opensearch
OpenSearch — это распределённая поисковая и аналитическая система, основанная на Apache Lucene. После добавления данных в OpenSearch вы можете выполнять полнотекстовый поиск с полным набором ожидаемых функций: поиск по полям, поиск по нескольким индексам, усиление полей, ранжирование результатов по релевантности, сортировка по полям и агрегация результатов.
Неудивительно, что разработчики часто используют поисковые системы, такие как OpenSearch, в качестве бэкенда для поисковых приложений — например, для Википедии или интернет-магазинов. Он обеспечивает отличную производительность и может масштабироваться в зависимости от потребностей приложения.
Ещё один популярный, но менее очевидный сценарий использования — анализ логов. В этом случае логи приложения загружаются в OpenSearch, а мощные функции поиска и визуализации помогают выявлять проблемы. Например, неисправный веб-сервер может выдавать ошибку 500 в 0,5% случаев, что сложно заметить без графика в реальном времени, отображающего все HTTP-статусы за последние четыре часа. С помощью OpenSearch Dashboards можно создавать такие визуализации на основе данных из OpenSearch.
Компоненты
OpenSearch — это не только поисковый движок. В его состав также входят:
- OpenSearch Dashboards — интерфейс для визуализации данных OpenSearch.
- Data Prepper — серверный сборщик данных, способный фильтровать, обогащать, преобразовывать, нормализовать и агрегировать данные для последующего анализа и визуализации.
- Клиенты — языковые API, позволяющие взаимодействовать с OpenSearch на популярных языках программирования.
Сценарии использования
OpenSearch поддерживает множество сценариев, например:
- Наблюдаемость (Observability) — визуализация событий на основе данных с помощью Piped Processing Language (PPL) для исследования, обнаружения и запросов к данным в OpenSearch.
- Поиск — выбор оптимального метода поиска для вашего приложения: от стандартного лексического поиска до диалогового поиска на базе машинного обучения (ML).
- Машинное обучение — интеграция ML-моделей в приложения на OpenSearch.
- Анализ безопасности — расследование, обнаружение, анализ и реагирование на угрозы, которые могут повлиять на успех организации и её онлайн-операции.
Следующие шаги
- Ознакомьтесь с [Введением в OpenSearch](Introduction to OpenSearch), чтобы изучить основные концепции OpenSearch.
1 - Введение в Opensearch
OpenSearch — это распределённая поисковая и аналитическая система, которая поддерживает различные сценарии использования: от реализации поисковой строки на веб-сайте до анализа данных безопасности для выявления угроз.
Введение в OpenSearch
Термин распределённая означает, что OpenSearch можно запускать на нескольких компьютерах. Поиск и аналитика подразумевают, что после загрузки данных в OpenSearch их можно искать и анализировать. Независимо от типа данных, их можно хранить и исследовать с помощью OpenSearch.
Документ
Документ — это единица хранения информации (текстовой или структурированной). В OpenSearch документы хранятся в формате JSON.
Документ можно представить несколькими способами:
- В базе данных студентов документ может представлять одного учащегося.
- При поиске информации OpenSearch возвращает документы, соответствующие запросу.
- Документ аналогичен строке в традиционной реляционной базе данных.
Например, в школьной базе данных документ может представлять студента и содержать следующие данные:
| ID |
Имя |
GPA |
Год выпуска |
| 1 |
John Doe |
3.89 |
2022 |
Вот как этот документ выглядит в формате JSON:
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
Вы узнаете, как назначаются идентификаторы документов, в разделе Индексация документов.
Индекс
Индекс — это коллекция документов.
Индекс можно рассматривать несколькими способами:
- В базе данных студентов индекс представляет всех учащихся в базе.
- При поиске информации запрос выполняется к данным внутри индекса.
- Индекс соответствует таблице в традиционной реляционной базе данных.
Например, в школьной базе данных индекс может содержать всех студентов школы:
| ID |
Имя |
GPA |
Год выпуска |
| 1 |
John Doe |
3.89 |
2022 |
| 2 |
Jonathan Powers |
3.85 |
2025 |
| 3 |
Jane Doe |
3.52 |
2024 |
| … |
… |
… |
… |
Кластеры и узлы
OpenSearch разработан как распределённая поисковая система, что означает возможность работы на одном или нескольких узлах — серверах, хранящих данные и обрабатывающих поисковые запросы. Кластер OpenSearch — это совокупность таких узлов.
Вы можете запустить OpenSearch локально на ноутбуке (системные требования минимальны), но также можно масштабировать кластер до сотен мощных серверов в дата-центре.
В одноузловом кластере (например, развёрнутом на ноутбуке) одна машина выполняет все задачи:
- управляет состоянием кластера,
- индексирует данные и обрабатывает поисковые запросы,
- выполняет предварительную обработку данных перед индексацией.
Однако по мере роста кластера обязанности можно распределить:
- Узлы с быстрыми дисками и большим объёмом ОЗУ подходят для индексации и поиска.
- Узлы с мощными CPU, но малым дисковым пространством, могут управлять состоянием кластера.
В каждом кластере выбирается главный узел (cluster manager node), который координирует операции на уровне кластера (например, создание индекса). Узлы взаимодействуют между собой: если запрос направлен к одному узлу, он может запрашивать данные у других узлов, агрегировать их ответы и возвращать итоговый результат.
Подробнее о других типах узлов см. в разделе Формирование кластера.
Шарды (Shards)
OpenSearch разделяет индексы на шарды. Каждый шард хранит подмножество всех документов индекса, как показано на следующей диаграмме:
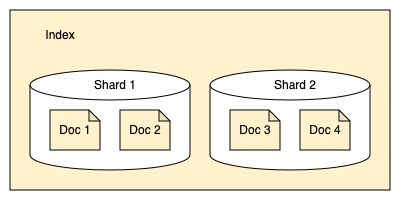
Шарды используются для равномерного распределения данных между узлами кластера. Например:
- Индекс размером 400 ГБ может быть слишком большим для обработки на одном узле
- Если разделить его на 10 шардов по 40 ГБ каждый, OpenSearch сможет распределить их между 10 узлами
- Каждый шард будет обрабатываться независимо
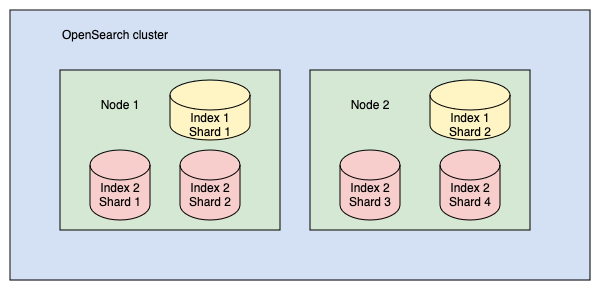
Рассмотрим кластер с двумя индексами:
- Индекс 1 разделён на 2 шарда
- Индекс 2 разделён на 4 шарда
Эти шарды распределены между двумя узлами, как показано на схеме:
Хотя каждый шард является частью индекса OpenSearch, технически он представляет собой полноценный индекс Lucene. Это важно учитывать, потому что:
- Каждый экземпляр Lucene - это отдельный процесс
- Каждый процесс потребляет ресурсы CPU и памяти
- Слишком большое количество шардов может перегрузить кластер
Рекомендации по работе с шардами:
- Не стоит разделять индекс на чрезмерное количество шардов
- Например, деление индекса 400 ГБ на 1000 шардов создаст ненужную нагрузку
- Оптимальный размер шарда - от 10 до 50 ГБ
Первичные и реплицированные шарды
В OpenSearch шарды могут быть двух типов:
- Первичные (primary) - оригинальные шарды
- Реплики (replica) - копии шардов
По умолчанию OpenSearch создаёт по одной реплике для каждого первичного шарда. Таким образом:
- Если индекс разделён на 10 шардов, будет создано 10 реплик
- В примере из предыдущего раздела (2 индекса):
- Индекс 1: 2 шарда + 2 реплики
- Индекс 2: 4 шарда + 4 реплики
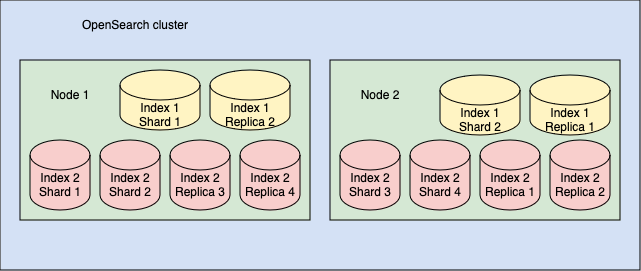
Функции реплик:
- Резервное копирование на случай сбоя узла
- Реплики размещаются на разных узлах от первичных шардов
- Ускорение обработки поисковых запросов
- Для нагрузок с интенсивным поиском можно создать несколько реплик
Инвертированный индекс
OpenSearch использует структуру данных под названием инвертированный индекс, которая:
- Сопоставляет слова с документами, где они встречаются
- Пример для двух документов:
- Документ 1: “Красота в глазах смотрящего”
- Документ 2: “Красавица и чудовище”
Инвертированный индекс будет выглядеть так:
| Слово |
Документы |
| красота |
1 |
| в |
1 |
| глазах |
1 |
| смотрящего |
1 |
| красавица |
2 |
| и |
2 |
| чудовище |
2 |
Дополнительно OpenSearch хранит:
- Позиции слов в документах
- Это позволяет выполнять поиск по фразам
Релевантность
При поиске OpenSearch:
- Сопоставляет слова запроса с документами
- Присваивает каждому документу оценку релевантности
Факторы оценки:
- Частота термина (TF):
- Чем чаще слово встречается в документе, тем выше оценка
- Обратная частота документа (IDF):
- Редкие слова имеют больший вес (например, “аксолотль” vs “синий”)
- Нормализация по длине:
- Более короткие документы получают преимущество
OpenSearch использует алгоритм BM25 для расчёта релевантности и сортировки результатов.
Следующие шаги
Узнайте, как быстро установить OpenSearch, в разделе Быстрый старт установки.
1.1 - Быстрый старт установки
Для быстрого запуска OpenSearch и OpenSearch Dashboards используйте контейнеры Docker.
Для быстрого запуска OpenSearch и OpenSearch Dashboards используйте контейнеры Docker. Полное руководство по установке доступно в разделе Установка и обновление OpenSearch.
Предварительные требования:
- Установите Docker и Docker Compose на локальную машину
Запуск кластера
-
Настройка системы
Перед запуском рекомендуется:
- Отключить подкачку памяти для повышения производительности:
- Увеличить максимальное количество memory maps:
Добавьте строку:
Примените изменения:
-
Получение файла конфигурации
Загрузите образец docker-compose.yml:
- Через cURL:
curl -O https://raw.githubusercontent.com/opensearch-project/documentation-website/3.1/assets/examples/docker-compose.yml
- Через wget:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/3.1/assets/examples/docker-compose.yml
-
Запуск кластера
Перейдите в директорию с файлом и выполните:
Проверьте статус контейнеров:
Ожидаемый вывод:
NAME COMMAND SERVICE STATUS PORTS
opensearch-dashboards "./opensearch-dashbo…" opensearch-dashboards running 0.0.0.0:5601->5601/tcp
opensearch-node1 "./opensearch-docker…" opensearch-node1 running 0.0.0.0:9200->9200/tcp, 9300/tcp, 0.0.0.0:9600->9600/tcp, 9650/tcp
opensearch-node2 "./opensearch-docker…" opensearch-node2 running 9200/tcp, 9300/tcp, 9600/tcp, 9650/tcp
-
Проверка работы
Выполните тестовый запрос к API:
curl https://localhost:9200 -ku admin:ВАШ_ПАРОЛЬ
Успешный ответ:
{
"name": "opensearch-node1",
"cluster_name": "opensearch-cluster",
"version": {
"distribution": "opensearch",
"number": "2.6.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
-
Доступ к Dashboards
Откройте в браузере:
http://localhost:5601/
Логин: admin
Пароль: указан в OPENSEARCH_INITIAL_ADMIN_PASSWORD файла docker-compose.yml
Примечания:
- Для безопасности отключается проверка хоста (
-k) при использовании демо-сертификатов
- Все команды предполагают работу в Linux-окружении
- Пароль администратора задаётся при первом запуске
Распространённые проблемы
Рассмотрите эти типичные проблемы и способы их решения, если контейнеры не запускаются или завершаются неожиданно.
Необходимость прав sudo для Docker команд
Проблема:
Требуется использовать sudo для выполнения Docker команд.
Решение:
Добавьте пользователя в группу docker:
sudo usermod -aG docker $USER
Подробнее: Post-installation steps for Linux
Ошибка: “-bash: docker-compose: command not found”
Ситуация:
При использовании Docker Desktop.
Решение:
Используйте команду без дефиса:
См. документацию Docker Compose
Ошибка: “docker: ‘compose’ is not a docker command”
Ситуация:
При использовании Docker Engine.
Решение:
Установите Docker Compose отдельно и используйте команду с дефисом:
Ошибка: “max virtual memory areas vm.max_map_count [65530] is too low”
Симптомы:
В логах сервиса появляется сообщение:
opensearch-node1 | ERROR: [1] bootstrap checks failed
opensearch-node1 | [1]: max virtual memory areas vm.max_map_count [65530] is too low...
Решение:
Увеличьте значение vm.max_map_count (см. раздел “Важные системные настройки”):
sudo sysctl -w vm.max_map_count=262144
Альтернативные способы установки
Помимо Docker, OpenSearch можно установить:
- На различные дистрибутивы Linux
- На Windows
Полные руководства: Установка и обновление OpenSearch
Дальнейшее изучение
После успешного развёртывания кластера рекомендуется изучить:
- Плагин безопасности
- Конфигурация OpenSearch
- Установка плагинов
Следующие шаги
Ознакомьтесь с разделом Взаимодействие с OpenSearch, чтобы узнать как отправлять запросы в систему.
1.2 - Взаимодействие с OpenSearch
Вы можете работать с OpenSearch через REST API или используя клиентские библиотеки для различных языков программирования.
На этой странице рассматривается REST API. Список доступных клиентов для языков программирования вы найдёте в разделе Клиенты.
REST API OpenSearch
REST API предоставляет гибкий способ взаимодействия с кластерами OpenSearch. Через API вы можете:
- Изменять настройки OpenSearch
- Управлять индексами
- Проверять состояние кластера
- Получать статистику
- И многое другое
Для отправки запросов можно использовать:
- Командную строку (cURL)
- Консоль Dev Tools в OpenSearch Dashboards
- Любой язык программирования с поддержкой HTTP-запросов
Отправка запросов через терминал
Формат запросов зависит от использования плагина безопасности.
Без плагина безопасности:
curl -X GET "http://localhost:9200/_cluster/health"
С плагином безопасности (требуются учётные данные):
curl -X GET "https://localhost:9200/_cluster/health" -ku admin:ВАШ_ПАРОЛЬ
По умолчанию:
- Логин:
admin
- Пароль: задаётся в параметре
OPENSEARCH_INITIAL_ADMIN_PASSWORD файла docker-compose.yml
Форматирование ответа:
Для удобочитаемого JSON добавьте параметр pretty:
curl -X GET "https://localhost:9200/_cluster/health?pretty"
Запросы с телом:
Укажите заголовок Content-Type и передайте данные через параметр -d:
curl -X GET "https://localhost:9200/students/_search?pretty" \
-H 'Content-Type: application/json' \
-d '{
"query": {
"match_all": {}
}
}'
Консоль Dev Tools в OpenSearch Dashboards использует упрощённый синтаксис:
- Откройте Dashboards:
https://localhost:5601/
- Перейдите: Management > Dev Tools
- Введите запрос (например):
GET _cluster/health
- Отправьте запрос:
- Клик по иконке ▶
- Ctrl+Enter (Cmd+Enter на Mac)
В документации OpenSearch запросы чаще всего приводятся в формате Dev Tools.
Дополнительно:
Индексация документов
Для добавления JSON-документа в индекс OpenSearch (индексации документа) отправьте HTTP-запрос со следующим форматом:
PUT https://<хост>:<порт>/<имя-индекса>/_doc/<идентификатор-документа>
Пример индексации документа о студенте:
PUT /students/_doc/1
{
"name": "Иван Иванов",
"gpa": 4.5,
"grad_year": 2023
}
После выполнения запроса:
- OpenSearch создаст индекс
students (если не существует)
- Сохранит документ с указанным ID (
1)
- Если ID не указан - сгенерирует его автоматически
Динамическое маппинг
OpenSearch автоматически определяет типы полей на основе JSON-структуры документа.
Просмотр схемы полей:
GET /students/_mapping
Пример ответа:
{
"students": {
"mappings": {
"properties": {
"gpa": {"type": "float"},
"grad_year": {"type": "long"},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
Особенности типов:
- Числовые значения:
float, long
- Текстовые поля:
- Основное поле (
text): для полнотекстового поиска (с анализом)
- Подполе (
keyword): для точного поиска по терминам
Важно: Для изменения типов (например, преобразования grad_year в дату) требуется пересоздание индекса с явным указанием маппинга.
Поиск документов
Базовый запрос (возвращает все документы):
GET /students/_search
{
"query": {
"match_all": {}
}
}
Пример ответа:
{
"took": 12,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 1,
"_source": {
"name": "Иван Иванов",
"gpa": 4.5,
"grad_year": 2023
}
}
]
}
}
Ключевые элементы ответа:
took: время выполнения (мс)hits.total: количество найденных документовhits.hits: массив результатов_score: релевантность документа
Дополнительные материалы:
Обновление документов
В OpenSearch документы неизменяемы, но их можно обновить, полностью заменив содержимое или изменив отдельные поля.
Полное обновление (переиндексация)
Используйте Index Document API для полного обновления:
PUT /students/_doc/1
{
"name": "Иван Иванов",
"gpa": 4.7, // Обновлённое значение
"grad_year": 2023,
"address": "ул. Ленина, 123" // Новое поле
}
Частичное обновление
Используйте Update Document API для изменения отдельных полей:
POST /students/_update/1/
{
"doc": {
"gpa": 4.7,
"address": "ул. Ленина, 123"
}
}
Удаление данных
Удаление документа
Удаление индекса
Настройка индексов
Маппинги и параметры
Индексы настраиваются через:
- Маппинги - определяют типы полей
- Параметры - настройки индекса (количество шардов и т.д.)
Пример создания индекса с явными настройками:
PUT /students
{
"settings": {
"index.number_of_shards": 1
},
"mappings": {
"properties": {
"name": {"type": "text"},
"grad_year": {"type": "date"}
}
}
}
Проверка маппинга:
Важно:
- Типы полей нельзя изменить после создания
- Для изменения требуется пересоздание индекса
Дополнительные материалы
Следующие шаги
Ознакомьтесь с разделом Загрузка данных в OpenSearch для изучения способов импорта данных.
1.3 - Загрузка данных в OpenSearch
Добавление отдельных документов. Массовая загрузка документов. Использование Data Prepper.
Существует несколько способов импорта данных:
-
Добавление отдельных документов
См. раздел Индексация документов
-
Массовая загрузка документов
См. раздел Пакетная индексация
-
Использование Data Prepper
Серверного сборщика данных OpenSearch для обработки перед анализом
-
Другие инструменты
См. Инструменты OpenSearch
Пакетная индексация
Для массовой загрузки используйте Bulk API:
POST _bulk
{ "create": { "_index": "students", "_id": "2" } }
{ "name": "Алексей Петров", "gpa": 4.2, "grad_year": 2025 }
{ "create": { "_index": "students", "_id": "3" } }
{ "name": "Мария Смирнова", "gpa": 4.8, "grad_year": 2024 }
Работа с тестовыми данными
OpenSearch предоставляет демонстрационный набор данных электронной коммерции.
Шаги для создания тестового индекса:
-
Скачайте файлы:
# Маппинг полей
curl -O https://raw.githubusercontent.com/.../ecommerce-field_mappings.json
# Данные для загрузки
curl -O https://raw.githubusercontent.com/.../ecommerce.ndjson
-
Примените схему полей:
curl -H "Content-Type: application/json" -X PUT "https://localhost:9200/ecommerce" \
-ku admin:ПАРОЛЬ --data-binary "@ecommerce-field_mappings.json"
-
Загрузите данные:
curl -H "Content-Type: application/x-ndjson" -X POST "https://localhost:9200/ecommerce/_bulk" \
-ku admin:ПАРОЛЬ --data-binary "@ecommerce.ndjson"
Пример поиска:
GET ecommerce/_search
{
"query": {
"match": {
"customer_first_name": "Светлана"
}
}
}
Визуализация данных
Инструкции по работе с визуализациями см. в руководстве по OpenSearch Dashboards.
Дополнительные материалы
Следующие шаги
Изучите раздел Поиск по данным для получения информации о возможностях поиска.
1.4 - Поиск данных в OpenSearch
OpenSearch предлагает несколько методов поиска: Query DSL, Query string, SQL, PPL, DQL
OpenSearch предлагает несколько методов поиска:
- Query DSL - основной язык запросов для сложных поисковых сценариев
- Query string - упрощённый синтаксис для параметров запроса
- SQL - традиционный язык запросов для реляционных данных
- PPL (Piped Processing Language) - язык для задач observability
- DQL (Dashboards Query Language) - текстовый язык фильтрации в Dashboards
Подготовка данных
Перед началом загрузим тестовые данные о студентах:
POST _bulk
{ "create": { "_index": "students", "_id": "1" } }
{ "name": "Иван Петров", "gpa": 4.5, "grad_year": 2023}
{ "create": { "_index": "students", "_id": "2" } }
{ "name": "Алексей Смирнов", "gpa": 4.2, "grad_year": 2025 }
{ "create": { "_index": "students", "_id": "3" } }
{ "name": "Мария Иванова", "gpa": 4.8, "grad_year": 2024 }
Базовые запросы
Получение всех документов:
Эквивалентно:
GET /students/_search
{
"query": { "match_all": {} }
}
Структура ответа:
took - время выполнения (мс)timed_out - флаг превышения таймаута_shards - статистика по шардамhits - результаты поиска:
total - общее количество совпаденийmax_score - максимальная релевантностьhits - массив документов с оценкой релевантности
Query string поиск
Пример поиска по имени:
GET /students/_search?q=name:john
вернет ответ:
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "John Doe",
"grade": 12,
"gpa": 3.89,
"grad_year": 2022,
"future_plans": "John plans to be a computer science major"
}
}
]
}
}
Полнотекстовый поиск (Query DSL)
Поиск с анализом текста:
GET /students/_search
{
"query": {
"match": {
"name": "иван" # Найдёт "Иван Петров" и "Мария Иванова"
}
}
}
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "Иван Петров",
"gpa": 3.89,
"grad_year": 2022
}
}
]
}
}
Поиск по ключевым словам
Точное совпадение (без анализа):
GET /students/_search
{
"query": {
"match": {
"name.keyword": "john doe" # Только полное совпадение
}
}
}
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
}
]
}
}
Фильтры
Точное значение:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "grad_year": 2023 }}
]
}
}
}
Диапазон значений:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "range": { "gpa": { "gt": 4.0 }}}
]
}
}
}
Составные запросы
Комбинация условий:
GET students/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "иван" } },
{ "range": { "gpa": { "gte": 4.0 } } },
{ "term": { "grad_year": 2023 }}
]
}
}
}
Расширенные возможности
OpenSearch поддерживает современные методы поиска:
- k-NN (поиск ближайших соседей)
- Семантический поиск
- Мультимодальный поиск
- Гибридный поиск
Дополнительные материалы
1.5 - Начало работы с безопасностью в OpenSearch
Демонстрационная конфигурация безопасности и настройка демонстрационной конфигурации
Демонстрационная конфигурация безопасности
Наиболее простой способ начать работу с безопасностью OpenSearch - использовать демонстрационную конфигурацию. OpenSearch включает полезные скрипты, в том числе:
install_demo_configuration.sh (для Linux/macOS)install_demo_configuration.bat (для Windows)
Расположение скрипта:
plugins/opensearch-security/tools/
Действия скрипта:
- Создает демонстрационные сертификаты для TLS-шифрования на транспортном и REST-уровнях
- Настраивает тестовых пользователей, роли и привязки ролей
- Конфигурирует плагин безопасности для использования внутренней базы данных аутентификации
- Обновляет
opensearch.yml базовой конфигурацией для запуска кластера
Важно! Демонстрационные сертификаты и пароли по умолчанию не должны использоваться в production. Перед развертыванием в продакшене их необходимо заменить на собственные.
Настройка демонстрационной конфигурации
Перед запуском скрипта:
- Установите переменную окружения с надежным паролем администратора:
export OPENSEARCH_INITIAL_ADMIN_PASSWORD=<ваш_надежный_пароль>
- Проверьте надежность пароля с помощью инструмента Zxcvbn
Запуск скрипта:
./plugins/opensearch-security/tools/install_demo_configuration.sh
Проверка конфигурации:
curl -k -XGET -u admin:<пароль> https://<ip-opensearch>:9200
Ожидаемый ответ:
{
"name": "smoketestnode",
"cluster_name": "opensearch",
"version": {
"distribution": "opensearch",
"number": "2.13.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
Настройка OpenSearch Dashboards
Добавьте в opensearch_dashboards.yml следующую конфигурацию:
opensearch.hosts: [https://localhost:9200]
opensearch.ssl.verificationMode: none
opensearch.username: kibanaserver
opensearch.password: kibanaserver
opensearch.requestHeadersWhitelist: [authorization, securitytenant]
opensearch_security.multitenancy.enabled: true
opensearch_security.multitenancy.tenants.preferred: [Private, Global]
opensearch_security.readonly_mode.roles: [kibana_read_only]
opensearch_security.cookie.secure: false # Отключено для HTTP
Запуск Dashboards:
yarn start --no-base-path
После запуска в логах появятся строки:
[info][listening] Server running at http://localhost:5601
[info][server][OpenSearchDashboards][http] http server running at http://localhost:5601
Доступ через браузер: http://localhost:5601
Логин: admin
Пароль: значение из OPENSEARCH_INITIAL_ADMIN_PASSWORD
Управление пользователями и ролями
1. Добавление пользователей
Способы:
- Редактирование
internal_users.yml
- Использование API
- Через интерфейс OpenSearch Dashboards
Пример добавления пользователя в internal_users.yml:
test-user:
hash: "$2y$12$CkxFoTAJKsZaWv/m8VoZ6ePG3DBeBTAvoo4xA2P21VCS9w2RYumsG"
backend_roles:
- "test-backend-role"
- "kibanauser"
description: "Тестовый пользователь"
Генерация хеша пароля:
./plugins/opensearch-security/tools/hash.sh
Введите пароль (например, secretpassword), скопируйте полученный хеш.
2. Создание ролей
Формат roles.yml:
<имя_роли>:
cluster_permissions:
- <разрешение_кластера>
index_permissions:
- index_patterns:
- <шаблон_индекса>
allowed_actions:
- <разрешения_индекса>
Пример роли для доступа к индексу:
human_resources:
index_permissions:
- index_patterns:
- "humanresources"
allowed_actions:
- "READ"
3. Привязка пользователей к ролям
Формат roles_mapping.yml:
<имя_роли>:
users:
- <имя_пользователя>
backend_roles:
- <имя_роли>
Пример привязки:
human_resources:
backend_roles:
- "test-backend-role"
kibana_user:
backend_roles:
- "kibanauser"
Применение изменений конфигурации
После изменения файлов необходимо загрузить конфигурацию в security index:
./plugins/opensearch-security/tools/securityadmin.sh \
-cd "config/opensearch-security" \
-icl \
-key "../kirk-key.pem" \
-cert "../kirk.pem" \
-cacert "../root-ca.pem" \
-nhnv
Дальнейшие шаги
- Ознакомьтесь с Рекомендациями по безопасности OpenSearch
- Изучите Обзор конфигурации безопасности для кастомизации под ваши задачи
Примечания:
- Все команды предполагают выполнение из корневой директории OpenSearch
- Для production-окружений обязательно замените демонстрационные сертификаты
- Регулярно обновляйте пароли администраторов
1.6 - Основные концепции OpenSearch
Полное руководство по OpenSearch: документы, индексы, шарды, узлы кластера, текстовый анализ и жизненный цикл данных. Узнайте, как работают индексация, поиск и агрегация в распределенной поисковой системе.
Базовые понятия
Документ
Базовая единица информации в OpenSearch, хранимая в формате JSON. Представляет собой структурированные данные в виде пар “ключ-значение”.
Индекс
Коллекция логически связанных документов. Аналог таблицы в реляционных БД.
JSON (JavaScript Object Notation)
Текстовый формат для хранения данных, использующий структуру ключ-значение. Основной формат представления данных в OpenSearch.
Маппинг
Схема индекса, определяющая:
- Типы полей документов
- Способы индексации и хранения
- Параметры анализа текста
Архитектура кластера
Узел (Node)
Отдельный сервер, являющийся частью кластера OpenSearch.
Кластер
Совокупность узлов, работающих как единая система.
Управляющий узел (Cluster Manager)
Специальный узел, координирующий кластерные операции:
- Создание/удаление индексов
- Балансировка нагрузки
- Мониторинг состояния узлов
Шард (Shard)
Часть индекса, содержащая подмножество его данных. Индексы разделяются на шарды для:
- Горизонтального масштабирования
- Распределения нагрузки
Типы шардов:
- Первичный (Primary) - основной шард с данными
- Реплика (Replica) - копия первичного шарда для:
- Отказоустойчивости
- Повышения производительности поиска
Структуры данных и хранение
Doc Values
Оптимизированная on-disk структура для:
- Сортировки
- Агрегации
- Доступа к значениям полей
Инвертированный индекс
Структура данных, отображающая термины на документы, которые их содержат. Основа полнотекстового поиска.
Lucene
Библиотека поиска, лежащая в основе OpenSearch. Отвечает за:
- Индексацию
- Хранение
- Поиск данных
Сегмент (Segment)
Неизменяемая единица хранения данных внутри шарда. Особенности:
- Создается при операции refresh
- Объединяется в процессе merge
- Оптимизирован для быстрого поиска
Операции с данными
Ингestion
Процесс добавления данных в OpenSearch. Включает:
- Прием данных
- Парсинг
- Подготовку к индексации
Индексация
Процесс организации данных для эффективного поиска:
- Анализ текста
- Построение инвертированного индекса
- Хранение документов
Пакетная индексация
Массовая загрузка документов через Bulk API:
- Высокая производительность
- Минимизация сетевых издержек
- Атомарность операций
Анализ текста
Текстовый анализ
Процесс преобразования неструктурированного текста в последовательность терминов для индексации.
Компоненты анализатора:
-
Character Filter
Обрабатывает сырой текст:
- Удаление/замена символов
- HTML-разметка
-
Tokenizer
Разбивает текст на токены (слова) с метаданными:
-
Token Filter
Модифицирует токены:
- Приведение к нижнему регистру
- Удаление стоп-слов
- Добавление синонимов
- Стемминг
Типы анализаторов:
Стемминг
Приведение слов к базовой форме (например: “running” → “run”)
Поиск и запросы
Типы запросов:
- Query DSL - основной язык сложных запросов
- Query String - упрощенный синтаксис для URL
- DQL - язык фильтрации в Dashboards
- PPL - язык для observability с pipe-синтаксисом
Контексты выполнения:
Типы поиска:
Агрегации
Механизм анализа и суммирования данных:
- Метрики (avg, sum)
- Бакетизация (histogram, date_histogram)
- Вложенные агрегации
Жизненный цикл обновлений
-
Транзакционный лог (translog)
- Операция записывается в translog
- Гарантия durability через fsync
- Подтверждение клиенту
-
In-memory буфер
- Данные добавляются в буфер Lucene
- Еще не видны для поиска
-
Refresh
- Сброс буфера в сегменты
- Данные становятся видимыми для поиска
- Без гарантии durability
-
Flush
- Запись сегментов на диск (fsync)
- Очистка translog
- Гарантия сохранности данных
-
Merge
- Объединение мелких сегментов
- Оптимизация:
- Уменьшение количества файлов
- Освобождение места
- Улучшение производительности
Критические операции
Translog
Журнал операций для гарантии сохранности данных. Особенности:
- Записывается синхронно перед подтверждением
- Ограничен по размеру
- Очищается после flush
Refresh
Периодическая операция (по умолчанию каждые 1с):
- Делает данные доступными для поиска
- Создает новые сегменты
- Не гарантирует сохранность при сбое
Flush
Операция записи на диск:
- Обеспечивает durability
- Выполняется автоматически при:
- Достижении лимита translog
- Плановом обслуживании
Merge
Фоновая оптимизация:
- Управляется политикой слияния
- Регулирует:
- Частоту слияний
- Максимальный размер сегментов
- Параллелизм операций
2 - Install and upgrade OpenSearch
OpenSearch и OpenSearch Dashboards доступны на любом совместимом хосте, который поддерживает Docker
OpenSearch и OpenSearch Dashboards доступны на любом совместимом хосте, который поддерживает Docker (таких как Linux, MacOS или Windows). Кроме того, вы можете установить оба продукта на различных дистрибутивах Linux и на Windows.
Скачайте OpenSearch для вашей предпочтительной платформы, а затем выберите один из следующих руководств по установке.
| OpenSearch |
OpenSearch Dashboards |
| Docker |
Docker |
| Helm |
Helm |
| Tarball |
Tarball |
| RPM |
RPM |
| Debian |
Debian |
| Ansible playbook |
|
| Windows |
Windows |
После установки OpenSearch ознакомьтесь с его настройкой для вашего развертывания.
Для получения дополнительной информации об обновлении вашего кластера OpenSearch смотрите руководство по обновлению.
Для информации об инструментах обновления смотрите инструменты обновления, миграции и сравнения OpenSearch.
Для установки плагинов смотрите раздел Установка плагинов.
2.1 - Установка OpenSearch
В этом разделе представлена информация о том, как установить OpenSearch на вашем хосте, включая порты, которые необходимо открыть, и важные настройки, которые нужно сконфигурировать на вашем хосте.
Рекомендации по файловой системе
Избегайте использования сетевой файловой системы для хранения узлов в рабочем процессе в производственной среде. Использование сетевой файловой системы для хранения узлов может вызвать проблемы с производительностью в вашем кластере из-за таких факторов, как условия сети (например, задержка или ограниченная пропускная способность) или скорости чтения/записи. Вам следует использовать твердотельные накопители (SSD), установленные на хосте, для хранения узлов, где это возможно.
Совместимость с Java
Распределение OpenSearch для Linux поставляется с совместимой версией JDK Adoptium Java в каталоге jdk. Чтобы узнать версию JDK, выполните команду ./jdk/bin/java -version. Например, архив OpenSearch 1.0.0 поставляется с Java 15.0.1+9 (не LTS), OpenSearch 1.3.0 поставляется с Java 11.0.14.1+1 (LTS), а OpenSearch 2.0.0 поставляется с Java 17.0.2+8 (LTS). OpenSearch тестируется со всеми совместимыми версиями Java.
| Версия OpenSearch |
Совместимые версии Java |
Встроенная версия Java |
| 1.0–1.2.x |
11, 15 |
15.0.1+9 |
| 1.3.x |
8, 11, 14 |
11.0.25+9 |
| 2.0.0–2.11.x |
11, 17 |
17.0.2+8 |
| 2.12.0+ |
11, 17, 21 |
21.0.5+11 |
Чтобы использовать другую установку Java, установите переменную окружения OPENSEARCH_JAVA_HOME или JAVA_HOME на расположение установки Java. Например:
export OPENSEARCH_JAVA_HOME=/path/to/opensearch-3.1.0/jdk
Сетевые требования
Следующие порты необходимо открыть для компонентов OpenSearch.
| Номер порта |
Компонент OpenSearch |
| 443 |
OpenSearch Dashboards в AWS OpenSearch Service с шифрованием в пути (TLS) |
| 5601 |
OpenSearch Dashboards |
| 9200 |
OpenSearch REST API |
| 9300 |
Внутреннее взаимодействие узлов и транспорт, поиск по кластерам |
| 9600 |
Анализатор производительности |
Важные настройки
Для рабочих нагрузок в производственной среде убедитесь, что настройка Linux vm.max_map_count установлена как минимум на 262144. Даже если вы используете образ Docker, установите это значение на хост-машине. Чтобы проверить текущее значение, выполните следующую команду:
cat /proc/sys/vm/max_map_count
Чтобы увеличить значение, добавьте следующую строку в файл /etc/sysctl.conf:
Затем выполните команду sudo sysctl -p, чтобы перезагрузить настройки.
Для рабочих нагрузок Windows вы можете установить vm.max_map_count, выполнив следующие команды:
wsl -d docker-desktop
sysctl -w vm.max_map_count=262144
Пример файла docker-compose.yml
Файл docker-compose.yml также содержит несколько ключевых настроек:
bootstrap.memory_lock: true
Эта настройка отключает свопинг (вместе с memlock). Свопинг может значительно снизить производительность и стабильность, поэтому вы должны убедиться, что он отключен на производственных кластерах.
Включение настройки bootstrap.memory_lock заставит JVM зарезервировать всю необходимую память. Руководство по настройке сборки мусора Java SE Hotspot VM документирует резервирование 1 гигабайта (ГБ) нативной памяти для метаданных классов по умолчанию. В сочетании с кучей Java это может привести к ошибке из-за нехватки нативной памяти на ВМ с меньшим объемом памяти, чем эти требования. Чтобы предотвратить ошибки, ограничьте размер резервируемой памяти с помощью -XX:CompressedClassSpaceSize или -XX:MaxMetaspaceSize и установите размер кучи Java, чтобы убедиться, что у вас достаточно системной памяти.
OPENSEARCH_JAVA_OPTS: -Xms512m -Xmx512m
Эта настройка устанавливает размер кучи Java (рекомендуем использовать половину системной ОЗУ).
OpenSearch по умолчанию использует -Xms1g -Xmx1g для выделения памяти кучи, что имеет приоритет над конфигурациями, указанными с использованием процентной нотации (-XX:MinRAMPercentage, -XX:MaxRAMPercentage). Например, если вы установите OPENSEARCH_JAVA_OPTS=-XX:MinRAMPercentage=30 -XX:MaxRAMPercentage=70, предустановленные значения -Xms1g -Xmx1g переопределят эти настройки. При использовании OPENSEARCH_JAVA_OPTS для определения выделения памяти убедитесь, что вы используете нотацию -Xms и -Xmx.
Эта настройка устанавливает лимит в 65536 открытых файлов для пользователя OpenSearch.
Эта настройка позволяет вам получить доступ к Анализатору производительности на порту 9600.
Не объявляйте одни и те же параметры JVM в нескольких местах, так как это может привести к непредсказуемому поведению или сбою запуска службы OpenSearch. Если вы объявляете параметры JVM с помощью переменной окружения, такой как OPENSEARCH_JAVA_OPTS=-Xms3g -Xmx3g, то вам следует закомментировать любые ссылки на этот параметр JVM в config/jvm.options. Напротив, если вы определяете параметры JVM в config/jvm.options, то не следует определять эти параметры JVM с помощью переменных окружения.
Важные системные свойства
OpenSearch имеет ряд системных свойств, перечисленных в следующей таблице, которые вы можете указать в файле config/jvm.options или в переменной OPENSEARCH_JAVA_OPTS, используя нотацию аргументов командной строки -D.
| Свойство |
Описание |
opensearch.xcontent.string.length.max=<value> |
По умолчанию OpenSearch не накладывает ограничений на максимальную длину строковых полей JSON/YAML/CBOR/Smile. Чтобы защитить ваш кластер от потенциальных атак типа “отказ в обслуживании” (DDoS) или проблем с памятью, вы можете установить это свойство на разумный предел (максимум 2,147,483,647), например, -Dopensearch.xcontent.string.length.max=5000000. |
| `opensearch.xcontent.fast_double_writer=[true |
false]` |
opensearch.xcontent.name.length.max=<value> |
По умолчанию OpenSearch не накладывает ограничений на максимальную длину имен полей JSON/YAML/CBOR/Smile. Чтобы защитить ваш кластер от потенциальных DDoS или проблем с памятью, вы можете установить это свойство на разумный предел (максимум 2,147,483,647), например, -Dopensearch.xcontent.name.length.max=50000. |
opensearch.xcontent.depth.max=<value> |
По умолчанию OpenSearch не накладывает ограничений на максимальную глубину вложенности для документов JSON/YAML/CBOR/Smile. Чтобы защитить ваш кластер от потенциальных DDoS или проблем с памятью, вы можете установить это свойство на разумный предел (максимум 2,147,483,647), например, -Dopensearch.xcontent.depth.max=1000. |
opensearch.xcontent.codepoint.max=<value> |
По умолчанию OpenSearch накладывает ограничение в 52428800 на максимальный размер YAML-документов (в кодовых точках). Чтобы защитить ваш кластер от потенциальных DDoS или проблем с памятью, вы можете изменить это свойство на разумный предел (максимум 2,147,483,647). Например, -Dopensearch.xcontent.codepoint.max=5000000. |
2.1.1 - Docker
Docker значительно упрощает процесс настройки и управления вашими кластерами OpenSearch.
Docker значительно упрощает процесс настройки и управления вашими кластерами OpenSearch. Вы можете загружать официальные образы из Docker Hub или Amazon Elastic Container Registry (Amazon ECR) и быстро развернуть кластер, используя Docker Compose и любой из примеров файлов Docker Compose, включенных в этот гид. Опытные пользователи OpenSearch могут дополнительно настроить свое развертывание, создав собственный файл Docker Compose.
Контейнеры Docker являются портативными и будут работать на любом совместимом хосте, который поддерживает Docker (таких как Linux, MacOS или Windows). Портативность контейнера Docker предлагает гибкость по сравнению с другими методами установки, такими как RPM или ручная установка из Tarball, которые требуют дополнительной конфигурации после загрузки и распаковки.
Этот гид предполагает, что вы уверенно работаете с интерфейсом командной строки (CLI) Linux. Вы должны понимать, как вводить команды, перемещаться между директориями и редактировать текстовые файлы. Для получения помощи по Docker или Docker Compose обратитесь к официальной документации на их веб-сайтах.
Установка Docker и Docker Compose
Посетите страницу Get Docker для получения рекомендаций по установке и настройке Docker для вашей среды. Если вы устанавливаете Docker Engine с помощью CLI, то по умолчанию Docker не будет иметь никаких ограничений на доступные ресурсы хоста. В зависимости от вашей среды вы можете настроить ограничения ресурсов в Docker. См. раздел Runtime options with Memory, CPUs, and GPUs для получения информации.
Пользователи Docker Desktop должны установить использование памяти хоста на минимум 4 ГБ, открыв Docker Desktop и выбрав Settings → Resources.
Docker Compose — это утилита, которая позволяет пользователям запускать несколько контейнеров с одной командой. Вы передаете файл Docker Compose при его вызове. Docker Compose читает эти настройки и запускает запрашиваемые контейнеры. Docker Compose устанавливается автоматически с Docker Desktop, но пользователи, работающие в командной строке, должны установить Docker Compose вручную. Вы можете найти информацию о установке Docker Compose на официальной странице Docker Compose GitHub.
Если вам нужно установить Docker Compose вручную и ваш хост поддерживает Python, вы можете использовать pip для автоматической установки пакета Docker Compose.
Настройка важных параметров хоста
Перед установкой OpenSearch с использованием Docker настройте следующие параметры. Это самые важные настройки, которые могут повлиять на производительность ваших сервисов, но для дополнительной информации смотрите раздел о важных системных настройках.
Настройки для Linux
Для среды Linux выполните следующие команды:
-
Отключите производительность памяти с помощью свопинга для улучшения производительности:
-
Увеличьте количество доступных для OpenSearch карт памяти:
# Отредактируйте файл конфигурации sysctl
sudo vi /etc/sysctl.conf
# Добавьте строку для определения желаемого значения
# или измените значение, если ключ существует,
# а затем сохраните изменения.
vm.max_map_count=262144
# Перезагрузите параметры ядра с помощью sysctl
sudo sysctl -p
# Проверьте, что изменение было применено, проверив значение
cat /proc/sys/vm/max_map_count
Настройки для Windows
Для рабочих нагрузок Windows, использующих WSL через Docker Desktop, выполните следующие команды в терминале, чтобы установить vm.max_map_count:
wsl -d docker-desktop
sysctl -w vm.max_map_count=262144
Запуск OpenSearch в контейнере Docker
Официальные образы OpenSearch размещены на Docker Hub и Amazon ECR. Если вы хотите просмотреть образы, вы можете загружать их по отдельности, используя команду docker pull, как в следующих примерах.
Docker Hub:
docker pull opensearchproject/opensearch:3
docker pull opensearchproject/opensearch-dashboards:3
Amazon ECR:
docker pull public.ecr.aws/opensearchproject/opensearch:3
docker pull public.ecr.aws/opensearchproject/opensearch-dashboards:3
Чтобы загрузить конкретную версию OpenSearch или OpenSearch Dashboards, отличную от последней доступной версии, измените тег образа, где он упоминается (либо в командной строке, либо в файле Docker Compose). Например, opensearchproject/opensearch:3.1.0 загрузит версию OpenSearch 3.1.0. Чтобы загрузить последнюю версию, используйте opensearchproject/opensearch:latest. Обратитесь к официальным репозиториям образов для доступных версий.
Перед тем как продолжить, вы должны убедиться, что Docker работает корректно, развернув OpenSearch в одном контейнере.
Запуск OpenSearch в контейнере Docker
- Выполните следующую команду:
# Эта команда сопоставляет порты 9200 и 9600, устанавливает тип обнаружения на "single-node" и запрашивает самый новый образ OpenSearch
docker run -d -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" opensearchproject/opensearch:latest
Для OpenSearch версии 2.12 или выше установите новый пользовательский пароль администратора перед установкой, используя следующую команду:
docker run -d -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" -e "OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password>" opensearchproject/opensearch:latest
- Отправьте запрос на порт 9200. Имя пользователя и пароль по умолчанию —
admin.
curl https://localhost:9200 -ku admin:<custom-admin-password>
Вы должны получить ответ, который выглядит следующим образом:
{
"name" : "a937e018cee5",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "GLAjAG6bTeWErFUy_d-CLw",
"version" : {
"distribution" : "opensearch",
"number" : "<version>",
"build_type" : "<build-type>",
"build_hash" : "<build-hash>",
"build_date" : "<build-date>",
"build_snapshot" : false,
"lucene_version" : "<lucene-version>",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
- Перед остановкой работающего контейнера отобразите список всех работающих контейнеров и скопируйте идентификатор контейнера для узла OpenSearch, который вы тестируете. В следующем примере идентификатор контейнера —
a937e018cee5:
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a937e018cee5 opensearchproject/opensearch:latest "./opensearch-docker…" 19 minutes ago Up 19 minutes 0.0.0.0:9200->9200/tcp, 9300/tcp, 0.0.0.0:9600->9600/tcp, 9650/tcp wonderful_boyd
- Остановите работающий контейнер, передав идентификатор контейнера в команду
docker stop.
docker stop <containerId>
Помните, что команда docker container ls не отображает остановленные контейнеры. Если вы хотите просмотреть остановленные контейнеры, используйте команду docker container ls -a. Вы можете удалить ненужные контейнеры вручную с помощью команды docker container rm <containerId_1> <containerId_2> <containerId_3> [...] (укажите все идентификаторы контейнеров, которые вы хотите остановить, разделенные пробелами), или, если вы хотите удалить все остановленные контейнеры, вы можете использовать более короткую команду docker container prune.
Развертывание кластера OpenSearch с использованием Docker Compose
Хотя технически возможно создать кластер OpenSearch, создавая контейнеры по одной команде за раз, гораздо проще определить вашу среду в YAML-файле и позволить Docker Compose управлять кластером. В следующем разделе содержатся примеры YAML-файлов, которые вы можете использовать для запуска предопределенного кластера с OpenSearch и OpenSearch Dashboards. Эти примеры полезны для тестирования и разработки, но не подходят для производственной среды. Если у вас нет опыта работы с Docker Compose, вам может быть полезно ознакомиться со спецификацией Docker Compose для получения рекомендаций по синтаксису и форматированию перед внесением изменений в структуры словарей в примерах.
Файл YAML, который определяет среду, называется файлом Docker Compose. По умолчанию команды docker-compose сначала проверяют вашу текущую директорию на наличие файла, который соответствует любому из следующих имен:
docker-compose.ymldocker-compose.yamlcompose.ymlcompose.yaml
Если ни один из этих файлов не существует в вашей текущей директории, команда docker-compose завершится с ошибкой.
Вы можете указать пользовательское местоположение и имя файла при вызове docker-compose с помощью флага -f:
# Используйте относительный или абсолютный путь к файлу.
docker compose -f /path/to/your-file.yml up
Если вы впервые запускаете кластер OpenSearch с использованием Docker Compose, используйте следующий пример файла docker-compose.yml. Сохраните его в домашнем каталоге вашего хоста и назовите его docker-compose.yml. Этот файл создает кластер, который содержит три контейнера: два контейнера, работающих с сервисом OpenSearch, и один контейнер, работающий с OpenSearch Dashboards. Эти контейнеры общаются через мостовую сеть под названием opensearch-net и используют два тома, по одному для каждого узла OpenSearch. Поскольку этот файл явно не отключает демонстрационную конфигурацию безопасности, устанавливаются самоподписанные TLS-сертификаты, и создаются внутренние пользователи с именами и паролями по умолчанию.
Установка пользовательского пароля администратора
Начиная с OpenSearch 2.12, для настройки демонстрационной конфигурации безопасности требуется пользовательский пароль администратора. Выполните одно из следующих действий:
-
Перед запуском docker-compose.yml установите новый пользовательский пароль администратора, используя следующую команду:
export OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password>
-
Создайте файл .env в той же папке, что и ваш файл docker-compose.yml, с переменной OPENSEARCH_INITIAL_ADMIN_PASSWORD и значением надежного пароля.
Требования к паролям
OpenSearch по умолчанию обеспечивает высокую безопасность паролей, используя библиотеку оценки прочности паролей zxcvbn, разработанную компанией Dropbox.
Эта библиотека оценивает пароли на основе энтропии, а не жестких правил сложности, используя следующие рекомендации:
-
Сосредоточьтесь на энтропии, а не только на правилах: Вместо того чтобы просто добавлять цифры или специальные символы, придавайте приоритет общей непредсказуемости. Длинные пароли, состоящие из случайных слов или символов, обеспечивают более высокую энтропию, что делает их более безопасными, чем короткие пароли, соответствующие традиционным правилам сложности.
-
Избегайте общих шаблонов и слов из словаря: Библиотека zxcvbn обнаруживает распространенные шаблоны и слова из словаря, что помогает предотвратить использование легко угадываемых паролей.
Следуя этим рекомендациям, вы сможете создать более надежные пароли, которые обеспечат лучшую защиту ваших учетных записей и данных в OpenSearch.
Sample docker-compose.yml
services:
opensearch-node1: # This is also the hostname of the container within the Docker network (i.e. https://opensearch-node1/)
image: opensearchproject/opensearch:latest # Specifying the latest available image - modify if you want a specific version
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster # Name the cluster
- node.name=opensearch-node1 # Name the node that will run in this container
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligible to serve as cluster manager
- bootstrap.memory_lock=true # Disable JVM heap memory swapping
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Set min and max JVM heap sizes to at least 50% of system RAM
- OPENSEARCH_INITIAL_ADMIN_PASSWORD=${OPENSEARCH_INITIAL_ADMIN_PASSWORD} # Sets the demo admin user password when using demo configuration, required for OpenSearch 2.12 and later
ulimits:
memlock:
soft: -1 # Set memlock to unlimited (no soft or hard limit)
hard: -1
nofile:
soft: 65536 # Maximum number of open files for the opensearch user - set to at least 65536
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data # Creates volume called opensearch-data1 and mounts it to the container
ports:
- 9200:9200 # REST API
- 9600:9600 # Performance Analyzer
networks:
- opensearch-net # All of the containers will join the same Docker bridge network
opensearch-node2:
image: opensearchproject/opensearch:latest # This should be the same image used for opensearch-node1 to avoid issues
container_name: opensearch-node2
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node2
- discovery.seed_hosts=opensearch-node1,opensearch-node2
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- OPENSEARCH_INITIAL_ADMIN_PASSWORD=${OPENSEARCH_INITIAL_ADMIN_PASSWORD}
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch-data2:/usr/share/opensearch/data
networks:
- opensearch-net
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest # Make sure the version of opensearch-dashboards matches the version of opensearch installed on other nodes
container_name: opensearch-dashboards
ports:
- 5601:5601 # Map host port 5601 to container port 5601
expose:
- "5601" # Expose port 5601 for web access to OpenSearch Dashboards
environment:
OPENSEARCH_HOSTS: '["https://opensearch-node1:9200","https://opensearch-node2:9200"]' # Define the OpenSearch nodes that OpenSearch Dashboards will query
networks:
- opensearch-net
volumes:
opensearch-data1:
opensearch-data2:
networks:
opensearch-net:
Если вы переопределяете настройки opensearch_dashboards.yml, используя переменные окружения в вашем файле Compose, используйте все заглавные буквы и заменяйте точки на подчеркивания. Например, для opensearch.hosts используйте OPENSEARCH_HOSTS.
Это поведение отличается от переопределения настроек opensearch.yml, где преобразование заключается только в изменении оператора присваивания. Например, discovery.type: single-node в opensearch.yml определяется как discovery.type=single-node в docker-compose.yml.
Запуск и управление контейнерами OpenSearch с использованием Docker Compose
-
Создайте и запустите контейнеры в фоновом режиме из домашнего каталога вашего хоста (содержащего docker-compose.yml):
-
Проверьте, что сервисные контейнеры запустились корректно:
-
Если контейнер не удалось запустить, вы можете просмотреть логи сервиса:
# Если вы не укажете имя сервиса, docker compose покажет логи всех узлов
docker compose logs <serviceName>
-
Проверьте доступ к OpenSearch Dashboards, подключившись к http://localhost:5601 из браузера. Для OpenSearch версии 2.12 и выше вы должны использовать ваш настроенный логин и пароль. Для более ранних версий логин и пароль по умолчанию — admin. Мы не рекомендуем использовать эту конфигурацию на хостах, доступных из публичного интернета, пока вы не настроите конфигурацию безопасности вашего развертывания.
Помните, что localhost не может быть доступен удаленно. Если вы развертываете эти контейнеры на удаленном хосте, вам нужно установить сетевое соединение и заменить localhost на IP-адрес или DNS-запись, соответствующую хосту.
-
Остановите работающие контейнеры в вашем кластере:
Команда docker compose down остановит работающие контейнеры, но не удалит Docker-тома, которые существуют на хосте. Если вам не важны содержимое этих томов, используйте опцию -v, чтобы удалить все тома, например:
Настройка OpenSearch
В отличие от RPM-распределения OpenSearch, которое требует значительного объема конфигурации после установки, запуск кластеров OpenSearch с помощью Docker позволяет вам определить среду еще до создания контейнеров. Это возможно как при использовании Docker, так и при использовании Docker Compose.
Пример команды Docker
Рассмотрим следующую команду:
docker run \
-p 9200:9200 -p 9600:9600 \
-e "discovery.type=single-node" \
-v /path/to/custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml \
opensearchproject/opensearch:latest
Разберем каждую часть команды:
- Сопоставляет порты 9200 и 9600 (HOST_PORT:CONTAINER_PORT).
- Устанавливает
discovery.type в single-node, чтобы проверки загрузки не завершились неудачей для этого развертывания с одним узлом.
- Использует флаг
-v, чтобы передать локальный файл с именем custom-opensearch.yml в контейнер, заменяя файл opensearch.yml, включенный в образ.
- Запрашивает образ
opensearchproject/opensearch:latest из Docker Hub.
- Запускает контейнер.
Если вы сравните эту команду с примером файла docker-compose.yml, вы можете заметить некоторые общие настройки, такие как сопоставление портов и ссылка на образ. Однако эта команда только развертывает один контейнер, работающий с OpenSearch, и не создает контейнер для OpenSearch Dashboards. Более того, если вы хотите использовать пользовательские TLS-сертификаты, пользователей или роли, или определить дополнительные тома и сети, то эта “однострочная” команда быстро становится непрактичной. Вот где полезность Docker Compose становится очевидной.
Использование Docker Compose
Когда вы строите свой кластер OpenSearch с помощью Docker Compose, вам может быть проще передавать пользовательские файлы конфигурации с вашего хоста в контейнер, вместо того чтобы перечислять каждую отдельную настройку в docker-compose.yml. Аналогично тому, как в примере команды docker run был смонтирован том с хоста в контейнер с помощью флага -v, файлы Compose могут указывать тома для монтирования как подопцию для соответствующей службы. Следующий сокращенный YAML-файл демонстрирует, как смонтировать файл или директорию в контейнер:
services:
opensearch-node1:
volumes:
- opensearch-data1:/usr/share/opensearch/data
- ./custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml
opensearch-node2:
volumes:
- opensearch-data2:/usr/share/opensearch/data
- ./custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml
opensearch-dashboards:
volumes:
- ./custom-opensearch_dashboards.yml:/usr/share/opensearch-dashboards/config/opensearch_dashboards.yml
Обратите внимание, что в этом примере каждый узел OpenSearch использует один и тот же файл конфигурации, что упрощает управление настройками. Для получения более подробной информации о использовании томов и синтаксисе обратитесь к официальной документации Docker по томам.
Пример файла Docker Compose для разработки
Если вы хотите создать свой собственный файл compose на основе примера, ознакомьтесь с следующим образцом файла docker-compose.yml. Этот образец создает два узла OpenSearch и один узел OpenSearch Dashboards с отключенным плагином безопасности. Вы можете использовать этот образец в качестве отправной точки, просматривая Настройка основных параметров безопасности.
services:
opensearch-node1:
image: opensearchproject/opensearch:latest
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster # Название кластера
- node.name=opensearch-node1 # Название узла, который будет работать в этом контейнере
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Узлы, которые будут использоваться для обнаружения кластера
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Узлы, которые могут служить менеджерами кластера
- bootstrap.memory_lock=true # Отключить свопинг памяти кучи JVM
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Установить минимальный и максимальный размеры кучи JVM не менее 50% от системной оперативной памяти
- "DISABLE_INSTALL_DEMO_CONFIG=true" # Предотвращает выполнение встроенного демо-скрипта, который устанавливает демо-сертификаты и конфигурации безопасности в OpenSearch
- "DISABLE_SECURITY_PLUGIN=true" # Отключает плагин безопасности
ulimits:
memlock:
soft: -1 # Установить memlock на неограниченное (без мягкого или жесткого ограничения)
hard: -1
nofile:
soft: 65536 # Максимальное количество открытых файлов для пользователя opensearch - установить не менее 65536
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data # Создает том с именем opensearch-data1 и монтирует его в контейнер
ports:
- 9200:9200 # REST API
- 9600:9600 # Анализатор производительности
networks:
- opensearch-net # Все контейнеры будут присоединены к одной и той же сети Docker bridge
opensearch-node2:
image: opensearchproject/opensearch:latest
container_name: opensearch-node2
environment:
- cluster.name=opensearch-cluster # Название кластера
- node.name=opensearch-node2 # Название узла, который будет работать в этом контейнере
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Узлы, которые будут использоваться для обнаружения кластера
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Узлы, которые могут служить менеджерами кластера
- bootstrap.memory_lock=true # Отключить свопинг памяти кучи JVM
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Установить минимальный и максимальный размеры кучи JVM не менее 50% от системной оперативной памяти
- "DISABLE_INSTALL_DEMO_CONFIG=true" # Предотвращает выполнение встроенного демо-скрипта, который устанавливает демо-сертификаты и конфигурации безопасности в OpenSearch
- "DISABLE_SECURITY_PLUGIN=true" # Отключает плагин безопасности
ulimits:
memlock:
soft: -1 # Установить memlock на неограниченное (без мягкого или жесткого ограничения)
hard: -1
nofile:
soft: 65536 # Максимальное количество открытых файлов для пользователя opensearch - установить не менее 65536
hard: 65536
volumes:
- opensearch-data2:/usr/share/opensearch/data # Создает том с именем opensearch-data2 и монтирует его в контейнер
networks:
- opensearch-net # Все контейнеры будут присоединены к одной и той же сети Docker bridge
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
ports:
- 5601:5601 # Привязка порта хоста 5601 к порту контейнера 5601
expose:
- "5601" # Открыть порт 5601 для веб-доступа к OpenSearch Dashboards
environment:
- 'OPENSEARCH_HOSTS=["http://opensearch-node1:9200","http://opensearch-node2:9200"]' # Указать узлы OpenSearch для Dashboards
- "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true" # Отключает плагин безопасности в OpenSearch Dashboards
networks:
- opensearch-net
volumes:
opensearch-data1: {} # Создает том opensearch-data1
opensearch-data2: {} # Создает том opensearch-data2
networks:
opensearch-net: {} # Создает сеть opensearch-net
Настройка основных параметров безопасности
Перед тем как сделать ваш кластер OpenSearch доступным для внешних хостов, рекомендуется ознакомиться с конфигурацией безопасности развертывания. Вы можете вспомнить из первого примера файла docker-compose.yml, что, если не отключить плагин безопасности, установив DISABLE_SECURITY_PLUGIN=true, встроенный скрипт применит стандартную демо-конфигурацию безопасности к узлам в кластере. Поскольку эта конфигурация используется для демонстрационных целей, стандартные имена пользователей и пароли известны. Поэтому мы рекомендуем создать собственные файлы конфигурации безопасности и использовать тома для передачи этих файлов в контейнеры. Для получения конкретных рекомендаций по настройке безопасности OpenSearch смотрите Конфигурация безопасности.
Чтобы использовать свои собственные сертификаты в конфигурации, добавьте все необходимые сертификаты в раздел томов файла compose:
volumes:
- ./root-ca.pem:/usr/share/opensearch/config/root-ca.pem
- ./admin.pem:/usr/share/opensearch/config/admin.pem
- ./admin-key.pem:/usr/share/opensearch/config/admin-key.pem
- ./node1.pem:/usr/share/opensearch/config/node1.pem
- ./node1-key.pem:/usr/share/opensearch/config/node1-key.pem
Когда вы добавляете сертификаты TLS к узлам OpenSearch с помощью томов Docker Compose, вы также должны включить пользовательский файл opensearch.yml, который определяет эти сертификаты. Например:
volumes:
- ./root-ca.pem:/usr/share/opensearch/config/root-ca.pem
- ./admin.pem:/usr/share/opensearch/config/admin.pem
- ./admin-key.pem:/usr/share/opensearch/config/admin-key.pem
- ./node1.pem:/usr/share/opensearch/config/node1.pem
- ./node1-key.pem:/usr/share/opensearch/config/node1-key.pem
- ./custom-opensearch.yml:/usr/share/opensearch/config/opensearch.yml
Помните, что сертификаты, которые вы указываете в файле compose, должны совпадать с сертификатами, определенными в вашем пользовательском файле opensearch.yml. Вам следует заменить корневые, администраторские и узловые сертификаты на свои собственные. Для получения дополнительной информации смотрите Настройка сертификатов TLS.
Пример конфигурации в вашем пользовательском файле opensearch.yml может выглядеть следующим образом, добавляя сертификаты TLS и отличительное имя (DN) сертификата администратора, определяя несколько разрешений и включая подробное аудиторское логирование:
plugins.security.ssl.transport.pemcert_filepath: node1.pem
plugins.security.ssl.transport.pemkey_filepath: node1-key.pem
plugins.security.ssl.transport.pemtrustedcas_filepath: root-ca.pem
plugins.security.ssl.transport.enforce_hostname_verification: false
plugins.security.ssl.http.enabled: true
plugins.security.ssl.http.pemcert_filepath: node1.pem
plugins.security.ssl.http.pemkey_filepath: node1-key.pem
plugins.security.ssl.http.pemtrustedcas_filepath: root-ca.pem
plugins.security.allow_default_init_securityindex: true
plugins.security.authcz.admin_dn:
- CN=A,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA
plugins.security.nodes_dn:
- 'CN=N,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA'
plugins.security.audit.type: internal_opensearch
plugins.security.enable_snapshot_restore_privilege: true
plugins.security.check_snapshot_restore_write_privileges: true
plugins.security.restapi.roles_enabled: ["all_access", "security_rest_api_access"]
cluster.routing.allocation.disk.threshold_enabled: false
opendistro_security.audit.config.disabled_rest_categories: NONE
opendistro_security.audit.config.disabled_transport_categories: NONE
Полный список настроек
Для получения полного списка настроек смотрите Безопасность.
Используйте тот же процесс для указания конфигурации Backend в файле /usr/share/opensearch/config/opensearch-security/config.yml, а также для создания новых внутренних пользователей, ролей, сопоставлений, групп действий и арендаторов в соответствующих YAML-файлах.
После замены сертификатов и создания собственных внутренних пользователей, ролей, сопоставлений, групп действий и арендаторов, используйте Docker Compose для запуска кластера:
Работа с плагинами
Чтобы использовать образ OpenSearch с пользовательским плагином, вам сначала нужно создать Dockerfile. Ознакомьтесь с официальной документацией Docker для получения информации о создании Dockerfile.
FROM opensearchproject/opensearch:latest
RUN /usr/share/opensearch/bin/opensearch-plugin install --batch <pluginId>
Затем выполните следующие команды:
# Создание образа из Dockerfile
docker build --tag=opensearch-custom-plugin .
# Запуск контейнера из пользовательского образа
docker run -p 9200:9200 -p 9600:9600 -v /usr/share/opensearch/data opensearch-custom-plugin
В качестве альтернативы, вы можете удалить плагин из образа перед его развертыванием. Этот пример Dockerfile удаляет плагин безопасности:
FROM opensearchproject/opensearch:latest
RUN /usr/share/opensearch/bin/opensearch-plugin remove opensearch-security
Вы также можете использовать Dockerfile для передачи своих собственных сертификатов для использования с плагином безопасности:
FROM opensearchproject/opensearch:latest
COPY --chown=opensearch:opensearch opensearch.yml /usr/share/opensearch/config/
COPY --chown=opensearch:opensearch my-key-file.pem /usr/share/opensearch/config/
COPY --chown=opensearch:opensearch my-certificate-chain.pem /usr/share/opensearch/config/
COPY --chown=opensearch:opensearch my-root-cas.pem /usr/share/opensearch/config/
2.1.2 - Установка OpenSearch на Debian
Установка OpenSearch с использованием менеджера пакетов Advanced Packaging Tool (APT)
Установка OpenSearch с использованием менеджера пакетов Advanced Packaging Tool (APT) значительно упрощает процесс по сравнению с методом Tarball. Несколько технических аспектов, таких как путь установки, расположение конфигурационных файлов и создание службы, управляемой systemd, обрабатываются автоматически менеджером пакетов.
В общем, установка OpenSearch из дистрибутива Debian может быть разбита на несколько шагов:
- Скачать и установить OpenSearch.
- Установить вручную из Debian-пакета или из APT-репозитория.
- (Необязательно) Протестировать OpenSearch.
- Подтвердите, что OpenSearch может работать, прежде чем применять какую-либо пользовательскую конфигурацию.
- Это можно сделать без какой-либо безопасности (без пароля, без сертификатов) или с демо-конфигурацией безопасности, которая может быть применена с помощью упакованного скрипта.
- Настроить OpenSearch для вашей среды.
- Примените основные настройки к OpenSearch и начните использовать его в вашей среде.
Дистрибутив Debian предоставляет все необходимое для запуска OpenSearch внутри дистрибутивов Linux на базе Debian, таких как Ubuntu.
Этот гид предполагает, что вы уверенно работаете с интерфейсом командной строки (CLI) Linux. Вы должны понимать, как вводить команды, перемещаться между директориями и редактировать текстовые файлы. Некоторые примеры команд ссылаются на текстовый редактор vi, но вы можете использовать любой доступный текстовый редактор.
Шаг 1: Скачивание и установка OpenSearch
Установка OpenSearch из пакета
Скачайте Debian-пакет для желаемой версии непосредственно с страницы загрузок OpenSearch. Debian-пакет можно скачать как для архитектуры x64, так и для arm64.
Из командной строки установите пакет с помощью dpkg:
Для новых установок OpenSearch 2.12 и более поздних версий необходимо определить пользовательский пароль администратора для настройки демо-конфигурации безопасности. Используйте одну из следующих команд для определения пользовательского пароля администратора:
# x64
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> dpkg -i opensearch-3.1.0-linux-x64.deb
# arm64
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> dpkg -i opensearch-3.1.0-linux-arm64.deb
Используйте следующую команду для версий OpenSearch 2.11 и более ранних:
# x64
sudo dpkg -i opensearch-3.1.0-linux-x64.deb
# arm64
sudo dpkg -i opensearch-3.1.0-linux-arm64.deb
После успешной установки включите OpenSearch как службу:
sudo systemctl enable opensearch
Запустите службу OpenSearch:
sudo systemctl start opensearch
Проверьте, что OpenSearch запустился корректно:
sudo systemctl status opensearch
Проверка отпечатка
Debian-пакет не подписан. Если вы хотите проверить отпечаток, проект OpenSearch предоставляет файл .sig, а также пакет .deb для использования с GNU Privacy Guard (GPG).
Скачайте желаемый Debian-пакет:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch/3.1.0/opensearch-3.1.0-linux-x64.deb
Скачайте соответствующий файл подписи:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch/3.1.0/opensearch-3.1.0-linux-x64.deb.sig
Скачайте и импортируйте GPG-ключ:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | gpg --import -
Проверьте подпись:
gpg --verify opensearch-3.1.0-linux-x64.deb.sig opensearch-3.1.0-linux-x64.deb
Установка OpenSearch из APT-репозитория
APT, основной инструмент управления пакетами для операционных систем на базе Debian, позволяет загружать и устанавливать Debian-пакет из APT-репозитория.
- Установите необходимые пакеты:
sudo apt-get update && sudo apt-get -y install lsb-release ca-certificates curl gnupg2
- Импортируйте публичный GPG-ключ. Этот ключ используется для проверки подписи APT-репозитория:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | sudo gpg --dearmor --batch --yes -o /usr/share/keyrings/opensearch-release-keyring
- Создайте APT-репозиторий для OpenSearch:
echo "deb [signed-by=/usr/share/keyrings/opensearch-release-keyring] https://artifacts.opensearch.org/releases/bundle/opensearch/3.x/apt stable main" | sudo tee /etc/apt/sources.list.d/opensearch-3.x.list
- Проверьте, что репозиторий был успешно создан:
- С добавленной информацией о репозитории перечислите все доступные версии OpenSearch:
sudo apt list -a opensearch
- Выбор версии OpenSearch для установки
- Если не указано иное, будет установлена последняя доступная версия OpenSearch.
# Для новых установок OpenSearch 2.12 и более поздних версий необходимо определить пользовательский пароль администратора для настройки демо-конфигурации безопасности.
# Используйте одну из следующих команд для определения пользовательского пароля:
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> apt-get install opensearch
# Для версий OpenSearch 2.11 и более ранних используйте следующую команду:
sudo apt-get install opensearch
- Установка конкретной версии OpenSearch
# Чтобы установить конкретную версию OpenSearch, укажите версию вручную, используя `opensearch=<version>`:
# Для новых установок OpenSearch 2.12 и более поздних версий:
sudo env OPENSEARCH_INITIAL_ADMIN_PASSWORD=<custom-admin-password> apt-get install opensearch=3.1.0
# Для версий OpenSearch 2.11 и более ранних:
sudo apt-get install opensearch=3.1.0
- Во время установки установщик предоставит вам отпечаток GPG-ключа. Убедитесь, что информация совпадает с указанной ниже:
Fingerprint: c5b7 4989 65ef d1c2 924b a9d5 39d3 1987 9310 d3fc
- Проверьте, что отпечаток ключа соответствует ожидаемому значению, чтобы гарантировать целостность и подлинность пакета.
sudo systemctl enable opensearch
- Запуск OpenSearch
Чтобы запустить OpenSearch, выполните следующую команду:
sudo systemctl start opensearch
- Проверка статуса OpenSearch
После запуска проверьте, что OpenSearch запустился корректно, с помощью следующей команды:
sudo systemctl status opensearch
Шаг 2: (Необязательно) Тестирование OpenSearch
Перед тем как продолжить с любой конфигурацией, рекомендуется протестировать вашу установку OpenSearch. В противном случае может быть сложно определить, связаны ли будущие проблемы с установочными ошибками или с пользовательскими настройками, которые вы применили после установки.
Когда OpenSearch установлен с использованием Debian-пакета, некоторые демо-настройки безопасности автоматически применяются. Это включает в себя самоподписанные TLS-сертификаты и несколько пользователей и ролей. Если вы хотите настроить их самостоятельно, смотрите раздел Настройка OpenSearch в вашей среде.
Узел OpenSearch в своей стандартной конфигурации (с демо-сертификатами и пользователями с стандартными паролями) не подходит для производственной среды. Если вы планируете использовать узел в производственной среде, вам следует, как минимум, заменить демо TLS-сертификаты на ваши собственные и обновить список внутренних пользователей и паролей. Смотрите Конфигурация безопасности для получения дополнительной информации, чтобы убедиться, что ваши узлы настроены в соответствии с вашими требованиями безопасности.
Отправка запросов на сервер
Отправьте запросы на сервер, чтобы проверить, что OpenSearch работает. Обратите внимание на использование флага --insecure, который необходим, поскольку TLS-сертификаты самоподписаны.
Отправьте запрос на порт 9200:
curl -X GET https://localhost:9200 -u 'admin:<custom-admin-password>' --insecure
Ожидаемый ответ
Вы должны получить ответ, который выглядит примерно так:
{
"name": "hostname",
"cluster_name": "opensearch",
"cluster_uuid": "QqgpHCbnSRKcPAizqjvoOw",
"version": {
"distribution": "opensearch",
"number": <version>,
"build_type": <build-type>,
"build_hash": <build-hash>,
"build_date": <build-date>,
"build_snapshot": false,
"lucene_version": <lucene-version>,
"minimum_wire_compatibility_version": "7.10.0",
"minimum_index_compatibility_version": "7.0.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
Запрос к конечной точке плагинов
Запросите конечную точку плагинов:
curl -X GET https://localhost:9200/_cat/plugins?v -u 'admin:<custom-admin-password>' --insecure
Этот запрос вернет список установленных плагинов, что также подтвердит, что OpenSearch работает корректно.
Ожидаемый ответ для запроса к конечной точке плагинов
| Name |
Component |
Version |
| hostname |
opensearch-alerting |
3.1.0 |
| hostname |
opensearch-anomaly-detection |
3.1.0 |
| hostname |
opensearch-asynchronous-search |
3.1.0 |
| hostname |
opensearch-cross-cluster-replication |
3.1.0 |
| hostname |
opensearch-geospatial |
3.1.0 |
| hostname |
opensearch-index-management |
3.1.0 |
| hostname |
opensearch-job-scheduler |
3.1.0 |
| hostname |
opensearch-knn |
3.1.0 |
| hostname |
opensearch-ml |
3.1.0 |
| hostname |
opensearch-neural-search |
3.1.0 |
| hostname |
opensearch-notifications |
3.1.0 |
| hostname |
opensearch-notifications-core |
3.1.0 |
| hostname |
opensearch-observability |
3.1.0 |
| hostname |
opensearch-performance-analyzer |
3.1.0 |
| hostname |
opensearch-reports-scheduler |
3.1.0 |
| hostname |
opensearch-security |
3.1.0 |
| hostname |
opensearch-security-analytics |
3.1.0 |
| hostname |
opensearch-sql |
3.1.0 |
Шаг 3: Настройка OpenSearch в вашей среде
Пользователи, не имеющие предварительного опыта работы с OpenSearch, могут захотеть получить список рекомендуемых настроек для начала работы с сервисом. По умолчанию OpenSearch не привязан к сетевому интерфейсу и не может быть доступен внешними хостами. Кроме того, настройки безопасности заполняются стандартными именами пользователей и паролями. Следующие рекомендации позволят пользователю привязать OpenSearch к сетевому интерфейсу, создать и подписать TLS-сертификаты, а также настроить базовую аутентификацию.
Рекомендуемые настройки
Следующие настройки позволят вам:
- Привязать OpenSearch к IP-адресу или сетевому интерфейсу на хосте.
- Установить начальные и максимальные размеры кучи JVM.
- Определить переменную окружения, указывающую на встроенный JDK.
- Настроить собственные TLS-сертификаты — сторонний центр сертификации (CA) не требуется.
- Создать администратора с пользовательским паролем.
Если вы запускали демо-скрипт безопасности, вам нужно будет вручную перенастроить настройки, которые были изменены. Обратитесь к Конфигурации безопасности для получения рекомендаций перед продолжением.
Перед внесением каких-либо изменений в конфигурационные файлы всегда полезно сохранить резервную копию. Резервный файл можно использовать для устранения любых проблем, вызванных неправильной конфигурацией.
- Открытие файла
opensearch.yml
Откройте файл opensearch.yml:
sudo vi /etc/opensearch/opensearch.yml
- Добавление следующих строк
Добавьте следующие строки в файл:
# Привязать OpenSearch к правильному сетевому интерфейсу. Используйте 0.0.0.0
# для включения всех доступных интерфейсов или укажите IP-адрес,
# назначенный конкретному интерфейсу.
network.host: 0.0.0.0
# Если вы еще не настроили кластер, установите
# discovery.type в single-node, иначе проверки загрузки
# не пройдут, когда вы попытаетесь запустить службу.
discovery.type: single-node
# Если вы ранее отключили плагин безопасности в opensearch.yml,
# обязательно включите его снова. В противном случае вы можете пропустить эту настройку.
plugins.security.disabled: false
-
Сохраните изменения и закройте файл
-
Укажите начальные и максимальные размеры кучи JVM
- Откройте файл
jvm.options:
vi /etc/opensearch/jvm.options
-
Измените значения для начального и максимального размеров кучи. В качестве отправной точки вы должны установить эти значения на половину доступной системной памяти. Для выделенных хостов это значение можно увеличить в зависимости от ваших рабочих требований.
-
Например, если у хост-машины 8 ГБ памяти, вы можете установить начальные и максимальные размеры кучи на 4 ГБ:
- Сохраните изменения и закройте файл.
Настройка TLS
Сертификаты TLS обеспечивают дополнительную безопасность для вашего кластера, позволяя клиентам подтверждать личность хостов и шифровать трафик между клиентом и хостом. Для получения дополнительной информации обратитесь к разделам “Настройка сертификатов TLS” и “Генерация сертификатов”, которые включены в документацию по плагину безопасности. Для работы в среде разработки обычно достаточно самоподписанных сертификатов. Этот раздел проведет вас через основные шаги, необходимые для генерации собственных сертификатов TLS и их применения к вашему хосту OpenSearch.
- Перейдите в директорию, где будут храниться сертификаты
- Удалите демонстрационные сертификаты
- Сгенерируйте корневой сертификат
Это то, что вы будете использовать для подписания других сертификатов.
# Создайте закрытый ключ для корневого сертификата
sudo openssl genrsa -out root-ca-key.pem 2048
# Используйте закрытый ключ для создания самоподписанного корневого сертификата. Обязательно
# замените аргументы, переданные в -subj, чтобы они отражали ваш конкретный хост.
sudo openssl req -new -x509 -sha256 -key root-ca-key.pem -subj "/C=CA/ST=ONTARIO/L=TORONTO/O=ORG/OU=UNIT/CN=ROOT" -out root-ca.pem -days 730
- Создайте сертификат администратора
Этот сертификат используется для получения повышенных прав для выполнения административных задач, связанных с плагином безопасности.
# Создайте закрытый ключ для сертификата администратора
sudo openssl genrsa -out admin-key-temp.pem 2048
# Преобразуйте закрытый ключ в PKCS#8
sudo openssl pkcs8 -inform PEM -outform PEM -in admin-key-temp.pem -topk8 -nocrypt -v1 PBE-SHA1-3DES -out admin-key.pem
# Создайте запрос на подпись сертификата (CSR). Общим именем (CN) "A" можно пользоваться, так как этот сертификат
# используется для аутентификации повышенного доступа и не привязан к хосту.
sudo openssl req -new -key admin-key.pem -subj "/C=CA/ST=ONTARIO/L=TORONTO/O=ORG/OU=UNIT/CN=A" -out admin.csr
# Подпишите сертификат администратора с помощью корневого сертификата и закрытого ключа, которые вы создали ранее.
sudo openssl x509 -req -in admin.csr -CA root-ca.pem -CAkey root-ca-key.pem -CAcreateserial -sha256 -out admin.pem -days 730
- Создайте закрытый ключ для сертификата узла
sudo openssl genrsa -out node1-key-temp.pem 2048
# Преобразуйте закрытый ключ в PKCS#8
sudo openssl pkcs8 -inform PEM -outform PEM -in node1-key-temp.pem -topk8 -nocrypt -v1 PBE-SHA1-3DES -out node1-key.pem
# Создайте CSR и замените аргументы, переданные в -subj, чтобы они отражали ваш конкретный хост
# Обратите внимание, что CN должен соответствовать DNS A записи для хоста — не используйте имя хоста.
sudo openssl req -new -key node1-key.pem -subj "/C=CA/ST=ONTARIO/L=TORONTO/O=ORG/OU=UNIT/CN=node1.dns.a-record" -out node1.csr
# Создайте файл расширений, который определяет SAN DNS имя для хоста
# Этот файл должен соответствовать DNS A записи хоста.
sudo sh -c 'echo subjectAltName=DNS:node1.dns.a-record > node1.ext'
# Подпишите сертификат узла с помощью корневого сертификата и закрытого ключа, которые вы создали ранее
sudo openssl x509 -req -in node1.csr -CA root-ca.pem -CAkey root-ca-key.pem -CAcreateserial -sha256 -out node1.pem -days 730 -extfile node1.ext
- Удалите временные файлы, которые больше не нужны
sudo rm -f *temp.pem *csr *ext
- Убедитесь, что оставшиеся сертификаты принадлежат пользователю opensearch
sudo chown opensearch:opensearch admin-key.pem admin.pem node1-key.pem node1.pem root-ca-key.pem root-ca.pem root-ca.srl
- Добавьте эти сертификаты в
opensearch.yml
Как описано в разделе “Генерация сертификатов”. Продвинутые пользователи также могут выбрать добавление настроек с помощью скрипта.
#! /bin/bash
# Before running this script, make sure to replace the CN in the
# node's distinguished name with a real DNS A record.
echo "plugins.security.ssl.transport.pemcert_filepath: /etc/opensearch/node1.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.transport.pemkey_filepath: /etc/opensearch/node1-key.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.transport.pemtrustedcas_filepath: /etc/opensearch/root-ca.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.enabled: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.pemcert_filepath: /etc/opensearch/node1.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.pemkey_filepath: /etc/opensearch/node1-key.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.ssl.http.pemtrustedcas_filepath: /etc/opensearch/root-ca.pem" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.allow_default_init_securityindex: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.authcz.admin_dn:" | sudo tee -a /etc/opensearch/opensearch.yml
echo " - 'CN=A,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA'" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.nodes_dn:" | sudo tee -a /etc/opensearch/opensearch.yml
echo " - 'CN=node1.dns.a-record,OU=UNIT,O=ORG,L=TORONTO,ST=ONTARIO,C=CA'" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.audit.type: internal_opensearch" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.enable_snapshot_restore_privilege: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.check_snapshot_restore_write_privileges: true" | sudo tee -a /etc/opensearch/opensearch.yml
echo "plugins.security.restapi.roles_enabled: [\"all_access\", \"security_rest_api_access\"]" | sudo tee -a /etc/opensearch/opensearch.yml
- (Необязательно) Добавление доверия к самоподписанному корневому сертификату
# Скопируйте корневой сертификат в правильную директорию
sudo cp /etc/opensearch/root-ca.pem /etc/pki/ca-trust/source/anchors/
# Добавьте доверие
sudo update-ca-trust
Настройка пользователя
Пользователи определяются и аутентифицируются OpenSearch различными способами. Один из методов, который не требует дополнительной инфраструктуры на стороне сервера, — это ручная настройка пользователей в файле internal_users.yml. В следующих шагах объясняется, как добавить нового внутреннего пользователя и как заменить пароль по умолчанию для администратора с помощью скрипта.
- Перейдите в директорию инструментов плагина безопасности
cd /usr/share/opensearch/plugins/opensearch-security/tools
- Запустите
hash.sh для генерации нового пароля
- Этот скрипт завершится с ошибкой, если путь к JDK не был определен.
# Пример вывода, если JDK не найден...
$ ./hash.sh
**************************************************************************
** Этот инструмент будет устаревшим в следующем крупном релизе OpenSearch **
** https://github.com/opensearch-project/security/issues/1755 **
**************************************************************************
which: no java in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/user/.local/bin:/home/user/bin)
WARNING: nor OPENSEARCH_JAVA_HOME nor JAVA_HOME is set, will use
./hash.sh: line 35: java: command not found
- Объявите переменную окружения при вызове скрипта, чтобы избежать проблем
OPENSEARCH_JAVA_HOME=/usr/share/opensearch/jdk ./hash.sh
- Введите желаемый пароль на запросе и запомните хэш, который будет выведен
- Откройте файл
internal_users.yml
sudo vi /etc/opensearch/opensearch-security/internal_users.yml
- Добавьте нового внутреннего пользователя и замените хэш внутри
internal_users.yml на вывод, предоставленный hash.sh на шаге 2
Файл должен выглядеть примерно так:
---
# This is the internal user database
# The hash value is a bcrypt hash and can be generated with plugin/tools/hash.sh
_meta:
type: "internalusers"
config_version: 2
# Define your internal users here
admin:
hash: "$2y$1EXAMPLEQqwS8TUcoEXAMPLEeZ3lEHvkEXAMPLERqjyh1icEXAMPLE."
reserved: true
backend_roles:
- "admin"
description: "Admin user"
user1:
hash: "$2y$12$zoHpvTCRjjQr6h0PEaabueCaGam3/LDvT6rZZGDGMusD7oehQjw/O"
reserved: false
backend_roles: []
description: "New internal user"
# Other users
...
Применение изменений
Теперь, когда сертификаты TLS установлены, а демонстрационные пользователи были удалены или им были назначены новые пароли, последний шаг — применить изменения конфигурации. Этот последний шаг конфигурации требует вызова securityadmin.sh, пока OpenSearch работает на хосте.
Убедитесь, что OpenSearch запущен
OpenSearch должен быть запущен, чтобы securityadmin.sh мог применить изменения. Если вы внесли изменения в opensearch.yml, перезапустите OpenSearch:
sudo systemctl restart opensearch
Откройте отдельную сессию терминала на хосте и перейдите в директорию, содержащую securityadmin.sh
# Перейдите в правильную директорию
cd /usr/share/opensearch/plugins/opensearch-security/tools
Вызовите скрипт
Смотрите раздел “Применение изменений с помощью securityadmin.sh” для определения аргументов, которые вы должны передать.
# Вы можете опустить переменную окружения, если вы объявили ее в вашем $PATH.
OPENSEARCH_JAVA_HOME=/usr/share/opensearch/jdk ./securityadmin.sh -cd /etc/opensearch/opensearch-security/ -cacert /etc/opensearch/root-ca.pem -cert /etc/opensearch/admin.pem -key /etc/opensearch/admin-key.pem -icl -nhnv
Параметры скрипта:
-cd: указывает директорию конфигурации.-cacert: указывает путь к корневому сертификату.-cert: указывает путь к сертификату администратора.-key: указывает путь к закрытому ключу администратора.-icl: включает режим конфигурации.-nhnv: отключает проверку хоста и не выводит информацию о версии.
Проверка работы сервиса
OpenSearch теперь работает на вашем хосте с пользовательскими сертификатами TLS и безопасным пользователем для базовой аутентификации. Вы можете проверить внешнюю доступность, отправив API-запрос к вашему узлу OpenSearch с другого хоста.
Во время предыдущего теста вы направляли запросы на localhost. Теперь, когда сертификаты TLS были применены и новые сертификаты ссылаются на фактическую DNS-запись вашего хоста, запросы к localhost не пройдут проверку CN, и сертификат будет считаться недействительным. Вместо этого запросы должны быть отправлены на адрес, который вы указали при генерации сертификата.
Перед отправкой запросов вы должны добавить доверие к корневому сертификату на вашем клиенте. Если вы не добавите доверие, вам нужно будет использовать опцию -k, чтобы cURL игнорировал проверку CN и корневого сертификата.
$ curl https://your.host.address:9200 -u admin:yournewpassword -k
{
"name":"hostname",
"cluster_name":"opensearch",
"cluster_uuid":"QqgpHCbnSRKcPAizqjvoOw",
"version":{
"distribution":"opensearch",
"number":<version>,
"build_type":<build-type>,
"build_hash":<build-hash>,
"build_date":<build-date>,
"build_snapshot":false,
"lucene_version":<lucene-version>,
"minimum_wire_compatibility_version":"7.10.0",
"minimum_index_compatibility_version":"7.0.0"
},
"tagline":"The OpenSearch Project: https://opensearch.org/"
}
Обновление до новой версии
Экземпляры OpenSearch, установленные с помощью dpkg или apt-get, можно легко обновить до более новой версии.
Ручное обновление с помощью DPKG
Скачайте Debian-пакет для желаемой версии обновления непосредственно со страницы загрузок OpenSearch Project.
Перейдите в директорию, содержащую дистрибутив, и выполните следующую команду:
sudo dpkg -i opensearch-3.1.0-linux-x64.deb
Обновление с помощью APT-GET
Чтобы обновить до последней версии OpenSearch с помощью apt-get, выполните:
sudo apt-get upgrade opensearch
Вы также можете обновить до конкретной версии OpenSearch:
sudo apt-get upgrade opensearch=<version>
Автоматическая перезагрузка сервиса после обновления пакета (2.13.0+)
Чтобы автоматически перезапустить OpenSearch после обновления пакета, включите opensearch.service через systemd:
sudo systemctl enable opensearch.service
2.2 - Установка OpenSearch Dashboards
OpenSearch Dashboards предоставляет полностью интегрированное решение для визуального изучения, обнаружения и запроса ваших данных наблюдаемости.
OpenSearch Dashboards предоставляет полностью интегрированное решение для визуального изучения, обнаружения и запроса ваших данных наблюдаемости. Вы можете установить OpenSearch Dashboards с помощью одного из следующих вариантов:
- Docker
- Tarball
- RPM
- Debian
- Helm
- Windows
Совместимость с браузерами
OpenSearch Dashboards поддерживает следующие веб-браузеры:
- Chrome
- Firefox
- Safari
- Edge (Chromium)
Другие браузеры на основе Chromium также могут работать. Internet Explorer и Microsoft Edge Legacy не поддерживаются.
Совместимость с Node.js
OpenSearch Dashboards требует бинарный файл среды выполнения Node.js для работы. Один из них включен в дистрибутивные пакеты, доступные на странице загрузок OpenSearch.
OpenSearch Dashboards версии 2.8.0 и новее могут использовать версии Node.js 14, 16 и 18. Дистрибутивные пакеты для OpenSearch Dashboards версии 2.10.0 и новее включают Node.js 18 и 14 (для обратной совместимости).
Чтобы использовать бинарный файл среды выполнения Node.js, отличный от включенных в дистрибутивные пакеты, выполните следующие шаги:
-
Скачайте и установите Node.js; совместимые версии: >=14.20.1 <19.
-
Установите путь установки в переменные окружения NODE_HOME или NODE_OSD_HOME.
-
На UNIX, если Node.js установлен в /usr/local/nodejs, а бинарный файл среды выполнения находится по пути /usr/local/nodejs/bin/node:
export NODE_HOME=/usr/local/nodejs
-
Если Node.js установлен с помощью NVM, а бинарный файл среды выполнения находится по пути /Users/user/.nvm/versions/node/v18.19.0/bin/node:
export NODE_HOME=/Users/user/.nvm/versions/node/v18.19.0
# или, если NODE_HOME используется для чего-то другого:
export NODE_OSD_HOME=/Users/user/.nvm/versions/node/v18.19.0
-
На Windows, если Node.js установлен в C:\Program Files\nodejs, а бинарный файл среды выполнения находится по пути C:\Program Files\nodejs\node.exe:
set "NODE_HOME=C:\Program Files\nodejs"
# или с использованием PowerShell:
$Env:NODE_HOME = 'C:\Program Files\nodejs'
-
Ознакомьтесь с документацией вашей операционной системы, чтобы внести постоянные изменения в переменные окружения.
Скрипт запуска OpenSearch Dashboards, bin/opensearch-dashboards, ищет бинарный файл среды выполнения Node.js, используя NODE_OSD_HOME, затем NODE_HOME, прежде чем использовать бинарные файлы, включенные в дистрибутивные пакеты. Если подходящий бинарный файл среды выполнения Node.js не найден, скрипт запуска попытается найти его в системном PATH, прежде чем завершить работу с ошибкой.
Конфигурация
Чтобы узнать, как настроить TLS для OpenSearch Dashboards, смотрите раздел Настройка TLS.
2.2.1 - Запуск OpenSearch Dashboards с использованием Docker
“Вы можете запустить OpenSearch Dashboards с помощью команды docker run после создания сети Docker и запуска OpenSearch, но процесс подключения OpenSearch Dashboards к OpenSearch значительно проще с использованием файла Docker Compose.”
-
Выполните команду для загрузки образа OpenSearch Dashboards:
docker pull opensearchproject/opensearch-dashboards:2
-
Создайте файл docker-compose.yml, соответствующий вашей среде. Пример файла, который включает OpenSearch Dashboards, доступен на странице установки OpenSearch Docker.
-
Так же, как и для opensearch.yml, вы можете передать пользовательский файл opensearch_dashboards.yml в контейнер в файле Docker Compose.
-
Запустите команду:
-
Подождите, пока контейнеры запустятся. Затем ознакомьтесь с документацией OpenSearch Dashboards.
-
Когда закончите, выполните команду:
2.2.2 - Установка OpenSearch Dashboards (Debian)
Установка OpenSearch Dashboards с использованием менеджера пакетов Advanced Packaging Tool (APT)
Установка OpenSearch Dashboards с использованием менеджера пакетов Advanced Packaging Tool (APT) значительно упрощает процесс по сравнению с методом Tarball. Например, менеджер пакетов обрабатывает несколько технических аспектов, таких как путь установки, расположение конфигурационных файлов и создание службы, управляемой systemd.
Перед установкой OpenSearch Dashboards необходимо настроить кластер OpenSearch. Обратитесь к руководству по установке OpenSearch для Debian для получения инструкций.
Данное руководство предполагает, что вы уверенно работаете с интерфейсом командной строки (CLI) Linux. Вы должны понимать, как вводить команды, перемещаться между директориями и редактировать текстовые файлы. Некоторые примеры команд ссылаются на текстовый редактор vi, но вы можете использовать любой доступный текстовый редактор.
Установка OpenSearch Dashboards из пакета
-
Скачайте пакет Debian для нужной версии непосредственно с страницы загрузок OpenSearch. Пакет Debian доступен для архитектур x64 и arm64.
-
Установите пакет с помощью dpkg из командной строки:
-
Для x64:
sudo dpkg -i opensearch-dashboards-3.1.0-linux-x64.deb
-
Для arm64:
sudo dpkg -i opensearch-dashboards-3.1.0-linux-arm64.deb
-
После завершения установки перезагрузите конфигурацию менеджера systemd:
sudo systemctl daemon-reload
-
Включите OpenSearch как службу:
sudo systemctl enable opensearch-dashboards
-
Запустите службу OpenSearch:
sudo systemctl start opensearch-dashboards
-
Проверьте, что OpenSearch запустился корректно:
sudo systemctl status opensearch-dashboards
Проверка подписи
Пакет Debian не подписан. Если вы хотите проверить подпись, проект OpenSearch предоставляет файл .sig, а также .deb пакет для использования с GNU Privacy Guard (GPG).
-
Скачайте нужный пакет Debian:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/3.1.0/opensearch-dashboards-3.1.0-linux-x64.deb
-
Скачайте соответствующий файл подписи:
curl -SLO https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/3.1.0/opensearch-dashboards-3.1.0-linux-x64.deb.sig
-
Скачайте и импортируйте GPG-ключ:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | gpg --import -
-
Проверьте подпись:
gpg --verify opensearch-dashboards-3.1.0-linux-x64.deb.sig opensearch-dashboards-3.1.0-linux-x64.deb
Установка OpenSearch Dashboards из репозитория APT
APT, основной инструмент управления пакетами для операционных систем на базе Debian, позволяет загружать и устанавливать пакет Debian из репозитория APT.
-
Установите необходимые пакеты:
sudo apt-get update && sudo apt-get -y install lsb-release ca-certificates curl gnupg2
-
Импортируйте публичный GPG-ключ. Этот ключ используется для проверки подписи репозитория APT:
curl -o- https://artifacts.opensearch.org/publickeys/opensearch-release.pgp | sudo gpg --dearmor --batch --yes -o /usr/share/keyrings/opensearch-release-keyring
-
Создайте репозиторий APT для OpenSearch:
echo "deb [signed-by=/usr/share/keyrings/opensearch-release-keyring] https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/3.x/apt stable main" | sudo tee /etc/apt/sources.list.d/opensearch-dashboards-3.x.list
-
Проверьте, что репозиторий был успешно создан:
-
С добавленной информацией о репозитории, перечислите все доступные версии OpenSearch:
sudo apt list -a opensearch-dashboards
-
Выберите версию OpenSearch, которую хотите установить:
-
Если не указано иное, будет установлена последняя доступная версия OpenSearch:
sudo apt-get install opensearch-dashboards
-
Чтобы установить конкретную версию OpenSearch Dashboards, укажите номер версии после имени пакета:
# Укажите версию вручную с помощью opensearch=<version>
sudo apt-get install opensearch-dashboards=3.1.0
-
После завершения установки включите OpenSearch:
sudo systemctl enable opensearch-dashboards
-
Запустите OpenSearch:
sudo systemctl start opensearch-dashboards
-
Проверьте, что OpenSearch запустился корректно:
sudo systemctl status opensearch-dashboards
Изучение OpenSearch Dashboards
По умолчанию OpenSearch Dashboards, как и OpenSearch, связывается с localhost при первоначальной установке. В результате OpenSearch Dashboards недоступен с удаленного хоста, если конфигурация не обновлена.
-
Откройте файл opensearch_dashboards.yml:
sudo vi /etc/opensearch-dashboards/opensearch_dashboards.yml
-
Укажите сетевой интерфейс, к которому должен связываться OpenSearch Dashboards:
# Используйте 0.0.0.0, чтобы связаться с любым доступным интерфейсом.
server.host: 0.0.0.0
-
Сохраните изменения и выйдите из редактора.
-
Перезапустите OpenSearch Dashboards, чтобы применить изменения конфигурации:
sudo systemctl restart opensearch-dashboards
-
В веб-браузере перейдите к OpenSearch Dashboards. Порт по умолчанию — 5601.
-
Войдите с использованием имени пользователя admin и пароля admin. (Для OpenSearch 2.12 и новее пароль должен быть пользовательским паролем администратора.)
-
Посетите раздел “Начало работы с OpenSearch Dashboards”, чтобы узнать больше.
Обновление до новой версии
Экземпляры OpenSearch Dashboards, установленные с помощью dpkg или apt-get, можно легко обновить до новой версии.
Ручное обновление с помощью DPKG
-
Скачайте пакет Debian для желаемой версии обновления непосредственно со страницы загрузок проекта OpenSearch.
-
Перейдите в директорию, содержащую дистрибутив, и выполните следующую команду:
sudo dpkg -i opensearch-dashboards-3.1.0-linux-x64.deb
Обновление с помощью APT-GET
Чтобы обновить до последней версии OpenSearch Dashboards с помощью apt-get, выполните следующую команду:
sudo apt-get upgrade opensearch-dashboards
Вы также можете обновить до конкретной версии OpenSearch Dashboards, указав номер версии:
sudo apt-get upgrade opensearch-dashboards=<version>
Автоматический перезапуск службы после обновления пакета (2.13.0+)
Чтобы автоматически перезапустить OpenSearch Dashboards после обновления пакета, включите службу opensearch-dashboards.service через systemd:
sudo systemctl enable opensearch-dashboards.service
2.2.3 - Настройка TLS для OpenSearch Dashboards
По умолчанию, для упрощения тестирования и начала работы, OpenSearch Dashboards работает по протоколу HTTP. Чтобы включить TLS для HTTPS, обновите следующие настройки в файле opensearch_dashboards.yml.
| Настройка |
Описание |
server.ssl.enabled |
Включает SSL-соединение между сервером OpenSearch Dashboards и веб-браузером пользователя. Установите значение true для HTTPS или false для HTTP. |
server.ssl.supportedProtocols |
Указывает массив поддерживаемых протоколов TLS. Возможные значения: TLSv1, TLSv1.1, TLSv1.2, TLSv1.3. По умолчанию: ['TLSv1.1', 'TLSv1.2', 'TLSv1.3']. |
server.ssl.cipherSuites |
Указывает массив шифров TLS. Необязательная настройка. |
server.ssl.certificate |
Если server.ssl.enabled установлено в true, указывает полный путь к действительному сертификату сервера Privacy Enhanced Mail (PEM) для OpenSearch Dashboards. Вы можете сгенерировать свой сертификат или получить его у центра сертификации (CA). |
server.ssl.key |
Если server.ssl.enabled установлено в true, указывает полный путь к ключу для вашего серверного сертификата, например, /usr/share/opensearch-dashboards-1.0.0/config/my-client-cert-key.pem. Вы можете сгенерировать свой сертификат или получить его у CA. |
server.ssl.keyPassphrase |
Устанавливает пароль для ключа. Удалите эту настройку, если у ключа нет пароля. Необязательная настройка. |
server.ssl.keystore.path |
Использует файл JKS (Java KeyStore) или PKCS12/PFX (Public-Key Cryptography Standards) вместо сертификата и ключа PEM. |
server.ssl.keystore.password |
Устанавливает пароль для хранилища ключей. Обязательная настройка. |
server.ssl.clientAuthentication |
Указывает режим аутентификации клиента TLS. Может быть одним из следующих: none, optional или required. Если установлено в required, ваш веб-браузер должен отправить действительный клиентский сертификат, подписанный CA, настроенным в server.ssl.certificateAuthorities. По умолчанию: none. |
server.ssl.certificateAuthorities |
Указывает полный путь к одному или нескольким сертификатам CA в массиве, которые выдают сертификат, используемый для аутентификации клиента. Обязательная настройка, если server.ssl.clientAuthentication установлено в optional или required. |
server.ssl.truststore.path |
Использует файл JKS или PKCS12/PFX trust store вместо сертификатов CA PEM. |
server.ssl.truststore.password |
Устанавливает пароль для trust store. Обязательная настройка. |
opensearch.ssl.verificationMode |
Устанавливает связь между OpenSearch и OpenSearch Dashboards. Допустимые значения: full, certificate или none. Рекомендуется использовать full, если TLS включен, что включает проверку имени хоста. certificate проверяет сертификат, но не имя хоста. none не выполняет никаких проверок (подходит для HTTP). По умолчанию: full. |
opensearch.ssl.certificateAuthorities |
Если opensearch.ssl.verificationMode установлено в full или certificate, указывает полный путь к одному или нескольким сертификатам CA в массиве, которые составляют доверенную цепочку для кластера OpenSearch. Например, вам может потребоваться включить корневой CA и промежуточный CA, если вы использовали промежуточный CA для выдачи ваших сертификатов администратора, клиента и узла. |
opensearch.ssl.truststore.path |
Использует файл trust store JKS или PKCS12/PFX вместо сертификатов CA PEM. |
opensearch.ssl.truststore.password |
Устанавливает пароль для trust store. Обязательная настройка. |
opensearch.ssl.alwaysPresentCertificate |
Отправляет клиентский сертификат в кластер OpenSearch, если установлено значение true, что необходимо, когда mTLS включен в OpenSearch. По умолчанию: false. |
opensearch.ssl.certificate |
Если opensearch.ssl.alwaysPresentCertificate установлено в true, указывает полный путь к действительному клиентскому сертификату для кластера OpenSearch. Вы можете сгенерировать свой сертификат или получить его у CA. |
opensearch.ssl.key |
Если opensearch.ssl.alwaysPresentCertificate установлено в true, указывает полный путь к ключу для клиентского сертификата. Вы можете сгенерировать свой сертификат или получить его у CA. |
opensearch.ssl.keyPassphrase |
Устанавливает пароль для ключа. Удалите эту настройку, если у ключа нет пароля. Необязательная настройка. |
opensearch.ssl.keystore.path |
Использует файл хранилища ключей JKS или PKCS12/PFX вместо сертификата и ключа PEM. |
opensearch.ssl.keystore.password |
Устанавливает пароль для хранилища ключей. Обязательная настройка. |
opensearch_security.cookie.secure |
Если TLS включен для OpenSearch Dashboards, измените эту настройку на true. Для HTTP установите значение false. |
Пример конфигурации opensearch_dashboards.yml
Следующая конфигурация opensearch_dashboards.yml показывает, как OpenSearch и OpenSearch Dashboards могут работать на одной машине с демонстрационной конфигурацией:
server.host: '0.0.0.0'
server.ssl.enabled: true
server.ssl.certificate: /usr/share/opensearch-dashboards/config/client-cert.pem
server.ssl.key: /usr/share/opensearch-dashboards/config/client-cert-key.pem
opensearch.hosts: ["https://localhost:9200"]
opensearch.ssl.verificationMode: full
opensearch.ssl.certificateAuthorities: [ "/usr/share/opensearch-dashboards/config/root-ca.pem", "/usr/share/opensearch-dashboards/config/intermediate-ca.pem" ]
opensearch.username: "kibanaserver"
opensearch.password: "kibanaserver"
opensearch.requestHeadersAllowlist: [ authorization,securitytenant ]
opensearch_security.multitenancy.enabled: true
opensearch_security.multitenancy.tenants.preferred: ["Private", "Global"]
opensearch_security.readonly_mode.roles: ["kibana_read_only"]
opensearch_security.cookie.secure: true
Если вы используете опцию установки через Docker, вы можете передать пользовательский файл opensearch_dashboards.yml в контейнер. Чтобы узнать больше, посетите страницу установки Docker.
После включения этих настроек и запуска приложения вы можете подключиться к OpenSearch Dashboards по адресу https://localhost:5601. Возможно, вам потребуется подтвердить предупреждение браузера, если ваши сертификаты самоподписанные. Чтобы избежать такого предупреждения (или полной несовместимости с браузером), рекомендуется использовать сертификаты от доверенного центра сертификации (CA).
2.3 - configuring opensearch
Существует два типа настроек OpenSearch: динамические и статические.
Динамические настройки
Динамические настройки индекса — это настройки, которые вы можете обновлять в любое время. Вы можете настраивать динамические параметры OpenSearch через API настроек кластера. Для получения подробной информации смотрите раздел Обновление настроек кластера с помощью API.
При возможности используйте API настроек кластера; файл opensearch.yml локален для каждого узла, в то время как API применяет настройки ко всем узлам в кластере.
Статические настройки
Некоторые операции являются статическими и требуют изменения конфигурационного файла opensearch.yml и перезапуска кластера. В общем, эти настройки относятся к сетевым параметрам, формированию кластера и локальной файловой системе. Чтобы узнать больше, смотрите раздел Формирование кластера.
Указание настроек в виде переменных окружения
Вы можете указывать переменные окружения следующими способами:
Аргументы при запуске
Вы можете указать переменные окружения в качестве аргументов, используя -E при запуске OpenSearch:
./opensearch -Ecluster.name=opensearch-cluster -Enode.name=opensearch-node1 -Ehttp.host=0.0.0.0 -Ediscovery.type=single-node
Непосредственно в среде оболочки
Вы можете настроить переменные окружения непосредственно в среде оболочки перед запуском OpenSearch, как показано в следующем примере:
export OPENSEARCH_JAVA_OPTS="-Xms2g -Xmx2g"
export OPENSEARCH_PATH_CONF="/etc/opensearch"
./opensearch
Файл службы systemd
При запуске OpenSearch как службы, управляемой systemd, вы можете указать переменные окружения в файле службы, как показано в следующем примере:
# /etc/systemd/system/opensearch.service.d/override.conf
[Service]
Environment="OPENSEARCH_JAVA_OPTS=-Xms2g -Xmx2g"
Environment="OPENSEARCH_PATH_CONF=/etc/opensearch"
После создания или изменения файла перезагрузите конфигурацию systemd и перезапустите службу с помощью следующих команд:
sudo systemctl daemon-reload
sudo systemctl restart opensearch
Переменные окружения Docker
При запуске OpenSearch в Docker вы можете указать переменные окружения, используя опцию -e с командой docker run, как показано в следующей команде:
docker run -e "OPENSEARCH_JAVA_OPTS=-Xms2g -Xmx2g" -e "OPENSEARCH_PATH_CONF=/usr/share/opensearch/config" opensearchproject/opensearch:latest
Обновление настроек кластера с помощью API
Первый шаг в изменении настройки — это просмотр текущих настроек, отправив следующий запрос:
GET _cluster/settings?include_defaults=true
Для более краткого резюме нестандартных настроек отправьте следующий запрос:
В API настроек кластера существуют три категории настроек: постоянные, временные и стандартные. Постоянные настройки сохраняются после перезапуска кластера. После перезапуска OpenSearch очищает временные настройки.
Если вы указываете одну и ту же настройку в нескольких местах, OpenSearch использует следующий порядок приоритета:
- Временные настройки
- Постоянные настройки
- Настройки из
opensearch.yml
- Стандартные настройки
Чтобы изменить настройку, используйте API настроек кластера и укажите новое значение как постоянное или временное. Этот пример показывает форму плоских настроек:
PUT _cluster/settings
{
"persistent" : {
"action.auto_create_index" : false
}
}
Вы также можете использовать расширенную форму, которая позволяет вам копировать и вставлять из ответа GET и изменять существующие значения:
PUT _cluster/settings
{
"persistent": {
"action": {
"auto_create_index": false
}
}
}
Конфигурационный файл
Вы можете найти файл opensearch.yml по следующему пути:
- Для Docker:
/usr/share/opensearch/config/opensearch.yml
- Для большинства дистрибутивов Linux:
/etc/opensearch/opensearch.yml
Вы можете отредактировать переменную OPENSEARCH_PATH_CONF=/etc/opensearch, чтобы изменить расположение каталога конфигурации. Эта переменная берется из /etc/default/opensearch (для Debian-пакета) и /etc/sysconfig/opensearch (для RPM-пакета).
Если вы установите свою пользовательскую переменную OPENSEARCH_PATH_CONF, имейте в виду, что другие стандартные переменные окружения не будут загружены.
В файле opensearch.yml вы не помечаете настройки как постоянные или временные, и настройки используют плоскую форму:
cluster.name: my-application
action.auto_create_index: true
compatibility.override_main_response_version: true
Демонстрационная конфигурация включает в себя ряд настроек для плагина безопасности, которые вы должны изменить перед использованием OpenSearch для производственной нагрузки. Чтобы узнать больше, смотрите раздел Безопасность.
(Необязательно) Конфигурация заголовков CORS
Если вы работаете над клиентским приложением, которое взаимодействует с кластером OpenSearch на другом домене, вы можете настроить заголовки в opensearch.yml, чтобы разрешить разработку локального приложения на той же машине. Используйте механизм Cross Origin Resource Sharing (CORS), чтобы ваше приложение могло делать вызовы к API OpenSearch, работающему локально. Добавьте следующие строки в ваш файл custom-opensearch.yml (обратите внимание, что символ “-” должен быть первым символом в каждой строке):
- http.host: 0.0.0.0
- http.port: 9200
- http.cors.allow-origin: "http://localhost"
- http.cors.enabled: true
- http.cors.allow-headers: X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
- http.cors.allow-credentials: true
2.3.1 - Настройки доступности и восстановления
Настройки доступности и восстановления включают настройки для следующих компонентов
- Снимки
- Ограничение задач менеджера кластера
- Хранение с удаленной поддержкой
- Обратное давление при поиске
- Обратное давление при индексации шардов
- Репликация сегментов
- Репликация между кластерами
Чтобы узнать больше о статических и динамических настройках, см. Настройка OpenSearch.
Настройки снимков
OpenSearch поддерживает следующие настройки снимков:
- snapshot.max_concurrent_operations (Динамическое, целое число): Максимальное количество одновременных операций снимков. По умолчанию 1000.
Настройки снимков, связанные с безопасностью
Для настроек снимков, связанных с безопасностью, см. Настройки безопасности.
Настройки файловой системы
Для получения информации о настройках файловой системы см. Общая файловая система.
Настройки Amazon S3
Для получения информации о настройках репозитория Amazon S3 см. Amazon S3.
Настройки ограничения задач менеджера кластера
Для получения информации о настройках ограничения задач менеджера кластера см. Установка пределов ограничения.
Настройки хранения с удаленной поддержкой
OpenSearch поддерживает следующие настройки хранения с удаленной поддержкой на уровне кластера:
-
cluster.remote_store.translog.buffer_interval (Динамическое, единица времени): Значение по умолчанию для интервала буфера транзакционного лога, используемого при выполнении периодических обновлений транзакционного лога. Эта настройка эффективна только в том случае, если настройка индекса index.remote_store.translog.buffer_interval отсутствует.
-
remote_store.moving_average_window_size (Динамическое, целое число): Размер окна скользящего среднего, используемый для расчета значений скользящей статистики, доступных через API статистики удаленного хранилища. По умолчанию 20. Минимально допустимое значение - 5.
Для получения дополнительной информации о настройках хранения с удаленной поддержкой см. Хранение с удаленной поддержкой и Настройка хранения с удаленной поддержкой.
Для получения информации о настройках обратного давления сегментов см. Настройки обратного давления сегментов.
Настройки обратного давления при поиске
Обратное давление при поиске - это механизм, используемый для выявления ресурсоемких запросов на поиск и их отмены, когда узел испытывает нагрузку. Для получения дополнительной информации см. Настройки обратного давления при поиске.
Настройки обратного давления при индексации шардов
Обратное давление при индексации шардов - это механизм умного отклонения на уровне шардов, который динамически отклоняет запросы на индексацию, когда ваш кластер испытывает нагрузку. Для получения дополнительной информации см. Настройки обратного давления при индексации шардов.
Настройки репликации сегментов
Для получения информации о настройках репликации сегментов см. Репликация сегментов.
Для получения информации о настройках обратного давления репликации сегментов см. Обратное давление репликации сегментов.
Настройки репликации между кластерами
Для получения информации о настройках репликации между кластерами см. Настройки репликации.
2.3.2 - Конфигурация и системные настройки
Обзор настрек Opensearch
Для получения обзора создания кластера OpenSearch и примеров настроек конфигурации см. раздел Создание кластера. Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
OpenSearch поддерживает следующие системные настройки:
-
cluster.name (Статическая, строка): Имя кластера.
-
node.name (Статическая, строка): Описательное имя для узла.
-
node.roles (Статическая, список): Определяет одну или несколько ролей для узла OpenSearch. Допустимые значения: cluster_manager, data, ingest, search, ml, remote_cluster_client и coordinating_only.
-
path.data (Статическая, строка): Путь к директории, где хранятся ваши данные. Разделяйте несколько местоположений запятыми.
-
path.logs (Статическая, строка): Путь к файлам журналов.
-
bootstrap.memory_lock (Статическая, логическое): Блокирует память при запуске. Рекомендуется установить размер кучи примерно на половину доступной памяти в системе и убедиться, что владелец процесса имеет право использовать этот лимит. OpenSearch работает неэффективно, когда система использует свопинг памяти.
2.3.3 - Сетевые настройки
OpenSearch использует настройки HTTP для конфигурации связи с внешними клиентами через REST API и транспортные настройки для внутренней связи между узлами в OpenSearch.
Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
OpenSearch поддерживает следующие общие сетевые настройки:
-
network.host (Статическая, список): Привязывает узел OpenSearch к адресу. Используйте 0.0.0.0, чтобы включить все доступные сетевые интерфейсы, или укажите IP-адрес, назначенный конкретному интерфейсу. Настройка network.host является комбинацией network.bind_host и network.publish_host, если они имеют одинаковое значение. Альтернативой network.host является отдельная настройка network.bind_host и network.publish_host по мере необходимости. См. раздел Расширенные сетевые настройки.
-
http.port (Статическая, одно значение или диапазон): Привязывает узел OpenSearch к пользовательскому порту или диапазону портов для HTTP-связи. Вы можете указать адрес или диапазон адресов. По умолчанию — 9200-9300.
-
transport.port (Статическая, одно значение или диапазон): Привязывает узел OpenSearch к пользовательскому порту для связи между узлами. Вы можете указать адрес или диапазон адресов. По умолчанию — 9300-9400.
Расширенные сетевые настройки
OpenSearch поддерживает следующие расширенные сетевые настройки:
-
network.bind_host (Статическая, список): Привязывает узел OpenSearch к адресу или адресам для входящих соединений. По умолчанию — значение из network.host.
-
network.publish_host (Статическая, список): Указывает адрес или адреса, которые узел OpenSearch публикует для других узлов в кластере, чтобы они могли подключиться к нему.
Расширенные HTTP-настройки
OpenSearch поддерживает следующие расширенные сетевые настройки для HTTP-связи:
-
http.host (Статическая, список): Устанавливает адрес узла OpenSearch для HTTP-связи. Настройка http.host является комбинацией http.bind_host и http.publish_host, если они имеют одинаковое значение. Альтернативой http.host является отдельная настройка http.bind_host и http.publish_host по мере необходимости.
-
http.bind_host (Статическая, список): Указывает адрес или адреса, к которым узел OpenSearch привязывается для прослушивания входящих HTTP-соединений.
-
http.publish_host (Статическая, список): Указывает адрес или адреса, которые узел OpenSearch публикует для других узлов для HTTP-связи.
-
http.compression (Статическая, логическое): Включает поддержку сжатия с использованием Accept-Encoding, когда это применимо. Когда включен HTTPS, по умолчанию — false, в противном случае — true. Отключение сжатия для HTTPS помогает снизить потенциальные риски безопасности, такие как атаки BREACH. Чтобы включить сжатие для HTTPS-трафика, явно установите http.compression в true.
-
http.max_header_size (Статическая, строка): Максимальный общий размер всех HTTP-заголовков, разрешенный в запросе. По умолчанию — 16KB.
Расширенные транспортные настройки
OpenSearch поддерживает следующие расширенные сетевые настройки для транспортной связи:
-
transport.host (Статическая, список): Устанавливает адрес узла OpenSearch для транспортной связи. Настройка transport.host является комбинацией transport.bind_host и transport.publish_host, если они имеют одинаковое значение. Альтернативой transport.host является отдельная настройка transport.bind_host и transport.publish_host по мере необходимости.
-
transport.bind_host (Статическая, список): Указывает адрес или адреса, к которым узел OpenSearch привязывается для прослушивания входящих транспортных соединений.
-
transport.publish_host (Статическая, список): Указывает адрес или адреса, которые узел OpenSearch публикует для других узлов для транспортной связи.OpenSearch использует настройки HTTP для конфигурации связи с внешними клиентами через REST API и транспортные настройки для внутренней связи между узлами в OpenSearch.
Выбор транспорта
По умолчанию OpenSearch использует транспорт, предоставляемый модулем transport-netty4, который использует движок Netty 4 как для внутренней TCP-связи между узлами в кластере, так и для внешней HTTP-связи с клиентами. Эта связь полностью асинхронна и неблокирующая. В следующей таблице перечислены другие доступные плагины транспорта, которые могут использоваться взаимозаменяемо.
| Плагин |
Описание |
| transport-reactor-netty4 |
HTTP-транспорт OpenSearch на основе Project Reactor и Netty 4 (экспериментальный) |
Установка
./bin/opensearch-plugin install transport-reactor-netty4
Конфигурация (с использованием opensearch.yml)
http.type: reactor-netty4
http.type: reactor-netty4-secure
2.3.4 - Настройки обнаружения и шлюза
Следующие настройки относятся к процессу обнаружения и локальному шлюзу.
Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
Настройки обнаружения
Процесс обнаружения используется при формировании кластера. Он включает в себя обнаружение узлов и выбор узла-менеджера кластера. OpenSearch поддерживает следующие настройки обнаружения:
-
discovery.seed_hosts (Статическая, список): Список хостов, которые выполняют обнаружение при запуске узла. По умолчанию список хостов: ["127.0.0.1", "[::1]"].
-
discovery.seed_providers (Статическая, список): Указывает типы провайдеров начальных хостов, которые будут использоваться для получения адресов начальных узлов с целью запуска процесса обнаружения.
-
discovery.type (Статическая, строка): По умолчанию OpenSearch формирует кластер с несколькими узлами. Установите discovery.type в single-node, чтобы сформировать кластер с одним узлом.
-
cluster.initial_cluster_manager_nodes (Статическая, список): Список узлов, имеющих право быть узлами-менеджерами кластера, используемых для начальной загрузки кластера.
Настройки шлюза
Локальный шлюз хранит состояние кластера и данные шардов, которые используются при перезапуске кластера. OpenSearch поддерживает следующие настройки локального шлюза:
-
gateway.recover_after_nodes (Статическая, целое число): После полного перезапуска кластера количество узлов, которые должны присоединиться к кластеру, прежде чем может начаться восстановление.
-
gateway.recover_after_data_nodes (Статическая, целое число): После полного перезапуска кластера количество узлов данных, которые должны присоединиться к кластеру, прежде чем может начаться восстановление.
-
gateway.expected_data_nodes (Статическая, целое число): Ожидаемое количество узлов данных, которые должны существовать в кластере. После того как ожидаемое количество узлов присоединится к кластеру, может начаться восстановление локальных шардов.
-
gateway.recover_after_time (Статическая, значение времени): Количество времени, которое нужно подождать перед началом восстановления, если количество узлов данных меньше ожидаемого количества узлов данных.
2.3.5 - Настройки безопасности
Плагин безопасности предоставляет ряд файлов конфигурации YAML, которые используются для хранения необходимых настроек, определяющих, как плагин безопасности управляет пользователями, ролями и активностью внутри кластера.
Для полного списка файлов конфигурации плагина безопасности см. раздел Изменение файлов YAML.
Следующие разделы описывают настройки, связанные с безопасностью, в файле opensearch.yml. Вы можете найти opensearch.yml в <OPENSEARCH_HOME>/config/opensearch.yml. Чтобы узнать больше о статических и динамических настройках, см. раздел Настройка OpenSearch.
Общие настройки
Плагин безопасности поддерживает следующие общие настройки:
-
plugins.security.nodes_dn (Статическая): Указывает список отличительных имен (DN), обозначающих другие узлы в кластере. Эта настройка поддерживает подстановочные знаки и регулярные выражения. Список DN также считывается из индекса безопасности, помимо конфигурации YAML, когда plugins.security.nodes_dn_dynamic_config_enabled установлено в true. Если эта настройка не настроена правильно, кластер не сможет сформироваться, так как узлы не смогут доверять друг другу, что приведет к следующей ошибке: “Аутентификация транспортного клиента больше не поддерживается”.
-
plugins.security.nodes_dn_dynamic_config_enabled (Статическая): Актуально для сценариев использования кросс-кластера, где необходимо управлять разрешенными узлами DN без необходимости перезапускать узлы каждый раз, когда настраивается новый удаленный кросс-кластер. Установка nodes_dn_dynamic_config_enabled в true включает доступные для супер-администратора API для отличительных имен, которые предоставляют средства для динамического обновления или получения узлов DN. Эта настройка имеет эффект только если plugins.security.cert.intercluster_request_evaluator_class не установлено. По умолчанию — false.
-
plugins.security.authcz.admin_dn (Статическая): Определяет DN сертификатов, к которым должны быть назначены административные привилегии. Обязательно.
-
plugins.security.roles_mapping_resolution (Статическая): Определяет, как бэкенд-ролям сопоставляются роли безопасности. Поддерживаются следующие значения:
- MAPPING_ONLY (По умолчанию): Сопоставления должны быть явно настроены в
roles_mapping.yml.
- BACKENDROLES_ONLY: Бэкенд-роли сопоставляются с ролями безопасности напрямую. Настройки в
roles_mapping.yml не имеют эффекта.
- BOTH: Бэкенд-роли сопоставляются с ролями безопасности как напрямую, так и через
roles_mapping.yml.
-
plugins.security.dls.mode (Статическая): Устанавливает режим оценки безопасности на уровне документа (DLS). По умолчанию — адаптивный. См. раздел Как установить режим оценки DLS.
-
plugins.security.compliance.salt (Статическая): Соль, используемая при генерации хеш-значения для маскирования полей. Должна содержать не менее 32 символов. Разрешены только ASCII-символы. Необязательно.
-
plugins.security.compliance.immutable_indices (Статическая): Документы в индексах, помеченных как неизменяемые, следуют парадигме “запись один раз, чтение много раз”. Документы, созданные в этих индексах, не могут быть изменены и, следовательно, являются неизменяемыми.
-
config.dynamic.http.anonymous_auth_enabled (Статическая): Включает анонимную аутентификацию. Это приведет к тому, что все HTTP-аутентификаторы не будут вызывать запросы на аутентификацию. По умолчанию — false.
-
http.detailed_errors.enabled (Статическая): Включает подробное сообщение об ошибке для REST-вызовов, выполненных против кластера OpenSearch. Если установлено в true, предоставляет root_cause вместе с кодом ошибки. По умолчанию — true.
Настройки API управления REST
Плагин безопасности поддерживает следующие настройки API управления REST:
-
plugins.security.restapi.roles_enabled (Статическая): Включает доступ к API управления REST на основе ролей для указанных ролей. Роли разделяются запятой. По умолчанию — пустой список (ни одна роль не имеет доступа к API управления REST). См. раздел Контроль доступа для API.
-
plugins.security.restapi.endpoints_disabled.. (Статическая): Отключает конкретные конечные точки и их HTTP-методы для ролей. Значения для этой настройки составляют массив HTTP-методов. Например: plugins.security.restapi.endpoints_disabled.all_access.ACTIONGROUPS: ["PUT","POST","DELETE"]. По умолчанию все конечные точки и методы разрешены. Существующие конечные точки включают ACTIONGROUPS, CACHE, CONFIG, ROLES, ROLESMAPPING, INTERNALUSERS, SYSTEMINFO, PERMISSIONSINFO и LICENSE. См. раздел Контроль доступа для API.
-
plugins.security.restapi.password_validation_regex (Статическая): Указывает регулярное выражение для задания критериев для пароля при входе. Для получения дополнительной информации см. раздел Настройки пароля.
-
plugins.security.restapi.password_validation_error_message (Статическая): Указывает сообщение об ошибке, которое отображается, когда пароль не проходит проверку. Эта настройка используется вместе с plugins.security.restapi.password_validation_regex.
-
plugins.security.restapi.password_min_length (Статическая): Устанавливает минимальное количество символов для длины пароля при использовании оценщика силы пароля на основе баллов. По умолчанию — 8. Это также является минимальным значением. Для получения дополнительной информации см. раздел Настройки пароля.
-
plugins.security.restapi.password_score_based_validation_strength (Статическая): Устанавливает порог для определения, является ли пароль сильным или слабым. Допустимые значения: fair, good, strong и very_strong. Эта настройка используется вместе с plugins.security.restapi.password_min_length.
-
plugins.security.unsupported.restapi.allow_securityconfig_modification (Статическая): Включает использование методов PUT и PATCH для API конфигурации.
Расширенные настройки
Плагин безопасности поддерживает следующие расширенные настройки:
-
plugins.security.authcz.impersonation_dn (Статическая): Включает подмену на уровне транспортного слоя. Это позволяет DN выдавать себя за других пользователей. См. раздел Подмена пользователей.
-
plugins.security.authcz.rest_impersonation_user (Статическая): Включает подмену на уровне REST. Это позволяет пользователям выдавать себя за других пользователей. См. раздел Подмена пользователей.
-
plugins.security.allow_default_init_securityindex (Статическая): При установке в true OpenSearch Security автоматически инициализирует индекс конфигурации с файлами из директории /config, если индекс не существует.
Это будет использовать известные стандартные пароли. Используйте только в частной сети/окружении.
-
plugins.security.allow_unsafe_democertificates (Статическая): При установке в true OpenSearch запускается с демонстрационными сертификатами. Эти сертификаты выданы только для демонстрационных целей.
Эти сертификаты хорошо известны и, следовательно, небезопасны для использования в производственной среде. Используйте только в частной сети/окружении.
-
plugins.security.system_indices.permission.enabled (Статическая): Включает функцию разрешений для системных индексов. При установке в true функция включена, и пользователи с разрешением на изменение ролей могут создавать роли, которые включают разрешения, предоставляющие доступ к системным индексам. При установке в false разрешение отключено, и только администраторы с административным сертификатом могут вносить изменения в системные индексы. По умолчанию разрешение установлено в false в новом кластере.
Настройки уровня эксперта
Настройки уровня эксперта должны настраиваться и развертываться только администратором, который полностью понимает данную функцию. Неправильное понимание функции может привести к рискам безопасности, неправильной работе плагина безопасности или потере данных.
Плагин безопасности поддерживает следующие настройки уровня эксперта:
-
plugins.security.config_index_name (Статическая): Имя индекса, в котором .opendistro_security хранит свою конфигурацию.
-
plugins.security.cert.oid (Статическая): Определяет идентификатор объекта (OID) сертификатов узлов сервера.
-
plugins.security.cert.intercluster_request_evaluator_class (Статическая): Указывает реализацию org.opensearch.security.transport.InterClusterRequestEvaluator, которая используется для оценки межкластерных запросов. Экземпляры org.opensearch.security.transport.InterClusterRequestEvaluator должны реализовывать конструктор с одним аргументом, принимающим объект org.opensearch.common.settings.Settings.
-
plugins.security.enable_snapshot_restore_privilege (Статическая): При установке в false эта настройка отключает восстановление снимков для обычных пользователей. В этом случае принимаются только запросы на восстановление снимков, подписанные административным TLS-сертификатом. При установке в true (по умолчанию) обычные пользователи могут восстанавливать снимки, если у них есть привилегии cluster:admin/snapshot/restore, indices:admin/create и indices:data/write/index.
Снимок можно восстановить только в том случае, если он не содержит глобального состояния и не восстанавливает индекс .opendistro_security.
-
plugins.security.check_snapshot_restore_write_privileges (Статическая): При установке в false дополнительные проверки индекса пропускаются. При установке по умолчанию в true попытки восстановить снимки оцениваются на наличие привилегий indices:admin/create и indices:data/write/index.
-
plugins.security.cache.ttl_minutes (Статическая): Определяет, как долго кэш аутентификации будет действителен. Кэш аутентификации помогает ускорить аутентификацию, временно храня объекты пользователей, возвращаемые из бэкенда, чтобы плагин безопасности не требовал повторных запросов к ним. Установите значение в минутах. По умолчанию — 60. Отключите кэширование, установив значение в 0.
-
plugins.security.disabled (Статическая): Отключает OpenSearch Security.
Отключение этого плагина может подвергнуть вашу конфигурацию (включая пароли) публичному доступу.
-
plugins.security.protected_indices.enabled (Статическая): Если установлено в true, включает защищенные индексы. Защищенные индексы более безопасны, чем обычные индексы. Эти индексы требуют роли для доступа, как и любой другой традиционный индекс, и требуют дополнительной роли для видимости. Эта настройка используется вместе с настройками plugins.security.protected_indices.roles и plugins.security.protected_indices.indices.
-
plugins.security.protected_indices.roles (Статическая): Указывает список ролей, к которым пользователь должен быть сопоставлен для доступа к защищенным индексам.
-
plugins.security.protected_indices.indices (Статическая): Указывает список индексов, которые следует пометить как защищенные. Эти индексы будут видны только пользователям, сопоставленным с ролями, указанными в plugins.security.protected_indices.roles. После выполнения этого требования пользователю все равно потребуется быть сопоставленным с традиционной ролью, используемой для предоставления разрешения на доступ к индексу.
-
plugins.security.system_indices.enabled (Статическая): Если установлено в true, включает системные индексы. Системные индексы аналогичны индексу безопасности, за исключением того, что их содержимое не зашифровано. Индексы, настроенные как системные индексы, могут быть доступны либо супер-администратором, либо пользователем с ролью, включающей разрешение на системный индекс. Для получения дополнительной информации о системных индексах см. раздел Системные индексы.
-
plugins.security.system_indices.indices (Статическая): Список индексов, которые будут использоваться как системные индексы. Эта настройка контролируется настройкой plugins.security.system_indices.enabled.
-
plugins.security.allow_default_init_securityindex (Статическая): При установке в true устанавливает плагин безопасности в его стандартные настройки безопасности, если попытка создать индекс безопасности завершается неудачей при запуске OpenSearch. Стандартные настройки безопасности хранятся в YAML-файлах, находящихся в директории opensearch-project/security/config. По умолчанию — false.
-
plugins.security.cert.intercluster_request_evaluator_class (Статическая): Класс, который будет использоваться для оценки межкластерной связи.
-
plugins.security.enable_snapshot_restore_privilege (Статическая): Включает предоставление привилегии восстановления снимков. Необязательно. По умолчанию — true.
-
plugins.security.check_snapshot_restore_write_privileges (Статическая): Обеспечивает оценку привилегий записи при создании снимков. По умолчанию — true.
Если вы измените любое из следующих свойств хеширования паролей, вам необходимо повторно хешировать все внутренние пароли для обеспечения совместимости и безопасности.
-
plugins.security.password.hashing.algorithm (Статическая): Указывает алгоритм хеширования паролей, который следует использовать. Поддерживаются следующие значения:
- BCrypt (По умолчанию)
- PBKDF2
- Argon2
-
plugins.security.password.hashing.bcrypt.rounds (Статическая): Указывает количество раундов, используемых для хеширования паролей с помощью BCrypt. Допустимые значения находятся в диапазоне от 4 до 31, включая. По умолчанию — 12.
-
plugins.security.password.hashing.bcrypt.minor (Статическая): Указывает минорную версию алгоритма BCrypt, используемую для хеширования паролей. Поддерживаются следующие значения:
-
plugins.security.password.hashing.pbkdf2.function (Статическая): Указывает псевдослучайную функцию, применяемую к паролю. Поддерживаются следующие значения:
- SHA1
- SHA224
- SHA256 (По умолчанию)
- SHA384
- SHA512
-
plugins.security.password.hashing.pbkdf2.iterations (Статическая): Указывает количество раз, которое псевдослучайная функция применяется к паролю. По умолчанию — 600,000.
-
plugins.security.password.hashing.pbkdf2.length (Статическая): Указывает желаемую длину окончательного производного ключа. По умолчанию — 256.
-
plugins.security.password.hashing.argon2.iterations (Статическая): Указывает количество проходов по памяти, которые выполняет алгоритм. Увеличение этого значения увеличивает время вычислений на ЦП и улучшает устойчивость к атакам грубой силы. По умолчанию — 3.
-
plugins.security.password.hashing.argon2.memory (Статическая): Указывает количество памяти (в кибибайтах), используемой во время хеширования. По умолчанию — 65536 (64 МиБ).
-
plugins.security.password.hashing.argon2.parallelism (Статическая): Указывает количество параллельных потоков, используемых для вычислений. По умолчанию — 1.
-
plugins.security.password.hashing.argon2.length (Статическая): Указывает длину (в байтах) результирующего хеш-выхода. По умолчанию — 32.
-
plugins.security.password.hashing.argon2.type (Статическая): Указывает, какой вариант Argon2 использовать. Поддерживаются следующие значения:
- Argon2i
- Argon2d
- Argon2id (по умолчанию)
-
plugins.security.password.hashing.argon2.version (Статическая): Указывает, какую версию Argon2 использовать. Поддерживаются следующие значения:
Настройки журнала аудита
Плагин безопасности поддерживает следующие настройки журнала аудита:
-
plugins.security.audit.enable_rest (Динамическая): Включает или отключает ведение журнала REST-запросов. По умолчанию установлено в true (включено).
-
plugins.security.audit.enable_transport (Динамическая): Включает или отключает ведение журнала запросов на уровне транспорта. По умолчанию установлено в false (выключено).
-
plugins.security.audit.resolve_bulk_requests (Динамическая): Включает или отключает ведение журнала пакетных запросов. При включении все подзапросы в пакетных запросах также записываются в журнал. По умолчанию установлено в false (выключено).
-
plugins.security.audit.config.disabled_categories (Динамическая): Отключает указанные категории событий.
-
plugins.security.audit.ignore_requests (Динамическая): Исключает указанные запросы из ведения журнала. Поддерживает подстановочные знаки и регулярные выражения, содержащие действия или пути REST-запросов.
-
plugins.security.audit.threadpool.size (Статическая): Определяет количество потоков в пуле потоков, используемом для ведения журнала событий. По умолчанию установлено в 10. Установка этого значения в 0 отключает пул потоков, что означает, что плагин ведет журнал событий синхронно.
-
plugins.security.audit.threadpool.max_queue_len (Статическая): Устанавливает максимальную длину очереди на поток. По умолчанию установлено в 100000.
-
plugins.security.audit.ignore_users (Динамическая): Массив пользователей. Запросы аудита от пользователей в списке не будут записываться в журнал.
-
plugins.security.audit.type (Статическая): Назначение событий журнала аудита. Допустимые значения: internal_opensearch, external_opensearch, debug и webhook.
-
plugins.security.audit.config.http_endpoints (Статическая): Список конечных точек для localhost.
-
plugins.security.audit.config.index (Статическая): Индекс журнала аудита. По умолчанию установлен auditlog6. Индекс может быть статическим или индексом, который включает дату, чтобы он вращался ежедневно, например, “‘auditlog6-‘YYYY.MM.dd”. В любом случае убедитесь, что индекс защищен должным образом.
-
plugins.security.audit.config.type (Статическая): Укажите тип журнала аудита как auditlog.
-
plugins.security.audit.config.username (Статическая): Имя пользователя для конфигурации журнала аудита.
-
plugins.security.audit.config.password (Статическая): Пароль для конфигурации журнала аудита.
-
plugins.security.audit.config.enable_ssl (Статическая): Включает или отключает SSL для ведения журнала аудита.
-
plugins.security.audit.config.verify_hostnames (Статическая): Включает или отключает проверку имени хоста для SSL/TLS сертификатов. По умолчанию установлено в true (включено).
-
plugins.security.audit.config.enable_ssl_client_auth (Статическая): Включает или отключает аутентификацию клиента SSL/TLS. По умолчанию установлено в false (выключено).
-
plugins.security.audit.config.cert_alias (Статическая): Псевдоним для сертификата, используемого для доступа к журналу аудита.
-
plugins.security.audit.config.pemkey_filepath (Статическая): Относительный путь к файлу ключа Privacy Enhanced Mail (PEM), используемого для ведения журнала аудита.
-
plugins.security.audit.config.pemkey_content (Статическая): Содержимое PEM-ключа, закодированное в base64, используемого для ведения журнала аудита. Это альтернатива …config.pemkey_filepath.
-
plugins.security.audit.config.pemkey_password (Статическая): Пароль для частного ключа в формате PEM, используемого клиентом.
-
plugins.security.audit.config.pemcert_filepath (Статическая): Относительный путь к файлу PEM-сертификата, используемого для ведения журнала аудита.
-
plugins.security.audit.config.pemcert_content (Статическая): Содержимое PEM-сертификата, закодированное в base64, используемого для ведения журнала аудита. Это альтернатива указанию пути к файлу с помощью …config.pemcert_filepath.
-
plugins.security.audit.config.pemtrustedcas_filepath (Статическая): Относительный путь к файлу доверенного корневого центра сертификации.
-
plugins.security.audit.config.pemtrustedcas_content (Статическая): Содержимое корневого центра сертификации, закодированное в base64. Это альтернатива …config.pemtrustedcas_filepath.
-
plugins.security.audit.config.webhook.url (Статическая): URL вебхука.
-
plugins.security.audit.config.webhook.format (Статическая): Формат, используемый для вебхука. Допустимые значения: URL_PARAMETER_GET, URL_PARAMETER_POST, TEXT, JSON и SLACK.
-
plugins.security.audit.config.webhook.ssl.verify (Статическая): Включает или отключает проверку любых SSL/TLS сертификатов, отправленных с любым запросом вебхука. По умолчанию установлено в true (включено).
-
plugins.security.audit.config.webhook.ssl.pemtrustedcas_filepath (Статическая): Относительный путь к файлу доверенного центра сертификации, против которого проверяются запросы вебхука.
-
plugins.security.audit.config.webhook.ssl.pemtrustedcas_content (Статическая): Содержимое центра сертификации, используемого для проверки запросов вебхука, закодированное в base64. Это альтернатива …config.pemtrustedcas_filepath.
-
plugins.security.audit.config.log4j.logger_name (Статическая): Пользовательское имя для логгера Log4j.
-
plugins.security.audit.config.log4j.level (Статическая): Устанавливает уровень журнала по умолчанию для логгера Log4j. Допустимые значения: OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE и ALL. По умолчанию установлено в INFO.
-
opendistro_security.audit.config.disabled_rest_categories (Динамическая): Список категорий REST, которые будут игнорироваться логгером. Допустимые значения: AUTHENTICATED и GRANTED_PRIVILEGES.
-
opendistro_security.audit.config.disabled_transport_categories (Динамическая): Список категорий на транспортном уровне, которые будут игнорироваться логгером. Допустимые значения: AUTHENTICATED и GRANTED_PRIVILEGES.
Настройки проверки имени хоста и DNS
Плагин безопасности поддерживает следующие настройки проверки имени хоста и DNS:
-
plugins.security.ssl.transport.enforce_hostname_verification (Статическая): Указывает, следует ли проверять имена хостов на транспортном уровне. Необязательно. По умолчанию установлено в true.
-
plugins.security.ssl.transport.resolve_hostname (Статическая): Указывает, следует ли разрешать имена хостов через DNS на транспортном уровне. Необязательно. По умолчанию установлено в true. Работает только если включена проверка имени хоста.
Для получения дополнительной информации см. раздел Проверка имени хоста и разрешение DNS.
Настройки аутентификации клиента
Плагин безопасности поддерживает следующую настройку аутентификации клиента:
- plugins.security.ssl.http.clientauth_mode (Статическая): Режим аутентификации клиента TLS, который следует использовать. Допустимые значения: OPTIONAL (по умолчанию), REQUIRE и NONE. Необязательно.
Для получения дополнительной информации см. раздел Аутентификация клиента.
Настройки включенных шифров и протоколов
Плагин безопасности поддерживает следующие настройки включенных шифров и протоколов. Каждая настройка должна быть выражена в массиве:
-
plugins.security.ssl.http.enabled_ciphers (Статическая): Включенные шифры TLS для REST-уровня. Поддерживается только формат Java.
-
plugins.security.ssl.http.enabled_protocols (Статическая): Включенные протоколы TLS для REST-уровня. Поддерживается только формат Java.
-
plugins.security.ssl.transport.enabled_ciphers (Статическая): Включенные шифры TLS для транспортного уровня. Поддерживается только формат Java.
-
plugins.security.ssl.transport.enabled_protocols (Статическая): Включенные протоколы TLS для транспортного уровня. Поддерживается только формат Java.
Для получения дополнительной информации см. раздел Включенные шифры и протоколы.
Файлы хранилища ключей и доверенных сертификатов — настройки TLS на транспортном уровне
Плагин безопасности поддерживает следующие настройки хранилища ключей и доверенных сертификатов для транспортного уровня TLS:
-
plugins.security.ssl.transport.keystore_type (Статическая): Тип файла хранилища ключей. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
-
plugins.security.ssl.transport.keystore_filepath (Статическая): Путь к файлу хранилища ключей, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.transport.keystore_alias (Статическая): Имя псевдонима хранилища ключей. Необязательно. По умолчанию используется первый псевдоним.
-
plugins.security.ssl.transport.keystore_password (Статическая): Пароль для хранилища ключей. По умолчанию установлено в changeit.
-
plugins.security.ssl.transport.truststore_type (Статическая): Тип файла доверенного хранилища. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
-
plugins.security.ssl.transport.truststore_filepath (Статическая): Путь к файлу доверенного хранилища, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.transport.truststore_alias (Статическая): Имя псевдонима доверенного хранилища. Необязательно. По умолчанию используются все сертификаты.
-
plugins.security.ssl.transport.truststore_password (Статическая): Пароль для доверенного хранилища. По умолчанию установлено в changeit.
Для получения дополнительной информации о файлах хранилища ключей и доверенных сертификатов см. раздел TLS на транспортном уровне.
Файлы хранилища ключей и доверенных сертификатов — настройки TLS на уровне REST
Плагин безопасности поддерживает следующие настройки хранилища ключей и доверенных сертификатов для уровня REST TLS:
-
plugins.security.ssl.http.enabled (Статическая): Указывает, следует ли включить TLS на уровне REST. Если включено, разрешен только HTTPS. Необязательно. По умолчанию установлено в false.
-
plugins.security.ssl.http.keystore_type (Статическая): Тип файла хранилища ключей. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
-
plugins.security.ssl.http.keystore_filepath (Статическая): Путь к файлу хранилища ключей, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.http.keystore_alias (Статическая): Имя псевдонима хранилища ключей. Необязательно. По умолчанию используется первый псевдоним.
-
plugins.security.ssl.http.keystore_password (Статическая): Пароль для хранилища ключей. По умолчанию установлено в changeit.
-
plugins.security.ssl.http.truststore_type (Статическая): Тип файла доверенного хранилища. Необязательно. Допустимые значения: JKS или PKCS12/PFX. По умолчанию установлено в JKS.
-
plugins.security.ssl.http.truststore_filepath (Статическая): Путь к файлу доверенного хранилища, который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.http.truststore_alias (Статическая): Имя псевдонима доверенного хранилища. Необязательно. По умолчанию используются все сертификаты.
-
plugins.security.ssl.http.truststore_password (Статическая): Пароль для доверенного хранилища. По умолчанию установлено в changeit.
Для получения дополнительной информации см. раздел TLS на уровне REST.
X.509 PEM-сертификаты и ключи PKCS #8 — настройки TLS на транспортном уровне
Плагин безопасности поддерживает следующие настройки TLS на транспортном уровне, связанные с X.509 PEM-сертификатами и ключами PKCS #8:
-
plugins.security.ssl.transport.pemkey_filepath (Статическая): Путь к файлу ключа сертификата (PKCS #8), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.transport.pemkey_password (Статическая): Пароль для ключа. Укажите эту настройку, если у ключа есть пароль. Необязательно.
-
plugins.security.ssl.transport.pemcert_filepath (Статическая): Путь к цепочке сертификатов узла X.509 (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.transport.pemtrustedcas_filepath (Статическая): Путь к корневым центрам сертификации (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
Для получения дополнительной информации см. раздел TLS на транспортном уровне.
X.509 PEM-сертификаты и ключи PKCS #8 — настройки TLS на уровне REST
Плагин безопасности поддерживает следующие настройки TLS на уровне REST, связанные с X.509 PEM-сертификатами и ключами PKCS #8:
-
plugins.security.ssl.http.enabled (Статическая): Указывает, следует ли включить TLS на уровне REST. Если включено, разрешен только HTTPS. Необязательно. По умолчанию установлено в false.
-
plugins.security.ssl.http.pemkey_filepath (Статическая): Путь к файлу ключа сертификата (PKCS #8), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.http.pemkey_password (Статическая): Пароль для ключа. Укажите эту настройку, если у ключа есть пароль. Необязательно.
-
plugins.security.ssl.http.pemcert_filepath (Статическая): Путь к цепочке сертификатов узла X.509 (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
-
plugins.security.ssl.http.pemtrustedcas_filepath (Статическая): Путь к корневым центрам сертификации (формат PEM), который должен находиться в каталоге конфигурации и указываться с использованием относительного пути. Обязательно.
Для получения дополнительной информации см. раздел TLS на уровне REST.
Настройки безопасности на транспортном уровне
Плагин безопасности поддерживает следующие настройки безопасности на транспортном уровне:
-
plugins.security.ssl.transport.enabled (Статическая): Указывает, следует ли включить TLS на уровне REST.
-
plugins.security.ssl.transport.client.pemkey_password (Статическая): Пароль для частного ключа в формате PEM, используемого клиентом на транспортном уровне.
-
plugins.security.ssl.transport.keystore_keypassword (Статическая): Пароль для ключа внутри хранилища ключей.
-
plugins.security.ssl.transport.server.keystore_keypassword (Статическая): Пароль для ключа внутри хранилища ключей сервера.
-
plugins.security.ssl.transport.server.keystore_alias (Статическая): Имя псевдонима для хранилища ключей сервера.
-
plugins.security.ssl.transport.client.keystore_alias (Статическая): Имя псевдонима для хранилища ключей клиента.
-
plugins.security.ssl.transport.server.truststore_alias (Статическая): Имя псевдонима для доверенного хранилища сервера.
-
plugins.security.ssl.transport.client.truststore_alias (Статическая): Имя псевдонима для доверенного хранилища клиента.
-
plugins.security.ssl.client.external_context_id (Статическая): Предоставляет клиенту на транспортном уровне идентификатор для использования внешнего SSL-контекста.
-
plugins.security.ssl.transport.principal_extractor_class (Статическая): Указывает класс, реализующий извлечение, чтобы использовать пользовательскую часть сертификата в качестве основного.
-
plugins.security.ssl.http.crl.file_path (Статическая): Путь к файлу списка отозванных сертификатов (CRL).
-
plugins.security.ssl.http.crl.validate (Статическая): Включает проверку списка отозванных сертификатов (CRL). По умолчанию установлено в false (выключено).
-
plugins.security.ssl.http.crl.prefer_crlfile_over_ocsp (Статическая): Указывает, следует ли предпочитать запись сертификата CRL перед записью протокола статуса сертификата в режиме онлайн (OCSP), если сертификат содержит обе записи. Необязательно. По умолчанию установлено в false.
-
plugins.security.ssl.http.crl.check_only_end_entities (Статическая): Если установлено в true, проверяются только конечные сертификаты. По умолчанию установлено в true.
-
plugins.security.ssl.http.crl.disable_ocsp (Статическая): Отключает OCSP. По умолчанию установлено в false (OCSP включен).
-
plugins.security.ssl.http.crl.disable_crldp (Статическая): Отключает конечные точки CRL в сертификатах. По умолчанию установлено в false (конечные точки CRL включены).
-
plugins.security.ssl.allow_client_initiated_renegotiation (Статическая): Включает или отключает повторнуюNegotiation, инициированную клиентом. По умолчанию установлено в false (повторнаяNegotiation, инициированная клиентом, не разрешена).
Примеры настроек плагина безопасности
# Common configuration settings
plugins.security.nodes_dn:
- "CN=*.example.com, OU=SSL, O=Test, L=Test, C=DE"
- "CN=node.other.com, OU=SSL, O=Test, L=Test, C=DE"
- "CN=node.example.com, OU=SSL\\, Inc., L=Test, C=DE" # escape additional comma with `\\`
plugins.security.authcz.admin_dn:
- CN=kirk,OU=client,O=client,L=test, C=de
plugins.security.roles_mapping_resolution: MAPPING_ONLY
plugins.security.ssl.transport.pemcert_filepath: esnode.pem
plugins.security.ssl.transport.pemkey_filepath: esnode-key.pem
plugins.security.ssl.transport.pemtrustedcas_filepath: root-ca.pem
plugins.security.ssl.transport.enforce_hostname_verification: false
plugins.security.ssl.http.enabled: true
plugins.security.ssl.http.pemcert_filepath: esnode.pem
plugins.security.ssl.http.pemkey_filepath: esnode-key.pem
plugins.security.ssl.http.pemtrustedcas_filepath: root-ca.pem
plugins.security.allow_unsafe_democertificates: true
plugins.security.allow_default_init_securityindex: true
plugins.security.nodes_dn_dynamic_config_enabled: false
plugins.security.cert.intercluster_request_evaluator_class: # need example value for this.
plugins.security.audit.type: internal_opensearch
plugins.security.enable_snapshot_restore_privilege: true
plugins.security.check_snapshot_restore_write_privileges: true
plugins.security.cache.ttl_minutes: 60
plugins.security.restapi.roles_enabled: ["all_access", "security_rest_api_access"]
plugins.security.system_indices.enabled: true
plugins.security.system_indices.indices: [".opendistro-alerting-config", ".opendistro-alerting-alert*", ".opendistro-anomaly-results*", ".opendistro-anomaly-detector*", ".opendistro-anomaly-checkpoints", ".opendistro-anomaly-detection-state", ".opendistro-reports-*", ".opendistro-notifications-*", ".opendistro-notebooks", ".opendistro-asynchronous-search-response*"]
node.max_local_storage_nodes: 3
plugins.security.restapi.password_validation_regex: '(?=.*[A-Z])(?=.*[^a-zA-Z\d])(?=.*[0-9])(?=.*[a-z]).{8,}'
plugins.security.restapi.password_validation_error_message: "Password must be minimum 8 characters long and must contain at least one uppercase letter, one lowercase letter, one digit, and one special character."
plugins.security.allow_default_init_securityindex: true
plugins.security.cache.ttl_minutes: 60
#
# REST Management API configuration settings
plugins.security.restapi.roles_enabled: ["all_access","xyz_role"]
plugins.security.restapi.endpoints_disabled.all_access.ACTIONGROUPS: ["PUT","POST","DELETE"] # Alternative example: plugins.security.restapi.endpoints_disabled.xyz_role.LICENSE: ["DELETE"] #
# Audit log configuration settings
plugins.security.audit.enable_rest: true
plugins.security.audit.enable_transport: false
plugins.security.audit.resolve_bulk_requests: false
plugins.security.audit.config.disabled_categories: ["AUTHENTICATED","GRANTED_PRIVILEGES"]
plugins.security.audit.ignore_requests: ["indices:data/read/*","*_bulk"]
plugins.security.audit.threadpool.size: 10
plugins.security.audit.threadpool.max_queue_len: 100000
plugins.security.audit.ignore_users: ['kibanaserver','some*user','/also.*regex possible/']
plugins.security.audit.type: internal_opensearch
#
# external_opensearch settings
plugins.security.audit.config.http_endpoints: ['localhost:9200','localhost:9201','localhost:9202']
plugins.security.audit.config.index: "'auditlog6-'2023.06.15"
plugins.security.audit.config.type: auditlog
plugins.security.audit.config.username: auditloguser
plugins.security.audit.config.password: auditlogpassword
plugins.security.audit.config.enable_ssl: false
plugins.security.audit.config.verify_hostnames: false
plugins.security.audit.config.enable_ssl_client_auth: false
plugins.security.audit.config.cert_alias: mycert
plugins.security.audit.config.pemkey_filepath: key.pem
plugins.security.audit.config.pemkey_content: <...pem base 64 content>
plugins.security.audit.config.pemkey_password: secret
plugins.security.audit.config.pemcert_filepath: cert.pem
plugins.security.audit.config.pemcert_content: <...pem base 64 content>
plugins.security.audit.config.pemtrustedcas_filepath: ca.pem
plugins.security.audit.config.pemtrustedcas_content: <...pem base 64 content>
#
# Webhook settings
plugins.security.audit.config.webhook.url: "http://mywebhook/endpoint"
plugins.security.audit.config.webhook.format: JSON
plugins.security.audit.config.webhook.ssl.verify: false
plugins.security.audit.config.webhook.ssl.pemtrustedcas_filepath: ca.pem
plugins.security.audit.config.webhook.ssl.pemtrustedcas_content: <...pem base 64 content>
#
# log4j settings
plugins.security.audit.config.log4j.logger_name: auditlogger
plugins.security.audit.config.log4j.level: INFO
#
# Advanced configuration settings
plugins.security.authcz.impersonation_dn:
"CN=spock,OU=client,O=client,L=Test,C=DE":
- worf
"cn=webuser,ou=IT,ou=IT,dc=company,dc=com":
- user2
- user1
plugins.security.authcz.rest_impersonation_user:
"picard":
- worf
"john":
- steve
- martin
plugins.security.allow_default_init_securityindex: false
plugins.security.allow_unsafe_democertificates: false
plugins.security.cache.ttl_minutes: 60
plugins.security.restapi.password_validation_regex: '(?=.*[A-Z])(?=.*[^a-zA-Z\d])(?=.*[0-9])(?=.*[a-z]).{8,}'
plugins.security.restapi.password_validation_error_message: "A password must be at least 8 characters long and contain at least one uppercase letter, one lowercase letter, one digit, and one special character."
plugins.security.restapi.password_min_length: 8
plugins.security.restapi.password_score_based_validation_strength: very_strong
#
# Advanced SSL settings - use only if you understand SSL ins and outs
plugins.security.ssl.transport.client.pemkey_password: superSecurePassword1
plugins.security.ssl.transport.keystore_keypassword: superSecurePassword2
plugins.security.ssl.transport.server.keystore_keypassword: superSecurePassword3
plugins.security.ssl.http.keystore_keypassword: superSecurePassword4
plugins.security.ssl.http.clientauth_mode: REQUIRE
plugins.security.ssl.transport.enabled: true
plugins.security.ssl.transport.server.keystore_alias: my_alias
plugins.security.ssl.transport.client.keystore_alias: my_other_alias
plugins.security.ssl.transport.server.truststore_alias: trustore_alias_1
plugins.security.ssl.transport.client.truststore_alias: trustore_alias_2
plugins.security.ssl.client.external_context_id: my_context_id
plugins.security.ssl.transport.principal_extractor_class: org.opensearch.security.ssl.ExampleExtractor
plugins.security.ssl.http.crl.file_path: ssl/crl/revoked.crl
plugins.security.ssl.http.crl.validate: true
plugins.security.ssl.http.crl.prefer_crlfile_over_ocsp: true
plugins.security.ssl.http.crl.check_only_end_entitites: false
plugins.security.ssl.http.crl.disable_ocsp: true
plugins.security.ssl.http.crl.disable_crldp: true
plugins.security.ssl.allow_client_initiated_renegotiation: true
#
# Expert settings - use only if you understand their use completely: accidental values can potentially cause security risks or failures to OpenSearch Security.
plugins.security.config_index_name: .opendistro_security
plugins.security.cert.oid: '1.2.3.4.5.5'
plugins.security.cert.intercluster_request_evaluator_class: org.opensearch.security.transport.DefaultInterClusterRequestEvaluator
plugins.security.enable_snapshot_restore_privilege: true
plugins.security.check_snapshot_restore_write_privileges: true
plugins.security.cache.ttl_minutes: 60
plugins.security.disabled: false
plugins.security.protected_indices.enabled: true
plugins.security.protected_indices.roles: ['all_access']
plugins.security.protected_indices.indices: []
plugins.security.system_indices.enabled: true
plugins.security.system_indices.indices: ['.opendistro-alerting-config', '.opendistro-ism-*', '.opendistro-reports-*', '.opensearch-notifications-*', '.opensearch-notebooks', '.opensearch-observability', '.opendistro-asynchronous-search-response*', '.replication-metadata-store']
2.3.6 - Настройки предохранителей
Предохранители предотвращают возникновение ошибки Java OutOfMemoryError в OpenSearch.
Родительский предохранитель указывает общее доступное количество памяти для всех дочерних предохранителей. Дочерние предохранители указывают общее доступное количество памяти для себя.
Для получения дополнительной информации о статических и динамических настройках см. раздел Конфигурация OpenSearch.
Настройки родительского предохранителя
OpenSearch поддерживает следующие настройки родительского предохранителя:
-
indices.breaker.total.use_real_memory (Статическая, логическая): Если установлено в true, родительский предохранитель учитывает фактическое использование памяти. В противном случае родительский предохранитель учитывает количество памяти, зарезервированной дочерними предохранителями. По умолчанию установлено в true.
-
indices.breaker.total.limit (Динамическая, процент): Указывает начальный лимит памяти для родительского предохранителя. Если indices.breaker.total.use_real_memory установлено в true, по умолчанию составляет 95% кучи JVM. Если indices.breaker.total.use_real_memory установлено в false, по умолчанию составляет 70% кучи JVM.
Настройки предохранителя данных полей
Предохранитель данных полей ограничивает объем памяти кучи, необходимый для загрузки поля в кэш данных полей. OpenSearch поддерживает следующие настройки предохранителя данных полей:
-
indices.breaker.fielddata.limit (Динамическая, процент): Указывает лимит памяти для предохранителя данных полей. По умолчанию составляет 40% кучи JVM.
-
indices.breaker.fielddata.overhead (Динамическая, дробное число): Константа, на которую умножаются оценки данных полей для определения окончательной оценки. По умолчанию составляет 1.03.
Настройки предохранителя запросов
Предохранитель запросов ограничивает объем памяти, необходимый для построения структур данных, необходимых для запроса (например, при вычислении агрегатов). OpenSearch поддерживает следующие настройки предохранителя запросов:
-
indices.breaker.request.limit (Динамическая, процент): Указывает лимит памяти для предохранителя запросов. По умолчанию составляет 60% кучи JVM.
-
indices.breaker.request.overhead (Динамическая, дробное число): Константа, на которую умножаются оценки запросов для определения окончательной оценки. По умолчанию составляет 1.
Настройки предохранителя текущих запросов
Предохранитель текущих запросов ограничивает использование памяти для всех текущих входящих запросов на транспортном и HTTP-уровне. Использование памяти для запроса основано на длине содержимого запроса и включает память, необходимую для необработанного запроса и структурированного объекта, представляющего запрос. OpenSearch поддерживает следующие настройки предохранителя текущих запросов:
-
network.breaker.inflight_requests.limit (Динамическая, процент): Указывает лимит памяти для предохранителя текущих запросов. По умолчанию составляет 100% кучи JVM (таким образом, лимит использования памяти для текущего запроса определяется лимитом памяти родительского предохранителя).
-
network.breaker.inflight_requests.overhead (Динамическая, дробное число): Константа, на которую умножаются оценки текущих запросов для определения окончательной оценки. По умолчанию составляет 2.
Настройки предохранителя компиляции скриптов
Предохранитель компиляции скриптов ограничивает количество компиляций встроенных скриптов в течение временного интервала. OpenSearch поддерживает следующую настройку предохранителя компиляции скриптов:
- script.max_compilations_rate (Динамическая, ставка): Максимальное количество уникальных динамических скриптов, скомпилированных в течение временного интервала для данного контекста. По умолчанию составляет 150 каждые 5 минут (150/5m).
Настройки предохранителя регулярных выражений
Предохранитель регулярных выражений включает или отключает регулярные выражения и ограничивает их сложность. OpenSearch поддерживает следующие настройки предохранителя регулярных выражений:
-
script.painless.regex.enabled (Статическая, строка): Включает регулярные выражения в скриптах Painless. Допустимые значения:
- limited: Включает регулярные выражения и ограничивает их сложность с помощью настройки script.painless.regex.limit-factor.
- true: Включает регулярные выражения. Отключает предохранитель регулярных выражений и не ограничивает сложность регулярных выражений.
- false: Отключает регулярные выражения. Если скрипт Painless содержит регулярное выражение, возвращает ошибку.
По умолчанию установлено в limited.
-
script.painless.regex.limit-factor (Статическая, целое число): Применяется только если script.painless.regex.enabled установлено в limited. Ограничивает количество символов, которые может содержать регулярное выражение в скрипте Painless. Лимит символов рассчитывается путем умножения количества символов во входных данных скрипта на script.painless.regex.limit-factor. По умолчанию составляет 6 (таким образом, если входные данные содержат 5 символов, максимальное количество символов в регулярном выражении составляет 5 · 6 = 30).
2.3.7 - Настройка кластера
Следующие настройки относятся к кластеру OpenSearch.
Чтобы узнать больше о статических и динамических настройках, смотрите раздел Настройка OpenSearch.
Настройки маршрутизации и распределения на уровне кластера
OpenSearch поддерживает следующие настройки маршрутизации на уровне кластера и распределения шардов:
cluster.routing.allocation.enable (Динамическая, строка)
Включает или отключает распределение для определенных типов шардов.
Допустимые значения:
- all – Разрешает распределение шардов для всех типов шардов.
- primaries – Разрешает распределение шардов только для первичных шардов.
- new_primaries – Разрешает распределение шардов только для первичных шардов новых индексов.
- none – Распределение шардов не разрешено для любых индексов.
По умолчанию установлено значение all.
cluster.routing.allocation.node_concurrent_incoming_recoveries (Динамическая, целое число)
Настраивает, сколько параллельных входящих восстановлений шардов разрешено на узле. По умолчанию установлено значение 2.
cluster.routing.allocation.node_concurrent_outgoing_recoveries (Динамическая, целое число)
Настраивает, сколько параллельных исходящих восстановлений шардов разрешено на узле. По умолчанию установлено значение 2.
cluster.routing.allocation.node_concurrent_recoveries (Динамическая, строка)
Используется для установки значений cluster.routing.allocation.node_concurrent_incoming_recoveries и cluster.routing.allocation.node_concurrent_outgoing_recoveries на одно и то же значение.
cluster.routing.allocation.node_initial_primaries_recoveries (Динамическая, целое число)
Устанавливает количество восстановлений для нераспределенных первичных шардов после перезапуска узла. По умолчанию установлено значение 4.
cluster.routing.allocation.same_shard.host (Динамическая, логическое)
При установке в true предотвращает распределение нескольких копий шарда на разные узлы на одном хосте. По умолчанию установлено значение false.
cluster.routing.rebalance.enable (Динамическая, строка)
Включает или отключает перераспределение для определенных типов шардов.
Допустимые значения:
- all – Разрешает балансировку шардов для всех типов шардов.
- primaries – Разрешает балансировку шардов только для первичных шардов.
- replicas – Разрешает балансировку шардов только для реплик.
- none – Балансировка шардов не разрешена для любых индексов.
По умолчанию установлено значение all.
cluster.routing.allocation.allow_rebalance (Динамическая, строка)
Указывает, когда разрешено перераспределение шардов.
Допустимые значения:
- always – Всегда разрешать перераспределение.
- indices_primaries_active – Разрешать перераспределение только когда все первичные шары в кластере распределены.
- indices_all_active – Разрешать перераспределение только когда все шары в кластере распределены.
По умолчанию установлено значение indices_all_active.
cluster.routing.allocation.cluster_concurrent_rebalance (Динамическая, целое число)
Позволяет контролировать, сколько параллельных перераспределений шардов разрешено в кластере. По умолчанию установлено значение 2.
cluster.routing.allocation.balance.shard (Динамическая, число с плавающей точкой)
Определяет весовой коэффициент для общего количества шардов, распределенных на узел. По умолчанию установлено значение 0.45.
cluster.routing.allocation.balance.index (Динамическая, число с плавающей точкой)
Определяет весовой коэффициент для количества шардов на индекс, распределенных на узел. По умолчанию установлено значение 0.55.
cluster.routing.allocation.balance.threshold (Динамическая, число с плавающей точкой)
Минимальное значение оптимизации операций, которые должны быть выполнены. По умолчанию установлено значение 1.0.
cluster.routing.allocation.balance.prefer_primary (Динамическая, логическое)
При установке в true OpenSearch пытается равномерно распределить первичные шары между узлами кластера. Включение этой настройки не всегда гарантирует равное количество первичных шардов на каждом узле, особенно в случае сбоя. Изменение этой настройки на false после установки в true не вызывает перераспределение первичных шардов. По умолчанию установлено значение false.
cluster.routing.allocation.rebalance.primary.enable (Динамическая, логическое)
При установке в true OpenSearch пытается перераспределить первичные шары между узлами кластера. При включении кластер пытается поддерживать количество первичных шардов на каждом узле, с максимальным буфером, определенным настройкой cluster.routing.allocation.rebalance.primary.buffer. Изменение этой настройки на false после установки в true не вызывает перераспределение первичных шардов. По умолчанию установлено значение false.
cluster.routing.allocation.rebalance.primary.buffer (Динамическая, число с плавающей точкой)
Определяет максимальный допустимый буфер первичных шардов между узлами, когда включена настройка cluster.routing.allocation.rebalance.primary.enable. По умолчанию установлено значение 0.1.
cluster.routing.allocation.disk.threshold_enabled (Динамическая, логическое)
При установке в false отключает решение о распределении по диску. Это также удалит любые существующие блокировки индекса index.blocks.read_only_allow_delete, когда отключено. По умолчанию установлено значение true.
Настройки водяных знаков дискового пространства
cluster.routing.allocation.disk.watermark.low (Динамическая, строка)
Контролирует низкий водяной знак для использования дискового пространства. При установке в процентном соотношении OpenSearch не будет распределять шары на узлы с указанным процентом использования диска. Это также можно указать в виде дробного значения, например, 0.85. Наконец, это можно установить в байтовом значении, например, 400mb. Эта настройка не влияет на первичные шары новых индексов, но предотвратит распределение их реплик. По умолчанию установлено значение 85%.
cluster.routing.allocation.disk.watermark.high (Динамическая, строка)
Контролирует высокий водяной знак. OpenSearch попытается переместить шары с узла, использование диска на котором превышает установленный процент. Это также можно указать в виде дробного значения, например, 0.85. Наконец, это можно установить в байтовом значении, например, 400mb. Эта настройка влияет на распределение всех шардов. По умолчанию установлено значение 90%.
cluster.routing.allocation.disk.watermark.flood_stage (Динамическая, строка)
Контролирует водяной знак на уровне затопления. Это последний шаг для предотвращения исчерпания дискового пространства на узлах. OpenSearch применяет блокировку индекса только для чтения (index.blocks.read_only_allow_delete) ко всем индексам, на которых есть один или несколько шардов, распределенных на узле, и хотя бы один диск превышает уровень затопления. Блокировка индекса снимается, как только использование диска падает ниже высокого водяного знака. Это также можно указать в виде дробного значения, например, 0.85. Наконец, это можно установить в байтовом значении, например, 400mb. По умолчанию установлено значение 95%.
cluster.info.update.interval (Динамическая, единица времени)
Устанавливает, как часто OpenSearch должен проверять использование диска для каждого узла в кластере. По умолчанию установлено значение 30s.
Настройки распределения шардов по атрибутам
cluster.routing.allocation.include. (Динамическая, перечисление)
Распределяет шары на узел, атрибут которого содержит хотя бы одно из включенных значений, разделенных запятыми.
cluster.routing.allocation.require. (Динамическая, перечисление)
Распределяет шары только на узел, атрибут которого содержит все включенные значения, разделенные запятыми.
cluster.routing.allocation.exclude. (Динамическая, перечисление)
Не распределяет шары на узел, атрибут которого содержит любое из включенных значений, разделенных запятыми. Настройки распределения кластера поддерживают следующие встроенные атрибуты.
Допустимые значения:
- _name – Совпадение узлов по имени узла.
- _host_ip – Совпадение узлов по IP-адресу хоста.
- _publish_ip – Совпадение узлов по публикуемому IP-адресу.
- _ip – Совпадение по _host_ip или _publish_ip.
- _host – Совпадение узлов по имени хоста.
- _id – Совпадение узлов по идентификатору узла.
- _tier – Совпадение узлов по роли уровня данных.
Настройки перемещения шардов
cluster.routing.allocation.shard_movement_strategy (Динамическая, перечисление)
Определяет порядок, в котором шары перемещаются с исходящих узлов на входящие.
Эта настройка поддерживает следующие стратегии:
- PRIMARY_FIRST – Первичные шары перемещаются первыми, перед репликами. Эта приоритизация может помочь предотвратить переход состояния здоровья кластера в красный, если узлы, на которые перемещаются шары, выйдут из строя в процессе.
- REPLICA_FIRST – Репликационные шары перемещаются первыми, перед первичными. Эта приоритизация может помочь предотвратить переход состояния здоровья кластера в красный при выполнении перемещения шардов в кластере OpenSearch с смешанными версиями и включенной репликацией сегментов. В этой ситуации первичные шары, перемещенные на узлы OpenSearch более новой версии, могут попытаться скопировать файлы сегментов на репликационные шары более старой версии OpenSearch, что приведет к сбою шардов. Перемещение репликационных шардов первыми может помочь избежать этого в кластерах с несколькими версиями.
- NO_PREFERENCE – Поведение по умолчанию, при котором порядок перемещения шардов не имеет значения.
cluster.routing.search_replica.strict (Динамическая, логическое)
Контролирует, как маршрутизируются поисковые запросы, когда для индекса существуют репликационные шары, например, когда index.number_of_search_replicas больше 0. Эта настройка применяется только в случае, если для индекса настроены поисковые реплики. При установке в true все поисковые запросы для таких индексов маршрутизируются только на репликационные шары. Если репликационные шары не назначены, запросы завершаются неудачей. При установке в false, если репликационные шары не назначены, запросы возвращаются к любому доступному шару. По умолчанию установлено значение true.
cluster.allocator.gateway.batch_size (Динамическая, целое число)
Ограничивает количество шардов, отправляемых на узлы данных в одной партии для получения метаданных любых нераспределенных шардов. По умолчанию установлено значение 2000.
cluster.allocator.existing_shards_allocator.batch_enabled (Статическая, логическая)
Включает пакетное распределение нераспределенных шардов, которые уже существуют на диске, вместо распределения одного шара за раз. Это снижает нагрузку на память и транспорт, получая метаданные любых нераспределенных шардов в пакетном вызове. По умолчанию установлено значение false.
cluster.routing.allocation.total_shards_per_node (Динамическая, целое число)
Максимальное общее количество первичных и репликационных шардов, которые могут быть распределены на один узел. По умолчанию установлено значение -1 (без ограничений). Помогает равномерно распределять шары по узлам, ограничивая общее количество шардов на узел. Используйте с осторожностью, так как шары могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
cluster.routing.allocation.total_primary_shards_per_node (Динамическая, целое число)
Максимальное количество первичных шардов, которые могут быть распределены на один узел. Эта настройка применима только для кластеров с удаленной поддержкой. По умолчанию установлено значение -1 (без ограничений). Помогает равномерно распределять первичные шары по узлам, ограничивая количество первичных шардов на узел. Используйте с осторожностью, так как первичные шары могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
Настройки шардов, блокировок и задач на уровне кластера
OpenSearch поддерживает следующие настройки шардов, блокировок и задач на уровне кластера:
action.search.shard_count.limit (Целое число)
Ограничивает максимальное количество шардов, которые могут быть задействованы во время поиска. Запросы, превышающие этот лимит, будут отклонены.
cluster.blocks.read_only (Логическое)
Устанавливает весь кластер в режим только для чтения. По умолчанию установлено значение false.
cluster.blocks.read_only_allow_delete (Логическое)
Похоже на cluster.blocks.read_only, но позволяет удалять индексы.
cluster.max_shards_per_node (Целое число)
Ограничивает общее количество первичных и репликационных шардов для кластера. Лимит рассчитывается следующим образом: cluster.max_shards_per_node умножается на количество не замороженных узлов данных. Шары для закрытых индексов не учитываются в этом лимите. По умолчанию установлено значение 1000.
cluster.persistent_tasks.allocation.enable (Строка)
Включает или отключает распределение для постоянных задач.
Допустимые значения:
- all – Разрешает назначение постоянных задач на узлы.
- none – Распределение для постоянных задач не разрешено. Это не влияет на уже работающие постоянные задачи.
По умолчанию установлено значение all.
cluster.persistent_tasks.allocation.recheck_interval (Единица времени)
Менеджер кластера автоматически проверяет, нужно ли назначать постоянные задачи, когда состояние кластера изменяется значительным образом. Существуют и другие факторы, такие как использование памяти, которые повлияют на то, будут ли постоянные задачи назначены на узлы, но не вызывают изменения состояния кластера. Эта настройка определяет, как часто выполняются проверки назначения в ответ на эти факторы. По умолчанию установлено значение 30 секунд, при этом минимальное значение составляет 10 секунд.
Настройки медленных логов на уровне кластера
Для получения дополнительной информации смотрите раздел Медленные логи запросов поиска.
cluster.search.request.slowlog.threshold.warn (Единица времени)
Устанавливает порог WARN для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.threshold.info (Единица времени)
Устанавливает порог INFO для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.threshold.debug (Единица времени)
Устанавливает порог DEBUG для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.threshold.trace (Единица времени)
Устанавливает порог TRACE для медленных логов на уровне запросов. По умолчанию установлено значение -1.
cluster.search.request.slowlog.level (Строка)
Устанавливает минимальный уровень медленного лога для записи: WARN, INFO, DEBUG и TRACE. По умолчанию установлено значение TRACE.
Настройки индекса на уровне кластера
Для получения информации о настройках индекса на уровне индекса смотрите раздел Настройки индекса на уровне кластера.
Настройки координации на уровне кластера
OpenSearch поддерживает следующие настройки координации на уровне кластера. Все настройки в этом списке являются динамическими:
cluster.fault_detection.leader_check.timeout (Единица времени)
Количество времени, в течение которого узел ждет ответа от избранного менеджера кластера во время проверки лидера, прежде чем считать проверку неудачной. Допустимые значения от 1ms до 60s, включая. По умолчанию установлено значение 10s. Изменение этой настройки на значение, отличное от значения по умолчанию, может привести к нестабильности кластера.
cluster.fault_detection.follower_check.timeout (Единица времени)
Количество времени, в течение которого избранный менеджер кластера ждет ответа во время проверки последователя, прежде чем считать проверку неудачной. Допустимые значения от 1ms до 60s, включая. По умолчанию установлено значение 10s. Изменение этой настройки на значение, отличное от значения по умолчанию, может привести к нестабильности кластера.
cluster.fault_detection.follower_check.interval (Единица времени)
Количество времени, в течение которого избранный менеджер кластера ждет между отправкой проверок последователей другим узлам в кластере. Допустимые значения 100ms и выше. По умолчанию установлено значение 1000ms. Изменение этой настройки на значение, отличное от значения по умолчанию, может привести к нестабильности кластера.
cluster.follower_lag.timeout (Единица времени)
Количество времени, в течение которого избранный менеджер кластера ждет получения подтверждений обновлений состояния кластера от отстающих узлов. По умолчанию установлено значение 90s. Если узел не успешно применяет обновление состояния кластера в течение этого времени, он считается неудавшимся и удаляется из кластера.
cluster.publish.timeout (Единица времени)
Количество времени, в течение которого менеджер кластера ждет, пока каждое обновление состояния кластера будет полностью опубликовано на всех узлах, если только discovery.type не установлен на single-node. По умолчанию установлено значение 30s.
Настройки пределов ответов CAT на уровне кластера
OpenSearch поддерживает следующие настройки пределов ответов CAT API на уровне кластера, все из которых являются динамическими:
cat.indices.response.limit.number_of_indices (Целое число)
Устанавливает предел на количество индексов, возвращаемых API CAT Indices. Значение по умолчанию -1 (без ограничений). Если количество индексов в ответе превышает этот предел, API возвращает ошибку 429. Чтобы избежать этого, вы можете указать фильтр по шаблону индекса в вашем запросе (например, _cat/indices/<index-pattern>).
cat.shards.response.limit.number_of_shards (Целое число)
Устанавливает предел на количество шардов, возвращаемых API CAT Shards. Значение по умолчанию -1 (без ограничений). Если количество шардов в ответе превышает этот предел, API возвращает ошибку 429. Чтобы избежать этого, вы можете указать фильтр по шаблону индекса в вашем запросе (например, _cat/shards/<index-pattern>).
cat.segments.response.limit.number_of_indices (Целое число)
Устанавливает предел на количество индексов, возвращаемых API CAT Segments. Значение по умолчанию -1 (без ограничений). Если количество индексов в ответе превышает этот предел, API возвращает ошибку 429. Чтобы избежать этого, вы можете указать фильтр по шаблону индекса в вашем запросе (например, _cat/segments/<index-pattern>).
2.3.8 - Настройка индекса
Настройки индекса могут быть двух типов: настройки уровня кластера, которые влияют на все индексы в кластере, и настройки уровня индекса, которые влияют на отдельные индексы.
Чтобы узнать больше о статических и динамических настройках, смотрите Конфигурирование OpenSearch.
Настройки индекса уровня кластера
Существует два типа настроек кластера:
- Статические настройки индекса уровня кластера — это настройки, которые нельзя обновить, пока кластер работает. Чтобы обновить статическую настройку, необходимо остановить кластер, обновить настройку, а затем перезапустить кластер.
- Динамические настройки индекса уровня кластера — это настройки, которые можно обновлять в любое время.
Статические настройки индекса уровня кластера
OpenSearch поддерживает следующие статические настройки индекса уровня кластера:
-
indices.cache.cleanup_interval (Единица времени): Запланирует периодическую фоновую задачу, которая очищает истекшие записи из кэша с указанным интервалом. По умолчанию 1m (1 минута). Для получения дополнительной информации смотрите Кэш запросов индекса.
-
indices.requests.cache.size (Строка): Размер кэша в процентах от размера кучи (например, чтобы использовать 1% кучи, укажите 1%). По умолчанию 1%. Для получения дополнительной информации смотрите Кэш запросов индекса.
Динамические настройки индекса уровня кластера
OpenSearch поддерживает следующие динамические настройки индекса уровня кластера:
-
action.auto_create_index (Булевый): Автоматически создает индекс, если индекс еще не существует. Также применяет любые конфигурации шаблонов индексов. По умолчанию true.
-
indices.recovery.max_concurrent_file_chunks (Целое число): Количество частей файлов, отправляемых параллельно для каждой операции восстановления. По умолчанию 2.
-
indices.recovery.max_concurrent_operations (Целое число): Количество операций, отправляемых параллельно для каждого восстановления. По умолчанию 1.
-
indices.recovery.max_concurrent_remote_store_streams (Целое число): Количество потоков к удаленному репозиторию, которые могут быть открыты параллельно при восстановлении индекса из удаленного хранилища. По умолчанию 20.
-
indices.replication.max_bytes_per_sec (Строка): Ограничивает общий входящий и исходящий трафик репликации для каждого узла. Если значение не указано в конфигурации, используется настройка indices.recovery.max_bytes_per_sec, по умолчанию равная 40 МБ. Если вы установите значение трафика репликации меньше или равным 0 МБ, ограничение скорости будет отключено, что приведет к передаче данных репликации с максимальной возможной скоростью.
-
indices.fielddata.cache.size (Строка): Максимальный размер кэша данных полей. Может быть указан как абсолютное значение (например, 8 ГБ) или процент от кучи узла (например, 50%). Это значение статическое, поэтому его необходимо указать в файле opensearch.yml. Если вы не укажете эту настройку, максимальный размер будет неограниченным. Это значение должно быть меньше, чем indices.breaker.fielddata.limit. Для получения дополнительной информации смотрите Систему защиты от переполнения кэша данных полей.
-
indices.query.bool.max_clause_count (Целое число): Определяет максимальное произведение полей и терминов, которые могут быть запрошены одновременно. До версии OpenSearch 2.16 для применения этой статической настройки требовалась перезагрузка кластера. Теперь она динамическая, существующие пулы потоков поиска могут использовать старое статическое значение, что может привести к исключениям TooManyClauses. Новые пулы потоков используют обновленное значение. По умолчанию 1024.
-
cluster.remote_store.index.path.type (Строка): Стратегия пути для данных, хранящихся в удаленном хранилище. Эта настройка эффективна только для кластеров с включенным удаленным хранилищем. Эта настройка поддерживает следующие значения:
fixed: Хранит данные в структуре пути <repository_base_path>/<index_uuid>/<shard_id>/.hashed_prefix: Хранит данные в структуре пути hash(<shard-data-identifier>)/<repository_base_path>/<index_uuid>/<shard_id>/.hashed_infix: Хранит данные в структуре пути <repository_base_path>/hash(<shard-data-identifier>)/<index_uuid>/<shard_id>/. shard-data-identifier характеризуется index_uuid, shard_id, типом данных (translog, segments) и типом данных (data, metadata, lock_files). По умолчанию fixed.
-
cluster.remote_store.index.path.hash_algorithm (Строка): Хеш-функция, используемая для получения хеш-значения, когда cluster.remote_store.index.path.type установлено на hashed_prefix или hashed_infix. Эта настройка эффективна только для кластеров с включенным удаленным хранилищем. Эта настройка поддерживает следующие значения:
fnv_1a_base64: Использует хеш-функцию FNV1a и генерирует безопасное для URL 20-битное хеш-значение в формате base64.fnv_1a_composite_1: Использует хеш-функцию FNV1a и генерирует пользовательское закодированное хеш-значение, которое хорошо масштабируется с большинством опций удаленного хранилища. Функция FNV1a генерирует 64-битное значение. Пользовательское кодирование использует 6 старших бит для создания безопасного для URL символа base64 и следующие 14 бит для создания двоичной строки. По умолчанию fnv_1a_composite_1.
-
cluster.remote_store.translog.transfer_timeout (Единица времени): Управляет значением таймаута при загрузке файлов translog и контрольных точек во время синхронизации с удаленным хранилищем. Эта настройка применяется только для кластеров с включенным удаленным хранилищем. По умолчанию 30 секунд.
-
cluster.remote_store.index.segment_metadata.retention.max_count (Целое число): Управляет минимальным количеством файлов метаданных, которые необходимо сохранить в репозитории сегментов на удаленном хранилище. Значение ниже 1 отключает удаление устаревших файлов метаданных сегментов. По умолчанию 10.
-
cluster.remote_store.segment.transfer_timeout (Единица времени): Управляет максимальным временем ожидания обновления всех новых сегментов после обновления в удаленное хранилище. Если загрузка не завершится в течение указанного времени, будет выброшено исключение SegmentUploadFailedException. По умолчанию 30 минут. Минимальное ограничение составляет 10 минут.
-
cluster.remote_store.translog.path.prefix (Строка): Управляет фиксированным префиксом пути для данных translog на кластере с включенным удаленным хранилищем. Эта настройка применяется только в том случае, если настройка cluster.remote_store.index.path.type установлена на HASHED_PREFIX или HASHED_INFIX. По умолчанию пустая строка, “”.
-
cluster.remote_store.segments.path.prefix (Строка): Управляет фиксированным префиксом пути для данных сегментов на кластере с включенным удаленным хранилищем. Эта настройка применяется только в том случае, если настройка cluster.remote_store.index.path.type установлена на HASHED_PREFIX или HASHED_INFIX. По умолчанию пустая строка, “”.
-
cluster.snapshot.shard.path.prefix (Строка): Управляет фиксированным префиксом пути для блобов уровня сегмента снимка. Эта настройка применяется только в том случае, если настройка repository.shard_path_type установлена на HASHED_PREFIX или HASHED_INFIX. По умолчанию пустая строка, “”.
-
cluster.default_number_of_replicas (Целое число): Управляет значением по умолчанию для количества реплик индексов в кластере. Настройка уровня индекса index.number_of_replicas по умолчанию принимает это значение, если не настроена. По умолчанию 1.
-
cluster.thread_pool.<fixed-threadpool>.size (Целое число): Управляет размерами как фиксированных, так и изменяемых очередей пулов потоков. Переопределяет значения по умолчанию, указанные в opensearch.yml.
-
cluster.thread_pool.<scaling-threadpool>.max (Целое число): Устанавливает максимальный размер пула потоков с изменяемым размером. Переопределяет значение по умолчанию, указанное в opensearch.yml.
-
cluster.thread_pool.<scaling-threadpool>.core (Целое число): Указывает базовый размер пула потоков с изменяемым размером. Переопределяет значение по умолчанию, указанное в opensearch.yml.
Прежде чем настраивать параметры пула потоков динамически, обратите внимание, что это настройки для экспертов, которые могут потенциально дестабилизировать ваш кластер. Изменение настроек пула потоков применяет один и тот же размер пула потоков ко всем узлам, поэтому это не рекомендуется для кластеров с различным оборудованием для одних и тех же ролей. Аналогично, избегайте настройки пулов потоков, которые используются как узлами данных, так и узлами управления кластером. После внесения этих изменений рекомендуется следить за вашим кластером, чтобы убедиться, что он остается стабильным и работает как ожидается.
Настройки индекса уровня индекса
Вы можете указать настройки индекса при создании индекса. Существует два типа настроек индекса:
-
Статические настройки индекса уровня индекса — это настройки, которые нельзя обновить, пока индекс открыт. Чтобы обновить статическую настройку, необходимо закрыть индекс, обновить настройку, а затем снова открыть индекс.
-
Динамические настройки индекса уровня индекса — это настройки, которые можно обновлять в любое время.
Указание настройки при создании индекса
При создании индекса вы можете указать его статические или динамические настройки следующим образом:
PUT /testindex
{
"settings": {
"index.number_of_shards": 1,
"index.number_of_replicas": 2
}
}
Статические настройки индекса уровня индекса
OpenSearch поддерживает следующие статические настройки индекса уровня индекса:
-
index.number_of_shards (Целое число): Количество первичных шардов в индексе. По умолчанию 1.
-
index.number_of_routing_shards (Целое число): Количество шардов маршрутизации, используемых для разделения индекса.
-
index.shard.check_on_startup (Булевый): Указывает, следует ли проверять шардов индекса на наличие повреждений. Доступные опции:
false (не проверять на повреждения),checksum (проверять на физические повреждения),true (проверять как на физические, так и на логические повреждения).
По умолчанию false.
-
index.codec (Строка): Определяет, как сжимаются и хранятся на диске сохраненные поля индекса. Эта настройка влияет на размер шардов индекса и производительность операций индексации.
Допустимые значения:
defaultbest_compressionzstd (OpenSearch 2.9 и позже)zstd_no_dict (OpenSearch 2.9 и позже)qat_lz4 (OpenSearch 2.14 и позже, на поддерживаемых системах)qat_deflate (OpenSearch 2.14 и позже, на поддерживаемых системах)
Для zstd, zstd_no_dict, qat_lz4 и qat_deflate вы можете указать уровень сжатия в настройке index.codec.compression_level. Для получения дополнительной информации смотрите Настройки кодека индекса. Опционально. По умолчанию default.
-
index.codec.compression_level (Целое число): Настройка уровня сжатия обеспечивает компромисс между коэффициентом сжатия и скоростью. Более высокий уровень сжатия приводит к более высокому коэффициенту сжатия (меньший размер хранения), но замедляет скорость сжатия и распаковки, что приводит к увеличению задержек при индексации и поиске. Эта настройка может быть указана только если index.codec установлен на zstd и zstd_no_dict в OpenSearch 2.9 и позже или qat_lz4 и qat_deflate в OpenSearch 2.14 и позже. Допустимые значения — целые числа в диапазоне [1, 6]. Для получения дополнительной информации смотрите Настройки кодека индекса. Опционально. По умолчанию 3.
-
index.codec.qatmode (Строка): Режим аппаратного ускорения, используемый для кодеков сжатия qat_lz4 и qat_deflate. Допустимые значения: auto и hardware. Для получения дополнительной информации смотрите Настройки кодека индекса. Опционально. По умолчанию auto.
-
index.routing_partition_size (Целое число): Количество шардов, к которым может быть направлено значение пользовательской маршрутизации. Маршрутизация помогает несбалансированному кластеру, перемещая значения к подмножеству шардов, а не к одному шару. Чтобы включить маршрутизацию, установите это значение больше 1, но меньше index.number_of_shards. По умолчанию 1.
-
index.soft_deletes.retention_lease.period (Единица времени): Максимальное время хранения истории операций шара. По умолчанию 12 часов.
-
index.load_fixed_bitset_filters_eagerly (Булевый): Указывает, должен ли OpenSearch предварительно загружать кэшированные фильтры. Доступные опции: true и false. По умолчанию true.
-
index.hidden (Булевый): Указывает, должен ли индекс быть скрытым. Скрытые индексы не возвращаются в результате запросов, содержащих подстановочные знаки. Доступные опции: true и false. По умолчанию false.
-
index.merge.policy (Строка): Эта настройка управляет политикой слияния для сегментов Lucene. Доступные опции: tiered и log_byte_size. По умолчанию tiered, но для временных данных, таких как журналы событий, рекомендуется использовать политику слияния log_byte_size, которая может улучшить производительность запросов при выполнении диапазонных запросов по полю @timestamp. Рекомендуется не изменять политику слияния существующего индекса. Вместо этого настройте эту опцию при создании нового индекса.
-
index.merge_on_flush.enabled (Булевый): Эта настройка управляет функцией слияния при обновлении Apache Lucene, которая направлена на уменьшение количества сегментов путем выполнения слияний при обновлении (или, в терминах OpenSearch, при сбросе). По умолчанию true.
-
index.merge_on_flush.max_full_flush_merge_wait_time (Единица времени): Эта настройка устанавливает время ожидания для слияний, когда index.merge_on_flush.enabled включен. По умолчанию 10 секунд.
-
index.merge_on_flush.policy (Строка): Эта настройка управляет тем, какая политика слияния должна использоваться, когда index.merge_on_flush.enabled включен. По умолчанию default.
-
index.check_pending_flush.enabled (Булевый): Эта настройка управляет параметром checkPendingFlushOnUpdate индексации Apache Lucene, который указывает, должен ли поток индексации проверять наличие ожидающих сбросов при обновлении, чтобы сбросить буферы индексации на диск. По умолчанию true.
-
index.use_compound_file (Булевый): Эта настройка управляет параметрами useCompoundFile индексации Apache Lucene, которые указывают, будут ли новые файлы сегментов упакованы в составной файл. По умолчанию true.
-
index.append_only.enabled (Булевый): Установите значение true, чтобы предотвратить любые обновления документов в индексе. По умолчанию false.
Обновление статической настройки индекса
Вы можете обновить статическую настройку индекса только для закрытого индекса. Следующий пример демонстрирует обновление настройки кодека индекса.
Сначала закройте индекс:
Затем обновите настройки, отправив запрос к конечной точке _settings:
PUT /testindex/_settings
{
"index": {
"codec": "zstd_no_dict",
"codec.compression_level": 3
}
}
Наконец, снова откройте индекс, чтобы включить операции чтения и записи:
Для получения дополнительной информации об обновлении настроек, включая поддерживаемые параметры запроса, смотрите Обновление настроек.
Динамические настройки индекса уровня индекса
OpenSearch поддерживает следующие динамические настройки индекса уровня индекса:
-
index.number_of_replicas (Целое число): Количество реплик, которые должен иметь каждый первичный шард. Например, если у вас 4 первичных шарда и вы установите index.number_of_replicas на 3, индекс будет иметь 12 реплик. Если не установлено, по умолчанию используется значение cluster.default_number_of_replicas (по умолчанию 1).
-
index.number_of_search_replicas (Целое число): Количество поисковых реплик, которые должен иметь каждый первичный шард. Например, если у вас 4 первичных шарда и вы установите index.number_of_search_replicas на 3, индекс будет иметь 12 поисковых реплик. По умолчанию 0.
-
index.auto_expand_replicas (Строка): Указывает, должен ли кластер автоматически добавлять реплики на основе количества узлов данных. Укажите нижнюю и верхнюю границы (например, 0–9) или all для верхней границы. Например, если у вас 5 узлов данных и вы установите index.auto_expand_replicas на 0–3, кластер не добавит еще одну реплику. Однако, если вы установите это значение на 0-all и добавите 2 узла, всего 7, кластер расширится до 6 реплик. По умолчанию отключено.
-
index.auto_expand_search_replicas (Строка): Управляет тем, автоматически ли кластер регулирует количество поисковых реплик на основе количества доступных узлов поиска. Укажите значение в виде диапазона с нижней и верхней границей, например, 0-3 или 0-all. Если вы не укажете значение, эта функция отключена.
Например, если у вас 5 узлов данных и вы установите index.auto_expand_search_replicas на 0-3, индекс может иметь до 3 поисковых реплик, и кластер не добавит еще одну поисковую реплику. Однако, если вы установите index.auto_expand_search_replicas на 0-all и добавите 2 узла, всего 7, кластер расширится до 7 поисковых реплик. Эта настройка по умолчанию отключена.
-
index.search.idle.after (Единица времени): Время, в течение которого шард должен ждать запроса поиска или получения, прежде чем перейти в состояние ожидания. По умолчанию 30 секунд.
-
index.search.default_pipeline (Строка): Имя поискового конвейера, который используется, если при поиске индекса не установлен явный конвейер. Если установлен конвейер по умолчанию и он не существует, запросы к индексу завершатся неудачей. Используйте имя конвейера _none, чтобы указать отсутствие конвейера поиска по умолчанию. Для получения дополнительной информации смотрите Конвейер поиска по умолчанию.
-
index.refresh_interval (Единица времени): Как часто индекс должен обновляться, что публикует его последние изменения и делает их доступными для поиска. Может быть установлено на -1 для отключения обновления. По умолчанию 1 секунда.
-
index.max_result_window (Целое число): Максимальное значение from + size для запросов к индексу. from — это начальный индекс для поиска, а size — количество результатов для возврата. По умолчанию 10000.
-
index.max_inner_result_window (Целое число): Максимальное значение from + size, которое указывает количество возвращаемых вложенных результатов поиска и наиболее релевантных документов, агрегированных во время запроса. from — это начальный индекс для поиска, а size — количество верхних результатов для возврата. По умолчанию 100.
-
index.max_rescore_window (Целое число): Максимальное значение window_size для запросов пересчета к индексу. Запросы пересчета изменяют порядок документов индекса и возвращают новый балл, который может быть более точным. По умолчанию такое же, как index.max_inner_result_window, или 10000 по умолчанию.
-
index.max_docvalue_fields_search (Целое число): Максимальное количество docvalue_fields, разрешенных в запросе. По умолчанию 100.
-
index.max_script_fields (Целое число): Максимальное количество script_fields, разрешенных в запросе. По умолчанию 32.
-
index.max_ngram_diff (Целое число): Максимальная разница между значениями min_gram и max_gram для NGramTokenizer и NGramTokenFilter. По умолчанию 1.
-
index.max_shingle_diff (Целое число): Максимальная разница между max_shingle_size и min_shingle_size, которая подается в фильтр токенов shingle. По умолчанию 3.
-
index.max_refresh_listeners (Целое число): Максимальное количество слушателей обновления, которые может иметь каждый шард.
-
index.analyze.max_token_count (Целое число): Максимальное количество токенов, которые могут быть возвращены из операции API _analyze. По умолчанию 10000.
-
index.highlight.max_analyzed_offset (Целое число): Количество символов, которые может анализировать запрос на выделение. По умолчанию 1000000.
-
index.max_terms_count (Целое число): Максимальное количество терминов, которые может принять запрос терминов. По умолчанию 65536.
-
index.max_regex_length (Целое число): Максимальная длина символов регулярного выражения, которое может быть в запросе regexp. По умолчанию 1000.
-
index.query.default_field (Список): Поле или список полей, которые OpenSearch использует в запросах, если поле не указано в параметрах.
-
index.query.max_nested_depth (Целое число): Максимальное количество уровней вложенности для вложенных запросов. По умолчанию 20. Минимум 1 (один вложенный запрос).
-
index.requests.cache.enable (Булевый): Включает или отключает кэш запросов индекса. По умолчанию true. Для получения дополнительной информации смотрите Кэш запросов индекса.
-
index.routing.allocation.enable (Строка): Указывает параметры для распределения шардов индекса. Доступные опции:
all (разрешить распределение для всех шардов),primaries (разрешить распределение только для первичных шардов),new_primaries (разрешить распределение только для новых первичных шардов),none (не разрешать распределение).
По умолчанию all.
-
index.routing.rebalance.enable (Строка): Включает перераспределение шардов для индекса. Доступные опции:
all (разрешить перераспределение для всех шардов),primaries (разрешить перераспределение только для первичных шардов),replicas (разрешить перераспределение только для реплик),none (не разрешать перераспределение).
По умолчанию all.
-
index.gc_deletes (Единица времени): Время хранения номера версии удаленного документа. По умолчанию 60 секунд.
-
index.default_pipeline (Строка): Конвейер узла обработки по умолчанию для индекса. Если установлен конвейер по умолчанию и он не существует, запросы к индексу завершатся неудачей. Имя конвейера _none указывает на то, что у индекса нет конвейера обработки.
-
index.final_pipeline (Строка): Конечный конвейер узла обработки для индекса. Если установлен конечный конвейер и он не существует, запросы к индексу завершатся неудачей. Имя конвейера _none указывает на то, что у индекса нет конвейера обработки.
-
index.optimize_doc_id_lookup.fuzzy_set.enabled (Булевый): Эта настройка управляет тем, следует ли включать fuzzy_set для оптимизации поиска идентификаторов документов в индексах или запросах, используя дополнительную структуру данных, в данном случае структуру данных Bloom filter. Включение этой настройки улучшает производительность операций upsert и поиска, которые зависят от идентификаторов документов, создавая новую структуру данных (Bloom filter). Bloom filter позволяет обрабатывать отрицательные случаи (то есть идентификаторы, отсутствующие в существующем индексе) с помощью более быстрых обращений вне кучи. Обратите внимание, что создание Bloom filter требует дополнительного использования кучи во время индексации. По умолчанию false.
-
index.optimize_doc_id_lookup.fuzzy_set.false_positive_probability (Число с плавающей точкой)
Устанавливает вероятность ложного срабатывания для базового fuzzy_set (то есть, фильтра Блума). Более низкая вероятность ложного срабатывания обеспечивает более высокую пропускную способность для операций upsert и get, но приводит к увеличению использования памяти и хранилища. Допустимые значения находятся в диапазоне от 0.01 до 0.50. По умолчанию установлено значение 0.20.
index.routing.allocation.total_shards_per_node (Целое число)
Максимальное общее количество первичных и репликационных шардов из одного индекса, которые могут быть распределены на один узел. По умолчанию установлено значение -1 (без ограничений). Помогает контролировать распределение шардов по узлам для каждого индекса, ограничивая количество шардов на узел. Используйте с осторожностью, так как шары из этого индекса могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
index.routing.allocation.total_primary_shards_per_node (Целое число)
Максимальное количество первичных шардов из одного индекса, которые могут быть распределены на один узел. Эта настройка применима только для кластеров с удаленной поддержкой. По умолчанию установлено значение -1 (без ограничений). Помогает контролировать распределение первичных шардов по узлам для каждого индекса, ограничивая количество первичных шардов на узел. Используйте с осторожностью, так как первичные шары из этого индекса могут оставаться нераспределенными, если узлы достигнут своих настроенных лимитов.
Обновление динамической настройки индекса
Вы можете обновить динамическую настройку индекса в любое время через API. Например, чтобы обновить интервал обновления, используйте следующий запрос:
PUT /testindex/_settings
{
"index": {
"refresh_interval": "2s"
}
}
Для получения дополнительной информации об обновлении настроек, включая поддерживаемые параметры запроса, смотрите раздел Обновление настроек.
2.3.9 - Настройки поиска
OpenSearch поддерживает следующие настройки поиска
-
search.max_buckets (Динамическое, целое число): Максимальное количество агрегатных бакетов, разрешенных в одном ответе. По умолчанию 65535.
-
search.phase_took_enabled (Динамическое, логическое): Включает возврат значений времени на уровне фаз в ответах на поиск. По умолчанию false.
-
search.allow_expensive_queries (Динамическое, логическое): Разрешает или запрещает дорогостоящие запросы. Для получения дополнительной информации см. Дорогостоящие запросы.
-
search.default_allow_partial_results (Динамическое, логическое): Настройка на уровне кластера, которая позволяет возвращать частичные результаты поиска, если запрос превышает время ожидания или если шард не отвечает. Если запрос на поиск содержит параметр allow_partial_search_results, этот параметр имеет приоритет над данной настройкой. По умолчанию true.
-
search.cancel_after_time_interval (Динамическое, единица времени): Настройка на уровне кластера, которая устанавливает значение по умолчанию для таймаута всех запросов на поиск на уровне координирующего узла. После достижения указанного времени запрос останавливается, и все связанные задачи отменяются. По умолчанию -1 (без таймаута).
-
search.default_search_timeout (Динамическое, единица времени): Настройка на уровне кластера, которая указывает максимальное время, в течение которого запрос на поиск может выполняться, прежде чем он будет отменен на уровне шарда. Если интервал таймаута указан в запросе на поиск, этот интервал имеет приоритет над настроенной настройкой. По умолчанию -1.
-
search.default_keep_alive (Динамическое, единица времени): Указывает значение по умолчанию для поддержания активности для запросов с прокруткой и точкой во времени (PIT). Поскольку запрос может попадать на шард несколько раз (например, во время фаз запроса и извлечения), OpenSearch открывает контекст запроса, который существует на протяжении всего времени запроса, чтобы обеспечить согласованность состояния шарда для каждого отдельного запроса к шард. В стандартном поиске, как только фаза извлечения завершается, контекст запроса закрывается. Для запроса с прокруткой или PIT OpenSearch сохраняет контекст запроса открытым до явного закрытия (или до достижения времени поддержания активности). Фоновый поток периодически проверяет все открытые контексты прокрутки и PIT и удаляет те, которые превысили свой таймаут поддержания активности. Настройка search.keep_alive_interval указывает, как часто контексты проверяются на истечение срока. Настройка search.default_keep_alive является значением по умолчанию для истечения срока. Запрос с прокруткой или PIT может явно указать время поддержания активности, которое имеет приоритет над этой настройкой. По умолчанию 5m.
-
search.keep_alive_interval (Статическое, единица времени): Определяет интервал, с которым OpenSearch проверяет контексты запросов, которые превысили свой лимит поддержания активности. По умолчанию 1m.
-
search.max_keep_alive (Динамическое, единица времени): Указывает максимальное значение поддержания активности. Настройка max_keep_alive используется в качестве меры безопасности по отношению к другим настройкам поддержания активности (например, default_keep_alive) и настройкам поддержания активности на уровне запроса (для контекстов прокрутки и PIT). Если запрос превышает значение max_keep_alive в любом из случаев, операция завершится неудачей. По умолчанию 24h.
-
search.low_level_cancellation (Динамическое, логическое): Включает механизм низкоуровневой отмены запросов. Классический механизм таймаута Lucene проверяет время только во время сбора результатов поиска. Однако дорогостоящий запрос, такой как запрос с подстановочными знаками или префиксами, может занять много времени для расширения перед началом сбора результатов. В этом случае запрос может выполняться в течение времени, превышающего значение таймаута. Механизм низкоуровневой отмены решает эту проблему, устанавливая таймаут не только во время сбора результатов поиска, но и во время фазы расширения запроса или перед выполнением любой операции Lucene. По умолчанию true.
-
search.max_open_scroll_context (Динамическое, целое число): Настройка на уровне узла, которая указывает максимальное количество открытых контекстов прокрутки для узла. По умолчанию 500.
-
search.request_stats_enabled (Динамическое, логическое): Включает сбор статистики времени фаз на уровне узла с точки зрения координирующего узла. Статистика на уровне запроса отслеживает, сколько времени (всего) запросы на поиск проводят в каждой из различных фаз поиска. Вы можете получить эти счетчики, используя API статистики узлов. По умолчанию false.
-
search.highlight.term_vector_multi_value (Статическое, логическое): Указывает на необходимость выделять фрагменты по значениям многозначного поля. По умолчанию true.
-
search.max_aggregation_rewrite_filters (Динамическое, целое число): Определяет максимальное количество фильтров переписывания, разрешенных во время агрегации. Установите это значение в 0, чтобы отключить оптимизацию переписывания фильтров для агрегаций. Это экспериментальная функция и может измениться или быть удалена в будущих версиях.
-
search.dynamic_pruning.cardinality_aggregation.max_allowed_cardinality (Динамическое, целое число): Определяет порог для применения динамической обрезки в агрегации по кардинальности. Если кардинальность поля превышает этот порог, агрегация возвращается к методу по умолчанию. Это экспериментальная функция и может измениться или быть удалена в будущих версиях.
-
search.keyword_index_or_doc_values_enabled (Динамическое, логическое): Определяет, использовать ли индекс или значения документа при выполнении запросов multi_term на полях ключевых слов. Значение по умолчанию - false.
Настройки точки во времени (PIT)
Для получения информации о настройках PIT см. Настройки PIT.
Чтобы узнать больше о статических и динамических настройках, см. Настройка OpenSearch.
2.3.10 - Настройки плагинов
Следующие настройки относятся к плагинам OpenSearch.
Настройки плагина оповещений
Для получения информации о настройках оповещений см. Настройки оповещений.
Настройки плагина обнаружения аномалий
Для получения информации о настройках обнаружения аномалий см. Настройки обнаружения аномалий.
Настройки плагина асинхронного поиска
Для получения информации о настройках асинхронного поиска см. Настройки асинхронного поиска.
Настройки плагина репликации между кластерами
Для получения информации о настройках репликации между кластерами см. Настройки репликации.
Настройки плагина Flow Framework
Для получения информации о настройках автоматического рабочего процесса см. Настройки рабочего процесса.
Настройки плагина геопространственных данных
Для получения информации о настройках процессора IP2Geo плагина геопространственных данных см. Настройки кластера.
Настройки плагина управления индексами
Для получения информации о настройках управления состоянием индекса (ISM) см. Настройки ISM.
Настройки сворачивания индексов
Для получения информации о настройках сворачивания индексов см. Настройки сворачивания индексов.
Настройки плагина планировщика задач
Для получения информации о настройках плагина планировщика задач см. Настройки кластера планировщика задач.
Настройки плагина k-NN
Для получения информации о настройках k-NN см. Настройки k-NN.
Настройки плагина ML Commons
Для получения информации о настройках машинного обучения см. Настройки кластера ML Commons.
Настройки плагина нейронного поиска
Плагин Security Analytics поддерживает следующие настройки:
- plugins.neural_search.hybrid_search_disabled (Динамическое, логическое): Отключает гибридный поиск. По умолчанию false.
Настройки плагина уведомлений
Плагин уведомлений поддерживает следующие настройки. Все настройки в этом списке являются динамическими:
-
opensearch.notifications.core.allowed_config_types (Список): Разрешенные типы конфигурации плагина уведомлений. Используйте API GET /_plugins/_notifications/features, чтобы получить значение этой настройки. Типы конфигурации включают slack, chime, microsoft_teams, webhook, email, sns, ses_account, smtp_account и email_group.
-
opensearch.notifications.core.email.minimum_header_length (Целое число): Минимальная длина заголовка электронной почты. Используется для проверки общей длины сообщения электронной почты. По умолчанию 160.
-
opensearch.notifications.core.email.size_limit (Целое число): Лимит размера электронной почты. Используется для проверки общей длины сообщения электронной почты. По умолчанию 10000000.
-
opensearch.notifications.core.http.connection_timeout (Целое число): Таймаут подключения внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 5000.
-
opensearch.notifications.core.http.host_deny_list (Список): Список запрещенных хостов. HTTP-клиент не отправляет уведомления на URL вебхуков из этого списка.
-
opensearch.notifications.core.http.max_connection_per_route (Целое число): Максимальное количество HTTP-соединений на маршрут внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 20.
-
opensearch.notifications.core.http.max_connections (Целое число): Максимальное количество HTTP-соединений внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 60.
-
opensearch.notifications.core.http.socket_timeout (Целое число): Конфигурация таймаута сокета внутреннего HTTP-клиента. Клиент используется для каналов уведомлений на основе вебхуков. По умолчанию 50000.
-
opensearch.notifications.core.tooltip_support (Логическое): Включает поддержку подсказок для плагина уведомлений. Используйте API GET /_plugins/_notifications/features, чтобы получить значение этой настройки. По умолчанию true.
-
opensearch.notifications.general.filter_by_backend_roles (Логическое): Включает фильтрацию по ролям бэкенда (контроль доступа на основе ролей для каналов уведомлений). По умолчанию false.
Настройки плагина Query Insights
Для получения информации о настройках плагина Query Insights см. Функции и настройки Query Insights.
Настройки плагина безопасности
Для получения информации о настройках плагина безопасности см. Настройки безопасности.
Настройки плагина Security Analytics
Для получения информации о настройках аналитики безопасности см. Настройки Security Analytics.
Настройки плагина SQL
Для получения информации о настройках, связанных с SQL и PPL, см. Настройки SQL.
2.3.11 - Экспериментальные флаги функций
Релизы OpenSearch могут содержать экспериментальные функции, которые вы можете включать или отключать по мере необходимости. Существует несколько способов включения флагов функций в зависимости от типа установки.
Включение в opensearch.yml
Если вы запускаете кластер OpenSearch и хотите включить флаги функций в конфигурационном файле, добавьте следующую строку в opensearch.yml:
opensearch.experimental.feature.<feature_name>.enabled: true
Включение в контейнерах Docker
Если вы используете Docker, добавьте следующую строку в docker-compose.yml в разделе opensearch-node > environment:
OPENSEARCH_JAVA_OPTS="-Dopensearch.experimental.feature.<feature_name>.enabled=true"
Включение в установке tarball
Чтобы включить флаги функций в установке tarball, укажите новый параметр JVM либо в config/jvm.options, либо в OPENSEARCH_JAVA_OPTS.
Вариант 1: Изменение jvm.options
Добавьте следующие строки в config/jvm.options перед запуском процесса OpenSearch, чтобы включить функцию и ее зависимости:
-Dopensearch.experimental.feature.<feature_name>.enabled=true
Затем запустите OpenSearch:
Вариант 2: Включение с помощью переменной окружения
В качестве альтернативы прямому изменению config/jvm.options, вы можете определить свойства, используя переменную окружения. Это можно сделать с помощью одной команды при запуске OpenSearch или определив переменную с помощью export.
Чтобы добавить флаги функций в строке при запуске OpenSearch, выполните следующую команду:
OPENSEARCH_JAVA_OPTS="-Dopensearch.experimental.feature.<feature_name>.enabled=true" ./opensearch-3.1.0/bin/opensearch
Если вы хотите определить переменную окружения отдельно перед запуском OpenSearch, выполните следующие команды:
export OPENSEARCH_JAVA_OPTS="-Dopensearch.experimental.feature.<feature_name>.enabled=true"
./bin/opensearch
Включение для разработки OpenSearch
Чтобы включить флаги функций для разработки, вы должны добавить правильные свойства в run.gradle перед сборкой OpenSearch. См. Руководство для разработчиков для получения информации о том, как использовать Gradle для сборки OpenSearch.
Добавьте следующие свойства в run.gradle, чтобы включить функцию:
testClusters {
runTask {
testDistribution = 'archive'
if (numZones > 1) numberOfZones = numZones
if (numNodes > 1) numberOfNodes = numNodes
systemProperty 'opensearch.experimental.feature.<feature_name>.enabled', 'true'
}
}
2.3.12 - Logs
Логи OpenSearch содержат ценную информацию для мониторинга операций кластера и устранения неполадок. Местоположение логов зависит от типа установки:
- В Docker OpenSearch записывает большинство логов в консоль и сохраняет оставшиеся в
opensearch/logs/. Установка tarball также использует opensearch/logs/.
- В большинстве установок на Linux OpenSearch записывает логи в
/var/log/opensearch/.
Логи доступны в формате .log (обычный текст) и .json. Права доступа к логам OpenSearch по умолчанию составляют -rw-r--r--, что означает, что любой пользователь на узле может их читать. Вы можете изменить это поведение для каждого типа логов в log4j2.properties, используя опцию filePermissions. Например, вы можете добавить appender.rolling.filePermissions = rw-r-----, чтобы изменить права доступа для JSON-сервера логов. Для получения подробной информации см. документацию Log4j 2.
Логи приложений
Для своих логов приложений OpenSearch использует Apache Log4j 2 и его встроенные уровни логирования (от наименее до наиболее серьезных). В следующей таблице описаны настройки логирования.
| Настройка |
Тип данных |
Описание |
logger.org.opensearch.discovery |
Строка |
Логгеры принимают встроенные уровни логирования Log4j2: OFF, FATAL, ERROR, WARN, INFO, DEBUG и TRACE. По умолчанию INFO. |
Вместо изменения уровня логирования по умолчанию (logger.level), вы можете изменить уровень логирования для отдельных модулей OpenSearch:
PUT /_cluster/settings
{
"persistent" : {
"logger.org.opensearch.index.reindex" : "DEBUG"
}
}
Самый простой способ идентифицировать модули — не по логам, которые сокращают путь (например, o.o.i.r), а по исходному коду OpenSearch.
После этого изменения OpenSearch будет генерировать гораздо более подробные логи во время операций повторной индексации:
[2019-10-18T16:52:51,184][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: starting
[2019-10-18T16:52:51,186][DEBUG][o.o.i.r.TransportReindexAction] [node1] executing initial scroll against [some-index]
[2019-10-18T16:52:51,291][DEBUG][o.o.i.r.TransportReindexAction] [node1] scroll returned [3] documents with a scroll id of [DXF1Z==]
[2019-10-18T16:52:51,292][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: got scroll response with [3] hits
[2019-10-18T16:52:51,294][DEBUG][o.o.i.r.WorkerBulkByScrollTaskState] [node1] [1626]: preparing bulk request for [0s]
[2019-10-18T16:52:51,297][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: preparing bulk request
[2019-10-18T16:52:51,299][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: sending [3] entry, [222b] bulk request
[2019-10-18T16:52:51,310][INFO ][o.e.c.m.MetaDataMappingService] [node1] [some-new-index/R-j3adc6QTmEAEb-eAie9g] create_mapping [_doc]
[2019-10-18T16:52:51,383][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: got scroll response with [0] hits
[2019-10-18T16:52:51,384][DEBUG][o.o.i.r.WorkerBulkByScrollTaskState] [node1] [1626]: preparing bulk request for [0s]
[2019-10-18T16:52:51,385][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: preparing bulk request
[2019-10-18T16:52:51,386][DEBUG][o.o.i.r.TransportReindexAction] [node1] [1626]: finishing without any catastrophic failures
[2019-10-18T16:52:51,395][DEBUG][o.o.i.r.TransportReindexAction] [node1] Freed [1] contexts
Уровни DEBUG и TRACE являются чрезвычайно подробными. Если вы включаете один из них для устранения проблемы, отключите его после завершения.
Существуют и другие способы изменения уровней логирования:
- Добавление строк в
opensearch.yml
logger.org.opensearch.index.reindex: debug
Изменение opensearch.yml имеет смысл, если вы хотите повторно использовать свою конфигурацию логирования для нескольких кластеров или отлаживать проблемы запуска с одним узлом.
- Изменение
log4j2.properties
# Определите новый логгер с уникальным ID для повторной индексации
logger.reindex.name = org.opensearch.index.reindex
# Установите уровень логирования для этого ID
logger.reindex.level = debug
Этот подход является чрезвычайно гибким, но требует знакомства с синтаксисом файла свойств Log4j 2. В общем, другие варианты предлагают более простую конфигурацию.
Если вы изучите файл log4j2.properties по умолчанию в каталоге конфигурации, вы увидите несколько специфичных для OpenSearch переменных:
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %m%n
appender.rolling_old.fileName = ${sys:opensearch.logs.base_path}${sys:file.separator}${sys:opensearch.logs.cluster_name}.log
${sys:opensearch.logs.base_path} — это каталог для логов (например, /var/log/opensearch/).${sys:opensearch.logs.cluster_name} — это имя кластера.${sys:opensearch.logs.node_name} — это имя узла.[%node_name] — это имя узла.
Медленные логи запросов поиска
Новая функция в версии 2.12, OpenSearch предлагает медленные логи на уровне запросов для поиска. Эти логи основываются на пороговых значениях, чтобы определить, что квалифицируется как “медленно”. Все запросы, которые превышают порог, записываются в логи.
Медленные логи запросов поиска включаются динамически через API настроек кластера. В отличие от медленных логов шардов, пороги медленных логов запросов поиска настраиваются для общего времени выполнения запроса. По умолчанию логи отключены (все пороги установлены на -1).
PUT /_cluster/settings
{
"persistent" : {
"cluster.search.request.slowlog.level" : "TRACE",
"cluster.search.request.slowlog.threshold.warn": "10s",
"cluster.search.request.slowlog.threshold.info": "5s",
"cluster.search.request.slowlog.threshold.debug": "2s",
"cluster.search.request.slowlog.threshold.trace": "10ms"
}
}
Строка из opensearch_index_search_slowlog.log может выглядеть следующим образом:
[2023-10-30T15:47:42,630][TRACE][c.s.r.slowlog] [runTask-0] took[80.8ms], took_millis[80], phase_took_millis[{expand=0, query=39, fetch=22}], total_hits[4 hits], search_type[QUERY_THEN_FETCH], shards[{total: 10, successful: 10, skipped: 0, failed: 0}], source[{"query":{"match_all":{"boost":1.0}}}], id[]
Медленные логи запросов поиска могут занимать значительное место на диске и влиять на производительность, если вы установите низкие пороговые значения. Рассмотрите возможность временного включения их для устранения неполадок или настройки производительности. Чтобы отключить медленные логи запросов поиска, верните все пороги к -1.
Медленные логи шардов
OpenSearch имеет два типа медленных логов шардов, которые помогают выявлять проблемы с производительностью: медленный лог поиска и медленный лог индексации.
Эти логи основываются на пороговых значениях, чтобы определить, что квалифицируется как “медленный” поиск или “медленная” операция индексации. Например, вы можете решить, что запрос считается медленным, если его выполнение занимает более 15 секунд. В отличие от логов приложений, которые настраиваются для модулей, медленные логи настраиваются для индексов. По умолчанию оба лога отключены (все пороги установлены на -1).
В отличие от медленных логов запросов поиска, пороги медленных логов шардов настраиваются для времени выполнения отдельных шардов.
GET <some-index>/_settings?include_defaults=true
{
"indexing": {
"slowlog": {
"reformat": "true",
"threshold": {
"index": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
}
},
"source": "1000",
"level": "TRACE"
}
},
"search": {
"slowlog": {
"level": "TRACE",
"threshold": {
"fetch": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
},
"query": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
}
}
}
}
}
Чтобы включить эти логи, увеличьте один или несколько порогов:
PUT <some-index>/_settings
{
"indexing": {
"slowlog": {
"threshold": {
"index": {
"warn": "15s",
"trace": "750ms",
"debug": "3s",
"info": "10s"
}
},
"source": "500",
"level": "INFO"
}
}
}
Пример настройки медленных логов индексации
В этом примере OpenSearch записывает операции индексации, которые занимают 15 секунд или дольше, на уровне WARN, а операции, которые занимают от 10 до 14.x секунд, на уровне INFO. Если вы установите порог в 0 секунд, OpenSearch будет записывать все операции, что может быть полезно для проверки, действительно ли медленные логи включены.
- reformat указывает, следует ли записывать поле _source документа в одной строке (true) или позволить ему занимать несколько строк (false).
- source — это количество символов поля _source документа, которые нужно записать.
- level — это минимальный уровень логирования, который следует включить.
Строка из opensearch_index_indexing_slowlog.log может выглядеть следующим образом:
node1 | [2019-10-24T19:48:51,012][WARN][i.i.s.index] [node1] [some-index/i86iF5kyTyy-PS8zrdDeAA] took[3.4ms], took_millis[3], type[_doc], id[1], routing[], source[{"title":"Your Name", "Director":"Makoto Shinkai"}]
Медленные логи шардов могут занимать значительное место на диске и влиять на производительность, если вы установите низкие пороговые значения. Рассмотрите возможность временного включения их для устранения неполадок или настройки производительности. Чтобы отключить медленные логи шардов, верните все пороги к -1.
Журналы задач
OpenSearch может записывать время ЦП и использование памяти для N самых затратных по памяти поисковых задач, когда включены потребители ресурсов задач. По умолчанию потребители ресурсов задач будут записывать 10 самых затратных поисковых задач с интервалом в 60 секунд. Эти значения можно настроить в файле opensearch.yml.
Запись задач включается динамически через API настроек кластера:
PUT _cluster/settings
{
"persistent" : {
"task_resource_consumers.enabled" : "true"
}
}
Включение потребителей ресурсов задач может повлиять на задержку поиска.
После включения журналы будут записываться в файлы logs/opensearch_task_detailslog.json и logs/opensearch_task_detailslog.log.
Чтобы настроить интервал записи и количество записываемых поисковых задач, добавьте следующие строки в opensearch.yml:
# Количество затратных поисковых задач для записи
cluster.task.consumers.top_n.size: 100
# Интервал записи
cluster.task.consumers.top_n.frequency: 30s
Журналы устаревания
Журналы устаревания фиксируют, когда клиенты делают устаревшие вызовы API к вашему кластеру. Эти журналы могут помочь вам выявить и исправить проблемы до обновления до новой основной версии. По умолчанию OpenSearch записывает устаревшие вызовы API на уровне WARN, что хорошо подходит для почти всех случаев использования. При необходимости настройте logger.deprecation.level, используя _cluster/settings, opensearch.yml или log4j2.properties.
2.4 - Сравнение ОС
Совместимость OpenSearch и OpenSearch Dashboards
Совместимость OpenSearch и OpenSearch Dashboards
OpenSearch и OpenSearch Dashboards совместимы с Red Hat Enterprise Linux (RHEL) и дистрибутивами Linux на базе Debian, которые используют systemd, такими как Amazon Linux и Ubuntu Long-Term Support (LTS). Хотя OpenSearch и OpenSearch Dashboards должны работать на большинстве дистрибутивов Linux, мы тестируем только подмножество из них.
Поддерживаемые операционные системы
Следующая таблица перечисляет версии операционных систем, которые мы в настоящее время тестируем:
| ОС |
Версия |
| Rocky Linux |
8 |
| Alma Linux |
8 |
| Amazon Linux |
2/2023 |
| Ubuntu |
24.04 |
| Windows Server |
2019 |
Журнал изменений
Следующая таблица перечисляет изменения, внесенные в совместимость операционных систем.
| Дата |
Проблема |
PR |
Подробности |
| 2025-02-06 |
opensearch-build Issue 5270 |
PR 9165 |
Удаление Ubuntu 20.04 |
| 2024-07-23 |
opensearch-build Issue 4379 |
PR 7821 |
Удаление CentOS7 |
| 2024-03-08 |
opensearch-build Issue 4573 |
PR 6637 |
Удаление CentOS8, добавление Almalinux8/Rockylinux8 и удаление Ubuntu 16.04/18.04, так как мы в настоящее время тестируем только на 20.04 |
| 2023-06-06 |
documentation-website Issue 4217 |
PR 4218 |
Создание матрицы поддержки |
2.5 - Настройка OpenSearch Dashboards
OpenSearch Dashboards использует файл конфигурации opensearch_dashboards.yml
OpenSearch Dashboards использует файл конфигурации opensearch_dashboards.yml для чтения настроек при запуске кластера. Вы можете найти opensearch_dashboards.yml по следующему пути: /usr/share/opensearch-dashboards/config/opensearch_dashboards.yml (Docker) или /etc/opensearch-dashboards/opensearch_dashboards.yml (большинство дистрибутивов Linux) на каждом узле.
Для получения информации о настройках OpenSearch Dashboards ознакомьтесь с образцом файла opensearch_dashboards.yml.
2.6 - Upgrading OpenSearch
OpenSearch использует семантическое версионирование, что означает, что разрушающие изменения вводятся только между основными версиями.
Проект OpenSearch регулярно выпускает обновления, которые включают новые функции, улучшения и исправления ошибок. OpenSearch использует семантическое версионирование, что означает, что разрушающие изменения вводятся только между основными версиями. Чтобы узнать о предстоящих функциях и исправлениях, ознакомьтесь с дорожной картой проекта OpenSearch на GitHub. Чтобы просмотреть список предыдущих релизов или узнать больше о том, как OpenSearch использует версионирование, смотрите раздел “График релизов и политика обслуживания”.
Мы понимаем, что пользователи заинтересованы в обновлении OpenSearch, чтобы воспользоваться последними функциями, и мы будем продолжать расширять эти документы по обновлению и миграции, чтобы охватить дополнительные темы, такие как обновление OpenSearch Dashboards и сохранение пользовательских конфигураций, например, для плагинов.
Если вы хотите, чтобы был добавлен конкретный процесс или хотите внести свой вклад, создайте задачу на GitHub. Ознакомьтесь с Руководством для участников, чтобы узнать, как вы можете помочь.
Учет рабочих процессов
Потратьте время на планирование процесса перед внесением каких-либо изменений в ваш кластер. Например, рассмотрите следующие вопросы:
- Сколько времени займет процесс обновления?
- Если ваш кластер используется в производственной среде, насколько критично время простоя?
- У вас есть инфраструктура для развертывания нового кластера в тестовой или разработческой среде перед его переводом в эксплуатацию, или вам нужно обновить производственные узлы напрямую?
Ответы на такие вопросы помогут вам определить, какой путь обновления будет наиболее подходящим для вашей среды.
Минимально вы должны:
- Ознакомиться с разрушающими изменениями.
- Ознакомиться с матрицами совместимости инструментов OpenSearch.
- Ознакомиться с совместимостью плагинов.
- Создать резервные копии файлов конфигурации.
- Создать снимок.
Остановить любую несущественную индексацию перед началом процедуры обновления, чтобы устранить ненужные требования к ресурсам кластера во время выполнения обновления.
Ознакомление с разрушающими изменениями
Важно определить, как новая версия OpenSearch будет интегрироваться с вашей средой. Ознакомьтесь с разделом “Разрушающие изменения” перед началом любых процедур обновления, чтобы определить, нужно ли вам вносить изменения в ваш рабочий процесс. Например, компоненты, находящиеся выше или ниже по потоку, могут потребовать модификации для совместимости с изменением API (см. мета-проблему #2589).
Ознакомление с матрицами совместимости инструментов OpenSearch
Если ваш кластер OpenSearch взаимодействует с другими службами в вашей среде, такими как Logstash или Beats, вам следует проверить матрицы совместимости инструментов OpenSearch, чтобы определить, нужно ли обновлять другие компоненты.
Ознакомление с совместимостью плагинов
Проверьте плагины, которые вы используете, чтобы определить их совместимость с целевой версией OpenSearch. Официальные плагины проекта OpenSearch можно найти в репозитории проекта OpenSearch на GitHub. Если вы используете сторонние плагины, вам следует ознакомиться с документацией для этих плагинов, чтобы определить, совместимы ли они.
Перейдите в раздел “Доступные плагины”, чтобы увидеть справочную таблицу, которая подчеркивает совместимость версий для встроенных плагинов OpenSearch.
Основные, второстепенные и патч-версии плагинов должны соответствовать основным, второстепенным и патч-версиям OpenSearch для обеспечения совместимости. Например, версии плагинов 2.3.0.x работают только с OpenSearch 2.3.0.
Резервное копирование файлов конфигурации
Снизьте риск потери данных, создав резервные копии любых важных файлов перед началом обновления. Обычно эти файлы будут находиться в одной из двух директорий:
opensearch/configopensearch-dashboards/config
Некоторые примеры включают opensearch.yml, opensearch_dashboards.yml, файлы конфигурации плагинов и сертификаты TLS. Как только вы определите, какие файлы хотите сохранить, скопируйте их на удаленное хранилище для безопасности.
Если вы используете функции безопасности, обязательно ознакомьтесь с разделом “Предостережение” для получения информации о резервном копировании и восстановлении ваших настроек безопасности.
Создание снимка
Рекомендуется создать резервную копию состояния вашего кластера и индексов с помощью снимков. Снимки, сделанные перед обновлением, могут быть использованы в качестве точек восстановления, если вам нужно будет откатить кластер к его оригинальной версии.
Вы можете дополнительно снизить риск потери данных, храня ваши снимки на внешнем хранилище, таком как смонтированная файловая система сети (NFS) или облачное хранилище, как указано в следующей таблице.
| Местоположение репозитория снимков |
Требуемый плагин OpenSearch |
| Amazon Simple Storage Service (Amazon S3) |
repository-s3 |
| Google Cloud Storage (GCS) |
repository-gcs |
| Apache Hadoop Distributed File System (HDFS) |
repository-hdfs |
| Microsoft Azure Blob Storage |
repository-azure |
Методы обновления
Выберите подходящий метод для обновления вашего кластера до новой версии OpenSearch в зависимости от ваших требований:
- Постепенное обновление (rolling upgrade) обновляет узлы по одному без остановки кластера.
- Обновление с перезапуском кластера (cluster restart upgrade) обновляет службы, пока кластер остановлен.
Обновления, охватывающие более одной основной версии OpenSearch, потребуют дополнительных усилий из-за необходимости повторной индексации. Для получения дополнительной информации обратитесь к API повторной индексации. См. таблицу совместимости индексов, включенную позже в этом руководстве, для помощи в планировании миграции данных.
Постепенное обновление
Постепенное обновление — отличный вариант, если вы хотите сохранить работоспособность вашего кластера на протяжении всего процесса. Данные могут продолжать поступать, анализироваться и запрашиваться, пока узлы поочередно останавливаются, обновляются и перезапускаются. Вариация постепенного обновления, называемая “замена узла” (node replacement), следует точно такому же процессу, за исключением того, что хосты и контейнеры не повторно используются для нового узла. Вы можете выполнить замену узла, если также обновляете базовые хосты.
Узлы OpenSearch не могут присоединиться к кластеру, если менеджер кластера работает на более новой версии OpenSearch, чем узел, запрашивающий членство. Чтобы избежать этой проблемы, обновляйте узлы, имеющие право на управление кластером, последними.
Смотрите раздел “Постепенное обновление” для получения дополнительной информации о процессе.
Обновление с перезапуском кластера
Администраторы OpenSearch могут выбрать выполнение обновления с перезапуском кластера по нескольким причинам, например, если администратор не хочет проводить обслуживание работающего кластера или если кластер мигрируется в другую среду.
В отличие от постепенного обновления, при котором только один узел отключен в любой момент времени, обновление с перезапуском кластера требует остановки OpenSearch и OpenSearch Dashboards на всех узлах кластера перед продолжением. После остановки узлов устанавливается новая версия OpenSearch. Затем OpenSearch запускается, и кластер загружается на новую версию.
Совместимость
Узлы OpenSearch совместимы с другими узлами OpenSearch, работающими на любой другой минорной версии в рамках одного основного релиза. Например, версия 1.1.0 совместима с 1.3.7, поскольку они являются частью одной основной версии (1.x). Кроме того, узлы OpenSearch и индексы обратно совместимы с предыдущей основной версией. Это означает, что, например, индекс, созданный узлом OpenSearch, работающим на любой версии 1.x, может быть восстановлен из снимка в кластер OpenSearch, работающий на любой версии 2.x.
Узлы OpenSearch 1.x совместимы с узлами, работающими на Elasticsearch 7.x, но продолжительность работы смешанной версии не должна превышать период обновления кластера.
Совместимость индексов определяется версией Apache Lucene, которая создала индекс. Если индекс был создан кластером OpenSearch, работающим на версии 1.0.0, то этот индекс может использоваться любым другим кластером OpenSearch, работающим до последнего релиза 1.x или 2.x. См. таблицу совместимости индексов для версий Lucene, работающих в OpenSearch 1.0.0 и более поздних версиях, а также в Elasticsearch 6.8 и более поздних версиях.
Если ваш путь обновления охватывает более одной основной версии и вы хотите сохранить существующие индексы, вы можете использовать API повторной индексации (Reindex API), чтобы сделать ваши индексы совместимыми с целевой версией OpenSearch перед обновлением. Например, если ваш кластер в настоящее время работает на Elasticsearch 6.8 и вы хотите обновиться до OpenSearch 2.x, вам сначала нужно обновиться до OpenSearch 1.x, заново создать ваши индексы с помощью API повторной индексации и, наконец, обновиться до 2.x. Одной из альтернатив повторной индексации является повторное извлечение данных из источника, например, воспроизведение потока данных или извлечение данных из базы данных.
Справочная таблица совместимости индексов
Если вы планируете сохранить старые индексы после обновления версии OpenSearch, вам может потребоваться повторная индексация или повторное извлечение данных. Обратитесь к следующей таблице для версий Lucene в недавних релизах OpenSearch и Elasticsearch.
| Версия Lucene |
Версия OpenSearch |
Версия Elasticsearch |
| 9.10.0 |
2.14.0 |
|
| 2.13.0 |
|
8.13 |
| 9.9.2 |
2.12.0 |
— |
| 9.7.0 |
2.11.1 |
|
| 2.9.0 |
8.9.0 |
|
| 9.6.0 |
2.8.0 |
8.8.0 |
| 9.5.0 |
2.7.0 |
|
| 2.6.0 |
8.7.0 |
|
| 9.4.2 |
2.5.0 |
|
| 2.4.1 |
8.6 |
|
| 9.4.1 |
2.4.0 |
— |
| 9.4.0 |
— |
8.5 |
| 9.3.0 |
2.3.0 |
|
| 2.2.x |
8.4 |
|
| 9.2.0 |
2.1.0 |
8.3 |
| 9.1.0 |
2.0.x |
8.2 |
| 9.0.0 |
— |
8.1 |
| 8.0 |
|
|
| 8.11.1 |
— |
7.17 |
| 8.10.1 |
1.3.x |
|
| 1.2.x |
7.16 |
|
| 8.9.0 |
1.1.0 |
7.15 |
| 7.14 |
|
|
| 8.8.2 |
1.0.0 |
7.13 |
| 8.8.0 |
— |
7.12 |
| 8.7.0 |
— |
7.11 |
| 7.10 |
|
|
| 8.6.2 |
— |
7.9 |
| 8.5.1 |
— |
7.8 |
| 7.7 |
|
|
| 8.4.0 |
— |
7.6 |
| 8.3.0 |
— |
7.5 |
| 8.2.0 |
— |
7.4 |
| 8.1.0 |
— |
7.3 |
| 8.0.0 |
— |
7.2 |
| 7.1 |
|
|
| 7.7.3 |
— |
6.8 |
Тире (—) указывает на то, что нет версии продукта, содержащей указанную версию Apache Lucene.
2.6.1 - Приложение по обновлениям
Используйте приложение по обновлениям, чтобы найти дополнительную вспомогательную документацию, такую как лабораторные работы, которые включают примеры API-запросов и конфигурационных файлов для дополнения соответствующей документации по процессам.
Конкретные процедуры, изложенные в разделе приложения, могут быть использованы различными способами:
- Новые пользователи OpenSearch могут использовать шаги и примеры ресурсов, которые мы предоставляем, чтобы узнать о конфигурации и использовании OpenSearch и OpenSearch Dashboards.
- Системные администраторы, работающие с кластерами OpenSearch, могут использовать предоставленные примеры для симуляции обслуживания кластера в тестовой среде перед применением любых изменений к рабочей нагрузке в производственной среде.
Если вы хотите запросить конкретную тему, пожалуйста, оставьте комментарий по вопросу #2830 в проекте OpenSearch на GitHub.
Конкретные команды, включенные в это приложение, служат примерами взаимодействия с API OpenSearch и основным хостом, чтобы продемонстрировать шаги, описанные в связанных документах по процессу обновления. Цель состоит не в том, чтобы быть чрезмерно предписывающим, а в том, чтобы добавить контекст для пользователей, которые новы в OpenSearch и хотят увидеть практические примеры.
2.6.2 - Постепенное обновление
Постепенные обновления, иногда называемые обновлениями замены узлов, могут выполняться на работающих кластерах с практически нулевым временем простоя.
Постепенные обновления, иногда называемые “обновлениями замены узлов”, могут выполняться на работающих кластерах с практически нулевым временем простоя. Узлы поочередно останавливаются и обновляются на месте. В качестве альтернативы узлы могут быть остановлены и заменены, один за другим, хостами, работающими на новой версии. В процессе вы можете продолжать индексировать и запрашивать данные в вашем кластере.
Этот документ служит общим обзором процедуры постепенного обновления, не зависящим от платформы. Для конкретных примеров команд, скриптов и файлов конфигурации смотрите Приложение.
Подготовка к обновлению
Ознакомьтесь с разделом “Обновление OpenSearch” для получения рекомендаций по резервному копированию ваших файлов конфигурации и созданию снимка состояния кластера и индексов перед внесением каких-либо изменений в ваш кластер OpenSearch.
Важно: Узлы OpenSearch не могут быть понижены. Если вам нужно отменить обновление, вам потребуется выполнить новую установку OpenSearch и восстановить кластер из снимка. Сделайте снимок и сохраните его в удаленном репозитории перед началом процедуры обновления.
Выполнение обновления
- Проверьте состояние вашего кластера OpenSearch перед началом. Вам следует решить любые проблемы с индексами или распределением шардов перед обновлением, чтобы гарантировать сохранность ваших данных. Статус “green” указывает на то, что все первичные и реплика-шарды распределены. См. раздел “Состояние кластера” для получения дополнительной информации. Следующая команда запрашивает конечную точку API _cluster/health:
GET "/_cluster/health?pretty"
Ответ должен выглядеть примерно так:
{
"cluster_name": "opensearch-dev-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 4,
"number_of_data_nodes": 4,
"active_primary_shards": 1,
"active_shards": 4,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
- Отключите репликацию шардов, чтобы предотвратить создание реплик шардов, пока узлы отключаются. Это остановит перемещение сегментов индекса Lucene на узлах в вашем кластере. Вы можете отключить репликацию шардов, запросив конечную точку API _cluster/settings:
PUT "/_cluster/settings?pretty"
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}
Ответ должен выглядеть примерно так:
{
"acknowledged": true,
"persistent": {
"cluster": {
"routing": {
"allocation": {
"enable": "primaries"
}
}
}
},
"transient": {}
}
- Выполните операцию сброса на кластере, чтобы зафиксировать записи журнала транзакций в индексе Lucene:
Ответ должен выглядеть примерно так:
{
"_shards": {
"total": 4,
"successful": 4,
"failed": 0
}
}
-
Ознакомьтесь с вашим кластером и определите первый узел для обновления. Узлы, имеющие право на управление кластером, должны обновляться последними, поскольку узлы OpenSearch могут присоединиться к кластеру с управляющими узлами, работающими на более старой версии, но не могут присоединиться к кластеру, в котором все управляющие узлы работают на более новой версии.
-
Запросите конечную точку _cat/nodes, чтобы определить, какой узел был повышен до управляющего узла кластера. Следующая команда включает дополнительные параметры запроса, которые запрашивают только имя, версию, роль узла и заголовки master. Обратите внимание, что версии OpenSearch 1.x используют термин “master”, который был устаревшим и заменен на “cluster_manager” в OpenSearch 2.x и более поздних версиях.
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-01 7.10.2 dimr -
os-node-04 7.10.2 dimr -
os-node-03 7.10.2 dimr -
os-node-02 7.10.2 dimr *
-
Остановите узел, который вы обновляете. Не удаляйте объем, связанный с контейнером, когда вы удаляете контейнер. Новый контейнер OpenSearch будет использовать существующий объем. Удаление объема приведет к потере данных.
-
Подтвердите, что связанный узел был исключен из кластера, запросив конечную точку API _cat/nodes:
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-02 7.10.2 dimr *
os-node-04 7.10.2 dimr -
os-node-03 7.10.2 dimr -
Узел os-node-01 больше не отображается, потому что контейнер был остановлен и удален.
-
Разверните новый контейнер, работающий на желаемой версии OpenSearch и подключенный к тому же объему, что и удаленный контейнер.
-
Запросите конечную точку _cat/nodes после того, как OpenSearch запустится на новом узле, чтобы подтвердить, что он присоединился к кластеру:
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-02 7.10.2 dimr *
os-node-04 7.10.2 dimr -
os-node-01 7.10.2 dimr -
os-node-03 7.10.2 dimr -
В примере вывода новый узел OpenSearch сообщает о работающей версии 7.10.2 в кластер. Это результат compatibility.override_main_response_version, который используется при подключении к кластеру с устаревшими клиентами, проверяющими версию. Вы можете вручную подтвердить версию узла, вызвав конечную точку API /_nodes, как в следующей команде. Замените <nodeName> на имя вашего узла. См. раздел “API узлов”, чтобы узнать больше.
GET "/_nodes/<nodeName>?pretty=true" | jq -r '.nodes | .[] | "\(.name) v\(.version)"'
Подтвердите, что ответ выглядит примерно так:
- Включите репликацию шардов снова:
PUT "/_cluster/settings?pretty"
{
"persistent": {
"cluster.routing.allocation.enable": "all"
}
}
Ответ должен выглядеть примерно так:
{
"acknowledged": true,
"persistent": {
"cluster": {
"routing": {
"allocation": {
"enable": "all"
}
}
}
},
"transient": {}
}
- Подтвердите, что кластер здоров:
GET "/_cluster/health?pretty"
Ответ должен выглядеть примерно так:
{
"cluster_name": "opensearch-dev-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 4,
"number_of_data_nodes": 4,
"discovered_master": true,
"active_primary_shards": 1,
"active_shards": 4,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
- Повторите шаги 2–11 для каждого узла в вашем кластере. Не забудьте обновить узел управляющего кластера последним. После замены последнего узла запросите конечную точку
_cat/nodes, чтобы подтвердить, что все узлы присоединились к кластеру. Кластер теперь загружен на новую версию OpenSearch. Вы можете проверить версию кластера, запросив конечную точку API _cat/nodes:
GET "/_cat/nodes?v&h=name,version,node.role,master" | column -t
Ответ должен выглядеть примерно так:
name version node.role master
os-node-04 1.3.7 dimr -
os-node-02 1.3.7 dimr *
os-node-01 1.3.7 dimr -
os-node-03 1.3.7 dimr -
Обновление завершено, и вы можете начать пользоваться последними функциями и исправлениями!
Пошаговая перезагрузка
Пошаговая перезагрузка следует той же пошаговой процедуре, что и пошаговое обновление, за исключением обновления самих узлов. Во время пошаговой перезагрузки узлы перезагружаются по одному — обычно для применения изменений конфигурации, обновления сертификатов или выполнения системного обслуживания — без нарушения доступности кластера.
Чтобы выполнить пошаговую перезагрузку, следуйте шагам, описанным в разделе “Пошаговое обновление”, исключая шаги, связанные с обновлением бинарного файла OpenSearch или образа контейнера:
-
Проверьте состояние кластера
Убедитесь, что статус кластера зеленый и все шардов назначены.
(Шаг 1 пошагового обновления)
-
Отключите перераспределение шардов
Предотвратите попытки OpenSearch перераспределить шардов, пока узлы находятся в оффлайне.
(Шаг 2 пошагового обновления)
-
Сбросьте журналы транзакций
Зафиксируйте недавние операции в Lucene, чтобы сократить время восстановления.
(Шаг 3 пошагового обновления)
-
Просмотрите и определите следующий узел для перезагрузки
Убедитесь, что вы перезагрузите текущий узел-менеджер кластера последним.
(Шаг 4 пошагового обновления)
-
Проверьте, какой узел является текущим менеджером кластера
Используйте API _cat/nodes, чтобы определить, какой узел является текущим активным менеджером кластера.
(Шаг 5 пошагового обновления)
-
Остановите узел
Корректно завершите работу узла. Не удаляйте связанный объем данных.
(Шаг 6 пошагового обновления)
-
Подтвердите, что узел покинул кластер
Используйте _cat/nodes, чтобы убедиться, что он больше не указан в списке.
(Шаг 7 пошагового обновления)
-
Перезагрузите узел
Запустите тот же узел (тот же бинарный файл/версия/конфигурация) и дайте ему повторно присоединиться к кластеру.
(Шаг 8 пошагового обновления — без обновления бинарного файла)
-
Проверьте, что перезагруженный узел повторно присоединился
Проверьте _cat/nodes, чтобы подтвердить, что узел присутствует и работает корректно.
(Шаг 9 пошагового обновления)
-
Включите перераспределение шардов
Восстановите полную возможность перемещения шардов.
(Шаг 10 пошагового обновления)
-
Подтвердите, что состояние кластера зеленое
Проверьте стабильность перед перезагрузкой следующего узла.
(Шаг 11 пошагового обновления)
-
Повторите процесс для всех остальных узлов
Перезагрузите каждый узел по одному. Если узел подходит для роли менеджера кластера, перезагрузите его последним.
(Шаг 12 пошагового обновления — снова без шага обновления)
Сохраняя кворум и перезагружая узлы последовательно, пошаговые перезагрузки обеспечивают нулевое время простоя и полную непрерывность данных.
2.6.3 - Лаборатория последовательного обновления
Вы можете следовать этим шагам на своем совместимом хосте, чтобы воссоздать то же состояние кластера, которое использовался в проекте OpenSearch для тестирования пошаговых обновлений.
Это упражнение полезно, если вы хотите протестировать процесс обновления в среде разработки.
Шаги, использованные в этой лаборатории, были проверены на произвольно выбранном экземпляре Amazon Elastic Compute Cloud (Amazon EC2) t2.large с использованием ядра Amazon Linux 2 версии Linux 5.10.162-141.675.amzn2.x86_64 и Docker версии 20.10.17, сборка 100c701. Экземпляр был предоставлен с прикрепленным корневым томом Amazon EBS объемом 20 GiB gp2. Эти спецификации включены для информационных целей и не представляют собой аппаратные требования для OpenSearch или OpenSearch Dashboards.
Ссылки в этой процедуре на путь $HOME на хост-машине представлены символом тильда (“~”), чтобы сделать инструкции более переносимыми. Если вы предпочитаете указывать абсолютный путь, измените пути томов, определенные в upgrade-demo-cluster.sh, и используемые в соответствующих командах в этом документе, чтобы отразить вашу среду.
Настройка окружения
Следуя шагам в этом документе, вы определите несколько ресурсов Docker, включая контейнеры, тома и выделенную сеть Docker, с помощью предоставленного нами скрипта. Вы можете очистить свою среду с помощью следующей команды, если хотите перезапустить процесс:
docker container stop $(docker container ls -aqf name=os-); \
docker container rm $(docker container ls -aqf name=os-); \
docker volume rm -f $(docker volume ls -q | egrep 'data-0|repo-0'); \
docker network rm opensearch-dev-net
Эта команда удаляет контейнеры с именами, соответствующими регулярному выражению os-, тома данных, соответствующие data-0 и repo-0*, а также сеть Docker с именем opensearch-dev-net. Если у вас есть другие ресурсы Docker, работающие на вашем хосте, вам следует просмотреть и изменить команду, чтобы избежать случайного удаления других ресурсов. Эта команда не отменяет изменения конфигурации хоста, такие как поведение обмена памяти.
После выбора хоста вы можете начать лабораторию:
-
Установите соответствующую версию Docker Engine для вашего дистрибутива Linux и архитектуры системы.
-
Настройте важные системные параметры на вашем хосте:
- Отключите обмен и пейджинг памяти на хосте для повышения производительности:
- Увеличьте количество доступных для OpenSearch карт памяти. Откройте файл конфигурации sysctl для редактирования. Эта команда использует текстовый редактор vim, но вы можете использовать любой доступный текстовый редактор:
sudo vim /etc/sysctl.conf
- Добавьте следующую строку в
/etc/sysctl.conf:
- Сохраните и выйдите. Если вы используете текстовые редакторы vi или vim, сохраните и выйдите, переключившись в командный режим и введя
:wq! или ZZ.
- Примените изменение конфигурации:
-
Создайте новую директорию с именем deploy в вашем домашнем каталоге, затем перейдите в нее. Вы будете использовать ~/deploy для путей в скрипте развертывания, конфигурационных файлах и TLS-сертификатах:
mkdir ~/deploy && cd ~/deploy
-
Скачайте upgrade-demo-cluster.sh из репозитория документации проекта OpenSearch:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/main/assets/examples/upgrade-demo-cluster.sh
-
Запустите скрипт без каких-либо изменений, чтобы развернуть четыре контейнера, работающих с OpenSearch, и один контейнер, работающий с OpenSearch Dashboards, с пользовательскими самоподписанными TLS-сертификатами и заранее определенным набором внутренних пользователей:
sh upgrade-demo-cluster.sh
- Проверьте, что контейнеры были успешно запущены:
Пример ответа
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6e5218c8397d opensearchproject/opensearch-dashboards:1.3.7 "./opensearch-dashbo…" 24 seconds ago Up 22 seconds 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp os-dashboards-01
cb5188308b21 opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 25 seconds ago Up 24 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9204->9200/tcp, :::9204->9200/tcp, 0.0.0.0:9604->9600/tcp, :::9604->9600/tcp os-node-04
71b682aa6671 opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 26 seconds ago Up 25 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9203->9200/tcp, :::9203->9200/tcp, 0.0.0.0:9603->9600/tcp, :::9603->9600/tcp os-node-03
f894054a9378 opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 27 seconds ago Up 26 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9202->9200/tcp, :::9202->9200/tcp, 0.0.0.0:9602->9600/tcp, :::9602->9600/tcp os-node-02
2e9c91c959cd opensearchproject/opensearch:1.3.7 "./opensearch-docker…" 28 seconds ago Up 27 seconds 9300/tcp, 9650/tcp, 0.0.0.0:9201->9200/tcp, :::9201->9200/tcp, 0.0.0.0:9601->9600/tcp, :::9601->9600/tcp os-node-01
- Время, необходимое OpenSearch для инициализации кластера, варьируется в зависимости от производительности хоста. Вы можете следить за журналами контейнеров, чтобы увидеть, что делает OpenSearch в процессе загрузки:
- Введите следующую команду, чтобы отобразить журналы для контейнера os-node-01 в терминальном окне:
docker logs -f os-node-01
- Вы увидите запись в журнале, похожую на следующий пример, когда узел будет готов:
Пример
[INFO ][o.o.s.c.ConfigurationRepository] [os-node-01] Node 'os-node-01' initialized
- Нажмите
Ctrl+C, чтобы остановить просмотр журналов контейнера и вернуться к командной строке.
- Используйте cURL для запроса к OpenSearch REST API. В следующей команде os-node-01 запрашивается, отправляя запрос на порт 9201 хоста, который сопоставлен с портом 9200 на контейнере:
curl -s "https://localhost:9201" -ku admin:<custom-admin-password>
Пример ответа
{
"name" : "os-node-01",
"cluster_name" : "opensearch-dev-cluster",
"cluster_uuid" : "g1MMknuDRuuD9IaaNt56KA",
"version" : {
"distribution" : "opensearch",
"number" : "1.3.7",
"build_type" : "tar",
"build_hash" : "db18a0d5a08b669fb900c00d81462e221f4438ee",
"build_date" : "2022-12-07T22:59:20.186520Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
Совет: Используйте опцию -s с curl, чтобы скрыть индикатор прогресса и сообщения об ошибках.
Добавление данных и настройка безопасности OpenSearch
Теперь, когда кластер OpenSearch работает, пришло время добавить данные и настроить некоторые параметры безопасности OpenSearch. Данные, которые вы добавите, и настройки, которые вы сконфигурируете, будут проверены снова после завершения обновления версии.
Этот раздел можно разбить на две части:
- Индексация данных с помощью REST API
- Добавление данных с использованием OpenSearch Dashboards
Индексация данных с помощью REST API
- Скачайте файл с образцом сопоставления полей:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/main/assets/examples/ecommerce-field_mappings.json
- Затем скачайте объемные данные, которые вы будете загружать в этот индекс:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/main/assets/examples/ecommerce.ndjson
- Используйте API создания индекса, чтобы создать индекс, используя сопоставления, определенные в
ecommerce-field_mappings.json:
curl -H "Content-Type: application/json" \
-X PUT "https://localhost:9201/ecommerce?pretty" \
--data-binary "@ecommerce-field_mappings.json" \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "ecommerce"
}
- Используйте Bulk API, чтобы добавить данные в новый индекс
ecommerce из ecommerce.ndjson:
curl -H "Content-Type: application/x-ndjson" \
-X PUT "https://localhost:9201/ecommerce/_bulk?pretty" \
--data-binary "@ecommerce.ndjson" \
-ku admin:<custom-admin-password>
Пример ответа (усеченный)
{
"took": 123,
"errors": false,
"items": [
{
"index": {
"_index": "ecommerce",
"_id": "1",
"_version": 1,
"result": "created",
"status": 201,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
},
...
]
}
5. Запрос поиска также может подтвердить, что данные были успешно проиндексированы. Следующий запрос возвращает количество документов, в которых ключевое слово `customer_first_name` равно `Sonya`:
```bash
curl -H 'Content-Type: application/json' \
-X GET "https://localhost:9201/ecommerce/_search?pretty=true&filter_path=hits.total" \
-d'{"query":{"match":{"customer_first_name":"Sonya"}}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"hits" : {
"total" : {
"value" : 106,
"relation" : "eq"
}
}
}
Добавление данных с использованием OpenSearch Dashboards
-
Откройте веб-браузер и перейдите на порт 5601 вашего Docker-хоста (например, https://HOST_ADDRESS:5601). Если OpenSearch Dashboards работает и у вас есть сетевой доступ к хосту из вашего клиентского браузера, вы будете перенаправлены на страницу входа.
- Если веб-браузер выдает ошибку из-за того, что TLS-сертификаты самоподписанные, вам может потребоваться обойти проверки сертификатов в вашем браузере. Обратитесь к документации браузера для получения информации о том, как обойти проверки сертификатов. Общее имя (CN) для каждого сертификата генерируется в соответствии с именами контейнеров и узлов для внутрикластерной связи, поэтому подключение к хосту из браузера все равно приведет к предупреждению “недействительное CN”.
-
Введите имя пользователя по умолчанию (admin) и пароль (admin).
-
На главной странице OpenSearch Dashboards выберите Добавить образцы данных.
-
В разделе Образцы веб-журналов выберите Добавить данные.
- (Необязательно) Выберите Просмотреть данные, чтобы просмотреть [Логи] панель веб-трафика.
-
Выберите кнопку меню, чтобы открыть панель навигации, затем перейдите в Безопасность > Внутренние пользователи.
-
Выберите Создать внутреннего пользователя.
-
Укажите имя пользователя и пароль.
-
В поле Роль в бэкенде введите admin.
-
Выберите Создать.
Резервное копирование важных файлов
Всегда создавайте резервные копии перед внесением изменений в ваш кластер, особенно если кластер работает в производственной среде.
В этом разделе вы будете:
- Регистрировать репозиторий снимков.
- Создавать снимок.
- Резервировать настройки безопасности.
Регистрация репозитория снимков
Зарегистрируйте репозиторий, используя том, который был смонтирован с помощью upgrade-demo-cluster.sh:
curl -H 'Content-Type: application/json' \
-X PUT "https://localhost:9201/_snapshot/snapshot-repo?pretty" \
-d '{"type":"fs","settings":{"location":"/usr/share/opensearch/snapshots"}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true
}
Необязательно: Выполните дополнительную проверку, чтобы убедиться, что репозиторий был успешно создан:
curl -H 'Content-Type: application/json' \
-X POST "https://localhost:9201/_snapshot/snapshot-repo/_verify?timeout=0s&master_timeout=50s&pretty" \
-ku admin:<custom-admin-password>
Пример ответа
{
"nodes" : {
"UODBXfAlRnueJ67grDxqgw" : {
"name" : "os-node-03"
},
"14I_OyBQQXio8nmk0xsVcQ" : {
"name" : "os-node-04"
},
"tQp3knPRRUqHvFNKpuD2vQ" : {
"name" : "os-node-02"
},
"rPe8D6ssRgO5twIP00wbCQ" : {
"name" : "os-node-01"
}
}
}
Создание снимка
Снимки — это резервные копии индексов и состояния кластера. См. раздел Снимки, чтобы узнать больше.
Создайте снимок, который включает все индексы и состояние кластера:
curl -H 'Content-Type: application/json' \
-X PUT "https://localhost:9201/_snapshot/snapshot-repo/cluster-snapshot-v137?wait_for_completion=true&pretty" \
-ku admin:<custom-admin-password>
Пример ответа
{
"snapshot" : {
"snapshot" : "cluster-snapshot-v137",
"uuid" : "-IYB8QNPShGOTnTtMjBjNg",
"version_id" : 135248527,
"version" : "1.3.7",
"indices" : [
"opensearch_dashboards_sample_data_logs",
".opendistro_security",
"security-auditlog-2023.02.27",
".kibana_1",
".kibana_92668751_admin_1",
"ecommerce",
"security-auditlog-2023.03.06",
"security-auditlog-2023.02.28",
"security-auditlog-2023.03.07"
],
"data_streams" : [ ],
"include_global_state" : true,
"state" : "SUCCESS",
"start_time" : "2023-03-07T18:33:00.656Z",
"start_time_in_millis" : 1678213980656,
"end_time" : "2023-03-07T18:33:01.471Z",
"end_time_in_millis" : 1678213981471,
"duration_in_millis" : 815,
"failures" : [ ],
"shards" : {
"total" : 9,
"failed" : 0,
"successful" : 9
}
}
}
Резервное копирование настроек безопасности
Администраторы кластера могут изменять настройки безопасности OpenSearch, используя любой из следующих методов:
- Изменение YAML-файлов и запуск
securityadmin.sh
- Выполнение REST API запросов с использованием сертификата администратора
- Внесение изменений с помощью OpenSearch Dashboards
Независимо от выбранного метода, OpenSearch Security записывает вашу конфигурацию в специальный системный индекс, называемый .opendistro_security. Этот системный индекс сохраняется в процессе обновления и также сохраняется в созданном вами снимке. Однако восстановление системных индексов требует повышенного доступа, предоставленного сертификатом администратора. Чтобы узнать больше, смотрите разделы Системные индексы и Настройка TLS-сертификатов.
Вы также можете экспортировать настройки безопасности OpenSearch в виде YAML-файлов, запустив securityadmin.sh с опцией -backup на любом из ваших узлов OpenSearch. Эти YAML-файлы могут быть использованы для повторной инициализации индекса .opendistro_security с вашей существующей конфигурацией. Следующие шаги помогут вам сгенерировать эти резервные файлы и скопировать их на ваш хост для хранения:
-
Откройте интерактивную сессию псевдо-TTY с os-node-01:
docker exec -it os-node-01 bash
-
Создайте директорию с именем backups и перейдите в нее:
mkdir /usr/share/opensearch/backups && cd /usr/share/opensearch/backups
-
Используйте securityadmin.sh, чтобы создать резервные копии ваших настроек безопасности OpenSearch в /usr/share/opensearch/backups/:
/usr/share/opensearch/plugins/opensearch-security/tools/securityadmin.sh \
-backup /usr/share/opensearch/backups \
-icl \
-nhnv \
-cacert /usr/share/opensearch/config/root-ca.pem \
-cert /usr/share/opensearch/config/admin.pem \
-key /usr/share/opensearch/config/admin-key.pem
Пример ответа
Security Admin v7
Will connect to localhost:9300 ... done
Connected as CN=A,OU=DOCS,O=OPENSEARCH,L=PORTLAND,ST=OREGON,C=US
OpenSearch Version: 1.3.7
OpenSearch Security Version: 1.3.7.0
Contacting opensearch cluster 'opensearch' and wait for YELLOW clusterstate ...
Clustername: opensearch-dev-cluster
Clusterstate: GREEN
Number of nodes: 4
Number of data nodes: 4
.opendistro_security index already exists, so we do not need to create one.
Will retrieve '/config' into /usr/share/opensearch/backups/config.yml
SUCC: Configuration for 'config' stored in /usr/share/opensearch/backups/config.yml
Will retrieve '/roles' into /usr/share/opensearch/backups/roles.yml
SUCC: Configuration for 'roles' stored in /usr/share/opensearch/backups/roles.yml
Will retrieve '/rolesmapping' into /usr/share/opensearch/backups/roles_mapping.yml
SUCC: Configuration for 'rolesmapping' stored in /usr/share/opensearch/backups/roles_mapping.yml
Will retrieve '/internalusers' into /usr/share/opensearch/backups/internal_users.yml
SUCC: Configuration for 'internalusers' stored in /usr/share/opensearch/backups/internal_users.yml
Will retrieve '/actiongroups' into /usr/share/opensearch/backups/action_groups.yml
SUCC: Configuration for 'actiongroups' stored in /usr/share/opensearch/backups/action_groups.yml
Will retrieve '/tenants' into /usr/share/opensearch/backups/tenants.yml
SUCC: Configuration for 'tenants' stored in /usr/share/opensearch/backups/tenants.yml
Will retrieve '/nodesdn' into /usr/share/opensearch/backups/nodes_dn.yml
SUCC: Configuration for 'nodesdn' stored in /usr/share/opensearch/backups/nodes_dn.yml
Will retrieve '/whitelist' into /usr/share/opensearch/backups/whitelist.yml
SUCC: Configuration for 'whitelist' stored in /usr/share/opensearch/backups/whitelist.yml
Will retrieve '/audit' into /usr/share/opensearch/backups/audit.yml
SUCC: Configuration for 'audit' stored in /usr/share/opensearch/backups/audit.yml
-
Необязательно: Создайте резервную директорию для TLS-сертификатов и сохраните копии сертификатов. Повторите это для каждого узла, если вы используете уникальные TLS-сертификаты: Создайте директорию для сертификатов и скопируйте сертификаты в нее:
mkdir /usr/share/opensearch/backups/certs && cp /usr/share/opensearch/config/*pem /usr/share/opensearch/backups/certs/
-
Завершите сессию псевдо-TTY:
-
Скопируйте файлы на ваш хост:
docker cp os-node-01:/usr/share/opensearch/backups ~/deploy/
Выполнение обновления
Теперь, когда кластер настроен и вы сделали резервные копии важных файлов и настроек, пришло время начать обновление версии.
Некоторые шаги, включенные в этот раздел, такие как отключение репликации шардов и сброс журнала транзакций, не повлияют на производительность вашего кластера. Эти шаги включены в качестве лучших практик и могут значительно улучшить производительность кластера в ситуациях, когда клиенты продолжают взаимодействовать с кластером OpenSearch на протяжении всего обновления, например, запрашивая существующие данные или индексируя документы.
- Отключите репликацию шардов, чтобы остановить перемещение сегментов индекса Lucene внутри вашего кластера:
curl -H 'Content-type: application/json' \
-X PUT "https://localhost:9201/_cluster/settings?pretty" \
-d'{"persistent":{"cluster.routing.allocation.enable":"primaries"}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true,
"persistent" : {
"cluster" : {
"routing" : {
"allocation" : {
"enable" : "primaries"
}
}
}
},
"transient" : { }
}
- Выполните операцию сброса на кластере, чтобы зафиксировать записи журнала транзакций в индексе Lucene:
curl -X POST "https://localhost:9201/_flush?pretty" -ku admin:<custom-admin-password>
Пример ответа
{
"_shards" : {
"total" : 20,
"successful" : 20,
"failed" : 0
}
}
- Вы можете обновлять узлы в любом порядке, так как все узлы в этом демонстрационном кластере являются подходящими менеджерами кластера. Следующая команда остановит и удалит контейнер
os-node-01, не удаляя смонтированный том данных:
docker stop os-node-01 && docker container rm os-node-01
- Запустите новый контейнер с именем
os-node-01 с образом opensearchproject/opensearch:2.5.0 и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9201:9200 -p 9601:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-01:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-01.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-01.pem:/usr/share/opensearch/config/os-node-01.pem \
-v ~/deploy/os-node-01-key.pem:/usr/share/opensearch/config/os-node-01-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.11 \
--name os-node-01 \
opensearchproject/opensearch:2.5.0
Пример ответа
d26d0cb2e1e93e9c01bb00f19307525ef89c3c3e306d75913860e6542f729ea4
- Опционально: Запросите кластер, чтобы определить, какой узел выполняет функции менеджера кластера.
Вы можете выполнить эту команду в любое время в процессе, чтобы увидеть, когда будет избран новый менеджер кластера:
curl -s "https://localhost:9201/_cat/nodes?v&h=name,version,node.role,master" \
-ku admin:<custom-admin-password> | column -t
Пример ответа
name version node.role master
os-node-01 2.5.0 dimr -
os-node-04 1.3.7 dimr *
os-node-02 1.3.7 dimr -
os-node-03 1.3.7 dimr -
- Опционально: Запросите кластер, чтобы увидеть, как изменяется распределение шардов по мере удаления и замены узлов.
Вы можете выполнить эту команду в любое время в процессе, чтобы увидеть, как изменяются статусы шардов:
curl -s "https://localhost:9201/_cat/shards" \
-ku admin:<custom-admin-password>
Пример ответа
security-auditlog-2023.03.06 0 p STARTED 53 214.5kb 172.20.0.13 os-node-03
security-auditlog-2023.03.06 0 r UNASSIGNED
.kibana_1 0 p STARTED 3 14.5kb 172.20.0.12 os-node-02
.kibana_1 0 r STARTED 3 14.5kb 172.20.0.13 os-node-03
ecommerce 0 p STARTED 4675 3.9mb 172.20.0.12 os-node-02
ecommerce 0 r STARTED 4675 3.9mb 172.20.0.14 os-node-04
security-auditlog-2023.03.07 0 p STARTED 37 175.7kb 172.20.0.14 os-node-04
security-auditlog-2023.03.07 0 r UNASSIGNED
.opendistro_security 0 p STARTED 10 67.9kb 172.20.0.12 os-node-02
.opendistro_security 0 r STARTED 10 67.9kb 172.20.0.13 os-node-03
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.14 os-node-04
.opendistro_security 0 r UNASSIGNED
security-auditlog-2023.02.27 0 p STARTED 4 80.5kb 172.20.0.12 os-node-02
security-auditlog-2023.02.27 0 r UNASSIGNED
security-auditlog-2023.02.28 0 p STARTED 6 104.1kb 172.20.0.14 os-node-04
security-auditlog-2023.02.28 0 r UNASSIGNED
opensearch_dashboards_sample_data_logs 0 p STARTED 14074 9.1mb 172.20.0.12 os-node-02
opensearch_dashboards_sample_data_logs 0 r STARTED 14074 8.9mb 172.20.0.13 os-node-03
.kibana_92668751_admin_1 0 r STARTED 33 37.3kb 172.20.0.13 os-node-03
.kibana_92668751_admin_1 0 p STARTED 33 37.3kb 172.20.0.14 os-node-04
- Остановите os-node-02:
docker stop os-node-02 && docker container rm os-node-02
- Запустите новый контейнер с именем os-node-02 с образом opensearchproject/opensearch:2.5.0 и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9202:9200 -p 9602:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-02:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-02.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-02.pem:/usr/share/opensearch/config/os-node-02.pem \
-v ~/deploy/os-node-02-key.pem:/usr/share/opensearch/config/os-node-02-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.12 \
--name os-node-02 \
opensearchproject/opensearch:2.5.0
Пример ответа
7b802865bd6eb420a106406a54fc388ed8e5e04f6cbd908c2a214ea5ce72ac00
- Остановите os-node-03:
docker stop os-node-03 && docker container rm os-node-03
- Запустите новый контейнер с именем os-node-03 с образом opensearchproject/opensearch:2.5.0 и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9203:9200 -p 9603:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-03:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-03.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-03.pem:/usr/share/opensearch/config/os-node-03.pem \
-v ~/deploy/os-node-03-key.pem:/usr/share/opensearch/config/os-node-03-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.13 \
--name os-node-03 \
opensearchproject/opensearch:2.5.0
Пример ответа
d7f11726841a89eb88ff57a8cbecab392399f661a5205f0c81b60a995fc6c99d
- Остановите os-node-04:
docker stop os-node-04 && docker container rm os-node-04
- Запустите новый контейнер с именем os-node-04 с образом opensearchproject/opensearch:2.5.0 и используя те же смонтированные тома, что и у оригинального контейнера:
docker run -d \
-p 9204:9200 -p 9604:9600 \
-e "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit memlock=-1:-1 \
-v data-04:/usr/share/opensearch/data \
-v repo-01:/usr/share/opensearch/snapshots \
-v ~/deploy/opensearch-04.yml:/usr/share/opensearch/config/opensearch.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch/config/root-ca.pem \
-v ~/deploy/admin.pem:/usr/share/opensearch/config/admin.pem \
-v ~/deploy/admin-key.pem:/usr/share/opensearch/config/admin-key.pem \
-v ~/deploy/os-node-04.pem:/usr/share/opensearch/config/os-node-04.pem \
-v ~/deploy/os-node-04-key.pem:/usr/share/opensearch/config/os-node-04-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.14 \
--name os-node-04 \
opensearchproject/opensearch:2.5.0
Пример ответа
26f8286ab11e6f8dcdf6a83c95f265172f9557578a1b292af84c6f5ef8738e1d
- Подтвердите, что ваш кластер работает на новой версии:
curl -s "https://localhost:9201/_cat/nodes?v&h=name,version,node.role,master" \
-ku admin:<custom-admin-password> | column -t
Пример ответа
name version node.role master
os-node-01 2.5.0 dimr *
os-node-02 2.5.0 dimr -
os-node-04 2.5.0 dimr -
os-node-03 2.5.0 dimr -
- Последний компонент, который вы должны обновить, это узел OpenSearch Dashboards. Сначала остановите и удалите старый контейнер:
docker stop os-dashboards-01 && docker rm os-dashboards-01
- Создайте новый контейнер, работающий на целевой версии OpenSearch Dashboards:
docker run -d \
-p 5601:5601 --expose 5601 \
-v ~/deploy/opensearch_dashboards.yml:/usr/share/opensearch-dashboards/config/opensearch_dashboards.yml \
-v ~/deploy/root-ca.pem:/usr/share/opensearch-dashboards/config/root-ca.pem \
-v ~/deploy/os-dashboards-01.pem:/usr/share/opensearch-dashboards/config/os-dashboards-01.pem \
-v ~/deploy/os-dashboards-01-key.pem:/usr/share/opensearch-dashboards/config/os-dashboards-01-key.pem \
--network opensearch-dev-net \
--ip 172.20.0.10 \
--name os-dashboards-01 \
opensearchproject/opensearch-dashboards:2.5.0
Пример ответа
310de7a24cf599ca0b39b241db07fa8865592ebe15b6f5fda26ad19d8e1c1e09
- Убедитесь, что контейнер OpenSearch Dashboards запустился правильно. Команда, подобная следующей, может быть использована для подтверждения того, что запросы к
https://HOST_ADDRESS:5601 перенаправляются (HTTP статус код 302) на /app/login?:
curl https://localhost:5601 -kI
Пример ответа
HTTP/1.1 302 Found
location: /app/login?
osd-name: opensearch-dashboards-dev
cache-control: private, no-cache, no-store, must-revalidate
set-cookie: security_authentication=; Max-Age=0; Expires=Thu, 01 Jan 1970 00:00:00 GMT; Secure; HttpOnly; Path=/
content-length: 0
Date: Wed, 08 Mar 2023 15:36:53 GMT
Connection: keep-alive
Keep-Alive: timeout=120
- Включите распределение реплик шардов:
curl -H 'Content-type: application/json' \
-X PUT "https://localhost:9201/_cluster/settings?pretty" \
-d'{"persistent":{"cluster.routing.allocation.enable":"all"}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"acknowledged" : true,
"persistent" : {
"cluster" : {
"routing" : {
"allocation" : {
"enable" : "all"
}
}
}
},
"transient" : { }
}
Проверка обновления
Вы успешно развернули защищенный кластер OpenSearch, проиндексировали данные, создали панель управления, заполненную образцами данных, создали нового внутреннего пользователя, сделали резервную копию важных файлов и обновили кластер с версии 1.3.7 до 2.5.0. Прежде чем продолжить исследовать и экспериментировать с OpenSearch и OpenSearch Dashboards, вам следует проверить результаты обновления.
Для этого кластера шаги по проверке после обновления могут включать в себя проверку следующего:
- Запущенная версия
- Здоровье и распределение шардов
- Согласованность данных
Проверка текущей запущенной версии ваших узлов OpenSearch:
curl -s "https://localhost:9201/_cat/nodes?v&h=name,version,node.role,master" \
-ku admin:<custom-admin-password> | column -t
Пример ответа
name version node.role master
os-node-01 2.5.0 dimr *
os-node-02 2.5.0 dimr -
os-node-04 2.5.0 dimr -
os-node-03 2.5.0 dimr -
Проверка текущей запущенной версии OpenSearch Dashboards:
Вариант 1: Проверьте версию OpenSearch Dashboards через веб-интерфейс.
- Откройте веб-браузер и перейдите на порт 5601 вашего Docker-хоста (например,
https://HOST_ADDRESS:5601).
- Войдите с использованием имени пользователя по умолчанию (admin) и пароля по умолчанию (admin).
- Нажмите кнопку “Справка” в правом верхнем углу. Версия отображается в всплывающем окне.
- Снова нажмите кнопку “Справка”, чтобы закрыть всплывающее окно.
Вариант 2: Проверьте версию OpenSearch Dashboards, проверив файл manifest.yml.
- Из командной строки откройте интерактивную сессию псевдо-TTY с контейнером OpenSearch Dashboards:
docker exec -it os-dashboards-01 bash
- Проверьте файл manifest.yml на наличие версии:
Пример ответа
---
schema-version: '1.1'
build:
name: OpenSearch Dashboards
version: 2.5.0
Завершите сессию псевдо-TTY:
Проверка состояния кластера и распределения шардов
Запросите API-эндпоинт состояния кластера, чтобы увидеть информацию о здоровье вашего кластера. Вы должны увидеть статус “green”, что указывает на то, что все первичные и репликатные шарды распределены:
curl -s "https://localhost:9201/_cluster/health?pretty" -ku admin:<custom-admin-password>
Пример ответа
{
"cluster_name" : "opensearch-dev-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 4,
"number_of_data_nodes" : 4,
"discovered_master" : true,
"discovered_cluster_manager" : true,
"active_primary_shards" : 16,
"active_shards" : 36,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Запросите API-эндпоинт CAT shards, чтобы увидеть, как шардов распределены после обновления кластера:
curl -s "https://localhost:9201/_cat/shards" -ku admin:<custom-admin-password>
Пример ответа
security-auditlog-2023.02.27 0 r STARTED 4 80.5kb 172.20.0.13 os-node-03
security-auditlog-2023.02.27 0 p STARTED 4 80.5kb 172.20.0.11 os-node-01
security-auditlog-2023.03.08 0 p STARTED 30 95.2kb 172.20.0.13 os-node-03
security-auditlog-2023.03.08 0 r STARTED 30 123.8kb 172.20.0.11 os-node-01
ecommerce 0 p STARTED 4675 3.9mb 172.20.0.12 os-node-02
ecommerce 0 r STARTED 4675 3.9mb 172.20.0.13 os-node-03
.kibana_1 0 p STARTED 3 5.9kb 172.20.0.12 os-node-02
.kibana_1 0 r STARTED 3 5.9kb 172.20.0.11 os-node-01
.kibana_92668751_admin_1 0 p STARTED 33 37.3kb 172.20.0.13 os-node-03
.kibana_92668751_admin_1 0 r STARTED 33 37.3kb 172.20.0.11 os-node-01
opensearch_dashboards_sample_data_logs 0 p STARTED 14074 9.1mb 172.20.0.12 os-node-02
opensearch_dashboards_sample_data_logs 0 r STARTED 14074 9.1mb 172.20.0.14 os-node-04
security-auditlog-2023.02.28 0 p STARTED 6 26.2kb 172.20.0.11 os-node-01
security-auditlog-2023.02.28 0 r STARTED 6 26.2kb 172.20.0.14 os-node-04
.opendistro-reports-definitions 0 p STARTED 0 208b 172.20.0.12 os-node-02
.opendistro-reports-definitions 0 r STARTED 0 208b 172.20.0.13 os-node-03
.opendistro-reports-definitions 0 r STARTED 0 208b 172.20.0.14 os-node-04
security-auditlog-2023.03.06 0 r STARTED 53 174.6kb 172.20.0.12 os-node-02
security-auditlog-2023.03.06 0 p STARTED 53 174.6kb 172.20.0.14 os-node-04
.kibana_101107607_newuser_1 0 r STARTED 1 5.1kb 172.20.0.13 os-node-03
.kibana_101107607_newuser_1 0 p STARTED 1 5.1kb 172.20.0.11 os-node-01
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.12 os-node-02
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.13 os-node-03
.opendistro_security 0 r STARTED 10 64.5kb 172.20.0.11 os-node-01
.opendistro_security 0 p STARTED 10 64.5kb 172.20.0.14 os-node-04
.kibana_-152937574_admintenant_1 0 r STARTED 1 5.1kb 172.20.0.12 os-node-02
.kibana_-152937574_admintenant_1 0 p STARTED 1 5.1kb 172.20.0.14 os-node-04
security-auditlog-2023.03.07 0 r STARTED 37 175.7kb 172.20.0.12 os-node-02
security-auditlog-2023.03.07 0 p STARTED 37 175.7kb 172.20.0.14 os-node-04
.kibana_92668751_admin_2 0 p STARTED 34 38.6kb 172.20.0.13 os-node-03
.kibana_92668751_admin_2 0 r STARTED 34 38.6kb 172.20.0.11 os-node-01
.kibana_2 0 p STARTED 3 6kb 172.20.0.13 os-node-03
.kibana_2 0 r STARTED 3 6kb 172.20.0.14 os-node-04
.opendistro-reports-instances 0 r STARTED 0 208b 172.20.0.12 os-node-02
.opendistro-reports-instances 0 r STARTED 0 208b 172.20.0.11 os-node-01
.opendistro-reports-instances 0 p STARTED 0 208b 172.20.0.14 os-node-04
Проверка согласованности данных
Вам нужно снова запросить индекс ecommerce, чтобы подтвердить, что образцы данных все еще присутствуют:
- Сравните ответ на этот запрос с ответом, который вы получили на последнем шаге индексации данных с помощью REST API:
curl -H 'Content-Type: application/json' \
-X GET "https://localhost:9201/ecommerce/_search?pretty=true&filter_path=hits.total" \
-d'{"query":{"match":{"customer_first_name":"Sonya"}}}' \
-ku admin:<custom-admin-password>
Пример ответа
{
"hits" : {
"total" : {
"value" : 106,
"relation" : "eq"
}
}
}
- Откройте веб-браузер и перейдите на порт 5601 вашего Docker-хоста (например,
https://HOST_ADDRESS:5601).
- Введите имя пользователя по умолчанию (admin) и пароль (admin).
- На главной странице OpenSearch Dashboards выберите кнопку Меню в верхнем левом углу веб-интерфейса, чтобы открыть панель навигации.
- Выберите “Панель управления”.
- Выберите
[Logs] Web Traffic, чтобы открыть панель управления, созданную при добавлении образцов данных ранее в процессе.
- Когда вы закончите просмотр панели управления, выберите кнопку Профиль. Выберите “Выйти”, чтобы войти как другой пользователь.
- Введите имя пользователя и пароль, которые вы создали перед обновлением, затем выберите “Войти”.
2.7 - Установка плагинов
OpenSearch включает в себя ряд плагинов, которые добавляют функции и возможности к основной платформе.
Доступные вам плагины зависят от того, как был установлен OpenSearch и какие плагины были добавлены или удалены впоследствии. Например, минимальная дистрибуция OpenSearch включает только основные функции, такие как индексация и поиск. Использование минимальной дистрибуции OpenSearch полезно, когда вы работаете в тестовой среде, имеете собственные плагины или планируете интегрировать OpenSearch с другими сервисами.
Стандартная дистрибуция OpenSearch включает гораздо больше плагинов, предлагающих значительно больше функциональности. Вы можете выбрать добавление дополнительных плагинов или удалить любые плагины, которые вам не нужны.
Для получения списка доступных плагинов смотрите Доступные плагины.
Для корректной работы плагина с OpenSearch он может запрашивать определенные разрешения в процессе установки. Ознакомьтесь с запрашиваемыми разрешениями и действуйте соответственно. Важно понимать функциональность плагина перед его установкой. При выборе плагина, предоставленного сообществом, убедитесь, что источник надежен и заслуживает доверия.
Управление плагинами
Для управления плагинами в OpenSearch вы можете использовать инструмент командной строки под названием opensearch-plugin. Этот инструмент позволяет выполнять следующие действия:
- Список установленных плагинов.
- Установка плагинов.
- Удаление установленного плагина.
Вы можете вывести текст справки, передав -h или --help. В зависимости от конфигурации вашего хоста, вам также может потребоваться запускать команду с привилегиями sudo.
Если вы запускаете OpenSearch в контейнере Docker, плагины должны быть установлены, удалены и настроены путем изменения образа Docker. Для получения дополнительной информации смотрите Работа с плагинами.
Список
Используйте list, чтобы увидеть список плагинов, которые уже были установлены.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin list
ПРИМЕР
$ ./opensearch-plugin list
opensearch-alerting
opensearch-anomaly-detection
opensearch-asynchronous-search
opensearch-cross-cluster-replication
opensearch-geospatial
opensearch-index-management
opensearch-job-scheduler
opensearch-knn
opensearch-ml
opensearch-notifications
opensearch-notifications-core
opensearch-observability
opensearch-performance-analyzer
opensearch-reports-scheduler
opensearch-security
opensearch-sql
Список (с помощью CAT API)
Вы также можете перечислить установленные плагины, используя CAT API.
ИСПОЛЬЗОВАНИЕ
ПРИМЕР ОТВЕТА
opensearch-node1 opensearch-alerting 2.0.1.0
opensearch-node1 opensearch-anomaly-detection 2.0.1.0
opensearch-node1 opensearch-asynchronous-search 2.0.1.0
opensearch-node1 opensearch-cross-cluster-replication 2.0.1.0
opensearch-node1 opensearch-index-management 2.0.1.0
opensearch-node1 opensearch-job-scheduler 2.0.1.0
opensearch-node1 opensearch-knn 2.0.1.0
opensearch-node1 opensearch-ml 2.0.1.0
opensearch-node1 opensearch-notifications 2.0.1.0
opensearch-node1 opensearch-notifications-core 2.0.1.0
Установка
Существует три способа установки плагинов с помощью инструмента opensearch-plugin:
- Установить плагин по имени.
- Установить плагин из zip-файла.
- Установить плагин, используя координаты Maven.
Установка плагина по имени
Вы можете установить плагины, которые еще не предустановлены в вашей установке, используя имя плагина. Для получения списка плагинов, которые могут не быть предустановленными, смотрите Дополнительные плагины.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <plugin-name>
ПРИМЕР
$ sudo ./opensearch-plugin install analysis-icu
-> Установка analysis-icu
-> Загрузка analysis-icu из opensearch
[=================================================] 100%
-> Установлен analysis-icu с именем папки analysis-icu
Установка плагина из zip-файла
Вы можете установить удаленные zip-файлы, заменив <zip-file> на URL размещенного файла. Инструмент поддерживает загрузку только по протоколам HTTP/HTTPS. Для локальных zip-файлов замените <zip-file> на file:, за которым следует абсолютный или относительный путь к zip-файлу плагина, как показано во втором примере ниже.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <zip-file>
Пример
# Zip file is hosted on a remote server - in this case, Maven central repository.
$ sudo ./opensearch-plugin install https://repo1.maven.org/maven2/org/opensearch/plugin/opensearch-anomaly-detection/2.2.0.0/opensearch-anomaly-detection-2.2.0.0.zip
-> Installing https://repo1.maven.org/maven2/org/opensearch/plugin/opensearch-anomaly-detection/2.2.0.0/opensearch-anomaly-detection-2.2.0.0.zip
-> Downloading https://repo1.maven.org/maven2/org/opensearch/plugin/opensearch-anomaly-detection/2.2.0.0/opensearch-anomaly-detection-2.2.0.0.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessClassInPackage.sun.misc
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.net.SocketPermission * connect,resolve
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] registerMBean
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] unregisterMBean
* javax.management.MBeanServerPermission createMBeanServer
* javax.management.MBeanTrustPermission register
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed opensearch-anomaly-detection with folder name opensearch-anomaly-detection
# Zip file in a local directory.
$ sudo ./opensearch-plugin install file:/home/user/opensearch-anomaly-detection-2.2.0.0.zip
-> Installing file:/home/user/opensearch-anomaly-detection-2.2.0.0.zip
-> Downloading file:/home/user/opensearch-anomaly-detection-2.2.0.0.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessClassInPackage.sun.misc
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.net.SocketPermission * connect,resolve
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] registerMBean
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] unregisterMBean
* javax.management.MBeanServerPermission createMBeanServer
* javax.management.MBeanTrustPermission register
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed opensearch-anomaly-detection with folder name opensearch-anomaly-detection
Установка плагина, используя координаты Maven
Инструмент opensearch-plugin install также позволяет вам указывать координаты Maven для доступных артефактов и версий, размещенных на Maven Central. Инструмент анализирует предоставленные вами координаты Maven и формирует URL. В результате хост должен иметь возможность напрямую подключаться к сайту Maven Central. Установка плагина завершится неудачей, если вы передадите координаты прокси-серверу или локальному репозиторию.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <groupId>:<artifactId>:<version>
ПРИМЕР
$ sudo ./opensearch-plugin install org.opensearch.plugin:opensearch-anomaly-detection:2.2.0.0
-> Installing org.opensearch.plugin:opensearch-anomaly-detection:2.2.0.0
-> Downloading org.opensearch.plugin:opensearch-anomaly-detection:2.2.0.0 from maven central
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.lang.RuntimePermission accessClassInPackage.sun.misc
* java.lang.RuntimePermission accessDeclaredMembers
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.lang.reflect.ReflectPermission suppressAccessChecks
* java.net.SocketPermission * connect,resolve
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] registerMBean
* javax.management.MBeanPermission org.apache.commons.pool2.impl.GenericObjectPool#-[org.apache.commons.pool2:name=pool,type=GenericObjectPool] unregisterMBean
* javax.management.MBeanServerPermission createMBeanServer
* javax.management.MBeanTrustPermission register
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed opensearch-anomaly-detection with folder name opensearch-anomaly-detection
Перезапустите узел OpenSearch после установки плагина.
Установка нескольких плагинов
Несколько плагинов можно установить за одну команду.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin install <plugin-name> <plugin-name> ... <plugin-name>
ПРИМЕР
$ sudo ./opensearch-plugin install analysis-nori repository-s3
Удаление
Вы можете удалить плагин, который уже был установлен, с помощью опции remove.
ИСПОЛЬЗОВАНИЕ
bin/opensearch-plugin remove <plugin-name>
ПРИМЕР
$ sudo ./opensearch-plugin remove opensearch-anomaly-detection
-> Удаление [opensearch-anomaly-detection]...
После удаления плагина перезапустите узел OpenSearch.
Пакетный режим
При установке плагина, который требует дополнительных привилегий, не включенных по умолчанию, плагин запросит у вас подтверждение необходимых привилегий. Чтобы предоставить все запрашиваемые привилегии, используйте пакетный режим, чтобы пропустить запрос на подтверждение.
Чтобы принудительно включить пакетный режим при установке плагинов, добавьте опцию -b или --batch:
bin/opensearch-plugin install --batch <plugin-name>
Доступные плагины
OpenSearch предоставляет несколько встроенных плагинов, которые доступны для немедленного использования со всеми дистрибуциями OpenSearch, за исключением минимальной дистрибуции. Дополнительные плагины доступны, но их необходимо установить отдельно, используя один из вариантов установки.
Встроенные плагины
Следующие плагины входят во все дистрибуции OpenSearch, за исключением минимальной дистрибуции. Если вы используете минимальную дистрибуцию, вы можете добавить эти плагины, используя один из методов установки.
| Название плагина |
Репозиторий |
Самая ранняя доступная версия |
| Alerting |
opensearch-alerting |
1.0.0 |
| Anomaly Detection |
opensearch-anomaly-detection |
1.0.0 |
| Asynchronous Search |
opensearch-asynchronous-search |
1.0.0 |
| Cross Cluster Replication |
opensearch-cross-cluster-replication |
1.1.0 |
| Custom Codecs |
opensearch-custom-codecs |
2.10.0 |
| Flow Framework |
flow-framework |
2.12.0 |
| Notebooks |
opensearch-notebooks |
1.0.0 до 1.1.0 |
| Notifications |
notifications |
2.0.0 |
| Reports Scheduler |
opensearch-reports-scheduler |
1.0.0 |
| Geospatial |
opensearch-geospatial |
2.2.0 |
| Index Management |
opensearch-index-management |
1.0.0 |
| Job Scheduler |
opensearch-job-scheduler |
1.0.0 |
| k-NN |
opensearch-knn |
1.0.0 |
| Learning to Rank |
opensearch-ltr |
2.19.0 |
| ML Commons |
opensearch-ml |
1.3.0 |
| Skills |
opensearch-skills |
2.12.0 |
| Neural Search |
neural-search |
2.4.0 |
| Observability |
opensearch-observability |
1.2.0 |
| Performance Analyzer |
opensearch-performance-analyzer |
1.0.0 |
| Security |
opensearch-security |
1.0.0 |
| Security Analytics |
opensearch-security-analytics |
2.4.0 |
| SQL |
opensearch-sql |
1.0.0 |
| Learning to Rank Base |
opensearch-learning-to-rank-base |
2.19.0 |
| Remote Metadata SDK |
opensearch-remote-metadata-sdk |
2.19.0 |
| Query Insights |
query-insights |
2.16.0 |
| System Templates |
opensearch-system-templates |
2.17.0 |
| User Behavior Insights |
ubi |
3.0.0 |
| Search Relevance |
search-relevance |
3.1.0 |
Примечания:
- Dashboard Notebooks были объединены с плагином Observability с выходом OpenSearch 1.2.0.
- Performance Analyzer недоступен на Windows.
СКАЧИВАНИЕ ВСТРОЕННЫХ ПЛАГИНОВ ДЛЯ ОФЛАЙН-УСТАНОВКИ
Каждый встроенный плагин можно скачать и установить оффлайн из zip-файла.
URL для соответствующего плагина можно найти в файле manifest.yml, который расположен в корневом каталоге извлеченного пакета.
Основные плагины
Основной (или нативный) плагин в OpenSearch — это плагин, который находится в репозитории основного движка OpenSearch. Эти плагины тесно интегрированы с движком OpenSearch, версионируются вместе с основными релизами и по умолчанию не включены в стандартную дистрибуцию OpenSearch.
СКАЧИВАНИЕ ОСНОВНЫХ ПЛАГИНОВ ДЛЯ ОФЛАЙН-УСТАНОВКИ
Каждый из основных плагинов в этом списке можно скачать и установить оффлайн из zip-файла, используя официальный шаблон URL репозитория плагинов:
https://artifacts.opensearch.org/releases/plugins/<plugin-name>/<version>/<plugin-name>-<version>.zip
Где <plugin-name> соответствует имени встроенного плагина (например, analysis-icu). <version> должен соответствовать версии дистрибуции OpenSearch (например, 2.19.1).
Например, используйте следующий URL для скачивания дистрибуции встроенного плагина analysis-icu для версии OpenSearch 2.19.1:
https://artifacts.opensearch.org/releases/plugins/analysis-icu/2.19.1/analysis-icu-2.19.1.zip
Дополнительные плагины
Существует множество других плагинов, доступных помимо тех, что предоставлены в стандартной дистрибуции. Эти дополнительные плагины были разработаны разработчиками OpenSearch или членами сообщества OpenSearch. Для получения списка дополнительных плагинов, которые вы можете установить, смотрите Дополнительные плагины.
Совместимость плагинов
Вы можете указать совместимость плагина с определенной версией OpenSearch в файле plugin-descriptor.properties. Например, плагин с следующим свойством совместим только с OpenSearch 2.3.0:
В качестве альтернативы вы можете указать диапазон совместимых версий OpenSearch, установив свойство dependencies в файле plugin-descriptor.properties в одну из следующих нотаций:
dependencies={ opensearch: "2.3.0" }: Плагин совместим только с версией OpenSearch 2.3.0.dependencies={ opensearch: "=2.3.0" }: Плагин совместим только с версией OpenSearch 2.3.0.dependencies={ opensearch: "~2.3.0" }: Плагин совместим со всеми версиями от 2.3.0 до следующей минорной версии, в данном примере — 2.4.0 (исключительно).dependencies={ opensearch: "^2.3.0" }: Плагин совместим со всеми версиями от 2.3.0 до следующей мажорной версии, в данном примере — 3.0.0 (исключительно).
Вы можете указать только одно из свойств opensearch.version или dependencies.
Связанные ссылки
2.7.1 - Дополнительные плагины
Существует множество других плагинов, доступных помимо тех, что предоставлены в стандартной дистрибуции OpenSearch.
Эти дополнительные плагины были разработаны разработчиками OpenSearch или членами сообщества OpenSearch. Хотя невозможно предоставить исчерпывающий список (поскольку многие плагины не поддерживаются в репозитории OpenSearch на GitHub), ниже приведены некоторые из плагинов, доступных в каталоге OpenSearch/plugins на GitHub, которые можно установить с помощью одного из вариантов установки, например, используя команду bin/opensearch-plugin install <plugin-name>.
| Название плагина |
Самая ранняя доступная версия |
| analysis-icu |
1.0.0 |
| analysis-kuromoji |
1.0.0 |
| analysis-nori |
1.0.0 |
| analysis-phonenumber |
2.18.0 |
| analysis-phonetic |
1.0.0 |
| analysis-smartcn |
1.0.0 |
| analysis-stempel |
1.0.0 |
| analysis-ukrainian |
1.0.0 |
| discovery-azure-classic |
1.0.0 |
| discovery-ec2 |
1.0.0 |
| discovery-gce |
1.0.0 |
| ingest-attachment |
1.0.0 |
| ingestion-kafka |
3.0.0 |
| ingestion-kinesis |
3.0.0 |
| mapper-annotated-text |
1.0.0 |
| mapper-murmur3 |
1.0.0 |
| mapper-size |
1.0.0 |
| query-insights |
2.12.0 |
| repository-azure |
1.0.0 |
| repository-gcs |
1.0.0 |
| repository-hdfs |
1.0.0 |
| repository-s3 |
1.0.0 |
| store-smb |
1.0.0 |
| transport-grpc |
3.0.0 |
2.7.2 - mapper-size
Плагин mapper-size позволяет использовать поле _size в индексах OpenSearch. Поле _size хранит размер каждого документа в байтах.
Установка плагина
Вы можете установить плагин mapper-size, используя следующую команду:
./bin/opensearch-plugin install mapper-size
Примеры
После запуска кластера вы можете создать индекс с включенным отображением размера, индексировать документ и выполнять поиск по документам, как показано в следующих примерах.
Создание индекса с включенным отображением размера
curl -XPUT example-index -H "Content-Type: application/json" -d '{
"mappings": {
"_size": {
"enabled": true
},
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}'
Индексация документа
curl -XPOST example-index/_doc -H "Content-Type: application/json" -d '{
"name": "John Doe",
"age": 30
}'
Запрос к индексу
curl -XGET example-index/_search -H "Content-Type: application/json" -d '{
"query": {
"match_all": {}
},
"stored_fields": ["_size", "_source"]
}'
Результаты запроса
В следующем примере поле _size включено в результаты запроса и показывает размер индексированного документа в байтах:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "example_index",
"_id": "Pctw0I8BLto8I5f_NLKK",
"_score": 1.0,
"_size": 37,
"_source": {
"name": "John Doe",
"age": 30
}
}
]
}
}
2.7.3 - ingest-attachment
Плагин ingest-attachment позволяет OpenSearch извлекать содержимое и другую информацию из файлов с использованием библиотеки извлечения текста Apache Tika.
Поддерживаемые форматы документов включают PPT, PDF, RTF, ODF и многие другие (см. Поддерживаемые форматы документов Tika).
Входное поле должно быть закодировано в формате base64.
Установка плагина
Установите плагин ingest-attachment, используя следующую команду:
./bin/opensearch-plugin install ingest-attachment
Опции процессора вложений
| Название |
Обязательный |
Значение по умолчанию |
Описание |
| field |
Да |
|
Имя поля, в котором будет храниться извлеченное содержимое. |
Пример использования плагина ingest-attachment
Следующие шаги покажут вам, как начать работу с плагином ingest-attachment.
Шаг 1: Создайте индекс для хранения ваших вложений
Следующая команда создает индекс для хранения ваших вложений:
PUT /example-attachment-index
{
"mappings": {
"properties": {}
}
}
Шаг 2: Создайте конвейер
Следующая команда создает конвейер, содержащий процессор вложений:
PUT _ingest/pipeline/attachment
{
"description" : "Извлечение информации о вложениях",
"processors" : [
{
"attachment" : {
"field" : "data"
}
}
]
}
Шаг 3: Сохраните вложение
Преобразуйте вложение в строку base64, чтобы передать его как данные. В этом примере команда base64 преобразует файл lorem.rtf:
В качестве альтернативы вы можете использовать Node.js для чтения файла в формате base64, как показано в следующих командах:
import * as fs from "node:fs/promises";
import path from "node:path";
const filePath = path.join(import.meta.dirname, "lorem.rtf");
const base64File = await fs.readFile(filePath, { encoding: "base64" });
console.log(base64File);
Файл .rtf содержит следующий текст в формате base64:
Lorem ipsum dolor sit amet: e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=.
Теперь вы можете сохранить вложение, используя следующую команду:
PUT example-attachment-index/_doc/lorem_rtf?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0="
}
Результаты запроса
После обработки вложения вы можете выполнять поиск по данным, используя поисковые запросы, как показано в следующем примере:
POST example-attachment-index/_search
{
"query": {
"match": {
"attachment.content": "ipsum"
}
}
}
OpenSearch ответит следующим образом:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.1724279,
"hits": [
{
"_index": "example-attachment-index",
"_id": "lorem_rtf",
"_score": 1.1724279,
"_source": {
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"attachment": {
"content_type": "application/rtf",
"language": "pt",
"content": "Lorem ipsum dolor sit amet",
"content_length": 28
}
}
}
]
}
}
Извлеченная информация
Следующие поля могут быть извлечены с помощью плагина:
- content
- language
- date
- title
- author
- keywords
- content_type
- content_length
Чтобы извлечь только подмножество этих полей, определите их в свойствах процессора конвейера, как показано в следующем примере:
PUT _ingest/pipeline/attachment
{
"description" : "Извлечение информации о вложениях",
"processors" : [
{
"attachment" : {
"field" : "data",
"properties": ["content", "title", "author"]
}
}
]
}
Ограничение извлекаемого содержимого
Чтобы предотвратить извлечение слишком большого количества символов и перегрузку памяти узла, значение по умолчанию составляет 100_000. Вы можете изменить это значение, используя настройку indexed_chars. Например, вы можете использовать -1 для неограниченного количества символов, но необходимо убедиться, что у вас достаточно памяти HEAP на узле OpenSearch для извлечения содержимого больших документов.
Вы также можете определить этот лимит для каждого документа, используя поле запроса indexed_chars_field. Если документ содержит indexed_chars_field, оно перезапишет настройку indexed_chars, как показано в следующем примере:
PUT _ingest/pipeline/attachment
{
"description" : "Извлечение информации о вложениях",
"processors" : [
{
"attachment" : {
"field" : "data",
"indexed_chars" : 10,
"indexed_chars_field" : "max_chars"
}
}
]
}
С настроенным конвейером вложений вы можете извлечь 10 символов по умолчанию, не указывая max_chars в запросе, как показано в следующем примере:
PUT example-attachment-index/_doc/lorem_rtf?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0="
}
В качестве альтернативы вы можете изменить max_chars для каждого документа, чтобы извлечь до 15 символов, как показано в следующем примере:
PUT example-attachment-index/_doc/lorem_rtf?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kNCkxvcmVtIGlwc3VtIGRvbG9yIHNpdCBhbWV0DQpccGFyIH0=",
"max_chars": 15
}
2.8 - Управление плагинами OpenSearch Dashboards
OpenSearch Dashboards предоставляет инструмент командной строки под названием opensearch-dashboards-plugin для управления плагинами.
OpenSearch Dashboards предоставляет инструмент командной строки под названием opensearch-dashboards-plugin для управления плагинами. Этот инструмент позволяет вам:
- Список установленных плагинов.
- Установить плагины.
- Удалить установленный плагин.
Совместимость плагинов
Основные, второстепенные и патч-версии плагинов должны соответствовать основным, второстепенным и патч-версиям OpenSearch для обеспечения совместимости. Например, версии плагинов 2.3.0.x работают только с OpenSearch 2.3.0.
Предварительные требования
- Совместимый кластер OpenSearch
- Соответствующие плагины OpenSearch, установленные на этом кластере
- Соответствующая версия OpenSearch Dashboards (например, OpenSearch Dashboards 2.3.0 работает с OpenSearch 2.3.0)
Доступные плагины
Следующая таблица перечисляет доступные плагины OpenSearch Dashboards.
| Название плагина |
Репозиторий |
Самая ранняя доступная версия |
| Alerting Dashboards |
alerting-dashboards-plugin |
1.0.0 |
| Anomaly Detection Dashboards |
anomaly-detection-dashboards-plugin |
1.0.0 |
| Custom Import Maps Dashboards |
dashboards-maps |
2.2.0 |
| Search Relevance Dashboards |
dashboards-search-relevance |
2.4.0 |
| Index Management Dashboards |
index-management-dashboards-plugin |
1.0.0 |
| Notebooks Dashboards |
dashboards-notebooks |
1.0.0 |
| Notifications Dashboards |
dashboards-notifications |
2.0.0 |
| Observability Dashboards |
dashboards-observability |
2.0.0 |
| Query Insights Dashboards |
query-insights-dashboards |
2.19.0 |
| Query Workbench Dashboards |
query-workbench |
1.0.0 |
| Reports Dashboards |
dashboards-reporting |
1.0.0 |
| Security Analytics Dashboards |
security-analytics-dashboards-plugin |
2.4.0 |
| Security Dashboards |
security-dashboards-plugin |
1.0.0 |
Вот переведенная документация на русский язык с сохранением оформления Markdown для Hugo Docsy:
Установка
Перейдите в домашний каталог OpenSearch Dashboards (например, /usr/share/opensearch-dashboards) и выполните команду установки для каждого плагина.
Просмотр списка установленных плагинов
Чтобы просмотреть список установленных плагинов из командной строки, используйте следующую команду:
sudo bin/opensearch-dashboards-plugin list
Удаление плагинов
Чтобы удалить плагин, выполните команду:
sudo bin/opensearch-dashboards-plugin remove <plugin-name>
Затем удалите все связанные записи из opensearch_dashboards.yml.
Для некоторых плагинов также необходимо удалить пакет “оптимизации”. Вот пример команды для плагина Anomaly Detection:
sudo rm /usr/share/opensearch-dashboards/optimize/bundles/opensearch-anomaly-detection-opensearch-dashboards.*
После этого перезапустите OpenSearch Dashboards. После удаления любого плагина OpenSearch Dashboards выполняет операцию оптимизации при следующем запуске. Эта операция занимает несколько минут, даже на быстрых машинах, поэтому наберитесь терпения.
Обновление плагинов
OpenSearch Dashboards не обновляет плагины. Вместо этого вам нужно удалить старую версию и ее оптимизированный пакет, переустановить их и перезапустить OpenSearch Dashboards:
-
Удалите старую версию:
sudo bin/opensearch-dashboards-plugin remove <plugin-name>
-
Удалите оптимизированный пакет:
sudo rm /usr/share/opensearch-dashboards/optimize/bundles/<bundle-name>
-
Переустановите новую версию:
sudo bin/opensearch-dashboards-plugin install <plugin-name>
-
Перезапустите OpenSearch Dashboards.
Например, чтобы удалить и переустановить плагин Anomaly Detection:
sudo bin/opensearch-dashboards-plugin remove anomalyDetectionDashboards
sudo rm /usr/share/opensearch-dashboards/optimize/bundles/opensearch-anomaly-detection-opensearch-dashboards.*
sudo bin/opensearch-dashboards-plugin install <AD OpenSearch Dashboards plugin artifact URL>
3 - Query DSL - язык запросов OpenSearch
OpenSearch предоставляет мощный язык запросов (Query Domain-Specific Language), основанный на JSON-синтаксисе. Этот язык позволяет выполнять гибкий и точный поиск по данным.
Введение в Query DSL
OpenSearch предоставляет мощный язык запросов (Query Domain-Specific Language), основанный на JSON-синтаксисе. Этот язык позволяет выполнять гибкий и точный поиск по данным.
Базовый пример запроса:
GET testindex/_search
{
"query": {
"match_all": {}
}
Этот запрос возвращает все документы в указанном индексе.
Типы запросов
Запросы делятся на две основные категории:
1. Листовые запросы (Leaf queries)
Особенности:
- Выполняют поиск по конкретным полям
- Могут использоваться самостоятельно
- Не содержат других запросов
Основные типы:
1.1 Полнотекстовые запросы:
- Анализируют текст запроса
- Применяют тот же анализатор, что и при индексации
- Примеры:
match, match_phrase, multi_match
1.2 Термино-уровневые запросы:
- Ищут точные значения без анализа текста
- Не учитывают релевантность
- Примеры:
term, terms, range, exists
1.3 Геопространственные запросы:
- Работают с географическими данными
- Примеры:
geo_distance, geo_bounding_box
1.4 Запросы соединений:
- Для работы с вложенными документами
- Примеры:
nested, has_child, has_parent
1.5 Позиционные запросы (Span queries):
- Точный поиск с учетом позиции терминов
- Часто используются для юридических документов
1.6 Специализированные запросы:
more_like_this - поиск похожих документовscript - запросы с использованием скриптовpercolate - обратный поиск
2. Составные запросы (Compound queries)
Особенности:
- Объединяют несколько запросов
- Модифицируют поведение дочерних запросов
- Управляют логикой выполнения
Основные типы:
bool - булева комбинация запросовdis_max - поиск по нескольким полямconstant_score - задает фиксированную релевантностьfunction_score - кастомные алгоритмы релевантности
Особенности обработки специальных символов
Проблема:
Стандартный анализатор некорректно обрабатывает Unicode-символы (например, дефис), что может привести к:
- Неожиданным результатам поиска
- Проблемам контроля доступа
Пример проблемы:
{
"match": {
"user.id": "User-1"
}
}
Анализатор может интерпретировать “User-1” как два отдельных термина.
Решение:
- Использовать
keyword тип поля для точного совпадения
- Настроить кастомный анализатор
Ресурсоемкие запросы
Типы затратных запросов:
- Нечеткий поиск (
fuzzy)
- Поиск по префиксу (
prefix)
- Диапазонные запросы по текстовым полям
- Регулярные выражения (
regexp)
- Wildcard-запросы
- Сложные
query_string запросы
Защита от ресурсоемких запросов:
PUT _cluster/settings
{
"persistent": {
"search.allow_expensive_queries": false
}
}
Мониторинг:
Для отслеживания медленных запросов используйте shard slow logs.
Рекомендации по использованию
- Для точного соответствия используйте
keyword тип полей
- Избегайте специальных символов в текстовых полях
- Мониторьте ресурсоемкие запросы
- Для сложной логики комбинируйте запросы через
bool
- Используйте
explain для анализа работы запросов
3.1 - Контекст запроса и фильтра
Запросы состоят из условий (query clauses), которые могут выполняться в Контексте фильтра - проверяет соответствие документа условию Да/Нет и Контексте запроса - оценивает степень соответствия документа условию с расчетом релевантности
Основные концепции
Запросы состоят из условий (query clauses), которые могут выполняться в:
- Контексте фильтра - проверяет соответствие документа условию (“Да/Нет”)
- Контексте запроса - оценивает степень соответствия документа условию с расчетом релевантности
Оценка релевантности (_score)
Релевантность измеряется числовым значением в поле _score:
"hits" : [
{
"_index" : "shakespeare",
"_id" : "32437",
"_score" : 18.781435,
"_source" : {
"type" : "line",
"line_id" : 32438,
"play_name" : "Hamlet",
"speech_number" : 3,
"line_number" : "1.1.3",
"speaker" : "BERNARDO",
"text_entry" : "Long live the king!"
}
},
...
Чем выше значение _score, тем более релевантен документ. Разные типы запросов используют различные алгоритмы расчета релевантности, но все учитывают тип контекста выполнения условия.
Контекст фильтра
Характеристики:
- Возвращает только факт соответствия (бинарный результат)
- Не вычисляет оценку релевантности
- Оптимален для точных значений
- Результаты кэшируются для повышения производительности
Пример использования:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "honors": true }},
{ "range": { "graduation_year": { "gte": 2020, "lte": 2022 }}}
]
}
}
}
Этот запрос ищет студентов:
- С отличием (
honors: true)
- Выпустившихся в 2020-2022 годах
Контекст запроса
Характеристики:
- Оценивает степень соответствия документа
- Возвращает численную оценку релевантности
- Используется для полнотекстового поиска
- Поддерживает анализ текста (морфологию, синонимы)
Пример использования:
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "long live king"
}
}
}
Этот запрос:
- Ищет вариации фразы “long live king”
- Учитывает словоформы и синонимы
- Сортирует результаты по релевантности
Особенности вычисления _score
- Используется 24-битная точность (числа с плавающей запятой)
- При превышении точности может происходить потеря данных
- Разные типы запросов используют различные алгоритмы расчета
Рекомендации по применению:
- Для точных значений (ID, даты, категории) используйте контекст фильтра
- Для текстового поиска применяйте контекст запроса
- Комбинируйте оба подхода в сложных запросах через
bool запрос
3.2 - Сравнение термовых и полнотекстовых запросов
Термовые (term-level) и полнотекстовые (full-text) запросы используются для поиска по тексту, но имеют принципиальные отличия
Основные различия
Термовые (term-level) и полнотекстовые (full-text) запросы используются для поиска по тексту, но имеют принципиальные отличия:
| Характеристика |
Термовые запросы |
Полнотекстовые запросы |
| Описание |
Определяют, какие документы соответствуют запросу |
Оценивают, насколько хорошо документы соответствуют запросу |
| Анализатор |
Поисковый терм не анализируется |
Используется тот же анализатор, что и при индексации поля |
| Релевантность |
Не сортируют результаты по релевантности |
Рассчитывают оценку релевантности и сортируют результаты |
| Использование |
Точные значения (числа, даты, теги) |
Текстовые поля с учетом морфологии и вариантов слов |
OpenSearch использует алгоритм ранжирования BM25 для расчета оценок релевантности.
Когда использовать каждый тип запроса?
Пример 1: Поиск фразы
Рассмотрим поиск фразы “To be, or not to be” в произведениях Шекспира.
Термовый запрос:
GET shakespeare/_search
{
"query": {
"term": {
"text_entry": "To be, or not to be"
}
}
}
Результат:
{
"took": 3,
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"hits": []
}
}
Запрос не нашел совпадений, так как ищет точную неизмененную фразу.
Полнотекстовый запрос:
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "To be, or not to be"
}
}
}
Результат (сокращенный):
{
"took": 19,
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"hits": [
{
"_score": 17.419369,
"_source": {
"text_entry": "To be, or not to be: that is the question:"
}
},
{
"_score": 14.883024,
"_source": {
"text_entry": "Not like a corse; or if, not to be buried,"
}
}
]
}
}
Полнотекстовый запрос нашел релевантные результаты, проанализировав фразу.
Пример 2: Поиск точного термина
Для поиска точного значения “HAMLET” в поле speaker эффективнее термовый запрос:
GET shakespeare/_search
{
"query": {
"term": {
"speaker": "HAMLET"
}
}
}
Результат (сокращенный):
{
"took": 5,
"hits": {
"total": {
"value": 1582,
"relation": "eq"
},
"hits": [
{
"_score": 4.2540946,
"_source": {
"speaker": "HAMLET",
"text_entry": "[Aside] A little more than kin..."
}
},
{
"_score": 4.2540946,
"_source": {
"speaker": "HAMLET",
"text_entry": "Not so, my lord..."
}
}
]
}
}
Важно: Поиск по “Hamlet” не даст результатов, так как поле speaker является keyword и хранится в исходном регистре.
Рекомендации по выбору типа запроса
-
Используйте термовые запросы для:
- Точных значений (ID, коды, категории)
- Полям типа keyword
- Когда не нужна сортировка по релевантности
-
Используйте полнотекстовые запросы для:
- Текстового поиска с анализом
- Когда важна оценка релевантности
- Поиска по словоформам и синонимам
-
Для полей text:
Всегда используйте полнотекстовые запросы, так как их значения анализируются при индексации.
-
Для полей keyword:
Используйте термовые запросы для точного соответствия.
3.3 - Термино-уровневые запросы
Ищут точные значения без анализа текста. Не учитывают релевантность
Общее описание
Термино-уровневые запросы (term-level queries) выполняют поиск по индексу для нахождения документов, содержащих точное соответствие указанному термину. В отличие от полнотекстовых запросов, результаты термино-уровневых запросов не сортируются по оценке релевантности.
Ключевые особенности:
- Работают только с точными значениями
- Не анализируют поисковый термин
- Оптимальны для поиска по полям типа
keyword
- Не подходят для анализа текстовых полей (используйте полнотекстовые запросы)
Типы термино-уровневых запросов
В таблице представлены все виды термино-уровневых запросов:
| Тип запроса |
Описание |
term |
Поиск документов, содержащих точное соответствие указанному термину в заданном поле |
terms |
Поиск документов, содержащих один или несколько указанных терминов в заданном поле |
terms_set |
Поиск документов, соответствующих минимальному количеству указанных терминов |
ids |
Поиск документов по их идентификаторам |
range |
Поиск документов, значения поля которых попадают в указанный диапазон |
prefix |
Поиск документов, содержащих термины с указанным префиксом |
exists |
Поиск документов, имеющих любое проиндексированное значение в указанном поле |
fuzzy |
Поиск документов, содержащих термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна (количество односимвольных изменений для преобразования одного термина в другой) |
wildcard |
Поиск документов, содержащих термины, соответствующие шаблону с подстановочными символами |
regexp |
Поиск документов, содержащих термины, соответствующие регулярному выражению |
Практические рекомендации
-
Для полей keyword всегда используйте термино-уровневые запросы:
GET products/_search
{
"query": {
"term": {
"product_code": "ABC-123"
}
}
}
-
Избегайте использования термино-уровневых запросов для полей типа text, так как они проходят анализ при индексации.
-
Для сложных условий комбинируйте несколько термино-уровневых запросов через bool:
GET logs/_search
{
"query": {
"bool": {
"must": [
{ "term": { "status": "error" } },
{ "range": { "timestamp": { "gte": "2023-01-01" }}}
]
}
}
}
-
Для нечеткого поиска используйте fuzzy с указанием максимального расстояния:
GET contacts/_search
{
"query": {
"fuzzy": {
"last_name": {
"value": "Smith",
"fuzziness": 2
}
}
}
}
Все технические термины сохранены в оригинальном написании (term, fuzzy, wildcard и т.д.) для соответствия международной практике, с добавлением пояснений на русском языке для лучшего понимания.
3.3.1 - exists
Поиск документов, имеющих любое проиндексированное значение в указанном поле
Запрос exists
Назначение
Запрос exists используется для поиска документов, содержащих указанное поле.
Когда поле считается отсутствующим?
Индексированное значение будет отсутствовать для поля документа в следующих случаях:
- В маппинге поля указано
"index": false
- Значение поля в исходном JSON равно
null или [] (пустой массив)
- Длина значения поля превышает параметр
ignore_above в маппинге
- Значение поля имеет некорректный формат и в маппинге определен
ignore_malformed
Когда поле считается существующим?
Индексированное значение будет присутствовать для поля документа в следующих случаях:
- Значение является массивом, содержащим как
null, так и не-null элементы (например, ["один", null])
- Значение представляет собой пустую строку (
"" или "-")
- Значение является кастомным
null_value, определенным в маппинге поля
Пример использования
Добавление тестовых документов:
PUT testindex/_doc/1
{
"title": "Ветер крепчает"
}
PUT testindex/_doc/2
{
"title": "Унесенные ветром",
"description": "Американский эпический исторический фильм 1939 года"
}
Поиск документов с полем description:
GET testindex/_search
{
"query": {
"exists": {
"field": "description"
}
}
}
Результат выполнения:
{
"took": 3,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "testindex",
"_id": "2",
"_source": {
"title": "Унесенные ветром",
"description": "Американский эпический исторический фильм 1939 года"
}
}
]
}
}
Поиск документов с отсутствующими полями
Для поиска документов без определенного поля используйте комбинацию must_not и exists:
GET testindex/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "description"
}
}
}
}
}
Результат выполнения:
{
"took": 19,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "testindex",
"_id": "1",
"_source": {
"title": "Ветер крепчает"
}
}
]
}
}
Параметры запроса
Запрос принимает следующие параметры:
| Параметр |
Тип данных |
Описание |
field |
Строка |
Обязательное поле. Имя поля, которое должно существовать в документе. |
boost |
Число с плавающей точкой |
Определяет вес поля при расчете релевантности. Значения >1 увеличивают вес, значения между 0 и 1 уменьшают вес. По умолчанию: 1.0. |
Пример с параметром boost:
GET testindex/_search
{
"query": {
"exists": {
"field": "description",
"boost": 2.0
}
}
}
Особенности работы
- Запрос
exists проверяет именно наличие индексированного значения поля, а не его наличие в исходном документе.
- Для проверки отсутствия поля всегда используйте комбинацию
bool + must_not + exists.
- Запрос можно комбинировать с другими типами запросов в составе
bool запроса.
3.3.2 - fuzzy
Поиск документов, содержащих термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна
Нечеткий поиск (Fuzzy query)
Основные понятия
Нечеткий запрос (fuzzy query) ищет документы, содержащие термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна. Это расстояние измеряет количество односимвольных изменений, необходимых для преобразования одного термина в другой:
- Замены: кот → бот
- Вставки: кот → коты
- Удаления: кот → от
- Транспозиции: кот → кто
Принцип работы
- Запрос генерирует все возможные варианты поискового термина, попадающие в заданное расстояние редактирования
- Количество вариантов ограничивается параметром
max_expansions
- Поиск выполняется по всем сгенерированным вариантам
Примеры запросов
Базовый пример с поиском ошибочного написания “HALET” вместо “HAMLET”:
GET shakespeare/_search
{
"query": {
"fuzzy": {
"speaker": {
"value": "HALET"
}
}
}
}
Примечание: Используется автоматическое определение расстояния (AUTO)
Расширенный пример с настройкой параметров:
GET shakespeare/_search
{
"query": {
"fuzzy": {
"speaker": {
"value": "HALET",
"fuzziness": "2",
"max_expansions": 40,
"prefix_length": 0,
"transpositions": true,
"rewrite": "constant_score"
}
}
}
}
Параметры запроса
Синтаксис запроса:
GET _search
{
"query": {
"fuzzy": {
"<поле>": {
"value": "образец",
...
}
}
}
}
Доступные параметры:
| Параметр |
Тип данных |
Описание |
value |
Строка |
Обязательный. Искомый термин |
boost |
Число с плавающей точкой |
Влияет на вес поля при расчете релевантности (>1 - увеличивает, 0-1 - уменьшает). По умолчанию: 1.0 |
fuzziness |
AUTO, 0 или положительное число |
Максимальное расстояние редактирования. AUTO - автоматический расчет на основе длины термина |
max_expansions |
Положительное целое |
Максимальное количество вариантов термина для поиска. По умолчанию: 50 |
prefix_length |
Неотрицательное целое |
Количество начальных символов, не учитываемых при нечетком сравнении. По умолчанию: 0 |
rewrite |
Строка |
Стратегия перезаписи запроса. Допустимые значения: constant_score, scoring_boolean и др. По умолчанию: constant_score |
transpositions |
Логическое |
Разрешать перестановки соседних символов (ab→ba). По умолчанию: true |
Особенности производительности
- Большие значения
max_expansions (особенно с prefix_length=0) могут снизить производительность из-за генерации множества вариантов
- При
search.allow_expensive_queries=false нечеткие запросы не выполняются
- Для длинных слов рекомендуется использовать
prefix_length>0
Практические рекомендации
- Для исправления опечаток используйте
fuzziness=1 или fuzziness=2
- Для профессиональных терминов уменьшайте
max_expansions
- Для ускорения поиска увеличивайте
prefix_length
- Для точных полей отключайте транспозиции (
transpositions=false)
3.3.3 - ids
Поиск документов по их идентификаторам
Запрос IDs (поиск по идентификаторам)
Назначение
Запрос ids позволяет находить документы по их уникальным идентификаторам в поле _id.
Синтаксис запроса
GET shakespeare/_search
{
"query": {
"ids": {
"values": [
"34229",
"91296"
]
}
}
}
Параметры запроса
| Параметр |
Тип данных |
Описание |
Обязательный |
По умолчанию |
values |
Массив строк |
Список идентификаторов документов для поиска |
Да |
- |
boost |
Число с плавающей точкой |
Коэффициент усиления релевантности. Значения >1 увеличивают вес, 0-1 уменьшают вес |
Нет |
1.0 |
Особенности работы
-
Тип идентификаторов:
Идентификаторы всегда передаются как строки, даже если в системе они числовые.
-
Производительность:
Запрос оптимален для выборки небольшого количества документов по известным ID.
-
Использование с boost:
Пример с изменением релевантности:
GET shakespeare/_search
{
"query": {
"ids": {
"values": ["34229", "91296"],
"boost": 2.0
}
}
}
-
Ограничения:
- Не поддерживает шаблоны или диапазоны ID
- Для поиска по >1000 ID рекомендуется использовать
terms запрос
-
Ответ системы:
Возвращает только те документы, чьи ID присутствуют в индексе (несуществующие ID игнорируются без ошибки)
Альтернативные подходы
Для сложных сценариев поиска по ID можно использовать:
GET _search
{
"query": {
"terms": {
"_id": ["34229", "91296"]
}
}
}
3.3.4 - prefix
Поиск документов, содержащих термины с указанным префиксом
Запрос prefix (поиск по префиксу)
Назначение
Запрос prefix выполняет поиск терминов, начинающихся с указанной приставки (префикса). Используется для:
- Автодополнения
- Поиска по начальным символам
- Классификации данных с общими префиксами
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"prefix": {
"speaker": "KING H"
}
}
}
Этот запрос ищет документы, где поле speaker содержит термины, начинающиеся на “KING H”.
Расширенный синтаксис с параметрами
GET shakespeare/_search
{
"query": {
"prefix": {
"speaker": {
"value": "KING H",
"boost": 1.5,
"case_insensitive": true,
"rewrite": "scoring_boolean"
}
}
}
}
Параметры запроса
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
Строка |
Обязательный. Искомый префикс |
- |
boost |
Число с плавающей точкой |
Коэффициент усиления релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
case_insensitive |
Логический |
Регистронезависимый поиск. Если true, игнорирует регистр символов |
false |
rewrite |
Строка |
Метод перезаписи запроса. Допустимые значения: constant_score, scoring_boolean и др. |
constant_score |
Особенности работы
-
Производительность:
- При включенной настройке
index_prefixes в маппинге поля запрос выполняется оптимально
- При
search.allow_expensive_queries=false запросы prefix не выполняются (кроме случаев с index_prefixes)
-
Регистр символов:
- По умолчанию поиск чувствителен к регистру
- Для регистронезависимого поиска используйте
"case_insensitive": true
-
Примеры использования:
// Поиск продуктов с кодом, начинающимся на "A12"
GET products/_search
{
"query": {
"prefix": {
"product_code": "A12"
}
}
}
// Поиск городов, названия которых начинаются на "сан"
GET cities/_search
{
"query": {
"prefix": {
"name": {
"value": "сан",
"case_insensitive": true
}
}
}
}
-
Рекомендации:
- Для полей с длинными значениями установите
index_prefixes в маппинге
- Избегайте очень коротких префиксов (1-2 символа) на больших индексах
- Для сложных сценариев автодополнения рассмотрите
completion suggester
3.3.5 - range
Поиск документов, значения поля которых попадают в указанный диапазон
Запрос range (диапазонный запрос)
Основные возможности
Запрос range позволяет выполнять поиск документов, значения полей которых попадают в указанный диапазон.
Синтаксис базового запроса
GET shakespeare/_search
{
"query": {
"range": {
"line_id": {
"gte": 10,
"lte": 20
}
}
}
}
Этот запрос находит документы, где значение поля line_id находится в диапазоне от 10 до 20 включительно.
Операторы сравнения
Параметр поля в запросе range принимает следующие операторы:
| Оператор |
Описание |
gte |
Больше или равно |
gt |
Строго больше |
lte |
Меньше или равно |
lt |
Строго меньше |
Работа с датами
Пример поиска по датам:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "2019/01/01",
"lte": "2019/12/31"
}
}
}
}
Этот запрос находит все товары, добавленные в 2019 году.
Указание формата даты:
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "01/01/2022",
"lte": "31/12/2022",
"format":"dd/MM/yyyy"
}
}
}
}
Параметр format позволяет указать формат даты, отличный от формата, заданного в маппинге поля.
Особенности обработки дат
Автозаполнение отсутствующих компонентов даты:
OpenSearch заполняет отсутствующие компоненты даты следующими значениями:
- MONTH_OF_YEAR: 01
- DAY_OF_MONTH: 01
- HOUR_OF_DAY: 23
- MINUTE_OF_HOUR: 59
- SECOND_OF_MINUTE: 59
- NANO_OF_SECOND: 999_999_999
Пример:
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2022",
"lte": "2022-12-31"
}
}
}
}
В этом случае начальная дата будет интерпретирована как 2022-01-01T23:59:59.999999999Z.
Относительные даты
Использование математики дат:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "2019/01/01||-1y-1d"
}
}
}
}
Здесь 2019/01/01 - это опорная дата, от которой вычитается 1 год и 1 день.
Округление дат:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "now-1y/M"
}
}
}
}
Ключевое слово now ссылается на текущую дату и время, /M означает округление по месяцам.
Правила округления относительных дат
| Параметр | Правило округления | Пример для 2022-05-18||/M |
|———-|—————————————-|—————————–|
| gt | Округляет вверх | 2022-06-01T00:00:00.000 |
| gte | Округляет вниз | 2022-05-01T00:00:00.000 |
| lt | Округляет вниз до последней миллисекунды | 2022-04-30T23:59:59.999 |
| lte | Округляет вверх до последней миллисекунды | 2022-05-31T23:59:59.999 |
Часовые пояса
По умолчанию даты считаются в UTC. Можно указать часовой пояс параметром time_zone:
GET /products/_search
{
"query": {
"range": {
"created": {
"time_zone": "-04:00",
"gte": "2022-04-17T06:00:00"
}
}
}
}
Значение 2022-04-17T06:00:00-04:00 будет преобразовано в 2022-04-17T10:00:00 UTC.
Дополнительные параметры
Синтаксис с параметрами:
GET _search
{
"query": {
"range": {
"<поле>": {
"gt": 10,
...
}
}
}
}
Доступные параметры:
| Параметр |
Тип данных |
Описание |
format |
Строка |
Формат даты для этого запроса. По умолчанию используется формат, заданный в маппинге поля. |
relation |
Строка |
Определяет способ сопоставления значений для полей диапазона. Допустимые значения:
- INTERSECTS (по умолчанию): Находит документы, чей диапазон пересекается с запросом
- CONTAINS: Находит документы, чей диапазон полностью содержит запрос
- WITHIN: Находит документы, чей диапазон полностью внутри запроса |
boost |
Число с плавающей точкой |
Коэффициент усиления релевантности (>1 - увеличивает, 0-1 - уменьшает). По умолчанию: 1.0. |
time_zone |
Строка |
Часовой пояс для преобразования дат в UTC. Допустимы смещения UTC (например, -04:00) или идентификаторы IANA (например, America/New_York). |
Важно: При search.allow_expensive_queries=false диапазонные запросы по текстовым и ключевым полям не выполняются.
3.3.6 - regexp
Поиск документов, содержащих термины, соответствующие регулярному выражению
Запрос regexp (поиск по регулярным выражениям)
Назначение
Запрос regexp позволяет выполнять поиск терминов, соответствующих указанному регулярному выражению. Подробнее о синтаксисе регулярных выражений см. в документации по синтаксису регулярных выражений.
Базовый пример
GET shakespeare/_search
{
"query": {
"regexp": {
"play_name": "[a-zA-Z]amlet"
}
}
}
Этот запрос ищет любые термины в поле play_name, которые начинаются с любой буквы (верхнего или нижнего регистра), за которой следует “amlet”.
Ключевые особенности
-
Область применения:
Регулярные выражения применяются к отдельным терминам (токенам) в поле, а не ко всему полю целиком.
-
Ограничения:
- Максимальная длина регулярного выражения по умолчанию: 1,000 символов (настраивается через
index.max_regex_length)
- Используется синтаксис Lucene, который отличается от стандартных реализаций
-
Производительность:
- Избегайте шаблонов с
.* или .*?+ без префикса/суффикса
- Ресурсоемкие операции, требуют
search.allow_expensive_queries=true
- Для частых запросов рекомендуется тестировать влияние на кластер
-
Оптимизация:
Тип поля wildcard специально оптимизирован для эффективных запросов с регулярными выражениями.
Расширенный синтаксис с параметрами
GET _search
{
"query": {
"regexp": {
"<поле>": {
"value": "[Ss]ample",
"boost": 1.5,
"case_insensitive": true,
"flags": "INTERSECTION|COMPLEMENT",
"max_determinized_states": 20000,
"rewrite": "constant_score"
}
}
}
}
Параметры запроса
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
Строка |
Обязательный. Регулярное выражение для поиска |
- |
boost |
Число с плавающей точкой |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
case_insensitive |
Логический |
Регистронезависимый поиск |
false |
flags |
Строка |
Дополнительные операторы Lucene (INTERSECTION, COMPLEMENT и др.) |
- |
max_determinized_states |
Целое число |
Максимальное число состояний автомата (защита от перегрузки) |
10000 |
rewrite |
Строка |
Метод перезаписи запроса (constant_score, scoring_boolean и др.) |
constant_score |
Рекомендации по использованию
-
Тестирование:
Всегда проверяйте регулярные выражения на тестовых данных перед использованием в production.
-
Производительность:
// Неэффективно:
{ "regexp": { "text": ".*pattern.*" } }
// Оптимально:
{ "regexp": { "text": "prefix.*suffix" } }
-
Альтернативы:
Для сложных сценариев рассмотрите:
- Использование
wildcard типа поля
- Применение
match_phrase для текстовых фраз
- Использование
keyword полей для точного соответствия
-
Безопасность:
Ограничивайте max_determinized_states для предотвращения DoS-атак через сложные регулярные выражения.
Примечание: При search.allow_expensive_queries=false запросы regexp не выполняются.
3.3.7 - term
Поиск документов, содержащих точное соответствие указанному термину в заданном поле
Запрос term (поиск точного термина)
Назначение
Запрос term выполняет поиск точного соответствия указанному термину в поле. Основные характеристики:
- Ищет неизмененное значение без анализа текста
- Чувствителен к регистру по умолчанию
- Оптимален для полей типа
keyword, дат и чисел
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"term": {
"line_id": {
"value": "61809"
}
}
}
}
Этот запрос ищет строку с точным значением line_id = "61809".
Важные особенности
-
Отличие от match запросов:
term не анализирует поисковый термин- Не подходит для текстовых полей (
text), так как они анализируются при индексации
- Для текстовых полей используйте
match запросы
-
Регистронезависимый поиск (начиная с OpenSearch 2.x):
GET shakespeare/_search
{
"query": {
"term": {
"speaker": {
"value": "HAMLET",
"case_insensitive": true
}
}
}
}
Внимание! В версиях OpenSearch 2.x и ранее регистронезависимый поиск может значительно снижать производительность. Рекомендуется:
- Использовать lowercase фильтр при индексации
- Применять термины в нижнем регистре в запросах
Пример ответа
{
"hits": {
"total": {
"value": 1582,
"relation": "eq"
},
"hits": [
{
"_index": "shakespeare",
"_id": "32700",
"_score": 2,
"_source": {
"speaker": "HAMLET",
"text_entry": "[Aside] A little more than kin..."
}
}
]
}
}
Параметры запроса
Синтаксис с параметрами:
GET _search
{
"query": {
"term": {
"<поле>": {
"value": "образец",
...
}
}
}
}
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
Строка |
Обязательный. Точное значение для поиска (учитывает регистр и пробелы) |
- |
boost |
Число с плавающей точкой |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
_name |
Строка |
Имя запроса для тегирования (опционально) |
- |
case_insensitive |
Логический |
Регистронезависимый поиск (только для OpenSearch 2.x+) |
false |
Практические рекомендации
-
Для текстовых полей всегда используйте match вместо term:
// Неправильно (для text полей):
{ "term": { "description": "quick brown fox" } }
// Правильно:
{ "match": { "description": "quick brown fox" } }
-
Для точных значений (ID, коды, категории):
GET products/_search
{
"query": {
"term": {
"product_code": "ABC-123"
}
}
}
-
Комбинируйте с другими запросами:
GET logs/_search
{
"query": {
"bool": {
"must": [
{ "term": { "status": "error" } },
{ "range": { "timestamp": { "gte": "2023-01-01" }}}
]
}
}
}
-
Производительность:
- Для частых запросов добавьте индекс на поле
- Избегайте
case_insensitive в favor lowercase анализаторов
3.3.8 - terms
Поиск документов, содержащих один или несколько указанных терминов в заданном поле
Terms Query (Поиск по нескольким значениям)
Основное назначение
Запрос terms позволяет искать документы, содержащие одно или несколько указанных значений в заданном поле. Документ возвращается в результатах, если значение его поля точно соответствует хотя бы одному термину из списка.
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"terms": {
"line_id": [
"61809",
"61810"
]
}
}
}
Ключевые особенности
-
Лимит терминов:
По умолчанию максимальное количество терминов в запросе - 65,536. Настраивается через параметр index.max_terms_count.
-
Производительность:
Для оптимизации производительности с длинными списками терминов рекомендуется:
- Передавать термины в отсортированном порядке (по возрастанию UTF-8 byte values)
- Использовать механизм Terms Lookup для больших наборов терминов
-
Подсветка результатов:
Возможность подсветки результатов зависит от:
- Типа highlighter’а
- Количества терминов в запросе
Параметры запроса
| Параметр |
Тип данных |
Описание |
По умолчанию |
<field> |
String |
Поле для поиска (точное соответствие хотя бы одному термину) |
- |
boost |
Float |
Вес поля в расчете релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
_name |
String |
Имя запроса для тегирования |
- |
value_type |
String |
Тип значений для фильтрации (default или bitmap) |
default |
Terms Lookup (Поиск терминов из другого документа)
Общие принципы
Механизм Terms Lookup позволяет:
- Извлекать значения полей из указанного документа
- Использовать эти значения как условия поиска
- Работать с большими наборами терминов
Требования:
- Поле
_source должно быть включено (включено по умолчанию)
- Для уменьшения сетевого трафика рекомендуется использовать индекс с:
- Одним первичным шардом
- Полными репликами на всех узлах данных
Пример использования
- Создаем индекс студентов:
PUT students
{
"mappings": {
"properties": {
"student_id": { "type": "keyword" }
}
}
}
- Добавляем данные студентов:
PUT students/_doc/1
{
"name": "Jane Doe",
"student_id" : "111"
}
PUT students/_doc/2
{
"name": "Mary Major",
"student_id" : "222"
}
PUT students/_doc/3
{
"name": "John Doe",
"student_id" : "333"
}
- Создаем индекс классов с информацией о зачисленных студентах:
PUT classes/_doc/101
{
"name": "CS101",
"enrolled" : ["111" , "222"]
}
- Поиск студентов, зачисленных на CS101:
GET students/_search
{
"query": {
"terms": {
"student_id": {
"index": "classes",
"id": "101",
"path": "enrolled"
}
}
}
}
- Результат содержит соответствующих студентов:
{
"took": 13,
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_source": {
"name": "Jane Doe",
"student_id": "111"
}
},
{
"_index": "students",
"_id": "2",
"_source": {
"name": "Mary Major",
"student_id": "222"
}
}
]
}
}
Работа с вложенными полями
- Добавляем документ с вложенной структурой:
PUT classes/_doc/102
{
"name": "CS102",
"enrolled_students" : {
"id_list" : ["111" , "333"]
}
}
- Поиск с указанием пути к вложенному полю:
GET students/_search
{
"query": {
"terms": {
"student_id": {
"index": "classes",
"id": "102",
"path": "enrolled_students.id_list"
}
}
}
}
- Результат поиска:
{
"took": 18,
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_source": {
"name": "Jane Doe",
"student_id": "111"
}
},
{
"_index": "students",
"_id": "3",
"_source": {
"name": "John Doe",
"student_id": "333"
}
}
]
}
}
Параметры Terms Lookup
| Параметр |
Тип данных |
Описание |
Обязательность |
index |
String |
Индекс, из которого извлекаются значения |
Обязательно |
id |
String |
ID документа-источника |
Обязательно |
path |
String |
Путь к полю (для вложенных полей - точечная нотация) |
Обязательно |
routing |
String |
Кастомное значение маршрутизации документа |
Опционально* |
store |
Boolean |
Использовать stored fields вместо _source |
Опционально |
*Обязателен, если при индексации использовалось кастомное routing
Важные замечания
- Для полей типа
text используйте match вместо terms
- При работе с большими наборами терминов (>10,000) рассмотрите возможность использования Bitmap Filtering
- Убедитесь, что поле
_source включено для документов-источников
Bitmap Filtering (Фильтрация с использованием битовых карт)
Введение
Начиная с версии 2.17, OpenSearch предлагает механизм bitmap filtering для эффективной фильтрации по большому количеству терминов (10,000+). Этот подход решает проблему высокой нагрузки на сеть и память при работе с обычными terms-запросами.
Основные концепции
-
Проблема:
Обычные terms-запросы становятся неэффективными при большом количестве терминов из-за:
- Высокого сетевого трафика
- Чрезмерного потребления памяти
-
Решение:
Использование roaring bitmap для кодирования условий фильтрации:
- Эффективное сжатие данных
- Быстрые битовые операции
- Оптимизированное использование памяти
Пример реализации
1. Подготовка индексов
Индекс продуктов:
PUT /products
{
"mappings": {
"properties": {
"product_id": { "type": "integer" }
}
}
}
Добавление продуктов:
PUT /products/_doc/1
{
"name": "Product 1",
"product_id" : 111
}
PUT /products/_doc/2
{
"name": "Product 2",
"product_id" : 222
}
PUT /products/_doc/3
{
"name": "Product 3",
"product_id" : 333
}
Индекс клиентов с bitmap-полем:
PUT /customers
{
"mappings": {
"properties": {
"customer_filter": {
"type": "binary",
"store": true
}
}
}
}
2. Генерация bitmap
Пример кода на Python с использованием PyRoaringBitMap:
from pyroaring import BitMap
import base64
bm = BitMap([111, 222, 333]) # ID продуктов клиента
encoded = base64.b64encode(BitMap.serialize(bm))
encoded_bm_str = encoded.decode('utf-8')
print(f"Encoded Bitmap: {encoded_bm_str}")
3. Индексация bitmap
POST customers/_doc/customer123
{
"customer_filter": "OjAAAAEAAAAAAAIAEAAAAG8A3gBNAQ=="
}
Использование bitmap в запросах
Вариант 1: Lookup из документа
POST /products/_search
{
"query": {
"terms": {
"product_id": {
"index": "customers",
"id": "customer123",
"path": "customer_filter",
"store": true
},
"value_type": "bitmap"
}
}
}
Вариант 2: Прямая передача bitmap
POST /products/_search
{
"query": {
"terms": {
"product_id": [
"OjAAAAEAAAAAAAIAEAAAAG8A3gBNAQ=="
],
"value_type": "bitmap"
}
}
}
Ключевые параметры
| Параметр |
Тип данных |
Описание |
Обязательность |
value_type |
String |
Должно быть bitmap для активации этого режима |
Обязательно |
store |
Boolean |
true для поиска в stored field вместо _source |
Опционально |
index |
String |
Индекс-источник bitmap (для lookup) |
Для lookup |
id |
String |
ID документа с bitmap |
Для lookup |
path |
String |
Поле с bitmap данными |
Для lookup |
Преимущества подхода
-
Эффективность:
- Снижение сетевого трафика до 10 раз
- Уменьшение использования памяти на 50-90%
-
Гибкость:
- Поддержка динамического обновления фильтров
- Возможность комбинирования условий
-
Производительность:
- Быстрое выполнение даже для 100,000+ терминов
- Оптимизированные битовые операции на уровне ядра
Рекомендации
- Используйте для сложных фильтров с >10,000 значений
- Регулярно обновляйте bitmap при изменении данных
- Тестируйте производительность для вашего конкретного сценария
- Рассмотрите использование сжатых форматов bitmap для экономии места
3.3.9 - terms set
Поиск документов, соответствующих минимальному количеству указанных терминов
Terms Set Query (Запрос с условием минимального соответствия терминов)
Основное назначение
Запрос terms_set позволяет искать документы, которые соответствуют минимальному количеству точных терминов в указанном поле. В отличие от обычного terms запроса, terms_set требует явного указания минимального количества совпадений, которое может быть задано либо через поле индекса, либо через скрипт.
Основные характеристики
- Ищет точные соответствия терминов (без анализа текста)
- Требует указания минимального количества совпадающих терминов
- Поддерживает два способа определения минимального количества:
- Через поле документа (
minimum_should_match_field)
- Через скрипт (
minimum_should_match_script)
- Оптимален для работы с полями типа
keyword
Пример использования
1. Подготовка индекса
PUT students
{
"mappings": {
"properties": {
"name": { "type": "keyword" },
"classes": { "type": "keyword" },
"min_required": { "type": "integer" }
}
}
}
2. Индексация документов
PUT students/_doc/1
{
"name": "Mary Major",
"classes": [ "CS101", "CS102", "MATH101" ],
"min_required": 2
}
PUT students/_doc/2
{
"name": "John Doe",
"classes": [ "CS101", "MATH101", "ENG101" ],
"min_required": 2
}
3. Поиск с использованием поля для минимального соответствия
GET students/_search
{
"query": {
"terms_set": {
"classes": {
"terms": [ "CS101", "CS102", "MATH101" ],
"minimum_should_match_field": "min_required"
}
}
}
}
4. Поиск с использованием скрипта для минимального соответствия
GET students/_search
{
"query": {
"terms_set": {
"classes": {
"terms": [ "CS101", "CS102", "MATH101" ],
"minimum_should_match_script": {
"source": "Math.min(params.num_terms, doc['min_required'].value)"
}
}
}
}
}
Параметры запроса
Базовый синтаксис:
GET _search
{
"query": {
"terms_set": {
"<поле>": {
"terms": [ "term1", "term2" ],
...
}
}
}
}
| Параметр |
Тип данных |
Описание |
Обязательность |
terms |
Массив строк |
Термины для поиска (точное соответствие) |
Обязательно |
minimum_should_match_field |
Строка |
Поле, содержащее минимальное количество совпадений |
Один из двух |
minimum_should_match_script |
Строка |
Скрипт, возвращающий минимальное количество совпадений |
Один из двух |
boost |
Число с плавающей точкой |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
Опционально |
Особенности работы
-
Механизм подсчета:
Документ считается соответствующим, если количество совпадающих терминов из массива terms ≥ указанного минимума.
-
Определение минимума:
- Через поле: значение берется из указанного поля документа
- Через скрипт: вычисляется динамически для каждого документа
-
Производительность:
- Использование поля
minimum_should_match_field обычно более эффективно
- Скрипты обеспечивают гибкость, но могут снижать производительность
Рекомендации по использованию
- Для статических условий используйте
minimum_should_match_field
- Для сложной логики применяйте
minimum_should_match_script
- Всегда индексируйте поля, используемые для определения минимума
- Для текстовых полей предварительно применяйте нормализацию
- Тестируйте производительность на реалистичных объемах данных
Примеры скриптов
- Фиксированное значение:
"minimum_should_match_script": {
"source": "2"
}
- Динамическое вычисление:
"minimum_should_match_script": {
"source": "doc['min_required'].value * params.factor",
"params": {
"factor": 1.5
}
}
- Ограничение сверху:
"minimum_should_match_script": {
"source": "Math.min(5, doc['min_required'].value)"
}
3.3.10 - wildcard
Поиск документов, содержащих термины, соответствующие шаблону с подстановочными символами
Wildcard Query (Поиск с подстановочными символами)
Основное назначение
Запрос wildcard позволяет выполнять поиск терминов по шаблону с использованием подстановочных символов. Особенно полезен для:
- Поиска по частичным совпадениям
- Нечеткого поиска с известной структурой
- Работы с кодами, артикулами и другими структурированными данными
Поддерживаемые операторы
| Оператор |
Описание |
Пример |
* |
Соответствует нулю или более символов |
H*Y найдет “HAPPY”, “HALLEY” |
? |
Соответствует любому одному символу |
H?Y найдет “HAY”, но не “HAPPY” |
case_insensitive |
Флаг регистронезависимости |
true/false (по умолчанию false) |
Примеры запросов
1. Чувствительный к регистру поиск:
GET shakespeare/_search
{
"query": {
"wildcard": {
"speaker": {
"value": "H*Y",
"case_insensitive": false
}
}
}
}
2. Использование разных операторов:
H*Y - найдет любые значения, начинающиеся на H и заканчивающиеся на YH?Y - найдет только 3-символьные значения типа “HMY”
Параметры запроса
Базовый синтаксис:
GET _search
{
"query": {
"wildcard": {
"<поле>": {
"value": "шаб*лон",
...
}
}
}
}
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
String |
Шаблон для поиска с подстановочными символами |
Обязательный |
boost |
Float |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
case_insensitive |
Boolean |
Регистронезависимый поиск |
false |
rewrite |
String |
Метод перезаписи запроса (constant_score, scoring_boolean и др.) |
constant_score |
Критические особенности производительности
-
Предупреждение:
Wildcard-запросы могут быть медленными, так как требуют перебора множества терминов.
-
Золотое правило:
Избегайте размещения подстановочных символов в начале шаблона (например, *pattern), так как это:
- Крайне ресурсоемко
- Может привести к таймаутам
- Создает нагрузку на кластер
-
Оптимизация:
Для частых wildcard-запросов используйте специальный wildcard тип поля, который:
- Создает оптимизированный индекс
- Обеспечивает высокую производительность
- Поддерживает сложные шаблоны
Практические рекомендации
-
Для префиксного поиска используйте prefix запрос вместо H*:
{
"query": {
"prefix": {
"field": "H"
}
}
}
-
Для сложных шаблонов рассмотрите:
- Использование
wildcard типа поля
- Применение
regexp запросов для более сложных паттернов
-
При работе с большими индексами:
- Ограничивайте время выполнения через
timeout
- Используйте
search.allow_expensive_queries для контроля
-
Пример безопасного шаблона:
{
"query": {
"wildcard": {
"product_code": {
"value": "ABC-202?-*",
"case_insensitive": true
}
}
}
}
Такой шаблон найдет коды типа “ABC-2023-XXX” и безопасен для выполнения.
Важные ограничения
- При
search.allow_expensive_queries=false wildcard-запросы не выполняются
- Максимальная длина шаблона ограничена параметром
index.max_regex_length (по умолчанию 1000 символов)
- Не поддерживает стандартные regex-конструкции (используйте
regexp запрос для сложных выражений)
3.4 - full_text
Анализируют текст запроса, применяют тот же анализатор, что и при индексации. match, match_phrase, multi_match
Полнотекстовые запросы
Эта страница перечисляет все типы полнотекстовых запросов и общие параметры. Существует множество необязательных полей, которые вы можете использовать для создания тонких поисковых поведений, поэтому мы рекомендуем протестировать некоторые базовые типы запросов на представительных индексах и проверить вывод, прежде чем выполнять более сложные или комплексные поиски с несколькими параметрами.
OpenSearch использует библиотеку поиска Apache Lucene, которая предоставляет высокоэффективные структуры данных и алгоритмы для загрузки, индексации, поиска и агрегации данных.
Чтобы узнать больше о классах запросов поиска, смотрите JavaDocs по запросам Lucene.
Типы полнотекстовых запросов, показанные в этом разделе, используют стандартный анализатор, который автоматически анализирует текст при отправке запроса.
В следующей таблице перечислены все типы полнотекстовых запросов.
| Тип запроса |
Описание |
| intervals |
Позволяет точно контролировать близость и порядок совпадающих терминов. |
| match |
Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости. |
| match_bool_prefix |
Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс. |
| match_phrase |
Похож на запрос match, но соответствует целой фразе с настраиваемым слопом. |
| match_phrase_prefix |
Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс. |
| multi_match |
Похож на запрос match, но используется для нескольких полей. |
| query_string |
Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса. |
| simple_query_string |
Более простая, менее строгая версия запроса query_string. |
3.4.1 - match
Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости.
Запрос Match
Используйте запрос match для полнотекстового поиска по конкретному полю документа. Если вы выполняете запрос match по текстовому полю, он анализирует предоставленную строку поиска и возвращает документы, которые соответствуют любым терминам этой строки. Если вы выполняете запрос match по полю с точным значением, он возвращает документы, которые соответствуют этому точному значению. Предпочтительный способ поиска по полям с точными значениями — использовать фильтр, поскольку, в отличие от запроса, фильтр кэшируется.
Пример
Следующий пример показывает базовый запрос match для слова “wind” в заголовке:
GET _search
{
"query": {
"match": {
"title": "wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match": {
"title": {
"query": "wind",
"analyzer": "stop"
}
}
}
}
Примеры
В следующих примерах вы будете использовать индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "Let the wind rise"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
PUT testindex/_doc/3
{
"title": "Rise is gone"
}
Оператор
Если запрос match выполняется по текстовому полю, текст анализируется с помощью анализатора, указанного в параметре analyzer. Затем полученные токены объединяются в логический запрос с использованием оператора, указанного в параметре operator. Оператор по умолчанию — OR, поэтому запрос “wind rise” преобразуется в “wind OR rise”. В этом примере этот запрос возвращает документы 1–3, поскольку каждый документ содержит термин, соответствующий запросу. Чтобы указать оператор AND, используйте следующий запрос:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "and"
}
}
}
}
Запрос формируется как “wind AND rise” и возвращает документ 1 как совпадающий документ.
Минимальное количество совпадений
Вы можете контролировать минимальное количество терминов, которые документ должен совпадать, чтобы быть возвращенным в результатах, указав параметр minimum_should_match:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "or",
"minimum_should_match": 2
}
}
}
}
Теперь документы должны совпадать с обоими терминами, поэтому возвращается только документ 1 (это эквивалентно оператору AND).
Анализатор
Поскольку в этом примере вы не указали анализатор, используется анализатор по умолчанию — стандартный анализатор. Стандартный анализатор не выполняет стемминг, поэтому если вы выполните запрос “the wind rises”, вы не получите результатов, поскольку токен “rises” не совпадает с токеном “rise”. Чтобы изменить анализатор поиска, укажите его в поле analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "the wind rises",
"operator": "and",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токены “wind” и “rise”. Последний токен совпадает с документом 1, который возвращается в результатах.
Пустой запрос
В некоторых случаях анализатор может удалить все токены из запроса. Например, английский анализатор удаляет стоп-слова, поэтому в запросе “and OR or” все токены удаляются. Чтобы проверить поведение анализатора, вы можете использовать API анализа:
GET testindex/_analyze
{
"analyzer": "english",
"text": "and OR or"
}
Как и ожидалось, запрос не производит токенов:
Вы можете задать поведение для пустого запроса с помощью параметра zero_terms_query. Установка zero_terms_query в значение all возвращает все документы в индексе, а установка в none не возвращает ни одного документа:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "and OR or",
"analyzer": "english",
"zero_terms_query": "all"
}
}
}
}
Неопределенность (Fuzziness)
Чтобы учесть опечатки, вы можете указать уровень нечеткости для вашего запроса в одном из следующих форматов:
- Целое число, которое указывает максимальное допустимое расстояние по Дамерау-Левенштейну для этого редактирования.
- AUTO:
- Строки длиной 0–2 символа должны совпадать точно.
- Строки длиной 3–5 символов допускают 1 редактирование.
- Строки длиной более 5 символов допускают 2 редактирования.
Установка нечеткости на значение по умолчанию AUTO работает лучше всего в большинстве случаев:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO"
}
}
}
}
Токен “wnid” совпадает с “wind”, и запрос возвращает документы 1 и 2.
Длина префикса
Опечатки редко встречаются в начале слов. Таким образом, вы можете указать минимальную длину, которую должен иметь совпадающий префикс, чтобы документ был возвращен в результатах. Например, вы можете изменить предыдущий запрос, добавив параметр prefix_length:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"prefix_length": 2
}
}
}
}
Предыдущий запрос не возвращает результатов. Если вы измените prefix_length на 1, документы 1 и 2 будут возвращены, поскольку первая буква токена “wnid” не ошибочна.
Транспозиции
В предыдущем примере слово “wnid” содержало транспозицию (буквы “i” и “n” были поменяны местами). По умолчанию транспозиции допускаются в нечетком совпадении, но вы можете запретить их, установив fuzzy_transpositions в false:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"fuzzy_transpositions": false
}
}
}
}
Теперь запрос не возвращает результатов.
Синонимы
Если вы используете фильтр synonym_graph и параметр auto_generate_synonyms_phrase_query установлен в true (по умолчанию), OpenSearch разбивает запрос на термины, а затем объединяет термины для генерации фразового запроса для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average”.
Чтобы сопоставить многословные синонимы с союзами, установите auto_generate_synonyms_phrase_query в false:
GET /testindex/_search
{
"query": {
"match": {
"text": {
"query": "good ba",
"auto_generate_synonyms_phrase_query": false
}
}
}
}
Сформированный запрос будет “ba” OR (“batting” AND “average”).
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Строка запроса, используемая для поиска. Обязательный параметр. |
| auto_generate_synonyms_phrase_query |
Boolean |
Указывает, следует ли автоматически создавать фразовый запрос match для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average” (если этот параметр true) или “ba” OR (“batting” AND “average”) (если этот параметр false). По умолчанию true. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| boost |
Floating-point |
Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| enable_position_increments |
Boolean |
Если true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fuzziness |
String |
Количество редактирований символов (вставок, удалений, замен или транспозиций), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite |
String |
Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| lenient |
Boolean |
Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_expansions |
Positive integer |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match |
Positive or negative integer, positive or negative percentage, combination |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения:
- OR: строка интерпретируется как “или”
- AND: строка интерпретируется как “и”. По умолчанию используется OR. |
| prefix_length |
Non-negative integer |
Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
| zero_terms_query |
String |
В некоторых случаях анализатор удаляет все термины из строки запроса. Например, стоп-анализатор удаляет все термины из строки “an”, но оставляет “this”. В таких случаях zero_terms_query указывает, следует ли не совпадать ни с одним документом (none) или совпадать со всеми документами (all). Допустимые значения: none и all. По умолчанию none. |
3.4.2 - match-bool-prefix
Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс.
Запрос Match Boolean Prefix
Запрос match_bool_prefix анализирует предоставленную строку поиска и создает логический запрос из терминов строки. Он использует каждый термин, кроме последнего, как целое слово для совпадения. Последний термин используется как префикс. Запрос match_bool_prefix возвращает документы, которые содержат либо термины целых слов, либо термины, начинающиеся с префиксного термина, в любом порядке.
Пример
Следующий пример показывает базовый запрос match_bool_prefix:
GET _search
{
"query": {
"match_bool_prefix": {
"title": "the wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "the wind",
"analyzer": "stop"
}
}
}
}
Пример документов
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
Следующий запрос match_bool_prefix ищет целое слово “rises” и слова, начинающиеся с “wi”, в любом порядке:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"should": [
{ "term": { "title": "rises" }},
{ "prefix": { "title": "wi" }}
]
}
}
}
Ответ содержит оба документа:
Ответ
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.73617,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1.73617,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1,
"_source": {
"title": "Gone with the wind"
}
}
]
}
}
Запросы match_bool_prefix и match_phrase_prefix
Запрос match_bool_prefix сопоставляет термины в любой позиции, в то время как запрос match_phrase_prefix сопоставляет термины как целую фразу. Чтобы проиллюстрировать разницу, снова рассмотрим запрос match_bool_prefix из предыдущего раздела:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Оба документа “The wind rises” и “Gone with the wind” соответствуют поисковым терминам, поэтому запрос возвращает оба документа.
Теперь выполните запрос match_phrase_prefix по тому же индексу:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "rises wi"
}
}
}
Ответ не возвращает документов, потому что ни один из документов не содержит фразу “rises wi” в указанном порядке.
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "rise the wi",
"analyzer": "stop"
}
}
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match_bool_prefix": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Текст, число, логическое значение или дата, используемые для поиска. Обязательный параметр. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| fuzziness |
AUTO, 0 или положительное целое число |
Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. По умолчанию используется значение AUTO, которое выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite |
String |
Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match |
Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения: OR и AND. По умолчанию используется OR. |
| prefix_length |
Ненегативное целое число |
Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
Параметры fuzziness, fuzzy_transpositions, fuzzy_rewrite, max_expansions и prefix_length могут применяться к подзапросам term, созданным для всех терминов, кроме последнего. Они не оказывают никакого влияния на префиксный запрос, созданный для последнего термина.
3.4.3 - match-phrase
Похож на запрос match, но соответствует целой фразе с настраиваемым слопом.
Запрос match_phrase
Используйте запрос match_phrase, чтобы находить документы, содержащие точную фразу в указанном порядке. Вы можете добавить гибкость к фразовому соответствию, указав параметр slop.
Запрос match_phrase создает фразовый запрос, который соответствует последовательности терминов.
Пример базового запроса match_phrase:
GET _search
{
"query": {
"match_phrase": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase ищет фразу “wind rises”, где слово “ветер” следует за словом “поднимается”:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": "wind rises"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "The wind rises"
}
}
]
}
}
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": {
"query": "ветра",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токен “ветер”. Оба документа соответствуют этому токену и возвращаются в результатах:
Slop
Если вы укажете параметр slop, запрос допускает перестановку поисковых терминов. Параметр slop указывает количество других слов, разрешенных между словами в фразе запроса. Например, в следующем запросе текст поиска переставлен по сравнению с текстом документа:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер поднимается",
"slop": 3
}
}
}
}
Запрос все равно возвращает соответствующий документ:
Пустой запрос
Для информации о возможном пустом запросе смотрите соответствующий раздел запроса match.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
Строка |
Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для поля по умолчанию на этапе индексации. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
| slop |
0 (по умолчанию) или положительное целое число |
Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
| zero_terms_query |
Строка |
В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки “an”, кроме “but”. В таких случаях zero_terms_query указывает, следует ли не находить ни одного документа (none) или находить все документы (all). Допустимые значения: none и all. По умолчанию используется none. |
3.4.4 - match-phrase-prefix
Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс.
Запрос match_phrase_prefix
Используйте запрос match_phrase_prefix, чтобы указать фразу для поиска в заданном порядке. Документы, содержащие указанную вами фразу, будут возвращены. Последний неполный термин в фразе интерпретируется как префикс, поэтому любые документы, содержащие фразы, начинающиеся с указанной фразы и префикса последнего термина, будут возвращены.
Запрос аналогичен match_phrase, но создает префиксный запрос из последнего термина в строке запроса.
Для различий между запросами match_phrase_prefix и match_bool_prefix смотрите раздел о запросах match_bool_prefix и match_phrase_prefix.
Пример базового запроса match_phrase_prefix:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "Ветер поднимается"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase_prefix ищет полное слово “ветер”, за которым следует слово, начинающееся на “под”:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "ветер под"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "Ветер поднимается"
}
}
]
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase_prefix": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
Строка |
Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. |
| max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Неопределенные запросы “расширяются” на количество совпадающих терминов, находящихся на расстоянии, указанном в параметре fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию значение равно 50. |
| slop |
0 (по умолчанию) или положительное целое число |
Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
3.4.5 - multi-match
Похож на запрос match, но используется для нескольких полей.
Многофункциональные запросы (Multi-match queries)
Операция multi-match функционирует аналогично операции match. Вы можете использовать запрос multi_match для поиска по нескольким полям.
Символ ^ “увеличивает” вес определенных полей. Увеличения — это множители, которые придают больший вес совпадениям в одном поле по сравнению с совпадениями в других полях. В следующем примере совпадение для “ветер” в поле title влияет на _score в четыре раза больше, чем совпадение в поле plot:
GET _search
{
"query": {
"multi_match": {
"query": "ветер",
"fields": ["title^4", "plot"]
}
}
}
В результате фильмы, такие как “Ветер поднимается” и “Ушедший с ветром”, находятся в верхней части результатов поиска, а фильмы, такие как “Ураган”, которые, предположительно, содержат “ветер” в своих аннотациях, находятся внизу.
Вы можете использовать подстановочные знаки в имени поля. Например, следующий запрос будет искать поле speaker и все поля, начинающиеся с play_, например, play_name или play_title:
GET _search
{
"query": {
"multi_match": {
"query": "гамлет",
"fields": ["speaker", "play_*"]
}
}
}
Если вы не укажете параметр fields, запрос multi_match будет искать в полях, указанных в настройке index.query.default_field, которая по умолчанию равна *. Поведение по умолчанию заключается в извлечении всех полей в отображении, которые подходят для запросов на уровне терминов, фильтрации метаданных и комбинировании всех извлеченных полей для построения запроса.
Максимальное количество клауз в запросе определяется настройкой indices.query.bool.max_clause_count, которая по умолчанию равна 1,024.
Типы многофункциональных запросов
OpenSearch поддерживает следующие типы многофункциональных запросов, которые различаются по способу внутреннего выполнения запроса:
- best_fields (по умолчанию): Возвращает документы, которые соответствуют любому полю. Использует
_score лучшего совпадающего поля.
- most_fields: Возвращает документы, которые соответствуют любому полю. Использует комбинированный балл каждого совпадающего поля.
- cross_fields: Обрабатывает все поля так, как если бы они были одним полем. Обрабатывает поля с одинаковым анализатором и сопоставляет слова в любом поле.
- phrase: Выполняет запрос
match_phrase для каждого поля. Использует _score лучшего совпадающего поля.
- phrase_prefix: Выполняет запрос
match_phrase_prefix для каждого поля. Использует _score лучшего совпадающего поля.
- bool_prefix: Выполняет запрос
match_bool_prefix для каждого поля. Использует комбинированный балл каждого совпадающего поля.
Лучшие поля (Best fields)
Если вы ищете два слова, которые определяют концепцию, вы хотите, чтобы результаты, в которых два слова находятся рядом друг с другом, имели более высокий балл.
Например, рассмотрим индекс, содержащий следующие научные статьи:
PUT /articles/_doc/1
{
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
PUT /articles/_doc/2
{
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
Вы можете искать статьи, содержащие “северные огни” в заголовке или описании:
GET articles/_search
{
"query": {
"multi_match" : {
"query": "северные огни",
"type": "best_fields",
"fields": [ "title", "description" ],
"tie_breaker": 0.3
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с запросом match для каждого поля:
Запрос multi_match позволяет искать по нескольким полям. Он работает аналогично запросу match, но с возможностью указания нескольких полей для поиска.
Пример запроса dis_max
GET /articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "северные огни" }},
{ "match": { "description": "северные огни" }}
],
"tie_breaker": 0.3
}
}
}
Результаты содержат оба документа, но документ 1 имеет более высокий балл, потому что оба слова находятся в поле description:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.6322521,
"_source": {
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
}
]
}
}
Запрос best_fields использует балл лучшего совпадающего поля. Если вы укажете tie_breaker, балл рассчитывается по следующему алгоритму:
- Возьмите балл лучшего совпадающего поля.
- Добавьте (tie_breaker * _score) для всех других совпадающих полей.
Запрос most_fields
Используйте запрос most_fields для нескольких полей, которые содержат один и тот же текст, анализируемый разными способами. Например, оригинальное поле может содержать текст, проанализированный с помощью стандартного анализатора, а другое поле может содержать тот же текст, проанализированный с помощью английского анализатора, который выполняет стемминг:
PUT /articles
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Рассмотрим следующие два документа, которые индексируются в индексе articles:
PUT /articles/_doc/1
{
"title": "Гренки с маслом"
}
PUT /articles/_doc/2
{
"title": "Масло на тосте"
}
Стандартный анализатор анализирует заголовок “Гренки с маслом” в [гренки, масло], а заголовок “Масло на тосте” в [масло, на, тосте]. С другой стороны, английский анализатор производит один и тот же список токенов [масло, тост] для обоих заголовков из-за стемминга.
Вы можете использовать запрос most_fields, чтобы вернуть как можно больше документов:
GET /articles/_search
{
"query": {
"multi_match": {
"query": "гренки с маслом",
"fields": [
"title",
"title.english"
],
"type": "most_fields"
}
}
}
Предыдущий запрос выполняется как следующий булев запрос:
GET articles/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "гренки с маслом" }},
{ "match": { "title.english": "гренки с маслом" }}
]
}
}
}
Расчет релевантности
Чтобы рассчитать релевантность, баллы документа для всех клауз совпадений складываются, а затем результат делится на количество клауз совпадений.
Включение поля title.english позволяет получить второй документ, который соответствует стеммированным токенам:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.4418206,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 1.4418206,
"_source": {
"title": "Гренки с маслом"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.09304003,
"_source": {
"title": "Масло на тосте"
}
}
]
}
}
Поскольку оба поля title и title.english совпадают для первого документа, он имеет более высокий балл релевантности.
Оператор и минимальное количество совпадений
Запросы best_fields и most_fields генерируют запрос match на основе полей (по одному для каждого поля). Таким образом, параметры minimum_should_match и operator применяются к каждому полю, что обычно не является желаемым поведением.
Например, рассмотрим индекс customers со следующими документами:
PUT customers/_doc/1
{
"first_name": "John",
"last_name": "Doe"
}
PUT customers/_doc/2
{
"first_name": "Jane",
"last_name": "Doe"
}
Если вы ищете “John Doe” в индексе customers, вы можете составить следующий запрос:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Цель оператора and в этом запросе — найти документ, который соответствует “John” и “Doe”. Однако запрос не возвращает никаких результатов. Вы можете узнать, как выполняется запрос, запустив API валидации:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос пытается сопоставить как “John”, так и “Doe” с полем first_name или last_name:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "((+first_name:john +first_name:doe) | (+last_name:john +last_name:doe))"
}
]
}
Поскольку ни одно из полей не содержит оба слова, результаты не возвращаются.
Лучшей альтернативой для поиска по полям является использование запроса cross_fields. В отличие от ориентированных на поля запросов best_fields и most_fields, запрос cross_fields ориентирован на термины.
Запрос cross_fields
Используйте запрос cross_fields, чтобы искать данные по нескольким полям. Например, если индекс содержит данные о клиентах, имя и фамилия клиента находятся в разных полях. Тем не менее, когда вы ищете “John Doe”, вы хотите получить документы, в которых “John” находится в поле first_name, а “Doe” — в поле last_name.
Запрос most_fields не работает в этом случае по следующим причинам:
- Параметры
operator и minimum_should_match применяются на уровне полей, а не на уровне терминов.
- Частоты терминов в полях
first_name и last_name могут привести к неожиданным результатам. Например, если чье-то имя — “Doe”, документ с этим именем будет считаться лучшим совпадением, поскольку это имя не появится в других документах.
Запрос cross_fields анализирует строку запроса на отдельные термины и затем ищет каждый из терминов в любом из полей, как если бы они были одним полем.
Пример запроса cross_fields для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Ответ содержит единственный документ, в котором присутствуют как “John”, так и “Doe”:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.8754687,
"hits": [
{
"_index": "customers",
"_id": "1",
"_score": 0.8754687,
"_source": {
"first_name": "John",
"last_name": "Doe"
}
}
]
}
}
Вы можете использовать операцию API валидации, чтобы получить представление о том, как выполняется предыдущий запрос:
GET /customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос ищет все термины хотя бы в одном поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "+blended(terms:[last_name:john, first_name:john]) +blended(terms:[last_name:doe, first_name:doe])"
}
]
}
Таким образом, смешивание частот терминов для всех полей решает проблему различия частот терминов, корректируя различия.
Запрос cross_fields обычно полезен только для коротких строковых полей с коэффициентом 1. В других случаях балл не дает значимого смешивания статистики терминов из-за того, как коэффициенты, частоты терминов и нормализация длины влияют на балл.
Параметр fuzziness не поддерживается для запросов cross_fields.
Анализ
Запрос cross_fields работает как термоцентричный запрос для полей с одинаковым анализатором. Поля с одинаковым анализатором группируются вместе, и эти группы комбинируются с помощью булевого запроса.
Например, рассмотрим индекс, в котором поля first_name и last_name анализируются с использованием стандартного анализатора, а их подполе .edge анализируется с помощью анализатора edge n-gram:
Пример
Вы индексируете один документ в индексе customers:
PUT /customers/_doc/1
{
"first": "John",
"last": "Doe"
}
Вы можете использовать запрос cross_fields для поиска по полям для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Чтобы увидеть, как выполняется запрос, вы можете использовать API валидации:
GET /customers/_validate/query?explain
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Ответ показывает, что поля last_name и first_name сгруппированы вместе и рассматриваются как одно поле. Аналогично, поля last_name.edge и first_name.edge также сгруппированы и рассматриваются как одно поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "(blended(terms:[last_name:john, first_name:john]) | (blended(terms:[last_name.edge:Jo, first_name.edge:Jo]) blended(terms:[last_name.edge:Joh, first_name.edge:Joh]) blended(terms:[last_name.edge:John, first_name.edge:John])))"
}
]
}
Использование параметров operator или minimum_should_match с несколькими группами полей, как описано выше, может привести к проблемам. Чтобы избежать этого, вы можете переписать предыдущий запрос как два подзапроса cross_fields, объединенных с помощью булевого запроса, и применить minimum_should_match к одному из подзапросов:
GET /customers/_search
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name",
"last_name"
],
"minimum_should_match": "1"
}
},
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name.edge",
"last_name.edge"
]
}
}
]
}
}
}
Чтобы создать одну группу для всех полей, укажите анализатор в вашем запросе:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"analyzer": "standard",
"fields": ["first_name", "last_name", "*.edge"]
}
}
}
Запуск API валидации для предыдущего запроса показывает, как выполняется запрос:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "blended(terms:[last_name.edge:john, last_name:john, first_name:john, first_name.edge:john]) blended(terms:[last_name.edge:doe, last_name:doe, first_name:doe, first_name.edge:doe])"
}
]
}
Фразовый запрос
Фразовый запрос ведет себя аналогично запросу best_fields, но использует запрос match_phrase вместо match.
Следующий пример демонстрирует фразовый запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern lights",
"type": "phrase",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase": { "title": "northern lights" }},
{ "match_phrase": { "description": "northern lights" }}
]
}
}
}
Поскольку по умолчанию фразовый запрос совпадает с текстом только тогда, когда термины появляются в одном и том же порядке, в результатах возвращается только документ 1:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Aurora borealis",
"description": "Northern lights, or aurora borealis, explained"
}
}
]
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса. Например, следующий запрос принимает текст как совпадение, если между словами “fluorescent” и “therapy” находится до двух слов:
GET articles/_search
{
"query": {
"multi_match": {
"query": "fluorescent therapy",
"type": "phrase",
"fields": ["title", "description"],
"slop": 2
}
}
}
Ответ
В этом случае ответ содержит документ 2:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.7003825,
"hits": [
{
"_index": "articles",
"_id": "2",
"_score": 0.7003825,
"_source": {
"title": "Sun deprivation in the Northern countries",
"description": "Using fluorescent lights for therapy"
}
}
]
}
}
Для значений slop, меньших чем 2, документы не возвращаются.
Параметр fuzziness не поддерживается для фразовых запросов.
Фразовый префиксный запрос
Фразовый префиксный запрос ведет себя аналогично фразовому запросу, но использует запрос match_phrase_prefix вместо match_phrase.
Следующий пример демонстрирует фразовый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern light",
"type": "phrase_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase_prefix": { "title": "northern light" }},
{ "match_phrase_prefix": { "description": "northern light" }}
]
}
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса.
Параметр fuzziness не поддерживается для фразовых префиксных запросов.
Булевый префиксный запрос
Булевый префиксный запрос оценивает документы аналогично запросу most_fields, но использует запрос match_bool_prefix вместо match.
Следующий пример демонстрирует булевый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "li northern",
"type": "bool_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_bool_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_bool_prefix": { "title": "li northern" }},
{ "match_bool_prefix": { "description": "li northern" }}
]
}
}
}
Параметры fuzziness, prefix_length, max_expansions, fuzzy_rewrite и fuzzy_transpositions поддерживаются для терминов, которые используются для построения термовых запросов, но они не оказывают влияния на префиксный запрос, построенный из конечного термина.
Параметры
Запрос принимает следующие параметры. Все параметры, кроме query, являются необязательными.
-
query (Строка): Строка запроса, используемая для поиска. Обязательный параметр.
-
auto_generate_synonyms_phrase_query (Булев): Указывает, следует ли автоматически создавать фразу запроса для многословных синонимов. Например, если вы укажете ba, batting average как синонимы и выполните поиск по ba, OpenSearch будет искать ba ИЛИ “batting average” (если этот параметр установлен в true) или ba ИЛИ (batting И average) (если этот параметр установлен в false). По умолчанию true.
-
analyzer (Строка): Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля default_field на этапе индексации. Если анализатор не указан для default_field, используется стандартный анализатор для индекса.
-
boost (Число с плавающей запятой): Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1.
-
fields (Массив строк): Список полей, в которых следует выполнять поиск. Если вы не укажете параметр fields, запрос multi_match будет искать в полях, указанных в настройке index.query.default_field, которая по умолчанию равна *.
-
fuzziness (Строка): Количество изменений символов (вставка, удаление, замена), необходимых для преобразования одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между wined и wind равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев.
-
fuzzy_rewrite (Строка): Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод переписывания fuzzy_rewrite по умолчанию top_terms_blended_freqs_${max_expansions}. По умолчанию constant_score.
-
fuzzy_transpositions (Булев): Установка fuzzy_transpositions в true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между wind и wnid равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если false (удаление “n”, вставка “n”). По умолчанию является хорошим выбором для большинства случаев.
-
lenient (Булев): Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false.
-
max_expansions (Положительное целое число): Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа соответствующих терминов, которые находятся в пределах указанного расстояния в параметре fuzziness. По умолчанию 50.
-
minimum_should_match (Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация): Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны соответствовать, чтобы документ считался совпадением. Например, если minimum_should_match равно 2, wind often rising не соответствует The Wind Rises. Если minimum_should_match равно 1, совпадает. Для подробностей см. Minimum should match.
-
operator (Строка): Если строка запроса содержит несколько поисковых терминов, нужно ли, чтобы все термины соответствовали (AND) или только один термин должен соответствовать (OR), чтобы документ считался совпадением. Допустимые значения:
- OR: Строка интерпретируется как “или”.
- AND: Строка интерпретируется как “и”.
По умолчанию используется OR.
-
prefix_length (Неотрицательное целое число): Количество начальных символов, которые не учитываются при вычислении fuzziness. По умолчанию 0.
-
slop (0 по умолчанию или положительное целое число): Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Из документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова друг на друга), поэтому для разрешения перестановок фраз значение slop должно быть не менее двух. Значение ноль требует точного совпадения.” Поддерживается для типов запросов phrase и phrase_prefix.
-
tie_breaker (Число с плавающей запятой): Фактор между 0 и 1.0, который используется для придания большего веса документам, соответствующим нескольким условиям запроса. Для получения дополнительной информации см. параметр tie_breaker.
-
type (Строка): Тип запроса multi-match. Допустимые значения: best_fields, most_fields, cross_fields, phrase, phrase_prefix, bool_prefix. По умолчанию используется best_fields.
-
zero_terms_query (Строка): В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки, кроме “this”. В таких случаях zero_terms_query указывает, следует ли не соответствовать ни одному документу (none) или всем документам (all). Допустимые значения: none и all. По умолчанию используется none.
Параметр fuzziness не поддерживается для запросов типов phrase, phrase_prefix и cross_fields.
Параметр slop поддерживается только для запросов типов phrase и phrase_prefix.
Параметр tie_breaker:
Каждый запрос на уровне терминов с объединением вычисляет оценку документа как наилучшую оценку, возвращенную любым полем в группе. Оценки от всех объединенных запросов складываются, чтобы получить окончательную оценку. Вы можете изменить способ вычисления оценки, используя параметр tie_breaker. Параметр tie_breaker принимает следующие значения:
-
0.0 (по умолчанию для запросов типов best_fields, cross_fields, phrase и phrase_prefix): Берется единственная наилучшая оценка, возвращенная любым полем в группе.
-
1.0 (по умолчанию для запросов типов most_fields и bool_prefix): Складываются оценки для всех полей в группе.
-
Число с плавающей запятой в диапазоне (0, 1): Берется единственная наилучшая оценка наилучшего соответствующего поля и добавляется (tie_breaker * _score) для всех других соответствующих полей.
3.4.6 - query-string
Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса.
Запрос типа query_string
Запрос типа query_string разбирает строку запроса на основе синтаксиса строки запроса. Он позволяет создавать мощные, но лаконичные запросы, которые могут включать подстановочные знаки и осуществлять поиск по нескольким полям.
Поиски с использованием запросов типа query_string не возвращают вложенные документы. Для поиска по вложенным полям используйте вложенный запрос.
Запрос типа query_string имеет строгий синтаксис и возвращает ошибку в случае недопустимого синтаксиса. Поэтому он не подходит для приложений с текстовыми полями поиска. Для менее строгой альтернативы рассмотрите использование запроса simple_query_string. Если вам не нужна поддержка синтаксиса запроса, используйте запрос match.
Синтаксис строки запроса
Синтаксис строки запроса основан на синтаксисе запросов Apache Lucene.
Вы можете использовать синтаксис строки запроса в следующих случаях:
-
В запросе типа query_string, например:
GET _search
{
"query": {
"query_string": {
"query": "the wind AND (rises OR rising)"
}
}
}
-
В приложениях OpenSearch Dashboards Discover или Dashboard, если вы отключите DQL, как показано на следующем изображении. Использование синтаксиса строки запроса в OpenSearch Dashboards Discover.
DQL и язык запросов query_string (Lucene) являются двумя вариантами языка для строк поиска в Discover и Dashboards. Для сравнения этих языковых опций смотрите раздел о строках поиска Discover и Dashboard.
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises термины — это wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова сопоставляются в порядке их появления (например, "wind rises"). Операторы (такие как OR, AND и NOT) определяют логическую связь, используемую для интерпретации текста в строке запроса.
Примеры в этом разделе используют индекс, содержащий следующую схему и документы:
PUT /testindex
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
PUT /testindex/_doc/1
{
"title": "The wind rises"
}
PUT /testindex/_doc/2
{
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
PUT /testindex/_doc/3
{
"title": "Windy city"
}
PUT /testindex/_doc/4
{
"article title": "Wind turbines"
}
Зарезервированные символы
Следующий список содержит зарезервированные символы для запроса типа query_string:
+, -, =, &&, ||, >, <, !, (, ), {, }, [, ], ^, ", ~, *, ?, :, \, /
Экранируйте зарезервированные символы с помощью обратной косой черты (). При отправке JSON-запроса используйте двойную обратную косую черту (\) для экранирования зарезервированных символов (поскольку символ обратной косой черты сам по себе является зарезервированным, вы должны экранировать его с помощью другой обратной косой черты).
Например, чтобы выполнить поиск по выражению 2*3, укажите строку запроса: 2\\*3:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: 2\\*3"
}
}
}
Знаки > и < не могут быть экранированы. Они интерпретируются как запрос диапазона.
Пробелы и пустые запросы
Символы пробела не считаются операторами. Если строка запроса пуста или содержит только символы пробела, запрос не возвращает результатов.
Имена полей
Укажите имя поля перед двоеточием. В следующей таблице приведены примеры запросов с именами полей.
| Запрос в запросе типа query_string |
Запрос в Discover |
Критерий для соответствия документа |
Соответствующие документы из индекса testindex |
| title: wind |
title: wind |
Поле title содержит слово wind. |
1, 2 |
| title: (wind OR windy) |
title: (wind OR windy) |
Поле title содержит слово wind или слово windy. |
1, 2, 3 |
| title: "wind rises" |
title: “wind rises” |
Поле title содержит фразу wind rises. Экранируйте кавычки с помощью обратной косой черты. |
1 |
| article\ title: wind |
article\ title: wind |
Поле article title содержит слово wind. Экранируйте пробел с помощью обратной косой черты. |
4 |
| title.\*: rise |
title.*: rise |
Каждое поле, начинающееся с title. (в этом примере, title.english) содержит слово rise. Экранируйте символ подстановки с помощью обратной косой черты. |
1 |
| exists: description |
exists: description |
Поле description существует. |
2 |
Подстановочные выражения
Вы можете указывать подстановочные выражения, используя специальные символы: ? заменяет один символ, а * заменяет ноль или более символов.
Пример
Следующий запрос ищет заголовок, содержащий слово “gone”, и описание, которое содержит слово, начинающееся с “hist”:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: gone AND description: hist*"
}
}
}
Запросы с подстановочными знаками могут использовать значительное количество памяти, что может ухудшить производительность. Подстановочные знаки в начале слова (например, *cal) являются наиболее затратными, поскольку сопоставление документов с такими подстановочными знаками требует проверки всех терминов в индексе. Чтобы отключить ведущие подстановочные знаки, установите параметр allow_leading_wildcard в значение false.
Для повышения эффективности чистые подстановочные знаки, такие как *, переписываются как запросы на существование. Таким образом, запрос description: * будет соответствовать документам, содержащим пустое значение в поле описания, но не будет соответствовать документам, в которых поле описания отсутствует или имеет значение null.
Если вы установите analyze_wildcard в значение true, OpenSearch будет анализировать запросы, которые заканчиваются на * (например, hist*). В результате OpenSearch создаст логический запрос, состоящий из полученных токенов, принимая точные совпадения для первых n-1 токенов и префиксное совпадение для последнего токена.
Регулярные выражения
Чтобы указать шаблоны регулярных выражений в строке запроса, окружите их косыми чертами (/), например, title: /w[a-z]nd/.
Параметр allow_leading_wildcard не применяется к регулярным выражениям. Например, строка запроса, такая как /.*d/, будет проверять все термины в индексе.
Нечеткий поиск
Вы можете выполнять нечеткие запросы, используя оператор ~, например, title: rise~.
Запрос ищет документы, содержащие термины, похожие на искомый термин в пределах максимального допустимого расстояния редактирования. Расстояние редактирования определяется как расстояние Дамерау-Левенштейна, которое измеряет количество изменений одного символа (вставок, удалений, замен или перестановок), необходимых для преобразования одного термина в другой.
По умолчанию расстояние редактирования равно 2, что должно охватывать 80% опечаток. Чтобы изменить значение по умолчанию для расстояния редактирования, укажите новое расстояние редактирования после оператора ~. Например, чтобы установить расстояние редактирования равным 1, используйте запрос title: rise~1.
Не смешивайте нечеткие и подстановочные операторы. Если вы укажете как нечеткий, так и подстановочный операторы, один из операторов не будет применен. Например, если вы можете выполнить поиск по wnid*~1, подстановочный оператор * будет применен, но нечеткий оператор ~1 не будет применен.
Запросы на близость
Запрос на близость не требует, чтобы искомая фраза была в указанном порядке. Он позволяет словам в фразе находиться в другом порядке или разделяться другими словами. Запрос на близость указывает максимальное расстояние редактирования между словами в фразе. Например, следующий запрос позволяет расстояние редактирования равное 4 при сопоставлении слов в указанной фразе:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: \"wind gone\"~4"
}
}
}
Когда OpenSearch сопоставляет документы, чем ближе слова в документе к порядку слов, указанному в запросе (тем меньше расстояние редактирования), тем выше оценка релевантности документа.
Диапазоны
Чтобы указать диапазон для числового, строкового или датированного поля, используйте квадратные скобки ([min TO max]) для включающего диапазона и фигурные скобки ({min TO max}) для исключающего диапазона. Вы также можете комбинировать квадратные и фигурные скобки, чтобы включить или исключить нижнюю и верхнюю границы (например, {min TO max]).
Даты для диапазона дат должны быть предоставлены в формате, который вы использовали при сопоставлении поля, содержащего дату. Для получения дополнительной информации о поддерживаемых форматах дат смотрите раздел Форматы.
Следующая таблица предоставляет примеры синтаксиса диапазонов.
| Тип данных |
Запрос |
Строка запроса |
| Числовой |
Документы, у которых номера счетов от 1 до 15, включительно. |
account_number: [1 TO 15] или account_number: (>=1 AND <=15) или account_number: (+>=1 +<=15) |
|
Документы, у которых номера счетов 15 и больше. |
account_number: [15 TO *] или account_number: >=15 (обратите внимание, что после знака >= нет пробела) |
| Строковой |
Документы, где фамилия от Bates, включительно, до Duke, исключительно. |
lastname: [Bates TO Duke} или lastname: (>=Bates AND <Duke) |
|
Документы, где фамилия предшествует Bates в алфавитном порядке. |
lastname: {* TO Bates} или lastname: <Bates (обратите внимание, что после знака < нет пробела) |
| Дата |
Документы, где дата выпуска между 21.03.2023 и 25.09.2023, включительно. |
release_date: [03/21/2023 TO 09/25/2023] |
В качестве альтернативы указанию диапазона в строке запроса вы можете использовать запрос диапазона, который предоставляет более надежный синтаксис.
Увеличение релевантности
Используйте оператор увеличения (^) для увеличения оценки релевантности документов на заданный множитель. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию используется 1.
Следующая таблица предоставляет примеры увеличения релевантности.
| Тип |
Описание |
Строка запроса |
| Увеличение слова |
Найти все адреса, содержащие слово street, и увеличить вес тех, которые содержат слово Madison. |
address: Madison^2 street |
| Увеличение фразы |
Найти документы с заголовком, содержащим фразу wind rises, увеличив вес на 2. |
title: \"wind rises\"^2 |
|
Найти документы с заголовком, содержащим слова wind rises, и увеличить вес документов, содержащих фразу wind rises, на 2. |
title: (wind rises)^2 |
Логические операторы
Когда вы указываете поисковые термины в запросе, по умолчанию запрос возвращает документы, содержащие хотя бы один из указанных терминов. Вы можете использовать параметр default_operator, чтобы задать оператор для всех терминов. Таким образом, если вы установите default_operator в значение AND, все термины будут обязательными, в то время как если вы установите его в значение OR, все термины будут необязательными.
Операторы + и -
Если вы хотите более детально контролировать обязательные и необязательные термины, вы можете использовать операторы + и -. Оператор + делает следующий за ним термин обязательным, в то время как оператор - исключает следующий за ним термин.
Например, в строке запроса title: (gone +wind -turbines) указывается, что термин gone является необязательным, термин wind должен присутствовать, а термин turbines не должен присутствовать в заголовке соответствующих документов:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone +wind -turbines)"
}
}
}
Запрос возвращает два соответствующих документа:
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "wind"
}
},
"should": {
"match": {
"title": "gone"
}
},
"must_not": {
"match": {
"title": "turbines"
}
}
}
}
}
Обычные логические операторы
В качестве альтернативы вы можете использовать следующие логические операторы: AND, &&, OR, ||, NOT, !. Однако эти операторы не следуют правилам приоритета, поэтому вы должны использовать скобки, чтобы указать приоритет при использовании нескольких логических операторов. Например, строку запроса title: (gone +wind -turbines) можно переписать следующим образом, используя логические операторы:
title: ((gone AND wind) OR wind) AND NOT turbines
Запустите следующий запрос, содержащий переписанную строку запроса:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: ((gone AND wind) OR wind) AND NOT turbines"
}
}
}
Запрос возвращает те же результаты, что и запрос, использующий операторы + и -. Однако обратите внимание, что оценки релевантности соответствующих документов могут отличаться от предыдущих результатов:
{
"_index": "testindex",
"_id": "2",
"_score": 1.6166971,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Группировка
Группируйте несколько условий или терминов в подзапросы, используя скобки. Например, следующий запрос ищет документы, содержащие слова “gone” или “rises”, которые обязательно должны содержать слово “wind” в заголовке:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone OR rises) AND wind"
}
}
}
Результаты содержат два соответствующих документа:
{
"_index": "testindex",
"_id": "1",
"_score": 1.5046883,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
}
Вы также можете использовать группировку для увеличения веса результатов подзапросов или для указания конкретного поля, например: title:(gone AND wind) description:(historical film)^2.
Поиск по нескольким полям
Чтобы выполнить поиск по нескольким полям, используйте параметр fields. Когда вы указываете параметр fields, запрос переписывается в формате field_1: query OR field_2: query ....
Например, следующий запрос ищет термины “ветер” или “фильм” в полях заголовка и описания:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title", "description" ],
"query": "ветер AND фильм"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields:
GET testindex/_search
{
"query": {
"query_string": {
"query": "(title:ветер OR description:ветер) AND (title:фильм OR description:фильм)"
}
}
}
Поиск по нескольким подполям поля
Чтобы выполнить поиск по всем внутренним полям, вы можете использовать подстановочный знак. Например, чтобы искать по всем подполям в поле address, используйте следующий запрос:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields" : ["address.*"],
"query" : "Нью AND (Йорк OR Джерси)"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields (обратите внимание, что * экранируется с помощью \\):
GET /testindex/_search
{
"query": {
"query_string" : {
"query": "address.\\*: Нью AND (Йорк OR Джерси)"
}
}
}
Увеличение веса (Boosting)
Подзапросы, которые генерируются для каждого поискового термина, комбинируются с помощью запроса dis_max с параметром tie_breaker. Чтобы увеличить вес отдельных полей, используйте оператор ^. Например, следующий запрос увеличивает вес поля заголовка в 2 раза:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title^2", "description" ],
"query": "ветер AND фильм"
}
}
}
Чтобы увеличить вес всех подполей поля, укажите оператор увеличения после подстановочного знака:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields": ["work_address", "address.*^2"],
"query": "Нью AND (Йорк OR Джерси)"
}
}
}
Параметры для поиска по нескольким полям
При выполнении поиска по нескольким полям вы можете передать дополнительный необязательный параметр type в запрос query_string.
| Параметр |
Тип данных |
Описание |
| type |
String |
Определяет, как OpenSearch выполняет запрос и оценивает результаты. Допустимые значения: best_fields, bool_prefix, most_fields, cross_fields, phrase и phrase_prefix. Значение по умолчанию — best_fields. Для описания допустимых значений см. раздел о типах многоцелевых запросов. |
Описание допустимых значений для параметра type
- best_fields: Использует наилучшие поля для оценки результатов. Это значение по умолчанию.
- bool_prefix: Позволяет использовать префиксы для логических операторов, что позволяет более гибко формировать запросы.
- most_fields: Оценивает результаты, используя все поля, что может быть полезно для более широкого поиска.
- cross_fields: Объединяет все поля в один общий запрос, что позволяет искать по всем полям одновременно.
- phrase: Ищет точные фразы в указанных полях.
- phrase_prefix: Позволяет искать фразы с префиксами, что может быть полезно для автозаполнения.
Эти параметры позволяют более точно настраивать поведение поиска в OpenSearch в зависимости от ваших потребностей.
Синонимы в запросе query_string
Запрос query_string поддерживает расширение синонимов с несколькими терминами с помощью фильтра токенов synonym_graph. Если вы используете фильтр synonym_graph, OpenSearch создает запрос на совпадение фразы для каждого синонима.
Параметр auto_generate_synonyms_phrase_query указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. По умолчанию auto_generate_synonyms_phrase_query установлен в true, поэтому, если вы укажете “ml” и “machine learning” как синонимы и выполните поиск по “ml”, OpenSearch будет искать ml OR "machine learning".
В качестве альтернативы вы можете сопоставлять многословные синонимы, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в false, OpenSearch будет искать ml OR (machine AND learning).
Пример запроса с отключенной авто-генерацией фраз
Следующий запрос ищет текст “ml models” и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Минимальное количество совпадений
Запрос query_string разбивает запрос вокруг каждого оператора и создает булев запрос для всего ввода. Параметр minimum_should_match указывает минимальное количество терминов, которые документ должен соответствовать, чтобы быть возвращенным в результатах поиска. Например, следующий запрос указывает, что поле description должно соответствовать как минимум двум терминам для каждого результата поиска:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"description"
],
"query": "historical epic film",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (description:historical description:epic description:film)~2.
Эти функции позволяют более гибко настраивать поиск и управлять тем, как обрабатываются синонимы и минимальные условия для совпадений.
Минимальное количество совпадений с несколькими полями
Если вы указываете несколько полей в запросе query_string, OpenSearch создает запрос dis_max для указанных полей. Если вы не указываете оператор для терминов запроса, весь текст запроса рассматривается как одно условие. OpenSearch строит запрос для каждого поля, используя это одно условие. В конечном булевом запросе содержится одно условие, соответствующее запросу dis_max для всех полей, поэтому параметр minimum_should_match не применяется.
Пример без явных операторов
В следующем запросе “historical epic heroic” рассматривается как одно условие:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical title:epic title:heroic) | (description:historical description:epic description:heroic)).
Пример с явными операторами
Если вы добавите явные операторы (AND или OR) к терминам запроса, каждый термин будет рассматриваться как отдельное условие, к которому можно применить параметр minimum_should_match. Например, в следующем запросе “historical”, “epic” и “heroic” считаются отдельными условиями:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical OR epic OR heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Запрос соответствует как минимум двум из трех условий. Каждое условие представляет собой запрос dis_max по полям title и description для каждого термина.
Использование параметра type
В качестве альтернативы, чтобы гарантировать применение minimum_should_match, вы можете установить параметр type в значение cross_fields. Это указывает на то, что поля с одинаковым анализатором должны быть сгруппированы вместе при анализе входного текста:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"type": "cross_fields",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Однако, если вы используете разные анализаторы, вам необходимо использовать явные операторы в запросе, чтобы гарантировать применение параметра minimum_should_match к каждому термину.
Параметры запроса query_string
Следующая таблица перечисляет параметры, поддерживаемые запросом query_string. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Текст, который может содержать выражения в синтаксисе строки запроса для поиска. Обязательный параметр. |
| allow_leading_wildcard |
Boolean |
Указывает, разрешены ли символы * и ? в качестве первых символов поискового термина. По умолчанию true. |
| analyze_wildcard |
Boolean |
Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию false. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Дополнительную информацию о index.query.default_field см. в разделе о динамических настройках уровня индекса. |
| auto_generate_synonyms_phrase_query |
Boolean |
Указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. Например, если вы укажете “ba” и “batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать ba OR "batting average" (если этот параметр установлен в true) или ba OR (batting AND average) (если установлен в false). По умолчанию true. |
| boost |
Floating-point |
Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| default_field |
String |
Поле, в котором следует выполнять поиск, если поле не указано в строке запроса. Поддерживает подстановочные знаки. По умолчанию используется значение, указанное в настройках индекса index.query.default_field. По умолчанию index.query.default_field равно *, что означает извлечение всех полей, подходящих для термового запроса, и фильтрацию метаданных. Извлеченные поля объединяются в запрос, если префикс не указан. Подходящие поля не включают вложенные документы. Поиск по всем подходящим полям может быть ресурсоемкой операцией. Настройка indices.query.bool.max_clause_count определяет максимальное значение для произведения количества полей и количества терминов, которые могут быть запрошены одновременно. Значение по умолчанию для indices.query.bool.max_clause_count равно 1,024. |
| default_operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины соответствовали (AND) или достаточно, чтобы соответствовал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения:
- OR: строка интерпретируется как “или”
- AND: строка интерпретируется как “и”. По умолчанию OR. |
| enable_position_increments |
Boolean |
Когда установлено в true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fields |
String array |
Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется значение, указанное в настройках индекса index.query.default_field, которое по умолчанию равно ["*"]. |
| fuzziness |
String |
Количество изменений символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, что является хорошим выбором для большинства случаев. |
| fuzzy_max_expansions |
Positive integer |
Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false. По умолчанию — хороший выбор для большинства случаев. |
| lenient |
Boolean |
Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_determinized_states |
Positive integer |
Максимальное количество “состояний” (меры сложности), которые Lucene может создать для строк запросов, содержащих регулярные выражения (например, "query": "/wind.+?/"). Более крупные числа позволяют выполнять запросы, использующие больше памяти. По умолчанию 10,000. |
| minimum_should_match |
Positive or negative integer, positive or negative percentage, combination |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор OR, количество терминов, которые должны соответствовать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не соответствует “The Wind Rises”. Если minimum_should_match равно 1, он соответствует. |
| phrase_slop |
Integer |
Максимальное количество слов, которые могут находиться между совпадающими словами. Если phrase_slop равно 2, максимальное количество двух слов разрешено между совпадающими словами в фразе. Переставленные слова имеют слоп 2. По умолчанию 0 (точное совпадение фразы, где совпадающие слова должны находиться рядом друг с другом). |
| quote_analyzer |
String |
Анализатор, используемый для токенизации текста в кавычках в строке запроса. Переопределяет параметр analyzer для текста в кавычках. По умолчанию используется search_quote_analyzer, указанный для default_field. |
| quote_field_suffix |
String |
Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неточных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово “lightly” в поле title.exact. Это второе поле может использовать другой тип (например, keyword вместо text) или другой анализатор. |
| rewrite |
String |
Определяет, как OpenSearch переписывает и оценивает многословные запросы. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. По умолчанию используется constant_score. |
| time_zone |
String |
Указывает количество часов для смещения желаемого часового пояса от UTC. Необходимо указать номер смещения часового пояса, если строка запроса содержит диапазон дат. Например, установите time_zone": "-08:00" для запроса с диапазоном дат, таким как "query": "wind rises release_date[2012-01-01 TO 2014-01-01]". Формат часового пояса по умолчанию для указания количества смещения часов — UTC. |
Дополнительные сведения
Запросы строки запроса могут быть внутренне преобразованы в префиксные запросы. Если параметр search.allow_expensive_queries установлен в false, префиксные запросы не выполняются. Если index_prefixes включен, настройка search.allow_expensive_queries игнорируется, и создается и выполняется оптимизированный запрос.
3.4.7 - simple-query-string
Более простая, менее строгая версия запроса query_string.
Простой запрос с использованием simple_query_string
Используйте тип simple_query_string, чтобы указать несколько аргументов, разделенных регулярными выражениями, непосредственно в строке запроса. Простой запрос имеет менее строгий синтаксис, чем обычный запрос, поскольку отбрасывает любые недопустимые части строки и не возвращает ошибки за недопустимый синтаксис.
Этот запрос выполняет нечеткий поиск по полю title:
GET _search
{
"query": {
"simple_query_string": {
"query": "\"rises wind the\"~4 | *ising~2",
"fields": ["title"]
}
}
}
Синтаксис простого запроса
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises терминами являются wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова совпадают в порядке их появления (например, "wind rises"). Операторы, такие как +, | и -, определяют логическую связь, используемую для интерпретации текста в строке запроса.
Операторы
Синтаксис простого запроса поддерживает следующие операторы:
| Оператор |
Описание |
+ |
Действует как оператор AND. |
| ` |
` |
* |
Когда используется в конце термина, обозначает префиксный запрос. |
" |
Обрамляет несколько терминов в фразу (например, "wind rises"). |
(, ) |
Обрамляет клаузу для приоритета (например, `wind + (rises |
~n |
Когда используется после термина (например, wind~3), устанавливает нечеткость. Когда используется после фразы, устанавливает слоп. |
- |
Отрицает термин. |
Все вышеперечисленные операторы являются зарезервированными символами. Чтобы ссылаться на них как на обычные символы, необходимо экранировать их с помощью обратной косой черты. При отправке JSON-запроса используйте \\, чтобы экранировать зарезервированные символы (поскольку символ обратной косой черты сам по себе является зарезервированным, его необходимо экранировать еще одной обратной косой чертой).
Оператор по умолчанию
Оператор по умолчанию — OR (если вы не установите default_operator в AND). Оператор по умолчанию определяет общее поведение запроса. Например, рассмотрим индекс, содержащий следующие документы:
PUT /customers/_doc/1
{
"first_name":"Amber",
"last_name":"Duke",
"address":"880 Holmes Lane"
}
PUT /customers/_doc/2
{
"first_name":"Hattie",
"last_name":"Bond",
"address":"671 Bristol Street"
}
PUT /customers/_doc/3
{
"first_name":"Nanette",
"last_name":"Bates",
"address":"789 Madison St"
}
PUT /customers/_doc/4
{
"first_name":"Dale",
"last_name":"Amber",
"address":"467 Hutchinson Court"
}
Следующий запрос пытается найти документы, в которых адрес содержит слова street или st и не содержит слово madison:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st -madison"
}
}
}
Однако результаты включают не только ожидаемый документ, но и все четыре документа:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
},
{
"_index": "customers",
"_id": "3",
"_score": 1.2039728,
"_source": {
"first_name": "Nanette",
"last_name": "Bates",
"address": "789 Madison St"
}
},
{
"_index": "customers",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "Amber",
"last_name": "Duke",
"address": "880 Holmes Lane"
}
},
{
"_index": "customers",
"_id": "4",
"_score": 1,
"_source": {
"first_name": "Dale",
"last_name": "Amber",
"address": "467 Hutchinson Court"
}
}
]
}
}
Поскольку оператор по умолчанию — OR, этот запрос включает документы, которые содержат слова street или st (документы 2 и 3), а также документы, которые не содержат слово madison (документы 1 и 4).
Чтобы правильно выразить намерение запроса, предшествуйте -madison знаком +:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st +-madison"
}
}
}
Альтернативный подход
Или укажите AND в качестве оператора по умолчанию и используйте дизъюнкцию для слов street и st:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "st|street -madison",
"default_operator": "AND"
}
}
}
Предыдущий запрос возвращает документ 2:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
}
]
}
}
Таким образом, использование правильного оператора и синтаксиса позволяет точно формулировать запросы и получать ожидаемые результаты.
Ограничение операторов
Чтобы ограничить поддерживаемые операторы для парсера простого запроса, включите операторы, которые вы хотите поддерживать, разделенные символом |, в параметр flags. Например, следующий запрос включает только операторы OR, AND и FUZZY:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "bristol | madison +stre~2",
"flags": "OR|AND|FUZZY"
}
}
}
Доступные флаги операторов
Следующая таблица перечисляет все доступные флаги операторов:
| Флаг |
Описание |
ALL (по умолчанию) |
Включает все операторы. |
AND |
Включает оператор + (AND). |
ESCAPE |
Включает \ как символ экранирования. |
FUZZY |
Включает оператор ~n после слова, где n — целое число, обозначающее допустимое расстояние редактирования для совпадения. |
NEAR |
Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и SLOP. |
NONE |
Отключает все операторы. |
NOT |
Включает оператор - (NOT). |
OR |
Включает оператор ` |
PHRASE |
Включает кавычки " для поиска фраз. |
PRECEDENCE |
Включает операторы ( и ) (скобки) для приоритета операторов. |
PREFIX |
Включает оператор * (префикс). |
SLOP |
Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и NEAR. |
WHITESPACE |
Включает пробелы как символы, по которым текст разбивается. |
Эти флаги позволяют гибко настраивать поведение парсера простого запроса в зависимости от ваших потребностей.
Шаблоны с подстановочными знаками
Вы можете указывать шаблоны с подстановочными знаками, используя специальный символ *, который заменяет ноль или более символов. Например, следующий запрос ищет во всех полях, которые заканчиваются на name:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber Bond",
"fields": [ "*name" ]
}
}
}
Увеличение значимости
Используйте оператор увеличения значимости (^) для увеличения оценки релевантности поля с помощью множителя. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. Значение по умолчанию — 1.
Например, следующий запрос ищет в полях first_name и last_name и увеличивает значимость совпадений из поля first_name в 2 раза:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber",
"fields": [ "first_name^2", "last_name" ]
}
}
}
Мультипозиционные токены
Для мультипозиционных токенов простой запрос создает запрос на совпадение фразы. Таким образом, если вы укажете ml, machine learning как синонимы и выполните поиск по ml, OpenSearch будет искать ml ИЛИ "machine learning".
В качестве альтернативы вы можете сопоставить мультипозиционные токены, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в значение false, OpenSearch будет искать ml ИЛИ (machine И learning).
Например, следующий запрос ищет текст ml models и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"simple_query_string": {
"fields": ["title"],
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Параметры
Следующая таблица перечисляет параметры верхнего уровня, которые поддерживает запрос simple_query_string. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
query |
Строка |
Текст, который может содержать выражения в синтаксисе простого запроса для использования в поиске. Обязательный параметр. |
analyze_wildcard |
Логический |
Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию — false. |
analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
auto_generate_synonyms_phrase_query |
Логический |
Указывает, следует ли автоматически создавать запросы на совпадение фразы для многословных синонимов. По умолчанию — true. |
default_operator |
Строка |
Если строка запроса содержит несколько поисковых терминов, указывает, должны ли совпадать все термины (AND) или только один термин (OR) для того, чтобы документ считался совпадением. Допустимые значения:
- OR: строка интерпретируется как OR
- AND: строка интерпретируется как AND
По умолчанию — OR. |
fields |
Массив строк |
Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется настройка index.query.default_field, которая по умолчанию равна ["*"]. Максимальное количество полей, которые могут быть одновременно исследованы, определяется параметром indices.query.bool.max_clause_count, который по умолчанию равен 1,024. |
flags |
Строка |
Строка, разделенная символом ` |
fuzzy_max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах указанного расстояния нечеткости. Затем OpenSearch пытается сопоставить эти термины. По умолчанию — 50. |
fuzzy_transpositions |
Логический |
Установка fuzzy_transpositions в значение true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в опции нечеткости. Например, расстояние между wind и wnid равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, rewind и wnid имеют одинаковое расстояние (2) от wind, несмотря на более человеческое мнение, что wnid является очевидной опечаткой. Значение по умолчанию является хорошим выбором для большинства случаев использования. |
fuzzy_prefix_length |
Целое число |
Количество начальных символов, которые остаются неизменными для нечеткого сопоставления. По умолчанию — 0. |
lenient |
Логический |
Установка lenient в значение true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию — false. |
minimum_should_match |
Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадением. Например, если minimum_should_match равно 2, wind often rising не совпадает с The Wind Rises. Если minimum_should_match равно 1, совпадение происходит. Для получения подробной информации смотрите раздел “Минимальное количество совпадений”. |
quote_field_suffix |
Строка |
Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неполных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово lightly в поле title.exact. Это второе поле может использовать другой тип (например, keyword, а не text) или другой анализатор. |
3.4.8 - intervals query
Позволяет точно контролировать близость и порядок совпадающих терминов.
Запрос интервалов
Запрос интервалов сопоставляет документы на основе близости и порядка совпадающих терминов. Он применяет набор правил сопоставления к терминам, содержащимся в указанном поле. Запрос генерирует последовательности минимальных интервалов, охватывающих термины в тексте. Вы можете комбинировать интервалы и фильтровать их по родительским источникам.
Рассмотрим индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "пары ключ-значение эффективно хранятся в хэш-таблице"
}
PUT /testindex/_doc/2
{
"title": "хранить пары ключ-значение в хэш-карте"
}
Например, следующий запрос ищет документы, содержащие фразу “пары ключ-значение” (без промежутков между терминами), за которой следует либо “хэш-таблица”, либо “хэш-карта”:
GET /testindex/_search
{
"query": {
"intervals": {
"title": {
"all_of": {
"ordered": true,
"intervals": [
{
"match": {
"query": "пары ключ-значение",
"max_gaps": 0,
"ordered": true
}
},
{
"any_of": {
"intervals": [
{
"match": {
"query": "хэш-таблица"
}
},
{
"match": {
"query": "хэш-карта"
}
}
]
}
}
]
}
}
}
}
}
Запрос возвращает оба документа.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"intervals": {
"<field>": {
...
}
}
}
}
Поле <field> принимает следующие объекты правил, которые используются для сопоставления документов на основе терминов, порядка и близости.
| Правило |
Описание |
| match |
Сопоставляет анализируемый текст. |
| prefix |
Сопоставляет термины, которые начинаются с заданного набора символов. |
| wildcard |
Сопоставляет термины, используя шаблон с подстановочными знаками. |
| fuzzy |
Сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. |
| all_of |
Объединяет несколько правил с использованием конъюнкции (AND). |
| any_of |
Объединяет несколько правил с использованием дизъюнкции (OR). |
Правило match
Правило match сопоставляет анализируемый текст. В следующей таблице перечислены все параметры, которые поддерживает правило match.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| query |
Обязательный |
Строка |
Текст, по которому нужно выполнить поиск. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для анализа текста запроса. По умолчанию используется анализатор, указанный для <field>. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps |
Необязательный |
Целое число |
Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered |
Необязательный |
Логическое |
Указывает, должны ли совпадающие термины появляться в указанном порядке. По умолчанию false. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Термины анализируются с использованием анализатора поиска, указанного для этого поля. Указав use_field, вы можете искать по нескольким полям, как если бы они были одним и тем же полем. Например, если вы индексируете один и тот же текст в полях с корнями и без корней, вы можете искать корневые токены, которые находятся рядом с некорневыми. |
Правило prefix
Правило prefix сопоставляет термины, которые начинаются с заданного набора символов (префикс). Префикс может расширяться для сопоставления максимум 128 терминов. Если префикс соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило prefix.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| prefix |
Обязательный |
Строка |
Префикс, используемый для сопоставления терминов. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации префикса. По умолчанию используется анализатор, указанный для <field>. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Префикс нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило wildcard
Правило wildcard сопоставляет термины, используя шаблон с подстановочными знаками. Шаблон с подстановочными знаками может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило wildcard.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| pattern |
Обязательный |
Строка |
Шаблон с подстановочными знаками, используемый для сопоставления терминов. Укажите ? для сопоставления любого одного символа или * для сопоставления нуля или более символов. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации шаблона. По умолчанию используется анализатор, указанный для <field>. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Шаблон нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Указание шаблонов, начинающихся с * или ?, может ухудшить производительность поиска, так как увеличивает количество итераций, необходимых для сопоставления терминов.
Правило fuzzy
Правило fuzzy сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. Шаблон fuzzy может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило fuzzy.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| term |
Обязательный |
Строка |
Термин для сопоставления. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации термина. По умолчанию используется анализатор, указанный для <field>. |
| fuzziness |
Необязательный |
Строка |
Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова на другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение на основе длины каждого термина и является хорошим выбором для большинства случаев использования. |
| transpositions |
Необязательный |
Логическое |
Установка transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если transpositions равно true (обмен “n” и “i”), и 2, если false (удаление “n”, вставка “n”). Если transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” является очевидной опечаткой. По умолчанию является хорошим выбором для большинства случаев использования. |
| prefix_length |
Необязательный |
Целое число |
Количество начальных символов, оставляемых неизменными для нечеткого сопоставления. По умолчанию 0. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Термин нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило all_of
Правило all_of объединяет несколько правил с использованием конъюнкции (AND). В следующей таблице перечислены все параметры, которые поддерживает правило all_of.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| intervals |
Обязательный |
Массив объектов правил |
Массив правил для объединения. Документ должен соответствовать всем правилам, чтобы быть возвращенным в результатах. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps |
Необязательный |
Целое число |
Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered |
Необязательный |
Логическое |
Если true, интервалы, сгенерированные правилами, должны появляться в указанном порядке. По умолчанию false. |
Правило any_of
Правило any_of объединяет несколько правил с использованием дизъюнкции (OR). В следующей таблице перечислены все параметры, которые поддерживает правило any_of.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| intervals |
Обязательный |
Массив объектов правил |
Массив правил для объединения. Документ должен соответствовать хотя бы одному правилу, чтобы быть возвращенным в результатах. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
Правило filter
Правило filter используется для ограничения результатов. В следующей таблице перечислены все параметры, которые поддерживает правило filter.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| after |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые следуют за интервалом, указанным в правиле фильтра. |
| before |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые находятся перед интервалом, указанным в правиле фильтра. |
| contained_by |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, содержащихся в интервале, указанном в правиле фильтра. |
| containing |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые содержат интервал, указанный в правиле фильтра. |
| not_contained_by |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не содержатся в интервале, указанном в правиле фильтра. |
| not_containing |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не содержат интервал, указанный в правиле фильтра. |
| not_overlapping |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не перекрываются с интервалом, указанным в правиле фильтра. |
| overlapping |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые перекрываются с интервалом, указанным в правиле фильтра. |
| script |
Необязательный |
Объект скрипта |
Скрипт, используемый для сопоставления документов. Этот скрипт должен возвращать true или false. |
Пример: Фильтры
Следующий запрос ищет документы, содержащие слова “пары” и “хэш”, которые находятся в пределах пяти позиций друг от друга и не содержат слово “эффективно” между ними:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "пары хэш",
"max_gaps" : 5,
"filter" : {
"not_containing" : {
"match" : {
"query" : "эффективно"
}
}
}
}
}
}
}
}
Ответ содержит только документ 2.
Ответ
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.25,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.25,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Пример: Скриптовые фильтры
В качестве альтернативы вы можете написать свой собственный скриптовый фильтр для включения в запрос интервалов, используя следующие переменные:
interval.start: Позиция (номер термина), где начинается интервал.interval.end: Позиция (номер термина), где заканчивается интервал.interval.gap: Количество слов между терминами.
Например, следующий запрос ищет слова “карта” и “хэш”, которые находятся рядом друг с другом в указанном интервале. Термины нумеруются, начиная с 0, поэтому в тексте “хранить пары ключ-значение в хэш-карте” слово “хранить” находится на позиции 0, “пары” на позиции 1 и так далее. Указанный интервал должен начинаться после “а” и заканчиваться перед концом строки:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "карта хэш",
"filter" : {
"script" : {
"source" : "interval.start > 5 && interval.end < 8 && interval.gaps == 0"
}
}
}
}
}
}
}
Ответ
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.5,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.5,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Минимизация интервалов
Чтобы гарантировать, что запросы выполняются за линейное время, запрос интервалов минимизирует интервалы. Например, рассмотрим документ, содержащий текст “a b c d c”. Вы можете использовать следующий запрос для поиска “d”, который содержится между “a” и “c”:
POST /testindex/_search
{
"query": {
"intervals" : {
"my_text" : {
"match" : {
"query" : "d",
"filter" : {
"contained_by" : {
"match" : {
"query" : "a c"
}
}
}
}
}
}
}
}
Запрос не возвращает результатов, потому что он сопоставляет первые два термина “a” и “c” и не находит “d” между этими терминами.
3.5 - compound queries
Объединяют несколько запросов. Модифицируют поведение дочерних запросов. Управляют логикой выполнения
Составные запросы
Составные запросы служат обертками для нескольких листовых или составных клауз, чтобы либо объединить их результаты, либо изменить их поведение.
В следующей таблице перечислены все типы составных запросов.
| Тип запроса |
Описание |
| bool (логический) |
Объединяет несколько клауз запросов с помощью логики AND/OR. |
| boosting |
Изменяет релевантность документов, не удаляя их из результатов поиска. Возвращает документы, которые соответствуют положительному запросу, но понижает релевантность документов в результатах, которые соответствуют отрицательному запросу. |
| constant_score |
Оборачивает запрос или фильтр и присваивает постоянный балл всем совпадающим документам. Этот балл равен значению boost. |
| dis_max (максимум дизъюнкции) |
Возвращает документы, которые соответствуют одному или нескольким клаузам запроса. Если документ соответствует нескольким клаузам запроса, ему присваивается более высокий балл релевантности. Балл релевантности рассчитывается с использованием наивысшего балла из любых совпадающих клауз и, при необходимости, баллов из других совпадающих клауз, умноженных на значение tiebreaker. |
| function_score |
Пересчитывает балл релевантности документов, которые возвращаются запросом, с использованием функции, которую вы определяете. |
| hybrid |
Объединяет баллы релевантности из нескольких запросов в один балл для данного документа. |
3.5.1 - boolean query
Объединяет несколько клауз запросов с помощью логики AND/OR.
Булевый запрос
Булевый (bool) запрос может комбинировать несколько клауз в один расширенный запрос. Клаузи объединяются с помощью булевой логики для поиска соответствующих документов, возвращаемых в результатах.
Используйте следующие клаузи в булевом запросе:
| Клауз |
Поведение |
| must |
Логический оператор “и”. Результаты должны соответствовать всем запросам в этой клаузе. |
| must_not |
Логический оператор “не”. Все совпадения исключаются из результатов. Если must_not содержит несколько клауз, возвращаются только документы, которые не соответствуют ни одной из этих клауз. Например, “must_not”:[{clause_A}, {clause_B}] эквивалентно NOT(A OR B). |
| should |
Логический оператор “или”. Результаты должны соответствовать хотя бы одному из запросов. Чем больше клауз should совпадает, тем выше оценка релевантности документа. Вы можете установить минимальное количество запросов, которые должны совпадать, с помощью параметра minimum_should_match. Если запрос содержит клаузу must или filter, значение по умолчанию для minimum_should_match равно 0. В противном случае значение по умолчанию равно 1. |
| filter |
Логический оператор “и”, который применяется в первую очередь для уменьшения вашего набора данных перед применением запросов. Запрос внутри клаузи filter является бинарным: да или нет. Если документ соответствует запросу, он возвращается в результатах; в противном случае он не возвращается. Результаты фильтрующего запроса обычно кэшируются для более быстрого возврата. Используйте фильтрующий запрос для фильтрации результатов на основе точных совпадений, диапазонов, дат или чисел. |
Булевый запрос имеет следующую структуру:
GET _search
{
"query": {
"bool": {
"must": [
{}
],
"must_not": [
{}
],
"should": [
{}
],
"filter": {}
}
}
}
Например, предположим, что у вас есть полные произведения Шекспира, индексированные в кластере OpenSearch. Вы хотите построить один запрос, который соответствует следующим требованиям:
- Поле text_entry должно содержать слово “love” и должно содержать либо “life”, либо “grace”.
- Поле speaker не должно содержать “ROMEO”.
- Отфильтровать эти результаты по пьесе “Ромео и Джульетта”, не влияя на оценку релевантности.
Эти требования могут быть объединены в следующий запрос:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": "love"
}
}
],
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": "ROMEO"
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 4,
"successful": 4,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.356054,
"hits": [
{
"_index": "shakespeare",
"_id": "88020",
"_score": 11.356054,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Если вы хотите определить, какие из этих клауз фактически вызвали совпадение результатов, назовите каждый запрос с помощью параметра _name. Чтобы добавить параметр _name, измените имя поля в запросе сопоставления на объект:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": {
"query": "love",
"_name": "love-must"
}
}
}
],
"should": [
{
"match": {
"text_entry": {
"query": "life",
"_name": "life-should"
}
}
},
{
"match": {
"text_entry": {
"query": "grace",
"_name": "grace-should"
}
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": {
"query": "ROMEO",
"_name": "ROMEO-must-not"
}
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
OpenSearch возвращает массив matched_queries, который перечисляет запросы, соответствующие этим результатам:
"matched_queries": [
"love-must",
"life-should"
]
Если вы удалите запросы, не входящие в этот список, вы все равно увидите точно такой же результат. Изучая, какая клаузa should совпала, вы можете лучше понять оценку релевантности результатов.
Вы также можете строить сложные булевы выражения, вложив булевы запросы. Например, используйте следующий запрос, чтобы найти поле text_entry, которое соответствует (love ИЛИ hate) И (life ИЛИ grace) в пьесе “Ромео и Джульетта”:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"text_entry": "love"
}
},
{
"match": {
"text_entry": "hate"
}
}
]
}
},
{
"bool": {
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
]
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.37006,
"hits": [
{
"_index": "shakespeare",
"_type": "doc",
"_id": "88020",
"_score": 11.37006,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Таким образом, вы можете использовать вложенные булевы запросы для создания более сложных логических выражений, что позволяет более точно настраивать поиск и получать релевантные результаты в OpenSearch.
3.5.2 - boosting query
Изменяет релевантность документов, не удаляя их из результатов поиска. Возвращает документы, которые соответствуют положительному запросу, но понижает релевантность документов в результатах, которые соответствуют отрицательному запросу.
Запрос с бустингом
Если вы ищете слово “pitcher” (питчер), ваши результаты могут относиться как к бейсбольным игрокам, так и к контейнерам для жидкостей. Для поиска в контексте бейсбола вы можете полностью исключить результаты, содержащие слова “glass” (стекло) или “water” (вода), используя клаузу must_not. Однако, если вы хотите сохранить эти результаты, но понизить их релевантность, вы можете сделать это с помощью запросов с бустингом.
Запрос с бустингом возвращает документы, которые соответствуют положительному запросу. Среди этих документов те, которые также соответствуют отрицательному запросу, получают более низкую оценку релевантности (их оценка релевантности умножается на отрицательный коэффициент бустинга).
Пример
Рассмотрим индекс с двумя документами, которые вы индексируете следующим образом:
PUT testindex/_doc/1
{
"article_name": "The greatest pitcher in baseball history"
}
PUT testindex/_doc/2
{
"article_name": "The making of a glass pitcher"
}
Используйте следующий запрос match, чтобы искать документы, содержащие слово “pitcher”:
GET testindex/_search
{
"query": {
"match": {
"article_name": "pitcher"
}
}
}
Оба возвращенных документа имеют одинаковую оценку релевантности:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.18232156,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Теперь используйте следующий запрос с бустингом, чтобы искать документы, содержащие слово “pitcher”, но понизить оценку документов, содержащих слова “glass”, “crystal” или “water”:
GET testindex/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"article_name": "pitcher"
}
},
"negative": {
"match": {
"article_name": "glass crystal water"
}
},
"negative_boost": 0.1
}
}
}
Оба документа все еще возвращаются, но документ со словом “glass” имеет оценку релевантности, которая в 10 раз ниже, чем в предыдущем случае:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.018232157,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами с бустингом.
| Параметр |
Описание |
| positive |
Запрос, которому документ должен соответствовать, чтобы быть возвращенным в результатах. Обязательный параметр. |
| negative |
Если документ в результатах соответствует этому запросу, его оценка релевантности уменьшается путем умножения его исходной оценки релевантности (полученной от положительного запроса) на параметр negative_boost. Обязательный параметр. |
| negative_boost |
Плавающий коэффициент в диапазоне от 0 до 1.0, на который умножается исходная оценка релевантности для уменьшения релевантности документов, соответствующих отрицательному запросу. Обязательный параметр. |
3.5.3 - constant_score
Оборачивает запрос или фильтр и присваивает постоянный балл всем совпадающим документам. Этот балл равен значению boost.
Запрос constant_score
Если вам нужно вернуть документы, содержащие определенное слово, независимо от того, сколько раз это слово встречается, вы можете использовать запрос constant_score. Запрос constant_score оборачивает фильтрующий запрос и присваивает всем документам в результатах релевантный балл, равный значению параметра boost. Таким образом, все возвращенные документы имеют равный релевантный балл, и частота термина/обратная документная частота (TF/IDF) не учитываются. Фильтрующие запросы не вычисляют релевантные баллы. Кроме того, OpenSearch кэширует часто используемые фильтрующие запросы для повышения производительности.
Пример
Используйте следующий запрос, чтобы вернуть документы, содержащие слово “Hamlet” в индексе shakespeare:
GET shakespeare/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"text_entry": "Hamlet"
}
},
"boost": 1.2
}
}
}
Все документы в результатах получают релевантный балл 1.2.
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 96,
"relation": "eq"
},
"max_score": 1.2,
"hits": [
{
"_index": "shakespeare",
"_id": "32535",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32536,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.97",
"speaker": "HORATIO",
"text_entry": "Dared to the combat; in which our valiant Hamlet--"
}
},
{
"_index": "shakespeare",
"_id": "32546",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32547,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.108",
"speaker": "HORATIO",
"text_entry": "His fell to Hamlet. Now, sir, young Fortinbras,"
}
},
{
"_index": "shakespeare",
"_id": "32625",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32626,
"play_name": "Hamlet",
"speech_number": 59,
"line_number": "1.1.184",
"speaker": "HORATIO",
"text_entry": "Unto young Hamlet; for, upon my life,"
}
},
{
"_index": "shakespeare",
"_id": "32633",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32634,
"play_name": "Hamlet",
"speech_number": 60,
"line_number": "",
"speaker": "MARCELLUS",
"text_entry": "Enter KING CLAUDIUS, QUEEN GERTRUDE, HAMLET, POLONIUS, LAERTES, VOLTIMAND, CORNELIUS, Lords, and Attendants"
}
},
{
"_index": "shakespeare",
"_id": "32634",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32635,
"play_name": "Hamlet",
"speech_number": 1,
"line_number": "1.2.1",
"speaker": "KING CLAUDIUS",
"text_entry": "Though yet of Hamlet our dear brothers death"
}
},
{
"_index": "shakespeare",
"_id": "32699",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32700,
"play_name": "Hamlet",
"speech_number": 8,
"line_number": "1.2.65",
"speaker": "KING CLAUDIUS",
"text_entry": "But now, my cousin Hamlet, and my son,--"
}
},
{
"_index": "shakespeare",
"_id": "32703",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32704,
"play_name": "Hamlet",
"speech_number": 12,
"line_number": "1.2.69",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Good Hamlet, cast thy nighted colour off,"
}
},
{
"_index": "shakespeare",
"_id": "32723",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32724,
"play_name": "Hamlet",
"speech_number": 16,
"line_number": "1.2.89",
"speaker": "KING CLAUDIUS",
"text_entry": "Tis sweet and commendable in your nature, Hamlet,"
}
},
{
"_index": "shakespeare",
"_id": "32754",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32755,
"play_name": "Hamlet",
"speech_number": 17,
"line_number": "1.2.120",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Let not thy mother lose her prayers, Hamlet:"
}
},
{
"_index": "shakespeare",
"_id": "32759",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32760,
"play_name": "Hamlet",
"speech_number": 19,
"line_number": "1.2.125",
"speaker": "KING CLAUDIUS",
"text_entry": "This gentle and unforced accord of Hamlet"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами constant_score.
| Параметр |
Описание |
| filter |
Фильтрующий запрос, которому должен соответствовать документ, чтобы быть возвращенным в результатах. Обязательный. |
| boost |
Числовое значение с плавающей запятой, которое присваивается как релевантный балл всем возвращенным документам. Необязательный. По умолчанию 1.0. |
3.5.4 - disjunction_max
Возвращает документы, которые соответствуют одному или нескольким клаузам запроса. Если документ соответствует нескольким клаузам запроса, ему присваивается более высокий балл релевантности.
Запрос disjunction max (dis_max)
Запрос disjunction max (dis_max) возвращает любой документ, который соответствует одному или нескольким условиям запроса. Для документов, которые соответствуют нескольким условиям запроса, релевантный балл устанавливается на основе наивысшего релевантного балла из всех соответствующих условий запроса.
Когда релевантные баллы возвращаемых документов идентичны, вы можете использовать параметр tie_breaker, чтобы придать больше веса документам, которые соответствуют нескольким условиям запроса.
Пример
Рассмотрим индекс с двумя документами, которые вы индексируете следующим образом:
PUT testindex1/_doc/1
{
"title": " The Top 10 Shakespeare Poems",
"description": "Top 10 sonnets of England's national poet and the Bard of Avon"
}
PUT testindex1/_doc/2
{
"title": "Sonnets of the 16th Century",
"body": "The poems written by various 16-th century poets"
}
Используйте запрос dis_max, чтобы искать документы, содержащие слова “Shakespeare poems”:
GET testindex1/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Shakespeare poems" }},
{ "match": { "body": "Shakespeare poems" }}
]
}
}
}
Ответ содержит оба документа:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1.3862942,
"_source": {
"title": " The Top 10 Shakespeare Poems",
"description": "Top 10 sonnets of England's national poet and the Bard of Avon"
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 0.2876821,
"_source": {
"title": "Sonnets of the 16th Century",
"body": "The poems written by various 16-th century poets"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами dis_max.
| Параметр |
Описание |
| queries |
Массив одного или нескольких условий запроса, которые используются для сопоставления документов. Документ должен соответствовать хотя бы одному условию запроса, чтобы быть возвращенным в результатах. Если документ соответствует нескольким условиям запроса, релевантный балл устанавливается на основе наивысшего релевантного балла из всех соответствующих условий запроса. Обязательный. |
| tie_breaker |
Числовой коэффициент с плавающей запятой от 0 до 1.0, который используется для придания большего веса документам, соответствующим нескольким условиям запроса. В этом случае релевантный балл документа рассчитывается с использованием следующего алгоритма: берется наивысший релевантный балл из всех соответствующих условий запроса, умножаются баллы всех других соответствующих условий на значение tie_breaker, и затем баллы складываются, нормализуя их. Необязательный. По умолчанию 0 (что означает, что учитывается только наивысший балл). |
3.5.5 - function_score
Пересчитывает балл релевантности документов, которые возвращаются запросом, с использованием функции, которую вы определяете.
Запрос function score
Используйте запрос function_score, если вам нужно изменить релевантные баллы документов, возвращаемых в результатах. Запрос function_score определяет запрос и одну или несколько функций, которые могут быть применены ко всем результатам или подмножествам результатов для перерасчета их релевантных баллов.
Использование одной функции оценки
Самый простой пример запроса function_score использует одну функцию для перерасчета балла. Следующий запрос использует функцию weight, чтобы удвоить все релевантные баллы. Эта функция применяется ко всем документам в результатах, поскольку в запросе function_score не указаны параметры запроса:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
Применение функции оценки к подмножеству документов
Чтобы применить функцию оценки к подмножеству документов, укажите запрос внутри функции:
GET shakespeare/_search
{
"query": {
"function_score": {
"query": {
"match": {
"play_name": "Hamlet"
}
},
"weight": "2"
}
}
}
Поддерживаемые функции
Тип запроса function_score поддерживает следующие функции:
-
Встроенные:
- weight: Умножает балл документа на предопределенный коэффициент увеличения.
- random_score: Предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями.
- field_value_factor: Использует значение указанного поля документа для перерасчета балла.
- Функции затухания (gauss, exp и linear): Перерасчитывают балл с использованием заданной функции затухания.
-
Пользовательские:
- script_score: Использует скрипт для оценки документов.
Функция weight
Когда вы используете функцию weight, оригинальный релевантный балл умножается на значение с плавающей запятой weight:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
В отличие от значения boost, функция weight не нормализуется.
Функция random_score
Функция random_score предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями. Балл представляет собой число с плавающей запятой в диапазоне [0, 1). По умолчанию функция random_score использует внутренние идентификаторы документов Lucene в качестве значений семени, что делает случайные значения невоспроизводимыми, поскольку документы могут быть перенумерованы после слияний. Чтобы добиться согласованности в генерации случайных значений, вы можете предоставить параметры seed и field. Поле должно быть полем, для которого включены данные поля (обычно это числовое поле). Балл рассчитывается с использованием семени, значений данных поля для указанного поля и соли, рассчитанной с использованием имени индекса и идентификатора шардов. Поскольку имя индекса и идентификатор шардов одинаковы для документов, находящихся в одном шард, документы с одинаковыми значениями полей будут получать одинаковый балл. Чтобы обеспечить разные баллы для всех документов в одном шарде, используйте поле, которое имеет уникальные значения для всех документов. Одним из вариантов является использование поля _seq_no. Однако, если вы выберете это поле, баллы могут измениться, если документ будет обновлен из-за соответствующего обновления _seq_no.
Следующий запрос использует функцию random_score с семенем и полем:
GET shakespeare/_search
{
"query": {
"function_score": {
"random_score": {
"seed": 12345,
"field": "some_numeric_field"
}
}
}
}
Функция field_value_factor
Функция field_value_factor перерасчитывает балл, используя значение указанного поля документа. Если поле является многозначным, используется только его первое значение для расчетов, остальные значения не учитываются.
Функция field_value_factor поддерживает следующие параметры:
-
field: Поле, которое будет использоваться в расчетах баллов.
-
factor: Необязательный коэффициент, на который умножается значение поля. По умолчанию 1.
-
modifier: Один из модификаторов, который будет применен к значению поля.
Поддерживаемые модификаторы
Следующая таблица перечисляет все поддерживаемые модификаторы.
| Модификатор |
Формула |
Описание |
| log |
[\log v] |
Возьмите десятичный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать log1p или log2p вместо log. |
| log1p |
[\log(1+v)] |
Возьмите десятичный логарифм суммы 1 и значения. |
| log2p |
[\log(2+v)] |
Возьмите десятичный логарифм суммы 2 и значения. |
| ln |
[\ln v] |
Возьмите натуральный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать ln1p или ln2p вместо ln. |
| ln1p |
[\ln(1+v)] |
Возьмите натуральный логарифм суммы 1 и значения. |
| ln2p |
[\ln(2+v)] |
Возьмите натуральный логарифм суммы 2 и значения. |
| reciprocal |
[\frac{1}{v}] |
Возьмите обратное значение. |
| square |
[v^2] |
Возведите значение в квадрат. |
| sqrt |
[\sqrt{v}] |
Возьмите квадратный корень из значения. Взятие квадратного корня из отрицательного числа является недопустимой операцией и приведет к ошибке. Убедитесь, что значение неотрицательно. |
| none |
N/A |
Не применять никакой модификатор. |
- missing: Значение, которое будет использоваться, если поле отсутствует в документе. Коэффициент и модификатор применяются к этому значению вместо отсутствующего значения поля.
Пример
Например, следующий запрос использует функцию field_value_factor, чтобы придать больше веса полю views:
GET blogs/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
}
}
}
}
Предыдущий запрос рассчитывает релевантный балл, используя следующую формулу:
[
score = original \ score \cdot log(1+1.5 \cdot views)
]
Функция script_score
Используя функцию script_score, вы можете написать пользовательский скрипт для оценки документов, при этом опционально включая значения полей в документе. Оригинальный релевантный балл доступен в переменной _score.
Рассчитанный балл не может быть отрицательным. Отрицательный балл приведет к ошибке. Баллы документов имеют положительные 32-битные значения с плавающей запятой. Балл с большей точностью преобразуется в ближайшее 32-битное число с плавающей запятой.
Пример
Например, следующий запрос использует функцию script_score для расчета балла на основе оригинального балла и количества просмотров и лайков для блога. Чтобы уменьшить вес количества просмотров и лайков, эта формула берет логарифм суммы просмотров и лайков. Чтобы сделать логарифм допустимым, даже если количество просмотров и лайков равно 0, к их сумме добавляется 1:
GET blogs/_search
{
"query": {
"function_score": {
"query": {"match": {"name": "opensearch"}},
"script_score": {
"script": "_score * Math.log(1 + doc['likes'].value + doc['views'].value)"
}
}
}
}
Скрипты компилируются и кэшируются для повышения производительности. Таким образом, предпочтительно повторно использовать один и тот же скрипт и передавать любые параметры, которые необходимы скрипту:
GET blogs/_search
{
"query": {
"function_score": {
"query": {
"match": { "name": "opensearch" }
},
"script_score": {
"script": {
"params": {
"add": 1
},
"source": "_score * Math.log(params.add + doc['likes'].value + doc['views'].value)"
}
}
}
}
}
Функции Decay (затухания)
Для многих приложений необходимо сортировать результаты на основе близости или недавности. Вы можете сделать это с помощью функций затухания. Функции затухания вычисляют балл документа, используя одну из трех кривых затухания: гауссову, экспоненциальную или линейную.
Функции decay (затухания) работают только с числовыми, датированными и геопунктовыми полями.
Функции затухания вычисляют баллы на основе начала, масштаба, смещения и затухания, как показано на следующем рисунке.
Примеры: Геопунктовые поля
Предположим, вы ищете отель рядом с вашим офисом. Вы создаете индекс отелей, который сопоставляет поле location как геопункт:
PUT hotels
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Вы индексируете два документа, которые соответствуют ближайшим отелям:
PUT hotels/_doc/1
{
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74.00
}
}
PUT hotels/_doc/2
{
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74.00
}
}
Начало определяет точку, от которой рассчитывается расстояние (местоположение офиса). Смещение указывает расстояние от начала, в пределах которого документам присваивается полный балл 1. Вы можете присвоить отелям, находящимся в пределах 200 футов от офиса, одинаковый наивысший балл. Масштаб определяет скорость затухания графика, а затухание определяет балл, который следует присвоить документу на расстоянии масштаб + смещение от начала. Как только вы выходите за пределы радиуса 200 футов, вы можете решить, что если вам нужно пройти еще 300 футов, чтобы добраться до отеля (масштаб = 300 футов), вы присвоите ему четверть оригинального балла (затухание = 0.25).
Вы создаете следующий запрос с началом в точке (74.00, 40.71):
GET hotels/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"location": {
"origin": "40.71,74.00",
"offset": "200ft",
"scale": "300ft",
"decay": 0.25
}
}
}
]
}
}
}
Ответ содержит оба отеля. Отель в пределах 200 футов от офиса имеет балл 1, а отель за пределами радиуса 500 футов имеет балл 0.20, что меньше параметра затухания 0.25.
{
"took": 854,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "hotels",
"_id": "1",
"_score": 1,
"_source": {
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74
}
}
},
{
"_index": "hotels",
"_id": "2",
"_score": 0.20099315,
"_source": {
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры, поддерживаемые функциями gauss, exp и linear.
| Параметр |
Описание |
| origin |
Точка, от которой рассчитывается расстояние. Должна быть указана как число для числовых полей, дата для полей даты или геопункт для геопунктовых полей. Обязательна для геопунктовых и числовых полей. Необязательна для полей даты (по умолчанию используется текущее время). Для полей даты поддерживается математическое вычисление дат (например, now-2d). |
| offset |
Определяет расстояние от начала, в пределах которого документам присваивается балл 1. Необязательный. По умолчанию 0. |
| scale |
Документам на расстоянии scale + offset от начала присваивается балл decay. Обязательный. Для числовых полей scale может быть любым числом. Для полей даты scale может быть определен как число с единицами (5h, 1d). Если единицы не указаны, scale по умолчанию равен миллисекундам. Для геопунктовых полей scale может быть определен как число с единицами (1mi, 5km). Если единицы не указаны, scale по умолчанию равен метрам. |
| decay |
Определяет балл документа на расстоянии scale + offset от начала. Необязательный. По умолчанию 0.5. |
Для полей, отсутствующих в документе, функции затухания возвращают балл 1.
Пример: Числовые поля
Следующий запрос использует экспоненциальную функцию затухания, чтобы приоритизировать блоги по количеству комментариев:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"comments_count": {
"origin": 10,
"scale": 5,
"decay": 0.5
}
}
}
]
}
}
}
Первые два блога в результатах имеют балл 1, потому что один находится в начале (20), а другой на расстоянии 16, что находится в пределах смещения (диапазон, в пределах которого документы получают полный балл, рассчитывается как 20 - 5 и составляет [15, 25]). Третий блог находится на расстоянии scale + offset от начала (20 - (5 + 10) = 15), поэтому ему присваивается стандартный балл затухания (0.5):
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "1",
"_score": 1,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 1,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "3",
"_score": 0.5,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0.4352753,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Пример: Поля даты
Следующий запрос использует гауссову функцию затухания, чтобы приоритизировать блоги, опубликованные около 24 апреля 2002 года:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d",
"decay": 0.25
}
}
}
]
}
}
}
В результатах первый блог был опубликован в течение одного дня после 24 апреля 2022 года, поэтому он имеет наивысший балл 1. Второй блог был опубликован 17 апреля 2022 года, что находится в пределах смещения + масштаба (1 день + 6 дней), и поэтому имеет балл, равный затуханию (0.25). Третий блог был опубликован более чем через 7 дней после 24 апреля 2022 года, поэтому у него более низкий балл. Последний блог имеет балл 0, потому что он был опубликован много лет назад:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 1,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 0.25,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 0.15154076,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Многозначные поля
Если поле, которое вы указываете для расчета затухания, содержит несколько значений, вы можете использовать параметр multi_value_mode. Этот параметр указывает одну из следующих функций для определения значения поля, которое будет использоваться для расчетов:
- min: (по умолчанию) Минимальное расстояние от начала.
- max: Максимальное расстояние от начала.
- avg: Среднее расстояние от начала.
- sum: Сумма всех расстояний от начала.
Пример
Например, вы индексируете документ с массивом расстояний:
PUT testindex/_doc/1
{
"distances": [1, 2, 3, 4, 5]
}
Следующий запрос использует максимальное расстояние многозначного поля distances для расчета затухания:
GET testindex/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"distances": {
"origin": "6",
"offset": "5",
"scale": "1"
},
"multi_value_mode": "max"
}
}
]
}
}
}
Документ получает балл 1, потому что максимальное расстояние от начала (1) находится в пределах смещения от начала:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1,
"_source": {
"distances": [
1,
2,
3,
4,
5
]
}
}
]
}
}
Расчет кривой затухания
Следующие формулы определяют вычисление оценки для различных функций затухания (обозначает значение поля документа).
Гауссовская функция затухания
[
\text{score} = \exp \left(-\frac {(\max(0, \lvert v - \text{origin} \rvert - \text{offset}))^2} {2\sigma^2} \right),
]
где (\sigma) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
\sigma^2 = - \frac {\text{scale}^2} {2 \ln(\text{decay})}
]
Экспоненциальная функция затухания
[
\text{score} = \exp (\lambda \cdot \max(0, \lvert v - \text{origin} \rvert - \text{offset})),
]
где (\lambda) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
\lambda = \frac {\ln(\text{decay})} {\text{scale}}
]
Линейная функция затухания
[
\text{score} = \max \left(\frac {s - \max(0, \lvert v - \text{origin} \rvert - \text{offset})} {s} \right),
]
где (s) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
s = \frac {\text{scale}} {1 - \text{decay}}
]
Использование нескольких функций оценки
Вы можете указать несколько функций оценки в запросе функции оценки, перечислив их в массиве functions.
Комбинирование оценок от нескольких функций
Разные функции могут использовать разные масштабы для оценки. Например, функция random_score предоставляет оценку в диапазоне от 0 до 1, но field_value_factor не имеет конкретного масштаба для оценки. Кроме того, вы можете захотеть по-разному взвешивать оценки, полученные от различных функций. Чтобы скорректировать оценки для разных функций, вы можете указать параметр weight для каждой функции. Оценка, полученная от каждой функции, затем умножается на вес, чтобы получить окончательную оценку для этой функции. Параметр weight должен быть указан в массиве functions, чтобы отличать его от функции веса.
Оценки, полученные от каждой функции, комбинируются с помощью параметра score_mode, который принимает одно из следующих значений:
-
multiply: (по умолчанию) Оценки умножаются.
-
sum: Оценки складываются.
-
avg: Оценки усредняются. Если указан вес, это средневзвешенное. Например, если первая функция с весом w1 возвращает оценку s1, а вторая функция с весом w2 возвращает оценку s2, среднее значение рассчитывается как:
[
\text{average} = \frac{w1 \cdot s1 + w2 \cdot s2}{w1 + w2}
]
-
first: Берется оценка от первой функции, которая имеет соответствующий фильтр.
-
max: Берется максимальная оценка.
-
min: Берется минимальная оценка.
Указание верхнего предела для оценки
Вы можете указать верхний предел для функции оценки в параметре max_boost. Значение по умолчанию для верхнего предела — это максимальная величина для значения с плавающей запятой: ((2 - 2^{-23}) \cdot 2^{127}).
Комбинирование оценки для всех функций с оценкой запроса
Вы можете указать, как оценка, вычисленная с использованием всех функций, комбинируется с оценкой запроса, в параметре boost_mode, который принимает одно из следующих значений:
- multiply: (по умолчанию) Умножает оценку запроса на оценку функции.
- replace: Игнорирует оценку запроса и использует оценку функции.
- sum: Складывает оценку запроса и оценку функции.
- avg: Усредняет оценку запроса и оценку функции.
- max: Берет большее значение между оценкой запроса и оценкой функции.
- min: Берет меньшее значение между оценкой запроса и оценкой функции.
Фильтрация документов, которые не соответствуют порогу
Изменение оценки релевантности не изменяет список соответствующих документов. Чтобы исключить некоторые документы, которые не соответствуют порогу, укажите значение порога в параметре min_score. Все документы, возвращенные запросом, затем оцениваются и фильтруются с использованием значения порога.
Пример
Следующий запрос ищет блоги, которые содержат слова “OpenSearch Data Prepper”, предпочитая посты, опубликованные около 24 апреля 2022 года. Кроме того, учитывается количество просмотров и лайков. Наконец, пороговое значение установлено на уровне 10:
GET blogs/_search
{
"query": {
"function_score": {
"boost": "5",
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d"
}
},
"weight": 1
},
{
"gauss": {
"likes": {
"origin": 200,
"scale": 200
}
},
"weight": 4
},
{
"gauss": {
"views": {
"origin": 1000,
"scale": 800
}
},
"weight": 2
}
],
"query": {
"match": {
"name": "opensearch data prepper"
}
},
"max_boost": 10,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 10
}
}
}
Результаты содержат три соответствующих блога:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 31.191923,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 31.191923,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 13.907352,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 11.150461,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
}
]
}
}
Именованные функции
При определении функции вы можете указать ее имя, используя параметр _name на верхнем уровне. Это имя полезно для отладки и понимания процесса оценки. После указания имя функции включается в объяснение расчета оценки, когда это возможно (это относится к функциям, фильтрам и запросам). Вы можете идентифицировать функцию по ее _name в ответе.
Пример
Следующий запрос устанавливает explain в значение true для целей отладки, чтобы получить объяснение оценки в ответе. Каждая функция содержит параметр _name, чтобы вы могли однозначно идентифицировать функцию:
GET blogs/_search
{
"explain": true,
"size": 1,
"query": {
"function_score": {
"functions": [
{
"_name": "likes_function",
"script_score": {
"script": {
"lang": "painless",
"source": "return doc['likes'].value * 2;"
}
},
"weight": 0.6
},
{
"_name": "views_function",
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
},
"weight": 0.3
},
{
"_name": "comments_function",
"gauss": {
"comments": {
"origin": 1000,
"scale": 800
}
},
"weight": 0.1
}
]
}
}
}
Ответ объясняет процесс оценки. Для каждой функции объяснение содержит name функции в своем описании:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 6.1600614,
"hits": [
{
"_shard": "[blogs][0]",
"_node": "_yndTaZHQWimcDgAfOfRtQ",
"_index": "blogs",
"_id": "1",
"_score": 6.1600614,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
},
"_explanation": {
"value": 6.1600614,
"description": "function score, product of:",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
},
{
"value": 6.1600614,
"description": "min of:",
"details": [
{
"value": 6.1600614,
"description": "function score, score mode [multiply]",
"details": [
{
"value": 180,
"description": "product of:",
"details": [
{
"value": 300,
"description": "script score function(_name: likes_function), computed with script:\"Script{type=inline, lang='painless', idOrCode='return doc['likes'].value * 2;', options={}, params={}}\"",
"details": [
{
"value": 1,
"description": "_score: ",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
}
]
}
]
},
{
"value": 0.6,
"description": "weight",
"details": []
}
]
},
{
"value": 0.9766541,
"description": "product of:",
"details": [
{
"value": 3.2555137,
"description": "field value function(_name: views_function): log1p(doc['views'].value?:1.0 * factor=1.5)",
"details": []
},
{
"value": 0.3,
"description": "weight",
"details": []
}
]
},
{
"value": 0.035040613,
"description": "product of:",
"details": [
{
"value": 0.35040614,
"description": "Function for field comments:",
"details": [
{
"value": 0.35040614,
"description": "exp(-0.5*pow(MIN[Math.max(Math.abs(16.0(=doc value) - 1000.0(=origin))) - 0.0(=offset), 0)],2.0)/461662.4130844683, _name: comments_function)",
"details": []
}
]
},
{
"value": 0.1,
"description": "weight",
"details": []
}
]
}
]
},
{
"value": 3.4028235e+38,
"description": "maxBoost",
"details": []
}
]
}
]
}
}
]
}
}
3.5.6 - hibrid
Объединяет баллы релевантности из нескольких запросов в один балл для данного документа.
Гибридный запрос
Вы можете использовать гибридный запрос для комбинирования оценок релевантности из нескольких запросов в одну оценку для данного документа. Гибридный запрос содержит список из одного или нескольких запросов и независимо вычисляет оценки документов на уровне шардов для каждого подзапроса. Переписывание подзапросов выполняется на уровне координирующего узла, чтобы избежать дублирования вычислений.
Пример
Узнайте, как использовать гибридный запрос, следуя шагам в разделе Гибридный поиск.
Для получения более полного примера следуйте разделу Начало работы с семантическим и гибридным поиском.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые гибридными запросами.
| Параметр |
Описание |
queries |
Массив из одного или нескольких условий запроса, которые используются для поиска документов. Документ должен соответствовать хотя бы одному условию запроса, чтобы быть возвращенным в результатах. Оценки релевантности документов из всех условий запроса комбинируются в одну оценку с помощью поискового конвейера. Максимальное количество условий запроса — 5. Обязательно. |
filter |
Фильтр, который применяется ко всем подзапросам гибридного запроса. |
Отключение гибридных запросов
По умолчанию гибридные запросы включены. Чтобы отключить гибридные запросы в вашем кластере, установите параметр plugins.neural_search.hybrid_search_disabled в значение true в файле opensearch.yml.
3.6 - geographic and xy query
Географические и xy-запросы позволяют искать поля, содержащие точки и фигуры на карте или в координатной плоскости.
Географические и xy-запросы
Географические и xy-запросы позволяют искать поля, содержащие точки и фигуры на карте или в координатной плоскости. Географические запросы работают с геопространственными данными, в то время как xy-запросы работают с двумерными координатными данными. Из всех географических запросов запрос geoshape очень похож на xy-запрос, но первый ищет географические поля, в то время как второй ищет декартовы поля.
xy-запросы
xy-запросы ищут документы, содержащие геометрии в декартовой системе координат. Эти геометрии могут быть указаны в полях xy_point, которые поддерживают точки, и в полях xy_shape, которые поддерживают точки, линии, круги и многоугольники.
xy-запросы возвращают документы, которые содержат:
- xy-формы и xy-точки, имеющие одно из четырех пространственных отношений к предоставленной форме: INTERSECTS (пересекает), DISJOINT (разъединены), WITHIN (внутри) или CONTAINS (содержит).
- xy-точки, которые пересекают предоставленную форму.
Географические запросы
Географические запросы ищут документы, содержащие геопространственные геометрии. Эти геометрии могут быть указаны в полях geo_point, которые поддерживают точки на карте, и в полях geo_shape, которые поддерживают точки, линии, круги и многоугольники.
OpenSearch предоставляет следующие типы географических запросов:
- Запросы по гео-ограничивающему прямоугольнику (Geo-bounding box queries): возвращают документы с значениями поля geopoint, которые находятся в пределах ограничивающего прямоугольника.
- Запросы по гео-расстоянию (Geodistance queries): возвращают документы с геоточками, которые находятся на заданном расстоянии от предоставленной геоточки.
- Запросы по гео-многоугольнику (Geopolygon queries): возвращают документы, содержащие геоточки, которые находятся внутри многоугольника.
- Запросы по гео-форме (Geoshape queries): возвращают документы, которые содержат:
- Геоформы и геоточки, имеющие одно из четырех пространственных отношений к предоставленной форме: INTERSECTS (пересекает), DISJOINT (разъединены), WITHIN (внутри) или CONTAINS (содержит).
- Геоточки, которые пересекают предоставленную форму.
3.6.1 - Запрос по гео-ограничивающему прямоугольнику
Запрос по гео-ограничивающему прямоугольнику возвращает документы, чьи геоточки находятся в пределах ограничивающего прямоугольника, указанного в запросе.
Чтобы искать документы, содержащие поля geopoint, используйте запрос по гео-ограничивающему прямоугольнику. Запрос по гео-ограничивающему прямоугольнику возвращает документы, чьи геоточки находятся в пределах ограничивающего прямоугольника, указанного в запросе. Документ с несколькими геоточками соответствует запросу, если хотя бы одна геоточка находится в пределах ограничивающего прямоугольника.
Пример
Вы можете использовать запрос по гео-ограничивающему прямоугольнику для поиска документов, содержащих геоточки.
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте три геоточки как объекты с широтой и долготой:
PUT testindex1/_doc/1
{
"point": {
"lat": 74.00,
"lon": 40.71
}
}
PUT testindex1/_doc/2
{
"point": {
"lat": 72.64,
"lon": 22.62
}
}
PUT testindex1/_doc/3
{
"point": {
"lat": 75.00,
"lon": 28.00
}
}
Ищите все документы и фильтруйте документы, чьи точки находятся внутри прямоугольника, определенного в запросе:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": {
"lat": 75,
"lon": 28
},
"bottom_right": {
"lat": 73,
"lon": 41
}
}
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "testindex1",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"point" : {
"lat" : 74.0,
"lon" : 40.71
}
}
}
]
}
}
Предыдущий ответ не включает документ с геоточкой “lat”: 75.00, “lon”: 28.00 из-за ограниченной точности геоточки.
Точность
Координаты геоточек всегда округляются вниз во время индексации. Во время выполнения запроса верхние границы ограничивающего прямоугольника округляются вниз, а нижние границы округляются вверх. Поэтому документы с геоточками, которые находятся на нижних и левых границах ограничивающего прямоугольника, могут не быть включены в результаты из-за ошибки округления. С другой стороны, геоточки, находящиеся на верхних и правых границах ограничивающего прямоугольника, могут быть включены в результаты, даже если они находятся за пределами границ. Ошибка округления составляет менее 4.20 × 10^−8 градусов для широты и менее 8.39 × 10^−8 градусов для долготы (примерно 1 см).
Указание ограничивающего прямоугольника
Вы можете указать ограничивающий прямоугольник, предоставив любую из следующих комбинаций координат его вершин:
- top_left и bottom_right
- top_right и bottom_left
- top, left, bottom и right
Следующий пример показывает, как указать ограничивающий прямоугольник, используя координаты top, left, bottom и right:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top": 75,
"left": 28,
"bottom": 73,
"right": 41
}
}
}
}
}
}
Параметры
Запросы по гео-ограничивающему прямоугольнику принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| _name |
String |
Имя фильтра. Необязательный параметр. |
| validation_method |
String |
Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). По умолчанию - STRICT. |
| type |
String |
Указывает, как выполнять фильтр. Допустимые значения: indexed (индексировать фильтр) и memory (выполнять фильтр в памяти). По умолчанию - memory. |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы с неотображаемым полем. Если установлено в false, при неотображаемом поле возникает исключение. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты вершин ограничивающего прямоугольника в любом формате, который принимает тип поля geopoint.
Использование геохеша для указания ограничивающего прямоугольника
Если вы используете геохеш для указания ограничивающего прямоугольника, геохеш рассматривается как прямоугольник. Верхний левый угол ограничивающего прямоугольника соответствует верхнему левому углу геохеша top_left, а нижний правый угол ограничивающего прямоугольника соответствует нижнему правому углу геохеша bottom_right.
Следующий пример показывает, как использовать геохеш для указания того же ограничивающего прямоугольника, что и в предыдущих примерах:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": "ut7ftjkfxm34",
"bottom_right": "uuvpkcprc4rc"
}
}
}
}
}
}
Чтобы указать ограничивающий прямоугольник, который охватывает всю область геохеша, укажите этот геохеш как параметры top_left и bottom_right ограничивающего прямоугольника:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": "ut",
"bottom_right": "ut"
}
}
}
}
}
}
3.6.2 - Запрос по гео-расстоянию
Запрос по гео-расстоянию возвращает документы с геоточками, которые находятся в пределах заданного расстояния от предоставленной геоточки.
Документ с несколькими геоточками соответствует запросу, если хотя бы одна геоточка соответствует запросу.
Поле, в котором хранятся геоточки, должно быть правильно настроено в индексе как тип geo_point
Пример
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте геоточку, указав ее широту и долготу:
PUT testindex1/_doc/1
{
"point": {
"lat": 74.00,
"lon": 40.71
}
}
Ищите документы, чьи объекты точки находятся в пределах заданного расстояния от указанной точки:
GET /testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "50mi",
"point": {
"lat": 73.5,
"lon": 40.5
}
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"point": {
"lat": 74,
"lon": 40.71
}
}
}
]
}
}
Параметры
Запросы по гео-расстоянию принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| _name |
String |
Имя фильтра. Необязательный параметр. |
| distance |
String |
Расстояние, в пределах которого следует сопоставить точки. Это расстояние является радиусом круга, центрированного на указанной точке. Для поддерживаемых единиц расстояния см. раздел “Единицы расстояния”. Обязательный параметр. |
| distance_type |
String |
Указывает, как рассчитывать расстояние. Допустимые значения: arc (дуга) или plane (плоскость, быстрее, но менее точно для больших расстояний или точек, близких к полюсам). Необязательный параметр. По умолчанию - arc. |
| validation_method |
String |
Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). Необязательный параметр. По умолчанию - STRICT. |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы, содержащие неотображаемое поле. Если установлено в false, при неотображаемом поле возникает исключение. Необязательный параметр. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты геоточки при индексации документа и поиске документов в любом формате, который принимает тип поля geopoint.
3.6.3 - Запрос по гео-многоугольнику
Запрос по гео-многоугольнику возвращает документы, содержащие геоточки, которые находятся внутри указанного многоугольника.
Запрос по гео-многоугольнику возвращает документы, содержащие геоточки, которые находятся внутри указанного многоугольника. Документ, содержащий несколько геоточек, соответствует запросу, если хотя бы одна геоточка соответствует запросу.
Многоугольник задается списком вершин в координатной форме. В отличие от указания многоугольника для поля geoshape, многоугольник не обязательно должен быть замкнутым (не нужно указывать первую и последнюю точки одновременно). Хотя точки не обязательно должны следовать в порядке часовой или против часовой стрелки, рекомендуется перечислять их в одном из этих порядков. Это обеспечит правильное определение многоугольника.
Иск searched document field must be mapped as geo_point.
Пример
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT /testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте геоточку, указав ее широту и долготу:
PUT testindex1/_doc/1
{
"point": {
"lat": 73.71,
"lon": 41.32
}
}
Ищите документы, чьи объекты точки находятся внутри указанного гео-многоугольника:
GET /testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 74.0060, "lon": 40.7128 }
]
}
}
}
}
}
}
Многоугольник, указанный в предыдущем запросе, представляет собой четырехугольник. Соответствующий документ находится внутри этого четырехугольника. Координаты вершин четырехугольника указаны в формате (широта, долгота).
 Ответ содержит соответствующий документ:
Ответ содержит соответствующий документ:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"point": {
"lat": 73.71,
"lon": 41.32
}
}
}
]
}
}
В предыдущем запросе вы указали вершины многоугольника в порядке часовой стрелки:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 74.0060, "lon": 40.7128 }
]
}
}
Альтернативно, вы можете указать вершины в порядке против часовой стрелки:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 74.0060, "lon": 40.7128 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 73.7562, "lon": 42.6526 }
]
}
}
Ответ на запрос будет содержать тот же соответствующий документ.
Однако, если вы укажете вершины в следующем порядке:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 74.0060, "lon": 40.7128 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 }
]
}
}
Ответ не вернет никаких результатов.
Параметры
Запросы по гео-многоугольнику принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| _name |
String |
Имя фильтра. Необязательный параметр. |
| validation_method |
String |
Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). Необязательный параметр. По умолчанию - STRICT. |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы, содержащие неотображаемое поле. Если установлено в false, при неотображаемом поле возникает исключение. Необязательный параметр. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты геоточки при индексации документа и поиске документов в любом формате, который принимает тип поля geopoint.
3.6.4 - Запрос по гео-форме
Вы можете фильтровать документы, используя гео-форму, определенную в запросе, или использовать заранее индексированную гео-форму.
Используйте запрос по гео-форме для поиска документов, которые содержат поля geopoint или geoshape. Вы можете фильтровать документы, используя гео-форму, определенную в запросе, или использовать заранее индексированную гео-форму.
Иск searched document field must be mapped as geo_point или geo_shape.
Пространственные отношения
Когда вы предоставляете гео-форму для запроса по гео-форме, поля geopoint и geoshape в документах сопоставляются с использованием следующих пространственных отношений к предоставленной форме:
| Отношение |
Описание |
Поддерживаемый тип географического поля |
| INTERSECTS |
(По умолчанию) Соответствует документам, чьи geopoint или geoshape пересекаются с формой, предоставленной в запросе. |
geo_point, geo_shape |
| DISJOINT |
Соответствует документам, чьи geoshape не пересекаются с формой, предоставленной в запросе. |
geo_shape |
| WITHIN |
Соответствует документам, чьи geoshape полностью находятся внутри формы, предоставленной в запросе. |
geo_shape |
| CONTAINS |
Соответствует документам, чьи geoshape полностью содержат форму, предоставленную в запросе. |
geo_shape |
Определение формы в запросе по гео-форме
Вы можете определить форму для фильтрации документов в запросе по гео-форме, предоставив новое определение формы во время запроса или сославшись на имя формы, заранее индексированной в другом индексе.
Использование нового определения формы
Чтобы предоставить новую форму для запроса по гео-форме, определите ее в поле geo_shape. Вы должны определить гео-форму в формате GeoJSON.
Следующий пример иллюстрирует поиск документов, содержащих гео-формы, которые соответствуют гео-форме, определенной во время запроса.
Шаг 1: Создание индекса
Сначала создайте индекс и сопоставьте поле location как geo_shape:
PUT /testindex
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
Шаг 2: Индексация документов
Индексуйте один документ, содержащий точку, и другой, содержащий многоугольник:
PUT testindex/_doc/1
{
"location": {
"type": "point",
"coordinates": [ 73.0515, 41.5582 ]
}
}
PUT testindex/_doc/2
{
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
Шаг 3: Выполнение запроса по гео-форме
Наконец, определите гео-форму для фильтрации документов. Следующие разделы иллюстрируют предоставление различных гео-форм в запросе. Для получения дополнительной информации о различных форматах гео-форм см. раздел “Тип поля гео-формы”.
Конверт
Конверт — это ограничивающий прямоугольник в формате [[minLon, maxLat], [maxLon, minLat]]. Ищите документы, содержащие поля geoshape, которые пересекаются с предоставленным конвертом:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
71.0589,
42.3601
],
[
74.006,
40.7128
]
]
},
"relation": "WITHIN"
}
}
}
}
Ответ содержит оба документа:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0,
"_source": {
"location": {
"type": "point",
"coordinates": [
73.0515,
41.5582
]
}
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0,
"_source": {
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
}
]
}
}
Точка
Ищите документы, чьи поля geoshape содержат предоставленную точку:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "point",
"coordinates": [
72.8000,
41.6300
]
},
"relation": "CONTAINS"
}
}
}
}
Linestring
Поиск документов, геошейпы которых не пересекаются с предоставленным линией:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "linestring",
"coordinates": [[74.0060, 40.7128], [71.0589, 42.3601]]
},
"relation": "DISJOINT"
}
}
}
}
Запросы геошейпа с линией не поддерживают отношение WITHIN.
Полигон
В формате GeoJSON необходимо перечислить вершины полигона в порядке обхода против часовой стрелки и замкнуть полигон, чтобы первая и последняя вершины совпадали.
Поиск документов, геошейпы которых находятся внутри предоставленного полигона:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "polygon",
"coordinates": [
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]
]
},
"relation": "WITHIN"
}
}
}
}
Мультипоинт
Поиск документов, геошейпы которых не пересекаются с предоставленными точками:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multipoint",
"coordinates": [
[74.0060, 40.7128],
[71.0589, 42.3601]
]
},
"relation": "DISJOINT"
}
}
}
}
Мультилиния
Поиск документов, геошейпы которых не пересекаются с предоставленными линиями:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multilinestring",
"coordinates": [
[[74.0060, 40.7128], [71.0589, 42.3601]],
[[73.7562, 42.6526], [72.6734, 41.7658]]
]
},
"relation": "disjoint"
}
}
}
}
Запросы геошейпа с мультилинией не поддерживают отношение WITHIN.
Мультиполигоны
Поиск документов, геошейпы которых находятся внутри предоставленного мультиполигона:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multipolygon",
"coordinates": [
[
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
],
[
[73.0515, 41.5582],
[72.6506, 41.5623],
[72.6734, 41.7658],
[73.0515, 41.5582]
]
],
[
[
[73.9146, 40.8252],
[73.8871, 41.0389],
[73.6853, 40.9747],
[73.9146, 40.8252]
]
]
]
},
"relation": "WITHIN"
}
}
}
}
Коллекция геометрий
Поиск документов, геошейпы которых находятся внутри предоставленных полигонов:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "geometrycollection",
"geometries": [
{
"type": "polygon",
"coordinates": [[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]]
},
{
"type": "polygon",
"coordinates": [[
[73.0515, 41.5582],
[72.6506, 41.5623],
[72.6734, 41.7658],
[73.0515, 41.5582]
]]
}
]
},
"relation": "WITHIN"
}
}
}
}
Запросы геошейпа, содержащие в коллекции геометрий линию или мультилинии, не поддерживают отношение WITHIN.
Использование прединдексированного определения формы
При построении запроса геошейпа вы также можете ссылаться на имя формы, прединдексированной в другом индексе. С помощью этого метода вы можете определить геошейп во время индексации и ссылаться на него по имени во время поиска.
Вы можете определить прединдексированный геошейп в формате GeoJSON или Well-Known Text (WKT). Для получения дополнительной информации о различных форматах геошейпа см. тип поля Geoshape.
Объект indexed_shape поддерживает следующие параметры:
| Параметр |
Обязательный/Необязательный |
Описание |
| id |
Обязательный |
Идентификатор документа, содержащего прединдексированную форму. |
| index |
Необязательный |
Имя индекса, содержащего прединдексированную форму. По умолчанию - shapes. |
| path |
Необязательный |
Имя поля, содержащего прединдексированную форму в виде пути. По умолчанию - shape. |
| routing |
Необязательный |
Маршрутизация документа, содержащего прединдексированную форму. |
Следующий пример иллюстрирует, как ссылаться на имя формы, прединдексированной в другом индексе. В этом примере индекс pre-indexed-shapes содержит форму, определяющую границы, а индекс testindex содержит формы, которые проверяются на соответствие этим границам.
Сначала создайте индекс pre-indexed-shapes и задайте поле boundaries для этого индекса как geo_shape:
PUT /pre-indexed-shapes
{
"mappings": {
"properties": {
"boundaries": {
"type": "geo_shape",
"orientation": "left"
}
}
}
}
Для получения дополнительной информации о том, как задать другую ориентацию вершин для полигонов, см. Полигон.
Индексируйте полигон, указывая границы поиска, в индекс pre-indexed-shapes. Идентификатор полигона - search_triangle. В этом примере вы индексируете полигон в формате WKT:
PUT /pre-indexed-shapes/_doc/search_triangle
{
"boundaries":
"POLYGON ((74.0060 40.7128, 71.0589 42.3601, 73.7562 42.6526, 74.0060 40.7128))"
}
Если вы еще не сделали этого, индексируйте один документ, содержащий точку, и другой документ, содержащий полигон, в индекс testindex:
PUT /testindex/_doc/1
{
"location": {
"type": "point",
"coordinates": [ 73.0515, 41.5582 ]
}
}
PUT /testindex/_doc/2
{
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
Поиск документов, геошейпы которых находятся внутри search_triangle:
GET /testindex/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_shape": {
"location": {
"indexed_shape": {
"index": "pre-indexed-shapes",
"id": "search_triangle",
"path": "boundaries"
},
"relation": "WITHIN"
}
}
}
}
}
}
Ответ содержит оба документа.
Запрос геоточек
Вы также можете использовать запрос геошейпа для поиска документов, содержащих геоточки.
Запросы геошейпа по полям геоточек поддерживают только пространственное отношение по умолчанию INTERSECTS, поэтому вам не нужно указывать параметр отношения.
Запросы геошейпа по полям геоточек не поддерживают следующие геошейпы:
- Точки
- Линии
- Мультипоинты
- Мультилинии
- Коллекции геометрий, содержащие один из вышеперечисленных типов геошейпа
Создайте отображение, где location является geo_point:
PUT /testindex1
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Индексируйте две точки в индекс. В этом примере вы предоставите координаты геоточек в виде строк:
PUT /testindex1/_doc/1
{
"location": "41.5623, 72.6506"
}
PUT /testindex1/_doc/2
{
"location": "76.0254, 39.2467"
}
Для получения информации о предоставлении координат геоточек в различных форматах см. Форматы.
Поиск геоточек, которые пересекаются с предоставленным полигоном:
GET /testindex1/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "polygon",
"coordinates": [
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]
]
}
}
}
}
}
Ответ на запрос
Ответ возвращает документ 1:
{
"took": 21,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0,
"_source": {
"location": "41.5623, 72.6506"
}
}
]
}
}
Обратите внимание, что при индексации геоточек вы указали их координаты в формате “широта, долгота”. Когда вы ищете соответствующие документы, массив координат находится в формате [долгота, широта]. Таким образом, документ 1 возвращается в результатах, но документ 2 - нет.
Параметры
Запросы геошейпа принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неразмеченное поле. Если установлено в true, то запрос не возвращает документы, содержащие неразмеченное поле. Если установлено в false, то при отсутствии поля выбрасывается исключение. Необязательный. По умолчанию - false. |
3.6.5 - xy запрос
Для поиска документов, содержащих поля xy point или xy shape, используйте xy запрос.
Пространственные отношения
Когда вы предоставляете xy форму в xy запросе, поля xy в документах сопоставляются с использованием следующих пространственных отношений к предоставленной форме.
| Отношение |
Описание |
Поддерживаемый тип поля xy |
| INTERSECTS |
(По умолчанию) Сопоставляет документы, чьи xy point или xy shape пересекают форму, предоставленную в запросе. |
xy_point, xy_shape |
| DISJOINT |
Сопоставляет документы, чьи xy shape не пересекаются с формой, предоставленной в запросе. |
xy_shape |
| WITHIN |
Сопоставляет документы, чьи xy shape полностью находятся внутри формы, предоставленной в запросе. |
xy_shape |
| CONTAINS |
Сопоставляет документы, чьи xy shape полностью содержат форму, предоставленную в запросе. |
xy_shape |
Следующие примеры иллюстрируют поиск документов, содержащих xy формы. Чтобы узнать, как искать документы, содержащие xy точки, смотрите раздел “Запросы xy точек”.
Определение формы в xy запросе
Вы можете определить форму в xy запросе, предоставив новое определение формы во время запроса или сославшись на имя формы, предварительно индексированной в другом индексе.
Использование нового определения формы
Чтобы предоставить новую форму в xy запросе, определите ее в поле xy_shape.
Следующий пример иллюстрирует, как искать документы, содержащие xy формы, которые соответствуют xy форме, определенной во время запроса.
Сначала создайте индекс и сопоставьте поле геометрии как xy_shape:
PUT testindex
{
"mappings": {
"properties": {
"geometry": {
"type": "xy_shape"
}
}
}
}
Индексируйте документ с точкой и документ с многоугольником:
PUT testindex/_doc/1
{
"geometry": {
"type": "point",
"coordinates": [0.5, 3.0]
}
}
PUT testindex/_doc/2
{
"geometry" : {
"type" : "polygon",
"coordinates" : [
[[2.5, 6.0],
[0.5, 4.5],
[1.5, 2.0],
[3.5, 3.5],
[2.5, 6.0]]
]
}
}
Определите оболочку — ограничивающий прямоугольник в формате [[minX, maxY], [maxX, minY]]. Ищите документы с xy точками или формами, которые пересекают эту оболочку:
GET testindex/_search
{
"query": {
"xy_shape": {
"geometry": {
"shape": {
"type": "envelope",
"coordinates": [ [ 0.0, 6.0], [ 4.0, 2.0] ]
},
"relation": "WITHIN"
}
}
}
}
Следующее изображение иллюстрирует пример. И точка, и многоугольник находятся внутри ограничивающей оболочки.
Использование предварительно индексированного определения формы
При построении xy запроса вы также можете ссылаться на имя формы, предварительно индексированной в другом индексе. Используя этот метод, вы можете определить xy форму во время индексации и ссылаться на нее по имени, предоставляя следующие параметры в объекте indexed_shape.
| Параметр |
Описание |
| index |
Имя индекса, содержащего предварительно индексированную форму. |
| id |
Идентификатор документа, содержащего предварительно индексированную форму. |
| path |
Имя поля, содержащего предварительно индексированную форму, в виде пути. |
Следующий пример иллюстрирует ссылку на имя формы, предварительно индексированной в другом индексе. В этом примере индекс pre-indexed-shapes содержит форму, определяющую границы, а индекс testindex содержит формы, местоположения которых проверяются относительно этих границ.
Сначала создайте индекс pre-indexed-shapes и сопоставьте поле геометрии для этого индекса как xy_shape:
PUT pre-indexed-shapes
{
"mappings": {
"properties": {
"geometry": {
"type": "xy_shape"
}
}
}
}
Индексируйте оболочку, которая определяет границы, и назовите ее rectangle:
PUT pre-indexed-shapes/_doc/rectangle
{
"geometry": {
"type": "envelope",
"coordinates" : [ [ 0.0, 6.0], [ 4.0, 2.0] ]
}
}
Индексируйте документ с точкой и документ с многоугольником в индекс testindex:
PUT testindex/_doc/1
{
"geometry": {
"type": "point",
"coordinates": [0.5, 3.0]
}
}
PUT testindex/_doc/2
{
"geometry" : {
"type" : "polygon",
"coordinates" : [
[[2.5, 6.0],
[0.5, 4.5],
[1.5, 2.0],
[3.5, 3.5],
[2.5, 6.0]]
]
}
}
Теперь выполните поиск документов с формами, которые пересекают rectangle в индексе testindex, используя фильтр:
GET testindex/_search
{
"query": {
"bool": {
"filter": {
"xy_shape": {
"geometry": {
"indexed_shape": {
"index": "pre-indexed-shapes",
"id": "rectangle",
"path": "geometry"
}
}
}
}
}
}
}
Этот запрос вернет документы из индекса testindex, которые пересекают предварительно индексированную форму rectangle, определенную в индексе pre-indexed-shapes.
Запрос xy точек
Вы также можете использовать xy запрос для поиска документов, содержащих xy точки.
Создание сопоставления с типом xy_point
Сначала создайте сопоставление с полем типа xy_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "xy_point"
}
}
}
}
Индексация трех точек
Индексируйте три точки:
PUT testindex1/_doc/1
{
"point": "1.0, 1.0"
}
PUT testindex1/_doc/2
{
"point": "2.0, 0.0"
}
PUT testindex1/_doc/3
{
"point": "-2.0, 2.0"
}
Поиск точек в круге
Теперь выполните поиск точек, которые находятся внутри круга с центром в (0, 0) и радиусом 2:
GET testindex1/_search
{
"query": {
"xy_shape": {
"point": {
"shape": {
"type": "circle",
"coordinates": [0.0, 0.0],
"radius": 2
}
}
}
}
}
Форма xy point поддерживает только пространственное отношение по умолчанию INTERSECTS, поэтому вам не нужно указывать параметр отношения.
Результаты запроса
Следующее изображение иллюстрирует пример. Точки 1 и 2 находятся внутри круга, а точка 3 находится вне круга.
Ответ на запрос возвращает документы 1 и 2, которые находятся внутри заданного круга:
{
"took" : 575,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "testindex1",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"point" : "1.0, 1.0"
}
},
{
"_index" : "testindex1",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"point" : "2.0, 0.0"
}
}
]
}
}
Объяснение результатов
- Документ 1: Содержит точку с координатами (1.0, 1.0), которая находится внутри круга.
- Документ 2: Содержит точку с координатами (2.0, 0.0), которая также находится внутри круга.
Обе точки соответствуют критериям поиска, так как они находятся в пределах радиуса 2 от центра (0, 0). Точка 3, с координатами (-2.0, 2.0), не была возвращена, так как она находится вне круга.
3.7 - Объединение запросов
OpenSearch предоставляет следующие запросы, которые выполняют операции объединения и оптимизированы для масштабирования на нескольких узлах:
OpenSearch является распределенной системой, в которой данные распределены по нескольким узлам. Поэтому выполнение операции JOIN, аналогичной SQL, в OpenSearch требует значительных ресурсов. В качестве альтернативы OpenSearch предоставляет следующие запросы, которые выполняют операции объединения и оптимизированы для масштабирования на нескольких узлах:
Запросы для поиска вложенных полей
- Вложенные запросы (nested queries): Действуют как обертки для других запросов, чтобы искать вложенные поля. Объекты вложенных полей ищутся так, как будто они индексированы как отдельные документы.
Запросы для поиска документов, связанных через тип поля объединения
Эти запросы устанавливают родительско-дочерние отношения между документами в одном индексе:
- has_child запросы: Ищут родительские документы, дочерние документы которых соответствуют запросу.
- has_parent запросы: Ищут дочерние документы, родительские документы которых соответствуют запросу.
- parent_id запросы: Ищут дочерние документы, которые связаны с конкретным родительским документом.
Настройка выполнения запросов
Если параметр search.allow_expensive_queries установлен в значение false, то объединяющие запросы не будут выполняться.
3.7.1 - Запрос has_child
Запрос has_child возвращает родительские документы, дочерние документы которых соответствуют определенному запросу.
Запрос has_child возвращает родительские документы, дочерние документы которых соответствуют определенному запросу. Вы можете установить родительско-дочерние отношения между документами в одном индексе, используя тип поля join.
Запрос has_child медленнее, чем другие запросы, из-за операции соединения, которую он выполняет. Производительность снижается по мере увеличения количества соответствующих дочерних документов, указывающих на разные родительские документы. Каждый запрос has_child в вашем поиске может значительно повлиять на производительность запроса. Если вы придаете приоритет скорости, избегайте использования этого запроса или ограничьте его использование насколько возможно.
Пример
Перед тем как вы сможете выполнить запрос has_child, ваш индекс должен содержать поле join для установления родительско-дочерних отношений. Запрос на отображение индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
В этом примере вы настроите индекс, который содержит документы, представляющие продукты и их бренды.
Сначала создайте индекс и установите родительско-дочерние отношения между брендом и продуктом:
PUT testindex1
{
"mappings": {
"properties": {
"product_to_brand": {
"type": "join",
"relations": {
"brand": "product"
}
}
}
}
}
Индексуйте два родительских (брендовых) документа:
PUT testindex1/_doc/1
{
"name": "Luxury brand",
"product_to_brand" : "brand"
}
PUT testindex1/_doc/2
{
"name": "Economy brand",
"product_to_brand" : "brand"
}
Индексуйте три дочерних (продуктовых) документа:
PUT testindex1/_doc/3?routing=1
{
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
PUT testindex1/_doc/4?routing=2
{
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
PUT testindex1/_doc/5?routing=2
{
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
Чтобы найти родителя дочернего документа, используйте запрос has_child. Следующий запрос возвращает родительские документы (бренды), которые производят часы:
GET testindex1/_search
{
"query" : {
"has_child": {
"type":"product",
"query": {
"match" : {
"name": "watch"
}
}
}
}
}
Ответ возвращает оба бренда:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 1,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
Извлечение внутренних результатов (inner hits)
Чтобы вернуть дочерние документы, которые соответствуют запросу, укажите параметр inner_hits:
GET testindex1/_search
{
"query" : {
"has_child": {
"type":"product",
"query": {
"match" : {
"name": "watch"
}
},
"inner_hits": {}
}
}
}
Ответ содержит дочерние документы в поле inner_hits:
{
"took": 52,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
},
"inner_hits": {
"product": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.53899646,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 0.53899646,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
}
]
}
}
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 1,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
},
"inner_hits": {
"product": {
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.53899646,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 0.53899646,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 0.53899646,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
}
}
]
}
}
Для получения дополнительной информации о извлечении внутренних результатов, смотрите раздел “Внутренние результаты” (Inner hits).
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами has_child.
| Параметр |
Обязательный/Необязательный |
Описание |
| type |
Обязательный |
Указывает имя дочерней связи, как определено в отображении поля join. |
| query |
Обязательный |
Запрос, который будет выполнен на дочерних документах. Если дочерний документ соответствует запросу, возвращается родительский документ. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неотображаемые поля типов и не возвращать документы вместо того, чтобы вызывать ошибку. Этот параметр можно указать при запросе нескольких индексов, некоторые из которых могут не содержать поле типа. По умолчанию false. |
| max_children |
Необязательный |
Максимальное количество соответствующих дочерних документов для родительского документа. Если превышено, родительский документ исключается из результатов поиска. |
| min_children |
Необязательный |
Минимальное количество соответствующих дочерних документов, необходимых для включения родительского документа в результаты. Если не достигнуто, родитель исключается. По умолчанию 1. |
| score_mode |
Необязательный |
Определяет, как оценки соответствующих дочерних документов влияют на оценку родительского документа. Допустимые значения: |
|
|
- none: Игнорирует оценки релевантности дочерних документов и присваивает родительскому документу оценку 0. |
|
|
- avg: Использует среднюю оценку релевантности всех соответствующих дочерних документов. |
|
|
- max: Присваивает наивысшую оценку релевантности из соответствующих дочерних документов родителю. |
|
|
- min: Присваивает наименьшую оценку релевантности из соответствующих дочерних документов родителю. |
|
|
- sum: Суммирует оценки релевантности всех соответствующих дочерних документов. |
| По умолчанию none. |
|
|
| inner_hits |
Необязательный |
Если указан, возвращает внутренние результаты (дочерние документы), которые соответствуют запросу. |
Ограничения сортировки
Запрос has_child не поддерживает сортировку результатов с использованием стандартных опций сортировки. Если вам необходимо отсортировать родительские документы по полям их дочерних документов, вы можете использовать запрос function_score и сортировать по оценке родительского документа.
В приведенном выше примере вы можете отсортировать родительские документы (бренды) на основе поля sales_count их дочерних продуктов. Этот запрос умножает оценку на поле sales_count дочерних документов и присваивает наивысшую оценку релевантности из соответствующих дочерних документов родителю:
GET testindex1/_search
{
"query": {
"has_child": {
"type": "product",
"query": {
"function_score": {
"script_score": {
"script": "_score * doc['sales_count'].value"
}
}
},
"score_mode": "max"
}
}
}
Ответ содержит бренды, отсортированные по наивысшему значению sales_count дочерних документов:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 300,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 300,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
},
{
"_index": "testindex1",
"_id": "1",
"_score": 150,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
}
}
]
}
}
3.7.2 - Запрос has_parent
Запрос has_parent возвращает дочерние документы, родительские документы которых соответствуют определенному запросу.
Запрос has_parent возвращает дочерние документы, родительские документы которых соответствуют определенному запросу. Вы можете установить родительско-дочерние отношения между документами в одном индексе, используя тип поля join.
Запрос has_parent медленнее, чем другие запросы, из-за операции соединения, которую он выполняет. Производительность снижается по мере увеличения количества соответствующих родительских документов. Каждый запрос has_parent в вашем поиске может значительно повлиять на производительность запроса. Если вы придаете приоритет скорости, избегайте использования этого запроса или ограничьте его использование насколько возможно.
Пример
Перед тем как вы сможете выполнить запрос has_parent, ваш индекс должен содержать поле join для установления родительско-дочерних отношений. Запрос на отображение индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
Для этого примера сначала настройте индекс, который содержит документы, представляющие продукты и их бренды, как описано в примере запроса has_child.
Чтобы найти дочерний документ родителя, используйте запрос has_parent. Следующий запрос возвращает дочерние документы (продукты), произведенные брендом, соответствующим запросу “economy”:
GET testindex1/_search
{
"query" : {
"has_parent": {
"parent_type":"brand",
"query": {
"match" : {
"name": "economy"
}
}
}
}
}
Ответ возвращает все продукты, произведенные брендом:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
Извлечение внутренних результатов (inner hits)
Чтобы вернуть родительские документы, которые соответствуют запросу, укажите параметр inner_hits:
GET testindex1/_search
{
"query" : {
"has_parent": {
"parent_type":"brand",
"query": {
"match" : {
"name": "economy"
}
},
"inner_hits": {}
}
}
}
Ответ содержит родительские документы в поле inner_hits:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
},
"inner_hits": {
"brand": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 1.3862942,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
},
"inner_hits": {
"brand": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 1.3862942,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
}
}
]
}
}
Для получения дополнительной информации о извлечении внутренних результатов, смотрите раздел “Внутренние результаты” (Inner hits).
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами has_parent.
| Параметр |
Обязательный/Необязательный |
Описание |
| parent_type |
Обязательный |
Указывает имя родительской связи, как определено в отображении поля join. |
| query |
Обязательный |
Запрос, который будет выполнен на родительских документах. Если родительский документ соответствует запросу, возвращается дочерний документ. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неотображаемые поля типа parent_type и не возвращать документы вместо того, чтобы вызывать ошибку. Этот параметр можно указать при запросе нескольких индексов, некоторые из которых могут не содержать поле parent_type. По умолчанию false. |
| score |
Необязательный |
Указывает, учитывается ли оценка релевантности соответствующего родительского документа в дочерних документах. Если false, то оценка релевантности родительского документа игнорируется, и каждому дочернему документу присваивается оценка релевантности, равная коэффициенту увеличения запроса, который по умолчанию равен 1. Если true, то оценка релевантности соответствующего родительского документа агрегируется в оценки релевантности его дочерних документов. По умолчанию false. |
| inner_hits |
Необязательный |
Если указан, возвращает внутренние результаты (родительские документы), которые соответствуют запросу. |
Ограничения сортировки
Запрос has_parent не поддерживает сортировку результатов с использованием стандартных опций сортировки. Если вам необходимо отсортировать дочерние документы по полям их родительских документов, вы можете использовать запрос function_score и сортировать по оценке дочернего документа.
Для предыдущего примера сначала добавьте поле customer_satisfaction, по которому вы будете сортировать дочерние документы, принадлежащие родительским (брендовым) документам:
PUT testindex1/_doc/1
{
"name": "Luxury watch brand",
"product_to_brand" : "brand",
"customer_satisfaction": 4.5
}
PUT testindex1/_doc/2
{
"name": "Economy watch brand",
"product_to_brand" : "brand",
"customer_satisfaction": 3.9
}
Теперь вы можете сортировать дочерние документы (продукты) на основе поля customer_satisfaction их родительских брендов. Этот запрос умножает оценку на поле customer_satisfaction родительских документов:
GET testindex1/_search
{
"query": {
"has_parent": {
"parent_type": "brand",
"score": true,
"query": {
"function_score": {
"script_score": {
"script": "_score * doc['customer_satisfaction'].value"
}
}
}
}
}
}
Ответ содержит продукты, отсортированные по наивысшему значению customer_satisfaction родительских документов:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 4.5,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 4.5,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
},
{
"_index": "testindex1",
"_id": "4",
"_score": 3.9,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 3.9,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
3.7.3 - Вложенный запрос
Вложенный запрос служит оберткой для других запросов, позволяя искать во вложенных полях.
Вложенный запрос служит оберткой для других запросов, позволяя искать во вложенных полях. Объекты вложенных полей ищутся так, как будто они индексированы как отдельные документы. Если объект соответствует запросу, вложенный запрос возвращает родительский документ на корневом уровне.
Пример
Перед тем как выполнить вложенный запрос, ваш индекс должен содержать вложенное поле.
Чтобы настроить пример индекса, содержащего вложенные поля, отправьте следующий запрос:
PUT /testindex
{
"mappings": {
"properties": {
"patient": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
}
}
Далее, индексируйте документ в пример индекса:
PUT /testindex/_doc/1
{
"patient": {
"name": "John Doe",
"age": 56
}
}
Чтобы выполнить поиск по вложенному полю пациента, оберните ваш запрос во вложенный запрос и укажите путь к вложенному полю:
GET /testindex/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"match": {
"patient.name": "John"
}
}
}
}
}
Запрос возвращает соответствующий документ:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.2876821,
"_source": {
"patient": {
"name": "John Doe",
"age": 56
}
}
}
]
}
}
Получение внутренних результатов
Чтобы вернуть внутренние результаты, соответствующие запросу, укажите параметр inner_hits:
GET /testindex/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"match": {
"patient.name": "John"
}
},
"inner_hits": {}
}
}
}
Ответ содержит дополнительное поле inner_hits. Поле _nested идентифицирует конкретный внутренний объект, из которого произошел внутренний результат. Оно содержит вложенный результат и смещение относительно его положения в _source. Из-за сортировки и оценки положение объектов результатов во inner_hits часто отличается от их исходного местоположения во вложенном объекте.
По умолчанию _source объектов результатов внутри inner_hits возвращается относительно поля _nested. В этом примере _source внутри inner_hits содержит поля name и age, в отличие от верхнего уровня _source, который содержит весь объект пациента:
{
"took": 38,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.2876821,
"_source": {
"patient": {
"name": "John Doe",
"age": 56
}
},
"inner_hits": {
"patient": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_nested": {
"field": "patient",
"offset": 0
},
"_score": 0.2876821,
"_source": {
"name": "John Doe",
"age": 56
}
}
]
}
}
}
}
]
}
}
Многоуровневые вложенные запросы
Вы можете искать документы, которые содержат вложенные объекты внутри других вложенных объектов, используя многоуровневые вложенные запросы. В этом примере вы будете запрашивать несколько уровней вложенных полей, указывая вложенный запрос для каждого уровня иерархии.
Создание индекса с многоуровневыми вложенными полями
Сначала создайте индекс с многоуровневыми вложенными полями:
PUT /patients
{
"mappings": {
"properties": {
"patient": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"contacts": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"relationship": {
"type": "text"
},
"phone": {
"type": "keyword"
}
}
}
}
}
}
}
}
Индексация документа
Далее, индексируйте документ в пример индекса:
PUT /patients/_doc/1
{
"patient": {
"name": "John Doe",
"contacts": [
{
"name": "Jane Doe",
"relationship": "mother",
"phone": "5551111"
},
{
"name": "Joe Doe",
"relationship": "father",
"phone": "5552222"
}
]
}
}
Поиск по вложенному полю пациента
Чтобы выполнить поиск по вложенному полю пациента, используйте многоуровневый вложенный запрос. Следующий запрос ищет пациентов, чья контактная информация включает человека по имени Джейн с отношением “мать”:
GET /patients/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"nested": {
"path": "patient.contacts",
"query": {
"bool": {
"must": [
{ "match": { "patient.contacts.relationship": "mother" } },
{ "match": { "patient.contacts.name": "Jane" } }
]
}
}
}
}
}
}
}
Результаты запроса
Запрос возвращает пациента, у которого есть контактная запись, соответствующая этим данным:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "patients",
"_id": "1",
"_score": 1.3862942,
"_source": {
"patient": {
"name": "John Doe",
"contacts": [
{
"name": "Jane Doe",
"relationship": "mother",
"phone": "5551111"
},
{
"name": "Joe Doe",
"relationship": "father",
"phone": "5552222"
}
]
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые вложенными запросами.
| Параметр |
Обязательный/Необязательный |
Описание |
| path |
Обязательный |
Указывает путь к вложенному объекту, который вы хотите искать. |
| query |
Обязательный |
Запрос, который будет выполнен на вложенных объектах в указанном пути. Если вложенный объект соответствует запросу, возвращается корневой родительский документ. Вы можете искать вложенные поля, используя нотацию с точками, например, nested_object.subfield. Поддерживается многоуровневое вложение, которое автоматически определяется. Таким образом, внутренний вложенный запрос внутри другого вложенного запроса автоматически соответствует правильному уровню вложенности, а не корню. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неразмеченные поля пути и не возвращать документы вместо того, чтобы вызывать ошибку. Вы можете указать этот параметр при запросе нескольких индексов, некоторые из которых могут не содержать поле пути. По умолчанию значение - false. |
| score_mode |
Необязательный |
Определяет, как оценки соответствующих внутренних документов влияют на оценку родительского документа. Допустимые значения:
- avg: Использует среднюю релевантность всех соответствующих внутренних документов.
- max: Присваивает наивысшую релевантность из соответствующих внутренних документов родителю.
- min: Присваивает наименьшую релевантность из соответствующих внутренних документов родителю.
- sum: Суммирует релевантности всех соответствующих внутренних документов.
- none: Игнорирует релевантности внутренних документов и присваивает оценку 0 родительскому документу. По умолчанию - avg. |
| inner_hits |
Необязательный |
Если указан, возвращает внутренние результаты, которые соответствуют запросу. |
3.7.4 - Запрос по идентификатору родителя
апрос parent_id возвращает дочерние документы, у которых родительский документ имеет указанный идентификатор.
Запрос parent_id возвращает дочерние документы, у которых родительский документ имеет указанный идентификатор. Вы можете установить отношения родитель/дочерний между документами в одном индексе, используя тип поля join.
Пример
Перед тем как выполнить запрос parent_id, ваш индекс должен содержать поле join, чтобы установить отношения родитель/дочерний. Запрос на создание индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
Для этого примера сначала настройте индекс, который содержит документы, представляющие продукты и их бренды, как описано в примере запроса has_child.
Чтобы искать дочерние документы конкретного родительского документа, используйте запрос parent_id. Следующий запрос возвращает дочерние документы (продукты), у которых родительский документ имеет идентификатор 1:
GET testindex1/_search
{
"query": {
"parent_id": {
"type": "product",
"id": "1"
}
}
}
Ответ возвращает дочерний продукт:
{
"took": 57,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.87546873,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 0.87546873,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами parent_id.
| Параметр |
Обязательный/Необязательный |
Описание |
| type |
Обязательный |
Указывает имя дочерней связи, как определено в сопоставлении поля join. |
| id |
Обязательный |
Идентификатор родительского документа. Запрос возвращает дочерние документы, связанные с этим родительским документом. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неразмеченные поля типа и не возвращать документы вместо того, чтобы вызывать ошибку. Вы можете указать этот параметр при запросе нескольких индексов, некоторые из которых могут не содержать поле типа. По умолчанию значение - false. |
3.8 - Запросы Span
Запросы Span являются низкоуровневыми, специфическими запросами, которые предоставляют контроль над порядком и близостью указанных терминов запроса.
Вы можете использовать запросы Span для выполнения точных позиционных поисков. Запросы Span являются низкоуровневыми, специфическими запросами, которые предоставляют контроль над порядком и близостью указанных терминов запроса. Они в основном используются для поиска юридических документов и патентов.
Запросы Span включают следующие типы запросов:
Span containing
Возвращает более крупные диапазоны, которые содержат меньшие диапазоны внутри них. Полезно для поиска конкретных терминов или фраз в более широком контексте. Противоположность запросу span_within.
Span field masking
Позволяет запросам Span работать с различными полями, заставляя одно поле выглядеть как другое. Особенно полезно, когда один и тот же текст индексируется с использованием различных анализаторов.
Span first
Совпадает с терминами или фразами, которые появляются в пределах указанного количества позиций от начала поля. Полезно для поиска контента в начале текста.
Span multi-term
Позволяет многотерминным запросам (таким как префиксные, с подстановочными знаками или нечеткие) работать в рамках запросов Span. Позволяет использовать более гибкие шаблоны соответствия в поисках Span.
Span near
Находит термины или фразы, которые появляются на указанном расстоянии друг от друга. Вы можете требовать, чтобы совпадения появлялись в определенном порядке и контролировать, сколько слов может находиться между ними.
Span not
Исключает совпадения, которые пересекаются с другим запросом Span. Полезно для поиска терминов, когда они не появляются в конкретных фразах или контекстах.
Span or
Совпадает с документами, которые удовлетворяют любому из предоставленных запросов Span. Объединяет несколько шаблонов Span с логикой OR.
Span term
Основной строительный блок для запросов Span. Совпадает с одним термином, сохраняя информацию о позиции для использования в других запросах Span.
Span within
Возвращает меньшие диапазоны, которые заключены в более крупные диапазоны. Противоположность запросу span_containing.
Настройка
Чтобы попробовать примеры в этом разделе, выполните следующие шаги для настройки примера индекса.
Шаг 1: Создание индекса
Сначала создайте индекс для веб-сайта электронной коммерции по продаже одежды. Поле описания использует стандартный анализатор по умолчанию, в то время как подполе description.stemmed применяет английский анализатор для включения стемминга:
PUT /clothing
{
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "standard",
"fields": {
"stemmed": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Шаг 2: Индексация данных
Индексиуйте образцы документов в индекс:
POST /clothing/_doc/1
{
"description": "Рубашка с длинными рукавами и формальным воротником с пуговицами."
}
POST /clothing/_doc/2
{
"description": "Красивое длинное платье из красного шелка, идеально подходит для формальных мероприятий."
}
POST /clothing/_doc/3
{
"description": "Рубашка с короткими рукавами и воротником на пуговицах, можно носить как в повседневном, так и в формальном стиле."
}
POST /clothing/_doc/4
{
"description": "Комплект из двух шелковых платьев-рубашек миди с длинными рукавами черного цвета."
}
3.8.1 - Запрос Span containing
Запрос span_containing находит совпадения, где более крупный текстовый шаблон (например, фраза или набор слов) содержит меньший текстовый шаблон в своих границах.
Рассматривайте это как поиск слова или фразы, но только когда они появляются в определенном более широком контексте.
Например, вы можете использовать запрос span_containing для выполнения следующих поисков:
- Найти слово “quick”, но только когда оно появляется в предложениях, которые упоминают как лисиц, так и поведение.
- Убедиться, что определенные термины появляются в контексте других терминов — не просто где-то в документе.
- Искать конкретные слова, которые появляются в рамках более значимых фраз.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет вхождения слова “red”, которые появляются в более крупном диапазоне, содержащем слова “silk” и “dress” (не обязательно в этом порядке) в пределах 5 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_containing": {
"little": {
"span_term": {
"description": "red"
}
},
"big": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "silk"
}
},
{
"span_term": {
"description": "dress"
}
}
],
"slop": 5,
"in_order": false
}
}
}
}
}
Запрос соответствует документу 1, потому что:
- Он находит диапазон, в котором “silk” и “dress” появляются на расстоянии не более 5 слов друг от друга ("…dress in red silk…"). Термины “silk” и “dress” находятся на расстоянии 2 слов друг от друга (между ними 2 слова).
- Внутри этого более крупного диапазона он находит термин “red”.
Ответ
Оба параметра little и big могут содержать любой тип запроса span, что позволяет создавать сложные вложенные запросы span при необходимости.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_containing. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| little |
Объект |
Запрос span, который должен быть содержим внутри большого диапазона. Это определяет диапазон, который вы ищете в более широком контексте. |
| big |
Объект |
Содержащий запрос span, который определяет границы, в пределах которых должен появиться маленький диапазон. Это устанавливает контекст для вашего поиска. |
3.8.2 - Запрос Span field masking
Запрос field_masking_span позволяет запросам Span соответствовать различным полям, “маскируя” истинное поле запроса.
Это особенно полезно при работе с многопольными индексами (один и тот же контент индексируется с использованием различных анализаторов) или когда вам нужно выполнять запросы Span, такие как span_near или span_or, по различным полям (что обычно не разрешено).
Например, вы можете использовать запрос field_masking_span для:
- Совпадения терминов между сырым полем и его стеммированной версией.
- Объединения запросов Span по различным полям в одной операции Span.
- Работы с одним и тем же контентом, индексированным с использованием различных анализаторов.
При использовании маскирования поля релевантность рассчитывается с использованием характеристик (норм) маскированного поля, а не фактического поля, по которому выполняется поиск. Это означает, что если маскированное поле имеет другие свойства (например, длину или значения увеличения), чем поле, по которому выполняется поиск, вы можете получить неожиданные результаты оценки.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “long” рядом с вариациями слова “sleeve” в стеммированном поле:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "long"
}
},
{
"field_masking_span": {
"query": {
"span_term": {
"description.stemmed": "sleev"
}
},
"field": "description"
}
}
],
"slop": 1,
"in_order": true
}
}
}
Запрос соответствует документам 1 и 4:
- Термин “long” появляется в поле описания в обоих документах.
- Документ 1 содержит слово “sleeved”, а документ 4 содержит слово “sleeves”.
- Запрос field_masking_span делает так, что совпадение стеммированного поля выглядит так, как будто оно находится в сыром поле.
- Термины появляются на расстоянии 1 позиции друг от друга в указанном порядке (“long” должен появляться перед “sleeve”).
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.7444251,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 0.7444251,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.4291246,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами field_masking_span. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| query |
Объект |
Запрос span, который будет выполнен на фактическом поле. |
| field |
Строка |
Имя поля, используемое для маскирования запроса. Другие запросы span будут рассматривать этот запрос так, как будто он выполняется на этом поле. |
3.8.3 - Запрос Span first
Запрос span_first соответствует диапазонам, которые начинаются в начале поля и заканчиваются в пределах указанного количества позиций.
Этот запрос полезен, когда вы хотите найти термины или фразы, которые появляются в начале документа.
Например, вы можете использовать запрос span_first для выполнения следующих поисков:
- Найти документы, в которых определенные термины появляются в первых нескольких словах поля.
- Убедиться, что определенные фразы встречаются в начале текста или рядом с ним.
- Совпадать с шаблонами только тогда, когда они появляются в пределах указанного расстояния от начала.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет стеммированное слово “dress”, которое появляется в первых 4 позициях поля описания:
GET /clothing/_search
{
"query": {
"span_first": {
"match": {
"span_term": {
"description.stemmed": "dress"
}
},
"end": 4
}
}
}
Запрос соответствует документам 1 и 2:
- Документы 1 и 2 содержат слово “dress” на третьей позиции (“Long-sleeved dress…” и “Beautiful long dress”). Индексация слов начинается с 0, поэтому слово “dress” находится на позиции 2.
- Позиция слова “dress” должна быть меньше 4, как указано в параметре end.
Ответ
Параметр match может содержать любой тип запроса span, что позволяет сопоставлять более сложные шаблоны в начале полей.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_first. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| match |
Объект |
Запрос span для соответствия. Это определяет шаблон, который вы ищете в начале поля. |
| end |
Целое число |
Максимальная конечная позиция (исключительно), разрешенная для совпадения запроса span. Например, end: 4 соответствует терминам на позициях 0–3. |
3.8.4 - Запрос Span multi-term
Запрос span_multi позволяет обернуть многотерминный запрос (например, с подстановочными знаками, нечеткий, префиксный, диапазонный или регулярное выражение) в запрос Span.
Это позволяет использовать более гибкие запросы соответствия внутри других запросов Span.
Например, вы можете использовать запрос span_multi для:
- Поиска слов с общими префиксами рядом с другими терминами.
- Совпадения нечетких вариаций слов в пределах диапазонов.
- Использования регулярных выражений в запросах Span.
Запросы span_multi могут потенциально соответствовать многим терминам. Чтобы избежать чрезмерного использования памяти, вы можете:
- Установить параметр rewrite для многотерминного запроса.
- Использовать метод переписывания top_terms_*.
- Рассмотреть возможность включения опции index_prefixes для текстового поля, если вы используете span_multi только для префиксного запроса. Это автоматически переписывает любой префиксный запрос на поле в однотерминный запрос, который соответствует индексированному префиксу.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Запрос span_multi использует следующую синтаксис для обертывания префиксного запроса:
"span_multi": {
"match": {
"prefix": {
"description": {
"value": "flutter"
}
}
}
}
Следующий запрос ищет слова, начинающиеся с “dress”, рядом с любой формой “sleeve” в пределах 5 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_multi": {
"match": {
"prefix": {
"description": {
"value": "dress"
}
}
}
}
},
{
"field_masking_span": {
"query": {
"span_term": {
"description.stemmed": "sleev"
}
},
"field": "description"
}
}
],
"slop": 5,
"in_order": false
}
}
}
Запрос соответствует документам 1 (“Long-sleeved dress…”) и 4 ("…dresses with long fluttered sleeves…"), потому что “dress” и “long” встречаются в пределах максимального расстояния в обоих документах.
Ответ
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.7590723,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 1.7590723,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.84792376,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_multi. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| match |
Объект |
Многотерминный запрос для обертывания (может быть префиксным, с подстановочными знаками, нечетким, диапазонным или регулярным выражением). |
3.8.5 - Запрос Span near
Запрос span_near соответствует диапазонам, которые находятся близко друг к другу.
Вы можете указать, насколько далеко могут находиться диапазоны и нужно ли, чтобы они появлялись в определенном порядке.
Например, вы можете использовать запрос span_near для:
- Поиска терминов, которые появляются на определенном расстоянии друг от друга.
- Совпадения фраз, в которых слова появляются в определенном порядке.
- Поиска связанных концепций, которые находятся близко друг к другу в тексте.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет любые формы слова “sleeve” и “long”, которые появляются рядом друг с другом в любом порядке:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_term": {
"description.stemmed": "sleev"
}
},
{
"span_term": {
"description.stemmed": "long"
}
}
],
"slop": 1,
"in_order": false
}
}
}
Запрос соответствует документам 1 (“Long-sleeved…”) и 2 ("…long fluttered sleeves…"). В документе 1 слова находятся рядом друг с другом, в то время как в документе 2 они находятся в пределах указанного расстояния slop равного 1 (между ними 1 слово).
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.36496973,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 0.36496973,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.25312424,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Запрос span_near позволяет находить термины и фразы, которые имеют определенные отношения по близости и порядку, что делает его полезным для анализа текстов и поиска связанных понятий.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_near.
| Параметр |
Тип данных |
Описание |
| clauses |
Массив |
Массив запросов span, которые определяют термины или фразы для соответствия. Все указанные термины должны появляться в пределах заданного расстояния slop. Обязательный параметр. |
| slop |
Целое число |
Максимальное количество промежуточных несоответствующих позиций между диапазонами. Обязательный параметр. |
| in_order |
Логический |
Указывает, должны ли диапазоны появляться в том же порядке, что и в массиве clauses. Необязательный параметр. По умолчанию false. |
3.8.6 - span_not
Запрос Span not
Запрос span_not исключает диапазоны, которые пересекаются с другим запросом span. Вы также можете указать расстояние до или после исключенных диапазонов, в пределах которого совпадения не могут происходить.
Например, вы можете использовать запрос span_not для:
- Поиска терминов, кроме тех случаев, когда они появляются в определенных фразах.
- Совпадения диапазонов, если они не находятся рядом с определенными терминами.
- Исключения совпадений, которые происходят в пределах определенного расстояния от других шаблонов.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “dress”, но не когда оно появляется в фразе “dress shirt”:
GET /clothing/_search
{
"query": {
"span_not": {
"include": {
"span_term": {
"description": "dress"
}
},
"exclude": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "dress"
}
},
{
"span_term": {
"description": "shirt"
}
}
],
"slop": 0,
"in_order": true
}
}
}
}
}
Запрос соответствует документу 2, потому что он содержит слово “dress” (“Beautiful long dress…”). Документ 1 не соответствует, потому что он содержит фразу “dress shirt”, которая исключена. Документы 3 и 4 не соответствуют, потому что они содержат вариации слова “dress” (“dressed” и “dresses”), а запрос ищет в сыром поле.
Ответ
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_not.
| Параметр |
Тип данных |
Описание |
| include |
Объект |
Запрос span, совпадения которого вы хотите найти. Обязательный параметр. |
| exclude |
Объект |
Запрос span, совпадения которого должны быть исключены. Обязательный параметр. |
| pre |
Целое число |
Указывает, что исключенный диапазон не может появляться в пределах указанного количества позиций токенов перед включенным диапазоном. Необязательный параметр. По умолчанию 0. |
| post |
Целое число |
Указывает, что исключенный диапазон не может появляться в пределах указанного количества позиций токенов после включенного диапазона. Необязательный параметр. По умолчанию 0. |
| dist |
Целое число |
Эквивалентно установке как pre, так и post на одно и то же значение. Необязательный параметр. |
3.8.7 - Запрос Span or
Запрос span_or объединяет несколько запросов span и соответствует объединению их диапазонов.
Совпадение происходит, если хотя бы один из содержащихся запросов span соответствует.
Например, вы можете использовать запрос span_or для:
- Поиска диапазонов, соответствующих любому из нескольких шаблонов.
- Объединения различных шаблонов span в качестве альтернатив.
- Совпадения нескольких вариаций span в одном запросе.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет либо “formal collar”, либо “button collar”, которые появляются в пределах 2 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_or": {
"clauses": [
{
"span_near": {
"clauses": [
{
"span_term": {
"description": "formal"
}
},
{
"span_term": {
"description": "collar"
}
}
],
"slop": 0,
"in_order": true
}
},
{
"span_near": {
"clauses": [
{
"span_term": {
"description": "button"
}
},
{
"span_term": {
"description": "collar"
}
}
],
"slop": 2,
"in_order": true
}
}
]
}
}
}
Запрос соответствует документам 1 ("…formal collar…") и 3 ("…button-down collar…") в пределах указанного расстояния slop.
Ответ
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.170027,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 2.170027,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "3",
"_score": 1.2509141,
"_source": {
"description": "Short-sleeved shirt with a button-down collar, can be dressed up or down."
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_or.
| Параметр |
Тип данных |
Описание |
| clauses |
Массив |
Массив запросов span для соответствия. Запрос соответствует, если любой из этих запросов span совпадает. Должен содержать как минимум один запрос span. Обязательный параметр. |
3.8.8 - Запрос Span term
Запрос span_term является самым базовым запросом span, который соответствует диапазонам, содержащим один термин.
Он служит строительным блоком для более сложных запросов span.
Например, вы можете использовать запрос span_term для:
- Поиска точных совпадений термина, которые могут быть использованы в других запросах span.
- Совпадения конкретных слов с сохранением информации о позиции.
- Создания базовых диапазонов, которые могут быть объединены с другими запросами span.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет точный термин “formal”:
GET /clothing/_search
{
"query": {
"span_term": {
"description": "formal"
}
}
}
В качестве альтернативы вы можете указать искомый термин в параметре value:
GET /clothing/_search
{
"query": {
"span_term": {
"description": {
"value": "formal"
}
}
}
}
Вы также можете указать значение boost, чтобы увеличить оценку документа:
GET /clothing/_search
{
"query": {
"span_term": {
"description": {
"value": "formal",
"boost": 2
}
}
}
}
Запрос соответствует документам 1 и 2, потому что они содержат точный термин “formal”. Информация о позиции сохраняется для использования в других запросах span.
Ответ
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.498922,
"hits": [
{
"_index": "clothing",
"_id": "2",
"_score": 1.498922,
"_source": {
"description": "Beautiful long dress in red silk, perfect for formal events."
}
},
{
"_index": "clothing",
"_id": "1",
"_score": 1.4466847,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_term.
| Параметр |
Тип данных |
Описание |
|
Строка или объект |
Имя поля, в котором нужно выполнить поиск. |
3.8.9 - Запрос Span within
Запрос span_within соответствует диапазонам, которые заключены в другой запрос span.
Это противоположность запросу span_containing: span_containing возвращает более крупные диапазоны, содержащие меньшие, в то время как span_within возвращает меньшие диапазоны, заключенные в более крупные.
Например, вы можете использовать запрос span_within для:
- Поиска более коротких фраз, которые появляются внутри более длинных фраз.
- Совпадения терминов, которые встречаются в определенных контекстах.
- Идентификации меньших шаблонов, заключенных в более крупные шаблоны.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “dress”, когда оно появляется внутри диапазона, содержащего “shirt” и “long”:
GET /clothing/_search
{
"query": {
"span_within": {
"little": {
"span_term": {
"description": "dress"
}
},
"big": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "shirt"
}
},
{
"span_term": {
"description": "long"
}
}
],
"slop": 2,
"in_order": false
}
}
}
}
}
Запрос соответствует документу 1, потому что:
- Слово “dress” появляется внутри более крупного диапазона (“Long-sleeved dress shirt…”).
- Более крупный диапазон содержит “shirt” и “long” в пределах 2 слов друг от друга (между ними 2 слова).
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.4677674,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 1.4677674,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_within. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| little |
Объект |
Запрос span, который должен быть содержим внутри большого диапазона. Это определяет диапазон, который вы ищете в более широком контексте. |
| big |
Объект |
Содержащий запрос span, который определяет границы, в пределах которых должен появиться маленький диапазон. Это устанавливает контекст для вашего поиска. |
3.9 - Запрос Match all
Запрос match_all возвращает все документы. Этот запрос может быть полезен для тестирования больших наборов документов, если вам нужно вернуть весь набор.
GET _search
{
"query": {
"match_all": {}
}
}
Запрос match_all имеет аналог match_none, который редко бывает полезен:
GET _search
{
"query": {
"match_none": {}
}
}
Параметры
Оба запроса match_all и match_none принимают следующие параметры. Все параметры являются необязательными.
| Параметр |
Тип данных |
Описание |
| boost |
Число с плавающей запятой |
Значение с плавающей запятой, которое указывает на вес этого поля в отношении оценки релевантности. Значения выше 1.0 увеличивают релевантность поля. Значения от 0.0 до 1.0 уменьшают релевантность поля. По умолчанию 1.0. |
| _name |
Строка |
Имя запроса для тегирования запроса. Необязательный параметр. |
3.10 - Специализированные запросы
OpenSearch поддерживает следующие специализированные запросы: distance_feature, more_like_this и др.
-
distance_feature: Вычисляет оценки документов на основе динамически рассчитанного расстояния между исходной точкой и полями даты, date_nanos или geo_point документа. Этот запрос может пропускать неконкурентные результаты.
-
more_like_this: Находит документы, похожие на предоставленный текст, документ или коллекцию документов.
-
knn: Используется для поиска сырых векторов во время векторного поиска.
-
neural: Используется для поиска по тексту или изображению в векторном поиске.
-
neural_sparse: Используется для поиска по векторным полям в разреженном нейронном поиске.
-
percolate: Находит запросы (сохраненные в виде документов), которые соответствуют предоставленному документу.
-
rank_feature: Вычисляет оценки на основе значений числовых признаков. Этот запрос может пропускать неконкурентные результаты.
-
script: Использует скрипт в качестве фильтра.
-
script_score: Вычисляет пользовательскую оценку для соответствующих документов с использованием скрипта.
-
wrapper: Принимает другие запросы в виде строк JSON или YAML.
3.10.1 - distance_feature
distance_feature для увеличения релевантности документов, которые ближе к определенной дате или географической точке.
Используйте запрос distance_feature для увеличения релевантности документов, которые ближе к определенной дате или географической точке. Это может помочь вам приоритизировать более свежий или близкий контент в результатах поиска. Например, вы можете присвоить больший вес продуктам, произведенным более недавно, или повысить рейтинг товаров, находящихся ближе к указанному пользователем местоположению.
Вы можете применять этот запрос к полям, содержащим данные о дате или местоположении. Он часто используется в условии should запроса bool для улучшения оценки релевантности без фильтрации результатов.
Настройка индекса
Перед использованием запроса distance_feature убедитесь, что ваш индекс содержит хотя бы один из следующих типов полей:
- date
- date_nanos
- geo_point
В этом примере вы настроите поля opening_date и coordinates, которые можно использовать для выполнения запросов distance_feature:
PUT /stores
{
"mappings": {
"properties": {
"opening_date": {
"type": "date"
},
"coordinates": {
"type": "geo_point"
}
}
}
}
Добавьте пример документов в индекс:
PUT /stores/_doc/1
{
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [74.00, 40.70]
}
PUT /stores/_doc/2
{
"store_name": "Fresh Foods",
"opening_date": "2025-04-01",
"coordinates": [73.98, 40.75]
}
PUT /stores/_doc/3
{
"store_name": "City Organics",
"opening_date": "2021-04-20",
"coordinates": [74.02, 40.68]
}
Пример: Увеличение оценок на основе свежести
Следующий запрос ищет документы с store_name, соответствующим слову “market”, и увеличивает оценки недавно открытых магазинов:
GET /stores/_search
{
"query": {
"bool": {
"must": {
"match": {
"store_name": "market"
}
},
"should": {
"distance_feature": {
"field": "opening_date",
"origin": "2025-04-07",
"pivot": "10d"
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.2372394,
"hits": [
{
"_index": "stores",
"_id": "1",
"_score": 1.2372394,
"_source": {
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [
74,
40.7
]
}
}
]
}
}
Пример: Увеличение оценок на основе географической близости
Следующий запрос ищет документы с store_name, соответствующим слову “market”, и увеличивает результаты, находящиеся ближе к заданной исходной точке:
GET /stores/_search
{
"query": {
"bool": {
"must": {
"match": {
"store_name": "market"
}
},
"should": {
"distance_feature": {
"field": "coordinates",
"origin": [74.00, 40.71],
"pivot": "500m"
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.2910118,
"hits": [
{
"_index": "stores",
"_id": "1",
"_score": 1.2910118,
"_source": {
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [
74,
40.7
]
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами distance_feature.
| Параметр |
Обязательный/Необязательный |
Описание |
| field |
Обязательный |
Имя поля, используемого для расчета расстояний. Должно быть полем типа date, date_nanos или geo_point с параметрами index: true (по умолчанию) и doc_values: true (по умолчанию). |
| origin |
Обязательный |
Точка отсчета, используемая для расчета расстояний. Используйте дату или математическое выражение даты (например, now-1h) для полей даты или геопункт для полей geo_point. |
| pivot |
Обязательный |
Расстояние от исходной точки, при котором оценки получают половину значения увеличения. Используйте единицу времени (например, 10d) для полей даты или единицу расстояния (например, 1km) для географических полей. Для получения дополнительной информации см. раздел “Единицы”. |
| boost |
Необязательный |
Множитель для оценки релевантности соответствующих документов. Должен быть неотрицательным числом с плавающей запятой. По умолчанию 1.0. |
Как рассчитываются оценки
Запрос distance_feature вычисляет оценку релевантности документа, используя следующую формулу:
[
\text{score} = \text{boost} \cdot \frac {\text{pivot}} {\text{pivot} + \text{distance}}
]
где distance — это абсолютная разница между origin и значением поля.
Пропуск неконкурентных результатов
В отличие от других запросов, модифицирующих оценки, таких как запрос function_score, запрос distance_feature оптимизирован для эффективного пропуска неконкурентных результатов, когда отслеживание общего количества результатов (track_total_hits) отключено. Это позволяет улучшить производительность запросов, особенно при работе с большими объемами данных, так как система может сосредоточиться только на наиболее релевантных результатах.
3.10.2 - k-NN
Используйте запрос k-NN для выполнения поиска ближайших соседей по векторным полям.
Поля тела запроса
Укажите векторное поле в запросе k-NN и задайте дополнительные поля запроса в объекте векторного поля:
"knn": {
"<vector_field>": {
"vector": [<vector_values>],
"k": <k_value>,
...
}
}
Верхний уровень vector_field указывает на векторное поле, по которому будет выполняться запрос поиска. Следующая таблица перечисляет все поддерживаемые поля запроса.
| Поле |
Тип данных |
Обязательный/Необязательный |
Описание |
| vector |
Массив чисел с плавающей запятой или байтов |
Обязательный |
Вектор запроса, используемый для векторного поиска. Тип данных элементов вектора должен соответствовать типу данных векторов, индексированных в поле knn_vector. |
| k |
Целое число |
Необязательный |
Количество ближайших соседей для возврата. Допустимые значения находятся в диапазоне [1, 10,000]. Обязательно, если не указаны max_distance или min_score. |
| max_distance |
Число с плавающей запятой |
Необязательный |
Максимальный порог расстояния для результатов поиска. Можно указать только одно из k, max_distance или min_score. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| min_score |
Число с плавающей запятой |
Необязательный |
Минимальный порог оценки для результатов поиска. Можно указать только одно из k, max_distance или min_score. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| filter |
Объект |
Необязательный |
Фильтр, который применяется к поиску k-NN. Для получения дополнительной информации см. раздел “Векторный поиск с фильтрами”. Важно: фильтр можно использовать только с движками faiss или lucene. |
| method_parameters |
Объект |
Необязательный |
Дополнительные параметры для тонкой настройки поиска:
- ef_search (Целое число): количество векторов для проверки (для метода hnsw)
- nprobes (Целое число): количество корзин для проверки (для метода ivf). Для получения дополнительной информации см. раздел “Указание параметров метода в запросе”. |
| rescore |
Объект или логическое значение |
Необязательный |
Параметры для настройки функциональности повторной оценки:
- oversample_factor (Число с плавающей запятой): контролирует, сколько кандидатных векторов извлекается перед повторной оценкой. Допустимые значения находятся в диапазоне [1.0, 100.0]. По умолчанию false для полей с режимом in_memory (без повторной оценки) и включено (с динамическими значениями) для полей с режимом on_disk. В режиме on_disk значение по умолчанию для oversample_factor определяется уровнем сжатия. Для получения дополнительной информации см. таблицу уровня сжатия. Чтобы явно включить повторную оценку с значением по умолчанию для oversample_factor равным 1.0, установите rescore в true. Для получения дополнительной информации см. раздел “Повторная оценка результатов”. |
| expand_nested_docs |
Логическое значение |
Необязательный |
Если true, извлекает оценки для всех документов вложенных полей в каждом родительском документе. Используется с вложенными запросами. Для получения дополнительной информации см. раздел “Векторный поиск с вложенными полями”. |
Пример запроса
Запрос для выполнения поиска ближайших соседей:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [1.5, 2.5],
"k": 3
}
}
}
}
Пример запроса: Вложенные поля
Запрос для выполнения поиска ближайших соседей во вложенных полях:
GET /my-vector-index/_search
{
"_source": false,
"query": {
"nested": {
"path": "nested_field",
"query": {
"knn": {
"nested_field.my_vector": {
"vector": [1, 1, 1],
"k": 2,
"expand_nested_docs": true
}
}
},
"inner_hits": {
"_source": false,
"fields": ["nested_field.color"]
},
"score_mode": "max"
}
}
}
Пример запроса: Радиальный поиск с max_distance
Следующий пример демонстрирует радиальный поиск с использованием max_distance:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [
7.1,
8.3
],
"max_distance": 2
}
}
}
}
Пример запроса: Радиальный поиск с min_score
Следующий пример демонстрирует радиальный поиск с использованием min_score:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [7.1, 8.3],
"min_score": 0.95
}
}
}
}
Указание параметров метода в запросе
Начиная с версии 2.16, вы можете предоставлять параметры метода в запросе поиска:
GET /my-vector-index/_search
{
"size": 2,
"query": {
"knn": {
"target-field": {
"vector": [2, 3, 5, 6],
"k": 2,
"method_parameters": {
"ef_search": 100
}
}
}
}
}
Эти параметры зависят от комбинации движка и метода, использованных для создания индекса. Следующие разделы предоставляют информацию о поддерживаемых параметрах метода.
ef_search
Вы можете указать параметр ef_search при поиске в индексе, созданном с использованием метода hnsw. Параметр ef_search указывает количество векторов, которые необходимо проверить для нахождения k ближайших соседей. Более высокие значения ef_search улучшают полноту поиска за счет увеличения задержки поиска. Значение должно быть положительным.
Следующая таблица предоставляет информацию о параметре ef_search для поддерживаемых движков.
| Движок |
Поддержка радиального запроса |
Примечания |
| nmslib (устаревший) |
Нет |
Если ef_search присутствует в запросе, он переопределяет настройку index.knn.algo_param.ef_search индекса. |
| faiss |
Да |
Если ef_search присутствует в запросе, он переопределяет настройку index.knn.algo_param.ef_search индекса. |
| lucene |
Нет |
При создании поискового запроса необходимо указать k. Если вы укажете и k, и ef_search, то будет передано большее значение. Если ef_search больше k, вы можете указать параметр size, чтобы ограничить окончательное количество результатов до k. |
nprobes
Вы можете указать параметр nprobes при поиске в индексе, созданном с использованием метода ivf. Параметр nprobes указывает количество корзин, которые необходимо проверить для нахождения k ближайших соседей. Более высокие значения nprobes улучшают полноту поиска за счет увеличения задержки поиска. Значение должно быть положительным.
Следующая таблица предоставляет информацию о параметре nprobes для поддерживаемых движков.
| Движок |
Примечания |
| faiss |
Если nprobes присутствует в запросе, он переопределяет значение, указанное при создании индекса. |
Повторная оценка результатов
Вы можете тонко настроить поиск, предоставив параметры ef_search и oversample_factor.
Параметр oversample_factor контролирует фактор, на который поиск увеличивает количество кандидатных векторов перед их ранжированием. Использование более высокого значения oversample_factor означает, что больше кандидатов будет рассмотрено перед ранжированием, что улучшает точность, но также увеличивает время поиска. При выборе значения oversample_factor учитывайте компромисс между точностью и эффективностью. Например, установка oversample_factor на 2.0 удвоит количество кандидатов, рассматриваемых на этапе ранжирования, что может помочь достичь лучших результатов.
Следующий запрос указывает параметры ef_search и oversample_factor:
GET /my-vector-index/_search
{
"size": 2,
"query": {
"knn": {
"my_vector_field": {
"vector": [1.5, 5.5, 1.5, 5.5, 1.5, 5.5, 1.5, 5.5],
"k": 10,
"method_parameters": {
"ef_search": 10
},
"rescore": {
"oversample_factor": 10.0
}
}
}
}
}
3.10.3 - k-NN explain
При включении этот параметр предоставляет подробную информацию о процессе оценки для каждого результата поиска.
Запрос k-NN: Параметр explain
С версии 3.0 вы можете использовать параметр explain, чтобы понять, как рассчитываются, нормализуются и комбинируются оценки в запросах k-NN. При включении этот параметр предоставляет подробную информацию о процессе оценки для каждого результата поиска. Это включает в себя раскрытие используемых техник нормализации оценок, способы комбинирования различных оценок и расчеты для индивидуальных подзапросов. Этот всесторонний анализ упрощает понимание и оптимизацию результатов ваших запросов k-NN. Для получения дополнительной информации о параметре explain смотрите раздел API объяснения.
Обратите внимание, что использование параметра explain является ресурсоемкой операцией как по времени, так и по ресурсам. Для производственных кластеров рекомендуется использовать его экономно, в основном для устранения неполадок.
Использование параметра explain
Вы можете указать параметр explain в URL при выполнении полного запроса k-NN для движка Faiss, используя следующий синтаксис:
GET <index>/_search?explain=true
POST <index>/_search?explain=true
Для поиска k-NN с использованием движка Lucene параметр explain не возвращает подробное объяснение, как это делает движок Faiss.
Поддерживаемые типы запросов с параметром explain для движка Faiss:
- Приблизительный поиск k-NN
- Приблизительный поиск k-NN с точным поиском
- Поиск на диске
- Поиск k-NN с эффективной фильтрацией
- Радиальный поиск
- Поиск k-NN с термовым запросом
Для поиска k-NN с вложенными полями параметр explain не возвращает подробное объяснение, как это происходит с другими запросами.
Примеры использования параметра explain
Вы можете указать параметр explain как параметр запроса:
GET my-knn-index/_search?explain=true
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3, 5, 7],
"k": 2
}
}
}
}
Или вы можете указать параметр explain в теле запроса:
GET my-knn-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3, 5, 7],
"k": 2
}
}
},
"explain": true
}
Пример: Приблизительный поиск k-NN
{
"took": 216038,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 88.4,
"hits": [
{
"_shard": "[my-knn-index-1][0]",
"_node": "VHcyav6OTsmXdpsttX2Yug",
"_index": "my-knn-index-1",
"_id": "5",
"_score": 88.4,
"_source": {
"my_vector1": [
2.5,
3.5,
5.5,
7.4
],
"price": 8.9
},
"_explanation": {
"value": 88.4,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 88.4,
"description": "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details": [
{
"value": -87.4,
"description": "rawScore, returned from FAISS library",
"details": []
}
]
}
]
}
},
{
"_shard": "[my-knn-index-1][0]",
"_node": "VHcyav6OTsmXdpsttX2Yug",
"_index": "my-knn-index-1",
"_id": "2",
"_score": 84.7,
"_source": {
"my_vector1": [
2.5,
3.5,
5.6,
6.7
],
"price": 5.5
},
"_explanation": {
"value": 84.7,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 84.7,
"description": "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details": [
{
"value": -83.7,
"description": "rawScore, returned from FAISS library",
"details": []
}
]
}
]
}
}
]
}
}
Пример: Приблизительный поиск k-NN с точным поиском
{
"took": 87,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 84.7,
"hits": [
{
"_shard": "[my-knn-index-1][0]",
"_node": "MQVux8dZRWeznuEYKhMq0Q",
"_index": "my-knn-index-1",
"_id": "7",
"_score": 84.7,
"_source": {
"my_vector2": [
2.5,
3.5,
5.6,
6.7
],
"price": 5.5
},
"_explanation": {
"value": 84.7,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 84.7,
"description": "the type of knn search executed at leaf was Exact with spaceType = INNER_PRODUCT, vectorDataType = FLOAT, queryVector = [2.0, 3.0, 5.0, 6.0]",
"details": []
}
]
}
},
{
"_shard": "[my-knn-index-1][0]",
"_node": "MQVux8dZRWeznuEYKhMq0Q",
"_index": "my-knn-index-1",
"_id": "8",
"_score": 82.2,
"_source": {
"my_vector2": [
4.5,
5.5,
6.7,
3.7
],
"price": 4.4
},
"_explanation": {
"value": 82.2,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 82.2,
"description": "the type of knn search executed at leaf was Exact with spaceType = INNER_PRODUCT, vectorDataType = FLOAT, queryVector = [2.0, 3.0, 5.0, 6.0]",
"details": []
}
]
}
}
]
}
Пример: Поиск на диске
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 381.0,
"hits" : [
{
"_shard" : "[my-vector-index][0]",
"_node" : "pLaiqZftTX-MVSKdQSu7ow",
"_index" : "my-vector-index",
"_id" : "9",
"_score" : 381.0,
"_source" : {
"my_vector_field" : [
9.5,
9.5,
9.5,
9.5,
9.5,
9.5,
9.5,
9.5
],
"price" : 8.9
},
"_explanation" : {
"value" : 381.0,
"description" : "the type of knn search executed was Disk-based and the first pass k was 100 with vector dimension of 8, over sampling factor of 5.0, shard level rescoring enabled",
"details" : [
{
"value" : 381.0,
"description" : "the type of knn search executed at leaf was Approximate-NN with spaceType = HAMMING, vectorDataType = FLOAT, queryVector = [1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5]",
"details" : [ ]
}
]
}
}
]
}
}
Пример: поиск k-NN с эффективной фильтрацией
{
"took" : 51,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.8620689,
"hits" : [
{
"_shard" : "[products-shirts][0]",
"_node" : "9epk8WoFT8yvnUI0tAaJgQ",
"_index" : "products-shirts",
"_id" : "8",
"_score" : 0.8620689,
"_source" : {
"item_vector" : [
2.4,
4.0,
3.0
],
"size" : "small",
"rating" : 8
},
"_explanation" : {
"value" : 0.8620689,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 0.8620689,
"description" : "the type of knn search executed at leaf was Exact since filteredIds = 2 is less than or equal to K = 10 with spaceType = L2, vectorDataType = FLOAT, queryVector = [2.0, 4.0, 3.0]",
"details" : [ ]
}
]
}
},
{
"_shard" : "[products-shirts][0]",
"_node" : "9epk8WoFT8yvnUI0tAaJgQ",
"_index" : "products-shirts",
"_id" : "6",
"_score" : 0.029691212,
"_source" : {
"item_vector" : [
6.4,
3.4,
6.6
],
"size" : "small",
"rating" : 9
},
"_explanation" : {
"value" : 0.029691212,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 0.029691212,
"description" : "the type of knn search executed at leaf was Exact since filteredIds = 2 is less than or equal to K = 10 with spaceType = L2, vectorDataType = FLOAT, queryVector = [2.0, 4.0, 3.0]",
"details" : [ ]
}
]
}
}
]
}
}
Пример: Радиальный поиск
GET my-knn-index/_search?explain=true
{
"query": {
"knn": {
"my_vector": {
"vector": [7.1, 8.3],
"max_distance": 2
}
}
}
}
Ответ:
{
"took" : 376529,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.98039204,
"hits" : [
{
"_shard" : "[knn-index-test][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "knn-index-test",
"_id" : "1",
"_score" : 0.98039204,
"_source" : {
"my_vector" : [
7.0,
8.2
],
"price" : 4.4
},
"_explanation" : {
"value" : 0.98039204,
"description" : "the type of knn search executed was Radial with the radius of 2.0",
"details" : [
{
"value" : 0.98039204,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = l2 where score is computed as `1 / (1 + rawScore)` from:",
"details" : [
{
"value" : 0.020000057,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
},
{
"_shard" : "[knn-index-test][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "knn-index-test",
"_id" : "3",
"_score" : 0.9615384,
"_source" : {
"my_vector" : [
7.3,
8.3
],
"price" : 19.1
},
"_explanation" : {
"value" : 0.9615384,
"description" : "the type of knn search executed was Radial with the radius of 2.0",
"details" : [
{
"value" : 0.9615384,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = l2 where score is computed as `1 / (1 + rawScore)` from:",
"details" : [
{
"value" : 0.040000115,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
}
]
}
}
Пример: поиск k-NN с запросом по термину
GET my-knn-index/_search?explain=true
{
"query": {
"bool": {
"should": [
{
"knn": {
"my_vector2": { // vector field name
"vector": [2, 3, 5, 6],
"k": 2
}
}
},
{
"term": {
"price": "4.4"
}
}
]
}
}
}
Ответ:
{
"took" : 51,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 84.7,
"hits" : [
{
"_shard" : "[my-knn-index-1][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "my-knn-index-1",
"_id" : "7",
"_score" : 84.7,
"_source" : {
"my_vector2" : [
2.5,
3.5,
5.6,
6.7
],
"price" : 5.5
},
"_explanation" : {
"value" : 84.7,
"description" : "sum of:",
"details" : [
{
"value" : 84.7,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 84.7,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details" : [
{
"value" : -83.7,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
]
}
},
{
"_shard" : "[my-knn-index-1][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "my-knn-index-1",
"_id" : "8",
"_score" : 83.2,
"_source" : {
"my_vector2" : [
4.5,
5.5,
6.7,
3.7
],
"price" : 4.4
},
"_explanation" : {
"value" : 83.2,
"description" : "sum of:",
"details" : [
{
"value" : 82.2,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 82.2,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details" : [
{
"value" : -81.2,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
},
{
"value" : 1.0,
"description" : "price:[1082969293 TO 1082969293]",
"details" : [ ]
}
]
}
}
]
}
}
Поля ответа
Ответ содержит следующие поля:
- explanation: Объект объяснения, который включает следующие поля:
- value: Содержит результат расчета.
- description: Объясняет, какой тип расчета был выполнен. Для нормализации оценок информация в поле описания включает используемую технику нормализации или комбинации и соответствующую оценку.
- details: Показывает любые подрасчеты, выполненные в процессе.
3.10.4 - neural
Используйте запрос neural для поиска по векторным полям с помощью текста или изображения в векторном поиске.
Поля тела запроса
Включите следующие поля запроса в neural query:
"neural": {
"<vector_field>": {
"query_text": "<query_text>",
"query_image": "<image_binary>",
"model_id": "<model_id>",
"k": 100
}
}
Верхний уровень vector_field указывает на векторное или семантическое поле, по которому будет выполняться запрос поиска. Следующая таблица перечисляет другие поля запроса neural.
| Поле |
Тип данных |
Обязательный/Необязательный |
Описание |
| query_text |
Строка |
Необязательный |
Текст запроса, из которого будут генерироваться векторные эмбеддинги. Необходимо указать хотя бы одно из полей query_text или query_image. |
| query_image |
Строка |
Необязательный |
Строка, закодированная в base-64, соответствующая изображению запроса, из которого будут генерироваться векторные эмбеддинги. Необходимо указать хотя бы одно из полей query_text или query_image. |
| model_id |
Строка |
Необязательный, если целевое поле является семантическим. Обязательно, если целевое поле является полем knn_vector и значение по умолчанию для модели не установлено. |
Идентификатор модели, которая будет использоваться для генерации векторных эмбеддингов из текста запроса. Модель должна быть развернута в OpenSearch перед использованием в нейронном поиске. Не может быть указана вместе с semantic_field_search_analyzer. |
| k |
Целое число |
Необязательный |
Количество результатов, возвращаемых при поиске k-NN. Можно указать только одну переменную: k, min_score или max_distance. Если переменная не указана, по умолчанию используется k со значением 10. |
| min_score |
Число с плавающей запятой |
Необязательный |
Минимальный порог оценки для результатов поиска. Можно указать только одну переменную: k, min_score или max_distance. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| max_distance |
Число с плавающей запятой |
Необязательный |
Максимальный порог расстояния для результатов поиска. Можно указать только одну переменную: k, min_score или max_distance. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| filter |
Объект |
Необязательный |
Запрос, который можно использовать для уменьшения количества рассматриваемых документов. Для получения дополнительной информации о использовании фильтров см. раздел “Векторный поиск с фильтрами”. |
| method_parameters |
Объект |
Необязательный |
Дополнительные параметры для тонкой настройки поиска:
- ef_search (Целое число): количество векторов для проверки (для метода hnsw)
- nprobes (Целое число): количество корзин для проверки (для метода ivf). Для получения дополнительной информации см. раздел “Указание параметров метода в запросе”. |
| rescore |
Объект или логическое значение |
Необязательный |
Параметры для настройки функциональности повторной оценки:
- oversample_factor (Число с плавающей запятой): контролирует, сколько кандидатных векторов извлекается перед повторной оценкой. Допустимые значения находятся в диапазоне [1.0, 100.0]. По умолчанию false для полей с режимом in_memory (без повторной оценки) и включено (с динамическими значениями) для полей с режимом on_disk. В режиме on_disk значение по умолчанию для oversample_factor определяется уровнем сжатия. Для получения дополнительной информации см. таблицу уровня сжатия. Чтобы явно включить повторную оценку с значением по умолчанию для oversample_factor равным 1.0, установите rescore в true. Для получения дополнительной информации см. раздел “Повторная оценка результатов”. |
expand_nested_docs |
Логическое |
Необязательное |
Если установлено в true, извлекает оценки для всех документов вложенных полей в каждом родительском документе. Используется с вложенными запросами. |
semantic_field_search_analyzer |
Строка |
Необязательное |
Указывает анализатор для токенизации query_text при использовании модели разреженного кодирования. Допустимые значения: standard, bert-uncased и mbert-uncased. Не может использоваться вместе с model_id. |
query_tokens |
Карта токенов (строка) к весу (число с плавающей точкой) |
Необязательное |
Сырой разреженный вектор в виде токенов и их весов. Используется в качестве альтернативы query_text для прямого ввода вектора. Необходимо указать либо query_text, либо query_tokens. |
Пример запроса
Следующий пример демонстрирует поиск с значением k равным 100 и фильтром, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"k": 100,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий запрос поиска включает минимальный порог оценки min_score для k-NN радиального поиска, равный 0.95, и фильтр, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"min_score": 0.95,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий запрос поиска включает максимальное расстояние max_distance, равное 10, и фильтр, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"max_distance": 10,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий пример демонстрирует поиск по семантическому полю с использованием плотной модели. Семантическое поле хранит информацию о модели в своей конфигурации. Нейронный запрос автоматически извлекает model_id из конфигурации семантического поля в индексе и переписывает запрос для нацеливания на соответствующее поле эмбеддинга:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage": {
"query_text": "Hi world",
"k": 100
}
}
}
}
Следующий пример демонстрирует поиск по семантическому полю с использованием модели разреженного кодирования. Этот поиск использует разреженные эмбеддинги:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage": {
"query_tokens": {
"worlds": 0.57605183
}
}
}
}
}
Для получения дополнительной информации смотрите тип семантического поля.
3.10.5 - Нейронный разреженный запрос
Используйте нейронный разреженный запрос для поиска по векторному полю в нейронном разреженном поиске.
Вы можете выполнить запрос следующими способами:
- Предоставьте разреженные векторные эмбеддинги для сопоставления. Для получения дополнительной информации смотрите раздел “Нейронный разреженный поиск с использованием сырых векторов”:
"neural_sparse": {
"<vector_field>": {
"query_tokens": {
"<token>": <weight>,
...
}
}
}
- Предоставьте текст для токенизации и использования для сопоставления. Для токенизации текста вы можете использовать следующие компоненты:
- Встроенный анализатор DL модели:
"neural_sparse": {
"<vector_field>": {
"query_text": "<input text>",
"analyzer": "bert-uncased"
}
}
"neural_sparse": {
"<vector_field>": {
"query_text": "<input text>",
"model_id": "<model ID>"
}
}
Для получения дополнительной информации смотрите раздел “Автоматическая генерация разреженных векторных эмбеддингов”.
Поля тела запроса
Верхний уровень vector_field указывает на векторное поле, по которому будет выполняться запрос поиска. Необходимо указать либо query_text, либо query_tokens для определения входных данных. Следующие поля могут быть использованы для настройки запроса:
| Поле |
Тип данных |
Обязательное/Необязательное |
Описание |
query_text |
Строка |
Необязательное |
Текст запроса, который будет преобразован в разреженные векторные эмбеддинги. Необходимо указать либо query_text, либо query_tokens. |
analyzer |
Строка |
Необязательное |
Используется с query_text. Указывает встроенный анализатор DL модели для токенизации текста запроса. Допустимые значения: bert-uncased и mbert-uncased. По умолчанию используется bert-uncased. Не может использоваться одновременно с model_id. |
model_id |
Строка |
Необязательное |
Используется с query_text. Идентификатор модели разреженного кодирования (для режима би-кодировщика) или токенизатора (для режима только документа), используемый для генерации векторных эмбеддингов из текста запроса. Модель/токенизатор должна быть развернута в OpenSearch перед использованием в нейронном разреженном поиске. Не может использоваться одновременно с analyzer. |
query_tokens |
Карта токенов (строка) к весу (число с плавающей точкой) |
Необязательное |
Сырой разреженный вектор в виде токенов и их весов. Используется в качестве альтернативы query_text для прямого ввода вектора. Необходимо указать либо query_text, либо query_tokens. |
max_token_score |
Число с плавающей точкой |
Необязательное (устарело) |
Этот параметр устарел с версии OpenSearch 2.12. Он поддерживается только для обратной совместимости и больше не влияет на функциональность. Параметр все еще может быть указан в запросах, но его значение не имеет значения. Ранее использовался как теоретическая верхняя граница оценки для всех токенов в словаре. |
Примеры запросов
Поиск с использованием текста, токенизированного анализатором
Чтобы выполнить поиск, используя текст, токенизированный анализатором, укажите анализатор в запросе. Анализатор должен быть совместим с моделью, которую вы использовали для анализа текста во время загрузки:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world",
"analyzer": "bert-uncased"
}
}
}
}
Для получения дополнительной информации смотрите раздел “Анализаторы DL модели”.
Поиск с использованием текста без указания анализатора
Если вы не укажете анализатор, будет использован анализатор по умолчанию bert-uncased:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world"
}
}
}
}
Поиск с использованием текста, токенизированного моделью токенизатора
Чтобы выполнить поиск, используя текст, токенизированный моделью токенизатора, укажите идентификатор модели в запросе:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world",
"model_id": "aP2Q8ooBpBj3wT4HVS8a"
}
}
}
}
Поиск с использованием разреженного вектора
Чтобы выполнить поиск, используя разреженный вектор, укажите разреженный вектор в параметре query_tokens:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_tokens": {
"hi": 4.338913,
"planets": 2.7755864,
"planet": 5.0969057,
"mars": 1.7405145,
"earth": 2.6087382,
"hello": 3.3210192
}
}
}
}
}
3.10.6 - Перколяция
Используйте запрос перколяции для поиска сохраненных запросов, которые соответствуют данному документу.
Используйте запрос перколяции для поиска сохраненных запросов, которые соответствуют данному документу. Эта операция является противоположностью обычного поиска: вместо того чтобы находить документы, соответствующие запросу, вы находите запросы, соответствующие документу. Запросы перколяции часто используются для оповещений, уведомлений и обратных поисковых случаев.
Основные моменты
- Вы можете перколировать документ, предоставленный в строке, или извлечь существующий документ из индекса.
- Документ и сохраненные запросы должны использовать одни и те же имена и типы полей.
- Вы можете комбинировать перколяцию с фильтрацией и оценкой, чтобы создать сложные системы соответствия.
- Запросы перколяции считаются дорогими запросами и будут выполняться только если настройка кластера
search.allow_expensive_queries установлена в true (по умолчанию). Если эта настройка установлена в false, запросы перколяции будут отклонены.
Примеры использования
Запросы перколяции полезны в различных сценариях реального времени. Некоторые распространенные случаи использования включают:
-
Уведомления для электронной коммерции: Пользователи могут зарегистрировать интерес к продуктам, например, “Уведомите меня, когда новые ноутбуки Apple будут в наличии”. Когда новые документы о продуктах индексируются, система находит всех пользователей с соответствующими сохраненными запросами и отправляет уведомления.
-
Уведомления о вакансиях: Соискатели сохраняют запросы на основе предпочтительных должностей или местоположений, и новые вакансии сопоставляются с этими запросами для триггера уведомлений.
-
Системы безопасности и оповещения: Перколируйте входящие данные журналов или событий по сохраненным правилам или паттернам аномалий.
-
Фильтрация новостей: Сопоставляйте входящие статьи с сохраненными профилями тем, чтобы классифицировать или доставлять релевантный контент.
Как работает перколяция
Сохраненные запросы хранятся в специальном типе поля перколятора. Документы сравниваются со всеми сохраненными запросами. Каждый соответствующий запрос возвращается с его _id. Если включено выделение, также возвращаются совпадающие текстовые фрагменты. Если отправляется несколько документов, поле _percolator_document_slot отображает соответствующий документ.
Пример запроса перколяции
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Новый ноутбук Apple",
"price": 1500,
"availability": "в наличии"
}
}
}
}
В этом примере запрос перколяции ищет сохраненные запросы, которые соответствуют документу о новом ноутбуке Apple.
Пример использования перколяции
Следующие примеры демонстрируют, как сохранять запросы перколяции и тестировать документы против них, используя различные методы.
Создание индекса для хранения сохраненных запросов
Сначала создайте индекс и настройте его маппинги с типом поля перколятора для хранения сохраненных запросов:
PUT /my_percolator_index
{
"mappings": {
"properties": {
"query": {
"type": "percolator"
},
"title": {
"type": "text"
}
}
}
}
Добавление запроса, соответствующего “apple” в поле title
Добавьте запрос, который соответствует слову “apple” в поле заголовка:
POST /my_percolator_index/_doc/1
{
"query": {
"match": {
"title": "apple"
}
}
}
Добавление запроса, соответствующего “banana” в поле title
Добавьте запрос, который соответствует слову “banana” в поле заголовка:
POST /my_percolator_index/_doc/2
{
"query": {
"match": {
"title": "banana"
}
}
}
Перколяция встроенного документа
Проверьте встроенный документ против сохраненных запросов:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Fresh Apple Harvest"
}
}
}
}
Ответ
Ответ предоставляет сохраненный запрос перколяции, который ищет документы, содержащие слово “apple” в поле заголовка, идентифицированный по _id: 1:
{
...
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
}
}
]
}
}
Перколяция с несколькими документами
Чтобы протестировать несколько документов в одном запросе, используйте следующий запрос:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Banana flavoured ice-cream" },
{ "title": "Apple pie recipe" },
{ "title": "Banana bread instructions" },
{ "title": "Cherry tart" }
]
}
}
}
Ответ
Поле _percolator_document_slot помогает вам идентифицировать каждый документ (по индексу), соответствующий каждому сохраненному запросу:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.54726034,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.54726034,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
0,
2
]
}
}
]
}
}
Перколяция существующего индексированного документа
Вы можете ссылаться на существующий документ, уже хранящийся в другом индексе, чтобы проверить соответствие запросов перколяции.
Создание отдельного индекса для ваших документов
Создайте индекс для хранения документов:
PUT /products
{
"mappings": {
"properties": {
"title": {
"type": "text"
}
}
}
}
Добавление документа
Добавьте документ:
POST /products/_doc/1
{
"title": "Banana Smoothie Special"
}
Проверка соответствия сохраненных запросов индексированному документу
Проверьте, соответствуют ли сохраненные запросы индексированному документу:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"index": "products",
"id": "1"
}
}
}
Вы должны предоставить как индекс, так и идентификатор при использовании сохраненного документа.
Перколяция пакетов (несколько документов)
Вы можете проверить несколько документов в одном запросе:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Apple event coming soon" },
{ "title": "Banana farms expand" },
{ "title": "Cherry season starts" }
]
}
}
}
Ответ
Каждое совпадение указывает на соответствующий документ в поле _percolator_document_slot:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.46484798,
"hits": [
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.46484798,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.41211313,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
}
}
]
}
}
Многоуровневая перколяция с использованием именованного запроса
Вы можете перколировать разные документы внутри именованного запроса:
GET /my_percolator_index/_search
{
"query": {
"bool": {
"should": [
{
"percolate": {
"field": "query",
"document": {
"title": "Apple pie recipe"
},
"name": "apple_doc"
}
},
{
"percolate": {
"field": "query",
"document": {
"title": "Banana bread instructions"
},
"name": "banana_doc"
}
}
]
}
}
}
Ответ
Параметр name добавляется к полю _percolator_document_slot, чтобы предоставить соответствующий запрос:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot_apple_doc": [
0
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot_banana_doc": [
0
]
}
}
]
}
}
Этот подход позволяет вам настраивать более индивидуальную логику запросов для отдельных документов. В следующем примере поле title запрашивается в первом документе, а поле description запрашивается во втором документе. Также предоставляется параметр boost:
GET /my_percolator_index/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"filter": {
"percolate": {
"field": "query",
"document": {
"title": "Apple pie recipe"
},
"name": "apple_doc"
}
},
"boost": 1.0
}
},
{
"constant_score": {
"filter": {
"percolate": {
"field": "query",
"document": {
"description": "Banana bread with honey"
},
"name": "banana_doc"
}
},
"boost": 3.0
}
}
]
}
}
}
Сравнение пакетной перколяции и именованной перколяции
Обе методы — пакетная перколяция (с использованием документов) и именованная перколяция (с использованием bool и name) — могут использоваться для перколяции нескольких документов, но они различаются по тому, как результаты маркируются, интерпретируются и контролируются. Они предоставляют функционально схожие результаты, но с важными структурными различиями, описанными в следующей таблице.
| Характеристика |
Пакетная (документы) |
Именованная (bool + percolate + name) |
| Формат ввода |
Один клауз перколяции, массив документов |
Несколько клауз перколяции, по одному на документ |
| Прослеживаемость по документу |
По индексу слота (0, 1, …) |
По имени (apple_doc, banana_doc) |
| Поле ответа для слота совпадения |
_percolator_document_slot: [0] |
_percolator_document_slot_<name>: [0] |
| Префикс выделения |
0_title, 1_title |
apple_doc_title, banana_doc_title |
| Индивидуальный контроль по документу |
Не поддерживается |
Можно настроить каждую клаузу |
| Поддержка увеличений и фильтров |
Нет |
Да (по каждой клаузе) |
| Производительность |
Лучше для больших партий |
Немного медленнее при большом количестве клауз |
| Случай использования |
Массовое соответствие, большие потоки событий |
Прослеживание по документам, тестирование, индивидуальный контроль |
Подсветка совпадений
Запросы перколяции обрабатывают подсветку иначе, чем обычные запросы:
- В обычном запросе документ хранится в индексе, и поисковый запрос используется для подсветки совпадающих терминов.
- В запросе перколяции роли меняются: сохраненные запросы (в индексе перколятора) используются для подсветки документа.
Это означает, что документ, предоставленный в поле document или documents, является целью для подсветки, и запросы перколяции определяют, какие разделы будут подсвечены.
Подсветка одного документа
Этот пример использует ранее определенные запросы в my_percolator_index. Используйте следующий запрос для подсветки совпадений в поле заголовка:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Apple banana smoothie"
}
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
Ответ
Совпадения подсвечиваются в зависимости от соответствующего запроса:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"title": [
"<em>Apple</em> banana smoothie"
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"title": [
"Apple <em>banana</em> smoothie"
]
}
}
]
}
}
Подсветка нескольких документов
При перколяции нескольких документов с использованием массива documents каждому документу присваивается индекс слота. Ключи подсветки принимают следующую форму, где <slot> — это индекс документа в вашем массиве documents:
"<slot>_<fieldname>": [ ... ]
Используйте следующую команду для перколяции двух документов с подсветкой:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Apple pie recipe" },
{ "title": "Banana smoothie ideas" }
]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
Ответ
Ответ содержит поля подсветки с префиксами, соответствующими слотам документов, такими как 0_title и 1_title:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.31506687,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"0_title": [
"<em>Apple</em> pie recipe"
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
},
"highlight": {
"1_title": [
"<em>Banana</em> smoothie ideas"
]
}
}
]
}
}
Параметры запроса перколяции
Запрос перколяции поддерживает следующие параметры:
| Параметр |
Обязательный/Необязательный |
Описание |
field |
Обязательный |
Поле, содержащее сохраненные запросы перколяции. |
document |
Необязательный |
Один встроенный документ для сопоставления с сохраненными запросами. |
documents |
Необязательный |
Массив нескольких встроенных документов для сопоставления с сохраненными запросами. |
index |
Необязательный |
Индекс, содержащий документ, с которым вы хотите сопоставить. |
id |
Необязательный |
Идентификатор документа для извлечения из индекса. |
routing |
Необязательный |
Значение маршрутизации, используемое при извлечении документа. |
preference |
Необязательный |
Предпочтение для маршрутизации шардов при извлечении документа. |
name |
Необязательный |
Имя, присвоенное клаузе перколяции. Полезно при использовании нескольких клауз перколяции в запросе bool. |
3.10.7 - script query
Этот запрос возвращает документы, для которых скрипт оценивается как истинный, что позволяет использовать сложную логику фильтрации, которую нельзя выразить с помощью стандартных запросов.
Используйте запрос скрипта для фильтрации документов на основе пользовательского условия, написанного на языке скриптов Painless. Этот запрос возвращает документы, для которых скрипт оценивается как истинный, что позволяет использовать сложную логику фильтрации, которую нельзя выразить с помощью стандартных запросов.
Запрос скрипта является вычислительно затратным и должен использоваться с осторожностью. Используйте его только при необходимости и убедитесь, что параметр search.allow_expensive_queries включен (по умолчанию установлен в true). Для получения дополнительной информации смотрите раздел “Дорогие запросы”.
Пример
Создайте индекс с именем products со следующими настройками:
PUT /products
{
"mappings": {
"properties": {
"title": { "type": "text" },
"price": { "type": "float" },
"rating": { "type": "float" }
}
}
}
Индексируйте пример документов, используя следующий запрос:
POST /products/_bulk
{ "index": { "_id": 1 } }
{ "title": "Беспроводные наушники", "price": 99.99, "rating": 4.5 }
{ "index": { "_id": 2 } }
{ "title": "Bluetooth колонка", "price": 79.99, "rating": 4.8 }
{ "index": { "_id": 3 } }
{ "title": "Наушники с шумоподавлением", "price": 199.99, "rating": 4.7 }
Базовый запрос скрипта
Верните продукты с рейтингом выше 4.6:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['rating'].value > 4.6"
}
}
}
}
Возвращенные результаты будут включать только документы с рейтингом выше 4.6:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
},
{
"_index": "products",
"_id": "3",
"_score": 1,
"_source": {
"title": "Наушники с шумоподавлением",
"price": 199.99,
"rating": 4.7
}
}
]
}
}
Параметры
Запрос скрипта принимает следующие параметры верхнего уровня.
| Параметр |
Обязательный/Необязательный |
Описание |
script.source |
Обязательный |
Код скрипта, который оценивается как истинный или ложный. |
script.params |
Необязательный |
Пользовательские параметры, на которые ссылается скрипт. |
Использование параметров скрипта
Вы можете использовать params для безопасной передачи значений, используя кэширование компиляции скриптов:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['price'].value < params.max_price",
"params": {
"max_price": 100
}
}
}
}
}
Возвращенные результаты будут включать только документы с ценой менее 100:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "1",
"_score": 1,
"_source": {
"title": "Беспроводные наушники",
"price": 99.99,
"rating": 4.5
}
},
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
}
]
}
}
Объединение нескольких условий
Используйте следующий запрос для поиска продуктов с рейтингом выше 4.5 и ценой ниже 100:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['rating'].value > 4.5 && doc['price'].value < 100"
}
}
}
}
Только документы, соответствующие требованиям, будут возвращены:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
}
]
}
}
3.10.8 - Запрос с оценкой скрипта
Используйте запрос script_score, чтобы настроить расчет оценки, используя скрипт.
Используйте запрос script_score, чтобы настроить расчет оценки, используя скрипт. Для вычислительно затратной функции оценки вы можете использовать запрос script_score, чтобы вычислить оценку только для возвращенных документов, которые были отфильтрованы.
Пример
Например, следующий запрос создает индекс, содержащий один документ:
PUT testindex1/_doc/1
{
"name": "John Doe",
"multiplier": 0.5
}
Вы можете использовать запрос match, чтобы вернуть все документы, содержащие “John” в поле имени:
GET testindex1/_search
{
"query": {
"match": {
"name": "John"
}
}
}
В ответе документ 1 имеет оценку 0.2876821:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "John Doe",
"multiplier": 0.5
}
}
]
}
}
Теперь давайте изменим оценку документа, используя скрипт, который вычисляет оценку как значение поля _score, умноженное на значение поля multiplier. В следующем запросе вы можете получить текущую релевантность документа в переменной _score, а значение множителя как doc['multiplier'].value:
GET testindex1/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "John"
}
},
"script": {
"source": "_score * doc['multiplier'].value"
}
}
}
}
В ответе оценка для документа 1 составляет половину от первоначальной оценки:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.14384104,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0.14384104,
"_source": {
"name": "John Doe",
"multiplier": 0.5
}
}
]
}
}
Параметры
Запрос script_score поддерживает следующие параметры верхнего уровня.
| Параметр |
Тип данных |
Описание |
query |
Объект |
Запрос, используемый для поиска. Обязательный. |
script |
Объект |
Скрипт, используемый для вычисления оценки документов, возвращаемых запросом. Обязательный. |
min_score |
Число с плавающей запятой |
Исключает документы с оценкой ниже min_score из результатов. Необязательный. |
boost |
Число с плавающей запятой |
Увеличивает оценки документов на заданный множитель. Значения меньше 1.0 уменьшают релевантность, а значения больше 1.0 увеличивают релевантность. По умолчанию 1.0. |
Оценки релевантности, вычисленные запросом script_score, не могут быть отрицательными.
Настройка вычисления оценки с помощью встроенных функций
Чтобы настроить вычисление оценки, вы можете использовать одну из встроенных функций Painless. Для каждой функции OpenSearch предоставляет один или несколько методов Painless, которые вы можете использовать в контексте оценки скрипта. Вы можете вызывать методы Painless, перечисленные в следующих разделах, напрямую, без использования имени класса или имени экземпляра.
Сатурация
Функция сатурации вычисляет сатурацию как score = value / (value + pivot), где value — это значение поля, а pivot выбирается так, чтобы оценка была больше 0.5, если value больше pivot, и меньше 0.5, если value меньше pivot. Оценка находится в диапазоне (0, 1). Чтобы применить функцию сатурации, вызовите следующий метод Painless:
double saturation(double <field-value>, double <pivot>)
ПРИМЕР
Следующий пример запроса ищет текст “neural search” в индексе статей. Он комбинирует оригинальную оценку релевантности документа с значением article_rank, которое сначала преобразуется с помощью функции сатурации:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "_score + saturation(doc['article_rank'].value, 11)"
}
}
}
}
Сигмоид
Аналогично функции сатурации, функция сигмоид вычисляет оценку как score = value^exp / (value^exp + pivot^exp), где value — это значение поля, exp — это коэффициент масштабирования степени, а pivot выбирается так, чтобы оценка была больше 0.5, если value больше pivot, и меньше 0.5, если value меньше pivot. Чтобы применить функцию сигмоид, вызовите следующий метод Painless:
double sigmoid(double <field-value>, double <pivot>, double <exp>)
Пример
Следующий пример запроса ищет текст “neural search” в индексе статей. Он комбинирует оригинальную оценку релевантности документа со значением article_rank, которое сначала преобразуется с помощью функции сигмоид:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "_score + sigmoid(doc['article_rank'].value, 11, 2)"
}
}
}
}
Случайная оценка
Функция случайной оценки генерирует равномерно распределенные случайные оценки в диапазоне [0, 1). Чтобы узнать, как работает эта функция, смотрите раздел “Функция случайной оценки”. Чтобы применить функцию случайной оценки, вызовите один из следующих методов Painless:
double randomScore(int <seed>): Использует внутренние идентификаторы документов Lucene в качестве значений семени.
double randomScore(int <seed>, String <field-name>)
Пример
Следующий запрос использует функцию random_score с семенем и полем:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "randomScore(20, '_seq_no')"
}
}
}
}
Функции затухания
С помощью функций затухания вы можете оценивать результаты на основе близости или недавности. Чтобы узнать больше, смотрите раздел “Функции затухания”. Вы можете вычислять оценки, используя экспоненциальную, гауссову или линейную кривую затухания. Чтобы применить функцию затухания, вызовите один из следующих методов Painless в зависимости от типа поля:
Числовые поля:
double decayNumericGauss(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
double decayNumericExp(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
double decayNumericLinear(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
Геопоинтовые поля:
double decayGeoGauss(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
double decayGeoExp(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
double decayGeoLinear(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
Поля даты:
double decayDateGauss(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
double decayDateExp(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
double decayDateLinear(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
Пример: Числовые поля
Следующий запрос использует функцию экспоненциального затухания на числовом поле:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": {
"article_name": "neural search"
}
},
"script": {
"source": "decayNumericExp(params.origin, params.scale, params.offset, params.decay, doc['article_rank'].value)",
"params": {
"origin": 50,
"scale": 20,
"offset": 30,
"decay": 0.5
}
}
}
}
}
Пример: Геопоинтовые поля
Следующий запрос использует функцию гауссового затухания на геопоинтовом поле:
GET hotels/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "hotel"
}
},
"script": {
"source": "decayGeoGauss(params.origin, params.scale, params.offset, params.decay, doc['location'].value)",
"params": {
"origin": "40.71,74.00",
"scale": "300ft",
"offset": "200ft",
"decay": 0.25
}
}
}
}
}
Пример: Поля даты
Следующий запрос использует функцию линейного затухания на поле даты:
GET blogs/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "opensearch"
}
},
"script": {
"source": "decayDateLinear(params.origin, params.scale, params.offset, params.decay, doc['date_posted'].value)",
"params": {
"origin": "2022-04-24",
"scale": "6d",
"offset": "1d",
"decay": 0.25
}
}
}
}
}
Функции частоты термина
Функции частоты термина предоставляют статистику на уровне термина в источнике скрипта оценки. Вы можете использовать эту статистику для реализации пользовательских алгоритмов извлечения информации и ранжирования, таких как умножение или сложение оценки по популярности во время запроса. Чтобы применить функцию частоты термина, вызовите один из следующих методов Painless:
int termFreq(String <field-name>, String <term>): Извлекает частоту термина в поле для конкретного термина.long totalTermFreq(String <field-name>, String <term>): Извлекает общую частоту термина в поле для конкретного термина.long sumTotalTermFreq(String <field-name>): Извлекает сумму общих частот термина в поле.
Пример
Следующий запрос вычисляет оценку как общую частоту термина для каждого поля в списке полей, умноженную на значение множителя:
GET /demo_index_v1/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"script_score": {
"script": {
"source": """
for (int x = 0; x < params.fields.length; x++) {
String field = params.fields[x];
if (field != null) {
return params.multiplier * totalTermFreq(field, params.term);
}
}
return params.default_value;
""",
"params": {
"fields": ["title", "description"],
"term": "ai",
"multiplier": 2,
"default_value": 1
}
}
}
}
}
}
3.10.9 - Запрос шаблона
Используйте запрос шаблона для создания поисковых запросов, которые содержат переменные-заполнители.
Используйте запрос шаблона для создания поисковых запросов, которые содержат переменные-заполнители. Заполнители указываются с помощью синтаксиса “${variable_name}” (обратите внимание, что переменные должны быть заключены в кавычки). Когда вы отправляете поисковый запрос, эти заполнители остаются неразрешенными до тех пор, пока они не будут обработаны процессорами запросов поиска. Этот подход особенно полезен, когда ваш начальный поисковый запрос содержит данные, которые необходимо преобразовать или сгенерировать во время выполнения.
Например, вы можете использовать запрос шаблона при работе с процессором запросов поиска ml_inference, который преобразует текстовый ввод в векторные эмбеддинги во время процесса поиска. Процессор заменит заполнители сгенерированными значениями перед выполнением окончательного запроса.
Для полного примера смотрите раздел “Переписывание запросов с использованием запросов шаблонов”.
Пример
Следующий пример показывает запрос шаблона k-NN с заполнителем “vector”: “${text_embedding}”. Заполнитель “${text_embedding}” будет заменен эмбеддингами, сгенерированными процессором запросов ml_inference из текстового поля ввода:
GET /template-knn-index/_search?search_pipeline=my_knn_pipeline
{
"query": {
"template": {
"knn": {
"text_embedding": {
"vector": "${text_embedding}", // Заполнитель для векторного поля
"k": 2
}
}
}
},
"ext": {
"ml_inference": {
"text": "sneakers" // Входной текст для процессора ml_inference
}
}
}
Конфигурация процессора запросов поиска
Чтобы использовать запрос шаблона с процессором запросов поиска, вам необходимо настроить конвейер поиска. Следующая конфигурация является примером для процессора запросов ml_inference. input_map сопоставляет поля документа с входами модели. В этом примере поле источника ext.ml_inference.text в документе сопоставляется с полем inputText — ожидаемым входным полем для модели. output_map сопоставляет выходы модели с полями документа. В этом примере поле выходного эмбеддинга из модели сопоставляется с полем назначения text_embedding в вашем документе:
PUT /_search/pipeline/my_knn_pipeline
{
"request_processors": [
{
"ml_inference": {
"model_id": "Sz-wFZQBUpPSu0bsJTBG",
"input_map": [
{
"inputText": "ext.ml_inference.text" // Сопоставить входной текст из запроса
}
],
"output_map": [
{
"text_embedding": "embedding" // Сопоставить выходные данные с заполнителем
}
]
}
}
]
}
После выполнения процессора запросов ml_inference запрос поиска переписывается. Поле вектора содержит эмбеддинги, сгенерированные процессором, а поле text_embedding содержит выходные данные процессора:
GET /template-knn-1/_search
{
"query": {
"template": {
"knn": {
"text_embedding": {
"vector": [0.6328125, 0.26953125, ...],
"k": 2
}
}
}
},
"ext": {
"ml_inference": {
"text": "sneakers",
"text_embedding": [0.6328125, 0.26953125, ...]
}
}
}
Ограничения
Запросы шаблона требуют как минимум одного процессора запросов поиска для разрешения заполнителей. Процессоры запросов поиска должны быть настроены для генерации переменных, ожидаемых в конвейере.
3.10.10 - Обертка
Запрос обертки позволяет отправлять полный запрос в формате JSON, закодированном в Base64.
Запрос обертки позволяет отправлять полный запрос в формате JSON, закодированном в Base64. Это полезно, когда запрос необходимо встроить в контексты, которые поддерживают только строковые значения.
Используйте этот запрос только в тех случаях, когда необходимо управлять системными ограничениями. Для читаемости и удобства обслуживания лучше использовать стандартные запросы на основе JSON, когда это возможно.
Пример
Создайте индекс с именем products со следующими настройками:
PUT /products
{
"mappings": {
"properties": {
"title": { "type": "text" }
}
}
}
Индексируйте пример документов:
POST /products/_bulk
{ "index": { "_id": 1 } }
{ "title": "Беспроводные наушники с шумоподавлением" }
{ "index": { "_id": 2 } }
{ "title": "Bluetooth колонка" }
{ "index": { "_id": 3 } }
{ "title": "Наушники накладного типа с глубоким басом" }
Закодируйте следующий запрос в формате Base64:
echo -n '{ "match": { "title": "headphones" } }' | base64
Выполните закодированный запрос:
POST /products/_search
{
"query": {
"wrapper": {
"query": "eyAibWF0Y2giOiB7ICJ0aXRsZSI6ICJoZWFkcGhvbmVzIiB9IH0="
}
}
}
Ответ
Ответ содержит два соответствующих документа:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.20098841,
"hits": [
{
"_index": "products",
"_id": "1",
"_score": 0.20098841,
"_source": {
"title": "Беспроводные наушники с шумоподавлением"
}
},
{
"_index": "products",
"_id": "3",
"_score": 0.18459359,
"_source": {
"title": "Наушники накладного типа с глубоким басом"
}
}
]
}
}
3.11 - Minimum should match (Минимальное соответствие)
Параметр minimum_should_match может использоваться для полнотекстового поиска и указывает минимальное количество терминов, с которыми документ должен соответствовать, чтобы быть возвращенным в результатах поиска.
Пример
Следующий пример требует, чтобы документ соответствовал как минимум двум из трех поисковых терминов, чтобы быть возвращенным в качестве результата поиска:
GET /shakespeare/_search
{
"query": {
"match": {
"text_entry": {
"query": "prince king star",
"minimum_should_match": "2"
}
}
}
}
В этом примере запрос имеет три необязательных условия, которые объединены с помощью оператора OR, поэтому документ должен соответствовать либо “prince” и “king”, либо “prince” и “star”, либо “king” и “star”.
Допустимые значения
Вы можете указать параметр minimum_should_match как одно из следующих значений.
| Тип значения |
Пример |
Описание |
| Ненегативное целое число |
2 |
Документ должен соответствовать этому количеству необязательных условий. |
| Отрицательное целое число |
-1 |
Документ должен соответствовать общему количеству необязательных условий минус это число. |
| Ненегативный процент |
70% |
Документ должен соответствовать этому проценту от общего количества необязательных условий. Количество условий округляется вниз до ближайшего целого числа. |
| Отрицательный процент |
-30% |
Документ может не соответствовать этому проценту от общего количества необязательных условий. Количество условий, которые документ может не соответствовать, округляется вниз до ближайшего целого числа. |
| Комбинация |
2<75% |
Выражение в формате n<p%. Если количество необязательных условий меньше или равно n, документ должен соответствовать всем необязательным условиям. Если количество необязательных условий больше n, то документ должен соответствовать p процентам необязательных условий. |
| Множественные комбинации |
3<-1 5<50% |
Более одной комбинации, разделенной пробелом. Каждое условие применяется к количеству необязательных условий, которое больше числа слева от знака <. В этом примере, если есть три или меньше необязательных условий, документ должен соответствовать всем им. Если есть четыре или пять необязательных условий, документ должен соответствовать всем, кроме одного из них. Если есть 6 или более необязательных условий, документ должен соответствовать 50% из них. |
Пусть n будет количеством необязательных условий, с которыми документ должен соответствовать. Когда n рассчитывается как процент, если n меньше 1, то используется 1. Если n больше количества необязательных условий, используется количество необязательных условий.
Использование параметра в булевых запросах
Булевый запрос перечисляет необязательные условия в разделе should и обязательные условия в разделе must. Опционально он может содержать раздел filter для фильтрации результатов.
Пример индекса
Рассмотрим пример индекса, содержащего следующие пять документов:
PUT testindex/_doc/1
{
"text": "one OpenSearch"
}
PUT testindex/_doc/2
{
"text": "one two OpenSearch"
}
PUT testindex/_doc/3
{
"text": "one two three OpenSearch"
}
PUT testindex/_doc/4
{
"text": "one two three four OpenSearch"
}
PUT testindex/_doc/5
{
"text": "OpenSearch"
}
Пример запроса
Следующий запрос содержит четыре необязательных условия:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
],
"minimum_should_match": "80%"
}
}
}
Поскольку minimum_should_match указан как 80%, количество необязательных условий для соответствия рассчитывается как 4 · 0.8 = 3.2 и затем округляется вниз до 3. Поэтому результаты содержат документы, которые соответствуют как минимум трем условиям:
{
"took": 40,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.5744598,
"_source": {
"text": "one two three OpenSearch"
}
}
]
}
}
Указание minimum_should_match как -20%
Следующий запрос устанавливает minimum_should_match как -20%:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
],
"minimum_should_match": "-20%"
}
}
}
Количество необязательных условий, которые документ может не соответствовать, рассчитывается как 4 · 0.2 = 0.8 и округляется вниз до 0. Таким образом, результаты содержат только один документ, который соответствует всем необязательным условиям:
{
"took": 41,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
}
]
}
}
Обратите внимание, что указание положительного процента (80%) и отрицательного процента (-20%) не привело к одинаковому количеству необязательных условий, с которыми документ должен соответствовать, поскольку в обоих случаях результат округляется вниз. Если бы количество необязательных условий, например, было 5, то как 80%, так и -20% привели бы к одинаковому количеству необязательных условий, с которыми документ должен соответствовать (4).
Значение по умолчанию для minimum_should_match
Если запрос содержит условие must или filter, значение по умолчанию для minimum_should_match равно 0. Например, следующий запрос ищет документы, которые соответствуют “OpenSearch” и не имеют необязательных условий в разделе should:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
]
}
}
}
Этот запрос возвращает все пять документов в индексе:
{
"took": 34,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.5744598,
"_source": {
"text": "one two three OpenSearch"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.91368985,
"_source": {
"text": "one two OpenSearch"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.4338556,
"_source": {
"text": "one OpenSearch"
}
},
{
"_index": "testindex",
"_id": "5",
"_score": 0.11964063,
"_source": {
"text": "OpenSearch"
}
}
]
}
}
Таким образом, поскольку значение minimum_should_match по умолчанию равно 0, все документы, соответствующие обязательному условию, будут возвращены, независимо от соответствия необязательным условиям.
Исключение условия must
Если вы опустите условие must, то запрос будет искать документы, которые соответствуют хотя бы одному из необязательных условий в разделе should:
GET testindex/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
]
}
}
}
Результаты содержат только четыре документа, которые соответствуют как минимум одному из необязательных условий:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2.426633,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.426633,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.4978898,
"_source": {
"text": "one two three OpenSearch"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.8266785,
"_source": {
"text": "one two OpenSearch"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3331056,
"_source": {
"text": "one OpenSearch"
}
}
]
}
}
Таким образом, без условия must запрос возвращает документы, которые соответствуют хотя бы одному из указанных необязательных условий, что приводит к меньшему количеству результатов по сравнению с запросом, содержащим обязательные условия.
3.12 - Синтаксис регулярных выражений
Регулярное выражение (regex) — это способ определения шаблонов поиска с использованием специальных символов и операторов.
Регулярное выражение (regex) — это способ определения шаблонов поиска с использованием специальных символов и операторов. Эти шаблоны позволяют вам сопоставлять последовательности символов в строках.
В OpenSearch вы можете использовать регулярные выражения в следующих типах запросов:
OpenSearch использует движок регулярных выражений Apache Lucene, который имеет свой собственный синтаксис и ограничения. Он не использует регулярные выражения, совместимые с Perl (PCRE), поэтому некоторые знакомые функции регулярных выражений могут вести себя иначе или не поддерживаться.
Выбор между запросами regexp и query_string
Оба запроса regexp и query_string поддерживают регулярные выражения, но они ведут себя по-разному и служат для разных случаев использования.
| Особенность |
Запрос regexp |
Запрос query_string |
| Сопоставление шаблонов |
Шаблон regex должен соответствовать всему значению поля |
Шаблон regex может соответствовать любой части поля |
| Поддержка флагов |
Флаги включают необязательные операторы regex |
Флаги не поддерживаются |
| Тип запроса |
Запрос на уровне термина (не оценивается) |
Полнотекстовый запрос (оценивается и разбирается) |
| Лучший случай использования |
Строгое сопоставление шаблонов для полей типа keyword или exact |
Поиск в анализируемых полях с использованием гибкой строки запроса, поддерживающей шаблоны regex |
| Сложная композиция запросов |
Ограничена шаблонами regex |
Поддерживает AND, OR, подстановочные знаки, поля, увеличение и другие функции. См. Запрос query_string. |
Зарезервированные символы
Движок регулярных выражений Lucene поддерживает все символы Unicode. Однако следующие символы рассматриваются как специальные операторы:
. ? + * | { } [ ] ( ) " \
В зависимости от включенных флагов, которые указывают необязательные операторы, следующие символы также могут быть зарезервированы:
Чтобы сопоставить эти символы буквально, либо экранируйте их с помощью обратной косой черты (), либо оберните всю строку в двойные кавычки:
\&: Сопоставляет литерал &\\: Сопоставляет литерал обратной косой черты ()"hello@world": Сопоставляет полную строку hello@world
Стандартные операторы регулярных выражений
Lucene поддерживает основной набор операторов регулярных выражений:
-
. – Сопоставляет любой одиночный символ. Пример: f.n соответствует f, за которым следует любой символ, а затем n (например, fan или fin).
-
? – Сопоставляет ноль или один из предыдущих символов. Пример: colou?r соответствует color и colour.
-
+ – Сопоставляет один или более из предыдущих символов. Пример: go+ соответствует g, за которым следует один или более o (go, goo, gooo и так далее).
-
* – Сопоставляет ноль или более из предыдущих символов. Пример: lo*se соответствует l, за которым следует ноль или более o, а затем se (lse, lose, loose, loooose и так далее).
-
{min,max} – Сопоставляет конкретный диапазон повторений. Если max опущен, нет верхнего предела на количество сопоставляемых символов. Пример: x{3} соответствует ровно 3 x (xxx); x{2,4} соответствует от 2 до 4 x (xx, xxx или xxxx); x{3,} соответствует 3 или более x (xxx, xxxx, xxxxx и так далее).
-
| – Действует как логическое ИЛИ. Пример: apple|orange соответствует apple или orange.
-
( ) – Группирует символы в подпаттерн. Пример: ab(cd)? соответствует ab и abcd.
-
[ ] – Сопоставляет один символ из набора или диапазона. Пример: [aeiou] соответствует любой гласной.
-
- – Когда предоставляется внутри скобок, указывает диапазон, если не экранирован или является первым символом внутри скобок. Пример: [a-z] соответствует любой строчной букве; [-az] соответствует -, a или z; [a\\-z] соответствует a, -, или z.
-
^ – Когда предоставляется внутри скобок, действует как логическое НЕ, отрицая диапазон символов или любой символ в наборе. Пример: [^az] соответствует любому символу, кроме a или z; [^a-z] соответствует любому символу, кроме строчных букв; [^-az] соответствует любому символу, кроме -, a и z; [^a\\-z] соответствует любому символу, кроме a, -, и z.
Необязательные операторы
Вы можете включить дополнительные операторы регулярных выражений, используя параметр flags. Разделяйте несколько флагов с помощью |.
Следующие флаги доступны:
-
ALL (по умолчанию) – Включает все необязательные операторы.
-
COMPLEMENT – Включает ~, который отрицает следующее выражение. Пример: d~ef соответствует dgf, dxf, но не def.
-
INTERSECTION – Включает & как логический оператор И. Пример: ab.+&.+cd соответствует строкам, содержащим ab в начале и cd в конце.
-
INTERVAL – Включает синтаксис <min-max> для сопоставления числовых диапазонов. Пример: id<10-12> соответствует id10, id11 и id12.
-
ANYSTRING – Включает @ для сопоставления любой строки. Вы можете комбинировать это с ~ и & для исключений. Пример: @&.*error.*&.*[0-9]{3}.* соответствует строкам, содержащим как слово “error”, так и последовательность из трех цифр.
Неподдерживаемые функции
Движок Lucene не поддерживает следующие часто используемые якоря регулярных выражений:
- ^ – Начало строки
- $ – Конец строки
Вместо этого ваш шаблон должен соответствовать всей строке, чтобы произвести совпадение.
Пример использования регулярных выражений
Чтобы попробовать регулярные выражения, индексируйте следующие документы в индекс logs:
PUT /logs/_doc/1
{
"message": "error404"
}
PUT /logs/_doc/2
{
"message": "error500"
}
PUT /logs/_doc/3
{
"message": "error1a"
}
Пример: Базовый запрос с использованием регулярных выражений
Следующий запрос regexp возвращает документы, в которых полное значение поля message соответствует шаблону “error”, за которым следует одна или более цифр. Значение не соответствует, если оно содержит шаблон только как подстроку:
GET /logs/_search
{
"query": {
"regexp": {
"message": {
"value": "error[0-9]+"
}
}
}
}
Этот запрос соответствует error404 и error500:
{
"took": 28,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Пример: Использование необязательных операторов
Следующий запрос соответствует документам, в которых поле message точно соответствует строке, начинающейся с “error”, за которой следует число от 400 до 500, включительно. Флаг INTERVAL позволяет использовать синтаксис <min-max> для числовых диапазонов:
GET /logs/_search
{
"query": {
"regexp": {
"message": {
"value": "error<400-500>",
"flags": "INTERVAL"
}
}
}
}
Этот запрос также соответствует error404 и error500:
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Пример: Использование ANYSTRING
Когда флаг ANYSTRING включен, оператор @ соответствует всей строке. Это полезно в сочетании с пересечением (&), поскольку позволяет вам строить запросы, которые соответствуют полным строкам при определенных условиях.
Следующий запрос соответствует сообщениям, которые содержат как слово “error”, так и последовательность из трех цифр. Используйте ANYSTRING, чтобы утверждать, что все поле должно соответствовать пересечению обоих шаблонов:
GET /logs/_search
{
"query": {
"regexp": {
"message.keyword": {
"value": "@&.*error.*&.*[0-9]{3}.*",
"flags": "ANYSTRING|INTERSECTION"
}
}
}
}
Этот запрос соответствует error404 и error500:
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Обратите внимание, что этот запрос также будет соответствовать xerror500, error500x и errorxx500.
4 - goclient
Клиент OpenSearch Go позволяет подключить ваше приложение Go к данным в кластере OpenSearch.
Клиент Go
В этом руководстве по началу работы описано, как подключиться к OpenSearch, индексировать документы и выполнять запросы. Полную документацию по API клиента и дополнительные примеры см. в документации по API клиента Go.
Исходный код клиента см. в репозитории opensearch-go.
Настройка
Если вы начинаете новый проект, создайте новый модуль, выполнив следующую команду:
go mod init <mymodulename>
Чтобы добавить клиент Go в свой проект, импортируйте его как любой другой модуль:
go get github.com/opensearch-project/opensearch-go