("Ширина 10 символов: %10.2f\n", pi) // " 3.14"
1.3. Строки (string) и символы (rune)
str := "Hello"
fmt.Printf("Строка: %s\n", str) // Hello
fmt.Printf("Строка в кавычках: %q\n", str) // "Hello"
fmt.Printf("Ширина 10 символов: %10s\n", str) // " Hello"
fmt.Printf("Символ: %c\n", 'A') // A
fmt.Printf("Юникод-символ: %U\n", 'Я') // U+042F
1.4. Логические значения (bool)
flag := true
fmt.Printf("Логическое: %t\n", flag) // true
1.5. Указатели (*int, *string)
x := 42
ptr := &x
fmt.Printf("Указатель: %p\n", ptr) // 0xc0000180a8
fmt.Printf("Значение по указателю: %v\n", *ptr) // 42
2. Форматирование структур (struct) и массивов (slice, array)
2.1. Вывод структуры
type Person struct {
Name string
Age int
}
p := Person{"Alice", 25}
fmt.Printf("Универсальный формат: %v\n", p) // {Alice 25}
fmt.Printf("С полями: %+v\n", p) // {Name:Alice Age:25}
fmt.Printf("Go-синтаксис: %#v\n", p) // main.Person{Name:"Alice", Age:25}
2.2. Форматирование слайсов и массивов
arr := [3]int{1, 2, 3}
slice := []string{"a", "b", "c"}
fmt.Printf("Массив: %v\n", arr) // [1 2 3]
fmt.Printf("Слайс: %v\n", slice) // [a b c]
fmt.Printf("Go-синтаксис: %#v\n", slice) // []string{"a", "b", "c"}
3. Форматирование с помощью fmt.Append (Go 1.19+)
Функция fmt.Append позволяет форматировать данные и добавлять их в слайс байт ([]byte).
3.1. Базовое использование
buf := []byte("Данные: ")
buf = fmt.Append(buf, 42, " ", true)
fmt.Println(string(buf)) // Данные: 42 true
3.2. Форматированный вывод (Appendf)
buf := []byte("Число: ")
buf = fmt.Appendf(buf, "%05d", 42)
fmt.Println(string(buf)) // Число: 00042
3.3. Добавление в буфер (bytes.Buffer)
var buffer bytes.Buffer
buffer.WriteString("Строка: ")
fmt.Fprintf(&buffer, "%q", "Hello")
fmt.Println(buffer.String()) // Строка: "Hello"
4. Специальные форматы
4.1. Вывод времени (time.Time)
t := time.Now()
fmt.Printf("RFC3339: %v\n", t.Format(time.RFC3339)) // 2024-03-15T14:20:10Z
fmt.Printf("Кастомный формат: %02d.%02d.%04d\n", t.Day(), t.Month(), t.Year()) // 15.03.2024
4.2. Форматирование JSON
data := map[string]any{"name": "Alice", "age": 25}
jsonStr := fmt.Sprintf("%+v", data) // map[age:25 name:Alice]
4.3. Ширина и выравнивание
fmt.Printf("|%10s|\n", "left") // | left|
fmt.Printf("|%-10s|\n", "right") // |right |
fmt.Printf("|%10.2f|\n", 3.1415) // | 3.14|
5. Полезные примеры
5.1. Таблица с выравниванием
fmt.Printf("|%-10s|%10s|\n", "Name", "Age")
fmt.Printf("|%-10s|%10d|\n", "Alice", 25)
fmt.Printf("|%-10s|%10d|\n", "Bob", 30)
Вывод:
|Name | Age|
|Alice | 25|
|Bob | 30|
5.2. Форматирование ошибок
err := fmt.Errorf("ошибка: значение %d недопустимо", 100)
fmt.Println(err) // ошибка: значение 100 недопустимо
5.3. Чтение и запись в файл
// Запись
file, _ := os.Create("data.txt")
fmt.Fprintf(file, "Число: %d", 42)
file.Close()
// Чтение
file, _ = os.Open("data.txt")
var num int
fmt.Fscanf(file, "Число: %d", &num)
fmt.Println(num) // 42
12.4.9 - Описание пакета io языка программирования Go
Пакет io предоставляет базовые интерфейсы для примитивов ввода-вывода.
Его основная задача - обернуть существующие реализации таких примитивов, например, в пакете os, в общие публичные интерфейсы, которые абстрагируют эту функциональность, а также некоторые другие связанные с ней примитивы.
Поскольку эти интерфейсы и примитивы обертывают операции нижнего уровня с различными реализациями, если клиенты не проинформированы об ином, не следует полагать, что они безопасны для параллельного выполнения.
Константы
const (
SeekStart = 0 // поиск относительно начала файла
SeekCurrent = 1 // поиск относительно текущего смещения
SeekEnd = 2 // поиск относительно конца)
Значения whence поиска.
Переменные
var EOF = errors.New(«EOF»)
EOF — это ошибка, возвращаемая Read, когда входные данные больше не доступны. (Read должен возвращать сам EOF, а не ошибку, оборачивающую EOF, потому что вызывающие функции будут проверять EOF с помощью ==.) Функции должны возвращать EOF только для сигнализации о корректном завершении ввода. Если EOF возникает неожиданно в структурированном потоке данных, соответствующей ошибкой является либо ErrUnexpectedEOF, либо какая-либо другая ошибка, дающая более подробную информацию.
var ErrClosedPipe = errors.New(«io: read/write on closed pipe»)
ErrClosedPipe — это ошибка, используемая для операций чтения или записи в закрытом канале.
var ErrNoProgress = errors.New(«multiple Read calls return no data or error»)
ErrNoProgress возвращается некоторыми клиентами Reader, когда много вызовов Read не возвращают никаких данных или ошибок, что обычно является признаком неисправной реализации Reader.
var ErrShortBuffer = errors.New(«короткий буфер»)
ErrShortBuffer означает, что для чтения потребовался буфер большего размера, чем был предоставлен.
var ErrShortWrite = errors.New(«короткая запись»)
ErrShortWrite означает, что запись приняла меньше байтов, чем было запрошено, но не вернула явную ошибку.
var ErrUnexpectedEOF = errors.New(«неожиданный EOF»)
ErrUnexpectedEOF означает, что EOF был обнаружен в середине чтения блока фиксированного размера или структуры данных.
12.4.9.1 - Описание функций пакета io
Спецификация функций пакета io с примерами на языке Go
func Copy
func Copy(dst Writer, src Reader) (written int64, err error)
Copy копирует данные из src в dst до тех пор, пока не будет достигнут EOF в src или не произойдет ошибка. Функция возвращает количество скопированных байтов и первую ошибку, возникшую при копировании, если таковая имеется.
Успешная функция Copy возвращает err == nil, а не err == EOF. Поскольку функция Copy определена для чтения из src до EOF, она не рассматривает EOF из Read как ошибку, о которой следует сообщать.
Если src реализует WriterTo, копирование реализуется вызовом src.WriteTo(dst). В противном случае, если dst реализует ReaderFrom, копирование реализуется вызовом dst.ReadFrom(src).
Пример
package main
import (
"io"
"log"
"os"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
if _, err := io.Copy(os.Stdout, r); err != nil {
log.Fatal(err)
}
}
Output:
some io.Reader stream to be read
func CopyBuffer
func CopyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error)
CopyBuffer идентична Copy, за исключением того, что она проходит через предоставленный буфер (если он требуется), а не выделяет временный. Если buf равна nil, выделяется один; в противном случае, если она имеет нулевую длину, CopyBuffer вызывает панику.
Если src реализует WriterTo или dst реализует ReaderFrom, buf не будет использоваться для выполнения копирования.
Пример
package main
import (
"io"
"log"
"os"
"strings"
)
func main() {
r1 := strings.NewReader("first reader\n")
r2 := strings.NewReader("second reader\n")
buf := make([]byte, 8)
// buf is used here...
if _, err := io.CopyBuffer(os.Stdout, r1, buf); err != nil {
log.Fatal(err)
}
// ... reused here also. No need to allocate an extra buffer.
if _, err := io.CopyBuffer(os.Stdout, r2, buf); err != nil {
log.Fatal(err)
}
}
Output:
first reader
second reader
func CopyN
func CopyN(dst Writer, src Reader, n int64) (written int64, err error)
CopyN копирует n байт (или до возникновения ошибки) из src в dst. Он возвращает количество скопированных байтов и самую раннюю ошибку, возникшую во время копирования. При возвращении written == n тогда и только тогда, когда err == nil.
Если dst реализует ReaderFrom, копирование реализуется с его помощью.
Пример
package main
import (
"io"
"log"
"os"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read")
if _, err := io.CopyN(os.Stdout, r, 4); err != nil {
log.Fatal(err)
}
}
Output:
some
func Pipe
func Pipe() (*PipeReader, *PipeWriter)
Pipe создает синхронный конвейер в памяти. Его можно использовать для соединения кода, ожидающего io.Reader, с кодом, ожидающим io.Writer.
Чтение и запись в канале сопоставляются один к одному, за исключением случаев, когда для потребления одной записи требуется несколько чтений. То есть каждая запись в PipeWriter блокируется до тех пор, пока не будет удовлетворено одно или несколько чтений из PipeReader, которые полностью потребляют записанные данные. Данные копируются непосредственно из записи в соответствующее чтение (или чтения); внутренней буферизации нет.
Безопасно вызывать Read и Write параллельно друг с другом или с Close. Параллельные вызовы Read и параллельные вызовы Write также безопасны: отдельные вызовы будут последовательно блокироваться.
Пример
package main
import (
"fmt"
"io"
"log"
"os"
)
func main() {
r, w := io.Pipe()
go func() {
fmt.Fprint(w, "some io.Reader stream to be read\n")
w.Close()
}()
if _, err := io.Copy(os.Stdout, r); err != nil {
log.Fatal(err)
}
}
Output:
some io.Reader stream to be read
func ReadAll
func ReadAll(r Reader) ([]byte, error)
ReadAll читает из r до ошибки или EOF и возвращает прочитанные данные. Успешный вызов возвращает err == nil, а не err == EOF. Поскольку ReadAll определено для чтения из src до EOF, оно не рассматривает EOF из Read как ошибку, о которой следует сообщать.
Пример
package main
import (
"fmt"
"io"
"log"
"strings"
)
func main() {
r := strings.NewReader("Go is a general-purpose language designed with systems programming in mind.")
b, err := io.ReadAll(r)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s", b)
}
Output:
Go is a general-purpose language designed with systems programming in mind.
func ReadAtLeast
func ReadAtLeast(r Reader, buf []byte, min int) (n int, err error)
ReadAtLeast читает из r в buf, пока не прочитает как минимум min байт. Он возвращает количество скопированных байтов и ошибку, если было прочитано меньше байтов. Ошибка EOF возникает только в том случае, если не было прочитано ни одного байта. Если EOF возникает после чтения менее min байтов, ReadAtLeast возвращает ErrUnexpectedEOF. Если min больше длины buf, ReadAtLeast возвращает ErrShortBuffer. При возвращении n >= min, если и только если err == nil. Если r возвращает ошибку, прочитав не менее min байтов, ошибка игнорируется.
Пример
package main
import (
"fmt"
"io"
"log"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
buf := make([]byte, 14)
if _, err := io.ReadAtLeast(r, buf, 4); err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", buf)
// buffer smaller than minimal read size.
shortBuf := make([]byte, 3)
if _, err := io.ReadAtLeast(r, shortBuf, 4); err != nil {
fmt.Println("error:", err)
}
// minimal read size bigger than io.Reader stream
longBuf := make([]byte, 64)
if _, err := io.ReadAtLeast(r, longBuf, 64); err != nil {
fmt.Println("error:", err)
}
}
Output:
some io.Reader
error: short buffer
error: unexpected EOF
func ReadFull
func ReadFull(r Reader, buf []byte) (n int, err error)
ReadFull читает ровно len(buf) байтов из r в buf. Он возвращает количество скопированных байтов и ошибку, если было прочитано меньше байтов. Ошибка EOF возникает только в том случае, если не было прочитано ни одного байта. Если EOF возникает после чтения некоторых, но не всех байтов, ReadFull возвращает ErrUnexpectedEOF. При возвращении n == len(buf) тогда и только тогда, когда err == nil. Если r возвращает ошибку после чтения по крайней мере len(buf) байтов, ошибка игнорируется.
Пример
package main
import (
"fmt"
"io"
"log"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
buf := make([]byte, 4)
if _, err := io.ReadFull(r, buf); err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", buf)
// minimal read size bigger than io.Reader stream
longBuf := make([]byte, 64)
if _, err := io.ReadFull(r, longBuf); err != nil {
fmt.Println("error:", err)
}
}
Output:
some
error: unexpected EOF
func WriteString
func WriteString(w Writer, s string) (n int, err error)
WriteString записывает содержимое строки s в w, который принимает набор байтов. Если w реализует StringWriter, [StringWriter.WriteString] вызывается напрямую. В противном случае [Writer.Write] вызывается ровно один раз.
Пример
package main
import (
"io"
"log"
"os"
)
func main() {
if _, err := io.WriteString(os.Stdout, "Hello World"); err != nil {
log.Fatal(err)
}
}
Output:
Hello World
12.4.9.2 - Описание типов пакета io языка программирования GO
Описание типов и их функций пакета io языка программирования GO
type ByteReader
type ByteReader interface {
ReadByte() (byte, error)
}
ByteReader — это интерфейс, который оборачивает метод ReadByte.
ReadByte считывает и возвращает следующий байт из ввода или любую возникшую ошибку. Если ReadByte возвращает ошибку, входной байт не был обработан, и возвращаемое значение байта не определено.
ReadByte предоставляет эффективный интерфейс для обработки по одному байту за раз. Reader, который не реализует ByteReader, можно обернуть с помощью bufio.NewReader, чтобы добавить этот метод.
type ByteScanner
type ByteScanner interface {
ByteReader
UnreadByte() error
}
ByteScanner — это интерфейс, который добавляет метод UnreadByte к базовому методу ReadByte.
UnreadByte заставляет следующий вызов ReadByte возвращать последний прочитанный байт. Если последняя операция не была успешным вызовом ReadByte, UnreadByte может вернуть ошибку, не прочитать последний прочитанный байт (или байт, предшествующий последнему непрочитанному байту), или (в реализациях, поддерживающих интерфейс Seeker) перейти на один байт перед текущим смещением.
type ByteWriter
type ByteWriter interface {
WriteByte(c byte) error
}
ByteWriter — это интерфейс, который оборачивает метод WriteByte.
type Closer
type Closer interface {
Close() error
}
Closer — это интерфейс, который оборачивает базовый метод Close.
Поведение Close после первого вызова не определено. Конкретные реализации могут документировать свое собственное поведение.
type LimitedReader
type LimitedReader struct {
R Reader // базовый читатель
N int64 // максимальное количество оставшихся байтов
}
LimitedReader читает из R, но ограничивает количество возвращаемых данных до N байтов. Каждый вызов Read обновляет N, чтобы отразить новое количество оставшихся данных. Read возвращает EOF, когда N <= 0 или когда базовый R возвращает EOF.
func (*LimitedReader) Read
func (l *LimitedReader) Read(p []byte) (n int, err error)
Пример
package main
import (
"fmt"
"io"
"strings"
)
func main() {
// Создаем источник данных - строка длиной 100 символов
data := strings.Repeat("abcdefghij", 10) // 100 байт
reader := strings.NewReader(data)
// Создаем LimitedReader, который прочитает только первые 35 байт
limitedReader := &io.LimitedReader{
R: reader, // базовый reader
N: 35, // лимит в 35 байт
}
// Буфер для чтения
buf := make([]byte, 10) // читаем по 10 байт за раз
var totalRead int
for {
// Читаем данные
n, err := limitedReader.Read(buf)
if err != nil {
if err == io.EOF {
fmt.Println("\nДостигнут лимит или конец данных")
} else {
fmt.Println("\nОшибка чтения:", err)
}
break
}
totalRead += n
fmt.Printf("Прочитано %d байт: %q\n", n, buf[:n])
fmt.Printf("Осталось прочитать: %d байт\n", limitedReader.N)
}
fmt.Println("Всего прочитано:", totalRead, "байт")
fmt.Println("Осталось данных в основном reader:", reader.Len(), "байт")
}
Прочитано 10 байт: "abcdefghij"
Осталось прочитать: 25 байт
Прочитано 10 байт: "abcdefghij"
Осталось прочитать: 15 байт
Прочитано 10 байт: "abcdefghij"
Осталось прочитать: 5 байт
Прочитано 5 байт: "abcde"
Осталось прочитать: 0 байт
Достигнут лимит или конец данных
Всего прочитано: 35 байт
Осталось данных в основном reader: 65 байт
type OffsetWriter
type OffsetWriter struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Объяснение OffsetWriter
OffsetWriter в Go — это обёртка вокруг WriterAt, которая позволяет записывать данные, начиная с указанного смещения в базовом потоке. Он автоматически управляет позицией записи и предоставляет три ключевые функции: Write (пишет с текущей позиции), WriteAt (пишет по конкретному смещению без изменения позиции) и Seek (меняет текущую позицию). Это особенно полезно для записи в определённые места файлов (например, при обновлении заголовков или работе с бинарными форматами), когда нужно контролировать точное расположение данных без ручного управления позицией в базовом WriterAt.
Пример с использованием всех методов OffsetWriter:
package main
import (
"fmt"
"io"
"os"
)
func main() {
// Создаем временный файл
tmpFile, err := os.CreateTemp("", "offset-writer-demo")
if err != nil {
panic(err)
}
defer os.Remove(tmpFile.Name())
defer tmpFile.Close()
// Заполняем файл пробельными символами для наглядности
_, err = tmpFile.WriteString("=== Начало файла ===\n" +
strings.Repeat(".", 100) + "\n=== Конец файла ===")
if err != nil {
panic(err)
}
// Создаем OffsetWriter с начальным смещением 20 байт
ow := io.NewOffsetWriter(tmpFile, 20)
// 1. Используем Write - пишет с текущего смещения
fmt.Println("\n1. Запись через Write()")
_, err = ow.Write([]byte("ПЕРВАЯ ЗАПИСЬ"))
if err != nil {
panic(err)
}
printFileContent(tmpFile.Name())
// 2. Используем Seek для изменения позиции
fmt.Println("\n2. Seek(10, io.SeekCurrent)")
newPos, err := ow.Seek(10, io.SeekCurrent) // Перемещаемся на +10 байт от текущей позиции
if err != nil {
panic(err)
}
fmt.Printf("Новая позиция: %d\n", newPos)
// 3. Еще одна запись через Write
_, err = ow.Write([]byte("ВТОРАЯ ЗАПИСЬ"))
if err != nil {
panic(err)
}
printFileContent(tmpFile.Name())
// 4. Используем WriteAt - пишет по абсолютному смещению (не меняет текущую позицию)
fmt.Println("\n4. WriteAt() по смещению 5")
_, err = ow.WriteAt([]byte("ТРЕТЬЯ"), 5)
if err != nil {
panic(err)
}
printFileContent(tmpFile.Name())
// 5. Проверяем текущую позицию после WriteAt
pos, _ := ow.Seek(0, io.SeekCurrent)
fmt.Printf("\n5. Текущая позиция после WriteAt: %d\n", pos)
// 6. Возвращаемся в начало и пишем еще
fmt.Println("\n6. Seek(0, io.SeekStart) + Write()")
ow.Seek(0, io.SeekStart)
ow.Write([]byte("НАЧАЛО"))
printFileContent(tmpFile.Name())
}
func printFileContent(filename string) {
data, _ := os.ReadFile(filename)
fmt.Println("Содержимое файла:")
fmt.Println(string(data))
fmt.Println("Длина:", len(data), "байт")
fmt.Println(strings.Repeat("-", 50))
}
Разбор функциональности:
Write(p []byte):
- Записывает данные с текущей позиции
- Автоматически увеличивает текущую позицию
Seek(offset, whence):
whenceможет быть:io.SeekStart- от начала файлаio.SeekCurrent- от текущей позицииio.SeekEnd- от конца файла
- Возвращает новую позицию
WriteAt(p []byte, off int64):
- Записывает данные по абсолютному смещению
off - Не изменяет текущую позицию записи
- Полезен для точечных модификаций
- Записывает данные по абсолютному смещению
Пример вывода:
1. Запись через Write()
Содержимое файла:
=== Начало файла ===
ПЕРВАЯ ЗАПИСЬ....................
=== Конец файла ===
Длина: 132 байт
--------------------------------------------------
2. Seek(10, io.SeekCurrent)
Новая позиция: 42
3. Запись через Write()
Содержимое файла:
=== Начало файла ===
ПЕРВАЯ ЗАПИСЬ..........ВТОРАЯ ЗАПИСЬ.....
=== Конец файла ===
Длина: 154 байт
--------------------------------------------------
4. WriteAt() по смещению 5
Содержимое файла:
=== Начало файла ===
ПЕРТЬЯ ЗАПИСЬ..........ВТОРАЯ ЗАПИСЬ.....
=== Конец файла ===
Длина: 154 байт
--------------------------------------------------
5. Текущая позиция после WriteAt: 42
6. Seek(0, io.SeekStart) + Write()
Содержимое файла:
=== Начало файла ===
НАЧАЛО ЗАПИСЬ..........ВТОРАЯ ЗАПИСЬ.....
=== Конец файла ===
Длина: 154 байт
--------------------------------------------------
Практические сценарии использования:
Редактирование файлов:
// Исправление заголовка в существующем файле ow := io.NewOffsetWriter(file, 0) ow.WriteAt(correctHeader, 0)Работа с бинарными форматами:
// Запись данных в определенные секции файла ow.Seek(headerSize, io.SeekStart) ow.Write(dataChunk)Многопоточная запись:
// Каждая горутина пишет в свой раздел go func() { sectionWriter := io.NewOffsetWriter(file, sectionOffset) sectionWriter.Write(sectionData) }()
func NewOffsetWriter
func NewOffsetWriter(w WriterAt, off int64) *OffsetWriter
NewOffsetWriter возвращает OffsetWriter, который записывает в w, начиная с смещения off.
func (*OffsetWriter) Seek
func (o *OffsetWriter) Seek(offset int64, whence int) (int64, error)
func (*OffsetWriter) Write
func (o *OffsetWriter) Write(p []byte) (n int, err error)
func (*OffsetWriter) WriteAt
func (o *OffsetWriter) WriteAt(p []byte, off int64) (n int, err error)
type PipeReader
type PipeReader struct {
// содержит отфильтрованные или неэкспортируемые поля
}
PipeReader — это читающая часть канала (pipe).
Объяснение PipeReader и PipeWriter
PipeReader представляет читающую часть именованного канала (pipe).
PipeWriter представляет записывающую часть именованного канала (pipe).
package main
import (
"fmt"
"io"
"time"
)
func main() {
// Создаем pipe
pipeReader, pipeWriter := io.Pipe()
// Горутина для чтения из канала
go func() {
buf := make([]byte, 256)
// 1. Обычное чтение
n, err := pipeReader.Read(buf)
if err != nil {
fmt.Printf("Ошибка чтения: %v\n", err)
return
}
fmt.Printf("Прочитано %d байт: %s\n", n, buf[:n])
// 2. Попытка чтения после закрытия записи
n, err = pipeReader.Read(buf)
if err == io.EOF {
fmt.Println("Канал закрыт (EOF)")
} else if err != nil {
fmt.Printf("Ошибка чтения: %v\n", err)
}
// 3. Чтение после CloseWithError
_, err = pipeReader.Read(buf)
if err != nil {
fmt.Printf("Ошибка после CloseWithError: %v\n", err)
}
}()
// Горутина для записи в канал
go func() {
// Записываем данные
_, err := pipeWriter.Write([]byte("Тестовые данные"))
if err != nil {
fmt.Printf("Ошибка записи: %v\n", err)
}
// Закрываем запись (обычное закрытие)
pipeWriter.Close()
// Даем время на обработку
time.Sleep(100 * time.Millisecond)
// Пытаемся записать после закрытия чтения
_, err = pipeWriter.Write([]byte("Новые данные"))
if err == io.ErrClosedPipe {
fmt.Println("Попытка записи в закрытый канал (ErrClosedPipe)")
}
}()
// Даем время на выполнение
time.Sleep(200 * time.Millisecond)
// Закрываем читатель с ошибкой
err := pipeReader.CloseWithError(fmt.Errorf("кастомная ошибка"))
if err != nil {
fmt.Printf("Ошибка при CloseWithError: %v\n", err)
}
// Пытаемся записать после CloseWithError
_, err = pipeWriter.Write([]byte("Последние данные"))
if err != nil {
fmt.Printf("Ошибка записи после CloseWithError: %v\n", err)
}
time.Sleep(100 * time.Millisecond)
}
Разбор методов:
Read():
- Блокируется, пока не появятся данные или не закроется записывающая часть
- При закрытии записывающей части возвращает
io.EOF - При
CloseWithErrorвозвращает указанную ошибку
Close():
- Закрывает читающую часть
- Последующие записи будут возвращать
io.ErrClosedPipe
CloseWithError():
- Закрывает читающую часть с указанной ошибкой
- Последующие операции чтения вернут эту ошибку
- Не перезаписывает предыдущие ошибки
Пример вывода:
Прочитано 28 байт: Тестовые данные
Канал закрыт (EOF)
Попытка записи в закрытый канал (ErrClosedPipe)
Ошибка после CloseWithError: кастомная ошибка
Ошибка записи после CloseWithError: io: read/write on closed pipe
Практическое применение:
- Связь между горутинами
- Преобразование данных “на лету”
- Тестирование кода, работающего с интерфейсами
io.Reader/io.Writer - Реализация прокси-серверов и middleware
func (*PipeReader) Close
func (r *PipeReader) Close() error
Close закрывает читатель; последующие записи в записывающую половину канала будут возвращать ошибку ErrClosedPipe.
func (*PipeReader) CloseWithError
func (r *PipeReader) CloseWithError(err error) error
CloseWithError закрывает читатель; последующие записи в записывающую половину канала будут возвращать ошибку err.
CloseWithError никогда не перезаписывает предыдущую ошибку, если она существует, и всегда возвращает nil.
func (*PipeReader) Read
func (r *PipeReader) Read(data []byte) (n int, err error)
Read реализует стандартный интерфейс Read: он считывает данные из канала, блокируя до тех пор, пока не появится записывающее устройство или не будет закрыта записывающая часть. Если записывающая часть закрыта с ошибкой, эта ошибка возвращается как err; в противном случае err равен EOF.
type PipeWriter
type PipeWriter struct {
// содержит отфильтрованные или неэкспортируемые поля
}
PipeWriter — это записывающая часть канала (pipe).
func (*PipeWriter) Close
func (w *PipeWriter) Close() error
Close закрывает записывающее устройство; последующие чтения из читающей половины канала не будут возвращать байты и EOF.
func (*PipeWriter) CloseWithError
func (w *PipeWriter) CloseWithError(err error) error
CloseWithError закрывает запись; последующие чтения из части трубы, отвечающей за чтение, не будут возвращать байты и будут возвращать ошибку err или EOF, если err равна nil.
CloseWithError никогда не перезаписывает предыдущую ошибку, если она существует, и всегда возвращает nil.
func (*PipeWriter) Write
func (w *PipeWriter) Write(data []byte) (n int, err error)
Write реализует стандартный интерфейс Write: он записывает данные в канал, блокируя его до тех пор, пока один или несколько читателей не потребят все данные или читающая сторона не будет закрыта. Если читающая сторона закрыта с ошибкой, эта ошибка возвращается как err; в противном случае err равна ErrClosedPipe.
type ReadCloser
type ReadCloser интерфейс {
Reader
Closer
}
ReadCloser — это интерфейс, который группирует основные методы Read и Close.
Объяснение ReadCloser
ReadCloser - это просто комбинация двух возможностей:
- Чтение данных (как у обычного
Reader) - Закрытие ресурса (как у
Closer)
Это интерфейс для объектов, которые:
- Могут отдавать данные (например, файл, сетевое соединение)
- И требуют закрытия после использования (чтобы освободить ресурсы)
Примеры использования:
- Открыли файл → читаем из него → закрываем
- Установили сетевое соединение → получаем данные → разрываем соединение
NopCloser - это “адаптер”:
- Берет обычный
Reader(который не умеет закрываться) - Возвращает
ReadCloser, где методClose()ничего не делает (“no-op” - операция-пустышка)
Зачем это нужно?
Когда функция требует ReadCloser, а у вас есть только Reader (который не нужно закрывать)
Пример:
// Есть строка (она реализует Reader)
data := strings.NewReader("Привет, мир!")
// Но нам нужно передать ReadCloser
rc := io.NopCloser(data)
// Теперь можно использовать везде, где требуется ReadCloser
// При вызове rc.Close() ничего не произойдет
Где применяется:
- Когда работаем с API, требующим
ReadCloser - Когда нужно подставить “фейковый” closer для тестирования
- При работе с данными в памяти, которые не требуют очистки
func NopCloser
func NopCloser(r Reader) ReadCloser
NopCloser возвращает ReadCloser с методом Close, не выполняющим никаких действий, который оборачивает предоставленный Reader r. Если r реализует WriterTo, возвращаемый ReadCloser будет реализовывать WriterTo, перенаправляя вызовы r.
type ReadSeekCloser
type ReadSeekCloser интерфейс {
Reader
Seeker
Closer
}
ReadSeekCloser — интерфейс, который группирует основные методы Read, Seek и Close.
Объяснение ReadSeekCloser, ReadSeeker, ReadWriteCloser…
1. ReadSeekCloser
Назначение: Объединяет чтение, произвольный доступ и закрытие ресурса.
Пример с файлом:
func processFile(rsc io.ReadSeekCloser) error {
data := make([]byte, 100)
// Чтение
if _, err := rsc.Read(data); err != nil {
return err
}
// Перемещение в начало
if _, err := rsc.Seek(0, io.SeekStart); err != nil {
return err
}
// Закрытие
defer rsc.Close()
return nil
}
// Использование
file, _ := os.Open("data.txt")
processFile(file) // *os.File реализует ReadSeekCloser
Зачем: Нужен для работы с ресурсами (файлы, сетевые потоки), где требуется:
- Чтение данных
- Перемещение по содержимому
- Обязательное закрытие
2. ReadSeeker
Назначение: Чтение + перемещение по данным без закрытия.
Пример с буфером:
func analyze(data io.ReadSeeker) {
// Первое чтение
buf := make([]byte, 10)
data.Read(buf)
// Возврат в начало
data.Seek(0, io.SeekStart)
}
// Использование
buffer := strings.NewReader("abcdefghij")
analyze(buffer) // strings.Reader реализует ReadSeeker
Зачем: Для данных, где нужно:
- Многократное чтение
- Навигация (например, парсинг заголовков)
3. ReadWriteCloser
Назначение: Чтение + запись + закрытие.
Пример с сетевым соединением:
func handleConnection(conn io.ReadWriteCloser) {
defer conn.Close()
// Чтение
buf := make([]byte, 1024)
conn.Read(buf)
// Ответ
conn.Write([]byte("OK"))
}
// Использование (псевдокод)
// conn, _ := net.Dial("tcp", "example.com:80")
// handleConnection(conn) // net.Conn реализует ReadWriteCloser
Зачем: Для двусторонних ресурсов:
- Файлы с записью
- Сетевые соединения
- Драйверы устройств
4. ReadWriteSeeker
Назначение: Чтение + запись + навигация.
Пример с файлом логов:
func updateLog(rws io.ReadWriteSeeker, msg string) {
// Перемещение в конец
rws.Seek(0, io.SeekEnd)
// Запись
rws.Write([]byte(msg))
}
// Использование
file, _ := os.OpenFile("log.txt", os.O_RDWR, 0644)
updateLog(file, "New entry\n")
Зачем: Для редактируемых ресурсов:
- Файлы баз данных
- Логи
- Память с произвольным доступом
5. ReadWriter
Назначение: Только чтение + запись.
Пример с буфером в памяти:
func process(rw io.ReadWriter) {
rw.Write([]byte("ping"))
response, _ := io.ReadAll(rw)
fmt.Println(string(response))
}
// Использование
var buf bytes.Buffer
buf.WriteString("pong")
process(&buf) // bytes.Buffer реализует ReadWriter
Зачем: Для простых двусторонних потоков:
- Буферы
- Шифрование/сжатие “на лету”
- Тестирование
Ключевые отличия:
| Тип | Read | Write | Seek | Close | Примеры использования |
|---|---|---|---|---|---|
ReadSeekCloser | ✓ | ✗ | ✓ | ✓ | Файлы, сетевые потоки |
ReadSeeker | ✓ | ✗ | ✓ | ✗ | Парсинг данных |
ReadWriteCloser | ✓ | ✓ | ✗ | ✓ | Сокеты, открытые файлы на запись |
ReadWriteSeeker | ✓ | ✓ | ✓ | ✗ | Файлы БД, лог-файлы |
ReadWriter | ✓ | ✓ | ✗ | ✗ | Буферы, преобразователи данных |
type ReadSeeker
type ReadSeeker интерфейс {
Reader
Seeker
}
ReadSeeker — интерфейс, который группирует основные методы Read и Seek.
type ReadWriteCloser
type ReadWriteCloser интерфейс {
Reader
Writer
Closer
}
ReadWriteCloser — это интерфейс, который группирует основные методы Read, Write и Close.
type ReadWriteSeeker
type ReadWriteSeeker интерфейс {
Reader
Writer
Seeker
}
ReadWriteSeeker — интерфейс, который группирует основные методы Read, Write и Seek.
type ReadWriter
type ReadWriter интерфейс {
Reader
Writer
}
ReadWriter — интерфейс, который группирует основные методы Read и Write.
type Reader
type Reader interface {
Read(p []byte) (n int, err error)
}
Reader — это интерфейс, который оборачивает базовый метод Read.
Read считывает до len(p) байт в p. Он возвращает количество прочитанных байтов (0 <= n <= len(p)) и любую возникшую ошибку. Даже если Read возвращает n < len(p), он может использовать все p в качестве временного пространства во время вызова. Если некоторые данные доступны, но не len(p) байтов, Read по умолчанию возвращает то, что доступно, вместо того, чтобы ждать больше.
Когда Read встречает ошибку или условие конца файла после успешного чтения n > 0 байтов, он возвращает количество прочитанных байтов. Он может вернуть ошибку (не nil) из того же вызова или вернуть ошибку (и n == 0) из последующего вызова. Примером этого общего случая является то, что Reader, возвращающий ненулевое количество байтов в конце входного потока, может возвращать либо err == EOF, либо err == nil. Следующий Read должен возвращать 0, EOF.
Вызывающие функции должны всегда обрабатывать возвращенные n > 0 байтов, прежде чем рассматривать ошибку err. Это позволяет правильно обрабатывать ошибки ввода-вывода, возникающие после чтения некоторых байтов, а также оба допустимых поведения EOF.
Если len(p) == 0, Read всегда должен возвращать n == 0. Он может возвращать ошибку, отличную от nil, если известно о каком-либо условии ошибки, таком как EOF.
Реализации Read не рекомендуется возвращать нулевое количество байтов с ошибкой nil, за исключением случаев, когда len(p) == 0. Вызывающие должны рассматривать возвращение 0 и nil как указание на то, что ничего не произошло; в частности, это не указывает на EOF.
Реализации не должны сохранять p.
func LimitReader
func LimitReader(r Reader, n int64) Reader
LimitReader возвращает Reader, который читает из r, но останавливается с EOF после n байтов. Базовой реализацией является *LimitedReader.
Пример
package main
import (
"io"
"log"
"os"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
lr := io.LimitReader(r, 4)
if _, err := io.Copy(os.Stdout, lr); err != nil {
log.Fatal(err)
}
}
Output:
some
func MultiReader
func MultiReader(readers ...Reader) Reader
MultiReader возвращает Reader, который является логическим соединением предоставленных входных считывателей. Они считываются последовательно. Как только все входы вернут EOF, Read вернет EOF. Если какой-либо из считывателей вернет ошибку, отличную от nil и EOF, Read вернет эту ошибку.
Пример
package main
import (
"io"
"log"
"os"
"strings"
)
func main() {
r1 := strings.NewReader("first reader ")
r2 := strings.NewReader("second reader ")
r3 := strings.NewReader("third reader\n")
r := io.MultiReader(r1, r2, r3)
if _, err := io.Copy(os.Stdout, r); err != nil {
log.Fatal(err)
}
}
Output:
first reader second reader third reader
func TeeReader
func TeeReader(r Reader, w Writer) Reader
TeeReader возвращает Reader, который записывает в w то, что он читает из r. Все чтения из r, выполняемые через него, сопоставляются с соответствующими записями в w. Внутренней буферизации нет — запись должна быть завершена до завершения чтения. Любая ошибка, возникшая во время записи, сообщается как ошибка чтения.
Пример
package main
import (
"io"
"log"
"os"
"strings"
)
func main() {
var r io.Reader = strings.NewReader("some io.Reader stream to be read\n")
r = io.TeeReader(r, os.Stdout)
// Everything read from r will be copied to stdout.
if _, err := io.ReadAll(r); err != nil {
log.Fatal(err)
}
}
Output:
some io.Reader stream to be read
type ReaderAt
type ReaderAt interface {
ReadAt(p []byte, off int64) (n int, err error)
}
ReaderAt — это интерфейс, который оборачивает базовый метод ReadAt.
ReadAt считывает len(p) байт в p, начиная с смещения off в базовом источнике ввода. Он возвращает количество прочитанных байтов (0 <= n <= len(p)) и любую возникшую ошибку.
Когда ReadAt возвращает n < len(p), он возвращает не нулевую ошибку, объясняющую, почему не было возвращено больше байтов. В этом отношении ReadAt более строг, чем Read.
Даже если ReadAt возвращает n < len(p), он может использовать все p в качестве временного пространства во время вызова. Если некоторые данные доступны, но не len(p) байтов, ReadAt блокируется до тех пор, пока не будут доступны все данные или не произойдет ошибка. В этом отношении ReadAt отличается от Read.
Если n = len(p) байтов, возвращаемых ReadAt, находятся в конце источника ввода, ReadAt может вернуть либо err == EOF, либо err == nil.
Если ReadAt читает из источника ввода с смещением поиска, ReadAt не должен влиять на базовое смещение поиска и не должен подвергаться его влиянию.
Клиенты ReadAt могут выполнять параллельные вызовы ReadAt на одном и том же источнике ввода.
Реализации не должны сохранять p.
Объяснение ReaderAt
Интерфейс ReaderAt в Go
Интерфейс ReaderAt определён в пакете io и позволяет читать данные из произвольного смещения (offset) без изменения состояния “читателя”.
Сигнатура метода
ReadAt(p []byte, off int64) (n int, err error)
p []byte— буфер, куда записываются прочитанные данные.off int64— смещение (в байтах) от начала источника данных.- Возвращает:
n— количество прочитанных байтов.err— ошибку (например,io.EOFпри достижении конца данных).
Пример использования ReaderAt
1. Чтение файла с произвольного смещения
package main
import (
"fmt"
"io"
"os"
)
func main() {
file, err := os.Open("example.txt")
if err != nil {
panic(err)
}
defer file.Close()
// Читаем 10 байт, начиная с 5-го байта
buf := make([]byte, 10)
n, err := file.ReadAt(buf, 5)
if err != nil && err != io.EOF {
panic(err)
}
fmt.Printf("Прочитано %d байт: %q\n", n, buf[:n])
}
Вывод (если example.txt содержит "Hello, world!"):
Прочитано 10 байт: ", world!"
2. Реализация собственного ReaderAt
Допустим, у нас есть структура, хранящая данные в памяти:
type MemoryReader struct {
data []byte
}
func (r *MemoryReader) ReadAt(p []byte, off int64) (n int, err error) {
if off >= int64(len(r.data)) {
return 0, io.EOF
}
n = copy(p, r.data[off:])
if n < len(p) {
err = io.EOF
}
return
}
func main() {
reader := &MemoryReader{data: []byte("RandomAccessData")}
buf := make([]byte, 5)
// Читаем 5 байт с 7-й позиции
n, err := reader.ReadAt(buf, 7)
if err != nil && err != io.EOF {
panic(err)
}
fmt.Printf("Прочитано: %q\n", buf[:n]) // "Access"
}
Назначение ReaderAt
- Произвольный доступ (random access) — чтение с любого места без последовательного перемещения.
- Потокобезопасность — метод
ReadAtможно вызывать из разных горутин (если реализация поддерживает). - Используется в:
- Файловых системах (
os.FileреализуетReaderAt). - Бинарных форматах (например, чтение заголовков архивов).
- Базах данных (чтение данных по смещению).
- Файловых системах (
Отличие от Reader
Reader (io.Reader) | ReaderAt (io.ReaderAt) |
|---|---|
Читает последовательно (Read меняет состояние). | Читает с любого места (ReadAt не меняет состояние). |
| Используется в потоковых данных (сети, pipes). | Используется для произвольного доступа (файлы, память). |
Пример: http.Response.Body. | Пример: os.File. |
Вывод
ReaderAt полезен, когда нужно читать данные с произвольных позиций, например, при работе с файлами или бинарными структурами. В отличие от Reader, он не зависит от текущей позиции и поддерживает конкурентный доступ.
type ReaderFrom
type ReaderFrom interface {
ReadFrom(r Reader) (n int64, err error)
}
ReaderFrom — это интерфейс, который оборачивает метод ReadFrom.
ReadFrom читает данные из r до EOF или ошибки. Возвращаемое значение n — это количество прочитанных байтов. Любая ошибка, кроме EOF, возникшая во время чтения, также возвращается.
Функция Copy использует ReaderFrom, если он доступен.
type RuneReader
type RuneReader interface {
ReadRune() (r rune, size int, err error)
}
RuneReader — это интерфейс, который оборачивает метод ReadRune.
ReadRune считывает один закодированный символ Unicode и возвращает руну и ее размер в байтах. Если символ недоступен, будет установлено err.
type RuneScanner
type RuneScanner interface {
RuneReader
UnreadRune() error
}
RuneScanner — это интерфейс, который добавляет метод UnreadRune к базовому методу ReadRune.
UnreadRune заставляет следующий вызов ReadRune возвращать последнюю прочитанную руну. Если последняя операция не была успешным вызовом ReadRune, UnreadRune может вернуть ошибку, не прочитать последнюю прочитанную руну (или руну, предшествующую последней непрочитанной руне), или (в реализациях, поддерживающих интерфейс Seeker) перейти к началу руны перед текущим смещением.
type SectionReader
type SectionReader struct {
// содержит отфильтрованные или неэкспортированные поля
}
SectionReader реализует Read, Seek и ReadAt на секции базового ReaderAt.
Объяснение SectionReader
Назначение SectionReader
SectionReader в Go (пакет io) позволяет читать только определённую часть (секцию) данных из базового источника, реализующего ReaderAt. Это полезно, когда нужно:
- Ограничить чтение определённым диапазоном байтов
- Работать с частью файла или данных как с самостоятельным потоком
- Читать данные с произвольных позиций (
ReadAt) и перемещаться по ним (Seek)
Пример использования всех методов
package main
import (
"fmt"
"io"
"strings"
)
func main() {
// Исходные данные
data := "Hello, World! This is a SectionReader example."
baseReader := strings.NewReader(data)
// Создаём SectionReader (база: data, смещение: 7, длина: 12 байтов)
section := io.NewSectionReader(baseReader, 7, 12)
// 1. Чтение всего раздела (Read)
buf := make([]byte, 12)
n, _ := section.Read(buf)
fmt.Printf("Read: %q (%d bytes)\n", buf[:n], n) // "World! This"
// 2. Чтение с позиции (ReadAt)
n, _ = section.ReadAt(buf, 2)
fmt.Printf("ReadAt(2): %q\n", buf[:n]) // "rld! This "
// 3. Перемещение (Seek)
section.Seek(5, io.SeekStart) // Перемещаемся на 5 байт от начала
n, _ = section.Read(buf)
fmt.Printf("After Seek(5): %q\n", buf[:n]) // "! This"
// 4. Получение параметров секции (Outer)
r, off, n := section.Outer()
fmt.Printf("Base: %T, Offset: %d, Size: %d\n", r, off, n)
// 5. Размер секции (Size)
fmt.Println("Section size:", section.Size()) // 12
}
Вывод:
Read: "World! This" (12 bytes)
ReadAt(2): "rld! This "
After Seek(5): "! This"
Base: *strings.Reader, Offset: 7, Size: 12
Section size: 12
Разбор методов
| Метод | Описание |
|---|---|
NewSectionReader() | Создаёт читатель для диапазона [off, off+n) из базового ReaderAt |
Read() | Читает данные последовательно (меняет текущую позицию) |
ReadAt() | Читает данные с указанного смещения (не меняет текущую позицию) |
Seek() | Перемещает текущую позицию (io.SeekStart/SeekCurrent/SeekEnd) |
Size() | Возвращает максимальный размер секции в байтах |
Outer() | Возвращает исходный ReaderAt, смещение и размер, переданные при создании |
Типичные сценарии использования
Чтение заголовков файлов
// Читаем первые 512 байт (например, заголовок ZIP) headerSection := io.NewSectionReader(file, 0, 512)Обработка частей больших файлов
// Читаем блок с 1024 по 2048 байт chunk := io.NewSectionReader(file, 1024, 1024)Виртуализация подмножества данных
// Работаем с частью данных как с самостоятельным io.Reader processData(section)
SectionReader особенно полезен при работе с бинарными форматами (архивы, медиафайлы), где нужно читать данные по чанкам или с определённых смещений.
func NewSectionReader
func NewSectionReader(r ReaderAt, off int64, n int64) *SectionReader
NewSectionReader возвращает SectionReader, который читает из r, начиная с смещения off, и останавливается с EOF после n байтов.
func (*SectionReader) Outer
func (s *SectionReader) Outer() (r ReaderAt, off int64, n int64)
Outer возвращает базовый ReaderAt и смещения для секции.
Возвращаемые значения совпадают с теми, которые были переданы в NewSectionReader при создании SectionReader.
func (*SectionReader) Read
func (s *SectionReader) Read(p []byte) (n int, err error)
Пример
import (
"fmt"
"io"
"log"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
s := io.NewSectionReader(r, 5, 17)
buf := make([]byte, 9)
if _, err := s.Read(buf); err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", buf)
}
Output:
io.Reader
func (*SectionReader) ReadAt
func (s *SectionReader) ReadAt(p []byte, off int64) (n int, err error)
Пример
import (
"fmt"
"io"
"log"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
s := io.NewSectionReader(r, 5, 17)
buf := make([]byte, 6)
if _, err := s.ReadAt(buf, 10); err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", buf)
}
Output:
stream
func (*SectionReader) Seek
func (s *SectionReader) Seek(offset int64, whence int) (int64, error)
Пример
package main
import (
"io"
"log"
"os"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
s := io.NewSectionReader(r, 5, 17)
if _, err := s.Seek(10, io.SeekStart); err != nil {
log.Fatal(err)
}
if _, err := io.Copy(os.Stdout, s); err != nil {
log.Fatal(err)
}
}
Output:
stream
func (*SectionReader) Size
func (s *SectionReader) Size() int64
Size возвращает размер секции в байтах.
Пример
package main
import (
"fmt"
"io"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
s := io.NewSectionReader(r, 5, 17)
fmt.Println(s.Size())
}
Output:
17
type Seeker
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}
Seeker — это интерфейс, который оборачивает базовый метод Seek.
Seek устанавливает смещение для следующего Read или Write в offset, интерпретируемое в соответствии с whence: SeekStart означает относительно начала файла, SeekCurrent означает относительно текущего смещения, а SeekEnd означает относительно конца (например, offset = -2 указывает предпоследний байт файла). Seek возвращает новое смещение относительно начала файла или ошибку, если таковая имеется.
Переход к смещению перед началом файла является ошибкой. Переход к любому положительному смещению может быть разрешен, но если новое смещение превышает размер базового объекта, поведение последующих операций ввода-вывода зависит от реализации.
Объяснение Seeker
Назначение интерфейса Seeker в пакете io
Интерфейс Seeker определяет метод Seek(), который позволяет произвольно перемещаться по потоку данных (файлу, буферу в памяти, сетевому соединению и т.д.). Это ключевая возможность для работы с данными не только последовательно, но и в произвольном порядке.
Для чего нужен Seeker?
Произвольный доступ к данным
Возможность “перепрыгивать” к любому месту в потоке без чтения предыдущих данных.Чтение/запись в разные части файла
Например, обновление заголовка файла после записи основного содержимого.Реализация сложных протоколов
Парсинг структур, где нужно “заглядывать” вперед и возвращаться назад.Оптимизация работы с большими файлами
Чтение только нужных фрагментов без загрузки всего файла в память.
Детали метода Seek()
Seek(offset int64, whence int) (int64, error)
| Параметр | Значения (whence) | Описание |
|---|---|---|
offset | Любое число | Смещение в байтах (может быть отрицательным для SeekCurrent/SeekEnd) |
whence | io.SeekStart (0) | Отсчёт от начала данных |
io.SeekCurrent (1) | Отсчёт от текущей позиции | |
io.SeekEnd (2) | Отсчёт от конца данных |
Возвращает:
- Новую позицию (абсолютный offset от начала)
- Ошибку (например, попытка выйти за границы данных)
Примеры использования
1. Перемещение в файле
file, _ := os.Open("data.txt")
defer file.Close()
// Перемещаемся на 100-й байт от начала
pos, _ := file.Seek(100, io.SeekStart)
// Читаем 50 байт с этой позиции
buf := make([]byte, 50)
file.Read(buf)
2. Чтение с конца
// Перемещаемся на 10 байт назад от конца
pos, _ := file.Seek(-10, io.SeekEnd)
3. Относительное перемещение
// Текущая позиция: 200
// Перемещаемся на +50 байт вперёд
pos, _ := file.Seek(50, io.SeekCurrent) // Новый pos = 250
Где реализован Seeker?
Стандартные типы, поддерживающие интерфейс:
*os.File(файлы)*bytes.Reader(буфер в памяти)*strings.Reader(строка как поток)*SectionReader(часть другогоReaderAt)
Ограничения
Не все источники поддерживают
Например, сетевые соединения (net.Conn) не реализуютSeeker.Поведение зависит от типа
При работе с файлами на дискеSeekэффективен, но для сжатых данных (например, ZIP) может требовать декомпрессии.
Комбинация с другими интерфейсами
Часто используется вместе с:
Reader→io.ReadSeekerWriter→io.WriteSeekerReaderAt/WriterAtдля произвольного доступа без изменения позиции
Пример объединённого интерфейса:
type ReadSeeker interface {
Reader
Seeker
}
Итог
Seeker добавляет потокам данных критически важную возможность — произвольный доступ. Это фундамент для:
- Работы с бинарными форматами (архивы, медиафайлы)
- Оптимизированного чтения больших файлов
- Реализации сложных алгоритмов парсинга
- Многопроходной обработки данных без переоткрытия источника
type StringWriter
type StringWriter interface {
WriteString(s string) (n int, err error)
}
StringWriter — это интерфейс, который оборачивает метод WriteString.
type WriteCloser
type WriteCloser interface {
Writer
Closer
}
WriteCloser — это интерфейс, который группирует базовые методы Write и Close.
type WriteSeeker
type WriteSeeker interface {
Writer
Seeker
}
WriteSeeker — это интерфейс, который группирует базовые методы Write и Seek.
type Writer
type Writer interface {
Write(p []byte) (n int, err error)
}
Writer — это интерфейс, который оборачивает базовый метод Write.
Write записывает len(p) байт из p в базовый поток данных. Он возвращает количество байт, записанных из p (0 <= n <= len(p)), и любую ошибку, которая привела к преждевременному прекращению записи. Write должен возвращать ошибку, отличную от nil, если он возвращает n < len(p). Write не должен изменять данные слайса, даже временно.
Реализации не должны сохранять p.
var Discard Writer = discard{}
Discard — это Writer, на котором все вызовы Write выполняются успешно, не выполняя никаких действий.
Объяснение Writer
Интерфейс Writer в Go — это простой контракт для записи данных куда-либо. Он требует реализации всего одного метода:Write(p []byte) (n int, err error).
Как это работает?
Вы передаёте данные
Метод принимает байтовый слайс (p []byte), который нужно записать (например: текст, файл, сетевой пакет).Он пытается записать
Записывает часть или все данные изpв целевое место (файл, память, сеть и т.д.).Возвращает результат
n— сколько байт удалось записать (может быть меньше, чемlen(p)при ошибке).err— ошибка (например, диск заполнен, соединение разорвано).
Аналогия из жизни
Представьте, что Writer — это лестница в доме:
- Люди постепенно заходят на лестницу и поднимаются вверх (
p []byte). - На последнем этаже большой зал, люди заполняют его.
- Если зал заполнился полностью людьми, то часть останется на лестнице и в зал не войдут (
n < len(p)иerr != nil).
Где используется?
Примеры реализаций:
Запись в файл
file, _ := os.Create("log.txt") file.Write([]byte("Hello!")) // Реализует WriterОтправка данных по сети
conn, _ := net.Dial("tcp", "example.com:80") conn.Write([]byte("GET / HTTP/1.1\r\n\r\n"))Буфер в памяти
var buf bytes.Buffer buf.Write([]byte("Сохраняем в RAM"))Игнорирование данных (
Discard)io.Discard.Write([]byte("Эти данные никуда не пойдут"))
Правила для Write
Не изменяет
p
Даже временно. Ваши исходные данные останутся целыми.Не сохраняет
p
После завершения метода реализация не должна хранить ссылку на переданные данные.Ошибка = неполная запись
Если вернулосьn < len(p), метод обязан вернуть ошибку.
Особый случай: Discard
Это “пустышка”, которая реализует Writer, но просто выбрасывает все записываемые данные:
io.Discard.Write([]byte("Это исчезнет")) // Никуда не запишется
Зачем нужно? Например:
- Когда нужно прочитать данные, но не сохранять их.
- Для тестирования, чтобы имитировать запись без реальных операций.
Пример с кастомным Writer
Создадим простой Writer, который пишет данные в консоль:
type ConsoleWriter struct{}
func (cw ConsoleWriter) Write(p []byte) (int, error) {
n, err := fmt.Print(string(p))
return n, err
}
func main() {
var writer Writer = ConsoleWriter{}
writer.Write([]byte("Привет, Writer!"))
}
Вывод:
Привет, Writer!
func MultiWriter
func MultiWriter(writers ...Writer) Writer
MultiWriter создает писатель, который дублирует свои записи во всех предоставленных писателях, аналогично команде Unix tee(1).
Каждая запись записывается в каждый из перечисленных writer, по одному за раз. Если перечисленный writer возвращает ошибку, вся операция записи останавливается и возвращает ошибку; она не продолжается по списку.
Пример
package main
import (
"fmt"
"io"
"log"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
var buf1, buf2 strings.Builder
w := io.MultiWriter(&buf1, &buf2)
if _, err := io.Copy(w, r); err != nil {
log.Fatal(err)
}
fmt.Print(buf1.String())
fmt.Print(buf2.String())
}
Output:
some io.Reader stream to be read
some io.Reader stream to be read
type WriterAt
type WriterAt interface {
WriteAt(p []byte, off int64) (n int, err error)
}
WriterAt — это интерфейс, который оборачивает базовый метод WriteAt.
WriteAt записывает len(p) байт из p в базовый поток данных со смещением off. Он возвращает количество байт, записанных из p (0 <= n <= len(p)), и любую ошибку, которая привела к преждевременному прекращению записи. WriteAt должен возвращать ошибку, отличную от nil, если он возвращает n < len(p).
Если WriteAt записывает в место назначения со смещением поиска, WriteAt не должен влиять на базовое смещение поиска и не должен подвергаться его влиянию.
Клиенты WriteAt могут выполнять параллельные вызовы WriteAt на одном и том же месте назначения, если диапазоны не пересекаются.
Реализации не должны сохранять p.
type WriterTo
type WriterTo interface {
WriteTo(w Writer) (n int64, err error)
}
WriterTo — это интерфейс, который оборачивает метод WriteTo.
WriteTo записывает данные в w до тех пор, пока не закончатся данные для записи или не произойдет ошибка. Возвращаемое значение n — это количество записанных байтов. Любая ошибка, возникшая во время записи, также возвращается.
Функция Copy использует WriterTo, если он доступен.
Объяснение WriterTo
Интерфейс WriterTo — это продвинутая версия записи данных, которая позволяет объекту самому решать, как эффективно отправить свои данные в любой Writer (файл, сеть, буфер и т.д.).
Чем отличается от обычного Writer?
| Особенность | Writer (простой интерфейс) | WriterTo (продвинутый интерфейс) |
|---|---|---|
| Кто управляет? | Получатель (Writer) решает, как записать данные | Источник данных сам решает, как отправить данные |
| Эффективность | Может требовать промежуточных копирований | Позволяет оптимизировать запись (например, отправлять данные кусками) |
| Использование | Базовый уровень | Оптимизированные сценарии (например, io.Copy) |
Как работает метод WriteTo?
type WriterTo interface {
WriteTo(w Writer) (n int64, err error)
}
Вызывается у объекта-источника
Объект (например, буфер или файл) получает целевойWriter(w), куда нужно записать данные.Сам решает, как писать
Источник может:- Отправить данные одним куском
- Разбить на части
- Использовать специальные оптимизации (например, DMA для дисков)
Возвращает результат
n— сколько байт было записаноerr— ошибка (если что-то пошло не так)
Примеры использования
1. Стандартные типы с WriterTo
// bytes.Buffer реализует WriterTo
buf := bytes.NewBufferString("Hello!")
buf.WriteTo(os.Stdout) // Выведет "Hello!" в консоль
// strings.Reader тоже реализует WriterTo
reader := strings.NewReader("Text")
reader.WriteTo(file) // Запишет "Text" в файл
2. Кастомная реализация
Создадим объект, который знает, как эффективно записать свои данные:
type CustomData struct {
chunks [][]byte
}
func (d *CustomData) WriteTo(w io.Writer) (int64, error) {
var total int64
for _, chunk := range d.chunks {
n, err := w.Write(chunk)
total += int64(n)
if err != nil {
return total, err
}
}
return total, nil
}
// Использование:
data := CustomData{chunks: [][]byte{[]byte("Hello "), []byte("world!")}}
data.WriteTo(os.Stdout) // Выведет "Hello world!"
Зачем это нужно?
Оптимизация производительности
Объект может выбрать самый эффективный способ записи (например, избежать лишних копирований).Гибкость
Разные типы данных могут по-разному реализовывать запись:- Файл может отправлять данные кусками
- Буфер в памяти — одним вызовом
- Сетевое соединение — с контролем скорости
Интеграция с
io.Copy
Функцияio.Copy(dst, src)автоматически используетWriteTo, если он есть у источника:// Если src реализует WriterTo, Copy вызовет src.WriteTo(dst) io.Copy(file, buffer) // Будет эффективнее, чем обычное копирование
Особый случай: Discard
Как и с Writer, существует “пустышка”:
io.Discard.WriteTo(...) // Ничего не делает
Используется для тестирования или игнорирования данных.
12.4.9.3 - Пакет для работы с файловой системой io/fs
“Пакет fs определяет базовые интерфейсы для файловой системы. Файловая система может быть предоставлена операционной системой хоста, а также другими пакетами.”
Для поддержки тестирования реализаций файловых систем смотрите пакет testing/fstest.
Переменные
var (
ErrInvalid = errInvalid() // "недопустимый аргумент"
ErrPermission = errPermission() // "разрешение отклонено"
ErrExist = errExist() // "файл уже существует"
ErrNotExist = errNotExist() // "файл не существует"
ErrClosed = errClosed() // "файл уже закрыт"
)
Общие ошибки файловой системы. Ошибки, возвращаемые файловыми системами, можно проверить на соответствие этим ошибкам с помощью errors.Is.
var SkipAll = errors.New("пропустить все и остановить прогулку")
SkipAll используется как возвращаемое значение из WalkDirFunc, чтобы указать, что все оставшиеся файлы и каталоги должны быть пропущены. Ни одна функция не возвращает его в качестве ошибки.
var SkipDir = errors.New("пропустить этот каталог")
SkipDir используется в качестве возвращаемого значения WalkDirFunc, чтобы указать, что каталог, названный в вызове, должен быть пропущен. Ни одна функция не возвращает его в качестве ошибки.
Функции
func FormatDirEntry
func FormatDirEntry(dir DirEntry) string
FormatDirEntry возвращает отформатированную версию dir для удобства чтения. Реализации DirEntry могут вызывать эту функцию из метода String. Результаты для каталога с именем subdir и файла с именем hello.go:
d subdir/
- hello.go
func FormatFileInfo
func FormatFileInfo(info FileInfo) string
FormatFileInfo возвращает отформатированную версию info для удобства чтения. Реализации FileInfo могут вызывать эту функцию из метода String. Результатом для файла с именем «hello.go», размером 100 байт, режимом 0o644, созданного 1 января 1970 года в полдень, будет
-rw-r--r-- 100 1970-01-01 12:00:00 hello.go
func Glob
func Glob(fsys FS, pattern string) (matches []string, err error)
Glob возвращает имена всех файлов, соответствующих pattern, или nil, если нет соответствующих файлов. Синтаксис шаблонов такой же, как в path.Match. Шаблон может описывать иерархические имена, такие как usr/*/bin/ed.
Glob игнорирует ошибки файловой системы, такие как ошибки ввода-вывода при чтении каталогов. Единственная возможная возвращаемая ошибка — path.ErrBadPattern, сообщающая о неверном формате шаблона.
Если fs реализует GlobFS, Glob вызывает fs.Glob. В противном случае Glob использует ReadDir для обхода дерева каталогов и поиска совпадений с шаблоном.
func ReadFile
func ReadFile(fsys FS, name string) ([]byte, error)
ReadFile читает файл с указанным именем из файловой системы fs и возвращает его содержимое. Успешный вызов возвращает ошибку nil, а не io.EOF. (Поскольку ReadFile читает весь файл, ожидаемый EOF от последнего Read не рассматривается как ошибка, о которой следует сообщать).
Если fs реализует ReadFileFS, ReadFile вызывает fs.ReadFile. В противном случае ReadFile вызывает fs.Open и использует Read и Close на возвращенном File.
func ValidPath
func ValidPath(name string) bool
ValidPath сообщает, является ли данное имя пути действительным для использования в вызове Open.
Имена путей, передаваемые в open, представляют собой закодированные в UTF-8, не имеющие корня, разделенные косой чертой последовательности элементов пути, например «x/y/z». Имена путей не должны содержать элемент «.» или «..» или пустую строку, за исключением особого случая, когда имя «.» может использоваться для корневого каталога. Пути не должны начинаться или заканчиваться косой чертой: «/x» и «x/» являются недопустимыми.
Обратите внимание, что пути разделяются косой чертой во всех системах, даже в Windows. Пути, содержащие другие символы, такие как обратная косая черта и двоеточие, принимаются как действительные, но эти символы никогда не должны интерпретироваться реализацией FS как разделители элементов пути.
func WalkDir
func WalkDir(fsys FS, root string, fn WalkDirFunc) error
WalkDir проходит по дереву файлов, корнем которого является root, вызывая fn для каждого файла или каталога в дереве, включая root.
Все ошибки, возникающие при посещении файлов и каталогов, фильтруются fn: подробности см. в документации fs.WalkDirFunc.
Файлы просматриваются в лексическом порядке, что делает вывод детерминированным, но требует, чтобы WalkDir считывал весь каталог в память, прежде чем приступать к просмотру этого каталога.
WalkDir не следует по символьным ссылкам, найденным в каталогах, но если root сам является символьной ссылкой, то будет пройдена его цель.
Пример
package main
import (
"fmt"
"io/fs"
"log"
"os"
"path/filepath"
"time"
)
func main() {
// Создаем временную файловую систему для демонстрации
tmpDir, err := os.MkdirTemp("", "fs-example-*")
if err != nil {
log.Fatal(err)
}
defer os.RemoveAll(tmpDir)
// Создаем тестовые файлы и директории
createTestFS(tmpDir)
// Получаем файловую систему os.DirFS
fsys := os.DirFS(tmpDir)
// 1. Пример использования FormatDirEntry и FormatFileInfo
demoFormatFunctions(fsys)
// 2. Пример использования Glob
demoGlob(fsys)
// 3. Пример использования ReadFile
demoReadFile(fsys)
// 4. Пример использования ValidPath
demoValidPath()
// 5. Пример использования WalkDir
demoWalkDir(fsys)
}
func createTestFS(root string) {
// Создаем структуру:
// /tmp/fs-example-12345/
// ├── docs/
// │ ├── notes.md
// │ └── draft.txt
// ├── src/
// │ └── main.go
// └── README.txt
dirs := []string{
filepath.Join(root, "docs"),
filepath.Join(root, "src"),
}
files := map[string]string{
filepath.Join(root, "README.txt"): "Пример файла README",
filepath.Join(root, "docs", "notes.md"): "# Заметки\nПример содержимого",
filepath.Join(root, "docs", "draft.txt"): "Черновик документа",
filepath.Join(root, "src", "main.go"): "package main\n\nfunc main() {\n\tprintln(\"Hello\")\n}",
}
// Создаем директории
for _, dir := range dirs {
if err := os.MkdirAll(dir, 0755); err != nil {
log.Fatal(err)
}
}
// Создаем файлы
for path, content := range files {
if err := os.WriteFile(path, []byte(content), 0644); err != nil {
log.Fatal(err)
}
}
// Устанавливаем время модификации для демонстрации FormatFileInfo
modTime := time.Date(2023, time.January, 15, 12, 30, 0, 0, time.UTC)
for path := range files {
if err := os.Chtimes(path, modTime, modTime); err != nil {
log.Fatal(err)
}
}
}
func demoFormatFunctions(fsys fs.FS) {
fmt.Println("\n=== FormatDirEntry и FormatFileInfo ===")
entries, err := fs.ReadDir(fsys, ".")
if err != nil {
log.Fatal(err)
}
for _, entry := range entries {
// FormatDirEntry
fmt.Printf("DirEntry: %s\n", fs.FormatDirEntry(entry))
// Получаем FileInfo для FormatFileInfo
info, err := entry.Info()
if err != nil {
log.Fatal(err)
}
fmt.Printf("FileInfo: %s\n", fs.FormatFileInfo(info))
}
}
func demoGlob(fsys fs.FS) {
fmt.Println("\n=== Glob ===")
// Ищем все .txt файлы
matches, err := fs.Glob(fsys, "*.txt")
if err != nil {
log.Fatal(err)
}
fmt.Println("Файлы .txt в корне:", matches)
// Ищем все .go файлы в любых поддиректориях
matches, err = fs.Glob(fsys, "*/*.go")
if err != nil {
log.Fatal(err)
}
fmt.Println("Файлы .go в поддиректориях:", matches)
// Ищем все .md файлы рекурсивно
matches, err = fs.Glob(fsys, "**/*.md")
if err != nil {
log.Fatal(err)
}
fmt.Println("Файлы .md рекурсивно:", matches)
}
func demoReadFile(fsys fs.FS) {
fmt.Println("\n=== ReadFile ===")
// Читаем содержимое файла
content, err := fs.ReadFile(fsys, "src/main.go")
if err != nil {
log.Fatal(err)
}
fmt.Printf("Содержимое main.go:\n%s\n", content)
// Попытка чтения несуществующего файла
_, err = fs.ReadFile(fsys, "nonexistent.txt")
fmt.Println("Ошибка при чтении несуществующего файла:", err)
}
func demoValidPath() {
fmt.Println("\n=== ValidPath ===")
paths := []string{
"valid/path",
"invalid/../path",
"invalid\\path", // Обратные слеши не считаются разделителями
"",
"trailing/slash/",
}
for _, path := range paths {
fmt.Printf("%q valid: %t\n", path, fs.ValidPath(path))
}
}
func demoWalkDir(fsys fs.FS) {
fmt.Println("\n=== WalkDir ===")
fmt.Println("Содержимое файловой системы:")
err := fs.WalkDir(fsys, ".", func(path string, d fs.DirEntry, err error) error {
if err != nil {
return err
}
fmt.Printf("- %s\n", fs.FormatDirEntry(d))
return nil
})
if err != nil {
log.Fatal(err)
}
}
=== FormatDirEntry и FormatFileInfo ===
DirEntry: d docs/
FileInfo: drwxr-xr-x 4096 2023-01-15 12:30:00 docs
DirEntry: d src/
FileInfo: drwxr-xr-x 4096 2023-01-15 12:30:00 src
DirEntry: - README.txt
FileInfo: -rw-r--r-- 19 2023-01-15 12:30:00 README.txt
=== Glob ===
Файлы .txt в корне: [README.txt]
Файлы .go в поддиректориях: [src/main.go]
Файлы .md рекурсивно: [docs/notes.md]
=== ReadFile ===
Содержимое main.go:
package main
func main() {
println("Hello")
}
Ошибка при чтении несуществующего файла: open nonexistent.txt: file does not exist
=== ValidPath ===
"valid/path" valid: true
"invalid/../path" valid: false
"invalid\\path" valid: true
"" valid: false
"trailing/slash/" valid: false
=== WalkDir ===
Содержимое файловой системы:
- .
- d docs/
- - docs/draft.txt
- - docs/notes.md
- d src/
- - src/main.go
- - README.txt
Типы
type DirEntry
type DirEntry interface {
// Name возвращает имя файла (или подкаталога), описанного записью.
// Это имя является только конечным элементом пути (базовым именем), а не всем путем.
// Например, Name вернет «hello.go», а не «home/gopher/hello.go».
Name() string
// IsDir сообщает, описывает ли запись каталог.
IsDir() bool
// Type возвращает биты типа для запис
// Биты типа являются подмножеством обычных битов FileMode, возвращаемых методом FileMode.Type.
Type() FileMode
// Info возвращает FileInfo для файла или подкаталога, описанного записью.
// Возвращаемая информация FileInfo может быть взята из времени первоначального чтения каталога
// или из времени вызова Info. Если файл был удален или переименован
// после чтения каталога, Info может вернуть ошибку, удовлетворяющую errors.Is(err, ErrNotExist).
// Если запись обозначает символическую ссылку, Info сообщает информацию о самой ссылке,
// а не о цели ссылки.
Info() (FileInfo, error)
}
DirEntry — это запись, прочитанная из каталога (с помощью функции ReadDir или метода ReadDir класса ReadDirFile).
func FileInfoToDirEntry
func FileInfoToDirEntry(info FileInfo) DirEntry
FileInfoToDirEntry возвращает DirEntry, который возвращает информацию из info. Если info равно nil, FileInfoToDirEntry возвращает nil.
func ReadDir
func ReadDir(fsys FS, name string) ([]DirEntry, error)
ReadDir считывает указанный каталог и возвращает список записей каталога, отсортированных по имени файла.
Если fs реализует ReadDirFS, ReadDir вызывает fs.ReadDir. В противном случае ReadDir вызывает fs.Open и использует ReadDir и Close для возвращенного файла.
type FS
type FS interface {
// Open открывает указанный файл.
// [File.Close] должен быть вызван для освобождения всех связанных ресурсов.
//
// Когда Open возвращает ошибку, она должна быть типа *PathError
// с полем Op, установленным в «open», полем Path, установленным в name,
// и полем Err, описывающим проблему.
//
// Open должен отклонять попытки открыть имена, которые не удовлетворяют
// ValidPath(name), возвращая *PathError с Err, установленным в
// ErrInvalid или ErrNotExist.
Open(name string) (File, error)
}
FS обеспечивает доступ к иерархической файловой системе.
Интерфейс FS является минимальной реализацией, необходимой для файловой системы. Файловая система может реализовывать дополнительные интерфейсы, такие как ReadFileFS, для предоставления дополнительных или оптимизированных функций.
testing/fstest.TestFS может использоваться для проверки правильности реализации FS.
Объяснение FS
Объяснение интерфейса fs.FS
fs.FS - это базовый интерфейс в Go для работы с иерархическими файловыми системами. Он представляет минимальный контракт, который должна реализовать любая файловая система (реальная, виртуальная, в памяти и т.д.).
Ключевые особенности:
- Минималистичный дизайн - только один обязательный метод
Open() - Абстракция - позволяет работать с разными ФС одинаковым способом
- Расширяемость - через дополнительные интерфейсы (
ReadFileFS,GlobFSи др.)
Основной метод:
Open(name string) (File, error)
- Открывает файл по имени
- Возвращает объект, реализующий
fs.File - В случае ошибки возвращает
*fs.PathError
Пример реализации и использования
1. Создаем простую in-memory файловую систему
package main
import (
"io/fs"
"log"
"os"
"time"
)
// MemoryFS - простая in-memory реализация fs.FS
type MemoryFS struct {
files map[string]*MemoryFile
}
type MemoryFile struct {
name string
content []byte
mode fs.FileMode
modTime time.Time
}
func (m *MemoryFile) Stat() (fs.FileInfo, error) {
return &MemoryFileInfo{m}, nil
}
func (m *MemoryFile) Read(p []byte) (int, error) {
// Реализация чтения
}
func (m *MemoryFile) Close() error {
return nil
}
// MemoryFileInfo реализует fs.FileInfo
type MemoryFileInfo struct {
file *MemoryFile
}
func (m *MemoryFileInfo) Name() string { return m.file.name }
func (m *MemoryFileInfo) Size() int64 { return int64(len(m.file.content)) }
func (m *MemoryFileInfo) Mode() fs.FileMode { return m.file.mode }
func (m *MemoryFileInfo) ModTime() time.Time { return m.file.modTime }
func (m *MemoryFileInfo) IsDir() bool { return m.file.mode.IsDir() }
func (m *MemoryFileInfo) Sys() interface{} { return nil }
// Open реализует fs.FS
func (mfs *MemoryFS) Open(name string) (fs.File, error) {
if !fs.ValidPath(name) {
return nil, &fs.PathError{
Op: "open",
Path: name,
Err: fs.ErrInvalid,
}
}
file, exists := mfs.files[name]
if !exists {
return nil, &fs.PathError{
Op: "open",
Path: name,
Err: fs.ErrNotExist,
}
}
return file, nil
}
2. Используем нашу реализацию
func main() {
// Инициализируем нашу ФС
mfs := &MemoryFS{
files: map[string]*MemoryFile{
"hello.txt": {
name: "hello.txt",
content: []byte("Hello, MemoryFS!"),
mode: 0644,
modTime: time.Now(),
},
"dir": {
name: "dir",
mode: fs.ModeDir | 0755,
modTime: time.Now(),
},
},
}
// Пример 1: Открываем и читаем файл
file, err := mfs.Open("hello.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
info, _ := file.Stat()
fmt.Printf("Файл: %s, размер: %d\n", info.Name(), info.Size())
// Пример 2: Пытаемся открыть несуществующий файл
_, err = mfs.Open("missing.txt")
if err != nil {
fmt.Printf("Ошибка: %v\n", err) // Выведет PathError
}
// Пример 3: Используем с другими функциями пакета fs
content, err := fs.ReadFile(mfs, "hello.txt")
if err != nil {
log.Fatal(err)
}
fmt.Printf("Содержимое: %s\n", content)
}
3. Пример вывода:
Файл: hello.txt, размер: 15
Ошибка: open missing.txt: file does not exist
Содержимое: Hello, MemoryFS!
Где используется fs.FS?
В стандартной библиотеке:
os.DirFS- доступ к реальной файловой системеembed.FS- доступ к встроенным файламhttp.FileSystem- интеграция с веб-сервером
В популярных библиотеках:
- Виртуальные файловые системы
- Работа с архивами (zip, tar)
- Тестирование (testing/fstest)
В пользовательских реализациях:
- ФС в памяти
- ФС поверх облачного хранилища
- ФС для специализированных форматов
Преимущества такого подхода:
- Единообразие - один интерфейс для разных ФС
- Тестируемость - легко подменять реальную ФС на mock
- Гибкость - можно комбинировать разные реализации
Интерфейс fs.FS стал стандартным способом работы с файловыми системами в Go 1.16+, заменив множество специализированных решений.
func Sub
func Sub(fsys FS, dir string) (FS, error)
Sub возвращает FS, соответствующую поддереву с корнем в fsys’s dir.
Если dir равна «.», Sub возвращает fsys без изменений. В противном случае, если fs реализует SubFS, Sub возвращает fsys.Sub(dir). В противном случае Sub возвращает новую реализацию FS sub, которая фактически реализует sub.Open(name) как fsys.Open(path.Join(dir, name)). Реализация также соответствующим образом преобразует вызовы ReadDir, ReadFile и Glob.
Обратите внимание, что Sub(os.DirFS(«/»), „prefix“) эквивалентно os.DirFS(«/prefix») и что ни одно из них не гарантирует отсутствие доступа операционной системы за пределами «/prefix», поскольку реализация os.DirFS не проверяет символьные ссылки внутри «/prefix», которые указывают на другие каталоги. То есть os.DirFS не является общей заменой механизма безопасности типа chroot, и Sub не меняет этот факт.
type File
type File interface {
Stat() (FileInfo, error)
Read([]byte) (int, error)
Close() error
}
File предоставляет доступ к одному файлу. Интерфейс File является минимальной реализацией, требуемой для файла. Файлы каталогов также должны реализовывать ReadDirFile. Файл может реализовывать io.ReaderAt или io.Seeker в качестве оптимизаций.
type FileInfo
type FileInfo interface {
Name() string // базовое имя файла
Size() int64 // длина в байтах для обычных файлов; зависит от системы для других
Mode() FileMode // биты режима файла
ModTime() time.Time // время изменения
IsDir() bool // сокращение для Mode().IsDir()
Sys() any // базовый источник данных (может возвращать nil)
}
FileInfo описывает файл и возвращается Stat.
func Stat
func Stat(fsys FS, name string) (FileInfo, error)
Stat возвращает FileInfo, описывающий файл с указанным именем из файловой системы.
Если fs реализует StatFS, Stat вызывает fs.Stat. В противном случае Stat открывает файл для его статистики.
type FileMode
type FileMode uint32
FileMode представляет режим файла и биты разрешений. Биты имеют одинаковое определение во всех системах, поэтому информация о файлах может быть перенесена из одной системы в другую. Не все биты применимы ко всем системам. Единственный обязательный бит — ModeDir для каталогов.
const (
// Одиночные буквы являются аббревиатурами,
// используемыми для форматирования методом String.
ModeDir FileMode = 1 << (32 - 1 - iota) // d: является каталогом
ModeAppend // a: только для добавления
ModeExclusive // l: исключительное использование
ModeTemporary // T: временный файл; только Plan 9
ModeSymlink // L: символическая ссылка
ModeDevice // D: файл устройства
ModeNamedPipe // p: именованный канал (FIFO)
ModeSocket // S: сокет домена Unix
ModeSetuid // u: setuid
ModeSetgid // g: setgid
ModeCharDevice // c: символьное устройство Unix, когда установлен ModeDevice
ModeSticky // t: sticky
ModeIrregular // ?: нерегулярный файл; ничего больше не известно об этом файле
// Маска для битов типа. Для обычных файлов не будет установлено ничего.
ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice | ModeCharDevice | ModeIrregular
ModePerm FileMode = 0777 // биты разрешений Unix)
Определенные биты режима файла являются наиболее значимыми битами FileMode. Девять наименее значимых битов являются стандартными разрешениями Unix rwxrwxrwx. Значения этих битов следует рассматривать как часть общедоступного API и могут использоваться в протоколах передачи данных или представлениях диска: они не должны изменяться, хотя могут быть добавлены новые биты.
func (FileMode) IsDir
func (m FileMode) IsDir() bool
IsDir сообщает, описывает ли m каталог. То есть, он проверяет, установлен ли бит ModeDir в m.
func (FileMode) IsRegular
func (m FileMode) IsRegular() bool
IsRegular сообщает, описывает ли m обычный файл. То есть, он проверяет, что биты типа режима не установлены.
func (FileMode) Perm
func (m FileMode) Perm() FileMode
Perm возвращает биты разрешений Unix в m (m & ModePerm).
func (FileMode) String
func (m FileMode) String() string
func (FileMode) Type
func (m FileMode) Type() FileMode
Type возвращает биты типа в m (m & ModeType).
type GlobFS
type GlobFS interface {
FS
// Glob возвращает имена всех файлов, соответствующих шаблону,
// предоставляя реализацию функции верхнего уровня
// Glob.
Glob(pattern string) ([]string, error)
}
GlobFS — это файловая система с методом Glob.
type PathError
type PathError struct {
Op string
Path string
Err error
}
PathError регистрирует ошибку, а также операцию и путь к файлу, которые ее вызвали.
func (*PathError) Error
func (e *PathError) Error() string
func (*PathError) Timeout
func (e *PathError) Timeout() bool
Timeout сообщает, является ли эта ошибка тайм-аутом.
func (*PathError) Unwrap
func (e *PathError) Unwrap() error
type ReadDirFS
type ReadDirFS interface {
FS
// ReadDir читает указанный каталог
// и возвращает список записей каталога, отсортированных по имени файла.
ReadDir(name string) ([]DirEntry, error)
}
ReadDirFS — это интерфейс, реализованный файловой системой, который обеспечивает оптимизированную реализацию ReadDir.
type ReadDirFile
type ReadDirFile interface {
file
// ReadDir считывает содержимое каталога и возвращает
// массив из n значений DirEntry в порядке каталога.
// Последующие вызовы для того же файла будут возвращать дальнейшие значения DirEntry.
//
// Если n > 0, ReadDir возвращает не более n структур DirEntry.
// В этом случае, если ReadDir возвращает пустой срез, он вернет
// не нулевую ошибку с объяснением причины.
// В конце каталога ошибкой будет io.EOF.
// (ReadDir должен возвращать io.EOF сам, а не ошибку, оборачивающую io.EOF.)
//
// Если n <= 0, ReadDir возвращает все значения DirEntry из каталога
// в одном срезе. В этом случае, если ReadDir завершается успешно (считывает все
// до конца каталога), он возвращает срез и ошибку nil.
// Если он встречает ошибку до конца каталога,
// ReadDir возвращает список DirEntry, прочитанный до этого момента, и ошибку, отличную от nil.
ReadDir(n int) ([]DirEntry, error)
}
ReadDirFile — это файл каталога, записи которого можно прочитать с помощью метода ReadDir. Каждый файл каталога должен реализовывать этот интерфейс. (Любой файл может реализовывать этот интерфейс, но в этом случае ReadDir должен возвращать ошибку для некаталогов.)
type ReadFileFS
type ReadFileFS interface {
FS
// ReadFile читает указанный файл и возвращает его содержимое.
// Успешный вызов возвращает ошибку nil, а не io.EOF.
// (Поскольку ReadFile считывает весь файл, ожидаемый EOF
// от последнего Read не рассматривается как ошибка, о которой следует сообщать.)
//
// Вызывающему разрешается изменять возвращаемый байтовый срез.
// Этот метод должен возвращать копию базовых данных.
ReadFile(name string) ([]byte, error)
}
ReadFileFS — это интерфейс, реализованный файловой системой, который обеспечивает оптимизированную реализацию ReadFile.
type StatFS
type StatFS interface {
FS
// Stat возвращает FileInfo, описывающий файл.
// Если происходит ошибка, она должна быть типа *PathError.
Stat(name string) (FileInfo, error)
}
StatFS — это файловая система с методом Stat.
type SubFS
type SubFS interface {
FS
// Sub возвращает FS, соответствующий поддереву с корнем в dir.
Sub(dir string) (FS, error)
}
SubFS — это файловая система с методом Sub.
type WalkDirFunc
type WalkDirFunc func(path string, d DirEntry, err error) error
WalkDirFunc — это тип функции, вызываемой WalkDir для посещения каждого файла или каталога.
Аргумент path содержит аргумент WalkDir в качестве префикса. То есть, если WalkDir вызывается с корневым аргументом «dir» и находит файл с именем «a» в этом каталоге, функция walk будет вызвана с аргументом «dir/a».
Аргумент d — это DirEntry для указанного пути.
Результат error, возвращаемый функцией, контролирует продолжение работы WalkDir. Если функция возвращает специальное значение SkipDir, WalkDir пропускает текущий каталог (path, если d.IsDir() равно true, в противном случае — родительский каталог path). Если функция возвращает специальное значение SkipAll, WalkDir пропускает все оставшиеся файлы и каталоги. В противном случае, если функция возвращает ошибку, отличную от nil, WalkDir полностью останавливается и возвращает эту ошибку.
Аргумент err сообщает об ошибке, связанной с путем, сигнализируя, что WalkDir не будет проходить в этот каталог. Функция может решить, как обработать эту ошибку; как описано ранее, возврат ошибки приведет к тому, что WalkDir прекратит прохождение всего дерева.
WalkDir вызывает функцию с аргументом err, отличным от nil, в двух случаях.
Во-первых, если первоначальная Stat в корневом каталоге завершается с ошибкой, WalkDir вызывает функцию с path, установленным в root, d, установленным в nil, и err, установленным в ошибку из fs.Stat.
Во-вторых, если метод ReadDir каталога (см. ReadDirFile) завершается с ошибкой, WalkDir вызывает функцию с path, установленным в путь каталога, d, установленным в DirEntry, описывающий каталог, и err, установленным в ошибку из ReadDir. Во втором случае функция вызывается дважды с путем к каталогу: первый вызов происходит до попытки чтения каталога, и err установлен в nil, что дает функции возможность вернуть SkipDir или SkipAll и полностью избежать ReadDir. Второй вызов происходит после неудачного ReadDir и сообщает об ошибке из ReadDir. (Если ReadDir завершается успешно, второго вызова не происходит.)
Различия между WalkDirFunc и path/filepath.WalkFunc заключаются в следующем:
Второй аргумент имеет тип DirEntry вместо FileInfo. Функция вызывается перед чтением каталога, чтобы SkipDir или SkipAll могли полностью обойти чтение каталога или пропустить все оставшиеся файлы и каталоги соответственно. Если чтение каталога завершилось неудачно, функция вызывается второй раз для этого каталога, чтобы сообщить об ошибке.
12.4.10 - Пакет Sync для Go
Пакет sync предоставляет базовые примитивы синхронизации, такие как взаимоисключающие блокировки.
За исключением типов Once и WaitGroup, большинство из них предназначены для использования низкоуровневыми библиотечными процедурами. Синхронизацию более высокого уровня лучше выполнять через каналы и коммуникации.
Значения, содержащие типы, определенные в этом пакете, не должны копироваться.
Функции
func OnceFunc
func OnceFunc(f func()) func()
OnceFunc возвращает функцию, которая вызывает f только один раз. Возвращаемая функция может вызываться одновременно.
Если f вызывает панику, возвращаемая функция будет вызывать панику с тем же значением при каждом вызове.
func OnceValue
func OnceValue[T any](f func() T) func() T
OnceValue возвращает функцию, которая вызывает f только один раз и возвращает значение, возвращаемое f. Возвращаемая функция может вызываться одновременно.
Если f вызывает панику, возвращаемая функция будет вызывать панику с тем же значением при каждом вызове.
Пример
В этом примере OnceValue используется для выполнения «дорогостоящего» вычисления только один раз, даже при одновременном использовании.
package main
import (
"fmt"
"sync"
)
func main() {
once := sync.OnceValue(func() int {
sum := 0
for i := 0; i < 1000; i++ {
sum += i
}
fmt.Println("Computed once:", sum)
return sum
})
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
const want = 499500
got := once()
if got != want {
fmt.Println("want", want, "got", got)
}
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
Output:
Computed once: 499500
func OnceValues
func OnceValues[T1, T2 any](f func() (T1, T2)) func() (T1, T2)
OnceValues возвращает функцию, которая вызывает f только один раз и возвращает значения, возвращаемые f. Возвращаемая функция может вызываться одновременно.
Если f вызывает панику, возвращаемая функция будет вызывать панику с тем же значением при каждом вызове.
Пример
В этом примере используется OnceValues для однократного чтения файла.
package main
import (
"fmt"
"os"
"sync"
)
func main() {
once := sync.OnceValues(func() ([]byte, error) {
fmt.Println("Reading file once")
return os.ReadFile("example_test.go")
})
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
data, err := once()
if err != nil {
fmt.Println("error:", err)
}
_ = data // Ignore the data for this example
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
Типы
type Cond
type Cond struct {
// L удерживается во время наблюдения или изменения условия
L Locker
// содержит отфильтрованные или неэкспортируемые поля
}
Cond реализует переменную условия, точку встречи для goroutines, ожидающих или объявляющих о наступлении события.
Каждый Cond имеет связанный с ним Locker L (часто *Mutex или *RWMutex), который должен удерживаться при изменении условия и при вызове метода Cond.Wait.
Cond не должен копироваться после первого использования.
В терминологии модели памяти Go, Cond организует так, что вызов Cond.Broadcast или Cond.Signal «синхронизируется перед» любым вызовом Wait, который он разблокирует.
Для многих простых случаев использования пользователям будет удобнее использовать каналы, чем Cond (Broadcast соответствует закрытию канала, а Signal — отправке по каналу).
Для получения дополнительной информации о заменах sync.Cond см. серию статей Роберто Клаписа о расширенных моделях параллелизма, а также доклад Брайана Миллса о моделях параллелизма.
func NewCond
func NewCond(l Locker) *Cond
NewCond возвращает новый Cond с Locker l.
func (*Cond) Broadcast
func (c *Cond) Broadcast()
Broadcast пробуждает все goroutines, ожидающие c.
Вызывающему разрешается, но не требуется, удерживать c.L во время вызова.
func (*Cond) Signal
func (c *Cond) Signal()
Signal пробуждает одну goroutine, ожидающую c, если таковая имеется.
Вызывающему разрешается, но не требуется, удерживать c.L во время вызова.
Signal() не влияет на приоритет планирования goroutine; если другие goroutines пытаются заблокировать c.L, они могут быть пробуждены раньше «ожидающей» goroutine.
func (*Cond) Wait
func (c *Cond) Wait()
Wait атомарно разблокирует c.L и приостанавливает выполнение вызывающего goroutine. После возобновления выполнения Wait блокирует c.L перед возвратом. В отличие от других систем, Wait не может вернуться, если его не разбудит Cond.Broadcast или Cond.Signal.
Поскольку c.L не блокируется во время ожидания Wait, вызывающий обычно не может предполагать, что условие будет выполнено, когда Wait вернется. Вместо этого вызывающий должен ждать в цикле:
c.L.Lock()
for !condition() {
c.Wait()
}...
использовать условие ...
c.L.Unlock()
Подробное объяснение типа Cond
Что такое Cond?
Cond (от слова “condition” - условие) - это примитив синхронизации из пакета sync, который позволяет горутинам ожидать или объявлять о наступлении некоторого события.
Проще говоря, Cond нужен для того, чтобы:
- Одни горутины могли “уснуть” и ждать какого-то условия
- Другие горутины могли их “разбудить”, когда это условие выполнится
Основные методы:
Wait()- блокирует горутину до получения уведомленияSignal()- пробуждает одну случайную горутину из ожидающихBroadcast()- пробуждает все ожидающие горутины
Зачем это нужно?
Cond особенно полезен в ситуациях, где:
- Несколько горутин ожидают какого-то общего условия
- Состояние может измениться в любой момент
- Вы не хотите постоянно опрашивать условие в цикле (busy waiting)
Реальный пример: Ограниченная очередь
Допустим, у нас есть очередь с ограниченным размером, и мы хотим:
- Блокировать писателей, когда очередь полна
- Блокировать читателей, когда очередь пуста
package main
import (
"fmt"
"sync"
"time"
)
type BoundedQueue struct {
mu sync.Mutex
cond *sync.Cond
queue []int
size int
cap int
}
func NewBoundedQueue(capacity int) *BoundedQueue {
q := &BoundedQueue{
queue: make([]int, 0, capacity),
cap: capacity,
}
q.cond = sync.NewCond(&q.mu)
return q
}
func (q *BoundedQueue) Put(item int) {
q.mu.Lock()
defer q.mu.Unlock()
// Ждем, пока освободится место
for q.size == q.cap {
q.cond.Wait()
}
q.queue = append(q.queue, item)
q.size++
fmt.Printf("Добавлен элемент %d. Размер очереди: %d\n", item, q.size)
// Уведомляем ожидающих читателей
q.cond.Broadcast()
}
func (q *BoundedQueue) Get() int {
q.mu.Lock()
defer q.mu.Unlock()
// Ждем, пока появится элемент
for q.size == 0 {
q.cond.Wait()
}
item := q.queue[0]
q.queue = q.queue[1:]
q.size--
fmt.Printf("Извлечен элемент %d. Размер очереди: %d\n", item, q.size)
// Уведомляем ожидающих писателей
q.cond.Broadcast()
return item
}
func main() {
queue := NewBoundedQueue(3)
// Писатели
for i := 0; i < 5; i++ {
go func(val int) {
queue.Put(val)
}(i)
}
// Читатели
for i := 0; i < 5; i++ {
go func() {
time.Sleep(1 * time.Second)
queue.Get()
}()
}
time.Sleep(5 * time.Second)
}
Когда использовать Cond вместо каналов?
Cond полезен, когда:
- У вас сложное условие ожидания (не просто “есть данные”)
- Нужно уведомлять сразу несколько горутин
- Состояние может меняться часто и нужно минимизировать накладные расходы
Каналы лучше подходят для более простых случаев передачи данных между горутинами.
sync.Cond - это инструмент для сложных сценариев синхронизации, где горутинам нужно ждать выполнения определенных условий. Он особенно полезен при реализации структур данных с ограничениями (как в нашем примере с очередью), пулов ресурсов или других сценариев, где состояние может меняться и нужно эффективно уведомлять ожидающие горутины.
type Locker
type Locker интерфейс {
Lock()
Unlock()
}
Locker - это интерфейс из пакета sync, который определяет базовые методы для блокировки:
Подробное объяснение типа Locker
Этот интерфейс реализуют:
sync.Mutex- обычная мьютекс-блокировкаsync.RWMutex- блокировка с возможностью множественного чтения- Любые другие типы, которые реализуют эти два метода
Зачем нужен Locker?
- Унификация работы с разными типами блокировок - вы можете писать функции, которые работают с любым типом блокировки
- Абстракция - позволяет не зависеть от конкретной реализации блокировки
- Тестирование - можно создавать mock-объекты для тестирования
Пример 1: Использование с sync.Mutex
package main
import (
"fmt"
"sync"
"time"
)
func increment(counter *int, locker sync.Locker) {
locker.Lock()
defer locker.Unlock()
*counter++
fmt.Println(*counter)
}
func main() {
var counter int
var mu sync.Mutex
for i := 0; i < 5; i++ {
go increment(&counter, &mu)
}
time.Sleep(1 * time.Second)
}
Пример 2: Собственная реализация Locker
type DebugLocker struct {
mu sync.Mutex
}
func (d *DebugLocker) Lock() {
fmt.Println("Lock acquired")
d.mu.Lock()
}
func (d *DebugLocker) Unlock() {
fmt.Println("Lock released")
d.mu.Unlock()
}
func main() {
var counter int
locker := &DebugLocker{}
for i := 0; i < 5; i++ {
go increment(&counter, locker)
}
time.Sleep(1 * time.Second)
}
Реальный пример использования
Допустим, у нас есть кэш, который может использовать разные виды блокировок:
type Cache struct {
locker sync.Locker
data map[string]string
}
func NewCache(locker sync.Locker) *Cache {
return &Cache{
locker: locker,
data: make(map[string]string),
}
}
func (c *Cache) Set(key, value string) {
c.locker.Lock()
defer c.locker.Unlock()
c.data[key] = value
}
func (c *Cache) Get(key string) (string, bool) {
c.locker.Lock()
defer c.locker.Unlock()
val, ok := c.data[key]
return val, ok
}
func main() {
// Можно использовать обычный Mutex
cache1 := NewCache(&sync.Mutex{})
// Или RWMutex для оптимизации чтения
cache2 := NewCache(&sync.RWMutex{})
// Или даже нашу DebugLocker
cache3 := NewCache(&DebugLocker{})
}Locker представляет объект, который можно заблокировать и разблокировать.
Когда использовать Locker?
- Когда ваша функция/метод должен работать с разными типами блокировок
- Когда вы хотите сделать код более гибким для тестирования
- Когда вы разрабатываете библиотеку и хотите оставить выбор блокировки пользователю
Locker - это простой интерфейс, который позволяет абстрагироваться от конкретного типа блокировки. Он делает ваш код более гибким и переиспользуемым, особенно когда речь идет о конкурентных операциях.
type Map
type Map struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Map похож на Go map[any]any, но безопасен для одновременного использования несколькими goroutines без дополнительной блокировки или координации. Загрузка, хранение и удаление выполняются за амортизированное постоянное время.
Тип Map является специализированным. В большинстве случаев следует использовать обычный Go map с отдельной блокировкой или координацией, чтобы обеспечить лучшую типовую безопасность и упростить поддержание других инвариантов наряду с содержимым карты.
Тип Map оптимизирован для двух распространенных случаев использования:
- когда запись для данного ключа записывается только один раз, но читается много раз, как в кэшах, которые только растут, или
- когда несколько goroutines читают, записывают и перезаписывают записи для непересекающихся наборов ключей.
В этих двух случаях использование Map может значительно уменьшить конфликты блокировок по сравнению с Go map в паре с отдельным Mutex или RWMutex.
Карта с нулевым значением пуста и готова к использованию. Карту нельзя копировать после первого использования.
В терминологии модели памяти Go карта организует так, что операция записи «синхронизируется перед» любой операцией чтения, которая наблюдает эффект записи, где операции чтения и записи определяются следующим образом.
- Map.Load, Map.LoadAndDelete, Map.LoadOrStore, Map.Swap, Map.CompareAndSwap и Map.CompareAndDelete — операции чтения;
- Map.Delete, Map.LoadAndDelete, Map.Store и Map.Swap — операции записи;
- Map.LoadOrStore — операция записи, когда она возвращает загруженный набор, установленный в false;
- Map.CompareAndSwap — операция записи, когда она возвращает помененный набор, установленный в true; и
- Map.CompareAndDelete — операция записи, когда она возвращает удаленный набор, установленный в true.
func (*Map) Clear
func (m *Map) Clear()
Clear удаляет все записи, в результате чего карта становится пустой.
func (*Map) CompareAndDelete
func (m *Map) CompareAndDelete(key, old any) (deleted bool)
CompareAndDelete удаляет запись для ключа, если его значение равно old. Старое значение должно быть сопоставимого типа.
Если в карте нет текущего значения для ключа, CompareAndDelete возвращает false (даже если старое значение является значением интерфейса nil).
Подробное объяснение типа Map и функции CompareAndDelete
Что делает CompareAndDelete?
Метод CompareAndDelete выполняет атомарную операцию:
- Проверяет, соответствует ли текущее значение для указанного ключа
oldзначению - Если значения совпадают - удаляет запись из мапы
- Возвращает
true, если удаление произошло, иfalseв противном случае
Это операция “compare-and-delete” (сравнить и удалить), аналогичная атомарным операциям CAS (Compare-And-Swap).
Как это работает?
deleted := m.CompareAndDelete(key, oldValue)
- Если в мапе
keyотсутствует → возвращаетfalse - Если в мапе
keyесть, но значение ≠oldValue→ возвращаетfalse - Если в мапе
keyесть и значение ==oldValue→ удаляет запись и возвращаетtrue
Пример использования
package main
import (
"fmt"
"sync"
)
func main() {
var m sync.Map
// Добавляем значения в мапу
m.Store("counter", 42)
m.Store("flag", true)
m.Store("name", "Alice")
// Попытка удалить с неправильным старым значением
deleted := m.CompareAndDelete("counter", 100)
fmt.Printf("Удаление counter=100: %v\n", deleted) // false
// Удаление с правильным значением
deleted = m.CompareAndDelete("counter", 42)
fmt.Printf("Удаление counter=42: %v\n", deleted) // true
// Проверяем, что counter удален
_, ok := m.Load("counter")
fmt.Printf("counter существует: %v\n", ok) // false
// Попытка удалить несуществующий ключ
deleted = m.CompareAndDelete("nonexistent", nil)
fmt.Printf("Удаление nonexistent: %v\n", deleted) // false
// Пример с nil значением
m.Store("nil-value", nil)
deleted = m.CompareAndDelete("nil-value", nil)
fmt.Printf("Удаление nil-value: %v\n", deleted) // true
}
Реальный кейс использования
Представим систему, где несколько горутин обновляют статус задач:
type TaskStatus string
const (
Pending TaskStatus = "pending"
Running TaskStatus = "running"
Completed TaskStatus = "completed"
)
func completeTask(m *sync.Map, taskID string) bool {
// Пытаемся перевести задачу из running в completed
return m.CompareAndDelete(taskID, Running)
}
func main() {
var tasks sync.Map
// Инициализируем задачи
tasks.Store("task1", Pending)
tasks.Store("task2", Running)
tasks.Store("task3", Running)
// Горутины пытаются завершить задачи
var wg sync.WaitGroup
for i := 0; i < 3; i++ {
wg.Add(1)
go func() {
defer wg.Done()
if completeTask(&tasks, "task2") {
fmt.Println("Задача task2 завершена")
}
}()
}
wg.Wait()
// Проверяем оставшиеся задачи
tasks.Range(func(key, value interface{}) bool {
fmt.Printf("%s: %s\n", key, value)
return true
})
}
Особенности работы
- Безопасность для concurrent-использования: метод можно вызывать из нескольких горутин без дополнительной синхронизации
- Сравнение значений: сравнение происходит через
==, поэтому для сложных типов нужно быть внимательным - nil значения: даже если
old- nil, метод вернетfalseесли ключа нет в мапе
Когда использовать?
CompareAndDelete полезен в сценариях:
- Удаление устаревших данных (когда значение соответствует ожидаемому)
- Реализация конечных автоматов (state machines)
- Оптимистичные блокировки (optimistic locking)
- Удаление элементов только при определенных условиях
Этот метод особенно полезен в конкурентных сценариях, где нужно атомарно проверить и удалить значение без явных блокировок.
func (*Map) CompareAndSwap
func (m *Map) CompareAndSwap(key, old, new any) (swapped bool)
CompareAndSwap меняет местами старое и новое значения для ключа, если значение, хранящееся в карте, равно old. Старое значение должно быть сравнимого типа.
func (*Map) Delete
func (m *Map) Delete(key any)
Delete удаляет значение для ключа.
func (*Map) Load
func (m *Map) Load(key any) (value any, ok bool)
Load возвращает значение, хранящееся в карте для ключа, или nil, если значение отсутствует. Результат ok указывает, было ли найдено значение в карте.
func (*Map) LoadAndDelete
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
LoadAndDelete удаляет значение для ключа, возвращая предыдущее значение, если оно есть. Результат loaded сообщает, присутствовал ли ключ.
func (*Map) LoadOrStore
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
Метод LoadOrStore выполняет атомарную операцию “загрузить или сохранить” и особенно полезен в конкурентных сценариях, когда несколько горутин могут одновременно пытаться работать с одними и теми же ключами.
Объяснеие, что происходит на самом деле
Как это работает?
actual, loaded := m.LoadOrStore(key, value)
Если ключ
keyуже существует в мапе:- Возвращает существующее значение (в
actual) loaded = true(значение было загружено)
- Возвращает существующее значение (в
Если ключ
keyне существует в мапе:- Сохраняет переданное
valueпо этому ключу - Возвращает это же значение (в
actual) loaded = false(значение было сохранено)
- Сохраняет переданное
Простой пример
package main
import (
"fmt"
"sync"
)
func main() {
var m sync.Map
// Пытаемся сохранить значение "apple" по ключу "fruit"
// Так как ключа нет - оно будет сохранено
actual, loaded := m.LoadOrStore("fruit", "apple")
fmt.Printf("Ключ 'fruit': actual=%v, loaded=%v\n", actual, loaded)
// Вывод: Ключ 'fruit': actual=apple, loaded=false
// Пытаемся сохранить "banana" по тому же ключу
// Но ключ уже существует - возвращается текущее значение
actual, loaded = m.LoadOrStore("fruit", "banana")
fmt.Printf("Ключ 'fruit': actual=%v, loaded=%v\n", actual, loaded)
// Вывод: Ключ 'fruit': actual=apple, loaded=true
// Проверяем текущее значение
value, _ := m.Load("fruit")
fmt.Println("Текущее значение для 'fruit':", value)
// Вывод: Текущее значение для 'fruit': apple
}
Реальный пример: кэширование результатов
Представим сервис, который кэширует результаты дорогих вычислений:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var cache sync.Map
func expensiveCalculation(id int) int {
// Имитация долгого вычисления
time.Sleep(time.Second)
return rand.Intn(1000)
}
func getCachedResult(id int) int {
// Пытаемся получить результат из кэша
result, loaded := cache.LoadOrStore(id, expensiveCalculation(id))
if loaded {
fmt.Printf("Результат для %d взят из кэша\n", id)
} else {
fmt.Printf("Результат для %d вычислен и сохранен\n", id)
}
return result.(int)
}
func main() {
rand.Seed(time.Now().UnixNano())
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
getCachedResult(id % 3) // Используем только 3 разных ID
}(i)
}
wg.Wait()
}
Возможный вывод:
Результат для 0 вычислен и сохранен
Результат для 1 вычислен и сохранен
Результат для 2 вычислен и сохранен
Результат для 0 взят из кэша
Результат для 1 взят из кэша
Особенности LoadOrStore
- Атомарность: Операция выполняется атомарно, что делает её безопасной для использования из нескольких горутин
- Эффективность: Избегает “гонки” при инициализации значений
- Удобство: Заменяет распространённый паттерн “проверить-затем-сохранить”
Когда использовать?
LoadOrStore идеально подходит для:
- Кэширования результатов
- Инициализации синглтонов
- Создания элементов по требованию
- Любых сценариев, где нужно “получить или создать” значение атомарно
Этот метод особенно полезен в высоконагруженных системах, где несколько горутин могут одновременно запрашивать одни и те же ресурсы.
func (*Map) Range
func (m *Map) Range(f func(key, value any) bool)
Range вызывает f последовательно для каждого ключа и значения, присутствующих в карте. Если f возвращает false, range останавливает итерацию.
Range не обязательно соответствует какому-либо последовательному снимку содержимого карты: ни один ключ не будет посещен более одного раза, но если значение для любого ключа хранится или удаляется одновременно (в том числе f), Range может отражать любое сопоставление для этого ключа из любой точки во время вызова Range. Range не блокирует другие методы на приемнике; даже f может вызывать любой метод на m.
Range может быть O(N) с количеством элементов в карте, даже если f возвращает false после постоянного числа вызовов.
func (*Map) Store
func (m *Map) Store(key, value any)
Store устанавливает значение для ключа.
func (*Map) Swap
func (m *Map) Swap(key, value any) (previous any, loaded bool)
Swap заменяет значение ключа и возвращает предыдущее значение, если оно есть. Результат loaded сообщает, присутствовал ли ключ.
type Mutex
type Mutex struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Mutex — это блокировка взаимного исключения. Нулевое значение для Mutex — это разблокированный мьютекс.
Mutex не должен копироваться после первого использования.
В терминологии модели памяти Go n-й вызов Mutex.Unlock «синхронизирует перед» m-й вызов Mutex.Lock для любого n < m. Успешный вызов Mutex.TryLock эквивалентен вызову Lock. Неудачный вызов TryLock не устанавливает никаких отношений «синхронизирует перед».
Объяснение Mutex
Mutex (сокращение от “mutual exclusion” - взаимное исключение) - это примитив синхронизации, который позволяет только одной горутине за раз получать доступ к общему ресурсу.
Представьте его как дверь в туалет:
- Когда кто-то внутри, дверь заперта (Lock)
- Другие ждут снаружи (блокируются)
- Когда человек выходит, он открывает дверь (Unlock)
- Тогда следующий может войти
Основные методы:
Lock()- захватывает мьютекс (блокирует, если он уже захвачен)Unlock()- освобождает мьютексTryLock()- пытается захватить мьютекс без блокировки (возвращает успех/неудачу)
Простой пример:
package main
import (
"fmt"
"sync"
"time"
)
var counter int
var mu sync.Mutex // Создаем мьютекс
func increment() {
mu.Lock() // Захватываем мьютекс
defer mu.Unlock() // Гарантируем освобождение
temp := counter
time.Sleep(1 * time.Millisecond) // Имитируем работу
counter = temp + 1
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
increment()
}()
}
wg.Wait()
fmt.Println("Итоговое значение счетчика:", counter) // Всегда 100
}
Реальный пример: Банковский перевод
type BankAccount struct {
balance int
mu sync.Mutex
}
func (acc *BankAccount) Deposit(amount int) {
acc.mu.Lock()
defer acc.mu.Unlock()
acc.balance += amount
}
func (acc *BankAccount) Withdraw(amount int) bool {
acc.mu.Lock()
defer acc.mu.Unlock()
if acc.balance < amount {
return false
}
acc.balance -= amount
return true
}
func (acc *BankAccount) Transfer(to *BankAccount, amount int) bool {
// Важно: блокируем оба счета в одном порядке, чтобы избежать deadlock
acc.mu.Lock()
defer acc.mu.Unlock()
to.mu.Lock()
defer to.mu.Unlock()
if acc.balance < amount {
return false
}
acc.balance -= amount
to.balance += amount
return true
}
Когда использовать Mutex?
- Когда несколько горутин работают с общими данными
- Когда нужно гарантировать целостность данных
- Для защиты операций, которые должны выполняться атомарно
Важные правила:
- Всегда освобождайте мьютекс (лучше через
defer) - Не копируйте мьютекс после использования
- Избегайте блокировок на долгое время
- Соблюдайте порядок блокировки нескольких мьютексов
TryLock пример:
func tryUpdate(data *string) {
var mu sync.Mutex
if mu.TryLock() {
defer mu.Unlock()
*data = "updated"
} else {
fmt.Println("Не удалось получить блокировку")
}
}
func (*Mutex) Lock
func (m *Mutex) Lock()
Lock блокирует m. Если блокировка уже используется, вызывающая goroutine блокируется до тех пор, пока мьютекс не станет доступным.
func (*Mutex) TryLock
func (m *Mutex) TryLock() bool
TryLock пытается заблокировать m и сообщает, удалось ли это.
Обратите внимание, что хотя правильные способы использования TryLock существуют, они редки, и использование TryLock часто является признаком более глубокой проблемы в конкретном использовании мьютексов.
func (*Mutex) Unlock
func (m *Mutex) Unlock()
Unlock разблокирует m. Если m не заблокирован при входе в Unlock, возникает ошибка выполнения.
Заблокированный мьютекс не связан с конкретной горутиной. Одна горутина может заблокировать мьютекс, а затем организовать его разблокировку другой горутиной.
type Once
type Once struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Once — это объект, который выполнит ровно одно действие.
Once нельзя копировать после первого использования.
В терминологии модели памяти Go возврат из f «синхронизируется перед» возвратом из любого вызова once.Do(f).
Пример
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
once.Do(onceBody)
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
Этот код демонстрирует использование sync.Once в Go - структуры, которая гарантирует, что определённая функция будет выполнена ровно один раз, даже если её вызов происходит из нескольких горутин.
Разберём код по частям:
- Инициализация:
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
- Создаётся объект
sync.Once - Определяется функция
onceBody, которая будет выполнена один раз
- Канал для синхронизации:
done := make(chan bool)
- Создаётся буферизированный канал для ожидания завершения всех горутин
- Запуск горутин:
for i := 0; i < 10; i++ {
go func() {
once.Do(onceBody)
done <- true
}()
}
- Запускается 10 горутин
- Каждая вызывает
once.Do(onceBody) - После выполнения отправляет сигнал в канал
done
- Ожидание завершения:
for i := 0; i < 10; i++ {
<-done
}
- Основная горутина ждёт 10 сигналов (по одному от каждой горутины)
Что произойдёт при выполнении:
- Все 10 горутин попытаются выполнить
onceBodyчерезonce.Do() sync.Onceгарантирует, что:- Функция
onceBodyбудет выполнена только один раз - Остальные горутин будут ждать завершения этого выполнения
- Все последующие вызовы будут проигнорированы
- Функция
- В результате в консоли мы увидим только одно сообщение “Only once”
Практическое применение:
- Инициализация глобальных ресурсов
- Ленивая инициализация
- Создание синглтонов
- Однократное выполнение настройки
Этот пример наглядно показывает мощь sync.Once для решения задач, требующих однократного выполнения в конкурентной среде.
func (*Once) Do
func (o *Once) Do(f func())
Do вызывает функцию f, если и только если Do вызывается впервые для этого экземпляра Once. Другими словами, при условии
var once Once
если once.Do(f) вызывается несколько раз, только первый вызов вызовет f, даже если f имеет разное значение при каждом вызове. Для выполнения каждой функции требуется новый экземпляр Once.
Do предназначен для инициализации, которая должна выполняться ровно один раз. Поскольку f является нулевым, может потребоваться использовать функциональный литерал для захвата аргументов функции, которая будет вызвана Do:
config.once.Do(func() { config.init(filename) })
Поскольку ни один вызов Do не возвращается до тех пор, пока не вернется один вызов f, если f вызывает Do, это приведет к тупиковой ситуации.
Если f вызывает панику, Do считает, что она вернулась; будущие вызовы Do возвращаются без вызова f.
type Pool
type Pool struct {
// New опционально указывает функцию для генерации
// значения, когда Get в противном случае вернул бы nil.
// Он не может быть изменен одновременно с вызовами Get.
New func() any
// содержит отфильтрованные или неэкспортируемые поля
}
Pool — это набор временных объектов, которые могут быть индивидуально сохранены и извлечены.
Любой элемент, хранящийся в Pool, может быть удален автоматически в любое время без уведомления. Если Pool содержит единственную ссылку, когда это происходит, элемент может быть деаллоцирован.
Pool безопасен для одновременного использования несколькими goroutines.
Цель пула — кэшировать выделенные, но неиспользуемые элементы для повторного использования в будущем, снимая нагрузку с сборщика мусора. То есть он упрощает создание эффективных, потокобезопасных списков свободных элементов. Однако он подходит не для всех списков свободных элементов.
Пул целесообразно использовать для управления группой временных элементов, которые незаметно совместно используются и потенциально повторно используются одновременно независимыми клиентами пакета. Пул позволяет амортизировать накладные расходы на выделение памяти между многими клиентами.
Примером правильного использования пула является пакет fmt, который поддерживает хранилище временных буферов вывода динамического размера. Хранилище масштабируется под нагрузкой (когда многие goroutines активно печатают) и сокращается в состоянии покоя.
С другой стороны, свободный список, поддерживаемый как часть короткоживущего объекта, не подходит для использования в пуле, поскольку в этом сценарии накладные расходы не амортизируются должным образом. Более эффективно, чтобы такие объекты реализовывали свой собственный свободный список.
Пул не должен копироваться после первого использования.
В терминологии модели памяти Go вызов Put(x) «синхронизируется перед» вызовом Pool.Get, возвращающим то же значение x. Аналогично, вызов New, возвращающий x, «синхронизируется перед» вызовом Get, возвращающим то же значение x.
Пример
package main
import (
"bytes"
"io"
"os"
"sync"
"time"
)
var bufPool = sync.Pool{
New: func() any {
return new(bytes.Buffer)
},
}
func timeNow() time.Time {
return time.Unix(1136214245, 0)
}
func Log(w io.Writer, key, val string) {
b := bufPool.Get().(*bytes.Buffer)
b.Reset()
b.WriteString(timeNow().UTC().Format(time.RFC3339))
b.WriteByte(' ')
b.WriteString(key)
b.WriteByte('=')
b.WriteString(val)
w.Write(b.Bytes())
bufPool.Put(b)
}
func main() {
Log(os.Stdout, "path", "/search?q=flowers")
}
Этот пример демонстрирует эффективное использование sync.Pool для оптимизации работы с временными объектами (в данном случае - bytes.Buffer).
1. Пул буферов (sync.Pool)
var bufPool = sync.Pool{
New: func() any {
return new(bytes.Buffer)
},
}
- Создается пул объектов
bytes.Buffer - Функция
Newсоздает новый буфер, когда пул пуст - Важно: возвращаются указатели (
new(bytes.Buffer)), чтобы избежать лишних аллокаций
2. Функция логирования
func Log(w io.Writer, key, val string) {
// 1. Получаем буфер из пула (или создаем новый)
b := bufPool.Get().(*bytes.Buffer)
// 2. Сбрасываем состояние буфера перед использованием
b.Reset()
// 3. Формируем строку лога
b.WriteString(timeNow().UTC().Format(time.RFC3339))
b.WriteByte(' ')
b.WriteString(key)
b.WriteByte('=')
b.WriteString(val)
// 4. Выводим лог
w.Write(b.Bytes())
// 5. Возвращаем буфер в пул для повторного использования
bufPool.Put(b)
}
3. Тестовая реализация времени
func timeNow() time.Time {
return time.Unix(1136214245, 0) // Фиксированное время для демонстрации
}
Как это работает:
При первом вызове
Log:- Пул пуст, поэтому вызывается
Newи создается новыйbytes.Buffer - Буфер используется и возвращается в пул
- Пул пуст, поэтому вызывается
При последующих вызовах:
- Буфер берется из пула (без аллокации)
- Сбрасывается (
Reset()) - Используется повторно
Преимущества подхода:
Снижение нагрузки на GC:
- Буферы переиспользуются, а не создаются заново
- Меньше работы для сборщика мусора
Экономия памяти:
- Не нужно постоянно выделять/освобождать память
- Размер пула автоматически регулируется
Потокобезопасность:
sync.Poolбезопасен для использования из нескольких горутин
Важные нюансы:
Обязательно сбрасывайте состояние:
- Перед использованием вызовите
Reset(), чтобы очистить предыдущие данные
- Перед использованием вызовите
Не сохраняйте объекты из пула:
- После
Put()считайте объект более недоступным
- После
Подходит для часто создаваемых объектов:
- Идеально для объектов, которые:
- Дорого создавать
- Используются кратковременно
- Имеют примерно одинаковый размер
- Идеально для объектов, которые:
Реальный вывод программы:
2006-01-02T15:04:05Z path=/search?q=flowers
Этот паттерн особенно полезен в:
- Логгерах
- HTTP middleware
- Любом коде, где часто создаются временные буферы
func (*Pool) Get
func (p *Pool) Get() any
Get выбирает произвольный элемент из пула, удаляет его из пула и возвращает вызывающему. Get может игнорировать пул и рассматривать его как пустой. Вызывающие не должны предполагать какую-либо связь между значениями, переданными в Pool.Put, и значениями, возвращаемыми Get.
Если Get в противном случае вернул бы nil, а p.New не равен nil, Get возвращает результат вызова p.New.
func (*Pool) Put
func (p *Pool) Put(x any)
Put добавляет x в пул.
type RWMutex
type RWMutex struct {
// содержит отфильтрованные или неэкспортируемые поля
}
RWMutex — это блокировка взаимного исключения для чтения/записи. Блокировка может удерживаться произвольным количеством читателей или одним записывающим устройством. Нулевое значение для RWMutex — это разблокированный мьютекс.
RWMutex не должен копироваться после первого использования.
Если какой-либо goroutine вызывает RWMutex.Lock, когда блокировка уже удерживается одним или несколькими читателями, одновременные вызовы RWMutex.RLock будут блокироваться до тех пор, пока записывающий не получит (и не освободит) блокировку, чтобы обеспечить доступность блокировки для записывающего. Обратите внимание, что это запрещает рекурсивную блокировку чтения. RWMutex.RLock не может быть повышен до RWMutex.Lock, а RWMutex.Lock не может быть понижен до RWMutex.RLock.
В терминологии модели памяти Go n-й вызов RWMutex.Unlock «синхронизируется перед» m-м вызовом Lock для любого n < m, так же как и для Mutex. Для любого вызова RLock существует n, такое что n-й вызов Unlock «синхронизируется перед» этим вызовом RLock, а соответствующий вызов RWMutex.RUnlock «синхронизируется перед» n+1-м вызовом Lock.
func (*RWMutex) Lock
func (rw *RWMutex) Lock()
Lock блокирует rw для записи. Если блокировка уже заблокирована для чтения или записи, Lock блокируется до тех пор, пока блокировка не станет доступной.
func (*RWMutex) RLock
func (rw *RWMutex) RLock()
RLock блокирует rw для чтения.
Его не следует использовать для рекурсивной блокировки чтения; заблокированный вызов Lock исключает возможность получения блокировки новыми читателями. См. документацию по типу RWMutex.
func (*RWMutex) RLocker
func (rw *RWMutex) RLocker() Locker
RLocker возвращает интерфейс Locker, который реализует методы [Locker.Lock] и [Locker.Unlock] путем вызова rw.RLock и rw.RUnlock.
func (*RWMutex) RUnlock
func (rw *RWMutex) RUnlock()
RUnlock отменяет один вызов RWMutex.RLock; это не влияет на других одновременных читателей. Если rw не заблокирован для чтения при входе в RUnlock, возникает ошибка выполнения.
func (*RWMutex) TryLock
func (rw *RWMutex) TryLock() bool
TryLock пытается заблокировать rw для записи и сообщает, удалось ли это.
Обратите внимание, что хотя правильное использование TryLock существует, оно встречается редко, и использование TryLock часто является признаком более глубокой проблемы в конкретном использовании мьютексов.
func (*RWMutex) TryRLock
func (rw *RWMutex) TryRLock() bool
TryRLock пытается заблокировать rw для чтения и сообщает, удалось ли это.
Обратите внимание, что хотя правильное использование TryRLock существует, оно встречается редко, и использование TryRLock часто является признаком более глубокой проблемы в конкретном использовании мьютексов.
func (*RWMutex) Unlock
func (rw *RWMutex) Unlock()
Unlock разблокирует rw для записи. Если rw не заблокирован для записи при входе в Unlock, возникает ошибка выполнения.
Как и в случае с мьютексами, заблокированный RWMutex не связан с конкретной горутиной. Одна горутина может RWMutex.RLock (RWMutex.Lock) RWMutex, а затем организовать, чтобы другая горутина RWMutex.RUnlock (RWMutex.Unlock) его.
type WaitGroup
type WaitGroup struct {
// содержит отфильтрованные или неэкспортируемые поля
}
WaitGroup ожидает завершения работы набора goroutines. Основной goroutine вызывает WaitGroup.Add, чтобы установить количество goroutines, которые необходимо дождаться. Затем каждый из goroutines запускается и вызывает WaitGroup.Done по завершении работы. В то же время WaitGroup.Wait можно использовать для блокировки до тех пор, пока все goroutines не завершат работу.
WaitGroup нельзя копировать после первого использования.
В терминологии модели памяти Go вызов WaitGroup.Done «синхронизирует перед» возвратом любого вызова Wait, который он разблокирует.
Пример
package main
import (
"sync"
)
type httpPkg struct{}
func (httpPkg) Get(url string) {}
var http httpPkg
func main() {
var wg sync.WaitGroup
var urls = []string{
"http://www.golang.org/",
"http://www.google.com/",
"http://www.example.com/",
}
for _, url := range urls {
// Increment the WaitGroup counter.
wg.Add(1)
// Launch a goroutine to fetch the URL.
go func(url string) {
// Decrement the counter when the goroutine completes.
defer wg.Done()
// Fetch the URL.
http.Get(url)
}(url)
}
// Wait for all HTTP fetches to complete.
wg.Wait()
}
Этот пример демонстрирует классический паттерн использования sync.WaitGroup для ожидания завершения группы горутин.
1. Структура и имитация HTTP-клиента
type httpPkg struct{}
func (httpPkg) Get(url string) {} // Пустой метод для демонстрации
var http httpPkg // Глобальная переменная "HTTP-клиента"
- Создается пустая структура
httpPkgс методомGet(имитация HTTP-запроса) - Создается глобальная переменная
httpэтого типа
2. Основная функция
func main() {
var wg sync.WaitGroup // Создаем WaitGroup
urls := []string{ // Список URL для обработки
"http://www.golang.org/",
"http://www.google.com/",
"http://www.example.com/",
}
- Инициализируется
WaitGroupдля отслеживания горутин - Определяется список URL для обработки
3. Запуск горутин
for _, url := range urls {
wg.Add(1) // Увеличиваем счетчик WaitGroup перед запуском горутины
go func(url string) { // Запускаем горутину для каждого URL
defer wg.Done() // Уменьшаем счетчик при завершении (defer гарантирует выполнение)
http.Get(url) // "Выполняем" HTTP-запрос
}(url) // Важно: передаем url как параметр, чтобы избежать проблем с замыканием
}
- Для каждого URL:
wg.Add(1)- увеличиваем счетчик ожидаемых горутин- Запускаем анонимную функцию как горутину
defer wg.Done()- гарантируем уменьшение счетчика при любом выходе из функции- Выполняем “запрос” с помощью
http.Get
4. Ожидание завершения
wg.Wait() // Блокируемся, пока счетчик не станет 0
}
- Основная горутина блокируется, пока все запущенные горутины не вызовут
Done()
Как это работает:
- Изначально счетчик WaitGroup = 0
- Для каждого URL:
Add(1)увеличивает счетчик (становится 1, 2, 3…)- Горутина запускается
- Каждая горутина при завершении вызывает
Done()(уменьшает счетчик) Wait()блокируется, пока счетчик не вернется к 0
Важные моменты:
Порядок операций:
- Всегда вызывайте
Add()ДО запуска горутины - Используйте
defer wg.Done()для надежности
- Всегда вызывайте
Передача параметров:
- URL передается как аргумент в горутину (
go func(url string)) - Это избегает проблем с общим доступом к переменной цикла
- URL передается как аргумент в горутину (
Реальные применения:
- Параллельные HTTP-запросы
- Обработка файлов/данных в нескольких горутинах
- Любые задачи, которые можно распараллелить
Что произойдет при выполнении:
- Запустятся 3 горутины (по одной на каждый URL)
- Основная горутина заблокируется на
wg.Wait() - Когда все 3 горутины завершатся (вызовут
Done()) - Основная горутина продолжит выполнение (и завершит программу)
Этот паттерн - основа для многих конкурентных операций в Go, где нужно дождаться завершения группы горутин.
func (*WaitGroup) Add
func (wg *WaitGroup) Add(delta int)
Add добавляет delta, которая может быть отрицательной, к счетчику WaitGroup. Если счетчик становится равным нулю, все goroutines, заблокированные WaitGroup.Wait, освобождаются. Если счетчик становится отрицательным, Add вызывает панику.
Обратите внимание, что вызовы с положительной дельтой, которые происходят, когда счетчик равен нулю, должны происходить перед Wait. Вызовы с отрицательной дельтой или вызовы с положительной дельтой, которые начинаются, когда счетчик больше нуля, могут происходить в любое время. Обычно это означает, что вызовы Add должны выполняться до оператора, создающего goroutine или другое событие, которое необходимо ожидать. Если WaitGroup повторно используется для ожидания нескольких независимых наборов событий, новые вызовы Add должны происходить после того, как все предыдущие вызовы Wait вернулись. См. пример WaitGroup.
func (*WaitGroup) Done
func (wg *WaitGroup) Done()
Done уменьшает счетчик WaitGroup на единицу.
func (*WaitGroup) Wait
func (wg *WaitGroup) Wait()
Wait блокируется до тех пор, пока счетчик WaitGroup не станет равным нулю.
12.4.10.1 - Описание пакета sync/atomic
Пакет atomic предоставляет низкоуровневые примитивы атомарной памяти, полезные для реализации алгоритмов синхронизации.
Для правильного использования этих функций требуется большая осторожность. За исключением специальных низкоуровневых приложений, синхронизацию лучше выполнять с помощью каналов или средств пакета sync. Делитесь памятью, общаясь; не общайтесь, делясь памятью.
Объяснение atomic
Низкоуровневые примитивы атомарной памяти в Go
Атомарные операции - это операции, которые выполняются полностью (как единое целое) без возможности прерывания их другими потоками. В Go они предоставляются пакетом
sync/atomicи используются для безопасной работы с разделяемой памятью в многопоточных программах.
Основные понятия
- Атомарность - операция либо выполняется полностью, либо не выполняется вообще
- Гонка данных (data race) - ситуация, когда несколько горутин одновременно обращаются к одной переменной, и хотя бы одна из них выполняет запись
- Примитивы - базовые строительные блоки для синхронизации
Основные типы и функции
Пакет sync/atomic работает с:
int32,int64,uint32,uint64,uintptr- Указателями (через
unsafe.Pointer)
Примеры использования
1. Атомарное увеличение счетчика
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var counter int64
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
atomic.AddInt64(&counter, 1)
wg.Done()
}()
}
wg.Wait()
fmt.Println("Counter:", counter) // Гарантированно выведет 100
}
2. Атомарное чтение и запись
package main
import (
"fmt"
"sync/atomic"
"time"
)
func main() {
var value int32
// Горутина, которая изменяет значение
go func() {
time.Sleep(time.Millisecond * 100)
atomic.StoreInt32(&value, 42)
}()
// Главная горутина ждет изменения значения
for {
if atomic.LoadInt32(&value) == 42 {
fmt.Println("Value has been updated to 42")
break
}
time.Sleep(time.Millisecond * 10)
}
}
3. Сравнение и замена (CAS - Compare And Swap)
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var value int32 = 10
// Пытаемся заменить 10 на 20
swapped := atomic.CompareAndSwapInt32(&value, 10, 20)
fmt.Println("Swapped:", swapped, "Value:", value) // Swapped: true Value: 20
// Пытаемся заменить 10 на 30 (но текущее значение уже 20)
swapped = atomic.CompareAndSwapInt32(&value, 10, 30)
fmt.Println("Swapped:", swapped, "Value:", value) // Swapped: false Value: 20
}
4. Атомарный указатель
package main
import (
"fmt"
"sync/atomic"
"unsafe"
)
type Data struct {
value int
}
func main() {
var ptr unsafe.Pointer
// Создаем данные
data1 := &Data{value: 42}
data2 := &Data{value: 100}
// Атомарно сохраняем указатель
atomic.StorePointer(&ptr, unsafe.Pointer(data1))
// Атомарно читаем указатель
current := (*Data)(atomic.LoadPointer(&ptr))
fmt.Println("Current value:", current.value) // 42
// Атомарно меняем указатель
atomic.StorePointer(&ptr, unsafe.Pointer(data2))
current = (*Data)(atomic.LoadPointer(&ptr))
fmt.Println("New value:", current.value) // 100
}
Когда использовать atomic
- Когда нужны простые операции над разделяемыми переменными
- Когда производительность критична (atomic обычно быстрее мьютексов)
- Для реализации более сложных примитивов синхронизации
Когда НЕ использовать atomic
- Когда логика сложная - лучше использовать мьютексы или каналы
- Когда нужно работать со сложными структурами данных
- Когда важна читаемость кода (atomic код может быть сложнее для понимания)
Атомарные операции - это низкоуровневый механизм, который требует аккуратного использования, но может быть очень эффективным в правильных сценариях.
Операция обмена, реализуемая функциями SwapT, является атомарным эквивалентом:
old = *addr
*addr = new
return old
Операция сравнения и замены, реализуемая функциями CompareAndSwapT, является атомарным эквивалентом:
if *addr == old {
*addr = new
return true
}
return false
Операция сложения, реализуемая функциями AddT, является атомарным эквивалентом:
*addr += delta
return *addr
Операции load и store, реализуемые функциями LoadT и StoreT, являются атомарными эквивалентами “return *addr” и “*addr = val”.
В терминологии модели памяти Go, если эффект атомарной операции A наблюдается атомарной операцией B, то A “синхронизируется раньше” B. Кроме того, все атомарные операции, выполняемые в программе, ведут себя так, как будто выполняются в некотором последовательно согласованном порядке. Это определение обеспечивает ту же семантику, что и последовательные атомики в C++ и волатильные переменные в Java.
Функции
func AddInt32
func AddInt32(addr *int32, delta int32) (new int32)
AddInt32 атомарно добавляет delta к *addr и возвращает новое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int32.Add.
func AddInt64
func AddInt64(addr *int64, delta int64) (new int64)
AddInt64 атомарно добавляет delta к *addr и возвращает новое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int64.Add (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func AddUint32
func AddUint32(addr *uint32, delta uint32) (new uint32)
AddUint32 атомарно добавляет дельту к *addr и возвращает новое значение. Чтобы вычесть из x знаковое положительное константное значение c, выполните AddUint32(&x, ^uint32(c-1)). В частности, чтобы уменьшить x, выполните AddUint32(&x, ^uint32(0)). Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint32.Add.
func AddUint64
func AddUint64(addr *uint64, delta uint64) (new uint64)
AddUint64 атомарно добавляет delta к *addr и возвращает новое значение. Чтобы вычесть из x знаковое положительное константное значение c, выполните AddUint64(&x, ^uint64(c-1)). В частности, чтобы уменьшить x, выполните AddUint64(&x, ^uint64(0)). Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint64.Add (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func AddUintptr
func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
AddUintptr атомарно добавляет delta к *addr и возвращает новое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uintptr.Add.
func AndInt32
func AndInt32(addr *int32, mask int32) (old int32)
AndInt32 атомарно выполняет побитовую операцию AND над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int32.And.
func AndInt64
func AndInt64(addr *int64, mask int64) (old int64)
AndInt64 атомарно выполняет побитовую операцию AND над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int64.And вместо этого.
func AndUint32
func AndUint32(addr *uint32, mask uint32) (old uint32)
AndUint32 атомарно выполняет побитовую операцию AND над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint32.And вместо него.
func AndUint64
func AndUint64(addr *uint64, mask uint64) (old uint64)
AndUint64 атомарно выполняет побитовую операцию AND над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint64.And вместо этого.
func AndUintptr
func AndUintptr(addr *uintptr, mask uintptr) (old uintptr)
AndUintptr атомарно выполняет побитовую операцию AND над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uintptr.And вместо этого.
func CompareAndSwapInt32
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
CompareAndSwapInt32 выполняет операцию сравнения и замены для значения int32. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int32.CompareAndSwap.
func CompareAndSwapInt64
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)
CompareAndSwapInt64 выполняет операцию сравнения и замены для значения int64. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int64.CompareAndSwap (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func CompareAndSwapPointer
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
CompareAndSwapPointer выполняет операцию сравнения и обмена для значения unsafe.Pointer. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Pointer.CompareAndSwap.
func CompareAndSwapUint32
func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)
CompareAndSwapUint32 выполняет операцию сравнения и замены для значения uint32. Рассмотрите возможность использования более удобной и менее подверженной ошибкам функции Uint32.CompareAndSwap.
func CompareAndSwapUint64
func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)
CompareAndSwapUint64 выполняет операцию сравнения и замены для значения uint64. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint64.CompareAndSwap (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func CompareAndSwapUintptr
func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool)
CompareAndSwapUintptr выполняет операцию сравнения и замены для значения uintptr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uintptr.CompareAndSwap.
func LoadInt32
func LoadInt32(addr *int32) (val int32)
LoadInt32 атомарно загружает *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int32.Load.
func LoadInt64
func LoadInt64(addr *int64) (val int64)
LoadInt64 атомарно загружает *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int64.Load (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func LoadPointer
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
LoadPointer атомарно загружает *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Pointer.Load.
func LoadUint32
func LoadUint32(addr *uint32) (val uint32)
LoadUint32 атомарно загружает *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint32.Load.
func LoadUint64
func LoadUint64(addr *uint64) (val uint64)
LoadUint64 атомарно загружает *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint64.Load (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func LoadUintptr
func LoadUintptr(addr *uintptr) (val uintptr)
LoadUintptr атомарно загружает *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uintptr.Load.
func OrInt32
func OrInt32(addr *int32, mask int32) (old int32)
OrInt32 атомарно выполняет побитовую операцию OR над *addr, используя битовую маску, указанную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int32.Or.
func OrInt64
func OrInt64(addr *int64, mask int64) (old int64)
OrInt64 атомарно выполняет побитовую операцию OR над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int64.Or вместо него.
func OrUint32
func OrUint32(addr *uint32, mask uint32) (старый uint32)
OrUint32 атомарно выполняет побитовую операцию OR над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint32.Or.
func OrUint64
func OrUint64(addr *uint64, mask uint64) (old uint64)
OrUint64 атомарно выполняет побитовую операцию OR над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint64.Or вместо него.
func OrUintptr
func OrUintptr(addr *uintptr, mask uintptr) (old uintptr)
OrUintptr атомарно выполняет побитовую операцию OR над *addr, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uintptr.Or.
func StoreInt32
func StoreInt32(addr *int32, val int32)
StoreInt32 атомарно сохраняет val в *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int32.Store.
func StoreInt64
func StoreInt64(addr *int64, val int64)
StoreInt64 атомарно сохраняет val в *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int64.Store (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func StorePointer
func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
StorePointer атомарно сохраняет val в *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Pointer.Store.
func StoreUint32
func StoreUint32(addr *uint32, val uint32)
StoreUint32 атомарно сохраняет val в *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint32.Store.
func StoreUint64
func StoreUint64(addr *uint64, val uint64)
StoreUint64 атомарно сохраняет val в *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint64.Store (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func StoreUintptr
func StoreUintptr(addr *uintptr, val uintptr)
StoreUintptr атомарно сохраняет val в *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uintptr.Store.
func SwapInt32
func SwapInt32(addr *int32, new int32) (old int32)
SwapInt32 атомарно сохраняет new в *addr и возвращает предыдущее значение *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int32.Swap.
func SwapInt64
func SwapInt64(addr *int64, new int64) (old int64)
SwapInt64 атомарно сохраняет new в *addr и возвращает предыдущее значение *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Int64.Swap (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func SwapPointer
func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)
SwapPointer атомарно сохраняет new в *addr и возвращает предыдущее значение *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Pointer.Swap.
func SwapUint32
func SwapUint32(addr *uint32, new uint32) (old uint32)
SwapUint32 атомарно сохраняет new в *addr и возвращает предыдущее значение *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint32.Swap.
func SwapUint64
func SwapUint64(addr *uint64, new uint64) (old uint64)
SwapUint64 атомарно сохраняет new в *addr и возвращает предыдущее значение *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uint64.Swap (особенно если вы ориентируетесь на 32-разрядные платформы; см. раздел «Ошибки»).
func SwapUintptr
func SwapUintptr(addr *uintptr, new uintptr) (old uintptr)
SwapUintptr атомарно сохраняет new в *addr и возвращает предыдущее значение *addr. Рассмотрите возможность использования более эргономичного и менее подверженного ошибкам Uintptr.Swap.
Типы
type Bool
type Bool struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Bool — это атомарное булево значение. Нулевое значение — false.
func (*Bool) CompareAndSwap
func (x *Bool) CompareAndSwap(old, new bool) (swapped bool)
CompareAndSwap выполняет операцию сравнения и замены для булевого значения x.
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var flag atomic.Bool
flag.Store(false)
// Пытаемся изменить false → true (успешно)
swapped := flag.CompareAndSwap(false, true)
fmt.Println("Swapped (false→true):", swapped, "Flag:", flag.Load())
// Пытаемся изменить false → true (неуспешно, текущее значение уже true)
swapped = flag.CompareAndSwap(false, true)
fmt.Println("Swapped (false→true):", swapped, "Flag:", flag.Load())
}
func (*Bool) Load
func (x *Bool) Load() bool
Load атомарно загружает и возвращает значение, хранящееся в x.
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
func main() {
var ready atomic.Bool
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
time.Sleep(500 * time.Millisecond)
ready.Store(true)
}()
for !ready.Load() {
fmt.Println("Waiting...")
time.Sleep(100 * time.Millisecond)
}
fmt.Println("Ready!")
wg.Wait()
}
func (*Bool) Store
func (x *Bool) Store(val bool)
Store атомарно сохраняет val в x.
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var initialized atomic.Bool
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
if initialized.Load() {
fmt.Printf("Worker %d: already initialized\n", id)
return
}
initialized.Store(true)
fmt.Printf("Worker %d: did initialization\n", id)
}(i)
}
wg.Wait()
}
func (*Bool) Swap
func (x *Bool) Swap(new bool) (old bool)
Swap атомарно сохраняет new в x и возвращает предыдущее значение.
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var toggle atomic.Bool
toggle.Store(false)
// Переключаем значение и получаем старое
old := toggle.Swap(true)
fmt.Println("Old value:", old, "New value:", toggle.Load())
// Переключаем ещё раз
old = toggle.Swap(false)
fmt.Println("Old value:", old, "New value:", toggle.Load())
}
type Int32/Int64/Uint32/Uint64/Uintptr
type Int32 struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Int32 — это атомарное целое число int32. Нулевое значение — ноль. Int64 — это атомарное целое число int64. Нулевое значение — ноль. Uint32 - это атомарный uint32. Нулевое значение равно нулю. Uint64 - это атомарный uint64. Нулевое значение равно нулю. Uintptr - это атомарный uintptr. Нулевое значение равно нулю.
Пример
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var num atomic.Int32
// Store - установка начального значения
num.Store(10)
fmt.Printf("Store(10): %d\n", num.Load())
// Add - атомарное добавление
newVal := num.Add(5)
fmt.Printf("Add(5): new=%d, loaded=%d\n", newVal, num.Load())
// Swap - замена значения
old := num.Swap(20)
fmt.Printf("Swap(20): old=%d, new=%d\n", old, num.Load())
// CompareAndSwap - условная замена
swapped := num.CompareAndSwap(20, 30)
fmt.Printf("CompareAndSwap(20→30): %t, value=%d\n", swapped, num.Load())
// Пытаемся сделать замену с неверным old значением
swapped = num.CompareAndSwap(20, 40)
fmt.Printf("CompareAndSwap(20→40): %t, value=%d\n", swapped, num.Load())
// Побитовые операции
// Устанавливаем значение для битовых операций
num.Store(0b00001111) // 15 в десятичной
// And - побитовое И
old = num.And(0b00110011) // 0b00000011 = 3
fmt.Printf("And(0b00110011): old=0b%08b, new=0b%08b (%d)\n",
old, num.Load(), num.Load())
// Or - побитовое ИЛИ
old = num.Or(0b11001100) // 0b11001111 = 207
fmt.Printf("Or(0b11001100): old=0b%08b, new=0b%08b (%d)\n",
old, num.Load(), num.Load())
// Load - просто чтение
current := num.Load()
fmt.Printf("Load(): %d (0b%08b)\n", current, current)
}
Вывод программы:
Store(10): 10
Add(5): new=15, loaded=15
Swap(20): old=15, new=20
CompareAndSwap(20→30): true, value=30
CompareAndSwap(20→40): false, value=30
And(0b00110011): old=0b00001111, new=0b00000011 (3)
Or(0b11001100): old=0b00000011, new=0b11001111 (207)
Load(): 207 (0b11001111)
Объяснение Uintptr
atomic.Uintptr в Go
atomic.Uintptr — это тип, добавленный в Go 1.19, который предоставляет атомарные операции для беззнаковых целых чисел размером с указатель (uintptr).
Основное назначение
Атомарные операции с указателями:
uintptrчасто используется для низкоуровневых операций с указателямиatomic.Uintptrпозволяет безопасно работать с ними в конкурентных сценариях
Реализация lock-free структур данных:
- Полезен при создании собственных конкурентных структур данных
- Позволяет избежать блокировок при определенных операциях
Работа с небезопасными указателями:
- Когда нужно сохранить
uintptrзначение атомарно (например, при работе черезunsafe)
- Когда нужно сохранить
Ключевые особенности
- Обеспечивает атомарность операций без использования мьютексов
- Поддерживает все стандартные атомарные операции:
func (u *Uintptr) Add(delta uintptr) (new uintptr) func (u *Uintptr) Load() uintptr func (u *Uintptr) Store(val uintptr) func (u *Uintptr) Swap(new uintptr) (old uintptr) func (u *Uintptr) CompareAndSwap(old, new uintptr) (swapped bool)
Пример использования
package main
import (
"fmt"
"sync/atomic"
"unsafe"
)
type Data struct {
value int
}
func main() {
var addr atomic.Uintptr
data := &Data{value: 42}
// Сохраняем указатель как uintptr
addr.Store(uintptr(unsafe.Pointer(data)))
// Атомарно загружаем и преобразуем обратно
ptr := (*Data)(unsafe.Pointer(addr.Load()))
fmt.Println("Data value:", ptr.value) // 42
// Атомарное добавление к значению (если используется как число)
var counter atomic.Uintptr
counter.Store(100)
newVal := counter.Add(50)
fmt.Println("Counter:", newVal) // 150
}
Когда использовать
- При работе с
unsafe.Pointerи низкоуровневыми операциями - Для атомарного управления памятью или ресурсами
- В высокопроизводительных сценариях, где важна lock-free синхронизация
Отличие от других атомарных типов
Uintptrработает именно с размером указателя (архитектурно-зависимым)- Более безопасная альтернатива прямому использованию
atomic.AddUintptrи подобных функций - Типобезопасная обертка (по сравнению с использованием
atomicфункций напрямую)
Этот тип особенно полезен в системном программировании и при реализации высокопроизводительных параллельных алгоритмов.
func (*Int32) Add
func (x *Int32) Add(delta int32) (new int32)
Add атомарно добавляет delta к x и возвращает новое значение.
func (*Int32) And
func (x *Int32) And(mask int32) (old int32)
And атомарно выполняет побитовую операцию AND над x, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение.
func (*Int32) CompareAndSwap
func (x *Int32) CompareAndSwap(old, new int32) (swapped bool)
CompareAndSwap выполняет операцию сравнения и замены для x.
func (*Int32) Load
func (x *Int32) Load() int32
Load атомарно загружает и возвращает значение, хранящееся в x.
func (*Int32) Or
func (x *Int32) Or(mask int32) (old int32)
Or атомарно выполняет операцию побитового ИЛИ над x, используя битовую маску, предоставленную в качестве mask, и возвращает старое значение.
func (*Int32) Store
func (x *Int32) Store(val int32)
Store атомарно сохраняет val в x.
func (*Int32) Swap
func (x *Int32) Swap(new int32) (old int32)
Swap атомарно сохраняет new в x и возвращает предыдущее значение.
type Pointer
type Pointer[T any] struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Pointer — это атомарный указатель типа *T. Нулевое значение — nil *T.
Пример
package main
import (
"fmt"
"sync/atomic"
)
type Data struct {
value int
}
func main() {
var ptr atomic.Pointer[Data]
// Исходные данные
data1 := &Data{value: 10}
data2 := &Data{value: 20}
data3 := &Data{value: 30}
// Store - атомарное сохранение указателя
ptr.Store(data1)
printState("Store(data1)", &ptr)
// Load - атомарное чтение указателя
current := ptr.Load()
fmt.Printf("Load(): %+v\n", current)
// Swap - атомарная замена указателя
old := ptr.Swap(data2)
printState("Swap(data2)", &ptr)
fmt.Printf("Old value: %+v\n", old)
// CompareAndSwap успешный (текущее значение = data2)
swapped := ptr.CompareAndSwap(data2, data3)
printState("CompareAndSwap(data2→data3)", &ptr)
fmt.Printf("Swapped: %v\n", swapped)
// CompareAndSwap неудачный (текущее значение уже data3)
swapped = ptr.CompareAndSwap(data2, data1)
printState("CompareAndSwap(data2→data1) [expected fail]", &ptr)
fmt.Printf("Swapped: %v\n", swapped)
// Демонстрация конкурентного доступа
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
ptr.Store(&Data{value: i})
}
}()
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
_ = ptr.Load()
}
}()
wg.Wait()
fmt.Println("Concurrent access completed")
}
func printState(op string, p *atomic.Pointer[Data]) {
fmt.Printf("%-30s: %+v\n", op, p.Load())
}
Вывод программы:
Store(data1) : &{value:10}
Load(): &{value:10}
Swap(data2) : &{value:20}
Old value: &{value:10}
CompareAndSwap(data2→data3) : &{value:30}
Swapped: true
CompareAndSwap(data2→data1) [expected fail]: &{value:30}
Swapped: false
Concurrent access completed
func (*Pointer[T]) CompareAndSwap
func (x *Pointer[T]) CompareAndSwap(old, new *T) (swapped bool)
CompareAndSwap выполняет операцию сравнения и замены для x.
func (*Pointer[T]) Load
func (x *Pointer[T]) Load() *T
Load атомарно загружает и возвращает значение, хранящееся в x.
func (*Pointer[T]) Store
func (x *Pointer[T]) Store(val *T)
Store атомарно сохраняет val в x.
func (*Pointer[T]) Swap
func (x *Pointer[T]) Swap(new *T) (old *T)
Swap атомарно сохраняет new в x и возвращает предыдущее значение.
type Value
type Value struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Value обеспечивает атомарную загрузку и хранение значения с постоянным типом. Нулевое значение для Value возвращает nil из Value.Load. После вызова Value.Store Value не должен копироваться.
Value не должен копироваться после первого использования.
Объяснение Value
atomic.Value — это контейнер для безопасного хранения и обмена значениями между горутинами. Главная особенность — все операции с ним атомарны (не требуют мьютексов).
Основные правила:
- После первого использования нельзя копировать Value
- Все хранимые значения должны быть одного типа
- Нельзя хранить nil
Примеры использования:
1. Базовое использование (Store/Load)
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var config atomic.Value
// Сохраняем конфиг
config.Store(map[string]string{
"host": "localhost",
"port": "8080",
})
// Читаем конфиг в другой горутине
go func() {
c := config.Load().(map[string]string)
fmt.Println("Config in goroutine:", c["host"])
}()
// Читаем в main
fmt.Println("Port:", config.Load().(map[string]string)["port"])
}
2. Swap (атомарная замена)
var lastUser atomic.Value
func updateUser(user string) {
old := lastUser.Swap(user)
fmt.Printf("User changed from %v to %v\n", old, user)
}
func main() {
updateUser("Alice") // User changed from <nil> to Alice
updateUser("Bob") // User changed from Alice to Bob
}
3. CompareAndSwap (условная замена)
var currentID atomic.Value
func updateID(expected, new int) bool {
return currentID.CompareAndSwap(expected, new)
}
func main() {
currentID.Store(100)
success := updateID(100, 200)
fmt.Println("Update 100→200:", success) // true
success = updateID(100, 300)
fmt.Println("Update 100→300:", success) // false (текущее значение уже 200)
}
4. Хранение структур
type Config struct {
Timeout int
Mode string
}
func main() {
var cfg atomic.Value
cfg.Store(Config{Timeout: 30, Mode: "production"})
// Обновление конфига
newCfg := cfg.Load().(Config)
newCfg.Timeout = 60
cfg.Store(newCfg)
}
Когда использовать:
- Для “горячей” замены конфигурации без блокировок
- При частом чтении и редком обновлении данных
- Для реализации кэшей с атомарным обновлением
На заметку
- При Load всегда нужно делать type assertion (
.(type)) - Тип значения нельзя менять после первого Store
- Для сложных структур лучше хранить указатели (но не nil)
Пример config
package main
import (
"fmt"
"math/rand"
"sync/atomic"
"time"
)
// ServerConfig содержит конфигурацию сервера
type ServerConfig struct {
Host string
Port int
Timeout time.Duration
Debug bool
}
var (
config atomic.Value // Текущая конфигурация
counter atomic.Int32 // Счетчик запросов
)
func loadConfig() ServerConfig {
// Имитация загрузки конфигурации (в реальности может быть из файла, БД и т.д.)
rand.Seed(time.Now().UnixNano())
return ServerConfig{
Host: fmt.Sprintf("server-%d.example.com", rand.Intn(3)+1),
Port: 8000 + rand.Intn(100),
Timeout: time.Duration(rand.Intn(5)+1) * time.Second,
Debug: rand.Intn(2) == 0,
}
}
func processRequest(workerID int) {
for {
// Имитация обработки запроса
time.Sleep(time.Duration(rand.Intn(1500)) * time.Millisecond)
// Атомарно получаем текущую конфигурацию
conf := config.Load().(ServerConfig)
reqID := counter.Add(1)
fmt.Printf("Worker %d processing request #%d with config: %+v\n",
workerID, reqID, conf)
}
}
func configUpdater() {
for {
time.Sleep(5 * time.Second)
newConfig := loadConfig()
config.Store(newConfig)
fmt.Printf("\nConfig updated: %+v\n\n", newConfig)
}
}
func main() {
// Инициализация начальной конфигурации
config.Store(loadConfig())
fmt.Println("Initial config:", config.Load())
// Запускаем обновление конфигурации в фоне
go configUpdater()
// Запускаем воркеров для обработки запросов
for i := 1; i <= 5; i++ {
go processRequest(i)
}
// Даем поработать 30 секунд
time.Sleep(30 * time.Second)
fmt.Println("Server shutting down...")
}
Вывод программы:
Initial config: {Host:server-3.example.com Port:8034 Timeout:4s Debug:false}
Worker 5 processing request #1 with config: {Host:server-3.example.com Port:8034 Timeout:4s Debug:false}
Worker 3 processing request #2 with config: {Host:server-3.example.com Port:8034 Timeout:4s Debug:false}
Config updated: {Host:server-1.example.com Port:8067 Timeout:2s Debug:true}
Worker 1 processing request #3 with config: {Host:server-1.example.com Port:8067 Timeout:2s Debug:true}
Worker 4 processing request #4 with config: {Host:server-1.example.com Port:8067 Timeout:2s Debug:true}
Пример ReadMostly
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
// ConcurrentMap реализует потокобезопасную map с помощью atomic.Value
type ConcurrentMap struct {
data atomic.Value // хранит map[string]string
mu sync.Mutex // только для записи
}
// NewConcurrentMap создает новую потокобезопасную map
func NewConcurrentMap() *ConcurrentMap {
cm := &ConcurrentMap{}
cm.data.Store(make(map[string]string))
return cm
}
// Get безопасно получает значение по ключу
func (cm *ConcurrentMap) Get(key string) (string, bool) {
currentMap := cm.data.Load().(map[string]string)
val, ok := currentMap[key]
return val, ok
}
// Set безопасно устанавливает значение по ключу
func (cm *ConcurrentMap) Set(key, value string) {
cm.mu.Lock()
defer cm.mu.Unlock()
// Копируем текущую map
oldMap := cm.data.Load().(map[string]string)
newMap := make(map[string]string, len(oldMap)+1)
// Копируем все элементы
for k, v := range oldMap {
newMap[k] = v
}
// Добавляем/обновляем элемент
newMap[key] = value
// Атомарно заменяем map
cm.data.Store(newMap)
}
// Delete безопасно удаляет элемент по ключу
func (cm *ConcurrentMap) Delete(key string) {
cm.mu.Lock()
defer cm.mu.Unlock()
oldMap := cm.data.Load().(map[string]string)
if _, exists := oldMap[key]; !exists {
return
}
newMap := make(map[string]string, len(oldMap))
for k, v := range oldMap {
if k != key {
newMap[k] = v
}
}
cm.data.Store(newMap)
}
func main() {
config := NewConcurrentMap()
// Записываем начальные значения
config.Set("host", "localhost")
config.Set("port", "8080")
config.Set("timeout", "30s")
// Запускаем 5 читателей
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for j := 0; j < 3; j++ {
time.Sleep(time.Millisecond * 100)
if val, ok := config.Get("host"); ok {
fmt.Printf("Reader %d: host=%s\n", id, val)
}
}
}(i)
}
// Запускаем 2 писателя
for i := 0; i < 2; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for j := 0; j < 2; j++ {
time.Sleep(time.Millisecond * 200)
newHost := fmt.Sprintf("server-%d-%d", id, j)
config.Set("host", newHost)
fmt.Printf("Writer %d updated host to %s\n", id, newHost)
}
}(i)
}
// Запускаем удаление через некоторое время
wg.Add(1)
go func() {
defer wg.Done()
time.Sleep(time.Millisecond * 300)
config.Delete("timeout")
fmt.Println("Deleted timeout key")
}()
wg.Wait()
// Финальное состояние
fmt.Println("\nFinal config:")
if host, ok := config.Get("host"); ok {
fmt.Println("host:", host)
}
if port, ok := config.Get("port"); ok {
fmt.Println("port:", port)
}
if _, ok := config.Get("timeout"); !ok {
fmt.Println("timeout: (deleted)")
}
}
Вывод программы:
Reader 4: host=localhost
Reader 0: host=localhost
Reader 2: host=localhost
Reader 1: host=localhost
Writer 0 updated host to server-0-0
Reader 3: host=server-0-0
Reader 0: host=server-0-0
Reader 4: host=server-0-0
Writer 1 updated host to server-1-0
Reader 2: host=server-1-0
Deleted timeout key
Reader 1: host=server-1-0
Writer 0 updated host to server-0-1
Writer 1 updated host to server-1-1
Reader 3: host=server-1-1
Final config:
host: server-1-1
port: 8080
timeout: (deleted)
func (*Value) CompareAndSwap
func (v *Value) CompareAndSwap(old, new any) (swapped bool)
CompareAndSwap выполняет операцию сравнения и замены для Value.
Все вызовы CompareAndSwap для данного значения должны использовать значения одного и того же конкретного типа. CompareAndSwap несовместимого типа вызывает панику, как и CompareAndSwap(old, nil).
func (*Value) Load
func (v *Value) Load() (val any)
Load возвращает значение, установленное последним Store. Он возвращает nil, если для этого значения не было вызова Store.
func (*Value) Store
func (v *Value) Store(val any)
Store устанавливает значение Value v равным val. Все вызовы Store для данного Value должны использовать значения одного и того же конкретного типа. Store несовместимого типа вызывает панику, как и Store(nil).
func (*Value) Swap
func (v *Value) Swap(new any) (old any)
Swap сохраняет new в Value и возвращает предыдущее значение. Он возвращает nil, если Value пуст.
Все вызовы Swap для данного Value должны использовать значения одного и того же конкретного типа. Swap несовместимого типа вызывает панику, как и Swap(nil).
12.4.11 - Пакет os языка программирования Go
Пакет os предоставляет платформонезависимый интерфейс к функциональности операционной системы.
Пакет os предоставляет платформонезависимый интерфейс к функциональности операционной системы. Дизайн Unix-подобный, хотя обработка ошибок Go-подобная; неудачные вызовы возвращают значения типа error, а не номера ошибок. Часто в ошибке содержится больше информации. Например, если вызов, принимающий имя файла, не работает, например Open или Stat, ошибка будет включать имя файла, который не работает, и будет иметь тип *PathError, который может быть распакован для получения дополнительной информации.
Интерфейс os должен быть единообразным для всех операционных систем. Функции, которые не являются общедоступными, представлены в специфическом для системы пакете syscall.
Приведем простой пример: открытие файла и чтение его части.
file, err := os.Open("file.go") // For read access.
if err != nil {
log.Fatal(err)
}
Если открытие завершится неудачей, строка ошибки будет иметь понятный вид, например
open file.go: no such file or directory
Затем данные файла могут быть считаны в виде фрагмента байтов. Команды Read и Write берут количество байтов из длины фрагмента аргумента.
data := make([]byte, 100)
count, err := file.Read(data)
if err != nil {
log.Fatal(err)
}
fmt.Printf("read %d bytes: %q\n", count, data[:count])
Concurrency (Параллелизм)
Методы File соответствуют операциям файловой системы. Все они безопасны для одновременного использования. Максимальное количество одновременных операций над файлом может быть ограничено ОС или системой. Это число должно быть большим, но его превышение может снизить производительность или вызвать другие проблемы.
Константы
const (
// Должно быть указано ровно одно из значений O_RDONLY, O_WRONLY или O_RDWR.
O_RDONLY int = syscall.O_RDONLY // открыть файл только для чтения.
O_WRONLY int = syscall.O_WRONLY // открыть файл только для записи.
O_RDWR int = syscall.O_RDWR // открыть файл для чтения и записи.
// Остальные значения могут быть объединены с помощью оператора OR для управления поведением.
O_APPEND int = syscall.O_APPEND // добавлять данные в файл при записи.
O_CREATE int = syscall.O_CREAT // создать новый файл, если его нет.
O_EXCL int = syscall.O_EXCL // используется с O_CREATE, файл не должен существовать.
O_SYNC int = syscall.O_SYNC // открыть для синхронного ввода-вывода.
O_TRUNC int = syscall.O_TRUNC // усечь обычный файл с правом записи при открытии.
)
Флаги для OpenFile, оборачивающие флаги базовой системы. Не все флаги могут быть реализованы в данной системе.
Устарело
const (
SEEK_SET int = 0 // поиск относительно начала файла
SEEK_CUR int = 1 // поиск относительно текущего смещения
SEEK_END int = 2 // поиск относительно конца
)
Значения поиска.
Устарело: используйте io.SeekStart, io.SeekCurrent и io.SeekEnd.
const (
// Одиночные буквы являются аббревиатурами,
// используемыми для форматирования методом String.
ModeDir = fs.ModeDir // d: каталог
ModeAppend = fs.ModeAppend // a: только добавление
ModeExclusive = fs.ModeExclusive // l: исключительное использование
ModeTemporary = fs.ModeTemporary // T: временный файл; только Plan 9
ModeSymlink = fs.ModeSymlink // L: символическая ссылка
ModeDevice = fs.ModeDevice // D: файл устройства
ModeNamedPipe = fs.ModeNamedPipe // p: именованный канал (FIFO)
ModeSocket = fs.ModeSocket // S: сокет домена Unix
ModeSetuid = fs.ModeSetuid // u: setuid
ModeSetgid = fs.ModeSetgid // g: setgid
ModeCharDevice = fs.ModeCharDevice // c: символьное устройство Unix, когда установлен ModeDevice
ModeSticky = fs.ModeSticky // t: sticky
ModeIrregular = fs.ModeIrregular // ?: нерегулярный файл; ничего больше не известно об этом файле
// Маска для битов типа. Для обычных файлов не будет установлено ничего.
ModeType = fs.ModeType
ModePerm = fs.ModePerm // Биты разрешений Unix, 0o777
)
Определенные биты режима файла являются наиболее значимыми битами FileMode. Девять наименее значимых битов являются стандартными разрешениями Unix rwxrwxrwx. Значения этих битов следует рассматривать как часть общедоступного API и могут использоваться в протоколах передачи данных или представлениях диска: их нельзя изменять, хотя могут быть добавлены новые биты.
const DevNull = "/dev/null"
DevNull — это имя «нулевого устройства» операционной системы. В Unix-подобных системах оно имеет вид «/dev/null», в Windows — «NUL».
Переменные
var (
// ErrInvalid указывает на недействительный аргумент.
// Методы File возвращают эту ошибку, когда получатель равен nil.
ErrInvalid = fs.ErrInvalid // «недействительный аргумент»
ErrPermission = fs.ErrPermission // «разрешение отказано»
ErrExist = fs.ErrExist // «файл уже существует»
ErrNotExist = fs.ErrNotExist // «файл не существует»
ErrClosed = fs.ErrClosed // «файл уже закрыт»
ErrNoDeadline = errNoDeadline() // «тип файла не поддерживает срок»
ErrDeadlineExceeded = errDeadlineExceeded() // «тайм-аут ввода-вывода»
)
Портативные аналоги некоторых распространенных ошибок системных вызовов.
Ошибки, возвращаемые из этого пакета, можно проверить на наличие этих ошибок с помощью errors.Is.
var (
Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin")
Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout")
Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr"))
Stdin, Stdout и Stderr — открытые файлы, указывающие на дескрипторы стандартного ввода, стандартного вывода и стандартных ошибок.
Обратите внимание, что среда выполнения Go записывает в стандартный файл ошибок сообщения о паниках и сбоях; закрытие Stderr может привести к тому, что эти сообщения будут отправляться в другое место, например в файл, открытый позже.
var Args []string
Args содержит аргументы командной строки, начиная с имени программы.
var ErrProcessDone = errors.New("os: process already finished")
ErrProcessDone указывает, что процесс завершен.
12.4.11.1 - Описание функций пакета os
Основные функции пакета os языка программирования GO
func Chdir
func Chdir(dir string) error
Chdir изменяет текущий рабочий каталог на указанный каталог. Если произошла ошибка, она будет типа *PathError.
func Chmod
func Chmod(name string, mode FileMode) error
Chmod изменяет режим указанного файла на mode. Если файл является символической ссылкой, то изменяется режим цели ссылки. Если произошла ошибка, то она будет типа *PathError.
В зависимости от операционной системы используется разный поднабор битов режима.
В Unix используются биты разрешений режима ModeSetuid, ModeSetgid и ModeSticky.
В Windows используется только бит 0o200 (доступ на запись для владельца) режима; он контролирует, установлен ли или снят атрибут «только для чтения» файла. Остальные биты в настоящее время не используются. Для совместимости с Go 1.12 и более ранними версиями используйте режим, отличный от нуля. Используйте режим 0o400 для файла, доступного только для чтения, и 0o600 для файла, доступного для чтения и записи.
В Plan 9 используются биты разрешений режима ModeAppend, ModeExclusive и ModeTemporary.
Пример
package main
import (
"log"
"os"
)
func main() {
if err := os.Chmod("some-filename", 0644); err != nil {
log.Fatal(err)
}
}
func Chown
func Chown(name string, uid, gid int) error
Chown изменяет числовые значения uid и gid указанного файла. Если файл является символической ссылкой, он изменяет uid и gid цели ссылки. uid или gid равные -1 означают, что это значение не изменяется. Если происходит ошибка, она будет типа *PathError.
В Windows или Plan 9 Chown всегда возвращает ошибку syscall.EWINDOWS или EPLAN9, обернутую в *PathError.
func Chtimes
func Chtimes(name string, atime time.Time, mtime time.Time) error
Chtimes изменяет время доступа и изменения указанного файла, аналогично функциям Unix utime() или utimes(). Нулевое значение time.Time оставит время соответствующего файла без изменений.
Базовая файловая система может усечь или округлить значения до менее точной единицы времени. Если произошла ошибка, она будет типа *PathError.
Пример
package main
import (
"log"
"os"
"time"
)
func main() {
mtime := time.Date(2006, time.February, 1, 3, 4, 5, 0, time.UTC)
atime := time.Date(2007, time.March, 2, 4, 5, 6, 0, time.UTC)
if err := os.Chtimes("some-filename", atime, mtime); err != nil {
log.Fatal(err)
}
}
func Clearenv
func Clearenv()
Clearenv удаляет все переменные окружения.
func CopyFS
func CopyFS(dir string, fsys fs.FS) error
CopyFS копирует файловую систему fsys в каталог dir, создавая dir при необходимости.
Файлы создаются с режимом 0o666 плюс любые права на выполнение из источника, а каталоги создаются с режимом 0o777 (до umask).
CopyFS не перезаписывает существующие файлы. Если имя файла в fsys уже существует в месте назначения, CopyFS вернет ошибку, так что errors.Is(err, fs.ErrExist) будет true.
Символьные ссылки в fsys не поддерживаются. При копировании из символьной ссылки возвращается *PathError с Err, установленным в ErrInvalid.
Символьные ссылки в dir прослеживаются.
Новые файлы, добавленные в fsys (в том числе, если dir является подкаталогом fsys) во время работы CopyFS, не гарантированно будут скопированы.
Копирование останавливается при возникновении первой ошибки и возвращает ее.
func DirFS
func DirFS(dir string) fs.FS
DirFS возвращает файловую систему (fs.FS) для дерева файлов, корнем которого является каталог dir.
Обратите внимание, что DirFS(«/prefix») гарантирует только то, что вызовы Open, которые он делает в операционной системе, будут начинаться с «/prefix»: DirFS(«/prefix»).Open(„file“) равно os.Open(«/prefix/file»). Поэтому, если /prefix/file является символической ссылкой, указывающей за пределы дерева /prefix, то использование DirFS не останавливает доступ больше, чем использование os.Open. Кроме того, корень fs.FS, возвращаемый для относительного пути, DirFS(«prefix»), будет затронут последующими вызовами Chdir. Поэтому DirFS не является общей заменой механизма безопасности типа chroot, когда дерево каталогов содержит произвольное содержимое.
Используйте Root.FS, чтобы получить fs.FS, который предотвращает выход из дерева через символьные ссылки.
Каталог dir не должен быть «».
Результат реализует io/fs.StatFS, io/fs.ReadFileFS и io/fs.ReadDirFS.
func Environ
func Environ() []string
Environ возвращает копию строк, представляющих среду, в форме «ключ=значение».
func Executable
func Executable() (string, error)
Executable возвращает имя пути к исполняемому файлу, который запустил текущий процесс. Нет гарантии, что путь по-прежнему указывает на правильный исполняемый файл. Если для запуска процесса использовалась символьная ссылка, в зависимости от операционной системы результатом может быть символьная ссылка или путь, на который она указывала. Если требуется стабильный результат, может помочь path/filepath.EvalSymlinks.
Executable возвращает абсолютный путь, если не произошла ошибка.
Основной случай использования — поиск ресурсов, расположенных относительно исполняемого файла.
func Exit
func Exit(code int)
Exit вызывает завершение текущей программы с заданным кодом состояния. По соглашению, код нуль означает успех, ненулевой — ошибку. Программа завершается немедленно; отложенные функции не выполняются.
Для обеспечения переносимости код статуса должен находиться в диапазоне [0, 125].
func Expand
func Expand(s string, mapping func(string) string) string
Expand заменяет ${var} или $var в строке на основе функции сопоставления. Например, os.ExpandEnv(s) эквивалентно os.Expand(s, os.Getenv).
Пример
package main
import (
"fmt"
"os"
)
func main() {
mapper := func(placeholderName string) string {
switch placeholderName {
case "DAY_PART":
return "morning"
case "NAME":
return "Gopher"
}
return ""
}
fmt.Println(os.Expand("Good ${DAY_PART}, $NAME!", mapper))
}
Output:
Good morning, Gopher!func ExpandEnv
func ExpandEnv(s string) string
ExpandEnv заменяет ${var} или $var в строке в соответствии со значениями текущих переменных окружения. Ссылки на неопределенные переменные заменяются пустой строкой.
Пример
package main
import (
"fmt"
"os"
)
func main() {
os.Setenv("NAME", "gopher")
os.Setenv("BURROW", "/usr/gopher")
fmt.Println(os.ExpandEnv("$NAME lives in ${BURROW}."))
}
Output:
gopher lives in /usr/gopher.func Getegid
func Getegid() int
Getegid возвращает числовой идентификатор эффективной группы вызывающего.
В Windows возвращает -1.
func Getenv
func Getenv(key string) string
Getenv извлекает значение переменной окружения, указанной ключом. Возвращает значение, которое будет пустым, если переменная отсутствует. Чтобы отличить пустое значение от не заданного значения, используйте LookupEnv.
Пример
package main
import (
"fmt"
"os"
)
func main() {
os.Setenv("NAME", "gopher")
os.Setenv("BURROW", "/usr/gopher")
fmt.Printf("%s lives in %s.\n", os.Getenv("NAME"), os.Getenv("BURROW"))
}
Output:
gopher lives in /usr/gopher.func Geteuid
func Geteuid() int
Geteuid возвращает числовой эффективный идентификатор пользователя вызывающего.
В Windows возвращает -1.
func Getgid
func Getgid() int
Getgid возвращает числовой идентификатор группы вызывающего.
В Windows возвращает -1.
func Getgroups
func Getgroups() ([]int, error)
Getgroups возвращает список числовых идентификаторов групп, к которым принадлежит вызывающий.
В Windows возвращает syscall.EWINDOWS. Возможную альтернативу см. в пакете os/user.
func Getpagesize
func Getpagesize() int
Getpagesize возвращает размер страницы памяти базовой системы.
func Getpid
func Getpid() int
Getpid возвращает идентификатор процесса вызывающего.
func Getppid
func Getppid() int
Getppid возвращает идентификатор процесса родителя вызывающего.
func Getuid
func Getuid() int
Getuid возвращает числовой идентификатор пользователя вызывающего.
В Windows возвращает -1.
func Getwd
func Getwd() (dir string, err error)
Getwd возвращает абсолютное имя пути, соответствующее текущему каталогу. Если к текущему каталогу можно перейти по нескольким путям (из-за символьных ссылок), Getwd может вернуть любой из них.
На платформах Unix, если переменная окружения PWD предоставляет абсолютное имя, и оно является именем текущего каталога, оно возвращается.
func Hostname
func Hostname() (name string, err error)
Hostname возвращает имя хоста, сообщаемое ядром.
func IsExist
func IsExist(err error) bool
IsExist возвращает булево значение, указывающее, известно ли, что файл или каталог уже существует. Оно удовлетворяется ErrExist, а также некоторыми ошибками системных вызовов.
Эта функция предшествует errors.Is. Она поддерживает только ошибки, возвращаемые пакетом os. В новом коде следует использовать errors.Is(err, fs.ErrExist).
func IsNotExist
func IsNotExist(err error) bool
IsNotExist возвращает булево значение, указывающее, известно ли, что аргумент сообщает о том, что файл или каталог не существует. Это условие выполняется для ErrNotExist, а также для некоторых ошибок системных вызовов.
Эта функция предшествует errors.Is. Она поддерживает только ошибки, возвращаемые пакетом os. В новом коде следует использовать errors.Is(err, fs.ErrNotExist).
func IsPathSeparator
func IsPathSeparator(c uint8) bool
IsPathSeparator сообщает, является ли c символом разделителя каталогов.
func IsPermission
func IsPermission(err error) bool
IsPermission возвращает булево значение, указывающее, известно ли, что аргумент сообщает об отказе в разрешении. Это условие выполняется ErrPermission, а также некоторыми ошибками системных вызовов.
Эта функция предшествует errors.Is. Она поддерживает только ошибки, возвращаемые пакетом os. В новом коде следует использовать errors.Is(err, fs.ErrPermission).
func IsTimeout
func IsTimeout(err error) bool
IsTimeout возвращает булево значение, указывающее, известно ли, что аргумент сообщает о возникновении таймаута.
Эта функция предшествует errors.Is, и понятие о том, указывает ли ошибка на тайм-аут, может быть неоднозначным. Например, ошибка Unix EWOULDBLOCK иногда указывает на тайм-аут, а иногда нет. В новом коде следует использовать errors.Is со значением, соответствующим вызову, возвращающему ошибку, например os.ErrDeadlineExceeded.
func Lchown
func Lchown(name string, uid, gid int) error
Lchown изменяет числовые значения uid и gid указанного файла. Если файл является символической ссылкой, то изменяются значения uid и gid самой ссылки. Если происходит ошибка, то она будет типа *PathError.
В Windows всегда возвращается ошибка syscall.EWINDOWS, обернутая в *PathError.
func Link
func Link(oldname, newname string) error
Link создает newname как жесткую ссылку на файл oldname. Если происходит ошибка, она будет типа *LinkError.
func LookupEnv
func LookupEnv(key string) (string, bool)
LookupEnv извлекает значение переменной окружения, указанной ключом. Если переменная присутствует в окружении, возвращается значение (которое может быть пустым) и булево значение true. В противном случае возвращаемое значение будет пустым, а булево значение будет false.
Пример
package main
import (
"fmt"
"os"
)
func main() {
show := func(key string) {
val, ok := os.LookupEnv(key)
if !ok {
fmt.Printf("%s not set\n", key)
} else {
fmt.Printf("%s=%s\n", key, val)
}
}
os.Setenv("SOME_KEY", "value")
os.Setenv("EMPTY_KEY", "")
show("SOME_KEY")
show("EMPTY_KEY")
show("MISSING_KEY")
}
Output:
SOME_KEY=value
EMPTY_KEY=
MISSING_KEY not set
func Mkdir
func Mkdir(name string, perm FileMode) error
Mkdir создает новый каталог с указанным именем и битами разрешений (до umask). Если произошла ошибка, она будет типа *PathError.
Пример
package main
import (
"log"
"os"
)
func main() {
err := os.Mkdir("testdir", 0750)
if err != nil && !os.IsExist(err) {
log.Fatal(err)
}
err = os.WriteFile("testdir/testfile.txt", []byte("Hello, Gophers!"), 0660)
if err != nil {
log.Fatal(err)
}
}
func MkdirAll
func MkdirAll(path string, perm FileMode) error
MkdirAll создает каталог с именем path, а также все необходимые родительские каталоги, и возвращает nil, или же возвращает ошибку. Биты прав доступа perm (до umask) используются для всех каталогов, которые создает MkdirAll. Если path уже является каталогом, MkdirAll ничего не делает и возвращает nil.
Пример
package main
import (
"log"
"os"
)
func main() {
err := os.MkdirAll("test/subdir", 0750)
if err != nil {
log.Fatal(err)
}
err = os.WriteFile("test/subdir/testfile.txt", []byte("Hello, Gophers!"), 0660)
if err != nil {
log.Fatal(err)
}
}
func MkdirTemp
func MkdirTemp(dir, pattern string) (string, error)
MkdirTemp создает новый временный каталог в каталоге dir и возвращает путь к новому каталогу. Имя нового каталога генерируется путем добавления случайной строки в конец pattern. Если pattern содержит “*”, случайная строка заменяет последний “*”. Каталог создается с режимом 0o700 (до umask). Если dir — пустая строка, MkdirTemp использует каталог по умолчанию для временных файлов, возвращаемый TempDir. Несколько программ или goroutines, вызывающих MkdirTemp одновременно, не будут выбирать один и тот же каталог. Ответственность за удаление каталога, когда он больше не нужен, лежит на вызывающем.
Пример
package main
import (
"log"
"os"
"path/filepath"
)
func main() {
dir, err := os.MkdirTemp("", "example")
if err != nil {
log.Fatal(err)
}
defer os.RemoveAll(dir) // clean up
file := filepath.Join(dir, "tmpfile")
if err := os.WriteFile(file, []byte("content"), 0666); err != nil {
log.Fatal(err)
}
}
Пример suffix
package main
import (
"log"
"os"
"path/filepath"
)
func main() {
logsDir, err := os.MkdirTemp("", "*-logs")
if err != nil {
log.Fatal(err)
}
defer os.RemoveAll(logsDir) // clean up
// Logs can be cleaned out earlier if needed by searching
// for all directories whose suffix ends in *-logs.
globPattern := filepath.Join(os.TempDir(), "*-logs")
matches, err := filepath.Glob(globPattern)
if err != nil {
log.Fatalf("Failed to match %q: %v", globPattern, err)
}
for _, match := range matches {
if err := os.RemoveAll(match); err != nil {
log.Printf("Failed to remove %q: %v", match, err)
}
}
}
func NewSyscallError
func NewSyscallError(syscall string, err error) error
NewSyscallError возвращает в качестве ошибки новый SyscallError с указанным именем системного вызова и подробностями ошибки. Для удобства, если err равен nil, NewSyscallError возвращает nil.
func Pipe
func Pipe() (r *File, w *File, err error)
Pipe возвращает соединенную пару файлов; считывает из r байты, записанные в w. Он возвращает файлы и ошибку, если таковая имеется.
func ReadFile
func ReadFile(name string) ([]byte, error)
ReadFile считывает файл с указанным именем и возвращает его содержимое. Успешный вызов возвращает err == nil, а не err == EOF. Поскольку ReadFile считывает весь файл, он не рассматривает EOF из Read как ошибку, о которой следует сообщать.
Пример
package main
import (
"log"
"os"
)
func main() {
data, err := os.ReadFile("testdata/hello")
if err != nil {
log.Fatal(err)
}
os.Stdout.Write(data)
}
Output:
Hello, Gophers!func Readlink
func Readlink(name string) (string, error)
Readlink возвращает место назначения символической ссылки с указанным именем. Если произошла ошибка, она будет типа *PathError.
Если место назначения ссылки является относительным, Readlink возвращает относительный путь, не преобразуя его в абсолютный.
Пример
package main
import (
"errors"
"fmt"
"log"
"os"
"path/filepath"
)
func main() {
// First, we create a relative symlink to a file.
d, err := os.MkdirTemp("", "")
if err != nil {
log.Fatal(err)
}
defer os.RemoveAll(d)
targetPath := filepath.Join(d, "hello.txt")
if err := os.WriteFile(targetPath, []byte("Hello, Gophers!"), 0644); err != nil {
log.Fatal(err)
}
linkPath := filepath.Join(d, "hello.link")
if err := os.Symlink("hello.txt", filepath.Join(d, "hello.link")); err != nil {
if errors.Is(err, errors.ErrUnsupported) {
// Allow the example to run on platforms that do not support symbolic links.
fmt.Printf("%s links to %s\n", filepath.Base(linkPath), "hello.txt")
return
}
log.Fatal(err)
}
// Readlink returns the relative path as passed to os.Symlink.
dst, err := os.Readlink(linkPath)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s links to %s\n", filepath.Base(linkPath), dst)
var dstAbs string
if filepath.IsAbs(dst) {
dstAbs = dst
} else {
// Symlink targets are relative to the directory containing the link.
dstAbs = filepath.Join(filepath.Dir(linkPath), dst)
}
// Check that the target is correct by comparing it with os.Stat
// on the original target path.
dstInfo, err := os.Stat(dstAbs)
if err != nil {
log.Fatal(err)
}
targetInfo, err := os.Stat(targetPath)
if err != nil {
log.Fatal(err)
}
if !os.SameFile(dstInfo, targetInfo) {
log.Fatalf("link destination (%s) is not the same file as %s", dstAbs, targetPath)
}
}
Output:
hello.link links to hello.txtfunc Remove
func Remove(name string) error
Remove удаляет указанный файл или (пустой) каталог. Если происходит ошибка, она будет типа *PathError.
func RemoveAll
func RemoveAll(path string) error
RemoveAll удаляет путь и все вложенные в него элементы. Он удаляет все, что может, но возвращает первую встреченную ошибку. Если путь не существует, RemoveAll возвращает nil (без ошибки). Если произошла ошибка, она будет типа *PathError.
func Rename
func Rename(oldpath, newpath string) error
Rename переименовывает (перемещает) oldpath в newpath. Если newpath уже существует и не является каталогом, Rename заменяет его. Если newpath уже существует и является каталогом, Rename возвращает ошибку. Ограничения, специфичные для ОС, могут применяться, когда oldpath и newpath находятся в разных каталогах. Даже в пределах одного каталога на платформах, отличных от Unix, Rename не является атомарной операцией. Если произошла ошибка, она будет типа *LinkError.
func SameFile
func SameFile(fi1, fi2 FileInfo) bool
SameFile сообщает, описывают ли fi1 и fi2 один и тот же файл. Например, в Unix это означает, что поля device и inode двух базовых структур идентичны; в других системах решение может основываться на именах путей. SameFile применяется только к результатам, возвращаемым Stat этого пакета. В других случаях она возвращает false.
func Setenv
func Setenv(key, value string) error
Setenv устанавливает значение переменной среды, указанной ключом. Возвращает ошибку, если таковая имеется.
func Symlink
func Symlink(oldname, newname string) error
Symlink создает newname как символическую ссылку на oldname. В Windows символическая ссылка на несуществующий oldname создает файловую символическую ссылку; если oldname позже будет создан как каталог, символическая ссылка не будет работать. Если произойдет ошибка, она будет типа *LinkError.
func TempDir
func TempDir() string
TempDir возвращает каталог по умолчанию, который будет использоваться для временных файлов.
В системах Unix она возвращает $TMPDIR, если он не пуст, в противном случае — /tmp. В Windows она использует GetTempPath, возвращая первое непустое значение из %TMP%, %TEMP%, %USERPROFILE% или каталога Windows. В Plan 9 она возвращает /tmp.
Существование каталога и наличие прав доступа к нему не гарантируются.
func Truncate
func Truncate(name string, size int64) error
Truncate изменяет размер указанного файла. Если файл является символической ссылкой, изменяется размер цели ссылки. Если происходит ошибка, она будет типа *PathError.
func Unsetenv
func Unsetenv(key string) error
Unsetenv снимает установку одной переменной среды.
Пример
package main
import (
"os"
)
func main() {
os.Setenv("TMPDIR", "/my/tmp")
defer os.Unsetenv("TMPDIR")
}
func UserCacheDir
func UserCacheDir() (string, error)
UserCacheDir возвращает корневой каталог по умолчанию, который будет использоваться для кэшированных данных конкретного пользователя. Пользователи должны создать свой собственный подкаталог для конкретного приложения в этом каталоге и использовать его.
В системах Unix она возвращает $XDG_CACHE_HOME, как указано в https://specifications.freedesktop.org/basedir-spec/basedir-spec-latest.html, если он не пустой, в противном случае — $HOME/.cache. В Darwin она возвращает $HOME/Library/Caches. В Windows она возвращает %LocalAppData%. В Plan 9 она возвращает $home/lib/cache.
Если местоположение не может быть определено (например, $HOME не определено) или путь в $XDG_CACHE_HOME является относительным, то будет возвращена ошибка.
Пример
import (
"log"
"os"
"path/filepath"
"sync"
)
func main() {
dir, dirErr := os.UserCacheDir()
if dirErr == nil {
dir = filepath.Join(dir, "ExampleUserCacheDir")
}
getCache := func(name string) ([]byte, error) {
if dirErr != nil {
return nil, &os.PathError{Op: "getCache", Path: name, Err: os.ErrNotExist}
}
return os.ReadFile(filepath.Join(dir, name))
}
var mkdirOnce sync.Once
putCache := func(name string, b []byte) error {
if dirErr != nil {
return &os.PathError{Op: "putCache", Path: name, Err: dirErr}
}
mkdirOnce.Do(func() {
if err := os.MkdirAll(dir, 0700); err != nil {
log.Printf("can't create user cache dir: %v", err)
}
})
return os.WriteFile(filepath.Join(dir, name), b, 0600)
}
// Read and store cached data.
// …
_ = getCache
_ = putCache
}
func UserConfigDir
func UserConfigDir() (string, error)
UserConfigDir возвращает корневой каталог по умолчанию, который используется для данных конфигурации, специфичных для пользователя. Пользователи должны создать свой собственный подкаталог для конкретного приложения в этом каталоге и использовать его.
В системах Unix она возвращает $XDG_CONFIG_HOME, как указано в https://specifications.freedesktop.org/basedir-spec/basedir-spec-latest.html, если он не пустой, в противном случае — $HOME/.config. В Darwin она возвращает $HOME/Library/Application Support. В Windows она возвращает %AppData%. В Plan 9 она возвращает $home/lib.
Если местоположение не может быть определено (например, $HOME не определено) или путь в $XDG_CONFIG_HOME является относительным, то будет возвращена ошибка.
Пример
package main
import (
"bytes"
"log"
"os"
"path/filepath"
)
func main() {
dir, dirErr := os.UserConfigDir()
var (
configPath string
origConfig []byte
)
if dirErr == nil {
configPath = filepath.Join(dir, "ExampleUserConfigDir", "example.conf")
var err error
origConfig, err = os.ReadFile(configPath)
if err != nil && !os.IsNotExist(err) {
// The user has a config file but we couldn't read it.
// Report the error instead of ignoring their configuration.
log.Fatal(err)
}
}
// Use and perhaps make changes to the config.
config := bytes.Clone(origConfig)
// …
// Save changes.
if !bytes.Equal(config, origConfig) {
if configPath == "" {
log.Printf("not saving config changes: %v", dirErr)
} else {
err := os.MkdirAll(filepath.Dir(configPath), 0700)
if err == nil {
err = os.WriteFile(configPath, config, 0600)
}
if err != nil {
log.Printf("error saving config changes: %v", err)
}
}
}
}
func UserHomeDir
func UserHomeDir() (string, error)
UserHomeDir возвращает домашний каталог текущего пользователя.
В Unix, включая macOS, возвращает переменную среды $HOME. В Windows возвращает %USERPROFILE%. В Plan 9 возвращает переменную среды $home.
Если ожидаемая переменная не задана в среде, UserHomeDir возвращает либо значение по умолчанию, специфичное для платформы, либо ошибку, отличную от nil.
func WriteFile
func WriteFile(name string, data []byte, perm FileMode) error
WriteFile записывает данные в файл с указанным именем, создавая его при необходимости. Если файл не существует, WriteFile создает его с правами доступа perm (до umask); в противном случае WriteFile обрезает его перед записью, не изменяя права доступа. Поскольку WriteFile требует нескольких системных вызовов для завершения, сбой в середине операции может оставить файл в частично записанном состоянии.
Пример
package main
import (
"log"
"os"
)
func main() {
err := os.WriteFile("testdata/hello", []byte("Hello, Gophers!"), 0666)
if err != nil {
log.Fatal(err)
}
}
12.4.11.2 - Описание типов пакета os языка программирования Go
Основные типы пакета os языка программирования GO
type DirEntry
type DirEntry = fs.DirEntry
DirEntry — это запись, прочитанная из каталога (с помощью функции ReadDir или метода File.ReadDir).
func ReadDir
func ReadDir(name string) ([]DirEntry, error)
ReadDir считывает указанный каталог и возвращает все его записи, отсортированные по имени файла. Если при чтении каталога происходит ошибка, ReadDir возвращает записи, которые удалось прочитать до ошибки, вместе с ошибкой.
Пример
package main
import (
"fmt"
"log"
"os"
)
func main() {
files, err := os.ReadDir(".")
if err != nil {
log.Fatal(err)
}
for _, file := range files {
fmt.Println(file.Name())
}
}
type File
type File struct {
// содержит отфильтрованные или неэкспортируемые поля
}
File представляет открытый файловый дескриптор.
Методы File безопасны для одновременного использования.
func Create
func Create(name string) (*File, error)
Create создает или обрезает файл с указанным именем. Если файл уже существует, он обрезается. Если файл не существует, он создается с режимом 0o666 (до umask). В случае успеха методы возвращенного File могут использоваться для ввода-вывода; связанный файловый дескриптор имеет режим O_RDWR. Каталог, содержащий файл, должен уже существовать. Если произошла ошибка, она будет типа *PathError.
func CreateTemp
func CreateTemp(dir, pattern string) (*File, error)
CreateTemp создает новый временный файл в каталоге dir, открывает файл для чтения и записи и возвращает полученный файл. Имя файла генерируется путем добавления случайной строки в конец pattern. Если pattern содержит "*", случайная строка заменяет последний "*". Файл создается с режимом 0o600 (до umask). Если dir — пустая строка, CreateTemp использует каталог по умолчанию для временных файлов, возвращаемый TempDir. Несколько программ или goroutines, вызывающих CreateTemp одновременно, не будут выбирать один и тот же файл. Вызывающий может использовать метод Name файла, чтобы найти путь к файлу. Вызывающий несет ответственность за удаление файла, когда он больше не нужен.
Пример
package main
import (
"log"
"os"
)
func main() {
f, err := os.CreateTemp("", "example")
if err != nil {
log.Fatal(err)
}
defer os.Remove(f.Name()) // clean up
if _, err := f.Write([]byte("content")); err != nil {
log.Fatal(err)
}
if err := f.Close(); err != nil {
log.Fatal(err)
}
}
Пример suffix
package main
import (
"log"
"os"
)
func main() {
f, err := os.CreateTemp("", "example.*.txt")
if err != nil {
log.Fatal(err)
}
defer os.Remove(f.Name()) // clean up
if _, err := f.Write([]byte("content")); err != nil {
f.Close()
log.Fatal(err)
}
if err := f.Close(); err != nil {
log.Fatal(err)
}
}
func NewFile
func NewFile(fd uintptr, name string) *File
NewFile возвращает новый File с заданным файловым дескриптором и именем. Возвращаемое значение будет nil, если fd не является действительным файловым дескриптором. В системах Unix, если файловый дескриптор находится в неблокирующем режиме, NewFile попытается вернуть опрашиваемый File (такой, для которого работают методы SetDeadline).
После передачи в NewFile fd может стать недействительным при тех же условиях, что описаны в комментариях к методу Fd, и применяются те же ограничения.
func Open
func Open(name string) (*File, error)
Open открывает указанный файл для чтения. В случае успеха методы возвращенного файла могут быть использованы для чтения; связанный файловый дескриптор имеет режим O_RDONLY. Если произошла ошибка, она будет типа *PathError.
func OpenFile
func OpenFile(name string, flag int, perm FileMode) (*File, error)
OpenFile — это обобщенный вызов open; большинство пользователей вместо него будут использовать Open или Create. Он открывает файл с указанным флагом (O_RDONLY и т. д.). Если файл не существует и передан флаг O_CREATE, он создается с режимом perm (до umask); содержащий его каталог должен существовать. В случае успеха методы возвращенного File можно использовать для ввода-вывода. Если произошла ошибка, она будет типа *PathError.
Пример
package main
import (
"log"
"os"
)
func main() {
f, err := os.OpenFile("notes.txt", os.O_RDWR|os.O_CREATE, 0644)
if err != nil {
log.Fatal(err)
}
if err := f.Close(); err != nil {
log.Fatal(err)
}
}
Пример добавление
package main
import (
"log"
"os"
)
func main() {
// If the file doesn't exist, create it, or append to the file
f, err := os.OpenFile("access.log", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
log.Fatal(err)
}
if _, err := f.Write([]byte("appended some data\n")); err != nil {
f.Close() // ignore error; Write error takes precedence
log.Fatal(err)
}
if err := f.Close(); err != nil {
log.Fatal(err)
}
}
func OpenInRoot
func OpenInRoot(dir, name string) (*File, error)
OpenInRoot открывает файл name в каталоге dir. Это эквивалентно OpenRoot(dir) с последующим открытием файла в корневом каталоге.
OpenInRoot возвращает ошибку, если какой-либо компонент имени name ссылается на местоположение за пределами dir.
См. Root для получения подробной информации и ограничений.
func (*File) Chdir
func (f *File) Chdir() error
Chdir изменяет текущий рабочий каталог на файл, который должен быть каталогом. Если произошла ошибка, она будет типа *PathError.
func (*File) Chmod
func (f *File) Chmod(mode FileMode) error
Chmod изменяет режим файла на mode. Если произошла ошибка, она будет типа *PathError.
func (*File) Chown
func (f *File) Chown(uid, gid int) error
Chown изменяет числовые значения uid и gid указанного файла. Если произошла ошибка, она будет типа *PathError.
В Windows всегда возвращается ошибка syscall.EWINDOWS, обернутая в *PathError.
func (*File) Close
func (f *File) Close() error
Close закрывает файл, делая его недоступным для ввода-вывода. Для файлов, поддерживающих File.SetDeadline, все ожидающие операции ввода-вывода будут отменены и немедленно возвращены с ошибкой ErrClosed. Close вернет ошибку, если он уже был вызван.
func (*File) Fd
func (f *File) Fd() uintptr
Fd возвращает целое число Unix-дескриптора файла, ссылающегося на открытый файл. Если f закрыт, дескриптор файла становится недействительным. Если f подвергается сборке мусора, финализатор может закрыть дескриптор файла, сделав его недействительным; см. runtime.SetFinalizer для получения дополнительной информации о том, когда может быть запущен финализатор. В системах Unix это приведет к прекращению работы методов File.SetDeadline. Поскольку файловые дескрипторы могут быть повторно использованы, возвращенный файловый дескриптор может быть закрыт только с помощью метода File.Close f или его финализатором во время сборки мусора. В противном случае во время сборки мусора финализатор может закрыть не связанный файловый дескриптор с тем же (повторно используемым) номером.
В качестве альтернативы см. метод f.SyscallConn.
func (*File) Name
func (f *File) Name() string
Name возвращает имя файла, представленное в Open.
Безопасно вызывать Name после [Close].
func (*File) Read
func (f *File) Read(b []byte) (n int, err error)
Read считывает до len(b) байтов из File и сохраняет их в b. Он возвращает количество прочитанных байтов и любую возникшую ошибку. В конце файла Read возвращает 0, io.EOF.
func (*File) ReadAt
func (f *File) ReadAt(b []byte, off int64) (n int, err error)
ReadAt считывает len(b) байт из файла, начиная с байтового смещения off. Она возвращает количество прочитанных байтов и ошибку, если таковая имеется. ReadAt всегда возвращает ошибку, отличную от nil, когда n < len(b). В конце файла эта ошибка равна io.EOF.
func (*File) ReadDir
func (f *File) ReadDir(n int) ([]DirEntry, error)
ReadDir считывает содержимое каталога, связанного с файлом f, и возвращает массив значений DirEntry в порядке каталога. Последующие вызовы для того же файла будут возвращать последующие записи DirEntry в каталоге.
Если n > 0, ReadDir возвращает не более n записей DirEntry. В этом случае, если ReadDir возвращает пустой срез, он вернет ошибку с объяснением причины. В конце каталога ошибкой является io.EOF.
Если n <= 0, ReadDir возвращает все записи DirEntry, оставшиеся в каталоге. При успешном выполнении он возвращает ошибку nil (не io.EOF).
func (*File) ReadFrom
func (f *File) ReadFrom(r io.Reader) (n int64, err error)
ReadFrom реализует io.ReaderFrom.
func (*File) Readdir
func (f *File) Readdir(n int) ([]FileInfo, error)
Readdir считывает содержимое каталога, связанного с файлом, и возвращает массив из n значений FileInfo, как это было бы возвращено Lstat, в порядке каталога. Последующие вызовы для того же файла будут возвращать дополнительные FileInfos.
Если n > 0, Readdir возвращает не более n структур FileInfo. В этом случае, если Readdir возвращает пустой срез, он вернет не нулевую ошибку с объяснением причины. В конце каталога ошибкой является io.EOF.
Если n <= 0, Readdir возвращает все FileInfo из каталога в одном срезе. В этом случае, если Readdir выполняется успешно (считывает до конца каталога), он возвращает срез и ошибку nil. Если он встречает ошибку до конца каталога, Readdir возвращает FileInfo, прочитанные до этого момента, и ошибку, отличную от nil.
Большинству клиентов лучше подходит более эффективный метод ReadDir.
func (*File) Readdirnames
func (f *File) Readdirnames(n int) (names []string, err error)
Readdirnames считывает содержимое каталога, связанного с файлом, и возвращает срез из n имен файлов в каталоге в порядке их расположения в каталоге. Последующие вызовы для того же файла будут возвращать дальнейшие имена.
Если n > 0, Readdirnames возвращает не более n имен. В этом случае, если Readdirnames возвращает пустой срез, он возвращает не нулевую ошибку с объяснением причины. В конце каталога ошибкой является io.EOF.
Если n <= 0, Readdirnames возвращает все имена из каталога в одном фрагменте. В этом случае, если Readdirnames выполняется успешно (считывает до конца каталога), он возвращает фрагмент и ошибку nil. Если перед концом каталога возникает ошибка, Readdirnames возвращает имена, прочитанные до этого момента, и ошибку, отличную от nil.
func (*File) Seek
func (f *File) Seek(offset int64, whence int) (ret int64, err error)
Seek устанавливает смещение для следующего чтения или записи в файл, интерпретируемое в соответствии с whence: 0 означает относительно начала файла, 1 означает относительно текущего смещения, а 2 означает относительно конца. Возвращает новое смещение и ошибку, если она есть. Поведение Seek для файла, открытого с O_APPEND, не определено.
func (*File) SetDeadline
func (f *File) SetDeadline(t time.Time) error
SetDeadline устанавливает сроки чтения и записи для файла. Это эквивалентно вызову SetReadDeadline и SetWriteDeadline.
Только некоторые типы файлов поддерживают установку срока. Вызов SetDeadline для файлов, которые не поддерживают сроки, вернет ErrNoDeadline. В большинстве систем обычные файлы не поддерживают сроки, но каналы поддерживают.
Срок — это абсолютное время, по истечении которого операции ввода-вывода завершаются с ошибкой, а не блокируются. Срок применяется ко всем будущим и ожидающим операциям ввода-вывода, а не только к следующему вызову Read или Write. После превышения срока соединение можно обновить, установив срок в будущем.
Если срок превышен, вызов Read или Write или других методов ввода-вывода вернет ошибку, которая оборачивает ErrDeadlineExceeded. Это можно проверить с помощью errors.Is(err, os.ErrDeadlineExceeded). Эта ошибка реализует метод Timeout, и вызов метода Timeout вернет true, но есть и другие возможные ошибки, для которых Timeout вернет true, даже если срок не был превышен.
Таймаут простоя можно реализовать путем многократного продления срока после успешных вызовов Read или Write.
Нулевое значение t означает, что операции ввода-вывода не будут прерываться по истечении таймаута.
func (*File) SetReadDeadline
func (f *File) SetReadDeadline(t time.Time) error
SetReadDeadline устанавливает срок для будущих вызовов Read и любых заблокированных в данный момент вызовов Read. Нулевое значение t означает, что Read не будет прерываться по истечении времени ожидания. Не все файлы поддерживают установку сроков; см. SetDeadline.
func (*File) SetWriteDeadline
func (f *File) SetWriteDeadline(t time.Time) error
SetWriteDeadline устанавливает срок для любых будущих вызовов Write и любых заблокированных в данный момент вызовов Write. Даже если Write превышает время ожидания, он может вернуть n > 0, указывая, что часть данных была успешно записана. Нулевое значение t означает, что Write не превысит время ожидания. Не все файлы поддерживают установку сроков; см. SetDeadline.
func (*File) Stat
func (f *File) Stat() (FileInfo, error)
Stat возвращает структуру FileInfo, описывающую файл. Если произошла ошибка, она будет иметь тип *PathError.
func (*File) Sync
func (f *File) Sync() error
Sync фиксирует текущее содержимое файла в стабильном хранилище. Обычно это означает сброс в память файловой системы копии недавно записанных данных на диск.
func (*File) SyscallConn
func (f *File) SyscallConn() (syscall.RawConn, error)
SyscallConn возвращает необработанный файл. Это реализует интерфейс syscall.Conn.
func (*File) Truncate
func (f *File) Truncate(size int64) error
Truncate изменяет размер файла. Он не изменяет смещение ввода-вывода. Если происходит ошибка, она будет типа *PathError.
func (*File) Write
func (f *File) Write(b []byte) (n int, err error)
Write записывает len(b) байт из b в File. Он возвращает количество записанных байт и ошибку, если она есть. Write возвращает ошибку, отличную от nil, когда n != len(b).
func (*File) WriteAt
func (f *File) WriteAt(b []byte, off int64) (n int, err error)
WriteAt записывает len(b) байт в файл, начиная с байтового смещения off. Он возвращает количество записанных байтов и ошибку, если она есть. WriteAt возвращает ошибку, отличную от nil, когда n != len(b).
Если файл был открыт с флагом O_APPEND, WriteAt возвращает ошибку.
func (*File) WriteString
func (f *File) WriteString(s string) (n int, err error)
WriteString похож на Write, но записывает содержимое строки s, а не фрагмент байтов.
func (*File) WriteTo
func (f *File) WriteTo(w io.Writer) (n int64, err error)
WriteTo реализует io.WriterTo.
type FileInfo
type FileInfo = fs.FileInfo
FileInfo описывает файл и возвращается Stat и Lstat.
func Lstat
func Lstat(name string) (FileInfo, error)
Lstat возвращает FileInfo, описывающий файл с указанным именем. Если файл является символической ссылкой, возвращаемый FileInfo описывает символическую ссылку. Lstat не пытается следовать по ссылке. Если происходит ошибка, она будет типа *PathError.
В Windows, если файл является точкой повторного анализа, которая является заменителем другого именованного объекта (например, символической ссылки или смонтированной папки), возвращаемый FileInfo описывает точку повторного анализа и не пытается ее разрешить.
func Stat
func Stat(name string) (FileInfo, error)
Stat возвращает FileInfo, описывающий именованный файл. Если произошла ошибка, она будет типа *PathError.
type FileMode
type FileMode = fs.FileMode
FileMode представляет режим файла и биты разрешений. Биты имеют одинаковое определение во всех системах, поэтому информация о файлах может быть перенесена из одной системы в другую. Не все биты применимы ко всем системам. Единственный обязательный бит — ModeDir для каталогов.
Пример ¶
type LinkError
type LinkError struct {
Op string
Old string
New string
Err error
}
LinkError записывает ошибку, возникшую во время системного вызова link, symlink или rename, а также пути, которые ее вызвали.
func (*LinkError) Error
func (e *LinkError) Error() string
func (*LinkError) Unwrap
func (e *LinkError) Unwrap() error
type PathError
type PathError = fs.PathError
PathError регистрирует ошибку, а также операцию и путь к файлу, которые ее вызвали.
type ProcAttr
type ProcAttr struct {
// Если Dir не пустой, дочерний процесс переходит в этот каталог перед
// созданием процесса.
Dir string
// Если Env не равно nil, оно возвращает переменные окружения для
// нового процесса в форме, возвращаемой Environ.
// Если оно равно nil, будет использован результат Environ.
Env []string
// Files указывает открытые файлы, унаследованные новым процессом.
// Первые три записи соответствуют стандартному вводу, стандартному выводу и
// стандартной ошибке. Реализация может поддерживать дополнительные записи,
// в зависимости от базовой операционной системы. Запись nil соответствует
// закрытию этого файла при запуске процесса.
// В системах Unix StartProcess изменит эти значения File
// в режим блокировки, что означает, что SetDeadline перестанет работать,
// а вызов Close не прервет Read или Write.
Files []*File
// Атрибуты создания процесса, специфичные для операционной системы.
// Обратите внимание, что установка этого поля означает, что ваша программа
// может не работать должным образом или даже не компилироваться в некоторых
// операционных системах.
Sys *syscall.SysProcAttr
}
ProcAttr содержит атрибуты, которые будут применены к новому процессу, запущенному StartProcess.
type Process
type Process struct {
Pid int
// содержит отфильтрованные или неэкспортируемые поля
}
Process хранит информацию о процессе, созданном StartProcess.
func FindProcess
func FindProcess(pid int) (*Process, error)
FindProcess ищет запущенный процесс по его pid.
Возвращаемый им Process можно использовать для получения информации о процессе базовой операционной системы.
В системах Unix FindProcess всегда выполняется успешно и возвращает Process для заданного pid, независимо от того, существует ли процесс. Чтобы проверить, действительно ли процесс существует, посмотрите, сообщает ли p.Signal(syscall.Signal(0)) об ошибке.
func StartProcess
func StartProcess(name string, argv []string, attr *ProcAttr) (*Process, error)
StartProcess запускает новый процесс с программой, аргументами и атрибутами, указанными в name, argv и attr. Срез argv станет os.Args в новом процессе, поэтому он обычно начинается с имени программы.
Если вызывающая goroutine заблокировала поток операционной системы с помощью runtime.LockOSThread и изменила любое наследуемое состояние потока на уровне ОС (например, пространства имен Linux или Plan 9), новый процесс унаследует состояние потока вызывающего.
StartProcess является низкоуровневым интерфейсом. Пакет os/exec предоставляет интерфейсы более высокого уровня.
Если произошла ошибка, она будет иметь тип *PathError.
func (*Process) Kill
func (p *Process) Kill() error
Kill вызывает немедленный выход Process. Kill не ждет, пока Process действительно завершится. Это убивает только сам Process, а не другие процессы, которые он мог запустить.
func (*Process) Release
func (p *Process) Release() error
Release освобождает все ресурсы, связанные с процессом p, делая его непригодным для использования в будущем. Release нужно вызывать только в том случае, если Process.Wait не вызывается.
func (*Process) Signal
func (p *Process) Signal(sig Signal) error
Signal посылает сигнал процессу. Отправка Interrupt в Windows не реализована.
func (*Process) Wait
func (p *Process) Wait() (*ProcessState, error)
Wait ожидает завершения процесса, а затем возвращает ProcessState, описывающий его состояние, и ошибку, если она есть. Wait освобождает все ресурсы, связанные с процессом. В большинстве операционных систем процесс должен быть дочерним по отношению к текущему процессу, иначе будет возвращена ошибка.
type ProcessState
type ProcessState struct {
// содержит отфильтрованные или неэкспортируемые поля
}
ProcessState хранит информацию о процессе, как сообщается Wait.
func (*ProcessState) ExitCode
func (p *ProcessState) ExitCode() int
ExitCode возвращает код завершения завершившегося процесса или -1, если процесс не завершился или был прерван сигналом.
func (*ProcessState) Exited
func (p *ProcessState) Exited() bool
Exited сообщает, завершилась ли программа. В системах Unix это возвращает true, если программа завершилась из-за вызова exit, но false, если программа была прервана сигналом.
func (*ProcessState) Pid
func (p *ProcessState) Pid() int
Pid возвращает идентификатор завершившегося процесса.
func (*ProcessState) String
func (p *ProcessState) String() string
func (*ProcessState) Success
func (p *ProcessState) Success() bool
Success сообщает, завершилась ли программа успешно, например, со статусом завершения 0 в Unix.
func (*ProcessState) Sys
func (p *ProcessState) Sys() any
Sys возвращает системную информацию о завершении процесса. Преобразуйте ее в соответствующий базовый тип, например syscall.WaitStatus в Unix, чтобы получить доступ к ее содержимому.
func (*ProcessState) SysUsage
func (p *ProcessState) SysUsage() any
SysUsage возвращает системную информацию об использовании ресурсов завершенного процесса. Преобразуйте ее в соответствующий базовый тип, например *syscall.Rusage в Unix, чтобы получить доступ к ее содержимому. (В Unix *syscall.Rusage соответствует struct rusage, как определено в справочной странице getrusage(2).)
func (*ProcessState) SystemTime
func (p *ProcessState) SystemTime() time.Duration
SystemTime возвращает системное время ЦП завершенного процесса и его дочерних процессов.
func (*ProcessState) UserTime
func (p *ProcessState) UserTime() time.Duration
UserTime возвращает пользовательское время ЦП завершенного процесса и его дочерних процессов.
type Root
type Root struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Root может использоваться только для доступа к файлам в пределах одного дерева каталогов.
Методы Root могут обращаться только к файлам и каталогам, расположенным ниже корневого каталога. Если какой-либо компонент имени файла, переданного методу Root, ссылается на местоположение за пределами корня, метод возвращает ошибку. Имена файлов могут ссылаться на сам каталог (.).
Методы Root будут следовать символьным ссылкам, но символьные ссылки не могут ссылаться на местоположение за пределами корня. Символьные ссылки не должны быть абсолютными.
Методы Root не запрещают переход через границы файловой системы, монтирование Linux, специальные файлы /proc или доступ к файлам устройств Unix.
Методы Root можно безопасно использовать одновременно из нескольких goroutines.
На большинстве платформ создание Root открывает файловый дескриптор или дескриптор, ссылающийся на каталог. Если каталог перемещен, методы Root ссылаются на исходный каталог в его новом местоположении.
Поведение Root отличается на некоторых платформах:
- Когда GOOS=windows, имена файлов не могут ссылаться на зарезервированные Windows имена устройств, такие как NUL и COM1.
- Когда GOOS=js, Root уязвим для атак TOCTOU (time-of-check-time-of-use) при проверке символьных ссылок и не может гарантировать, что операции не выйдут за пределы корня.
- Когда GOOS=plan9 или GOOS=js, Root не отслеживает каталоги при переименовании. На этих платформах Root ссылается на имя каталога, а не на файловый дескриптор.
func OpenRoot
func OpenRoot(name string) (*Root, error)
OpenRoot открывает указанный каталог. Если произошла ошибка, она будет типа *PathError.
func (*Root) Close
func (r *Root) Close() error
Close закрывает Root. После вызова Close методы Root возвращают ошибки.
func (*Root) Create
func (r *Root) Create(name string) (*File, error)
Create создает или обрезает указанный файл в корне. Подробнее см. Create.
func (*Root) FS
func (r *Root) FS() fs.FS
FS возвращает файловую систему (fs.FS) для дерева файлов в корне.
Результат реализует io/fs.StatFS, io/fs.ReadFileFS и io/fs.ReadDirFS.
func (*Root) Lstat
func (r *Root) Lstat(name string) (FileInfo, error)
Lstat возвращает FileInfo, описывающий указанный файл в корневом каталоге. Если файл является символической ссылкой, возвращаемый FileInfo описывает символическую ссылку. Подробнее см. Lstat.
func (*Root) Mkdir
func (r *Root) Mkdir(name string, perm FileMode) error
Mkdir создает новый каталог в корне с указанным именем и битами разрешений (до umask). Подробнее см. Mkdir.
Если perm содержит биты, отличные от девяти младших битов (0o777), OpenFile возвращает ошибку.
func (*Root) Name
func (r *Root) Name() string
Name возвращает имя каталога, представленного OpenRoot.
Безопасно вызывать Name после [Close].
func (*Root) Open
func (r *Root) Open(name string) (*File, error)
Open открывает указанный файл в корне для чтения. Подробнее см. Open.
func (*Root) OpenFile
func (r *Root) OpenFile(name string, flag int, perm FileMode) (*File, error)
OpenFile открывает указанный файл в корне. Подробнее см. OpenFile.
Если perm содержит биты, отличные от девяти младших битов (0o777), OpenFile возвращает ошибку.
func (*Root) OpenRoot
func (r *Root) OpenRoot(name string) (*Root, error)
OpenRoot открывает указанный каталог в корневом каталоге. Если произошла ошибка, она будет типа *PathError.
func (*Root) Remove
func (r *Root) Remove(name string) error
Remove удаляет указанный файл или (пустой) каталог в корневом каталоге. Подробнее см. в разделе Remove.
func (*Root) Stat
func (r *Root) Stat(name string) (FileInfo, error)
Stat возвращает FileInfo, описывающий файл с указанным именем в корне. Подробнее см. Stat.
type Signal
type Signal interface {
String() string
Signal() // для отличия от других Stringers
}
Signal представляет сигнал операционной системы. Обычная базовая реализация зависит от операционной системы: в Unix это syscall.Signal.
var (
Interrupt Signal = syscall.SIGINT
Kill Signal = syscall.SIGKILL)
Единственные значения сигналов, которые гарантированно присутствуют в пакете os на всех системах, — это os.Interrupt (отправить процессу прерывание) и os.Kill (принудительно завершить процесс). В Windows отправка os.Interrupt процессу с помощью os.Process.Signal не реализована; вместо отправки сигнала будет возвращена ошибка.
type SyscallError
type SyscallError struct {
Syscall string
Err error
}
SyscallError регистрирует ошибку от конкретного системного вызова.
func (*SyscallError) Error
func (e *SyscallError) Error() string
func (*SyscallError) Timeout
func (e *SyscallError) Timeout() bool
Timeout сообщает, является ли эта ошибка тайм-аутом.
func (*SyscallError) Unwrap
func (e *SyscallError) Unwrap() error
12.4.11.3 - Описание функций и типов пакета os/exec языка программирования Go
Пакет exec запускает внешние команды. Он оборачивает os.StartProcess, чтобы упростить перенаправление stdin и stdout, подключение ввода-вывода с помощью труб и другие настройки.
В отличие от вызова библиотеки «system» из C и других языков, пакет os/exec намеренно не вызывает системную оболочку и не расширяет никакие шаблоны glob, а также не обрабатывает другие расширения, конвейеры или перенаправления, которые обычно выполняются оболочками. Пакет ведет себя больше как семейство функций «exec» в C. Чтобы расширить шаблоны glob, либо вызовите оболочку напрямую, позаботившись об экранировании опасных входных данных, либо используйте функцию Glob из пакета path/filepath. Для расширения переменных окружения используйте ExpandEnv из пакета os.
Обратите внимание, что примеры в этом пакете предполагают использование системы Unix. Они могут не работать в Windows и не работают в Go Playground, используемом golang.org и godoc.org.
Исполняемые файлы в текущем каталоге
Функции Command и LookPath ищут программу в каталогах, перечисленных в текущем пути, следуя соглашениям операционной системы хоста. На протяжении десятилетий операционные системы включали текущий каталог в этот поиск, иногда неявно, а иногда явно настраивая его таким образом по умолчанию. Современная практика такова, что включение текущего каталога обычно является неожиданным и часто приводит к проблемам безопасности.
Чтобы избежать этих проблем безопасности, начиная с Go 1.19, этот пакет не будет разрешать программу, используя явную или неявную запись пути относительно текущего каталога. То есть, если вы запустите LookPath(“go”), он не вернет ./go в Unix и .\go.exe в Windows, независимо от того, как настроен путь. Вместо этого, если обычные алгоритмы пути приведут к такому ответу, эти функции возвращают ошибку err, удовлетворяющую errors.Is(err, ErrDot).
Рассмотрим, например, эти два фрагмента программы:
path, err := exec.LookPath("prog")
if err != nil {
log.Fatal(err)
}
use(path)
cmd := exec.Command("prog")
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
Они не найдут и не запустят ./prog или .\prog.exe, независимо от того, как настроен текущий путь.
Код, который всегда хочет запускать программу из текущего каталога, можно переписать так, чтобы вместо “prog” он говорил “./prog”.
Код, который настаивает на включении результатов из записей относительных путей, может вместо этого отменить ошибку с помощью проверки errors.Is:
path, err := exec.LookPath("prog")
if errors.Is(err, exec.ErrDot) {
err = nil
}
if err != nil {
log.Fatal(err)
}
use(path)
cmd := exec.Command("prog")
if errors.Is(cmd.Err, exec.ErrDot) {
cmd.Err = nil
}
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
Установка переменной окружения GODEBUG=execerrdot=0 полностью отключает генерацию ErrDot, временно восстанавливая поведение, существовавшее до Go 1.19, для программ, которые не могут применить более целевые исправления. В будущих версиях Go поддержка этой переменной может быть удалена.
Прежде чем добавлять такие переопределения, убедитесь, что вы понимаете последствия этого для безопасности. Дополнительные сведения см. на сайте https://go.dev/blog/path-security.
Переменные
var ErrDot = errors.New("cannot run executable found relative to current directory")
ErrDot указывает, что поиск пути привел к появлению исполняемого файла в текущем каталоге из-за ‘.’ в пути, либо неявно, либо явно. Подробности см. в документации к пакету.
Обратите внимание, что функции этого пакета не возвращают ErrDot напрямую. Для проверки того, связана ли возвращаемая ошибка err с этим условием, в коде следует использовать errors.Is(err, ErrDot), а не err == ErrDot.
var ErrNotFound = errors.New("исполняемый файл не найден в $PATH")
ErrNotFound - это ошибка, возникающая, если при поиске по пути не удалось найти исполняемый файл.
var ErrWaitDelay = errors.New("exec: WaitDelay expired before I/O complete")
ErrWaitDelay возвращается Cmd.Wait, если процесс завершается с успешным кодом состояния, но его выходные трубы не закрыты до истечения WaitDelay команды.
Функции
func LookPath
func LookPath(file string) (string, error)
LookPath ищет исполняемый файл с именем file в каталогах, указанных переменной окружения PATH. Если файл содержит косую черту, то поиск ведется напрямую и PATH не используется. В противном случае, при успехе, результатом будет абсолютный путь.
В старых версиях Go LookPath мог возвращать путь относительно текущего каталога. Начиная с Go 1.19, LookPath будет возвращать этот путь вместе с ошибкой, удовлетворяющей errors.Is(err, ErrDot). Более подробную информацию см. в документации к пакету.
Пример
package main
import (
"fmt"
"log"
"os/exec"
)
func main() {
path, err := exec.LookPath("fortune")
if err != nil {
log.Fatal("installing fortune is in your future")
}
fmt.Printf("fortune is available at %s\n", path)
}
Типы
type Cmd
type Cmd struct {
// Path — путь к выполняемой команде.
//
// Это единственное поле, которое должно иметь значение, отличное от нуля.
// Если Path является относительным, оно оценивается относительно
// Dir.
Path string
// Args содержит аргументы командной строки, включая команду как Args[0].
// Если поле Args пустое или равно nil, Run использует {Path}.
//
// В типичном случае Path и Args задаются вызовом Command.
Args []string
// Env задает среду процесса.
// Каждая запись имеет вид «ключ=значение».
// Если Env равно nil, новый процесс использует среду текущего процесса.
//
// Если Env содержит дубликаты ключей среды, используется только последнее
// значение в срезе для каждого дубликата ключа.
// В качестве особого случая в Windows SYSTEMROOT всегда добавляется, если
// отсутствует и явно не установлен в пустую строку.
//
// См. также поле Dir, которое может устанавливать PWD в среде.
Env []string
// Dir указывает рабочий каталог команды.
// Если Dir является пустой строкой, Run запускает команду в
// текущем каталоге вызывающего процесса.
//
// В системах Unix значение Dir также определяет
// переменную окружения PWD дочернего процесса, если не указано иное
//. Процесс Unix представляет свой рабочий каталог
// не по имени, а как неявную ссылку на узел в
// дереве файлов. Таким образом, если дочерний процесс получает свой рабочий
// каталог путем вызова функции, такой как getcwd в C, которая
// вычисляет каноническое имя, проходя по дереву файлов, он
// не восстановит исходное значение Dir, если это значение
// было псевдонимом, включающим символьные ссылки. Однако, если
// дочерний процесс вызывает [os.Getwd] в Go или
// get_current_dir_name из GNU C, и значение PWD является псевдонимом для
// текущего каталога, эти функции вернут
// значение PWD, которое совпадает со значением Dir.
Dir string
// Stdin указывает стандартный ввод процесса.
//
// Если Stdin равно nil, процесс читает из нулевого устройства (os.DevNull).
//
// Если Stdin является *os.File, стандартный ввод процесса подключается
// непосредственно к этому файлу.
//
// В противном случае во время выполнения команды отдельная
// goroutine считывает данные из Stdin и передает их команде
// через канал. В этом случае Wait не завершается, пока goroutine
// не прекратит копирование, либо потому что достиг конца Stdin
// (EOF или ошибка чтения), либо потому, что запись в канал вернула ошибку,
// либо потому, что было установлено ненулевое значение WaitDelay, которое истекло.
Stdin io.Reader
// Stdout и Stderr указывают стандартный вывод и ошибки процесса.
//
// Если любой из них равен nil, Run подключает соответствующий файловый дескриптор
// к нулевому устройству (os.DevNull).
//
// Если любой из них является *os.File, соответствующий вывод из процесса
// подключается непосредственно к этому файлу.
//
// В противном случае во время выполнения команды отдельная goroutine
// считывает данные из процесса через канал и доставляет их в
// соответствующий Writer. В этом случае Wait не завершается, пока
// goroutine не достигнет EOF, не столкнется с ошибкой или не истечет ненулевое значение WaitDelay
//.
//
// Если Stdout и Stderr являются одним и тем же writer и имеют тип, который можно
// сравнить с помощью ==, то одновременно Write будет вызывать не более одного goroutine.
Stdout io.Writer
Stderr io.Writer
// ExtraFiles указывает дополнительные открытые файлы, которые будут унаследованы
// новый процесс. Он не включает стандартный ввод, стандартный вывод или
// стандартную ошибку. Если не равен nil, запись i становится файловым дескриптором 3+i.
//
// ExtraFiles не поддерживается в Windows.
ExtraFiles []*os.File
// SysProcAttr содержит дополнительные атрибуты, специфичные для операционной системы.
// Run передает его os.StartProcess как поле Sys os.ProcAttr.
SysProcAttr *syscall.SysProcAttr
// Process — это базовый процесс после запуска.
Process *os.Process
// ProcessState содержит информацию о завершенном процессе.
// Если процесс был запущен успешно, Wait или Run
// заполнят его ProcessState по завершении команды.
ProcessState *os.ProcessState
Err error // Ошибка LookPath, если есть.
// Если Cancel не равен nil, команда должна быть создана с помощью
// CommandContext, и Cancel будет вызван, когда
// Context команды будет выполнен. По умолчанию CommandContext устанавливает Cancel в
// вызывает метод Kill в процессе команды.
//
// Обычно пользовательский Cancel посылает сигнал процессу команды
//, но вместо этого он может предпринять другие действия для инициирования отмены,
// такие как закрытие канала stdin или stdout или отправка запроса на завершение работы
// сетевого сокета.
//
// Если команда завершается с успешным статусом после вызова Cancel
//, а Cancel не возвращает ошибку, эквивалентную
// os.ErrProcessDone, то Wait и подобные методы будут возвращать не нулевую
// ошибку: либо ошибку, оборачивающую ошибку, возвращенную Cancel,
// либо ошибку из Context.
// (Если команда завершается с неуспешным статусом или Cancel
// возвращает ошибку, которая оборачивает os.ErrProcessDone, Wait и подобные методы
// продолжают возвращать обычный статус завершения команды.)
//
// Если Cancel установлен в nil, ничего не произойдет сразу после завершения
// Context команды, но WaitDelay, отличное от нуля, все равно будет действовать. Это может
// быть полезно, например, для обхода тупиковых ситуаций в командах, которые не
// поддерживают сигналы завершения, но должны всегда завершаться быстро.
//
// Cancel не будет вызван, если Start возвращает ошибку, отличную от nil.
Cancel func() error
// Если WaitDelay отлично от нуля, оно ограничивает время ожидания двух источников
// непредвиденной задержки в Wait: дочернего процесса, который не завершается после
// отмены связанного Context, и дочернего процесса, который завершается, но оставляет
// свои каналы ввода-вывода незакрытыми.
//
// Таймер WaitDelay запускается, когда связанный контекст завершается или
// вызов Wait обнаруживает, что дочерний процесс завершился, в зависимости от того, что произойдет
// первым. По истечении задержки команда завершает дочерний процесс
// и/или его каналы ввода-вывода.
//
// Если дочерний процесс не завершился — возможно, потому что он проигнорировал или
// не получил сигнал о завершении от функции Cancel, или потому что не была
// установлена функция Cancel — то он будет завершен с помощью os.Process.Kill.
//
// Затем, если каналы ввода-вывода, связывающиеся с дочерним процессом, все еще открыты,
// эти каналы закрываются, чтобы разблокировать все goroutines, которые в данный момент заблокированы
// вызовами Read или Write.
//
// Если трубы закрыты из-за WaitDelay, вызов Cancel не произошел,
// и команда завершилась с успешным статусом, Wait и
// подобные методы вернут ErrWaitDelay вместо nil.
//
// Если WaitDelay равен нулю (по умолчанию), трубы ввода-вывода будут читаться до EOF,
// что может не произойти, пока осиротевшие подпроцессы команды
// также не закроют свои дескрипторы для каналов.
WaitDelay time.Duration
// содержит отфильтрованные или неэкспортированные поля
}
Cmd представляет внешнюю команду, которая готовится или запускается.
Cmd не может быть повторно использован после вызова методов Cmd.Run, Cmd.Output или Cmd.CombinedOutput.
func Command
func Command(name string, arg ...string) *Cmd
Command возвращает структуру Cmd для выполнения именованной программы с заданными аргументами.
В возвращаемой структуре задаются только Path и Args.
Если имя не содержит разделителей путей, Command использует LookPath для преобразования имени в полный путь, если это возможно. В противном случае она использует имя непосредственно в качестве Path.
Возвращаемое поле Args Cmd строится из имени команды, за которым следуют элементы arg, поэтому arg не должно включать само имя команды. Например, Command(“echo”, “hello”). Args[0] - это всегда имя, а не возможно разрешенный Path.
В Windows процессы получают всю командную строку как единую строку и выполняют собственный разбор. Command объединяет и заключает Args в кавычки в строку командной строки с помощью алгоритма, совместимого с приложениями, использующими CommandLineToArgvW (это наиболее распространенный способ). Заметными исключениями являются msiexec.exe и cmd.exe (и, соответственно, все пакетные файлы), которые имеют другой алгоритм снятия кавычек. В этих и других подобных случаях вы можете выполнить котирование самостоятельно и указать полную командную строку в SysProcAttr.CmdLine, оставив Args пустым.
Пример
package main
import (
"fmt"
"log"
"os/exec"
"strings"
)
func main() {
cmd := exec.Command("tr", "a-z", "A-Z")
cmd.Stdin = strings.NewReader("some input")
var out strings.Builder
cmd.Stdout = &out
err := cmd.Run()
if err != nil {
log.Fatal(err)
}
fmt.Printf("in all caps: %q\n", out.String())
}
Пример с окружением среды
package main
import (
"log"
"os"
"os/exec"
)
func main() {
cmd := exec.Command("prog")
cmd.Env = append(os.Environ(),
"FOO=duplicate_value", // ignored
"FOO=actual_value", // this value is used
)
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
func CommandContext
func CommandContext(ctx context.Context, name string, arg ...string) *Cmd
CommandContext похож на Command, но включает в себя контекст.
Предоставленный контекст используется для прерывания процесса (путем вызова cmd.Cancel или os.Process.Kill), если контекст завершается до того, как команда завершит свою работу.
CommandContext устанавливает функцию Cancel команды для вызова метода Kill в ее Process и оставляет WaitDelay не установленным. Вызывающая сторона может изменить поведение отмены, изменив эти поля перед запуском команды.
Пример
package main
import (
"context"
"os/exec"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 100*time.Millisecond)
defer cancel()
if err := exec.CommandContext(ctx, "sleep", "5").Run(); err != nil {
// This will fail after 100 milliseconds. The 5 second sleep
// will be interrupted.
}
}
func (*Cmd) CombinedOutput
func (c *Cmd) CombinedOutput() ([]byte, error)
CombinedOutput запускает команду и возвращает ее объединенный стандартный вывод и стандартную ошибку.
Пример
package main
import (
"fmt"
"log"
"os/exec"
)
func main() {
cmd := exec.Command("sh", "-c", "echo stdout; echo 1>&2 stderr")
stdoutStderr, err := cmd.CombinedOutput()
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", stdoutStderr)
}
func (*Cmd) Environ
func (c *Cmd) Environ() []string
Environ возвращает копию среды, в которой будет запущена команда, в том виде, в котором она настроена в данный момент.
Пример
package main
import (
"fmt"
"log"
"os/exec"
)
func main() {
cmd := exec.Command("pwd")
// Set Dir before calling cmd.Environ so that it will include an
// updated PWD variable (on platforms where that is used).
cmd.Dir = ".."
cmd.Env = append(cmd.Environ(), "POSIXLY_CORRECT=1")
out, err := cmd.Output()
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", out)
}
func (*Cmd) Output
func (c *Cmd) Output() ([]byte, error)
Output запускает команду и возвращает ее стандартный вывод. Любая возвращаемая ошибка обычно будет иметь тип *ExitError. Если c.Stderr было nil, а возвращаемая ошибка имеет тип *ExitError, Output заполняет поле Stderr возвращаемой ошибки.
Пример
package main
import (
"fmt"
"log"
"os/exec"
)
func main() {
out, err := exec.Command("date").Output()
if err != nil {
log.Fatal(err)
}
fmt.Printf("The date is %s\n", out)
}
func (*Cmd) Run
func (c *Cmd) Run() error
Run запускает указанную команду и ждет ее завершения.
Возвращаемая ошибка равна nil, если команда запущена, не возникло проблем с копированием stdin, stdout и stderr, и она завершилась с нулевым статусом выхода.
Если команда запущена, но не завершилась успешно, ошибка будет типа *ExitError. В других ситуациях могут возвращаться ошибки других типов.
Если вызывающая goroutine заблокировала поток операционной системы с помощью runtime.LockOSThread и изменила любое наследуемое состояние потока на уровне ОС (например, пространства имен Linux или Plan 9), новый процесс унаследует состояние потока вызывающего.
Пример
package main
import (
"log"
"os/exec"
)
func main() {
cmd := exec.Command("sleep", "1")
log.Printf("Running command and waiting for it to finish...")
err := cmd.Run()
log.Printf("Command finished with error: %v", err)
}
func (*Cmd) Start
func (c *Cmd) Start() error
Start запускает указанную команду, но не ждет ее завершения.
Если Start возвращается успешно, поле c.Process будет установлено.
После успешного вызова Start необходимо вызвать метод Cmd.Wait, чтобы освободить связанные системные ресурсы.
Пример
package main
import (
"log"
"os/exec"
)
func main() {
cmd := exec.Command("sleep", "5")
err := cmd.Start()
if err != nil {
log.Fatal(err)
}
log.Printf("Waiting for command to finish...")
err = cmd.Wait()
log.Printf("Command finished with error: %v", err)
}
func (*Cmd) StderrPipe
func (c *Cmd) StderrPipe() (io.ReadCloser, error)
StderrPipe возвращает канал, который будет подключен к стандартной ошибке команды при ее запуске.
Cmd.Wait закроет канал после завершения команды, поэтому большинству вызывающих не нужно закрывать канал самостоятельно. Таким образом, неправильно вызывать Wait до завершения всех операций чтения из канала. По той же причине неправильно использовать Cmd.Run при использовании StderrPipe. Идиоматическое использование см. в примере StdoutPipe.
Пример
package main
import (
"fmt"
"io"
"log"
"os/exec"
)
func main() {
cmd := exec.Command("sh", "-c", "echo stdout; echo 1>&2 stderr")
stderr, err := cmd.StderrPipe()
if err != nil {
log.Fatal(err)
}
if err := cmd.Start(); err != nil {
log.Fatal(err)
}
slurp, _ := io.ReadAll(stderr)
fmt.Printf("%s\n", slurp)
if err := cmd.Wait(); err != nil {
log.Fatal(err)
}
}
func (*Cmd) StdinPipe
func (c *Cmd) StdinPipe() (io.WriteCloser, error)
StdinPipe возвращает канал, который будет подключен к стандартному входу команды при ее запуске. Канал будет автоматически закрыт после того, как Cmd.Wait увидит выход команды. Вызывающему достаточно вызвать Close, чтобы заставить канал закрыться раньше. Например, если запускаемая команда не завершится до закрытия стандартного ввода, вызывающий должен закрыть канал.
Пример
package main
import (
"fmt"
"io"
"log"
"os/exec"
)
func main() {
cmd := exec.Command("cat")
stdin, err := cmd.StdinPipe()
if err != nil {
log.Fatal(err)
}
go func() {
defer stdin.Close()
io.WriteString(stdin, "values written to stdin are passed to cmd's standard input")
}()
out, err := cmd.CombinedOutput()
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", out)
}
func (*Cmd) StdoutPipe
func (c *Cmd) StdoutPipe() (io.ReadCloser, error)
StdoutPipe возвращает канал, который будет подключен к стандартному выводу команды при ее запуске.
Cmd.Wait закроет канал после завершения команды, поэтому большинству вызывающих не нужно закрывать канал самостоятельно. Таким образом, неправильно вызывать Wait до завершения всех операций чтения из канала. По той же причине неправильно вызывать Cmd.Run при использовании StdoutPipe. См. пример для идиоматического использования.
Пример
package main
import (
"encoding/json"
"fmt"
"log"
"os/exec"
)
func main() {
cmd := exec.Command("echo", "-n", `{"Name": "Bob", "Age": 32}`)
stdout, err := cmd.StdoutPipe()
if err != nil {
log.Fatal(err)
}
if err := cmd.Start(); err != nil {
log.Fatal(err)
}
var person struct {
Name string
Age int
}
if err := json.NewDecoder(stdout).Decode(&person); err != nil {
log.Fatal(err)
}
if err := cmd.Wait(); err != nil {
log.Fatal(err)
}
fmt.Printf("%s is %d years old\n", person.Name, person.Age)
func (*Cmd) String
func (c *Cmd) String() string
String возвращает удобочитаемое описание c. Предназначено только для отладки. В частности, не подходит для использования в качестве ввода в оболочку. Вывод String может различаться в разных версиях Go.
func (*Cmd) Wait
func (c *Cmd) Wait() error
Wait ожидает завершения команды и завершения копирования в stdin или копирования из stdout или stderr.
Команда должна быть запущена с помощью Cmd.Start.
Возвращаемая ошибка равна nil, если команда запущена, не имеет проблем с копированием stdin, stdout и stderr и завершается с нулевым статусом выхода.
Если команда не запускается или не завершается успешно, ошибка имеет тип *ExitError. Другие типы ошибок могут возвращаться при проблемах с вводом-выводом.
Если c.Stdin, c.Stdout или c.Stderr не являются *os.File, Wait также ожидает завершения соответствующего цикла ввода-вывода в процесс или из процесса.
Wait освобождает все ресурсы, связанные с Cmd.
type Error
type Error struct {
// Name — имя файла, для которого произошла ошибка.
Name string
// Err — базовая ошибка.
Err error
}
Error возвращается LookPath, когда он не может классифицировать файл как исполняемый.
func (*Error) Error
func (e *Error) Error() string
func (*Error) Unwrap
func (e *Error) Unwrap() error
type ExitError
type ExitError struct {
*os.ProcessState
// Stderr содержит подмножество стандартного вывода ошибок из
// метода Cmd.Output, если стандартные ошибки не были
// собраны иным способом.
//
// Если вывод ошибок длинный, Stderr может содержать только префикс
// и суффикс вывода, а середина будет заменена
// текстом о количестве пропущенных байтов.
//
// Stderr предоставляется для отладки, для включения в сообщения об ошибках.
// Пользователи с другими потребностями должны перенаправить Cmd.Stderr по мере необходимости.
Stderr []byte
}
ExitError сообщает о неудачном завершении команды.
func (*ExitError) Error
func (e *ExitError) Error() string
12.4.11.4 - Пакет os/user языка программирования Go
Пакет user позволяет искать учетные записи пользователей по имени или идентификатору.
Для большинства систем Unix этот пакет имеет две внутренние реализации преобразования идентификаторов пользователей и групп в имена, а также вывода списка дополнительных идентификаторов групп. Одна из них написана на чистом Go и анализирует файлы /etc/passwd и /etc/group. Другая основана на cgo и использует стандартные процедуры библиотеки C (libc), такие как getpwuid_r, getgrnam_r и getgrouplist.
Если cgo доступен, а необходимые процедуры реализованы в libc для конкретной платформы, используется код на основе cgo (с поддержкой libc). Это можно переопределить с помощью тега сборки osusergo, который принудительно использует реализацию на чистом Go.
type Group
type Group struct {
Gid string // идентификатор группы
Name string // название группы
}
Group представляет группу пользователей.
В системах POSIX Gid содержит десятичное число, представляющее идентификатор группы.
func LookupGroup
func LookupGroup(name string) (*Group, error)
LookupGroup ищет группу по имени. Если группа не найдена, возвращается ошибка типа UnknownGroupError.
func LookupGroupId
func LookupGroupId(gid string) (*Group, error)
LookupGroupId ищет группу по groupid. Если группа не найдена, возвращается ошибка типа UnknownGroupIdError.
type UnknownGroupError
type UnknownGroupError string
UnknownGroupError возвращается LookupGroup, когда группа не может быть найдена.
func (UnknownGroupError) Error
func (e UnknownGroupError) Error() string
type UnknownGroupIdError
type UnknownGroupIdError string
UnknownGroupIdError возвращается LookupGroupId, когда группа не может быть найдена.
func (UnknownGroupIdError) Error
func (e UnknownGroupIdError) Error() string
type UnknownUserError
type UnknownUserError string
UnknownUserError возвращается Lookup, когда пользователь не может быть найден.
func (UnknownUserError) Error
func (e UnknownUserError) Error() string
type UnknownUserIdError
type UnknownUserIdError int
UnknownUserIdError возвращается LookupId, когда пользователь не может быть найден.
func (UnknownUserIdError) Error
func (e UnknownUserIdError) Error() string
type User ¶
type User struct {
// Uid — это идентификатор пользователя.
// В системах POSIX это десятичное число, представляющее uid.
// В Windows это идентификатор безопасности (SID) в формате строки.
// В Plan 9 это содержимое /dev/user.
Uid string
// Gid — это идентификатор основной группы.
// В системах POSIX это десятичное число, представляющее gid.
// В Windows это SID в формате строки.
// В Plan 9 это содержимое /dev/user.
Gid string
// Username — это имя для входа в систему.
Username string
// Name — это настоящее или отображаемое имя пользователя.
// Оно может быть пустым.
// В системах POSIX это первая (или единственная) запись в поле GECOS
// списка GECOS.
// В Windows это отображаемое имя пользователя.
// В Plan 9 это содержимое /dev/user.
Строка имени
// HomeDir — это путь к домашнему каталогу пользователя (если он есть).
Строка HomeDir
}
User представляет учетную запись пользователя.
func Current
func Current() (*User, error)
Current возвращает текущего пользователя.
При первом вызове информация о текущем пользователе будет сохранена в кэше. Последующие вызовы будут возвращать значение из кэша и не будут отражать изменения текущего пользователя.
func Lookup
func Lookup(username string) (*User, error)
Lookup ищет пользователя по имени. Если пользователь не найден, возвращается ошибка типа UnknownUserError.
func LookupId
func LookupId(uid string) (*User, error)
LookupId ищет пользователя по идентификатору. Если пользователь не найден, возвращается ошибка типа UnknownUserIdError.
func (*User) GroupIds
func (u *User) GroupIds() ([]string, error)
GroupIds возвращает список идентификаторов групп, членом которых является пользователь.
12.4.11.5 - Пакет os/signal языка программирования Go
Пакет signal реализует доступ к входящим сигналам.
Сигналы в основном используются в Unix-подобных системах. Для использования этого пакета в Windows и Plan 9 см. ниже.
Типы сигналов
Сигналы SIGKILL и SIGSTOP не могут быть перехвачены программой и, следовательно, не могут быть затронуты этим пакетом.
Синхронные сигналы — это сигналы, вызываемые ошибками при выполнении программы: SIGBUS, SIGFPE и SIGSEGV. Они считаются синхронными только в том случае, если вызваны выполнением программы, а не отправлены с помощью os.Process.Kill, программы kill или аналогичного механизма. В общем случае, за исключением описанного ниже, программы Go преобразуют синхронный сигнал в панику во время выполнения.
Остальные сигналы являются асинхронными. Они не вызываются ошибками программы, а отправляются из ядра или из другой программы.
Из асинхронных сигналов сигнал SIGHUP отправляется, когда программа теряет свой управляющий терминал. Сигнал SIGINT отправляется, когда пользователь на управляющем терминале нажимает символ прерывания, который по умолчанию является ^C (Control-C). Сигнал SIGQUIT отправляется, когда пользователь на управляющем терминале нажимает символ выхода, который по умолчанию является ^\ (Control-Backslash). Как правило, вы можете просто завершить программу, нажав ^C, а также завершить ее с дампом стека, нажав ^.
Поведение сигналов по умолчанию в программах Go
По умолчанию синхронный сигнал преобразуется в панику во время выполнения. Сигнал SIGHUP, SIGINT или SIGTERM приводит к завершению программы. Сигнал SIGQUIT, SIGILL, SIGTRAP, SIGABRT, SIGSTKFLT, SIGEMT или SIGSYS приводит к завершению программы с дампом стека. Сигнал SIGTSTP, SIGTTIN или SIGTTOU получает поведение по умолчанию системы (эти сигналы используются оболочкой для управления задачами). Сигнал SIGPROF обрабатывается непосредственно средой выполнения Go для реализации runtime.CPUProfile. Другие сигналы будут перехвачены, но никаких действий не будет предпринято.
Если программа Go запущена с игнорированием сигналов SIGHUP или SIGINT (обработчик сигналов установлен в SIG_IGN), они будут по-прежнему игнорироваться.
Если программа Go запущена с непустой маской сигналов, она, как правило, будет соблюдаться. Однако некоторые сигналы явно разблокированы: синхронные сигналы, SIGILL, SIGTRAP, SIGSTKFLT, SIGCHLD, SIGPROF, а в Linux — сигналы 32 (SIGCANCEL) и 33 (SIGSETXID) (SIGCANCEL и SIGSETXID используются внутренне glibc). Подпроцессы, запущенные с помощью os.Exec или os/exec, унаследуют измененную маску сигналов.
Изменение поведения сигналов в программах Go
Функции в этом пакете позволяют программе изменять способ обработки сигналов программами Go.
Notify отключает поведение по умолчанию для заданного набора асинхронных сигналов и вместо этого доставляет их по одному или нескольким зарегистрированным каналам. В частности, это относится к сигналам SIGHUP, SIGINT, SIGQUIT, SIGABRT и SIGTERM. Это также относится к сигналам управления задачами SIGTSTP, SIGTTIN и SIGTTOU, в этом случае поведение по умолчанию системы не происходит. Она также применяется к некоторым сигналам, которые в противном случае не вызывают никаких действий: SIGUSR1, SIGUSR2, SIGPIPE, SIGALRM, SIGCHLD, SIGCONT, SIGURG, SIGXCPU, SIGXFSZ, SIGVTALRM, SIGWINCH, SIGIO, SIGPWR, SIGINFO, SIGTHR, SIGWAITING, SIGLWP, SIGFREEZE, SIGTHAW, SIGLOST, SIGXRES, SIGJVM1, SIGJVM2 и любые сигналы реального времени, используемые в системе. Обратите внимание, что не все эти сигналы доступны во всех системах.
Если программа была запущена с игнорированием SIGHUP или SIGINT, и для любого из этих сигналов вызван Notify, для этого сигнала будет установлен обработчик сигналов, и он больше не будет игнорироваться. Если позже для этого сигнала вызван Reset или Ignore, или вызван Stop для всех каналов, переданных Notify для этого сигнала, сигнал снова будет игнорироваться. Reset восстановит поведение системы по умолчанию для сигнала, а Ignore заставит систему полностью игнорировать сигнал.
Если программа запущена с непустой маской сигналов, некоторые сигналы будут явно разблокированы, как описано выше. Если Notify вызывается для заблокированного сигнала, он будет разблокирован. Если позже для этого сигнала вызывается Reset или Stop для всех каналов, переданных Notify для этого сигнала, сигнал снова будет заблокирован.
SIGPIPE
Когда программа на Go записывает в разорванный канал, ядро генерирует сигнал SIGPIPE.
Если программа не вызвала Notify для получения сигналов SIGPIPE, то поведение зависит от номера файлового дескриптора. Запись в разорванный канал на файловых дескрипторах 1 или 2 (стандартный вывод или стандартная ошибка) приведет к завершению программы с сигналом SIGPIPE. Запись в разорванный канал на каком-либо другом файловом дескрипторе не вызовет никаких действий по сигналу SIGPIPE, и запись завершится с ошибкой EPIPE.
Если программа вызвала Notify для получения сигналов SIGPIPE, номер файлового дескриптора не имеет значения. Сигнал SIGPIPE будет доставлен в канал Notify, и запись завершится с ошибкой EPIPE.
Это означает, что по умолчанию программы командной строки будут вести себя как типичные программы командной строки Unix, в то время как другие программы не будут завершаться с SIGPIPE при записи в закрытое сетевое соединение.
Программы Go, использующие cgo или SWIG
В программе Go, которая включает код, не относящийся к Go, обычно код C/C++, доступ к которому осуществляется с помощью cgo или SWIG, сначала запускается код запуска Go. Он настраивает обработчики сигналов в соответствии с ожиданиями среды выполнения Go, прежде чем запускается код запуска, не относящийся к Go. Если код запуска, не относящийся к Go, желает установить свои собственные обработчики сигналов, он должен предпринять определенные шаги, чтобы Go продолжал работать нормально. В этом разделе описаны эти шаги и общие изменения, которые могут быть внесены в настройки обработчиков сигналов кодом, не относящимся к Go, в программах Go. В редких случаях код, не относящийся к Go, может запускаться перед кодом Go, и в этом случае также применяется следующий раздел.
Если код, не относящийся к Go, вызываемый программой Go, не изменяет обработчики сигналов или маски, то поведение будет таким же, как и для чистой программы Go.
Если код, не относящийся к Go, устанавливает какие-либо обработчики сигналов, он должен использовать флаг SA_ONSTACK с sigaction. Невыполнение этого требования может привести к сбою программы при получении сигнала. Программы Go обычно работают с ограниченным стеком, поэтому настраивают альтернативный стек сигналов.
Если код, не относящийся к Go, устанавливает обработчик сигналов для любого из синхронных сигналов (SIGBUS, SIGFPE, SIGSEGV), то он должен записывать существующий обработчик сигналов Go. Если эти сигналы возникают во время выполнения кода Go, он должен вызывать обработчик сигналов Go (возникновение сигнала во время выполнения кода Go можно определить, посмотрев на PC, передаваемый обработчику сигналов). В противном случае некоторые паники времени выполнения Go не будут происходить, как ожидается.
Если код, не относящийся к Go, устанавливает обработчик сигналов для любого из асинхронных сигналов, он может вызывать обработчик сигналов Go или нет, по своему усмотрению. Естественно, если он не вызывает обработчик сигналов Go, описанное выше поведение Go не будет происходить. Это может быть проблемой, в частности, с сигналом SIGPROF.
Код, не относящийся к Go, не должен изменять маску сигналов в любых потоках, созданных средой выполнения Go. Если код, не относящийся к Go, сам запускает новые потоки, эти потоки могут устанавливать маску сигналов по своему усмотрению.
Если код, не относящийся к Go, запускает новый поток, изменяет маску сигналов, а затем вызывает функцию Go в этом потоке, среда выполнения Go автоматически разблокирует определенные сигналы: синхронные сигналы, SIGILL, SIGTRAP, SIGSTKFLT, SIGCHLD, SIGPROF, SIGCANCEL и SIGSETXID. Когда функция Go возвращается, маска сигналов, не относящаяся к Go, будет восстановлена.
Если обработчик сигналов Go вызывается в потоке, не относящемся к Go и не выполняющем код Go, обработчик обычно пересылает сигнал в код, не относящийся к Go, следующим образом. Если сигнал является SIGPROF, обработчик Go ничего не делает. В противном случае обработчик Go удаляет себя, разблокирует сигнал и снова его генерирует, чтобы вызвать любой обработчик, не относящийся к Go, или системный обработчик по умолчанию. Если программа не завершается, обработчик Go переустанавливает себя и продолжает выполнение программы.
Если получен сигнал SIGPIPE, программа Go вызовет специальную обработку, описанную выше, если SIGPIPE получен в потоке Go. Если SIGPIPE получен в потоке, не относящемся к Go, сигнал будет перенаправлен в обработчик, не относящийся к Go, если таковой имеется; если его нет, обработчик по умолчанию системы приведет к завершению программы.
Программы, не написанные на Go, которые вызывают код Go
Когда код Go компилируется с такими опциями, как -buildmode=c-shared, он будет запускаться как часть существующей программы, не написанной на Go. Код, не написанный на Go, может уже иметь установленные обработчики сигналов, когда запускается код Go (это также может произойти в необычных случаях при использовании cgo или SWIG; в этом случае применимо обсуждение, приведенное здесь). Для -buildmode=c-archive среда выполнения Go инициализирует сигналы во время глобального конструктора. Для -buildmode=c-shared среда выполнения Go инициализирует сигналы при загрузке разделяемой библиотеки.
Если среда выполнения Go обнаруживает существующий обработчик сигналов для сигналов SIGCANCEL или SIGSETXID (которые используются только в Linux), она включает флаг SA_ONSTACK и в остальном сохраняет обработчик сигналов.
Для синхронных сигналов и SIGPIPE среда выполнения Go установит обработчик сигналов. Она сохранит любой существующий обработчик сигналов. Если синхронный сигнал поступает во время выполнения кода, не относящегося к Go, среда выполнения Go вызовет существующий обработчик сигналов вместо обработчика сигналов Go.
Код Go, скомпилированный с -buildmode=c-archive или -buildmode=c-shared, по умолчанию не будет устанавливать никаких других обработчиков сигналов. Если существующий обработчик сигналов, среда выполнения Go включит флаг SA_ONSTACK и сохранит обработчик сигналов. Если Notify вызывается для асинхронного сигнала, для этого сигнала будет установлен обработчик сигналов Go. Если позже для этого сигнала вызывается Reset, исходная обработка этого сигнала будет переустановлена, восстанавливая обработчик сигналов, не относящийся к Go, если таковой имеется.
Код Go, скомпилированный без -buildmode=c-archive или -buildmode=c-shared, установит обработчик сигналов для асинхронных сигналов, перечисленных выше, и сохранит любой существующий обработчик сигналов. Если сигнал доставляется в поток, не относящийся к Go, он будет действовать, как описано выше, за исключением того, что если существует обработчик сигналов, не относящийся к Go, этот обработчик будет установлен перед генерацией сигнала. Windows ¶
В Windows ^C (Control-C) или ^BREAK (Control-Break) обычно приводят к завершению программы. Если Notify вызывается для os.Interrupt, ^C или ^BREAK приводят к отправке os.Interrupt по каналу, и программа не завершается. Если вызывается Reset или Stop на всех каналах, переданных Notify, то поведение по умолчанию будет восстановлено.
Кроме того, если вызывается Notify, и Windows отправляет CTRL_CLOSE_EVENT, CTRL_LOGOFF_EVENT или CTRL_SHUTDOWN_EVENT процессу, Notify вернет syscall.SIGTERM. В отличие от Control-C и Control-Break, Notify не изменяет поведение процесса при получении CTRL_CLOSE_EVENT, CTRL_LOGOFF_EVENT или CTRL_SHUTDOWN_EVENT — процесс все равно будет завершен, если он не завершится самостоятельно. Но получение syscall.SIGTERM даст процессу возможность очиститься перед завершением.
Plan 9
В Plan 9 сигналы имеют тип syscall.Note, который представляет собой строку. Вызов Notify с syscall.Note приведет к отправке этого значения по каналу, когда эта строка будет отправлена в качестве заметки.
Функции
func Ignore
func Ignore(sig ...os.Signal)
Ignore заставляет игнорировать указанные сигналы. Если они будут получены программой, ничего не произойдет. Ignore отменяет действие всех предыдущих вызовов Notify для указанных сигналов. Если сигналы не указаны, все входящие сигналы будут игнорироваться.
func Ignored
func Ignored(sig os.Signal) bool
Ignored сообщает, игнорируется ли sig в данный момент.
func Notify
func Notify(c chan<- os.Signal, sig ...os.Signal)
Notify заставляет пакет signal ретранслировать входящие сигналы в c. Если сигналы не предоставлены, все входящие сигналы будут ретранслированы в c. В противном случае будут ретранслированы только предоставленные сигналы.
Пакет signal не будет блокировать отправку в c: вызывающий должен убедиться, что c имеет достаточное буферное пространство, чтобы справиться с ожидаемой скоростью сигналов. Для канала, используемого для уведомления только об одном значении сигнала, достаточно буфера размером 1.
Разрешается вызывать Notify несколько раз с одним и тем же каналом: каждый вызов расширяет набор сигналов, отправляемых на этот канал. Единственный способ удалить сигналы из набора — вызвать Stop.
Разрешается вызывать Notify несколько раз с разными каналами и одними и теми же сигналами: каждый канал получает копии входящих сигналов независимо.
Пример
package main
import (
"fmt"
"os"
"os/signal"
)
func main() {
// Set up channel on which to send signal notifications.
// We must use a buffered channel or risk missing the signal
// if we're not ready to receive when the signal is sent.
c := make(chan os.Signal, 1)
signal.Notify(c, os.Interrupt)
// Block until a signal is received.
s := <-c
fmt.Println("Got signal:", s)
}
Пример AllSignals
package main
import (
"fmt"
"os"
"os/signal"
)
func main() {
// Set up channel on which to send signal notifications.
// We must use a buffered channel or risk missing the signal
// if we're not ready to receive when the signal is sent.
c := make(chan os.Signal, 1)
// Passing no signals to Notify means that
// all signals will be sent to the channel.
signal.Notify(c)
// Block until any signal is received.
s := <-c
fmt.Println("Got signal:", s)
}
func NotifyContext
func NotifyContext(parent context.Context, signals ...os.Signal) (ctx context.Context, stop context.CancelFunc)
NotifyContext возвращает копию родительского контекста, который помечается как выполненный (его канал Done закрывается), когда поступает один из перечисленных сигналов, когда вызывается возвращаемая функция stop или когда канал Done родительского контекста закрывается, в зависимости от того, что произойдет раньше.
Функция stop отменяет регистрацию поведения сигнала, что, как и signal.Reset, может восстановить поведение по умолчанию для данного сигнала. Например, поведением по умолчанию для программы Go, получающей os.Interrupt, является выход. Вызов NotifyContext(parent, os.Interrupt) изменит поведение на отмену возвращенного контекста. Будущие прерывания не будут вызывать поведение по умолчанию (выход) до тех пор, пока не будет вызвана возвращенная функция stop.
Функция stop освобождает связанные с ней ресурсы, поэтому код должен вызывать stop, как только операции, выполняемые в этом контексте, завершатся и сигналы больше не нужно будет перенаправлять в контекст.
Пример
//go:build unix
package main
import (
"context"
"fmt"
"log"
"os"
"os/signal"
)
var neverReady = make(chan struct{}) // never closed
// This example passes a context with a signal to tell a blocking function that
// it should abandon its work after a signal is received.
func main() {
ctx, stop := signal.NotifyContext(context.Background(), os.Interrupt)
defer stop()
p, err := os.FindProcess(os.Getpid())
if err != nil {
log.Fatal(err)
}
// On a Unix-like system, pressing Ctrl+C on a keyboard sends a
// SIGINT signal to the process of the program in execution.
//
// This example simulates that by sending a SIGINT signal to itself.
if err := p.Signal(os.Interrupt); err != nil {
log.Fatal(err)
}
select {
case <-neverReady:
fmt.Println("ready")
case <-ctx.Done():
fmt.Println(ctx.Err()) // prints "context canceled"
stop() // stop receiving signal notifications as soon as possible.
}
}
Output:
context canceledfunc Reset
func Reset(sig ...os.Signal)
Reset отменяет эффект всех предыдущих вызовов Notify для предоставленных сигналов. Если сигналы не указаны, все обработчики сигналов будут сброшены.
func Stop
func Stop(c chan<- os.Signal)
Stop заставляет пакет signal прекратить ретрансляцию входящих сигналов в c. Он отменяет эффект всех предыдущих вызовов Notify с использованием c. Когда Stop возвращается, гарантируется, что c больше не будет получать сигналы.
12.4.12 - Описание пакета strconv
Пакет strconv реализует преобразования в строковые представления основных типов данных и обратно.
Числовые преобразования
Наиболее распространенными числовыми преобразованиями являются Atoi (строка в int) и Itoa (int в String).
i, err := strconv.Atoi(«-42»)
s := strconv.Itoa(-42)
Они предполагают десятичную систему счисления и тип Go int.
ParseBool, ParseFloat, ParseInt и ParseUint преобразуют строки в значения:
b, err := strconv.ParseBool(«true»)
f, err := strconv.ParseFloat(«3.1415», 64)
i, err := strconv.ParseInt(«-42», 10, 64)
u, err := strconv.ParseUint(«42», 10, 64)
Функции преобразования возвращают самый широкий тип (float64, int64 и uint64), но если аргумент size указывает более узкую ширину, результат может быть преобразован в этот более узкий тип без потери данных:
s := «2147483647» // самый большой int32
i64, err := strconv.ParseInt(s, 10, 32)
...
i := int32(i64)
FormatBool, FormatFloat, FormatInt и FormatUint преобразуют значения в строки:
s := strconv.FormatBool(true)
s := strconv.FormatFloat(3.1415, „E“, -1, 64)
s := strconv.FormatInt(-42, 16)
s := strconv.FormatUint(42, 16)
AppendBool, AppendFloat, AppendInt и AppendUint аналогичны, но добавляют отформатированное значение в целевой срез.
Преобразование строк
Quote и QuoteToASCII преобразуют строки в строчные литералы Go в кавычках. Последний гарантирует, что результатом будет строка ASCII, экранируя любой не-ASCII Unicode с помощью \u:
q := strconv.Quote(«Hello, 世界»)
q := strconv.QuoteToASCII(«Hello, 世界»)
QuoteRune и QuoteRuneToASCII похожи, но принимают руны и возвращают зацикленные литералы Go.
Unquote и UnquoteChar разъединяют литералы строк и рун Go.
Константы
const IntSize = intSize
IntSize - это размер в битах значения int или uint.
Переменные
var ErrRange = errors.New("значение вне диапазона")
ErrRange указывает, что значение выходит за пределы диапазона для целевого типа.
var ErrSyntax = errors.New("invalid syntax")
ErrSyntax указывает, что значение не имеет правильного синтаксиса для целевого типа.
12.4.12.1 - Описание функций пакета strconv
Описание функция из пакета strconv
func AppendBool
func AppendBool(dst []byte, b bool) []byte
AppendBool добавляет «true» или «false» в зависимости от значения b к dst и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b := []byte("bool:")
b = strconv.AppendBool(b, true)
fmt.Println(string(b))
}
func AppendFloat
func AppendFloat(dst []byte, f float64, fmt byte, prec, bitSize int) []byte
AppendFloat добавляет строковую форму числа с плавающей запятой f, сгенерированную FormatFloat, к dst и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b32 := []byte("float32:")
b32 = strconv.AppendFloat(b32, 3.1415926535, 'E', -1, 32)
fmt.Println(string(b32))
b64 := []byte("float64:")
b64 = strconv.AppendFloat(b64, 3.1415926535, 'E', -1, 64)
fmt.Println(string(b64))
}
func AppendInt
func AppendInt(dst []byte, i int64, base int) []byte
AppendInt добавляет строковую форму целого числа i, сгенерированную FormatInt, к dst и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b10 := []byte("int (base 10):")
b10 = strconv.AppendInt(b10, -42, 10)
fmt.Println(string(b10))
b16 := []byte("int (base 16):")
b16 = strconv.AppendInt(b16, -42, 16)
fmt.Println(string(b16))
}
func AppendQuote
func AppendQuote(dst []byte, s string) []byte
AppendQuote добавляет к dst строковый литерал Go в двойных кавычках, представляющий s, сгенерированный Quote, и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b := []byte("quote:")
b = strconv.AppendQuote(b, `"Fran & Freddie's Diner"`)
fmt.Println(string(b))
}
Output:
quote:"\"Fran & Freddie's Diner\""
func AppendQuoteRune
func AppendQuoteRune(dst []byte, r rune) []byte
AppendQuoteRune добавляет к dst однострочный литерал Go, представляющий руну, сгенерированный QuoteRune, и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b := []byte("rune:")
b = strconv.AppendQuoteRune(b, '☺')
fmt.Println(string(b))
}
Output:
rune:'☺'
func AppendQuoteRuneToASCII
func AppendQuoteRuneToASCII(dst []byte, r rune) []byte
AppendQuoteRuneToASCII добавляет в dst однострочный литерал символа Go, представляющий руну, сгенерированный QuoteRuneToASCII, и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b := []byte("rune (ascii):")
b = strconv.AppendQuoteRuneToASCII(b, '☺')
fmt.Println(string(b))
}
Output:
rune (ascii):'\u263a'
func AppendQuoteRuneToGraphic
func AppendQuoteRuneToGraphic(dst []byte, r rune) []byte
AppendQuoteRuneToGraphic добавляет к dst однострочный литерал символа Go, представляющий руну, сгенерированный QuoteRuneToGraphic, и возвращает расширенный буфер.
func AppendQuoteToASCII
func AppendQuoteToASCII(dst []byte, s string) []byte
AppendQuoteToASCII добавляет к dst строковый литерал Go в двойных кавычках, представляющий s, сгенерированный QuoteToASCII, и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b := []byte("quote (ascii):")
b = strconv.AppendQuoteToASCII(b, `"Fran & Freddie's Diner"`)
fmt.Println(string(b))
}
Output:
quote (ascii):"\"Fran & Freddie's Diner\""
func AppendQuoteToGraphic
func AppendQuoteToGraphic(dst []byte, s string) []byte
AppendQuoteToGraphic добавляет к dst строковый литерал Go в двойных кавычках, представляющий s, сгенерированный QuoteToGraphic, и возвращает расширенный буфер.
func AppendUint
func AppendUint(dst []byte, i uint64, base int) []byte
AppendUint добавляет строковую форму целого числа без знака i, сгенерированную FormatUint, к dst и возвращает расширенный буфер.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
b10 := []byte("uint (base 10):")
b10 = strconv.AppendUint(b10, 42, 10)
fmt.Println(string(b10))
b16 := []byte("uint (base 16):")
b16 = strconv.AppendUint(b16, 42, 16)
fmt.Println(string(b16))
}
Output:
uint (base 10):42
uint (base 16):2a
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := "10"
if s, err := strconv.Atoi(v); err == nil {
fmt.Printf("%T, %v", s, s)
}
}
Output:
int, 10
func CanBackquote
func CanBackquote(s string) bool
CanBackquote сообщает, может ли строка s быть представлена без изменений в виде однострочной строки с обратными кавычками, не содержащей контрольных символов, кроме табуляции.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
fmt.Println(strconv.CanBackquote("Fran & Freddie's Diner ☺"))
fmt.Println(strconv.CanBackquote("`can't backquote this`"))
}
Output:
true
false
func FormatBool
func FormatBool(b bool) string
FormatBool возвращает «true» или «false» в зависимости от значения b.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := true
s := strconv.FormatBool(v)
fmt.Printf("%T, %v\n", s, s)
}
Output:
string, true
func FormatComplex
func FormatComplex(c complex128, fmt byte, prec, bitSize int) string
FormatComplex преобразует комплексное число c в строку вида (a+bi), где a и b — действительная и мнимая части, отформатированные в соответствии с форматом fmt и точностью prec.
Формат fmt и точность prec имеют то же значение, что и в FormatFloat. Он округляет результат, предполагая, что исходное значение было получено из комплексного значения bitSize бит, которое должно быть 64 для complex64 и 128 для complex128.
func FormatFloat
func FormatFloat(f float64, fmt byte, prec, bitSize int) string
FormatFloat преобразует число с плавающей запятой f в строку в соответствии с форматом fmt и точностью prec. Оно округляет результат, предполагая, что исходное значение было получено из значения с плавающей запятой bitSize бит (32 для float32, 64 для float64).
Формат fmt может быть одним из следующих
- “b” (-ddddp±ddd, двоичный экспонента),
- “e” (-d.dddde±dd, десятичный экспонент),
- “E” (-d.ddddE±dd, десятичный экспонент),
- “f” (-ddd.dddd, без экспонента),
- “g” („e“ для больших экспонентов, „f“ в остальных случаях),
- “G” („E“ для больших экспонентов, „f“ в остальных случаях),
- “x” (-0xd.ddddp±ddd, шестнадцатеричная дробь и двоичный показатель), или
- “X” (-0Xd.ddddP±ddd, шестнадцатеричная дробь и двоичный показатель).
Точность prec контролирует количество цифр (исключая экспоненту), выводимых форматами „e“, „E“, „f“, „g“, „G“, „x“ и „X“. Для „e“, „E“, „f“, „x“ и „X“ это количество цифр после десятичной запятой. Для „g“ и „G“ это максимальное количество значимых цифр (конечные нули удаляются). Специальная точность -1 использует минимальное количество цифр, необходимое для того, чтобы ParseFloat вернул точное значение f. Экспонента записывается в виде десятичного целого числа; для всех форматов, кроме „b“, она будет состоять как минимум из двух цифр.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := 3.1415926535
s32 := strconv.FormatFloat(v, 'E', -1, 32)
fmt.Printf("%T, %v\n", s32, s32)
s64 := strconv.FormatFloat(v, 'E', -1, 64)
fmt.Printf("%T, %v\n", s64, s64)
// fmt.Println uses these arguments to print floats
fmt64 := strconv.FormatFloat(v, 'g', -1, 64)
fmt.Printf("%T, %v\n", fmt64, fmt64)
}
Output:
string, 3.1415927E+00
string, 3.1415926535E+00
string, 3.1415926535
func FormatInt
func FormatInt(i int64, base int) string
FormatInt возвращает строковое представление i в заданной базе, для 2 <= base <= 36. Результат использует строчные буквы от «a» до «z» для значений цифр >= 10.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := int64(-42)
s10 := strconv.FormatInt(v, 10)
fmt.Printf("%T, %v\n", s10, s10)
s16 := strconv.FormatInt(v, 16)
fmt.Printf("%T, %v\n", s16, s16)
}
Output:
string, -42
string, -2a
func FormatUint
func FormatUint(i uint64, base int) string
FormatUint возвращает строковое представление i в заданной базе, для 2 <= base <= 36. В результате для значений цифр >= 10 используются строчные буквы от „a“ до „z“.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := uint64(42)
s10 := strconv.FormatUint(v, 10)
fmt.Printf("%T, %v\n", s10, s10)
s16 := strconv.FormatUint(v, 16)
fmt.Printf("%T, %v\n", s16, s16)
}
Output:
string, 42
string, 2a
func IsGraphic
func IsGraphic(r rune) bool
IsGraphic сообщает, определена ли руна как графический символ в Unicode. К таким символам относятся буквы, знаки, цифры, знаки препинания, символы и пробелы из категорий L, M, N, P, S и Zs.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
shamrock := strconv.IsGraphic('☘')
fmt.Println(shamrock)
a := strconv.IsGraphic('a')
fmt.Println(a)
bel := strconv.IsGraphic('\007')
fmt.Println(bel)
}
Output:
true
true
false
func IsPrint
func IsPrint(r rune) bool
IsPrint сообщает, определена ли руна как печатная в Go, с тем же определением, что и unicode.IsPrint: буквы, цифры, знаки препинания, символы и пробел ASCII.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
c := strconv.IsPrint('\u263a')
fmt.Println(c)
bel := strconv.IsPrint('\007')
fmt.Println(bel)
}
Output:
true
false
func Itoa
func Itoa(i int) string
Itoa эквивалентна FormatInt(int64(i), 10).
package main
import (
"fmt"
"strconv"
)
func main() {
i := 10
s := strconv.Itoa(i)
fmt.Printf("%T, %v\n", s, s)
}
Output:
string, 10
func ParseBool
func ParseBool(str string) (bool, error)
ParseBool возвращает булево значение, представленное строкой. Принимает 1, t, T, TRUE, true, True, 0, f, F, FALSE, false, False. Любое другое значение возвращает ошибку.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := "true"
if s, err := strconv.ParseBool(v); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
}
Output:
bool, true
func ParseComplex
func ParseComplex(s string, bitSize int) (complex128, error)
ParseComplex преобразует строку s в комплексное число с точностью, указанной в bitSize: 64 для complex64 или 128 для complex128. Когда bitSize=64, результат по-прежнему имеет тип complex128, но его можно преобразовать в complex64 без изменения его значения.
Число, представленное s, должно иметь вид N, Ni или N±Ni, где N обозначает число с плавающей запятой, распознаваемое ParseFloat, а i — мнимую составляющую. Если второе N не имеет знака, между двумя составляющими требуется знак +, как указано ±. Если второе N равно NaN, допускается только знак +. Форма может быть заключена в скобки и не может содержать пробелов. Результирующее комплексное число состоит из двух компонентов, преобразованных ParseFloat.
Ошибки, возвращаемые ParseComplex, имеют конкретный тип *NumError и включают err.Num = s.
Если s не является синтаксически правильным, ParseComplex возвращает err.Err = ErrSyntax.
Если s является синтаксически правильным, но любой из компонентов находится на расстоянии более 1/2 ULP от наибольшего числа с плавающей запятой заданного размера компонента, ParseComplex возвращает err.Err = ErrRange и c = ±Inf для соответствующего компонента.
func ParseFloat
func ParseFloat(s string, bitSize int) (float64, error)
ParseFloat преобразует строку s в число с плавающей запятой с точностью, указанной в bitSize: 32 для float32 или 64 для float64. Когда bitSize=32, результат по-прежнему имеет тип float64, но его можно преобразовать в float32 без изменения его значения.
ParseFloat принимает десятичные и шестнадцатеричные числа с плавающей запятой, как определено синтаксисом Go для литералов с плавающей запятой. Если s имеет правильную форму и близка к действительному числу с плавающей запятой, ParseFloat возвращает ближайшее число с плавающей запятой, округленное с использованием беспристрастного округления IEEE754. (При разборе шестнадцатеричного числа с плавающей запятой округление происходит только в том случае, если в шестнадцатеричном представлении больше битов, чем может поместиться в мантиссе).
Ошибки, которые возвращает ParseFloat, имеют конкретный тип *NumError и включают err.Num = s.
Если s не является синтаксически правильно сформированным, ParseFloat возвращает err.Err = ErrSyntax.
Если s является синтаксически правильным, но находится на расстоянии более 1/2 ULP от наибольшего числа с плавающей запятой заданного размера, ParseFloat возвращает f = ±Inf, err.Err = ErrRange.
ParseFloat распознает строку «NaN» и строки «Inf» и «Infinity» (возможно со знаком) как соответствующие специальные значения с плавающей запятой. При сопоставлении он игнорирует регистр.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := "3.1415926535"
if s, err := strconv.ParseFloat(v, 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseFloat(v, 64); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseFloat("NaN", 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
// ParseFloat is case insensitive
if s, err := strconv.ParseFloat("nan", 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseFloat("inf", 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseFloat("+Inf", 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseFloat("-Inf", 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseFloat("-0", 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseFloat("+0", 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
}
Output:
float64, 3.1415927410125732
float64, 3.1415926535
float64, NaN
float64, NaN
float64, +Inf
float64, +Inf
float64, -Inf
float64, -0
float64, 0
func ParseInt
func ParseInt(s string, base int, bitSize int) (i int64, err error)
ParseInt интерпретирует строку s в заданной базе (от 0 до 36) и размере бита (от 0 до 64) и возвращает соответствующее значение i.
Строка может начинаться с ведущего знака: «+» или «-».
Если аргумент base равен 0, истинная база подразумевается префиксом строки, следующим за знаком (если он есть): 2 для «0b», 8 для «0» или «0o», 16 для «0x» и 10 в остальных случаях. Кроме того, только для аргумента base 0 допускаются символы подчеркивания, как определено синтаксисом Go для целочисленных литералов.
Аргумент bitSize указывает тип целого числа, в который должен помещаться результат. Размеры битов 0, 8, 16, 32 и 64 соответствуют int, int8, int16, int32 и int64. Если bitSize меньше 0 или больше 64, возвращается ошибка.
Ошибки, которые возвращает ParseInt, имеют конкретный тип *NumError и включают err.Num = s. Если s пустое или содержит недопустимые цифры, err.Err = ErrSyntax, и возвращаемое значение равно 0; если значение, соответствующее s, не может быть представлено целым числом с знаком заданного размера, err.Err = ErrRange, и возвращаемое значение является целым числом максимальной величины с соответствующим bitSize и знаком.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v32 := "-354634382"
if s, err := strconv.ParseInt(v32, 10, 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseInt(v32, 16, 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
v64 := "-3546343826724305832"
if s, err := strconv.ParseInt(v64, 10, 64); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseInt(v64, 16, 64); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
}
Output:
int64, -354634382
int64, -3546343826724305832
func ParseUint
func ParseUint(s string, base int, bitSize int) (uint64, error)
ParseUint похож на ParseInt, но для чисел без знака.
Префикс знака не допускается.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
v := "42"
if s, err := strconv.ParseUint(v, 10, 32); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
if s, err := strconv.ParseUint(v, 10, 64); err == nil {
fmt.Printf("%T, %v\n", s, s)
}
}
Output:
uint64, 42
uint64, 42
func Quote
func Quote(s string) string
Quote возвращает строковый литерал Go в двойных кавычках, представляющий s. Возвращаемая строка использует экранирующие последовательности Go (\t, \n, \xFF, \u0100) для управляющих символов и непечатаемых символов, как определено в IsPrint.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
// This string literal contains a tab character.
s := strconv.Quote(`"Fran & Freddie's Diner ☺"`)
fmt.Println(s)
}
Output:
"\"Fran & Freddie's Diner\t☺\""
func QuoteRune
func QuoteRune(r rune) string
QuoteRune возвращает строковый литерал Go в одинарных кавычках, представляющий руну. Возвращаемая строка использует экранирующие последовательности Go (\t, \n, \xFF, \u0100) для управляющих символов и непечатаемых символов, как определено в IsPrint. Если r не является действительным кодом Unicode, он интерпретируется как символ замены Unicode U+FFFD.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
s := strconv.QuoteRune('☺')
fmt.Println(s)
}
Output:
'☺'
func QuoteRuneToASCII
func QuoteRuneToASCII(r rune) string
QuoteRuneToASCII возвращает однострочный литерал символа Go, представляющий руну. Возвращаемая строка использует экранирующие последовательности Go (\t, \n, \xFF, \u0100) для не-ASCII символов и непечатаемых символов, как определено в IsPrint. Если r не является действительным кодом Unicode, он интерпретируется как заменяющий символ Unicode U+FFFD.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
s := strconv.QuoteRuneToASCII('☺')
fmt.Println(s)
}
Output:
'\u263a'
func QuoteRuneToGraphic
func QuoteRuneToGraphic(r rune) string
QuoteRuneToGraphic возвращает однострочный литерал Go, представляющий руну. Если руна не является графическим символом Unicode, как определено IsGraphic, возвращаемая строка будет использовать экранирующие последовательности Go (\t, \n, \xFF, \u0100). Если r не является допустимым кодовым пунктом Unicode, он интерпретируется как символ замены Unicode U+FFFD.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
s := strconv.QuoteRuneToGraphic('☺')
fmt.Println(s)
s = strconv.QuoteRuneToGraphic('\u263a')
fmt.Println(s)
s = strconv.QuoteRuneToGraphic('\u000a')
fmt.Println(s)
s = strconv.QuoteRuneToGraphic(' ') // tab character
fmt.Println(s)
}
Output:
'☺'
'☺'
'\n'
'\t'
func QuoteToASCII
func QuoteToASCII(s string) string
QuoteToASCII возвращает строковый литерал Go в двойных кавычках, представляющий s. Возвращаемая строка использует экранирующие последовательности Go (\t, \n, \xFF, \u0100) для не-ASCII символов и непечатаемых символов, как определено IsPrint.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
// This string literal contains a tab character.
s := strconv.QuoteToASCII(`"Fran & Freddie's Diner ☺"`)
fmt.Println(s)
}
Output:
"\"Fran & Freddie's Diner\t\u263a\""
func QuoteToGraphic
func QuoteToGraphic(s string) string
QuoteToGraphic возвращает строковый литерал Go в двойных кавычках, представляющий s. Возвращаемая строка оставляет графические символы Unicode, как определено IsGraphic, без изменений и использует экранирующие последовательности Go (\t, \n, \xFF, \u0100) для неграфических символов.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
s := strconv.QuoteToGraphic("☺")
fmt.Println(s)
// This string literal contains a tab character.
s = strconv.QuoteToGraphic("This is a \u263a \u000a")
fmt.Println(s)
s = strconv.QuoteToGraphic(`" This is a ☺ \n "`)
fmt.Println(s)
}
Output:
"☺"
"This is a ☺\t\n"
"\" This is a ☺ \\n \""
func QuotedPrefix
func QuotedPrefix(s string) (string, error)
QuotedPrefix возвращает строку в кавычках (как понимает Unquote) в префиксе s. Если s не начинается с действительной строки в кавычках, QuotedPrefix возвращает ошибку.
package main
import (
"fmt"
"strconv"
)
func main() {
s, err := strconv.QuotedPrefix("not a quoted string")
fmt.Printf("%q, %v\n", s, err)
s, err = strconv.QuotedPrefix("\"double-quoted string\" with trailing text")
fmt.Printf("%q, %v\n", s, err)
s, err = strconv.QuotedPrefix("`or backquoted` with more trailing text")
fmt.Printf("%q, %v\n", s, err)
s, err = strconv.QuotedPrefix("'\u263a' is also okay")
fmt.Printf("%q, %v\n", s, err)
}
Output:
"", invalid syntax
"\"double-quoted string\"", <nil>
"`or backquoted`", <nil>
"'☺'", <nil>
func Unquote
func Unquote(s string) (string, error)
Unquote интерпретирует s как строковый литерал Go в одинарных, двойных или обратных кавычках, возвращая значение строки, которое s заключает в кавычки. (Если s заключено в одинарные кавычки, это будет символьный литерал Go; Unquote возвращает соответствующую односимвольную строку. Для пустого символьного литерала Unquote возвращает пустую строку.)
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
s, err := strconv.Unquote("You can't unquote a string without quotes")
fmt.Printf("%q, %v\n", s, err)
s, err = strconv.Unquote("\"The string must be either double-quoted\"")
fmt.Printf("%q, %v\n", s, err)
s, err = strconv.Unquote("`or backquoted.`")
fmt.Printf("%q, %v\n", s, err)
s, err = strconv.Unquote("'\u263a'") // single character only allowed in single quotes
fmt.Printf("%q, %v\n", s, err)
s, err = strconv.Unquote("'\u2639\u2639'")
fmt.Printf("%q, %v\n", s, err)
}
Output:
"", invalid syntax
"The string must be either double-quoted", <nil>
"or backquoted.", <nil>
"☺", <nil>
"", invalid syntax
func UnquoteChar
func UnquoteChar(s string, quote byte) (value rune, multibyte bool, tail string, err error)
UnquoteChar декодирует первый символ или байт в экранированной строке или символьном литерале, представленном строкой s. Он возвращает четыре значения:
value, декодированный код Unicode или значение байта; multibyte, булево значение, указывающее, требует ли декодированный символ многобайтового представления UTF-8; tail, остаток строки после символа; и ошибка, которая будет nil, если символ синтаксически валиден. Второй аргумент, quote, указывает тип анализируемого литерала и, следовательно, какой экранированный символ кавычки разрешен. Если установлен в одиночную кавычку, он разрешает последовательность \„ и запрещает неэкранированный “. Если установлен в двойную кавычку, он разрешает \« и запрещает неэкранированный ». Если установлен в ноль, он не разрешает ни один из экранированных символов и позволяет обоим символам кавычки появляться неэкранированными.
Пример
package main
import (
"fmt"
"log"
"strconv"
)
func main() {
v, mb, t, err := strconv.UnquoteChar(`\"Fran & Freddie's Diner\"`, '"')
if err != nil {
log.Fatal(err)
}
fmt.Println("value:", string(v))
fmt.Println("multibyte:", mb)
fmt.Println("tail:", t)
}
Output:
value: "
multibyte: false
tail: Fran & Freddie's Diner\"
12.4.12.2 - Тип NumError пакета strconv
Ошибка NumError фиксирует неудачное преобразование.
type NumError
type NumError struct {
Func string // сбойная функция (ParseBool, ParseInt, ParseUint, ParseFloat, ParseComplex)
Num string // входные данные
Err error // причина сбоя преобразования (например, ErrRange, ErrSyntax и т. д.)
}
Ошибка NumError фиксирует неудачное преобразование.
Пример
package main
import (
"fmt"
"strconv"
)
func main() {
str := "Not a number"
if _, err := strconv.ParseFloat(str, 64); err != nil {
e := err.(*strconv.NumError)
fmt.Println("Func:", e.Func)
fmt.Println("Num:", e.Num)
fmt.Println("Err:", e.Err)
fmt.Println(err)
}
}
Output:
Func: ParseFloat
Num: Not a number
Err: invalid syntax
strconv.ParseFloat: parsing "Not a number": invalid syntax
func (*NumError) Error
func (e *NumError) Error() string
func (*NumError) Unwrap
func (e *NumError) Unwrap() error
12.4.13 - Описание пакета error языка программирования Go
Пакет errors реализует функции для манипуляции ошибками
Функция New создает ошибки, содержащие только текстовое сообщение.
Ошибка e оборачивает другую ошибку, если тип e имеет один из методов:
Unwrap() error
Unwrap() []error
Если e.Unwrap() возвращает не nil ошибку w или срез, содержащий w, то говорится, что e оборачивает w. Возвращение nil ошибки из e.Unwrap() указывает на то, что e не оборачивает никакую ошибку. Недопустимо, чтобы метод Unwrap() возвращал срез, содержащий nil значение ошибки.
Легкий способ создать обернутые ошибки — вызвать fmt.Errorf и применить шаблон %w к аргументу ошибки:
wrapsErr := fmt.Errorf("... %w ...", ..., err, ...)
Последовательное разворачивание ошибки создает дерево. Функции Is и As исследуют дерево ошибки, проверяя сначала саму ошибку, а затем дерево каждого из ее потомков по очереди (префиксный, глубинный обход).
См. https://go.dev/blog/go1.13-errors для более глубокого обсуждения философии оборачивания и когда следует оборачивать.
Функция Is исследует дерево своего первого аргумента в поисках ошибки, совпадающей со вторым. Она сообщает, найдено ли совпадение. Ее следует использовать вместо простых проверок на равенство:
if errors.Is(err, fs.ErrExist)
лучше, чем
if err == fs.ErrExist
потому что первая будет успешной, если err оборачивает io/fs.ErrExist.
Функция As исследует дерево своего первого аргумента в поисках ошибки, которую можно присвоить второму аргументу, который должен быть указателем. Если она успешна, она выполняет присваивание и возвращает true. В противном случае она возвращает false. Форма
var perr *fs.PathError
if errors.As(err, &perr) {
fmt.Println(perr.Path)
}
лучше, чем
if perr, ok := err.(*fs.PathError); ok {
fmt.Println(perr.Path)
}
потому что первая будет успешной, если err оборачивает *io/fs.PathError.
Пример
package main
import (
"fmt"
"time"
)
// MyError is an error implementation that includes a time and message.
type MyError struct {
When time.Time
What string
}
func (e MyError) Error() string {
return fmt.Sprintf("%v: %v", e.When, e.What)
}
func oops() error {
return MyError{
time.Date(1989, 3, 15, 22, 30, 0, 0, time.UTC),
"the file system has gone away",
}
}
func main() {
if err := oops(); err != nil {
fmt.Println(err)
}
}
Output:
1989-03-15 22:30:00 +0000 UTC: the file system has gone awayПеременные
var ErrUnsupported = New("unsupported operation")
ErrUnsupported указывает на то, что запрашиваемая операция не может быть выполнена, потому что она не поддерживается. Например, вызов os.Link при использовании файловой системы, которая не поддерживает жесткие ссылки.
Функции и методы не должны возвращать эту ошибку, а вместо этого должны возвращать ошибку, включающую соответствующий контекст, который удовлетворяет
errors.Is(err, errors.ErrUnsupported)
либо путем прямого оборачивания ErrUnsupported, либо путем реализации метода Is.
Функции и методы должны документировать случаи, в которых будет возвращена ошибка, оборачивающая эту.
Функции
func As
Объяснение As
📌 Пример 1: Простая кастомная ошибка
Допустим, у нас есть своя ошибка с дополнительными полями:
type NetworkError struct {
Code int
Message string
}
// Реализуем метод Error(), чтобы NetworkError соответствовала интерфейсу error
func (e *NetworkError) Error() string {
return fmt.Sprintf("Network error %d: %s", e.Code, e.Message)
}
Теперь создадим ошибку и проверим её тип с помощью As:
func main() {
err := &NetworkError{Code: 404, Message: "Not Found"} // создаём ошибку
var netErr *NetworkError
if errors.As(err, &netErr) { // проверяем тип и извлекаем
fmt.Printf("Ошибка сети! Код: %d, Текст: %s\n", netErr.Code, netErr.Message)
} else {
fmt.Println("Это не ошибка сети")
}
}
Вывод:
Ошибка сети! Код: 404, Текст: Not Found
👉 Что произошло?
errors.Asпроверила, чтоerrимеет тип*NetworkError.- Если да — сохранила её в
netErr, и мы можем использовать её поля (Code,Message).
📌 Пример 2: Ошибка обёрнута в другую ошибку
Часто ошибки “заворачивают” в другие ошибки с помощью fmt.Errorf и %w. As умеет “пробираться” через такие обёртки.
func fetchData() error {
return &NetworkError{Code: 500, Message: "Server Error"}
}
func main() {
err := fetchData()
wrappedErr := fmt.Errorf("не удалось получить данные: %w", err) // оборачиваем
var netErr *NetworkError
if errors.As(wrappedErr, &netErr) { // всё равно находит NetworkError внутри!
fmt.Printf("Ошибка сети: %d - %s\n", netErr.Code, netErr.Message)
}
}
Вывод:
Ошибка сети: 500 - Server Error
👉 Почему это полезно?
Даже если ошибка была обёрнута (%w), As “достанет” её исходный тип.
📌 Пример 3: Проверка нескольких типов ошибок
Иногда ошибка может быть одного из нескольких типов. As позволяет это проверить.
type TimeoutError struct {
TimeoutSec int
}
func (e *TimeoutError) Error() string {
return fmt.Sprintf("Timeout after %d sec", e.TimeoutSec)
}
func main() {
err := &TimeoutError{TimeoutSec: 30} // допустим, это наша ошибка
// Пробуем разные типы:
var timeoutErr *TimeoutError
var networkErr *NetworkError
if errors.As(err, &timeoutErr) {
fmt.Println("Это TimeoutError:", timeoutErr.TimeoutSec)
}
if errors.As(err, &networkErr) {
fmt.Println("Это NetworkError:", networkErr.Code)
} else {
fmt.Println("Это не NetworkError") // сработает это
}
}
Вывод:
Это TimeoutError: 30
Это не NetworkError
👉 Вывод:As проверяет по очереди каждый тип. Если ошибка не соответствует типу — просто возвращает false.
📌 Пример 4: Работа со стандартными ошибками
As можно использовать и со встроенными типами ошибок, например, с *os.PathError.
func main() {
_, err := os.Open("non-existent-file.txt") // вернёт PathError
var pathErr *os.PathError
if errors.As(err, &pathErr) {
fmt.Printf("Ошибка файла: %s (операция: %s)\n", pathErr.Path, pathErr.Op)
}
}
Вывод (примерно):
Ошибка файла: non-existent-file.txt (операция: open)
🎯 Итог: Когда использовать As?
- Если нужно проверить тип ошибки (например,
MyCustomError). - Если нужно достать поля ошибки (например,
err.Code,err.TimeoutSec). - Если ошибка может быть обёрнута (
%w), но тебе нужна исходная.
❌ As vs Is
Is→ проверяет конкретное значение ошибки (err == io.EOF).As→ проверяет тип ошибки (err— это*MyError?).
func As(err error, target any) bool
As находит первую ошибку в дереве err, которая совпадает с target, и если такая найдена, устанавливает target в значение этой ошибки и возвращает true. В противном случае возвращает false.
Дерево состоит из err самой по себе, за которой следуют ошибки, полученные путем многократного вызова ее метода Unwrap() error или Unwrap() []error. Когда err оборачивает несколько ошибок, As проверяет err, за которой следует глубинный обход ее потомков.
Ошибка совпадает с target, если конкретное значение ошибки может быть присвоено значению, на которое указывает target, или если у ошибки есть метод As(any) bool, такой что As(target) возвращает true. В последнем случае метод As отвечает за установку target.
Тип ошибки может предоставить метод As, чтобы его можно было рассматривать как если бы он был другим типом ошибки.
As вызывает панику, если target не является не nil указателем на тип, реализующий error, или на любой интерфейсный тип.
Пример
package main
import (
"errors"
"fmt"
"io/fs"
"os"
)
func main() {
if _, err := os.Open("non-existing"); err != nil {
var pathError *fs.PathError
if errors.As(err, &pathError) {
fmt.Println("Failed at path:", pathError.Path)
} else {
fmt.Println(err)
}
}
}
Output:
Failed at path: non-existingfunc Is
Объяснение Is и As
В Go пакет errors предоставляет функции Is и As для работы с ошибками. Они помогают сравнивать ошибки и проверять их тип. Давай разберём их простым языком.
errors.Is – проверка на конкретную ошибку
Что делает?
Проверяет, содержит ли цепочка ошибок (error) конкретную ошибку.
Аналог из жизни:
Представь, что у тебя есть коробка с вложенными коробками (ошибка, которая обёрнута в другие ошибки). Ты ищешь конкретную вещь (например, ключ). errors.Is рекурсивно открывает все коробки и проверяет, есть ли там нужный ключ.
Пример:
var ErrNotFound = errors.New("not found")
err := fmt.Errorf("ошибка: %w", ErrNotFound) // оборачиваем ошибку
if errors.Is(err, ErrNotFound) {
fmt.Println("Ошибка 'not found' найдена!")
}
Вывод:
Ошибка 'not found' найдена!
Здесь errors.Is “распаковала” err и обнаружила внутри ErrNotFound.
errors.As – проверка типа ошибки
Что делает?
Проверяет, можно ли привести ошибку к определённому типу (например, к твоей кастомной структуре-ошибке). Если да – сохраняет её в переменную.
Аналог из жизни:
У тебя есть коробка, в которой может лежать либо книга, либо ручка. Ты говоришь: “Если там книга, положи её на стол”. errors.As проверяет тип и “кладёт” ошибку в переменную, если тип подходит.
Пример:
type MyError struct {
Code int
Msg string
}
err := &MyError{Code: 404, Msg: "Not Found"} // создаём ошибку типа *MyError
var myErr *MyError
if errors.As(err, &myErr) { // передаём указатель на переменную
fmt.Printf("Код: %d, Сообщение: %s\n", myErr.Code, myErr.Msg)
}
Вывод:
Код: 404, Сообщение: Not Found
Здесь errors.As проверила, что err имеет тип *MyError, и сохранила её в myErr.
Разница между Is и As
| Функция | Для чего? | Работает с |
|---|---|---|
Is | Проверить, что ошибка именно X | Конкретными ошибками (==) |
As | Проверить, что ошибка типа X | Кастомными типами ошибок (структуры) |
Когда использовать?
Is– если нужно проверить, что ошибка равна конкретному значению (например,io.EOF).As– если нужно проверить, что ошибка имеет определённый тип, и достать её поля.
Обе функции поддерживают обёрнутые ошибки (с %w в fmt.Errorf), поэтому они умеют “заглядывать” внутрь цепочек ошибок. 🚀
func Is(err, target error) bool
Is сообщает, совпадает ли какая-либо ошибка в дереве err с target.
Дерево состоит из err самой по себе, за которой следуют ошибки, полученные путем многократного вызова ее метода Unwrap() error или Unwrap() []error. Когда err оборачивает несколько ошибок, Is проверяет err, за которой следует глубинный обход ее потомков.
Ошибка считается совпадающей с целевой, если она равна этой целевой или если она реализует метод Is(error) bool, такой что Is(target) возвращает true.
Тип ошибки может предоставить метод Is, чтобы его можно было рассматривать как эквивалентный существующей ошибке. Например, если MyError определяет
func (m MyError) Is(target error) bool { return target == fs.ErrExist }
то Is(MyError{}, fs.ErrExist) возвращает true. См. syscall.Errno.Is для примера в стандартной библиотеке. Метод Is должен только поверхностно сравнивать err и цель и не вызывать Unwrap для обоих.
Пример
package main
import (
"errors"
"fmt"
"io/fs"
"os"
)
func main() {
if _, err := os.Open("non-existing"); err != nil {
if errors.Is(err, fs.ErrNotExist) {
fmt.Println("file does not exist")
} else {
fmt.Println(err)
}
}
}
Output:
file does not existfunc Join
func Join(errs ...error) error
Join возвращает ошибку, которая оборачивает переданные ошибки. Любые значения nil ошибки отбрасываются. Join возвращает nil, если все значения в errs равны nil. Ошибка форматируется как конкатенация строк, полученных путем вызова метода Error каждого элемента errs, с новой строкой между каждой строкой.
Не nil ошибка, возвращенная Join, реализует метод Unwrap() []error.
Пример:
package main
import (
"errors"
"fmt"
)
func main() {
err1 := errors.New("first error")
err2 := errors.New("second error")
err3 := errors.New("third error")
combinedErr := errors.Join(err1, err2, err3)
fmt.Println(combinedErr)
}
func New
func New(text string) error
New возвращает ошибку, которая форматируется как заданный текст. Каждый вызов New возвращает уникальное значение ошибки, даже если текст идентичен.
Пример:
package main
import (
"errors"
"fmt"
)
func main() {
err := errors.New("something went wrong")
fmt.Println(err)
}
Пример
package main
import (
"fmt"
)
func main() {
const name, id = "bimmler", 17
err := fmt.Errorf("user %q (id %d) not found", name, id)
if err != nil {
fmt.Print(err)
}
}
Output:
user "bimmler" (id 17) not found
func Unwrap
func Unwrap(err error) error
Unwrap возвращает основную ошибку, обернутую в err, если она существует. Если err не оборачивает никакую ошибку, Unwrap возвращает nil.
Пример
package main
import (
"errors"
"fmt"
)
func main() {
err1 := errors.New("error1")
err2 := fmt.Errorf("error2: [%w]", err1)
fmt.Println(err2)
fmt.Println(errors.Unwrap(err2))
}
Output:
error2: [error1]
error112.4.14 - Описание пакета iter языка программирования Go
Пакет iter предоставляет базовые определения и операции, связанные с итераторами по последовательностям.
Итераторы
Итераторы
Итератор — это функция, которая передает последовательные элементы последовательности в функцию обратного вызова, традиционно называемую yield. Функция останавливается либо когда последовательность завершена, либо когда yield возвращает false, указывая на необходимость прекратить итерацию раньше. Этот пакет определяет Seq и Seq2 (произносится как seek — первая слог последовательности) как сокращения для итераторов, которые передают 1 или 2 значения на элемент последовательности в yield:type (
Seq[V any] func(yield func(V) bool)
Seq2[K, V any] func(yield func(K, V) bool)
)
Seq2 представляет последовательность пар значений, традиционно ключ-значение или индекс-значение.
Yield возвращает true, если итератор должен продолжить с следующим элементом последовательности, и false, если он должен остановиться.
Например, maps.Keys возвращает итератор, который производит последовательность ключей карты m, реализованную следующим образом:
func Keys[Map ~map[K]V, K comparable, V any](m Map) iter.Seq[K] {
return func(yield func(K) bool) {
for k := range m {
if !yield(k) {
return
}
}
}
}
Дополнительные примеры можно найти в блоге Go: Range Over Function Types.
Функции итераторов чаще всего вызываются в цикле range, как в следующем примере:
func PrintAll[V any](seq iter.Seq[V]) {
for v := range seq {
fmt.Println(v)
}
}
Конвенции именования
Функции и методы итераторов называются в зависимости от последовательности, по которой они проходят:
// All возвращает итератор по всем элементам в s.
func (s *Set[V]) All() iter.Seq[V]
Метод итератора на типе коллекции традиционно называется All, потому что он итерирует последовательность всех значений в коллекции.
Для типа, содержащего несколько возможных последовательностей, имя итератора может указывать, какая последовательность предоставляется:
// Cities возвращает итератор по основным городам страны.
func (c *Country) Cities() iter.Seq[*City]
// Languages возвращает итератор по официальным языкам страны.
func (c *Country) Languages() iter.Seq[string]
Если итератор требует дополнительной конфигурации, конструкторная функция может принимать дополнительные аргументы конфигурации:
// Scan возвращает итератор по парам ключ-значение с min ≤ key ≤ max.
func (m *Map[K, V]) Scan(min, max K) iter.Seq2[K, V]
// Split возвращает итератор по (возможно, пустым) подстрокам s,
// разделенным sep.
func Split(s, sep string) iter.Seq[string]
Когда существует несколько возможных порядков итерации, имя метода может указывать на этот порядок:
// All возвращает итератор по списку от начала к концу.
func (l *List[V]) All() iter.Seq[V]
// Backward возвращает итератор по списку от конца к началу.
func (l *List[V]) Backward() iter.Seq[V]
// Preorder возвращает итератор по всем узлам синтаксического дерева
// под (и включая) указанный корень, в глубину, в порядке preorder,
// посещая родительский узел перед его дочерними узлами.
func Preorder(root Node) iter.Seq[Node]
Одноразовые итераторы
Большинство итераторов предоставляют возможность пройти по всей последовательности: при вызове итератор выполняет любую необходимую настройку для начала последовательности, затем вызывает yield для последовательных элементов последовательности и затем очищает перед возвратом. Повторный вызов итератора снова проходит по последовательности.
Некоторые итераторы нарушают это правило, предоставляя возможность пройти по последовательности только один раз. Эти “одноразовые итераторы” обычно сообщают значения из потока данных, который нельзя перемотать назад для начала. Повторный вызов итератора после ранней остановки может продолжить поток, но повторный вызов после завершения последовательности не вернет никаких значений. Документационные комментарии для функций или методов, возвращающих одноразовые итераторы, должны документировать этот факт:
// Lines возвращает итератор по строкам, прочитанным из r.
// Он возвращает одноразовый итератор.
func (r *Reader) Lines() iter.Seq[string]
Извлечение значений
Функции и методы, которые принимают или возвращают итераторы, должны использовать стандартные типы Seq или Seq2, чтобы обеспечить совместимость с циклами range и другими адаптерами итераторов. Стандартные итераторы можно рассматривать как “push-итераторы”, которые передают значения в функцию yield.
Иногда цикл range не является наиболее естественным способом потребления значений последовательности. В этом случае Pull преобразует стандартный push-итератор в “pull-итератор”, который можно вызвать для извлечения одного значения за раз из последовательности. Pull запускает итератор и возвращает пару функций — next и stop, которые возвращают следующее значение из итератора и останавливают его соответственно.
Например:
// Pairs возвращает итератор по последовательным парам значений из seq.
func Pairs[V any](seq iter.Seq[V]) iter.Seq2[V, V] {
return func(yield func(V, V) bool) {
next, stop := iter.Pull(seq)
defer stop()
for {
v1, ok1 := next()
if !ok1 {
return
}
v2, ok2 := next()
// Если ok2 равно false, v2 должно быть
// нулевым значением; yield одна последняя пара.
if !yield(v1, v2) {
return
}
if !ok2 {
return
}
}
}
}
Если клиенты не потребляют последовательность до конца, они должны вызвать stop, что позволяет функции итератора завершить выполнение и вернуться. Как показано в примере, традиционный способ обеспечить это — использовать defer.
Использование стандартной библиотеки
Некоторые пакеты в стандартной библиотеке предоставляют API на основе итераторов, наиболее заметными из которых являются пакеты maps и slices. Например, maps.Keys возвращает итератор по ключам карты, в то время как slices.Sorted собирает значения итератора в срез, сортирует их и возвращает срез. Чтобы итерировать по отсортированным ключам карты, можно использовать следующий код:
for _, key := range slices.Sorted(maps.Keys(m)) {
...
}
Мутация
Итераторы предоставляют только значения последовательности, но не прямой способ их изменения. Если итератор хочет предоставить механизм для изменения последовательности во время итерации, обычное решение — определить тип позиции с дополнительными операциями и затем предоставить итератор по позициям.
Например, реализация дерева может предоставить:
// Positions возвращает итератор по позициям в последовательности.
func (t *Tree[V]) Positions() iter.Seq[*Pos]
// Pos представляет позицию в последовательности.
// Он действителен только во время вызова yield, в который он передается.
type Pos[V any] struct { ... }
// Value возвращает значение в курсоре.
func (p *Pos[V]) Value() V
// Delete удаляет значение в этой точке итерации.
func (p *Pos[V]) Delete()
// Set изменяет значение v в курсоре.
func (p *Pos[V]) Set(v V)
И затем клиент может удалить boring значения из дерева, используя:
for p := range t.Positions() {
if boring(p.Value()) {
p.Delete()
}
}
Этот подход позволяет итератору предоставлять механизм для изменения последовательности во время итерации, сохраняя при этом чистоту итератора как такового.
Функции
func Pull
func Pull[V any](seq Seq[V]) (next func() (V, bool), stop func())
Pull преобразует последовательность итератора в стиле “push” seq в итератор в стиле “pull”, доступный через две функции next и stop.
Next возвращает следующее значение в последовательности и булево значение, указывающее, является ли значение действительным. Когда последовательность завершена, next возвращает нулевое значение V и false. Вызов next после достижения конца последовательности или после вызова stop является допустимым. Эти вызовы будут продолжать возвращать нулевое значение V и false.
Stop завершает итерацию. Его нужно вызвать, когда вызывающий не заинтересован в следующих значениях, и next еще не сигнализировал о завершении последовательности (с возвратом false). Вызов stop несколько раз и после того, как next уже вернул false, является допустимым. Обычно вызывающие должны использовать “defer stop()”.
Ошибкой является вызов next или stop из нескольких горутин одновременно.
Если итератор вызывает панику во время вызова next (или stop), то next (или stop) сам вызывает панику с тем же значением.
func Pull2
func Pull2[K, V any](seq Seq2[K, V]) (next func() (K, V, bool), stop func())
Pull2 преобразует последовательность итератора в стиле “push” seq в итератор в стиле “pull”, доступный через две функции next и stop.
Next возвращает следующую пару в последовательности и булево значение, указывающее, является ли пара действительной. Когда последовательность завершена, next возвращает пару нулевых значений и false. Вызов next после достижения конца последовательности или после вызова stop является допустимым. Эти вызовы будут продолжать возвращать пару нулевых значений и false.
Stop завершает итерацию. Его нужно вызвать, когда вызывающий не заинтересован в следующих значениях, и next еще не сигнализировал о завершении последовательности (с возвратом false). Вызов stop несколько раз и после того, как next уже вернул false, является допустимым. Обычно вызывающие должны использовать “defer stop()”.
Ошибкой является вызов next или stop из нескольких горутин одновременно.
Если итератор вызывает панику во время вызова next (или stop), то next (или stop) сам вызывает панику с тем же значением.
Типы
type Seq
type Seq[V any] func(yield func(V) bool)
Seq — это итератор по последовательностям отдельных значений. Когда вызывается как seq(yield), seq вызывает yield(v) для каждого значения v в последовательности, останавливаясь раньше, если yield возвращает false. Подробнее см. в документации пакета iter.
type Seq2
type Seq2[K, V any] func(yield func(K, V) bool)
Seq2 — это итератор по последовательностям пар значений, наиболее часто ключ-значение. Когда вызывается как seq(yield), seq вызывает yield(k, v) для каждой пары (k, v) в последовательности, останавливаясь раньше, если yield возвращает false. Подробнее см. в документации пакета iter.
12.4.15 - Пакет net встроенных функций и типов языка Go
Пакет net предоставляет переносимый интерфейс для сетевого ввода-вывода, включая TCP/IP, UDP, разрешение доменных имен и сокеты доменов Unix.
Пакет обеспечивает доступ к примитивам низкоуровневых сетей, большинству клиентов понадобится только базовый интерфейс, предоставляемый функциями Dial, Listen и Accept и связанными интерфейсами Conn и Listener. Пакет crypto/tls использует те же интерфейсы и похожие функции Dial и Listen.
Функция Dial подключается к серверу:
conn, err := net.Dial("tcp", "golang.org:80")
if err != nil {
// handle error
}
fmt.Fprintf(conn, "GET / HTTP/1.0\r\n\r\n")
status, err := bufio.NewReader(conn).ReadString('\n')
// ...
Функция Listen создает серверы:
ln, err := net.Listen("tcp", ":8080")
if err != nil {
// handle error
}
for {
conn, err := ln.Accept()
if err != nil {
// handle error
}
go handleConnection(conn)
}
Разрешение имен (Name Resolution)
Метод разрешения доменных имен (DNS) в пакете net зависит от операционной системы. Функции, такие как Dial, используют разрешение имен косвенно, а функции вроде LookupHost и LookupAddr делают это напрямую.
На Unix-системах
Ресолвер имеет два варианта работы:
- Чистый Go-ресолвер – отправляет DNS-запросы напрямую к серверам, указанным в
/etc/resolv.conf. - CGO-ресолвер – использует системные вызовы C (
getaddrinfo,getnameinfo).
Чистый Go-ресолвер предпочтительнее, потому что:
- Заблокированный DNS-запрос потребляет только горутину (легковесный поток Go).
- Заблокированный вызов C занимает системный поток ОС (более затратно).
Когда используется CGO-ресолвер?
- На системах, где запрещены прямые DNS-запросы (например, macOS).
- Если заданы переменные окружения:
LOCALDOMAIN(даже пустая),RES_OPTIONS,HOSTALIASES(не пустые),ASR_CONFIG(только OpenBSD).
- Если
/etc/resolv.confили/etc/nsswitch.confтребуют функциональности, не реализованной в Go.
Лимит на CGO-запросы
Во всех системах (кроме Plan 9) действует ограничение в 500 одновременных CGO-запросов, чтобы избежать исчерпания системных потоков.
Управление выбором ресолвера
Можно переопределить выбор ресолвера через переменную окружения GODEBUG:
export GODEBUG=netdns=go # принудительно использовать чистый Go-ресолвер
export GODEBUG=netdns=cgo # принудительно использовать нативный (CGO) ресолвер
Также можно задать поведение при сборке через теги:
netgo– только Go-ресолвер (CGO полностью отключен).netcgo– оба ресолвера, но CGO имеет приоритет (можно переопределить черезGODEBUG=netdns=go).
Отладочная информация
Если установить GODEBUG=netdns=1, ресолвер будет выводить отладочную информацию. Можно комбинировать:
export GODEBUG=netdns=go+1 # принудительно Go + отладка
EDNS0 и проблемы с роутерами
Go-ресолвер по умолчанию отправляет EDNS0-заголовок, чтобы запрашивать большие DNS-пакеты. Это может вызывать ошибки на некоторых модемах/роутерах. Отключить:
export GODEBUG=netedns0=0
Особенности на разных ОС
- macOS:
- Если Go-код собран с
-buildmode=c-archive, для линковки в C-программу требуется флаг-lresolv.
- Если Go-код собран с
- Plan 9:
- Ресолвер всегда использует
/net/csи/net/dns.
- Ресолвер всегда использует
- Windows (Go 1.18.x и старше):
- Всегда используются C-функции (
GetAddrInfo,DnsQuery).
- Всегда используются C-функции (
Ключевые термины
- Ресолвер (Resolver) – механизм преобразования доменных имен в IP-адреса.
- CGO – вызовы C-кода из Go.
- EDNS0 – расширение DNS, позволяющее увеличить размер пакета.
- GODEBUG – переменная окружения для настройки поведения Go-рантайма.
12.4.15.1 - Функции пакета net языка Go
Функции пакета net
func JoinHostPort
func JoinHostPort(host, port string) string
JoinHostPort объединяет хост и порт в сетевой адрес вида «хост:порт». Если хост содержит двоеточие, как в буквенных IPv6-адресах, то JoinHostPort возвращает «[хост]:порт».
Описание параметров хоста и порта см. в func Dial.
func LookupAddr
func LookupAddr(addr string) (names []string, err error)
LookupAddr выполняет обратный поиск по заданному адресу, возвращая список имен, сопоставленных с этим адресом.
Возвращаемые имена проверяются на правильность форматирования доменных имен в формате представления. Если в ответе содержатся недопустимые имена, эти записи отфильтровываются, и вместе с оставшимися результатами, если таковые имеются, возвращается ошибка.
При использовании хост-резольвера библиотеки C будет возвращено не более одного результата. Чтобы обойти хост-резольвер, используйте собственный резольвер.
LookupAddr внутренне использует context.Background; чтобы указать контекст, используйте Resolver.LookupAddr.
func LookupCNAME
func LookupCNAME(host string) (cname string, err error)
LookupCNAME возвращает каноническое имя для заданного хоста. Те, кому не важно каноническое имя, могут вызвать LookupHost или LookupIP напрямую; оба они позаботятся о разрешении канонического имени в процессе поиска.
Каноническое имя - это конечное имя после следования нуля или более записей CNAME. LookupCNAME не возвращает ошибку, если хост не содержит записей DNS «CNAME», при условии, что хост разрешается в адресные записи.
Возвращаемое каноническое имя проверяется на то, что оно является правильно отформатированным доменным именем формата представления.
LookupCNAME внутренне использует context.Background; чтобы указать контекст, используйте Resolver.LookupCNAME.
func LookupHost
func LookupHost(host string) (addrs []string, err error)
LookupHost ищет заданный хост с помощью локального резольвера. Он возвращает фрагмент адресов этого хоста.
Внутри LookupHost используется context.Background; чтобы указать контекст, используйте Resolver.LookupHost.
func LookupPort
func LookupPort(network, service string) (port int, err error)
LookupPort ищет порт для заданной сети и сервиса.
Внутри LookupPort используется context.Background; чтобы указать контекст, используйте Resolver.LookupPort.
func LookupTXT
func LookupTXT(name string) ([]string, error)
LookupTXT возвращает записи DNS TXT для заданного доменного имени.
Если DNS TXT-запись содержит несколько строк, они объединяются в одну строку.
Внутри LookupTXT используется context.Background; чтобы указать контекст, используйте Resolver.LookupTXT.
func ParseCIDR
func ParseCIDR(s string) (IP, *IPNet, error)
ParseCIDR анализирует s как IP-адрес в нотации CIDR и длину префикса, например «192.0.2.0/24» или «2001:db8::/32», как определено в RFC 4632 и RFC 4291.
Он возвращает IP-адрес и сеть, подразумеваемую IP-адресом и длиной префикса. Например, ParseCIDR(«192.0.2.1/24») возвращает IP-адрес 192.0.2.1 и сеть 192.0.2.0/24.
Пример
package main
import (
"fmt"
"log"
"net"
)
func main() {
ipv4Addr, ipv4Net, err := net.ParseCIDR("192.0.2.1/24")
if err != nil {
log.Fatal(err)
}
fmt.Println(ipv4Addr)
fmt.Println(ipv4Net)
ipv6Addr, ipv6Net, err := net.ParseCIDR("2001:db8:a0b:12f0::1/32")
if err != nil {
log.Fatal(err)
}
fmt.Println(ipv6Addr)
fmt.Println(ipv6Net)
}Output:
192.0.2.1
192.0.2.0/24
2001:db8:a0b:12f0::1
2001:db8::/32
func Pipe ¶
func Pipe() (Conn, Conn)
Pipe создает синхронное, в памяти, полнодуплексное сетевое соединение; оба конца реализуют интерфейс Conn. Чтение на одном конце совпадает с записью на другом, копируя данные непосредственно между ними; внутренней буферизации нет.
Объяснение Pipe
Функция Pipe из пакета net в языке Go позволяет создать синхронный in-memory канал между двумя сетевыми соединениями. Она возвращает два Conn (интерфейсы соединения), где запись в одно соединение сразу же становится доступной для чтения из другого, и наоборот.
Практическое значение net.Pipe()
Эта функция полезна в тестировании и имитации сетевых взаимодействий без реального использования сети (TCP/IP, Unix-сокетов и т. д.).
Примеры использования
1. Тестирование сетевого клиента и сервера без реального соединения
Допустим, у вас есть клиент и сервер, которые обмениваются данными по сети. Вместо запуска реального сервера в тестах можно использовать net.Pipe().
package main
import (
"io"
"net"
"testing"
)
// Серверная логика (обрабатывает соединение)
func handleConn(conn net.Conn) {
defer conn.Close()
_, _ = conn.Write([]byte("Hello, client!"))
}
// Клиентская логика (читает данные)
func readFromServer(conn net.Conn) string {
buf := make([]byte, 1024)
n, _ := conn.Read(buf)
return string(buf[:n])
}
func TestClientServer(t *testing.T) {
// Создаём "виртуальное" соединение
clientConn, serverConn := net.Pipe()
// Запускаем сервер в горутине
go handleConn(serverConn)
// Клиент читает ответ
response := readFromServer(clientConn)
if response != "Hello, client!" {
t.Errorf("Expected 'Hello, client!', got '%s'", response)
} else {
t.Log("Test passed!")
}
}
Что происходит:
net.Pipe()создаёт два конца соединения.- Сервер пишет в
serverConn, клиент читает изclientConn. - Всё происходит в памяти, без реального сетевого взаимодействия.
2. Мокирование сетевых вызовов в unit-тестах
Если ваш код зависит от внешнего API или базы данных, можно подменить реальное соединение моком через net.Pipe().
func TestDatabaseClient(t *testing.T) {
clientConn, mockServerConn := net.Pipe()
// Эмуляция сервера БД
go func() {
defer mockServerConn.Close()
request := make([]byte, 1024)
n, _ := mockServerConn.Read(request)
if string(request[:n]) == "GET user:123" {
_, _ = mockServerConn.Write([]byte(`{"id": "123", "name": "Alice"}`))
}
}()
// Клиентский код
_, _ = clientConn.Write([]byte("GET user:123"))
response := make([]byte, 1024)
n, _ := clientConn.Read(response)
expected := `{"id": "123", "name": "Alice"}`
if string(response[:n]) != expected {
t.Errorf("Expected '%s', got '%s'", expected, string(response[:n]))
}
}
Что происходит:
- Клиент отправляет запрос в
clientConn. - “Сервер” (горутина) читает запрос и возвращает моковый ответ.
- Тест проверяет, что клиент корректно обрабатывает ответ.
Преимущества net.Pipe()
✅ Не требует реального сетевого соединения – работает в памяти.
✅ Синхронная работа – запись блокируется, пока кто-то не прочитает данные.
✅ Удобно для тестирования – не нужно поднимать TCP-сервер или использовать mock-библиотеки.
Ограничения
❌ Только для локального использования – нельзя заменить реальный сетевой обмен в продакшене.
❌ Блокирующие операции – если одна сторона не читает данные, вторая заблокируется при записи.
Вывод
net.Pipe() – это мощный инструмент для тестирования сетевого кода в Go без реальных соединений. Он особенно полезен в unit-тестах, где важна изоляция и скорость выполнения.
func SplitHostPort
func SplitHostPort(hostport string) (host, port string, err error)
SplitHostPort разделяет сетевой адрес вида «host:port», «host%zone:port», «[host]:port» или «[host%zone]:port» на host или host%zone и port.
Буквальный IPv6-адрес в hostport должен быть заключен в квадратные скобки, как в «[::1]:80», «[::1%lo0]:80».
Описание параметра hostport, а также результатов хоста и порта см. в разделе func Dial.
12.4.15.2 - Типы и методы пакета net языка Go
Типы и методы пакета net
type Addr
type Addr интерфейс {
Network() string // имя сети (например, "tcp", "udp")
String() string // строковая форма адреса (например, "192.0.2.1:25", "[2001:db8::1]:80")
}
Addr представляет адрес конечной точки сети.
Два метода [Addr.Network] и [Addr.String] условно возвращают строки, которые могут быть переданы в качестве аргументов в Dial, но точная форма и значение строк зависят от реализации.
func InterfaceAddrs
func InterfaceAddrs() ([]Addr, error)
InterfaceAddrs возвращает список адресов одноадресных интерфейсов системы.
Возвращаемый список не идентифицирует связанный с ним интерфейс; для получения более подробной информации используйте Interfaces и Interface.Addrs.
type AddrError
type AddrError struct {
строка Err
Addr string
}
func (*AddrError) Error
func (e *AddrError) Error() string
func (*AddrError) Temporary
func (e *AddrError) Temporary() bool
func (*AddrError) Timeout
func (e *AddrError) Timeout() bool
type Buffers
type Buffers [][]byte
Buffers содержит ноль или более байтов для записи.
На некоторых машинах для определенных типов соединений это оптимизируется в специфическую для ОС операцию пакетной записи (например, “writev”).
func (*Buffers) Read
func (v *Буферы) Read(p []byte) (n int, err error)
Чтение из буферов.
Read реализует io.Reader для буферов.
Read изменяет фрагмент v, а также v[i] для 0 <= i < len(v), но не изменяет v[i][j] для любых i, j.
func (*Buffers) WriteTo
func (v *Буферы) WriteTo(w io.Writer) (n int64, err error)
WriteTo записывает содержимое буферов в w.
WriteTo реализует io.WriterTo для буферов.
WriteTo изменяет фрагмент v, а также v[i] для 0 <= i < len(v), но не изменяет v[i][j] для любых i, j.
type Conn ¶
type Conn interface {
// Read считывает данные из соединения.
// Чтение можно сделать тайм-аутом и вернуть ошибку по истечении фиксированного
// времени; см. SetDeadline и SetReadDeadline.
Read(b []byte) (n int, err error)
// Write записывает данные в соединение.
// Запись может быть сделана так, чтобы тайм-аут и возврат ошибки происходили через фиксированное
// времени; см. SetDeadline и SetWriteDeadline.
Write(b []byte) (n int, err error)
// Close закрывает соединение.
// Любые заблокированные операции чтения или записи будут разблокированы и вернут ошибку.
Close() error
// LocalAddr возвращает адрес локальной сети, если он известен.
LocalAddr() Addr
// RemoteAddr возвращает адрес удаленной сети, если он известен.
RemoteAddr() Addr
// SetDeadline устанавливает крайние сроки чтения и записи, связанные
// с данным соединением. Это эквивалентно вызову обеих функций.
// SetReadDeadline и SetWriteDeadline.
//
// Крайний срок - это абсолютное время, по истечении которого операции ввода-вывода
// прекращаются, а не блокируются. Крайний срок применяется ко всем будущим
// и ожидающим операциям ввода-вывода, а не только к непосредственно следующему вызову
// чтения или записи. После превышения крайнего срока
// соединение можно обновить, установив крайний срок в будущем.
//
// Если крайний срок превышен, вызов Read или Write или других
// методы ввода/вывода вернут ошибку, обернутую в os.ErrDeadlineExceeded.
// Это можно проверить с помощью errors.Is(err, os.ErrDeadlineExceeded).
// Метод Timeout ошибки вернет true, но обратите внимание, что существуют
// есть и другие возможные ошибки, для которых метод Timeout
// вернет true, даже если срок не был превышен.
//
// Таймаут простоя может быть реализован путем многократного продления
// крайнего срока после успешных вызовов чтения или записи.
//
// Нулевое значение t означает, что операции ввода-вывода не будут выполняться по тайм-ауту.
SetDeadline(t time.Time) error
// SetReadDeadline устанавливает крайний срок для будущих вызовов Read
// и любого заблокированного в данный момент вызова Read.
// Нулевое значение t означает, что операции Read не будут завершаться.
SetReadDeadline(t time.Time) error
// SetWriteDeadline устанавливает крайний срок для будущих вызовов записи
// и любого заблокированного в данный момент вызова Write.
// Даже если запись завершится, она может вернуть n > 0, указывая на то, что
// часть данных была успешно записана.
// Нулевое значение t означает, что Write не будет завершаться.
SetWriteDeadline(t time.Time) error
}
Conn - это общее потоково-ориентированное сетевое соединение.
Несколько горутинов могут вызывать методы на Conn одновременно.
func Dial
func Dial(network, address string) (Conn, error)
Dial подключается к адресу в указанной сети.
Известные сети: “tcp”, “tcp4” (только для IPv4), “tcp6” (только для IPv6), “udp”, “udp4” (только для IPv4), “udp6” (только для IPv6), “ip”, “ip4” (только для IPv4), “ip6” (только для IPv6), “unix”, “unixgram” и “unixpacket”.
Для сетей TCP и UDP адрес имеет вид “хост:порт”. Хост должен быть буквальным IP-адресом или именем хоста, которое может быть преобразовано в IP-адрес. Порт должен быть буквенным номером порта или именем службы. Если хост является литеральным IPv6-адресом, он должен быть заключен в квадратные скобки, как в “[2001:db8::1]:80” или “[fe80::1%zone]:80”. Зона определяет область действия буквального IPv6-адреса, как определено в RFC 4007. Функции JoinHostPort и SplitHostPort манипулируют парой хост-порт в таком виде. При использовании TCP, когда хост разрешается в несколько IP-адресов, Dial будет пробовать каждый IP-адрес по порядку, пока один не будет успешным.
Примеры:
Dial("tcp", "golang.org:http")
Dial("tcp", "192.0.2.1:http")
Dial("tcp", "198.51.100.1:80")
Dial("udp", "[2001:db8::1]:domain")
Dial("udp", "[fe80::1%lo0]:53")
Dial("tcp", ":80")
Для IP-сетей сеть должна быть “ip”, “ip4” или “ip6”, за которой следует двоеточие и литеральный номер протокола или имя протокола, а адрес имеет вид “host”. Хост должен быть буквальным IP-адресом или буквальным IPv6-адресом с зоной. От каждой операционной системы зависит, как она поведет себя с номером протокола, не являющимся общеизвестным, например “0” или “255”.
Примеры:
Dial("ip4:1", "192.0.2.1")
Dial("ip6:ipv6-icmp", "2001:db8::1")
Dial("ip6:58", "fe80::1%lo0")
Для сетей TCP, UDP и IP, если хост пуст или является буквальным неопределенным IP-адресом, как в “:80”, “0.0.0.0:80” или “[::]:80” для TCP и UDP, “”, “0.0.0.0” или “::” для IP, предполагается локальная система.
Для сетей Unix адрес должен быть путем к файловой системе.
func DialTimeout
func DialTimeout(network, address string, timeout time.Duration) (Conn, error)
DialTimeout действует как Dial, но берет таймаут.
Таймаут включает разрешение имен, если это необходимо. Если используется TCP и хост в параметре адреса разрешается в несколько IP-адресов, таймаут распределяется на каждый последовательный набор, так что каждому дается соответствующая доля времени для соединения.
Описание параметров сети и адреса см. в func Dial.
func FileConn
func FileConn(f *os.File) (c Conn, err error)
FileConn возвращает копию сетевого соединения, соответствующего открытому файлу f. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие c не влияет на f, а закрытие f не влияет на c.
type DNSConfigError
type DNSConfigError struct {
Err error
}
DNSConfigError представляет ошибку чтения конфигурации DNS машины. (Больше не используется; сохранено для совместимости).
func (*DNSConfigError) Error
func (e *DNSConfigError) Error() string
func (*DNSConfigError) Temporary
func (e *DNSConfigError) Temporary() bool
func (*DNSConfigError) Timeout
func (e *DNSConfigError) Timeout() bool
func (*DNSConfigError) Unwrap
func (e *DNSConfigError) Unwrap() error
type DNSError
type DNSError struct {
UnwrapErr error // ошибка, возвращаемая методом [DNSError.Unwrap], может быть nil
Err string // описание ошибки
Name string // искомое имя
Server string // используемый сервер
IsTimeout bool // если true, то таймаут истек; не все таймауты устанавливают это значение
IsTemporary bool // если true, то ошибка временная; не все ошибки устанавливают это
// IsNotFound устанавливается в true, если запрашиваемое имя не
// не содержит записей запрашиваемого типа (данные не найдены),
// или само имя не найдено (NXDOMAIN).
IsNotFound bool
}
DNSError представляет ошибку поиска DNS.
func (*DNSError) Error
func (e *DNSError) Error() string
func (*DNSError) Temporary
func (e *DNSError) Temporary() bool
Temporary сообщает, является ли ошибка DNS временной. Это не всегда известно; поиск DNS может завершиться неудачей из-за временной ошибки и вернуть DNSError, для которого Temporary возвращает false.
func (*DNSError) Timeout
func (e *DNSError) Timeout() bool
Таймаут сообщает о том, что поиск DNS завершился по таймеру. Это не всегда известно; поиск DNS может завершиться неудачей из-за таймаута и вернуть DNSError, для которого Timeout возвращает false.
func (*DNSError) Unwrap
func (e *DNSError) Unwrap() error
Unwrap возвращает e.UnwrapErr.
type Dialer
type Dialer struct {
// Timeout - это максимальное количество времени, в течение которого набор будет ждать
// завершения соединения. Если также задано значение Deadline, то соединение может завершиться
// раньше.
//
// По умолчанию таймаут отсутствует.
//
// При использовании TCP и наборе имени хоста с несколькими IP
// адресов, тайм-аут может быть разделен между ними.
//
// С таймаутом или без него операционная система может установить
// свой собственный более ранний тайм-аут. Например, тайм-ауты TCP
// часто составляет около 3 минут.
Timeout time.Duration
// Крайний срок - это абсолютный момент времени, после которого набор номера
// завершится неудачей. Если установлен таймаут, то отказ может произойти раньше.
// Ноль означает отсутствие крайнего срока, или зависит от операционной системы.
// как в случае с параметром Timeout.
Deadline time.Time
// LocalAddr - локальный адрес, который следует использовать при наборе
// адреса. Адрес должен быть совместимого типа для
// набираемой сети.
// Если nil, локальный адрес выбирается автоматически.
LocalAddr Addr
// В DualStack ранее была включена поддержка RFC 6555 Fast Fallback
// поддержка, также известная как "Happy Eyeballs", при которой IPv4
// пробует вскоре, если IPv6 оказывается неправильно сконфигурированным и
// зависает.
//
// Утративший силу: Fast Fallback включен по умолчанию. Чтобы
// отключить, установите FallbackDelay в отрицательное значение.
DualStack bool
// FallbackDelay задает время ожидания перед тем, как
// порождения соединения RFC 6555 Fast Fallback. То есть это
// это время ожидания успеха IPv6, прежде чем
// предположить, что IPv6 неправильно сконфигурирован, и вернуться к
// IPv4.
//
// Если значение равно нулю, то по умолчанию используется задержка 300 мс.
// Отрицательное значение отключает поддержку быстрого отката.
FallbackDelay time.Duration
// KeepAlive задает интервал между попытками сохранить активное сетевое соединение.
// зондами активного сетевого соединения.
//
// KeepAlive игнорируется, если KeepAliveConfig.Enable равен true.
//
// Если значение равно нулю, то зонды keep-alive отправляются со значением по умолчанию.
// (в настоящее время 15 секунд), если это поддерживается протоколом и операционной // системой.
// системой. Сетевые протоколы или операционные системы, которые.
// не поддерживают keep-alive, игнорируют это поле.
// Если значение отрицательное, то запросы keep-alive отключаются.
KeepAlive time.Duration
// KeepAliveConfig определяет конфигурацию зонда keep-alive
// для активного сетевого соединения, если оно поддерживается
// протоколом и операционной системой.
//
// Если KeepAliveConfig.Enable равен true, то зонды keep-alive включены.
// Если KeepAliveConfig.Enable ложно и KeepAlive отрицательно,
// зонды keep-alive отключены.
KeepAliveConfig KeepAliveConfig
// Resolver опционально указывает альтернативный резолвер для использования.
Resolver *Resolver
// Cancel - необязательный канал, закрытие которого указывает, что
// набор должен быть отменен. Не все типы циферблатов поддерживают
// отмену.
//
// Утратил актуальность: Вместо этого используйте DialContext.
Cancel <-chan struct{}
// Если Control не nil, то вызывается после создания сетевого
// соединения, но до фактического набора номера.
//
// Параметры сети и адреса, передаваемые в функцию Control, не являются
// обязательно те, которые передаются в Dial. Вызов Dial с сетями TCP
// приведет к вызову функции Control с параметрами "tcp4" или "tcp6",
// UDP-сети станут "udp4" или "udp6", IP-сети - "ip4" или "ip6",
// а другие известные сети передаются как есть.
//
// Контроль игнорируется, если ControlContext не равен nil.
Control func(network, address string, c syscall.RawConn) error
// Если ControlContext не равен nil, то эта функция вызывается после создания сетевого
// соединения, но до фактического набора номера.
//
// Параметры сети и адреса, передаваемые в функцию ControlContext, не являются
// обязательно те, что переданы в Dial. Вызов Dial с сетями TCP
// приведет к вызову функции ControlContext с параметрами "tcp4" или "tcp6",
// UDP-сети станут "udp4" или "udp6", IP-сети - "ip4" или "ip6",
// а другие известные сети передаются как есть.
//
// Если ControlContext не равен nil, Control игнорируется.
ControlContext func(ctx context.Context, network, address string, c syscall.RawConn) error
// содержит отфильтрованные или неэкспонированные поля
}
Dialer содержит опции для соединения с адресом.
Нулевое значение для каждого поля эквивалентно дозвону без этой опции. Поэтому набор номера с нулевым значением Dialer эквивалентен простому вызову функции Dial.
Безопасно вызывать методы Dialer одновременно.
Пример
package main
import (
"context"
"log"
"net"
"time"
)
func main() {
var d net.Dialer
ctx, cancel := context.WithTimeout(context.Background(), time.Minute)
defer cancel()
conn, err := d.DialContext(ctx, "tcp", "localhost:12345")
if err != nil {
log.Fatalf("Failed to dial: %v", err)
}
defer conn.Close()
if _, err := conn.Write([]byte("Hello, World!")); err != nil {
log.Fatal(err)
}
}
Пример Unix
package main
import (
"context"
"log"
"net"
"time"
)
func main() {
// DialUnix does not take a context.Context parameter. This example shows
// how to dial a Unix socket with a Context. Note that the Context only
// applies to the dial operation; it does not apply to the connection once
// it has been established.
var d net.Dialer
ctx, cancel := context.WithTimeout(context.Background(), time.Minute)
defer cancel()
d.LocalAddr = nil // if you have a local addr, add it here
raddr := net.UnixAddr{Name: "/path/to/unix.sock", Net: "unix"}
conn, err := d.DialContext(ctx, "unix", raddr.String())
if err != nil {
log.Fatalf("Failed to dial: %v", err)
}
defer conn.Close()
if _, err := conn.Write([]byte("Hello, socket!")); err != nil {
log.Fatal(err)
}
}
func (*Dialer) Dial
func (d *Dialer) Dial(network, address string) (Conn, error)
Dial соединяется с адресом в указанной сети.
Описание параметров сети и адреса см. в func Dial.
Dial внутренне использует context.Background; чтобы указать контекст, используйте Dialer.DialContext.
func (*Dialer) DialContext
func (d *Dialer) DialContext(ctx context.Context, network, address string) (Conn, error)
DialContext соединяется с адресом в названной сети, используя предоставленный контекст.
Предоставленный контекст должен быть ненулевым. Если срок действия контекста истекает до завершения соединения, возвращается ошибка. После успешного соединения любое истечение срока действия контекста не повлияет на соединение.
При использовании TCP, когда хост в параметре адреса разрешается в несколько сетевых адресов, таймаут набора номера (из d.Timeout или ctx) распределяется на каждый последовательный набор, так что каждому дается соответствующая доля времени для соединения. Например, если у хоста есть 4 IP-адреса и таймаут составляет 1 минуту, то на соединение с каждым отдельным адресом будет дано 15 секунд, прежде чем будет выполнена попытка соединения со следующим адресом.
Описание параметров сети и адреса см. в func Dial.
func (*Dialer) MultipathTCP
func (d *Dialer) MultipathTCP() bool
MultipathTCP сообщает, будет ли использоваться MPTCP.
Этот метод не проверяет, поддерживается ли MPTCP операционной системой или нет.
func (*Dialer) SetMultipathTCP
func (d *Dialer) SetMultipathTCP(use bool)
SetMultipathTCP направляет методы Dial на использование или неиспользование MPTCP, если это поддерживается операционной системой. Этот метод отменяет системное значение по умолчанию и настройку GODEBUG=multipathtcp=…, если таковая имеется.
Если MPTCP недоступен на хосте или не поддерживается сервером, методы набора будут возвращаться к TCP.
type Error
type Error interface {
error
Timeout() bool // Является ли ошибка тайм-аутом?
// Исправлено: Временные ошибки не имеют четкого определения.
// Большинство "временных" ошибок - это таймауты, а редкие исключения вызывают удивление.
// Не используйте этот метод.
Temporary() bool
}
Error представляет сетевую ошибку.
type Flags
type Flags uint
const (
FlagUp Flags = 1 << iota // интерфейс административно поднят
FlagBroadcast // интерфейс поддерживает возможность широковещательного доступа
FlagLoopback // интерфейс является интерфейсом обратной связи
FlagPointToPoint // интерфейс принадлежит к каналу "точка-точка
FlagMulticast // интерфейс поддерживает возможность многоадресного доступа
FlagRunning // интерфейс находится в рабочем состоянии
)
func (Flags) String
func (f Flags) String() string
type HardwareAddr
type HardwareAddr []byte
HardwareAddr представляет физический аппаратный адрес.
func ParseMAC
func ParseMAC(s string) (hw HardwareAddr, err error)
ParseMAC анализирует s как IEEE 802 MAC-48, EUI-48, EUI-64 или 20-октетный адрес канального уровня IP поверх InfiniBand, используя один из следующих форматов:
00:00:5e:00:53:01
02:00:5e:10:00:00:00:01
00:00:00:00:fe:80:00:00:00:00:00:00:02:00:5e:10:00:00:00:01
00-00-5e-00-53-01
02-00-5e-10-00-00-00-01
00-00-00-00-fe-80-00-00-00-00-00-00-02-00-5e-10-00-00-00-01
0000.5e00.5301
0200.5e10.0000.0001
0000.0000.fe80.0000.0000.0000.0200.5e10.0000.0001
func (HardwareAddr) String
func (a HardwareAddr) String() string
type IP
type IP []byte
IP - это один IP-адрес, представляющий собой фрагмент байтов. Функции этого пакета принимают на вход 4-байтовые (IPv4) или 16-байтовые (IPv6) фрагменты.
Обратите внимание, что в этой документации обращение к IP-адресу как к IPv4-адресу или IPv6-адресу является семантическим свойством адреса, а не просто длиной байтового фрагмента: 16-байтовый фрагмент все еще может быть IPv4-адресом.
func IPv4
func IPv4(a, b, c, d byte) IP
IPv4 возвращает IP-адрес (в 16-байтовой форме) IPv4-адреса a.b.c.d.
Пример
package main
import (
"fmt"
"net"
)
func main() {
fmt.Println(net.IPv4(8, 8, 8, 8))
}
Output:
8.8.8.8func LookupIP
func LookupIP(host string) ([]IP, error)
LookupIP ищет хост с помощью локального резольвера. Он возвращает фрагмент IPv4 и IPv6 адресов этого хоста.
func ParseIP
func ParseIP(s string) IP
ParseIP разбирает s как IP-адрес, возвращая результат. Строка s может быть в десятичном точечном формате IPv4 (“192.0.2.1”), IPv6 (“2001:db8::68”) или IPv4-mapped IPv6 ("::ffff:192.0.2.1"). Если s не является корректным текстовым представлением IP-адреса, ParseIP возвращает nil. Возвращаемый адрес всегда имеет размер 16 байт, IPv4-адреса возвращаются в IPv4-сопоставленной IPv6-форме.
Пример
package main
import (
"fmt"
"net"
)
func main() {
fmt.Println(net.ParseIP("192.0.2.1"))
fmt.Println(net.ParseIP("2001:db8::68"))
fmt.Println(net.ParseIP("192.0.2"))
}
Output:
192.0.2.1
2001:db8::68
<nil>func (IP) AppendText
func (ip IP) AppendText(b []byte) ([]byte, error)
AppendText реализует интерфейс encoding.TextAppender. Кодировка такая же, как и у IP.String, за одним исключением: Если len(ip) равно нулю, то ничего не добавляется.
func (IP) DefaultMask
func (ip IP) DefaultMask() IPMask
DefaultMask возвращает IP-маску по умолчанию для IP-адреса ip. Маски по умолчанию есть только у IPv4-адресов; DefaultMask возвращает nil, если ip не является действительным IPv4-адресом.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ip := net.ParseIP("192.0.2.1")
fmt.Println(ip.DefaultMask())
}
Output:
ffffff00func (IP) Equal
func (ip IP) Equal(x IP) bool
Equal сообщает, являются ли ip и x одним и тем же IP-адресом. IPv4-адрес и тот же адрес в форме IPv6 считаются равными.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv4DNS := net.ParseIP("8.8.8.8")
ipv4Lo := net.ParseIP("127.0.0.1")
ipv6DNS := net.ParseIP("0:0:0:0:0:FFFF:0808:0808")
fmt.Println(ipv4DNS.Equal(ipv4DNS))
fmt.Println(ipv4DNS.Equal(ipv4Lo))
fmt.Println(ipv4DNS.Equal(ipv6DNS))
}
Output:
true
false
truefunc (IP) IsGlobalUnicast
func (ip IP) IsGlobalUnicast() bool
IsGlobalUnicast сообщает, является ли ip глобальным одноадресным адресом.
Для идентификации глобальных одноадресных адресов используется идентификация типа адреса, как определено в RFC 1122, RFC 4632 и RFC 4291, за исключением адресов направленной широковещательной рассылки IPv4. Возвращает true, даже если ip находится в частном адресном пространстве IPv4 или локальном адресном пространстве IPv6 одноадресной рассылки.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6Global := net.ParseIP("2000::")
ipv6UniqLocal := net.ParseIP("2000::")
ipv6Multi := net.ParseIP("FF00::")
ipv4Private := net.ParseIP("10.255.0.0")
ipv4Public := net.ParseIP("8.8.8.8")
ipv4Broadcast := net.ParseIP("255.255.255.255")
fmt.Println(ipv6Global.IsGlobalUnicast())
fmt.Println(ipv6UniqLocal.IsGlobalUnicast())
fmt.Println(ipv6Multi.IsGlobalUnicast())
fmt.Println(ipv4Private.IsGlobalUnicast())
fmt.Println(ipv4Public.IsGlobalUnicast())
fmt.Println(ipv4Broadcast.IsGlobalUnicast())
}
Output:
true
true
false
true
true
falsefunc (IP) IsInterfaceLocalMulticast
func (ip IP) IsInterfaceLocalMulticast() bool
IsInterfaceLocalMulticast сообщает, является ли ip интерфейсно-локальным многоадресным адресом.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6InterfaceLocalMulti := net.ParseIP("ff01::1")
ipv6Global := net.ParseIP("2000::")
ipv4 := net.ParseIP("255.0.0.0")
fmt.Println(ipv6InterfaceLocalMulti.IsInterfaceLocalMulticast())
fmt.Println(ipv6Global.IsInterfaceLocalMulticast())
fmt.Println(ipv4.IsInterfaceLocalMulticast())
}
Output:
true
false
falsefunc (IP) IsLinkLocalMulticast
func (ip IP) IsLinkLocalMulticast() bool
IsLinkLocalMulticast сообщает, является ли ip адресом link-local multicast.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6LinkLocalMulti := net.ParseIP("ff02::2")
ipv6LinkLocalUni := net.ParseIP("fe80::")
ipv4LinkLocalMulti := net.ParseIP("224.0.0.0")
ipv4LinkLocalUni := net.ParseIP("169.254.0.0")
fmt.Println(ipv6LinkLocalMulti.IsLinkLocalMulticast())
fmt.Println(ipv6LinkLocalUni.IsLinkLocalMulticast())
fmt.Println(ipv4LinkLocalMulti.IsLinkLocalMulticast())
fmt.Println(ipv4LinkLocalUni.IsLinkLocalMulticast())
}
Output:
true
false
true
falsefunc (IP) IsLinkLocalUnicast
func (ip IP) IsLinkLocalUnicast() bool
IsLinkLocalUnicast сообщает, является ли ip адресом link-local unicast.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6LinkLocalUni := net.ParseIP("fe80::")
ipv6Global := net.ParseIP("2000::")
ipv4LinkLocalUni := net.ParseIP("169.254.0.0")
ipv4LinkLocalMulti := net.ParseIP("224.0.0.0")
fmt.Println(ipv6LinkLocalUni.IsLinkLocalUnicast())
fmt.Println(ipv6Global.IsLinkLocalUnicast())
fmt.Println(ipv4LinkLocalUni.IsLinkLocalUnicast())
fmt.Println(ipv4LinkLocalMulti.IsLinkLocalUnicast())
}
Output:
true
false
true
falsefunc (IP) IsLoopback
func (ip IP) IsLoopback() bool
IsLoopback сообщает, является ли ip адресом loopback.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6Lo := net.ParseIP("::1")
ipv6 := net.ParseIP("ff02::1")
ipv4Lo := net.ParseIP("127.0.0.0")
ipv4 := net.ParseIP("128.0.0.0")
fmt.Println(ipv6Lo.IsLoopback())
fmt.Println(ipv6.IsLoopback())
fmt.Println(ipv4Lo.IsLoopback())
fmt.Println(ipv4.IsLoopback())
}Output:
true
false
true
falsefunc (IP) IsMulticast
func (ip IP) IsMulticast() bool
IsMulticast сообщает, является ли ip адресом многоадресной рассылки.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6Multi := net.ParseIP("FF00::")
ipv6LinkLocalMulti := net.ParseIP("ff02::1")
ipv6Lo := net.ParseIP("::1")
ipv4Multi := net.ParseIP("239.0.0.0")
ipv4LinkLocalMulti := net.ParseIP("224.0.0.0")
ipv4Lo := net.ParseIP("127.0.0.0")
fmt.Println(ipv6Multi.IsMulticast())
fmt.Println(ipv6LinkLocalMulti.IsMulticast())
fmt.Println(ipv6Lo.IsMulticast())
fmt.Println(ipv4Multi.IsMulticast())
fmt.Println(ipv4LinkLocalMulti.IsMulticast())
fmt.Println(ipv4Lo.IsMulticast())
}
Output:
true
true
false
true
true
falsefunc (IP) IsPrivate
func (ip IP) IsPrivate() bool
IsPrivate сообщает, является ли ip частным адресом, в соответствии с RFC 1918 (IPv4-адреса) и RFC 4193 (IPv6-адреса).
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6Private := net.ParseIP("fc00::")
ipv6Public := net.ParseIP("fe00::")
ipv4Private := net.ParseIP("10.255.0.0")
ipv4Public := net.ParseIP("11.0.0.0")
fmt.Println(ipv6Private.IsPrivate())
fmt.Println(ipv6Public.IsPrivate())
fmt.Println(ipv4Private.IsPrivate())
fmt.Println(ipv4Public.IsPrivate())
}
Output:
true
false
true
falsefunc (IP) IsUnspecified
func (ip IP) IsUnspecified() bool
IsUnspecified сообщает, является ли ip неопределенным адресом, либо IPv4-адресом “0.0.0.0”, либо IPv6-адресом “::”.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6Unspecified := net.ParseIP("::")
ipv6Specified := net.ParseIP("fe00::")
ipv4Unspecified := net.ParseIP("0.0.0.0")
ipv4Specified := net.ParseIP("8.8.8.8")
fmt.Println(ipv6Unspecified.IsUnspecified())
fmt.Println(ipv6Specified.IsUnspecified())
fmt.Println(ipv4Unspecified.IsUnspecified())
fmt.Println(ipv4Specified.IsUnspecified())
}
Output:
true
false
true
falsefunc (IP) MarshalText
func (ip IP) MarshalText() ([]byte, error)
MarshalText реализует интерфейс encoding.TextMarshaler. Кодировка та же, что возвращается IP.String, за одним исключением: Если len(ip) равен нулю, возвращается пустой фрагмент.
func (IP) Mask
func (ip IP) Mask(mask IPMask) IP
Mask возвращает результат маскирования IP-адреса ip с помощью маски.
func (IP) String
func (ip IP) String() string
String возвращает строковую форму IP-адреса ip. Возвращается одна из 4 форм:
- “
”, если ip имеет длину 0 - десятичная точка (“192.0.2.1”), если ip - это IPv4 или IP4-сопоставленный IPv6-адрес.
- IPv6 в соответствии с RFC 5952 (“2001:db8::1”), если ip - действительный IPv6-адрес
- шестнадцатеричная форма ip без знаков препинания, если другие случаи не применимы.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6 := net.IP{0xfc, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
ipv4 := net.IPv4(10, 255, 0, 0)
fmt.Println(ipv6.String())
fmt.Println(ipv4.String())
}
Output:
fc00::
10.255.0.0func (IP) To16
func (ip IP) To16() IP
To16 преобразует IP-адрес ip в 16-байтовое представление. Если ip не является IP-адресом (имеет неправильную длину), To16 возвращает nil.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6 := net.IP{0xfc, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
ipv4 := net.IPv4(10, 255, 0, 0)
fmt.Println(ipv6.To16())
fmt.Println(ipv4.To16())
}
Output:
fc00::
10.255.0.0func (IP) To4
func (ip IP) To4() IP
To4 преобразует IPv4-адрес ip в 4-байтовое представление. Если ip не является IPv4-адресом, To4 возвращает nil.
Пример
package main
import (
"fmt"
"net"
)
func main() {
ipv6 := net.IP{0xfc, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
ipv4 := net.IPv4(10, 255, 0, 0)
fmt.Println(ipv6.To4())
fmt.Println(ipv4.To4())
}
Output:
<nil>
10.255.0.0func (*IP) UnmarshalText
func (ip *IP) UnmarshalText(text []byte) error
UnmarshalText реализует интерфейс encoding.TextUnmarshaler. IP-адрес ожидается в форме, принимаемой ParseIP.
type IPAddr
type IPAddr struct {
IP-АДРЕС
Zone string // Зона масштабируемой адресации IPv6
}
IPAddr представляет адрес конечной точки IP.
func ResolveIPAddr
func ResolveIPAddr(network, address string) (*IPAddr, error)
ResolveIPAddr возвращает адрес конечной IP-точки.
Сеть должна быть именем IP-сети.
Если хост в параметре address не является литеральным IP-адресом, ResolveIPAddr преобразует адрес в адрес конечной точки IP. В противном случае он анализирует адрес как литеральный IP-адрес. В качестве параметра адреса может использоваться имя хоста, но это не рекомендуется, так как будет возвращен не более одного из IP-адресов имени хоста.
Описание параметров сети и адреса см. в разделе func Dial.
func (*IPAddr) Сеть
func (a *IPAddr) Network() string
Network возвращает сетевое имя адреса, “ip”.
func (*IPAddr) String
func (a *IPAddr) String() string
type IPConn
type IPConn struct {
// содержит отфильтрованные или неотправленные поля
}
IPConn - это реализация интерфейсов Conn и PacketConn для сетевых IP-соединений.
func DialIP
func DialIP(network string, laddr, raddr *IPAddr) (*IPConn, error)
DialIP действует как Dial для IP-сетей.
Сеть должна быть именем IP-сети; подробности см. в func Dial.
Если laddr равен nil, автоматически выбирается локальный адрес. Если поле IP в raddr равно nil или является неопределенным IP-адресом, предполагается локальная система.
func ListenIP
func ListenIP(network string, laddr *IPAddr) (*IPConn, error)
ListenIP действует как ListenPacket для IP-сетей.
Сеть должна быть именем IP-сети; подробности см. в func Dial.
Если поле IP в laddr равно nil или неопределенному IP-адресу, ListenIP прослушивает все доступные IP-адреса локальной системы, кроме IP-адресов многоадресной рассылки.
func (*IPConn) Закрыть
func (c *IPConn) Close() error
Close закрывает соединение.
func (*IPConn) File
func (c *IPConn) File() (f *os.File, err error)
File возвращает копию базового файла os.File. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие c не влияет на f, а закрытие f не влияет на c.
Дескриптор файла возвращаемого os.File отличается от дескриптора соединения. Попытка изменить свойства оригинала с помощью этого дубликата может привести к желаемому результату, а может и не привести.
func (*IPConn) LocalAddr
func (c *IPConn) LocalAddr() Addr
LocalAddr возвращает адрес локальной сети. Возвращаемый Addr является общим для всех вызовов LocalAddr, поэтому не следует его изменять.
func (*IPConn) Read
func (c *IPConn) Read(b []byte) (int, error)
Read реализует метод Conn Read.
func (*IPConn) ReadFrom
func (c *IPConn) ReadFrom(b []byte) (int, Addr, error)
ReadFrom реализует метод PacketConn ReadFrom.
func (*IPConn) ReadFromIP
func (c *IPConn) ReadFromIP(b []byte) (int, *IPAddr, error)
ReadFromIP действует как ReadFrom, но возвращает IPAddr.
func (*IPConn) ReadMsgIP
func (c *IPConn) ReadMsgIP(b, oob []byte) (n, oobn, flags int, addr *IPAddr, err error)
ReadMsgIP считывает сообщение из c, копируя полезную нагрузку в b и связанные с ней внеполосные данные в oob. Возвращается количество байт, скопированных в b, количество байт, скопированных в oob, флаги, которые были установлены для сообщения, и адрес источника сообщения.
Пакеты golang.org/x/net/ipv4 и golang.org/x/net/ipv6 могут быть использованы для манипулирования опциями сокетов IP-уровня в oob.
func (*IPConn) RemoteAddr
func (c *IPConn) RemoteAddr() Addr
RemoteAddr возвращает удаленный сетевой адрес. Возвращаемый Addr является общим для всех вызовов RemoteAddr, поэтому не изменяйте его.
func (*IPConn) SetDeadline
func (c *IPConn) SetDeadline(t time.Time) error
SetDeadline реализует метод Conn SetDeadline.
func (*IPConn) SetReadBuffer
func (c *IPConn) SetReadBuffer(bytes int) error
SetReadBuffer устанавливает размер буфера приема операционной системы, связанного с соединением.
func (*IPConn) SetReadDeadline
func (c *IPConn) SetReadDeadline(t time.Time) error
SetReadDeadline реализует метод Conn SetReadDeadline.
func (*IPConn) SetWriteBuffer
func (c *IPConn) SetWriteBuffer(bytes int) error
SetWriteBuffer устанавливает размер буфера передачи операционной системы, связанного с соединением.
func (*IPConn) SetWriteDeadline
func (c *IPConn) SetWriteDeadline(t time.Time) error
SetWriteDeadline реализует метод Conn SetWriteDeadline.
func (*IPConn) SyscallConn
func (c *IPConn) SyscallConn() (syscall.RawConn, error)
SyscallConn возвращает необработанное сетевое соединение. Оно реализует интерфейс syscall.Conn.
func (*IPConn) Write
func (c *IPConn) Write(b []byte) (int, error)
Write реализует метод Conn Write.
func (*IPConn) WriteMsgIP
func (c *IPConn) WriteMsgIP(b, oob []byte, addr *IPAddr) (n, oobn int, err error)
WriteMsgIP записывает сообщение на addr через c, копируя полезную нагрузку из b и связанные с ней внеполосные данные из oob. Возвращается количество записанных байт полезной нагрузки и внеполосных данных.
Пакеты golang.org/x/net/ipv4 и golang.org/x/net/ipv6 могут быть использованы для манипулирования опциями сокетов IP-уровня в oob.
func (*IPConn) WriteTo
func (c *IPConn) WriteTo(b []byte, addr Addr) (int, error)
WriteTo реализует метод PacketConn WriteTo.
func (*IPConn) WriteToIP
func (c *IPConn) WriteToIP(b []байт, addr *IPAddr) (int, error)
WriteToIP действует подобно IPConn.WriteTo, но принимает IPAddr.
type IPMask
type IPMask []байт
IPMask - это битовая маска, которая может быть использована для манипулирования IP-адресами для IP-адресации и маршрутизации.
Подробнее см. в разделе type IPNet и func ParseCIDR.
func CIDRMask
func CIDRMask(ones, bits int) IPMask
CIDRMask возвращает IPMask, состоящую из битов ‘ones’ 1, за которыми следуют 0 до общей длины ‘bits’ бит. Для маски такой формы CIDRMask является обратной величиной к IPMask.Size.
Пример
package main
import (
"fmt"
"net"
)
func main() {
// This mask corresponds to a /31 subnet for IPv4.
fmt.Println(net.CIDRMask(31, 32))
// This mask corresponds to a /64 subnet for IPv6.
fmt.Println(net.CIDRMask(64, 128))
}
Output:
fffffffe
ffffffffffffffff0000000000000000func IPv4Mask
func IPv4Mask(a, b, c, d byte) IPMask
IPv4Mask возвращает IP-маску (в 4-байтовой форме) IPv4-маски a.b.c.d.
Пример
package main
import (
"fmt"
"net"
)
func main() {
fmt.Println(net.IPv4Mask(255, 255, 255, 0))
}
Output:
ffffff00func (IPMask) Size
func (m IPMask) Size() (ones, bits int)
Size возвращает количество ведущих единиц и общее количество битов в маске. Если маска не имеет канонической формы - за единицами следуют нули - то Size возвращает 0, 0.
func (IPMask) String
func (m IPMask) String() string
String возвращает шестнадцатеричную форму m, без знаков препинания.
type IPNet
type IPNet struct {
IP IP // номер сети
Mask IPMask // маска сети
}
IPNet представляет IP-сеть.
func (*IPNet) Contains
func (n *IPNet) Contains(ip IP) bool
Contains сообщает, включает ли сеть ip.
func (*IPNet) Network
func (n *IPNet) Network() string
Network возвращает сетевое имя адреса, “ip+net”.
func (*IPNet) String
func (n *IPNet) String() string
String возвращает CIDR-нотацию n, например “192.0.2.0/24” или “2001:db8::/48”, как определено в RFC 4632 и RFC 4291. Если маска не имеет канонической формы, возвращается строка, состоящая из IP-адреса, за которым следует символ косой черты и маска, выраженная в шестнадцатеричной форме без знаков препинания, например “198.51.100.0/c000ff00”.
type Interface
type Interface struct {
Index int // положительное целое число, начинающееся с единицы, ноль никогда не используется
MTU int // максимальная единица передачи
Name string // например, "en0", "lo0", "eth0.100".
HardwareAddr HardwareAddr // форма IEEE MAC-48, EUI-48 и EUI-64
Flags Флаги // например, FlagUp, FlagLoopback, FlagMulticast
}
Интерфейс представляет собой сопоставление между именем и индексом сетевого интерфейса. Он также представляет информацию об объекте сетевого интерфейса.
func InterfaceByIndex
func InterfaceByIndex(index int) (*Interface, error)
InterfaceByIndex возвращает интерфейс, указанный индексом.
В Solaris возвращается один из логических сетевых интерфейсов, разделяющих логический канал данных; для большей точности используйте InterfaceByName.
func InterfaceByName
func InterfaceByName(name string) (*Interface, error)
InterfaceByName возвращает интерфейс, указанный именем.
func Интерфейсы
func Interfaces() ([]Interface, error)
Interfaces возвращает список сетевых интерфейсов системы.
func (*Interface) Addrs
func (ifi *Интерфейс) Addrs() ([]Addr, error)
Addrs возвращает список адресов одноадресных интерфейсов для конкретного интерфейса.
func (*Interface) MulticastAddrs
func (ifi *Интерфейс) MulticastAddrs() ([]Addr, error)
MulticastAddrs возвращает список адресов многоадресной рассылки, объединенных групп для определенного интерфейса.
type InvalidAddrError
type InvalidAddrError string
func (InvalidAddrError) Error
func (e InvalidAddrError) Error() string
func (InvalidAddrError) Temporary
func (e InvalidAddrError) Temporary() bool
func (InvalidAddrError) Timeout
func (e InvalidAddrError) Timeout() bool
type KeepAliveConfig
type KeepAliveConfig struct {
// Если Enable равно true, то зонды keep-alive включены.
Enable bool
// Idle - время, в течение которого соединение должно простаивать, прежде чем
// отправки первого зонда keep-alive.
// Если значение равно нулю, то по умолчанию используется значение 15 секунд.
Idle time.Duration
// Интервал - время между зондами keep-alive.
// Если ноль, по умолчанию используется значение 15 секунд.
Interval time.Duration
// Count - максимальное количество зондов keep-alive, которые
// может остаться без ответа до разрыва соединения.
// Если значение равно нулю, то по умолчанию используется значение 9.
Count int
}
KeepAliveConfig содержит параметры TCP keep-alive.
Если поля Idle, Interval или Count равны нулю, выбирается значение по умолчанию. Если поле отрицательно, соответствующая опция уровня сокета будет оставлена без изменений.
Обратите внимание, что до версии Windows 10 1709 ни установка Idle и Interval по отдельности, ни изменение Count (которое обычно равно 10) не поддерживаются. Поэтому, если вы хотите настроить параметры TCP keep-alive, рекомендуется установить неотрицательные значения Idle и Interval в сочетании с -1 для Count в старых версиях Windows. Напротив, если только один из Idle и Interval установлен в неотрицательное значение, другой будет установлен в значение по умолчанию, и в конечном итоге установите оба Idle и Interval в отрицательные значения, если вы хотите оставить их без изменений.
Обратите внимание, что Solaris и ее производные не поддерживают установку Interval в неотрицательное значение и Count в отрицательное значение, или наоборот.
type ListenConfig
type ListenConfig struct {
// Если Control не nil, то вызывается после создания сетевого
// соединения, но до его привязки к операционной системе.
//
// Параметры сети и адреса, передаваемые в функцию Control, не являются
// обязательно те, которые передаются в функцию Listen. Вызов Listen с сетями TCP
// приведет к вызову функции Control с параметрами "tcp4" или "tcp6",
// UDP-сети станут "udp4" или "udp6", IP-сети - "ip4" или "ip6",
// и другие известные сети передаются как есть.
Control func(network, address string, c syscall.RawConn) error
// KeepAlive задает период ожидания для сетевых
// соединений, принимаемых этим слушателем.
//
// KeepAlive игнорируется, если KeepAliveConfig.Enable равен true.
//
// Если ноль, то keep-alive включается, если поддерживается протоколом
// и операционной системой. Сетевые протоколы или операционные системы.
// которые не поддерживают keep-alive, игнорируют это поле.
// Если значение отрицательно, keep-alive отключены.
KeepAlive time.Duration
// KeepAliveConfig определяет конфигурацию зонда keep-alive
// для активного сетевого соединения, если оно поддерживается
// протоколом и операционной системой.
//
// Если KeepAliveConfig.Enable равен true, то зонды keep-alive включены.
// Если KeepAliveConfig.Enable ложно и KeepAlive отрицательно,
// зонды keep-alive отключены.
KeepAliveConfig KeepAliveConfig
// содержит отфильтрованные или неэкспонированные поля
}
ListenConfig содержит опции для прослушивания адреса.
func (*ListenConfig) Listen
func (lc *ListenConfig) Listen(ctx context.Context, network, address string) (Listener, error)
Listener сообщает об адресе локальной сети.
Описание параметров сети и адреса см. в разделе func Listen.
Аргумент ctx используется при разрешении адреса для прослушивания; он не влияет на возвращаемый error.
func (*ListenConfig) ListenPacket
func (lc *ListenConfig) ListenPacket(ctx context.Context, network, address string) (PacketConn, error)
ListenPacket сообщает об адресе локальной сети.
Описание параметров сети и адреса см. в func ListenPacket.
Аргумент ctx используется при разрешении адреса для прослушивания; он не влияет на возвращаемый слушатель.
func (*ListenConfig) MultipathTCP
func (lc *ListenConfig) MultipathTCP() bool
MultipathTCP сообщает, будет ли использоваться MPTCP.
Этот метод не проверяет, поддерживается ли MPTCP операционной системой или нет.
func (*ListenConfig) SetMultipathTCP
func (lc *ListenConfig) SetMultipathTCP(use bool)
SetMultipathTCP направляет метод Listen на использование или неиспользование MPTCP, если это поддерживается операционной системой. Этот метод отменяет системное значение по умолчанию и настройку GODEBUG=multipathtcp=…, если таковая имеется.
Если MPTCP недоступен на хосте или не поддерживается клиентом, метод Listen вернется к TCP.
type Listener ¶
type Listener interface {
// Accept ожидает и возвращает следующее соединение со слушателем.
Accept() (Conn, error)
// Close закрывает слушателя.
// Любые заблокированные операции Accept будут разблокированы и вернут ошибки.
Close() error
// Addr возвращает сетевой адрес слушателя.
Addr() Addr
}
Listener - это общий сетевой слушатель для потоково-ориентированных протоколов.
Несколько горутинов могут одновременно вызывать методы одного Listener.
Пример
package main
import (
"io"
"log"
"net"
)
func main() {
// Listen on TCP port 2000 on all available unicast and
// anycast IP addresses of the local system.
l, err := net.Listen("tcp", ":2000")
if err != nil {
log.Fatal(err)
}
defer l.Close()
for {
// Wait for a connection.
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
// Handle the connection in a new goroutine.
// The loop then returns to accepting, so that
// multiple connections may be served concurrently.
go func(c net.Conn) {
// Echo all incoming data.
io.Copy(c, c)
// Shut down the connection.
c.Close()
}(conn)
}
}func FileListener
func FileListener(f *os.File) (ln Listener, err error)
FileListener возвращает копию сетевого слушателя, соответствующего открытому файлу f. Ответственность за закрытие ln по завершении работы лежит на вызывающей стороне. Закрытие ln не влияет на f, а закрытие f не влияет на ln.
func Listen
func Listen(network, address string) (Listener, error)
Listener сообщает об адресе локальной сети.
Сеть должна быть “tcp”, “tcp4”, “tcp6”, “unix” или “unixpacket”.
Для TCP-сетей, если параметр host в параметре address пуст или является буквальным неуказанным IP-адресом, Listen прослушивает все доступные одноадресные и одноадресные IP-адреса локальной системы. Чтобы использовать только IPv4, используйте сеть “tcp4”. В качестве адреса может использоваться имя хоста, но это не рекомендуется, поскольку в этом случае будет создан слушатель только для одного из IP-адресов хоста. Если порт в параметре адреса пустой или “0”, как в “127.0.0.1:” или “[::1]:0”, номер порта выбирается автоматически. Для определения выбранного порта можно использовать метод Addr Слушателя.
Описание параметров сети и адреса см. в func Dial.
Listen внутренне использует context.Background; чтобы указать контекст, используйте ListenConfig.Listen.
type MX
type MX struct {
Host string
Pref uint16
}
MX представляет собой одну запись DNS MX.
func LookupMX
func LookupMX(name string) ([]*MX, error)
LookupMX возвращает DNS MX-записи для заданного доменного имени, отсортированные по предпочтениям.
Возвращаемые имена почтовых серверов проверяются на правильность форматирования доменных имен в формате представления. Если ответ содержит недопустимые имена, эти записи отфильтровываются, и вместе с оставшимися результатами, если таковые имеются, возвращается ошибка.
Внутри LookupMX используется context.Background; чтобы указать контекст, используйте Resolver.LookupMX.
type NS
type NS struct {
Host string
}
NS представляет собой одну запись DNS NS.
func LookupNS
func LookupNS(name string) ([]*NS, error)
LookupNS возвращает записи DNS NS для заданного доменного имени.
Возвращаемые имена серверов имен проверяются на правильность форматирования доменных имен в формате представления. Если в ответе содержатся недопустимые имена, эти записи отфильтровываются, и вместе с оставшимися результатами возвращается ошибка, если таковая имеется.
Внутри LookupNS используется context.Background; чтобы указать контекст, используйте Resolver.LookupNS.
type OpError
type OpError struct {
// Op - это операция, вызвавшая ошибку, например.
// "чтение" или "запись".
Op string
// Net - тип сети, в которой произошла ошибка,
// например, "tcp" или "udp6".
Net string
// Для операций, связанных с удаленным сетевым соединением, например.
// набор, чтение или запись, Source - это соответствующий локальный
// сетевой адрес.
Source Addr
// Addr - это сетевой адрес, для которого произошла ошибка.
// Для локальных операций, таких как Listen или SetDeadline, Addr - это
// адрес локальной конечной точки, с которой производится манипуляция.
// Для операций с удаленным сетевым соединением, таких как.
// Dial, Read или Write, Addr - это удаленный адрес этого
// соединения.
Addr Addr
// Err - это ошибка, произошедшая во время операции.
// Метод Error паникует, если ошибка равна nil.
Err error
}
OpError - это тип ошибки, обычно возвращаемый функциями пакета net. Он описывает операцию, тип сети и адрес ошибки.
func (*OpError) Error
func (e *OpError) Error() string
func (*OpError) Temporary
func (e *OpError) Temporary() bool
func (*OpError) Timeout
func (e *OpError) Timeout() bool
func (*OpError) Unwrap
func (e *OpError) Unwrap() error
type PacketConn
type PacketConn interface {
// ReadFrom читает пакет из соединения,
// копируя полезную нагрузку в p. Возвращается количество
// байт, скопированных в p, и адрес возврата, который
// был в пакете.
// Возвращается количество прочитанных байт (0 <= n <= len(p))
// и любую возникшую ошибку. Вызывающая сторона всегда должна обрабатывать
// возвращенные n > 0 байт, прежде чем рассматривать ошибку err.
// ReadFrom можно сделать так, чтобы тайм-аут и возврат ошибки происходили через
// фиксированного лимита времени; см. SetDeadline и SetReadDeadline.
ReadFrom(p []byte) (n int, addr Addr, err error)
// WriteTo записывает пакет с полезной нагрузкой p в addr.
// WriteTo можно сделать так, чтобы по истечении фиксированного времени она завершилась и вернула ошибку.
// фиксированного лимита времени; см. SetDeadline и SetWriteDeadline.
// На пакетно-ориентированных соединениях таймаут записи случается редко.
WriteTo(p []byte, addr Addr) (n int, err error)
// Close закрывает соединение.
// Любые заблокированные операции ReadFrom или WriteTo будут разблокированы и вернут ошибки.
Close() error
// LocalAddr возвращает адрес локальной сети, если он известен.
LocalAddr() Addr
// SetDeadline устанавливает крайние сроки чтения и записи, связанные
// с данным соединением. Это эквивалентно вызову обеих функций.
// SetReadDeadline и SetWriteDeadline.
//
// Крайний срок - это абсолютное время, по истечении которого операции ввода-вывода
// прекращаются, а не блокируются. Крайний срок применяется ко всем будущим
// и ожидающим операциям ввода-вывода, а не только к непосредственно следующему вызову
// чтения или записи. После превышения крайнего срока
// соединение можно обновить, установив крайний срок в будущем.
//
// Если крайний срок превышен, вызов Read или Write или других
// методы ввода/вывода вернут ошибку, обернутую в os.ErrDeadlineExceeded.
// Это можно проверить с помощью errors.Is(err, os.ErrDeadlineExceeded).
// Метод Timeout ошибки вернет true, но обратите внимание, что существуют
// есть и другие возможные ошибки, для которых метод Timeout
// вернет true, даже если срок не был превышен.
//
// Таймаут ожидания может быть реализован путем многократного продления
// крайнего срока после успешных вызовов ReadFrom или WriteTo.
//
// Нулевое значение t означает, что операции ввода-вывода не будут выполняться по тайм-ауту.
SetDeadline(t time.Time) error
// SetReadDeadline устанавливает крайний срок для будущих вызовов ReadFrom
// и любого заблокированного в данный момент вызова ReadFrom.
// Нулевое значение t означает, что ReadFrom не будет завершаться по времени.
SetReadDeadline(t time.Time) error
// SetWriteDeadline устанавливает крайний срок для будущих вызовов WriteTo
// и любого текущего заблокированного вызова WriteTo.
// Даже если запись завершилась, она может вернуть n > 0, указывая на то, что
// часть данных была успешно записана.
// Нулевое значение t означает, что WriteTo не прервется.
SetWriteDeadline(t time.Time) error
}
PacketConn - это общее сетевое соединение, ориентированное на пакеты.
Несколько горутинов могут вызывать методы на PacketConn одновременно.
func FilePacketConn
func FilePacketConn(f *os.File) (c PacketConn, err error)
FilePacketConn возвращает копию пакетного сетевого соединения, соответствующего открытому файлу f. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие c не влияет на f, а закрытие f не влияет на c.
func ListenPacket
func ListenPacket(network, address string) (PacketConn, error)
ListenPacket сообщает адрес локальной сети.
Сеть должна быть “udp”, “udp4”, “udp6”, “unixgram” или IP-транспортом. IP-транспорт - это “ip”, “ip4” или “ip6”, за которым следует двоеточие и буквенный номер протокола или имя протокола, как в “ip:1” или “ip:icmp”.
Для UDP- и IP-сетей, если в параметре address значение host пустое или это буквальный неопределенный IP-адрес, ListenPacket прослушивает все доступные IP-адреса локальной системы, кроме IP-адресов многоадресной рассылки. Чтобы использовать только IPv4, используйте сеть “udp4” или “ip4:proto”. В качестве адреса можно использовать имя хоста, но это не рекомендуется, поскольку в этом случае будет создан слушатель только для одного из IP-адресов хоста. Если порт в параметре адреса пустой или “0”, как в “127.0.0.1:” или “[::1]:0”, номер порта выбирается автоматически. Для обнаружения выбранного порта можно использовать метод LocalAddr программы PacketConn.
Описание параметров сети и адреса см. в func Dial.
ListenPacket внутренне использует context.Background; чтобы указать контекст, используйте ListenConfig.ListenPacket.
type ParseError
type ParseError struct {
// Тип - это тип ожидаемой строки, например.
// "IP-адрес", "CIDR-адрес".
Type string
// Text - неправильно сформированная текстовая строка.
Text string
}
ParseError - это тип ошибки синтаксического анализатора сетевых адресов.
func (*ParseError) Error
func (e *ParseError) Error() string
func (*ParseError) Temporary
func (e *ParseError) Temporary() bool
func (*ParseError) Timeout
func (e *ParseError) Timeout() bool
type Resolver
type Resolver struct {
// PreferGo управляет тем, предпочтителен ли встроенный DNS-резольвер Go.
// на платформах, где он доступен. Это эквивалентно настройке
// GODEBUG=netdns=go, но относится только к этому резольверу.
PreferGo bool
// StrictErrors управляет поведением временных ошибок
// (включая таймаут, ошибки сокетов и SERVFAIL) при использовании
// встроенного в Go резолвера. Для запроса, состоящего из нескольких
// подзапросов (например, поиск адреса A+AAA или переход по
// список поиска DNS), эта опция заставляет такие ошибки прерывать
// весь запрос, а не возвращать частичный результат. Эта опция
// не включена по умолчанию, поскольку это может повлиять на совместимость
// с резолверами, которые некорректно обрабатывают запросы AAAA.
StrictErrors bool
// Dial опционально задает альтернативный дозвон для использования
// встроенным DNS-резольвером Go для создания TCP- и UDP-соединений
// к службам DNS. Хост в параметре address будет
// всегда будет буквальным IP-адресом, а не именем хоста, а
// порт в параметре адреса будет буквальным номером порта
// а не имя службы.
// Если возвращаемый Conn также является PacketConn, отправленные и полученные DNS
// сообщения должны соответствовать разделу 4.2.1 RFC 1035, "Использование UDP".
// В противном случае DNS-сообщения, передаваемые через Conn, должны соответствовать
// разделу 5 RFC 7766, "Выбор транспортного протокола".
// Если nil, используется дозвонщик по умолчанию.
Dial func(ctx context.Context, network, address string) (Conn, error)
// содержит отфильтрованные или неэкспонированные поля
}
Резольвер ищет имена и номера.
Нулевой *Resolver эквивалентен нулевому Resolver.
func (*Resolver) LookupAddr
func (r *Resolver) LookupAddr(ctx context.Context, addr string) ([]string, error)
LookupAddr выполняет обратный поиск для заданного адреса, возвращая список имен, сопоставленных с этим адресом.
Возвращаемые имена проверяются на правильность форматирования доменных имен в формате представления. Если ответ содержит недопустимые имена, эти записи отфильтровываются, и вместе с оставшимися результатами, если таковые имеются, возвращается ошибка.
func (*Resolver) LookupCNAME
func (r *Resolver) LookupCNAME(ctx context.Context, host string) (string, error)
LookupCNAME возвращает каноническое имя для данного хоста. Пользователи, которым не важно каноническое имя, могут вызвать LookupHost или LookupIP напрямую; оба они позаботятся о разрешении канонического имени как части поиска.
Каноническое имя - это окончательное имя после следования нуля или более записей CNAME. LookupCNAME не возвращает ошибку, если хост не содержит записей DNS “CNAME”, при условии, что хост разрешается в адресные записи.
Возвращаемое каноническое имя проверяется на то, что оно является правильно отформатированным доменным именем формата представления.
func (*Resolver) LookupHost
func (r *Resolver) LookupHost(ctx context.Context, host string) (addrs []string, err error)
LookupHost ищет заданный хост с помощью локального резольвера. Возвращается фрагмент адресов этого хоста.
func (*Resolver) LookupIP
func (r *Resolver) LookupIP(ctx context.Context, network, host string) ([]IP, error)
LookupIP ищет хост для заданной сети с помощью локального резольвера. Возвращается фрагмент IP-адресов этого хоста типа, указанного network. network должен быть одним из “ip”, “ip4” или “ip6”.
func (*Resolver) LookupIPAddr
func (r *Resolver) LookupIPAddr(ctx context.Context, host string) ([]IPAddr, error)
LookupIPAddr ищет хост с помощью локального резольвера. Возвращается фрагмент IPv4- и IPv6-адресов этого хоста.
func (*Resolver) LookupMX
func (r *Resolver) LookupMX(ctx context.Context, name string) ([]*MX, error)
LookupMX возвращает DNS MX-записи для заданного доменного имени, отсортированные по предпочтению.
Возвращаемые имена почтовых серверов проверяются на правильность форматирования доменных имен в формате представления. Если в ответе содержатся недопустимые имена, эти записи отфильтровываются, и вместе с оставшимися результатами, если таковые имеются, возвращается ошибка.
func (*Resolver) LookupNS
func (r *Resolver) LookupNS(ctx context.Context, name string) ([]*NS, error)
LookupNS возвращает NS-записи DNS для заданного доменного имени.
Возвращаемые имена серверов имен проверяются на правильность форматирования доменных имен в формате представления. Если ответ содержит недопустимые имена, эти записи отфильтровываются, и вместе с оставшимися результатами, если таковые имеются, возвращается ошибка.
func (*Resolver) LookupNetIP
func (r *Resolver) LookupNetIP(ctx context.Context, network, host string) ([]netip.Addr, error)
LookupNetIP ищет хост с помощью локального резольвера. Возвращается фрагмент IP-адресов этого хоста типа, указанного в network. Сеть должна быть одной из “ip”, “ip4” или “ip6”.
func (*Resolver) LookupPort
func (r *Resolver) LookupPort(ctx context.Context, network, service string) (port int, err error)
LookupPort ищет порт для заданной сети и сервиса.
Сеть должна быть одной из “tcp”, “tcp4”, “tcp6”, “udp”, “udp4”, “udp6” или “ip”.
func (*Resolver) LookupSRV
func (r *Resolver) LookupSRV(ctx context.Context, service, proto, name string) (string, []*SRV, error)
LookupSRV пытается разрешить SRV-запрос данного сервиса, протокола и доменного имени. Протоколом является “tcp” или “udp”. Возвращаемые записи сортируются по приоритету и рандомизируются по весу в пределах приоритета.
LookupSRV строит DNS-имя для поиска в соответствии с RFC 2782. То есть, он ищет _service._proto.name. Для удобства сервисов, публикующих SRV-записи под нестандартными именами, если service и proto являются пустыми строками, LookupSRV ищет имя напрямую.
Возвращаемые имена сервисов проверяются на правильность форматирования доменных имен в формате представления. Если ответ содержит недопустимые имена, эти записи отфильтровываются и возвращается ошибка вместе с оставшимися результатами, если таковые имеются.
func (*Resolver) LookupTXT
func (r *Resolver) LookupTXT(ctx context.Context, name string) ([]string, error)
LookupTXT возвращает записи DNS TXT для заданного доменного имени.
Если DNS TXT-запись содержит несколько строк, они объединяются в одну строку.
type SRV
type SRV struct {
Target string
Port uint16
Priority uint16
Weight uint16
}
SRV представляет собой одну запись DNS SRV.
func LookupSRV
func LookupSRV(service, proto, name string) (cname string, addrs []*SRV, err error)
LookupSRV пытается разрешить SRV-запрос для данного сервиса, протокола и доменного имени. Протоколом является “tcp” или “udp”. Возвращаемые записи сортируются по приоритету и рандомизируются по весу в пределах приоритета.
LookupSRV строит DNS-имя для поиска в соответствии с RFC 2782. То есть, он ищет _service._proto.name. Для удобства сервисов, публикующих SRV-записи под нестандартными именами, если service и proto являются пустыми строками, LookupSRV ищет имя напрямую.
Возвращаемые имена сервисов проверяются на правильность форматирования доменных имен в формате представления. Если ответ содержит недопустимые имена, эти записи отфильтровываются, и вместе с оставшимися результатами, если таковые имеются, возвращается ошибка.
type TCPAddr
type TCPAddr struct {
IP IP
Port int
Zone string // Зона масштабируемой адресации IPv6
}
TCPAddr представляет адрес конечной точки TCP.
func ResolveTCPAddr
func ResolveTCPAddr(network, address string) (*TCPAddr, error)
ResolveTCPAddr возвращает адрес конечной точки TCP.
Сеть должна быть именем TCP-сети.
Если хост в параметре address не является литеральным IP-адресом или порт не является литеральным номером порта, ResolveTCPAddr преобразует адрес в адрес конечной точки TCP. В противном случае он разбирает адрес как пару из буквального IP-адреса и номера порта. В качестве параметра address может использоваться имя хоста, но это не рекомендуется, так как вернется не более одного из IP-адресов имени хоста.
Описание параметров сети и адреса см. в разделе func Dial.
func TCPAddrFromAddrPort
func TCPAddrFromAddrPort(addr netip.AddrPort) *TCPAddr
TCPAddrFromAddrPort возвращает addr как TCPAddr. Если addr.IsValid() равен false, то возвращаемый TCPAddr будет содержать нулевое поле IP, указывающее на неопределенный адрес, не зависящий от семейства адресов.
func (*TCPAddr) AddrPort
func (a *TCPAddr) AddrPort() netip.AddrPort
AddrPort возвращает TCPAddr a в виде netip.AddrPort.
Если a.Port не помещается в uint16, он тихо усекается.
Если a равно nil, возвращается нулевое значение.
func (*TCPAddr) Network
func (a *TCPAddr) Network() string
Network возвращает сетевое имя адреса, “tcp”.
func (*TCPAddr) String
func (a *TCPAddr) String() string
type TCPConn
type TCPConn struct {
// содержит отфильтрованные или неэкспонированные поля
}
TCPConn - это реализация интерфейса Conn для сетевых соединений TCP.
func DialTCP
func DialTCP(network string, laddr, raddr *TCPAddr) (*TCPConn, error)
DialTCP действует как Dial для сетей TCP.
Сеть должна быть именем TCP-сети; подробности см. в func Dial.
Если laddr равен nil, автоматически выбирается локальный адрес. Если поле IP в raddr равно nil или является неопределенным IP-адресом, предполагается локальная система.
func (*TCPConn) Закрыть
func (c *TCPConn) Close() error
Close закрывает соединение.
func (*TCPConn) CloseRead
func (c *TCPConn) CloseRead() error
CloseRead закрывает TCP-соединение со стороны чтения. Большинство вызывающих должны просто использовать Close.
func (*TCPConn) CloseWrite
func (c *TCPConn) CloseWrite() error
CloseWrite закрывает пишущую сторону TCP-соединения. Большинству вызывающих следует просто использовать Close.
func (*TCPConn) File
func (c *TCPConn) File() (f *os.File, err error)
File возвращает копию базового файла os.File. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие c не влияет на f, а закрытие f не влияет на c.
Дескриптор файла возвращаемого os.File отличается от дескриптора соединения. Попытка изменить свойства оригинала с помощью этого дубликата может привести к желаемому результату, а может и не привести.
func (*TCPConn) LocalAddr
func (c *TCPConn) LocalAddr() Addr
LocalAddr возвращает адрес локальной сети. Возвращаемый Addr является общим для всех вызовов LocalAddr, поэтому не изменяйте его.
func (*TCPConn) MultipathTCP
func (c *TCPConn) MultipathTCP() (bool, error)
MultipathTCP сообщает, использует ли текущее соединение MPTCP.
Если Multipath TCP не поддерживается хостом, другим пиром или намеренно/случайно отфильтровывается каким-либо устройством между ними, будет выполнен откат к TCP. Этот метод делает все возможное, чтобы проверить, используется ли MPTCP или нет.
В Linux больше условий проверяется на ядрах >= v5.16, что улучшает результаты.
func (*TCPConn) Read
func (c *TCPConn) Read(b []byte) (int, error)
Read реализует метод Conn Read.
func (*TCPConn) ReadFrom
func (c *TCPConn) ReadFrom(r io.Reader) (int64, error)
ReadFrom реализует метод io.ReaderFrom ReadFrom.
func (*TCPConn) RemoteAddr
func (c *TCPConn) RemoteAddr() Addr
RemoteAddr возвращает адрес удаленной сети. Возвращаемый Addr является общим для всех вызовов RemoteAddr, поэтому не изменяйте его.
func (*TCPConn) SetDeadline
func (c *TCPConn) SetDeadline(t time.Time) error
SetDeadline реализует метод Conn SetDeadline.
func (*TCPConn) SetKeepAlive
func (c *TCPConn) SetKeepAlive(keepalive bool) error
SetKeepAlive устанавливает, должна ли операционная система отправлять сообщения keep-alive на соединение.
func (*TCPConn) SetKeepAliveConfig
func (c *TCPConn) SetKeepAliveConfig(config KeepAliveConfig) error
SetKeepAliveConfig настраивает сообщения keep-alive, отправляемые операционной системой.
func (*TCPConn) SetKeepAlivePeriod
func (c *TCPConn) SetKeepAlivePeriod(d time.Duration) error
SetKeepAlivePeriod устанавливает время, в течение которого соединение должно простаивать, прежде чем TCP начнет посылать keepalive зонды.
Обратите внимание, что вызов этого метода на Windows до Windows 10 версии 1709 сбросит KeepAliveInterval на системное значение по умолчанию, которое обычно составляет 1 секунду.
func (*TCPConn) SetLinger
func (c *TCPConn) SetLinger(sec int) error
SetLinger задает поведение Close на соединении, которое все еще ожидает отправки или подтверждения данных.
Если sec < 0 (по умолчанию), операционная система завершает отправку данных в фоновом режиме.
Если sec == 0, операционная система отбрасывает все неотправленные или неподтвержденные данные.
Если sec > 0, данные отправляются в фоновом режиме, как и в случае sec < 0. В некоторых операционных системах, включая Linux, это может привести к блокировке Close до тех пор, пока все данные не будут отправлены или отброшены. В некоторых операционных системах по истечении sec все оставшиеся неотправленные данные могут быть отброшены.
func (*TCPConn) SetNoDelay
func (c *TCPConn) SetNoDelay(noDelay bool) error
SetNoDelay управляет тем, должна ли операционная система задерживать передачу пакетов в надежде отправить меньше пакетов (алгоритм Нагла). По умолчанию установлено значение true (без задержки), что означает, что данные отправляются как можно быстрее после записи.
func (*TCPConn) SetReadBuffer
func (c *TCPConn) SetReadBuffer(bytes int) error
SetReadBuffer устанавливает размер буфера приема операционной системы, связанного с соединением.
func (*TCPConn) SetReadDeadline
func (c *TCPConn) SetReadDeadline(t time.Time) error
SetReadDeadline реализует метод Conn SetReadDeadline.
func (*TCPConn) SetWriteBuffer
func (c *TCPConn) SetWriteBuffer(bytes int) error
SetWriteBuffer устанавливает размер буфера передачи операционной системы, связанного с соединением.
func (*TCPConn) SetWriteDeadline
func (c *TCPConn) SetWriteDeadline(t time.Time) error
SetWriteDeadline реализует метод Conn SetWriteDeadline.
func (*TCPConn) SyscallConn
func (c *TCPConn) SyscallConn() (syscall.RawConn, error)
SyscallConn возвращает необработанное сетевое соединение. Оно реализует интерфейс syscall.Conn.
func (*TCPConn) Write
func (c *TCPConn) Write(b []byte) (int, error)
Write реализует метод записи Conn.
func (*TCPConn) WriteTo
func (c *TCPConn) WriteTo(w io.Writer) (int64, error)
WriteTo реализует метод io.WriterTo WriteTo.
type TCPListener
type TCPListener struct {
// содержит отфильтрованные или неэкспонированные поля
}
TCPListener - это сетевой слушатель TCP. Клиенты обычно должны использовать переменные типа Listener, а не предполагать, что это TCP.
func ListenTCP
func ListenTCP(network string, laddr *TCPAddr) (*TCPListener, error)
ListenTCP действует как Listen для сетей TCP.
Сеть должна быть именем TCP-сети; подробности см. в func Dial.
Если поле IP в laddr равно nil или неопределенному IP-адресу, ListenTCP прослушивает все доступные одноадресные и одноадресные IP-адреса локальной системы. Если поле Port в laddr равно 0, номер порта выбирается автоматически.
func (*TCPListener) Accept
func (l *TCPListener) Accept() (Conn, error)
Accept реализует метод Accept в интерфейсе Listener; он ожидает следующего вызова и возвращает общий Conn.
func (*TCPListener) AcceptTCP
func (l *TCPListener) AcceptTCP() (*TCPConn, error)
AcceptTCP принимает следующий входящий вызов и возвращает новое соединение.
func (*TCPListener) Addr
func (l *TCPListener) Addr() Addr
Addr возвращает сетевой адрес слушателя, *TCPAddr. Возвращаемый Addr является общим для всех вызовов Addr, поэтому не изменяйте его.
func (*TCPListener) Close
func (l *TCPListener) Close() error
Close прекращает прослушивание TCP-адреса. Уже принятые соединения не закрываются.
func (*TCPListener) File
func (l *TCPListener) File() (f *os.File, err error)
File возвращает копию базового файла os.File. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие l не влияет на f, а закрытие f не влияет на l.
Файловый дескриптор возвращаемого os.File отличается от дескриптора соединения. Попытка изменить свойства оригинала с помощью этого дубликата может привести к желаемому результату, а может и не привести.
func (*TCPListener) SetDeadline
func (l *TCPListener) SetDeadline(t time.Time) error
SetDeadline устанавливает крайний срок, связанный со слушателем. Нулевое значение времени отключает дедлайн.
func (*TCPListener) SyscallConn
func (l *TCPListener) SyscallConn() (syscall.RawConn, error)
SyscallConn возвращает необработанное сетевое соединение. Оно реализует интерфейс syscall.Conn.
Возвращаемое RawConn поддерживает только вызов Control. Чтение и запись возвращают ошибку.
type UDPAddr
type UDPAddr struct {
IP IP
Порт int
Zone string // Зона масштабируемой адресации IPv6
}
UDPAddr представляет адрес конечной точки UDP.
func ResolveUDPAddr
func ResolveUDPAddr(network, address string) (*UDPAddr, error)
ResolveUDPAddr возвращает адрес конечной точки UDP.
Сеть должна быть именем UDP-сети.
Если хост в параметре address не является литеральным IP-адресом или порт не является литеральным номером порта, ResolveUDPAddr преобразует адрес в адрес конечной точки UDP. В противном случае он разбирает адрес как пару из буквального IP-адреса и номера порта. В качестве параметра address может использоваться имя хоста, но это не рекомендуется, так как вернется не более одного из IP-адресов имени хоста.
Описание параметров сети и адреса см. в разделе func Dial.
func UDPAddrFromAddrPort
func UDPAddrFromAddrPort(addr netip.AddrPort) *UDPAddr
UDPAddrFromAddrPort возвращает addr как UDPAddr. Если addr.IsValid() равен false, то возвращаемый UDPAddr будет содержать нулевое поле IP, указывающее на неопределенный адрес, не зависящий от семейства адресов.
func (*UDPAddr) AddrPort
func (a *UDPAddr) AddrPort() netip.AddrPort
AddrPort возвращает UDPAddr a в виде netip.AddrPort.
Если a.Port не помещается в uint16, он тихо усекается.
Если a равно nil, возвращается нулевое значение.
func (*UDPAddr) Network
func (a *UDPAddr) Network() string
Network возвращает сетевое имя адреса, “udp”.
func (*UDPAddr) String
func (a *UDPAddr) String() string
type UDPConn
type UDPConn struct {
// содержит отфильтрованные или неэкспонированные поля
}
UDPConn - это реализация интерфейсов Conn и PacketConn для сетевых соединений UDP.
func DialUDP
func DialUDP(network string, laddr, raddr *UDPAddr) (*UDPConn, error)
DialUDP действует как Dial для сетей UDP.
Сеть должна быть именем UDP-сети; подробности см. в func Dial.
Если laddr равно nil, автоматически выбирается локальный адрес. Если поле IP в raddr равно nil или является неопределенным IP-адресом, предполагается локальная система.
func ListenMulticastUDP
func ListenMulticastUDP(network string, ifi *Interface, gaddr *UDPAddr) (*UDPConn, error)
ListenMulticastUDP действует подобно ListenPacket для UDP сетей, но принимает групповой адрес на определенном сетевом интерфейсе.
Сеть должна быть именем UDP-сети; подробности см. в func Dial.
ListenMulticastUDP прослушивает все доступные IP-адреса локальной системы, включая групповой, многоадресный IP-адрес. Если ifi равно nil, ListenMulticastUDP использует назначенный системой многоадресный интерфейс, хотя это не рекомендуется, поскольку назначение зависит от платформ и иногда может потребовать настройки маршрутизации. Если поле Port в gaddr равно 0, номер порта выбирается автоматически.
ListenMulticastUDP предназначен только для удобства простых, небольших приложений. Для общего назначения существуют пакеты golang.org/x/net/ipv4 и golang.org/x/net/ipv6.
Обратите внимание, что ListenMulticastUDP установит опцию сокета IP_MULTICAST_LOOP в 0 в IPPROTO_IP, чтобы отключить обратную петлю для многоадресных пакетов.
func ListenUDP
func ListenUDP(network string, laddr *UDPAddr) (*UDPConn, error)
ListenUDP действует как ListenPacket для сетей UDP.
Сеть должна быть именем UDP-сети; подробности см. в func Dial.
Если поле IP в laddr равно nil или неопределенному IP-адресу, ListenUDP прослушивает все доступные IP-адреса локальной системы, кроме IP-адресов многоадресной рассылки. Если поле Port в laddr равно 0, номер порта выбирается автоматически.
func (*UDPConn) Close
func (c *UDPConn) Close() error
Close закрывает соединение.
func (*UDPConn) File
func (c *UDPConn) File() (f *os.File, err error)
File возвращает копию базового файла os.File. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие c не влияет на f, а закрытие f не влияет на c.
Дескриптор файла возвращаемого os.File отличается от дескриптора соединения. Попытка изменить свойства оригинала с помощью этого дубликата может привести к желаемому результату, а может и не привести.
func (*UDPConn) LocalAddr
func (c *UDPConn) LocalAddr() Addr
LocalAddr возвращает адрес локальной сети. Возвращаемый Addr является общим для всех вызовов LocalAddr, поэтому не изменяйте его.
func (*UDPConn) Read
func (c *UDPConn) Read(b []byte) (int, error)
Read реализует метод Conn Read.
func (*UDPConn) ReadFrom
func (c *UDPConn) ReadFrom(b []byte) (int, Addr, error)
ReadFrom реализует метод PacketConn ReadFrom.
func (*UDPConn) ReadFromUDP
func (c *UDPConn) ReadFromUDP(b []byte) (n int, addr *UDPAddr, err error)
ReadFromUDP действует как UDPConn.ReadFrom, но возвращает UDPAddr.
func (*UDPConn) ReadFromUDPAddrPort
func (c *UDPConn) ReadFromUDPAddrPort(b []byte) (n int, addr netip.AddrPort, err error)
ReadFromUDPAddrPort действует аналогично ReadFrom, но возвращает netip.AddrPort.
Если c привязан к неопределенному адресу, возвращаемый адрес netip.AddrPort может быть IPv4-маппированным IPv6-адресом. Используйте netip.Addr.Unmap, чтобы получить адрес без префикса IPv6.
func (*UDPConn) ReadMsgUDP
func (c *UDPConn) ReadMsgUDP(b, oob []byte) (n, oobn, flags int, addr *UDPAddr, err error)
ReadMsgUDP считывает сообщение из c, копируя полезную нагрузку в b и связанные с ней внеполосные данные в oob. Возвращается количество байт, скопированных в b, количество байт, скопированных в oob, флаги, которые были установлены для сообщения, и адрес источника сообщения.
Пакеты golang.org/x/net/ipv4 и golang.org/x/net/ipv6 могут быть использованы для манипулирования опциями сокетов IP-уровня в oob.
func (*UDPConn) ReadMsgUDPAddrPort
func (c *UDPConn) ReadMsgUDPAddrPort(b, oob []byte) (n, oobn, flags int, addr netip.AddrPort, err error)
ReadMsgUDPAddrPort подобен UDPConn.ReadMsgUDP, но возвращает netip.AddrPort вместо UDPAddr.
func (*UDPConn) RemoteAddr
func (c *UDPConn) RemoteAddr() Addr
RemoteAddr возвращает адрес удаленной сети. Возвращаемый Addr является общим для всех вызовов RemoteAddr, поэтому не изменяйте его.
func (*UDPConn) SetDeadline
func (c *UDPConn) SetDeadline(t time.Time) error
SetDeadline реализует метод Conn SetDeadline.
func (*UDPConn) SetReadBuffer
func (c *UDPConn) SetReadBuffer(bytes int) error
SetReadBuffer устанавливает размер буфера приема операционной системы, связанного с соединением.
func (*UDPConn) SetReadDeadline
func (c *UDPConn) SetReadDeadline(t time.Time) error
SetReadDeadline реализует метод Conn SetReadDeadline.
func (*UDPConn) SetWriteBuffer
func (c *UDPConn) SetWriteBuffer(bytes int) error
SetWriteBuffer устанавливает размер буфера передачи операционной системы, связанного с соединением.
func (*UDPConn) SetWriteDeadline
func (c *UDPConn) SetWriteDeadline(t time.Time) error
SetWriteDeadline реализует метод Conn SetWriteDeadline.
func (*UDPConn) SyscallConn
func (c *UDPConn) SyscallConn() (syscall.RawConn, error)
SyscallConn возвращает необработанное сетевое соединение. Оно реализует интерфейс syscall.Conn.
func (*UDPConn) Write
func (c *UDPConn) Write(b []byte) (int, error)
Write реализует метод записи Conn.
func (*UDPConn) WriteMsgUDP
func (c *UDPConn) WriteMsgUDP(b, oob []byte, addr *UDPAddr) (n, oobn int, err error)
WriteMsgUDP записывает сообщение на addr через c, если c не подключен, или на удаленный адрес c, если c подключен (в этом случае addr должен быть nil). Полезная нагрузка копируется из b, а связанные с ней внеполосные данные - из oob. Возвращает количество записанных байтов полезной нагрузки и внеполосных данных.
Пакеты golang.org/x/net/ipv4 и golang.org/x/net/ipv6 могут быть использованы для манипулирования опциями сокетов IP-уровня в oob.
func (*UDPConn) WriteMsgUDPAddrPort
func (c *UDPConn) WriteMsgUDPAddrPort(b, oob []byte, addr netip.AddrPort) (n, oobn int, err error)
WriteMsgUDPAddrPort подобен UDPConn.WriteMsgUDP, но принимает netip.AddrPort вместо UDPAddr.
func (*UDPConn) WriteTo
func (c *UDPConn) WriteTo(b []byte, addr Addr) (int, error)
WriteTo реализует метод PacketConn WriteTo.
Пример
package main
import (
"log"
"net"
)
func main() {
// Unlike Dial, ListenPacket creates a connection without any
// association with peers.
conn, err := net.ListenPacket("udp", ":0")
if err != nil {
log.Fatal(err)
}
defer conn.Close()
dst, err := net.ResolveUDPAddr("udp", "192.0.2.1:2000")
if err != nil {
log.Fatal(err)
}
// The connection can write data to the desired address.
_, err = conn.WriteTo([]byte("data"), dst)
if err != nil {
log.Fatal(err)
}
}
func (*UDPConn) WriteToUDP
func (c *UDPConn) WriteToUDP(b []byte, addr *UDPAddr) (int, error)
WriteToUDP действует как UDPConn.WriteTo, но принимает UDPAddr.
func (*UDPConn) WriteToUDPAddrPort
func (c *UDPConn) WriteToUDPAddrPort(b []byte, addr netip.AddrPort) (int, error)
WriteToUDPAddrPort действует как UDPConn.WriteTo, но принимает netip.AddrPort.
type UnixAddr
type UnixAddr struct {
строка имени
Net string
}
UnixAddr представляет адрес конечной точки сокета домена Unix.
func ResolveUnixAddr
func ResolveUnixAddr(network, address string) (*UnixAddr, error)
ResolveUnixAddr возвращает адрес конечной точки сокета домена Unix.
Сеть должна быть именем сети Unix.
Описание параметров сети и адреса см. в разделе func Dial.
func (*UnixAddr) Network
func (a *UnixAddr) Network() string
Network возвращает сетевое имя адреса, “unix”, “unixgram” или “unixpacket”.
func (*UnixAddr) String
func (a *UnixAddr) String() string
type UnixConn
type UnixConn struct {
// содержит отфильтрованные или неэкспонированные поля
}
UnixConn - это реализация интерфейса Conn для соединений с сокетами домена Unix.
func DialUnix
func DialUnix(network string, laddr, raddr *UnixAddr) (*UnixConn, error)
DialUnix действует как Dial для сетей Unix.
Сеть должна быть именем сети Unix; подробности см. в func Dial.
Если laddr не равен nil, он используется в качестве локального адреса для соединения.
func ListenUnixgram
func ListenUnixgram(network string, laddr *UnixAddr) (*UnixConn, error)
ListenUnixgram действует как ListenPacket для сетей Unix.
Сеть должна быть “unixgram”.
func (*UnixConn) Закрыть
func (c *UnixConn) Close() error
Close закрывает соединение.
func (*UnixConn) CloseRead
func (c *UnixConn) CloseRead() error
CloseRead закрывает сторону чтения соединения с доменом Unix. Большинство вызывающих должны просто использовать Close.
func (*UnixConn) CloseWrite
func (c *UnixConn) CloseWrite() error
CloseWrite закрывает пишущую сторону соединения с доменом Unix. Большинство вызывающих должны просто использовать Close.
func (*UnixConn) File
func (c *UnixConn) File() (f *os.File, err error)
File возвращает копию базового файла os.File. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие c не влияет на f, а закрытие f не влияет на c.
Дескриптор файла возвращаемого os.File отличается от дескриптора соединения. Попытка изменить свойства оригинала с помощью этого дубликата может привести к желаемому результату, а может и не привести.
func (*UnixConn) LocalAddr
func (c *UnixConn) LocalAddr() Addr
LocalAddr возвращает адрес локальной сети. Возвращаемый Addr является общим для всех вызовов LocalAddr, поэтому не изменяйте его.
func (*UnixConn) Read
func (c *UnixConn) Read(b []byte) (int, error)
Read реализует метод Conn Read.
func (*UnixConn) ReadFrom
func (c *UnixConn) ReadFrom(b []byte) (int, Addr, error)
ReadFrom реализует метод PacketConn ReadFrom.
func (*UnixConn) ReadFromUnix
func (c *UnixConn) ReadFromUnix(b []byte) (int, *UnixAddr, error)
ReadFromUnix действует как UnixConn.ReadFrom, но возвращает UnixAddr.
func (*UnixConn) ReadMsgUnix
func (c *UnixConn) ReadMsgUnix(b, oob []byte) (n, oobn, flags int, addr *UnixAddr, err error)
ReadMsgUnix считывает сообщение из c, копируя полезную нагрузку в b и связанные с ней внеполосные данные в oob. Возвращается количество байт, скопированных в b, количество байт, скопированных в oob, флаги, которые были установлены для сообщения, и адрес источника сообщения.
Обратите внимание, что если len(b) == 0 и len(oob) > 0, эта функция все равно прочитает (и отбросит) 1 байт из соединения.
func (*UnixConn) RemoteAddr
func (c *UnixConn) RemoteAddr() Addr
RemoteAddr возвращает адрес удаленной сети. Возвращаемый Addr является общим для всех вызовов RemoteAddr, поэтому не изменяйте его.
func (*UnixConn) SetDeadline
func (c *UnixConn) SetDeadline(t time.Time) error
SetDeadline реализует метод Conn SetDeadline.
func (*UnixConn) SetReadBuffer
func (c *UnixConn) SetReadBuffer(bytes int) error
SetReadBuffer устанавливает размер буфера приема операционной системы, связанного с соединением.
func (*UnixConn) SetReadDeadline
func (c *UnixConn) SetReadDeadline(t time.Time) error
SetReadDeadline реализует метод Conn SetReadDeadline.
func (*UnixConn) SetWriteBuffer
func (c *UnixConn) SetWriteBuffer(bytes int) error
SetWriteBuffer устанавливает размер буфера передачи операционной системы, связанного с соединением.
func (*UnixConn) SetWriteDeadline
func (c *UnixConn) SetWriteDeadline(t time.Time) error
SetWriteDeadline реализует метод Conn SetWriteDeadline.
func (*UnixConn) SyscallConn
func (c *UnixConn) SyscallConn() (syscall.RawConn, error)
SyscallConn возвращает необработанное сетевое соединение. Оно реализует интерфейс syscall.Conn.
func (*UnixConn) Write
func (c *UnixConn) Write(b []byte) (int, error)
Write реализует метод Conn Write.
func (*UnixConn) WriteMsgUnix
func (c *UnixConn) WriteMsgUnix(b, oob []byte, addr *UnixAddr) (n, oobn int, err error)
WriteMsgUnix записывает сообщение в addr через c, копируя полезную нагрузку из b и связанные с ней внеполосные данные из oob. Возвращается количество записанных байт полезной нагрузки и внеполосных данных.
Обратите внимание, что если len(b) == 0 и len(oob) > 0, эта функция все равно запишет 1 байт в соединение.
func (*UnixConn) WriteTo
func (c *UnixConn) WriteTo(b []byte, addr Addr) (int, error)
WriteTo реализует метод PacketConn WriteTo.
func (*UnixConn) WriteToUnix
func (c *UnixConn) WriteToUnix(b []byte, addr *UnixAddr) (int, error)
WriteToUnix действует как UnixConn.WriteTo, но принимает UnixAddr.
type UnixListener
type UnixListener struct {
// содержит отфильтрованные или неэкспонированные поля
}
UnixListener - это слушатель сокетов домена Unix. Клиенты обычно должны использовать переменные типа Listener вместо того, чтобы предполагать сокеты домена Unix.
func ListenUnix
func ListenUnix(network string, laddr *UnixAddr) (*UnixListener, error)
ListenUnix действует как Listen для сетей Unix.
Сеть должна быть “unix” или “unixpacket”.
func (*UnixListener) Принять
func (l *UnixListener) Accept() (Conn, error)
Accept реализует метод Accept в интерфейсе Listener. Возвращаемые соединения будут иметь тип *UnixConn.
func (*UnixListener) AcceptUnix
func (l *UnixListener) AcceptUnix() (*UnixConn, error)
AcceptUnix принимает следующий входящий вызов и возвращает новое соединение.
func (*UnixListener) Addr
func (l *UnixListener) Addr() Addr
Addr возвращает сетевой адрес слушателя. Возвращаемый Addr является общим для всех вызовов Addr, поэтому не изменяйте его.
func (*UnixListener) Close
func (l *UnixListener) Close() error
Close прекращает прослушивание Unix-адреса. Уже принятые соединения не закрываются.
func (*UnixListener) File
func (l *UnixListener) File() (f *os.File, err error)
File возвращает копию базового файла os.File. Ответственность за закрытие f по завершении работы лежит на вызывающей стороне. Закрытие l не влияет на f, а закрытие f не влияет на l.
Файловый дескриптор возвращаемого os.File отличается от дескриптора соединения. Попытки изменить свойства оригинала с помощью этого дубликата могут привести к желаемому результату, а могут и не привести.
func (*UnixListener) SetDeadline
func (l *UnixListener) SetDeadline(t time.Time) error
SetDeadline устанавливает крайний срок, связанный со слушателем. Нулевое значение времени отключает дедлайн.
func (*UnixListener) SetUnlinkOnClose
func (l *UnixListener) SetUnlinkOnClose(unlink bool)
SetUnlinkOnClose устанавливает, должен ли базовый файл сокета быть удален из файловой системы при закрытии слушателя.
Поведение по умолчанию заключается в том, что файл сокета отсоединяется только тогда, когда пакет net создал его. То есть, если слушатель и базовый файл сокета были созданы вызовом Listen или ListenUnix, то по умолчанию закрытие слушателя приведет к удалению файла сокета. Но если слушатель был создан вызовом FileListener для использования уже существующего файла сокета, то по умолчанию закрытие слушателя не приведет к удалению файла сокета.
func (*UnixListener) SyscallConn
func (l *UnixListener) SyscallConn() (syscall.RawConn, error)
SyscallConn возвращает необработанное сетевое соединение. Оно реализует интерфейс syscall.Conn.
Возвращаемое RawConn поддерживает только вызов Control. Чтение и запись возвращают ошибку.
type UnknownNetworkError
type UnknownNetworkError string
func (UnknownNetworkError) Error
func (e UnknownNetworkError) Error() string
func (UnknownNetworkError) Temporary
func (e UnknownNetworkError) Temporary() bool
func (UnknownNetworkError) Timeout
func (e UnknownNetworkError) Timeout() bool
Примечания
Ошибки
- В JS и Windows функции FileConn, FileListener и FilePacketConn не реализованы.
- В JS методы и функции, связанные с Interface, не реализованы.
- В AIX, DragonFly BSD, NetBSD, OpenBSD, Plan 9 и Solaris метод MulticastAddrs интерфейса Interface не реализован.
- На всех платформах POSIX чтение из сети “ip4” с помощью метода ReadFrom или ReadFromIP может не возвращать полный пакет IPv4, включая его заголовок, даже если есть свободное место. Это может произойти даже в тех случаях, когда Read или ReadMsgIP могут вернуть полный пакет. По этой причине рекомендуется не использовать эти методы, если важно получить полный пакет.
- Рекомендации по совместимости Go 1 не позволяют нам изменить поведение этих методов; вместо них используйте Read или ReadMsgIP.
- На JS и Plan 9 методы и функции, связанные с IPConn, не реализованы.
- На Windows метод File интерфейса IPConn не реализован.
- В DragonFly BSD и OpenBSD прослушивание сетей “tcp” и “udp” не прослушивает соединения IPv4 и IPv6. Это связано с тем, что трафик IPv4 не будет маршрутизироваться в сокет IPv6 — для поддержки обеих семейств адресов требуются два отдельных сокета. Подробности см. в inet6(4).
- В Windows метод Write syscall.RawConn не интегрирован с сетевым опросником среды выполнения. Он не может ждать, пока соединение станет доступным для записи, и не учитывает deadli
12.4.15.3 - Пакет net/http встроенных функций и типов языка Go
Пакет http предоставляет реализации HTTP-клиента и сервера. Get, Head, Post и PostForm выполняют HTTP- (или HTTPS)-запросы.
resp, err := http.Get("http://example.com/")
...
resp, err := http.Post("http://example.com/upload", "image/jpeg", &buf)
...
resp, err := http.PostForm("http://example.com/form",
url.Values{"key": {"Value"}, "id": {"123"}})
Вызывающий абонент должен закрыть тело Resp, когда закончит с ним работать:
resp, err := http.Get("http://example.com/")
if err != nil {
// handle error
}
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
// ...
Клиенты и транспорты (Clients and Transports)
Для управления HTTP-заголовками, политикой перенаправлений (redirects) и другими настройками клиента, создайте http.Client:
client := &http.Client{
CheckRedirect: redirectPolicyFunc, // политика перенаправлений
}
resp, err := client.Get("http://example.com")
// ...
req, err := http.NewRequest("GET", "http://example.com", nil)
req.Header.Add("If-None-Match", `W/"wyzzy"`) // добавление кастомного заголовка
resp, err := client.Do(req)
// ...
Для более низкоуровневого контроля (прокси, TLS, keep-alive, сжатие и др.) настройте http.Transport:
tr := &http.Transport{
MaxIdleConns: 10, // макс. число бездействующих соединений
IdleConnTimeout: 30 * time.Second, // таймаут для idle-соединений
DisableCompression: true, // отключение сжатия (gzip)
}
client := &http.Client{Transport: tr}
resp, err := client.Get("https://example.com")
⚠ Важно:
ClientиTransportпотокобезопасны (можно использовать в нескольких горутинах).- Их следует создавать один раз и переиспользовать для эффективности.
Серверы (Servers)
ListenAndServe запускает HTTP-сервер с указанным адресом и обработчиком (handler). Если handler = nil, используется DefaultServeMux:
http.Handle("/foo", fooHandler) // регистрация обработчика для пути "/foo"
http.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, %q", html.EscapeString(r.URL.Path))
})
log.Fatal(http.ListenAndServe(":8080", nil)) // запуск сервера на :8080
Для тонкой настройки сервера создайте http.Server:
s := &http.Server{
Addr: ":8080", // адрес сервера
Handler: myHandler, // кастомный обработчик
ReadTimeout: 10 * time.Second, // таймаут на чтение запроса
WriteTimeout: 10 * time.Second, // таймаут на запись ответа
MaxHeaderBytes: 1 << 20, // макс. размер заголовков (1 MB)
}
log.Fatal(s.ListenAndServe())
Поддержка HTTP/2
С Go 1.6+ HTTP/2 поддерживается автоматически при использовании HTTPS.
Как отключить HTTP/2?
- Для клиента: задать
Transport.TLSNextProto = make(map[string]func(...))(пустойmap). - Для сервера: задать
Server.TLSNextProto = make(map[string]func(...)).
Через переменную GODEBUG:
GODEBUG=http2client=0 # отключить HTTP/2 для клиентов
GODEBUG=http2server=0 # отключить HTTP/2 для серверов
GODEBUG=http2debug=1 # логировать отладочную информацию
GODEBUG=http2debug=2 # расширенные логи (дампы фреймов)
⚠ Перед отключением HTTP/2 сообщите о проблеме: golang.org/s/http2bug.
Расширенная настройка HTTP/2
Для сложных сценариев (например, ручная конфигурация HTTP/2) используйте пакет golang.org/x/net/http2:
import "golang.org/x/net/http2"
// Для клиента:
http2.ConfigureTransport(tr) // tr — ваш *http.Transport
// Для сервера:
http2.ConfigureServer(s, nil) // s — ваш *http.Server
Ручная настройка через golang.org/x/net/http2 имеет приоритет над встроенной поддержкой HTTP/2 в net/http.
Ключевые термины
DefaultServeMux– стандартный муксер (роутер) HTTP-запросов.Transport– управление низкоуровневыми параметрами HTTP-соединений.TLSNextProto– настройка протоколов, работающих поверх TLS (например, HTTP/2).GODEBUG– переменная окружения для отладки поведения Go-программ.
Константы
const (
MethodGet = "GET"
MethodHead = "HEAD"
MethodPost = "POST"
MethodPut = "PUT"
MethodPatch = "PATCH" // RFC 5789
MethodDelete = "DELETE"
MethodConnect = "CONNECT"
MethodOptions = "OPTIONS"
MethodTrace = "TRACE"
)
Общие методы HTTP. Если не указано иное, они определены в разделе 4.3 RFC 7231.
const (
StatusContinue = 100 // RFC 9110, 15.2.1
StatusSwitchingProtocols = 101 // RFC 9110, 15.2.2
StatusProcessing = 102 // RFC 2518, 10.1
StatusEarlyHints = 103 // RFC 8297
StatusOK = 200 // RFC 9110, 15.3.1
StatusCreated = 201 // RFC 9110, 15.3.2
StatusAccepted = 202 // RFC 9110, 15.3.3
StatusNonAuthoritativeInfo = 203 // RFC 9110, 15.3.4
StatusNoContent = 204 // RFC 9110, 15.3.5
StatusResetContent = 205 // RFC 9110, 15.3.6
StatusPartialContent = 206 // RFC 9110, 15.3.7
StatusMultiStatus = 207 // RFC 4918, 11.1
StatusAlreadyReported = 208 // RFC 5842, 7.1
StatusIMUsed = 226 // RFC 3229, 10.4.1
StatusMultipleChoices = 300 // RFC 9110, 15.4.1
StatusMovedPermanently = 301 // RFC 9110, 15.4.2
StatusFound = 302 // RFC 9110, 15.4.3
StatusSeeOther = 303 // RFC 9110, 15.4.4
StatusNotModified = 304 // RFC 9110, 15.4.5
StatusUseProxy = 305 // RFC 9110, 15.4.6
StatusTemporaryRedirect = 307 // RFC 9110, 15.4.8
StatusPermanentRedirect = 308 // RFC 9110, 15.4.9
StatusBadRequest = 400 // RFC 9110, 15.5.1
StatusUnauthorized = 401 // RFC 9110, 15.5.2
StatusPaymentRequired = 402 // RFC 9110, 15.5.3
StatusForbidden = 403 // RFC 9110, 15.5.4
StatusNotFound = 404 // RFC 9110, 15.5.5
StatusMethodNotAllowed = 405 // RFC 9110, 15.5.6
StatusNotAcceptable = 406 // RFC 9110, 15.5.7
StatusProxyAuthRequired = 407 // RFC 9110, 15.5.8
StatusRequestTimeout = 408 // RFC 9110, 15.5.9
StatusConflict = 409 // RFC 9110, 15.5.10
StatusGone = 410 // RFC 9110, 15.5.11
StatusLengthRequired = 411 // RFC 9110, 15.5.12
StatusPreconditionFailed = 412 // RFC 9110, 15.5.13
StatusRequestEntityTooLarge = 413 // RFC 9110, 15.5.14
StatusRequestURITooLong = 414 // RFC 9110, 15.5.15
StatusUnsupportedMediaType = 415 // RFC 9110, 15.5.16
StatusRequestedRangeNotSatisfiable = 416 // RFC 9110, 15.5.17
StatusExpectationFailed = 417 // RFC 9110, 15.5.18
StatusTeapot = 418 // RFC 9110, 15.5.19 (Unused)
StatusMisdirectedRequest = 421 // RFC 9110, 15.5.20
StatusUnprocessableEntity = 422 // RFC 9110, 15.5.21
StatusLocked = 423 // RFC 4918, 11.3
StatusFailedDependency = 424 // RFC 4918, 11.4
StatusTooEarly = 425 // RFC 8470, 5.2.
StatusUpgradeRequired = 426 // RFC 9110, 15.5.22
StatusPreconditionRequired = 428 // RFC 6585, 3
StatusTooManyRequests = 429 // RFC 6585, 4
StatusRequestHeaderFieldsTooLarge = 431 // RFC 6585, 5
StatusUnavailableForLegalReasons = 451 // RFC 7725, 3
StatusInternalServerError = 500 // RFC 9110, 15.6.1
StatusNotImplemented = 501 // RFC 9110, 15.6.2
StatusBadGateway = 502 // RFC 9110, 15.6.3
StatusServiceUnavailable = 503 // RFC 9110, 15.6.4
StatusGatewayTimeout = 504 // RFC 9110, 15.6.5
StatusHTTPVersionNotSupported = 505 // RFC 9110, 15.6.6
StatusVariantAlsoNegotiates = 506 // RFC 2295, 8.1
StatusInsufficientStorage = 507 // RFC 4918, 11.5
StatusLoopDetected = 508 // RFC 5842, 7.2
StatusNotExtended = 510 // RFC 2774, 7
StatusNetworkAuthenticationRequired = 511 // RFC 6585, 6
)
HTTP коды состояния (HTTP status codes)
Коды состояния HTTP зарегистрированы в IANA. См.: https://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml
Константы
const DefaultMaxHeaderBytes = 1 << 20 // 1 МБ
DefaultMaxHeaderBytes - максимально допустимый размер заголовков в HTTP-запросе. Можно переопределить через [Server.MaxHeaderBytes].
const DefaultMaxIdleConnsPerHost = 2
DefaultMaxIdleConnsPerHost - значение по умолчанию для Transport.MaxIdleConnsPerHost.
const TimeFormat = "Mon, 02 Jan 2006 15:04:05 GMT"
TimeFormat - формат времени для генерации временных меток в HTTP-заголовках. Аналогичен time.RFC1123, но использует GMT. Время должно быть в UTC.
const TrailerPrefix = "Trailer:"
TrailerPrefix - префикс для ключей [ResponseWriter.Header], указывающий, что значение относится к трейлерам ответа, а не к заголовкам.
Переменные
var (
ErrNotSupported = &ProtocolError{"feature not supported"}
ErrMissingBoundary = &ProtocolError{"no multipart boundary param in Content-Type"}
ErrNotMultipart = &ProtocolError{"request Content-Type isn't multipart/form-data"}
// Устаревшие ошибки...
)
var (
ErrBodyNotAllowed = errors.New("http: request method or response status code does not allow body")
ErrHijacked = errors.New("http: connection has been hijacked")
ErrContentLength = errors.New("http: wrote more than the declared Content-Length")
// Устаревшие ошибки...
)
Ошибки, используемые HTTP-сервером.
var (
ServerContextKey = &contextKey{"http-server"}
LocalAddrContextKey = &contextKey{"local-addr"}
)
Ключи контекста для доступа к серверу и локальному адресу.
var DefaultClient = &Client{}
DefaultClient - клиент по умолчанию, используемый Get, Head и Post.
var DefaultServeMux = &defaultServeMux
DefaultServeMux - ServeMux по умолчанию, используемый Serve.
var ErrAbortHandler = errors.New("net/http: abort Handler")
ErrAbortHandler - значение для прерывания обработчика без логирования стека.
var ErrBodyReadAfterClose = errors.New("http: invalid Read on closed Body")
Ошибка при чтении закрытого тела запроса/ответа.
var NoBody = noBody{}
NoBody - пустое тело запроса (io.ReadCloser), всегда возвращает EOF.
12.4.15.3.1 - Функции пакета net/http языка Go
Функции пакета http для реализации HTTP-клиента и сервера.
func CanonicalHeaderKey
func CanonicalHeaderKey(s string) string
CanonicalHeaderKey возвращает канонический формат заголовка. Преобразует первую букву и буквы после дефиса в верхний регистр, остальные - в нижний. Например, “accept-encoding” → “Accept-Encoding”. Если s содержит пробелы или недопустимые символы, возвращается без изменений.
func DetectContentType
func DetectContentType(data []byte) string
DetectContentType определяет Content-Type данных по алгоритму https://mimesniff.spec.whatwg.org/. Анализирует первые 512 байт. Всегда возвращает валидный MIME-тип, по умолчанию “application/octet-stream”.
func Error
func Error(w ResponseWriter, error string, code int)
Error отправляет ответ с указанным HTTP-кодом и текстом ошибки. Устанавливает заголовки:
- Удаляет Content-Length
- Content-Type: “text/plain; charset=utf-8”
- X-Content-Type-Options: “nosniff”
func Handle
func Handle(pattern string, handler Handler)
Регистрирует обработчик для шаблона в DefaultServeMux.
Пример
package main
import (
"fmt"
"log"
"net/http"
"sync"
)
type countHandler struct {
mu sync.Mutex // guards n
n int
}
func (h *countHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
h.mu.Lock()
defer h.mu.Unlock()
h.n++
fmt.Fprintf(w, "count is %d\n", h.n)
}
func main() {
http.Handle("/count", new(countHandler))
log.Fatal(http.ListenAndServe(":8080", nil))
}
func HandleFunc
func HandleFunc(pattern string, handler func(ResponseWriter, *Request))
Регистрирует функцию-обработчик для шаблона в DefaultServeMux.
Пример
package main
import (
"io"
"log"
"net/http"
)
func main() {
h1 := func(w http.ResponseWriter, _ *http.Request) {
io.WriteString(w, "Hello from a HandleFunc #1!\n")
}
h2 := func(w http.ResponseWriter, _ *http.Request) {
io.WriteString(w, "Hello from a HandleFunc #2!\n")
}
http.HandleFunc("/", h1)
http.HandleFunc("/endpoint", h2)
log.Fatal(http.ListenAndServe(":8080", nil))
}
func ListenAndServe
func ListenAndServe(addr string, handler Handler) error
Запускает HTTP-сервер на указанном адресе. Если handler=nil, используется DefaultServeMux.
Пример
package main
import (
"io"
"log"
"net/http"
)
func main() {
// Hello world, the web server
helloHandler := func(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "Hello, world!\n")
}
http.HandleFunc("/hello", helloHandler)
log.Fatal(http.ListenAndServe(":8080", nil))
}func ListenAndServeTLS
func ListenAndServeTLS(addr, certFile, keyFile string, handler Handler) error
Аналогично ListenAndServe, но для HTTPS-соединений. Требует сертификат и приватный ключ.
Пример
package main
import (
"io"
"log"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "Hello, TLS!\n")
})
// One can use generate_cert.go in crypto/tls to generate cert.pem and key.pem.
log.Printf("About to listen on 8443. Go to https://127.0.0.1:8443/")
err := http.ListenAndServeTLS(":8443", "cert.pem", "key.pem", nil)
log.Fatal(err)
}
func MaxBytesReader
func MaxBytesReader(w ResponseWriter, r io.ReadCloser, n int64) io.ReadCloser
Ограничивает размер тела запроса. В отличие от io.LimitReader:
- Возвращает ReadCloser
- При превышении лимита возвращает ошибку *MaxBytesError
- Закрывает исходный reader при вызове Close
func NotFound
func NotFound(w ResponseWriter, r *Request)
Отправляет ответ с HTTP 404.
func ParseHTTPVersion
func ParseHTTPVersion(vers string) (major, minor int, ok bool)
Разбирает строку версии HTTP (например, “HTTP/1.1” → (1, 1, true)).
func ParseTime
func ParseTime(text string) (t time.Time, err error)
Разбирает временную метку из заголовка, поддерживая три формата: TimeFormat, RFC850 и ANSIC.
func ProxyFromEnvironment
func ProxyFromEnvironment(req *Request) (*url.URL, error)
ProxyFromEnvironment возвращает URL прокси-сервера для указанного запроса на основе переменных окружения:
HTTP_PROXY/https_proxy- для HTTP-запросовHTTPS_PROXY/https_proxy- для HTTPS-запросовNO_PROXY/no_proxy- исключения из проксирования
Форматы значений:
- Полный URL (
http://proxy.example.com:8080) host:port(подразумевается схемаhttp)
Возвращаемые значения:
- Если прокси не задан или запрос исключен через
NO_PROXY→nil, nil - При некорректном формате → ошибка
- Для
localhost(с портом или без) →nil, nil(специальный случай)
Примеры использования:
proxyUrl, err := http.ProxyFromEnvironment(req)
if err != nil {
// обработка ошибки конфигурации прокси
}
if proxyUrl != nil {
// настроить транспорт с этим прокси
}
Особенности:
- Автоматически выбирает переменную окружения по схеме запроса
- Учитывает исключения в
NO_PROXY - Всегда пропускает запросы к localhost
- Поддерживает оба регистра переменных (UPPER и lower case)
func ProxyURL
func ProxyURL(fixedURL *url.URL) func(*Request) (*url.URL, error)
Возвращает функцию прокси, всегда возвращающую указанный URL.
func Redirect
func Redirect(w ResponseWriter, r *Request, url string, code int)
Перенаправляет запрос на указанный URL (может быть относительным путем). Код ответа должен быть в диапазоне 3xx (обычно 301, 302 или 303). Если Content-Type не установлен, автоматически добавляет “text/html; charset=utf-8” и простой HTML-ответ. Установка любого значения Content-Type отключает это поведение.
func Serve
func Serve(l net.Listener, handler Handler) error
Принимает входящие HTTP-соединения через listener, создавая новую горутину для каждого соединения. Если handler=nil, используется DefaultServeMux. Поддержка HTTP/2 требует TLS-соединений с “h2” в Config.NextProtos. Всегда возвращает non-nil ошибку.
func ServeContent
func ServeContent(w ResponseWriter, req *Request, name string, modtime time.Time, content io.ReadSeeker)
Отвечает на запрос содержимым из ReadSeeker с поддержкой:
- Range-запросов
- Заголовков If-Match/If-None-Match
- If-Modified-Since/If-Unmodified-Since
Автоматически определяет Content-Type (по расширению файла или через DetectContentType). Использует modtime для Last-Modified и проверки If-Modified-Since. Требует работающий Seek() для определения размера.
func ServeFile
func ServeFile(w ResponseWriter, r *Request, name string)
Отправляет содержимое файла или директории. Особенности:
- Отклоняет пути с “..” (защита от traversal-атак)
- Перенаправляет запросы к “/index.html” на родительский каталог
- Использует только параметр name (игнорирует r.URL.Path)
- Относительные пути разрешаются от текущего каталога
func ServeFileFS
func ServeFileFS(w ResponseWriter, r *Request, fsys fs.FS, name string)
Отправляет содержимое указанного файла или директории из файловой системы fsys в ответ на запрос. Файлы в fsys должны реализовывать интерфейс io.Seeker.
Меры предосторожности:
- Если имя (
name) формируется из пользовательского ввода, его необходимо санировать перед вызовом - Автоматически отклоняет запросы с “..” в
r.URL.Path(защита от path traversal) - Специальный случай: перенаправляет запросы, оканчивающиеся на “/index.html”, на путь без этого суффикса
Важно: выбор файла/директории осуществляется только по параметру name, r.URL.Path игнорируется (кроме двух указанных случаев).
func ServeTLS
func ServeTLS(l net.Listener, handler Handler, certFile, keyFile string) error
Принимает входящие HTTPS-соединения через listener l, создавая новую горутину для обработки каждого соединения. Требования:
- Если
handlerне указан (nil), используетсяDefaultServeMux - Необходимо указать файлы сертификата (
certFile) и приватного ключа (keyFile) - Для цепочки сертификатов
certFileдолжен содержать: серверный сертификат, промежуточные и корневой CA
Особенности:
- Всегда возвращает non-nil ошибку
- Для корректной работы требуется правильная настройка TLS
Технические детали:
Для
ServeFileFS:- Работает с абстрактной файловой системой (
fs.FS) - Требуется поддержка
Seek()для обработки Range-запросов - Поведение с “index.html” аналогично классическим веб-серверам
- Работает с абстрактной файловой системой (
Для
ServeTLS:- Автоматически активирует HTTP/2 при поддержке
- Рекомендуется использовать современные параметры шифрования
- Для production-среды следует использовать полную цепочку сертификатов
func SetCookie
func SetCookie(w ResponseWriter, cookie *Cookie)
Добавляет Set-Cookie заголовок в ответ. Некорректные cookie могут игнорироваться.
func StatusText
func StatusText(code int) string
Возвращает текстовое описание HTTP-статуса. Для неизвестных кодов возвращает пустую строку.
12.4.15.3.2 - Типы пакета net/http языка Go
Типы и методы пакета http для реализации HTTP-клиента и сервера.
type Client
type Client struct {
// Transport определяет механизм выполнения HTTP-запросов.
// Если nil, используется DefaultTransport.
Transport RoundTripper
// CheckRedirect определяет политику обработки редиректов.
// Если задан, вызывается перед каждым редиректом.
// Принимает новый запрос (req) и цепочку выполненных запросов (via).
// Если возвращает ошибку, клиент прекращает выполнение.
// Особый случай: ErrUseLastResponse возвращает последний Response без закрытия тела.
// Если nil, используется политика по умолчанию (максимум 10 редиректов).
CheckRedirect func(req *Request, via []*Request) error
// Jar хранит куки для автоматической подстановки в запросы.
// Обновляется при получении ответов с Set-Cookie.
// Если nil, куки отправляются только если явно заданы в Request.
Jar CookieJar
// Timeout устанавливает общий таймаут для запроса:
// включает подключение, редиректы и чтение тела ответа.
// Таймер продолжает работать после вызова Get/Post/Do.
// Нулевое значение отключает таймаут.
// Для отмены используется контекст запроса.
Timeout time.Duration
}
Client представляет HTTP-клиент. Нулевое значение (DefaultClient) - готовый к использованию клиент с DefaultTransport.
Особенности реализации:
Transportобычно содержит состояние (кешированные TCP-соединения), поэтому клиенты должны переиспользоваться- Потокобезопасен для использования из нескольких горутин
- Работает на более высоком уровне, чем
RoundTripper, обрабатывая:- Куки (через
Jar) - Редиректы (через
CheckRedirect) - Таймауты
- Куки (через
Политика редиректов:
При перенаправлениях клиент:
- Не пересылает sensitive-заголовки (
Authorization,WWW-Authenticate,Cookie) на:- Домены, не являющиеся поддоменами исходного (с
foo.comнаbar.com)
- Домены, не являющиеся поддоменами исходного (с
- Особенности Cookie:
- При наличии
Jar: мутировавшие куки исключаются (Jar сам добавит обновленные) - Без
Jar: исходные куки пересылаются без изменений
- При наличии
Пример использования:
client := &http.Client{
Timeout: 10 * time.Second,
Jar: cookieJar,
}
resp, err := client.Get("https://example.com")
func (*Client) CloseIdleConnections
(добавлено в Go 1.12)
func (c *Client) CloseIdleConnections()
Закрывает все бездействующие keep-alive соединения в Transport. Не прерывает активные соединения. Если Transport не поддерживает этот метод, операция не выполняется.
func (*Client) Do
func (c *Client) Do(req *Request) (*Response, error)
Выполняет HTTP-запрос с учетом настроек клиента (редиректы, куки, аутентификация). Особенности:
- Возвращает ошибку только при проблемах сети или срабатывании политик (CheckRedirect)
- Не считает HTTP-коды ≠ 2xx ошибкой
- Тело ответа (Body) всегда требует закрытия, даже при ошибках
- При редиректах:
- 301/302/303 → GET/HEAD (тело не сохраняется)
- 307/308 → сохраняет метод и тело (если определен Request.GetBody)
- Ошибки имеют тип *url.Error с флагом Timeout()
Пример:
req, _ := http.NewRequest("GET", url, nil)
resp, err := client.Do(req)
if err != nil { /* обработка */ }
defer resp.Body.Close()
func (*Client) Get
func (c *Client) Get(url string) (*Response, error)
Выполняет GET-запрос с автоматическим следованием редиректам (301, 302, 303, 307, 308). Особенности:
- Не возвращает ошибку при кодах ≠ 2xx
- Тело ответа требует закрытия
- Для кастомных заголовков используйте NewRequest + Do
func (*Client) Head
func (c *Client) Head(url string) (*Response, error)
Аналогично Get, но отправляет HEAD-запрос. Также обрабатывает редиректы.
func (*Client) Post
func (c *Client) Post(url, contentType string, body io.Reader) (*Response, error)
Выполняет POST-запрос с указанным Content-Type. Особенности:
- Если body реализует io.Closer, оно закрывается автоматически
- Для сложных запросов используйте NewRequest + Do
func (*Client) PostForm
func (c *Client) PostForm(url string, data url.Values) (*Response, error)
Отправляет POST с x-www-form-urlencoded данными. Автоматически:
- Кодирует данные
- Устанавливает Content-Type
- Обрабатывает редиректы
type ConnState
type ConnState int
ConnState представляет состояние клиентского соединения с сервером. Используется в хуке Server.ConnState для отслеживания жизненного цикла соединений.
Состояния соединения:
const (
// StateNew - новое соединение, ожидается отправка запроса
StateNew ConnState = iota
// StateActive - соединение получило данные запроса (1+ байт)
StateActive
// StateIdle - соединение в режиме keep-alive между запросами
StateIdle
// StateHijacked - соединение было захвачено (hijacked)
StateHijacked
// StateClosed - соединение закрыто
StateClosed
)
Особенности:
Для HTTP/2:
StateActiveактивируется при переходе от 0 к 1 активному запросу- Переход в другое состояние только после завершения всех запросов
Терминальные состояния:
StateHijacked- не переходит вStateClosedStateClosed- конечное состояние
func (ConnState) String
func (c ConnState) String() string
Возвращает строковое представление состояния соединения.
Примеры использования:
- Базовый мониторинг соединений:
server := &http.Server{
ConnState: func(conn net.Conn, state http.ConnState) {
log.Printf("Соединение %v: %v -> %v",
conn.RemoteAddr(),
conn.LocalAddr(),
state.String())
},
}
- Ограничение активных соединений:
var activeConns int32
server := &http.Server{
ConnState: func(conn net.Conn, state http.ConnState) {
switch state {
case http.StateActive:
if atomic.AddInt32(&activeConns, 1) > 100 {
conn.Close() // закрываем при превышении лимита
}
case http.StateClosed, http.StateHijacked:
atomic.AddInt32(&activeConns, -1)
}
},
}
- Логирование времени жизни соединения:
type connInfo struct {
start time.Time
}
server := &http.Server{
ConnState: func(conn net.Conn, state http.ConnState) {
ctx := conn.Context()
if state == http.StateNew {
ctx = context.WithValue(ctx, "connInfo", &connInfo{
start: time.Now(),
})
conn = conn.WithContext(ctx)
return
}
if state == http.StateClosed {
if info, ok := ctx.Value("connInfo").(*connInfo); ok {
duration := time.Since(info.start)
log.Printf("Соединение жило %v", duration)
}
}
},
}
Типичный жизненный цикл соединения:
StateNew → StateActive → StateIdle → StateActive → ... → StateClosed
\ /
→ StateHijacked
Для HTTP/2 состояния меняются реже, так как одно соединение обслуживает множество запросов параллельно.
Вот профессиональный перевод документации типа Cookie с примерами использования:
type Cookie
type Cookie struct {
Name string // Название cookie (обязательное)
Value string // Значение cookie
Quoted bool // Флаг, было ли значение в кавычках
// Опциональные атрибуты:
Path string // Путь действия cookie
Domain string // Домен действия
Expires time.Time // Время истечения
RawExpires string // Оригинальное значение Expires (только для чтения)
// MaxAge определяет срок жизни в секундах:
// 0 - без Max-Age
// <0 - немедленное удаление (аналог Max-Age: 0)
// >0 - срок жизни в секундах
MaxAge int
Secure bool // Только для HTTPS
HttpOnly bool // Недоступно для JavaScript
SameSite SameSite // Политика SameSite
Partitioned bool // Разделенные cookie (CHIPS)
Raw string // Оригинальное значение заголовка
Unparsed []string // Неразобранные атрибуты
}
Тип Cookie представляет HTTP-куки, используемые в заголовках:
Set-Cookie- при установке серверомCookie- при отправке клиентом
Соответствует спецификации RFC 6265.
Примеры создания cookie:
// Простая cookie
sessionCookie := &http.Cookie{
Name: "session_id",
Value: "abc123",
}
// Защищенная cookie с атрибутами
secureCookie := &http.Cookie{
Name: "prefs",
Value: "dark_theme=true",
Path: "/",
Domain: "example.com",
MaxAge: 3600, // 1 час
Secure: true,
HttpOnly: true,
SameSite: http.SameSiteLaxMode,
}
func ParseCookie
(добавлено в Go 1.23)
func ParseCookie(line string) ([]*Cookie, error)
Разбирает заголовок Cookie (клиентские куки), возвращая все найденные куки. Одно имя может встречаться несколько раз.
Пример:
cookies, err := http.ParseCookie("name1=val1; name2=val2; name1=val3")
if err != nil { /* обработка ошибки */ }
for _, c := range cookies {
fmt.Printf("%s: %s\n", c.Name, c.Value)
}
// Вывод:
// name1: val1
// name2: val2
// name1: val3
func ParseSetCookie
(добавлено в Go 1.23)
func ParseSetCookie(line string) (*Cookie, error)
Разбирает заголовок Set-Cookie (серверные куки), возвращая одну куку.
Пример:
cookie, err := http.ParseSetCookie("session=abc123; Path=/; HttpOnly; Max-Age=3600")
if err != nil { /* обработка ошибки */ }
fmt.Printf("Cookie: %s=%s, Path=%s\n", cookie.Name, cookie.Value, cookie.Path)
func (*Cookie) String
func (c *Cookie) String() string
Форматирует куку для заголовка:
- Для
Cookie: только имя и значение (name=value) - Для
Set-Cookie: со всеми атрибутами
Пример:
c := &http.Cookie{Name: "test", Value: "123"}
fmt.Println(c.String()) // "test=123"
c.Path = "/"
c.HttpOnly = true
fmt.Println(c.String()) // "test=123; Path=/; HttpOnly"
func (*Cookie) Valid
func (c *Cookie) Valid() error
Проверяет валидность куки (корректность имени и других атрибутов).
Пример:
err := (&http.Cookie{Name: "invalid name", Value: "test"}).Valid()
if err != nil {
fmt.Println("Invalid cookie:", err)
}
Практические примеры:
- Установка cookie в ResponseWriter:
func handler(w http.ResponseWriter, r *http.Request) {
cookie := &http.Cookie{
Name: "user",
Value: "john",
Path: "/",
}
http.SetCookie(w, cookie)
}
- Чтение cookie из Request:
func handler(w http.ResponseWriter, r *http.Request) {
cookie, err := r.Cookie("session_id")
if err != nil {
// Обработка отсутствия cookie
}
fmt.Fprintf(w, "Value: %s", cookie.Value)
}
- Удаление cookie:
func logoutHandler(w http.ResponseWriter, r *http.Request) {
http.SetCookie(w, &http.Cookie{
Name: "session",
Value: "",
Path: "/",
MaxAge: -1, // Удалить cookie
})
}
- Проверка SameSite политики:
cookie := &http.Cookie{
Name: "csrf_token",
Value: generateToken(),
SameSite: http.SameSiteStrictMode,
Secure: true,
}
Вот перевод документации с примерами:
type CookieJar
type CookieJar interface {
// SetCookies сохраняет полученные куки для указанного URL
SetCookies(u *url.URL, cookies []*Cookie)
// Cookies возвращает куки, которые должны быть отправлены для URL
Cookies(u *url.URL) []*Cookie
}
CookieJar управляет хранением и использованием кук в HTTP-запросах. Реализации должны быть потокобезопасными.
Пример использования:
jar, _ := cookiejar.New(nil)
client := &http.Client{
Jar: jar,
}
// Первый запрос (получаем куки)
resp, _ := client.Get("https://example.com/login")
// Последующие запросы автоматически включают куки
resp, _ = client.Get("https://example.com/dashboard")
type Dir
type Dir string
Dir реализует FileSystem для работы с файловой системой в пределах указанной директории.
Важные предупреждения:
- Может предоставлять доступ к чувствительным файлам
- Следует по символическим ссылкам за пределы директории
- Не фильтрует файлы, начинающиеся с точки (например,
.git)
Пример:
fs := http.Dir("/var/www")
http.Handle("/static/", http.FileServer(fs))
func (Dir) Open
func (d Dir) Open(name string) (File, error)
Открывает файл для чтения, используя os.Open. Пути должны использовать / как разделитель.
Пример:
fs := http.Dir("public")
file, err := fs.Open("css/styles.css")
if err != nil {
// обработка ошибки
}
defer file.Close()
type File
type File interface {
io.Closer
io.Reader
io.Seeker
Readdir(count int) ([]fs.FileInfo, error)
Stat() (fs.FileInfo, error)
}
Интерфейс файла, возвращаемый FileSystem.Open. Аналогичен *os.File.
type FileSystem
type FileSystem interface {
Open(name string) (File, error)
}
Интерфейс для работы с коллекцией файлов. Использует / как разделитель путей.
Пример реализации:
type CustomFS struct {
base string
}
func (c CustomFS) Open(name string) (http.File, error) {
return os.Open(filepath.Join(c.base, name))
}
func FS
func FS(fsys fs.FS) FileSystem
Конвертирует fs.FS в FileSystem. Файлы должны реализовывать io.Seeker.
Пример с embed:
//go:embed static/*
var staticFiles embed.FS
func main() {
http.Handle("/", http.FileServer(http.FS(staticFiles)))
http.ListenAndServe(":8080", nil)
}
Дополнительные примеры:
- Защищенная FileSystem (без доступа к скрытым файлам):
type SafeFS struct {
http.Dir
}
func (s SafeFS) Open(name string) (http.File, error) {
if strings.Contains(name, "..") || strings.HasPrefix(filepath.Base(name), ".") {
return nil, os.ErrNotExist
}
return s.Dir.Open(name)
}
- Кастомный CookieJar:
type MemoryJar struct {
cookies map[string][]*http.Cookie
sync.Mutex
}
func (j *MemoryJar) SetCookies(u *url.URL, cookies []*http.Cookie) {
j.Lock()
defer j.Unlock()
j.cookies[u.Host] = cookies
}
func (j *MemoryJar) Cookies(u *url.URL) []*http.Cookie {
j.Lock()
defer j.Unlock()
return j.cookies[u.Host]
}
type Flusher
type Flusher interface {
// Flush sends any buffered data to the client.
Flush()
}
Интерфейс Flusher реализуется в ResponseWriter, которые позволяют HTTP-обработчику отправлять буферизованные данные клиенту.
Реализации ResponseWriter по умолчанию HTTP/1.x и HTTP/2 поддерживают Flusher, но обертки ResponseWriter могут этого не делать. Обработчики всегда должны проверять эту возможность во время выполнения.
Обратите внимание, что даже для ResponseWriter, поддерживающих Flush, если клиент подключен через HTTP-прокси, буферизованные данные могут не дойти до клиента до завершения ответа.
type HTTP2Config
type HTTP2Config struct {
// MaxConcurrentStreams опционально задает количество
// параллельных потоков, которые могут быть открыты у пира одновременно.
// Если значение равно нулю, то по умолчанию MaxConcurrentStreams равно как минимум 100.
MaxConcurrentStreams int
// MaxDecoderHeaderTableSize опционально задает верхний предел для
// размера таблицы сжатия заголовков, используемой для декодирования заголовков, отправленных
// пиром.
// Допустимое значение - менее 4 Мбайт.
// Если значение равно нулю или недействительно, используется значение по умолчанию.
MaxDecoderHeaderTableSize int
// MaxEncoderHeaderTableSize опционально задает верхний предел для
// таблицы сжатия заголовков, используемой для отправки заголовков сверстнику.
// Допустимое значение - менее 4 Мбайт.
// Если значение равно нулю или недействительно, используется значение по умолчанию.
MaxEncoderHeaderTableSize int
// MaxReadFrameSize опционально указывает самый большой кадр.
// который эта конечная точка готова прочитать.
// Допустимое значение - от 16КиБ до 16МиБ, включительно.
// Если значение равно нулю или недействительно, используется значение по умолчанию.
MaxReadFrameSize int
// MaxReceiveBufferPerConnection - это максимальный размер
// окна управления потоком для данных, получаемых по соединению.
// Допустимое значение - не менее 64КиБ и не более 4МиБ.
// Если значение недействительно, используется значение по умолчанию.
MaxReceiveBufferPerConnection int
// MaxReceiveBufferPerStream - это максимальный размер
// окна управления потоком для данных, получаемых в потоке (запросе).
// Допустимое значение - менее 4 Мбайт.
// Если значение равно нулю или недействительно, используется значение по умолчанию.
MaxReceiveBufferPerStream int
// SendPingTimeout - таймаут, по истечении которого проверка работоспособности с помощью ping
// кадра будет проведена, если на соединении не будет получено ни одного кадра.
// Если ноль, проверка работоспособности не выполняется.
SendPingTimeout time.Duration
// PingTimeout - таймаут, по истечении которого соединение будет закрыто.
// если не будет получен ответ на пинг.
// Если значение равно нулю, используется значение по умолчанию 15 секунд.
PingTimeout time.Duration
// WriteByteTimeout - таймаут, по истечении которого соединение будет // закрыто, если не удастся записать данные.
// закрыто, если в него не могут быть записаны данные. Таймаут начинается, когда данные // доступны для записи.
// доступны для записи, и продлевается каждый раз, когда записываются какие-либо байты.
WriteByteTimeout time.Duration
// PermitProhibitedCipherSuites, если true, разрешает использование
// наборов шифров, запрещенных спецификацией HTTP/2.
PermitProhibitedCipherSuites bool
// CountError, если не равен nil, вызывается при ошибках HTTP/2.
// Она предназначена для инкрементирования метрики для мониторинга.
// Тип errType содержит только строчные буквы, цифры и символы подчеркивания.
// (a-z, 0-9, _).
CountError func(errType string)
}
HTTP2Config определяет параметры конфигурации HTTP/2, общие для транспорта и сервера.
type Handler
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
Обработчик отвечает на HTTP-запрос.
[Handler.ServeHTTP] должен записать заголовки и данные ответа в ResponseWriter, а затем вернуться. Возврат сигнализирует о том, что запрос завершен; использование ResponseWriter или чтение из [Request.Body] после или одновременно с завершением вызова ServeHTTP недопустимо.
В зависимости от программного обеспечения HTTP-клиента, версии протокола HTTP и любых посредников между клиентом и Go-сервером, чтение из [Request.Body] после записи в ResponseWriter может быть невозможным. Осторожные обработчики должны сначала прочитать [Request.Body], а затем ответить.
Кроме чтения тела, обработчики не должны изменять предоставленный Запрос.
Если ServeHTTP паникует, сервер (вызывающий ServeHTTP) предполагает, что эффект паники был изолирован от активного запроса. Он восстанавливает панику, записывает трассировку стека в журнал ошибок сервера и либо закрывает сетевое соединение, либо отправляет HTTP/2 RST_STREAM, в зависимости от протокола HTTP. Чтобы прервать обработчик, чтобы клиент увидел прерванный ответ, но сервер не зафиксировал ошибку, вызовите панику со значением ErrAbortHandler.
Обработчик отвечает на HTTP-запрос.
[Handler.ServeHTTP] должен записать заголовки и данные ответа в ResponseWriter, а затем вернуться. Возврат сигнализирует о том, что запрос завершен; использование ResponseWriter или чтение из [Request.Body] после или одновременно с завершением вызова ServeHTTP недопустимо.
В зависимости от программного обеспечения HTTP-клиента, версии протокола HTTP и любых посредников между клиентом и Go-сервером, чтение из [Request.Body] после записи в ResponseWriter может быть невозможным. Осторожные обработчики должны сначала прочитать [Request.Body], а затем ответить.
Кроме чтения тела, обработчики не должны изменять предоставленный Запрос.
Если ServeHTTP паникует, сервер (вызывающий ServeHTTP) предполагает, что эффект паники был изолирован от активного запроса. Он восстанавливает панику, записывает трассировку стека в журнал ошибок сервера и либо закрывает сетевое соединение, либо отправляет HTTP/2 RST_STREAM, в зависимости от протокола HTTP. Чтобы прервать обработчик, чтобы клиент увидел прерванный ответ, но сервер не зафиксировал ошибку, вызовите панику со значением ErrAbortHandler.
func AllowQuerySemicolons
func AllowQuerySemicolons(h Handler) Handler
AllowQuerySemicolons возвращает обработчик, который обслуживает запросы, преобразуя любые неэскэпированные точки с запятой в URL-запросе в амперсанд и вызывая обработчик h.
Это восстанавливает поведение, существовавшее до версии Go 1.17, когда параметры запроса разделялись как на точки с запятой, так и на амперсанд. (См. golang.org/issue/25192). Обратите внимание, что такое поведение не соответствует поведению многих прокси-серверов, и это несоответствие может привести к проблемам безопасности.
AllowQuerySemicolons должен быть вызван до вызова Request.ParseForm.
func FileServer
func FileServer(root FileSystem) Handler
FileServer возвращает обработчик, который обслуживает HTTP-запросы с содержимым файловой системы, укорененной в root.
В качестве особого случая, возвращаемый файловый сервер перенаправляет любой запрос, заканчивающийся на «/index.html», на тот же путь, без конечного «index.html».
Чтобы использовать реализацию файловой системы операционной системы, используйте http.Dir:
http.Handle(«/», http.FileServer(http.Dir(«/tmp»)))
Чтобы использовать реализацию fs.FS, используйте http.FileServerFS.
Пример
package main
import (
"log"
"net/http"
)
func main() {
// Simple static webserver:
log.Fatal(http.ListenAndServe(":8080", http.FileServer(http.Dir("/usr/share/doc"))))
}
Пример DotFileHiding
пакет main
импорт (
«io»
«io/fs»
«log»
«net/http»
«strings»
)
// containsDotFile сообщает, содержит ли имя элемент пути, начинающийся с точки.
// Предполагается, что имя представляет собой файл, разделенный прямыми косыми чертами, как это гарантируется
// интерфейсом http.FileSystem.
func containsDotFile(name string) bool {
parts := strings.Split(name, «/»)
for _, part := range parts {
if strings.HasPrefix(part, «.») {
return true
}
}
return false
}
// dotFileHidingFile - это http.File, используемый в dotFileHidingFileSystem.
// Он используется для обертывания метода Readdir из http.File, чтобы мы могли
// удалять из его вывода файлы и каталоги, начинающиеся с точки.
тип dotFileHidingFile struct {
http.File
}
// Readdir - это обертка вокруг метода Readdir встроенного File.
// которая отфильтровывает все файлы, имя которых начинается с точки.
func (f dotFileHidingFile) Readdir(n int) (fis []fs.FileInfo, err error) {
files, err := f.File.Readdir(n)
for _, file := range files { // Отфильтровываем файлы с точками
if !strings.HasPrefix(file.Name(), «.») {
fis = append(fis, file)
}
}
if err == nil && n > 0 && len(fis) == 0 {
err = io.EOF
}
return
}
// dotFileHidingFileSystem - это http.FileSystem, которая скрывает
// скрытые «dot-файлы» от обслуживания.
тип dotFileHidingFileSystem struct {
http.FileSystem
}
// Open - это обертка вокруг метода Open встроенной файловой системы.
// который выдает ошибку разрешения 403, если в имени есть файл или каталог
// в пути которого имя начинается с точки.
func (fsys dotFileHidingFileSystem) Open(name string) (http.File, error) {
if containsDotFile(name) { // Если файл с точкой, возвращаем ответ 403
return nil, fs.ErrPermission
}
file, err := fsys.FileSystem.Open(name)
if err != nil {
return nil, err
}
return dotFileHidingFile{file}, err
}
func main() {
fsys := dotFileHidingFileSystem{http.Dir(«.»)}
http.Handle(«/», http.FileServer(fsys))
log.Fatal(http.ListenAndServe(«:8080», nil))
}
Пример StripPrefix
пакет main
импорт (
«net/http»
)
func main() {
// Чтобы обслужить каталог на диске (/tmp) по альтернативному URL
// пути (/tmpfiles/), используйте StripPrefix для изменения пути запроса
// путь URL до того, как его увидит файловый сервер:
http.Handle(«/tmpfiles/», http.StripPrefix(«/tmpfiles/», http.FileServer(http.Dir(«/tmp»))))
}func FileServerFS
func FileServerFS(root fs.FS) Обработчик
FileServerFS возвращает обработчик, который обслуживает HTTP-запросы с содержимым файловой системы fsys. Файлы, предоставляемые fsys, должны реализовывать io.Seeker.
В качестве особого случая, возвращаемый файловый сервер перенаправляет любой запрос, заканчивающийся на «/index.html», на тот же путь, без конечного «index.html».
http.Handle(«/», http.FileServerFS(fsys))
func MaxBytesHandler
func MaxBytesHandler(h Handler, n int64) Handler
MaxBytesHandler возвращает обработчик, который запускает h с его ResponseWriter и [Request.Body], обернутыми MaxBytesReader.
func NotFoundHandler
func NotFoundHandler() Handler
NotFoundHandler возвращает простой обработчик запросов, который отвечает на каждый запрос ответом «404 страница не найдена».
Пример
package main
import (
"fmt"
"log"
"net/http"
)
func newPeopleHandler() http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "This is the people handler.")
})
}
func main() {
mux := http.NewServeMux()
// Create sample handler to returns 404
mux.Handle("/resources", http.NotFoundHandler())
// Create sample handler that returns 200
mux.Handle("/resources/people/", newPeopleHandler())
log.Fatal(http.ListenAndServe(":8080", mux))
}func RedirectHandler
func RedirectHandler(url string, code int) Обработчик
RedirectHandler возвращает обработчик запроса, который перенаправляет каждый полученный запрос на заданный url с использованием заданного кода состояния.
Заданный код должен быть в диапазоне 3xx и обычно является StatusMovedPermanently, StatusFound или StatusSeeOther.
func StripPrefix
func StripPrefix(prefix string, h Handler) Handler
StripPrefix возвращает обработчик, который обслуживает HTTP-запросы, удаляя заданный префикс из Path (и RawPath, если задан) URL запроса и вызывая обработчик h. StripPrefix обрабатывает запрос на путь, который не начинается с префикса, отвечая ошибкой HTTP 404 not found. Префикс должен точно совпадать: если префикс в запросе содержит экранированные символы, ответом также будет ошибка HTTP 404 not found.
Пример
package main
import (
"net/http"
)
func main() {
// To serve a directory on disk (/tmp) under an alternate URL
// path (/tmpfiles/), use StripPrefix to modify the request
// URL's path before the FileServer sees it:
http.Handle("/tmpfiles/", http.StripPrefix("/tmpfiles/", http.FileServer(http.Dir("/tmp"))))
}
func TimeoutHandler
func TimeoutHandler(h Handler, dt time.Duration, msg string) Handler
TimeoutHandler возвращает обработчик, который запускает h с заданным лимитом времени.
Новый обработчик вызывает h.ServeHTTP для обработки каждого запроса, но если вызов выполняется дольше установленного лимита времени, обработчик отвечает ошибкой 503 Service Unavailable с заданным сообщением в теле. (Если msg пустое, будет отправлено подходящее сообщение по умолчанию). После такого таймаута запись h в свой ResponseWriter будет возвращать ErrHandlerTimeout.
TimeoutHandler поддерживает интерфейс Pusher, но не поддерживает интерфейсы Hijacker и Flusher.
type HandlerFunc
type HandlerFunc func(ResponseWriter, *Request)
Тип HandlerFunc - это адаптер, позволяющий использовать обычные функции в качестве HTTP-обработчиков. Если f - функция с соответствующей сигнатурой, то HandlerFunc(f) - это обработчик, вызывающий f.
func (HandlerFunc) ServeHTTP
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request)
ServeHTTP вызывает f(w, r).
type Header
type Header map[string][]string
Header представляет пары ключ-значение в HTTP-заголовке.
Ключи должны быть в канонической форме, как возвращает CanonicalHeaderKey.
func (Header) Add
func (h Header) Add(key, value string)
Add добавляет пару ключ-значение в заголовок. Она добавляется ко всем существующим значениям, связанным с ключом. Ключ не чувствителен к регистру; он канонизируется с помощью CanonicalHeaderKey.
func (Header) Clone
func (h Header) Clone() Header
Clone возвращает копию h или nil, если h - nil.
func (Header) Del
func (h Header) Del(key string)
Del удаляет значения, связанные с ключом. Ключ не чувствителен к регистру; он канонизируется с помощью CanonicalHeaderKey.
func (Header) Get
func (h Header) Get(key string) string
Get получает первое значение, связанное с заданным ключом. Если значений, связанных с ключом, нет, Get возвращает “”. Нечувствительно к регистру; textproto.CanonicalMIMEHeaderKey используется для канонизации предоставленного ключа. Get предполагает, что все ключи хранятся в канонической форме. Чтобы использовать неканонические ключи, обращайтесь к карте напрямую.
func (Header) Set
func (h Header) Set(key, value string)
Set устанавливает записи заголовка, связанные с ключом, в значение одного элемента. Она заменяет все существующие значения, связанные с ключом. Ключ не чувствителен к регистру; он канонизируется с помощью textproto.CanonicalMIMEHeaderKey. Чтобы использовать неканонические ключи, присваивайте их непосредственно карте.
func (Header) Values
func (h Header) Values(key string) []string
Values возвращает все значения, связанные с заданным ключом. Нечувствительно к регистру; textproto.CanonicalMIMEHeaderKey используется для канонизации заданного ключа. Чтобы использовать неканонические ключи, обращайтесь к карте напрямую. Возвращаемый фрагмент не является копией.
func (Header) Write
func (h Header) Write(w io.Writer) error
Write записывает заголовок в формате wire.
func (Header) WriteSubset
func (h Header) WriteSubset(w io.Writer, exclude map[string]bool) error
WriteSubset записывает заголовок в формате wire. Если exclude не равно nil, ключи, для которых exclude[key] == true, не записываются. Ключи не канонизируются перед проверкой карты exclude.
type Hijacker
type Hijacker interface
// Hijack позволяет вызывающей стороне взять на себя управление соединением.
// После вызова Hijack библиотека HTTP-сервера
// больше ничего не будет делать с соединением.
//
// Ответственность за управление // и закрытие соединения ложится на вызывающую сторону.
// и закрывать соединение.
//
// Возвращаемый net.Conn может иметь дедлайны чтения или записи.
// уже установленными, в зависимости от конфигурации
// сервера. Вызывающая сторона несет ответственность за установку
// или очистить эти сроки по мере необходимости.
//
// Возвращаемый файл bufio.Reader может содержать необработанные буферизованные
// данные от клиента.
//
// После вызова Hijack исходное Request.Body не должно
// использоваться. Контекст исходного запроса остается действительным и
// не отменяется до тех пор, пока метод ServeHTTP запроса
// возвращается.
Hijack() (net.Conn, *bufio.ReadWriter, error)
}
Интерфейс Hijacker реализуется в ResponseWriter’ах, которые позволяют HTTP-обработчику взять на себя управление соединением.
ResponseWriter по умолчанию для соединений HTTP/1.x поддерживает Hijacker, но соединения HTTP/2 намеренно не поддерживают его. Обертки ResponseWriter также могут не поддерживать Hijacker. Обработчики всегда должны проверять эту возможность во время выполнения.
Пример
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/hijack", func(w http.ResponseWriter, r *http.Request) {
hj, ok := w.(http.Hijacker)
if !ok {
http.Error(w, "webserver doesn't support hijacking", http.StatusInternalServerError)
return
}
conn, bufrw, err := hj.Hijack()
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// Don't forget to close the connection:
defer conn.Close()
bufrw.WriteString("Now we're speaking raw TCP. Say hi: ")
bufrw.Flush()
s, err := bufrw.ReadString('\n')
if err != nil {
log.Printf("error reading string: %v", err)
return
}
fmt.Fprintf(bufrw, "You said: %q\nBye.\n", s)
bufrw.Flush()
})
}
type MaxBytesError
type MaxBytesError struct {
Limit int64
}
MaxBytesError возвращается MaxBytesReader, когда его лимит чтения превышен.
func (*MaxBytesError) Error
func (e *MaxBytesError) Error() string
type ProtocolError
устаревший
type Protocols
type Protocols struct {
// содержит отфильтрованные или неэкспонированные поля
}
Protocols - это набор протоколов HTTP. Нулевое значение - это пустой набор протоколов.
Поддерживаются следующие протоколы:
- HTTP1 - протоколы HTTP/1.0 и HTTP/1.1. HTTP1 поддерживается как на незащищенных TCP, так и на защищенных TLS соединениях.
- HTTP2 - протокол HTTP/2 через TLS-соединение.
- UnencryptedHTTP2 - протокол HTTP/2 через незащищенное TCP-соединение.
Пример Http1
package main
import (
"log"
"net/http"
)
func main() {
srv := http.Server{
Addr: ":8443",
}
// Serve only HTTP/1.
srv.Protocols = new(http.Protocols)
srv.Protocols.SetHTTP1(true)
log.Fatal(srv.ListenAndServeTLS("cert.pem", "key.pem"))
}
Пример Http1or2
package main
import (
"log"
"net/http"
)
func main() {
t := http.DefaultTransport.(*http.Transport).Clone()
// Use either HTTP/1 and HTTP/2.
t.Protocols = new(http.Protocols)
t.Protocols.SetHTTP1(true)
t.Protocols.SetHTTP2(true)
cli := &http.Client{Transport: t}
res, err := cli.Get("http://www.google.com/robots.txt")
if err != nil {
log.Fatal(err)
}
res.Body.Close()
}
func (Protocols) HTTP1
func (p Protocols) HTTP1() bool
HTTP1 сообщает, включает ли p протокол HTTP/1.
func (Протоколы) HTTP2
func (p Protocols) HTTP2() bool
HTTP2 сообщает, включает ли p протокол HTTP/2.
func (*Protocols) SetHTTP1
func (p *Protocols) SetHTTP1(ok bool)
SetHTTP1 добавляет или удаляет HTTP/1 из p.
func (*Protocols) SetHTTP2
func (p *Protocols) SetHTTP2(ok bool)
SetHTTP2 добавляет или удаляет HTTP/2 из p.
func (*Protocols) SetUnencryptedHTTP2
func (p *Protocols) SetUnencryptedHTTP2(ok bool)
SetUnencryptedHTTP2 добавляет или удаляет незашифрованный HTTP/2 из p.
func (Protocols) String
func (p Protocols) String() string
func (Protocols) UnencryptedHTTP2
func (p Protocols) UnencryptedHTTP2() bool
UnencryptedHTTP2 сообщает, включает ли p незашифрованный HTTP/2.
type PushOptions
type PushOptions struct {
// Method указывает HTTP-метод для обещанного запроса.
// Если установлен, он должен быть «GET» или «HEAD». Пустое значение означает «GET».
Method string
// Header указывает дополнительные заголовки обещанного запроса. Они не могут
// включать поля псевдозаголовков HTTP/2, такие как «:path» и «:scheme»,
// которые будут добавлены автоматически.
Заголовок Header
}
PushOptions описывает опции для [Pusher.Push].
type Pusher
type Pusher interface {
// Push инициирует HTTP/2 серверный push. При этом создается синтетический
// запрос, используя заданную цель и опции, сериализует этот запрос
// в фрейм PUSH_PROMISE, затем отправляет этот запрос с помощью
// обработчика запроса сервера. Если opts равно nil, используются параметры по умолчанию.
//
// Цель должна быть либо абсолютным путем (например, «/path»), либо абсолютным
// URL, содержащий действительный хост и ту же схему, что и родительский запрос.
// Если цель - это путь, то она наследует схему и хост // родительского запроса.
// родительского запроса.
//
// Спецификация HTTP/2 запрещает рекурсивные и кросс-авторитарные проталкивания.
// Push может обнаружить или не обнаружить эти недействительные проталкивания; однако недействительные
// push будут обнаружены и отменены соответствующими клиентами.
//
// Обработчики, желающие передать URL X, должны вызывать Push перед отправкой любых
// данные, которые могут вызвать запрос на URL X. Это позволяет избежать гонки, когда
// клиент отправляет запрос на X до получения PUSH_PROMISE для X.
//
// Push будет выполняться в отдельной горутине, что делает порядок прибытия
// недетерминированным. Любая требуемая синхронизация должна быть реализована
// вызывающей стороной.
//
// Push возвращает ErrNotSupported, если клиент отключил push или если push
// не поддерживается на базовом соединении.
Ошибка Push(target string, opts *PushOptions)
}
Pusher - это интерфейс, реализованный в ResponseWriters, которые поддерживают HTTP/2 server push. Более подробную информацию можно найти на сайте https://tools.ietf.org/html/rfc7540#section-8.2.
type Request
type Request struct {
// Method задает метод HTTP (GET, POST, PUT и т.д.).
// Для клиентских запросов пустая строка означает GET.
Строка Method
// URL указывает либо запрашиваемый URI (для серверных
// запросов), либо URL для доступа (для клиентских запросов).
//
// Для серверных запросов URL анализируется из URI.
// предоставленного в строке запроса и хранящегося в RequestURI. Для
// большинства запросов поля, кроме Path и RawQuery, будут // пустыми.
// пустыми. (См. RFC 7230, раздел 5.3)
//
// Для клиентских запросов URL's Host указывает сервер, к которому нужно // подключиться.
// соединиться с ним, а поле Request's Host опционально
// определяет значение заголовка Host для отправки в HTTP
// запросе.
URL *url.URL
// Версия протокола для входящих запросов сервера.
//
// Для клиентских запросов эти поля игнорируются. HTTP
// клиентский код всегда использует либо HTTP/1.1, либо HTTP/2.
// Подробнее см. документацию по транспорту.
Proto string // «HTTP/1.0»
ProtoMajor int // 1
ProtoMinor int // 0
// Заголовок содержит поля заголовка запроса, которые либо получены
// сервером, либо должны быть отправлены клиентом.
//
// Если сервер получил запрос со строками заголовка,
//
// Host: example.com
// accept-encoding: gzip, deflate
// Accept-Language: en-us
// fOO: Bar
// foo: two
//
// тогда
//
// Header = map[string][]string{
// «Accept-Encoding»: { «gzip», «deflate» }
// «Accept-Language»: {«en-us»},
// «Foo»: { «Bar», «2»},
// }
//
// Для входящих запросов заголовок Host переводится в поле
// поле Request.Host и удаляется из карты Header.
//
// HTTP определяет, что имена заголовков не чувствительны к регистру. В
// парсер запросов реализует это с помощью CanonicalHeaderKey,
// делая первый символ и все символы, следующие за
// дефисом прописными, а остальные - строчными.
//
// Для клиентских запросов некоторые заголовки, такие как Content-Length
// и Connection, записываются автоматически, когда это необходимо, и
// значения в Header могут игнорироваться. См. документацию
// по методу Request.Write.
Request Header
// Body - это тело запроса.
//
// Для клиентских запросов нулевое тело означает, что запрос не имеет
// тело, например, запрос GET. Транспорт HTTP-клиента
// отвечает за вызов метода Close.
//
// Для серверных запросов тело запроса всегда не является nil
// но при отсутствии тела немедленно возвращается EOF.
// Сервер закроет тело запроса. Обработчику ServeHTTP
// обработчику не нужно.
//
// Тело должно позволять вызывать Read одновременно с Close.
// В частности, вызов Close должен разблокировать Read, ожидающий
// ввода.
Body io.ReadCloser
// GetBody определяет необязательную функцию для возврата новой копии
// Body. Она используется для клиентских запросов, когда перенаправление требует.
// чтения тела более одного раза. Использование GetBody по-прежнему
// требует установки Body.
//
// Для серверных запросов он не используется.
GetBody func() (io.ReadCloser, error)
// ContentLength записывает длину связанного содержимого.
// Значение -1 указывает на то, что длина неизвестна.
// Значения >= 0 указывают, что данное количество байт может быть
// быть прочитано из Body.
//
// Для клиентских запросов значение 0 с ненулевым Body
// также рассматривается как неизвестное.
ContentLength int64
// TransferEncoding перечисляет кодировки передачи данных от крайних к
// внутренней. Пустой список обозначает «идентичную» кодировку.
// TransferEncoding обычно можно игнорировать; кодировка chunked
// автоматически добавляется и удаляется по мере необходимости при отправке и
// получении запросов.
TransferEncoding []string
// Close указывает, закрывать ли соединение после
// ответа на этот запрос (для серверов) или после отправки этого
// запроса и чтения его ответа (для клиентов).
//
// Для серверных запросов HTTP-сервер обрабатывает это автоматически.
// и это поле не нужно обработчикам.
//
// Для клиентских запросов установка этого поля предотвращает повторное использование
// TCP-соединений между запросами к одним и тем же хостам, как если бы
// Transport.DisableKeepAlives был установлен.
Close bool
// Для серверных запросов поле Host указывает хост, на котором
// URL-адрес. Для HTTP/1 (согласно RFC 7230, раздел 5.4), это
// это либо значение заголовка «Host», либо имя хоста.
// указанное в самом URL. Для HTTP/2 это значение заголовка
// поля псевдозаголовка «:authority».
// Оно может иметь вид «хост:порт». Для международных доменных
// имен, Host может быть в форме Punycode или Unicode. Используйте
// golang.org/x/net/idna для преобразования его в любой формат, если
// необходимо.
// Для предотвращения атак перепривязки DNS обработчики сервера должны
// проверять, что заголовок Host имеет значение, для которого обработчик считает себя авторитетным.
// обработчик считает себя авторитетным. Включенный
// ServeMux поддерживает шаблоны, зарегистрированные на определенные хосты.
// называет и таким образом защищает свои зарегистрированные обработчики.
//
// Для клиентских запросов Host опционально переопределяет заголовок Host
// заголовок для отправки. Если он пуст, метод Request.Write использует
// значение URL.Host. Host может содержать международное
// доменное имя.
Host String
// Form содержит разобранные данные формы, включая параметры запроса поля URL
// параметры запроса поля, так и данные формы PATCH, POST или PUT.
// Это поле доступно только после вызова ParseForm.
// HTTP-клиент игнорирует Form и использует вместо нее Body.
Form url.Values
// PostForm содержит разобранные данные формы из параметров тела PATCH, POST
// или параметров тела PUT.
//
// Это поле доступно только после вызова ParseForm.
// HTTP-клиент игнорирует PostForm и использует вместо него Body.
PostForm url.Values
// MultipartForm - это разобранная многочастная форма, включая загрузку файлов.
// Это поле доступно только после вызова ParseMultipartForm.
// HTTP-клиент игнорирует MultipartForm и использует вместо нее Body.
MultipartForm *multipart.Form
// Trailer определяет дополнительные заголовки, которые отправляются после запроса
// body.
//
// Для серверных запросов карта Trailer изначально содержит только
// ключи трейлеров, со значениями nil. (Клиент объявляет, какие трейлеры он
// будет отправлять позже.) Пока обработчик читает из Body, он не должен // ссылаться на Trailer.
// не ссылаться на Trailer. После того как чтение из Body возвращает EOF, Trailer
// может быть прочитан снова и будет содержать значения non-nil, если они были отправлены
// клиентом.
//
// Для клиентских запросов Trailer должен быть инициализирован картой, содержащей
// ключи трейлера для последующей отправки. Значения могут быть nil или их конечные
// значениями. ContentLength должен быть 0 или -1, чтобы отправить чанкированный запрос.
// После отправки HTTP-запроса значения карты могут быть обновлены, пока
// пока читается тело запроса. Как только тело вернется в EOF, вызывающая сторона должна.
// не мутировать Trailer.
//
// Немногие HTTP-клиенты, серверы или прокси поддерживают HTTP-трейлеры.
Trailer Header
// RemoteAddr позволяет HTTP-серверам и другому программному обеспечению записывать.
// сетевой адрес, отправивший запрос, обычно для
// протоколирования. Это поле не заполняется ReadRequest и // не имеет определенного формата.
// не имеет определенного формата. HTTP-сервер в этом пакете
// устанавливает RemoteAddr в адрес «IP:порт» перед вызовом
// обработчика.
// Это поле игнорируется HTTP-клиентом.
RemoteAddr String
// RequestURI - это немодифицированный запрос-цель в
// Request-Line (RFC 7230, раздел 3.1.1), отправленный клиентом
// на сервер. Обычно вместо этого поля следует использовать поле URL.
// Ошибкой является установка этого поля в HTTP-запросе клиента.
RequestURI String
// TLS позволяет HTTP-серверам и другому программному обеспечению записывать
// информацию о TLS-соединении, по которому был получен запрос
// был получен. Это поле не заполняется ReadRequest.
// HTTP-сервер в этом пакете устанавливает поле для
// соединений с поддержкой TLS перед вызовом обработчика;
// в противном случае он оставляет поле нулевым.
// Это поле игнорируется HTTP-клиентом.
TLS *tls.ConnectionState
// Cancel - необязательный канал, закрытие которого указывает на то, что клиентский
// запрос следует считать отмененным. Не все реализации
// RoundTripper могут поддерживать Cancel.
//
// Для серверных запросов это поле неприменимо.
//
// Исправлено: Установите контекст запроса с помощью NewRequestWithContext
// вместо этого. Если поле Cancel и контекст запроса одновременно // установлены.
// установлены, не определено, соблюдается ли Cancel.
Cancel <-chan struct{}
// Response - это ответ перенаправления, который вызвал этот запрос.
// быть создан. Это поле заполняется только во время клиентских
// перенаправления.
Response *Response
// Pattern - шаблон [ServeMux], который соответствует запросу.
// Оно пустое, если запрос не был сопоставлен с шаблоном.
Строка Pattern
// содержит отфильтрованные или неотфильтрованные поля
}
Запрос представляет собой HTTP-запрос, полученный сервером или отправляемый клиентом.
Семантика полей немного отличается при использовании клиентом и сервером. В дополнение к примечаниям к полям, приведенным ниже, смотрите документацию по Request.Write и RoundTripper.
func NewRequest
func NewRequest(method, url string, body io.Reader) (*Request, error)
NewRequest оборачивает NewRequestWithContext, используя context.Background.
func NewRequestWithContext
func NewRequestWithContext(ctx context.Context, method, url string, body io.Reader) (*Request, error)
NewRequestWithContext возвращает новый запрос, заданный методом, URL и необязательным телом.
Если предоставленное тело также является io.Closer, возвращаемое [Request.Body] устанавливается в body и будет закрыто (возможно, асинхронно) методами клиента Do, Post и PostForm, а также Transport.RoundTrip.
NewRequestWithContext возвращает запрос, подходящий для использования с Client.Do или Transport.RoundTrip. Чтобы создать запрос для использования при тестировании обработчика сервера, используйте функцию net/http/httptest.NewRequest, ReadRequest или вручную обновите поля Request. Для исходящего клиентского запроса контекст контролирует все время жизни запроса и его ответа: получение соединения, отправку запроса, чтение заголовков и тела ответа. Разницу между полями входящего и исходящего запроса смотрите в документации к типу Request.
Если body имеет тип *bytes.Buffer, *bytes.Reader или *strings.Reader, то ContentLength возвращаемого запроса устанавливается в точное значение (вместо -1), GetBody заполняется (чтобы 307 и 308 редиректы могли воспроизвести тело), а Body устанавливается в NoBody, если ContentLength равен 0.
func ReadRequest
func ReadRequest(b *bufio.Reader) (*Request, error)
ReadRequest читает и разбирает входящий запрос от b.
ReadRequest является низкоуровневой функцией и должна использоваться только в специализированных приложениях; большинство кода должно использовать сервер для чтения запросов и обрабатывать их через интерфейс Handler. ReadRequest поддерживает только запросы HTTP/1.x. Для HTTP/2 используйте golang.org/x/net/http2.
func (*Request) AddCookie
func (r *Request) AddCookie(c *Cookie)
AddCookie добавляет cookie в запрос. Согласно разделу 5.4 RFC 6265, AddCookie не добавляет более одного поля заголовка Cookie. Это означает, что все куки, если они есть, записываются в одну строку, разделенную точкой с запятой. AddCookie дезинфицирует только имя и значение c, и не дезинфицирует заголовок Cookie, уже присутствующий в запросе.
func (*Request) BasicAuth
func (r *Request) BasicAuth() (имя пользователя, строка пароля, ok bool)
BasicAuth возвращает имя пользователя и пароль, указанные в заголовке авторизации запроса, если запрос использует базовую аутентификацию HTTP. См. RFC 2617, раздел 2.
func (*Request) Clone
func (r *Request) Clone(ctx context.Context) *Request
Clone возвращает глубокую копию r с измененным контекстом на ctx. Предоставленный ctx должен быть ненулевым.
Clone делает неглубокую копию только поля Body.
Для исходящего клиентского запроса контекст контролирует все время жизни запроса и его ответа: получение соединения, отправку запроса, чтение заголовков и тела ответа.
func (*Request) Context
func (r *Request) Context() context.Context
Context возвращает контекст запроса. Чтобы изменить контекст, используйте Request.Clone или Request.WithContext.
Возвращаемый контекст всегда не имеет значения nil; по умолчанию это фоновый контекст.
Для исходящих клиентских запросов контекст управляет отменой.
Для входящих запросов сервера контекст отменяется при закрытии соединения клиента, отмене запроса (при использовании HTTP/2) или при возврате метода ServeHTTP.
func (*Request) Cookie
func (r *Request) Cookie(name string) (*Cookie, error)
Cookie возвращает именованный cookie, указанный в запросе, или ErrNoCookie, если он не найден. Если несколько cookie соответствуют заданному имени, будет возвращен только один cookie.
func (*Request) Cookies
func (r *Request) Cookies() []*Cookie
Cookies разбирает и возвращает HTTP-куки, отправленные вместе с запросом.
func (*Request) CookiesNamed
func (r *Request) CookiesNamed(name string) []*Cookie
CookiesNamed анализирует и возвращает именованные HTTP-куки, отправленные с запросом, или пустой фрагмент, если ни один из них не соответствует.
func (*Request) FormFile
func (r *Request) FormFile(key string) (multipart.File, *multipart.FileHeader, error)
FormFile возвращает первый файл для предоставленного ключа формы. При необходимости FormFile вызывает Request.ParseMultipartForm и Request.ParseForm.
func (*Request) FormValue
func (r *Request) FormValue(key string) string
FormValue возвращает первое значение для именованного компонента запроса. Порядок старшинства:
- тело формы в формате application/x-www-form-urlencoded (только POST, PUT, PATCH)
- параметры запроса (всегда)
- тело формы multipart/form-data (всегда)
FormValue вызывает Request.ParseMultipartForm и Request.ParseForm, если это необходимо, и игнорирует любые ошибки, возвращаемые этими функциями. Если ключ отсутствует, FormValue возвращает пустую строку. Чтобы получить доступ к нескольким значениям одного и того же ключа, вызовите ParseForm, а затем проверьте [Request.Form] напрямую.
func (*Request) MultipartReader
func (r *Request) MultipartReader() (*multipart.Reader, error)
MultipartReader возвращает читателя MIME multipart, если это запрос multipart/form-data или multipart/mixed POST, иначе возвращает nil и ошибку. Используйте эту функцию вместо Request.ParseMultipartForm для обработки тела запроса в виде потока.
func (*Request) ParseForm
func (r *Request) ParseForm() error
ParseForm заполняет r.Form и r.PostForm.
Для всех запросов ParseForm разбирает необработанный запрос из URL и обновляет r.Form.
Для запросов POST, PUT и PATCH он также считывает тело запроса, разбирает его как форму и помещает результаты в r.PostForm и r.Form. Параметры тела запроса имеют приоритет перед значениями строки запроса URL в r.Form.
Если размер тела запроса еще не был ограничен MaxBytesReader, его размер ограничивается 10 МБ.
Для других методов HTTP или если Content-Type не является application/x-www-form-urlencoded, тело запроса не считывается, а r.PostForm инициализируется не нулевым, пустым значением.
Request.ParseMultipartForm автоматически вызывает ParseForm. ParseForm является идемпотентным.
func (*Request) ParseMultipartForm
func (r *Request) ParseMultipartForm(maxMemory int64) error
ParseMultipartForm разбирает тело запроса как multipart/form-data. Разбирается все тело запроса, и не более maxMemory байт его файловых частей сохраняется в памяти, а остальная часть хранится на диске во временных файлах. При необходимости ParseMultipartForm вызывает Request.ParseForm. Если ParseForm возвращает ошибку, ParseMultipartForm возвращает ее, но при этом продолжает разбирать тело запроса. После одного вызова ParseMultipartForm последующие вызовы не имеют эффекта.
func (*Request) PathValue
func (r *Request) PathValue(name string) string
PathValue возвращает значение именованного подстановочного знака пути в шаблоне ServeMux, который соответствует запросу. Возвращается пустая строка, если запрос не был сопоставлен с шаблоном или в шаблоне нет такого подстановочного знака.
func (*Request) PostFormValue
func (r *Request) PostFormValue(key string) string
PostFormValue возвращает первое значение для именованного компонента в теле запроса POST, PUT или PATCH. Параметры запроса URL игнорируются. При необходимости PostFormValue вызывает Request.ParseMultipartForm и Request.ParseForm и игнорирует любые ошибки, возвращаемые этими функциями. Если ключ отсутствует, PostFormValue возвращает пустую строку.
func (*Request) ProtoAtLeast
func (r *Request) ProtoAtLeast(major, minor int) bool
ProtoAtLeast сообщает, является ли протокол HTTP, используемый в запросе, хотя бы мажорным и минорным.
func (*Request) Referer
func (r *Request) Referer() string
Referer возвращает ссылающийся URL, если он был отправлен в запросе.
Referer пишется неправильно, как и в самом запросе, что является ошибкой с самых ранних дней существования HTTP. Это значение также может быть получено из карты Header как Header[«Referer»]; преимущество предоставления его в виде метода заключается в том, что компилятор может диагностировать программы, использующие альтернативное (правильное английское) написание req.Referrer(), но не может диагностировать программы, использующие Header[«Referrer»].
func (*Request) SetBasicAuth
func (r *Request) SetBasicAuth(имя пользователя, пароль string)
SetBasicAuth устанавливает заголовок авторизации запроса на использование базовой аутентификации HTTP с указанными именем пользователя и паролем.
При использовании HTTP Basic Authentication предоставленные имя пользователя и пароль не шифруются. Обычно их следует использовать только в запросах HTTPS.
Имя пользователя не должно содержать двоеточие. Некоторые протоколы могут предъявлять дополнительные требования к предварительному введению имени пользователя и пароля. Например, при использовании OAuth2 оба аргумента должны быть сначала закодированы в URL с помощью url.QueryEscape.
func (*Request) SetPathValue
func (r *Request) SetPathValue(name, value string)
SetPathValue устанавливает имя в значение, так что последующие вызовы r.PathValue(name) возвращают значение.
func (*Request) UserAgent
func (r *Request) UserAgent() string
UserAgent возвращает User-Agent клиента, если он был отправлен в запросе.
func (*Request) WithContext
func (r *Request) WithContext(ctx context.Context) *Request
WithContext возвращает неглубокую копию r с измененным контекстом на ctx. Предоставленный ctx должен быть ненулевым.
Для исходящего клиентского запроса контекст контролирует все время жизни запроса и его ответа: получение соединения, отправку запроса, чтение заголовков и тела ответа.
Чтобы создать новый запрос с контекстом, используйте NewRequestWithContext. Чтобы создать глубокую копию запроса с новым контекстом, используйте Request.Clone.
func (*Request) Write
func (r *Request) Write(w io.Writer) error
Write записывает HTTP/1.1 запрос, который представляет собой заголовок и тело, в формате wire. Этот метод обрабатывает следующие поля запроса:
Host
URL
Method (defaults to "GET")
Header
ContentLength
TransferEncoding
Body
Если присутствует Body, Content-Length <= 0 и для [Request.TransferEncoding] не установлено значение «identity», Write добавляет в заголовок «Transfer-Encoding: chunked». Тело закрывается после отправки.
func (*Request) WriteProxy
func (r *Request) WriteProxy(w io.Writer) error
WriteProxy похож на Request.Write, но записывает запрос в форме, ожидаемой HTTP-прокси. В частности, Request.WriteProxy записывает начальную строку Request-URI запроса с абсолютным URI, согласно разделу 5.3 RFC 7230, включая схему и хост. В любом случае WriteProxy также записывает заголовок Host, используя либо r.Host, либо r.URL.Host.
type Response
type Response struct {
Status string // например, «200 OK»
StatusCode int // например, 200
Proto string // например, «HTTP/1.0»
ProtoMajor int // например, 1
ProtoMinor int // например, 0
// Header сопоставляет ключи заголовков со значениями. Если в ответе было несколько
// заголовков с одним и тем же ключом, они могут быть объединены с помощью запятой
// разделителями. (RFC 7230, раздел 3.2.2 требует, чтобы несколько заголовков
// были семантически эквивалентны последовательности, разделенной запятыми.) Когда
// значения заголовков дублируются другими полями в этой структуре (например,
// ContentLength, TransferEncoding, Trailer), значения полей являются
// авторитетное.
//
// Ключи в карте канонизированы (см. CanonicalHeaderKey).
Header Header
// Body представляет собой тело ответа.
//
// Тело ответа передается по требованию, когда поле Body
// считывается. Если сетевое соединение обрывается или сервер
// завершает ответ, вызов Body.Read возвращает ошибку.
//
// Клиент и транспорт http гарантируют, что Body всегда
// non-nil, даже в ответах без тела или в ответах с
// телом нулевой длины. Вызывающая сторона обязана // закрыть Body.
// закрыть Body. Транспорт HTTP-клиента по умолчанию не может
// повторно использовать TCP-соединения HTTP/1.x «keep-alive», если тело
// не прочитано до конца и не закрыто.
//
// Тело автоматически дешанкируется, если сервер ответил
// с «chunked» Transfer-Encoding.
//
// Начиная с Go 1.12, тело также будет реализовывать io.Writer
// при успешном ответе «101 Switching Protocols»,
// как это используется в WebSockets и режиме «h2c» HTTP/2.
Body io.ReadCloser
// ContentLength записывает длину связанного содержимого. Значение
// значение -1 указывает на то, что длина неизвестна. Если Request.Method
// является «HEAD», значения >= 0 указывают, что данное количество байт может быть
// быть прочитано из Body.
ContentLength int64
// Содержит кодировки передачи данных от крайнего внешнего к крайнему внутреннему. Значение
// nil, означает, что используется кодировка «identity».
TransferEncoding []string
// Close записывает, указывал ли заголовок, что соединение должно быть
// закрыть после прочтения Body. Значение является рекомендательным для клиентов: ни
// ни ReadResponse, ни Response.Write никогда не закрывают соединение.
Close bool
// Uncompressed сообщает, был ли ответ отправлен в сжатом виде, но
// был распакован пакетом http. Если значение равно true, чтение из
// Body выдает несжатое содержимое вместо сжатого
// содержимое, фактически переданное с сервера, ContentLength устанавливается в -1,
// а поля «Content-Length» и «Content-Encoding» удаляются
// из responseHeader. Чтобы получить оригинальный ответ от
// сервера, установите Transport.DisableCompression в true.
Uncompressed bool
// Трейлер сопоставляет ключи трейлера со значениями в том же
// формате, что и Header.
//
// Изначально трейлер содержит только значения nil, по одному для
// каждого ключа, указанного в заголовке «Trailer» сервера.
// значение. Эти значения не добавляются в Header.
//
// К трейлеру нельзя обращаться одновременно с вызовами Read
// на Body.
//
// После того как Body.Read вернет io.EOF, Trailer будет содержать.
// любые значения трейлера, отправленные сервером.
Trailer Header
// Request - это запрос, который был отправлен для получения данного Response.
// Тело запроса равно нулю (оно уже было использовано).
// Это значение заполняется только для клиентских запросов.
Request *Request
// TLS содержит информацию о TLS-соединении, по которому был получен
// был получен ответ. Он равен nil для незашифрованных ответов.
// Указатель разделяется между ответами и не должен быть // изменен.
// изменяться.
TLS *tls.ConnectionState
}
Response представляет собой ответ на HTTP-запрос.
Клиент и транспорт возвращают ответы от серверов после получения заголовков ответа. Тело ответа передается по запросу по мере считывания поля Body.
func Get
func Get(url string) (resp *Response, err error)
Get выполняет GET на указанный URL. Если ответ содержит один из следующих кодов перенаправления, Get следует за этим перенаправлением, максимум 10 перенаправлений:
301 (Moved Permanently)
302 (найдено)
303 (См. другое)
307 (Временное перенаправление)
308 (постоянное перенаправление)
Ошибка возвращается, если было слишком много перенаправлений или если произошла ошибка протокола HTTP. Ответ не-2xx не приводит к ошибке. Любая возвращаемая ошибка будет иметь тип *url.Error. Метод Timeout значения url.Error сообщит true, если запрос завершился по таймеру.
Если err равен nil, resp всегда содержит ненулевой resp.Body. Вызывающая сторона должна закрыть resp.Body, когда закончит чтение из него.
Get - это обертка вокруг DefaultClient.Get.
Чтобы сделать запрос с пользовательскими заголовками, используйте NewRequest и DefaultClient.Do.
Чтобы сделать запрос с заданным контекстом (context.Context), используйте NewRequestWithContext и DefaultClient.Do.
Пример
package main
import (
"fmt"
"io"
"log"
"net/http"
)
func main() {
res, err := http.Get("http://www.google.com/robots.txt")
if err != nil {
log.Fatal(err)
}
body, err := io.ReadAll(res.Body)
res.Body.Close()
if res.StatusCode > 299 {
log.Fatalf("Response failed with status code: %d and\nbody: %s\n", res.StatusCode, body)
}
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s", body)
}
func Head
func Head(url string) (resp *Response, err error)
Head выдает HEAD на указанный URL. Если ответ представляет собой один из следующих кодов перенаправления, Head следует за этим перенаправлением, максимум 10 перенаправлений:
301 (Moved Permanently)
302 (найдено)
303 (См. другое)
307 (Временное перенаправление)
308 (постоянный редирект)
Head - это обертка вокруг DefaultClient.Head.
Чтобы сделать запрос с указанным контекстом, используйте NewRequestWithContext и DefaultClient.Do.
func Post
func Post(url, contentType string, body io.Reader) (resp *Response, err error)
Post выполняет POST на указанный URL.
Вызывающая сторона должна закрыть resp.Body, когда закончит читать из него.
Если предоставленное тело является io.Closer, оно будет закрыто после выполнения запроса.
Post является оберткой вокруг DefaultClient.Post.
Чтобы установить пользовательские заголовки, используйте NewRequest и DefaultClient.Do.
Подробнее о том, как обрабатываются перенаправления, смотрите документацию по методу Client.Do.
Чтобы выполнить запрос с указанным контекстом (context.Context), используйте NewRequestWithContext и DefaultClient.Do.
func PostForm
func PostForm(url string, data url.Values) (resp *Response, err error)
PostForm выполняет POST-запрос на указанный URL, с ключами и значениями данных в URL-кодировке в качестве тела запроса.
Заголовок Content-Type имеет значение application/x-www-form-urlencoded. Чтобы установить другие заголовки, используйте NewRequest и DefaultClient.Do.
Когда err равен nil, resp всегда содержит ненулевое resp.Body. Вызывающая сторона должна закрыть resp.Body, когда закончит чтение из него.
PostForm - это обертка вокруг DefaultClient.PostForm.
Подробнее о том, как обрабатываются перенаправления, смотрите документацию метода Client.Do.
Чтобы выполнить запрос с указанным контекстом (context.Context), используйте NewRequestWithContext и DefaultClient.Do.
func ReadResponse
func ReadResponse(r *bufio.Reader, req *Request) (*Response, error)
ReadResponse считывает и возвращает HTTP-ответ от r. Параметр req опционально указывает запрос, который соответствует этому ответу. Если параметр nil, предполагается, что это GET-запрос. Клиенты должны вызвать resp.Body.Close после завершения чтения resp.Body. После этого вызова клиенты могут просмотреть resp.Trailer, чтобы найти пары ключ/значение, включенные в трейлер ответа.
func (*Response) Cookies
func (r *Response) Cookies() []*Cookie
Cookies разбирает и возвращает cookie, установленные в заголовках Set-Cookie.
func (*Response) Location
func (r *Response) Location() (*url.URL, error)
Location возвращает URL заголовка «Location» ответа, если он присутствует. Относительные перенаправления разрешаются относительно [Response.Request]. Возвращается ErrNoLocation, если заголовок Location отсутствует.
func (*Response) ProtoAtLeast
func (r *Response) ProtoAtLeast(major, minor int) bool
ProtoAtLeast сообщает, является ли протокол HTTP, используемый в ответе, хотя бы мажорным и минорным.
func (*Response) Write
func (r *Response) Write(w io.Writer) error
Write записывает r в w в формате ответа сервера HTTP/1.x, включая строку состояния, заголовки, тело и необязательный трейлер.
Этот метод обрабатывает следующие поля ответа r:
StatusCode
ProtoMajor
ProtoMinor
Request.Method
TransferEncoding
Trailer
Body
ContentLength
Header, значения для неканонических ключей будут иметь непредсказуемое поведение
Тело ответа закрывается после отправки.
type ResponseController
type ResponseController struct {
// содержит отфильтрованные или неэкспонированные поля
}
ResponseController используется HTTP-обработчиком для управления ответом.
ResponseController не может быть использован после возврата метода [Handler.ServeHTTP].
func NewResponseController
func NewResponseController(rw ResponseWriter) *ResponseController
NewResponseController создает ResponseController для запроса.
ResponseWriter должен быть исходным значением, переданным в метод [Handler.ServeHTTP], или иметь метод Unwrap, возвращающий исходный ResponseWriter.
Если ResponseWriter реализует любой из следующих методов, ResponseController будет вызывать их по мере необходимости:
Flush()
FlushError() error // альтернативный вариант Flush, возвращающий ошибку
Hijack() (net.Conn, *bufio.ReadWriter, error)
SetReadDeadline(deadline time.Time) error
SetWriteDeadline(deadline time.Time) ошибка
EnableFullDuplex() error
Если ResponseWriter не поддерживает метод, ResponseController возвращает ошибку, соответствующую ErrNotSupported.
func (*ResponseController) EnableFullDuplex
func (c *ResponseController) EnableFullDuplex() error
EnableFullDuplex указывает, что обработчик запроса будет чередовать чтение из [Request.Body] с записью в ResponseWriter.
Для запросов HTTP/1 HTTP-сервер Go по умолчанию потребляет всю непрочитанную часть тела запроса перед началом записи ответа, что не позволяет обработчикам одновременно читать из запроса и записывать ответ. Вызов EnableFullDuplex отключает это поведение и позволяет обработчикам продолжать читать из запроса, одновременно записывая ответ.
Для запросов HTTP/2 HTTP-сервер Go всегда разрешает одновременное чтение и запись ответа.
func (*ResponseController) Flush
func (c *ResponseController) Flush() error
Flush сбрасывает буферизованные данные клиенту.
func (*ResponseController) Hijack
func (c *ResponseController) Hijack() (net.Conn, *bufio.ReadWriter, error)
Hijack позволяет вызывающей стороне взять на себя управление соединением. Подробности см. в интерфейсе Hijacker.
func (*ResponseController) SetReadDeadline
func (c *ResponseController) SetReadDeadline(deadline time.Time) error
SetReadDeadline устанавливает крайний срок для чтения всего запроса, включая тело. Чтение из тела запроса после превышения установленного срока вернет ошибку. Нулевое значение означает отсутствие дедлайна.
Установка крайнего срока чтения после того, как он был превышен, не продлевает его.
func (*ResponseController) SetWriteDeadline
func (c *ResponseController) SetWriteDeadline(deadline time.Time) error
SetWriteDeadline устанавливает крайний срок для написания ответа. Запись в тело ответа после превышения установленного срока не блокируется, но может быть успешной, если данные были забуферизированы. Нулевое значение означает отсутствие крайнего срока.
Установка крайнего срока записи после его превышения не приведет к его продлению.
type ResponseWriter
type ResponseWriter interface {
// Header возвращает карту заголовков, которая будет отправлена
// [ResponseWriter.WriteHeader]. Карта [Header] также является механизмом, с помощью которого
// реализации [Handler] могут устанавливать HTTP-трейлеры.
//
// Изменение карты заголовков после вызова [ResponseWriter.WriteHeader] (или
// [ResponseWriter.Write]) не имеет никакого эффекта, если только код состояния HTTP не был класса
// 1xx или измененные заголовки являются трейлерами.
//
// Существует два способа установки трейлеров. Предпочтительным является.
// заранее объявить в заголовках, какие трейлеры вы будете впоследствии
// отправлять, устанавливая в заголовке «Trailer» имена
// ключей трейлеров, которые появятся позже. В этом случае эти
// ключи карты заголовков рассматриваются так, как если бы они были
// трейлерами. См. пример. Второй способ - для трейлеров.
// ключей, не известных [Обработчику] до первого [ResponseWriter.Write],
// является префикс ключей карты [Header] с помощью константного значения [TrailerPrefix]
// константным значением.
//
// Чтобы подавить автоматические заголовки ответа (например, «Дата»), установите
// их значение в nil.
Header() Header
// Write записывает данные в соединение как часть HTTP-ответа.
//
// Если функция [ResponseWriter.WriteHeader] еще не была вызвана, Write вызывает
// WriteHeader(http.StatusOK) перед записью данных. Если заголовок
// не содержит строки Content-Type, Write добавляет набор Content-Type
// к результату передачи начальных 512 байт записанных данных в
// [DetectContentType]. Кроме того, если общий размер всех записанных
// данных меньше нескольких КБ и нет вызовов Flush, то
// заголовок Content-Length добавляется автоматически.
//
// В зависимости от версии протокола HTTP и клиента, вызов
// Write или WriteHeader может предотвратить последующее чтение // Request.Body.
// Request.Body. Для запросов HTTP/1.x обработчики должны считывать любые // необходимые данные тела запроса перед записью ответа.
// необходимые данные тела запроса перед записью ответа. После того как
// заголовки будут смыты (либо из-за явного вызова Flusher.Flush
// вызова или записи достаточного количества данных, чтобы вызвать флэш), тело запроса
// может быть недоступно. Для запросов HTTP/2 HTTP-сервер Go разрешает // обработчикам продолжать считывать // тело запроса.
// обработчикам продолжать читать тело запроса, одновременно // записывая ответ.
// записи ответа. Однако такое поведение может поддерживаться не // всеми клиентами HTTP/2.
// всеми клиентами HTTP/2. Обработчики должны читать перед записью, если
// по возможности, чтобы обеспечить максимальную совместимость.
Write([]byte) (int, error)
// WriteHeader отправляет заголовок ответа HTTP с указанным
// кодом состояния.
//
// Если WriteHeader не вызывается явно, то первый вызов Write
// вызовет неявный WriteHeader(http.StatusOK).
// Таким образом, явные вызовы WriteHeader используются в основном для.
// отправки кодов ошибок или информационных ответов 1xx.
//
// Предоставленный код должен быть действительным кодом состояния HTTP 1xx-5xx.
// Может быть записано любое количество заголовков 1xx, за которыми следует не более
// один заголовок 2xx-5xx. Заголовки 1xx отправляются немедленно, но заголовки 2xx-5xx
// заголовки могут буферизироваться. Используйте интерфейс Flusher для отправки
// буферизованных данных. Карта заголовков очищается при отправке заголовков 2xx-5xx.
// при отправке заголовков 2xx-5xx, но не при отправке заголовков 1xx.
//
// Сервер автоматически отправляет заголовок 100 (Continue)
// при первом чтении из тела запроса, если в запросе есть
// заголовок «Expect: 100-continue».
WriteHeader(statusCode int)
}
Интерфейс ResponseWriter используется HTTP-обработчиком для создания HTTP-ответа.
ResponseWriter не может быть использован после возврата [Handler.ServeHTTP].
Пример трейлеры
HTTP-трейлеры — это набор пар «ключ/значение», подобных заголовкам, которые следуют после HTTP-ответа, а не перед ним.
package main
import (
"io"
"net/http"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/sendstrailers", func(w http.ResponseWriter, req *http.Request) {
// Before any call to WriteHeader or Write, declare
// the trailers you will set during the HTTP
// response. These three headers are actually sent in
// the trailer.
w.Header().Set("Trailer", "AtEnd1, AtEnd2")
w.Header().Add("Trailer", "AtEnd3")
w.Header().Set("Content-Type", "text/plain; charset=utf-8") // normal header
w.WriteHeader(http.StatusOK)
w.Header().Set("AtEnd1", "value 1")
io.WriteString(w, "This HTTP response has both headers before this text and trailers at the end.\n")
w.Header().Set("AtEnd2", "value 2")
w.Header().Set("AtEnd3", "value 3") // These will appear as trailers.
})
}
type RoundTripper
type RoundTripper interface {
// RoundTrip выполняет одну HTTP-транзакцию, возвращая
// ответ на предоставленный запрос.
//
// RoundTrip не должен пытаться интерпретировать ответ. В
// частности, RoundTrip должен вернуть err == nil, если он получил
// ответ, независимо от кода состояния ответа HTTP.
// Ненулевое значение err должно быть зарезервировано на случай неудачи в получении
// ответа. Аналогично, RoundTrip не должен пытаться.
// обрабатывать детали протокола более высокого уровня, такие как перенаправления,
// аутентификация или cookies.
//
// RoundTrip не должен модифицировать запрос, кроме как.
// потребления и закрытия тела запроса. RoundTrip может.
// читать поля запроса в отдельной горутине. Вызывающие стороны
// не должны мутировать или повторно использовать запрос до тех пор, пока не будет закрыто тело ответа
// Body не будет закрыто.
//
// RoundTrip должен всегда закрывать тело, в том числе при ошибках,
// но в зависимости от реализации может делать это в отдельной
// горутине даже после возвращения RoundTrip. Это означает, что
// вызывающие стороны, желающие повторно использовать тело для последующих запросов
// должны дождаться вызова Close, прежде чем сделать это.
//
// Поля URL и Header запроса должны быть инициализированы.
RoundTrip(*Request) (*Response, error)
}
RoundTripper - это интерфейс, представляющий возможность выполнения одной HTTP-транзакции с получением ответа на заданный запрос.
RoundTripper должен быть безопасным для одновременного использования несколькими горутинами.
var DefaultTransport RoundTripper = &Transport{
Proxy: ProxyFromEnvironment,
DialContext: defaultTransportDialContext(&net.Dialer{
Таймаут: 30 * time.Second,
KeepAlive: 30 * time.Second,
}),
ForceAttemptHTTP2: true,
MaxIdleConns: 100,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
}
DefaultTransport является реализацией Transport по умолчанию и используется DefaultClient. Он устанавливает сетевые соединения по мере необходимости и кэширует их для повторного использования при последующих вызовах. Он использует HTTP-прокси по указанию переменных окружения HTTP_PROXY, HTTPS_PROXY и NO_PROXY (или их строчных версий).
func NewFileTransport
func NewFileTransport(fs FileSystem) RoundTripper
NewFileTransport возвращает новый RoundTripper, обслуживающий предоставленную FileSystem. Возвращаемый RoundTripper игнорирует URL host в своих входящих запросах, а также большинство других свойств запроса.
Типичным случаем использования NewFileTransport является регистрация «файлового» протокола на транспорте, как показано ниже:
t := &http.Transport{}
t.RegisterProtocol(«file», http.NewFileTransport(http.Dir(«/»)))
c := &http.Client{Transport: t}
res, err := c.Get(«file:///etc/passwd»)
...
func NewFileTransportFS
func NewFileTransportFS(fsys fs.FS) RoundTripper
NewFileTransportFS возвращает новый RoundTripper, обслуживающий предоставленную файловую систему fsys. Возвращаемый RoundTripper игнорирует URL host в своих входящих запросах, а также большинство других свойств запроса. Файлы, предоставляемые fsys, должны реализовывать io.Seeker.
Типичным случаем использования NewFileTransportFS является регистрация «файлового» протокола в транспорте, как показано ниже:
fsys := os.DirFS(«/»)
t := &http.Transport{}
t.RegisterProtocol(«file», http.NewFileTransportFS(fsys))
c := &http.Client{Transport: t}
res, err := c.Get(«file:///etc/passwd»)
...
type SameSite
type SameSite int
SameSite позволяет серверу определить атрибут cookie, делающий невозможным для браузера отправку этого cookie вместе с межсайтовыми запросами. Основная цель - снизить риск утечки межсайтовой информации и обеспечить некоторую защиту от атак подделки межсайтовых запросов.
Подробности см. на сайте https://tools.ietf.org/html/draft-ietf-httpbis-cookie-same-site-00.
const (
SameSiteDefaultMode SameSite = iota + 1
SameSiteLaxMode
SameSiteStrictMode
SameSiteNoneMode
)
type ServeMux
type ServeMux struct {
// содержит отфильтрованные или неотфильтрованные поля
}
ServeMux - это мультиплексор HTTP-запросов. Он сопоставляет URL каждого входящего запроса со списком зарегистрированных шаблонов и вызывает обработчик шаблона, который наиболее точно соответствует URL.
Шаблоны
Шаблоны могут соответствовать методу, хосту и пути запроса. Некоторые примеры:
- «/index.html» соответствует пути „/index.html“ для любого хоста и метода.
- «GET /static/» соответствует GET-запросу, путь которого начинается с „/static/“.
- «example.com/» соответствует любому запросу к хосту „example.com“.
- «example.com/{$}» соответствует запросам с хостом „example.com“ и путем „/“.
- «/b/{bucket}/o/{objectname...}» соответствует путям, первый сегмент которых - „b“, а третий - „o“. Имя «bucket» обозначает второй сегмент, а «objectname» - оставшуюся часть пути.
В общем случае шаблон выглядит следующим образом
[METHOD ][HOST]/[PATH]
Все три части необязательны; «/» является допустимым шаблоном. Если присутствует METHOD, за ним должен следовать хотя бы один пробел или табуляция.
Буквальные (т. е. не содержащие символы дикого символа) части шаблона соответствуют соответствующим частям запроса с учетом регистра.
Шаблон без метода соответствует любому методу. Шаблон с методом GET соответствует запросам GET и HEAD. В противном случае метод должен совпадать в точности.
Шаблон без хоста соответствует всем хостам. Шаблон с указанием хоста соответствует URL-адресам только на этом хосте.
Путь может включать сегменты подстановочных знаков вида {NAME} или {NAME…}. Например, «/b/{bucket}/o/{objectname…}». Имя подстановочного знака должно быть действительным идентификатором Go. Подстановочные знаки должны быть полными сегментами пути: им должна предшествовать косая черта, а за ней следовать либо косая черта, либо конец строки. Например, «/b_{bucket}» не является правильным шаблоном.
Обычно подстановочный знак соответствует только одному сегменту пути, заканчивающемуся следующим буквенным слешем (не %2F) в URL-адресе запроса. Но если присутствует «…», то подстановочный знак соответствует оставшейся части пути URL, включая косые черты. (Поэтому подстановочный знак «…» не должен появляться нигде, кроме конца шаблона). Соответствие для подстановочного знака можно получить, вызвав Request.PathValue с именем подстановочного знака. Косая черта в пути действует как анонимный подстановочный знак «…».
Специальный подстановочный знак {$} совпадает только с концом URL. Например, шаблон «/{$}» соответствует только пути «/», в то время как шаблон «/» соответствует всем путям.
Для сопоставления пути шаблонов и пути входящих запросов сегментно разгруппировываются. Так, например, путь «/a%2Fb/100%25» рассматривается как состоящий из двух сегментов, «a/b» и «100%». Шаблон «/a%2fb/» соответствует ему, а шаблон «/a/b/» - нет.
Приоритет
Если запросу соответствуют два или более шаблонов, то приоритет имеет наиболее специфичный шаблон. Шаблон P1 более специфичен, чем P2, если P1 соответствует строгому подмножеству запросов P2; то есть, если P2 соответствует всем запросам P1 и более. Если ни один из шаблонов не является более специфичным, то они конфликтуют. Из этого правила есть одно исключение для обратной совместимости: если два шаблона в противном случае будут конфликтовать, но один из них имеет хост, а другой - нет, то приоритет имеет шаблон с хостом. Если шаблон, переданный в ServeMux.Handle или ServeMux.HandleFunc, конфликтует с другим шаблоном, который уже зарегистрирован, эти функции паникуют.
В качестве примера общего правила можно привести «/images/thumbnails/», который является более конкретным, чем «/images/», поэтому оба шаблона могут быть зарегистрированы. Первый соответствует путям, начинающимся с «/images/thumbnails/», а второй будет соответствовать любому другому пути в поддереве «/images/».
В качестве другого примера рассмотрим шаблоны «GET /» и «/index.html»: оба соответствуют GET-запросу на «/index.html», но первый шаблон соответствует всем остальным GET- и HEAD-запросам, а второй - любому запросу на «/index.html», который использует другой метод. Шаблоны конфликтуют.
Перенаправление по следам косой черты
Рассмотрим ServeMux с обработчиком для поддерева, зарегистрированного с использованием слэша в конце или подстановочного символа «…». Если ServeMux получает запрос на корень поддерева без скрепки, он перенаправляет запрос, добавляя скрепку. Это поведение можно отменить, зарегистрировав отдельный путь без косой черты или подстановочного знака «…». Например, регистрация «/images/» заставляет ServeMux перенаправлять запрос «/images» на «/images/», если только «/images» не был зарегистрирован отдельно.
Санирование запросов
ServeMux также заботится о дезинфекции пути запроса URL и заголовка Host, удаляя номер порта и перенаправляя любой запрос, содержащий сегменты . или … или повторяющиеся косые черты, на эквивалентный, более чистый URL. Сбегающие элементы пути, такие как «%2e» для «.» и «%2f» для «/», сохраняются и не считаются разделителями при маршрутизации запроса.
Совместимость
Синтаксис шаблонов и поведение ServeMux при сопоставлении значительно изменились в Go 1.22. Чтобы восстановить старое поведение, установите переменную окружения GODEBUG в значение «httpmuxgo121=1». Эта настройка считывается один раз, при запуске программы; изменения во время выполнения будут проигнорированы.
Изменения, несовместимые с предыдущими, включают:
- Дикие символы в 1.21 - это обычные литеральные сегменты пути. Например, шаблон «/{x}» будет соответствовать только этому пути в 1.21, но будет соответствовать любому односегментному пути в 1.22.
- В 1.21 ни один шаблон не отклонялся, если он не был пустым или не конфликтовал с существующим шаблоном. В 1.22 синтаксически некорректные шаблоны приводят к панике ServeMux.Handle и ServeMux.HandleFunc. Например, в 1.21 шаблоны «/{» и «/a{x}» совпадают сами по себе, но в 1.22 они недействительны и при регистрации вызовут панику.
- В 1.22 каждый сегмент шаблона разгруппировывается; в 1.21 этого не делалось. Например, в 1.22 шаблон «/%61» соответствует пути «/a» («%61» - управляющая последовательность URL для «a»), а в 1.21 он соответствовал бы только пути «/%2561» (где «%25» - управляющая последовательность для знака процента).
- При сопоставлении шаблонов с путями в версии 1.22 каждый сегмент пути раскрывается, а в версии 1.21 раскрывается весь путь. Это изменение в основном влияет на то, как обрабатываются пути с эскейпами %2F, расположенными рядом со слешами. Подробности см. на https://go.dev/issue/21955.
func NewServeMux
func NewServeMux() *ServeMux
NewServeMux выделяет и возвращает новый ServeMux.
func (*ServeMux) Handle
func (mux *ServeMux) Handle(pattern string, handler Handler)
Handle регистрирует обработчик для заданного шаблона. Если заданный шаблон конфликтует с уже зарегистрированным, Handle паникует.
Пример
package main
import (
"fmt"
"net/http"
)
type apiHandler struct{}
func (apiHandler) ServeHTTP(http.ResponseWriter, *http.Request) {}
func main() {
mux := http.NewServeMux()
mux.Handle("/api/", apiHandler{})
mux.HandleFunc("/", func(w http.ResponseWriter, req *http.Request) {
// The "/" pattern matches everything, so we need to check
// that we're at the root here.
if req.URL.Path != "/" {
http.NotFound(w, req)
return
}
fmt.Fprintf(w, "Welcome to the home page!")
})
}
func (*ServeMux) HandleFunc
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request))
HandleFunc регистрирует функцию-обработчик для заданного шаблона. Если заданный шаблон конфликтует с уже зарегистрированным, HandleFunc паникует.
func (*ServeMux) Handler
func (mux *ServeMux) Handler(r *Request) (h Handler, pattern string)
Handler возвращает обработчик, который будет использоваться для данного запроса, консультируясь с r.Method, r.Host и r.URL.Path. Всегда возвращается ненулевой обработчик. Если путь не является каноническим, то обработчик будет внутренне сгенерированным обработчиком, который перенаправляет на канонический путь. Если хост содержит порт, он игнорируется при подборе обработчиков.
Путь и хост используются без изменений для запросов CONNECT.
Обработчик также возвращает зарегистрированный шаблон, соответствующий запросу, или, в случае внутренне сгенерированных перенаправлений, путь, который будет соответствовать после выполнения перенаправления.
Если для запроса не существует зарегистрированного обработчика, Handler возвращает обработчик «страница не найдена» и пустой шаблон.
func (*ServeMux) ServeHTTP
func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request)
ServeHTTP отправляет запрос обработчику, чей шаблон наиболее точно соответствует URL запроса.
type Server
type Server struct {
// Addr опционально указывает TCP-адрес сервера для прослушивания,
// в форме «host:port». Если он пуст, то используется «:http» (порт 80).
// Имена служб определены в RFC 6335 и назначены IANA.
// Подробнее о формате адресов см. в разделе net.Dial.
Addr string
Handler Handler // обработчик для вызова, http.DefaultServeMux, если nil
// DisableGeneralOptionsHandler, если true, передает запросы «OPTIONS *» обработчику,
// в противном случае отвечает 200 OK и Content-Length: 0.
DisableGeneralOptionsHandler bool
// TLSConfig опционально предоставляет конфигурацию TLS для использования
// функциями ServeTLS и ListenAndServeTLS. Обратите внимание, что это значение
// клонируется ServeTLS и ListenAndServeTLS, поэтому не
// невозможно изменить конфигурацию с помощью методов типа
// tls.Config.SetSessionTicketKeys. Чтобы использовать
// SetSessionTicketKeys, используйте Server.Serve с TLS-слушателем
// вместо него.
TLSConfig *tls.Config
// ReadTimeout - максимальная продолжительность чтения всего // запроса.
// запроса, включая тело. Нулевое или отрицательное значение означает.
// что таймаута не будет.
//
// Поскольку ReadTimeout не позволяет обработчикам принимать по каждому запросу
// решения о допустимом сроке выполнения или // скорости загрузки каждого тела запроса, большинство пользователей предпочтут использовать ReadTimeout.
// скорости загрузки, большинство пользователей предпочтут использовать
// ReadHeaderTimeout. Вполне допустимо использовать их оба.
ReadTimeout time.Duration
// ReadHeaderTimeout - это количество времени, разрешенное для чтения
// заголовков запросов. Срок чтения соединения сбрасывается.
// после чтения заголовков, и обработчик может решить, что
// считается слишком медленным для тела запроса. Если значение равно нулю, используется значение
// ReadTimeout используется. Если отрицательно, или если ноль и ReadTimeout
// равно нулю или отрицательно, то таймаут не используется.
ReadHeaderTimeout time.Duration
// WriteTimeout - максимальная продолжительность до завершения тайминга
// записи ответа. Она сбрасывается каждый раз, когда считывается новый
// чтении заголовка запроса. Как и ReadTimeout, он не // позволяет обработчикам принимать решения.
// позволяет обработчикам принимать решения на основе каждого запроса.
// Нулевое или отрицательное значение означает, что таймаута не будет.
WriteTimeout time.Duration
// IdleTimeout - это максимальное время ожидания
// следующего запроса, когда включены keep-alives. Если значение равно нулю, то используется значение
// из ReadTimeout используется. Если отрицательно, или если ноль и ReadTimeout
// равно нулю или отрицательно, таймаут не используется.
IdleTimeout time.Duration
// MaxHeaderBytes управляет максимальным количеством байтов, которые
// сервер будет читать, разбирая ключи и // значения заголовка запроса, включая строку запроса.
// значения, включая строку запроса. Оно не ограничивает
// размер тела запроса.
// Если значение равно нулю, используется значение DefaultMaxHeaderBytes.
MaxHeaderBytes int
// TLSNextProto опционально указывает функцию, которая принимает на себя
// владение предоставленным TLS-соединением, когда происходит обновление протокола ALPN
// произошло обновление протокола. Ключом карты является протокол.
// согласованное имя. Аргумент Handler должен использоваться для.
// обработки HTTP-запросов и инициализирует TLS запроса
// и RemoteAddr, если они еще не заданы. Соединение
// автоматически закрывается при возврате функции.
// Если TLSNextProto не равно nil, поддержка HTTP/2 не включается
// автоматически.
TLSNextProto map[string]func(*Server, *tls.Conn, Handler)
// ConnState задает необязательную функцию обратного вызова, которая
// вызывается при изменении состояния клиентского соединения. См.
// Тип ConnState и связанные с ним константы для получения подробной информации.
ConnState func(net.Conn, ConnState)
// ErrorLog задает необязательный регистратор ошибок при принятии // соединения, неожиданного поведения обработчиков.
// соединения, неожиданного поведения обработчиков и
// базовых ошибок файловой системы.
// Если nil, то протоколирование осуществляется через стандартный логгер пакета log.
ErrorLog *log.Logger
// BaseContext опционально указывает функцию, которая возвращает
// базовый контекст для входящих запросов на этом сервере.
// Предоставленный слушатель - это конкретный слушатель, который
// собирается начать принимать запросы.
// Если BaseContext равен nil, по умолчанию используется context.Background().
// Если не nil, то должен быть возвращен не nil контекст.
BaseContext func(net.Listener) context.Context
// ConnContext опционально задает функцию, которая изменяет
// контекст, используемый для нового соединения c. Предоставляемый ctx
// является производным от базового контекста и имеет ServerContextKey
// значение.
ConnContext func(ctx context.Context, c net.Conn) context.Context
// HTTP2 настраивает HTTP/2 соединения.
//
// Это поле пока не имеет никакого эффекта.
// См. https://go.dev/issue/67813.
HTTP2 *HTTP2Config
// Протоколы - это набор протоколов, принимаемых сервером.
//
// Если Protocols включает UnencryptedHTTP2, сервер будет принимать
// незашифрованные соединения HTTP/2. Сервер может обслуживать как
// HTTP/1 и незашифрованный HTTP/2 на одном и том же адресе и порту.
//
// Если значение Protocols равно nil, по умолчанию обычно используются HTTP/1 и HTTP/2.
// Если TLSNextProto не имеет значения nil и не содержит записи «h2»,
// по умолчанию используется только HTTP/1.
Protocols *Protocols
// содержит отфильтрованные или неэкспонированные поля
}
Server определяет параметры для запуска HTTP-сервера. Нулевое значение для Server является допустимой конфигурацией.
func (*Server) Close
func (s *Server) Close() error
Close немедленно закрывает все активные net.Listeners и все соединения в состоянии StateNew, StateActive или StateIdle. Для изящного завершения работы используйте Server.Shutdown.
Close не пытается закрыть (и даже не знает об этом) любые перехваченные соединения, такие как WebSockets.
Close возвращает любую ошибку, возникшую при закрытии базового слушателя(ей) сервера.
func (*Server) ListenAndServe
func (s *Server) ListenAndServe() error
ListenAndServe прослушивает сетевой TCP-адрес s.Addr и затем вызывает Serve для обработки запросов на входящих соединениях. Принимаемые соединения настроены на включение TCP keep-alives.
Если s.Addr пуст, используется «:http».
ListenAndServe всегда возвращает ошибку, отличную от нуля. После Server.Shutdown или Server.Close возвращаемая ошибка будет ErrServerClosed.
func (*Server) ListenAndServeTLS
func (s *Server) ListenAndServeTLS(certFile, keyFile string) error
ListenAndServeTLS прослушивает сетевой TCP-адрес s.Addr и затем вызывает ServeTLS для обработки запросов на входящих TLS-соединениях. Принимаемые соединения настроены на включение TCP keep-alives.
Если не заполнены ни TLSConfig.Certificates, ни TLSConfig.GetCertificate сервера, необходимо предоставить файлы, содержащие сертификат и соответствующий закрытый ключ для сервера. Если сертификат подписан центром сертификации, certFile должен представлять собой объединение сертификата сервера, всех промежуточных сертификатов и сертификата центра сертификации.
Если s.Addr пуст, используется «:https».
ListenAndServeTLS всегда возвращает ошибку, отличную от нуля. После Server.Shutdown или Server.Close возвращаемая ошибка - ErrServerClosed.
func (*Server) RegisterOnShutdown
func (s *Server) RegisterOnShutdown(f func())
RegisterOnShutdown регистрирует функцию для вызова на Server.Shutdown. Она может использоваться для изящного завершения соединений, которые подверглись обновлению протокола ALPN или были перехвачены. Эта функция должна запускать специфическое для данного протокола изящное отключение, но не должна ждать завершения отключения.
func (*Server) Serve
func (s *Server) Serve(l net.Listener) error
Serve принимает входящие соединения на слушателе l, создавая для каждого новую сервисную горутину. Сервисные программы читают запросы и затем вызывают s.Handler для ответа на них.
Поддержка HTTP/2 включена только в том случае, если Слушатель возвращает соединения *tls.Conn и они были настроены на «h2» в TLS Config.NextProtos.
Serve всегда возвращает ненулевую ошибку и закрывает l. После Server.Shutdown или Server.Close возвращаемая ошибка будет ErrServerClosed.
func (*Server) ServeTLS
func (s *Server) ServeTLS(l net.Listener, certFile, keyFile string) error
ServeTLS принимает входящие соединения на слушателе l, создавая для каждого новую сервисную горутину. Сервисные программы выполняют настройку TLS, а затем считывают запросы, вызывая s.Handler для ответа на них.
Если не заполнены ни TLSConfig.Certificates, ни TLSConfig.GetCertificate, ни config.GetConfigForClient сервера, необходимо предоставить файлы, содержащие сертификат и соответствующий закрытый ключ для сервера. Если сертификат подписан центром сертификации, файл certFile должен быть конкатенацией сертификата сервера, всех промежуточных сертификатов и сертификата центра сертификации.
ServeTLS всегда возвращает ошибку, отличную от нуля. После Server.Shutdown или Server.Close возвращаемая ошибка будет ErrServerClosed.
func (*Server) SetKeepAlivesEnabled
func (s *Server) SetKeepAlivesEnabled(v bool)
SetKeepAlivesEnabled управляет тем, включены ли HTTP keep-alives. По умолчанию keep-alives всегда включены. Только очень ограниченные ресурсы или серверы, находящиеся в процессе выключения, должны отключать их.
func (*Server) Shutdown
func (s *Server) Shutdown(ctx context.Context) error
Выключение изящно отключает сервер, не прерывая активных соединений. Shutdown работает, сначала закрывая все открытые слушатели, затем закрывая все простаивающие соединения, а затем ожидая неопределенное время, пока соединения не вернутся в состояние простоя, и затем выключается. Если предоставленный контекст истекает до завершения выключения, Shutdown возвращает ошибку контекста, в противном случае возвращается любая ошибка, возникшая при закрытии базового слушателя (слушателей) сервера.
Когда вызывается Shutdown, Serve, ListenAndServe и ListenAndServeTLS немедленно возвращают ErrServerClosed. Убедитесь, что программа не завершается, а ждет возврата Shutdown.
Shutdown не пытается закрыть или дождаться перехваченных соединений, таких как WebSockets. Вызывающая Shutdown программа должна отдельно уведомить такие долгоживущие соединения о закрытии и дождаться их закрытия, если это необходимо. Способ регистрации функций уведомления о выключении см. в Server.RegisterOnShutdown.
После вызова Shutdown на сервере его нельзя использовать повторно; будущие вызовы таких методов, как Serve, будут возвращать ErrServerClosed.
Пример
package main
import (
"context"
"log"
"net/http"
"os"
"os/signal"
)
func main() {
var srv http.Server
idleConnsClosed := make(chan struct{})
go func() {
sigint := make(chan os.Signal, 1)
signal.Notify(sigint, os.Interrupt)
<-sigint
// We received an interrupt signal, shut down.
if err := srv.Shutdown(context.Background()); err != nil {
// Error from closing listeners, or context timeout:
log.Printf("HTTP server Shutdown: %v", err)
}
close(idleConnsClosed)
}()
if err := srv.ListenAndServe(); err != http.ErrServerClosed {
// Error starting or closing listener:
log.Fatalf("HTTP server ListenAndServe: %v", err)
}
<-idleConnsClosed
}
type Transport
type Transport struct {
// Proxy определяет функцию для возврата прокси для данного
// запроса. Если функция возвращает ошибку, отличную от нуля, то
// запрос будет прерван с указанной ошибкой.
//
// Тип прокси определяется схемой URL. «http»,
// «https», «socks5» и «socks5h» поддерживаются. Если схема пуста,
// предполагается «http».
// «socks5» обрабатывается так же, как и «socks5h».
//
// Если URL прокси содержит подкомпонент userinfo,
// в прокси-запросе будут переданы имя пользователя и пароль
// в заголовке Proxy-Authorization.
//
// Если Proxy равно nil или возвращает nil *URL, прокси не используется.
Proxy func(*Request) (*url.URL, error)
// OnProxyConnectResponse вызывается, когда транспорт получает HTTP-ответ от
// прокси для запроса CONNECT. Он вызывается перед проверкой ответа 200 OK.
// Если он возвращает ошибку, запрос завершается с этой ошибкой.
OnProxyConnectResponse func(ctx context.Context, proxyURL *url.URL, connectReq *Request, connectRes *Response) error
// DialContext задает функцию dial для создания незашифрованных TCP-соединений.
// Если DialContext равен nil (и устаревшая Dial ниже также равна nil),
// то транспорт набирает номер, используя пакет net.
//
// DialContext работает параллельно с вызовами RoundTrip.
// Вызов RoundTrip, инициирующий набор номера, может в конечном итоге использовать
// соединение, набранное ранее, когда предыдущее соединение
// становится нерабочим до завершения последующего DialContext.
DialContext func(ctx context.Context, network, addr string) (net.Conn, error)
// Dial определяет функцию dial для создания незашифрованных TCP-соединений.
//
// Dial выполняется одновременно с вызовами RoundTrip.
// Вызов RoundTrip, инициирующий набор, может в конечном итоге использовать
// соединение, набранное ранее, если предыдущее соединение
// становится нерабочим до завершения последующего Dial.
//
// Исправлено: Вместо этого используйте DialContext, который позволяет транспорту
// отменять дозвоны, как только они больше не нужны.
// Если оба значения установлены, приоритет имеет DialContext.
Dial func(network, addr string) (net.Conn, error)
// DialTLSContext задает необязательную функцию набора номера для создания
// TLS-соединений для непроксированных HTTPS-запросов.
//
// Если DialTLSContext равен nil (и устаревшая DialTLS ниже также равна nil),
// используются DialContext и TLSClientConfig.
//
// Если DialTLSContext установлен, крючки Dial и DialContext не используются для HTTPS
// запросы, а параметры TLSClientConfig и TLSHandshakeTimeout
// игнорируются. Предполагается, что возвращаемый net.Conn уже // прошел квитирование TLS.
// прошло рукопожатие TLS.
DialTLSContext func(ctx context.Context, network, addr string) (net.Conn, error)
// DialTLS определяет необязательную функцию набора номера для создания
// TLS-соединений для непроксированных HTTPS-запросов.
//
// Исправлено: Вместо этого используйте DialTLSContext, который позволяет транспорту
// отменять циклы, как только они больше не нужны.
// Если оба значения установлены, приоритет имеет DialTLSContext.
DialTLS func(network, addr string) (net.Conn, error)
// TLSClientConfig задает конфигурацию TLS для использования с
// tls.Client.
// Если nil, используется конфигурация по умолчанию.
// Если не nil, то поддержка HTTP/2 может быть не включена по умолчанию.
TLSClientConfig *tls.Config
// TLSHandshakeTimeout задает максимальное количество времени.
// ожидание рукопожатия TLS. Ноль означает отсутствие таймаута.
TLSHandshakeTimeout time.Duration
// DisableKeepAlives, если true, отключает HTTP keep-alives и
// будет использовать соединение с сервером только для одного
// HTTP-запроса.
//
// Это не связано с аналогичным названием TCP keep-alives.
DisableKeepAlives bool
// DisableCompression, если значение равно true, запрещает транспорту
// запрашивать сжатие с помощью заголовка запроса «Accept-Encoding: gzip»
// заголовком запроса, если запрос не содержит существующего
// значение Accept-Encoding. Если Транспорт запрашивает gzip самостоятельно
// самостоятельно и получает gzip-ответ, то он прозрачно
// декодируется в Response.Body. Однако если пользователь
// явно запросил gzip, он не будет автоматически // распакован.
// не сжимается.
DisableCompression bool
// MaxIdleConns контролирует максимальное количество простаивающих (keep-alive)
// соединений на всех хостах. Ноль означает отсутствие ограничения.
MaxIdleConns int
// MaxIdleConnsPerHost, если ненулевое значение, контролирует максимальное количество простаивающих
// (keep-alive) соединений для каждого хоста. Если ноль,
// используется значение по умолчаниюMaxIdleConnsPerHost.
MaxIdleConnsPerHost int
// MaxConnsPerHost опционально ограничивает общее количество
// соединений на хост, включая соединения в состоянии дозвона,
// активном и неактивном состояниях. При нарушении лимита соединения будут блокироваться.
//
// Ноль означает отсутствие ограничения.
MaxConnsPerHost int
// IdleConnTimeout - это максимальное количество времени, в течение которого неработающее
// (keep-alive) соединение будет простаивать перед закрытием
// само.
// Ноль означает отсутствие ограничений.
IdleConnTimeout time.Duration
// ResponseHeaderTimeout, если ненулевое значение, определяет количество
// времени для ожидания заголовков ответа сервера после полной
// записи запроса (включая его тело, если таковое имеется). Это
// время не включает время на чтение тела ответа.
ResponseHeaderTimeout time.Duration
// ExpectContinueTimeout, если ненулевое значение, определяет количество
// времени для ожидания первых заголовков ответа сервера после полной
// записи заголовков запроса, если запрос содержит
// заголовок «Expect: 100-continue». Ноль означает отсутствие таймаута и
// приводит к тому, что тело запроса отправляется немедленно, без
// ожидания одобрения сервера.
// Это время не включает время отправки заголовка запроса.
ExpectContinueTimeout time.Duration
// TLSNextProto определяет, как транспорт переключается на.
// альтернативному протоколу (например, HTTP/2) после TLS ALPN
// согласования протокола. Если транспорт набирает TLS-соединение
// с непустым именем протокола и TLSNextProto содержит
// запись в карте для этого ключа (например, «h2»), то функция
// вызывается с полномочиями запроса (например, «example.com»
// или «example.com:1234») и TLS-соединением. Функция
// должна возвращать RoundTripper, который затем обрабатывает запрос.
// Если TLSNextProto не равно nil, поддержка HTTP/2 не включается
// автоматически.
TLSNextProto map[string]func(authority string, c *tls.Conn) RoundTripper
// ProxyConnectHeader опционально указывает заголовки, которые следует отправлять на
// прокси во время запросов CONNECT.
// Чтобы динамически установить заголовок, смотрите GetProxyConnectHeader.
ProxyConnectHeader Header
// GetProxyConnectHeader опционально указывает функцию для возврата
// заголовки для отправки в proxyURL во время запроса CONNECT к
// ip:port target.
// Если она возвращает ошибку, то раундтрип транспорта завершается с ошибкой.
// этой ошибкой. Он может вернуть (nil, nil), чтобы не добавлять заголовки.
// Если GetProxyConnectHeader не равен nil, ProxyConnectHeader
// игнорируется.
GetProxyConnectHeader func(ctx context.Context, proxyURL *url.URL, target string) (Header, error)
// MaxResponseHeaderBytes задает ограничение на то, сколько
// байтов в ответе сервера
// заголовок.
//
// Ноль означает использование ограничения по умолчанию.
MaxResponseHeaderBytes int64
// WriteBufferSize определяет размер буфера записи, используемого
// при записи на транспорт.
// Если ноль, то используется значение по умолчанию (в настоящее время 4 КБ).
WriteBufferSize int
// ReadBufferSize задает размер буфера чтения, используемого
// при чтении с транспорта.
// Если ноль, то используется значение по умолчанию (в настоящее время 4 КБ).
ReadBufferSize int
// ForceAttemptHTTP2 определяет, будет ли включен HTTP/2 при ненулевом значении
// Dial, DialTLS, или DialContext func или TLSClientConfig.
// По умолчанию использование любого из этих полей консервативно отключает HTTP/2.
// Чтобы использовать пользовательские конфигурации дозвона или TLS и при этом пытаться HTTP/2
// обновления, установите это значение в true.
ForceAttemptHTTP2 bool
// HTTP2 настраивает HTTP/2 соединения.
//
// Это поле пока не имеет никакого эффекта.
// См. https://go.dev/issue/67813.
HTTP2 *HTTP2Config
// Протоколы - это набор протоколов, поддерживаемых транспортом.
//
// Если Protocols включает UnencryptedHTTP2 и не включает HTTP1,
// транспорт будет использовать незашифрованный HTTP/2 для запросов к URL http://.
//
// Если Protocols равно nil, то по умолчанию обычно используется только HTTP/1.
// Если ForceAttemptHTTP2 равен true, или если TLSNextProto содержит запись «h2»,
// по умолчанию используются HTTP/1 и HTTP/2.
Protocols *Protocols
// содержит отфильтрованные или неэкспонированные поля
}
Transport - это реализация RoundTripper, поддерживающая HTTP, HTTPS и HTTP-прокси (для HTTP или HTTPS с CONNECT).
По умолчанию Transport кэширует соединения для последующего повторного использования. Это может оставить много открытых соединений при доступе ко многим хостам. Таким поведением можно управлять с помощью метода Transport.CloseIdleConnections и полей [Transport.MaxIdleConnsPerHost] и [Transport.DisableKeepAlives].
Транспорты следует использовать повторно, а не создавать по мере необходимости. Транспорты безопасны для одновременного использования несколькими горутинами.
Транспорт - это низкоуровневый примитив для выполнения HTTP- и HTTPS-запросов. Для высокоуровневой функциональности, такой как куки и редиректы, смотрите раздел Клиент.
Транспорт использует HTTP/1.1 для HTTP URL и либо HTTP/1.1, либо HTTP/2 для HTTPS URL, в зависимости от того, поддерживает ли сервер HTTP/2, и как настроен транспорт. DefaultTransport поддерживает HTTP/2. Чтобы явно включить HTTP/2 на транспорте, установите [Transport.Protocols].
Ответы с кодами состояния в диапазоне 1xx либо обрабатываются автоматически (100 expect-continue), либо игнорируются. Исключением является код состояния HTTP 101 (Switching Protocols), который считается терминальным статусом и возвращается Transport.RoundTrip. Чтобы увидеть проигнорированные ответы 1xx, используйте ClientTrace.Got1xxResponse пакета трассировки httptrace.
Transport повторяет запрос при возникновении сетевой ошибки только в том случае, если соединение уже было успешно использовано и если запрос является идемпотентным и либо не имеет тела, либо определено его [Request.GetBody]. HTTP-запросы считаются идемпотентными, если они имеют HTTP-методы GET, HEAD, OPTIONS или TRACE; или если их карта заголовков содержит запись «Idempotency-Key» или «X-Idempotency-Key». Если значение ключа idempotency является фрагментом нулевой длины, запрос рассматривается как idempotent, но заголовок не передается по проводам.
func (*Transport) CancelRequest deprecated
func (*Transport) Clone
func (t *Transport) Clone() *Transport
Clone возвращает глубокую копию экспортированных полей t.
func (*Transport) CloseIdleConnections
func (t *Транспорт) CloseIdleConnections()
CloseIdleConnections закрывает все соединения, которые были ранее подключены в результате предыдущих запросов, но теперь простаивают в состоянии «keep-alive». Она не прерывает используемые в данный момент соединения.
func (*Transport) RegisterProtocol
func (t *Transport) RegisterProtocol(scheme string, rt RoundTripper)
RegisterProtocol регистрирует новый протокол с помощью схемы. Транспорт будет передавать запросы, использующие заданную схему, в rt. Ответственность rt заключается в имитации семантики HTTP-запросов.
RegisterProtocol может быть использован другими пакетами для обеспечения реализаций схем протоколов типа «ftp» или «file».
Если rt.RoundTrip возвращает ErrSkipAltProtocol, транспорт будет сам обрабатывать Transport.RoundTrip для этого одного запроса, как если бы протокол не был зарегистрирован.
func (*Transport) RoundTrip
func (t *Transport) RoundTrip(req *Request) (*Response, error)
RoundTrip реализует интерфейс RoundTripper.
Для более высокоуровневой поддержки HTTP-клиентов (например, обработка cookies и перенаправлений) смотрите Get, Post и тип Client.
Как и в интерфейсе RoundTripper, типы ошибок, возвращаемых RoundTrip, не определены.
12.4.15.4 - Описание пакета для управления маршрутизацией github.com/julienschmidt/httprouter для GO
HttpRouter — это легкий высокопроизводительный маршрутизатор HTTP-запросов (также называемый мультиплексором или просто мультиплексором) для Go.
HttpRouter
HttpRouter — это легковесный высокопроизводительный маршрутизатор HTTP-запросов (также называемый мультиплексором или просто “mux”) для Go.
В отличие от стандартного мультиплексора пакета net/http в Go, этот роутер поддерживает:
- Переменные в шаблонах маршрутов
- Соответствие HTTP-методам запроса
- Лучшую масштабируемость
Роутер оптимизирован для высокой производительности и малого потребления памяти. Эффективно работает даже с очень длинными путями и большим количеством маршрутов благодаря использованию сжимающей динамической trie-структуры (радиксное дерево).
Ключевые особенности
1. Только точные совпадения
В отличие от других роутеров (например, http.ServeMux), где URL может соответствовать нескольким шаблонам (с приоритетами типа “самое длинное совпадение” или “первый зарегистрированный — первый обработанный”), здесь запрос может соответствовать только одному маршруту или ни одному. Это исключает неожиданные совпадения, что полезно для SEO и UX.
2. Автоматическая обработка слэшей
Роутер автоматически перенаправляет при отсутствии или избытке trailing slash (косой черты в конце пути), если для нового пути есть обработчик. Можно отключить.
3. Коррекция пути
Дополнительные возможности:
- Исправление регистра символов (например, для
CAPTAIN CAPS LOCK) - Удаление избыточных элементов (
../,//) - Case-insensitive поиск с редиректом
4. Параметры в путях
Динамические сегменты пути (например, /user/:id) извлекаются без ручного парсинга URL. Реализовано с минимальными накладными расходами.
5. Zero Garbage
Процесс сопоставления и диспетчеризации не создает мусора (zero bytes allocation). Единственные выделения памяти:
- Создание slice для параметров пути
- Создание контекста и объекта запроса (только в стандартном Handler API)
- В 3-аргументном API при отсутствии параметров — аллокаций нет вообще.
6. Максимальная производительность
Реализация оптимизирована (см. бенчмарки). Используется радиксное дерево для эффективного сопоставления длинных путей.
7. Обработка паник
Можно установить PanicHandler для перехвата паник во время обработки запроса. Роутер восстановит работу и отправит клиенту ошибку.
8. Идеально для API
- Поощряет построение RESTful API с иерархической структурой
- Нативная поддержка OPTIONS-запросов
- Автоматические ответы
405 Method Not Allowed - Возможность кастомизации
NotFoundиMethodNotAllowedобработчиков - Поддержка статических файлов
Технические детали
Используется радиксное дерево (trie) с компрессией для:
- Эффективного хранения длинных путей
- Быстрого поиска даже при тысячах маршрутов
- Минимизации использования памяти
Возможности
Именованные параметры
Как видно из примеров, :name представляет собой именованный параметр. Его значения доступны через httprouter.Params — это срез (slice) параметров. Получить значение можно двумя способами:
- По индексу в срезе
- Через метод
ByName(name): например, параметр:nameизвлекается вызовомByName("name")
Важно:
При использовании стандартного http.Handler (через router.Handler или http.HandlerFunc) вместо 3-аргументного API HttpRouter, именованные параметры хранятся в контексте запроса (request.Context). Подробнее см. раздел «Почему это не работает с http.Handler?».
Особенности именованных параметров:
- Соответствуют только одному сегменту пути
Пример шаблона:/user/:user
| Путь | Совпадение |
|---|---|
/user/gordon | ✅ |
/user/you | ✅ |
/user/gordon/profile | ❌ |
/user/ | ❌ |
Ограничение:
Так как роутер использует только явные совпадения, нельзя зарегистрировать одновременно статический маршрут и параметр для одного сегмента. Например, эти шаблоны не могут сосуществовать для одного HTTP-метода:
/user/new(статический)/user/:user(параметр)
При этом маршрутизация для разных методов запроса (GET, POST и т.д.) обрабатывается независимо.
Параметры Catch-All (перехват всего)
Имеют формат *name и, как следует из названия, соответствуют любому пути. Всегда должны находиться в конце шаблона.
Пример шаблона: /src/*filepath
| Путь | Совпадение |
|---|---|
/src/ | ✅ |
/src/somefile.go | ✅ |
/src/subdir/somefile.go | ✅ |
Особенности:
- Перехватывают все оставшиеся сегменты пути, включая слэши
- Полезны для реализации «обработчиков-прокси» (например, статических файлов в подкаталогах)
Как это работает?
Роутер использует древовидную структуру, активно использующую общие префиксы — по сути, это компактное префиксное дерево (радиксное дерево). Узлы с общим префиксом имеют общего родителя. Вот пример структуры дерева для GET-запросов:
Приоритет Путь Обработчик
9 \ *<1>
3 ├s nil
2 |├earch\ *<2>
1 |└upport\ *<3>
2 ├blog\ *<4>
1 | └:post nil
1 | └\ *<5>
2 ├about-us\ *<6>
1 | └team\ *<7>
1 └contact\ *<8>
Здесь каждый *<num> представляет адрес обработчика (указатель на функцию). При прохождении пути от корня до листа формируется полный маршрут, например \blog\:post\, где :post — это параметр-заполнитель. В отличие от хэш-таблиц, дерево позволяет работать с динамическими параметрами, поскольку сопоставление происходит по шаблонам, а не через сравнение хэшей. Бенчмарки подтверждают эффективность этого подхода.
Оптимизации структуры:
- Иерархичность URL:
Ограниченный набор символов в путях URL создает множество общих префиксов, что позволяет декомпозировать задачу маршрутизации на меньшие подзадачи. - Раздельные деревья для методов:
Для каждого HTTP-метода (GET, POST и т.д.) строится отдельное дерево. Это:- Экономит память (не требует хранения
map[метод]->обработчикв каждом узле). - Сокращает пространство поиска до актуального метода.
- Экономит память (не требует хранения
- Приоритизация узлов:
Дочерние узлы сортируются по приоритету — количеству обработчиков в поддеревьях. Это дает:- Быстрый доступ к популярным маршрутам.
- Приоритетную обработку длинных путей (с максимальной «стоимостью»).
Визуализация приоритетов:
├------------
├---------
├-----
├----
├--
├--
└-
Почему это не работает с http.Handler?
Работает! Роутер сам реализует интерфейс http.Handler и предоставляет адаптеры для интеграции стандартных http.Handler и http.HandlerFunc в качестве httprouter.Handle.
Доступ к параметрам:
Для http.Handler именованные параметры доступны через контекст запроса:
func Hello(w http.ResponseWriter, r *http.Request) {
params := httprouter.ParamsFromContext(r.Context())
fmt.Fprintf(w, "hello, %s!\n", params.ByName("name"))
}
Альтернативный вариант:
params := r.Context().Value(httprouter.ParamsKey)
Автоматические OPTIONS-ответы и CORS
Для кастомизации автоматических ответов на OPTIONS-запросы (например, для поддержки CORS preflight или добавления заголовков) используйте обработчик Router.GlobalOPTIONS:
router.GlobalOPTIONS = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Если это CORS preflight запрос
if r.Header.Get("Access-Control-Request-Method") != "" {
header := w.Header()
// Разрешаем методы из заголовка Allow
header.Set("Access-Control-Allow-Methods", r.Header.Get("Allow"))
// Открываем доступ для всех доменов
header.Set("Access-Control-Allow-Origin", "*")
}
// Возвращаем статус 204 No Content
w.WriteHeader(http.StatusNoContent)
})
Где найти Middleware X?
HttpRouter — это исключительно высокопроизводительный роутер с минималистичным функционалом. Поскольку он реализует интерфейс http.Handler, вы можете:
- Цеплять любые совместимые middleware перед роутером (например, из библиотеки Gorilla).
- Создавать собственные middleware — это достаточно просто.
- Использовать фреймворки на основе HttpRouter.
Мультидомены и поддомены
Пример реализации маршрутизации для разных доменов/поддоменов:
// HostSwitch - карта для хранения обработчиков по доменам
type HostSwitch map[string]http.Handler
// Реализуем интерфейс http.Handler
func (hs HostSwitch) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// Ищем обработчик для текущего хоста
if handler := hs[r.Host]; handler != nil {
handler.ServeHTTP(w, r)
} else {
http.Error(w, "Forbidden", http.StatusForbidden) // Или редирект
}
}
func main() {
// Инициализация роутера
router := httprouter.New()
router.GET("/", Index)
router.GET("/hello/:name", Hello)
// Настройка HostSwitch
hs := make(HostSwitch)
hs["example.com:12345"] = router // Для основного домена
hs["api.example.com:12345"] = anotherRouter // Для поддомена
// Запуск сервера
log.Fatal(http.ListenAndServe(":12345", hs))
}
Ключевые моменты:
- Каждый домен/поддомен может иметь собственный роутер
- Порт указывается вместе с доменом (
example.com:12345) - Для необрабатываемых доменов возвращается 403 Forbidden (можно заменить на редирект)
Базовая аутентификация (Basic Auth)
Пример реализации HTTP Basic Authentication (RFC 2617) для обработчиков:
package main
import (
"fmt"
"log"
"net/http"
"github.com/julienschmidt/httprouter"
)
// BasicAuth - middleware для проверки учетных данных
func BasicAuth(h httprouter.Handle, requiredUser, requiredPassword string) httprouter.Handle {
return func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
// Получаем учетные данные из заголовка
user, password, hasAuth := r.BasicAuth()
if hasAuth && user == requiredUser && password == requiredPassword {
// Если аутентификация успешна - передаем запрос обработчику
h(w, r, ps)
} else {
// Иначе запрашиваем аутентификацию
w.Header().Set("WWW-Authenticate", "Basic realm=Restricted")
http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
}
}
}
func Index(w http.ResponseWriter, r *http.Request, _ httprouter.Params) {
fmt.Fprint(w, "Открытая зона!\n")
}
func Protected(w http.ResponseWriter, r *http.Request, _ httprouter.Params) {
fmt.Fprint(w, "Защищенная зона!\n")
}
func main() {
user := "gordon"
pass := "secret!"
router := httprouter.New()
router.GET("/", Index)
router.GET("/protected/", BasicAuth(Protected, user, pass))
log.Fatal(http.ListenAndServe(":8080", router))
}
Цепочка обработчиков через NotFound
Примечание: Для корректной работы может потребоваться отключить Router.HandleMethodNotAllowed.
Вы можете использовать другой http.Handler (например, дополнительный роутер) для обработки запросов, которые не были найдены основным роутером:
router.NotFound = anotherRouter
Обслуживание статических файлов
Обработчик NotFound можно использовать для раздачи статических файлов из корневого пути /:
// Раздаем файлы из директории ./public
router.NotFound = http.FileServer(http.Dir("public"))
Однако такой подход нарушает строгие правила маршрутизации. Рекомендуется:
- Использовать выделенные подпути:
router.ServeFiles("/static/*filepath", http.Dir("public")) - Или явно задавать маршруты:
router.GET("/files/*filepath", func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) { http.ServeFile(w, r, path.Join("public", ps.ByName("filepath"))) })
Веб-фреймворки на основе HttpRouter
Если HttpRouter кажется вам слишком минималистичным, рассмотрите эти высокоуровневые сторонние фреймворки, построенные на его основе:
Популярные решения
Gin
API в стиле Martini с значительно лучшей производительностью.
Особенности: Middleware-цепочки, JSON-валидация, маршрутизация без рефлексии.Ace (устаревший, но исторически значимый)
Один из первых быстрых фреймворков для Go.
Преемник: Перешел в Gin.api2go
Полноценная реализация JSON API с поддержкой JSON:API спецификации.
Использование: Создание RESTful API с CRUD-операциями.
Для специфичных задач
Goat
Минималистичный REST API сервер.
Философия: “Меньше кода — больше производительности”.Hitch
Интегрирует HttpRouter с контекстом и middleware.
Ключевая особенность: Простота связывания компонентов.Kami
Работает черезx/net/context.
Для чего: Создание масштабируемых приложений с пробросом контекста.Siesta
Композиция HTTP-обработчиков с поддержкой контекста.
Паттерн: “Middleware как сервисы”.
Специализированные
Medeina
Вдохновлен Ruby-фреймворками Roda и Cuba.
Подход: Древовидная маршрутизация.pbgo
Мини-фреймворк для RPC/REST на основе Protobuf.
Сценарии: Микросервисы с gRPC-like API.xmux
Форк HttpRouter с поддержкойnet/context.
Отличие: Наследует производительность с расширенным API.
Для продакшена
Hikaru
Поддержка standalone-режима и Google App Engine.
Плюсы: Кроссплатформенность.River
Упрощенный REST-сервер для быстрого прототипирования.
Фишка: Нулевая настройка для базовых сценариев.httpway
Добавляет middleware-цепочки и graceful shutdown.
Особенность: Совместимость с native HTTP-пакетами.
Как выбрать?
- Для API: Gin, api2go, pbgo
- Микросервисы: Siesta, xmux
- Минимализм: Goat, River
- Унаследованные проекты: Ace (переход на Gin)
Использование
Это всего лишь краткое введение, подробности смотрите в GoDoc. Давайте начнем с простого примера:
package main
import (
"fmt"
"net/http"
"log"
"github.com/julienschmidt/httprouter"
)
func Index(w http.ResponseWriter, r *http.Request, _ httprouter.Params) {
fmt.Fprint(w, "Welcome!\n")
}
func Hello(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
fmt.Fprintf(w, "hello, %s!\n", ps.ByName("name"))
}
func main() {
router := httprouter.New()
router.GET("/", Index)
router.GET("/hello/:name", Hello)
log.Fatal(http.ListenAndServe(":8080", router))
}
Принцип работы маршрутизации
Роутер сопоставляет входящие запросы по HTTP-методу и пути. Если для комбинации метод-путь зарегистрирован обработчик, запрос передается соответствующей функции. Для стандартных методов существуют сокращенные функции регистрации:
router.GET("/path", handler) // GET
router.POST("/path", handler) // POST
router.PUT("/path", handler) // PUT
router.PATCH("/path", handler) // PATCH
router.DELETE("/path", handler) // DELETE
Для других методов используйте универсальный метод:
router.Handle("OPTIONS", "/path", handler)
Типы параметров пути
| Синтаксис | Тип |
|---|---|
:name | Именованный параметр |
*name | Catch-all параметр |
1. Именованные параметры
Динамические сегменты пути. Соответствуют любому значению до следующего / или конца пути.
Шаблон:
/blog/:category/:post
Примеры соответствия:
| Запрос | Совпадение | Параметры |
|---|---|---|
/blog/go/request-routers | ✅ | category="go", post="request-routers" |
/blog/go/request-routers/ | ❌ (редирект) | - |
/blog/go/ | ❌ | - |
/blog/go/request-routers/comments | ❌ | - |
2. Catch-all параметры
Соответствуют любой части пути до конца, включая /. Всегда должны быть последним элементом.
Шаблон:
/files/*filepath
Примеры соответствия:
| Запрос | Совпадение | Параметры |
|---|---|---|
/files/ | ✅ | filepath="/" |
/files/LICENSE | ✅ | filepath="/LICENSE" |
/files/templates/article.html | ✅ | filepath="/templates/article.html" |
/files | ❌ (редирект) | - |
Работа с параметрами
Параметры хранятся в срезе структур Param (ключ-значение) и передаются обработчику третьим аргументом:
func Handler(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
// Получение значения по имени
user := ps.ByName("user") // для :user или *user
// Получение по индексу (с доступом к имени параметра)
param := ps[2]
key := param.Key // имя 3-го параметра
value := param.Value // значение 3-го параметра
}
Особенности:
- Доступ к параметрам за O(1) по имени (использует внутреннюю оптимизацию)
- Индексный доступ полезен при обработке неизвестных параметров
- Параметры автоматически URL-decoded
Важные нюансы
Редиректы:
- Для путей с
/в конце роутер автоматически делает редирект на каноничную версию - Можно отключить через
router.RedirectTrailingSlash = false
- Для путей с
Кодировка:
// Пример значения с спецсимволами // Запрос: /search/%D1%82%D0%B5%D1%81%D1%82 query := ps.ByName("query") // автоматически декодируется в "тест"Производительность:
- Параметры не аллоцируют память при отсутствии в пути
- Используется slice pooling для повторного использования структур Param
Переменные
var ParamsKey = paramsKey{}
ParamsKey — это ключ контекста запроса, под которым хранятся параметры URL.
Функции
CleanPath
func CleanPath(p string) string
CleanPath — это URL-версия функции path.Clean. Она возвращает канонизированный путь, удаляя элементы . и ...
Правила обработки (применяются итеративно до полной обработки):
Слэши
Заменяет множественные слэши на один:///→/Текущая директория (.)
Удаляет элементы.:/././path→/pathРодительская директория (..)
Удаляет комбинации../с предыдущим не-..элементом:/a/b/../c→/a/c/a/b/../../c→/cКорневые
..
Заменяет/..в начале пути на/:/../a→/aПустой результат
Если после обработки путь пуст, возвращает/:
`` →/
Примеры:
CleanPath("//foo///bar") // "/foo/bar"
CleanPath("/./foo/../bar") // "/bar"
CleanPath("/../") // "/"
CleanPath("") // "/"
Особенности:
- Не выполняет URL-декодирование (работает с уже декодированным путем)
- Сохраняет регистр символов
- Полезен для нормализации путей перед маршрутизацией
Технические детали
Использование в роутере:
HttpRouter автоматически применяетCleanPathк входящим запросам перед сопоставлением маршрутов.Безопасность:
Защищает от path traversal атак:// Запрос "/secret/../../etc/passwd" будет преобразован в "/etc/passwd", // но роутер обработает его только если есть явный маршрутПроизводительность:
Реализация использует zero-allocation алгоритм для минимизации нагрузк
Типы
type Handle
type Handle func(http.ResponseWriter, *http.Request, Params)
Handle — функция, которая может быть зарегистрирована для обработки HTTP-запросов. Аналог http.HandlerFunc, но с третьим параметром для значений параметров URL.
type Param (добавлено в v1.1.0)
type Param struct {
Key string // Ключ параметра
Value string // Значение параметра
}
Param представляет отдельный параметр URL, состоящий из ключа и значения.
type Params (добавлено в v1.1.0)
type Params []Param
Params — это срез параметров Param, возвращаемый роутером. Срез упорядочен: первый параметр URL соответствует первому элементу среза. Безопасен для доступа по индексу.
Методы:
ParamsFromContext(добавлено в v1.2.0)
func ParamsFromContext(ctx context.Context) Params
Извлекает параметры URL из контекста запроса. Возвращает nil, если параметров нет.
ByName(добавлено в v1.1.0)
func (ps Params) ByName(name string) string
Возвращает значение первого параметра с указанным ключом. Если параметр не найден, возвращает пустую строку.
type Router
type Router struct {
// Автоматический редирект при несовпадении пути,
// но наличии обработчика для пути с/без завершающего слэша.
// Пример: /foo/ → /foo (код 301 для GET, 307 для других методов)
RedirectTrailingSlash bool
// Автокоррекция пути при отсутствии обработчика:
// 1. Удаляет избыточные элементы (../, //)
// 2. Поиск без учета регистра
// 3. Редирект на исправленный путь (301/307)
RedirectFixedPath bool
// Проверка допустимых методов при неудачной маршрутизации.
// Если включено, отправляет 405 Method Not Allowed с заголовком Allow.
HandleMethodNotAllowed bool
// Автоматическая обработка OPTIONS-запросов.
// Пользовательские обработчики OPTIONS имеют приоритет.
HandleOPTIONS bool
// Глобальный обработчик для автоматических OPTIONS-запросов.
// Вызывается только если HandleOPTIONS=true и нет специфичного обработчика.
GlobalOPTIONS http.Handler
// Обработчик для ненайденных маршрутов (по умолчанию — http.NotFound).
NotFound http.Handler
// Обработчик для недопустимых методов (код 405).
// По умолчанию — http.Error с StatusMethodNotAllowed.
MethodNotAllowed http.Handler
// Обработчик паник (код 500).
// Предотвращает аварийное завершение сервера.
PanicHandler func(http.ResponseWriter, *http.Request, interface{})
// содержит скрытые или неэкспортируемые поля
}
Router реализует интерфейс http.Handler и предоставляет конфигурируемую систему маршрутизации.
Ключевые особенности
Гибкость обработчиков:
Handleподдерживает параметры черезParams- Совместимость со стандартными
http.Handler/http.HandlerFunc
Безопасность:
ParamsFromContextдля безопасного доступа к параметрам из middlewarePanicHandlerдля обработки критических ошибок
Производительность:
- Срезы
Paramsизбегают аллокаций памяти - Прямой доступ к параметрам по индексу (
O(1))
- Срезы
Пример использования параметров:
router.GET("/user/:id", func(w http.ResponseWriter, r *http.Request, ps Params) {
id := ps.ByName("id") // или ps[0].Value
})
Методы типа Router
func New() *Router
func New() *Router
Создает и возвращает новый инициализированный роутер. Автокоррекция путей (включая обработку trailing slashes) включена по умолчанию.
Методы-сокращения для HTTP-методов
| Метод | Описание |
|---|---|
DELETE(path string, handle Handle) | Сокращение для router.Handle(http.MethodDelete, path, handle) |
GET(path string, handle Handle) | Сокращение для GET-запросов |
HEAD(path string, handle Handle) (v1.1.0+) | Сокращение для HEAD-запросов |
OPTIONS(path string, handle Handle) (v1.1.0+) | Сокращение для OPTIONS-запросов |
PATCH(path string, handle Handle) | Сокращение для PATCH-запросов |
POST(path string, handle Handle) | Сокращение для POST-запросов |
PUT(path string, handle Handle) | Сокращение для PUT-запросов |
func (r *Router) DELETE(path string, handle Handle)
func (r *Router) GET(path string, handle Handle)
Пример:
router := httprouter.New()
router.GET("/users", listUsers)
router.POST("/users", createUser)
func (*Router) Handle(method, path string, handle Handle)
Регистрирует обработчик для указанного HTTP-метода и пути.
router.Handle("PROPFIND", "/resource", handleResource)
func (*Router) Handler(method, path string, handler http.Handler)
Адаптер для использования стандартного http.Handler. Параметры доступны через контекст:
router.Handler("GET", "/user/:id", customHandler)
// В обработчике:
params := httprouter.ParamsFromContext(r.Context())
func (*Router) HandlerFunc(method, path string, handler http.HandlerFunc)
Адаптер для http.HandlerFunc:
router.HandlerFunc("GET", "/", indexHandler)
func (*Router) Lookup(method, path string) (Handle, Params, bool)
Ручной поиск обработчика для комбинации метод+путь. Возвращает:
- Обработчик
- Параметры пути
- Флаг необходимости редиректа (добавить/убрать trailing slash)
Пример использования в middleware:
if handle, ps, _ := router.Lookup(r.Method, r.URL.Path); handle != nil {
// Кастомная обработка
}
func (*Router) ServeFiles(path string, root http.FileSystem)
Обслуживает статические файлы из указанной файловой системы. Путь должен содержать /*filepath в конце:
// Доступ к /var/www/file.txt по URL /src/file.txt
router.ServeFiles("/src/*filepath", http.Dir("/var/www"))
Особенности:
- Использует стандартный
http.FileServer - Для 404 ошибок применяется
http.NotFound, а не роутерскийNotFound-обработчик
func (*Router) ServeHTTP(w http.ResponseWriter, req *http.Request)
Позволяет роутеру удовлетворять интерфейсу http.Handler:
http.ListenAndServe(":8080", router)
Особенности использования
Порядок регистрации:
Нет приоритета “первый зарегистрированный — первый обработанный”. Каждый путь+метод соответствует ровно одному обработчику.Производительность:
Все методы регистрации используют единую оптимизированную логику:// Эти вызовы эквивалентны по производительности router.GET("/path", handler) router.Handle("GET", "/path", handler)Безопасность:
ServeFilesавтоматически защищает от directory traversal атак:// Запрос `/src/../../../etc/passwd` будет отклонен
12.4.16 - Пакет OAuth2 языка программирования Go
Пакет oauth2 содержит реализацию клиента для спецификации OAuth 2.0.
sequenceDiagram
participant ClientApp
participant User
participant AuthServer
participant ResourceServer
%% Регистрация нового пользователя
Note over ClientApp: 1. Создание нового пользователя
ClientApp->>AuthServer: POST /register (не часть OAuth)
AuthServer-->>ClientApp: client_id, client_secret
%% Авторизация (Authorization Code Flow)
Note over ClientApp,User: 2. Авторизация пользователя
ClientApp->>User: Redirect to AuthURL (config.AuthCodeURL())
User->>AuthServer: Авторизация/согласие
AuthServer->>User: Redirect с code и state
User->>ClientApp: Передача code
ClientApp->>AuthServer: Exchange code на token (config.Exchange())
AuthServer-->>ClientApp: access_token, refresh_token
%% Использование токена
Note over ClientApp,ResourceServer: 3. Доступ к ресурсам
ClientApp->>ResourceServer: Запрос с токеном (transport)
ResourceServer-->>ClientApp: Данные пользователя
%% Другие поддерживаемые события
Note over ClientApp,AuthServer: 4. Другие сценарии
%% Refresh Token Flow
ClientApp->>AuthServer: Запрос нового токена (TokenSource.Token())
AuthServer-->>ClientApp: Новый access_token
%% Client Credentials Flow
ClientApp->>AuthServer: Запрос токена (clientcredentials.Config)
AuthServer-->>ClientApp: Сервисный токен
%% Device Flow
ClientApp->>AuthServer: Запрос device code (DeviceAuth())
AuthServer-->>ClientApp: user_code, verification_uri
User->>AuthServer: Ввод user_code
ClientApp->>AuthServer: Polling для токена (DeviceAccessToken())
AuthServer-->>ClientApp: Устройственный токенКлючевые элементы модели:
Типы пакета OAuth2:
Config- основной объект конфигурацииEndpoint- URLs сервера авторизацииToken- содержит access/refresh токеныTokenSource- механизм обновления токеновTransport- HTTP-транспорт с авторизацией
Основные методы:
AuthCodeURL()- генерация URL авторизацииExchange()- обмен code на токенClient()- создание авторизованного HTTP-клиентаTokenSource()- автоматическое обновление токенов
Поддерживаемые потоки:
- Authorization Code Flow (основной)
- Client Credentials Flow (для сервисов)
- Device Flow (для ТВ/IoT)
- Refresh Token Flow
Дополнительные компоненты:
- PKCE (защита от CSRF)
- Различные AuthStyle (методы аутентификации)
- Кастомные AuthCodeOption
Эта модель охватывает полный жизненный цикл OAuth 2.0 в Go-приложениях, от регистрации клиента до доступа к защищенным ресурсам.
Переменные
var HTTPClient internal.ContextKey
HTTPClient - это ключ контекста, используемый с context.WithValue для ассоциации *http.Client с контекстом.
var NoContext = context.TODO()
NoContext - контекст по умолчанию, который следует использовать, если не применяется собственный context.Context.
Устарело: Вместо этого используйте context.Background или context.TODO.
Функции
func GenerateVerifier
func GenerateVerifier() string
GenerateVerifier генерирует верификатор кода PKCE со случайными 32 октетами. Соответствует рекомендациям RFC 7636.
Новый верификатор должен генерироваться для каждой авторизации. Полученный верификатор следует передавать в Config.AuthCodeURL или Config.DeviceAuth с S256ChallengeOption, а в Config.Exchange или Config.DeviceAccessToken - с VerifierOption.
func NewClient
func NewClient(ctx context.Context, src TokenSource) *http.Client
NewClient создает *http.Client из context.Context и TokenSource. Возвращенный клиент действителен только в течение времени жизни контекста.
Примечание: если пользовательский *http.Client предоставлен через context.Context, он используется только для получения токена и не влияет на *http.Client, возвращаемый из NewClient.
Особый случай: если src равен nil, возвращается не-OAuth2 клиент с использованием предоставленного контекста.
func RegisterBrokenAuthHeaderProvider
Устарело.
func S256ChallengeFromVerifier
func S256ChallengeFromVerifier(verifier string) string
S256ChallengeFromVerifier возвращает challenge-код PKCE, полученный из верификатора методом S256.
Предпочтительнее использовать S256ChallengeOption, где это возможно.
Типы
type AuthCodeOption
type AuthCodeOption interface {
// содержит неэкспортируемые методы
}
AuthCodeOption передается в Config.AuthCodeURL.
Варианты:
var (
// AccessTypeOnline и AccessTypeOffline - параметры для Options.AuthCodeURL.
// Они изменяют поле "access_type" в URL, возвращаемом AuthCodeURL.
AccessTypeOnline AuthCodeOption = SetAuthURLParam("access_type", "online")
AccessTypeOffline AuthCodeOption = SetAuthURLParam("access_type", "offline")
// ApprovalForce требует от пользователя подтверждения запроса разрешений
ApprovalForce AuthCodeOption = SetAuthURLParam("prompt", "consent")
)
Объяснение AuthCodeOption
AuthCodeOption - это интерфейс, который позволяет настраивать параметры Authorization Code Flow в OAuth 2.0. Он используется для:
- Модификации URL авторизации
- Передачи дополнительных параметров на endpoint авторизации
- Контроля поведения OAuth-диалога
Основные варианты использования
1. Управление типом доступа
// Запрос online-токена (по умолчанию)
url := conf.AuthCodeURL("state", oauth2.AccessTypeOnline)
// Запрос offline-токена с refresh token
url := conf.AuthCodeURL("state", oauth2.AccessTypeOffline)
Различие:
AccessTypeOnline- токен действителен только во время текущей сессииAccessTypeOffline- позволяет получить refresh token для долгоживущих доступов
2. Принудительное подтверждение разрешений
// Пользователь всегда увидит диалог подтверждения
url := conf.AuthCodeURL("state", oauth2.ApprovalForce)
Применение: Когда нужно гарантировать, что пользователь явно подтвердит запрашиваемые разрешения, даже если уже давал согласие ранее.
Дополнительные возможности
3. PKCE (защита от CSRF)
verifier := oauth2.GenerateVerifier()
url := conf.AuthCodeURL(
"state",
oauth2.AccessTypeOffline,
oauth2.S256ChallengeOption(verifier),
)
4. Кастомные параметры
// Добавление произвольных параметров
customParam := oauth2.SetAuthURLParam("custom_param", "value")
url := conf.AuthCodeURL("state", customParam)
Техническая реализация
Интерфейс реализуется через скрытые методы, а на практике используются:
SetAuthURLParam- для установки произвольных параметров- Предопределенные варианты (AccessTypeOnline и др.)
- PKCE-реализации
Пример комплексного использования
func GetAuthURL(config *oauth2.Config) string {
verifier := oauth2.GenerateVerifier()
return config.AuthCodeURL(
"random-state-123",
oauth2.AccessTypeOffline, // Запрашиваем refresh token
oauth2.ApprovalForce, // Всегда показывать диалог подтверждения
oauth2.S256ChallengeOption(verifier), // Включение PKCE
oauth2.SetAuthURLParam("hd", "example.com"), // Ограничение домена
)
}
Ключевые преимущества:
- Гибкость настройки OAuth-потока
- Поддержка современных механизмов безопасности
- Единообразный API для всех параметров
- Возможность расширения функциональности
func S256ChallengeOption
func S256ChallengeOption(verifier string) AuthCodeOption
S256ChallengeOption создает PKCE challenge из верификатора методом S256. Должен передаваться только в Config.AuthCodeURL или Config.DeviceAuth.
func SetAuthURLParam
func SetAuthURLParam(key, value string) AuthCodeOption
SetAuthURLParam создает AuthCodeOption для передачи параметров key/value на endpoint авторизации провайдера.
func VerifierOption
func VerifierOption(verifier string) AuthCodeOption
VerifierOption возвращает AuthCodeOption с верификатором кода PKCE. Должен передаваться только в Config.Exchange или Config.DeviceAccessToken.
type AuthStyle
type AuthStyle int
AuthStyle определяет способ аутентификации запросов токенов.
Варианты:
const (
// Автоопределение стиля аутентификации
AuthStyleAutoDetect AuthStyle = 0
// Передача client_id и client_secret в теле POST
AuthStyleInParams AuthStyle = 1
// Использование HTTP Basic Authorization OAuth2 RFC 6749 section 2.3.1.
AuthStyleInHeader AuthStyle = 2
)
Объяснение AuthStyle
AuthStyle определяет способ передачи учетных данных клиента (client_id и client_secret) при запросе токена в OAuth 2.0 flow. Это важный аспект безопасности, который влияет на:
- Способ передачи конфиденциальных данных
- Совместимость с различными OAuth-провайдерами
- Соответствие стандартам безопасности
Детальное описание вариантов
1. AuthStyleAutoDetect (значение 0)
AuthStyleAutoDetect AuthStyle = 0
Поведение:
- Автоматически определяет предпочтительный метод на основе:
- Ответа сервера
- Известных особенностей провайдера
- Пробует разные методы при необходимости
Пример использования:
endpoint := oauth2.Endpoint{
AuthURL: "https://provider.com/auth",
TokenURL: "https://provider.com/token",
AuthStyle: oauth2.AuthStyleAutoDetect,
}
Когда использовать: Когда провайдер поддерживает оба метода или его требования неизвестны.
2. AuthStyleInParams (значение 1)
AuthStyleInParams AuthStyle = 1
Поведение:
- Передает client_id и client_secret в теле POST-запроса
- Формат:
application/x-www-form-urlencoded - Пример тела запроса:
client_id=CLIENT_ID&client_secret=CLIENT_SECRET&...
Пример использования:
endpoint := oauth2.Endpoint{
AuthURL: "https://provider.com/auth",
TokenURL: "https://provider.com/token",
AuthStyle: oauth2.AuthStyleInParams,
}
Когда использовать:
- Когда провайдер явно требует этот метод
- Для совместимости со старыми OAuth-реализациями
3. AuthStyleInHeader (значение 2)
AuthStyleInHeader AuthStyle = 2
Поведение:
- Использует HTTP Basic Authentication (RFC 6749 section 2.3.1)
- Данные передаются в заголовке Authorization:
Authorization: Basic BASE64(client_id:client_secret)
Пример использования:
endpoint := oauth2.Endpoint{
AuthURL: "https://provider.com/auth",
TokenURL: "https://provider.com/token",
AuthStyle: oauth2.AuthStyleInHeader,
}
Преимущества:
- Более безопасный метод (не попадает в логи)
- Рекомендуется стандартом OAuth 2.0
- Поддерживается большинством современных провайдеров
Практические рекомендации
Для публичных клиентов (SPA, мобильные приложения):
// Не используйте client_secret, только PKCE conf := &oauth2.Config{ ClientID: "public_client_id", Scopes: []string{"openid"}, Endpoint: oauth2.Endpoint{ AuthStyle: oauth2.AuthStyleInHeader, // Или AutoDetect }, }Для конфиденциальных клиентов (серверные приложения):
conf := &oauth2.Config{ ClientID: "client_id", ClientSecret: "client_secret", Scopes: []string{"api:read"}, Endpoint: oauth2.Endpoint{ AuthStyle: oauth2.AuthStyleInHeader, // Предпочтительно }, }При проблемах совместимости:
// Пробуем разные варианты styles := []oauth2.AuthStyle{ oauth2.AuthStyleInHeader, oauth2.AuthStyleInParams, } for _, style := range styles { endpoint.AuthStyle = style // Пробуем запрос токена }
Соответствие стандартам
AuthStyleInHeaderсоответствует RFC 6749 section 2.3.1AuthStyleInParams- устаревший, но широко поддерживаемый методAuthStyleAutoDetect- удобная обертка для максимальной совместимости
Выбор правильного AuthStyle критически важен для безопасности и работоспособности OAuth-интеграции.
type Config
type Config struct {
// ClientID - публичный идентификатор вашего приложения,
// выдается провайдером при регистрации OAuth-клиента
ClientID string
// ClientSecret - секретный ключ вашего приложения,
// должен храниться безопасно (не в клиентском коде)
ClientSecret string
// Endpoint - содержит URL-адреса сервера авторизации:
// AuthURL - endpoint для получения authorization code
// TokenURL - endpoint для обмена code на access token
Endpoint Endpoint
// RedirectURL - URL, на который провайдер перенаправит
// пользователя после авторизации. Должен точно совпадать
// с URL, зарегистрированным у провайдера
RedirectURL string
// Scopes - запрашиваемые области доступа (разрешения),
// определяют, к каким ресурсам будет доступ у приложения
Scopes []string
}
Config описывает стандартный 3-этапный OAuth2-поток с информацией о клиентском приложении и URL endpoint’ов сервера.
Объяснение Config
Структура Config является центральной конфигурацией для OAuth 2.0 Authorization Code Flow (3-legged OAuth). Она содержит все необходимые параметры для:
- Идентификации приложения (клиента)
- Настройки взаимодействия с OAuth-провайдером
- Управления процессом авторизации
Детальная расшифровка полей структуры
type Config struct {
// ClientID - публичный идентификатор вашего приложения,
// выдается провайдером при регистрации OAuth-клиента
ClientID string
// ClientSecret - секретный ключ вашего приложения,
// должен храниться безопасно (не в клиентском коде)
ClientSecret string
// Endpoint - содержит URL-адреса сервера авторизации:
// AuthURL - endpoint для получения authorization code
// TokenURL - endpoint для обмена code на access token
Endpoint Endpoint
// RedirectURL - URL, на который провайдер перенаправит
// пользователя после авторизации. Должен точно совпадать
// с URL, зарегистрированным у провайдера
RedirectURL string
// Scopes - запрашиваемые области доступа (разрешения),
// определяют, к каким ресурсам будет доступ у приложения
Scopes []string
}
Основные методы Config
1. AuthCodeURL - генерация URL для авторизации
func (c *Config) AuthCodeURL(state string, opts ...AuthCodeOption) string
Пример использования:
// Базовый вариант
authURL := config.AuthCodeURL("random-state-123")
// С дополнительными параметрами
authURL := config.AuthCodeURL(
"state-xyz",
oauth2.AccessTypeOffline, // запросить refresh token
oauth2.ApprovalForce, // всегда показывать диалог подтверждения
oauth2.SetAuthURLParam("hd", "example.com"), // ограничение домена
)
2. Exchange - обмен authorization code на токен
func (c *Config) Exchange(ctx context.Context, code string, opts ...AuthCodeOption) (*Token, error)
Пример использования:
// Обработка callback'а с code
func handleCallback(w http.ResponseWriter, r *http.Request) {
code := r.URL.Query().Get("code")
token, err := config.Exchange(r.Context(), code)
if err != nil {
// обработка ошибки
}
// использование токена...
}
3. Client - создание HTTP-клиента с авторизацией
func (c *Config) Client(ctx context.Context, t *Token) *http.Client
Пример использования:
// Создание клиента с автоматическим обновлением токенов
client := config.Client(context.Background(), token)
// Использование клиента для API-запросов
resp, err := client.Get("https://api.example.com/userinfo")
if err != nil {
// обработка ошибки
}
4. TokenSource - создание источника токенов
func (c *Config) TokenSource(ctx context.Context, t *Token) oauth2.TokenSource
Пример использования:
// Создание источника токенов с автоматическим обновлением
tokenSource := config.TokenSource(context.Background(), initialToken)
// Получение свежего токена
newToken, err := tokenSource.Token()
if err != nil {
// обработка ошибки
}
Полный пример использования
package main
import (
"context"
"fmt"
"log"
"net/http"
"golang.org/x/oauth2"
)
func main() {
config := &oauth2.Config{
ClientID: "YOUR_CLIENT_ID",
ClientSecret: "YOUR_CLIENT_SECRET",
Scopes: []string{"user:read", "files:write"},
RedirectURL: "https://yourapp.com/callback",
Endpoint: oauth2.Endpoint{
AuthURL: "https://auth.example.com/authorize",
TokenURL: "https://auth.example.com/token",
},
}
// Шаг 1: Перенаправление пользователя на авторизацию
authURL := config.AuthCodeURL("state-token", oauth2.AccessTypeOffline)
fmt.Printf("Перейдите по ссылке для авторизации:\n%v\n", authURL)
// Шаг 2: Обработка callback'а (эмулируем получение code)
var code string
fmt.Print("Введите полученный code: ")
if _, err := fmt.Scan(&code); err != nil {
log.Fatal(err)
}
// Шаг 3: Обмен code на токен
token, err := config.Exchange(context.Background(), code)
if err != nil {
log.Fatal(err)
}
// Шаг 4: Использование токена
client := config.Client(context.Background(), token)
resp, err := client.Get("https://api.example.com/user")
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
// Обработка ответа...
fmt.Println("Успешный запрос к API!")
}
Особенности и рекомендации
Безопасность:
- Никогда не храните ClientSecret в клиентском коде
- Всегда используйте HTTPS для RedirectURL
- Реализуйте проверку параметра state для защиты от CSRF
Жизненный цикл токенов:
- AccessToken обычно имеет ограниченное время жизни
- RefreshToken (если есть) позволяет получать новые AccessToken
- TokenSource автоматически обрабатывает обновление токенов
Для production-использования:
- Добавьте обработку ошибок на всех этапах
- Реализуйте хранение токенов между сессиями
- Добавьте PKCE для улучшенной безопасности
Тип Config предоставляет полный набор инструментов для реализации OAuth 2.0 Authorization Code Flow в Go-приложениях, охватывая все этапы процесса авторизации.
Пример
package main
import (
"context"
"fmt"
"log"
"golang.org/x/oauth2"
)
func main() {
ctx := context.Background()
conf := &oauth2.Config{
ClientID: "ВАШ_CLIENT_ID",
ClientSecret: "ВАШ_CLIENT_SECRET",
Scopes: []string{"ДОСТУП1", "ДОСТУП2"},
Endpoint: oauth2.Endpoint{
AuthURL: "https://provider.com/o/oauth2/auth", // URL авторизации
TokenURL: "https://provider.com/o/oauth2/token", // URL получения токена
},
}
// Используем PKCE для защиты от CSRF атак
// Спецификация: https://www.ietf.org/archive/id/draft-ietf-oauth-security-topics-22.html#name-countermeasures-6
verifier := oauth2.GenerateVerifier() // Генерируем верификатор для PKCE
// Перенаправляем пользователя на страницу согласия для запроса разрешений
// на указанные выше области доступа (scopes)
url := conf.AuthCodeURL(
"state", // Уникальный state для защиты
oauth2.AccessTypeOffline, // Запрашиваем refresh-токен
oauth2.S256ChallengeOption(verifier), // Добавляем PKCE challenge
)
fmt.Printf("Перейдите по URL для авторизации: %v", url)
// Получаем authorization code из redirect URL.
// Exchange выполнит обмен кода на токен доступа.
// HTTP клиент от conf.Client будет автоматически обновлять токен.
var code string
if _, err := fmt.Scan(&code); err != nil {
log.Fatal(err)
}
// Обмениваем код на токен, передавая верификатор PKCE
tok, err := conf.Exchange(ctx, code, oauth2.VerifierOption(verifier))
if err != nil {
log.Fatal(err)
}
// Создаем HTTP клиент с автоматическим обновлением токенов
client := conf.Client(ctx, tok)
client.Get("...") // Делаем авторизованные запросы
}Пример CustomHTTP
package main
import (
"context"
"fmt"
"log"
"net/http"
"time"
"golang.org/x/oauth2"
)
func main() {
ctx := context.Background()
// Конфигурация OAuth2 клиента
conf := &oauth2.Config{
ClientID: "ВАШ_CLIENT_ID", // Идентификатор клиента
ClientSecret: "ВАШ_CLIENT_SECRET", // Секретный ключ клиента
Scopes: []string{"ДОСТУП1", "ДОСТУП2"}, // Запрашиваемые разрешения
Endpoint: oauth2.Endpoint{
TokenURL: "https://provider.com/o/oauth2/token", // URL для получения токена
AuthURL: "https://provider.com/o/oauth2/auth", // URL для авторизации
},
}
// Перенаправляем пользователя на страницу авторизации для получения разрешений
// на указанные области доступа (scopes)
url := conf.AuthCodeURL("state", oauth2.AccessTypeOffline) // "state" для защиты от CSRF
fmt.Printf("Перейдите по ссылке для авторизации: %v", url)
// Получаем код авторизации из redirect URL.
// Exchange выполняет обмен кода на токен доступа.
// HTTP клиент, возвращаемый conf.Client, будет автоматически обновлять токен.
var code string
if _, err := fmt.Scan(&code); err != nil {
log.Fatal(err)
}
// Используем кастомный HTTP клиент с таймаутом 2 секунды для запроса токена
httpClient := &http.Client{Timeout: 2 * time.Second}
ctx = context.WithValue(ctx, oauth2.HTTPClient, httpClient)
// Получаем токен доступа
tok, err := conf.Exchange(ctx, code)
if err != nil {
log.Fatal(err)
}
// Создаем HTTP клиент с автоматической авторизацией
client := conf.Client(ctx, tok)
_ = client // Используйте client для авторизованных запросов
}func (*Config) AuthCodeURL
func (c *Config) AuthCodeURL(state string, opts ...AuthCodeOption) string
AuthCodeURL возвращает URL страницы согласия OAuth 2.0 провайдера, которая явно запрашивает разрешения для требуемых областей доступа (scopes).
Параметры:
state
Случайное значение (опaque), используемое клиентом для поддержания состояния между запросом и callback-вызовом. Сервер авторизации включает это значение при перенаправлении пользователя обратно в клиентское приложение.opts(дополнительные опции)
Может включать:AccessTypeOnlineилиAccessTypeOffline- тип доступаApprovalForce- принудительное подтверждение разрешений
Защита от CSRF-атак:
Рекомендуемый способ:
Включите PKCE challenge черезS256ChallengeOption.
Примечание: Не все серверы поддерживают PKCE.Альтернативный способ:
Генерация случайного параметраstateс последующей проверкой после обмена токена.
Ссылки на стандарты:
- RFC 6749, раздел 10.12 (предшествовал PKCE)
- PKCE в OAuth
- Защита от CSRF в OAuth 2.1
func (*Config) Client
func (c *Config) Client(ctx context.Context, t *Token) *http.Client
Клиент возвращает HTTP-клиента, используя предоставленный токен. Токен будет автоматически обновляться по мере необходимости. Базовый HTTP-транспорт будет получен с использованием предоставленного контекста. Возвращенный клиент и его Transport не должны быть изменены.
func (*Config) DeviceAccessToken
func (c *Config) DeviceAccessToken(ctx context.Context, da *DeviceAuthResponse, opts ...AuthCodeOption) (*Token, error)
DeviceAccessToken опрашивает сервер для обмена device code на токен.
func (*Config) DeviceAuth
func (c *Config) DeviceAuth(ctx context.Context, opts ...AuthCodeOption) (*DeviceAuthResponse, error)
DeviceAuth возвращает структуру с device code для авторизации на другом устройстве.
Пример
var config Config
ctx := context.Background()
response, err := config.DeviceAuth(ctx)
if err != nil {
panic(err)
}
fmt.Printf("please enter code %s at %s\n", response.UserCode, response.VerificationURI)
token, err := config.DeviceAccessToken(ctx, response)
if err != nil {
panic(err)
}
fmt.Println(token)
func (*Config) Exchange
func (c *Config) Exchange(ctx context.Context, code string, opts ...AuthCodeOption) (*Token, error)
Выполняет обмен authorization code на токен доступа.
Использование: Вызывается после перенаправления пользователя обратно на Redirect URI (URL, полученный из AuthCodeURL).
Параметры:
ctx- контекст, может содержать кастомный HTTP-клиент (см. переменную HTTPClient)code- authorization code из параметраhttp.Request.FormValue("code")opts- опции, при использовании PKCE должен включать VerifierOption
Безопасность:
- Обязательно проверяйте параметр
state(изhttp.Request.FormValue("state")) перед вызовом для защиты от CSRF - Для PKCE передавайте верификатор через VerifierOption
func (*Config) PasswordCredentialsToken
func (c *Config) PasswordCredentialsToken(ctx context.Context, username, password string) (*Token, error)
Получает токен по связке username/password (Resource Owner Password Credentials flow).
Рекомендации RFC 6749: Следует использовать ТОЛЬКО при:
- Высокой степени доверия между клиентом и владельцем ресурса
- Когда клиент является частью ОС или привилегированного приложения
- При отсутствии других доступных способов авторизации
Ссылка: RFC 6749 Section 4.3
Параметры:
ctx- может содержать кастомный HTTP-клиентusername,password- учетные данные владельца ресурса
Примечание: Этот grant type считается менее безопасным и должен применяться в исключительных случаях.
func (*Config) TokenSource
func (c *Config) TokenSource(ctx context.Context, t *Token) TokenSource
TokenSource возвращает источник токенов с автоматическим обновлением.
type DeviceAuthResponse
type DeviceAuthResponse struct {
// DeviceCode - код устройства для OAuth-потока
DeviceCode string `json:"device_code"`
// UserCode - код, который пользователь должен ввести
// на странице верификации
UserCode string `json:"user_code"`
// VerificationURI - URL страницы, куда пользователь
// должен ввести user code
VerificationURI string `json:"verification_uri"`
// VerificationURIComplete (опционально) - полный URL верификации
// с уже подставленным user code. Обычно отображается пользователю
// в графической форме (например, QR-код)
VerificationURIComplete string `json:"verification_uri_complete,omitempty"`
// Expiry - время истечения срока действия
// device code и user code
Expiry time.Time `json:"expires_in,omitempty"`
// Interval - интервал в секундах между запросами
// на проверку авторизации (polling)
Interval int64 `json:"interval,omitempty"`
}
DeviceAuthResponse описывает успешный ответ Device Authorization по RFC 8628.
Объяснение DeviceAuthResponse
DeviceAuthResponse представляет ответ сервера авторизации в OAuth 2.0 Device Authorization Grant Flow (RFC 8628). Этот тип используется для реализации “потока устройства” - специального сценария авторизации для устройств с ограниченными возможностями ввода (Smart TV, IoT устройства, принтеры и т.д.).
Основные функции:
- Получение кодов верификации для пользователя
- Предоставление инструкций для завершения авторизации
- Управление процессом polling для получения токена
Пример полного цикла использования
1. Инициализация потока устройства
func InitDeviceFlow(config *oauth2.Config) (*oauth2.DeviceAuthResponse, error) {
ctx := context.Background()
// Запрос параметров device flow
deviceAuth, err := config.DeviceAuth(ctx)
if err != nil {
return nil, fmt.Errorf("ошибка инициализации device flow: %v", err)
}
return deviceAuth, nil
}
2. Отображение инструкций пользователю
func ShowUserInstructions(deviceAuth *oauth2.DeviceAuthResponse) {
fmt.Printf("1. Перейдите на страницу: %s\n", deviceAuth.VerificationURI)
fmt.Printf("2. Введите код: %s\n", deviceAuth.UserCode)
// Если доступен QR-код
if deviceAuth.VerificationURIComplete != "" {
fmt.Printf("Или отсканируйте QR-код: %s\n", deviceAuth.VerificationURIComplete)
}
fmt.Printf("Код действителен до: %v\n", deviceAuth.Expiry)
}
3. Получение токена (polling)
func PollForToken(config *oauth2.Config, deviceAuth *oauth2.DeviceAuthResponse) (*oauth2.Token, error) {
ctx := context.Background()
for {
// Запрос токена с использованием device code
token, err := config.DeviceAccessToken(ctx, deviceAuth)
if err == nil {
return token, nil
}
// Обработка ошибок
if oauth2Err, ok := err.(*oauth2.RetrieveError); ok {
if oauth2Err.ErrorCode == "authorization_pending" {
// Ожидание следующего polling-запроса
time.Sleep(time.Duration(deviceAuth.Interval) * time.Second)
continue
}
}
return nil, fmt.Errorf("ошибка получения токена: %v", err)
}
}
Полный пример интеграции
package main
import (
"context"
"fmt"
"log"
"time"
"golang.org/x/oauth2"
)
func main() {
config := &oauth2.Config{
ClientID: "your-client-id",
Scopes: []string{"user.read"},
Endpoint: oauth2.Endpoint{
AuthURL: "https://login.microsoftonline.com/common/oauth2/v2.0/authorize",
TokenURL: "https://login.microsoftonline.com/common/oauth2/v2.0/token",
DeviceURL: "https://login.microsoftonline.com/common/oauth2/v2.0/devicecode",
},
}
// 1. Инициализация device flow
deviceAuth, err := config.DeviceAuth(context.Background())
if err != nil {
log.Fatalf("Ошибка инициализации: %v", err)
}
// 2. Показ инструкций пользователю
fmt.Println("\n=== Инструкции по авторизации ===")
fmt.Printf("Пожалуйста, откройте %s\n", deviceAuth.VerificationURI)
fmt.Printf("И введите код: %s\n\n", deviceAuth.UserCode)
// 3. Polling для получения токена
fmt.Println("Ожидание авторизации...")
token, err := PollForToken(config, deviceAuth)
if err != nil {
log.Fatalf("Ошибка получения токена: %v", err)
}
fmt.Printf("\nУспешная авторизация! Токен: %v\n", token.AccessToken)
}
Особенности работы с DeviceAuthResponse
Таймауты и интервалы:
- Учитывайте
Expiry- код устройства имеет ограниченное время жизни - Соблюдайте
Intervalмежду polling-запросами
- Учитывайте
Пользовательский опыт:
- Для лучшего UX используйте
VerificationURIComplete(QR-код) - Предусмотрите возможность отмены ожидания
- Для лучшего UX используйте
Безопасность:
- Не кэшируйте device code без необходимости
- Обрабатывайте все возможные ошибки сервера
Поддерживаемые провайдеры:
- Microsoft Identity Platform
- Google OAuth 2.0
- Другие совместимые с RFC 8628
Этот тип особенно полезен для:
- Устройств без браузера
- Приложений с ограниченным вводом
- Сценариев, где нельзя использовать стандартный OAuth flow
func (DeviceAuthResponse) MarshalJSON
func (d DeviceAuthResponse) MarshalJSON() ([]byte, error)
func (*DeviceAuthResponse) UnmarshalJSON
func (c *DeviceAuthResponse) UnmarshalJSON(data []byte) error
type Endpoint
type Endpoint struct {
AuthURL string // URL endpoint'а авторизации (для получения authorization code)
DeviceAuthURL string // URL для Device Flow авторизации (RFC 8628)
TokenURL string // URL endpoint'а получения токенов (для обмена code на token)
AuthStyle AuthStyle // Предпочтительный метод аутентификации клиента
}
Предназначение: Содержит все необходимые URL для OAuth 2.0 flow.
Использование: Конфигурация клиента для взаимодействия с OAuth провайдером.
type RetrieveError
type RetrieveError struct {
Response *http.Response // HTTP-ответ сервера
Body []byte // Тело ответа (может быть усечено)
ErrorCode string // Код ошибки OAuth (RFC 6749 Section 5.2)
ErrorDescription string // Человекочитаемое описание ошибки
ErrorURI string // Ссылка на документацию по ошибке
}
RetrieveError - ошибка, возвращаемая при неверном статусе HTTP или ошибке OAuth2.
Предназначение: Ошибки, возвращаемые OAuth сервером.
Особенности:
- Соответствует стандарту OAuth 2.0 (RFC 6749)
- Включает как HTTP-детали, так и специфичные OAuth ошибки
type Token
type Token struct {
AccessToken string // Основной токен доступа
TokenType string // Тип токена (обычно "Bearer")
RefreshToken string // Токен для обновления (опционально)
Expiry time.Time // Время истечения срока действия
ExpiresIn int64 // Срок жизни токена в секундах
}
Token содержит учетные данные для авторизации запросов.
Предназначение: Хранит OAuth 2.0 токены и метаданные.
- AccessToken всегда обязателен
- RefreshToken может отсутствовать в некоторых flow
- Expiry вычисляется из ExpiresIn при получении токена
type TokenSource
type TokenSource interface {
Token() (*Token, error) // Возвращает текущий/новый токен
}
TokenSource - любой источник, который может возвращать токен.
Предназначение: Абстракция для источников токенов.
Реализации:
- StaticTokenSource (фиксированный токен)
- ReuseTokenSource (с автоматическим обновлением)
- Config.TokenSource (получение токенов из Config)
type Transport
type Transport struct {
Source TokenSource // Источник токенов для авторизации
Base http.RoundTripper // Базовый RoundTripper (по умолчанию http.DefaultTransport)
}
Transport - это http.RoundTripper для OAuth 2.0 запросов.
Предназначение: Добавляет OAuth-авторизацию к HTTP-запросам.
Принцип работы:
- Получает токен из Source
- Добавляет Authorization header
- Делегирует запрос базовому RoundTripper
12.4.16.1 - Пакет jwt (JSON Web Token)
Пакет jwt реализует поток OAuth 2.0 с использованием JSON Web Token, известный как “двухногая OAuth 2.0” (two-legged OAuth 2.0).
Спецификация: https://tools.ietf.org/html/draft-ietf-oauth-jwt-bearer-12
Типы
type Config
type Config struct {
// Email - идентификатор OAuth-клиента
Email string
// PrivateKey содержит содержимое RSA-ключа или PEM-файла
PrivateKey []byte
// PrivateKeyID - необязательный идентификатор ключа
PrivateKeyID string
// Subject - необязательный пользователь для имперсонации
Subject string
// Scopes - запрашиваемые области доступа
Scopes []string
// TokenURL - endpoint для JWT-потока
TokenURL string
// Expires - срок действия токена
Expires time.Duration
// Audience - целевая аудитория запроса
Audience string
// PrivateClaims - кастомные JWT-claims
PrivateClaims map[string]any
// UseIDToken - использовать ID-токен вместо access-токена
UseIDToken bool
}
Config содержит конфигурацию для получения токенов через JWT (“двухногая OAuth 2.0”).
Пример
package main
import (
"context"
"golang.org/x/oauth2/jwt"
)
func main() {
ctx := context.Background()
conf := &jwt.Config{
Email: "xxx@developer.com",
// The contents of your RSA private key or your PEM file
// that contains a private key.
// If you have a p12 file instead, you
// can use `openssl` to export the private key into a pem file.
//
// $ openssl pkcs12 -in key.p12 -out key.pem -nodes
//
// It only supports PEM containers with no passphrase.
PrivateKey: []byte("-----BEGIN RSA PRIVATE KEY-----..."),
Subject: "user@example.com",
TokenURL: "https://provider.com/o/oauth2/token",
}
// Initiate an http.Client, the following GET request will be
// authorized and authenticated on the behalf of user@example.com.
client := conf.Client(ctx)
client.Get("...")
}
Методы Config
func (*Config) Client
func (c *Config) Client(ctx context.Context) *http.Client
Client возвращает HTTP-клиент, который автоматически добавляет Authorization-заголовки с токенами, полученными из конфигурации.
Возвращенный клиент и его Transport не должны изменяться.
func (*Config) TokenSource
func (c *Config) TokenSource(ctx context.Context) oauth2.TokenSource
TokenSource возвращает источник токенов JWT, используя конфигурацию и HTTP-клиент из переданного контекста.
Особенности реализации
Формат ключей:
- Поддерживаются RSA-ключи и PEM-файлы без пароля
- Для конвертации PKCS#12 в PEM используйте:
openssl pkcs12 -in key.p12 -out key.pem -nodes
Кастомные claims:
- Можно добавлять собственные claims через PrivateClaims
- Спецификация: https://tools.ietf.org/html/draft-jones-json-web-token-10#section-4.3
Аудитория:
- Если Audience не указан, используется TokenURL
Тип токена:
- При UseIDToken=true будет использоваться ID-токен вместо access-токена
12.4.16.2 - Пакет jws (JSON Web Signature)
Пакет jws предоставляет частичную реализацию кодирования и декодирования JSON Web Signature. Существует для поддержки пакета golang.org/x/oauth2.
Устарело: этот пакет не предназначен для публичного использования и может быть удален в будущем. Существует только для внутреннего использования. Рекомендуется использовать другой JWS-пакет или скопировать этот пакет в свой исходный код.
Функции
func Encode
func Encode(header *Header, c *ClaimSet, key *rsa.PrivateKey) (string, error)
Encode кодирует подписанный JWS с предоставленными заголовком и набором claims. Использует crypto/rsa.SignPKCS1v15 с указанным RSA-приватным ключом.
func EncodeWithSigner
func EncodeWithSigner(header *Header, c *ClaimSet, sg Signer) (string, error)
EncodeWithSigner кодирует заголовок и набор claims с использованием предоставленного подписывающего устройства.
func Verify
func Verify(token string, key *rsa.PublicKey) error
Verify проверяет, была ли подпись JWT-токена создана приватным ключом, соответствующим предоставленному публичному ключу.
Типы
type ClaimSet
type ClaimSet struct {
Iss string `json:"iss"` // email клиентского приложения
Scope string `json:"scope,omitempty"` // запрашиваемые разрешения
Aud string `json:"aud"` // целевая аудитория (опционально)
Exp int64 `json:"exp"` // время истечения (Unix epoch)
Iat int64 `json:"iat"` // время выдачи (Unix epoch)
Typ string `json:"typ,omitempty"` // тип токена (опционально)
Sub string `json:"sub,omitempty"` // email для делегированного доступа
Prn string `json:"prn,omitempty"` // устаревший аналог Sub
PrivateClaims map[string]any `json:"-"` // кастомные claims
}
ClaimSet содержит информацию о JWT-подписи, включая запрашиваемые разрешения, цель токена, издателя, время выдачи и срок действия.
func Decode
func Decode(payload string) (*ClaimSet, error)
Decode декодирует набор claims из JWS-полезной нагрузки.
type Header
type Header struct {
Algorithm string `json:"alg"` // алгоритм подписи
Typ string `json:"typ"` // тип токена
KeyID string `json:"kid,omitempty"` // идентификатор ключа (опционально)
}
Header представляет заголовок для подписанных JWS-полезных нагрузок.
type Signer
type Signer func(data []byte) (sig []byte, err error)
Signer возвращает подпись для предоставленных данных.
Особенности реализации
Поддержка алгоритмов:
- Основная реализация использует RSA с PKCS1v15
- Возможность подключения кастомных подписывающих устройств
Устаревшие поля:
- Поле
Prnсохраняется для обратной совместимости - Рекомендуется использовать
SubвместоPrn
- Поле
Кастомные claims:
- Поддерживаются через поле PrivateClaims
- Не включаются в стандартную JSON-маршализацию
Безопасность:
- Пакет помечен как устаревший для публичного использования
- Рекомендуется использовать более полные реализации JWS
12.4.16.3 - Пакет authhandler (Three-Legged OAuth 2.0)
Пакет authhandler реализует TokenSource для поддержки “трехногового OAuth 2.0” через кастомный AuthorizationHandler.
Функции
func TokenSource
func TokenSource(
ctx context.Context,
config *oauth2.Config,
state string,
authHandler AuthorizationHandler,
) oauth2.TokenSource
TokenSource возвращает oauth2.TokenSource, который получает access-токены, используя трехноговый OAuth-поток.
Параметры:
ctx- контекст для операции Exchangeconfig- полная конфигурация OAuth (AuthURL, TokenURL, Scope)state- уникальная строка состояния для защиты от CSRFauthHandler- обработчик авторизации для получения согласия пользователя
Особенности:
- Проверяет соответствие параметра
stateв запросе и ответе - Обменивает auth-код на OAuth-токен после проверки
func TokenSourceWithPKCE
func TokenSourceWithPKCE(
ctx context.Context,
config *oauth2.Config,
state string,
authHandler AuthorizationHandler,
pkce *PKCEParams,
) oauth2.TokenSource
TokenSourceWithPKCE - расширенная версия с поддержкой PKCE (Proof Key for Code Exchange).
Дополнительный параметр:
pkce- параметры для защиты от CSRF через code challenge и code verifier
Рекомендации:
- Генерировать уникальные challenge/verifier во время выполнения
- Подробнее: https://www.oauth.com/oauth2-servers/pkce/
Типы
type AuthorizationHandler
type AuthorizationHandler func(authCodeURL string) (code string, state string, err error)
AuthorizationHandler - обработчик для трехногового OAuth, который:
- Перенаправляет пользователя по URL для получения согласия
- Возвращает auth-код и состояние после подтверждения
type PKCEParams
type PKCEParams struct {
Challenge string // Зашифрованный code verifier (base64-url)
ChallengeMethod string // Метод шифрования (напр. S256)
Verifier string // Оригинальный секрет (незашифрованный)
}
PKCEParams содержит параметры для защиты потока PKCE.
Особенности реализации
Безопасность:
- Обязательная проверка параметра
state - Поддержка современных методов защиты PKCE
- Обязательная проверка параметра
Гибкость:
- Возможность кастомной обработки авторизации
- Поддержка различных методов шифрования PKCE
Рекомендации:
- Всегда использовать уникальный
stateдля каждого запроса - Для мобильных приложений предпочтительнее TokenSourceWithPKCE
- Всегда использовать уникальный
12.4.16.4 - Пакет clientcredentials OAuth 2.0 Client Credentials Flow
Пакет реализует поток OAuth 2.0 учетные данные клиента client credentials, также известный как двухногая OAuth 2.0
Используется, когда:
- Клиент действует от своего имени
- Клиент является владельцем ресурса
- Запрашивается доступ к защищенным ресурсам на основе предварительной авторизации
Спецификация: https://tools.ietf.org/html/rfc6749#section-4.4
Тип Config
type Config struct {
// ClientID - идентификатор приложения
ClientID string
// ClientSecret - секрет приложения
ClientSecret string
// TokenURL - endpoint сервера для получения токенов
TokenURL string
// Scopes - запрашиваемые разрешения (опционально)
Scopes []string
// EndpointParams - дополнительные параметры запроса
EndpointParams url.Values
// AuthStyle - способ аутентификации клиента
AuthStyle oauth2.AuthStyle
}
Config описывает двухноговый OAuth2 поток, содержащий информацию о клиентском приложении и URL endpoint’ов сервера.
Методы Config
func (*Config) Client
func (c *Config) Client(ctx context.Context) *http.Client
Возвращает HTTP-клиент, который:
- Автоматически добавляет токены авторизации
- Обновляет токены по истечении срока
- Использует HTTP-клиент из контекста (через oauth2.HTTPClient)
Важно: возвращенный клиент и его Transport не должны изменяться.
func (*Config) Token
func (c *Config) Token(ctx context.Context) (*oauth2.Token, error)
Получает токен, используя учетные данные клиента (client credentials).
Может использовать кастомный HTTP-клиент из контекста.
func (*Config) TokenSource
func (c *Config) TokenSource(ctx context.Context) oauth2.TokenSource
Возвращает источник токенов, который:
- Возвращает текущий токен, пока он действителен
- Автоматически обновляет токен при истечении срока
- Использует client ID и client secret для обновления
Рекомендация: большинству пользователей следует использовать Config.Client вместо прямого использования TokenSource.
Особенности реализации
Сценарии использования:
- Сервер-серверное взаимодействие
- Микросервисная архитектура
- Фоновые процессы без участия пользователя
Безопасность:
- ClientSecret должен храниться защищенно
- Рекомендуется использовать HTTPS для всех запросов
Гибкость:
- Поддержка различных методов аутентификации (AuthStyle)
- Возможность передачи дополнительных параметров (EndpointParams)
12.4.17 - Описание пакета string языка программирования Go
Пакет strings реализует простые функции для работы со строками в кодировке UTF-8.
Информацию о строках UTF-8 в Go см. на сайте https://blog.golang.org/strings.
12.4.17.1 - Функции пакета string языка программирования Go
Подробное описание функций пакета string языка программирования Go
func Clone
func Clone(s string) string
Clone возвращает новую копию s. Оно гарантирует создание копии s в новом выделении памяти, что может быть важно при сохранении только небольшой подстроки из гораздо более длинной строки.
Использование Clone может помочь таким программам использовать меньше памяти.
Конечно, поскольку использование Clone создает копию, чрезмерное использование Clone может привести к увеличению потребления памяти программами. Обычно Clone следует использовать редко и только в тех случаях, когда профилирование показывает, что это необходимо. Для строк длиной ноль будет возвращена строка "" и выделение памяти не будет производиться.
Пример
package main
import (
"fmt"
"strings"
"unsafe"
)
func main() {
s := "abc"
clone := strings.Clone(s)
fmt.Println(s == clone)
fmt.Println(unsafe.StringData(s) == unsafe.StringData(clone))
}
Output:
true
falsefunc Compare
func Compare(a, b string) int
Compare возвращает целое число, сравнивающее две строки лексикографически. Результат будет 0, если a == b, -1, если a < b, и +1, если a > b.
Используйте Compare, когда вам нужно выполнить трехстороннее сравнение (например, с помощью slices.SortFunc). Обычно более понятно и всегда быстрее использовать встроенные операторы сравнения строк ==, <, > и т. д.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Compare("a", "b"))
fmt.Println(strings.Compare("a", "a"))
fmt.Println(strings.Compare("b", "a"))
}
Output:
-1
0
1func Contains
func Contains(s, substr string) bool
Contains сообщает, находится ли substr в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Contains("seafood", "foo"))
fmt.Println(strings.Contains("seafood", "bar"))
fmt.Println(strings.Contains("seafood", ""))
fmt.Println(strings.Contains("", ""))
}
Output:
true
false
true
truefunc ContainsAny
func ContainsAny(s, chars string) bool
ContainsAny сообщает, находятся ли какие-либо кодовые точки Unicode в chars в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.ContainsAny("team", "i"))
fmt.Println(strings.ContainsAny("fail", "ui"))
fmt.Println(strings.ContainsAny("ure", "ui"))
fmt.Println(strings.ContainsAny("failure", "ui"))
fmt.Println(strings.ContainsAny("foo", ""))
fmt.Println(strings.ContainsAny("", ""))
}
Output:
false
true
true
true
false
falsefunc ContainsFunc
func ContainsFunc(s string, f func(rune) bool) bool
ContainsFunc сообщает, удовлетворяют ли какие-либо кодовые точки Unicode r в s условию f(r).
Пример
package main
import (
"fmt"
"strings"
)
func main() {
f := func(r rune) bool {
return r == 'a' || r == 'e' || r == 'i' || r == 'o' || r == 'u'
}
fmt.Println(strings.ContainsFunc("hello", f))
fmt.Println(strings.ContainsFunc("rhythms", f))
}
Output:
true
falsefunc ContainsRune
func ContainsRune(s string, r rune) bool
ContainsRune сообщает, находится ли кодовая точка Unicode r в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
// Finds whether a string contains a particular Unicode code point.
// The code point for the lowercase letter "a", for example, is 97.
fmt.Println(strings.ContainsRune("aardvark", 97))
fmt.Println(strings.ContainsRune("timeout", 97))
}
Output:
true
falsefunc Count
func Count(s, substr string) int
Count подсчитывает количество непересекающихся вхождений substr в s. Если substr является пустой строкой, Count возвращает 1 + количество кодовых точек Unicode в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Count("cheese", "e"))
fmt.Println(strings.Count("five", "")) // before & after each rune
}
Output:
3
5func Cut
func Cut(s, sep string) (before, after string, found bool)
Cut разрезает s вокруг первого вхождения sep, возвращая текст до и после sep. Результат found сообщает, встречается ли sep в s. Если sep не встречается в s, cut возвращает s, «», false.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
show := func(s, sep string) {
before, after, found := strings.Cut(s, sep)
fmt.Printf("Cut(%q, %q) = %q, %q, %v\n", s, sep, before, after, found)
}
show("Gopher", "Go")
show("Gopher", "ph")
show("Gopher", "er")
show("Gopher", "Badger")
}
Output:
Cut("Gopher", "Go") = "", "pher", true
Cut("Gopher", "ph") = "Go", "er", true
Cut("Gopher", "er") = "Goph", "", true
Cut("Gopher", "Badger") = "Gopher", "", falsefunc CutPrefix
func CutPrefix(s, prefix string) (after string, found bool)
CutPrefix возвращает s без указанной начальной префиксной строки и сообщает, был ли найден префикс. Если s не начинается с prefix, CutPrefix возвращает s, false. Если prefix является пустой строкой, CutPrefix возвращает s, true.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
show := func(s, sep string) {
after, found := strings.CutPrefix(s, sep)
fmt.Printf("CutPrefix(%q, %q) = %q, %v\n", s, sep, after, found)
}
show("Gopher", "Go")
show("Gopher", "ph")
}
Output:
CutPrefix("Gopher", "Go") = "pher", true
CutPrefix("Gopher", "ph") = "Gopher", false
func CutSuffix
func CutSuffix(s, suffix string) (before string, found bool)
CutSuffix возвращает s без указанной конечной строки суффикса и сообщает, был ли найден суффикс. Если s не заканчивается суффиксом, CutSuffix возвращает s, false. Если суффикс является пустой строкой, CutSuffix возвращает s, true.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
show := func(s, sep string) {
before, found := strings.CutSuffix(s, sep)
fmt.Printf("CutSuffix(%q, %q) = %q, %v\n", s, sep, before, found)
}
show("Gopher", "Go")
show("Gopher", "er")
}
Output:
CutSuffix("Gopher", "Go") = "Gopher", false
CutSuffix("Gopher", "er") = "Goph", truefunc EqualFold
func EqualFold(s, t string) bool
EqualFold сообщает, равны ли s и t, интерпретируемые как строки UTF-8, при простом преобразовании регистра Unicode, которое является более общей формой нечувствительности к регистру.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.EqualFold("Go", "go"))
fmt.Println(strings.EqualFold("AB", "ab")) // true because comparison uses simple case-folding
fmt.Println(strings.EqualFold("ß", "ss")) // false because comparison does not use full case-folding
}
Output:
true
true
false
func Fields
func Fields(s string) []string
Fields разбивает строку s по каждому вхождению одного или нескольких последовательных пробелов, как определено в unicode.IsSpace, возвращая массив подстрок s или пустой массив, если s содержит только пробелы.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Printf("Fields are: %q", strings.Fields(" foo bar baz "))
}
Output:
Fields are: ["foo" "bar" "baz"]func FieldsFunc
func FieldsFunc(s string, f func(rune) bool) []string
FieldsFunc разбивает строку s на каждом проходе кодовых точек Unicode c, удовлетворяющих f(c), и возвращает массив фрагментов s. Если все кодовые точки в s удовлетворяют f(c) или строка пуста, возвращается пустой фрагмент.
FieldsFunc не дает никаких гарантий относительно порядка вызова f(c) и предполагает, что f всегда возвращает одно и то же значение для данного c.
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
f := func(c rune) bool {
return !unicode.IsLetter(c) && !unicode.IsNumber(c)
}
fmt.Printf("Fields are: %q", strings.FieldsFunc(" foo1;bar2,baz3...", f))
}
Output:
Fields are: ["foo1" "bar2" "baz3"]
func FieldsFuncSeq
func FieldsFuncSeq(s string, f func(rune) bool) iter.Seq[string]
FieldsFuncSeq возвращает итератор над подстроками s, разбитыми по последовательностям кодовых точек Unicode, удовлетворяющих f(c). Итератор возвращает те же строки, что и FieldsFunc(s), но без построения среза.
func FieldsSeq
func FieldsSeq(s string) iter.Seq[string]
FieldsSeq возвращает итератор над подстроками s, разбитыми по последовательностям пробельных символов, как определено в unicode.IsSpace. Итератор возвращает те же строки, что и Fields(s), но без построения среза.
func HasPrefix
func HasPrefix(s, prefix string) bool
HasPrefix сообщает, начинается ли строка s с префикса.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.HasPrefix("Gopher", "Go"))
fmt.Println(strings.HasPrefix("Gopher", "C"))
fmt.Println(strings.HasPrefix("Gopher", ""))
}
Output:
true
false
truefunc HasSuffix
func HasSuffix(s, suffix string) bool
HasSuffix сообщает, заканчивается ли строка s суффиксом.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.HasSuffix("Amigo", "go"))
fmt.Println(strings.HasSuffix("Amigo", "O"))
fmt.Println(strings.HasSuffix("Amigo", "Ami"))
fmt.Println(strings.HasSuffix("Amigo", ""))
}
Output:
true
false
false
truefunc Index
func Index(s, substr string) int
Index возвращает индекс первого вхождения substr в s или -1, если substr отсутствует в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Index("chicken", "ken"))
fmt.Println(strings.Index("chicken", "dmr"))
}
Output:
4
-1func IndexAny
func IndexAny(s, chars string) int
IndexAny возвращает индекс первого вхождения любого кодового пункта Unicode из chars в s, или -1, если ни один кодовый пункт Unicode из chars не присутствует в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.IndexAny("chicken", "aeiouy"))
fmt.Println(strings.IndexAny("crwth", "aeiouy"))
}
Output:
2
-1func IndexByte
func IndexByte(s string, c byte) int
IndexByte возвращает индекс первого вхождения c в s, или -1, если c отсутствует в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.IndexByte("golang", 'g'))
fmt.Println(strings.IndexByte("gophers", 'h'))
fmt.Println(strings.IndexByte("golang", 'x'))
}
Output:
0
3
-1func IndexFunc
func IndexFunc(s string, f func(rune) bool) int
IndexFunc возвращает индекс в s первого кодового пункта Unicode, удовлетворяющего f(c), или -1, если такового нет.
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
f := func(c rune) bool {
return unicode.Is(unicode.Han, c)
}
fmt.Println(strings.IndexFunc("Hello, 世界", f))
fmt.Println(strings.IndexFunc("Hello, world", f))
}
Output:
7
-1func IndexRune
func IndexRune(s string, r rune) int
IndexRune возвращает индекс первого вхождения кодовой точки Unicode r, или -1, если rune отсутствует в s. Если r является utf8.RuneError, то возвращается первое вхождение любой недопустимой последовательности байтов UTF-8.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.IndexRune("chicken", 'k'))
fmt.Println(strings.IndexRune("chicken", 'd'))
}
Output:
4
-1func Join
func Join(elems []string, sep string) string
Join объединяет элементы своего первого аргумента, создавая одну строку. Разделитель sep помещается между элементами в результирующей строке.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
s := []string{"foo", "bar", "baz"}
fmt.Println(strings.Join(s, ", "))
}
Output:
foo, bar, bazfunc LastIndex
func LastIndex(s, substr string) int
LastIndex возвращает индекс последнего вхождения substr в s, или -1, если substr отсутствует в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Index("go gopher", "go"))
fmt.Println(strings.LastIndex("go gopher", "go"))
fmt.Println(strings.LastIndex("go gopher", "rodent"))
}
Output:
0
3
-1func LastIndexAny
func LastIndexAny(s, chars string) int
LastIndexAny возвращает индекс последнего вхождения любого кодового пункта Unicode из chars в s, или -1, если в s нет кодовых пунктов Unicode из chars.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.LastIndexAny("go gopher", "go"))
fmt.Println(strings.LastIndexAny("go gopher", "rodent"))
fmt.Println(strings.LastIndexAny("go gopher", "fail"))
}
Output:
4
8
-1func LastIndexByte
func LastIndexByte(s string, c byte) int
LastIndexByte возвращает индекс последнего вхождения c в s, или -1, если c отсутствует в s.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.LastIndexByte("Hello, world", 'l'))
fmt.Println(strings.LastIndexByte("Hello, world", 'o'))
fmt.Println(strings.LastIndexByte("Hello, world", 'x'))
}
Output:
10
8
-1func LastIndexFunc
func LastIndexFunc(s string, f func(rune) bool) int
LastIndexFunc возвращает индекс в s последней кодовой точки Unicode, удовлетворяющей f(c), или -1, если таковой нет.
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
fmt.Println(strings.LastIndexFunc("go 123", unicode.IsNumber))
fmt.Println(strings.LastIndexFunc("123 go", unicode.IsNumber))
fmt.Println(strings.LastIndexFunc("go", unicode.IsNumber))
}
Output:
5
2
-1func Lines
func Lines(s string) iter.Seq[string]
Lines возвращает итератор по строкам, отделенным символом новой строки, в строке s. Строки, возвращаемые итератором, включают в себя символы новой строки, отделяющие их. Если s пуста, итератор не возвращает никаких строк. Если s не заканчивается символом новой строки, последняя возвращаемая строка не будет заканчиваться символом новой строки. Возвращает итератор однократного использования.
func Map
func Map(mapping func(rune) rune, s string) string
Map возвращает копию строки s со всеми ее символами, измененными в соответствии с функцией отображения. Если отображение возвращает отрицательное значение, символ удаляется из строки без замены.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
rot13 := func(r rune) rune {
switch {
case r >= 'A' && r <= 'Z':
return 'A' + (r-'A'+13)%26
case r >= 'a' && r <= 'z':
return 'a' + (r-'a'+13)%26
}
return r
}
fmt.Println(strings.Map(rot13, "'Twas brillig and the slithy gopher..."))
}
Output:
'Gjnf oevyyvt naq gur fyvgul tbcure...func Repeat
func Repeat(s string, count int) string
Repeat возвращает новую строку, состоящую из count копий строки s.
Функция выдает ошибку, если count отрицательно или если результат (len(s) * count) переполняет буфер.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println("ba" + strings.Repeat("na", 2))
}
Output:
bananafunc Replace
func Replace(s, old, new string, n int) string
Replace возвращает копию строки s, в которой первые n неперекрывающихся экземпляров old заменены на new. Если old пустое, оно совпадает в начале строки и после каждой последовательности UTF-8, давая до k+1 замен для строки k-рун. Если n < 0, количество замен не ограничено.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Replace("oink oink oink", "k", "ky", 2))
fmt.Println(strings.Replace("oink oink oink", "oink", "moo", -1))
}
Output:
oinky oinky oink
moo moo moofunc ReplaceAll
func ReplaceAll(s, old, new string) string
ReplaceAll возвращает копию строки s со всеми неперекрывающимися вхождениями old, замененными на new. Если old пустое, оно совпадает с началом строки и после каждой последовательности UTF-8, давая до k+1 замен для строки из k рун.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.ReplaceAll("oink oink oink", "oink", "moo"))
}
Output:
moo moo moofunc Split
func Split(s, sep string) []string
Split разделяет s на все подстроки, разделенные sep, и возвращает набор подстрок между этими разделителями.
Если s не содержит sep, а sep не пустой, Split возвращает набор длиной 1, единственным элементом которого является s.
Если sep пустой, Split разделяет после каждой последовательности UTF-8. Если и s, и sep пустые, Split возвращает пустой набор.
Это эквивалентно SplitN с количеством -1.
Чтобы разделить вокруг первого вхождения разделителя, см. Cut.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Printf("%q\n", strings.Split("a,b,c", ","))
fmt.Printf("%q\n", strings.Split("a man a plan a canal panama", "a "))
fmt.Printf("%q\n", strings.Split(" xyz ", ""))
fmt.Printf("%q\n", strings.Split("", "Bernardo O'Higgins"))
}
Output:
["a" "b" "c"]
["" "man " "plan " "canal panama"]
[" " "x" "y" "z" " "]
[""]func SplitAfter
func SplitAfter(s, sep string) []string
SplitAfter разделяет s на все подстроки после каждого вхождения sep и возвращает срез этих подстрок.
Если s не содержит sep, а sep не пустой, SplitAfter возвращает срез длиной 1, единственным элементом которого является s.
Если sep пусто, SplitAfter разделяет после каждой последовательности UTF-8. Если и s, и sep пусты, SplitAfter возвращает пустой срез.
Это эквивалентно SplitAfterN с количеством -1.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Printf("%q\n", strings.SplitAfter("a,b,c", ","))
}
Output:
["a," "b," "c"]func SplitAfterN
func SplitAfterN(s, sep string, n int) []string
SplitAfterN разделяет s на подстроки после каждого вхождения sep и возвращает срез этих подстрок.
Число определяет количество подстрок, которые будут возвращены:
n > 0: не более n подстрок; последняя подстрока будет неразделенным остатком; n == 0: результат равен nil (ноль подстрок); n < 0: все подстроки. Крайние случаи для s и sep (например, пустые строки) обрабатываются, как описано в документации для SplitAfter.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Printf("%q\n", strings.SplitAfterN("a,b,c", ",", 2))
}
Output:
["a," "b,c"]func SplitAfterSeq
func SplitAfterSeq(s, sep string) iter.Seq[string]
SplitAfterSeq возвращает итератор над подстроками s, разделенными после каждого вхождения sep. Итератор возвращает те же строки, которые были бы возвращены SplitAfter(s, sep), но без построения слайса. Он возвращает итератор однократного использования.
func SplitN
func SplitN(s, sep string, n int) []string
SplitN разделяет s на подстроки, разделенные sep, и возвращает срез подстрок между этими разделителями.
Число определяет количество подстрок, которые будут возвращены:
n > 0: не более n подстрок; последняя подстрока будет неразделенной остаточной частью; n == 0: результат равен nil (ноль подстрок); n < 0: все подстроки. Крайние случаи для s и sep (например, пустые строки) обрабатываются, как описано в документации по Split.
Чтобы разделить вокруг первого вхождения разделителя, см. Cut.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Printf("%q\n", strings.SplitN("a,b,c", ",", 2))
z := strings.SplitN("a,b,c", ",", 0)
fmt.Printf("%q (nil = %v)\n", z, z == nil)
}
Output:
["a" "b,c"]
[] (nil = true)func SplitSeq
func SplitSeq(s, sep string) iter.Seq[string]
SplitSeq возвращает итератор по всем подстрокам s, разделенным sep. Итератор возвращает те же строки, что и Split(s, sep), но без создания слайса. Он возвращает итератор однократного использования.
func Title (устарело)
func ToLower
func ToLower(s string) string
ToLower возвращает s со всеми буквами Unicode, преобразованными в нижний регистр.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.ToLower("Gopher"))
}
Output:
gopherfunc ToLowerSpecial
func ToLowerSpecial(c unicode.SpecialCase, s string) string
ToLowerSpecial возвращает копию строки s со всеми буквами Unicode, преобразованными в нижний регистр с использованием преобразования регистра, указанного c.
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
fmt.Println(strings.ToLowerSpecial(unicode.TurkishCase, "Örnek İş"))
}
Output:
örnek işfunc ToTitle
func ToTitle(s string) string
ToTitle возвращает копию строки s, в которой все буквы Unicode преобразованы в заглавные.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
// Compare this example to the Title example.
fmt.Println(strings.ToTitle("her royal highness"))
fmt.Println(strings.ToTitle("loud noises"))
fmt.Println(strings.ToTitle("брат"))
}
HER ROYAL HIGHNESS
LOUD NOISES
БРАТfunc ToTitleSpecial
func ToTitleSpecial(c unicode.SpecialCase, s string) string
ToTitleSpecial возвращает копию строки s, в которой все буквы Unicode преобразованы в заглавные, с приоритетом специальных правил преобразования регистра.
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
fmt.Println(strings.ToTitleSpecial(unicode.TurkishCase, "dünyanın ilk borsa yapısı Aizonai kabul edilir"))
}
Output:
DÜNYANIN İLK BORSA YAPISI AİZONAİ KABUL EDİLİRfunc ToUpper
func ToUpper(s string) string
ToUpper возвращает s, в которой все буквы Unicode преобразованы в заглавные.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.ToUpper("Gopher"))
}
Output:
GOPHERfunc ToUpperSpecial
func ToUpperSpecial(c unicode.SpecialCase, s string) string
ToUpperSpecial возвращает копию строки s, в которой все буквы Unicode преобразованы в верхний регистр с использованием преобразования регистра, указанного в c.
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
fmt.Println(strings.ToUpperSpecial(unicode.TurkishCase, "örnek iş"))
}
Output:
ÖRNEK İŞfunc ToValidUTF8
func ToValidUTF8(s, replacement string) string
ToValidUTF8 возвращает копию строки s, в которой каждая последовательность недопустимых байтов UTF-8 заменена строкой replacement, которая может быть пустой.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Printf("%s\n", strings.ToValidUTF8("abc", "\uFFFD"))
fmt.Printf("%s\n", strings.ToValidUTF8("a\xffb\xC0\xAFc\xff", ""))
fmt.Printf("%s\n", strings.ToValidUTF8("\xed\xa0\x80", "abc"))
}
Output:
abc
abc
abcfunc Trim
func Trim(s, cutset string) string
Trim возвращает фрагмент строки s, из которого удалены все начальные и конечные кодовые точки Unicode, содержащиеся в cutset.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Print(strings.Trim("¡¡¡Hello, Gophers!!!", "!¡"))
}
Output:
Hello, Gophersfunc TrimFunc
func TrimFunc(s string, f func(rune) bool) string
TrimFunc возвращает фрагмент строки s, из которого удалены все начальные и конечные кодовые точки Unicode c, удовлетворяющие f(c).
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
fmt.Print(strings.TrimFunc("¡¡¡Hello, Gophers!!!", func(r rune) bool {
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
}))
}
Output:
Hello, Gophersfunc TrimLeft
func TrimLeft(s, cutset string) string
TrimLeft возвращает фрагмент строки s, из которого удалены все начальные кодовые точки Unicode, содержащиеся в cutset.
Чтобы удалить префикс, используйте вместо этого TrimPrefix.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Print(strings.TrimLeft("¡¡¡Hello, Gophers!!!", "!¡"))
}
Output:
Hello, Gophers!!!func TrimLeftFunc
func TrimLeftFunc(s string, f func(rune) bool) string
TrimLeftFunc возвращает фрагмент строки s, из которого удалены все начальные кодовые точки Unicode c, удовлетворяющие f(c).
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
fmt.Print(strings.TrimLeftFunc("¡¡¡Hello, Gophers!!!", func(r rune) bool {
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
}))
}
Output:
Hello, Gophers!!!func TrimPrefix
func TrimPrefix(s, prefix string) string
TrimPrefix возвращает s без указанного начального префикса string. Если s не начинается с префикса, s возвращается без изменений.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
var s = "¡¡¡Hello, Gophers!!!"
s = strings.TrimPrefix(s, "¡¡¡Hello, ")
s = strings.TrimPrefix(s, "¡¡¡Howdy, ")
fmt.Print(s)
}
Output:
Gophers!!!func TrimRight
func TrimRight(s, cutset string) string
TrimRight возвращает фрагмент строки s, из которого удалены все конечные кодовые точки Unicode, содержащиеся в cutset.
Чтобы удалить суффикс, используйте вместо этого TrimSuffix.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Print(strings.TrimRight("¡¡¡Hello, Gophers!!!", "!¡"))
}
Output:
¡¡¡Hello, Gophersfunc TrimRightFunc
func TrimRightFunc(s string, f func(rune) bool) string
TrimRightFunc возвращает фрагмент строки s, из которого удалены все конечные кодовые точки Unicode c, удовлетворяющие f(c).
Пример
package main
import (
"fmt"
"strings"
"unicode"
)
func main() {
fmt.Print(strings.TrimRightFunc("¡¡¡Hello, Gophers!!!", func(r rune) bool {
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
}))
}
Output:
¡¡¡Hello, Gophersfunc TrimSpace
func TrimSpace(s string) string
TrimSpace возвращает фрагмент строки s, из которого удалены все ведущие и конечные пробелы, как определено в Unicode.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.TrimSpace(" \t\n Hello, Gophers \n\t\r\n"))
}
Output:
Hello, Gophersfunc TrimSuffixy
func TrimSuffix(s, suffix string) string
TrimSuffix возвращает s без указанного конечного суффикса string. Если s не заканчивается суффиксом, s возвращается без изменений.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
var s = "¡¡¡Hello, Gophers!!!"
s = strings.TrimSuffix(s, ", Gophers!!!")
s = strings.TrimSuffix(s, ", Marmots!!!")
fmt.Print(s)
}
Output:
¡¡¡Hello12.4.17.2 - Описание типов пакета string языка программирования Go
Описание типов и их функций из пакета string для языка Go с примерами
type Builder
type Builder struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Builder используется для эффективного построения строки с помощью методов Builder.Write. Он минимизирует копирование памяти. Нулевое значение готово к использованию. Не копируйте Builder, отличное от нуля.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
var b strings.Builder
for i := 3; i >= 1; i-- {
fmt.Fprintf(&b, "%d...", i)
}
b.WriteString("ignition")
fmt.Println(b.String())
}
Output:
3...2...1...ignitionОбъяснение Builder
Builder из пакета strings - это специальный тип для эффективного построения строк в Go. Он особенно полезен, когда вам нужно собрать строку из множества частей, так как он минимизирует копирование памяти и аллокации.
Основные преимущества Builder:
- Эффективность памяти - избегает лишних копирований данных
- Простота использования - предоставляет удобные методы для добавления содержимого
- Готовность к использованию - нулевое значение (
var b strings.Builder) сразу готово к работе
Основные методы:
Write()- добавляет байтыWriteString()- добавляет строкуWriteByte()- добавляет один байтWriteRune()- добавляет руну (Unicode символ)String()- возвращает собранную строкуReset()- очищает builder для повторного использованияLen()- возвращает текущую длинуCap()- возвращает текущую емкостьGrow()- заранее резервирует память
Примеры использования:
1. Базовый пример
package main
import (
"fmt"
"strings"
)
func main() {
var builder strings.Builder
builder.WriteString("Hello, ")
builder.WriteString("World!")
builder.WriteByte(' ')
builder.WriteRune('😊')
result := builder.String()
fmt.Println(result) // Hello, World! 😊
}
2. Эффективная конкатенация множества строк
func joinStrings(words []string) string {
var builder strings.Builder
// Заранее выделяем память для приблизительного размера
total := 0
for _, w := range words {
total += len(w)
}
builder.Grow(total)
for _, word := range words {
builder.WriteString(word)
}
return builder.String()
}
3. Построение JSON или HTML
func buildHTMLPage(title, body string) string {
var builder strings.Builder
builder.Grow(len(title) + len(body) + 50) // Примерный расчет
builder.WriteString("<html><head><title>")
builder.WriteString(title)
builder.WriteString("</title></head><body>")
builder.WriteString(body)
builder.WriteString("</body></html>")
return builder.String()
}
4. Повторное использование Builder
var builder strings.Builder
func logMessage(msg string) string {
builder.Reset() // Очищаем для повторного использования
builder.WriteString("[LOG] ")
builder.WriteString(time.Now().Format("2006-01-02 15:04:05"))
builder.WriteString(": ")
builder.WriteString(msg)
return builder.String()
}
Почему Builder лучше обычной конкатенации?
При обычной конкатенации строк с помощью +:
s := "a" + "b" + "c" + "d"
Каждая операция создает новую строку, что приводит к лишним аллокациям памяти.
Builder же:
- Накапливает данные в буфере
- Увеличивает буфер только когда нужно
- Копирует данные минимальное количество раз
Когда использовать strings.Builder?
- Когда нужно собрать строку из многих частей
- Когда важна производительность (особенно в циклах)
- Когда заранее известен приблизительный размер результата (можно использовать Grow)
- Когда нужно минимизировать аллокации памяти
Builder особенно полезен в высоконагруженных участках кода, где важна эффективность работы со строками.
func (*Builder) Cap
func (b *Builder) Cap() int
Cap возвращает емкость базового байтового слайса builder. Это общее пространство, выделенное для строчки, которая создается, и включает в себя все уже записанные байты.
func (*Builder) Grow
func (b *Builder) Grow(n int)
Grow увеличивает емкость b, если это необходимо, чтобы гарантировать пространство для еще n байтов. После Grow(n) в b можно записать как минимум n байтов без дополнительного выделения памяти. Если n отрицательно, Grow вызывает панику.
func (*Builder) Len
func (b *Builder) Len() int
Len возвращает количество накопленных байтов; b.Len() == len(b.String()).
func (*Builder) Reset
func (b *Builder) Reset()
Reset сбрасывает Builder в пустое состояние.
func (*Builder) String
func (b *Builder) String() string
String возвращает накопленную строку.
func (*Builder) Write
func (b *Builder) Write(p []byte) (int, error)
Write добавляет содержимое p в буфер b. Write всегда возвращает len(p), nil.
func (*Builder) WriteByte
func (b *Builder) WriteByte(c byte) error
WriteByte добавляет байт c в буфер b. Возвращаемая ошибка всегда равна nil.
func (*Builder) WriteRune
func (b *Builder) WriteRune(r rune) (int, error)
WriteRune добавляет UTF-8-кодировку кодовой точки Unicode r в буфер b. Возвращает длину r и ошибку nil.
func (*Builder) WriteString
func (b *Builder) WriteString(s string) (int, error)
WriteString добавляет содержимое s в буфер b. Возвращает длину s и ошибку nil.
type Reader
type Reader struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Reader реализует интерфейсы io.Reader, io.ReaderAt, io.ByteReader, io.ByteScanner, io.RuneReader, io.RuneScanner, io.Seeker и io.WriterTo, читая из строки. Нулевое значение для Reader работает как Reader пустой строки.
Объяснение Reader
Reader из пакета strings - это тип, который реализует множество интерфейсов для чтения из строки как из потока данных. Это мощный инструмент, когда вам нужно работать со строкой как с последовательностью байт или рун, поддерживающий различные операции чтения и навигации.
Основные особенности Reader:
- Чтение строки как потока - позволяет обрабатывать строку постепенно
- Реализация множества интерфейсов - совместим со стандартными интерфейсами ввода-вывода Go
- Поддержка позиционирования - можно перемещаться по строке
- Нулевое значение готово к работе -
var r strings.Readerработает с пустой строкой
Реализуемые интерфейсы:
io.Reader- базовое чтение байтовio.ReaderAt- чтение с определенной позицииio.ByteReader- чтение отдельных байтовio.ByteScanner- чтение и возврат байтовio.RuneReader- чтение рун (Unicode символов)io.RuneScanner- чтение и возврат рунio.Seeker- перемещение по строкеio.WriterTo- запись содержимого в io.Writer
Основные методы:
Len() int- количество непрочитанных байтовRead(b []byte) (n int, err error)- чтение байтов в срезReadAt(b []byte, off int64) (n int, err error)- чтение с определенной позицииReadByte() (byte, error)- чтение одного байтаUnreadByte() error- возврат последнего прочитанного байтаReadRune() (ch rune, size int, err error)- чтение одной руныUnreadRune() error- возврат последней прочитанной руныSeek(offset int64, whence int) (int64, error)- перемещение по строкеWriteTo(w io.Writer) (n int64, err error)- запись всего содержимого в WriterReset(s string)- сброс Reader для чтения новой строки
Примеры использования:
1. Базовое чтение
package main
import (
"fmt"
"strings"
)
func main() {
r := strings.NewReader("Пример строки")
buf := make([]byte, 7)
n, err := r.Read(buf)
fmt.Printf("Прочитано %d байт: %q\n", n, buf[:n])
// Прочитано 7 байт: "Пример"
}
2. Чтение рун
func printRunes(s string) {
r := strings.NewReader(s)
for {
ch, size, err := r.ReadRune()
if err != nil {
break
}
fmt.Printf("%c (%d байт)\n", ch, size)
}
}
// Для строки "Привет" выведет:
// П (2 байт)
// р (2 байт)
// и (2 байт)
// в (2 байт)
// е (2 байт)
// т (2 байт)
3. Использование Seek для навигации
func seekExample() {
r := strings.NewReader("Hello, World!")
// Пропускаем "Hello, "
r.Seek(7, io.SeekStart)
b, _ := r.ReadByte()
fmt.Printf("Первый байт после Seek: %c\n", b) // W
}
4. Чтение с определенной позиции (ReadAt)
func readAtExample() {
r := strings.NewReader("abcdefghij")
buf := make([]byte, 3)
r.ReadAt(buf, 4)
fmt.Println(string(buf)) // efg
}
5. Запись содержимого в другой Writer
func writeToExample(w io.Writer) {
r := strings.NewReader("Данные для записи")
r.WriteTo(w) // Запишет всю строку в w
}
6. Комбинирование методов
func processString(s string) {
r := strings.NewReader(s)
// Читаем первые 5 байт
prefix := make([]byte, 5)
r.Read(prefix)
// Читаем оставшуюся часть по рунам
for {
ch, _, err := r.ReadRune()
if err != nil {
break
}
// Обработка руны...
}
}
Когда использовать strings.Reader?
- Когда нужно читать строку по частям - как из потока
- Для совместимости с API, ожидающими io.Reader - многие функции принимают io.Reader
- Когда нужен произвольный доступ к частям строки - через ReadAt/Seek
- Для обработки Unicode текста - через ReadRune
- Когда нужно повторно “проиграть” часть данных - через UnreadByte/UnreadRune
Преимущества перед работой со строкой напрямую:
- Постепенная обработка - не нужно загружать всю строку в память
- Стандартные интерфейсы - совместимость с другими пакетами
- Гибкость навигации - возможность перемещаться по строке
- Безопасность - Reader неизменяем, исходная строка защищена от модификаций
Reader особенно полезен при парсинге, обработке больших строк или когда вам нужно интегрировать строку в систему, работающую с потоками данных.
func NewReader
func NewReader(s string) *Reader
NewReader возвращает новый Reader, читающий из s. Он похож на bytes.NewBufferString, но более эффективен и не поддается записи.
func (*Reader) Len
func (r *Reader) Len() int
Len возвращает количество байтов непрочитанной части строки.
func (*Reader) Read
func (r *Reader) Read(b []byte) (n int, err error)
Read реализует интерфейс io.Reader.
func (*Reader) ReadAt
func (r *Reader) ReadAt(b []byte, off int64) (n int, err error)
ReadAt реализует интерфейс io.ReaderAt.
func (*Reader) ReadByte
func (r *Reader) ReadByte() (byte, error)
ReadByte реализует интерфейс io.ByteReader.
func (*Reader) ReadRune
func (r *Reader) ReadRune() (ch rune, size int, err error)
ReadRune реализует интерфейс io.RuneReader.
func (*Reader) Reset
func (r *Reader) Reset(s string)
Reset сбрасывает Reader для чтения из s.
func (*Reader) Seek
func (r *Reader) Seek(offset int64, whence int) (int64, error)
Seek реализует интерфейс io.Seeker.
func (*Reader) Size
func (r *Reader) Size() int64
Size возвращает исходную длину базовой строки. Size — это количество байтов, доступных для чтения с помощью Reader.ReadAt. Возвращаемое значение всегда одинаково и не зависит от вызовов других методов.
func (*Reader) UnreadByte
func (r *Reader) UnreadByte() error
UnreadByte реализует интерфейс io.ByteScanner.
func (*Reader) UnreadRune
func (r *Reader) UnreadRune() error
UnreadRune реализует интерфейс io.RuneScanner.
func (*Reader) WriteTo
func (r *Reader) WriteTo(w io.Writer) (n int64, err error)
WriteTo реализует интерфейс io.WriterTo.
type Replacer
type Replacer struct {
// содержит отфильтрованные или неэкспортируемые поля
}
Replacer заменяет список строк на замены. Он безопасен для одновременного использования несколькими goroutines.
Объяснение Replacer
Replacer - это мощный инструмент для замены подстрок в Go, который оптимизирован для многократного использования и безопасен для конкурентного использования в горутинах.
Основные характеристики
- Горутин-безопасность: Можно использовать из нескольких горутин одновременно
- Оптимизированная производительность: Быстрее, чем последовательные вызовы
strings.Replace() - Поддержка множественных замен: Может обрабатывать множество замен за один проход по строке
- Кэширование: Сохраняет оптимизированное состояние для повторного использования
Создание Replacer
Создается с помощью strings.NewReplacer(), который принимает пары “старая строка - новая строка”:
replacer := strings.NewReplacer(
"старое1", "новое1",
"старое2", "новое2",
// ...
)
Основные методы
Replace(input string) string
Заменяет все вхождения заданных подстрок в входной строке:
func main() {
r := strings.NewReplacer("мир", "Go", "Привет", "Здравствуй")
result := r.Replace("Привет, мир!")
fmt.Println(result) // "Здравствуй, Go!"
}
WriteString(w io.Writer, s string) (n int, err error)
Записывает строку с выполненными заменами непосредственно в io.Writer:
func writeReplaced(w io.Writer) {
r := strings.NewReplacer("\n", "\\n", "\t", "\\t")
r.WriteString(w, "Строка с\nпереносами\tи табуляцией")
// Запишет: "Строка с\nпереносами\tи табуляцией"
}
Примеры использования
1. Экранирование специальных символов
func escapeHTML(s string) string {
replacer := strings.NewReplacer(
"&", "&",
"<", "<",
">", ">",
"\"", """,
)
return replacer.Replace(s)
}
2. Транслитерация
func transliterate(s string) string {
return strings.NewReplacer(
"щ", "shh", "ш", "sh", "ч", "ch",
"я", "ya", "ю", "yu", "ж", "zh",
).Replace(s)
}
3. Множественные замены в большом тексте
func processText(text string) string {
replacer := strings.NewReplacer(
"красный", "синий",
"яблоко", "апельсин",
"собака", "кошка",
)
return replacer.Replace(text)
}
4. Обработка логов
func cleanLog(log string) string {
return strings.NewReplacer(
"\n", " | ",
"\t", " ",
"\r", "",
).Replace(log)
}
Особенности производительности
- Однопроходная обработка: Все замены выполняются за один проход по строке
- Оптимизация для повторного использования: Созданный
Replacerкэширует свои внутренние структуры - Эффективность для большого числа замен: Лучше использовать один
Replacerсо многими заменами, чем несколько вызововReplace
Рекомендации по использованию
- Для многократного использования: Создавайте
Replacerодин раз и используйте многократно - Для большого числа замен: Когда нужно сделать более 2-3 замен в одной строке
- В конкурентной среде: Когда замены могут выполняться из нескольких горутин
- Для записи в Writer: Когда нужно сразу записывать результат в выходной поток
Сравнение с другими методами замены
| Метод | Многопоточность | Множественные замены | Производительность | Повторное использование |
|---|---|---|---|---|
strings.Replace() | Нет | Нет (одна замена) | Средняя | Нет |
regexp.Regexp.ReplaceAllString() | Да (с sync) | Да | Низкая (для простых замен) | Да |
strings.Replacer | Да | Да | Высокая | Да |
Replacer особенно полезен в веб-серверах, обработчиках запросов и других высоконагруженных приложениях, где требуется выполнять одни и те же замены многократно.
func NewReplacer
func NewReplacer(oldnew ...string) *Replacer
NewReplacer возвращает новый Replacer из списка пар старых и новых строк. Замены выполняются в том порядке, в котором они появляются в целевой строке, без перекрывающихся совпадений. Сравнение старых строк выполняется в порядке аргументов.
NewReplacer вызывает панику, если ему передано нечетное количество аргументов.
Пример
package main
import (
"fmt"
"strings"
)
func main() {
r := strings.NewReplacer("<", "<", ">", ">")
fmt.Println(r.Replace("This is <b>HTML</b>!"))
}
Output:
This is <b>HTML</b>!func (*Replacer) Replace
func (r *Replacer) Replace(s string) string
Replace возвращает копию s со всеми выполненными заменами.
func (*Replacer) WriteString
func (r *Replacer) WriteString(w io.Writer, s string) (n int, err error)
WriteString записывает s в w со всеми выполненными заменами.
12.4.18 - Полное описание пакета log в Go
Полное описание пакета log в Go с примерами применения и разными потоками вывода
Пакет log в Go предоставляет простые и эффективные инструменты для логирования. Он поддерживает:
- Вывод логов в стандартный вывод (
stdout/stderr). - Настройку формата вывода (префиксы, дата/время, уровень логирования).
- Запись логов в файлы.
- Гибкую настройку через
log.Logger.
1. Основные функции пакета log
1.1. Простое логирование
Пакет log предоставляет стандартные функции:
log.Print("Обычное сообщение") // Вывод без формата
log.Printf("Формат: %d", 123) // Форматированный вывод
log.Println("Сообщение с новой строкой") // Вывод с \n
1.2. Логирование с уровнем FATAL (завершение программы)
log.Fatal("Сообщение и выход с os.Exit(1)") // Вывод + exit(1)
log.Fatalf("Формат: %s", "ошибка") // Форматированный вывод + exit(1)
log.Fatalln("Фатальная ошибка") // Вывод + exit(1)
1.3. Логирование с уровнем PANIC (вызов паники)
log.Panic("Паника с выводом стека") // Вывод + panic()
log.Panicf("Ошибка: %v", err) // Форматированный вывод + panic()
log.Panicln("Критическая ошибка") // Вывод + panic()
2. Настройка формата вывода
2.1. Добавление префикса (дата, время, уровень)
log.SetPrefix("ERROR: ") // Установка префикса
log.SetFlags(log.Ldate | log.Ltime | log.Lshortfile) // Формат
log.Println("Сообщение с префиксом")
Вывод:
ERROR: 2024/03/15 14:20:10 main.go:10: Сообщение с префиксом
2.2. Доступные флаги для log.SetFlags
| Флаг | Описание |
|---|---|
log.Ldate | Дата (2006/01/02) |
log.Ltime | Время (15:04:05) |
log.Lmicroseconds | Микросекунды (15:04:05.000000) |
log.Llongfile | Полный путь к файлу (/a/b/c.go:10) |
log.Lshortfile | Короткое имя файла (c.go:10) |
log.LUTC | Вывод времени в UTC |
log.Lmsgprefix | Префикс перед сообщением (Go 1.14+) |
Пример комбинации флагов:
log.SetFlags(log.Ldate | log.Ltime | log.Lshortfile | log.Lmsgprefix)
3. Запись логов в файл
file, err := os.OpenFile("app.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
log.Fatal("Ошибка открытия файла:", err)
}
defer file.Close()
log.SetOutput(file) // Перенаправляем вывод в файл
log.Println("Сообщение записано в app.log")
4. Создание нескольких логгеров
Можно создавать отдельные логгеры для разных целей:
logger := log.New(os.Stdout, "INFO: ", log.Ldate|log.Ltime)
errorLogger := log.New(os.Stderr, "ERROR: ", log.Ldate|log.Ltime|log.Lshortfile)
logger.Println("Информационное сообщение")
errorLogger.Println("Ошибка в программе")
Вывод:
INFO: 2024/03/15 14:20:10 Информационное сообщение
ERROR: 2024/03/15 14:20:10 main.go:15: Ошибка в программе
5. Продвинутое использование (JSON-логирование, уровни)
Стандартный log не поддерживает уровни (DEBUG, INFO, WARN, ERROR), но их можно эмулировать:
5.1. Логирование в JSON
type LogEntry struct {
Level string `json:"level"`
Message string `json:"message"`
Time string `json:"time"`
}
func JSONLog(level, message string) {
entry := LogEntry{
Level: level,
Message: message,
Time: time.Now().Format(time.RFC3339),
}
data, _ := json.Marshal(entry)
log.Println(string(data))
}
JSONLog("INFO", "Запуск сервера")
Вывод:
{"level":"INFO","message":"Запуск сервера","time":"2024-03-15T14:20:10Z"}
5.2. Уровни логирования
const (
LevelDebug = "DEBUG"
LevelInfo = "INFO"
LevelWarn = "WARN"
LevelError = "ERROR"
)
func Log(level, message string) {
log.Printf("[%s] %s", level, message)
}
Log(LevelError, "Сервер не отвечает")
Вывод:
[ERROR] Сервер не отвечает
6. Когда использовать log, а когда другие пакеты?
log— для простых задач (CLI-утилиты, маленькие сервисы).slog(Go 1.21+) — структурированное логирование с уровнями.zap/zerolog— для высоконагруженных приложений (минимальные аллокации).
Вывод
- Пакет
logпрост, но гибок (префиксы, файлы, форматирование). - Подходит для базового логирования.
- Для сложных сценариев лучше использовать
slog,zapилиzerolog. - Можно комбинировать с
io.MultiWriterдля вывода в несколько мест.
Пример MultiWriter:
file, _ := os.OpenFile("app.log", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
multiWriter := io.MultiWriter(os.Stdout, file)
log.SetOutput(multiWriter)
log.Println("Сообщение в консоль и файл")
12.4.19 - Описание пакета unsafe языка программирования Go
Пакет unsafe содержит операции, которые обходят типовую безопасность программ Go.
Пакеты, которые импортируют unsafe, могут быть непереносимыми и не защищены правилами совместимости Go 1.
Функции
func Alignof
func Alignof(x ArbitraryType) uintptr
Alignof принимает выражение x любого типа и возвращает требуемое выравнивание гипотетической переменной v, как если бы v была объявлена с помощью var v = x. Это наибольшее значение m, такое что адрес v всегда равен нулю по модулю m. Оно совпадает со значением, возвращаемым reflect.TypeOf(x).Align(). В качестве особого случая, если переменная s имеет тип struct, а f является полем в этой структуре, то Alignof(s.f) вернет требуемое выравнивание поля этого типа в структуре. Этот случай аналогичен значению, возвращаемому reflect.TypeOf(s.f).FieldAlign(). Возвращаемое значение Alignof является константой Go, если тип аргумента не имеет переменного размера. (Определение типов переменного размера см. в описании Sizeof.)
func Offsetof
func Offsetof(x ArbitraryType) uintptr
Offsetof возвращает смещение в структуре поля, представленного x, которое должно иметь форму structValue.field. Другими словами, она возвращает количество байтов между началом структуры и началом поля. Возвращаемое значение Offsetof является константой Go, если тип аргумента x не имеет переменного размера. (Определение типов переменного размера см. в описании Sizeof.)
func Sizeof
func Sizeof(x ArbitraryType) uintptr
Sizeof принимает выражение x любого типа и возвращает размер в байтах гипотетической переменной v, как если бы v была объявлена с помощью var v = x. Размер не включает в себя память, на которую может ссылаться x. Например, если x является срезом, Sizeof возвращает размер дескриптора среза, а не размер памяти, на которую ссылается срез; если x является интерфейсом, Sizeof возвращает размер самого значения интерфейса, а не размер значения, хранящегося в интерфейсе. Для структуры размер включает в себя любую заполняющую пробел, введенную выравниванием полей. Возвращаемое значение Sizeof является константой Go, если тип аргумента x не имеет переменного размера. (Тип имеет переменный размер, если он является параметром типа или если он является типом массива или структуры с элементами переменного размера).
func String
func String(ptr *byte, len IntegerType) string
String возвращает строковое значение, байты которого начинаются с ptr и длина которого равна len.
Аргумент len должен быть целочисленного типа или нетипизированной константой. Константа len должна быть неотрицательной и представляться значением типа int; если это константа без типа, ей присваивается тип int. Во время выполнения, если len отрицательна или если ptr равна nil, а len не равна нулю, возникает паника во время выполнения.
Поскольку строки Go являются неизменяемыми, байты, переданные в String, не должны изменяться, пока существует возвращаемое строковое значение. 6
func StringData
func StringData(str string) *byte
StringData возвращает указатель на базовые байты str. Для пустой строки возвращаемое значение не определено и может быть nil.
Поскольку строки Go являются неизменяемыми, байты, возвращаемые StringData, не должны изменяться.
Объяснение unsafe
Пакет unsafe в Go
Пакет unsafe предоставляет низкоуровневые операции, которые обходят безопасность типов Go. Он используется для взаимодействия с операционной системой, оптимизации производительности или работы с особыми структурами данных.
Основные функции пакета unsafe:
1. Alignof(x ArbitraryType) uintptr
Что делает: Возвращает требуемое выравнивание для типа переменной x.
Простыми словами: Компьютер оптимизирует доступ к памяти, размещая данные по определенным адресам (обычно кратным 2, 4, 8 и т.д.). Эта функция показывает, какое выравнивание требуется для типа.
Пример:
type Sample struct {
a bool // 1 байт
b int32 // 4 байта
}
fmt.Println(unsafe.Alignof(Sample{}.b)) // 4 (выравнивание для int32)
2. Offsetof(x ArbitraryType) uintptr
Что делает: Возвращает смещение (в байтах) поля в структуре.
Простыми словами: Показывает, на сколько байтов от начала структуры находится конкретное поле.
Пример:
type Sample struct {
a bool // 1 байт
b int32 // 4 байта
}
fmt.Println(unsafe.Offsetof(Sample{}.b)) // 4 (может быть 4 из-за выравнивания)
3. Sizeof(x ArbitraryType) uintptr
Что делает: Возвращает размер переменной в байтах.
Простыми словами: Показывает, сколько места в памяти занимает переменная.
Пример:
type Sample struct {
a bool // 1 байт
b int32 // 4 байта
}
fmt.Println(unsafe.Sizeof(Sample{})) // 8 (может быть 8 из-за выравнивания)
4. String(ptr *byte, len IntegerType) string
Что делает: Создает строку из указателя на байты и длины.
Простыми словами: Позволяет создать строку напрямую из участка памяти.
Пример:
bytes := []byte{'h', 'e', 'l', 'l', 'o'}
str := unsafe.String(&bytes[0], len(bytes))
fmt.Println(str) // "hello"
5. StringData(str string) *byte
Что делает: Возвращает указатель на базовые байты строки.
Простыми словами: Позволяет получить доступ к внутреннему представлению строки.
Пример:
str := "hello"
ptr := unsafe.StringData(str)
fmt.Println(*ptr) // 104 (байт 'h')
Когда использовать unsafe?
- Для оптимизации критического по производительности кода
- При работе с системными вызовами или аппаратным обеспечением
- Для сериализации/десериализации данных
- При реализации специальных структур данных
Важно: Использование unsafe может привести к нестабильности программы и проблемам с безопасностью. Применяйте только когда действительно необходимо и полностью понимаете последствия.
type ArbitraryType
type ArbitraryType int
ArbitraryType используется здесь только в целях документирования и на самом деле не входит в состав пакета unsafe. Он представляет тип произвольного выражения Go.
func Slice
func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType
Функция Slice возвращает срез, базовый массив которого начинается с ptr, а длина и емкость — len. Slice(ptr, len) эквивалентно
(*[len]ArbitraryType)(unsafe.Pointer(ptr))[:] за исключением того, что в особом случае, если ptr равно nil, а len равно нулю, Slice возвращает nil.
Аргумент len должен быть целочисленного типа или нетипизированной константой. Константа len должна быть неотрицательной и представляться значением типа int; если это нетипизированная константа, ей присваивается тип int. Во время выполнения, если len отрицательно, или если ptr равно nil, а len не равно нулю, возникает паника во время выполнения.
func SliceData
func SliceData(slice []ArbitraryType) *ArbitraryType
SliceData возвращает указатель на базовый массив аргумента slice.
Если cap(slice) > 0, SliceData возвращает &slice[:1][0]. Если slice == nil, SliceData возвращает nil. В противном случае SliceData возвращает не нулевой указатель на неуказанный адрес памяти.
type IntegerType
type IntegerType int
IntegerType используется здесь только для целей документирования и на самом деле не является частью пакета unsafe. Он представляет любой произвольный целочисленный тип.
type Pointer
type Pointer *ArbitraryType
Pointer представляет указатель на произвольный тип. Для типа Pointer доступны четыре специальные операции, которые недоступны для других типов:
- Значение указателя любого типа может быть преобразовано в Pointer.
- Pointer может быть преобразован в значение указателя любого типа.
- uintptr может быть преобразован в Pointer.
- Pointer может быть преобразован в uintptr.
Таким образом, Pointer позволяет программе обойти систему типов и читать и записывать произвольную память. Его следует использовать с особой осторожностью.
Следующие шаблоны, связанные с Pointer, являются действительными. Код, не использующий эти шаблоны, вероятно, является недействительным сегодня или станет недействительным в будущем. Даже действительные шаблоны, приведенные ниже, сопровождаются важными предостережениями.
Запуск «go vet» может помочь найти использования Pointer, которые не соответствуют этим шаблонам, но отсутствие сообщений от «go vet» не является гарантией того, что код является действительным.
Объяснение Pointer
Тип unsafe.Pointer в Go - простое объяснение
unsafe.Pointer - это специальный тип указателя в Go, который позволяет обходить систему типов и работать с памятью напрямую.
Простыми словами
Представьте, что обычные указатели в Go - это строгие охранники: они следят, чтобы вы обращались только к тем данным, тип которых точно соответствует. unsafe.Pointer - это универсальный пропуск, который позволяет вам обойти эти ограничения и работать с памятью напрямую.
Основные возможности
- Преобразование между разными типами указателей
- Преобразование указателя в
uintptrи обратно - Работа с памятью на низком уровне
Примеры использования
1. Преобразование типов
package main
import (
"fmt"
"unsafe"
)
func main() {
var x int64 = 42
// Обычный указатель на int64
ptrInt := &x
// Преобразуем в unsafe.Pointer (универсальный указатель)
ptrUnsafe := unsafe.Pointer(ptrInt)
// Теперь можем преобразовать в указатель на другой тип
ptrFloat := (*float64)(ptrUnsafe)
fmt.Printf("Исходное значение: %d\n", x)
fmt.Printf("Как float64: %f\n", *ptrFloat)
}
2. Доступ к структурам
type SecretStruct struct {
a int
b string
c bool
}
func main() {
s := SecretStruct{a: 10, b: "secret", c: true}
// Получаем указатель на структуру
ptr := unsafe.Pointer(&s)
// Получаем доступ к полю 'b' (пропуская проверки типов)
bPtr := (*string)(unsafe.Add(ptr, unsafe.Offsetof(s.b)))
fmt.Println("Секретное поле b:", *bPtr) // Выведет: secret
}
3. Работа с массивами
func main() {
arr := [3]int{1, 2, 3}
// Получаем указатель на первый элемент
ptr := unsafe.Pointer(&arr[0])
// Преобразуем в указатель на байты
bytePtr := (*byte)(ptr)
// Теперь можем работать с памятью как с байтами
fmt.Printf("Первый байт: %x\n", *bytePtr)
}
Важные правила
- Безопасность:
unsafe.Pointerобходит проверки типов - вы полностью отвечаете за корректность операций. - Совместимость: Гарантии работы есть только при преобразованиях:
- Указатель ↔ unsafe.Pointer ↔ uintptr
- Ограничения: Нельзя арифметику указателей делать напрямую - используйте
unsafe.Addиunsafe.Slice.
Когда это полезно?
- Взаимодействие с системными вызовами
- Высокопроизводительные операции
- Специальные структуры данных
- Работа с foreign function interface (FFI)
Предупреждение
unsafe называется “небезопасным” не просто так. Используйте только когда действительно необходимо и полностью понимаете последствия. Неправильное использование может привести к:
- Падениям программы
- Повреждению данных
- Проблемам с безопасностью
Лучшая практика - изолировать unsafe-код в отдельных пакетах с четкими контрактами.
1. Преобразование *T1 в Pointer в *T2.
При условии, что T2 не больше T1 и что оба имеют одинаковую структуру памяти, это преобразование позволяет переосмыслить данные одного типа как данные другого типа. Примером является реализация math.Float64bits:
func Float64bits(f float64) uint64
return *(*uint64)(unsafe.Pointer(&f))
}
2. Преобразование указателя в uintptr (но не обратно в указатель).
Преобразование указателя в uintptr дает адрес памяти указанного значения в виде целого числа. Обычно uintptr используется для вывода на печать.
Преобразование uintptr обратно в указатель в целом не допускается.
uintptr — это целое число, а не ссылка. Преобразование указателя в uintptr создает целое значение без семантики указателя. Даже если uintptr содержит адрес какого-либо объекта, сборщик мусора не обновит значение uintptr, если объект переместится, и uintptr не помешает объекту быть восстановленным.
Остальные шаблоны перечисляют единственные допустимые преобразования из uintptr в Pointer.
3. Преобразование Pointer в uintptr и обратно с помощью арифметики.
Если p указывает на выделенный объект, его можно продвинуть по объекту путем преобразования в uintptr, добавления смещения и преобразования обратно в Pointer.
p = unsafe.Pointer(uintptr(p) + offset)
Наиболее распространенное использование этого шаблона — доступ к полям в структуре или элементам массива:
// эквивалентно f := unsafe.Pointer(&s.f)
f := unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Offsetof(s.f))
// эквивалентно e := unsafe.Pointer(&x[i])
e := unsafe.Pointer(uintptr(unsafe.Pointer(&x[0])) + i*unsafe.Sizeof(x[0]))
Таким образом можно как добавлять, так и вычитать смещения из указателя. Также допустимо использовать &^ для округления указателей, обычно для выравнивания. Во всех случаях результат должен продолжать указывать на исходный выделенный объект.
В отличие от C, не допускается перемещение указателя за пределы его исходного выделения:
// НЕПРАВИЛЬНО: конечная точка находится за пределами выделенного пространства.
var s thing
end = unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Sizeof(s))
// НЕПРАВИЛЬНО: конец указывает за пределы выделенного пространства.
b := make([]byte, n)
end = unsafe.Pointer(uintptr(unsafe.Pointer(&b[0])) + uintptr(n))
Обратите внимание, что оба преобразования должны появляться в одном выражении, с арифметическими операциями между ними:
// НЕПРАВИЛЬНО: uintptr не может быть сохранен в переменной
// до преобразования обратно в Pointer.
u := uintptr(p)
p = unsafe.Pointer(u + offset)
Обратите внимание, что указатель должен указывать на выделенный объект, поэтому он не может быть nil.
// НЕПРАВИЛЬНО: преобразование указателя nil
u := unsafe.Pointer(nil)
p := unsafe.Pointer(uintptr(u) + offset)
4. Преобразование указателя в uintptr при вызове функций типа syscall.Syscall.
Функции Syscall в пакете syscall передают свои аргументы uintptr непосредственно операционной системе, которая затем, в зависимости от деталей вызова, может переинтерпретировать некоторые из них как указатели. То есть реализация системного вызова неявно преобразует определенные аргументы обратно из uintptr в указатель.
Если аргумент-указатель должен быть преобразован в uintptr для использования в качестве аргумента, это преобразование должно появиться в самом выражении вызова:
syscall.Syscall(SYS_READ, uintptr(fd), uintptr(unsafe.Pointer(p)), uintptr(n))
Компилятор обрабатывает указатель, преобразованный в uintptr в списке аргументов вызова функции, реализованной на ассемблере, путем обеспечения того, что ссылка на выделенный объект, если таковой имеется, сохраняется и не перемещается до завершения вызова, даже если по типам кажется, что объект больше не нужен во время вызова.
Чтобы компилятор распознал этот паттерн, преобразование должно появиться в списке аргументов:
// НЕПРАВИЛЬНО: uintptr не может быть сохранен в переменной
// до неявного преобразования обратно в Pointer во время системного вызова.
u := uintptr(unsafe.Pointer(p))
syscall.Syscall(SYS_READ, uintptr(fd), u, uintptr(n))
5. Преобразование результата reflect.Value.Pointer или reflect.Value.UnsafeAddr из uintptr в Pointer.
Методы Value пакета reflect с именами Pointer и UnsafeAddr возвращают тип uintptr вместо unsafe.Pointer, чтобы вызывающие функции не могли изменить результат на произвольный тип без предварительного импорта «unsafe». Однако это означает, что результат является неустойчивым и должен быть преобразован в Pointer сразу после вызова, в том же выражении:
p := (*int)(unsafe.Pointer(reflect.ValueOf(new(int)).Pointer()))
Как и в приведенных выше случаях, хранение результата до преобразования является недопустимым:
// НЕПРАВИЛЬНО: uintptr не может быть сохранен в переменной
// до преобразования обратно в Pointer.
u := reflect.ValueOf(new(int)).Pointer()
p := (*int)(unsafe.Pointer(u))
6. Преобразование поля данных reflect.SliceHeader или reflect.StringHeader в Pointer или из Pointer.
Как и в предыдущем случае, структуры данных reflect SliceHeader и StringHeader объявляют поле Data как uintptr, чтобы вызывающие функции не могли изменить результат на произвольный тип без предварительного импорта «unsafe». Однако это означает, что SliceHeader и StringHeader действительны только при интерпретации содержимого фактического значения slice или string.
var s string
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // случай 1
hdr.Data = uintptr(unsafe.Pointer(p)) // случай 6 (этот случай)
hdr.Len = n
В этом случае hdr.Data на самом деле является альтернативным способом ссылки на базовый указатель в заголовке строки, а не самой переменной uintptr.
В общем случае reflect.SliceHeader и reflect.StringHeader следует использовать только как *reflect.SliceHeader и *reflect.StringHeader, указывающие на фактические срезы или строки, но никогда как простые структуры. Программа не должна объявлять или выделять переменные этих типов структур.
// НЕПРАВИЛЬНО: непосредственно объявленный заголовок не будет содержать Data в качестве ссылки.
var hdr reflect.StringHeader
hdr.Data = uintptr(unsafe.Pointer(p))
hdr.Len = n
s := *(*string)(unsafe.Pointer(&hdr)) // p, возможно, уже утрачен
func Add
func Add(ptr Pointer, len IntegerType) Pointer
Функция Add добавляет len к ptr и возвращает обновленный указатель Pointer(uintptr(ptr) + uintptr(len)). Аргумент len должен быть целочисленного типа или нетипизированной константой. Константный аргумент len должен быть представлен значением типа int; если он является нетипизированной константой, ему присваивается тип int. Правила допустимого использования Pointer по-прежнему применяются.
12.4.20 - Пакет time языка программирования Go
Пакет time предоставляет функции для измерения и отображения времени.
Календарные вычисления всегда основаны на григорианском календаре без учета високосных секунд.
Монотонные часы
Операционные системы предоставляют как “системные часы” (которые могут корректироваться для синхронизации времени), так и “монотонные часы” (которые не подвержены таким изменениям). Общее правило гласит: системные часы используются для определения текущего времени, а монотонные часы - для измерения временных интервалов. Вместо разделения API, в данном пакете Time, возвращаемый функцией time.Now, содержит показания как системных, так и монотонных часов. Последующие операции определения времени используют показания системных часов, тогда как операции измерения времени (в частности, сравнения и вычитания) используют показания монотонных часов.
Например, следующий код всегда вычисляет положительный интервал времени около 20 миллисекунд, даже если системные часы были изменены во время выполнения измеряемой операции:
start := time.Now()
... operation that takes 20 milliseconds ...
t := time.Now()
elapsed := t.Sub(start)
Другие идиомы, такие как time.Since(start), time.Until(deadline) и time.Now().Before(deadline), также устойчивы к сбросам системных часов.
Остальная часть этого раздела содержит точные детали использования монотонных часов в операциях, но для работы с пакетом понимание этих деталей не требуется.
Особенности работы с монотонными часами
Функция
time.Now()
Возвращаемое значениеTimeсодержит показания монотонных часов. Если времяtвключает монотонные часы:t.Addдобавляет длительность как к системным, так и к монотонным часамt.AddDate,t.Roundиt.Truncateработают только с системным временем и удаляют монотонные показанияt.In,t.Localиt.UTCтакже удаляют монотонные показания- Стандартный способ удалить монотонные показания:
t = t.Round(0)
Сравнение времен
Если оба значенияtиuсодержат монотонные показания:t.After(u),t.Before(u),t.Equal(u),t.Compare(u)иt.Sub(u)используют только монотонные часы- Если одно из значений не имеет монотонных показаний, используются системные часы
Особые случаи
- На некоторых системах монотонные часы останавливаются при переходе в спящий режим
- В таких случаях
t.Sub(u)и аналогичные операции могут давать неточные результаты - Иногда требуется удалить монотонные показания для получения точных данных
Сериализация и форматирование
Монотонные показания:- Не включаются при сериализации (
GobEncode,MarshalJSONи др.) - Не имеют формата вывода в
t.Format - Не создаются конструкторами (
Date,Parse,Unixи др.)
- Не включаются при сериализации (
Особенности реализации
- Монотонные показания существуют только в значениях
Time - Не входят в
Durationили Unix-время (t.Unix) - Оператор
==сравнивает Location и монотонные показания
- Монотонные показания существуют только в значениях
Отладка
t.String()показывает монотонные показания при их наличии- Различия в монотонных показаниях видны при выводе
Разрешение таймеров ¶
Разрешение таймеров зависит от:
- Версии Go
- Операционной системы
- Аппаратного обеспечения
Типичные значения:
- Unix: ~1 мс
- Windows 1803+: ~0.5 мс
- Старые версии Windows: ~16 мс (можно улучшить через
windows.TimeBeginPeriod)
Константы
const (
Layout = «01/02 03:04:05PM '06 -0700» // Время отсчета, в числовом порядке.
ANSIC = «Mon Jan _2 15:04:05 2006»
UnixDate = «Mon Jan _2 15:04:05 MST 2006»
RubyDate = «Mon Jan 02 15:04:05 -0700 2006»
RFC822 = «02 Jan 06 15:04 MST»
RFC822Z = «02 Jan 06 15:04 -0700» // RFC822 с числовой зоной
RFC850 = «Monday, 02-Jan-06 15:04:05 MST»
RFC1123 = «Mon, 02 Jan 2006 15:04:05 MST»
RFC1123Z = «Mon, 02 Jan 2006 15:04:05 -0700» // RFC1123 с числовой зоной
RFC3339 = «2006-01-02T15:04:05Z07:00»
RFC3339Nano = «2006-01-02T15:04:05.9999999Z07:00»
Kitchen = «3:04PM»
// Удобные временные метки.
Stamp = «Jan _2 15:04:05»
StampMilli = «Jan _2 15:04:05.000»
StampMicro = «Jan _2 15:04:05.000000»
StampNano = «Jan _2 15:04:05.000000000»
DateTime = «2006-01-02 15:04:05»
DateOnly = «2006-01-02»
TimeOnly = «15:04:05»
)
Это предопределенные макеты для использования в Time.Format и time.Parse. В качестве опорного времени в этих макетах используется конкретная временная метка:
01/02 03:04:05PM '06 -0700
(2 января, 15:04:05, 2006, в часовом поясе на семь часов западнее GMT). Это значение записывается как константа с именем Layout, приведенным ниже. В качестве времени Unix это 1136239445. Поскольку MST - это GMT-0700, команда Unix date выведет ссылку в виде:
Mon Jan 2 15:04:05 MST 2006.
Досадная историческая ошибка заключается в том, что в дате используется американская конвенция, согласно которой числовой месяц ставится перед днем.
Пример Time.Format подробно демонстрирует работу со строкой компоновки и является хорошей ссылкой.
Обратите внимание, что форматы RFC822, RFC850 и RFC1123 следует применять только к местному времени. При их использовании для времени UTC в качестве сокращения часового пояса будет использоваться «UTC», в то время как, строго говоря, эти RFC требуют использовать «GMT» в этом случае. При использовании форматов RFC1123 или RFC1123Z для разбора, обратите внимание, что эти форматы определяют ведущий ноль для части «день-месяц», что строго не разрешено RFC 1123. Это приведет к ошибке при разборе строк дат, которые приходятся на первые 9 дней данного месяца. В общем случае RFC1123Z следует использовать вместо RFC1123 для серверов, которые настаивают на этом формате, а RFC3339 следует предпочесть для новых протоколов. RFC3339, RFC822, RFC822Z, RFC1123 и RFC1123Z полезны для форматирования; при использовании с time.Parse они принимают не все форматы времени, разрешенные RFC, и принимают форматы времени, не определенные формально. Формат RFC3339Nano удаляет нули в конце поля секунд, поэтому после форматирования он может сортироваться некорректно.
Большинство программ могут использовать одну из определенных констант в качестве макета, передаваемого в Format или Parse. Остальную часть этого комментария можно игнорировать, если только вы не создаете собственную строку макета.
Чтобы определить свой собственный формат, запишите, как будет выглядеть эталонное время, отформатированное вашим способом; в качестве примера можно посмотреть значения таких констант, как ANSIC, StampMicro или Kitchen. Модель призвана продемонстрировать, как выглядит эталонное время, чтобы методы Format и Parse могли применить то же преобразование к общему значению времени.
Ниже приводится краткое описание компонентов строки макета. Каждый элемент показывает на примере форматирование элемента эталонного времени. Распознаются только эти значения. Текст в компоновочной строке, который не распознается как часть эталонного времени, дословно повторяется во время Format и, как ожидается, дословно отображается на входе в Parse.
Year: "2006" "06"
Month: "Jan" "January" "01" "1"
Day of the week: "Mon" "Monday"
Day of the month: "2" "_2" "02"
Day of the year: "__2" "002"
Hour: "15" "3" "03" (PM or AM)
Minute: "4" "04"
Second: "5" "05"
AM/PM mark: "PM"
Числовые смещения часовых поясов форматируются следующим образом:
"-0700" ±hhmm
"-07:00" ±hh:mm
"-07" ±hh
"-070000" ±hhmmss
"-07:00:00" ±hh:mm:ss
Если в формате заменить знак на Z, это включит режим ISO 8601, где для UTC отображается Z вместо указания смещения. Например:
"Z0700" Z or ±hhmm
"Z07:00" Z or ±hh:mm
"Z07" Z or ±hh
"Z070000" Z or ±hhmmss
"Z07:00:00" Z or ±hh:mm:ss
В строке формата подчёркивания в "_2" и "__2" обозначают пробелы, которые могут заменяться цифрами, если следующее число состоит из нескольких цифр, для совместимости с фиксированными форматами времени Unix. Ноль в начале означает дополнение нулями.
Форматы __2 и 002 обозначают день года, дополненный пробелами или нулями до трёх символов; формата без дополнения для дня года не существует.
Запятая или точка, за которыми следуют один или несколько нулей, обозначают долю секунды, выводимую с указанным количеством знаков после запятой. Запятая или точка, за которыми следуют одна или несколько девяток, обозначают долю секунды, выводимую с указанным количеством знаков после запятой, но с удалением завершающих нулей. Например, форматы "15:04:05,000" или "15:04:05.000" форматируют или парсят время с миллисекундной точностью.
Некоторые допустимые форматы являются недопустимыми значениями времени для time.Parse, из-за элементов вроде _ (пробельного дополнения) или Z (информации о временной зоне).
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)
Стандартные длительности (Common durations)
Не существует определения для единиц измерения “День” или больше, чтобы избежать путаницы из-за перехода на летнее/зимнее время в разных часовых поясах.
Чтобы подсчитать количество единиц в Duration (длительности), выполните деление:
second := time.Second
fmt.Print(int64(second/time.Millisecond)) // prints 1000
Чтобы преобразовать целое количество единиц в Duration (длительность), выполните умножение:
seconds := 10
fmt.Print(time.Duration(seconds)*time.Second) // prints 10s
func After
func After(d Duration) <-chan Time
After ожидает истечения указанной длительности d, после чего отправляет текущее время в возвращаемом канале. Эквивалентно NewTimer(d).C.
Изменения в Go 1.23:
В ранних версиях документация предупреждала, что таймер не освобождался сборщиком мусора до срабатывания, и рекомендовала использовать NewTimer с ручным вызовом Timer.Stop для оптимизации. Начиная с Go 1.23, сборщик мусора может освобождать неиспользуемые таймеры, даже если они не остановлены. Нет необходимости использовать NewTimer вместо After.
Пример использования:
package main
import (
"fmt"
"time"
)
var c chan int
func handle(int) {}
func main() {
select {
case m := <-c:
handle(m)
case <-time.After(10 * time.Second):
fmt.Println("timed out")
}
}
func Sleep
func Sleep(d Duration)
Sleep приостанавливает выполнение текущей горутины как минимум на указанную длительность d. Отрицательное или нулевое значение приводит к немедленному возврату.
Пример:
package main
import (
"time"
)
func main() {
time.Sleep(100 * time.Millisecond) // Пауза на 100 мс
}
func Tick
func Tick(d Duration) <-chan Time
Tick — это удобная обёртка над NewTicker, предоставляющая только канал с тиками. В отличие от NewTicker, возвращает nil при d <= 0.
Изменения в Go 1.23:
Ранее документация указывала, что сборщик мусора не освобождает неостановленные тикеры, и рекомендовала использовать NewTicker с Ticker.Stop. В Go 1.23 сборщик может освобождать неиспользуемые тикеры, даже без вызова Stop. Нет причин предпочитать NewTicker, если достаточно Tick.
Пример использования:
package main
import (
"fmt"
"time"
)
func statusUpdate() string { return "" }
func main() {
c := time.Tick(5 * time.Second) // Тикер каждые 5 секунд
for next := range c {
fmt.Printf("%v %s\n", next, statusUpdate())
}
}
Вот перевод технической документации пакета time на русский язык:
Типы
type Duration
type Duration int64
Тип Duration представляет промежуток времени между двумя моментами в виде количества наносекунд int64. Представление ограничивает максимальную продолжительность примерно 290 годами.
Пример
package main
import (
"fmt"
"time"
)
func expensiveCall() {}
func main() {
t0 := time.Now()
expensiveCall()
t1 := time.Now()
fmt.Printf("The call took %v to run.\n", t1.Sub(t0))
}func ParseDuration
func ParseDuration(s string) (Duration, error)
ParseDuration разбирает строку продолжительности. Строка продолжительности - это возможно знаковая последовательность десятичных чисел, каждое с необязательной дробной частью и суффиксом единицы, например “300ms”, “-1.5h” или “2h45m”. Допустимые единицы времени: “ns”, “us” (или “µs”), “ms”, “s”, “m”, “h”.
Пример
import (
"fmt"
"time"
)
func main() {
hours, _ := time.ParseDuration("10h")
complex, _ := time.ParseDuration("1h10m10s")
micro, _ := time.ParseDuration("1µs")
// The package also accepts the incorrect but common prefix u for micro.
micro2, _ := time.ParseDuration("1us")
fmt.Println(hours)
fmt.Println(complex)
fmt.Printf("There are %.0f seconds in %v.\n", complex.Seconds(), complex)
fmt.Printf("There are %d nanoseconds in %v.\n", micro.Nanoseconds(), micro)
fmt.Printf("There are %6.2e seconds in %v.\n", micro2.Seconds(), micro2)
}
Output:
10h0m0s
1h10m10s
There are 4210 seconds in 1h10m10s.
There are 1000 nanoseconds in 1µs.
There are 1.00e-06 seconds in 1µs.func Since
func Since(t Time) Duration
Since возвращает время, прошедшее с момента t. Это сокращение для time.Now().Sub(t).
Пример
package main
import (
"fmt"
"time"
)
func expensiveCall() {}
func main() {
start := time.Now()
expensiveCall()
elapsed := time.Since(start)
fmt.Printf("The call took %v to run.\n", elapsed)
}func Until
func Until(t Time) Duration
Until возвращает продолжительность до момента t. Это сокращение для t.Sub(time.Now()).
Пример
package main
import (
"fmt"
"math"
"time"
)
func main() {
futureTime := time.Now().Add(5 * time.Second)
durationUntil := time.Until(futureTime)
fmt.Printf("Duration until future time: %.0f seconds", math.Ceil(durationUntil.Seconds()))
}
Output:
Duration until future time: 5 secondsfunc (Duration) Abs
func (d Duration) Abs() Duration
Abs возвращает абсолютное значение d. В особом случае Duration(math.MinInt64) преобразуется в Duration(math.MaxInt64), уменьшая его величину на 1 наносекунду.
Пример
package main
import (
"fmt"
"math"
"time"
)
func main() {
positiveDuration := 5 * time.Second
negativeDuration := -3 * time.Second
minInt64CaseDuration := time.Duration(math.MinInt64)
absPositive := positiveDuration.Abs()
absNegative := negativeDuration.Abs()
absSpecial := minInt64CaseDuration.Abs() == time.Duration(math.MaxInt64)
fmt.Printf("Absolute value of positive duration: %v\n", absPositive)
fmt.Printf("Absolute value of negative duration: %v\n", absNegative)
fmt.Printf("Absolute value of MinInt64 equal to MaxInt64: %t\n", absSpecial)
}
Output:
Absolute value of positive duration: 5s
Absolute value of negative duration: 3s
Absolute value of MinInt64 equal to MaxInt64: truefunc (Duration) Hours
func (d Duration) Hours() float64
Hours возвращает продолжительность как число часов с плавающей точкой.
Пример
package main
import (
"fmt"
"time"
)
func main() {
h, _ := time.ParseDuration("4h30m")
fmt.Printf("I've got %.1f hours of work left.", h.Hours())
}Output:
I've got 4.5 hours of work left.func (Duration) Microseconds
func (d Duration) Microseconds() int64
Microseconds возвращает продолжительность как целое количество микросекунд.
Пример
package main
import (
"fmt"
"time"
)
func main() {
u, _ := time.ParseDuration("1s")
fmt.Printf("One second is %d microseconds.\n", u.Microseconds())
}
Output:
One second is 1000000 microseconds.func (Duration) Milliseconds
func (d Duration) Milliseconds() int64
Milliseconds возвращает продолжительность как целое количество миллисекунд.
func (Duration) Minutes
func (d Duration) Minutes() float64
Minutes возвращает продолжительность как число минут с плавающей точкой.
func (Duration) Nanoseconds
func (d Duration) Nanoseconds() int64
Nanoseconds возвращает продолжительность как целое количество наносекунд.
func (Duration) Round
func (d Duration) Round(m Duration) Duration
Round возвращает результат округления d до ближайшего кратного m. При округлении половинных значений округление выполняется от нуля. Если результат превышает максимальное (или минимальное) значение, которое может храниться в Duration, возвращается максимальная (или минимальная) продолжительность. Если m <= 0, Round возвращает d без изменений.
Пример
package main
import (
"fmt"
"time"
)
func main() {
d, err := time.ParseDuration("1h15m30.918273645s")
if err != nil {
panic(err)
}
round := []time.Duration{
time.Nanosecond,
time.Microsecond,
time.Millisecond,
time.Second,
2 * time.Second,
time.Minute,
10 * time.Minute,
time.Hour,
}
for _, r := range round {
fmt.Printf("d.Round(%6s) = %s\n", r, d.Round(r).String())
}
}
d.Round( 1ns) = 1h15m30.918273645s
d.Round( 1µs) = 1h15m30.918274s
d.Round( 1ms) = 1h15m30.918s
d.Round( 1s) = 1h15m31s
d.Round( 2s) = 1h15m30s
d.Round( 1m0s) = 1h16m0s
d.Round( 10m0s) = 1h20m0s
d.Round(1h0m0s) = 1h0m0sfunc (Duration) Seconds
func (d Duration) Seconds() float64
Seconds возвращает продолжительность как число секунд с плавающей точкой.
func (Duration) String
func (d Duration) String() string
String возвращает строковое представление продолжительности в виде “72h3m0.5s”. Ведущие нулевые единицы опускаются. В особом случае продолжительности менее одной секунды используют меньшие единицы (милли-, микро- или наносекунды), чтобы ведущая цифра была не нулевой. Нулевая продолжительность форматируется как “0s”.
Пример
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println(1*time.Hour + 2*time.Minute + 300*time.Millisecond)
fmt.Println(300 * time.Millisecond)
}
Output:
1h2m0.3s
300msfunc (Duration) Truncate
func (d Duration) Truncate(m Duration) Duration
Truncate возвращает результат округления d к нулю до кратного m. Если m <= 0, Truncate возвращает d без изменений.
Пример
package main
import (
"fmt"
"time"
)
func main() {
d, err := time.ParseDuration("1h15m30.918273645s")
if err != nil {
panic(err)
}
trunc := []time.Duration{
time.Nanosecond,
time.Microsecond,
time.Millisecond,
time.Second,
2 * time.Second,
time.Minute,
10 * time.Minute,
time.Hour,
}
for _, t := range trunc {
fmt.Printf("d.Truncate(%6s) = %s\n", t, d.Truncate(t).String())
}
}
Output:
d.Truncate( 1ns) = 1h15m30.918273645s
d.Truncate( 1µs) = 1h15m30.918273s
d.Truncate( 1ms) = 1h15m30.918s
d.Truncate( 1s) = 1h15m30s
d.Truncate( 2s) = 1h15m30s
d.Truncate( 1m0s) = 1h15m0s
d.Truncate( 10m0s) = 1h10m0s
d.Truncate(1h0m0s) = 1h0m0stype Location
type Location struct {
// содержит неэкспортируемые поля
}
Тип Location отображает моменты времени в часовом поясе, используемом в этот момент. Обычно Location представляет набор смещений времени, используемых в географическом регионе. Для многих Location смещение времени варьируется в зависимости от того, действует ли летнее время в данный момент.
Location используется для предоставления часового пояса в печатном значении Time и для вычислений, включающих интервалы, которые могут пересекать границы перехода на летнее время.
Пример
package main
import (
"fmt"
"time"
)
func main() {
// China doesn't have daylight saving. It uses a fixed 8 hour offset from UTC.
secondsEastOfUTC := int((8 * time.Hour).Seconds())
beijing := time.FixedZone("Beijing Time", secondsEastOfUTC)
// If the system has a timezone database present, it's possible to load a location
// from that, e.g.:
// newYork, err := time.LoadLocation("America/New_York")
// Creating a time requires a location. Common locations are time.Local and time.UTC.
timeInUTC := time.Date(2009, 1, 1, 12, 0, 0, 0, time.UTC)
sameTimeInBeijing := time.Date(2009, 1, 1, 20, 0, 0, 0, beijing)
// Although the UTC clock time is 1200 and the Beijing clock time is 2000, Beijing is
// 8 hours ahead so the two dates actually represent the same instant.
timesAreEqual := timeInUTC.Equal(sameTimeInBeijing)
fmt.Println(timesAreEqual)
}
Output:
truevar Local *Location = &localLoc
Local представляет локальный часовой пояс системы. В Unix-системах Local обращается к переменной окружения TZ для определения используемого часового пояса. Отсутствие TZ означает использование системного значения по умолчанию /etc/localtime. TZ="" означает использование UTC. TZ=“foo” означает использование файла foo в системном каталоге часовых поясов.
var UTC *Location = &utcLoc
UTC представляет Универсальное Координированное Время (UTC).
func FixedZone
func FixedZone(name string, offset int) *Location
FixedZone возвращает Location, который всегда использует заданное имя пояса и смещение (в секундах к востоку от UTC).
Пример
package main
import (
"fmt"
"time"
)
func main() {
loc := time.FixedZone("UTC-8", -8*60*60)
t := time.Date(2009, time.November, 10, 23, 0, 0, 0, loc)
fmt.Println("The time is:", t.Format(time.RFC822))
}
Output:
The time is: 10 Nov 09 23:00 UTC-8func LoadLocation
func LoadLocation(name string) (*Location, error)
LoadLocation возвращает Location с заданным именем.
Если имя "" или “UTC”, LoadLocation возвращает UTC. Если имя “Local”, LoadLocation возвращает Local.
В противном случае имя считается именем местоположения, соответствующим файлу в базе данных часовых поясов IANA, например “America/New_York”.
LoadLocation ищет базу данных часовых поясов IANA в следующих местах по порядку:
- Каталог или распакованный zip-файл, указанный переменной окружения ZONEINFO
- В Unix-системах - стандартное системное местоположение установки
- $GOROOT/lib/time/zoneinfo.zip
- Пакет time/tzdata, если он был импортирован
Пример
package main
import (
"fmt"
"time"
)
func main() {
location, err := time.LoadLocation("America/Los_Angeles")
if err != nil {
panic(err)
}
timeInUTC := time.Date(2018, 8, 30, 12, 0, 0, 0, time.UTC)
fmt.Println(timeInUTC.In(location))
}
Output:
2018-08-30 05:00:00 -0700 PDTfunc LoadLocationFromTZData
func LoadLocationFromTZData(name string, data []byte) (*Location, error)
LoadLocationFromTZData возвращает Location с заданным именем, инициализированный из данных в формате базы данных часовых поясов IANA. Данные должны быть в формате стандартного файла часового пояса IANA (например, содержимое /etc/localtime в Unix-системах).
func (*Location) String
func (l *Location) String() string
String возвращает описательное имя для информации о часовом поясе, соответствующее аргументу name для LoadLocation или FixedZone.
type Month
type Month int
Month определяет месяц года (January = 1, …).
Пример
package main
import (
"fmt"
"time"
)
func main() {
_, month, day := time.Now().Date()
if month == time.November && day == 10 {
fmt.Println("Happy Go day!")
}
}
Константы:
const (
January Month = 1 + iota
February
March
April
May
June
July
August
September
October
November
December
)
func (Month) String
func (m Month) String() string
String возвращает английское название месяца (“January”, “February”, …).
type ParseError
type ParseError struct {
Layout string
Value string
LayoutElem string
ValueElem string
Message string
}
ParseError описывает проблему при разборе строки времени.
func (*ParseError) Error
func (e *ParseError) Error() string
Error возвращает строковое представление ParseError.
type Ticker
type Ticker struct {
C <-chan Time // Канал, по которому доставляются "тики"
// содержит неэкспортируемые поля
}
Ticker содержит канал, который доставляет “тики” часов с заданными интервалами.
Объяснение Ticker
Тип Ticker в Go
Тип Ticker в пакете time представляет собой механизм для получения повторяющихся сигналов (“тиков”) через регулярные промежутки времени. Это полезный инструмент для выполнения периодических операций.
Основные характеристики:
Структура:
type Ticker struct { C <-chan Time // Канал для получения тиков // скрытые поля }- Поле
C- это канал только для чтения (<-chan), по которому будут приходить значения времени при каждом тике
- Поле
Назначение:
- Регулярное выполнение кода (например, каждые 5 секунд)
- Создание таймеров с повторяющимся срабатыванием
- Периодический опрос или проверка состояния
- Реализация heartbeat-механизмов
Типичное использование:
ticker := time.NewTicker(1 * time.Second) defer ticker.Stop() for { select { case t := <-ticker.C: fmt.Println("Tick at", t) // выполнить периодическую операцию } }Особенности:
- Тикер продолжает работать, пока не будет явно остановлен
- Интервал между тиками остается постоянным (в отличие от
time.Sleepв цикле) - Если получатель не успевает обрабатывать тики, они могут быть пропущены
Важные методы:
NewTicker(d Duration)- создает новый тикерStop()- останавливает тикерReset(d Duration)- изменяет интервал (добавлен в Go 1.15)
Когда использовать:
- Для регулярных фоновых задач (например, обновление кэша)
- Для реализации таймаутов с повторением
- Для периодического сбора метрик или логирования
- В долгоживущих горутинах для поддержания активности
Пример реального использования:
func startMonitoring() {
ticker := time.NewTicker(5 * time.Minute)
defer ticker.Stop()
for {
select {
case <-ticker.C:
err := checkSystemHealth()
if err != nil {
log.Printf("Health check failed: %v", err)
}
case <-ctx.Done():
return // завершение при отмене контекста
}
}
}
Важно всегда вызывать Stop() для тикера, когда он больше не нужен, чтобы избежать утечек ресурсов. В современных версиях Go (1.23+) сборщик мусора может автоматически очищать неиспользуемые тикеры, но явная остановка остается хорошей практикой.
func NewTicker
func NewTicker(d Duration) *Ticker
NewTicker создает новый Ticker, содержащий канал, который будет отправлять текущее время на канал после каждого тика. Период тиков задается аргументом duration. Ticker будет корректировать интервал времени или пропускать тики для компенсации медленных получателей. Длительность d должна быть больше нуля; в противном случае NewTicker вызовет панику.
Пример
package main
import (
"fmt"
"time"
)
func main() {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
done := make(chan bool)
go func() {
time.Sleep(10 * time.Second)
done <- true
}()
for {
select {
case <-done:
fmt.Println("Done!")
return
case t := <-ticker.C:
fmt.Println("Current time: ", t)
}
}
}
func (*Ticker) Reset
func (t *Ticker) Reset(d Duration)
Reset останавливает тикер и устанавливает его период в заданную продолжительность. Следующий тик придет после истечения нового периода. Длительность d должна быть больше нуля; в противном случае Reset вызовет панику.
func (*Ticker) Stop
func (t *Ticker) Stop()
Stop выключает тикер. После Stop больше не будет отправляться тиков. Stop не закрывает канал, чтобы предотвратить ошибочное чтение “тика” параллельной горутиной.
type Time
type Time struct {
// содержит неэкспортируемые поля
}
Time представляет момент времени с наносекундной точностью.
Программы, использующие время, обычно должны хранить и передавать его как значения, а не указатели. То есть переменные времени и поля структур должны быть типа time.Time, а не *time.Time.
Значение Time может использоваться несколькими горутинами одновременно, за исключением того, что методы Time.GobDecode, Time.UnmarshalBinary, Time.UnmarshalJSON и Time.UnmarshalText не являются безопасными для конкурентного использования.
Моменты времени можно сравнивать с помощью методов Time.Before, Time.After и Time.Equal. Метод Time.Sub вычитает два момента, производя Duration. Метод Time.Add добавляет Time и Duration, производя Time.
Нулевое значение типа Time - January 1, year 1, 00:00:00.000000000 UTC. Поскольку это время вряд ли встретится на практике, метод Time.IsZero дает простой способ обнаружения времени, которое не было инициализировано явно.
Каждое время имеет связанный Location. Методы Time.Local, Time.UTC и Time.In возвращают Time с конкретным Location. Изменение Location значения Time с помощью этих методов не изменяет фактический момент, который оно представляет, только часовой пояс, в котором оно интерпретируется.
func Date
func Date(year int, month Month, day, hour, min, sec, nsec int, loc *Location) Time
Date возвращает Time, соответствующее
yyyy-mm-dd hh:mm:ss + nsec наносекунд
в соответствующем часовом поясе для этого времени в заданном местоположении.
Значения month, day, hour, min, sec и nsec могут быть вне их обычных диапазонов и будут нормализованы во время преобразования. Например, 32 октября преобразуется в 1 ноября.
Переход на летнее время пропускает или повторяет моменты времени. Например, в США March 13, 2011 2:15am никогда не происходило, а November 6, 2011 1:15am произошло дважды. В таких случаях выбор часового пояса, а следовательно и времени, не определен однозначно. Date возвращает время, которое корректно в одном из двух участвующих в переходе часовых поясов, но не гарантирует, в каком именно.
Date вызывает панику, если loc равен nil.
Пример
package main
import (
"fmt"
"time"
)
func main() {
t := time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC)
fmt.Printf("Go launched at %s\n", t.Local())
}
Output:
Go launched at 2009-11-10 15:00:00 -0800 PSTfunc Now
func Now() Time
Now возвращает текущее локальное время.
func Parse
func Parse(layout, value string) (Time, error)
Parse разбирает форматированную строку и возвращает значение времени, которое она представляет. Смотрите документацию для константы Layout, чтобы понять, как представить формат. Второй аргумент должен быть разбираемым с использованием строки формата (layout), предоставленной в качестве первого аргумента.
Пример
package main
import (
"fmt"
"time"
)
func main() {
// Пример с Time.Format содержит подробное описание того, как
// определять строку формата для разбора значения time.Time;
// Parse и Format используют одну и ту же модель для описания
// входных и выходных данных.
// longForm демонстрирует на примере, как эталонное время будет представлено
// в желаемом формате.
const longForm = "Jan 2, 2006 at 3:04pm (MST)"
t, _ := time.Parse(longForm, "Feb 3, 2013 at 7:54pm (PST)")
fmt.Println(t)
// shortForm - это альтернативный способ представления эталонного времени
// в желаемом формате; он не содержит информации о часовом поясе.
// Примечание: без явного указания пояса возвращает время в UTC.
const shortForm = "2006-Jan-02"
t, _ = time.Parse(shortForm, "2013-Feb-03")
fmt.Println(t)
// Некоторые допустимые форматы могут быть недопустимыми значениями времени,
// из-за спецификаторов формата, таких как _ для заполнения пробелами
// и Z для информации о часовом поясе.
// Например, формат RFC3339 2006-01-02T15:04:05Z07:00
// содержит как Z, так и смещение часового пояса, чтобы обрабатывать оба варианта:
// 2006-01-02T15:04:05Z
// 2006-01-02T15:04:05+07:00
t, _ = time.Parse(time.RFC3339, "2006-01-02T15:04:05Z")
fmt.Println(t)
t, _ = time.Parse(time.RFC3339, "2006-01-02T15:04:05+07:00")
fmt.Println(t)
_, err := time.Parse(time.RFC3339, time.RFC3339)
fmt.Println("ошибка", err) // Возвращает ошибку, так как формат не является допустимым значением времени
}Output:
2013-02-03 19:54:00 -0800 PST
2013-02-03 00:00:00 +0000 UTC
2006-01-02 15:04:05 +0000 UTC
2006-01-02 15:04:05 +0700 +0700
error parsing time "2006-01-02T15:04:05Z07:00": extra text: "07:00"func ParseInLocation
func ParseInLocation(layout, value string, loc *Location) (Time, error)
ParseInLocation похож на Parse, но отличается в двух важных аспектах. Во-первых, при отсутствии информации о часовом поясе Parse интерпретирует время как UTC; ParseInLocation интерпретирует время как в заданном местоположении. Во-вторых, при заданном смещении или аббревиатуре часового пояса Parse пытается сопоставить его с местоположением Local; ParseInLocation использует заданное местоположение.
Пример
package main
import (
"fmt"
"time"
)
func main() {
loc, _ := time.LoadLocation("Europe/Berlin")
// This will look for the name CEST in the Europe/Berlin time zone.
const longForm = "Jan 2, 2006 at 3:04pm (MST)"
t, _ := time.ParseInLocation(longForm, "Jul 9, 2012 at 5:02am (CEST)", loc)
fmt.Println(t)
// Note: without explicit zone, returns time in given location.
const shortForm = "2006-Jan-02"
t, _ = time.ParseInLocation(shortForm, "2012-Jul-09", loc)
fmt.Println(t)
}
Output:
2012-07-09 05:02:00 +0200 CEST
2012-07-09 00:00:00 +0200 CESTfunc Unix
func Unix(sec int64, nsec int64) Time
Unix возвращает локальное Time, соответствующее заданному Unix-времени, sec секунд и nsec наносекунд с 1 января 1970 UTC. Допустимо передавать nsec вне диапазона [0, 999999999]. Не все значения sec имеют соответствующее значение времени. Одним из таких значений является 1«63-1 (максимальное значение int64).
Пример
package main
import (
"fmt"
"time"
)
func main() {
unixTime := time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC)
fmt.Println(unixTime.Unix())
t := time.Unix(unixTime.Unix(), 0).UTC()
fmt.Println(t)
}Output:
1257894000
2009-11-10 23:00:00 +0000 UTCfunc UnixMicro
func UnixMicro(usec int64) Time
UnixMicro возвращает локальное Time, соответствующее заданному Unix-времени, usec микросекунд с 1 января 1970 UTC.
Пример
package main
import (
"fmt"
"time"
)
func main() {
umt := time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC)
fmt.Println(umt.UnixMicro())
t := time.UnixMicro(umt.UnixMicro()).UTC()
fmt.Println(t)
}
Output:
1257894000000000
2009-11-10 23:00:00 +0000 UTCfunc UnixMilli
func UnixMilli(msec int64) Time
UnixMilli возвращает локальное Time, соответствующее заданному Unix-времени, msec миллисекунд с 1 января 1970 UTC.
func (Time) Add
func (t Time) Add(d Duration) Time
Add возвращает время t+d.
Пример
import (
"fmt"
"time"
)
func main() {
start := time.Date(2009, 1, 1, 12, 0, 0, 0, time.UTC)
afterTenSeconds := start.Add(time.Second * 10)
afterTenMinutes := start.Add(time.Minute * 10)
afterTenHours := start.Add(time.Hour * 10)
afterTenDays := start.Add(time.Hour * 24 * 10)
fmt.Printf("start = %v\n", start)
fmt.Printf("start.Add(time.Second * 10) = %v\n", afterTenSeconds)
fmt.Printf("start.Add(time.Minute * 10) = %v\n", afterTenMinutes)
fmt.Printf("start.Add(time.Hour * 10) = %v\n", afterTenHours)
fmt.Printf("start.Add(time.Hour * 24 * 10) = %v\n", afterTenDays)
}Output:
start = 2009-01-01 12:00:00 +0000 UTC
start.Add(time.Second * 10) = 2009-01-01 12:00:10 +0000 UTC
start.Add(time.Minute * 10) = 2009-01-01 12:10:00 +0000 UTC
start.Add(time.Hour * 10) = 2009-01-01 22:00:00 +0000 UTC
start.Add(time.Hour * 24 * 10) = 2009-01-11 12:00:00 +0000 UTCfunc (Time) AddDate
func (t Time) AddDate(years int, months int, days int) Time
AddDate возвращает время, соответствующее добавлению заданного количества лет, месяцев и дней к t. Например, AddDate(-1, 2, 3), примененное к 1 января 2011, возвращает 4 марта 2010.
Пример
package main
import (
"fmt"
"time"
)
func main() {
start := time.Date(2023, 03, 25, 12, 0, 0, 0, time.UTC)
oneDayLater := start.AddDate(0, 0, 1)
dayDuration := oneDayLater.Sub(start)
oneMonthLater := start.AddDate(0, 1, 0)
oneYearLater := start.AddDate(1, 0, 0)
zurich, err := time.LoadLocation("Europe/Zurich")
if err != nil {
panic(err)
}
// This was the day before a daylight saving time transition in Zürich.
startZurich := time.Date(2023, 03, 25, 12, 0, 0, 0, zurich)
oneDayLaterZurich := startZurich.AddDate(0, 0, 1)
dayDurationZurich := oneDayLaterZurich.Sub(startZurich)
fmt.Printf("oneDayLater: start.AddDate(0, 0, 1) = %v\n", oneDayLater)
fmt.Printf("oneMonthLater: start.AddDate(0, 1, 0) = %v\n", oneMonthLater)
fmt.Printf("oneYearLater: start.AddDate(1, 0, 0) = %v\n", oneYearLater)
fmt.Printf("oneDayLaterZurich: startZurich.AddDate(0, 0, 1) = %v\n", oneDayLaterZurich)
fmt.Printf("Day duration in UTC: %v | Day duration in Zürich: %v\n", dayDuration, dayDurationZurich)
}
Output:
oneDayLater: start.AddDate(0, 0, 1) = 2023-03-26 12:00:00 +0000 UTC
oneMonthLater: start.AddDate(0, 1, 0) = 2023-04-25 12:00:00 +0000 UTC
oneYearLater: start.AddDate(1, 0, 0) = 2024-03-25 12:00:00 +0000 UTC
oneDayLaterZurich: startZurich.AddDate(0, 0, 1) = 2023-03-26 12:00:00 +0200 CEST
Day duration in UTC: 24h0m0s | Day duration in Zürich: 23h0m0sfunc (Time) After
func (t Time) After(u Time) bool
After сообщает, является ли момент времени t после u.
Пример
package main
import (
"fmt"
"time"
)
func main() {
year2000 := time.Date(2000, 1, 1, 0, 0, 0, 0, time.UTC)
year3000 := time.Date(3000, 1, 1, 0, 0, 0, 0, time.UTC)
isYear3000AfterYear2000 := year3000.After(year2000) // True
isYear2000AfterYear3000 := year2000.After(year3000) // False
fmt.Printf("year3000.After(year2000) = %v\n", isYear3000AfterYear2000)
fmt.Printf("year2000.After(year3000) = %v\n", isYear2000AfterYear3000)
}
Output:
year3000.After(year2000) = true
year2000.After(year3000) = falsefunc (Time) AppendBinary
func (t Time) AppendBinary(b []byte) ([]byte, error)
AppendBinary реализует интерфейс encoding.BinaryAppender. Добавляет бинарное представление времени в срез байт b и возвращает расширенный буфер.
func (Time) AppendFormat
func (t Time) AppendFormat(b []byte, layout string) []byte
AppendFormat аналогичен Time.Format, но добавляет текстовое представление времени в буфер b и возвращает расширенный буфер. Формат определяется параметром layout.
Пример
package main
import (
"fmt"
"time"
)
func main() {
t := time.Date(2017, time.November, 4, 11, 0, 0, 0, time.UTC)
text := []byte("Time: ")
text = t.AppendFormat(text, time.Kitchen)
fmt.Println(string(text))
}Output:
Time: 11:00AMfunc (Time) AppendText
func (t Time) AppendText(b []byte) ([]byte, error)
AppendText реализует интерфейс encoding.TextAppender. Форматирует время в формате RFC 3339 с субсекундной точностью и добавляет в буфер b. Возвращает ошибку, если время невозможно представить в корректном формате RFC 3339 (например, при выходе года за допустимый диапазон).
func (Time) Before
func (t Time) Before(u Time) bool
Before сообщает, является ли момент времени t до u.
Пример
ackage main
import (
"fmt"
"time"
)
func main() {
year2000 := time.Date(2000, 1, 1, 0, 0, 0, 0, time.UTC)
year3000 := time.Date(3000, 1, 1, 0, 0, 0, 0, time.UTC)
isYear2000BeforeYear3000 := year2000.Before(year3000) // True
isYear3000BeforeYear2000 := year3000.Before(year2000) // False
fmt.Printf("year2000.Before(year3000) = %v\n", isYear2000BeforeYear3000)
fmt.Printf("year3000.Before(year2000) = %v\n", isYear3000BeforeYear2000)
}
Output:
year2000.Before(year3000) = true
year3000.Before(year2000) = falsefunc (Time) Clock
func (t Time) Clock() (hour, min, sec int)
Clock возвращает час, минуту и секунду в пределах дня, указанного t.
func (Time) Compare
func (t Time) Compare(u Time) int
Compare сравнивает момент времени t с u. Если t до u, возвращает -1; если t после u, возвращает +1; если они одинаковы, возвращает 0.
func (Time) Date
func (t Time) Date() (year int, month Month, day int)
Date возвращает год, месяц и день, в которые происходит t.
Пример
package main
import (
"fmt"
"time"
)
func main() {
d := time.Date(2000, 2, 1, 12, 30, 0, 0, time.UTC)
year, month, day := d.Date()
fmt.Printf("year = %v\n", year)
fmt.Printf("month = %v\n", month)
fmt.Printf("day = %v\n", day)
}Output:
year = 2000
month = February
day = 1func (Time) Day
func (t Time) Day() int
Day возвращает день месяца, указанный t.
Пример
package main
import (
"fmt"
"time"
)
func main() {
d := time.Date(2000, 2, 1, 12, 30, 0, 0, time.UTC)
day := d.Day()
fmt.Printf("day = %v\n", day)
}
Output:
day = 1func (Time) Equal
func (t Time) Equal(u Time) bool
Equal сообщает, представляют ли t и u один и тот же момент времени. Два времени могут быть равны, даже если они находятся в разных местоположениях. Например, 6:00 +0200 и 4:00 UTC равны.
Пример
package main
import (
"fmt"
"time"
)
func main() {
secondsEastOfUTC := int((8 * time.Hour).Seconds())
beijing := time.FixedZone("Beijing Time", secondsEastOfUTC)
// Unlike the equal operator, Equal is aware that d1 and d2 are the
// same instant but in different time zones.
d1 := time.Date(2000, 2, 1, 12, 30, 0, 0, time.UTC)
d2 := time.Date(2000, 2, 1, 20, 30, 0, 0, beijing)
datesEqualUsingEqualOperator := d1 == d2
datesEqualUsingFunction := d1.Equal(d2)
fmt.Printf("datesEqualUsingEqualOperator = %v\n", datesEqualUsingEqualOperator)
fmt.Printf("datesEqualUsingFunction = %v\n", datesEqualUsingFunction)
}
Output:
datesEqualUsingEqualOperator = false
datesEqualUsingFunction = truefunc (Time) Format
func (t Time) Format(layout string) string
Format возвращает текстовое представление значения времени, отформатированное согласно layout. Смотрите документацию для константы Layout, чтобы понять, как представить формат.
Пример
package main
import (
"fmt"
"time"
)
func main() {
// Разбираем строку времени в стандартном Unix формате
t, err := time.Parse(time.UnixDate, "Wed Feb 25 11:06:39 PST 2015")
if err != nil { // Всегда проверяем ошибки, даже если они не должны возникать
panic(err)
}
tz, err := time.LoadLocation("Asia/Shanghai")
if err != nil { // Всегда проверяем ошибки
panic(err)
}
// Метод Stringer типа time.Time удобен для вывода без указания формата
fmt.Println("формат по умолчанию:", t)
// Предопределенные константы пакета реализуют распространенные форматы
fmt.Println("Unix формат:", t.Format(time.UnixDate))
// Часовой пояс, связанный со значением времени, влияет на его вывод
fmt.Println("То же время в UTC:", t.UTC().Format(time.UnixDate))
fmt.Println("в Шанхае с секундами:", t.In(tz).Format("2006-01-02T15:04:05 -070000"))
fmt.Println("в Шанхае с секундами и двоеточиями:", t.In(tz).Format("2006-01-02T15:04:05 -07:00:00"))
// Оставшаяся часть функции демонстрирует свойства
// строки формата, используемой в Format
// Строка формата, используемая функциями Parse и Format,
// на примере показывает, как должно быть представлено эталонное время.
// Важно подчеркнуть, что нужно показывать, как форматируется именно эталонное время,
// а не произвольное время пользователя. Таким образом, каждая строка формата -
// это представление временной метки:
// Jan 2 15:04:05 2006 MST
// Простой способ запомнить это значение - заметить, что при таком порядке
// оно содержит следующие значения (соответствующие элементам выше):
// 1 2 3 4 5 6 -7
// Ниже показаны некоторые особенности.
// Большинство использований Format и Parse применяют константные строки формата,
// такие как определенные в этом пакете, но интерфейс гибкий,
// как показывают следующие примеры.
// Вспомогательная функция для красивого вывода примеров
do := func(name, layout, want string) {
got := t.Format(layout)
if want != got {
fmt.Printf("ошибка: для %q получено %q; ожидалось %q\n", layout, got, want)
return
}
fmt.Printf("%-16s %q дает %q\n", name, layout, got)
}
// Заголовок для вывода
fmt.Printf("\nФорматы:\n\n")
// Простые начальные примеры
do("Полная дата", "Mon Jan 2 15:04:05 MST 2006", "Wed Feb 25 11:06:39 PST 2015")
do("Краткая дата", "2006/01/02", "2015/02/25")
// Час эталонного времени - 15 (3PM). Формат может выражать это
// любым способом, и так как наше значение утреннее, мы должны видеть его
// в AM-формате. Покажем оба варианта в одной строке формата. И в нижнем регистре.
do("AM/PM", "3PM==3pm==15h", "11AM==11am==11h")
// При разборе, если за секундами следует точка
// и цифры, это воспринимается как доля секунды, даже если
// строка формата не включает представление долей секунды.
// Добавим доли секунды к нашему значению времени
t, err = time.Parse(time.UnixDate, "Wed Feb 25 11:06:39.1234 PST 2015")
if err != nil {
panic(err)
}
// Доли секунды не отображаются, если строка формата не содержит
// их представления
do("Без долей секунды", time.UnixDate, "Wed Feb 25 11:06:39 PST 2015")
// Доли секунды можно вывести, добавив последовательность 0 или 9
// после точки в значении секунд в строке формата.
// Если используются 0, выводится указанное количество знаков.
// Обратите внимание, что вывод содержит завершающий ноль.
do("0 для долей секунды", "15:04:05.00000", "11:06:39.12340")
// Если используются 9, завершающие нули отбрасываются.
do("9 для долей секунды", "15:04:05.99999999", "11:06:39.1234")
}формат по умолчанию: 2015-02-25 11:06:39 -0800 PST
Unix формат: Wed Feb 25 11:06:39 PST 2015
То же время в UTC: Wed Feb 25 19:06:39 UTC 2015
в Шанхае с секундами: 2015-02-26T03:06:39 +080000
в Шанхае с секундами и двоеточиями: 2015-02-26T03:06:39 +08:00:00
Форматы:
Полная дата "Mon Jan 2 15:04:05 MST 2006" дает "Wed Feb 25 11:06:39 PST 2015"
Краткая дата "2006/01/02" дает "2015/02/25"
AM/PM "3PM==3pm==15h" дает "11AM==11am==11h"
Без долей секунды "Mon Jan _2 15:04:05 MST 2006" дает "Wed Feb 25 11:06:39 PST 2015"
0 для долей секунды "15:04:05.00000" дает "11:06:39.12340"
9 для долей секунды "15:04:05.99999999" дает "11:06:39.1234"Пример (Pad)
package main
import (
"fmt"
"time"
)
func main() {
// Разбор строки времени в стандартном Unix формате
t, err := time.Parse(time.UnixDate, "Sat Mar 7 11:06:39 PST 2015")
if err != nil { // Всегда проверяем ошибки, даже если они маловероятны
panic(err)
}
// Вспомогательная функция для форматированного вывода примеров
do := func(name, layout, want string) {
got := t.Format(layout)
if want != got {
fmt.Printf("ошибка: для формата %q получено %q; ожидалось %q\n", layout, got, want)
return
}
fmt.Printf("%-16s %q → %q\n", name, layout, got)
}
// Предопределенная константа Unix использует подчеркивание для выравнивания дня
do("Unix формат", time.UnixDate, "Sat Mar 7 11:06:39 PST 2015")
// Для выравнивания значений переменной ширины (например, дня месяца)
// используйте _ вместо пробела в строке формата
do("Без выравнивания", "<2>", "<7>")
// Подчеркивание добавляет пробел для однозначных чисел
do("С пробелом", "<_2>", "< 7>")
// "0" добавляет нулевое заполнение для однозначных чисел
do("С нулями", "<02>", "<07>")
// Если значение уже имеет нужную ширину, заполнение не применяется
// Например, секунды (39) не требуют заполнения, а минуты (06) - требуют
do("Пропуск заполнения", "04:05", "06:39")
}Unix формат "Mon Jan _2 15:04:05 MST 2006" → "Sat Mar 7 11:06:39 PST 2015"
Без выравнивания "<2>" → "<7>"
С пробелом "<_2>" → "< 7>"
С нулями "<02>" → "<07>"
Пропуск заполнения "04:05" → "06:39"func (Time) GoString
func (t Time) GoString() string
GoString реализует fmt.GoStringer и форматирует t для вывода в исходном коде Go.
Пример
package main
import (
"fmt"
"time"
)
func main() {
t := time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC)
fmt.Println(t.GoString())
t = t.Add(1 * time.Minute)
fmt.Println(t.GoString())
t = t.AddDate(0, 1, 0)
fmt.Println(t.GoString())
t, _ = time.Parse("Jan 2, 2006 at 3:04pm (MST)", "Feb 3, 2013 at 7:54pm (UTC)")
fmt.Println(t.GoString())
}
Output:
time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC)
time.Date(2009, time.November, 10, 23, 1, 0, 0, time.UTC)
time.Date(2009, time.December, 10, 23, 1, 0, 0, time.UTC)
time.Date(2013, time.February, 3, 19, 54, 0, 0, time.UTC)func (*Time) GobDecode
func (t *Time) GobDecode(data []byte) error
GobDecode реализует интерфейс gob.GobDecoder.
func (Time) GobEncode
func (t Time) GobEncode() ([]byte, error)
GobEncode реализует интерфейс gob.GobEncoder.
func (Time) Hour
func (t Time) Hour() int
Hour возвращает час в пределах дня, указанного t, в диапазоне [0, 23].
func (Time) ISOWeek
func (t Time) ISOWeek() (year, week int)
ISOWeek возвращает год и номер недели ISO 8601, в которые происходит t. Неделя находится в диапазоне от 1 до 53. 1-3 января года n могут принадлежать 52 или 53 неделе года n-1, а 29-31 декабря могут принадлежать 1 неделе года n+1.
func (Time) In
func (t Time) In(loc *Location) Time
In возвращает копию t, представляющую тот же момент времени, но с информацией о местоположении, установленной в loc для целей отображения.
In вызывает панику, если loc равен nil.
func (Time) IsDST
func (t Time) IsDST() bool
IsDST сообщает, находится ли время в настроенном местоположении в летнем времени.
func (Time) IsZero
func (t Time) IsZero() bool
IsZero сообщает, представляет ли t нулевой момент времени, 1 января, год 1, 00:00:00 UTC.
func (Time) Local
func (t Time) Local() Time
Local возвращает t с местоположением, установленным в локальное время.
func (Time) Location
func (t Time) Location() *Location
Location возвращает информацию о часовом поясе, связанную с t.
func (Time) MarshalBinary
func (t Time) MarshalBinary() ([]byte, error)
MarshalBinary реализует интерфейс encoding.BinaryMarshaler.
func (Time) MarshalJSON
func (t Time) MarshalJSON() ([]byte, error)
MarshalJSON реализует интерфейс encoding/json.Marshaler. Время — это строка в формате RFC 3339 с точностью до секунды. Если временная метка не может быть представлена как допустимая RFC 3339 (например, год выходит за пределы диапазона), то выдается сообщение об ошибке.
func (Time) MarshalText
func (t Time) MarshalText() ([]byte, error)
MarshalText реализует интерфейс encoding.TextMarshaler. Вывод соответствует вызову метода Time.AppendText.
См. Time.AppendText для получения дополнительной информации.
func (Time) Minute
func (t Time) Minute() int
Minute возвращает минуту в пределах часа, указанного t, в диапазоне [0, 59].
func (Time) Month
func (t Time) Month() Month
Month возвращает месяц года, указанный t.
func (Time) Nanosecond
func (t Time) Nanosecond() int
Nanosecond возвращает наносекунду в пределах секунды, указанной t, в диапазоне [0, 999999999].
func (Time) Round
func (t Time) Round(d Duration) Time
Round возвращает результат округления t до ближайшего кратного d (с нулевого времени). При округлении половинных значений округление выполняется от нуля. Если d <= 0, Round возвращает t, лишенное любого монотонного показания часов, но в остальном неизменное.
Пример
package main
import (
"fmt"
"time"
)
func main() {
t := time.Date(0, 0, 0, 12, 15, 30, 918273645, time.UTC)
round := []time.Duration{
time.Nanosecond,
time.Microsecond,
time.Millisecond,
time.Second,
2 * time.Second,
time.Minute,
10 * time.Minute,
time.Hour,
}
for _, d := range round {
fmt.Printf("t.Round(%6s) = %s\n", d, t.Round(d).Format("15:04:05.999999999"))
}
}
Output:
t.Round( 1ns) = 12:15:30.918273645
t.Round( 1µs) = 12:15:30.918274
t.Round( 1ms) = 12:15:30.918
t.Round( 1s) = 12:15:31
t.Round( 2s) = 12:15:30
t.Round( 1m0s) = 12:16:00
t.Round( 10m0s) = 12:20:00
t.Round(1h0m0s) = 12:00:00func (Time) Second
func (t Time) Second() int
Second возвращает секунду в пределах минуты, указанной t, в диапазоне [0, 59].
func (Time) String
func (t Time) String() string
String возвращает время, отформатированное с использованием строки формата
"2006-01-02 15:04:05.999999999 -0700 MST"
Если время имеет монотонное показание часов, возвращаемая строка включает конечное поле “m=±
Пример
import (
"fmt"
"time"
)
func main() {
timeWithNanoseconds := time.Date(2000, 2, 1, 12, 13, 14, 15, time.UTC)
withNanoseconds := timeWithNanoseconds.String()
timeWithoutNanoseconds := time.Date(2000, 2, 1, 12, 13, 14, 0, time.UTC)
withoutNanoseconds := timeWithoutNanoseconds.String()
fmt.Printf("withNanoseconds = %v\n", string(withNanoseconds))
fmt.Printf("withoutNanoseconds = %v\n", string(withoutNanoseconds))
}Output:
withNanoseconds = 2000-02-01 12:13:14.000000015 +0000 UTC
withoutNanoseconds = 2000-02-01 12:13:14 +0000 UTCfunc (Time) Sub
func (t Time) Sub(u Time) Duration
Sub возвращает продолжительность t-u. Если результат превышает максимальное (или минимальное) значение, которое может храниться в Duration, будет возвращена максимальная (или минимальная) продолжительность.
Пример
package main
import (
"fmt"
"time"
)
func main() {
start := time.Date(2000, 1, 1, 0, 0, 0, 0, time.UTC)
end := time.Date(2000, 1, 1, 12, 0, 0, 0, time.UTC)
difference := end.Sub(start)
fmt.Printf("difference = %v\n", difference)
}
Output:
difference = 12h0m0sfunc (Time) Truncate
func (t Time) Truncate(d Duration) Time
Truncate возвращает результат округления t вниз до кратного d (с нулевого времени). Если d <= 0, Truncate возвращает t, лишенное любого монотонного показания часов, но в остальном неизменное.
Пример
import (
"fmt"
"time"
)
func main() {
t, _ := time.Parse("2006 Jan 02 15:04:05", "2012 Dec 07 12:15:30.918273645")
trunc := []time.Duration{
time.Nanosecond,
time.Microsecond,
time.Millisecond,
time.Second,
2 * time.Second,
time.Minute,
10 * time.Minute,
}
for _, d := range trunc {
fmt.Printf("t.Truncate(%5s) = %s\n", d, t.Truncate(d).Format("15:04:05.999999999"))
}
// To round to the last midnight in the local timezone, create a new Date.
midnight := time.Date(t.Year(), t.Month(), t.Day(), 0, 0, 0, 0, time.Local)
_ = midnight
}Output:
t.Truncate( 1ns) = 12:15:30.918273645
t.Truncate( 1µs) = 12:15:30.918273
t.Truncate( 1ms) = 12:15:30.918
t.Truncate( 1s) = 12:15:30
t.Truncate( 2s) = 12:15:30
t.Truncate( 1m0s) = 12:15:00
t.Truncate(10m0s) = 12:10:00func (Time) UTC
func (t Time) UTC() Time
UTC возвращает t с местоположением, установленным в UTC.
func (Time) Unix
func (t Time) Unix() int64
Unix возвращает t как Unix-время, количество секунд, прошедших с 1 января 1970 UTC. Результат не зависит от местоположения, связанного с t.
Пример
package main
import (
"fmt"
"time"
)
func main() {
// 1 billion seconds of Unix, three ways.
fmt.Println(time.Unix(1e9, 0).UTC()) // 1e9 seconds
fmt.Println(time.Unix(0, 1e18).UTC()) // 1e18 nanoseconds
fmt.Println(time.Unix(2e9, -1e18).UTC()) // 2e9 seconds - 1e18 nanoseconds
t := time.Date(2001, time.September, 9, 1, 46, 40, 0, time.UTC)
fmt.Println(t.Unix()) // seconds since 1970
fmt.Println(t.UnixNano()) // nanoseconds since 1970
}Output:
2001-09-09 01:46:40 +0000 UTC
2001-09-09 01:46:40 +0000 UTC
2001-09-09 01:46:40 +0000 UTC
1000000000
1000000000000000000func (Time) UnixMicro
func (t Time) UnixMicro() int64
UnixMicro возвращает t как Unix-время, количество микросекунд, прошедших с 1 января 1970 UTC.
func (Time) UnixMilli
func (t Time) UnixMilli() int64
UnixMilli возвращает t как Unix-время, количество миллисекунд, прошедших с 1 января 1970 UTC.
func (Time) UnixNano
func (t Time) UnixNano() int64
UnixNano возвращает t как Unix-время, количество наносекунд, прошедших с 1 января 1970 UTC.
func (*Time) UnmarshalBinary
func (t *Time) UnmarshalBinary(data []byte) error
UnmarshalBinary реализует интерфейс encoding.BinaryUnmarshaler.
func (*Time) UnmarshalJSON
func (t *Time) UnmarshalJSON(data []byte) error
UnmarshalJSON реализует интерфейс encoding/json.Unmarshaler. Время должно быть строкой в кавычках в формате RFC 3339.
func (*Time) UnmarshalText
func (t *Time) UnmarshalText(data []byte) error
UnmarshalText реализует интерфейс encoding.TextUnmarshaler. Время должно быть в формате RFC 3339.
func (Time) Weekday
func (t Time) Weekday() Weekday
Weekday возвращает день недели, указанный t.
func (Time) Year
func (t Time) Year() int
Year возвращает год, в который происходит t.
func (Time) YearDay
func (t Time) YearDay() int
YearDay возвращает день года, указанный t, в диапазоне [1,365] для невисокосных лет и [1,366] в високосных годах.
func (Time) Zone
func (t Time) Zone() (name string, offset int)
Zone вычисляет часовой пояс, действующий в момент времени t, возвращая сокращенное название пояса (например, “CET”) и его смещение в секундах к востоку от UTC.
func (Time) ZoneBounds
func (t Time) ZoneBounds() (start, end Time)
ZoneBounds возвращает границы часового пояса, действующего в момент времени t. Пояс начинается в start, а следующий пояс начинается в end. Если пояс начинается в начале времен, start будет возвращен как нулевое Time. Если пояс продолжается вечно, end будет возвращен как нулевое Time. Местоположение возвращаемых времен будет таким же, как у t.
type Timer
type Timer struct {
C <-chan Time
// содержит неэкспортируемые поля
}
Timer представляет единичное событие. Когда Timer истекает, текущее время будет отправлено на C, если только Timer не был создан с помощью AfterFunc. Timer должен быть создан с помощью NewTimer или AfterFunc.
func AfterFunc
func AfterFunc(d Duration, f func()) *Timer
AfterFunc ждет истечения продолжительности, а затем вызывает f в своей собственной горутине. Возвращает Timer, который можно использовать для отмены вызова с помощью его метода Stop. Поле C возвращаемого Timer не используется и будет nil.
func NewTimer
func NewTimer(d Duration) *Timer
NewTimer создает новый Timer, который отправит текущее время на свой канал после как минимум продолжительности d.
func (*Timer) Reset
func (t *Timer) Reset(d Duration) bool
Reset изменяет таймер на истечение после продолжительности d. Возвращает true, если таймер был активен, false, если таймер уже истек или был остановлен.
func (t *Timer) Reset(d Duration) bool
Reset изменяет таймер для срабатывания через интервал d. Возвращает true, если таймер был активен, и false, если таймер уже сработал или был остановлен.
Для функционального таймера, созданного через AfterFunc(d, f):
Resetлибо переносит время выполненияf(возвращаетtrue)- либо планирует новое выполнение
f(возвращаетfalse)
При возврате false:
Resetне ожидает завершения предыдущего выполненияf- Не гарантируется отсутствие конкурентного выполнения предыдущей и новой версий
f - Для контроля завершения нужно реализовать собственную синхронизацию
Для канального таймера (создан через NewTimer), начиная с Go 1.23:
- Гарантируется, что после
Resetканалt.Cне получит значений от предыдущих настроек - Если программа еще не читала из
t.Cи таймер активен,Resetгарантированно вернетtrue
До Go 1.23 безопасное использование требовало:
- Вызова
Timer.Stop() - Явного чтения из канала (если
Stopвернулаfalse)
func (*Timer) Stop
func (t *Timer) Stop() bool
Stop предотвращает срабатывание таймера. Возвращает:
true- если таймер был успешно остановленfalse- если таймер уже сработал или был остановлен
Для функционального таймера (AfterFunc):
- При
falseфункцияfуже запущена в отдельной горутине Stopне ожидает завершенияf- Для контроля завершения нужна дополнительная синхронизация
Для канального таймера (Go 1.23+):
- После
Stopчтение изt.Cгарантированно блокируется - Не будет получено “устаревших” значений времени
- Если таймер активен и канал не читался,
Stopгарантированно вернетtrue
До Go 1.23 требовалось:
- При
falseвыполнять дополнительное чтение<-t.Cдля очистки канала
type Weekday
type Weekday int
Weekday определяет день недели (Sunday = 0, …).
Константы:
const (
Sunday Weekday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
func (Weekday) String
func (d Weekday) String() string
String возвращает английское название дня (“Sunday”, “Monday”, …).
Пакет time/tzdata
Пакет tzdata предоставляет встроенную копию базы данных часовых поясов. Если этот пакет импортируется в любое место программы, то, если пакет времени не может найти файлы tzdata в системе, он будет использовать эту встроенную информацию.
Импорт этого пакета увеличит размер программы примерно на 450 КБ.
Обычно этот пакет должен импортироваться основным пакетом программы, а не библиотекой. Библиотеки обычно не должны решать, включать ли базу данных часовых поясов в программу.
Этот пакет будет автоматически импортирован, если вы построите с -tags timetzdata.
12.4.21 - SCS: Управление HTTP-сессиями для Go
Менеджер сессий для GO
Возможности
Автоматическая загрузка и сохранение данных сессии через middleware
Выбор из 19 серверных хранилищ для сессий, включая:
- Базы данных: PostgreSQL, MySQL, MSSQL, SQLite
- Кэш-системы: Redis
- Поддержка пользовательских хранилищ
Расширенные функции:
- Несколько сессий на один запрос
- “Flash”-сообщения (одноразовые уведомления)
- Регенерация токенов сессии
- Таймауты: по бездействию и абсолютные
- Функция “запомнить меня”
Гибкость:
- Простота расширения и кастомизации
- Передача токенов сессии через HTTP-заголовки или тела запросов/ответов
Производительность:
- Оптимизированная архитектура
- Меньший размер, выше скорость и меньше потребление памяти по сравнению с gorilla/sessions
Установка
Этот пакет требует Go версии 1.12 или новее.
go get github.com/alexedwards/scs/v2
Примечание: Если вы используете традиционный механизм GOPATH для управления зависимостями (вместо модулей), вам нужно использовать go get и импортировать github.com/alexedwards/scs без суффикса v2.
Рекомендуется использовать версионные релизы. Код в ветке tip может содержать экспериментальные функции, которые могут измениться.
Базовое использование
SCS реализует механизм управления сессиями в соответствии с рекомендациями по безопасности OWASP. Данные сессии хранятся на сервере, а случайно сгенерированный уникальный токен сессии (или ID сессии) передается клиенту и обратно через cookie сессии.
package main
import (
"io"
"net/http"
"time"
"github.com/alexedwards/scs/v2"
)
var sessionManager *scs.SessionManager
func main() {
// Инициализация нового менеджера сессий и настройка времени жизни сессии
sessionManager = scs.New()
sessionManager.Lifetime = 24 * time.Hour
mux := http.NewServeMux()
mux.HandleFunc("/put", putHandler)
mux.HandleFunc("/get", getHandler)
// Оберните ваши обработчики middleware LoadAndSave()
http.ListenAndServe(":4000", sessionManager.LoadAndSave(mux))
}
func putHandler(w http.ResponseWriter, r *http.Request) {
// Сохранение нового ключа и значения в данных сессии
sessionManager.Put(r.Context(), "message", "Hello from a session!")
}
func getHandler(w http.ResponseWriter, r *http.Request) {
// Использование вспомогательной функции GetString для получения строкового значения
// по ключу. Возвращается нулевое значение, если ключ не существует.
msg := sessionManager.GetString(r.Context(), "message")
io.WriteString(w, msg)
}
Пример работы с curl:
$ curl -i --cookie-jar cj --cookie cj localhost:4000/put
HTTP/1.1 200 OK
Cache-Control: no-cache="Set-Cookie"
Set-Cookie: session=lHqcPNiQp_5diPxumzOklsSdE-MJ7zyU6kjch1Ee0UM; Path=/; Expires=Sat, 27 Apr 2019 10:28:20 GMT; Max-Age=86400; HttpOnly; SameSite=Lax
Vary: Cookie
Date: Fri, 26 Apr 2019 10:28:19 GMT
Content-Length: 0
$ curl -i --cookie-jar cj --cookie cj localhost:4000/get
HTTP/1.1 200 OK
Date: Fri, 26 Apr 2019 10:28:24 GMT
Content-Length: 21
Content-Type: text/plain; charset=utf-8
Hello from a session!
Настройка поведения сессии
Поведение сессии можно настроить через поля SessionManager:
sessionManager = scs.New()
sessionManager.Lifetime = 3 * time.Hour // Общее время жизни сессии
sessionManager.IdleTimeout = 20 * time.Minute // Таймаут бездействия
sessionManager.Cookie.Name = "session_id" // Имя cookie
sessionManager.Cookie.Domain = "example.com" // Домен cookie
sessionManager.Cookie.HttpOnly = true // Доступ только через HTTP
sessionManager.Cookie.Path = "/example/" // Путь cookie
sessionManager.Cookie.Persist = true // Сохранение после закрытия браузера
sessionManager.Cookie.SameSite = http.SameSiteStrictMode // Политика SameSite
sessionManager.Cookie.Secure = true // Только HTTPS
sessionManager.Cookie.Partitioned = true // Partitioned cookies
Документация по всем доступным настройкам и их значениям по умолчанию доступна [здесь](ссылка на документацию).
Работа с данными сессии
Установка и получение данных
Данные можно устанавливать с помощью метода Put() и получать с помощью Get(). Для распространённых типов данных предусмотрены вспомогательные методы, такие как GetString(), GetInt() и GetBytes(). Полный список вспомогательных методов доступен в документации.
Одноразовое получение данных
Метод Pop() (и соответствующие вспомогательные методы для распространённых типов данных) работает как одноразовый Get() - извлекает данные и сразу удаляет их из сессии. Это полезно для реализации функционала “flash”-сообщений, которые показываются пользователю только один раз.
Дополнительные функции
Exists()- возвращаетbool, указывающий на наличие ключа в данных сессииKeys()- возвращает отсортированный срез всех ключей в данных сессии
Удаление данных
Отдельные элементы можно удалить с помощью метода Remove(). Для полной очистки данных сессии используйте метод Destroy(). После вызова Destroy() любые последующие операции в рамках того же цикла запроса приведут к созданию новой сессии - с новым токеном и временем жизни.
Хранение пользовательских типов
SCS использует кодировку gob для хранения данных сессии. Пользовательские типы должны быть зарегистрированы в пакете encoding/gob. Поля структур пользовательских типов должны быть экспортируемыми (начинаться с заглавной буквы), чтобы быть видимыми для пакета encoding/gob. Пример работы можно посмотреть [здесь](ссылка на пример).
Загрузка и сохранение сессий
Стандартное использование
Большинство приложений используют middleware LoadAndSave(). Этот middleware:
- Загружает и сохраняет данные сессии в хранилище
- Управляет передачей токена сессии клиенту через cookie
Кастомизация поведения
Если требуется изменить стандартное поведение (например, передавать токен сессии через HTTP-заголовки или устанавливать распределённую блокировку токена сессии на время запроса), можно создать собственный middleware, используя код LoadAndSave() в качестве шаблона. Пример доступен [здесь](ссылка на пример).
Точный контроль
Для более точного управления можно загружать и сохранять сессии непосредственно в обработчиках запросов или в любом другом месте приложения. Пример такого подхода приведён [здесь](ссылка на пример).
Настройка хранилища сессий
Хранилище по умолчанию
По умолчанию SCS использует in-memory хранилище для данных сессии. Это:
- Удобно (не требует настройки)
- Очень быстро
- Но все данные теряются при остановке или перезапуске приложения
Это решение подходит для:
- Приложений, где допустима потеря данных в обмен на высокую производительность
- Прототипирования
- Тестирования
Продукционные решения
Для большинства рабочих приложений рекомендуется использовать постоянные хранилища, такие как:
- PostgreSQL
- MySQL
- Другие поддерживаемые системы (список ниже)
Полный список поддерживаемых хранилищ сессий с инструкциями по использованию доступен в таблице (ссылки в оригинальной документации).
Поддерживаемые хранилища сессий
Вот полный список доступных хранилищ сессий в SCS с их характеристиками:
| Пакет | Бэкенд | Встроенный | In-Memory | Мультипроцессорный |
|---|---|---|---|---|
badgerstore | BadgerDB | Да | Нет | Нет |
boltstore | BBolt | Да | Нет | Нет |
bunstore | Bun ORM (PostgreSQL/MySQL/MSSQL/SQLite) | Нет | Нет | Да |
buntdbstore | BuntDB | Да | Да | Нет |
cockroachdbstore | CockroachDB | Нет | Нет | Да |
consulstore | Consul | Нет | Да | Да |
etcdstore | Etcd | Нет | Нет | Да |
firestore | Google Cloud Firestore | Нет | ? | Да |
gormstore | GORM ORM (PostgreSQL/MySQL/SQLite/MSSQL/TiDB) | Нет | Нет | Да |
leveldbstore | LevelDB | Да | Нет | Нет |
memstore | In-memory (по умолчанию) | Да | Да | Нет |
mongodbstore | MongoDB | Нет | Нет | Да |
mssqlstore | Microsoft SQL Server | Нет | Нет | Да |
mysqlstore | MySQL | Нет | Нет | Да |
pgxstore | PostgreSQL (драйвер pgx) | Нет | Нет | Да |
postgresstore | PostgreSQL (драйвер pq) | Нет | Нет | Да |
redisstore | Redis | Нет | Да | Да |
sqlite3store | SQLite3 (CGO-драйвер mattn/go-sqlite3) | Да | Нет | Да |
Ключевые характеристики:
- Встроенный - Не требует отдельного сервера/процесса
- In-Memory - Хранит данные в оперативной памяти
- Мультипроцессорный - Поддерживает работу в распределённой среде
Пользовательские хранилища
SCS также поддерживает создание собственных хранилищ сессий. Подробная информация доступна [здесь](ссылка на документацию).
Выбор хранилища зависит от требований вашего приложения:
- Для тестирования/разработки -
memstoreилиbuntdbstore - Для продакшена -
postgresstore,mysqlstoreилиredisstore - Для встраиваемых решений -
badgerstoreилиboltstore
Использование пользовательских хранилищ сессий
Базовый интерфейс хранилища
Интерфейс scs.Store определяет контракт для пользовательских хранилищ сессий. Любой объект, реализующий этот интерфейс, может быть установлен как хранилище при настройке сессии.
type Store interface {
// Delete удаляет токен сессии и соответствующие данные из хранилища.
// Если токен не существует, Delete должен завершиться без ошибки.
Delete(token string) (err error)
// Find возвращает данные для указанного токена сессии.
// Если токен не найден или истек, возвращает found=false.
// Для повреждённых токенов также возвращает found=false.
// Ошибка возвращается только для системных сбоев.
Find(token string) (b []byte, found bool, err error)
// Commit добавляет или обновляет данные сессии с указанным сроком действия.
Commit(token string, b []byte, expiry time.Time) (err error)
}
type IterableStore interface {
// All возвращает map со всеми активными (не истекшими) сессиями.
// Ключ - токен сессии, значение - данные сессии.
// Если активных сессий нет, возвращает пустую (не nil) map.
All() (map[string][]byte, error)
}
Интерфейс с поддержкой контекста
scs.CtxStore расширяет базовый интерфейс, добавляя методы с поддержкой context.Context:
type CtxStore interface {
Store
// Версии методов с контекстом
DeleteCtx(ctx context.Context, token string) (err error)
FindCtx(ctx context.Context, token string) (b []byte, found bool, err error)
CommitCtx(ctx context.Context, token string, b []byte, expiry time.Time) (err error)
}
type IterableCtxStore interface {
// AllCtx - версия All с поддержкой контекста
AllCtx(ctx context.Context) (map[string][]byte, error)
}
Защита от фиксации сессии
Для предотвращения атак фиксации сессии следует обновлять токен сессии при любом изменении уровня привилегий. Обычно это делается при входе/выходе пользователя:
func loginHandler(w http.ResponseWriter, r *http.Request) {
userID := 123
// 1. Сначала обновляем токен сессии
err := sessionManager.RenewToken(r.Context())
if err != nil {
http.Error(w, err.Error(), 500)
return
}
// 2. Затем изменяем уровень привилегий
sessionManager.Put(r.Context(), "userID", userID)
}
Важные моменты:
RenewToken()должен вызываться ДО изменения данных сессии- При ошибке обновления токена следует прервать операцию
- Такой же подход применяется при выходе пользователя
Этот механизм гарантирует, что после аутентификации сессия получает новый токен, делая недействительным любой ранее перехваченный злоумышленником токен.
Расширенные возможности SCS
Несколько сессий в одном запросе
SCS позволяет использовать несколько параллельных сессий в рамках одного запроса с разными:
- Временем жизни
- Хранилищами данных
Пример реализации доступен [здесь](ссылка на пример).
Перебор всех сессий
Для работы со всеми активными сессиями SCS предоставляет метод Iterate(), который принимает функцию-обработчик:
err := sessionManager.Iterate(r.Context(), func(ctx context.Context) error {
userID := sessionManager.GetInt(ctx, "userID")
if userID == 4 {
// Удаляем сессию для пользователя с ID=4
return sessionManager.Destroy(ctx)
}
return nil
})
if err != nil {
log.Fatal(err)
}
Ключевые особенности:
- Обработчик получает контекст каждой сессии
- Можно выполнять любые операции с сессией
- Возврат ошибки прерывает процесс итерации
Потоковая передача ответов (Flushing)
Поддержка потоковой передачи реализована через http.NewResponseController (доступно в Go ≥1.20):
func flushingHandler(w http.ResponseWriter, r *http.Request) {
sessionManager.Put(r.Context(), "message", "Hello from flushing handler!")
rc := http.NewResponseController(w)
for i := 0; i < 5; i++ {
fmt.Fprintf(w, "Write %d\n", i)
err := rc.Flush()
if err != nil {
log.Println(err)
return
}
time.Sleep(time.Second)
}
}
Важно:
- Стандартная реализация middleware
LoadAndSave()не поддерживает интерфейсhttp.Flusher - Потоковая передача работает только в Go версии 1.20 и выше
Полный рабочий пример можно найти [здесь](ссылка на пример).
Совместимость с фреймворками
Возможны проблемы при интеграции с фреймворками, которые не передают контекст запроса через стандартные middleware:
- Для Echo рекомендуется использовать пакет echo-scs-session
- Fiber и другие нестандартные фреймворки могут требовать дополнительной адаптации
Вклад в разработку
Приветствуются:
- Исправления ошибок
- Улучшения документации
Для новых функций или изменений поведения:
- Создайте issue для обсуждения
- После согласования - отправляйте PR
Для новых реализаций хранилищ:
- Как правило, не добавляются в основной репозиторий
- Можно создать отдельный репозиторий и добавить ссылку в README через PR
12.4.21.1 - Официальное API SCS: Управление HTTP-сессиями для Go
Менеджер сессий для GO
Использование пользовательских хранилищ сеансов scs.Store определяет интерфейс для пользовательских хранилищ сеансов. Любой объект, реализующий этот интерфейс, может быть установлен как хранилище при настройке сеанса.
Работа с пользовательскими хранилищами сессий
Интерфейсы хранилищ
Базовый интерфейс Store
Определяет контракт для реализации пользовательских хранилищ:
type Store interface {
// Delete удаляет токен и данные сессии из хранилища
// Если токен не существует - операция должна завершиться успешно
Delete(token string) error
// Find ищет данные по токену сессии
// Возвращает:
// - данные (если найдены)
// - флаг found (найдено/не найдено)
// - ошибку (только для системных сбоев)
Find(token string) ([]byte, bool, error)
// Commit сохраняет или обновляет данные сессии
Commit(token string, data []byte, expiry time.Time) error
}
Интерфейс IterableStore
Добавляет возможность перебора всех сессий:
type IterableStore interface {
// All возвращает все активные (не истекшие) сессии
// В формате map[токен]данные
All() (map[string][]byte, error)
}
Версии с поддержкой контекста
CtxStore
Расширяет базовый интерфейс с добавлением context.Context:
type CtxStore interface {
Store
// Версии методов с поддержкой контекста
DeleteCtx(ctx context.Context, token string) error
FindCtx(ctx context.Context, token string) ([]byte, bool, error)
CommitCtx(ctx context.Context, token string, data []byte, expiry time.Time) error
}
IterableCtxStore
Аналогично для перебора сессий:
type IterableCtxStore interface {
AllCtx(ctx context.Context) (map[string][]byte, error)
}
Защита от фиксации сессии
Для предотвращения атак фиксации сессии необходимо:
func loginHandler(w http.ResponseWriter, r *http.Request) {
userID := 123
// 1. Сначала обновляем токен сессии
if err := sessionManager.RenewToken(r.Context()); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// 2. Затем сохраняем данные пользователя
sessionManager.Put(r.Context(), "userID", userID)
}
Ключевые моменты:
- Всегда обновляйте токен при изменении прав доступа
- Порядок операций критически важен
- Такой же подход применяйте при выходе пользователя
Это гарантирует, что после аутентификации будет создан новый токен сессии, делая недействительными любые ранее перехваченные токены.
Типы данных в SCS
Интерфейс Codec
Добавлен в v2.2.0
type Codec interface {
// Encode преобразует срок действия и значения сессии в байтовый срез
Encode(deadline time.Time, values map[string]interface{}) ([]byte, error)
// Decode восстанавливает срок действия и значения сессии из байтового среза
Decode([]byte) (deadline time.Time, values map[string]interface{}, err error)
}
Интерфейс для кодирования/декодирования данных сессии при работе с хранилищем.
Интерфейс CtxStore
Добавлен в v2.5.0
type CtxStore interface {
Store
// Версии методов с поддержкой контекста:
DeleteCtx(ctx context.Context, token string) error
FindCtx(ctx context.Context, token string) ([]byte, bool, error)
CommitCtx(ctx context.Context, token string, b []byte, expiry time.Time) error
}
Расширенный интерфейс хранилища с поддержкой context.Context.
Структура GobCodec
Добавлена в v2.3.1
type GobCodec struct{}
Реализация Codec с использованием encoding/gob для сериализации данных.
Методы GobCodec:
// Decode преобразует байты в срок действия и данные сессии
func (GobCodec) Decode(b []byte) (time.Time, map[string]interface{}, error)
// Encode сериализует данные сессии в байтовый срез
func (GobCodec) Encode(deadline time.Time, values map[string]interface{}) ([]byte, error)
Интерфейс IterableCtxStore
Добавлен в v2.5.0
type IterableCtxStore interface {
// AllCtx возвращает все активные сессии (с поддержкой контекста)
AllCtx(ctx context.Context) (map[string][]byte, error)
}
Интерфейс для перечислимых хранилищ с поддержкой context.Context.
Интерфейс IterableStore
Добавлен в v2.5.0
type IterableStore interface {
// All возвращает все активные (не истекшие) сессии
All() (map[string][]byte, error)
}
Базовый интерфейс для хранилищ с возможностью перебора сессий.
Ключевые особенности:
Codec- абстракция для сериализации данныхGobCodec- стандартная реализация через encoding/gobCtxStoreдобавляет поддержку контекста к базовому хранилищу- Интерфейсы
Iterableпозволяют работать со всеми сессиями
Конфигурация сессий в SCS
Структура SessionCookie
type SessionCookie struct {
// Имя cookie сессии (не должно содержать спецсимволы)
// По умолчанию: "session"
Name string
// Домен cookie (по умолчанию - текущий домен)
Domain string
// HttpOnly флаг (по умолчанию true)
HttpOnly bool
// Путь cookie (по умолчанию "/")
Path string
// Сохранять cookie после закрытия браузера (по умолчанию true)
Persist bool
// Политика SameSite (по умолчанию Lax)
SameSite http.SameSite
// Secure флаг (только HTTPS, по умолчанию false)
Secure bool
}
Настройки cookie для управления сессиями.
Структура SessionManager
Добавлена в v2.1.0
type SessionManager struct {
// Таймаут бездействия (опционально)
IdleTimeout time.Duration
// Максимальное время жизни сессии (по умолчанию 24 часа)
Lifetime time.Duration
// Хранилище сессий
Store Store
// Настройки cookie
Cookie SessionCookie
// Кодек для сериализации данных (по умолчанию GobCodec)
Codec Codec
// Обработчик ошибок (по умолчанию HTTP 500)
ErrorFunc func(http.ResponseWriter, *http.Request, error)
// Хэшировать токен в хранилище
HashTokenInStore bool
// содержит скрытые поля
}
Основные настройки:
- IdleTimeout: автоматическое завершение неактивных сессий
- Lifetime: абсолютное время жизни сессии
- Store: подключение к Redis, PostgreSQL и другим хранилищам
- Cookie: тонкая настройка параметров безопасности cookie
- Codec: кастомная сериализация данных
- ErrorFunc: обработка ошибок на уровне middleware
Рекомендации по безопасности:
- Всегда устанавливайте
Secure=trueв production - Используйте
SameSite=Strictдля критичных операций - Для API можно отключить
HttpOnlyи работать через заголовки - Регулируйте
Lifetimeв соответствии с требованиями приложения
Пример инициализации:
manager := scs.New()
manager.Lifetime = 12 * time.Hour
manager.Cookie.Secure = true
manager.Cookie.SameSite = http.SameSiteStrictMode
manager.Store = redisstore.New(redisPool)
Методы SessionManager
Основные функции
New
Добавлено в v2.1.0
func New() *SessionManager
Создает новый менеджер сессий с настройками по умолчанию. Потокобезопасен.
Clear (устаревший)
func (s *SessionManager) Clear(ctx context.Context) error
Очищает все данные текущей сессии, не затрагивая токен и время жизни. Если данных нет - операция не выполняется.
Управление сессиями
Commit
Добавлено в v2.1.0
func (s *SessionManager) Commit(ctx context.Context) (string, time.Time, error)
Сохраняет данные сессии в хранилище и возвращает:
- Токен сессии
- Время истечения
- Ошибку (если есть)
Обычно используется автоматически middleware LoadAndSave().
Deadline
Добавлено в v2.5.0
func (s *SessionManager) Deadline(ctx context.Context) time.Time
Возвращает абсолютное время истечения сессии. При использовании IdleTimeout сессия может завершиться раньше из-за неактивности.
Destroy
Добавлено в v2.1.0
func (s *SessionManager) Destroy(ctx context.Context) error
Полностью удаляет сессию:
- Удаляет данные из хранилища
- Помечает сессию как уничтоженную
- Новые операции создадут свежую сессию
Работа с данными
Exists
Добавлено в v2.1.0
func (s *SessionManager) Exists(ctx context.Context, key string) bool
Проверяет наличие ключа в данных сессии.
Get
Добавлено в v2.1.0
func (s *SessionManager) Get(ctx context.Context, key string) interface{}
Возвращает значение по ключу как interface{}, требующее приведения типа:
foo, ok := session.Get(ctx, "foo").(string)
if !ok {
return errors.New("ошибка приведения типа")
}
GetBool
Добавлено в v2.1.0
func (s *SessionManager) GetBool(ctx context.Context, key string) bool
Возвращает значение как bool (по умолчанию false если ключ отсутствует или тип не совпадает).
GetBytes
Добавлено в v2.1.0
func (s *SessionManager) GetBytes(ctx context.Context, key string) []byte
Возвращает значение как []byte (по умолчанию nil).
Методы работы с данными сессии
Получение типизированных значений
GetFloat
func (s *SessionManager) GetFloat(ctx context.Context, key string) float64
Возвращает значение как float64 (0 если ключ отсутствует или тип не совпадает)
GetInt
func (s *SessionManager) GetInt(ctx context.Context, key string) int
Возвращает значение как int (0 если ключ отсутствует)
GetInt32
func (s *SessionManager) GetInt32(ctx context.Context, key string) int32
Возвращает значение как int32 (0 по умолчанию)
GetInt64
func (s *SessionManager) GetInt64(ctx context.Context, key string) int64
Возвращает значение как int64 (0 по умолчанию)
GetString
func (s *SessionManager) GetString(ctx context.Context, key string) string
Возвращает строковое значение (пустая строка "" если ключ отсутствует)
GetTime
func (s *SessionManager) GetTime(ctx context.Context, key string) time.Time
Возвращает значение времени (time.IsZero() == true если ключ отсутствует)
Управление сессиями
Iterate
func (s *SessionManager) Iterate(ctx context.Context, fn func(context.Context) error) error
Итерируется по всем активным сессиям и выполняет функцию fn для каждой. Требует поддержки итерации в хранилище.
Keys
func (s *SessionManager) Keys(ctx context.Context) []string
Возвращает отсортированный список всех ключей сессии (пустой слайс если данных нет)
Middleware и загрузка данных
Load
func (s *SessionManager) Load(ctx context.Context, token string) (context.Context, error)
Загружает данные сессии по токену и возвращает новый контекст. Создает новую сессию если токен не найден.
LoadAndSave
func (s *SessionManager) LoadAndSave(next http.Handler) http.Handler
Middleware для автоматической загрузки/сохранения сессии и управления cookie.
Пример:
router := http.NewServeMux()
router.HandleFunc("/", handler)
// Обертывание роутера middleware
app := sessionManager.LoadAndSave(router)
http.ListenAndServe(":4000", app)
Методы управления сессиями в SCS
Работа с данными сессии
MergeSession (v2.5.0+)
func (s *SessionManager) MergeSession(ctx context.Context, token string) error
Объединяет данные из другой сессии (полезно при OAuth-редиректах). Для полной замены данных используйте Clear().
Pop-методы
Одноразовое получение данных с удалением ключа:
func (s *SessionManager) Pop(ctx context.Context, key string) interface{}
func (s *SessionManager) PopBool(ctx context.Context, key string) bool
func (s *SessionManager) PopBytes(ctx context.Context, key string) []byte
func (s *SessionManager) PopFloat(ctx context.Context, key string) float64
func (s *SessionManager) PopInt(ctx context.Context, key string) int
func (s *SessionManager) PopString(ctx context.Context, key string) string
func (s *SessionManager) PopTime(ctx context.Context, key string) time.Time
Пример для flash-сообщений:
// Установка
sessionManager.Put(ctx, "flash", "Сообщение")
// Получение с удалением
msg := sessionManager.PopString(ctx, "flash")
Основные операции
Put (v2.1.0+)
func (s *SessionManager) Put(ctx context.Context, key string, val interface{})
Добавляет или обновляет значение в сессии. Автоматически помечает сессию как измененную.
Remove (v2.1.0+)
func (s *SessionManager) Remove(ctx context.Context, key string)
Удаляет ключ из сессии. Если ключ не существует - операция игнорируется.
Управление токенами и временем жизни
RenewToken (v2.1.0+)
func (s *SessionManager) RenewToken(ctx context.Context) error
Генерирует новый токен сессии, сохраняя данные. Критично для:
- Входа/выхода пользователей
- Изменения прав доступа
- Защиты от фиксации сессии
RememberMe (v2.5.0+)
func (s *SessionManager) RememberMe(ctx context.Context, val bool)
Управляет постоянством сессии (работает только при Cookie.Persist = false).
SetDeadline (v2.7.0+)
func (s *SessionManager) SetDeadline(ctx context.Context, expire time.Time)
Устанавливает абсолютное время истечения сессии (может быть перекрыто IdleTimeout).
Информационные методы
Status (v2.1.0+)
func (s *SessionManager) Status(ctx context.Context) Status
Возвращает текущее состояние сессии (новые/измененные/уничтоженные).
Token (v2.5.0+)
func (s *SessionManager) Token(ctx context.Context) string
Возвращает токен сессии (пустую строку до коммита).
WriteSessionCookie (v2.3.0+)
func (s *SessionManager) WriteSessionCookie(ctx context.Context, w http.ResponseWriter, token string, expiry time.Time)
Низкоуровневый метод записи cookie (обычно используется через middleware).
Типы данных и интерфейсы SCS
Тип Status
type Status int
Статус представляет состояние данных сессии в течение цикла запроса.
Константы статусов:
const (
// Unmodified - данные сессии не изменялись
Unmodified Status = iota
// Modified - данные были изменены
Modified
// Destroyed - сессия была уничтожена
Destroyed
)
Использование:
status := sessionManager.Status(ctx)
switch status {
case scs.Unmodified:
// Сессия не изменялась
case scs.Modified:
// Требуется сохранение изменений
case scs.Destroyed:
// Сессия закрыта
}
Интерфейс Store
type Store interface {
// Delete удаляет токен и данные сессии
// Если токен не существует - операция игнорируется
Delete(token string) error
// Find ищет данные по токену сессии
// Возвращает:
// - данные (если найдены)
// - флаг существования
// - ошибку (только для системных сбоев)
Find(token string) ([]byte, bool, error)
// Commit сохраняет/обновляет данные сессии
Commit(token string, data []byte, expiry time.Time) error
}
Базовый интерфейс для реализации хранилищ сессий.
Особенности реализации:
- Delete должен быть идемпотентным
- Find возвращает
found=falseдля:- Несуществующих токенов
- Истекших сессий
- Поврежденных данных
- Commit должен перезаписывать существующие данные
Пример проверки сессии:
data, found, err := store.Find(token)
if err != nil {
// Обработка системной ошибки
}
if !found {
// Сессия не существует/истекла
}
Этот интерфейс позволяет интегрировать SCS с любыми системами хранения данных.
12.5 - Горутина (goroutine) в Go, Каналы (channels) в Go и Конвейеры (Pipelines) в Go.
Горутина (goroutine) в Go — это легковесный “поток”, который позволяет выполнять код конкурентно (почти одновременно) без создания полноценных потоков ОС. Каналы (channels) в Go — это специальный тип данных, который позволяет безопасно передавать данные между горутинами
goroutine
Горутина (goroutine) в Go — это легковесный “поток”, который позволяет выполнять код конкурентно (почти одновременно) без создания полноценных потоков ОС.Простыми словами о Goroutine:
- Это как виртуальный работник, который выполняет задачи параллельно с другими горутинами.
- Горутины дешевле настоящих потоков (их можно создавать тысячи без нагрузки на систему).
- Управляются средой Go (runtime), а не операционной системой.
Пример:
package main
import (
"fmt"
"time"
)
func sayHello() {
fmt.Println("Привет!")
}
func main() {
// Запуск горутины (выполняется параллельно с main)
go sayHello()
// Главная функция продолжает работу
fmt.Println("Главная функция...")
time.Sleep(1 * time.Second) // Ждём, чтобы горутина успела выполниться
}
Вывод:
Главная функция...
Привет!
Особенности:
- Легковесные — занимают всего ~2 КБ памяти (потоки ОС — от 1 МБ).
- Быстрый старт — создаются и запускаются почти мгновенно.
- Автомасштабирование — Go сам распределяет их по доступным ядрам CPU.
- Не блокируют main — если главная функция завершится, все горутины умрут.
Важно:
- Горутины не гарантируют порядок выполнения.
- Для обмена данными между горутинами используют каналы (channels).
Аналог из жизни:
Представьте, что вы (главная функция) даёте задание коллеге (горутине):
- Вы можете продолжать работать, пока коллега выполняет свою часть.
- Вам не нужно ждать его — всё происходит конкурентно.
Горутины — одна из главных “фишек” Go, делающая его мощным для многозадачных программ!
channels
Каналы (channels) в Go — это специальный тип данных, который позволяет безопасно передавать данные между горутинами.Представьте их как трубы, по которым одна горутина отправляет данные, а другая — принимает. Это помогает избежать гонок данных (data races) и синхронизировать работу горутин.
Базовые операции с каналами
1. Создание канала
Каналы бывают:
- Буферизированные (с фиксированной ёмкостью)
- Небуферизированные (ждёт, пока получатель заберёт данные)
ch := make(chan int) // Небуферизированный канал для int
chBuf := make(chan int, 3) // Буферизированный (ёмкость = 3)
2. Отправка данных (<-)
ch <- 42 // Отправить число 42 в канал
3. Получение данных (<-)
value := <-ch // Получить данные из канала
fmt.Println(value) // 42
4. Закрытие канала (close)
Закрытый канал нельзя использовать для отправки, но можно читать оставшиеся данные.
close(ch)
Пример: Простая передача данных
package main
import "fmt"
func sendData(ch chan string) {
ch <- "Привет из горутины!" // Отправляем данные
}
func main() {
ch := make(chan string) // Создаём канал
go sendData(ch) // Запускаем горутину
msg := <-ch // Получаем данные
fmt.Println(msg) // "Привет из горутины!"
close(ch) // Закрываем канал
}
Вывод:
Привет из горутины!
Важные особенности каналов
1. Блокировка операций
Небуферизированный канал:
- Отправка (
ch <- data) блокирует горутину, пока другая горутина не прочитает данные. - Чтение (
<-ch) блокирует, пока не поступят данные.
- Отправка (
Буферизированный канал:
- Отправка блокируется только если буфер заполнен.
- Чтение блокируется только если буфер пуст.
2. Проверка на закрытие
value, ok := <-ch
if !ok {
fmt.Println("Канал закрыт!")
}
3. range по каналу
Можно перебирать данные, пока канал не закроется:
for msg := range ch {
fmt.Println(msg)
}
Пример: Синхронизация горутин
package main
import (
"fmt"
"time"
)
func worker(done chan bool) {
fmt.Println("Работаю...")
time.Sleep(2 * time.Second)
fmt.Println("Готово!")
done <- true // Сигнализируем о завершении
}
func main() {
done := make(chan bool)
go worker(done)
<-done // Ждём сигнал от worker
fmt.Println("Рабочая горутина завершилась.")
}
Вывод:
Работаю...
Готово!
Рабочая горутина завершилась.
Когда использовать каналы?
- Для синхронизации (ожидание завершения горутин).
- Для передачи данных между горутинами.
- Для организации конвейеров (pipeline) обработки данных.
Ошибки при работе с каналами
- Deadlock — если нет получателя/отправителя.
ch := make(chan int) ch <- 42 // Ошибка: никто не читает из канала! - Паника при отправке в закрытый канал.
close(ch) ch <- 10 // panic: send on closed channel - Чтение из пустого закрытого канала вернёт нулевое значение.
Аналог из жизни
Канал — как почтовый ящик:
- Вы (горутина) кладёте письмо (
ch <- data). - Другой человек (горутина) забирает его (
<-ch). - Если ящик переполнен (буфер заполнен), вы ждёте, пока освободится место.
Каналы — это безопасный и удобный способ общения между горутинами в Go!
Pipelines
Конвейеры (Pipelines) в Go: примеры и особенностиКонвейер (pipeline) — это цепочка горутин, где каждая выполняет свою часть работы, передавая данные следующей через каналы. Это мощный паттерн для:
- Обработки данных по этапам (фильтрация, преобразование, агрегация).
- Параллельного выполнения задач с контролируемым потоком данных.
- Управления ресурсами (ограничение числа одновременно работающих горутин).
Базовый конвейер (3 этапа)
1. Генерация данных → Обработка → Вывод
package main
import "fmt"
// Этап 1: Генерация чисел (producer)
func generate(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
// Этап 2: Умножение (processor)
func multiply(in <-chan int, factor int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * factor
}
close(out)
}()
return out
}
// Этап 3: Вывод (consumer)
func print(in <-chan int) {
for n := range in {
fmt.Println(n)
}
}
func main() {
// Конвейер: generate → multiply → print
data := generate(1, 2, 3, 4)
processed := multiply(data, 10)
print(processed)
}
Вывод:
10
20
30
40
Особенности конвейеров
1. Каждый этап — отдельная горутина
- Этапы работают параллельно (если CPU позволяет).
- Данные передаются последовательно через каналы.
2. Закрытие каналов
- Когда producer закрывает канал, все processors и consumer получают сигнал завершения.
- Использование
rangeдля чтения из канала автоматически завершается приclose().
3. Буферизация для ускорения
Буферизированные каналы уменьшают блокировки:
out := make(chan int, 100) // Буфер на 100 элементов
Фильтрация в конвейере
Добавим этап, который оставляет только чётные числа:
// Этап 2.5: Фильтрация чётных чисел
func filterEven(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
if n%2 == 0 {
out <- n
}
}
close(out)
}()
return out
}
func main() {
data := generate(1, 2, 3, 4, 5, 6)
processed := multiply(data, 3) // Умножаем на 3
evenOnly := filterEven(processed) // Оставляем чётные
print(evenOnly)
}
Вывод:
6
12
18
Fan-Out/Fan-In: Параллельная обработка
- Fan-Out: Разделение работы между несколькими горутинами.
- Fan-In: Объединение результатов в один канал.
Пример:
// Fan-In: объединяет несколько каналов в один
func merge(channels ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Запускаем для каждого канала горутину, которая перенаправляет данные в out
for _, ch := range channels {
wg.Add(1)
go func(c <-chan int) {
for n := range c {
out <- n
}
wg.Done()
}(ch)
}
// Закрываем out после завершения всех горутин
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
data := generate(1, 2, 3, 4, 5, 6, 7, 8)
// Fan-Out: Запускаем 3 обработчика
proc1 := multiply(data, 10)
proc2 := multiply(data, 20)
proc3 := multiply(data, 30)
// Fan-In: Объединяем результаты
merged := merge(proc1, proc2, proc3)
print(merged)
}
Вывод (порядок может меняться):
10
20
30
40
50
60
70
80
20
40
60
80
100
120
140
160
30
60
90
120
150
180
210
240
Ошибки и подводные камни
Утечки горутин
- Если канал не закрыт, горутина может зависнуть в ожидании.
- Всегда закрывайте каналы на стороне отправителя.
Deadlock
- Если канал не читается, отправляющая горутина заблокируется навсегда.
Ограничение параллелизма
- Если запустить 1000 горутин, они могут перегрузить систему.
- Решение: пул воркеров с использованием
semaphoreилиbuffered channels.
Когда использовать конвейеры?
- ETL-процессы (извлечение, преобразование, загрузка данных).
- Параллельная обработка большого количества задач (например, скачивание файлов).
- Построение многопоточных приложений с чёткой структурой.
Аналог из жизни
Конвейер — как заводская линия сборки:
- Этап 1: Детали поступают на ленту (генерация данных).
- Этап 2: Робот красит детали (обработка).
- Этап 3: Другой робот упаковывает (фильтрация).
- Этап 4: Готовые изделия отправляются на склад (вывод).
Каждый этап работает независимо, но согласованно через общий механизм (каналы).
Итог
Конвейеры в Go — это:
✅ Гибкость (можно добавлять/удалять этапы).
✅ Параллелизм (эффективное использование CPU).
✅ Безопасность (данные передаются через каналы, нет гонок).
Используйте их для сложных многопоточных задач!
12.6 - Подключение к SQLite в Go: Полное руководство
Основные команды по управлению базой данных SQLite на языке программирования Go.
Установка драйвера SQLite для Go
Перед началом работы установите драйвер SQLite:
go get github.com/mattn/go-sqlite3
Базовое подключение к базе данных
Простое подключение
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/mattn/go-sqlite3"
)
func main() {
// Открытие соединения с базой данных
db, err := sql.Open("sqlite3", "./test.db")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Проверка соединения
err = db.Ping()
if err != nil {
log.Fatal(err)
}
fmt.Println("Successfully connected to SQLite database")
}
Подключение с параметрами
db, err := sql.Open("sqlite3", "file:test.db?cache=shared&mode=memory")
if err != nil {
log.Fatal(err)
}
Выполнение запросов
Создание таблицы
func createTable(db *sql.DB) error {
query := `
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
)`
_, err := db.Exec(query)
return err
}
Вставка данных
func insertUser(db *sql.DB, name, email string) (int64, error) {
res, err := db.Exec("INSERT INTO users(name, email) VALUES(?, ?)", name, email)
if err != nil {
return 0, err
}
return res.LastInsertId()
}
Выборка данных
type User struct {
ID int
Name string
Email string
CreatedAt string
}
func getUsers(db *sql.DB) ([]User, error) {
rows, err := db.Query("SELECT id, name, email, created_at FROM users")
if err != nil {
return nil, err
}
defer rows.Close()
var users []User
for rows.Next() {
var u User
err := rows.Scan(&u.ID, &u.Name, &u.Email, &u.CreatedAt)
if err != nil {
return nil, err
}
users = append(users, u)
}
return users, nil
}
Транзакции
func transferMoney(db *sql.DB, from, to int, amount float64) error {
tx, err := db.Begin()
if err != nil {
return err
}
// Откат транзакции при ошибке
defer func() {
if err != nil {
tx.Rollback()
}
}()
// Снимаем деньги с первого аккаунта
_, err = tx.Exec("UPDATE accounts SET balance = balance - ? WHERE id = ?", amount, from)
if err != nil {
return err
}
// Добавляем деньги на второй аккаунт
_, err = tx.Exec("UPDATE accounts SET balance = balance + ? WHERE id = ?", amount, to)
if err != nil {
return err
}
// Фиксируем транзакцию
return tx.Commit()
}
Подготовленные выражения (Prepared Statements)
func getUserByEmail(db *sql.DB, email string) (*User, error) {
stmt, err := db.Prepare("SELECT id, name, email FROM users WHERE email = ?")
if err != nil {
return nil, err
}
defer stmt.Close()
var u User
err = stmt.QueryRow(email).Scan(&u.ID, &u.Name, &u.Email)
if err != nil {
return nil, err
}
return &u, nil
}
Практические советы
- Пулинг соединений: SQLite не поддерживает множественные соединения на запись, но вы можете использовать пулинг для чтения:
db.SetMaxOpenConns(1) // Важно для SQLite
- Режим WAL: Для лучшей производительности:
_, err = db.Exec("PRAGMA journal_mode=WAL")
if err != nil {
log.Fatal(err)
}
- Обработка ошибок: Всегда проверяйте ошибки при закрытии ресурсов:
defer func() {
if err := rows.Close(); err != nil {
log.Printf("failed to close rows: %v", err)
}
}()
Полный пример приложения
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/mattn/go-sqlite3"
)
type User struct {
ID int
Name string
Email string
}
func main() {
// Подключение к базе данных
db, err := sql.Open("sqlite3", "./app.db")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Настройка базы данных
if err := initDB(db); err != nil {
log.Fatal(err)
}
// Добавление пользователя
id, err := addUser(db, "John Doe", "john@example.com")
if err != nil {
log.Fatal(err)
}
fmt.Printf("Added user with ID: %d\n", id)
// Получение списка пользователей
users, err := getUsers(db)
if err != nil {
log.Fatal(err)
}
fmt.Println("Users:")
for _, u := range users {
fmt.Printf("%d: %s (%s)\n", u.ID, u.Name, u.Email)
}
}
func initDB(db *sql.DB) error {
_, err := db.Exec(`
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
)
`)
return err
}
func addUser(db *sql.DB, name, email string) (int64, error) {
res, err := db.Exec("INSERT INTO users(name, email) VALUES(?, ?)", name, email)
if err != nil {
return 0, err
}
return res.LastInsertId()
}
func getUsers(db *sql.DB) ([]User, error) {
rows, err := db.Query("SELECT id, name, email FROM users")
if err != nil {
return nil, err
}
defer rows.Close()
var users []User
for rows.Next() {
var u User
if err := rows.Scan(&u.ID, &u.Name, &u.Email); err != nil {
return nil, err
}
users = append(users, u)
}
return users, nil
}
Заключение
Работа с SQLite в Go проста и эффективна благодаря пакету database/sql и драйверу go-sqlite3. Основные принципы:
- Всегда закрывайте ресурсы (деферы для
Close()) - Используйте подготовленные выражения для защиты от SQL-инъекций
- Для операций записи используйте транзакции
- Настраивайте параметры SQLite для оптимальной производительности
12.7 - Спецификация языка программирования Go
Спецификация языка программирования Go на русском языке
“The Go Programming Language Specification”
Introduction (Введение)
Это справочное руководство по языку программирования Go. Версию до Go1.18, без дженериков, можно найти здесь. Дополнительную информацию и другие документы можно найти на сайте go.dev
Go - это язык общего назначения, разработанный для системного программирования. Он сильно типизирован, имеет сборщик мусора, а также имеет явную поддержку параллельного программирования. Программы строятся из пакетов, свойства которых позволяют эффективно управлять зависимостями.
Синтаксис компактен и прост в разборе, что позволяет легко анализировать его с помощью автоматических инструментов, таких как интегрированные среды разработки.
Notation (Нотация)
Синтаксис задается с помощью варианта расширенной формы Бэкуса-Наура (EBNF):
Production = production_name "=" [ Expression ] "." .
Expression = Alternative { "|" Alternative } .
Alternative = Term { Term } .
Term = production_name | token [ "…" token ] | Group | Option | Repetition .
Group = "(" Expression ")" .
Option = "[" Expression "]" .
Repetition = "{" Expression "}" .
“Productions” (продукции) — это правила в формальной грамматике, которые описывают синтаксис языка Go.
Productions - это выражения, построенные из терминов и следующих операторов в порядке возрастания старшинства:
| alternation
() grouping
[] option (0 or 1 times)
{} repetition (0 to n times)
Для обозначения лексических (терминальных) лексем используются строчные имена, написанные строчными буквами. Нетерминалы обозначаются в CamelCase. Лексические лексемы заключаются в двойные кавычки "" или обратные кавычки ``.
Форма a ... b представляет собой набор символов от a до b в качестве альтернатив. Горизонтальное многоточие ... также используется в других местах спецификации для неформального обозначения различных перечислений или фрагментов кода, которые не уточняются далее. Символ ... (в отличие от трех символов …) не является лексемой языка Go.
Ссылка вида [Go 1.xx] указывает на то, что описанная функция языка (или какой-то ее аспект) была изменена или добавлена в версии языка 1.xx и поэтому для сборки требуется как минимум эта версия языка. Подробнее см. раздел со ссылками в приложении.
Source code representation (Представление исходного кода)
Исходный код - это текст Юникода, закодированный в UTF-8. Текст не канонизирован, поэтому одна точка кода с ударением отличается от того же символа, построенного из сочетания ударения и буквы; они рассматриваются как две точки кода. Для простоты в этом документе будет использоваться неквалифицированный термин “символ” для обозначения кодовой точки Юникода в исходном тексте.
Каждая кодовая точка является отдельной; например, прописные и строчные буквы - это разные символы.
Ограничение на реализацию: Для совместимости с другими инструментами компилятор может запретить использование символа NUL (U+0000) в исходном тексте.
Ограничение на реализацию: Для совместимости с другими инструментами компилятор может игнорировать метку порядка байтов в кодировке UTF-8 (U+FEFF), если она является первой точкой кода Юникода в исходном тексте. В любом другом месте исходного текста знак порядка байтов может быть запрещен.
Символы
Следующие термины используются для обозначения определенных категорий символов Unicode:
newline = /* кодовая позиция Юникода U+000A */ .
unicode_char = /* произвольная кодовая позиция Юникода, кроме newline */ .
unicode_letter = /* кодовая позиция Юникода, отнесенная к категории "Буква" */ .
unicode_digit = /* кодовая позиция Юникода, отнесенная к категории "Число, десятичная цифра" */ .```
В стандарте Юникод 8.0 в разделе 4.5 “Общая категория” определен набор категорий символов. Go рассматривает все символы в любой из буквенных категорий Lu, Ll, Lt, Lm или Lo как буквы Юникода, а символы в числовой категории Nd - как цифры Юникода.
Символы и числа
Символ подчеркивания _ (U+005F) считается строчной буквой.
letter = unicode_letter | "_" .
decimal_digit = "0" … "9" .
binary_digit = "0" | "1" .
octal_digit = "0" … "7" .
hex_digit = "0" … "9" | "A" … "F" | "a" … "f" .
Лексические элементы
Комментарии
Комментарии служат в качестве программной документации. Существует две формы:
- Строчные комментарии начинаются с последовательности символов
//и останавливаются в конце строки. - Общие комментарии начинаются с последовательности символов
/*и заканчиваются первой последующей последовательностью символов*/.
Комментарий не может начинаться внутри руны или строкового литерала, а также внутри комментария. Общий комментарий, не содержащий новых строк, действует как пробел. Любой другой комментарий действует как новая строка.
Токены
Токены составляют словарный запас языка Go. Существует четыре класса:
- идентификаторы (Identifiers),
- ключевые слова, (Keywords)
- операторы и пунктуация,
- литералы.
Пространство пробелов, образованное символами (U+0020), горизонтальных табуляций (U+0009), возвратов каретки (U+000D) и новых строк (U+000A), игнорируется, за исключением случаев, когда оно разделяет лексемы, которые в противном случае были бы объединены в одну лексему. Кроме того, новая строка или конец файла могут вызвать вставку точки с запятой.
При разбиении вводимого текста на лексемы следующей лексемой является самая длинная последовательность символов, образующая допустимую лексему.
Точки с запятой
Формальный синтаксис использует точки с запятой ";" в качестве терминаторов в ряде последовательности команд. Программы на Go могут опускать большинство этих точек с запятой, используя следующие два правила:
- Когда ввод разбивается на токены, точка с запятой автоматически вставляется в поток токенов сразу после последнего токена строки, если этот токен
- идентификатор
- целое число, плавающая точка, мнимое число, руна или строковый литерал
- одно из ключевых слов break, continue, fallthrough или return
- один из операторов и пунктуации ++, –, ), ], или }.
- Чтобы сложные операторы занимали одну строку, перед закрывающим оператором “)” или “}” можно опустить точку с запятой.
Чтобы отразить идиоматическое использование, в примерах кода в этом документе точки с запятой опускаются в соответствии с этими правилами.
(Идентификаторы) Identifiers
Идентификаторы называют программные объекты, такие как переменные и типы. Идентификатор - это последовательность из одной или нескольких букв и цифр. Первый символ в идентификаторе должен быть буквой.
identifier = letter { letter | unicode_digit } .
a
_x9
ThisVariableIsExported
αβ
Ключевые слова (Keywords)
Следующие ключевые слова зарезервированы и не могут быть использованы в качестве идентификаторов.
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
Операторы и пунктуация
Следующие последовательности символов представляют операторы (включая операторы присваивания) и пунктуацию:
+ & += &= && == != ( )
- | -= |= || < <= [ ]
* ^ *= ^= <- > >= { }
/ << /= <<= ++ = := , ;
% >> %= >>= -- ! ... . :
&^ &^=
Целочисленные литералы
Целочисленный литерал - это последовательность цифр, представляющая целочисленную константу. Необязательный префикс задает недесятичное основание: 0b или 0B для двоичной системы, 0, 0o или 0O для восьмеричной и 0x или 0X для шестнадцатеричной [Go 1.13]. Одиночный 0 считается десятичным нулем. В шестнадцатеричных литералах буквы от a до f и от A до F обозначают значения от 10 до 15.
Для удобства чтения после базового префикса или между последовательными цифрами может стоять символ подчеркивания _; такое подчеркивание не меняет значения литерала.
int_lit = decimal_lit | binary_lit | octal_lit | hex_lit .
decimal_lit = "0" | ( "1" … "9" ) [ [ "_" ] decimal_digits ] .
binary_lit = "0" ( "b" | "B" ) [ "_" ] binary_digits .
octal_lit = "0" [ "o" | "O" ] [ "_" ] octal_digits .
hex_lit = "0" ( "x" | "X" ) [ "_" ] hex_digits .
decimal_digits = decimal_digit { [ "_" ] decimal_digit } .
binary_digits = binary_digit { [ "_" ] binary_digit } .
octal_digits = octal_digit { [ "_" ] octal_digit } .
hex_digits = hex_digit { [ "_" ] hex_digit } .
42
4_2
0600
0_600
0o600
0O600 // second character is capital letter 'O'
0xBadFace
0xBad_Face
0x_67_7a_2f_cc_40_c6
170141183460469231731687303715884105727
170_141183_460469_231731_687303_715884_105727
_42 // an identifier, not an integer literal
42_ // invalid: _ must separate successive digits
4__2 // invalid: only one _ at a time
0_xBadFace // invalid: _ must separate successive digits
Литералы с плавающей точкой
Литерал с плавающей точкой - это десятичное или шестнадцатеричное представление константы с плавающей точкой.
Десятичный литерал с плавающей точкой состоит из целой части (десятичных цифр), десятичной точки, дробной части (десятичных цифр) и экспоненты (e или E, за которой следует необязательный знак и десятичные цифры). Одна из частей целого числа или дробная часть могут быть опущены; одна из десятичных точек или часть экспоненты могут быть опущены. Значение экспоненты exp увеличивает мантиссу (целую и дробную части) на (10^{exp}).
Шестнадцатеричный литерал с плавающей точкой состоит из префикса 0x или 0X, целой части (шестнадцатеричные цифры), точки радикса, дробной части (шестнадцатеричные цифры) и части экспоненты (p или P, за которой следует необязательный знак и десятичные цифры). Одна из частей целого числа или дробная часть могут быть опущены; точка радикса также может быть опущена, но часть экспоненты обязательна. (Этот синтаксис соответствует синтаксису, приведенному в IEEE 754-2008 §5.12.3.) Значение экспоненты exp увеличивает мантиссу (целую и дробную части) на (2^{exp}) [Go 1.13].
Для удобства чтения после базового префикса или между последовательными цифрами может стоять символ подчеркивания _; такое подчеркивание не меняет буквенного значения.
float_lit = decimal_float_lit | hex_float_lit .
decimal_float_lit = decimal_digits "." [ decimal_digits ] [ decimal_exponent ] |
decimal_digits decimal_exponent |
"." decimal_digits [ decimal_exponent ] .
decimal_exponent = ( "e" | "E" ) [ "+" | "-" ] decimal_digits .
hex_float_lit = "0" ( "x" | "X" ) hex_mantissa hex_exponent .
hex_mantissa = [ "_" ] hex_digits "." [ hex_digits ] |
[ "_" ] hex_digits |
"." hex_digits .
hex_exponent = ( "p" | "P" ) [ "+" | "-" ] decimal_digits .
0.
72.40
072.40 // == 72.40
2.71828
1.e+0
6.67428e-11
1E6
.25
.12345E+5
1_5. // == 15.0
0.15e+0_2 // == 15.0
0x1p-2 // == 0.25
0x2.p10 // == 2048.0
0x1.Fp+0 // == 1.9375
0X.8p-0 // == 0.5
0X_1FFFP-16 // == 0.1249847412109375
0x15e-2 // == 0x15e - 2 (integer subtraction)
0x.p1 // invalid: mantissa has no digits
1p-2 // invalid: p exponent requires hexadecimal mantissa
0x1.5e-2 // invalid: hexadecimal mantissa requires p exponent
1_.5 // invalid: _ must separate successive digits
1._5 // invalid: _ must separate successive digits
1.5_e1 // invalid: _ must separate successive digits
1.5e_1 // invalid: _ must separate successive digits
1.5e1_ // invalid: _ must separate successive digits
Мнимые литералы (imaging)
Мнимый литерал представляет собой мнимую часть комплексной константы. Он состоит из целого литерала или литерала с плавающей точкой, за которым следует строчная буква i. Значение мнимого литерала - это значение соответствующего целого литерала или литерала с плавающей точкой, умноженное на мнимую единицу i [Go 1.13].
imaginary_lit = (decimal_digits | int_lit | float_lit) "i" .
В целях обратной совместимости целая часть мнимого литерала, полностью состоящая из десятичных цифр (и, возможно, знаков подчеркивания), считается десятичным целым числом, даже если оно начинается с ведущего 0.
0i
0123i // == 123i for backward-compatibility
0o123i // == 0o123 * 1i == 83i
0xabci // == 0xabc * 1i == 2748i
0.i
2.71828i
1.e+0i
6.67428e-11i
1E6i
.25i
.12345E+5i
0x1p-2i // == 0x1p-2 * 1i == 0.25i
Литералы рун
Литерал руны представляет собой константу руны, целочисленное значение, идентифицирующее код Юникода. Рунический литерал выражается в виде одного или нескольких символов, заключенных в одинарные кавычки, как, например, 'x' или '\n'. Внутри кавычек может находиться любой символ, кроме новой строки и неэкранированной одинарной кавычки. Одиночный символ в кавычках представляет собой значение Unicode самого символа, а многосимвольные последовательности, начинающиеся с обратной косой черты, кодируют значения в различных форматах.
Простейшая форма представляет собой одиночный символ внутри кавычек; поскольку исходный текст Go - это символы Юникода, закодированные в UTF-8, несколько байтов в кодировке UTF-8 могут представлять одно целое значение.
Например, литерал
'a'содержит один байт, представляющий литералa,Unicode U+0061, значение0x61, а литерал'ä'содержит два байта(0xc3 0xa4), представляющих литералa-dieresis,U+00E4, значение0xe4.
Несколько обратных косых черточек позволяют кодировать произвольные значения как ASCII-текст. Существует четыре способа представления целочисленного значения в виде числовой константы:
\xс последующими ровно двумя шестнадцатеричными цифрами;\uс последующими ровно четырьмя шестнадцатеричными цифрами;\Uс последующими ровно восемью шестнадцатеричными цифрами,- и обычный обратный слеш
\с последующими ровно тремя восьмеричными цифрами.
В каждом случае значение литерала - это значение, представленное цифрами в соответствующем базисе.
Хотя все эти представления приводят к целому числу, они имеют разные диапазоны допустимых значений.
Октальные эскейпы должны представлять значение от 0 до 255 включительно. Шестнадцатеричные эскейпы удовлетворяют этому условию по своей конструкции. Эскапады \u и \U представляют кодовые точки Юникода, поэтому в них некоторые значения являются недопустимыми, в частности, значения выше 0x10FFFF и суррогатные половинки.
После обратной косой черты некоторые односимвольные эскейпы представляют специальные значения:
\a U+0007 alert or bell
\b U+0008 backspace
\f U+000C form feed
\n U+000A line feed or newline
\r U+000D carriage return
\t U+0009 horizontal tab
\v U+000B vertical tab
\\ U+005C backslash
\' U+0027 single quote (valid escape only within rune literals)
\" U+0022 double quote (valid escape only within string literals)
Нераспознанный символ, следующий за обратной косой чертой в литерале руны, является незаконным.
rune_lit = "'" ( unicode_value | byte_value ) "'" .
unicode_value = unicode_char | little_u_value | big_u_value | escaped_char .
byte_value = octal_byte_value | hex_byte_value .
octal_byte_value = `\` octal_digit octal_digit octal_digit .
hex_byte_value = `\` "x" hex_digit hex_digit .
little_u_value = `\` "u" hex_digit hex_digit hex_digit hex_digit .
big_u_value = `\` "U" hex_digit hex_digit hex_digit hex_digit
hex_digit hex_digit hex_digit hex_digit .
escaped_char = `\` ( "a" | "b" | "f" | "n" | "r" | "t" | "v" | `\` | "'" | `"` ) .
'a'
'ä'
'本'
'\t'
'\000'
'\007'
'\377'
'\x07'
'\xff'
'\u12e4'
'\U00101234'
'\'' // rune literal containing single quote character
'aa' // illegal: too many characters
'\k' // illegal: k is not recognized after a backslash
'\xa' // illegal: too few hexadecimal digits
'\0' // illegal: too few octal digits
'\400' // illegal: octal value over 255
'\uDFFF' // illegal: surrogate half
'\U00110000' // illegal: invalid Unicode code point
Строковые литералы
Строковый литерал представляет собой строковую константу, полученную в результате конкатенации последовательности символов. Существует две формы: необработанные строковые литералы и интерпретированные строковые литералы.
Необработанные строковые литералы - это последовательности символов между обратными кавычками, как в `foo`.
Внутри кавычек может находиться любой символ, кроме обратной кавычки. Значением сырого строкового литерала является строка, состоящая из неинтерпретированных (неявно UTF-8-кодированных) символов между кавычками; в частности, обратные косые черты не имеют специального значения, и строка может содержать новые строки. Символы возврата каретки ('\r') внутри необработанных строковых литералов отбрасываются из значения необработанной строки.
Интерпретируемые строковые литералы - это последовательности символов между двойными кавычками, как в слове “bar”. Внутри кавычек может появиться любой символ, кроме новой строки и двойной кавычки без сопровождения. Текст между кавычками образует значение литерала, при этом обратные косые черты интерпретируются так же, как и в рунных литералах (за исключением того, что \' является незаконным, а \" - законным), с теми же ограничениями. Трехзначные восьмеричные (\nnn) и двузначные шестнадцатеричные (\xnn) эскапады представляют отдельные байты результирующей строки; все остальные эскапады представляют (возможно, многобайтовую) кодировку UTF-8 отдельных символов. Таким образом, внутри строки литералы \377 и \xFF представляют один байт значения 0xFF=255, а ÿ, \u00FF, \U000000FF и \xc3\xbf представляют два байта 0xc3 0xbf кодировки UTF-8 символа U+00FF.
string_lit = raw_string_lit | interpreted_string_lit .
raw_string_lit = "`" { unicode_char | newline } "`" .
interpreted_string_lit = `"` { unicode_value | byte_value } `"` .
`abc` // same as "abc"
`\n
\n` // same as "\\n\n\\n"
"\n"
"\"" // same as `"`
"Hello, world!\n"
"日本語"
"\u65e5本\U00008a9e"
"\xff\u00FF"
"\uD800" // illegal: surrogate half
"\U00110000" // illegal: invalid Unicode code point
Все эти примеры представляют одну и ту же строку:
"日本語" // UTF-8 input text
`日本語` // UTF-8 input text as a raw literal
"\u65e5\u672c\u8a9e" // the explicit Unicode code points
"\U000065e5\U0000672c\U00008a9e" // the explicit Unicode code points
"\xe6\x97\xa5\xe6\x9c\xac\xe8\xaa\x9e" // the explicit UTF-8 bytes
Если исходный код представляет символ как две кодовые позиции, например, комбинированную форму, включающую ударение и букву, то при помещении в литерал руны результат будет ошибкой (это не одна кодовая позиция), а при помещении в строковый литерал - двумя кодовыми позициями.
Константы
Существуют булевы константы, рунные константы, целочисленные константы, константы с плавающей точкой, комплексные константы и строковые константы.
Руны, целые числа, константы с плавающей точкой и комплексные константы в совокупности называются числовыми константами.
Постоянное значение представлено руной, целым числом, плавающей точкой, мнимым или строковым литералом, идентификатором, обозначающим константу, постоянным выражением, преобразованием с результатом, являющимся константой, или значением результата некоторых встроенных функций, таких как min или max, применяемых к аргументам констант, unsafe.Sizeof, применяемых к определенным значениям, cap или len, применяемых к некоторым выражениям, real и imag, применяемых к комплексной константе, и complex, применяемых к числовым константам. Булевы истинностные значения представлены заранее объявленными константами true и false. Объявленный идентификатор iota обозначает целочисленную константу.
В общем случае комплексные константы являются одной из форм выражения констант и рассматриваются в этом разделе.
Числовые константы представляют собой точные значения произвольной точности и не переполняются. Следовательно, не существует констант, обозначающих отрицательный ноль, бесконечность и не-число по стандарту IEEE 754.
Константы могут быть типизированными или нетипизированными. Буквальные константы, true, false, iota, а также некоторые константные выражения, содержащие только нетипизированные операнды констант, являются нетипизированными.
Тип константы может быть задан явно при объявлении или преобразовании константы, или неявно при использовании в объявлении переменной, операторе присваивания или в качестве операнда в выражении. Если значение константы не может быть представлено как значение соответствующего типа, то это ошибка. Если тип является параметром типа, константа преобразуется в неконстантное значение параметра типа.
Ограничение на реализацию:
Хотя числовые константы имеют произвольную точность в языке, компилятор может реализовать их, используя внутреннее представление с ограниченной точностью. Тем не менее, каждая реализация должна:
- Представлять целочисленные константы не менее чем 256 битами.
- Представлять константы с плавающей точкой, включая части комплексной константы, с мантиссой не менее 256 бит и знаковой двоичной экспонентой не менее 16 бит.
- Указывать ошибку, если не может точно представить целую константу.
- Давать ошибку, если не может представить константу с плавающей точкой или комплексную константу из-за переполнения.
- Округлять до ближайшей представимой константы, если не может представить константу с плавающей точкой или комплексную константу из-за ограничений на точность.
Эти требования относятся как к литеральным константам, так и к результатам вычисления константных выражений.
Переменные
Переменная - это место хранения значения. Набор допустимых значений определяется типом переменной.
Объявление переменной или, для параметров и результатов функций, подпись объявления функции или литерала функции резервирует место для хранения именованной переменной. Вызов встроенной функции new или получение адреса составного литерала выделяет место для хранения переменной во время выполнения. На такую анонимную переменную ссылаются через (возможно, неявный) указатель.
Структурированные переменные типов array, slice и struct имеют элементы и поля, к которым можно обращаться по отдельности. Каждый такой элемент действует как переменная.
Статический тип (или просто тип) переменной - это тип, указанный в ее объявлении, тип, указанный в новом вызове или составном литерале, или тип элемента структурированной переменной. Переменные интерфейсного типа также имеют отдельный динамический тип, который представляет собой (неинтерфейсный) тип значения, присваиваемого переменной во время выполнения (если только это значение не является заранее объявленным идентификатором nil, который не имеет типа). Динамический тип может меняться в процессе выполнения, но значения, хранящиеся в интерфейсных переменных, всегда можно присвоить статическому типу переменной.
var x interface{} // x is nil and has static type interface{}
var v *T // v has value nil, static type *T
x = 42 // x has value 42 and dynamic type int
x = v // x has value (*T)(nil) and dynamic type *T
Значение переменной можно получить, обратившись к ней в выражении; это самое последнее значение, присвоенное переменной. Если переменной еще не присвоено значение, ее значение равно нулю для ее типа.
Типы
Тип определяет набор значений вместе с операциями и методами, характерными для этих значений. Тип может обозначаться именем типа, если оно есть, за которым должны следовать аргументы типа, если тип является общим. Тип также может быть указан с помощью литерала типа, который составляет тип из существующих типов.
Type = TypeName [ TypeArgs ] | TypeLit | "(" Type ")" .
TypeName = identifier | QualifiedIdent .
TypeArgs = "[" TypeList [ "," ] "]" .
TypeList = Type { "," Type } .
TypeLit = ArrayType | StructType | PointerType | FunctionType | InterfaceType |
SliceType | MapType | ChannelType .
Язык заранее объявляет некоторые имена типов. Другие вводятся с помощью деклараций типов или списков параметров типов. Составные типы - массив, структура, указатель, функция, интерфейс, фрагмент, карта и канальный тип - могут быть построены с помощью литералов типов.
Объявленные типы, определенные типы и параметры типов называются именованными типами. Псевдоним обозначает именованный тип, если тип, указанный в объявлении псевдонима, является именованным типом.
Boolean types (Булевы типы)
Булевый тип представляет собой набор булевых истинностных значений, обозначаемых заранее объявленными константами true и false. Предварительно объявленный булевский тип - bool; это определенный тип.
Numeric types (Числовые типы)
Целый, плавающий или комплексный тип представляет собой набор целых, плавающих или комплексных значений, соответственно. Все они называются числовыми типами. К заранее объявленным независимым от архитектуры числовым типам относятся:
uint8 the set of all unsigned 8-bit integers (0 to 255)
uint16 the set of all unsigned 16-bit integers (0 to 65535)
uint32 the set of all unsigned 32-bit integers (0 to 4294967295)
uint64 the set of all unsigned 64-bit integers (0 to 18446744073709551615)
int8 the set of all signed 8-bit integers (-128 to 127)
int16 the set of all signed 16-bit integers (-32768 to 32767)
int32 the set of all signed 32-bit integers (-2147483648 to 2147483647)
int64 the set of all signed 64-bit integers (-9223372036854775808 to 9223372036854775807)
float32 the set of all IEEE 754 32-bit floating-point numbers
float64 the set of all IEEE 754 64-bit floating-point numbers
complex64 the set of all complex numbers with float32 real and imaginary parts
complex128 the set of all complex numbers with float64 real and imaginary parts
byte alias for uint8
rune alias for int32
Значение n-битного целого числа имеет ширину n бит и представляется с помощью арифметики дополнения двойки.
Существует также набор предопределенных целочисленных типов с размерами, зависящими от реализации:
uint //32 или 64 бита
int //тот же размер, что и uint
uintptr //целое число без знака, достаточно большое для хранения неинтерпретированных битов значения указателя
Чтобы избежать проблем с переносимостью, все числовые типы являются определенными типами и, следовательно, отдельными, за исключением byte, который является псевдонимом для uint8, и rune, который является псевдонимом для int32. Явные преобразования требуются, когда различные числовые типы смешиваются в выражении или присваивании.
Например,
int32иintне являются одним и тем же типом, даже если они могут иметь одинаковый размер на определенной архитектуре.
String types (Строковые типы)
Строковый тип представляет собой набор строковых значений.
Строковое значение - это последовательность байтов (возможно, пустая). Количество байтов называется длиной строки и никогда не бывает отрицательным. Строки неизменяемы: после создания содержимое строки невозможно изменить. Объявленный тип строки - string; это определенный тип.
Длина строки s может быть определена с помощью встроенной функции len. Длина является константой времени компиляции, если строка является константой. Доступ к байтам строки осуществляется по целочисленным индексам от 0 до len(s)-1. Взятие адреса такого элемента недопустимо; если s[i] - это i-й байт строки, то &s[i] недопустимо.
Array types (Типы массивов)
Массив - это пронумерованная последовательность элементов одного типа, называемого типом элемента. Количество элементов называется длиной массива и никогда не бывает отрицательным.
ArrayType = "[" ArrayLength "]" ElementType .
ArrayLength = Expression .
ElementType = Type .
Длина является частью типа массива; она должна быть оценена неотрицательной константой, представляемой значением типа int. Длину массива a можно узнать с помощью встроенной функции len. Элементы можно адресовать по целочисленным индексам от 0 до len(a)-1. Типы массивов всегда одномерны, но могут образовывать многомерные типы.
[32]byte
[2*N] struct { x, y int32 }
[1000]*float64
[3][5]int
[2][2][2]float64 // same as [2]([2]([2]float64))
Массив типа T не может иметь элемент типа T или типа, содержащего T в качестве компонента, прямо или косвенно, если эти содержащие типы являются только типами array или struct.
// недопустимые типы массивов
type (
T1 [10]T1 // тип элемента T1 - T1
T2 [10]struct{ f T2 } // T2 содержит T2 как компонент struct
T3 [10]T4 // T3 содержит T3 как компонент struct в T4
T4 struct{ f T3 } // T4 содержит T4 как компонент массива T3 в struct
)
// допустимые типы массивов
type (
T5 [10]*T5 // T5 содержит T5 как компонент указателя
T6 [10]func() T6 // T6 содержит T6 как компонент функции типа
T7 [10]struct{ f []T7 } // T7 содержит T7 как компонент фрагмента в структуре
)
Slice types (Типы срезов)
Срез - это дескриптор для непрерывного сегмента нижележащего массива, который обеспечивает доступ к пронумерованной последовательности элементов из этого массива. Тип slice обозначает множество всех срезов массивов его типа элемента. Количество элементов называется длиной среза и никогда не бывает отрицательным. Значение неинициализированного среза равно nil.
SliceType = "[" "]" ElementType .
Длину фрагмента s можно определить с помощью встроенной функции len; в отличие от массивов, она может меняться в процессе выполнения. К элементам можно обращаться по целочисленным индексам от 0 до len(s)-1. Индекс фрагмента данного элемента может быть меньше, чем индекс того же элемента в нижележащем массиве.
Слайс, после инициализации, всегда связан с нижележащим массивом, в котором хранятся его элементы. Таким образом, фрагмент разделяет хранилище со своим массивом и с другими фрагментами того же массива; напротив, отдельные массивы всегда представляют собой отдельные хранилища.
Массив, лежащий в основе фрагмента, может простираться за пределы фрагмента. Емкость - это мера этой протяженности: она равна сумме длины среза и длины массива за пределами среза; срез длиной до этой емкости может быть создан путем нарезки нового среза из исходного среза. Вместимость среза a можно узнать с помощью встроенной функции cap(a).
Новое инициализированное значение среза для заданного типа элемента T можно создать с помощью встроенной функции make, которая принимает тип среза и параметры, указывающие длину и, опционально, емкость. При создании среза с помощью make всегда выделяется новый скрытый массив, на который ссылается возвращаемое значение среза. Иными словами, выполнение функции
make([]T, length, capacity)
дает тот же срез, что и выделение массива и его срез, поэтому эти два выражения эквивалентны:
make([]int, 50, 100)
new([100]int)[0:50]
Как и массивы, срезы всегда одномерны, но могут быть скомпонованы для создания объектов более высокой размерности. В массивах массивов внутренние массивы, по конструкции, всегда имеют одинаковую длину; однако в срезах срезов (или массивах срезов) внутренние длины могут динамически изменяться. Более того, внутренние срезы должны инициализироваться по отдельности.
Struct types (Типы структур)
Структура - это последовательность именованных элементов, называемых полями, каждый из которых имеет имя и тип. Имена полей могут быть заданы явно (IdentifierList) или неявно (EmbeddedField). Внутри структуры непустые имена полей должны быть уникальными.
StructType = "struct" "{" { FieldDecl ";" } "}" .
FieldDecl = (IdentifierList Type | EmbeddedField) [ Tag ] .
EmbeddedField = [ "*" ] TypeName .
Tag = string_lit .
// Пустая структура.
struct {}
// Структура с 6 полями.
struct {
x, y int
u float32
_ float32 // подложка (пустышка)
A *[]int
F func()
}
Поле, объявленное с типом, но без явного имени поля, называется встроенным полем. Встроенное поле должно быть указано как имя типа T или как указатель на имя неинтерфейсного типа *T, причем сам T не может быть типом-указателем или параметром типа. Неквалифицированное имя типа выступает в качестве имени поля.
// Структура с четырьмя встроенными полями типов T1, *T2, P.T3 и *P.T4
struct {
T1 // имя поля - T1
*T2 // имя поля - T2
P.T3 // имя поля - T3
*P.T4 // имя поля - T4
x, y int // имена полей - x и y
}
Следующее объявление является незаконным, поскольку имена полей должны быть уникальными в типе struct:
struct {
T // конфликтует со встроенным полем *T и *P.T
*T // конфликтует со встроенным полем T и *P.T
*P.T // конфликтует со встроенным полем T и *T
}
Поле или метод f встроенного поля в структуре x называется продвинутым, если x.f является легальным селектором, обозначающим это поле или метод f.
Продвигаемые поля действуют как обычные поля структуры, за исключением того, что они не могут быть использованы в качестве имен полей в составных литералах структуры.
Если задан тип struct S и имя типа T, то продвигаемые методы включаются в набор методов struct следующим образом:
- Если
Sсодержит встроенное полеT, то наборы методовSи*Sоба включают продвигаемые методы с приемникомT. Набор методов*Sтакже включает продвигаемые методы с приемником*T. - Если
Sсодержит встроенное поле*T, то наборы методовSи*Sоба включают продвигаемые методы с приемникомTили*T.
За объявлением поля может следовать необязательный строковый литерал tag, который становится атрибутом для всех полей в соответствующем объявлении поля.
Пустая строка тега эквивалентна отсутствию тега. Теги становятся видимыми через интерфейс отражения и участвуют в идентификации типов для структур, но в остальном игнорируются.
struct {
x, y float64 "" // пустая строка тега подобна отсутствующему тегу
name string "в качестве тега допускается любая строка"
_ [4]byte "Это не структурное поле"
}
// Структура, соответствующая буферу протокола TimeStamp.
// Строки тегов определяют номера полей буфера протокола;
// они следуют соглашению, изложенному в пакете reflect.
struct {
microsec uint64 `protobuf: "1"`
serverIP6 uint64 `protobuf: "2"`
}
Тип struct T не может содержать поле типа T или типа, содержащего T в качестве компонента, прямо или косвенно, если эти содержащие типы являются только типами array или struct.
// недопустимые типы структур
type (
T1 struct{ T1 } // T1 содержит поле T1
T2 struct{ f [10]T2 } // T2 содержит T2 как компонент массива
T3 struct{ T4 } // T3 содержит T3 как компонент массива в struct T4
T4 struct{ f [10]T3 } // T4 содержит T4 как компонент struct T3 в массиве
)
// допустимые типы struct
type (
T5 struct{ f *T5 } // T5 содержит T5 как компонент указателя
T6 struct{ f func() T6 } // T6 содержит T6 как компонент функции type
T7 struct{ f [10][]T7 } // T7 содержит T7 как компонент фрагмента массива
)
Pointer types (Типы указателей)
Тип указателя обозначает множество всех указателей на переменные данного типа, называемого базовым типом указателя. Значением неинициализированного указателя является nil.
PointerType = "*" BaseType .
BaseType = Type .
*Point
*[4]int
Function types (Типы функций)
Тип функции обозначает множество всех функций с одинаковыми типами параметров и результатов. Значением неинициализированной переменной типа функции является nil.
FunctionType = "func" Signature .
Signature = Parameters [ Result ] .
Result = Parameters | Type .
Parameters = "(" [ ParameterList [ "," ] ] ")" .
ParameterList = ParameterDecl { "," ParameterDecl } .
ParameterDecl = [ IdentifierList ] [ "..." ] Type .
В списке параметров или результатов имена (IdentifierList) должны либо все присутствовать, либо все отсутствовать. Если они присутствуют, каждое имя обозначает один элемент (параметр или результат) указанного типа, и все непустые имена в сигнатуре должны быть уникальными. Если они отсутствуют, то каждый тип обозначает один элемент этого типа. Списки параметров и результатов всегда заключаются в круглые скобки, за исключением того, что если имеется ровно один безымянный результат, он может быть записан как тип без скобок.
Последний входящий параметр в сигнатуре функции может иметь тип с префиксом .... Функция с таким параметром называется переменной и может быть вызвана с нулем или более аргументов для этого параметра.
func()
func(x int) int
func(a, _ int, z float32) bool
func(a, b int, z float32) (bool)
func(prefix string, values ...int)
func(a, b int, z float64, opt ...interface{}) (success bool)
func(int, int, float64) (float64, *[]int)
func(n int) func(p *T)
Interface types (Типы интерфейсов)
Тип интерфейса определяет набор типов. Переменная интерфейсного типа может хранить значение любого типа, входящего в набор типов интерфейса. Считается, что такой тип реализует интерфейс. Значение неинициализированной переменной интерфейсного типа равно nil.
InterfaceType = "interface" "{" { InterfaceElem ";" } "}" .
InterfaceElem = MethodElem | TypeElem .
MethodElem = MethodName Signature .
MethodName = identifier .
TypeElem = TypeTerm { "|" TypeTerm } .
TypeTerm = Type | UnderlyingType .
UnderlyingType = "~" Type .
Тип интерфейса задается списком элементов интерфейса. Элемент интерфейса - это либо метод, либо элемент типа, где элемент типа - это объединение одного или нескольких терминов типа. Термин типа - это либо один тип, либо один базовый тип.
Основные интерфейсы
В своей самой простой форме интерфейс задает (возможно, пустой) список методов. Набор типов, определяемый таким интерфейсом, - это набор типов, реализующих все эти методы, а соответствующий набор методов состоит именно из методов, указанных интерфейсом. Интерфейсы, чьи наборы типов могут быть полностью определены списком методов, называются базовыми интерфейсами.
// Простой интерфейс File.
interface {
Read([]byte) (int, error)
Write([]byte) (int, error)
Close() error
}
Имя каждого явно указанного метода должно быть уникальным и не пустым.
interface {
String() string
String() string // ошибка: String не уникальна
_(x int) // ошибка: метод не должен иметь пустого имени
}
Интерфейс может быть реализован более чем одним типом. Например, если два типа S1 и S2 имеют набор методов
func (p T) Read(p []byte) (n int, err error)
func (p T) Write(p []byte) (n int, err error)
func (p T) Close() error
(где T обозначает S1 или S2), то интерфейс File реализуется как S1, так и S2, независимо от того, какие еще методы могут быть у S1 и S2.
Каждый тип, входящий в набор типов интерфейса, реализует этот интерфейс. Любой тип может реализовывать несколько различных интерфейсов. Например, все типы реализуют пустой интерфейс, который обозначает множество всех (неинтерфейсных) типов:
interface{}
Для удобства предопределенный тип any является псевдонимом для пустого интерфейса. [Go 1.18].
Аналогично, рассмотрим эту спецификацию интерфейса, которая появляется внутри объявления типа для определения интерфейса под названием Locker:
type Locker interface {
Lock()
Unlock()
}
Если S1 и S2 также реализуют
func (p T) Lock() { … }
func (p T) Unlock() { … }
они реализуют интерфейс Locker, а также интерфейс File.
Встроенные интерфейсы
В несколько более общей форме интерфейс T может использовать (возможно, квалифицированное) имя типа интерфейса E в качестве элемента интерфейса. Это называется встраиванием интерфейса E в T [Go 1.14]. Набор типов T - это пересечение наборов типов, определяемых явно объявленными методами T, и наборов типов встроенных интерфейсов T. Другими словами, набор типов T - это множество всех типов, реализующих все явно объявленные методы T, а также все методы E [Go 1.18].
type Reader interface {
Read(p []byte) (n int, err error)
Close() error
}
type Writer interface {
Write(p []byte) (n int, err error)
Close() error
}
// Методы ReadWriter - это Read, Write, и Close.
type ReadWriter interface {
Reader // includes methods of Reader in ReadWriter's method set
Writer // includes methods of Writer in ReadWriter's method set
}
При встраивании интерфейсов методы с одинаковыми именами должны иметь идентичные сигнатуры.
type ReadCloser interface {
Reader // includes methods of Reader in ReadCloser's method set
Close() // ошибка: сигнатуры Reader.Close и Close отличаются друг от друга
}
Общие интерфейсы
В самом общем виде элемент интерфейса может быть также термином произвольного типа T, или термином вида ~T, задающим базовый тип T, или объединением терминов t1|t2|...|tn [Go 1.18]. Вместе со спецификациями методов эти элементы позволяют точно определить набор типов интерфейса следующим образом:
- Набор типов пустого интерфейса - это набор всех типов, не входящих в интерфейс.
- Набор типов непустого интерфейса - это пересечение наборов типов его интерфейсных элементов.
- Набор типов спецификации метода - это набор всех неинтерфейсных типов, чьи наборы методов включают этот метод.
- Набор типов термина типа, не являющегося интерфейсом, - это множество, состоящее только из этого типа.
- Множество типов термина вида
~T- это множество всех типов, базовым типом которых являетсяT. - Множество типов объединения терминов
t1|t2|...|tn- это объединение множеств типов этих терминов.
Квантификация “множество всех неинтерфейсных типов” относится не только ко всем (неинтерфейсным) типам, объявленным в рассматриваемой программе, но и ко всем возможным типам во всех возможных программах, и, следовательно, является бесконечной. Аналогично, если задано множество всех неинтерфейсных типов, реализующих определенный метод, то пересечение множеств методов этих типов будет содержать именно этот метод, даже если все типы в рассматриваемой программе всегда используют этот метод в паре с другим методом.
По конструкции, набор типов интерфейса никогда не содержит интерфейсного типа.
// Интерфейс, представляющий только тип int.
interface {
int
}
// Интерфейс, представляющий все типы с базовым типом int.
interface {
~int
}
// Интерфейс, представляющий все типы с базовым типом int, реализующие метод String.
interface {
~int
String() string
}
// Интерфейс, представляющий пустой набор типов: не существует типа, который был бы одновременно и int, и string.
interface {
int
string
}
В термине вида ~T базовым типом T должен быть он сам, и T не может быть интерфейсом.
type MyInt int
interface {
~[]byte // базовым типом []byte является он сам
~MyInt // ошибка: базовым типом MyInt не является MyInt
~error // ошибка: ошибка является интерфейсом
}
Элементы Union обозначают объединения наборов типов:
// Интерфейс Float представляет все типы с плавающей точкой
// (включая любые именованные типы, базовыми типами которых являются
// либо float32, либо float64).
type Float interface {
~float32 | ~float64
}
Тип T в термине вида T или ~T не может быть параметром типа, а наборы типов всех неинтерфейсных терминов должны быть попарно расходящимися (попарное пересечение наборов типов должно быть пустым). Если задан параметр типа P:
interface {
P // ошибка: P является параметром типа
int | ~P // ошибка: P является параметром типа
~int | MyInt // ошибка: наборы типов для ~int и MyInt не разделяются (~int включает MyInt)
float32 | Float // пересекающиеся наборы типов, но Float - это интерфейс
}
Ограничение на реализацию: Объединение (с более чем одним членом) не может содержать заранее объявленный идентификатор comparable или интерфейсов, определяющих методы, или встраивать comparable или интерфейсы, определяющие методы.
Интерфейсы, которые не являются базовыми, могут использоваться только как ограничения типов или как элементы других интерфейсов, используемых в качестве ограничений. Они не могут быть типами значений или переменных, или компонентами других, неинтерфейсных типов.
var x Float // illegal: Float is not a basic interface
var x interface{} = Float(nil) // illegal
type Floatish struct {
f Float // illegal
}
Интерфейсный тип T не может встраивать элемент типа, который является, содержит или встраивает T, прямо или косвенно.
// illegal: Bad не может встраивать себя
type Bad interface {
Bad
}
// illegal: Bad1 не может встраивать себя, используя Bad2
type Bad1 interface {
Bad2
}
type Bad2 interface {
Bad1
}
// illegal: Bad3 не может встраивать объединение, содержащее Bad3
type Bad3 interface {
~int | ~string | Bad3
}
// illegal: Bad4 не может встраивать массив, содержащий Bad4 в качестве элемента type
type Bad4 interface {
[10]Bad4
}
Реализация интерфейса
Тип T реализует интерфейс I, если
Tне является интерфейсом и является элементом множества типовI; илиTявляется интерфейсом и множество типовTявляется подмножеством множества типовI.
Значение типа T реализует интерфейс, если T реализует интерфейс.
Map types (Типы карт)
Карта - это неупорядоченная группа элементов одного типа, называемого типом элемента, индексируемых набором уникальных ключей другого типа, называемого типом ключа. Значением неинициализированной карты является nil.
MapType = "map" "[" KeyType "]" ElementType .
KeyType = Type .
Операторы сравнения == и != должны быть полностью определены для операндов типа ключа; таким образом, тип ключа не должен быть функцией, картой или срезом. Если тип ключа является типом интерфейса, эти операторы сравнения должны быть определены для динамических значений ключа; в противном случае произойдет паника во время выполнения.
map[string]int
map[*T]struct{ x, y float64 }
map[string]interface{}
Количество элементов карты называется ее длиной. Для карты m она может быть определена с помощью встроенной функции len и может меняться в процессе выполнения. Элементы могут добавляться в процессе выполнения с помощью присваиваний и извлекаться с помощью индексных выражений; они могут быть удалены с помощью встроенных функций delete и clear.
Новое, пустое значение карты создается с помощью встроенной функции make, которая принимает в качестве аргументов тип карты и необязательную подсказку емкости:
make(map[string]int)
make(map[string]int, 100)
Начальная емкость карты не ограничивает ее размер: карты растут по мере увеличения количества хранимых в них элементов, за исключением карт nil. Карта nil эквивалентна пустой карте, за исключением того, что никакие элементы не могут быть добавлены.
Channel types (Типы каналов)
Канал обеспечивает механизм взаимодействия параллельно выполняющихся функций, посылая и принимая значения определенного типа элементов. Значение неинициализированного канала равно nil.
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
Необязательный оператор <- задает направление канала, отправку или прием. Если указано направление, канал является направленным, в противном случае - двунаправленным. Канал может быть ограничен только на отправку или только на прием путем присваивания или явного преобразования.
chan T // может использоваться для отправки и получения значений типа T
chan <- float64 // может использоваться только для отправки float64
<-chan int // может использоваться только для получения ints
Оператор <- ассоциируется с самым левым возможным chan:
chan<- chan int // то же, что chan <- (chan int)
chan<- <-chan int // то же, что chan<- (<-chan int)
<-chan <-chan int // то же, что <-chan (<-chan int)
chan (<-chan int)
Новое инициализированное значение канала может быть создано с помощью встроенной функции make, которая принимает в качестве аргументов тип канала и необязательную емкость:
make(chan int, 100)
Емкость, выраженная в количестве элементов, задает размер буфера в канале. Если емкость равна нулю или отсутствует, канал является небуферизованным, и обмен данными происходит только тогда, когда отправитель и получатель готовы. В противном случае канал является буферизованным, и обмен данными происходит без блокировки, если буфер не заполнен (отправка) или не пуст (прием). Канал с нулевым значением никогда не готов к обмену данными.
Канал может быть закрыт с помощью встроенной функции close. Многозначная форма присваивания оператора receive сообщает, было ли полученное значение отправлено до того, как канал был закрыт.
Один канал может использоваться в операторах send, receive, вызовах встроенных функций cap и len любым количеством горутин без дополнительной синхронизации.
Каналы действуют как очереди “первым пришел - первым ушел”.
Например, если одна горутина отправляет значения по каналу, а вторая получает их, то значения будут получены в порядке отправки.
Свойства типов и значений
Представление значений
Значения предопределенных типов (см. ниже интерфейсы any и error), массивов и структур являются самодостаточными: Каждое такое значение содержит полную копию всех своих данных, а переменные таких типов хранят все значение.
Например, переменная массива обеспечивает хранение (переменных) для всех элементов массива. Соответствующие нулевые значения характерны для типов значений; они никогда не бывают нулевыми.
Ненулевые значения указателей, функций, фрагментов, карт и каналов содержат ссылки на базовые данные, которые могут быть общими для нескольких значений:
- Значение указателя - это ссылка на переменную, содержащую значение базового типа указателя.
- Значение функции содержит ссылки на (возможно, анонимную) функцию и вложенные переменные.
- Значение среза содержит длину среза, емкость и ссылку на его базовый массив.
- Значение карты или канала - это ссылка на специфическую для реализации структуру данных карты или канала.
- Значение интерфейса может быть самостоятельным или содержать ссылки на базовые данные в зависимости от динамического типа интерфейса. Объявленный идентификатор
nilявляется нулевым значением для типов, значения которых могут содержать ссылки.
Когда несколько значений совместно используют базовые данные, изменение одного значения может изменить другое.
Например, изменение элемента среза приводит к изменению этого элемента в базовом массиве для всех срезов, разделяющих этот массив.
Базовые типы
Каждый тип T имеет базовый тип: Если T - один из предопределенных булевых, числовых или строковых типов или литерал типа, то соответствующий базовый тип - это сам T. В противном случае базовый тип T - это базовый тип типа, на который T ссылается в своем объявлении. Для параметра типа это базовый тип его ограничения типа, которое всегда является интерфейсом.
type (
A1 = string
A2 = A1
)
type (
B1 string
B2 B1
B3 []B1
B4 B3
)
func f[P any](x P) { … }
Базовым типом строк A1, A2, B1 и B2 является string. Базовым типом []B1, B3 и B4 является []B1. Базовым типом P является interface{}.
Основные типы
Каждый неинтерфейсный тип T имеет основной тип, который совпадает с базовым типом T.
Интерфейс T имеет основной тип, если выполняется одно из следующих условий:
- Существует единственный тип
U, который является базовым типом всех типов в наборе типовT; или - набор типов
Tсодержит только типы каналов с идентичным типом элементаE, и все направленные каналы имеют одинаковое направление.
Никакие другие интерфейсы не имеют базового типа.
Основным типом интерфейса, в зависимости от выполняемого условия, является либо:
- тип
U; либо - тип
chan E, еслиTсодержит только двунаправленные каналы, либо типchan<- Eили<-chan Eв зависимости от направления присутствующих направленных каналов.
По определению, основной тип никогда не является определенным типом, параметром типа или типом интерфейса.
Примеры интерфейсов с основными типами:
type Celsius float32
type Kelvin float32
interface{ int } // int
interface{ Celsius|Kelvin } // float32
interface{ ~chan int } // chan int
interface{ ~chan int|~chan<- int } // chan<- int
interface{ ~[]*data; String() string } // []*data
Примеры интерфейсов без основных типов:
interface{} // нет ни одного базового типа
interface{ Celsius|float64 } // нет единого базового типа
interface{ chan int | chan<- string } // каналы имеют разные типы элементов
interface{ <-chan int | chan<- int } // направленные каналы имеют разные направления
Некоторые операции (выражения slice, append и copy) опираются на несколько более свободную форму основных типов, которые принимают байтовые фрагменты и строки. В частности, если существует ровно два типа, []byte и string, которые являются базовыми типами всех типов в наборе типов интерфейса T, то основной тип T называется bytestring.
Примеры интерфейсов с базовыми типами bytestring:
interface{ int } // int (то же, что и обычный основной тип)
interface{ []byte | string } // bytestring
interface{ ~[]byte | myString } // bytestring
Обратите внимание, что bytestring не является реальным типом; его нельзя использовать для объявления переменных или составления других типов. Он существует исключительно для описания поведения некоторых операций чтения из последовательности байтов, которая может быть байтовым фрагментом или строкой.
Идентичность типов
Два типа могут быть либо одинаковыми, либо разными.
Именованный тип всегда отличается от любого другого типа. В противном случае два типа идентичны, если их базовые литералы типов структурно эквивалентны; то есть они имеют одинаковую структуру литералов и соответствующие компоненты имеют одинаковые типы. Подробнее:
- Два типа массивов идентичны, если у них одинаковые типы элементов и одинаковая длина массива.
- Два типа
sliceидентичны, если у них одинаковые типы элементов. - Два типа
structидентичны, если у них одинаковая последовательность полей, и если соответствующие пары полей имеют одинаковые имена, одинаковые типы и одинаковые теги, и либо оба встроены, либо оба не встроены. Имена неэкспортируемых полей из разных пакетов всегда различны. - Два типа указателей идентичны, если у них одинаковые базовые типы.
- Два типа функций идентичны, если у них одинаковое количество параметров и значений результата, соответствующие типы параметров и результатов идентичны, и либо обе функции являются переменными, либо ни одна из них не является таковой. Имена параметров и результатов не обязаны совпадать.
- Два интерфейсных типа идентичны, если они определяют один и тот же набор типов.
- Два типа карт идентичны, если у них одинаковые типы ключей и элементов.
- Два типа каналов идентичны, если у них одинаковые типы элементов и одинаковое направление.
- Два инстанцированных типа идентичны, если их определенные типы и все аргументы типа идентичны.
Учитывая скаазанное:
type (
A0 = []string
A1 = A0
A2 = struct{ a, b int }
A3 = int
A4 = func(A3, float64) *A0
A5 = func(x int, _ float64) *[]string
B0 A0
B1 []string
B2 struct{ a, b int }
B3 struct{ a, c int }
B4 func(int, float64) *B0
B5 func(x int, y float64) *A1
C0 = B0
D0[P1, P2 any] struct{ x P1; y P2 }
E0 = D0[int, string]
)
эти типы идентичны:
A0, A1, and []string
A2 and struct{ a, b int }
A3 and int
A4, func(int, float64) *[]string, and A5
B0 and C0
D0[int, string] and E0
[]int and []int
struct{ a, b *B5 } and struct{ a, b *B5 }
func(x int, y float64) *[]string, func(int, float64) (result *[]string), and A5
B0 и B1 отличаются, потому что это новые типы, созданные разными определениями типов; func(int, float64) *B0 и func(x int, y float64) *[]string отличаются, потому что B0 отличается от []string; а P1 и P2 отличаются, потому что это разные параметры типа. D0[int, string] и struct{ x int; y string } отличаются тем, что первый является инстанцированным определенным типом, а второй - литералом типа (но они все равно присваиваемые).
Назначаемость
Значение x типа V является назначаемым переменной типа T ("x является назначаемым T"), если выполняется одно из следующих условий:
VиTидентичны.VиTимеют одинаковые базовые типы, но не являются параметрами типа, и хотя бы один изVилиTне является именованным типом.VиT- канальные типы с идентичными типами элементов,V- двунаправленный канал, и хотя бы один изVилиTне является именованным типом.T- интерфейсный тип, но не параметр типа, иxреализуетT.x- это объявленный идентификаторnil, аT- указатель, функция, фрагмент, карта, канал или интерфейсный тип, но не параметр типа.x- это нетипизированная константа, представляемая значением типаT.
Кроме того, если для x тип V или T является параметром типа, x можно присвоить переменной типа T, если выполняется одно из следующих условий:
x- предопределенный идентификаторnil,T- параметр типа, иxможет быть присвоен каждому типу в наборе типовT.Vне является именованным типом,T- параметр типа, иxможет быть присвоен каждому типу в наборе типовT.V- параметр типа,T- не именованный тип, и значения каждого типа в наборе типовVмогут быть присвоеныT.
Представимость
Константа x представима значением типа T, где T не является параметром типа, если выполняется одно из следующих условий:
xнаходится в множестве значений, определяемыхT.T- тип с плавающей точкой, иxможет быть округлена до точностиTбез переполнения. При округлении используются правила округленияIEEE 754, но при этом отрицательный нольIEEEупрощается до беззнакового нуля. Обратите внимание, что постоянные значения никогда не приводят к отрицательному нулюIEEE,NaNили бесконечности.T- комплексный тип, и компонентыx-real(x)иimag(x)- могут быть представлены значениями типа компонентаT(float32илиfloat64).
Если T - параметр типа, то x может быть представлен значением типа T, если x может быть представлен значением каждого типа в наборе типов T.
| x | T | x может быть представлено значением T, потому что |
|---|---|---|
| ‘a’ | bite | 97 находится в наборе значений байтов |
| 97 | rune | rune - псевдоним для int32, и 97 находится в наборе 32-битных целых чисел |
| “foo” | string | “foo” находится в наборе значений строк |
| 1024 | int16 | 1024 находится в наборе 16-битных целых чисел |
| 42.0 byte | 42 | находится в наборе беззнаковых 8-битных целых чисел |
| 1e10 | uint64 | 10000000000 находится в наборе беззнаковых 64-битных целых чисел |
| 2.718281828459045 | float32 | 2.718281828459045 округляется до 2.7182817, который находится в наборе значений float32 |
| -1e-1000 | float64 | -1e-1000 округляется до IEEE -0.0, которое далее упрощается до 0.0 |
| 0i | int | 0 - целое значение |
| (42 + 0i) | float32 | 42.0 (с нулевой мнимой частью) находится в наборе значений float32 |
| x | T | x не может быть представлено значением T, потому что |
|---|---|---|
| 0 | bool | 0 не входит в набор булевых значений |
| ‘a’ | string | ‘a’ - это руна, она не входит в набор строковых значений |
| 1024 | byte | 1024 не входит в набор беззнаковых 8-битных целых чисел |
| -1 | uint16 | -1 не входит в набор беззнаковых 16-битных целых чисел |
| 1.1 | int | 1.1 не является целым числом |
| 42i | float32 | (0 + 42i) не входит в набор значений float32 |
| 1e1000 | float64 | 1e1000 после округления переполняется до IEEE +Inf |
Наборы методов
Набор методов типа определяет методы, которые могут быть вызваны на операнде этого типа. Каждый тип имеет (или пустой) набор методов, связанный с ним:
- Набор методов определенного типа
Tсостоит из всех методов, объявленных для типа-приемникаT. - Набор методов указателя на определенный тип
T(гдеTне является ни указателем, ни интерфейсом) - это набор всех методов, объявленных с приемником*TилиT. - Набор методов интерфейсного типа - это пересечение наборов методов каждого типа в наборе типов интерфейса (результирующий набор методов обычно представляет собой просто набор объявленных методов в интерфейсе).
К структурам (и указателям на структуры), содержащим встроенные поля, применяются дополнительные правила, описанные в разделе о типах struct. Любой другой тип имеет пустой набор методов.
В наборе методов каждый метод должен иметь уникальное непустое имя метода.
Blocks (Блоки)
Блок - это возможно пустая последовательность деклараций и утверждений, заключенных в соответствующие скобки.
Block = "{" StatementList "}" .
StatementList = { Statement ";" } .
Помимо явных блоков в исходном коде, существуют и неявные блоки:
- Вселенский блок
universe blockвключает в себя весь исходный текст Go. - Каждый пакет имеет
package blockблок пакета, содержащий весь исходный текст Go для этого пакета. - Каждый файл имеет
file blockблок файла, содержащий весь исходный текст Go в этом файле. - Каждый оператор “
if”, “for” и “switch” считается находящимся в своем собственном неявном блоке. - Каждый пункт в операторе “
switch” или “select” действует как неявный блок.
Блоки вложены друг в друга и влияют на область видимости.
Декларации и области видимости
Декларация связывает непустой идентификатор с константой, типом, параметром типа, переменной, функцией, меткой или пакетом. Каждый идентификатор в программе должен быть объявлен. Ни один идентификатор не может быть объявлен дважды в одном и том же блоке, и ни один идентификатор не может быть объявлен как в блоке файла, так и в блоке пакета.
Пустой идентификатор может использоваться как любой другой идентификатор в объявлении, но он не вводит привязку и поэтому не объявляется. В блоке пакетов идентификатор init может использоваться только для объявления функции init, и, как и пустой идентификатор, он не вводит нового связывания.
Declaration = ConstDecl | TypeDecl | VarDecl .
TopLevelDecl = Declaration | FunctionDecl | MethodDecl .
Область видимости объявленного идентификатора - это часть исходного текста, в которой идентификатор обозначает указанную константу, тип, переменную, функцию, метку или пакет.
В Go лексическая область видимости определяется с помощью блоков:
- Область видимости заранее объявленного идентификатора - это блок
universe(вселенной). - Областью видимости идентификатора, обозначающего константу, тип, переменную или функцию (но не метод), объявленную на верхнем уровне (вне любой функции), является блок
package. - Областью видимости имени импортируемого пакета является блок файла, содержащий объявление импорта.
- Областью видимости идентификатора, обозначающего приемник метода, параметр функции или переменную результата, является тело функции.
- Область видимости идентификатора, обозначающего параметр типа функции или объявленный приемником метода, начинается после имени функции и заканчивается в конце тела функции.
- Область видимости идентификатора, обозначающего параметр типа, начинается после имени типа и заканчивается в конце
TypeSpec. - Область видимости идентификатора константы или переменной, объявленной внутри функции, начинается в конце
ConstSpecилиVarSpec(ShortVarDeclдля объявлений коротких переменных) и заканчивается в конце самого внутреннего содержащего блока. - Область видимости идентификатора типа, объявленного внутри функции, начинается с идентификатора в
TypeSpecи заканчивается в конце самого внутреннего содержащего блока.
Идентификатор, объявленный в блоке, может быть повторно объявлен во внутреннем блоке. Пока идентификатор внутреннего объявления находится в области видимости, он обозначает объект, объявленный внутренним объявлением.
Клаузула package не является объявлением; имя пакета не появляется ни в какой области видимости. Его назначение - идентифицировать файлы, принадлежащие одному пакету, и указать имя пакета по умолчанию для объявлений импорта.
Области применения меток
Метки объявляются в операторах с метками и используются в операторах “break”, “continue” и “goto”. Запрещено определять метку, которая никогда не используется. В отличие от других идентификаторов, метки не имеют блочного диапазона и не конфликтуют с идентификаторами, которые не являются метками. Областью действия метки является тело функции, в которой она объявлена, и исключает тело любой вложенной функции.
Пустой идентификатор
Пустой идентификатор обозначается символом подчеркивания _. Он служит анонимным заполнителем вместо обычного (непустого) идентификатора и имеет особое значение в объявлениях, в качестве операнда и в операторах присваивания.
Объявленные идентификаторы
Следующие идентификаторы неявно объявлены в блоке universe [Go 1.18] [Go 1.21]:
Types:
any bool byte comparable
complex64 complex128 error float32 float64
int int8 int16 int32 int64 rune string
uint uint8 uint16 uint32 uint64 uintptr
Constants:
true false iota
Zero value:
nil
Functions:
append cap clear close complex copy delete imag len
make max min new panic print println real recover
Экспортируемые идентификаторы
Идентификатор может быть экспортирован, чтобы разрешить доступ к нему из другого пакета. Идентификатор экспортируется, если:
- первый символ имени идентификатора является заглавной буквой Юникода (категория символов Юникода
Lu); и - идентификатор объявлен в блоке пакета или является именем поля или метода.
Все остальные идентификаторы не экспортируются.
Уникальность идентификаторов
Если задан набор идентификаторов, то идентификатор называется уникальным, если он отличается от всех остальных в этом наборе. Два идентификатора отличаются друг от друга, если они пишутся по-разному или если они находятся в разных пакетах и не экспортируются. В противном случае они одинаковы.
Объявление констант
Объявление констант связывает список идентификаторов (имена констант) со значениями списка константных выражений. Количество идентификаторов должно быть равно количеству выражений, и n-й идентификатор слева привязывается к значению n-го выражения справа.
ConstDecl = "const" ( ConstSpec | "(" { ConstSpec ";" } ")" ) .
ConstSpec = IdentifierList [ [ Type ] "=" ExpressionList ] .
IdentifierList = identifier { "," identifier } .
ExpressionList = Expression { "," Expression } .
Если тип присутствует, все константы принимают указанный тип, а выражения должны быть присваиваемыми этому типу, который не должен быть параметром типа.
Если тип опущен, константы принимают индивидуальные типы соответствующих выражений.
Если значения выражений являются нетипизированными константами, объявленные константы остаются нетипизированными, а идентификаторы констант обозначают значения констант.
Например, если выражение представляет собой литерал с плавающей точкой, идентификатор константы обозначает константу с плавающей точкой, даже если дробная часть литерала равна нулю.
const Pi float64 = 3.14159265358979323846
const zero = 0.0 // untyped floating-point constant
const (
size int64 = 1024
eof = -1 // untyped integer constant
)
const a, b, c = 3, 4, "foo" // a = 3, b = 4, c = "foo", untyped integer and string constants
const u, v float32 = 0, 3 // u = 0.0, v = 3.0
Внутри списка объявлений const с круглыми скобками список выражений может быть опущен в любом ConstSpec, кроме первого. Такой пустой список эквивалентен текстовой подстановке первого предшествующего непустого списка выражений и его типа, если таковой имеется. Поэтому пропуск списка выражений эквивалентен повторению предыдущего списка. Количество идентификаторов должно быть равно количеству выражений в предыдущем списке. Вместе с генератором констант iota этот механизм позволяет легко объявлять последовательные значения:
const (
Sunday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Partyday
numberOfDays // this constant is not exported
)
Iota
В объявлении константы заранее объявленный идентификатор iota представляет последовательные нетипизированные целочисленные константы. Его значение - это индекс соответствующей константы в объявлении константы, начиная с нуля. Его можно использовать для построения набора связанных констант:
const (
c0 = iota // c0 == 0
c1 = iota // c1 == 1
c2 = iota // c2 == 2
)
const (
a = 1 << iota // a == 1 (iota == 0)
b = 1 << iota // b == 2 (iota == 1)
c = 3 // c == 3 (iota == 2, unused)
d = 1 << iota // d == 8 (iota == 3)
)
const (
u = iota * 42 // u == 0 (untyped integer constant)
v float64 = iota * 42 // v == 42.0 (float64 constant)
w = iota * 42 // w == 84 (untyped integer constant)
)
const x = iota // x == 0
const y = iota // y == 0
По определению, несколько применений iota в одном и том же ConstSpec имеют одно и то же значение:
const (
bit0, mask0 = 1 << iota, 1<<iota - 1 // bit0 == 1, mask0 == 0 (iota == 0)
bit1, mask1 // bit1 == 2, mask1 == 1 (iota == 1)
_, _ // (iota == 2, unused)
bit3, mask3 // bit3 == 8, mask3 == 7 (iota == 3)
)
В последнем примере используется неявное повторение последнего непустого списка выражений.
Декларации типов
Декларация типа связывает идентификатор, имени типа, с типом. Декларации типов бывают двух видов: декларации псевдонимов и определения типов.
TypeDecl = "type" ( TypeSpec | "(" { TypeSpec ";" } ")" ) .
TypeSpec = AliasDecl | TypeDef .
Объявление псевдонимов
Объявление псевдонимов связывает идентификатор с заданным типом [Go 1.9].
AliasDecl = identifier [ TypeParameters ] "=" Type .
В пределах области действия идентификатора он служит псевдонимом для данного типа.
type (
nodeList = []*Node // nodeList и []*Node являются идентичными типами
Polar = polar // Polar и polar обозначают идентичные типы
)
Если в объявлении псевдонима указаны параметры типа [Go 1.24], то имя типа обозначает общий псевдоним. Общие псевдонимы должны быть инстанцированы при их использовании.
type set[P comparable] = map[P]bool
В объявлении псевдонима заданный тип не может быть параметром типа.
type A[P any] = P // ошибка: P является параметром типа
Определения типов
Определение типа создает новый, отдельный тип с теми же базовыми типами и операциями, что и данный тип, и привязывает к нему идентификатор, имя типа.
TypeDef = identifier [ TypeParameters ] Type .
Новый тип называется определенным типом. Он отличается от любого другого типа, включая тип, на основе которого он создан.
type (
Point struct{ x, y float64 } // Point and struct{ x, y float64 } are different types
polar Point // polar and Point denote different types
)
type TreeNode struct {
left, right *TreeNode
value any
}
type Block interface {
BlockSize() int
Encrypt(src, dst []byte)
Decrypt(src, dst []byte)
}
Определенный тип может иметь методы, связанные с ним. Он не наследует никаких методов, связанных с данным типом, но набор методов интерфейсного типа или элементов составного типа остается неизменным:
// Mutex - это тип данных с двумя методами, Lock и Unlock.
type Mutex struct { /* Поля Mutex */ }
func (m *Mutex) Lock() { /* Реализация Lock */ }
func (m *Mutex) Unlock() { /* Реализация Unlock */ }
// NewMutex имеет тот же состав, что и Mutex, но его набор методов пуст.
type NewMutex Mutex
// Набор методов PtrMutex, лежащий в основе типа *Mutex, остается неизменным,
// но набор методов PtrMutex пуст.
type PtrMutex *Mutex
// Набор методов *PrintableMutex содержит методы
// Lock и Unlock, привязанные к его встроенному полю Mutex.
type PrintableMutex struct {
Mutex
}
// MyBlock - интерфейсный тип, имеющий тот же набор методов, что и Block.
type MyBlock Block
Определения типов могут использоваться для определения различных булевых, числовых или строковых типов и связывания с ними методов:
type TimeZone int
const (
EST TimeZone = -(5 + iota)
CST
MST
PST
)
func (tz TimeZone) String() string {
return fmt.Sprintf("GMT%+dh", tz)
}
Если в определении типа указаны параметры типа, то имя типа обозначает общий тип. Общие типы должны быть инстанцированы при их использовании.
type List[T any] struct {
next *List[T]
value T
}
В определении типа заданный тип не может быть параметром типа.
type T[P any] P // ошибка: P - параметр типа
func f[T any]() {
type L T // ошибка: T - параметр типа, объявленный в объемлющей функции
}
Родовой тип может также иметь методы, связанные с ним. В этом случае приемники методов должны объявить то же количество параметров типа, что и в определении родового типа.
// Метод Len возвращает количество элементов в связанном списке l.
func (l *List[T]) Len() int { ... }
Объявление параметров типа
Список параметров типа объявляет параметры типа общей функции или объявления типа. Список параметров типа выглядит как обычный список параметров функции, за исключением того, что имена параметров типа должны присутствовать все, и список заключен в квадратные скобки, а не в круглые [Go 1.18].
TypeParameters = "[" TypeParamList [ "," ] "]" .
TypeParamList = TypeParamDecl { "," TypeParamDecl } .
TypeParamDecl = IdentifierList TypeConstraint .
Все непустые имена в списке должны быть уникальными. Каждое имя объявляет параметр типа, который представляет собой новый и отличный от других именованный тип, выступающий в качестве заполнителя для (пока) неизвестного типа в объявлении. Параметр типа заменяется аргументом типа при инстанцировании родовой функции или типа.
[P any]
[S interface{ ~[]byte|string }]
[S ~[]E, E any]
[P Constraint[int]]
[_ any]
Подобно тому, как каждый параметр обычной функции имеет тип параметра, каждый параметр типа имеет соответствующий (мета-)тип, который называется ограничением типа.
Неоднозначность при разборе возникает, когда в списке параметров типа для общего типа объявляется единственный параметр типа P с ограничением C таким образом, что текст P C образует допустимое выражение:
type T[P *C] …
type T[P (C)] …
type T[P *C|Q] …
…
В этих редких случаях список параметров типа неотличим от выражения, и объявление типа разбирается как объявление типа массива. Чтобы устранить двусмысленность, включите ограничение в интерфейс или используйте запятую в конце:
type T[P interface{*C}] …
type T[P *C,] …
Параметры типа также могут быть объявлены спецификацией приемника объявления метода, связанного с родовым типом.
В списке параметров типа родового типа T ограничение типа не может (прямо или косвенно через список параметров типа другого родового типа) ссылаться на T.
type T1[P T1[P]] ... // illegal: T1 ссылается на себя
type T2[P interface{ T2[int] }] ... // illegal: T2 ссылается на себя
type T3[P interface{ m(T3[int])}] ... // illegal: T3 ссылается на себя
type T4[P T5[P]] ... // illegal: T4 ссылается на T5 и
type T5[P T4[P]] ... // T5 ссылается на T4
type T6[P int] struct{ f *T6[P] } // нормально: ссылка на T6 отсутствует в списке параметров типа
Ограничения типа
Ограничение типа - это интерфейс, определяющий набор допустимых аргументов типа для соответствующего параметра типа и контролирующий операции, поддерживаемые значениями этого параметра типа [Go 1.18].
TypeConstraint = TypeElem .
Если ограничение представляет собой интерфейсный литерал вида interface{E}, где E - элемент встроенного типа (не метод), то в списке параметров типа вложенный интерфейс{ ...} может быть опущен для удобства:
[T []P] // = [T interface{[]P}]
[T ~int] // = [T interface{~int}]
[T int|string] // = [T interface{int|string}]
type Constraint ~int // illegal: ~int is not in a type parameter list
Объявленный тип интерфейса comparable обозначает множество всех неинтерфейсных типов, которые строго сравнимы [Go 1.18].
Даже если интерфейсы, не являющиеся параметрами типов, сравнимы, они не являются строго сравнимыми и поэтому не реализуют comparable. Однако они удовлетворяют требованиям comparable.
int // реализует сравнимость (int строго сравнимо)
[]byte // не реализует сравнимость (кусочки не могут быть сравнимы)
interface{} // не реализует сравнимое (см. выше)
interface{ ~int | ~string } // только параметр типа: реализует сравнимость (типы int, string строго сравнимы)
interface{ comparable } // только параметр типа: реализует comparable (comparable реализует сам себя)
interface{ ~int | ~[]byte } // только параметр типа: не реализует сравнимое (срезы не сравнимы)
interface{ ~struct{ any } } // только параметр типа: не реализует сравнимое (поле any не является строго сравнимым)
Сопоставимый интерфейс и интерфейсы, которые (прямо или косвенно) встраивают сопоставимый, могут использоваться только в качестве ограничений типа. Они не могут быть типами значений или переменных, или компонентами других, неинтерфейсных типов.
Удовлетворение ограничения типа
Аргумент типа T удовлетворяет ограничению типа C, если T является элементом множества типов, определяемого C; другими словами, если T реализует C. В качестве исключения, строго сравнимое ограничение типа может быть также удовлетворено сравнимым (не обязательно строго сравнимым) аргументом типа [Go 1.20]. Точнее:
Тип T удовлетворяет ограничению C, если
TреализуетC; илиCможет быть записан в видеinterface{ comparable; E }, гдеE- базовый интерфейс, аTсопоставим и реализуетE.
| тип аргумента | тип ограничения | удовлетворение ограничений |
|---|---|---|
int | interface{ ~int } | удовлетворено: int реализует интерфейс{ ~int } |
string | comparable | удовлетворено: string реализует comparable (string строго сравнима) |
[]byte | comparable | не удовлетворено: срезы не сравнимы |
any | interface{ comparable; int } | не удовлетворено: any не реализует интерфейс{ int } |
any | comparable | удовлетворено: any сравнимо и реализует базовый интерфейс any |
struct{f any} | comparable | удовлетворено: struct{f any} сравнимо и реализует базовый интерфейс any |
any | interface{ comparable; m() } | не удовлетворено: any не реализует базовый интерфейс interface{ m() } |
interface{ m() } | interface{ comparable; m() } | удовлетворено: интерфейс{ m() } сопоставим и реализует базовый интерфейс интерфейс{ m() } |
Из-за исключения в правиле удовлетворения ограничений сравнение операндов типа parameter может вызвать панику во время выполнения (несмотря на то, что параметры сравнимого типа всегда строго сравнимы).
Объявление переменных
Объявление переменной создает одну или несколько переменных, привязывает к ним соответствующие идентификаторы и присваивает каждой из них тип и начальное значение.
VarDecl = "var" ( VarSpec | "(" { VarSpec ";" } ")" ) .
VarSpec = IdentifierList ( Type [ "=" ExpressionList ] | "=" ExpressionList ) .
var i int
var U, V, W float64
var k = 0
var x, y float32 = -1, -2
var (
i int
u, v, s = 2.0, 3.0, "bar"
)
var re, im = complexSqrt(-1)
var _, found = entries[name] // map lookup; only interested in "found"
Если задан список выражений, переменные инициализируются этими выражениями в соответствии с правилами для операторов присваивания. В противном случае каждая переменная инициализируется нулевым значением.
Если задан тип, то каждой переменной присваивается этот тип. В противном случае каждой переменной присваивается тип соответствующего инициализирующего значения в присваивании. Если это значение является нетипизированной константой, то оно сначала неявно преобразуется к типу по умолчанию; если это нетипизированное булево значение, то оно сначала неявно преобразуется к типу bool. Объявленный идентификатор nil не может использоваться для инициализации переменной без явного типа.
var d = math.Sin(0.5) // d is float64
var i = 42 // i is int
var t, ok = x.(T) // t is T, ok is bool
var n = nil // illegal
Ограничение реализации: Компилятор может сделать незаконным объявление переменной внутри тела функции, если переменная никогда не будет использоваться.
Объявление коротких переменных
Объявление короткой переменной использует синтаксис:
ShortVarDecl = IdentifierList ":=" ExpressionList .
Это сокращение для обычного объявления переменной с выражениями-инициализаторами, но без типов:
"var" IdentifierList "=" ExpressionList .
i, j := 0, 10
f := func() int { return 7 }
ch := make(chan int)
r, w, _ := os.Pipe() // os. Pipe() возвращает соединенную пару Files и ошибку, если таковая имеется
_, y, _ := coord(p) // coord() возвращает три значения; интересует только координата y
В отличие от обычных объявлений переменных, короткое объявление переменных может повторно объявлять переменные, если они были первоначально объявлены ранее в том же блоке (или в списках параметров, если блок является телом функции) с тем же типом, и хотя бы одна из непустых переменных является новой. Как следствие, повторное объявление может появиться только в коротком объявлении с несколькими переменными. Повторное объявление не вводит новую переменную; оно просто присваивает новое значение исходной. Непустые имена переменных в левой части := должны быть уникальными.
field1, offset := nextField(str, 0)
field2, offset := nextField(str, offset) // повторно объявляет смещение
x, y, x := 1, 2, 3 // незаконно: x повторяется в левой части :=
Короткие объявления переменных могут появляться только внутри функций. В некоторых контекстах, например в инициализаторах операторов “if”, “for” или “switch”, они могут использоваться для объявления локальных временных переменных.
Объявление функций
Объявление функции связывает идентификатор, имя функции, с функцией.
FunctionDecl = "func" FunctionName [ TypeParameters ] Signature [ FunctionBody ] .
FunctionName = identifier .
FunctionBody = Block .
Если в сигнатуре функции объявлены параметры результата, то список утверждений тела функции должен заканчиваться завершающим утверждением.
func IndexRune(s string, r rune) int {
for i, c := range s {
if c == r {
return i
}
}
// недопустимо: отсутствует оператор return
}
Если в объявлении функции указаны параметры типа, то имя функции обозначает родовую функцию. Родовая функция должна быть инстанцирована, прежде чем ее можно будет вызвать или использовать в качестве значения.
func min[T ~int|~float64](x, y T) T {
if x < y {
return x
}
return y
}
Объявление функции без параметров типа может не содержать тела. Такое объявление представляет собой сигнатуру для функции, реализованной вне Go, например, в ассемблере.
func flushICache(begin, end uintptr) // реализовано извне
Объявление методов
Метод - это функция с приемником. Объявление метода привязывает к методу идентификатор, имя метода, и связывает метод с базовым типом приемника.
MethodDecl = "func" Receiver MethodName Signature [ FunctionBody ] .
Receiver = Parameters .
Приемник указывается в дополнительной секции параметров, предшествующей имени метода. В этой секции параметров должен быть объявлен единственный невариативный параметр - приемник. Его тип должен быть определенным типом T или указателем на определенный тип T, за которым, возможно, следует список имен параметров типа [P1, P2, ...], заключенных в квадратные скобки. T называется базовым типом приемника. Базовый тип-приемник не может быть указателем или интерфейсным типом и должен быть определен в том же пакете, что и метод. Считается, что метод привязан к базовому типу-приемнику, и имя метода видно только в селекторах для типа T или *T.
Непустой идентификатор приемника должен быть уникальным в сигнатуре метода. Если на значение приемника не ссылаются в теле метода, его идентификатор можно не указывать в объявлении. То же самое относится и к параметрам функций и методов.
Для базового типа непустые имена методов, связанных с ним, должны быть уникальными. Если базовым типом является тип struct, то непустые имена методов и полей должны быть разными.
Заданный определенный тип Point
func (p *Point) Length() float64 {
return math.Sqrt(p.x * p.x + p.y * p.y)
}
func (p *Point) Scale(factor float64) {
p.x *= factor
p.y *= factor
}
привязать методы Length и Scale, с типом приемника *Point, к базовому типу Point.
Если базовый тип приемника является общим типом, спецификация приемника должна объявить соответствующие параметры типа для используемого метода. Это делает параметры типа-приемника доступными для метода.
Синтаксически объявление параметров типа выглядит как инстанцирование базового типа-приемника: аргументы типа должны быть идентификаторами, обозначающими объявляемые параметры типа, по одному на каждый параметр типа базового типа-приемника. Имена параметров типа не обязательно должны совпадать с соответствующими именами параметров в определении базового типа-приемника, а все непустые имена параметров должны быть уникальными в секции параметров приемника и в сигнатуре метода.
Ограничения параметров типа-приемника подразумеваются определением базового типа-приемника: соответствующие параметры типа имеют соответствующие ограничения.
type Pair[A, B any] struct {
a A
b B
}
func (p Pair[A, B]) Swap() Pair[B, A] { ... } // приемник объявляет A, B
func (p Pair[First, _]) First() First { ... } // получатель объявляет First, соответствует A в Pair
Если тип-приемник обозначается псевдонимом (указателем на него), то этот псевдоним не должен быть общим и не должен обозначать инстанцированный общий тип, ни прямо, ни косвенно через другой псевдоним, и независимо от перенаправления указателей.
type GPoint[P any] = Point
type HPoint = *GPoint[int]
type IPair = Pair[int, int]
func (*GPoint[P]) Draw(P) { ... } // illegal: alias не должен быть общим
func (HPPoint) Draw(P) { ... } // illegal: alias не должен обозначать инстанцированный тип GPoint[int]
func (*IPair) Second() int { ... } // illegal: псевдоним не должен обозначать инстанцированный тип Pair[int, int]
Выражения
Выражение задает вычисление значения путем применения операторов и функций к операндам.
Операнды
Операнды обозначают элементарные значения в выражении. Операнд может быть литералом, (возможно, квалифицированным) непустым идентификатором, обозначающим константу, переменную или функцию, или выражением в круглых скобках.
Operand = Literal | OperandName [ TypeArgs ] | "(" Expression ")" .
Literal = BasicLit | CompositeLit | FunctionLit .
BasicLit = int_lit | float_lit | imaginary_lit | rune_lit | string_lit .
OperandName = identifier | QualifiedIdent .
За именем операнда, обозначающего общую функцию, может следовать список аргументов типа; результирующий операнд является инстанцированной функцией.
Пустой идентификатор может появляться в качестве операнда только в левой части оператора присваивания.
Ограничение на реализацию: Компилятор не должен сообщать об ошибке, если тип операнда является параметром типа с пустым набором типов. Функции с такими параметрами типа не могут быть инстанцированы; любая попытка приведет к ошибке в месте инстанцирования.
Квалифицированные идентификаторы
Квалифицированный идентификатор - это идентификатор, снабженный префиксом имени пакета. И имя пакета, и идентификатор не должны быть пустыми.
QualifiedIdent = PackageName "." identifier .
Квалифицированный идентификатор обращается к идентификатору в другом пакете, который должен быть импортирован. Идентификатор должен быть экспортирован и объявлен в блоке пакета этого пакета.
math.Sin // обозначает функцию Sin в пакете math
Составные литералы
Составные литералы создают новые составные значения каждый раз, когда их объявляют. Они состоят из типа литерала, за которым следует ограниченный скобками список элементов. Каждому элементу может предшествовать соответствующий ключ.
CompositeLit = LiteralType LiteralValue .
LiteralType = StructType | ArrayType | "[" "..." "]" ElementType |
SliceType | MapType | TypeName [ TypeArgs ] .
LiteralValue = "{" [ ElementList [ "," ] ] "}" .
ElementList = KeyedElement { "," KeyedElement } .
KeyedElement = [ Key ":" ] Element .
Key = FieldName | Expression | LiteralValue .
FieldName = identifier .
Element = Expression | LiteralValue .
Основной тип LiteralType T должен быть типом struct, array, slice или map (в синтаксисе это ограничение соблюдается, за исключением случаев, когда тип задан как TypeName). Типы элементов и ключей должны быть присваиваемыми соответствующим типам поля, элемента и ключа типа T; дополнительное преобразование не требуется.
Ключ интерпретируется как имя поля для литералов struct, индекс для литералов array и slice и ключ для литералов map. Для литералов map все элементы должны иметь ключ. Ошибкой является указание нескольких элементов с одним и тем же именем поля или постоянным значением ключа. О непостоянных ключах map см. раздел о порядке объявлений.
Для литералов struct действуют следующие правила:
- Ключ должен быть именем поля, объявленного в типе
struct. - Список элементов, не содержащий ключей, должен содержать элемент для каждого поля
structв том порядке, в котором эти поля объявлены. - Если любой элемент имеет ключ, то каждый элемент должен иметь ключ.
- Список элементов, содержащий ключи, не обязательно должен содержать элемент для каждого поля
struct. Опущенные поля получают нулевое значение для этого поля. - Литерал может не содержать список элементов; такой литерал оценивается в нулевое значение для своего типа.
- Ошибкой является указание элемента для неэкспортируемого поля структуры, принадлежащей другому пакету.
Учитывая сказанное
type Point3D struct { x, y, z float64 }
type Line struct { p, q Point3D }
и теперь можно написать
origin := Point3D{} // zero value for Point3D
line := Line{origin, Point3D{y: -4, z: 12.3}} // zero value for line.q.x
Для литералов массивов и фрагментов действуют следующие правила:
- Каждый элемент имеет связанный с ним целочисленный индекс, отмечающий его положение в массиве.
- Элемент с ключом использует ключ в качестве своего индекса. Ключ должен быть неотрицательной константой, представляемой значением типа
int; а если он типизирован, то должен быть целочисленного типа. - Элемент без ключа использует индекс предыдущего элемента плюс один. Если первый элемент не имеет ключа, его индекс равен нулю.
При получении адреса составного литерала генерируется указатель на уникальную переменную, инициализированную значением литерала.
var pointer *Point3D = &Point3D{y: 1000}
Обратите внимание, что нулевое значение для типа slice или map - это не то же самое, что инициализированное, но пустое значение того же типа. Следовательно, получение адреса пустого составного литерала slice или map не имеет того же эффекта, что и выделение нового значения slice или map с помощью new.
p1 := &[]int{} // p1 указывает на инициализированный, пустой фрагмент со значением []int{} и длиной 0
p2 := new([]int) // p2 указывает на неинициализированный фрагмент со значением nil и длиной 0
Длина литерала массива равна длине, указанной в типе литерала. Если в литерале указано меньше элементов, чем длина, то недостающие элементы устанавливаются в нулевое значение для типа элемента массива. Предоставление элементов со значениями индексов вне диапазона индексов массива является ошибкой. Обозначение ... задает длину массива, равную максимальному индексу элемента плюс один.
buffer := [10]string{} // len(buffer) == 10
intSet := [6]int{1, 2, 3, 5} // len(intSet) == 6
days := [...]string{"Sat", "Sun"} // len(days) == 2
Литерал slice описывает весь лежащий в его основе литерал массива. Таким образом, длина и емкость литерала slice равны максимальному индексу элемента плюс единица.
Литерал среза имеет вид
[]T{x1, x2, ... xn}
и является сокращением для операции slice, применяемой к массиву:
tmp := [n]T{x1, x2, ... xn}
tmp[0 : n]
Внутри составного литерала массива, среза или карты типа T элементы или ключи карты, которые сами являются составными литералами, могут элиминировать соответствующий тип литерала, если он идентичен типу элемента или ключа T. Аналогично, элементы или ключи, которые являются адресами составных литералов, могут элиминировать &T, если тип элемента или ключа *T.
[...]Point{{1.5, -3.5}, {0, 0}} // аналогично [...]Point{Point{1.5, -3.5}, Point{0, 0}}
[][]int{{1, 2, 3}, {4, 5}} // аналогично [][]int{[]int{1, 2, 3}, []int{4, 5}}
[][]Point{{{0, 1}, {1, 2}}} // аналогично map[string]Point{"orig": Point{0, 0}}
map[Point]string{{0, 0}: "orig"} // аналогично map[Point]string{Point{0, 0}: "orig"}
type PPoint *Point
[2]*Point{{1.5, -3.5}, {}} // аналогично [2]*Point{&Point{1.5, -3.5}, &Point{}}
[2]PPoint{{1.5, -3.5}, {}} // аналогично [2]PPoint{PPoint(&Point{1.5, -3.5}), PPoint(&Point{})}
Неоднозначность разбора возникает, когда составной литерал, использующий форму TypeName типа LiteralType, появляется в качестве операнда между ключевым словом и открывающей скобкой блока оператора “if”, “for” или “switch”, а составной литерал не заключен в круглые скобки, квадратные скобки или фигурные скобки. В этом редком случае открывающая скобка литерала ошибочно воспринимается как скобка, вводящая блок операторов. Чтобы устранить двусмысленность, составной литерал должен быть заключен в круглые скобки.
if x == (T{a,b,c}[i]) { … }
if (x == T{a,b,c}[i]) { … }
Примеры допустимых литералов массивов, фрагментов и карт:
// список простых чисел
primes := []int{2, 3, 5, 7, 9, 2147483647}
// vowels[ch] - true, если ch - гласная
vowels := [128]bool{'a': true, 'e': true, 'i': true, 'o': true, 'u': true, 'y': true}
// массив [10]float32{-1, 0, 0, 0, -0.1, -0.1, 0, 0, 0, -1}
filter := [10]float32{-1, 4: -0.1, -0.1, 9: -1}
// частоты в Гц для равнотемперированной шкалы (A4 = 440 Гц)
noteFrequency := map[string]float32{
"C0": 16.35, "D0": 18.35, "E0": 20.60, "F0": 21.83,
"G0": 24.50, "A0": 27.50, "B0": 30.87,
}
Литералы функций
Литерал функции представляет собой анонимную функцию. Функциональные литералы не могут объявлять параметры типа.
FunctionLit = "func" Signature FunctionBody .
func(a, b int, z float64) bool { return a*b < int(z) }
Литерал функции может быть присвоен переменной или вызван напрямую.
f := func(x, y int) int { return x + y }
func(ch chan int) { ch <- ACK }(replyChan)
Функциональные литералы являются закрывающими: они могут ссылаться на переменные, определенные в окружающей функции. Эти переменные затем разделяются между окружающей функцией и литералом функции, и они сохраняются до тех пор, пока доступны.
Первичные выражения
Первичные выражения - это операнды для унарных и бинарных выражений.
PrimaryExpr = Operand |
Conversion |
MethodExpr |
PrimaryExpr Selector |
PrimaryExpr Index |
PrimaryExpr Slice |
PrimaryExpr TypeAssertion |
PrimaryExpr Arguments .
Selector = "." identifier .
Index = "[" Expression [ "," ] "]" .
Slice = "[" [ Expression ] ":" [ Expression ] "]" |
"[" [ Expression ] ":" Expression ":" Expression "]" .
TypeAssertion = "." "(" Type ")" .
Arguments = "(" [ ( ExpressionList | Type [ "," ExpressionList ] ) [ "..." ] [ "," ] ] ")" .
x
2
(s + ".txt")
f(3.1415, true)
Point{1, 2}
m["foo"]
s[i : j + 1]
obj.color
f.p[i].x()
Selectors (Селекторы)
Для первичного выражения x, не являющегося именем пакета, селекторное выражение
x.f
обозначает поле или метод f значения x (или иногда *x; см. ниже). Идентификатор f называется селектором (поля или метода); он не должен быть пустым идентификатором. Тип выражения селектора равен типу f. Если x - это имя пакета, см. раздел о квалифицированных идентификаторах.
Селектор f может обозначать поле или метод f типа T, либо ссылаться на поле или метод f вложенного в него вложенного поля T. Количество вложенных полей, пройденных для достижения f, называется его глубиной в T. Глубина поля или метода f, объявленного в T, равна нулю. Глубина поля или метода f, объявленного во вложенном поле A в T, равна глубине f в A плюс один.
К селекторам применяются следующие правила:
- Для значения
xтипаTили*T, гдеTне является указателем или интерфейсным типом,x.fобозначает поле или метод на самой малой глубине вT, где есть такойf. Если не существует ровно одногоfс самой малой глубиной, то выражение селектора является незаконным. - Для значения
xтипаI, гдеI- интерфейсный тип,x.fобозначает фактический метод с именемfдинамического значенияx. Если в наборе методовIнет метода с именемf, то селекторное выражение незаконно. - В качестве исключения, если тип
xявляется определенным типом указателя и(*x).fявляется допустимым селекторным выражением, обозначающим поле (но не метод),x.fявляется сокращением для(*x).f. - Во всех остальных случаях
x.fявляется незаконным. - Если
xимеет тип указателя и значениеnil, аx.fобозначает полеstruct, присваивание или вычислениеx.fвызовет панику во время выполнения. - Если
xимеет тип интерфейса и значениеnil, вызов или оценка методаx.fприводит к панике во время выполнения.
Например, учитывая сказанное:
type T0 struct {
x int
}
func (*T0) M0()
type T1 struct {
y int
}
func (T1) M1()
type T2 struct {
z int
T1
*T0
}
func (*T2) M2()
type Q *T2
var t T2 // with t.T0 != nil
var p *T2 // with p != nil and (*p).T0 != nil
var q Q = p
можно написать:
t.z // t.z
t.y // t.T1.y
t.x // (*t.T0).x
p.z // (*p).z
p.y // (*p).T1.y
p.x // (*(*p).T0).x
q.x // (*(*q).T0).x (*q).x является допустимым селектором поля
p.M0() // ((*p).T0).M0() M0 ожидает приемник *T0
p.M1() // ((*p).T1).M1() M1 ожидает приемник T1
p.M2() // p.M2() M2 ожидает приемник *T2
t.M2() // (&t).M2() M2 ожидает *T2-приемник, см. раздел Calls (Вызовы)
но следующее недействительно:
q.M0() // (*q).M0 действителен, но не является селектором поля
Выражения в методах
Если M находится в наборе методов типа T, то T.M - это функция, которая может быть вызвана как обычная функция с теми же аргументами, что и M, с префиксом в виде дополнительного аргумента, который является приемником метода.
MethodExpr = ReceiverType "." MethodName .
ReceiverType = Type .
Рассмотрим структуру типа T с двумя методами, Mv, приемник который имеет тип T, и Mp, приемник который имеет тип *T.
type T struct {
a int
}
func (tv T) Mv(a int) int { return 0 } // приемник значений
func (tp *T) Mp(f float32) float32 { return 1 } // приемник указателей
var t T
Выражение
T.Mv
дает функцию, эквивалентную Mv, но с явным приемником в качестве первого аргумента; она имеет сигнатуру
func(tv T, a int) int
Эта функция может быть вызвана обычным образом с явным приемником, так что эти пять вызовов эквивалентны:
t.Mv(7)
T.Mv(t, 7)
(T).Mv(t, 7)
f1 := T.Mv; f1(t, 7)
f2 := (T).Mv; f2(t, 7)
Аналогично, выражение
(*T).Mp
дает функцию, представляющую значение Mp с сигнатурой
func(tp *T, f float32) float32
Для метода с приемником значений можно вывести функцию с явным приемником указателей, так что
(*T).Mv
дает функцию, представляющую значение Mv с сигнатурой
func(tv *T, a int) int
Такая функция косвенно через приемник создает значение для передачи в качестве приемника базовому методу; при этом метод не перезаписывает значение, адрес которого передается в вызове функции.
Последний случай, функция-приемник значения для метода-приемника указателя, является незаконным, поскольку методы-приемники указателей не входят в набор методов типа значения.
Функции-значения, получаемые из методов, вызываются с помощью синтаксиса вызова функции; приемник предоставляется в качестве первого аргумента вызова. То есть, если дано f := T.Mv, то f вызывается как f(t, 7), а не t.f(7). Чтобы сконструировать функцию, связывающую приемник, используйте литерал функции или значение метода.
Законно выводить значение функции из метода интерфейсного типа. Результирующая функция принимает явный приемник этого интерфейсного типа.
Значения метода
Если выражение x имеет статический тип T, а M находится в наборе методов типа T, то x.M называется значением метода. Значение метода x.M - это значение функции, которое можно вызвать с теми же аргументами, что и вызов метода x.M. Выражение x рассчитывается и сохраняется во время вычислений значения метода; сохраненная копия затем используется в качестве приемника в любых вызовах, которые могут быть выполнены позже.
type S struct { *T }
type T int
func (t T) M() { print(t) }
t := new(T)
s := S{T: t}
f := t.M // приемник *t рассчитывается и хранится в f
g := s.M // приемник *(s.T) рассчитывается и хранится в g
*t = 42 // не влияет на сохраненные приемники в f и g
Тип T может быть интерфейсным или неинтерфейсным типом.
Как и при обсуждении выражений методов выше, рассмотрим тип ёstruct Tё с двумя методами, Mv, приемник которого имеет тип T, и Mp, приемник которого имеет тип *T.
type T struct {
a int
}
func (tv T) Mv(a int) int { return 0 } // value receiver
func (tp *T) Mp(f float32) float32 { return 1 } // pointer receiver
var t T
var pt *T
func makeT() T
Выражение
t.Mv
дает значение функции типа
func(int) int
Эти два вызова эквивалентны:
t.Mv(7)
f := t.Mv; f(7)
Аналогично, выражение
pt.Mp
дает значение функции типа
func(float32) float32
Как и в случае с селекторами, ссылка на неинтерфейсный метод с приемником значения, использующим указатель, автоматически разыменовывает этот указатель: pt.Mv эквивалентно (*pt).Mv.
Как и в случае с вызовами методов, ссылка на неинтерфейсный метод с приемником указателя, использующим адресуемое значение, автоматически принимает адрес этого значения: t.Mp эквивалентно (&t).Mp.
f := t.Mv; f(7) // like t.Mv(7)
f := pt.Mp; f(7) // like pt.Mp(7)
f := pt.Mv; f(7) // like (*pt).Mv(7)
f := t.Mp; f(7) // like (&t).Mp(7)
f := makeT().Mp // invalid: result of makeT() is not addressable
Хотя в приведенных выше примерах используются неинтерфейсные типы, создание значения метода из значения интерфейсного типа также законно.
var i interface { M(int) } = myVal
f := i.M; f(7) // like i.M(7)
Индексные выражения
Первичное выражение вида
a[x]
обозначает элемент массива, указатель на массив, фрагмент, строку или карту a, проиндексированный по x. Значение x называется индексом или ключом карты соответственно. При этом действуют следующие правила:
Если a не является ни картой, ни параметром типа:
- индекс
xдолжен быть нетипизированной константой или его основной тип должен быть целым числом - константный индекс должен быть неотрицательным и представляемым значением типа
int - нетипизированный константный индекс имеет тип
int - индекс
xнаходится в диапазоне, если0 <= x < len(a), иначе он вне диапазона
Для a типа массива A:
- постоянный индекс должен быть в диапазоне
- если
xвыходит за пределы диапазона во время выполнения, возникает паника во время выполнения a[x]- это элемент массива с индексомx, а типa[x]- это тип элементаA
Для a типа указателя на массив:
a[x]- сокращение от(*a)[x]
Для a типа slice S:
- если
xвыходит за пределы диапазона во время выполнения, возникает паника во время выполнения a[x]- это элемент среза по индексуx, а типa[x]- это тип элементаS
Для a строкового типа:
- константный индекс должен быть в диапазоне, если строка
aтакже константна - если
xвыходит за пределы диапазона во время выполнения, происходит паника во время выполнения a[x]- это непостоянное байтовое значение по индексуxи типa[x]- байтa[x]не может быть присвоен
Для a типа map M:
- Тип
xдолжен быть назначен типу ключаM - если
mapсодержит запись с ключомx,a[x]является элементомmapс ключомxи типa[x]является типом элементаM - если
mapравенnilили не содержит такой записи,a[x]является нулевым значением для типа элементаM
Для a типа параметра типа P:
- Индексное выражение
a[x]должно быть допустимым для значений всех типов в наборе типовP. - Типы элементов всех типов в наборе типов
Pдолжны быть одинаковыми. В данном контексте типом элемента строкового типа является байт. - Если в наборе типов
Pесть типmap, то все типы в этом наборе типов должны быть типамиmap, а соответствующие типы ключей должны быть идентичными. a[x]- это элемент массива, среза или строки по индексуxили элементmapс ключомxаргумента типа, с которым инстанцируетсяP, а типa[x]- это тип (идентичных) типов элементов.a[x]не может быть присвоен, если набор типовPвключает типыstring.
В противном случае a[x] является незаконным.
Индексное выражение на карте a типа map[K]V, используемое в операторе присваивания или инициализации специальной формы
v, ok = a[x]
v, ok := a[x]
var v, ok = a[x]
дает дополнительное нетипизированное булево значение. Значение ok равно true, если ключ x присутствует в карте, и false в противном случае.
Присвоение элементу карты nil приводит к панике во время выполнения.
Выражения срезов (частей массивов)
Выражения-срезов строят подстроку или фрагмент из строки, массива, указателя на массив или фрагмента. Существует два варианта: простая форма, в которой указываются нижняя и верхняя границы, и полная форма, в которой также указывается ограничение на емкость.
Простые выражения срезов
Основное выражение
a[low : high]
строит подстроку или фрагмент. Основной тип a должен быть строкой, массивом, указателем на массив, фрагментом или байтовой строкой. Индексы low и high определяют, какие элементы операнда a появятся в результате. Результат имеет индексы, начинающиеся с 0, и длину, равную high - low. После нарезки массива a
a := [5]int{1, 2, 3, 4, 5}
s := a[1:4]
срез s имеет тип []int, длину 3, емкость 4 и элементы
s[0] == 2
s[1] == 3
s[2] == 4
Для удобства любой из индексов может быть опущен. Отсутствующий младший индекс по умолчанию равен нулю; отсутствующий старший индекс по умолчанию равен длине нарезанного операнда:
a[2:] // то же, что a[2 : len(a)]
a[:3] // то же, что a[0 : 3]
a[:] // то же, что a[0 : len(a)]
Если a - указатель на массив, то a[low : high] - это сокращение от (*a)[low : high].
Для массивов или строк индексы находятся в диапазоне, если 0 <= low <= high <= len(a), в противном случае они выходят за пределы диапазона. Для срезов верхней границей индекса является емкость среза cap(a), а не его длина. Постоянный индекс должен быть неотрицательным и представляться значением типа int; для массивов или постоянных строк постоянные индексы также должны находиться в диапазоне. Если оба индекса постоянны, они должны удовлетворять условию low <= high. Если индексы выходят за пределы диапазона во время выполнения, происходит паника во время выполнения.
За исключением нетипизированных строк, если нарезанный операнд является строкой или фрагментом, результатом операции нарезки является неконстантное значение того же типа, что и операнд. Для нетипизированных строковых операндов результатом является неконстантное значение типа string. Если нарезанный операнд является массивом, он должен быть адресуемым, а результатом операции slice является фрагмент с тем же типом элемента, что и массив.
Если нарезанный операнд допустимого выражения slice является nil-фрагментом, то результатом будет nil-фрагмент. В противном случае, если результат является срезом, он разделяет с операндом его базовый массив.
var a [10]int
s1 := a[3:7] // базовый массив s1 - это массив a; &s1[2] == &a[5]
s2 := s1[1:4] // базовый массив s2 - это базовый массив s1, который является массивом a; &s2[1] == &a[5]
s2[1] = 42 // s2[1] == s1[2] == a[5] == 42; все они ссылаются на один и тот же элемент базового массива
var s []int
s3 := s[:0] // s3 == nil
Выражения полного среза
Первичное выражение
a[low : high : max]
строит срез того же типа, с той же длиной и элементами, что и простое выражение a[low : high]. Кроме того, оно контролирует емкость результирующего среза, устанавливая ее в значение max - low. Только первый индекс может быть опущен; по умолчанию он равен 0. Основной тип a должен быть массивом, указателем на массив или срез (но не строкой). После нарезки массива a
a := [5]int{1, 2, 3, 4, 5}
t := a[1:3:5]
Срез t имеет тип []int, длину 2, емкость 4 и элементы
t[0] == 2
t[1] == 3
Что касается простых выражений нарезки, то если a - указатель на массив, то a[low : high : max] - это сокращение от (*a)[low : high : max]. Если нарезаемый операнд является массивом, он должен быть адресуемым.
Индексы находятся в диапазоне, если 0 <= low <= high <= max <= cap(a), иначе они выходят за пределы диапазона. Постоянный индекс должен быть неотрицательным и представляться значением типа int; для массивов постоянные индексы также должны находиться в диапазоне. Если константными являются несколько индексов, то присутствующие константы должны находиться в диапазоне относительно друг друга. Если индексы выходят за пределы диапазона во время выполнения, возникает паника.
Утверждения типа
Для выражения x интерфейсного типа, но не параметра типа, и типа T, первичное выражение
x.(T)
утверждает, что x не является nil и что значение, хранящееся в x, имеет тип T. Выражение x.(T) называется утверждением типа.
Точнее, если T не является типом интерфейса, x.(T) утверждает, что динамический тип x идентичен типу T. В этом случае T должен реализовывать (интерфейсный) тип x; в противном случае утверждение типа недействительно, поскольку для x невозможно хранить значение типа T. Если T - интерфейсный тип, то x.(T) утверждает, что динамический тип x реализует интерфейс T.
Если утверждение типа верно, то значением выражения будет значение, хранящееся в x, а его типом - T. Если утверждение типа ложно, то произойдет паника во время выполнения. Другими словами, несмотря на то, что динамический тип x известен только во время выполнения, в корректной программе тип x.(T) заведомо равен T.
var x interface{} = 7 // x has dynamic type int and value 7
i := x.(int) // i has type int and value 7
type I interface { m() }
func f(y I) {
s := y.(string) // illegal: string does not implement I (missing method m)
r := y.(io.Reader) // r has type io.Reader and the dynamic type of y must implement both I and io.Reader
…
}
Утверждение типа, используемое в операторе присваивания или инициализации специального вида
v, ok = x.(T)
v, ok := x.(T)
var v, ok = x.(T)
var v, ok interface{} = x.(T) // динамические типы v и ok - T и bool
дает дополнительное нетипизированное булево значение. Значение ok будет истинным, если утверждение верно. В противном случае оно ложно, а значение v является нулевым значением для типа T. Паники во время выполнения в этом случае не возникает.
Calls (Вызовы)
Дано выражение типа функции f с основным типом F
f(a1, a2, ... an)
вызывает f с аргументами a1, a2, ... an. За исключением одного особого случая, аргументы должны быть однозначными выражениями, присваиваемыми типам параметров F, и оцениваются до вызова функции. Тип выражения - это тип результата F. Вызов метода аналогичен, но сам метод указывается как селектор на значение типа приемника метода.
math.Atan2(x, y) // вызов функции
var pt *Point
pt.Scale(3.5) // вызов метода с приемником pt
Если f обозначает общую функцию, то перед вызовом или использованием в качестве значения функции она должна быть инстанцирована.
При вызове функции значение функции и аргументы оцениваются в обычном порядке. После их оценки выделяется новое хранилище для переменных функции, в которое входят ее параметры и результаты. Затем аргументы вызова передаются функции, то есть присваиваются соответствующим параметрам функции, и вызываемая функция начинает выполнение. Возвращаемые параметры функции передаются обратно вызывающему, когда функция возвращается.
Вызов функции с нулевым значением вызывает панику во время выполнения.
В качестве особого случая, если возвращаемые значения функции или метода g равны по числу и могут быть индивидуально назначены параметрам другой функции или метода f, то вызов f(g(параметры_от_g)) вызовет f после передачи возвращаемых значений g параметрам f по порядку. Вызов f не должен содержать никаких параметров, кроме вызова g, а g должен иметь хотя бы одно возвращаемое значение. Если у f есть конечный параметр ..., ему присваиваются возвращаемые значения g, оставшиеся после присвоения обычных параметров.
func Split(s string, pos int) (string, string) {
return s[0:pos], s[pos:]
}
func Join(s, t string) string {
return s + t
}
if Join(Split(value, len(value)/2)) != value {
log.Panic("test fails")
}
Вызов метода x.m() допустим, если набор методов (или типов) x содержит m и список аргументов может быть присвоен списку параметров m. Если x является адресуемым и набор методов &x содержит m, то x.m() - это сокращение от (&x).m():
var p Point
p.Scale(3.5)
Не существует отдельного типа метода и литералов метода.
Передача аргументов в ... параметры
Если f является переменной с конечным параметром p типа ...T, то внутри f тип p эквивалентен типу []T. Если f вызывается без фактических аргументов для p, то значение, передаваемое p, равно nil. В противном случае передаваемое значение - это новый фрагмент типа []T с новым нижележащим массивом, последовательными элементами которого являются фактические аргументы, которые все должны быть присваиваемыми в T. Длина и емкость фрагмента, таким образом, равна количеству аргументов, связанных с p, и может быть разной для каждого места вызова.
Даны функция и вызовы
func Greeting(prefix string, who ...string)
Greeting("nobody")
Greeting("hello:", "Joe", "Anna", "Eileen")
внутри Greeting, who будет иметь значение nil в первом вызове, и []string{"Joe", "Anna", "Eileen"} во втором
Если последний аргумент может быть отнесен к типу slice []T и за ним следует ..., он передается без изменений как значение для параметра ...T. В этом случае новый срез не создается.
Учитывая срез s и вызов
s := []string{"Джеймс", "Жасмин"}
Greeting("goodbye:", s...)
внутри Greeting, который будет иметь то же значение, что и s, с тем же базовым массивом.
Инстанцирование
Общая функция или тип инстанцируется путем замены аргументов типа на параметры типа [Go 1.18]. Инстанцирование происходит в два этапа:
Пояснение инстанцирования
Подробнее
В языке программирования Go термин “instantiation” (инстанцирование) относится к процессу создания конкретного экземпляра (реализации) обобщённого типа или функции с подставленными конкретными типами или значениями.
Instantiations в Go (на примере дженериков, появившихся в Go 1.18)
В Go инстанцирование чаще всего связано с дженериками (generics).
Инстанцирование обобщённого типа
При объявлении обобщённого типа (с параметрами типа[T any]) сам по себе тип является лишь шаблоном. Инстанцирование происходит, когда указывается конкретный тип вместо параметраT.Пример:
type Stack[T any] struct { items []T } // Инстанцирование Stack для типа int var intStack Stack[int] // Stack[T] инстанцируется как Stack[int]Инстанцирование обобщённой функции
Аналогично, обобщённые функции требуют подстановки конкретных типов при вызове, что приводит к созданию специализированной версии функции.Пример:
func PrintSlice[T any](slice []T) { for _, v := range slice { fmt.Println(v) } } // Инстанцирование функции для []string PrintSlice[string]([]string{"hello", "world"}) // Компилятор Go может также вывести тип автоматически: PrintSlice([]int{1, 2, 3}) // Инстанцируется как PrintSlice[int]
Когда происходит инстанцирование?
- Во время компиляции: Go создаёт конкретные реализации обобщённых типов и функций на этапе компиляции.
- Для каждого уникального типа: Например,
Stack[int]иStack[string]— это два разных инстанцированных типа.
Важно
- В Go инстанцирование не происходит во время выполнения (в отличие, например, от некоторых реализаций шаблонов в C++).
- Компилятор стремится избегать дублирования кода, где это возможно, используя оптимизации.
Если вы работаете с дженериками в Go, понимание инстанцирования помогает избежать неожиданностей при использовании обобщённых типов и функций.
- Каждый аргумент типа заменяется на соответствующий параметр типа в родовом объявлении. Эта замена происходит во всем объявлении функции или типа, включая сам список параметров типа и любые типы в этом списке.
- После подстановки каждый аргумент типа должен удовлетворять ограничениям (инстанцированным, если необходимо) соответствующего параметра типа. В противном случае инстанцирование не происходит.
Инстанцирование типа приводит к созданию нового негенетического именованного типа; инстанцирование функции приводит к созданию новой негенетической функции.
| список параметров | типа аргументы | типа после подстановки |
|---|---|---|
| [P any] | int | int удовлетворяет any |
| [S ~[]E, E any] | []int, int | []int удовлетворяет ~[]int, int удовлетворяет any |
| [P io.Writer] | string | illegal: string не удовлетворяет io.Writer |
| [P comparable] | any | any удовлетворяет (но не реализует) comparable |
При использовании родовой функции аргументы типа могут быть указаны явно, либо они могут быть частично или полностью выведены из контекста, в котором используется функция. При условии, что они могут быть выведены, список аргументов типа может быть полностью опущен, если функция:
- вызывается с обычными аргументами,
- присваивается переменной с известным типом
- передается в качестве аргумента другой функции или
- возвращается как результат.
Во всех остальных случаях список аргументов типа (возможно, неполный) должен присутствовать. Если список аргументов типа отсутствует или является неполным, все недостающие аргументы типа должны быть выведены из контекста, в котором используется функция.
// sum возвращает сумму (конкатенацию, для строк) своих аргументов.
func sum[T ~int | ~float64 | ~string](x... T) T { ... }
x := sum // illegal: тип x неизвестен
intSum := sum[int] // intSum имеет тип func(x... int) int
a := intSum(2, 3) // a имеет значение 5 типа int
b := sum[float64](2.0, 3) // b имеет значение 5.0 типа float64
c := sum(b, -1) // c имеет значение 4.0 типа float64
type sumFunc func(x... string) string
var f sumFunc = sum // то же, что var f sumFunc = sum[string]
f = sum // то же, что f = sum[string]
Частичный список аргументов типа не может быть пустым; в нем должен присутствовать как минимум первый аргумент. Список является префиксом полного списка аргументов типа, оставляя остальные аргументы для вывода. Грубо говоря, аргументы типа могут быть опущены “справа налево”.
func apply[S ~[]E, E any](s S, f func(E) E) S { ... }
f0 := apply[] // illegal: список аргументов типа не может быть пустым
f1 := apply[[]int] // аргумент типа для S указан явно, аргумент типа для E выведен
f2 := apply[[]string, string] // оба аргумента типа указаны явно
var bytes []byte
r := apply(bytes, func(byte) byte { ... }) // оба аргумента типа выводятся из аргументов функции
Для общего типа все аргументы типа всегда должны быть предоставлены явно.
Выведение типа
При использовании общей функции могут отсутствовать некоторые или все аргументы типа, если они могут быть выведены из контекста, в котором используется функция, включая ограничения на параметры типа функции. Выведение типа проходит успешно, если он может вывести недостающие аргументы типа, и инстанцирование проходит успешно с аргументами типа, которые были выведены. В противном случае вывод типа не удается, и программа считается недействительной.
При выводе типов используются отношения типов между парами типов: Например, аргумент функции должен быть присваиваемым соответствующему параметру функции; это устанавливает связь между типом аргумента и типом параметра. Если один из этих двух типов содержит параметры типа, то при выводе типов ищутся аргументы типа, которыми можно заменить параметры типа так, чтобы отношение присваиваемости было выполнено. Аналогично, при выводе типов используется тот факт, что аргумент типа должен удовлетворять ограничению соответствующего параметра типа.
Каждая такая пара сопоставленных типов соответствует уравнению типа, содержащему один или несколько параметров типа, от одной или, возможно, нескольких родовых функций. Вывод недостающих аргументов типа означает решение полученного набора уравнений типа для соответствующих параметров типа.
Например, учитывая
// dedup возвращает копию аргумента slice с удаленными дублирующимися записями.
func dedup[S ~[]E, E comparable](S) S { ... }
type Slice []int
var s Slice
s = dedup(s) // то же самое, что s = dedup[Slice, int](s)
переменная s типа Slice должна быть присваиваема параметру функции типа S, чтобы программа была корректной. Для уменьшения сложности вывод типов игнорирует направленность присваиваний, поэтому отношение типов между Slice и S можно выразить через (симметричное) уравнение типа (Slice ≡_A S) (или (S ≡_A Slice)), где A в (≡_A) указывает на то, что типы LHS и RHS должны совпадать в соответствии с правилами присваиваемости (подробнее см. раздел об унификации типов). Аналогично, параметр типа S должен удовлетворять своему ограничению ~[]E. Это можно выразить как (S ≡_C ~[\ ]E), где (X ≡_C Y) означает X удовлетворяет ограничению Y. Эти наблюдения приводят к набору двух уравнений
$$ Slice ≡_A S (1) $$ $$ S ≡_C ~[\ ]E (2) $$
который теперь можно решить для параметров типа S и E. Из (1) компилятор может сделать вывод, что аргументом типа для S является Slice. Аналогично, поскольку базовым типом Slice является []int, а []int должен соответствовать []E ограничения, компилятор может сделать вывод, что E должно быть int. Таким образом, для этих двух уравнений вывод типа дает следующее
S ➞ Slice
E ➞ int
Если задан набор уравнений типа, то параметрами типа для решения являются параметры типа функций, которые должны быть инстанцированы и для которых не заданы явные аргументы типа. Такие параметры типа называются связанными параметрами типа. Например, в приведенном выше примере dedup параметры типа S и E привязаны к dedup. Аргументом вызова обобщенной функции может быть сама обобщенная функция. Параметры типа этой функции включаются в набор связанных параметров типа. Типы аргументов функции могут содержать параметры типа из других функций (например, родовой функции, заключающей в себе вызов функции). Эти параметры типа также могут встречаться в уравнениях типов, но в данном контексте они не связаны. Уравнения типов всегда решаются только для связанных параметров типа.
Вывод типов поддерживает вызовы общих функций и присваивание общих функций переменным (явно типизированным для функций). Это включает передачу общих функций в качестве аргументов другим (возможно, также общим) функциям и возврат общих функций в качестве результатов. Вывод типа оперирует набором уравнений, специфичных для каждого из этих случаев. Уравнения выглядят следующим образом (списки аргументов типов опущены для ясности): Для вызова функции (f(a_0, a_1, …)), где (f) или аргумент функции (a_i) - общая функция:
- Каждая пара ((a_i, p_i)) соответствующих аргументов и параметров функции, где (a_i) не является нетипизированной константой, дает уравнение (typeof(p_i) ≡_A typeof(a_i)).
Если (a_i) - нетипизированная константа (c_j), а (typeof(p_i)) - параметр связанного типа (P_k), то пара ((c_j, P_k)) собирается отдельно от уравнений типа.
Для присваивания (v = f) родовой функции (f) переменной
v(неродовой) типа функции: (typeof(v) ≡_A typeof(f)).Для оператора
return ..., f, ...,гдеf- родовая функция, возвращаемая в качестве результата в (неродовую) переменнуюrтипа функцииresult: (typeof(r) ≡_A typeof(f)).
Кроме того, каждый параметр типа (P_k) и соответствующее ограничение типа (C_k) дают уравнение типа (P_k ≡_C C_k).
При выводе типов приоритет отдается информации о типе, полученной от типизированных операндов, перед рассмотрением нетипизированных констант. Поэтому вывод выполняется в два этапа:
Уравнения типов решаются для параметров связанных типов с помощью унификации типов. Если унификация не удается, то вывод типа не удается.
Для каждого связанного параметра типа (P_k), для которого еще не выведен аргумент типа и для которого собраны одна или несколько пар ((c_j, P_k)) с этим же параметром типа, определите константный вид констант (c_j) во всех этих парах так же, как и для константных выражений. Аргумент типа для (P_k) - это тип по умолчанию для определенного вида константы. Если вид константы не может быть определен из-за конфликтующих видов констант, вывод типа завершается неудачей.
Если после этих двух фаз не все аргументы типа были найдены, вывод типа завершается неудачей.
Если эти две фазы прошли успешно, то вывод типа определил аргумент типа для каждого связанного параметра типа: (P_k ➞ A_k)
Аргумент типа (A_k) может быть составным типом, содержащим другие связанные параметры типа (P_k) в качестве типов элементов (или даже быть просто другим связанным параметром типа). В процессе многократного упрощения связанные параметры типа в каждом аргументе типа заменяются соответствующими аргументами типа для этих параметров типа до тех пор, пока каждый аргумент типа не будет свободен от связанных параметров типа.
Если аргументы типа содержат циклические ссылки на себя через связанные параметры типа, упрощение и, следовательно, вывод типа не удается. В противном случае вывод типов проходит успешно.
Унификация типов
Вывод типа решает уравнения типа с помощью унификации типов.
Унификация типов рекурсивно сравнивает типы LHS и RHS уравнения, где один или оба типа могут быть или содержать связанные параметры типа, и ищет аргументы типа для этих параметров типа так, чтобы LHS и RHS совпадали (становились идентичными или совместимыми по присваиванию, в зависимости от контекста).
Для этого при выводе типов хранится карта связанных параметров типа и аргументов типа, которая обновляется во время унификации типов. Изначально параметры связанного типа известны, но карта пуста. При унификации типа, если выводится новый аргумент типа A, в карту добавляется соответствующее отображение P ➞ A из параметра типа в аргумент.
И наоборот, при сравнении типов аргумент известного типа (аргумент типа, для которого уже существует запись в карте) занимает место соответствующего параметра типа. По мере продвижения вывода типов карта заполняется все больше и больше, пока не будут рассмотрены все уравнения или пока унификация не завершится неудачей.
Вывод типа успешен, если ни один шаг унификации не завершился неудачей и в карте есть запись для каждого параметра типа.
Например, для уравнения типа с параметром связанного типа P
([10]struct{ elem P, list [\ ]P } ≡_A [10]struct{ elem string; list [\ ]string })
Вывод типа начинается с пустой карты. Сначала унификация сравнивает структуру верхнего уровня типов LHS и RHS. Оба типа являются массивами одинаковой длины; они унифицируются, если типы элементов унифицируются. Оба типа элементов являются структурами; они унифицируются, если у них одинаковое количество полей с одинаковыми именами и если типы полей унифицируются.
Аргумент типа для P пока неизвестен (нет записи в карте), поэтому унификация P со строкой добавляет в карту отображение P ➞ string. Унификация типов поля списка требует унификации []P и []string, а значит, P и string. Поскольку аргумент типа P на данный момент известен (есть запись map для P), его аргумент типа string занимает место P. А поскольку string идентичен string, этот шаг унификации также успешен. Унификация LHS и RHS уравнения теперь завершена. Вывод типа прошел успешно, поскольку существует только одно уравнение типа, ни один шаг унификации не завершился неудачей, и карта полностью заполнена.
Унификация использует комбинацию точной и свободной унификации в зависимости от того, должны ли два типа быть идентичными, совместимыми по назначению или только структурно одинаковыми. Соответствующие правила унификации типов подробно описаны в Приложении.
Для уравнения вида (X ≡_A Y), где X и Y - типы, участвующие в присваивании (включая передачу параметров и операторы возврата), структуры типов верхнего уровня могут объединяться слабо, но типы элементов должны объединяться точно, что соответствует правилам для присваиваний.
Для уравнения вида (P ≡_C C), где P - параметр типа, а C - соответствующее ограничение, правила унификации немного сложнее:
- Если
Cимеет основной типcore(C), аPимеет аргумент известного типаA, тоcore(C)иAдолжны слабо унифицироваться. Если уPнет аргумента известного типа иCсодержит ровно один терм типаT, который не является базовым (тильда) типом, унификация добавляет отображениеP ➞ Tв карту. - Если
Cне имеет базового типа, аPимеет аргумент известного типаA, тоAдолжен иметь все методыC, если таковые имеются, и соответствующие типы методов должны точно унифицироваться.
При решении уравнений типа из ограничений типа, решение одного уравнения может вывести дополнительные аргументы типа, которые, в свою очередь, могут позволить решить другие уравнения, зависящие от этих аргументов типа. Вывод типов повторяет унификацию типов до тех пор, пока выводятся новые аргументы типов.
Операторы
Операторы объединяют операнды в выражения.
Expression = UnaryExpr | Expression binary_op Expression .
UnaryExpr = PrimaryExpr | unary_op UnaryExpr .
binary_op = "||" | "&&" | rel_op | add_op | mul_op .
rel_op = "==" | "!=" | "<" | "<=" | ">" | ">=" .
add_op = "+" | "-" | "|" | "^" .
mul_op = "*" | "/" | "%" | "<<" | ">>" | "&" | "&^" .
unary_op = "+" | "-" | "!" | "^" | "*" | "&" | "<-" .
Сравнения обсуждаются в другом разделе. Для других бинарных операторов типы операндов должны быть одинаковыми, если только операция не включает сдвиги или нетипизированные константы. Об операциях, связанных только с константами, см. раздел о константных выражениях.
За исключением операций сдвига, если один из операндов является нетипизированной константой, а другой - нет, константа неявно преобразуется к типу другого операнда.
Правый операнд в выражении сдвига должен иметь тип integer [Go 1.13] или быть нетипизированной константой, представляемой значением типа uint. Если левый операнд неконстантного выражения сдвига является нетипизированной константой, он сначала неявно преобразуется к тому типу, который он принял бы, если бы выражение сдвига было заменено только его левым операндом.
var a [1024]byte
var s uint = 33
// Результаты следующих примеров приведены для 64-битных интов.
var i = 1<<s // 1 имеет тип int
var j int32 = 1<<s // 1 имеет тип int32; j == 0
var k = uint64(1<<s) // 1 имеет тип uint64; k == 1<<33
var m int = 1. 0<<s // 1.0 имеет тип int; m == 1<<33
var n = 1.0<<s == j // 1.0 имеет тип int32; n == true
var o = 1<<s == 2<<s // 1 и 2 имеют тип int; o == false
var p = 1<<s == 1<<33 // 1 имеет тип int; p == true
var u = 1.0<<s // illegal: 1.0 имеет тип float64, не может сдвигаться
var u1 = 1.0<<s != 0 // illegal: 1.0 имеет тип float64, сдвиг невозможен
var u2 = 1<<s != 1.0 // illegal: 1 имеет тип float64, сдвиг невозможен
var v1 float32 = 1<<s // illegal: 1 имеет тип float32, сдвиг невозможен
var v2 = string(1<<s) // illegal: 1 преобразуется в строку, сдвиг невозможен
var w int64 = 1.0<<33 // 1.0<<33 - постоянное выражение сдвига; w == 1<<33
var x = a[1.0<<s] // паника: 1.0 имеет тип int, но 1<<33 переполняет границы массива
var b = make([]byte, 1.0<<s) // 1.0 имеет тип int; len(b) == 1<<33
// Результаты следующих примеров приведены для 32-битных интов,
// что означает, что сдвиги будут переполняться.
var mm int = 1.0<<s // 1.0 имеет тип int; mm == 0
var oo = 1<<s == 2<<s // 1 и 2 имеют тип int; oo == true
var pp = 1<<s == 1<<33 // незаконно: 1 имеет тип int, но 1<<33 переполняет int
var xx = a[1.0<<s] // 1.0 имеет тип int; xx == a[0]
var bb = make([]byte, 1.0<<s) // 1.0 имеет тип int; len(bb) == 0
Старшинство операторов
Унарные операторы имеют наивысшее старшинство. Поскольку операторы ++ и -- формируют утверждения, а не выражения, они не входят в иерархию операторов. Как следствие, оператор *p++ - это то же самое, что и (*p)++.
Существует пять уровней старшинства для бинарных операторов. Операторы умножения связываются сильнее всего, затем следуют операторы сложения, сравнения, && (логическое И) и, наконец, || (логическое ИЛИ):
| Старшинство | Оператор |
|---|---|
| 5 | * / % << >> & &^ |
| 4 | + - ^ | |
| 3 | == != < <= > >= |
| 2 | && |
| 1 | || |
Бинарные операторы с одинаковым старшинством связываются слева направо. Например, x / y * z - это то же самое, что (x / y) * z.
+x // x
42 + a - b // (42 + a) - b
23 + 3*x[i] // 23 + (3 * x[i])
x <= f() // x <= f()
^a >> b // (^a) >> b
f() || g() // f() || g()
x == y+1 && <-chanInt > 0 // (x == (y+1)) && ((<-chanInt) > 0)
Арифметические операторы
Арифметические операторы применяются к числовым значениям и дают результат того же типа, что и первый операнд. Четыре стандартных арифметических оператора (+, -, *, /) применяются к целым, плавающим точкам и комплексным типам; + также применяется к строкам. Побитовые логические операторы и операторы сдвига применяются только к целым числам.
+ sum integers, floats, complex values, strings
- difference integers, floats, complex values
* product integers, floats, complex values
/ quotient integers, floats, complex values
% remainder integers
& bitwise AND integers
| bitwise OR integers
^ bitwise XOR integers
&^ bit clear (AND NOT) integers
<< left shift integer << integer >= 0
>> right shift integer >> integer >= 0
Если тип операнда является параметром типа, оператор должен применяться к каждому типу в этом наборе типов. Операнды представляются как значения аргумента типа, с которым инстанцирован параметр типа, а операция вычисляется с точностью этого аргумента типа. Например, для функции:
func dotProduct[F ~float32|~float64](v1, v2 []F) F {
var s F
for i, x := range v1 {
y := v2[i]
s += x * y
}
return s
}
произведение x * y и сложение s += x * y вычисляются с точностью float32 или float64, соответственно, в зависимости от аргумента типа для F.
Целочисленные операторы¶
Для двух целых значений x и y целочисленный коэффициент q = x / y и остаток r = x % y удовлетворяют следующим соотношениям:
x = q*y + r and |r| < |y|
при усечении x / y до нуля (“усеченное деление”).
x y x / y x % y
5 3 1 2
-5 3 -1 -2
5 -3 -1 2
-5 -3 1 -2
Единственным исключением из этого правила является то, что если делитель x является отрицательным значением для типа int, то коэфициент q = x / -1 равен x (и r = 0) из-за переполнения двух дополняющих целых чисел:
x, q
int8 -128
int16 -32768
int32 -2147483648
int64 -9223372036854775808
Если делитель является константой, он не должен быть нулевым. Если делитель равен нулю во время выполнения, возникает паника во время выполнения. Если делимое неотрицательно, а делитель - постоянная степень 2, деление можно заменить сдвигом вправо, а вычисление остатка - побитовой операцией AND:
x x / 4 x % 4 x >> 2 x & 3
11 2 3 2 3
-11 -2 -3 -3 1
Операторы сдвига сдвигают левый операнд на заданный правым операндом счетчик сдвига, который должен быть неотрицательным. Если во время выполнения счетчик сдвигов отрицателен, возникает паника во время выполнения.
Операторы сдвига выполняют арифметические сдвиги, если левый операнд является знаковым целым числом, и логические сдвиги, если он является беззнаковым целым числом.
Верхнее ограничение на количество сдвигов отсутствует. Операторы сдвига ведут себя так, как будто левый операнд сдвигается n раз на 1 при количестве сдвигов n. В результате x << 1 - то же самое, что x*2, а x >> 1 - то же самое, что x/2, но усеченное в сторону отрицательной бесконечности.
Для целочисленных операндов унарные операторы +, - и ^ определяются следующим образом:
+x 0 + x
-x негатив 0 - x
^x побитовое дополнение m ^ x, причем m = "все биты установлены в 1" для беззнакового x
и m = -1 для знакового x
Переполнение целого числа
Для беззнаковых целых значений операции +, -, * и << вычисляются по модулю 2n, где n - битовая ширина типа беззнакового целого числа. Грубо говоря, эти беззнаковые целочисленные операции отбрасывают старшие биты при переполнении, и программы могут полагаться на “обход”.
Для знаковых целых чисел операции +, -, *, / и << могут легально переполняться, а результирующее значение существует и детерминированно определяется представлением знакового целого, операцией и ее операндами. Переполнение не вызывает паники во время выполнения. Компилятор не может оптимизировать код в предположении, что переполнение не произойдет. Например, он не может считать, что x < x + 1 всегда истинно.
Операторы с плавающей точкой
Для чисел с плавающей точкой и комплексных чисел +x равно x, а -x - отрицание x. Результат деления на ноль с плавающей точкой или комплексного числа не определен за пределами стандарта IEEE 754; возникнет ли паника во время выполнения, зависит от конкретной реализации.
Реализация может объединить несколько операций с плавающей точкой в одну операцию, возможно, в нескольких операторах, и получить результат, отличающийся от значения, полученного при выполнении и округлении инструкций по отдельности. Явное преобразование типа с плавающей точкой округляет с точностью целевого типа, предотвращая слияние, которое отменит это округление.
Например, в некоторых архитектурах предусмотрена инструкция “слитного умножения и сложения” (FMA), которая вычисляет x*y + z без округления промежуточного результата x*y. Эти примеры показывают, когда реализация Go может использовать эту инструкцию:
// FMA допускает вычисление r, поскольку x*y не округляется явно:
r = x*y + z
r = z; r += x*y
t = x*y; r = t + z
*p = x*y; r = *p + z
r = x*y + float64(z)
// FMA запрещено для вычисления r, так как при этом опускается округление x*y:
r = float64(x*y) + z
r = z; r += float64(x*y)
t = float64(x*y); r = t + z
Конкатенация строк
Строки можно конкатенировать с помощью оператора + или оператора присваивания +=
s := "hi" + string(c)
s += " and good bye"
Сложение строк создает новую строку путем конкатенации операндов.
Операторы сравнения
Операторы сравнения сравнивают два операнда и выдают нетипизированное булево значение.
== equal
!= not equal
< less
<= less or equal
> greater
>= greater or equal
В любом сравнении первый операнд должен быть приписан к типу второго операнда, или наоборот.
Операторы равенства == и != применяются к операндам сравниваемых типов. Операторы упорядочивания <, <=, > и >= применяются к операндам упорядоченных типов. Эти термины и результат сравнения определяются следующим образом:
- Булевы типы сравнимы. Два булевых значения равны, если они либо оба истинны, либо оба ложны.
- Целочисленные типы сравнимы и упорядочены. Два целочисленных значения сравниваются обычным способом.
- Типы с плавающей точкой сравнимы и упорядочены. Два значения с плавающей точкой сравниваются в соответствии со стандартом IEEE 754.
- Комплексные типы сравнимы. Два комплексных значения
uиvравны, еслиreal(u) == real(v)иimag(u) == imag(v). - Строковые типы сравнимы и упорядочены. Два строковых значения сравниваются лексически побайтно.
- Типы указателей сравнимы. Два значения указателя равны, если они указывают на одну и ту же переменную или если оба имеют значение
nil. Указатели на разные переменные нулевого размера могут быть равны, а могут и не быть. - Типы каналов сопоставимы. Два значения канала равны, если они были созданы одним и тем же вызовом
makeили если оба имеют значениеnil. - Типы интерфейсов, которые не являются параметрами типа, сравнимы. Два значения интерфейса равны, если у них одинаковые динамические типы и одинаковые динамические значения или если оба имеют значение
nil. - Значение
xнеинтерфейсного типаXи значениеtинтерфейсного типаTможно сравнивать, если типXсопоставим иXреализуетT. Они равны, если динамический типtидентиченX, а динамическое значениеtравноx. - Типы структур сопоставимы, если все их типы полей сопоставимы. Два значения структуры равны, если их соответствующие непустые значения полей равны. Поля сравниваются в исходном порядке, и сравнение прекращается, как только два значения полей различаются (или все поля были сравнены).
- Типы массивов сравнимы, если типы их элементов сравнимы. Два значения массива равны, если равны значения соответствующих элементов. Элементы сравниваются в порядке возрастания индекса, и сравнение прекращается, как только два значения элемента различаются (или все элементы были сравнены).
- Параметры типа сравнимы, если они строго сравнимы (см. ниже).
Сравнение двух значений интерфейса с одинаковыми динамическими типами вызывает панику во время выполнения, если этот тип не является сопоставимым. Это поведение применимо не только к прямому сравнению значений интерфейса, но и к сравнению массивов значений интерфейса или структур с полями, имеющими значения интерфейса.
Типы slice, map и function не поддаются сравнению. Однако в качестве особого случая значение slice, map или function может быть сравнено с заранее объявленным идентификатором nil. Сравнение значений указателя, канала и интерфейса с nil также допускается и следует из общих правил, приведенных выше.
const c = 3 < 4 // c — нетипизированная булева константа true
type MyBool bool
var x, y int
var (
// Результат сравнения — булево значение без типа.
// Применяются обычные правила присваивания.
b3 = x == y // b3 имеет тип bool
b4 bool = x == y // b4 имеет тип bool
b5 MyBool = x == y // b5 имеет тип MyBool)
Тип строго сопоставим, если он сопоставим, не является интерфейсным типом и не состоит из интерфейсных типов. В частности:
- Булевы, числовые, строковые, указательные и канальные типы строго сопоставимы.
- Типы структур строго сопоставимы, если все их типы полей строго сопоставимы.
- Типы массивов строго сопоставимы, если типы их элементов строго сопоставимы.
- Параметры типа строго сравнимы, если все типы в их наборе типов строго сравнимы.
Логические операторы
Логические операторы применяются к булевым значениям и дают результат того же типа, что и операнды. Сначала вычисляется левый операнд, а затем правый, если этого требует условие.
&& conditional AND p && q is "if p then q else false"
|| conditional OR p || q is "if p then true else q"
! NOT !p is "not p"
Операторы адресации
Для операнда x типа T операция адресации &x генерирует указатель типа *T на x. Операнд должен быть адресуемым, то есть либо операцией индексации переменной, указателя или фрагмента; либо селектором поля адресуемого операнда struct; либо операцией индексации массива адресуемого массива. В качестве исключения из требования адресуемости x может также быть составным литералом (возможно, со скобками). Если вычисление x приведет к панике во время выполнения, то и вычисление &x тоже.
Для операнда x типа указателя *T, указатель *x обозначает переменную типа T, на которую указывает x. Если x - nil, попытка вычислить *x вызовет панику во время выполнения.
&x
&a[f(2)]
&Point{2, 3}
*p
*pf(x)
var x *int = nil
*x // вызывает панику во время выполнения
&*x // вызывает панику во время выполнения
Оператор приема
Для операнда ch, основной тип которого - канал, значением операции приема <-ch является значение, полученное из канала ch. Направление канала должно разрешать операции приема, а тип операции приема - тип элемента канала. Выражение блокируется до тех пор, пока не будет получено значение. Получение из канала нулевого значения блокируется навсегда. Операция приема по закрытому каналу всегда может быть выполнена немедленно, выдавая нулевое значение типа элемента после получения всех ранее отправленных значений.
v1 := <-ch
v2 = <-ch
f(<-ch)
<-strobe // подождать до появления тактового импульса и отбросить полученное значение
Выражение приема, используемое в операторе присваивания или инициализации специальной формы
x, ok = <-ch
x, ok := <-ch
var x, ok = <-ch
var x, ok T = <-ch
возвращает дополнительный нетипизированный результат типа boolean, сообщающий об успешности связи. Значение ok равно true, если полученное значение было успешно отправлено в канал, или false, если это нулевое значение, сгенерированное из-за того, что канал закрыт и пуст.
Преобразования
Преобразование изменяет тип выражения на тип, указанный преобразованием. Преобразование может появляться буквально в исходном коде или подразумеваться контекстом, в котором появляется выражение.
Явное преобразование — это выражение вида T(x), где T — тип, а x — выражение, которое может быть преобразовано в тип T.
Conversion = Type "(" Expression [ "," ] ")" .
Если тип начинается с оператора * или <-, или если тип начинается с ключевого слова func и не имеет списка результатов, он должен быть заключен в круглые скобки, когда это необходимо, чтобы избежать двусмысленности:
*Point(p) // то же, что *(Point(p))
(*Point)(p) // p преобразуется в *Point
<-chan int(c) // то же, что <-(chan int(c))
(<-chan int)(c) // c преобразуется в <- chan int
func()(x) // сигнатура функции func() x
(func())(x) // x преобразуется в func()
(func() int)(x) // x преобразуется в func() int
func() int(x) // x преобразуется в func() int (недвусмысленно)
Константное значение x может быть приведено к типу T, если x может быть представлено значением T. Как частный случай, целочисленная константа x может быть явно приведена к строковому типу по тому же правилу, что и для неконстантных x.
Преобразование константы к типу, который не является параметром типа, дает типизированную константу.
uint(iota) // йота значение типа uint
float32(2.718281828) // 2.718281828 типа float32
complex128(1) // 1.0 + 0.0i типа complex128
float32(0.49999999) // 0.5 типа float32
float64(-1e-1000) // 0.0 типа float64
string('x') // "x" типа string
string(0x266c) // "♬" типа string
myString("foo" + "bar") // "foobar" типа myString
string([]byte{'a'}) // не константа: []byte{'a'} не является константой
(*int)(nil) // не является константой: nil не является константой, *int не является булевым, числовым или строковым типом
int(1.2) // незаконно: 1.2 не может быть представлено как int
string(65.0) // незаконно: 65.0 не является целочисленной константой
Преобразование константы в параметр типа дает неконстантное значение этого типа, причем это значение представлено как значение аргумента типа, с которым инстанцирован параметр типа. Например, для функции:
func f[P ~float32|~float64]() {
… P(1.1) …
}
преобразование P(1.1) приводит к непостоянному значению типа P, а значение 1.1 представляется как float32 или float64 в зависимости от аргумента типа для f. Соответственно, если f инстанцировано с типом float32, то числовое значение выражения P(1.1) + 1.2 будет вычислено с той же точностью, что и соответствующее непостоянное сложение float32.
Неконстантное значение x может быть преобразовано к типу T в любом из этих случаев:
xприсваиваетсяT.- без учета тегов
struct(см. ниже), типxиTне являются параметрами типа, но имеют одинаковые базовые типы. - без учета тегов
struct(см. ниже), типxиTявляются типами-указателями, которые не являются именованными типами, а их базовые типы-указатели не являются параметрами типа, но имеют одинаковые базовые типы. - Тип
xиT- оба целочисленные типы или типы с плавающей точкой. - Тип
xиT- оба комплексные типы. x- целое число или фрагмент байтов или рун, аT- строковый тип.x- строка, аT- фрагмент байтов или рун.x- фрагмент,T- массив [Go 1.20] или указатель на массив [Go 1.17], причем типы фрагмента и массива имеют одинаковые типы элементов.
Кроме того, если T или x типа V являются параметрами типа, x также может быть преобразован в тип T, если выполняется одно из следующих условий:
- И
V, иTявляются параметрами типа, и значение каждого типа в наборе типовVможет быть преобразовано в каждый тип в наборе типовT. - Только
Vявляется параметром типа и значение каждого типа из набора типовVможет быть преобразовано вT. - Только
Tявляется параметром типа иxможет быть преобразовано в каждый тип из набора типовT. - Теги
structигнорируются при сравнении типовstructна идентичность для целей преобразования:
type Person struct {
Name string
Address *struct {
Street string
City string
}
}
var data *struct {
Name string `json:"name"`
Address *struct {
Street string `json:"street"`
City string `json:"city"`
} `json:"address"`
}
var person = (*Person)(data) // // игнорируя теги, базовые типы идентичны
Особые правила применяются к (неконстантным) преобразованиям между числовыми типами или к и от строкового типа. Эти преобразования могут изменить представление x и повлечь за собой затраты времени выполнения. Все остальные преобразования изменяют только тип, но не представление x.
Не существует лингвистического механизма для преобразования между указателями и целыми числами. Пакет unsafe реализует эту функциональность в ограниченных условиях.
Преобразования между числовыми типами
Для преобразования неконстантных числовых значений применяются следующие правила:
- При преобразовании между целочисленными типами, если значение является целым числом со знаком, оно расширяется по знаку до неявной бесконечной точности; в противном случае оно расширяется до нуля. Затем оно усекается, чтобы поместиться в размер типа результата. Например, если
v := uint16(0x10F0), тоuint32(int8(v)) == 0xFFFFFFF0. Преобразование всегда дает действительное значение; нет никаких признаков переполнения. - При преобразовании числа с плавающей запятой в целое число дробная часть отбрасывается (усечение в сторону нуля).
- При преобразовании целого числа или числа с плавающей запятой в тип с плавающей запятой или комплексного числа в другой комплексный тип, значение результата округляется с точностью, указанной типом назначения. Например, значение переменной
xтипаfloat32может храниться с дополнительной точностью, превышающей точность 32-разрядного числа IEEE 754, ноfloat32(x)представляет результат округления значенияxдо 32-разрядной точности. Аналогично,x + 0.1может использовать более 32 бит точности, ноfloat32(x + 0.1)— нет. - Во всех неконстантных преобразованиях, включающих значения с плавающей запятой или комплексные значения, если тип результата не может представить значение, преобразование выполняется успешно, но значение результата зависит от реализации.
Преобразования в строковый тип и из него
- Преобразование фрагмента байтов в строковый тип дает строку, последовательные байты которой являются элементами фрагмента.
string([]byte{'h', 'e', 'l', 'l', '\xc3', '\xb8'}) // "hellø"
string([]byte{}) // ""
string([]byte(nil)) // ""
type bytes []byte
string(bytes{'h', 'e', 'l', 'l', '\xc3', '\xb8'}) // "hellø"
type myByte byte
string([]myByte{'w', 'o', 'r', 'l', 'd', '!'}) // "world!"
myString([]myByte{'\xf0', '\x9f', '\x8c', '\x8d'}) // "🌍"
- Преобразование фрагмента рун в строковый тип дает строку, которая представляет собой конкатенацию отдельных значений рун, преобразованных в строки.
string([]rune{0x767d, 0x9d6c, 0x7fd4}) // "\u767d\u9d6c\u7fd4" == "白鵬翔"
string([]rune{}) // ""
string([]rune(nil)) // ""
type runes []rune
string(runes{0x767d, 0x9d6c, 0x7fd4}) // "\u767d\u9d6c\u7fd4" == "白鵬翔"
type myRune rune
string([]myRune{0x266b, 0x266c}) // "\u266b\u266c" == "♫♬"
myString([]myRune{0x1f30e}) // "\U0001f30e" == "🌎"
- Преобразование значения типа
stringв фрагмент типаbytesдает ненулевой фрагмент, последовательными элементами которого являются байты строки. Объем результирующего фрагмента зависит от реализации и может быть больше длины фрагмента.
[]byte("hellø") // []byte{'h', 'e', 'l', 'l', '\xc3', '\xb8'}
[]byte("") // []byte{}
bytes("hellø") // []byte{'h', 'e', 'l', 'l', '\xc3', '\xb8'}
[]myByte("world!") // []myByte{'w', 'o', 'r', 'l', 'd', '!'}
[]myByte(myString("🌏")) // []myByte{'\xf0', '\x9f', '\x8c', '\x8f'}
- Преобразование значения типа
stringв фрагмент типаrunesдает фрагмент, содержащий отдельные кодовые позицииUnicodeстроки. Объем результирующего фрагмента зависит от реализации и может быть больше длины фрагмента.
[]rune(myString("白鵬翔")) // []rune{0x767d, 0x9d6c, 0x7fd4}
[]rune("") // []rune{}
runes("白鵬翔") // []rune{0x767d, 0x9d6c, 0x7fd4}
[]myRune("♫♬") // []myRune{0x266b, 0x266c}
[]myRune(myString("🌐")) // []myRune{0x1f310}
- Наконец, по историческим причинам целочисленное значение может быть преобразовано в строковый тип. При таком преобразовании получается строка, содержащая (возможно, многобайтовое) представление UTF-8 кодовой точки Юникода с заданным целочисленным значением. Значения, выходящие за пределы диапазона допустимых кодовых точек Юникода, преобразуются в
"\uFFFD".
string('a') // "a"
string(65) // "A"
string('\xf8') // "\u00f8" == "ø" == "\xc3\xb8"
string(-1) // "\ufffd" == "\xef\xbf\xbd"
type myString string
myString('\u65e5') // "\u65e5" == "日" == "\xe6\x97\xa5"
Примечание: Возможно, со временем эта форма преобразования будет удалена из языка. Инструмент
go vetотмечает некоторые преобразования целых чисел в строки как потенциальные ошибки. Вместо них следует использовать библиотечные функции, такие какutf8.AppendRuneилиutf8.EncodeRune.
Преобразования из среза в массив или указатель массива
Преобразование среза в массив дает массив, содержащий элементы массива, лежащего в основе среза. Аналогично, преобразование среза в указатель массива дает указатель на массив, лежащий в основе среза. В обоих случаях, если длина фрагмента меньше длины массива, возникает паника во время выполнения.
s := make([]byte, 2, 4)
a0 := [0]byte(s)
a1 := [1]byte(s[1:]) // a1[0] == s[1]
a2 := [2]byte(s) // a2[0] == s[0]
a4 := [4]byte(s) // panics: len([4]byte) > len(s)
s0 := (*[0]byte)(s) // s0 != nil
s1 := (*[1]byte)(s[1:]) // &s1[0] == &s[1]
s2 := (*[2]byte)(s) // &s2[0] == &s[0]
s4 := (*[4]byte)(s) // panics: len([4]byte) > len(s)
var t []string
t0 := [0]string(t) // ok for nil slice t
t1 := (*[0]string)(t) // t1 == nil
t2 := (*[1]string)(t) // panics: len([1]string) > len(t)
u := make([]byte, 0)
u0 := (*[0]byte)(u) // u0 != nil
Константные выражения
Константные выражения могут содержать только константные операнды и оцениваются во время компиляции.
Нетипизированные булевы, числовые и строковые константы могут использоваться в качестве операндов везде, где допустимо использовать операнд булевого, числового или строкового типа соответственно.
Сравнение констант всегда дает нетипизированную булеву константу. Если левый операнд выражения сдвига констант является нетипизированной константой, то результатом будет целочисленная константа, в противном случае - константа того же типа, что и левый операнд, который должен быть целочисленного типа.
Любая другая операция над нетипизированными константами приводит к нетипизированной константе того же типа, то есть к булевой, целочисленной, с плавающей точкой, комплексной или строковой константе. Если нетипизированные операнды бинарной операции (кроме сдвига) имеют разные типы, то результатом будет операнд того типа, который встречается далее в этом списке: целое число, руна, плавающая точка, комплекс. Например, нетипизированная целочисленная константа, деленная на нетипизированную комплексную константу, дает нетипизированную комплексную константу.
const a = 2 + 3.0 // a == 5.0 (untyped floating-point constant)
const b = 15 / 4 // b == 3 (untyped integer constant)
const c = 15 / 4.0 // c == 3.75 (untyped floating-point constant)
const Θ float64 = 3/2 // Θ == 1.0 (type float64, 3/2 is integer division)
const Π float64 = 3/2. // Π == 1.5 (type float64, 3/2. is float division)
const d = 1 << 3.0 // d == 8 (untyped integer constant)
const e = 1.0 << 3 // e == 8 (untyped integer constant)
const f = int32(1) << 33 // illegal (constant 8589934592 overflows int32)
const g = float64(2) >> 1 // illegal (float64(2) is a typed floating-point constant)
const h = "foo" > "bar" // h == true (untyped boolean constant)
const j = true // j == true (untyped boolean constant)
const k = 'w' + 1 // k == 'x' (untyped rune constant)
const l = "hi" // l == "hi" (untyped string constant)
const m = string(k) // m == "x" (type string)
const Σ = 1 - 0.707i // (untyped complex constant)
const Δ = Σ + 2.0e-4 // (untyped complex constant)
const Φ = iota*1i - 1/1i // (untyped complex constant)
Применение встроенной функции complex к нетипизированным константам типа integer, rune или floating-point дает нетипизированную константу типа complex.
const ic = complex(0, c) // ic == 3.75i (untyped complex constant)
const iΘ = complex(0, Θ) // iΘ == 1i (type complex128)
Выражения констант всегда оцениваются точно; промежуточные значения и сами константы могут требовать точности, значительно большей, чем поддерживается любым заранее объявленным типом в языке. Следующие объявления являются законными:
const Huge = 1 << 100 // Huge == 1267650600228229401496703205376 (untyped integer constant)
const Four int8 = Huge >> 98 // Four == 4 (type int8)
Делитель постоянной операции деления или остатка не должен быть равен нулю:
3.14 / 0.0 // illegal: division by zero
Значения типизированных констант всегда должны быть точно представлены значениями типа константы. Следующие константные выражения являются незаконными:
uint(-1) // -1 cannot be represented as a uint
int(3.14) // 3.14 cannot be represented as an int
int64(Huge) // 1267650600228229401496703205376 cannot be represented as an int64
Four * 300 // operand 300 cannot be represented as an int8 (type of Four)
Four * 100 // product 400 cannot be represented as an int8 (type of Four)
Маска, используемая унарным оператором побитового дополнения ^, соответствует правилу для неконстант: маска - это все 1 для беззнаковых констант и -1 для знаковых и нетипизированных констант.
^1 // untyped integer constant, equal to -2
uint8(^1) // illegal: same as uint8(-2), -2 cannot be represented as a uint8
^uint8(1) // typed uint8 constant, same as 0xFF ^ uint8(1) = uint8(0xFE)
int8(^1) // same as int8(-2)
^int8(1) // same as -1 ^ int8(1) = -2
Ограничение на реализацию: Компилятор может использовать округление при вычислении нетипизированных выражений с плавающей точкой или сложных констант; см. ограничение на реализацию в разделе о константах. Такое округление может привести к тому, что константное выражение с плавающей точкой окажется недопустимым в контексте целого числа, даже если оно будет целочисленным при вычислении с бесконечной точностью, и наоборот.
Порядок вычислений
На уровне пакета зависимости инициализации определяют порядок вычислений отдельных выражений инициализации в объявлениях переменных. В противном случае при вычислении операндов выражения, присваивания или оператора return все вызовы функций, вызовы методов, операции приема и двоичные логические операции вычисляются в лексическом порядке слева направо.
Например, в присваивании (локальном для функции)
y[f()], ok = g(z || h(), i()+x[j()], <-c), k()
вызовы функций и обмен данными происходят в порядке f(), h() (если z оценивается как false), i(), j(), <-c, g() и k(). Однако порядок этих событий по сравнению с вычислением и индексацией x и вычислением y и z не определен, за исключением лексических требований. Например, функция g не может быть вызвана до того, как будут вычислены ее аргументы.
a := 1
f := func() int { a++; return a }
x := []int{a, f()} // x может быть [1, 2] или [2, 2]: порядок оценки между a и f() не указан
m := map[int]int{a: 1, a: 2} // m может быть {2: 1} или {2: 2}: порядок оценки между двумя присваиваниями map не указан
n := map[int]int{a: f()} // n может быть {2: 3} или {3: 3}: порядок оценки между ключом и значением не указан
На уровне пакетов зависимости инициализации отменяют правило “слева направо” для отдельных выражений инициализации, но не для операндов внутри каждого выражения:
var a, b, c = f() + v(), g(), sqr(u()) + v()
func f() int { return c }
func g() int { return a }
func sqr(x int) int { return x*x }
// функции u и v независимы от всех других переменных и функций
Вызовы функций происходят в порядке u(), sqr(), v(), f(), v() и g().
Операции с плавающей точкой в одном выражении оцениваются в соответствии с ассоциативностью операторов. Явные круглые скобки влияют на оценку, переопределяя ассоциативность по умолчанию. В выражении x + (y + z) сложение y + z выполняется до сложения x.
Операторы
Операторы управляют исполнением.
Statement = Declaration | LabeledStmt | SimpleStmt |
GoStmt | ReturnStmt | BreakStmt | ContinueStmt | GotoStmt |
FallthroughStmt | Block | IfStmt | SwitchStmt | SelectStmt | ForStmt |
DeferStmt .
SimpleStmt = EmptyStmt | ExpressionStmt | SendStmt | IncDecStmt | Assignment | ShortVarDecl .
Завершающие операторы
Завершающий оператор прерывает обычный поток управления в блоке. Следующие операторы являются завершающими:
- Оператор
«return»или«goto». - Вызов встроенной функции
panic. - Блок, в котором список операторов заканчивается завершающим оператором.
- Оператор
«if», в котором:
- присутствует ветвь
«else», и - обе ветви являются завершающими операторами.
- Оператор
«for», в котором:
- нет операторов
«break», относящихся к оператору«for», и - отсутствует условие цикла, и
- оператор
«for»не использует диапазон (range).
- Оператор
«switch», в котором:
- нет операторов
«break», относящихся к оператору«switch», - есть
default case, и - списки операторов в каждом случае, включая случай по умолчанию (
default case), заканчиваются завершающим оператором или, возможно, помеченным оператором«fallthrough».
- Оператор
«select», в котором:
- нет операторов
«break», относящихся к оператору«select», и - списки операторов в каждом случае, включая (
default case), если он присутствует, заканчиваются завершающим оператором.
Маркированный оператор, обозначает завершающий оператор.
Все остальные операторы не являются завершающими.
Список операторов заканчивается завершающим оператором, если список не пустой и его последний непустой оператор является завершающим.
Пустые операторы
Пустой оператор ничего не делает.
EmptyStmt = .
Маркированные операторы
Маркированный оператор может быть целью оператора goto, break или continue.
LabeledStmt = Label ":" Statement .
Label = identifier .
Error: log.Panic("error encountered")
Выражения
За исключением специальных встроенных функций, вызовы функций и методов, а также операции получения могут появляться в контексте выражений. Такие выражения могут быть заключены в круглые скобки.
ExpressionStmt = Expression .
Следующие встроенные функции не допускаются в контексте оператора:
append cap complex imag len make new real
unsafe.Add unsafe.Alignof unsafe.Offsetof unsafe.Sizeof unsafe.Slice unsafe.SliceData unsafe.String unsafe.StringData
h(x+y)
f.Close()
<-ch
(<-ch)
len("foo") // illegal if len is the built-in function
Операторы отправки
Оператор отправки отправляет значение по каналу. Тип ядра выражения канала должен быть каналом, направление канала должно разрешать операции отправки, а тип отправляемого значения должен быть присвоен типу элемента канала.
SendStmt = Channel "<-" Expression .
Channel = Expression .
И канал, и выражение значения оцениваются перед началом обмена данными. Обмен данными блокируется до тех пор, пока отправка не будет выполнена. Отправка по небуферизованному каналу может продолжаться, если приемник готов. Отправка по буферизованному каналу может продолжаться, если в буфере есть место. Отправка по закрытому каналу продолжается, вызывая панику во время выполнения. Отправка по нулевому каналу блокируется навсегда.
ch <- 3 // отправляем значение 3 в канал ch
Операторы IncDec
Операторы "++" и "--" инкрементируют или декрементируют свои операнды на нетипизированную константу 1. Как и в случае с присваиванием, операнд должен быть адресуемым или выражением индекса карты.
IncDecStmt = Expression ( "++" | "--" ) .
Следующие операторы присваивания семантически эквивалентны:
IncDec statement Assignment
x++ x += 1
x-- x -= 1
Операторы присваивания
Оператор присваивания заменяет текущее значение, хранящееся в переменной, новым значением, заданным выражением. Оператор присваивания может присваивать одно значение одной переменной или несколько значений соответствующему числу переменных.
Assignment = ExpressionList assign_op ExpressionList .
assign_op = [ add_op | mul_op ] "=" .
Каждый операнд левой стороны должен быть адресуемым, выражением индекса карты или (только для присваивания =) идентификатором пробела. Операнды могут быть заключены в круглые скобки.
x = 1
*p = f()
a[i] = 23
(k) = <-ch // same as: k = <-ch
Операция присваивания x op= y, где op - двоичный арифметический оператор, эквивалентна x = x op (y), но оценивает x только один раз. Конструкция op= является единственной лексемой. В операциях присваивания и левый, и правый списки выражений должны содержать ровно по одному однозначному выражению, причем левое выражение не должно быть пустым идентификатором.
a[i] <<= 2
i &^= 1<<n
Кортеж присваивает отдельные элементы многозначной операции списку переменных. Существует две формы. В первом случае правым операндом является одно многозначное выражение, например вызов функции, операция канала или карты, или утверждение типа. Количество операндов в левой части должно соответствовать количеству значений. Например, если f - функция, возвращающая два значения,
x, y = f()
присваивает первое значение x, а второе - y. Во второй форме количество операндов слева должно быть равно количеству выражений справа, каждое из которых должно быть однозначным, и n-е выражение справа присваивается n-му операнду слева:
one, two, three = '一', '二', '三'
Идентификатор blank _ позволяет игнорировать значения правой стороны в присваивании:
_ = x // evaluate x but ignore it
x, _ = f() // evaluate f() but ignore second result value
Присваивание выполняется в два этапа. Во-первых, операнды индексных выражений и указателей (включая неявные указатели в селекторах) слева и выражения справа оцениваются в обычном порядке. Во-вторых, присваивания выполняются в порядке слева направо.
a, b = b, a // exchange a and b
x := []int{1, 2, 3}
i := 0
i, x[i] = 1, 2 // set i = 1, x[0] = 2
i = 0
x[i], i = 2, 1 // set x[0] = 2, i = 1
x[0], x[0] = 1, 2 // set x[0] = 1, then x[0] = 2 (so x[0] == 2 at end)
x[1], x[3] = 4, 5 // set x[1] = 4, then panic setting x[3] = 5.
type Point struct { x, y int }
var p *Point
x[2], p.x = 6, 7 // set x[2] = 6, then panic setting p.x = 7
i = 2
x = []int{3, 5, 7}
for i, x[i] = range x { // set i, x[2] = 0, x[0]
break
}
// after this loop, i == 0 and x is []int{3, 5, 3}
В присваиваниях каждое значение должно быть присваиваемым типу операнда, которому оно присваивается, за исключением следующих особых случаев:
- Любое типизированное значение может быть присвоено пустому идентификатору.
- Если нетипизированная константа присваивается переменной типа
interfaceили идентификаторуblank, константа сначала неявно преобразуется к своему типу по умолчанию. - Если переменной типа
interfaceили идентификаторуblankприсваивается нетипизированное булево значение, оно сначала неявно преобразуется к типуbool.
Когда переменной присваивается значение, заменяются только те данные, которые хранятся в переменной. Если значение содержит ссылку, присваивание копирует ссылку, но не делает копию данных, на которые ссылается переменная (например, базового массива фрагмента).
var s1 = []int{1, 2, 3}
var s2 = s1 // s2 хранит дескриптор среза s1
s1 = s1[:1] // длина s1 равна 1, но он по-прежнему разделяет свой базовый массив с s2
s2[0] = 42 // установка s2[0] изменяет и s1[0]
fmt.Println(s1, s2) // выводит [42] [42 2 3]
var m1 = make(map[string]int)
var m2 = m1 // m2 хранит дескриптор карты m1
m1["foo"] = 42 // установка m1["foo"] изменяет m2["foo"] также
fmt.Println(m2["foo"]) // печатает 42
Операторы If
Операторы If задают условное выполнение двух ветвей в зависимости от значения булева выражения. Если выражение равно true, то выполняется ветвь "if", в противном случае, если оно присутствует, выполняется ветвь "else".
IfStmt = "if" [ SimpleStmt ";" ] Expression Block [ "else" ( IfStmt | Block ) ] .
if x > max {
x = max
}
Выражению может предшествовать простой оператор, который выполняется до того, как выражение if будет выполнено.
if x := f(); x < y {
return x
} else if x > z {
return z
} else {
return y
}
Оператор Switch
Операторы "Switch" обеспечивают многоходовое выполнение. Выражение или тип сравнивается с "case" внутри "switch", чтобы определить, какую ветвь следует выполнить.
SwitchStmt = ExprSwitchStmt | TypeSwitchStmt .
Существует две формы: переключатели выражений и переключатели типов. В переключателе выражений case содержат выражения, которые сравниваются со значением выражения switch. В переключателе типов case содержат типы, которые сравниваются с типом специально аннотированного выражения switch. Выражение switch оценивается ровно один раз в операторе switch.
Переключатели выражений
В switch оценивается выражение, а выражения case, которые не обязательно должны быть константами, оцениваются слева направо и сверху вниз; первое из них, которое совпадает с выражением switch, запускает выполнение утверждений связанного с ним case; остальные case пропускаются. Если ни один случай не совпадает и существует случай “по умолчанию”, то выполняются его утверждения. Может быть не более одного case по умолчанию, и он может находиться в любом месте оператора “switch”. Отсутствующее выражение switch эквивалентно булевому значению true.
ExprSwitchStmt = "switch" [ SimpleStmt ";" ] [ Expression ] "{" { ExprCaseClause } "}" .
ExprCaseClause = ExprSwitchCase ":" StatementList .
ExprSwitchCase = "case" ExpressionList | "default" .
Если выражение switch оценивается как константа без типа, оно сначала неявно преобразуется в свой тип по умолчанию. Предварительно объявленное значение без типа nil не может использоваться в качестве выражения switch. Тип выражения switch должен быть сопоставимым.
Если выражение case не имеет типа, оно сначала неявно преобразуется в тип выражения switch. Для каждого выражения case x и значения t выражения switch должно быть допустимым сравнение x == t.
Другими словами, выражение switch обрабатывается так, как если бы оно использовалось для объявления и инициализации временной переменной t без явного типа; именно это значение t используется для проверки равенства каждого выражения case x.
В case или default последнее непустое выражение может быть выражением «fallthrough», указывающим, что управление должно перейти от конца этого условия к первому выражению следующего условия. В противном случае управление переходит к концу выражения «switch». Выражение «fallthrough» может появляться в качестве последнего выражения всех условий, кроме последнего, выражения switch.
Выражение switch может предваряться простым оператором, который выполняется до вычисления выражения.
switch tag {
default: s3()
case 0, 1, 2, 3: s1()
case 4, 5, 6, 7: s2()
}
switch x := f(); { // missing switch expression means "true"
case x < 0: return -x
default: return x
}
switch {
case x < y: f1()
case x < z: f2()
case x == 4: f3()
}
Ограничение на реализацию: Компилятор может запретить несколько выражений case, оценивающих одну и ту же константу. Например, современные компиляторы не допускают дублирования целых чисел, констант с плавающей точкой или строк в выражениях case.
Переключатели типов
Переключатель типов сравнивает типы, а не значения. В остальном он похож на переключатель выражений. Он обозначается специальным выражением switch, которое имеет вид утверждения типа с использованием ключевого слова type, а не фактического типа:
switch x.(type) {
// cases
}
Как и в утверждениях типа, x должен быть типом интерфейса, но не параметром типа, и каждый неинтерфейсный тип T, перечисленный в случае, должен реализовывать тип x. Типы, перечисленные в случаях переключателя типов, должны быть разными.
TypeSwitchStmt = "switch" [ SimpleStmt ";" ] TypeSwitchGuard "{" { TypeCaseClause } "}" .
TypeSwitchGuard = [ identifier ":=" ] PrimaryExpr "." "(" "type" ")" .
TypeCaseClause = TypeSwitchCase ":" StatementList .
TypeSwitchCase = "case" TypeList | "default" .
TypeSwitchGuard может включать короткое объявление переменной. Если используется такая форма, переменная объявляется в конце TypeSwitchCase в неявном блоке каждого условия. В условиях с регистром, перечисляющим ровно один тип, переменная имеет этот тип; в противном случае переменная имеет тип выражения в TypeSwitchGuard.
Вместо типа в case может использоваться заранее объявленный идентификатор nil; этот case выбирается, когда выражение в TypeSwitchGuard является значением интерфейса nil. Может существовать не более одного case nil.
Для выражения x типа interface{} используется следующий переключатель типов:
switch i := x.(type) {
case nil:
printString("x is nil") // type of i is type of x (interface{})
case int:
printInt(i) // type of i is int
case float64:
printFloat64(i) // type of i is float64
case func(int) float64:
printFunction(i) // type of i is func(int) float64
case bool, string:
printString("type is bool or string") // type of i is type of x (interface{})
default:
printString("don't know the type") // type of i is type of x (interface{})
}
или в нотации if else
v := x // x is evaluated exactly once
if v == nil {
i := v // type of i is type of x (interface{})
printString("x is nil")
} else if i, isInt := v.(int); isInt {
printInt(i) // type of i is int
} else if i, isFloat64 := v.(float64); isFloat64 {
printFloat64(i) // type of i is float64
} else if i, isFunc := v.(func(int) float64); isFunc {
printFunction(i) // type of i is func(int) float64
} else {
_, isBool := v.(bool)
_, isString := v.(string)
if isBool || isString {
i := v // type of i is type of x (interface{})
printString("type is bool or string")
} else {
i := v // type of i is type of x (interface{})
printString("don't know the type")
}
}
В качестве типа в case может использоваться параметр типа или общий тип. Если при инстанцировании этот тип окажется дублирующим другую запись в switch, то будет выбран первый подходящий case.
func f[P any](x any) int {
switch x.(type) {
case P:
return 0
case string:
return 1
case []P:
return 2
case []byte:
return 3
default:
return 4
}
}
var v1 = f[string]("foo") // v1 == 0
var v2 = f[byte]([]byte{}) // v2 == 2
Защите переключателя типов может предшествовать простой оператор, который выполняется до того, как будет оценена защита.
Оператор "fallthrough" не допускается в переключателе типов.
Операторы for
Оператор "for" задает повторное выполнение блока. Существует три формы: Итерация может управляться одним условием, предложением "for" или предложением "range".
ForStmt = "for" [ Condition | ForClause | RangeClause ] Block .
Condition = Expression .
Операторы For с одним условием
В своей простейшей форме оператор "for" задает повторное выполнение блока, пока булево условие оценивается как истинное. Условие оценивается перед каждой итерацией. Если условие отсутствует, оно эквивалентно булевому значению true.
for a < b {
a *= 2
}
Операторы for с предложением for
Оператор "for" с предложением ForClause также управляется условием, но дополнительно может содержать начальный и конечный оператор, например присваивание, оператор инкремента или декремента. Оператор InitStmt может быть коротким объявлением переменной, а оператор PostStmt - нет.
ForClause = [ InitStmt ] ";" [ Condition ] ";" [ PostStmt ] .
InitStmt = SimpleStmt .
PostStmt = SimpleStmt .
for i := 0; i < 10; i++ {
f(i)
}
Если он непустой, оператор init выполняется один раз перед оценкой условия для первой итерации; оператор post выполняется после каждого выполнения блока (и только если блок был выполнен). Любой элемент ForClause может быть пустым, но точка с запятой обязательна, если нет только условия. Если условие отсутствует, оно эквивалентно булевому значению true.
for cond { S() } is the same as for ; cond ; { S() }
for { S() } is the same as for true { S() }
Каждая итерация имеет свою отдельную объявленную переменную (или переменные) [Go 1.22]. Переменная, используемая в первой итерации, объявляется в операторе init. Переменная, используемая в каждой последующей итерации, объявляется неявно перед выполнением оператора post и инициализируется значением переменной предыдущей итерации в этот момент.
var prints []func()
for i := 0; i < 5; i++ {
prints = append(prints, func() { println(i) })
i++
}
for _, p := range prints {
p()
}
напечатает
1
3
5
До версии [Go 1.22] итерации использовали один набор переменных, а не отдельные переменные. В этом случае пример выше выводит
6
6
6
Операторы for с предложением range
Оператор "for" с предложением range выполняет итерацию по всем элементам массива, фрагмента, строки или карты, значениям, полученным по каналу, целочисленным значениям от нуля до верхнего предела [Go 1.22] или значениям, переданным в функцию yield функции итератора [Go 1.23]. Для каждой записи он присваивает значения итерации соответствующим переменным итерации, если они есть, а затем выполняет блок.
RangeClause = [ ExpressionList "=" | IdentifierList ":=" ] "range" Expression .
Выражение справа в предложении "range" называется выражением диапазона, его основной тип должен быть массивом, указателем на массив, фрагментом, строкой, картой, каналом, разрешающим операции приема, целым числом или функцией с определенной сигнатурой (см. ниже).
Как и в случае с присваиванием, операнды слева, если они присутствуют, должны быть адресными или индексными выражениями карты; они обозначают итерационные переменные.
- Если выражение диапазона является функцией, максимальное количество итерационных переменных зависит от сигнатуры функции.
- Если выражение диапазона является каналом или целым числом, допускается не более одной итерационной переменной; в противном случае их может быть до двух.
- Если последняя итерационная переменная является пустым идентификатором, то выражение range эквивалентно тому же выражению без этого идентификатора.
Выражение диапазона x оценивается перед началом цикла, за одним исключением: если присутствует не более одной итерационной переменной и x или len(x) постоянны, выражение диапазона не оценивается.
Вызовы функций слева оцениваются один раз за итерацию. Для каждой итерации значения итераций формируются следующим образом, если присутствуют соответствующие переменные итерации:
Range expression 1st value 2nd value
array or slice a [n]E, *[n]E, or []E index i int a[i] E
string s string type index i int see below rune
map m map[K]V key k K m[k] V
channel c chan E, <-chan E element e E
integer value n integer type, or untyped int value i see below
function, 0 values f func(func() bool)
function, 1 value f func(func(V) bool) value v V
function, 2 values f func(func(K, V) bool) key k K v V
- Для массива, указателя на массив или значения среза a значения итерации индекса генерируются в порядке возрастания, начиная с индекса элемента
0. Если присутствует не более одной переменной итерации, циклrangeгенерирует значения итерации от0доlen(a)-1и не индексирует сам массив или срез. Для нулевого среза количество итераций равно0. - Для строкового значения оператор
«range»итерирует кодовые позиции Unicode в строке, начиная с байтового индекса0. При последующих итерациях значение индекса будет индексом первого байта последующих кодовых позиций, закодированных в UTF-8, в строке, а второе значение типаruneбудет значением соответствующей кодовой позиции. Если при итерации встречается недопустимая последовательность UTF-8, второе значение будет0xFFFD, замещающий символ Unicode, и следующая итерация продвинется на один байт в строке. - Порядок итерации по картам не указан и не гарантируется, что он будет одинаковым от одной итерации к другой. Если запись карты, которая еще не была достигнута, удаляется во время итерации, соответствующее значение итерации не будет произведено. Если запись карты создается во время итерации, эта запись может быть произведена во время итерации или может быть пропущена. Выбор может варьироваться для каждой созданной записи и от одной итерации к другой. Если карта равна
nil, количество итераций равно0. - Для каналов произведенные значения итерации являются последовательными значениями, отправленными по каналу, пока канал не будет закрыт. Если канал равен
nil, выражение диапазона блокируется навсегда. - Для целочисленного значения
n, гдеnявляется целочисленным типом или нетипизированной целочисленной константой, значения итерации от0доn-1генерируются в порядке возрастания. Еслиnявляется целочисленным типом, значения итерации имеют тот же тип. В противном случае типnопределяется так, как если бы он был присвоен переменной итерации. В частности: если переменная итерации уже существует, тип значений итерации является типом переменной итерации, который должен быть целочисленным типом. В противном случае, если переменная итерации объявлена с помощью клаузулы«range»или отсутствует, тип значений итерации является типом по умолчанию дляn. Еслиn <= 0, цикл не выполняет никаких итераций. - Для функции
fитерация продолжается путем вызоваfс новой синтезированной функциейyieldв качестве аргумента. Еслиyieldвызывается до возвратаf, аргументыyieldстановятся значениями итерации для однократного выполнения тела цикла. После каждой последующей итерации циклаyieldвозвращаетtrueи может быть вызван снова для продолжения цикла. Пока тело цикла не завершается, команда«range»будет продолжать генерировать значения итерации таким образом для каждого вызоваyield, покаfне вернет результат. Если тело цикла завершается (например, операторомbreak),yieldвозвращаетfalseи не должен вызываться снова.
Переменные итерации могут быть объявлены командой «range» с использованием формы короткого объявления переменной (:=). В этом случае их область действия — блок оператора «for», и каждая итерация имеет свои собственные новые переменные [Go 1.22] (см. также операторы «for» с ForClause). Переменные имеют типы своих соответствующих значений итерации.
Если переменные итерации явно не объявлены с помощью команды «range», они должны существовать ранее. В этом случае значения итерации присваиваются соответствующим переменным, как в операторе присваивания.
var testdata *struct {
a *[7]int
}
for i, _ := range testdata.a {
// testdata.a is never evaluated; len(testdata.a) is constant
// i ranges from 0 to 6
f(i)
}
var a [10]string
for i, s := range a {
// type of i is int
// type of s is string
// s == a[i]
g(i, s)
}
var key string
var val interface{} // element type of m is assignable to val
m := map[string]int{"mon":0, "tue":1, "wed":2, "thu":3, "fri":4, "sat":5, "sun":6}
for key, val = range m {
h(key, val)
}
// key == last map key encountered in iteration
// val == map[key]
var ch chan Work = producer()
for w := range ch {
doWork(w)
}
// empty a channel
for range ch {}
// call f(0), f(1), ... f(9)
for i := range 10 {
// type of i is int (default type for untyped constant 10)
f(i)
}
// invalid: 256 cannot be assigned to uint8
var u uint8
for u = range 256 {
}
// invalid: 1e3 is a floating-point constant
for range 1e3 {
}
// fibo generates the Fibonacci sequence
fibo := func(yield func(x int) bool) {
f0, f1 := 0, 1
for yield(f0) {
f0, f1 = f1, f0+f1
}
}
// print the Fibonacci numbers below 1000:
for x := range fibo {
if x >= 1000 {
break
}
fmt.Printf("%d ", x)
}
// output: 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
// iteration support for a recursive tree data structure
type Tree[K cmp.Ordered, V any] struct {
left, right *Tree[K, V]
key K
value V
}
func (t *Tree[K, V]) walk(yield func(key K, val V) bool) bool {
return t == nil || t.left.walk(yield) && yield(t.key, t.value) && t.right.walk(yield)
}
func (t *Tree[K, V]) Walk(yield func(key K, val V) bool) {
t.walk(yield)
}
// walk tree t in-order
var t Tree[string, int]
for k, v := range t.Walk {
// process k, v
}
Операторы Go
Оператор "go" запускает выполнение вызова функции как независимого параллельного потока управления, или goroutine, в том же адресном пространстве.
GoStmt = «go» Expression .
Выражение должно быть вызовом функции или метода; оно не может быть заключено в скобки. Вызовы встроенных функций ограничены, как и для выражений-операторов.
Значение функции и параметры оцениваются как обычно в вызывающей goroutine, но в отличие от обычного вызова, выполнение программы не ожидает завершения вызванной функции. Вместо этого функция начинает выполняться независимо в новой goroutine. Когда функция заканчивается, ее goroutine также заканчивается. Если функция имеет какие-либо возвращаемые значения, они отбрасываются по завершении функции.
go Server()
go func(ch chan<- bool) { for { sleep(10); ch <- true }} (c)
Операторы select
Оператор select выбирает, какая из множества возможных операций отправки или получения будет выполнена. Он похож на оператор "switch", но все случаи относятся к коммуникационным операциям.
SelectStmt = "select" "{" { CommClause } "}" .
CommClause = CommCase ":" StatementList .
CommCase = "case" ( SendStmt | RecvStmt ) | "default" .
RecvStmt = [ ExpressionList "=" | IdentifierList ":=" ] RecvExpr .
RecvExpr = Expression .
В случае с RecvStmt результат RecvExpr может быть присвоен одной или двум переменным, которые могут быть объявлены с помощью короткого объявления переменной. RecvExpr должен быть операцией приема (возможно в скобках). Может быть не более одного случая по умолчанию, и он может появляться в любом месте списка случаев.
Выполнение оператора «select» происходит в несколько этапов:
- Для всех случаев в операторе канал-операнды операций приема и канал и выражения правой части операторов отправки оцениваются ровно один раз, в порядке источника, при входе в оператор
«select». Результатом является набор каналов для приема или отправки и соответствующие значения для отправки. Любые побочные эффекты в этой оценке будут происходить независимо от того, какая (если таковая имеется) операция связи выбрана для выполнения. Выражения в левой частиRecvStmtс коротким объявлением переменной или присваиванием еще не оцениваются. - Если одна или несколько коммуникаций могут быть выполнены, выбирается одна из них с помощью единого псевдослучайного выбора. В противном случае, если есть случай по умолчанию, выбирается этот случай. Если случая по умолчанию нет, оператор
«select»блокируется до тех пор, пока хотя бы одна из коммуникаций не сможет быть выполнена. - Если выбранный случай не является случаем по умолчанию, выполняется соответствующая операция связи.
- Если выбранный случай является
RecvStmtс коротким объявлением переменной или присваиванием, выражения в левой части оцениваются, и полученное значение (или значения) присваиваются. - Выполняется список операторов выбранного случая.
Поскольку связь по нулевым каналам никогда не может быть выполнена, оператор select, содержащий только нулевые каналы и не имеющий случая по умолчанию, блокируется навсегда.
var a []int
var c, c1, c2, c3, c4 chan int
var i1, i2 int
select {
case i1 = <-c1:
print("received ", i1, " from c1\n")
case c2 <- i2:
print("sent ", i2, " to c2\n")
case i3, ok := (<-c3): // same as: i3, ok := <-c3
if ok {
print("received ", i3, " from c3\n")
} else {
print("c3 is closed\n")
}
case a[f()] = <-c4:
// same as:
// case t := <-c4
// a[f()] = t
default:
print("no communication\n")
}
for { // send random sequence of bits to c
select {
case c <- 0: // note: no statement, no fallthrough, no folding of cases
case c <- 1:
}
}
select {} // block forever
Операторы возврата
Оператор "return" в функции F завершает выполнение F и, по желанию, предоставляет одно или несколько значений результата. Любые функции, отложенные F, выполняются до того, как F вернется к своему вызывающему устройству.
ReturnStmt = "return" [ ExpressionList ] .
В функции без типа результата оператор "return" не должен указывать никаких значений результата.
func noResult() {
return
}
Существует три способа возврата значений из функции с типом результата:
- Возвращаемое значение или значения могут быть явно перечислены в операторе
"return". Каждое выражение должно быть однозначным и присваиваться соответствующему элементу типа результата функции.
func simpleF() int {
return 2
}
func complexF1() (re float64, im float64) {
return -7.0, -4.0
}
- Список выражений в операторе
"return"может быть одним вызовом многозначной функции. Эффект будет таким, как если бы каждое значение, возвращаемое функцией, присваивалось временной переменной с типом соответствующего значения, а затем следовал оператор"return", перечисляющий эти переменные, и в этот момент применялись бы правила предыдущего случая.
func complexF2() (re float64, im float64) {
return complexF1()
}
- Список выражений может быть пустым, если тип результата функции задает имена для параметров результата. Параметры результата действуют как обычные локальные переменные, и функция может присваивать им значения по мере необходимости. Оператор
"return"возвращает значения этих переменных.
func complexF3() (re float64, im float64) {
re = 7.0
im = 4.0
return
}
func (devnull) Write(p []byte) (n int, _ error) {
n = len(p)
return
}
Независимо от того, как они объявлены, все значения результатов инициализируются нулевыми значениями для своего типа при входе в функцию. Оператор "return", указывающий результаты, устанавливает параметры результата до выполнения любых отложенных функций.
Ограничение на реализацию: Компилятор может запретить пустой список выражений в операторе "return", если в месте возврата в области видимости находится другая сущность (константа, тип или переменная) с тем же именем, что и параметр результата.
func f(n int) (res int, err error) {
if _, err := f(n-1); err != nil {
return // invalid return statement: err is shadowed
}
return
}
Операторы break
Оператор break завершает выполнение самого внутреннего оператора "for", "switch" или "select" внутри одной и той же функции.
BreakStmt = "break" [ Label ] .
Если есть метка, то она должна быть меткой вложенного оператора "for", "switch" или "select", и именно он завершает выполнение.
OuterLoop:
for i = 0; i < n; i++ {
for j = 0; j < m; j++ {
switch a[i][j] {
case nil:
state = Error
break OuterLoop
case item:
state = Found
break OuterLoop
}
}
}
Операторы continue
Оператор "continue" начинает следующую итерацию внутреннего цикла for, переводя управление в конец блока цикла. Цикл "for" должен находиться внутри одной и той же функции.
ContinueStmt = "continue" [ Label ] .
Если есть метка, то она должна быть меткой вложенного оператора "for", и именно он продолжает выполнение.
RowLoop:
for y, row := range rows {
for x, data := range row {
if data == endOfRow {
continue RowLoop
}
row[x] = data + bias(x, y)
}
}
Операторы goto
Оператор "goto" передает управление оператору с соответствующей меткой в той же функции.
GotoStmt = "goto" Label .
goto Error
Выполнение оператора "goto" не должно приводить к появлению в области видимости переменных, которые еще не были в области видимости в момент перехода к нему.
Например:
goto L // BAD
v := 3
L:
является ошибочным, поскольку переход к метке L пропускает создание v.
Оператор "goto" вне блока не может перейти к метке внутри этого блока.
Например:
if n%2 == 1 {
goto L1
}
for n > 0 {
f()
n--
L1:
f()
n--
}
является ошибочным, поскольку метка L1 находится внутри блока оператора "for", а goto - нет.
Операторы перехода (fallthrough)
Оператор “fallthrough” передает управление первому оператору следующего выражения case в выражении "switch". Он может использоваться только в качестве последнего непустого оператора в таком выражении.
FallthroughStmt = "fallthrough" .
Операторы defer
Оператор «defer» вызывает функцию, выполнение которой откладывается до момента возврата окружающей функции, либо потому, что окружающая функция выполнила оператор return, достигла конца своего тела, либо потому, что соответствующая goroutine находится в состоянии паники.
DeferStmt = «defer» Expression .
Выражение должно быть вызовом функции или метода; оно не может быть заключено в скобки. Вызовы встроенных функций ограничены, как и для операторов выражений.
Каждый раз, когда выполняется оператор «defer», значение функции и параметры вызова оцениваются как обычно и сохраняются заново, но сама функция не вызывается. Вместо этого отложенные функции вызываются непосредственно перед возвратом окружающей функции в обратном порядке, в котором они были отложены. То есть, если окружающая функция возвращается с помощью явного оператора return, отложенные функции выполняются после того, как все параметры результата установлены этим оператором return, но до того, как функция возвращается к вызывающему ее. Если значение отложенной функции вычисляется как nil, при вызове функции происходит сбой выполнения, а не при выполнении оператора «defer».
Например, если отложенная функция является функциональным литералом, а окружающая функция имеет именованные параметры результата, которые находятся в области действия литерала, отложенная функция может получить доступ к параметрам результата и изменить их до того, как они будут возвращены. Если отложенная функция имеет какие-либо возвращаемые значения, они отбрасываются по завершении функции. (См. также раздел об обработке паники.)
lock(l)
defer unlock(l) // unlocking happens before surrounding function returns
// prints 3 2 1 0 before surrounding function returns
for i := 0; i <= 3; i++ {
defer fmt.Print(i)
}
// f returns 42
func f() (result int) {
defer func() {
// result is accessed after it was set to 6 by the return statement
result *= 7
}()
return 6
}
Built-in функции
Встроенные функции объявляются заранее. Они вызываются как любая другая функция, но некоторые из них принимают в качестве первого аргумента не выражение, а тип.
append,cap,close,complex,copy,delete,imag,len,make,new,panic,print,println,real,recover
Встроенные функции не имеют стандартных типов Go, поэтому они могут появляться только в выражениях вызова; их нельзя использовать в качестве значений функций.
Добавление append к срезам и копирование copy срезов
Встроенные функции append и copy помогают выполнять распространенные операции со срезами. Для обеих функций результат не зависит от того, перекрывается ли память, на которую ссылаются аргументы.
Вариативная функция append добавляет ноль или более значений x к срезу s и возвращает результирующий срез того же типа, что и s. Основной тип s должен быть срезом типа []E. Значения x передаются в параметр типа ...E, и к ним применяются соответствующие правила передачи параметров. В качестве особого случая, если основной тип s - []byte, append также принимает второй аргумент с основным типом bytestring, за которым следует .... Эта форма добавляет байты байтового фрагмента или строки.
append(s S, x ...E) S // core type of S is []E
емкость s недостаточно велика, чтобы вместить дополнительные значения, append выделяет новый, достаточно большой базовый массив, в который помещаются как существующие элементы среза, так и дополнительные значения. В противном случае append повторно использует базовый массив.
s0 := []int{0, 0}
s1 := append(s0, 2) // append a single element s1 is []int{0, 0, 2}
s2 := append(s1, 3, 5, 7) // append multiple elements s2 is []int{0, 0, 2, 3, 5, 7}
s3 := append(s2, s0...) // append a slice s3 is []int{0, 0, 2, 3, 5, 7, 0, 0}
s4 := append(s3[3:6], s3[2:]...) // append overlapping slice s4 is []int{3, 5, 7, 2, 3, 5, 7, 0, 0}
var t []interface{}
t = append(t, 42, 3.1415, "foo") // t is []interface{}{42, 3.1415, "foo"}
var b []byte
b = append(b, "bar"...) // append string contents b is []byte{'b', 'a', 'r' }
Функция copy копирует элементы среза из источника src в пункт назначения dst и возвращает количество скопированных элементов. Типы ядра обоих аргументов должны быть срезами с одинаковым типом элемента. Количество скопированных элементов равно минимальному из len(src) и len(dst). В качестве особого случая, если основной тип места назначения - []byte, copy также принимает аргумент источника с основным типом bytestring. Эта форма копирует байты из байтового фрагмента или строки в байтовый фрагмент.
copy(dst, src []T) int
copy(dst []byte, src string) int
Например:
var a = [...]int{0, 1, 2, 3, 4, 5, 6, 7}
var s = make([]int, 6)
var b = make([]byte, 5)
n1 := copy(s, a[0:]) // n1 == 6, s is []int{0, 1, 2, 3, 4, 5}
n2 := copy(s, s[2:]) // n2 == 4, s is []int{2, 3, 4, 5, 4, 5}
n3 := copy(b, "Hello, World!") // n3 == 5, b is []byte("Hello")
Clear
Встроенная функция clear принимает аргумент типа map, slice или параметр type и удаляет или обнуляет все элементы [Go 1.21].
Вызов Тип аргумента Результат
clear(m) map[K]T удаляет все элементы, в результате чего получается пустая карта
(len(m) == 0)
clear(s) []T устанавливает все элементы длиной до
s в нулевое значение T
clear(t) параметр типа см. ниже
Если тип аргумента clear является параметром типа, то все типы в его наборе типов должны быть картами или срезами, и clear выполняет операцию, соответствующую фактическому типу аргумента.
Если map или slice равен nil, clear не выполняется.
Close
Для аргумента ch с типом ядра, являющимся каналом, встроенная функция close фиксирует, что по этому каналу больше не будут передаваться значения. Ошибкой будет, если ch является каналом только для приема. Отправка в закрытый канал или его закрытие вызывают панику во время выполнения. Закрытие канала nil также вызывает панику во время выполнения. После вызова close и после получения всех ранее отправленных значений операции приема возвращают нулевое значение для типа канала без блокировки. Многозначная операция receive возвращает полученное значение вместе с указанием того, закрыт ли канал.
Работа с комплексными числами
Три функции собирают и разбирают комплексные числа. Встроенная функция complex строит комплексное значение из действительной и мнимой частей с плавающей запятой, а real и imag извлекают действительную и мнимую части комплексного значения.
complex(realPart, imaginaryPart floatT) complexT
real(complexT) floatT
imag(complexT) floatT
Тип аргументов и возвращаемого значения соответствуют друг другу. Для complex оба аргумента должны быть одного типа с плавающей точкой, а возвращаемое значение - это комплексный тип с соответствующими составляющими с плавающей точкой: complex64 для аргументов float32 и complex128 для аргументов float64.
Если один из аргументов оценивается как нетипизированная константа, он сначала неявно преобразуется к типу другого аргумента. Если оба аргумента оцениваются как нетипизированные константы, они должны быть некомплексными числами или их мнимые части должны быть равны нулю, а возвращаемое значение функции - нетипизированная комплексная константа.
Для real и imag аргумент должен быть комплексного типа, а возвращаемый тип - соответствующий тип с плавающей точкой: float32 для аргумента complex64 и float64 для аргумента complex128. Если аргумент оценивается в нетипизированную константу, он должен быть числом, а возвращаемое значение функции - нетипизированная константа с плавающей точкой.
Функции real и imag вместе образуют обратную функцию complex, поэтому для значения z комплексного типа Z, z == Z(complex(real(z), imag(z))).
Если все операнды этих функций - константы, то возвращаемое значение - константа.
var a = complex(2, -2) // complex128
const b = complex(1.0, -1.4) // нетипизированная комплексная константа 1 - 1.4i
x := float32(math.Cos(math.Pi/2)) // float32
var c64 = complex(5, -x) // complex64
var s int = complex(1, 0) // нетипизированная комплексная константа 1 + 0i может быть преобразована в int
_ = complex(1, 2<<s) // illegal: 2 предполагает тип с плавающей точкой, нельзя сдвигать
var rl = real(c64) // float32
var im = imag(a) // float64
const c = imag(b) // нетипизированная константа -1.4
_ = imag(3 << s) // illegal: 3 предполагает комплексный тип, сдвиг невозможен
Аргументы типа parameter type недопустимы.
Удаление элементов карты (map)
Встроенная функция delete удаляет элемент с ключом k из карты m. Значение k должно быть присваиваемым типу ключа m.
delete(m, k) // удалить элемент m[k] из карты m
Если тип m - это параметр типа, то все типы в этом наборе типов должны быть картами, и все они должны иметь одинаковые типы ключей.
Если map m равен nil или элемент m[k] не существует, delete не выполняется.
Длина и емкость
Встроенные функции len и cap принимают аргументы различных типов и возвращают результат типа int. Реализация гарантирует, что результат всегда помещается в int.
Вызов Тип аргумента Результат
len(s) тип string длина строки в байтах
[n]T, *[n]T длина массива (== n)
[]T длина фрагмента
map[K]T длина карты (количество определенных ключей)
chan T количество элементов в очереди буфера канала
тип параметра см. ниже
cap(s) [n]T, *[n]T длина массива (== n)
[]T емкость фрагмента
chan T емкость буфера канала
тип параметра см. ниже
Если тип аргумента является типовым параметром P, вызов len(e) (или cap(e) соответственно) должен быть действительным для каждого типа в наборе типов P. Результатом является длина (или емкость, соответственно) аргумента, тип которого соответствует типовому аргументу, с которым был создан экземпляр P.
Емкость фрагмента — это количество элементов, для которых выделено место в базовом массиве. В любой момент времени выполняется следующее соотношение:
0 <= len(s) <= cap(s)
Длина нулевого фрагмента, карты или канала равна 0. Емкость нулевого фрагмента или канала равна 0.
Выражение len(s) является константой, если s является строковой константой. Выражения len(s) и cap(s) являются константами, если тип s является массивом или указателем на массив, а выражение s не содержит приёмов канала или (неконстантных) вызовов функций; в этом случае s не вычисляется. В противном случае вызовы len и cap не являются константами, и s вычисляется.
const (
c1 = imag(2i) // imag(2i) = 2.0 is a constant
c2 = len([10]float64{2}) // [10]float64{2} contains no function calls
c3 = len([10]float64{c1}) // [10]float64{c1} contains no function calls
c4 = len([10]float64{imag(2i)}) // imag(2i) is a constant and no function call is issued
c5 = len([10]float64{imag(z)}) // invalid: imag(z) is a (non-constant) function call
)
var z complex128
Make (Создание срезов, карт и каналов)
Встроенная функция make принимает тип T, за которым опционально следует список выражений, специфичных для данного типа. Основной тип T должен быть срезом, картой или каналом. Она возвращает значение типа T (не *T) Память инициализируется, как описано в разделе об начальных значениях.
Вызов Основной тип Результат
make(T, n) slice срез типа T с длиной n и емкостью n
make(T, n, m) slice срез типа T с длиной n и емкостью m
make(T) map карта типа T
make(T, n) map карта типа T с начальным пространством примерно для n элементов
make(T) channel небуферизованный канал типа T
make(T, n) канал буферизованный канал типа T, размер буфера n
Каждый из аргументов размера n и m должен быть целочисленного типа, иметь набор типов, содержащий только целочисленные типы, или быть константой без типа. Аргумент постоянного размера должен быть неотрицательным и представляться значением типа int; если это константа без типа, ей присваивается тип int. Если указаны оба аргумента n и m и они являются константами, то n не должен быть больше m. Для срезов и каналов, если n является отрицательным или больше m во время выполнения, возникает паника во время выполнения.
s := make([]int, 10, 100) // срез с len(s) == 10, cap(s) == 100
s := make([]int, 1e3) // срез с len(s) == cap(s) == 1000
s := make([]int, 1<<63) // недопустимо: len(s) не может быть представлено значением типа int
s := make([]int, 10, 0) // недопустимо: len(s) > cap(s)
c := make(chan int, 10) // канал с размером буфера 10
m := make(map[string]int, 100) // карта с начальным пространством примерно для 100 элементов
Вызов make с типом карты и подсказкой размера n создаст карту с начальным пространством для хранения n элементов карты. Точное поведение зависит от реализации.
Min и max
Встроенные функции min и max вычисляют соответственно наименьшее или наибольшее значение из фиксированного числа аргументов упорядоченных типов. Должно быть как минимум один аргумент [Go 1.21].
Применяются те же правила типов, что и для операторов: для упорядоченных аргументов x и y min(x , y) является действительным, если x + y является действительным, и тип min(x, y) является типом x + y (аналогично для max). Если все аргументы являются константами, результат является константой.
var x, y int
m := min(x) // m == x
m := min(x, y) // m — меньшее из x и y
m := max(x, y, 10) // m — большее из x и y, но не меньше 10
c := max(1, 2.0, 10) // c == 10.0 (тип с плавающей запятой)
f := max(0, float32(x)) // тип f — float32
var s []string
_ = min(s...) // недопустимо: аргументы slice не допускаются
t := max(«», «foo», „bar“) // t == «foo» (тип string)
Для числовых аргументов, предполагая, что все NaN равны, min и max являются коммутативными и ассоциативными:
min(x, y) == min(y, x)
min(x, y, z) == min(min(x, y), z) == min(x, min(y, z))
Для аргументов с плавающей запятой отрицательный ноль, NaN и бесконечность применяются следующие правила:
x y min(x, y) max(x, y)
-0.0 0.0 -0.0 0.0 // отрицательный ноль меньше (неотрицательного) нуля
-Inf y -Inf y // отрицательная бесконечность меньше любого другого числа
+Inf y y +Inf // положительная бесконечность больше любого другого числа
NaN y NaN NaN // если любой аргумент является NaN, результат будет NaN
Для строковых аргументов результатом для min будет первый аргумент с наименьшим (или для max — наибольшим) значением, сравниваемым лексически побайтно:
min(x, y) == if x <= y then x else y
min(x, y, z) == min(min(x, y), z)
New (Выделение памяти)
Встроенная функция new принимает тип T, выделяет память для переменной этого типа во время выполнения и возвращает значение типа *T, указывающее на нее. Переменная инициализируется, как описано в разделе об начальных значениях.
new(T)
Например
type S struct { a int; b float64 }
new(S)
выделяет память для переменной типа S, инициализирует ее (a=0, b=0.0) и возвращает значение типа *S, содержащее адрес этого места.
Обработка панических состояний
Две встроенные функции, panic и recover, помогают в отчетности и обработке панических состояний во время выполнения и определенных программой условий ошибок.
func panic(interface{})
func recover() interface{}
Во время выполнения функции F явный вызов panic или паническое состояние во время выполнения прерывает выполнение F. Любые функции, отложенные F, затем выполняются как обычно. Далее выполняются все отложенные функции, запущенные вызывающим F, и так далее, вплоть до всех отложенных функций верхнего уровня в выполняющейся goroutine. На этом программа завершается и сообщается об ошибке, включая значение аргумента panic. Эта последовательность завершения называется паникой.
panic(42)
panic(«unreachable»)
panic(Error(«cannot parse»))
Функция recover позволяет программе управлять поведением паникующего goroutine. Предположим, что функция G откладывает функцию D, которая вызывает recover, и происходит паника в функции того же goroutine, в котором выполняется G. Когда выполнение отложенных функций достигает D, возвращаемое значение вызова D для recover будет значением, переданным вызову panic. Если D возвращается нормально, не запуская новую панику, последовательность паники останавливается. В этом случае состояние функций, вызванных между G и вызовом panic, отбрасывается, и возобновляется нормальное выполнение. Затем выполняются все функции, отложенные G перед D, и выполнение G завершается возвратом к вызывающему.
Возвращаемое значение recover равно nil, если goroutine не находится в состоянии паники или recover не был вызван непосредственно отложенной функцией. И наоборот, если goroutine находится в состоянии паники и recover был вызван непосредственно отложенной функцией, возвращаемое значение recover гарантированно не будет nil. Чтобы обеспечить это, вызов panic с нулевым значением интерфейса (или нетипизированным nil) вызывает панику во время выполнения.
Функция protect в примере ниже вызывает функцию-аргумент g и защищает вызывающих от паники во время выполнения, вызванной g.
func protect(g func()) {
defer func() {
log.Println(«done») // Println выполняется нормально, даже если происходит паника
if x := recover(); x != nil {
log.Printf(«run time panic: %v», x)
}
}()
log.Println(«start»)
g()
}
Загрузка
Текущие реализации предоставляют несколько встроенных функций, полезных во время загрузки. Эти функции задокументированы для полноты, но их сохранение в языке не гарантируется. Они не возвращают результат.
Функция Поведение
print выводит все аргументы; форматирование аргументов зависит от реализации
println как print, но выводит пробелы между аргументами и новую строку в конце
Ограничение реализации: print и println не обязательно должны принимать произвольные типы аргументов, но должна поддерживаться печать типов boolean, numeric и string.
Packages (Пакеты)
Программы Go создаются путем связывания пакетов. Пакет, в свою очередь, состоит из одного или нескольких исходных файлов, которые вместе объявляют константы, типы, переменные и функции, принадлежащие пакету и доступные во всех файлах того же пакета. Эти элементы могут быть экспортированы и использованы в другом пакете.
Организация исходных файлов
Каждый исходный файл состоит из пакетного предложения, определяющего пакет, к которому он принадлежит, за которым следует, возможно, пустой набор деклараций импорта, объявляющих пакеты, содержимое которых он хочет использовать, а за ним следует, возможно, пустой набор деклараций функций, типов, переменных и констант.
SourceFile = PackageClause «;» { ImportDecl «;» } { TopLevelDecl «;» } .
Пакетное предложение
Пакетное объявление начинает каждый исходный файл и определяет пакет, к которому принадлежит файл.
PackageClause = «package» PackageName .
PackageName = identifier .
PackageName не должен быть пустым идентификатором.
package math
Набор файлов, имеющих один и тот же PackageName, образует реализацию пакета. Реализация может требовать, чтобы все исходные файлы пакета находились в одном каталоге.
Декларации импорта
Декларация импорта указывает, что исходный файл, содержащий декларацию, зависит от функциональности импортируемого пакета и обеспечивает доступ к экспортируемым идентификаторам этого пакета. Импорт указывает идентификатор (PackageName), который будет использоваться для доступа, и ImportPath, который указывает пакет, который будет импортирован.
ImportDecl = «import» ( ImportSpec | «(» { ImportSpec «;» } «)» ) .
ImportSpec = [ «.» | PackageName ] ImportPath .
ImportPath = string_lit .
PackageName используется в квалифицированных идентификаторах для доступа к экспортируемым идентификаторам пакета в импортирующем исходном файле. Он объявляется в блоке файла. Если PackageName опущен, по умолчанию используется идентификатор, указанный в объявлении package импортируемого пакета. Если вместо имени явно указана точка (.), все экспортированные идентификаторы пакета, объявленные в блоке пакета этого пакета, будут объявлены в блоке файла импортирующего исходного файла и должны быть доступны без квалификатора.
Интерпретация ImportPath зависит от реализации, но обычно это подстрока полного имени файла скомпилированного пакета и может быть относительной по отношению к репозиторию установленных пакетов.
Ограничение реализации: компилятор может ограничить ImportPaths непустыми строками, использующими только символы, принадлежащие общим категориям Unicode L, M, N, P и S (графические символы без пробелов), а также может исключить символы !"#$%&'()*,:;<=>?[\]^`{\|} и символ замены Unicode U+FFFD.
Рассмотрим скомпилированный пакет, содержащий объявление package math, которая экспортирует функцию Sin, и установим скомпилированный пакет в файл, идентифицируемый как «lib/math». В этой таблице показано, как Sin доступен в файлах, которые импортируют пакет после различных типов деклараций импорта.
Декларация импорта Локальное имя Sin
import "lib/math" math.Sin
import m "lib/math" m.Sin
import . "lib/math" Sin
Декларация импорта объявляет зависимость между импортирующим и импортируемым пакетом. Не допускается, чтобы пакет импортировал сам себя, прямо или косвенно, или напрямую импортировал пакет, не ссылаясь на какие-либо из его экспортируемых идентификаторов. Чтобы импортировать пакет исключительно для его побочных эффектов (инициализации), используйте пустой идентификатор в качестве явного имени пакета:
import _ "lib/math"
Пример package
Полный пакет Go, который реализует параллельное сито простых чисел.
package main
import «fmt»
// Отправить последовательность 2, 3, 4, … в канал „ch“.
func generate(ch chan<- int) {
for i := 2; ; i++ {
ch <- i // Отправить „i“ в канал „ch“.
}
}
// Скопировать значения из канала „src“ в канал „dst“,
// удалив те, которые делятся на „prime“.
func filter(src <-chan int, dst chan<- int, prime int) {
for i := range src { // Цикл по значениям, полученным из „src“.
if i%prime != 0 {
dst <- i // Отправить „i“ в канал „dst“.
}
}
}
// Простое сито: последовательный фильтр обрабатывает вместе.
func sieve() {
ch := make(chan int) // Создать новый канал.
go generate(ch) // Запустить generate() как подпроцесс.
for {
prime := <-ch
fmt.Print(prime, «\n»)
ch1 := make(chan int)
go filter(ch, ch1, prime)
ch = ch1
}
}
func main() {
sieve()
}
Инициализация и выполнение программы
Нулевое значение
Когда для переменной выделяется память, либо через объявление, либо через вызов new, либо когда создается новое значение, либо через составной литерал, либо через вызов make, и явная инициализация не предоставляется, переменной или значению присваивается значение по умолчанию. Каждый элемент такой переменной или значения устанавливается в нулевое значение для своего типа: false для булевых значений, 0 для числовых типов, "" для строк и nil для указателей, функций, интерфейсов, срезов, каналов и карт. Эта инициализация выполняется рекурсивно, поэтому, например, каждый элемент массива структур будет иметь обнуленные поля, если значение не указано.
Эти два простых объявления эквивалентны:
var i int
var i int = 0
После
type T struct { i int; f float64; next *T }
t := new(T)
имеет место следующее:
t.i == 0
t.f == 0.0
t.next == nil
То же самое будет верно и после
var t T
Инициализация пакета
Внутри пакета инициализация переменных на уровне пакета происходит пошагово, причем на каждом шаге выбирается переменная, которая находится в начале порядка объявления и не имеет зависимостей от неинициализированных переменных.
Точнее, переменная на уровне пакета считается готовой к инициализации, если она еще не инициализирована и либо не имеет выражения инициализации, либо ее выражение инициализации не зависит от неинициализированных переменных. Инициализация происходит путем повторной инициализации следующей переменной на уровне пакета, которая является самой ранней в порядке объявления и готова к инициализации, пока не останется переменных, готовых к инициализации.
Если по окончании этого процесса какие-либо переменные остаются неинициализированными, эти переменные являются частью одного или нескольких циклов инициализации, и программа является недействительной.
Несколько переменных в левой части объявления переменной, инициализируемых одним (многозначным) выражением в правой части, инициализируются вместе: если какая-либо из переменных в левой части инициализирована, все эти переменные инициализируются на одном и том же шаге.
var x = a
var a, b = f() // a и b инициализируются вместе, перед инициализацией x
Для целей инициализации пакета пустые переменные обрабатываются как любые другие переменные в объявлениях.
Порядок объявления переменных, объявленных в нескольких файлах, определяется порядком, в котором файлы представлены компилятору: переменные, объявленные в первом файле, объявляются перед любыми переменными, объявленными во втором файле, и так далее. Для обеспечения воспроизводимого поведения инициализации рекомендуется, чтобы системы сборки представляли компилятору несколько файлов, принадлежащих одному пакету, в порядке лексического имени файла.
Анализ зависимостей не зависит от фактических значений переменных, а только от лексических ссылок на них в исходном коде, анализируемых транзитивно. Например, если выражение инициализации переменной x ссылается на функцию, тело которой ссылается на переменную y, то x зависит от y. В частности:
- Ссылка на переменную или функцию — это идентификатор, обозначающий эту переменную или функцию.
- Ссылка на метод
m— это значение метода или выражение метода в формеt.m, где (статический) типtне является типом интерфейса, а методmнаходится в наборе методовt. Не имеет значения, вызывается ли результирующее значение функцииt.m. - Переменная, функция или метод
xзависит от переменнойy, если выражение инициализации или телоx(для функций и методов) содержит ссылку наyили на функцию или метод, которые зависят отy.
Например, при следующих объявлениях
var (
a = c + b // == 9
b = f() // == 4
c = f() // == 5
d = 3 // == 5 после завершения инициализации)
func f() int {
d++
return d
}
порядок инициализации будет d, b, c, a. Обратите внимание, что порядок подвыражений в выражениях инициализации не имеет значения: a = c + b и a = b + c приводят к одинаковому порядку инициализации в этом примере.
Анализ зависимостей выполняется для каждого пакета; учитываются только ссылки на переменные, функции и методы (не интерфейсы), объявленные в текущем пакете. Если между переменными существуют другие, скрытые зависимости данных, порядок инициализации между этими переменными не определён.
Например, при следующих объявлениях
var x = I(T{}).ab() // x имеет не обнаруженную, скрытую зависимость от a и b
var _ = sideEffect() // не связан с x, a или b
var a = b
var b = 42
type I interface { ab() []int }
type T struct{}
func (T) ab() []int { return []int{a, b} }
переменная a будет инициализирована после b, но не определено, будет ли x инициализирована до b, между b и a или после a, и, следовательно, также не определено, в какой момент будет вызвана sideEffect() (до или после инициализации x).
Переменные также могут инициализироваться с помощью функций с именем init, объявленных в блоке пакета, без аргументов и без параметров результата.
func init() { … }
В одном пакете может быть определено несколько таких функций, даже в одном исходном файле. В блоке пакетов идентификатор init может использоваться только для объявления функций init, но сам идентификатор не объявляется. Таким образом, на функции init нельзя ссылаться нигде в программе.
Весь пакет инициализируется путем присвоения начальных значений всем его переменным уровня пакета с последующим вызовом всех функций init в том порядке, в котором они появляются в исходном тексте, возможно, в нескольких файлах, как это представлено компилятору.
Инициализация программы
Пакеты полной программы инициализируются пошагово, по одному пакету за раз. Если пакет имеет импорты, импортируемые пакеты инициализируются перед инициализацией самого пакета. Если несколько пакетов импортируют один пакет, импортируемый пакет будет инициализирован только один раз. Импорт пакетов по конструкции гарантирует, что не может быть циклических зависимостей инициализации. Точнее:
Имея список всех пакетов, отсортированный по пути импорта, на каждом шаге инициализируется первый неинициализированный пакет в списке, для которого все импортированные пакеты (если таковые имеются) уже инициализированы. Этот шаг повторяется до тех пор, пока не будут инициализированы все пакеты.
Инициализация пакета — инициализация переменных и вызов функций init — происходит в одной goroutine, последовательно, по одному пакету за раз. Функция init может запускать другие goroutines, которые могут выполняться одновременно с кодом инициализации. Однако инициализация всегда последовательно выполняет функции init: она не вызовет следующую, пока предыдущая не вернется.
Выполнение программы
Полная программа создается путем связывания одного неимпортированного пакета, называемого основным пакетом, со всеми пакетами, которые он импортирует, транзитивно.
Основной пакет должен иметь имя main и объявлять функцию main, которая не принимает аргументов и не возвращает значения.
func main() { … }
Выполнение программы начинается с инициализации программы, а затем вызова функции main в пакете main. Когда этот вызов функции возвращается, программа завершается. Она не ждет завершения других (не основных) горутин.
Errors (Ошибки)
Объявленный тип error определяется как
type error interface {
Error() string
}
Это обычный интерфейс для представления состояния ошибки, причем значение nil означает отсутствие ошибки. Например, может быть определена функция для чтения данных из файла:
func Read(f *File, b []byte) (n int, err error)
Паника во время выполнения
Ошибки выполнения, такие как попытка индексировать массив за пределами границ, вызывают панику во время выполнения, эквивалентную вызову встроенной функции panic со значением типа runtime.Error, определяемого интерфейсом реализации. Этот тип удовлетворяет заранее объявленному интерфейсному типу error. Точные значения ошибок, которые представляют различные условия ошибки во время выполнения, не определены.
package runtime
type Error interface {
error
// и, возможно, другие методы
}
Системные аспекты
Пакет unsafe
Встроенный пакет unsafe, известный компилятору и доступный через путь импорта "unsafe", предоставляет средства для низкоуровневого программирования, включая операции, нарушающие систему типов. Пакет, использующий unsafe, должен быть проверен вручную на безопасность типов и может быть не переносимым. Пакет предоставляет следующий интерфейс:
package unsafe
type ArbitraryType int // shorthand for an arbitrary Go type; it is not a real type
type Pointer *ArbitraryType
func Alignof(variable ArbitraryType) uintptr
func Offsetof(selector ArbitraryType) uintptr
func Sizeof(variable ArbitraryType) uintptr
type IntegerType int // shorthand for an integer type; it is not a real type
func Add(ptr Pointer, len IntegerType) Pointer
func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType
func SliceData(slice []ArbitraryType) *ArbitraryType
func String(ptr *byte, len IntegerType) string
func StringData(str string) *byte
Pointer - это тип указателя, но значение Pointer не может быть разыменовано. Любой указатель или значение основного типа uintptr может быть преобразован в основной тип Pointer и наоборот. Эффект преобразования между Pointer и uintptr определяется реализацией.
var f float64
bits = *(*uint64)(unsafe.Pointer(&f))
type ptr unsafe.Pointer
bits = *(*uint64)(ptr(&f))
func f[P ~*B, B any](p P) uintptr {
return uintptr(unsafe.Pointer(p))
}
var p ptr = nil
Функции Alignof и Sizeof принимают выражение x любого типа и возвращают выравнивание или размер, соответственно, гипотетической переменной v, как если бы v была объявлена через var v = x.
Функция Offsetof принимает (возможно, заключенный в скобки) селектор s.f, обозначающий поле f структуры, обозначенной s или *s, и возвращает смещение поля в байтах относительно адреса структуры. Если f является встроенным полем, оно должно быть доступно без косвенных указателей через поля структуры. Для структуры s с полем f:
uintptr(unsafe.Pointer(&s)) + unsafe.Offsetof(s.f) == uintptr(unsafe.Pointer(&s.f))
Архитектуры компьютеров могут требовать выравнивания адресов памяти, то есть адреса переменной должны быть кратными коэффициенту, выравниванию типа переменной. Функция Alignof принимает выражение, обозначающее переменную любого типа, и возвращает выравнивание (типа) переменной в байтах. Для переменной x:
uintptr(unsafe.Pointer(&x)) % unsafe.Alignof(x) == 0
Переменная типа T имеет переменный размер, если T является параметром типа или если это тип массива или структуры, содержащий элементы или поля переменного размера. В противном случае размер является постоянным. Вызовы Alignof, Offsetof и Sizeof являются константами времени компиляции типа uintptr, если их аргументы (или структура s в выражении селектора s.f для Offsetof) являются типами постоянного размера.
Функция Add добавляет len к ptr и возвращает обновленный указатель unsafe.Pointer(uintptr(ptr) + uintptr(len)) [Go 1.17]. Аргумент len должен быть целочисленного типа или нетипизированной константой. Константный аргумент len должен быть представлен значением типа int; если он является нетипизированной константой, ему присваивается тип int. Правила допустимого использования Pointer по-прежнему применяются.
Функция Slice возвращает фрагмент, базовый массив которого начинается с ptr, а длина и емкость — len. Slice(ptr, len) эквивалентно
(*[len]ArbitraryType)(unsafe.Pointer(ptr))[:]
за исключением того, что в особом случае, если ptr равно nil, а len равно нулю, Slice возвращает nil [Go 1.17].
Аргумент len должен быть целочисленного типа или нетипизированной константой. Константа len должна быть неотрицательной и представляться значением типа int; если это нетипизированная константа, ей присваивается тип int. Во время выполнения, если len отрицательно, или если ptr равно nil, а len не равно нулю, возникает паника во время выполнения [Go 1.17].
Функция SliceData возвращает указатель на базовый массив аргумента slice. Если емкость slice cap(slice) не равна нулю, этот указатель равен &slice[:1][0]. Если slice равен nil, результат равен nil. В противном случае это не равный nil указатель на неуказанный адрес памяти [Go 1.20].
Функция String возвращает строковое значение, байты которого начинаются с ptr и длина которых равна len. К аргументам ptr и len применяются те же требования, что и в функции Slice. Если len равно нулю, результатом будет пустая строка "". Поскольку строки Go являются неизменяемыми, байты, переданные в String, не должны изменяться впоследствии [Go 1.20].
Функция StringData возвращает указатель на базовые байты аргумента str. Для пустой строки возвращаемое значение не определено и может быть nil. Поскольку строки Go являются неизменяемыми, байты, возвращаемые StringData, не должны изменяться [Go 1.20].
Гарантии размеров и выравнивания
Для числовых типов гарантируются следующие размеры:
type size in bytes
byte, uint8, int8 1
uint16, int16 2
uint32, int32, float32 4
uint64, int64, float64, complex64 8
complex128 16
Гарантируются следующие минимальные свойства выравнивания:
- Для переменной
xлюбого типа:unsafe.Alignof(x)не меньше1. - Для переменной
xтипаstruct:unsafe.Alignof(x)- наибольшее из всех значенийunsafe.Alignof(x.f)для каждого поляfизx, но не менее1. - Для переменной
xтипаarray:unsafe.Alignof(x)- это то же самое, что и выравнивание переменной типа элемента массива.
Тип struct или array имеет нулевой размер, если он не содержит полей (или элементов, соответственно), имеющих размер больше нуля. Две разные переменные нулевого размера могут иметь один и тот же адрес в памяти.
Приложение
Версии языка
Гарантия совместимости Go 1 гарантирует, что программы, написанные в соответствии со спецификацией Go 1, будут продолжать компилироваться и работать правильно, без изменений, в течение всего срока действия этой спецификации. В более общем случае, по мере внесения изменений и добавления возможностей в язык, гарантия совместимости гарантирует, что программа на Go, работающая с определенной версией языка Go, будет продолжать работать и с любой последующей версией.
Например, возможность использовать префикс 0b для двоичных целочисленных литералов была введена в Go 1.13, на что указывает [Go 1.13] в разделе о целочисленных литералах. Исходный код, содержащий целочисленный литерал, например 0b1011, будет отклонен, если подразумеваемая или требуемая версия языка, используемая компилятором, старше Go 1.13.
В следующей таблице описана минимальная версия языка, необходимая для функций, появившихся после Go 1.
Go 1.9
- Декларация псевдонима может использоваться для объявления псевдонима для типа.
Go 1.13
- Целые литералы могут использовать префиксы 0b, 0B, 0o и 0O для двоичных и восьмеричных литералов соответственно.
- Шестнадцатеричные литералы с плавающей запятой могут быть написаны с использованием префиксов 0x и 0X.
- Суффикс i может использоваться с любыми (двоичными, десятичными, шестнадцатеричными) целыми или плавающими литералами, а не только с десятичными литералами.
- Цифры любого числового литерала могут быть разделены (сгруппированы) с помощью подчеркиваний _.
- Число сдвига в операции сдвига может быть целым числом со знаком.
Go 1.14
- Внедрение метода более одного раза через разные встроенные интерфейсы не является ошибкой.
Go 1.17
- Срез может быть преобразован в указатель массива, если типы элементов среза и массива совпадают, а массив не длиннее среза.
- Встроенный пакет unsafe включает новые функции Add и Slice.
Go 1.18
В версии 1.18 в язык добавлены полиморфные функции и типы («генерики»). В частности:
- Набор операторов и знаков препинания включает новый токен ~.
- В объявлениях функций и типов можно объявлять параметры типов.
- Типы интерфейсов могут встраивать произвольные типы (а не только имена типов интерфейсов), а также элементы типов union и ~T.
- Набор предварительно объявленных типов включает новые типы any и comparable.
Go 1.20
- Срез может быть преобразован в массив, если типы элементов среза и массива совпадают, а массив не длиннее среза.
- Встроенный пакет unsafe включает новые функции SliceData, String и StringData.
- Сравнимые типы (такие как обычные интерфейсы) могут удовлетворять сравнимым ограничениям, даже если аргументы типа не являются строго сравнимыми.
Go 1.21
- Набор предварительно объявленных функций включает новые функции min, max и clear.
- Типовое выведение использует типы методов интерфейса для выведения. Оно также выводит типовые аргументы для обобщенных функций, назначенных переменным или переданных в качестве аргументов другим (возможно, обобщенным) функциям.
Go 1.22
- В операторе «for» каждая итерация имеет свой собственный набор переменных итерации, а не использует одни и те же переменные в каждой итерации.
- Оператор «for» с клаузулой «range» может выполнять итерацию над целыми значениями от нуля до верхнего предела.
Go 1.23
- Оператор «for» с клаузулой «range» принимает функцию итератора в качестве выражения диапазона.
Go 1.24
- Объявление псевдонима может объявлять параметры типа.
Правила унификации типов
Правила унификации типов описывают, могут ли и как два типа унифицироваться. Точные детали имеют значение для реализаций Go, влияют на особенности сообщений об ошибках (например, сообщает ли компилятор об ошибке вывода типа или другой ошибке) и могут объяснить, почему вывод типа не работает в необычных ситуациях в коде. Но в целом эти правила можно игнорировать при написании кода Go: вывод типов в основном «работает как ожидается», и правила унификации настроены соответствующим образом.
Унификация типов контролируется режимом сопоставления, который может быть точным или приблизительным. Поскольку унификация рекурсивно спускается по структуре составного типа, режим сопоставления, используемый для элементов типа, режим сопоставления элементов, остается таким же, как режим сопоставления, за исключением случаев, когда два типа унифицируются для присваиваемости (≡A): в этом случае режим сопоставления является неточным на верхнем уровне, но затем меняется на точный для типов элементов, отражая тот факт, что типы не должны быть идентичными, чтобы быть присваиваемыми.
Два типа, которые не являются связанными типовыми параметрами, унифицируются точно, если выполняется любое из следующих условий:
- Оба типа идентичны.
- Оба типа имеют идентичную структуру, и их типы элементов унифицируются точно.
- Точно один тип является несвязанным типовым параметром с базовым типом, и этот базовый тип унифицируется с другим типом в соответствии с правилами унификации для ≡A (нестрогая унификация на верхнем уровне и точная унификация для типов элементов).
Если оба типа являются связанными параметрами типа, они унифицируются в соответствии с заданными режимами сопоставления, если:
- Оба параметра типа идентичны.
- Не более одного из параметров типа имеет известный аргумент типа. В этом случае параметры типа объединяются: оба они обозначают один и тот же аргумент типа. Если ни один из параметров типа еще не имеет известного аргумента типа, будущий аргумент типа, выведенный для одного из параметров типа, одновременно выводится для обоих.
- Оба типа-параметра имеют известный тип-аргумент, и типы-аргументы унифицируются в соответствии с заданными режимами сопоставления.
Один связанный тип-параметр P и другой тип T унифицируются в соответствии с заданными режимами сопоставления, если:
- P не имеет известного типа-аргумента. В этом случае T выводится как тип-аргумент для P.
- P имеет известный тип-аргумент A, A и T унифицируются в соответствии с заданными режимами сопоставления, и выполняется одно из следующих условий:
- И A, и T являются типами интерфейса: в этом случае, если A и T также являются определёнными типами, они должны быть идентичными. В противном случае, если ни один из них не является определённым типом, они должны иметь одинаковое количество методов (унификация A и T уже установила, что методы совпадают).
- Ни A, ни T не являются типами интерфейса: в этом случае, если T является определённым типом, T заменяет A в качестве выведенного аргумента типа для P.
Наконец, два типа, которые не являются связанными параметрами типа, объединяются слабо (и в соответствии с режимом сопоставления элементов), если:
- Оба типа унифицируются точно.
- Один тип является определенным типом, другой тип является типовым литералом, но не интерфейсом, и их базовые типы унифицируются в соответствии с режимом сопоставления элементов.
- Оба типа являются интерфейсами (но не параметрами типа) с идентичными типами термов, оба или ни один из них не встраивают предварительно объявленный тип comparable, соответствующие типы методов унифицируются точно, а набор методов одного из интерфейсов является подмножеством набора методов другого интерфейса.
- Только один тип является интерфейсом (но не параметром типа), соответствующие методы двух типов унифицируются в соответствии с режимом сопоставления элементов, а набор методов интерфейса является подмножеством набора методов другого типа.
- Оба типа имеют одинаковую структуру, и их типы элементов унифицируются в соответствии с режимом сопоставления элементов.
12.8 - Спецификация по модулям языка программирования Go
Этот документ представляет собой подробное справочное руководство по системе модулей Go.
Введение
Модули — это способ, с помощью которого Go управляет зависимостями.
Этот документ является подробным справочным руководством по модульной системе Go. Введение в создание проектов Go см. в статье «Как писать код на Go». Информацию об использовании модулей, переносе проектов на модули и других темах см. в серии статей в блоге, начиная с «Использование модулей Go».
Модули, пакеты и версии
Модуль — это набор пакетов, которые выпускаются, версионируются и распространяются вместе. Модули можно загружать напрямую из репозиториев контроля версий или с прокси-серверов модулей.
Модуль идентифицируется по пути модуля, который объявляется в файле go.mod вместе с информацией о зависимостях модуля. Корневой каталог модуля — это каталог, содержащий файл go.mod. Главный модуль — это модуль, содержащий каталог, в котором вызывается команда go.
Каждый пакет в модуле представляет собой набор исходных файлов в одном каталоге, которые компилируются вместе. Путь к пакету — это путь к модулю, соединенный с подкаталогом, содержащим пакет (относительно корня модуля). Например, модуль «golang.org/x/net» содержит пакет в каталоге «html». Путь к этому пакету — «golang.org/x/net/html».
Пути к модулям
Путь модуля — это каноническое имя модуля, объявленное с помощью директивы module в файле go.mod модуля. Путь модуля является префиксом для путей пакетов внутри модуля.
Путь модуля должен описывать как то, что делает модуль, так и то, где его найти. Обычно путь модуля состоит из пути корня репозитория, каталога внутри репозитория (обычно пустого) и суффикса основной версии (только для основной версии 2 или выше).
Путь корня репозитория — это часть пути модуля, которая соответствует корневому каталогу репозитория контроля версий, в котором разрабатывается модуль. Большинство модулей определены в корневом каталоге своего репозитория, поэтому обычно это весь путь. Например,
golang.org/x/net— это путь корня репозитория для модуля с таким же именем. См. раздел Поиск репозитория для пути модуля, чтобы узнать, как команда go находит репозиторий с помощью HTTP-запросов, полученных из пути модуля.Если модуль не определен в корневом каталоге репозитория, подкаталог модуля является частью пути модуля, которая называет каталог, не включая суффикс основной версии. Это также служит префиксом для семантических тегов версии. Например, модуль
golang.org/x/tools/goplsнаходится в подкаталогеgoplsрепозитория с корневым путемgolang.org/x/tools, поэтому он имеет подкаталог модуляgopls. См. раздел «Сопоставление версий с коммитами» и «Каталоги модулей в репозитории».Если модуль выпускается с основной версией 2 или выше, путь модуля должен заканчиваться суффиксом основной версии, например
/v2. Это может быть частью имени подкаталога или нет. Например, модуль с путемgolang.org/x/repo/sub/v2может находиться в подкаталоге/subили/sub/v2репозиторияgolang.org/x/repo.
Если модуль может зависеть от других модулей, необходимо соблюдать эти правила, чтобы команда go могла найти и загрузить модуль. Существует также несколько лексических ограничений на символы, разрешенные в путях модулей.
Модуль, который никогда не будет загружен в качестве зависимости другого модуля, может использовать любой допустимый путь пакета в качестве пути модуля, но необходимо следить за тем, чтобы он не конфликтовал с путями, которые могут использоваться зависимостями модуля или стандартной библиотекой Go. Стандартная библиотека Go использует пути к пакетам, которые не содержат точку в первом элементе пути, и команда go не пытается разрешить такие пути с сетевых серверов. Пути example и test зарезервированы для пользователей: они не будут использоваться в стандартной библиотеке и подходят для использования в автономных модулях, таких как те, которые определены в учебных пособиях или примерах кода, или созданы и обрабатываются как часть теста.
Версии
Версия идентифицирует неизменяемый снимок модуля, который может быть либо релизом, либо предварительной версией. Каждая версия начинается с буквы v, за которой следует семантическая версия. Подробнее о том, как версии форматируются, интерпретируются и сравниваются, см. Semantic Versioning 2.0.0.
Вкратце, семантическая версия состоит из трех неотрицательных целых чисел (версии major, minor и patch, слева направо), разделенных точками. За версией patch может следовать необязательная строка предварительной версии, начинающаяся с дефиса. За строкой предварительной версии или версией patch может следовать строка метаданных сборки, начинающаяся с плюса. Например, v0.0.0, v1.12.134, v8.0.5-pre и v2.0.9+meta являются действительными версиями.
Каждая часть версии указывает, является ли версия стабильной и совместимой с предыдущими версиями.
- Основная версия должна быть увеличена, а второстепенная и патч-версия должны быть установлены в ноль после внесения обратно несовместимых изменений в публичный интерфейс модуля или задокументированную функциональность, например, после удаления пакета.
- Второстепенная версия должна быть увеличена, а патч-версия установлена в ноль после внесения обратно совместимых изменений, например, после добавления новой функции. Версия патча должна быть увеличена после изменения, которое не влияет на публичный интерфейс модуля, например исправления ошибки или оптимизации.
- Суффикс предварительной версии указывает, что версия является предварительной. Предварительные версии сортируются перед соответствующими выпусками. Например,
v1.2.3-preидет передv1.2.3. - Суффикс метаданных сборки игнорируется при сравнении версий. Команда
goпринимает версии с метаданными сборки и преобразует их в псевдоверсии, чтобы сохранить полный порядок между версиями.- Специальный суффикс
+incompatibleобозначает версию, выпущенную до перехода на модули версии2или более поздней (см. Совместимость с репозиториями, не являющимися модулями). - Специальный суффикс
+dirtyдобавляется к информации о версии бинарного файла, когда он скомпилирован с помощью инструментария Go 1.24 или более поздней версии в рамках действительного локального репозитория системы контроля версий(VCS), который содержит нефиксированные изменения в рабочем каталоге.
- Специальный суффикс
Версия считается нестабильной, если ее основная версия равна 0 или она имеет суффикс предварительной версии. Нестабильные версии не подпадают под требования совместимости. Например, v0.2.0 может быть несовместима с v0.1.0, а v1.5.0-beta может быть несовместима с v1.5.0.
Go может получать доступ к модулям в системах контроля версий, используя теги, ветки или ревизии, которые не соответствуют этим соглашениям.
Однако в основном модуле команда go автоматически преобразует имена ревизий, которые не соответствуют этому стандарту, в канонические версии.
Команда go также удаляет суффиксы метаданных сборки (за исключением +incompatible) в рамках этого процесса. Это может привести к появлению псевдоверсии, предварительной версии, которая кодирует идентификатор ревизии (например, хэш Git commit) и временную метку из системы контроля версий.
Например, команда
go get golang.org/x/net@daa7c041преобразует хеш коммитаdaa7c041в псевдоверсиюv0.0.0-20191109021931-daa7c04131f5. Канонические версии требуются за пределами основного модуля, и командаgoсообщит об ошибке, если в файлеgo.modпоявится неканоническая версия, такая какmaster.
Псевдоверсии
Псевдоверсия — это специально отформатированная предварительная версия, которая кодирует информацию об определенной ревизии в репозитории системы контроля версий. Например, v0.0.0-20191109021931-daa7c04131f5 — это псевдоверсия.
Псевдоверсии могут относиться к ревизиям, для которых нет семантических тегов версий. Они могут использоваться для тестирования коммитов перед созданием тегов версий, например, в ветке разработки.
Каждая псевдоверсия состоит из трех частей:
- Префикс базовой версии (
vX.0.0илиvX.Y.Z-0), который либо получен из семантического тега версии, предшествующего ревизии, либоvX.0.0, если такого тега нет. - Временная метка (ггггммддччммсс), которая представляет собой время UTC, когда была создана ревизия. В Git это время коммита, а не время автора.
- Идентификатор ревизии (abcdefabcdef), который представляет собой 12-символьный префикс хеша коммита или, в Subversion, номер ревизии с нулевым заполнением.
Каждая псевдоверсия может иметь одну из трех форм, в зависимости от базовой версии. Эти формы гарантируют, что псевдоверсия будет выше базовой версии, но ниже следующей версии с тегом.
vX.0.0-yyyymmddhhmmss-abcdefabcdefиспользуется, когда базовая версия неизвестна. Как и во всех версиях, основная версияXдолжна совпадать с суффиксом основной версии модуля.vX.Y.Z-pre.0.yyyymmddhhmmss-abcdefabcdefиспользуется, когда базовая версия является предварительной версией, такой какvX.Y.Z-pre.vX.Y.(Z+1)-0.yyyymmddhhmmss-abcdefabcdefиспользуется, когда базовая версия является релизной версией, такой какvX.Y.Z. Например, если базовая версия —v1.2.3, псевдоверсия может бытьv1.2.4-0.20191109021931-daa7c04131f5.
Несколько псевдоверсий могут ссылаться на одну и ту же фиксацию, используя разные базовые версии. Это происходит естественным образом, когда после записи псевдоверсии помечается более низкая версия.
Эти формы придают псевдоверсиям два полезных свойства:
- Псевдоверсии с известными базовыми версиями сортируются выше этих версий, но ниже других предварительных версий для более поздних версий.
- Псевдоверсии с одинаковым префиксом базовой версии сортируются в хронологическом порядке.
Команда go выполняет несколько проверок, чтобы убедиться, что авторы модулей контролируют сравнение псевдоверсий с другими версиями и что псевдоверсии ссылаются на ревизии, которые действительно являются частью истории коммитов модуля.
- Если указана базовая версия, должен быть соответствующий семантический тег версии, который является предком ревизии, описанной псевдоверсией. Это предотвращает обход минимального выбора версии разработчиками с помощью псевдоверсии, которая сравнивается выше всех тегированных версий, таких как
v1.999.999-99999999999999-daa7c04131f5. - Временная метка должна совпадать с временной меткой ревизии. Это предотвращает затопление прокси-серверов модулей неограниченным количеством идентичных псевдоверсий. Это также предотвращает изменение относительного порядка версий потребителями модулей.
- Ревизия должна быть предком одной из веток или тегов репозитория модуля. Это предотвращает ссылки злоумышленников на не утвержденные изменения или запросы на извлечение.
Псевдоверсии никогда не нужно вводить вручную. Многие команды принимают хэш коммита или имя ветки и автоматически преобразуют его в псевдоверсию (или версию с тегом, если она доступна).
Например:
go get example.com/mod@master
go list -m -json example.com/mod@abcd1234
Суффиксы основных версий
Начиная с основной версии 2, пути к модулям должны иметь суффикс основной версии, такой как /v2, который соответствует основной версии. Например, если модуль имеет путь example.com/mod в версии v1.0.0, он должен иметь путь example.com/mod/v2 в версии v2.0.0.
Суффиксы основных версий реализуют правило совместимости импорта:
- Если старый пакет и новый пакет имеют одинаковый путь импорта, новый пакет должен быть обратно совместим со старым пакетом.
По определению, пакеты в новой основной версии модуля не являются обратно совместимыми с соответствующими пакетами в предыдущей основной версии. Следовательно, начиная с v2, пакетам требуются новые пути импорта. Это достигается путем добавления суффикса основной версии к пути модуля.
Поскольку путь модуля является префиксом пути импорта для каждого пакета в модуле, добавление суффикса основной версии к пути модуля обеспечивает отдельный путь импорта для каждой несовместимой версии.
Суффиксы основной версии не допускаются в основных версиях v0 или v1. Нет необходимости изменять путь модуля между v0 и v1, поскольку версии v0 нестабильны и не имеют гарантии совместимости. Кроме того, для большинства модулей v1 обратно совместима с последней версией v0; версия v1 действует как обязательство по совместимости, а не как указание на несовместимые изменения по сравнению с v0.
В качестве особого случая пути модулей, начинающиеся с gopkg.in/, всегда должны иметь суффикс основной версии, даже в v0 и v1. Суффикс должен начинаться с точки, а не с косой черты (например, gopkg.in/yaml.v2).
Суффиксы основных версий позволяют нескольким основным версиям модуля сосуществовать в одной сборке. Это может быть необходимо из-за проблемы алмазной зависимости.
Обычно, если модуль требуется в двух разных версиях по транзитивным зависимостям, будет использоваться более высокая версия. Однако, если две версии несовместимы, ни одна из них не удовлетворит всех клиентов.
Поскольку несовместимые версии должны иметь разные номера основных версий, они также должны иметь разные пути модулей из-за суффиксов основных версий. Это разрешает конфликт: модули с разными суффиксами рассматриваются как отдельные модули, и их пакеты — даже пакеты в одном и том же подкаталоге относительно корней модулей — являются разными.
Многие проекты Go выпускали версии v2 или выше без использования суффикса основной версии до перехода на модули (возможно, даже до того, как модули были введены). Эти версии помечены тегом +incompatible build (например, v2.0.0+incompatible). Дополнительную информацию см. в разделе «Совместимость с репозиториями, не являющимися модулями».
Преобразование пакета в модуль
Когда команда go загружает пакет, используя путь к пакету, ей необходимо определить, какой модуль предоставляет этот пакет.
Команда go начинает с поиска в списке сборки модулей с путями, которые являются префиксами пути пакета.
Например, если импортирован пакет example.com/a/b, а модуль example.com/a находится в списке сборки, команда go проверит, содержит ли example.com/a пакет в каталоге b.
Чтобы каталог считался пакетом, в нем должен присутствовать хотя бы один файл с расширением .go. Ограничения сборки для этой цели не применяются. Если ровно один модуль в списке сборки предоставляет пакет, используется этот модуль. Если ни один модуль не предоставляет пакет или если два или более модулей предоставляют пакет, команда go сообщает об ошибке.
Флаг -mod=mod указывает команде go попытаться найти новые модули, предоставляющие отсутствующие пакеты, и обновить go.mod и go.sum. Команды go get и go mod tidy делают это автоматически.
Когда команда go ищет новый модуль для пути пакета, она проверяет переменную окружения GOPROXY, которая представляет собой разделенный запятыми список URL-адресов прокси или ключевые слова direct или off. URL-адрес прокси указывает, что команда go должна связаться с прокси модуля, используя протокол GOPROXY. direct указывает, что команда go должна связываться с системой контроля версий. off указывает, что попытки связи не должны предприниматься. Переменные окружения GOPRIVATE и GONOPROXY также могут использоваться для управления этим поведением.
Для каждой записи в списке GOPROXY команда go запрашивает последнюю версию каждого пути модуля, который может предоставить пакет (то есть каждый префикс пути пакета). Для каждого успешно запрошенного пути модуля команда go загрузит модуль в последней версии и проверит, содержит ли модуль запрошенный пакет. Если один или несколько модулей содержат запрошенный пакет, используется модуль с самым длинным путем. Если найден один или несколько модулей, но ни один из них не содержит запрошенный пакет, выводится сообщение об ошибке. Если модули не найдены, команда go пробует следующую запись в списке GOPROXY. Если записей не осталось, выводится сообщение об ошибке.
Например, предположим, что команда
goищет модуль, который предоставляет пакетgolang.org/x/net/html, аGOPROXYустановлен наhttps://corp.example.com,https://proxy.golang.org. Командаgoможет сделать следующие запросы:
- К
https://corp.example.com/(параллельно):- Запрос на последнюю версию
golang.org/x/net/html - Запрос на последнюю версию
golang.org/x/net - Запрос на последнюю версию
golang.org/x - Запрос на последнюю версию
golang.org
- Запрос на последнюю версию
- К
https://proxy.golang.org/, если все запросы кhttps://corp.example.com/завершились с ошибкой 404 или 410:- Запрос на последнюю версию
golang.org/x/net/html - Запрос на последнюю версию
golang.org/x/net - Запрос на последнюю версию
golang.org/x - Запрос на последнюю версию
golang.org
- Запрос на последнюю версию
После того, как подходящий модуль найден, команда go добавляет новое требование с путем и версией нового модуля в файл go.mod основного модуля. Это гарантирует, что при загрузке того же пакета в будущем будет использоваться тот же модуль той же версии. Если разрешенный пакет не импортируется пакетом в основном модуле, новое требование будет иметь // косвенный комментарий.
Файлы go.mod
Модуль определяется текстовым файлом go.mod в кодировке UTF-8 в его корневом каталоге. Файл go.mod ориентирован на строки. Каждая строка содержит одну директиву, состоящую из ключевого слова и аргументов.
Например:
module example.com/my/thing
go 1.23.0
require example.com/other/thing v1.0.2
require example.com/new/thing/v2 v2.3.4
exclude example.com/old/thing v1.2.3
replace example.com/bad/thing v1.4.5 => example.com/good/thing v1.4.5
retract [v1.9.0, v1.9.5]
Ведущее ключевое слово может быть разложено на соседние строки, чтобы создать блок, как в импорте Go.
require (
example.com/new/thing/v2 v2.3.4
example.com/old/thing v1.2.3
)
Файл go.mod разработан таким образом, чтобы его можно было читать и записывать. Команда go предоставляет несколько подкоманд, которые изменяют файлы go.mod. Например, go get может обновить или понизить уровень определенных зависимостей.
Команды, загружающие граф модулей, автоматически обновляют go.mod, когда это необходимо. go mod edit может выполнять низкоуровневые правки. Пакет golang.org/x/mod/modfile может быть использован программами на Go для внесения тех же изменений программно.
Файл go.mod требуется для основного модуля и для любого заменяющего его модуля, указанного с помощью локального пути к файлу. Однако модуль, не имеющий явного файла go.mod, все равно может быть востребован в качестве зависимости или использоваться в качестве замены, указанной с помощью пути к модулю и его версии; см. раздел Совместимость с немодульными репозиториями.
Лексические элементы
При разборе файла go.mod его содержимое разбивается на последовательность токенов. Существует несколько видов токенов: пробелы, комментарии, знаки препинания, ключевые слова, идентификаторы и строки.
Пробелы состоят из пробелов (U+0020), табуляции (U+0009), возврата каретки (U+000D) и новой строки (U+000A). Пробелы, кроме новой строки, не имеют никакого эффекта, кроме разделения токенов, которые в противном случае были бы объединены. Новые строки являются значимыми токенами.
Комментарии начинаются с // и продолжаются до конца строки. Комментарии /* */ не допускаются.
Знаки препинания включают (, ) и =>.
Ключевые слова различают различные типы директив в файле go.mod. Допустимые ключевые слова: module, go, require, replace, exclude и retract.
Идентификаторы — это последовательности символов, не являющихся пробелами, такие как пути модулей или семантические версии.
Строки — это последовательности символов в кавычках. Существует два вида строк: интерпретируемые строки, начинающиеся и заканчивающиеся кавычками (", U+0022), и необработанные строки, начинающиеся и заканчивающиеся грависными акцентами (`, U+0060). Интерпретируемые строки могут содержать экранирующие последовательности, состоящие из обратной косой черты (\, U+005C), за которой следует другой символ. Экранированная кавычка (\») не завершает интерпретируемую строку. Незаключенное в кавычки значение интерпретируемой строки — это последовательность символов между кавычками, в которой каждая экранирующая последовательность заменяется символом, следующим за обратной косой чертой (например, \" заменяется на ", \n заменяется на n). Напротив, незаключенное в кавычки значение необработанной строки — это просто последовательность символов между грависами; обратные косые черты не имеют особого значения в необработанных строках.
Идентификаторы и строки взаимозаменяемы в грамматике go.mod.
Пути к модулям и версии
Большинство идентификаторов и строк в файле go.mod являются либо путями к модулям, либо версиями.
Путь к модулю должен удовлетворять следующим требованиям:
- Путь должен состоять из одного или нескольких элементов, разделенных косыми чертами
(/, U+002F). Он не должен начинаться или заканчиваться косой чертой. - Каждый элемент пути представляет собой непустую строку, состоящую из букв
ASCII, цифрASCIIи ограниченного набора знаков препинанияASCII(-,.,_и~). - Элемент пути не может начинаться или заканчиваться точкой
(., U+002E). - Префикс элемента до первой точки не должен быть зарезервированным именем файла в Windows, независимо от регистра (CON, com1, NuL и т. д.).
- Префикс элемента до первой точки не должен заканчиваться на тильду, за которой следует одна или несколько цифр (например, EXAMPL~1.COM).
Если путь к модулю появляется в директиве require и не заменяется, или если путь к модулю появляется в правой части директивы replace, команде go может потребоваться загрузить модули с этим путем, и должны быть выполнены некоторые дополнительные требования.
- Ведущий элемент пути (до первой косой черты, если она есть), по соглашению являющийся доменным именем, должен содержать только строчные буквы ASCII, цифры ASCII, точки (., U+002E) и тире (-, U+002D); он должен содержать по крайней мере одну точку и не может начинаться с тире.
- Для конечного элемента пути в форме /vN, где N выглядит как число (цифры ASCII и точки), N не должно начинаться с нуля, не должно быть /v1 и не должно содержать точек.
- Для путей, начинающихся с gopkg.in/, это требование заменяется требованием, чтобы путь соответствовал соглашениям службы gopkg.in.
Версии в файлах
go.modмогут быть каноническими или неканоническими.
- Для путей, начинающихся с gopkg.in/, это требование заменяется требованием, чтобы путь соответствовал соглашениям службы gopkg.in.
Версии в файлах
Каноническая версия начинается с буквы v, за которой следует семантическая версия, соответствующая спецификации Semantic Versioning 2.0.0. Дополнительные сведения см. в разделе «Версии».
Большинство других идентификаторов и строк могут использоваться в качестве неканонических версий, хотя существуют некоторые ограничения, позволяющие избежать проблем с файловыми системами, репозиториями и прокси-серверами модулей. Неканонические версии допускаются только в файле go.mod главного модуля. Команда go попытается заменить каждую неканоническую версию эквивалентной канонической версией при автоматическом обновлении файла go.mod.
В местах, где путь модуля связан с версией (как в директивах require, replace и exclude), конечный элемент пути должен соответствовать версии. См. Суффиксы основных версий.
Грамматика
Синтаксис go.mod указан ниже с использованием расширенной формы Бэкуса-Наура (EBNF). Подробнее о синтаксисе EBNF см. раздел “Нотация” в спецификации языка Go.
GoMod = { Directive } .
Directive = ModuleDirective |
GoDirective |
ToolDirective |
IgnoreDirective |
RequireDirective |
ExcludeDirective |
ReplaceDirective |
RetractDirective .
Новая строка, идентификаторы и строки обозначаются символами newline, ident и string, соответственно.
Пути и версии модулей обозначаются ModulePath и Version.
ModulePath = ident | string . /* см. ограничения выше */
Версия = ident | string . /* см. ограничения выше */
module директива
Директива module определяет путь к главному модулю. Файл go.mod должен содержать ровно одну директиву модуля.
Например:
module golang.org/x/net
Deprecation (Устаревший)
Модуль может быть помечен как устаревший в блоке комментариев, содержащем строку Deprecated: (с учетом регистра) в начале абзаца. Сообщение об устаревании начинается после двоеточия и идет до конца абзаца. Комментарии могут располагаться непосредственно перед директивой модуля или после нее в той же строке.
Например:
// Deprecated: use example.com/mod/v2 instead.
module example.com/mod
Начиная с Go 1.17, go list -m -u проверяет информацию обо всех устаревших модулях в списке сборки. go get проверяет устаревшие модули, необходимые для сборки пакетов, указанных в командной строке.
Когда команда go извлекает информацию об устаревании модуля, она загружает файл go.mod из версии, соответствующей запросу @latest, без учета отзывов или исключений. Команда go загружает список отозванных версий из того же файла go.mod.
Чтобы объявить модуль устаревшим, автор может добавить комментарий // Deprecated: и пометить новый выпуск. Автор может изменить или удалить сообщение об устаревании в более позднем выпуске.
Устаревание применяется ко всем второстепенным версиям модуля. Основные версии выше v2 считаются отдельными модулями для этой цели, поскольку их суффиксы основных версий дают им отличные пути модулей.
Сообщения об устаревании предназначены для информирования пользователей о том, что модуль больше не поддерживается, и для предоставления инструкций по миграции, например, на последнюю основную версию. Отдельные второстепенные и исправленные версии не могут быть признаны устаревшими; для этого более подходящим может быть отзыв.
go директива
Директива go указывает, что модуль был написан с учетом семантики определенной версии Go. Версия должна быть действительной версией Go, например 1.14, 1.21rc1 или 1.23.0.
Директива go устанавливает минимальную версию Go, необходимую для использования этого модуля. До Go 1.21 эта директива носила только рекомендательный характер, теперь же она является обязательным требованием: инструментарий Go отказывается использовать модули, объявляющие более новые версии Go.
Директива go является входными данными для выбора инструментария Go, который будет запущен. Подробности см. в разделе «Инструментарий Go».
Директива go влияет на использование новых языковых функций:
- Для пакетов в модуле компилятор отклоняет использование языковых функций, введенных после версии, указанной в директиве
go. Например, если модуль имеет директивуgo 1.12, его пакеты не могут использовать числовые литералы, такие как1_000_000, которые были введены в Go 1.13. - Если более старая версия Go компилирует один из пакетов модуля и встречает ошибку компиляции, в сообщении об ошибке указывается, что модуль был написан для более новой версии Go. Например, предположим, что модуль имеет директиву
go 1.13, а пакет использует числовой литерал1_000_000. Если этот пакет компилируется с помощью Go 1.12, компилятор отмечает, что код написан для Go 1.13.
Директива go также влияет на поведение команды go:
В go 1.14 и выше может быть включена автоматическая продажа. Если файл
vendor/modules.txtприсутствует и соответствуетgo.mod, нет необходимости явно использовать флаг-mod=vendor.В go 1.16 и выше шаблон
allpackage соответствует только пакетам, транзитивно импортированным пакетами и тестами в главном модуле. Это тот же набор пакетов, который сохраняетсяgo mod vendorс момента введения модулей. В более ранних версияхallтакже включает тесты пакетов, импортированных пакетами в главном модуле, тесты этих пакетов и т. д.В go 1.17 и выше:
- Файл
go.modвключает явную директиву require для каждого модуля, который предоставляет любой пакет, транзитивно импортированный пакетом или тестом в главном модуле. (В go 1.16 и ниже косвенная зависимость включается только в том случае, если при выборе минимальной версии в противном случае была бы выбрана другая версия.) Эта дополнительная информация позволяет выполнять обрезку графа модулей и отложенную загрузку модулей. - Поскольку
//косвенных зависимостей может быть гораздо больше, чем в предыдущих версияхgo, косвенные зависимости записываются в отдельном блоке в файлеgo.mod. go mod vendorопускает файлыgo.modиgo.sumдля зависимостей, поставляемых поставщиком. (Это позволяет вызывать командуgoв подкаталогахvendorдля определения правильного основного модуля.)go mod vendorзаписывает версиюgoиз файлаgo.modкаждой зависимости вvendor/modules.txt.
- Файл
В go 1.21 или выше:
- Строка
goобъявляет минимальную версию Go, необходимую для использования с этим модулем. - Строка
goдолжна быть больше или равна строке go всех зависимостей. - Команда
goбольше не пытается поддерживать совместимость с предыдущей старой версией Go. - Команда
goболее тщательно следит за сохранением контрольных сумм файловgo.modв файлеgo.sum.
- Строка
Файл go.mod может содержать не более одной директивы go. Большинство команд добавляют директиву go с текущей версией Go, если она отсутствует.
Если директива go отсутствует, предполагается, что используется go 1.16.
GoDirective = «go» GoVersion newline .
GoVersion = string | ident . /* действительная версия выпуска; см. выше */
Пример:
go 1.23.0
toolchain директива
Директива toolchain объявляет предлагаемую цепочку инструментов Go для использования с модулем. Версия предлагаемой цепочки инструментов Go не может быть меньше требуемой версии Go, объявленной в директиве go. Директива toolchain действует только в том случае, если модуль является главным модулем и версия инструментальной цепочки по умолчанию меньше версии предлагаемой инструментальной цепочки.
Для воспроизводимости команда go записывает собственное имя цепочки инструментов в строку toolchain каждый раз, когда обновляет версию go в файле go.mod (обычно во время go get).
Подробности см. в разделе “Инструментальные цепочки Go”.
ToolchainDirective = "toolchain" ToolchainName newline .
ToolchainName = string | ident . /* действительное имя цепочки инструментов; см. "Цепочки инструментов Go" */
Пример:
toolchain go1.21.0
godebug деректива
Директива godebug объявляет единственную настройку GODEBUG, которая должна применяться, когда данный модуль является основным. Таких строк может быть несколько, и они могут быть разделены по факторам. Ошибкой является то, что главный модуль называет несуществующий ключ GODEBUG. Эффект от применения godebug key=value такой, как если бы каждый компилируемый основной пакет содержал исходный файл, в котором был бы указан //go:debug key=value.
GodebugDirective = "godebug" ( GodebugSpec | "(" newline { GodebugSpec } ")" newline ) .
GodebugSpec = GodebugKey "=" GodebugValue newline.
GodebugKey = GodebugChar { GodebugChar }.
GodebugValue = GodebugChar { GodebugChar }.
GodebugChar = any non-space character except , " ` ' (comma and quotes).
Например:
godebug default=go1.21
godebug (
panicnil=1
asynctimerchan=0
)
require директива
Директива require объявляет минимальную требуемую версию данной зависимости модуля. Для каждой требуемой версии модуля команда go загружает файл go.mod для этой версии и включает требования из этого файла. После загрузки всех требований команда go разрешает их с помощью минимального выбора версии (MVS) для создания списка сборки.
Команда go автоматически добавляет // косвенные комментарии для некоторых требований. Косвенный комментарий // указывает, что ни один пакет из требуемого модуля не импортируется напрямую каким-либо пакетом в основном модуле.
Если директива go указывает go 1.16 или ниже, команда go добавляет косвенное требование, когда выбранная версия модуля выше, чем то, что уже подразумевается (транзитивно) другими зависимостями основного модуля. Это может произойти из-за явного обновления (go get -u ./...), удаления какой-либо другой зависимости, которая ранее налагала требование (go mod tidy), или зависимости, которая импортирует пакет без соответствующего требования в своем собственном файле go.mod (например, зависимость, у которой вообще отсутствует файл go.mod).
В go 1.17 и выше команда go добавляет косвенное требование для каждого модуля, который предоставляет любой пакет, импортируемый (даже косвенно) пакетом или тестом в основном модуле или передаваемый в качестве аргумента go get. Эти более комплексные требования позволяют выполнять обрезку графа модулей и отложенную загрузку модулей.
RequireDirective = "require" ( RequireSpec | "(" newline { RequireSpec } ")" newline ) .
RequireSpec = ModulePath Version newline .
Например:
require golang.org/x/net v1.2.3
require (
golang.org/x/crypto v1.4.5 // indirect
golang.org/x/text v1.6.7
)
tool директива
Директива tool добавляет пакет в качестве зависимости от текущего модуля. Она также делает его доступным для запуска с помощью инструмента go, если текущий рабочий каталог находится в этом модуле или в рабочей области, содержащей этот модуль.
Если пакет инструмента не находится в текущем модуле, должна присутствовать директива require, указывающая версию используемого инструмента.
Меташаблон tool разрешается в список инструментов, определенных в go.mod текущего модуля, или в режиме рабочего пространства - в объединение всех инструментов, определенных во всех модулях рабочего пространства.
ToolDirective = "tool" ( ToolSpec | "(" newline { ToolSpec } ")" newline ) .
ToolSpec = ModulePath newline .
Например:
tool golang.org/x/tools/cmd/stringer
tool (
example.com/module/cmd/a
example.com/module/cmd/b
)
ignore директива
Директива ignore заставляет команду go игнорировать разделенные косой чертой пути к каталогам, а также любые файлы или каталоги, рекурсивно содержащиеся в них, при поиске шаблонов пакетов.
Если путь начинается с ./, то он интерпретируется относительно корневого каталога модуля, и этот каталог и любые каталоги или файлы, рекурсивно содержащиеся в нем, будут игнорироваться при поиске шаблонов пакетов.
В противном случае все каталоги с таким путем на любой глубине модуля и любые каталоги или файлы, рекурсивно содержащиеся в них, будут проигнорированы.
Например:
ignore ./node_modules
ignore (
static
content/html
./third_party/javascript
)
exclude директива
Директива exclude предотвращает загрузку версии модуля командой go.
Начиная с Go 1.16, если версия, на которую ссылается директива require в любом файле go.mod, исключена директивой exclude в файле go.mod основного модуля, требование игнорируется. Это может привести к тому, что команды go get и go mod tidy добавят новые требования к более высоким версиям в go.mod с // косвенным комментарием, если это уместно.
До Go 1.16, если исключенная версия была указана директивой require, команда go перечисляла доступные версии для модуля (как показано с помощью go list -m -versions) и загружала следующую более высокую неисключенную версию. Это могло привести к недетерминированному выбору версии, поскольку следующая более высокая версия могла измениться со временем. Для этой цели учитывались как релизные, так и предрелизные версии, но не учитывались псевдоверсии. Если более высоких версий не было, команда go сообщала об ошибке.
Директивы exclude применяются только в файле go.mod основного модуля и игнорируются в других модулях. Подробности см. в разделе «Минимальный выбор версии».
ExcludeDirective = "exclude" ( ExcludeSpec | "(" newline { ExcludeSpec } ")" newline ) .
ExcludeSpec = ModulePath Version newline .
Например:
exclude golang.org/x/net v1.2.3
exclude (
golang.org/x/crypto v1.4.5
golang.org/x/text v1.6.7
)
replace директива
Директива replace заменяет содержимое определенной версии модуля или всех версий модуля содержимым, найденным в другом месте. Замена может быть указана либо другим путем к модулю и версии, либо путем к файлу, специфичному для платформы.
Если версия указана слева от стрелки (=>), заменяется только эта конкретная версия модуля; доступ к другим версиям будет осуществляться в обычном режиме. Если левая версия опущена, заменяются все версии модуля.
Если путь справа от стрелки является абсолютным или относительным (начинается с ./ или ../), он интерпретируется как локальный путь к корневому каталогу модуля замены, который должен содержать файл go.mod. В этом случае версия замены должна быть опущена.
Если путь справа не является локальным путем, он должен быть действительным путем к модулю. В этом случае требуется указать версию. Та же версия модуля не должна также фигурировать в списке сборки.
Независимо от того, указана ли замена с помощью локального пути или пути к модулю, если модуль замены имеет файл go.mod, его директива модуля должна соответствовать пути к модулю, который он заменяет.
Директивы replace применяются только в файле go.mod главного модуля и игнорируются в других модулях. Подробности см. в разделе «Выбор минимальной версии».
Если есть несколько главных модулей, применяются файлы go.mod всех главных модулей. Конфликтующие директивы replace между главными модулями не допускаются и должны быть удалены или переопределены в replace в файле go.work.
Обратите внимание, что сама по себе директива replace не добавляет модуль в граф модулей. Также необходима директива require, которая ссылается на замененную версию модуля, либо в файле go.mod основного модуля, либо в файле go.mod зависимости. Директива replace не имеет эффекта, если версия модуля слева не требуется.
ReplaceDirective = "replace" ( ReplaceSpec | "(" newline { ReplaceSpec } ")" newline ) .
ReplaceSpec = ModulePath [ Version ] "=>" FilePath newline
| ModulePath [ Version ] "=>" ModulePath Version newline .
FilePath = /* platform-specific relative or absolute file path */
Например:
replace golang.org/x/net v1.2.3 => example.com/fork/net v1.4.5
replace (
golang.org/x/net v1.2.3 => example.com/fork/net v1.4.5
golang.org/x/net => example.com/fork/net v1.4.5
golang.org/x/net v1.2.3 => ./fork/net
golang.org/x/net => ./fork/net
)
retract директива
Директива retract указывает, что версия или диапазон версий модуля, определенные в go.mod, не должны использоваться. Директива retract полезна, когда версия была опубликована преждевременно или после публикации версии была обнаружена серьезная проблема. Отмененные версии должны оставаться доступными в репозиториях контроля версий и на прокси-серверах модулей, чтобы обеспечить работоспособность сборок, которые от них зависят. Слово retract заимствовано из академической литературы: отмененная научная статья по-прежнему доступна, но в ней есть проблемы, и она не должна служить основой для будущих работ.
Когда версия модуля отзывается, пользователи не будут автоматически обновляться до нее с помощью go get, go mod tidy или других команд. Сборки, которые зависят от отозванных версий, должны продолжать работать, но пользователи будут уведомлены об отзывах, когда они будут проверять обновления с помощью go list -m -u или обновлять связанный модуль с помощью go get.
Чтобы отозвать версию, автор модуля должен добавить директиву retract в go.mod, а затем опубликовать новую версию, содержащую эту директиву. Новая версия должна быть выше других выпущенных или предварительных версий; то есть запрос @latest version должен возвращать новую версию, прежде чем будут рассмотрены отзывы. Команда go загружает и применяет отзывы из версии, показанной командой go list -m -retracted $modpath@latest (где $modpath — путь к модулю).
Отмененные версии скрываются из списка версий, выводимого командой go list -m -versions, если не используется флаг -retracted. Отмененные версии исключаются при разрешении запросов версий, таких как @>=v1.2.3 или @latest.
Версия, содержащая отмены, может отменить себя. Если самая высокая релизная или предрелизная версия модуля отменяет себя, запрос @latest разрешается в более низкую версию после исключения отмененных версий.
В качестве примера рассмотрим случай, когда автор модуля example.com/m случайно публикует версию v1.0.0. Чтобы пользователи не обновлялись до v1.0.0, автор может добавить две директивы retract в go.mod, а затем пометить v1.0.1 с отзывами.
retract (
v1.0.0 // Опубликовано случайно.
v1.0.1 // Содержит только отмены.)
Когда пользователь запускает go get example.com/m@latest, команда go считывает отмены из v1.0.1, которая теперь является самой высокой версией. И v1.0.0, и v1.0.1 отменены, поэтому команда go обновит (или понизит!) версию до следующей самой высокой версии, возможно v0.9.5.
Директивы retract могут быть написаны с одной версией (например, v1.0.0) или с закрытым интервалом версий с верхней и нижней границами, ограниченными символами [ и ] (например, [v1.1.0, v1.2.0]). Одна версия эквивалентна интервалу, где верхняя и нижняя границы одинаковы. Как и другие директивы, несколько директив retract могут быть сгруппированы в блок, ограниченный символами ( в конце строки и ) в отдельной строке.
Каждая директива retract должна иметь комментарий, объясняющий причину отзыва, хотя это не является обязательным. Команда go может отображать комментарии с объяснением причин в предупреждениях об отозванных версиях и в выводе go list. Комментарий с обоснованием может быть написан непосредственно над директивой retract (без пробела между ними) или после нее в той же строке. Если комментарий находится над блоком, он применяется ко всем директивам retract в блоке, которые не имеют собственных комментариев. Комментарий с обоснованием может занимать несколько строк.
RetractDirective = "retract" ( RetractSpec | "(" newline { RetractSpec } ")" newline ) .
RetractSpec = ( Version | "[" Version "," Version "]" ) newline .
Примеры:
- Извлечение всех версий между v1.0.0 и v1.9.9:
retract v1.0.0
retract [v1.0.0, v1.9.9]
retract (
v1.0.0
[v1.0.0, v1.9.9]
)
- Возврат к предварительной версии после преждевременного выпуска версии v1.0.0:
retract [v0.0.0, v1.0.1] // assuming v1.0.1 contains this retraction.
- Стирание модуля, включая все псевдо-версии и помеченные версии:
retract [v0.0.0-0, v0.15.2] // assuming v0.15.2 contains this retraction.
Директива retract была добавлена в Go 1.16. Go 1.15 и ниже сообщает об ошибке, если директива retract записана в файле go.mod главного модуля, и игнорирует директивы retract в файлах go.mod зависимых модулей.
Автоматические обновления
Большинство команд сообщают об ошибке, если в go.mod отсутствует информация или он не совсем точно отражает реальность. Команды go get и go mod tidy могут быть использованы для устранения большинства этих проблем. Кроме того, флаг -mod=mod можно использовать с большинством команд с поддержкой модулей (go build, go test и т. д.), чтобы указать команде go исправить проблемы в go.mod и go.sum автоматически.
Например, рассмотрим этот файл
go.mod:
module example.com/M
go 1.23.0
require (
example.com/A v1
example.com/B v1.0.0
example.com/C v1.0.0
example.com/D v1.2.3
example.com/E dev
)
exclude example.com/D v1.2.3
Обновление, запущенное с помощью -mod=mod, переписывает неканонические идентификаторы версий в каноническую форму semver, поэтому v1 example.com/A становится v1.0.0, а dev example.com/E становится псевдоверсией для последней фиксации в ветке dev, возможно, v0.0. 0-20180523231146-b3f5c0f6e5f1.
Обновление изменяет требования с учетом исключений, поэтому требование к исключенному example.com/D v1.2.3 обновляется для использования следующей доступной версии example.com/D, возможно, v1.2.4 или v1.3.0.
Обновление удаляет избыточные или вводящие в заблуждение требования. Например, если example.com/A v1.0.0 сам требует example.com/B v1.2.0 и example.com/C v1.0.0, то требование go.mod к example.com/B v1.0.0 вводит в заблуждение (заменяется требованием example.com/A к v1.2.0), а его требование к example. com/C v1.0.0 является избыточным (поскольку example.com/A требует ту же версию), поэтому оба требования будут удалены. Если основной модуль содержит пакеты, которые напрямую импортируют пакеты из example.com/B или example.com/C, то требования будут сохранены, но обновлены до фактически используемых версий.
Наконец, обновление переформатирует go.mod в каноническом формате, так что будущие механические изменения приведут к минимальным различиям. Команда go не будет обновлять go.mod, если требуются только изменения форматирования.
Поскольку граф модулей определяет значение операторов import, любые команды, которые загружают пакеты, также используют go.mod и поэтому могут его обновлять, включая go build, go get, go install, go list, go test, go mod tidy.
В Go 1.15 и ниже флаг -mod=mod был включен по умолчанию, поэтому обновления выполнялись автоматически. Начиная с Go 1.16, команда go действует так, как если бы был установлен флаг -mod=readonly: если требуются какие-либо изменения в go.mod, команда go сообщает об ошибке и предлагает исправление.
Выбор минимальной версии (MVS)
Go использует алгоритм под названием «Выбор минимальной версии» (MVS) для выбора набора версий модулей, которые будут использоваться при сборке пакетов. MVS подробно описан в статье «Выбор минимальной версии» Расса Кокса.
Концептуально MVS работает с направленным графом модулей, указанным в файлах go.mod. Каждая вершина графа представляет версию модуля. Каждая ребро представляет минимальную требуемую версию зависимости, указанную с помощью директивы require. Граф может быть изменен с помощью директив exclude и replace в файлах go.mod основных модулей и с помощью директив replace в файле go.work.
MVS генерирует список сборок в качестве вывода, то есть список версий модулей, используемых для сборки.
MVS начинает с основных модулей (специальных вершин в графе, не имеющих версии) и проходит по графу, отслеживая наивысшую требуемую версию каждого модуля. В конце прохождения наивысшие требуемые версии составляют список сборок: это минимальные версии, удовлетворяющие всем требованиям.
Список сборки можно просмотреть с помощью команды go list -m all. В отличие от других систем управления зависимостями, список сборки не сохраняется в файле «lock». MVS является детерминированным, и список сборки не изменяется при выпуске новых версий зависимостей, поэтому MVS используется для его вычисления в начале каждой команды, учитывающей модули.
Рассмотрим пример на диаграмме ниже. Основной модуль требует модуль A версии 1.2 или выше и модуль B версии 1.2 или выше. A 1.2 и B 1.2 требуют C 1.3 и C 1.4 соответственно. C 1.3 и C 1.4 требуют D 1.2.

MVS посещает и загружает файл go.mod для каждой из версий модуля, выделенных синим цветом. В конце обхода графа MVS возвращает список сборок, содержащий выделенные жирным шрифтом версии: A 1.2, B 1.2, C 1.4 и D 1.2. Обратите внимание, что доступны более высокие версии B и D, но MVS не выбирает их, поскольку они не требуются.
Replacement (Замена)
Содержимое модуля (включая его файл go.mod) может быть заменено с помощью директивы replace в файле go.mod главного модуля или в файле go.work рабочего пространства. Директива replace может применяться к определенной версии модуля или ко всем версиям модуля.
Замены изменяют граф модулей, так как заменяющий модуль может иметь другие зависимости, чем заменяемые версии.
Рассмотрим пример ниже, где C 1.4 был заменен на R. R зависит от D 1.3, а не от D 1.2, поэтому MVS возвращает список сборки, содержащий A 1.2, B 1.2, C 1.4 (замененный на R) и D 1.3.

Exclusion (Исключение)
Модуль также может быть исключен из определенных версий с помощью директивы exclude в файле go.mod главного модуля.
Исключения также изменяют граф модулей. Когда версия исключается, она удаляется из графа модулей, а требования к ней перенаправляются на следующую более высокую версию.
Рассмотрим пример ниже. Версия C 1.3 была исключена. MVS будет действовать так, как если бы A 1.2 требовал C 1.4 (следующую более высокую версию), а не C 1.3.

Upgrades (Обновления)
Команда go get может быть использована для обновления набора модулей. Чтобы выполнить обновление, команда go изменяет граф модулей перед запуском MVS, добавляя ребра от посещенных версий к обновленным.
Рассмотрим пример ниже. Модуль B может быть обновлен с 1.2 до 1.3, C может быть обновлен с 1.3 до 1.4, а D может быть обновлен с 1.2 до 1.3.

Обновления (и понижения) могут добавлять или удалять косвенные зависимости. В этом случае E 1.1 и F 1.1 появляются в списке сборки после обновления, поскольку E 1.1 требуется B 1.3.
Чтобы сохранить обновления, команда go обновляет требования в файле go.mod. Она изменит требования к B на версию 1.3. Она также добавит требования к C 1.4 и D 1.3 с // косвенными комментариями, поскольку в противном случае эти версии не были бы выбраны.
Downgrade
Команда go get также может быть использована для понижения рейтинга набора модулей. Чтобы выполнить понижение, команда go изменяет граф модулей, удаляя версии выше пониженных версий. Она также удаляет версии других модулей, которые зависят от удаленных версий, поскольку они могут быть несовместимы с пониженными версиями своих зависимостей. Если главный модуль требует версию модуля, удаленную в результате понижения, требование меняется на предыдущую версию, которая не была удалена. Если предыдущая версия недоступна, требование отменяется.
Рассмотрим приведенный ниже пример. Предположим, что была обнаружена проблема с C 1.4, поэтому мы понижаем версию до C 1.3. C 1.4 удаляется из графа модулей. B 1.2 также удаляется, поскольку для него требуется C 1.4 или выше. Требование главного модуля к B изменяется на 1.1.

go get также может полностью удалить зависимости, используя суффикс @none после аргумента. Это работает аналогично Downgrade. Все версии именованного модуля удаляются из графа модулей.
Обрезка графа модулей
Если основной модуль находится на версии go 1.17 или выше, граф модулей, используемый для выбора минимальной версии, включает только непосредственные требования для каждой зависимости модуля, которая указывает go 1.17 или выше в своем собственном файле go.mod, за исключением случаев, когда эта версия модуля также (транзитивно) требуется какой-либо другой зависимостью на версии go 1.16 или ниже. (Транзитивные зависимости зависимостей go 1.17 удаляются из графа модулей.)
Поскольку файл go.mod go 1.17 включает директиву require для каждой зависимости, необходимой для сборки любого пакета или теста в этом модуле, обрезанный граф модулей включает все зависимости, необходимые для сборки или тестирования пакетов в любой зависимости, явно требуемой основным модулем. Модуль, который не требуется для сборки какого-либо пакета или теста в данном модуле, не может повлиять на поведение его пакетов во время выполнения, поэтому зависимости, удаленные из графа модулей, могут вызвать только помехи между модулями, которые в противном случае не были бы связаны между собой.
Модули, требования которых были удалены, по-прежнему отображаются в графе модулей и по-прежнему отображаются в go list -m all: их выбранные версии известны и четко определены, и пакеты могут быть загружены из этих модулей (например, как транзитивные зависимости тестов, загруженных из других модулей). Однако, поскольку команда go не может легко определить, какие зависимости этих модулей удовлетворены, аргументы go build и go test не могут включать пакеты из модулей, требования которых были удалены. go get продвигает модуль, содержащий каждый названный пакет, в явную зависимость, позволяя вызывать go build или go test для этого пакета.
Поскольку Go 1.16 и более ранние версии не поддерживали удаление графа модулей, полное транзитивное закрытие зависимостей — включая транзитивные зависимости go 1.17 — по-прежнему включено для каждого модуля, который указывает go 1.16 или ниже. (В go 1.16 и ниже файл go.mod включает только прямые зависимости, поэтому для обеспечения включения всех косвенных зависимостей необходимо загрузить гораздо более крупный граф).
Файл go.sum, записанный go mod tidy для модуля по умолчанию, включает контрольные суммы, необходимые для версии Go, на одну ниже версии, указанной в директиве go. Таким образом, модуль go 1.17 включает контрольные суммы, необходимые для полного графа модулей, загруженного Go 1.16, но модуль go 1.18 будет включать только контрольные суммы, необходимые для обрезанного графа модулей, загруженного Go 1.17. Флаг -compat можно использовать для переопределения версии по умолчанию (например, для более агрессивной обрезки файла go.sum в модуле go 1.17).
Более подробную информацию см. в документе по проектированию.
Ленивая загрузка модуля
Более полные требования, добавленные для обрезки графа модуля, также позволяют еще одну оптимизацию при работе внутри модуля. Если основной модуль находится на уровне go 1.17 или выше, команда go избегает загрузки полного графа модуля, пока (и если) это не требуется. Вместо этого она загружает только файл go.mod главного модуля, а затем пытается загрузить пакеты, которые нужно собрать, используя только эти требования. Если импортируемый пакет (например, зависимость теста для пакета вне основного модуля) не найден среди этих требований, то остальная часть графа модулей загружается по требованию.
Если все импортируемые пакеты могут быть найдены без загрузки графа модулей, команда go загружает файлы go.mod только для модулей, содержащих эти пакеты, и их требования сверяются с требованиями основного модуля, чтобы убедиться, что они локально согласованы. (Несоответствия могут возникнуть из-за слияния версий, ручного редактирования и изменений в модулях, которые были заменены с использованием путей локальной файловой системы).
Workspaces (Рабочие пространства)
Рабочее пространство - это набор модулей на диске, которые используются в качестве основных модулей при запуске минимального выбора версий (MVS).
Рабочее пространство может быть объявлено в файле go.work, в котором указываются относительные пути к каталогам модулей каждого из модулей рабочего пространства. Если файл go.work отсутствует, рабочая область состоит из единственного модуля, содержащего текущий каталог.
Большинство подкоманд go, работающих с модулями, работают с набором модулей, определяемым текущим рабочим пространством. go mod init, go mod why, go mod edit, go mod tidy, go mod vendor и go get всегда работают с одним основным модулем.
Команда определяет, находится ли она в контексте рабочего пространства, сначала изучив переменную окружения GOWORK. Если GOWORK имеет значение off, команда будет находиться в одномодульном контексте.
Если она пуста или не указана, команда будет искать файл go.work в текущем рабочем каталоге, а затем в последовательных родительских каталогах.
Если файл найден, команда будет работать в определенном ею рабочем пространстве; в противном случае рабочее пространство будет включать только модуль, содержащий рабочий каталог.
Если GOWORK называет путь к существующему файлу, который заканчивается на .work, режим рабочего пространства будет включен.
Любое другое значение является ошибкой. Вы можете использовать команду go env GOWORK, чтобы определить, какой файл go.work использует команда go. go env GOWORK будет пустой, если команда go не находится в режиме рабочего пространства.
Файлы go.work
Рабочая область определяется текстовым файлом с кодировкой UTF-8 под названием go.work. Файл go.work ориентирован на строки. Каждая строка содержит одну директиву, состоящую из ключевого слова, за которым следуют аргументы. Например:
go 1.23.0
use ./my/first/thing
use ./my/second/thing
replace example.com/bad/thing v1.4.5 => example.com/good/thing v1.4.5
Как и в файлах go.mod, начальное ключевое слово может быть вынесено из соседних строк для создания блока.
use (
./my/first/thing
./my/second/thing
)
Команда go предоставляет несколько подкоманд для работы с файлами go.work.
go work initсоздает новые файлыgo.work.go work useдобавляет каталоги модулей в файлgo.work.go work editвыполняет низкоуровневые изменения.
Пакет golang.org/x/mod/modfile может использоваться программами Go для программного внесения тех же изменений.
Команда go будет поддерживать файл go.work.sum, который отслеживает хэши, используемые рабочим пространством, которые не находятся в файлах go.sum модулей коллективного рабочего пространства.
Обычно не рекомендуется фиксировать файлы go.work в системах контроля версий по двум причинам:
- Зарегистрированный файл
go.workможет переопределить собственный файлgo.workразработчика из родительского каталога, что приведет к путанице, когда их директивы использования не будут применяться. - Зарегистрированный файл
go.workможет привести к тому, что система непрерывной интеграции(CI)выберет и, следовательно, протестирует неправильные версии зависимостей модуля. СистемамCI, как правило, не следует разрешать использовать файлgo.work, чтобы они могли тестировать поведение модуля так, как он будет использоваться при необходимости другими модулями, где файлgo.workвнутри модуля не имеет никакого эффекта.
Тем не менее, в некоторых случаях фиксация файла go.work имеет смысл. Например, когда модули в репозитории разрабатываются исключительно друг с другом, но не вместе с внешними модулями, у разработчика может не быть причин использовать другую комбинацию модулей в рабочей области. В этом случае автор модуля должен убедиться, что отдельные модули протестированы и выпущены надлежащим образом.
Лексические элементы
Лексические элементы в файлах go.work определяются точно так же, как и в файлах go.mod.
Грамматика
Синтаксис go.work указан ниже с использованием расширенной формы Бэкуса-Наура (EBNF). Подробнее о синтаксисе EBNF см. раздел “Нотация” в спецификации языка Go.
GoWork = { Directive } .
Directive = GoDirective |
ToolchainDirective |
UseDirective |
ReplaceDirective .
Новая строка, идентификаторы и строки обозначаются символами newline, ident и string, соответственно.
Пути и версии модулей обозначаются ModulePath и Version. Пути и версии модулей указываются точно так же, как и для файлов go.mod.
ModulePath = ident | string . /* see restrictions above */
Version = ident | string . /* see restrictions above */
go директива
Директива go необходима в правильном файле go.work. Версия должна быть действительной версией релиза Go: целое положительное число, за которым следует точка и целое неотрицательное число (например, 1.18, 1.19).
Директива go указывает на версию инструментария go, с которым должен работать файл go.work. Если в формат файла go.work будут внесены изменения, будущие версии цепочки инструментов будут интерпретировать файл в соответствии с указанной версией.
Файл go.work может содержать не более одной директивы go.
GoDirective = "go" GoVersion newline .
GoVersion = string | ident . /* действительная версия релиза; см. выше */
Пример:
go 1.23.0
toolchain директива
Директива toolchain объявляет предлагаемую цепочку инструментов Go для использования в рабочем пространстве. Она действует только в том случае, если цепочка инструментов по умолчанию старше предлагаемой цепочки инструментов.
Подробнее см. в разделе “Цепочки инструментов Go”.
ToolchainDirective = "toolchain" ToolchainName newline .
ToolchainName = string | ident . /* действительное имя цепочки инструментов; см. раздел "Цепочки инструментов Go" */
Пример:
toolchain go1.21.0
godebug директива
Директива godebug объявляет единственную настройку GODEBUG, которая должна применяться при работе в этом рабочем пространстве. Синтаксис и действие такие же, как у директивы godebug в файле go.mod. Когда рабочая область используется, директивы godebug в файлах go.mod игнорируются.
use директива
Директива use добавляет модуль на диск к набору основных модулей в рабочей области. Ее аргумент - относительный путь к директории, содержащей файл go.mod модуля. Директива use не добавляет модули, содержащиеся в подкаталогах каталога-аргумента. Эти модули могут быть добавлены в каталог, содержащий их файл go.mod, в отдельных директивах use.
UseDirective = "use" ( UseSpec | "(" newline { UseSpec } ")" newline ) .
UseSpec = FilePath newline .
FilePath = /* platform-specific relative or absolute file path */
Например:
use ./mymod // example.com/mymod
use (
../othermod
./subdir/thirdmod
)
replace директива
Подобно директиве replace в файле go.mod, директива replace в файле go.work заменяет содержимое определенной версии модуля или всех версий модуля на содержимое, найденное в другом месте. Директива replace в go.work отменяет замену в файле go.mod для конкретной версии.
Директивы replace в файлах go.work переопределяют любые замены того же модуля или версии модуля в модулях рабочего пространства.
ReplaceDirective = "replace" ( ReplaceSpec | "(" newline { ReplaceSpec } ")" newline ) .
ReplaceSpec = ModulePath [ Version ] "=>" FilePath newline
| ModulePath [ Version ] "=>" ModulePath Version newline .
FilePath = /* platform-specific relative or absolute file path */
Например:
replace golang.org/x/net v1.2.3 => example.com/fork/net v1.4.5
replace (
golang.org/x/net v1.2.3 => example.com/fork/net v1.4.5
golang.org/x/net => example.com/fork/net v1.4.5
golang.org/x/net v1.2.3 => ./fork/net
golang.org/x/net => ./fork/net
)
Совместимость с немодульными репозиториями
Чтобы обеспечить плавный переход от GOPATH к модулям, команда go может загружать и собирать пакеты в модульно-ориентированном режиме из репозиториев, которые не перешли на модули, добавив файл go.mod.
Когда команда go загружает модуль заданной версии непосредственно из репозитория, она ищет URL репозитория для пути к модулю, сопоставляет версию с ревизией в репозитории, а затем извлекает архив репозитория с этой ревизией. Если путь модуля равен корневому пути репозитория, а корневой каталог репозитория не содержит файла go.mod, команда go синтезирует в кэше модулей файл go.mod, содержащий директиву модуля и ничего больше. Поскольку синтетические файлы go.mod не содержат директив require для своих зависимостей, другим модулям, зависящим от них, могут потребоваться дополнительные директивы require (с косвенными комментариями //), чтобы гарантировать, что каждая зависимость будет получена в одной и той же версии при каждой сборке.
Когда команда go загружает модуль с прокси, она загружает файл go.mod отдельно от остального содержимого модуля. Предполагается, что прокси-сервер предоставит синтетический файл go.mod, если у исходного модуля его не было.
+incompatible (Несовместимые версии)
Модуль, выпущенный в основной версии 2 или выше, должен иметь соответствующий суффикс основной версии в своем пути модуля. Например, если модуль выпущен в версии v2.0.0, его путь должен иметь суффикс /v2. Это позволяет команде go обрабатывать несколько основных версий проекта как отдельные модули, даже если они разработаны в одном репозитории.
Требование о суффиксе основной версии было введено, когда в команду go была добавлена поддержка модулей, и многие репозитории уже имели теги с основной версией 2 или выше до этого. Для обеспечения совместимости с этими репозиториями команда go добавляет суффикс +incompatible к версиям с основной версией 2 или выше без файла go.mod. +incompatible указывает, что версия является частью того же модуля, что и версии с более низкими номерами основных версий; следовательно, команда go может автоматически обновлять до более высоких версий +incompatible, даже если это может привести к сбою сборки.
Рассмотрим пример требования ниже:
require example.com/m v4.1.2+incompatible
Версия v4.1.2+incompatible относится к семантическому тегу версии v4.1.2 в репозитории, который предоставляет модуль example.com/m. Модуль должен находиться в корневом каталоге репозитория (то есть корневой путь репозитория также должен быть example.com/m), и файл go.mod не должен присутствовать. Модуль может иметь версии с более низкими номерами основных версий, такие как v1.5.2, и команда go может автоматически обновить их до v4.1.2+incompatible (см. минимальный выбор версии (MVS) для получения информации о том, как работают обновления).
Репозиторий, который переходит на модули после того, как версия v2.0.0 была помечена тегом, обычно должен выпустить новую основную версию. В приведенном выше примере автор должен создать модуль с путем example.com/m/v5 и выпустить версию v5.0.0. Автор также должен обновить импорт пакетов в модуле, чтобы использовать префикс example.com/m/v5 вместо example.com/m. Более подробный пример см. в разделе Go Modules: v2 and Beyond.
Обратите внимание, что суффикс +incompatible не должен появляться в теге в репозитории; тег типа v4.1.2+incompatible будет игнорироваться. Суффикс появляется только в версиях, используемых командой go. Подробнее о различиях между версиями и тегами см. в разделе Сопоставление версий с коммитами.
Обратите внимание, что суффикс +incompatible может появляться в псевдоверсиях. Например, v2.0.1-20200722182040-012345abcdef+incompatible может быть действительной псевдоверсией.
Минимальная совместимость модулей
Модуль, выпущенный в основной версии 2 или выше, должен иметь суффикс основной версии в своем пути модуля. Модуль может быть разработан в подкаталоге основной версии в своем репозитории, а может и нет. Это имеет значение для пакетов, которые импортируют пакеты внутри модуля при сборке в режиме GOPATH.
Обычно в режиме GOPATH пакет хранится в каталоге, соответствующем корневому пути его репозитория, соединенному с его каталогом в репозитории. Например, пакет в репозитории с корневым путем example.com/repo в подкаталоге sub будет храниться в $GOPATH/src/example.com/repo/sub и будет импортироваться как example.com/repo/sub.
Для модуля с суффиксом основной версии можно ожидать, что пакет example.com/repo/v2/sub будет находиться в каталоге $GOPATH/src/example.com/repo/v2/sub. Для этого модуль должен быть разработан в подкаталоге v2 своего репозитория. Команда go поддерживает это, но не требует (см. Сопоставление версий с коммитами).
Если модуль не разрабатывается в подкаталоге основной версии, то его каталог в GOPATH не будет содержать суффикс основной версии, и его пакеты могут быть импортированы без суффикса основной версии. В приведенном выше примере пакет будет находиться в каталоге $GOPATH/src/example.com/repo/sub и будет импортирован как example.com/repo/sub.
Это создает проблему для пакетов, предназначенных для сборки как в режиме модуля, так и в режиме GOPATH: режим модуля требует суффикса, а режим GOPATH — нет.
Чтобы исправить это, в Go 1.11 была добавлена минимальная совместимость модулей, которая была обратно портирована в Go 1.9.7 и 1.10.3. Когда путь импорта разрешается в каталог в режиме GOPATH:
При разрешении импорта в форме
$modpath/$vn/$dir, где:$modpath— действительный путь к модулю,$vn— суффикс основной версии,$dir— возможно пустой подкаталог,
Если выполняются все следующие условия:
- Пакет
$modpath/$vn/$dirотсутствует в любом соответствующем каталоге поставщика. - Файл
go.modприсутствует в том же каталоге, что и импортирующий файл, или в любом родительском каталоге до корня$GOPATH/src. - Не существует каталога
$GOPATH[i]/src/$modpath/$vn/$suffix(для любого корня$GOPATH[i]), - Существует файл
$GOPATH[d]/src/$modpath/go.mod(для некоторого корня$GOPATH[d]), который объявляет путь к модулю как$modpath/$vn,
- Пакет
Тогда импорт
$modpath/$vn/$dirразрешается в каталог$GOPATH[d]/src/$modpath/$dir.
Эти правила позволяют пакетам, которые были перенесены в модули, импортировать другие пакеты, которые были перенесены в модули при сборке в режиме GOPATH, даже если не использовался подкаталог основной версии.
Команды с поддержкой модулей
Большинство команд go могут работать в режиме с поддержкой модулей или в режиме GOPATH. В режиме с поддержкой модулей команда go использует файлы go.mod для поиска версионных зависимостей и обычно загружает пакеты из кэша модулей, скачивая модули, если они отсутствуют. В режиме GOPATH команда go игнорирует модули; она ищет зависимости в каталогах поставщиков и в GOPATH.
Начиная с Go 1.16, режим с поддержкой модулей включен по умолчанию, независимо от наличия файла go.mod. В более ранних версиях режим с поддержкой модулей включался, если файл go.mod присутствовал в текущем каталоге или любом родительском каталоге.
Режим с поддержкой модулей можно контролировать с помощью переменной среды GO111MODULE, которую можно установить в значение on, off или auto.
- Если
GO111MODULE=off, командаgoигнорирует файлыgo.modи работает в режимеGOPATH. - Если
GO111MODULE=onили не установлено, командаgoработает в режиме распознавания модулей, даже если файлgo.modотсутствует. Не все команды работают без файлаgo.mod: см. Команды модулей вне модуля. - Если
GO111MODULE=auto, командаgoработает в режиме с поддержкой модулей, если файлgo.modприсутствует в текущем каталоге или любом родительском каталоге. В Go 1.15 и ниже это было поведением по умолчанию. Подкомандыgo modиgo installс запросом версии работают в режиме с поддержкой модулей, даже если файлgo.modотсутствует.
В режиме распознавания модулей GOPATH больше не определяет значение импортов во время сборки, но по-прежнему хранит загруженные зависимости (в GOPATH/pkg/mod; см. Кэш модулей) и установленные команды (в GOPATH/bin, если не установлен GOBIN).
(builds) Команды сборки
Все команды, которые загружают информацию о пакетах, учитывают модули. К ним относятся:
go build
go fix
go generate
go install
go list
go run
go test
go vet
При запуске в режиме распознавания модулей эти команды используют файлы go.mod для интерпретации путей импорта, указанных в командной строке или записанных в исходных файлах Go. Эти команды принимают следующие флаги, общие для всех команд модулей.
- Флаг
-modконтролирует, может лиgo.modобновляться автоматически и используется ли каталогvendor.-mod=modуказывает командеgoигнорировать каталог vendor и автоматически обновлятьgo.mod, например, когда импортируемый пакет не предоставляется ни одним из известных модулей.-mod=readonlyуказывает командеgoигнорировать каталогvendorи сообщать об ошибке, еслиgo.modнеобходимо обновить.-mod=vendorуказывает командеgoиспользовать каталогvendor. В этом режиме командаgoне будет использовать сеть или кэш модулей.- По умолчанию, если версия
goвgo.modравна 1.14 или выше и присутствует каталогvendor, командаgoдействует так, как если бы был использован флаг-mod=vendor. В противном случае командаgoдействует так, как если бы был использован флаг-mod=readonly. go getотклоняет этот флаг, поскольку цель команды — изменить зависимости, что разрешено только с помощью-mod=mod.
- Флаг
-modcacherwуказывает командеgoсоздавать новые каталоги в кэше модулей с правами на чтение и запись, а не делать их доступными только для чтения. При постоянном использовании этого флага (обычно путем установкиGOFLAGS=-modcacherwв среде или запускаgo env -w GOFLAGS=-modcacherw) кэш модулей можно удалить с помощью таких команд, какrm -r, без предварительного изменения прав доступа. Командаgo clean -modcacheможет использоваться для удаления кэша модулей, независимо от того, использовался ли флаг-modcacherw. - Флаг
-modfile=file.modуказывает командеgoчитать (и, возможно, записывать) альтернативный файл вместоgo.modв корневом каталоге модулей. Имя файла должно заканчиваться на.mod. Файл с именемgo.modпо-прежнему должен присутствовать, чтобы определить корневой каталог модулей, но доступ к нему не осуществляется. Когда указан-modfile, также используется альтернативный файлgo.sum: его путь получается из флага-modfileпутем удаления расширения.modи добавления.sum.
Vendoring
При использовании модулей команда go обычно удовлетворяет зависимости, загружая модули из их источников в кэш модулей, а затем загружая пакеты из этих загруженных копий. Vendoring может использоваться для обеспечения взаимодействия со старыми версиями Go или для обеспечения хранения всех файлов, используемых для сборки, в одном дереве файлов.
Команда go mod vendor создает каталог с именем vendor в корневом каталоге главного модуля, содержащий копии всех пакетов, необходимых для сборки и тестирования пакетов в главном модуле. Пакеты, которые импортируются только тестами пакетов вне главного модуля, не включаются. Как и в случае с go mod tidy и другими командами модулей, ограничения сборки, за исключением ignore, не учитываются при создании каталога vendor.
go mod vendor также создает файл vendor/modules.txt, который содержит список пакетов vendor и версии модулей, из которых они были скопированы. Когда vendoring включен, этот манифест используется в качестве источника информации о версии модуля, как сообщается go list -m и go version -m. Когда команда go читает vendor/modules.txt, она проверяет, что версии модулей соответствуют go.mod. Если go.mod изменился с момента создания vendor/modules.txt, команда go сообщит об ошибке. go mod vendor следует запустить снова, чтобы обновить каталог vendor.
Если каталог vendor присутствует в корневом каталоге основного модуля, он будет использоваться автоматически, если версия go в файле go.mod основного модуля равна 1.14 или выше. Чтобы явно включить vendoring, вызовите команду go с флагом -mod=vendor. Чтобы отключить vendoring, используйте флаг -mod=readonly или -mod=mod.
Когда vendoring включен, команды сборки, такие как go build и go test, загружают пакеты из каталога vendor вместо доступа к сети или локальному кэшу модулей. Команда go list -m выводит только информацию о модулях, перечисленных в go.mod. Команды go mod, такие как go mod download и go mod tidy, не работают по-другому, когда vendoring включен, и по-прежнему загружают модули и обращаются к кэшу модулей. go get также не работает по-другому, когда vendoring включен.
В отличие от вендоринга в режиме GOPATH, команда go игнорирует каталоги vendor, расположенные не в корневом каталоге основного модуля. Кроме того, поскольку каталоги vendor в других модулях не используются, команда go не включает каталоги vendor при сборке zip-файлов модулей (но см. известные ошибки #31562 и #37397).
go get
Использование:
go get [-d] [-t] [-u] [build flags] [packages]
Примеры:
# Upgrade a specific module.
$ go get golang.org/x/net
# Upgrade modules that provide packages imported by packages in the main module.
$ go get -u ./...
# Upgrade or downgrade to a specific version of a module.
$ go get golang.org/x/text@v0.3.2
# Update to the commit on the module's master branch.
$ go get golang.org/x/text@master
# Remove a dependency on a module and downgrade modules that require it
# to versions that don't require it.
$ go get golang.org/x/text@none
# Upgrade the minimum required Go version for the main module.
$ go get go
# Upgrade the suggested Go toolchain, leaving the minimum Go version alone.
$ go get toolchain
# Upgrade to the latest patch release of the suggested Go toolchain.
$ go get toolchain@patch
Команда go get обновляет зависимости модулей в файле go.mod для основного модуля, а затем собирает и устанавливает пакеты, указанные в командной строке.
Первый шаг — определить, какие модули необходимо обновить.
go getпринимает в качестве аргументов список пакетов, шаблоны пакетов и пути к модулям.- Если указан аргумент пакета,
go getобновляет модуль, который предоставляет этот пакет. - Если указан шаблон пакета (например,
allили путь с подстановочным символом …),go getрасширяет шаблон до набора пакетов, а затем обновляет модули, которые предоставляют эти пакеты. - Если аргумент указывает модуль, но не пакет (например, модуль
golang.org/x/netне имеет пакета в своем корневом каталоге),go getобновит модуль, но не скомпилирует пакет. - Если аргументы не указаны,
go getдействует так, как если бы был указан (пакет в текущем каталоге); это можно использовать вместе с флагом-uдля обновления модулей, которые предоставляют импортированные пакеты.
Каждый аргумент может включать суффикс запроса версии, указывающий желаемую версию, как в go get golang.org/x/text@v0.3.0. Суффикс запроса версии состоит из символа @, за которым следует запрос версии, который может указывать конкретную версию (v0.3.0), префикс версии (v0.3), имя ветки или тега (master), ревизию (1234abcd) или один из специальных запросов latest, upgrade, patch или none. Если версия не указана, go get использует запрос @upgrade.
После того как go get разрешит свои аргументы для конкретных модулей и версий, go get добавит, изменит или удалит директивы require в файле go.mod основного модуля, чтобы обеспечить сохранение модулей в желаемых версиях в будущем. Обратите внимание, что требуемые версии в файлах go.mod являются минимальными версиями и могут быть автоматически увеличены при добавлении новых зависимостей. См. раздел «Выбор минимальной версии (MVS)» для получения подробной информации о том, как версии выбираются и конфликты разрешаются командами, учитывающими модули.
Другие модули могут быть обновлены, когда модуль, указанный в командной строке, добавляется, обновляется или понижается, если новая версия указанного модуля требует другие модули более высоких версий. Например, предположим, что модуль example.com/a обновлен до версии v1.5.0, и эта версия требует модуль example.com/b версии v1.2.0. Если в настоящее время требуется модуль example.com/b версии v1.1.0, то go get example.com/a@v1.5.0 также обновит example.com/b до v1.2.0.

Другие модули могут быть понижены, когда модуль, названный в командной строке, понижается или удаляется. Продолжая приведенный выше пример, предположим, что модуль example.com/b понижен до версии v1.1.0. Модуль example.com/a также будет понижен до версии, которая требует example.com/b версии v1.1.0 или ниже.

Требование модуля может быть удалено с помощью суффикса версии @none. Это особый вид понижения версии. Модули, которые зависят от удаленного модуля, будут понижены или удалены по мере необходимости. Требование модуля может быть удалено, даже если один или несколько его пакетов импортируются пакетами в основном модуле. В этом случае следующая команда сборки может добавить новое требование модуля.
Если модуль требуется в двух разных версиях (явно указанных в аргументах командной строки или для удовлетворения требований обновлений и понижений версии), go get выдаст ошибку.
После того, как go get выбрал новый набор версий, он проверяет, не были ли отозваны или не стали ли устаревшими какие-либо вновь выбранные версии модулей или какие-либо модули, предоставляющие пакеты, указанные в командной строке. go get выводит предупреждение для каждой найденной отозванной версии или устаревшего модуля. go list -m -u all можно использовать для проверки отзывов и устаревания во всех зависимостях.
После обновления файла go.mod go get собирает пакеты, указанные в командной строке. Исполняемые файлы будут установлены в каталог, указанный переменной окружения GOBIN, которая по умолчанию равна $GOPATH/bin или $HOME/go/bin, если переменная окружения GOPATH не установлена.
go get поддерживает следующие флаги:
- Флаг
-dуказываетgo getне собирать и не устанавливать пакеты. При использовании-dgo getбудет только управлять зависимостями вgo.mod. Использованиеgoget без-dдля сборки и установки пакетов является устаревшим (начиная с Go 1.17). В Go 1.18-dбудет всегда включен. - Флаг
-uуказываетgo getобновить модули, предоставляющие пакеты, импортируемые прямо или косвенно пакетами, указанными в командной строке. Каждый модуль, выбранный с помощью-u, будет обновлен до последней версии, если он уже не требуется в более поздней версии (предварительная версия). - Флаг
-u=patch(не-u patch) также указываетgo getобновить зависимости, ноgo getобновит каждую зависимость до последней патч-версии (аналогично запросу версии@patch). - Флаг
-tуказываетgo getучитывать модули, необходимые для сборки тестов пакетов, указанных в командной строке. При совместном использовании-tи-ugo getтакже обновит тестовые зависимости. - Флаг
-insecureбольше не следует использовать. Он позволяетgo getразрешать пользовательские пути импорта и загружать из репозиториев и прокси-серверов модулей, используя небезопасные схемы, такие какHTTP. Переменная средыGOINSECUREобеспечивает более тонкий контроль и должна использоваться вместо него.
go get больше ориентирован на управление требованиями в go.mod. Флаг -d является устаревшим, и в Go 1.18 он будет всегда включен.
go install
Начиная с Go 1.16,
go installявляется рекомендуемой командой для сборки и установки программ. При использовании с суффиксом версии (например,@latestили@v1.4.6)go installсобирает пакеты в режиме с учетом модулей, игнорируя файлgo.modв текущем каталоге или любом родительском каталоге, если таковой имеется.
Использование:
go install [build flags] [packages]
Примеры:
# Install the latest version of a program,
# ignoring go.mod in the current directory (if any).
$ go install golang.org/x/tools/gopls@latest
# Install a specific version of a program.
$ go install golang.org/x/tools/gopls@v0.6.4
# Install a program at the version selected by the module in the current directory.
$ go install golang.org/x/tools/gopls
# Install all programs in a directory.
$ go install ./cmd/...
Команда go install собирает и устанавливает пакеты, указанные в командной строке. Исполняемые файлы (основные пакеты) устанавливаются в каталог, указанный переменной среды GOBIN, которая по умолчанию равна $GOPATH/bin или $HOME/go/bin, если переменная среды GOPATH не задана. Исполняемые файлы в $GOROOT устанавливаются в $GOROOT/bin или $GOTOOLDIR вместо $GOBIN. Неисполняемые пакеты собираются и кэшируются, но не устанавливаются.
Начиная с Go 1.16, если аргументы имеют суффиксы версии (такие как @latest или @v1.0.0), go install собирает пакеты в режиме с учетом модулей, игнорируя файл go.mod в текущем каталоге или любом родительском каталоге, если таковой имеется. Это полезно для установки исполняемых файлов без влияния на зависимости основного модуля.
Чтобы устранить неоднозначность в отношении того, какие версии модулей используются в сборке, аргументы должны удовлетворять следующим ограничениям:
- Аргументы должны быть путями к пакетам или шаблонами пакетов (с подстановочными знаками
«...»). Они не должны быть стандартными пакетами (такими какfmt), меташаблонами (std,cmd,all,work,tool) или относительными или абсолютными путями к файлам. - Все аргументы должны иметь одинаковый суффикс версии. Различные запросы не допускаются, даже если они относятся к одной и той же версии.
- Все аргументы должны относиться к пакетам в одном и том же модуле с одной и той же версией.
- Аргументы пути к пакету должны относиться к основным пакетам. Аргументы шаблона будут соответствовать только основным пакетам.
- Ни один модуль не считается основным модулем.
- Если модуль, содержащий пакеты, указанные в командной строке, имеет файл
go.mod, он не должен содержать директивы (replaceиexclude), которые привели бы к его интерпретации по-другому, если бы он был основным модулем. - Модуль не должен требовать более высокой версии самого себя.
- Каталоги поставщиков не используются ни в одном модуле. (Каталоги поставщиков не включаются в zip-файлы модулей, поэтому
go installне загружает их).
- Если модуль, содержащий пакеты, указанные в командной строке, имеет файл
См. Запросы версии для поддерживаемого синтаксиса запросов версии. Go 1.15 и ниже не поддерживали использование запросов версии с go install.
Если аргументы не имеют суффиксов версии, go install может работать в режиме с поддержкой модулей или в режиме GOPATH, в зависимости от переменной среды GO111MODULE и наличия файла go.mod. Подробности см. в разделе Команды с поддержкой модулей. Если режим с поддержкой модулей включен, go install работает в контексте основного модуля, который может отличаться от модуля, содержащего устанавливаемый пакет.
go list -m
Использование:
go list -m [-u] [-retracted] [-versions] [list flags] [modules]
Примеры:
$ go list -m all
$ go list -m -versions example.com/m
$ go list -m -json example.com/m@latest
Флаг -m заставляет go list перечислять модули, а не пакеты. В этом режиме аргументами go list могут быть модули, шаблоны модулей (содержащие подстановочный знак ...), запросы версий или специальный шаблон all, который соответствует всем модулям в списке сборки. Если аргументы не указаны, то в списке будет указан главный модуль.
При перечислении модулей флаг -f по-прежнему задает шаблон формата, применяемый к структуре Go, но теперь уже к структуре Module:
type Module struct {
Path string // путь к модулю
Version string // версия модуля
Versions []string // доступные версии модуля
Replace *Module // заменяется этим модулем
Time *time.Time // время создания версии
Update *Module // доступное обновление (с -u)
Main bool // является ли это главным модулем?
Indirect bool // модуль требуется основному модулю только косвенно
Dir string // каталог, содержащий локальную копию файлов, если таковая имеется
GoMod string // путь к файлу go.mod, описывающему модуль, если таковой имеется
GoVersion string // версия go, используемая в модуле
Retracted []string // информация об отзыве, если таковая имеется (с -retracted или -u)
Deprecated string // сообщение об устаревании, если есть (с -u)
Error *ModuleError // ошибка при загрузке модуля
}
type ModuleError struct {
Err string // сама ошибка
}
По умолчанию выводится путь к модулю, а затем информация о версии и замене, если таковая имеется. Например, go list -m all может вывести:
example.com/main/module
golang.org/x/net v0.1.0
golang.org/x/text v0.3.0 => /tmp/text
rsc.io/pdf v0.1.1
В структуре Module есть метод String, который форматирует эту строку вывода, так что формат по умолчанию эквивалентен -f '{{.String}}'.
Обратите внимание, что если модуль был заменен, его поле Replace описывает заменяющий модуль, а его поле Dir устанавливается в исходный код заменяющего модуля, если он присутствует. (То есть, если Replace не имеет значения nil, то Dir устанавливается в Replace.Dir, без доступа к исходному коду замененного модуля).
Флаг -u добавляет информацию о доступных обновлениях. Если последняя версия данного модуля новее текущей, list -u устанавливает в поле Update модуля информацию о более новом модуле.
list -u также выводит, является ли выбранная в данный момент версия отмененной и является ли модуль устаревшим. Метод String модуля указывает на доступное обновление путем форматирования новой версии в скобках после текущей версии.
Например,
go list -m -u allможет вывести:
example.com/main/module
golang.org/x/old v1.9.9 (deprecated)
golang.org/x/net v0.1.0 (retracted) [v0.2.0]
golang.org/x/text v0.3.0 [v0.4.0] => /tmp/text
rsc.io/pdf v0.1.1 [v0.1.2]
(Для инструментов может быть удобнее использовать команду go list -m -u -json all для анализа.)
Флаг -versions заставляет list установить поле Versions модуля в список всех известных версий этого модуля, упорядоченных в соответствии с семантической версией, от самой низкой к самой высокой. Флаг также изменяет формат вывода по умолчанию, чтобы отобразить путь к модулю, за которым следует список версий, разделенных пробелами. Отмененные версии опускаются из этого списка, если не указан флаг -retracted.
Флаг -retracted указывает list показывать отозванные версии в списке, выведенном с помощью флага -versions, и учитывать отозванные версии при разрешении запросов версий.
Например,
go list -m -retracted example.com/m@latestпоказывает самую последнюю версию или предрелизную версию модуляexample.com/m, даже если эта версия отозвана. Директивыretractиdeprecationsзагружаются из файлаgo.modв этой версии. Флаг-retractedбыл добавлен в Go 1.16.
Шаблонная функция module принимает один строковый аргумент, который должен быть путем к модулю или запросом, и возвращает указанный модуль в виде структуры Module. Если происходит ошибка, результатом будет структура Module с полем Error, не равным nil.
go mod download
Использование:
go mod download [-x] [-json] [-reuse=old.json] [modules]
Например:
$ go mod download
$ go mod download golang.org/x/mod@v0.2.0
Команда go mod download загружает именованные модули в кэш модулей. Аргументами могут быть пути к модулям или шаблоны модулей, выбирающие зависимости основного модуля, или запросы версий вида path@version. При отсутствии аргументов загрузка применяется ко всем зависимостям основного модуля.
Команда go будет автоматически загружать модули по мере необходимости во время обычного выполнения. Команда go mod download полезна в основном для предварительного заполнения кэша модулей или для загрузки данных, которые будут обслуживаться прокси-модулем.
По умолчанию команда загрузки ничего не пишет в стандартный вывод. Она печатает сообщения о ходе выполнения и ошибках в стандартную ошибку.
Флаг -json заставляет команду download выводить на стандартный вывод последовательность JSON-объектов, описывающих каждый загруженный модуль (или сбой), соответствующий данной Go-структуре:
type Module struct {
Path string // module path
Query string // version query corresponding to this version
Version string // module version
Error string // error loading module
Info string // absolute path to cached .info file
GoMod string // absolute path to cached .mod file
Zip string // absolute path to cached .zip file
Dir string // absolute path to cached source root directory
Sum string // checksum for path, version (as in go.sum)
GoModSum string // checksum for go.mod (as in go.sum)
Origin any // provenance of module
Reuse bool // reuse of old module info is safe
}
Флаг -x заставляет download выводить команды, выполняемые download, в стандартную ошибку.
Флаг -reuse принимает имя файла, содержащего JSON-вывод предыдущего вызова ‘go mod download -json’. Команда go может использовать этот файл, чтобы определить, что модуль не изменился с момента предыдущего вызова, и избежать его повторной загрузки. Модули, которые не будут перезагружены, будут отмечены в новом выводе установкой поля Reuse в true. Обычно кэш модулей обеспечивает такое повторное использование автоматически; флаг -reuse может быть полезен в системах, не сохраняющих кэш модулей.
go mod edit
Использование:
go mod edit [editing flags] [-fmt|-print|-json] [go.mod]
Например:
# Add a replace directive.
$ go mod edit -replace example.com/a@v1.0.0=./a
# Remove a replace directive.
$ go mod edit -dropreplace example.com/a@v1.0.0
# Set the go version, add a requirement, and print the file
# instead of writing it to disk.
$ go mod edit -go=1.14 -require=example.com/m@v1.0.0 -print
# Format the go.mod file.
$ go mod edit -fmt
# Format and print a different .mod file.
$ go mod edit -print tools.mod
# Print a JSON representation of the go.mod file.
$ go mod edit -json
Команда go mod edit предоставляет интерфейс командной строки для редактирования и форматирования файлов go.mod, предназначенный в первую очередь для использования инструментами и скриптами. go mod edit читает только один файл go.mod; он не ищет информацию о других модулях. По умолчанию go mod edit читает и записывает файл go.mod основного модуля, но после флагов редактирования можно указать другой целевой файл.
Флаги редактирования определяют последовательность операций редактирования.
- Флаг
-moduleизменяет путь модуля (строку модуля в файлеgo.mod). - Флаг
-go=versionустанавливает ожидаемую версию языка Go. - Флаги
-require=path@versionи-droprequire=pathдобавляют и удаляют требование к указанному пути и версии модуля. Обратите внимание, что-requireпереопределяет все существующие требования к пути. Эти флаги в основном предназначены для инструментов, которые понимают граф модулей. Пользователям следует отдавать предпочтениеgo get path@versionилиgo get path@none, которые производят другие настройкиgo.modпо мере необходимости, чтобы удовлетворить ограничения, налагаемые другими модулями. См.go get. - Флаги
-exclude=path@versionи-dropexclude=path@versionдобавляют и удаляют исключение для указанного пути модуля и версии. Обратите внимание, что-exclude=path@versionне выполняется, если такое исключение уже существует. - Флаг
-replace=old[@v]=new[@v]добавляет замену указанной пары пути модуля и версии. Если@vвold@vопущено, добавляется замена без версии в левой части, которая применяется ко всем версиям старого пути модуля. Если@vвnew@vопущено, новый путь должен быть локальным корневым каталогом модуля, а не путем модуля. Обратите внимание, что-replaceпереопределяет любые избыточные замены дляold[@v], поэтому опущение@vудалит замены для определенных версий. - Флаг
-dropreplace=old[@v]отменяет замену заданного пути модуля и пары версий. Если@vуказан, то отменяется замена с заданной версией. Существующая замена без версии в левой части может по-прежнему заменять модуль. Если@vопущен, то отменяется замена без версии. - Флаги
-retract=versionи-dropretract=versionдобавляют и удаляют отзыв для заданной версии, которая может быть одной версией (например,v1.2.3) или интервалом (например,[v1.1.0,v1.2.0]). Обратите внимание, что флаг-retractне может добавлять комментарий с обоснованием для директивы отзыва. Комментарии с обоснованием рекомендуются и могут отображаться с помощьюgo list -m -uи других команд. - Флаги
-tool=pathи-droptool=pathдобавляют и удаляют директивуtoolдля указанных путей. Обратите внимание, что это не добавит необходимые зависимости в граф сборки. Пользователям рекомендуется использоватьgo get -tool pathдля добавления инструмента илиgo get -tool path@noneдля его удаления.
Флаги редактирования могут повторяться. Изменения применяются в указанном порядке.
go mod edit имеет дополнительные флаги, которые контролируют его вывод.
- Флаг
-fmtпереформатирует файлgo.modбез внесения других изменений. Это переформатирование также подразумевается любыми другими изменениями, которые используют или переписывают файлgo.mod. Этот флаг нужен только в том случае, если не указаны другие флаги, как вgo mod edit -fmt. - Флаг
-printвыводит окончательный файлgo.modв текстовом формате вместо записи обратно на диск. - Флаг
-jsonвыводит окончательный файлgo.modв формате JSON вместо записи обратно на диск в текстовом формате. Вывод JSON соответствует следующим типам Go:
type Module struct {
Path string
Version string
}
type GoMod struct {
Module ModPath
Go string
Require []Require
Exclude []Module
Replace []Replace
Retract []Retract
}
type ModPath struct {
Path string
Deprecated string
}
type Require struct {
Path string
Version string
Indirect bool
}
type Replace struct {
Old Module
New Module
}
type Retract struct {
Low string
High string
Rationale string
}
type Tool struct {
Path string
}
Обратите внимание, что здесь описывается только сам файл go.mod, а не другие модули, на которые есть косвенные ссылки. Для получения полного набора модулей, доступных для сборки, используйте go list -m -json all. См. go list -m.
Например, инструмент может получить файл
go.modв виде структуры данных, разобрав выводgo mod edit -json, а затем внести изменения, вызвавgo mod editс параметрами-require,-excludeи так далее.
Инструменты также могут использовать пакет golang.org/x/mod/modfile для разбора, редактирования и форматирования файлов go.mod.
go mod graph
Использование:
go mod graph [-go=version]
Команда go mod graph выводит граф требований к модулю (с примененными заменами) в текстовом виде.
Например:
example.com/main example.com/a@v1.1.0
example.com/main example.com/b@v1.2.0
example.com/a@v1.1.0 example.com/b@v1.1.1
example.com/a@v1.1.0 example.com/c@v1.3.0
example.com/b@v1.1.0 example.com/c@v1.1.0
example.com/b@v1.2.0 example.com/c@v1.2.0
Каждая вершина в графе модуля представляет собой определенную версию модуля. Каждое ребро в графе представляет собой требование к минимальной версии зависимости.
go mod graph выводит ребра графа по одному в строке. Каждая строка содержит два поля, разделенных пробелами: версию модуля и одну из его зависимостей. Каждая версия модуля идентифицируется как строка вида path@version. Главный модуль не имеет суффикса @version, так как у него нет версии.
Флаг -go заставляет go mod graph сообщать о том, что граф модуля загружен данной версией Go, а не версией, указанной директивой go в файле go.mod.
Дополнительные сведения о том, как выбираются версии, см. в разделе Минимальный выбор версии (MVS). См. также go list -m для печати выбранных версий и go mod why для понимания того, зачем нужен тот или иной модуль.
go mod init
Использование:
go mod init [module-path]
Пример:
go mod init
go mod init example.com/m
Команда go mod init инициализирует и записывает новый файл go.mod в текущем каталоге, фактически создавая новый модуль, укорененный в текущем каталоге. Файл go.mod не должен уже существовать.
init принимает один необязательный аргумент - путь к модулю для нового модуля. Инструкции по выбору пути к модулю см. в разделе Пути к модулю. Если аргумент путь к модулю опущен, init попытается определить путь к модулю, используя комментарии импорта в файлах .go и текущий каталог (если он есть в GOPATH).
go mod tidy
Использование:
go mod tidy [-e] [-v] [-x] [-diff] [-go=версия] [-compat=версия]
go mod tidy обеспечивает соответствие файла go.mod исходному коду в модуле. Он добавляет все недостающие требования к модулям, необходимые для сборки пакетов и зависимостей текущего модуля, и удаляет требования к модулям, которые не предоставляют никаких соответствующих пакетов. Он также добавляет все недостающие записи в go.sum и удаляет ненужные записи.
- Флаг
-e(добавлен в Go 1.16) заставляетgo mod tidyпытаться продолжить работу, несмотря на ошибки, возникшие при загрузке пакетов. - Флаг
-vзаставляетgo mod tidyвыводить информацию об удаленных модулях в стандартный вывод ошибок. - Флаг
-xзаставляетgo mod tidyвыводить команды, которые выполняетtidy. - Флаг
-diffзаставляетgo mod tidyне изменятьgo.modилиgo.sum, а вместо этого выводить необходимые изменения в виде унифицированногоdiff. Он завершается с кодом, отличным от нуля, еслиdiffне пустой.
go mod tidy работает, загружая все пакеты в основном модуле, все его инструменты и все пакеты, которые они импортируют, рекурсивно. Сюда входят пакеты, импортированные тестами (включая тесты в других модулях).
go mod tidy действует так, как если бы все теги сборки были включены, поэтому он будет учитывать платформозависимые исходные файлы и файлы, которые требуют настраиваемых тегов сборки, даже если эти исходные файлы обычно не собираются.
Есть одно исключение: тег сборки ignore не включен, поэтому файл с ограничением сборки // +build ignore не будет учитываться.
Обратите внимание, что go mod tidy не будет учитывать пакеты в главном модуле в каталогах с именем testdata или с именами, начинающимися с . или _, если эти пакеты явно не импортируются другими пакетами.
После загрузки этого набора пакетов go mod tidy убеждается, что каждый модуль, предоставляющий один или несколько пакетов, имеет директиву require в файле go.mod основного модуля или — если основной модуль находится на go 1.16 или ниже — требуется другим необходимым модулем.
go mod tidyдобавит требование к последней версии каждого отсутствующего модуля (определение последней версии см. в разделе «Запросы версии»).go mod tidyудалит директивы require для модулей, которые не предоставляют никаких пакетов в описанном выше наборе.go mod tidyтакже может добавлять или удалять// косвенные комментариик директивамrequire.
// Косвенный комментарий обозначает модуль, который не предоставляет пакет, импортируемый пакетом в основном модуле. (См. директиву require для получения более подробной информации о том, когда добавляются // косвенные зависимости и комментарии).
Если установлен флаг -go, go mod tidy обновит директиву go до указанной версии, включив или отключив обрезку графа модулей и отложенную загрузку модулей (а также добавив или удалив косвенные требования по мере необходимости) в соответствии с этой версией.
По умолчанию go mod tidy проверяет, что выбранные версии модулей не изменяются при загрузке графа модулей версией Go, непосредственно предшествующей версии, указанной в директиве go. Версию, проверяемую на совместимость, также можно явно указать с помощью флага -compat.
go mod vendor
Использование:
go mod vendor [-e] [-v] [-o]
Команда go mod vendor создает в корневом каталоге основного модуля каталог с именем vendor, который содержит копии всех пакетов, необходимых для поддержки сборки и тестирования пакетов в основном модуле. Пакеты, которые импортируются только тестами пакетов вне основного модуля, не включаются. Как и в случае с go mod tidy и другими командами модуля, при создании каталога vendor не учитываются ограничения сборки, за исключением ignore.
Когда vendoring включен, команда go загружает пакеты из каталога vendor вместо того, чтобы загружать модули из их источников в кэш модулей и использовать пакеты из этих загруженных копий. Дополнительную информацию см. в разделе Vendoring.
go mod vendor также создает файл vendor/modules.txt, который содержит список пакетов vendored и версии модулей, из которых они были скопированы.
Когда vendoring включен, этот манифест используется в качестве источника информации о версии модуля, как сообщается go list -m и go version -m. Когда команда go читает vendor/modules.txt, она проверяет, что версии модулей соответствуют go.mod.
Если go.mod изменился с момента создания vendor/modules.txt, go mod vendor следует запустить снова.
Обратите внимание, что go mod vendor удаляет каталог vendor, если он существует, перед его повторным созданием. Не следует вносить локальные изменения в пакеты, включенные в vendor. Команда go не проверяет, не были ли изменены пакеты в каталоге vendor, но можно проверить целостность каталога vendor, запустив go mod vendor и убедившись, что никаких изменений не было.
- Флаг
-e(добавлен в Go 1.16) заставляетgo mod vendorпытаться продолжить работу, несмотря на ошибки, возникшие при загрузке пакетов. - Флаг
-vзаставляетgo mod vendorвыводить имена модулей и пакетов vendor в стандартный поток ошибок. - Флаг
-o(добавлен в Go 1.18) заставляетgo mod vendorвыводить деревоvendorв указанном каталоге вместоvendor. Аргументом может быть либо абсолютный путь, либо путь относительно корня модуля.
go mod verify
Использование:
go mod verify
go mod verify проверяет, что зависимости основного модуля, хранящиеся в кэше модулей, не были изменены с момента их загрузки.
Для выполнения этой проверки go mod verify хеширует каждый загруженный файл .zip модуля и извлеченный каталог, а затем сравнивает эти хеши с хешем, записанным при первой загрузке модуля.
go mod verify проверяет каждый модуль в списке сборки (который можно вывести с помощью go list -m all).
Если все модули не изменены, go mod verify выводит сообщение «all modules verified» (все модули проверены). В противном случае он сообщает, какие модули были изменены, и завершает работу с ненулевым статусом.
Обратите внимание, что все команды, поддерживающие модули, проверяют, что хэши в файле go.sum основного модуля совпадают с хэшами, записанными для модулей, загруженных в кэш модулей. Если хеш отсутствует в go.sum (например, потому что модуль используется впервые), команда go проверяет его хеш с помощью базы данных контрольных сумм (если путь к модулю не соответствует GOPRIVATE или GONOSUMDB). Подробности см. в разделе Аутентификация модулей.
В отличие от этого, go mod verify проверяет, что файлы .zip модулей и их извлеченные каталоги имеют хеши, которые соответствуют хешам, записанным в кэше модулей при их первоначальной загрузке.
Это полезно для обнаружения изменений в файлах в кэше модулей после загрузки и проверки модуля.
go mod verify не загружает содержимое для модулей, которые нет в кэше, и не использует файлы go.sum для проверки содержимого модулей. Однако go mod verify может загружать файлы go.mod для выполнения минимального выбора версии. Он будет использовать go.sum для проверки этих файлов и может добавлять записи go.sum для отсутствующих хэшей.
go mod why
Использование:
go mod why [-m] [-vendor] packages...
go mod why показывает кратчайший путь в графе импорта от главного модуля до каждого из перечисленных пакетов.
Вывод представляет собой последовательность строк, по одной для каждого пакета или модуля, указанного в командной строке, разделенных пустыми строками. Каждая строка начинается с комментария, начинающегося с #, в котором указан целевой пакет или модуль.
Последующие строки содержат путь через граф импорта, по одному пакету в строке. Если пакет или модуль не упоминается в основном модуле, в строке будет отображаться одно примечание в скобках, указывающее на этот факт.
Например:
$ go mod why golang.org/x/text/language golang.org/x/text/encoding
# golang.org/x/text/language
rsc.io/quote
rsc.io/sampler
golang.org/x/text/language
# golang.org/x/text/encoding
(главный модуль не нуждается в пакете golang.org/x/text/encoding)
Флаг
-mзаставляетgo mod whyобрабатывать свои аргументы как список модулей.go mod whyвыведет путь к любому пакету в каждом из модулей. Обратите внимание, что даже при использовании-mgo mod whyзапрашивает граф пакетов, а не граф модулей, выведенныйgo mod graph.Флаг
-vendorзаставляетgo mod whyигнорировать импорты в тестах пакетов вне основного модуля (как это делаетgo mod vendor). По умолчаниюgo mod whyрассматривает граф пакетов, соответствующих шаблонуall. Этот флаг не имеет эффекта после Go 1.16 в модулях, которые объявляютgo 1.16или выше (используя директивуgoвgo.mod), поскольку значениеallизменилось, чтобы соответствовать набору пакетов, соответствующихgo mod vendor.
go version -m
Использование:
go version [-m] [-v] [файл ...]
Пример:
# Вывести версию Go, использованную для сборки go.
$ go version
# Вывести версию Go, использованную для сборки конкретного исполняемого файла.
$ go version ~/go/bin/gopls
# Вывести версию Go и версии модулей, использованные для сборки конкретного исполняемого файла.
$ go version -m ~/go/bin/gopls
# Вывести версию Go и версии модулей, использованные для сборки исполняемых файлов в каталоге.
$ go version -m ~/go/bin/
go version сообщает версию Go, использованную для сборки каждого исполняемого файла, указанного в командной строке.
Если в командной строке не указаны файлы, go version выводит информацию о своей версии.
Если указан каталог, go version рекурсивно просматривает этот каталог, ищет распознаваемые бинарные файлы Go и сообщает их версии.
По умолчанию go version не сообщает о нераспознанных файлах, найденных во время сканирования каталога.
- Флаг
-vзаставляет его сообщать о нераспознанных файлах. - Флаг
-mзаставляетgo versionвыводить информацию о версии встроенного модуля каждого исполняемого файла, если она доступна. Для каждого исполняемого файлаgo version -mвыводит таблицу с разделёнными табуляцией столбцами, как показано ниже.
$ go version -m ~/go/bin/goimports
/home/jrgopher/go/bin/goimports: go1.14.3
path golang.org/x/tools/cmd/goimports
mod golang.org/x/tools v0.0.0-20200518203908-8018eb2c26ba h1:0Lcy64USfQQL6GAJma8BdHCgeofcchQj+Z7j0SXYAzU=
dep golang.org/x/mod v0.2.0 h1:KU7oHjnv3XNWfa5COkzUifxZmxp1TyI7ImMXqFxLwvQ=
dep golang.org/x/xerrors v0.0.0-20191204190536-9bdfabe68543 h1:E7g+9GITq07hpfrRu66IVDexMakfv52eLZ2CXBWiKr4=
Формат таблицы может измениться в будущем. Ту же информацию можно получить из runtime/debug.ReadBuildInfo.
Значение каждой строки в таблице определяется словом в первом столбце.
- path: путь к основному пакету, использованному для сборки исполняемого файла.
- mod: модуль, содержащий основной пакет. Столбцы соответственно представляют путь к модулю, версию и сумму. Основной модуль имеет версию (
devel) и не имеет суммы. - dep: модуль, который предоставил один или несколько пакетов, связанных с исполняемым файлом. Тот же формат, что и
mod. - =>: замена модуля в предыдущей строке. Если замена является локальным каталогом, то указывается только путь к каталогу (без версии и суммы). Если замена является версией модуля, то указываются путь, версия и сумма, как в
modиdep. Замененный модуль не имеет суммы.
go clean -modcache
Использование:
go clean [-modcache]
- Флаг
-modcacheзаставляетgo cleanудалить весь кэш модулей, включая распакованный исходный код версионных зависимостей.
Обычно это лучший способ удалить кэш модулей. По умолчанию большинство файлов и каталогов в кэше модулей доступны только для чтения, чтобы тесты и редакторы не могли непреднамеренно изменить файлы после их аутентификации. К сожалению, это приводит к сбою таких команд, как
rm -r, поскольку файлы не могут быть удалены без предварительного предоставления права на запись в их родительские каталоги.
- Флаг
-modcacherw(принимаемыйgo buildи другими командами, поддерживающими модули) приводит к тому, что новые каталоги в кэше модулей становятся доступными для записи. Чтобы передать-modcacherwвсем командам, поддерживающим модули, добавьте его в переменнуюGOFLAGS.
GOFLAGS может быть установлена в среде или с помощью go env -w. Например, приведенная ниже команда устанавливает ее навсегда:
go env -w GOFLAGS=-modcacherw
-modcacherw следует использовать с осторожностью; разработчики должны быть осторожны и не вносить изменения в файлы в кэше модулей.
go mod verify можно использовать для проверки соответствия файлов в кэше хэшам в файле go.sum основного модуля.
Запросы версии
Несколько команд позволяют указать версию модуля с помощью запроса версии, который появляется после символа @, следующего за путем к модулю или пакету в командной строке.
Примеры:
go get example.com/m@latest
go mod download example.com/m@master
go list -m -json example.com/m@e3702bed2
Запрос версии может быть одним из следующих:
- Полностью указанная семантическая версия, такая как
v1.2.3, которая выбирает конкретную версию. Синтаксис см. в разделе «Версии». - Префикс семантической версии, такой как
v1илиv1.2, который выбирает самую высокую доступную версию с этим префиксом. - Сравнение семантических версий, например
<v1.2.3или>=v1.5.6, которое выбирает ближайшую доступную версию к объекту сравнения (самую низкую версию для>и>=и самую высокую версию для<и<=). - Идентификатор ревизии для базового репозитория исходного кода, например префикс хеша коммита, тег ревизии или имя ветки. Если ревизия помечена семантической версией, этот запрос выбирает эту версию. В противном случае этот запрос выбирает псевдоверсию для базового коммита. Обратите внимание, что ветки и теги с именами, совпадающими с другими запросами версий, не могут быть выбраны таким образом. Например, запрос
v2выбирает последнюю версию, начинающуюся сv2, а не ветку с именемv2. - Строка
latest, которая выбирает самую последнюю доступную версию релиза. Если версий релиза нет,latestвыбирает самую последнюю предрелизную версию. Если нет помеченных версий,latestвыбирает псевдоверсию для коммита в конце ветки по умолчанию репозитория. - Строка
upgrade, которая похожа наlatest, за исключением того, что если модуль в настоящее время требуется в более высокой версии, чем та, которую выбрала быlatest(например, предварительная версия),upgradeвыберет текущую версию. - Строка
patch, которая выбирает последнюю доступную версию с теми же номерами основной и второстепенной версий, что и текущая требуемая версия. Если в настоящее время не требуется никакая версия,patchэквивалентнаlatest. Начиная с Go 1.16, go get требует текущую версию при использовании patch (но флаг-u=patchне имеет этого требования).
За исключением запросов на конкретные именованные версии или ревизии, все запросы учитывают доступные версии, указанные в go list -m -versions (см. go list -m). Этот список содержит только тегированные версии, а не псевдоверсии. Версии модулей, запрещенные директивами exclude в файле go.mod основного модуля, не учитываются. Версии, на которые распространяются директивы retract в файле go.mod из последней версии того же модуля, также игнорируются, за исключением случаев, когда флаг -retracted используется с go list -m и за исключением случаев загрузки директив retract.
Релизные версии предпочтительнее предварительных версий. Например, если доступны версии v1.2.2 и v1.2.3-pre, последний запрос выберет v1.2.2, даже если v1.2.3-pre выше. Запрос <v1.2.4 также выберет v1.2.2, даже если v1.2.3-pre ближе к v1.2.4. Если нет доступных релизных или предварительных версий, запросы latest, upgrade и patch выберут псевдоверсию для коммита в конце ветки по умолчанию репозитория. Другие запросы выдадут ошибку.
Команды модуля вне модуля
Команды Go, поддерживающие модули, обычно запускаются в контексте главного модуля, определенного файлом go.mod в рабочем каталоге или родительском каталоге. Некоторые команды могут запускаться в режиме поддержки модулей без файла go.mod, но большинство команд работают по-разному или выдают ошибку, если файл go.mod отсутствует.
См. Команды, поддерживающие модули для получения информации о включении и отключении режима поддержки модулей.
| Команда | Поведение |
|---|---|
| go build | |
| go doc | |
| go fix | |
| go fmt | |
| go generate | Только пакеты из стандартной библиотеки и пакеты, указанные в командной строке как файлы .go, могут быть загружены, импортированы и скомпилированы. Пакеты из других модулей не могут быть скомпилированы, поскольку нет места для записи требований модулей и обеспечения детерминированной компиляции. |
| go install | |
| go list | |
| go run | |
| go test | |
| go vet | |
| go get | Пакеты и исполняемые файлы могут быть скомпилированы и установлены как обычно. Обратите внимание, что при запуске go get без файла go.mod нет главного модуля, поэтому директивы replace и exclude не применяются. |
| go list -m | Для большинства аргументов требуются явные запросы версии, за исключением случаев, когда используется флаг -versions. |
| go mod download | Для большинства аргументов требуются явные запросы версии. |
| go mod edit | Требуется явный аргумент файла. |
| go mod graph | |
| go mod tidy | |
| go mod vendor | Эти команды требуют файл go.mod и выдают ошибку, если он отсутствует. |
| go mod verify | |
| go mod why |
go work init
Использование:
go work init [moddirs]
Init инициализирует и записывает новый файл go.work в текущем каталоге, фактически создавая новую рабочую область в текущем каталоге.
go work init опционально принимает пути к модулям рабочей области в качестве аргументов. Если аргумент опущен, будет создана пустая рабочая область без модулей.
Каждый путь аргумента добавляется в директиву use в файле go.work. Текущая версия go также будет указана в файле go.work.
go work edit
Использование:
go work edit [флаги редактирования] [go.work]
Команда go work edit предоставляет интерфейс командной строки для редактирования go.work, предназначенный в первую очередь для использования инструментами или скриптами.
- Она только читает
go.work; - она не ищет информацию о вовлеченных модулях.
Если файл не указан, Edit ищет файл go.work в текущем каталоге и его родительских каталогах
Флаги редактирования определяют последовательность операций редактирования.
- Флаг
-fmtпереформатирует файлgo.workбез внесения других изменений. Это переформатирование также подразумевается при любых других изменениях, которые используют или перезаписывают файлgo.work. Этот флаг необходим только в том случае, если не указаны другие флаги, как в «go work edit -fmt». - Флаги
-use=pathи-dropuse=pathдобавляют и удаляют директивуuseиз набора каталогов модулей файлаgo.work. - Флаг
-replace=old[@v]=new[@v]добавляет замену заданной пары пути модуля и версии. Если@vвold@vопущено, добавляется замена без версии в левой части, которая применяется ко всем версиям старого пути модуля. Если@vвnew@vопущено, новый путь должен быть локальным корневым каталогом модуля, а не путем модуля. Обратите внимание, что-replaceпереопределяет любые избыточные замены дляold[@v], поэтому опущение@vприведет к удалению существующих замен для определенных версий. - Флаг
-dropreplace=old[@v]удаляет замену заданного пути модуля и пары версий. Если@vопущено, удаляется замена без версии в левой части. - Флаг
-go=versionустанавливает ожидаемую версию языка Go.
Флаги редактирования могут повторяться. Изменения применяются в указанном порядке.
go work edit имеет дополнительные флаги, которые контролируют его вывод
- Флаг
-printвыводит окончательныйgo.workв текстовом формате вместо записи обратно вgo.mod. - Флаг
-jsonвыводит окончательный файлgo.workв формате JSON вместо записи обратно вgo.mod. Вывод JSON соответствует следующим типам Go:
type Module struct {
Path string
Version string
}
type GoWork struct {
Go string
Directory []Directory
Replace []Replace
}
type Use struct {
Path string
ModulePath string
}
type Replace struct {
Old Module
New Module
}
go work use
Использование:
go work use [-r] [moddirs]
Команда go work use предоставляет интерфейс командной строки для добавления каталогов, по желанию рекурсивно, в файл go.work.
Директива use будет добавлена в файл go.work для каждого каталога, указанного в командной строке go.work, если он существует на диске, или удалена из файла go.work, если он не существует на диске.
- Флаг
-rрекурсивно ищет модули в указанных каталогах, и командаuseработает так, как если бы каждый из каталогов был указан в качестве аргумента.
go work sync
Использование:
go work sync
Команда go work sync синхронизирует список сборок рабочего пространства с модулями рабочего пространства.
Список сборок рабочего пространства - это набор версий всех (переходных) зависимых модулей, используемых для выполнения сборок в рабочем пространстве. go work sync генерирует этот список сборок, используя алгоритм минимального выбора версий (MVS), а затем синхронизирует эти версии с каждым из модулей, указанных в рабочем пространстве (с помощью директив use).
После того как список сборок рабочего пространства вычислен, файл go.mod для каждого модуля в рабочем пространстве переписывается с обновлением зависимостей, относящихся к этому модулю, чтобы соответствовать списку сборок рабочего пространства. Обратите внимание, что минимальный выбор версий гарантирует, что версия каждого модуля в списке сборки всегда будет такой же или выше, чем в каждом модуле рабочего пространства.
Прокси-модули
Протокол GOPROXY
Прокси-модуль — это HTTP-сервер, который может отвечать на запросы GET для указанных ниже путей. Запросы не содержат параметров запроса и не требуют специальных заголовков, поэтому даже сайт, обслуживающийся из фиксированной файловой системы (включая URL file://), может быть прокси-модулем.
Успешные HTTP-ответы должны иметь статус-код 200 (OK). Перенаправления (3xx) принимаются. Ответы с кодами состояния 4xx и 5xx рассматриваются как ошибки. Коды ошибок 404 (Not Found) и 410 (Gone) указывают, что запрошенный модуль или версия недоступны на прокси, но могут быть найдены в другом месте. Ответы с ошибками должны иметь тип содержимого text/plain с кодировкой utf-8 или us-ascii.
Команда go может быть настроена для связи с прокси-серверами или серверами контроля версий с помощью переменной среды GOPROXY, которая принимает список URL-адресов прокси-серверов.
Список может включать ключевые слова direct или off (подробности см. в разделе «Переменные среды»).
Элементы списка могут быть разделены запятыми (,) или вертикальными чертами (|), которые определяют поведение при ошибке.
Когда за URL следует запятая, команда go переходит к более поздним источникам только после ответа 404 (Not Found) или 410 (Gone).
Когда за URL следует вертикальная черта, команда go переходит к более поздним источникам после любой ошибки, включая не-HTTP ошибки, такие как таймауты.
Такое поведение при обработке ошибок позволяет прокси действовать как шлюз для неизвестных модулей.
Например, прокси может ответить ошибкой 403 (Forbidden) для модулей, не входящих в утвержденный список (см. Частный прокси, обслуживающий частные модули).
В таблице ниже указаны запросы, на которые должен отвечать прокси модуля. Для каждого пути $base — это часть пути URL-адреса прокси, $module — путь модуля, а $version — версия.
Например, если URL-адрес прокси-сервера —
https://example.com/mod, а клиент запрашивает файл go.mod для модуляgolang.org/x/textверсииv0.3.2, клиент отправит запросGETнаhttps://example.com/mod/golang.org/x/text/@v/v0.3.2.mod.
Чтобы избежать неоднозначности при обслуживании из файловых систем, нечувствительных к регистру, элементы $module и $version кодируются с учетом регистра, заменяя каждую заглавную букву восклицательным знаком, за которым следует соответствующая строчная буква. Это позволяет хранить на диске модули example.com/M и example.com/m, поскольку первый кодируется как example.com/!m.
| Путь | Описание |
|---|---|
$base/$module/@v/list | Возвращает список известных версий данного модуля в виде простого текста, по одной на строку. Этот список не должен включать псевдоверсии. Возвращает метаданные в формате JSON о конкретной версии модуля. Ответ должен быть объектом JSON, соответствующим приведенной ниже структуре данных Go: |
type Info struct {
Version string // строка версии
Time time.Time // время фиксации
}
| Путь | Описание |
|---|---|
$base/$module/@v/$version.info | Поле Version является обязательным и должно содержать действительную каноническую версию (см. Версии). $version в пути запроса не обязательно должна быть той же версией или даже действительной версией; этот конечный пункт может использоваться для поиска версий для имен ветвей или идентификаторов ревизий. Однако, если $version является канонической версией с основной версией, совместимой с $module, поле Version в успешном ответе должно быть таким же.Поле Time является необязательным. Если оно присутствует, оно должно быть строкой в формате RFC 3339. Оно указывает время создания версии. В будущем могут быть добавлены дополнительные поля, поэтому другие имена зарезервированы. |
$base/$module/@v/$version.mod | Возвращает файл go.mod для определенной версии модуля. Если модуль не имеет файла go.mod для запрошенной версии, должен быть возвращен файл, содержащий только оператор модуля с запрошенным путем к модулю. В противном случае должен быть возвращен исходный, немодифицированный файл go.mod. |
$base/$module/@v/$version.zip | Возвращает zip-файл, содержащий содержимое определенной версии модуля. См. раздел «Zip-файлы модулей» для получения подробной информации о том, как должен быть отформатирован этот zip-файл. |
$base/$module/@latest | Возвращает метаданные в формате JSON о последней известной версии модуля в том же формате, что и $base/$module/@v/$version.info. Последняя версия должна быть версией модуля, которую команда go должна использовать, если $base/$module/@v/list пуст или ни одна из перечисленных версий не подходит. Этот конечный пункт является опциональным, и прокси-серверы модулей не обязаны его реализовывать. |
При определении последней версии модуля команда go запрашивает $base/$module/@v/list, затем, если подходящих версий не найдено, $base/$module/@latest.
Команда go предпочитает в порядке убывания: семантически наивысшую релизную версию, семантически наивысшую предрелизную версию и хронологически самую последнюю псевдо-версию. В Go 1.12 и более ранних версиях команда go считала псевдоверсии в $base/$module/@v/list предрелизными версиями, но начиная с Go 1.13 это уже не так.
Прокси модуляь должен всегда предоставлять одно и то же содержимое для успешных ответов на запросы $base/$module/$version.mod и $base/$module/$version.zip. Это содержимое проходит криптографическую проверку подлинности с помощью файлов go.sum и, по умолчанию, базы данных контрольных сумм.
Команда go кэширует большую часть содержимого, загружаемого с прокси модулей, в своем кэше модулей в $GOPATH/pkg/mod/cache/download. Даже при загрузке непосредственно из систем контроля версий команда go синтезирует явные файлы info, mod и zip и сохраняет их в этом каталоге, как если бы она загружала их непосредственно с прокси. Расположение кэша совпадает с пространством URL прокси, поэтому, обслуживая $GOPATH/pkg/mod/cache/download по адресу (или копируя его на) https://example.com/proxy, пользователи смогут получить доступ к кэшированным версиям модулей, установив GOPROXY на https://example.com/proxy.
Взаимодействие с прокси
Команда go может загружать исходный код модулей и метаданные из прокси модулей. Переменная окружения GOPROXY может использоваться для настройки прокси, к которым команда go может подключаться, а также для определения, может ли она напрямую взаимодействовать с системами контроля версий. Загруженные данные модулей сохраняются в кэше модулей. Команда go связывается с прокси только в том случае, если ей требуется информация, которой нет в кэше.
В разделе «Протокол GOPROXY» описаны запросы, которые могут отправляться на сервер GOPROXY. Однако также полезно понимать, когда команда go отправляет эти запросы. Например, go build выполняет следующую процедуру:
- Вычисляет список сборки, читая файлы
go.modи выполняя минимальный выбор версии (MVS). - Считывает пакеты, указанные в командной строке, и пакеты, которые они импортируют.
- Если пакет не предоставляется ни одним модулем в списке сборки, находит модуль, который его предоставляет. Добавляет требование модуля в его последней версии в
go.modи начинает заново. - Строит пакеты после того, как все загружено.
Когда команда go вычисляет список сборки, она загружает файл go.mod для каждого модуля в графе модулей.
Если файл go.mod отсутствует в кэше, команда go загрузит его из прокси с помощью запроса $module/@v/$version.mod (где $module — путь к модулю, а $version — версия).
Эти запросы можно протестировать с помощью такого инструмента, как curl. Например, приведенная ниже команда загружает файл go.mod для golang.org/x/mod версии v0.2.0:
$ curl https://proxy.golang.org/golang.org/x/mod/@v/v0.2.0.mod
module golang.org/x/mod
go 1.12
require (
golang.org/x/crypto v0.0.0-20191011191535-87dc89f01550
golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e
golang.org/x/xerrors v0.0.0-20191011141410-1b5146add898
)
Чтобы загрузить пакет, команде go нужен исходный код модуля, который его предоставляет. Исходный код модуля распространяется в файлах .zip, которые извлекаются в кэш модулей. Если .zip модуля нет в кэше, команда go загрузит его с помощью запроса $module/@v/$version.zip.
$ curl -O https://proxy.golang.org/golang.org/x/mod/@v/v0.2.0.zip
$ unzip -l v0.2.0.zip | head
Archive: v0.2.0.zip
Length Date Time Name
--------- ---------- ----- ----
1479 00-00-1980 00:00 golang.org/x/mod@v0.2.0/LICENSE
1303 00-00-1980 00:00 golang.org/x/mod@v0.2.0/PATENTS
559 00-00-1980 00:00 golang.org/x/mod@v0.2.0/README
21 00-00-1980 00:00 golang.org/x/mod@v0.2.0/codereview.cfg
214 00-00-1980 00:00 golang.org/x/mod@v0.2.0/go.mod
1476 00-00-1980 00:00 golang.org/x/mod@v0.2.0/go.sum
5224 00-00-1980 00:00 golang.org/x/mod@v0.2.0/gosumcheck/main.go
Обратите внимание, что запросы .mod и .zip являются отдельными, даже если файлы go.mod обычно содержатся в файлах .zip. Команде go может потребоваться загрузить файлы go.mod для многих различных модулей, а файлы .mod намного меньше по размеру, чем файлы .zip. Кроме того, если в проекте Go нет файла go.mod, прокси будет предоставлять синтетический файл go.mod, содержащий только директиву модуля. Синтетические файлы go.mod генерируются командой go при загрузке из системы контроля версий.
Если команде go необходимо загрузить пакет, который не предоставляется ни одним модулем в списке сборки, она попытается найти новый модуль, который его предоставляет. Этот процесс описан в разделе «Преобразование пакета в модуль». Вкратце, команда go запрашивает информацию о последней версии каждого пути модуля, который может содержать пакет.
Например, для пакета golang.org/x/net/html команда go попытается найти последние версии модулей golang.org/x/net/html, golang.org/x/net, golang.org/x/ и golang.org. Только golang.org/x/net действительно существует и предоставляет этот пакет, поэтому команда go использует последнюю версию этого модуля.
Если пакет предоставляется более чем одним модулем, команда go использует модуль с самым длинным путем.
Когда команда go запрашивает последнюю версию модуля, она сначала отправляет запрос на $module/@v/list. Если список пуст или ни одна из возвращенных версий не может быть использована, она отправляет запрос на $module/@latest. После выбора версии команда go отправляет запрос $module/@v/$version.info для получения метаданных. Затем она может отправить запросы $module/@v/$version.mod и $module/@v/$version.zip для загрузки файла go.mod и исходного кода.
$ curl https://proxy.golang.org/golang.org/x/mod/@v/list
v0.1.0
v0.2.0
$ curl https://proxy.golang.org/golang.org/x/mod/@v/v0.2.0.info
{«Version»:«v0.2.0»,„Time“:«2020-01-02T17:33:45Z»}
После загрузки файла .mod или .zip команда go вычисляет криптографический хеш и проверяет, соответствует ли он хешу в файле go.sum основного модуля. Если хеш отсутствует в go.sum, по умолчанию команда go извлекает его из базы данных контрольных сумм.
Если вычисленный хеш не совпадает, команда go сообщает об ошибке безопасности и не устанавливает файл в кэш модулей. Переменные среды GOPRIVATE и GONOSUMDB могут использоваться для отключения запросов к базе данных контрольных сумм для определенных модулей.
Переменная среды GOSUMDB также может быть установлена в значение off, чтобы полностью отключить запросы к базе данных контрольных сумм.
Дополнительные сведения см. в разделе Аутентификация модулей. Обратите внимание, что списки версий и метаданные версий, возвращаемые для запросов .info, не аутентифицируются и могут изменяться со временем.
Обслуживание модулей напрямую из прокси
Большинство модулей разрабатываются и обслуживаются из репозитория системы контроля версий.
В прямом режиме команда go загружает такой модуль с помощью инструмента контроля версий (см. Системы контроля версий). Также можно обслуживать модуль напрямую из прокси модуля. Это полезно для организаций, которые хотят обслуживать модули, не раскрывая свои серверы контроля версий, а также для организаций, которые используют инструменты контроля версий, не поддерживаемые командой go.
Когда команда go загружает модуль в прямом режиме, она сначала ищет URL-адрес сервера модулей с помощью HTTP-запроса GET на основе пути модуля.
Она ищет тег <meta> с именем go-import в HTML-ответе. Содержимое тега должно содержать корневой путь репозитория, систему контроля версий и URL-адрес, разделенные пробелами. Подробнее см. в разделе Поиск репозитория для пути модуля.
Если системой контроля версий является mod, команда go загружает модуль с указанного URL-адреса с помощью протокола GOPROXY.
Например, предположим, что команда
goпытается загрузить модульexample.com/gopherверсииv1.0.0. Она отправляет запрос наhttps://example.com/gopher?go-get=1. Сервер отвечает HTML-документом, содержащим тег:
<meta name="go-import" content="example.com/gopher mod https://modproxy.example.com">
На основании этого ответа команда go загружает модуль, отправляя запросы на https://modproxy.example.com/example.com/gopher/@v/v1.0.0.info, v1.0.0.mod и v1.0.0.zip.
Обратите внимание, что модули, обслуживаемые непосредственно с прокси, не могут быть загружены с помощью go get в режиме GOPATH.
Системы контроля версий
Команда go может загружать исходный код модулей и метаданные непосредственно из репозитория системы контроля версий. Загрузка модуля через прокси-сервер обычно происходит быстрее, но прямое подключение к репозиторию необходимо, если прокси-сервер недоступен или если репозиторий модуля недоступен для прокси-сервера (часто это относится к частным репозиториям). Поддерживаются Git, Subversion, Mercurial, Bazaar и Fossil. Чтобы команда go могла использовать инструмент контроля версий, он должен быть установлен в каталоге, включенном в PATH.
Чтобы загружать определенные модули из репозиториев исходного кода, а не через прокси, установите переменные окружения GOPRIVATE или GONOPROXY. Чтобы настроить команду go на загрузку всех модулей напрямую из репозиториев исходного кода, установите GOPROXY в значение direct. Дополнительные сведения см. в разделе Переменные окружения.
Поиск репозитория для пути модуля
Когда команда go загружает модуль в прямом режиме, она сначала находит репозиторий, содержащий модуль.
Если путь к модулю имеет квалификатор VCS (один из .bzr, .fossil, .git, .hg, .svn) в конце компонента пути, команда go будет использовать все до этого квалификатора пути в качестве URL-адреса репозитория. Например, для модуля example.com/foo.git/bar команда go загружает репозиторий по адресу example.com/foo с помощью git, ожидая найти модуль в подкаталоге bar. Команда go угадывает протокол, который следует использовать, на основе протоколов, поддерживаемых инструментом контроля версий.
Если путь модуля не имеет квалификатора, команда go отправляет HTTP-запрос GET на URL, полученный из пути модуля с строкой запроса ?go-get=1. Например, для модуля golang.org/x/mod команда go может отправить следующие запросы:
https://golang.org/x/mod?go-get=1 (preferred)
http://golang.org/x/mod?go-get=1 (fallback, only with GOINSECURE)
Команда go следует за перенаправлениями, но игнорирует коды статуса ответа, поэтому сервер может ответить кодом 404 или любым другим кодом ошибки. Переменная среды GOINSECURE может быть установлена, чтобы разрешить переход на незашифрованный HTTP для определенных модулей.
Сервер должен отвечать HTML-документом, содержащим тег <meta> в <head> документа.
Тег <meta> должен появляться в начале документа, чтобы не сбивать с толку ограниченный парсер команды go. В частности, он должен появляться перед любым необработанным JavaScript или CSS. Тег <meta> должен иметь следующий вид:
<meta name="go-import" content="root-path vcs repo-url [subdirectory]">
- root-path — это корневой путь репозитория, часть пути модуля, которая соответствует корневому каталогу репозитория или подкаталогу, если он присутствует и используется Go 1.25 или более поздней версии (см. раздел о подкаталогах ниже). Он должен быть префиксом или точно соответствовать запрошенному пути модуля. Если он не соответствует точно, делается другой запрос на префикс, чтобы проверить соответствие тегов
<meta>. - vcs — это система контроля версий. Это должен быть один из инструментов, перечисленных в таблице ниже, или ключевое слово
mod, которое указывает команде go загрузить модуль с указанного URL-адреса с использованием протоколаGOPROXY. Подробности см. в разделе «Обслуживание модулей напрямую с прокси». - repo-url — это URL-адрес репозитория. Если URL не содержит схему (либо потому, что путь к модулю имеет квалификатор
VCS, либо потому, что в теге<meta>отсутствует схема), команда go попробует каждый протокол, поддерживаемый системой контроля версий. Например, сGitкомандаgoпопробуетhttps://, а затемgit+ssh://. Небезопасные протоколы (такие какhttp://иgit://) могут использоваться только в том случае, если путь к модулю соответствует переменной средыGOINSECURE. - Подкаталог, если он присутствует, является подкаталогом репозитория, разделенным косой чертой, которому соответствует root-path, переопределяя по умолчанию корневой каталог репозитория. Мета-теги go-import, предоставляющие подкаталог, распознаются только Go 1.25 и более поздними версиями. Попытки извлечь модули в более ранних версиях Go будут игнорировать мета-тег и приведут к сбою разрешения, если модуль не может быть разрешен в другом месте.
| Name | Command | GOVCS default | Secure schemes |
|---|---|---|---|
| Bazaar | bzr | Private only | https, bzr+ssh |
| Fossil | fossil | Private only | https |
| Git | git | Public and private | https, git+ssh, ssh |
| Mercurial | hg | Public and private | https, ssh |
| Subversion | svn | Private only | https, svn+ssh |
В качестве примера снова рассмотрим golang.org/x/mod. Команда go отправляет запрос на https://golang.org/x/mod?go-get=1. Сервер отвечает HTML-документом, содержащим тег:
<meta name="go-import" content="golang.org/x/mod git https://go.googlesource.com/mod">
На основании этого ответа команда go будет использовать репозиторий Git по удаленному URL-адресу https://go.googlesource.com/mod.
GitHub и другие популярные хостинговые сервисы отвечают на запросы ?go-get=1 для всех репозиториев, поэтому обычно для модулей, размещенных на этих сайтах, не требуется настройка сервера.
После нахождения URL-адреса репозитория команда go клонирует репозиторий в кэш модулей. Как правило, команда go старается избегать извлечения ненужных данных из репозитория. Однако фактические используемые команды варьируются в зависимости от системы контроля версий и могут меняться со временем. Для Git команда go может перечислить большинство доступных версий без загрузки коммитов. Обычно она извлекает коммиты без загрузки коммитов предков, но иногда это необходимо.
Сопоставление версий с коммитами
Команда go может проверить модуль в репозитории с определенной канонической версией, такой как v1.2.3, v2.4.0-beta или v3.0.0+incompatible. Каждая версия модуля должна иметь семантический тег версии в репозитории, который указывает, какая ревизия должна быть проверена для данной версии.
Если модуль определен в корневом каталоге репозитория или в подкаталоге основной версии корневого каталога, то каждое имя тега версии равно соответствующей версии. Например, модуль golang.org/x/text определен в корневом каталоге своего репозитория, поэтому версия v0.3.2 имеет тег v0.3.2 в этом репозитории. Это верно для большинства модулей.
Если модуль определен в подкаталоге внутри репозитория, то есть часть пути модуля, относящаяся к подкаталогу модуля, не пуста, то каждое имя тега должно начинаться с префикса подкаталога модуля, за которым следует косая черта. Например, модуль golang.org/x/tools/gopls определен в подкаталоге gopls репозитория с корневым путем golang.org/x/tools. Версия v0.4.0 этого модуля должна иметь тег с именем gopls/v0.4.0 в этом репозитории.
Номер основной версии тега семантической версии должен соответствовать суффиксу основной версии пути модуля (если таковой имеется). Например, тег v1.0.0 может принадлежать модулю example.com/mod, но не example.com/mod/v2, который будет иметь теги типа v2.0.0.
Теги с основной версией v2 или выше могут принадлежать модулю без суффикса основной версии, если файл go.mod отсутствует, а модуль находится в корневом каталоге репозитория. Такая версия обозначается суффиксом +incompatible. Сам тег версии не должен иметь суффикса. См. раздел «Совместимость с репозиториями, не являющимися модулями».
После создания тег не должен удаляться или изменяться на другую ревизию. Версии проходят аутентификацию для обеспечения безопасных и повторяемых сборок. Если тег изменен, клиенты могут увидеть ошибку безопасности при его загрузке. Даже после удаления тега его содержимое может оставаться доступным на прокси-серверах модулей.
Сопоставление псевдоверсий с коммитами
Команда go может проверить модуль в репозитории с определенной ревизией, закодированной как псевдоверсия, например v1.3.2-0.20191109021931-daa7c04131f5.
Последние 12 символов псевдоверсии (daa7c04131f5 в примере выше) указывают на ревизию в репозитории, которую необходимо проверить. Значение этого зависит от системы контроля версий. Для Git и Mercurial это префикс хеша коммита. Для Subversion это номер ревизии с нулевым заполнением.
Перед проверкой коммита команда go проверяет, что временная метка (20191109021931 выше) соответствует дате коммита. Она также проверяет, что базовая версия (v1.3.1, версия перед v1.3.2 в примере выше) соответствует семантическому тегу версии, который является предком коммита. Эти проверки гарантируют, что авторы модулей имеют полный контроль над тем, как псевдоверсии сопоставляются с другими выпущенными версиями.
Дополнительную информацию см. в разделе Псевдоверсии.
Сопоставление веток и коммитов с версиями
Модуль может быть проверен в определенной ветке, теге или ревизии с помощью запроса версии.
go get example.com/mod@master
Команда go преобразует эти имена в канонические версии, которые можно использовать с минимальным выбором версии (MVS). MVS зависит от возможности однозначно упорядочить версии. Имена веток и ревизии не могут быть надежно сопоставлены во времени, поскольку они зависят от структуры репозитория, которая может изменяться.
Если ревизия помечена одним или несколькими семантическими тегами версии, такими как v1.2.3, будет использован тег для самой высокой действительной версии. Команда go учитывает только семантические теги версии, которые могут принадлежать целевому модулю; например, тег v1.5.2 не будет учитываться для example.com/mod/v2, поскольку основная версия не соответствует суффиксу пути модуля.
Если ревизия не помечена действительным тегом семантической версии, команда go сгенерирует псевдоверсию. Если у ревизии есть предки с действительными тегами семантической версии, в качестве базы псевдоверсии будет использована версия самого старшего предка. См. Псевдоверсии.
Каталоги модулей в репозитории
После того, как репозиторий модуля был проверен на определенную ревизию, команда go должна найти каталог, содержащий файл go.mod модуля (корневой каталог модуля).
Напомним, что путь к модулю состоит из трех частей: корневой путь репозитория (соответствующий корневому каталогу репозитория), подкаталог модуля и суффикс основной версии (только для модулей, выпущенных в версии v2 или выше).
Для большинства модулей путь к модулю равен корневому пути репозитория, поэтому корневой каталог модуля является корневым каталогом репозитория.
Иногда модули определяются в подкаталогах репозитория. Обычно это делается для больших репозиториев с несколькими компонентами, которые необходимо выпускать и версионировать независимо друг от друга. Такой модуль должен находиться в подкаталоге, который соответствует части пути к модулю после корневого пути репозитория. Например, предположим, что модуль example.com/monorepo/foo/bar находится в репозитории с корневым путем example.com/monorepo. Его файл go.mod должен находиться в подкаталоге foo/bar.
Если модуль выпускается в основной версии v2 или выше, его путь должен иметь суффикс основной версии. Модуль с суффиксом основной версии может быть определен в одном из двух подкаталогов: одном с суффиксом и одном без него. Например, предположим, что новая версия вышеуказанного модуля выпущена с путем example.com/monorepo/foo/bar/v2. Его файл go.mod может находиться либо в foo/bar, либо в foo/bar/v2.
Подкаталоги с суффиксом основной версии являются подкаталогами основной версии. Они могут использоваться для разработки нескольких основных версий модуля в одной ветке. Это может быть ненужным, когда разработка нескольких основных версий ведется в отдельных ветках. Однако подкаталоги основной версии имеют важное свойство: в режиме GOPATH пути импорта пакетов точно соответствуют каталогам в GOPATH/src. Команда go обеспечивает минимальную совместимость модулей в режиме GOPATH (см. Совместимость с репозиториями, не являющимися модулями), поэтому подкаталоги основной версии не всегда необходимы для совместимости с проектами, созданными в режиме GOPATH. Однако у старых инструментов, которые не поддерживают минимальную совместимость модулей, могут возникнуть проблемы.
Как только команда go находит корневой каталог модуля, она создает файл .zip с содержимым каталога, а затем извлекает файл .zip в кэш модуля. См. Ограничения по пути и размеру файлов для получения подробной информации о том, какие файлы могут быть включены в файл .zip. Содержимое файла .zip проверяется перед извлечением в кэш модуля так же, как если бы файл .zip был загружен с прокси-сервера.
Файлы zip модулей не включают содержимое каталогов поставщиков или вложенных модулей (подкаталогов, содержащих файлы go.mod). Это означает, что модуль не должен ссылаться на файлы, расположенные за пределами своего каталога или в других модулях. Например, шаблоны //go:embed не должны совпадать с файлами во вложенных модулях. Такое поведение может служить полезным обходным путем в ситуациях, когда файлы не должны включаться в модуль. Например, если в репозитории есть большие файлы, зарегистрированные в каталоге testdata, автор модуля может добавить пустой файл go.mod в testdata, чтобы пользователи не должны были загружать эти файлы. Конечно, это может уменьшить охват для пользователей, тестирующих свои зависимости.
Особый случай для файлов LICENSE
Когда команда go создает файл .zip для модуля, который не находится в корневом каталоге репозитория, если в корневом каталоге модуля (рядом с go.mod) нет файла с именем LICENSE, команда go скопирует файл с именем LICENSE из корневого каталога репозитория, если он присутствует в той же ревизии.
Этот особый случай позволяет применять один и тот же файл LICENSE ко всем модулям в репозитории. Это относится только к файлам с именем LICENSE, без расширений, таких как .txt. К сожалению, это нельзя расширить без нарушения криптографических сумм существующих модулей; см. Аутентификация модулей. Другие инструменты и веб-сайты, такие как pkg.go.dev, могут распознавать файлы с другими именами.
Обратите также внимание, что команда go не включает символические ссылки при создании файлов .zip модулей; см. Ограничения по пути и размеру файлов. Следовательно, если в корневом каталоге репозитория нет файла LICENSE, авторы могут вместо этого создать копии своих файлов лицензий в модулях, определенных в подкаталогах, чтобы обеспечить включение этих файлов в файлы .zip модулей.
Управление инструментами контроля версий с помощью GOVCS
Возможность команды go загружать модули с помощью команд контроля версий, таких как git, имеет решающее значение для децентрализованной экосистемы пакетов, в которой код может быть импортирован с любого сервера. Это также может представлять потенциальную угрозу безопасности, если злоумышленный сервер найдет способ заставить вызванную команду контроля версий выполнить непреднамеренный код.
Чтобы сбалансировать функциональность и проблемы безопасности, команда go по умолчанию будет использовать только git и hg для загрузки кода с публичных серверов. Она будет использовать любую известную систему контроля версий для загрузки кода с частных серверов, определенных как те, которые хостят пакеты, соответствующие переменной среды GOPRIVATE. Причина, по которой разрешены только Git и Mercurial, заключается в том, что эти две системы уделяют наибольшее внимание проблемам запуска в качестве клиентов недоверенных серверов. В отличие от них, Bazaar, Fossil и Subversion в основном используются в доверенных, аутентифицированных средах и не подвергаются столь тщательному анализу с точки зрения уязвимостей.
Ограничения команд управления версиями применяются только при использовании прямого доступа к управлению версиями для загрузки кода. При загрузке модулей с прокси-сервера команда go использует протокол GOPROXY, который всегда разрешен. По умолчанию команда go использует зеркало модулей Go (proxy.golang.org) для общедоступных модулей и переключается на управление версиями только для частных модулей или когда зеркало отказывается обслуживать общедоступный пакет (обычно по юридическим причинам). Таким образом, клиенты по-прежнему могут по умолчанию получать доступ к общедоступному коду, обслуживаемому репозиториями Bazaar, Fossil или Subversion, поскольку для этих загрузок используется зеркало модулей Go, которое принимает на себя риск безопасности, связанный с запуском команд системы контроля версий с использованием настраиваемой песочницы.
Переменная GOVCS может использоваться для изменения разрешенных систем контроля версий для определенных модулей. Переменная GOVCS применяется при сборке пакетов как в режиме с поддержкой модулей, так и в режиме GOPATH. При использовании модулей шаблоны сопоставляются с путем модуля. При использовании GOPATH шаблоны сопоставляются с путем импорта, соответствующим корню репозитория системы контроля версий.
Общая форма переменной GOVCS — это разделенный запятыми список правил pattern:vcslist. Pattern — это шаблон glob, который должен соответствовать одному или нескольким начальным элементам пути модуля или импорта. Vcslist — это разделенный вертикальной чертой список разрешенных команд управления версиями, или all, чтобы разрешить использование любой известной команды, или off, чтобы ничего не разрешать.
Обратите внимание, что если модуль соответствует шаблону с vcslist off, он все равно может быть загружен, если исходный сервер использует схему mod, которая указывает команде go загрузить модуль с помощью протокола GOPROXY. Применяется самый ранний соответствующий шаблон в списке, даже если более поздние шаблоны также могут соответствовать.
Рассмотрим, например:
GOVCS=github.com:git,evil.com:off,*:git|hg
С этой настройкой код с модулем или путем импорта, начинающимся с github.com/, может использовать только git; пути на evil.com не могут использовать никакие команды управления версиями, а все остальные пути (* соответствует всему) могут использовать только git или hg.
Специальные шаблоны public и private соответствуют публичным и частным модулям или путям импорта. Путь является частным, если он соответствует переменной GOPRIVATE; в противном случае он является публичным.
Если ни одно из правил в переменной GOVCS не соответствует конкретному модулю или пути импорта, команда go применяет свое правило по умолчанию, которое теперь можно обозначить в нотации GOVCS как public:git|hg,private:all.
Чтобы разрешить неограниченное использование любой системы контроля версий для любого пакета, используйте:
GOVCS=*:all
Чтобы отключить все использование контроля версий, используйте:
GOVCS=*:off
Команда go env -w может быть использована для установки переменной GOVCS для будущих вызовов команды go.
GOVCS был введен в Go 1.16. Более ранние версии Go могут использовать любой известный инструмент контроля версий для любого модуля.
Zip-файлы модулей
Версии модулей распространяются в виде zip-файлов. Редко возникает необходимость в прямом взаимодействии с этими файлами, поскольку команда go автоматически создает, загружает и извлекает их из прокси-серверов модулей и репозиториев системы контроля версий. Однако знание об этих файлах все же полезно для понимания ограничений кроссплатформенной совместимости или при реализации прокси-сервера модулей.
Команда go mod download загружает zip-файлы для одного или нескольких модулей, а затем извлекает эти файлы в кэш модулей. В зависимости от GOPROXY и других переменных окружения, команда go может либо загружать zip-файлы с прокси, либо клонировать репозитории контроля версий и создавать из них zip-файлы. Флаг -json может использоваться для поиска местоположения загруженных zip-файлов и их извлеченного содержимого в кэше модулей.
Пакет golang.org/x/mod/zip можно использовать для программного создания, извлечения или проверки содержимого zip-файлов.
Ограничения по пути к файлу и размеру
Существует ряд ограничений на содержимое zip-файлов модулей. Эти ограничения гарантируют, что zip-файлы могут быть безопасно и последовательно извлечены на широком спектре платформ.
- Размер
zip-файла модуля не может превышать 500 МБ. Общий размер его файлов в несжатом виде также ограничен 500 МБ. Размер файловgo.modограничен 16 МБ. ФайлыLICENSEтакже ограничены 16 МБ. Эти ограничения существуют для смягчения атак типа «отказ в обслуживании» на пользователей, прокси и другие части экосистемы модулей. Репозитории, содержащие более 500 МБ файлов в дереве каталогов модулей, должны помечать версии модулей при фиксации, которые включают только файлы, необходимые для сборки пакетов модуля; видео, модели и другие большие ресурсы обычно не нужны для сборки. - Каждый файл в
zip-файле модуля должен начинаться с префикса$module@$version/, где$module— это путь к модулю, а$version— версия, например,golang.org/x/mod@v0.3.0/. Путь к модулю должен быть действительным, версия должна быть действительной и канонической, а версия должна соответствовать суффиксу основной версии пути к модулю. Конкретные определения и ограничения см. в разделе «Пути и версии модулей». - Режимы файлов, временные метки и другие метаданные игнорируются.
- Пустые каталоги (записи с путями, заканчивающимися косой чертой) могут быть включены в
zip-файлы модулей, но не извлекаются. Командаgoне включает пустые каталоги в создаваемые еюzip-файлы. - Символьные ссылки и другие нестандартные файлы игнорируются при создании
zip-файлов, поскольку они не переносимы между операционными системами и файловыми системами, и нет переносимого способа их представления в форматеzip-файла. - Файлы в каталогах с именем vendor игнорируются при создании
zip-файлов, поскольку каталоги vendor вне основного модуля никогда не используются. - Файлы в каталогах, содержащих файлы
go.mod, кроме корневого каталога модуля, игнорируются при созданииzip-файлов, поскольку они не являются частью модуля. Командаgoигнорирует подкаталоги, содержащие файлыgo.mod, при извлеченииzip-файлов. - Ни два файла в
zip-файле не могут иметь одинаковые пути при сгибании регистра Unicode (см.strings.EqualFold). Это гарантирует, чтоzip-файлы могут быть извлечены в файловых системах, нечувствительных к регистру, без коллизий. - Файл
go.modможет присутствовать или отсутствовать в каталоге верхнего уровня ($module@$version/go.mod). Если он присутствует, он должен иметь имяgo.mod(все строчные буквы). Файлы с именемgo.modне допускаются в других каталогах. - Имена файлов и каталогов в модуле могут состоять из букв Unicode, цифр ASCII, символа пробела
ASCII (U+0020)и символов пунктуации ASCII!#$%&()+,-.=@[]^_{}~. Обратите внимание, что пути к пакетам не могут содержать все эти символы. См.module.CheckFilePathиmodule.CheckImportPathдля ознакомления с различиями. - Имя файла или каталога до первой точки не должно быть зарезервированным именем файла в Windows, независимо от регистра (CON, com1, NuL и т. д.).
Private (Частные модули)
Модули Go часто разрабатываются и распространяются на серверах контроля версий и прокси-серверах модулей, которые недоступны в общедоступном Интернете. Команда go может загружать и собирать модули из частных источников, хотя для этого обычно требуется некоторая настройка.
Для настройки доступа к частным модулям можно использовать перечисленные ниже переменные окружения. Подробности см. в разделе Переменные окружения. См. также раздел Конфиденциальность для получения информации об управлении информацией, отправляемой на общедоступные серверы.
- GOPROXY — список URL-адресов прокси-серверов модулей. Команда
goбудет пытаться загрузить модули с каждого сервера по очереди. Ключевое словоdirectуказывает командеgoзагружать модули из репозиториев контроля версий, где они разрабатываются, вместо использования прокси-сервера. - GOPRIVATE — список шаблонов префиксов путей к модулям, которые должны считаться частными. Действует как значение по умолчанию для
GONOPROXYиGONOSUMDB. - GONOPROXY — список шаблонов
globпрефиксов путей модулей, которые не должны загружаться с прокси. Команда go загрузит соответствующие модули из репозиториев контроля версий, где они разрабатываются, независимо отGOPROXY. - GONOSUMDB — список шаблонов
globпрефиксов путей модулей, которые не должны проверяться с помощью общедоступной базы данных контрольных суммsum.golang.org. - GOINSECURE — список шаблонов
globпрефиксов путей модулей, которые могут быть получены черезHTTPи другие небезопасные протоколы. Эти переменные могут быть установлены в среде разработки (например, в файле.profile) или они могут быть установлены навсегда с помощьюgo env -w.
В остальной части этого раздела описаны общие шаблоны для предоставления доступа к частным прокси-серверам модулей и репозиториям контроля версий.
Частный прокси-сервер, обслуживающий все модули
Центральный частный прокси-сервер, обслуживающий все модули (публичные и частные), обеспечивает максимальный контроль для администраторов и требует минимальной настройки для отдельных разработчиков.
Чтобы настроить команду go для использования такого сервера, установите следующие переменные среды, заменив https://proxy.corp.example.com на URL вашего прокси и corp.example.com на префикс вашего модуля:
GOPROXY=https://proxy.corp.example.com
GONOSUMDB=corp.example.com
Настройка GOPROXY указывает команде go загружать модули только с https://proxy.corp.example.com; команда go не будет подключаться к другим прокси-серверам или репозиториям контроля версий.
Настройка GONOSUMDB указывает команде go не использовать публичную базу данных контрольных сумм для аутентификации модулей с путями, начинающимися с corp.example.com.
Прокси, работающий в этой конфигурации, скорее всего, потребует доступ на чтение к частным серверам контроля версий. Ему также потребуется доступ к общедоступному Интернету для загрузки новых версий общедоступных модулей.
Существует несколько реализаций серверов GOPROXY, которые можно использовать таким образом. Минимальная реализация будет обслуживать файлы из каталога кэша модулей и использовать go mod download (с соответствующей конфигурацией) для извлечения отсутствующих модулей.
Частный прокси-сервер, обслуживающий частные модули
Частный прокси-сервер может обслуживать частные модули, не обслуживая при этом общедоступные модули. Команду go можно настроить так, чтобы она переключалась на общедоступные источники для модулей, которые недоступны на частном сервере.
Чтобы настроить команду go для работы в таком режиме, установите следующие переменные среды, заменив https://proxy.corp.example.com на URL прокси-сервера, а corp.example.com на префикс модуля:
GOPROXY=https://proxy.corp.example.com,https://proxy.golang.org,direct
GONOSUMDB=corp.example.com
Настройка GOPROXY указывает команде go сначала пытаться загрузить модули с https://proxy.corp.example.com. Если этот сервер отвечает кодом 404 (Not Found) или 410 (Gone), команда go переходит к https://proxy.golang.org, а затем к прямым подключениям к репозиториям.
Настройка GONOSUMDB указывает команде go не использовать общедоступную базу данных контрольных сумм для аутентификации модулей, пути к которым начинаются с corp.example.com.
Обратите внимание, что прокси, используемый в этой конфигурации, может по-прежнему контролировать доступ к общедоступным модулям, даже если он их не обслуживает. Если прокси отвечает на запрос со статусом ошибки, отличным от 404 или 410, команда go не будет переходить к более поздним записям в списке GOPROXY. Например, прокси может ответить 403 (Forbidden) для модуля с неподходящей лицензией или с известными уязвимостями безопасности.
Прямой доступ к частным модулям
Команду go можно настроить так, чтобы она обходила общедоступные прокси-серверы и загружала частные модули напрямую с серверов контроля версий. Это полезно, когда запуск частного прокси-сервера невозможен.
Чтобы настроить команду go для работы в таком режиме, установите GOPRIVATE, заменив corp.example.com префиксом частного модуля:
GOPRIVATE=corp.example.com
В этой ситуации переменную GOPROXY менять не нужно. По умолчанию она имеет значение https://proxy.golang.org,direct, что указывает команде go сначала пытаться загрузить модули с https://proxy.golang.org, а затем перейти к прямому подключению, если этот прокси отвечает 404 (Not Found) или 410 (Gone).
Настройка GOPRIVATE указывает команде go не подключаться к прокси или базе данных контрольных сумм для модулей, начинающихся с corp.example.com.
Для преобразования путей модулей в URL-адреса репозиториев по-прежнему может потребоваться внутренний HTTP-сервер. Например, когда команда go загружает модуль corp.example.com/mod, она отправляет запрос GET на https://corp.example.com/mod?go-get=1 и ищет URL-адрес репозитория в ответе. Чтобы избежать этого требования, убедитесь, что каждый частный путь модуля имеет суффикс VCS (например, .git), обозначающий префикс корня репозитория. Например, когда команда go загружает модуль corp.example.com/repo.git/mod, она клонирует репозиторий Git по адресу https://corp.example.com/repo.git или ssh://corp.example.com/repo.git без необходимости делать дополнительные запросы.
Разработчикам потребуется доступ на чтение к репозиториям, содержащим частные модули. Это можно настроить в глобальных файлах конфигурации VCS, таких как .gitconfig. Лучше всего, если инструменты VCS настроены так, чтобы не требовать интерактивных запросов аутентификации. По умолчанию при вызове Git команда go отключает интерактивные запросы, устанавливая GIT_TERMINAL_PROMPT=0, но она учитывает явные настройки.
Передача учетных данных частным прокси-серверам
Команда go поддерживает базовую аутентификацию HTTP при взаимодействии с прокси-серверами.
Учетные данные могут быть указаны в файле .netrc. Например, файл .netrc, содержащий приведенные ниже строки, настроит команду go на подключение к машине proxy.corp.example.com с указанным именем пользователя и паролем.
machine proxy.corp.example.com
login jrgopher
password hunter2
Расположение файла можно установить с помощью переменной среды NETRC. Если NETRC не установлена, команда go будет читать $HOME/.netrc на UNIX-подобных платформах или %USERPROFILE%\_netrc в Windows.
Поля в .netrc разделены пробелами, табуляциями и символами новой строки. К сожалению, эти символы не могут использоваться в именах пользователей или паролях. Также обратите внимание, что имя машины не может быть полным URL-адресом, поэтому невозможно указать разные имена пользователей и пароли для разных путей на одной машине.
В качестве альтернативы учетные данные можно указать непосредственно в URL-адресах GOPROXY. Например:
GOPROXY=https://jrgopher:hunter2@proxy.corp.example.com
Будьте осторожны при использовании этого подхода: переменные среды могут появляться в истории оболочки и в журналах.
Передача учетных данных в частные репозитории
Команда go может загружать модуль непосредственно из репозитория системы контроля версий. Это необходимо для частных модулей, если не используется частный прокси. См. раздел Прямой доступ к частным модулям для настройки.
Команда go запускает инструменты контроля версий, такие как git, при прямой загрузке модулей. Эти инструменты выполняют собственную аутентификацию, поэтому вам может потребоваться настроить учетные данные в конфигурационном файле, специфичном для инструмента, например .gitconfig.
Чтобы обеспечить бесперебойную работу, убедитесь, что команда go использует правильный URL-адрес репозитория и что инструмент контроля версий не требует ввода пароля в интерактивном режиме. Команда go предпочитает URL-адреса https:// другим схемам, таким как ssh://, если схема не была указана при поиске URL-адреса репозитория. Специально для репозиториев GitHub команда go предполагает использование https://.
Для большинства серверов вы можете настроить клиент на аутентификацию по HTTP. Например, GitHub поддерживает использование личных токенов доступа OAuth в качестве паролей HTTP. Вы можете хранить пароли HTTP в файле .netrc, как при передаче учетных данных частным прокси-серверам.
В качестве альтернативы можно переписать URL-адреса https:// в другую схему. Например, в .gitconfig:
[url «git@github.com:»]
insteadOf = https://github.com/
Для получения дополнительной информации см. Почему «go get» использует HTTPS при клонировании репозитория?
Конфиденциальность
Команда go может загружать модули и метаданные с прокси-серверов модулей и систем контроля версий. Переменная окружения GOPROXY контролирует, какие серверы используются. Переменные окружения GOPRIVATE и GONOPROXY контролируют, какие модули загружаются с прокси-серверов.
Значение по умолчанию для GOPROXY:
https://proxy.golang.org,direct
С этой настройкой, когда команда go загружает модуль или метаданные модуля, она сначала отправляет запрос на proxy.golang.org, общедоступный прокси-сервер модулей, управляемый Google (политика конфиденциальности). См. протокол GOPROXY для получения подробной информации о том, какая информация отправляется в каждом запросе. Команда go не передает личную информацию, но передает полный путь к запрашиваемому модулю. Если прокси отвечает со статусом 404 (Not Found) или 410 (Gone), команда go попытается подключиться напрямую к системе контроля версий, предоставляющей модуль. Подробности см. в разделе Системы контроля версий.
Переменные среды GOPRIVATE или GONOPROXY могут быть установлены в виде списков шаблонов glob, соответствующих префиксам модулей, которые являются частными и не должны запрашиваться у какого-либо прокси. Например:
GOPRIVATE=*.corp.example.com,*.research.example.com
GOPRIVATE просто действует как значение по умолчанию для GONOPROXY и GONOSUMDB, поэтому нет необходимости устанавливать GONOPROXY, если GONOSUMDB не должен иметь другое значение. Когда путь к модулю соответствует GONOPROXY, команда go игнорирует GOPROXY для этого модуля и извлекает его напрямую из репозитория системы контроля версий. Это полезно, когда ни один прокси не обслуживает частные модули. См. Прямой доступ к частным модулям.
Если есть доверенный прокси, обслуживающий все модули, то GONOPROXY не следует устанавливать. Например, если GOPROXY установлен на один источник, команда go не будет загружать модули из других источников. В этой ситуации GONOSUMDB все равно следует установить.
GOPROXY=https://proxy.corp.example.com
GONOSUMDB=*.corp.example.com,*.research.example.com
Если есть доверенный прокси-сервер, обслуживающий только частные модули, GONOPROXY не следует устанавливать, но необходимо убедиться, что прокси-сервер отвечает с правильными кодами статуса. Рассмотрим, например, следующую конфигурацию:
GOPROXY=https://proxy.corp.example.com,https://proxy.golang.org
GONOSUMDB=*.corp.example.com,*.research.example.com
Предположим, что из-за опечатки разработчик пытается загрузить модуль, которого не существует.
go mod download corp.example.com/secret-product/typo@latest
Команда go сначала запрашивает этот модуль у proxy.corp.example.com. Если этот прокси отвечает кодом 404 (Not Found) или 410 (Gone), команда go переходит к proxy.golang.org, передавая путь secret-product в URL-адресе запроса. Если частный прокси отвечает любым другим кодом ошибки, команда go выводит ошибку и не переходит к другим источникам.
В дополнение к прокси, команда go может подключаться к базе данных контрольных сумм для проверки криптографических хэшей модулей, не указанных в go.sum. Переменная среды GOSUMDB устанавливает имя, URL и открытый ключ базы данных контрольных сумм. По умолчанию GOSUMDB имеет значение sum.golang.org, открытая база данных контрольных сумм, управляемая Google (политика конфиденциальности). См. База данных контрольных сумм для получения подробной информации о том, что передается с каждым запросом. Как и в случае с прокси-серверами, команда go не передает личную информацию, но передает полный путь к запрашиваемому модулю, а база данных контрольных сумм не может вычислять контрольные суммы для непубличных модулей.
Переменная среды GONOSUMDB может быть установлена на шаблоны, указывающие, какие модули являются частными и не должны запрашиваться из базы данных контрольных сумм. GOPRIVATE действует как значение по умолчанию для GONOSUMDB и GONOPROXY, поэтому нет необходимости устанавливать GONOSUMDB, если GONOPROXY не должен иметь другое значение.
Прокси может зеркалировать базу данных контрольных сумм. Если прокси в GOPROXY делает это, команда go не будет подключаться к базе данных контрольных сумм напрямую.
GOSUMDB может быть установлена в off, чтобы полностью отключить использование базы данных контрольных сумм. С этой настройкой команда go не будет аутентифицировать загруженные модули, если они уже не находятся в go.sum. См. Аутентификация модулей.
Кэш модулей
Кэш модулей — это каталог, в котором команда go хранит загруженные файлы модулей. Кэш модулей отличается от кэша сборки, который содержит скомпилированные пакеты и другие артефакты сборки.
По умолчанию кэш модулей находится в каталоге $GOPATH/pkg/mod. Чтобы использовать другое местоположение, установите переменную среды GOMODCACHE.
Кэш модулей не имеет максимального размера, и команда go не удаляет его содержимое автоматически.
Кэш может использоваться совместно несколькими проектами Go, разрабатываемыми на одном компьютере. Команда go будет использовать один и тот же кэш независимо от местоположения главного модуля. Несколько экземпляров команды go могут безопасно одновременно обращаться к одному и тому же кэшу модулей.
Команда go создает исходные файлы модулей и каталоги в кэше с правами только для чтения, чтобы предотвратить случайные изменения модулей после их загрузки. Это имеет нежелательный побочный эффект, затрудняющий удаление кэша с помощью таких команд, как rm -rf. Вместо этого кэш можно удалить с помощью go clean -modcache.
В качестве альтернативы, при использовании флага -modcacherw команда go создаст новые каталоги с правами на чтение и запись. Это увеличивает риск изменения файлов в кэше модулей редакторами, тестами и другими программами.
Команда go mod verify может использоваться для обнаружения изменений в зависимостях основного модуля. Она сканирует извлеченное содержимое каждой зависимости модуля и подтверждает, что оно соответствует ожидаемому хешу в go.sum.
В таблице ниже объясняется назначение большинства файлов в кэше модулей. Некоторые временные файлы (файлы блокировки, временные каталоги) опущены. Для каждого пути $module — это путь к модулю, а $version — версия. Пути, заканчивающиеся косыми чертами (/), являются каталогами. Заглавные буквы в путях к модулям и версиях экранируются с помощью восклицательных знаков (Azure экранируется как !azure), чтобы избежать конфликтов в файловых системах, нечувствительных к регистру.
| Путь | Описание |
|---|---|
| $module@$version/ | Каталог, содержащий извлеченное содержимое файла .zip модуля. Он служит корневым каталогом для загруженного модуля. Он не будет содержать файл go.mod, если исходный модуль не имел такого файла. |
| cache/download/ | Каталог, содержащий файлы, загруженные с прокси-серверов модулей, и файлы, полученные из систем контроля версий. Структура этого каталога соответствует протоколу GOPROXY, поэтому этот каталог может использоваться в качестве прокси-сервера при обслуживании HTTP-файловым сервером или при обращении по URL-адресу file://. |
| cache/download/$module/@v/list | Список известных версий (см. протокол GOPROXY). Он может меняться со временем, поэтому команда go обычно загружает новую копию вместо повторного использования этого файла. |
| cache/download/$module/@v/$version.info | JSON-метаданные о версии. (см. протокол GOPROXY). Это может измениться со временем, поэтому команда go обычно загружает новую копию вместо повторного использования этого файла. |
| cache/download/$module/@v/$version.mod | Файл go.mod для этой версии (см. протокол GOPROXY). Если исходный модуль не имел файла go.mod, это синтезированный файл без требований. |
| cache/download/$module/@v/$version.zip | Сжатое содержимое модуля (см. протокол GOPROXY и zip-файлы модулей). |
| cache/download/$module/@v/$version.ziphash | Криптографический хеш файлов в файле .zip. Обратите внимание, что сам файл .zip не хешируется, поэтому порядок файлов, сжатие, выравнивание и метаданные не влияют на хеш. При использовании модуля команда go проверяет, что этот хеш соответствует соответствующей строке в go.sum. Команда go mod verify проверяет, что хеши файлов .zip модуля и извлеченных каталогов соответствуют этим файлам. |
| cache/download/sumdb/ | Каталог, содержащий файлы, загруженные из базы данных контрольных сумм (обычно sum.golang.org). |
| cache/vcs/ | Содержит клонированные репозитории контроля версий для модулей, полученных непосредственно из их источников. Имена каталогов представляют собой хэши в шестнадцатеричном кодировании, полученные из типа репозитория и URL. Репозитории оптимизированы по размеру на диске. Например, клонированные репозитории Git являются «голыми» и «неглубокими», когда это возможно. |
Аутентификация модулей
Когда команда go загружает zip-файл модуля или файл go.mod в кэш модулей, она вычисляет криптографический хеш и сравнивает его с известным значением, чтобы убедиться, что файл не изменился с момента его первой загрузки. Команда go сообщает об ошибке безопасности, если загруженный файл не имеет правильного хеша.
Для файлов go.mod команда go вычисляет хеш из содержимого файла. Для zip-файлов модулей команда go вычисляет хеш из имен и содержимого файлов в архиве в детерминированном порядке. На хеш не влияют порядок файлов, сжатие, выравнивание и другие метаданные. См. golang.org/x/mod/sumdb/dirhash для получения подробной информации о реализации хеша.
Команда go сравнивает каждый хеш с соответствующей строкой в файле go.sum основного модуля. Если хеш отличается от хеша в go.sum, команда go сообщает об ошибке безопасности и удаляет загруженный файл, не добавляя его в кэш модуля.
Если файл go.sum отсутствует или не содержит хэш для загруженного файла, команда go может проверить хэш с помощью базы данных контрольных сумм, глобального источника хэшей для общедоступных модулей. После проверки хеша команда go добавляет его в go.sum и добавляет загруженный файл в кэш модулей. Если модуль является частным (соответствует переменным окружения GOPRIVATE или GONOSUMDB) или если база данных контрольных сумм отключена (путем установки GOSUMDB=off), команда go принимает хеш и добавляет файл в кэш модулей без проверки.
Кэш модулей обычно используется всеми проектами Go в системе, и каждый модуль может иметь свой собственный файл go.sum с потенциально разными хэшами. Чтобы избежать необходимости доверять другим модулям, команда go проверяет хэши с помощью go.sum основного модуля при каждом доступе к файлу в кэше модулей. Вычисление хэшей zip-файлов требует больших затрат, поэтому команда go проверяет заранее вычисленные хэши, хранящиеся вместе с zip-файлами, вместо повторного хеширования файлов. Команда go mod verify может использоваться для проверки того, что zip-файлы и извлеченные каталоги не были изменены с момента их добавления в кэш модулей.
Файлы go.sum
Модуль может иметь текстовый файл с именем go.sum в своем корневом каталоге, наряду с файлом go.mod. Файл go.sum содержит криптографические хэши прямых и косвенных зависимостей модуля. Когда команда go загружает файл .mod или .zip модуля в кэш модулей, она вычисляет хеш и проверяет, что он совпадает с соответствующим хешем в файле go.sum основного модуля. go.sum может быть пустым или отсутствовать, если модуль не имеет зависимостей или если все зависимости заменены локальными каталогами с помощью директив replace.
Каждая строка в go.sum имеет три поля, разделенных пробелами: путь к модулю, версия (возможно, заканчивающаяся на /go.mod) и хеш.
- Путь к модулю — это имя модуля, к которому принадлежит хеш.
- Версия — это версия модуля, к которому принадлежит хеш. Если версия заканчивается на
/go.mod, хеш относится только к файлуgo.modмодуля; в противном случае хеш относится к файлам в файле.zipмодуля. - Столбец хеша состоит из имени алгоритма (например, h1) и криптографического хеша, закодированного в base64, разделенных двоеточием (:). В настоящее время SHA-256 (h1) является единственным поддерживаемым алгоритмом хеширования. Если в будущем будет обнаружена уязвимость в SHA-256, будет добавлена поддержка другого алгоритма (с именем h2 и так далее).
Файл go.sum может содержать хэши для нескольких версий модуля. Команде go может потребоваться загрузить файлы go.mod из нескольких версий зависимости, чтобы выполнить выбор минимальной версии. go.sum также может содержать хэши для версий модулей, которые больше не нужны (например, после обновления). go mod tidy добавит отсутствующие хэши и удалит ненужные хэши из go.sum.
База данных контрольных сумм
База данных контрольных сумм является глобальным источником строк go.sum. Команда go может использовать ее во многих ситуациях для обнаружения некорректного поведения прокси-серверов или исходных серверов.
База данных контрольных сумм обеспечивает глобальную согласованность и надежность всех общедоступных версий модулей. Она делает возможным использование ненадежных прокси-серверов, поскольку они не могут предоставлять неверный код, который останется незамеченным. Она также гарантирует, что биты, связанные с конкретной версией, не изменятся со дня на день, даже если автор модуля впоследствии изменит теги в своем репозитории.
База данных контрольных сумм обслуживается sum.golang.org, который управляется Google. Это прозрачный журнал (или «дерево Меркла») хэшей строк go.sum, который поддерживается Trillian. Главное преимущество дерева Меркла заключается в том, что независимые аудиторы могут проверить, что оно не было подделано, поэтому оно более надежно, чем простая база данных.
Команда go взаимодействует с базой данных контрольных сумм, используя протокол, первоначально описанный в предложении: «Обеспечение безопасности экосистемы публичных модулей Go».
В таблице ниже указаны запросы, на которые должна отвечать база данных контрольных сумм. Для каждого пути $base — это часть URL-адреса базы данных контрольных сумм, $module — путь к модулю, а $version — версия. Например, если URL базы данных контрольных сумм — https://sum.golang.org, а клиент запрашивает запись для модуля golang.org/x/text версии v0.3.2, клиент отправит запрос GET на https://sum.golang.org/lookup/golang.org/x/text@v0.3.2.
Чтобы избежать неоднозначности при обслуживании из файловых систем, нечувствительных к регистру, элементы $module и $version кодируются с учетом регистра, заменяя каждую заглавную букву восклицательным знаком, за которым следует соответствующая строчная буква. Это позволяет хранить на диске модули example.com/M и example.com/m, поскольку первый кодируется как example.com/!m.
Части пути, заключенные в квадратные скобки, такие как [.p/$W], обозначают необязательные значения.
| Путь | Описание |
|---|---|
| $base/latest | Возвращает подписанное, закодированное описание дерева для последнего журнала. Это подписанное описание имеет форму примечания, которое представляет собой текст, подписанный одним или несколькими ключами сервера и который можно проверить с помощью открытого ключа сервера. Описание дерева содержит размер дерева и хэш вершины дерева при данном размере. Это кодирование описано в golang.org/x/mod/sumdb/tlog#FormatTree. |
| $base/lookup/$module@$version | Возвращает номер записи журнала для записи о $module в $version, за которым следуют данные для записи (то есть строки go.sum для $module в $version) и подписанное, закодированное описание дерева, которое содержит запись. |
| $base/tile/$H/$L/$K[.p/$W] | Возвращает блоку журнала, который представляет собой набор хешей, составляющих раздел журнала. Каждый блок определяется в двумерных координатах на уровне блока $L, $K-м слева, с высотой блока $H. Необязательный суффикс .p/$W указывает на частичную плитку журнала, содержащую только $W хешей. Клиенты должны перейти к извлечению полной плитки, если частичная плитка не найдена. |
| $base/tile/$H/data/$K[.p/$W] | Возвращает данные записи для листьевых хешей в /tile/$H/0/$K[.p/$W] (с буквальным элементом пути данных). |
Если команда go обращается к базе данных контрольных сумм, то первым шагом является извлечение данных записи через конечную точку /lookup. Если версия модуля еще не записана в журнале, база данных контрольных сумм попытается получить ее с исходного сервера перед ответом. Эти данные /lookup предоставляют сумму для этой версии модуля, а также ее положение в журнале, что информирует клиента о том, какие плитки следует загрузить для выполнения проверок. Команда go выполняет проверки «включения» (наличие определенной записи в журнале) и «согласованности» (отсутствие подделки дерева) перед добавлением новых строк go.sum в файл go.sum основного модуля. Важно, чтобы данные из /lookup никогда не использовались без предварительной аутентификации по подписанному хешу дерева и аутентификации подписанного хеша дерева по временной шкале подписанных хешей дерева клиента.
Подписанные хеши дерева и новые плитки, обслуживаемые базой данных контрольных сумм, хранятся в кэше модуля, поэтому команде go нужно загружать только отсутствующие плитки.
Команде go не нужно напрямую подключаться к базе данных контрольных сумм. Она может запрашивать суммы модулей через прокси-сервер модулей, который зеркалирует базу данных контрольных сумм и поддерживает вышеуказанный протокол. Это может быть особенно полезно для частных корпоративных прокси-серверов, которые блокируют запросы за пределами организации.
Переменная среды GOSUMDB определяет имя базы данных контрольных сумм, которую следует использовать, и, опционально, ее открытый ключ и URL, как в примере:
GOSUMDB="sum.golang.org"
GOSUMDB="sum.golang.org+<publickey>"
GOSUMDB="sum.golang.org+<publickey> https://sum.golang.org"
Команда go знает открытый ключ sum.golang.org, а также то, что имя sum.golang.google.cn (доступно на территории материкового Китая) соединяет с базой данных контрольных сумм sum.golang.org; использование любой другой базы данных требует явного указания открытого ключа. URL по умолчанию https://, за которым следует имя базы данных.
GOSUMDB по умолчанию указывает на sum.golang.org, базу данных контрольных сумм Go, управляемую Google. Политику конфиденциальности сервиса смотрите на https://sum.golang.org/privacy.
Если для GOSUMDB установлено значение off, или если go get вызывается с флагом -insecure, база данных контрольных сумм не проверяется, и все нераспознанные модули принимаются, ценой отказа от гарантии безопасности проверенных повторяющихся загрузок для всех модулей. Лучший способ обойти базу данных контрольных сумм для определенных модулей - использовать переменные окружения GOPRIVATE или GONOSUMDB. Подробности см. в разделе Приватные модули.
Команда go env -w может быть использована для установки этих переменных для последующих вызовов команды go.
Переменные окружения
Поведение модуля в команде go может быть настроено с помощью переменных окружения, перечисленных ниже. В этот список включены только переменные окружения, связанные с модулем. Список всех переменных окружения, распознаваемых командой go, см. в go help environment.
- GO111MODULE
Управляет тем, будет ли команда go работать в режиме с поддержкой модулей или в режиме
GOPATH. Поддерживаются три значения:- off: команда go игнорирует файлы
go.modи работает в режимеGOPATH. - on (или unset): команда
goработает в режиме с поддержкой модулей, даже если файлgo.modотсутствует. - auto: команда
goработает в режиме с поддержкой модулей, если файлgo.modприсутствует в текущем каталоге или любом родительском каталоге. В Go 1.15 и ниже это было значением по умолчанию.
Дополнительные сведения см. в разделе Команды с поддержкой модулей.
- off: команда go игнорирует файлы
- GOMODCACHE
Каталог, в котором команда
goбудет хранить загруженные модули и связанные файлы. Подробные сведения о структуре этого каталога см. в разделе Кэш модулей.Если
GOMODCACHEне установлен, по умолчанию используется$GOPATH/pkg/mod.
- GOINSECURE
Разделенный запятыми список шаблонов
glob(в синтаксисеpath.Match Go) префиксов путей модулей, которые всегда могут быть загружены небезопасным способом. Применяется только к зависимостям, которые загружаются напрямую.В отличие от флага
-insecureвgo get,GOINSECUREне отключает проверку базы данных контрольных сумм модулей. Для этого можно использоватьGOPRIVATEилиGONOSUMDB.
- GONOPROXY
Разделенный запятыми список шаблонов
glob(в синтаксисеpath.Match Go) префиксов путей модулей, которые всегда должны загружаться напрямую из репозиториев контроля версий, а не из прокси-серверов модулей.Если
GONOPROXYне установлен, по умолчанию используетсяGOPRIVATE. См. раздел «Конфиденциальность».
- GONOSUMDB
Разделенный запятыми список шаблонов
glob(в синтаксисеpath.Match Go) префиксов путей модулей, для которыхgoне должен проверять контрольные суммы с помощью базы данных контрольных сумм.Если
GONOSUMDBне установлен, по умолчанию используетсяGOPRIVATE. См. раздел «Конфиденциальность».
- GOPATH
В режиме
GOPATHпеременнаяGOPATHпредставляет собой список каталогов, которые могут содержать кодGo.В режиме с поддержкой модулей кэш модулей хранится в подкаталоге
pkg/modпервого каталогаGOPATH. Исходный код модулей, не входящих в кэш, может храниться в любом каталоге.Если
GOPATHне задан, по умолчанию используется подкаталогgoв домашнем каталоге пользователя.
- GOPRIVATE
- Разделенный запятыми список шаблонов
glob(в синтаксисеpath.Match Go) префиксов путей модулей, которые должны считаться частными.GOPRIVATEявляется значением по умолчанию дляGONOPROXYиGONOSUMDB. См. раздел «Конфиденциальность».GOPRIVATEтакже определяет, считается ли модуль частным дляGOVCS.
- GOPROXY
Список URL-адресов прокси-серверов модулей, разделенных запятыми (
,) или вертикальными чертами (|). Когда командаgoищет информацию о модуле, она обращается к каждому прокси-серверу в списке по порядку, пока не получит успешный ответ или терминальную ошибку. Прокси-сервер может ответить статусом 404 (Not Found) или 410 (Gone), чтобы указать, что модуль недоступен на этом сервере.Поведение команды
goпри ошибке определяется разделителями между URL-адресами. Если за URL-адресом прокси следует запятая, команда go переходит к следующему URL-адресу после ошибки 404 или 410; все другие ошибки считаются терминальными. Если за URL-адресом прокси следует вертикальная черта, команда go переходит к следующему источнику после любой ошибки, включая ошибки, не связанные с HTTP, такие как таймауты.URL-адреса
GOPROXYмогут иметь схемыhttps,httpилиfile. Если URL-адрес не имеет схемы, предполагается, что он имеет схемуhttps. Кэш модулей может использоваться непосредственно в качестве прокси-файла:GOPROXY=file://$(go env GOMODCACHE)/cache/downloadВместо URL-адресов прокси могут использоваться два ключевых слова:
- off: запрещает загрузку модулей из любого источника.
- direct: загрузка напрямую из репозиториев контроля версий вместо использования прокси-сервера модулей.
По умолчанию
GOPROXYимеет значениеhttps://proxy.golang.org,direct. При такой конфигурации команда go сначала связывается с зеркалом модулей Go, управляемым Google, а затем переходит к прямому подключению, если зеркало не имеет модуля. Политику конфиденциальности зеркала см. на страницеhttps://proxy.golang.org/privacy. Переменные средыGOPRIVATEиGONOPROXYмогут быть установлены, чтобы предотвратить загрузку определенных модулей с помощью прокси. См. раздел «Конфиденциальность» для получения информации о настройке частного прокси.См. разделы «Прокси модулей» и «Преобразование пакета в модуль» для получения дополнительной информации об использовании прокси.
- GOSUMDB
Определяет имя базы данных контрольных сумм, которую следует использовать, а также, по желанию, ее открытый ключ и URL. Например:
GOSUMDB="sum.golang.org" GOSUMDB="sum.golang.org+<publickey>" GOSUMDB="sum.golang.org+<publickey> https://sum.golang.org"Команда go знает открытый ключ
sum.golang.org, а также то, что имяsum.golang.google.cn(доступное на территории Китая) подключается к базе данныхsum.golang.org; для использования любой другой базы данных необходимо явно указать открытый ключ. По умолчанию URL-адрес имеет видhttps://, за которым следует имя базы данных.По умолчанию
GOSUMDBимеет значениеsum.golang.org, базу данных контрольных сумм Go, управляемую Google. См.https://sum.golang.org/privacyдля ознакомления с политикой конфиденциальности службы.Если
GOSUMDBустановлен в положение«off»или еслиgo getвызывается с флагом-insecure, база данных контрольных сумм не используется, и все нераспознанные модули принимаются, что приводит к потере гарантии безопасности проверенных повторяемых загрузок для всех модулей. Лучший способ обойти базу данных контрольных сумм для определенных модулей — использовать переменные средыGOPRIVATEилиGONOSUMDB.Дополнительную информацию см. в разделах «Аутентификация модулей» и «Конфиденциальность».
- GOVCS
Управляет набором инструментов контроля версий, которые команда
goможет использовать для загрузки общедоступных и частных модулей (определяемых по тому, соответствуют ли их пути шаблону вGOPRIVATE) или других модулей, соответствующих шаблонуglob.Если
GOVCSне установлен или если модуль не соответствует ни одному шаблону вGOVCS, команда go может использоватьgitиhgдля публичного модуля или любой известный инструмент контроля версий для частного модуля. Конкретно, команда go действует так, как если быGOVCSбыл установлен на:public:git|hg,private:allСм. Управление инструментами контроля версий с помощью
GOVCSдля полного объяснения.
- GOWORK
- Переменная окружения
GOWORKуказывает командеgoперейти в режим рабочего пространства, используя предоставленный файлgo.workдля определения рабочего пространства. ЕслиGOWORKустановлен вoff, режим рабочего пространства отключается. Это можно использовать для запуска командыgoв режиме одного модуля: например,GOWORK=off go build .собирает пакет.в режиме одного модуля. ЕслиGOWORKпуста, командаgoбудет искать файлgo.work, как описано в разделе Рабочие пространства.
Глоссарий
Ограничение сборки: условие, которое определяет, будет ли использоваться исходный файл Go при компиляции пакета. Ограничения сборки могут быть выражены с помощью суффиксов имен файлов (например, foo_linux_amd64.go) или с помощью комментариев об ограничениях сборки (например, // +build linux,amd64). См. Ограничения сборки.
Список сборки: список версий модулей, которые будут использоваться для команды сборки, такой как go build, go list или go test. Список сборки определяется из файла go.mod основного модуля и файлов go.mod в транзитивно требуемых модулях с использованием минимального выбора версии. Список сборки содержит версии для всех модулей в графе модулей, а не только для тех, которые относятся к конкретной команде.
каноническая версия: правильно отформатированная версия без суффикса метаданных сборки, кроме +incompatible. Например, v1.2.3 является канонической версией, а v1.2.3+meta — нет.
текущий модуль: синоним основного модуля.
Устаревший модуль: модуль, который больше не поддерживается его авторами (хотя основные версии считаются отдельными модулями для этой цели). Устаревший модуль помечается комментарием об устаревании в последней версии его файла go.mod.
Прямая зависимость: пакет, путь к которому появляется в декларации импорта в исходном файле .go для пакета или теста в основном модуле, или модуль, содержащий такой пакет. (Сравните с косвенной зависимостью.)
Прямой режим: настройка переменных среды, которая заставляет команду go загружать модуль напрямую из системы контроля версий, а не через прокси-сервер модулей. GOPROXY=direct делает это для всех модулей. GOPRIVATE и GONOPROXY делают это для модулей, соответствующих списку шаблонов.
Файл go.mod: файл, который определяет путь к модулю, требования и другие метаданные. Появляется в корневом каталоге модуля. См. раздел о файлах go.mod.
Файл go.work: файл, который определяет набор модулей, которые будут использоваться в рабочей области. См. раздел о файлах go.work.
Путь импорта: строка, используемая для импорта пакета в исходном файле Go. Синоним пути к пакету.
Косвенная зависимость: пакет, транзитивно импортируемый пакетом или тестом в главном модуле, но путь к которому не появляется ни в одной декларации импорта в главном модуле; или модуль, который появляется в графе модулей, но не предоставляет никаких пакетов, напрямую импортируемых главным модулем. (Сравните с прямой зависимостью.)
отложенная загрузка модулей: изменение в Go 1.17, которое позволяет избежать загрузки графа модулей для команд, которые в этом не нуждаются, в модулях, которые указывают go 1.17 или выше. См. Отложенная загрузка модулей.
главный модуль: модуль, в котором вызывается команда go. Главный модуль определяется файлом go.mod в текущем каталоге или родительском каталоге. См. Модули, пакеты и версии.
Основная версия: первое число в семантической версии (1 в v1.2.3). В выпуске с несовместимыми изменениями основная версия должна быть увеличена, а второстепенная версия и патч-версия должны быть установлены на 0. Семантические версии с основной версией 0 считаются нестабильными.
подкаталог основной версии: подкаталог в репозитории контроля версий, соответствующий суффиксу основной версии модуля, в котором может быть определен модуль. Например, модуль example.com/mod/v2 в репозитории с корневым путем example.com/mod может быть определен в корневом каталоге репозитория или в подкаталоге основной версии v2. См. Каталоги модулей в репозитории.
суффикс основной версии: суффикс пути модуля, соответствующий номеру основной версии. Например, /v2 в example.com/mod/v2. Суффиксы основной версии требуются в v2.0.0 и более поздних версиях и не допускаются в более ранних версиях. См. раздел «Суффиксы основной версии».
Выбор минимальной версии (MVS): алгоритм, используемый для определения версий всех модулей, которые будут использоваться в сборке. Подробности см. в разделе «Выбор минимальной версии».
Второстепенная версия: второе число в семантической версии (2 в v1.2.3). В выпуске с новой, обратно совместимой функциональностью второстепенная версия должна быть увеличена, а патч-версия должна быть установлена на 0.
Модуль: набор пакетов, которые выпускаются, версионируются и распространяются вместе.
Кэш модулей: локальный каталог, в котором хранятся загруженные модули, расположенный в GOPATH/pkg/mod. См. Кэш модулей.
Граф модулей: ориентированный граф требований модулей, корнем которого является главный модуль. Каждая вершина в графе — это модуль; каждая ребро — это версия из оператора require в файле go.mod (с учетом операторов replace и exclude в файле go.mod главного модуля).
Обрезка графа модулей: изменение в Go 1.17, которое уменьшает размер графа модулей за счет исключения транзитивных зависимостей модулей, которые указывают go 1.17 или выше. См. Обрезка графа модулей.
Путь модуля: путь, который идентифицирует модуль и действует как префикс для путей импорта пакетов внутри модуля. Например, «golang.org/x/net».
Прокси модуля: веб-сервер, который реализует протокол GOPROXY. Команда go загружает информацию о версии, файлы go.mod и zip-файлы модулей с прокси модулей.
Корневой каталог модуля: каталог, который содержит файл go.mod, определяющий модуль.
Подкаталог модуля: часть пути к модулю после корневого пути репозитория, которая указывает подкаталог, в котором определен модуль. Если подкаталог модуля не пустой, он также является префиксом для семантических тегов версии. Подкаталог модуля не включает суффикс основной версии, если таковой имеется, даже если модуль находится в подкаталоге основной версии. См. «Пути к модулям».
Пакет: набор исходных файлов в одном каталоге, которые компилируются вместе. См. раздел «Пакеты» в спецификации языка Go.
Путь к пакету: путь, который однозначно идентифицирует пакет. Путь к пакету — это путь к модулю, соединенный с подкаталогом внутри модуля. Например, «golang.org/x/net/html» — это путь к пакету в модуле «golang.org/x/net» в подкаталоге «html». Синоним пути импорта.
версия патча: третье число в семантической версии (3 в v1.2.3). В выпуске без изменений в публичном интерфейсе модуля версия патча должна быть увеличена.
Предварительная версия: версия с тире, за которым следует ряд идентификаторов, разделенных точками, непосредственно после патч-версии, например, v1.2.3-beta4. Предварительные версии считаются нестабильными и не предполагают совместимости с другими версиями. Предварительная версия сортируется перед соответствующей релизной версией: v1.2.3-pre идет перед v1.2.3. См. также релизная версия.
Псевдоверсия: версия, которая кодирует идентификатор ревизии (например, хэш Git commit) и временную метку из системы контроля версий. Например, v0.0.0-20191109021931-daa7c04131f5. Используется для совместимости с репозиториями, не являющимися модулями, и в других ситуациях, когда версия с тегом недоступна.
релизная версия: версия без суффикса предварительной версии. Например, v1.2.3, а не v1.2.3-pre. См. также предварительная версия.
корневой путь репозитория: часть пути модуля, которая соответствует корневому каталогу репозитория системы контроля версий. См. Пути модулей.
Отзывная версия: версия, на которую не следует полагаться, либо потому что она была опубликована преждевременно, либо потому что после ее публикации была обнаружена серьезная проблема. См. директиву retract.
Семантическая метка версии: метка в репозитории контроля версий, которая сопоставляет версию с конкретной ревизией. См. Сопоставление версий с коммитами.
выбранная версия: версия данного модуля, выбранная с помощью минимального выбора версии. Выбранная версия — это самая высокая версия для пути модуля, найденная в графе модулей.
каталог поставщика: каталог с именем vendor, содержащий пакеты из других модулей, необходимые для сборки пакетов в основном модуле. Обслуживается с помощью go mod vendor. См. раздел «Поставщики».
версия: идентификатор неизменяемого моментального снимка модуля, записываемый в виде буквы v, за которой следует семантическая версия. См. раздел «Версии».
рабочая область: набор модулей на диске, которые используются в качестве основных модулей при выполнении минимального выбора версии (MVS). См. раздел «Рабочие области».
12.9.1 - Alex Edwards Let's Go часть 1
edwardsLetsGo учебный материал по написанию приложения на Go с авторизацией пользователя. Краткий конспект с основными мыслями (главы с 1 по 8)
Основы Web приложения
package main
import (
"log" //пакет для логирования
"net/http" //пакет для создания web приложений
)
func home(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello from Snippetbox"))
}
//основная функция, `home` которая получает на вход указатель кто слушает канал:
//w http.ResponseWriter чтобы выводить значения в web
//r *http.Request - структура, которую получаем на вход
func main() {
mux := http.NewServeMux()
//указатель на web сервер
mux.HandleFunc("/", home)
//обработчик запросов
log.Println("Starting server on :4000")
//логируем подключение
err := http.ListenAndServe(":4000", mux)
//слушаем порт
log.Fatal(err)
}
type ResponseWriter interface {
// Header возвращает карту заголовков, которая будет отправлена
// [ResponseWriter.WriteHeader].
Header() Header
// Write записывает данные в соединение как часть HTTP-ответа.
Write([]byte) (int, error)
// WriteHeader отправляет заголовок ответа HTTP с указанным
// кодом состояния.
WriteHeader(statusCode int)
}
type Request struct {
// Method задает метод HTTP (GET, POST, PUT и т.д.).
Method string
// Для клиентских запросов URL's Host указывает сервер, к которому нужно // подключиться.
URL *url.URL
// Версия протокола для входящих запросов сервера.
Proto string // «HTTP/1.0»
ProtoMajor int // 1
ProtoMinor int // 0
// Заголовок содержит поля заголовка запроса, которые либо получены
// сервером, либо должны быть отправлены клиентом.
//
// Host: example.com
// accept-encoding: gzip, deflate
// Accept-Language: en-us
// fOO: Bar
// foo: two
Request Header
// Body - это тело запроса.
Body io.ReadCloser
// GetBody определяет необязательную функцию для возврата новой копии Body.
GetBody func() (io.ReadCloser, error)
// ContentLength записывает длину связанного содержимого.
ContentLength int64
// TransferEncoding перечисляет кодировки передачи данных от крайних к внутренней.
TransferEncoding []string
Close bool
// Для серверных запросов поле Host указывает хост, на котором URL-адрес.
Host String
// Form содержит разобранные данные формы
Form url.Values
// PostForm содержит разобранные данные формы из параметров тела PATCH, POST
// или параметров тела PUT.
PostForm url.Values
// MultipartForm - это разобранная многочастная форма, включая загрузку файлов.
MultipartForm *multipart.Form
// Trailer определяет дополнительные заголовки, которые отправляются после запроса
// body.
Trailer Header
// RemoteAddr позволяет HTTP-серверам и другому программному обеспечению записывать сетевой адрес, отправивший запрос
RemoteAddr String
// RequestURI - это немодифицированный запрос-цель в
RequestURI String
// TLS позволяет HTTP-серверам и другому программному обеспечению записывать информацию о TLS-соединении
TLS *tls.ConnectionState
// Cancel - необязательный канал, закрытие которого указывает на то, что клиентский
// запрос следует считать отмененным.
Cancel <-chan struct{}
// Response - это ответ перенаправления, который вызвал этот запрос.
Response *Response
// Pattern - шаблон [ServeMux], который соответствует запросу.
Pattern string
// содержит отфильтрованные или неотфильтрованные поля
}
Расширение обработчиков
package main
import (
"log"
"net/http"
)
func home(w http.ResponseWriter, r *http.Request) { w
.Write([]byte("Hello from Snippetbox"))
} создаем функции обработчики каждого адреса
func snippetView(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Display a specific snippet..."))
} // для теста просто выводим что-нибудь
func snippetCreate(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Create a new snippet...")) }
func main() {
// Register the two new handler functions and corresponding URL patterns with // the servemux, in exactly the same way that we did before.
mux := http.NewServeMux()
mux.HandleFunc("/", home)
mux.HandleFunc("/snippet/view", snippetView)
mux.HandleFunc("/snippet/create", snippetCreate)
// обрабатываем каждый адрес из браузера и запускаем функцию обработчик
log.Println("Starting server on :4000")
err := http.ListenAndServe(":4000", mux)
log.Fatal(err)
}
Типы адресов в обработчике
/snippet/view— фиксированный адрес/snippet/view/— не фиксированный адрес и под ним обрабатывается поддерево- Для корня проверка если указано что-то отличающееся от
/
if r.URL.Path != "/" {
http.NotFound(w, r)
return
}
w.Write([]byte("Hello from Snippetbox"))
DefaultServeMux
var DefaultServeMux = NewServeMux()
это неявная переменная, которая хранит указатель на сервер и используется глобально. Поэтому сервера нужно создавать локально внутри main
У маршрутизатора Go могут быть проблемы с обработкой переменных
Но это по всей видимости в старых версиях. Новые могут больше и есть дополнительные модули, которые полноценно обрабатывают строку запроса
Отправка статуса
func snippetCreate(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" { // просто покажет каким методом отправили запрос
w.Header().Set("Allow", "POST")` //- эта настройка подскажет в ответе, какой метод разрешен
w.WriteHeader(405) // отправим код статуса в заголовке ответа
w.Write([]byte("Method Not Allowed")) // и просто напишем сообщение в случае неправильного кода
return
}
w.Write([]byte("Create a new snippet...")) //это сообщение успеха
}
curl -i -X POST http://localhost:4000/snippet/create // это для тестирования из командной строки
w.Header().Set("Allow", "POST") - эта настройка подскажет в ответе, какой метод разрешен
w.Write([]byte("Method Not Allowed")) у этой команды есть альтернатива более приемлемая: http.Error(w, "Method Not Allowed", 405)
и еще есть специальные константы с указанием статусов: http.StatusMethodNotAllowed вместо 405
Статусы
const (
StatusContinue = 100 // RFC 9110, 15.2.1
StatusSwitchingProtocols = 101 // RFC 9110, 15.2.2
StatusProcessing = 102 // RFC 2518, 10.1
StatusEarlyHints = 103 // RFC 8297
StatusOK = 200 // RFC 9110, 15.3.1
StatusCreated = 201 // RFC 9110, 15.3.2
StatusAccepted = 202 // RFC 9110, 15.3.3
StatusNonAuthoritativeInfo = 203 // RFC 9110, 15.3.4
StatusNoContent = 204 // RFC 9110, 15.3.5
StatusResetContent = 205 // RFC 9110, 15.3.6
StatusPartialContent = 206 // RFC 9110, 15.3.7
StatusMultiStatus = 207 // RFC 4918, 11.1
StatusAlreadyReported = 208 // RFC 5842, 7.1
StatusIMUsed = 226 // RFC 3229, 10.4.1
StatusMultipleChoices = 300 // RFC 9110, 15.4.1
StatusMovedPermanently = 301 // RFC 9110, 15.4.2
StatusFound = 302 // RFC 9110, 15.4.3
StatusSeeOther = 303 // RFC 9110, 15.4.4
StatusNotModified = 304 // RFC 9110, 15.4.5
StatusUseProxy = 305 // RFC 9110, 15.4.6
StatusTemporaryRedirect = 307 // RFC 9110, 15.4.8
StatusPermanentRedirect = 308 // RFC 9110, 15.4.9
StatusBadRequest = 400 // RFC 9110, 15.5.1
StatusUnauthorized = 401 // RFC 9110, 15.5.2
StatusPaymentRequired = 402 // RFC 9110, 15.5.3
StatusForbidden = 403 // RFC 9110, 15.5.4
StatusNotFound = 404 // RFC 9110, 15.5.5
StatusMethodNotAllowed = 405 // RFC 9110, 15.5.6
StatusNotAcceptable = 406 // RFC 9110, 15.5.7
StatusProxyAuthRequired = 407 // RFC 9110, 15.5.8
StatusRequestTimeout = 408 // RFC 9110, 15.5.9
StatusConflict = 409 // RFC 9110, 15.5.10
StatusGone = 410 // RFC 9110, 15.5.11
StatusLengthRequired = 411 // RFC 9110, 15.5.12
StatusPreconditionFailed = 412 // RFC 9110, 15.5.13
StatusRequestEntityTooLarge = 413 // RFC 9110, 15.5.14
StatusRequestURITooLong = 414 // RFC 9110, 15.5.15
StatusUnsupportedMediaType = 415 // RFC 9110, 15.5.16
StatusRequestedRangeNotSatisfiable = 416 // RFC 9110, 15.5.17
StatusExpectationFailed = 417 // RFC 9110, 15.5.18
StatusTeapot = 418 // RFC 9110, 15.5.19 (Unused)
StatusMisdirectedRequest = 421 // RFC 9110, 15.5.20
StatusUnprocessableEntity = 422 // RFC 9110, 15.5.21
StatusLocked = 423 // RFC 4918, 11.3
StatusFailedDependency = 424 // RFC 4918, 11.4
StatusTooEarly = 425 // RFC 8470, 5.2.
StatusUpgradeRequired = 426 // RFC 9110, 15.5.22
StatusPreconditionRequired = 428 // RFC 6585, 3
StatusTooManyRequests = 429 // RFC 6585, 4
StatusRequestHeaderFieldsTooLarge = 431 // RFC 6585, 5
StatusUnavailableForLegalReasons = 451 // RFC 7725, 3
StatusInternalServerError = 500 // RFC 9110, 15.6.1
StatusNotImplemented = 501 // RFC 9110, 15.6.2
StatusBadGateway = 502 // RFC 9110, 15.6.3
StatusServiceUnavailable = 503 // RFC 9110, 15.6.4
StatusGatewayTimeout = 504 // RFC 9110, 15.6.5
StatusHTTPVersionNotSupported = 505 // RFC 9110, 15.6.6
StatusVariantAlsoNegotiates = 506 // RFC 2295, 8.1
StatusInsufficientStorage = 507 // RFC 4918, 11.5
StatusLoopDetected = 508 // RFC 5842, 7.2
StatusNotExtended = 510 // RFC 2774, 7
StatusNetworkAuthenticationRequired = 511 // RFC 6585, 6
)
Заголовок запроса
Автоматически устанавливаются три переменные запроса:
Date и Content-Length и Content-Type.
Content-Length определяется автоматически, но лучше установить явно:
w.Header().Set("Content-Type", "application/json")
w.Write([]byte(`{"name":"Alex"}`))
Методы управления заголовком
- w.Header().Set()
- w.Header().Add()
- w.Header().Del()
- w.Header().Get()
- w.Header().Values()
w.Header().Set("Cache-Control", "public, max-age=31536000")
w.Header().Add("Cache-Control", "public")
w.Header().Add("Cache-Control", "max-age=31536000")
w.Header().Del("Cache-Control")
w.Header().Get("Cache-Control")
w.Header().Values("Cache-Control")
Канонические имена в заголовке
Все имена в заголовке преобразуются в канонические: Первая буква с заглавной
Если нужно отменить преобразование:
w.Header()["X-XSS-Protection"] = []string{"1; mode=block"}
Подавление системных заголовков
w.Header()["Date"] = nil
потому-что DEL не удаляет их
Query
/snippet/view?id=1 // обработка строки запроса
id, err := strconv.Atoi(r.URL.Query().Get("id"))
if err != nil || id < 1 {
http.NotFound(w, r)
return
}
Структура проекта
- Main оставить в одном файле
- Handler вынести в отдельный файл с такой же структурой
internal
создадим директорию для зависимых пакетов для проекта
html шаблоны
ui/html/pages/home.tmpl
<!doctype html>
<html lang='en'>
<head>
<meta charset='utf-8'>
<title>Home - Snippetbox</title>
</head>
<body>
<header>
<h1><a href='/'>Snippetbox</a></h1>
</header>
<main>
<h2>Latest Snippets</h2>
<p>There's nothing to see here yet!</p>
</main>
<footer>Powered by <a href='https://golang.org/'>Go</a></footer>
</body>
</html>
html/template - управляет шаблонами html из GO
ts, err := template.ParseFiles("./ui/html/pages/home.tmpl")
if err != nil {
log.Println(err.Error())
http.Error(w, "Internal Server Error", 500)
return
}
загружаем и парсим шаблон. Теперь он в переменной ts
err = ts.Execute(w, nil) //отправляет шаблон в поток w
if err != nil {
log.Println(err.Error())
http.Error(w, "Internal Server Error", 500)
}
Шаблоны отдельно
Делаем составные шаблоны
- Базовый шаблон base.tmpl
Задает основную структуру страницы:
{{define "base"}}
<!doctype html>
<html lang='en'>
<head>
<meta charset='utf-8'>
<title>{{template "title" .}} - Snippetbox</title>
</head>
<body>
<header>
<h1><a href='/'>Snippetbox</a></h1>
</header>
<main>
{{template "main" .}}
</main>
<footer>Powered by <a href='https://golang.org/'>Go</a></footer>
</body>
</html>
{{end}}
{{define "base"}} - определяет основной блок, внутри вся структура
{{template "title" .}} - заголовок указанный в переменной title, которую потом подставим
{{template "main" .}} - название другого блока с именем main
чтобы вставить template их нужно объявить как define
{{define "title"}}Home{{end}}
{{define "main"}}
<h2>Latest Snippets</h2>
<p>There's nothing to see here yet!</p>
{{end}}
Создание слайса с шаблонами
files := []string{
"./ui/html/base.tmpl",
"./ui/html/pages/home.tmpl",
}
что примечательного в этом коде: здесь нужно перечислить все шаблоны с их путями, которые будут собираться для вывода страницы
и немного поменялся парсер, теперь ему передадим не один шаблон, а слайсер с шаблонами
ts, err := template.ParseFiles(files...)
if err != nil {
log.Println(err.Error())
http.Error(w, "Internal Server Error", 500)
return
}
и поменяется метод для сборки всех шаблонов в одну страницу:
err = ts.ExecuteTemplate(w, "base", nil)
if err != nil {
log.Println(err.Error())
http.Error(w, "Internal Server Error", 500)
}
ts.ExecuteTemplate(w, "base", nil) - указываем главный шаблон base, в который будут собираться остальные
в итоге получили такой шаблон:
Итоговый шаблон
{{define "base"}}
<!doctype html>
<html lang='en'>
<head>
<meta charset='utf-8'>
<title>{{template "title" .}} - Snippetbox</title>
</head>
<body>
<header>
<h1><a href='/'>Snippetbox</a></h1>
</header>
<!-- Invoke the navigation template -->
{{template "nav" .}}
<main>
{{template "main" .}}
</main>
<footer>Powered by <a href='https://golang.org/'>Go</a></footer>
</body>
</html>
{{end}}
Block
Это похоже на template, только является необязательным
{{define "base"}}
<h1>An example template</h1>
{{block "sidebar" .}}
<p>My default sidebar content</p>
{{end}}
{{end}}
Еще есть функционал для встраивания файлов прямо в код с пакетом: embed
Статические файлы
http.FileServer - встроенный обработчик статическийх файлов
fileServer := http.FileServer(http.Dir("./ui/static/"))
для подключения обработчика статических файлов необходимо:
mux.Handle("/static/", http.StripPrefix("/static", fileServer)) //http.StripPrefix позволяет правильно работать в адресной строке с именами файлов
Что можно положить в статику:
- CSS файлы
- JS файлы
Пример
{{define "base"}}
<!doctype html>
<html lang='en'>
<head>
<meta charset='utf-8'>
<title>{{template "title" .}} - Snippetbox</title>
<!-- Link to the CSS stylesheet and favicon -->
<link rel='stylesheet' href='/static/css/main.css'>
<link rel='shortcut icon' href='/static/img/favicon.ico' type='image/x-icon'>
<!-- Also link to some fonts hosted by Google -->
<link rel='stylesheet' href='https://fonts.googleapis.com/css?family=Ubuntu+Mono:400,700'>
</head>
<body>
<header>
<h1><a href='/'>Snippetbox</a></h1>
</header>
{{template "nav" .}}
<main>
{{template "main" .}}
</main>
<footer>Powered by <a href='https://golang.org/'>Go</a></footer>
<!-- And include the JavaScript file -->
<script src="/static/js/main.js" type="text/javascript"></script>
</body>
</html>
{{end}}
<script src="/static/js/main.js" type="text/javascript"></script> - загрузит статический файл с JS
<link rel='stylesheet' href='/static/css/main.css'> - загрузит CSS на страницу
Hundle что делает
Отступление с объяснением Hundle
В пакете net/http языка Go есть два способа зарегистрировать обработчик (handler) для определённого пути (path):
func (*ServeMux) Handle– это метод структурыServeMux.func Handle– это функция уровня пакета, которая использует дефолтныйServeMux.
Разница между ними:
| Критерий | (*ServeMux).Handle | http.Handle |
|---|---|---|
| Тип | Метод (ServeMux.Handle) | Функция (http.Handle) |
| Принадлежность | Работает с конкретным ServeMux (роутером) | Работает с дефолтным ServeMux |
| Где используется | Когда нужно кастомное мультиплексирование | Для простых случаев (использует DefaultServeMux) |
| Пример использования | mux := http.NewServeMux(); mux.Handle("/", handler) | http.Handle("/", handler) |
Примеры:
1. Использование (*ServeMux).Handle (кастомный ServeMux)
mux := http.NewServeMux() // создаём свой мультиплексор
mux.Handle("/path", myHandler) // регистрируем обработчик
http.ListenAndServe(":8080", mux) // запускаем сервер с этим мультиплексором
2. Использование http.Handle (дефолтный ServeMux)
http.Handle("/path", myHandler) // регистрируем обработчик в DefaultServeMux
http.ListenAndServe(":8080", nil) // nil означает использование DefaultServeMux
Важно:
- Если вы используете
http.Handle, то обработчик регистрируется вDefaultServeMux. - Если вы хотите кастомный роутер (например, для middleware, изоляции путей и т. д.), нужно использовать
NewServeMux()и(*ServeMux).Handle. - В продакшене часто избегают
DefaultServeMuxиз-за возможных конфликтов (например, если несколько библиотек тоже регистрируют пути в нём).
Вывод:
(*ServeMux).Handle– для кастомных роутеров.http.Handle– для быстрого использования дефолтного роутера.
Hundler для чего нужен
Функция (*ServeMux).Handler в пакете net/http используется для поиска обработчика (http.Handler) и шаблона пути (pattern), который соответствует переданному HTTP-запросу (*http.Request).
📌 Сигнатура функции:
func (mux *ServeMux) Handler(r *Request) (h Handler, pattern string)
r *Request– входящий HTTP-запрос.- Возвращает:
h Handler– обработчик, который должен обработать запрос.pattern string– шаблон пути, который совпал с URL запроса (например,"/users/").
🔹 Когда используется?
- Когда нужно вручную определить обработчик для запроса (например, для кастомной логики маршрутизации).
- В middleware, чтобы проверить, какой обработчик будет вызван для запроса.
- Для логирования или отладки (чтобы узнать, какой
patternсоответствует запросу).
🔹 Примеры использования
1️⃣ Пример 1: Получение обработчика для запроса
package main
import (
"fmt"
"net/http"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/hello", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello, World!")
})
// Создаём тестовый запрос
req, _ := http.NewRequest("GET", "http://example.com/hello", nil)
// Получаем обработчик и шаблон пути
handler, pattern := mux.Handler(req)
fmt.Println("Handler:", handler != nil) // true
fmt.Println("Pattern:", pattern) // "/hello"
}
Вывод:
Handler: true
Pattern: /hello
2️⃣ Пример 2: Использование в middleware
func loggingMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Получаем обработчик и шаблон до вызова next
handler, pattern := http.DefaultServeMux.Handler(r)
log.Printf("Request: %s %s → Handler: %T, Pattern: %s", r.Method, r.URL.Path, handler, pattern)
next.ServeHTTP(w, r)
})
}
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Home"))
})
http.ListenAndServe(":8080", loggingMiddleware(http.DefaultServeMux))
}
При запросе GET / в логах появится:
Request: GET / → Handler: http.HandlerFunc, Pattern: /
🔹 Как работает внутри?
- Проверяет
Host(если задан вServeMux). - Ищет точное совпадение пути (например,
/users). - Ищет самое длинное совпадение по префиксу (если путь зарегистрирован с
/users/, то запрос/users/123тоже сработает). - Если ничего не найдено – возвращает
NotFoundHandler(который отвечает с404).
🔹 Отличие от http.Handler()
(*ServeMux).Handler– метод конкретногоServeMux.http.Handler()– работает сDefaultServeMux.
Пример:
// С кастомным ServeMux
mux := http.NewServeMux()
handler, pattern := mux.Handler(req)
// С DefaultServeMux
handler, pattern := http.DefaultServeMux.Handler(req)
// Или просто:
handler, pattern := http.Handler(req) // работает с DefaultServeMux
🔹 Вывод
(*ServeMux).Handlerполезен, когда нужно динамически определить обработчик для запроса.- Используется в middleware, кастомных роутерах, логировании.
- Возвращает как сам обработчик, так и шаблон пути, что помогает в отладке.
ServeHTTP объяснение
Функция (*ServeMux).ServeHTTP — это основной метод обработки HTTP-запросов в ServeMux, который реализует интерфейс http.Handler. Она отвечает за:
- Поиск подходящего обработчика (на основе URL пути)
- Вызов этого обработчика (или возврат
404 Not Found)
🔍 Развёрнутое объяснение
📌 Сигнатура
func (mux *ServeMux) ServeHTTP(w http.ResponseWriter, r *http.Request)
w ResponseWriter— интерфейс для записи HTTP-ответа.r *Request— входящий HTTP-запрос.
🔧 Как работает? (Mermaid-схема)
flowchart TD
A[Запрос поступает в ServeMux.ServeHTTP] --> B{Есть Host в URL?}
B -->|Да| C[Ищем обработчик по host + path]
B -->|Нет| D[Ищем обработчик только по path]
C --> E{Найден обработчик?}
D --> E
E -->|Да| F[Вызываем handler.ServeHTTP(w, r)]
E -->|Нет| G[Возвращаем 404 Not Found]Пошаговый алгоритм:
- Проверяет
Host(если вServeMuxесть пути с указанием хоста, например"example.com"). - Ищет точное совпадение пути (например,
/users). - Ищет самое длинное совпадение по префиксу (если путь зарегистрирован как
/users/, то/users/123тоже сработает). - Если обработчик не найден — вызывает
NotFoundHandler(отправляет404).
📂 Пример кода
package main
import (
"net/http"
)
func main() {
mux := http.NewServeMux()
// Регистрируем обработчики
mux.HandleFunc("/", homeHandler)
mux.HandleFunc("/about", aboutHandler)
// Запускаем сервер
http.ListenAndServe(":8080", mux)
}
func homeHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Home Page"))
}
func aboutHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("About Page"))
}
🛠 Что происходит при запросе?
Запрос
GET /ServeHTTPнаходит точное совпадение с/→ вызываетhomeHandler.
Запрос
GET /about- Совпадение с
/about→ вызываетaboutHandler.
- Совпадение с
Запрос
GET /unknown- Совпадений нет → возвращает
404.
- Совпадений нет → возвращает
⚙️ Кастомизация ServeMux
Можно переопределить ServeHTTP для своей логики (например, для middleware):
type CustomMux struct {
*http.ServeMux
}
func (m *CustomMux) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// Логирование перед вызовом обработчика
log.Println("Request:", r.URL.Path)
m.ServeMux.ServeHTTP(w, r) // Вызов оригинального ServeHTTP
}
func main() {
mux := &CustomMux{http.NewServeMux()}
mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Custom Mux!"))
})
http.ListenAndServe(":8080", mux)
}
🔥 Ключевые особенности
Иерархия путей:
/images/совпадёт с/images/logo.png./images(без слеша) — только с точным совпадением.
Host-specific пути:
mux.Handle("example.com/", handler) // Сработает только для example.comДефолтный обработчик 404:
Можно заменить черезmux.NotFound = customHandler.
🎯 Вывод
ServeHTTP— ядро роутинга вnet/http.- Автоматически обрабатывает префиксы, хосты и 404.
- Может быть переопределён для кастомной логики.
Что нужно сделать,чтобы получить Handle
- Создать структуру
type home struct {}- или любой объект - Создать функцию обработчик с вызовом
ServeHTTP
func (h *home) ServeHTTP(w http.ResponseWriter, r *http.Request) { w.Write([]byte("This is my home page")) }
- Используем в коде
mux := http.NewServeMux()
mux.Handle("/", &home{})
ВСЁ!!!
А это синтетический сахар для обертывания обычных функций в Handle
mux := http.NewServeMux()
mux.HandleFunc("/", home) // home здесь обычная функция
http.ListenAndServe()
Это собственно сам сервер у которого тоже есть такой же метод ServeHTTP и который отправляет на него запросы по цепочке
Работаем с флагами командной строки
Пакет: flag
addr := flag.String("addr", ":4000", "HTTP network address") // прочитали адрес
flag.Parse()
...
log.Printf("Starting server on %s", *addr) //вывели на печать
err := http.ListenAndServe(*addr, mux) //слушаем порт, который получили из адресной строки
log.Fatal(err)
Флаги могут преобразовываться сразу в нужный тип:
- flag.String()
- flag.Int(),
- flag.Bool()
- flag.Float64().
help автоматически
для команды help автоматически сформируется все параметры вместе с подсказками
os.Getenv
Прочитает значение из переменной среды:
addr := os.Getenv("SNIPPETBOX_ADDR")
Структура флагов
type config struct {
addr string
staticDir string
}
создаем структуру для флагов и определяем переменные из структуры:
var cfg config
flag.StringVar(&cfg.addr, "addr", ":4000", "HTTP network address")
flag.StringVar(&cfg.staticDir, "static-dir", "./ui/static", "Path to static assets")
flag.Parse()
для этого используем функции:
- flag.StringVar(),
- flag.IntVar(),
- flag.BoolVar()
Логирование
- Стандартный лог выводит в терминал
log.Printf("Starting server on %s", *addr) // Information message
err := http.ListenAndServe(*addr, mux)
log.Fatal(err) // Error message
Продвинутый лог
infoLog := log.New(os.Stdout, "INFO\t", log.Ldate|log.Ltime) // создали макет лога для сообщений
errorLog := log.New(os.Stderr, "ERROR\t", log.Ldate|log.Ltime|log.Lshortfile) //макет лога для ошибок
... //вывод лога
infoLog.Printf("Starting server on %s", *addr)
err := http.ListenAndServe(*addr, mux)
errorLog.Fatal(err)
$ go run ./cmd/web
INFO 2022/01/29 16:00:50 Starting server on :4000
ERROR 2022/01/29 16:00:50 main.go:37: listen tcp :4000: bind: address already in use
exit status 1
log.Llongfile, log.Lshortfile — эти флаги определяют полноту выводимых данных
перенаправим вывод журнала в файлы
$ go run ./cmd/web >>/tmp/info.log 2>>/tmp/error.log
Логирование работы сервера
- Создать структуру для параметров сервера HTTP
infoLog := log.New(os.Stdout, "INFO\t", log.Ldate|log.Ltime)
errorLog := log.New(os.Stderr, "ERROR\t", log.Ldate|log.Ltime|log.Lshortfile)
srv := &http.Server{
Addr: *addr,
ErrorLog: errorLog,
Handler: mux,
}
// включаем сервер с обработчиком ошибок
err := srv.ListenAndServe()
Логирование в файл
f, err := os.OpenFile("/tmp/info.log", os.O_RDWR|os.O_CREATE, 0666)
if err != nil {
log.Fatal(err)
}
defer f.Close()
infoLog := log.New(f, "INFO\t", log.Ldate|log.Ltime)
Логирование во всех зависимостях приложения
Создать структуру приложения с его переменными
type application struct {
errorLog *log.Logger
infoLog *log.Logger
}
в main.go задать значения:
infoLog := log.New(os.Stdout, "INFO\t", log.Ldate|log.Ltime)
errorLog := log.New(os.Stderr, "ERROR\t", log.Ldate|log.Ltime|log.Lshortfile)
app := &application{
errorLog: errorLog,
infoLog: infoLog,
}
и использовать во всех зависимостях
так в обработчиках добавляем зависимость от структуры:
func (app *application) home(w http.ResponseWriter, r *http.Request) {
if r.URL.Path != "/" {
http.NotFound(w, r)
return
}
Вариант использования пакета config
func main() {
app := &config.Application{
ErrorLog: log.New(os.Stderr, "ERROR\t", log.Ldate|log.Ltime|log.Lshortfile)
}
mux.Handle("/", examplePackage.ExampleHandler(app))
}
func ExampleHandler(app *config.Application) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
...
ts, err := template.ParseFiles(files...)
if err != nil {
app.ErrorLog.Println(err.Error())
http.Error(w, "Internal Server Error", 500)
return
}
...
}
}
пакет позволяет применять конфигурацию для всех зависимостей
Динамические данные в шаблоне
Объявление внутреннего модуля в проекте
в проекте может быть несколько внутренних и не только внутренних модулей. В нашем случае внутренний модуль лежит в папке /internal/models. Учитывая, что основной проект называется: snippetbox.alexedwards.net, то полный путь к модулю будет: "snippetbox.alexedwards.net/internal/models"
package main
import (
"errors"
"fmt"
"html/template" // Uncomment import
"net/http"
"strconv"
"snippetbox.alexedwards.net/internal/models"
)
Для работы динамических шаблонов нужно:
- Создать шаблоны
- Выстроить иерархию внутри них (каждый блок и раздел лучше делать в отдельном шаблоне и соединять в один, например
base) - Создать массив строк с наименованием шаблонов и путей к ним
files := []string{
"./ui/html/base.tmpl",
"./ui/html/partials/nav.tmpl",
"./ui/html/pages/view.tmpl",
}
- Пропарсить шаблоны
ts, err := template.ParseFiles(files...)
if err != nil {
app.serverError(w, err)
return
}
- Собрать html из шаблонов
err = ts.ExecuteTemplate(w, "base", snippet) //собираем в шаблоне base и передаем в него структуру данных snippet
if err != nil {
app.serverError(w, err)
}
Базовые понятия работы с шаблонами html/template
Для работы с сущностями создадим структуру в дополнительном модуле.
type Snippet struct {
ID int
Title string
Content string
Created time.Time
Expires time.Time
}
Эта структура будет работать с базой данных и шаблонами
.— весь контекст переданный в этот блок- Передать структуру в шаблон:
err = ts.ExecuteTemplate(w, "base", snippet) - Использовать поля структуры в шаблоне
{{.Title}}и т.д.
{{define "title"}}Snippet #{{.ID}}{{end}}
{{define "main"}}
<div class='snippet'>
<div class='metadata'>
<strong>{{.Title}}</strong>
<span>#{{.ID}}</span>
</div>
<pre><code>{{.Content}}</code></pre>
<div class='metadata'>
<time>Created: {{.Created}}</time>
<time>Expires: {{.Expires}}</time>
</div>
</div>
{{end}}
Особенности пакета template
В структуру шаблонов можно передавать только одну переменную. Поэтому для передачи нескольких переменных их нужно собрать всех в одну структуру.- Создать структуру
type templateData struct {
Snippet *models.Snippet
}
- Выполнить все действия, описанные выше по парсингу шаблонов
- Создать экземпляр структуры данных
data := &templateData{
Snippet: snippet,
}
- Передать данные в генератор html кода
err = ts.ExecuteTemplate(w, "base", data)
if err != nil {
app.serverError(w, err)
}
- В шаблоне значения полей тогда будут вызываться с указанием полного пути поля:
{{.Snippet.ID}}или{{.Snippet.Title}}
{{define "title"}}Snippet #{{.Snippet.ID}}{{end}}
{{define "main"}}
<div class='snippet'>
<div class='metadata'>
<strong>{{.Snippet.Title}}</strong>
<span>#{{.Snippet.ID}}</span>
</div>
<pre><code>{{.Snippet.Content}}</code></pre>
<div class='metadata'>
<time>Created: {{.Snippet.Created}}</time>
<time>Expires: {{.Snippet.Expires}}</time>
</div>
</div>
{{end}}
Вложенные структуры в шаблонах
Объявили шаблон
{{define "base"}}
...
{{end}}
Использование шаблона
В основном шаблоне можно указывать другие шаблоны, которые определены в других файлах. В других файлах может быть определено несколько шаблонов в каждом файле.
{{define "title"}}Home{{end}}
{{define "main"}}
<h2>Latest Snippets</h2>
<p>There's nothing to see here yet!</p>
{{end}}
Вставка встроенного шаблона в точку основного шаблона
{{template "title" .}}
{{define "base"}}
<!doctype html>
<html lang='en'>
<head>
<meta charset='utf-8'>
<title>{{template "title" .}} - Snippetbox</title>
</head>
<body>
<header>
<h1><a href='/'>Snippetbox</a></h1>
</header>
<main>
{{template "main" .}}
</main>
<footer>Powered by <a href='https://golang.org/'>Go</a></footer>
</body>
</html>
{{end}}
{{block}}…{{end}}
{{define "base"}}
<h1>An example template</h1>
{{block "sidebar" .}}
<p>My default sidebar content</p>
{{end}}
{{end}}
этот параметр можем использовать для передачи значений по умолчанию. Если нет в этом блоке данных, то он и не выведется, в отличии от {{template}}, который будет требовать обязательного вывода контента.
Вызов методов к полям
{{.Snippet.Created.Weekday}} к нашему полю .Snippet.Created вызовем метод Weekday
или {{.Snippet.Created.AddDate 0 6 0}}
{{if .Foo}} C1 {{else}} C2 {{end}}
{{with .Foo}} C1 {{else}} C2 {{end}}
{{define "title"}}Snippet #{{.Snippet.ID}}{{end}}
{{define "main"}}
{{with .Snippet}}
<div class='snippet'>
<div class='metadata'>
<strong>{{.Title}}</strong>
<span>#{{.ID}}</span>
</div>
<pre><code>{{.Content}}</code></pre>
<div class='metadata'>
<time>Created: {{.Created}}</time>
<time>Expires: {{.Expires}}</time>
</div>
</div>
{{end}}
{{end}}
собственно метод with позволяет далее в этом блоке работать с полями указанной структуры без указания ее полного пути
{{range .Foo}} C1 {{else}} C2 {{end}}
range пройдется по всем элементам .Foo как цикл и выполнит все действия как делает with с одним элементом
Операторы сравнения и логики
{{eq .Foo .Bar}} {{ne .Foo .Bar}} {{not .Foo}} {{or .Foo .Bar}}
{{index .Foo i}}
возвращает текущий индекс массива
{{printf “%s-%s” .Foo .Bar}}
форматированная печать значений
{{len .Foo}}
{{$bar := len .Foo}} — в этом варианте присвоит переменной длину .Foo
{{break}} {{continue}}
используется в if для разветвленной логики
Кэширование
Объяснение создания кэша
Подробный разбор map[string]*template.Template
1. Базовый анализ структуры
map[string]*template.Template
Это декларация типа в Go, представляющая:
- map - ассоциативный массив/словарь
- string - тип ключа (строка)
- *template.Template - тип значения (указатель на объект Template)
2. Компоненты:
- template.Template - тип из пакета
html/templateилиtext/template, представляющий:- Разобранный шаблон
- Методы для выполнения шаблонов
- Ассоциированные именованные шаблоны
- Указатель (*) - используется для:
- Работы с одним экземпляром шаблона
- Избегания копирования больших структур
- Модификации шаблона после создания
3. Типичное использование:
templates := make(map[string]*template.Template)
// Добавление шаблона
templates["home"] = template.Must(template.ParseFiles("home.html"))
templates["about"] = template.Must(template.ParseFiles("about.html"))
// Использование
err := templates["home"].Execute(w, data)
4. Преимущества такого подхода:
Организация шаблонов:
- Группировка по функциональности (страницы, компоненты)
- Быстрый доступ по имени
Производительность:
- Парсинг шаблонов один раз при инициализации
- Кэширование готовых шаблонов
Гибкость:
- Динамический выбор шаблона
- Возможность горячей перезагрузки
5. Пример расширенного использования:
// Инициализация кэша шаблонов
var templateCache = map[string]*template.Template{
"home": parseTemplate("home.html", "layout.html"),
"about": parseTemplate("about.html", "layout.html"),
}
func parseTemplate(files ...string) *template.Template {
ts, err := template.ParseFiles(files...)
if err != nil {
log.Fatal(err)
}
return ts
}
// Обработчик HTTP
func homeHandler(w http.ResponseWriter, r *http.Request) {
data := struct{ Title string }{Title: "Главная"}
err := templateCache["home"].ExecuteTemplate(w, "layout", data)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
}
}
6. Особенности работы:
- Потокобезопасность: Шаблоны безопасны для конкурентного использования после создания
- Жизненный цикл: Обычно создаются при старте приложения
- Ошибки: Проверка должна быть при:
- Создании мапы
- Парсинге шаблонов
- Выполнении шаблонов
7. Альтернативные подходы:
sync.Map - для конкурентного доступа
var templates sync.Map templates.Store("home", template.Must(template.ParseFiles("home.html")))Вложенные мапы - для сложных структур:
map[string]map[string]*template.Template
Такой подход широко используется в веб-фреймворках и приложениях для эффективного управления шаблонами.
создали функцию, которая будет кэшировать шаблоны в памяти map
package main
import (
"html/template" // New import
"path/filepath" // New import
"snippetbox.alexedwards.net/internal/models"
)
...
func newTemplateCache() (map[string]*template.Template, error) {
// Initialize a new map to act as the cache.
cache := map[string]*template.Template{}
// Use the filepath.Glob() function to get a slice of all filepaths that
// match the pattern "./ui/html/pages/*.tmpl". This will essentially gives
// us a slice of all the filepaths for our application 'page' templates
// like: [ui/html/pages/home.tmpl ui/html/pages/view.tmpl]
pages, err := filepath.Glob("./ui/html/pages/*.tmpl")
if err != nil {
return nil, err
}
// Loop through the page filepaths one-by-one.
for _, page := range pages {
// Extract the file name (like 'home.tmpl') from the full filepath
// and assign it to the name variable.
name := filepath.Base(page)
// Create a slice containing the filepaths for our base template, any
// partials and the page.
files := []string{
"./ui/html/base.tmpl",
"./ui/html/partials/nav.tmpl",
page,
}
// Parse the files into a template set.
ts, err := template.ParseFiles(files...)
if err != nil {
return nil, err
}
// Add the template set to the map, using the name of the page
// (like 'home.tmpl') as the key.
cache[name] = ts
}
// Return the map.
return cache, nil
}
в структуру приложения добавим поле
type application struct {
errorLog *log.Logger
infoLog *log.Logger
snippets *models.SnippetModel
templateCache map[string]*template.Template //это кэш
}
инициализация кэш
// Initialize a new template cache...
templateCache, err := newTemplateCache() //вызываем функцию и создаем кэш
if err != nil {
errorLog.Fatal(err)
}
создаем экземпляр приложения app с кэшем
app := &application{
errorLog: errorLog,
infoLog: infoLog,
snippets: &models.SnippetModel{DB: db},
templateCache: templateCache,
}
выдача кэшированных страниц
создадим функцию render
package main
...
func (app *application) render(w http.ResponseWriter, status int, page string, data *templateData) {
// Retrieve the appropriate template set from the cache based on the page
// name (like 'home.tmpl'). If no entry exists in the cache with the
// provided name, then create a new error and call the serverError() helper
// method that we made earlier and return.
ts, ok := app.templateCache[page]
if !ok {
err := fmt.Errorf("the template %s does not exist", page)
app.serverError(w, err)
return
}
// Write out the provided HTTP status code ('200 OK', '400 Bad Request'
// etc).
w.WriteHeader(status)
// Execute the template set and write the response body. Again, if there
// is any error we call the the serverError() helper.
err := ts.ExecuteTemplate(w, "base", data)
if err != nil {
app.serverError(w, err)
}
}
в эту функцию передаем название страницы и получаем готовый html код, только теперь уже из кэша
пример функции обращения к кэшу
func (app *application) home(w http.ResponseWriter, r *http.Request) {
if r.URL.Path != "/" {
app.notFound(w)
return
}
snippets, err := app.snippets.Latest()
if err != nil {
app.serverError(w, err)
return
}
// Use the new render helper.
app.render(w, http.StatusOK, "home.tmpl", &templateData{
Snippets: snippets,
})
}
полный код создания кэша
package main
...
func newTemplateCache() (map[string]*template.Template, error) {
cache := map[string]*template.Template{}
pages, err := filepath.Glob("./ui/html/pages/*.tmpl")
if err != nil {
return nil, err
}
for _, page := range pages {
name := filepath.Base(page)
// Parse the base template file into a template set.
ts, err := template.ParseFiles("./ui/html/base.tmpl")
if err != nil {
return nil, err
}
// Call ParseGlob() *on this template set* to add any partials.
ts, err = ts.ParseGlob("./ui/html/partials/*.tmpl")
if err != nil {
return nil, err
}
// Call ParseFiles() *on this template set* to add the page template.
ts, err = ts.ParseFiles(page)
if err != nil {
return nil, err
}
// Add the template set to the map as normal...
cache[name] = ts
}
return cache, nil
}
Объяснение парсинга шаблонов в кэш
Развернутое объяснение функции newTemplateCache()
Эта функция создает кэш шаблонов для веб-приложения, загружая и компилируя все шаблоны страниц вместе с базовым шаблоном и частичными шаблонами (partials). Рассмотрим ее построчно:
1. Объявление функции
func newTemplateCache() (map[string]*template.Template, error)
- Назначение: Создает и возвращает кэш шаблонов
- Возвращаемые значения:
map[string]*template.Template- кэш шаблонов, где ключ - имя файла шаблонаerror- ошибка, если что-то пошло не так
2. Инициализация кэша
cache := map[string]*template.Template{}
- Создается пустая мапа для хранения шаблонов
3. Поиск файлов страниц
pages, err := filepath.Glob("./ui/html/pages/*.tmpl")
- Использует
filepath.Globдля поиска всех файлов с расширением.tmplв директории./ui/html/pages/ - Возвращает список путей к файлам или ошибку
4. Обработка ошибок поиска
if err != nil {
return nil, err
}
- Если при поиске файлов произошла ошибка, возвращает ее
5. Цикл по найденным страницам
for _, page := range pages {
- Перебирает все найденные файлы шаблонов страниц
6. Получение имени файла
name := filepath.Base(page)
- Извлекает базовое имя файла (без пути) с помощью
filepath.Base() - Например, для “./ui/html/pages/home.tmpl” вернет “home.tmpl”
7. Парсинг базового шаблона
ts, err := template.ParseFiles("./ui/html/base.tmpl")
- Создает новый набор шаблонов (
*template.Template), загружая базовый шаблон - Базовый шаблон обычно содержит общую структуру HTML (doctype, head, общие скрипты/стили)
8. Обработка ошибок парсинга
if err != nil {
return nil, err
}
- Если не удалось загрузить базовый шаблон, возвращает ошибку
9. Добавление частичных шаблонов
ts, err = ts.ParseGlob("./ui/html/partials/*.tmpl")
- Добавляет в набор шаблонов все файлы из директории partials
- Частичные шаблоны - это повторно используемые компоненты (header, footer и т.д.)
10. Обработка ошибок добавления partials
if err != nil {
return nil, err
}
- Возвращает ошибку, если не удалось загрузить partials
11. Добавление шаблона страницы
ts, err = ts.ParseFiles(page)
- Загружает конкретный шаблон страницы в тот же набор шаблонов
- Это позволяет странице использовать базовый шаблон и partials
12. Обработка ошибок добавления страницы
if err != nil {
return nil, err
}
- Возвращает ошибку, если не удалось загрузить шаблон страницы
13. Сохранение в кэш
cache[name] = ts
- Сохраняет готовый набор шаблонов в кэш под именем файла страницы
14. Возврат результата
return cache, nil
- После обработки всех страниц возвращает заполненный кэш и nil в качестве ошибки
Особенности работы:
Иерархия шаблонов:
- Базовый шаблон (base.tmpl)
- Частичные шаблоны (partials/*.tmpl)
- Шаблоны страниц (pages/*.tmpl)
Преимущества:
- Все шаблоны парсятся один раз при старте приложения
- Готовые к использованию шаблоны хранятся в памяти
- Быстрый доступ к шаблонам по имени
Использование в обработчиках:
// Где-то в обработчике: err := cache["home.tmpl"].ExecuteTemplate(w, "base", data)Расширения:
- Можно добавить горячую перезагрузку в dev-режиме
- Можно кэшировать не только по имени файла, но и по логическому имени страницы
Эта реализация обеспечивает удобное управление шаблонами в веб-приложении, следуя принципам DRY (Don’t Repeat Yourself) и обеспечивая хорошую производительность.
Как избежать ошибок при рендеринге динамического кода
- Делать рендер кода
- Записывать результат в буфер
- Проверять на отсутствие ошибок
- делать выдачу в
http.ResponseWriter.
Обновленный код обработчика с промежуточной записью результата в буфер
package main
import (
"bytes" // New import
"fmt"
"net/http"
"runtime/debug"
)
...
func (app *application) render(w http.ResponseWriter, status int, page string, data *templateData) {
ts, ok := app.templateCache[page]
if !ok {
err := fmt.Errorf("the template %s does not exist", page)
app.serverError(w, err)
return
}
// инициализация буфера
buf := new(bytes.Buffer)
// записываем результат рендеринга в буфер
err := ts.ExecuteTemplate(buf, "base", data)
if err != nil {
app.serverError(w, err)
return
}
// запишем статус в заголовок ответа
w.WriteHeader(status)
// возвращаем результат успешного рендеринга
buf.WriteTo(w)
}
Динамические данные в шаблонах
- Создадим специальную структуру для передачи динамических данных в шаблон
type templateData struct {
CurrentYear int
Snippet *models.Snippet
Snippets []*models.Snippet
}
- Создадим функцию helpers для возврата указателя на структуру с данными и расчетом динамических данных
func (app *application) newTemplateData(r *http.Request) *templateData {//получаем на вход указатель с данными запроса
return &templateData{ //и возвращаем указатель с данными ответа
CurrentYear: time.Now().Year(),// по дороге посчитаем какой текущий год
}
}
- Делаем вызов функции
renderи передаем ей на вход структуру с даннымиtemplateData
//загружаем из базы данные в переменную snippets
snippets, err := app.snippets.Latest()
if err != nil {
app.serverError(w, err)
return
}
data := app.newTemplateData(r) //создаем переменную типа templateData
data.Snippets = snippets //записываем в структуру переменной значения из базы данных
//вызываем функцию render и передаем ей структуру с изменяемыми данными
app.render(w, http.StatusOK, "home.tmpl", data)
- Повторяем такие вызовы для всех обработчиков
- В шаблонах обрабатываем данные из структуры
templateDataкак {{.Snippets}} или {{.Snippet}} и текущий год как {{.CurrentYear}}
Пользовательские функции в шаблонах
- Создаем функцию, которую планируем добавить в шаблон
func humanDate(t time.Time) string {
return t.Format("02 Jan 2006 at 15:04")
}
- Создаем объект
template.FuncMapи в нем объявляем свою функцию (напримерhumanDate()). Фактически в переменной function создается карта: ключ - значение, где значение, это название функции, которое мы передаем в шаблон.
var functions = template.FuncMap{
"humanDate": humanDate,
}
- Метод должен быть зарегистрирован до парсинга шаблона
for _, page := range pages {
name := filepath.Base(page)
//перед парсером файла с шаблоном, передаем переменную functions с объявленными функциями
//функций может быть несколько
ts, err := template.New(name).Funcs(functions).ParseFiles("./ui/html/base.tmpl")
if err != nil {
return nil, err
}
ts, err = ts.ParseGlob("./ui/html/partials/*.tmpl")
if err != nil {
return nil, err
}
ts, err = ts.ParseFiles(page)
if err != nil {
return nil, err
}
cache[name] = ts
}
- Используем функцию в шаблоне как и другие функции
<td>{{humanDate .Created}}</td>
или
<time>Created: {{.Created | humanDate}}</time>
или
<time>{{.Created | humanDate | printf "Created: %s"}}</time>
Объяснение порядка добавления функций в шаблон
Подробный разбор команды ts, err := template.New(name).Funcs(functions).ParseFiles("./ui/html/base.tmpl")
Эта строка кода создает и настраивает новый шаблон в Go. Разберем ее по цепочке вызовов:
1. template.New(name)
- Назначение: Создает новый пустой шаблон
- Параметр:
name(string) - уникальное имя шаблона
- Возвращает: Указатель на
*template.Template - Особенности:
- Имя используется для вызова шаблона через
{{template "name"}} - Если шаблон с таким именем уже существует, он будет заменен
- Имя используется для вызова шаблона через
2. .Funcs(functions)
- Назначение: Регистрирует пользовательские функции для использования в шаблоне
- Параметр:
functions(типtemplate.FuncMap) - мапа функций видаmap[string]interface{}
- Пример:
functions := template.FuncMap{ "uppercase": strings.ToUpper, "add": func(a, b int) int { return a + b }, } - Важно:
- Должен вызываться до парсинга шаблона
- Функции должны возвращать 1 или 2 значения (второе - error)
3. .ParseFiles("./ui/html/base.tmpl")
- Назначение: Парсит указанные файлы как тело шаблона
- Параметр:
- Путь к файлу шаблона (может принимать несколько файлов)
- Особенности:
- Первый файл становится “ассоциированным” с этим шаблоном
- Может содержать определения других шаблонов через
{{define}}
Возвращаемые значения:
ts(*template.Template) - созданный шаблонerr(error) - ошибка, если что-то пошло не так
Полный пример использования:
funcs := template.FuncMap{
"formatDate": func(t time.Time) string { return t.Format("2006-01-02") },
}
ts, err := template.New("base").Funcs(funcs).ParseFiles("./ui/html/base.tmpl")
if err != nil {
log.Fatal(err)
}
// Использование в обработчике
err = ts.Execute(w, data)
Что происходит под капотом:
- Создается новый именованный шаблон
- Регистрируются пользовательские функции
- Читается и парсится файл шаблона
- Все определения шаблонов из файла добавляются в набор
Особенности безопасности при использовании html/template:
- Автоматическое экранирование в зависимости от контекста
- Защита от XSS-атак
- Контекстно-зависимое экранирование для HTML, JS, CSS
Типичные ошибки:
- Регистрация функций после парсинга
- Использование несуществующих путей к файлам
- Попытка использовать недопустимые имена функций (например, с точками)
Эта цепочка вызовов является идиоматическим способом создания шаблонов в Go и часто используется при инициализации веб-приложений.
Middleware
Стандартный паттерн middlware
func myMiddleware(next http.Handler) http.Handler {
fn := func(w http.ResponseWriter, r *http.Request) {
// TODO: Execute our middleware logic here...
next.ServeHTTP(w, r)
}
return http.HandlerFunc(fn)
}
или использование анонимной функции
func myMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// TODO: Execute our middleware logic here...
next.ServeHTTP(w, r)
})
}
Объяснение middleware
Middleware в Go: кратко и понятно
Middleware — это промежуточный слой между HTTP-запросом и вашим обработчиком. Он позволяет выполнять код до или после основного обработчика (например, логирование, проверку авторизации, сжатие данных).
1. Глобальный Middleware (для всех запросов)
Если middleware добавлен до servemux (роутера), то он будет выполняться для всех запросов.
Схема:
Запрос → Middleware → Servemux → Обработчик
Пример:
func logRequest(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
log.Printf("Запрос: %s %s", r.Method, r.URL.Path)
next.ServeHTTP(w, r) // Передаем запрос дальше
})
}
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/", homeHandler)
// Middleware применяется ко ВСЕМ запросам
app := logRequest(mux)
http.ListenAndServe(":8080", app)
}
Когда использовать:
✅ Логирование
✅ Сжатие ответов (gzip)
✅ Добавление заголовков CORS
2. Локальный Middleware (для конкретных маршрутов)
Если middleware добавлен после servemux (оборачивает конкретный обработчик), то он работает только для определенных маршрутов.
Схема:
Запрос → Servemux → Middleware → Обработчик
Пример:
func checkAuth(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if !isAuthenticated(r) {
http.Error(w, "Доступ запрещен", http.StatusUnauthorized)
return
}
next.ServeHTTP(w, r) // Пропускаем авторизованных
})
}
func main() {
mux := http.NewServeMux()
mux.Handle("/admin", checkAuth(adminHandler)) // Только для /admin
mux.HandleFunc("/", homeHandler) // Без middleware
http.ListenAndServe(":8080", mux)
}
Когда использовать:
✅ Проверка авторизации
✅ Валидация данных
✅ Лимитирование запросов (rate limiting)
Вывод:
- До
servemux→ Middleware на все запросы. - После
servemux→ Middleware только для выбранных маршрутов.
Это дает гибкость в управлении логикой приложения без дублирования кода. 🚀
Создадим обработчик заголовков для всех страниц
Будем возвращать шаблоны html и к каждому будем записывать правильный заголовок в ответе
Content-Security-Policy: default-src 'self'; style-src 'self' fonts.googleapis.com; font-src fonts.gstatic.com
Referrer-Policy: origin-when-cross-origin
X-Content-Type-Options: nosniff
X-Frame-Options: deny
X-XSS-Protection: 0
Объяснение HEADERS
Краткое описание HTTP-заголовков безопасности
Эти заголовки защищают веб-приложение от распространённых атак (XSS, clickjacking, MIME-sniffing и др.).
1. Content-Security-Policy (CSP)
Назначение: Ограничивает источники загрузки ресурсов (JS, CSS, шрифты, изображения).
Пример:
Content-Security-Policy: default-src 'self'; font-src fonts.gstatic.com; style-src fonts.googleapis.com 'self'
Эффект:
- Блокирует inline-JS (
unsafe-inline) - Разрешает шрифты только с
fonts.gstatic.com - Стили — с
fonts.googleapis.comи своего домена
Другие варианты:
script-src 'self' https://trusted.cdn.com— разрешает скрипты только с указанных источниковimg-src *— разрешает изображения с любых доменов (небезопасно!)
2. Referrer-Policy
Назначение: Контролирует, какие данные отправляются в заголовке Referer при переходе на другой сайт.
Пример:
Referrer-Policy: origin-when-cross-origin
Эффект:
- При переходе внутри сайта (
same-origin) передаётся полный URL. - При переходе на другой домен — только источник (без пути и параметров).
Другие варианты:
no-referrer— вообще не отправлятьRefererstrict-origin— всегда отправлять только домен (без протокола и пути)
3. X-Content-Type-Options: nosniff
Назначение: Запрещает браузеру “угадывать” тип контента (MIME-sniffing).
Пример:
X-Content-Type-Options: nosniff
Эффект:
- Браузер строго следует указанному
Content-Type. - Защищает от атак, когда вредоносный файл маскируется под изображение/JS.
4. X-Frame-Options: deny
Назначение: Блокирует встраивание страницы в <iframe> (защита от clickjacking).
Пример:
X-Frame-Options: deny
Альтернативы:
sameorigin— разрешает iframe только с текущего домена- Устарел в пользу CSP с
frame-ancestors 'none'
5. X-XSS-Protection: 0
Назначение: Отключает встроенный XSS-фильтр браузера (устаревший механизм).
Почему 0?
- Современные браузеры используют CSP для защиты от XSS.
- Старые версии
X-XSS-Protectionиногда сами вызывали уязвимости.
Другие важные заголовки безопасности
Strict-Transport-Security(HSTS)- Принудительное использование HTTPS:
Strict-Transport-Security: max-age=63072000; includeSubDomains; preloadPermissions-Policy- Отключает нежелательные API (камера, геолокация и др.):
Permissions-Policy: geolocation=(), microphone=()Cross-Origin-Opener-Policy(COOP)- Защищает от атак типа Spectre:
Cross-Origin-Opener-Policy: same-originCross-Origin-Embedder-Policy(COEP)- Блокирует загрузку кросс-доменных ресурсов без CORS:
Cross-Origin-Embedder-Policy: require-corp
Итог
| Заголовок | Защита от | Современная альтернатива |
|---|---|---|
CSP | XSS, data injection | — |
Referrer-Policy | Утечка URL | — |
X-Content-Type-Options | MIME-sniffing | — |
X-Frame-Options | Clickjacking | CSP: frame-ancestors 'none' |
X-XSS-Protection | Устаревший XSS-фильтр | CSP |
Оптимальный набор:
Content-Security-Policy: default-src 'self'; script-src 'self' https://trusted.cdn.com; frame-ancestors 'none'
Strict-Transport-Security: max-age=63072000; includeSubDomains
Referrer-Policy: strict-origin-when-cross-origin
X-Content-Type-Options: nosniff
- Создадим функцию для создания заголовков
package main
import (
"net/http"
)
func secureHeaders(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Note: This is split across multiple lines for readability. You don't
// need to do this in your own code.
w.Header().Set("Content-Security-Policy",
"default-src 'self'; style-src 'self' fonts.googleapis.com; font-src fonts.gstatic.com")
w.Header().Set("Referrer-Policy", "origin-when-cross-origin")
w.Header().Set("X-Content-Type-Options", "nosniff")
w.Header().Set("X-Frame-Options", "deny")
w.Header().Set("X-XSS-Protection", "0")
next.ServeHTTP(w, r)
})
}
- Создадим функцию обработчик маршрутов
package main
import "net/http"
// Update the signature for the routes() method so that it returns a
// http.Handler instead of *http.ServeMux.
func (app *application) routes() http.Handler {
mux := http.NewServeMux()
fileServer := http.FileServer(http.Dir("./ui/static/"))
mux.Handle("/static/", http.StripPrefix("/static", fileServer))
mux.HandleFunc("/", app.home)
mux.HandleFunc("/snippet/view", app.snippetView)
mux.HandleFunc("/snippet/create", app.snippetCreate)
// Pass the servemux as the 'next' parameter to the secureHeaders middleware.
// Because secureHeaders is just a function, and the function returns a
// http.Handler we don't need to do anything else.
return secureHeaders(mux)
}
- После обработки маршрута для каждой страницы будут создан заголовок
Функция логирования запросов
func (app *application) logRequest(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
app.infoLog.Printf("%s - %s %s %s", r.RemoteAddr, r.Proto, r.Method, r.URL.RequestURI())
next.ServeHTTP(w, r)
})
}
и для нашего случая выстроим цепочку middleware запросов
return app.logRequest(secureHeaders(mux))
полный код routes.go
package main
import "net/http"
func (app *application) routes() http.Handler {
mux := http.NewServeMux()
fileServer := http.FileServer(http.Dir("./ui/static/"))
mux.Handle("/static/", http.StripPrefix("/static", fileServer))
mux.HandleFunc("/", app.home)
mux.HandleFunc("/snippet/view", app.snippetView)
mux.HandleFunc("/snippet/create", app.snippetCreate)
// Wrap the existing chain with the logRequest middleware.
return app.logRequest(secureHeaders(mux))
}
Обработка паники в HTTP сервере
func (app *application) recoverPanic(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Create a deferred function (which will always be run in the event
// of a panic as Go unwinds the stack).
defer func() {
// Use the builtin recover function to check if there has been a
// panic or not. If there has...
if err := recover(); err != nil {
// Set a "Connection: close" header on the response.
w.Header().Set("Connection", "close")
// Call the app.serverError helper method to return a 500
// Internal Server response.
app.serverError(w, fmt.Errorf("%s", err))
}
}()
next.ServeHTTP(w, r)
})
}
Разбор HTTP-заголовка Connection: Close и работы recover() в Go
1. Заголовок Connection: Close
Назначение:
- Принудительно закрывает HTTP-соединение после отправки ответа.
- Сообщает клиенту, что сервер разорвёт соединение.
Особенности:
- В HTTP/1.x заголовок
Connection: Closeкорректен и заставляет сервер закрыть соединение. - В HTTP/2 Go автоматически удаляет этот заголовок (чтобы не нарушать спецификацию) и вместо этого отправляет фрейм
GOAWAYдля graceful-закрытия.
Пример использования:
w.Header().Set("Connection", "Close") // Закрыть соединение после ответа
Когда применять:
- Для серверов с высокой нагрузкой, чтобы уменьшить число висящих соединений.
- В тестовых средах для принудительного сброса соединений.
2. Функция recover() и обработка паник
Как работает recover():
- Возвращает значение, переданное в
panic()(типany). - Это значение может быть:
string,error, или любым другим типом.
justinas/alice Пример:
func handlePanic() {
if r := recover(); r != nil {
// Нормализация в error
err := fmt.Errorf("panic: %v", r)
app.serverError(err) // Обработка ошибки
}
}
Что происходит:
- Если вызвана
panic("oops! something went wrong"),recover()вернёт строку"oops! something went wrong". fmt.Errorf()преобразует это значение вerror.- Ошибка передаётся в метод
app.serverError()для логирования/отправки клиенту.
Зачем это нужно:
- Чтобы избежать аварийного завершения программы при панике.
- Логировать ошибки и отправлять клиенту понятный ответ (например,
500 Internal Server Error).
Важно:
recover()работает только внутриdefer.- Всегда проверяйте, что
recover()вернул неnil.
Заключительный вариант вызова middleware
return app.recoverPanic(app.logRequest(secureHeaders(mux)))
Делается обработка для всех запускаемых горутин.
Автор рекомендует пакет justinas/alice
Для удобного и читабельного управления middleware можно использовать пакет justinas/alice
Особенности:
- вместо
return myMiddleware1(myMiddleware2(myMiddleware3(myHandler)))будем писатьreturn alice.New(myMiddleware1, myMiddleware2, myMiddleware3).Then(myHandler) - есть методы Append и Then
myChain := alice.New(myMiddlewareOne, myMiddlewareTwo)
myOtherChain := myChain.Append(myMiddleware3)
return myOtherChain.Then(myHandler)
для нашего примера будет выглядеть:
standard := alice.New(app.recoverPanic, app.logRequest, secureHeaders)
// Return the 'standard' middleware chain followed by the servemux.
return standard.Then(mux)
Расширенные обработчики маршрутов
Автор предлагает вместо стандартной библиотеки Go использовать сторонних разработчиков:
- julienschmidt/httprouter,
- go-chi/chi,
- gorilla/mux.
сделав анализ современного развития этих пакетов можно прийти к выводу:
Сравнение пакетов
Вот сравнительный анализ трёх популярных HTTP-роутеров для Go (julienschmidt/httprouter, go-chi/chi, gorilla/mux) в сравнении со стандартным net/http, а также рекомендации по их применению:
1. julienschmidt/httprouter
Отличия от net/http:
✅ Высокая производительность – один из самых быстрых роутеров благодаря оптимизированному алгоритму сопоставления путей.
✅ Поддержка параметров в пути (например, /user/:id) с синтаксисом :param и *catch-all.
✅ Четкое разделение методов HTTP (GET, POST и т. д.), что предотвращает коллизии.
❌ Нет встроенного middleware-стека (но можно подключить вручную).
❌ Менее гибкий, чем chi и gorilla/mux, из-за строгого подхода к роутингу.
Рекомендации:
✔ Используйте, если нужна максимальная скорость (например, в high-load API).
✔ Хорош для RESTful-сервисов с четкой структурой эндпоинтов.
✔ Не подходит, если нужна сложная логика маршрутизации или встроенная поддержка middleware.
2. go-chi/chi
Отличия от net/http:
✅ Полная совместимость с net/http – можно использовать стандартные http.Handler и http.HandlerFunc.
✅ Гибкость и простота – удобный синтаксис для группировки роутов и middleware.
✅ Встроенная поддержка middleware (например, CORS, логирование, аутентификация).
✅ Поддержка параметров в URL (/posts/{id}) и regex-ограничений.
❌ Чуть медленнее, чем httprouter, но разница незначительна в большинстве сценариев.
Рекомендации:
✔ Идеален для REST API и веб-приложений с middleware (аутентификация, логирование и т. д.).
✔ Подходит, если важна простота и совместимость со стандартной библиотекой.
✔ Лучший выбор для проектов, где баланс между скоростью и функциональностью критичен.
3. gorilla/mux
Отличия от net/http:
✅ Богатые возможности маршрутизации – поддержка regex, условий на методы HTTP, query-параметров.
✅ Гибкость – можно задавать сложные правила для роутов (например, r.Host("example.com").Methods("GET")).
✅ Поддержка middleware (через gorilla/handlers или совместимость с http.Handler).
❌ Медленнее, чем httprouter и chi.
❌ Сложнее в настройке из-за обилия возможностей.
❌ Проект в архиве (maintenance mode), но стабилен и используется в многих проектах.
Рекомендации:
✔ Хорош для legacy-проектов или сложных маршрутов с regex и условиями.
✔ Подходит, если нужен максимальный контроль над роутингом (например, поддомены, строгие условия).
✔ Лучше избегать в новых проектах (из-за статуса “архивный”), но старые проекты могут продолжать его использовать.
Сравнение со стандартным net/http
| Роутер | Скорость | Гибкость | Middleware | Простота | Поддержка |
|---|---|---|---|---|---|
net/http | ⚡️ Быстрый | ❌ Низкая | ❌ Нет | ✅ Простой | ✅ Активен |
httprouter | ⚡️⚡️ Очень быстрый | ❌ Жёсткий | ❌ Требует костылей | ✅ Простой | ✅ Активен |
chi | ⚡️ Быстрый | ✅ Высокая | ✅ Встроенный | ✅ Простой | ✅ Активен |
gorilla/mux | 🐢 Умеренный | ✅ Очень высокая | ✅ Через handlers | ❌ Сложный | ❌ Архивный |
Итоговые рекомендации:
- Для высоконагруженных API →
httprouter. - Для баланса скорости и функциональности →
chi. - Для сложных условий маршрутизации →
gorilla/mux(но лучше мигрировать наchi). - Для минимализма и обучения → стандартный
net/http.
Если нужна максимальная скорость – httprouter.
Если нужен удобный и современный роутер – chi.
Если проект уже использует gorilla/mux – можно оставить, но для новых проектов лучше chi.
Чистые URL и маршрутизация на основе методов
Установка пакета julienschmidt/httprouter,
go get github.com/julienschmidt/httprouter@v1
Синтаксис пакета:
package main
import (
"net/http"
"github.com/julienschmidt/httprouter" // New import
"github.com/justinas/alice"
)
func (app *application) routes() http.Handler {
// Initialize the router.
router := httprouter.New()
// Update the pattern for the route for the static files.
fileServer := http.FileServer(http.Dir("./ui/static/"))
router.Handler(http.MethodGet, "/static/*filepath", http.StripPrefix("/static", fileServer))
// And then create the routes using the appropriate methods, patterns and
// handlers.
router.HandlerFunc(http.MethodGet, "/", app.home)
router.HandlerFunc(http.MethodGet, "/snippet/view/:id", app.snippetView)
router.HandlerFunc(http.MethodGet, "/snippet/create", app.snippetCreate)
router.HandlerFunc(http.MethodPost, "/snippet/create", app.snippetCreatePost)
// Create the middleware chain as normal.
standard := alice.New(app.recoverPanic, app.logRequest, secureHeaders)
// Wrap the router with the middleware and return it as normal.
return standard.Then(router)
}
Особенности передачи параметров в пакете httprouter
//данные передаются в контексте типа Params
func (app *application) snippetView(w http.ResponseWriter, r *http.Request) {
params := httprouter.ParamsFromContext(r.Context()) //получаем данные запроса
id, err := strconv.Atoi(params.ByName("id")) //считываем по ключу id значение переданного id
if err != nil || id < 1 {
app.notFound(w)
return
}
//далее продолжаем обработку
поменяли обработку запроса в шаблоне
<td><a href='/snippet/view/{{.ID}}'>{{.Title}}</a></td>
Обработка ошибок
в пакете есть специальный метод app.notFound()
настройка в начале файла routes.go
func (app *application) routes() http.Handler {
router := httprouter.New()
router.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
app.notFound(w)
})
позволит несуществующие пути обрабатывать ошибкой 404
Обработка форм
- Выполнить запрос GET к серверу для запроса формы
- Заполнение формы и отправка на сервер результата методом POST
- Обработка формы и валидация handler-ом
snippetCreatePost - После проверки и добавление редирект на
/snippet/view/:idдля просмотра результата
Шаблон формы create.tmpl
{{define "title"}}Create a New Snippet{{end}}
{{define "main"}}
<form action='/snippet/create' method='POST'>
<div>
<label>Title:</label>
<input type='text' name='title'>
</div>
<div>
<label>Content:</label>
<textarea name='content'></textarea>
</div>
<div>
<label>Delete in:</label>
<input type='radio' name='expires' value='365' checked> One Year
<input type='radio' name='expires' value='7'> One Week
<input type='radio' name='expires' value='1'> One Day
</div>
<div>
<input type='submit' value='Publish snippet'>
</div>
</form>
{{end}}
Ссылка на вызов формы nav.html
в меню добавим пункт с вызовом формы
{{define "nav"}}
<nav>
<a href='/'>Home</a>
<!-- Add a link to the new form -->
<a href='/snippet/create'>Create snippet</a>
</nav>
{{end}}
Обработчик формы handler
func (app *application) snippetCreate(w http.ResponseWriter, r *http.Request) {
data := app.newTemplateData(r)
app.render(w, http.StatusOK, "create.tmpl", data)
}
Парсинг формы
r.ParseForm()
метод парсинга и проверки формы. Парсит форму и сохраняет значения в map r.ParseForm
Для получения значений из полей формы, используем r.PostForm.Get() метод. Например: r.PostForm.Get("title")
Функция обработчик формы:
func (app *application) snippetCreatePost(w http.ResponseWriter, r *http.Request) {
//парсинг формы и проверка ошибок
err := r.ParseForm()
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
//получение значений title и content
title := r.PostForm.Get("title")
content := r.PostForm.Get("content")
//преобразование в целое число, так как все значения приходят в формате string
expires, err := strconv.Atoi(r.PostForm.Get("expires"))
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
//выполнение запроса к базе данных
id, err := app.snippets.Insert(title, content, expires)
if err != nil {
app.serverError(w, err)
return
}
http.Redirect(w, r, fmt.Sprintf("/snippet/view/%d", id), http.StatusSeeOther)
}
Для справки
r.PostForm map популярен только для POST, PATCH и PUT запросов. Но еще есть карта r.Form которая сохраняет не только значение тела запроса но и из строки /snippet/create?foo=barСтандартные методы r.FormValue() и r.PostFormValue() автор не рекомендует использовать из-за сложностей в обработке ошибок.
Обработка множественных значений
r.PostForm.Get() метод Get не работает с множественными значениями и вернет только первый
например флажки чекбокса
В этом случае вам нужно будет работать непосредственно с картой r.PostForm. Основным типом карты r.PostForm является url.Values, который, в свою очередь, имеет базовый тип map[string][]string. Таким образом, для полей с несколькими значениями вы можете пройтись по базовой карте, чтобы получить к ним доступ следующим образом:
for i, item := range r.PostForm["items"] {
fmt.Fprintf(w, "%d: Item %s\n", i, item)
}
Ограничение размера формы
Если вы не отправляете составные данные (т.е. ваша форма имеет атрибут enctype="multipart/form-data"), то тела запросов POST, PUT и PATCH ограничены 10 МБ. Если это значение будет превышено, то r.ParseForm() вернет ошибку.
Если вы хотите изменить это ограничение, вы можете использовать http.MaxBytesReader() функцию.
// Limit the request body size to 4096 bytes
r.Body = http.MaxBytesReader(w, r.Body, 4096)
err := r.ParseForm()
if err != nil {
http.Error(w, "Bad Request", http.StatusBadRequest)
return
}
Кроме того, при достижении лимита MaxBytesReader устанавливает флаг на http.ResponseWriter, который указывает серверу закрыть базовое TCP-соединение.
Валидация формы
// создадим переменную для валидации
fieldErrors := make(map[string]string)
// проверка, что title не пусто и не больше 100 знаков. Результат проблем записываем в нашу map с ключом именем поля
if strings.TrimSpace(title) == "" {
fieldErrors["title"] = "This field cannot be blank"
} else if utf8.RuneCountInString(title) > 100 {
fieldErrors["title"] = "This field cannot be more than 100 characters long"
}
// проверяем на пустоту content и записываем в map если есть проблемы
if strings.TrimSpace(content) == "" {
fieldErrors["content"] = "This field cannot be blank"
}
// проверяем что поле равно 1 7 или 365
if expires != 1 && expires != 7 && expires != 365 {
fieldErrors["expires"] = "This field must equal 1, 7 or 365"
}
// а теперь простая проверка всего map. Если map не пустой, значит есть ошибки и возвращаем ошибку. Точнее возвращаем весь map.
if len(fieldErrors) > 0 {
fmt.Fprint(w, fieldErrors)
return
}
Отображение ошибок на форме
- В обработчик шаблонов templates.go добавим поле Form
type templateData struct {
CurrentYear int
Snippet *models.Snippet
Snippets []*models.Snippet
Form any
}
поле Form необходимо для отправки результатов валидации формы
- В handlers.go добавим map с результатами валидации в структуру snippetCreateForm
type snippetCreateForm struct {
Title string
Content string
Expires int
FieldErrors map[string]string
}
- Заполним структуру значениями
form := snippetCreateForm{
Title: r.PostForm.Get("title"),
Content: r.PostForm.Get("content"),
Expires: expires,
FieldErrors: map[string]string{},
}
- Выполним валидацию
- Если есть ошибки то возвращаем ответ с ошибками
if len(form.FieldErrors) > 0 {
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "create.tmpl", data)
return
}
т.е. вызываем эту же форму, только с заполненным map с ошибками, но если ошибок нет, то этот шаг не выполнится и пойдет обращение к базе данных
Изменяем шаблон для отображения ошибок
- Обновим create.tmpl шаблон формы
- Для повторного отображения введенных значений, используем значения поля Form
{{.Form.Title}}и{{.Form.Content}} - Для отображения ошибок валидации используем значения map:
{{.Form.FieldErrors.title}}и другие - Шаблон стал теперь таким
{{define "title"}}Create a New Snippet{{end}}
{{define "main"}}
<form action='/snippet/create' method='POST'>
<div>
<label>Title:</label>
<!-- Use the `with` action to render the value of .Form.FieldErrors.title
if it is not empty. -->
{{with .Form.FieldErrors.title}}
<label class='error'>{{.}}</label>
{{end}}
<!-- Re-populate the title data by setting the `value` attribute. -->
<input type='text' name='title' value='{{.Form.Title}}'>
</div>
<div>
<label>Content:</label>
<!-- Likewise render the value of .Form.FieldErrors.content if it is not
empty. -->
{{with .Form.FieldErrors.content}}
<label class='error'>{{.}}</label>
{{end}}
<!-- Re-populate the content data as the inner HTML of the textarea. -->
<textarea name='content'>{{.Form.Content}}</textarea>
</div>
<div>
<label>Delete in:</label>
<!-- And render the value of .Form.FieldErrors.expires if it is not empty. -->
{{with .Form.FieldErrors.expires}}
<label class='error'>{{.}}</label>
{{end}}
<!-- Here we use the `if` action to check if the value of the re-populated
expires field equals 365. If it does, then we render the `checked`
attribute so that the radio input is re-selected. -->
<input type='radio' name='expires' value='365' {{if (eq .Form.Expires 365)}}checked{{end}}> One Year
<!-- And we do the same for the other possible values too... -->
<input type='radio' name='expires' value='7' {{if (eq .Form.Expires 7)}}checked{{end}}> One Week
<input type='radio' name='expires' value='1' {{if (eq .Form.Expires 1)}}checked{{end}}> One Day
</div>
<div>
<input type='submit' value='Publish snippet'>
</div>
</form>
{{end}}
- В обработчик handlers.go нужно обязательно добавить инициализацию Form для пустых значений, чтобы не было ошибки
func (app *application) snippetCreate(w http.ResponseWriter, r *http.Request) {
data := app.newTemplateData(r)
data.Form = snippetCreateForm{
Expires: 365,
}
app.render(w, http.StatusOK, "create.tmpl", data)
}
Создание хелперов валидации
Просто выносим всю валидацию из кода в отдельный модуль internal/validator
mkdir internal/validator
touch internal/validator/validator.go
создаем файл validator.go
File: internal/validator/validator.go
package validator
import (
"strings"
"unicode/utf8"
)
// Define a new Validator type which contains a map of validation errors for our
// form fields.
type Validator struct {
FieldErrors map[string]string
}
// Valid() returns true if the FieldErrors map doesn't contain any entries.
func (v *Validator) Valid() bool {
return len(v.FieldErrors) == 0
}
// AddFieldError() adds an error message to the FieldErrors map (so long as no
// entry already exists for the given key).
func (v *Validator) AddFieldError(key, message string) {
// Note: We need to initialize the map first, if it isn't already
// initialized.
if v.FieldErrors == nil {
v.FieldErrors = make(map[string]string)
}
if _, exists := v.FieldErrors[key]; !exists {
v.FieldErrors[key] = message
}
}
// CheckField() adds an error message to the FieldErrors map only if a
// validation check is not 'ok'.
func (v *Validator) CheckField(ok bool, key, message string) {
if !ok {
v.AddFieldError(key, message)
}
}
// NotBlank() returns true if a value is not an empty string.
func NotBlank(value string) bool {
return strings.TrimSpace(value) != ""
}
// MaxChars() returns true if a value contains no more than n characters.
func MaxChars(value string, n int) bool {
return utf8.RuneCountInString(value) <= n
}
// PermittedInt() returns true if a value is in a list of permitted integers.
func PermittedInt(value int, permittedValues ...int) bool {
for i := range permittedValues {
if value == permittedValues[i] {
return true
}
}
return false
}
Корректируем handlers.go
для использования валидатора внесем изменения
добавим импорт:
"snippetbox.alexedwards.net/internal/validator" // New import
- Убрали map и поставили validator.Validator
type snippetCreateForm struct {
Title string
Content string
Expires int
validator.Validator
}
основное преимущество validator.Validator в том, что он содержит все поля map и методы обработки
- При заполнении структуры Form, теперь не нужно заполонять map с ошибками
form := snippetCreateForm{
Title: r.PostForm.Get("title"),
Content: r.PostForm.Get("content"),
Expires: expires,
// Remove the FieldErrors assignment from here.
}
- Вызов проверок валидации теперь доступны прямо на переменной form
form.CheckField(validator.NotBlank(form.Title), "title", "This field cannot be blank")
form.CheckField(validator.MaxChars(form.Title, 100), "title", "This field cannot be more than 100 characters long")
form.CheckField(validator.NotBlank(form.Content), "content", "This field cannot be blank")
form.CheckField(validator.PermittedInt(form.Expires, 1, 7, 365), "expires", "This field must equal 1, 7 or 365")
- Проверяем валидность формы
if !form.Valid() {
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "create.tmpl", data)
return
}
Автоматический парсинг форм
Автор предлагает использовать сторонний пакет go-playground/form который по сути делает тоже самое, но более гибко и универсально
12.9.2 - Alex Edwards Let's Go часть 2
edwardsLetsGo учебный материал по написанию приложения на Go с авторизацией пользователя. Краткий конспект с основными мыслями (главы с 9 по 12)
Stateful HTTP
Отслеживание состояний в HTTP
Будем выводить для начала сообщение по результатам добавления новой формы
Выбор менеджера сессий
Сравнение и анализ менеджеров сессий
1. Сравнение gorilla/sessions и alexedwards/scs
| Характеристика | gorilla/sessions | alexedwards/scs |
|---|---|---|
| Тип хранилища | Cookie, файлы, Redis, Memcached, другие (через сторонние адаптеры) | Cookie, Redis, PostgreSQL, MySQL, SQLite, in-memory |
| Безопасность | Поддержка подписанных кук, но требует ручной настройки | Встроенная защита от подделки (secure cookies), автоматическое обновление токенов |
| Производительность | Зависит от бэкенда (Redis быстрее, чем куки) | Оптимизирован для работы с разными хранилищами, меньше накладных расходов |
| Гибкость | Гибкий API, можно настраивать под разные сценарии | Более структурированный API, но менее гибкий |
| Поддержка контекста | Нет встроенной поддержки context.Context | Полная интеграция с context.Context |
| Автоматическое продление | Нет (нужно реализовывать вручную) | Есть (автоматически обновляет сессии) |
| Зависимости | Часть Gorilla Toolkit (можно использовать отдельно) | Независимая библиотека |
| Активность разработки | Заморожен (Gorilla Toolkit больше не поддерживается) | Активно развивается |
| Использование в продакшене | Широко использовался, но сейчас менее предпочтителен | Рекомендуется для новых проектов |
Вывод:
- Gorilla/sessions — устаревающий, но проверенный вариант. Подходит, если уже используется Gorilla Toolkit.
- SCS (alexedwards/scs) — современный, безопасный и более удобный для новых проектов.
2. Другие популярные менеджеры сессий в Go
a) Gin Sessions (для фреймворка Gin)
- Особенности: Интеграция с Gin, поддержка Redis, Cookie, Memcached.
- Плюсы: Простота использования в Gin-приложениях.
- Минусы: Зависит от Gin, не подходит для других фреймворков.
- Ссылка: github.com/gin-contrib/sessions
b) Beego Session
- Особенности: Встроен в фреймворк Beego, поддерживает файлы, Redis, Memcached, MySQL, PostgreSQL.
- Плюсы: Готовое решение для Beego.
- Минусы: Привязан к Beego.
- Ссылка: beego.me
c) Go-chi/session (от создателей Chi)
- Особенности: Минималистичный, работает с
context.Context, поддерживает Redis и куки. - Плюсы: Легковесный, хорош для микрофреймворков.
- Минусы: Меньше возможностей, чем у SCS.
- Ссылка: github.com/go-chi/session
d) Iriris Sessions
- Особенности: Интеграция с фреймворком Iris, поддержка Redis, BoltDB, Badger, файлы.
- Плюсы: Высокая производительность, удобство в Iris.
- Минусы: Привязан к Iris.
- Ссылка: github.com/kataras/iris/sessions
3. Какой выбрать?
- Для новых проектов → alexedwards/scs (безопасность, контекст, активная разработка).
- Для Gin → gin-contrib/sessions.
- Для микрофреймворков (Chi, Echo) → go-chi/session или scs.
- Legacy-проекты на Gorilla → gorilla/sessions (но лучше мигрировать на scs).
Установка alexedwards/scs
go get github.com/alexedwards/scs/v2@v2
go get github.com/alexedwards/scs/mysqlstore
Создать таблицу в базе данных для хранения сессий
Поддерживает много различных баз данных о чем говорит в документации: https://github.com/alexedwards/scs
USE snippetbox;
CREATE TABLE sessions (
token CHAR(43) PRIMARY KEY,
data BLOB NOT NULL,
expiry TIMESTAMP(6) NOT NULL
);
CREATE INDEX sessions_expiry_idx ON sessions (expiry);
этот пример для нашей базы snippetbox
- Поле токена (tocken) будет содержать уникальный, случайно сгенерированный идентификатор для каждого сеанса.
- Поле данных (data) будет содержать фактические данные сеанса, которые вы хотите использовать совместно с HTTP-запросами. Они хранятся в виде двоичных данных типа BLOB (двоичный большой объект).
- Поле истечения срока действия (expiry) будет содержать время истечения срока действия сеанса.
Пакет scs автоматически удалит истекшие сеансы из таблицы сеансов, чтобы она не стала слишком большой.
Изменения в main.go
- Добавим импорты
"github.com/alexedwards/scs/mysqlstore" // New import
"github.com/alexedwards/scs/v2" // New import
- Добавим поле сессии в структуру приложения
type application struct {
errorLog *log.Logger
infoLog *log.Logger
snippets *models.SnippetModel
templateCache map[string]*template.Template
formDecoder *form.Decoder
sessionManager *scs.SessionManager
}
- Настройка менеджера сессий
sessionManager := scs.New() // Используем scs.New() для инициализации нового менеджера сессий.
sessionManager.Store = mysqlstore.New(db) //настраиваем его на использование нашей базы данных MySQL в качестве хранилища сессий
sessionManager.Lifetime = 12 * time.Hour //устанавливаем время жизни 12 часов
- Добавить менеджер сессий в структуру приложения
app := &application{
errorLog: errorLog,
infoLog: infoLog,
snippets: &models.SnippetModel{DB: db},
templateCache: templateCache,
formDecoder: formDecoder,
sessionManager: sessionManager,
}
Обернуть обработчики запросов
Чтобы сеансы работали, нам также необходимо обернуть маршруты наших приложений в промежуточное ПО, предоставляемое методом SessionManager.LoadAndSave(). Это промежуточное ПО автоматически загружает и сохраняет данные сеанса при каждом HTTP-запросе и ответе.
/static/*filepath - оборачивать не будем
Создадим ноувую цепочку для динамических данных сайта
Корректируем файл: routes.go
- Создаем переменную для учета сессий
dynamic := alice.New(app.sessionManager.LoadAndSave)
- Обертываем обработчики
router.Handler(http.MethodGet, "/", dynamic.ThenFunc(app.home))
router.Handler(http.MethodGet, "/snippet/view/:id", dynamic.ThenFunc(app.snippetView))
router.Handler(http.MethodGet, "/snippet/create", dynamic.ThenFunc(app.snippetCreate))
router.Handler(http.MethodPost, "/snippet/create", dynamic.ThenFunc(app.snippetCreatePost))
- Остальное оставляем без изменений
standard := alice.New(app.recoverPanic, app.logRequest, secureHeaders)
return standard.Then(router)
Если не используется пакет alice
синтаксис вызова будет другой
router := httprouter.New()
router.Handler(http.MethodGet, "/", app.sessionManager.LoadAndSave(http.HandlerFunc(app.home)))
router.Handler(http.MethodGet, "/snippet/view/:id", app.sessionManager.LoadAndSave(http.HandlerFunc(app.snippetView)))
// ... etc
Работа с данными сессии
Добавление сообщения об успешном добавлении сниппета
- Внесем изменения в файл handlers.go
Используйте метод Put() для добавления строкового значения (“Сниппет успешно создан!”) и соответствующего ключа (“flash”) к данным сессии.
func (app *application) snippetCreatePost(w http.ResponseWriter, r *http.Request) {
var form snippetCreateForm
...
app.sessionManager.Put(r.Context(), "flash", "Snippet successfully created!")
- Первый параметр, который мы передаем в app.sessionManager.Put(), — это текущий контекст запроса (это место, где менеджер сеансов временно хранит информацию, пока ваши обработчики работают с запросом.)
- Второй параметр (в нашем случае строка “flash”) является ключом для конкретного сообщения, которое мы добавляем в данные сессии. Впоследствии мы получим сообщение из данных сеанса также с помощью этого ключа.
Если для текущего пользователя нет существующего сеанса (или срок его сеанса истек), то новый пустой сеанс для него будет автоматически создан промежуточным программным обеспечением сеанса.
- Далее мы хотим, чтобы наш обработчик snippetView извлек флэш-сообщение (если оно существует в сессии для текущего пользователя) и передал его в HTML-шаблон для последующего отображения.
Поскольку мы хотим отобразить флэш-сообщение только один раз, на самом деле мы хотим извлечь и удалить сообщение из данных сеанса. Мы можем выполнить обе эти операции одновременно с помощью метода PopString().
func (app *application) snippetView(w http.ResponseWriter, r *http.Request) {
params := httprouter.ParamsFromContext(r.Context())
...
flash := app.sessionManager.PopString(r.Context(), "flash")
data := app.newTemplateData(r)
data.Snippet = snippet
// Pass the flash message to the template.
data.Flash = flash
app.render(w, http.StatusOK, "view.tmpl", data)
}
Информация
Информация: Если вы хотите получить значение только из данных сеанса (и оставить его там), вы можете использовать метод GetString(). Пакет scs также предоставляет методы для получения других распространенных типов данных, включая GetInt(), GetBool(), GetBytes() и GetTime().- Добавить поле Flash в структуру данных templateData (в файле templates.go)
type templateData struct {
CurrentYear int
Snippet *models.Snippet
Snippets []*models.Snippet
Form any
Flash string // Add a Flash field to the templateData struct.
}
- Внесем изменения в шаблон base.tmpl
{{define "base"}}
<!doctype html>
<html lang='en'>
<head>
<meta charset='utf-8'>
<title>{{template "title" .}} - Snippetbox</title>
<link rel='stylesheet' href='/static/css/main.css'>
<link rel='shortcut icon' href='/static/img/favicon.ico' type='image/x-icon'>
<link rel='stylesheet' href='https://fonts.googleapis.com/css?family=Ubuntu+Mono:400,700'>
</head>
<body>
<header>
<h1><a href='/'>Snippetbox</a></h1>
</header>
{{template "nav" .}}
<main>
<!-- Display the flash message if one exists -->
{{with .Flash}}
<div class='flash'>{{.}}</div>
{{end}}
{{template "main" .}}
</main>
<footer>
Powered by <a href='https://golang.org/'>Go</a> in {{.CurrentYear}}
</footer>
<script src="/static/js/main.js" type="text/javascript"></script>
</body>
</html>
{{end}}
Помните
{{with .Flash}} будет выполнен только в том случае, если значение .Flash не является пустой строкой. Таким образом, если в сеансе текущего пользователя нет ключа «flash», то в результате часть новой разметки просто не будет отображаться.- Модернизируем функцию newTemplateData в файле helpers.go для вывода других сообщений при совершении действий на сайте.
func (app *application) newTemplateData(r *http.Request) *templateData {
return &templateData{
CurrentYear: time.Now().Year(),
// Add the flash message to the template data, if one exists.
Flash: app.sessionManager.PopString(r.Context(), "flash"),
}
}
поэтому теперь можно убрать строки из файла handlers.go
flash := app.sessionManager.PopString(r.Context(), "flash") //убрать
...
data.Flash = flash //убрать
Безопасность данных
Создание самозаверяющего сертификата TLS
HTTPS — это, по сути, HTTP, отправляемый через соединение TLS (Transport Layer Security).
Поскольку данные отправляются через соединение TLS, они шифруются и подписываются, что помогает обеспечить их конфиденциальность и целостность во время передачи.
Прежде чем наш сервер сможет начать использовать HTTPS, нам необходимо сгенерировать сертификат TLS.
Удобно отметить, что пакет crypto/tls в стандартной библиотеке Go включает в себя инструмент generate_cert.go, который мы можем использовать для простого создания собственного самоподписанного сертификата.
Создание своего самозаписывающего сертификата
cd $HOME/code/snippetbox
mkdir tls
cd tls
Чтобы запустить инструмент generate_cert.go, вам нужно знать место на вашем компьютере, где установлен исходный код стандартной библиотеки Go.
Если вы используете Linux, macOS или FreeBSD и следуете официальным инструкциям по установке, то файл generate_cert.go должен находиться в папке /usr/local/go/src/crypto/tls.
Запуск генерации сертификата
$ go run /usr/local/go/src/crypto/tls/generate_cert.go --rsa-bits=2048 --host=localhost
на manjaro оказался на /usr/lib/go/src/crypto/tls/generate_cert.go
для поиска можно воспользоваться командой:
find /usr -name 'generate_cert.go'
За кулисами инструмент generate_cert.go работает в два этапа:
- сначала он генерирует 2048-битную пару ключей RSA, которая является криптографически защищенным открытым ключом и закрытым ключом.
- Затем он сохраняет закрытый ключ в файле key.pem и генерирует самоподписанный сертификат TLS для хоста localhost, содержащий открытый ключ, который он хранит в файле cert.pem.
Как закрытый ключ, так и сертификат закодированы в PEM, что является стандартным форматом, используемым в большинстве реализаций TLS.
Запуск HTTPS сервера
- Заменить в файле main.go srv.ListenAndServe() на srv.ListenAndServeTLS()
err = srv.ListenAndServeTLS("./tls/cert.pem", "./tls/key.pem")
errorLog.Fatal(err)
- Запустить приложение
- Открыть сайт https://localhost:4000/ по протоколу https
Важно
Важно отметить, что пользователь, которого вы используете для запуска приложения Go, должен иметь разрешения на чтение файлов cert.pem и key.pem, в противном случае ListenAndServeTLS() вернет ошибку отказа в разрешении.Занесите каталог tls в .gitignore
нежелательно пушить сертификаты в репозиторий
Настройка параметров HTTPS
Go имеет хорошие настройки по умолчанию для своего HTTPS-сервера, но можно оптимизировать и настроить поведение сервера.
tls.CurveP256 and tls.X25519 - рекомендуется использовать эти протоколы
Добавим настройки в файл main.go
- Добавим импорт
import (
"crypto/tls" // New import
- Добавим tlsConfig
tlsConfig := &tls.Config{
CurvePreferences: []tls.CurveID{tls.X25519, tls.CurveP256},
}
- Добавим tls настройки в структуру srv
srv := &http.Server{
Addr: *addr,
ErrorLog: errorLog,
Handler: app.routes(),
TLSConfig: tlsConfig,
}
Настройка версий TLS
tlsConfig := &tls.Config{
MinVersion: tls.VersionTLS12,
MaxVersion: tls.VersionTLS12,
}
Ограничение наборов шифров Полный набор наборов шифров, поддерживаемых Go,
tlsConfig := &tls.Config{
CipherSuites: []uint16{
tls.TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,
tls.TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,
tls.TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305,
tls.TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,
tls.TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,
tls.TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,
},
}
Тайм-ауты подключения
Давайте уделим немного времени, чтобы повысить отказоустойчивость нашего сервера, добавив некоторые настройки тайм-аута, например:
srv := &http.Server{
Addr: *addr,
ErrorLog: errorLog,
Handler: app.routes(),
TLSConfig: tlsConfig,
// Add Idle, Read and Write timeouts to the server.
IdleTimeout: time.Minute,
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
}
добавляем в структуру srv необходимые поля для настройки таймаута
Все эти три тайм-аута — IdleTimeout, ReadTimeout и WriteTimeout — являются общесерверными настройками, которые действуют на базовое соединение и применяются ко всем запросам независимо от их обработчика или URL-адреса.
Параметр IdleTimeout
По умолчанию Go включает проверку активности для всех принятых подключений. Это помогает уменьшить задержку (особенно для подключений HTTPS), поскольку клиент может повторно использовать одно и то же соединение для нескольких запросов без необходимости повторять рукопожатие.
В нашем случае мы установили IdleTimeout на 1 минуту, что означает, что все keep-alive соединения будут автоматически закрыты после 1 минуты бездействия.
Параметр ReadTimeout
В нашем коде мы также установили параметр ReadTimeout равным 5 секундам. Это означает, что если заголовки или тело запроса все еще считываются через 5 секунд после первого принятия запроса, то Go закроет базовое соединение. Поскольку это “жесткое” замыкание соединения, пользователь не получит никакого ответа HTTP(S). Установка короткого периода ReadTimeout помогает снизить риск атак на медленных клиентов, таких как Slowloris, которые в противном случае могли бы держать соединение открытым на неопределенный срок, отправляя частичные, неполные HTTP(S) запросы.
Параметр WriteTimeout
Параметр WriteTimeout закроет базовое соединение, если наш сервер попытается записать данные в соединение через определенный период времени (в нашем коде это 10 секунд).
Но это ведет себя немного по-разному в зависимости от используемого протокола.
Для HTTP-соединений, если некоторые данные записываются в соединение более чем через 10 секунд после завершения чтения заголовка запроса, Go закроет базовое соединение, а не запишет данные.
Для соединений HTTPS, если некоторые данные записываются в соединение более чем через 10 секунд после первого принятия запроса, Go закроет базовое соединение вместо записи данных.
Это означает, что если вы используете HTTPS (как мы), имеет смысл установить значение WriteTimeout больше, чем ReadTimeout.
Важно помнить, что записи, выполненные обработчиком, буферизуются и записываются в соединение как единое целое при возврате обработчика. Таким образом, идея WriteTimeout обычно заключается не в том, чтобы предотвратить длительную работу обработчиков, а в том, чтобы предотвратить слишком долгую запись данных, возвращаемых обработчиком.
Настройка ReadHeaderTimeout
Функция http.Server также предоставляет параметр ReadHeaderTimeout, который мы не использовали в нашем приложении. Это работает аналогично ReadTimeout, за исключением того, что применяется только к чтению заголовков HTTP(S).
Это может быть полезно, если вы хотите применить ограничение на уровне сервера для чтения заголовков запросов, но хотите реализовать разные тайм-ауты на разных маршрутах, когда дело доходит до чтения тела запроса (возможно, с использованием http.TimeoutHandler() промежуточное ПО).
Для нашего веб-приложения Snippetbox у нас нет никаких действий, которые гарантируют тайм-ауты чтения для каждого маршрута — чтение заголовков и тел запросов для всех наших маршрутов должно быть комфортно завершено за 5 секунд, поэтому мы будем использовать ReadTimeout.
Настройка MaxHeaderBytes
http.Server также предоставляет поле MaxHeaderBytes, которое можно использовать для управления максимальным количеством байтов, которое сервер будет считывать при анализе заголовков запросов. По умолчанию Go разрешает максимальную длину заголовка 1 МБ.
Например, если вы хотите ограничить максимальную длину заголовка до 0,5 МБ, вы должны написать:
srv := &http.Server{
Addr: *addr,
MaxHeaderBytes: 524288,
...
}
Аутентификация пользователей
- Пользователь должен зарегистрироваться, посетив форму по адресу /user/signup и введя свое имя, адрес электронной почты и пароль. Мы сохраним эту информацию в новой таблице базы данных пользователей.
- Пользователь войдет в систему, посетив форму по адресу /user/login и введя свой адрес электронной почты и пароль.
- Затем мы проверим базу данных, чтобы увидеть, совпадают ли введенные ими адрес электронной почты и пароль с одним из пользователей в таблице пользователей. Если совпадение найдено, пользователь успешно прошел проверку подлинности, и мы добавляем соответствующее значение id для пользователя в данные его сеанса с помощью ключа “authenticatedUserID”.
- Когда мы получаем какие-либо последующие запросы, мы можем проверить данные сеанса пользователя на наличие значения “authenticatedUserID”. Если она существует, мы знаем, что пользователь уже успешно вошел в систему. Мы можем продолжать проверять это до тех пор, пока сессия не истечет, когда пользователю потребуется снова войти в систему. Если в сеансе отсутствует “authenticatedUserID”, мы знаем, что пользователь не вошел в систему.
Подготовительные мероприятия для создания инфраструктуры данных
Добавим новые маршруты для регистрации пользователей
| HTTP Method | Route | Handler | Description |
|---|---|---|---|
| GET | /user/signup | userSignup | Display a HTML form for signing up a new user |
| POST | /user/signup | userSignupPost | Create a new user |
| GET | /user/login | userLogin | Display a HTML form for logging in a user |
| POST | /user/login | userLoginPost | Authenticate and login the user |
| POST | /user/logout | userLogoutPost | Logout the user |
Пропишем в файле routes.go данные маршруты:
router.Handler(http.MethodGet, "/user/signup", dynamic.ThenFunc(app.userSignup))
router.Handler(http.MethodPost, "/user/signup", dynamic.ThenFunc(app.userSignupPost))
router.Handler(http.MethodGet, "/user/login", dynamic.ThenFunc(app.userLogin))
router.Handler(http.MethodPost, "/user/login", dynamic.ThenFunc(app.userLoginPost))
router.Handler(http.MethodPost, "/user/logout", dynamic.ThenFunc(app.userLogoutPost))
Создание обработчиков для маршрутов handlers.go
func (app *application) userSignup(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Display a HTML form for signing up a new user...")
}
func (app *application) userSignupPost(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Create a new user...")
}
func (app *application) userLogin(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Display a HTML form for logging in a user...")
}
func (app *application) userLoginPost(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Authenticate and login the user...")
}
func (app *application) userLogoutPost(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Logout the user...")
}
Создать ссылки на экране для вызова функций nav.tmpl
{{define "nav"}}
<nav>
<div>
<a href='/'>Home</a>
<a href='/snippet/create'>Create snippet</a>
</div>
<div>
<a href='/user/signup'>Signup</a>
<a href='/user/login'>Login</a>
<form action='/user/logout' method='POST'>
<button>Logout</button>
</form>
</div>
</nav>
{{end}}
Создать таблицу для пользователей
USE snippetbox;
CREATE TABLE users (
id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
hashed_password CHAR(60) NOT NULL,
created DATETIME NOT NULL
);
ALTER TABLE users ADD CONSTRAINT users_uc_email UNIQUE (email);
Мы также добавили ограничение UNIQUE в столбец электронной почты и назвали его users_uc_email. Это ограничение гарантирует, что у нас не будет двух пользователей с одинаковым адресом электронной почты. Если мы попытаемся вставить запись в эту таблицу с дубликатом электронной почты, MySQL выдаст ошибку 1062: ER_DUP_ENTRY ошибку.
Создать аналогичные методы и структуры для работы с данными пользователей
Добавить необходимые типы ошибок для обработки пользователей в файл errors.go
package models
import (
"errors"
)
var (
ErrNoRecord = errors.New("models: no matching record found")
// Add a new ErrInvalidCredentials error. We'll use this later if a user
// tries to login with an incorrect email address or password.
ErrInvalidCredentials = errors.New("models: invalid credentials")
// Add a new ErrDuplicateEmail error. We'll use this later if a user
// tries to signup with an email address that's already in use.
ErrDuplicateEmail = errors.New("models: duplicate email")
)
Создаем отдельный файл для обработки пользователей users.go
cd $HOME/code/snippetbox
touch internal/models/users.go
package models
import (
"database/sql"
"time"
)
// Define a new User type. Notice how the field names and types align
// with the columns in the database "users" table?
type User struct {
ID int
Name string
Email string
HashedPassword []byte
Created time.Time
}
// Define a new UserModel type which wraps a database connection pool.
type UserModel struct {
DB *sql.DB
}
// We'll use the Insert method to add a new record to the "users" table.
func (m *UserModel) Insert(name, email, password string) error {
return nil
}
// We'll use the Authenticate method to verify whether a user exists with
// the provided email address and password. This will return the relevant
// user ID if they do.
func (m *UserModel) Authenticate(email, password string) (int, error) {
return 0, nil
}
// We'll use the Exists method to check if a user exists with a specific ID.
func (m *UserModel) Exists(id int) (bool, error) {
return false, nil
}
Добавить новое поле в структуру приложения main.go
добавим поле users
type application struct {
errorLog *log.Logger
infoLog *log.Logger
snippets *models.SnippetModel
users *models.UserModel
templateCache map[string]*template.Template
formDecoder *form.Decoder
sessionManager *scs.SessionManager
}
func main() {
...
// Initialize a models.UserModel instance and add it to the application
// dependencies.
app := &application{
errorLog: errorLog,
infoLog: infoLog,
snippets: &models.SnippetModel{DB: db},
users: &models.UserModel{DB: db},
templateCache: templateCache,
formDecoder: formDecoder,
sessionManager: sessionManager,
}
...
Регистрация пользователей
Создадим форму регистрации ui/html/pages/signup.tmpl
$ cd $HOME/code/snippetbox
$ touch ui/html/pages/signup.tmpl
{{define "title"}}Signup{{end}}
{{define "main"}}
<form action='/user/signup' method='POST' novalidate>
<div>
<label>Name:</label>
{{with .Form.FieldErrors.name}}
<label class='error'>{{.}}</label>
{{end}}
<input type='text' name='name' value='{{.Form.Name}}'>
</div>
<div>
<label>Email:</label>
{{with .Form.FieldErrors.email}}
<label class='error'>{{.}}</label>
{{end}}
<input type='email' name='email' value='{{.Form.Email}}'>
</div>
<div>
<label>Password:</label>
{{with .Form.FieldErrors.password}}
<label class='error'>{{.}}</label>
{{end}}
<input type='password' name='password'>
</div>
<div>
<input type='submit' value='Signup'>
</div>
</form>
{{end}}
Создадим новую структуру данных для регистрации пользователя
В файле handlers.go:
package main
...
// Create a new userSignupForm struct.
type userSignupForm struct {
Name string `form:"name"`
Email string `form:"email"`
Password string `form:"password"`
validator.Validator `form:"-"`
}
// Update the handler so it displays the signup page.
func (app *application) userSignup(w http.ResponseWriter, r *http.Request) {
data := app.newTemplateData(r)
data.Form = userSignupForm{}
app.render(w, http.StatusOK, "signup.tmpl", data)
}
...
Валидация формы регистрации
Добавим новые методы валидации в файле: internal/validator/validator.go
package validator
import (
"regexp" // New import
"strings"
"unicode/utf8"
)
// Use the regexp.MustCompile() function to parse a regular expression pattern
// for sanity checking the format of an email address. This returns a pointer to
// a 'compiled' regexp.Regexp type, or panics in the event of an error. Parsing
// this pattern once at startup and storing the compiled *regexp.Regexp in a
// variable is more performant than re-parsing the pattern each time we need it.
var EmailRX = regexp.MustCompile("^[a-zA-Z0-9.!#$%&'*+\\/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$")
...
// MinChars() returns true if a value contains at least n characters.
func MinChars(value string, n int) bool {
return utf8.RuneCountInString(value) >= n
}
// Matches() returns true if a value matches a provided compiled regular
// expression pattern.
func Matches(value string, rx *regexp.Regexp) bool {
return rx.MatchString(value)
}
Добавим обработчик формы в handlers.go
func (app *application) userSignupPost(w http.ResponseWriter, r *http.Request) {
// Declare an zero-valued instance of our userSignupForm struct.
var form userSignupForm
// Parse the form data into the userSignupForm struct.
err := app.decodePostForm(r, &form)
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
// Validate the form contents using our helper functions.
form.CheckField(validator.NotBlank(form.Name), "name", "This field cannot be blank")
form.CheckField(validator.NotBlank(form.Email), "email", "This field cannot be blank")
form.CheckField(validator.Matches(form.Email, validator.EmailRX), "email", "This field must be a valid email address")
form.CheckField(validator.NotBlank(form.Password), "password", "This field cannot be blank")
form.CheckField(validator.MinChars(form.Password, 8), "password", "This field must be at least 8 characters long")
// If there are any errors, redisplay the signup form along with a 422
// status code.
if !form.Valid() {
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "signup.tmpl", data)
return
}
// Otherwise send the placeholder response (for now!).
fmt.Fprintln(w, "Create a new user...")
}
Краткое введение в bcrypt
- Хорошей практикой — является хранение одностороннего хеша пароля, полученного с помощью ресурсоемкой функции извлечения ключа, такой как Argon2, scrypt или bcrypt. Go имеет реализации всех 3 алгоритмов в пакете golang.org/x/crypto.
- Тем не менее, плюсом реализации bcrypt является то, что она включает в себя вспомогательные функции, специально разработанные для хеширования и проверки паролей, и именно их мы будем использовать здесь.
- Установка bcrypt
go get golang.org/x/crypto/bcrypt@latest
- Создать хэш пароля
hash, err := bcrypt.GenerateFromPassword([]byte("my plain text password"), 12)
- Эта функция вернет хеш длиной 60 символов, который выглядит примерно так:
$2a$12$NuTjWXm3KKntReFwyBVHyuf/to.HEwTy.eS206TNfkGfr6HzGJSWG
Второй параметр мы передаем в bcrypt.GenerateFromPassword() указывает стоимость, которая представлена целым числом от 4 до 31. 12 означает, что для генерации хэша пароля будет использовано 4096 (2^12) итераций bcrypt.
- Проверка пароля: функция
bcrypt.CompareHashAndPassword()
hash := []byte("$2a$12$NuTjWXm3KKntReFwyBVHyuf/to.HEwTy.eS206TNfkGfr6GzGJSWG")
err := bcrypt.CompareHashAndPassword(hash, []byte("my plain text password"))
Хранение информации о пользователе
Следующим этапом нашей сборки является обновление метода UserModel.Insert() таким образом, чтобы он создал новую запись в нашей таблице пользователей, содержащую проверенное имя, адрес электронной почты и хэшированный пароль.
- Для обработки ошибок в базе данных и сохранения хэша понадобятся библиотеки
import (
"database/sql"
"errors" // New import
"strings" // New import
"time"
"github.com/go-sql-driver/mysql" // New import
"golang.org/x/crypto/bcrypt" // New import
)
- Файл
internal/models/users.goдля обработки запросов к базе данных
type UserModel struct {
DB *sql.DB
}
func (m *UserModel) Insert(name, email, password string) error {
// Create a bcrypt hash of the plain-text password.
hashedPassword, err := bcrypt.GenerateFromPassword([]byte(password), 12)
if err != nil {
return err
}
stmt := `INSERT INTO users (name, email, hashed_password, created)
VALUES(?, ?, ?, UTC_TIMESTAMP())`
// Use the Exec() method to insert the user details and hashed password
// into the users table.
_, err = m.DB.Exec(stmt, name, email, string(hashedPassword))
if err != nil {
// If this returns an error, we use the errors.As() function to check
// whether the error has the type *mysql.MySQLError. If it does, the
// error will be assigned to the mySQLError variable. We can then check
// whether or not the error relates to our users_uc_email key by
// checking if the error code equals 1062 and the contents of the error
// message string. If it does, we return an ErrDuplicateEmail error.
var mySQLError *mysql.MySQLError
if errors.As(err, &mySQLError) {
if mySQLError.Number == 1062 && strings.Contains(mySQLError.Message, "users_uc_email") {
return ErrDuplicateEmail
}
}
return err
}
return nil
}
- В основном приложении handlers.go отрабатывает запросы по маршрутам
func (app *application) userSignupPost(w http.ResponseWriter, r *http.Request) {
var form userSignupForm
...
err = app.users.Insert(form.Name, form.Email, form.Password)
if err != nil {
if errors.Is(err, models.ErrDuplicateEmail) {
form.AddFieldError("email", "Email address is already in use")
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "signup.tmpl", data)
} else {
app.serverError(w, err)
}
return
}
...
Внимание
Автор не рекомендует использовать встроенные функции преобразования паролей в хэш в базах данных.User login
Для начала обновим internal/validator/validator.go
package validator
...
// Add a new NonFieldErrors []string field to the struct, which we will use to
// hold any validation errors which are not related to a specific form field.
type Validator struct {
NonFieldErrors []string
FieldErrors map[string]string
}
// Update the Valid() method to also check that the NonFieldErrors slice is
// empty.
func (v *Validator) Valid() bool {
return len(v.FieldErrors) == 0 && len(v.NonFieldErrors) == 0
}
// Create an AddNonFieldError() helper for adding error messages to the new
// NonFieldErrors slice.
func (v *Validator) AddNonFieldError(message string) {
v.NonFieldErrors = append(v.NonFieldErrors, message)
}
основная идея изменений, это добавить в основной валидатор проверку не только некорректных данных в форме, но и проверок в базе данных
Создадим шаблон для login (ui/html/pages/login.tmpl)
{{define "title"}}Login{{end}}
{{define "main"}}
<form action='/user/login' method='POST' novalidate>
<!-- Notice that here we are looping over the NonFieldErrors and displaying
them, if any exist -->
{{range .Form.NonFieldErrors}}
<div class='error'>{{.}}</div>
{{end}}
<div>
<label>Email:</label>
{{with .Form.FieldErrors.email}}
<label class='error'>{{.}}</label>
{{end}}
<input type='email' name='email' value='{{.Form.Email}}'>
</div>
<div>
<label>Password:</label>
{{with .Form.FieldErrors.password}}
<label class='error'>{{.}}</label>
{{end}}
<input type='password' name='password'>
</div>
<div>
<input type='submit' value='Login'>
</div>
</form>
{{end}}
Создадим структуру данных для login (handlers.go)
// Create a new userLoginForm struct.
type userLoginForm struct {
Email string `form:"email"`
Password string `form:"password"`
validator.Validator `form:"-"`
}
// Update the handler so it displays the login page.
func (app *application) userLogin(w http.ResponseWriter, r *http.Request) {
data := app.newTemplateData(r)
data.Form = userLoginForm{}
app.render(w, http.StatusOK, "login.tmpl", data)
}
Проверка пользователя
- Проверить есть такой email — если нет, то вернуть ошибку
- Сравнить хэш пароля — если не совпадает, вернуть ошибку
- Если все ОК — вернем ID пользователя
Внесем изменения в internal/models/users.go
func (m *UserModel) Authenticate(email, password string) (int, error) {
// Retrieve the id and hashed password associated with the given email. If
// no matching email exists we return the ErrInvalidCredentials error.
var id int
var hashedPassword []byte
stmt := "SELECT id, hashed_password FROM users WHERE email = ?"
err := m.DB.QueryRow(stmt, email).Scan(&id, &hashedPassword)
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
return 0, ErrInvalidCredentials
} else {
return 0, err
}
}
// Check whether the hashed password and plain-text password provided match.
// If they don't, we return the ErrInvalidCredentials error.
err = bcrypt.CompareHashAndPassword(hashedPassword, []byte(password))
if err != nil {
if errors.Is(err, bcrypt.ErrMismatchedHashAndPassword) {
return 0, ErrInvalidCredentials
} else {
return 0, err
}
}
// Otherwise, the password is correct. Return the user ID.
return id, nil
}
- После подтверждения пользователя создадим текущую сессию с пользователем. Внесем изменения в handlers.go
func (app *application) userLoginPost(w http.ResponseWriter, r *http.Request) {
// Decode the form data into the userLoginForm struct.
var form userLoginForm
err := app.decodePostForm(r, &form)
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
form.CheckField(validator.NotBlank(form.Email), "email", "This field cannot be blank")
form.CheckField(validator.Matches(form.Email, validator.EmailRX), "email", "This field must be a valid email address")
form.CheckField(validator.NotBlank(form.Password), "password", "This field cannot be blank")
if !form.Valid() {
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "login.tmpl", data)
return
}
// Check whether the credentials are valid. If they're not, add a generic
// non-field error message and re-display the login page.
id, err := app.users.Authenticate(form.Email, form.Password)
if err != nil {
if errors.Is(err, models.ErrInvalidCredentials) {
form.AddNonFieldError("Email or password is incorrect")
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "login.tmpl", data)
} else {
app.serverError(w, err)
}
return
}
//после каждого изменения состояния пользователя login/logout изменяем хэш текущей сессии
err = app.sessionManager.RenewToken(r.Context())
if err != nil {
app.serverError(w, err)
return
}
// Add the ID of the current user to the session, so that they are now
// 'logged in'.
app.sessionManager.Put(r.Context(), "authenticatedUserID", id)
// Redirect the user to the create snippet page.
http.Redirect(w, r, "/snippet/create", http.StatusSeeOther)
}
Примечание: Метод SessionManager.RenewToken(), который мы используем в приведенном выше коде, изменит идентификатор текущей сессии пользователя, но сохранит все данные, связанные с сессией. Рекомендуется делать это перед входом в систему, чтобы снизить риск атаки фиксации сеанса. Для получения дополнительной информации и информации по этому вопросу, пожалуйста, ознакомьтесь со шпаргалкой по управлению сеансами OWASP.
User logout
- Нужно удалить authenticatedUserID из сессии и все.
Обновим файл handlers.go
func (app *application) userLogoutPost(w http.ResponseWriter, r *http.Request) {
// обновим токен сессии
err := app.sessionManager.RenewToken(r.Context())
if err != nil {
app.serverError(w, err)
return
}
// удалим authenticatedUserID из сессии'logged out'.
app.sessionManager.Remove(r.Context(), "authenticatedUserID")
// Add a flash message to the session to confirm to the user that they've been
// logged out.
app.sessionManager.Put(r.Context(), "flash", "You've been logged out successfully!")
// Redirect the user to the application home page.
http.Redirect(w, r, "/", http.StatusSeeOther)
}
User authorization
В этом разделе включаются те полезности, которые доступны только аутентифицированным пользователям
- они могут создавать сниппеты
- в меню появляются новые пункты и убираются ненужные
Содержимое панели навигации меняется в зависимости от того, аутентифицирован ли пользователь (вошел в систему) или нет. В частности:
- аутентифицированные пользователи должны видеть ссылки на «Главную», «Создать сниппет» и «Выйти».
- Неаутентифицированные пользователи должны видеть ссылки на «Главную», «Регистрация» и «Вход».
Проверка аутентификации
Чтобы проверить аутентификацию пользователя, нужно проверить значение authenticatedUserID в сессии.
Чтобы не забыть, мы при аутентификации выполнили команду:
app.sessionManager.Put(r.Context(), "authenticatedUserID", id)
и эта информация записалась в базу данных в поле data. С этим контекстом работает пакет SCS и выполняет все проверки через свои команды.
Добавим вспомогательную функцию isAuthenticated() для возврата статуса аутентификации (helpers.go):
func (app *application) isAuthenticated(r *http.Request) bool {
return app.sessionManager.Exists(r.Context(), "authenticatedUserID")
}
Добавим новое поле IsAuthenticated в нашу структуру templateData (templates.go):
type templateData struct {
CurrentYear int
Snippet *models.Snippet
Snippets []*models.Snippet
Form any
Flash string
IsAuthenticated bool // Add an IsAuthenticated field to the templateData struct.
}
Обновить newTemplateData() в helpers.go, чтобы эта информация автоматически добавлялась в структуру templateData каждый раз, когда мы отрисовываем шаблон.
func (app *application) newTemplateData(r *http.Request) *templateData {
return &templateData{
CurrentYear: time.Now().Year(),
Flash: app.sessionManager.PopString(r.Context(), "flash"),
// Add the authentication status to the template data.
IsAuthenticated: app.isAuthenticated(r),
}
}
Проверяем поле {{if .IsAuthenticated}} в шаблонах nav.tmpl
{{define "nav"}}
<nav>
<div>
<a href='/'>Home</a>
<!-- Toggle the link based on authentication status -->
{{if .IsAuthenticated}}
<a href='/snippet/create'>Create snippet</a>
{{end}}
</div>
<div>
<!-- Toggle the links based on authentication status -->
{{if .IsAuthenticated}}
<form action='/user/logout' method='POST'>
<button>Logout</button>
</form>
{{else}}
<a href='/user/signup'>Signup</a>
<a href='/user/login'>Login</a>
{{end}}
</div>
</nav>
{{end}}
Ограничение доступа к страницам
Ограничение доступа
В настоящее время мы скрываем навигационную ссылку «Создать сниппет» для всех пользователей, которые не вошли в систему. Но пользователь, не прошедший аутентификацию, все равно может создать новый сниппет, посетив страницу https://localhost:4000/snippet/create напрямую.
Давайте исправим это, так что если неаутентифицированный пользователь попытается посетить какие-либо маршруты с URL-адресом /snippet/create, он будет перенаправлен на /user/login.
Будем использовать middleware
Внесем изменения в middleware.go
func (app *application) requireAuthentication(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Если пользователь не аутентифицирован, перенаправьте его на страницу входа и
// вернитесь из цепочки промежуточного ПО, чтобы последующие обработчики в
// цепочке не выполнялись.
if !app.isAuthenticated(r) {
http.Redirect(w, r, "/user/login", http.StatusSeeOther)
return
}
//В противном случае установите заголовок "Cache-Control: no-store" так, чтобы страницы,
// требующие аутентификации, не сохранялись в кэше браузера пользователя (или
// другом промежуточном кэше).
w.Header().Add("Cache-Control", "no-store")
// And call the next handler in the chain.
next.ServeHTTP(w, r)
})
}
В нашем случае мы захотим защитить маршруты GET /snippet/create и POST /snippet/create.
И нет особого смысла выходить из системы пользователя, если он не вошел в систему, поэтому имеет смысл использовать его также и в маршруте POST /user/logout.
Чтобы помочь в этом, давайте разделим маршруты наших приложений на две «группы».
- Первая группа будет содержать наши «незащищенные» маршруты и использовать нашу существующую динамическую цепочку промежуточного программного обеспечения.
- Вторая группа будет содержать наши «защищенные» маршруты и будет использовать новую защищенную цепочку промежуточного ПО, состоящую из динамической цепочки промежуточного ПО и нашего нового промежуточного ПО requireAuthentication().
Корректируем файл routes.go
func (app *application) routes() http.Handler {
router := httprouter.New()
router.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
app.notFound(w)
})
fileServer := http.FileServer(http.Dir("./ui/static/"))
router.Handler(http.MethodGet, "/static/*filepath", http.StripPrefix("/static", fileServer))
// Unprotected application routes using the "dynamic" middleware chain.
dynamic := alice.New(app.sessionManager.LoadAndSave)
router.Handler(http.MethodGet, "/", dynamic.ThenFunc(app.home))
router.Handler(http.MethodGet, "/snippet/view/:id", dynamic.ThenFunc(app.snippetView))
router.Handler(http.MethodGet, "/user/signup", dynamic.ThenFunc(app.userSignup))
router.Handler(http.MethodPost, "/user/signup", dynamic.ThenFunc(app.userSignupPost))
router.Handler(http.MethodGet, "/user/login", dynamic.ThenFunc(app.userLogin))
router.Handler(http.MethodPost, "/user/login", dynamic.ThenFunc(app.userLoginPost))
// Protected (authenticated-only) application routes, using a new "protected"
// middleware chain which includes the requireAuthentication middleware.
protected := dynamic.Append(app.requireAuthentication)
router.Handler(http.MethodGet, "/snippet/create", protected.ThenFunc(app.snippetCreate))
router.Handler(http.MethodPost, "/snippet/create", protected.ThenFunc(app.snippetCreatePost))
router.Handler(http.MethodPost, "/user/logout", protected.ThenFunc(app.userLogoutPost))
standard := alice.New(app.recoverPanic, app.logRequest, secureHeaders)
return standard.Then(router)
}
Без использования alice
Если вы не используете пакет justinas/alice — вы можете вручную обернуть обработчики следующим образом:
router.Handler(http.MethodPost, "/snippet/create", app.sessionManager.LoadAndSave(app.requireAuthentication(http.HandlerFunc(app.snippetCreate))))
CSRF protection
Что такое CSRF Protection
Что такое CSRF Protection?
CSRF (Cross-Site Request Forgery) — это тип атаки, при которой злоумышленник заставляет пользователя выполнить нежелательное действие на веб-сайте, на котором он аутентифицирован. Это может привести к несанкционированным действиям, таким как изменение паролей, отправка сообщений или выполнение финансовых транзакций.
Зачем нужна защита от CSRF?
Защита от CSRF необходима для предотвращения таких атак, чтобы обеспечить безопасность пользователей и защитить их данные. Без этой защиты злоумышленники могут использовать доверие пользователя к веб-приложению для выполнения вредоносных действий.
Автор рекомендует использовать пакет justinas/nosurf для борьбы с CSRF
go get github.com/justinas/nosurf@v1
Добавление функции в middleware.go
import (
"fmt"
"net/http"
"github.com/justinas/nosurf" // New import
)
...
// Create a NoSurf middleware function which uses a customized CSRF cookie with
// the Secure, Path and HttpOnly attributes set.
func noSurf(next http.Handler) http.Handler {
csrfHandler := nosurf.New(next)
csrfHandler.SetBaseCookie(http.Cookie{
HttpOnly: true,
Path: "/",
Secure: true,
})
return csrfHandler
}
Защита формы logout
Одной из форм, которую нам необходимо защитить от CSRF-атак, является форма выхода из системы, которая включена в наш partial nav.tmpl и потенциально может появиться на любой странице нашего приложения. Таким образом, из-за этого нам необходимо использовать промежуточное ПО noSurf() на всех маршрутах нашего приложения (кроме /static/*filepath).
Исправим routes.go
dynamic := alice.New(app.sessionManager.LoadAndSave, noSurf)
остальные маршруты получают настройку автоматически
Добавление скрытых полей с токеном на каждую форму
Исправим templates.go
добавим поле с токеном в структуру templateData
package main
import (
"html/template"
"path/filepath"
"time"
"snippetbox.alexedwards.net/internal/models"
)
type templateData struct {
CurrentYear int
Snippet *models.Snippet
Snippets []*models.Snippet
Form any
Flash string
IsAuthenticated bool
CSRFToken string // Add a CSRFToken field.
}
Исправим helpers.go
внесем изменения в помощник для всех форм
func (app *application) newTemplateData(r *http.Request) *templateData {
return &templateData{
CurrentYear: time.Now().Year(),
Flash: app.sessionManager.PopString(r.Context(), "flash"),
IsAuthenticated: app.isAuthenticated(r),
CSRFToken: nosurf.Token(r), // Add the CSRF token.
}
}
Исправим все шаблоны и внесем в них скрытые поля
<input type='hidden' name='csrf_token' value='{{.CSRFToken}}'>
Using request context
Мы могли бы сделать эту проверку более надежной, запросив таблицу базы данных наших пользователей, чтобы убедиться, что значение “authenticatedUserID” является реальным, действительным значением (т.е. мы не удаляли учетную запись пользователя с момента его последнего входа в систему).
Поэтому сейчас будем изучать контекст запроса.
Как работает контекст запроса
Синтаксис контекста запроса
Основной код для добавления информации в контекст запроса выглядит следующим образом:
// Где r — это *http.Request...
ctx := r.Context()
ctx = context.WithValue(ctx, "isAuthenticated", true)
r = r.WithContext(ctx)
Давайте разберем это построчно.
- Сначала мы используем метод r.Context(), чтобы получить существующий контекст из запроса и присваиваем его переменной ctx.
- Затем мы используем метод context.WithValue(), чтобы создать новую копию существующего контекста, содержащую ключ “isAuthenticated” и значение true.
- Наконец, мы используем метод r.WithContext(), чтобы создать копию запроса с нашим новым контекстом.
Важно
Обратите внимание, что мы не обновляем контекст запроса напрямую. Мы создаем новую копию объекта http.Request с нашим новым контекстом.Также стоит отметить, что для ясности я сделал этот фрагмент кода немного более многословным, чем это необходимо. Обычно его пишут так:
ctx = context.WithValue(r.Context(), "isAuthenticated", true)
r = r.WithContext(ctx)
Итак, вот как вы добавляете данные в контекст запроса. Но как их снова извлечь?
Важно объяснить, что за кулисами значения контекста запроса хранятся с типом any. Это означает, что после извлечения их из контекста вам нужно будет привести их к исходному типу перед использованием.
Чтобы извлечь значение, нам нужно использовать метод r.Context().Value(), вот так:
isAuthenticated, ok := r.Context().Value("isAuthenticated").(bool)
if !ok {
return errors.New("не удалось преобразовать значение в bool")
}
В этом коде мы пытаемся получить значение, связанное с ключом “isAuthenticated”, и одновременно проверяем, удалось ли нам привести его к типу bool. Если преобразование не удалось, мы возвращаем ошибку.
Избежание коллизий ключей
В приведенных выше примерах кода я использовал строку “isAuthenticated” в качестве ключа для хранения и извлечения данных из контекста запроса. Однако это не рекомендуется, поскольку существует риск, что другие сторонние пакеты, используемые вашим приложением, также захотят хранить данные с использованием ключа “isAuthenticated”, что приведет к коллизии имен.
Чтобы избежать этого, хорошей практикой является создание собственного пользовательского типа, который вы можете использовать для своих ключей контекста. Расширяя наш пример кода, гораздо лучше сделать что-то вроде этого:
// Объявляем пользовательский тип "contextKey" для ваших ключей контекста.
type contextKey string
// Создаем константу с типом contextKey, которую мы можем использовать.
const isAuthenticatedContextKey = contextKey("isAuthenticated")
...
// Устанавливаем значение в контексте запроса, используя нашу константу isAuthenticatedContextKey в качестве ключа.
ctx := r.Context()
ctx = context.WithValue(ctx, isAuthenticatedContextKey, true)
r = r.WithContext(ctx)
...
// Извлекаем значение из контекста запроса, используя нашу константу в качестве ключа.
isAuthenticated, ok := r.Context().Value(isAuthenticatedContextKey).(bool)
if !ok {
return errors.New("не удалось преобразовать значение в bool")
}
Таким образом, мы избегаем возможных коллизий ключей, используя пользовательский тип для ключей контекста.
Request context для authentication/authorization
Теперь, когда мы разобрали эти объяснения, давайте начнем использовать функциональность контекста запроса в нашем приложении.
Мы начнем с того, что вернемся к файлу internal/models/users.go и обновим метод UserModel.Exists(), чтобы он возвращал true, если пользователь с определенным ID существует в нашей таблице пользователей, и false в противном случае. Вот так:
Файл: internal/models/users.go
package models
...
func (m *UserModel) Exists(id int) (bool, error) {
var exists bool
stmt := "SELECT EXISTS(SELECT true FROM users WHERE id = ?)"
err := m.DB.QueryRow(stmt, id).Scan(&exists)
return exists, err
}
Затем давайте создадим новый файл cmd/web/context.go. В этом файле мы определим пользовательский тип contextKey и переменную isAuthenticatedContextKey, чтобы у нас был уникальный ключ, который мы можем использовать для хранения и извлечения статуса аутентификации из контекста запроса (без риска коллизий имен).
package main
type contextKey string
const isAuthenticatedContextKey = contextKey("isAuthenticated")
Давайте создадим новый метод промежуточного ПО authenticate(), который:
- Извлекает ID пользователя из данных сессии.
- Проверяет базу данных, чтобы узнать, соответствует ли ID действительному пользователю, используя метод
UserModel.Exists(). - Обновляет контекст запроса, добавляя ключ
isAuthenticatedContextKeyсо значением true.
Вот код:
Файл: cmd/web/middleware.go
package main
import (
"context" // Новый импорт
"fmt"
"net/http"
"github.com/justinas/nosurf"
)
...
func (app *application) authenticate(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Извлекаем значение authenticatedUserID из сессии, используя метод
// GetInt(). Это вернет нулевое значение для int (0), если в сессии
// нет значения "authenticatedUserID" — в этом случае мы
// вызываем следующий обработчик в цепочке как обычно и прерываем обработку.
id := app.sessionManager.GetInt(r.Context(), "authenticatedUserID")
if id == 0 {
next.ServeHTTP(w, r)
return
}
// В противном случае мы проверяем, существует ли пользователь с этим ID
// в нашей базе данных.
exists, err := app.users.Exists(id)
if err != nil {
app.serverError(w, err)
return
}
// Если найден соответствующий пользователь, мы знаем, что запрос
// поступает от аутентифицированного пользователя, который существует
// в нашей базе данных. Мы создаем новую копию запроса (с
// значением isAuthenticatedContextKey равным true в контексте запроса)
// и присваиваем ее переменной r.
if exists {
ctx := context.WithValue(r.Context(), isAuthenticatedContextKey, true)
r = r.WithContext(ctx)
}
// Вызываем следующий обработчик в цепочке.
next.ServeHTTP(w, r)
})
}
Важно подчеркнуть следующее различие:
- Когда у нас нет действительного аутентифицированного пользователя, мы передаем оригинальный и неизмененный *http.Request следующему обработчику в цепочке.
- Когда у нас есть действительный аутентифицированный пользователь, мы создаем копию запроса с ключом
isAuthenticatedContextKeyи значением true, хранящимся в контексте запроса. Затем мы передаем эту копию *http.Request следующему обработчику в цепочке.
Хорошо, давайте обновим файл cmd/web/routes.go, чтобы включить промежуточное ПО authenticate() в нашу динамическую цепочку промежуточного ПО.
package main
...
func (app *application) routes() http.Handler {
router := httprouter.New()
router.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
app.notFound(w)
})
fileServer := http.FileServer(http.Dir("./ui/static/"))
router.Handler(http.MethodGet, "/static/*filepath", http.StripPrefix("/static", fileServer))
// Add the authenticate() middleware to the chain.
dynamic := alice.New(app.sessionManager.LoadAndSave, noSurf, app.authenticate)
router.Handler(http.MethodGet, "/", dynamic.ThenFunc(app.home))
router.Handler(http.MethodGet, "/snippet/view/:id", dynamic.ThenFunc(app.snippetView))
router.Handler(http.MethodGet, "/user/signup", dynamic.ThenFunc(app.userSignup))
router.Handler(http.MethodPost, "/user/signup", dynamic.ThenFunc(app.userSignupPost))
router.Handler(http.MethodGet, "/user/login", dynamic.ThenFunc(app.userLogin))
router.Handler(http.MethodPost, "/user/login", dynamic.ThenFunc(app.userLoginPost))
protected := dynamic.Append(app.requireAuthentication)
router.Handler(http.MethodGet, "/snippet/create", protected.ThenFunc(app.snippetCreate))
router.Handler(http.MethodPost, "/snippet/create", protected.ThenFunc(app.snippetCreatePost))
router.Handler(http.MethodPost, "/user/logout", protected.ThenFunc(app.userLogoutPost))
standard := alice.New(app.recoverPanic, app.logRequest, secureHeaders)
return standard.Then(router)
}
Последнее, что нам нужно сделать, — это обновить наш вспомогательный метод isAuthenticated(), чтобы вместо проверки данных сессии он теперь проверял контекст запроса, чтобы определить, аутентифицирован ли пользователь или нет.
Мы можем сделать это следующим образом:
Файл: cmd/web/helpers.go
package main
...
func (app *application) isAuthenticated(r *http.Request) bool {
isAuthenticated, ok := r.Context().Value(isAuthenticatedContextKey).(bool)
if !ok {
return false
}
return isAuthenticated
}
Важно отметить, что если в контексте запроса нет значения с ключом isAuthenticatedContextKey или если подлежащие значение не является типом bool, то это приведение типов завершится неудачей. В этом случае мы принимаем «безопасный» запасной вариант и возвращаем false (т.е. предполагаем, что пользователь не аутентифицирован).
Если хотите, попробуйте снова запустить приложение. Оно должно корректно скомпилироваться, и если вы войдете как определенный пользователь и будете перемещаться по приложению, оно должно работать точно так же, как и раньше.
Дополнительная информация
Неправильное использование контекста запроса
Важно подчеркнуть, что контекст запроса следует использовать только для хранения информации, относящейся к времени жизни конкретного запроса. Документация Go для context.Context предупреждает:
Используйте значения контекста только для данных, ограниченных запросом, которые передаются между процессами и API.
Это означает, что не следует использовать его для передачи зависимостей, которые существуют вне времени жизни запроса — таких как логгеры, кэши шаблонов и пул соединений с базой данных — в ваше промежуточное ПО и обработчики.
По причинам безопасности типов и ясности кода почти всегда лучше явно предоставлять эти зависимости вашим обработчикам, либо делая ваши обработчики методами структуры приложения (как мы делаем в этой книге), либо передавая их в замыкании.
12.9.3 - Alex Edwards Let's Go часть 3
edwardsLetsGo учебный материал по написанию приложения на Go с авторизацией пользователя. Краткий конспект с основными мыслями (глава с 13)
Дополнительные возможности Go
В этом разделе книги мы поговорим о двух функциях Go, которые являются относительно новыми дополнениями к языку: встраивании файлов и обобщениях.
По сути:
- Встраивание файлов позволяет встраивать внешние файлы непосредственно в вашу программу на Go.
- Обобщения могут помочь сократить количество шаблонного кода, который вам нужно писать, при этом сохраняя безопасность типов на этапе компиляции.
Использование встроенных файлов
Одной из ключевых функций релиза Go 1.16 стал пакет embed, который позволяет встраивать внешние файлы непосредственно в вашу программу на Go.
Эта функция действительно полезна, поскольку она позволяет создавать (а затем и распространять) программы на Go, которые полностью самодостаточны и содержат все необходимое для их работы в составе исполняемого бинарного файла.
Чтобы проиллюстрировать, как использовать пакет embed, мы обновим наше приложение, чтобы встроить и использовать файлы из нашей существующей директории ui (которая содержит наши статические файлы CSS/JavaScript/изображения и HTML-шаблоны).
Если вы хотите следовать за нами, сначала создайте новый файл ui/efs.go:
package ui
import (
"embed"
)
//go:embed "html" "static"
var Files embed.FS
Ключевая строка здесь — //go:embed "html" "static".
Хотя это выглядит как комментарий, на самом деле это специальная директива. При компиляции приложения она указывает Go сохранить файлы из папок ui/html и ui/static в embedded-файловой системе embed.FS, связанной с глобальной переменной Files.
Вот несколько важных деталей, которые нужно учитывать:
Расположение директивы
Директиваgo:embedдолжна находиться непосредственно перед переменной, в которую нужно встроить файлы.Формат директивы
Общий формат:go:embed <пути>. Можно указывать несколько путей в одной директиве (как в примере выше). Пути должны быть относительными к файлу с исходным кодом, содержащему директиву. В нашем случаеgo:embed "static" "html"встраивает папкиui/staticиui/html.Область применения
Директиваgo:embedработает только с глобальными переменными на уровне пакета, но не внутри функций или методов. При попытке использовать её внутри функции возникнет ошибка компиляции:"go:embed cannot apply to var inside func".Ограничения путей
- Пути не могут содержать
.или... - Они не должны начинаться или заканчиваться на
/. - Это ограничивает встраивание файлами, находящимися в той же директории (или её поддиректориях), что и исходный файл с директивой.
- Пути не могут содержать
Встраивание директорий
Если путь ведёт к папке, все её файлы встраиваются рекурсивно, кроме файлов, имена которых начинаются с.или_. Чтобы включить такие файлы, используйте префиксall:, например://go:embed "all:static"Разделитель путей
Всегда используйте прямой слеш (/), даже в Windows.Корневая директория embedded-файловой системы
Она всегда соответствует расположению файла с директивойgo:embed. В нашем примереFilesсодержит файловую системуembed.FS, корнем которой является папкаui.
Использование статических файлов
Давайте изменим наше приложение так, чтобы оно обслуживало наши статические файлы CSS, JavaScript и изображения из встроенной файловой системы, а не считывало их с диска во время выполнения.
Откройте файл cmd/web/routes.go и обновите его следующим образом:
Файл: cmd/web/routes.go
package main
import (
"net/http"
"snippetbox.alexedwards.net/ui" // Новый импорт
"github.com/julienschmidt/httprouter"
"github.com/justinas/alice"
)
func (app *application) routes() http.Handler {
router := httprouter.New()
router.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
app.notFound(w)
})
// Берем встроенную файловую систему ui.Files и преобразуем ее в тип http.FS, чтобы
// она соответствовала интерфейсу http.FileSystem. Затем передаем это в функцию
// http.FileServer() для создания обработчика файлового сервера.
fileServer := http.FileServer(http.FS(ui.Files))
// Наши статические файлы содержатся в папке "static" встроенной файловой системы ui.Files.
// Например, наш CSS-стилист находится по адресу "static/css/main.css". Это означает, что
// нам больше не нужно удалять префикс из URL запроса — любые запросы, начинающиеся с /static/,
// могут просто передаваться непосредственно файловому серверу, и соответствующий статический
// файл будет обслужен (если он существует).
router.Handler(http.MethodGet, "/static/*filepath", fileServer)
dynamic := alice.New(app.sessionManager.LoadAndSave, noSurf, app.authenticate)
router.Handler(http.MethodGet, "/", dynamic.ThenFunc(app.home))
router.Handler(http.MethodGet, "/snippet/view/:id", dynamic.ThenFunc(app.snippetView))
router.Handler(http.MethodGet, "/user/signup", dynamic.ThenFunc(app.userSignup))
router.Handler(http.MethodPost, "/user/signup", dynamic.ThenFunc(app.userSignupPost))
router.Handler(http.MethodGet, "/user/login", dynamic.ThenFunc(app.userLogin))
router.Handler(http.MethodPost, "/user/login", dynamic.ThenFunc(app.userLoginPost))
protected := dynamic.Append(app.requireAuthentication)
router.Handler(http.MethodGet, "/snippet/create", protected.ThenFunc(app.snippetCreate))
router.Handler(http.MethodPost, "/snippet/create", protected.ThenFunc(app.snippetCreatePost))
router.Handler(http.MethodPost, "/user/logout", protected.ThenFunc(app.userLogoutPost))
standard := alice.New(app.recoverPanic, app.logRequest, secureHeaders)
return standard.Then(router)
}
Если вы сохраните файлы и затем перезапустите приложение, вы должны увидеть, что все компилируется и работает корректно. Когда вы посетите https://localhost:4000 в вашем браузере, статические файлы должны обслуживаться из встроенной файловой системы, и все должно выглядеть нормально.
Встраивание HTML-шаблонов
Теперь давайте обновим файл cmd/web/templates.go, чтобы наш кэш шаблонов использовал встроенные HTML-шаблоны из ui.Files, а не те, что находятся на диске.
Чтобы помочь нам с этим, мы воспользуемся несколькими специальными функциями, которые Go 1.16 представил для работы с встроенными файловыми системами:
fs.Glob()возвращает срез путей файлов, соответствующих шаблону glob. Это фактически то же самое, что и функцияfilepath.Glob(), которую мы использовали ранее в книге, за исключением того, что она работает с встроенными файловыми системами.Template.ParseFS()можно использовать для разбора HTML-шаблонов из встроенной файловой системы в набор шаблонов. Это фактически замена как для методовTemplate.ParseFiles(), так иTemplate.ParseGlob(), которые мы использовали ранее.Template.ParseFiles()также является функцией с переменным числом аргументов, что позволяет вам разбирать несколько шаблонов за один вызовParseFiles().
Давайте применим это в нашем файле cmd/web/templates.go:
Файл: cmd/web/templates.go
package main
import (
"html/template"
"io/fs" // Новый импорт
"path/filepath"
"time"
"snippetbox.alexedwards.net/internal/models"
"snippetbox.alexedwards.net/ui" // Новый импорт
)
...
func newTemplateCache() (map[string]*template.Template, error) {
cache := map[string]*template.Template{}
// Используем fs.Glob() для получения среза всех путей файлов в
// встроенной файловой системе ui.Files, которые соответствуют шаблону
// 'html/pages/*.tmpl'. Это фактически дает нам срез всех 'page' шаблонов
// для приложения, как и раньше.
pages, err := fs.Glob(ui.Files, "html/pages/*.tmpl")
if err != nil {
return nil, err
}
for _, page := range pages {
name := filepath.Base(page)
// Создаем срез, содержащий шаблоны, которые мы хотим разобрать.
patterns := []string{
"html/base.tmpl",
"html/partials/*.tmpl",
page,
}
// Используем ParseFS() вместо ParseFiles() для разбора файлов шаблонов
// из встроенной файловой системы ui.Files.
ts, err := template.New(name).Funcs(functions).ParseFS(ui.Files, patterns...)
if err != nil {
return nil, err
}
cache[name] = ts
}
return cache, nil
}
Теперь, когда это сделано, когда наше приложение будет собрано в бинарный файл, оно будет содержать все необходимые UI-файлы для работы.
Вы можете быстро попробовать это, собрав исполняемый бинарный файл в вашей директории /tmp, скопировав сертификаты TLS и запустив бинарный файл. Вот так:
go build -o /tmp/web ./cmd/web/
cp -r ./tls /tmp/
cd /tmp/
./web
Использование обобщений
Go 1.18 — это первая версия языка, которая поддерживает обобщения, также известные под более техническим названием параметрический полиморфизм.
В общем, новая функциональность обобщений позволяет вам писать код, который работает с различными конкретными типами.
Например, в более ранних версиях Go, если вы хотели проверить, содержится ли определенное значение в срезе []string и срезе []int, вам нужно было бы написать две отдельные функции — одну для типа строк и другую для типа целых чисел. Это выглядело бы примерно так:
func containsString(v string, s []string) bool {
for i, vs := range s {
if v == vs {
return true
}
}
return false
}
func containsInt(v int, s []int) bool {
for i, vs := range s {
if v == vs {
return true
}
}
return false
}
Теперь, с обобщениями, возможно написать одну единственную функцию contains(), которая будет работать для строк, целых чисел и всех других сопоставимых типов. Код выглядит так:
func contains[T comparable](v T, s []T) bool {
for i := range s {
if v == s[i] {
return true
}
}
return false
}
Когда использовать обобщения?
Вы можете рассмотреть возможность использования обобщений, когда:
- Вы часто пишете повторяющийся шаблонный код для различных типов данных. Примеры этого могут включать общие операции над срезами, картами или каналами — или вспомогательные функции для выполнения проверок валидации или тестовых утверждений для различных типов данных.
- Вы пишете код и часто обращаетесь к типу
any(пустой интерфейс). Примером этого может быть создание структуры данных (например, очереди, кэша или связного списка), которая должна работать с различными типами.
В то же время, вероятно, вам не следует использовать обобщения:
- Если это делает ваш код труднее для понимания или менее ясным.
- Если все типы, с которыми вам нужно работать, имеют общий набор методов — в этом случае лучше определить и использовать обычный интерфейс.
- Просто потому, что вы можете. В первую очередь пишите простой не обобщенный код, и переходите к обобщенной версии только в том случае, если это действительно необходимо.
Использование обобщений в нашем приложении
В следующем разделе книги мы начнем писать тесты для нашего приложения, и в процессе этого мы сгенерируем много повторяющегося шаблонного кода. Мы воспользуемся функциональностью обобщений Go, чтобы помочь нам управлять этим и создать несколько универсальных вспомогательных функций для выполнения проверок тестов на различных типах данных.
Возможно, единственное, что действительно подходит для обобщений, — это функция PermittedInt() в нашем файле internal/validator/validator.go.
Давайте изменим ее на универсальную функцию PermittedValue(), которую мы сможем использовать каждый раз, когда захотим проверить, находится ли предоставленное пользователем значение в наборе разрешенных значений — независимо от того, является ли предоставленное пользователем значение строкой, целым числом, float64 или любым другим сопоставимым типом.
Вот так: Вот технический перевод документации с соблюдением терминологии языка Go:
Файл: internal/validator/validator.go
package validator
// Замените функцию PermittedInt() на универсальную функцию PermittedValue().
// Эта функция возвращает true, если значение типа T равно одному из
// параметров variadic permittedValues.
func PermittedValue[T comparable](value T, permittedValues ...T) bool {
for i := range permittedValues {
if value == permittedValues[i] {
return true
}
}
return false
}
Затем мы можем обновить обработчик snippetCreatePost, чтобы использовать новую функцию PermittedValue() в проверках валидации, следующим образом:
Файл: cmd/web/handlers.go
package main
func (app *application) snippetCreatePost(w http.ResponseWriter, r *http.Request) {
var form snippetCreateForm
err := app.decodePostForm(r, &form)
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
form.CheckField(validator.NotBlank(form.Title), "title", "Это поле не может быть пустым")
form.CheckField(validator.MaxChars(form.Title, 100), "title", "Это поле не может содержать более 100 символов")
form.CheckField(validator.NotBlank(form.Content), "content", "Это поле не может быть пустым")
// Используйте универсальную функцию PermittedValue() вместо
// специфичной для типа функции PermittedInt().
form.CheckField(validator.PermittedValue(form.Expires, 1, 7, 365), "expires", "Это поле должно равняться 1, 7 или 365")
if !form.Valid() {
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "create.tmpl", data)
return
}
id, err := app.snippets.Insert(form.Title, form.Content, form.Expires)
if err != nil {
app.serverError(w, err)
return
}
app.sessionManager.Put(r.Context(), "flash", "Сниппет успешно создан!")
http.Redirect(w, r, fmt.Sprintf("/snippet/view/%d", id), http.StatusSeeOther)
}
После внесения этих изменений вы должны убедиться, что ваше приложение компилируется корректно и продолжает функционировать так же, как и раньше.
12.9.4 - Alex Edwards Let's Go часть 4
edwardsLetsGo учебный материал по написанию приложения на Go с авторизацией пользователя. Краткий конспект с основными мыслями (глава 14) Тестирование
Тестирование
И вот мы наконец-то подошли к теме тестирования.
Как и структурирование и организация кода приложения, нет единственного “правильного” способа структурировать и организовать тесты в Go. Но есть некоторые соглашения, шаблоны и лучшие практики, которые вы можете соблюдать.
В этом разделе мы добавим тесты для части кода нашего приложения с целью продемонстрировать общий синтаксис для создания тестов и проиллюстрировать некоторые шаблоны, которые можно повторно использовать в широком спектре приложений.
Вы узнаете:
- Как создавать и запускать табличные юнит-тесты и подтесты в Go.
- Как тестировать HTTP-обработчики и middleware.
- Как проводить сквозное тестирование маршрутов веб-приложения, middleware и обработчиков.
- Как создавать мок-объекты моделей базы данных и использовать их в юнит-тестах.
- Шаблон для тестирования отправки HTML-форм с CSRF-защитой.
- Как использовать тестовый экземпляр MySQL для интеграционного тестирования.
- Как легко рассчитывать и профилировать покрытие кода тестами.
Юнит-тестирование и подтесты
В этой главе мы создадим юнит-тест, чтобы убедиться, что наша функция humanDate() (которую мы создали в главе о пользовательских функциях шаблонизации) выводит значения типа time.Time в точно таком формате, как нам нужно.
Если вы не помните, функция humanDate() выглядит так:
Файл: cmd/web/templates.go
package main
...
func humanDate(t time.Time) string {
return t.UTC().Format("02 Jan 2006 at 15:04")
}
...
Создание юнит-теста
Давайте сразу же создадим юнит-тест для этой функции.
В Go общепринятой практикой является создание тестов в файлах *_test.go, которые находятся непосредственно рядом с кодом, который вы тестируете. Итак, в этом случае первым делом мы создадим новый файл cmd/web/templates_test.go для хранения теста:
touch cmd/web/templates_test.go
Файл: cmd/web/templates_test.go
package main
import (
"testing"
"time"
)
func TestHumanDate(t *testing.T) {
// Initialize a new time.Time object and pass it to the humanDate function.
tm := time.Date(2022, 3, 17, 10, 15, 0, 0, time.UTC)
hd := humanDate(tm)
// Check that the output from the humanDate function is in the format we
// expect. If it isn't what we expect, use the t.Errorf() function to
// indicate that the test has failed and log the expected and actual
// values.
if hd != "17 Mar 2022 at 10:15" {
t.Errorf("got %q; want %q", hd, "17 Mar 2022 at 10:15")
}
}
Этот шаблон является базовым, который вы будете использовать почти для всех тестов, которые пишете на Go.
Важно запомнить:
Тест является обычным кодом на Go, который вызывает функцию humanDate() и проверяет, что результат соответствует ожидаемому.
Ваши юнит-тесты содержатся в обычной функции Go с сигнатурой
func(*testing.T).Чтобы быть действительным юнит-тестом, имя этой функции должно начинаться с слова Test. Обычно за ним следует имя функции, метода или типа, который вы тестируете, чтобы сделать очевидным, что тестируется.
Вы можете использовать функцию
t.Errorf(), чтобы пометить тест как не прошедший и зарегистрировать описательное сообщение о сбое. Важно отметить, что вызовt.Errorf()не останавливает выполнение вашего теста — после вызова Go продолжит выполнять любой оставшийся тестовый код как обычно.
Давайте попробуем это. Сохраните файл, затем используйте команду go test, чтобы запустить все тесты в нашем пакете cmd/web:
$ go test ./cmd/web
ok snippetbox.igorra.net/cmd/web 0.002s
Итак, это хорошо. ok в этом выводе указывает, что все тесты в пакете (пока только наш тест TestHumanDate()) прошли без проблем.
Если вы хотите получить больше информации, вы можете увидеть, какие тесты выполняются, используя флаг -v, чтобы получить подробный вывод:
$ go test -v ./cmd/web
=== RUN TestHumanDate
--- PASS: TestHumanDate (0.00s)
PASS
ok snippetbox.igorra.net/cmd/web 0.002s
Табличные тесты
Теперь давайте расширим нашу функцию TestHumanDate(), чтобы охватить некоторые дополнительные тестовые случаи. В частности, мы обновим ее, чтобы также проверить, что:
Если входные данные для
humanDate()являются нулевым временем, то она возвращает пустую строку “”.Вывод функции
humanDate()всегда использует часовой пояс UTC.
В Go идиоматическим способом запуска нескольких тестовых случаев является использование табличных тестов.
По сути, идея табличных тестов заключается в создании «таблицы» тестовых случаев, содержащих входные данные и ожидаемые выходные данные, а затем в итерации по ним, запуская каждый тестовый случай в подтесте. Есть несколько способов настроить это, но распространенным подходом является определение тестовых случаев в срезе анонимных структур.
Я продемонстрирую: Файл: cmd/web/templates_test.go
package main
import (
"testing"
"time"
)
func TestHumanDate(t *testing.T) {
// Создаем срез анонимных структур, содержащих имя тестового случая,
// входные данные для нашей функции humanDate() (поле tm) и ожидаемый вывод
// (поле want).
tests := []struct {
name string
tm time.Time
want string
}{
{
name: "UTC",
tm: time.Date(2022, 3, 17, 10, 15, 0, 0, time.UTC),
want: "17 Mar 2022 at 10:15",
},
{
name: "Empty",
tm: time.Time{},
want: "",
},
{
name: "CET",
tm: time.Date(2022, 3, 17, 10, 15, 0, 0, time.FixedZone("CET", 1*60*60)),
want: "17 Mar 2022 at 09:15",
},
}
// Итерируем по тестовым случаям.
for _, tt := range tests {
// Используем функцию t.Run(), чтобы запустить подтест для каждого тестового случая.
// Первый параметр — имя теста (которое используется для идентификации подтеста в любом выводе журнала),
// а второй параметр — анонимная функция, содержащая фактический тест для каждого случая.
t.Run(tt.name, func(t *testing.T) {
hd := humanDate(tt.tm)
if hd != tt.want {
t.Errorf("got %q; want %q", hd, tt.want)
}
})
}
}
Примечание: В третьем тестовом случае мы используем CET (Центральноевропейское время) в качестве часового пояса, который на один час опережает UTC. Итак, мы хотим, чтобы вывод humanDate() (в UTC) был “17 Mar 2022 at 09:15”, а не “17 Mar 2022 at 10:15”.
Хорошо, давайте запустим это и посмотрим, что произойдет:
$ go test -v ./cmd/web
=== RUN TestHumanDate
=== RUN TestHumanDate/UTC
=== RUN TestHumanDate/Empty
templates_test.go:44: got "01 Jan 0001 at 00:00"; want ""
=== RUN TestHumanDate/CET
templates_test.go:44: got "17 Mar 2022 at 10:15"; want "17 Mar 2022 at 09:15"
--- FAIL: TestHumanDate (0.00s)
--- PASS: TestHumanDate/UTC (0.00s)
--- FAIL: TestHumanDate/Empty (0.00s)
--- FAIL: TestHumanDate/CET (0.00s)
FAIL
FAIL snippetbox.alexedwards.net/cmd/web 0.003s
FAIL
Итак, здесь мы можем видеть индивидуальный вывод для каждого из наших подтестов. Как вы, возможно, догадались, наш первый тестовый случай прошел, но Empty и CET-тесты оба не прошли. Заметим, как для неудавшихся тестовых случаев мы получаем соответствующее сообщение об ошибке и имя файла и номер строки в выводе?
Давайте вернемся к нашей функции humanDate() и обновим ее, чтобы исправить эти две проблемы:
Файл: cmd/web/templates.go
package main
...
func humanDate(t time.Time) string {
// Возвращаем пустую строку, если время имеет нулевое значение.
if t.IsZero() {
return ""
}
// Преобразуем время в UTC, прежде чем форматировать его.
return t.UTC().Format("02 Jan 2006 at 15:04")
}
...
И когда вы повторно запустите тесты,
$ go test -v ./cmd/web
=== RUN TestHumanDate
=== RUN TestHumanDate/UTC
=== RUN TestHumanDate/Empty
=== RUN TestHumanDate/CET
--- PASS: TestHumanDate (0.00s)
--- PASS: TestHumanDate/UTC (0.00s)
--- PASS: TestHumanDate/Empty (0.00s)
--- PASS: TestHumanDate/CET (0.00s)
PASS
ok snippetbox.alexedwards.net/cmd/web 0.003s
Вспомогательные функции для тестовых утверждений
Как я упоминал ранее в книге, в течение следующих нескольких глав мы будем писать много тестовых утверждений, которые являются вариацией этого шаблона:
if actualValue != expectedValue {
t.Errorf("got %v; want %v", actualValue, expectedValue)
}
Давайте быстро абстрагируем этот код в вспомогательную функцию.
Если вы следите за ходом событий, создайте новый пакет internal/assert:
$ mkdir internal/assert
$ touch internal/assert/assert.go
И затем добавьте следующий код: Файл: internal/assert/assert.go
package assert
import (
"testing"
)
func Equal[T comparable](t *testing.T, actual, expected T) {
t.Helper()
if actual != expected {
t.Errorf("got: %v; want: %v", actual, expected)
}
}
Заметим, как мы настроили это так, что Equal() является универсальной функцией? Это означает, что мы сможем использовать ее независимо от типа фактических и ожидаемых значений. Пока фактические и ожидаемые значения имеют один и тот же тип (например, они оба являются строковыми значениями или оба являются целыми числами), наш тестовый код должен компилироваться и работать нормально, когда мы вызываем Equal().
Примечание
Функция t.Helper(), которую мы используем в приведенном выше коде, указывает Go-тест, что наша функция Equal() является тестовым помощником. Это означает, что когда t.Errorf() вызывается из нашей функции Equal(), Go-тест будет сообщать имя файла и номер строки кода, который вызвал нашу функцию Equal(), в выводе.
Без t.Helper() вывод теста будет указывать на строку внутри функции Equal(), где была вызвана t.Errorf(), а не на строку в фактическом тестовом коде, где была вызвана Equal(). Это может затруднить отладку и понимание, что именно пошло не так.
Используя t.Helper(), мы можем получить более точную и полезную информацию об ошибках в наших тестах.
package main
import (
"testing"
"time"
"snippetbox.alexedwards.net/internal/assert" // New import
)
func TestHumanDate(t *testing.T) {
tests := []struct {
name string
tm time.Time
want string
}{
{
name: "UTC",
tm: time.Date(2022, 3, 17, 10, 15, 0, 0, time.UTC),
want: "17 Mar 2022 at 10:15",
},
{
name: "Empty",
tm: time.Time{},
want: "",
},
{
name: "CET",
tm: time.Date(2022, 3, 17, 10, 15, 0, 0, time.FixedZone("CET", 1*60*60)),
want: "17 Mar 2022 at 09:15",
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
hd := humanDate(tt.tm)
// Use the new assert.Equal() helper to compare the expected and
// actual values.
assert.Equal(t, hd, tt.want)
})
}
}
Дополнительная информация
Субтесты без таблицы тестовых случаев
Важно отметить, что вам не нужно использовать субтесты в сочетании с табличными тестами (как мы делали до сих пор в этой главе). Полностью допустимо выполнять субтесты, вызывая t.Run() последовательно в ваших тестовых функциях, подобно этому:
func TestExample(t *testing.T) {
t.Run("Example sub-test 1", func(t *testing.T) {
// Выполняем один тест.
})
t.Run("Example sub-test 2", func(t *testing.T) {
// Выполняем другой тест.
})
t.Run("Example sub-test 3", func(t *testing.T) {
// И еще один...
})
}
Этот подход может быть полезен, когда у вас есть несколько независимых тестов, которые не связаны между собой таблицей тестовых случаев. Однако табличные тесты часто более удобны и кратки, когда у вас есть много тестов с похожими входными и выходными данными.
Тестирование HTTP-обработчиков и middleware
Давайте перейдем к конкретным техникам юнит-тестирования HTTP-обработчиков.
Все обработчики, которые мы написали для этого проекта, пока что довольно сложны для тестирования. Чтобы проще разобраться в теме, начнем с чего-то более простого.
Простой пример: обработчик ping
Откройте файл handlers.go и создайте новый обработчик ping, который:
- Возвращает статус-код 200 OK
- Отправляет тело ответа “OK”
Такой обработчик может использоваться для проверки работоспособности сервера (например, в мониторинге uptime).
package main
...
func ping(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("OK"))
}
В этой главе мы создадим юнит-тест TestPing, который проверит:
- Что обработчик ping возвращает HTTP-статус 200.
- Что тело ответа содержит строго “OK”.
Запись ответов
Для помощи в тестировании ваших обработчиков HTTP пакет net/http/httptest в Go предоставляет набор полезных инструментов.
Одним из этих инструментов является тип httptest.ResponseRecorder. По сути, это реализация http.ResponseWriter, которая записывает код состояния ответа, заголовки и тело вместо того, чтобы фактически записывать их в соединение HTTP.
Таким образом, простым способом тестирования ваших обработчиков является создание нового объекта httptest.ResponseRecorder, передача его в функцию обработчика, а затем проверка его после возврата обработчика.
Давайте попробуем сделать именно это, чтобы протестировать функцию обработчика ping.
Сначала, следуя соглашениям Go, создайте новый файл handlers_test.go,
$ touch cmd/web/handlers_test.go
Затем добавьте следующий код:
Файл: cmd/web/handlers_test.go
package main
import (
"bytes"
"io"
"net/http"
"net/http/httptest"
"testing"
"snippetbox.igorra.net/internal/assert"
)
func TestPing(t *testing.T) {
// Инициализируйте новый `httptest.ResponseRecorder`.
rr := httptest.NewRecorder()
// Инициализируйте новый фиктивный `http.Request`.
r, err := http.NewRequest(http.MethodGet, "/", nil)
if err != nil {
t.Fatal(err)
}
// Вызовите функцию обработчика `ping`, передав `httptest.ResponseRecorder` и `http.Request`.
ping(rr, r)
// Вызовите метод `Result()` для `http.ResponseRecorder`, чтобы получить `http.Response`, сгенерированный обработчиком `ping`.
rs := rr.Result()
// Проверьте, что код состояния, записанный обработчиком `ping`, был 200.
assert.Equal(t, rs.StatusCode, http.StatusOK)
// И мы можем проверить, что тело ответа, записанное обработчиком `ping`, равно "OK".
defer rs.Body.Close()
body, err := io.ReadAll(rs.Body)
if err != nil {
t.Fatal(err)
}
bytes.TrimSpace(body)
assert.Equal(t, string(body), "OK")
}
Примечание
В приведенном выше коде мы используем функцию t.Fatal() в нескольких местах для обработки ситуаций, когда в нашем тестовом коде возникает неожиданная ошибка. При вызове t.Fatal() пометит тест как неудачный, запишет ошибку и затем полностью остановит выполнение текущего теста (или подтеста).
Обычно следует вызывать t.Fatal() в ситуациях, когда не имеет смысла продолжать текущий тест — например, при ошибке во время шага настройки или когда неожиданная ошибка от функции стандартной библиотеки Go означает, что вы не можете продолжить тест.
Сохраните файл, затем попробуйте запустить go test снова с установленным флагом verbose. Вот так:
go test -v ./cmd/web
=== RUN TestPing
--- PASS: TestPing (0.00s)
=== RUN TestHumanDate
=== RUN TestHumanDate/UTC
=== RUN TestHumanDate/Empty
=== RUN TestHumanDate/CET
--- PASS: TestHumanDate (0.00s)
--- PASS: TestHumanDate/UTC (0.00s)
--- PASS: TestHumanDate/Empty (0.00s)
--- PASS: TestHumanDate/CET (0.00s)
PASS
ok snippetbox.igorra.net/cmd/web 0.002s
Тестирование middleware
Также возможно использовать тот же общий шаблон для модульного тестирования вашего middleware.
Мы продемонстрируем это, создав новый тест TestSecureHeaders для middleware secureHeaders(), который мы создали ранее в книге. В рамках этого теста мы хотим проверить, что:
Middleware `secureHeaders()` устанавливает все ожидаемые заголовки в ответе HTTP.
Middleware `secureHeaders()` корректно вызывает следующий обработчик в цепочке.
Сначала вам нужно создать файл cmd/web/middleware_test.go, чтобы содержать тест:
$ touch cmd/web/middleware_test.go
Затем добавьте следующий код:
Файл: cmd/web/middleware_test.go
package main
import (
"bytes"
"io"
"net/http"
"net/http/httptest"
"testing"
"snippetbox.alexedwards.net/internal/assert"
)
func TestSecureHeaders(t *testing.T) {
// Инициализируйте новый `httptest.ResponseRecorder` и фиктивный `http.Request`.
rr := httptest.NewRecorder()
r, err := http.NewRequest(http.MethodGet, "/", nil)
if err != nil {
t.Fatal(err)
}
// Создайте фиктивный обработчик HTTP, который можно передать нашему middleware `secureHeaders`,
// который пишет код состояния 200 и тело ответа "OK".
next := http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("OK"))
})
// Передайте фиктивный обработчик HTTP нашему middleware `secureHeaders`. Поскольку
// `secureHeaders` *возвращает* `http.Handler`, мы можем вызвать его метод `ServeHTTP()`,
// передав `http.ResponseRecorder` и фиктивный `http.Request`, чтобы выполнить его.
secureHeaders(next).ServeHTTP(rr, r)
// Вызовите метод `Result()` для `http.ResponseRecorder`, чтобы получить результаты теста.
rs := rr.Result()
// Проверьте, что middleware корректно установил заголовок `Content-Security-Policy` в ответе.
expectedValue := "default-src 'self'; style-src 'self' fonts.googleapis.com; font-src fonts.gstatic.com"
assert.Equal(t, rs.Header.Get("Content-Security-Policy"), expectedValue)
// Проверьте, что middleware корректно установил заголовок `Referrer-Policy` в ответе.
expectedValue = "origin-when-cross-origin"
assert.Equal(t, rs.Header.Get("Referrer-Policy"), expectedValue)
// Проверьте, что middleware корректно установил заголовок `X-Content-Type-Options` в ответе.
expectedValue = "nosniff"
assert.Equal(t, rs.Header.Get("X-Content-Type-Options"), expectedValue)
// Проверьте, что middleware корректно установил заголовок `X-Frame-Options` в ответе.
expectedValue = "deny"
assert.Equal(t, rs.Header.Get("X-Frame-Options"), expectedValue)
// Проверьте, что middleware корректно установил заголовок `X-XSS-Protection` в ответе.
expectedValue = "0"
assert.Equal(t, rs.Header.Get("X-XSS-Protection"), expectedValue)
// Проверьте, что middleware корректно вызвал следующий обработчик в цепочке,
// и код состояния ответа и тело ответа соответствуют ожиданиям.
assert.Equal(t, rs.StatusCode, http.StatusOK)
defer rs.Body.Close()
body, err := io.ReadAll(rs.Body)
if err != nil {
t.Fatal(err)
}
bytes.TrimSpace(body)
assert.Equal(t, string(body), "OK")
}
Если вы запустите тесты сейчас, вы должны увидеть, что тест TestSecureHeaders проходит без каких-либо проблем.
go test -v ./cmd/web
=== RUN TestPing
--- PASS: TestPing (0.00s)
=== RUN TestSecureHeaders
--- PASS: TestSecureHeaders (0.00s)
=== RUN TestHumanDate
=== RUN TestHumanDate/UTC
=== RUN TestHumanDate/Empty
=== RUN TestHumanDate/CET
--- PASS: TestHumanDate (0.00s)
--- PASS: TestHumanDate/UTC (0.00s)
--- PASS: TestHumanDate/Empty (0.00s)
--- PASS: TestHumanDate/CET (0.00s)
PASS
ok snippetbox.igorra.net/cmd/web 0.002s
End-to-end testing (Сквозное тестирование)
В предыдущей главе мы обсудили общий шаблон для модульного тестирования ваших обработчиков HTTP в изоляции.
Но — в большинстве случаев — ваши обработчики HTTP не используются в изоляции. Итак, в этой главе мы объясним, как запустить сквозные тесты на вашем веб-приложении, которые охватывают маршрутизацию, middleware и обработчики.
Чтобы проиллюстрировать это, мы адаптируем нашу функцию TestPing так, чтобы она запускала сквозной тест на нашем коде. В частности, мы хотим, чтобы тест гарантировал, что GET-запрос к /ping нашему приложению вызывает функцию обработчика ping и приводит к статусу 200 OK и телу ответа “OK”.
По сути, мы хотим проверить, что наше приложение имеет маршрут, подобный этому:
| Метод | Шаблон | Обработчик | Действие |
|---|---|---|---|
| GET | /ping | ping | Вернуть ответ 200 OK |
Использование httptest.Server
Ключом к сквозному тестированию нашего приложения является функция httptest.NewTLSServer(), которая создает экземпляр httptest.Server, которому можно отправлять HTTPS-запросы.
С учетом этого, вернитесь к вашему файлу handlers_test.go и обновите тест TestPing так, чтобы он выглядел следующим образом:
Файл: cmd/web/handlers_test.go
package main
import (
"bytes"
"io"
"log" // Новый импорт
"net/http"
"net/http/httptest"
"testing"
"snippetbox.alexedwards.net/internal/assert"
)
func TestPing(t *testing.T) {
// Создайте новый экземпляр нашей структуры приложения. На данный момент это просто
// содержит пару фиктивных логгеров (которые игнорируют все, что пишется в них).
app := &application{
errorLog: log.New(io.Discard, "", 0),
infoLog: log.New(io.Discard, "", 0),
}
// Затем мы используем функцию `httptest.NewTLSServer()`, чтобы создать новый тестовый
// сервер, передав значение, возвращенное нашим методом `app.routes()`, в качестве
// обработчика для сервера. Это запускает HTTPS-сервер, который слушает на
// случайно выбранном порту вашей локальной машины в течение теста.
// Обратите внимание, что мы откладываем вызов `ts.Close()`, чтобы сервер был закрыт
// после завершения теста.
ts := httptest.NewTLSServer(app.routes())
defer ts.Close()
// Адрес сети, на котором тестовый сервер слушает, содержится в поле `ts.URL`.
// Мы можем использовать это вместе с методом `ts.Client().Get()`, чтобы отправить
// GET-запрос к `/ping` тестовому серверу. Это возвращает структуру `http.Response`,
// содержащую ответ.
rs, err := ts.Client().Get(ts.URL + "/ping")
if err != nil {
t.Fatal(err)
}
// Затем мы можем проверить значение кода состояния ответа и тела, используя
// тот же шаблон, что и раньше.
assert.Equal(t, rs.StatusCode, http.StatusOK)
defer rs.Body.Close()
body, err := io.ReadAll(rs.Body)
if err != nil {
t.Fatal(err)
}
bytes.TrimSpace(body)
assert.Equal(t, string(body), "OK")
}
Есть несколько вещей в этом коде, на которые стоит обратить внимание и обсудить.
- Когда мы вызываем
httptest.NewTLSServer(), чтобы инициализировать тестовый сервер, нам нужно передатьhttp.Handlerв качестве параметра — и этот обработчик вызывается каждый раз, когда тестовый сервер получает HTTPS-запрос. В нашем случае мы передали возвращаемое значение из нашего методаapp.routes(), что означает, что запрос к тестовому серверу будет использовать все наши реальные маршруты приложения, middleware и обработчики. - Это большое преимущество работы, которую мы проделали ранее в книге, чтобы изолировать всю маршрутизацию нашего приложения в методе
app.routes(). - Если вы тестируете HTTP-сервер (а не HTTPS), вы должны использовать функцию
httptest.NewServer(), чтобы создать тестовый сервер. - Метод
ts.Client()возвращает клиент тестового сервера — который имеет типhttp.Client— и мы всегда должны использовать этого клиента, чтобы отправлять запросы к тестовому серверу. Возможно настроить клиента, чтобы изменить его поведение, и мы объясним, как это сделать, в конце этой главы. - Вы можете задаться вопросом, почему мы установили поля
errorLogиinfoLogнашей структуры приложения, но не все остальные поля. Причина этого в том, что логгеры необходимы middlewarelogRequestиrecoverPanic, которые используются нашим приложением на каждом маршруте. Попытка запустить этот тест без установки этих двух зависимостей приведет к панике.
В любом случае, давайте попробуем новый тест:
go test -v ./cmd/web
=== RUN TestPing
handlers_test.go:42: got: 404; want: 200
handlers_test.go:51: got: Not Found
; want: OK
--- FAIL: TestPing (0.00s)
Из тестового вывода мы видим, что ответ на наш запрос GET /ping имеет код состояния 404, а не 200, как мы ожидали. И это потому, что мы еще не зарегистрировали маршрут GET /ping с помощью нашего маршрутизатора. Внесем правку в файл File: cmd/web/routes.go
router.HandlerFunc(http.MethodGet, "/ping", ping)
Итог:
go test -v ./cmd/web
=== RUN TestPing
--- PASS: TestPing (0.00s)
ok snippetbox.igorra.net/cmd/web 0.005s
Использование тестовых помощников
Наш тест TestPing теперь работает хорошо. Но есть хорошая возможность выделить некоторые части этого кода в функции-помощники, которые мы можем повторно использовать, добавляя больше сквозных тестов к нашему проекту.
Нет жестких и быстрых правил о том, где размещать методы-помощники для тестов. Если помощник используется только в определенном файле *_test.go, то, вероятно, имеет смысл включить его встроенным в этот файл рядом с вашими тестами. С другой стороны, если вы собираетесь использовать помощник в тестах в нескольких пакетах, то вы можете поместить его в повторно используемый пакет, называемый internal/testutils (или аналогичный), который может быть импортирован вашими тестовыми файлами.
В нашем случае помощники будут использоваться только в нашем пакете cmd/web, и мы поместим их в новый файл cmd/web/testutils_test.go.
Если вы следите за ходом, пожалуйста, создайте этот файл сейчас…
$ touch cmd/web/testutils_test.go
Затем добавьте следующий код:
Файл: cmd/web/testutils_test.go
package main
import (
"bytes"
"io"
"log"
"net/http"
"net/http/httptest"
"testing"
)
// Создайте помощник `newTestApplication`, который возвращает экземпляр нашей
// структуры приложения, содержащий фиктивные зависимости.
func newTestApplication(t *testing.T) *application {
return &application{
errorLog: log.New(io.Discard, "", 0),
infoLog: log.New(io.Discard, "", 0),
}
}
// Определите пользовательский тип `testServer`, который включает экземпляр `httptest.Server`.
type testServer struct {
*httptest.Server
}
// Создайте помощник `newTestServer`, который инициализирует и возвращает новый экземпляр
// нашего пользовательского типа `testServer`.
func newTestServer(t *testing.T, h http.Handler) *testServer {
ts := httptest.NewTLSServer(h)
return &testServer{ts}
}
// Реализуйте метод `get()` на нашем пользовательском типе `testServer`. Это делает GET-запрос
// к заданному пути URL, используя клиент тестового сервера, и возвращает код состояния,
// заголовки и тело ответа.
func (ts *testServer) get(t *testing.T, urlPath string) (int, http.Header, string) {
rs, err := ts.Client().Get(ts.URL + urlPath)
if err != nil {
t.Fatal(err)
}
defer rs.Body.Close()
body, err := io.ReadAll(rs.Body)
if err != nil {
t.Fatal(err)
}
bytes.TrimSpace(body)
return rs.StatusCode, rs.Header, string(body)
}
По сути, это просто обобщение кода, который мы уже написали в этой главе, чтобы запустить тестовый сервер и отправить GET-запрос к нему.
Давайте вернемся к нашему тесту TestPing и используем эти новые помощники:
package main
import (
"net/http"
"testing"
"snippetbox.alexedwards.net/internal/assert"
)
func TestPing(t *testing.T) {
app := newTestApplication(t)
ts := newTestServer(t, app.routes())
defer ts.Close()
code, _, body := ts.get(t, "/ping")
assert.Equal(t, code, http.StatusOK)
assert.Equal(t, body, "OK")
}
все сработало
go test -v ./cmd/web
ok snippetbox.igorra.net/cmd/web 0.005s
Cookies and redirections
До сих пор в этой главе мы использовали настройки клиента тестового сервера по умолчанию. Но есть несколько изменений, которые я хотел бы внести, чтобы сделать его более подходящим для тестирования нашего веб-приложения. В частности:
- Мы хотим, чтобы клиент автоматически хранил любые куки, отправленные в ответе HTTPS, чтобы мы могли включить их (если это необходимо) в любые последующие запросы обратно к тестовому серверу. Это пригодится позже в книге, когда нам нужно будет поддерживать куки на нескольких запросах, чтобы протестировать наши меры противодействия CSRF.
- Мы не хотим, чтобы клиент автоматически следовал перенаправлениям. Вместо этого мы хотим, чтобы он возвращал первый ответ HTTPS, отправленный нашим сервером, чтобы мы могли протестировать ответ на этот конкретный запрос.
Изменим testutils_test.go и обновим функцию newTestServer():
Файл: cmd/web/testutils_test.go
package main
import (
"bytes"
"io"
"log"
"net/http"
"net/http/cookiejar" // Новый импорт
"net/http/httptest"
"testing"
)
...
func newTestServer(t *testing.T, h http.Handler) *testServer {
// Инициализируйте тестовый сервер как обычно.
ts := httptest.NewTLSServer(h)
// Инициализируйте новый контейнер для куки.
jar, err := cookiejar.New(nil)
if err != nil {
t.Fatal(err)
}
// Добавьте контейнер для куки к клиенту тестового сервера. Любые куки ответа теперь
// будут храниться и отправляться с последующими запросами при использовании этого клиента.
ts.Client().Jar = jar
// Отключите следование за перенаправлениями для клиента тестового сервера, установив
// пользовательскую функцию `CheckRedirect`. Эта функция будет вызвана всякий раз, когда
// клиент получит ответ 3xx, и, всегда возвращая ошибку `http.ErrUseLastResponse`,
// она заставляет клиента немедленно вернуть полученный ответ.
ts.Client().CheckRedirect = func(req *http.Request, via []*http.Request) error {
return http.ErrUseLastResponse
}
return &testServer{ts}
}
...
Настройка тестирования
Управление запуском тестов
До сих пор в этой книге мы запускали тесты в определенном пакете (пакете cmd/web) следующим образом:
$ go test ./cmd/web
Но также возможно запустить все тесты в вашем текущем проекте, используя шаблон ./.... В нашем случае мы можем использовать его для запуска всех тестов в нашем проекте следующим образом:
$ go test ./...
ok snippetbox.alexedwards.net/cmd/web 0.007s
? snippetbox.alexedwards.net/internal/models [no test files]
? snippetbox.alexedwards.net/internal/validator [no test files]
? snippetbox.alexedwards.net/ui [no test files]
Или, идя в другом направлении, можно запустить только определенные тесты, используя флаг -run. Это позволяет вам передать регулярное выражение — и только тесты с именем, совпадающим с регулярным выражением, будут запущены.
Например, мы могли бы запустить только тест TestPing следующим образом:
$ go test -v -run="^TestPing$" ./cmd/web/
=== RUN TestPing
--- PASS: TestPing (0.00s)
PASS
ok snippetbox.alexedwards.net/cmd/web 0.008s
Вы также можете использовать флаг -run, чтобы ограничить тестирование до определенных подтестов, используя формат {regexp}/{sub-test regexp}. Например, чтобы запустить подтест UTC нашего теста TestHumanDate, мы можем сделать это:
$ go test -v -run="^TestHumanDate$/^UTC$" ./cmd/web
=== RUN TestHumanDate
=== RUN TestHumanDate/UTC
--- PASS: TestHumanDate (0.00s)
--- PASS: TestHumanDate/UTC (0.00s)
PASS
ok snippetbox.alexedwards.net/cmd/web 0.003s
Кэширование тестов
Если вы запустите один и тот же тест дважды — без внесения каких-либо изменений в пакет, который вы тестируете — то отображается кэшированная версия результата теста (указанная аннотацией (cached) рядом с именем пакета).
$ go test ./cmd/web
ok snippetbox.alexedwards.net/cmd/web (cached)
В большинстве случаев кэширование результатов тестов действительно полезно (особенно для больших кодовых баз), поскольку оно помогает сократить общее время выполнения тестов. Но если вы хотите принудительно запустить свои тесты в полном объеме (и избежать кэша), вы можете использовать флаг -count=1:
$ go test -count=1 ./cmd/web
Примечание
Флагcount используется для указания go test, сколько раз вы хотите выполнить каждый тест. Это не кэшируемый флаг, что означает, что каждый раз, когда вы его используете, go test не будет ни читать, ни записывать результаты тестов в кэш. Таким образом, использование count=1 — это своего рода трюк, чтобы избежать кэша без влияния на выполнение тестов.Кроме того, вы можете очистить кэшированные результаты для всех тестов с помощью команды go clean:
$ go clean -testcache
Быстрое завершение
Когда мы используем функцию t.Errorf(), чтобы пометить тест как неудачный, она не вызывает немедленное завершение go test. Все остальные тесты (и подтесты) будут продолжать выполняться после сбоя.
Если вы предпочитаете завершить тесты сразу после первого сбоя, вы можете использовать флаг -failfast:
$ go test -failfast ./cmd/web
Важно отметить, что флаг -failfast останавливает тесты только в пакете, где произошел сбой. Если вы запускаете тесты в нескольких пакетах (например, используя go test ./...), то тесты в других пакетах будут продолжать выполняться.
Параллельное тестирование
По умолчанию команда go test выполняет все тесты последовательно, один за другим. Когда у вас небольшое количество тестов (как у нас) и время выполнения очень быстрое, это абсолютно нормально.
Но если у вас сотни или тысячи тестов, общее время выполнения может начать накапливаться до чего-то более существенного. И в этом сценарии вы можете сэкономить себе некоторое время, запустив тесты параллельно.
Вы можете указать, что тест можно запускать одновременно с другими тестами, вызвав функцию t.Parallel() в начале теста. Например:
func TestPing(t *testing.T) {
t.Parallel()
...
}
Важно отметить, что:
Тесты, отмеченные с помощью
t.Parallel(), будут запускаться параллельно с другими параллельными тестами и только с ними.По умолчанию максимальное количество тестов, которые будут запускаться одновременно, равно текущему значению
GOMAXPROCS. Вы можете переопределить это, установив конкретное значение с помощью флага-parallel. Например:$ go test -parallel 4 ./...Не все тесты подходят для параллельного выполнения. Например, если у вас есть интеграционный тест, который требует, чтобы таблица базы данных находилась в определенном известном состоянии, то вы не хотели бы запускать его параллельно с другими тестами, которые изменяют ту же таблицу базы данных.
Включение детектора гонок
Команда go test включает флаг -race, который активирует детектор гонок Go при запуске тестов.
Если код, который вы тестируете, использует конкурентность, или вы запускаете тесты параллельно, включение этого может быть хорошей идеей, чтобы помочь выявить гонки, существующие в вашем приложении. Вы можете использовать его следующим образом:
$ go test -race ./cmd/web/
Важно отметить, что детектор гонок — это просто инструмент, который выявляет гонки данных, если и когда они обнаруживаются во время выполнения тестов. Он не проводит статический анализ вашего кода, и чистый запуск не гарантирует, что ваш код свободен от гонок.
Включение детектора гонок также увеличит общее время выполнения ваших тестов. Поэтому, если вы запускаете тесты очень часто в рамках рабочего процесса TDD, вы можете предпочесть использовать флаг -race только во время выполнения тестов перед коммитом.
Мокирование зависимостей
Мокирование зависимостей
Мокирование зависимостей (или “mocking dependencies”) — это техника, используемая в тестировании программного обеспечения, которая позволяет создавать поддельные (мок) версии зависимостей, с которыми взаимодействует тестируемый компонент. Это делается для того, чтобы изолировать тестируемый код от реальных зависимостей, что позволяет:
Избежать побочных эффектов: Использование реальных зависимостей может привести к нежелательным изменениям состояния (например, запись в базу данных или отправка сетевых запросов). Моки позволяют избежать этих побочных эффектов.
Упростить тестирование: Моки могут быть настроены для возврата предопределенных значений, что упрощает тестирование различных сценариев, включая ошибки и исключительные ситуации.
Ускорить тесты: Тесты с моками обычно выполняются быстрее, так как они не зависят от внешних систем, таких как базы данных или API.
Улучшить контроль: Моки позволяют контролировать и проверять, как тестируемый код взаимодействует с зависимостями, что помогает выявить ошибки в логике.
В Go для мокирования зависимостей часто используются библиотеки, такие как gomock или testify, которые позволяют создавать моки и определять их поведение в тестах.
Новые тесты для нашего обработчика snippetView и маршрута GET /snippet/view/:id.
На протяжении всего этого проекта мы внедряли зависимости в наши обработчики через структуру application, которая сейчас выглядит следующим образом:
type application struct {
errorLog *log.Logger
infoLog *log.Logger
snippets *models.SnippetModel
users *models.UserModel
templateCache map[string]*template.Template
formDecoder *form.Decoder
sessionManager *scs.SessionManager
}
При тестировании иногда имеет смысл мокировать эти зависимости вместо использования точно таких же, как в вашем производственном приложении.
Например, в предыдущей главе мы мокировали зависимости errorLog и infoLog логгерами, которые пишут сообщения в io.Discard, вместо потоков os.Stdout и os.Stderr, как мы делаем в нашем производственном приложении:
func newTestApplication(t *testing.T) *application {
return &application{
errorLog: log.New(io.Discard, "", 0),
infoLog: log.New(io.Discard, "", 0),
}
}
Причина мокирования этих и записи в io.Discard заключается в том, чтобы избежать засорения вывода наших тестов ненужными сообщениями журнала при запуске go test -v (с включенным режимом verbose).
Примечание: В зависимости от вашего происхождения и опыта программирования, вы можете не считать эти логгеры моками. Вы можете назвать их фейками, заглушками или чем-то совсем другим. Но название не имеет значения — и разные люди называют их по-разному. Главное, что мы используем что-то, что exposes тот же интерфейс, что и производственный объект, для целей тестирования.
Две другие зависимости, которые имеет смысл мокировать, — это модели базы данных models.SnippetModel и models.UserModel. Создавая моки этих моделей, можно тестировать поведение наших обработчиков без необходимости настраивать весь тестовый экземпляр базы данных MySQL.
Мокирование моделей базы данных
Создайте новый пакет internal/models/mocks, содержащий файлы snippets.go и users.go для хранения моков моделей базы данных, следующим образом:
$ mkdir internal/models/mocks
$ touch internal/models/mocks/snippets.go
$ touch internal/models/mocks/users.go
Давайте начнем с создания мока для нашей модели models.SnippetModel. Для этого мы создадим простую структуру, которая реализует те же методы, что и наша производственная модель models.SnippetModel, но методы будут возвращать фиксированные тестовые данные.
Файл: internal/models/mocks/snippets.go
package mocks
import (
"time"
"snippetbox.alexedwards.net/internal/models"
)
var mockSnippet = &models.Snippet{
ID: 1,
Title: "Старый тихий пруд",
Content: "Старый тихий пруд...",
Created: time.Now(),
Expires: time.Now(),
}
type SnippetModel struct{}
func (m *SnippetModel) Insert(title string, content string, expires int) (int, error) {
return 2, nil
}
func (m *SnippetModel) Get(id int) (*models.Snippet, error) {
switch id {
case 1:
return mockSnippet, nil
default:
return nil, models.ErrNoRecord
}
}
func (m *SnippetModel) Latest() ([]*models.Snippet, error) {
return []*models.Snippet{mockSnippet}, nil
}
Теперь сделаем то же самое для нашей модели models.UserModel:
Файл: internal/models/mocks/users.go
package mocks
import (
"snippetbox.alexedwards.net/internal/models"
)
type UserModel struct{}
func (m *UserModel) Insert(name, email, password string) error {
switch email {
case "dupe@example.com":
return models.ErrDuplicateEmail
default:
return nil
}
}
func (m *UserModel) Authenticate(email, password string) (int, error) {
if email == "alice@example.com" && password == "pa$$word" {
return 1, nil
}
return 0, models.ErrInvalidCredentials
}
func (m *UserModel) Exists(id int) (bool, error) {
switch id {
case 1:
return true, nil
default:
return false, nil
}
}
Инициализация моков
На следующем этапе нашего проекта давайте вернемся к файлу testutils_test.go и обновим функцию newTestApplication(), чтобы она создавала структуру приложения со всеми необходимыми зависимостями для тестирования.
Файл: cmd/web/testutils_test.go
package main
import (
"bytes"
"io"
"log"
"net/http"
"net/http/cookiejar"
"net/http/httptest"
"testing"
"time" // Новый импорт
"snippetbox.alexedwards.net/internal/models/mocks" // Новый импорт
"github.com/alexedwards/scs/v2" // Новый импорт
"github.com/go-playground/form/v4" // Новый импорт
)
func newTestApplication(t *testing.T) *application {
// Создаем экземпляр кеша шаблонов.
templateCache, err := newTemplateCache()
if err != nil {
t.Fatal(err)
}
// И декодер форм.
formDecoder := form.NewDecoder()
// И экземпляр менеджера сессий. Обратите внимание, что мы используем те же настройки, что и
// в производственной среде, за исключением того, что мы *не* устанавливаем Store для менеджера сессий.
// Если Store не установлен, пакет SCS по умолчанию будет использовать временное
// хранилище в памяти, что идеально подходит для тестирования.
sessionManager := scs.New()
sessionManager.Lifetime = 12 * time.Hour
sessionManager.Cookie.Secure = true
return &application{
errorLog: log.New(io.Discard, "", 0),
infoLog: log.New(io.Discard, "", 0),
snippets: &mocks.SnippetModel{}, // Используем мок.
users: &mocks.UserModel{}, // Используем мок.
templateCache: templateCache,
formDecoder: formDecoder,
sessionManager: sessionManager,
}
}
…
Если вы попробуете запустить тесты сейчас, они не скомпилируются и выдадут следующие ошибки:
$ go test ./cmd/web
# snippetbox.alexedwards.net/cmd/web [snippetbox.alexedwards.net/cmd/web.test]
cmd/web/testutils_test.go:40:19: cannot use &mocks.SnippetModel{} (value of type *mocks.SnippetModel) as type *models.SnippetModel in struct literal
cmd/web/testutils_test.go:41:19: cannot use &mocks.UserModel{} (value of type *mocks.UserModel) as type *models.UserModel in struct literal
FAIL snippetbox.alexedwards.net/cmd/web [build failed]
FAIL
Это происходит потому, что наша структура приложения ожидает указатели на экземпляры models.SnippetModel и models.UserModel, но мы пытаемся использовать указатели на экземпляры mocks.SnippetModel и mocks.UserModel.
Идиоматическое решение этой проблемы — изменить нашу структуру приложения так, чтобы она использовала интерфейсы, которые удовлетворяются как нашими моками, так и производственными моделями базы данных.
Для этого давайте вернемся к файлу internal/models/snippets.go и создадим новый тип интерфейса SnippetModelInterface, который описывает методы, которые есть у нашей фактической структуры SnippetModel.
Файл: internal/models/snippets.go
package models
import (
"database/sql"
"errors"
"time"
)
type SnippetModelInterface interface {
Insert(title string, content string, expires int) (int, error)
Get(id int) (*Snippet, error)
Latest() ([]*Snippet, error)
}
…
Теперь сделаем то же самое для нашей структуры UserModel:
Файл: internal/models/users.go
package models
import (
"database/sql"
"errors"
"strings"
"time"
"github.com/go-sql-driver/mysql"
"golang.org/x/crypto/bcrypt"
)
type UserModelInterface interface {
Insert(name, email, password string) error
Authenticate(email, password string) (int, error)
Exists(id int) (bool, error)
}
…
Теперь, когда мы определили эти интерфейсы, давайте обновим нашу структуру приложения, чтобы она использовала их вместо конкретных типов SnippetModel и UserModel. Вот так:
Файл: cmd/web/main.go
package main
import (
"crypto/tls"
"database/sql"
"flag"
"html/template"
"log"
"net/http"
"os"
"time"
"snippetbox.alexedwards.net/internal/models"
"github.com/alexedwards/scs/mysqlstore"
"github.com/alexedwards/scs/v2"
"github.com/go-playground/form/v4"
_ "github.com/go-sql-driver/mysql"
)
type application struct {
errorLog *log.Logger
infoLog *log.Logger
snippets models.SnippetModelInterface // Используем наш новый интерфейс.
users models.UserModelInterface // Используем наш новый интерфейс.
templateCache map[string]*template.Template
formDecoder *form.Decoder
sessionManager *scs.SessionManager
}
…
Если вы снова попробуете запустить тесты, все должно работать корректно.
go test -v ./cmd/web
ok snippetbox.igorra.net/cmd/web 0.005s
Мы обновили структуру приложения так, что вместо того, чтобы поля snippets и users имели конкретные типы *models.SnippetModel и *models.UserModel, теперь они являются интерфейсами.
Пока объект имеет необходимые методы для удовлетворения интерфейса, мы можем использовать его в нашей структуре приложения. Как наши «реальные» модели базы данных (например, models.SnippetModel), так и моковые модели базы данных (например, mocks.SnippetModel) удовлетворяют этим интерфейсам, поэтому мы теперь можем использовать их взаимозаменяемо.
Тестирование обработчика snippetView
Перейдем к написанию сквозного теста для нашего обработчика snippetView, который использует эти мокированные зависимости.
В рамках этого теста код в нашем обработчике snippetView будет вызывать метод mock.SnippetModel.Get(). Напоминаем, что этот мокированный метод модели возвращает models.ErrNoRecord, если ID сниппета не равен 1 — в противном случае он вернет следующий мок-сниппет:
var mockSnippet = &models.Snippet{
ID: 1,
Title: "Старый тихий пруд",
Content: "Старый тихий пруд...",
Created: time.Now(),
Expires: time.Now(),
}
Таким образом, мы хотим протестировать следующее:
- Для запроса
GET /snippet/view/1мы получаем ответ 200 OK с соответствующим мок-сниппетом, содержащимся в теле HTML-ответа. - Для всех остальных запросов к
GET /snippet/view/*мы должны получить ответ 404 Not Found.
Для первой части теста мы хотим проверить, что тело ответа содержит определенное содержимое, а не является точно равным ему. Давайте быстро добавим новую функцию StringContains() в наш пакет assert, чтобы помочь с этим:
Файл: assert/assert.go
package assert
import (
"strings" // Новый импорт
"testing"
)
...
func StringContains(t *testing.T, actual, expectedSubstring string) {
t.Helper()
if !strings.Contains(actual, expectedSubstring) {
t.Errorf("got: %q; expected to contain: %q", actual, expectedSubstring)
}
}
Затем откройте файл cmd/web/handlers_test.go и создайте новый тест TestSnippetView, как показано ниже:
Файл: cmd/web/handlers_test.go
package main
...
func TestSnippetView(t *testing.T) {
// Создаем новый экземпляр нашей структуры приложения, который использует мокированные зависимости.
app := newTestApplication(t)
// Устанавливаем новый тестовый сервер для выполнения сквозных тестов.
ts := newTestServer(t, app.routes())
defer ts.Close()
// Настраиваем тесты с использованием таблицы для проверки ответов, отправляемых нашим приложением для различных URL.
tests := []struct {
name string
urlPath string
wantCode int
wantBody string
}{
{
name: "Valid ID",
urlPath: "/snippet/view/1",
wantCode: http.StatusOK,
wantBody: "Старый тихий пруд...",
},
{
name: "Non-existent ID",
urlPath: "/snippet/view/2",
wantCode: http.StatusNotFound,
},
{
name: "Negative ID",
urlPath: "/snippet/view/-1",
wantCode: http.StatusNotFound,
},
{
name: "Decimal ID",
urlPath: "/snippet/view/1.23",
wantCode: http.StatusNotFound,
},
{
name: "String ID",
urlPath: "/snippet/view/foo",
wantCode: http.StatusNotFound,
},
{
name: "Empty ID",
urlPath: "/snippet/view/",
wantCode: http.StatusNotFound,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
code, _, body := ts.get(t, tt.urlPath)
assert.Equal(t, code, tt.wantCode)
if tt.wantBody != "" {
assert.StringContains(t, body, tt.wantBody)
}
})
}
}
Когда вы снова запустите тесты, все должно пройти успешно, и вы увидите вывод, включая новые тесты TestSnippetView, который будет выглядеть примерно так:
--- PASS: TestSnippetView (0.01s)
--- PASS: TestSnippetView/Valid_ID (0.00s)
--- PASS: TestSnippetView/Non-existent_ID (0.00s)
--- PASS: TestSnippetView/Negative_ID (0.00s)
--- PASS: TestSnippetView/Decimal_ID (0.00s)
--- PASS: TestSnippetView/String_ID (0.00s)
--- PASS: TestSnippetView/Empty_ID (0.00s)
Обратите внимание, как названия субтестов были канонизированы? Все пробелы в названии подтеста были заменены символом подчеркивания (и все непечатаемые символы также будут экранированы) в выходных данных теста.
Тестирование HTML-форм
В этой главе мы добавим сквозной тест для маршрута POST /user/signup, который обрабатывается нашим обработчиком userSignupPost.
Тестирование этого маршрута немного усложняется из-за проверки на наличие CSRF-токена, которую выполняет наше приложение. Любой запрос к POST /user/signup всегда будет получать ответ 400 Bad Request, если запрос не содержит действительный CSRF-токен и куки. Чтобы обойти это, нам нужно эмулировать рабочий процесс реального пользователя в рамках нашего теста, следующим образом:
- Сделать запрос
GET /user/signup. Это вернет ответ, который содержит CSRF-куку в заголовках ответа и CSRF-токен для страницы регистрации в теле ответа. - Извлечь CSRF-токен из HTML-тела ответа.
- Сделать запрос
POST /user/signup, используя тот жеhttp.Client, который мы использовали на шаге 1 (чтобы он автоматически передал CSRF-куку с POST-запросом) и включая CSRF-токен вместе с другими данными POST, которые мы хотим протестировать.
Давайте начнем с добавления новой вспомогательной функции в наш файл cmd/web/testutils_test.go для извлечения CSRF-токена (если он существует) из HTML-тела ответа:
Файл: cmd/web/testutils_test.go
package main
import (
"bytes"
"html" // Новый импорт
"io"
"log"
"net/http"
"net/http/cookiejar"
"net/http/httptest"
"regexp" // Новый импорт
"testing"
"time"
"snippetbox.alexedwards.net/internal/models/mocks"
"github.com/alexedwards/scs/v2"
"github.com/go-playground/form/v4"
)
// Определяем регулярное выражение, которое захватывает значение CSRF-токена из
// HTML для нашей страницы регистрации пользователя.
var csrfTokenRX = regexp.MustCompile(`<input type='hidden' name='csrf_token' value='(.+)'>`)
func extractCSRFToken(t *testing.T, body string) string {
// Используем метод FindStringSubmatch для извлечения токена из HTML-тела.
// Обратите внимание, что это возвращает массив с полным совпадением в
// первой позиции и значениями любых захваченных данных в последующих
// позициях.
matches := csrfTokenRX.FindStringSubmatch(body)
if len(matches) < 2 {
t.Fatal("no csrf token found in body")
}
return html.UnescapeString(string(matches[1]))
}
Примечание
Вы можете задаться вопросом, почему мы используем функцию html.UnescapeString() перед возвратом CSRF-токена.
Причина в том, что пакет html/template в Go автоматически экранирует все динамически отображаемые данные, включая наш CSRF-токен. Поскольку CSRF-токен является строкой, закодированной в base64, он потенциально может содержать символ +, который будет экранирован как +. Поэтому после извлечения токена из HTML нам нужно пропустить его через html.UnescapeString(), чтобы получить оригинальное значение токена.
Теперь, когда это сделано, давайте вернемся к файлу cmd/web/handlers_test.go и создадим новый тест TestUserSignup.
Для начала мы сделаем запрос GET /user/signup, а затем извлечем и выведем CSRF-токен из тела HTML-ответа. Вот так:
Файл: cmd/web/handlers_test.go
package main
...
func TestUserSignup(t *testing.T) {
// Создаем структуру приложения, содержащую наши мокированные зависимости, и настраиваем
// тестовый сервер для выполнения сквозного теста.
app := newTestApplication(t)
ts := newTestServer(t, app.routes())
defer ts.Close()
// Выполняем запрос GET /user/signup и затем извлекаем CSRF-токен из
// тела ответа.
_, _, body := ts.get(t, "/user/signup")
csrfToken := extractCSRFToken(t, body)
// Логируем значение CSRF-токена в нашем тестовом выводе, используя функцию t.Logf().
// Функция t.Logf() работает так же, как fmt.Printf(), но записывает
// предоставленное сообщение в тестовый вывод.
t.Logf("CSRF token is: %q", csrfToken)
}
Важно, чтобы вы запускали тесты с флагом -v (для включения подробного вывода), чтобы увидеть любой вывод от функции t.Logf().
Давайте сделаем это сейчас:
go test -v -run="TestUserSignup" ./cmd/web/
=== RUN TestUserSignup
handlers_test.go:96: CSRF token is: "+mBVJFv/BJOlinbDGyrjuB4noDRwCDctcf/gckiVWc2z2zo8mdY52+uuPiXNxqGnhZnFh7udQvsIehQx7/NO4Q=="
--- PASS: TestUserSignup (0.00s)
PASS
ok snippetbox.igorra.net/cmd/web 0.006s
Тестирование POST-запросов
Теперь давайте вернемся к файлу cmd/web/testutils_test.go и создадим новый метод postForm() для нашего типа testServer, который мы можем использовать для отправки POST-запроса на наш тестовый сервер с конкретными данными формы в теле запроса.
Добавьте следующий код (который следует тому же общему паттерну, что и метод get(), описанный ранее в книге):
Файл: cmd/web/testutils_test.go
package main
import (
"bytes"
"html"
"io"
"log"
"net/http"
"net/http/cookiejar"
"net/http/httptest"
"net/url" // Новый импорт
"regexp"
"testing"
"time"
"snippetbox.alexedwards.net/internal/models/mocks"
"github.com/alexedwards/scs/v2"
"github.com/go-playground/form/v4"
)
...
// Создаем метод postForm для отправки POST-запросов на тестовый сервер.
// Последний параметр этого метода — это объект url.Values, который может
// содержать любые данные формы, которые вы хотите отправить в теле запроса.
func (ts *testServer) postForm(t *testing.T, urlPath string, form url.Values) (int, http.Header, string) {
rs, err := ts.Client().PostForm(ts.URL+urlPath, form)
if err != nil {
t.Fatal(err)
}
// Читаем тело ответа от тестового сервера.
defer rs.Body.Close()
body, err := io.ReadAll(rs.Body)
if err != nil {
t.Fatal(err)
}
bytes.TrimSpace(body)
// Возвращаем статус ответа, заголовки и тело.
return rs.StatusCode, rs.Header, string(body)
}
Теперь, наконец, мы готовы добавить несколько тестов с использованием таблицы для проверки поведения маршрута POST /user/signup нашего приложения. В частности, мы хотим протестировать, что:
- Действительная регистрация приводит к ответу 303 See Other.
- Отправка формы без действительного CSRF-токена приводит к ответу 400 Bad Request.
- Неверная отправка формы приводит к ответу 422 Unprocessable Entity и повторному отображению формы регистрации. Это должно происходить, когда:
- Поля имени, электронной почты или пароля пустые.
- Электронная почта не имеет действительного формата.
- Пароль короче 8 символов.
- Адрес электронной почты уже используется.
Давайте обновим функцию TestUserSignup, чтобы выполнить эти тесты следующим образом:
package main
import (
"net/http"
"net/url" // New import
"testing"
"snippetbox.alexedwards.net/internal/assert"
)
...
func TestUserSignup(t *testing.T) {
app := newTestApplication(t)
ts := newTestServer(t, app.routes())
defer ts.Close()
_, _, body := ts.get(t, "/user/signup")
validCSRFToken := extractCSRFToken(t, body)
const (
validName = "Bob"
validPassword = "validPa$$word"
validEmail = "bob@example.com"
formTag = "<form action='/user/signup' method='POST' novalidate>"
)
tests := []struct {
name string
userName string
userEmail string
userPassword string
csrfToken string
wantCode int
wantFormTag string
}{
{
name: "Valid submission",
userName: validName,
userEmail: validEmail,
userPassword: validPassword,
csrfToken: validCSRFToken,
wantCode: http.StatusSeeOther,
},
{
name: "Invalid CSRF Token",
userName: validName,
userEmail: validEmail,
userPassword: validPassword,
csrfToken: "wrongToken",
wantCode: http.StatusBadRequest,
},
{
name: "Empty name",
userName: "",
userEmail: validEmail,
userPassword: validPassword,
csrfToken: validCSRFToken,
wantCode: http.StatusUnprocessableEntity,
wantFormTag: formTag,
},
{
name: "Empty email",
userName: validName,
userEmail: "",
userPassword: validPassword,
csrfToken: validCSRFToken,
wantCode: http.StatusUnprocessableEntity,
wantFormTag: formTag,
},
{
name: "Empty password",
userName: validName,
userEmail: validEmail,
userPassword: "",
csrfToken: validCSRFToken,
wantCode: http.StatusUnprocessableEntity,
wantFormTag: formTag,
},
{
name: "Invalid email",
userName: validName,
userEmail: "bob@example.",
userPassword: validPassword,
csrfToken: validCSRFToken,
wantCode: http.StatusUnprocessableEntity,
wantFormTag: formTag,
},
{
name: "Short password",
userName: validName,
userEmail: validEmail,
userPassword: "pa$$",
csrfToken: validCSRFToken,
wantCode: http.StatusUnprocessableEntity,
wantFormTag: formTag,
},
{
name: "Duplicate email",
userName: validName,
userEmail: "dupe@example.com",
userPassword: validPassword,
csrfToken: validCSRFToken,
wantCode: http.StatusUnprocessableEntity,
wantFormTag: formTag,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
form := url.Values{}
form.Add("name", tt.userName)
form.Add("email", tt.userEmail)
form.Add("password", tt.userPassword)
form.Add("csrf_token", tt.csrfToken)
code, _, body := ts.postForm(t, "/user/signup", form)
assert.Equal(t, code, tt.wantCode)
if tt.wantFormTag != "" {
assert.StringContains(t, body, tt.wantFormTag)
}
})
}
}
12.9.5 - Alex Edwards Let's Go часть 5
edwardsLetsGo учебный материал по написанию приложения на Go с авторизацией пользователя. Краткий конспект с основными мыслями (глава 17)
Добавьте страницу «О программе» в приложение
Создайте обработчик about
File: cmd/web/handlers.go
package main
...
func (app *application) about(w http.ResponseWriter, r *http.Request) {
data := app.newTemplateData(r)
data.About = "Это приложение создано для того,чтобы тренироваться. <br />И я думаю, здесь потом написать markdown текст."
app.render(w, http.StatusOK, "about.tmpl", data)
}
Создайте маршрут GET /about
File: cmd/web/routes.go
router.Handler(http.MethodGet, "/about", dynamic.ThenFunc(app.about))
Создайте шаблон about .tmpl
File: ui/html/pages/about.tmpl
{{define "title"}}О приложении{{end}}
{{define "main"}}
{{with .About}}
<div class='snippet'>
<p>{{.}}</p>
</div>
{{end}}
{{end}}
Создать навигацию в nav.tmpl
<a href='/about'>About</a>
Создать новый флаг -debug
Создаем описание флага
Три точки правки для добавления флага:
type application struct {
debug bool // 1. Добавить в структуру приложения
errorLog *log.Logger
infoLog *log.Logger
snippets models.SnippetModelInterface
users models.UserModelInterface
templateCache map[string]*template.Template
formDecoder *form.Decoder
sessionManager *scs.SessionManager
}
...
debug := flag.Bool("debug", false, "Включить режим отладки, по умолчанию false") //2. добавить описание флага до Parse
...
app := &application{
debug: *debug, // Инициализация флага в экземпляре приложения
errorLog: errorLog,
infoLog: infoLog,
snippets: &models.SnippetModel{DB: db},
users: &models.UserModel{DB: db},
templateCache: templateCache,
formDecoder: formDecoder,
sessionManager: sessionManager,
}
Настройка cmd/web/helpers.go для serverError()
Добавим условие для проверки флага app.debug.
func (app *application) serverError(w http.ResponseWriter, err error) {
trace := fmt.Sprintf("%s\n%s", err.Error(), debug.Stack())
app.errorLog.Output(2, trace)
if app.debug { //Добавил условие проверки флага
http.Error(w, trace, http.StatusInternalServerError)
return
}
http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
}
Продолжаем тестирование. Тестирование обработчика snippetCreate
Создадим сквозной тест для маршрута GET /snippet/create.
- Пользователи, не прошедшие аутентификацию, перенаправляются на форму входа.
- Пользователям, прошедшим проверку подлинности, отображается форма для создания нового сниппета.
Создадим заготовку для теста handlers_test.go
func TestSnippetCreate(t *testing.T) {
// Создаем новый экземпляр нашей структуры приложения, который использует мокированные зависимости.
app := newTestApplication(t)
// Устанавливаем новый тестовый сервер для выполнения сквозных тестов.
ts := newTestServer(t, app.routes())
defer ts.Close()
}
Создадим подтест с проверкой доступа неаутентифицированного пользователя
func TestSnippetCreate(t *testing.T) {
// Создаем новый экземпляр нашей структуры приложения, который использует мокированные зависимости.
app := newTestApplication(t)
// Устанавливаем новый тестовый сервер для выполнения сквозных тестов.
ts := newTestServer(t, app.routes())
defer ts.Close()
t.Run("Unauthenticated", func(t *testing.T) {//название теста и безымянная функция
code, headers, _ := ts.get(t, "/snippet/create") //запрос к серверу с моками по адресу проверки
//code и headers - запишем ответы от сервера кода и заголовка
assert.Equal(t, code, http.StatusSeeOther) //проверим код
assert.Equal(t, headers.Get("Location"), "/user/login") //проверим заголовок Location
//location показывает адрес текущей страницы
})
}
Страница личного кабинета
Добавить новую страницу «Ваша учетная запись» в приложение. Он должен быть сопоставлен с новым маршрутом GET /account/view и отображать имя, адрес электронной почты и дату регистрации для текущего аутентифицированного пользователя
Создадим в файле internal/models/users.go функция UserModel.Get()
- Добавим метод Get в интерфейс UserModelInterface
type UserModelInterface interface {
Insert(name, email, password string) error
Authenticate(email, password string) (int, error)
Exists(id int) (bool, error)
Get(id int) (*User, error) //добавил метод Get
}
- Создадим метод Get
func (m *UserModel) Get(id int) (*User, error) {
var user User
stmt := `SELECT id, name, email, created FROM users WHERE id = ?`
err := m.DB.QueryRow(stmt, id).Scan(&user.ID, &user.Name, &user.Email, &user.Created)
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
return nil, ErrNoRecord
} else {
return nil, err
}
}
return &user, err
}
routes.go
router.Handler(http.MethodGet, "/account/view", protected.ThenFunc(app.accountView))
handlers.go
Добавим функцию accountView
func (app *application) accountView(w http.ResponseWriter, r *http.Request) {
userID := app.sessionManager.GetInt(r.Context(), "authenticatedUserID")
user, err := app.users.Get(userID)
if err != nil {
if errors.Is(err, models.ErrNoRecord) {
http.Redirect(w, r, "/user/login", http.StatusSeeOther)
} else {
app.serverError(w, err)
}
return
}
fmt.Fprintf(w, "%+v", user)
}
templates.go
добавим поле User
type templateData struct {
CurrentYear int
Snippet *models.Snippet
Snippets []*models.Snippet
Form any
Flash string
IsAuthenticated bool
CSRFToken string
User *models.User //добавили User
}
ui/html/pages/account.tmpl
Создаем шаблон
{{define "title"}}Your Account{{end}}
{{define "main"}}
<h2>Your Account</h2>
{{with .User}}
<table>
<tr>
<th>Name</th>
<td>{{.Name}}</td>
</tr>
<tr>
<th>Email</th>
<td>{{.Email}}</td>
</tr>
<tr>
<th>Joined</th>
<td>{{humanDate .Created}}</td>
</tr>
</table>
{{end }}
{{end}}
handkers.go
func (app *application) accountView(w http.ResponseWriter, r *http.Request) {
userID := app.sessionManager.GetInt(r.Context(), "authenticatedUserID")
user, err := app.users.Get(userID)
if err != nil {
if errors.Is(err, models.ErrNoRecord) {
http.Redirect(w, r, "/user/login", http.StatusSeeOther)
} else {
app.serverError(w, err)
}
return
}
data := app.newTemplateData(r)
data.User = user
app.render(w, http.StatusOK, "account.tmpl", data)
}
Настроим меню приложения
{{define "nav"}}
<nav>
<div>
<a href='/'>Home</a>
<a href='/about'>About</a>
{{if .IsAuthenticated}}
<a href='/snippet/create'>Create snippet</a>
{{end}}
</div>
<div>
{{if .IsAuthenticated}}
<!-- Add the view account link for authenticated users -->
<a href='/account/view'>Account</a>
<form action='/user/logout' method='POST'>
<input type='hidden' name='csrf_token' value='{{.CSRFToken}}'>
<button>Logout</button>
</form>
{{else}}
<a href='/user/signup'>Signup</a>
<a href='/user/login'>Login</a>
{{end}}
</div>
</nav>
{{end}}
Перенаправление пользователя после входа в систему
Обновить middleware requireAuthentication()
чтобы перед тем, как неаутентифицированный пользователь будет перенаправлен на страницу входа, URL-путь, который он пытается посетить, был добавлен в данные его сеанса.
func (app *application) requireAuthentication(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if !app.isAuthenticated(r) {
// Add the path that the user is trying to access to their session
// data.
app.sessionManager.Put(r.Context(), "redirectPathAfterLogin", r.URL.Path)
http.Redirect(w, r, "/user/login", http.StatusSeeOther)
return
}
w.Header().Add("Cache-Control", "no-store")
next.ServeHTTP(w, r)
})
}
Обновите обработчик userLogin
чтобы проверить путь URL-адреса пользователя в сеансе после успешного входа в систему. Если он существует, удалите его из данных сеанса и перенаправьте пользователя на этот URL-путь. В противном случае по умолчанию пользователь будет перенаправлен в /snippet/create.
path := app.sessionManager.PopString(r.Context(), "redirectPathAfterLogin")
if path != "" {
http.Redirect(w, r, path, http.StatusSeeOther)
return
}
http.Redirect(w, r, "/snippet/create", http.StatusSeeOther)
Восстановление пароля
Создадим 2 новых routes и handlers
GET /account/password/update — accountPasswordUpdate
POST /account/password/update — accountPasswordUpdatePost
handlers.go
func (app *application) accountPasswordUpdate(w http.ResponseWriter, r *http.Request) {
data := app.newTemplateData(r)
data.Form = userPasswordUpdate{}
app.render(w, http.StatusOK, "password.tmpl", data)
}
func (app *application) accountPasswordUpdatePost(w http.ResponseWriter, r *http.Request) {
var form userPasswordUpdate
err := app.decodePostForm(r, &form)
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
routes.go
router.Handler(http.MethodGet, "/account/password/update", protected.ThenFunc(app.accountPasswordUpdate))
router.Handler(http.MethodPost, "/account/password/update", protected.ThenFunc(app.accountPasswordUpdatePost))
ui/html/pages/password.tmpl
{{define "title"}}Change Password{{end}}
{{define "main"}}
<h2>Change Password</h2>
<form action='/account/password/update' method='POST' novalidate>
<input type='hidden' name='csrf_token' value='{{.CSRFToken}}'>
<div>
<label>Current password:</label>
{{with .Form.FieldErrors.currentPassword}}
<label class='error'>{{.}}</label>
{{end}}
<input type='password' name='currentPassword'>
</div>
<div>
<label>New password:</label>
{{with .Form.FieldErrors.newPassword}}
<label class='error'>{{.}}</label>
{{end}}
<input type='password' name='newPassword'>
</div>
<div>
<label>Confirm new password:</label>
{{with .Form.FieldErrors.newPasswordConfirmation}}
<label class='error'>{{.}}</label>
{{end}}
<input type='password' name='newPasswordConfirmation'>
</div>
<div>
<input type='submit' value='Change password'>
</div>
</form>
{{end}}
handlers.go
Обработчик Get
type accountPasswordUpdateForm struct {
CurrentPassword string `form:"currentPassword"`
NewPassword string `form:"newPassword"`
NewPasswordConfirmation string `form:"newPasswordConfirmation"`
validator.Validator `form:"-"`
}
func (app *application) accountPasswordUpdate(w http.ResponseWriter, r *http.Request) {
data := app.newTemplateData(r)
data.Form = accountPasswordUpdateForm{}
app.render(w, http.StatusOK, "password.tmpl", data)
}
обработчик Post
func (app *application) accountPasswordUpdatePost(w http.ResponseWriter, r *http.Request) {
var form accountPasswordUpdateForm
err := app.decodePostForm(r, &form)
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
form.CheckField(validator.NotBlank(form.CurrentPassword), "currentPassword", "This field cannot be blank")
form.CheckField(validator.NotBlank(form.NewPassword), "newPassword", "This field cannot be blank")
form.CheckField(validator.MinChars(form.NewPassword, 8), "newPassword", "This field must be at least 8 characters long")
form.CheckField(validator.NotBlank(form.NewPasswordConfirmation), "newPasswordConfirmation", "This field cannot be blank")
form.CheckField(form.NewPassword == form.NewPasswordConfirmation, "newPasswordConfirmation", "Passwords do not match")
if !form.Valid() {
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "password.tmpl", data)
return
}
}
users.go
- добавим интерфейс PasswordUpdate
type UserModelInterface interface {
Insert(name, email, password string) error
Authenticate(email, password string) (int, error)
Exists(id int) (bool, error)
Get(id int) (*User, error)
PasswordUpdate(id int, currentPassword, newPassword string) error
}
- добавим метод PasswordUpdate
func (m *UserModel) PasswordUpdate(id int, currentPassword, newPassword string) error {
var currentHashedPassword []byte
stmt := "SELECT hashed_password FROM users WHERE id = ?"
err := m.DB.QueryRow(stmt, id).Scan(¤tHashedPassword)
if err != nil {
return err
}
err = bcrypt.CompareHashAndPassword(currentHashedPassword, []byte(currentPassword))
if err != nil {
if errors.Is(err, bcrypt.ErrMismatchedHashAndPassword) {
return ErrInvalidCredentials
} else {
return err
}
}
newHashedPassword, err := bcrypt.GenerateFromPassword([]byte(newPassword), 12)
if err != nil {
return err
}
stmt = "UPDATE users SET hashed_password = ? WHERE id = ?"
_, err = m.DB.Exec(stmt, string(newHashedPassword), id)
return err
}
handlers.go
окончательный вариантфункции accountPasswordUpdatePost
func (app *application) accountPasswordUpdatePost(w http.ResponseWriter, r *http.Request) {
var form accountPasswordUpdateForm
err := app.decodePostForm(r, &form)
if err != nil {
app.clientError(w, http.StatusBadRequest)
return
}
form.CheckField(validator.NotBlank(form.CurrentPassword), "currentPassword", "This field cannot be blank")
form.CheckField(validator.NotBlank(form.NewPassword), "newPassword", "This field cannot be blank")
form.CheckField(validator.MinChars(form.NewPassword, 8), "newPassword", "This field must be at least 8 characters long")
form.CheckField(validator.NotBlank(form.NewPasswordConfirmation), "newPasswordConfirmation", "This field cannot be blank")
form.CheckField(form.NewPassword == form.NewPasswordConfirmation, "newPasswordConfirmation", "Passwords do not match")
if !form.Valid() {
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "password.tmpl", data)
return
}
userID := app.sessionManager.GetInt(r.Context(), "authenticatedUserID")
err = app.users.PasswordUpdate(userID, form.CurrentPassword, form.NewPassword)
if err != nil {
if errors.Is(err, models.ErrInvalidCredentials) {
form.AddFieldError("currentPassword", "Current password is incorrect")
data := app.newTemplateData(r)
data.Form = form
app.render(w, http.StatusUnprocessableEntity, "password.tmpl", data)
} else if err != nil {
app.serverError(w, err)
}
return
}
app.sessionManager.Put(r.Context(), "flash", "Your password has been updated!")
http.Redirect(w, r, "/account/view", http.StatusSeeOther)
}
account.tmpl
поставим ссылку на изменение пароля
{{define "title"}}Your Account{{end}}
{{define "main"}}
<h2>Your Account</h2>
{{with .User}}
<table>
<tr>
<th>Name</th>
<td>{{.Name}}</td>
</tr>
<tr>
<th>Email</th>
<td>{{.Email}}</td>
</tr>
<tr>
<th>Joined</th>
<td>{{humanDate .Created}}</td>
</tr>
<tr>
<!-- Add a link to the change password form -->
<th>Password</th>
<td><a href="/account/password/update">Change password</a></td>
</tr>
</table>
{{end }}
{{end}}
12.10 - Памятка по примерам GO
Описание различных примеров и подходов в GO
12.10.1 - таблица с основными форматами Printf в Go
Шпаргалка по форматным строкам fmt.Printf
Шпаргалка по форматным строкам fmt.Printf
| Формат | Тип данных | Пример вывода | Описание | С # (если применимо) |
|---|---|---|---|---|
| Общие | ||||
%v | Любой | {John 25} | Универсальный формат | %#v → main.Person{Name:"John"} |
%+v | Структуры | {Name:John Age:25} | С именами полей | — |
%T | Любой | string | Тип переменной | — |
%% | — | % | Вывод знака % | — |
| Целые числа | ||||
%d | int | 42 | Десятичное число | — |
%#x | int | 0x2a | Шестнадцатеричное с 0x | Без #: 2a |
%#o | int | 052 | Восьмеричное с 0 | Без #: 52 |
%b | int | 101010 | Двоичное | %#b → 0b101010 (редко) |
| Символы | ||||
%c | rune | A | Символ по коду | — |
%U | rune | U+0041 | Код Unicode | %#U → U+0041 'A' |
%q | rune/string | 'A' / "A" | Кавычки вокруг значения | %#q → 'A' (для рун) |
| Строки | ||||
%s | string | Hello | Чистая строка | — |
%x | string/[]byte | 48656c6c6f | Шестнадцатеричный дамп | %#x → 0x48656c6c6f |
| Плавающие | ||||
%f | float64 | 3.141593 | Обычный формат | — |
%g | float64 | 3.14159 | Автовыбор (%f или %e) | %#g → Без изменений |
%e | float64 | 3.141593e+00 | Экспоненциальный формат | — |
| Указатели | ||||
%p | Указатель | 0xc0000180a8 | Адрес памяти | %#p → c0000180a8 (без 0x) |
| Ширина/Точность | ||||
%5d | int | 42 | Фиксированная ширина (5 символов) | — |
%05d | int | 00042 | Дополнение нулями | — |
%.2f | float64 | 3.14 | Ограничение знаков после точки | — |
Примеры использования
fmt.Printf("|%#v|%5d|%05d|\n", struct{ X int }{1}, 42, 42)
// |struct { X int }{X:1}| 42|00042|
fmt.Printf("|%#x|%#U|\n", 42, 'A')
// |0x2a|U+0041 'A'|
⚠️ Особенности
- Флаг
#работает только с%v,%x,%X,%o,%U,%p,%q. - Для
%g,%s,%dи других — игнорируется. %#qдля строк оставляет двойные кавычки, для рун — одинарные.
12.10.2 - Closure
В этом примере на Go демонстрируется замыкание (closure) — функция, которая запоминает окружение, в котором она была создана.
1. Функция intSeq() создаёт замыкание
func intSeq() func() int {
i := 0 // Локальная переменная внутри intSeq
return func() int { // Возвращаемая анонимная функция
i++ // Замыкание "видит" переменную i
return i
}
}
i := 0— это локальная переменная внутриintSeq.- Возвращаемая функция
func() int“замыкается” вокругi, то есть запоминает её и может изменять.
2. Создаём экземпляр замыкания
nextInt := intSeq() // Переменная nextInt теперь — функция
- При вызове
intSeq():- Создаётся переменная
i = 0. - Возвращается функция-замыкание, которая удерживает ссылку на
i.
- Создаётся переменная
3. Вызов nextInt() изменяет состояние i
p(nextInt()) // Выведет: === 1 ===
p(nextInt()) // Выведет: === 2 ===
p(nextInt()) // Выведет: === 3 ===
- Каждый вызов
nextInt():- Увеличивает
iна 1 (i++). - Возвращает новое значение.
- Увеличивает
iсохраняется между вызовами — это и есть “запомненное окружение”.
4. Новое замыкание — новый экземпляр i
newInts := intSeq() // Создаётся новый экземпляр замыкания
p(newInts()) // Выведет: === 1 === (не 4!)
newInts— это новое замыкание с собственной переменнойi = 0.- Оно не связано с
nextInt— их состояния (i) независимы.
Итог: как работает замыкание
- Запоминает окружение (переменные, например
i), даже после выхода из внешней функции. - Сохраняет состояние между вызовами (
iувеличивается). - Каждое новое замыкание создаёт свой экземпляр переменных.
Это полезно для:
- Генераторов (как в примере).
- Callback-функций с сохранением состояния.
- Инкапсуляции данных (аналог private переменных в ООП).
Пример в JavaScript (для сравнения):
function intSeq() {
let i = 0;
return () => ++i;
}
Работает аналогично!
12.10.3 - Создание модуля в GO
Создание и подключение новых модулей локально
Создание проекта
Создать директорию с проектом
mkdir greetings
cd greetings
Инициализация
$ go mod init example.com/greetings
go: creating new go.mod: module example.com/greetings
Команда init создает файл go.mod с основными параметрами модуля:
module example.com/hello
go 1.24.3
Создать файл GO
В редакторе создаю файл: напрмер greetings.go
package greetings
import "fmt"
// Hello returns a greeting for the named person.
func Hello(name string) string {
// Return a greeting that embeds the name in a message.
message := fmt.Sprintf("Hi, %v. Welcome!", name)
return message
}
важно указать в package название пакета для последующей ссылки на него
Создание основного модуля MAIN
Если проект многомодульный, то повторяем из корня проекта создание нового модуля:
cd ..
mkdir hello
cd hello
Выполняем инициализацию
$ go mod init example.com/hello
go: creating new go.mod: module example.com/hello
Создаем файл основного проекта
имя файла должно быть таким, каким потом будет исполняемый файл, но в файле обязательно должен быть: package main
package main
import (
"fmt"
"example.com/greetings"
)
func main() {
// Get a greeting message and print it.
message := greetings.Hello("Gladys")
fmt.Println(message)
}
Корректируем путь на зависимый модуль
go mod edit -replace example.com/greetings=../greetings
изменит в файле go.mod на фактический путь зависимого модуля
Получаем файл:
module example.com/hello
go 1.24.3
replace example.com/greetings => ../greetings
Выполняем go mod tidy
$ go mod tidy
go: found example.com/greetings in example.com/greetings v0.0.0-00010101000000-000000000000
для фактической связки только нужных пакетов и проверки go.mod
получаем go.mod
module example.com/hello
go 1.24.3
replace example.com/greetings => ../greetings
require example.com/greetings v0.0.0-00010101000000-000000000000
Запуск проекта
$ go run .
Hi, Gladys. Welcome!
12.10.4 - Создание тестов в GO
Создание и запуск тестов в GO + Emacs
Основные правила написания тестов в Go
Именование файлов:
- Тестовые файлы должны заканчиваться на
_test.go. - Пример:
main.go→main_test.go.
- Тестовые файлы должны заканчиваться на
Именование функций:
- Тестовые функции должны начинаться с
Test(для юнит-тестов) илиBenchmark(для бенчмарков). - Пример:
func TestAdd(t *testing.T) { ... } func BenchmarkAdd(b *testing.B) { ... }
- Тестовые функции должны начинаться с
Параметры тестовых функций:
- Юнит-тесты принимают
*testing.T. - Бенчмарки принимают
*testing.B. - Примеры тестов (
t.Error,t.Fail,t.Runдля подтестов).
- Юнит-тесты принимают
Табличные тесты (Table-Driven Tests):
- Рекомендуемый подход для покрытия разных сценариев.
- Пример:
func TestAdd(t *testing.T) { cases := []struct { a, b, expected int }{ {1, 2, 3}, {0, 0, 0}, {-1, 1, 0}, } for _, tc := range cases { result := Add(tc.a, tc.b) if result != tc.expected { t.Errorf("Add(%d, %d) = %d; want %d", tc.a, tc.b, result, tc.expected) } } }
Покрытие кода (Coverage):
- Замер покрытия:
go test -cover go test -coverprofile=coverage.out && go tool cover -html=coverage.out
- Замер покрытия:
Моки и тестовые данные:
- Используйте интерфейсы для замены зависимостей (например,
sqlmockдля тестирования SQL-запросов).
- Используйте интерфейсы для замены зависимостей (например,
Автоматизация тестов в Emacs для Go
go-mode:
- Основной режим для работы с Go в Emacs.
- Установка:
(use-package go-mode :ensure t)
go-test.el:
- Пакет для запуска тестов (встроен в
go-mode). - Команды:
M-x go-test-current-test— запуск текущего теста.M-x go-test-current-file— тестирование текущего файла.M-x go-test-current-project— тесты всего проекта.M-x go-test-current-benchmark— запуск бенчмарка.
- Пакет для запуска тестов (встроен в
flycheck / golangci-lint:
- Проверка кода и тестов в реальном времени.
dap-mode (Debug Adapter Protocol):
- Отладка тестов (аналог VS Code).
Требования к тестовым файлам
Расположение:
- Тестовые файлы должны быть в том же пакете (
package math→package math_testдля black-box тестирования).
- Тестовые файлы должны быть в том же пакете (
Доступ к символам:
- Если тестируемые функции/переменные должны быть экспортированы (
UpperCase).
- Если тестируемые функции/переменные должны быть экспортированы (
Использование
testing:- Обязателен импорт
"testing".
- Обязателен импорт
Тестовые данные:
- Можно использовать
testdata/для дополнительных файлов (например, JSON-фикстур).
- Можно использовать
Основные команды для тестов
Запуск всех тестов:
go test ./...Запуск конкретного теста:
go test -run TestAddПокрытие кода:
go test -coverprofile=cover.out && go tool cover -html=cover.outБенчмарки:
go test -bench .Пропуск кеширования:
go test -count=1Вербозный вывод:
go test -vПараллельные тесты:
func TestParallel(t *testing.T) { t.Parallel() // ... }
Бенчмарки (Benchmarks) в Go
Бенчмарки в Go — это тесты производительности, которые измеряют скорость выполнения кода (время на операцию, аллокации памяти и т. д.). Они помогают находить узкие места в программе и сравнивать разные реализации алгоритмов.
Как работают бенчмарки?
Именование функции:
- Должно начинаться с
Benchmark. - Принимает
*testing.B(аналог*testing.Tв обычных тестах). - Пример:
func BenchmarkSum(b *testing.B) { for i := 0; i < b.N; i++ { Sum(1, 2) // Тестируемая функция } }
- Должно начинаться с
Цикл
b.N:- Go автоматически подбирает
N(количество итераций), чтобы получить стабильные результаты. - Чем быстрее функция, тем больше итераций будет сделано.
- Go автоматически подбирает
Запуск бенчмарка:
go test -bench .- Флаг
-benchпринимает регулярное выражение для выбора бенчмарков (.— все). - Пример вывода:
BenchmarkSum-8 1000000000 0.265 ns/opBenchmarkSum-8— название теста (-8— количество CPU).1000000000— количество итераций (b.N).0.265 ns/op— время на одну операцию (наносекунды).
- Флаг
Полезные флаги для бенчмарков
| Флаг | Описание | Пример |
|---|---|---|
-benchmem | Показывать аллокации памяти | go test -bench . -benchmem |
-benchtime | Установить время выполнения | go test -bench . -benchtime=5s |
-count | Количество прогонов | go test -bench . -count=3 |
-cpu | Тестировать на разном числе CPU | go test -bench . -cpu=1,2,4 |
Пример бенчмарка
Допустим, есть функция сложения:
// sum.go
package math
func Sum(a, b int) int {
return a + b
}
Тест и бенчмарк:
// sum_test.go
package math
import "testing"
func TestSum(t *testing.T) {
if Sum(1, 2) != 3 {
t.Error("Ожидается 3")
}
}
func BenchmarkSum(b *testing.B) {
for i := 0; i < b.N; i++ {
Sum(1, 2)
}
}
Запуск:
go test -bench . -benchmem
Вывод:
BenchmarkSum-8 1000000000 0.265 ns/op 0 B/op 0 allocs/op
0.265 ns/op— 0.265 наносекунд на операцию.0 B/op— 0 байт выделено за итерацию.0 allocs/op— 0 аллокаций памяти.
Сравнение производительности
Бенчмарки полезны для сравнения разных реализаций. Например:
func BenchmarkSlow(b *testing.B) {
for i := 0; i < b.N; i++ {
SlowFunction()
}
}
func BenchmarkFast(b *testing.B) {
for i := 0; i < b.N; i++ {
FastFunction()
}
}
Запуск:
go test -bench . -benchmem
Покажет, какая функция работает быстрее и использует меньше памяти.
Бенчмарки в Go — это тесты производительности.
- Запускаются через
go test -bench. - Показывают время на операцию (
ns/op), аллокации памяти (B/op,allocs/op).
Если нужно углублённо анализировать производительность, можно использовать pprof:
go test -bench . -cpuprofile=cpu.out
go tool pprof cpu.out
12.10.5 - Работа с Workspace в Go: Полное руководство
Workspace (рабочее пространство) в Go — это мощный инструмент для управления несколькими модулями в одном проекте. Он появился в Go 1.18 и упрощает разработку, когда у вас есть взаимосвязанные модули.
1. Что такое Workspace и зачем он нужен?
Workspace позволяет:
- Работать с несколькими модулями одновременно без необходимости публиковать их в
GOPATHилиgo.mod replace. - Упрощать разработку в монолитных репозиториях (monorepo).
- Управлять зависимостями между локальными модулями без
replaceвgo.mod.
2. Создание Workspace
Шаг 1: Инициализация Workspace
go work init
Создается файл go.work в корне проекта.
Шаг 2: Добавление модулей в Workspace
go work use ./module1 ./module2
Теперь go.work выглядит так:
go 1.21
use (
./module1
./module2
)
3. Структура Workspace
Пример структуры проекта:
myproject/
├── go.work # Workspace файл
├── module1/ # Первый модуль
│ ├── go.mod # go.mod модуля 1
│ └── main.go
└── module2/ # Второй модуль
├── go.mod # go.mod модуля 2
└── utils.go
4. Основные команды для работы с Workspace
| Команда | Описание |
|---|---|
go work init | Создает go.work |
go work use [dir] | Добавляет модуль в Workspace |
go work edit | Редактирует go.work вручную |
go work sync | Синхронизирует зависимости |
5. Пример: Разработка двух связанных модулей
Модуль 1 (module1/main.go)
package main
import (
"fmt"
"github.com/user/module2/utils" // Локальный модуль
)
func main() {
fmt.Println(utils.Add(1, 2)) // Используем функцию из module2
}
Модуль 2 (module2/utils.go)
package utils
func Add(a, b int) int {
return a + b
}
Файл go.work
go 1.21
use (
./module1
./module2
)
Теперь module1 может использовать module2 без replace в go.mod!
6. Преимущества Workspace перед replace
| Workspace | replace в go.mod |
|---|---|
| Глобальная настройка для всех модулей | Требует правки в каждом go.mod |
Не нужно коммитить изменения в go.mod | replace должен быть в go.mod |
| Удобен для монолитных репозиториев | Подходит для временных изменений |
7. Отключение Workspace
Если нужно временно отключить Workspace:
go env -w GOWORK=off
Вернуть обратно:
go env -w GOWORK=$(pwd)/go.work
8. Советы по работе с Workspace
- Не коммитьте
go.workв общий репозиторий (если это не шаблон для команды). - Используйте Workspace для локальной разработки, а
go.mod— для продакшена. go work syncпомогает при обновлении зависимостей.
12.10.6 - массивы (arrays) и срезы (slices)
В Go массивы (arrays) и срезы (slices) — это разные структуры данных, а len и cap — функции, которые работают со срезами (и массивами, но для массивов они всегда равны).
🔹 Массив vs Срез
| Характеристика | Массив ([n]T) | Срез ([]T) |
|---|---|---|
| Размер | Фиксированный (известен на этапе компиляции) | Динамический (может расти и уменьшаться) |
| Передача в функцию | По значению (копируется) | По ссылке (указатель на массив) |
| Инициализация | arr := [3]int{1, 2, 3} | sl := []int{1, 2, 3} или make([]int, len, cap) |
| Гибкость | Неизменяемый размер | Можно изменять с помощью append |
Примеры:
// Массив (фиксированная длина)
arr := [3]int{1, 2, 3} // len=3, cap=3 (для массива len == cap)
// Срез (динамическая длина)
sl := []int{1, 2, 3} // len=3, cap=3
sl = append(sl, 4) // len=4, cap=6 (удвоился)
🔹 len vs cap
Обе функции применяются к срезам (и массивам), но имеют разный смысл:
len(s)— текущее количество элементов в срезе.cap(s)— максимальное количество элементов, которое может вместить базовый массив без переаллокации.
Пример:
sl := make([]int, 2, 5) // len=2, cap=5
fmt.Println(len(sl)) // 2 (элементы: [0, 0])
fmt.Println(cap(sl)) // 5 (может вместить ещё 3 элемента)
sl = append(sl, 1, 2, 3) // len=5, cap=5
sl = append(sl, 4) // len=6, cap=10 (удваивается при переполнении)
Вывод:
- Массивы — статические, срезы — динамические.
len— текущая длина,cap— ёмкость внутреннего массива.appendможет увеличитьlen, а если места нет (len == cap), то Go выделит новый массив (обычно с удвоеннойcap).
12.10.7 - Назначение пакетов net и net/http
В языке Go пакеты
net и net/http тесно связаны, но имеют разные уровни абстракции и предназначены для разных задач.1. Пакет net
Для чего используется:
- Предоставляет низкоуровневые сетевые примитивы для работы с различными сетевыми протоколами (TCP, UDP, IP, Unix-сокеты, DNS и др.).
- Позволяет создавать серверы и клиенты на уровне сокетов.
- Используется, когда нужен полный контроль над сетевым взаимодействием.
Основные возможности:
- Работа с TCP (
net.TCPConn,net.ListenTCP) - Работа с UDP (
net.UDPConn) - Разрешение DNS (
net.LookupHost,net.ResolveIP) - Управление сетевыми интерфейсами (
net.Interface)
Пример TCP-сервера:
package main
import (
"net"
)
func main() {
ln, _ := net.Listen("tcp", ":8080")
for {
conn, _ := ln.Accept()
go func(c net.Conn) {
c.Write([]byte("Hello from TCP server\n"))
c.Close()
}(conn)
}
}
2. Пакет net/http
Для чего используется:
- Реализует высокоуровневый HTTP-стек (клиент и сервер).
- Подходит для создания веб-серверов, REST API, работы с HTTP-запросами.
- Включает роутинг, middleware, куки, сессии и другие HTTP-специфичные функции.
Основные возможности:
- HTTP-сервер (
http.Server,http.HandleFunc) - HTTP-клиент (
http.Client,http.Get,http.Post) - Работа с заголовками, куками, формами
- Поддержка HTTPS (через
http.ListenAndServeTLS)
Пример HTTP-сервера:
package main
import (
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello from HTTP server"))
})
http.ListenAndServe(":8080", nil)
}
Ключевые отличия
| Критерий | net | net/http |
|---|---|---|
| Уровень | Низкоуровневый (TCP, UDP, IP) | Высокоуровневый (HTTP/HTTPS) |
| Использование | Сокеты, DNS, RAW-соединения | Веб-серверы, API, HTTP-клиенты |
| Сложность | Требует больше кода | Упрощает HTTP-взаимодействие |
| Примеры | Чат-сервер, DNS-резолвер | Веб-сайт, RESTful API |
Когда что использовать?
net– если нужен контроль над сетевым уровнем (например, пишете свой протокол поверх TCP/UDP).net/http– для стандартных HTTP-задач (веб-сервисы, API, скачивание данных).
Иногда их комбинируют: например, net/http использует net под капотом для работы с TCP-соединениями.
13 - Linux
Linux — это семейство операционных систем, работающих на основе одноименного ядра.
LINUX
Linux — это семейство операционных систем (ОС), работающих на основе одноименного ядра.
Линус Торвальдс — первый разработчик и создатель Linux. Именно в честь него и была названа ОС. В 1991 году Линус начал работу над собственной ОС семейства Unix.
13.1 - Шпаргалка по полезным командам Linux для работы с дисками и устройствами
Шпаргалка по полезным командам Linux для работы с дисками и устройствами и не только
1. dd – Копирование и конвертация данных
Основное использование:
dd if=входной_файл of=выходной_файл [опции]
Примеры:
- Создать образ диска:
dd if=/dev/sda of=backup.img bs=4M status=progress - Записать образ на USB:
dd if=ubuntu.iso of=/dev/sdb bs=4M status=progress - Создать файл-заполнитель (1 ГБ):
dd if=/dev/zero of=testfile bs=1G count=1
Опции:
bs=N– размер блока (например,4M,1K).count=N– количество блоков.status=progress– показывает прогресс.- Флаг
conv=(convert) позволяет задать дополнительные преобразования данных. Можно указывать несколько параметров через запятую.
1. conv=sync
- Назначение: Дополняет каждый ввод (input block) нулями до полного размера блока, если он был прочитан не полностью.
- Пример использования:
dd if=/dev/sda of=image.img bs=4K conv=sync- Если при чтении блока в 4 КБ считалось только 2 КБ (например, из-за ошибки), оставшиеся 2 КБ будут заполнены нулями.
- Полезно для сохранения выравнивания блоков при копировании повреждённых данных.
2. conv=noerror
- Назначение: Продолжать копирование, даже если встретились ошибки чтения.
- Пример:
dd if=/dev/sda of=image.img bs=4K conv=noerror,sync- Без
noerrorddостановится при первой ошибке. - Важно: Обычно используется вместе с
sync, чтобы сохранить размер блока.
- Без
3. Другие полезные флаги conv=
| Флаг | Описание |
|---|---|
notrunc | Не обрезать выходной файл (полезно при дозаписи). |
fsync | Синхронизировать данные на диск перед завершением. |
fdatasync | Синхронизировать только данные (без метаданных). |
excl | Запретить перезапись существующего файла. |
nocreat | Не создавать выходной файл, если его нет. |
Примеры комбинаций
Копирование диска с игнорированием ошибок и синхронизацией блоков:
dd if=/dev/sda of=backup.img bs=1M conv=noerror,sync status=progress- Продолжает копирование при ошибках, дополняя неполные блоки нулями.
Дозапись в файл без его обрезки:
dd if=data.bin of=output.bin bs=1M conv=notruncКопирование с гарантированной записью на диск:
dd if=source.iso of=/dev/sdb bs=4M conv=fsync
- Комбинация
noerror,syncчасто используется при копировании повреждённых дисков. - Если нужно создать точную копию с возможными ошибками, лучше использовать
ddrescue(из пакетаgddrescue), так как он более эффективен при восстановлении данных.
2. df – Информация о свободном месте на дисках
Основное использование:
df [опции] [файл/устройство]
Примеры:
- Показать место в человеко-читаемом формате:
df -h - Показать только определённую файловую систему:
df -h /dev/sda1 - Показать тип файловой системы:
df -Th
Опции:
-h– человеко-читаемый формат (KB, MB, GB).-T– показать тип файловой системы.-i– показать использование inodes.
3. du – Анализ использования диска файлами и папками
Основное использование:
du [опции] [путь]
Примеры:
- Проверить размер папки:
du -sh /home/user/ - Показать размер всех подпапок:
du -h --max-depth=1 /var/ - Найти самые большие файлы:
du -ah / | sort -rh | head -10
Опции:
-s– только итоговая сумма.-h– человеко-читаемый формат.--max-depth=N– глубина вложенности.
4. ncdu – Интерактивный анализ дискового пространства
Установка (если нет):
sudo apt install ncdu # Debian/Ubuntu
sudo dnf install ncdu # Fedora
Примеры:
- Анализ текущей папки:
ncdu - Анализ всей системы (требует root):
sudo ncdu /
Управление в ncdu:
↑/↓– навигация.Enter– войти в папку.d– удалить файл/папку.q– выход.
5. lsblk – Список блочных устройств (диски, разделы)
Основное использование:
lsblk [опции]
Примеры:
- Показать все устройства в дереве:
lsblk - Показать UUID и файловую систему:
lsblk -f - Показать размеры в человеко-читаемом формате:
lsblk -o NAME,SIZE,FSTYPE,MOUNTPOINT -e7
Опции:
-f– показать файловые системы.-o– выбрать поля для вывода.-e7– исключить loop-устройства.
6. lsusb – Список USB-устройств
Основное использование:
lsusb [опции]
Примеры:
- Показать все USB-устройства:
lsusb - Подробный вывод:
lsusb -v
Опции:
-v– подробная информация.-t– вывод в виде дерева.
7. lspci – Список PCI-устройств
Основное использование:
lspci [опции]
Примеры:
- Показать все устройства:
lspci - Подробно о видеокарте:
lspci -v -s $(lspci | grep VGA | cut -d' ' -f1)
Опции:
-v– подробный вывод.-nn– показать ID производителя.-k– показать драйверы.
Итог
| Команда | Описание |
|---|---|
dd | Копирование данных на низком уровне |
df | Свободное место на дисках |
du | Размер файлов и папок |
ncdu | Интерактивный анализ диска |
lsblk | Список дисков и разделов |
lsusb | Список USB-устройств |
lspci | Список PCI-устройств |
🚀 Полезные сочетания:
df -h | grep -v loop– показать только реальные диски.du -sh * | sort -h– сортировка файлов по размеру.lsblk -o NAME,SIZE,MOUNTPOINT,FSTYPE– удобный вывод дисков.
13.1.1 - Разбор конструкции find -exec и варианты использования
Эти команды — мощные инструменты для поиска, обработки и фильтрации данных в Linux.
1. Что означает {} \; в команде find?
{}– это специальный placeholder, который заменяется на имя каждого найденного файла.\;– завершает команду, передаваемую в-exec. Обратный слэш (\) экранирует точку с запятой, чтобы shell не интерпретировал её как конец команды.
Пример:
find /home -user olduser -exec chown newuser {} \;
Здесь:
findищет все файлы в/home, принадлежащиеolduser.- Для каждого файла выполняется
chown newuser filename. {}подставляется как имя файла, а\;указывает на конец команды.
2. Альтернативные форматы -exec
Вариант 1: + вместо \; (группировка файлов)
+в конце передаёт все найденные файлы одной командой (эффективно для массовых операций).
Пример:
find /var/log -name "*.log" -exec tar -czvf logs.tar.gz {} +
- Создаёт один архив со всеми
.log-файлами (вместо запускаtarдля каждого файла отдельно).
Вариант 2: -execdir (безопасное выполнение)
- Выполняет команду в директории файла (защита от path injection).
Пример:
find /tmp -type f -execdir rm {} \;
- Удаляет файлы, запуская
rmиз их родительских директорий.
3. Другие полезные команды с -exec
Изменение прав (chmod)
find /path -type f -exec chmod 644 {} \;
- Устанавливает права
644на все файлы.
Поиск и замена текста (sed)
find . -name "*.txt" -exec sed -i 's/foo/bar/g' {} \;
- Заменяет
fooнаbarво всех.txt-файлах.
Копирование файлов (cp)
find /src -name "*.jpg" -exec cp {} /dest \;
- Копирует все
.jpgиз/srcв/dest.
Подсчёт строк (wc)
find . -type f -exec wc -l {} \;
- Считает строки в каждом файле.
Удаление файлов старше 30 дней
find /backups -mtime +30 -exec rm {} \;
- Удаляет файлы, не изменявшиеся больше месяца.
4. Комбинации с xargs (альтернатива -exec)
Если -exec неудобен, можно использовать xargs:
find /path -name "*.tmp" | xargs rm
xargsпередаёт имена файлов вrmпачками (аналогично+в-exec).
С обработкой пробелов в именах:
find /path -name "*.log" -print0 | xargs -0 tar -czvf logs.tar.gz
-print0и-0корректно обрабатывают пробелы в путях.
5. Полезные опции find для -exec
| Опция | Пример | Описание |
|---|---|---|
-type f | find /path -type f -exec ... | Только файлы. |
-type d | find /path -type d -exec ... | Только директории. |
-mtime -7 | find /log -mtime -7 -exec ... | Файлы, изменённые за последние 7 дней. |
-size +1G | find / -size +1G -exec ... | Файлы >1 ГБ. |
-perm 777 | find / -perm 777 -exec ... | Файлы с правами 777. |
Итог
{} \;– подставляет имя файла и завершает команду.+– группирует файлы для одной команды (эффективнее).-execdir– безопасное выполнение в директории файла.- Альтернативы:
xargs,-delete,-printf.
Пример на все случаи:
find ~/Downloads -name "*.iso" -size +1G -exec ls -lh {} +
- Находит ISO-файлы >1 ГБ в
~/Downloadsи выводит их список с размерами.
13.1.2 - Шпаргалка по find, sed, ugrep
Эти команды — мощные инструменты для поиска, обработки и фильтрации данных в Linux. Здесь собраны примеры для ежедневного использования.
**Шпаргалка по find, sed, ugrep (+ grep)
1. find – Поиск файлов и выполнение действий
🔍 Базовый поиск
- Найти файлы по имени (регистронезависимо):
find /path -iname "*.txt" - Найти файлы, изменённые за последние 7 дней:
find /path -mtime -7 - Найти файлы размером >100 МБ:
find /path -size +100M - Найти пустые файлы и директории:
find /path -empty - Найти файлы с правами 755:
find /path -perm 755
⚡ Действия с найденными файлами
- Удалить все
.tmp-файлы:find /path -name "*.tmp" -delete - Изменить владельца файлов:
find /path -user olduser -exec chown newuser {} \; - Архивировать все
.log-файлы:find /var/log -name "*.log" -exec tar -czvf logs.tar.gz {} + - Найти и заменить права:
find /path -type f -exec chmod 644 {} \; - Найти файлы и вывести их размер:
find /path -type f -exec du -h {} \;
2. sed – Потоковый редактор (поиск и замена текста)
🔧 Базовые замены
- Заменить первое вхождение в строке:
echo "Hello World" | sed 's/World/Linux/' - Заменить все вхождения:
echo "a b a b" | sed 's/a/c/g' - Удалить строки, содержащие
error:sed '/error/d' file.txt - Удалить пустые строки:
sed '/^$/d' file.txt - Заменить только в строках, содержащих
debug:sed '/debug/s/old/new/' file.txt
📂 Работа с файлами
- Заменить в файле на месте (с бэкапом):
sed -i.bak 's/old/new/g' file.txt - Удалить строки с 5 по 10:
sed '5,10d' file.txt - Вывести только строки с 20 по 30:
sed -n '20,30p' file.txt - Добавить текст в начало файла:
sed -i '1i New Header' file.txt - Добавить текст в конец файла:
sed -i '$a Footer Text' file.txt
3. grep/ugrep – Поиск текста в файлах
🔎 Базовый поиск
- Найти слово в файле (регистронезависимо):
grep -i "pattern" file.txt - Найти точное совпадение (целое слово):
grep -w "word" file.txt - Вывести только совпадающую часть:
grep -o "pattern" file.txt - Найти строки, НЕ содержащие шаблон:
grep -v "exclude" file.txt - Подсчитать количество совпадений:
grep -c "pattern" file.txt
📂 Рекурсивный поиск
- Искать в всех файлах директории:
grep -r "pattern" /path/ - Искать только в
.php-файлах:grep -r --include="*.php" "pattern" /path/ - Искать в файлах без
.log:grep -r --exclude="*.log" "pattern" /path/ - Искать в скрытых файлах:
grep -r --hidden "pattern" /path/ - Искать в файлах изменённых за последние 2 дня:
find /path -mtime -2 -type f -exec grep -l "pattern" {} \;
🚀 ugrep – Улучшенный grep
- Поиск с подсветкой и нумерацией строк:
ugrep -n --color=auto "pattern" file.txt - Поиск с контекстом (строки до/после):
ugrep -C 3 "pattern" file.txt # 3 строки вокруг - Поиск с инвертированным контекстом:
ugrep -v -C 2 "pattern" file.txt - Поиск сжатых файлов (
.gz,.zip):ugrep -z "pattern" archive.gz - Поиск с регулярными выражениями:
ugrep -P "\d{3}-\d{2}-\d{4}" file.txt # Поиск SSN
4. Комбинации команд (find + grep + sed)
🔗 Поиск + обработка
- Найти все
.conf-файлы и заменитьhttpнаhttps:find /etc -name "*.conf" -exec sed -i 's/http/https/g' {} \; - Найти файлы, содержащие
password, и вывести их имена:find /path -type f -exec grep -l "password" {} \; - Удалить все строки с
# TODOиз.py-файлов:find . -name "*.py" -exec sed -i '/# TODO/d' {} \;
📊 Анализ логов
- Найти ошибки в логах за последний час:
grep "ERROR" /var/log/syslog | grep "$(date -d '1 hour ago' '+%b %d %H')" - Посчитать уникальные IP в Nginx-логе:
awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -nr
📂 Массовая обработка файлов
- Переименовать все
.jpg→.png:find . -name "*.jpg" | sed 's/\.jpg$//' | xargs -I {} mv {}.jpg {}.png - Удалить BOM из UTF-8 файлов:
find . -type f -exec sed -i '1s/^\xEF\xBB\xBF//' {} \; - Удалить все пробелы в конце строк:
find . -type f -exec sed -i 's/[[:space:]]*$//' {} \;
🔒 Безопасность
- Найти файлы с SUID/SGID:
find / -type f \( -perm -4000 -o -perm -2000 \) -exec ls -la {} \; - Найти открытые порты и процессы:
netstat -tulnp | grep -E '0.0.0.0|:::'
📜 Разное
- Извлечь все email из файла:
grep -E -o "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b" file.txt - Заменить
CRLF→LF(Windows → Unix):sed -i 's/\r$//' file.txt - Удалить HTML-теги из файла:
sed 's/<[^>]*>//g' file.html - Найти дубликаты файлов по содержимому:
find . -type f -exec md5sum {} + | sort | uniq -w32 -dD - Случайная строка из файла:
shuf -n 1 file.txt
Итоговая таблица
| Задача | Команда |
|---|---|
| Поиск файлов | find /path -name "*.txt" |
| Замена текста | sed 's/old/new/g' file.txt |
| Рекурсивный поиск текста | grep -r "pattern" /path/ |
| Удаление строк | sed '/pattern/d' file.txt |
| Поиск в логах | grep "ERROR" /var/log/syslog |
🚀 Совет:
ugrepбыстрееgrepи поддерживает расширенные regex (-P).find + execмощнееxargs, ноxargsлучше для большого числа файлов.
13.2 - Что такое PGP?
PGP (Pretty Good Privacy) — это криптографическая программа, обеспечивающая конфиденциальность и аутентификацию данных при передаче. По сути, это стандарт для шифрования сообщений электронной почты, файлов, каталогов и даже целых дисков.
PGP использует гибридную криптосистему, сочетающую в себе симметричное и асимметричное шифрование, что делает его одновременно эффективным и безопасным.
Ключевые концепции: как это работает
- Асимметричное шифрование (Криптография с открытым ключом):
- У каждого пользователя есть пара ключей:
- Закрытый ключ (Private Key): Должен храниться в строжайшем секрете. Никогда и никому не передается. Используется для расшифровки данных, предназначенных вам, и для подписи ваших сообщений.
- Открытый ключ (Public Key): Может свободно распространяться кому угодно (публиковаться на сайте, в ключевых серверах, отправляться по почте). Используется для шифрования данных, которые сможете расшифровать только вы, и для проверки вашей цифровой подписи.
- Принцип: То, что зашифровано открытым ключом, может быть расшифровано только соответствующим закрытым ключом, и наоборот.
- У каждого пользователя есть пара ключей:
flowchart TD
subgraph Sender [Отправитель]
A[Исходное сообщение] --> B{Создать цифровую подпись}
B --> C[Зашифровать своим<br>Закрытым ключом]
C --> D[Цифровая подпись]
A --> E[Исходное сообщение]
D --> F{Объединить сообщение и подпись}
E --> F
F --> G[Подписанное сообщение]
G --> H{Зашифровать сообщение}
H --> I[Сгенерировать случайный<br>сеансовый ключ]
I --> J[Зашифровать сообщение<br>сеансовым ключом симметрично]
J --> K[Зашифрованное сообщение]
I --> L[Зашифровать сеансовый ключ<br>Открытым ключом получателя]
L --> M[Зашифрованный сеансовый ключ]
K --> N{Объединить для отправки}
M --> N
N --> O[Итоговые данные для отправки]
end
O --> P[Передача по незащищенному каналу<br>e.g. Интернет, почтовый сервер]
subgraph Receiver [Получатель]
P --> Q[Итоговые данные для отправки]
Q --> R{Разделить данные}
R --> S[Зашифрованный сеансовый ключ]
R --> T[Зашифрованное сообщение]
S --> U[Расшифровать сеансовый ключ<br>своим Закрытым ключом]
U --> V[Сеансовый ключ]
T --> W[Расшифровать сообщение<br>сеансовым ключом]
V --> W
W --> X[Подписанное сообщение]
X --> Y{Разделить сообщение и подпись}
Y --> Z[Полученное сообщение]
Y --> AA[Цифровая подпись]
AA --> AB[Расшифровать подпись<br>Открытым ключом отправителя]
AB --> AC[Оригинальный хэш отправителя]
Z --> AD[Вычислить хэш от<br>полученного сообщения]
AD --> AE[Хэш полученного сообщения]
AC --> AF{Сравнить хэши}
AE --> AF
AF -- Совпали --> AG[✅ Подпись верна<br>Сообщение аутентично и не изменено]
AF -- Не совпали --> AH[❌ Подпись неверна!<br>Сообщение отклонено]
endЦифровая подпись:
- Позволяет получателю убедиться в двух вещах:
- Аутентичность: Сообщение действительно отправлено вами.
- Целостность: Сообщение не было изменено во время передачи.
- Как создается: Вы создаете хэш (отпечаток) вашего сообщения и шифруете этот хэш своим закрытым ключом. Получатель расшифровывает хэш вашим открытым ключом, вычисляет хэш полученного сообщения самостоятельно и сравнивает их. Если они совпали — подпись верна.
- Позволяет получателю убедиться в двух вещах:
Гибридная система:
- Шифровать большие объемы данных (например, длинное письмо) асимметричным шифрованием computationally expensive (требует много вычислительных ресурсов).
- Решение PGP:
- Программа создает случайный сеансовый ключ (симметричный, один и тот же для шифрования и расшифровки).
- Этим сеансовым ключом шифруется само сообщение (быстро и эффективно).
- Этот сеансовый ключ сам шифруется открытым ключом получателя.
- Зашифрованное сообщение и зашифрованный сеансовый ключ отправляются получателю.
- Получатель:
- Своим закрытым ключом расшифровывает сеансовый ключ.
- Расшифрованным сеансовым ключом расшифровывает всё сообщение.
flowchart TD
subgraph Sender [Отправитель]
direction LR
A[Исходные данные<br>Сообщение или файл] --> B[Сгенерировать случайный<br>сеансовый ключ]
B --> C[Зашифровать данные<br>сеансовым ключом<br>Симметричное шифрование AES]
B --> D[Зашифровать сеансовый ключ<br>Открытым ключом получателя<br>Асимметричное шифрование RSA]
C --> E[Зашифрованные данные]
D --> F[Зашифрованный сеансовый ключ]
E --> G[Объединить и отправить]
F --> G
end
G --> H[Передача]
subgraph Receiver [Получатель]
direction LR
H --> I[Принять данные]
I --> J[Извлечь зашифрованный<br>сеансовый ключ]
I --> K[Извлечь зашифрованные данные]
J --> L[Расшифровать сеансовый ключ<br>своим Закрытым ключом]
L --> M[Сеансовый ключ]
K --> N[Расшифровать данные<br>сеансовым ключом]
M --> N
N --> O[Исходные данные]
endСхема омена ключами
flowchart TD
A[Алиса генерирует свою<br>пару ключей] --> B[Алиса публикует свой<br>Открытый ключ на сервере]
A --> C[Алиса отправляет свой<br>Открытый ключ Бобу по email]
subgraph Bob [Действия Боба]
D[Боб генерирует свою<br>пару ключей] --> E[Боб получает ключ Алисы]
B -.-> E
C --> E
E --> F{Верифицировать отпечаток ключа}
F -- "Звонок Алисе,<br>сверка отпечатков" --> G[✅ Ключ доверен]
F -- "Отпечаток не проверен" --> H[❌ Ключ не доверен]
G --> I[Боб может отправлять<br>Алисе зашифрованные сообщения]
end
subgraph Alice [Действия Алисы]
J[Алиса получает ключ Боба] --> K[Алиса верифицирует<br>отпечаток ключа Боба]
K --> L[✅ Ключ доверен]
L --> M[Алиса может отправлять<br>Бобу зашифрованные сообщения]
endПошаговое руководство по применению PGP
Современное применение PGP чаще всего сводится к использованию его реализаций с графическим интерфейсом, которые упрощают процесс.
Шаг 1: Установка необходимого ПО
Вам не нужна оригинальная коммерческая программа PGP. Существует ее бесплатный и открытый аналог — GnuPG (GPG). Это движок командной строки. Для удобства ставьте программы с графическим интерфейсом:
- Для электронной почты:
- Thunderbird (почтовый клиент) + дополнение Enigmail. Это классическая и очень мощная связка.
- Mailvelope — расширение для браузеров (Chrome, Firefox), которое позволяет работать с PGP прямо в веб-интерфейсах, таких как Gmail, Outlook.com и т.д.
- Для шифрования файлов/текста:
- Gpg4win (для Windows) — комплект, включающий GPG, Kleopatra (менеджер ключей), плагины для Outlook и др.
- GPG Suite (для macOS) — аналогичный комплект для Mac.
- Kleopatra — кроссплатформенный менеджер ключей и сертификатов.
Шаг 2: Генерация пары ключей
- Установите, например, Gpg4win или GPG Suite.
- Запустите менеджер ключей (Kleopatra или другой).
- Нажмите «Создать новую пару ключей» («New Key Pair»).
- Введите свои данные:
- Имя и Email: Это идентифицирует ваш ключ. Указывайте реальный email, на который планируете получать зашифрованные письма.
- Парольная фраза (Passphrase): Это ОЧЕНЬ ВАЖНО. Парольная фраза защищает ваш закрытый ключ на диске. Она должна быть длинной и сложной (например, 4-5 случайных слов). Без нее даже кража вашего закрытого ключа будет бесполезна.
- Дождитесь завершения генерации. Процесс может занять несколько минут, так как программа собирает энтропию (случайные данные) от ваших действий с мышкой и клавиатурой.
Шаг 3: Обмен открытыми ключами
Чтобы кто-то мог отправить вам зашифрованное сообщение, ему нужен ваш открытый ключ.
- Экспорт: В вашем менеджере ключей (Kleopatra) вы можете экспортировать открытый ключ в файл (обычно с расширением
.ascили.pub). Этот файл представляет собой блок текста между строками-----BEGIN PGP PUBLIC KEY BLOCK-----и-----END PGP PUBLIC KEY BLOCK-----. - Способы распространения:
- Отправить по email: Просто прикрепите файл
.ascк письму. - Скопировать текст: Скопируйте текстовый блок и вставьте его в тело письма.
- Ключевые серверы (Keyservers): Это специальные публичные базы данных открытых ключей. Вы можете «залить» (upload) свой ключ на сервер (например,
keys.openpgp.org). Тогда любой человек, зная ваш email, сможет его найти. (Важно: удалить ключ с ключевого сервера обычно невозможно!)
- Отправить по email: Просто прикрепите файл
Шаг 4: Импорт и проверка чужих открытых ключей
Чтобы отправить сообщение кому-то, вам нужен их открытый ключ.
- Импорт: Получите файл ключа или текстовый блок. В вашем менеджере ключей будет функция «Импорт» («Import»), где вы можете указать файл или вставить текст.
- Верификация (Крайне важный шаг!): Как убедиться, что импортированный ключ действительно принадлежит тому, кто вам его прислал, а не злоумышленнику (атака “man-in-the-middle”)?
- Сравнение отпечатка (Fingerprint): У каждого ключа есть уникальный «отпечаток» — длинная строка из букв и цифр (например,
AB12 CD34 EF56 7890 ...). Свяжитесь с человеком другим, доверенным каналом связи (телефонный звонок, мессенджер с E2EE типа Signal/Telegram, личная встреча) и сравните отпечатки. Если они совпали — ключ подлинный. - Подпись ключей (Web of Trust): Более продвинутый метод, когда ваши доверенные контакты digitally подписывают ваш ключ, подтверждая его подлинность для третьих лиц.
- Сравнение отпечатка (Fingerprint): У каждого ключа есть уникальный «отпечаток» — длинная строка из букв и цифр (например,
Шаг 5: Шифрование и подпись
- В почтовом клиенте (Thunderbird + Enigmail): После настройки в интерфейсе письма появятся кнопки «Зашифровать» (иконка с ключом) и «Подписать» (иконка с ручкой). Просто отметьте нужные галочки перед отправкой. Плагин сам найдет открытый ключ получателя в вашей связке и всё сделает.
- В веб-почте (Mailvelope): Расширение добавит свою кнопку в интерфейс Gmail/Yahoo и т.д. Нажав на нее, вы откроете окно, где можно ввести текст, выбрать получателя (чей открытый ключ использовать) и зашифровать. Результат вставится в тело письма.
- Для файлов (Kleopatra): Через меню «Файл» -> «Зашифровать/Расшифровать» можно выбрать файлы и указать получателей.
Шаг 6: Расшифровка и проверка
- Когда вы получаете зашифрованное письмо, ваш почтовый плагин (Enigmail/Mailvelope) автоматически распознает его.
- Он проверит, есть ли у вас в связке закрытый ключ, соответствующий адресу получателя.
- Если есть, он запросит у вас парольную фразу для доступа к этому закрытому ключу и автоматически расшифрует сообщение.
- Если письмо было подписано, плагин также покажет результат проверки подписи (например, зеленую галочку и текст “Проверенная подпись от Имя Отправителя”).
Сценарии применения
- Конфиденциальная переписка: Самая частая цель. Защита содержимого писем от прочтения провайдерами, хакерами, правительственными агентствами.
- Защита целостности данных: Отправка важных документов (договоров, инструкций) с подписью, чтобы получатель мог быть уверен, что их не подменили.
- Шифрование файлов на диске: Можно зашифровать чувствительные файлы на своем компьютере или на флеш-накопителе, чтобы даже в случае утери устройства данные были защищены.
- Анонимность в darknet: PGP — обязательный стандарт для безопасного общения на теневых форумах и в рынках, где анонимность критически важна.
Сильные и слабые стороны
Сильные стороны:
- Высокий уровень безопасности при правильном использовании.
- Де-факто стандарт, поддерживается многими платформами.
- Децентрализованность — не зависит от единого центра сертификации.
Слабые стороны:
- Сложность для обычных пользователей: Основная причина, почему PGP не стал мейнстримом.
- Проблема верификации ключей: Сложно надежно проверить, что ключ действительно принадлежит нужному человеку.
- Уязвимости метаданных: PGP шифрует тело письма, но не скрывает метаданные (тему, отправителя, получателя, дату отправки). Эта информация остается открытой.
- Управление ключами: Потеря закрытого ключа или парольной фразы означает безвозвратную потерю доступа к данным. Компрометация ключа требует его отзыва и генерации нового.
Вывод
PGP — это мощный, проверенный временем инструмент для защиты приватности, который остается золотым стандартом для шифрования email. Его применение требует определенных усилий для изучения и дисциплины для постоянного использования. Для большинства пользователей лучшей отправной точкой является установка Thunderbird с плагином Enigmail или браузерного расширения Mailvelope.
13.2.1 - Структура хранения ключей
Описание структуры хранения ключей при установке GnuPG
1. База данных и структура хранения GnuPG на компьютере
GnuPG не использует единую базу данных в традиционном понимании (как SQLite или MySQL). Вместо этого он использует набор файлов в специальном каталоге (обычно ~/.gnupg/ в Linux/macOS или %APPDATA%\gnupg в Windows). Это портативная и простая в резервном копировании структура.
Вот ключевые файлы и их назначение:
| Файл / Каталог | Назначение и описание |
|---|---|
~/.gnupg/ | Домашний каталог GnuPG. Основное место хранения всех данных. Его местоположение можно изменить через переменную окружения GNUPGHOME или опцию --homedir. |
pubring.kbx | Основной файл с открытыми ключами (публичными). Это ключевой файл в современном формате “keybox” (KBX), который используется по умолчанию в версиях GnuPG 2.1 и новее. Хранит импортированные открытые ключи. |
trustdb.gpg | База данных доверия (Trust DB). Это самая близкая к “базе данных” часть. Она не содержит самих ключей, а хранит информацию о уровне доверия, который вы назначили владельцам ключей (например, “полное”, “ограниченное”, “недоверенное”), и вычисленные на основе этой информации валидности ключей (ultimate, full, marginal, expired, revoked и т.д.). |
private-keys-v1.d/ | Каталог с секретными ключами. Это очень важный каталог. В современных версиях каждый секретный ключ (закрытый) хранится в отдельном файле с расширением .key. Файлы зашифрованы с использованием вашей парольной фразы. Это то, что нужно бэкопировать в первую очередь и максимально защищать! |
openpgp-revocs.d/ | Каталог с предварительно сгенерированными отзывными сертификатами. Когда вы создаете новый ключ, GnuPG автоматически генерирует сертификат для его отзыва (чтобы вы могли объявить ключ недействительным, если забыли пароль или потеряли доступ к нему). Имена файлов соответствуют отпечаткам ключей. |
gpg.conf | Главный файл конфигурации для команды gpg. Сюда можно прописать все часто используемые опции (например, используемый keyserver, алгоритмы по умолчанию и т.д.). |
dirmngr.conf | Файл конфигурации для dirmngr — демона, отвечающего за взаимодействие с keyserver-ами и проверку сертификатов OCSP. |
gpg-agent.conf | Файл конфигурации для gpg-agent — демона, который управляет секретными ключами, кэширует парольные фразы и обеспечивает безопасность их использования. |
Устаревшие файлы (встречаются в старых системах или после обновления):
pubring.gpg,secring.gpg: Публичные и секретные ключи в старом формате. Современные версии GnuPG (>2.1) используютpubring.kbxи каталогprivate-keys-v1.d/вместоsecring.gpg.
Как это работает вместе?
- Когда вы выполняете
gpg --list-keys, программа читает список открытых ключей изpubring.kbx. - Когда вы проверяете подпись,
gpgсверяется сtrustdb.gpg, чтобы узнать, насколько ключ, которым подписан файл, валиден с точки зрения вашей сети доверия. - Когда вы подписываете или расшифровываете что-либо,
gpgобращается кgpg-agent. gpg-agentнаходит нужный секретный ключ в каталогеprivate-keys-v1.d/, запрашивает у вас пароль для его расшифровки (если он еще не закэширован) и выполняет криптографическую операцию.
2. Что устанавливается при установке GnuPG
При установке GnuPG (пакет gnupg, gnupg2 или установщик для Windows) устанавливается не одна программа, а целый набор взаимосвязанных компонентов:
| Компонент | Назначение |
|---|---|
gpg / gpg2 | Основная программа (бинарник). Это командная утилита, с которой взаимодействует пользователь. Именно она вызывает все остальные компоненты для выполнения задач. В версиях 2.x основной бинарник называется gpg2, но часто существует символьная ссылка gpg на него для совместимости. |
gpg-agent | Агент управления ключами. Это фоновый процесс (демон), который: • Управляет секретными ключами. • Кэширует введенные парольные фразы в течение заданного времени (чтобы не вводить пароль каждый раз). • Перенаправляет запросы на ввод пароля на правильный PIN-entry. Это ключевой компонент для безопасности и удобства. |
gpg-connect-agent | Утилита для отладки и отправки команд gpg-agentу напрямую. |
gpgconf | Утилита для управления конфигурацией runtime-процессов GnuPG (например, для перезагрузки агента или просмотра используемых опций). |
dirmngr | Менеджер каталогов. Еще один фоновый процесс, который отвечает за: • Связь с keyserver-ами (получение ключей, отправка ключей, поиск). • Проверку отозванных сертификатов (CRL/OCSP) для технологии S/MIME (используется в gpgsm). |
gpgsm | Утилита для работы с сертификатами S/MIME (стандарт, часто используемый в почтовых клиентах). Работает с X.509 сертификатами, а не с OpenPGP ключами. |
gpgparsemail, gpgscm и др. | Вспомогательные скрипты и утилиты для обработки почты и тестирования. |
pinentry-* | Набор программ для ввода пароля. Это отдельные пакеты (например, pinentry-gtk2, pinentry-qt, pinentry-curses, pinentry-tty), которые должны быть установлены вместе с GnuPG. Агент gpg-agent вызывает pinentry, чтобы показать графический или текстовый диалог ввода пароля. Это сделано для изоляции и безопасности — сам gpg-agent не имеет доступа к дисплею. |
Итог:
Установка GnuPG — это установка целой экосистемы (gpg, gpg-agent, dirmngr), которая работает вместе, чтобы предоставить полнофункциональную криптографическую инфраструктуру. Данные хранятся в виде набора файлов в домашнем каталоге, а не в единой монолитной базе, что упрощает резервное копирование и перенос.
13.2.2 - gpg-agent
gpg-agent — это демон для управления секретными (приватными) ключами независимо от какого-либо протокола. Он используется в качестве бэкенда для gpg и gpgsm, а также для нескольких других утилит.
Агент автоматически запускается по требованию gpg, gpgsm, gpgconf или gpg-connect-agent. Таким образом, нет необходимости запускать его вручную. Если вы хотите использовать включенный агент Secure Shell, вы можете запустить агент с помощью:
gpg-connect-agent /bye
Если вы хотите вручную завершить текущий работающий агент, вы можете сделать это безопасно с помощью:
gpgconf --kill gpg-agent
Вы всегда должны добавить следующие строки в ваш .bashrc или любой другой файл инициализации, используемый для всех вызовов оболочки:
GPG_TTY=$(tty)
export GPG_TTY
Важно, чтобы эта переменная окружения всегда отражала вывод команды tty. Для систем W32 эта опция не требуется.
Пожалуйста, убедитесь, что подходящая программа pinentry установлена под именем по умолчанию (что зависит от системы) или используйте опцию pinentry-program, чтобы указать полное имя этой программы. Часто полезно установить символическую ссылку от фактически используемого pinentry (например, /usr/local/bin/pinentry-gtk) к ожидаемому (например, /usr/local/bin/pinentry).
13.2.3 - dirmngr
С версии 2.1 GnuPG dirmngr отвечает за доступ к серверам ключей OpenPGP. Как и в предыдущих версиях, он также используется в качестве сервера для управления и загрузки списков отзыва сертификатов (CRL) для сертификатов X.509, загрузки сертификатов X.509 и предоставления доступа к провайдерам OCSP. Dirmngr вызывается внутренне через gpg, gpgsm или с помощью инструмента gpg-connect-agent.
13.2.4 - gpg
gpg — это часть OpenPGP в GNU Privacy Guard (GnuPG). Это инструмент для предоставления услуг цифрового шифрования и подписи с использованием стандарта OpenPGP. gpg предлагает полное управление ключами и все функции, которые вы ожидаете от полноценной реализации OpenPGP.
Существуют две основные версии GnuPG: GnuPG 1.x и GnuPG 2.x. GnuPG 2.x поддерживает современные алгоритмы шифрования и, следовательно, должен быть предпочтительным вариантом по сравнению с GnuPG 1.x. Вам нужно использовать GnuPG 1.x только в том случае, если ваша платформа не поддерживает GnuPG 2.x или вам нужна поддержка некоторых функций, которые были устаревшими в GnuPG 2.x по соображениям безопасности, например, расшифровка данных, созданных с помощью ключей PGP-2.
Если вы ищете первую версию GnuPG, вы можете обнаружить, что эта версия установлена под именем gpg1.
Команды и опции
Команды не отличаются от опций, за исключением того факта, что разрешена только одна команда. Вообще говоря, нерелевантные опции тихо игнорируются, и их корректность может не проверяться.
gpg может быть запущен без команд. В этом случае он выведет предупреждение и выполнит разумное действие в зависимости от типа файла, переданного ему на вход (зашифрованное сообщение будет расшифровано, подпись будет проверена, файл с ключами будет выведен на экран и т.д.).
Если у вас возникли какие-либо проблемы, добавьте опцию --verbose (подробно) к вызову команды, чтобы увидеть больше диагностической информации.
13.2.4.1 - Команды GPG
Полный список команда GPG
Команды, не привязанные к конкретной функции
--version
Выводит информацию о версии программы и лицензировании. Обратите внимание, что эту команду нельзя сокращать.
--help
-h
Выводит сообщение о использовании, суммирующее наиболее полезные опции командной строки. Обратите внимание, что эту команду нельзя произвольно сокращать (хотя можно использовать её короткую форму -h).
--warranty
Выводит информацию о гарантиях.
--dump-options
Выводит список всех доступных опций и команд. Обратите внимание, что эту команду нельзя сокращать.
Конечно, вот перевод и структурированная таблица с командами, а также примеры использования.
Команды для выбора типа операции
| Команда (короткая) | Описание |
|---|---|
--sign (-s) | Подписать сообщение. Можно комбинировать с --encrypt (для подписи и шифрования) и/или --symmetric. Ключ для подписи выбирается по умолчанию или задаётся опциями --local-user и --default-key. |
--clear-sign--clearsign | Создать подпись в чистом тексте (cleartext signature). Содержимое читаемо без специального ПО, которое нужно только для проверки подписи. Может изменять пробельные символы в конце строк. |
--detach-sign (-b) | Создать отделённую подпись (detached signature). |
--encrypt (-e) | Зашифровать данные для одного или нескольких открытых ключей. Комбинируется с --sign и/или --symmetric. Получатели задаются опциями --recipient. |
--symmetric (-c) | Зашифровать симметричным шифром с использованием парольной фразы (по умолчанию AES-128). Комбинируется с --sign и/или --encrypt. Пароль кэшируется. |
--store | Только сохранить (создать простой пакет literal data). |
--decrypt (-d) | Расшифровать файл, переданный в командной строке (или из STDIN) и записать в STDOUT. Если файл подписан, подпись также проверяется. |
--verify | Проверить подпись файла, не выводя содержимое. Для проверки отделённой подписи нужно указать файл подписи и файл(ы) данных. |
--multifile | Модифицирует другие команды (--verify, --encrypt, --decrypt) для обработки нескольких файлов, переданных в командной строке или из STDIN. |
--verify-files | Аналогично --multifile --verify. |
--encrypt-files | Аналогично --multifile --encrypt. |
--decrypt-files | Аналогично --multifile --decrypt. |
--list-keys (-k)--list-public-keys | Вывести список указанных или всех открытых ключей. Не использовать для парсинга в скриптах (используйте --with-colons). |
--list-secret-keys (-K) | Вывести список указанных или всех секретных ключей. # означает, что ключ не используется, > — ключ на смарт-карте. |
--check-signatures--check-sigs | Аналогично --list-keys, но также проверяет и выводит подписи ключей. ! — хорошая подпись, - — плохая, % — ошибка проверки. |
--locate-keys--locate-external-keys | Найти ключи по аргументам (использует те же методы, что и при шифровании). Вторая команда не ищет в локальных хранилищах. |
--show-keys | Анализирует переданные ключи (не из ключевых колец) и выводит информацию о них, как --list-keys. |
--fingerprint | Вывести список ключей вместе с их отпечатками. Если указать дважды, покажет отпечатки всех субключей. |
--list-packets | Вывести только последовательность пакетов (для отладки). |
--edit-card--card-edit | Открыть меню для работы со смарт-картой. |
--card-status | Показать содержимое смарт-карты. |
--change-pin | Позволить сменить PIN-код смарт-карты. |
--delete-keys | Удалить ключ из открытого ключевого кольца. В пакетном режиме требуется --yes или указание отпечатка. |
--delete-secret-keys | Удалить ключ из секретного ключевого кольца. В пакетном режиме требуется указание отпечатка. |
--delete-secret-and-public-key | Удалить и секретный, и открытый ключ. |
--export | Экспортировать указанные или все открытые ключи в STDOUT или файл. |
--send-keys | Отправить указанные ключи на keyserver. |
--export-secret-keys--export-secret-subkeys | Экспортировать секретные ключи. Вторая форма делает первичный ключ непригодным для использования (GNU расширение). |
--export-ssh-key | Экспортировать ключ в формате OpenSSH. |
--import--fast-import | Импортировать/объединить ключи в ключевое кольцо. |
--receive-keys--recv-keys | Импортировать ключи с заданными keyIDs с keyserver’а. |
--refresh-keys | Запросить обновления для существующих в ключевом кольце ключей с keyserver’а. |
--search-keys | Найти ключи по именам на keyserver’е. |
--fetch-keys | Загрузить ключи по указанным URI. |
--update-trustdb | Обслуживание базы доверия (интерактивно, запрашивает ownertrust). |
--check-trustdb | Обслуживание базы доверия без взаимодействия с пользователем. |
--export-ownertrust | Экспортировать значения ownertrust (для резервного копирования). |
--import-ownertrust | Импортировать значения ownertrust из файла. |
--rebuild-keydb-caches | Перестроить кэши в ключевом кольце. |
--print-md--print-mds | Вывести дайджест сообщения для указанного или всех алгоритмов. |
--gen-random | Сгенерировать count случайных байт заданного уровня качества (0, 1, 2). |
--gen-prime | Сгенерировать простое число. (Use the source, Luke :-)) |
--enarmor--dearmor | Упаковать/распаковать произвольные данные в/из ASCII-armor OpenPGP. |
--unwrap | Модифицирует --decrypt для вывода исходного сообщения без слоя шифрования (выводит структуру OpenPGP). |
--tofu-policy | Установить политику TOFU (Trust On First Use) для указанных ключей. |
Конкретные примеры использования
1. Шифрование и подпись:
# Зашифровать и подписать файл 'document.txt' для получателя alice@example.com, используя свой ключ bob@example.com для подписи.
# Результат в файле 'document.txt.gpg'
gpg --encrypt --sign --recipient alice@example.com --local-user bob@example.com --output document.txt.gpg document.txt
# Короткая форма:
gpg -e -s -r alice@example.com -u bob@example.com -o document.txt.gpg document.txt
2. Создание и проверка отделённой подписи:
# Создать отделённую подпись для файла 'package.zip'
gpg --detach-sign --output package.zip.sig package.zip
# Проверить отделённую подпись
gpg --verify package.zip.sig package.zip
3. Симметричное шифрование:
# Зашифровать файл 'secret.txt' симметричным шифром с помощью пароля
gpg --symmetric --output secret.txt.gpg secret.txt
# Расшифровать полученный файл (gpg запросит пароль)
gpg --decrypt --output secret.txt secret.txt.gpg
4. Работа с ключами:
# Вывести список открытых ключей с отпечатками
gpg --list-keys --fingerprint
# Импортировать ключ из файла
gpg --import public_key.asc
# Экспортировать открытый ключ с ID 12345678 в файл
gpg --export --armor 12345678 > public_key.asc
# Обновить все ключи в ключевом кольце с keyserver'а
gpg --refresh-keys
5. Проверка подписи чистого текста:
# Проверить подпись файла 'message.txt.asc'
gpg --verify message.txt.asc
# Если нужно извлечь подписанное содержимое в файл 'message.txt'
gpg --output message.txt --decrypt message.txt.asc
Конечно, вот перевод, структурированная таблица и практические примеры.
Как управлять своими ключами
В этом разделе объясняются основные команды для управления ключами.
Таблица команд управления ключами
| Команда (короткая) | Описание |
|---|---|
--quick-generate-key--quick-gen-key | Быстро сгенерировать стандартный ключ с одним ID пользователя. Без диалогов. |
--quick-set-expire | Установить срок действия основного ключа (fpr) и/или его субключей. |
--quick-add-key | Добавить субключ к существующему ключу (по отпечатку fpr). |
--quick-add-adsk | Добавить Дополнительный Субключ для Расшифровки (ADSK) из другого ключа. |
--generate-key--gen-key | Сгенерировать новую пару ключей, используя параметры по умолчанию (интерактивно). |
--full-generate-key--full-gen-key | Сгенерировать новую пару ключей с диалогами для всех опций. |
--generate-revocation--gen-revoke | Создать сертификат отзыва для всего ключа. |
--generate-designated-revocation--desig-revoke | Создать назначенный сертификат отзыва (позволяет отозвать чужой ключ). |
--edit-key | Основная команда для интерактивного управления ключами через меню. |
--sign-key | Подписать открытый ключ вашим секретным ключом (ярлык для sign в --edit-key). |
--lsign-key | Подписать ключ с пометкой “не для экспорта” (ярлык для lsign). |
--quick-sign-key--quick-lsign-key--quick-tsign-key | Быстро подписать ключ без дополнительного взаимодействия. |
--quick-add-uid | Добавить новый ID пользователя к существующему ключу. |
--quick-revoke-uid | Отозвать ID пользователя на существующем ключе. |
--quick-revoke-sig | Отозвать подписи ключей, сделанные указанным ключом. |
--quick-set-primary-uid | Установить или обновить флаг основного ID пользователя. |
--quick-update-pref | Обновить список предпочтений ключа до текущего значения по умолчанию. |
--quick-set-ownertrust | Установить уровень доверия (ownertrust) для ключа. |
--change-passphrase--passwd | Изменить парольную фразу секретного ключа. |
Ключевые понятия из --edit-key:
sign/lsign/tsign/nrsign– Подписать ключ (обычная/локальная/доверительная/безотзывная).adduid– Добавить user ID.addkey– Добавить субключ.passwd– Сменить парольную фразу.revkey/revuid– Отозвать субключ / user ID.expire– Изменить срок действия.save– Сохранить изменения и выйти.quit– Выйти без сохранения.
Примеры использования
1. Быстрое создание ключа
# Создать ключ для Alice, который никогда не истекает, используя алгоритмы по умолчанию
gpg --quick-generate-key "Alice Lovelace <alice@example.com>" default default never
# Создать ключ для Bob с истечением через 1 год
gpg --quick-gen-key "Bob Babbage <bob@example.com>" default default 1y
# Создать ключ, защищённый паролем "secret", в пакетном режиме
echo "secret" | gpg --batch --pinentry-mode loopback --passphrase-fd 0 --quick-gen-key "Test User" default default
2. Управление сроком действия и субключами
# Установить срок действия основного ключа (с отпечатком XYZ123...) на 2025-12-31
gpg --quick-set-expire XYZ1234567890ABCDEFGH 2025-12-31
# Добавить субключ шифрования (алгоритм по умолчанию) к существующему ключу
gpg --quick-add-key XYZ1234567890ABCDEFGH default encr
# Добавить субключ для аутентификации (Ed25519) с истечением через 6 месяцев
gpg --quick-add-key XYZ1234567890ABCDEFGH ed25519 auth 6m
3. Работа с существующими ключами (подпись, отзыв)
# Подписать ключ с отпечатком ABCD... (все его user IDs)
gpg --quick-sign-key ABCD0987654321ABCD0987654321ABCD0987654321
# Подписать ключ, но только конкретный user ID ('=*@company.org' - точное совпадение)
gpg --quick-sign-key ABCD0987654321ABCD0987654321ABCD0987654321 "=*@company.org"
# Отозвать user ID 'old@email.com' у ключа 'user@example.com'
gpg --quick-revoke-uid "user@example.com" "old@email.com"
4. Импорт и экспорт
# Импортировать ключ из файла
gpg --import public_key.asc
# Экспортировать открытый ключ с отпечатком XYZ... в файл
gpg --export --armor XYZ1234567890ABCDEFGH > alice_public.asc
# Экспортировать секретный ключ для резервной копии (ОСТОРОЖНО!)
gpg --export-secret-keys --armor XYZ1234567890ABCDEFGH > alice_secret_backup.asc
5. Просмотр и проверка
# Показать список открытых ключей с отпечатками
gpg --list-keys --fingerprint
# Показать список секретных ключей
gpg --list-secret-keys
# Проверить подписи на всех ключах в ключевом кольце
gpg --check-signatures
6. Интерактивное управление через --edit-key
# Начать редактирование ключа (заменить 'user@example.com' на свой ID)
gpg --edit-key user@example.com
# В появившемся интерактивном меню (prompt: gpg>) можно использовать:
# gpg> adduid # Добавить новый user ID
# gpg> addkey # Добавить новый субключ
# gpg> passwd # Сменить пароль
# gpg> expire # Изменить срок действия
# gpg> key 1 # Выбрать первый субключ (для операций с ним)
# gpg> trust # Изменить уровень доверия
# gpg> save # Сохранить изменения и выйти
Конечно, вот подробная таблица всех субкоманд --edit-key и дополнительные примеры.
Таблица субкоманд интерактивного меню --edit-key
Команда вводится после приглашения gpg>.
| Субкоманда | Описание |
|---|---|
uid n | Переключить выбор пользователя (user ID) или фотографии с индексом n. * — выбрать всех, 0 — отменить выбор всех. |
key n | Переключить выбор субключа с индексом n или key ID n. * — выбрать все, 0 — отменить выбор всех. |
sign | Создать подпись на ключе. Если ключ ещё не подписан вашим ключом по умолчанию, будет запрошено подтверждение. |
lsign | То же, что sign, но подпись помечается как неэкспортируемая (local). |
nrsign | То же, что sign, но подпись помечается как безотзывная (non-revocable). |
tsign | Создать доверительную подпись (trust signature). Требует указания глубины цепи доверия и значения. |
delsig | Удалить подпись с ключа. Не может отозвать подпись, уже отправленную публично. |
revsig | Отозвать подпись. Для каждой вашей подписи будет предложено создать сертификат отзыва. |
check | Проверить подписи на всех выбранных user IDs. С опцией selfsig показываются только самоподписи. |
adduid | Добавить дополнительный user ID (имя и email). |
addphoto | Добавить фотографию (JPEG) в качестве user ID. |
showphoto | Показать выбранную фотографию user ID. |
deluid | Удалить user ID или фотографию. Не может отозвать user ID, уже отправленный публично. |
revuid | Отозвать user ID или фотографию. |
primary | Пометить текущий user ID как основной. Снимает эту пометку с других user IDs. |
keyserver | Установить предпочтительный keyserver для выбранных user IDs. "none" — удалить. |
notation | Установить нотацию (name=value) для выбранных user IDs. "none" — удалить все. |
pref | Показать фактические предпочтения (шифры, хэши, сжатие) для выбранного user ID. |
showpref | Показать предпочтения с учётом значений по умолчанию (более подробно). |
setpref [string] | Установить список предпочтений. Без аргументов — сбросить на значения по умолчанию. "none" — очистить. |
addkey | Добавить новый субключ к основному ключу. |
addcardkey | Сгенерировать субключ на смарт-карте и добавить его к этому ключу. |
keytocard | Перенести выбранный секретный субключ на смарт-карту. Ключ в keyring будет заменён на заглушку. |
bkuptocard file | Восстановить ключ из файла-бэкапа на новую смарт-карту. |
keytotpm | Перенести выбранный секретный ключ в форму, защищённую TPM (Trusted Platform Module). |
delkey | Удалить публичную часть субключа. Не может отозвать субключ, уже отправленный публично. |
revkey | Отозвать субключ. |
expire | Изменить срок действия основного ключа или выбранного субключа. |
trust | Изменить уровень доверия (ownertrust) для ключа. Изменения в trustdb применяются сразу. |
disable | Отключить весь ключ. Отключённый ключ нельзя использовать. |
enable | Включить ключ. |
addrevoker | Добавить назначенного отзывающего (designated revoker) для ключа. Опция "sensitive" — не экспортировать по умолчанию. |
addadsk | Добавить Дополнительный Субключ для Расшифровки (Additional Decryption Subkey) с другого ключа. |
passwd | Изменить парольную фразу для секретного ключа. |
toggle | Пустая команда для обратной совместимости. |
clean | Очистить ключ: удалить невалидные, устаревшие, отозванные подписи и подписи от отсутствующих ключей. |
minimize | Сжать ключ до минимального размера, оставив для каждого user ID только последнюю самоподпись. |
change-usage | Изменить флаги использования (возможности) основного ключа или субключей (например, добавить Authenticate). |
cross-certify | Добавить перекрёстные сертифицирующие подписи на подписывающие субключи для защиты от атак. |
save | Сохранить все изменения в ключевое кольцо и выйти. |
quit | Выйти без сохранения изменений. |
Примеры использования --edit-key
1. Базовое управление ключом
# Начать редактирование ключа для alice@example.com
gpg --edit-key alice@example.com
# В интерактивном меню:
gpg> adduid # Добавить новый user ID (запрос имени и email)
Real name: Alice Lovelace
Email address: alice@work.com
Comment: Work account
(Подтвердить)
gpg> uid 2 # Выбрать второй user ID (только что добавленный)
gpg> primary # Сделать его основным
gpg> passwd # Изменить парольную фразу
gpg> save # Сохранить изменения и выйти
2. Управление субключами
gpg --edit-key bob@example.com
gpg> addkey # Добавить новый субключ
Please select what kind of key you want:
(3) DSA (sign only)
(4) RSA (sign only)
(5) Elgamal (encrypt only)
(6) RSA (encrypt only)
(7) DSA (set your own capabilities)
(8) RSA (set your own capabilities)
(10) ECC (sign only)
(11) ECC (set your own capabilities)
(12) ECC (encrypt only)
(13) Existing key
Your selection? 6 # Выбираем RSA (только шифрование)
What keysize do you want? 4096 # Указываем размер ключа
Key is valid for? 1y # Указываем срок действия (1 год)
(Подтвердить создание)
gpg> key 1 # Выбрать первый субключ (для операций с ним)
gpg> expire # Изменить его срок действия
Key is valid for? (0) 0
Key does not expire at all
Is this correct? (y/N) y # Сделать бессрочным
gpg> revkey # ОТОЗВАТЬ этот субключ (если он скомпрометирован)
gpg> save
3. Подписание чужих ключей и управление доверием
# Предполагается, что ключ друга уже импортирован
gpg --edit-key friend@example.com
gpg> sign # Подписать ключ друга
... Вывод информации о ключе и его отпечатка ...
Really sign? (y/N) y # Подтверждаем подписание
gpg> tsign # Создать доверительную подпись
Enter the depth of this trust signature (1-255): 1
Enter the trust value (60=marginal, 120=full, 0-255): 120
Enter a domain name (optional): our-community.org
Really sign? (y/N) y
gpg> trust # Изменить уровень доверия к владельцу ключа
Your decision? 5 # Указываем: "I trust ultimately"
gpg> save
4. Работа со смарт-картой (YubiKey и аналоги)
gpg --edit-key mykey@example.com
gpg> keytocard # Перенести выбранный секретный ключ на карту
Please select where to store the key:
(1) Signature key
(2) Encryption key
(3) Authentication key
Your selection? 1 # Переносим подписывающий ключ в слот для подписи
(Введите пароль админа карты)
gpg> key 1 # Выбрать следующий ключ
gpg> keytocard
Your selection? 2 # Переносим шифрующий ключ в слот для шифрования
gpg> save # Секретные ключи теперь на карте, в keyring - заглушки
5. Отзыв компонентов ключа
# Ключ скомпрометирован, нужно отозвать старый email и создать сертификат отзыва
gpg --edit-key compromised@example.com
gpg> uid 1 # Выбрать user ID со старым email
gpg> revuid # ОТОЗВАТЬ этот user ID
Create a revocation certificate for this user ID? (y/N) y
Enter the reason for the revocation: 1 # 1 = Key has been compromised
Enter an optional description; ...:
(Подтвердить)
gpg> genrevoke # Создать сертификат отзыва для всего ключа
Create a revocation certificate? (y/N) y
Enter the reason for the revocation: 1
... (Описание) ...
Вывод ASCII-armored сертификата отзыва
Сохранить его в надёжное место!
gpg> quit # Пока не сохраняем изменения, только создали сертификат
# Позже, чтобы применить отзыв, импортируем сертификат
gpg --import revocation_certificate.asc
13.2.4.2 - Опции PGP
Список опций PGP
В GnuPG (gpg) имеется множество опций для точного контроля поведения и изменения конфигурации по умолчанию.
• Опции конфигурации GPG: Как изменить конфигурацию. • Опции GPG, связанные с ключами: Опции, связанные с ключами. • Ввод и вывод GPG: Опции ввода и вывода. • Опции OpenPGP: Специфичные для протокола OpenPGP опции. • Опции соответствия (Compliance): Опции соответствия. • Эзотерические опции GPG: Выполнение действий, которые обычно не требуются. • Устаревшие опции: Опции, признанные устаревшими.
Длинные опции (long options) можно поместить в файл настроек (по умолчанию ~/.gnupg/gpg.conf). Короткие имена опций (short option names) работать не будут — например, armor является допустимой опцией для файла настроек, а a — нет. Не нужно писать 2 дефиса, достаточно указать имя опции и любые необходимые аргументы. Строки, у которых первый непробельный символ является решёткой (#), игнорируются. Команды также можно помещать в этот файл, но обычно это бесполезно, так как команда будет выполняться автоматически при каждом запуске gpg.
Пожалуйста, помните, что разбор опций останавливается, как только встречается не-опция. Вы можете явно остановить разбор с помощью специальной опции --.
Таблица опций конфигурации GPG
| Опция (короткая) | Описание |
|---|---|
--default-key name | Использовать name как ключ по умолчанию для подписи. Рекомендуется использовать отпечаток или длинный ключевой ID. Переопределяется опцией -u. |
--default-recipient name | Использовать name как получателя по умолчанию, если не используется --recipient. Не запрашивать подтверждение. |
--default-recipient-self | Использовать ключ по умолчанию в качестве получателя по умолчанию. |
--no-default-recipient | Сбросить --default-recipient и --default-recipient-self. Не для файла опций. |
-v, --verbose | Выдавать больше информации при обработке. Если использовать дважды, входные данные выводятся подробно. |
--no-verbose | Сбросить уровень детализации до 0. Не для файла опций. |
-q, --quiet | Работать как можно тише. Не для файла опций. |
--batch | Использовать пакетный режим. Никогда не спрашивать, не разрешать интерактивные команды. |
--no-batch | Отключить пакетный режим. |
--no-tty | Убедиться, что TTY (терминал) никогда не используется для вывода. |
--yes | Предполагать ответ “да” на большинство вопросов. Не для файла опций. |
--no | Предполагать ответ “нет” на большинство вопросов. Не для файла опций. |
--proc-all-sigs | Отменить поведение --batch для остановки проверки подписи при первой плохой подписи. |
--list-filter {select=expr} | Фильтр списка для вывода только определенных ключей при выводе списка ключей. |
--list-options parameters | Строка параметров для настройки вывода списков ключей и подписей. См. подопции ниже. |
show-photos | Показывать фото ID ключей. По умолчанию no. |
show-usage | Показывать информацию об использовании ключей (E=шифрование, S=подпись, C=сертификация, A=аутентификация). По умолчанию yes. |
show-ownertrust | Показывать значение доверия (ownertrust) для ключей. По умолчанию no. |
show-trustsig | Показывать информацию о доверительных подписях. По умолчанию no. |
show-policy-urls | Показывать URL политик в списках --check-signatures. По умолчанию no. |
show-notations | Показывать все notations подписей. По умолчанию no. |
show-std-notations | Показывать только стандартные (IETF) notations подписей. По умолчанию no. |
show-user-notations | Показывать пользовательские notations подписей. По умолчанию no. |
show-x509-notations | Выводить сертификаты X.509, встроенные в подписи ключей, в формате PEM (для отладки). |
store-x509-notations | Сохранять сертификаты X.509, встроенные в подписи ключей, как файлы PEM. |
show-keyserver-urls | Показывать предпочтительные URL keyserver’ов. По умолчанию no. |
show-uid-validity | Показывать расчетную валидность user ID. По умолчанию yes. |
show-unusable-uids | Показывать отозванные и просроченные user ID. По умолчанию no. |
show-unusable-subkeys | Показывать отозванные и просроченные субключи. По умолчанию no. |
show-unusable-sigs | Показывать подписи ключей, сделанные с использованием слабых или неподдерживаемых алгоритмов. |
show-keyring | Показывать имя ключевого кольца в заголовке списков ключей. По умолчанию no. |
show-sig-expire | Показывать даты истечения срока действия подписей. По умолчанию no. |
show-sig-subpackets | Включать подпакеты подписи в список ключей (только с --with-colons). По умолчанию no. |
show-only-fpr-mbox | Для каждого user ID с действительным email выводить только отпечаток и адрес. |
sort-sigs | Сортировать подписи по keyID и времени создания для --list-sigs и --check-sigs. По умолчанию yes. |
--verify-options parameters | Строка параметров для настройки проверки подписей. См. подопции ниже. |
show-photos | Показывать фото ID на ключе, выпустившем подпись. По умолчанию no. |
show-policy-urls | Показывать URL политик в проверяемой подписи. По умолчанию yes. |
show-notations | Показывать все notations в проверяемой подписи. |
show-std-notations | Показывать только стандартные (IETF) notations в проверяемой подписи. По умолчанию yes. |
show-user-notations | Показывать пользовательские notations в проверяемой подписи. |
show-keyserver-urls | Показывать предпочтительные URL keyserver’ов в проверяемой подписи. По умолчанию yes. |
show-uid-validity | Показывать расчетную валидность user ID на ключе, выпустившем подпись. По умолчанию yes. |
show-unusable-uids | Показывать отозванные и просроченные user ID при проверке подписи. По умолчанию no. |
show-primary-uid-only | Показывать только основной user ID при проверке подписи. |
--enable-large-rsa | Разрешить создание RSA-ключей размером до 8192 бит (с --generate-key --batch). |
--disable-large-rsa | Запретить создание больших RSA-ключей. |
--enable-dsa2 | Включить усечение хэша для всех DSA-ключей. |
--disable-dsa2 | Отключить усечение хэша для DSA-ключей. |
--photo-viewer string | Командная строка для просмотра фото ID. Замещает %i, %I, %k, %K, %f, %t, %T, %v, %V, %U, %%. |
--exec-path string | Задать список каталогов для поиска программ просмотра фото. |
--keyring file | Добавить файл file в текущий список ключевых колец. |
--primary-keyring file | Обозначить file как основное ключевое кольцо (сюда импортируются новые ключи). |
--secret-keyring file | Устаревшая опция, игнорируется. |
--trustdb-name file | Использовать file вместо trustdb по умолчанию. |
--homedir dir | Установить домашний каталог в dir. |
--display-charset name | Установить кодировку для преобразования строк (например, iso-8859-1, koi8-r, utf-8). |
--utf8-strings | Считать аргументы командной строки строками в UTF-8. |
--no-utf8-strings | Считать аргументы в кодировке, указанной --display-charset. |
--options file | Читать опции из файла file, а не из файла по умолчанию. |
--no-options | Явно не читать никакой файл опций. Сокращение для --options /dev/null. |
-z n | Установить уровень сжатия n для алгоритмов ZIP/ZLIB. 0 - отключить сжатие. -1 - принудительное сжатие уровнем по умолчанию. |
--compress-level n | Установить уровень сжатия для ZIP/ZLIB. |
--bzip2-compress-level n | Установить уровень сжатия для BZIP2. |
--no-compress | Отключить сжатие. Identical to -z0. |
--bzip2-decompress-lowmem | Использовать метод распаковки BZIP2 с низким потреблением памяти (медленнее). |
--mangle-dos-filenames | Заменять расширение выходного файла для совместимости со старыми версиями Windows. |
--no-mangle-dos-filenames | Не изменять имена файлов (по умолчанию). |
--ask-cert-level | Запрашивать уровень сертификации при подписании ключа. |
--no-ask-cert-level | Не запрашивать уровень сертификации. |
--default-cert-level n | Уровень сертификации по умолчанию при подписании ключа (0-3). По умолчанию 0. |
--min-cert-level | Минимальный уровень сертификации для принятия подписи при построении базы доверия. По умолчанию 2. |
--trusted-key long key ID or fingerprint | Считать указанный ключ таким же доверенным, как свой собственный секретный ключ. |
--add-desig-revoker [sensitive:]fingerprint | Добавить указанный ключ как назначенного отзывающего для вновь создаваемых ключей. |
--default-new-key-adsk fingerprint | Добавить указанный субключ как ADSK (Additional Decryption Subkey) для вновь создаваемых ключей. |
--trust-model {pgp|classic|tofu|tofu+pgp|direct|always|auto} | Установить модель доверия. По умолчанию pgp. |
--always-trust | Идентично --trust-model always. |
--assert-signer fpr_or_file | Убедиться, что хотя бы одна действительная подпись сделана указанным ключом (по отпечатку). |
--assert-pubkey-algo algolist | Убедиться, что при проверке подписи использовался алгоритм из algolist. |
--auto-key-locate mechanisms | Механизмы автоматического поиска ключей (local, wkd, keyserver, ldap, cert, dane, ntds, nodefault, clear). По умолчанию local,wkd. |
--no-auto-key-locate | Отключить автоматический поиск ключей. |
--auto-key-import | Импортировать ключ, встроенный в подпись, при успешной проверке. |
--no-auto-key-import | Не импортировать встроенные ключи (по умолчанию). |
--auto-key-retrieve | Автоматически получать ключи с keyserver’а при проверке подписей неизвестных ключей. |
--no-auto-key-retrieve | Не получать ключи автоматически (по умолчанию). |
--keyid-format {none|short|0xshort|long|0xlong} | Формат отображения key ID. По умолчанию 0xlong. |
--keyserver name | Устарело. Использовать name в качестве keyserver’а. Используйте dirmngr.conf вместо этого. |
--keyserver-options {name=value} | Опции для keyserver’а (include-revoked, include-disabled, honor-keyserver-url, include-subkeys и др.). |
--completes-needed n | Количество полностью доверенных пользователей для представления нового подписанта (по умолчанию 1). |
--marginals-needed n | Количество частично доверенных пользователей для представления нового подписанта (по умолчанию 3). |
--tofu-default-policy {auto|good|unknown|bad|ask} | Политика TOFU по умолчанию (по умолчанию auto). |
--max-cert-depth n | Максимальная глубина цепочки сертификации (по умолчанию 5). |
--no-sig-cache | Не кэшировать статус проверки подписей ключей. |
--auto-check-trustdb | Автоматически запускать --check-trustdb при необходимости. |
--no-auto-check-trustdb | Отключить автоматическую проверку trustdb. |
--use-agent | Фиктивная опция. gpg всегда требует агент. |
--no-use-agent | Фиктивная опция. |
--gpg-agent-info | Фиктивная опция. Не имеет эффекта. |
--agent-program file | Указать программу-агент для операций с секретными ключами. |
--dirmngr-program file | Указать программу dirmngr для доступа к keyserver’ам. |
--disable-dirmngr | Полностью отключить использование Dirmngr. |
--no-autostart | Не запускать gpg-agent или dirmngr автоматически, если они еще не запущены. |
--lock-once | Заблокировать базы данных один раз и не снимать блокировку до завершения процесса. |
--lock-multiple | Снимать блокировки, когда они больше не нужны. |
--lock-never | Полностью отключить блокировку. |
--exit-on-status-write-error | Немедленно завершать процесс при ошибках записи в status FD. |
--limit-card-insert-tries n | Ограничить количество запросов на вставку смарт-карты числом n-1. |
--no-random-seed-file | Не использовать файл для хранения пула случайных чисел между вызовами. |
--no-greeting | Не показывать начальное сообщение об авторских правах. |
--no-secmem-warning | Не показывать предупреждение о “использовании незащищенной памяти”. |
--no-permission-warning | Не показывать предупреждение о небезопасных разрешениях файлов и каталогов. |
--require-secmem | Отказаться работать, если невозможно получить защищенную память. |
--no-require-secmem | Работать, даже если нет защищенной памяти (по умолчанию, с предупреждением). |
--require-cross-certification | Требовать наличия действительной перекрестной сертификации для субключей при проверке подписи. |
--no-require-cross-certification | Не требовать перекрестной сертификации. |
--expert | Разрешить пользователю выполнять определенные нестандартные или потенциально несовместимые действия. |
--no-expert | Запретить экспертный режим (по умолчанию). |
Таблица ключевых опций GPG (4.2.2 Key related options)
| Опция (короткая) | Описание |
|---|---|
--recipient name-r | Зашифровать для пользователя с ID name. Если эта опция или --hidden-recipient не указана, GnuPG запросит user-id (если не задан --default-recipient). |
--hidden-recipient name-R | Зашифровать для пользователя с ID name, но скрыть key ID его ключа. Помогает скрыть получателя сообщения и является ограниченной мерой против анализа трафика. |
--recipient-file file-f | Аналогично --recipient, но шифрует для ключа, хранящегося в указанном файле file. Файл должен содержать ровно один ключ. GnuPG считает ключ в файле полностью valid. |
--hidden-recipient-file file-F | Аналогично --hidden-recipient, но шифрует для ключа, хранящегося в указанном файле file. |
--encrypt-to name | То же, что --recipient, но предназначена для использования в файле опций. Может использоваться с вашим собственным user-id как “encrypt-to-self” (зашифровать для себя). Рекомендуется использовать отпечаток или длинный keyID. Эти ключи используются только при наличии других получателей. Проверка доверия для этих user id не выполняется, можно использовать даже отключенные ключи. |
--hidden-encrypt-to name | То же, что --hidden-recipient, но предназначена для использования в файле опций. Может использоваться как скрытый “encrypt-to-self”. |
--no-encrypt-to | Отключить использование всех ключей, заданных через --encrypt-to и --hidden-encrypt-to. |
--group {name=value} | Создает именованную группу, подобную псевдонимам в почтовых программах. Когда имя группы указывается как получатель, оно раскрывается в указанные значения. Значениями могут быть key IDs или отпечатки. Пространства в значениях обрабатываются как разделители. |
--ungroup name | Удалить заданную запись из списка групп. |
--no-groups | Удалить все записи из списка групп. |
--local-user name-u | Использовать name как ключ для подписи. Переопределяет --default-key. |
--sender mbox | При создании подписи: указывает user ID ключа для подписи и встраивает его в создаваемую подпись (используя subpacket “Signer’s User ID” OpenPGP). При проверке подписи: mbox используется для ограничения информации, выводимой кодом TOFU, соответствующими user IDs. GnuPG учитывает только почтовую часть User ID. |
--try-secret-key name | Для скрытых получателей GPG нужно знать ключи для пробной расшифровки. Эта опция позволяет задать дополнительные ключи для использования. Рекомендуется использовать long keyid во избежание неоднозначностей. |
--try-all-secrets | Не смотреть на key ID, хранящийся в сообщении, а пробовать все секретные ключи по очереди, чтобы найти правильный ключ для расшифровки. Принудительно включает поведение, используемое для анонимных получателей. |
--skip-hidden-recipients | При расшифровке пропускать всех анонимных получателей. Помогает избежать перебора всех секретных ключей, когда функция скрытых получателей используется для сокрытия ключа encrypt-to. |
--no-skip-hidden-recipients | Не пропускать анонимных получателей при расшифровке (поведение по умолчанию). |
13.2.4.3 - Ввод и вывод
Описание настроек для ввода и вывода
Ввод и Вывод
--armor
-a
Создавать вывод в формате ASCII-armor (защищенный ASCII). По умолчанию создается бинарный формат OpenPGP.
--no-armor
Предполагать, что входные данные не в формате ASCII-armor.
--output file
-o file
Записывать вывод в файл file. Для записи в стандартный поток вывода (stdout) используйте - в качестве имени файла.
--max-output n
Эта опция устанавливает лимит на количество байт, которые будут сгенерированы при обработке файла. Поскольку OpenPGP поддерживает различные уровни сжатия, возможно, что открытый текст данного сообщения может быть значительно больше исходного сообщения OpenPGP. Хотя GnuPG корректно работает с такими сообщениями, часто возникает желание установить максимальный размер файла, который будет сгенерирован, прежде чем обработка будет принудительно остановлена из-за ограничений ОС. По умолчанию 0, что означает «без ограничений».
--chunk-size n
Режим шифрования AEAD шифрует данные блоками (chunks), чтобы принимающая сторона могла проверять ошибки передачи или подделку в конце каждого блока, а не откладывать это до получения всех данных. Используемый размер блока составляет 2^n байт. Наименьшее разрешенное значение для n — 6 (64 байта), а наибольшее — значение по умолчанию 22, что создает блоки размером не более 4 МиБ.
--input-size-hint n
Эта опция может быть использована, чтобы сообщить GPG размер входных данных в байтах. n должно быть положительным числом в десятичной системе счисления. Эта опция полезна только если ввод осуществляется не из файла. GPG может использовать эту подсказку для оптимизации стратегии выделения буферов. Она также используется в строке --status-fd «PROGRESS» для предоставления значения «total», если оно недоступно другими способами.
--key-origin string[,url]
gpg может отслеживать происхождение ключа. Некоторые источники известны неявно (например, keyserver, web key directory) и устанавливаются автоматически. Для стандартного импорта происхождение импортируемых ключей можно задать с помощью этой опции. Чтобы узнать возможные значения, используйте "help" в качестве string. Некоторые источники могут хранить необязательный аргумент url; такой URL можно добавить к string через запятую.
--import-options parameters
Это строка, разделенная пробелами или запятыми, которая задает параметры для импорта ключей. К параметрам можно добавлять префикс ‘no-’, чтобы придать противоположное значение. Параметры:
import-local-sigs
Разрешить импорт подписей ключей, помеченных как “local” (локальные). Обычно это не полезно, если не используется схема с общим ключевым кольцом. По умолчанию no.
keep-ownertrust
Обычно возможные, но все еще существующие значения доверия (ownertrust) ключа очищаются, если ключ импортируется. Это в целом желательно, чтобы ранее удаленный ключ не получал автоматически значения доверия仅仅 из-за импорта. С другой стороны, иногда необходимо повторно импортировать набор доверенных ключей, сохраняя уже назначенные значения доверия. Этого можно достичь, используя эту опцию.
repair-pks-subkey-bug
При импорте пытаться исправить повреждения, вызванные ошибкой keyserver PKS (версии до 0.9.6), которая искажает ключи с несколькими подключами. Обратите внимание, что это не может полностью восстановить поврежденный ключ, так как некоторые crucial данные удаляются keyserver’ом, но это, по крайней мере, возвращает вам один подключ. По умолчанию no для обычного --import и yes для keyserver --receive-keys.
import-show
show-only
Показывать список ключа непосредственно перед его сохранением. Это можно комбинировать с опцией --dry-run, чтобы только просмотреть ключи; опция show-only является ярлыком для этой комбинации. Команда --show-keys — это еще один ярлык для этого. Обратите внимание, что суффиксы, такие как ’#’ для строк “sec” и “sbb”, могут выводиться, а могут и нет.
import-export
Запустить весь код импорта, но вместо сохранения ключа в локальное ключевое кольцо записать его в вывод. Опция экспорта export-dane влияет на вывод. Эта опция может быть использована, например, для удаления всех недействительных частей из ключа без необходимости его сохранять.
merge-only
Во время импорта разрешать обновления существующих ключей, но не разрешать импорт любых новых ключей. По умолчанию no.
import-clean
После импорта compact (удалить все подписи, кроме самоподписи) любые user ID из нового ключа, которые не пригодны для использования. Затем удалить любые подписи из нового ключа, которые не пригодны для использования. Это включает подписи, выпущенные ключами, которых нет в ключевом кольце. Эта опция эквивалентна выполнению команды --edit-key “clean” после импорта. По умолчанию no.
self-sigs-only
Принимать только самоподписи при импорте ключа. Все другие подписи ключей пропускаются на раннем этапе импорта. Эту опцию можно использовать с keyserver-options для смягчения попыток flooding ключа поддельными подписями с keyserver’а. Недостаток заключается в том, что все другие действительные подписи ключей, требуемые Web of Trust, также не импортируются. Обратите внимание, что при использовании этой опции вместе с import-clean она подавляет финальный шаг очистки после объединения импортированного ключа с существующим ключом.
ignore-attributes
Игнорировать все attribute user ID (photo ID) и их подписи при импорте ключа.
repair-keys
После импорта исправлять различные проблемы с ключами. Например, это переупорядочивает подписи и удаляет дубликаты подписей. По умолчанию yes.
bulk-import
При использовании keyboxd (опция use-keyboxd в common.conf) выполняет импорт в рамках одной транзакции.
import-minimal
Импортировать минимально возможный ключ. Это удаляет все подписи, кроме самой последней самоподписи на каждом user ID. Эта опция эквивалентна выполнению команды --edit-key “minimize” после импорта. По умолчанию no.
restore
import-restore
Импортировать в режиме восстановления ключа. Это импортирует все данные, которые обычно пропускаются во время импорта; включая все специфичные для GnuPG данные. Все другие противоречащие опции переопределяются.
--import-filter {name=expr}
--export-filter {name=expr}
Эти опции определяют фильтр импорта/экспорта, который применяется к импортируемому/экспортируемому ключевому блоку непосредственно перед его сохранением/записью. name определяет тип используемого фильтра, expr — выражение для вычисления. Опцию можно использовать несколько раз, что добавляет больше выражений к тому же имени name.
Доступные типы фильтров:
keep-uid
Этот фильтр будет сохранять пакет user id и зависящие от него пакеты в ключевом блоке, если выражение оценивается как истина.
drop-subkey
Этот фильтр удаляет выбранные подключи. В настоящее время реализовано только для --export-filter.
drop-sig
Этот фильтр удаляет выбранные подписи ключей на user ids. Самоподписи не рассматриваются. В настоящее время реализовано только для --import-filter.
select
Этот фильтр реализован только для --list-filter. Можно использовать все имена свойств.
Синтаксис выражения см. в главе «ВЫРАЖЕНИЯ ФИЛЬТРА». Имена свойств для выражений зависят от фактического типа фильтра и указаны в следующей таблице. Обратите внимание, что все имена свойств также могут использоваться --list-filter.
Имена свойств могут иметь префикс с областью видимости, разделенной косой чертой. Допустимые области видимости: "pub" для открытых и секретных первичных ключей, "sub" для открытых и секретных подключей, "uid" для пакетов user-ID и "sig" для пакетов подписей. Неверные области видимости в настоящее время игнорируются.
Доступные свойства:
uid
Строка с user id. (keep-uid)
mbox
Часть addr-spec user id с почтовым ящиком или пустая строка. (keep-uid)
algostr
Строка с описанием алгоритма ключа. Например, “rsa3072” или “ed25519”.
key_algo
Число с алгоритмом открытого ключа пакета ключа или подключа. (drop-subkey)
key_size
Число с эффективным размером ключа пакета ключа или подключа. (drop-subkey)
key_created
key_created_d
Первое — это метка времени создания пакета открытого ключа или подключа. Второе — то же самое, но представленное в виде строки ISO, например, “2016-08-17”. (drop-subkey)
key_expires
key_expires_d
Время истечения срока действия открытого ключа или подключа или 0, если срок действия не истекает. Второе — то же самое, но представленное в виде строки с датой ISO или пустой строки, например, “2038-01-19”.
fpr
Шестнадцатеричный отпечаток (fingerprint) текущего подключа или первичного ключа. (drop-subkey)
primary
Логическое значение, указывающее, является ли user id первичным. (keep-uid)
expired
Логическое значение, указывающее, истек ли срок действия user id (keep-uid), ключа (drop-subkey) или подписи (drop-sig).
revoked
Логическое значение, указывающее, был ли отозван user id (keep-uid) или ключ (drop-subkey).
disabled
Логическое значение, указывающее, отключен ли первичный ключ.
secret
Логическое значение, указывающее, является ли ключ или подключ секретным. (drop-subkey)
usage
Строка, указывающая флаги использования для подключа, из последовательности «ecsa?». Например, подключ, способный только подписывать и аутентифицировать, будет точным совпадением для “sa”. (drop-subkey)
sig_created
sig_created_d
Первое — это метка времени создания пакета подписи. Второе — то же самое, но представленное в виде строки с датой ISO, например, “2016-08-17”. (drop-sig)
sig_expires
sig_expires_d
Время истечения срока действия пакета подписи или 0, если срок действия не истекает. Второе — то же самое, но представленное в виде строки с датой ISO или пустой строки, например, “2038-01-19”.
sig_algo
Число с алгоритмом открытого ключа пакета подписи. (drop-sig)
sig_digest_algo
Число с алгоритмом хеширования пакета подписи. (drop-sig)
origin
Строка с происхождением ключа или вопросительный знак. Например, строка “wkd” используется, если ключ получен из Web Key Directory.
lastupd
Метка времени последнего обновления ключа с keyserver’а или из Web Key Directory.
url
Строка с URL, связанным с последним поиском ключа.
--export-options parameters
Это строка, разделенная пробелами или запятыми, которая задает параметры для экспорта ключей. К параметрам можно добавлять префикс ‘no-’, чтобы придать противоположное значение. Параметры:
export-local-sigs
Разрешить экспорт подписей ключей, помеченных как “local” (локальные). Обычно это не полезно, если не используется схема с общим ключевым кольцом. По умолчанию no.
export-attributes
Включать attribute user IDs (photo IDs) при экспорте. Не включение attribute user IDs полезно для экспорта ключей, которые будут использоваться программой OpenPGP, не принимающей attribute user IDs. По умолчанию yes.
export-sensitive-revkeys
Включать информацию о назначенном отзывающем (designated revoker), которая была помечена как “sensitive” (чувствительная). По умолчанию no.
backup
export-backup
Экспортировать для использования в качестве резервной копии. Экспортируемые данные включают все данные, необходимые для последующего восстановления ключа или ключей с помощью GnuPG. Формат基本上是 OpenPGP формат, но расширенный специфичными для GnuPG данными. Все другие противоречащие опции переопределяются.
export-clean
Compact (удалить все подписи) user IDs экспортируемого ключа, если user IDs не пригодны для использования. Также не экспортировать любые подписи, которые не пригодны для использования. Это включает подписи, выпущенные ключами, которых нет в ключевом кольце. Эта опция эквивалентна выполнению команды --edit-key “clean” перед экспортом, за исключением того, что локальная копия ключа не изменяется. По умолчанию no.
export-minimal
Экспортировать минимально возможный ключ. Это удаляет все подписи, кроме самой последней самоподписи на каждом user ID. Эта опция эквивалентна выполнению команды --edit-key “minimize” перед экспортом, за исключением того, что локальная копия ключа не изменяется. По умолчанию no.
export-revocs
Экспортировать только отдельные (standalone) сертификаты отзыва ключа. Эта опция не экспортирует отзывы сторонних сертификатов отзыва.
export-dane
Вместо вывода material ключа выводить записи OpenPGP DANE, пригодные для размещения в файлах зон DNS. Перед каждой записью выводится строка ORIGIN, чтобы позволить направлять записи в соответствующую зону.
mode1003
Включить использование нового формата экспорта секретного ключа. Этот формат избегает повторного шифрования, требуемого текущим форматом OpenPGP, а также улучшает безопасность секретного ключа, если он был защищен парольной фразой. Обратите внимание, что незащищенный ключ экспортируется как есть и, следовательно, небезопасен; общее правило передачи секретных ключей в зашифрованном OpenPGP файле все равно применяется в этом режиме. Версии GnuPG до 2.4.0 не могут импортировать такой секретный файл.
--with-colons
Выводить списки ключей, разделенные двоеточиями. Обратите внимание, что вывод будет закодирован в UTF-8 независимо от каких-либо настроек --display-charset. Этот формат полезен, когда GnuPG вызывается из скриптов и других программ, так как он легко анализируется машиной. Подробности этого формата документированы в файле doc/DETAILS, который включен в дистрибутив исходного кода GnuPG.
--fixed-list-mode
Не объединять primary user ID и primary key в режиме листинга --with-colon и выводить все метки времени в виде секунд с 1970-01-01. Начиная с GnuPG 2.0.10, этот режим всегда используется, и поэтому эта опция устарела; однако использовать ее не вредно.
--legacy-list-mode
Вернуться к режиму списка открытых ключей до версии 2.1. Это влияет только на удобочитаемый вывод, а не на машинный интерфейс (т.е. --with-colons). Обратите внимание, что устаревший формат не передает подходящую информацию для эллиптических кривых.
--with-fingerprint
То же, что и команда --fingerprint, но изменяет только формат вывода и может использоваться вместе с другой командой.
--with-subkey-fingerprint
--without-subkey-fingerprint
Если для первичного ключа выводится отпечаток, эта опция принудительно выводит отпечаток для всех подключей. Этого также можно было бы достичь, используя --with-fingerprint дважды, но используя эту опцию вместе с форматом keyid по умолчанию “none”, выводится compact отпечаток. Начиная с версии 2.6.0 эта опция активна по умолчанию; используйте вариант «without», чтобы отключить ее.
--with-v5-fingerprint
В режиме листинга с двоеточиями выводить строки “fp2” для ключей OpenPGP версии 4, имеющих отпечаток ключа в стиле v5.
--with-icao-spelling
Печатать spelling отпечатка по стандарту ICAO в дополнение к шестнадцатеричным цифрам.
--with-keygrip
Включать keygrip в списки ключей. В режиме --with-colons это неявно включено для секретных ключей.
--with-key-origin
Включать локально хранящуюся информацию о происхождении и последнем обновлении ключа в список ключей. В режиме --with-colons это выводится всегда. Эти данные в настоящее время являются экспериментальными и не должны рассматриваться как часть стабильного API.
--with-wkd-hash
Выводить идентификатор Web Key Directory вместе с каждым user ID в списках ключей. Это экспериментальная функция, и семантика может измениться.
--with-secret
Включать информацию о наличии секретного ключа в списках открытых ключей, выполненных с помощью --with-colons.
Таблица опций GnuPG
| Опция (короткая) | Опция (полная) | Описание |
|---|---|---|
-a | --armor | Создавать вывод в формате ASCII-armor (защищенный ASCII). |
--no-armor | Предполагать, что входные данные не в формате ASCII-armor. | |
-o | --output file | Записывать вывод в указанный файл. Используйте - для stdout. |
--max-output n | Установить лимит (в байтах) на размер генерируемых данных. 0 = без лимита. | |
--chunk-size n | Установить размер блока (chunk) для AEAD шифрования (2^n байт, n=6..22). | |
--input-size-hint n | Сообщить GPG предполагаемый размер входных данных (в байтах) для оптимизации. | |
--key-origin string[,url] | Установить происхождение импортируемых ключей. | |
--import-options parameters | Задать параметры импорта (см. список значений ниже). | |
--import-filter {name=expr} | Применить фильтр к импортируемому ключевому блоку. | |
--export-filter {name=expr} | Применить фильтр к экспортируемому ключевому блоку. | |
--export-options parameters | Задать параметры экспорта (см. список значений ниже). | |
--with-colons | Выводить списки ключей в машиночитаемом формате (разделены двоеточиями). | |
--fixed-list-mode | (Устарело) Не объединять primary user ID и key, выводить время в секундах. | |
--legacy-list-mode | Использовать устаревший (до 2.1) формат человекочитаемого вывода. | |
--with-fingerprint | Выводить отпечатки пальцев ключей (изменяет только формат вывода). | |
--with-subkey-fingerprint | Принудительно выводить отпечатки для всех подключей (по умолчанию вкл. с 2.6.0). | |
--without-subkey-fingerprint | Отключить вывод отпечатков для подключей. | |
--with-v5-fingerprint | В colon-режиме выводить строки “fp2” для v4 ключей с v5-отпечатком. | |
--with-icao-spelling | Выводить spelling отпечатка по стандарту ICAO. | |
--with-keygrip | Включать keygrip в списки ключей. | |
--with-key-origin | Включать информацию о происхождении и времени обновления ключа. | |
--with-wkd-hash | Выводить Web Key Directory хеш для каждого user ID. | |
--with-secret | Включать информацию о наличии секретного ключа в списках открытых ключей (для --with-colons). |
Параметры для --import-options:
| Параметр | Описание |
|---|---|
import-local-sigs | Разрешить импорт подписей, помеченных как “local”. |
keep-ownertrust | Сохранять существующие значения доверия (ownertrust) при импорте. |
repair-pks-subkey-bug | Пытаться исправить ключи, поврежденные из-за ошибки keyserver PKS. |
import-show, show-only | Показывать ключ перед сохранением. show-only + --dry-run = только просмотр. |
import-export | Запустить импорт, но записать результат в вывод, а не в keyring. |
merge-only | Разрешить только обновление существующих ключей, запретить импорт новых. |
import-clean | Очистить ключ от невалидных user ID и подписей после импорта. |
self-sigs-only | Импортировать только самоподписи, игнорируя все другие подписи ключей. |
ignore-attributes | Игнорировать attribute user IDs (photo IDs) и их подписи. |
repair-keys | Исправлять проблемы с ключами (упорядочить подписи, убрать дубли) после импорта. |
bulk-import | Выполнять импорт в keyboxd в рамках одной транзакции. |
import-minimal | Импортировать минимальный ключ (только последние самоподписи на каждом user ID). |
restore, import-restore | Импорт в режиме восстановления (включает все данные, обычно пропускаемые). |
Параметры для --export-options:
| Параметр | Описание |
|---|---|
export-local-sigs | Разрешить экспорт подписей, помеченных как “local”. |
export-attributes | Включать attribute user IDs (photo IDs) в экспорт. |
export-sensitive-revkeys | Включать информацию о “sensitive” назначенных отзывающих (designated revokers). |
backup, export-backup | Экспорт в формате резервной копии (включает все данные для восстановления). |
export-clean | Очистить ключ от невалидных user ID и подписей перед экспортом (не изменяет локальный ключ). |
export-minimal | Экспортировать минимальный ключ (только последние самоподписи на каждом user ID). |
export-revocs | Экспортировать только standalone сертификаты отзыва. |
export-dane | Выводить записи OpenPGP DANE для DNS вместо material ключа. |
mode1003 | Использовать новый, более безопасный формат экспорта секретных ключей (GnuPG >= 2.4.0). |
Типы фильтров для --import-filter / --export-filter:
| Тип фильтра | Описание |
|---|---|
keep-uid | Сохранять user ID пакет, если выражение истинно. |
drop-subkey | Удалять выбранные подключи (только для --export-filter). |
drop-sig | Удалять выбранные подписи ключей (не самоподписи) (только для --import-filter). |
select | Фильтр для выбора (только для --list-filter). |
13.2.4.4 - OpenGPG опции
Опции для настройки работы Open GPG
Специфичные опции для протокола OpenPGP
--force-ocb
--force-aead
Принудительно использовать AEAD шифрование вместо MDC шифрования. AEAD — это современный и более быстрый способ аутентифицированного шифрования, чем старый метод MDC. --force-aead является псевдонимом и устарел. См. также опцию --chunk-size.
--force-mdc
--disable-mdc
Эти опции устарели и не имеют эффекта начиная с GnuPG 2.2.8. MDC всегда используется, если только ключи не указывают, что можно использовать алгоритм AEAD, и в этом случае используется AEAD. Но обратите внимание: если исключительно требуется создание устаревшего сообщения без MDC, опция --rfc2440 позволяет это сделать.
--disable-signer-uid
По умолчанию идентификатор пользователя (user ID) ключа подписи встраивается в подпись данных. На данный момент это делается только в том случае, если ключ подписи был указан с помощью local-user с использованием почтового адреса или с помощью sender. Эта информация может быть полезна проверяющему для поиска ключа; см. опцию --auto-key-retrieve.
--include-key-block
--no-include-key-block
Эта опция используется для встраивания фактического ключа подписи в подпись данных. Встраиваемый ключ сокращается до одного идентификатора пользователя и включает только подключ подписи, использованный для создания подписи, а также действительные подключи шифрования. Вся остальная информация удаляется из ключа, чтобы сохранить его, и, следовательно, подпись небольшой. Эта опция является аналогом опции gpgsm --include-certs в OpenPGP и позволяет получателю подписанного сообщения отвечать зашифрованно отправителю без использования каких-либо онлайн-каталогов для поиска ключа. По умолчанию установлено --no-include-key-block. См. также опцию --auto-key-import.
--personal-cipher-preferences string
Установить список личных предпочтений шифров на строку string. Используйте gpg --version, чтобы получить список доступных алгоритмов, и используйте none, чтобы вообще не устанавливать предпочтений. Это позволяет пользователю безопасно переопределить алгоритм, выбранный предпочтениями ключа получателя, поскольку GPG будет выбирать только алгоритм, пригодный для использования всеми получателями. Самый высокорейтинговый шифр в этом списке также используется для команды шифрования --symmetric.
--personal-digest-preferences string
Установить список личных предпочтений хеширования на строку string. Используйте gpg --version, чтобы получить список доступных алгоритмов, и используйте none, чтобы вообще не устанавливать предпочтений. Это позволяет пользователю безопасно переопределить алгоритм, выбранный предпочтениями ключа получателя, поскольку GPG будет выбирать только алгоритм, пригодный для использования всеми получателями. Самый высокорейтинговый алгоритм хеширования в этом списке также используется при подписании без шифрования (например, --clear-sign или --sign).
--personal-compress-preferences string
Установить список личных предпочтений сжатия на строку string. Используйте gpg --version, чтобы получить список доступных алгоритмов, и используйте none, чтобы вообще не устанавливать предпочтений. Это позволяет пользователю безопасно переопределить алгоритм, выбранный предпочтениями ключа получателя, поскольку GPG будет выбирать только алгоритм, пригодный для использования всеми получателями. Самый высокорейтинговый алгоритм сжатия в этом списке также используется, когда нет ключей получателей для рассмотрения (например, --symmetric).
--s2k-cipher-algo name
Использовать name в качестве алгоритма шифрования для симметричного шифрования с парольной фразой, если не заданы --personal-cipher-preferences и --cipher-algo. По умолчанию используется AES-128.
--s2k-digest-algo name
Использовать name в качестве алгоритма хеширования, используемого для преобразования (mangling) парольных фраз для симметричного шифрования. По умолчанию используется SHA-1.
--s2k-mode n
Выбирает способ преобразования парольных фраз для симметричного шифрования. Если n равно 0, будет использоваться обычная парольная фраза (что в целом не рекомендуется), 1 добавляет соль (salt) (которую не следует использовать) к парольной фразе, а 3 (по умолчанию) повторяет весь процесс несколько раз (см. --s2k-count).
--s2k-count n
Указать, сколько раз повторяется процесс преобразования парольных фраз для симметричного шифрования. Это значение может находиться в диапазоне от 1024 до 65011712 включительно. Значение по умолчанию запрашивается у gpg-agent. Обратите внимание, что не все значения в диапазоне 1024–65011712 являются допустимыми, и если выбрано недопустимое значение, GnuPG округлит его до ближайшего допустимого значения. Эта опция имеет смысл только если --s2k-mode установлен в значение по умолчанию 3.
Таблица опций GnuPG (OpenPGP protocol specific)
| Опция (полная) | Описание |
|---|---|
--force-ocb, --force-aead | Принудительно использовать современное AEAD шифрование вместо устаревшего MDC. --force-aead — устаревший псевдоним. |
--force-mdc, --disable-mdc | Устарели (не действуют с GnuPG 2.2.8). MDC используется всегда, если только ключи не предписывают использовать AEAD. |
--disable-signer-uid | Не внедрять идентификатор пользователя (User ID) ключа подписи в подпись данных. |
--include-key-block | Встроить фактический ключ подписи (сокращенный) в подпись данных для облегчения ответного шифрования. |
--no-include-key-block | По умолчанию. Не встраивать ключ подписи в подпись данных. |
--personal-cipher-preferences string | Задать личный порядок предпочтения алгоритмов шифрования. none — сбросить предпочтения. |
--personal-digest-preferences string | Задать личный порядок предпочтения алгоритмов хеширования. none — сбросить предпочтения. |
--personal-compress-preferences string | Задать личный порядок предпочтения алгоритмов сжатия. none — сбросить предпочтения. |
--s2k-cipher-algo name | Задать алгоритм шифрования по умолчанию для симметричного шифрования (паролем). По умолчанию: AES-128. |
--s2k-digest-algo name | Задать алгоритм хеширования по умолчанию для преобразования парольных фраз. По умолчанию: SHA-1. |
--s2k-mode n | Выбрать метод преобразования парольной фразы. 0 - плохо, 1 - с солью (плохо), 3 - итерации (хорошо, по умолчанию). |
--s2k-count n | Задать количество итераций для преобразования парольной фразы (если --s2k-mode=3). Диапазон: 1024–65011712. Значение по умолчанию запрашивается у gpg-agent. |
13.2.4.5 - Опции соответствия
Эти опции контролируют, каким стандартам соответствует GnuPG. Одновременно может быть активна только одна из этих опций.
Опции соответствия (Compliance options)
Эти опции контролируют, каким стандартам соответствует GnuPG. Одновременно может быть активна только одна из этих опций. Если указано несколько опций, последняя из них отменяет все предыдущие. Обратите внимание, что настройка по умолчанию почти всегда является правильной. Перед использованием любой из этих опций ознакомьтесь с разделом «ВЗАИМОДЕЙСТВИЕ С ДРУГИМИ ПРОГРАММАМИ OPENPGP» ниже.
--gnupg
Использовать стандартное поведение GnuPG. Это, по сути, поведение OpenPGP (см. --openpgp), но с расширениями из предлагаемого обновления OpenPGP и с некоторыми дополнительными обходными путями для распространенных проблем совместимости в разных версиях PGP. Это опция по умолчанию, поэтому обычно в ней нет необходимости, но она может быть полезна для переопределения другой опции соответствия в файле gpg.conf.
--openpgp
Сбросить все параметры пакетов, шифрования и хеширования до строгого поведения OpenPGP. Эта опция подразумевает --allow-old-cipher-algos. Используйте эту опцию, чтобы сбросить все предыдущие настройки, такие как --s2k-*, --cipher-algo, --digest-algo и --compress-algo, к значениям, соответствующим OpenPGP. Все обходные пути для PGP отключены.
--rfc4880
Сбросить все параметры пакетов, шифрования и хеширования до строгого поведения RFC-4880. Эта опция подразумевает --allow-old-cipher-algos. Обратите внимание, что в настоящее время это то же самое, что и --openpgp.
--rfc4880bis
Сбросить все параметры пакетов, шифрования и хеширования в строгое соответствие предлагаемым обновлениям RFC-4880.
--rfc2440
Сбросить все параметры пакетов, шифрования и хеширования до строгого поведения RFC-2440. Обратите внимание, что при использовании этой опции пакеты шифрования создаются в устаревшем режиме без защиты MDC. Это опасно, и поэтому должно использоваться только для экспериментов. Эта опция подразумевает --allow-old-cipher-algos. См. также опцию --ignore-mdc-error.
--pgp6
Эта опция устарела; она обрабатывается как псевдоним для --pgp7.
--pgp7
Настроить все параметры для максимального соответствия PGP 7. Это разрешало шифры IDEA, 3DES, CAST5, AES128, AES192, AES256 и TWOFISH, хеши MD5, SHA1 и RIPEMD160, а также алгоритмы сжатия “none” и ZIP. Эта опция подразумевает --escape-from-lines и отключает --throw-keyids.
--pgp8
Настроить все параметры для максимального соответствия PGP 8. PGP 8 гораздо ближе к стандарту OpenPGP, чем предыдущие версии PGP, поэтому все, что она делает, это отключает --throw-keyids и устанавливает --escape-from-lines. Разрешены все алгоритмы, кроме хешей SHA224, SHA384 и SHA512.
--compliance string
Эта опция может быть использована вместо одной из опций выше. Допустимые значения для string — это названия опций выше (без двойного дефиса) и, возможно, другие, как показано при использовании "help" для string.
--min-rsa-length n
Эта опция настраивает режим соответствия "de-vs" для более строгих требований к размеру ключа. Например, значение 3000 превращает ключи rsa2048 и dsa2048 в ключи, не соответствующие стандарту VS-NfD.
--require-pqc-encryption
Эта опция принудительно требует использование квантово-устойчивых (quantum-resistant) алгоритмов шифрования. Если не все открытые ключи являются квантово-устойчивыми, шифрование завершится ошибкой. Использование алгоритма симметричного шифрования AES-256 также обеспечивается этой опцией. При расшифровке выводится предупреждение для всех неквантово-устойчивых ключей. На данный момент алгоритмы Kyber (ML-KEM768 и ML-KEM1024) и AES-256 считаются квантово-устойчивыми; Kyber всегда используется в композитной схеме вместе с классическим ECC-алгоритмом.
--disable-pqc-encryption
Эта опция отключает использование квантово-устойчивых подключей и использует подключ с неквантово-устойчивым алгоритмом, если он доступен, или выдает ошибку в противном случае. Опция игнорируется, если активна --require-pqc-encryption.
--require-compliance
Чтобы проверить, что данные были зашифрованы в соответствии с правилами текущего режима соответствия, пользователю gpg необходимо анализировать строки статуса (status lines). Это позволяет интерфейсам (frontends) обрабатывать проверку соответствия более гибким способом. Однако для использования в скриптах необходимый анализ строк статуса требует значительных усилий; вместо этого можно использовать эту опцию, чтобы убедиться, что процесс gpg завершится с ошибкой, если правила соответствия не выполнены. Обратите внимание, что в настоящее время эта опция имеет эффект только в режиме "de-vs".
Таблица опций соответствия GnuPG
| Опция | Описание |
|---|---|
--gnupg | По умолчанию. Поведение GnuPG (OpenPGP + расширения + обходные пути для совместимости с PGP). |
--openpgp | Строгое соответствие OpenPGP. Сбрасывает алгоритмы к стандартным значениям. Разрешает старые алгоритмы шифрования. |
--rfc4880 | Строгое соответствие RFC-4880 (в настоящее время эквивалентно --openpgp). Разрешает старые алгоритмы шифрования. |
--rfc4880bis | Строгое соответствие предлагаемым обновлениям RFC-4880. |
--rfc2440 | Опасно. Строгое соответствие устаревшему RFC-2440. Создает шифрование без защиты MDC. Разрешает старые алгоритмы. |
--pgp7 | Максимальная совместимость с PGP 7. Разрешает старые алгоритмы (IDEA, 3DES, CAST5, MD5 и др.), включает --escape-from-lines, отключает --throw-keyids. |
--pgp8 | Совместимость с PGP 8. Близко к OpenPGP. Отключает --throw-keyids, включает --escape-from-lines. Запрещает только хеши SHA224/384/512. |
--compliance string | Универсальная опция. В качестве string используйте значения выше без -- (например, openpgp, rfc4880). |
--min-rsa-length n | Ужесточает требования к размеру ключа в режиме "de-vs" (например, n=3000 сделает ключи RSA2048 несоответствующими). |
--require-pqc-encryption | Требует использования квантово-устойчивых алгоритмов шифрования (Kyber) и AES-256. Шифрование завершится ошибкой, если не все ключи соответствуют. |
--disable-pqc-encryption | Отключает использование квантово-устойчивых подключей. Предпочитает классические алгоритмы. Игнорируется, если активен --require-pqc-encryption. |
--require-compliance | Заставляет gpg завершаться с ошибкой, если правила текущего режима соответствия (например, de-vs) не выполнены. Упрощает проверку в скриптах. |
13.2.4.6 - Дополнительные опции
Дополнительные опции для настройки и управления pgp
Таблица опций GnuPG (PGP)
| Опция (Оригинал) | Короткая опция | Перевод на русский язык и пояснение |
|---|---|---|
| –dry-run | -n | Пробный запуск. Не вносить никаких изменений (реализовано не полностью). |
| –list-only | Только список. Изменяет поведение некоторых команд. Похоже на --dry-run, но в некоторых случаях работает иначе. | |
| –interactive | -i | Интерактивный режим. Запрашивать подтверждение перед перезаписью любых файлов. |
| –compatibility-flags flags | Флаги совместимости. Установить флаги для обхода проблем, вызванных несоответствующими стандарту ключами или данными. | |
| –debug-level level | Уровень отладки. Выбрать уровень детализации отладочных сообщений для исследования проблем. | |
| –debug flags | Флаги отладки. Установить конкретные флаги отладки. Полезно только для разработчиков. | |
| –debug-all | Отладка всё. Установить все полезные флаги отладки. | |
| –debug-iolbf | Буферизация вывода. Установить буферизацию stdout построчной. | |
| –debug-set-iobuf-size n | Размер буфера I/O. Изменить размер буфера IOBUFs до n килобайт. Только для сопровождающих. | |
| –debug-allow-large-chunks | Большие чанки. Для тестов позволяет указать размер блока до 4 ЭиБ. | |
| –debug-ignore-expiration | Игнорировать истечение срока. Пытается переопределить даты истечения срока действия ключа. Для тестов. | |
| –faked-system-time epoch | Поддельное системное время. Устанавливает системное время назад или вперед. Только для тестирования. | |
| –full-timestrings | Полные строки времени. Изменяет формат вывода времени создания и истечения с даты на дату и время. | |
| –enable-progress-filter | Фильтр прогресса. Включает вывод статуса PROGRESS для индикации прогресса обработки больших файлов. | |
| –status-fd n | Дескриптор статуса. Записывает специальные статусные строки в файловый дескриптор n. | |
| –status-file file | Файл статуса. То же, что и --status-fd, но записывает данные в файл. | |
| –logger-fd n | Дескриптор лога. Записывает вывод лога в файловый дескриптор n, а не в STDERR. | |
| –log-file, –logger-file file | Файл лога. То же, что и --logger-fd, но записывает данные в файл. | |
| –log-time | Время в логе. Добавляет ко всему лог-выводу временную метку, даже если файл лога не используется. | |
| –attribute-fd n | Дескриптор атрибутов. Записывает подпакеты атрибутов в файловый дескриптор n. | |
| –attribute-file file | Файл атрибутов. То же, что и --attribute-fd, но записывает данные в файл. | |
| –comment string | Комментарий. Использовать string как строку комментария в чистых подписях и ASCII-зашифрованных сообщениях. | |
| –no-comments | Без комментариев. Удалить все комментарии. | |
| –emit-version | Выводить версию. Принудительно добавлять строку версии в ASCII-вывод. | |
| –no-emit-version | Не выводить версию. Не добавлять строку версии (по умолчанию). | |
| –sig-notation, –cert-notation, –set-notation {name=value} | -N | Нотация подписи/сертификата. Поместить пару “имя=значение” в подпись в качестве данных нотации. |
| –known-notation name | Известная нотация. Добавить name в список известных критических нотаций подписи. | |
| –sig-policy-url, –cert-policy-url, –set-policy-url string | URL политики. Использовать string как URL политики для подписей. | |
| –sig-keyserver-url string | URL keyserver’а. Использовать string как предпочтительный URL keyserver’а для подписей данных. | |
| –set-filename string | Установить имя файла. Использовать string как имя файла, хранящееся внутри сообщений. | |
| –for-your-eyes-only | Только для ваших глаз. Установить флаг ‘только для ваших глаз’ в сообщении. | |
| –no-for-your-eyes-only | Не только для ваших глаз. Отключить опцию выше. | |
| –use-embedded-filename | Исп. встроенное имя файла. Попытаться создать файл с именем, встроенным в данные. Опасно. | |
| –no-use-embedded-filename | Не исп. встроенное имя. Не использовать встроенное имя файла (по умолчанию). | |
| –cipher-algo name | Алгоритм шифрования. Использовать name как алгоритм шифрования. Нарушает стандарт. | |
| –digest-algo name | Алгоритм хеширования. Использовать name как алгоритм хеш-суммы. Нарушает стандарт. | |
| –compress-algo name | Алгоритм сжатия. Использовать алгоритм сжатия name. Нарушает стандарт. | |
| –cert-digest-algo name | Алгоритм хеша для сертификатов. Использовать name как алгоритм хеш-суммы при подписи ключа. | |
| –disable-cipher-algo name | Запретить алгоритм шифр. Никогда не разрешать использование алгоритма name. | |
| –disable-pubkey-algo name | Запретить алгоритм подписи. Никогда не разрешать использование алгоритма name. | |
| –throw-keyids | Скрыть ID ключей. Не помещать ID ключей получателей в зашифрованные сообщения. | |
| –no-throw-keyids | Не скрывать ID ключей. Отключает опцию выше. | |
| –not-dash-escaped | Без экранирования дефисом. Меняет поведение чистых подписей для использования с файлами патчей. | |
| –escape-from-lines | Экранировать строки “From”. Обрабатывать строки, начинающиеся с “From “, особым образом. | |
| –no-escape-from-lines | Не экранировать “From”. Отключает опцию выше. | |
| –passphrase-repeat n | Повтор пароля. Указать, сколько раз запрашивать повторение новой парольной фразы. | |
| –passphrase-fd n | Дескриптор пароля. Читать парольную фразу из файлового дескриптора n. | |
| –passphrase-file file | Файл пароля. Читать парольную фразу из файла file. | |
| –passphrase string | Парольная фраза. Использовать string как парольную фразу. Опасно. | |
| –pinentry-mode mode | Режим pinentry. Установить режим ввода пароля (ask, cancel, error, loopback). | |
| –no-symkey-cache | Отключить кеш пароля. Отключает кеш парольных фраз, используемый для симметричного шифрования. | |
| –request-origin origin | Источник запроса. Сообщить GnuPG, откуда пришел запрос (local, remote, browser). | |
| –command-fd n | Дескриптор команд. Читать пользовательский ввод для вопросов из файлового дескриптора n. | |
| –command-file file | Файл команд. То же, что и --command-fd, но читает команды из файла. | |
| –allow-non-selfsigned-uid | Разрешить не самоподписанные UID. Разрешить импорт ключей с пользовательскими ID, которые не самоподписаны. Не рекомендуется. | |
| –no-allow-non-selfsigned-uid | Запретить не самоподписанные UID. Запрещает опцию выше. | |
| –allow-freeform-uid | Свободная форма UID. Отключить все проверки формы пользовательского ID при генерации нового. | |
| –ignore-time-conflict | Игнорировать конфликт времени. Превратить проверки временных меток в предупреждения. | |
| –ignore-valid-from | Игнорировать “действует с”. Разрешить использование подобранных ключей, созданных в будущем. | |
| –ignore-crc-error | Игнорировать ошибку CRC. Позволить GnuPG игнорировать ошибки контрольной суммы CRC в ASCII-armor. | |
| –ignore-mdc-error | Игнорировать ошибку MDC. Превратить сбой защиты целостности MDC в предупреждение. Используйте с осторожностью. | |
| –allow-old-cipher-algos | Разрешить старые шифры. Разрешить использование старых алгоритмов с размером блока 64 бита (3DES, IDEA). | |
| –allow-weak-digest-algos | Разрешить слабые хеши. Разрешить проверку подписей, сделанных со слабыми алгоритмами хеширования (напр., MD5). | |
| –weak-digest name | Слабый хеш. Считать указанный алгоритм хеширования слабым. | |
| –allow-weak-key-signatures | Разрешить слабые подписи ключей. Разрешить подписи ключей третьих сторон, сделанные с использованием SHA-1. | |
| –override-compliance-check | Переопределить проверку соответствия. Устаревшая опция, больше не имеет эффекта. | |
| –no-default-keyring | Без ключевого кольца по умолчанию. Не добавлять ключевое кольцо по умолчанию в список keyring’ов. | |
| –no-keyring | Без ключевых колец. Не использовать никакие ключевые кольца вообще. | |
| –skip-verify | Пропустить проверку. Пропустить шаг проверки подписи для ускорения расшифровки. | |
| –with-key-data | С данными ключа. Печатать данные открытого ключа в выводе списка. | |
| –list-signatures, –list-sigs | Список подписей. То же, что --list-keys, но также列出 подписи (без их проверки). | |
| –fast-list-mode | Быстрый режим списка. Изменить вывод команд списка для более быстрой работы (опуская часть информации). | |
| –no-literal | Без literal. Не для нормального использования. | |
| –set-filesize | Установить размер файла. Не для нормального использования. | |
| –show-session-key | Показать сеансовый ключ. Показать сеансовый ключ, использованный для сообщения. | |
| –show-only-session-key | Только показать сеансовый ключ. Только показать сеансовый ключ, но не обрабатывать сообщение дальше. | |
| –override-session-key string | Переопределить сеансовый ключ. Не использовать открытый ключ, а использовать указанный сеансовый ключ. | |
| –override-session-key-fd fd | Переопределить сеансовый ключ (fd). То же, что и выше, но ключ читается из файлового дескриптора. | |
| –ask-sig-expire | Спрашивать срок подписи. При создании подписи данных запрашивать срок ее действия. | |
| –no-ask-sig-expire | Не спрашивать срок подписи. Отключает опцию выше. | |
| –default-sig-expire value | Срок подписи по умолчанию. Срок действия по умолчанию для подписей данных (напр., “2m”, “5y”). | |
| –ask-cert-expire | Спрашивать срок сертификата. При подписи ключа запрашивать срок действия подписи. | |
| –no-ask-cert-expire | Не спрашивать срок сертификата. Отключает опцию выше. | |
| –default-cert-expire value | Срок сертификата по умолчанию. Срок действия по умолчанию для подписей ключей. | |
| –default-new-key-algo string | Алгоритм ключа по умолчанию. Изменить алгоритмы по умолчанию для генерации ключей (напр., “ed25519/cert,sign+cv25519/encr”). | |
| –no-auto-trust-new-key | Не доверять новому ключу автоматически. Не устанавливать доверие новому ключу в “ultimate” при создании. | |
| –force-sign-key | Принудительная подпись ключа. Принудительно создавать подпись ключа, даже если она уже существует. | |
| –forbid-gen-key | Запретить генерацию ключа. Запретить использование команд генерации ключей. | |
| –allow-secret-key-import | Разрешить импорт секретных ключей. Устаревшая опция, не используется. | |
| –allow-multiple-messages | Разрешить множественные сообщения. Устаревшая опция, не имеет эффекта. | |
| –no-allow-multiple-messages | Запретить множественные сообщения. Устаревшая опция, не имеет эффекта. | |
| –enable-special-filenames | Специальные имена файлов. Включить режим, где имена вида -&n ссылаются на файловый дескриптор n. | |
| –disable-fd-translation | Отключить трансляцию дескрипторов. Только для Windows. | |
| –no-expensive-trust-checks | Без дорогих проверок доверия. Только для экспериментального использования. | |
| –preserve-permissions | Сохранить права доступа. Не менять права доступа к файлу секретного ключа. Только для экспертов. | |
| –default-preference-list string | Список предпочтений по умолчанию. Установить список предпочтений по умолчанию для новых ключей. | |
| –default-keyserver-url name | URL keyserver’а по умолчанию. Установить URL keyserver’а по умолчанию для записи в самоподписи. | |
| –list-config | Список конфигурации. Показать различные внутренние параметры конфигурации GnuPG. | |
| –list-gcrypt-config | Конфигурация Libgcrypt. Показать параметры конфигурации Libgcrypt. | |
| –gpgconf-list | Список для gpgconf. Аналогично --list-config, но для использования утилитой gpgconf. | |
| –gpgconf-test | Тест gpgconf. Провести синтаксическую проверку файла конфигурации. | |
| –chuid uid | Сменить пользователя. Сменить текущего пользователя на uid (число или имя). Только из-под root. |
13.2.4.7 - Config
Создание и редактирование конфигурационного файла.
Файлы конфигурации
Существует несколько файлов конфигурации для управления определенными аспектами работы gpg. Если не указано иное, они ожидаются в текущем домашнем каталоге (см. опцию --homedir).
gpg.conf
Это стандартный файл конфигурации, читаемый gpg при запуске. Он может содержать любые допустимые длинные опции; начальные два дефиса указывать не нужно, и опцию нельзя сокращать. Это имя по умолчанию можно изменить в командной строке (см. опцию gpg --options). Вам следует создавать резервные копии этого файла.
common.conf
Это необязательный файл конфигурации, читаемый gpg при запуске. Он может содержать опции, относящиеся ко всем компонентам GnuPG. В настоящее время его основное использование — для опции "use-keyboxd". Если домашний каталог по умолчанию ~/.gnupg не существует, GnuPG создает этот каталог и файл common.conf с "use-keyboxd".
Примечание: В крупных системах полезно размещать предопределенные файлы в каталоге
/usr/local/etc/skel/.gnupg, чтобы новые пользователи начинали работу с готовой конфигурацией. Для существующих пользователей предоставляется небольшой вспомогательный скрипт для создания этих файлов (см.addgnupghome).
Для внутренних целей gpg создает и поддерживает несколько других файлов; все они находятся в текущем домашнем каталоге (см. опцию --homedir). Только программа gpg может изменять эти файлы.
~/.gnupg
Это домашний каталог по умолчанию, который используется, если не задана ни переменная окружения GNUPGHOME, ни опция --homedir.
~/.gnupg/pubring.gpg
Публичный ключевой контейнер (keyring) в устаревшем формате. Вам следует создавать резервные копии этого файла.
Если этот файл недоступен, gpg по умолчанию использует новый формат keybox и создает файл pubring.kbx, если только этот файл уже не существует, в этом случае он также будет использоваться для ключей OpenPGP.
Примечание: Если существуют оба файла,
pubring.gpgиpubring.kbx, но в последнем нет ключей OpenPGP, будет использоваться устаревший файлpubring.gpg. Будьте осторожны: версии GnuPG до 2.1 всегда будут использовать файлpubring.gpg, потому что они не знают о новом формате keybox. Если вам придется использовать GnuPG 1.4 для расшифровки архивных данных, вам следует сохранить этот файл.
~/.gnupg/pubring.gpg.lock
Файл блокировки (lock file) для публичного ключевого контейнера.
~/.gnupg/pubring.kbx
Публичный ключевой контейнер в новом формате keybox. Этот файл используется совместно с gpgsm. Вам следует создавать резервные копии этого файла. См. выше связь между этим файлом и его предшественником.
Чтобы преобразовать существующий файл pubring.gpg в формат keybox, вы сначала создаете резервную копию значений доверия (ownertrust), затем переименовываете pubring.gpg в publickeys.backup (чтобы он не распознавался любой версией GnuPG), запускаете импорт и, наконец, восстанавливаете значения доверия:
$ cd ~/.gnupg
$ gpg --export-ownertrust >otrust.lst
$ mv pubring.gpg publickeys.backup
$ gpg --import-options restore --import publickeys.backup
$ gpg --import-ownertrust otrust.lst
~/.gnupg/pubring.kbx.lock
Файл блокировки для pubring.kbx.
~/.gnupg/secring.gpg
Устаревший контейнер секретных ключей, используемый версиями GnuPG до 2.1. Он не используется GnuPG 2.1 и позднее. Вы можете захотеть сохранить его на случай, если вам придется использовать GnuPG 1.4 для расшифровки архивных данных.
~/.gnupg/secring.gpg.lock
Файл блокировки для устаревшего контейнера секретных ключей.
~/.gnupg/.gpg-v21-migrated
Файл, указывающий, что миграция на GnuPG 2.1 была выполнена.
~/.gnupg/trustdb.gpg
База данных доверия (trust database). Нет необходимости создавать резервные копии этого файла; лучше создать резервную копию значений доверия владельца (см. опцию --export-ownertrust).
~/.gnupg/trustdb.gpg.lock
Файл блокировки для базы данных доверия.
~/.gnupg/random_seed
Файл, используемый для сохранения состояния внутреннего пула случайных чисел.
~/.gnupg/openpgp-revocs.d/
Это каталог, в котором gpg хранит предварительно сгенерированные отзывные сертификаты. Имя файла соответствует отпечатку OpenPGP соответствующего ключа. Рекомендуется создавать резервные копии этих сертификатов и, если основной закрытый ключ не хранится на диске, перемещать их на внешнее запоминающее устройство. Любой, кто имеет доступ к этим файлам, может отозвать соответствующий ключ. Вы можете распечатать их. Вам следует создавать резервные копии всех файлов в этом каталоге и позаботиться о том, чтобы эта резервная копия хранилась в надежном месте.
Работа дополнительно контролируется несколькими переменными окружения:
HOME
Используется для определения местоположения домашнего каталога по умолчанию.
GNUPGHOME
Если установлена, указывает каталог, используемый вместо "~/.gnupg".
GPG_AGENT_INFO
Эта переменная устарела; она использовалась версиями GnuPG до 2.1.
PINENTRY_USER_DATA
Это значение передается через gpg-agent в pinentry. Это полезно для передачи дополнительной информации пользовательскому pinentry.
COLUMNS
LINES
Используются для масштабирования некоторых дисплеев под полный размер экрана.
LANGUAGE
Помимо своего использования в GNU, она используется в версии для W32 (Windows) для переопределения выбора языка, сделанного через реестр. Если она используется и установлена в допустимое и доступное имя языка (langid), файл с переводом загружается из gpgdir/gnupg.nls/langid.mo. Здесь gpgdir — это каталог, из которого был загружен бинарный файл gpg. Если его не удается загрузить, предпринимается попытка использовать реестр, и в крайнем случае используется родная система локалей Windows.
GNUPG_BUILD_ROOT
Эта переменная используется только набором регрессионных тестов в качестве вспомогательного средства в операционных системах без надлежащей поддержки для определения имени текстового файла процесса.
GNUPG_EXEC_DEBUG_FLAGS
Эта переменная позволяет включить диагностику для управления процессами. Ожидается десятичное числовое значение. Бит 0 включает общую диагностику, бит 1 включает определенные предупреждения в Windows.
GNUPG_ASSUME_COMPLIANCE
Вспомогательная переменная для отладки, чтобы перевести систему в состояние предположения о соответствии. Например, в режиме de-vs это вернет 2023 в качестве идентификатора вместо 23.
При вызове компонента gpg-agent программа gpg отправляет набор переменных окружения в gpg-agent. Имена этих переменных можно перечислить с помощью команды:
gpg-connect-agent 'getinfo std_env_names' /bye | awk '$1=="D" {print $2}'
13.2.5 - gpgsm
gpgsm — это инструмент, аналогичный gpg, который предоставляет услуги цифрового шифрования и подписи для сертификатов X.509 и протокола CMS. Он в основном используется в качестве бэкенда для обработки электронной почты S/MIME. gpgsm включает в себя полноценное управление сертификатами и соответствует всем правилам, установленным для немецкого проекта Sphinx.
13.2.6 - scdaemon
scdaemon — это демон для управления смарт-картами. Обычно он вызывается gpg-agent и, как правило, не используется напрямую.
13.2.7 - user id
Существует несколько способов указать идентификатор пользователя для GnuPG. Некоторые из них действительны только для gpg, другие — только для gpgsm. Вот полный список способов указания ключа:
По идентификатору ключа. Этот формат определяется по длине строки и её содержимому или префиксу 0x. Идентификатор ключа X.509 сертификата — это младшие 64 бита его SHA-1 отпечатка. Использование идентификаторов ключей — это просто сокращение; для всей автоматизированной обработки следует использовать отпечаток.
При использовании gpg можно добавить восклицательный знак (!), чтобы принудительно использовать указанный основной или вторичный ключ, а не пытаться вычислить, какой основной или вторичный ключ использовать.
Последние четыре строки примера дают идентификатор ключа в длинной форме, как это используется в протоколе OpenPGP. Вы можете увидеть длинный идентификатор ключа, используя опцию
--with-colons.234567C4 0F34E556E 01347A56A 0xAB123456 234AABBCC34567C4 0F323456784E56EAB 01AB3FED1347A5612 0x234AABBCC34567C4По отпечатку. Этот формат определяется по длине строки и её содержимому или префиксу 0x. Обратите внимание, что только 20-байтовая версия отпечатка доступна с gpgsm (т.е. SHA-1 хэш сертификата).
При использовании gpg можно добавить восклицательный знак (!), чтобы принудительно использовать указанный основной или вторичный ключ, а не пытаться вычислить, какой основной или вторичный ключ использовать.
Лучший способ указать идентификатор ключа — использовать отпечаток. Это избегает любых неоднозначностей в случае дублирования идентификаторов ключей.
1234343434343434C434343434343434 123434343434343C3434343434343734349A3434 0E12343434343434343434EAB3484343434343434 0xE12343434343434343434EAB3484343434343434gpgsm также принимает двоеточия между каждой парой шестнадцатеричных цифр, поскольку это де-факто стандарт представления отпечатков X.509. gpg также позволяет использовать SHA-1 отпечаток, разделенный пробелами, как это выводится командами для отображения ключей.
По точному совпадению с идентификатором пользователя OpenPGP. Это обозначается ведущим знаком равенства. Это не имеет смысла для сертификатов X.509.
=Heinrich Heine <heinrichh@uni-duesseldorf.de>По точному совпадению с адресом электронной почты. Это указывается заключением адреса электронной почты в угловые скобки.
<heinrichh@uni-duesseldorf.de>По частичному совпадению с адресом электронной почты. Это указывается префиксом строки поиска символом @. Это использует поиск подстроки, но учитывает только адрес электронной почты (т.е. внутри угловых скобок).
@heinrichhПо точному совпадению с DN субъекта. Это указывается ведущим слэшем, за которым непосредственно следует закодированный в RFC-2253 DN субъекта. Обратите внимание, что вы не можете использовать строку, напечатанную командой
gpgsm --list-keys, потому что она была переупорядочена и изменена для лучшей читаемости; используйте--with-colons, чтобы напечатать необработанную (но стандартно экранированную) строку RFC-2253./CN=Heinrich Heine,O=Poets,L=Paris,C=FRПо точному совпадению с DN издателя. Это указывается ведущим символом решетки, за которым непосредственно следует слэш, а затем закодированный в RFC-2253 DN издателя. Это должно вернуть корневой сертификат издателя. См. примечание выше.
#/CN=Root Cert,O=Poets,L=Paris,C=FR
13.2.8 - сравнение SSH и PGP
Наглядное сравнение SSH и PGP систем и их использование
SSH и PGP ключи — это два столпа современной кибербезопасности, но они решают совершенно разные задачи. Их часто путают, потому что оба используют асимметричную криптографию (пары из открытого и закрытого ключей).
Проще всего запомнить так:
- SSH-ключи — это пропуск. Их основная задача — аутентификация (доказательство того, что вы имеете право доступа к чему-либо).
- PGP-ключи — это универсальный инструмент. Их задачи — шифрование (чтобы не могли прочитать), подпись (чтобы могли проверить авторство и целостность) и иногда аутентификация.
Сравнительная таблица: SSH vs PGP ключи
| Критерий | SSH-ключи (Secure Shell) | PGP-ключи (Pretty Good Privacy) |
|---|---|---|
| Основное назначение | Аутентификация и установка безопасного канала. Предоставление доступа к чему-либо (серверу, Git-репозиторию, etc.) без пароля. | Шифрование, подпись, аутентификация. Защита конфиденциальности и целостности данных (почты, файлов, ПО). |
| Главная задача | Доказать серверу, что вы — это вы. | 1. Зашифровать данные для конкретного получателя. 2. Подписать данные, чтобы подтвердить авторство. 3. Зашифровать данные (например, файлы). |
| Типичное применение | Вход на удаленные серверы (Linux), безопасная передача файлов (SCP, SFTP), работа с Git (GitHub, GitLab). | Шифрование электронной почты, подписание коммитов в Git, проверка целостности скачанного ПО (например, дистрибутивов Linux), шифрование файлов. |
| Формат и структура | Относительно простой. Чаще всего это пары файлов: id_rsa (закрытый) и id_rsa.pub (открытый). Используют алгоритмы вроде RSA, Ed25519. | Сложная и богатая структура. Ключ содержит много метаданных: имя, email, даты создания/истечения, возможности ключа (может ли он шифровать, подписывать), отпечаток (fingerprint), а также может состоять из подключей. |
| Доверие (Trust Model) | Простое и централизованное. Вы вручную копируете свой открытый ключ на нужный сервер (в файл ~/.ssh/authorized_keys). Сервер доверяет тому, у кого есть соответствующий закрытый ключ. | Децентрализованное (Веб доверия - Web of Trust). Вы можете подписывать ключи других людей, подтверждая, что доверяете их подлинности. Цепочка таких подписей создает сеть доверия. |
| Идентификация | Понимается сервером. Обычно привязана к пользователю на конкретном сервере. | Привязана к человеку (через имя и email в ключе). |
| Отзыв ключа | Удаление открытого ключа из файла authorized_keys на сервере. | Создание и широкое распространение сертификата отзыва (Revocation Certificate), который объявляет ключ недействительным. |
Наглядные схемы работы
1. Схема работы SSH-ключа для доступа к серверу
flowchart TD
subgraph User [Пользователь на своем компьютере]
A[Запрос подключения к серверу] --> B[SSH-клиент предъявляет<br>свой Открытый ключ]
A --> C[Сервер отправляет<br>«Вызов» случайными данными]
C --> D[SSH-клиент подписывает «Вызов»<br>своим Закрытым ключом]
D --> E[Отправляет подпись серверу]
end
subgraph Server [Удаленный сервер]
B --> F[Сервер проверяет<br>есть ли присланный Открытый ключ<br>в файле authorized_keys]
E --> G[Сервер проверяет подпись<br>«Вызова» с помощью<br>найденного Открытого ключа]
G -- Подпись верна --> H[✅ Аутентификация успешна<br>Доступ разрешен]
G -- Подпись неверна --> I[❌ Доступ запрещен]
end2. Схема работы PGP-ключа для подписи данных
flowchart TD
subgraph Sender [Отправитель Подписывает данные]
A[Исходные данные] --> B[Создает их хэш отпечаток]
B --> C[Подписывает хэш<br>своим Закрытым PGP-ключом]
C --> D[Цифровая подпись]
A --> E[Объединяет исходные данные<br>и подпись для отправки]
D --> E
end
subgraph Receiver [Получатель Проверяет подпись]
E --> F[Разделяет полученное<br>на данные и подпись]
F --> G[Вычисляет хэш<br>от полученных данных]
F --> H[Расшифровывает подпись<br>Открытым PGP-ключом отправителя<br>и получает оригинальный хэш]
G --> I{Сравнивает хэши}
H --> I
I -- Совпали --> J[✅ Подпись верна<br>Данные подлинны и не изменены]
I -- Не совпали --> K[❌ Подпись неверна!<br>Данные отклонены]
endКлючевые выводы и аналогия
Представьте себе большую охраняемую территорию:
- SSH-ключ — это пропускная карта, которую вы прикладываете к турникету. Турникет (сервер) проверяет, есть ли номер вашей карты в базе разрешенных номеров. Если есть — вас пускают. Задача решена.
- PGP-ключ — это ваша печать и набор секретных кодов.
- Шифрование: Вы можете положить документ в шкатулку и запереть ее на кодовый замок, который откроется только кодом конкретного получателя.
- Подпись: Вы можете запечатать документ сургучной печатью. Любой, у кого есть оттиск вашей печати (ваш открытый ключ), может убедиться, что документ распечатали вы и его не вскрывали.
Можно ли использовать PGP-ключ для SSH?
Технически да, это возможно через дополнительные надстройки (например, gpg-agent может работать как ssh-agent). Это позволяет использовать один главный PGP-ключ для множества задач (почта, подпись кода, доступ к серверам). Но «из коробки» эти системы не совместимы.
13.3 - Инструкция по настройке клавиатуры для i2wm с xkb
Шпаргалка по основным командам XKB и настройки клавиатуры для Linux
1. Назначение клавиши для переключения раскладки
Ациклическое переключение (Caps+Shift → русская, Caps → US)
- Создайте конфигурационный файл
~/.config/xkb/configс содержимым:
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)" };
xkb_types { include "complete" };
xkb_compat { include "complete" };
xkb_geometry { include "pc(pc105)" };
xkb_symbols "my" {
include "pc+us+ru:2+inet(evdev)"
// Caps - US (первая группа), Caps+Shift - RU (последняя группа)
key <CAPS> { [ ISO_First_Group, ISO_Last_Group ] };
// Правая клавиша Alt работает как Compose
key <RALT> { [ Multi_key ] };
};
};
- Примените конфигурацию:
xkbcomp $HOME/.config/xkb/config $DISPLAY
Разъяснение по xkb_symbols и группам:
- Каждая раскладка — это группа (group).
us:2означает US-раскладка во второй группе ISO_First_Groupактивирует первую группу (US),ISO_Last_Group— последнюю (RU)- Клавиши могут иметь разное поведение для разных групп через
symbols[group1]иsymbols[group2]
2. Название системных клавиш
Основные клавиши и их xkb-имена:
<CAPS>— Caps Lock<LALT>,<RALT>— левый и правый Alt<LWIN>,<RWIN>— клавиши Windows/Super<LCTL>,<RCTL>— Control<LSGT>,<RSGT>— Shift<ESC>— Escape<SPCE>— пробел
Для просмотра всех клавиш текущей раскладки:
xev | grep keysym
3. Раздельное включение раскладок через Caps
Модифицированный вариант для раздельного управления:
xkb_symbols "split_layouts" {
include "pc+us+ru:2+inet(evdev)"
// Назначаем Caps как переключатель групп
key <CAPS> {
symbols[Group1] = [ ISO_First_Group ], // Только US для группы 1
symbols[Group2] = [ ISO_First_Group ] // Только US для группы 2
};
// Caps+Shift всегда переключает на русскую
modifier_map Shift { <CAPS> };
};
Добавьте в ~/.config/xkb/config и примените xkbcomp.
4. Переназначение клавиш
Примеры переназначения
- Поменять местами CapsLock и Escape:
xkb_symbols "swapescape" {
key <CAPS> { [ Escape ] };
key <ESC> { [ Caps_Lock ] };
};
- Поменять Alt и Win (удобно для i3):
xkb_symbols "altwin" {
key <LALT> { [ Super_L ] };
key <LWIN> { [ Alt_L ] };
};
- Двоеточие и точка с запятой
key <AC10> { [ colon, semicolon ] }; // Вместо [ semicolon, colon ]
5. Настройка Compose
- Установите необходимые пакеты:
# Для Arch Linux
sudo pacman -S xorg-xmodmap libx11 libxt
# Для Debian/Ubuntu
sudo apt install x11-xkb-utils libx11-dev
- Создайте файл
~/.XCompose:
include "%L"
# Пользовательские комбинации
<Multi_key> <apostrophe> <a> : "á"
<Multi_key> <apostrophe> <e> : "é"
<Multi_key> <quotedbl> <a> : "ä"
<Multi_key> <c> <slash> : "¢"
<Multi_key> <less> <less> : "«"
<Multi_key> <greater> <greater> : "»"
<Multi_key> <less> <less> : "«"
<Multi_key> <greater> <greater> : "»"
<Multi_key> <comma> <comma> : "«"
<Multi_key> <period> <period> : "»"
<Multi_key> <bracketleft> <bracketleft> : "«" # RAlt + [ + [
<Multi_key> <bracketright> <bracketright> : "»" # RAlt + ] + ]
- Добавьте в автозагрузку i3 (файл
~/.config/i3/config):
exec --no-startup-id setxkbmap -option compose:ralt # Правый Alt как Compose
exec --no-startup-id xmodmap ~/.Xmodmap # Если используете xmodmap
6. Работа с уровнями (Levels) и модификаторами
Третий уровень (Level3) для дополнительных символов
xkb_symbols "my_layers" {
// Назначаем Caps как модификатор Level3
key <CAPS> { [ ISO_Level3_Shift ] };
// Клавиши h,j,k,l со стрелками на Level3
key <AC06> { [ h, H, Left ] };
key <AC07> { [ j, J, Down ] };
key <AC08> { [ k, K, Up ] };
key <AC09> { [ l, L, Right ] };
// Для разных раскладок разное поведение Caps
name[Group1] = "English (US)";
name[Group2] = "Russian";
key <CAPS> {
symbols[Group1] = [ ISO_Level3_Shift ],
symbols[Group2] = [ ISO_First_Group ] // Или Caps_Lock
};
};
7. Автозагрузка в i3wm
Добавьте в ~/.config/i3/config:
# Загрузка xkb конфигурации
exec --no-startup-id xkbcomp $HOME/.config/xkb/config $DISPLAY
# Дополнительные настройки
exec --no-startup-id setxkbmap -option compose:ralt
exec --no-startup-id xcape -t 500 -e "ISO_Level3_Shift=Escape" # Caps как Escape при коротком нажатии
Важные примечания
- Проверка текущей конфигурации:
setxkbmap -print # Показать текущую xkb конфигурацию
setxkbmap -query # Показать активные опции
Файлы xkb находятся в
/usr/share/X11/xkb/:symbols/— файлы раскладокtypes/— типы клавишcompat/— совместимость модификаторов
Для отладки используйте
xevдля просмотра кодов клавиш.Сброс к настройкам по умолчанию:
setxkbmap -layout us,ru -option ''
8.1 Основные утилиты настройки клавиатуры
setxkbmap — основная утилита для настройки раскладки
Синтаксис:
setxkbmap [-model модель] [-layout раскладка] [-variant вариант] [-option опции]
Примеры использования:
Базовый пример с US и русской раскладкой:
setxkbmap -model pc105 -layout us,ru -option grp:alt_shift_toggleС несколькими опциями:
setxkbmap -model pc105 -layout us,ru -variant ",winkeys" -option "grp:caps_toggle,compose:ralt"Просмотр текущих настроек:
setxkbmap -print # Полная xkb конфигурация setxkbmap -query # Текущие параметры
xkbcomp — компилятор xkb конфигураций
Использование:
xkbcomp файл_конфигурации $DISPLAY
Пример загрузки пользовательской конфигурации:
xkbcomp ~/.config/xkb/keymap.xkb $DISPLAY
localectl — системная утилита (systemd)
Просмотр и установка системной раскладки:
localectl status # Текущая раскладка
localectl set-x11-keymap us,ru # Установка для X11
localectl set-keymap us,ru # Установка для консоли
xkbset — дополнительные опции (светодиоды, повторение)
Примеры:
xkbset led named # Светодиоды для Caps/Num Lock
xkbset repeatkeys rate 300 30 # Настройка autorepeat
xcape — двойное назначение клавиш
Синтаксис:
xcape -e "код_клавиши1=код_клавиши2;код_клавиши3=код_клавиши4"
Примеры:
CapsLock как Escape и модификатор:
xcape -t 500 -e "ISO_Level3_Shift=Escape"Shift как скобки при коротком нажатии:
xcape -e "Shift_L=parenleft;Shift_R=parenright"
8.2 Допустимые значения параметров
XkbModel — модели клавиатур
| Модель | Описание | Подходит для |
|---|---|---|
pc101 | Стандартная 101-клавишная (ANSI, США) | Настольные клавиатуры США |
pc102 | Расширенная 102-клавишная (ISO, Европа) | Европейские клавиатуры |
pc104 | 104-клавишная (ANSI с Win-клавишами) | Современные настольные |
pc105 | 105-клавишная (ISO с Win-клавишами) | Наиболее распространена в РФ |
thinkpad | Ноутбуки Lenovo ThinkPad | ThinkPad серии |
macbook79 | Ноутбуки Apple | MacBook Pro 2015+ |
chromebook | Хромбуки | Устройства Chrome OS |
Определение модели вашей клавиатуры:
# Посмотреть информацию о подключенных устройствах
lsusb
# Или
cat /proc/bus/input/devices | grep -i keyboard
XkbLayout — раскладки клавиатуры
Основные раскладки:
us— Английская (США)ru— Русскаяby— Белорусскаяde— Немецкаяfr— Французскаяes— Испанская
Множественные раскладки через запятую:
# Три раскладки
setxkbmap -layout us,ru
Пример комбинаций:
# Английская и русская с вариантом для программистов
setxkbmap -layout us,ru -variant ",winkeys"
XkbVariant — варианты раскладок
Для раскладки us (английская):
| Вариант | Описание |
|---|---|
basic | Стандартная qwerty |
dvorak | Альтернативная раскладка Dvorak |
colemak | Альтернативная раскладка Colemak |
intl | С международными символами |
altgr-intl | С AltGr для дополнительных символов |
rus | Фонетическая русская (яверты) |
Для раскладки ru (русская):
| Вариант | Описание |
|---|---|
basic | Стандартная йцукен |
winkeys | Как в Windows (ё в другом месте) |
dos | Как в старых DOS системах |
mac | Как в macOS |
legacy | Устаревший вариант |
phonetic | Фонетическая (я=ja, ш=sh) |
Примеры с вариантами:
# Русская раскладка как в Windows
setxkbmap -layout us,ru -variant ",winkeys"
# Английская Dvorak и русская стандартная
setxkbmap -layout us,ru -variant dvorak,
XkbOptions — дополнительные опции
Группы опций и их формат: категория:значение
1. Переключение раскладок (группы)
| Опция | Описание | Поведение |
|---|---|---|
grp:shift_caps_toggle | Shift+CapsLock | Переключение по Shift+Caps |
grp:alt_shift_toggle | Alt+Shift | Переключение по Alt+Shift |
grp:ctrl_shift_toggle | Ctrl+Shift | Переключение по Ctrl+Shift |
grp:caps_toggle | CapsLock | Переключение только по Caps |
grp:toggle | Правый Alt | Только правый Alt |
grp:lwin_toggle | Левая Win | Левая клавиша Super |
grp:switch | Правый Ctrl | Правый Control |
grp:alt_space_toggle | Alt+Space | Alt с пробелом |
grp:shifts_toggle | Оба Shift | Оба Shift одновременно |
grp:lctrl_lwin_toggle | Ctrl+Win слева | Комбинация слева |
Ациклические варианты:
# Caps → US, Caps+Shift → RU
setxkbmap -option grp:caps_switch
2. Индикация раскладки
| Опция | Описание |
|---|---|
grp_led:scroll | Индикация Scroll Lock |
grp_led:caps | Индикация Caps Lock |
grp_led:num | Индикация Num Lock |
Пример с индикацией:
setxkbmap -option "grp:alt_shift_toggle,grp_led:caps"
3. Режим Compose
| Опция | Описание |
|---|---|
compose:ralt | Правый Alt |
compose:lwin | Левая Win |
compose:rwin | Правая Win |
compose:menu | Клавиша Menu |
compose:caps | Caps Lock |
compose:paus | Pause/Break |
compose:prsc | Print Screen |
Пример:
setxkbmap -option compose:ralt
4. Прочие полезные опции
| Опция | Описание |
|---|---|
ctrl:nocaps | Делает CapsLock Control |
ctrl:swapcaps | Меняет местами Control и CapsLock |
terminate:ctrl_alt_bksp | Ctrl+Alt+Backspace завершает X-сессию |
lv3:switch | Правый Ctrl как Level3 |
lv3:menu_switch | Menu как Level3 |
numpad:microsoft | Цифровая клавиатура как в Windows |
keypad:atm | Раскладка банкомата |
eurosign:e | Евро на клавише E |
8.3 Примеры комплексных настроек
Пример 1: Полная настройка для i3wm
setxkbmap \
-model pc105 \
-layout us,ru \
-variant ",winkeys" \
-option "grp:caps_toggle,grp_led:caps,compose:ralt,ctrl:nocaps"
Объяснение:
pc105— стандартная 105-клавишная клавиатураus,ru— две раскладки: английская и русская,winkeys— для русской раскладки вариант “как в Windows”grp:caps_toggle— CapsLock переключает раскладкиgrp_led:caps— CapsLock светодиод показывает активную раскладкуcompose:ralt— правый Alt для ввода спецсимволовctrl:nocaps— CapsLock работает как Control
Пример 2: Для программиста
setxkbmap \
-model pc105 \
-layout us,ru \
-variant altgr-intl, \
-option "grp:alt_shift_toggle,lv3:ralt_switch,compose:menu"
Пример 3: Создание постоянного конфига для ~/.xprofile
#!/bin/bash
# Настройки клавиатуры
setxkbmap -model pc105 -layout us,ru -option "grp:caps_toggle"
# Дополнительные назначения клавиш
if command -v xcape &> /dev/null; then
xcape -t 200 -e "Control_L=Escape"
fi
# Настройка autorepeat
xset r rate 200 30
8.4 Просмотр всех доступных опций
Просмотр всех моделей:
localectl list-x11-keymap-models
Просмотр всех раскладок:
localectl list-x11-keymap-layouts
Просмотр вариантов для конкретной раскладки:
# Для русской раскладки
localectl list-x11-keymap-variants ru
# Для английской
localectl list-x11-keymap-variants us
Просмотр всех опций:
localectl list-x11-keymap-options | less
Просмотр конкретных файлов xkb:
# Файлы раскладок
ls /usr/share/X11/xkb/symbols/
# Файл с описанием опций
cat /usr/share/X11/xkb/rules/evdev.lst | grep grp:
8.5 Устранение проблем
Проблема: Настройки не сохраняются после перезагрузки
Решение 1 — добавить в автозагрузку i3 (~/.config/i3/config):
exec --no-startup-id setxkbmap -model pc105 -layout us,ru -option grp:caps_toggle
Решение 2 — создать файл ~/.xprofile:
#!/bin/sh
setxkbmap -model pc105 -layout us,ru -option "grp:caps_toggle,compose:ralt"
Решение 3 — системная настройка (для Arch Linux):
# Создать файл /etc/X11/xorg.conf.d/00-keyboard.conf
Section "InputClass"
Identifier "system-keyboard"
MatchIsKeyboard "on"
Option "XkbModel" "pc105"
Option "XkbLayout" "us,ru"
Option "XkbVariant" ",winkeys"
Option "XkbOptions" "grp:caps_toggle"
EndSection
Проблема: Не работают некоторые комбинации
Проверка текущих опций:
setxkbmap -query
Сброс и установка заново:
# Сброс всех опций
setxkbmap -option
# Установка нужных
setxkbmap -option "grp:alt_shift_toggle,compose:ralt"
8.6 Полезные команды для отладки
Просмотр кодов клавиш в реальном времени:
xev | grep -A2 --line-buffered '^KeyRelease' | sed -n '/keycode /s/^.*keycode \([0-9]*\).* (.*, \(.*\)).*$/\1 \2/p'
Проверка текущих модификаторов:
xmodmap
Тестирование compose-последовательностей:
# Введите RightAlt, затем o, затем c для ©
# Или настройте свои в ~/.XCompose
Экспорт текущей конфигурации в файл:
setxkbmap -print > ~/current_keymap.xkb
Развернутое толкование строки конфигурации xkb
Строка xkb_symbols является основной частью конфигурации клавиатуры в X Window System.
Структура строки
xkb_symbols {
include "pc+us+ru:2+inet(evdev)+compose(ralt)+group(caps_select)+terminate(ctrl_alt_bksp)+typo(base):1+typo(base):2"
}
Компоненты и их значение
1. pc — Базовый набор символов
- Что это: Базовая раскладка для 105-клавишной (PC) клавиатуры
- Что включает: Определения стандартных клавиш (Enter, Shift, Space и т.д.)
- Аналоги:
macдля клавиатур Apple,sunдля Sun Microsystems
2. us — Основная раскладка
- Что это: Английская раскладка QWERTY (США)
- Позиция: Основная (первая) раскладка в списке
- Варианты:
us(dvorak),us(colemak),us(intl)для альтернативных раскладок
3. ru:2 — Вторая раскладка с указанием группы
ru: Русская раскладка ЙЦУКЕН:2: Помещает русскую раскладку во вторую группу (group 2)- Группа 1:
us(по умолчанию) - Группа 2:
ru(активируется переключением)
- Группа 1:
- Варианты:
ru(winkeys)— раскладка как в Windows (ё в другом месте)
4. inet(evdev) — Поддержка мультимедийных клавиш
inet: Модуль для интернет/мультимедийных клавишevdev: Драйвер ввода для современных ядер Linux- Что включает: Клавиши VolumeUp/Down, Mute, Browser, Mail, Calculator и т.д.
5. compose(ralt) — Режим Compose
- Что это: Система ввода спецсимволов через последовательности
ralt: Активируется правым Alt (AltGr)- Примеры использования:
AltGr + " + a→äAltGr + o + c→©AltGr + < + <→«
- Альтернативы:
compose(lwin)— левая Win,compose:menu— клавиша Menu
6. group(caps_select) — Переключение раскладок
- Что делает: Назначает Caps Lock для переключения раскладок
- Поведение:
Caps Lock— переключает между группами (us ↔ ru)- Важно: Caps Lock не работает как обычный Caps Lock!
- Альтернативные варианты:
grp:alt_shift_toggle— Alt+Shiftgrp:ctrl_shift_toggle— Ctrl+Shiftgrp:toggle— только правый Alt
7. terminate(ctrl_alt_bksp) — Аварийное завершение
- Что делает:
Ctrl+Alt+Backspaceнемедленно завершает X-сессию - Зачем: Аварийный выход при зависании графического сервера
- Безопасность: В современных системах часто отключено по умолчанию
8. typo(base):1+typo(base):2 — Автозамена опечаток
typo: Модуль автокоррекции/заменыbase: Базовый набор правил:1и:2: Применяет правила к обеим группам (и us, и ru)- Примеры замен:
teh→the(английский)ащк→все(русский, для QWERTY-раскладки)
Полное описание поведения системы
С этой конфигурацией ваша клавиатура будет вести себя так:
| Элемент | Поведение |
|---|---|
| Основная раскладка | Английская (US QWERTY) |
| Альтернативная раскладка | Русская (ЙЦУКЕН) |
| Переключение раскладок | Клавиша Caps Lock (циклически us→ru→us) |
| Ввод спецсимволов | Правый Alt (AltGr) + последовательности символов |
| Мультимедийные клавиши | Работают через драйвер evdev |
| Автозамена опечаток | Включена для обеих раскладок |
| Аварийный выход | Ctrl+Alt+Backspace завершает X-сессию |
Где искать дополнительные опции
# Все доступные опции
less /usr/share/X11/xkb/rules/evdev.lst
# Файлы символов
ls /usr/share/X11/xkb/symbols/
# Конкретные варианты для us
cat /usr/share/X11/xkb/symbols/us
13.4 - JQ парсер JSON
Описание команд и синтаксиса парсера JSON
Памятка по jq (командный процессор для JSON)
jq — это мощный и гибкий инструмент командной строки для парсинга, фильтрации, преобразования и форматирования JSON-данных.
1. Базовый синтаксис вызова
# Чтение из файла
jq [опции] <фильтр> [файл.json]
# Чтение из stdin (стандартного ввода)
cat файл.json | jq [опции] <фильтр>
Основные опции:
-r(--raw-output): Выводит строки без кавычек (например, для plain-text).-c(--compact-output): Выводит JSON в одну компактную строку, а не в красивом формате.-s(--slurp): Обрабатывает весь входной поток как один большой массив JSON.--arg var value: Позволяет передавать переменные в скриптjqиз командной строки.
2. Основные фильтры и операции
| Команда/Фильтр | Описание | Пример (вход → выход) |
|---|---|---|
. | Просто выводит входные данные в отформатированном виде. | jq '.' data.json |
.key | Обращение к полю объекта. | {"name": "Alice"} → "Alice" |
.[] | Разворачивает массив в поток элементов или объект в поток значений. | [1,2,3] → 1, 2, 3 |
.[index].[start:end] | Обращение к элементу массива по индексу или к срезу. | `[10,20,30] |
, | Оператор запятой применяет несколько фильтров. | jq '.name, .age' |
| | Пайп (конвейер) передает вывод одного фильтра на вход другого. | jq '.[] | .name' |
select(условие) | Фильтрует элементы, удовлетворяющие условию. | jq '.[] | select(.age > 30)' |
map(фильтр) | Применяет фильтр к каждому элементу массива. | jq 'map(.age)' |
length | Возвращает длину массива или строки. | jq '.names | length' |
keys | Возвращает ключи объекта в виде массива. | jq '.user | keys' |
has("key") | Проверяет, существует ли ключ в объекте. | jq 'map(has("email"))' |
del(.path) | Удаляет указанное поле. | jq 'del(.user.password)' |
// default | Оператор по умолчанию. | jq '.email // "no email"' |
3. Создание новых объектов и массивов
| Команда | Описание | Пример |
|---|---|---|
{} | Создание нового объекта. | jq '{имя: .user, лет: .age}' |
[] | Создание нового массива. | jq '[.user, .age]' |
+, -, *, /, % | Математические операции. | jq '.items | length + 1' |
= / |= | Присваивание (обычно внутри {}). | jq '.new_field = "value"'jq '.age |= .+1' |
4. Условные конструкции и функции
# Условие if-then-else-end
if .age >= 18 then "adult" else "child" end
# Определение функции (синтаксис похож на JavaScript)
def increment: . + 1;
.[] | increment
# Работа со строками
jq '.[] | "Name: \(.name), Age: \(.age)"' # - Интерполяция строк
jq '.[] | .name | test("[Aa]lice")' # - Регулярные выражения (test, match)
5. Работа с вложенными структурами (рекурсивный спуск)
| Команда | Описание |
|---|---|
.. | Рекурсивный спуск. Находит все значения по пути, независимо от глубины вложенности. Очень мощный инструмент. |
Пример: Дан JSON:
{
"company": {
"name": "Tech Corp",
"employees": [
{"name": "Alice", "email": "alice@example.com"},
{"name": "Bob", "email": "bob@example.com"}
]
}
}
Команда:
jq '.. | .email? // empty' data.json
Результат:
"alice@example.com"
"bob@example.com"
..проходит через каждый элемент в JSON..email?пытается получить полеemailдля каждого элемента. Вопросительный знак?подавляет ошибки, если поля нет.// emptyотбрасывает всеnullили ложные результаты, оставляя только найденные email-адреса.
6. Практические примеры
Данные для примеров (data.json):
{
"users": [
{"id": 1, "name": "Alice", "age": 25, "active": true},
{"id": 2, "name": "Bob", "age": 35, "active": false},
{"id": 3, "name": "Charlie", "age": 28, "active": true}
]
}
Получить все имена:
jq '.users[].name' data.json # или jq '.users | map(.name)' data.jsonПолучить имена только активных пользователей:
jq '.users[] | select(.active == true) | .name' data.jsonСоздать новый JSON с полным именем и флагом “is_adult”:
jq '.users[] | {userName: .name, isAdult: (.age >= 18)}' data.jsonИспользование внешней переменной (–arg):
jq --arg user_id 2 '.users[] | select(.id == ($user_id | tonumber))' data.jsonПодсчитать количество пользователей:
jq '.users | length' data.json
13.5 - Шпаргалка по основным командам nano
Шпаргалка по основным командам nano для быстрого редактирования простых файлов
Шпаргалка для редактора nano
Запуск nano
- Открыть файл:
nano имя_файла - Создать новый файл:
nano(после сохранения нужно указать имя)
Основные команды (управляются через Ctrl + клавиша или ^)
^G– открыть справку (помощь)^O– сохранить файл (O – Write Out)^X– выйти из nano (если есть изменения, предложит сохранить)^K– вырезать строку (Kill)^U– вставить строку (Unpaste)^W– поиск по тексту (Where)^\– поиск и замена (ввести искомое, затем замену)^C– показать позицию курсора (строка/столбец)
Навигация
^F– вперед на 1 символ (Forward)^B– назад на 1 символ (Backward)^Право/Лево– перемещение по словам (Alt + стрелки в некоторых версиях)^A– в начало строки (A – Home)^E– в конец строки (E – End)^Y– вверх на страницу^V– вниз на страницу
Дополнительно
^T– проверка орфографии (если включено)^R– вставить содержимое другого файла (Read File)^D– удалить символ под курсором (Delete)^_(Ctrl + Shift + “-”) – перейти на номер строки
Выход и сохранение
^X→ если есть изменения, нажмите:Y– сохранить,N– не сохранять,Ctrl+C– отмена.
- Если сохраняете (
Y), введите имя файла и нажмите Enter.
Подсказка: Внизу экрана всегда отображаются основные комбинации. Для более продвинутых функций (например, подсветки синтаксиса) может потребоваться конфигурационный файл ~/.nanorc.
13.6 - Шпаргалка по основным командам Vim
Шпаргалка по основным командам Vim для быстрого редактирования простых файлов
Режимы в Vim
- Нормальный режим (командный) —
Esc
(используется для навигации и команд) - Режим вставки —
i,a,o
(для редактирования текста) - Визуальный режим (выделение) —
v,V,Ctrl+v - Командная строка —
:
(для сложных команд, например сохранения)
Основные команды (в нормальном режиме)
1. Навигация
h,j,k,l— влево, вниз, вверх, вправоw/b— вперед/назад по словам0/$— в начало/конец строкиgg/G— в начало/конец файлаCtrl+d/Ctrl+u— вниз/вверх на полэкрана:10— перейти на 10-ю строку
2. Редактирование
i— вставить перед курсоромa— вставить после курсораo/O— новая строка ниже/вышеx— удалить символ под курсоромdd— удалить строкуyy— скопировать строкуp/P— вставить после/перед курсоромu— отменить действиеCtrl+r— повторить отмененное
3. Поиск и замена
/слово— поиск слова вперед?слово— поиск слова назадn/N— следующее/предыдущее совпадение:%s/старое/новое/g— заменить все вхождения в файле:%s/старое/новое/gc— заменить с подтверждением
4. Работа с файлами
:w— сохранить:w имя_файла— сохранить как…:q— выйти:q!— выйти без сохранения:wqилиZZ— сохранить и выйти:e имя_файла— открыть другой файл
5. Полезные фишки
.— повторить последнюю команду%— перейти к парной скобке(),{},[]>>/<<— сдвинуть строку вправо/влевоCtrl+v→ выделение →I→ текст →Esc— вставить текст в несколько строк:set number— показать номера строк:sp файл/:vsp файл— разделить окно горизонтально/вертикально
Примеры использования
Редактирование конфига
vim /etc/nginx/nginx.conf- Нажать
iдля редактирования - Нажать
Esc, затем:wqдля сохранения и выхода
- Нажать
Поиск и замена
- Ввести
:%s/old/new/gдля замены всех “old” на “new”
- Ввести
Копирование строк
- Навести курсор на строку →
yy→ перейти куда нужно →p
- Навести курсор на строку →
Выход из Vim (шутка, но важно!)
- Если застряли — нажать
Esc, затем::q!→ выйти без сохранения:wq→ сохранить и выйти
Эта шпаргалка покрывает 90% повседневных задач в Vim. Для продвинутых возможностей (макросы, плагины) стоит изучить vimtutor (введите в терминале).
13.7 - Пакет scrcpy для управления Android устройством через Linux
scrcpy — это инструмент командной строки для зеркалирования экрана и управления Android-устройством с компьютера через USB или Wi-Fi. Он не требует root-доступа и работает на Linux, Windows и macOS.
scrcpy — это инструмент командной строки для зеркалирования экрана и управления Android-устройством с компьютера через USB или Wi-Fi. Он не требует root-доступа и работает на Linux, Windows и macOS.
Для чего нужен scrcpy в Linux?
Зеркалирование экрана Android
- Показывает экран телефона/планшета на ПК с низкой задержкой (до 60 FPS).
- Полезно для стриминга, записи экрана или демонстрации.
Управление Android с ПК
- Можно кликать мышкой, печатать с клавиатуры.
- Поддержка мультитача (если устройство поддерживает HID).
Передача файлов
- Drag & Drop файлов между ПК и Android (
scrcpy --push-target /sdcard/).
- Drag & Drop файлов между ПК и Android (
Запись экрана
- Сохранение видео без потери качества:
scrcpy --record screen.mp4
- Сохранение видео без потери качества:
Беспроводное подключение (Wi-Fi)
- После подключения по USB можно переключиться на Wi-Fi:
scrcpy --tcpip=192.168.1.100 # вместо USB
- После подключения по USB можно переключиться на Wi-Fi:
Экономия заряда
- Если экран телефона выключен, но управление работает (
scrcpy --turn-screen-off).
- Если экран телефона выключен, но управление работает (
Разработка и отладка
- Удобен для тестирования приложений без эмулятора.
Как установить scrcpy в Linux?
1. Установка из репозиториев (проще)
sudo apt install scrcpy # Debian/Ubuntu
sudo dnf install scrcpy # Fedora
sudo pacman -S scrcpy # Arch Linux
2. Установка вручную (последняя версия)
# Требуются зависимости:
sudo apt install ffmpeg adb gcc git meson ninja-build
# Сборка из исходников
git clone https://github.com/Genymobile/scrcpy
cd scrcpy
./install_release.sh
Базовые команды
| Команда | Описание |
|---|---|
scrcpy | Запуск по USB |
scrcpy --bit-rate 2M --max-size 800 | Настроить качество |
scrcpy --no-control | Только просмотр (без управления) |
scrcpy --fullscreen | Во весь экран |
scrcpy --show-touches | Показывать касания |
Плюсы и минусы
✅ Плюсы
- Низкая задержка (~35 мс)
- Не требует root
- Поддержка Linux, Windows, macOS
- Можно использовать мышку/клавиатуру
❌ Минусы
- Нет звука (можно через
sndcpyотдельно) - Для Wi-Fi нужно сначала подключиться по USB
13.8 - Yazi - Файловый менеджер
Молниеносный терминальный файловый менеджер
Yazi - Молниеносный файловый менеджер
Yazi (переводится как “утка”) — это файловый менеджер для терминала, написанный на Rust с использованием неблокирующего асинхронного ввода-вывода. Он нацелен на предоставление эффективного, удобного и настраиваемого опыта управления файлами.
Новая статья, объясняющая его внутреннее устройство: Why is Yazi Fast?
Возможности Yazi
- 🚀 Полная асинхронная поддержка: Все операции ввода-вывода асинхронны, задачи CPU распределены по нескольким потокам, что позволяет максимально использовать доступные ресурсы.
- 💪 Мощное планирование и управление асинхронными задачами: Предоставляет обновления прогресса в реальном времени, отмену задач и назначение внутренних приоритетов.
- 🖼️ Встроенная поддержка нескольких протоколов отображения изображений: Также интегрирован с Überzug++ и Chafa, охватывая почти все терминалы.
- 🌟 Встроенная подсветка кода и декодирование изображений: В сочетании с механизмом предзагрузки значительно ускоряет загрузку изображений и обычных файлов.
- 🔌 Конкурентная система плагинов: Плагины для UI (переопределяющие большую часть интерфейса), функциональные плагины, кастомные превьюеры/прелоадеры/споттеры/фетчеры; всё это на Lua.
- ☁️ Виртуальная файловая система: Управление удаленными файлами, пользовательские поисковые движки.
- 📡 Служба распространения данных: Построена на архитектуре клиент-сервер (не требует отдельного серверного процесса), интегрирована с Lua-моделью публикации-подписки, обеспечивая межэкземплярное взаимодействие и сохранение состояния.
- 📦 Менеджер пакетов: Установка плагинов и тем одной командой, поддержка актуальных версий или привязка к конкретной.
- 🧰 Интеграция с ripgrep, fd, fzf, zoxide
- 💫 Компоненты в стиле Vim для ввода/выбора/подтверждения/which/уведомлений, автодополнение для путей
cd - 🏷️ Поддержка нескольких вкладок, выделение в разных каталогах, прокручиваемый предпросмотр (для видео, PDF, архивов, кода, каталогов и т.д.)
- 🔄 Массовое переименование/создание, распаковка архивов, визуальный режим, выбор файлов, интеграция с Git, менеджер точек монтирования
- 🎨 Система тем, поддержка мыши, перетаскивание, корзина, кастомные макеты, CSI u, OSC 52
- … и многое другое!
Статус проекта
Публичная бета-версия, можно использовать для повседневной работы.
Yazi находится в активной разработке, ожидайте критических изменений.
Документация
- Использование: https://yazi-rs.github.io/docs/installation
- Возможности: https://yazi-rs.github.io/features
Обсуждение
- Discord Сервер (в основном английский): https://discord.gg/qfADduSdJu
- Telegram Группа (в основном китайский): https://t.me/yazi_rs
Предпросмотр изображений
Yazi автоматически выбирает подходящий метод предпросмотра на основе переменных окружения $TERM, $TERM_PROGRAM и $XDG_SESSION_TYPE. Убедитесь, что вы их не перезаписываете!
| Платформа | Протокол | Поддержка |
|---|---|---|
| kitty (>= 0.28.0) | Kitty unicode placeholders | ✅ Встроено |
| iTerm2 | Inline images protocol | ✅ Встроено |
| WezTerm | Inline images protocol | ✅ Встроено |
| Konsole | Kitty old protocol | ✅ Встроено |
| foot | Sixel graphics format | ✅ Встроено |
| Ghostty | Kitty unicode placeholders | ✅ Встроено |
| Windows Terminal (>= v1.22.10352.0) | Sixel graphics format | ✅ Встроено |
| st with Sixel patch | Sixel graphics format | ✅ Встроено |
| Warp (macOS/Linux only) | Inline images protocol | ✅ Встроено |
| Tabby | Inline images protocol | ✅ Встроено |
| VSCode | Inline images protocol | ✅ Встроено |
| Rio (>= 0.3.9) | Kitty unicode placeholders | ✅ Встроено |
| Black Box | Sixel graphics format | ✅ Встроено |
| Bobcat | Inline images protocol | ✅ Встроено |
| X11 / Wayland | Window system protocol | ☑️ Требуется Überzug++ |
| Fallback | ASCII art (Unicode block) | ☑️ Требуется Chafa (>= 1.16.0) |
Подробнее: https://yazi-rs.github.io/docs/image-preview
Лицензия
Yazi распространяется под лицензией MIT. Дополнительную информацию смотрите в файле LICENSE.
Установка
Для использования Yazi необходимо установить следующие зависимости:
file(для определения типа файлов)
Yazi также может быть расширен с помощью других утилит командной строки для дополнительных функций:
nerd-fonts(рекомендуется)ffmpeg(для миниатюр видео)7-Zip(для распаковки и предпросмотра архивов, требуется не standalone версия)jq(для предпросмотра JSON)poppler(для предпросмотра PDF)fd(для поиска файлов)rg(для поиска по содержимому файлов)fzf(для быстрой навигации по дереву файлов, >= 0.53.0)zoxide(для навигации по истории каталогов, требует fzf)resvg(для предпросмотра SVG)ImageMagick(для предпросмотра шрифтов, HEIC и JPEG XL, >= 7.1.1)xclip/wl-clipboard/xsel(для поддержки буфера обмена в Linux)
Обновите эти зависимости до последней версии, если какая-либо функция работает не так, как ожидалось.
Установка в Fedora (и Centos Stream 9+/RHEL 9+)
Информация
Этот метод использует неофициальный репозиторий COPR, поддерживаемый Peter Li.- Включите репозиторий COPR:
sudo dnf copr enable lihaohong/yazi - Установите Yazi:
sudo dnf install yazidnfавтоматически установит рекомендуемые зависимости (зависимостиRecommends). Чтобы установить только Yazi без них, выполните:Еслиsudo dnf install yazi --setopt=install_weak_deps=Falsednfсообщает об ошибке “No such command: copr”, сначала установите плагинdnf-plugins-core:а затем повторите команды включения репозитория и установки.sudo dnf install dnf-plugins-core
Установка дополнительных зависимостей (рекомендуется)
Для полной функциональности рекомендуется установить дополнительные утилиты:
sudo dnf install ffmpeg 7zip jq poppler fd-find ripgrep fzf zoxide resvg ImageMagick
Обратите внимание, что в Fedora пакет fd может называться fd-find. Если команда fd не работает после установки, возможно, потребуется создать симлинк:
sudo ln -s /usr/bin/fdfind /usr/bin/fd
Другие методы установки
Официальные бинарные файлы
Вы можете загрузить последние официальные бинарные файлы из GitHub Releases. На этой странице предлагаются сборки GNU/Musl для различных пользователей. Также доступна nightly-сборка, собранная из последнего кода за последние 6 часов.
Сборка из исходного кода
Установите последний стабильный Rust через rustup:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup update
Клонируйте репозиторий и соберите Yazi:
git clone https://github.com/sxyazi/yazi.git
cd yazi
cargo build --release --locked
Затем добавьте yazi и ya в ваш $PATH (например, скопировав в /usr/local/bin/):
sudo mv target/release/yazi target/release/ya /usr/local/bin/
Если сборка не удалась, проверьте, установлены ли make и gcc.
Другие менеджеры пакетов
- Arch Linux:
sudo pacman -S yazi(и дополнительные зависимости) - Nix:
nix-env -iA nixos.yaziилиnix-env -iA nixpkgs.yazi - Homebrew (macOS):
brew install yazi(и дополнительные зависимости черезbrew install ...) - Windows (Scoop):
scoop install yazi(и дополнительные зависимости) - Windows (WinGet):
winget install sxyazi.yazi(и дополнительные зависимости)
Быстрый старт
После установки запустите Yazi командой:
yazi
Нажмите q для выхода, F1 или ~ для открытия меню помощи.
Обёртка для оболочки (Shell Wrapper)
Рекомендуется использовать эту обёртку, которая позволяет изменить текущую рабочую директорию при выходе из Yazi. Добавьте эту функцию в ваш файл конфигурации оболочки (например, .bashrc, .zshrc):
Для Bash / Zsh:
function y() {
local tmp="$(mktemp -t "yazi-cwd.XXXXXX")" cwd
command yazi "$@" --cwd-file="$tmp"
IFS= read -r -d '' cwd < "$tmp"
[ "$cwd" != "$PWD" ] && [ -d "$cwd" ] && builtin cd -- "$cwd"
command rm -f -- "$tmp"
}
Теперь используйте команду y вместо yazi для запуска. Нажмите q для выхода и смены директории. Если не хотите менять директорию, нажмите Q (Shift+q).
Основные горячие клавиши
Все горячие клавиши описаны в файле keymap.toml. Вот некоторые из них:
Навигация
| Клавиша | Альтернатива | Действие |
|---|---|---|
k | ↑ | Переместить курсор вверх |
j | ↓ | Переместить курсор вниз |
l | → | Войти в выделенный каталог |
h | ← | Выйти из текущего каталога в родительский |
K | Прокрутить предпросмотр вверх на 5 | |
J | Прокрутить предпросмотр вниз на 5 | |
g g | Переместить курсор в начало | |
G | Переместить курсор в конец | |
z | Перейти в каталог или открыть файл через fzf | |
Z | Перейти в каталог через zoxide |
Выделение
| Клавиша | Действие |
|---|---|
Space | Переключить выделение текущего файла/каталога |
v | Войти в визуальный режим (режим выделения) |
V | Войти в визуальный режим (режим снятия выделения) |
Ctrl + a | Выделить все файлы |
Ctrl + r | Инвертировать выделение |
Esc | Отменить выделение |
Операции с файлами
| Клавиша | Действие |
|---|---|
o | Открыть выбранные файлы |
Enter | Открыть выбранные файлы |
Tab | Показать информацию о файле |
y | Скопировать выбранные файлы (yank) |
x | Вырезать выбранные файлы (yank cut) |
p | Вставить скопированные/вырезанные файлы |
P | Вставить с перезаписью, если файл существует |
Y или X | Отменить состояние копирования/вырезания |
d | Переместить выбранные файлы в корзину |
D | Безвозвратно удалить выбранные файлы |
a | Создать файл (с / на конце для каталога) |
r | Переименовать выбранный файл (или массовое переименование) |
. | Переключить отображение скрытых файлов |
; | Выполнить команду оболочки (в фоне) |
: | Выполнить команду оболочки (блокируя Yazi до завершения) |
Настройка горячих клавиш: keymap.toml
Файл ~/.config/yazi/keymap.toml позволяет полностью контролировать все горячие клавиши в Yazi. Он состоит из 8 слоев (layers), каждый из которых отвечает за определенную часть интерфейса:
[mgr]- Управление файлами (основной слой).[tasks]- Менеджер задач.[spot]- Просмотр информации о файле.[pick]- Компонент выбора (например, “открыть с помощью”).[input]- Поля ввода (создание, переименование и т.д.).[confirm]- Диалоги подтверждения (удаление, перезапись).[cmp]- Автодополнение (например, для командыcd).[help]- Меню справки.
Структура и приоритеты
В каждом слое вы можете определить новые сочетания клавиш, используя ключи prepend_keymap (добавить перед стандартными) или append_keymap (добавить после стандартных). Yazi выполняет первое подходящее сочетание, поэтому приоритет выше у prepend_keymap.
Синтаксис:
[mgr]
prepend_keymap = [
{ on = "<C-a>", run = "act1", desc = "Описание для Ctrl+a" },
]
append_keymap = [
{ on = [ "g", "b" ], run = "act2", desc = "Описание для g ⇒ b" },
{ on = "c", run = [ "act1", "act2" ], desc = "Несколько действий для c" }
]
Или в альтернативном стиле (таблицы):
[[mgr.prepend_keymap]]
on = "<C-a>"
run = "act1"
desc = "Описание для Ctrl+a"
Чтобы полностью переопределить все стандартные назначения клавиш, используйте ключ keymap:
[mgr]
keymap = [
{ on = "<C-a>", run = "act1" },
{ on = [ "g", "b" ], run = "act2" },
]
Обозначения клавиш
- Обычные клавиши:
a-z,A-Z,<Space>,<Enter>,<Tab>,<Esc>,<F1>-<F19>, стрелки (<Up>,<Down>,<Left>,<Right>) и т.д. - Модификаторы:
<C-...>: Ctrl (например,<C-a>)<S-...>: Shift (например,<S-Tab>или<BackTab>)<A-...>: Alt (может не работать на macOS без настройки терминала)<D-...>: Super/Windows (требуется поддержка CSI u в терминале)
- Комбинации:
<C-S-b>или<C-B>для Ctrl + Shift + b.
Привязка для разных ОС
С помощью параметра for можно ограничить действие клавиши определенной операционной системой ("linux", "macos", "windows", "android", "unix").
[mgr]
prepend_keymap = [
{ on = [ "g", "d" ], run = "cd ~/dev", desc = "Перейти в dev", for = "unix" },
{ on = [ "g", "d" ], run = 'cd C:\dev', desc = 'Перейти в C:\dev', for = "windows" },
]
Примеры часто используемых действий
1. Добавление “закладок” (быстрый переход):
[[mgr.prepend_keymap]]
on = [ "g", "d" ]
run = "cd ~/Downloads"
desc = "Перейти в папку Загрузки"
[[mgr.prepend_keymap]]
on = [ "g", "p" ]
run = "cd ~/Pictures"
desc = "Перейти в папку Изображения"
2. Отключение стандартной клавиши:
Чтобы отключить, например, стандартное сочетание g ⇒ c, используйте действие noop:
[[mgr.prepend_keymap]]
on = [ "g", "c" ]
run = "noop"
3. Навигация по вкладкам:
[[mgr.append_keymap]]
on = "<C-Tab>"
run = "tab_switch --relative 1"
desc = "Следующая вкладка"
[[mgr.append_keymap]]
on = "<C-S-Tab>"
run = "tab_switch --relative -1"
desc = "Предыдущая вкладка"
4. Выполнение команд оболочки:
Используйте действие shell. Специальные подстановки: %s (все выделенные файлы), %h (файл под курсором).
[[mgr.prepend_keymap]]
on = "<C-g>"
run = 'shell -- git status'
desc = "Показать статус Git"
# Интерактивная команда с предустановленным шаблоном
[[mgr.prepend_keymap]]
on = "<C-z>"
run = 'shell "zip -r archive.zip %s" --interactive'
desc = "Создать ZIP архив"
Полный список действий
Для получения исчерпывающей информации обо всех доступных действиях (actions) для каждого слоя и их аргументах, пожалуйста, обратитесь к официальной документации keymap.toml. Там вы найдете описание таких действий, как escape, quit, close, arrow, cd, reveal, toggle, yank, paste, remove, create, rename, copy, search, find, filter, sort, plugin и многих других.
Для более подробной информации о настройке keymap.toml, пожалуйста, обратитесь к полной документации.
Настройка
Конфигурация Yazi состоит из трех основных файлов в ~/.config/yazi/ (или %AppData%\yazi\config\ на Windows):
yazi.toml- Основные настройки менеджера, предпросмотра, задач.keymap.toml- Настройка горячих клавиш для всех слоев (менеджер, задачи, подсказки и т.д.).theme.toml- Настройка цветовой схемы.
По умолчанию Yazi использует встроенные предустановки. Вы можете переопределить любую настройку, создав соответствующий файл в директории конфигурации и указав в нем нужные параметры. Необязательно копировать весь файл целиком.
Основные параметры yazi.toml
Пример базовой конфигурации для отображения скрытых файлов и изменения сортировки:
# ~/.config/yazi/yazi.toml
[mgr]
show_hidden = true # Показывать скрытые файлы
sort_by = "natural" # Сортировка: "natural", "alphabetical", "mtime", "size"
sort_reverse = false # Обратный порядок сортировки
sort_dir_first = true # Показывать каталоги первыми
linemode = "mtime" # Показывать время модификации справа от имени файла
Настройка opener и open: открытие файлов по расширению
Это ключевой раздел для настройки, какие программы использовать для разных типов файлов.
1. Определение команд ([opener]):
Сначала в yazi.toml вы определяете команды, которые будут использоваться для открытия файлов.
# ~/.config/yazi/yazi.toml
[opener]
# Команда для редактирования
edit = [
{ run = 'nvim %s', block = true, for = "unix" }, # Для Unix (Linux/macOS)
{ run = 'notepad.exe %s', block = true, for = "windows" } # Для Windows
]
# Команда для просмотра (например, просмотрщик изображений)
view_image = [
{ run = 'feh %s', orphan = true, for = "unix" } # orphan = true - процесс не завершится при закрытии Yazi
]
# Команда для открытия в браузере
browser = [
{ run = 'firefox %s', orphan = true, for = "unix" }
]
# Универсальная команда для открытия системным способом
open_system = [
{ run = 'xdg-open %s1', desc = "Открыть системой", for = "unix" } # %s1 - путь к первому выделенному файлу
]
run: Команда.%s- пути всех выделенных файлов.%s1,%s2- путь к первому, второму и т.д. файлу.
block: Блокировать Yazi, пока программа не завершится (полезно для редакторов).orphan: Запустить программу как отдельный процесс (полезно для просмотрщиков, браузеров).for: Ограничить операционную систему ("unix","windows","macos","linux").
2. Применение правил ([open]):
Затем вы создаете правила, которые говорят Yazi, какую команду (use) использовать для файлов, соответствующих определенному шаблону (url или mime).
# ~/.config/yazi/yazi.toml
[open]
# ДОБАВЛЯЕМ правила ПЕРЕД стандартными (prepend)
prepend_rules = [
# Текстовые файлы открывать в редакторе
{ mime = "text/*", use = "edit" },
# Изображения открывать через просмотрщик
{ mime = "image/*", use = "view_image" },
# PDF открывать в браузере или системной программе
{ url = "*.pdf", use = "browser" },
# HTML файлы открывать в браузере
{ url = "*.html", use = "browser" },
# MP3 файлы открывать системным плеером
{ mime = "audio/*", use = "open_system" },
]
# Можно добавить правила И ПОСЛЕ стандартных (append)
append_rules = [
# Все остальные файлы открывать системным способом
{ url = "*", use = "open_system" },
]
url: Шаблон для пути файла (например,"*.pdf","*.jpg").mime: Шаблон для MIME-типа (например,"text/*","image/png").use: Имя команды из[opener].
Теперь при нажатии Enter на файле Yazi выберет первое подходящее правило.
Работа с плагинами
Yazi позволяет расширять свою функциональность с помощью плагинов на Lua. Установка и использование плагинов описана в полной документации. Вот краткий обзор:
- Структура: Плагины устанавливаются в
~/.config/yazi/plugins/. Каждый плагин — это папка с расширением.yazi, содержащая как минимумmain.lua. - Функциональные плагины: Связываются с клавишами в
keymap.tomlс помощью действияplugin. - Кастомные превьюеры: Позволяют настроить предпросмотр для специфических типов файлов и настраиваются в секции
[plugin]файлаyazi.toml.
Пример: подключение функционального плагина
Допустим, у вас есть плагин my_plugin.yazi в папке ~/.config/yazi/plugins/. Чтобы вызвать его по нажатию Ctrl + p, добавьте в keymap.toml:
# ~/.config/yazi/keymap.toml
[[mgr.prepend_keymap]]
on = "<C-p>"
run = "plugin my_plugin --arg1 value1"
desc = "Запустить мой плагин"
Внутри плагина (main.lua) аргументы будут доступны через job.args.
Пример: настройка кастомного превьюера
В yazi.toml вы можете переопределить или добавить правила для превью:
# ~/.config/yazi/yazi.toml
[plugin]
prepend_previewers = [
# Использовать плагин 'my_hex_previewer' для .bin файлов
{ url = "*.bin", run = "my_hex_previewer" },
# Использовать плагин 'my_sql_preview' для .sql файлов
{ mime = "text/x-sql", run = "my_sql_preview" },
]
Плагин my_hex_previewer должен реализовывать интерфейс peek и seek.
Отладка плагинов
Для отладки плагинов:
- Установите переменную окружения
YAZI_LOG=debugперед запуском Yazi:YAZI_LOG=debug yazi - Используйте в коде плагина
ya.dbg()для вывода отладочной информации. - Логи будут записаны в файл
~/.local/state/yazi/yazi.log.
Дополнительные источники
- Полная документация по плагинам: https://yazi-rs.github.io/docs/plugins/overview
- Основная документация Yazi: https://yazi-rs.github.io/docs/
13.9 - Установка Nextcloud AIO с Let's Encx
Пошаговый гайд: Установка Nextcloud AIO с Let’s Encrypt
Предварительные требования
- Сервер с Ubuntu/Debian
- Docker и Docker Compose установлены
- Домен, указывающий A-записью на IP сервера
- Порт 80 открыт на файерволе (для HTTP-01 проверки Let’s Encrypt)
Этап 1: Подготовка Nginx для валидации Let’s Encrypt
Первым делом настроим Nginx только на порт 80, чтобы certbot мог пройти HTTP-01 проверку.
1.1 Создайте временную конфигурацию Nginx
nano /etc/nginx/sites-available/yoursite.com
server {
listen 80;
server_name yoursite.com;
# Корень для Let's Encrypt валидации
root /var/www/html;
location /.well-known/acme-challenge/ {
root /var/www/html;
}
location / {
return 200 "Domain is ready for Nextcloud AIO setup";
}
}
1.2 Активируйте и проверьте
# Создайте символическую ссылку
ln -s /etc/nginx/sites-available/yoursite.com /etc/nginx/sites-enabled/yoursite.com
# Проверьте конфигурацию
nginx -t
# Перезагрузите Nginx
systemctl reload nginx
1.3 Создайте директорию для сертификатов
mkdir -p /etc/nginx/ssl/yoursite.com
Этап 2: Получение Let’s Encrypt сертификатов до установки Nextcloud
2.1 Установите certbot
apt update
apt install -y certbot
2.2 Выпустите сертификаты (варианты)
Вариант A: Certbot в ручном режиме (рекомендуется для точного контроля)
certbot certonly --webroot -w /var/www/html -d yoursite.com --non-interactive --agree-tos --email your@email.com
Вариант B: С плагином nginx (автоматически изменит конфиг)
apt install -y python3-certbot-nginx
certbot --nginx -d yoursite.com --non-interactive --agree-tos --email your@email.com
Вариант C: Если нужно и для основного домена и для www
certbot certonly --webroot -w /var/www/html -d yoursite.com -d www.yoursite.com --non-interactive --agree-tos --email your@email.com
2.3 Проверьте, что сертификаты созданы
ls -la /etc/letsencrypt/live/yoursite.com/
Этап 3: Обновление конфигурации Nginx для Nextcloud AIO
3.1 Замените конфиг на полноценный
nano /etc/nginx/sites-available/yoursite.com
Замените содержимое на:
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
# HTTP → HTTPS редирект
server {
listen 80;
server_name yoursite.com;
location /.well-known/acme-challenge/ {
root /var/www/html;
}
location / {
return 301 https://$server_name$request_uri;
}
}
# Основной HTTPS сервер
server {
listen 443 ssl http2;
server_name yoursite.com;
# Let's Encrypt сертификаты
ssl_certificate /etc/letsencrypt/live/yoursite.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/yoursite.com/privkey.pem;
# Современные настройки SSL
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384;
ssl_prefer_server_ciphers off;
# Заголовки безопасности
add_header Strict-Transport-Security "max-age=63072000" always;
add_header X-Content-Type-Options nosniff;
add_header X-Frame-Options "SAMEORIGIN";
add_header X-XSS-Protection "1; mode=block";
# Максимальный размер загрузки
client_max_body_size 0;
client_body_timeout 3600s;
client_header_timeout 3600s;
# Проксирование к Apache Nextcloud AIO
location / {
proxy_pass http://127.0.0.1:11000;
proxy_http_version 1.1;
# Прокси-заголовки
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Port $server_port;
# WebSocket поддержка (для Talk, Notify Push)
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
# Таймауты
proxy_read_timeout 3600s;
proxy_connect_timeout 3600s;
proxy_send_timeout 3600s;
# Буферизация
proxy_buffering off;
proxy_request_buffering off;
}
}
3.2 Проверьте и перезагрузите
nginx -t && systemctl reload nginx
Этап 4: Настройка Docker Compose для Nextcloud AIO
4.1 Создайте директорию и конфигурацию
mkdir -p /opt/nextcloud-aio
cd /opt/nextcloud-aio
nano docker-compose.yml
name: nextcloud-aio
services:
nextcloud-aio-mastercontainer:
image: ghcr.io/nextcloud-releases/all-in-one:latest
init: true
restart: always
container_name: nextcloud-aio-mastercontainer
volumes:
- nextcloud_aio_mastercontainer:/mnt/docker-aio-config
- /var/run/docker.sock:/var/run/docker.sock:ro
network_mode: bridge
ports:
- "127.0.0.1:8080:8080" # AIO интерфейс только локально
environment:
APACHE_PORT: 11000
APACHE_IP_BINDING: 127.0.0.1
volumes:
nextcloud_aio_mastercontainer:
name: nextcloud_aio_mastercontainer
4.2 Запустите мастер-контейнер
docker compose up -d
4.3 Проверьте логи
docker logs nextcloud-aio-mastercontainer --tail 30
Должны увидеть:
Initial startup of Nextcloud All-in-One complete!
You should be able to open the Nextcloud AIO Interface now on port 8080 of this server!
Этап 5: Инициализация Nextcloud AIO
5.1 Подключитесь к AIO интерфейсу через SSH-туннель
С вашего локального компьютера:
ssh -L 8080:127.0.0.1:8080 root@<IP-вашего-сервера>
Откройте в браузере: https://localhost:8080
5.2 Сохраните пароль AIO
На открывшейся странице скопируйте passphrase (12 случайных слов). Это пароль для входа в панель управления AIO.
Нажмите “Open Nextcloud AIO login” и войдите.
5.3 Введите домен
- В поле “Domain” введите:
yoursite.com - Нажмите Submit
5.4 Дождитесь проверки домена
Теперь у вас настоящий Let’s Encrypt сертификат, и проверка должна пройти успешно с первого раза!
Если вдруг не пройдёт — используйте SKIP_DOMAIN_VALIDATION: true в docker-compose.yml.
5.5 Сохраните пароль администратора Nextcloud
После проверки появится блок с учётными данными:
Username: admin
Password: **********
Скачайте файл с паролем или скопируйте его.
5.6 Запустите контейнеры
Нажмите “Start containers” и дождитесь, пока все контейнеры перейдут в статус Running (5-15 минут).
Этап 6: Автонастройка Let’s Encrypt для автообновления
6.1 Настройте автообновление сертификатов
Создайте systemd-таймер или cron-задачу:
# Создайте скрипт для обновления
nano /usr/local/bin/renew-cert.sh
#!/bin/bash
certbot renew --quiet --post-hook "systemctl reload nginx"
chmod +x /usr/local/bin/renew-cert.sh
6.2 Добавьте в cron
crontab -e
Добавьте:
0 3 * * * /usr/local/bin/renew-cert.sh
Этап 7: Финальная проверка
7.1 Проверьте, что всё работает
# Все контейнеры должны быть Running
docker ps --filter "name=nextcloud-aio"
# Проверьте доступность
curl -I https://yoursite.com
7.2 Войдите в Nextcloud
Откройте в браузере: https://yoursite.com
Логин: admin
Пароль: из шага 5.5
Восстановление пароля администратора Nextcloud (если потеряли)
docker exec -it --user www-data nextcloud-aio-nextcloud php occ user:resetpassword admin
Дополнительные рекомендации
Бэкап сертификатов
tar -czf /root/ssl-backup-$(date +%Y%m%d).tar.gz /etc/letsencrypt/
Мониторинг сертификатов
# Проверить срок действия
certbot certificates
Обновление Nextcloud AIO
Всё обновляется через AIO интерфейс автоматически, включая все контейнеры.
13.10 - Подключение Android телефона к Linux
Полный гайд Подключение Android к Linux через SSHFS
Оглавление
- Подготовка телефона (Termux)
- Подготовка компьютера Linux
- Настройка SSH-соединения
- Монтирование через SSHFS
- Автоматизация подключения
- Устранение проблем
1. Подготовка телефона (Termux)
1.1 Установка Termux
Скачайте Termux:
- Из F-Droid (рекомендуется)
- Или из Google Play Store
Установите и откройте Termux
Обновите пакеты:
pkg update && pkg upgrade -y
1.2 Установка необходимых пакетов
# Установка SSH-сервера
pkg install openssh -y
# Установка терминальных утилит
pkg install nano vim -y # или любой другой редактор
# Установка для работы с памятью
pkg install termux-api -y # опционально
1.3 Настройка доступа к хранилищу
# Запрос доступа к файлам телефона
termux-setup-storage
# На телефоне появится запрос на разрешение доступа к файлам
# Нажмите "Разрешить"
1.4 Настройка SSH-сервера
# Проверьте текущее имя пользователя
whoami
# Запомните вывод (например, u0_a123)
# Установите пароль для SSH
passwd
# Введите пароль дважды
# Запустите SSH-сервер
sshd
# Проверьте, что сервер работает
ps aux | grep sshd
1.5 Автозапуск SSH (опционально)
# Создайте скрипт автозапуска
vim ~/.bashrc
# Добавьте в конец:
# Запуск SSH-сервера, если не запущен
if ! pgrep -x "sshd" > /dev/null; then
sshd
fi
# Сохраните (Ctrl+O, Enter, Ctrl+X)
1.6 Узнайте IP-адрес телефона
# В Termux выполните:
ifconfig wlan0
# Найдите inet адрес (например, 192.168.1.100)
# Запомните его - это IP вашего телефона в локальной сети
2. Подготовка компьютера Linux
2.1 Установка SSHFS
# Для Ubuntu/Debian:
sudo apt update
sudo apt install sshfs -y
# Для Fedora/RHEL:
sudo dnf install sshfs -y
# Для Arch:
sudo pacman -S sshfs
# Для openSUSE:
sudo zypper install sshfs
2.2 Установка SSH-клиента (обычно уже установлен)
# Проверьте наличие SSH
which ssh
# Если нет, установите:
# Ubuntu/Debian:
sudo apt install openssh-client -y
2.3 Создание папки для монтирования
# Создайте директорию для монтирования
mkdir -p ~/data/android
# Или любую другую:
# mkdir -p ~/android
# mkdir -p ~/phone
3. Настройка SSH-соединения
3.1 Проверка подключения
# Используйте имя пользователя, полученное в Termux (whoami)
# Используйте IP-адрес телефона
ssh -p 8022 u0_a123@IP_АДРЕСА_ТЕЛЕФОНА
# Например:
ssh -p 8022 u0_a123@192.168.1.100
# При первом подключении подтвердите fingerprint (напишите yes)
# Введите пароль, установленный ранее
3.2 Настройка SSH-ключа (для входа без пароля)
# На компьютере создайте SSH-ключ (если нет)
ssh-keygen -t ed25519 -C "your_email@example.com"
# Нажимайте Enter для стандартных настроек
# Скопируйте публичный ключ на телефон
ssh-copy-id -p 8022 u0_a123@IP_АДРЕСА_ТЕЛЕФОНА
# Или вручную:
cat ~/.ssh/id_ed25519.pub | ssh -p 8022 u0_a123@IP_АДРЕСА_ТЕЛЕФОНА "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
3.3 Настройка .ssh/config (опционально)
# Создайте конфигурационный файл
vim ~/.ssh/config
# Добавьте:
Host android
HostName IP_АДРЕСА_ТЕЛЕФОНА
Port 8022
User u0_a123
IdentityFile ~/.ssh/id_ed25519
ServerAliveInterval 60
ServerAliveCountMax 3
# Сохраните и закройте
# Теперь можно подключаться просто:
ssh android
4. Монтирование через SSHFS
4.1 Создание скрипта монтирования
# Создайте файл для монтирования
vim ~/mount_android.sh
# Добавьте содержимое:
#!/bin/bash
# Переменные
PHONE_USER="u0_a123" # Замените на ваше имя пользователя
PHONE_IP="192.168.1.100" # Замените на ваш IP
PHONE_PORT="8022"
PHONE_PATH="/storage/emulated/0" # Путь к внутренней памяти
MOUNT_POINT="$HOME/data/android"
# Создайте точку монтирования если её нет
mkdir -p "$MOUNT_POINT"
# Проверка, уже смонтировано или нет
if mount | grep -q "$MOUNT_POINT"; then
echo "Папка уже смонтирована"
exit 0
fi
# Монтирование
sshfs -p $PHONE_PORT \
-o follow_symlinks \
-o idmap=user \
-o uid=$(id -u) \
-o gid=$(id -g) \
-o reconnect \
-o ServerAliveInterval=15 \
-o ServerAliveCountMax=3 \
-o compression=yes \
-o cache=yes \
$PHONE_USER@$PHONE_IP:$PHONE_PATH "$MOUNT_POINT"
if [ $? -eq 0 ]; then
echo "✅ Телефон смонтирован в $MOUNT_POINT"
ls -la "$MOUNT_POINT" | head -5
else
echo "❌ Ошибка монтирования"
exit 1
fi
4.2 Сделайте скрипт исполняемым
chmod +x ~/mount_android.sh
4.3 Выполните монтирование
./mount_android.sh
4.4 Команда для быстрого монтирования
# Если нет желания создавать скрипт
sshfs -p 8022 \
-o follow_symlinks \
-o idmap=user \
-o uid=$(id -u) \
-o gid=$(id -g) \
u0_a123@192.168.1.100:/storage/emulated/0 ~/data/android
4.5 Размонтирование
# Обычное размонтирование
fusermount -u ~/data/android
# Принудительное размонтирование
sudo umount -l ~/data/android
5. Автоматизация подключения
5.1 Создание алиасов в .bashrc
# Откройте .bashrc
vim ~/.bashrc
# Добавьте в конец:
# Монтирование телефона
alias mount-phone='~/mount_android.sh'
alias umount-phone='fusermount -u ~/data/android'
alias phone='cd ~/data/android'
# Сохраните и примените:
source ~/.bashrc
5.2 Автоматическое монтирование при входе (опционально)
# Добавьте в ~/.bashrc или ~/.profile:
if [ -f ~/mount_android.sh ]; then
~/mount_android.sh
fi
5.3 Создание systemd-сервиса (для автоматического монтирования)
# Создайте сервис
sudo vim /etc/systemd/system/mount-phone.service
# Добавьте:
[Unit]
Description=Mount Android phone via SSHFS
After=network.target
[Service]
Type=oneshot
User=ваше_имя_пользователя
ExecStart=/home/ваше_имя_пользователя/mount_android.sh
ExecStop=/usr/bin/fusermount -u /home/ваше_имя_пользователя/data/android
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
# Включите сервис
sudo systemctl enable mount-phone.service
sudo systemctl start mount-phone.service
6. Устранение проблем
6.1 Проблема: “Host key verification failed”
# Решение:
ssh-keygen -R [IP_АДРЕСА_ТЕЛЕФОНА]:8022
# Или удалите старый ключ:
vim ~/.ssh/known_hosts
# Удалите строку с IP телефона
6.2 Проблема: “Connection refused”
# Проверьте на телефоне в Termux:
sshd
# Проверьте порт:
netstat -tlnp | grep 8022
6.3 Проблема: “Permission denied”
# Проверьте пароль:
passwd # установите заново в Termux
# Проверьте права на .ssh:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
6.4 Проблема: Медленная работа
# Добавьте опции для ускорения:
sshfs -p 8022 \
-o compression=yes \
-o cache=yes \
-o Ciphers=arcfour \
u0_a123@IP:/storage/emulated/0 ~/data/android
6.5 Проблема: Телефон засыпает и отключается
# Настройки телефона:
# 1. Отключите оптимизацию батареи для Termux
# 2. Держите Wi-Fi включенным
# 3. Используйте опцию ServerAliveInterval:
sshfs -p 8022 \
-o ServerAliveInterval=15 \
-o ServerAliveCountMax=3 \
u0_a123@IP:/storage/emulated/0 ~/data/android
6.6 Проверка логов
# На телефоне в Termux:
cat ~/.ssh/sshd.log
# На компьютере:
dmesg | grep -i error
journalctl -xe | grep -i sshfs
6.7 Доступ к внешней SD-карте
# Для доступа к внешней SD-карте:
# В Termux сначала найдите путь:
ls -la /storage/
# Обычно это:
sshfs u0_a123@IP:/storage/XXXX-XXXX ~/data/sdcard
# Где XXXX-XXXX - идентификатор вашей SD-карты
Полезные команды
# Проверить, что смонтировано
df -h | grep sshfs
# Показать всё содержимое телефона
ls -la ~/data/android
# Скопировать файл с телефона
cp ~/data/android/DCIM/Camera/photo.jpg ~/Pictures/
# Скопировать файл на телефон
cp ~/Documents/file.pdf ~/data/android/Download/
# Найти файлы на телефоне
find ~/data/android -name "*.mp3"
# Создать ссылку для быстрого доступа
ln -s ~/data/android ~/android
Краткая последовательность действий
- Телефон: Установить Termux →
pkg install openssh→sshd→whoami→passwd→ узнать IP - Компьютер:
sudo apt install sshfs→ создать папкуmkdir -p ~/data/android - Подключение:
ssh -p 8022 u0_a123@IP(проверка) - Монтирование:
sshfs -p 8022 u0_a123@IP:/storage/emulated/0 ~/data/android - Работа:
cd ~/data/androidи пользуйтесь файлами!
13.11 - Установка виртуальных машин QEMU/KVM на рабочей станции или сервере
некоторые особенности и нюансы по установке виртуальных машин на рабочей станции
Зачем я использую виртуализацию?
Виртуализация — это когда на одном физическом компьютере работает несколько отдельных компьютеров одновременно. Или скорее мне это понадобилось, когда активно изучал загрузчик GRUB со всеми тонкостями. Так вообще хватает контейнеров, но для тестирования новой версии linux отличная идея.
Как это работает:
- Есть реальный компьютер (хост)
- На нём запускают специальную программу (гипервизор)
- Эта программа создаёт виртуальные компьютеры (гостевые ВМ)
- Каждая ВМ имеет свой процессор, память, диск, сеть (виртуальные)
Зачем нужно:
- Тестирование ПО без риска для основной системы
- Запуск Windows на Linux и наоборот
- Изоляция приложений
VirtualBox
Что это: Программа для виртуализации от Oracle. Бесплатная, простая, кроссплатформенная.
Плюсы:
- Очень простой интерфейс
- Работает на Windows, Linux, macOS
- Подходит для новичков
- Не требует включения VT-x в BIOS (это конструктивные особенности материнской платы вашего компьютера поддерживать виртуализацию, зайдите в BIOS и включите ее если она выключена)
Минусы:
- Медленнее чем KVM
- Проблемы с 3D-графикой
- Нет официальной поддержки в RHEL/CentOS (для меня не так существенно, хоть и очень люблю fedora)
virt-manager (KVM/QEMU)
Что это: Графическая программа для управления виртуализацией KVM/QEMU в Linux. Стандарт для RHEL/Fedora/CentOS.
Плюсы:
- Очень высокая производительность (почти как на реальном железе)
- Встроен в ядро Linux
- Поддержка огромных серверных конфигураций
- Тонкая настройка всех параметров
Минусы:
- Только для Linux
- Сложнее для новичков
- Требует включения виртуализации в BIOS (я про это написал выше)
Можно использовать: Для серверов, production-среды, ресурсоёмких ВМ, работы с Docker и Podman вместе с ВМ.
Установка VirtualBox на Fedora — пошаговая инструкция
Шаг 1: Удалите старые версии (если были)
sudo dnf remove VirtualBox virtualbox
Шаг 2: Установите зависимости
sudo dnf install kernel-devel kernel-headers dkms gcc make perl elfutils-libelf-devel
Важно: Перезагрузите систему после установки kernel-devel:
sudo reboot
Шаг 3: Добавьте репозиторий VirtualBox
sudo dnf config-manager --add-repo https://download.virtualbox.org/virtualbox/rpm/fedora/virtualbox.repo
Если нет config-manager:
sudo dnf install dnf-plugins-core
Шаг 4: Импортируйте ключ GPG
sudo rpm --import https://www.virtualbox.org/download/oracle_vbox.asc
Шаг 5: Установите VirtualBox
sudo dnf install VirtualBox-7.2.6
Шаг 6: Добавьте пользователя в группу vboxusers
sudo usermod -aG vboxusers $USER
Шаг 7: Соберите модули ядра
sudo /sbin/vboxconfig
Шаг 8: Перезагрузите систему
sudo reboot
Шаг 9: Проверьте установку
# Проверить загрузку модулей
lsmod | grep vbox
# Запустить VirtualBox
virtualbox
Если Secure Boot включён — два варианта:
Вариант А — Отключить Secure Boot (проще)
- Войдите в BIOS/UEFI (F2, F10, F12, Del)
- Найдите Secure Boot → Disable
- Сохраните и выйдите
Вариант Б — Подписать модули (безопаснее)
sudo dnf install kmodtool
sudo kmodgenca -a
sudo mokutil --import /etc/pki/akmods/certs/public_key.der
sudo reboot
При загрузке появится синий экран MOK — выберите “Enroll MOK” и подтвердите.
Установка Extension Pack (дополнительно)
Для USB 2.0/3.0, RDP, NVMe:
wget https://download.virtualbox.org/virtualbox/7.2.6/Oracle_VM_VirtualBox_Extension_Pack-7.2.6.vbox-extpack
sudo VBoxManage extpack install Oracle_VM_VirtualBox_Extension_Pack-7.2.6.vbox-extpack
Версию уточните на virtualbox.org
Гостевые дополнения (Guest Additions)
Внутри виртуальной машины:
Устройства → Подключить образ Guest Additions → Запустить
Проверка после установки:
vboxmanage --version
systemctl status vboxdrv
groups | grep vboxusers
VirtualBox установлен и готов к созданию виртуальных машин.
Установка QEMU/KVM на Fedora — пошаговая инструкция
Шаг 1: Проверьте поддержку виртуализации
# Проверка, включена ли виртуализация в BIOS
grep -E "vmx|svm" /proc/cpuinfo
Если есть вывод с vmx (Intel) или svm (AMD) — виртуализация включена.
Если вывод пустой:
- Войдите в BIOS/UEFI (F2, F10, F12, Del)
- Включите Intel VT-x / AMD-V
- Сохраните и перезагрузитесь
Шаг 2: Установите группу пакетов виртуализации
sudo dnf install @virtualization
Эта команда установит:
qemu-kvm— основной эмуляторlibvirt— управление виртуализациейvirt-manager— графический интерфейсvirt-install— создание ВМ из терминала- И другие необходимые компоненты
Шаг 3: Запустите и включите службу libvirtd
sudo systemctl start libvirtd
sudo systemctl enable libvirtd
Шаг 4: Добавьте пользователя в группу libvirt
sudo usermod -aG libvirt $USER
Важно! После этой команды нужно выйти из системы и зайти снова или перезагрузить компьютер:
sudo reboot
Шаг 5: Проверьте установку
# Проверить статус службы
systemctl status libvirtd
# Проверить, что пользователь в группе
groups | grep libvirt
# Проверить виртуальную сеть
virsh net-list --all
virsh net-start default
virsh net-autostart default
Шаг 6: Запустите virt-manager
virt-manager
Или через меню приложений
Создание первой виртуальной машины
Через графический интерфейс (virt-manager):
- Нажмите кнопку “Создать новую виртуальную машину”
- Выберите источник установки:
- Локальный ISO-файл
- Сетевая установка (HTTP/FTP)
- Импорт существующего образа
- Выберите ISO-образ ОС
- Настройте RAM и CPU
- Создайте виртуальный диск
- Завершите настройку и начните установку
Через терминал (virt-install):
sudo virt-install \
--name fedora-vm \
--ram 2048 \
--vcpus 2 \
--disk path=/var/lib/libvirt/images/fedora-vm.qcow2,size=20 \
--os-variant fedora38 \
--network network=default \
--graphics spice \
--cdrom /путь/к/fedora.iso
Полезные команды для управления
# Список виртуальных машин
virsh list --all
# Запустить ВМ
virsh start имя_вм
# Остановить ВМ
virsh shutdown имя_вм
# Принудительно выключить
virsh destroy имя_вм
# Удалить ВМ
virsh undefine имя_вм
virsh vol-delete --pool default имя_вм.qcow2
# Войти в консоль ВМ
virsh console имя_вм
Настройка сети (если нужно)
Мост (bridge) для внешнего доступа:
# Создать bridge
nmcli connection add type bridge ifname br0
# Подключить Ethernet к мосту
nmcli connection add type ethernet slave-type bridge con-name bridge-br0 ifname enp0s3 master br0
# Включить мост
nmcli connection up br0
Проброс USB-устройств
В virt-manager:
- Откройте настройки ВМ
- Добавить оборудование → USB Host Device
- Выберите устройство из списка
Оптимизация производительности
Включите hugepages:
echo 1024 | sudo tee /proc/sys/vm/nr_hugepages
Используйте virtio драйверы:
- Диски: virtio-scsi или virtio-blk
- Сеть: virtio-net
- Это даёт прирост производительности ~30%
Удаление KVM/libvirt
sudo dnf remove @virtualization
sudo rm -rf /var/lib/libvirt
sudo rm -rf /etc/libvirt
Проверочный лист после установки:
- Виртуализация включена в BIOS
- Пакеты установлены:
dnf groupinfo virtualization - Служба работает:
systemctl status libvirtd - Пользователь в группе:
groups | grep libvirt - Сеть работает:
virsh net-list --all - virt-manager запускается
QEMU/KVM установлен и готов к работе.
Команда sudo dnf install @virtualization устанавливает группу пакетов (пакетную группу) для виртуализации.
Что значит @ ?
Символ @ в DNF означает группу пакетов, а не отдельный пакет.
Что устанавливается:
Группа @virtualization включает все необходимые пакеты для работы с KVM/QEMU:
Основные компоненты:
qemu-kvm— основной эмуляторlibvirt— библиотека для управления виртуализациейvirt-install— утилита для создания ВМ из командной строкиvirt-viewer— клиент для просмотра ВМvirt-manager— графический интерфейс (GUI)libvirt-client— клиентские утилитыlibvirt-daemon-config-network— сетевые настройкиlibvirt-daemon-config-nwfilter— фильтры сетиedk2-ovmf— UEFI поддержкаguestfs-tools— инструменты для работы с образами дисков
Как посмотреть состав группы:
# Список всех групп
dnf group list
# Информация о группе virtualization
dnf group info virtualization
# Показать пакеты в группе
dnf group info virtualization | grep -E "Mandatory|Default|Optional"
Без GUI (только командная строка):
sudo dnf install @virtualization-headless
Установка отдельных компонентов:
# Только ядро виртуализации
sudo dnf install qemu-kvm libvirt
# Только virt-manager (GUI)
sudo dnf install virt-manager
После установки:
# Запустить libvirtd
sudo systemctl start libvirtd
sudo systemctl enable libvirtd
# Добавить пользователя в группу
sudo usermod -aG libvirt $USER
# Проверить установку
virsh list --all
Краткий справочник команд QEMU/KVM (CLI)
Управление виртуальными машинами (virsh)
# Список ВМ
virsh list # запущенные
virsh list --all # все
# Управление состоянием
virsh start vm-name # запуск
virsh shutdown vm-name # выключение (ACPI)
virsh destroy vm-name # принудительно
virsh reboot vm-name # перезагрузка
virsh reset vm-name # аппаратный сброс
virsh suspend vm-name # пауза
virsh resume vm-name # возобновить
# Удаление
virsh undefine vm-name # удалить конфиг
virsh undefine --remove-all-storage vm-name # удалить с диском
# Консоль
virsh console vm-name # подключиться к serial console
virsh vncdisplay vm-name # показать порт VNC
Создание ВМ (virt-install)
# Базовая установка с ISO
virt-install \
--name vm-name \
--ram 2048 \
--vcpus 2 \
--disk path=/var/lib/libvirt/images/vm.qcow2,size=20 \
--os-variant fedora38 \
--network network=default \
--graphics spice \
--cdrom /path/to/os.iso
# Без графики (текстовый режим)
virt-install \
--name vm-name \
--ram 2048 \
--vcpus 2 \
--disk size=10 \
--os-variant ubuntu22.04 \
--network default \
--graphics none \
--console pty,target_type=serial \
--location 'http://archive.ubuntu.com/ubuntu/dists/jammy/main/installer-amd64/'
# Импорт существующего образа
virt-install \
--name vm-name \
--ram 2048 \
--vcpus 2 \
--disk /var/lib/libvirt/images/existing.qcow2 \
--import \
--network default \
--os-variant fedora38
Управление образами дисков (qemu-img)
# Создать образ
qemu-img create -f qcow2 disk.qcow2 20G
# Информация об образе
qemu-img info disk.qcow2
# Увеличить размер
qemu-img resize disk.qcow2 +10G
# Конвертировать форматы
qemu-img convert -f qcow2 -O raw disk.qcow2 disk.raw
# Создать снапшот (qcow2)
qemu-img snapshot -c snap1 disk.qcow2
# Список снапшотов
qemu-img snapshot -l disk.qcow2
# Откатить снапшот
qemu-img snapshot -a snap1 disk.qcow2
Управление сетью
# NAT сеть (default)
virsh net-list --all
virsh net-start default
virsh net-autostart default
# Создать изолированную сеть
virsh net-define isolated-network.xml
virsh net-start isolated
virsh net-autostart isolated
# Мост (bridge)
brctl show
nmcli connection add type bridge ifname br0
nmcli connection add type ethernet slave-type bridge con-name br0-slave ifname eth0 master br0
# Информация о интерфейсах ВМ
virsh domiflist vm-name
virsh domifaddr vm-name # IP адреса
isolated-network.xml:
<network>
<name>isolated</name>
<bridge name='virbr1'/>
<ip address='192.168.100.1' netmask='255.255.255.0'>
<dhcp>
<range start='192.168.100.10' end='192.168.100.100'/>
</dhcp>
</ip>
</network>
Управление хранилищем
# Список пулов
virsh pool-list --all
# Информация о пуле
virsh pool-info default
# Список томов
virsh vol-list --pool default
# Создать том
virsh vol-create-as default newvm.qcow2 20G --format qcow2
# Клонировать том
virsh vol-clone --pool default source.qcow2 clone.qcow2
# Удалить том
virsh vol-delete --pool default vm.qcow2
Настройка ВМ (virsh edit)
# Редактировать конфиг
virsh edit vm-name
# Добавить CPU (горячее подключение)
virsh setvcpus vm-name 4 --live
# Добавить память
virsh setmem vm-name 4G --live
# Добавить диск
virsh attach-disk vm-name /path/to/disk.qcow2 vdb --live
# Отключить диск
virsh detach-disk vm-name vdb
# Добавить сетевой интерфейс
virsh attach-interface vm-name bridge virbr0 --live
# Проброс USB
virsh attach-device vm-name usb-device.xml
usb-device.xml:
<hostdev mode='subsystem' type='usb'>
<source>
<vendor id='0x1234'/>
<product id='0x5678'/>
</source>
</hostdev>
Снапшоты
# Создать снапшот
virsh snapshot-create-as vm-name snap1 "Описание"
# Список снапшотов
virsh snapshot-list vm-name
# Информация о снапшоте
virsh snapshot-info vm-name --snapshotname snap1
# Откатить
virsh snapshot-revert vm-name snap1
# Удалить снапшот
virsh snapshot-delete vm-name snap1
Мониторинг и отладка
# Статистика
virsh domstats vm-name
virsh dommemstat vm-name
virsh domblkstat vm-name
virsh domifstat vm-name vm-net
# Информация о ВМ
virsh dominfo vm-name
virsh vcpuinfo vm-name
virsh domblklist vm-name
virsh domiflist vm-name
# Логи
journalctl -u libvirtd -f
dmesg | grep -i kvm
Прямой запуск QEMU (без libvirt)
# Минимальный запуск
qemu-system-x86_64 \
-name vm1 \
-m 1024 \
-drive file=disk.qcow2,format=qcow2 \
-netdev user,id=net0 \
-device virtio-net-pci,netdev=net0
# С CD-ROM и загрузкой с него
qemu-system-x86_64 \
-cdrom os.iso \
-boot d \
-hda disk.qcow2 \
-m 2048 \
-enable-kvm
Полезные однострочники
# Узнать OS-variant
osinfo-query os
# Показать IP всех ВМ
for vm in $(virsh list --name); do echo "$vm: $(virsh domifaddr $vm | grep ipv4 | awk '{print $4}')"; done
# Завершить все ВМ
virsh list --name | xargs -I {} virsh shutdown {}
# Удалить все выключенные ВМ
virsh list --all --name | xargs -I {} virsh undefine {} --remove-all-storage
# Бэкап диска ВМ
virsh dumpxml vm-name > vm-backup.xml
cp /var/lib/libvirt/images/vm.qcow2 vm-backup.qcow2
Краткий справочник
| Действие | Команда |
|---|---|
| Создать ВМ | virt-install ... |
| Запустить | virsh start vm |
| Остановить | virsh shutdown vm |
| Удалить | virsh undefine --remove-all-storage vm |
| Список ВМ | virsh list --all |
| Консоль | virsh console vm |
| Создать диск | qemu-img create -f qcow2 disk.qcow2 20G |
| Инфо о диске | qemu-img info disk.qcow2 |
| Редакт. конфиг | virsh edit vm |
| Снапшот | virsh snapshot-create-as vm snap1 |
| Откат | virsh snapshot-revert vm snap1 |
13.12 - Шпаргалка по основным командам crone
Шпаргалка по основным командам crone с примерами
Формат команды cron
Команда 0 3 * * 0 /usr/bin/docker system prune -af --filter "until=168h" && /usr/bin/docker volume prune -f в cron состоит из двух частей:
- Расписание:
0 3 * * 0 - Команда:
/usr/bin/docker system prune -af --filter "until=168h" && /usr/bin/docker volume prune -f
Разбор расписания (пять полей):
┌───────────── минуты (0 - 59)
│ ┌───────────── час (0 - 23)
│ │ ┌───────────── день месяца (1 - 31)
│ │ │ ┌───────────── месяц (1 - 12)
│ │ │ │ ┌───────────── день недели (0 - 6) (0 - воскресенье)
│ │ │ │ │
│ │ │ │ │
0 3 * * 0
0- в 0 минут часа3- в 3 часа утра*- каждый день месяца*- каждый месяц0- только по воскресеньям
Итог: команда выполняется каждое воскресенье в 3:00 утра.
Где хранятся файлы конфигурации cron
1. Системные cron-задачи:
/etc/crontab- основной файл конфигурации/etc/cron.d/- каталог для дополнительных конфигураций/etc/cron.hourly/,/etc/cron.daily/,/etc/cron.weekly/,/etc/cron.monthly/- каталоги для скриптов, выполняемых с указанной периодичностью
2. Пользовательские cron-задачи:
/var/spool/cron/crontabs/- каталог с индивидуальными файлами для каждого пользователя (обычно редактируются черезcrontab -e)- Для просмотра:
crontab -l - Для редактирования:
crontab -e
Особенности:
- При редактировании через
crontab -eне нужно указывать пользователя - задача будет выполняться от имени текущего пользователя - В системных файлах (/etc/crontab) требуется указать пользователя:
0 3 * * 0 root /usr/bin/docker system prune -af... - Для root-задач лучше использовать
crontab -eот root или размещать в/etc/cron.d/
Проверка cron-задач
После добавления задачи можно проверить:
# Для пользовательских задач
crontab -l
# Для системных задач
cat /etc/crontab
ls /etc/cron.d/
Дополнительные параметры cron
В конец cron-задачи можно добавить перенаправление вывода:
0 3 * * 0 /usr/bin/docker system prune -af --filter "until=168h" && /usr/bin/docker volume prune -f > /var/log/docker-clean.log 2>&1
Где:
> /var/log/docker-clean.log- перенаправление stdout в файл2>&1- перенаправление stderr в тот же файл
13.13 - Шпаргалка по работе с ядрами в Linux
Шпаргалка по работе с ядрами в Linux. Добавление, удаление, обновление.
1. Узнать текущее ядро
uname -r
2. Список установленных ядер
sudo mhwd-kernel -l
3. Удалить ядро
sudo mhwd-kernel -r <kernel-name>
<kernel-name>— имя ядра, которое вы хотите удалить (например,linux515).
4. Обновить конфигурацию bootloader
sudo update-grub
или
sudo grub-mkconfig -o /boot/grub/grub.cfg
5. Установить новое ядро
sudo mhwd-kernel -i <kernel-name>
<kernel-name>— имя ядра, которое вы хотите установить (например,linux519).
6. Переключиться на другое ядро
- Установите новое ядро:
sudo mhwd-kernel -i <kernel-name> - Перезагрузите систему:
sudo reboot - В меню bootloader выберите новое ядро.
7. Проверка текущего ядра
uname -r
8. Ручное удаление ядра (не рекомендуется)
sudo pacman -Rdd <package-name>
<package-name>— имя пакета ядра, которое вы хотите удалить (например,linux515).
Внимание: Будьте осторожны при удалении ядер, особенно если вы не уверены, какое ядро активно используется.
13.14 - Создание собственных уроков для GNU Typist
Подробное руководство по созданию и настройке уроков для клавиатурного тренажёра GNU TypistS
Создание собственных уроков для GNU Typist
Это руководство объясняет, как создавать собственные уроки для программы GNU Typist (gtypist). Уроки создаются с помощью простого скриптового языка, что позволяет легко их модифицировать и адаптировать под любые нужды .
Структура файла уроков
Файл уроков имеет расширение .typ и состоит из строк, каждая из которых начинается с однобуквенной команды, за которой следует двоеточие (:) и данные команды.
# Это комментарий. Строки, начинающиеся с '#', игнорируются.
*:НАЧАЛО # Это метка. Она должна быть уникальной в файле.
B:Мой тренажёр # Отображает баннер в верхней части экрана.
T:Это текст урока. # Отображает текст и ждёт нажатия клавиши.
:Это продолжение текста урока.
I:Краткая инструкция. # Отображает инструкцию перед упражнением.
D:asdf jkl; # Упражнение-тренировка (drill). Нужно печатать в промежуточных строках.
:qwer uiop
Основные команды
| Команда | Описание | Пример |
|---|---|---|
# | Комментарий. Вся строка игнорируется. | # Это комментарий |
* | Метка. Точка перехода для команд G, Y, N, F. | *:УРОК_1 |
B | Banner (Баннер). Очищает экран и отображает текст в верхней строке. | B:Основы слепой печати |
T | Tutorial (Урок). Отображает многострочный текст и ждёт нажатия любой клавиши для продолжения. | T:Это обучающий текст.:Он может занимать несколько строк. |
I | Instruction (Инструкция). Отображает до двух строк инструкции над упражнением. Не ждёт нажатия клавиши. | I:Напечатайте строку ниже: |
D | Drill (Тренировка). Основное упражнение, где текст отображается в каждой второй строке, а пользователь печатает в промежуточных. | D:aaa sss ddd fff:jjj kkk lll ;;; |
d | Practice-only drill. То же, что и D, но пользователь не обязан повторять упражнение при большом количестве ошибок. | d:тренировочный текст |
S | Speed test (Тест скорости). Текст отображается на экране, и пользователь печатает поверх него. Ошибки можно исправлять, но они учитываются. | S:Это предложение для теста скорости. |
s | Practice-only speed test. Аналогично S, но без обязательного повторения. | s:Текст для практики. |
G | Go to label (Перейти к метке). Безусловный переход к указанной метке. | G:СЛЕДУЮЩИЙ_УРОК |
Q | Question (Вопрос). Отображает вопрос и ждёт ввода Y или N. | Q:Повторить урок? (Y/N) |
Y | Yes (Да). Переход к метке, если на последний вопрос Q был дан ответ Y. | Y:ПОВТОР |
N | No (Нет). Переход к метке, если на последний вопрос Q был дан ответ N. | N:СЛЕДУЮЩИЙ |
M | Menu (Меню). Создаёт меню для навигации. | M: UP=ВЫХОД "Главное меню":УРОК_1 "Урок 1":УРОК_2 "Урок 2" |
X | Exit (Выход). Завершает программу. | X: |
E | Error rate (Допустимый процент ошибок). Устанавливает максимальный процент ошибок для упражнения. | E:5.0%E:2.0%* (действует для всех последующих упражнений) |
F | Failure label (Метка при неудаче). Указывает метку, куда переходить при провале упражнения. | F:ПОВТОРF:ЗАВЕРШЕНИЕ* (действует для всех последующих упражнений) |
Пошаговое руководство по созданию урока
1. Создание файла
Создайте новый текстовый файл с расширением .typ, например, moj_urok.typ.
2. Структура урока
Начните с комментария и баннера, чтобы придать уроку профессиональный вид.
# ==============================================
# Мой первый урок для gtypist
# ==============================================
B:Урок 1: Основы
3. Добавление обучающего текста
Используйте команду T для объяснения материала.
T:Этот урок научит вас печатать буквы 'а', 'о', 'и' и 'е'.
:Начнём с простых упражнений.
4. Создание упражнений
Добавьте тренировки (D или d) и тесты скорости (S или s).
# Упражнение на буквы 'а' и 'о'
I:Напечатайте строки, используя указательные пальцы.
D:ао аоа оао ааа ооо
:оао аоа аоо оаа
# Упражнение на буквы 'и' и 'е'
I:Теперь буквы 'и' и 'е'.
D:ие иеи еие иии еее
:еие иеи иее еии
# Простой тест скорости
I:Тест скорости. Исправляйте ошибки!
S:Ехал грека через реку.
S:Видит грека в реке рак.
5. Добавление навигации и ветвления
Используйте метки, вопросы и переходы для создания структуры.
*:НАЧАЛО
T:Добро пожаловать!
*:УРОК_1
G:УПР_АО
*:УПР_АО
I:Упражнение на 'а' и 'о'.
D:ао аоа оао
G:ВОПРОС_АО
*:ВОПРОС_АО
Q:Повторить упражнение на 'а' и 'о'? (Y/N)
Y:УПР_АО
N:УРОК_2
*:УРОК_2
T:Переходим к следующему уроку.
# ... далее урок 2
6. Использование меню (рекомендуется)
Начиная с версии 2.7, для навигации удобно использовать команду M .
B:Мой тренажёр
*:ГЛАВНОЕ_МЕНЮ
M: UP=_EXIT "Главное меню"
:УРОК_1 "Урок 1: А и О"
:УРОК_2 "Урок 2: И и Е"
:ВЫХОД "Выйти"
*:УРОК_1
G:УПР_АО
# ... определение УПР_АО ...
*:УРОК_2
# ... Урок 2 ...
*:ВЫХОД
X:
Это создаст удобное меню для выбора уроков.
Примеры и шаблоны
Вот пример простого файла moj_urok.typ, который включает все основные элементы:
# ==============================================
# Мой первый полноценный урок для gtypist
# ==============================================
*:ГЛАВНОЕ_МЕНЮ
M: UP=_EXIT "Меню"
:УРОК_1_БУКВЫ "Урок 1: Буквы А,О,И,Е"
:УРОК_2_СЛОВА "Урок 2: Слова"
:ВЫХОД "Выйти"
# ----------------------------------------------
# Урок 1: Буквы А, О, И, Е
# ----------------------------------------------
*:УРОК_1_БУКВЫ
B:Урок 1
T:Этот урок научит вас печатать буквы 'а', 'о', 'и' и 'е' с помощью указательных пальцев.
*:УПР_АО
I:Напечатайте строки с буквами 'а' и 'о'.
D:ао аоа оао ааа ооо
:оао аоа аоо оаа
Q:Повторить упражнение на 'а' и 'о'? (Y/N)
Y:УПР_АО
N:УПР_ИЕ
*:УПР_ИЕ
I:Теперь буквы 'и' и 'е'.
D:ие иеи еие иии еее
:еие иеи иее еии
Q:Повторить упражнение на 'и' и 'е'? (Y/N)
Y:УПР_ИЕ
N:ТЕСТ_1
*:ТЕСТ_1
I:Тест скорости.
S:Ехал грека через реку.
S:Видит грека в реке рак.
Q:Повторить тест? (Y/N)
Y:ТЕСТ_1
N:ГЛАВНОЕ_МЕНЮ
# ----------------------------------------------
# Урок 2: Простые слова
# ----------------------------------------------
*:УРОК_2_СЛОВА
B:Урок 2
T:Теперь попробуем печатать простые слова.
*:УПР_СЛОВА
I:Печатайте слова.
D:мама папа мир
:море рама
Q:Повторить? (Y/N)
Y:УПР_СЛОВА
N:ГЛАВНОЕ_МЕНЮ
# ----------------------------------------------
# Выход
# ----------------------------------------------
*:ВЫХОД
X:
Советы и лучшие практики
- Используйте комментарии: Начинайте строки с
#, чтобы документировать свой код. - Структурируйте уроки: Разбивайте обучение на логические части: введение, тренировка, тест, повторение.
- Используйте
Iдля инструкций: Всегда давайте чёткие инструкции перед упражнениями. - Начинайте с малого: Вводите новые буквы постепенно, тренируйте их в комбинациях с уже изученными.
- Автоматизируйте проверку: Используйте
Q,Y,Nдля создания циклов повторения. - Используйте меню (
M): Это современный и удобный способ навигации. - Изучите примеры: Посмотрите на файлы уроков, которые поставляются с gtypist (например,
t.typилиru.typ), чтобы увидеть, как устроены сложные уроки .
Запуск вашего урока
Чтобы запустить созданный урок, используйте команду:
gtypist /путь/к/вашему/файлу/moj_urok.typ
Если вы хотите начать с определённой метки (например, УРОК_2_СЛОВА), используйте опцию -l:
gtypist -l УРОК_2_СЛОВА moj_urok.typ
Инструменты для создания уроков
- Режим Emacs (
gtypist-mode.el): Предоставляет подсветку синтаксиса, автозаполнение, вставку баннеров и другие удобные функции для создания файлов.typ. Инструмент находится вtools/gtypist-mode.el. - Скрипт
findwords: Помогает находить слова для упражнений, используя словариaspell. Например,./findwords asdfjkleruioнайдёт все слова, состоящие из этих букв. Находится вtools/findwords. - Конвертация из Ktouch: Скрипт
ktouch2typ.plпозволяет конвертировать уроки из формата Ktouch 1.6 (XML) в формат gtypist. Это отличный способ начать создавать коллекцию уроков .
13.15 - Find and Sed
Примеры использования поисковых запросов POSIX c SED FIND GREP
Потоковый редактор SED. В комбинации с UG и FIND. Примеры использования для практического применения.
Замена текста в множестве файлов с множеством вложенных директорий
Вариант с использованием FIND XARGS SED UG
#Заменяем в файлах md
find . -type f -name "*.md" | xargs sed -Ei 's/bx-apps/bx_apps/g'
#Проверяем, что ничего не осталось
ug -r -g'*.md' 'bx-apps' *
А теперь с толкованием по шагам:
find .- точка говорит что ищем в текущей директории-type f- говорит что будем искать имена файлов-type dимена директорий-name "*.md"- говорит что GLOB паттерн файлов с расширениемmd|принимаем на вход поток имен файлов от findxargs- запустит приложение и передаст ему на вход имя файлаsed -Ei- запустим потоковый редактор SED с расширенным функционалом POSIX (-E) и править будем прямо в самих файлах (i)'s/bx-apps/bx_apps/g'- regex строка замены словаbx-appsнаbx_appsс ключомg, т.е. глобально.
А теперь проверим, что получилось:
ug -r- это простоgrepтолько удобный и продвинутый,-rзначит от сюда и рекурсивно по всем директориям-g'*.md'- это glob поиск по файлам с расширением*.md'bx-apps'- собственно что должны искать
По результату ничего не должно показать. Кстати, перед началом выполнения find | sed можно выполнить тоже ug только с поиском того, что хотим заменить ug -r -g'*.md' 'bx-apps'
Вариант с использованием того же только без UG
#Проверим наличие строк для замены
find . -type f -name "*.md" | xargs sed -En '/bx-apps/p'
#Заменяем в файлах md
find . -type f -name "*.md" | xargs sed -Ei 's/bx-apps/bx_apps/g'
#Проверяем, что ничего не осталось
find . -type f -name "*.md" | xargs sed -En '/bx-apps/p'
Без повторений рассмотрим только изменения:
sed -En- не будет изменять файл, а только выведет строки в которых встретит искомую строку'/bx-apps/p'- искомая строка с ключомpэто просто напечатать.
Вариант с использованием того же только без FIND
#Проверяем, что ничего не осталось
ug -r -g'*.md' 'bx-apps' *
#Заменяем в файлах md
ug -r --format='%f' -g'*.md' | xargs sed -Ei 's/bx-apps/bx_apps/g'
#Проверяем, что ничего не осталось
ug -r -g'*.md' 'bx-apps' *
Объяснения:
ug -r -g'*.md' 'bx-apps'- уже знакомая строка, выведет все файлы и строки с искомой строкойug -r --format='%f' -g'*.md'- новое значение--format='%f'- это формат вывода данных, где:%f- путь и имя файла%n- номер строки в файле%O- контекст, с найденным словом%~- перевод строки
А также, наверно, существует еще 1000 вариантов как это сделать, но я в своих заметках пишу то, чем можно всегда быстро и удобно воспользоваться.
13.16 - Управление пакетами PACMAN
ARCH, MANJARO для управления пакетами, загрузка, удаление, обновление.
ARCH, MANJARO для управления пакетами, загрузка, удаление, обновление.
Менеджер пакетов для ARCH и MANJARO
Команды пакета PACMAN
Выполняются под правами администратора, поэтому пишем
sudo pacman --help
использование: pacman <действие> [...]
действия:
pacman {-h --help}
pacman {-V --version}
pacman {-D --database} <параметры> <пакет(ы)>
pacman {-F --files} [параметры] [файл(ы)]
pacman {-Q --query} [параметры] [пакет(ы)]
pacman {-R --remove} [параметры] <пакет(ы)>
pacman {-S --sync} [параметры] [пакет(ы)]
pacman {-T --deptest} [параметры] [пакет(ы)]
pacman {-U --upgrade} [параметры] <файл(ы)>
используйте 'pacman { -h --help}' вместе с другими операциями для просмотра параметров
Утилита -D
использование:
pacman {-D --database} <параметры> <пакет(ы)>
параметры:
| Параметр | Описание |
|---|---|
| -b, –dbpath <путь> | указать альтернативное расположение базы данных |
| -k, –check | проверить валидность локальной бд (-kk для синхронизации баз) |
| -q, –quiet | не показывать сообщения об удачных операциях |
| -r, –root <путь> | указать альтернативный корневой каталог |
| -v, –verbose | выводить больше информации |
| –arch | установить альтернативную архитектуру |
| –asdeps | отметить пакеты как неявно установленные |
| –asexplicit | отметить пакеты как явно установленные |
| –cachedir <каталог> | указать альтернативное расположение кэша |
| –color <когда> | раскрашивать вывод |
| –config <путь> | использовать альтернативный конфигурационный файл |
| –confirm | всегда спрашивать подтверждения |
| –debug | показывать отладочные сообщения |
| –disable-download-timeout | use relaxed timeouts for download |
| –disable-sandbox | disable the sandbox used for the downloader process |
| –gpgdir <путь> | установить альтернативный домашний каталог для GnuPG |
| –hookdir | установить альтернативное расположение hook |
| –logfile <путь> | использовать альтернативный файл журнала |
| –noconfirm | не спрашивать подтверждения |
| –sysroot | работать с подключенной гостевой системой (только root) |
Установочная информация о менеджере пакетов
| Параметр | ПУТЬ |
|---|---|
| Root | / |
| Conf File | /etc/pacman.conf |
| DB Path | /var/lib/pacman/ |
| Cache Dirs | /var/cache/pacman/pkg/ |
| Hook Dirs | /usr/share/libalpm/hooks/ /etc/pacman.d/hooks/ |
| Lock File | /var/lib/pacman/db.lck |
| Log File | /var/log/pacman.log |
| GPG Dir | /etc/pacman.d/gnupg/ |
| Targets | Нет |
Утилита -F
использование:
pacman {-F --files} [параметры] [файл(ы)]
параметры:
| Параметр | Описание |
|---|---|
| -b, –dbpath <путь> | указать альтернативное расположение базы данных |
| -l, –list | показать список файлов пакета |
| -q, –quiet | показывать меньше информации при запросах и поиске |
| -r, –root <путь> | указать альтернативный корневой каталог |
| -v, –verbose | выводить больше информации |
| -x, –regex | включить использование регулярных выражений в поиске |
| -y, –refresh | загрузить обновленные базы данных с серверов (-yy принудительно обновить даже если обновленные) |
| –arch | установить альтернативную архитектуру |
| –cachedir <каталог> | указать альтернативное расположение кэша |
| –color <когда> | раскрашивать вывод |
| –config <путь> | использовать альтернативный конфигурационный файл |
| –confirm | всегда спрашивать подтверждения |
| –debug | показывать отладочные сообщения |
| –disable-download-timeout | use relaxed timeouts for download |
| –disable-sandbox | disable the sandbox used for the downloader process |
| –gpgdir <путь> | установить альтернативный домашний каталог для GnuPG |
| –hookdir | установить альтернативное расположение hook |
| –logfile <путь> | использовать альтернативный файл журнала |
| –machinereadable | выдавать машинно-читаемый вывод |
| –noconfirm | не спрашивать подтверждения |
| –sysroot | работать с подключенной гостевой системой (только root) |
Утилита -Q
использование:
pacman {-Q --query} [параметры] [пакет(ы)]
параметры:
| Параметр | Описание |
|---|---|
| -b, –dbpath <путь> | указать альтернативное расположение базы данных |
| -c, –changelog | показать список изменений пакета |
| -d, –deps | показать все пакеты, установленные как зависимости [фильтр] |
| -e, –explicit | показать все явно установленные пакеты [фильтр] |
| -g, –groups | показать все пакеты данной группы |
| -i, –info | показать информацию о пакете (-ii для резервных копий) |
| -k, –check | проверить, что все файлы пакета существуют (-kk для вывода свойств файла) |
| -l, –list | показать список файлов пакета |
| -m, –foreign | показать установленные пакеты, не найденные в базе(ах) данных [фильтр] |
| -n, –native | показать установленные пакеты, найденные только в базе(ах) данных [фильтр] |
| -o, –owns <файл> | найти пакет, содержащий <файл> |
| -p, –file <пакет> | извлечь информацию из файла пакета, а не из базы данных |
| -q, –quiet | показывать меньше информации при запросах и поиске |
| -r, –root <путь> | указать альтернативный корневой каталог |
| -s, –search | искать указанную строку в локально установленных пакетах |
| -t, –unrequired | показать все пакеты, не требуемые ни одним пакетом(-tt игнорировать дополнительные зависимости) [фильтр] |
| -u, –upgrades | показать список устаревших пакетов [фильтр] |
| -v, –verbose | выводить больше информации |
| –arch | установить альтернативную архитектуру |
| –cachedir <каталог> | указать альтернативное расположение кэша |
| –color <когда> | раскрашивать вывод |
| –config <путь> | использовать альтернативный конфигурационный файл |
| –confirm | всегда спрашивать подтверждения |
| –debug | показывать отладочные сообщения |
| –disable-download-timeout | use relaxed timeouts for download |
| –disable-sandbox | disable the sandbox used for the downloader process |
| –gpgdir <путь> | установить альтернативный домашний каталог для GnuPG |
| –hookdir | установить альтернативное расположение hook |
| –logfile <путь> | использовать альтернативный файл журнала |
| –noconfirm | не спрашивать подтверждения |
| –sysroot | работать с подключенной гостевой системой (только root) |
Утилита -R
использование:
pacman {-R --remove} [параметры] <пакет(ы)>
параметры:
| Параметр | Описание |
|---|---|
| -b, –dbpath <путь> | указать альтернативное расположение базы данных |
| -c, –cascade | удалить пакет и все зависящие от него пакеты |
| -d, –nodeps | пропустить проверку версий (-dd пропускает все проверки) |
| -n, –nosave | удалять конфигурационные файлы |
| -p, –print | вывести список целей вместо выполнения операций |
| -r, –root <путь> | указать альтернативный корневой каталог |
| -s, –recursive | удалять ненужные зависимости (-ss включая явно установленные) |
| -u, –unneeded | удалить ненужные пакеты |
| -v, –verbose | выводить больше информации |
| –arch | установить альтернативную архитектуру |
| –assume-installed <пакет=версия> | добавить виртуальный пакет для удовлетворения зависимостей |
| –cachedir <каталог> | указать альтернативное расположение кэша |
| –color <когда> | раскрашивать вывод |
| –config <путь> | использовать альтернативный конфигурационный файл |
| –confirm | всегда спрашивать подтверждения |
| –dbonly | изменить только записи в базе данных, не файлы пакетов |
| –debug | показывать отладочные сообщения |
| –disable-download-timeout | use relaxed timeouts for download |
| –disable-sandbox | disable the sandbox used for the downloader process |
| –gpgdir <путь> | установить альтернативный домашний каталог для GnuPG |
| –hookdir | установить альтернативное расположение hook |
| –logfile <путь> | использовать альтернативный файл журнала |
| –noconfirm | не спрашивать подтверждения |
| –noprogressbar | не показывать индикатор выполнения при загрузке |
| –noscriptlet | не запускать установочные скрипты, если они есть |
| –print-format | <строка> |
| –sysroot | работать с подключенной гостевой системой (только root) |
Утилита -S
использование:
pacman {-S --sync} [параметры] [пакет(ы)]
параметры:
| Параметр | Описание |
|---|---|
| -b, –dbpath <путь> | указать альтернативное расположение базы данных |
| -c, –clean | удалить старые пакеты из кэша (-cc для всех) |
| -d, –nodeps | пропустить проверку версий (-dd пропускает все проверки) |
| -g, –groups | показать все пакеты данной группы (-gg показывает все группы и пакеты) |
| -i, –info | показать информацию о пакете (-ii показать детали) |
| -l, –list | показать все пакеты из этого репозитория |
| -p, –print | вывести список целей вместо выполнения операций |
| -q, –quiet | показывать меньше информации при запросах и поиске |
| -r, –root <путь> | указать альтернативный корневой каталог |
| -s, –search | искать указанную строку в удаленных репозиториях |
| -u, –sysupgrade | обновить установленные пакеты(-uu разрешает откат версий) |
| -v, –verbose | выводить больше информации |
| -w, –downloadonly | загрузить пакеты с сервера, но не устанавливать |
| -y, –refresh | загрузить обновленные базы данных с серверов (-yy принудительно обновить даже если обновленные) |
| –arch | установить альтернативную архитектуру |
| –asdeps | установить пакеты как неявно установленные |
| –asexplicit | установить пакеты как явно установленные |
| –assume-installed <пакет=версия> | добавить виртуальный пакет для удовлетворения зависимостей |
| –cachedir <каталог> | указать альтернативное расположение кэша |
| –color <когда> | раскрашивать вывод |
| –config <путь> | использовать альтернативный конфигурационный файл |
| –confirm | всегда спрашивать подтверждения |
| –dbonly | изменить только записи в базе данных, не файлы пакетов |
| –debug | показывать отладочные сообщения |
| –disable-download-timeout | use relaxed timeouts for download |
| –disable-sandbox | disable the sandbox used for the downloader process |
| –gpgdir <путь> | установить альтернативный домашний каталог для GnuPG |
| –hookdir | установить альтернативное расположение hook |
| –ignore <пакет> | пропустить пакет при обновлении (может быть использовано неоднократно) |
| –ignoregroup <группа> | пропустить группу при обновлении (может быть использовано неоднократно) |
| –logfile <путь> | использовать альтернативный файл журнала |
| –needed | переустанавливать только устаревшие пакеты |
| –noconfirm | не спрашивать подтверждения |
| –noprogressbar | не показывать индикатор выполнения при загрузке |
| –noscriptlet | не запускать установочные скрипты, если они есть |
| –overwrite | overwrite conflicting files (can be used more than once) |
| –print-format <строка> | укажите формат вывода целей |
| –sysroot | работать с подключенной гостевой системой (только root) |
Утилита -T
использование:
pacman {-T --deptest} [параметры] [пакет(ы)]
параметры:
| Параметр | Описание |
|---|---|
| -b, –dbpath <путь> | указать альтернативное расположение базы данных |
| -r, –root <путь> | указать альтернативный корневой каталог |
| -v, –verbose | выводить больше информации |
| –arch | установить альтернативную архитектуру |
| –cachedir <каталог> | указать альтернативное расположение кэша |
| –color <когда> | раскрашивать вывод |
| –config <путь> | использовать альтернативный конфигурационный файл |
| –confirm | всегда спрашивать подтверждения |
| –debug | показывать отладочные сообщения |
| –disable-download-timeout | use relaxed timeouts for download |
| –disable-sandbox | disable the sandbox used for the downloader process |
| –gpgdir <путь> | установить альтернативный домашний каталог для GnuPG |
| –hookdir | установить альтернативное расположение hook |
| –logfile <путь> | использовать альтернативный файл журнала |
| –noconfirm | не спрашивать подтверждения |
| –sysroot | работать с подключенной гостевой системой (только root) |
Утилита -U
использование:
pacman {-U --upgrade} [параметры] <файл(ы)>
параметры:
| Параметр | Описание |
|---|---|
| -b, –dbpath <путь> | указать альтернативное расположение базы данных |
| -d, –nodeps | пропустить проверку версий (-dd пропускает все проверки) |
| -p, –print | вывести список целей вместо выполнения операций |
| -r, –root <путь> | указать альтернативный корневой каталог |
| -v, –verbose | выводить больше информации |
| -w, –downloadonly | загрузить пакеты с сервера, но не устанавливать |
| –arch | установить альтернативную архитектуру |
| –asdeps | установить пакеты как неявно установленные |
| –asexplicit | установить пакеты как явно установленные |
| –assume-installed <пакет=версия> | добавить виртуальный пакет для удовлетворения зависимостей |
| –cachedir <каталог> | указать альтернативное расположение кэша |
| –color <когда> | раскрашивать вывод |
| –config <путь> | использовать альтернативный конфигурационный файл |
| –confirm | всегда спрашивать подтверждения |
| –dbonly | изменить только записи в базе данных, не файлы пакетов |
| –debug | показывать отладочные сообщения |
| –disable-download-timeout | use relaxed timeouts for download |
| –disable-sandbox | disable the sandbox used for the downloader process |
| –gpgdir <путь> | установить альтернативный домашний каталог для GnuPG |
| –hookdir | установить альтернативное расположение hook |
| –ignore <пакет> | пропустить пакет при обновлении (может быть использовано неоднократно) |
| –ignoregroup <группа> | пропустить группу при обновлении (может быть использовано неоднократно) |
| –logfile <путь> | использовать альтернативный файл журнала |
| –needed | переустанавливать только устаревшие пакеты |
| –noconfirm | не спрашивать подтверждения |
| –noprogressbar | не показывать индикатор выполнения при загрузке |
| –noscriptlet | не запускать установочные скрипты, если они есть |
| –overwrite | overwrite conflicting files (can be used more than once) |
| –print-format <строка> | укажите формат вывода целей |
| –sysroot | работать с подключенной гостевой системой (только root) |
13.17 - UGREP и все о нем
Удивительная поисковая программа на все случаи жизни. Детальный разбор
Примеры использования поисковых запросов POSIX
Обзор документации все ключи и команды UGREP
Установка UGREP
pkg install ugrep
Файл конфигурации .ugrep хранится в корне домашнего каталога
ug –save-config OPTIONS
сохранит новые настройки
Я уже в восторге от UGREP
Примеры
| Пример | Описание |
|---|---|
| ug -Q | запускает интерактивный режим поиска |
| ug -%% -jwQ | рекурсивный Google поиск по словам с интерактивностью |
| ug PATTERN | искать во всех файлах по паттерну рекурсивно |
| ug PATTERN FILE | искать в конкретном файле |
| ug PATTERN DIR | искать в конкретной директории |
| ug -3 PATTERN DIR | искать рекурсивно до 3-го уровня вложенности |
| ug -3 -g"foo*.txt" PATTERN DIR | искать только в именах файлов foo*.txt нужный паттерн в директории DIR не глубже 3-го уровня |
| ug -z PATTERN | искать в архивах |
| ug -z -tc,cpp -Z PATTERN | искать в архивах коды С и С++ с неточным совпадением -Z паттерна |
| ug -z -l "" package.zip | покажет все файлы в архиве |
| ug -z -W –pager "" mailattachment.zip | просмотреть 16-ричный дамп в архиве |
| ug –save-config –ignore-files –ignore-binary –decompress | сохранит файл конфигурации игнорируя bin и .git файлы и смотреть в архивах |
| ug –help regex | покажет help команды |
Опции UG со списком файлов
| Опция | Описание |
|---|---|
| -l | список файлов, удовлетворяющих паттрену |
| -l -m5, | список файлов, где есть не меньше 5 совпадений |
| -l –max-files=3 | только первые 3 файла с совпадениями |
| -L | все файлы не совпавшие с паттерном |
| -c | посчитать сколько совпадений в файле |
| -cv | посчитать сколько несовпадений в файле |
| -cu | посчитать совпадения |
| -cm1, | посчитать совпадения, но не показывать с 0 |
Опции UG для отображения результата
| Опция | Описание |
|---|---|
| -H | выводить имя файла |
| -n | выводить номер строки |
| -k | выводить номер колонки |
| -b | выводить номер байта с начала файла |
| -u | разделяет групповые запросы и выводит результат раздельно |
| -C3 | мощно! выводит 3 строки до совпадения (-B3) и 3 строки после (-A3) |
| -y | выводит весь файл и подсвечивает найденные строки |
| -o | выводит только найденные фразы |
| -o -C20 | выведет 40 строк вокруг каждого найденного значения |
| –width=40 | выведет результат шириной 40 знаков |
Опции управления паттерном
| Опция | Описание |
|---|---|
| -F | искать как fgrep |
| -G | искать как grep |
| -P | искать как perl |
| -Z | искать как fuzzy (приблизительно) |
| -U | искать не как Unicode |
| -Y | искать как grep |
| -i | искать регистронечувствительно |
| -j | искать умно регистронезависимо |
| -w | искать целиком слова, а не части слов |
| -x | искать целыми строками |
| -v | инверсия паттерна |
| -e PATTERN | можно складывать выражения поиска |
| -N PATTERN | -e “[0-9]+” -N “0+” ищет ненулевые числа |
| -f FILE | читает из файла паттерн |
| -f cpp/names | наверно очень нужная вещь, для тех кто пишет на С |
Googling files
непереводимая вещь, но смысл типа ищем как гуглинг
| Опция | Описание |
|---|---|
| -% “foo bar” | чтобы в одной строке было оба паттерна |
| -%% “foo bar” | чтобы в одном файле было оба паттерна |
| -% “foo -bar” | чтобы в одной строке был 1-й, но не было второго |
| -%% “foo -bar” | чтобы в одном файле был 1-й, но не было второго |
| -% “foo bar|baz” | чтобы в одной строке был или 1-й или 2-й |
| -% “foo -(bar|baz)” | чтобы в строке был 1-й, но не было ни второго и не третьего |
| -% “foo AND NOT (bar OR baz)” | аналогично выше |
| -% “foo -bar -baz” | чтобы в строке был 1-й и не было 2-го и 3-го вместе |
| -% ‘foo “-bar baz”’ | чтобы был первый без второго но с третьим |
| -F -% “foo bar?” | с фиксацией поиска |
Приблизительный поиск
| Опция | Описание |
|---|---|
| -Z | искать приблизительно, допускается один символ не совпадающий в шаблоне (вообще три темы в таком поиске: - недостающий символ; - лишний символ; - замененный символ) |
| -Z2 | все тоже самое, что выше но теперь с двумя символами |
| -Z+2 | этот поиск конкретно указывает, что только могут быть лишние 2 символа |
| -Z-2 | этот поиск конкретно указывает, что только могут быть недостающие 2 символа |
| -Z~2 | этот поиск конкретно указывает, что только могут быть 2 символа замененные |
| -Z+-2 | этот поиск конкретно указывает, что только могут быть лишние и недостающие 2 символа |
| -Z+-~2 | это аналог -Z2 |
| -c -Z | посчитаем сколько было таких неудачных совпадений |
| -c -Zbest2 | посчитаем только с лучшими вариантами, плохие отбросит |
| -c -Zbest2 –sort=best | посчитает все, но выведет в отсортированном виде по степени ухудшения |
Ищем в архивах
Это уже для меня конкретное откровение! Чтобы grep еще и в архивах искал
| Опция | Описание |
|---|---|
| -z | ищет в zip/7z/tar/pax/cpio архивах, и в сжатых файлах tarballs и gz/Z/bz/bz2/lzma/xz/lz4/zstd/brotli |
| -z –zmax=2 | ищет также, как и выше, но не больше 2-го уровня вложенности архивов в архивы |
| -z -I –zmax=2 | как и выше, но не ищет в двоичных файлах |
| -z -tc,cpp | ищет в архивах и файлы типа С и С++ (ключ t указывает тип файла) |
| -z -g".txt,.md" | работает как find и ищет в именах файлов и директорий в архивах |
| -z -g"^bak/" | ищет в архивах, исключая bak директории |
Двоичные файлы и устройства
| Опция | Описание |
|---|---|
| -I | игнорировать двоичные файлы |
| -W | hexdump — 16-ричный двоичный код искать, а текст, как обычный текст |
| -X | ищет двоичный код в hexdump |
| -U –hexdump | hexdump 8-битный двоичный шаблон регулярных выражений, соответствующий шаблону на основе символов Unicode (опция -U) |
| –hexdump=4a | выводит четырехколоночный дамп со всеми символами |
| –hexdump=4ch | это тоже в 4 колонки, но без символов и пробелов |
| –hexdump=4C3 | выводит дамп 3 строки перед и 3 строки после найденного паттерна |
| –hexdump=4C3 -u -b | похожа, как выше, но разгруппирует запрос и укажет байт адрес в файле |
| -Dread | ищет на специальном устройстве |
опции для –hexdump
получает аргументы
- [1-8] — количество колонок дампа
- [a] — все выводить
- [bch] — не выводить символы, пробелы и байт коды
- [A[NUM]][B[NUM]][C[NUM]] — строки перед и после
Ищет по двоичному коду:
ug -X 'ffffff'
000a9660 41 41 67 42 2c 43 41 43 70 42 2c 51 41 41 51 2c |AAgB,CACpB,QAAQ,|
000a9880 41 55 2c 43 41 41 43 2c 43 41 41 43 3b 4d 41 43 |AU,CAAC,CAAC;MAC|
000a9890 35 42 2c 49 41 41 49 2c 43 41 41 43 2c 43 41 41 |5B,IAAI,CAAC,CAA|
000a98a0 43 6a 42 2c 51 41 41 51 2c 47 41 41 47 2c 49 41 |CjB,QAAQ,GAAG,IA|
000a98b0 41 49 3b 4d 41 43 72 42 2c 49 41 41 49 2c 49 41 |AI;MACrB,IAAI,IA|
000a98c0 41 49 2c 43 41 41 43 2c 43 41 41 43 73 47 2c 65 |AI,CAAC,CAACsG,e|
000a98d0 41 41 65 2c 45 41 41 45 3b 51 41 43 7a 42 78 67 |AAe,EAAE;QACzBxg|
000a98e0 46 2c 59 41 41 59 2c 43 41 41 43 2c 49 41 41 49 |F,YAAY,CAAC,IAAI|
000a98f0 2c 43 41 41 43 2c 43 41 41 43 77 67 46 2c 65 41 |,CAAC,CAACwgF,eA|
000a9900 41 65 2c 43 41 41 43 3b 51 41 43 6e 43 2c 49 41 |Ae,CAAC;QACnC,IA|
000a9910 41 49 2c 43 41 41 43 2c 43 41 41 43 41 2c 65 41 |AI,CAAC,CAACA,eA|
000a9920 41 65 2c 47 41 41 47 2c 49 41 41 49 3b 4d 41 43 |Ae,GAAG,IAAI;MAC|
000a9930 39 42 3b 49 41 43 46 3b 49 41 43 41 2c 4b 41 41 |9B;IACF;IACA,KAA|
000a9940 4b 2c 43 41 41 43 6c 37 46 2c 4d 41 41 4d 2c 43 |K,CAACl7F,MAAM,C|
000a9950 41 41 43 2c 43 41 41 43 3b 45 41 43 68 42 3b 45 |AAC,CAAC;EAChB;E|
000a9960 41 47 41 36 6e 42 2c 4f 41 41 4f 41 2c 43 41 41 |AGA6nB,OAAOA,CAA|
000a9970 41 2c 45 41 41 47 3b 49 41 43 52 2c 49 41 41 49 |A,EAAG;IACR,IAAI|
000a9980 2c 43 41 41 43 2c 49 41 41 49 2c 43 41 41 43 35 |,CAAC,IAAI,CAAC5|
000a9990 59 2c 4d 41 41 4d 2c 45 41 41 45 3b 4d 41 47 68 |Y,MAAM,EAAE;MAGh|
000a99a0 42 2c 49 41 41 49 2c 49 41 41 49 2c 43 41 41 43 |B,IAAI,IAAI,CAAC|
000a99b0 2c 43 41 41 43 34 72 46 2c 51 41 41 51 2c 45 41 |,CAAC4rF,QAAQ,EA|
Ищет по Unicode:
ug -U --hexdump 'ffffff'
zotero-pdf-translate/node_modules/yauzl/index.js
140:
00001910 79 4f 66 66 73 65 74 20 3d 3d 3d 20 30 78 66 66 |yOffset === 0xff|
00001920 66 66 66 66 66 66 29 29 20 7b 0a -- -- -- -- -- |ffffff)) {J-----|
333:
00003b60 3d 3d 20 30 78 66 66 66 66 66 66 66 66 20 7c 7c |== 0xffffffff |||
334:
00003ba0 20 30 78 66 66 66 66 66 66 66 66 20 7c 7c 0a -- | 0xffffffff ||J-|
335:
00003be0 78 66 66 66 66 66 66 66 66 29 20 7b 0a -- -- -- |xffffffff) {J---|
выводит в красивом виде 16-ричного дампа в 4 колонки
ug --hexdump=4a 'ffffff'
zotero-pdf-translate/node_modules/yauzl/index.js
140:
00001900 20 63 65 6e 74 72 61 6c 44 69 72 65 63 74 6f 72 79 4f 66 66 73 65 74 20 3d 3d 3d 20 30 78 66 66 | centralDirectoryOffset === 0xff|
00001920 66 66 66 66 66 66 29 29 20 7b 0a -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- |ffffff)) {J---------------------|
333:
00003b60 3d 3d 20 30 78 66 66 66 66 66 66 66 66 20 7c 7c 0a -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- |== 0xffffffff ||J---------------|
334:
00003ba0 20 30 78 66 66 66 66 66 66 66 66 20 7c 7c 0a -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- | 0xffffffff ||J-----------------|
выводит в 4 колонки но без пробелов и символов
ug --hexdump=4ch 'ffffff'
zotero-pdf-preview/node_modules/pdfjs-dist/legacy/build/pdf.mjs.map
1:
000eb440 305c222026262062 67436f6c6f72203d 3d3d205c22236666 666666665c222920
1|
00112f20 7365656420262030 7866666666666666 66203a2053454544 3b5c6e2020202074
00112f40 6869732e6832203d 2073656564203f20 7365656420262030 7866666666666666
1|
00120c20 6865696768742c5c 6e20206e6f6e426c 61636b436f6c6f72 203d203078666666
00120c40 66666666662c5c6e 2020696e76657273 654465636f646520 3d2066616c73652c
1|
выводит 4 колонки и по 3 строки перед и после:
ug --hexdump=4C3 'afaf'
zotero-pdf-translate/node_modules/minimist/CHANGELOG.md
51:
00001200 -- -- -- 2d 20 5b 44 65 76 20 44 65 70 73 5d 20 61 64 64 20 6d 69 73 73 69 6e 67 20 60 6e 70 6d |---- [Dev Deps] add missing `npm|
00001220 69 67 6e 6f 72 65 60 20 64 65 76 20 64 65 70 20 5b 60 33 32 32 36 61 66 61 60 5d 28 68 74 74 70 |ignore` dev dep [`3226afa`](http|
00001240 73 3a 2f 2f 67 69 74 68 75 62 2e 63 6f 6d 2f 6d 69 6e 69 6d 69 73 74 6a 73 2f 6d 69 6e 69 6d 69 |s://github.com/minimistjs/minimi|
00001260 73 74 2f 63 6f 6d 6d 69 74 2f 33 32 32 36 61 66 61 66 30 39 65 39 64 31 32 37 63 61 33 36 39 37 |st/commit/3226afaf09e9d127ca3697|
00001280 34 32 34 33 37 66 65 36 65 38 38 66 37 35 32 64 36 62 29 0a -- -- -- -- -- -- -- -- -- -- -- -- |42437fe6e88f752d6b)J------------|
186:
000036c0 -- -- -- -- -- 2d 20 5b 44 65 76 20 44 65 70 73 5d 20 61 64 64 20 6d 69 73 73 69 6e 67 20 60 6e |------ [Dev Deps] add missing `n|
000036e0 70 6d 69 67 6e 6f 72 65 60 20 64 65 76 20 64 65 70 20 5b 60 33 32 32 36 61 66 61 60 5d 28 68 74 |pmignore` dev dep [`3226afa`](ht|
00003700 74 70 73 3a 2f 2f 67 69 74 68 75 62 2e 63 6f 6d 2f 6d 69 6e 69 6d 69 73 74 6a 73 2f 6d 69 6e 69 |tps://github.com/minimistjs/mini|
00003720 6d 69 73 74 2f 63 6f 6d 6d 69 74 2f 33 32 32 36 61 66 61 66 30 39 65 39 64 31 32 37 63 61 33 36 |mist/commit/3226afaf09e9d127ca36|
00003740 39 37 34 32 34 33 37 66 65 36 65 38 38 66 37 35 32 64 36 62 29 0a -- -- -- -- -- -- -- -- -- -- |9742437fe6e88f752d6b)J----------|
Исключения и включения
| Опция | Описание |
|---|---|
| -@ | (–all) ищет во всех нескрытых файлах и отменяет все ограничения до него |
| -. | (–hidden) включая скрытые файлы |
| -I | игнорировать двоичные файлы |
| -p | не переходить по символическим ссылкам |
| -r | искать рекурсивно без символических ссылок |
| -rS | искать рекурсивно по символическим ссылкам на файлы, но без директорий |
| -R | искать рекурсивно по символическим ссылкам с директориями |
| -tc,cpp | искат только файлы типом С и С++ |
| -Ohpp,cpp | сокращенная запись -g".hpp,.cpp" ищет по расширениям файлов |
| -g".hpp,.cpp" | ищет по имена файлов |
| -g"src/" | ищет все src/ директории рекрсивно |
| -g"^*.txt,^bak/" | ищет файлы и директории исключая файлы *.txt и директории bak/ |
| –iglob="^*.txt,^bak/" | тоже, что выше, но регистронезависимый поиск |
| -K10,99 | искать в файлах с 10-й по 99-ю строку |
| -m1 | выводить только первую найденную строку |
| -m2,9 | выводить только со 2-й по 9-ю строку поиска |
| -m2,9 -u | как выше, только разруппировать результат |
| -3 | рекурсия на 3 уроня вглубь |
| -2-3 | рекурсия со 2-го по 3-й уровень |
| –max-files=3 | возвращать результат для первых трех файлов |
| –ignore-files | соблюдать правила .gitignore при рекурсивном поиске |
| –exclude-fs=PATH | исключить поиск системных файлов по пути PATH |
| –exclude-fs | спускаться только в файловые системы с указанными целями |
| –include-fs=. | игнорирует поиск на смонтированных дисках |
| –exclude-from=FILE | игнорирует все файлы помеченные в переменной FILE |
| –include-from=FILE | обратное выше, включает все файлы определенные в FILE |
| –filter=“COMMANDS” | перед поиском, предварительно фильтрует файлы с помощью специальных комманд |
Форматированый вывод результата
| Опция | Описание |
|---|---|
| --csv | в CSV |
| --json | в JSON |
| --xml | в XML |
| --format=“FORMAT” | выводит в некоем условном формате |
╭─edge@bsd in ~
╰$ ug -% "sed 3d" ./sed --json
[
{
"file": "./sed/example.md",
"matches": [
{ "line": 6, "match": "╰$ seq 10 | sed -E '1,3d;5d'" }
]
},
{
"file": "./sed/example.md~",
"matches": [
{ "line": 6, "match": "╰$ seq 10 | sed -E '1,3d;5d'" }
]
}
]
получилось очень мило
У grep бывает все красиво
| Опция | Описание |
|---|---|
| --pretty | — выводит все красочно и красиво и включает -n, -T, --color, --tree, --heading, --break и --sort |
| --tree | — добавляет деревянной красоты к ключам -l и -c когда выводим списо файлов |
| --heading | — выводит имя файла как заголовок в поиске |
| --break | — выведет пустую линию между результатами поиска |
| -T | — добавит \tab в строке и колонке с номером |
| --color | — выводит в цвете |
| --colors=COLORS | — задать цвет вывода |
| --hyperlink=+ | — включает гиперссылки в вывод на терминал |
| --pager | — мне это очень напомнило редактор vi в режиме просмотра. Т.е. смотрим на вывод постранично |
| --tag | output matches as match instead of colorizing them, where --tag=TAG,TAG outputs TAGmatchTAG |
| --replace=“FORMAT” | replace matches in the output by FORMAT, see also ug --help format |
| --separator=SEP | specify SEP to separate line and column numbers from the match |
| --group-separator=SEP | specify SEP to separate context for options -ABC |
| --width | truncate lines to the terminal window width; --width=40 truncates to 40 characters |
Так будет выглядеть вывод в дереве
╭─edge@bsd in ~
╰$ ug -l ".*\.man"
.zsh_history
emacs-29.4.core
.cache/
╰╴chromium/
│ ╰╴Default/
│ │ ╰╴Cache/
│ │ │ ╰╴Cache_Data/
│ │ │ │ ╰╴02c12a7839f51358_0
│ │ │ │ ╰╴3c7eb053e143ec36_0
│ │ │ │ ╰╴40051ca56893c175_0
│ │ │ │ ╰╴6fa460d8b7921dfc_0
│ │ │ │ ╰╴87d71ae3063c69c0_0
│ │ │ │ ╰╴90a53aad17d58184_0
│ │ │ │ ╰╴9da1f7ca347c666b_0
│ │ │ │ ╰╴a96d92547e75daa0_0
│ │ │ │ ╰╴c1df79e2d6a936bc_0
│ │ │ │ ╰╴c4bbc1e0b652d750_0
│ │ │ │ ╰╴c7b98cb5b80c61a8_0
│ │ │ │ ╰╴d446ead8e6fafe30_0
│ │ │ │ ╰╴f48eb8aee3d80bd8_0
│ │ │ ▔
│ │ ╰╴Code Cache/
│ │ │ ╰╴js/
│ │ │ │ ╰╴00d8a21e14d11b61_0
Globs
эти шарики делают поиск по файлам и директориям
| Команда | Описание |
|---|---|
| -g | стандартны режим “паттерн” |
| --iglob= | поиск регистро нечувствительное имя файла или директории |
| --exclude= | исключить из поиска файлы |
| --include= | включить в поиск файлы |
| --include-dir= | включая директории |
| --exclude-dir= | исключая директории |
| --include-from=file | файл с именами включаемыми в поиск |
| --exclude-from=file | файл с имена не включаемыми в поиск |
| --ignore-files=file | файл с именами игнорируемые в поиске |
Паттерны glob
| Команда | Описание |
|---|---|
| * | ищет все |
| ? | ищет любой один символ |
| [abc-e] | ищет в этой позиции символы abcde |
| [^abc-e] | ищет символы в этой позиции кроме a,b,c,d,e,/ |
| [!abc-e] | тоже, что выше |
| / | ищет только в текущей директории |
| **/ | ищет в предыдущих дирикториях |
| /** | ищет в последующих директориях |
| \? | ищет любой спец.символ |
Продолжение следует…
13.18 - Find
Удивительная утилита, которая может найти все на диске и еще выполнить над тем, что нашла, все что угодно!
Удивительная утилита, которая может найти все на диске и еще выполнить над тем, что нашла, все что угодно!
Командная строка find
find [path...] [expression]
Аргумент path указывает директорию или список директорий с которой начинаем поиск.
Аргумент expression состоит из опций, тестов и действий. Одно выражение может объединять любое их количество, используя традиционные булевы операторы, такие как and и or.
OPTION
- -d, -depth: указывает на проход утилиты вглубь в дочерние каталоги
- -mindepth, -maxdepth: уровень обработки каталогов вглубь
TESTS
Тесты — это основные команды утилиты.
-name: проверяет, соответствует ли имя файла шаблону (использует простое сопоставление с шаблоном и смотрит только на имя файла)-regex: проверяет, соответствует ли имя файла шаблону (использует стандартные регулярные выражения Emacs и проверяет полный путь к файлу)-type: проверяет, относится ли файл к определенному типу (f– обычный файл,d– каталог,s– символическая ссылка и т. д.)
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -name "*.svg"
./content/docs/latex/pdfpages/adobe-pdf-icon.svg
./content/docs/latex/pdfpages/adobe-pdf-2.svg
./content/docs/linux/ssh/ssh.svg
./themes/hugo-theme-relearn/exampleSite/static/images/logo.svg
. — это поиск в текущей директории
-name — ищем файлы с именами по шаблону
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find config -type d
config
config/_default
выведем только директории в каталоге config
Работа со временем
-amin, -anewer, -atime: — проверяет последние изменения в файлах-cmin, -cnewer, -ctime: — проверяет время создания файлов относительно времени другого файла-mmin, -mnewer, -mtime: — проверяет время последнего изменения файла-newer: — сравнивает файлы новее исходного
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -name "*.png" -ctime -2
./public/docs/emacs/yasnippet/logo.png
./public/docs/emacs/magit/magit.png
./public/docs/latex/newfont/121751.png
./public/docs/latex/pdfpages/adobe.png
./public/docs/latex/titleps/131227.png
./public/docs/latex/titlesec/101100.png
./public/docs/latex/titlesec/101034.png
./public/docs/latex/titlesec/101112.png
вывести все файлы с расширением .png, созданные в течение последних двух дней
─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -newer ./public/docs/linux/ssh/ssh.png
./public
./public/tags/index.html
./public/tags/index.xml
./public/tags/documentation/index.html
./public/tags/documentation/index.xml
./public/tags/soft/index.html
вывести все файлы, которые новее ssh.png
Поиск по свойствам файлов
-perm: поиск по правам доступа файла-size: поиск по размеру файла
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -perm 777
./assets/images/big.jpg
./assets/images/width-title.jpg
./assets/images/logo.png
поиск всех файлов с правами 777
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -size 2M
./assets/images/ig.png
./themes/hugo-theme-relearn/exampleSite/content/introduction/quickstart/magic.gif
./themes/hugo-theme-relearn/static/js/mathjax/mml-svg.js
поиск файлов размером больше 2М
Действия над найденными файлами
-ls: выводит результат в форматеls-print, -print0, -printf: вывод результата в стандартный поток вывода-fprint, -fprint0, -fprintf: вывод результата в файл
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -name "ssh*" -ls
502782 0 drwxr-xr-x 1 edge edge 62 ноя 15 17:44 ./content/docs/linux/ssh
502783 8 -rw-r--r-- 1 edge edge 7865 ноя 13 11:52 ./content/docs/linux/ssh/ssh.svg
502784 136 -rw-r--r-- 1 edge edge 136846 ноя 13 11:53 ./content/docs/linux/ssh/ssh.png
502907 0 drwxr-xr-x 1 edge edge 70 ноя 14 17:55 ./public/ru/docs/linux/ssh
502853 0 drwxr-xr-x 1 edge edge 114 ноя 14 19:42 ./public/docs/linux/ssh
502854 136 -rw-r--r-- 1 edge edge 136846 ноя 17 19:26 ./public/docs/linux/ssh/ssh.png
502855 8 -rw-r--r-- 1 edge edge 7865 ноя 17 19:26 ./public/docs/linux/ssh/ssh.svg
выводит все файлы, где в имени есть ssh
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -name "ssh*" -printf '%s %p\n'
62 ./content/docs/linux/ssh
7865 ./content/docs/linux/ssh/ssh.svg
136846 ./content/docs/linux/ssh/ssh.png
70 ./public/ru/docs/linux/ssh
114 ./public/docs/linux/ssh
136846 ./public/docs/linux/ssh/ssh.png
7865 ./public/docs/linux/ssh/ssh.svg
выводит только размер и имя
-delete: удаляет все найденные файлы-exec: выполняет любую команду над результатом поиска
find /tmp -name "*.tmp" -delete
удалит все файлы с расширением tmp
─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -name "*.yaml" -type f -exec grep -l doc {} \;
./themes/hugo-theme-relearn/.github/actions/release_milestone/action.yaml
./themes/hugo-theme-relearn/.github/workflows/docs-build-deployment.yaml
./themes/hugo-theme-relearn/.github/workflows/docs-build.yaml
найдет все файлы с расширением yaml в которых есть слово doc
В конце команды
-exec обязательно поставить {} — результат выборки и в самом конце \; чтобы команда выполнилась над файлом 1 раз, если использовать + то в grep , будут переданы несколько файлов.╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find . -name "*.yaml" -type f | xargs grep -l doc
./themes/hugo-theme-relearn/.github/actions/release_milestone/action.yaml
./themes/hugo-theme-relearn/.github/workflows/docs-build-deployment.yaml
./themes/hugo-theme-relearn/.github/workflows/docs-build.yaml
это альтернативная команда xargs вместо exec. Получает на вход результат find и выполняет свою команду.
XARGS работает в разы быстрее EXEC
Операторы Find
Операторы можно комбинировать как обычные логические выражения
(expr): это обычные круглые скобки
!, -not: оператор отрицания НЕТ
-a, -and: оператор логическое И
-o, -or: оператор логическое ИЛИ
Расширенные параметры
find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path] [expressions]
H, L, P— порядок обработки символических ссылокO— уровень оптимизации от 0 до 3D— диагностическая информация
REGEX
Команда FIND в сочетании с регулярными выражениями и другими командами оболочки, становится супер инструментом.
find [path] [expression]
Этот раздел посвящен простому слову в команде exptession
find [path] -regex [regular_expression]
Будет выполнен поиск по указанному пути и возвращен список файлов, удовлетворяющих условию.
Шаблон regular_expression включает полное имя файла, включая корневой путь к каталогу.
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find ./ -type f -regex '.*css\/*'
./themes/hugo-theme-relearn/assets/css/auto.css
./themes/hugo-theme-relearn/assets/css/chroma-learn.css
./themes/hugo-theme-relearn/assets/css/chroma-neon.css
./themes/hugo-theme-relearn/assets/css/chroma-relearn-dark.css
./themes/hugo-theme-relearn/assets/css/chroma-relearn-light.css
./themes/hugo-theme-relearn/assets/css/format-print.css
выдал все файлы в которых есть в наименовании css/
╭─edge@edge-manjaro in ~/data/sites/doc10 on master ✘
╰$ find ./ -type f -regex '.*neon.*'
./themes/hugo-theme-relearn/assets/css/chroma-neon.css
./themes/hugo-theme-relearn/assets/css/theme-neon.css
./public/css/theme-neon.css
./public/css/chroma-neon.css
а в этом запросе должен быть neon
Для поиска через FIND всегда результат будет начинаться с ./, а это значит что в регулярном выражении мы должны поставить ./ - т.е экранировать точку и косую черту
Команда -iregex
find [path] -iregex [regular_expression]
почти тоже самое, только с регистронезависимым поиском. Будет искать и большие и маленькие буквы.
Команда -regextype
Выбирает тип регулярного выражения
- findutils
- emacs — установлено по умолчанию
- gnu-awk
- grep
- egrep
- posix-awk
- posix-basic
- posix-egrep
- posix-extended
На этой странице есть описание всех синтаксисов регулярных выражений
“https://www.gnu.org/software/findutils/manual/html_node/find_html/Regular-Expressions.html" “https://www.gnu.org/software/findutils/manual/html_node/find_html/Regular-Expressions.html"
13.19 - ZSH
Командная оболочка ZSH и все о ней
Первая версия ZSH была написана Паулем Фалстадом, когда он был студентом Принстонского университета в 1990 году. Название оболочки произошло от учетной записи “zsh” университетского ассистента Пауля по имени Чжун Шао. В настоящее время проект развивается энтузиастами под руководством Питера Стефенсона в рамках свободно распространяемого ПО.
ZSH является расширенным аналогом BASH и имеет с ним обратную совместимость, добавляя ему большое количество улучшений.
Установка по умолчанию ZSH
Официальный сайт “https://www.zsh.org/" “https://www.zsh.org/"
американское зеркало “https://zsh.sourceforge.io/" “https://zsh.sourceforge.io/"
документация на zsh “https://zsh.sourceforge.io/Doc/Release/zsh_toc.html" “https://zsh.sourceforge.io/Doc/Release/zsh_toc.html"
Проверить текущую оболочку
$ echo $SHELL
Проверить какие оболочки установлены
chsh -l
Установить по умолчанию zsh:
chsh -s /bin/zsh/
Если не установлен, то в Manjaro выполнить
sudo pacman -S zsh
zsh
если скрипт не запустился, то
autoload -Uz zsh-newuser-install
zsh-newuser-install -f
Поставим OH-MY-ZSH
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
Читаем документацию https://github.com/ohmyzsh/ohmyzsh/wiki
Редактируем ~/.zshrc
1. export ZSH="$HOME/.oh-my-zsh" — путь к настройкам oh-my-zsh
2. ZSH_THEME="strug" — тема оформления shell-а.
//
plugins=(git
bundler
copyfile
copybuffer
copypath
cp
emacs
node
npm
qrcode
rsync
)Продолжение настройки: подключаем плагины
19. source $ZSH/oh-my-zsh.sh — определяю источник для доступа к репозиторию oh-my-zsh
20. EDITOR='emacs' — назначаю редактор по умолчанию Emacs
21. [[ -s /home/edge/.autojump/etc/profile.d/autojump.sh ]] && source /home/edge/.autojump/etc/profile.d/autojump.sh — подключаю модуль autojump т.к. он отказался подключаться по умолчанию и его пришлось устанавливать в ручную.
О каждом модуле подробнее
autojump
Прыгает по директориям. Очень удобно.
Установка из репозитория https://github.com/wting/autojump
настройка обязательно написать в строке ~/.zshrc
[[ -s /home/edge/.autojump/etc/profile.d/autojump.sh ]] && source /home/edge/.autojump/etc/profile.d/autojump.sh
j foo— быстро переходит в директорию, в которой уже переходили поcdjc bar— переходит в дочернюю диреторию не набираяcdjo music— откроет директорию в стандартном файловом менеджереjco images— откроет дочернюю диреторию в стандартном файловом менеджере
bundler
copyfile
Копирует содержимое файла в буфер обмена, чтобы потом вставить в другое место.
copyfile <filename>
copybuffer
Копирует тукущую команду в строке в буфер обмена, чтобы потом вставить в другое место.
copybuffer
или горячая клавиша C-o
copypath
Копирует текущую дирректорию в буфер обмена, чтобы потом вставить в другое место.
copypath
cpv (модуль cp)
Копирует файлы или директории с сохранением Backup, прав доступа и показывает прогресс. Использует функцию
rcynccpv() {
rsync -pogbr -hhh --backup-dir="/tmp/rsync-${USERNAME}" -e /dev/null --progress "$@"
}
compdef _files cpv
Получает что-то вроде:
cpv doc10 doc11
doc10/themes/hugo-theme-relearn/static/
doc10/themes/hugo-theme-relearn/static/css/
doc10/themes/hugo-theme-relearn/static/css/auto-complete.css
1,75K 100% 1,75kB/s 0:00:00 (xfr#2254, to-chk=199/3084)
doc10/themes/hugo-theme-relearn/static/css/fontawesome-all.min.css
94,26K 100% 94,54kB/s 0:00:00 (xfr#2255, to-chk=198/3084)
doc10/themes/hugo-theme-relearn/static/css/fonts.css
2,72K 100% 2,73kB/s 0:00:00 (xfr#2256, to-chk=197/3084)
emacs
Создает несколько мощных ALIASES для работы с
emacsemacs— открывает редактор с файломe— аналогичноemacste— открывает клиента emacs в терминалеeeval— выполняет командуM-x evalне открывая Emacseframe— откроет новый frame emacsefile— печатает текущий путь файла в буферecd— печатает тукущую директорию в буфер
Теперь, чтобы открыть этот файл мне нужно набрать:
j hb3
e content/docs/linux/zsh/index/md
и я продолжаю работать. Но это еще не все.
ecode64
Создает текст и файлы в формате
base64Нужно для отправки картинок по почте, вставки на сайты в код и т.д. Иногда пользуюсь, поэтому поставил.
| Функция | Алиас | Описание |
|---|---|---|
| encode64 | e64 | Кодирует в base64 |
| encodefile64 | ef64 | Кодирует файл в base64 и помещает в одноименный файл с расширением .txt |
| decode64 | d64 | Декодирует из base64 |
╭─edge@edge-manjaro in ~
╰$ e64 "Игорь Ра"
0JjQs9C+0YDRjCDQoNCw
╭─edge@edge-manjaro in ~
╰$
╭─edge@edge-manjaro in ~
╰$ d64 0JjQs9C+0YDRjCDQoNCw
Игорь Ра%
╭─edge@edge-manjaro in ~
╰$
╭─edge@edge-manjaro in ~
╰$ echo "Игорь Ра" | e64
0JjQs9C+0YDRjCDQoNCwCg==
╭─edge@edge-manjaro in ~
╰$ echo "0JjQs9C+0YDRjCDQoNCwCg==" | d64
Игорь Ра
// Создам файл
╭─edge@edge-manjaro in ~
╰$ > etest.txt
Пример файла
^Z
[1] + 8113 suspended > etest.txt
// Закодирую файл
╭─edge@edge-manjaro in ~
╰$ ef64 etest.txt
etest.txt's content encoded in base64 and saved as etest.txt.txt
// Посмотрим, что получилось
╭─edge@edge-manjaro in ~
╰$ cat etest.txt.txt
0J/RgNC40LzQtdGAINGE0LDQudC70LAK
git
Это целая фабрика ALIASES для git
Легче посмотреть документацию, чем перечислять здесь: “https://github.com/ohmyzsh/ohmyzsh/tree/master/plugins/git" “https://github.com/ohmyzsh/ohmyzsh/tree/master/plugins/git"
Самые ключевые команды:
| Алиас | Команда |
|---|---|
| g | git |
| ga | git add |
| gaa | git add –all |
| gam | git am |
| gb | git branch |
| gco | git checkout |
| gccd | git clone –recurse-submodules “$@” && cd “$(basename $_ .git)” |
| gcam | git commit –all –message |
| gcmsg | git commit –message |
| gd | git diff |
| gf | git fetch |
| gfo | git fetch origin |
| gl | git pull |
| gp | git push |
| gpf! | git push –force |
| gpod | git push origin –delete |
| grb | git rebase |
| gr | git remote |
| grset | git remote set-url |
| grm | git rm |
| gsh | git show |
| gst | git status |
pass
Работает из терминала с программой PASS
Требует отдельной статьи, т.к. очень серьезная программа для хранения паролей.
qrcode
Генерит QRcode в TXT и SVG
Передаем текст в сервис “https://qrcode.show/" “https://qrcode.show/"
| Алиас | Комманда |
|---|---|
| qrcode [text] | curl -d “text” qrcode.show |
| qrsvg [text] | curl -d “text” qrcode.show -H “Accept: image/svg+xml” |
qrsvg "Игорь Ра"
<?xml version="1.0" standalone="yes"?><svg xmlns="http://www.w3.org/2000/svg" version="1.1" width="330" height="330" viewBox="0 0 330 330" shape-rendering="crispEdges"><rect x="0" y="0" width="330" height="330" fill="#fff"/><path fill="#000" d="M40 40h10v10H40V40M50 40h10v10H50V40M60 40h10v10H60V40M70 40h10v10H70V40M80 40h10v10H80V40M90 40h10v10H90V40M100 40h10v10H100V40M120 40h10v10H120V40M160 40h10v10H160V40M190 40h10v10H190V40M200 40h10v10H200V40M2
╭─edge@edge-manjaro in ~/data/sites
╰$ qrcode "Игорь Ра"
█████████████████████████████████
█████████████████████████████████
████ ▄▄▄▄▄ █ ▀▀▀▄██▄ █ ▄▄▄▄▄ ████
████ █ █ █▄█ ▄▀██▄ █ █ █ ████
████ █▄▄▄█ █▄▀▄▀██▄ █ █▄▄▄█ ████
████▄▄▄▄▄▄▄█▄█▄█▄▀▄▀ █▄▄▄▄▄▄▄████
████▄█▀ ▄ ▄ ▄▀█ ▀ ██ ▄▀█▄█ ████
████▄ ▀▀▄▄▀█▄ █ █▄▀▀▀▄▄▄█▀▀████
████ ▄█▀█▄█▄ ▄▄ ▀ █▄▄█▄██ ▀████
████ ▄ ▀█▄▄▀██▀ ▄▄██ █ ▄▀▀██▀████
████▄██▄▄▄▄▄▀▀▄▀▀▀ ▄▄▄ █▀▄ ████
████ ▄▄▄▄▄ █ ▀ ▄▀█▀ █▄█ ▄ ▀█████
████ █ █ █ ███▄▄ █ ▄▄ ▀█▄▀████
████ █▄▄▄█ ██ ▀█▄█ ▄█▀ ▀█ ▄ ████
████▄▄▄▄▄▄▄█▄▄███▄▄▄█▄▄▄▄█▄█▄████
█████████████████████████████████
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
rcync
Любимая команда для копирования, перемещения и синхронизации
Можно этой команде посвящать отдельный пост. Но в этом случае имеем четыре Алиаса:
| Алиас | Команда | Описание |
|---|---|---|
| rsync-copy | rsync -avz –progress -h | Копирует файлы и директории |
| rsync-move | rsync -avz –progress -h –remove-source-files | перемещает файлы и директории |
| rsync-update | rsync -avzu –progress -h | обновляет файлы |
| rsync-synchronize | rsync -avzu –delete –progress -h | синхронизирует |
Для этого сайта использую команду
hugo && rsync-synchronize ~/data/sites/hb3/public/ ftp_name@server.name:~/public_html/
13.20 - Строчный редактор SED
Основные команды редактора SED
Кто такой SED?
Sed - это неинтерактивный строчный редактор. Он принимает текст либо с устройства stdin, либо из текстового файла, выполняет некоторые операции над строками и затем выводит результат на устройство stdout или в файл. Как правило, в сценариях, sed используется в конвейерной обработке данных, совместно с другими командами и утилитами.
Синтаксис SED
Использование: sed [ПАРАМЕТР]… {только-сценарий-если-нет-другого-сценария}
[входной-файл]…
-n, --quiet, --silent
выключить автоматическую печать образца
--debug
комментировать выполнение программы
-e script, --expression=сценарий
добавить сценарий в исполняемые команды
-f script-file, --file=файл-сценария
добавить содержимое файла-сценария в исполняемые команды
--follow-symlinks
переходить по символьным ссылкам при обработке на месте
-i[СУФФИКС], --in-place[=СУФФИКС]
править файлы на месте (создаёт копию, если указан СУФФИКС)
-l N, --line-length=N
задать желаемую длину до переноса строки для команды «l»
--posix
отключить все расширения GNU
-E, -r, --regexp-extended
использовать в сценарии расширенные регулярные выражения
(для переносимости используйте -E (POSIX)
-s, --separate
рассматривать файлы раздельно, а не в виде одного
длинного непрерывного потока
--sandbox
работать в режиме «песочницы»
(отключает команды e/r/w)
-u, --unbuffered
загружать минимальный объём данных из входных файлов
и чаще сбрасывать выходные буферы на диск
-z, --null-data
разделять строки символами NUL
--help показать эту справку и выйти
--version показать информацию о версии и выйти
Если не указан параметр -e, --expression, -f или --file, то в качестве
интерпретируемого сценария sed берётся первый необязательный аргумент.
Все оставшиеся аргументы являются именами входных файлов; если входные
файлы не указаны, тогда читается стандартный ввод.
Домашняя страница GNU sed: <https://www.gnu.org/software/sed/>.
Справка по работе с программами GNU: <https://www.gnu.org/gethelp/>.
Сообщения об ошибках отправляйте на <bug-sed@gnu.org>.
Обзор опций SED
Опции настолько интересны, что я решил сделать в блоге специальный раздел для примеров по каждой опции по тегу #regexp
--version — очевидно выведет версию SED
--help — смотрим предыдущий раздел
-n --quiet --silent
Это полезная опция, которая выводит только строки, которые удовлетворяют запросам в выражении, по умолчанию выводится весь текст и дублируются строки, удовлетворяющие запросу.
Пример:
╭─edge@edge-manjaro in ~/tmp/sed
╰$ seq 3 | sed -E -e '2ia' -e '2ai' -e '3c100'
1
a
2
i
100
а теперь поставим -n:
╭─edge@edge-manjaro in ~/tmp/sed
╰$ seq 3 | sed -E -n -e '2ia' -e '2ai' -e '3c100'
a
i
100
вывелись только те строки, в которых были изменения
Работа с SED
Для образца, я загнал в файл sed.txt help
sed --help > sed.txt
Дальше работаю с этим файлом
ключ p:
— выводит строки в терминал (важно использовать параметр - n, а то выведет весь файл и продублирует условие отбора.
sed -n /script/p sed.txt
-e script, --expression=сценарий
-f script-file, --file=файл-сценария
вывести 5-ю строку sed -n 5p sed.txt
вывести с 1-й по 5-ю строку sed -n 1,5p sed.txt
вывести c 35-й строки до конца файла sed -n '35,$p' sed.txt
вообще лучше приучить себя ставить команды в апострофы, либо ' , либо "
ключ d:
— удаляет строку с выполненным условием
8d --- удалить 8-ю строку
/^$/d --- Удалить все пустые строки.
1,/^$/d --- Удалить все строки до первой пустой строки, включительно.
/GUI/d --- Удалить все строки, содержащие "GUI".
ключ s:
— заменяет по условию
's/Windows/Linux/' В каждой строке, заменить первое встретившееся слово "Windows" на слово "Linux".
's/BSOD/stability/g' В каждой строке, заменить все встретившиеся слова "BSOD" на "stability".
's/ *$//' Удалить все пробелы в конце каждой строки.
's/00*/0/g' Заменить все последовательности ведущих нулей одним символом "0".
'1,3 s/unix/linux/' Заменить в 1-й по 3-ю строки
ключ g:
— выполняет глобальную замену всех вхождений ’s/unix/linux/g’ Заменить все вхождения в строке ’s/unix/linux/1’ Заменить только первое вхождение в строке ’s/unix/linux/3’ Заменить только третье вхождение в строке ’s/unix/linux/3g’ Заменить все вхождения начиная с 3-го в строке
ключ i
игнорирует регистр в шаблоне
Синтаксис: sed 's/old_pattern/new_pattern/i' filename
Пример: sed 's/life/Love/i' a.txt
скрипт
/что искать/— просто пишем регулярное выражение, что будем искать.G— пустая строка.
Добавить пустые строки во всем файле:
sed G sed.txt
- вставить 2 пустые строки
G;G
знак ; перечисляет команды в скрипте
sed '/^$/d;G' sed.txt
- удалит все пустые строки и вставит пустые после каждой строки
выполним команду:
sed '/script/{x;p;x;}' sed.txt
- вставит пустые строки над каждой где есть слово script
выполним команду:
sed '/script/G' sed.txt
- Выполнить нумерацию строк
= выполняет нумерацию
sed = sed.txt | sed 'N;s/\n/\t/'
- Вывести все строки, содержащие шаблон, включая следующие за каждой из них x строк:
Синтаксис: sed -n '/pattern/,+xp' filename
Пример: sed -n '/learn/,+2p' a.txt
- Замена шаблона другим шаблоном, за исключением строки n:
Синтаксис: sed 'n!s/old_pattern/new_pattern/' filename
Пример: sed -i '5!s/life/love/' a.txt
- n — отключает печать образца
если не поставить, то выведет весь файл, а если поставить, то только результат выполненной работы
для
- e — параметр редактировать файл
13.21 - SSH на все случаи жизни
Полное руководство по настройке SSH-ключей и подключений
Содержание
- Генерация SSH-ключей
- Настройка подключения к удаленному серверу
- Настройка подключения к GitHub
- Настройка подключения к GitLab
- Настройка подключения к Gitea
- Настройка подключения между серверами
- Безопасность и дополнительные настройки
Генерация SSH-ключей
1. Генерация пары ключей
Откройте терминал и выполните:
ssh-keygen -t ed25519 -C "ваш_email@example.com"
Для большей совместимости (если ed25519 не поддерживается):
ssh-keygen -t rsa -b 4096 -C "ваш_email@example.com"
2. Выбор расположения ключей
При запросе расположения ключей:
- Нажмите Enter для сохранения в стандартном расположении (
~/.ssh/id_ed25519) - Или укажите свой путь (например,
~/.ssh/github_ed25519)
3. Задание парольной фразы
Рекомендуется задать надежную парольную фразу для дополнительной безопасности.
Настройка подключения к удаленному серверу
1. Копирование публичного ключа на сервер
ssh-copy-id -i ~/.ssh/id_ed25519.pub username@remote_server
Если ssh-copy-id недоступен:
cat ~/.ssh/id_ed25519.pub | ssh username@remote_server "mkdir -p ~/.ssh && chmod 700 ~/.ssh && cat >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keys"
2. Настройка SSH-конфигурации
Создайте/отредактируйте файл ~/.ssh/config:
nano ~/.ssh/config
Добавьте конфигурацию для сервера:
Host myserver
HostName server_ip_or_domain
User username
IdentityFile ~/.ssh/id_ed25519
Port 22 # измените, если используете нестандартный порт
3. Подключение к серверу
Теперь можно подключаться просто:
ssh myserver
Настройка подключения к GitHub
1. Копирование публичного ключа
Выведите содержимое публичного ключа:
cat ~/.ssh/id_ed25519.pub
2. Добавление ключа в GitHub
- Перейдите в GitHub → Settings → SSH and GPG keys
- Нажмите “New SSH key”
- Вставьте содержимое публичного ключа
- Сохраните
3. Тестирование подключения
ssh -T git@github.com
Должно появиться сообщение с вашим именем пользователя.
Настройка подключения к GitLab
1. Копирование публичного ключа
cat ~/.ssh/id_ed25519.pub
2. Добавление ключа в GitLab
- Перейдите в GitLab → Preferences → SSH Keys
- Вставьте содержимое публичного ключа
- Сохраните
3. Тестирование подключения
ssh -T git@gitlab.com
Настройка подключения к Gitea
1. Копирование публичного ключа
cat ~/.ssh/id_ed25519.pub
2. Добавление ключа в Gitea
- Перейдите в Gitea → Settings → SSH / GPG Keys
- Нажмите “Add Key”
- Вставьте содержимое публичного ключа
- Сохраните
3. Тестирование подключения
ssh -T git@gitea.example.com # замените на ваш домен Gitea
Настройка подключения между серверами
1. Генерация отдельного ключа для сервера
На сервере-источнике:
ssh-keygen -t ed25519 -f ~/.ssh/server_to_server -C "server1_to_server2"
2. Копирование ключа на целевой сервер
ssh-copy-id -i ~/.ssh/server_to_server.pub username@target_server
3. Настройка SSH-конфигурации
На сервере-источнике в ~/.ssh/config:
Host targetserver
HostName target_server_ip
User username
IdentityFile ~/.ssh/server_to_server
4. Проверка подключения
ssh targetserver
Безопасность и дополнительные настройки
1. Защита ключей
chmod 700 ~/.ssh
chmod 600 ~/.ssh/*
2. Использование ssh-agent
eval "$(ssh-agent -s)"
ssh-add ~/.ssh/id_ed25519
Для автоматического добавления при входе добавьте в ~/.bashrc или ~/.zshrc:
if [ -z "$SSH_AUTH_SOCK" ]; then
eval "$(ssh-agent -s)"
ssh-add ~/.ssh/id_ed25519 2>/dev/null
fi
3. Настройка двухфакторной аутентификации
Для серверов рекомендуется:
- Отключить вход по парню
- Использовать только SSH-ключи
- Настроить Fail2Ban
В /etc/ssh/sshd_config:
PasswordAuthentication no
ChallengeResponseAuthentication no
UsePAM no
PermitRootLogin no
4. Менеджер SSH-ключей (опционально)
Для удобного управления множеством ключей можно использовать:
sudo apt install keychain # для Debian/Ubuntu
Добавьте в ~/.bashrc:
eval `keychain --eval --agents ssh id_ed25519`
Заключение
Вы успешно настроили SSH-ключи для:
- Удаленных серверов
- GitHub, GitLab и Gitea
- Межсерверного взаимодействия
Дополнительные рекомендации:
- Регулярно обновляйте SSH-ключи (рекомендуется каждые 6-12 месяцев)
- Используйте разные ключи для разных сервисов
- Храните приватные ключи в безопасном месте
- Используйте менеджер паролей для хранения парольных фраз
13.22 - i3
Установка тайлингового оконного менеджера на Almalinux
Стандартная установка гласит:
dnf install i3
Но не все так просто!
Возникает ошибка на AlmaLinux
Ошибка возникает из-за того, что пакет i3 из репозитория EPEL требует perl(JSON::XS), который отсутствует в стандартных репозиториях AlmaLinux.
Решение:
Установите
perl-JSON-XSвручную
Сначала попробуйте установить зависимость:dnf install perl-JSON-XSЕсли пакет не найден, включите дополнительные репозитории
В AlmaLinux 9 (основанном на RHEL 9)perl-JSON-XSможет быть в репозитории CRB (CodeReady Builder) или PowerTools. Включите его:dnf config-manager --set-enabled crb dnf install perl-JSON-XSПовторите установку
i3
После установки зависимости:dnf install i3Если проблема сохраняется, попробуйте
--skip-brokendnf install i3 --skip-broken(но это нежелательно, так как может привести к нерабочему окружению).
Альтернатива: сборка из исходников
Если пакет недоступен, можно установитьi3вручную:dnf install @development-tools libxcb-devel xcb-util-keysyms-devel xcb-util-wm-devel libev-devel yajl-devel git clone https://github.com/i3/i3 cd i3 mkdir build && cd build meson .. ninja ninja install
Примечание:
- Убедитесь, что EPEL активирован:
dnf install epel-release dnf update
13.23 - Файловый менеджер ranger
Файловый менеджер для Linux RANGER
Команды файлового менеджера Ranger
Навигация
| Команда | Описание | Пример |
|---|---|---|
h, <left> | Перейти влево (на родительскую директорию) | |
j, <down> | Перейти вниз | |
k, <up> | Перейти вверх | |
l, <right> | Перейти вправо (войти в директорию) | |
gg | Перейти к первому файлу | |
G | Перейти к последнему файлу | |
H | Назад по истории | |
L | Вперёд по истории | |
] | Перейти к родительской директории | |
[ | Перейти к предыдущей директории | |
} | Обход директорий (traverse) | |
{ | Обратный обход директорий | |
gh | Перейти в домашнюю директорию (~) | |
gr | Перейти в корневую директорию (/) | |
gp | Перейти в /tmp | |
go | Перейти в /opt |
Работа с вкладками
| Команда | Описание | Пример |
|---|---|---|
<alt>1-9 | Перейти на вкладку 1-9 | <alt>1 |
gn | Новая вкладка | |
gc | Закрыть вкладку | |
gt, <c-i> | Следующая вкладка | |
gT, <s-tab> | Предыдущая вкладка | |
<alt><right> | Переместить вкладку вправо | |
<alt><left> | Переместить вкладку влево |
Выделение и отметка файлов
| Команда | Описание | Пример |
|---|---|---|
<space> | Отметить/снять отметку файла | |
v | Отметить/снять все файлы | |
V | Включить/выключить визуальный режим | |
uv | Снять все отметки | |
t | Добавить тег | |
ut | Удалить тег |
Копирование, вырезание, вставка
| Команда | Описание | Пример |
|---|---|---|
yy | Копировать | |
dd | Вырезать | |
pp | Вставить | |
po | Вставить с перезаписью | |
pP | Вставить с добавлением | |
pl | Вставить как симлинк | |
pL | Вставить как относительный симлинк |
Управление файлами
| Команда | Описание | Пример |
|---|---|---|
<f2>, a | Переименовать | |
<f5> | Копировать | |
<f6> | Вырезать | |
<f7> | Создать директорию | <f7>mkdir%space |
<f8>, dD | Удалить | |
dT | Переместить в корзину | |
<delete> | Удалить | |
cw | Массовое переименование | |
= | Изменить права доступа (chmod) |
Поиск и фильтрация
| Команда | Описание | Пример |
|---|---|---|
/ | Поиск | /pattern |
n | Следующий результат поиска | |
N | Предыдущий результат поиска | |
f | Поиск файлов (scout) | f*.txt |
zf | Установить фильтр | zf*.py |
.d | Фильтровать только директории | |
.f | Фильтровать только файлы | |
.l | Фильтровать только симлинки |
Сортировка
| Команда | Описание | Пример |
|---|---|---|
os | Сортировать по размеру | |
ob | Сортировать по имени | |
om | Сортировать по времени изменения | |
oc | Сортировать по времени создания | |
oa | Сортировать по времени доступа | |
oS | Сортировать по размеру (обратный порядок) | |
oB | Сортировать по имени (обратный порядок) | |
or | Переключить обратный порядок сортировки |
Режимы отображения
| Команда | Описание | Пример |
|---|---|---|
i | Просмотреть файл | |
E | Редактировать файл | |
~ | Переключить режим просмотра | |
Mf | Режим отображения: имя файла | |
Mi | Режим отображения: информация о файле | |
Mm | Режим отображения: время изменения | |
Mp | Режим отображения: права доступа |
Системные команды
| Команда | Описание | Пример |
|---|---|---|
S | Открыть shell | |
: | Открыть консоль | |
! | Выполнить shell команду | !ls -la |
du | Размер директории | |
dU | Размер директории (сортировка) |
Настройки отображения
| Команда | Описание | Пример |
|---|---|---|
zh | Показать/скрыть скрытые файлы | |
zc | Свернуть/развернуть preview | |
zi | Включить/выключить preview изображений | |
zp | Включить/выключить preview файлов | |
zP | Включить/выключить preview директорий |
Закладки
| Команда | Описание | Пример |
|---|---|---|
m<key> | Установить закладку | ma |
'<key> | Перейти к закладке | 'a |
`<key> | Перейти к закладке | `a |
um<key> | Удалить закладку | uma |
Выход и управление
| Команда | Описание | Пример |
|---|---|---|
q | Выйти | |
Q | Выйти принудительно | |
ZZ | Выйти и сохранить | |
ZQ | Выйти без сохранения | |
R | Перезагрузить текущую директорию | |
<c-l> | Перерисовать экран | |
<c-c> | Прервать операцию |
Режим консоли (console mode)
| Команда | Описание | Пример |
|---|---|---|
<c-j> | Выполнить команду | |
<escape> | Закрыть консоль | |
<c-p>, <up> | История команд назад | |
<c-n>, <down> | История команд вперёд | |
<c-w> | Удалить слово | |
<c-u> | Удалить до начала строки | |
<c-k> | Удалить до конца строки |
Режим просмотра (pager mode)
| Команда | Описание | Пример |
|---|---|---|
j, <down> | Прокрутить вниз | |
k, <up> | Прокрутить вверх | |
q | Выйти из просмотра | |
g | Перейти к началу | |
G | Перейти к концу | |
<space> | Прокрутить на страницу вниз | |
b | Прокрутить на страницу вверх |
14 - Mailu
14.1 - Установка mailu
Пошаговый план установки
Установка Docker
Версия установки 2024.06 имеет самую последнюю стабильную версию для Mailu.
Требования к оборудованию
При использовании антивируса (clamav):
- 3GB of memory
- 1GB of swap
Без антивируса (clamav):
- 1GB of memory
- 1GB of swap
Пошаговые действия
Создал сервер Debian 12 с параметрами
- 2GB of memory
- 1CPU
Настройка DOCKER
Настрой Докера apt хранилище.
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
Установить Docker
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Проверить установку Docker
sudo docker run hello-world
docker version
docker compose version
Установка MAILU
Создадим папку, где будет жить MAILU
mkdir /mailu
cd /mailu
Выполняем генерацию файлов настройки
https://setup.mailu.io/2024.06/
Настраиваем DNS
Прописываем A записи на exclusivesell.ru и на mail.exclusivesell.ru
docker compose up -d
запускаем docker
создаем админа
docker compose exec admin flask mailu admin me example.net ‘password’
14.2 - Установка и настройка Mailu на vps
Полная инструкция по установке и настройке Mailu на VPS с доменом
🔧 1. Требования
- VPS (Ubuntu 20.04/22.04, 1+ ядра, 2+ GB RAM, 25+ GB SSD)
- Доменное имя (например,
mail.yourdomain.com) - Доступ к DNS-панели домена
- Docker и Docker Compose (установятся автоматически)
🚀 2. Подготовка сервера
Обновление системы и установка зависимостей:
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl git nginx certbot python3-certbot-nginx #для ручной установки ssl (я не использовал)
📦 3. Установка Mailu
1. Скачайте официальный compose-файл:
mkdir mailu && cd mailu
curl -O https://mailu.io/2.0/docker-compose.yml
curl -O https://mailu.io/2.0/mailu.env
2. Настройте .env-файл:
Отредактируйте mailu.env:
DOMAIN=yourdomain.com
HOSTNAMES=mail.yourdomain.com
SECRET_KEY=сгенерируйте_ключ_openssl_rand_hex_32
DB_PASSWORD=strong_password
ADMIN=true
Сгенерируйте SECRET_KEY:
openssl rand -hex 32
3. Запустите Mailu:
docker-compose up -d
🌐 4. Настройка DNS
Добавьте записи в DNS-панели домена:
| Тип | Имя | Значение |
|---|---|---|
| A | mail.yourdomain.com | IP вашего VPS |
| MX | @ | 10 mail.yourdomain.com |
| TXT | @ | v=spf1 mx -all |
| TXT | _dmarc | v=DMARC1; p=none; rua=mailto:admin@yourdomain.com |
🔒 5. Настройка SSL (Let’s Encrypt)
Через Nginx:
sudo certbot --nginx -d mail.yourdomain.com
Или встроенными средствами Mailu:
В mailu.env добавьте: (лучше этот вариант)
TLS_FLAVOR=letsencrypt
⚙️ 6. Настройка почтовых клиентов
Рекомендуемые параметры:
- IMAP:
mail.yourdomain.com, порт 993 (SSL) - SMTP:
mail.yourdomain.com, порт 465 (STARTTLS) - Логин: Полный email (user@yourdomain.com)
📧 7. Создание почтовых ящиков
- Откройте админку:
https://mail.yourdomain.com/admin - Войдите с email
admin@yourdomain.comи паролем изmailu.env(ADMIN_PASSWORD) - Создайте пользователей: Users → Add user
🔥 8. Фаервол (UFW)
sudo ufw allow 80,443,25,587,465,993,995/tcp
sudo ufw enable
🛠 9. Дополнительные настройки
Включение DKIM:
- В админке: DNS → DKIM keys
- Добавьте TXT-запись в DNS:
mail._domainkey.yourdomain.com IN TXT "v=DKIM1; k=rsa; p=публичный_ключ"
Резервное копирование:
docker-compose exec admin flask mailu backup
🚨 10. Тестирование
- Проверьте SMTP:
telnet mail.yourdomain.com 25 EHLO yourdomain.com - Протестируйте отправку:
swaks --to test@yourdomain.com --from admin@yourdomain.com --server mail.yourdomain.com
⏳ 11. Обновление
docker-compose pull
docker-compose up -d
❌ 12. Решение проблем
- Почта не отправляется: Проверьте логи
docker-compose logs -f smtp - Нет доступа к админке: Убедитесь, что
ADMIN=trueв.env - Ошибки SSL: Перевыпустите сертификат
certbot renew
Готово! Ваш почтовый сервер с веб-интерфейсом доступен по https://mail.yourdomain.com. Для интеграции с сайтом используйте API (как в предыдущих шагах) или SMTP-аутентификацию.
15 - Nginx
Nginx — это программное обеспечение с открытым исходным кодом для создания легкого и мощного веб-сервера.
NGINX
Nginx (eNGIne X, «Энджинкс» или «Энджин-икс») — это программное обеспечение с открытым исходным кодом для создания легкого и мощного веб-сервера. Также его используют в качестве почтового сервера. Nginx решает проблему падения производительности с ростом трафика и является самым популярным веб-сервером в России и вторым в мире.
15.1 - Примеры настройки nginx
Настройка Nginx для управления контейнерами, разделами сайта и поддоменами
Оглавление
- Базовые настройки Nginx
- Конфигурация для контейнеров
- Настройка разделов сайта
- Работа с поддоменами
- Использование regex в Nginx
- Оптимизация и безопасность
Базовые настройки Nginx
Основная структура конфигурации
user www-data;
worker_processes auto;
pid /run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Базовые настройки
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
# Настройки логов
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
# Подключение конфигов из отдельных файлов
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
Конфигурация для контейнеров
1. Проксирование к контейнеру Docker
server {
listen 80;
server_name app.example.com;
location / {
proxy_pass http://localhost:3000; # Порт контейнера
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
2. Балансировка нагрузки между несколькими контейнерами
upstream myapp {
server 172.17.0.1:8001; # Контейнер 1
server 172.17.0.2:8002; # Контейнер 2
server 172.17.0.3:8003; # Контейнер 3
}
server {
listen 80;
server_name cluster.example.com;
location / {
proxy_pass http://myapp;
include proxy_params;
}
}
3. Проксирование WebSocket
server {
listen 80;
server_name ws.example.com;
location / {
proxy_pass http://localhost:8080;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
}
}
Настройка разделов сайта
1. Разделы как подкаталоги
server {
listen 80;
server_name example.com;
# Главная страница
location = / {
root /var/www/main;
index index.html;
}
# Блог
location /blog/ {
alias /var/www/blog/;
try_files $uri $uri/ /blog/index.html;
}
# API
location /api/ {
proxy_pass http://localhost:8000/;
proxy_set_header Host $host;
}
}
2. Разделы с разными обработчиками
server {
listen 80;
server_name example.com;
# Статические файлы
location ~ ^/static/ {
root /var/www/static;
expires 30d;
access_log off;
}
# PHP-обработчик
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/run/php/php7.4-fpm.sock;
}
# Обработка Python (uWSGI)
location /pythonapp {
include uwsgi_params;
uwsgi_pass unix:/run/uwsgi/app/pythonapp/socket;
}
}
Работа с поддоменами
1. Базовые поддомены
server {
listen 80;
server_name www.example.com;
return 301 https://example.com$request_uri;
}
server {
listen 80;
server_name example.com;
location / {
root /var/www/main;
index index.html;
}
}
server {
listen 80;
server_name blog.example.com;
location / {
root /var/www/blog;
index index.html;
}
}
2. Динамические поддомены (wildcard)
server {
listen 80;
server_name ~^(?<subdomain>.+)\.example\.com$;
location / {
root /var/www/$subdomain;
try_files $uri $uri/ /index.html;
}
}
3. Поддомены для пользователей
server {
listen 80;
server_name ~^(?<user>[a-z0-9-]+)\.users\.example\.com$;
location / {
proxy_pass http://unix:/home/$user/app.sock;
proxy_set_header Host $host;
}
}
Использование regex в Nginx
1. Основы регулярных выражений
Синтаксис: ~ (чувствительные к регистру) или ~* (нечувствительные)
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 365d;
access_log off;
}
2. Именованные захваты
location ~* ^/user/(?<user_id>\d+)/profile$ {
proxy_pass http://backend/users/$user_id;
}
3. Сложные маршруты
location ~ ^/(api|v2)/v(?<version>\d+)/(?<resource>\w+)/(?<id>\d+)$ {
proxy_pass http://backend/$version/$resource?id=$id;
}
4. Отрицательные условия
location ~* \.(?!jpg|png|gif).*$ {
add_header Cache-Control "no-store";
}
5. Оптимизация regex
Лучшие практики:
- Используйте
^и$для точного соответствия - Избегайте жадных квантификаторов (
.*) - Группируйте альтернативы в порядке вероятности
Пример оптимизированного regex:
location ~ ^/images/(thumb|large)/([a-z0-9-]+)\.(jpe?g|png)$ {
# Более эффективно, чем /images/.*
}
Оптимизация и безопасность
1. Безопасные заголовки
server {
# ...
add_header X-Frame-Options "SAMEORIGIN";
add_header X-Content-Type-Options "nosniff";
add_header X-XSS-Protection "1; mode=block";
add_header Content-Security-Policy "default-src 'self'";
add_header Referrer-Policy "strict-origin-when-cross-origin";
}
2. Ограничение доступа
location /admin/ {
allow 192.168.1.0/24;
allow 10.0.0.1;
deny all;
auth_basic "Admin Area";
auth_basic_user_file /etc/nginx/.htpasswd;
}
3. Кэширование и сжатие
gzip on;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript;
location ~* \.(?:jpg|jpeg|png|gif|ico|css|js)$ {
expires 30d;
access_log off;
add_header Cache-Control "public";
}
4. Мониторинг и логирование
# Логирование в формате JSON
log_format json_combined escape=json
'{'
'"time_local":"$time_local",'
'"remote_addr":"$remote_addr",'
'"request":"$request",'
'"status": "$status",'
'"body_bytes_sent":"$body_bytes_sent",'
'"http_referrer":"$http_referer",'
'"http_user_agent":"$http_user_agent"'
'}';
access_log /var/log/nginx/access.log json_combined;
Заключение
В этом руководстве мы рассмотрели:
- Базовую настройку Nginx
- Конфигурацию для работы с контейнерами
- Организацию разделов сайта
- Настройку поддоменов
- Использование регулярных выражений
- Оптимизацию и безопасность
- Тестирование конфигураций с помощью
nginx -t - Использование инструментов вроде Certbot для HTTPS
- Мониторинг производительности с помощью инструментов типа GoAccess
15.2 - Настройка Nginx для работы с почтовыми сервисами
Nginx может использоваться как прокси-сервер для различных почтовых протоколов (IMAP, POP3, SMTP) и веб-интерфейсов почтовых сервисов. Вот практические примеры конфигураций.
1. Проксирование веб-интерфейса почтового сервера (Roundcube, Rainloop)
server {
listen 80;
server_name mail.example.com;
# Перенаправление HTTP -> HTTPS
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
server_name mail.example.com;
# SSL сертификаты
ssl_certificate /etc/letsencrypt/live/mail.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/mail.example.com/privkey.pem;
# Настройки SSL
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
# Корневая директория
root /var/www/webmail;
index index.php;
# Обработка PHP для Roundcube
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/var/run/php/php8.1-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
# Статические файлы
location ~* \.(jpg|jpeg|gif|png|css|js|ico|svg)$ {
expires 30d;
access_log off;
}
# Запрет доступа к скрытым файлам
location ~ /\. {
deny all;
access_log off;
log_not_found off;
}
}
2. Проксирование почтовых протоколов (IMAP/POP3/SMTP)
Nginx может работать как TLS-терминатор для почтовых протоколов:
Конфигурация для IMAPS (SSL-порт 993):
stream {
upstream imap_backend {
server 127.0.0.1:143; # Внутренний IMAP сервер
}
server {
listen 993 ssl;
proxy_pass imap_backend;
ssl_certificate /etc/ssl/certs/mail.example.com.pem;
ssl_certificate_key /etc/ssl/private/mail.example.com.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
}
}
Конфигурация для SMTPS (SSL-порт 465):
stream {
upstream smtp_backend {
server 127.0.0.1:25; # Внутренний SMTP сервер
}
server {
listen 465 ssl;
proxy_pass smtp_backend;
ssl_certificate /etc/ssl/certs/mail.example.com.pem;
ssl_certificate_key /etc/ssl/private/mail.example.com.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
}
}
3. Проксирование Submission порта (587)
stream {
upstream submission_backend {
server 127.0.0.1:587; # Внутренний Submission порт
}
server {
listen 587;
proxy_pass submission_backend;
}
}
4. Конфигурация для почтового API (например, для Mailgun, SendGrid)
server {
listen 443 ssl;
server_name api.mail.example.com;
ssl_certificate /etc/ssl/certs/mail.example.com.pem;
ssl_certificate_key /etc/ssl/private/mail.example.com.key;
location /v3/ {
proxy_pass http://mail_api_server:8000/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# Ограничение методов
limit_except POST {
deny all;
}
# Ограничение скорости для API
limit_req zone=mailapi burst=20 nodelay;
}
location / {
return 403;
}
}
5. Аутентификация перед доступом к почтовому веб-интерфейсу
server {
listen 443 ssl;
server_name webmail.example.com;
# Базовая аутентификация
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.htpasswd;
# Двухфакторная аутентификация
location = /2fa {
proxy_pass http://auth_server:8000/verify;
proxy_pass_request_body off;
proxy_set_header Content-Length "";
proxy_set_header X-Original-URI $request_uri;
}
location / {
# Проверка 2FA перед доступом
auth_request /2fa;
proxy_pass http://webmail_server:8080;
proxy_set_header Host $host;
}
}
6. Виртуальные почтовые хосты (для разных доменов)
map $http_host $mail_backend {
hostnames;
default http://default_mail_server:8080;
mail.example.com http://primary_mail_server:8080;
mail.example.org http://secondary_mail_server:8080;
}
server {
listen 443 ssl;
server_name ~^mail\.(.*)$;
ssl_certificate /etc/ssl/certs/wildcard.$1.pem;
ssl_certificate_key /etc/ssl/private/wildcard.$1.key;
location / {
proxy_pass $mail_backend;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
7. Защита от спама и DDoS для почтовых сервисов
http {
# Зона для ограничения скорости
limit_req_zone $binary_remote_addr zone=mailauth:10m rate=5r/m;
server {
listen 443 ssl;
server_name smtp-auth.example.com;
location /auth {
limit_req zone=mailauth burst=10 nodelay;
proxy_pass http://auth_server:8000;
proxy_set_header Host $host;
}
}
}
stream {
# Защита SMTP-порта
server {
listen 25;
proxy_pass smtp_backend;
# Ограничение соединений
proxy_connect_timeout 5s;
proxy_timeout 30s;
# Защита от DDoS
limit_conn mail_conn 10;
limit_conn_log_level warn;
}
}
Важные замечания по безопасности
- Всегда используйте SSL/TLS для почтовых сервисов
- Ограничивайте доступ к административным интерфейсам по IP:
location /admin { allow 192.168.1.0/24; allow 10.0.0.1; deny all; } - Регулярно обновляйте SSL-сертификаты
- Настройте правильные заголовки безопасности:
add_header X-Frame-Options "DENY"; add_header X-Content-Type-Options "nosniff"; add_header Content-Security-Policy "default-src 'self'"; - Включайте логирование для мониторинга:
access_log /var/log/nginx/mail_access.log; error_log /var/log/nginx/mail_error.log;
Эти конфигурации предоставляют базовые примеры для настройки Nginx в качестве прокси для почтовых сервисов. В зависимости от вашего конкретного почтового сервера (Postfix, Dovecot, Exim и т.д.) могут потребоваться дополнительные настройки.
16 - Управление базами данных: основные команды
SQL раздел с описанием основных команд по управлению базами данных
Этот раздел содержит ключевые команды для работы с различными СУБД, включая:
- Создание и настройку баз данных и пользователей
- Управление таблицами (создание, изменение, удаление)
- Работу с индексами (добавление, удаление, оптимизация)
- Вставку, обновление и выборку данных
- Сложные запросы (JOIN, подзапросы, транзакции)
- Экспорт и импорт данных (CSV, JSON, SQL-дампы)
- Автоматизацию (хранимые процедуры, триггеры, скрипты)
Команды подходят для администрирования серверов, разработки приложений и аналитики данных. Для удобства они сгруппированы по темам и сопровождаются примерами.
16.1 - Справочный гайд по командам PostgreSQL
Основные команды по управлению базой данных PostgreSQL. Управление базой данных, управление пользователями базы данных, управление таблицами, управление индексами, управление записями таблиц, связанные запросы, выгрузки данных во внешние источники, создание скриптов, загрузка данных из разных форматов
1. Установка PostgreSQL на разные ОС
Ubuntu/Debian
# Обновление пакетов
sudo apt update
# Установка PostgreSQL
sudo apt install postgresql postgresql-contrib
# Проверка статуса
sudo systemctl status postgresql
# Включение автозапуска
sudo systemctl enable postgresql
Manjaro/Arch Linux
# Установка PostgreSQL
sudo pacman -S postgresql
# Инициализация БД
sudo su - postgres -c "initdb --locale en_US.UTF-8 -D /var/lib/postgres/data"
# Запуск службы
sudo systemctl start postgresql
# Включение автозапуска
sudo systemctl enable postgresql
AlmaLinux/RHEL/CentOS
# Установка PostgreSQL
sudo dnf install postgresql-server postgresql-contrib
# Инициализация БД
sudo postgresql-setup --initdb
# Запуск службы
sudo systemctl start postgresql
# Включение автозапуска
sudo systemctl enable postgresql
2. Подключение и настройка
Вход в консоль PostgreSQL
sudo -u postgres psql # Linux
psql -U postgres # Если настроен пароль
Создание пользователя и БД
-- Создание пользователя
CREATE USER myuser WITH PASSWORD 'mypassword';
-- Создание базы данных
CREATE DATABASE mydb OWNER myuser;
-- Выдача прав
GRANT ALL PRIVILEGES ON DATABASE mydb TO myuser;
-- Выход
\q
Подключение к БД
psql -U myuser -d mydb -h localhost -W
3. Управление базами данных
Основные команды
-- Показать все БД
\l
-- Переключиться на БД
\c dbname
-- Создать БД
CREATE DATABASE dbname;
-- Удалить БД
DROP DATABASE dbname;
4. Управление таблицами
Создание и изменение таблиц
-- Создание таблицы
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
created_at TIMESTAMP DEFAULT NOW()
);
-- Просмотр таблиц
\dt
-- Просмотр структуры таблицы
\d users
-- Добавление столбца
ALTER TABLE users ADD COLUMN age INT;
-- Удаление таблицы
DROP TABLE users;
5. Работа с данными
Вставка, обновление, удаление
-- Вставка данных
INSERT INTO users (name, email) VALUES ('Alice', 'alice@example.com');
-- Обновление данных
UPDATE users SET email = 'new@example.com' WHERE id = 1;
-- Удаление данных
DELETE FROM users WHERE id = 1;
-- Выборка данных
SELECT * FROM users;
SELECT name, email FROM users WHERE age > 18;
6. Индексы и оптимизация
Создание и удаление индексов
-- Создать индекс
CREATE INDEX idx_users_email ON users(email);
-- Удалить индекс
DROP INDEX idx_users_email;
-- Полнотекстовый поиск (если нужно)
CREATE EXTENSION pg_trgm;
CREATE INDEX idx_users_name_search ON users USING gin(name gin_trgm_ops);
7. Резервное копирование и восстановление
Экспорт и импорт БД
# Дамп всей БД
pg_dump -U myuser -d mydb -f backup.sql
# Дамп одной таблицы
pg_dump -U myuser -d mydb -t users -f users_backup.sql
# Восстановление БД
psql -U myuser -d mydb -f backup.sql
8. Расширенные возможности
Транзакции
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
COMMIT; -- или ROLLBACK в случае ошибки
Представления (Views)
CREATE VIEW active_users AS
SELECT * FROM users WHERE last_login > NOW() - INTERVAL '30 days';
Хранимые процедуры
CREATE OR REPLACE FUNCTION add_user(name TEXT, email TEXT)
RETURNS VOID AS $$
BEGIN
INSERT INTO users (name, email) VALUES (name, email);
END;
$$ LANGUAGE plpgsql;
-- Вызов
SELECT add_user('Bob', 'bob@example.com');
9. Внешние источники данных
Импорт из CSV
COPY users(name, email) FROM '/path/to/users.csv' DELIMITER ',' CSV HEADER;
Экспорт в CSV
COPY users TO '/path/to/users_export.csv' DELIMITER ',' CSV HEADER;
Заключение
Этот гайд охватывает основные команды PostgreSQL для администрирования, разработки и анализа данных. Для более сложных сценариев обратитесь к официальной документации.
🚀 Совет: Используйте pgAdmin (графический интерфейс) для удобного управления PostgreSQL.
16.2 - Справочный гайд по командам MySQL
“Основные команды по управлению базой данных MySql. Управление базой данных, управление пользователями базы данных, управление таблицами, управление индексами, управление записями таблиц, связанные запросы, выгрузки данных во внешние источники, создание скриптов, загрузка данных из разных форматов”
Установка MySQL/MariaDB на различные дистрибутивы Linux
Ubuntu/Debian
Установка MySQL
# Обновление пакетов
sudo apt update
# Установка MySQL сервера
sudo apt install mysql-server
# Запуск службы
sudo systemctl start mysql
# Включение автозапуска
sudo systemctl enable mysql
# Настройка безопасности (запустит интерактивный скрипт)
sudo mysql_secure_installation
# Проверка статуса
sudo systemctl status mysql
Установка MariaDB (альтернатива MySQL)
sudo apt update
sudo apt install mariadb-server
sudo systemctl start mariadb
sudo systemctl enable mariadb
sudo mysql_secure_installation
Manjaro/Arch Linux
Установка MySQL (Arch)
# Обновление системы
sudo pacman -Syu
# Установка MySQL
sudo pacman -S mysql
# Инициализация базы данных
sudo mysql_install_db --user=mysql --basedir=/usr --datadir=/var/lib/mysql
# Запуск службы
sudo systemctl start mysqld
# Включение автозапуска
sudo systemctl enable mysqld
# Настройка безопасности
sudo mysql_secure_installation
Установка MariaDB
sudo pacman -S mariadb
sudo mariadb-install-db --user=mysql --basedir=/usr --datadir=/var/lib/mysql
sudo systemctl start mariadb
sudo systemctl enable mariadb
sudo mysql_secure_installation
AlmaLinux/RHEL/CentOS
Установка MySQL (Alma)
# Для AlmaLinux 8/9 и RHEL 8/9:
# Добавление MySQL репозитория
sudo dnf install https://dev.mysql.com/get/mysql80-community-release-el9-4.noarch.rpm
# Установка MySQL сервера
sudo dnf install mysql-community-server
# Запуск службы
sudo systemctl start mysqld
# Включение автозапуска
sudo systemctl enable mysqld
# Временный пароль можно найти в логах
sudo grep 'temporary password' /var/log/mysqld.log
# Настройка безопасности
sudo mysql_secure_installation
Установка MariaDB (Alma)
# Установка MariaDB
sudo dnf install mariadb-server
# Запуск службы
sudo systemctl start mariadb
# Включение автозапуска
sudo systemctl enable mariadb
# Настройка безопасности
sudo mysql_secure_installation
Общие команды после установки
Подключение к MySQL/MariaDB
mysql -u root -p
Создание нового пользователя (из консоли MySQL)
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON *.* TO 'username'@'localhost' WITH GRANT OPTION;
FLUSH PRIVILEGES;
Резервное копирование
# Резервное копирование всех баз
mysqldump -u root -p --all-databases > all_databases.sql
# Резервное копирование конкретной базы
mysqldump -u root -p database_name > database_name.sql
Восстановление из резервной копии
mysql -u root -p database_name < database_name.sql
Примечания
Для MySQL 8.0+ используется новый плагин аутентификации
caching_sha2_password, что может вызвать проблемы с некоторыми старыми клиентами. Можно изменить на старый плагин:ALTER USER 'username'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';В некоторых дистрибутивах (особенно Manjaro/Arch) MariaDB является заменой MySQL по умолчанию.
Для AlmaLinux/RHEL 9 может потребоваться отключить модуль MySQL перед установкой:
sudo dnf module disable mysql
Управление базой данных
-- Создание базы данных
CREATE DATABASE db_name CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- Просмотр всех баз данных
SHOW DATABASES;
-- Выбор базы данных для работы
USE db_name;
-- Удаление базы данных
DROP DATABASE db_name;
-- Резервное копирование базы данных (из командной строки)
mysqldump -u username -p db_name > backup.sql
-- Восстановление базы данных (из командной строки)
mysql -u username -p db_name < backup.sql
Управление пользователями базы данных
-- Создание пользователя
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';
-- Изменение пароля пользователя
ALTER USER 'username'@'localhost' IDENTIFIED BY 'new_password';
-- Назначение прав пользователю
GRANT ALL PRIVILEGES ON db_name.* TO 'username'@'localhost';
-- Просмотр прав пользователя
SHOW GRANTS FOR 'username'@'localhost';
-- Отзыв прав
REVOKE ALL PRIVILEGES ON db_name.* FROM 'username'@'localhost';
-- Удаление пользователя
DROP USER 'username'@'localhost';
Управление таблицами
-- Создание таблицы
CREATE TABLE table_name (
id INT AUTO_INCREMENT PRIMARY KEY,
column1 VARCHAR(255) NOT NULL,
column2 INT,
column3 DATETIME DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (column2) REFERENCES other_table(id)
) ENGINE=InnoDB;
-- Просмотр структуры таблицы
DESCRIBE table_name;
SHOW CREATE TABLE table_name;
-- Изменение таблицы
ALTER TABLE table_name ADD COLUMN new_column VARCHAR(100);
ALTER TABLE table_name MODIFY COLUMN column1 TEXT;
ALTER TABLE table_name DROP COLUMN column2;
ALTER TABLE table_name RENAME TO new_table_name;
-- Удаление таблицы
DROP TABLE table_name;
-- Очистка таблицы (удаление всех данных)
TRUNCATE TABLE table_name;
Управление индексами
-- Создание индекса
CREATE INDEX idx_name ON table_name (column1);
CREATE UNIQUE INDEX idx_unique_name ON table_name (column1, column2);
-- Создание полнотекстового индекса
CREATE FULLTEXT INDEX idx_ft ON table_name (text_column);
-- Просмотр индексов таблицы
SHOW INDEX FROM table_name;
-- Удаление индекса
DROP INDEX idx_name ON table_name;
Управление записями таблиц
-- Вставка данных
INSERT INTO table_name (column1, column2) VALUES ('value1', 123);
INSERT INTO table_name VALUES (NULL, 'value1', 123, DEFAULT);
-- Множественная вставка
INSERT INTO table_name (column1, column2) VALUES
('value1', 123),
('value2', 456),
('value3', 789);
-- Обновление данных
UPDATE table_name SET column1 = 'new_value' WHERE id = 1;
UPDATE table_name SET column1 = 'value' WHERE column2 > 100 LIMIT 10;
-- Удаление данных
DELETE FROM table_name WHERE id = 1;
DELETE FROM table_name ORDER BY created_at LIMIT 100;
-- Выборка данных
SELECT * FROM table_name;
SELECT column1, column2 FROM table_name WHERE id > 100;
SELECT DISTINCT column1 FROM table_name;
SELECT COUNT(*) FROM table_name;
-- Сортировка и ограничение
SELECT * FROM table_name ORDER BY column1 DESC LIMIT 10 OFFSET 20;
-- Группировка
SELECT column1, COUNT(*) FROM table_name GROUP BY column1 HAVING COUNT(*) > 5;
Связанные запросы
-- Внутреннее соединение (INNER JOIN)
SELECT t1.*, t2.column
FROM table1 t1
JOIN table2 t2 ON t1.id = t2.table1_id;
-- Внешние соединения (LEFT/RIGHT JOIN)
SELECT t1.*, t2.column
FROM table1 t1
LEFT JOIN table2 t2 ON t1.id = t2.table1_id;
-- Подзапросы
SELECT * FROM table1 WHERE id IN (SELECT table1_id FROM table2 WHERE column = 'value');
-- Объединение результатов (UNION)
SELECT column1 FROM table1
UNION
SELECT column2 FROM table2;
-- Транзакции
START TRANSACTION;
INSERT INTO table1 VALUES (1, 'test');
UPDATE table2 SET column = 'value' WHERE id = 1;
COMMIT;
-- или ROLLBACK;
Выгрузка данных во внешние источники
-- Выгрузка в файл (из командной строки)
mysql -u username -p -e "SELECT * FROM db_name.table_name" > output.csv
-- Использование SELECT INTO OUTFILE
SELECT * INTO OUTFILE '/tmp/result.csv'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM table_name;
-- Экспорт в JSON (через клиент)
SELECT JSON_OBJECT('id', id, 'name', name) FROM table_name;
Создание скриптов
-- Хранимые процедуры
DELIMITER //
CREATE PROCEDURE procedure_name(IN param1 INT)
BEGIN
SELECT * FROM table_name WHERE id = param1;
END //
DELIMITER ;
-- Вызов процедуры
CALL procedure_name(1);
-- Функции
DELIMITER //
CREATE FUNCTION function_name(param1 INT) RETURNS INT
BEGIN
DECLARE result INT;
SELECT COUNT(*) INTO result FROM table_name WHERE id > param1;
RETURN result;
END //
DELIMITER ;
-- Триггеры
DELIMITER //
CREATE TRIGGER trigger_name BEFORE INSERT ON table_name
FOR EACH ROW
BEGIN
IF NEW.column1 IS NULL THEN
SET NEW.column1 = 'default';
END IF;
END //
DELIMITER ;
-- Представления (VIEW)
CREATE VIEW view_name AS SELECT column1, column2 FROM table_name WHERE column3 > 100;
Загрузка данных из разных форматов
-- Загрузка из CSV
LOAD DATA INFILE '/path/to/file.csv'
INTO TABLE table_name
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
-- Импорт JSON
INSERT INTO table_name (column1, column2)
SELECT j->>'$.field1', j->>'$.field2'
FROM JSON_TABLE('[{"field1":"value1","field2":123}]', '$[*]'
COLUMNS (
j JSON PATH '$'
)
) AS j;
-- Использование mysqlimport (из командной строки)
mysqlimport --ignore-lines=1 --fields-terminated-by=, --local -u username -p db_name /path/to/file.csv
Этот гайд охватывает основные команды MySQL для работы с базами данных. Для более сложных операций рекомендуется обращаться к официальной документации MySQL.
16.2.1 - Восстановление пароля root в MySQL
Восстановление пароля root в MariaDB выполняется в несколько шагов: остановка сервиса, запуск в безопасном режиме (без проверки прав), смена пароля и перезагрузка. Вот подробная инструкция.
1. Остановка MySQL/MariaDB
Linux (systemd)
sudo systemctl stop mariadb
Linux (SysVinit)
sudo service mysql stop # или sudo /etc/init.d/mysql stop
Windows
net stop mariadb
(Или через «Службы» в services.msc).
2. Запуск MySQL/MariaDB в безопасном режиме (без аутентификации)
sudo mysqld_safe --skip-grant-tables --skip-networking &
--skip-grant-tables— отключает проверку паролей.--skip-networking— запрещает удалённые подключения (для безопасности).
Важно: Не закрывайте терминал, пока меняете пароль!
3. Подключение к MySQL/MariaDB без пароля
Откройте новый терминал и выполните:
mysql -u root
Теперь вы в консоли MariaDB без пароля.
4. Смена пароля root
Способ 1 (для MariaDB 10.4 и новее)
FLUSH PRIVILEGES;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'новый_пароль';
Способ 2 (для старых версий)
USE mysql;
UPDATE user SET password=PASSWORD('новый_пароль') WHERE User='root';
FLUSH PRIVILEGES;
Если root привязан к unix_socket (например, в Debian/Ubuntu)
UPDATE mysql.user SET plugin='mysql_native_password' WHERE User='root';
ALTER USER 'root'@'localhost' IDENTIFIED BY 'новый_пароль';
FLUSH PRIVILEGES;
5. Выход и перезапуск MySQL/MariaDB
Выйдите из MySQL-консоли:
EXIT;Завершите процесс
mysqld_safe:sudo killall mysqld_safeПерезапустите MariaDB в обычном режиме:
sudo systemctl start mariadb # или sudo service mysql start
6. Проверка нового пароля
mysql -u root -p
Введите новый пароль. Если вход удался — пароль восстановлен!
Дополнительные сценарии
Если root не имеет прав (ошибка доступа)
Попробуйте создать временного пользователя с правами root:
GRANT ALL PRIVILEGES ON *.* TO 'tempadmin'@'localhost' IDENTIFIED BY 'temp_pass';
FLUSH PRIVILEGES;
После этого войдите как tempadmin и смените пароль root.
Windows (если mysqld_safe недоступен)
Откройте командную строку от имени администратора.
Перейдите в папку с MariaDB (например,
C:\Program Files\MariaDB\bin).Запустите:
mysqld --skip-grant-tablesВ другом окне выполните
mysql -u rootи смените пароль.
Важно!
Запишите новый пароль в надёжное место.
Удалите анонимных пользователей (если есть):
DROP USER ''@'localhost';Настройте брандмауэр, чтобы запретить внешний доступ к порту 3306, если это не требуется.
Итог
- Остановили MariaDB.
- Запустили в безопасном режиме.
- Вошли без пароля и обновили его.
- Перезапустили сервис.
Если что-то пошло не так — проверьте логи (/var/log/mysql/error.log) и попробуйте снова.
16.3 - Справочный гайд по командам SQLite
Основные команды по управлению базой данных SQLite. Управление базой данных, управление пользователями базы данных, управление таблицами, управление индексами, управление записями таблиц, связанные запросы, выгрузки данных во внешние источники, создание скриптов, загрузка данных из разных форматов
Полное руководство по SQLite: от установки до продвинутого использования
Оглавление
- Введение в SQLite
- Установка SQLite
- Основы работы с SQLite
- Управление базами данных
- Работа с таблицами
- Типы данных
- CRUD-операции
- Индексы и оптимизация
- Транзакции
- Представления и триггеры
- Импорт и экспорт данных
- Интеграция с языками программирования
- Оптимизация производительности
- Резервное копирование
- Безопасность
Введение в SQLite
SQLite — это встраиваемая реляционная СУБД, которая:
- Не требует сервера (работает с файлами напрямую)
- Поддерживает стандартный SQL
- Имеет минимальные требования к ресурсам
- Используется в мобильных приложениях, браузерах и встроенных системах
Установка SQLite
Windows
- Скачать предварительно скомпилированные бинарники с официального сайта
- Добавить путь к sqlite3.exe в переменную PATH
Linux (Ubuntu/Debian)
sudo apt update
sudo apt install sqlite3 libsqlite3-dev
MacOS
brew install sqlite
Проверка установки
sqlite3 --version
Основы работы с SQLite
Запуск интерфейса командной строки
sqlite3 mydatabase.db
Основные команды интерфейса
.help -- Показать все команды
.tables -- Показать список таблиц
.schema -- Показать структуру таблиц
.mode -- Изменить режим вывода (csv, column, json и др.)
.headers on -- Показать заголовки столбцов
.quit -- Выйти из интерфейса
Управление базами данных
Создание/открытие базы данных
sqlite3 database.db
Резервное копирование
-- В командной строке SQLite:
.output backup.sql
.dump
.output stdout
-- Или через командную строку ОС:
sqlite3 database.db .dump > backup.sql
Восстановление из резервной копии
sqlite3 newdatabase.db < backup.sql
Работа с таблицами
Создание таблицы
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT NOT NULL UNIQUE,
email TEXT NOT NULL UNIQUE,
age INTEGER,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
Изменение таблицы
-- Добавление столбца
ALTER TABLE users ADD COLUMN is_active INTEGER DEFAULT 1;
-- Удаление таблицы
DROP TABLE users;
Ограничения (Constraints)
CREATE TABLE products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
price REAL CHECK(price > 0),
category_id INTEGER REFERENCES categories(id),
UNIQUE(name, category_id)
);
Типы данных в SQLite
SQLite использует динамическую типизацию. Основные типы:
NULL- значение NULLINTEGER- целое числоREAL- число с плавающей точкойTEXT- текстовая строкаBLOB- бинарные данные
CRUD-операции
Вставка данных (Create)
INSERT INTO users (username, email, age)
VALUES ('john_doe', 'john@example.com', 30);
-- Множественная вставка
INSERT INTO users (username, email, age)
VALUES
('alice', 'alice@example.com', 25),
('bob', 'bob@example.com', 28);
Чтение данных (Read)
-- Простой запрос
SELECT * FROM users;
-- С условиями
SELECT username, email FROM users WHERE age > 25;
-- Сортировка
SELECT * FROM users ORDER BY age DESC;
-- Группировка
SELECT age, COUNT(*) FROM users GROUP BY age;
-- Ограничение вывода
SELECT * FROM users LIMIT 10 OFFSET 5;
Обновление данных (Update)
UPDATE users SET age = 31 WHERE username = 'john_doe';
Удаление данных (Delete)
DELETE FROM users WHERE id = 5;
Индексы и оптимизация
Создание индекса
CREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_users_age ON users(age);
Удаление индекса
DROP INDEX idx_users_email;
Анализ запросов
EXPLAIN QUERY PLAN SELECT * FROM users WHERE email = 'john@example.com';
Транзакции
Использование транзакций
BEGIN TRANSACTION;
INSERT INTO accounts (user_id, balance) VALUES (1, 1000);
UPDATE users SET last_transaction = CURRENT_TIMESTAMP WHERE id = 1;
COMMIT;
-- В случае ошибки:
ROLLBACK;
Представления и триггеры
Создание представления
CREATE VIEW active_users AS
SELECT * FROM users WHERE is_active = 1;
Создание триггера
CREATE TRIGGER update_timestamp
AFTER UPDATE ON users
FOR EACH ROW
BEGIN
UPDATE users SET updated_at = CURRENT_TIMESTAMP WHERE id = OLD.id;
END;
Импорт и экспорт данных
Импорт из CSV
.mode csv
.import data.csv tablename
Экспорт в CSV
.headers on
.mode csv
.output data.csv
SELECT * FROM tablename;
.output stdout
Импорт/экспорт JSON
-- Для работы с JSON требуется SQLite версии 3.38.0+
SELECT json_object('id', id, 'name', username) FROM users;
Интеграция с языками программирования
Python
import sqlite3
conn = sqlite3.connect('database.db')
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
conn.close()
Node.js
const sqlite3 = require('sqlite3').verbose();
const db = new sqlite3.Database('database.db');
db.all("SELECT * FROM users", (err, rows) => {
console.log(rows);
});
db.close();
Оптимизация производительности
- Используйте транзакции для групповых операций
- Создавайте индексы для часто используемых полей
- Используйте
PRAGMAкоманды для настройки:PRAGMA journal_mode = WAL; -- Режим записи журнала PRAGMA synchronous = NORMAL; -- Баланс между надежностью и скоростью PRAGMA cache_size = -2000; -- Размер кеша в KB
Резервное копирование
Полное резервное копирование
sqlite3 database.db ".backup backup.db"
Инкрементное резервное копирование
Используйте API SQLite для реализации инкрементного бэкапа в вашем приложении.
Безопасность
- Проверяйте входные данные перед выполнением SQL-запросов
- Используйте параметризованные запросы:
# Python пример cursor.execute("SELECT * FROM users WHERE id = ?", (user_id,)) - Ограничивайте права доступа к файлу базы данных на уровне ОС
Заключение
SQLite — мощная и легковесная СУБД, идеально подходящая для:
- Мобильных приложений
- Встраиваемых систем
- Локальных приложений
- Тестирования и прототипирования
Для более сложных сценариев обратитесь к официальной документации.
16.4 - Полное руководство по MongoDB: от основ до работы с JSON
Основные команды по управлению базой данных MongoDB. Управление базой данных, управление пользователями базы данных, управление таблицами, управление индексами, управление записями таблиц, связанные запросы, выгрузки данных во внешние источники, создание скриптов, загрузка данных из разных форматов
Оглавление
- Введение в MongoDB
- Установка MongoDB
- Подключение к базе
- Основные операции CRUD
- Работа с коллекциями
- Запросы и агрегации
- Индексы и оптимизация
- Транзакции
- Работа с JSON
- Интеграция с языками программирования
- Безопасность и администрирование
- Резервное копирование
1. Введение в MongoDB
MongoDB — это NoSQL-база данных, которая хранит данные в документах JSON-подобного формата (BSON).
🔹 Ключевые особенности:
- Гибкая схема (документы могут иметь разную структуру)
- Горизонтальная масштабируемость (шардирование)
- Поддержка сложных запросов и агрегаций
- Встроенная работа с JSON
🔹 Основные понятия:
- Документ ≈ строка в SQL (хранится в BSON)
- Коллекция ≈ таблица в SQL
- База данных ≈ схема в SQL
2. Установка MongoDB
Linux (Ubuntu/Debian)
# Импорт ключа и добавление репозитория
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu $(lsb_release -sc)/mongodb-org/4.4 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.4.list
# Установка MongoDB
sudo apt update
sudo apt install mongodb-org
# Запуск сервиса
sudo systemctl start mongod
sudo systemctl enable mongod
Windows
- Скачайте установщик с официального сайта
- Запустите
.msiфайл - Добавьте
C:\Program Files\MongoDB\Server\<версия>\binвPATH
MacOS (Homebrew)
brew tap mongodb/brew
brew install mongodb-community
brew services start mongodb-community
Проверка работы
mongosh # Запуск оболочки MongoDB
3. Подключение к базе
Через mongosh (CLI)
mongosh "mongodb://localhost:27017" # Локальное подключение
mongosh "mongodb://user:pass@host:27017/dbname" # С аутентификацией
В Node.js (драйвер mongodb)
const { MongoClient } = require('mongodb');
const uri = "mongodb://localhost:27017";
const client = new MongoClient(uri);
async function connect() {
try {
await client.connect();
console.log("Connected to MongoDB");
const db = client.db("mydb");
const collection = db.collection("users");
// ... операции с коллекцией
} finally {
await client.close();
}
}
connect();
4. Основные операции CRUD
Вставка документов (insertOne, insertMany)
// Вставка одного документа
db.users.insertOne({
name: "Alice",
age: 25,
skills: ["JavaScript", "MongoDB"]
});
// Вставка нескольких документов
db.users.insertMany([
{ name: "Bob", age: 30 },
{ name: "Charlie", age: 22 }
]);
Поиск (find, findOne)
// Найти всех пользователей
db.users.find();
// Найти пользователей старше 25
db.users.find({ age: { $gt: 25 } });
// Найти первого пользователя с именем "Alice"
db.users.findOne({ name: "Alice" });
Обновление (updateOne, updateMany)
// Обновить возраст Alice
db.users.updateOne(
{ name: "Alice" },
{ $set: { age: 26 } }
);
// Увеличить возраст всех пользователей на 1
db.users.updateMany(
{},
{ $inc: { age: 1 } }
);
Удаление (deleteOne, deleteMany)
// Удалить пользователя Bob
db.users.deleteOne({ name: "Bob" });
// Удалить всех младше 18
db.users.deleteMany({ age: { $lt: 18 } });
5. Работа с коллекциями
Создание и удаление коллекций
// Создать коллекцию
db.createCollection("products");
// Удалить коллекцию
db.products.drop();
Переименование коллекции
db.products.renameCollection("items");
6. Запросы и агрегации
Операторы сравнения
db.users.find({ age: { $gt: 20, $lte: 30 } }); // Возраст > 20 и ≤ 30
db.users.find({ name: { $regex: /^A/ } }); // Имя начинается на "A"
Агрегация ($match, $group, $sort)
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $group: { _id: "$customer", total: { $sum: "$amount" } } },
{ $sort: { total: -1 } }
]);
7. Индексы и оптимизация
Создание индекса
db.users.createIndex({ email: 1 }); // Уникальный индекс
db.users.createIndex({ name: "text" }); // Текстовый поиск
Просмотр индексов
db.users.getIndexes();
8. Транзакции
const session = client.startSession();
try {
session.startTransaction();
await db.users.updateOne(
{ name: "Alice" },
{ $inc: { balance: -100 } },
{ session }
);
await db.users.updateOne(
{ name: "Bob" },
{ $inc: { balance: 100 } },
{ session }
);
await session.commitTransaction();
} catch (e) {
await session.abortTransaction();
} finally {
session.endSession();
}
9. Работа с JSON
Экспорт данных в JSON
mongoexport --db=mydb --collection=users --out=users.json --jsonArray
Импорт JSON в MongoDB
mongoimport --db=mydb --collection=users --file=users.json --jsonArray
Запросы к JSON-полям
db.users.find({
"address.city": "New York" // Обращение к вложенным полям
});
10. Интеграция с языками
Python (PyMongo)
from pymongo import MongoClient
client = MongoClient("mongodb://localhost:27017")
db = client["mydb"]
collection = db["users"]
collection.insert_one({"name": "Alice"})
Go (MongoDB Driver)
client, err := mongo.Connect(context.TODO(), options.Client().ApplyURI("mongodb://localhost:27017"))
collection := client.Database("mydb").Collection("users")
_, err = collection.InsertOne(context.TODO(), bson.D{{"name", "Alice"}})
11. Безопасность
Включение аутентификации
use admin
db.createUser({
user: "admin",
pwd: "securepassword",
roles: ["root"]
});
Запуск MongoDB с аутентификацией
mongod --auth
12. Резервное копирование
Экспорт (mongodump)
mongodump --db=mydb --out=/backup
Восстановление (mongorestore)
mongorestore --db=mydb /backup/mydb
Заключение
MongoDB — мощная NoSQL-база, идеальная для:
- Гибких схем данных
- Масштабируемых приложений
- Работы с JSON
📌 Документация: https://docs.mongodb.com
16.5 - Полное руководство по OpenSearch: установка, настройка и использование
Основные команды по управлению базой данных OpenSearch. Управление базой данных, управление пользователями базы данных, управление таблицами, управление индексами, управление записями таблиц, связанные запросы, выгрузки данных во внешние источники, создание скриптов, загрузка данных из разных форматов
Оглавление
- Введение в OpenSearch
- Установка OpenSearch
- Настройка кластера
- Основные операции с индексами
- Работа с данными (CRUD)
- Поиск и агрегации
- Индексы и маппинги
- Безопасность и RBAC
- Мониторинг и логирование
- Резервное копирование
- Интеграция с Logstash и Kibana
- Использование в Python и Go
1. Введение в OpenSearch
OpenSearch — это форк Elasticsearch, созданный AWS после изменения лицензии Elastic.
🔹 Ключевые возможности:
- Полнотекстовый поиск
- Анализ логов и временных рядов
- Поддержка REST API
- Масштабируемость и отказоустойчивость
🔹 Основные компоненты:
- OpenSearch — ядро поиска и аналитики
- OpenSearch Dashboards (аналог Kibana) — визуализация данных
- Logstash (опционально) — сбор и обработка данных
2. Установка OpenSearch
Linux (Debian/Ubuntu)
# Добавление репозитория OpenSearch
echo "deb https://artifacts.opensearch.org/releases/bundle/opensearch/2.x/apt stable main" | sudo tee /etc/apt/sources.list.d/opensearch-2.x.list
# Установка
wget -qO - https://artifacts.opensearch.org/publickeys/opensearch.pgp | sudo apt-key add -
sudo apt update
sudo apt install opensearch
Запуск сервиса
sudo systemctl start opensearch
sudo systemctl enable opensearch
Проверка работы
curl -X GET "https://localhost:9200" -u 'admin:admin' --insecure
Ответ:
{
"name" : "opensearch-node1",
"cluster_name" : "opensearch-cluster",
"version" : {
"distribution" : "opensearch",
"number" : "2.11.0"
}
}
3. Настройка кластера
Конфигурация находится в /etc/opensearch/opensearch.yml.
Базовая настройка
cluster.name: opensearch-cluster
node.name: opensearch-node1
network.host: 0.0.0.0
discovery.type: single-node # Для однодоступной конфигурации
plugins.security.disabled: false # Включить безопасность
Настройка кластера из нескольких узлов
discovery.seed_hosts: ["node1:9300", "node2:9300"]
cluster.initial_master_nodes: ["node1", "node2"]
4. Основные операции с индексами
Создание индекса
curl -X PUT "https://localhost:9200/my-index" -u 'admin:admin' --insecure
Удаление индекса
curl -X DELETE "https://localhost:9200/my-index" -u 'admin:admin' --insecure
Просмотр списка индексов
curl -X GET "https://localhost:9200/_cat/indices?v" -u 'admin:admin' --insecure
5. Работа с данными (CRUD)
Добавление документа
curl -X POST "https://localhost:9200/my-index/_doc/1" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"title": "OpenSearch Guide",
"author": "admin",
"tags": ["search", "database"]
}'
Получение документа
curl -X GET "https://localhost:9200/my-index/_doc/1" -u 'admin:admin' --insecure
Обновление документа
curl -X POST "https://localhost:9200/my-index/_update/1" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"doc": {
"author": "new-author"
}
}'
Удаление документа
curl -X DELETE "https://localhost:9200/my-index/_doc/1" -u 'admin:admin' --insecure
6. Поиск и агрегации
Простой поиск
curl -X GET "https://localhost:9200/my-index/_search?q=title:OpenSearch" -u 'admin:admin' --insecure
Сложный запрос (JSON-тело)
curl -X GET "https://localhost:9200/my-index/_search" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"query": {
"match": {
"title": "OpenSearch"
}
}
}'
Агрегации (группировка по тегам)
curl -X GET "https://localhost:9200/my-index/_search" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"aggs": {
"tag_counts": {
"terms": { "field": "tags.keyword" }
}
}
}'
7. Индексы и маппинги
Создание индекса с маппингом
curl -X PUT "https://localhost:9200/books" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"mappings": {
"properties": {
"title": { "type": "text" },
"year": { "type": "integer" }
}
}
}'
Добавление нового поля
curl -X PUT "https://localhost:9200/books/_mapping" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"properties": {
"author": { "type": "keyword" }
}
}'
8. Безопасность и RBAC
Создание пользователя
curl -X PUT "https://localhost:9200/_plugins/_security/api/internalusers/user1" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"password": "secure123",
"backend_roles": ["readers"]
}'
Назначение роли
curl -X PUT "https://localhost:9200/_plugins/_security/api/roles/read_only" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"cluster_permissions": [],
"index_permissions": [{
"index_patterns": ["*"],
"allowed_actions": ["read"]
}]
}'
9. Мониторинг и логирование
Проверка состояния кластера
curl -X GET "https://localhost:9200/_cluster/health" -u 'admin:admin' --insecure
Логи OpenSearch
tail -f /var/log/opensearch/opensearch.log
10. Резервное копирование
Использование Snapshot API
curl -X PUT "https://localhost:9200/_snapshot/my-backup" -u 'admin:admin' --insecure -H 'Content-Type: application/json' -d '
{
"type": "fs",
"settings": {
"location": "/backups/opensearch"
}
}'
Создание снепшота
curl -X PUT "https://localhost:9200/_snapshot/my-backup/snapshot-1" -u 'admin:admin' --insecure
11. Интеграция с Logstash и OpenSearch Dashboards
Настройка Logstash для отправки данных
input {
file {
path => "/var/log/app.log"
start_position => "beginning"
}
}
output {
opensearch {
hosts => ["https://localhost:9200"]
index => "app-logs"
user => "admin"
password => "admin"
ssl_certificate_verification => false
}
}
Запуск OpenSearch Dashboards
sudo systemctl start opensearch-dashboards
Доступно по адресу: http://localhost:5601
12. Использование в Python и Go
Python (opensearch-py)
from opensearchpy import OpenSearch
client = OpenSearch(
hosts=["https://localhost:9200"],
http_auth=("admin", "admin"),
verify_certs=False
)
response = client.index(
index="my-index",
body={"title": "Python OpenSearch Guide"}
)
Go (opensearch-go)
package main
import (
"context"
"github.com/opensearch-project/opensearch-go"
)
func main() {
client, err := opensearch.NewClient(opensearch.Config{
Addresses: []string{"https://localhost:9200"},
Username: "admin",
Password: "admin",
})
res, err := client.Index(
"my-index",
strings.NewReader(`{"title": "Go OpenSearch Guide"}`),
)
}
Официальная документация: https://opensearch.org/docs
17 - WireGuard
WireGuard — быстрый, современный и безопасный VPN-туннель
WireGuard® — это чрезвычайно простой, но при этом быстрый и современный VPN, использующий передовую криптографию. Он стремится быть быстрее, проще, легче и полезнее IPsec, избегая при этом огромной головной боли. WireGuard значительно производительнее OpenVPN. WireGuard разработан как VPN общего назначения для работы как на встраиваемых интерфейсах, так и на суперкомпьютерах, подходя для множества различных сценариев. Изначально выпущенный для ядра Linux, теперь он кроссплатформенный (Windows, macOS, BSD, iOS, Android) и широко развертываемый. В настоящее время находится в активной разработке, но уже сейчас его можно считать самым безопасным, простым в использовании и самым простым VPN-решением в индустрии.
Простой и удобный в использовании
WireGuard стремится быть таким же простым в настройке и развертывании, как SSH. VPN-соединение устанавливается простым обменом открытыми ключами — точно так же, как при обмене SSH-ключами — а всё остальное прозрачно обрабатывается WireGuard. Он даже способен роумить между IP-адресами, как Mosh. Нет необходимости управлять соединениями, беспокоиться о состоянии, управлять демонами или беспокоиться о том, что находится под капотом. WireGuard предоставляет чрезвычайно простой, но мощный интерфейс.
Криптографическая надёжность
WireGuard использует современную криптографию, такую как фреймворк Noise, Curve25519, ChaCha20, Poly1305, BLAKE2, SipHash24, HKDF и безопасные доверенные конструкции. Он делает консервативные и разумные выборы и был проверен криптографами.
Минимальная поверхность атаки
WireGuard разработан с учётом простоты реализации и лёгкости. Он предназначен для простой реализации в очень небольшом количестве строк кода и лёгкого аудита на наличие уязвимостей безопасности. По сравнению с гигантами вроде *Swan/IPsec или OpenVPN/OpenSSL, аудит огромных кодовых баз которых является непосильной задачей даже для больших команд экспертов по безопасности, WireGuard предназначен для всесторонней проверки отдельными специалистами.
Высокая производительность
Сочетание чрезвычайно высокоскоростных криптографических примитивов и того факта, что WireGuard работает внутри ядра Linux, означает, что безопасная сеть может быть очень высокоскоростной. Он подходит как для небольших встраиваемых устройств, таких как смартфоны, так и для полностью загруженных магистральных маршрутизаторов.
Хорошо определённый и тщательно продуманный
WireGuard является результатом длительного и тщательно продуманного академического процесса, результатом которого стал технический документ — академическая исследовательская работа, которая чётко определяет протокол и тщательные соображения, лежащие в основе каждого решения.
Важно: WireGuard является зарегистрированным товарным знаком Jason A. Donenfeld. Подробнее см. политику использования товарных знаков.
17.1 - Обзор WireGuard
Концептуальный обзор WireGuard — быстрого, современного и безопасного VPN-туннеля
Концептуальный обзор
Если вы хотите получить общее концептуальное представление о том, что такое WireGuard, читайте дальше. Затем вы можете перейти к установке и прочитать инструкции по быстрому запуску о том, как его использовать.
Если вы заинтересованы во внутреннем устройстве, вас может заинтересовать краткое описание протокола или вы можете углубиться, прочитав технический документ, который более подробно описывает протокол, криптографию и основы. Если вы намерены реализовать WireGuard для новой платформы, пожалуйста, прочитайте заметки о кросс-платформенной разработке.
WireGuard безопасно инкапсулирует IP-пакеты через UDP. Вы добавляете интерфейс WireGuard, настраиваете его с вашим приватным ключом и открытыми ключами ваших пиров, а затем отправляете через него пакеты. Все вопросы распространения ключей и принудительной настройки находятся вне области WireGuard; эти вопросы гораздо лучше оставить другим уровням, чтобы не получить раздувание IKE или OpenVPN. Напротив, он больше имитирует модель SSH и Mosh: обе стороны имеют открытые ключи друг друга, а затем они просто могут начать обмениваться пакетами через интерфейс.
Простой сетевой интерфейс
WireGuard работает путём добавления сетевого интерфейса (или нескольких), например eth0 или wlan0, называемого wg0 (или wg1, wg2, wg3 и т.д.). Этот сетевой интерфейс затем можно настраивать обычным образом с помощью ifconfig(8) или ip-address(8), добавлять и удалять маршруты с помощью route(8) или ip-route(8) и так далее со всеми обычными сетевыми утилитами. Специфические для WireGuard аспекты интерфейса настраиваются с помощью инструмента wg(8). Этот интерфейс действует как туннельный интерфейс.
WireGuard связывает IP-адреса туннеля с открытыми ключами и удалёнными конечными точками. Когда интерфейс отправляет пакет пиру, он делает следующее:
Этот пакет предназначен для 192.168.30.8. Какой это пир? Позвольте мне посмотреть… Хорошо, это для пира
ABCDEFGH. (Или если он не предназначен ни для одного настроенного пира — отбросить пакет.)Зашифровать весь IP-пакет, используя открытый ключ пира
ABCDEFGH.Какова удалённая конечная точка пира
ABCDEFGH? Позвольте мне посмотреть… Хорошо, конечная точка — UDP-порт 53133 на хосте 216.58.211.110.Отправить зашифрованные байты из шага 2 через Интернет на 216.58.211.110:53133 через UDP.
Когда интерфейс получает пакет, происходит следующее:
Я только что получил пакет с UDP-порта 7361 от хоста 98.139.183.24. Давайте расшифруем его!
Он успешно расшифрован и аутентифицирован для пира
LMNOPQRS. Хорошо, давайте запомним, что последняя конечная точка пираLMNOPQRSв Интернете — 98.139.183.24:7361 через UDP.После расшифровки обычный текстовый пакет пришёл с 192.168.43.89. Разрешено ли пиру
LMNOPQRSотправлять нам пакеты с адреса 192.168.43.89?Если да — принять пакет на интерфейсе. Если нет — отбросить его.
За кулисами происходит многое для обеспечения надлежащей конфиденциальности, подлинности и совершенной прямой секретности с использованием современной криптографии.
Криптоключевая маршрутизация
В основе WireGuard лежит концепция, называемая Криптоключевой маршрутизацией, которая работает путём связывания открытых ключей со списком IP-адресов туннеля, которым разрешено находиться внутри туннеля. Каждый сетевой интерфейс имеет приватный ключ и список пиров. Каждый пир имеет открытый ключ. Открытые ключи короткие и простые и используются пирами для аутентификации друг друга. Их можно передавать для использования в конфигурационных файлах любым внешним методом, подобно тому, как можно отправить свой открытый ключ SSH другу для доступа к серверу оболочки.
Например, серверный компьютер может иметь такую конфигурацию:
[Interface]
PrivateKey = yAnz5TF+lXXJte14tji3zlMNq+hd2rYUIgJBgB3fBmk=
ListenPort = 51820
[Peer]
PublicKey = xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg=
AllowedIPs = 10.192.122.3/32, 10.192.124.1/24
[Peer]
PublicKey = TrMvSoP4jYQlY6RIzBgbssQqY3vxI2Pi+y71lOWWXX0=
AllowedIPs = 10.192.122.4/32, 192.168.0.0/16
[Peer]
PublicKey = gN65BkIKy1eCE9pP1wdc8ROUtkHLF2PfAqYdyYBz6EA=
AllowedIPs = 10.10.10.230/32
17.2 - Установка WireGuard
Инструкции по установке WireGuard на различные операционные системы и устройства
Обзор
WireGuard доступен для широкого спектра операционных систем и платформ. Ниже приведены инструкции по установке для наиболее популярных систем. Если ваша система не указана в списке, вы также можете легко скомпилировать WireGuard из исходного кода.
Краткая таблица установки
| Операционная система | Команда установки |
|---|---|
| Windows 10/11/2016/2019/2022/2025 | Скачать MSI-установщик |
| macOS (App Store) | Установить из App Store |
| Ubuntu | sudo apt install wireguard |
| Debian | # apt install wireguard |
| Fedora | sudo dnf install wireguard-tools |
| Arch Linux | sudo pacman -S wireguard-tools |
| Android | Google Play или APK-файл |
| iOS | Установить из App Store |
| OpenSUSE/SLE | sudo zypper install wireguard-tools |
| Alpine | # apk add -U wireguard-tools |
| Gentoo | # emerge wireguard-tools |
| FreeBSD | # pkg install wireguard |
| OpenBSD | # pkg_add wireguard-tools |
Подробные инструкции
Установка на сервере Ubuntu
WireGuard включён в репозитории Ubuntu, начиная с версии 20.04 (Focal Fossa). Для более ранних версий рекомендуется использовать PPA.
Ubuntu 20.04 и новее:
sudo apt update
sudo apt install wireguard
Ubuntu 18.04 (Bionic Beaver) и более ранние:
sudo add-apt-repository ppa:wireguard/wireguard
sudo apt update
sudo apt install wireguard
После установки модуль ядра и утилиты будут готовы к использованию. Модуль WireGuard автоматически загружается при создании интерфейса.
Проверка установки:
wg --version
modinfo wireguard
Установка на сервере Fedora
В Fedora WireGuard доступен в официальных репозиториях. Для установки требуются утилиты пользовательского пространства, так как модуль ядра встроен в ядро Linux начиная с версии 5.6.
Fedora 32 и новее (с ядром 5.6+):
sudo dnf install wireguard-tools
Fedora 31 и более ранние версии:
Для старых версий Fedora, где модуль ядра не встроен, необходимо установить модуль отдельно:
sudo dnf install wireguard-tools
sudo dnf copr enable jdoss/wireguard
sudo dnf install wireguard-dkms
Настройка автоматической загрузки модуля (для ядер < 5.6):
sudo modprobe wireguard
echo "wireguard" | sudo tee /etc/modules-load.d/wireguard.conf
Для Fedora 32 и новее модуль WireGuard встроен в ядро Linux, поэтому дополнительная установка модуля не требуется.
Установка на рабочей станции Fedora
На рабочей станции Fedora процесс установки аналогичен серверной версии. Однако для рабочей станции может потребоваться графический интерфейс для управления VPN-подключениями.
Установка базовых инструментов:
sudo dnf install wireguard-tools
Установка GUI-менеджера (опционально):
Для управления WireGuard через графический интерфейс можно установить NetworkManager:
sudo dnf install networkmanager-wireguard
sudo systemctl restart NetworkManager
После этого вы сможете настраивать WireGuard через стандартные сетевые настройки GNOME или KDE.
Настройка автозапуска (опционально):
Чтобы WireGuard автоматически поднимался при загрузке системы:
sudo systemctl enable wg-quick@wg0
sudo systemctl start wg-quick@wg0
Перед настройкой автозапуска убедитесь, что конфигурационный файл
/etc/wireguard/wg0.conf существует и правильно настроен.Установка на Android
WireGuard для Android доступен двумя способами:
Способ 1: Установка из Google Play Store
- Откройте Google Play Store на вашем устройстве
- Найдите “WireGuard”
- Нажмите “Установить”
- Дождитесь завершения установки
Способ 2: Установка из APK-файла
Если у вас нет доступа к Google Play, вы можете установить WireGuard напрямую из APK-файла:
- Загрузите последнюю версию APK с официального сайта WireGuard или из репозитория релизов
- На устройстве перейдите в
Настройки→Безопасностьи включите “Неизвестные источники” - Откройте загруженный APK-файл
- Нажмите “Установить”
- После установки запустите приложение
Импорт конфигурации на Android:
После установки приложения:
- Откройте приложение WireGuard
- Нажмите на кнопку “+” (плюс) в правом нижнем углу
- Выберите “Импортировать из файла” или “Импортировать из архива”
- Выберите конфигурационный файл (обычно имеет расширение
.conf) - Нажмите “Сохранить”
- Для активации VPN нажмите на переключатель рядом с именем конфигурации
Дополнительные дистрибутивы
Debian
Debian Bullseye (11) и новее:
# apt update
# apt install wireguard
Debian Buster (10) и более ранние:
Для старых версий Debian необходимо включить backports:
# echo "deb http://deb.debian.org/debian buster-backports main" >> /etc/apt/sources.list
# apt update
# apt -t buster-backports install wireguard
Arch Linux
Установка с модулем ядра (ядро 5.6+):
sudo pacman -S wireguard-tools
Для ядер < 5.6:
sudo pacman -S wireguard-lts # для LTS-ядра
# или
sudo pacman -S wireguard-dkms linux-headers # для DKMS с заголовками ядра
macOS
Установка из App Store:
- Откройте App Store
- Найдите “WireGuard”
- Нажмите “Получить” или кнопку установки
- Введите пароль Apple ID или используйте Touch ID
Установка через Homebrew (только CLI-инструменты):
brew install wireguard-tools
Установка через MacPorts:
port install wireguard-tools
Для полной интеграции WireGuard в macOS рекомендуется использовать версию из App Store, которая включает графический интерфейс.
iOS
WireGuard доступен в App Store для iPhone и iPad:
- Откройте App Store
- Найдите “WireGuard”
- Нажмите “Получить”
- Подтвердите установку с помощью Face ID, Touch ID или пароля Apple ID
После установки импортируйте конфигурацию через файлы или QR-код.
FreeBSD
# pkg install wireguard
OpenBSD
# pkg_add wireguard-tools
Alpine Linux
# apk add -U wireguard-tools
Gentoo
# emerge wireguard-tools
Для совместимости со старыми ядрами также доступен ebuild wireguard-modules:
# emerge wireguard-modules
OpenSUSE и SLE
sudo zypper install wireguard-tools
Slackware
sudo slackpkg install wireguard-tools
Mageia
sudo urpmi wireguard-tools
Termux (Android CLI)
pkg install wireguard-tools
NixOS
В конфигурации NixOS добавьте:
boot.extraModulePackages = [ config.boot.kernelPackages.wireguard ];
environment.systemPackages = [ pkgs.wireguard pkgs.wireguard-tools ];
Nix на Darwin (macOS CLI)
nix-env -iA nixpkgs.wireguard-tools
OpenWRT
opkg install wireguard
Дополнительные инструкции по установке и настройке можно найти в вики OpenWRT.
Enterprise Linux (RHEL/CentOS/Oracle)
Oracle Linux 8 (UEK6)
# dnf install oraclelinux-developer-release-el8
# dnf config-manager --disable ol8_developer
# dnf config-manager --enable ol8_developer_UEKR6
# dnf config-manager --save --setopt=ol8_developer_UEKR6.includepkgs='wireguard-tools*'
# dnf install wireguard-tools
Red Hat Enterprise Linux 8
Метод 1 (предварительно собранный модуль из ELRepo):
sudo yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm https://www.elrepo.org/elrepo-release-8.el8.elrepo.noarch.rpm
sudo yum install kmod-wireguard wireguard-tools
Метод 2 (DKMS для нестандартных ядер):
sudo yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
sudo subscription-manager repos --enable codeready-builder-for-rhel-8-$(arch)-rpms
sudo yum copr enable jdoss/wireguard
sudo yum install wireguard-dkms wireguard-tools
CentOS 8
Метод 1 (встроенный модуль в kernel-plus):
sudo yum install yum-utils epel-release
sudo yum-config-manager --setopt=centosplus.includepkgs="kernel-plus, kernel-plus-*" --setopt=centosplus.enabled=1 --save
sudo sed -e 's/^DEFAULTKERNEL=kernel-core$/DEFAULTKERNEL=kernel-plus-core/' -i /etc/sysconfig/kernel
sudo yum install kernel-plus wireguard-tools
sudo reboot
Метод 2 (предварительно собранный модуль из ELRepo):
sudo yum install elrepo-release epel-release
sudo yum install kmod-wireguard wireguard-tools
Метод 3 (DKMS):
sudo yum install epel-release
sudo yum config-manager --set-enabled PowerTools
sudo yum copr enable jdoss/wireguard
sudo yum install wireguard-dkms wireguard-tools
Oracle Linux 7 (UEK6)
# yum install oraclelinux-developer-release-el7
# yum-config-manager --disable ol7_developer
# yum-config-manager --enable ol7_developer_UEKR6
# yum-config-manager --save --setopt=ol7_developer_UEKR6.includepkgs='wireguard-tools*'
# yum install wireguard-tools
Red Hat Enterprise Linux 7
Метод 1 (предварительно собранный модуль из ELRepo):
sudo yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
sudo yum install kmod-wireguard wireguard-tools
Метод 2 (DKMS):
sudo yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
sudo curl -o /etc/yum.repos.d/jdoss-wireguard-epel-7.repo https://copr.fedorainfracloud.org/coprs/jdoss/wireguard/repo/epel-7/jdoss-wireguard-epel-7.repo
sudo yum install wireguard-dkms wireguard-tools
CentOS 7
Метод 1 (kernel-plus):
sudo yum install yum-utils epel-release
sudo yum-config-manager --setopt=centosplus.includepkgs=kernel-plus --enablerepo=centosplus --save
sudo sed -e 's/^DEFAULTKERNEL=kernel$/DEFAULTKERNEL=kernel-plus/' -i /etc/sysconfig/kernel
sudo yum install kernel-plus wireguard-tools
sudo reboot
Метод 2 (ELRepo):
sudo yum install epel-release elrepo-release
sudo yum install yum-plugin-elrepo
sudo yum install kmod-wireguard wireguard-tools
Метод 3 (DKMS):
sudo yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
sudo curl -o /etc/yum.repos.d/jdoss-wireguard-epel-7.repo https://copr.fedorainfracloud.org/coprs/jdoss/wireguard/repo/epel-7/jdoss-wireguard-epel-7.repo
sudo yum install wireguard-dkms wireguard-tools
Другие дистрибутивы
Void Linux
xbps-install -S wireguard-tools wireguard-dkms
Adélie Linux
apk add wireguard-tools wireguard-module
Source Mage
cast wireguard-tools
Buildroot
В конфигурации Buildroot добавьте:
BR2_PACKAGE_WIREGUARD_LINUX_COMPAT=y
BR2_PACKAGE_WIREGUARD_TOOLS=y
EdgeOS
Скачайте соответствующий предварительно собранный файл со страницы релизов, а затем установите его с помощью dpkg:
sudo dpkg -i wireguard-{type}-{version}.deb
AstLinux
В конфигурации AstLinux добавьте:
BR2_PACKAGE_WIREGUARD_TOOLS=y
BR2_PACKAGE_WIREGUARD=y
Milis Linux
# mps kur wireguard-tools wireguard-linux-compat
Дальнейшие шаги
После успешной установки переходите к руководству по быстрому запуску для настройки вашего первого WireGuard-подключения.
Если вашего дистрибутива нет в списке выше, вы можете легко скомпилировать WireGuard из исходного кода — это довольно простая процедура.
17.3 - Быстрый старт
Быстрый старт с WireGuard — настройка интерфейса, генерация ключей и базовое использование
Быстрый старт
Прежде всего, убедитесь, что вы хорошо понимаете концептуальный обзор, а затем установите WireGuard. После этого читайте дальше.
Видео параллельной настройки
Прежде чем подробно объяснять команды, будет чрезвычайно полезно посмотреть видео, где два пира настраиваются одновременно:
Или по отдельности, настройка одного узла выглядит так:

Интерфейс командной строки
Новый интерфейс можно добавить с помощью ip-link(8), который должен автоматически загрузить модуль:
# ip link add dev wg0 type wireguard
Пользователи не-Linux систем должны использовать
wireguard-go wg0 вместо этого.IP-адрес и пир можно назначить с помощью ifconfig(8) или ip-address(8):
# ip address add dev wg0 192.168.2.1/24
Или, если всего два пира, можно использовать такой синтаксис:
# ip address add dev wg0 192.168.2.1 peer 192.168.2.2
Интерфейс можно настроить с ключами и конечными точками пиров с помощью утилиты wg(8):
# wg setconf wg0 myconfig.conf
или
# wg set wg0 listen-port 51820 private-key /path/to/private-key peer ABCDEF... allowed-ips 192.168.88.0/24 endpoint 209.202.254.14:8172
Наконец, интерфейс можно активировать с помощью ifconfig(8) или ip-link(8):
# ip link set up dev wg0
Также доступны команды wg show и wg showconf для просмотра текущей конфигурации. Вызов wg без аргументов показывает все WireGuard-интерфейсы.
Подробнее в man-странице wg(8).
Большую часть рутинных операций по поднятию и опусканию интерфейса можно автоматизировать с помощью инструмента wg-quick(8):

Пример конфигурационного файла
Для использования wg-quick создайте файл конфигурации /etc/wireguard/wg0.conf:
[Interface]
PrivateKey = yAnz5TF+lXXJte14tji3zlMNq+hd2rYUIgJBgB3fBmk=
Address = 10.0.0.1/24
ListenPort = 51820
[Peer]
PublicKey = xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg=
AllowedIPs = 10.0.0.2/32
Endpoint = 192.95.5.69:51820
Затем поднимите интерфейс:
# wg-quick up wg0
И остановите его:
# wg-quick down wg0
Генерация ключей
WireGuard использует ключи в формате base64. Их можно сгенерировать с помощью утилиты wg(8):
$ umask 077
$ wg genkey > privatekey
Это создаст файл privatekey с новым приватным ключом.
Затем вы можете получить публичный ключ из приватного:
$ wg pubkey < privatekey > publickey
Это прочитает privatekey из stdin и запишет соответствующий публичный ключ в publickey.
Конечно, вы можете сделать всё за один раз:
$ wg genkey | tee privatekey | wg pubkey > publickey
Постоянство при обходе NAT и файерволов
По умолчанию WireGuard старается быть максимально тихим, когда не используется; это не болтливый протокол. В основном он передаёт данные только тогда, когда пир хочет отправить пакеты. Когда его не просят отправлять пакеты, он перестаёт отправлять их до следующего запроса. В большинстве конфигураций это работает хорошо.
Однако, когда пир находится за NAT или файерволом, он может захотеть получать входящие пакеты, даже если не отправляет их. Поскольку NAT и stateful-файерволы отслеживают “соединения”, если пир за NAT или файерволом хочет получать входящие пакеты, он должен поддерживать актуальность NAT/файервола, периодически отправляя keepalive-пакеты. Это называется постоянные keepalive.
Когда эта опция включена, keepalive-пакет отправляется на конечную точку сервера каждые interval секунд. Разумный интервал, который работает с большим количеством файерволов — 25 секунд. Установка значения 0 отключает функцию (это значение по умолчанию, так как большинству пользователей она не нужна и делает WireGuard немного более болтливым).
Эта функция может быть задана добавлением поля PersistentKeepalive = в конфигурации пира или установкой persistent-keepalive в командной строке:
[Peer]
PublicKey = xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg=
AllowedIPs = 10.0.0.2/32
Endpoint = 192.95.5.69:51820
PersistentKeepalive = 25
Если вам не нужна эта функция, не включайте её. Но если вы за NAT или файерволом и хотите получать входящие соединения через долгое время после того, как сетевой трафик затих, эта опция сохранит “соединение” открытым в глазах NAT.
Демо-сервер
После установки WireGuard, если вы хотите попробовать отправить несколько пакетов через WireGuard, вы можете использовать для тестирования скрипт из contrib/ncat-client-server/client.sh:
$ sudo contrib/examples/ncat-client-server/client.sh
#!/bin/bash
# SPDX-License-Identifier: GPL-2.0
#
# Copyright (C) 2015-2026 Jason A. Donenfeld <Jason@zx2c4.com>. All Rights Reserved.
set -e
[[ $UID == 0 ]] || { echo "You must be root to run this."; exit 1; }
exec 3<>/dev/tcp/demo.wireguard.com/42912
privatekey="$(wg genkey)"
wg pubkey <<<"$privatekey" >&3
IFS=: read -r status server_pubkey server_port internal_ip <&3
[[ $status == OK ]]
ip link del dev wg0 2>/dev/null || true
ip link add dev wg0 type wireguard
wg set wg0 private-key <(echo "$privatekey") peer "$server_pubkey" allowed-ips 0.0.0.0/0 endpoint "demo.wireguard.com:$server_port" persistent-keepalive 25
ip address add "$internal_ip"/24 dev wg0
ip link set up dev wg0
if [ "$1" == "default-route" ]; then
host="$(wg show wg0 endpoints | sed -n 's/.*\t\(.*\):.*/\1/p')"
ip route add $(ip route get $host | sed '/ via [0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/{s/^\(.* via [0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\).*/\1/}' | head -n 1) 2>/dev/null || true
ip route add 0/1 dev wg0
ip route add 128/1 dev wg0
fi
Это автоматически настроит интерфейс wg0 через очень небезопасный транспорт, который подходит только для демонстрационных целей. Затем вы можете попробовать загрузить скрытый сайт или отправить пинги:
$ chromium http://192.168.4.1
$ ping 192.168.4.1
Если вы хотите перенаправить ваш интернет-трафик, вы можете запустить его так:
$ sudo contrib/examples/ncat-client-server/client.sh default-route
$ curl zx2c4.com/ip
163.172.161.0
demo.wireguard.com
curl/7.49.1
Подключаясь к этому серверу, вы соглашаетесь с тем, что не будете использовать его в злонамеренных или незаконных целях и что ваш трафик может отслеживаться.
Отладочная информация
Если вы используете модуль ядра Linux и ваше ядро поддерживает динамическую отладку, вы можете получить полезный вывод во время выполнения, включив динамическую отладку для модуля:
# modprobe wireguard && echo module wireguard +p > /sys/kernel/debug/dynamic_debug/control
Если вы используете пользовательскую реализацию, установите переменную окружения:
export LOG_LEVEL=verbose
Пример полной настройки клиент-сервер
Серверная конфигурация (/etc/wireguard/wg0.conf)
[Interface]
PrivateKey = SERVER_PRIVATE_KEY
Address = 10.0.0.1/24
ListenPort = 51820
SaveConfig = true
[Peer]
PublicKey = CLIENT1_PUBLIC_KEY
AllowedIPs = 10.0.0.2/32
[Peer]
PublicKey = CLIENT2_PUBLIC_KEY
AllowedIPs = 10.0.0.3/32
Клиентская конфигурация (/etc/wireguard/wg0.conf)
[Interface]
PrivateKey = CLIENT_PRIVATE_KEY
Address = 10.0.0.2/24
DNS = 8.8.8.8
[Peer]
PublicKey = SERVER_PUBLIC_KEY
AllowedIPs = 0.0.0.0/0
Endpoint = server.example.com:51820
PersistentKeepalive = 25
Запуск
На сервере:
# wg-quick up wg0
# systemctl enable wg-quick@wg0
На клиенте:
# wg-quick up wg0
# systemctl enable wg-quick@wg0
Проверка статуса
Проверьте статус соединения:
# wg show
Вы должны увидеть информацию о рукопожатии и передаче данных:
interface: wg0
public key: SERVER_PUBLIC_KEY
private key: (hidden)
listening port: 51820
peer: CLIENT1_PUBLIC_KEY
endpoint: 192.168.1.100:51820
allowed ips: 10.0.0.2/32
latest handshake: 1 minute, 23 seconds ago
transfer: 1.23 MiB received, 4.56 MiB sent
Дальнейшие шаги
Теперь, когда у вас есть работающий WireGuard, вы можете:
- Настроить маршрутизацию для пропуска всего трафика через VPN
- Настроить несколько пиров для создания полной mesh-сети
- Изучить продвинутые темы
- Настроить автоматическое переподключение и мониторинг
Если у вас возникли проблемы, обратитесь к разделу известных ограничений или посетите IRC-канал #wireguard на Libera.Chat для получения помощи.
17.4 - wg-quick — руководство
Руководство по wg-quick — утилита для простой настройки интерфейсов WireGuard
ИМЯ
wg-quick — простая настройка интерфейса WireGuard
СИНТАКСИС
wg-quick [ up | down | save | strip ] [ CONFIG_FILE | INTERFACE ]
ОПИСАНИЕ
Это чрезвычайно простой скрипт для быстрого поднятия интерфейса WireGuard, подходящий для нескольких распространённых сценариев использования.
Используйте up для добавления и настройки интерфейса, и down для его отключения и удаления. Команда up добавляет интерфейс WireGuard, поднимает его с указанными IP-адресами, настраивает MTU и маршруты, и при необходимости выполняет предварительные/последующие скрипты. Команда down при необходимости сохраняет текущую конфигурацию, удаляет интерфейс WireGuard и при необходимости выполняет предварительные/последующие скрипты. Команда save сохраняет конфигурацию существующего интерфейса без его отключения. Используйте strip для вывода конфигурационного файла без специфичных для wg-quick опций, подходящего для использования с wg(8).
CONFIG_FILE — это конфигурационный файл, имя которого соответствует имени интерфейса с расширением .conf. В противном случае INTERFACE — это имя интерфейса, конфигурация для которого ищется сначала в /etc/wireguard/INTERFACE.conf, а затем в путях поиска, специфичных для дистрибутива.
Вообще говоря, эта утилита представляет собой простой скрипт-обёртку для вызовов wg(8) и ip(8) для настройки интерфейса WireGuard. Она предназначена для пользователей с простыми потребностями. Пользователям с более сложными требованиями настоятельно рекомендуется использовать более специализированные инструменты, более полноценные сетевые менеджеры или просто использовать wg(8) и ip(8) как обычно.
КОНФИГУРАЦИЯ
Конфигурационный файл добавляет несколько дополнительных параметров к формату, используемому wg(8), для настройки дополнительных атрибутов интерфейса. Он обрабатывает значения, которые понимает, а остальные передаёт напрямую wg(8) для дальнейшей обработки.
Инструмент определяет все маршруты из списка разрешённых IP-адресов пиров и автоматически добавляет их в системную таблицу маршрутизации. Если один из этих маршрутов является маршрутом по умолчанию (0.0.0.0/0 или ::/0), он использует ip-rule(8) для обработки переопределения шлюза по умолчанию.
Конфигурационный файл будет передан напрямую подкоманде setconf wg(8), за исключением следующих дополнений в секции [Interface], которые обрабатываются этим инструментом:
Параметры секции Interface
Address — разделённый запятыми список IP-адресов (v4 или v6) (опционально с масками CIDR), которые будут назначены интерфейсу. Может быть указан несколько раз.
DNS — разделённый запятыми список IP-адресов (v4 или v6), которые будут установлены как DNS-серверы интерфейса, или не-IP-имя хоста для установки в качестве доменов поиска DNS. Может быть указан несколько раз. При поднятии интерфейса выполняется
resolvconf -a tun.INTERFACE -m 0 -x, а при отключении —resolvconf -d tun.INTERFACE. Если эти вызовыresolvconf(8)нежелательны, вместо них можно использовать ключиPostUpиPostDownниже.MTU — если не указано, MTU автоматически определяется из адресов конечных точек или системного маршрута по умолчанию, что обычно является разумным выбором. Однако для ручного указания MTU это значение может быть задано явно.
Table — управляет таблицей маршрутизации, в которую добавляются маршруты. Есть два специальных значения:
offполностью отключает создание маршрутов, аauto(по умолчанию) добавляет маршруты в таблицу по умолчанию и включает специальную обработку маршрутов по умолчанию.PreUp, PostUp, PreDown, PostDown — фрагменты скриптов, которые будут выполнены
bash(1)до/после настройки/отключения интерфейса, чаще всего используются для настройки пользовательских DNS-опций или правил файервола. Специальная строка%iзаменяется на имя интерфейса. Каждый из них может быть указан несколько раз, в этом случае команды выполняются по порядку.SaveConfig — если установлено в
true, конфигурация сохраняется из текущего состояния интерфейса при его отключении. Любые изменения, внесённые в конфигурационный файл до удаления интерфейса, будут перезаписаны.
Имена интерфейсов
Рекомендуемые имена интерфейсов включают wg0, wgvpn0 или даже wgmgmtlan0. Однако число в конце необязательно, и действительно любое имя в формате [a-zA-Z0-9_=+.-]{1,15} будет работать. Так что даже имена интерфейсов, соответствующие географическим местоположениям, например cincinnati, nyc или paris, подойдут, если это по какой-то причине желательно.
ПРИМЕРЫ
Эти примеры используют тот же синтаксис, что и для wg(8), более полное описание можно найти там. Жирные строки ниже обозначают опции, расширяющие wg(8).
Пример 1: Клиент для VPN-шлюза
Следующий пример может использоваться для подключения в качестве клиента к VPN-шлюзу для туннелирования всего трафика:
[Interface]
Address = 10.200.100.8/24
DNS = 10.200.100.1
PrivateKey = oK56DE9Ue9zK76rAc8pBl6opph+1v36lm7cXXsQKrQM=
[Peer]
PublicKey = GtL7fZc/bLnqZldpVofMCD6hDjrK28SsdLxevJ+qtKU=
PresharedKey = /UwcSPg38hW/D9Y3tcS1FOV0K1wuURMbS0sesJEP5ak=
AllowedIPs = 0.0.0.0/0
Endpoint = demo.wireguard.com:51820
Поле Address добавлено для настройки адреса интерфейса. Поле DNS указывает, что DNS-сервер для интерфейса должен быть настроен через resolvconf(8). Запись разрешённых IP-адресов пира подразумевает, что этот интерфейс должен быть настроен как шлюз по умолчанию, что этот скрипт и делает.
Пример 2: “Выключатель” (kill-switch)
Развивая предыдущий пример, можно реализовать так называемый “выключатель” для предотвращения потока незашифрованных пакетов через интерфейсы, отличные от WireGuard, добавив следующие строки PostUp и PreDown в секцию [Interface]:
PostUp = iptables -I OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT
PreDown = iptables -D OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT
Поля PostUp и PreDown добавлены для указания команды iptables(8), которая при использовании с интерфейсами, имеющими пир с 0.0.0.0/0 в AllowedIPs, работает вместе с использованием fwmark в wg-quick для отбрасывания всех пакетов, которые либо не выходят из туннеля зашифрованными, либо не проходят через сам туннель. (Обратите внимание, что это продолжает пропускать большую часть DHCP-трафика, поскольку большинство DHCP-клиентов используют сокеты PF_PACKET, которые обходят Netfilter.) При использовании IPv6 могут быть добавлены дополнительные аналогичные строки с использованием ip6tables(8).
Пример 3: Хранение ключей в зашифрованном виде
Или, возможно, желательно хранить приватные ключи в зашифрованном виде, например, с использованием pass(1):
PreUp = wg set %i private-key <(pass WireGuard/private-keys/%i)
Пример 4: Сервер с несколькими пирами
Для использования на сервере следующий более сложный пример включает несколько пиров:
[Interface]
Address = 10.192.122.1/24
Address = 10.10.0.1/16
SaveConfig = true
PrivateKey = yAnz5TF+lXXJte14tji3zlMNq+hd2rYUIgJBgB3fBmk=
ListenPort = 51820
[Peer]
PublicKey = xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg=
AllowedIPs = 10.192.122.3/32, 10.192.124.1/24
[Peer]
PublicKey = TrMvSoP4jYQlY6RIzBgbssQqY3vxI2Pi+y71lOWWXX0=
AllowedIPs = 10.192.122.4/32, 192.168.0.0/16
[Peer]
PublicKey = gN65BkIKy1eCE9pP1wdc8ROUtkHLF2PfAqYdyYBz6EA=
AllowedIPs = 10.10.10.230/32
Обратите внимание на две строки Address вверху и что SaveConfig установлен в true, указывая, что конфигурационный файл должен быть сохранён при отключении, используя текущее состояние интерфейса.
Пример 5: Политика маршрутизации
Комбинация полей Table, PostUp и PreDown может использоваться для политики маршрутизации. Например, следующее может использоваться для отправки SSH-трафика (TCP-порт 22) через туннель:
[Interface]
Address = 10.192.122.1/24
PrivateKey = yAnz5TF+lXXJte14tji3zlMNq+hd2rYUIgJBgB3fBmk=
ListenPort = 51820
Table = 1234
PostUp = ip rule add ipproto tcp dport 22 table 1234
PreDown = ip rule delete ipproto tcp dport 22 table 1234
[Peer]
PublicKey = xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg=
AllowedIPs = 0.0.0.0/0
ИСПОЛЬЗОВАНИЕ
Эти конфигурационные файлы могут быть размещены в любой директории, указав желаемое имя интерфейса в имени файла:
# wg-quick up /path/to/wgnet0.conf
Для удобства, если указано только имя интерфейса, автоматически выбирается путь в /etc/wireguard/:
# wg-quick up wgnet0
Это загрузит конфигурационный файл /etc/wireguard/wgnet0.conf.
Команда strip полезна для перезагрузки конфигурационных файлов без прерывания активных сессий:
# wg syncconf wgnet0 <(wg-quick strip wgnet0)
СМОТРИТЕ ТАКЖЕ
- wg(8) — настройка интерфейсов WireGuard
- ip(8) — утилита управления сетевыми устройствами
- ip-link(8) — управление сетевыми интерфейсами
- ip-address(8) — управление IP-адресами
- ip-route(8) — управление таблицами маршрутизации
- ip-rule(8) — управление правилами политической маршрутизации
- resolvconf(8) — управление настройками DNS
АВТОР
wg-quick был написан Джейсоном А. Доненфельдом (Jason A. Donenfeld). Для обновлений и дополнительной информации доступна проектная страница во Всемирной паутине.
КРАТКИЙ СПРАВОЧНИК
Основные команды
| Команда | Описание |
|---|---|
wg-quick up INTERFACE | Поднять интерфейс |
wg-quick down INTERFACE | Остановить интерфейс |
wg-quick save INTERFACE | Сохранить конфигурацию |
wg-quick strip INTERFACE | Вывести конфигурацию без wg-quick опций |
Параметры конфигурации
| Параметр | Описание | Пример |
|---|---|---|
Address | IP-адреса интерфейса | 10.0.0.1/24 |
DNS | DNS-серверы | 8.8.8.8 |
MTU | Максимальный размер пакета | 1420 |
Table | Таблица маршрутизации | auto, off, 1234 |
PreUp | Команда перед поднятием | iptables ... |
PostUp | Команда после поднятия | iptables ... |
PreDown | Команда перед остановкой | iptables ... |
PostDown | Команда после остановки | iptables ... |
SaveConfig | Сохранять конфигурацию | true / false |
Примечание: Все команды в
PreUp, PostUp, PreDown и PostDown выполняются через bash(1), поэтому вы можете использовать все возможности оболочки, включая подстановку команд и переменные.Предупреждение: Будьте осторожны с использованием
SaveConfig = true. Любые изменения, внесённые в конфигурационный файл вручную, могут быть перезаписаны при остановке интерфейса.17.5 - wg — руководство
Руководство по wg — утилита для настройки и получения конфигурации интерфейсов WireGuard
ИМЯ
wg — установка и получение конфигурации интерфейсов WireGuard
СИНТАКСИС
wg [ КОМАНДА ] [ ОПЦИИ ]... [ АРГУМЕНТЫ ]...
ОПИСАНИЕ
wg — это утилита конфигурации для получения и установки параметров туннельных интерфейсов WireGuard. Сами интерфейсы могут быть добавлены и удалены с помощью ip-link(8), а их IP-адреса и таблицы маршрутизации могут быть настроены с помощью ip-address(8) и ip-route(8). Утилита wg предоставляет серию подкоманд для изменения специфичных для WireGuard аспектов интерфейсов.
Если КОМАНДА не указана, по умолчанию используется show. Подкоманды, принимающие ИНТЕРФЕЙС, должны получать интерфейс WireGuard.
КОМАНДЫ
show
wg show { <interface> | all | interfaces } [public-key | private-key | listen-port | fwmark | peers | preshared-keys | endpoints | allowed-ips | latest-handshakes | persistent-keepalive | transfer | dump]
Показывает текущую конфигурацию WireGuard и информацию о состоянии указанного интерфейса. Если интерфейс не указан, по умолчанию используется all. Если указано interfaces, выводит список всех интерфейсов WireGuard, по одному на строку, и завершает работу. Если после указания интерфейса не указаны опции, выводит список всех атрибутов в удобном для терминала формате. В противном случае выводит указанную информацию, сгруппированную переносами строк и табуляцией, предназначенную для использования в скриптах. При таком выводе, если указано all, первым полем для всех категорий информации является имя интерфейса. Если указано dump, выводится несколько строк; первая содержит в порядке, разделённом табуляцией: private-key, public-key, listen-port, fwmark. Последующие строки выводятся для каждого пира и содержат в порядке, разделённом табуляцией: public-key, preshared-key, endpoint, allowed-ips, latest-handshake, transfer-rx, transfer-tx, persistent-keepalive.
Примеры:
# Показать всю информацию об интерфейсе wg0
wg show wg0
# Показать только публичный ключ
wg show wg0 public-key
# Показать все интерфейсы в формате для скриптов
wg show all dump
# Список всех интерфейсов
wg show interfaces
showconf
wg showconf <interface>
Показывает текущую конфигурацию интерфейса в формате, описанном ниже в разделе ФОРМАТ КОНФИГУРАЦИОННОГО ФАЙЛА.
Пример:
wg showconf wg0
set
wg set <interface> [listen-port <port>] [fwmark <fwmark>] [private-key <file-path>] [peer <base64-public-key> [remove] [preshared-key <file-path>] [endpoint <ip>:<port>] [persistent-keepalive <interval seconds>] [allowed-ips [+|-]<ip1>/<cidr1>[,[+|-]<ip2>/<cidr2>]...] ]...
Устанавливает значения конфигурации для указанного интерфейса. Может быть указано несколько пиров, и если для пира указан аргумент remove, этот пир удаляется, а не настраивается.
Если listen-port не указан или установлен в 0, порт будет выбран случайно при поднятии интерфейса. И private-key, и preshared-key должны быть файлами, поскольку аргументы командной строки не считаются приватными в большинстве систем, но если вы используете bash(1), вы можете безопасно передать строку, указав в качестве private-key или preshared-key выражение: < (echo PRIVATEKEYSTRING). Если указан /dev/null или другой пустой файл в качестве имени файла для private-key или preshared-key, ключ удаляется из устройства.
Использование preshared-key необязательно и может быть опущено; оно добавляет дополнительный уровень симметричной криптографии к уже существующей криптографии с открытым ключом для устойчивости к квантовым атакам.
Если allowed-ips указан, но значение является пустой строкой, все разрешённые IP-адреса удаляются у пира. По умолчанию allowed-ips заменяет разрешённые IP-адреса пира. Если перед любым из IP-адресов указан + или -, обновление является инкрементальным; IP-адреса с префиксом + или без префикса добавляются к разрешённым IP-адресам пира, если их нет, а IP-адреса с префиксом - удаляются, если присутствуют.
Использование persistent-keepalive необязательно и по умолчанию отключено; установка в 0 или “off” отключает его. В противном случае он представляет собой интервал в секундах от 1 до 65535 включительно, как часто отправлять аутентифицированный пустой пакет пиру для поддержания актуальности stateful-файервола или NAT-маппинга. Например, если интерфейс очень редко отправляет трафик, но может в любое время получать трафик от пира и находится за NAT, интерфейс может выиграть от постоянного интервала keepalive в 25 секунд; однако большинству пользователей это не понадобится.
Использование fwmark необязательно и по умолчанию отключено; установка в 0 или “off” отключает его. В противном случае это 32-битная fwmark для исходящих пакетов, которая может быть указана в шестнадцатеричном формате с префиксом “0x”.
Примеры:
# Установить порт и приватный ключ
wg set wg0 listen-port 51820 private-key /etc/wireguard/private.key
# Добавить пира
wg set wg0 peer xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg= \
endpoint 192.95.5.67:1234 \
allowed-ips 10.192.122.3/32
# Удалить пира
wg set wg0 peer xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg= remove
# Инкрементальное добавление IP-адресов
wg set wg0 peer xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg= \
allowed-ips +192.168.1.0/24
setconf
wg setconf <interface> <configuration-filename>
Устанавливает текущую конфигурацию интерфейса в содержимое configuration-filename, которое должно быть в формате, описанном в разделе ФОРМАТ КОНФИГУРАЦИОННОГО ФАЙЛА.
Пример:
wg setconf wg0 /etc/wireguard/wg0.conf
addconf
wg addconf <interface> <configuration-filename>
Добавляет содержимое configuration-filename, которое должно быть в формате, описанном в разделе ФОРМАТ КОНФИГУРАЦИОННОГО ФАЙЛА, к текущей конфигурации интерфейса.
Пример:
wg addconf wg0 /etc/wireguard/peer.conf
syncconf
wg syncconf <interface> <configuration-filename>
Как setconf, но сначала считывает существующую конфигурацию и вносит только те изменения, которые явно отличаются между конфигурационным файлом и интерфейсом. Это гораздо менее эффективно, чем setconf, но имеет преимущество, не нарушая текущие сессии пиров. Содержимое configuration-filename должно быть в формате, описанном в разделе ФОРМАТ КОНФИГУРАЦИОННОГО ФАЙЛА.
Пример:
wg syncconf wg0 /etc/wireguard/wg0.conf
genkey
wg genkey
Генерирует случайный приватный ключ в формате base64 и выводит его в стандартный вывод.
Пример:
wg genkey > private.key
genpsk
wg genpsk
Генерирует случайный предварительный общий ключ в формате base64 и выводит его в стандартный вывод.
Пример:
wg genpsk > preshared.key
pubkey
wg pubkey
Вычисляет публичный ключ и выводит его в формате base64 в стандартный вывод из соответствующего приватного ключа (сгенерированного с помощью genkey), переданного в формате base64 в стандартный ввод.
Пример:
wg pubkey < private.key > public.key
Приватный ключ и соответствующий публичный ключ могут быть сгенерированы одновременно:
umask 077
wg genkey | tee private.key | wg pubkey > public.key
help
wg help
Показывает сообщение об использовании.
ФОРМАТ КОНФИГУРАЦИОННОГО ФАЙЛА
Формат конфигурационного файла основан на INI. Есть два раздела верхнего уровня — Interface и Peer. Может быть указано несколько разделов Peer, но только один раздел Interface.
Секция Interface
Секция Interface может содержать следующие поля:
| Поле | Описание | Обязательность |
|---|---|---|
| PrivateKey | Приватный ключ в формате base64, сгенерированный wg genkey | Обязательно |
| ListenPort | 16-битный порт для прослушивания. Необязательно; если не указан, выбирается случайно | Опционально |
| FwMark | 32-битная fwmark для исходящих пакетов. Если установлено в 0 или “off”, опция отключена. Может быть указана в шестнадцатеричном формате с префиксом “0x” | Опционально |
Секция Peer
Секции Peer могут содержать следующие поля:
| Поле | Описание | Обязательность |
|---|---|---|
| PublicKey | Публичный ключ в формате base64, вычисленный wg pubkey из приватного ключа и обычно передаваемый вне полосы автору конфигурационного файла | Обязательно |
| PresharedKey | Предварительный общий ключ в формате base64, сгенерированный wg genpsk. Необязательно, может быть опущено. Добавляет дополнительный уровень симметричной криптографии для устойчивости к квантовым атакам | Опционально |
| AllowedIPs | Разделённый запятыми список IP-адресов (v4 или v6) с масками CIDR, с которых разрешён входящий трафик для этого пира и на который направляется исходящий трафик. Может быть указан несколько раз | Обязательно |
| Endpoint | Конечная точка — IP-адрес или имя хоста, за которым следует двоеточие и номер порта. Эта конечная точка будет автоматически обновляться до последнего IP-адреса и порта источника правильно аутентифицированных пакетов от пира | Опционально |
| PersistentKeepalive | Интервал в секундах от 1 до 65535 включительно, как часто отправлять аутентифицированный пустой пакет пиру для поддержания stateful-файервола или NAT-маппинга. Если установлено в 0 или “off”, опция отключена | Опционально |
Пример конфигурационного файла
Этот пример может использоваться как модель для написания конфигурационных файлов, следуя INI-подобному синтаксису. Символы после и включая # считаются комментариями и игнорируются.
# Комментарий
[Interface]
PrivateKey = yAnz5TF+lXXJte14tji3zlMNq+hd2rYUIgJBgB3fBmk=
ListenPort = 51820
FwMark = 0x1234
[Peer]
PublicKey = xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg=
Endpoint = 192.95.5.67:1234
AllowedIPs = 10.192.122.3/32, 10.192.124.1/24
PersistentKeepalive = 25
[Peer]
PublicKey = TrMvSoP4jYQlY6RIzBgbssQqY3vxI2Pi+y71lOWWXX0=
Endpoint = [2607:5300:60:6b0::c05f:543]:2468
AllowedIPs = 10.192.122.4/32, 192.168.0.0/16
[Peer]
PublicKey = gN65BkIKy1eCE9pP1wdc8ROUtkHLF2PfAqYdyYBz6EA=
Endpoint = test.wireguard.com:18981
AllowedIPs = 10.10.10.230/32
Примечание: Для IPv6-адресов в поле
Endpoint используется квадратные скобки: [2607:5300:60:6b0::c05f:543]:2468ОТЛАДОЧНАЯ ИНФОРМАЦИЯ
Иногда полезно иметь информацию о текущем состоянии туннеля.
Linux (модуль ядра)
При использовании модуля ядра Linux на ядре, поддерживающем динамическую отладку, отладочная информация может быть записана в dmesg(1) запуском от root:
# modprobe wireguard && echo module wireguard +p > /sys/kernel/debug/dynamic_debug/control
OpenBSD и FreeBSD
На OpenBSD и FreeBSD отладочная информация может быть записана в dmesg(1) для конкретного интерфейса с помощью ifconfig(1):
# ifconfig wg0 debug
Пользовательские реализации
В пользовательских реализациях принято устанавливать переменную окружения LOG_LEVEL в verbose:
export LOG_LEVEL=verbose
ПЕРЕМЕННЫЕ ОКРУЖЕНИЯ
WG_COLOR_MODE
Управляет цветным выводом:
always— всегда выводить ANSI-цветаnever— никогда не выводить ANSI-цветаauto(или не установлено) — выводить цвета только при записи в TTY
Пример:
export WG_COLOR_MODE=never
WG_HIDE_KEYS
Управляет отображением ключей:
never— показывать приватные и предварительные общие ключиalways(или не установлено) — показывать ключи как “(hidden)”
Пример:
export WG_HIDE_KEYS=never
WG_ENDPOINT_RESOLUTION_RETRIES
Управляет повторными попытками разрешения DNS:
- Если установлено целое число или
infinity, разрешение DNS для конечной точки каждого пира будет повторяться указанное количество раз для непостоянных ошибок с увеличивающейся задержкой между попытками - По умолчанию: 15 попыток
Пример:
export WG_ENDPOINT_RESOLUTION_RETRIES=5
КРАТКИЙ СПРАВОЧНИК
Основные команды
| Команда | Описание |
|---|---|
wg show [interface] | Показать конфигурацию |
wg showconf interface | Показать конфигурацию в формате файла |
wg set interface ... | Установить параметры интерфейса |
wg setconf interface file | Установить конфигурацию из файла |
wg addconf interface file | Добавить конфигурацию из файла |
wg syncconf interface file | Синхронизировать конфигурацию |
wg genkey | Сгенерировать приватный ключ |
wg genpsk | Сгенерировать предварительный общий ключ |
wg pubkey | Вычислить публичный ключ |
Параметры секции Interface
| Параметр | Описание | Пример |
|---|---|---|
PrivateKey | Приватный ключ (base64) | yAnz5TF+lXX... |
ListenPort | Порт для прослушивания | 51820 |
FwMark | Метка для исходящих пакетов | 0x1234 |
Параметры секции Peer
| Параметр | Описание | Пример |
|---|---|---|
PublicKey | Публичный ключ пира (base64) | xTIBA5rboUvn... |
PresharedKey | Предварительный общий ключ (base64) | /UwcSPg38hW... |
AllowedIPs | Разрешённые IP-адреса | 10.0.0.0/24, 192.168.1.0/24 |
Endpoint | Конечная точка | 192.95.5.67:1234 |
PersistentKeepalive | Интервал keepalive (сек) | 25 |
СМОТРИТЕ ТАКЖЕ
- wg-quick(8) — простая настройка интерфейсов WireGuard
- ip(8) — утилита управления сетевыми устройствами
- ip-link(8) — управление сетевыми интерфейсами
- ip-address(8) — управление IP-адресами
- ip-route(8) — управление таблицами маршрутизации
АВТОР
wg был написан Джейсоном А. Доненфельдом (Jason A. Donenfeld). Для обновлений и дополнительной информации доступна проектная страница во Всемирной паутине.
17.6 - Компиляция из исходного кода
Пошаговое руководство по компиляции WireGuard из исходного кода для Ubuntu и Fedora
Компиляция модуля ядра из исходного кода
В этом руководстве вы узнаете, как скомпилировать WireGuard из исходного кода для Ubuntu и Fedora. Это может быть полезно, если вы используете нестандартное ядро, хотите получить самую свежую версию или если ваш дистрибутив не предоставляет готовые пакеты.
Требования: Вам понадобится gcc ≥ 4.7 и заголовочные файлы вашего ядра, расположенные в правильном месте, для успешной компиляции.
Шаг 1: Установка инструментов сборки
Ubuntu и Debian
sudo apt-get install libelf-dev linux-headers-$(uname -r) build-essential pkg-config
Fedora
sudo dnf install elfutils-libelf-devel kernel-devel pkg-config @development-tools
Red Hat Enterprise Linux / CentOS
sudo yum install elfutils-libelf-devel kernel-devel pkgconfig "@Development Tools"
Arch Linux
sudo pacman -S linux-headers base-devel pkg-config
OpenSUSE
sudo zypper install kernel-default-devel pkg-config
Alpine
apk add build-base linux-hardened-dev # или linux-vanilla-dev для ядра vanilla
Шаг 2: Получение исходного кода
Клонируйте репозитории WireGuard:
git clone https://git.zx2c4.com/wireguard-linux-compat
git clone https://git.zx2c4.com/wireguard-tools
Шаг 3: Компиляция и установка модуля ядра
make -C wireguard-linux-compat/src -j$(nproc)
sudo make -C wireguard-linux-compat/src install
Вы можете запустить
make debug вместо обычной сборки, если хотите получить дополнительную информацию о происходящем в вашем dmesg(1).Проверка загрузки модуля
После установки проверьте, что модуль загружается:
sudo modprobe wireguard
lsmod | grep wireguard
Вы должны увидеть вывод, содержащий wireguard.
Шаг 4: Компиляция и установка утилиты wg(8)
Утилита wg(8) необходима для управления интерфейсами WireGuard:
make -C wireguard-tools/src -j$(nproc)
sudo make -C wireguard-tools/src install
Проверка установки
Проверьте, что утилита установлена корректно:
wg --version
Вы должны увидеть информацию о версии утилиты.
Шаг 5: Дополнительная настройка (опционально)
Автоматическая загрузка модуля
Чтобы модуль WireGuard загружался автоматически при старте системы:
echo "wireguard" | sudo tee /etc/modules-load.d/wireguard.conf
Настройка прав доступа к конфигурационным файлам
Создайте директорию для конфигураций с правильными правами:
sudo mkdir -p /etc/wireguard
sudo chmod 600 /etc/wireguard
Шаг 6: Создание и настройка интерфейса
Генерация ключей
umask 077
wg genkey | tee /etc/wireguard/private.key | wg pubkey > /etc/wireguard/public.key
Создание конфигурационного файла
Создайте файл /etc/wireguard/wg0.conf:
[Interface]
PrivateKey = <ваш_приватный_ключ>
Address = 10.0.0.1/24
ListenPort = 51820
[Peer]
PublicKey = <публичный_ключ_пира>
AllowedIPs = 10.0.0.2/32
Endpoint = example.com:51820
Запуск интерфейса
sudo wg-quick up wg0
Проверка статуса
sudo wg show
Требования к ядру
WireGuard требует Linux ≥ 3.10 со следующими опциями конфигурации, которые, вероятно, уже настроены в вашем ядре:
| Опция | Описание |
|---|---|
CONFIG_NET | Базовая поддержка сети |
CONFIG_INET | Базовая поддержка IP |
CONFIG_NET_UDP_TUNNEL | Отправка и получение UDP-пакетов |
CONFIG_CRYPTO_ALGAPI | Криптографический API для crypto_xor |
CONFIG_CRYPTO_MANAGER | Менеджер криптографических алгоритмов |
Некоторые, но не все, из этих опций напрямую соответствуют записям в menuconfig. Для включения этих опций выберите следующие пункты в menuconfig:
[*] Networking support (NET) -->
Networking options -->
[*] TCP/IP networking (INET)
[*] IP: Foo (IP protocols) over UDP (NET_FOU)
[*] Cryptographic API (CRYPTO) -->
[*] Cryptographic algorithm manager (CRYPTO_MANAGER)
При сборке как внешнего модуля, вероятно, также потребуется установить
CONFIG_UNUSED_SYMBOLS.Сборка напрямую в дереве ядра
Если вы хотите собрать WireGuard как модуль или встроенный напрямую из дерева ядра, вы можете использовать скрипт create-patch.sh, который создаёт патч для добавления WireGuard непосредственно в дерево, или скрипт jury-rig.sh, который связывает исходный каталог WireGuard с деревом ядра:
Метод 1: Использование патча
cd /usr/src/linux
~/wireguard-linux-compat/kernel-tree-scripts/create-patch.sh | patch -p1
Метод 2: Использование jury-rig
~/wireguard-linux-compat/kernel-tree-scripts/jury-rig.sh /usr/src/linux
После этого вы сможете настроить следующие опции напрямую:
| Опция | Описание |
|---|---|
CONFIG_WIREGUARD | Управляет тем, будет ли WireGuard собран как модуль, встроенный или не собран вообще |
CONFIG_WIREGUARD_DEBUG | Включает подробные отладочные сообщения |
Эти опции легко выбираются через menuconfig, если также выбраны CONFIG_NET и CONFIG_INET:
[*] Networking support -->
Networking options -->
[*] TCP/IP networking
[*] IP: WireGuard secure network tunnel
[ ] Debugging checks and verbose messages
Устранение неполадок
Ошибка: “wireguard module not found”
Если модуль не загружается, проверьте:
# Проверка установки модуля
ls /lib/modules/$(uname -r)/kernel/net/wireguard/
# Проверка зависимостей
modinfo wireguard
# Проверка логов ядра
dmesg | grep -i wireguard
Ошибка: “kernel headers not found”
Убедитесь, что заголовки ядра установлены:
# Ubuntu/Debian
sudo apt install linux-headers-$(uname -r)
# Fedora
sudo dnf install kernel-devel-$(uname -r)
Проблемы с компиляцией
Если компиляция завершается с ошибками:
- Проверьте версию gcc:
gcc --version
- Убедитесь, что у вас установлены все зависимости:
# Ubuntu/Debian
sudo apt-get build-dep wireguard
# Fedora
sudo dnf builddep wireguard-tools
- Очистите предыдущие сборки:
make -C wireguard-linux-compat/src clean
make -C wireguard-tools/src clean
Дальнейшие шаги
После успешной компиляции и установки вы можете перейти к руководству по быстрому старту для настройки вашего первого WireGuard-подключения.
Связанные руководства
- Установка WireGuard — установка с помощью пакетных менеджеров
- Быстрый старт — настройка и использование WireGuard
- Протокол и криптография — подробности о работе WireGuard
17.7 - Протокол и криптография
Подробное описание протокола WireGuard, криптографических примитивов и обмена ключами
Более подробная информация доступна в техническом документе. Для краткого ознакомления читайте далее.
Криптографические примитивы
В WireGuard используются следующие протоколы и примитивы:
- ChaCha20 для симметричного шифрования, аутентифицированного с помощью Poly1305, с использованием AEAD-конструкции из RFC7539
- Curve25519 для ECDH (обмена ключами по эллиптическим кривым)
- BLAKE2s для хеширования и ключевого хеширования, описанный в RFC7693
- SipHash24 для ключей хеш-таблиц
- HKDF для производной ключей, как описано в RFC5869
Эти примитивы выбраны за их высокую производительность и криптографическую стойкость. Например, ChaCha20-Poly1305 обеспечивает скорость шифрования, сравнимую с AES, но без аппаратного ускорения, что делает его идеальным для встраиваемых устройств. Curve25519 считается одним из самых безопасных и быстрых алгоритмов для обмена ключами.
Протокол без установки соединения
Любой безопасный протокол требует сохранения некоторого состояния, поэтому существует начальное очень простое рукопожатие, которое устанавливает симметричные ключи для передачи данных. Это рукопожатие происходит каждые несколько минут для обеспечения вращения ключей и совершенной прямой секретности (Perfect Forward Secrecy — PFS). PFS означает, что даже если долговременный приватный ключ будет скомпрометирован, это не позволит расшифровать ранее перехваченные сессии.
Рукопожатие выполняется на основе времени, а не содержимого предыдущих пакетов, поскольку спроектировано для корректной обработки потери пакетов. Это важно, потому что в сетях с высокой загрузкой или нестабильным соединением пакеты могут теряться, и протокол должен продолжать работать без сбоев.
Используется умный механизм пульса (pulse mechanism), чтобы гарантировать, что последние ключи и рукопожатия актуальны, с повторным согласованием при необходимости. Этот механизм автоматически обнаруживает, когда рукопожатия устарели, и инициирует новые. Используется отдельная очередь пакетов на хост, чтобы минимизировать потерю пакетов во время рукопожатий, обеспечивая стабильную производительность для всех клиентов.
Другими словами, вы поднимаете устройство, и всё остальное обрабатывается автоматически. Вам не нужно беспокоиться о переподключении, отключении или переинициализации. WireGuard сам управляет всем жизненным циклом соединения.
Таймеры протокола
В протоколе используются следующие таймеры:
REKEY_TIMEOUT — повторная попытка рукопожатия выполняется через
REKEY_TIMEOUT + jitterмс, если ответ не был получен, гдеjitter— случайное значение от 0 до 333 мс. Случайная задержка предотвращает синхронизацию попыток от множества клиентов.KEEPALIVE — если пакет был получен от данного пира, но мы не отправили ему пакет в течение
KEEPALIVEмс, мы отправляем пустой пакет. Это поддерживает NAT-маппинг активным.Если мы отправили пакет данному пиру, но не получили пакет от него в течение
KEEPALIVE + REKEY_TIMEOUTмс, мы инициируем новое рукопожатие.Все эфемерные приватные ключи и симметричные сессионные ключи обнуляются после
REJECT_AFTER_TIME * 3мс, если новые ключи не были обменены. Это гарантирует, что старые ключи не будут случайно сохранены в памяти.После отправки пакета, если количество отправленных пакетов с использованием этого ключа превышает
REKEY_AFTER_MESSAGES, мы инициируем новое рукопожатие. Это ограничивает количество данных, зашифрованных одним ключом.После отправки пакета, если отправитель был первоначальным инициатором рукопожатия и текущий сессионный ключ старше
REKEY_AFTER_TIMEмс, мы инициируем новое рукопожатие. Если отправитель был первоначальным ответчиком, мы не инициируем новое рукопожатие послеREKEY_AFTER_TIMEмс, как это делает инициатор.После получения пакета, если получатель был первоначальным инициатором рукопожатия и текущий сессионный ключ старше
REKEY_AFTER_TIME - KEEPALIVE_TIMEOUT - REKEY_TIMEOUTмс, мы инициируем новое рукопожатие.Рукопожатия инициируются только один раз в
REKEY_TIMEOUTмс, с применением строгого ограничения скорости.Пакеты отбрасываются, если счётчик сессии больше
REJECT_AFTER_MESSAGESили если его ключ старшеREJECT_AFTER_TIMEмс.После
REKEY_ATTEMPT_TIMEмс попыток инициировать новое рукопожатие, попытки прекращаются, и очищаются все существующие пакеты, поставленные в очередь для отправки. Если пакет явно поставлен в очередь для отправки, этот таймер сбрасывается.
В будущем планируется настроить REKEY_TIMEOUT для использования экспоненциальной задержки (exponential back-off), что повысит эффективность при больших нагрузках.
Ключевое подтверждение
После завершения рукопожатия, с сообщением от инициатора к ответчику и затем обратно от ответчика к инициатору, инициатор может отправлять зашифрованные пакеты сессии, но ответчик не может. Ответчик обязан дождаться получения зашифрованного пакета сессии от инициатора для подтверждения ключа. Это требование обеспечивает подтверждение того, что инициатор действительно получил ключи и может использовать их.
До получения первого пакета с новым ключом ответчик должен либо поставить пакеты в очередь для отправки позже, либо использовать предыдущую сессию, если она существует и действительна. Поэтому после получения ответа от ответчика, если у инициатора нет немедленно готовых к отправке пакетов данных, он должен отправить пустой пакет для подтверждения ключа.
Пример: Представьте, что клиент устанавливает VPN-соединение с сервером. Клиент отправляет рукопожатие, сервер отвечает, и после этого клиент отправляет первый зашифрованный пакет данных. Только после получения этого пакета сервер начинает использовать новый ключ для ответов. Если клиенту нечего отправлять сразу, он отправляет пустой пакет, чтобы сервер знал, что ключ подтверждён.
Обмен ключами и пакеты данных
WireGuard использует рукопожатие Noise_IK из Noise Protocol Framework, основанное на работах CurveCP, NaCL, KEA+, SIGMA, FHMQV и HOMQV. Все эти протоколы внесли вклад в создание надёжного и безопасного механизма обмена ключами. Все пакеты передаются через UDP, что обеспечивает низкую задержку и высокую производительность.
Свойства обмена ключами
Обмен ключами обладает следующими свойствами:
Избегает компрометации ключей с подменой личности — даже если злоумышленник получит доступ к долговременному ключу одной стороны, он не сможет выдать себя за другую сторону.
Избегает атак повторного воспроизведения — каждый пакет содержит уникальные данные, предотвращающие его повторное использование.
Обеспечивает совершенную прямую секретность (PFS) — компрометация долговременных ключей не раскрывает содержимое прошлых сессий.
Достигает “AKE Security” — обеспечивает безопасность аутентифицированного обмена ключами в соответствии с современными криптографическими стандартами.
Обеспечивает скрытие идентичности — информация о сторонах, участвующих в обмене, защищена от пассивного наблюдения.
Предварительный общий ключ (PSK)
Если требуется дополнительный уровень симметричной криптографии (например, для устойчивости к квантовым атакам), WireGuard поддерживает опциональный предварительный общий ключ (Pre-Shared Key), который смешивается с криптографией с открытым ключом. Это обеспечивает дополнительный уровень защиты: даже если кто-то сможет взломать асимметричную криптографию с помощью квантового компьютера, PSK останется барьером.
Когда режим PSK не используется, значение предварительного общего ключа считается строкой из 32 нулевых байт. Таким образом, протокол всегда работает одинаково, независимо от использования PSK.
Используемые функции
В протоколе используются следующие криптографические функции:
DH(private key, public key)— умножение точек Curve25519, возвращает 32 байта общего секрета. Это основной механизм обмена ключами.DH_GENERATE()— генерация случайного приватного ключа Curve25519 (32 байта). Каждый раз генерируется новый ключ для обеспечения PFS.RAND(len)— возвращаетlenслучайных байт. Используется для генерации nonce и других случайных значений.DH_PUBKEY(private key)— вычисление публичного ключа Curve25519 из приватного ключа (32 байта).AEAD(key, counter, plain text, auth text)— ChaCha20Poly1305 AEAD, как указано в RFC7539, с nonce, состоящим из 32 бит нулей, за которыми следует 64-битное значениеcounterв little-endian. Обеспечивает одновременно шифрование и аутентификацию.XAEAD(key, nonce, plain text, auth text)— XChaCha20Poly1305 AEAD со случайным 24-байтовым nonce. Используется для cookie-пакетов.AEAD_LEN(plain len)—plain len + 16, где 16 байт — размер тега аутентификации.HMAC(key, input)— HMAC-Blake2s(key, input, 32), возвращает 32 байта. Используется для создания ключей.MAC(key, input)— Keyed-Blake2s(key, input, 16), возвращает 16 байт. Используется для создания MAC (Message Authentication Code).HASH(input)— Blake2s(input, 32), возвращает 32 байта. Используется для хеширования.TAI64N()— TAI64N-метка текущего времени (12 байт). Используется для защиты от атак повторного воспроизведения.CONSTRUCTION— UTF-8 значениеNoise_IKpsk2_25519_ChaChaPoly_BLAKE2s(37 байт). Идентифицирует используемую конструкцию Noise.IDENTIFIER— UTF-8 значениеWireGuard v1 zx2c4 Jason@zx2c4.com(34 байта). Идентифицирует реализацию WireGuard.LABEL_MAC1— UTF-8 значениеmac1----(8 байт). Используется для маркировки MAC1.LABEL_COOKIE— UTF-8 значениеcookie--(8 байт). Используется для маркировки cookie.
Структура пакетов
Первое сообщение: Инициатор → Ответчик
Инициатор отправляет это сообщение:
msg = handshake_initiation {
u8 message_type // Всегда 1
u8 reserved_zero[3] // Зарезервировано для будущего использования
u32 sender_index // Индекс отправителя
u8 unencrypted_ephemeral[32] // Эфемерный публичный ключ (не зашифрован)
u8 encrypted_static[AEAD_LEN(32)] // Зашифрованный статический публичный ключ
u8 encrypted_timestamp[AEAD_LEN(12)] // Зашифрованная метка времени
u8 mac1[16] // Первый MAC
u8 mac2[16] // Второй MAC (cookie)
}
Пример: Клиент (инициатор) отправляет это сообщение серверу (ответчику), чтобы начать установку VPN-соединения. Поле unencrypted_ephemeral содержит эфемерный публичный ключ, который не шифруется, чтобы сервер мог его использовать для вычисления общего секрета. Поля encrypted_static и encrypted_timestamp зашифрованы и содержат долговременный публичный ключ клиента и текущее время для защиты от повторных атак.
Второе сообщение: Ответчик → Инициатор
Ответчик отправляет это сообщение после обработки первого сообщения:
msg = handshake_response {
u8 message_type // Всегда 2
u8 reserved_zero[3] // Зарезервировано
u32 sender_index // Индекс отправителя
u32 receiver_index // Индекс получателя (из первого сообщения)
u8 unencrypted_ephemeral[32] // Эфемерный публичный ключ
u8 encrypted_nothing[AEAD_LEN(0)] // Зашифрованное пустое сообщение
u8 mac1[16] // Первый MAC
u8 mac2[16] // Второй MAC (cookie)
}
Пример: Сервер (ответчик) отвечает клиенту своим эфемерным публичным ключом. Поле receiver_index содержит индекс, полученный от клиента, что позволяет клиенту сопоставить ответ с правильной сессией. Зашифрованное пустое сообщение (encrypted_nothing) служит для подтверждения того, что сервер правильно вычислил ключи.
Пакеты данных
После завершения рукопожатия инициатор и ответчик обмениваются пакетами данных:
msg = packet_data {
u8 message_type // Всегда 4
u8 reserved_zero[3] // Зарезервировано
u32 receiver_index // Индекс получателя
u64 counter // Счётчик пакетов (nonce)
u8 encrypted_encapsulated_packet[] // Зашифрованный инкапсулированный пакет
}
Пример: После установления ключей клиент отправляет серверу зашифрованный IP-пакет. Поле counter увеличивается с каждым пакетом, предотвращая повторное использование nonce. Сами данные (encrypted_encapsulated_packet) содержат зашифрованный IP-пакет, который сервер расшифровывает и передаёт в сеть.
Производные ключей данных
После обмена двумя сообщениями ключи вычисляются инициатором и ответчиком для отправки и получения данных:
temp1 = HMAC(initiator.chaining_key, [empty])
temp2 = HMAC(temp1, 0x1)
temp3 = HMAC(temp1, temp2 || 0x2)
initiator.sending_key = temp2
initiator.receiving_key = temp3
initiator.sending_key_counter = 0
initiator.receiving_key_counter = 0
temp1 = HMAC(responder.chaining_key, [empty])
temp2 = HMAC(temp1, 0x1)
temp3 = HMAC(temp1, temp2 || 0x2)
responder.receiving_key = temp2
responder.sending_key = temp3
responder.receiving_key_counter = 0
responder.sending_key_counter = 0
Затем все предыдущие цепочки ключей, эфемерные ключи и хеши обнуляются. Это гарантирует, что даже если злоумышленник получит доступ к памяти, он не сможет восстановить предыдущие ключи.
Объяснение: Процесс использует HKDF (HMAC-based Key Derivation Function) для создания независимых ключей для каждого направления. temp1 — это начальный ключевой материал, из которого через серию HMAC-операций создаются sending_key (ключ для отправки) и receiving_key (ключ для приёма). Счётчики инициализируются нулём и увеличиваются с каждым пакетом.
Защита от DoS-атак
WireGuard требует аутентификации в первом сообщении рукопожатия, что не требует выделения состояния на сервере для потенциально неаутентифицированных сообщений. Это критически важно для защиты от DoS-атак: злоумышленник не может заставить сервер выделять ресурсы для каждого поддельного пакета.
Сервер вообще не отвечает неавторизованному клиенту; он молчит и невидим. Это делает WireGuard устойчивым к сканированию портов и DoS-атакам.
Защита от атак повторного воспроизведения
Однако это создаёт проблему: аутентификация в первом пакете всегда уязвима для атак повторного воспроизведения. Злоумышленник может воспроизвести начальные сообщения рукопожатия, чтобы заставить сервер перегенерировать свой эфемерный ключ, тем самым разорвав соединение легитимного клиента (хотя это не влияет на безопасность сообщений).
Для защиты используется TAI64N-метка времени в первом сообщении. Сервер отслеживает наибольшую полученную метку времени для каждого клиента и отбрасывает пакеты с метками, меньшими или равными предыдущей.
Пример: Клиент отправляет рукопожатие с меткой времени 2024-01-01 12:00:00.000. Сервер запоминает эту метку. Если злоумышленник попытается воспроизвести это же рукопожатие через час, сервер отбросит его, так как метка времени меньше или равна уже полученной.
Если сервер перезапускается и теряет это состояние, это не проблема: более ранний пакет может быть воспроизведён, но он не может нарушить текущие сессии, так как сервер только что перезапустился. После переподключения клиенты будут использовать более новые метки времени, делая предыдущие недействительными.
Cookie-пакеты
Вычисление функции DH() требует значительных вычислительных ресурсов. Для защиты от атак на исчерпание CPU сервер может не обрабатывать сообщения рукопожатия, а вместо этого отвечать cookie-пакетом, если он находится под нагрузкой.
Чтобы сервер оставался молчаливым, если не получает действительный пакет, все сообщения должны содержать MAC, который комбинирует публичный ключ получателя и опционально PSK в качестве ключа MAC. Когда сервер находится под нагрузкой, он принимает только пакеты, которые дополнительно имеют второй MAC предыдущих байтов сообщения, использующий cookie в качестве ключа MAC.
Cookie истекают через две минуты и представляют собой MAC IP-адреса отправителя с использованием меняющегося (каждые две минуты) секрета сервера в качестве ключа MAC. Это позволяет доказать владение IP-адресом, который затем может быть правильно ограничен по скорости.
Сервер, вычислив эти MAC и сравнив их с полученными в сообщении, должен отклонять сообщения с недействительным msg.mac1 и при нагрузке — сообщения с недействительным msg.mac2.
Cookie-пакет
Как упоминалось выше, когда получено сообщение с действительным msg.mac1, но msg.mac2 равен нулю или недействителен, и сервер находится под нагрузкой, сервер может отправить cookie-пакет:
msg = packet_cookie_reply {
u8 message_type // Всегда 3
u8 reserved_zero[3] // Зарезервировано
u32 receiver_index // Индекс получателя
u8 nonce[24] // Случайный nonce для XChaCha20
u8 encrypted_cookie[AEAD_LEN(16)] // Зашифрованный cookie
}
Пример: Злоумышленник пытается инициировать множество рукопожатий с сервера под нагрузкой. Сервер не выполняет дорогостоящие вычисления DH для каждого, а вместо этого отправляет cookie-пакет. Клиент должен расшифровать cookie и отправить его обратно в следующем рукопожатии, доказывая, что он может получить пакеты по указанному IP-адресу.
Защита от повторного использования nonce
Nonce никогда не повторяются. Используется 64-битный счётчик, который не может быть уменьшен. Это означает, что каждый пакет имеет уникальный nonce, что критически важно для безопасности ChaCha20-Poly1305.
UDP иногда доставляет сообщения в неправильном порядке. Для этого используется скользящее окно, в котором отслеживается наибольший полученный счётчик и окно примерно из 2000 предыдущих значений, проверяемых после верификации тега аутентификации. Это позволяет принимать пакеты, пришедшие не по порядку, но не позволяет повторно использовать уже принятые nonce.
Пример: Клиент отправляет пакеты с счётчиками 1, 2, 3, 4, 5. Пакет 4 приходит первым, затем пакет 2, затем пакет 5. Скользящее окно позволяет принять все эти пакеты, так как их счётчики находятся в допустимом диапазоне. Если злоумышленник попытается повторно отправить пакет с счётчиком 2, он будет отброшен, так как этот счётчик уже был принят.
DiffServ
При работе с IP-пакетами WireGuard учитывает следующие аспекты DiffServ:
DSCP рукопожатий: 0x88 (AF41) — эти пакеты имеют наивысший приоритет и наименьшую вероятность отбрасывания, так как они необходимы для управления туннелем. Это гарантирует, что даже при перегрузке сети рукопожатия будут доставлены.
DSCP данных: 0 — значение DSCP из внутреннего пакета никогда не копируется во внешний пакет. Это предотвращает утечку информации о типе трафика, проходящего через зашифрованный туннель.
ECN (Explicit Congestion Notification): Бит ECN копируется между внутренним и внешним пакетами в соответствии с логикой, описанной в RFC6040. Это позволяет сохранять информацию о перегрузке сети внутри туннеля.
Пример: Если внутри туннеля передаётся VoIP-трафик с высоким приоритетом, внешние пакеты WireGuard не будут показывать этот приоритет. Внешний наблюдатель увидит только обычные UDP-пакеты без информации о их содержимом.
Схема протокола
sequenceDiagram
participant I as Инициатор
participant R as Ответчик
Note over I,R: 1. Инициация рукопожатия
I->>R: message_type=1, ephemeral, encrypted_static, timestamp
Note over R: Проверка MAC, дешифрование<br/>Генерация ephemeral ключа
Note over I,R: 2. Ответ
R->>I: message_type=2, ephemeral, encrypted_nothing
Note over I: Проверка, дешифрование<br/>Производная ключей
Note over I,R: 3. Передача данных
I->>R: message_type=4, encrypted_data
Note over R: Дешифрование данными ключамиСсылки
17.8 - Формальная верификация
Формальная верификация протокола WireGuard, криптографии и реализации
Формальная верификация
WireGuard прошёл все виды формальной верификации, охватывающие аспекты криптографии, протокола и реализации. Ниже приведены подробности различных усилий по верификации.
Что такое формальная верификация? Это процесс математического доказательства того, что система соответствует своей спецификации и свободна от определённых классов ошибок. В контексте криптографических протоколов это означает доказательство того, что протокол безопасен против различных моделей атакующего.
Символическая верификация протокола с использованием Tamarin
Протокол WireGuard, описанный в техническом документе и основанный на Noise, был формально верифицирован в символической модели с использованием Tamarin. Это означает, что существует математическое доказательство безопасности протокола WireGuard.
Что такое символическая верификация? Символическая верификация рассматривает криптографические примитивы как “чёрные ящики” с идеальными свойствами. Она проверяет, что протокол логически корректен, при условии, что используемые криптографические примитивы безопасны. Это позволяет обнаруживать логические ошибки в протоколе, такие как неправильная последовательность сообщений или утечка информации.
Протокол был верифицирован на наличие следующих свойств безопасности:
| Свойство | Описание | Значение |
|---|---|---|
| Корректность | Протокол всегда завершается успешно при правильном выполнении | Гарантирует, что при отсутствии атак протокол работает как ожидается |
| Надёжное согласование ключей и аутентичность | Стороны уверены, что обмениваются ключами именно с той стороной, с которой намеревались | Предотвращает атаки “человек посередине” (MITM) |
| Устойчивость к компрометации ключей с подменой личности | Даже если долговременный ключ скомпрометирован, атакующий не может выдать себя за другую сторону | Защищает от ситуаций, когда злоумышленник получает доступ к приватному ключу |
| Устойчивость к атакам неизвестного общего ключа | Сторона не может быть обманута, чтобы использовать ключ, которого она не ожидает | Предотвращает ситуации, когда атакующий заставляет две стороны использовать разные ключи |
| Секретность ключа | Ключ остаётся известным только участвующим сторонам | Базовая гарантия конфиденциальности |
| Совершенная прямая секретность | Компрометация долговременных ключей не раскрывает содержимое прошлых сессий | Защищает прошлый трафик даже при компрометации ключей в будущем |
| Уникальность сессии | Каждая сессия уникальна и не может быть спутана с другой | Предотвращает смешивание сессий |
| Скрытие идентичности | Личности сторон защищены от пассивного наблюдения | Злоумышленник не может узнать, кто общается с кем |
Это совместная работа Джейсона Доненфельда (Jason Donenfeld) и Кевина Милнера (Kevin Milner).
Результаты широко обсуждаются в документе по формальной верификации WireGuard. Этот документ является черновиком, но основные результаты уже представлены.
Прочитать документ по верификации WireGuard в Tamarin
Модель Tamarin
Модель Tamarin является открытым исходным кодом и может быть запущена повторно для независимой верификации:
git clone https://git.zx2c4.com/wireguard-tamarin/
cd wireguard-tamarin
make
Для работы требуются:
- Tamarin — инструмент для символической верификации протоколов
- m4 — макропроцессор
- GraphViz — визуализация графов
- Maude — система для написания и выполнения спецификаций
Пример использования: Исследователь может запустить модель Tamarin для проверки нового свойства безопасности или для подтверждения существующих результатов. Модель генерирует доказательства, которые могут быть проверены математически.
Вычислительное доказательство протокола в модели eCK
При попытке построить вычислительное доказательство WireGuard в модели eCK (extended Canetti-Krawczyk) оказалось, что протокол WireGuard не вписывается аккуратно в традиционную модель eCK, потому что сообщение подтверждения ключа является частью транспортного уровня. Это техническая деталь, связанная с тем, как моделируются этапы протокола.
Что такое модель eCK? Это одна из самых сильных моделей безопасности для протоколов согласования ключей. Она учитывает широкий спектр атак, включая компрометацию эфемерных и долговременных ключей в различных комбинациях.
Поэтому в этом документе доказывается вариант протокола WireGuard, который морально эквивалентен реальному протоколу, давая очень сильный результат.
Что такое “морально эквивалентный”? Это означает, что вариант протокола имеет ту же логическую структуру и свойства безопасности, но адаптирован для соответствия формальным требованиям модели eCK. Доказательство для варианта применимо и к реальному протоколу.
Это совместная работа Бенджамина Даулинга (Benjamin Dowling) и Кеннета Г. Патерсона (Kenneth G. Paterson).
Прочитать документ по вычислительному доказательству в модели eCK
Вычислительное доказательство протокола в модели ACCE
Эта диссертация строит механизированное криптографическое доказательство всего протокола WireGuard, включая сообщения транспортных данных, в вычислительной модели, подобной ACCE (Authenticated and Confidential Channel Establishment), с использованием CryptoVerif.
Что такое модель ACCE? Это модель для протоколов, которые устанавливают аутентифицированные и конфиденциальные каналы. Она учитывает как установление ключей, так и последующую передачу данных, что делает её особенно подходящей для WireGuard.
Что такое CryptoVerif? Это инструмент для автоматического доказательства безопасности криптографических протоколов в вычислительной модели. В отличие от символической верификации, он учитывает реальные криптографические примитивы и их математические свойства.
Доказанные свойства:
| Свойство | Описание |
|---|---|
| Корректность | Протокол работает как ожидается |
| Секретность сообщений | Сообщения не могут быть прочитаны атакующим |
| Совершенная прямая секретность | Прошлые сообщения защищены при компрометации ключей |
| Взаимная аутентификация | Обе стороны уверены в личности друг друга |
| Устойчивость к компрометации ключей с подменой личности | Защита при компрометации ключей |
| Устойчивость к атакам неизвестного общего ключа | Защита от смешивания ключей |
| Устойчивость к повторному воспроизведению первого сообщения протокола | Первое сообщение не может быть повторно использовано |
Модель доступна для скачивания и может быть использована в CryptoVerif 2.00.
Это работа Бенджамина Липпа (Benjamin Lipp).
Прочитать документ по вычислительному доказательству в модели ACCE
Символическая верификация протокола с использованием ProVerif
Проект Noise Explorer стремится формально верифицировать все шаблоны протокола Noise путём генерации моделей ProVerif.
Что такое ProVerif? Это популярный инструмент для автоматической верификации криптографических протоколов в символической модели. Он может автоматически находить атаки или доказывать свойства безопасности.
Модель, относящаяся к WireGuard, — это модель IK от Noise Explorer, которая может быть подключена к ProVerif для генерации доказательств различных свойств.
Что такое шаблон IK в Noise? Это конкретный шаблон рукопожатия, используемый WireGuard. Он определяет, в каком порядке отправляются ключи и как вычисляются общие секреты.
Это работа Надима Кобейсси (Nadim Kobeissi) и Картикеяна Баргавана (Karthikeyan Bhargavan).
Прочитать документ Noise Explorer
Верифицированная C-реализация Curve25519
HACL*
WireGuard использует 64-битную реализацию умножения скаляра Curve25519 из HACL*. Кривая специфицирована в F*, что позволяет доказывать свойства стратегий реализации. KreMLin преобразует её в верифицированный C-код.
Что такое HACL?* Это библиотека криптографических примитивов, написанных на F* и верифицированных по безопасности и корректности. Она обеспечивает математические гарантии того, что реализация Curve25519 свободна от ошибок и уязвимостей.
Что такое F?* Это функциональный язык программирования с зависимыми типами, который позволяет выражать и доказывать свойства программ. Он используется для написания спецификаций криптографических примитивов.
Что такое KreMLin? Это компилятор, который преобразует код F* в верифицированный C-код, сохраняя все доказательства свойств.
HACL* — совместная работа Жана Карима Зинзиндууэ (Jean Karim Zinzindohoué), Картикеяна Баргавана (Karthikeyan Bhargavan), Джонатана Протценко (Jonathan Protzenko) и Бенджамина Беурдуше (Benjamin Beurdouche).
Fiat-Crypto
WireGuard также использует 32-битную реализацию умножения скаляра Curve25519 из Fiat-Crypto. Кривая специфицирована в Coq, что позволяет доказывать свойства стратегий реализации и генерировать верифицированный C-код.
Что такое Fiat-Crypto? Это проект по генерации верифицированного криптографического кода из формальных спецификаций в Coq. Он автоматически генерирует реализации, которые математически доказано корректны.
Что такое Coq? Это интерактивная система доказательства теорем, которая позволяет писать математические спецификации и доказывать их свойства. Она широко используется для формальной верификации программного обеспечения.
Преимущество 32-битной реализации: Она оптимизирована для устройств с 32-битными процессорами, таких как старые смартфоны или встраиваемые системы, что делает WireGuard доступным для более широкого спектра устройств.
Fiat-Crypto — совместная работа Андреса Эрбсена (Andres Erbsen), Джейд Филипум (Jade Philipoom), Джейсона Гросса (Jason Gross), Роберта Слоана (Robert Sloan) и Адама Члипала (Adam Chlipala).
Прочитать документ Fiat-Crypto
Почему формальная верификация важна?
Формальная верификация обеспечивает уровень уверенности, который невозможно достичь только тестированием или экспертной оценкой. Вот почему это критически важно для WireGuard:
Математические гарантии — Верификация даёт математическое доказательство того, что протокол безопасен против определённых классов атак. Это не просто “вероятно безопасно” — это “доказано безопасно”.
Обнаружение тонких ошибок — Некоторые уязвимости могут быть обнаружены только формальными методами. Например, атаки на протоколы, которые полагаются на тонкие логические ошибки.
Независимая проверка — Модели с открытым исходным кодом позволяют любому исследователю независимо проверить результаты, что повышает доверие к протоколу.
Документирование предположений — Верификация явно документирует предположения безопасности, на которых основан протокол, что помогает при его использовании и анализе.
Устойчивость к будущим атакам — Доказательства безопасности в различных моделях (символической, вычислительной) дают уверенность, что протокол устойчив к широкому спектру атакующих стратегий.
Обзор уровней верификации
graph TD
A[Формальная верификация WireGuard] --> B[Символическая верификация]
A --> C[Вычислительная верификация]
A --> D[Верификация реализации]
B --> B1[Tamarin]
B --> B2[ProVerif]
C --> C1[eCK модель]
C --> C2[ACCE модель]
D --> D1[HACL* 64-bit]
D --> D2[Fiat-Crypto 32-bit]
style A fill:#88171a,color:#fff
style B fill:#2c3e50,color:#fff
style C fill:#2c3e50,color:#fff
style D fill:#2c3e50,color:#fffСсылки
17.9 - Кроссплатформенная реализация
Описание пользовательской реализации WireGuard для кросс-платформенной работы и интерфейса конфигурации
Кроссплатформенная пользовательская реализация
Хотя WireGuard изначально был разработан для ядра Linux для максимальной производительности, он может работать в пользовательском пространстве с использованием отдельной реализации. В настоящее время wireguard-go вполне функционален, а wireguard-rs находится в разработке.
Что такое пользовательская реализация? В отличие от реализации в ядре, которая работает на уровне операционной системы, пользовательская реализация работает как обычное приложение. Это позволяет запускать WireGuard на платформах, где нет доступа к ядру, или когда требуется более простая интеграция с приложениями.
В любой момент документации, когда вы видите ip link add wg0 type wireguard, вы можете вместо этого написать wireguard-go wg0. Всё остальное должно быть идентичным.
Пример: На Windows или macOS, где нет прямой поддержки в ядре, вы запускаете
wireguard-go wg0, и он создаёт виртуальный сетевой интерфейс, эмулируя поведение ядерной версии.Чтобы предотвратить фрагментацию и обеспечить совместимость, все пользовательские реализации должны соответствовать одному и тому же протоколу и спецификации, имея точно такое же поведение, как и оригинальная реализация для ядра Linux. Кроме того, они должны соответствовать следующему интерфейсу конфигурации.
Интерфейс командной строки
Пользовательская реализация должна иметь следующий очень ограниченный интерфейс командной строки:
# userspace-wg [-f/--foreground] INTERFACE-NAME
Объяснение параметров:
-fили--foreground— опциональный флаг, который заставляет процесс оставаться на переднем плане (не демонизироваться). Это полезно для отладки и при запуске из системных менеджеров.INTERFACE-NAME— имя создаваемого интерфейса (например,wg0).
Например, реализация на Go будет вызываться следующим образом для создания интерфейса wg0:
# wireguard-go wg0
Что происходит при запуске? Выполнение этой команды создаёт виртуальное TUN-устройство с именем wg0 и затем демонизируется (переходит в фоновый режим). После успешной демонизации и поднятия интерфейса создаётся /var/run/wireguard/wg0.sock (или /run/wireguard/wg0.sock в зависимости от платформы) — это UNIX-сокет домена, работающий в потоковом режиме.
Что такое TUN-устройство? Это виртуальный сетевой интерфейс, который работает на уровне IP. Приложения могут читать и писать в него IP-пакеты, как если бы они работали с обычным сетевым интерфейсом. WireGuard использует TUN для получения и отправки зашифрованных пакетов.
Что такое UNIX-сокет? Это механизм межпроцессного взаимодействия (IPC), который позволяет процессам обмениваться данными. В данном случае он используется для того, чтобы утилита wg(8) могла управлять процессом WireGuard.
На Windows используются те же семантики с двунаправленным именованным каналом (named pipe) в \\.\pipe\WireGuard\wg0. Именованные каналы — это аналог UNIX-сокетов в Windows.
Использование wg(8) для конфигурации
Инструмент wg(8) используется для настройки интерфейса, что обеспечивает полное единообразие интерфейсов конфигурации во всех реализациях.
Почему это важно? Пользователи и скрипты могут использовать одни и те же команды для управления WireGuard независимо от того, работает ли он в ядре или в пользовательском пространстве. Это значительно упрощает автоматизацию и написание документации.
Инструмент wg(8) ищет интерфейсы в /var/run/wireguard/*.sock (или /run/wireguard/*.sock). Пользовательские реализации должны корректно завершать работу в ответ на SIGINT/SIGTERM, удаление TUN-интерфейса или удаление файла UNIX-сокета.
Как это работает:
- Вы запускаете
wireguard-go wg0— создаётся процесс и сокет - Вы запускаете
wg setconf wg0 config.conf— утилитаwg(8)находит сокет и отправляет команду - Процесс WireGuard получает команду через сокет и применяет конфигурацию
- Всё прозрачно работает как с ядерной версией
Инструмент wg(8) подключается к этим сокетам и отправляет и получает следующий текстовый протокол.
Протокол конфигурации
Реализация WireGuard должна отвечать на две команды: get и set, обе версии 1 на момент написания.
Что такое версия протокола? Это позволяет в будущем добавлять новые функции без нарушения совместимости. Номер версии указывает, какой формат команд и ответов используется.
Команда get
wg(8) отправляет команду get, которая выглядит так:
get=1
{empty line}
Объяснение: Команда get запрашивает текущую конфигурацию и статус интерфейса. Пустая строка в конце указывает на завершение команды.
Пользовательская реализация отвечает на команду get так:
key1=value1
key2=value2
key3=value3
key4=value4
key5=value5
...
errno=0
{empty line}
Объяснение ответа: После всех ключей и значений добавляется errno=0 (означает “успех”) и пустая строка. Если произошла ошибка, errno будет содержать код ошибки.
Команда set
wg(8) отправляет команду set, которая выглядит так:
set=1
key1=value1
key2=value2
key3=value3
key4=value4
key5=value5
...
{empty line}
Объяснение: Команда set отправляет новую конфигурацию. В отличие от get, она содержит ключи и значения для применения.
Пользовательская реализация отвечает на команду set так:
errno=0
{empty line}
Объяснение: Ответ на set проще — только код ошибки и пустая строка.
Если произошла ошибка, errno — соответствующее целое число из errno.h (стандартные коды ошибок POSIX).
Примечание: Обратите внимание на пустую строку в конце команд
get и set, а также в конце каждого соответствующего ответа от wg(8). Это необходимо для правильного разбора протокола.Ключи и значения
Уровень интерфейса
Эти ключи применяются ко всему интерфейсу:
| Ключ | Описание | Формат значения | Примечания |
|---|---|---|---|
private_key | Приватный ключ интерфейса | Шестнадцатеричная строка (в нижнем регистре) | Все нули = удалить ключ |
listen_port | Порт для прослушивания | Десятичное целое число | |
fwmark | Метка для исходящих пакетов | Десятичное целое число | 0 = удалить fwmark |
replace_peers=true | Заменить всех пиров | Только ключ | Последующие пиры заменяют существующих |
Пример использования replace_peers: Если у вас уже есть 5 пиров, и вы отправляете set с replace_peers=true и 3 новыми пирами, старые 5 пиров будут удалены, а останутся только 3 новых.
Уровень пира
Эти ключи применяются к конкретному пиру и следуют после ключа public_key:
| Ключ | Описание | Формат значения | Примечания |
|---|---|---|---|
public_key | Публичный ключ пира | Шестнадцатеричная строка (в нижнем регистре) | Начинает блок пира |
remove=true | Удалить пира | Только ключ | Применяется к предыдущему пиру |
update_only=true | Обновить только существующего | Только ключ | Ошибка, если пир не существует |
preshared_key | Предварительный общий ключ | Шестнадцатеричная строка | Все нули = удалить ключ |
endpoint | Конечная точка | IP:port или [IP]:port | Для IPv6 используются квадратные скобки |
persistent_keepalive_interval | Интервал keepalive | Десятичное целое число | 0 = отключить |
replace_allowed_ips=true | Заменить все разрешённые IP | Только ключ | Заменяет список, а не добавляет |
allowed_ip | Разрешённый IP-адрес | IP/cidr | Может быть указан несколько раз |
rx_bytes | Получено байт | Десятичное целое число | Только для get |
tx_bytes | Отправлено байт | Десятичное целое число | Только для get |
last_handshake_time_sec | Время рукопожатия (сек) | Десятичное целое число | Только для get, время Unix |
last_handshake_time_nsec | Время рукопожатия (нс) | Десятичное целое число | Только для get, время Unix |
protocol_version | Версия протокола | 1 | Обычно не используется |
Важные замечания о ключах
Порядок важен: Все ключи уровня интерфейса должны идти до ключей уровня пира. Это логично, так как сначала определяются общие параметры интерфейса, а затем параметры отдельных пиров.
Обработка
allowed_ip: Если одинаковое значениеallowed_ipуже существует у другого пира, запись IP будет удалена у того пира и добавлена к текущему. Это обеспечивает уникальность разрешённых IP-адресов.Формат ключей: Все ключи в шестнадцатеричном формате должны быть в нижнем регистре. Это стандарт для криптографических ключей в WireGuard.
Пример диалога
Команда get
wg(8) отправляет:
get=1
{empty line}
Пользовательская реализация WireGuard отвечает:
private_key=e84b5a6d2717c1003a13b431570353dbaca9146cf150c5f8575680feba52027a
listen_port=12912
public_key=b85996fecc9c7f1fc6d2572a76eda11d59bcd20be8e543b15ce4bd85a8e75a33
preshared_key=188515093e952f5f22e865cef3012e72f8b5f0b598ac0309d5dacce3b70fcf52
allowed_ip=192.168.4.4/32
endpoint=[abcd:23::33%2]:51820
public_key=58402e695ba1772b1cc9309755f043251ea77fdcf10fbe63989ceb7e19321376
tx_bytes=38333
rx_bytes=2224
allowed_ip=192.168.4.6/32
persistent_keepalive_interval=111
endpoint=182.122.22.19:3233
public_key=662e14fd594556f522604703340351258903b64f35553763f19426ab2a515c58
endpoint=5.152.198.39:51820
allowed_ip=192.168.4.10/32
allowed_ip=192.168.4.11/32
tx_bytes=1212111
rx_bytes=1929999999
protocol_version=1
errno=0
{empty line}
Разбор примера:
- Интерфейс имеет приватный ключ, слушает на порту 12912
- Пир 1: публичный ключ
b859..., preshared_key, разрешённый IP192.168.4.4/32, конечная точка IPv6 - Пир 2: публичный ключ
5840..., передано 38333 байт, получено 2224 байт, разрешённый IP192.168.4.6/32, keepalive 111 секунд - Пир 3: публичный ключ
662e..., два разрешённых IP, большая передача данных
Команда set
wg(8) отправляет:
set=1
private_key=e84b5a6d2717c1003a13b431570353dbaca9146cf150c5f8575680feba52027a
fwmark=0
listen_port=12912
replace_peers=true
public_key=b85996fecc9c7f1fc6d2572a76eda11d59bcd20be8e543b15ce4bd85a8e75a33
preshared_key=188515093e952f5f22e865cef3012e72f8b5f0b598ac0309d5dacce3b70fcf52
replace_allowed_ips=true
allowed_ip=192.168.4.4/32
endpoint=[abcd:23::33%2]:51820
public_key=58402e695ba1772b1cc9309755f043251ea77fdcf10fbe63989ceb7e19321376
replace_allowed_ips=true
allowed_ip=192.168.4.6/32
persistent_keepalive_interval=111
endpoint=182.122.22.19:3233
public_key=662e14fd594556f522604703340351258903b64f35553763f19426ab2a515c58
endpoint=5.152.198.39:51820
replace_allowed_ips=true
allowed_ip=192.168.4.10/32
allowed_ip=192.168.4.11/32
public_key=e818b58db5274087fcc1be5dc728cf53d3b5726b4cef6b9bab8f8f8c2452c25c
remove=true
{empty line}
Разбор примера:
replace_peers=true— все старые пиры будут удаленыfwmark=0— fwmark отключён- Добавляются 3 пира, последний (
e818...) помеченremove=trueдля удаления - У каждого пира используется
replace_allowed_ips=trueдля замены списков разрешённых IP
Пользовательская реализация WireGuard отвечает:
errno=0
{empty line}
Успех: Код ошибки 0 означает, что конфигурация успешно применена.
Практические примеры использования
Настройка интерфейса через командную строку
# Запуск пользовательской реализации
# wireguard-go wg0
# Настройка с использованием wg(8)
# wg set wg0 private-key /etc/wireguard/private.key listen-port 51820
# wg set wg0 peer xTIBA5rboUvnH4htodjb6e697QjLERt1NAB4mZqp8Dg= allowed-ips 10.0.0.2/32 endpoint 192.95.5.69:51820
# ip address add dev wg0 10.0.0.1/24
# ip link set up dev wg0
Использование с конфигурационным файлом
# Создаём конфигурационный файл /etc/wireguard/wg0.conf
# wg setconf wg0 /etc/wireguard/wg0.conf
# wg-quick up wg0
Получение статуса
# wg show wg0
Преимущества пользовательской реализации
- Кроссплатформенность — работает на Windows, macOS, BSD и других системах без поддержки в ядре
- Простота отладки — ошибки легче отслеживать в пользовательском пространстве
- Гибкость — можно интегрировать в приложения как библиотеку
- Безопасность — изоляция от ядра может быть преимуществом в некоторых сценариях
Недостатки пользовательской реализации
- Производительность — обычно медленнее, чем реализация в ядре
- Дополнительные накладные расходы — копирование данных между ядром и пользовательским пространством
- Потребление памяти — больше использования памяти для хранения состояния
Ссылки
- wireguard-go — реализация на Go
- wireguard-rs — реализация на Rust (в разработке)
- wg(8) man-страница
- Документация по TUN/TAP
17.10 - Маршрутизация и сетевые пространства имён
Интеграция WireGuard с сетевыми пространствами имён Linux для контейнеризации и маршрутизации трафика
Интеграция с маршрутизацией и сетевыми пространствами имён
Как и все сетевые интерфейсы Linux, WireGuard интегрируется в инфраструктуру сетевых пространств имён (network namespaces). Это означает, что администратор может иметь несколько полностью разных сетевых подсистем и выбирать, какие интерфейсы находятся в каждом из них.
Что такое сетевые пространства имён? Это механизм ядра Linux, который позволяет изолировать сетевые стеки. Каждое пространство имён имеет свои собственные сетевые интерфейсы, таблицы маршрутизации, правила файервола и сокеты. Это основа для контейнеризации (Docker, LXC и другие).
WireGuard делает кое-что довольно интересное. Когда интерфейс WireGuard создаётся (с помощью ip link add wg0 type wireguard), он запоминает пространство имён, в котором был создан: «Я был создан в пространстве имён A». Позже WireGuard может быть перемещён в новые пространства имён («Я перемещаюсь в пространство имён B»), но он всё равно будет помнить, что произошёл из пространства имён A.
Почему это важно? WireGuard использует UDP-сокет для фактической отправки и получения зашифрованных пакетов. Этот сокет всегда живёт в пространстве имён A — исходном пространстве имён рождения. Это обеспечивает очень интересные возможности. А именно, вы можете создать интерфейс WireGuard в одном пространстве имён (A), переместить его в другое (B) и отправлять незашифрованные пакеты из пространства имён B, которые будут отправляться зашифрованными через UDP-сокет в пространстве имён A.
Примечание: Та же техника доступна для пользовательских интерфейсов на основе TUN: создайте файловый дескриптор сокета в одном пространстве имён, затем переключитесь в другое пространство имён, сохранив файловый дескриптор из предыдущего пространства имён открытым.
Это открывает очень интересные возможности.
Обычная контейнеризация
Наиболее очевидное использование этого — предоставить контейнерам (например, Docker-контейнерам) интерфейс WireGuard в качестве единственного интерфейса.

Пример: Внутри контейнера видно только loopback-интерфейс и интерфейс WireGuard:
container # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
17: wg0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1423 qdisc noqueue state UNKNOWN group default qlen 1
link/none
inet 192.168.4.33/32 scope global wg0
valid_lft forever preferred_lft forever
Что это значит? Единственный способ доступа к сети — через wg0, интерфейс WireGuard. Весь трафик из контейнера автоматически шифруется и отправляется через VPN. Контейнер даже не знает о существовании физических сетевых интерфейсов хоста.
Настройка контейнера с WireGuard
Шаг 1: Создание сетевого пространства имён
Сначала создаём сетевое пространство имён с именем «container»:
# ip netns add container
Шаг 2: Создание интерфейса WireGuard
Создаём интерфейс WireGuard в исходном пространстве имён (init):
# ip link add wg0 type wireguard
Шаг 3: Перемещение интерфейса
Перемещаем интерфейс в новое пространство имён:
# ip link set wg0 netns container
Шаг 4: Настройка интерфейса
Теперь настраиваем wg0 как обычно, но указываем его новое пространство имён:
# ip -n container addr add 192.168.4.33/32 dev wg0
# ip netns exec container wg setconf wg0 /etc/wireguard/wg0.conf
# ip -n container link set wg0 up
# ip -n container route add default dev wg0
Результат: Теперь единственный способ доступа к сетевым ресурсам для «container» — через интерфейс WireGuard.
Для пользователей Docker: Вы можете указать PID Docker-процесса вместо имени сетевого пространства имён, чтобы использовать сетевое пространство имён, которое Docker уже создал для своего контейнера:
# ip link set wg0 netns 879
Маршрутизация всего трафика
Менее очевидное, но чрезвычайно мощное использование — применение этой характеристики WireGuard для перенаправления всего вашего обычного интернет-трафика через WireGuard.
Проблема: Как заставить весь трафик идти через VPN, но при этом позволить самому VPN-соединению использовать обычный интернет?
Классические решения
Классические решения основаны на различных конфигурациях таблиц маршрутизации. Для всех них нам нужно установить явный маршрут для фактической конечной точки WireGuard.
Пример: Предположим, конечная точка WireGuard — demo.wireguard.com, которая на момент написания резолвится в 163.172.161.0. Предположим также, что мы обычно подключаемся к интернету через eth0 со шлюзом 192.168.1.1.
Замена маршрута по умолчанию
Самая простая техника — просто заменить маршрут по умолчанию, но добавить явное правило для конечной точки WireGuard:
# ip route del default
# ip route add default dev wg0
# ip route add 163.172.161.0/32 via 192.168.1.1 dev eth0
Преимущества: Просто и понятно.
Недостатки: DHCP-демоны и другие программы любят отменять то, что мы только что сделали.
Переопределение маршрута по умолчанию
Вместо замены маршрута по умолчанию мы можем переопределить его двумя более специфичными правилами, которые в сумме дают маршрут по умолчанию, но совпадают раньше:
# ip route add 0.0.0.0/1 dev wg0
# ip route add 128.0.0.0/1 dev wg0
# ip route add 163.172.161.0/32 via 192.168.1.1 dev eth0
Объяснение: 0.0.0.0/1 + 128.0.0.0/1 = 0.0.0.0/0 (весь IPv4-диапазон). Эти маршруты имеют более высокий приоритет, чем маршрут по умолчанию, поэтому они используются для всего трафика, кроме явно исключённого.
Недостатки: Когда eth0 поднимается и опускается, явный маршрут для demo.wireguard.com забывается.
Маршрутизация на основе правил
Некоторые предпочитают использовать маршрутизацию на основе правил и несколько таблиц маршрутизации:
# ip rule add to 163.172.161.0 lookup main pref 30
# ip rule add to all lookup 80 pref 40
# ip route add default dev wg0 table 80
Объяснение: Правила определяют, какую таблицу маршрутизации использовать для каждого пакета. Для IP-адреса конечной точки используется основная таблица, для всего остального — таблица 80.
Недостатки: Нужно добавлять явные правила для конечных точек, нет очистки при удалении интерфейса, более сложные правила маршрутизации нужно дублировать.
Улучшенная маршрутизация на основе правил
Предыдущее решение требует знания явного IP-адреса конечной точки, который должен быть исключён из туннеля. Но конечные точки WireGuard могут роумить, что означает, что это правило может устареть.
Решение: Устанавливаем fwmark на все пакеты, выходящие из UDP-сокета WireGuard, которые затем будут исключены из туннеля:
# wg set wg0 fwmark 1234
# ip route add default dev wg0 table 2468
# ip rule add not fwmark 1234 table 2468
# ip rule add table main suppress_prefixlength 0
Объяснение:
- Устанавливаем
fwmarkна интерфейсе - Добавляем маршрут по умолчанию в альтернативную таблицу маршрутизации
- Указываем, что пакеты без
fwmarkдолжны использовать эту альтернативную таблицу - Добавляем удобство для доступа к локальной сети
Это техника, используемая инструментом wg-quick(8).
Новое решение с пространствами имён
Оказывается, мы можем маршрутизировать весь интернет-трафик через WireGuard, используя сетевые пространства имён, а не классические хаки с таблицами маршрутизации.
Основная идея: Перемещаем интерфейсы, подключающиеся к интернету (например, eth0 или wlan0), в пространство имён «physical», а интерфейс WireGuard делаем единственным интерфейсом в пространстве имён «init».

Пошаговая настройка
Шаг 1: Создание физического пространства имён
# ip netns add physical
Шаг 2: Перемещение физических интерфейсов
Перемещаем eth0 и wlan0 в пространство имён «physical»:
# ip link set eth0 netns physical
# iw phy phy0 set netns name physical
Примечание: Беспроводные устройства должны быть перемещены с помощью
iw путём указания физического устройства phy0.Теперь эти интерфейсы находятся в пространстве имён «physical», а в пространстве имён «init» интерфейсов нет:
# ip -n physical link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN mode DEFAULT group default qlen 1000
link/ether ab:cd:ef:g1:23:45 brd ff:ff:ff:ff:ff:ff
3: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DORMANT group default qlen 1000
link/ether 01:23:45:67:89:ab brd ff:ff:ff:ff:ff:ff
# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Шаг 3: Создание интерфейса WireGuard в физическом пространстве
# ip -n physical link add wg0 type wireguard
Пространство имён рождения wg0 теперь — «physical», что означает, что UDP-сокеты с зашифрованными данными будут привязаны к устройствам eth0 и wlan0.
Шаг 4: Перемещение интерфейса в init
Перемещаем wg0 в пространство имён «init». Он всё равно будет помнить своё место рождения для сокетов:
# ip -n physical link set wg0 netns 1
Мы указываем «1» как пространство имён «init», потому что это PID первого процесса в системе.
Теперь в пространстве имён «init» есть устройство wg0:
# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
17: wg0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1423 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/none
Шаг 5: Настройка физических устройств
Настраиваем физические устройства с помощью обычных инструментов, но запускаем их внутри пространства имён «physical»:
# ip netns exec physical dhcpcd wlan0
# ip netns exec physical wpa_supplicant -iwlan0 -c/etc/wpa_supplicant/wpa_supplicant.conf
# ip -n physical addr add 192.168.12.52/24 dev eth0
Шаг 6: Настройка WireGuard
Настраиваем интерфейс wg0 как обычно и устанавливаем его как маршрут по умолчанию:
# wg setconf wg0 /etc/wireguard/wg0.conf
# ip addr add 10.2.4.5/32 dev wg0
# ip link set wg0 up
# ip route add default dev wg0
Результат: Все обычные процессы в системе маршрутизируют свои пакеты через пространство имён «init», которое содержит только интерфейс wg0 и его маршруты. Однако wg0 имеет UDP-сокет, живущий в пространстве имён «physical», что означает, что он будет отправлять трафик через eth0 или wlan0. Обычные процессы даже не знают о существовании eth0 или wlan0, за исключением dhcpcd и wpa_supplicant, которые были запущены внутри пространства имён «physical».
Выполнение команд в физическом пространстве
Иногда вам может понадобиться открыть веб-страницу или быстро сделать что-то, используя пространство имён «physical». Например, вы можете планировать маршрутизировать весь трафик через WireGuard, но кофейня, в которой вы сидите, требует аутентификации через веб-сайт перед предоставлением реального интернет-соединения.
Выполнение процесса в физическом пространстве:
$ sudo -E ip netns exec physical sudo -E -u \#$(id -u) -g \#$(id -g) chromium
Создание удобной функции для .bashrc:
physexec() { sudo -E ip netns exec physical sudo -E -u \#$(id -u) -g \#$(id -g) "$@"; }
Использование:
$ physexec chromium # Открыть Chromium в физическом пространстве для аутентификации
После входа в сеть кофейни запускайте браузер как обычно:
$ chromium # Весь трафик защищён WireGuard
Пример скрипта
Следующий пример скрипта можно сохранить как /usr/local/bin/wgphys и использовать для команд wgphys up, wgphys down и wgphys exec:
#!/bin/bash
set -ex
[[ $UID != 0 ]] && exec sudo -E "$(readlink -f "$0")" "$@"
up() {
killall wpa_supplicant dhcpcd || true
ip netns add physical
ip -n physical link add wgvpn0 type wireguard
ip -n physical link set wgvpn0 netns 1
wg setconf wgvpn0 /etc/wireguard/wgvpn0.conf
ip addr add 192.168.4.33/32 dev wgvpn0
ip link set eth0 down
ip link set wlan0 down
ip link set eth0 netns physical
iw phy phy0 set netns name physical
ip netns exec physical dhcpcd -b eth0
ip netns exec physical dhcpcd -b wlan0
ip netns exec physical wpa_supplicant -B -c/etc/wpa_supplicant/wpa_supplicant-wlan0.conf -iwlan0
ip link set wgvpn0 up
ip route add default dev wgvpn0
}
down() {
killall wpa_supplicant dhcpcd || true
ip -n physical link set eth0 down
ip -n physical link set wlan0 down
ip -n physical link set eth0 netns 1
ip netns exec physical iw phy phy0 set netns 1
ip link del wgvpn0
ip netns del physical
dhcpcd -b eth0
dhcpcd -b wlan0
wpa_supplicant -B -c/etc/wpa_supplicant/wpa_supplicant-wlan0.conf -iwlan0
}
execi() {
exec ip netns exec physical sudo -E -u \#${SUDO_UID:-$(id -u)} -g \#${SUDO_GID:-$(id -g)} -- "$@"
}
command="$1"
shift
case "$command" in
up) up "$@" ;;
down) down "$@" ;;
exec) execi "$@" ;;
*) echo "Usage: $0 up|down|exec" >&2; exit 1 ;;
esac
Демонстрация работы скрипта:

Сравнение решений
| Решение | Преимущества | Недостатки |
|---|---|---|
| Замена default | Простота | DHCP отменяет изменения |
| Переопределение default | Не заменяет default | Маршрут забывается при переподключении |
| Правила (rule-based) | Разделение таблиц | Нужно знать IP конечной точки |
| Улучшенные правила (fwmark) | Устойчив к роумингу | Сложнее для понимания |
| Пространства имён | Полная изоляция, чистота | Требует настройки пространств имён |
Преимущества решения с пространствами имён
- Полная изоляция — обычные процессы не видят физические интерфейсы
- Автоматическая маршрутизация — весь трафик идёт через WireGuard без сложных правил
- Прозрачность — не нужно добавлять явные маршруты для конечных точек
- Чистота — нет хаков с таблицами маршрутизации
- Гибкость — можно запускать отдельные процессы в физическом пространстве
Ссылки
17.11 - Встраивание в приложения
Как встроить WireGuard в пользовательские приложения на различных платформах
Встраивание WireGuard в пользовательские приложения
Клиентские приложения проекта WireGuard были спроектированы с максимальной возможностью повторного использования, что позволяет создавать пользовательские приложения, использующие WireGuard. Ситуация несколько отличается на разных платформах, и эта страница пытается обобщить то, что доступно в проекте.
Важно: Если вы системный администратор, который просто пытается написать скрипты для существующих клиентов WireGuard, эта страница не для вас. Вместо этого ознакомьтесь с документацией по инструментам wg(8) и wg-quick(8), а также с руководством по корпоративному управлению для Windows.
Зачем встраивать WireGuard?
Встраивание WireGuard в приложения может быть полезно для:
- VPN-клиентов — создание собственного VPN-приложения с брендированным интерфейсом
- Систем управления — интеграция VPN в панели управления и оркестраторы
- Сетевых утилит — добавление безопасного туннелирования в существующие инструменты
- IoT-устройств — встраивание безопасного канала связи в嵌入式 системы
- Корпоративных решений — создание проприетарных решений поверх WireGuard
Платформо-специфичные решения
Windows: embeddable-dll-service
Что это? Библиотека, которая позволяет создавать полноценные автономные Windows-сервисы, встраивающие WireGuard.
Где найти: embeddable-dll-service код и документация
Для кого: Для разработчиков Windows-приложений, которые хотят добавить VPN-функциональность без написания низкоуровневого кода.
Как это работает: Библиотека предоставляет простой API для создания и управления WireGuard-туннелями из любого Windows-приложения. Она управляет всем циклом жизни VPN-соединения.
Пример использования:
// Псевдокод для понимания концепции
var wgService = new WireGuardService();
wgService.SetConfig(configFile);
wgService.Start();
// ... работа с VPN
wgService.Stop();
Преимущества:
- Полноценная интеграция с Windows Service Manager
- Автоматическое управление жизненным циклом
- Встроенная обработка ошибок и восстановление
- Простой API
Windows: WireGuardNT
Что это? Более низкоуровневая реализация WireGuard для Windows, чем embeddable-dll-service.
Где найти: Проект WireGuardNT
Для кого: Для разработчиков, которым нужен максимальный контроль над WireGuard на Windows, или для создания альтернативных реализаций.
Важное предупреждение: Настоятельно рекомендуется использовать embeddable-dll-service, а не WireGuardNT напрямую, так как первый использует второй внутри себя. WireGuardNT предоставляет более низкоуровневый API.
Что делает WireGuardNT:
- Реализует драйвер ядра для WireGuard в Windows
- Обеспечивает высокую производительность
- Предоставляет низкоуровневый интерфейс управления
Когда использовать WireGuardNT:
- Создание альтернативных менеджеров WireGuard
- Исследовательские проекты
- Интеграция с нестандартными системами управления
macOS и iOS: WireGuardKit
Что это? Библиотека для интеграции WireGuard в приложения для macOS и iOS.
Где найти: WireGuardKit из репозитория wireguard-apple
Для кого: Для разработчиков приложений для экосистемы Apple.
Как это работает: WireGuardKit предоставляет Swift-интерфейс для управления WireGuard-туннелями. Он интегрируется с сетевыми расширениями (Network Extensions) Apple для создания полноценных VPN-приложений.
Пример использования (Swift):
import WireGuardKit
// Создание туннеля
let tunnel = WireGuardTunnel()
tunnel.configuration = config
tunnel.start { error in
if let error = error {
print("Ошибка запуска: \(error)")
} else {
print("Туннель запущен")
}
}
Поддерживаемые платформы:
- macOS
- iOS
- iPadOS
Преимущества:
- Интеграция с Apple Network Extension API
- Поддержка Swift Package Manager (SPM)
- Нативная производительность
- Полная поддержка мобильных функций
Android: com.wireguard.android:tunnel
Что это? Библиотека для встраивания WireGuard в Android-приложения.
Где найти: Библиотека на Maven Central с обширной документацией классов и инструкцией для Gradle
Для кого: Для разработчиков Android-приложений, желающих добавить VPN-функциональность.
Подключение через Gradle:
dependencies {
implementation 'com.wireguard.android:tunnel:1.0.20201212'
}
Пример использования (Kotlin):
import com.wireguard.android.backend.Backend
import com.wireguard.config.Config
// Создание бэкенда
val backend = Backend()
// Настройка и запуск туннеля
val config = Config.Builder()
.setPrivateKey(privateKey)
.addPeer(peerConfig)
.build()
backend.setState(tunnelName, config, State.UP)
Возможности:
- Интеграция с Android VPN Service API
- Поддержка всех версий Android
- Оптимизация для мобильных устройств
- Обработка изменений сети
Linux: embeddable-wg-library
Что это? Однобиблиотечная C-библиотека для взаимодействия с WireGuard через ядро Linux.
Где найти: embeddable-wg-library в репозитории wireguard-tools
Для кого: Для разработчиков на C/C++ в среде Linux, которым нужен программный контроль над WireGuard.
Особенности:
- Один C-файл для включения в проект
- Простой API для управления WireGuard
- Использует системные вызовы ядра напрямую
- Минимальные зависимости
Пример использования (C):
// Псевдокод для понимания
#include "wg.h"
// Создание интерфейса
wg_interface_t *wg = wg_create("wg0");
wg_set_private_key(wg, private_key);
wg_add_peer(wg, public_key, allowed_ips, endpoint);
wg_set_up(wg);
Linux/BSD/Darwin: wgctrl-go
Что это? Проект для создания WireGuard-конфигураций и управления ими из Go.
Где найти: wgctrl-go на GitHub
Для кого: Для разработчиков на Go, создающих приложения для Linux, BSD и macOS.
Пример использования (Go):
import "github.com/WireGuard/wgctrl"
// Создание клиента
client, err := wgctrl.New()
if err != nil {
log.Fatal(err)
}
defer client.Close()
// Создание конфигурации
cfg := wgtypes.Config{
PrivateKey: privateKey,
ListenPort: &port,
Peers: []wgtypes.PeerConfig{...},
}
// Применение конфигурации
err = client.ConfigureDevice("wg0", cfg)
Поддерживаемые платформы:
- Linux (через netlink)
- BSD (через ioctl)
- macOS (через userspace)
Преимущества:
- Единый API для нескольких платформ
- Поддержка всех функций WireGuard
- Хорошая документация и примеры
- Активная поддержка
Linux: NetworkManager, Systemd, connman
Что это? Полноценная поддержка WireGuard в популярных сетевых менеджерах Linux.
Для кого: Для разработчиков, предпочитающих использовать существующие инфраструктуры, а не создавать собственные.
NetworkManager
NetworkManager имеет встроенную поддержку WireGuard. Управление осуществляется через DBus API.
Пример (через nmcli, для скриптов):
nmcli connection add type wireguard ifname wg0 con-name wg0
nmcli connection modify wg0 wireguard.private-key /path/to/key
nmcli connection up wg0
Systemd
Systemd также поддерживает WireGuard через сетевые конфигурации.
Конфигурация (в systemd-networkd):
[NetDev]
Name=wg0
Kind=wireguard
[WireGuard]
PrivateKey=...
Connman
Connman поддерживает WireGuard через свои конфигурационные файлы.
Сравнение решений по платформам
| Платформа | Решение | Уровень | Язык | Сложность |
|---|---|---|---|---|
| Windows | embeddable-dll-service | Высокий | C#/C++/любой | Низкая |
| Windows | WireGuardNT | Низкий | C/C++ | Высокая |
| macOS/iOS | WireGuardKit | Высокий | Swift | Низкая |
| Android | com.wireguard.android:tunnel | Высокий | Kotlin/Java | Низкая |
| Linux | embeddable-wg-library | Средний | C/C++ | Средняя |
| Linux/BSD/Darwin | wgctrl-go | Средний | Go | Средняя |
| Linux | NetworkManager/Systemd/Connman | Высокий | Любой | Низкая |
Руководство по выбору решения
Для Windows:
- В большинстве случаев: Используйте embeddable-dll-service
- Для экспериментов: Можно использовать WireGuardNT
Для Apple (macOS/iOS):
- Всегда используйте: WireGuardKit
Для Android:
- Всегда используйте: com.wireguard.android:tunnel
Для Linux:
- Если вы используете Go: wgctrl-go
- Если вы используете C/C++: embeddable-wg-library
- Если вы используете существующие сетевые менеджеры: NetworkManager/Systemd/Connman
- Для скриптов: Используйте wg(8) и wg-quick(8)
Для кроссплатформенных приложений:
- Используйте соответствующее решение для каждой платформы
- Или используйте wgctrl-go (для Linux, BSD, macOS) и отдельные решения для Windows/Android
Примеры интеграции
Создание простого VPN-клиента на Windows
# Использование embeddable-dll-service
$wgService = New-Object -ComObject WireGuard.Service
$wgService.Install("MyVPN")
$wgService.SetConfig("C:\Configs\myvpn.conf")
$wgService.Start()
Интеграция в мобильное приложение (iOS)
// Использование WireGuardKit
import WireGuardKit
class VPNManager {
let tunnel = WireGuardTunnel()
func startVPN() {
let config = try! Config(fromFile: "config.conf")
tunnel.configuration = config
tunnel.start()
}
}
Интеграция в веб-приложение (Linux)
// Использование wgctrl-go
package main
import (
"github.com/WireGuard/wgctrl"
"github.com/WireGuard/wgctrl/wgtypes"
)
func setupVPN() error {
client, _ := wgctrl.New()
defer client.Close()
key, _ := wgtypes.GeneratePrivateKey()
config := wgtypes.Config{
PrivateKey: &key,
ListenPort: ptr(51820),
}
return client.ConfigureDevice("wg0", config)
}
func ptr[T any](v T) *T { return &v }
Рекомендации по безопасности при встраивании
- Хранение ключей: Всегда храните приватные ключи в защищённом месте (Keychain, Secure Storage, TPM)
- Проверка конфигураций: Валидируйте все входящие конфигурации перед применением
- Логирование: Ведите журнал действий для аудита
- Обновления: Следите за обновлениями WireGuard и включайте их в свои приложения
- Тестирование: Тщательно тестируйте интеграцию на всех целевых платформах