full_text
Анализируют текст запроса, применяют тот же анализатор, что и при индексации. match, match_phrase, multi_match
Полнотекстовые запросы
Эта страница перечисляет все типы полнотекстовых запросов и общие параметры. Существует множество необязательных полей, которые вы можете использовать для создания тонких поисковых поведений, поэтому мы рекомендуем протестировать некоторые базовые типы запросов на представительных индексах и проверить вывод, прежде чем выполнять более сложные или комплексные поиски с несколькими параметрами.
OpenSearch использует библиотеку поиска Apache Lucene, которая предоставляет высокоэффективные структуры данных и алгоритмы для загрузки, индексации, поиска и агрегации данных.
Чтобы узнать больше о классах запросов поиска, смотрите JavaDocs по запросам Lucene.
Типы полнотекстовых запросов, показанные в этом разделе, используют стандартный анализатор, который автоматически анализирует текст при отправке запроса.
В следующей таблице перечислены все типы полнотекстовых запросов.
| Тип запроса |
Описание |
| intervals |
Позволяет точно контролировать близость и порядок совпадающих терминов. |
| match |
Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости. |
| match_bool_prefix |
Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс. |
| match_phrase |
Похож на запрос match, но соответствует целой фразе с настраиваемым слопом. |
| match_phrase_prefix |
Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс. |
| multi_match |
Похож на запрос match, но используется для нескольких полей. |
| query_string |
Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса. |
| simple_query_string |
Более простая, менее строгая версия запроса query_string. |
1 - match
Запрос по умолчанию для полнотекстового поиска, который можно использовать для нечеткого сопоставления и поиска фраз или близости.
Запрос Match
Используйте запрос match для полнотекстового поиска по конкретному полю документа. Если вы выполняете запрос match по текстовому полю, он анализирует предоставленную строку поиска и возвращает документы, которые соответствуют любым терминам этой строки. Если вы выполняете запрос match по полю с точным значением, он возвращает документы, которые соответствуют этому точному значению. Предпочтительный способ поиска по полям с точными значениями — использовать фильтр, поскольку, в отличие от запроса, фильтр кэшируется.
Пример
Следующий пример показывает базовый запрос match для слова “wind” в заголовке:
GET _search
{
"query": {
"match": {
"title": "wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match": {
"title": {
"query": "wind",
"analyzer": "stop"
}
}
}
}
Примеры
В следующих примерах вы будете использовать индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "Let the wind rise"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
PUT testindex/_doc/3
{
"title": "Rise is gone"
}
Оператор
Если запрос match выполняется по текстовому полю, текст анализируется с помощью анализатора, указанного в параметре analyzer. Затем полученные токены объединяются в логический запрос с использованием оператора, указанного в параметре operator. Оператор по умолчанию — OR, поэтому запрос “wind rise” преобразуется в “wind OR rise”. В этом примере этот запрос возвращает документы 1–3, поскольку каждый документ содержит термин, соответствующий запросу. Чтобы указать оператор AND, используйте следующий запрос:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "and"
}
}
}
}
Запрос формируется как “wind AND rise” и возвращает документ 1 как совпадающий документ.
Минимальное количество совпадений
Вы можете контролировать минимальное количество терминов, которые документ должен совпадать, чтобы быть возвращенным в результатах, указав параметр minimum_should_match:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wind rise",
"operator": "or",
"minimum_should_match": 2
}
}
}
}
Теперь документы должны совпадать с обоими терминами, поэтому возвращается только документ 1 (это эквивалентно оператору AND).
Анализатор
Поскольку в этом примере вы не указали анализатор, используется анализатор по умолчанию — стандартный анализатор. Стандартный анализатор не выполняет стемминг, поэтому если вы выполните запрос “the wind rises”, вы не получите результатов, поскольку токен “rises” не совпадает с токеном “rise”. Чтобы изменить анализатор поиска, укажите его в поле analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "the wind rises",
"operator": "and",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токены “wind” и “rise”. Последний токен совпадает с документом 1, который возвращается в результатах.
Пустой запрос
В некоторых случаях анализатор может удалить все токены из запроса. Например, английский анализатор удаляет стоп-слова, поэтому в запросе “and OR or” все токены удаляются. Чтобы проверить поведение анализатора, вы можете использовать API анализа:
GET testindex/_analyze
{
"analyzer": "english",
"text": "and OR or"
}
Как и ожидалось, запрос не производит токенов:
Вы можете задать поведение для пустого запроса с помощью параметра zero_terms_query. Установка zero_terms_query в значение all возвращает все документы в индексе, а установка в none не возвращает ни одного документа:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "and OR or",
"analyzer": "english",
"zero_terms_query": "all"
}
}
}
}
Неопределенность (Fuzziness)
Чтобы учесть опечатки, вы можете указать уровень нечеткости для вашего запроса в одном из следующих форматов:
- Целое число, которое указывает максимальное допустимое расстояние по Дамерау-Левенштейну для этого редактирования.
- AUTO:
- Строки длиной 0–2 символа должны совпадать точно.
- Строки длиной 3–5 символов допускают 1 редактирование.
- Строки длиной более 5 символов допускают 2 редактирования.
Установка нечеткости на значение по умолчанию AUTO работает лучше всего в большинстве случаев:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO"
}
}
}
}
Токен “wnid” совпадает с “wind”, и запрос возвращает документы 1 и 2.
Длина префикса
Опечатки редко встречаются в начале слов. Таким образом, вы можете указать минимальную длину, которую должен иметь совпадающий префикс, чтобы документ был возвращен в результатах. Например, вы можете изменить предыдущий запрос, добавив параметр prefix_length:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"prefix_length": 2
}
}
}
}
Предыдущий запрос не возвращает результатов. Если вы измените prefix_length на 1, документы 1 и 2 будут возвращены, поскольку первая буква токена “wnid” не ошибочна.
Транспозиции
В предыдущем примере слово “wnid” содержало транспозицию (буквы “i” и “n” были поменяны местами). По умолчанию транспозиции допускаются в нечетком совпадении, но вы можете запретить их, установив fuzzy_transpositions в false:
GET testindex/_search
{
"query": {
"match": {
"title": {
"query": "wnid",
"fuzziness": "AUTO",
"fuzzy_transpositions": false
}
}
}
}
Теперь запрос не возвращает результатов.
Синонимы
Если вы используете фильтр synonym_graph и параметр auto_generate_synonyms_phrase_query установлен в true (по умолчанию), OpenSearch разбивает запрос на термины, а затем объединяет термины для генерации фразового запроса для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average”.
Чтобы сопоставить многословные синонимы с союзами, установите auto_generate_synonyms_phrase_query в false:
GET /testindex/_search
{
"query": {
"match": {
"text": {
"query": "good ba",
"auto_generate_synonyms_phrase_query": false
}
}
}
}
Сформированный запрос будет “ba” OR (“batting” AND “average”).
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Строка запроса, используемая для поиска. Обязательный параметр. |
| auto_generate_synonyms_phrase_query |
Boolean |
Указывает, следует ли автоматически создавать фразовый запрос match для многословных синонимов. Например, если вы укажете “ba, batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать “ba” OR “batting average” (если этот параметр true) или “ba” OR (“batting” AND “average”) (если этот параметр false). По умолчанию true. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| boost |
Floating-point |
Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| enable_position_increments |
Boolean |
Если true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fuzziness |
String |
Количество редактирований символов (вставок, удалений, замен или транспозиций), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite |
String |
Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| lenient |
Boolean |
Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_expansions |
Positive integer |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match |
Positive or negative integer, positive or negative percentage, combination |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения:
- OR: строка интерпретируется как “или”
- AND: строка интерпретируется как “и”. По умолчанию используется OR. |
| prefix_length |
Non-negative integer |
Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
| zero_terms_query |
String |
В некоторых случаях анализатор удаляет все термины из строки запроса. Например, стоп-анализатор удаляет все термины из строки “an”, но оставляет “this”. В таких случаях zero_terms_query указывает, следует ли не совпадать ни с одним документом (none) или совпадать со всеми документами (all). Допустимые значения: none и all. По умолчанию none. |
2 - match-bool-prefix
Создает логический запрос, который соответствует всем терминам в любой позиции, рассматривая последний термин как префикс.
Запрос Match Boolean Prefix
Запрос match_bool_prefix анализирует предоставленную строку поиска и создает логический запрос из терминов строки. Он использует каждый термин, кроме последнего, как целое слово для совпадения. Последний термин используется как префикс. Запрос match_bool_prefix возвращает документы, которые содержат либо термины целых слов, либо термины, начинающиеся с префиксного термина, в любом порядке.
Пример
Следующий пример показывает базовый запрос match_bool_prefix:
GET _search
{
"query": {
"match_bool_prefix": {
"title": "the wind"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "the wind",
"analyzer": "stop"
}
}
}
}
Пример документов
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Gone with the wind"
}
Следующий запрос match_bool_prefix ищет целое слово “rises” и слова, начинающиеся с “wi”, в любом порядке:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"should": [
{ "term": { "title": "rises" }},
{ "prefix": { "title": "wi" }}
]
}
}
}
Ответ содержит оба документа:
Ответ
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.73617,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 1.73617,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1,
"_source": {
"title": "Gone with the wind"
}
}
]
}
}
Запросы match_bool_prefix и match_phrase_prefix
Запрос match_bool_prefix сопоставляет термины в любой позиции, в то время как запрос match_phrase_prefix сопоставляет термины как целую фразу. Чтобы проиллюстрировать разницу, снова рассмотрим запрос match_bool_prefix из предыдущего раздела:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": "rises wi"
}
}
}
Оба документа “The wind rises” и “Gone with the wind” соответствуют поисковым терминам, поэтому запрос возвращает оба документа.
Теперь выполните запрос match_phrase_prefix по тому же индексу:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "rises wi"
}
}
}
Ответ не возвращает документов, потому что ни один из документов не содержит фразу “rises wi” в указанном порядке.
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer:
GET testindex/_search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "rise the wi",
"analyzer": "stop"
}
}
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве верхнеуровневого параметра:
GET _search
{
"query": {
"match_bool_prefix": {
"<field>": {
"query": "text to search for",
...
}
}
}
}
Параметр <field> принимает следующие параметры. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Текст, число, логическое значение или дата, используемые для поиска. Обязательный параметр. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля по умолчанию. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. |
| fuzziness |
AUTO, 0 или положительное целое число |
Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. По умолчанию используется значение AUTO, которое выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев. |
| fuzzy_rewrite |
String |
Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод fuzzy_rewrite top_terms_blended_freqs_${max_expansions} по умолчанию. По умолчанию constant_score. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены параметра нечеткости. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (обмен “n” и “i”) и 2, если false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” — это очевидная опечатка. По умолчанию является хорошим выбором для большинства случаев. |
| max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| minimum_should_match |
Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не совпадает с “The Wind Rises”. Если minimum_should_match равно 1, совпадает. Для подробностей см. раздел “Минимальное количество совпадений”. |
| operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины совпадали (AND) или достаточно, чтобы совпадал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения: OR и AND. По умолчанию используется OR. |
| prefix_length |
Ненегативное целое число |
Количество начальных символов, которые не учитываются при определении нечеткости. По умолчанию 0. |
Параметры fuzziness, fuzzy_transpositions, fuzzy_rewrite, max_expansions и prefix_length могут применяться к подзапросам term, созданным для всех терминов, кроме последнего. Они не оказывают никакого влияния на префиксный запрос, созданный для последнего термина.
3 - match-phrase
Похож на запрос match, но соответствует целой фразе с настраиваемым слопом.
Запрос match_phrase
Используйте запрос match_phrase, чтобы находить документы, содержащие точную фразу в указанном порядке. Вы можете добавить гибкость к фразовому соответствию, указав параметр slop.
Запрос match_phrase создает фразовый запрос, который соответствует последовательности терминов.
Пример базового запроса match_phrase:
GET _search
{
"query": {
"match_phrase": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "The wind rises"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase ищет фразу “wind rises”, где слово “ветер” следует за словом “поднимается”:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": "wind rises"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "The wind rises"
}
}
]
}
}
Анализатор
По умолчанию, когда вы выполняете запрос по текстовому полю, текст поиска анализируется с использованием анализатора индекса, связанного с полем. Вы можете указать другой анализатор поиска в параметре analyzer. Например, следующий запрос использует английский анализатор:
GET testindex/_search
{
"query": {
"match_phrase": {
"title": {
"query": "ветра",
"analyzer": "english"
}
}
}
}
Английский анализатор удаляет стоп-слово “the” и выполняет стемминг, производя токен “ветер”. Оба документа соответствуют этому токену и возвращаются в результатах:
Slop
Если вы укажете параметр slop, запрос допускает перестановку поисковых терминов. Параметр slop указывает количество других слов, разрешенных между словами в фразе запроса. Например, в следующем запросе текст поиска переставлен по сравнению с текстом документа:
GET _search
{
"query": {
"match_phrase": {
"title": {
"query": "ветер поднимается",
"slop": 3
}
}
}
}
Запрос все равно возвращает соответствующий документ:
Пустой запрос
Для информации о возможном пустом запросе смотрите соответствующий раздел запроса match.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
Строка |
Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для поля по умолчанию на этапе индексации. Если для поля по умолчанию не указан анализатор, используется стандартный анализатор для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
| slop |
0 (по умолчанию) или положительное целое число |
Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
| zero_terms_query |
Строка |
В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки “an”, кроме “but”. В таких случаях zero_terms_query указывает, следует ли не находить ни одного документа (none) или находить все документы (all). Допустимые значения: none и all. По умолчанию используется none. |
4 - match-phrase-prefix
Похож на запрос match_phrase, но соответствует терминам как целой фразе, рассматривая последний термин как префикс.
Запрос match_phrase_prefix
Используйте запрос match_phrase_prefix, чтобы указать фразу для поиска в заданном порядке. Документы, содержащие указанную вами фразу, будут возвращены. Последний неполный термин в фразе интерпретируется как префикс, поэтому любые документы, содержащие фразы, начинающиеся с указанной фразы и префикса последнего термина, будут возвращены.
Запрос аналогичен match_phrase, но создает префиксный запрос из последнего термина в строке запроса.
Для различий между запросами match_phrase_prefix и match_bool_prefix смотрите раздел о запросах match_bool_prefix и match_phrase_prefix.
Пример базового запроса match_phrase_prefix:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": "ветер дует"
}
}
}
Чтобы передать дополнительные параметры, вы можете использовать расширенный синтаксис:
GET _search
{
"query": {
"match_phrase_prefix": {
"title": {
"query": "ветер дует",
"analyzer": "stop"
}
}
}
}
Пример
Рассмотрим индекс с следующими документами:
PUT testindex/_doc/1
{
"title": "Ветер поднимается"
}
PUT testindex/_doc/2
{
"title": "Ушедший с ветром"
}
Следующий запрос match_phrase_prefix ищет полное слово “ветер”, за которым следует слово, начинающееся на “под”:
GET testindex/_search
{
"query": {
"match_phrase_prefix": {
"title": "ветер под"
}
}
}
Ответ содержит соответствующий документ:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92980814,
"hits": [
{
"_index": "testindex",
"_id": "1",
"_score": 0.92980814,
"_source": {
"title": "Ветер поднимается"
}
}
]
}
}
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"match_phrase_prefix": {
"<field>": {
"query": "текст для поиска",
...
}
}
}
}
Параметры <field> принимают следующие значения. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
Строка |
Строка запроса, используемая для поиска. Обязательный параметр. |
| analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. |
| max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Неопределенные запросы “расширяются” на количество совпадающих терминов, находящихся на расстоянии, указанном в параметре fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию значение равно 50. |
| slop |
0 (по умолчанию) или положительное целое число |
Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Согласно документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова одно над другим), поэтому для разрешения перестановок фраз значение slop должно быть как минимум два. Значение ноль требует точного совпадения.” |
5 - multi-match
Похож на запрос match, но используется для нескольких полей.
Многофункциональные запросы (Multi-match queries)
Операция multi-match функционирует аналогично операции match. Вы можете использовать запрос multi_match для поиска по нескольким полям.
Символ ^ “увеличивает” вес определенных полей. Увеличения — это множители, которые придают больший вес совпадениям в одном поле по сравнению с совпадениями в других полях. В следующем примере совпадение для “ветер” в поле title влияет на _score в четыре раза больше, чем совпадение в поле plot:
GET _search
{
"query": {
"multi_match": {
"query": "ветер",
"fields": ["title^4", "plot"]
}
}
}
В результате фильмы, такие как “Ветер поднимается” и “Ушедший с ветром”, находятся в верхней части результатов поиска, а фильмы, такие как “Ураган”, которые, предположительно, содержат “ветер” в своих аннотациях, находятся внизу.
Вы можете использовать подстановочные знаки в имени поля. Например, следующий запрос будет искать поле speaker и все поля, начинающиеся с play_, например, play_name или play_title:
GET _search
{
"query": {
"multi_match": {
"query": "гамлет",
"fields": ["speaker", "play_*"]
}
}
}
Если вы не укажете параметр fields, запрос multi_match будет искать в полях, указанных в настройке index.query.default_field, которая по умолчанию равна *. Поведение по умолчанию заключается в извлечении всех полей в отображении, которые подходят для запросов на уровне терминов, фильтрации метаданных и комбинировании всех извлеченных полей для построения запроса.
Максимальное количество клауз в запросе определяется настройкой indices.query.bool.max_clause_count, которая по умолчанию равна 1,024.
Типы многофункциональных запросов
OpenSearch поддерживает следующие типы многофункциональных запросов, которые различаются по способу внутреннего выполнения запроса:
- best_fields (по умолчанию): Возвращает документы, которые соответствуют любому полю. Использует
_score лучшего совпадающего поля.
- most_fields: Возвращает документы, которые соответствуют любому полю. Использует комбинированный балл каждого совпадающего поля.
- cross_fields: Обрабатывает все поля так, как если бы они были одним полем. Обрабатывает поля с одинаковым анализатором и сопоставляет слова в любом поле.
- phrase: Выполняет запрос
match_phrase для каждого поля. Использует _score лучшего совпадающего поля.
- phrase_prefix: Выполняет запрос
match_phrase_prefix для каждого поля. Использует _score лучшего совпадающего поля.
- bool_prefix: Выполняет запрос
match_bool_prefix для каждого поля. Использует комбинированный балл каждого совпадающего поля.
Лучшие поля (Best fields)
Если вы ищете два слова, которые определяют концепцию, вы хотите, чтобы результаты, в которых два слова находятся рядом друг с другом, имели более высокий балл.
Например, рассмотрим индекс, содержащий следующие научные статьи:
PUT /articles/_doc/1
{
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
PUT /articles/_doc/2
{
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
Вы можете искать статьи, содержащие “северные огни” в заголовке или описании:
GET articles/_search
{
"query": {
"multi_match" : {
"query": "северные огни",
"type": "best_fields",
"fields": [ "title", "description" ],
"tie_breaker": 0.3
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с запросом match для каждого поля:
Запрос multi_match позволяет искать по нескольким полям. Он работает аналогично запросу match, но с возможностью указания нескольких полей для поиска.
Пример запроса dis_max
GET /articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "северные огни" }},
{ "match": { "description": "северные огни" }}
],
"tie_breaker": 0.3
}
}
}
Результаты содержат оба документа, но документ 1 имеет более высокий балл, потому что оба слова находятся в поле description:
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Аврора бореалис",
"description": "Северные огни, или аврора бореалис, объяснены"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.6322521,
"_source": {
"title": "Недостаток солнца в северных странах",
"description": "Использование флуоресцентных ламп для терапии"
}
}
]
}
}
Запрос best_fields использует балл лучшего совпадающего поля. Если вы укажете tie_breaker, балл рассчитывается по следующему алгоритму:
- Возьмите балл лучшего совпадающего поля.
- Добавьте (tie_breaker * _score) для всех других совпадающих полей.
Запрос most_fields
Используйте запрос most_fields для нескольких полей, которые содержат один и тот же текст, анализируемый разными способами. Например, оригинальное поле может содержать текст, проанализированный с помощью стандартного анализатора, а другое поле может содержать тот же текст, проанализированный с помощью английского анализатора, который выполняет стемминг:
PUT /articles
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Рассмотрим следующие два документа, которые индексируются в индексе articles:
PUT /articles/_doc/1
{
"title": "Гренки с маслом"
}
PUT /articles/_doc/2
{
"title": "Масло на тосте"
}
Стандартный анализатор анализирует заголовок “Гренки с маслом” в [гренки, масло], а заголовок “Масло на тосте” в [масло, на, тосте]. С другой стороны, английский анализатор производит один и тот же список токенов [масло, тост] для обоих заголовков из-за стемминга.
Вы можете использовать запрос most_fields, чтобы вернуть как можно больше документов:
GET /articles/_search
{
"query": {
"multi_match": {
"query": "гренки с маслом",
"fields": [
"title",
"title.english"
],
"type": "most_fields"
}
}
}
Предыдущий запрос выполняется как следующий булев запрос:
GET articles/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "гренки с маслом" }},
{ "match": { "title.english": "гренки с маслом" }}
]
}
}
}
Расчет релевантности
Чтобы рассчитать релевантность, баллы документа для всех клауз совпадений складываются, а затем результат делится на количество клауз совпадений.
Включение поля title.english позволяет получить второй документ, который соответствует стеммированным токенам:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.4418206,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 1.4418206,
"_source": {
"title": "Гренки с маслом"
}
},
{
"_index": "articles",
"_id": "2",
"_score": 0.09304003,
"_source": {
"title": "Масло на тосте"
}
}
]
}
}
Поскольку оба поля title и title.english совпадают для первого документа, он имеет более высокий балл релевантности.
Оператор и минимальное количество совпадений
Запросы best_fields и most_fields генерируют запрос match на основе полей (по одному для каждого поля). Таким образом, параметры minimum_should_match и operator применяются к каждому полю, что обычно не является желаемым поведением.
Например, рассмотрим индекс customers со следующими документами:
PUT customers/_doc/1
{
"first_name": "John",
"last_name": "Doe"
}
PUT customers/_doc/2
{
"first_name": "Jane",
"last_name": "Doe"
}
Если вы ищете “John Doe” в индексе customers, вы можете составить следующий запрос:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Цель оператора and в этом запросе — найти документ, который соответствует “John” и “Doe”. Однако запрос не возвращает никаких результатов. Вы можете узнать, как выполняется запрос, запустив API валидации:
GET customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "best_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос пытается сопоставить как “John”, так и “Doe” с полем first_name или last_name:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "((+first_name:john +first_name:doe) | (+last_name:john +last_name:doe))"
}
]
}
Поскольку ни одно из полей не содержит оба слова, результаты не возвращаются.
Лучшей альтернативой для поиска по полям является использование запроса cross_fields. В отличие от ориентированных на поля запросов best_fields и most_fields, запрос cross_fields ориентирован на термины.
Запрос cross_fields
Используйте запрос cross_fields, чтобы искать данные по нескольким полям. Например, если индекс содержит данные о клиентах, имя и фамилия клиента находятся в разных полях. Тем не менее, когда вы ищете “John Doe”, вы хотите получить документы, в которых “John” находится в поле first_name, а “Doe” — в поле last_name.
Запрос most_fields не работает в этом случае по следующим причинам:
- Параметры
operator и minimum_should_match применяются на уровне полей, а не на уровне терминов.
- Частоты терминов в полях
first_name и last_name могут привести к неожиданным результатам. Например, если чье-то имя — “Doe”, документ с этим именем будет считаться лучшим совпадением, поскольку это имя не появится в других документах.
Запрос cross_fields анализирует строку запроса на отдельные термины и затем ищет каждый из терминов в любом из полей, как если бы они были одним полем.
Пример запроса cross_fields для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Ответ содержит единственный документ, в котором присутствуют как “John”, так и “Doe”:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.8754687,
"hits": [
{
"_index": "customers",
"_id": "1",
"_score": 0.8754687,
"_source": {
"first_name": "John",
"last_name": "Doe"
}
}
]
}
}
Вы можете использовать операцию API валидации, чтобы получить представление о том, как выполняется предыдущий запрос:
GET /customers/_validate/query?explain
{
"query": {
"multi_match" : {
"query": "John Doe",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
}
Из ответа вы можете увидеть, что запрос ищет все термины хотя бы в одном поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "+blended(terms:[last_name:john, first_name:john]) +blended(terms:[last_name:doe, first_name:doe])"
}
]
}
Таким образом, смешивание частот терминов для всех полей решает проблему различия частот терминов, корректируя различия.
Запрос cross_fields обычно полезен только для коротких строковых полей с коэффициентом 1. В других случаях балл не дает значимого смешивания статистики терминов из-за того, как коэффициенты, частоты терминов и нормализация длины влияют на балл.
Параметр fuzziness не поддерживается для запросов cross_fields.
Анализ
Запрос cross_fields работает как термоцентричный запрос для полей с одинаковым анализатором. Поля с одинаковым анализатором группируются вместе, и эти группы комбинируются с помощью булевого запроса.
Например, рассмотрим индекс, в котором поля first_name и last_name анализируются с использованием стандартного анализатора, а их подполе .edge анализируется с помощью анализатора edge n-gram:
Пример
Вы индексируете один документ в индексе customers:
PUT /customers/_doc/1
{
"first": "John",
"last": "Doe"
}
Вы можете использовать запрос cross_fields для поиска по полям для “John Doe”:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Чтобы увидеть, как выполняется запрос, вы можете использовать API валидации:
GET /customers/_validate/query?explain
{
"query": {
"multi_match": {
"query": "John",
"type": "cross_fields",
"fields": [
"first_name", "first_name.edge",
"last_name", "last_name.edge"
]
}
}
}
Ответ показывает, что поля last_name и first_name сгруппированы вместе и рассматриваются как одно поле. Аналогично, поля last_name.edge и first_name.edge также сгруппированы и рассматриваются как одно поле:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "(blended(terms:[last_name:john, first_name:john]) | (blended(terms:[last_name.edge:Jo, first_name.edge:Jo]) blended(terms:[last_name.edge:Joh, first_name.edge:Joh]) blended(terms:[last_name.edge:John, first_name.edge:John])))"
}
]
}
Использование параметров operator или minimum_should_match с несколькими группами полей, как описано выше, может привести к проблемам. Чтобы избежать этого, вы можете переписать предыдущий запрос как два подзапроса cross_fields, объединенных с помощью булевого запроса, и применить minimum_should_match к одному из подзапросов:
GET /customers/_search
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name",
"last_name"
],
"minimum_should_match": "1"
}
},
{
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"fields": [
"first_name.edge",
"last_name.edge"
]
}
}
]
}
}
}
Чтобы создать одну группу для всех полей, укажите анализатор в вашем запросе:
GET /customers/_search
{
"query": {
"multi_match": {
"query": "John Doe",
"type": "cross_fields",
"analyzer": "standard",
"fields": ["first_name", "last_name", "*.edge"]
}
}
}
Запуск API валидации для предыдущего запроса показывает, как выполняется запрос:
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true,
"explanations": [
{
"index": "customers",
"valid": true,
"explanation": "blended(terms:[last_name.edge:john, last_name:john, first_name:john, first_name.edge:john]) blended(terms:[last_name.edge:doe, last_name:doe, first_name:doe, first_name.edge:doe])"
}
]
}
Фразовый запрос
Фразовый запрос ведет себя аналогично запросу best_fields, но использует запрос match_phrase вместо match.
Следующий пример демонстрирует фразовый запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern lights",
"type": "phrase",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase": { "title": "northern lights" }},
{ "match_phrase": { "description": "northern lights" }}
]
}
}
}
Поскольку по умолчанию фразовый запрос совпадает с текстом только тогда, когда термины появляются в одном и том же порядке, в результатах возвращается только документ 1:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.84407747,
"hits": [
{
"_index": "articles",
"_id": "1",
"_score": 0.84407747,
"_source": {
"title": "Aurora borealis",
"description": "Northern lights, or aurora borealis, explained"
}
}
]
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса. Например, следующий запрос принимает текст как совпадение, если между словами “fluorescent” и “therapy” находится до двух слов:
GET articles/_search
{
"query": {
"multi_match": {
"query": "fluorescent therapy",
"type": "phrase",
"fields": ["title", "description"],
"slop": 2
}
}
}
Ответ
В этом случае ответ содержит документ 2:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.7003825,
"hits": [
{
"_index": "articles",
"_id": "2",
"_score": 0.7003825,
"_source": {
"title": "Sun deprivation in the Northern countries",
"description": "Using fluorescent lights for therapy"
}
}
]
}
}
Для значений slop, меньших чем 2, документы не возвращаются.
Параметр fuzziness не поддерживается для фразовых запросов.
Фразовый префиксный запрос
Фразовый префиксный запрос ведет себя аналогично фразовому запросу, но использует запрос match_phrase_prefix вместо match_phrase.
Следующий пример демонстрирует фразовый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "northern light",
"type": "phrase_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_phrase_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_phrase_prefix": { "title": "northern light" }},
{ "match_phrase_prefix": { "description": "northern light" }}
]
}
}
}
Вы можете использовать параметр slop, чтобы разрешить наличие других слов между словами в фразе запроса.
Параметр fuzziness не поддерживается для фразовых префиксных запросов.
Булевый префиксный запрос
Булевый префиксный запрос оценивает документы аналогично запросу most_fields, но использует запрос match_bool_prefix вместо match.
Следующий пример демонстрирует булевый префиксный запрос для индекса, описанного в разделе best_fields:
GET articles/_search
{
"query": {
"multi_match": {
"query": "li northern",
"type": "bool_prefix",
"fields": ["title", "description"]
}
}
}
Предыдущий запрос выполняется как следующий запрос dis_max с match_bool_prefix для каждого поля:
GET articles/_search
{
"query": {
"dis_max": {
"queries": [
{ "match_bool_prefix": { "title": "li northern" }},
{ "match_bool_prefix": { "description": "li northern" }}
]
}
}
}
Параметры fuzziness, prefix_length, max_expansions, fuzzy_rewrite и fuzzy_transpositions поддерживаются для терминов, которые используются для построения термовых запросов, но они не оказывают влияния на префиксный запрос, построенный из конечного термина.
Параметры
Запрос принимает следующие параметры. Все параметры, кроме query, являются необязательными.
-
query (Строка): Строка запроса, используемая для поиска. Обязательный параметр.
-
auto_generate_synonyms_phrase_query (Булев): Указывает, следует ли автоматически создавать фразу запроса для многословных синонимов. Например, если вы укажете ba, batting average как синонимы и выполните поиск по ba, OpenSearch будет искать ba ИЛИ “batting average” (если этот параметр установлен в true) или ba ИЛИ (batting И average) (если этот параметр установлен в false). По умолчанию true.
-
analyzer (Строка): Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, указанный для поля default_field на этапе индексации. Если анализатор не указан для default_field, используется стандартный анализатор для индекса.
-
boost (Число с плавающей запятой): Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1.
-
fields (Массив строк): Список полей, в которых следует выполнять поиск. Если вы не укажете параметр fields, запрос multi_match будет искать в полях, указанных в настройке index.query.default_field, которая по умолчанию равна *.
-
fuzziness (Строка): Количество изменений символов (вставка, удаление, замена), необходимых для преобразования одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между wined и wind равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение в зависимости от длины каждого термина и является хорошим выбором для большинства случаев.
-
fuzzy_rewrite (Строка): Определяет, как OpenSearch переписывает запрос. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. Если параметр fuzziness не равен 0, запрос использует метод переписывания fuzzy_rewrite по умолчанию top_terms_blended_freqs_${max_expansions}. По умолчанию constant_score.
-
fuzzy_transpositions (Булев): Установка fuzzy_transpositions в true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между wind и wnid равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если false (удаление “n”, вставка “n”). По умолчанию является хорошим выбором для большинства случаев.
-
lenient (Булев): Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false.
-
max_expansions (Положительное целое число): Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа соответствующих терминов, которые находятся в пределах указанного расстояния в параметре fuzziness. По умолчанию 50.
-
minimum_should_match (Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация): Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны соответствовать, чтобы документ считался совпадением. Например, если minimum_should_match равно 2, wind often rising не соответствует The Wind Rises. Если minimum_should_match равно 1, совпадает. Для подробностей см. Minimum should match.
-
operator (Строка): Если строка запроса содержит несколько поисковых терминов, нужно ли, чтобы все термины соответствовали (AND) или только один термин должен соответствовать (OR), чтобы документ считался совпадением. Допустимые значения:
- OR: Строка интерпретируется как “или”.
- AND: Строка интерпретируется как “и”.
По умолчанию используется OR.
-
prefix_length (Неотрицательное целое число): Количество начальных символов, которые не учитываются при вычислении fuzziness. По умолчанию 0.
-
slop (0 по умолчанию или положительное целое число): Контролирует степень, в которой слова в запросе могут быть перепутаны и все еще считаться совпадением. Из документации Lucene: “Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы поменять местами два слова, требуется два перемещения (первое перемещение ставит слова друг на друга), поэтому для разрешения перестановок фраз значение slop должно быть не менее двух. Значение ноль требует точного совпадения.” Поддерживается для типов запросов phrase и phrase_prefix.
-
tie_breaker (Число с плавающей запятой): Фактор между 0 и 1.0, который используется для придания большего веса документам, соответствующим нескольким условиям запроса. Для получения дополнительной информации см. параметр tie_breaker.
-
type (Строка): Тип запроса multi-match. Допустимые значения: best_fields, most_fields, cross_fields, phrase, phrase_prefix, bool_prefix. По умолчанию используется best_fields.
-
zero_terms_query (Строка): В некоторых случаях анализатор удаляет все термины из строки запроса. Например, анализатор стоп-слов удаляет все термины из строки, кроме “this”. В таких случаях zero_terms_query указывает, следует ли не соответствовать ни одному документу (none) или всем документам (all). Допустимые значения: none и all. По умолчанию используется none.
Параметр fuzziness не поддерживается для запросов типов phrase, phrase_prefix и cross_fields.
Параметр slop поддерживается только для запросов типов phrase и phrase_prefix.
Параметр tie_breaker:
Каждый запрос на уровне терминов с объединением вычисляет оценку документа как наилучшую оценку, возвращенную любым полем в группе. Оценки от всех объединенных запросов складываются, чтобы получить окончательную оценку. Вы можете изменить способ вычисления оценки, используя параметр tie_breaker. Параметр tie_breaker принимает следующие значения:
-
0.0 (по умолчанию для запросов типов best_fields, cross_fields, phrase и phrase_prefix): Берется единственная наилучшая оценка, возвращенная любым полем в группе.
-
1.0 (по умолчанию для запросов типов most_fields и bool_prefix): Складываются оценки для всех полей в группе.
-
Число с плавающей запятой в диапазоне (0, 1): Берется единственная наилучшая оценка наилучшего соответствующего поля и добавляется (tie_breaker * _score) для всех других соответствующих полей.
6 - query-string
Использует строгий синтаксис для указания логических условий и поиска по нескольким полям в одной строке запроса.
Запрос типа query_string
Запрос типа query_string разбирает строку запроса на основе синтаксиса строки запроса. Он позволяет создавать мощные, но лаконичные запросы, которые могут включать подстановочные знаки и осуществлять поиск по нескольким полям.
Поиски с использованием запросов типа query_string не возвращают вложенные документы. Для поиска по вложенным полям используйте вложенный запрос.
Запрос типа query_string имеет строгий синтаксис и возвращает ошибку в случае недопустимого синтаксиса. Поэтому он не подходит для приложений с текстовыми полями поиска. Для менее строгой альтернативы рассмотрите использование запроса simple_query_string. Если вам не нужна поддержка синтаксиса запроса, используйте запрос match.
Синтаксис строки запроса
Синтаксис строки запроса основан на синтаксисе запросов Apache Lucene.
Вы можете использовать синтаксис строки запроса в следующих случаях:
-
В запросе типа query_string, например:
GET _search
{
"query": {
"query_string": {
"query": "the wind AND (rises OR rising)"
}
}
}
-
В приложениях OpenSearch Dashboards Discover или Dashboard, если вы отключите DQL, как показано на следующем изображении. Использование синтаксиса строки запроса в OpenSearch Dashboards Discover.
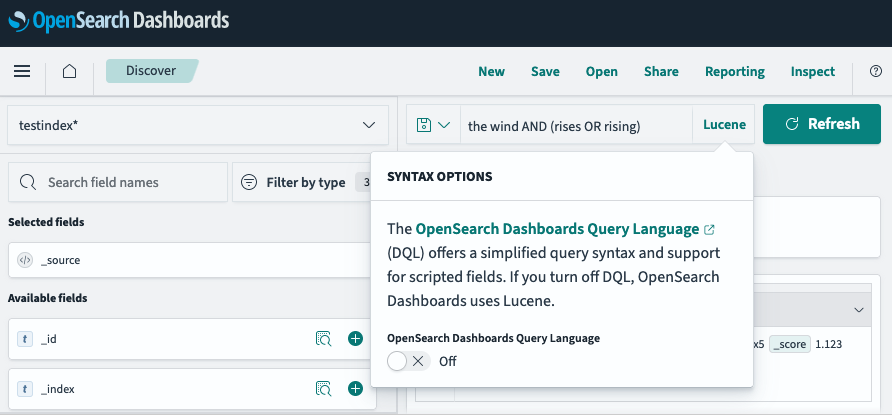
DQL и язык запросов query_string (Lucene) являются двумя вариантами языка для строк поиска в Discover и Dashboards. Для сравнения этих языковых опций смотрите раздел о строках поиска Discover и Dashboard.
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises термины — это wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова сопоставляются в порядке их появления (например, "wind rises"). Операторы (такие как OR, AND и NOT) определяют логическую связь, используемую для интерпретации текста в строке запроса.
Примеры в этом разделе используют индекс, содержащий следующую схему и документы:
PUT /testindex
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
PUT /testindex/_doc/1
{
"title": "The wind rises"
}
PUT /testindex/_doc/2
{
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
PUT /testindex/_doc/3
{
"title": "Windy city"
}
PUT /testindex/_doc/4
{
"article title": "Wind turbines"
}
Зарезервированные символы
Следующий список содержит зарезервированные символы для запроса типа query_string:
+, -, =, &&, ||, >, <, !, (, ), {, }, [, ], ^, ", ~, *, ?, :, \, /
Экранируйте зарезервированные символы с помощью обратной косой черты (). При отправке JSON-запроса используйте двойную обратную косую черту (\) для экранирования зарезервированных символов (поскольку символ обратной косой черты сам по себе является зарезервированным, вы должны экранировать его с помощью другой обратной косой черты).
Например, чтобы выполнить поиск по выражению 2*3, укажите строку запроса: 2\\*3:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: 2\\*3"
}
}
}
Знаки > и < не могут быть экранированы. Они интерпретируются как запрос диапазона.
Пробелы и пустые запросы
Символы пробела не считаются операторами. Если строка запроса пуста или содержит только символы пробела, запрос не возвращает результатов.
Имена полей
Укажите имя поля перед двоеточием. В следующей таблице приведены примеры запросов с именами полей.
| Запрос в запросе типа query_string |
Запрос в Discover |
Критерий для соответствия документа |
Соответствующие документы из индекса testindex |
| title: wind |
title: wind |
Поле title содержит слово wind. |
1, 2 |
| title: (wind OR windy) |
title: (wind OR windy) |
Поле title содержит слово wind или слово windy. |
1, 2, 3 |
| title: "wind rises" |
title: “wind rises” |
Поле title содержит фразу wind rises. Экранируйте кавычки с помощью обратной косой черты. |
1 |
| article\ title: wind |
article\ title: wind |
Поле article title содержит слово wind. Экранируйте пробел с помощью обратной косой черты. |
4 |
| title.\*: rise |
title.*: rise |
Каждое поле, начинающееся с title. (в этом примере, title.english) содержит слово rise. Экранируйте символ подстановки с помощью обратной косой черты. |
1 |
| exists: description |
exists: description |
Поле description существует. |
2 |
Подстановочные выражения
Вы можете указывать подстановочные выражения, используя специальные символы: ? заменяет один символ, а * заменяет ноль или более символов.
Пример
Следующий запрос ищет заголовок, содержащий слово “gone”, и описание, которое содержит слово, начинающееся с “hist”:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: gone AND description: hist*"
}
}
}
Запросы с подстановочными знаками могут использовать значительное количество памяти, что может ухудшить производительность. Подстановочные знаки в начале слова (например, *cal) являются наиболее затратными, поскольку сопоставление документов с такими подстановочными знаками требует проверки всех терминов в индексе. Чтобы отключить ведущие подстановочные знаки, установите параметр allow_leading_wildcard в значение false.
Для повышения эффективности чистые подстановочные знаки, такие как *, переписываются как запросы на существование. Таким образом, запрос description: * будет соответствовать документам, содержащим пустое значение в поле описания, но не будет соответствовать документам, в которых поле описания отсутствует или имеет значение null.
Если вы установите analyze_wildcard в значение true, OpenSearch будет анализировать запросы, которые заканчиваются на * (например, hist*). В результате OpenSearch создаст логический запрос, состоящий из полученных токенов, принимая точные совпадения для первых n-1 токенов и префиксное совпадение для последнего токена.
Регулярные выражения
Чтобы указать шаблоны регулярных выражений в строке запроса, окружите их косыми чертами (/), например, title: /w[a-z]nd/.
Параметр allow_leading_wildcard не применяется к регулярным выражениям. Например, строка запроса, такая как /.*d/, будет проверять все термины в индексе.
Нечеткий поиск
Вы можете выполнять нечеткие запросы, используя оператор ~, например, title: rise~.
Запрос ищет документы, содержащие термины, похожие на искомый термин в пределах максимального допустимого расстояния редактирования. Расстояние редактирования определяется как расстояние Дамерау-Левенштейна, которое измеряет количество изменений одного символа (вставок, удалений, замен или перестановок), необходимых для преобразования одного термина в другой.
По умолчанию расстояние редактирования равно 2, что должно охватывать 80% опечаток. Чтобы изменить значение по умолчанию для расстояния редактирования, укажите новое расстояние редактирования после оператора ~. Например, чтобы установить расстояние редактирования равным 1, используйте запрос title: rise~1.
Не смешивайте нечеткие и подстановочные операторы. Если вы укажете как нечеткий, так и подстановочный операторы, один из операторов не будет применен. Например, если вы можете выполнить поиск по wnid*~1, подстановочный оператор * будет применен, но нечеткий оператор ~1 не будет применен.
Запросы на близость
Запрос на близость не требует, чтобы искомая фраза была в указанном порядке. Он позволяет словам в фразе находиться в другом порядке или разделяться другими словами. Запрос на близость указывает максимальное расстояние редактирования между словами в фразе. Например, следующий запрос позволяет расстояние редактирования равное 4 при сопоставлении слов в указанной фразе:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: \"wind gone\"~4"
}
}
}
Когда OpenSearch сопоставляет документы, чем ближе слова в документе к порядку слов, указанному в запросе (тем меньше расстояние редактирования), тем выше оценка релевантности документа.
Диапазоны
Чтобы указать диапазон для числового, строкового или датированного поля, используйте квадратные скобки ([min TO max]) для включающего диапазона и фигурные скобки ({min TO max}) для исключающего диапазона. Вы также можете комбинировать квадратные и фигурные скобки, чтобы включить или исключить нижнюю и верхнюю границы (например, {min TO max]).
Даты для диапазона дат должны быть предоставлены в формате, который вы использовали при сопоставлении поля, содержащего дату. Для получения дополнительной информации о поддерживаемых форматах дат смотрите раздел Форматы.
Следующая таблица предоставляет примеры синтаксиса диапазонов.
| Тип данных |
Запрос |
Строка запроса |
| Числовой |
Документы, у которых номера счетов от 1 до 15, включительно. |
account_number: [1 TO 15] или account_number: (>=1 AND <=15) или account_number: (+>=1 +<=15) |
|
Документы, у которых номера счетов 15 и больше. |
account_number: [15 TO *] или account_number: >=15 (обратите внимание, что после знака >= нет пробела) |
| Строковой |
Документы, где фамилия от Bates, включительно, до Duke, исключительно. |
lastname: [Bates TO Duke} или lastname: (>=Bates AND <Duke) |
|
Документы, где фамилия предшествует Bates в алфавитном порядке. |
lastname: {* TO Bates} или lastname: <Bates (обратите внимание, что после знака < нет пробела) |
| Дата |
Документы, где дата выпуска между 21.03.2023 и 25.09.2023, включительно. |
release_date: [03/21/2023 TO 09/25/2023] |
В качестве альтернативы указанию диапазона в строке запроса вы можете использовать запрос диапазона, который предоставляет более надежный синтаксис.
Увеличение релевантности
Используйте оператор увеличения (^) для увеличения оценки релевантности документов на заданный множитель. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию используется 1.
Следующая таблица предоставляет примеры увеличения релевантности.
| Тип |
Описание |
Строка запроса |
| Увеличение слова |
Найти все адреса, содержащие слово street, и увеличить вес тех, которые содержат слово Madison. |
address: Madison^2 street |
| Увеличение фразы |
Найти документы с заголовком, содержащим фразу wind rises, увеличив вес на 2. |
title: \"wind rises\"^2 |
|
Найти документы с заголовком, содержащим слова wind rises, и увеличить вес документов, содержащих фразу wind rises, на 2. |
title: (wind rises)^2 |
Логические операторы
Когда вы указываете поисковые термины в запросе, по умолчанию запрос возвращает документы, содержащие хотя бы один из указанных терминов. Вы можете использовать параметр default_operator, чтобы задать оператор для всех терминов. Таким образом, если вы установите default_operator в значение AND, все термины будут обязательными, в то время как если вы установите его в значение OR, все термины будут необязательными.
Операторы + и -
Если вы хотите более детально контролировать обязательные и необязательные термины, вы можете использовать операторы + и -. Оператор + делает следующий за ним термин обязательным, в то время как оператор - исключает следующий за ним термин.
Например, в строке запроса title: (gone +wind -turbines) указывается, что термин gone является необязательным, термин wind должен присутствовать, а термин turbines не должен присутствовать в заголовке соответствующих документов:
GET /testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone +wind -turbines)"
}
}
}
Запрос возвращает два соответствующих документа:
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Предыдущий запрос эквивалентен следующему логическому запросу:
GET testindex/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "wind"
}
},
"should": {
"match": {
"title": "gone"
}
},
"must_not": {
"match": {
"title": "turbines"
}
}
}
}
}
Обычные логические операторы
В качестве альтернативы вы можете использовать следующие логические операторы: AND, &&, OR, ||, NOT, !. Однако эти операторы не следуют правилам приоритета, поэтому вы должны использовать скобки, чтобы указать приоритет при использовании нескольких логических операторов. Например, строку запроса title: (gone +wind -turbines) можно переписать следующим образом, используя логические операторы:
title: ((gone AND wind) OR wind) AND NOT turbines
Запустите следующий запрос, содержащий переписанную строку запроса:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: ((gone AND wind) OR wind) AND NOT turbines"
}
}
}
Запрос возвращает те же результаты, что и запрос, использующий операторы + и -. Однако обратите внимание, что оценки релевантности соответствующих документов могут отличаться от предыдущих результатов:
{
"_index": "testindex",
"_id": "2",
"_score": 1.6166971,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
},
{
"_index": "testindex",
"_id": "1",
"_score": 0.3438858,
"_source": {
"title": "The wind rises"
}
}
Группировка
Группируйте несколько условий или терминов в подзапросы, используя скобки. Например, следующий запрос ищет документы, содержащие слова “gone” или “rises”, которые обязательно должны содержать слово “wind” в заголовке:
GET testindex/_search
{
"query": {
"query_string": {
"query": "title: (gone OR rises) AND wind"
}
}
}
Результаты содержат два соответствующих документа:
{
"_index": "testindex",
"_id": "1",
"_score": 1.5046883,
"_source": {
"title": "The wind rises"
}
},
{
"_index": "testindex",
"_id": "2",
"_score": 1.3159468,
"_source": {
"title": "Gone with the wind",
"description": "A 1939 American epic historical film"
}
}
Вы также можете использовать группировку для увеличения веса результатов подзапросов или для указания конкретного поля, например: title:(gone AND wind) description:(historical film)^2.
Поиск по нескольким полям
Чтобы выполнить поиск по нескольким полям, используйте параметр fields. Когда вы указываете параметр fields, запрос переписывается в формате field_1: query OR field_2: query ....
Например, следующий запрос ищет термины “ветер” или “фильм” в полях заголовка и описания:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title", "description" ],
"query": "ветер AND фильм"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields:
GET testindex/_search
{
"query": {
"query_string": {
"query": "(title:ветер OR description:ветер) AND (title:фильм OR description:фильм)"
}
}
}
Поиск по нескольким подполям поля
Чтобы выполнить поиск по всем внутренним полям, вы можете использовать подстановочный знак. Например, чтобы искать по всем подполям в поле address, используйте следующий запрос:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields" : ["address.*"],
"query" : "Нью AND (Йорк OR Джерси)"
}
}
}
Предыдущий запрос эквивалентен следующему запросу, который не использует параметр fields (обратите внимание, что * экранируется с помощью \\):
GET /testindex/_search
{
"query": {
"query_string" : {
"query": "address.\\*: Нью AND (Йорк OR Джерси)"
}
}
}
Увеличение веса (Boosting)
Подзапросы, которые генерируются для каждого поискового термина, комбинируются с помощью запроса dis_max с параметром tie_breaker. Чтобы увеличить вес отдельных полей, используйте оператор ^. Например, следующий запрос увеличивает вес поля заголовка в 2 раза:
GET testindex/_search
{
"query": {
"query_string": {
"fields": [ "title^2", "description" ],
"query": "ветер AND фильм"
}
}
}
Чтобы увеличить вес всех подполей поля, укажите оператор увеличения после подстановочного знака:
GET /testindex/_search
{
"query": {
"query_string" : {
"fields": ["work_address", "address.*^2"],
"query": "Нью AND (Йорк OR Джерси)"
}
}
}
Параметры для поиска по нескольким полям
При выполнении поиска по нескольким полям вы можете передать дополнительный необязательный параметр type в запрос query_string.
| Параметр |
Тип данных |
Описание |
| type |
String |
Определяет, как OpenSearch выполняет запрос и оценивает результаты. Допустимые значения: best_fields, bool_prefix, most_fields, cross_fields, phrase и phrase_prefix. Значение по умолчанию — best_fields. Для описания допустимых значений см. раздел о типах многоцелевых запросов. |
Описание допустимых значений для параметра type
- best_fields: Использует наилучшие поля для оценки результатов. Это значение по умолчанию.
- bool_prefix: Позволяет использовать префиксы для логических операторов, что позволяет более гибко формировать запросы.
- most_fields: Оценивает результаты, используя все поля, что может быть полезно для более широкого поиска.
- cross_fields: Объединяет все поля в один общий запрос, что позволяет искать по всем полям одновременно.
- phrase: Ищет точные фразы в указанных полях.
- phrase_prefix: Позволяет искать фразы с префиксами, что может быть полезно для автозаполнения.
Эти параметры позволяют более точно настраивать поведение поиска в OpenSearch в зависимости от ваших потребностей.
Синонимы в запросе query_string
Запрос query_string поддерживает расширение синонимов с несколькими терминами с помощью фильтра токенов synonym_graph. Если вы используете фильтр synonym_graph, OpenSearch создает запрос на совпадение фразы для каждого синонима.
Параметр auto_generate_synonyms_phrase_query указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. По умолчанию auto_generate_synonyms_phrase_query установлен в true, поэтому, если вы укажете “ml” и “machine learning” как синонимы и выполните поиск по “ml”, OpenSearch будет искать ml OR "machine learning".
В качестве альтернативы вы можете сопоставлять многословные синонимы, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в false, OpenSearch будет искать ml OR (machine AND learning).
Пример запроса с отключенной авто-генерацией фраз
Следующий запрос ищет текст “ml models” и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Минимальное количество совпадений
Запрос query_string разбивает запрос вокруг каждого оператора и создает булев запрос для всего ввода. Параметр minimum_should_match указывает минимальное количество терминов, которые документ должен соответствовать, чтобы быть возвращенным в результатах поиска. Например, следующий запрос указывает, что поле description должно соответствовать как минимум двум терминам для каждого результата поиска:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"description"
],
"query": "historical epic film",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (description:historical description:epic description:film)~2.
Эти функции позволяют более гибко настраивать поиск и управлять тем, как обрабатываются синонимы и минимальные условия для совпадений.
Минимальное количество совпадений с несколькими полями
Если вы указываете несколько полей в запросе query_string, OpenSearch создает запрос dis_max для указанных полей. Если вы не указываете оператор для терминов запроса, весь текст запроса рассматривается как одно условие. OpenSearch строит запрос для каждого поля, используя это одно условие. В конечном булевом запросе содержится одно условие, соответствующее запросу dis_max для всех полей, поэтому параметр minimum_should_match не применяется.
Пример без явных операторов
В следующем запросе “historical epic heroic” рассматривается как одно условие:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical title:epic title:heroic) | (description:historical description:epic description:heroic)).
Пример с явными операторами
Если вы добавите явные операторы (AND или OR) к терминам запроса, каждый термин будет рассматриваться как отдельное условие, к которому можно применить параметр minimum_should_match. Например, в следующем запросе “historical”, “epic” и “heroic” считаются отдельными условиями:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical OR epic OR heroic",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Запрос соответствует как минимум двум из трех условий. Каждое условие представляет собой запрос dis_max по полям title и description для каждого термина.
Использование параметра type
В качестве альтернативы, чтобы гарантировать применение minimum_should_match, вы можете установить параметр type в значение cross_fields. Это указывает на то, что поля с одинаковым анализатором должны быть сгруппированы вместе при анализе входного текста:
GET /testindex/_search
{
"query": {
"query_string": {
"fields": [
"title",
"description"
],
"query": "historical epic heroic",
"type": "cross_fields",
"minimum_should_match": 2
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос:
((title:historical | description:historical) (description:epic | title:epic) (description:heroic | title:heroic))~2.
Однако, если вы используете разные анализаторы, вам необходимо использовать явные операторы в запросе, чтобы гарантировать применение параметра minimum_should_match к каждому термину.
Параметры запроса query_string
Следующая таблица перечисляет параметры, поддерживаемые запросом query_string. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
| query |
String |
Текст, который может содержать выражения в синтаксисе строки запроса для поиска. Обязательный параметр. |
| allow_leading_wildcard |
Boolean |
Указывает, разрешены ли символы * и ? в качестве первых символов поискового термина. По умолчанию true. |
| analyze_wildcard |
Boolean |
Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию false. |
| analyzer |
String |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Дополнительную информацию о index.query.default_field см. в разделе о динамических настройках уровня индекса. |
| auto_generate_synonyms_phrase_query |
Boolean |
Указывает, следует ли автоматически создавать запрос на совпадение фразы для многословных синонимов. Например, если вы укажете “ba” и “batting average” как синонимы и выполните поиск по “ba”, OpenSearch будет искать ba OR "batting average" (если этот параметр установлен в true) или ba OR (batting AND average) (если установлен в false). По умолчанию true. |
| boost |
Floating-point |
Увеличивает вес условия на заданный множитель. Полезно для оценки условий в составных запросах. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. По умолчанию 1. |
| default_field |
String |
Поле, в котором следует выполнять поиск, если поле не указано в строке запроса. Поддерживает подстановочные знаки. По умолчанию используется значение, указанное в настройках индекса index.query.default_field. По умолчанию index.query.default_field равно *, что означает извлечение всех полей, подходящих для термового запроса, и фильтрацию метаданных. Извлеченные поля объединяются в запрос, если префикс не указан. Подходящие поля не включают вложенные документы. Поиск по всем подходящим полям может быть ресурсоемкой операцией. Настройка indices.query.bool.max_clause_count определяет максимальное значение для произведения количества полей и количества терминов, которые могут быть запрошены одновременно. Значение по умолчанию для indices.query.bool.max_clause_count равно 1,024. |
| default_operator |
String |
Если строка запроса содержит несколько поисковых терминов, указывает, нужно ли, чтобы все термины соответствовали (AND) или достаточно, чтобы соответствовал только один термин (OR) для того, чтобы документ считался совпадающим. Допустимые значения:
- OR: строка интерпретируется как “или”
- AND: строка интерпретируется как “и”. По умолчанию OR. |
| enable_position_increments |
Boolean |
Когда установлено в true, результирующие запросы учитывают инкременты позиции. Эта настройка полезна, когда удаление стоп-слов оставляет нежелательный “разрыв” между терминами. По умолчанию true. |
| fields |
String array |
Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется значение, указанное в настройках индекса index.query.default_field, которое по умолчанию равно ["*"]. |
| fuzziness |
String |
Количество изменений символов (вставка, удаление, замена), необходимых для изменения одного слова в другое при определении, соответствует ли термин значению. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO, что является хорошим выбором для большинства случаев. |
| fuzzy_max_expansions |
Positive integer |
Максимальное количество терминов, к которым может расширяться запрос. Неопределенные запросы “расширяются” до числа совпадающих терминов, которые находятся в пределах расстояния, указанного в fuzziness. Затем OpenSearch пытается сопоставить эти термины. По умолчанию 50. |
| fuzzy_transpositions |
Boolean |
Установка fuzzy_transpositions в true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false. По умолчанию — хороший выбор для большинства случаев. |
| lenient |
Boolean |
Установка lenient в true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию false. |
| max_determinized_states |
Positive integer |
Максимальное количество “состояний” (меры сложности), которые Lucene может создать для строк запросов, содержащих регулярные выражения (например, "query": "/wind.+?/"). Более крупные числа позволяют выполнять запросы, использующие больше памяти. По умолчанию 10,000. |
| minimum_should_match |
Positive or negative integer, positive or negative percentage, combination |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор OR, количество терминов, которые должны соответствовать, чтобы документ считался совпадающим. Например, если minimum_should_match равно 2, “wind often rising” не соответствует “The Wind Rises”. Если minimum_should_match равно 1, он соответствует. |
| phrase_slop |
Integer |
Максимальное количество слов, которые могут находиться между совпадающими словами. Если phrase_slop равно 2, максимальное количество двух слов разрешено между совпадающими словами в фразе. Переставленные слова имеют слоп 2. По умолчанию 0 (точное совпадение фразы, где совпадающие слова должны находиться рядом друг с другом). |
| quote_analyzer |
String |
Анализатор, используемый для токенизации текста в кавычках в строке запроса. Переопределяет параметр analyzer для текста в кавычках. По умолчанию используется search_quote_analyzer, указанный для default_field. |
| quote_field_suffix |
String |
Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неточных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово “lightly” в поле title.exact. Это второе поле может использовать другой тип (например, keyword вместо text) или другой анализатор. |
| rewrite |
String |
Определяет, как OpenSearch переписывает и оценивает многословные запросы. Допустимые значения: constant_score, scoring_boolean, constant_score_boolean, top_terms_N, top_terms_boost_N и top_terms_blended_freqs_N. По умолчанию используется constant_score. |
| time_zone |
String |
Указывает количество часов для смещения желаемого часового пояса от UTC. Необходимо указать номер смещения часового пояса, если строка запроса содержит диапазон дат. Например, установите time_zone": "-08:00" для запроса с диапазоном дат, таким как "query": "wind rises release_date[2012-01-01 TO 2014-01-01]". Формат часового пояса по умолчанию для указания количества смещения часов — UTC. |
Дополнительные сведения
Запросы строки запроса могут быть внутренне преобразованы в префиксные запросы. Если параметр search.allow_expensive_queries установлен в false, префиксные запросы не выполняются. Если index_prefixes включен, настройка search.allow_expensive_queries игнорируется, и создается и выполняется оптимизированный запрос.
7 - simple-query-string
Более простая, менее строгая версия запроса query_string.
Простой запрос с использованием simple_query_string
Используйте тип simple_query_string, чтобы указать несколько аргументов, разделенных регулярными выражениями, непосредственно в строке запроса. Простой запрос имеет менее строгий синтаксис, чем обычный запрос, поскольку отбрасывает любые недопустимые части строки и не возвращает ошибки за недопустимый синтаксис.
Этот запрос выполняет нечеткий поиск по полю title:
GET _search
{
"query": {
"simple_query_string": {
"query": "\"rises wind the\"~4 | *ising~2",
"fields": ["title"]
}
}
}
Синтаксис простого запроса
Строка запроса состоит из терминов и операторов. Термин — это одно слово (например, в запросе wind rises терминами являются wind и rises). Если несколько терминов заключены в кавычки, они рассматриваются как одна фраза, где слова совпадают в порядке их появления (например, "wind rises"). Операторы, такие как +, | и -, определяют логическую связь, используемую для интерпретации текста в строке запроса.
Операторы
Синтаксис простого запроса поддерживает следующие операторы:
| Оператор |
Описание |
+ |
Действует как оператор AND. |
| ` |
` |
* |
Когда используется в конце термина, обозначает префиксный запрос. |
" |
Обрамляет несколько терминов в фразу (например, "wind rises"). |
(, ) |
Обрамляет клаузу для приоритета (например, `wind + (rises |
~n |
Когда используется после термина (например, wind~3), устанавливает нечеткость. Когда используется после фразы, устанавливает слоп. |
- |
Отрицает термин. |
Все вышеперечисленные операторы являются зарезервированными символами. Чтобы ссылаться на них как на обычные символы, необходимо экранировать их с помощью обратной косой черты. При отправке JSON-запроса используйте \\, чтобы экранировать зарезервированные символы (поскольку символ обратной косой черты сам по себе является зарезервированным, его необходимо экранировать еще одной обратной косой чертой).
Оператор по умолчанию
Оператор по умолчанию — OR (если вы не установите default_operator в AND). Оператор по умолчанию определяет общее поведение запроса. Например, рассмотрим индекс, содержащий следующие документы:
PUT /customers/_doc/1
{
"first_name":"Amber",
"last_name":"Duke",
"address":"880 Holmes Lane"
}
PUT /customers/_doc/2
{
"first_name":"Hattie",
"last_name":"Bond",
"address":"671 Bristol Street"
}
PUT /customers/_doc/3
{
"first_name":"Nanette",
"last_name":"Bates",
"address":"789 Madison St"
}
PUT /customers/_doc/4
{
"first_name":"Dale",
"last_name":"Amber",
"address":"467 Hutchinson Court"
}
Следующий запрос пытается найти документы, в которых адрес содержит слова street или st и не содержит слово madison:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st -madison"
}
}
}
Однако результаты включают не только ожидаемый документ, но и все четыре документа:
Ответ
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
},
{
"_index": "customers",
"_id": "3",
"_score": 1.2039728,
"_source": {
"first_name": "Nanette",
"last_name": "Bates",
"address": "789 Madison St"
}
},
{
"_index": "customers",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "Amber",
"last_name": "Duke",
"address": "880 Holmes Lane"
}
},
{
"_index": "customers",
"_id": "4",
"_score": 1,
"_source": {
"first_name": "Dale",
"last_name": "Amber",
"address": "467 Hutchinson Court"
}
}
]
}
}
Поскольку оператор по умолчанию — OR, этот запрос включает документы, которые содержат слова street или st (документы 2 и 3), а также документы, которые не содержат слово madison (документы 1 и 4).
Чтобы правильно выразить намерение запроса, предшествуйте -madison знаком +:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "street st +-madison"
}
}
}
Альтернативный подход
Или укажите AND в качестве оператора по умолчанию и используйте дизъюнкцию для слов street и st:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "st|street -madison",
"default_operator": "AND"
}
}
}
Предыдущий запрос возвращает документ 2:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.2039728,
"hits": [
{
"_index": "customers",
"_id": "2",
"_score": 2.2039728,
"_source": {
"first_name": "Hattie",
"last_name": "Bond",
"address": "671 Bristol Street"
}
}
]
}
}
Таким образом, использование правильного оператора и синтаксиса позволяет точно формулировать запросы и получать ожидаемые результаты.
Ограничение операторов
Чтобы ограничить поддерживаемые операторы для парсера простого запроса, включите операторы, которые вы хотите поддерживать, разделенные символом |, в параметр flags. Например, следующий запрос включает только операторы OR, AND и FUZZY:
GET /customers/_search
{
"query": {
"simple_query_string": {
"fields": [ "address" ],
"query": "bristol | madison +stre~2",
"flags": "OR|AND|FUZZY"
}
}
}
Доступные флаги операторов
Следующая таблица перечисляет все доступные флаги операторов:
| Флаг |
Описание |
ALL (по умолчанию) |
Включает все операторы. |
AND |
Включает оператор + (AND). |
ESCAPE |
Включает \ как символ экранирования. |
FUZZY |
Включает оператор ~n после слова, где n — целое число, обозначающее допустимое расстояние редактирования для совпадения. |
NEAR |
Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и SLOP. |
NONE |
Отключает все операторы. |
NOT |
Включает оператор - (NOT). |
OR |
Включает оператор ` |
PHRASE |
Включает кавычки " для поиска фраз. |
PRECEDENCE |
Включает операторы ( и ) (скобки) для приоритета операторов. |
PREFIX |
Включает оператор * (префикс). |
SLOP |
Включает оператор ~n после фразы, где n — максимальное количество позиций, разрешенных между совпадающими токенами. То же самое, что и NEAR. |
WHITESPACE |
Включает пробелы как символы, по которым текст разбивается. |
Эти флаги позволяют гибко настраивать поведение парсера простого запроса в зависимости от ваших потребностей.
Шаблоны с подстановочными знаками
Вы можете указывать шаблоны с подстановочными знаками, используя специальный символ *, который заменяет ноль или более символов. Например, следующий запрос ищет во всех полях, которые заканчиваются на name:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber Bond",
"fields": [ "*name" ]
}
}
}
Увеличение значимости
Используйте оператор увеличения значимости (^) для увеличения оценки релевантности поля с помощью множителя. Значения в диапазоне [0, 1) уменьшают релевантность, а значения больше 1 увеличивают релевантность. Значение по умолчанию — 1.
Например, следующий запрос ищет в полях first_name и last_name и увеличивает значимость совпадений из поля first_name в 2 раза:
GET /customers/_search
{
"query": {
"simple_query_string": {
"query": "Amber",
"fields": [ "first_name^2", "last_name" ]
}
}
}
Мультипозиционные токены
Для мультипозиционных токенов простой запрос создает запрос на совпадение фразы. Таким образом, если вы укажете ml, machine learning как синонимы и выполните поиск по ml, OpenSearch будет искать ml ИЛИ "machine learning".
В качестве альтернативы вы можете сопоставить мультипозиционные токены, используя соединения. Если вы установите auto_generate_synonyms_phrase_query в значение false, OpenSearch будет искать ml ИЛИ (machine И learning).
Например, следующий запрос ищет текст ml models и указывает, что не следует автоматически генерировать запрос на совпадение фразы для каждого синонима:
GET /testindex/_search
{
"query": {
"simple_query_string": {
"fields": ["title"],
"query": "ml models",
"auto_generate_synonyms_phrase_query": false
}
}
}
Для этого запроса OpenSearch создает следующий булев запрос: (ml OR (machine AND learning)) models.
Параметры
Следующая таблица перечисляет параметры верхнего уровня, которые поддерживает запрос simple_query_string. Все параметры, кроме query, являются необязательными.
| Параметр |
Тип данных |
Описание |
query |
Строка |
Текст, который может содержать выражения в синтаксисе простого запроса для использования в поиске. Обязательный параметр. |
analyze_wildcard |
Логический |
Указывает, должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. По умолчанию — false. |
analyzer |
Строка |
Анализатор, используемый для токенизации текста строки запроса. По умолчанию используется анализатор, заданный для default_field на этапе индексации. Если для default_field не указан анализатор, используется анализатор по умолчанию для индекса. Для получения дополнительной информации о index.query.default_field смотрите настройки динамического уровня индекса. |
auto_generate_synonyms_phrase_query |
Логический |
Указывает, следует ли автоматически создавать запросы на совпадение фразы для многословных синонимов. По умолчанию — true. |
default_operator |
Строка |
Если строка запроса содержит несколько поисковых терминов, указывает, должны ли совпадать все термины (AND) или только один термин (OR) для того, чтобы документ считался совпадением. Допустимые значения:
- OR: строка интерпретируется как OR
- AND: строка интерпретируется как AND
По умолчанию — OR. |
fields |
Массив строк |
Список полей для поиска (например, "fields": ["title^4", "description"]). Поддерживает подстановочные знаки. Если не указано, по умолчанию используется настройка index.query.default_field, которая по умолчанию равна ["*"]. Максимальное количество полей, которые могут быть одновременно исследованы, определяется параметром indices.query.bool.max_clause_count, который по умолчанию равен 1,024. |
flags |
Строка |
Строка, разделенная символом ` |
fuzzy_max_expansions |
Положительное целое число |
Максимальное количество терминов, на которые может расширяться запрос. Нечеткие запросы “расширяются” на количество совпадающих терминов, которые находятся в пределах указанного расстояния нечеткости. Затем OpenSearch пытается сопоставить эти термины. По умолчанию — 50. |
fuzzy_transpositions |
Логический |
Установка fuzzy_transpositions в значение true (по умолчанию) добавляет перестановки соседних символов к операциям вставки, удаления и замены в опции нечеткости. Например, расстояние между wind и wnid равно 1, если fuzzy_transpositions равно true (перестановка “n” и “i”) и 2, если оно равно false (удаление “n”, вставка “n”). Если fuzzy_transpositions равно false, rewind и wnid имеют одинаковое расстояние (2) от wind, несмотря на более человеческое мнение, что wnid является очевидной опечаткой. Значение по умолчанию является хорошим выбором для большинства случаев использования. |
fuzzy_prefix_length |
Целое число |
Количество начальных символов, которые остаются неизменными для нечеткого сопоставления. По умолчанию — 0. |
lenient |
Логический |
Установка lenient в значение true игнорирует несоответствия типов данных между запросом и полем документа. Например, строка запроса “8.2” может соответствовать полю типа float. По умолчанию — false. |
minimum_should_match |
Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация |
Если строка запроса содержит несколько поисковых терминов и вы используете оператор or, количество терминов, которые должны совпадать, чтобы документ считался совпадением. Например, если minimum_should_match равно 2, wind often rising не совпадает с The Wind Rises. Если minimum_should_match равно 1, совпадение происходит. Для получения подробной информации смотрите раздел “Минимальное количество совпадений”. |
quote_field_suffix |
Строка |
Этот параметр поддерживает поиск точных совпадений (окруженных кавычками) с использованием другого метода анализа, чем для неполных совпадений. Например, если quote_field_suffix равно .exact и вы ищете "lightly" в поле title, OpenSearch ищет слово lightly в поле title.exact. Это второе поле может использовать другой тип (например, keyword, а не text) или другой анализатор. |
8 - intervals query
Позволяет точно контролировать близость и порядок совпадающих терминов.
Запрос интервалов
Запрос интервалов сопоставляет документы на основе близости и порядка совпадающих терминов. Он применяет набор правил сопоставления к терминам, содержащимся в указанном поле. Запрос генерирует последовательности минимальных интервалов, охватывающих термины в тексте. Вы можете комбинировать интервалы и фильтровать их по родительским источникам.
Рассмотрим индекс, содержащий следующие документы:
PUT testindex/_doc/1
{
"title": "пары ключ-значение эффективно хранятся в хэш-таблице"
}
PUT /testindex/_doc/2
{
"title": "хранить пары ключ-значение в хэш-карте"
}
Например, следующий запрос ищет документы, содержащие фразу “пары ключ-значение” (без промежутков между терминами), за которой следует либо “хэш-таблица”, либо “хэш-карта”:
GET /testindex/_search
{
"query": {
"intervals": {
"title": {
"all_of": {
"ordered": true,
"intervals": [
{
"match": {
"query": "пары ключ-значение",
"max_gaps": 0,
"ordered": true
}
},
{
"any_of": {
"intervals": [
{
"match": {
"query": "хэш-таблица"
}
},
{
"match": {
"query": "хэш-карта"
}
}
]
}
}
]
}
}
}
}
}
Запрос возвращает оба документа.
Параметры
Запрос принимает имя поля (<field>) в качестве параметра верхнего уровня:
GET _search
{
"query": {
"intervals": {
"<field>": {
...
}
}
}
}
Поле <field> принимает следующие объекты правил, которые используются для сопоставления документов на основе терминов, порядка и близости.
| Правило |
Описание |
| match |
Сопоставляет анализируемый текст. |
| prefix |
Сопоставляет термины, которые начинаются с заданного набора символов. |
| wildcard |
Сопоставляет термины, используя шаблон с подстановочными знаками. |
| fuzzy |
Сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. |
| all_of |
Объединяет несколько правил с использованием конъюнкции (AND). |
| any_of |
Объединяет несколько правил с использованием дизъюнкции (OR). |
Правило match
Правило match сопоставляет анализируемый текст. В следующей таблице перечислены все параметры, которые поддерживает правило match.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| query |
Обязательный |
Строка |
Текст, по которому нужно выполнить поиск. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для анализа текста запроса. По умолчанию используется анализатор, указанный для <field>. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps |
Необязательный |
Целое число |
Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered |
Необязательный |
Логическое |
Указывает, должны ли совпадающие термины появляться в указанном порядке. По умолчанию false. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Термины анализируются с использованием анализатора поиска, указанного для этого поля. Указав use_field, вы можете искать по нескольким полям, как если бы они были одним и тем же полем. Например, если вы индексируете один и тот же текст в полях с корнями и без корней, вы можете искать корневые токены, которые находятся рядом с некорневыми. |
Правило prefix
Правило prefix сопоставляет термины, которые начинаются с заданного набора символов (префикс). Префикс может расширяться для сопоставления максимум 128 терминов. Если префикс соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило prefix.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| prefix |
Обязательный |
Строка |
Префикс, используемый для сопоставления терминов. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации префикса. По умолчанию используется анализатор, указанный для <field>. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Префикс нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило wildcard
Правило wildcard сопоставляет термины, используя шаблон с подстановочными знаками. Шаблон с подстановочными знаками может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило wildcard.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| pattern |
Обязательный |
Строка |
Шаблон с подстановочными знаками, используемый для сопоставления терминов. Укажите ? для сопоставления любого одного символа или * для сопоставления нуля или более символов. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации шаблона. По умолчанию используется анализатор, указанный для <field>. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Шаблон нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Указание шаблонов, начинающихся с * или ?, может ухудшить производительность поиска, так как увеличивает количество итераций, необходимых для сопоставления терминов.
Правило fuzzy
Правило fuzzy сопоставляет термины, которые похожи на предоставленный термин в пределах заданного расстояния редактирования. Шаблон fuzzy может расширяться для сопоставления максимум 128 терминов. Если шаблон соответствует более чем 128 терминам, возвращается ошибка. В следующей таблице перечислены все параметры, которые поддерживает правило fuzzy.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| term |
Обязательный |
Строка |
Термин для сопоставления. |
| analyzer |
Необязательный |
Строка |
Анализатор, используемый для нормализации термина. По умолчанию используется анализатор, указанный для <field>. |
| fuzziness |
Необязательный |
Строка |
Количество редактирований символов (вставка, удаление, замена), необходимых для изменения одного слова на другое при определении, совпадает ли термин со значением. Например, расстояние между “wined” и “wind” равно 1. Допустимые значения — неотрицательные целые числа или AUTO. По умолчанию AUTO выбирает значение на основе длины каждого термина и является хорошим выбором для большинства случаев использования. |
| transpositions |
Необязательный |
Логическое |
Установка transpositions в true (по умолчанию) добавляет обмены соседних символов к операциям вставки, удаления и замены в параметре fuzziness. Например, расстояние между “wind” и “wnid” равно 1, если transpositions равно true (обмен “n” и “i”), и 2, если false (удаление “n”, вставка “n”). Если transpositions равно false, “rewind” и “wnid” имеют одинаковое расстояние (2) от “wind”, несмотря на более человеческое мнение, что “wnid” является очевидной опечаткой. По умолчанию является хорошим выбором для большинства случаев использования. |
| prefix_length |
Необязательный |
Целое число |
Количество начальных символов, оставляемых неизменными для нечеткого сопоставления. По умолчанию 0. |
| use_field |
Необязательный |
Строка |
Указывает, что следует искать в этом поле вместо верхнего уровня. Термин нормализуется с использованием анализатора поиска, указанного для этого поля, если вы не укажете analyzer. |
Правило all_of
Правило all_of объединяет несколько правил с использованием конъюнкции (AND). В следующей таблице перечислены все параметры, которые поддерживает правило all_of.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| intervals |
Обязательный |
Массив объектов правил |
Массив правил для объединения. Документ должен соответствовать всем правилам, чтобы быть возвращенным в результатах. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
| max_gaps |
Необязательный |
Целое число |
Максимально допустимое количество позиций между совпадающими терминами. Термины, находящиеся дальше, чем max_gaps, не считаются совпадениями. Если max_gaps не указан или установлен в -1, термины считаются совпадениями независимо от их положения. Если max_gaps установлен в 0, совпадающие термины должны находиться рядом друг с другом. По умолчанию -1. |
| ordered |
Необязательный |
Логическое |
Если true, интервалы, сгенерированные правилами, должны появляться в указанном порядке. По умолчанию false. |
Правило any_of
Правило any_of объединяет несколько правил с использованием дизъюнкции (OR). В следующей таблице перечислены все параметры, которые поддерживает правило any_of.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| intervals |
Обязательный |
Массив объектов правил |
Массив правил для объединения. Документ должен соответствовать хотя бы одному правилу, чтобы быть возвращенным в результатах. |
| filter |
Необязательный |
Объект правила фильтра интервалов |
Правило, используемое для фильтрации возвращаемых интервалов. |
Правило filter
Правило filter используется для ограничения результатов. В следующей таблице перечислены все параметры, которые поддерживает правило filter.
| Параметр |
Обязательный/Необязательный |
Тип данных |
Описание |
| after |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые следуют за интервалом, указанным в правиле фильтра. |
| before |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые находятся перед интервалом, указанным в правиле фильтра. |
| contained_by |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, содержащихся в интервале, указанном в правиле фильтра. |
| containing |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые содержат интервал, указанный в правиле фильтра. |
| not_contained_by |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не содержатся в интервале, указанном в правиле фильтра. |
| not_containing |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не содержат интервал, указанный в правиле фильтра. |
| not_overlapping |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые не перекрываются с интервалом, указанным в правиле фильтра. |
| overlapping |
Необязательный |
Объект запроса |
Запрос, используемый для возврата интервалов, которые перекрываются с интервалом, указанным в правиле фильтра. |
| script |
Необязательный |
Объект скрипта |
Скрипт, используемый для сопоставления документов. Этот скрипт должен возвращать true или false. |
Пример: Фильтры
Следующий запрос ищет документы, содержащие слова “пары” и “хэш”, которые находятся в пределах пяти позиций друг от друга и не содержат слово “эффективно” между ними:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "пары хэш",
"max_gaps" : 5,
"filter" : {
"not_containing" : {
"match" : {
"query" : "эффективно"
}
}
}
}
}
}
}
}
Ответ содержит только документ 2.
Ответ
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.25,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.25,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Пример: Скриптовые фильтры
В качестве альтернативы вы можете написать свой собственный скриптовый фильтр для включения в запрос интервалов, используя следующие переменные:
interval.start: Позиция (номер термина), где начинается интервал.interval.end: Позиция (номер термина), где заканчивается интервал.interval.gap: Количество слов между терминами.
Например, следующий запрос ищет слова “карта” и “хэш”, которые находятся рядом друг с другом в указанном интервале. Термины нумеруются, начиная с 0, поэтому в тексте “хранить пары ключ-значение в хэш-карте” слово “хранить” находится на позиции 0, “пары” на позиции 1 и так далее. Указанный интервал должен начинаться после “а” и заканчиваться перед концом строки:
POST /testindex/_search
{
"query": {
"intervals" : {
"title" : {
"match" : {
"query" : "карта хэш",
"filter" : {
"script" : {
"source" : "interval.start > 5 && interval.end < 8 && interval.gaps == 0"
}
}
}
}
}
}
}
Ответ
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.5,
"hits": [
{
"_index": "testindex",
"_id": "2",
"_score": 0.5,
"_source": {
"title": "хранить пары ключ-значение в хэш-карте"
}
}
]
}
}
Минимизация интервалов
Чтобы гарантировать, что запросы выполняются за линейное время, запрос интервалов минимизирует интервалы. Например, рассмотрим документ, содержащий текст “a b c d c”. Вы можете использовать следующий запрос для поиска “d”, который содержится между “a” и “c”:
POST /testindex/_search
{
"query": {
"intervals" : {
"my_text" : {
"match" : {
"query" : "d",
"filter" : {
"contained_by" : {
"match" : {
"query" : "a c"
}
}
}
}
}
}
}
}
Запрос не возвращает результатов, потому что он сопоставляет первые два термина “a” и “c” и не находит “d” между этими терминами.