Query DSL - язык запросов OpenSearch
OpenSearch предоставляет мощный язык запросов (Query Domain-Specific Language), основанный на JSON-синтаксисе. Этот язык позволяет выполнять гибкий и точный поиск по данным.
Введение в Query DSL
OpenSearch предоставляет мощный язык запросов (Query Domain-Specific Language), основанный на JSON-синтаксисе. Этот язык позволяет выполнять гибкий и точный поиск по данным.
Базовый пример запроса:
GET testindex/_search
{
"query": {
"match_all": {}
}
Этот запрос возвращает все документы в указанном индексе.
Типы запросов
Запросы делятся на две основные категории:
1. Листовые запросы (Leaf queries)
Особенности:
- Выполняют поиск по конкретным полям
- Могут использоваться самостоятельно
- Не содержат других запросов
Основные типы:
1.1 Полнотекстовые запросы:
- Анализируют текст запроса
- Применяют тот же анализатор, что и при индексации
- Примеры:
match, match_phrase, multi_match
1.2 Термино-уровневые запросы:
- Ищут точные значения без анализа текста
- Не учитывают релевантность
- Примеры:
term, terms, range, exists
1.3 Геопространственные запросы:
- Работают с географическими данными
- Примеры:
geo_distance, geo_bounding_box
1.4 Запросы соединений:
- Для работы с вложенными документами
- Примеры:
nested, has_child, has_parent
1.5 Позиционные запросы (Span queries):
- Точный поиск с учетом позиции терминов
- Часто используются для юридических документов
1.6 Специализированные запросы:
more_like_this - поиск похожих документовscript - запросы с использованием скриптовpercolate - обратный поиск
2. Составные запросы (Compound queries)
Особенности:
- Объединяют несколько запросов
- Модифицируют поведение дочерних запросов
- Управляют логикой выполнения
Основные типы:
bool - булева комбинация запросовdis_max - поиск по нескольким полямconstant_score - задает фиксированную релевантностьfunction_score - кастомные алгоритмы релевантности
Особенности обработки специальных символов
Проблема:
Стандартный анализатор некорректно обрабатывает Unicode-символы (например, дефис), что может привести к:
- Неожиданным результатам поиска
- Проблемам контроля доступа
Пример проблемы:
{
"match": {
"user.id": "User-1"
}
}
Анализатор может интерпретировать “User-1” как два отдельных термина.
Решение:
- Использовать
keyword тип поля для точного совпадения
- Настроить кастомный анализатор
Ресурсоемкие запросы
Типы затратных запросов:
- Нечеткий поиск (
fuzzy)
- Поиск по префиксу (
prefix)
- Диапазонные запросы по текстовым полям
- Регулярные выражения (
regexp)
- Wildcard-запросы
- Сложные
query_string запросы
Защита от ресурсоемких запросов:
PUT _cluster/settings
{
"persistent": {
"search.allow_expensive_queries": false
}
}
Мониторинг:
Для отслеживания медленных запросов используйте shard slow logs.
Рекомендации по использованию
- Для точного соответствия используйте
keyword тип полей
- Избегайте специальных символов в текстовых полях
- Мониторьте ресурсоемкие запросы
- Для сложной логики комбинируйте запросы через
bool
- Используйте
explain для анализа работы запросов
1 - Контекст запроса и фильтра
Запросы состоят из условий (query clauses), которые могут выполняться в Контексте фильтра - проверяет соответствие документа условию Да/Нет и Контексте запроса - оценивает степень соответствия документа условию с расчетом релевантности
Основные концепции
Запросы состоят из условий (query clauses), которые могут выполняться в:
- Контексте фильтра - проверяет соответствие документа условию (“Да/Нет”)
- Контексте запроса - оценивает степень соответствия документа условию с расчетом релевантности
Оценка релевантности (_score)
Релевантность измеряется числовым значением в поле _score:
"hits" : [
{
"_index" : "shakespeare",
"_id" : "32437",
"_score" : 18.781435,
"_source" : {
"type" : "line",
"line_id" : 32438,
"play_name" : "Hamlet",
"speech_number" : 3,
"line_number" : "1.1.3",
"speaker" : "BERNARDO",
"text_entry" : "Long live the king!"
}
},
...
Чем выше значение _score, тем более релевантен документ. Разные типы запросов используют различные алгоритмы расчета релевантности, но все учитывают тип контекста выполнения условия.
Контекст фильтра
Характеристики:
- Возвращает только факт соответствия (бинарный результат)
- Не вычисляет оценку релевантности
- Оптимален для точных значений
- Результаты кэшируются для повышения производительности
Пример использования:
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "honors": true }},
{ "range": { "graduation_year": { "gte": 2020, "lte": 2022 }}}
]
}
}
}
Этот запрос ищет студентов:
- С отличием (
honors: true)
- Выпустившихся в 2020-2022 годах
Контекст запроса
Характеристики:
- Оценивает степень соответствия документа
- Возвращает численную оценку релевантности
- Используется для полнотекстового поиска
- Поддерживает анализ текста (морфологию, синонимы)
Пример использования:
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "long live king"
}
}
}
Этот запрос:
- Ищет вариации фразы “long live king”
- Учитывает словоформы и синонимы
- Сортирует результаты по релевантности
Особенности вычисления _score
- Используется 24-битная точность (числа с плавающей запятой)
- При превышении точности может происходить потеря данных
- Разные типы запросов используют различные алгоритмы расчета
Рекомендации по применению:
- Для точных значений (ID, даты, категории) используйте контекст фильтра
- Для текстового поиска применяйте контекст запроса
- Комбинируйте оба подхода в сложных запросах через
bool запрос
2 - Сравнение термовых и полнотекстовых запросов
Термовые (term-level) и полнотекстовые (full-text) запросы используются для поиска по тексту, но имеют принципиальные отличия
Основные различия
Термовые (term-level) и полнотекстовые (full-text) запросы используются для поиска по тексту, но имеют принципиальные отличия:
| Характеристика |
Термовые запросы |
Полнотекстовые запросы |
| Описание |
Определяют, какие документы соответствуют запросу |
Оценивают, насколько хорошо документы соответствуют запросу |
| Анализатор |
Поисковый терм не анализируется |
Используется тот же анализатор, что и при индексации поля |
| Релевантность |
Не сортируют результаты по релевантности |
Рассчитывают оценку релевантности и сортируют результаты |
| Использование |
Точные значения (числа, даты, теги) |
Текстовые поля с учетом морфологии и вариантов слов |
OpenSearch использует алгоритм ранжирования BM25 для расчета оценок релевантности.
Когда использовать каждый тип запроса?
Пример 1: Поиск фразы
Рассмотрим поиск фразы “To be, or not to be” в произведениях Шекспира.
Термовый запрос:
GET shakespeare/_search
{
"query": {
"term": {
"text_entry": "To be, or not to be"
}
}
}
Результат:
{
"took": 3,
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"hits": []
}
}
Запрос не нашел совпадений, так как ищет точную неизмененную фразу.
Полнотекстовый запрос:
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "To be, or not to be"
}
}
}
Результат (сокращенный):
{
"took": 19,
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"hits": [
{
"_score": 17.419369,
"_source": {
"text_entry": "To be, or not to be: that is the question:"
}
},
{
"_score": 14.883024,
"_source": {
"text_entry": "Not like a corse; or if, not to be buried,"
}
}
]
}
}
Полнотекстовый запрос нашел релевантные результаты, проанализировав фразу.
Пример 2: Поиск точного термина
Для поиска точного значения “HAMLET” в поле speaker эффективнее термовый запрос:
GET shakespeare/_search
{
"query": {
"term": {
"speaker": "HAMLET"
}
}
}
Результат (сокращенный):
{
"took": 5,
"hits": {
"total": {
"value": 1582,
"relation": "eq"
},
"hits": [
{
"_score": 4.2540946,
"_source": {
"speaker": "HAMLET",
"text_entry": "[Aside] A little more than kin..."
}
},
{
"_score": 4.2540946,
"_source": {
"speaker": "HAMLET",
"text_entry": "Not so, my lord..."
}
}
]
}
}
Важно: Поиск по “Hamlet” не даст результатов, так как поле speaker является keyword и хранится в исходном регистре.
Рекомендации по выбору типа запроса
-
Используйте термовые запросы для:
- Точных значений (ID, коды, категории)
- Полям типа keyword
- Когда не нужна сортировка по релевантности
-
Используйте полнотекстовые запросы для:
- Текстового поиска с анализом
- Когда важна оценка релевантности
- Поиска по словоформам и синонимам
-
Для полей text:
Всегда используйте полнотекстовые запросы, так как их значения анализируются при индексации.
-
Для полей keyword:
Используйте термовые запросы для точного соответствия.
3 - Термино-уровневые запросы
Ищут точные значения без анализа текста. Не учитывают релевантность
Общее описание
Термино-уровневые запросы (term-level queries) выполняют поиск по индексу для нахождения документов, содержащих точное соответствие указанному термину. В отличие от полнотекстовых запросов, результаты термино-уровневых запросов не сортируются по оценке релевантности.
Ключевые особенности:
- Работают только с точными значениями
- Не анализируют поисковый термин
- Оптимальны для поиска по полям типа
keyword
- Не подходят для анализа текстовых полей (используйте полнотекстовые запросы)
Типы термино-уровневых запросов
В таблице представлены все виды термино-уровневых запросов:
| Тип запроса |
Описание |
term |
Поиск документов, содержащих точное соответствие указанному термину в заданном поле |
terms |
Поиск документов, содержащих один или несколько указанных терминов в заданном поле |
terms_set |
Поиск документов, соответствующих минимальному количеству указанных терминов |
ids |
Поиск документов по их идентификаторам |
range |
Поиск документов, значения поля которых попадают в указанный диапазон |
prefix |
Поиск документов, содержащих термины с указанным префиксом |
exists |
Поиск документов, имеющих любое проиндексированное значение в указанном поле |
fuzzy |
Поиск документов, содержащих термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна (количество односимвольных изменений для преобразования одного термина в другой) |
wildcard |
Поиск документов, содержащих термины, соответствующие шаблону с подстановочными символами |
regexp |
Поиск документов, содержащих термины, соответствующие регулярному выражению |
Практические рекомендации
-
Для полей keyword всегда используйте термино-уровневые запросы:
GET products/_search
{
"query": {
"term": {
"product_code": "ABC-123"
}
}
}
-
Избегайте использования термино-уровневых запросов для полей типа text, так как они проходят анализ при индексации.
-
Для сложных условий комбинируйте несколько термино-уровневых запросов через bool:
GET logs/_search
{
"query": {
"bool": {
"must": [
{ "term": { "status": "error" } },
{ "range": { "timestamp": { "gte": "2023-01-01" }}}
]
}
}
}
-
Для нечеткого поиска используйте fuzzy с указанием максимального расстояния:
GET contacts/_search
{
"query": {
"fuzzy": {
"last_name": {
"value": "Smith",
"fuzziness": 2
}
}
}
}
Все технические термины сохранены в оригинальном написании (term, fuzzy, wildcard и т.д.) для соответствия международной практике, с добавлением пояснений на русском языке для лучшего понимания.
3.1 - exists
Поиск документов, имеющих любое проиндексированное значение в указанном поле
Запрос exists
Назначение
Запрос exists используется для поиска документов, содержащих указанное поле.
Когда поле считается отсутствующим?
Индексированное значение будет отсутствовать для поля документа в следующих случаях:
- В маппинге поля указано
"index": false
- Значение поля в исходном JSON равно
null или [] (пустой массив)
- Длина значения поля превышает параметр
ignore_above в маппинге
- Значение поля имеет некорректный формат и в маппинге определен
ignore_malformed
Когда поле считается существующим?
Индексированное значение будет присутствовать для поля документа в следующих случаях:
- Значение является массивом, содержащим как
null, так и не-null элементы (например, ["один", null])
- Значение представляет собой пустую строку (
"" или "-")
- Значение является кастомным
null_value, определенным в маппинге поля
Пример использования
Добавление тестовых документов:
PUT testindex/_doc/1
{
"title": "Ветер крепчает"
}
PUT testindex/_doc/2
{
"title": "Унесенные ветром",
"description": "Американский эпический исторический фильм 1939 года"
}
Поиск документов с полем description:
GET testindex/_search
{
"query": {
"exists": {
"field": "description"
}
}
}
Результат выполнения:
{
"took": 3,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "testindex",
"_id": "2",
"_source": {
"title": "Унесенные ветром",
"description": "Американский эпический исторический фильм 1939 года"
}
}
]
}
}
Поиск документов с отсутствующими полями
Для поиска документов без определенного поля используйте комбинацию must_not и exists:
GET testindex/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "description"
}
}
}
}
}
Результат выполнения:
{
"took": 19,
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "testindex",
"_id": "1",
"_source": {
"title": "Ветер крепчает"
}
}
]
}
}
Параметры запроса
Запрос принимает следующие параметры:
| Параметр |
Тип данных |
Описание |
field |
Строка |
Обязательное поле. Имя поля, которое должно существовать в документе. |
boost |
Число с плавающей точкой |
Определяет вес поля при расчете релевантности. Значения >1 увеличивают вес, значения между 0 и 1 уменьшают вес. По умолчанию: 1.0. |
Пример с параметром boost:
GET testindex/_search
{
"query": {
"exists": {
"field": "description",
"boost": 2.0
}
}
}
Особенности работы
- Запрос
exists проверяет именно наличие индексированного значения поля, а не его наличие в исходном документе.
- Для проверки отсутствия поля всегда используйте комбинацию
bool + must_not + exists.
- Запрос можно комбинировать с другими типами запросов в составе
bool запроса.
3.2 - fuzzy
Поиск документов, содержащих термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна
Нечеткий поиск (Fuzzy query)
Основные понятия
Нечеткий запрос (fuzzy query) ищет документы, содержащие термины, схожие с поисковым термином в пределах максимально допустимого расстояния Дамерау-Левенштейна. Это расстояние измеряет количество односимвольных изменений, необходимых для преобразования одного термина в другой:
- Замены: кот → бот
- Вставки: кот → коты
- Удаления: кот → от
- Транспозиции: кот → кто
Принцип работы
- Запрос генерирует все возможные варианты поискового термина, попадающие в заданное расстояние редактирования
- Количество вариантов ограничивается параметром
max_expansions
- Поиск выполняется по всем сгенерированным вариантам
Примеры запросов
Базовый пример с поиском ошибочного написания “HALET” вместо “HAMLET”:
GET shakespeare/_search
{
"query": {
"fuzzy": {
"speaker": {
"value": "HALET"
}
}
}
}
Примечание: Используется автоматическое определение расстояния (AUTO)
Расширенный пример с настройкой параметров:
GET shakespeare/_search
{
"query": {
"fuzzy": {
"speaker": {
"value": "HALET",
"fuzziness": "2",
"max_expansions": 40,
"prefix_length": 0,
"transpositions": true,
"rewrite": "constant_score"
}
}
}
}
Параметры запроса
Синтаксис запроса:
GET _search
{
"query": {
"fuzzy": {
"<поле>": {
"value": "образец",
...
}
}
}
}
Доступные параметры:
| Параметр |
Тип данных |
Описание |
value |
Строка |
Обязательный. Искомый термин |
boost |
Число с плавающей точкой |
Влияет на вес поля при расчете релевантности (>1 - увеличивает, 0-1 - уменьшает). По умолчанию: 1.0 |
fuzziness |
AUTO, 0 или положительное число |
Максимальное расстояние редактирования. AUTO - автоматический расчет на основе длины термина |
max_expansions |
Положительное целое |
Максимальное количество вариантов термина для поиска. По умолчанию: 50 |
prefix_length |
Неотрицательное целое |
Количество начальных символов, не учитываемых при нечетком сравнении. По умолчанию: 0 |
rewrite |
Строка |
Стратегия перезаписи запроса. Допустимые значения: constant_score, scoring_boolean и др. По умолчанию: constant_score |
transpositions |
Логическое |
Разрешать перестановки соседних символов (ab→ba). По умолчанию: true |
Особенности производительности
- Большие значения
max_expansions (особенно с prefix_length=0) могут снизить производительность из-за генерации множества вариантов
- При
search.allow_expensive_queries=false нечеткие запросы не выполняются
- Для длинных слов рекомендуется использовать
prefix_length>0
Практические рекомендации
- Для исправления опечаток используйте
fuzziness=1 или fuzziness=2
- Для профессиональных терминов уменьшайте
max_expansions
- Для ускорения поиска увеличивайте
prefix_length
- Для точных полей отключайте транспозиции (
transpositions=false)
3.3 - ids
Поиск документов по их идентификаторам
Запрос IDs (поиск по идентификаторам)
Назначение
Запрос ids позволяет находить документы по их уникальным идентификаторам в поле _id.
Синтаксис запроса
GET shakespeare/_search
{
"query": {
"ids": {
"values": [
"34229",
"91296"
]
}
}
}
Параметры запроса
| Параметр |
Тип данных |
Описание |
Обязательный |
По умолчанию |
values |
Массив строк |
Список идентификаторов документов для поиска |
Да |
- |
boost |
Число с плавающей точкой |
Коэффициент усиления релевантности. Значения >1 увеличивают вес, 0-1 уменьшают вес |
Нет |
1.0 |
Особенности работы
-
Тип идентификаторов:
Идентификаторы всегда передаются как строки, даже если в системе они числовые.
-
Производительность:
Запрос оптимален для выборки небольшого количества документов по известным ID.
-
Использование с boost:
Пример с изменением релевантности:
GET shakespeare/_search
{
"query": {
"ids": {
"values": ["34229", "91296"],
"boost": 2.0
}
}
}
-
Ограничения:
- Не поддерживает шаблоны или диапазоны ID
- Для поиска по >1000 ID рекомендуется использовать
terms запрос
-
Ответ системы:
Возвращает только те документы, чьи ID присутствуют в индексе (несуществующие ID игнорируются без ошибки)
Альтернативные подходы
Для сложных сценариев поиска по ID можно использовать:
GET _search
{
"query": {
"terms": {
"_id": ["34229", "91296"]
}
}
}
3.4 - prefix
Поиск документов, содержащих термины с указанным префиксом
Запрос prefix (поиск по префиксу)
Назначение
Запрос prefix выполняет поиск терминов, начинающихся с указанной приставки (префикса). Используется для:
- Автодополнения
- Поиска по начальным символам
- Классификации данных с общими префиксами
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"prefix": {
"speaker": "KING H"
}
}
}
Этот запрос ищет документы, где поле speaker содержит термины, начинающиеся на “KING H”.
Расширенный синтаксис с параметрами
GET shakespeare/_search
{
"query": {
"prefix": {
"speaker": {
"value": "KING H",
"boost": 1.5,
"case_insensitive": true,
"rewrite": "scoring_boolean"
}
}
}
}
Параметры запроса
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
Строка |
Обязательный. Искомый префикс |
- |
boost |
Число с плавающей точкой |
Коэффициент усиления релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
case_insensitive |
Логический |
Регистронезависимый поиск. Если true, игнорирует регистр символов |
false |
rewrite |
Строка |
Метод перезаписи запроса. Допустимые значения: constant_score, scoring_boolean и др. |
constant_score |
Особенности работы
-
Производительность:
- При включенной настройке
index_prefixes в маппинге поля запрос выполняется оптимально
- При
search.allow_expensive_queries=false запросы prefix не выполняются (кроме случаев с index_prefixes)
-
Регистр символов:
- По умолчанию поиск чувствителен к регистру
- Для регистронезависимого поиска используйте
"case_insensitive": true
-
Примеры использования:
// Поиск продуктов с кодом, начинающимся на "A12"
GET products/_search
{
"query": {
"prefix": {
"product_code": "A12"
}
}
}
// Поиск городов, названия которых начинаются на "сан"
GET cities/_search
{
"query": {
"prefix": {
"name": {
"value": "сан",
"case_insensitive": true
}
}
}
}
-
Рекомендации:
- Для полей с длинными значениями установите
index_prefixes в маппинге
- Избегайте очень коротких префиксов (1-2 символа) на больших индексах
- Для сложных сценариев автодополнения рассмотрите
completion suggester
3.5 - range
Поиск документов, значения поля которых попадают в указанный диапазон
Запрос range (диапазонный запрос)
Основные возможности
Запрос range позволяет выполнять поиск документов, значения полей которых попадают в указанный диапазон.
Синтаксис базового запроса
GET shakespeare/_search
{
"query": {
"range": {
"line_id": {
"gte": 10,
"lte": 20
}
}
}
}
Этот запрос находит документы, где значение поля line_id находится в диапазоне от 10 до 20 включительно.
Операторы сравнения
Параметр поля в запросе range принимает следующие операторы:
| Оператор |
Описание |
gte |
Больше или равно |
gt |
Строго больше |
lte |
Меньше или равно |
lt |
Строго меньше |
Работа с датами
Пример поиска по датам:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "2019/01/01",
"lte": "2019/12/31"
}
}
}
}
Этот запрос находит все товары, добавленные в 2019 году.
Указание формата даты:
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "01/01/2022",
"lte": "31/12/2022",
"format":"dd/MM/yyyy"
}
}
}
}
Параметр format позволяет указать формат даты, отличный от формата, заданного в маппинге поля.
Особенности обработки дат
Автозаполнение отсутствующих компонентов даты:
OpenSearch заполняет отсутствующие компоненты даты следующими значениями:
- MONTH_OF_YEAR: 01
- DAY_OF_MONTH: 01
- HOUR_OF_DAY: 23
- MINUTE_OF_HOUR: 59
- SECOND_OF_MINUTE: 59
- NANO_OF_SECOND: 999_999_999
Пример:
GET /products/_search
{
"query": {
"range": {
"created": {
"gte": "2022",
"lte": "2022-12-31"
}
}
}
}
В этом случае начальная дата будет интерпретирована как 2022-01-01T23:59:59.999999999Z.
Относительные даты
Использование математики дат:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "2019/01/01||-1y-1d"
}
}
}
}
Здесь 2019/01/01 - это опорная дата, от которой вычитается 1 год и 1 день.
Округление дат:
GET products/_search
{
"query": {
"range": {
"created": {
"gte": "now-1y/M"
}
}
}
}
Ключевое слово now ссылается на текущую дату и время, /M означает округление по месяцам.
Правила округления относительных дат
| Параметр | Правило округления | Пример для 2022-05-18||/M |
|———-|—————————————-|—————————–|
| gt | Округляет вверх | 2022-06-01T00:00:00.000 |
| gte | Округляет вниз | 2022-05-01T00:00:00.000 |
| lt | Округляет вниз до последней миллисекунды | 2022-04-30T23:59:59.999 |
| lte | Округляет вверх до последней миллисекунды | 2022-05-31T23:59:59.999 |
Часовые пояса
По умолчанию даты считаются в UTC. Можно указать часовой пояс параметром time_zone:
GET /products/_search
{
"query": {
"range": {
"created": {
"time_zone": "-04:00",
"gte": "2022-04-17T06:00:00"
}
}
}
}
Значение 2022-04-17T06:00:00-04:00 будет преобразовано в 2022-04-17T10:00:00 UTC.
Дополнительные параметры
Синтаксис с параметрами:
GET _search
{
"query": {
"range": {
"<поле>": {
"gt": 10,
...
}
}
}
}
Доступные параметры:
| Параметр |
Тип данных |
Описание |
format |
Строка |
Формат даты для этого запроса. По умолчанию используется формат, заданный в маппинге поля. |
relation |
Строка |
Определяет способ сопоставления значений для полей диапазона. Допустимые значения:
- INTERSECTS (по умолчанию): Находит документы, чей диапазон пересекается с запросом
- CONTAINS: Находит документы, чей диапазон полностью содержит запрос
- WITHIN: Находит документы, чей диапазон полностью внутри запроса |
boost |
Число с плавающей точкой |
Коэффициент усиления релевантности (>1 - увеличивает, 0-1 - уменьшает). По умолчанию: 1.0. |
time_zone |
Строка |
Часовой пояс для преобразования дат в UTC. Допустимы смещения UTC (например, -04:00) или идентификаторы IANA (например, America/New_York). |
Важно: При search.allow_expensive_queries=false диапазонные запросы по текстовым и ключевым полям не выполняются.
3.6 - regexp
Поиск документов, содержащих термины, соответствующие регулярному выражению
Запрос regexp (поиск по регулярным выражениям)
Назначение
Запрос regexp позволяет выполнять поиск терминов, соответствующих указанному регулярному выражению. Подробнее о синтаксисе регулярных выражений см. в документации по синтаксису регулярных выражений.
Базовый пример
GET shakespeare/_search
{
"query": {
"regexp": {
"play_name": "[a-zA-Z]amlet"
}
}
}
Этот запрос ищет любые термины в поле play_name, которые начинаются с любой буквы (верхнего или нижнего регистра), за которой следует “amlet”.
Ключевые особенности
-
Область применения:
Регулярные выражения применяются к отдельным терминам (токенам) в поле, а не ко всему полю целиком.
-
Ограничения:
- Максимальная длина регулярного выражения по умолчанию: 1,000 символов (настраивается через
index.max_regex_length)
- Используется синтаксис Lucene, который отличается от стандартных реализаций
-
Производительность:
- Избегайте шаблонов с
.* или .*?+ без префикса/суффикса
- Ресурсоемкие операции, требуют
search.allow_expensive_queries=true
- Для частых запросов рекомендуется тестировать влияние на кластер
-
Оптимизация:
Тип поля wildcard специально оптимизирован для эффективных запросов с регулярными выражениями.
Расширенный синтаксис с параметрами
GET _search
{
"query": {
"regexp": {
"<поле>": {
"value": "[Ss]ample",
"boost": 1.5,
"case_insensitive": true,
"flags": "INTERSECTION|COMPLEMENT",
"max_determinized_states": 20000,
"rewrite": "constant_score"
}
}
}
}
Параметры запроса
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
Строка |
Обязательный. Регулярное выражение для поиска |
- |
boost |
Число с плавающей точкой |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
case_insensitive |
Логический |
Регистронезависимый поиск |
false |
flags |
Строка |
Дополнительные операторы Lucene (INTERSECTION, COMPLEMENT и др.) |
- |
max_determinized_states |
Целое число |
Максимальное число состояний автомата (защита от перегрузки) |
10000 |
rewrite |
Строка |
Метод перезаписи запроса (constant_score, scoring_boolean и др.) |
constant_score |
Рекомендации по использованию
-
Тестирование:
Всегда проверяйте регулярные выражения на тестовых данных перед использованием в production.
-
Производительность:
// Неэффективно:
{ "regexp": { "text": ".*pattern.*" } }
// Оптимально:
{ "regexp": { "text": "prefix.*suffix" } }
-
Альтернативы:
Для сложных сценариев рассмотрите:
- Использование
wildcard типа поля
- Применение
match_phrase для текстовых фраз
- Использование
keyword полей для точного соответствия
-
Безопасность:
Ограничивайте max_determinized_states для предотвращения DoS-атак через сложные регулярные выражения.
Примечание: При search.allow_expensive_queries=false запросы regexp не выполняются.
3.7 - term
Поиск документов, содержащих точное соответствие указанному термину в заданном поле
Запрос term (поиск точного термина)
Назначение
Запрос term выполняет поиск точного соответствия указанному термину в поле. Основные характеристики:
- Ищет неизмененное значение без анализа текста
- Чувствителен к регистру по умолчанию
- Оптимален для полей типа
keyword, дат и чисел
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"term": {
"line_id": {
"value": "61809"
}
}
}
}
Этот запрос ищет строку с точным значением line_id = "61809".
Важные особенности
-
Отличие от match запросов:
term не анализирует поисковый термин- Не подходит для текстовых полей (
text), так как они анализируются при индексации
- Для текстовых полей используйте
match запросы
-
Регистронезависимый поиск (начиная с OpenSearch 2.x):
GET shakespeare/_search
{
"query": {
"term": {
"speaker": {
"value": "HAMLET",
"case_insensitive": true
}
}
}
}
Внимание! В версиях OpenSearch 2.x и ранее регистронезависимый поиск может значительно снижать производительность. Рекомендуется:
- Использовать lowercase фильтр при индексации
- Применять термины в нижнем регистре в запросах
Пример ответа
{
"hits": {
"total": {
"value": 1582,
"relation": "eq"
},
"hits": [
{
"_index": "shakespeare",
"_id": "32700",
"_score": 2,
"_source": {
"speaker": "HAMLET",
"text_entry": "[Aside] A little more than kin..."
}
}
]
}
}
Параметры запроса
Синтаксис с параметрами:
GET _search
{
"query": {
"term": {
"<поле>": {
"value": "образец",
...
}
}
}
}
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
Строка |
Обязательный. Точное значение для поиска (учитывает регистр и пробелы) |
- |
boost |
Число с плавающей точкой |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
_name |
Строка |
Имя запроса для тегирования (опционально) |
- |
case_insensitive |
Логический |
Регистронезависимый поиск (только для OpenSearch 2.x+) |
false |
Практические рекомендации
-
Для текстовых полей всегда используйте match вместо term:
// Неправильно (для text полей):
{ "term": { "description": "quick brown fox" } }
// Правильно:
{ "match": { "description": "quick brown fox" } }
-
Для точных значений (ID, коды, категории):
GET products/_search
{
"query": {
"term": {
"product_code": "ABC-123"
}
}
}
-
Комбинируйте с другими запросами:
GET logs/_search
{
"query": {
"bool": {
"must": [
{ "term": { "status": "error" } },
{ "range": { "timestamp": { "gte": "2023-01-01" }}}
]
}
}
}
-
Производительность:
- Для частых запросов добавьте индекс на поле
- Избегайте
case_insensitive в favor lowercase анализаторов
3.8 - terms
Поиск документов, содержащих один или несколько указанных терминов в заданном поле
Terms Query (Поиск по нескольким значениям)
Основное назначение
Запрос terms позволяет искать документы, содержащие одно или несколько указанных значений в заданном поле. Документ возвращается в результатах, если значение его поля точно соответствует хотя бы одному термину из списка.
Базовый синтаксис
GET shakespeare/_search
{
"query": {
"terms": {
"line_id": [
"61809",
"61810"
]
}
}
}
Ключевые особенности
-
Лимит терминов:
По умолчанию максимальное количество терминов в запросе - 65,536. Настраивается через параметр index.max_terms_count.
-
Производительность:
Для оптимизации производительности с длинными списками терминов рекомендуется:
- Передавать термины в отсортированном порядке (по возрастанию UTF-8 byte values)
- Использовать механизм Terms Lookup для больших наборов терминов
-
Подсветка результатов:
Возможность подсветки результатов зависит от:
- Типа highlighter’а
- Количества терминов в запросе
Параметры запроса
| Параметр |
Тип данных |
Описание |
По умолчанию |
<field> |
String |
Поле для поиска (точное соответствие хотя бы одному термину) |
- |
boost |
Float |
Вес поля в расчете релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
_name |
String |
Имя запроса для тегирования |
- |
value_type |
String |
Тип значений для фильтрации (default или bitmap) |
default |
Terms Lookup (Поиск терминов из другого документа)
Общие принципы
Механизм Terms Lookup позволяет:
- Извлекать значения полей из указанного документа
- Использовать эти значения как условия поиска
- Работать с большими наборами терминов
Требования:
- Поле
_source должно быть включено (включено по умолчанию)
- Для уменьшения сетевого трафика рекомендуется использовать индекс с:
- Одним первичным шардом
- Полными репликами на всех узлах данных
Пример использования
- Создаем индекс студентов:
PUT students
{
"mappings": {
"properties": {
"student_id": { "type": "keyword" }
}
}
}
- Добавляем данные студентов:
PUT students/_doc/1
{
"name": "Jane Doe",
"student_id" : "111"
}
PUT students/_doc/2
{
"name": "Mary Major",
"student_id" : "222"
}
PUT students/_doc/3
{
"name": "John Doe",
"student_id" : "333"
}
- Создаем индекс классов с информацией о зачисленных студентах:
PUT classes/_doc/101
{
"name": "CS101",
"enrolled" : ["111" , "222"]
}
- Поиск студентов, зачисленных на CS101:
GET students/_search
{
"query": {
"terms": {
"student_id": {
"index": "classes",
"id": "101",
"path": "enrolled"
}
}
}
}
- Результат содержит соответствующих студентов:
{
"took": 13,
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_source": {
"name": "Jane Doe",
"student_id": "111"
}
},
{
"_index": "students",
"_id": "2",
"_source": {
"name": "Mary Major",
"student_id": "222"
}
}
]
}
}
Работа с вложенными полями
- Добавляем документ с вложенной структурой:
PUT classes/_doc/102
{
"name": "CS102",
"enrolled_students" : {
"id_list" : ["111" , "333"]
}
}
- Поиск с указанием пути к вложенному полю:
GET students/_search
{
"query": {
"terms": {
"student_id": {
"index": "classes",
"id": "102",
"path": "enrolled_students.id_list"
}
}
}
}
- Результат поиска:
{
"took": 18,
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"hits": [
{
"_index": "students",
"_id": "1",
"_source": {
"name": "Jane Doe",
"student_id": "111"
}
},
{
"_index": "students",
"_id": "3",
"_source": {
"name": "John Doe",
"student_id": "333"
}
}
]
}
}
Параметры Terms Lookup
| Параметр |
Тип данных |
Описание |
Обязательность |
index |
String |
Индекс, из которого извлекаются значения |
Обязательно |
id |
String |
ID документа-источника |
Обязательно |
path |
String |
Путь к полю (для вложенных полей - точечная нотация) |
Обязательно |
routing |
String |
Кастомное значение маршрутизации документа |
Опционально* |
store |
Boolean |
Использовать stored fields вместо _source |
Опционально |
*Обязателен, если при индексации использовалось кастомное routing
Важные замечания
- Для полей типа
text используйте match вместо terms
- При работе с большими наборами терминов (>10,000) рассмотрите возможность использования Bitmap Filtering
- Убедитесь, что поле
_source включено для документов-источников
Bitmap Filtering (Фильтрация с использованием битовых карт)
Введение
Начиная с версии 2.17, OpenSearch предлагает механизм bitmap filtering для эффективной фильтрации по большому количеству терминов (10,000+). Этот подход решает проблему высокой нагрузки на сеть и память при работе с обычными terms-запросами.
Основные концепции
-
Проблема:
Обычные terms-запросы становятся неэффективными при большом количестве терминов из-за:
- Высокого сетевого трафика
- Чрезмерного потребления памяти
-
Решение:
Использование roaring bitmap для кодирования условий фильтрации:
- Эффективное сжатие данных
- Быстрые битовые операции
- Оптимизированное использование памяти
Пример реализации
1. Подготовка индексов
Индекс продуктов:
PUT /products
{
"mappings": {
"properties": {
"product_id": { "type": "integer" }
}
}
}
Добавление продуктов:
PUT /products/_doc/1
{
"name": "Product 1",
"product_id" : 111
}
PUT /products/_doc/2
{
"name": "Product 2",
"product_id" : 222
}
PUT /products/_doc/3
{
"name": "Product 3",
"product_id" : 333
}
Индекс клиентов с bitmap-полем:
PUT /customers
{
"mappings": {
"properties": {
"customer_filter": {
"type": "binary",
"store": true
}
}
}
}
2. Генерация bitmap
Пример кода на Python с использованием PyRoaringBitMap:
from pyroaring import BitMap
import base64
bm = BitMap([111, 222, 333]) # ID продуктов клиента
encoded = base64.b64encode(BitMap.serialize(bm))
encoded_bm_str = encoded.decode('utf-8')
print(f"Encoded Bitmap: {encoded_bm_str}")
3. Индексация bitmap
POST customers/_doc/customer123
{
"customer_filter": "OjAAAAEAAAAAAAIAEAAAAG8A3gBNAQ=="
}
Использование bitmap в запросах
Вариант 1: Lookup из документа
POST /products/_search
{
"query": {
"terms": {
"product_id": {
"index": "customers",
"id": "customer123",
"path": "customer_filter",
"store": true
},
"value_type": "bitmap"
}
}
}
Вариант 2: Прямая передача bitmap
POST /products/_search
{
"query": {
"terms": {
"product_id": [
"OjAAAAEAAAAAAAIAEAAAAG8A3gBNAQ=="
],
"value_type": "bitmap"
}
}
}
Ключевые параметры
| Параметр |
Тип данных |
Описание |
Обязательность |
value_type |
String |
Должно быть bitmap для активации этого режима |
Обязательно |
store |
Boolean |
true для поиска в stored field вместо _source |
Опционально |
index |
String |
Индекс-источник bitmap (для lookup) |
Для lookup |
id |
String |
ID документа с bitmap |
Для lookup |
path |
String |
Поле с bitmap данными |
Для lookup |
Преимущества подхода
-
Эффективность:
- Снижение сетевого трафика до 10 раз
- Уменьшение использования памяти на 50-90%
-
Гибкость:
- Поддержка динамического обновления фильтров
- Возможность комбинирования условий
-
Производительность:
- Быстрое выполнение даже для 100,000+ терминов
- Оптимизированные битовые операции на уровне ядра
Рекомендации
- Используйте для сложных фильтров с >10,000 значений
- Регулярно обновляйте bitmap при изменении данных
- Тестируйте производительность для вашего конкретного сценария
- Рассмотрите использование сжатых форматов bitmap для экономии места
3.9 - terms set
Поиск документов, соответствующих минимальному количеству указанных терминов
Terms Set Query (Запрос с условием минимального соответствия терминов)
Основное назначение
Запрос terms_set позволяет искать документы, которые соответствуют минимальному количеству точных терминов в указанном поле. В отличие от обычного terms запроса, terms_set требует явного указания минимального количества совпадений, которое может быть задано либо через поле индекса, либо через скрипт.
Основные характеристики
- Ищет точные соответствия терминов (без анализа текста)
- Требует указания минимального количества совпадающих терминов
- Поддерживает два способа определения минимального количества:
- Через поле документа (
minimum_should_match_field)
- Через скрипт (
minimum_should_match_script)
- Оптимален для работы с полями типа
keyword
Пример использования
1. Подготовка индекса
PUT students
{
"mappings": {
"properties": {
"name": { "type": "keyword" },
"classes": { "type": "keyword" },
"min_required": { "type": "integer" }
}
}
}
2. Индексация документов
PUT students/_doc/1
{
"name": "Mary Major",
"classes": [ "CS101", "CS102", "MATH101" ],
"min_required": 2
}
PUT students/_doc/2
{
"name": "John Doe",
"classes": [ "CS101", "MATH101", "ENG101" ],
"min_required": 2
}
3. Поиск с использованием поля для минимального соответствия
GET students/_search
{
"query": {
"terms_set": {
"classes": {
"terms": [ "CS101", "CS102", "MATH101" ],
"minimum_should_match_field": "min_required"
}
}
}
}
4. Поиск с использованием скрипта для минимального соответствия
GET students/_search
{
"query": {
"terms_set": {
"classes": {
"terms": [ "CS101", "CS102", "MATH101" ],
"minimum_should_match_script": {
"source": "Math.min(params.num_terms, doc['min_required'].value)"
}
}
}
}
}
Параметры запроса
Базовый синтаксис:
GET _search
{
"query": {
"terms_set": {
"<поле>": {
"terms": [ "term1", "term2" ],
...
}
}
}
}
| Параметр |
Тип данных |
Описание |
Обязательность |
terms |
Массив строк |
Термины для поиска (точное соответствие) |
Обязательно |
minimum_should_match_field |
Строка |
Поле, содержащее минимальное количество совпадений |
Один из двух |
minimum_should_match_script |
Строка |
Скрипт, возвращающий минимальное количество совпадений |
Один из двух |
boost |
Число с плавающей точкой |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
Опционально |
Особенности работы
-
Механизм подсчета:
Документ считается соответствующим, если количество совпадающих терминов из массива terms ≥ указанного минимума.
-
Определение минимума:
- Через поле: значение берется из указанного поля документа
- Через скрипт: вычисляется динамически для каждого документа
-
Производительность:
- Использование поля
minimum_should_match_field обычно более эффективно
- Скрипты обеспечивают гибкость, но могут снижать производительность
Рекомендации по использованию
- Для статических условий используйте
minimum_should_match_field
- Для сложной логики применяйте
minimum_should_match_script
- Всегда индексируйте поля, используемые для определения минимума
- Для текстовых полей предварительно применяйте нормализацию
- Тестируйте производительность на реалистичных объемах данных
Примеры скриптов
- Фиксированное значение:
"minimum_should_match_script": {
"source": "2"
}
- Динамическое вычисление:
"minimum_should_match_script": {
"source": "doc['min_required'].value * params.factor",
"params": {
"factor": 1.5
}
}
- Ограничение сверху:
"minimum_should_match_script": {
"source": "Math.min(5, doc['min_required'].value)"
}
3.10 - wildcard
Поиск документов, содержащих термины, соответствующие шаблону с подстановочными символами
Wildcard Query (Поиск с подстановочными символами)
Основное назначение
Запрос wildcard позволяет выполнять поиск терминов по шаблону с использованием подстановочных символов. Особенно полезен для:
- Поиска по частичным совпадениям
- Нечеткого поиска с известной структурой
- Работы с кодами, артикулами и другими структурированными данными
Поддерживаемые операторы
| Оператор |
Описание |
Пример |
* |
Соответствует нулю или более символов |
H*Y найдет “HAPPY”, “HALLEY” |
? |
Соответствует любому одному символу |
H?Y найдет “HAY”, но не “HAPPY” |
case_insensitive |
Флаг регистронезависимости |
true/false (по умолчанию false) |
Примеры запросов
1. Чувствительный к регистру поиск:
GET shakespeare/_search
{
"query": {
"wildcard": {
"speaker": {
"value": "H*Y",
"case_insensitive": false
}
}
}
}
2. Использование разных операторов:
H*Y - найдет любые значения, начинающиеся на H и заканчивающиеся на YH?Y - найдет только 3-символьные значения типа “HMY”
Параметры запроса
Базовый синтаксис:
GET _search
{
"query": {
"wildcard": {
"<поле>": {
"value": "шаб*лон",
...
}
}
}
}
| Параметр |
Тип данных |
Описание |
По умолчанию |
value |
String |
Шаблон для поиска с подстановочными символами |
Обязательный |
boost |
Float |
Коэффициент релевантности (>1 - увеличивает, 0-1 - уменьшает) |
1.0 |
case_insensitive |
Boolean |
Регистронезависимый поиск |
false |
rewrite |
String |
Метод перезаписи запроса (constant_score, scoring_boolean и др.) |
constant_score |
Критические особенности производительности
-
Предупреждение:
Wildcard-запросы могут быть медленными, так как требуют перебора множества терминов.
-
Золотое правило:
Избегайте размещения подстановочных символов в начале шаблона (например, *pattern), так как это:
- Крайне ресурсоемко
- Может привести к таймаутам
- Создает нагрузку на кластер
-
Оптимизация:
Для частых wildcard-запросов используйте специальный wildcard тип поля, который:
- Создает оптимизированный индекс
- Обеспечивает высокую производительность
- Поддерживает сложные шаблоны
Практические рекомендации
-
Для префиксного поиска используйте prefix запрос вместо H*:
{
"query": {
"prefix": {
"field": "H"
}
}
}
-
Для сложных шаблонов рассмотрите:
- Использование
wildcard типа поля
- Применение
regexp запросов для более сложных паттернов
-
При работе с большими индексами:
- Ограничивайте время выполнения через
timeout
- Используйте
search.allow_expensive_queries для контроля
-
Пример безопасного шаблона:
{
"query": {
"wildcard": {
"product_code": {
"value": "ABC-202?-*",
"case_insensitive": true
}
}
}
}
Такой шаблон найдет коды типа “ABC-2023-XXX” и безопасен для выполнения.
Важные ограничения
- При
search.allow_expensive_queries=false wildcard-запросы не выполняются
- Максимальная длина шаблона ограничена параметром
index.max_regex_length (по умолчанию 1000 символов)
- Не поддерживает стандартные regex-конструкции (используйте
regexp запрос для сложных выражений)
4 - full_text
Анализируют текст запроса, применяют тот же анализатор, что и при индексации. match, match_phrase, multi_match
Полнотекстовые запросы
Эта страница перечисляет все типы полнотекстовых запросов и общие параметры. Существует множество необязательных полей, которые вы можете использовать для создания тонких поисковых поведений, поэтому мы рекомендуем протестировать некоторые базовые типы запросов на представительных индексах и проверить вывод, прежде чем выполнять более сложные или комплексные поиски с несколькими параметрами.
OpenSearch использует библиотеку поиска Apache Lucene, которая предоставляет высокоэффективные структуры данных и алгоритмы для загрузки, индексации, поиска и агрегации данных.
Чтобы узнать больше о классах запросов поиска, смотрите JavaDocs по запросам Lucene.
Типы полнотекстовых запросов, показанные в этом разделе, используют стандартный анализатор, который автоматически анализирует текст при отправке запроса.
В следующей таблице перечислены все типы полнотекстовых запросов.
| Тип запроса |
Описание |
| intervals |
Позволяет точно контролировать близость и порядок совпадающих терминов. |
| match |
Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости. |
| match_bool_prefix |
Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс. |
| match_phrase |
Похож на запрос match, но соответствует целой фразе с настраиваемым слопом. |
| match_phrase_prefix |
Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс. |
| multi_match |
Похож на запрос match, но используется для нескольких полей. |
| query_string |
Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса. |
| simple_query_string |
Более простая, менее строгая версия запроса query_string. |
4.1 - match
Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости.
Запрос Match
Используйте запрос match для полнотекстового поиска по конкретному полю документа. Если вы выполняете запрос match по текстовому полю, он анализирует предоставленную строку поиска и возвращает документы, которые соответствуют любым терминам этой строки. Если вы выполняете запрос match по полю с точным значением, он возвращает документы, которые соответствуют этому точному значению. Предпочтительный способ поиска по полям с точными значениями — использовать фильтр, поскольку, в отличие от запроса, фильтр кэшируется.
Пример
Следующий пример показывает базовый запрос match для слова “wind” в заголовке:
GET _search
{
"query": {
"match": {
"title": "wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match": {
"title": {
"query": "wind",
"analyzer": "stop"
}
}
}
}
Примеры
В следующих примерах вы будете использовать индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "Let the wind rise"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
PUT testindex/_doc/3
{
"title": "Rise is gone"
}
Оператор
Если запрос match выполняется по текстовому полю, текст анализируется с помощью анализатора, указанного в параметре analyzer. Затем полученные токены объединяются в логический запрос с использованием оператора, указанного в параметре operator. Оператор по умолчанию — OR, поэтому запрос “wind rise” преобразуется в “wind OR rise”. В этом примере этот запрос возвращает документы 1–3, поскольку каждый документ содержит термин, соответствующий запросу. Чтобы указать оператор AND, используйте следующий запрос:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "and"
}
}
}
}
Запрос формируется как “wind AND rise” и возвращает документ 1 как совпадающий документ.
Минимальное количество совпадений
Вы можете контролировать минимальное количество терминов, которые документ должен совпадать, чтобы быть возвращенным в результатах, указав параметр minimum_should_match:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "or",
"minimum_should_match": 2
}
}
}
}
Теперь документы должны совпадать с обоими терминами, поэтому возвращается только документ 1 (это эквивалентно оператору AND).
Анализатор
Поскольку в этом примере вы не указали анализатор, используется анализатор по умолчанию — стандартный анализатор. Стандартный анализатор не выполняет стемминг, поэтому если вы выполните запрос “the wind rises”, вы не получите результатов, поскольку токен “rises” не совпадает с токеном “rise”. Чтобы изменить анализатор поиска, укажите его в поле analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "the wind rises",
"operator": "and",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токены “wind” и “rise”. Последний токен совпадает с документом 1, который возвращается в результатах.
Пустой запрос
В некоторых случаях анализатор может удалить все токены из запроса. Например, английский анализатор удаляет стоп-слова, поэтому в запросе “and OR or” все токены удаляются. Чтобы проверить поведение анализатора, вы можете использовать API анализа:
GET testindex/_analyze
{
"analyzer": "english",
"text": "and OR or"
}
Как и ожидалось, запрос не производит токенов:
Вы можете задать поведение для пустого запроса с помощью параметра zero_terms_query. Установка zero_terms_query в значение all возвращает все документы в индексе, а установка в none не возвращает ни одного документа:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "and OR or",
"analyzer": "english",
"zero_terms_query": "all"
}
}
}
}
Неопределенность (Fuzziness)
Чтобы учесть опечатки, вы можете указать уровень нечеткости для вашего запроса в одном из следующих форматов:
- Целое число, которое указывает максимальное допустимое расстояние по Дамерау-Левенштейну для этого редактирования.
- AUTO:
- Строки длиной 0–2 символа должны совпадать точно.
- Строки длиной 3–5 символов допускают 1 редактирование.
- Строки длиной более 5 символов допускают 2 редактирования.
Установка нечеткости на значение по умолчанию AUTO работает лучше всего в большинстве случаев:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO"
}
}
}
}
Токен “wnid” совпадает с “wind”, и запрос возвращает документы 1 и 2.
Длина префикса
Опечатки редко встречаются в начале слов. Таким образом, вы можете указать минимальную длину, которую должен иметь совпадающий префикс, чтобы документ был возвращен в результатах. Например, вы можете изменить предыдущий запрос, добавив параметр prefix_length:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"prefix_length": 2
}
}
}
}
Предыдущий запрос не возвращает результатов. Если вы измените prefix_length на 1, документы 1 и 2 будут возвращены, поскольку первая буква токена “wnid” не ошибочна.
Транспозиции
В предыдущем примере слово “wnid” содержало транспозицию (буквы “i” и “n” были поменяны местами). По умолчанию транспозиции допускаются в нечетком совпадении, но вы можете запретить их, установив fuzzy_transpositions в false:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"fuzzy_transpositions": false
}
}
}
}
Теперь запрос не возвращает результатов.
Синонимы
Если вы используете фильтр synonym_graph и параметр auto_generate_synonyms_phrase_query установлен в true (по умолчанию), OpenSearch разбивает запрос на термины, а затем объединяет термины для генерации фразового запроса для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average”.
Чтобы сопоставить многословные синонимы с союзами, установите auto_generate_synonyms_phrase_query в false:
GET /testindex/_search
{
"query": {
"match": {
"text": {
"query": "good ba",
"auto_generate_synonyms_phrase_query": false
}
}
}
}
Сформированный запрос будет “ba” OR (“batting” AND “average”).
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Строка запроса, используемая для поиска. Обязательный параметр. |
| auto_generate_synonyms_phrase_query |
Boolean |
Указывает, следует ли автоматически создавать фразовый запрос match для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average” (если этот параметр true) или “ba” OR (“batting” AND “average”) (если этот параметр false). По умолчанию true. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| boost |
Floating-point |
Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| enable_position_increments |
Boolean |
Если true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fuzziness |
String |
Количество редактирований символов (вставок, удалений, замен или транспозиций), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite |
String |
Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| lenient |
Boolean |
Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_expansions |
Positive integer |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match |
Positive or negative integer, positive or negative percentage, combination |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения:
- OR: строка интерпретируется как “или”
- AND: строка интерпретируется как “и”. По умолчанию используется OR. |
| prefix_length |
Non-negative integer |
Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
| zero_terms_query |
String |
В некоторых случаях анализатор удаляет все термины из строки запроса. Например, стоп-анализатор удаляет все термины из строки “an”, но оставляет “this”. В таких случаях zero_terms_query указывает, следует ли не совпадать ни с одним документом (none) или совпадать со всеми документами (all). Допустимые значения: none и all. По умолчанию none. |
4.2 - match-bool-prefix
Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс.
Запрос Match Boolean Prefix
Запрос match_bool_prefix анализирует предоставленную строку поиска и создает логический запрос из терминов строки. Он использует каждый термин, кроме последнего, как целое слово для совпадения. Последний термин используется как префикс. Запрос match_bool_prefix возвращает документы, которые содержат либо термины целых слов, либо термины, начинающиеся с префиксного термина, в любом порядке.
Пример
Следующий пример показывает базовый запрос match_bool_prefix:
GET _search
{
"query": {
"match_bool_prefix": {
"title": "the wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "the wind",
"analyzer": "stop"
}
}
}
}
Пример документов
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
Следующий запрос match_bool_prefix ищет целое слово “rises” и слова, начинающиеся с “wi”, в любом порядке:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"should": [
{ "term": { "title": "rises" }},
{ "prefix": { "title": "wi" }}
]
}
}
}
Ответ содержит оба документа:
Ответ
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.73617,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1.73617,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1,
"_source": {
"title": "Gone with the wind"
}
}
]
}
}
Запросы match_bool_prefix и match_phrase_prefix
Запрос match_bool_prefix сопоставляет термины в любой позиции, в то время как запрос match_phrase_prefix сопоставляет термины как целую фразу. Чтобы проиллюстрировать разницу, снова рассмотрим запрос match_bool_prefix из предыдущего раздела:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Оба документа “The wind rises” и “Gone with the wind” соответствуют поисковым терминам, поэтому запрос возвращает оба документа.
Теперь выполните запрос match_phrase_prefix по тому же индексу:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "rises wi"
}
}
}
Ответ не возвращает документов, потому что ни один из документов не содержит фразу “rises wi” в указанном порядке.
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "rise the wi",
"analyzer": "stop"
}
}
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match_bool_prefix": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Текст, число, логическое значение или дата, используемые для поиска. Обязательный параметр. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| fuzziness |
AUTO, 0 или положительное целое число |
Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. По умолчанию используется значение AUTO, которое выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite |
String |
Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match |
Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения: OR и AND. По умолчанию используется OR. |
| prefix_length |
Ненегативное целое число |
Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
Параметры fuzziness, fuzzy_transpositions, fuzzy_rewrite, max_expansions и prefix_length могут применяться к подзапросам term, созданным для всех терминов, кроме последнего. Они не оказывают никакого влияния на префиксный запрос, созданный для последнего термина.
4.3 - match-phrase
Похож на запрос match, но соответствует целой фразе с настраиваемым слопом.
Запрос match_phrase
Используйте запрос match_phrase, чтобы находить документы, содержащие точную фразу в указанном порядке. Вы можете добавить гибкость к фразовому соответствию, указав параметр slop.
Запрос match_phrase создает фразовый запрос, который соответствует последовательности терминов.
Пример базового запроса match_phrase:
GET _search
{
"query": {
"match_phrase": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase ищет фразу “wind rises”, где слово “ветер” следует за словом “поднимается”:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": "wind rises"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "The wind rises"
}
}
]
}
}
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": {
"query": "ветра",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токен “ветер”. Оба документа соответствуют этому токену и возвращаются в результатах:
Slop
Если вы укажете параметр slop, запрос допускает перестановку поисковых терминов. Параметр slop указывает количество других слов, разрешенных между словами в фразе запроса. Например, в следующем запросе текст поиска переставлен по сравнению с текстом документа:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер поднимается",
"slop": 3
}
}
}
}
Запрос все равно возвращает соответствующий документ:
Пустой запрос
Для информации о возможном пустом запросе смотрите соответствующий раздел запроса match.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
Строка |
Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для поля по умолчанию на этапе индексации. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
| slop |
0 (по умолчанию) или положительное целое число |
Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
| zero_terms_query |
Строка |
В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки “an”, кроме “but”. В таких случаях zero_terms_query указывает, следует ли не находить ни одного документа (none) или находить все документы (all). Допустимые значения: none и all. По умолчанию используется none. |
4.4 - match-phrase-prefix
Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс.
Запрос match_phrase_prefix
Используйте запрос match_phrase_prefix, чтобы указать фразу для поиска в заданном порядке. Документы, содержащие указанную вами фразу, будут возвращены. Последний неполный термин в фразе интерпретируется как префикс, поэтому любые документы, содержащие фразы, начинающиеся с указанной фразы и префикса последнего термина, будут возвращены.
Запрос аналогичен match_phrase, но создает префиксный запрос из последнего термина в строке запроса.
Для различий между запросами match_phrase_prefix и match_bool_prefix смотрите раздел о запросах match_bool_prefix и match_phrase_prefix.
Пример базового запроса match_phrase_prefix:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "Ветер поднимается"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase_prefix ищет полное слово “ветер”, за которым следует слово, начинающееся на “под”:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "ветер под"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "Ветер поднимается"
}
}
]
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase_prefix": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
Строка |
Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. |
| max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Неопределенные запросы “расширяются” на количество совпадающих терминов, находящихся на расстоянии, указанном в параметре fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию значение равно 50. |
| slop |
0 (по умолчанию) или положительное целое число |
Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
4.5 - multi-match
Похож на запрос match, но используется для нескольких полей.
Многофункциональные запросы (Multi-match queries)
Операция multi-match функционирует аналогично операции match. Вы можете использовать запрос multi_match для поиска по нескольким полям.
Символ ^ “увеличивает” вес определенных полей. Увеличения — это множители, которые придают больший вес совпадениям в одном поле по сравнению с совпадениями в других полях. В следующем примере совпадение для “ветер” в поле title влияет на _score в четыре раза больше, чем совпадение в поле plot:
GET _search
{
"query": {
"multi_match": {
"query": "ветер",
"fields": ["title^4", "plot"]
}
}
}
В результате фильмы, такие как “Ветер поднимается” и “Ушедший с ветром”, находятся в верхней части результатов поиска, а фильмы, такие как “Ураган”, которые, предположительно, содержат “ветер” в своих аннотациях, находятся внизу.
Вы можете использовать подстановочные знаки в имени поля. Например, следующий запрос будет искать поле speaker и все поля, начинающиеся с play_, например, play_name или play_title:
GET _search
{
"query": {
"multi_match": {
"query": "гамлет",
"fields": ["speaker", "play_*"]
}
}
}
Если вы не укажете параметр fields, запрос multi_match будет искать в полях, указанных в настройке index.query.default_field, которая по умолчанию равна *. Поведение по умолчанию заключается в извлечении всех полей в отображении, которые подходят для запросов на уровне терминов, фильтрации метаданных и комбинировании всех извлеченных полей для построения запроса.
Максимальное количество клауз в запросе определяется настройкой indices.query.bool.max_clause_count, которая по умолчанию равна 1,024.
Типы многофункциональных запросов
OpenSearch поддерживает следующие типы многофункциональных запросов, которые различаются по способу внутреннего выполнения запроса:
- best_fields (по умолчанию): Возвращает документы, которые соответствуют любому полю. Использует
_score лучшего совпадающего поля.
- most_fields: Возвращает документы, которые соответствуют любому полю. Использует комбинированный балл каждого совпадающего поля.
- cross_fields: Обрабатывает все поля так, как если бы они были одним полем. Обрабатывает поля с одинаковым анализатором и сопоставляет слова в любом поле.
- phrase: Выполняет запрос
match_phrase для каждого поля. Использует _score лучшего совпадающего поля.
- phrase_prefix: Выполняет запрос
match_phrase_prefix для каждого поля. Использует _score лучшего совпадающего поля.
- bool_prefix: Выполняет запрос
match_bool_prefix для каждого поля. Использует комбинированный балл каждого совпадающего поля.
Лучшие поля (Best fields)
Если вы ищете два слова, которые определяют концепцию, вы хотите, чтобы результаты, в которых два слова находятся рядом друг с другом, имели более высокий балл.
Например, рассмотрим индекс, содержащий следующие научные статьи:
PUT /articles/_doc/1
{
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
PUT /articles/_doc/2
{
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
Вы можете искать статьи, содержащие “северные огни” в заголовке или описании:
GET articles/_search
{
"query": {
"multi_match" : {
"query": "северные огни",
"type": "best_fields",
"fields": [ "title", "description" ],
"tie_breaker": 0.3
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с запросом match для каждого поля:
Запрос multi_match позволяет искать по нескольким полям. Он работает аналогично запросу match, но с возможностью указания нескольких полей для поиска.
Пример запроса dis_max
GET /articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "северные огни" }},
{ "match": { "description": "северные огни" }}
],
"tie_breaker": 0.3
}
}
}
Результаты содержат оба документа, но документ 1 имеет более высокий балл, потому что оба слова находятся в поле description:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.6322521,
"_source": {
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
}
]
}
}
Запрос best_fields использует балл лучшего совпадающего поля. Если вы укажете tie_breaker, балл рассчитывается по следующему алгоритму:
- Возьмите балл лучшего совпадающего поля.
- Добавьте (tie_breaker * _score) для всех других совпадающих полей.
Запрос most_fields
Используйте запрос most_fields для нескольких полей, которые содержат один и тот же текст, анализируемый разными способами. Например, оригинальное поле может содержать текст, проанализированный с помощью стандартного анализатора, а другое поле может содержать тот же текст, проанализированный с помощью английского анализатора, который выполняет стемминг:
PUT /articles
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Рассмотрим следующие два документа, которые индексируются в индексе articles:
PUT /articles/_doc/1
{
"title": "Гренки с маслом"
}
PUT /articles/_doc/2
{
"title": "Масло на тосте"
}
Стандартный анализатор анализирует заголовок “Гренки с маслом” в [гренки, масло], а заголовок “Масло на тосте” в [масло, на, тосте]. С другой стороны, английский анализатор производит один и тот же список токенов [масло, тост] для обоих заголовков из-за стемминга.
Вы можете использовать запрос most_fields, чтобы вернуть как можно больше документов:
GET /articles/_search
{
"query": {
"multi_match": {
"query": "гренки с маслом",
"fields": [
"title",
"title.english"
],
"type": "most_fields"
}
}
}
Предыдущий запрос выполняется как следующий булев запрос:
GET articles/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "гренки с маслом" }},
{ "match": { "title.english": "гренки с маслом" }}
]
}
}
}
Расчет релевантности
Чтобы рассчитать релевантность, баллы документа для всех клауз совпадений складываются, а затем результат делится на количество клауз совпадений.
Включение поля title.english позволяет получить второй документ, который соответствует стеммированным токенам:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.4418206,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 1.4418206,
"_source": {
"title": "Гренки с маслом"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.09304003,
"_source": {
"title": "Масло на тосте"
}
}
]
}
}
Поскольку оба поля title и title.english совпадают для первого документа, он имеет более высокий балл релевантности.
Оператор и минимальное количество совпадений
Запросы best_fields и most_fields генерируют запрос match на основе полей (по одному для каждого поля). Таким образом, параметры minimum_should_match и operator применяются к каждому полю, что обычно не является желаемым поведением.
Например, рассмотрим индекс customers со следующими документами:
PUT customers/_doc/1
{
"first_name": "John",
"last_name": "Doe"
}
PUT customers/_doc/2
{
"first_name": "Jane",
"last_name": "Doe"
}
Если вы ищете “John Doe” в индексе customers, вы можете составить следующий запрос:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Цель оператора and в этом запросе — найти документ, который соответствует “John” и “Doe”. Однако запрос не возвращает никаких результатов. Вы можете узнать, как выполняется запрос, запустив API валидации:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос пытается сопоставить как “John”, так и “Doe” с полем first_name или last_name:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "((+first_name:john +first_name:doe) | (+last_name:john +last_name:doe))"
}
]
}
Поскольку ни одно из полей не содержит оба слова, результаты не возвращаются.
Лучшей альтернативой для поиска по полям является использование запроса cross_fields. В отличие от ориентированных на поля запросов best_fields и most_fields, запрос cross_fields ориентирован на термины.
Запрос cross_fields
Используйте запрос cross_fields, чтобы искать данные по нескольким полям. Например, если индекс содержит данные о клиентах, имя и фамилия клиента находятся в разных полях. Тем не менее, когда вы ищете “John Doe”, вы хотите получить документы, в которых “John” находится в поле first_name, а “Doe” — в поле last_name.
Запрос most_fields не работает в этом случае по следующим причинам:
- Параметры
operator и minimum_should_match применяются на уровне полей, а не на уровне терминов.
- Частоты терминов в полях
first_name и last_name могут привести к неожиданным результатам. Например, если чье-то имя — “Doe”, документ с этим именем будет считаться лучшим совпадением, поскольку это имя не появится в других документах.
Запрос cross_fields анализирует строку запроса на отдельные термины и затем ищет каждый из терминов в любом из полей, как если бы они были одним полем.
Пример запроса cross_fields для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Ответ содержит единственный документ, в котором присутствуют как “John”, так и “Doe”:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.8754687,
"hits": [
{
"_index": "customers",
"_id": "1",
"_score": 0.8754687,
"_source": {
"first_name": "John",
"last_name": "Doe"
}
}
]
}
}
Вы можете использовать операцию API валидации, чтобы получить представление о том, как выполняется предыдущий запрос:
GET /customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос ищет все термины хотя бы в одном поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "+blended(terms:[last_name:john, first_name:john]) +blended(terms:[last_name:doe, first_name:doe])"
}
]
}
Таким образом, смешивание частот терминов для всех полей решает проблему различия частот терминов, корректируя различия.
Запрос cross_fields обычно полезен только для коротких строковых полей с коэффициентом 1. В других случаях балл не дает значимого смешивания статистики терминов из-за того, как коэффициенты, частоты терминов и нормализация длины влияют на балл.
Параметр fuzziness не поддерживается для запросов cross_fields.
Анализ
Запрос cross_fields работает как термоцентричный запрос для полей с одинаковым анализатором. Поля с одинаковым анализатором группируются вместе, и эти группы комбинируются с помощью булевого запроса.
Например, рассмотрим индекс, в котором поля first_name и last_name анализируются с использованием стандартного анализатора, а их подполе .edge анализируется с помощью анализатора edge n-gram:
Пример
Вы индексируете один документ в индексе customers:
PUT /customers/_doc/1
{
"first": "John",
"last": "Doe"
}
Вы можете использовать запрос cross_fields для поиска по полям для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Чтобы увидеть, как выполняется запрос, вы можете использовать API валидации:
GET /customers/_validate/query?explain
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Ответ показывает, что поля last_name и first_name сгруппированы вместе и рассматриваются как одно поле. Аналогично, поля last_name.edge и first_name.edge также сгруппированы и рассматриваются как одно поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "(blended(terms:[last_name:john, first_name:john]) | (blended(terms:[last_name.edge:Jo, first_name.edge:Jo]) blended(terms:[last_name.edge:Joh, first_name.edge:Joh]) blended(terms:[last_name.edge:John, first_name.edge:John])))"
}
]
}
Использование параметров operator или minimum_should_match с несколькими группами полей, как описано выше, может привести к проблемам. Чтобы избежать этого, вы можете переписать предыдущий запрос как два подзапроса cross_fields, объединенных с помощью булевого запроса, и применить minimum_should_match к одному из подзапросов:
GET /customers/_search
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name",
"last_name"
],
"minimum_should_match": "1"
}
},
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name.edge",
"last_name.edge"
]
}
}
]
}
}
}
Чтобы создать одну группу для всех полей, укажите анализатор в вашем запросе:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"analyzer": "standard",
"fields": ["first_name", "last_name", "*.edge"]
}
}
}
Запуск API валидации для предыдущего запроса показывает, как выполняется запрос:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "blended(terms:[last_name.edge:john, last_name:john, first_name:john, first_name.edge:john]) blended(terms:[last_name.edge:doe, last_name:doe, first_name:doe, first_name.edge:doe])"
}
]
}
Фразовый запрос
Фразовый запрос ведет себя аналогично запросу best_fields, но использует запрос match_phrase вместо match.
Следующий пример демонстрирует фразовый запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern lights",
"type": "phrase",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase": { "title": "northern lights" }},
{ "match_phrase": { "description": "northern lights" }}
]
}
}
}
Поскольку по умолчанию фразовый запрос совпадает с текстом только тогда, когда термины появляются в одном и том же порядке, в результатах возвращается только документ 1:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Aurora borealis",
"description": "Northern lights, or aurora borealis, explained"
}
}
]
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса. Например, следующий запрос принимает текст как совпадение, если между словами “fluorescent” и “therapy” находится до двух слов:
GET articles/_search
{
"query": {
"multi_match": {
"query": "fluorescent therapy",
"type": "phrase",
"fields": ["title", "description"],
"slop": 2
}
}
}
Ответ
В этом случае ответ содержит документ 2:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.7003825,
"hits": [
{
"_index": "articles",
"_id": "2",
"_score": 0.7003825,
"_source": {
"title": "Sun deprivation in the Northern countries",
"description": "Using fluorescent lights for therapy"
}
}
]
}
}
Для значений slop, меньших чем 2, документы не возвращаются.
Параметр fuzziness не поддерживается для фразовых запросов.
Фразовый префиксный запрос
Фразовый префиксный запрос ведет себя аналогично фразовому запросу, но использует запрос match_phrase_prefix вместо match_phrase.
Следующий пример демонстрирует фразовый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern light",
"type": "phrase_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase_prefix": { "title": "northern light" }},
{ "match_phrase_prefix": { "description": "northern light" }}
]
}
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса.
Параметр fuzziness не поддерживается для фразовых префиксных запросов.
Булевый префиксный запрос
Булевый префиксный запрос оценивает документы аналогично запросу most_fields, но использует запрос match_bool_prefix вместо match.
Следующий пример демонстрирует булевый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "li northern",
"type": "bool_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_bool_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_bool_prefix": { "title": "li northern" }},
{ "match_bool_prefix": { "description": "li northern" }}
]
}
}
}
Параметры fuzziness, prefix_length, max_expansions, fuzzy_rewrite и fuzzy_transpositions поддерживаются для терминов, которые используются для построения термовых запросов, но они не оказывают влияния на префиксный запрос, построенный из конечного термина.
Параметры
Запрос принимает следующие параметры. Все параметры, кроме query, являются необязательными.
-
query (Строка): Строка запроса, используемая для поиска. Обязательный параметр.
-
auto_generate_synonyms_phrase_query (Булев): Указывает, следует ли автоматически создавать фразу запроса для многословных синонимов. Например, если вы укажете ba, batting average как синонимы и выполните поиск по ba, OpenSearch будет искать ba ИЛИ “batting average” (если этот параметр установлен в true) или ba ИЛИ (batting И average) (если этот параметр установлен в false). По умолчанию true.
-
analyzer (Строка): Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля default_field на этапе индексации. Если анализатор не указан для default_field, используется стандартный анализатор для индекса.
-
boost (Число с плавающей запятой): Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1.
-
fields (Массив строк): Список полей, в которых следует выполнять поиск. Если вы не укажете параметр fields, запрос multi_match будет искать в полях, указанных в настройке index.query.default_field, которая по умолчанию равна *.
-
fuzziness (Строка): Количество изменений символов (вставка, удаление, замена), необходимых для преобразования одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между wined и wind равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев.
-
fuzzy_rewrite (Строка): Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод переписывания fuzzy_rewrite по умолчанию top_terms_blended_freqs_${max_expansions}. По умолчанию constant_score.
-
fuzzy_transpositions (Булев): Установка fuzzy_transpositions в true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между wind и wnid равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если false (удаление “n”, вставка “n”). По умолчанию является хорошим выбором для большинства случаев.
-
lenient (Булев): Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false.
-
max_expansions (Положительное целое число): Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа соответствующих терминов, которые находятся в пределах указанного расстояния в параметре fuzziness. По умолчанию 50.
-
minimum_should_match (Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация): Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны соответствовать, чтобы документ считался совпадением. Например, если minimum_should_match равно 2, wind often rising не соответствует The Wind Rises. Если minimum_should_match равно 1, совпадает. Для подробностей см. Minimum should match.
-
operator (Строка): Если строка запроса содержит несколько поисковых терминов, нужно ли, чтобы все термины соответствовали (AND) или только один термин должен соответствовать (OR), чтобы документ считался совпадением. Допустимые значения:
- OR: Строка интерпретируется как “или”.
- AND: Строка интерпретируется как “и”.
По умолчанию используется OR.
-
prefix_length (Неотрицательное целое число): Количество начальных символов, которые не учитываются при вычислении fuzziness. По умолчанию 0.
-
slop (0 по умолчанию или положительное целое число): Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Из документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова друг на друга), поэтому для разрешения перестановок фраз значение slop должно быть не менее двух. Значение ноль требует точного совпадения.” Поддерживается для типов запросов phrase и phrase_prefix.
-
tie_breaker (Число с плавающей запятой): Фактор между 0 и 1.0, который используется для придания большего веса документам, соответствующим нескольким условиям запроса. Для получения дополнительной информации см. параметр tie_breaker.
-
type (Строка): Тип запроса multi-match. Допустимые значения: best_fields, most_fields, cross_fields, phrase, phrase_prefix, bool_prefix. По умолчанию используется best_fields.
-
zero_terms_query (Строка): В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки, кроме “this”. В таких случаях zero_terms_query указывает, следует ли не соответствовать ни одному документу (none) или всем документам (all). Допустимые значения: none и all. По умолчанию используется none.
Параметр fuzziness не поддерживается для запросов типов phrase, phrase_prefix и cross_fields.
Параметр slop поддерживается только для запросов типов phrase и phrase_prefix.
Параметр tie_breaker:
Каждый запрос на уровне терминов с объединением вычисляет оценку документа как наилучшую оценку, возвращенную любым полем в группе. Оценки от всех объединенных запросов складываются, чтобы получить окончательную оценку. Вы можете изменить способ вычисления оценки, используя параметр tie_breaker. Параметр tie_breaker принимает следующие значения:
-
0.0 (по умолчанию для запросов типов best_fields, cross_fields, phrase и phrase_prefix): Берется единственная наилучшая оценка, возвращенная любым полем в группе.
-
1.0 (по умолчанию для запросов типов most_fields и bool_prefix): Складываются оценки для всех полей в группе.
-
Число с плавающей запятой в диапазоне (0, 1): Берется единственная наилучшая оценка наилучшего соответствующего поля и добавляется (tie_breaker * _score) для всех других соответствующих полей.
4.6 - query-string
Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса.
Запрос типа query_string
Запрос типа query_string разбирает строку запроса на основе синтаксиса строки запроса. Он позволяет создавать мощные, но лаконичные запросы, которые могут включать подстановочные знаки и осуществлять поиск по нескольким полям.
Поиски с использованием запросов типа query_string не возвращают вложенные документы. Для поиска по вложенным полям используйте вложенный запрос.
Запрос типа query_string имеет строгий синтаксис и возвращает ошибку в случае недопустимого синтаксиса. Поэтому он не подходит для приложений с текстовыми полями поиска. Для менее строгой альтернативы рассмотрите использование запроса simple_query_string. Если вам не нужна поддержка синтаксиса запроса, используйте запрос match.
Синтаксис строки запроса
Синтаксис строки запроса основан на синтаксисе запросов Apache Lucene.
Вы можете использовать синтаксис строки запроса в следующих случаях:
-
В запросе типа query_string, например:
GET _search
{
"query": {
"query_string": {
"query": "the wind AND (rises OR rising)"
}
}
}
-
В приложениях OpenSearch Dashboards Discover или Dashboard, если вы отключите DQL, как показано на следующем изображении. Использование синтаксиса строки запроса в OpenSearch Dashboards Discover.
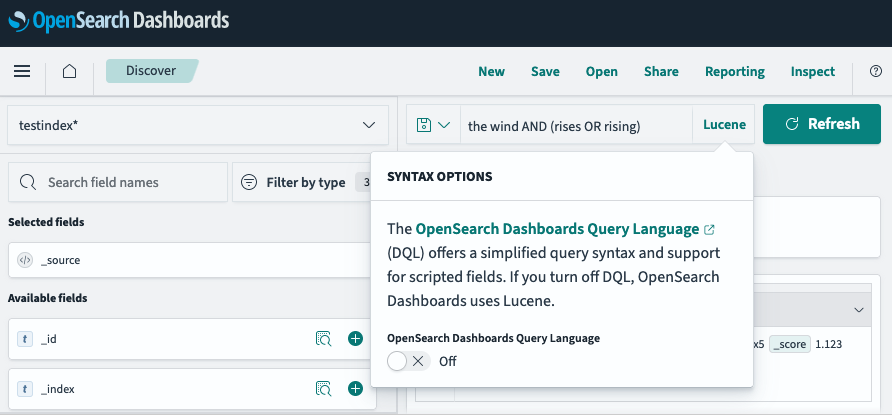
DQL и язык запросов query_string (Lucene) являются двумя вариантами языка для строк поиска в Discover и Dashboards. Для сравнения этих языковых опций смотрите раздел о строках поиска Discover и Dashboard.
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises термины — это wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова сопоставляются в порядке их появления (например, "wind rises"). Операторы (такие как OR, AND и NOT) определяют логическую связь, используемую для интерпретации текста в строке запроса.
Примеры в этом разделе используют индекс, содержащий следующую схему и документы:
PUT /testindex
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
PUT /testindex/_doc/1
{
"title": "The wind rises"
}
PUT /testindex/_doc/2
{
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
PUT /testindex/_doc/3
{
"title": "Windy city"
}
PUT /testindex/_doc/4
{
"article title": "Wind turbines"
}
Зарезервированные символы
Следующий список содержит зарезервированные символы для запроса типа query_string:
+, -, =, &&, ||, >, <, !, (, ), {, }, [, ], ^, ", ~, *, ?, :, \, /
Экранируйте зарезервированные символы с помощью обратной косой черты (). При отправке JSON-запроса используйте двойную обратную косую черту (\) для экранирования зарезервированных символов (поскольку символ обратной косой черты сам по себе является зарезервированным, вы должны экранировать его с помощью другой обратной косой черты).
Например, чтобы выполнить поиск по выражению 2*3, укажите строку запроса: 2\\*3:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: 2\\*3"
}
}
}
Знаки > и < не могут быть экранированы. Они интерпретируются как запрос диапазона.
Пробелы и пустые запросы
Символы пробела не считаются операторами. Если строка запроса пуста или содержит только символы пробела, запрос не возвращает результатов.
Имена полей
Укажите имя поля перед двоеточием. В следующей таблице приведены примеры запросов с именами полей.
| Запрос в запросе типа query_string |
Запрос в Discover |
Критерий для соответствия документа |
Соответствующие документы из индекса testindex |
| title: wind |
title: wind |
Поле title содержит слово wind. |
1, 2 |
| title: (wind OR windy) |
title: (wind OR windy) |
Поле title содержит слово wind или слово windy. |
1, 2, 3 |
| title: "wind rises" |
title: “wind rises” |
Поле title содержит фразу wind rises. Экранируйте кавычки с помощью обратной косой черты. |
1 |
| article\ title: wind |
article\ title: wind |
Поле article title содержит слово wind. Экранируйте пробел с помощью обратной косой черты. |
4 |
| title.\*: rise |
title.*: rise |
Каждое поле, начинающееся с title. (в этом примере, title.english) содержит слово rise. Экранируйте символ подстановки с помощью обратной косой черты. |
1 |
| exists: description |
exists: description |
Поле description существует. |
2 |
Подстановочные выражения
Вы можете указывать подстановочные выражения, используя специальные символы: ? заменяет один символ, а * заменяет ноль или более символов.
Пример
Следующий запрос ищет заголовок, содержащий слово “gone”, и описание, которое содержит слово, начинающееся с “hist”:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: gone AND description: hist*"
}
}
}
Запросы с подстановочными знаками могут использовать значительное количество памяти, что может ухудшить производительность. Подстановочные знаки в начале слова (например, *cal) являются наиболее затратными, поскольку сопоставление документов с такими подстановочными знаками требует проверки всех терминов в индексе. Чтобы отключить ведущие подстановочные знаки, установите параметр allow_leading_wildcard в значение false.
Для повышения эффективности чистые подстановочные знаки, такие как *, переписываются как запросы на существование. Таким образом, запрос description: * будет соответствовать документам, содержащим пустое значение в поле описания, но не будет соответствовать документам, в которых поле описания отсутствует или имеет значение null.
Если вы установите analyze_wildcard в значение true, OpenSearch будет анализировать запросы, которые заканчиваются на * (например, hist*). В результате OpenSearch создаст логический запрос, состоящий из полученных токенов, принимая точные совпадения для первых n-1 токенов и префиксное совпадение для последнего токена.
Регулярные выражения
Чтобы указать шаблоны регулярных выражений в строке запроса, окружите их косыми чертами (/), например, title: /w[a-z]nd/.
Параметр allow_leading_wildcard не применяется к регулярным выражениям. Например, строка запроса, такая как /.*d/, будет проверять все термины в индексе.
Нечеткий поиск
Вы можете выполнять нечеткие запросы, используя оператор ~, например, title: rise~.
Запрос ищет документы, содержащие термины, похожие на искомый термин в пределах максимального допустимого расстояния редактирования. Расстояние редактирования определяется как расстояние Дамерау-Левенштейна, которое измеряет количество изменений одного символа (вставок, удалений, замен или перестановок), необходимых для преобразования одного термина в другой.
По умолчанию расстояние редактирования равно 2, что должно охватывать 80% опечаток. Чтобы изменить значение по умолчанию для расстояния редактирования, укажите новое расстояние редактирования после оператора ~. Например, чтобы установить расстояние редактирования равным 1, используйте запрос title: rise~1.
Не смешивайте нечеткие и подстановочные операторы. Если вы укажете как нечеткий, так и подстановочный операторы, один из операторов не будет применен. Например, если вы можете выполнить поиск по wnid*~1, подстановочный оператор * будет применен, но нечеткий оператор ~1 не будет применен.
Запросы на близость
Запрос на близость не требует, чтобы искомая фраза была в указанном порядке. Он позволяет словам в фразе находиться в другом порядке или разделяться другими словами. Запрос на близость указывает максимальное расстояние редактирования между словами в фразе. Например, следующий запрос позволяет расстояние редактирования равное 4 при сопоставлении слов в указанной фразе:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: \"wind gone\"~4"
}
}
}
Когда OpenSearch сопоставляет документы, чем ближе слова в документе к порядку слов, указанному в запросе (тем меньше расстояние редактирования), тем выше оценка релевантности документа.
Диапазоны
Чтобы указать диапазон для числового, строкового или датированного поля, используйте квадратные скобки ([min TO max]) для включающего диапазона и фигурные скобки ({min TO max}) для исключающего диапазона. Вы также можете комбинировать квадратные и фигурные скобки, чтобы включить или исключить нижнюю и верхнюю границы (например, {min TO max]).
Даты для диапазона дат должны быть предоставлены в формате, который вы использовали при сопоставлении поля, содержащего дату. Для получения дополнительной информации о поддерживаемых форматах дат смотрите раздел Форматы.
Следующая таблица предоставляет примеры синтаксиса диапазонов.
| Тип данных |
Запрос |
Строка запроса |
| Числовой |
Документы, у которых номера счетов от 1 до 15, включительно. |
account_number: [1 TO 15] или account_number: (>=1 AND <=15) или account_number: (+>=1 +<=15) |
|
Документы, у которых номера счетов 15 и больше. |
account_number: [15 TO *] или account_number: >=15 (обратите внимание, что после знака >= нет пробела) |
| Строковой |
Документы, где фамилия от Bates, включительно, до Duke, исключительно. |
lastname: [Bates TO Duke} или lastname: (>=Bates AND <Duke) |
|
Документы, где фамилия предшествует Bates в алфавитном порядке. |
lastname: {* TO Bates} или lastname: <Bates (обратите внимание, что после знака < нет пробела) |
| Дата |
Документы, где дата выпуска между 21.03.2023 и 25.09.2023, включительно. |
release_date: [03/21/2023 TO 09/25/2023] |
В качестве альтернативы указанию диапазона в строке запроса вы можете использовать запрос диапазона, который предоставляет более надежный синтаксис.
Увеличение релевантности
Используйте оператор увеличения (^) для увеличения оценки релевантности документов на заданный множитель. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию используется 1.
Следующая таблица предоставляет примеры увеличения релевантности.
| Тип |
Описание |
Строка запроса |
| Увеличение слова |
Найти все адреса, содержащие слово street, и увеличить вес тех, которые содержат слово Madison. |
address: Madison^2 street |
| Увеличение фразы |
Найти документы с заголовком, содержащим фразу wind rises, увеличив вес на 2. |
title: \"wind rises\"^2 |
|
Найти документы с заголовком, содержащим слова wind rises, и увеличить вес документов, содержащих фразу wind rises, на 2. |
title: (wind rises)^2 |
Логические операторы
Когда вы указываете поисковые термины в запросе, по умолчанию запрос возвращает документы, содержащие хотя бы один из указанных терминов. Вы можете использовать параметр default_operator, чтобы задать оператор для всех терминов. Таким образом, если вы установите default_operator в значение AND, все термины будут обязательными, в то время как если вы установите его в значение OR, все термины будут необязательными.
Операторы + и -
Если вы хотите более детально контролировать обязательные и необязательные термины, вы можете использовать операторы + и -. Оператор + делает следующий за ним термин обязательным, в то время как оператор - исключает следующий за ним термин.
Например, в строке запроса title: (gone +wind -turbines) указывается, что термин gone является необязательным, термин wind должен присутствовать, а термин turbines не должен присутствовать в заголовке соответствующих документов:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone +wind -turbines)"
}
}
}
Запрос возвращает два соответствующих документа:
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "wind"
}
},
"should": {
"match": {
"title": "gone"
}
},
"must_not": {
"match": {
"title": "turbines"
}
}
}
}
}
Обычные логические операторы
В качестве альтернативы вы можете использовать следующие логические операторы: AND, &&, OR, ||, NOT, !. Однако эти операторы не следуют правилам приоритета, поэтому вы должны использовать скобки, чтобы указать приоритет при использовании нескольких логических операторов. Например, строку запроса title: (gone +wind -turbines) можно переписать следующим образом, используя логические операторы:
title: ((gone AND wind) OR wind) AND NOT turbines
Запустите следующий запрос, содержащий переписанную строку запроса:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: ((gone AND wind) OR wind) AND NOT turbines"
}
}
}
Запрос возвращает те же результаты, что и запрос, использующий операторы + и -. Однако обратите внимание, что оценки релевантности соответствующих документов могут отличаться от предыдущих результатов:
{
"_index": "testindex",
"_id": "2",
"_score": 1.6166971,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Группировка
Группируйте несколько условий или терминов в подзапросы, используя скобки. Например, следующий запрос ищет документы, содержащие слова “gone” или “rises”, которые обязательно должны содержать слово “wind” в заголовке:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone OR rises) AND wind"
}
}
}
Результаты содержат два соответствующих документа:
{
"_index": "testindex",
"_id": "1",
"_score": 1.5046883,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
}
Вы также можете использовать группировку для увеличения веса результатов подзапросов или для указания конкретного поля, например: title:(gone AND wind) description:(historical film)^2.
Поиск по нескольким полям
Чтобы выполнить поиск по нескольким полям, используйте параметр fields. Когда вы указываете параметр fields, запрос переписывается в формате field_1: query OR field_2: query ....
Например, следующий запрос ищет термины “ветер” или “фильм” в полях заголовка и описания:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title", "description" ],
"query": "ветер AND фильм"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields:
GET testindex/_search
{
"query": {
"query_string": {
"query": "(title:ветер OR description:ветер) AND (title:фильм OR description:фильм)"
}
}
}
Поиск по нескольким подполям поля
Чтобы выполнить поиск по всем внутренним полям, вы можете использовать подстановочный знак. Например, чтобы искать по всем подполям в поле address, используйте следующий запрос:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields" : ["address.*"],
"query" : "Нью AND (Йорк OR Джерси)"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields (обратите внимание, что * экранируется с помощью \\):
GET /testindex/_search
{
"query": {
"query_string" : {
"query": "address.\\*: Нью AND (Йорк OR Джерси)"
}
}
}
Увеличение веса (Boosting)
Подзапросы, которые генерируются для каждого поискового термина, комбинируются с помощью запроса dis_max с параметром tie_breaker. Чтобы увеличить вес отдельных полей, используйте оператор ^. Например, следующий запрос увеличивает вес поля заголовка в 2 раза:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title^2", "description" ],
"query": "ветер AND фильм"
}
}
}
Чтобы увеличить вес всех подполей поля, укажите оператор увеличения после подстановочного знака:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields": ["work_address", "address.*^2"],
"query": "Нью AND (Йорк OR Джерси)"
}
}
}
Параметры для поиска по нескольким полям
При выполнении поиска по нескольким полям вы можете передать дополнительный необязательный параметр type в запрос query_string.
| Параметр |
Тип данных |
Описание |
| type |
String |
Определяет, как OpenSearch выполняет запрос и оценивает результаты. Допустимые значения: best_fields, bool_prefix, most_fields, cross_fields, phrase и phrase_prefix. Значение по умолчанию — best_fields. Для описания допустимых значений см. раздел о типах многоцелевых запросов. |
Описание допустимых значений для параметра type
- best_fields: Использует наилучшие поля для оценки результатов. Это значение по умолчанию.
- bool_prefix: Позволяет использовать префиксы для логических операторов, что позволяет более гибко формировать запросы.
- most_fields: Оценивает результаты, используя все поля, что может быть полезно для более широкого поиска.
- cross_fields: Объединяет все поля в один общий запрос, что позволяет искать по всем полям одновременно.
- phrase: Ищет точные фразы в указанных полях.
- phrase_prefix: Позволяет искать фразы с префиксами, что может быть полезно для автозаполнения.
Эти параметры позволяют более точно настраивать поведение поиска в OpenSearch в зависимости от ваших потребностей.
Синонимы в запросе query_string
Запрос query_string поддерживает расширение синонимов с несколькими терминами с помощью фильтра токенов synonym_graph. Если вы используете фильтр synonym_graph, OpenSearch создает запрос на совпадение фразы для каждого синонима.
Параметр auto_generate_synonyms_phrase_query указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. По умолчанию auto_generate_synonyms_phrase_query установлен в true, поэтому, если вы укажете “ml” и “machine learning” как синонимы и выполните поиск по “ml”, OpenSearch будет искать ml OR "machine learning".
В качестве альтернативы вы можете сопоставлять многословные синонимы, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в false, OpenSearch будет искать ml OR (machine AND learning).
Пример запроса с отключенной авто-генерацией фраз
Следующий запрос ищет текст “ml models” и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Минимальное количество совпадений
Запрос query_string разбивает запрос вокруг каждого оператора и создает булев запрос для всего ввода. Параметр minimum_should_match указывает минимальное количество терминов, которые документ должен соответствовать, чтобы быть возвращенным в результатах поиска. Например, следующий запрос указывает, что поле description должно соответствовать как минимум двум терминам для каждого результата поиска:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"description"
],
"query": "historical epic film",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (description:historical description:epic description:film)~2.
Эти функции позволяют более гибко настраивать поиск и управлять тем, как обрабатываются синонимы и минимальные условия для совпадений.
Минимальное количество совпадений с несколькими полями
Если вы указываете несколько полей в запросе query_string, OpenSearch создает запрос dis_max для указанных полей. Если вы не указываете оператор для терминов запроса, весь текст запроса рассматривается как одно условие. OpenSearch строит запрос для каждого поля, используя это одно условие. В конечном булевом запросе содержится одно условие, соответствующее запросу dis_max для всех полей, поэтому параметр minimum_should_match не применяется.
Пример без явных операторов
В следующем запросе “historical epic heroic” рассматривается как одно условие:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical title:epic title:heroic) | (description:historical description:epic description:heroic)).
Пример с явными операторами
Если вы добавите явные операторы (AND или OR) к терминам запроса, каждый термин будет рассматриваться как отдельное условие, к которому можно применить параметр minimum_should_match. Например, в следующем запросе “historical”, “epic” и “heroic” считаются отдельными условиями:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical OR epic OR heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Запрос соответствует как минимум двум из трех условий. Каждое условие представляет собой запрос dis_max по полям title и description для каждого термина.
Использование параметра type
В качестве альтернативы, чтобы гарантировать применение minimum_should_match, вы можете установить параметр type в значение cross_fields. Это указывает на то, что поля с одинаковым анализатором должны быть сгруппированы вместе при анализе входного текста:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"type": "cross_fields",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Однако, если вы используете разные анализаторы, вам необходимо использовать явные операторы в запросе, чтобы гарантировать применение параметра minimum_should_match к каждому термину.
Параметры запроса query_string
Следующая таблица перечисляет параметры, поддерживаемые запросом query_string. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Текст, который может содержать выражения в синтаксисе строки запроса для поиска. Обязательный параметр. |
| allow_leading_wildcard |
Boolean |
Указывает, разрешены ли символы * и ? в качестве первых символов поискового термина. По умолчанию true. |
| analyze_wildcard |
Boolean |
Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию false. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Дополнительную информацию о index.query.default_field см. в разделе о динамических настройках уровня индекса. |
| auto_generate_synonyms_phrase_query |
Boolean |
Указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. Например, если вы укажете “ba” и “batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать ba OR "batting average" (если этот параметр установлен в true) или ba OR (batting AND average) (если установлен в false). По умолчанию true. |
| boost |
Floating-point |
Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| default_field |
String |
Поле, в котором следует выполнять поиск, если поле не указано в строке запроса. Поддерживает подстановочные знаки. По умолчанию используется значение, указанное в настройках индекса index.query.default_field. По умолчанию index.query.default_field равно *, что означает извлечение всех полей, подходящих для термового запроса, и фильтрацию метаданных. Извлеченные поля объединяются в запрос, если префикс не указан. Подходящие поля не включают вложенные документы. Поиск по всем подходящим полям может быть ресурсоемкой операцией. Настройка indices.query.bool.max_clause_count определяет максимальное значение для произведения количества полей и количества терминов, которые могут быть запрошены одновременно. Значение по умолчанию для indices.query.bool.max_clause_count равно 1,024. |
| default_operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины соответствовали (AND) или достаточно, чтобы соответствовал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения:
- OR: строка интерпретируется как “или”
- AND: строка интерпретируется как “и”. По умолчанию OR. |
| enable_position_increments |
Boolean |
Когда установлено в true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fields |
String array |
Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется значение, указанное в настройках индекса index.query.default_field, которое по умолчанию равно ["*"]. |
| fuzziness |
String |
Количество изменений символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, что является хорошим выбором для большинства случаев. |
| fuzzy_max_expansions |
Positive integer |
Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false. По умолчанию — хороший выбор для большинства случаев. |
| lenient |
Boolean |
Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_determinized_states |
Positive integer |
Максимальное количество “состояний” (меры сложности), которые Lucene может создать для строк запросов, содержащих регулярные выражения (например, "query": "/wind.+?/"). Более крупные числа позволяют выполнять запросы, использующие больше памяти. По умолчанию 10,000. |
| minimum_should_match |
Positive or negative integer, positive or negative percentage, combination |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор OR, количество терминов, которые должны соответствовать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не соответствует “The Wind Rises”. Если minimum_should_match равно 1, он соответствует. |
| phrase_slop |
Integer |
Максимальное количество слов, которые могут находиться между совпадающими словами. Если phrase_slop равно 2, максимальное количество двух слов разрешено между совпадающими словами в фразе. Переставленные слова имеют слоп 2. По умолчанию 0 (точное совпадение фразы, где совпадающие слова должны находиться рядом друг с другом). |
| quote_analyzer |
String |
Анализатор, используемый для токенизации текста в кавычках в строке запроса. Переопределяет параметр analyzer для текста в кавычках. По умолчанию используется search_quote_analyzer, указанный для default_field. |
| quote_field_suffix |
String |
Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неточных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово “lightly” в поле title.exact. Это второе поле может использовать другой тип (например, keyword вместо text) или другой анализатор. |
| rewrite |
String |
Определяет, как OpenSearch переписывает и оценивает многословные запросы. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. По умолчанию используется constant_score. |
| time_zone |
String |
Указывает количество часов для смещения желаемого часового пояса от UTC. Необходимо указать номер смещения часового пояса, если строка запроса содержит диапазон дат. Например, установите time_zone": "-08:00" для запроса с диапазоном дат, таким как "query": "wind rises release_date[2012-01-01 TO 2014-01-01]". Формат часового пояса по умолчанию для указания количества смещения часов — UTC. |
Дополнительные сведения
Запросы строки запроса могут быть внутренне преобразованы в префиксные запросы. Если параметр search.allow_expensive_queries установлен в false, префиксные запросы не выполняются. Если index_prefixes включен, настройка search.allow_expensive_queries игнорируется, и создается и выполняется оптимизированный запрос.
4.7 - simple-query-string
Более простая, менее строгая версия запроса query_string.
Простой запрос с использованием simple_query_string
Используйте тип simple_query_string, чтобы указать несколько аргументов, разделенных регулярными выражениями, непосредственно в строке запроса. Простой запрос имеет менее строгий синтаксис, чем обычный запрос, поскольку отбрасывает любые недопустимые части строки и не возвращает ошибки за недопустимый синтаксис.
Этот запрос выполняет нечеткий поиск по полю title:
GET _search
{
"query": {
"simple_query_string": {
"query": "\"rises wind the\"~4 | *ising~2",
"fields": ["title"]
}
}
}
Синтаксис простого запроса
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises терминами являются wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова совпадают в порядке их появления (например, "wind rises"). Операторы, такие как +, | и -, определяют логическую связь, используемую для интерпретации текста в строке запроса.
Операторы
Синтаксис простого запроса поддерживает следующие операторы:
| Оператор |
Описание |
+ |
Действует как оператор AND. |
| ` |
` |
* |
Когда используется в конце термина, обозначает префиксный запрос. |
" |
Обрамляет несколько терминов в фразу (например, "wind rises"). |
(, ) |
Обрамляет клаузу для приоритета (например, `wind + (rises |
~n |
Когда используется после термина (например, wind~3), устанавливает нечеткость. Когда используется после фразы, устанавливает слоп. |
- |
Отрицает термин. |
Все вышеперечисленные операторы являются зарезервированными символами. Чтобы ссылаться на них как на обычные символы, необходимо экранировать их с помощью обратной косой черты. При отправке JSON-запроса используйте \\, чтобы экранировать зарезервированные символы (поскольку символ обратной косой черты сам по себе является зарезервированным, его необходимо экранировать еще одной обратной косой чертой).
Оператор по умолчанию
Оператор по умолчанию — OR (если вы не установите default_operator в AND). Оператор по умолчанию определяет общее поведение запроса. Например, рассмотрим индекс, содержащий следующие документы:
PUT /customers/_doc/1
{
"first_name":"Amber",
"last_name":"Duke",
"address":"880 Holmes Lane"
}
PUT /customers/_doc/2
{
"first_name":"Hattie",
"last_name":"Bond",
"address":"671 Bristol Street"
}
PUT /customers/_doc/3
{
"first_name":"Nanette",
"last_name":"Bates",
"address":"789 Madison St"
}
PUT /customers/_doc/4
{
"first_name":"Dale",
"last_name":"Amber",
"address":"467 Hutchinson Court"
}
Следующий запрос пытается найти документы, в которых адрес содержит слова street или st и не содержит слово madison:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st -madison"
}
}
}
Однако результаты включают не только ожидаемый документ, но и все четыре документа:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
},
{
"_index": "customers",
"_id": "3",
"_score": 1.2039728,
"_source": {
"first_name": "Nanette",
"last_name": "Bates",
"address": "789 Madison St"
}
},
{
"_index": "customers",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "Amber",
"last_name": "Duke",
"address": "880 Holmes Lane"
}
},
{
"_index": "customers",
"_id": "4",
"_score": 1,
"_source": {
"first_name": "Dale",
"last_name": "Amber",
"address": "467 Hutchinson Court"
}
}
]
}
}
Поскольку оператор по умолчанию — OR, этот запрос включает документы, которые содержат слова street или st (документы 2 и 3), а также документы, которые не содержат слово madison (документы 1 и 4).
Чтобы правильно выразить намерение запроса, предшествуйте -madison знаком +:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st +-madison"
}
}
}
Альтернативный подход
Или укажите AND в качестве оператора по умолчанию и используйте дизъюнкцию для слов street и st:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "st|street -madison",
"default_operator": "AND"
}
}
}
Предыдущий запрос возвращает документ 2:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
}
]
}
}
Таким образом, использование правильного оператора и синтаксиса позволяет точно формулировать запросы и получать ожидаемые результаты.
Ограничение операторов
Чтобы ограничить поддерживаемые операторы для парсера простого запроса, включите операторы, которые вы хотите поддерживать, разделенные символом |, в параметр flags. Например, следующий запрос включает только операторы OR, AND и FUZZY:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "bristol | madison +stre~2",
"flags": "OR|AND|FUZZY"
}
}
}
Доступные флаги операторов
Следующая таблица перечисляет все доступные флаги операторов:
| Флаг |
Описание |
ALL (по умолчанию) |
Включает все операторы. |
AND |
Включает оператор + (AND). |
ESCAPE |
Включает \ как символ экранирования. |
FUZZY |
Включает оператор ~n после слова, где n — целое число, обозначающее допустимое расстояние редактирования для совпадения. |
NEAR |
Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и SLOP. |
NONE |
Отключает все операторы. |
NOT |
Включает оператор - (NOT). |
OR |
Включает оператор ` |
PHRASE |
Включает кавычки " для поиска фраз. |
PRECEDENCE |
Включает операторы ( и ) (скобки) для приоритета операторов. |
PREFIX |
Включает оператор * (префикс). |
SLOP |
Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и NEAR. |
WHITESPACE |
Включает пробелы как символы, по которым текст разбивается. |
Эти флаги позволяют гибко настраивать поведение парсера простого запроса в зависимости от ваших потребностей.
Шаблоны с подстановочными знаками
Вы можете указывать шаблоны с подстановочными знаками, используя специальный символ *, который заменяет ноль или более символов. Например, следующий запрос ищет во всех полях, которые заканчиваются на name:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber Bond",
"fields": [ "*name" ]
}
}
}
Увеличение значимости
Используйте оператор увеличения значимости (^) для увеличения оценки релевантности поля с помощью множителя. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. Значение по умолчанию — 1.
Например, следующий запрос ищет в полях first_name и last_name и увеличивает значимость совпадений из поля first_name в 2 раза:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber",
"fields": [ "first_name^2", "last_name" ]
}
}
}
Мультипозиционные токены
Для мультипозиционных токенов простой запрос создает запрос на совпадение фразы. Таким образом, если вы укажете ml, machine learning как синонимы и выполните поиск по ml, OpenSearch будет искать ml ИЛИ "machine learning".
В качестве альтернативы вы можете сопоставить мультипозиционные токены, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в значение false, OpenSearch будет искать ml ИЛИ (machine И learning).
Например, следующий запрос ищет текст ml models и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"simple_query_string": {
"fields": ["title"],
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Параметры
Следующая таблица перечисляет параметры верхнего уровня, которые поддерживает запрос simple_query_string. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
query |
Строка |
Текст, который может содержать выражения в синтаксисе простого запроса для использования в поиске. Обязательный параметр. |
analyze_wildcard |
Логический |
Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию — false. |
analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
auto_generate_synonyms_phrase_query |
Логический |
Указывает, следует ли автоматически создавать запросы на совпадение фразы для многословных синонимов. По умолчанию — true. |
default_operator |
Строка |
Если строка запроса содержит несколько поисковых терминов, указывает, должны ли совпадать все термины (AND) или только один термин (OR) для того, чтобы документ считался совпадением. Допустимые значения:
- OR: строка интерпретируется как OR
- AND: строка интерпретируется как AND
По умолчанию — OR. |
fields |
Массив строк |
Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется настройка index.query.default_field, которая по умолчанию равна ["*"]. Максимальное количество полей, которые могут быть одновременно исследованы, определяется параметром indices.query.bool.max_clause_count, который по умолчанию равен 1,024. |
flags |
Строка |
Строка, разделенная символом ` |
fuzzy_max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах указанного расстояния нечеткости. Затем OpenSearch пытается сопоставить эти термины. По умолчанию — 50. |
fuzzy_transpositions |
Логический |
Установка fuzzy_transpositions в значение true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в опции нечеткости. Например, расстояние между wind и wnid равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, rewind и wnid имеют одинаковое расстояние (2) от wind, несмотря на более человеческое мнение, что wnid является очевидной опечаткой. Значение по умолчанию является хорошим выбором для большинства случаев использования. |
fuzzy_prefix_length |
Целое число |
Количество начальных символов, которые остаются неизменными для нечеткого сопоставления. По умолчанию — 0. |
lenient |
Логический |
Установка lenient в значение true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию — false. |
minimum_should_match |
Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадением. Например, если minimum_should_match равно 2, wind often rising не совпадает с The Wind Rises. Если minimum_should_match равно 1, совпадение происходит. Для получения подробной информации смотрите раздел “Минимальное количество совпадений”. |
quote_field_suffix |
Строка |
Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неполных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово lightly в поле title.exact. Это второе поле может использовать другой тип (например, keyword, а не text) или другой анализатор. |
4.8 - intervals query
Позволяет точно контролировать близость и порядок совпадающих терминов.
Запрос интервалов
Запрос интервалов сопоставляет документы на основе близости и порядка совпадающих терминов. Он применяет набор правил сопоставления к терминам, содержащимся в указанном поле. Запрос генерирует последовательности минимальных интервалов, охватывающих термины в тексте. Вы можете комбинировать интервалы и фильтровать их по родительским источникам.
Рассмотрим индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "пары ключ-значение эффективно хранятся в хэш-таблице"
}
PUT /testindex/_doc/2
{
"title": "хранить пары ключ-значение в хэш-карте"
}
Например, следующий запрос ищет документы, содержащие фразу “пары ключ-значение” (без промежутков между терминами), за которой следует либо “хэш-таблица”, либо “хэш-карта”:
GET /testindex/_search
{
"query": {
"intervals": {
"title": {
"all_of": {
"ordered": true,
"intervals": [
{
"match": {
"query": "пары ключ-значение",
"max_gaps": 0,
"ordered": true
}
},
{
"any_of": {
"intervals": [
{
"match": {
"query": "хэш-таблица"
}
},
{
"match": {
"query": "хэш-карта"
}
}
]
}
}
]
}
}
}
}
}
Запрос возвращает оба документа.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"intervals": {
"<field>": {
...
}
}
}
}
Поле <field> принимает следующие объекты правил, которые используются для сопоставления документов на основе терминов, порядка и близости.
| Правило |
Описание |
| match |
Сопоставляет анализируемый текст. |
| prefix |
Сопоставляет термины, которые начинаются с заданного набора символов. |
| wildcard |
Сопоставляет термины, используя шаблон с подстановочными знаками. |
| fuzzy |
Сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. |
| all_of |
Объединяет несколько правил с использованием конъюнкции (AND). |
| any_of |
Объединяет несколько правил с использованием дизъюнкции (OR). |
Правило match
Правило match сопоставляет анализируемый текст. В следующей таблице перечислены все параметры, которые поддерживает правило match.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| query |
Обязательный |
Строка |
Текст, по которому нужно выполнить поиск. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для анализа текста запроса. По умолчанию используется анализатор, указанный для <field>. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps |
Необязательный |
Целое число |
Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered |
Необязательный |
Логическое |
Указывает, должны ли совпадающие термины появляться в указанном порядке. По умолчанию false. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Термины анализируются с использованием анализатора поиска, указанного для этого поля. Указав use_field, вы можете искать по нескольким полям, как если бы они были одним и тем же полем. Например, если вы индексируете один и тот же текст в полях с корнями и без корней, вы можете искать корневые токены, которые находятся рядом с некорневыми. |
Правило prefix
Правило prefix сопоставляет термины, которые начинаются с заданного набора символов (префикс). Префикс может расширяться для сопоставления максимум 128 терминов. Если префикс соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило prefix.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| prefix |
Обязательный |
Строка |
Префикс, используемый для сопоставления терминов. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации префикса. По умолчанию используется анализатор, указанный для <field>. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Префикс нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило wildcard
Правило wildcard сопоставляет термины, используя шаблон с подстановочными знаками. Шаблон с подстановочными знаками может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило wildcard.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| pattern |
Обязательный |
Строка |
Шаблон с подстановочными знаками, используемый для сопоставления терминов. Укажите ? для сопоставления любого одного символа или * для сопоставления нуля или более символов. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации шаблона. По умолчанию используется анализатор, указанный для <field>. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Шаблон нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Указание шаблонов, начинающихся с * или ?, может ухудшить производительность поиска, так как увеличивает количество итераций, необходимых для сопоставления терминов.
Правило fuzzy
Правило fuzzy сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. Шаблон fuzzy может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило fuzzy.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| term |
Обязательный |
Строка |
Термин для сопоставления. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации термина. По умолчанию используется анализатор, указанный для <field>. |
| fuzziness |
Необязательный |
Строка |
Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова на другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение на основе длины каждого термина и является хорошим выбором для большинства случаев использования. |
| transpositions |
Необязательный |
Логическое |
Установка transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если transpositions равно true (обмен “n” и “i”), и 2, если false (удаление “n”, вставка “n”). Если transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” является очевидной опечаткой. По умолчанию является хорошим выбором для большинства случаев использования. |
| prefix_length |
Необязательный |
Целое число |
Количество начальных символов, оставляемых неизменными для нечеткого сопоставления. По умолчанию 0. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Термин нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило all_of
Правило all_of объединяет несколько правил с использованием конъюнкции (AND). В следующей таблице перечислены все параметры, которые поддерживает правило all_of.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| intervals |
Обязательный |
Массив объектов правил |
Массив правил для объединения. Документ должен соответствовать всем правилам, чтобы быть возвращенным в результатах. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps |
Необязательный |
Целое число |
Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered |
Необязательный |
Логическое |
Если true, интервалы, сгенерированные правилами, должны появляться в указанном порядке. По умолчанию false. |
Правило any_of
Правило any_of объединяет несколько правил с использованием дизъюнкции (OR). В следующей таблице перечислены все параметры, которые поддерживает правило any_of.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| intervals |
Обязательный |
Массив объектов правил |
Массив правил для объединения. Документ должен соответствовать хотя бы одному правилу, чтобы быть возвращенным в результатах. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
Правило filter
Правило filter используется для ограничения результатов. В следующей таблице перечислены все параметры, которые поддерживает правило filter.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| after |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые следуют за интервалом, указанным в правиле фильтра. |
| before |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые находятся перед интервалом, указанным в правиле фильтра. |
| contained_by |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, содержащихся в интервале, указанном в правиле фильтра. |
| containing |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые содержат интервал, указанный в правиле фильтра. |
| not_contained_by |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не содержатся в интервале, указанном в правиле фильтра. |
| not_containing |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не содержат интервал, указанный в правиле фильтра. |
| not_overlapping |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не перекрываются с интервалом, указанным в правиле фильтра. |
| overlapping |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые перекрываются с интервалом, указанным в правиле фильтра. |
| script |
Необязательный |
Объект скрипта |
Скрипт, используемый для сопоставления документов. Этот скрипт должен возвращать true или false. |
Пример: Фильтры
Следующий запрос ищет документы, содержащие слова “пары” и “хэш”, которые находятся в пределах пяти позиций друг от друга и не содержат слово “эффективно” между ними:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "пары хэш",
"max_gaps" : 5,
"filter" : {
"not_containing" : {
"match" : {
"query" : "эффективно"
}
}
}
}
}
}
}
}
Ответ содержит только документ 2.
Ответ
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.25,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.25,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Пример: Скриптовые фильтры
В качестве альтернативы вы можете написать свой собственный скриптовый фильтр для включения в запрос интервалов, используя следующие переменные:
interval.start: Позиция (номер термина), где начинается интервал.interval.end: Позиция (номер термина), где заканчивается интервал.interval.gap: Количество слов между терминами.
Например, следующий запрос ищет слова “карта” и “хэш”, которые находятся рядом друг с другом в указанном интервале. Термины нумеруются, начиная с 0, поэтому в тексте “хранить пары ключ-значение в хэш-карте” слово “хранить” находится на позиции 0, “пары” на позиции 1 и так далее. Указанный интервал должен начинаться после “а” и заканчиваться перед концом строки:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "карта хэш",
"filter" : {
"script" : {
"source" : "interval.start > 5 && interval.end < 8 && interval.gaps == 0"
}
}
}
}
}
}
}
Ответ
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.5,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.5,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Минимизация интервалов
Чтобы гарантировать, что запросы выполняются за линейное время, запрос интервалов минимизирует интервалы. Например, рассмотрим документ, содержащий текст “a b c d c”. Вы можете использовать следующий запрос для поиска “d”, который содержится между “a” и “c”:
POST /testindex/_search
{
"query": {
"intervals" : {
"my_text" : {
"match" : {
"query" : "d",
"filter" : {
"contained_by" : {
"match" : {
"query" : "a c"
}
}
}
}
}
}
}
}
Запрос не возвращает результатов, потому что он сопоставляет первые два термина “a” и “c” и не находит “d” между этими терминами.
5 - compound queries
Объединяют несколько запросов. Модифицируют поведение дочерних запросов. Управляют логикой выполнения
Составные запросы
Составные запросы служат обертками для нескольких листовых или составных клауз, чтобы либо объединить их результаты, либо изменить их поведение.
В следующей таблице перечислены все типы составных запросов.
| Тип запроса |
Описание |
| bool (логический) |
Объединяет несколько клауз запросов с помощью логики AND/OR. |
| boosting |
Изменяет релевантность документов, не удаляя их из результатов поиска. Возвращает документы, которые соответствуют положительному запросу, но понижает релевантность документов в результатах, которые соответствуют отрицательному запросу. |
| constant_score |
Оборачивает запрос или фильтр и присваивает постоянный балл всем совпадающим документам. Этот балл равен значению boost. |
| dis_max (максимум дизъюнкции) |
Возвращает документы, которые соответствуют одному или нескольким клаузам запроса. Если документ соответствует нескольким клаузам запроса, ему присваивается более высокий балл релевантности. Балл релевантности рассчитывается с использованием наивысшего балла из любых совпадающих клауз и, при необходимости, баллов из других совпадающих клауз, умноженных на значение tiebreaker. |
| function_score |
Пересчитывает балл релевантности документов, которые возвращаются запросом, с использованием функции, которую вы определяете. |
| hybrid |
Объединяет баллы релевантности из нескольких запросов в один балл для данного документа. |
5.1 - boolean query
Объединяет несколько клауз запросов с помощью логики AND/OR.
Булевый запрос
Булевый (bool) запрос может комбинировать несколько клауз в один расширенный запрос. Клаузи объединяются с помощью булевой логики для поиска соответствующих документов, возвращаемых в результатах.
Используйте следующие клаузи в булевом запросе:
| Клауз |
Поведение |
| must |
Логический оператор “и”. Результаты должны соответствовать всем запросам в этой клаузе. |
| must_not |
Логический оператор “не”. Все совпадения исключаются из результатов. Если must_not содержит несколько клауз, возвращаются только документы, которые не соответствуют ни одной из этих клауз. Например, “must_not”:[{clause_A}, {clause_B}] эквивалентно NOT(A OR B). |
| should |
Логический оператор “или”. Результаты должны соответствовать хотя бы одному из запросов. Чем больше клауз should совпадает, тем выше оценка релевантности документа. Вы можете установить минимальное количество запросов, которые должны совпадать, с помощью параметра minimum_should_match. Если запрос содержит клаузу must или filter, значение по умолчанию для minimum_should_match равно 0. В противном случае значение по умолчанию равно 1. |
| filter |
Логический оператор “и”, который применяется в первую очередь для уменьшения вашего набора данных перед применением запросов. Запрос внутри клаузи filter является бинарным: да или нет. Если документ соответствует запросу, он возвращается в результатах; в противном случае он не возвращается. Результаты фильтрующего запроса обычно кэшируются для более быстрого возврата. Используйте фильтрующий запрос для фильтрации результатов на основе точных совпадений, диапазонов, дат или чисел. |
Булевый запрос имеет следующую структуру:
GET _search
{
"query": {
"bool": {
"must": [
{}
],
"must_not": [
{}
],
"should": [
{}
],
"filter": {}
}
}
}
Например, предположим, что у вас есть полные произведения Шекспира, индексированные в кластере OpenSearch. Вы хотите построить один запрос, который соответствует следующим требованиям:
- Поле text_entry должно содержать слово “love” и должно содержать либо “life”, либо “grace”.
- Поле speaker не должно содержать “ROMEO”.
- Отфильтровать эти результаты по пьесе “Ромео и Джульетта”, не влияя на оценку релевантности.
Эти требования могут быть объединены в следующий запрос:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": "love"
}
}
],
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": "ROMEO"
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 4,
"successful": 4,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.356054,
"hits": [
{
"_index": "shakespeare",
"_id": "88020",
"_score": 11.356054,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Если вы хотите определить, какие из этих клауз фактически вызвали совпадение результатов, назовите каждый запрос с помощью параметра _name. Чтобы добавить параметр _name, измените имя поля в запросе сопоставления на объект:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": {
"query": "love",
"_name": "love-must"
}
}
}
],
"should": [
{
"match": {
"text_entry": {
"query": "life",
"_name": "life-should"
}
}
},
{
"match": {
"text_entry": {
"query": "grace",
"_name": "grace-should"
}
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": {
"query": "ROMEO",
"_name": "ROMEO-must-not"
}
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
OpenSearch возвращает массив matched_queries, который перечисляет запросы, соответствующие этим результатам:
"matched_queries": [
"love-must",
"life-should"
]
Если вы удалите запросы, не входящие в этот список, вы все равно увидите точно такой же результат. Изучая, какая клаузa should совпала, вы можете лучше понять оценку релевантности результатов.
Вы также можете строить сложные булевы выражения, вложив булевы запросы. Например, используйте следующий запрос, чтобы найти поле text_entry, которое соответствует (love ИЛИ hate) И (life ИЛИ grace) в пьесе “Ромео и Джульетта”:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"text_entry": "love"
}
},
{
"match": {
"text_entry": "hate"
}
}
]
}
},
{
"bool": {
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
]
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.37006,
"hits": [
{
"_index": "shakespeare",
"_type": "doc",
"_id": "88020",
"_score": 11.37006,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Таким образом, вы можете использовать вложенные булевы запросы для создания более сложных логических выражений, что позволяет более точно настраивать поиск и получать релевантные результаты в OpenSearch.
5.2 - boosting query
Изменяет релевантность документов, не удаляя их из результатов поиска. Возвращает документы, которые соответствуют положительному запросу, но понижает релевантность документов в результатах, которые соответствуют отрицательному запросу.
Запрос с бустингом
Если вы ищете слово “pitcher” (питчер), ваши результаты могут относиться как к бейсбольным игрокам, так и к контейнерам для жидкостей. Для поиска в контексте бейсбола вы можете полностью исключить результаты, содержащие слова “glass” (стекло) или “water” (вода), используя клаузу must_not. Однако, если вы хотите сохранить эти результаты, но понизить их релевантность, вы можете сделать это с помощью запросов с бустингом.
Запрос с бустингом возвращает документы, которые соответствуют положительному запросу. Среди этих документов те, которые также соответствуют отрицательному запросу, получают более низкую оценку релевантности (их оценка релевантности умножается на отрицательный коэффициент бустинга).
Пример
Рассмотрим индекс с двумя документами, которые вы индексируете следующим образом:
PUT testindex/_doc/1
{
"article_name": "The greatest pitcher in baseball history"
}
PUT testindex/_doc/2
{
"article_name": "The making of a glass pitcher"
}
Используйте следующий запрос match, чтобы искать документы, содержащие слово “pitcher”:
GET testindex/_search
{
"query": {
"match": {
"article_name": "pitcher"
}
}
}
Оба возвращенных документа имеют одинаковую оценку релевантности:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.18232156,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Теперь используйте следующий запрос с бустингом, чтобы искать документы, содержащие слово “pitcher”, но понизить оценку документов, содержащих слова “glass”, “crystal” или “water”:
GET testindex/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"article_name": "pitcher"
}
},
"negative": {
"match": {
"article_name": "glass crystal water"
}
},
"negative_boost": 0.1
}
}
}
Оба документа все еще возвращаются, но документ со словом “glass” имеет оценку релевантности, которая в 10 раз ниже, чем в предыдущем случае:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.018232157,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами с бустингом.
| Параметр |
Описание |
| positive |
Запрос, которому документ должен соответствовать, чтобы быть возвращенным в результатах. Обязательный параметр. |
| negative |
Если документ в результатах соответствует этому запросу, его оценка релевантности уменьшается путем умножения его исходной оценки релевантности (полученной от положительного запроса) на параметр negative_boost. Обязательный параметр. |
| negative_boost |
Плавающий коэффициент в диапазоне от 0 до 1.0, на который умножается исходная оценка релевантности для уменьшения релевантности документов, соответствующих отрицательному запросу. Обязательный параметр. |
5.3 - constant_score
Оборачивает запрос или фильтр и присваивает постоянный балл всем совпадающим документам. Этот балл равен значению boost.
Запрос constant_score
Если вам нужно вернуть документы, содержащие определенное слово, независимо от того, сколько раз это слово встречается, вы можете использовать запрос constant_score. Запрос constant_score оборачивает фильтрующий запрос и присваивает всем документам в результатах релевантный балл, равный значению параметра boost. Таким образом, все возвращенные документы имеют равный релевантный балл, и частота термина/обратная документная частота (TF/IDF) не учитываются. Фильтрующие запросы не вычисляют релевантные баллы. Кроме того, OpenSearch кэширует часто используемые фильтрующие запросы для повышения производительности.
Пример
Используйте следующий запрос, чтобы вернуть документы, содержащие слово “Hamlet” в индексе shakespeare:
GET shakespeare/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"text_entry": "Hamlet"
}
},
"boost": 1.2
}
}
}
Все документы в результатах получают релевантный балл 1.2.
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 96,
"relation": "eq"
},
"max_score": 1.2,
"hits": [
{
"_index": "shakespeare",
"_id": "32535",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32536,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.97",
"speaker": "HORATIO",
"text_entry": "Dared to the combat; in which our valiant Hamlet--"
}
},
{
"_index": "shakespeare",
"_id": "32546",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32547,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.108",
"speaker": "HORATIO",
"text_entry": "His fell to Hamlet. Now, sir, young Fortinbras,"
}
},
{
"_index": "shakespeare",
"_id": "32625",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32626,
"play_name": "Hamlet",
"speech_number": 59,
"line_number": "1.1.184",
"speaker": "HORATIO",
"text_entry": "Unto young Hamlet; for, upon my life,"
}
},
{
"_index": "shakespeare",
"_id": "32633",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32634,
"play_name": "Hamlet",
"speech_number": 60,
"line_number": "",
"speaker": "MARCELLUS",
"text_entry": "Enter KING CLAUDIUS, QUEEN GERTRUDE, HAMLET, POLONIUS, LAERTES, VOLTIMAND, CORNELIUS, Lords, and Attendants"
}
},
{
"_index": "shakespeare",
"_id": "32634",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32635,
"play_name": "Hamlet",
"speech_number": 1,
"line_number": "1.2.1",
"speaker": "KING CLAUDIUS",
"text_entry": "Though yet of Hamlet our dear brothers death"
}
},
{
"_index": "shakespeare",
"_id": "32699",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32700,
"play_name": "Hamlet",
"speech_number": 8,
"line_number": "1.2.65",
"speaker": "KING CLAUDIUS",
"text_entry": "But now, my cousin Hamlet, and my son,--"
}
},
{
"_index": "shakespeare",
"_id": "32703",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32704,
"play_name": "Hamlet",
"speech_number": 12,
"line_number": "1.2.69",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Good Hamlet, cast thy nighted colour off,"
}
},
{
"_index": "shakespeare",
"_id": "32723",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32724,
"play_name": "Hamlet",
"speech_number": 16,
"line_number": "1.2.89",
"speaker": "KING CLAUDIUS",
"text_entry": "Tis sweet and commendable in your nature, Hamlet,"
}
},
{
"_index": "shakespeare",
"_id": "32754",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32755,
"play_name": "Hamlet",
"speech_number": 17,
"line_number": "1.2.120",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Let not thy mother lose her prayers, Hamlet:"
}
},
{
"_index": "shakespeare",
"_id": "32759",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32760,
"play_name": "Hamlet",
"speech_number": 19,
"line_number": "1.2.125",
"speaker": "KING CLAUDIUS",
"text_entry": "This gentle and unforced accord of Hamlet"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами constant_score.
| Параметр |
Описание |
| filter |
Фильтрующий запрос, которому должен соответствовать документ, чтобы быть возвращенным в результатах. Обязательный. |
| boost |
Числовое значение с плавающей запятой, которое присваивается как релевантный балл всем возвращенным документам. Необязательный. По умолчанию 1.0. |
5.4 - disjunction_max
Возвращает документы, которые соответствуют одному или нескольким клаузам запроса. Если документ соответствует нескольким клаузам запроса, ему присваивается более высокий балл релевантности.
Запрос disjunction max (dis_max)
Запрос disjunction max (dis_max) возвращает любой документ, который соответствует одному или нескольким условиям запроса. Для документов, которые соответствуют нескольким условиям запроса, релевантный балл устанавливается на основе наивысшего релевантного балла из всех соответствующих условий запроса.
Когда релевантные баллы возвращаемых документов идентичны, вы можете использовать параметр tie_breaker, чтобы придать больше веса документам, которые соответствуют нескольким условиям запроса.
Пример
Рассмотрим индекс с двумя документами, которые вы индексируете следующим образом:
PUT testindex1/_doc/1
{
"title": " The Top 10 Shakespeare Poems",
"description": "Top 10 sonnets of England's national poet and the Bard of Avon"
}
PUT testindex1/_doc/2
{
"title": "Sonnets of the 16th Century",
"body": "The poems written by various 16-th century poets"
}
Используйте запрос dis_max, чтобы искать документы, содержащие слова “Shakespeare poems”:
GET testindex1/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Shakespeare poems" }},
{ "match": { "body": "Shakespeare poems" }}
]
}
}
}
Ответ содержит оба документа:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1.3862942,
"_source": {
"title": " The Top 10 Shakespeare Poems",
"description": "Top 10 sonnets of England's national poet and the Bard of Avon"
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 0.2876821,
"_source": {
"title": "Sonnets of the 16th Century",
"body": "The poems written by various 16-th century poets"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами dis_max.
| Параметр |
Описание |
| queries |
Массив одного или нескольких условий запроса, которые используются для сопоставления документов. Документ должен соответствовать хотя бы одному условию запроса, чтобы быть возвращенным в результатах. Если документ соответствует нескольким условиям запроса, релевантный балл устанавливается на основе наивысшего релевантного балла из всех соответствующих условий запроса. Обязательный. |
| tie_breaker |
Числовой коэффициент с плавающей запятой от 0 до 1.0, который используется для придания большего веса документам, соответствующим нескольким условиям запроса. В этом случае релевантный балл документа рассчитывается с использованием следующего алгоритма: берется наивысший релевантный балл из всех соответствующих условий запроса, умножаются баллы всех других соответствующих условий на значение tie_breaker, и затем баллы складываются, нормализуя их. Необязательный. По умолчанию 0 (что означает, что учитывается только наивысший балл). |
5.5 - function_score
Пересчитывает балл релевантности документов, которые возвращаются запросом, с использованием функции, которую вы определяете.
Запрос function score
Используйте запрос function_score, если вам нужно изменить релевантные баллы документов, возвращаемых в результатах. Запрос function_score определяет запрос и одну или несколько функций, которые могут быть применены ко всем результатам или подмножествам результатов для перерасчета их релевантных баллов.
Использование одной функции оценки
Самый простой пример запроса function_score использует одну функцию для перерасчета балла. Следующий запрос использует функцию weight, чтобы удвоить все релевантные баллы. Эта функция применяется ко всем документам в результатах, поскольку в запросе function_score не указаны параметры запроса:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
Применение функции оценки к подмножеству документов
Чтобы применить функцию оценки к подмножеству документов, укажите запрос внутри функции:
GET shakespeare/_search
{
"query": {
"function_score": {
"query": {
"match": {
"play_name": "Hamlet"
}
},
"weight": "2"
}
}
}
Поддерживаемые функции
Тип запроса function_score поддерживает следующие функции:
-
Встроенные:
- weight: Умножает балл документа на предопределенный коэффициент увеличения.
- random_score: Предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями.
- field_value_factor: Использует значение указанного поля документа для перерасчета балла.
- Функции затухания (gauss, exp и linear): Перерасчитывают балл с использованием заданной функции затухания.
-
Пользовательские:
- script_score: Использует скрипт для оценки документов.
Функция weight
Когда вы используете функцию weight, оригинальный релевантный балл умножается на значение с плавающей запятой weight:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
В отличие от значения boost, функция weight не нормализуется.
Функция random_score
Функция random_score предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями. Балл представляет собой число с плавающей запятой в диапазоне [0, 1). По умолчанию функция random_score использует внутренние идентификаторы документов Lucene в качестве значений семени, что делает случайные значения невоспроизводимыми, поскольку документы могут быть перенумерованы после слияний. Чтобы добиться согласованности в генерации случайных значений, вы можете предоставить параметры seed и field. Поле должно быть полем, для которого включены данные поля (обычно это числовое поле). Балл рассчитывается с использованием семени, значений данных поля для указанного поля и соли, рассчитанной с использованием имени индекса и идентификатора шардов. Поскольку имя индекса и идентификатор шардов одинаковы для документов, находящихся в одном шард, документы с одинаковыми значениями полей будут получать одинаковый балл. Чтобы обеспечить разные баллы для всех документов в одном шарде, используйте поле, которое имеет уникальные значения для всех документов. Одним из вариантов является использование поля _seq_no. Однако, если вы выберете это поле, баллы могут измениться, если документ будет обновлен из-за соответствующего обновления _seq_no.
Следующий запрос использует функцию random_score с семенем и полем:
GET shakespeare/_search
{
"query": {
"function_score": {
"random_score": {
"seed": 12345,
"field": "some_numeric_field"
}
}
}
}
Функция field_value_factor
Функция field_value_factor перерасчитывает балл, используя значение указанного поля документа. Если поле является многозначным, используется только его первое значение для расчетов, остальные значения не учитываются.
Функция field_value_factor поддерживает следующие параметры:
-
field: Поле, которое будет использоваться в расчетах баллов.
-
factor: Необязательный коэффициент, на который умножается значение поля. По умолчанию 1.
-
modifier: Один из модификаторов, который будет применен к значению поля.
Поддерживаемые модификаторы
Следующая таблица перечисляет все поддерживаемые модификаторы.
| Модификатор |
Формула |
Описание |
| log |
[\log v] |
Возьмите десятичный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать log1p или log2p вместо log. |
| log1p |
[\log(1+v)] |
Возьмите десятичный логарифм суммы 1 и значения. |
| log2p |
[\log(2+v)] |
Возьмите десятичный логарифм суммы 2 и значения. |
| ln |
[\ln v] |
Возьмите натуральный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать ln1p или ln2p вместо ln. |
| ln1p |
[\ln(1+v)] |
Возьмите натуральный логарифм суммы 1 и значения. |
| ln2p |
[\ln(2+v)] |
Возьмите натуральный логарифм суммы 2 и значения. |
| reciprocal |
[\frac{1}{v}] |
Возьмите обратное значение. |
| square |
[v^2] |
Возведите значение в квадрат. |
| sqrt |
[\sqrt{v}] |
Возьмите квадратный корень из значения. Взятие квадратного корня из отрицательного числа является недопустимой операцией и приведет к ошибке. Убедитесь, что значение неотрицательно. |
| none |
N/A |
Не применять никакой модификатор. |
- missing: Значение, которое будет использоваться, если поле отсутствует в документе. Коэффициент и модификатор применяются к этому значению вместо отсутствующего значения поля.
Пример
Например, следующий запрос использует функцию field_value_factor, чтобы придать больше веса полю views:
GET blogs/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
}
}
}
}
Предыдущий запрос рассчитывает релевантный балл, используя следующую формулу:
[
score = original \ score \cdot log(1+1.5 \cdot views)
]
Функция script_score
Используя функцию script_score, вы можете написать пользовательский скрипт для оценки документов, при этом опционально включая значения полей в документе. Оригинальный релевантный балл доступен в переменной _score.
Рассчитанный балл не может быть отрицательным. Отрицательный балл приведет к ошибке. Баллы документов имеют положительные 32-битные значения с плавающей запятой. Балл с большей точностью преобразуется в ближайшее 32-битное число с плавающей запятой.
Пример
Например, следующий запрос использует функцию script_score для расчета балла на основе оригинального балла и количества просмотров и лайков для блога. Чтобы уменьшить вес количества просмотров и лайков, эта формула берет логарифм суммы просмотров и лайков. Чтобы сделать логарифм допустимым, даже если количество просмотров и лайков равно 0, к их сумме добавляется 1:
GET blogs/_search
{
"query": {
"function_score": {
"query": {"match": {"name": "opensearch"}},
"script_score": {
"script": "_score * Math.log(1 + doc['likes'].value + doc['views'].value)"
}
}
}
}
Скрипты компилируются и кэшируются для повышения производительности. Таким образом, предпочтительно повторно использовать один и тот же скрипт и передавать любые параметры, которые необходимы скрипту:
GET blogs/_search
{
"query": {
"function_score": {
"query": {
"match": { "name": "opensearch" }
},
"script_score": {
"script": {
"params": {
"add": 1
},
"source": "_score * Math.log(params.add + doc['likes'].value + doc['views'].value)"
}
}
}
}
}
Функции Decay (затухания)
Для многих приложений необходимо сортировать результаты на основе близости или недавности. Вы можете сделать это с помощью функций затухания. Функции затухания вычисляют балл документа, используя одну из трех кривых затухания: гауссову, экспоненциальную или линейную.
Функции decay (затухания) работают только с числовыми, датированными и геопунктовыми полями.
Функции затухания вычисляют баллы на основе начала, масштаба, смещения и затухания, как показано на следующем рисунке.
Примеры: Геопунктовые поля
Предположим, вы ищете отель рядом с вашим офисом. Вы создаете индекс отелей, который сопоставляет поле location как геопункт:
PUT hotels
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Вы индексируете два документа, которые соответствуют ближайшим отелям:
PUT hotels/_doc/1
{
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74.00
}
}
PUT hotels/_doc/2
{
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74.00
}
}
Начало определяет точку, от которой рассчитывается расстояние (местоположение офиса). Смещение указывает расстояние от начала, в пределах которого документам присваивается полный балл 1. Вы можете присвоить отелям, находящимся в пределах 200 футов от офиса, одинаковый наивысший балл. Масштаб определяет скорость затухания графика, а затухание определяет балл, который следует присвоить документу на расстоянии масштаб + смещение от начала. Как только вы выходите за пределы радиуса 200 футов, вы можете решить, что если вам нужно пройти еще 300 футов, чтобы добраться до отеля (масштаб = 300 футов), вы присвоите ему четверть оригинального балла (затухание = 0.25).
Вы создаете следующий запрос с началом в точке (74.00, 40.71):
GET hotels/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"location": {
"origin": "40.71,74.00",
"offset": "200ft",
"scale": "300ft",
"decay": 0.25
}
}
}
]
}
}
}
Ответ содержит оба отеля. Отель в пределах 200 футов от офиса имеет балл 1, а отель за пределами радиуса 500 футов имеет балл 0.20, что меньше параметра затухания 0.25.
{
"took": 854,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "hotels",
"_id": "1",
"_score": 1,
"_source": {
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74
}
}
},
{
"_index": "hotels",
"_id": "2",
"_score": 0.20099315,
"_source": {
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры, поддерживаемые функциями gauss, exp и linear.
| Параметр |
Описание |
| origin |
Точка, от которой рассчитывается расстояние. Должна быть указана как число для числовых полей, дата для полей даты или геопункт для геопунктовых полей. Обязательна для геопунктовых и числовых полей. Необязательна для полей даты (по умолчанию используется текущее время). Для полей даты поддерживается математическое вычисление дат (например, now-2d). |
| offset |
Определяет расстояние от начала, в пределах которого документам присваивается балл 1. Необязательный. По умолчанию 0. |
| scale |
Документам на расстоянии scale + offset от начала присваивается балл decay. Обязательный. Для числовых полей scale может быть любым числом. Для полей даты scale может быть определен как число с единицами (5h, 1d). Если единицы не указаны, scale по умолчанию равен миллисекундам. Для геопунктовых полей scale может быть определен как число с единицами (1mi, 5km). Если единицы не указаны, scale по умолчанию равен метрам. |
| decay |
Определяет балл документа на расстоянии scale + offset от начала. Необязательный. По умолчанию 0.5. |
Для полей, отсутствующих в документе, функции затухания возвращают балл 1.
Пример: Числовые поля
Следующий запрос использует экспоненциальную функцию затухания, чтобы приоритизировать блоги по количеству комментариев:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"comments_count": {
"origin": 10,
"scale": 5,
"decay": 0.5
}
}
}
]
}
}
}
Первые два блога в результатах имеют балл 1, потому что один находится в начале (20), а другой на расстоянии 16, что находится в пределах смещения (диапазон, в пределах которого документы получают полный балл, рассчитывается как 20 - 5 и составляет [15, 25]). Третий блог находится на расстоянии scale + offset от начала (20 - (5 + 10) = 15), поэтому ему присваивается стандартный балл затухания (0.5):
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "1",
"_score": 1,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 1,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "3",
"_score": 0.5,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0.4352753,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Пример: Поля даты
Следующий запрос использует гауссову функцию затухания, чтобы приоритизировать блоги, опубликованные около 24 апреля 2002 года:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d",
"decay": 0.25
}
}
}
]
}
}
}
В результатах первый блог был опубликован в течение одного дня после 24 апреля 2022 года, поэтому он имеет наивысший балл 1. Второй блог был опубликован 17 апреля 2022 года, что находится в пределах смещения + масштаба (1 день + 6 дней), и поэтому имеет балл, равный затуханию (0.25). Третий блог был опубликован более чем через 7 дней после 24 апреля 2022 года, поэтому у него более низкий балл. Последний блог имеет балл 0, потому что он был опубликован много лет назад:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 1,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 0.25,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 0.15154076,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Многозначные поля
Если поле, которое вы указываете для расчета затухания, содержит несколько значений, вы можете использовать параметр multi_value_mode. Этот параметр указывает одну из следующих функций для определения значения поля, которое будет использоваться для расчетов:
- min: (по умолчанию) Минимальное расстояние от начала.
- max: Максимальное расстояние от начала.
- avg: Среднее расстояние от начала.
- sum: Сумма всех расстояний от начала.
Пример
Например, вы индексируете документ с массивом расстояний:
PUT testindex/_doc/1
{
"distances": [1, 2, 3, 4, 5]
}
Следующий запрос использует максимальное расстояние многозначного поля distances для расчета затухания:
GET testindex/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"distances": {
"origin": "6",
"offset": "5",
"scale": "1"
},
"multi_value_mode": "max"
}
}
]
}
}
}
Документ получает балл 1, потому что максимальное расстояние от начала (1) находится в пределах смещения от начала:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1,
"_source": {
"distances": [
1,
2,
3,
4,
5
]
}
}
]
}
}
Расчет кривой затухания
Следующие формулы определяют вычисление оценки для различных функций затухания (обозначает значение поля документа).
Гауссовская функция затухания
[
\text{score} = \exp \left(-\frac {(\max(0, \lvert v - \text{origin} \rvert - \text{offset}))^2} {2\sigma^2} \right),
]
где (\sigma) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
\sigma^2 = - \frac {\text{scale}^2} {2 \ln(\text{decay})}
]
Экспоненциальная функция затухания
[
\text{score} = \exp (\lambda \cdot \max(0, \lvert v - \text{origin} \rvert - \text{offset})),
]
где (\lambda) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
\lambda = \frac {\ln(\text{decay})} {\text{scale}}
]
Линейная функция затухания
[
\text{score} = \max \left(\frac {s - \max(0, \lvert v - \text{origin} \rvert - \text{offset})} {s} \right),
]
где (s) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
s = \frac {\text{scale}} {1 - \text{decay}}
]
Использование нескольких функций оценки
Вы можете указать несколько функций оценки в запросе функции оценки, перечислив их в массиве functions.
Комбинирование оценок от нескольких функций
Разные функции могут использовать разные масштабы для оценки. Например, функция random_score предоставляет оценку в диапазоне от 0 до 1, но field_value_factor не имеет конкретного масштаба для оценки. Кроме того, вы можете захотеть по-разному взвешивать оценки, полученные от различных функций. Чтобы скорректировать оценки для разных функций, вы можете указать параметр weight для каждой функции. Оценка, полученная от каждой функции, затем умножается на вес, чтобы получить окончательную оценку для этой функции. Параметр weight должен быть указан в массиве functions, чтобы отличать его от функции веса.
Оценки, полученные от каждой функции, комбинируются с помощью параметра score_mode, который принимает одно из следующих значений:
-
multiply: (по умолчанию) Оценки умножаются.
-
sum: Оценки складываются.
-
avg: Оценки усредняются. Если указан вес, это средневзвешенное. Например, если первая функция с весом w1 возвращает оценку s1, а вторая функция с весом w2 возвращает оценку s2, среднее значение рассчитывается как:
[
\text{average} = \frac{w1 \cdot s1 + w2 \cdot s2}{w1 + w2}
]
-
first: Берется оценка от первой функции, которая имеет соответствующий фильтр.
-
max: Берется максимальная оценка.
-
min: Берется минимальная оценка.
Указание верхнего предела для оценки
Вы можете указать верхний предел для функции оценки в параметре max_boost. Значение по умолчанию для верхнего предела — это максимальная величина для значения с плавающей запятой: ((2 - 2^{-23}) \cdot 2^{127}).
Комбинирование оценки для всех функций с оценкой запроса
Вы можете указать, как оценка, вычисленная с использованием всех функций, комбинируется с оценкой запроса, в параметре boost_mode, который принимает одно из следующих значений:
- multiply: (по умолчанию) Умножает оценку запроса на оценку функции.
- replace: Игнорирует оценку запроса и использует оценку функции.
- sum: Складывает оценку запроса и оценку функции.
- avg: Усредняет оценку запроса и оценку функции.
- max: Берет большее значение между оценкой запроса и оценкой функции.
- min: Берет меньшее значение между оценкой запроса и оценкой функции.
Фильтрация документов, которые не соответствуют порогу
Изменение оценки релевантности не изменяет список соответствующих документов. Чтобы исключить некоторые документы, которые не соответствуют порогу, укажите значение порога в параметре min_score. Все документы, возвращенные запросом, затем оцениваются и фильтруются с использованием значения порога.
Пример
Следующий запрос ищет блоги, которые содержат слова “OpenSearch Data Prepper”, предпочитая посты, опубликованные около 24 апреля 2022 года. Кроме того, учитывается количество просмотров и лайков. Наконец, пороговое значение установлено на уровне 10:
GET blogs/_search
{
"query": {
"function_score": {
"boost": "5",
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d"
}
},
"weight": 1
},
{
"gauss": {
"likes": {
"origin": 200,
"scale": 200
}
},
"weight": 4
},
{
"gauss": {
"views": {
"origin": 1000,
"scale": 800
}
},
"weight": 2
}
],
"query": {
"match": {
"name": "opensearch data prepper"
}
},
"max_boost": 10,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 10
}
}
}
Результаты содержат три соответствующих блога:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 31.191923,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 31.191923,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 13.907352,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 11.150461,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
}
]
}
}
Именованные функции
При определении функции вы можете указать ее имя, используя параметр _name на верхнем уровне. Это имя полезно для отладки и понимания процесса оценки. После указания имя функции включается в объяснение расчета оценки, когда это возможно (это относится к функциям, фильтрам и запросам). Вы можете идентифицировать функцию по ее _name в ответе.
Пример
Следующий запрос устанавливает explain в значение true для целей отладки, чтобы получить объяснение оценки в ответе. Каждая функция содержит параметр _name, чтобы вы могли однозначно идентифицировать функцию:
GET blogs/_search
{
"explain": true,
"size": 1,
"query": {
"function_score": {
"functions": [
{
"_name": "likes_function",
"script_score": {
"script": {
"lang": "painless",
"source": "return doc['likes'].value * 2;"
}
},
"weight": 0.6
},
{
"_name": "views_function",
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
},
"weight": 0.3
},
{
"_name": "comments_function",
"gauss": {
"comments": {
"origin": 1000,
"scale": 800
}
},
"weight": 0.1
}
]
}
}
}
Ответ объясняет процесс оценки. Для каждой функции объяснение содержит name функции в своем описании:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 6.1600614,
"hits": [
{
"_shard": "[blogs][0]",
"_node": "_yndTaZHQWimcDgAfOfRtQ",
"_index": "blogs",
"_id": "1",
"_score": 6.1600614,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
},
"_explanation": {
"value": 6.1600614,
"description": "function score, product of:",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
},
{
"value": 6.1600614,
"description": "min of:",
"details": [
{
"value": 6.1600614,
"description": "function score, score mode [multiply]",
"details": [
{
"value": 180,
"description": "product of:",
"details": [
{
"value": 300,
"description": "script score function(_name: likes_function), computed with script:\"Script{type=inline, lang='painless', idOrCode='return doc['likes'].value * 2;', options={}, params={}}\"",
"details": [
{
"value": 1,
"description": "_score: ",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
}
]
}
]
},
{
"value": 0.6,
"description": "weight",
"details": []
}
]
},
{
"value": 0.9766541,
"description": "product of:",
"details": [
{
"value": 3.2555137,
"description": "field value function(_name: views_function): log1p(doc['views'].value?:1.0 * factor=1.5)",
"details": []
},
{
"value": 0.3,
"description": "weight",
"details": []
}
]
},
{
"value": 0.035040613,
"description": "product of:",
"details": [
{
"value": 0.35040614,
"description": "Function for field comments:",
"details": [
{
"value": 0.35040614,
"description": "exp(-0.5*pow(MIN[Math.max(Math.abs(16.0(=doc value) - 1000.0(=origin))) - 0.0(=offset), 0)],2.0)/461662.4130844683, _name: comments_function)",
"details": []
}
]
},
{
"value": 0.1,
"description": "weight",
"details": []
}
]
}
]
},
{
"value": 3.4028235e+38,
"description": "maxBoost",
"details": []
}
]
}
]
}
}
]
}
}
5.6 - hibrid
Объединяет баллы релевантности из нескольких запросов в один балл для данного документа.
Гибридный запрос
Вы можете использовать гибридный запрос для комбинирования оценок релевантности из нескольких запросов в одну оценку для данного документа. Гибридный запрос содержит список из одного или нескольких запросов и независимо вычисляет оценки документов на уровне шардов для каждого подзапроса. Переписывание подзапросов выполняется на уровне координирующего узла, чтобы избежать дублирования вычислений.
Пример
Узнайте, как использовать гибридный запрос, следуя шагам в разделе Гибридный поиск.
Для получения более полного примера следуйте разделу Начало работы с семантическим и гибридным поиском.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые гибридными запросами.
| Параметр |
Описание |
queries |
Массив из одного или нескольких условий запроса, которые используются для поиска документов. Документ должен соответствовать хотя бы одному условию запроса, чтобы быть возвращенным в результатах. Оценки релевантности документов из всех условий запроса комбинируются в одну оценку с помощью поискового конвейера. Максимальное количество условий запроса — 5. Обязательно. |
filter |
Фильтр, который применяется ко всем подзапросам гибридного запроса. |
Отключение гибридных запросов
По умолчанию гибридные запросы включены. Чтобы отключить гибридные запросы в вашем кластере, установите параметр plugins.neural_search.hybrid_search_disabled в значение true в файле opensearch.yml.
6 - geographic and xy query
Географические и xy-запросы позволяют искать поля, содержащие точки и фигуры на карте или в координатной плоскости.
Географические и xy-запросы
Географические и xy-запросы позволяют искать поля, содержащие точки и фигуры на карте или в координатной плоскости. Географические запросы работают с геопространственными данными, в то время как xy-запросы работают с двумерными координатными данными. Из всех географических запросов запрос geoshape очень похож на xy-запрос, но первый ищет географические поля, в то время как второй ищет декартовы поля.
xy-запросы
xy-запросы ищут документы, содержащие геометрии в декартовой системе координат. Эти геометрии могут быть указаны в полях xy_point, которые поддерживают точки, и в полях xy_shape, которые поддерживают точки, линии, круги и многоугольники.
xy-запросы возвращают документы, которые содержат:
- xy-формы и xy-точки, имеющие одно из четырех пространственных отношений к предоставленной форме: INTERSECTS (пересекает), DISJOINT (разъединены), WITHIN (внутри) или CONTAINS (содержит).
- xy-точки, которые пересекают предоставленную форму.
Географические запросы
Географические запросы ищут документы, содержащие геопространственные геометрии. Эти геометрии могут быть указаны в полях geo_point, которые поддерживают точки на карте, и в полях geo_shape, которые поддерживают точки, линии, круги и многоугольники.
OpenSearch предоставляет следующие типы географических запросов:
- Запросы по гео-ограничивающему прямоугольнику (Geo-bounding box queries): возвращают документы с значениями поля geopoint, которые находятся в пределах ограничивающего прямоугольника.
- Запросы по гео-расстоянию (Geodistance queries): возвращают документы с геоточками, которые находятся на заданном расстоянии от предоставленной геоточки.
- Запросы по гео-многоугольнику (Geopolygon queries): возвращают документы, содержащие геоточки, которые находятся внутри многоугольника.
- Запросы по гео-форме (Geoshape queries): возвращают документы, которые содержат:
- Геоформы и геоточки, имеющие одно из четырех пространственных отношений к предоставленной форме: INTERSECTS (пересекает), DISJOINT (разъединены), WITHIN (внутри) или CONTAINS (содержит).
- Геоточки, которые пересекают предоставленную форму.
6.1 - Запрос по гео-ограничивающему прямоугольнику
Запрос по гео-ограничивающему прямоугольнику возвращает документы, чьи геоточки находятся в пределах ограничивающего прямоугольника, указанного в запросе.
Чтобы искать документы, содержащие поля geopoint, используйте запрос по гео-ограничивающему прямоугольнику. Запрос по гео-ограничивающему прямоугольнику возвращает документы, чьи геоточки находятся в пределах ограничивающего прямоугольника, указанного в запросе. Документ с несколькими геоточками соответствует запросу, если хотя бы одна геоточка находится в пределах ограничивающего прямоугольника.
Пример
Вы можете использовать запрос по гео-ограничивающему прямоугольнику для поиска документов, содержащих геоточки.
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте три геоточки как объекты с широтой и долготой:
PUT testindex1/_doc/1
{
"point": {
"lat": 74.00,
"lon": 40.71
}
}
PUT testindex1/_doc/2
{
"point": {
"lat": 72.64,
"lon": 22.62
}
}
PUT testindex1/_doc/3
{
"point": {
"lat": 75.00,
"lon": 28.00
}
}
Ищите все документы и фильтруйте документы, чьи точки находятся внутри прямоугольника, определенного в запросе:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": {
"lat": 75,
"lon": 28
},
"bottom_right": {
"lat": 73,
"lon": 41
}
}
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "testindex1",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"point" : {
"lat" : 74.0,
"lon" : 40.71
}
}
}
]
}
}
Предыдущий ответ не включает документ с геоточкой “lat”: 75.00, “lon”: 28.00 из-за ограниченной точности геоточки.
Точность
Координаты геоточек всегда округляются вниз во время индексации. Во время выполнения запроса верхние границы ограничивающего прямоугольника округляются вниз, а нижние границы округляются вверх. Поэтому документы с геоточками, которые находятся на нижних и левых границах ограничивающего прямоугольника, могут не быть включены в результаты из-за ошибки округления. С другой стороны, геоточки, находящиеся на верхних и правых границах ограничивающего прямоугольника, могут быть включены в результаты, даже если они находятся за пределами границ. Ошибка округления составляет менее 4.20 × 10^−8 градусов для широты и менее 8.39 × 10^−8 градусов для долготы (примерно 1 см).
Указание ограничивающего прямоугольника
Вы можете указать ограничивающий прямоугольник, предоставив любую из следующих комбинаций координат его вершин:
- top_left и bottom_right
- top_right и bottom_left
- top, left, bottom и right
Следующий пример показывает, как указать ограничивающий прямоугольник, используя координаты top, left, bottom и right:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top": 75,
"left": 28,
"bottom": 73,
"right": 41
}
}
}
}
}
}
Параметры
Запросы по гео-ограничивающему прямоугольнику принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| _name |
String |
Имя фильтра. Необязательный параметр. |
| validation_method |
String |
Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). По умолчанию - STRICT. |
| type |
String |
Указывает, как выполнять фильтр. Допустимые значения: indexed (индексировать фильтр) и memory (выполнять фильтр в памяти). По умолчанию - memory. |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы с неотображаемым полем. Если установлено в false, при неотображаемом поле возникает исключение. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты вершин ограничивающего прямоугольника в любом формате, который принимает тип поля geopoint.
Использование геохеша для указания ограничивающего прямоугольника
Если вы используете геохеш для указания ограничивающего прямоугольника, геохеш рассматривается как прямоугольник. Верхний левый угол ограничивающего прямоугольника соответствует верхнему левому углу геохеша top_left, а нижний правый угол ограничивающего прямоугольника соответствует нижнему правому углу геохеша bottom_right.
Следующий пример показывает, как использовать геохеш для указания того же ограничивающего прямоугольника, что и в предыдущих примерах:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": "ut7ftjkfxm34",
"bottom_right": "uuvpkcprc4rc"
}
}
}
}
}
}
Чтобы указать ограничивающий прямоугольник, который охватывает всю область геохеша, укажите этот геохеш как параметры top_left и bottom_right ограничивающего прямоугольника:
GET testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"point": {
"top_left": "ut",
"bottom_right": "ut"
}
}
}
}
}
}
6.2 - Запрос по гео-расстоянию
Запрос по гео-расстоянию возвращает документы с геоточками, которые находятся в пределах заданного расстояния от предоставленной геоточки.
Документ с несколькими геоточками соответствует запросу, если хотя бы одна геоточка соответствует запросу.
Поле, в котором хранятся геоточки, должно быть правильно настроено в индексе как тип geo_point
Пример
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте геоточку, указав ее широту и долготу:
PUT testindex1/_doc/1
{
"point": {
"lat": 74.00,
"lon": 40.71
}
}
Ищите документы, чьи объекты точки находятся в пределах заданного расстояния от указанной точки:
GET /testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "50mi",
"point": {
"lat": 73.5,
"lon": 40.5
}
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"point": {
"lat": 74,
"lon": 40.71
}
}
}
]
}
}
Параметры
Запросы по гео-расстоянию принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| _name |
String |
Имя фильтра. Необязательный параметр. |
| distance |
String |
Расстояние, в пределах которого следует сопоставить точки. Это расстояние является радиусом круга, центрированного на указанной точке. Для поддерживаемых единиц расстояния см. раздел “Единицы расстояния”. Обязательный параметр. |
| distance_type |
String |
Указывает, как рассчитывать расстояние. Допустимые значения: arc (дуга) или plane (плоскость, быстрее, но менее точно для больших расстояний или точек, близких к полюсам). Необязательный параметр. По умолчанию - arc. |
| validation_method |
String |
Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). Необязательный параметр. По умолчанию - STRICT. |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы, содержащие неотображаемое поле. Если установлено в false, при неотображаемом поле возникает исключение. Необязательный параметр. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты геоточки при индексации документа и поиске документов в любом формате, который принимает тип поля geopoint.
6.3 - Запрос по гео-многоугольнику
Запрос по гео-многоугольнику возвращает документы, содержащие геоточки, которые находятся внутри указанного многоугольника.
Запрос по гео-многоугольнику возвращает документы, содержащие геоточки, которые находятся внутри указанного многоугольника. Документ, содержащий несколько геоточек, соответствует запросу, если хотя бы одна геоточка соответствует запросу.
Многоугольник задается списком вершин в координатной форме. В отличие от указания многоугольника для поля geoshape, многоугольник не обязательно должен быть замкнутым (не нужно указывать первую и последнюю точки одновременно). Хотя точки не обязательно должны следовать в порядке часовой или против часовой стрелки, рекомендуется перечислять их в одном из этих порядков. Это обеспечит правильное определение многоугольника.
Иск searched document field must be mapped as geo_point.
Пример
Создайте отображение с полем точки, сопоставленным как geo_point:
PUT /testindex1
{
"mappings": {
"properties": {
"point": {
"type": "geo_point"
}
}
}
}
Индексуйте геоточку, указав ее широту и долготу:
PUT testindex1/_doc/1
{
"point": {
"lat": 73.71,
"lon": 41.32
}
}
Ищите документы, чьи объекты точки находятся внутри указанного гео-многоугольника:
GET /testindex1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 74.0060, "lon": 40.7128 }
]
}
}
}
}
}
}
Многоугольник, указанный в предыдущем запросе, представляет собой четырехугольник. Соответствующий документ находится внутри этого четырехугольника. Координаты вершин четырехугольника указаны в формате (широта, долгота).
 Ответ содержит соответствующий документ:
Ответ содержит соответствующий документ:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"point": {
"lat": 73.71,
"lon": 41.32
}
}
}
]
}
}
В предыдущем запросе вы указали вершины многоугольника в порядке часовой стрелки:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 74.0060, "lon": 40.7128 }
]
}
}
Альтернативно, вы можете указать вершины в порядке против часовой стрелки:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 74.0060, "lon": 40.7128 },
{ "lat": 73.3245, "lon": 41.6189 },
{ "lat": 73.7562, "lon": 42.6526 }
]
}
}
Ответ на запрос будет содержать тот же соответствующий документ.
Однако, если вы укажете вершины в следующем порядке:
"geo_polygon": {
"point": {
"points": [
{ "lat": 74.5627, "lon": 41.8645 },
{ "lat": 74.0060, "lon": 40.7128 },
{ "lat": 73.7562, "lon": 42.6526 },
{ "lat": 73.3245, "lon": 41.6189 }
]
}
}
Ответ не вернет никаких результатов.
Параметры
Запросы по гео-многоугольнику принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| _name |
String |
Имя фильтра. Необязательный параметр. |
| validation_method |
String |
Метод валидации. Допустимые значения: IGNORE_MALFORMED (принимать геоточки с недопустимыми координатами), COERCE (попробовать привести координаты к допустимым значениям) и STRICT (возвращать ошибку при недопустимых координатах). Необязательный параметр. По умолчанию - STRICT. |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неотображаемое поле. Если установлено в true, запрос не возвращает документы, содержащие неотображаемое поле. Если установлено в false, при неотображаемом поле возникает исключение. Необязательный параметр. По умолчанию - false. |
Принятые форматы
Вы можете указывать координаты геоточки при индексации документа и поиске документов в любом формате, который принимает тип поля geopoint.
6.4 - Запрос по гео-форме
Вы можете фильтровать документы, используя гео-форму, определенную в запросе, или использовать заранее индексированную гео-форму.
Используйте запрос по гео-форме для поиска документов, которые содержат поля geopoint или geoshape. Вы можете фильтровать документы, используя гео-форму, определенную в запросе, или использовать заранее индексированную гео-форму.
Иск searched document field must be mapped as geo_point или geo_shape.
Пространственные отношения
Когда вы предоставляете гео-форму для запроса по гео-форме, поля geopoint и geoshape в документах сопоставляются с использованием следующих пространственных отношений к предоставленной форме:
| Отношение |
Описание |
Поддерживаемый тип географического поля |
| INTERSECTS |
(По умолчанию) Соответствует документам, чьи geopoint или geoshape пересекаются с формой, предоставленной в запросе. |
geo_point, geo_shape |
| DISJOINT |
Соответствует документам, чьи geoshape не пересекаются с формой, предоставленной в запросе. |
geo_shape |
| WITHIN |
Соответствует документам, чьи geoshape полностью находятся внутри формы, предоставленной в запросе. |
geo_shape |
| CONTAINS |
Соответствует документам, чьи geoshape полностью содержат форму, предоставленную в запросе. |
geo_shape |
Определение формы в запросе по гео-форме
Вы можете определить форму для фильтрации документов в запросе по гео-форме, предоставив новое определение формы во время запроса или сославшись на имя формы, заранее индексированной в другом индексе.
Использование нового определения формы
Чтобы предоставить новую форму для запроса по гео-форме, определите ее в поле geo_shape. Вы должны определить гео-форму в формате GeoJSON.
Следующий пример иллюстрирует поиск документов, содержащих гео-формы, которые соответствуют гео-форме, определенной во время запроса.
Шаг 1: Создание индекса
Сначала создайте индекс и сопоставьте поле location как geo_shape:
PUT /testindex
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
Шаг 2: Индексация документов
Индексуйте один документ, содержащий точку, и другой, содержащий многоугольник:
PUT testindex/_doc/1
{
"location": {
"type": "point",
"coordinates": [ 73.0515, 41.5582 ]
}
}
PUT testindex/_doc/2
{
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
Шаг 3: Выполнение запроса по гео-форме
Наконец, определите гео-форму для фильтрации документов. Следующие разделы иллюстрируют предоставление различных гео-форм в запросе. Для получения дополнительной информации о различных форматах гео-форм см. раздел “Тип поля гео-формы”.
Конверт
Конверт — это ограничивающий прямоугольник в формате [[minLon, maxLat], [maxLon, minLat]]. Ищите документы, содержащие поля geoshape, которые пересекаются с предоставленным конвертом:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
71.0589,
42.3601
],
[
74.006,
40.7128
]
]
},
"relation": "WITHIN"
}
}
}
}
Ответ содержит оба документа:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0,
"_source": {
"location": {
"type": "point",
"coordinates": [
73.0515,
41.5582
]
}
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0,
"_source": {
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
}
]
}
}
Точка
Ищите документы, чьи поля geoshape содержат предоставленную точку:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "point",
"coordinates": [
72.8000,
41.6300
]
},
"relation": "CONTAINS"
}
}
}
}
Linestring
Поиск документов, геошейпы которых не пересекаются с предоставленным линией:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "linestring",
"coordinates": [[74.0060, 40.7128], [71.0589, 42.3601]]
},
"relation": "DISJOINT"
}
}
}
}
Запросы геошейпа с линией не поддерживают отношение WITHIN.
Полигон
В формате GeoJSON необходимо перечислить вершины полигона в порядке обхода против часовой стрелки и замкнуть полигон, чтобы первая и последняя вершины совпадали.
Поиск документов, геошейпы которых находятся внутри предоставленного полигона:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "polygon",
"coordinates": [
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]
]
},
"relation": "WITHIN"
}
}
}
}
Мультипоинт
Поиск документов, геошейпы которых не пересекаются с предоставленными точками:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multipoint",
"coordinates": [
[74.0060, 40.7128],
[71.0589, 42.3601]
]
},
"relation": "DISJOINT"
}
}
}
}
Мультилиния
Поиск документов, геошейпы которых не пересекаются с предоставленными линиями:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multilinestring",
"coordinates": [
[[74.0060, 40.7128], [71.0589, 42.3601]],
[[73.7562, 42.6526], [72.6734, 41.7658]]
]
},
"relation": "disjoint"
}
}
}
}
Запросы геошейпа с мультилинией не поддерживают отношение WITHIN.
Мультиполигоны
Поиск документов, геошейпы которых находятся внутри предоставленного мультиполигона:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "multipolygon",
"coordinates": [
[
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
],
[
[73.0515, 41.5582],
[72.6506, 41.5623],
[72.6734, 41.7658],
[73.0515, 41.5582]
]
],
[
[
[73.9146, 40.8252],
[73.8871, 41.0389],
[73.6853, 40.9747],
[73.9146, 40.8252]
]
]
]
},
"relation": "WITHIN"
}
}
}
}
Коллекция геометрий
Поиск документов, геошейпы которых находятся внутри предоставленных полигонов:
GET /testindex/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "geometrycollection",
"geometries": [
{
"type": "polygon",
"coordinates": [[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]]
},
{
"type": "polygon",
"coordinates": [[
[73.0515, 41.5582],
[72.6506, 41.5623],
[72.6734, 41.7658],
[73.0515, 41.5582]
]]
}
]
},
"relation": "WITHIN"
}
}
}
}
Запросы геошейпа, содержащие в коллекции геометрий линию или мультилинии, не поддерживают отношение WITHIN.
Использование прединдексированного определения формы
При построении запроса геошейпа вы также можете ссылаться на имя формы, прединдексированной в другом индексе. С помощью этого метода вы можете определить геошейп во время индексации и ссылаться на него по имени во время поиска.
Вы можете определить прединдексированный геошейп в формате GeoJSON или Well-Known Text (WKT). Для получения дополнительной информации о различных форматах геошейпа см. тип поля Geoshape.
Объект indexed_shape поддерживает следующие параметры:
| Параметр |
Обязательный/Необязательный |
Описание |
| id |
Обязательный |
Идентификатор документа, содержащего прединдексированную форму. |
| index |
Необязательный |
Имя индекса, содержащего прединдексированную форму. По умолчанию - shapes. |
| path |
Необязательный |
Имя поля, содержащего прединдексированную форму в виде пути. По умолчанию - shape. |
| routing |
Необязательный |
Маршрутизация документа, содержащего прединдексированную форму. |
Следующий пример иллюстрирует, как ссылаться на имя формы, прединдексированной в другом индексе. В этом примере индекс pre-indexed-shapes содержит форму, определяющую границы, а индекс testindex содержит формы, которые проверяются на соответствие этим границам.
Сначала создайте индекс pre-indexed-shapes и задайте поле boundaries для этого индекса как geo_shape:
PUT /pre-indexed-shapes
{
"mappings": {
"properties": {
"boundaries": {
"type": "geo_shape",
"orientation": "left"
}
}
}
}
Для получения дополнительной информации о том, как задать другую ориентацию вершин для полигонов, см. Полигон.
Индексируйте полигон, указывая границы поиска, в индекс pre-indexed-shapes. Идентификатор полигона - search_triangle. В этом примере вы индексируете полигон в формате WKT:
PUT /pre-indexed-shapes/_doc/search_triangle
{
"boundaries":
"POLYGON ((74.0060 40.7128, 71.0589 42.3601, 73.7562 42.6526, 74.0060 40.7128))"
}
Если вы еще не сделали этого, индексируйте один документ, содержащий точку, и другой документ, содержащий полигон, в индекс testindex:
PUT /testindex/_doc/1
{
"location": {
"type": "point",
"coordinates": [ 73.0515, 41.5582 ]
}
}
PUT /testindex/_doc/2
{
"location": {
"type": "polygon",
"coordinates": [
[
[
73.0515,
41.5582
],
[
72.6506,
41.5623
],
[
72.6734,
41.7658
],
[
73.0515,
41.5582
]
]
]
}
}
Поиск документов, геошейпы которых находятся внутри search_triangle:
GET /testindex/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_shape": {
"location": {
"indexed_shape": {
"index": "pre-indexed-shapes",
"id": "search_triangle",
"path": "boundaries"
},
"relation": "WITHIN"
}
}
}
}
}
}
Ответ содержит оба документа.
Запрос геоточек
Вы также можете использовать запрос геошейпа для поиска документов, содержащих геоточки.
Запросы геошейпа по полям геоточек поддерживают только пространственное отношение по умолчанию INTERSECTS, поэтому вам не нужно указывать параметр отношения.
Запросы геошейпа по полям геоточек не поддерживают следующие геошейпы:
- Точки
- Линии
- Мультипоинты
- Мультилинии
- Коллекции геометрий, содержащие один из вышеперечисленных типов геошейпа
Создайте отображение, где location является geo_point:
PUT /testindex1
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Индексируйте две точки в индекс. В этом примере вы предоставите координаты геоточек в виде строк:
PUT /testindex1/_doc/1
{
"location": "41.5623, 72.6506"
}
PUT /testindex1/_doc/2
{
"location": "76.0254, 39.2467"
}
Для получения информации о предоставлении координат геоточек в различных форматах см. Форматы.
Поиск геоточек, которые пересекаются с предоставленным полигоном:
GET /testindex1/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "polygon",
"coordinates": [
[
[74.0060, 40.7128],
[73.7562, 42.6526],
[71.0589, 42.3601],
[74.0060, 40.7128]
]
]
}
}
}
}
}
Ответ на запрос
Ответ возвращает документ 1:
{
"took": 21,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0,
"_source": {
"location": "41.5623, 72.6506"
}
}
]
}
}
Обратите внимание, что при индексации геоточек вы указали их координаты в формате “широта, долгота”. Когда вы ищете соответствующие документы, массив координат находится в формате [долгота, широта]. Таким образом, документ 1 возвращается в результатах, но документ 2 - нет.
Параметры
Запросы геошейпа принимают следующие параметры:
| Параметр |
Тип данных |
Описание |
| ignore_unmapped |
Boolean |
Указывает, следует ли игнорировать неразмеченное поле. Если установлено в true, то запрос не возвращает документы, содержащие неразмеченное поле. Если установлено в false, то при отсутствии поля выбрасывается исключение. Необязательный. По умолчанию - false. |
6.5 - xy запрос
Для поиска документов, содержащих поля xy point или xy shape, используйте xy запрос.
Пространственные отношения
Когда вы предоставляете xy форму в xy запросе, поля xy в документах сопоставляются с использованием следующих пространственных отношений к предоставленной форме.
| Отношение |
Описание |
Поддерживаемый тип поля xy |
| INTERSECTS |
(По умолчанию) Сопоставляет документы, чьи xy point или xy shape пересекают форму, предоставленную в запросе. |
xy_point, xy_shape |
| DISJOINT |
Сопоставляет документы, чьи xy shape не пересекаются с формой, предоставленной в запросе. |
xy_shape |
| WITHIN |
Сопоставляет документы, чьи xy shape полностью находятся внутри формы, предоставленной в запросе. |
xy_shape |
| CONTAINS |
Сопоставляет документы, чьи xy shape полностью содержат форму, предоставленную в запросе. |
xy_shape |
Следующие примеры иллюстрируют поиск документов, содержащих xy формы. Чтобы узнать, как искать документы, содержащие xy точки, смотрите раздел “Запросы xy точек”.
Определение формы в xy запросе
Вы можете определить форму в xy запросе, предоставив новое определение формы во время запроса или сославшись на имя формы, предварительно индексированной в другом индексе.
Использование нового определения формы
Чтобы предоставить новую форму в xy запросе, определите ее в поле xy_shape.
Следующий пример иллюстрирует, как искать документы, содержащие xy формы, которые соответствуют xy форме, определенной во время запроса.
Сначала создайте индекс и сопоставьте поле геометрии как xy_shape:
PUT testindex
{
"mappings": {
"properties": {
"geometry": {
"type": "xy_shape"
}
}
}
}
Индексируйте документ с точкой и документ с многоугольником:
PUT testindex/_doc/1
{
"geometry": {
"type": "point",
"coordinates": [0.5, 3.0]
}
}
PUT testindex/_doc/2
{
"geometry" : {
"type" : "polygon",
"coordinates" : [
[[2.5, 6.0],
[0.5, 4.5],
[1.5, 2.0],
[3.5, 3.5],
[2.5, 6.0]]
]
}
}
Определите оболочку — ограничивающий прямоугольник в формате [[minX, maxY], [maxX, minY]]. Ищите документы с xy точками или формами, которые пересекают эту оболочку:
GET testindex/_search
{
"query": {
"xy_shape": {
"geometry": {
"shape": {
"type": "envelope",
"coordinates": [ [ 0.0, 6.0], [ 4.0, 2.0] ]
},
"relation": "WITHIN"
}
}
}
}
Следующее изображение иллюстрирует пример. И точка, и многоугольник находятся внутри ограничивающей оболочки.
Использование предварительно индексированного определения формы
При построении xy запроса вы также можете ссылаться на имя формы, предварительно индексированной в другом индексе. Используя этот метод, вы можете определить xy форму во время индексации и ссылаться на нее по имени, предоставляя следующие параметры в объекте indexed_shape.
| Параметр |
Описание |
| index |
Имя индекса, содержащего предварительно индексированную форму. |
| id |
Идентификатор документа, содержащего предварительно индексированную форму. |
| path |
Имя поля, содержащего предварительно индексированную форму, в виде пути. |
Следующий пример иллюстрирует ссылку на имя формы, предварительно индексированной в другом индексе. В этом примере индекс pre-indexed-shapes содержит форму, определяющую границы, а индекс testindex содержит формы, местоположения которых проверяются относительно этих границ.
Сначала создайте индекс pre-indexed-shapes и сопоставьте поле геометрии для этого индекса как xy_shape:
PUT pre-indexed-shapes
{
"mappings": {
"properties": {
"geometry": {
"type": "xy_shape"
}
}
}
}
Индексируйте оболочку, которая определяет границы, и назовите ее rectangle:
PUT pre-indexed-shapes/_doc/rectangle
{
"geometry": {
"type": "envelope",
"coordinates" : [ [ 0.0, 6.0], [ 4.0, 2.0] ]
}
}
Индексируйте документ с точкой и документ с многоугольником в индекс testindex:
PUT testindex/_doc/1
{
"geometry": {
"type": "point",
"coordinates": [0.5, 3.0]
}
}
PUT testindex/_doc/2
{
"geometry" : {
"type" : "polygon",
"coordinates" : [
[[2.5, 6.0],
[0.5, 4.5],
[1.5, 2.0],
[3.5, 3.5],
[2.5, 6.0]]
]
}
}
Теперь выполните поиск документов с формами, которые пересекают rectangle в индексе testindex, используя фильтр:
GET testindex/_search
{
"query": {
"bool": {
"filter": {
"xy_shape": {
"geometry": {
"indexed_shape": {
"index": "pre-indexed-shapes",
"id": "rectangle",
"path": "geometry"
}
}
}
}
}
}
}
Этот запрос вернет документы из индекса testindex, которые пересекают предварительно индексированную форму rectangle, определенную в индексе pre-indexed-shapes.
Запрос xy точек
Вы также можете использовать xy запрос для поиска документов, содержащих xy точки.
Создание сопоставления с типом xy_point
Сначала создайте сопоставление с полем типа xy_point:
PUT testindex1
{
"mappings": {
"properties": {
"point": {
"type": "xy_point"
}
}
}
}
Индексация трех точек
Индексируйте три точки:
PUT testindex1/_doc/1
{
"point": "1.0, 1.0"
}
PUT testindex1/_doc/2
{
"point": "2.0, 0.0"
}
PUT testindex1/_doc/3
{
"point": "-2.0, 2.0"
}
Поиск точек в круге
Теперь выполните поиск точек, которые находятся внутри круга с центром в (0, 0) и радиусом 2:
GET testindex1/_search
{
"query": {
"xy_shape": {
"point": {
"shape": {
"type": "circle",
"coordinates": [0.0, 0.0],
"radius": 2
}
}
}
}
}
Форма xy point поддерживает только пространственное отношение по умолчанию INTERSECTS, поэтому вам не нужно указывать параметр отношения.
Результаты запроса
Следующее изображение иллюстрирует пример. Точки 1 и 2 находятся внутри круга, а точка 3 находится вне круга.
Ответ на запрос возвращает документы 1 и 2, которые находятся внутри заданного круга:
{
"took" : 575,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "testindex1",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"point" : "1.0, 1.0"
}
},
{
"_index" : "testindex1",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"point" : "2.0, 0.0"
}
}
]
}
}
Объяснение результатов
- Документ 1: Содержит точку с координатами (1.0, 1.0), которая находится внутри круга.
- Документ 2: Содержит точку с координатами (2.0, 0.0), которая также находится внутри круга.
Обе точки соответствуют критериям поиска, так как они находятся в пределах радиуса 2 от центра (0, 0). Точка 3, с координатами (-2.0, 2.0), не была возвращена, так как она находится вне круга.
7 - Объединение запросов
OpenSearch предоставляет следующие запросы, которые выполняют операции объединения и оптимизированы для масштабирования на нескольких узлах:
OpenSearch является распределенной системой, в которой данные распределены по нескольким узлам. Поэтому выполнение операции JOIN, аналогичной SQL, в OpenSearch требует значительных ресурсов. В качестве альтернативы OpenSearch предоставляет следующие запросы, которые выполняют операции объединения и оптимизированы для масштабирования на нескольких узлах:
Запросы для поиска вложенных полей
- Вложенные запросы (nested queries): Действуют как обертки для других запросов, чтобы искать вложенные поля. Объекты вложенных полей ищутся так, как будто они индексированы как отдельные документы.
Запросы для поиска документов, связанных через тип поля объединения
Эти запросы устанавливают родительско-дочерние отношения между документами в одном индексе:
- has_child запросы: Ищут родительские документы, дочерние документы которых соответствуют запросу.
- has_parent запросы: Ищут дочерние документы, родительские документы которых соответствуют запросу.
- parent_id запросы: Ищут дочерние документы, которые связаны с конкретным родительским документом.
Настройка выполнения запросов
Если параметр search.allow_expensive_queries установлен в значение false, то объединяющие запросы не будут выполняться.
7.1 - Запрос has_child
Запрос has_child возвращает родительские документы, дочерние документы которых соответствуют определенному запросу.
Запрос has_child возвращает родительские документы, дочерние документы которых соответствуют определенному запросу. Вы можете установить родительско-дочерние отношения между документами в одном индексе, используя тип поля join.
Запрос has_child медленнее, чем другие запросы, из-за операции соединения, которую он выполняет. Производительность снижается по мере увеличения количества соответствующих дочерних документов, указывающих на разные родительские документы. Каждый запрос has_child в вашем поиске может значительно повлиять на производительность запроса. Если вы придаете приоритет скорости, избегайте использования этого запроса или ограничьте его использование насколько возможно.
Пример
Перед тем как вы сможете выполнить запрос has_child, ваш индекс должен содержать поле join для установления родительско-дочерних отношений. Запрос на отображение индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
В этом примере вы настроите индекс, который содержит документы, представляющие продукты и их бренды.
Сначала создайте индекс и установите родительско-дочерние отношения между брендом и продуктом:
PUT testindex1
{
"mappings": {
"properties": {
"product_to_brand": {
"type": "join",
"relations": {
"brand": "product"
}
}
}
}
}
Индексуйте два родительских (брендовых) документа:
PUT testindex1/_doc/1
{
"name": "Luxury brand",
"product_to_brand" : "brand"
}
PUT testindex1/_doc/2
{
"name": "Economy brand",
"product_to_brand" : "brand"
}
Индексуйте три дочерних (продуктовых) документа:
PUT testindex1/_doc/3?routing=1
{
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
PUT testindex1/_doc/4?routing=2
{
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
PUT testindex1/_doc/5?routing=2
{
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
Чтобы найти родителя дочернего документа, используйте запрос has_child. Следующий запрос возвращает родительские документы (бренды), которые производят часы:
GET testindex1/_search
{
"query" : {
"has_child": {
"type":"product",
"query": {
"match" : {
"name": "watch"
}
}
}
}
}
Ответ возвращает оба бренда:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 1,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
Извлечение внутренних результатов (inner hits)
Чтобы вернуть дочерние документы, которые соответствуют запросу, укажите параметр inner_hits:
GET testindex1/_search
{
"query" : {
"has_child": {
"type":"product",
"query": {
"match" : {
"name": "watch"
}
},
"inner_hits": {}
}
}
}
Ответ содержит дочерние документы в поле inner_hits:
{
"took": 52,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 1,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
},
"inner_hits": {
"product": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.53899646,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 0.53899646,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
}
]
}
}
}
},
{
"_index": "testindex1",
"_id": "2",
"_score": 1,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
},
"inner_hits": {
"product": {
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.53899646,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 0.53899646,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 0.53899646,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
}
}
]
}
}
Для получения дополнительной информации о извлечении внутренних результатов, смотрите раздел “Внутренние результаты” (Inner hits).
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами has_child.
| Параметр |
Обязательный/Необязательный |
Описание |
| type |
Обязательный |
Указывает имя дочерней связи, как определено в отображении поля join. |
| query |
Обязательный |
Запрос, который будет выполнен на дочерних документах. Если дочерний документ соответствует запросу, возвращается родительский документ. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неотображаемые поля типов и не возвращать документы вместо того, чтобы вызывать ошибку. Этот параметр можно указать при запросе нескольких индексов, некоторые из которых могут не содержать поле типа. По умолчанию false. |
| max_children |
Необязательный |
Максимальное количество соответствующих дочерних документов для родительского документа. Если превышено, родительский документ исключается из результатов поиска. |
| min_children |
Необязательный |
Минимальное количество соответствующих дочерних документов, необходимых для включения родительского документа в результаты. Если не достигнуто, родитель исключается. По умолчанию 1. |
| score_mode |
Необязательный |
Определяет, как оценки соответствующих дочерних документов влияют на оценку родительского документа. Допустимые значения: |
|
|
- none: Игнорирует оценки релевантности дочерних документов и присваивает родительскому документу оценку 0. |
|
|
- avg: Использует среднюю оценку релевантности всех соответствующих дочерних документов. |
|
|
- max: Присваивает наивысшую оценку релевантности из соответствующих дочерних документов родителю. |
|
|
- min: Присваивает наименьшую оценку релевантности из соответствующих дочерних документов родителю. |
|
|
- sum: Суммирует оценки релевантности всех соответствующих дочерних документов. |
| По умолчанию none. |
|
|
| inner_hits |
Необязательный |
Если указан, возвращает внутренние результаты (дочерние документы), которые соответствуют запросу. |
Ограничения сортировки
Запрос has_child не поддерживает сортировку результатов с использованием стандартных опций сортировки. Если вам необходимо отсортировать родительские документы по полям их дочерних документов, вы можете использовать запрос function_score и сортировать по оценке родительского документа.
В приведенном выше примере вы можете отсортировать родительские документы (бренды) на основе поля sales_count их дочерних продуктов. Этот запрос умножает оценку на поле sales_count дочерних документов и присваивает наивысшую оценку релевантности из соответствующих дочерних документов родителю:
GET testindex1/_search
{
"query": {
"has_child": {
"type": "product",
"query": {
"function_score": {
"script_score": {
"script": "_score * doc['sales_count'].value"
}
}
},
"score_mode": "max"
}
}
}
Ответ содержит бренды, отсортированные по наивысшему значению sales_count дочерних документов:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 300,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 300,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
},
{
"_index": "testindex1",
"_id": "1",
"_score": 150,
"_source": {
"name": "Luxury brand",
"product_to_brand": "brand"
}
}
]
}
}
7.2 - Запрос has_parent
Запрос has_parent возвращает дочерние документы, родительские документы которых соответствуют определенному запросу.
Запрос has_parent возвращает дочерние документы, родительские документы которых соответствуют определенному запросу. Вы можете установить родительско-дочерние отношения между документами в одном индексе, используя тип поля join.
Запрос has_parent медленнее, чем другие запросы, из-за операции соединения, которую он выполняет. Производительность снижается по мере увеличения количества соответствующих родительских документов. Каждый запрос has_parent в вашем поиске может значительно повлиять на производительность запроса. Если вы придаете приоритет скорости, избегайте использования этого запроса или ограничьте его использование насколько возможно.
Пример
Перед тем как вы сможете выполнить запрос has_parent, ваш индекс должен содержать поле join для установления родительско-дочерних отношений. Запрос на отображение индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
Для этого примера сначала настройте индекс, который содержит документы, представляющие продукты и их бренды, как описано в примере запроса has_child.
Чтобы найти дочерний документ родителя, используйте запрос has_parent. Следующий запрос возвращает дочерние документы (продукты), произведенные брендом, соответствующим запросу “economy”:
GET testindex1/_search
{
"query" : {
"has_parent": {
"parent_type":"brand",
"query": {
"match" : {
"name": "economy"
}
}
}
}
}
Ответ возвращает все продукты, произведенные брендом:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
Извлечение внутренних результатов (inner hits)
Чтобы вернуть родительские документы, которые соответствуют запросу, укажите параметр inner_hits:
GET testindex1/_search
{
"query" : {
"has_parent": {
"parent_type":"brand",
"query": {
"match" : {
"name": "economy"
}
},
"inner_hits": {}
}
}
}
Ответ содержит родительские документы в поле inner_hits:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex1",
"_id": "4",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
},
"inner_hits": {
"brand": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 1.3862942,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 1,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
},
"inner_hits": {
"brand": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "testindex1",
"_id": "2",
"_score": 1.3862942,
"_source": {
"name": "Economy brand",
"product_to_brand": "brand"
}
}
]
}
}
}
}
]
}
}
Для получения дополнительной информации о извлечении внутренних результатов, смотрите раздел “Внутренние результаты” (Inner hits).
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами has_parent.
| Параметр |
Обязательный/Необязательный |
Описание |
| parent_type |
Обязательный |
Указывает имя родительской связи, как определено в отображении поля join. |
| query |
Обязательный |
Запрос, который будет выполнен на родительских документах. Если родительский документ соответствует запросу, возвращается дочерний документ. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неотображаемые поля типа parent_type и не возвращать документы вместо того, чтобы вызывать ошибку. Этот параметр можно указать при запросе нескольких индексов, некоторые из которых могут не содержать поле parent_type. По умолчанию false. |
| score |
Необязательный |
Указывает, учитывается ли оценка релевантности соответствующего родительского документа в дочерних документах. Если false, то оценка релевантности родительского документа игнорируется, и каждому дочернему документу присваивается оценка релевантности, равная коэффициенту увеличения запроса, который по умолчанию равен 1. Если true, то оценка релевантности соответствующего родительского документа агрегируется в оценки релевантности его дочерних документов. По умолчанию false. |
| inner_hits |
Необязательный |
Если указан, возвращает внутренние результаты (родительские документы), которые соответствуют запросу. |
Ограничения сортировки
Запрос has_parent не поддерживает сортировку результатов с использованием стандартных опций сортировки. Если вам необходимо отсортировать дочерние документы по полям их родительских документов, вы можете использовать запрос function_score и сортировать по оценке дочернего документа.
Для предыдущего примера сначала добавьте поле customer_satisfaction, по которому вы будете сортировать дочерние документы, принадлежащие родительским (брендовым) документам:
PUT testindex1/_doc/1
{
"name": "Luxury watch brand",
"product_to_brand" : "brand",
"customer_satisfaction": 4.5
}
PUT testindex1/_doc/2
{
"name": "Economy watch brand",
"product_to_brand" : "brand",
"customer_satisfaction": 3.9
}
Теперь вы можете сортировать дочерние документы (продукты) на основе поля customer_satisfaction их родительских брендов. Этот запрос умножает оценку на поле customer_satisfaction родительских документов:
GET testindex1/_search
{
"query": {
"has_parent": {
"parent_type": "brand",
"score": true,
"query": {
"function_score": {
"script_score": {
"script": "_score * doc['customer_satisfaction'].value"
}
}
}
}
}
}
Ответ содержит продукты, отсортированные по наивысшему значению customer_satisfaction родительских документов:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 4.5,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 4.5,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
},
{
"_index": "testindex1",
"_id": "4",
"_score": 3.9,
"_routing": "2",
"_source": {
"name": "Electronic watch",
"sales_count": 300,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
},
{
"_index": "testindex1",
"_id": "5",
"_score": 3.9,
"_routing": "2",
"_source": {
"name": "Digital watch",
"sales_count": 100,
"product_to_brand": {
"name": "product",
"parent": "2"
}
}
}
]
}
}
7.3 - Вложенный запрос
Вложенный запрос служит оберткой для других запросов, позволяя искать во вложенных полях.
Вложенный запрос служит оберткой для других запросов, позволяя искать во вложенных полях. Объекты вложенных полей ищутся так, как будто они индексированы как отдельные документы. Если объект соответствует запросу, вложенный запрос возвращает родительский документ на корневом уровне.
Пример
Перед тем как выполнить вложенный запрос, ваш индекс должен содержать вложенное поле.
Чтобы настроить пример индекса, содержащего вложенные поля, отправьте следующий запрос:
PUT /testindex
{
"mappings": {
"properties": {
"patient": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
}
}
Далее, индексируйте документ в пример индекса:
PUT /testindex/_doc/1
{
"patient": {
"name": "John Doe",
"age": 56
}
}
Чтобы выполнить поиск по вложенному полю пациента, оберните ваш запрос во вложенный запрос и укажите путь к вложенному полю:
GET /testindex/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"match": {
"patient.name": "John"
}
}
}
}
}
Запрос возвращает соответствующий документ:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.2876821,
"_source": {
"patient": {
"name": "John Doe",
"age": 56
}
}
}
]
}
}
Получение внутренних результатов
Чтобы вернуть внутренние результаты, соответствующие запросу, укажите параметр inner_hits:
GET /testindex/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"match": {
"patient.name": "John"
}
},
"inner_hits": {}
}
}
}
Ответ содержит дополнительное поле inner_hits. Поле _nested идентифицирует конкретный внутренний объект, из которого произошел внутренний результат. Оно содержит вложенный результат и смещение относительно его положения в _source. Из-за сортировки и оценки положение объектов результатов во inner_hits часто отличается от их исходного местоположения во вложенном объекте.
По умолчанию _source объектов результатов внутри inner_hits возвращается относительно поля _nested. В этом примере _source внутри inner_hits содержит поля name и age, в отличие от верхнего уровня _source, который содержит весь объект пациента:
{
"took": 38,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.2876821,
"_source": {
"patient": {
"name": "John Doe",
"age": 56
}
},
"inner_hits": {
"patient": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_nested": {
"field": "patient",
"offset": 0
},
"_score": 0.2876821,
"_source": {
"name": "John Doe",
"age": 56
}
}
]
}
}
}
}
]
}
}
Многоуровневые вложенные запросы
Вы можете искать документы, которые содержат вложенные объекты внутри других вложенных объектов, используя многоуровневые вложенные запросы. В этом примере вы будете запрашивать несколько уровней вложенных полей, указывая вложенный запрос для каждого уровня иерархии.
Создание индекса с многоуровневыми вложенными полями
Сначала создайте индекс с многоуровневыми вложенными полями:
PUT /patients
{
"mappings": {
"properties": {
"patient": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"contacts": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"relationship": {
"type": "text"
},
"phone": {
"type": "keyword"
}
}
}
}
}
}
}
}
Индексация документа
Далее, индексируйте документ в пример индекса:
PUT /patients/_doc/1
{
"patient": {
"name": "John Doe",
"contacts": [
{
"name": "Jane Doe",
"relationship": "mother",
"phone": "5551111"
},
{
"name": "Joe Doe",
"relationship": "father",
"phone": "5552222"
}
]
}
}
Поиск по вложенному полю пациента
Чтобы выполнить поиск по вложенному полю пациента, используйте многоуровневый вложенный запрос. Следующий запрос ищет пациентов, чья контактная информация включает человека по имени Джейн с отношением “мать”:
GET /patients/_search
{
"query": {
"nested": {
"path": "patient",
"query": {
"nested": {
"path": "patient.contacts",
"query": {
"bool": {
"must": [
{ "match": { "patient.contacts.relationship": "mother" } },
{ "match": { "patient.contacts.name": "Jane" } }
]
}
}
}
}
}
}
}
Результаты запроса
Запрос возвращает пациента, у которого есть контактная запись, соответствующая этим данным:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "patients",
"_id": "1",
"_score": 1.3862942,
"_source": {
"patient": {
"name": "John Doe",
"contacts": [
{
"name": "Jane Doe",
"relationship": "mother",
"phone": "5551111"
},
{
"name": "Joe Doe",
"relationship": "father",
"phone": "5552222"
}
]
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые вложенными запросами.
| Параметр |
Обязательный/Необязательный |
Описание |
| path |
Обязательный |
Указывает путь к вложенному объекту, который вы хотите искать. |
| query |
Обязательный |
Запрос, который будет выполнен на вложенных объектах в указанном пути. Если вложенный объект соответствует запросу, возвращается корневой родительский документ. Вы можете искать вложенные поля, используя нотацию с точками, например, nested_object.subfield. Поддерживается многоуровневое вложение, которое автоматически определяется. Таким образом, внутренний вложенный запрос внутри другого вложенного запроса автоматически соответствует правильному уровню вложенности, а не корню. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неразмеченные поля пути и не возвращать документы вместо того, чтобы вызывать ошибку. Вы можете указать этот параметр при запросе нескольких индексов, некоторые из которых могут не содержать поле пути. По умолчанию значение - false. |
| score_mode |
Необязательный |
Определяет, как оценки соответствующих внутренних документов влияют на оценку родительского документа. Допустимые значения:
- avg: Использует среднюю релевантность всех соответствующих внутренних документов.
- max: Присваивает наивысшую релевантность из соответствующих внутренних документов родителю.
- min: Присваивает наименьшую релевантность из соответствующих внутренних документов родителю.
- sum: Суммирует релевантности всех соответствующих внутренних документов.
- none: Игнорирует релевантности внутренних документов и присваивает оценку 0 родительскому документу. По умолчанию - avg. |
| inner_hits |
Необязательный |
Если указан, возвращает внутренние результаты, которые соответствуют запросу. |
7.4 - Запрос по идентификатору родителя
апрос parent_id возвращает дочерние документы, у которых родительский документ имеет указанный идентификатор.
Запрос parent_id возвращает дочерние документы, у которых родительский документ имеет указанный идентификатор. Вы можете установить отношения родитель/дочерний между документами в одном индексе, используя тип поля join.
Пример
Перед тем как выполнить запрос parent_id, ваш индекс должен содержать поле join, чтобы установить отношения родитель/дочерний. Запрос на создание индекса использует следующий формат:
PUT /example_index
{
"mappings": {
"properties": {
"relationship_field": {
"type": "join",
"relations": {
"parent_doc": "child_doc"
}
}
}
}
}
Для этого примера сначала настройте индекс, который содержит документы, представляющие продукты и их бренды, как описано в примере запроса has_child.
Чтобы искать дочерние документы конкретного родительского документа, используйте запрос parent_id. Следующий запрос возвращает дочерние документы (продукты), у которых родительский документ имеет идентификатор 1:
GET testindex1/_search
{
"query": {
"parent_id": {
"type": "product",
"id": "1"
}
}
}
Ответ возвращает дочерний продукт:
{
"took": 57,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.87546873,
"hits": [
{
"_index": "testindex1",
"_id": "3",
"_score": 0.87546873,
"_routing": "1",
"_source": {
"name": "Mechanical watch",
"sales_count": 150,
"product_to_brand": {
"name": "product",
"parent": "1"
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами parent_id.
| Параметр |
Обязательный/Необязательный |
Описание |
| type |
Обязательный |
Указывает имя дочерней связи, как определено в сопоставлении поля join. |
| id |
Обязательный |
Идентификатор родительского документа. Запрос возвращает дочерние документы, связанные с этим родительским документом. |
| ignore_unmapped |
Необязательный |
Указывает, следует ли игнорировать неразмеченные поля типа и не возвращать документы вместо того, чтобы вызывать ошибку. Вы можете указать этот параметр при запросе нескольких индексов, некоторые из которых могут не содержать поле типа. По умолчанию значение - false. |
8 - Запросы Span
Запросы Span являются низкоуровневыми, специфическими запросами, которые предоставляют контроль над порядком и близостью указанных терминов запроса.
Вы можете использовать запросы Span для выполнения точных позиционных поисков. Запросы Span являются низкоуровневыми, специфическими запросами, которые предоставляют контроль над порядком и близостью указанных терминов запроса. Они в основном используются для поиска юридических документов и патентов.
Запросы Span включают следующие типы запросов:
Span containing
Возвращает более крупные диапазоны, которые содержат меньшие диапазоны внутри них. Полезно для поиска конкретных терминов или фраз в более широком контексте. Противоположность запросу span_within.
Span field masking
Позволяет запросам Span работать с различными полями, заставляя одно поле выглядеть как другое. Особенно полезно, когда один и тот же текст индексируется с использованием различных анализаторов.
Span first
Совпадает с терминами или фразами, которые появляются в пределах указанного количества позиций от начала поля. Полезно для поиска контента в начале текста.
Span multi-term
Позволяет многотерминным запросам (таким как префиксные, с подстановочными знаками или нечеткие) работать в рамках запросов Span. Позволяет использовать более гибкие шаблоны соответствия в поисках Span.
Span near
Находит термины или фразы, которые появляются на указанном расстоянии друг от друга. Вы можете требовать, чтобы совпадения появлялись в определенном порядке и контролировать, сколько слов может находиться между ними.
Span not
Исключает совпадения, которые пересекаются с другим запросом Span. Полезно для поиска терминов, когда они не появляются в конкретных фразах или контекстах.
Span or
Совпадает с документами, которые удовлетворяют любому из предоставленных запросов Span. Объединяет несколько шаблонов Span с логикой OR.
Span term
Основной строительный блок для запросов Span. Совпадает с одним термином, сохраняя информацию о позиции для использования в других запросах Span.
Span within
Возвращает меньшие диапазоны, которые заключены в более крупные диапазоны. Противоположность запросу span_containing.
Настройка
Чтобы попробовать примеры в этом разделе, выполните следующие шаги для настройки примера индекса.
Шаг 1: Создание индекса
Сначала создайте индекс для веб-сайта электронной коммерции по продаже одежды. Поле описания использует стандартный анализатор по умолчанию, в то время как подполе description.stemmed применяет английский анализатор для включения стемминга:
PUT /clothing
{
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "standard",
"fields": {
"stemmed": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Шаг 2: Индексация данных
Индексиуйте образцы документов в индекс:
POST /clothing/_doc/1
{
"description": "Рубашка с длинными рукавами и формальным воротником с пуговицами."
}
POST /clothing/_doc/2
{
"description": "Красивое длинное платье из красного шелка, идеально подходит для формальных мероприятий."
}
POST /clothing/_doc/3
{
"description": "Рубашка с короткими рукавами и воротником на пуговицах, можно носить как в повседневном, так и в формальном стиле."
}
POST /clothing/_doc/4
{
"description": "Комплект из двух шелковых платьев-рубашек миди с длинными рукавами черного цвета."
}
8.1 - Запрос Span containing
Запрос span_containing находит совпадения, где более крупный текстовый шаблон (например, фраза или набор слов) содержит меньший текстовый шаблон в своих границах.
Рассматривайте это как поиск слова или фразы, но только когда они появляются в определенном более широком контексте.
Например, вы можете использовать запрос span_containing для выполнения следующих поисков:
- Найти слово “quick”, но только когда оно появляется в предложениях, которые упоминают как лисиц, так и поведение.
- Убедиться, что определенные термины появляются в контексте других терминов — не просто где-то в документе.
- Искать конкретные слова, которые появляются в рамках более значимых фраз.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет вхождения слова “red”, которые появляются в более крупном диапазоне, содержащем слова “silk” и “dress” (не обязательно в этом порядке) в пределах 5 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_containing": {
"little": {
"span_term": {
"description": "red"
}
},
"big": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "silk"
}
},
{
"span_term": {
"description": "dress"
}
}
],
"slop": 5,
"in_order": false
}
}
}
}
}
Запрос соответствует документу 1, потому что:
- Он находит диапазон, в котором “silk” и “dress” появляются на расстоянии не более 5 слов друг от друга ("…dress in red silk…"). Термины “silk” и “dress” находятся на расстоянии 2 слов друг от друга (между ними 2 слова).
- Внутри этого более крупного диапазона он находит термин “red”.
Ответ
Оба параметра little и big могут содержать любой тип запроса span, что позволяет создавать сложные вложенные запросы span при необходимости.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_containing. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| little |
Объект |
Запрос span, который должен быть содержим внутри большого диапазона. Это определяет диапазон, который вы ищете в более широком контексте. |
| big |
Объект |
Содержащий запрос span, который определяет границы, в пределах которых должен появиться маленький диапазон. Это устанавливает контекст для вашего поиска. |
8.2 - Запрос Span field masking
Запрос field_masking_span позволяет запросам Span соответствовать различным полям, “маскируя” истинное поле запроса.
Это особенно полезно при работе с многопольными индексами (один и тот же контент индексируется с использованием различных анализаторов) или когда вам нужно выполнять запросы Span, такие как span_near или span_or, по различным полям (что обычно не разрешено).
Например, вы можете использовать запрос field_masking_span для:
- Совпадения терминов между сырым полем и его стеммированной версией.
- Объединения запросов Span по различным полям в одной операции Span.
- Работы с одним и тем же контентом, индексированным с использованием различных анализаторов.
При использовании маскирования поля релевантность рассчитывается с использованием характеристик (норм) маскированного поля, а не фактического поля, по которому выполняется поиск. Это означает, что если маскированное поле имеет другие свойства (например, длину или значения увеличения), чем поле, по которому выполняется поиск, вы можете получить неожиданные результаты оценки.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “long” рядом с вариациями слова “sleeve” в стеммированном поле:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "long"
}
},
{
"field_masking_span": {
"query": {
"span_term": {
"description.stemmed": "sleev"
}
},
"field": "description"
}
}
],
"slop": 1,
"in_order": true
}
}
}
Запрос соответствует документам 1 и 4:
- Термин “long” появляется в поле описания в обоих документах.
- Документ 1 содержит слово “sleeved”, а документ 4 содержит слово “sleeves”.
- Запрос field_masking_span делает так, что совпадение стеммированного поля выглядит так, как будто оно находится в сыром поле.
- Термины появляются на расстоянии 1 позиции друг от друга в указанном порядке (“long” должен появляться перед “sleeve”).
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.7444251,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 0.7444251,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.4291246,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами field_masking_span. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| query |
Объект |
Запрос span, который будет выполнен на фактическом поле. |
| field |
Строка |
Имя поля, используемое для маскирования запроса. Другие запросы span будут рассматривать этот запрос так, как будто он выполняется на этом поле. |
8.3 - Запрос Span first
Запрос span_first соответствует диапазонам, которые начинаются в начале поля и заканчиваются в пределах указанного количества позиций.
Этот запрос полезен, когда вы хотите найти термины или фразы, которые появляются в начале документа.
Например, вы можете использовать запрос span_first для выполнения следующих поисков:
- Найти документы, в которых определенные термины появляются в первых нескольких словах поля.
- Убедиться, что определенные фразы встречаются в начале текста или рядом с ним.
- Совпадать с шаблонами только тогда, когда они появляются в пределах указанного расстояния от начала.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет стеммированное слово “dress”, которое появляется в первых 4 позициях поля описания:
GET /clothing/_search
{
"query": {
"span_first": {
"match": {
"span_term": {
"description.stemmed": "dress"
}
},
"end": 4
}
}
}
Запрос соответствует документам 1 и 2:
- Документы 1 и 2 содержат слово “dress” на третьей позиции (“Long-sleeved dress…” и “Beautiful long dress”). Индексация слов начинается с 0, поэтому слово “dress” находится на позиции 2.
- Позиция слова “dress” должна быть меньше 4, как указано в параметре end.
Ответ
Параметр match может содержать любой тип запроса span, что позволяет сопоставлять более сложные шаблоны в начале полей.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_first. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| match |
Объект |
Запрос span для соответствия. Это определяет шаблон, который вы ищете в начале поля. |
| end |
Целое число |
Максимальная конечная позиция (исключительно), разрешенная для совпадения запроса span. Например, end: 4 соответствует терминам на позициях 0–3. |
8.4 - Запрос Span multi-term
Запрос span_multi позволяет обернуть многотерминный запрос (например, с подстановочными знаками, нечеткий, префиксный, диапазонный или регулярное выражение) в запрос Span.
Это позволяет использовать более гибкие запросы соответствия внутри других запросов Span.
Например, вы можете использовать запрос span_multi для:
- Поиска слов с общими префиксами рядом с другими терминами.
- Совпадения нечетких вариаций слов в пределах диапазонов.
- Использования регулярных выражений в запросах Span.
Запросы span_multi могут потенциально соответствовать многим терминам. Чтобы избежать чрезмерного использования памяти, вы можете:
- Установить параметр rewrite для многотерминного запроса.
- Использовать метод переписывания top_terms_*.
- Рассмотреть возможность включения опции index_prefixes для текстового поля, если вы используете span_multi только для префиксного запроса. Это автоматически переписывает любой префиксный запрос на поле в однотерминный запрос, который соответствует индексированному префиксу.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Запрос span_multi использует следующую синтаксис для обертывания префиксного запроса:
"span_multi": {
"match": {
"prefix": {
"description": {
"value": "flutter"
}
}
}
}
Следующий запрос ищет слова, начинающиеся с “dress”, рядом с любой формой “sleeve” в пределах 5 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_multi": {
"match": {
"prefix": {
"description": {
"value": "dress"
}
}
}
}
},
{
"field_masking_span": {
"query": {
"span_term": {
"description.stemmed": "sleev"
}
},
"field": "description"
}
}
],
"slop": 5,
"in_order": false
}
}
}
Запрос соответствует документам 1 (“Long-sleeved dress…”) и 4 ("…dresses with long fluttered sleeves…"), потому что “dress” и “long” встречаются в пределах максимального расстояния в обоих документах.
Ответ
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.7590723,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 1.7590723,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.84792376,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_multi. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| match |
Объект |
Многотерминный запрос для обертывания (может быть префиксным, с подстановочными знаками, нечетким, диапазонным или регулярным выражением). |
8.5 - Запрос Span near
Запрос span_near соответствует диапазонам, которые находятся близко друг к другу.
Вы можете указать, насколько далеко могут находиться диапазоны и нужно ли, чтобы они появлялись в определенном порядке.
Например, вы можете использовать запрос span_near для:
- Поиска терминов, которые появляются на определенном расстоянии друг от друга.
- Совпадения фраз, в которых слова появляются в определенном порядке.
- Поиска связанных концепций, которые находятся близко друг к другу в тексте.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет любые формы слова “sleeve” и “long”, которые появляются рядом друг с другом в любом порядке:
GET /clothing/_search
{
"query": {
"span_near": {
"clauses": [
{
"span_term": {
"description.stemmed": "sleev"
}
},
{
"span_term": {
"description.stemmed": "long"
}
}
],
"slop": 1,
"in_order": false
}
}
}
Запрос соответствует документам 1 (“Long-sleeved…”) и 2 ("…long fluttered sleeves…"). В документе 1 слова находятся рядом друг с другом, в то время как в документе 2 они находятся в пределах указанного расстояния slop равного 1 (между ними 1 слово).
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.36496973,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 0.36496973,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "4",
"_score": 0.25312424,
"_source": {
"description": "A set of two midi silk shirt dresses with long fluttered sleeves in black. "
}
}
]
}
}
Запрос span_near позволяет находить термины и фразы, которые имеют определенные отношения по близости и порядку, что делает его полезным для анализа текстов и поиска связанных понятий.
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_near.
| Параметр |
Тип данных |
Описание |
| clauses |
Массив |
Массив запросов span, которые определяют термины или фразы для соответствия. Все указанные термины должны появляться в пределах заданного расстояния slop. Обязательный параметр. |
| slop |
Целое число |
Максимальное количество промежуточных несоответствующих позиций между диапазонами. Обязательный параметр. |
| in_order |
Логический |
Указывает, должны ли диапазоны появляться в том же порядке, что и в массиве clauses. Необязательный параметр. По умолчанию false. |
8.6 - span_not
Запрос Span not
Запрос span_not исключает диапазоны, которые пересекаются с другим запросом span. Вы также можете указать расстояние до или после исключенных диапазонов, в пределах которого совпадения не могут происходить.
Например, вы можете использовать запрос span_not для:
- Поиска терминов, кроме тех случаев, когда они появляются в определенных фразах.
- Совпадения диапазонов, если они не находятся рядом с определенными терминами.
- Исключения совпадений, которые происходят в пределах определенного расстояния от других шаблонов.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “dress”, но не когда оно появляется в фразе “dress shirt”:
GET /clothing/_search
{
"query": {
"span_not": {
"include": {
"span_term": {
"description": "dress"
}
},
"exclude": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "dress"
}
},
{
"span_term": {
"description": "shirt"
}
}
],
"slop": 0,
"in_order": true
}
}
}
}
}
Запрос соответствует документу 2, потому что он содержит слово “dress” (“Beautiful long dress…”). Документ 1 не соответствует, потому что он содержит фразу “dress shirt”, которая исключена. Документы 3 и 4 не соответствуют, потому что они содержат вариации слова “dress” (“dressed” и “dresses”), а запрос ищет в сыром поле.
Ответ
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_not.
| Параметр |
Тип данных |
Описание |
| include |
Объект |
Запрос span, совпадения которого вы хотите найти. Обязательный параметр. |
| exclude |
Объект |
Запрос span, совпадения которого должны быть исключены. Обязательный параметр. |
| pre |
Целое число |
Указывает, что исключенный диапазон не может появляться в пределах указанного количества позиций токенов перед включенным диапазоном. Необязательный параметр. По умолчанию 0. |
| post |
Целое число |
Указывает, что исключенный диапазон не может появляться в пределах указанного количества позиций токенов после включенного диапазона. Необязательный параметр. По умолчанию 0. |
| dist |
Целое число |
Эквивалентно установке как pre, так и post на одно и то же значение. Необязательный параметр. |
8.7 - Запрос Span or
Запрос span_or объединяет несколько запросов span и соответствует объединению их диапазонов.
Совпадение происходит, если хотя бы один из содержащихся запросов span соответствует.
Например, вы можете использовать запрос span_or для:
- Поиска диапазонов, соответствующих любому из нескольких шаблонов.
- Объединения различных шаблонов span в качестве альтернатив.
- Совпадения нескольких вариаций span в одном запросе.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет либо “formal collar”, либо “button collar”, которые появляются в пределах 2 слов друг от друга:
GET /clothing/_search
{
"query": {
"span_or": {
"clauses": [
{
"span_near": {
"clauses": [
{
"span_term": {
"description": "formal"
}
},
{
"span_term": {
"description": "collar"
}
}
],
"slop": 0,
"in_order": true
}
},
{
"span_near": {
"clauses": [
{
"span_term": {
"description": "button"
}
},
{
"span_term": {
"description": "collar"
}
}
],
"slop": 2,
"in_order": true
}
}
]
}
}
}
Запрос соответствует документам 1 ("…formal collar…") и 3 ("…button-down collar…") в пределах указанного расстояния slop.
Ответ
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.170027,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 2.170027,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
},
{
"_index": "clothing",
"_id": "3",
"_score": 1.2509141,
"_source": {
"description": "Short-sleeved shirt with a button-down collar, can be dressed up or down."
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_or.
| Параметр |
Тип данных |
Описание |
| clauses |
Массив |
Массив запросов span для соответствия. Запрос соответствует, если любой из этих запросов span совпадает. Должен содержать как минимум один запрос span. Обязательный параметр. |
8.8 - Запрос Span term
Запрос span_term является самым базовым запросом span, который соответствует диапазонам, содержащим один термин.
Он служит строительным блоком для более сложных запросов span.
Например, вы можете использовать запрос span_term для:
- Поиска точных совпадений термина, которые могут быть использованы в других запросах span.
- Совпадения конкретных слов с сохранением информации о позиции.
- Создания базовых диапазонов, которые могут быть объединены с другими запросами span.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет точный термин “formal”:
GET /clothing/_search
{
"query": {
"span_term": {
"description": "formal"
}
}
}
В качестве альтернативы вы можете указать искомый термин в параметре value:
GET /clothing/_search
{
"query": {
"span_term": {
"description": {
"value": "formal"
}
}
}
}
Вы также можете указать значение boost, чтобы увеличить оценку документа:
GET /clothing/_search
{
"query": {
"span_term": {
"description": {
"value": "formal",
"boost": 2
}
}
}
}
Запрос соответствует документам 1 и 2, потому что они содержат точный термин “formal”. Информация о позиции сохраняется для использования в других запросах span.
Ответ
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.498922,
"hits": [
{
"_index": "clothing",
"_id": "2",
"_score": 1.498922,
"_source": {
"description": "Beautiful long dress in red silk, perfect for formal events."
}
},
{
"_index": "clothing",
"_id": "1",
"_score": 1.4466847,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_term.
| Параметр |
Тип данных |
Описание |
|
Строка или объект |
Имя поля, в котором нужно выполнить поиск. |
8.9 - Запрос Span within
Запрос span_within соответствует диапазонам, которые заключены в другой запрос span.
Это противоположность запросу span_containing: span_containing возвращает более крупные диапазоны, содержащие меньшие, в то время как span_within возвращает меньшие диапазоны, заключенные в более крупные.
Например, вы можете использовать запрос span_within для:
- Поиска более коротких фраз, которые появляются внутри более длинных фраз.
- Совпадения терминов, которые встречаются в определенных контекстах.
- Идентификации меньших шаблонов, заключенных в более крупные шаблоны.
Пример
Чтобы попробовать примеры в этом разделе, выполните шаги по настройке.
Следующий запрос ищет слово “dress”, когда оно появляется внутри диапазона, содержащего “shirt” и “long”:
GET /clothing/_search
{
"query": {
"span_within": {
"little": {
"span_term": {
"description": "dress"
}
},
"big": {
"span_near": {
"clauses": [
{
"span_term": {
"description": "shirt"
}
},
{
"span_term": {
"description": "long"
}
}
],
"slop": 2,
"in_order": false
}
}
}
}
}
Запрос соответствует документу 1, потому что:
- Слово “dress” появляется внутри более крупного диапазона (“Long-sleeved dress shirt…”).
- Более крупный диапазон содержит “shirt” и “long” в пределах 2 слов друг от друга (между ними 2 слова).
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.4677674,
"hits": [
{
"_index": "clothing",
"_id": "1",
"_score": 1.4677674,
"_source": {
"description": "Long-sleeved dress shirt with a formal collar and button cuffs. "
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами span_within. Все параметры обязательны.
| Параметр |
Тип данных |
Описание |
| little |
Объект |
Запрос span, который должен быть содержим внутри большого диапазона. Это определяет диапазон, который вы ищете в более широком контексте. |
| big |
Объект |
Содержащий запрос span, который определяет границы, в пределах которых должен появиться маленький диапазон. Это устанавливает контекст для вашего поиска. |
9 - Запрос Match all
Запрос match_all возвращает все документы. Этот запрос может быть полезен для тестирования больших наборов документов, если вам нужно вернуть весь набор.
GET _search
{
"query": {
"match_all": {}
}
}
Запрос match_all имеет аналог match_none, который редко бывает полезен:
GET _search
{
"query": {
"match_none": {}
}
}
Параметры
Оба запроса match_all и match_none принимают следующие параметры. Все параметры являются необязательными.
| Параметр |
Тип данных |
Описание |
| boost |
Число с плавающей запятой |
Значение с плавающей запятой, которое указывает на вес этого поля в отношении оценки релевантности. Значения выше 1.0 увеличивают релевантность поля. Значения от 0.0 до 1.0 уменьшают релевантность поля. По умолчанию 1.0. |
| _name |
Строка |
Имя запроса для тегирования запроса. Необязательный параметр. |
10 - Специализированные запросы
OpenSearch поддерживает следующие специализированные запросы: distance_feature, more_like_this и др.
-
distance_feature: Вычисляет оценки документов на основе динамически рассчитанного расстояния между исходной точкой и полями даты, date_nanos или geo_point документа. Этот запрос может пропускать неконкурентные результаты.
-
more_like_this: Находит документы, похожие на предоставленный текст, документ или коллекцию документов.
-
knn: Используется для поиска сырых векторов во время векторного поиска.
-
neural: Используется для поиска по тексту или изображению в векторном поиске.
-
neural_sparse: Используется для поиска по векторным полям в разреженном нейронном поиске.
-
percolate: Находит запросы (сохраненные в виде документов), которые соответствуют предоставленному документу.
-
rank_feature: Вычисляет оценки на основе значений числовых признаков. Этот запрос может пропускать неконкурентные результаты.
-
script: Использует скрипт в качестве фильтра.
-
script_score: Вычисляет пользовательскую оценку для соответствующих документов с использованием скрипта.
-
wrapper: Принимает другие запросы в виде строк JSON или YAML.
10.1 - distance_feature
distance_feature для увеличения релевантности документов, которые ближе к определенной дате или географической точке.
Используйте запрос distance_feature для увеличения релевантности документов, которые ближе к определенной дате или географической точке. Это может помочь вам приоритизировать более свежий или близкий контент в результатах поиска. Например, вы можете присвоить больший вес продуктам, произведенным более недавно, или повысить рейтинг товаров, находящихся ближе к указанному пользователем местоположению.
Вы можете применять этот запрос к полям, содержащим данные о дате или местоположении. Он часто используется в условии should запроса bool для улучшения оценки релевантности без фильтрации результатов.
Настройка индекса
Перед использованием запроса distance_feature убедитесь, что ваш индекс содержит хотя бы один из следующих типов полей:
- date
- date_nanos
- geo_point
В этом примере вы настроите поля opening_date и coordinates, которые можно использовать для выполнения запросов distance_feature:
PUT /stores
{
"mappings": {
"properties": {
"opening_date": {
"type": "date"
},
"coordinates": {
"type": "geo_point"
}
}
}
}
Добавьте пример документов в индекс:
PUT /stores/_doc/1
{
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [74.00, 40.70]
}
PUT /stores/_doc/2
{
"store_name": "Fresh Foods",
"opening_date": "2025-04-01",
"coordinates": [73.98, 40.75]
}
PUT /stores/_doc/3
{
"store_name": "City Organics",
"opening_date": "2021-04-20",
"coordinates": [74.02, 40.68]
}
Пример: Увеличение оценок на основе свежести
Следующий запрос ищет документы с store_name, соответствующим слову “market”, и увеличивает оценки недавно открытых магазинов:
GET /stores/_search
{
"query": {
"bool": {
"must": {
"match": {
"store_name": "market"
}
},
"should": {
"distance_feature": {
"field": "opening_date",
"origin": "2025-04-07",
"pivot": "10d"
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.2372394,
"hits": [
{
"_index": "stores",
"_id": "1",
"_score": 1.2372394,
"_source": {
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [
74,
40.7
]
}
}
]
}
}
Пример: Увеличение оценок на основе географической близости
Следующий запрос ищет документы с store_name, соответствующим слову “market”, и увеличивает результаты, находящиеся ближе к заданной исходной точке:
GET /stores/_search
{
"query": {
"bool": {
"must": {
"match": {
"store_name": "market"
}
},
"should": {
"distance_feature": {
"field": "coordinates",
"origin": [74.00, 40.71],
"pivot": "500m"
}
}
}
}
}
Ответ содержит соответствующий документ:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.2910118,
"hits": [
{
"_index": "stores",
"_id": "1",
"_score": 1.2910118,
"_source": {
"store_name": "Green Market",
"opening_date": "2025-03-10",
"coordinates": [
74,
40.7
]
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами distance_feature.
| Параметр |
Обязательный/Необязательный |
Описание |
| field |
Обязательный |
Имя поля, используемого для расчета расстояний. Должно быть полем типа date, date_nanos или geo_point с параметрами index: true (по умолчанию) и doc_values: true (по умолчанию). |
| origin |
Обязательный |
Точка отсчета, используемая для расчета расстояний. Используйте дату или математическое выражение даты (например, now-1h) для полей даты или геопункт для полей geo_point. |
| pivot |
Обязательный |
Расстояние от исходной точки, при котором оценки получают половину значения увеличения. Используйте единицу времени (например, 10d) для полей даты или единицу расстояния (например, 1km) для географических полей. Для получения дополнительной информации см. раздел “Единицы”. |
| boost |
Необязательный |
Множитель для оценки релевантности соответствующих документов. Должен быть неотрицательным числом с плавающей запятой. По умолчанию 1.0. |
Как рассчитываются оценки
Запрос distance_feature вычисляет оценку релевантности документа, используя следующую формулу:
[
\text{score} = \text{boost} \cdot \frac {\text{pivot}} {\text{pivot} + \text{distance}}
]
где distance — это абсолютная разница между origin и значением поля.
Пропуск неконкурентных результатов
В отличие от других запросов, модифицирующих оценки, таких как запрос function_score, запрос distance_feature оптимизирован для эффективного пропуска неконкурентных результатов, когда отслеживание общего количества результатов (track_total_hits) отключено. Это позволяет улучшить производительность запросов, особенно при работе с большими объемами данных, так как система может сосредоточиться только на наиболее релевантных результатах.
10.2 - k-NN
Используйте запрос k-NN для выполнения поиска ближайших соседей по векторным полям.
Поля тела запроса
Укажите векторное поле в запросе k-NN и задайте дополнительные поля запроса в объекте векторного поля:
"knn": {
"<vector_field>": {
"vector": [<vector_values>],
"k": <k_value>,
...
}
}
Верхний уровень vector_field указывает на векторное поле, по которому будет выполняться запрос поиска. Следующая таблица перечисляет все поддерживаемые поля запроса.
| Поле |
Тип данных |
Обязательный/Необязательный |
Описание |
| vector |
Массив чисел с плавающей запятой или байтов |
Обязательный |
Вектор запроса, используемый для векторного поиска. Тип данных элементов вектора должен соответствовать типу данных векторов, индексированных в поле knn_vector. |
| k |
Целое число |
Необязательный |
Количество ближайших соседей для возврата. Допустимые значения находятся в диапазоне [1, 10,000]. Обязательно, если не указаны max_distance или min_score. |
| max_distance |
Число с плавающей запятой |
Необязательный |
Максимальный порог расстояния для результатов поиска. Можно указать только одно из k, max_distance или min_score. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| min_score |
Число с плавающей запятой |
Необязательный |
Минимальный порог оценки для результатов поиска. Можно указать только одно из k, max_distance или min_score. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| filter |
Объект |
Необязательный |
Фильтр, который применяется к поиску k-NN. Для получения дополнительной информации см. раздел “Векторный поиск с фильтрами”. Важно: фильтр можно использовать только с движками faiss или lucene. |
| method_parameters |
Объект |
Необязательный |
Дополнительные параметры для тонкой настройки поиска:
- ef_search (Целое число): количество векторов для проверки (для метода hnsw)
- nprobes (Целое число): количество корзин для проверки (для метода ivf). Для получения дополнительной информации см. раздел “Указание параметров метода в запросе”. |
| rescore |
Объект или логическое значение |
Необязательный |
Параметры для настройки функциональности повторной оценки:
- oversample_factor (Число с плавающей запятой): контролирует, сколько кандидатных векторов извлекается перед повторной оценкой. Допустимые значения находятся в диапазоне [1.0, 100.0]. По умолчанию false для полей с режимом in_memory (без повторной оценки) и включено (с динамическими значениями) для полей с режимом on_disk. В режиме on_disk значение по умолчанию для oversample_factor определяется уровнем сжатия. Для получения дополнительной информации см. таблицу уровня сжатия. Чтобы явно включить повторную оценку с значением по умолчанию для oversample_factor равным 1.0, установите rescore в true. Для получения дополнительной информации см. раздел “Повторная оценка результатов”. |
| expand_nested_docs |
Логическое значение |
Необязательный |
Если true, извлекает оценки для всех документов вложенных полей в каждом родительском документе. Используется с вложенными запросами. Для получения дополнительной информации см. раздел “Векторный поиск с вложенными полями”. |
Пример запроса
Запрос для выполнения поиска ближайших соседей:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [1.5, 2.5],
"k": 3
}
}
}
}
Пример запроса: Вложенные поля
Запрос для выполнения поиска ближайших соседей во вложенных полях:
GET /my-vector-index/_search
{
"_source": false,
"query": {
"nested": {
"path": "nested_field",
"query": {
"knn": {
"nested_field.my_vector": {
"vector": [1, 1, 1],
"k": 2,
"expand_nested_docs": true
}
}
},
"inner_hits": {
"_source": false,
"fields": ["nested_field.color"]
},
"score_mode": "max"
}
}
}
Пример запроса: Радиальный поиск с max_distance
Следующий пример демонстрирует радиальный поиск с использованием max_distance:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [
7.1,
8.3
],
"max_distance": 2
}
}
}
}
Пример запроса: Радиальный поиск с min_score
Следующий пример демонстрирует радиальный поиск с использованием min_score:
GET /my-vector-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [7.1, 8.3],
"min_score": 0.95
}
}
}
}
Указание параметров метода в запросе
Начиная с версии 2.16, вы можете предоставлять параметры метода в запросе поиска:
GET /my-vector-index/_search
{
"size": 2,
"query": {
"knn": {
"target-field": {
"vector": [2, 3, 5, 6],
"k": 2,
"method_parameters": {
"ef_search": 100
}
}
}
}
}
Эти параметры зависят от комбинации движка и метода, использованных для создания индекса. Следующие разделы предоставляют информацию о поддерживаемых параметрах метода.
ef_search
Вы можете указать параметр ef_search при поиске в индексе, созданном с использованием метода hnsw. Параметр ef_search указывает количество векторов, которые необходимо проверить для нахождения k ближайших соседей. Более высокие значения ef_search улучшают полноту поиска за счет увеличения задержки поиска. Значение должно быть положительным.
Следующая таблица предоставляет информацию о параметре ef_search для поддерживаемых движков.
| Движок |
Поддержка радиального запроса |
Примечания |
| nmslib (устаревший) |
Нет |
Если ef_search присутствует в запросе, он переопределяет настройку index.knn.algo_param.ef_search индекса. |
| faiss |
Да |
Если ef_search присутствует в запросе, он переопределяет настройку index.knn.algo_param.ef_search индекса. |
| lucene |
Нет |
При создании поискового запроса необходимо указать k. Если вы укажете и k, и ef_search, то будет передано большее значение. Если ef_search больше k, вы можете указать параметр size, чтобы ограничить окончательное количество результатов до k. |
nprobes
Вы можете указать параметр nprobes при поиске в индексе, созданном с использованием метода ivf. Параметр nprobes указывает количество корзин, которые необходимо проверить для нахождения k ближайших соседей. Более высокие значения nprobes улучшают полноту поиска за счет увеличения задержки поиска. Значение должно быть положительным.
Следующая таблица предоставляет информацию о параметре nprobes для поддерживаемых движков.
| Движок |
Примечания |
| faiss |
Если nprobes присутствует в запросе, он переопределяет значение, указанное при создании индекса. |
Повторная оценка результатов
Вы можете тонко настроить поиск, предоставив параметры ef_search и oversample_factor.
Параметр oversample_factor контролирует фактор, на который поиск увеличивает количество кандидатных векторов перед их ранжированием. Использование более высокого значения oversample_factor означает, что больше кандидатов будет рассмотрено перед ранжированием, что улучшает точность, но также увеличивает время поиска. При выборе значения oversample_factor учитывайте компромисс между точностью и эффективностью. Например, установка oversample_factor на 2.0 удвоит количество кандидатов, рассматриваемых на этапе ранжирования, что может помочь достичь лучших результатов.
Следующий запрос указывает параметры ef_search и oversample_factor:
GET /my-vector-index/_search
{
"size": 2,
"query": {
"knn": {
"my_vector_field": {
"vector": [1.5, 5.5, 1.5, 5.5, 1.5, 5.5, 1.5, 5.5],
"k": 10,
"method_parameters": {
"ef_search": 10
},
"rescore": {
"oversample_factor": 10.0
}
}
}
}
}
10.3 - k-NN explain
При включении этот параметр предоставляет подробную информацию о процессе оценки для каждого результата поиска.
Запрос k-NN: Параметр explain
С версии 3.0 вы можете использовать параметр explain, чтобы понять, как рассчитываются, нормализуются и комбинируются оценки в запросах k-NN. При включении этот параметр предоставляет подробную информацию о процессе оценки для каждого результата поиска. Это включает в себя раскрытие используемых техник нормализации оценок, способы комбинирования различных оценок и расчеты для индивидуальных подзапросов. Этот всесторонний анализ упрощает понимание и оптимизацию результатов ваших запросов k-NN. Для получения дополнительной информации о параметре explain смотрите раздел API объяснения.
Обратите внимание, что использование параметра explain является ресурсоемкой операцией как по времени, так и по ресурсам. Для производственных кластеров рекомендуется использовать его экономно, в основном для устранения неполадок.
Использование параметра explain
Вы можете указать параметр explain в URL при выполнении полного запроса k-NN для движка Faiss, используя следующий синтаксис:
GET <index>/_search?explain=true
POST <index>/_search?explain=true
Для поиска k-NN с использованием движка Lucene параметр explain не возвращает подробное объяснение, как это делает движок Faiss.
Поддерживаемые типы запросов с параметром explain для движка Faiss:
- Приблизительный поиск k-NN
- Приблизительный поиск k-NN с точным поиском
- Поиск на диске
- Поиск k-NN с эффективной фильтрацией
- Радиальный поиск
- Поиск k-NN с термовым запросом
Для поиска k-NN с вложенными полями параметр explain не возвращает подробное объяснение, как это происходит с другими запросами.
Примеры использования параметра explain
Вы можете указать параметр explain как параметр запроса:
GET my-knn-index/_search?explain=true
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3, 5, 7],
"k": 2
}
}
}
}
Или вы можете указать параметр explain в теле запроса:
GET my-knn-index/_search
{
"query": {
"knn": {
"my_vector": {
"vector": [2, 3, 5, 7],
"k": 2
}
}
},
"explain": true
}
Пример: Приблизительный поиск k-NN
{
"took": 216038,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 88.4,
"hits": [
{
"_shard": "[my-knn-index-1][0]",
"_node": "VHcyav6OTsmXdpsttX2Yug",
"_index": "my-knn-index-1",
"_id": "5",
"_score": 88.4,
"_source": {
"my_vector1": [
2.5,
3.5,
5.5,
7.4
],
"price": 8.9
},
"_explanation": {
"value": 88.4,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 88.4,
"description": "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details": [
{
"value": -87.4,
"description": "rawScore, returned from FAISS library",
"details": []
}
]
}
]
}
},
{
"_shard": "[my-knn-index-1][0]",
"_node": "VHcyav6OTsmXdpsttX2Yug",
"_index": "my-knn-index-1",
"_id": "2",
"_score": 84.7,
"_source": {
"my_vector1": [
2.5,
3.5,
5.6,
6.7
],
"price": 5.5
},
"_explanation": {
"value": 84.7,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 84.7,
"description": "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details": [
{
"value": -83.7,
"description": "rawScore, returned from FAISS library",
"details": []
}
]
}
]
}
}
]
}
}
Пример: Приблизительный поиск k-NN с точным поиском
{
"took": 87,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 84.7,
"hits": [
{
"_shard": "[my-knn-index-1][0]",
"_node": "MQVux8dZRWeznuEYKhMq0Q",
"_index": "my-knn-index-1",
"_id": "7",
"_score": 84.7,
"_source": {
"my_vector2": [
2.5,
3.5,
5.6,
6.7
],
"price": 5.5
},
"_explanation": {
"value": 84.7,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 84.7,
"description": "the type of knn search executed at leaf was Exact with spaceType = INNER_PRODUCT, vectorDataType = FLOAT, queryVector = [2.0, 3.0, 5.0, 6.0]",
"details": []
}
]
}
},
{
"_shard": "[my-knn-index-1][0]",
"_node": "MQVux8dZRWeznuEYKhMq0Q",
"_index": "my-knn-index-1",
"_id": "8",
"_score": 82.2,
"_source": {
"my_vector2": [
4.5,
5.5,
6.7,
3.7
],
"price": 4.4
},
"_explanation": {
"value": 82.2,
"description": "the type of knn search executed was Approximate-NN",
"details": [
{
"value": 82.2,
"description": "the type of knn search executed at leaf was Exact with spaceType = INNER_PRODUCT, vectorDataType = FLOAT, queryVector = [2.0, 3.0, 5.0, 6.0]",
"details": []
}
]
}
}
]
}
Пример: Поиск на диске
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 381.0,
"hits" : [
{
"_shard" : "[my-vector-index][0]",
"_node" : "pLaiqZftTX-MVSKdQSu7ow",
"_index" : "my-vector-index",
"_id" : "9",
"_score" : 381.0,
"_source" : {
"my_vector_field" : [
9.5,
9.5,
9.5,
9.5,
9.5,
9.5,
9.5,
9.5
],
"price" : 8.9
},
"_explanation" : {
"value" : 381.0,
"description" : "the type of knn search executed was Disk-based and the first pass k was 100 with vector dimension of 8, over sampling factor of 5.0, shard level rescoring enabled",
"details" : [
{
"value" : 381.0,
"description" : "the type of knn search executed at leaf was Approximate-NN with spaceType = HAMMING, vectorDataType = FLOAT, queryVector = [1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5]",
"details" : [ ]
}
]
}
}
]
}
}
Пример: поиск k-NN с эффективной фильтрацией
{
"took" : 51,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.8620689,
"hits" : [
{
"_shard" : "[products-shirts][0]",
"_node" : "9epk8WoFT8yvnUI0tAaJgQ",
"_index" : "products-shirts",
"_id" : "8",
"_score" : 0.8620689,
"_source" : {
"item_vector" : [
2.4,
4.0,
3.0
],
"size" : "small",
"rating" : 8
},
"_explanation" : {
"value" : 0.8620689,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 0.8620689,
"description" : "the type of knn search executed at leaf was Exact since filteredIds = 2 is less than or equal to K = 10 with spaceType = L2, vectorDataType = FLOAT, queryVector = [2.0, 4.0, 3.0]",
"details" : [ ]
}
]
}
},
{
"_shard" : "[products-shirts][0]",
"_node" : "9epk8WoFT8yvnUI0tAaJgQ",
"_index" : "products-shirts",
"_id" : "6",
"_score" : 0.029691212,
"_source" : {
"item_vector" : [
6.4,
3.4,
6.6
],
"size" : "small",
"rating" : 9
},
"_explanation" : {
"value" : 0.029691212,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 0.029691212,
"description" : "the type of knn search executed at leaf was Exact since filteredIds = 2 is less than or equal to K = 10 with spaceType = L2, vectorDataType = FLOAT, queryVector = [2.0, 4.0, 3.0]",
"details" : [ ]
}
]
}
}
]
}
}
Пример: Радиальный поиск
GET my-knn-index/_search?explain=true
{
"query": {
"knn": {
"my_vector": {
"vector": [7.1, 8.3],
"max_distance": 2
}
}
}
}
Ответ:
{
"took" : 376529,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.98039204,
"hits" : [
{
"_shard" : "[knn-index-test][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "knn-index-test",
"_id" : "1",
"_score" : 0.98039204,
"_source" : {
"my_vector" : [
7.0,
8.2
],
"price" : 4.4
},
"_explanation" : {
"value" : 0.98039204,
"description" : "the type of knn search executed was Radial with the radius of 2.0",
"details" : [
{
"value" : 0.98039204,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = l2 where score is computed as `1 / (1 + rawScore)` from:",
"details" : [
{
"value" : 0.020000057,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
},
{
"_shard" : "[knn-index-test][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "knn-index-test",
"_id" : "3",
"_score" : 0.9615384,
"_source" : {
"my_vector" : [
7.3,
8.3
],
"price" : 19.1
},
"_explanation" : {
"value" : 0.9615384,
"description" : "the type of knn search executed was Radial with the radius of 2.0",
"details" : [
{
"value" : 0.9615384,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = l2 where score is computed as `1 / (1 + rawScore)` from:",
"details" : [
{
"value" : 0.040000115,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
}
]
}
}
Пример: поиск k-NN с запросом по термину
GET my-knn-index/_search?explain=true
{
"query": {
"bool": {
"should": [
{
"knn": {
"my_vector2": { // vector field name
"vector": [2, 3, 5, 6],
"k": 2
}
}
},
{
"term": {
"price": "4.4"
}
}
]
}
}
}
Ответ:
{
"took" : 51,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 84.7,
"hits" : [
{
"_shard" : "[my-knn-index-1][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "my-knn-index-1",
"_id" : "7",
"_score" : 84.7,
"_source" : {
"my_vector2" : [
2.5,
3.5,
5.6,
6.7
],
"price" : 5.5
},
"_explanation" : {
"value" : 84.7,
"description" : "sum of:",
"details" : [
{
"value" : 84.7,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 84.7,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details" : [
{
"value" : -83.7,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
}
]
}
},
{
"_shard" : "[my-knn-index-1][0]",
"_node" : "c9b4aPe4QGO8eOtb8P5D3g",
"_index" : "my-knn-index-1",
"_id" : "8",
"_score" : 83.2,
"_source" : {
"my_vector2" : [
4.5,
5.5,
6.7,
3.7
],
"price" : 4.4
},
"_explanation" : {
"value" : 83.2,
"description" : "sum of:",
"details" : [
{
"value" : 82.2,
"description" : "the type of knn search executed was Approximate-NN",
"details" : [
{
"value" : 82.2,
"description" : "the type of knn search executed at leaf was Approximate-NN with vectorDataType = FLOAT, spaceType = innerproduct where score is computed as `-rawScore + 1` from:",
"details" : [
{
"value" : -81.2,
"description" : "rawScore, returned from FAISS library",
"details" : [ ]
}
]
}
]
},
{
"value" : 1.0,
"description" : "price:[1082969293 TO 1082969293]",
"details" : [ ]
}
]
}
}
]
}
}
Поля ответа
Ответ содержит следующие поля:
- explanation: Объект объяснения, который включает следующие поля:
- value: Содержит результат расчета.
- description: Объясняет, какой тип расчета был выполнен. Для нормализации оценок информация в поле описания включает используемую технику нормализации или комбинации и соответствующую оценку.
- details: Показывает любые подрасчеты, выполненные в процессе.
10.4 - neural
Используйте запрос neural для поиска по векторным полям с помощью текста или изображения в векторном поиске.
Поля тела запроса
Включите следующие поля запроса в neural query:
"neural": {
"<vector_field>": {
"query_text": "<query_text>",
"query_image": "<image_binary>",
"model_id": "<model_id>",
"k": 100
}
}
Верхний уровень vector_field указывает на векторное или семантическое поле, по которому будет выполняться запрос поиска. Следующая таблица перечисляет другие поля запроса neural.
| Поле |
Тип данных |
Обязательный/Необязательный |
Описание |
| query_text |
Строка |
Необязательный |
Текст запроса, из которого будут генерироваться векторные эмбеддинги. Необходимо указать хотя бы одно из полей query_text или query_image. |
| query_image |
Строка |
Необязательный |
Строка, закодированная в base-64, соответствующая изображению запроса, из которого будут генерироваться векторные эмбеддинги. Необходимо указать хотя бы одно из полей query_text или query_image. |
| model_id |
Строка |
Необязательный, если целевое поле является семантическим. Обязательно, если целевое поле является полем knn_vector и значение по умолчанию для модели не установлено. |
Идентификатор модели, которая будет использоваться для генерации векторных эмбеддингов из текста запроса. Модель должна быть развернута в OpenSearch перед использованием в нейронном поиске. Не может быть указана вместе с semantic_field_search_analyzer. |
| k |
Целое число |
Необязательный |
Количество результатов, возвращаемых при поиске k-NN. Можно указать только одну переменную: k, min_score или max_distance. Если переменная не указана, по умолчанию используется k со значением 10. |
| min_score |
Число с плавающей запятой |
Необязательный |
Минимальный порог оценки для результатов поиска. Можно указать только одну переменную: k, min_score или max_distance. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| max_distance |
Число с плавающей запятой |
Необязательный |
Максимальный порог расстояния для результатов поиска. Можно указать только одну переменную: k, min_score или max_distance. Для получения дополнительной информации см. раздел “Радиальный поиск”. |
| filter |
Объект |
Необязательный |
Запрос, который можно использовать для уменьшения количества рассматриваемых документов. Для получения дополнительной информации о использовании фильтров см. раздел “Векторный поиск с фильтрами”. |
| method_parameters |
Объект |
Необязательный |
Дополнительные параметры для тонкой настройки поиска:
- ef_search (Целое число): количество векторов для проверки (для метода hnsw)
- nprobes (Целое число): количество корзин для проверки (для метода ivf). Для получения дополнительной информации см. раздел “Указание параметров метода в запросе”. |
| rescore |
Объект или логическое значение |
Необязательный |
Параметры для настройки функциональности повторной оценки:
- oversample_factor (Число с плавающей запятой): контролирует, сколько кандидатных векторов извлекается перед повторной оценкой. Допустимые значения находятся в диапазоне [1.0, 100.0]. По умолчанию false для полей с режимом in_memory (без повторной оценки) и включено (с динамическими значениями) для полей с режимом on_disk. В режиме on_disk значение по умолчанию для oversample_factor определяется уровнем сжатия. Для получения дополнительной информации см. таблицу уровня сжатия. Чтобы явно включить повторную оценку с значением по умолчанию для oversample_factor равным 1.0, установите rescore в true. Для получения дополнительной информации см. раздел “Повторная оценка результатов”. |
expand_nested_docs |
Логическое |
Необязательное |
Если установлено в true, извлекает оценки для всех документов вложенных полей в каждом родительском документе. Используется с вложенными запросами. |
semantic_field_search_analyzer |
Строка |
Необязательное |
Указывает анализатор для токенизации query_text при использовании модели разреженного кодирования. Допустимые значения: standard, bert-uncased и mbert-uncased. Не может использоваться вместе с model_id. |
query_tokens |
Карта токенов (строка) к весу (число с плавающей точкой) |
Необязательное |
Сырой разреженный вектор в виде токенов и их весов. Используется в качестве альтернативы query_text для прямого ввода вектора. Необходимо указать либо query_text, либо query_tokens. |
Пример запроса
Следующий пример демонстрирует поиск с значением k равным 100 и фильтром, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"k": 100,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий запрос поиска включает минимальный порог оценки min_score для k-NN радиального поиска, равный 0.95, и фильтр, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"min_score": 0.95,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий запрос поиска включает максимальное расстояние max_distance, равное 10, и фильтр, который включает диапазонный запрос и терминальный запрос:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage_embedding": {
"query_text": "Hi world",
"query_image": "iVBORw0KGgoAAAAN...",
"max_distance": 10,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
Следующий пример демонстрирует поиск по семантическому полю с использованием плотной модели. Семантическое поле хранит информацию о модели в своей конфигурации. Нейронный запрос автоматически извлекает model_id из конфигурации семантического поля в индексе и переписывает запрос для нацеливания на соответствующее поле эмбеддинга:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage": {
"query_text": "Hi world",
"k": 100
}
}
}
}
Следующий пример демонстрирует поиск по семантическому полю с использованием модели разреженного кодирования. Этот поиск использует разреженные эмбеддинги:
GET /my-nlp-index/_search
{
"query": {
"neural": {
"passage": {
"query_tokens": {
"worlds": 0.57605183
}
}
}
}
}
Для получения дополнительной информации смотрите тип семантического поля.
10.5 - Нейронный разреженный запрос
Используйте нейронный разреженный запрос для поиска по векторному полю в нейронном разреженном поиске.
Вы можете выполнить запрос следующими способами:
- Предоставьте разреженные векторные эмбеддинги для сопоставления. Для получения дополнительной информации смотрите раздел “Нейронный разреженный поиск с использованием сырых векторов”:
"neural_sparse": {
"<vector_field>": {
"query_tokens": {
"<token>": <weight>,
...
}
}
}
- Предоставьте текст для токенизации и использования для сопоставления. Для токенизации текста вы можете использовать следующие компоненты:
- Встроенный анализатор DL модели:
"neural_sparse": {
"<vector_field>": {
"query_text": "<input text>",
"analyzer": "bert-uncased"
}
}
"neural_sparse": {
"<vector_field>": {
"query_text": "<input text>",
"model_id": "<model ID>"
}
}
Для получения дополнительной информации смотрите раздел “Автоматическая генерация разреженных векторных эмбеддингов”.
Поля тела запроса
Верхний уровень vector_field указывает на векторное поле, по которому будет выполняться запрос поиска. Необходимо указать либо query_text, либо query_tokens для определения входных данных. Следующие поля могут быть использованы для настройки запроса:
| Поле |
Тип данных |
Обязательное/Необязательное |
Описание |
query_text |
Строка |
Необязательное |
Текст запроса, который будет преобразован в разреженные векторные эмбеддинги. Необходимо указать либо query_text, либо query_tokens. |
analyzer |
Строка |
Необязательное |
Используется с query_text. Указывает встроенный анализатор DL модели для токенизации текста запроса. Допустимые значения: bert-uncased и mbert-uncased. По умолчанию используется bert-uncased. Не может использоваться одновременно с model_id. |
model_id |
Строка |
Необязательное |
Используется с query_text. Идентификатор модели разреженного кодирования (для режима би-кодировщика) или токенизатора (для режима только документа), используемый для генерации векторных эмбеддингов из текста запроса. Модель/токенизатор должна быть развернута в OpenSearch перед использованием в нейронном разреженном поиске. Не может использоваться одновременно с analyzer. |
query_tokens |
Карта токенов (строка) к весу (число с плавающей точкой) |
Необязательное |
Сырой разреженный вектор в виде токенов и их весов. Используется в качестве альтернативы query_text для прямого ввода вектора. Необходимо указать либо query_text, либо query_tokens. |
max_token_score |
Число с плавающей точкой |
Необязательное (устарело) |
Этот параметр устарел с версии OpenSearch 2.12. Он поддерживается только для обратной совместимости и больше не влияет на функциональность. Параметр все еще может быть указан в запросах, но его значение не имеет значения. Ранее использовался как теоретическая верхняя граница оценки для всех токенов в словаре. |
Примеры запросов
Поиск с использованием текста, токенизированного анализатором
Чтобы выполнить поиск, используя текст, токенизированный анализатором, укажите анализатор в запросе. Анализатор должен быть совместим с моделью, которую вы использовали для анализа текста во время загрузки:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world",
"analyzer": "bert-uncased"
}
}
}
}
Для получения дополнительной информации смотрите раздел “Анализаторы DL модели”.
Поиск с использованием текста без указания анализатора
Если вы не укажете анализатор, будет использован анализатор по умолчанию bert-uncased:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world"
}
}
}
}
Поиск с использованием текста, токенизированного моделью токенизатора
Чтобы выполнить поиск, используя текст, токенизированный моделью токенизатора, укажите идентификатор модели в запросе:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_text": "Hi world",
"model_id": "aP2Q8ooBpBj3wT4HVS8a"
}
}
}
}
Поиск с использованием разреженного вектора
Чтобы выполнить поиск, используя разреженный вектор, укажите разреженный вектор в параметре query_tokens:
GET my-nlp-index/_search
{
"query": {
"neural_sparse": {
"passage_embedding": {
"query_tokens": {
"hi": 4.338913,
"planets": 2.7755864,
"planet": 5.0969057,
"mars": 1.7405145,
"earth": 2.6087382,
"hello": 3.3210192
}
}
}
}
}
10.6 - Перколяция
Используйте запрос перколяции для поиска сохраненных запросов, которые соответствуют данному документу.
Используйте запрос перколяции для поиска сохраненных запросов, которые соответствуют данному документу. Эта операция является противоположностью обычного поиска: вместо того чтобы находить документы, соответствующие запросу, вы находите запросы, соответствующие документу. Запросы перколяции часто используются для оповещений, уведомлений и обратных поисковых случаев.
Основные моменты
- Вы можете перколировать документ, предоставленный в строке, или извлечь существующий документ из индекса.
- Документ и сохраненные запросы должны использовать одни и те же имена и типы полей.
- Вы можете комбинировать перколяцию с фильтрацией и оценкой, чтобы создать сложные системы соответствия.
- Запросы перколяции считаются дорогими запросами и будут выполняться только если настройка кластера
search.allow_expensive_queries установлена в true (по умолчанию). Если эта настройка установлена в false, запросы перколяции будут отклонены.
Примеры использования
Запросы перколяции полезны в различных сценариях реального времени. Некоторые распространенные случаи использования включают:
-
Уведомления для электронной коммерции: Пользователи могут зарегистрировать интерес к продуктам, например, “Уведомите меня, когда новые ноутбуки Apple будут в наличии”. Когда новые документы о продуктах индексируются, система находит всех пользователей с соответствующими сохраненными запросами и отправляет уведомления.
-
Уведомления о вакансиях: Соискатели сохраняют запросы на основе предпочтительных должностей или местоположений, и новые вакансии сопоставляются с этими запросами для триггера уведомлений.
-
Системы безопасности и оповещения: Перколируйте входящие данные журналов или событий по сохраненным правилам или паттернам аномалий.
-
Фильтрация новостей: Сопоставляйте входящие статьи с сохраненными профилями тем, чтобы классифицировать или доставлять релевантный контент.
Как работает перколяция
Сохраненные запросы хранятся в специальном типе поля перколятора. Документы сравниваются со всеми сохраненными запросами. Каждый соответствующий запрос возвращается с его _id. Если включено выделение, также возвращаются совпадающие текстовые фрагменты. Если отправляется несколько документов, поле _percolator_document_slot отображает соответствующий документ.
Пример запроса перколяции
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Новый ноутбук Apple",
"price": 1500,
"availability": "в наличии"
}
}
}
}
В этом примере запрос перколяции ищет сохраненные запросы, которые соответствуют документу о новом ноутбуке Apple.
Пример использования перколяции
Следующие примеры демонстрируют, как сохранять запросы перколяции и тестировать документы против них, используя различные методы.
Создание индекса для хранения сохраненных запросов
Сначала создайте индекс и настройте его маппинги с типом поля перколятора для хранения сохраненных запросов:
PUT /my_percolator_index
{
"mappings": {
"properties": {
"query": {
"type": "percolator"
},
"title": {
"type": "text"
}
}
}
}
Добавление запроса, соответствующего “apple” в поле title
Добавьте запрос, который соответствует слову “apple” в поле заголовка:
POST /my_percolator_index/_doc/1
{
"query": {
"match": {
"title": "apple"
}
}
}
Добавление запроса, соответствующего “banana” в поле title
Добавьте запрос, который соответствует слову “banana” в поле заголовка:
POST /my_percolator_index/_doc/2
{
"query": {
"match": {
"title": "banana"
}
}
}
Перколяция встроенного документа
Проверьте встроенный документ против сохраненных запросов:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Fresh Apple Harvest"
}
}
}
}
Ответ
Ответ предоставляет сохраненный запрос перколяции, который ищет документы, содержащие слово “apple” в поле заголовка, идентифицированный по _id: 1:
{
...
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
}
}
]
}
}
Перколяция с несколькими документами
Чтобы протестировать несколько документов в одном запросе, используйте следующий запрос:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Banana flavoured ice-cream" },
{ "title": "Apple pie recipe" },
{ "title": "Banana bread instructions" },
{ "title": "Cherry tart" }
]
}
}
}
Ответ
Поле _percolator_document_slot помогает вам идентифицировать каждый документ (по индексу), соответствующий каждому сохраненному запросу:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.54726034,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.54726034,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
0,
2
]
}
}
]
}
}
Перколяция существующего индексированного документа
Вы можете ссылаться на существующий документ, уже хранящийся в другом индексе, чтобы проверить соответствие запросов перколяции.
Создание отдельного индекса для ваших документов
Создайте индекс для хранения документов:
PUT /products
{
"mappings": {
"properties": {
"title": {
"type": "text"
}
}
}
}
Добавление документа
Добавьте документ:
POST /products/_doc/1
{
"title": "Banana Smoothie Special"
}
Проверка соответствия сохраненных запросов индексированному документу
Проверьте, соответствуют ли сохраненные запросы индексированному документу:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"index": "products",
"id": "1"
}
}
}
Вы должны предоставить как индекс, так и идентификатор при использовании сохраненного документа.
Перколяция пакетов (несколько документов)
Вы можете проверить несколько документов в одном запросе:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Apple event coming soon" },
{ "title": "Banana farms expand" },
{ "title": "Cherry season starts" }
]
}
}
}
Ответ
Каждое совпадение указывает на соответствующий документ в поле _percolator_document_slot:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.46484798,
"hits": [
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.46484798,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.41211313,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
}
}
]
}
}
Многоуровневая перколяция с использованием именованного запроса
Вы можете перколировать разные документы внутри именованного запроса:
GET /my_percolator_index/_search
{
"query": {
"bool": {
"should": [
{
"percolate": {
"field": "query",
"document": {
"title": "Apple pie recipe"
},
"name": "apple_doc"
}
},
{
"percolate": {
"field": "query",
"document": {
"title": "Banana bread instructions"
},
"name": "banana_doc"
}
}
]
}
}
}
Ответ
Параметр name добавляется к полю _percolator_document_slot, чтобы предоставить соответствующий запрос:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot_apple_doc": [
0
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot_banana_doc": [
0
]
}
}
]
}
}
Этот подход позволяет вам настраивать более индивидуальную логику запросов для отдельных документов. В следующем примере поле title запрашивается в первом документе, а поле description запрашивается во втором документе. Также предоставляется параметр boost:
GET /my_percolator_index/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"filter": {
"percolate": {
"field": "query",
"document": {
"title": "Apple pie recipe"
},
"name": "apple_doc"
}
},
"boost": 1.0
}
},
{
"constant_score": {
"filter": {
"percolate": {
"field": "query",
"document": {
"description": "Banana bread with honey"
},
"name": "banana_doc"
}
},
"boost": 3.0
}
}
]
}
}
}
Сравнение пакетной перколяции и именованной перколяции
Обе методы — пакетная перколяция (с использованием документов) и именованная перколяция (с использованием bool и name) — могут использоваться для перколяции нескольких документов, но они различаются по тому, как результаты маркируются, интерпретируются и контролируются. Они предоставляют функционально схожие результаты, но с важными структурными различиями, описанными в следующей таблице.
| Характеристика |
Пакетная (документы) |
Именованная (bool + percolate + name) |
| Формат ввода |
Один клауз перколяции, массив документов |
Несколько клауз перколяции, по одному на документ |
| Прослеживаемость по документу |
По индексу слота (0, 1, …) |
По имени (apple_doc, banana_doc) |
| Поле ответа для слота совпадения |
_percolator_document_slot: [0] |
_percolator_document_slot_<name>: [0] |
| Префикс выделения |
0_title, 1_title |
apple_doc_title, banana_doc_title |
| Индивидуальный контроль по документу |
Не поддерживается |
Можно настроить каждую клаузу |
| Поддержка увеличений и фильтров |
Нет |
Да (по каждой клаузе) |
| Производительность |
Лучше для больших партий |
Немного медленнее при большом количестве клауз |
| Случай использования |
Массовое соответствие, большие потоки событий |
Прослеживание по документам, тестирование, индивидуальный контроль |
Подсветка совпадений
Запросы перколяции обрабатывают подсветку иначе, чем обычные запросы:
- В обычном запросе документ хранится в индексе, и поисковый запрос используется для подсветки совпадающих терминов.
- В запросе перколяции роли меняются: сохраненные запросы (в индексе перколятора) используются для подсветки документа.
Это означает, что документ, предоставленный в поле document или documents, является целью для подсветки, и запросы перколяции определяют, какие разделы будут подсвечены.
Подсветка одного документа
Этот пример использует ранее определенные запросы в my_percolator_index. Используйте следующий запрос для подсветки совпадений в поле заголовка:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"document": {
"title": "Apple banana smoothie"
}
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
Ответ
Совпадения подсвечиваются в зависимости от соответствующего запроса:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.13076457,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"title": [
"<em>Apple</em> banana smoothie"
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.13076457,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"title": [
"Apple <em>banana</em> smoothie"
]
}
}
]
}
}
Подсветка нескольких документов
При перколяции нескольких документов с использованием массива documents каждому документу присваивается индекс слота. Ключи подсветки принимают следующую форму, где <slot> — это индекс документа в вашем массиве documents:
"<slot>_<fieldname>": [ ... ]
Используйте следующую команду для перколяции двух документов с подсветкой:
POST /my_percolator_index/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{ "title": "Apple pie recipe" },
{ "title": "Banana smoothie ideas" }
]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
Ответ
Ответ содержит поля подсветки с префиксами, соответствующими слотам документов, такими как 0_title и 1_title:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.31506687,
"hits": [
{
"_index": "my_percolator_index",
"_id": "1",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "apple"
}
}
},
"fields": {
"_percolator_document_slot": [
0
]
},
"highlight": {
"0_title": [
"<em>Apple</em> pie recipe"
]
}
},
{
"_index": "my_percolator_index",
"_id": "2",
"_score": 0.31506687,
"_source": {
"query": {
"match": {
"title": "banana"
}
}
},
"fields": {
"_percolator_document_slot": [
1
]
},
"highlight": {
"1_title": [
"<em>Banana</em> smoothie ideas"
]
}
}
]
}
}
Параметры запроса перколяции
Запрос перколяции поддерживает следующие параметры:
| Параметр |
Обязательный/Необязательный |
Описание |
field |
Обязательный |
Поле, содержащее сохраненные запросы перколяции. |
document |
Необязательный |
Один встроенный документ для сопоставления с сохраненными запросами. |
documents |
Необязательный |
Массив нескольких встроенных документов для сопоставления с сохраненными запросами. |
index |
Необязательный |
Индекс, содержащий документ, с которым вы хотите сопоставить. |
id |
Необязательный |
Идентификатор документа для извлечения из индекса. |
routing |
Необязательный |
Значение маршрутизации, используемое при извлечении документа. |
preference |
Необязательный |
Предпочтение для маршрутизации шардов при извлечении документа. |
name |
Необязательный |
Имя, присвоенное клаузе перколяции. Полезно при использовании нескольких клауз перколяции в запросе bool. |
10.7 - script query
Этот запрос возвращает документы, для которых скрипт оценивается как истинный, что позволяет использовать сложную логику фильтрации, которую нельзя выразить с помощью стандартных запросов.
Используйте запрос скрипта для фильтрации документов на основе пользовательского условия, написанного на языке скриптов Painless. Этот запрос возвращает документы, для которых скрипт оценивается как истинный, что позволяет использовать сложную логику фильтрации, которую нельзя выразить с помощью стандартных запросов.
Запрос скрипта является вычислительно затратным и должен использоваться с осторожностью. Используйте его только при необходимости и убедитесь, что параметр search.allow_expensive_queries включен (по умолчанию установлен в true). Для получения дополнительной информации смотрите раздел “Дорогие запросы”.
Пример
Создайте индекс с именем products со следующими настройками:
PUT /products
{
"mappings": {
"properties": {
"title": { "type": "text" },
"price": { "type": "float" },
"rating": { "type": "float" }
}
}
}
Индексируйте пример документов, используя следующий запрос:
POST /products/_bulk
{ "index": { "_id": 1 } }
{ "title": "Беспроводные наушники", "price": 99.99, "rating": 4.5 }
{ "index": { "_id": 2 } }
{ "title": "Bluetooth колонка", "price": 79.99, "rating": 4.8 }
{ "index": { "_id": 3 } }
{ "title": "Наушники с шумоподавлением", "price": 199.99, "rating": 4.7 }
Базовый запрос скрипта
Верните продукты с рейтингом выше 4.6:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['rating'].value > 4.6"
}
}
}
}
Возвращенные результаты будут включать только документы с рейтингом выше 4.6:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
},
{
"_index": "products",
"_id": "3",
"_score": 1,
"_source": {
"title": "Наушники с шумоподавлением",
"price": 199.99,
"rating": 4.7
}
}
]
}
}
Параметры
Запрос скрипта принимает следующие параметры верхнего уровня.
| Параметр |
Обязательный/Необязательный |
Описание |
script.source |
Обязательный |
Код скрипта, который оценивается как истинный или ложный. |
script.params |
Необязательный |
Пользовательские параметры, на которые ссылается скрипт. |
Использование параметров скрипта
Вы можете использовать params для безопасной передачи значений, используя кэширование компиляции скриптов:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['price'].value < params.max_price",
"params": {
"max_price": 100
}
}
}
}
}
Возвращенные результаты будут включать только документы с ценой менее 100:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "1",
"_score": 1,
"_source": {
"title": "Беспроводные наушники",
"price": 99.99,
"rating": 4.5
}
},
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
}
]
}
}
Объединение нескольких условий
Используйте следующий запрос для поиска продуктов с рейтингом выше 4.5 и ценой ниже 100:
POST /products/_search
{
"query": {
"script": {
"script": {
"source": "doc['rating'].value > 4.5 && doc['price'].value < 100"
}
}
}
}
Только документы, соответствующие требованиям, будут возвращены:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "products",
"_id": "2",
"_score": 1,
"_source": {
"title": "Bluetooth колонка",
"price": 79.99,
"rating": 4.8
}
}
]
}
}
10.8 - Запрос с оценкой скрипта
Используйте запрос script_score, чтобы настроить расчет оценки, используя скрипт.
Используйте запрос script_score, чтобы настроить расчет оценки, используя скрипт. Для вычислительно затратной функции оценки вы можете использовать запрос script_score, чтобы вычислить оценку только для возвращенных документов, которые были отфильтрованы.
Пример
Например, следующий запрос создает индекс, содержащий один документ:
PUT testindex1/_doc/1
{
"name": "John Doe",
"multiplier": 0.5
}
Вы можете использовать запрос match, чтобы вернуть все документы, содержащие “John” в поле имени:
GET testindex1/_search
{
"query": {
"match": {
"name": "John"
}
}
}
В ответе документ 1 имеет оценку 0.2876821:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "John Doe",
"multiplier": 0.5
}
}
]
}
}
Теперь давайте изменим оценку документа, используя скрипт, который вычисляет оценку как значение поля _score, умноженное на значение поля multiplier. В следующем запросе вы можете получить текущую релевантность документа в переменной _score, а значение множителя как doc['multiplier'].value:
GET testindex1/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "John"
}
},
"script": {
"source": "_score * doc['multiplier'].value"
}
}
}
}
В ответе оценка для документа 1 составляет половину от первоначальной оценки:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.14384104,
"hits": [
{
"_index": "testindex1",
"_id": "1",
"_score": 0.14384104,
"_source": {
"name": "John Doe",
"multiplier": 0.5
}
}
]
}
}
Параметры
Запрос script_score поддерживает следующие параметры верхнего уровня.
| Параметр |
Тип данных |
Описание |
query |
Объект |
Запрос, используемый для поиска. Обязательный. |
script |
Объект |
Скрипт, используемый для вычисления оценки документов, возвращаемых запросом. Обязательный. |
min_score |
Число с плавающей запятой |
Исключает документы с оценкой ниже min_score из результатов. Необязательный. |
boost |
Число с плавающей запятой |
Увеличивает оценки документов на заданный множитель. Значения меньше 1.0 уменьшают релевантность, а значения больше 1.0 увеличивают релевантность. По умолчанию 1.0. |
Оценки релевантности, вычисленные запросом script_score, не могут быть отрицательными.
Настройка вычисления оценки с помощью встроенных функций
Чтобы настроить вычисление оценки, вы можете использовать одну из встроенных функций Painless. Для каждой функции OpenSearch предоставляет один или несколько методов Painless, которые вы можете использовать в контексте оценки скрипта. Вы можете вызывать методы Painless, перечисленные в следующих разделах, напрямую, без использования имени класса или имени экземпляра.
Сатурация
Функция сатурации вычисляет сатурацию как score = value / (value + pivot), где value — это значение поля, а pivot выбирается так, чтобы оценка была больше 0.5, если value больше pivot, и меньше 0.5, если value меньше pivot. Оценка находится в диапазоне (0, 1). Чтобы применить функцию сатурации, вызовите следующий метод Painless:
double saturation(double <field-value>, double <pivot>)
ПРИМЕР
Следующий пример запроса ищет текст “neural search” в индексе статей. Он комбинирует оригинальную оценку релевантности документа с значением article_rank, которое сначала преобразуется с помощью функции сатурации:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "_score + saturation(doc['article_rank'].value, 11)"
}
}
}
}
Сигмоид
Аналогично функции сатурации, функция сигмоид вычисляет оценку как score = value^exp / (value^exp + pivot^exp), где value — это значение поля, exp — это коэффициент масштабирования степени, а pivot выбирается так, чтобы оценка была больше 0.5, если value больше pivot, и меньше 0.5, если value меньше pivot. Чтобы применить функцию сигмоид, вызовите следующий метод Painless:
double sigmoid(double <field-value>, double <pivot>, double <exp>)
Пример
Следующий пример запроса ищет текст “neural search” в индексе статей. Он комбинирует оригинальную оценку релевантности документа со значением article_rank, которое сначала преобразуется с помощью функции сигмоид:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "_score + sigmoid(doc['article_rank'].value, 11, 2)"
}
}
}
}
Случайная оценка
Функция случайной оценки генерирует равномерно распределенные случайные оценки в диапазоне [0, 1). Чтобы узнать, как работает эта функция, смотрите раздел “Функция случайной оценки”. Чтобы применить функцию случайной оценки, вызовите один из следующих методов Painless:
double randomScore(int <seed>): Использует внутренние идентификаторы документов Lucene в качестве значений семени.
double randomScore(int <seed>, String <field-name>)
Пример
Следующий запрос использует функцию random_score с семенем и полем:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": { "article_name": "neural search" }
},
"script": {
"source": "randomScore(20, '_seq_no')"
}
}
}
}
Функции затухания
С помощью функций затухания вы можете оценивать результаты на основе близости или недавности. Чтобы узнать больше, смотрите раздел “Функции затухания”. Вы можете вычислять оценки, используя экспоненциальную, гауссову или линейную кривую затухания. Чтобы применить функцию затухания, вызовите один из следующих методов Painless в зависимости от типа поля:
Числовые поля:
double decayNumericGauss(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
double decayNumericExp(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
double decayNumericLinear(double <origin>, double <scale>, double <offset>, double <decay>, double <field-value>)
Геопоинтовые поля:
double decayGeoGauss(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
double decayGeoExp(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
double decayGeoLinear(String <origin>, String <scale>, String <offset>, double <decay>, GeoPoint <field-value>)
Поля даты:
double decayDateGauss(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
double decayDateExp(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
double decayDateLinear(String <origin>, String <scale>, String <offset>, double <decay>, JodaCompatibleZonedDateTime <field-value>)
Пример: Числовые поля
Следующий запрос использует функцию экспоненциального затухания на числовом поле:
GET articles/_search
{
"query": {
"script_score": {
"query": {
"match": {
"article_name": "neural search"
}
},
"script": {
"source": "decayNumericExp(params.origin, params.scale, params.offset, params.decay, doc['article_rank'].value)",
"params": {
"origin": 50,
"scale": 20,
"offset": 30,
"decay": 0.5
}
}
}
}
}
Пример: Геопоинтовые поля
Следующий запрос использует функцию гауссового затухания на геопоинтовом поле:
GET hotels/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "hotel"
}
},
"script": {
"source": "decayGeoGauss(params.origin, params.scale, params.offset, params.decay, doc['location'].value)",
"params": {
"origin": "40.71,74.00",
"scale": "300ft",
"offset": "200ft",
"decay": 0.25
}
}
}
}
}
Пример: Поля даты
Следующий запрос использует функцию линейного затухания на поле даты:
GET blogs/_search
{
"query": {
"script_score": {
"query": {
"match": {
"name": "opensearch"
}
},
"script": {
"source": "decayDateLinear(params.origin, params.scale, params.offset, params.decay, doc['date_posted'].value)",
"params": {
"origin": "2022-04-24",
"scale": "6d",
"offset": "1d",
"decay": 0.25
}
}
}
}
}
Функции частоты термина
Функции частоты термина предоставляют статистику на уровне термина в источнике скрипта оценки. Вы можете использовать эту статистику для реализации пользовательских алгоритмов извлечения информации и ранжирования, таких как умножение или сложение оценки по популярности во время запроса. Чтобы применить функцию частоты термина, вызовите один из следующих методов Painless:
int termFreq(String <field-name>, String <term>): Извлекает частоту термина в поле для конкретного термина.long totalTermFreq(String <field-name>, String <term>): Извлекает общую частоту термина в поле для конкретного термина.long sumTotalTermFreq(String <field-name>): Извлекает сумму общих частот термина в поле.
Пример
Следующий запрос вычисляет оценку как общую частоту термина для каждого поля в списке полей, умноженную на значение множителя:
GET /demo_index_v1/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"script_score": {
"script": {
"source": """
for (int x = 0; x < params.fields.length; x++) {
String field = params.fields[x];
if (field != null) {
return params.multiplier * totalTermFreq(field, params.term);
}
}
return params.default_value;
""",
"params": {
"fields": ["title", "description"],
"term": "ai",
"multiplier": 2,
"default_value": 1
}
}
}
}
}
}
10.9 - Запрос шаблона
Используйте запрос шаблона для создания поисковых запросов, которые содержат переменные-заполнители.
Используйте запрос шаблона для создания поисковых запросов, которые содержат переменные-заполнители. Заполнители указываются с помощью синтаксиса “${variable_name}” (обратите внимание, что переменные должны быть заключены в кавычки). Когда вы отправляете поисковый запрос, эти заполнители остаются неразрешенными до тех пор, пока они не будут обработаны процессорами запросов поиска. Этот подход особенно полезен, когда ваш начальный поисковый запрос содержит данные, которые необходимо преобразовать или сгенерировать во время выполнения.
Например, вы можете использовать запрос шаблона при работе с процессором запросов поиска ml_inference, который преобразует текстовый ввод в векторные эмбеддинги во время процесса поиска. Процессор заменит заполнители сгенерированными значениями перед выполнением окончательного запроса.
Для полного примера смотрите раздел “Переписывание запросов с использованием запросов шаблонов”.
Пример
Следующий пример показывает запрос шаблона k-NN с заполнителем “vector”: “${text_embedding}”. Заполнитель “${text_embedding}” будет заменен эмбеддингами, сгенерированными процессором запросов ml_inference из текстового поля ввода:
GET /template-knn-index/_search?search_pipeline=my_knn_pipeline
{
"query": {
"template": {
"knn": {
"text_embedding": {
"vector": "${text_embedding}", // Заполнитель для векторного поля
"k": 2
}
}
}
},
"ext": {
"ml_inference": {
"text": "sneakers" // Входной текст для процессора ml_inference
}
}
}
Конфигурация процессора запросов поиска
Чтобы использовать запрос шаблона с процессором запросов поиска, вам необходимо настроить конвейер поиска. Следующая конфигурация является примером для процессора запросов ml_inference. input_map сопоставляет поля документа с входами модели. В этом примере поле источника ext.ml_inference.text в документе сопоставляется с полем inputText — ожидаемым входным полем для модели. output_map сопоставляет выходы модели с полями документа. В этом примере поле выходного эмбеддинга из модели сопоставляется с полем назначения text_embedding в вашем документе:
PUT /_search/pipeline/my_knn_pipeline
{
"request_processors": [
{
"ml_inference": {
"model_id": "Sz-wFZQBUpPSu0bsJTBG",
"input_map": [
{
"inputText": "ext.ml_inference.text" // Сопоставить входной текст из запроса
}
],
"output_map": [
{
"text_embedding": "embedding" // Сопоставить выходные данные с заполнителем
}
]
}
}
]
}
После выполнения процессора запросов ml_inference запрос поиска переписывается. Поле вектора содержит эмбеддинги, сгенерированные процессором, а поле text_embedding содержит выходные данные процессора:
GET /template-knn-1/_search
{
"query": {
"template": {
"knn": {
"text_embedding": {
"vector": [0.6328125, 0.26953125, ...],
"k": 2
}
}
}
},
"ext": {
"ml_inference": {
"text": "sneakers",
"text_embedding": [0.6328125, 0.26953125, ...]
}
}
}
Ограничения
Запросы шаблона требуют как минимум одного процессора запросов поиска для разрешения заполнителей. Процессоры запросов поиска должны быть настроены для генерации переменных, ожидаемых в конвейере.
10.10 - Обертка
Запрос обертки позволяет отправлять полный запрос в формате JSON, закодированном в Base64.
Запрос обертки позволяет отправлять полный запрос в формате JSON, закодированном в Base64. Это полезно, когда запрос необходимо встроить в контексты, которые поддерживают только строковые значения.
Используйте этот запрос только в тех случаях, когда необходимо управлять системными ограничениями. Для читаемости и удобства обслуживания лучше использовать стандартные запросы на основе JSON, когда это возможно.
Пример
Создайте индекс с именем products со следующими настройками:
PUT /products
{
"mappings": {
"properties": {
"title": { "type": "text" }
}
}
}
Индексируйте пример документов:
POST /products/_bulk
{ "index": { "_id": 1 } }
{ "title": "Беспроводные наушники с шумоподавлением" }
{ "index": { "_id": 2 } }
{ "title": "Bluetooth колонка" }
{ "index": { "_id": 3 } }
{ "title": "Наушники накладного типа с глубоким басом" }
Закодируйте следующий запрос в формате Base64:
echo -n '{ "match": { "title": "headphones" } }' | base64
Выполните закодированный запрос:
POST /products/_search
{
"query": {
"wrapper": {
"query": "eyAibWF0Y2giOiB7ICJ0aXRsZSI6ICJoZWFkcGhvbmVzIiB9IH0="
}
}
}
Ответ
Ответ содержит два соответствующих документа:
{
...
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.20098841,
"hits": [
{
"_index": "products",
"_id": "1",
"_score": 0.20098841,
"_source": {
"title": "Беспроводные наушники с шумоподавлением"
}
},
{
"_index": "products",
"_id": "3",
"_score": 0.18459359,
"_source": {
"title": "Наушники накладного типа с глубоким басом"
}
}
]
}
}
11 - Minimum should match (Минимальное соответствие)
Параметр minimum_should_match может использоваться для полнотекстового поиска и указывает минимальное количество терминов, с которыми документ должен соответствовать, чтобы быть возвращенным в результатах поиска.
Пример
Следующий пример требует, чтобы документ соответствовал как минимум двум из трех поисковых терминов, чтобы быть возвращенным в качестве результата поиска:
GET /shakespeare/_search
{
"query": {
"match": {
"text_entry": {
"query": "prince king star",
"minimum_should_match": "2"
}
}
}
}
В этом примере запрос имеет три необязательных условия, которые объединены с помощью оператора OR, поэтому документ должен соответствовать либо “prince” и “king”, либо “prince” и “star”, либо “king” и “star”.
Допустимые значения
Вы можете указать параметр minimum_should_match как одно из следующих значений.
| Тип значения |
Пример |
Описание |
| Ненегативное целое число |
2 |
Документ должен соответствовать этому количеству необязательных условий. |
| Отрицательное целое число |
-1 |
Документ должен соответствовать общему количеству необязательных условий минус это число. |
| Ненегативный процент |
70% |
Документ должен соответствовать этому проценту от общего количества необязательных условий. Количество условий округляется вниз до ближайшего целого числа. |
| Отрицательный процент |
-30% |
Документ может не соответствовать этому проценту от общего количества необязательных условий. Количество условий, которые документ может не соответствовать, округляется вниз до ближайшего целого числа. |
| Комбинация |
2<75% |
Выражение в формате n<p%. Если количество необязательных условий меньше или равно n, документ должен соответствовать всем необязательным условиям. Если количество необязательных условий больше n, то документ должен соответствовать p процентам необязательных условий. |
| Множественные комбинации |
3<-1 5<50% |
Более одной комбинации, разделенной пробелом. Каждое условие применяется к количеству необязательных условий, которое больше числа слева от знака <. В этом примере, если есть три или меньше необязательных условий, документ должен соответствовать всем им. Если есть четыре или пять необязательных условий, документ должен соответствовать всем, кроме одного из них. Если есть 6 или более необязательных условий, документ должен соответствовать 50% из них. |
Пусть n будет количеством необязательных условий, с которыми документ должен соответствовать. Когда n рассчитывается как процент, если n меньше 1, то используется 1. Если n больше количества необязательных условий, используется количество необязательных условий.
Использование параметра в булевых запросах
Булевый запрос перечисляет необязательные условия в разделе should и обязательные условия в разделе must. Опционально он может содержать раздел filter для фильтрации результатов.
Пример индекса
Рассмотрим пример индекса, содержащего следующие пять документов:
PUT testindex/_doc/1
{
"text": "one OpenSearch"
}
PUT testindex/_doc/2
{
"text": "one two OpenSearch"
}
PUT testindex/_doc/3
{
"text": "one two three OpenSearch"
}
PUT testindex/_doc/4
{
"text": "one two three four OpenSearch"
}
PUT testindex/_doc/5
{
"text": "OpenSearch"
}
Пример запроса
Следующий запрос содержит четыре необязательных условия:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
],
"minimum_should_match": "80%"
}
}
}
Поскольку minimum_should_match указан как 80%, количество необязательных условий для соответствия рассчитывается как 4 · 0.8 = 3.2 и затем округляется вниз до 3. Поэтому результаты содержат документы, которые соответствуют как минимум трем условиям:
{
"took": 40,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.5744598,
"_source": {
"text": "one two three OpenSearch"
}
}
]
}
}
Указание minimum_should_match как -20%
Следующий запрос устанавливает minimum_should_match как -20%:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
],
"minimum_should_match": "-20%"
}
}
}
Количество необязательных условий, которые документ может не соответствовать, рассчитывается как 4 · 0.2 = 0.8 и округляется вниз до 0. Таким образом, результаты содержат только один документ, который соответствует всем необязательным условиям:
{
"took": 41,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
}
]
}
}
Обратите внимание, что указание положительного процента (80%) и отрицательного процента (-20%) не привело к одинаковому количеству необязательных условий, с которыми документ должен соответствовать, поскольку в обоих случаях результат округляется вниз. Если бы количество необязательных условий, например, было 5, то как 80%, так и -20% привели бы к одинаковому количеству необязательных условий, с которыми документ должен соответствовать (4).
Значение по умолчанию для minimum_should_match
Если запрос содержит условие must или filter, значение по умолчанию для minimum_should_match равно 0. Например, следующий запрос ищет документы, которые соответствуют “OpenSearch” и не имеют необязательных условий в разделе should:
GET testindex/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text": "OpenSearch"
}
}
],
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
]
}
}
}
Этот запрос возвращает все пять документов в индексе:
{
"took": 34,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 2.494999,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.494999,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.5744598,
"_source": {
"text": "one two three OpenSearch"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.91368985,
"_source": {
"text": "one two OpenSearch"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.4338556,
"_source": {
"text": "one OpenSearch"
}
},
{
"_index": "testindex",
"_id": "5",
"_score": 0.11964063,
"_source": {
"text": "OpenSearch"
}
}
]
}
}
Таким образом, поскольку значение minimum_should_match по умолчанию равно 0, все документы, соответствующие обязательному условию, будут возвращены, независимо от соответствия необязательным условиям.
Исключение условия must
Если вы опустите условие must, то запрос будет искать документы, которые соответствуют хотя бы одному из необязательных условий в разделе should:
GET testindex/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"text": "one"
}
},
{
"match": {
"text": "two"
}
},
{
"match": {
"text": "three"
}
},
{
"match": {
"text": "four"
}
}
]
}
}
}
Результаты содержат только четыре документа, которые соответствуют как минимум одному из необязательных условий:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2.426633,
"hits": [
{
"_index": "testindex",
"_id": "4",
"_score": 2.426633,
"_source": {
"text": "one two three four OpenSearch"
}
},
{
"_index": "testindex",
"_id": "3",
"_score": 1.4978898,
"_source": {
"text": "one two three OpenSearch"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.8266785,
"_source": {
"text": "one two OpenSearch"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3331056,
"_source": {
"text": "one OpenSearch"
}
}
]
}
}
Таким образом, без условия must запрос возвращает документы, которые соответствуют хотя бы одному из указанных необязательных условий, что приводит к меньшему количеству результатов по сравнению с запросом, содержащим обязательные условия.
12 - Синтаксис регулярных выражений
Регулярное выражение (regex) — это способ определения шаблонов поиска с использованием специальных символов и операторов.
Регулярное выражение (regex) — это способ определения шаблонов поиска с использованием специальных символов и операторов. Эти шаблоны позволяют вам сопоставлять последовательности символов в строках.
В OpenSearch вы можете использовать регулярные выражения в следующих типах запросов:
OpenSearch использует движок регулярных выражений Apache Lucene, который имеет свой собственный синтаксис и ограничения. Он не использует регулярные выражения, совместимые с Perl (PCRE), поэтому некоторые знакомые функции регулярных выражений могут вести себя иначе или не поддерживаться.
Выбор между запросами regexp и query_string
Оба запроса regexp и query_string поддерживают регулярные выражения, но они ведут себя по-разному и служат для разных случаев использования.
| Особенность |
Запрос regexp |
Запрос query_string |
| Сопоставление шаблонов |
Шаблон regex должен соответствовать всему значению поля |
Шаблон regex может соответствовать любой части поля |
| Поддержка флагов |
Флаги включают необязательные операторы regex |
Флаги не поддерживаются |
| Тип запроса |
Запрос на уровне термина (не оценивается) |
Полнотекстовый запрос (оценивается и разбирается) |
| Лучший случай использования |
Строгое сопоставление шаблонов для полей типа keyword или exact |
Поиск в анализируемых полях с использованием гибкой строки запроса, поддерживающей шаблоны regex |
| Сложная композиция запросов |
Ограничена шаблонами regex |
Поддерживает AND, OR, подстановочные знаки, поля, увеличение и другие функции. См. Запрос query_string. |
Зарезервированные символы
Движок регулярных выражений Lucene поддерживает все символы Unicode. Однако следующие символы рассматриваются как специальные операторы:
. ? + * | { } [ ] ( ) " \
В зависимости от включенных флагов, которые указывают необязательные операторы, следующие символы также могут быть зарезервированы:
Чтобы сопоставить эти символы буквально, либо экранируйте их с помощью обратной косой черты (), либо оберните всю строку в двойные кавычки:
\&: Сопоставляет литерал &\\: Сопоставляет литерал обратной косой черты ()"hello@world": Сопоставляет полную строку hello@world
Стандартные операторы регулярных выражений
Lucene поддерживает основной набор операторов регулярных выражений:
-
. – Сопоставляет любой одиночный символ. Пример: f.n соответствует f, за которым следует любой символ, а затем n (например, fan или fin).
-
? – Сопоставляет ноль или один из предыдущих символов. Пример: colou?r соответствует color и colour.
-
+ – Сопоставляет один или более из предыдущих символов. Пример: go+ соответствует g, за которым следует один или более o (go, goo, gooo и так далее).
-
* – Сопоставляет ноль или более из предыдущих символов. Пример: lo*se соответствует l, за которым следует ноль или более o, а затем se (lse, lose, loose, loooose и так далее).
-
{min,max} – Сопоставляет конкретный диапазон повторений. Если max опущен, нет верхнего предела на количество сопоставляемых символов. Пример: x{3} соответствует ровно 3 x (xxx); x{2,4} соответствует от 2 до 4 x (xx, xxx или xxxx); x{3,} соответствует 3 или более x (xxx, xxxx, xxxxx и так далее).
-
| – Действует как логическое ИЛИ. Пример: apple|orange соответствует apple или orange.
-
( ) – Группирует символы в подпаттерн. Пример: ab(cd)? соответствует ab и abcd.
-
[ ] – Сопоставляет один символ из набора или диапазона. Пример: [aeiou] соответствует любой гласной.
-
- – Когда предоставляется внутри скобок, указывает диапазон, если не экранирован или является первым символом внутри скобок. Пример: [a-z] соответствует любой строчной букве; [-az] соответствует -, a или z; [a\\-z] соответствует a, -, или z.
-
^ – Когда предоставляется внутри скобок, действует как логическое НЕ, отрицая диапазон символов или любой символ в наборе. Пример: [^az] соответствует любому символу, кроме a или z; [^a-z] соответствует любому символу, кроме строчных букв; [^-az] соответствует любому символу, кроме -, a и z; [^a\\-z] соответствует любому символу, кроме a, -, и z.
Необязательные операторы
Вы можете включить дополнительные операторы регулярных выражений, используя параметр flags. Разделяйте несколько флагов с помощью |.
Следующие флаги доступны:
-
ALL (по умолчанию) – Включает все необязательные операторы.
-
COMPLEMENT – Включает ~, который отрицает следующее выражение. Пример: d~ef соответствует dgf, dxf, но не def.
-
INTERSECTION – Включает & как логический оператор И. Пример: ab.+&.+cd соответствует строкам, содержащим ab в начале и cd в конце.
-
INTERVAL – Включает синтаксис <min-max> для сопоставления числовых диапазонов. Пример: id<10-12> соответствует id10, id11 и id12.
-
ANYSTRING – Включает @ для сопоставления любой строки. Вы можете комбинировать это с ~ и & для исключений. Пример: @&.*error.*&.*[0-9]{3}.* соответствует строкам, содержащим как слово “error”, так и последовательность из трех цифр.
Неподдерживаемые функции
Движок Lucene не поддерживает следующие часто используемые якоря регулярных выражений:
- ^ – Начало строки
- $ – Конец строки
Вместо этого ваш шаблон должен соответствовать всей строке, чтобы произвести совпадение.
Пример использования регулярных выражений
Чтобы попробовать регулярные выражения, индексируйте следующие документы в индекс logs:
PUT /logs/_doc/1
{
"message": "error404"
}
PUT /logs/_doc/2
{
"message": "error500"
}
PUT /logs/_doc/3
{
"message": "error1a"
}
Пример: Базовый запрос с использованием регулярных выражений
Следующий запрос regexp возвращает документы, в которых полное значение поля message соответствует шаблону “error”, за которым следует одна или более цифр. Значение не соответствует, если оно содержит шаблон только как подстроку:
GET /logs/_search
{
"query": {
"regexp": {
"message": {
"value": "error[0-9]+"
}
}
}
}
Этот запрос соответствует error404 и error500:
{
"took": 28,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Пример: Использование необязательных операторов
Следующий запрос соответствует документам, в которых поле message точно соответствует строке, начинающейся с “error”, за которой следует число от 400 до 500, включительно. Флаг INTERVAL позволяет использовать синтаксис <min-max> для числовых диапазонов:
GET /logs/_search
{
"query": {
"regexp": {
"message": {
"value": "error<400-500>",
"flags": "INTERVAL"
}
}
}
}
Этот запрос также соответствует error404 и error500:
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Пример: Использование ANYSTRING
Когда флаг ANYSTRING включен, оператор @ соответствует всей строке. Это полезно в сочетании с пересечением (&), поскольку позволяет вам строить запросы, которые соответствуют полным строкам при определенных условиях.
Следующий запрос соответствует сообщениям, которые содержат как слово “error”, так и последовательность из трех цифр. Используйте ANYSTRING, чтобы утверждать, что все поле должно соответствовать пересечению обоих шаблонов:
GET /logs/_search
{
"query": {
"regexp": {
"message.keyword": {
"value": "@&.*error.*&.*[0-9]{3}.*",
"flags": "ANYSTRING|INTERSECTION"
}
}
}
}
Этот запрос соответствует error404 и error500:
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "logs",
"_id": "1",
"_score": 1,
"_source": {
"message": "error404"
}
},
{
"_index": "logs",
"_id": "2",
"_score": 1,
"_source": {
"message": "error500"
}
}
]
}
}
Обратите внимание, что этот запрос также будет соответствовать xerror500, error500x и errorxx500.