Введение в Opensearch
OpenSearch — это распределённая поисковая и аналитическая система, которая поддерживает различные сценарии использования: от реализации поисковой строки на веб-сайте до анализа данных безопасности для выявления угроз.
Введение в OpenSearch
Термин распределённая означает, что OpenSearch можно запускать на нескольких компьютерах. Поиск и аналитика подразумевают, что после загрузки данных в OpenSearch их можно искать и анализировать. Независимо от типа данных, их можно хранить и исследовать с помощью OpenSearch.
Документ
Документ — это единица хранения информации (текстовой или структурированной). В OpenSearch документы хранятся в формате JSON.
Документ можно представить несколькими способами:
- В базе данных студентов документ может представлять одного учащегося.
- При поиске информации OpenSearch возвращает документы, соответствующие запросу.
- Документ аналогичен строке в традиционной реляционной базе данных.
Например, в школьной базе данных документ может представлять студента и содержать следующие данные:
| ID |
Имя |
GPA |
Год выпуска |
| 1 |
John Doe |
3.89 |
2022 |
Вот как этот документ выглядит в формате JSON:
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
Вы узнаете, как назначаются идентификаторы документов, в разделе Индексация документов.
Индекс
Индекс — это коллекция документов.
Индекс можно рассматривать несколькими способами:
- В базе данных студентов индекс представляет всех учащихся в базе.
- При поиске информации запрос выполняется к данным внутри индекса.
- Индекс соответствует таблице в традиционной реляционной базе данных.
Например, в школьной базе данных индекс может содержать всех студентов школы:
| ID |
Имя |
GPA |
Год выпуска |
| 1 |
John Doe |
3.89 |
2022 |
| 2 |
Jonathan Powers |
3.85 |
2025 |
| 3 |
Jane Doe |
3.52 |
2024 |
| … |
… |
… |
… |
Кластеры и узлы
OpenSearch разработан как распределённая поисковая система, что означает возможность работы на одном или нескольких узлах — серверах, хранящих данные и обрабатывающих поисковые запросы. Кластер OpenSearch — это совокупность таких узлов.
Вы можете запустить OpenSearch локально на ноутбуке (системные требования минимальны), но также можно масштабировать кластер до сотен мощных серверов в дата-центре.
В одноузловом кластере (например, развёрнутом на ноутбуке) одна машина выполняет все задачи:
- управляет состоянием кластера,
- индексирует данные и обрабатывает поисковые запросы,
- выполняет предварительную обработку данных перед индексацией.
Однако по мере роста кластера обязанности можно распределить:
- Узлы с быстрыми дисками и большим объёмом ОЗУ подходят для индексации и поиска.
- Узлы с мощными CPU, но малым дисковым пространством, могут управлять состоянием кластера.
В каждом кластере выбирается главный узел (cluster manager node), который координирует операции на уровне кластера (например, создание индекса). Узлы взаимодействуют между собой: если запрос направлен к одному узлу, он может запрашивать данные у других узлов, агрегировать их ответы и возвращать итоговый результат.
Подробнее о других типах узлов см. в разделе Формирование кластера.
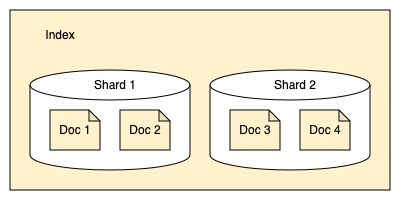
Шарды (Shards)
OpenSearch разделяет индексы на шарды. Каждый шард хранит подмножество всех документов индекса, как показано на следующей диаграмме:
Шарды используются для равномерного распределения данных между узлами кластера. Например:
- Индекс размером 400 ГБ может быть слишком большим для обработки на одном узле
- Если разделить его на 10 шардов по 40 ГБ каждый, OpenSearch сможет распределить их между 10 узлами
- Каждый шард будет обрабатываться независимо
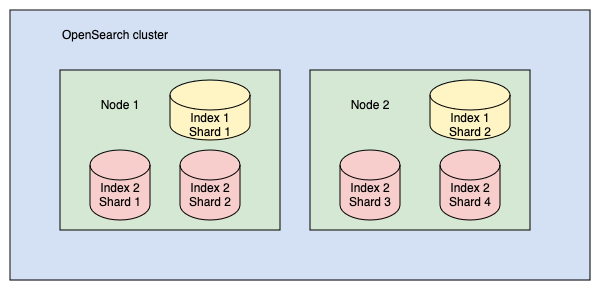
Рассмотрим кластер с двумя индексами:
- Индекс 1 разделён на 2 шарда
- Индекс 2 разделён на 4 шарда
Эти шарды распределены между двумя узлами, как показано на схеме:
Хотя каждый шард является частью индекса OpenSearch, технически он представляет собой полноценный индекс Lucene. Это важно учитывать, потому что:
- Каждый экземпляр Lucene - это отдельный процесс
- Каждый процесс потребляет ресурсы CPU и памяти
- Слишком большое количество шардов может перегрузить кластер
Рекомендации по работе с шардами:
- Не стоит разделять индекс на чрезмерное количество шардов
- Например, деление индекса 400 ГБ на 1000 шардов создаст ненужную нагрузку
- Оптимальный размер шарда - от 10 до 50 ГБ
Первичные и реплицированные шарды
В OpenSearch шарды могут быть двух типов:
- Первичные (primary) - оригинальные шарды
- Реплики (replica) - копии шардов
По умолчанию OpenSearch создаёт по одной реплике для каждого первичного шарда. Таким образом:
- Если индекс разделён на 10 шардов, будет создано 10 реплик
- В примере из предыдущего раздела (2 индекса):
- Индекс 1: 2 шарда + 2 реплики
- Индекс 2: 4 шарда + 4 реплики
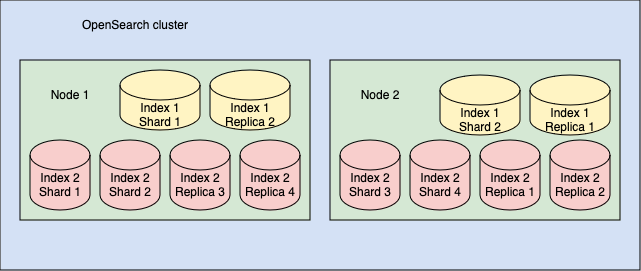
Функции реплик:
- Резервное копирование на случай сбоя узла
- Реплики размещаются на разных узлах от первичных шардов
- Ускорение обработки поисковых запросов
- Для нагрузок с интенсивным поиском можно создать несколько реплик
Инвертированный индекс
OpenSearch использует структуру данных под названием инвертированный индекс, которая:
- Сопоставляет слова с документами, где они встречаются
- Пример для двух документов:
- Документ 1: “Красота в глазах смотрящего”
- Документ 2: “Красавица и чудовище”
Инвертированный индекс будет выглядеть так:
| Слово |
Документы |
| красота |
1 |
| в |
1 |
| глазах |
1 |
| смотрящего |
1 |
| красавица |
2 |
| и |
2 |
| чудовище |
2 |
Дополнительно OpenSearch хранит:
- Позиции слов в документах
- Это позволяет выполнять поиск по фразам
Релевантность
При поиске OpenSearch:
- Сопоставляет слова запроса с документами
- Присваивает каждому документу оценку релевантности
Факторы оценки:
- Частота термина (TF):
- Чем чаще слово встречается в документе, тем выше оценка
- Обратная частота документа (IDF):
- Редкие слова имеют больший вес (например, “аксолотль” vs “синий”)
- Нормализация по длине:
- Более короткие документы получают преимущество
OpenSearch использует алгоритм BM25 для расчёта релевантности и сортировки результатов.
Следующие шаги
Узнайте, как быстро установить OpenSearch, в разделе Быстрый старт установки.
1 - Быстрый старт установки
Для быстрого запуска OpenSearch и OpenSearch Dashboards используйте контейнеры Docker.
Для быстрого запуска OpenSearch и OpenSearch Dashboards используйте контейнеры Docker. Полное руководство по установке доступно в разделе Установка и обновление OpenSearch.
Предварительные требования:
- Установите Docker и Docker Compose на локальную машину
Запуск кластера
-
Настройка системы
Перед запуском рекомендуется:
- Отключить подкачку памяти для повышения производительности:
- Увеличить максимальное количество memory maps:
Добавьте строку:
Примените изменения:
-
Получение файла конфигурации
Загрузите образец docker-compose.yml:
- Через cURL:
curl -O https://raw.githubusercontent.com/opensearch-project/documentation-website/3.1/assets/examples/docker-compose.yml
- Через wget:
wget https://raw.githubusercontent.com/opensearch-project/documentation-website/3.1/assets/examples/docker-compose.yml
-
Запуск кластера
Перейдите в директорию с файлом и выполните:
Проверьте статус контейнеров:
Ожидаемый вывод:
NAME COMMAND SERVICE STATUS PORTS
opensearch-dashboards "./opensearch-dashbo…" opensearch-dashboards running 0.0.0.0:5601->5601/tcp
opensearch-node1 "./opensearch-docker…" opensearch-node1 running 0.0.0.0:9200->9200/tcp, 9300/tcp, 0.0.0.0:9600->9600/tcp, 9650/tcp
opensearch-node2 "./opensearch-docker…" opensearch-node2 running 9200/tcp, 9300/tcp, 9600/tcp, 9650/tcp
-
Проверка работы
Выполните тестовый запрос к API:
curl https://localhost:9200 -ku admin:ВАШ_ПАРОЛЬ
Успешный ответ:
{
"name": "opensearch-node1",
"cluster_name": "opensearch-cluster",
"version": {
"distribution": "opensearch",
"number": "2.6.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
-
Доступ к Dashboards
Откройте в браузере:
http://localhost:5601/
Логин: admin
Пароль: указан в OPENSEARCH_INITIAL_ADMIN_PASSWORD файла docker-compose.yml
Примечания:
- Для безопасности отключается проверка хоста (
-k) при использовании демо-сертификатов
- Все команды предполагают работу в Linux-окружении
- Пароль администратора задаётся при первом запуске
Распространённые проблемы
Рассмотрите эти типичные проблемы и способы их решения, если контейнеры не запускаются или завершаются неожиданно.
Необходимость прав sudo для Docker команд
Проблема:
Требуется использовать sudo для выполнения Docker команд.
Решение:
Добавьте пользователя в группу docker:
sudo usermod -aG docker $USER
Подробнее: Post-installation steps for Linux
Ошибка: “-bash: docker-compose: command not found”
Ситуация:
При использовании Docker Desktop.
Решение:
Используйте команду без дефиса:
См. документацию Docker Compose
Ошибка: “docker: ‘compose’ is not a docker command”
Ситуация:
При использовании Docker Engine.
Решение:
Установите Docker Compose отдельно и используйте команду с дефисом:
Ошибка: “max virtual memory areas vm.max_map_count [65530] is too low”
Симптомы:
В логах сервиса появляется сообщение:
opensearch-node1 | ERROR: [1] bootstrap checks failed
opensearch-node1 | [1]: max virtual memory areas vm.max_map_count [65530] is too low...
Решение:
Увеличьте значение vm.max_map_count (см. раздел “Важные системные настройки”):
sudo sysctl -w vm.max_map_count=262144
Альтернативные способы установки
Помимо Docker, OpenSearch можно установить:
- На различные дистрибутивы Linux
- На Windows
Полные руководства: Установка и обновление OpenSearch
Дальнейшее изучение
После успешного развёртывания кластера рекомендуется изучить:
- Плагин безопасности
- Конфигурация OpenSearch
- Установка плагинов
Следующие шаги
Ознакомьтесь с разделом Взаимодействие с OpenSearch, чтобы узнать как отправлять запросы в систему.
2 - Взаимодействие с OpenSearch
Вы можете работать с OpenSearch через REST API или используя клиентские библиотеки для различных языков программирования.
На этой странице рассматривается REST API. Список доступных клиентов для языков программирования вы найдёте в разделе Клиенты.
REST API OpenSearch
REST API предоставляет гибкий способ взаимодействия с кластерами OpenSearch. Через API вы можете:
- Изменять настройки OpenSearch
- Управлять индексами
- Проверять состояние кластера
- Получать статистику
- И многое другое
Для отправки запросов можно использовать:
- Командную строку (cURL)
- Консоль Dev Tools в OpenSearch Dashboards
- Любой язык программирования с поддержкой HTTP-запросов
Отправка запросов через терминал
Формат запросов зависит от использования плагина безопасности.
Без плагина безопасности:
curl -X GET "http://localhost:9200/_cluster/health"
С плагином безопасности (требуются учётные данные):
curl -X GET "https://localhost:9200/_cluster/health" -ku admin:ВАШ_ПАРОЛЬ
По умолчанию:
- Логин:
admin
- Пароль: задаётся в параметре
OPENSEARCH_INITIAL_ADMIN_PASSWORD файла docker-compose.yml
Форматирование ответа:
Для удобочитаемого JSON добавьте параметр pretty:
curl -X GET "https://localhost:9200/_cluster/health?pretty"
Запросы с телом:
Укажите заголовок Content-Type и передайте данные через параметр -d:
curl -X GET "https://localhost:9200/students/_search?pretty" \
-H 'Content-Type: application/json' \
-d '{
"query": {
"match_all": {}
}
}'
Консоль Dev Tools в OpenSearch Dashboards использует упрощённый синтаксис:
- Откройте Dashboards:
https://localhost:5601/
- Перейдите: Management > Dev Tools
- Введите запрос (например):
GET _cluster/health
- Отправьте запрос:
- Клик по иконке ▶
- Ctrl+Enter (Cmd+Enter на Mac)
В документации OpenSearch запросы чаще всего приводятся в формате Dev Tools.
Дополнительно:
Индексация документов
Для добавления JSON-документа в индекс OpenSearch (индексации документа) отправьте HTTP-запрос со следующим форматом:
PUT https://<хост>:<порт>/<имя-индекса>/_doc/<идентификатор-документа>
Пример индексации документа о студенте:
PUT /students/_doc/1
{
"name": "Иван Иванов",
"gpa": 4.5,
"grad_year": 2023
}
После выполнения запроса:
- OpenSearch создаст индекс
students (если не существует)
- Сохранит документ с указанным ID (
1)
- Если ID не указан - сгенерирует его автоматически
Динамическое маппинг
OpenSearch автоматически определяет типы полей на основе JSON-структуры документа.
Просмотр схемы полей:
GET /students/_mapping
Пример ответа:
{
"students": {
"mappings": {
"properties": {
"gpa": {"type": "float"},
"grad_year": {"type": "long"},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
Особенности типов:
- Числовые значения:
float, long
- Текстовые поля:
- Основное поле (
text): для полнотекстового поиска (с анализом)
- Подполе (
keyword): для точного поиска по терминам
Важно: Для изменения типов (например, преобразования grad_year в дату) требуется пересоздание индекса с явным указанием маппинга.
Поиск документов
Базовый запрос (возвращает все документы):
GET /students/_search
{
"query": {
"match_all": {}
}
}
Пример ответа:
{
"took": 12,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 1,
"_source": {
"name": "Иван Иванов",
"gpa": 4.5,
"grad_year": 2023
}
}
]
}
}
Ключевые элементы ответа:
took: время выполнения (мс)hits.total: количество найденных документовhits.hits: массив результатов_score: релевантность документа
Дополнительные материалы:
Обновление документов
В OpenSearch документы неизменяемы, но их можно обновить, полностью заменив содержимое или изменив отдельные поля.
Полное обновление (переиндексация)
Используйте Index Document API для полного обновления:
PUT /students/_doc/1
{
"name": "Иван Иванов",
"gpa": 4.7, // Обновлённое значение
"grad_year": 2023,
"address": "ул. Ленина, 123" // Новое поле
}
Частичное обновление
Используйте Update Document API для изменения отдельных полей:
POST /students/_update/1/
{
"doc": {
"gpa": 4.7,
"address": "ул. Ленина, 123"
}
}
Удаление данных
Удаление документа
Удаление индекса
Настройка индексов
Маппинги и параметры
Индексы настраиваются через:
- Маппинги - определяют типы полей
- Параметры - настройки индекса (количество шардов и т.д.)
Пример создания индекса с явными настройками:
PUT /students
{
"settings": {
"index.number_of_shards": 1
},
"mappings": {
"properties": {
"name": {"type": "text"},
"grad_year": {"type": "date"}
}
}
}
Проверка маппинга:
Важно:
- Типы полей нельзя изменить после создания
- Для изменения требуется пересоздание индекса
Дополнительные материалы
Следующие шаги
Ознакомьтесь с разделом Загрузка данных в OpenSearch для изучения способов импорта данных.
3 - Загрузка данных в OpenSearch
Добавление отдельных документов. Массовая загрузка документов. Использование Data Prepper.
Существует несколько способов импорта данных:
-
Добавление отдельных документов
См. раздел Индексация документов
-
Массовая загрузка документов
См. раздел Пакетная индексация
-
Использование Data Prepper
Серверного сборщика данных OpenSearch для обработки перед анализом
-
Другие инструменты
См. Инструменты OpenSearch
Пакетная индексация
Для массовой загрузки используйте Bulk API:
POST _bulk
{ "create": { "_index": "students", "_id": "2" } }
{ "name": "Алексей Петров", "gpa": 4.2, "grad_year": 2025 }
{ "create": { "_index": "students", "_id": "3" } }
{ "name": "Мария Смирнова", "gpa": 4.8, "grad_year": 2024 }
Работа с тестовыми данными
OpenSearch предоставляет демонстрационный набор данных электронной коммерции.
Шаги для создания тестового индекса:
-
Скачайте файлы:
# Маппинг полей
curl -O https://raw.githubusercontent.com/.../ecommerce-field_mappings.json
# Данные для загрузки
curl -O https://raw.githubusercontent.com/.../ecommerce.ndjson
-
Примените схему полей:
curl -H "Content-Type: application/json" -X PUT "https://localhost:9200/ecommerce" \
-ku admin:ПАРОЛЬ --data-binary "@ecommerce-field_mappings.json"
-
Загрузите данные:
curl -H "Content-Type: application/x-ndjson" -X POST "https://localhost:9200/ecommerce/_bulk" \
-ku admin:ПАРОЛЬ --data-binary "@ecommerce.ndjson"
Пример поиска:
GET ecommerce/_search
{
"query": {
"match": {
"customer_first_name": "Светлана"
}
}
}
Визуализация данных
Инструкции по работе с визуализациями см. в руководстве по OpenSearch Dashboards.
Дополнительные материалы
Следующие шаги
Изучите раздел Поиск по данным для получения информации о возможностях поиска.
4 - Поиск данных в OpenSearch
OpenSearch предлагает несколько методов поиска: Query DSL, Query string, SQL, PPL, DQL
OpenSearch предлагает несколько методов поиска:
- Query DSL - основной язык запросов для сложных поисковых сценариев
- Query string - упрощённый синтаксис для параметров запроса
- SQL - традиционный язык запросов для реляционных данных
- PPL (Piped Processing Language) - язык для задач observability
- DQL (Dashboards Query Language) - текстовый язык фильтрации в Dashboards
Подготовка данных
Перед началом загрузим тестовые данные о студентах:
POST _bulk
{ "create": { "_index": "students", "_id": "1" } }
{ "name": "Иван Петров", "gpa": 4.5, "grad_year": 2023}
{ "create": { "_index": "students", "_id": "2" } }
{ "name": "Алексей Смирнов", "gpa": 4.2, "grad_year": 2025 }
{ "create": { "_index": "students", "_id": "3" } }
{ "name": "Мария Иванова", "gpa": 4.8, "grad_year": 2024 }
Базовые запросы
Получение всех документов:
Эквивалентно:
GET /students/_search
{
"query": { "match_all": {} }
}
Структура ответа:
took - время выполнения (мс)timed_out - флаг превышения таймаута_shards - статистика по шардамhits - результаты поиска:
total - общее количество совпаденийmax_score - максимальная релевантностьhits - массив документов с оценкой релевантности
Query string поиск
Пример поиска по имени:
GET /students/_search?q=name:john
вернет ответ:
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "John Doe",
"grade": 12,
"gpa": 3.89,
"grad_year": 2022,
"future_plans": "John plans to be a computer science major"
}
}
]
}
}
Полнотекстовый поиск (Query DSL)
Поиск с анализом текста:
GET /students/_search
{
"query": {
"match": {
"name": "иван" # Найдёт "Иван Петров" и "Мария Иванова"
}
}
}
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "Иван Петров",
"gpa": 3.89,
"grad_year": 2022
}
}
]
}
}
Поиск по ключевым словам
Точное совпадение (без анализа):
GET /students/_search
{
"query": {
"match": {
"name.keyword": "john doe" # Только полное совпадение
}
}
}
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
}
]
}
}
Фильтры
Точное значение:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "grad_year": 2023 }}
]
}
}
}
Диапазон значений:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "range": { "gpa": { "gt": 4.0 }}}
]
}
}
}
Составные запросы
Комбинация условий:
GET students/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "иван" } },
{ "range": { "gpa": { "gte": 4.0 } } },
{ "term": { "grad_year": 2023 }}
]
}
}
}
Расширенные возможности
OpenSearch поддерживает современные методы поиска:
- k-NN (поиск ближайших соседей)
- Семантический поиск
- Мультимодальный поиск
- Гибридный поиск
Дополнительные материалы
5 - Начало работы с безопасностью в OpenSearch
Демонстрационная конфигурация безопасности и настройка демонстрационной конфигурации
Демонстрационная конфигурация безопасности
Наиболее простой способ начать работу с безопасностью OpenSearch - использовать демонстрационную конфигурацию. OpenSearch включает полезные скрипты, в том числе:
install_demo_configuration.sh (для Linux/macOS)install_demo_configuration.bat (для Windows)
Расположение скрипта:
plugins/opensearch-security/tools/
Действия скрипта:
- Создает демонстрационные сертификаты для TLS-шифрования на транспортном и REST-уровнях
- Настраивает тестовых пользователей, роли и привязки ролей
- Конфигурирует плагин безопасности для использования внутренней базы данных аутентификации
- Обновляет
opensearch.yml базовой конфигурацией для запуска кластера
Важно! Демонстрационные сертификаты и пароли по умолчанию не должны использоваться в production. Перед развертыванием в продакшене их необходимо заменить на собственные.
Настройка демонстрационной конфигурации
Перед запуском скрипта:
- Установите переменную окружения с надежным паролем администратора:
export OPENSEARCH_INITIAL_ADMIN_PASSWORD=<ваш_надежный_пароль>
- Проверьте надежность пароля с помощью инструмента Zxcvbn
Запуск скрипта:
./plugins/opensearch-security/tools/install_demo_configuration.sh
Проверка конфигурации:
curl -k -XGET -u admin:<пароль> https://<ip-opensearch>:9200
Ожидаемый ответ:
{
"name": "smoketestnode",
"cluster_name": "opensearch",
"version": {
"distribution": "opensearch",
"number": "2.13.0"
},
"tagline": "The OpenSearch Project: https://opensearch.org/"
}
Настройка OpenSearch Dashboards
Добавьте в opensearch_dashboards.yml следующую конфигурацию:
opensearch.hosts: [https://localhost:9200]
opensearch.ssl.verificationMode: none
opensearch.username: kibanaserver
opensearch.password: kibanaserver
opensearch.requestHeadersWhitelist: [authorization, securitytenant]
opensearch_security.multitenancy.enabled: true
opensearch_security.multitenancy.tenants.preferred: [Private, Global]
opensearch_security.readonly_mode.roles: [kibana_read_only]
opensearch_security.cookie.secure: false # Отключено для HTTP
Запуск Dashboards:
yarn start --no-base-path
После запуска в логах появятся строки:
[info][listening] Server running at http://localhost:5601
[info][server][OpenSearchDashboards][http] http server running at http://localhost:5601
Доступ через браузер: http://localhost:5601
Логин: admin
Пароль: значение из OPENSEARCH_INITIAL_ADMIN_PASSWORD
Управление пользователями и ролями
1. Добавление пользователей
Способы:
- Редактирование
internal_users.yml
- Использование API
- Через интерфейс OpenSearch Dashboards
Пример добавления пользователя в internal_users.yml:
test-user:
hash: "$2y$12$CkxFoTAJKsZaWv/m8VoZ6ePG3DBeBTAvoo4xA2P21VCS9w2RYumsG"
backend_roles:
- "test-backend-role"
- "kibanauser"
description: "Тестовый пользователь"
Генерация хеша пароля:
./plugins/opensearch-security/tools/hash.sh
Введите пароль (например, secretpassword), скопируйте полученный хеш.
2. Создание ролей
Формат roles.yml:
<имя_роли>:
cluster_permissions:
- <разрешение_кластера>
index_permissions:
- index_patterns:
- <шаблон_индекса>
allowed_actions:
- <разрешения_индекса>
Пример роли для доступа к индексу:
human_resources:
index_permissions:
- index_patterns:
- "humanresources"
allowed_actions:
- "READ"
3. Привязка пользователей к ролям
Формат roles_mapping.yml:
<имя_роли>:
users:
- <имя_пользователя>
backend_roles:
- <имя_роли>
Пример привязки:
human_resources:
backend_roles:
- "test-backend-role"
kibana_user:
backend_roles:
- "kibanauser"
Применение изменений конфигурации
После изменения файлов необходимо загрузить конфигурацию в security index:
./plugins/opensearch-security/tools/securityadmin.sh \
-cd "config/opensearch-security" \
-icl \
-key "../kirk-key.pem" \
-cert "../kirk.pem" \
-cacert "../root-ca.pem" \
-nhnv
Дальнейшие шаги
- Ознакомьтесь с Рекомендациями по безопасности OpenSearch
- Изучите Обзор конфигурации безопасности для кастомизации под ваши задачи
Примечания:
- Все команды предполагают выполнение из корневой директории OpenSearch
- Для production-окружений обязательно замените демонстрационные сертификаты
- Регулярно обновляйте пароли администраторов
6 - Основные концепции OpenSearch
Полное руководство по OpenSearch: документы, индексы, шарды, узлы кластера, текстовый анализ и жизненный цикл данных. Узнайте, как работают индексация, поиск и агрегация в распределенной поисковой системе.
Базовые понятия
Документ
Базовая единица информации в OpenSearch, хранимая в формате JSON. Представляет собой структурированные данные в виде пар “ключ-значение”.
Индекс
Коллекция логически связанных документов. Аналог таблицы в реляционных БД.
JSON (JavaScript Object Notation)
Текстовый формат для хранения данных, использующий структуру ключ-значение. Основной формат представления данных в OpenSearch.
Маппинг
Схема индекса, определяющая:
- Типы полей документов
- Способы индексации и хранения
- Параметры анализа текста
Архитектура кластера
Узел (Node)
Отдельный сервер, являющийся частью кластера OpenSearch.
Кластер
Совокупность узлов, работающих как единая система.
Управляющий узел (Cluster Manager)
Специальный узел, координирующий кластерные операции:
- Создание/удаление индексов
- Балансировка нагрузки
- Мониторинг состояния узлов
Шард (Shard)
Часть индекса, содержащая подмножество его данных. Индексы разделяются на шарды для:
- Горизонтального масштабирования
- Распределения нагрузки
Типы шардов:
- Первичный (Primary) - основной шард с данными
- Реплика (Replica) - копия первичного шарда для:
- Отказоустойчивости
- Повышения производительности поиска
Структуры данных и хранение
Doc Values
Оптимизированная on-disk структура для:
- Сортировки
- Агрегации
- Доступа к значениям полей
Инвертированный индекс
Структура данных, отображающая термины на документы, которые их содержат. Основа полнотекстового поиска.
Lucene
Библиотека поиска, лежащая в основе OpenSearch. Отвечает за:
- Индексацию
- Хранение
- Поиск данных
Сегмент (Segment)
Неизменяемая единица хранения данных внутри шарда. Особенности:
- Создается при операции refresh
- Объединяется в процессе merge
- Оптимизирован для быстрого поиска
Операции с данными
Ингestion
Процесс добавления данных в OpenSearch. Включает:
- Прием данных
- Парсинг
- Подготовку к индексации
Индексация
Процесс организации данных для эффективного поиска:
- Анализ текста
- Построение инвертированного индекса
- Хранение документов
Пакетная индексация
Массовая загрузка документов через Bulk API:
- Высокая производительность
- Минимизация сетевых издержек
- Атомарность операций
Анализ текста
Текстовый анализ
Процесс преобразования неструктурированного текста в последовательность терминов для индексации.
Компоненты анализатора:
-
Character Filter
Обрабатывает сырой текст:
- Удаление/замена символов
- HTML-разметка
-
Tokenizer
Разбивает текст на токены (слова) с метаданными:
-
Token Filter
Модифицирует токены:
- Приведение к нижнему регистру
- Удаление стоп-слов
- Добавление синонимов
- Стемминг
Типы анализаторов:
Стемминг
Приведение слов к базовой форме (например: “running” → “run”)
Поиск и запросы
Типы запросов:
- Query DSL - основной язык сложных запросов
- Query String - упрощенный синтаксис для URL
- DQL - язык фильтрации в Dashboards
- PPL - язык для observability с pipe-синтаксисом
Контексты выполнения:
Типы поиска:
Агрегации
Механизм анализа и суммирования данных:
- Метрики (avg, sum)
- Бакетизация (histogram, date_histogram)
- Вложенные агрегации
Жизненный цикл обновлений
-
Транзакционный лог (translog)
- Операция записывается в translog
- Гарантия durability через fsync
- Подтверждение клиенту
-
In-memory буфер
- Данные добавляются в буфер Lucene
- Еще не видны для поиска
-
Refresh
- Сброс буфера в сегменты
- Данные становятся видимыми для поиска
- Без гарантии durability
-
Flush
- Запись сегментов на диск (fsync)
- Очистка translog
- Гарантия сохранности данных
-
Merge
- Объединение мелких сегментов
- Оптимизация:
- Уменьшение количества файлов
- Освобождение места
- Улучшение производительности
Критические операции
Translog
Журнал операций для гарантии сохранности данных. Особенности:
- Записывается синхронно перед подтверждением
- Ограничен по размеру
- Очищается после flush
Refresh
Периодическая операция (по умолчанию каждые 1с):
- Делает данные доступными для поиска
- Создает новые сегменты
- Не гарантирует сохранность при сбое
Flush
Операция записи на диск:
- Обеспечивает durability
- Выполняется автоматически при:
- Достижении лимита translog
- Плановом обслуживании
Merge
Фоновая оптимизация:
- Управляется политикой слияния
- Регулирует:
- Частоту слияний
- Максимальный размер сегментов
- Параллелизм операций