1 - boolean query
Объединяет несколько клауз запросов с помощью логики AND/OR.
Булевый запрос
Булевый (bool) запрос может комбинировать несколько клауз в один расширенный запрос. Клаузи объединяются с помощью булевой логики для поиска соответствующих документов, возвращаемых в результатах.
Используйте следующие клаузи в булевом запросе:
| Клауз |
Поведение |
| must |
Логический оператор “и”. Результаты должны соответствовать всем запросам в этой клаузе. |
| must_not |
Логический оператор “не”. Все совпадения исключаются из результатов. Если must_not содержит несколько клауз, возвращаются только документы, которые не соответствуют ни одной из этих клауз. Например, “must_not”:[{clause_A}, {clause_B}] эквивалентно NOT(A OR B). |
| should |
Логический оператор “или”. Результаты должны соответствовать хотя бы одному из запросов. Чем больше клауз should совпадает, тем выше оценка релевантности документа. Вы можете установить минимальное количество запросов, которые должны совпадать, с помощью параметра minimum_should_match. Если запрос содержит клаузу must или filter, значение по умолчанию для minimum_should_match равно 0. В противном случае значение по умолчанию равно 1. |
| filter |
Логический оператор “и”, который применяется в первую очередь для уменьшения вашего набора данных перед применением запросов. Запрос внутри клаузи filter является бинарным: да или нет. Если документ соответствует запросу, он возвращается в результатах; в противном случае он не возвращается. Результаты фильтрующего запроса обычно кэшируются для более быстрого возврата. Используйте фильтрующий запрос для фильтрации результатов на основе точных совпадений, диапазонов, дат или чисел. |
Булевый запрос имеет следующую структуру:
GET _search
{
"query": {
"bool": {
"must": [
{}
],
"must_not": [
{}
],
"should": [
{}
],
"filter": {}
}
}
}
Например, предположим, что у вас есть полные произведения Шекспира, индексированные в кластере OpenSearch. Вы хотите построить один запрос, который соответствует следующим требованиям:
- Поле text_entry должно содержать слово “love” и должно содержать либо “life”, либо “grace”.
- Поле speaker не должно содержать “ROMEO”.
- Отфильтровать эти результаты по пьесе “Ромео и Джульетта”, не влияя на оценку релевантности.
Эти требования могут быть объединены в следующий запрос:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": "love"
}
}
],
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": "ROMEO"
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 4,
"successful": 4,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.356054,
"hits": [
{
"_index": "shakespeare",
"_id": "88020",
"_score": 11.356054,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Если вы хотите определить, какие из этих клауз фактически вызвали совпадение результатов, назовите каждый запрос с помощью параметра _name. Чтобы добавить параметр _name, измените имя поля в запросе сопоставления на объект:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": {
"query": "love",
"_name": "love-must"
}
}
}
],
"should": [
{
"match": {
"text_entry": {
"query": "life",
"_name": "life-should"
}
}
},
{
"match": {
"text_entry": {
"query": "grace",
"_name": "grace-should"
}
}
}
],
"minimum_should_match": 1,
"must_not": [
{
"match": {
"speaker": {
"query": "ROMEO",
"_name": "ROMEO-must-not"
}
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
OpenSearch возвращает массив matched_queries, который перечисляет запросы, соответствующие этим результатам:
"matched_queries": [
"love-must",
"life-should"
]
Если вы удалите запросы, не входящие в этот список, вы все равно увидите точно такой же результат. Изучая, какая клаузa should совпала, вы можете лучше понять оценку релевантности результатов.
Вы также можете строить сложные булевы выражения, вложив булевы запросы. Например, используйте следующий запрос, чтобы найти поле text_entry, которое соответствует (love ИЛИ hate) И (life ИЛИ grace) в пьесе “Ромео и Джульетта”:
GET shakespeare/_search
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"text_entry": "love"
}
},
{
"match": {
"text_entry": "hate"
}
}
]
}
},
{
"bool": {
"should": [
{
"match": {
"text_entry": "life"
}
},
{
"match": {
"text_entry": "grace"
}
}
]
}
}
],
"filter": {
"term": {
"play_name": "Romeo and Juliet"
}
}
}
}
}
Ответ содержит соответствующие документы:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.37006,
"hits": [
{
"_index": "shakespeare",
"_type": "doc",
"_id": "88020",
"_score": 11.37006,
"_source": {
"type": "line",
"line_id": 88021,
"play_name": "Romeo and Juliet",
"speech_number": 19,
"line_number": "4.5.61",
"speaker": "PARIS",
"text_entry": "O love! O life! not life, but love in death!"
}
}
]
}
}
Таким образом, вы можете использовать вложенные булевы запросы для создания более сложных логических выражений, что позволяет более точно настраивать поиск и получать релевантные результаты в OpenSearch.
2 - boosting query
Изменяет релевантность документов, не удаляя их из результатов поиска. Возвращает документы, которые соответствуют положительному запросу, но понижает релевантность документов в результатах, которые соответствуют отрицательному запросу.
Запрос с бустингом
Если вы ищете слово “pitcher” (питчер), ваши результаты могут относиться как к бейсбольным игрокам, так и к контейнерам для жидкостей. Для поиска в контексте бейсбола вы можете полностью исключить результаты, содержащие слова “glass” (стекло) или “water” (вода), используя клаузу must_not. Однако, если вы хотите сохранить эти результаты, но понизить их релевантность, вы можете сделать это с помощью запросов с бустингом.
Запрос с бустингом возвращает документы, которые соответствуют положительному запросу. Среди этих документов те, которые также соответствуют отрицательному запросу, получают более низкую оценку релевантности (их оценка релевантности умножается на отрицательный коэффициент бустинга).
Пример
Рассмотрим индекс с двумя документами, которые вы индексируете следующим образом:
PUT testindex/_doc/1
{
"article_name": "The greatest pitcher in baseball history"
}
PUT testindex/_doc/2
{
"article_name": "The making of a glass pitcher"
}
Используйте следующий запрос match, чтобы искать документы, содержащие слово “pitcher”:
GET testindex/_search
{
"query": {
"match": {
"article_name": "pitcher"
}
}
}
Оба возвращенных документа имеют одинаковую оценку релевантности:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.18232156,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Теперь используйте следующий запрос с бустингом, чтобы искать документы, содержащие слово “pitcher”, но понизить оценку документов, содержащих слова “glass”, “crystal” или “water”:
GET testindex/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"article_name": "pitcher"
}
},
"negative": {
"match": {
"article_name": "glass crystal water"
}
},
"negative_boost": 0.1
}
}
}
Оба документа все еще возвращаются, но документ со словом “glass” имеет оценку релевантности, которая в 10 раз ниже, чем в предыдущем случае:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.18232156,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.18232156,
"_source": {
"article_name": "The greatest pitcher in baseball history"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 0.018232157,
"_source": {
"article_name": "The making of a glass pitcher"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами с бустингом.
| Параметр |
Описание |
| positive |
Запрос, которому документ должен соответствовать, чтобы быть возвращенным в результатах. Обязательный параметр. |
| negative |
Если документ в результатах соответствует этому запросу, его оценка релевантности уменьшается путем умножения его исходной оценки релевантности (полученной от положительного запроса) на параметр negative_boost. Обязательный параметр. |
| negative_boost |
Плавающий коэффициент в диапазоне от 0 до 1.0, на который умножается исходная оценка релевантности для уменьшения релевантности документов, соответствующих отрицательному запросу. Обязательный параметр. |
3 - constant_score
Оборачивает запрос или фильтр и присваивает постоянный балл всем совпадающим документам. Этот балл равен значению boost.
Запрос constant_score
Если вам нужно вернуть документы, содержащие определенное слово, независимо от того, сколько раз это слово встречается, вы можете использовать запрос constant_score. Запрос constant_score оборачивает фильтрующий запрос и присваивает всем документам в результатах релевантный балл, равный значению параметра boost. Таким образом, все возвращенные документы имеют равный релевантный балл, и частота термина/обратная документная частота (TF/IDF) не учитываются. Фильтрующие запросы не вычисляют релевантные баллы. Кроме того, OpenSearch кэширует часто используемые фильтрующие запросы для повышения производительности.
Пример
Используйте следующий запрос, чтобы вернуть документы, содержащие слово “Hamlet” в индексе shakespeare:
GET shakespeare/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"text_entry": "Hamlet"
}
},
"boost": 1.2
}
}
}
Все документы в результатах получают релевантный балл 1.2.
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 96,
"relation": "eq"
},
"max_score": 1.2,
"hits": [
{
"_index": "shakespeare",
"_id": "32535",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32536,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.97",
"speaker": "HORATIO",
"text_entry": "Dared to the combat; in which our valiant Hamlet--"
}
},
{
"_index": "shakespeare",
"_id": "32546",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32547,
"play_name": "Hamlet",
"speech_number": 48,
"line_number": "1.1.108",
"speaker": "HORATIO",
"text_entry": "His fell to Hamlet. Now, sir, young Fortinbras,"
}
},
{
"_index": "shakespeare",
"_id": "32625",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32626,
"play_name": "Hamlet",
"speech_number": 59,
"line_number": "1.1.184",
"speaker": "HORATIO",
"text_entry": "Unto young Hamlet; for, upon my life,"
}
},
{
"_index": "shakespeare",
"_id": "32633",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32634,
"play_name": "Hamlet",
"speech_number": 60,
"line_number": "",
"speaker": "MARCELLUS",
"text_entry": "Enter KING CLAUDIUS, QUEEN GERTRUDE, HAMLET, POLONIUS, LAERTES, VOLTIMAND, CORNELIUS, Lords, and Attendants"
}
},
{
"_index": "shakespeare",
"_id": "32634",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32635,
"play_name": "Hamlet",
"speech_number": 1,
"line_number": "1.2.1",
"speaker": "KING CLAUDIUS",
"text_entry": "Though yet of Hamlet our dear brothers death"
}
},
{
"_index": "shakespeare",
"_id": "32699",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32700,
"play_name": "Hamlet",
"speech_number": 8,
"line_number": "1.2.65",
"speaker": "KING CLAUDIUS",
"text_entry": "But now, my cousin Hamlet, and my son,--"
}
},
{
"_index": "shakespeare",
"_id": "32703",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32704,
"play_name": "Hamlet",
"speech_number": 12,
"line_number": "1.2.69",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Good Hamlet, cast thy nighted colour off,"
}
},
{
"_index": "shakespeare",
"_id": "32723",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32724,
"play_name": "Hamlet",
"speech_number": 16,
"line_number": "1.2.89",
"speaker": "KING CLAUDIUS",
"text_entry": "Tis sweet and commendable in your nature, Hamlet,"
}
},
{
"_index": "shakespeare",
"_id": "32754",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32755,
"play_name": "Hamlet",
"speech_number": 17,
"line_number": "1.2.120",
"speaker": "QUEEN GERTRUDE",
"text_entry": "Let not thy mother lose her prayers, Hamlet:"
}
},
{
"_index": "shakespeare",
"_id": "32759",
"_score": 1.2,
"_source": {
"type": "line",
"line_id": 32760,
"play_name": "Hamlet",
"speech_number": 19,
"line_number": "1.2.125",
"speaker": "KING CLAUDIUS",
"text_entry": "This gentle and unforced accord of Hamlet"
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры верхнего уровня, поддерживаемые запросами constant_score.
| Параметр |
Описание |
| filter |
Фильтрующий запрос, которому должен соответствовать документ, чтобы быть возвращенным в результатах. Обязательный. |
| boost |
Числовое значение с плавающей запятой, которое присваивается как релевантный балл всем возвращенным документам. Необязательный. По умолчанию 1.0. |
5 - function_score
Пересчитывает балл релевантности документов, которые возвращаются запросом, с использованием функции, которую вы определяете.
Запрос function score
Используйте запрос function_score, если вам нужно изменить релевантные баллы документов, возвращаемых в результатах. Запрос function_score определяет запрос и одну или несколько функций, которые могут быть применены ко всем результатам или подмножествам результатов для перерасчета их релевантных баллов.
Использование одной функции оценки
Самый простой пример запроса function_score использует одну функцию для перерасчета балла. Следующий запрос использует функцию weight, чтобы удвоить все релевантные баллы. Эта функция применяется ко всем документам в результатах, поскольку в запросе function_score не указаны параметры запроса:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
Применение функции оценки к подмножеству документов
Чтобы применить функцию оценки к подмножеству документов, укажите запрос внутри функции:
GET shakespeare/_search
{
"query": {
"function_score": {
"query": {
"match": {
"play_name": "Hamlet"
}
},
"weight": "2"
}
}
}
Поддерживаемые функции
Тип запроса function_score поддерживает следующие функции:
-
Встроенные:
- weight: Умножает балл документа на предопределенный коэффициент увеличения.
- random_score: Предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями.
- field_value_factor: Использует значение указанного поля документа для перерасчета балла.
- Функции затухания (gauss, exp и linear): Перерасчитывают балл с использованием заданной функции затухания.
-
Пользовательские:
- script_score: Использует скрипт для оценки документов.
Функция weight
Когда вы используете функцию weight, оригинальный релевантный балл умножается на значение с плавающей запятой weight:
GET shakespeare/_search
{
"query": {
"function_score": {
"weight": "2"
}
}
}
В отличие от значения boost, функция weight не нормализуется.
Функция random_score
Функция random_score предоставляет случайный балл, который постоянен для одного пользователя, но различен между пользователями. Балл представляет собой число с плавающей запятой в диапазоне [0, 1). По умолчанию функция random_score использует внутренние идентификаторы документов Lucene в качестве значений семени, что делает случайные значения невоспроизводимыми, поскольку документы могут быть перенумерованы после слияний. Чтобы добиться согласованности в генерации случайных значений, вы можете предоставить параметры seed и field. Поле должно быть полем, для которого включены данные поля (обычно это числовое поле). Балл рассчитывается с использованием семени, значений данных поля для указанного поля и соли, рассчитанной с использованием имени индекса и идентификатора шардов. Поскольку имя индекса и идентификатор шардов одинаковы для документов, находящихся в одном шард, документы с одинаковыми значениями полей будут получать одинаковый балл. Чтобы обеспечить разные баллы для всех документов в одном шарде, используйте поле, которое имеет уникальные значения для всех документов. Одним из вариантов является использование поля _seq_no. Однако, если вы выберете это поле, баллы могут измениться, если документ будет обновлен из-за соответствующего обновления _seq_no.
Следующий запрос использует функцию random_score с семенем и полем:
GET shakespeare/_search
{
"query": {
"function_score": {
"random_score": {
"seed": 12345,
"field": "some_numeric_field"
}
}
}
}
Функция field_value_factor
Функция field_value_factor перерасчитывает балл, используя значение указанного поля документа. Если поле является многозначным, используется только его первое значение для расчетов, остальные значения не учитываются.
Функция field_value_factor поддерживает следующие параметры:
-
field: Поле, которое будет использоваться в расчетах баллов.
-
factor: Необязательный коэффициент, на который умножается значение поля. По умолчанию 1.
-
modifier: Один из модификаторов, который будет применен к значению поля.
Поддерживаемые модификаторы
Следующая таблица перечисляет все поддерживаемые модификаторы.
| Модификатор |
Формула |
Описание |
| log |
[\log v] |
Возьмите десятичный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать log1p или log2p вместо log. |
| log1p |
[\log(1+v)] |
Возьмите десятичный логарифм суммы 1 и значения. |
| log2p |
[\log(2+v)] |
Возьмите десятичный логарифм суммы 2 и значения. |
| ln |
[\ln v] |
Возьмите натуральный логарифм значения. Взятие логарифма от неположительного числа является недопустимой операцией и приведет к ошибке. Для значений между 0 (исключительно) и 1 (включительно) эта функция возвращает неположительные значения, что также приведет к ошибке. Рекомендуется использовать ln1p или ln2p вместо ln. |
| ln1p |
[\ln(1+v)] |
Возьмите натуральный логарифм суммы 1 и значения. |
| ln2p |
[\ln(2+v)] |
Возьмите натуральный логарифм суммы 2 и значения. |
| reciprocal |
[\frac{1}{v}] |
Возьмите обратное значение. |
| square |
[v^2] |
Возведите значение в квадрат. |
| sqrt |
[\sqrt{v}] |
Возьмите квадратный корень из значения. Взятие квадратного корня из отрицательного числа является недопустимой операцией и приведет к ошибке. Убедитесь, что значение неотрицательно. |
| none |
N/A |
Не применять никакой модификатор. |
- missing: Значение, которое будет использоваться, если поле отсутствует в документе. Коэффициент и модификатор применяются к этому значению вместо отсутствующего значения поля.
Пример
Например, следующий запрос использует функцию field_value_factor, чтобы придать больше веса полю views:
GET blogs/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
}
}
}
}
Предыдущий запрос рассчитывает релевантный балл, используя следующую формулу:
[
score = original \ score \cdot log(1+1.5 \cdot views)
]
Функция script_score
Используя функцию script_score, вы можете написать пользовательский скрипт для оценки документов, при этом опционально включая значения полей в документе. Оригинальный релевантный балл доступен в переменной _score.
Рассчитанный балл не может быть отрицательным. Отрицательный балл приведет к ошибке. Баллы документов имеют положительные 32-битные значения с плавающей запятой. Балл с большей точностью преобразуется в ближайшее 32-битное число с плавающей запятой.
Пример
Например, следующий запрос использует функцию script_score для расчета балла на основе оригинального балла и количества просмотров и лайков для блога. Чтобы уменьшить вес количества просмотров и лайков, эта формула берет логарифм суммы просмотров и лайков. Чтобы сделать логарифм допустимым, даже если количество просмотров и лайков равно 0, к их сумме добавляется 1:
GET blogs/_search
{
"query": {
"function_score": {
"query": {"match": {"name": "opensearch"}},
"script_score": {
"script": "_score * Math.log(1 + doc['likes'].value + doc['views'].value)"
}
}
}
}
Скрипты компилируются и кэшируются для повышения производительности. Таким образом, предпочтительно повторно использовать один и тот же скрипт и передавать любые параметры, которые необходимы скрипту:
GET blogs/_search
{
"query": {
"function_score": {
"query": {
"match": { "name": "opensearch" }
},
"script_score": {
"script": {
"params": {
"add": 1
},
"source": "_score * Math.log(params.add + doc['likes'].value + doc['views'].value)"
}
}
}
}
}
Функции Decay (затухания)
Для многих приложений необходимо сортировать результаты на основе близости или недавности. Вы можете сделать это с помощью функций затухания. Функции затухания вычисляют балл документа, используя одну из трех кривых затухания: гауссову, экспоненциальную или линейную.
Функции decay (затухания) работают только с числовыми, датированными и геопунктовыми полями.
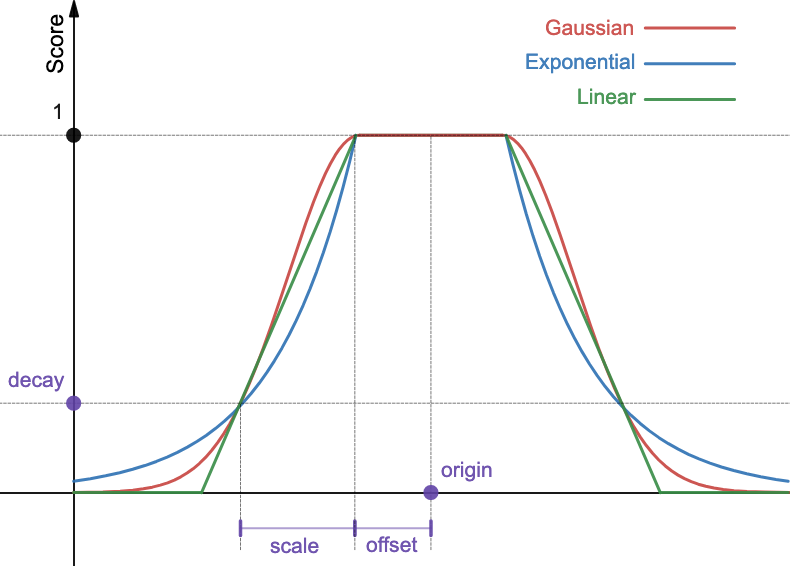
Функции затухания вычисляют баллы на основе начала, масштаба, смещения и затухания, как показано на следующем рисунке.
Примеры: Геопунктовые поля
Предположим, вы ищете отель рядом с вашим офисом. Вы создаете индекс отелей, который сопоставляет поле location как геопункт:
PUT hotels
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Вы индексируете два документа, которые соответствуют ближайшим отелям:
PUT hotels/_doc/1
{
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74.00
}
}
PUT hotels/_doc/2
{
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74.00
}
}
Начало определяет точку, от которой рассчитывается расстояние (местоположение офиса). Смещение указывает расстояние от начала, в пределах которого документам присваивается полный балл 1. Вы можете присвоить отелям, находящимся в пределах 200 футов от офиса, одинаковый наивысший балл. Масштаб определяет скорость затухания графика, а затухание определяет балл, который следует присвоить документу на расстоянии масштаб + смещение от начала. Как только вы выходите за пределы радиуса 200 футов, вы можете решить, что если вам нужно пройти еще 300 футов, чтобы добраться до отеля (масштаб = 300 футов), вы присвоите ему четверть оригинального балла (затухание = 0.25).
Вы создаете следующий запрос с началом в точке (74.00, 40.71):
GET hotels/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"location": {
"origin": "40.71,74.00",
"offset": "200ft",
"scale": "300ft",
"decay": 0.25
}
}
}
]
}
}
}
Ответ содержит оба отеля. Отель в пределах 200 футов от офиса имеет балл 1, а отель за пределами радиуса 500 футов имеет балл 0.20, что меньше параметра затухания 0.25.
{
"took": 854,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "hotels",
"_id": "1",
"_score": 1,
"_source": {
"name": "Hotel Within 200",
"location": {
"lat": 40.7105,
"lon": 74
}
}
},
{
"_index": "hotels",
"_id": "2",
"_score": 0.20099315,
"_source": {
"name": "Hotel Outside 500",
"location": {
"lat": 40.7115,
"lon": 74
}
}
}
]
}
}
Параметры
Следующая таблица перечисляет все параметры, поддерживаемые функциями gauss, exp и linear.
| Параметр |
Описание |
| origin |
Точка, от которой рассчитывается расстояние. Должна быть указана как число для числовых полей, дата для полей даты или геопункт для геопунктовых полей. Обязательна для геопунктовых и числовых полей. Необязательна для полей даты (по умолчанию используется текущее время). Для полей даты поддерживается математическое вычисление дат (например, now-2d). |
| offset |
Определяет расстояние от начала, в пределах которого документам присваивается балл 1. Необязательный. По умолчанию 0. |
| scale |
Документам на расстоянии scale + offset от начала присваивается балл decay. Обязательный. Для числовых полей scale может быть любым числом. Для полей даты scale может быть определен как число с единицами (5h, 1d). Если единицы не указаны, scale по умолчанию равен миллисекундам. Для геопунктовых полей scale может быть определен как число с единицами (1mi, 5km). Если единицы не указаны, scale по умолчанию равен метрам. |
| decay |
Определяет балл документа на расстоянии scale + offset от начала. Необязательный. По умолчанию 0.5. |
Для полей, отсутствующих в документе, функции затухания возвращают балл 1.
Пример: Числовые поля
Следующий запрос использует экспоненциальную функцию затухания, чтобы приоритизировать блоги по количеству комментариев:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"comments_count": {
"origin": 10,
"scale": 5,
"decay": 0.5
}
}
}
]
}
}
}
Первые два блога в результатах имеют балл 1, потому что один находится в начале (20), а другой на расстоянии 16, что находится в пределах смещения (диапазон, в пределах которого документы получают полный балл, рассчитывается как 20 - 5 и составляет [15, 25]). Третий блог находится на расстоянии scale + offset от начала (20 - (5 + 10) = 15), поэтому ему присваивается стандартный балл затухания (0.5):
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "1",
"_score": 1,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 1,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "3",
"_score": 0.5,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0.4352753,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Пример: Поля даты
Следующий запрос использует гауссову функцию затухания, чтобы приоритизировать блоги, опубликованные около 24 апреля 2002 года:
GET blogs/_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d",
"decay": 0.25
}
}
}
]
}
}
}
В результатах первый блог был опубликован в течение одного дня после 24 апреля 2022 года, поэтому он имеет наивысший балл 1. Второй блог был опубликован 17 апреля 2022 года, что находится в пределах смещения + масштаба (1 день + 6 дней), и поэтому имеет балл, равный затуханию (0.25). Третий блог был опубликован более чем через 7 дней после 24 апреля 2022 года, поэтому у него более низкий балл. Последний блог имеет балл 0, потому что он был опубликован много лет назад:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 1,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 0.25,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 0.15154076,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
},
{
"_index": "blogs",
"_id": "4",
"_score": 0,
"_source": {
"name": "A very old blog",
"views": 100,
"likes": 20,
"comments": 3,
"date_posted": "2000-04-25"
}
}
]
}
}
Многозначные поля
Если поле, которое вы указываете для расчета затухания, содержит несколько значений, вы можете использовать параметр multi_value_mode. Этот параметр указывает одну из следующих функций для определения значения поля, которое будет использоваться для расчетов:
- min: (по умолчанию) Минимальное расстояние от начала.
- max: Максимальное расстояние от начала.
- avg: Среднее расстояние от начала.
- sum: Сумма всех расстояний от начала.
Пример
Например, вы индексируете документ с массивом расстояний:
PUT testindex/_doc/1
{
"distances": [1, 2, 3, 4, 5]
}
Следующий запрос использует максимальное расстояние многозначного поля distances для расчета затухания:
GET testindex/_search
{
"query": {
"function_score": {
"functions": [
{
"exp": {
"distances": {
"origin": "6",
"offset": "5",
"scale": "1"
},
"multi_value_mode": "max"
}
}
]
}
}
}
Документ получает балл 1, потому что максимальное расстояние от начала (1) находится в пределах смещения от начала:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1,
"_source": {
"distances": [
1,
2,
3,
4,
5
]
}
}
]
}
}
Расчет кривой затухания
Следующие формулы определяют вычисление оценки для различных функций затухания (обозначает значение поля документа).
Гауссовская функция затухания
[
\text{score} = \exp \left(-\frac {(\max(0, \lvert v - \text{origin} \rvert - \text{offset}))^2} {2\sigma^2} \right),
]
где (\sigma) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
\sigma^2 = - \frac {\text{scale}^2} {2 \ln(\text{decay})}
]
Экспоненциальная функция затухания
[
\text{score} = \exp (\lambda \cdot \max(0, \lvert v - \text{origin} \rvert - \text{offset})),
]
где (\lambda) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
\lambda = \frac {\ln(\text{decay})} {\text{scale}}
]
Линейная функция затухания
[
\text{score} = \max \left(\frac {s - \max(0, \lvert v - \text{origin} \rvert - \text{offset})} {s} \right),
]
где (s) вычисляется для того, чтобы гарантировать, что оценка равна затуханию на расстоянии, равном смещению + масштабу от начала координат:
[
s = \frac {\text{scale}} {1 - \text{decay}}
]
Использование нескольких функций оценки
Вы можете указать несколько функций оценки в запросе функции оценки, перечислив их в массиве functions.
Комбинирование оценок от нескольких функций
Разные функции могут использовать разные масштабы для оценки. Например, функция random_score предоставляет оценку в диапазоне от 0 до 1, но field_value_factor не имеет конкретного масштаба для оценки. Кроме того, вы можете захотеть по-разному взвешивать оценки, полученные от различных функций. Чтобы скорректировать оценки для разных функций, вы можете указать параметр weight для каждой функции. Оценка, полученная от каждой функции, затем умножается на вес, чтобы получить окончательную оценку для этой функции. Параметр weight должен быть указан в массиве functions, чтобы отличать его от функции веса.
Оценки, полученные от каждой функции, комбинируются с помощью параметра score_mode, который принимает одно из следующих значений:
-
multiply: (по умолчанию) Оценки умножаются.
-
sum: Оценки складываются.
-
avg: Оценки усредняются. Если указан вес, это средневзвешенное. Например, если первая функция с весом w1 возвращает оценку s1, а вторая функция с весом w2 возвращает оценку s2, среднее значение рассчитывается как:
[
\text{average} = \frac{w1 \cdot s1 + w2 \cdot s2}{w1 + w2}
]
-
first: Берется оценка от первой функции, которая имеет соответствующий фильтр.
-
max: Берется максимальная оценка.
-
min: Берется минимальная оценка.
Указание верхнего предела для оценки
Вы можете указать верхний предел для функции оценки в параметре max_boost. Значение по умолчанию для верхнего предела — это максимальная величина для значения с плавающей запятой: ((2 - 2^{-23}) \cdot 2^{127}).
Комбинирование оценки для всех функций с оценкой запроса
Вы можете указать, как оценка, вычисленная с использованием всех функций, комбинируется с оценкой запроса, в параметре boost_mode, который принимает одно из следующих значений:
- multiply: (по умолчанию) Умножает оценку запроса на оценку функции.
- replace: Игнорирует оценку запроса и использует оценку функции.
- sum: Складывает оценку запроса и оценку функции.
- avg: Усредняет оценку запроса и оценку функции.
- max: Берет большее значение между оценкой запроса и оценкой функции.
- min: Берет меньшее значение между оценкой запроса и оценкой функции.
Фильтрация документов, которые не соответствуют порогу
Изменение оценки релевантности не изменяет список соответствующих документов. Чтобы исключить некоторые документы, которые не соответствуют порогу, укажите значение порога в параметре min_score. Все документы, возвращенные запросом, затем оцениваются и фильтруются с использованием значения порога.
Пример
Следующий запрос ищет блоги, которые содержат слова “OpenSearch Data Prepper”, предпочитая посты, опубликованные около 24 апреля 2022 года. Кроме того, учитывается количество просмотров и лайков. Наконец, пороговое значение установлено на уровне 10:
GET blogs/_search
{
"query": {
"function_score": {
"boost": "5",
"functions": [
{
"gauss": {
"date_posted": {
"origin": "2022-04-24",
"offset": "1d",
"scale": "6d"
}
},
"weight": 1
},
{
"gauss": {
"likes": {
"origin": 200,
"scale": 200
}
},
"weight": 4
},
{
"gauss": {
"views": {
"origin": 1000,
"scale": 800
}
},
"weight": 2
}
],
"query": {
"match": {
"name": "opensearch data prepper"
}
},
"max_boost": 10,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 10
}
}
}
Результаты содержат три соответствующих блога:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 31.191923,
"hits": [
{
"_index": "blogs",
"_id": "3",
"_score": 31.191923,
"_source": {
"name": "Distributed tracing with Data Prepper",
"views": 800,
"likes": 50,
"comments": 5,
"date_posted": "2022-04-25"
}
},
{
"_index": "blogs",
"_id": "1",
"_score": 13.907352,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
}
},
{
"_index": "blogs",
"_id": "2",
"_score": 11.150461,
"_source": {
"name": "Get started with OpenSearch 2.7",
"views": 1400,
"likes": 100,
"comments": 20,
"date_posted": "2022-05-02"
}
}
]
}
}
Именованные функции
При определении функции вы можете указать ее имя, используя параметр _name на верхнем уровне. Это имя полезно для отладки и понимания процесса оценки. После указания имя функции включается в объяснение расчета оценки, когда это возможно (это относится к функциям, фильтрам и запросам). Вы можете идентифицировать функцию по ее _name в ответе.
Пример
Следующий запрос устанавливает explain в значение true для целей отладки, чтобы получить объяснение оценки в ответе. Каждая функция содержит параметр _name, чтобы вы могли однозначно идентифицировать функцию:
GET blogs/_search
{
"explain": true,
"size": 1,
"query": {
"function_score": {
"functions": [
{
"_name": "likes_function",
"script_score": {
"script": {
"lang": "painless",
"source": "return doc['likes'].value * 2;"
}
},
"weight": 0.6
},
{
"_name": "views_function",
"field_value_factor": {
"field": "views",
"factor": 1.5,
"modifier": "log1p",
"missing": 1
},
"weight": 0.3
},
{
"_name": "comments_function",
"gauss": {
"comments": {
"origin": 1000,
"scale": 800
}
},
"weight": 0.1
}
]
}
}
}
Ответ объясняет процесс оценки. Для каждой функции объяснение содержит name функции в своем описании:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 6.1600614,
"hits": [
{
"_shard": "[blogs][0]",
"_node": "_yndTaZHQWimcDgAfOfRtQ",
"_index": "blogs",
"_id": "1",
"_score": 6.1600614,
"_source": {
"name": "Semantic search in OpenSearch",
"views": 1200,
"likes": 150,
"comments": 16,
"date_posted": "2022-04-17"
},
"_explanation": {
"value": 6.1600614,
"description": "function score, product of:",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
},
{
"value": 6.1600614,
"description": "min of:",
"details": [
{
"value": 6.1600614,
"description": "function score, score mode [multiply]",
"details": [
{
"value": 180,
"description": "product of:",
"details": [
{
"value": 300,
"description": "script score function(_name: likes_function), computed with script:\"Script{type=inline, lang='painless', idOrCode='return doc['likes'].value * 2;', options={}, params={}}\"",
"details": [
{
"value": 1,
"description": "_score: ",
"details": [
{
"value": 1,
"description": "*:*",
"details": []
}
]
}
]
},
{
"value": 0.6,
"description": "weight",
"details": []
}
]
},
{
"value": 0.9766541,
"description": "product of:",
"details": [
{
"value": 3.2555137,
"description": "field value function(_name: views_function): log1p(doc['views'].value?:1.0 * factor=1.5)",
"details": []
},
{
"value": 0.3,
"description": "weight",
"details": []
}
]
},
{
"value": 0.035040613,
"description": "product of:",
"details": [
{
"value": 0.35040614,
"description": "Function for field comments:",
"details": [
{
"value": 0.35040614,
"description": "exp(-0.5*pow(MIN[Math.max(Math.abs(16.0(=doc value) - 1000.0(=origin))) - 0.0(=offset), 0)],2.0)/461662.4130844683, _name: comments_function)",
"details": []
}
]
},
{
"value": 0.1,
"description": "weight",
"details": []
}
]
}
]
},
{
"value": 3.4028235e+38,
"description": "maxBoost",
"details": []
}
]
}
]
}
}
]
}
}