Микроразметка для СЕО поиска
Подборка материалов и переводов статей для объяснения механизмов, как выполняют поиск данных поисковые машины Google, Yandex и другие.
Микроразметка для поисковых систем: Google, Яндекс и другие
В современном цифровом мире важно не только создавать качественный контент, но и помогать поисковым системам правильно его интерпретировать. Микроразметка (Schema.org) — это мощный инструмент, который позволяет структурировать данные на сайте, улучшая их отображение в поисковой выдаче. С помощью микроразметки можно выделять рейтинги, цены, события, товары и многое другое, делая сниппеты более информативными и привлекательными для пользователей.
В этом разделе собраны подробные руководства по работе с микроразметкой для разных поисковых систем, включая Google, Яндекс и другие. Вы узнаете, какие форматы поддерживаются, как проверять разметку и какие ошибки стоит избегать.
1 - JSON-LD - микроразметка материалов для выдачи сниппетов в поиске Google
Перевод статьи с ресурса moz.com для начинающих и знакомящихся с микроразметкой JSON-LD
Оригинал статьи находится здесь
Руководство по JSON-LD для начинающих
Что такое JSON-LD?
JSON-LD расшифровывается как JavaScript Object Notation for Linked Data, что представляет собой многомерные массивы (представьте себе: список пар атрибут-значение).
Это формат реализации для структурирования данных, аналогичный Microdata и RDFa. Обычно, в контексте SEO, JSON-LD реализуется с использованием словаря Schema.org, совместной инициативы Google, Bing, Yahoo! и Yandex, созданной в 2011 году для создания единого словаря структурированных данных для веба. (Тем не менее, Bing и другие поисковые системы официально не заявили о своей поддержке реализаций JSON-LD для Schema.org.)
JSON-LD считается более простым в реализации, благодаря возможности просто вставить разметку в HTML-документ, в отличие от необходимости оборачивать разметку вокруг HTML-элементов (как это делается с Microdata).
Что делает JSON-LD?
JSON-LD аннотирует элементы на веб-странице, придавая данным структуру. Это позволяет поисковым системам лучше понимать содержимое, устранять неоднозначности и устанавливать связи между сущностями. В результате формируется более упорядоченная и понятная структура данных, что способствует созданию лучше организованного интернета в целом.
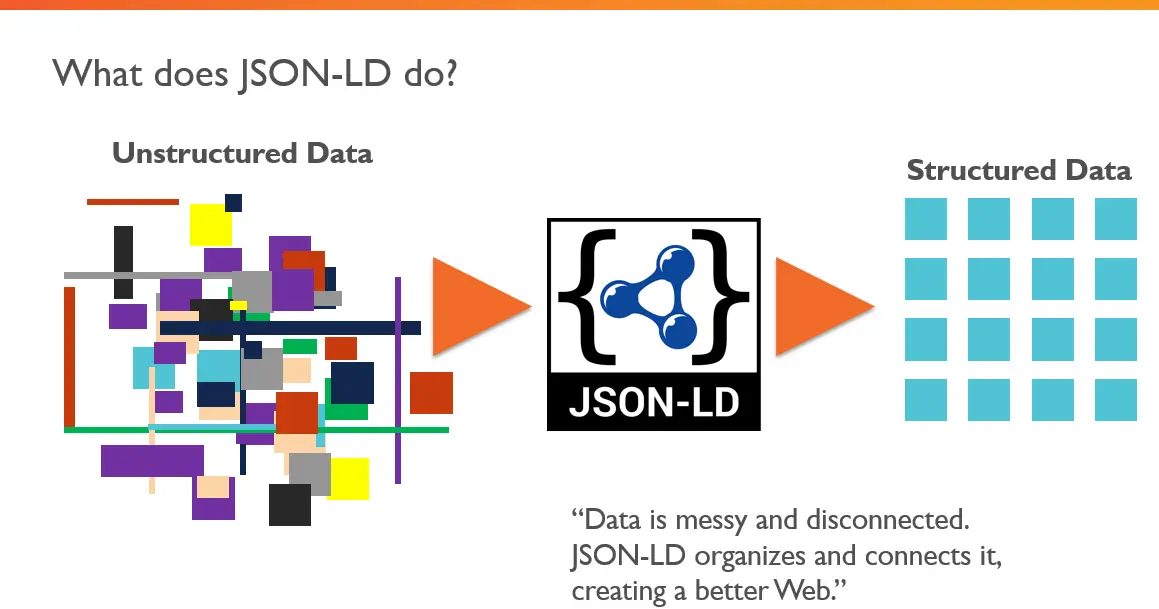
JSON-LD преобразует неструктурированные данные в структурированные
Рисунок 1 — Концептуальная визуализация работы JSON-LD: обработка неструктурированного контента в интернете, его аннотирование и структурирование для получения организованного результата.
Таким образом, JSON-LD помогает поисковым системам, таким как Google и Яндекс, точнее интерпретировать информацию на сайте, что может улучшить отображение страницы в результатах поиска (например, с помощью расширенных сниппетов).
Где в HTML-коде страницы должен располагаться JSON-LD?
Google рекомендует размещать JSON-LD в разделе <head> HTML-документа. Однако допустимо также добавлять его и внутри <body>. Кроме того, Google способен обрабатывать динамически сгенерированные JSON-LD теги в DOM (объектной модели документа).
Коротко:
- Лучше:
<head>
- Но можно:
<body>
- Динамические теги (например, загружаемые через JavaScript) тоже работают.
Это означает, что поисковые системы смогут распознать разметку независимо от её расположения в HTML, если она корректно сформирована.
Разбираем JSON-LD
Неизменяемые теги (Не нужно запоминать — просто копируйте и вставляйте)
<script type="application/ld+json">
{
...
}
</script>
Когда вы видите JSON-LD, первое, что должно бросаться в глаза — это тег <script>. Атрибут type="application/ld+json" сообщает браузеру: «Эй, здесь JavaScript, содержащий JSON-LD».
💡 Профессиональный совет
- Всегда закрывайте теги сразу после открытия.
Как соль и перец идут вместе, так и открывающие фигурные скобки { требуют закрывающих }.
- Важно: Если ваш JSON-LD не заключён в фигурные скобки
{}, он не будет обработан. (Держите его «завёрнутым» в скобки!)
Таким образом, правильная структура JSON-LD гарантирует, что поисковые системы смогут корректно прочитать и использовать вашу разметку.
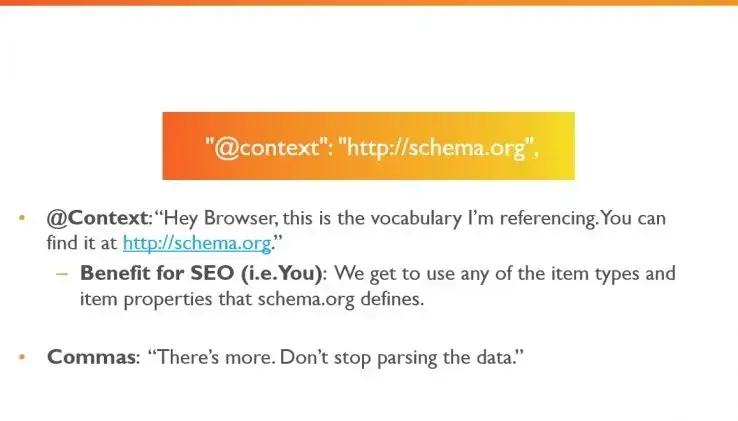
Второй обязательный элемент в JSON-LD разметке — это @context со значением http://schema.org.
Этот параметр сообщает браузеру: «Эй, вот словарь, на который я ссылаюсь — ты можешь найти его по адресу http://schema.org».
Преимущество для SEO-специалиста:
Мы получаем доступ ко всем типам элементов (item types) и их свойствам (item properties), которые определены в Schema.org.
 📌 Пример структуры:
📌 Пример структуры:
{
"@context": "http://schema.org",
"@type": "Article",
"headline": "Пример статьи",
"author": {
"@type": "Person",
"name": "Иван Петров"
}
}
🔍 Обратите внимание:
- Видите эту запятую после
"http://schema.org"? Она говорит парсеру: «Данные продолжаются, не останавливайся».
💡 Профессиональный совет
- Следите за запятыми (и всегда проверяйте разметку в Google’s Structured Data Testing Tool).
- Пропущенная запятая = невалидная разметка. Даже опытные разработчики часто ошибаются в этом месте.
JSON-LD строго требует правильного синтаксиса, поэтому всегда проверяйте свою разметку перед публикацией!
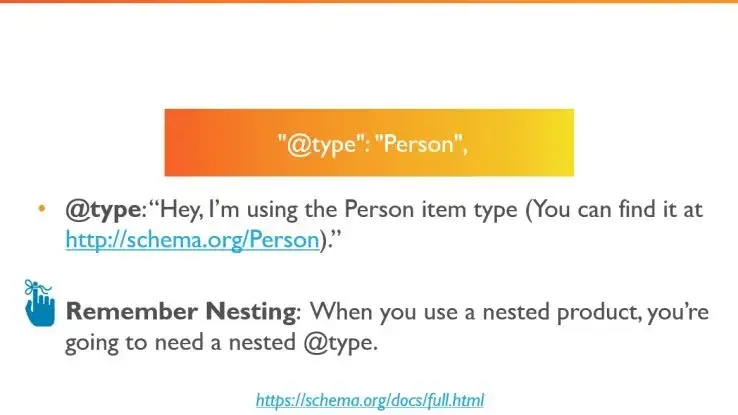
"@type": “…”
Третий ключевой элемент JSON-LD разметки — это указание @type. После двоеточия здесь начинается аннотация данных. Параметр @type определяет тип размеченной сущности. Полный список всех доступных типов можно найти в официальной документации: https://schema.org/docs/full.html.
Как это работает?
В примере ниже:
{
"@context": "http://schema.org",
"@type": "Person",
"name": "Иван Иванов"
}
@type сообщает: «Эй, здесь используется тип Person (его описание можно найти по адресу http://schema.org/Person)».
Если ввести эту ссылку в браузер, откроется документация Schema.org с:
- Техническими спецификациями этого типа
- Списком допустимых свойств (
item properties)
- Часто — примерами использования
Вложенные @type
При использовании вложенных структур потребуется указывать @type для каждого уровня. Это особенно важно в разметке:
- Товаров (
Product)
- Хлебных крошек (
BreadcrumbList)
- Организаций с сотрудниками (
Organization → Employee)
Пример вложенности:
{
"@context": "http://schema.org",
"@type": "Product",
"brand": {
"@type": "Brand",
"name": "Nike"
}
}
💡 Профессиональный совет:
Ошибка → Пропущенный
@type или его неверное указание сделает разметку бесполезной для поисковых систем!
Пары “атрибут-значение”
Следующий шаг — аннотирование информации о выбранном типе сущности (@type). Допустимые свойства для каждого типа можно найти на соответствующей странице Schema.org.
Синтаксис JSON-LD для свойств
Каждое свойство в разметке состоит из двух элементов:
-
Свойство (Item Property)
- Должно быть взято из словаря Schema.org.
- Обязательно заключайте в двойные прямые кавычки (
" ").
🔹 Важно: Использование фигурных (“ ”) или одинарных (' ') кавычек приведёт к ошибке валидации!
- Должно принадлежать к разрешённым свойствам для выбранного
@type (указаны в документации Schema.org).
-
Значение (Value)
- Сюда вписывается конкретное значение свойства.
- Правила форматирования:
- Текстовые строки и URL: всегда в двойных кавычках (
"пример").
- Числа (целые, дробные): можно без кавычек (
42), но допустимо и с ними ("42" — тогда тип данных будет строковым).
- Несколько значений: используйте квадратные скобки (
["значение1", "значение2"]).
Примеры
✅ Корректно:
{
"@type": "Book",
"name": "Война и мир",
"isbn": "978-5-699-12014-7", // Строка в кавычках
"price": 599.99, // Число без кавычек
"author": ["Лев Толстой", "Иван Тургенев"] // Массив значений
}
❌ Ошибки:
- Фигурные кавычки:
“Война и мир” → невалидно.
- Пропущенные кавычки:
name: Война и мир → синтаксическая ошибка.
- Неразрешённое свойство:
"pageCount": 1225 (если @type не поддерживает это свойство).
💡 Профессиональный совет:
- Всегда сверяйтесь со списком свойств для вашего
@type.
- Для сложных случаев (например, товары с вариантами) используйте вложенные структуры и массивы.
- Проверяйте разметку в Google Rich Results Test — он покажет не только ошибки, но и потенциальные улучшения.
Запомните:
Правильный синтаксис — это не педантичность, а необходимость. Поисковые системы обрабатывают только безупречно оформленные данные!
Квадратные скобки [ ] в JSON-LD
Квадратные скобки используются, когда у свойства есть несколько значений.
Примеры использования:
-
Несколько значений одного свойства
Например, если у человека два имени:
"givenName": ["Джейсон", "Деруло"]
Здесь скобки говорят: «У этого свойства несколько значений — у Джейсона Деруло два имени».
-
Ссылки на соцсети (sameAs)
Часто применяется для перечисления профилей в соцсетях:
"sameAs": [
"https://facebook.com/jasonderulo",
"https://twitter.com/jasonderulo",
"https://instagram.com/jasonderulo"
]
Важные правила:
-
Запятая после последнего элемента не ставится
"sameAs": [
"https://facebook.com/jasonderulo", // запятая
"https://twitter.com/jasonderulo" // НЕТ запятой в конце
]
Отсутствие запятой означает конец списка.
-
Не путать с фигурными скобками {}
Квадратные скобки — только для перечисления однотипных значений, а фигурные — для вложенных объектов (например, адреса или организации).
💡 Профессиональный совет:
- Используйте квадратные скобки для:
- Списков (например, авторов книги).
- Альтернативных URL (например,
sameAs для соцсетей).
- Любых свойств, допускающих множественные значения по Schema.org.
- Всегда проверяйте, поддерживает ли выбранный
@type множественные значения для конкретного свойства.
Ошибка → Лишняя запятая после последнего элемента вызовет ошибку валидации!
Пример корректной и некорректной разметки:
✅ Правильно:
"author": ["Лев Толстой", "Фёдор Достоевский"]
❌ Неправильно:
"author": ["Лев Толстой", "Фёдор Достоевский",]
→ Лишняя запятая после последнего элемента.
Для проверки используйте Google’s Structured Data Testing Tool.
Вложенность (Nesting) в JSON-LD
Вложенность означает организацию данных слоями, где одни объекты содержат другие объекты. Это можно сравнить с матрешкой, где большая кукла содержит внутри меньшую — так же и данные могут быть структурированы иерархически.
Зачем нужна вложенность?
Некоторые свойства относятся только к определенным типам сущностей. Например, в разметке события (Event):
name может означать название события,- но внутри могут быть вложены свойства
performer (исполнитель) и venue (место проведения), у которых тоже есть свои name.
Без вложенности поисковые системы не поймут, к чему относится каждое свойство.
Как правильно вкладывать данные в JSON-LD
-
Начните с основного типа (@type)
Например, Event.
-
Укажите свойство, требующее вложенности
Например, performer или offers.
-
Откройте фигурные скобки { } для нового объекта
Внутри укажите:
@type (тип вложенной сущности, например Person или Offer),- его свойства и значения.
-
Закройте вложенный объект
- Не ставьте запятую перед закрывающей скобкой
}.
- Запятая после
} нужна, только если дальше идут другие свойства.
Пример вложенности
Разметка музыкального события:
{
"@context": "http://schema.org",
"@type": "MusicEvent",
"name": "Концерт Jason Aldean",
"performer": { // ← Начало вложенного объекта
"@type": "MusicGroup",
"name": "Jason Aldean",
"sameAs": "https://www.jasonaldean.com"
}, // ← Запятая, потому что дальше есть еще свойства
"location": {
"@type": "Place",
"name": "Мэдисон-Сквер-Гарден",
"address": "Нью-Йорк, США"
} // ← Нет запятой, это последнее свойство
}
Чек-лист по вложенности
✅ Используйте свойства, допустимые для родительского @type (см. Schema.org).
✅ Значение вложенного объекта заключайте в { }.
✅ Указывайте @type для вложенной сущности.
✅ Добавляйте обязательные свойства для вложенного типа (например, price для Offer).
❌ Не ставьте запятую перед } (это вызовет ошибку).
✅ Запятая после }, если дальше идут другие свойства.
Где чаще всего встречается вложенность?
- Товары (
Product):
- Цена и условия предложения вкладываются в
offers (@type: Offer).
- Отзывы — в
review (@type: Review).
- Организации (
Organization):
- Адрес (
@type: PostalAddress),
- контакты, учредители.
- Рецепты (
Recipe):
- Ингредиенты, инструкции, питательная ценность.
💡 Профессиональный совет:
- Делайте отступы для вложенных объектов — так код легче читать.
- Проверяйте обязательные свойства для вложенных типов на Schema.org.
- Тестируйте разметку в Google Rich Results Test.
Ошибка → Пропущенный @type во вложенном объекте или лишние/недостающие запятые сделают разметку нерабочей!
Пример ошибки:
❌ Неправильно:
"performer": {
"name": "Jason Aldean" // ← Нет @type!
}
✅ Исправлено:
"performer": {
"@type": "MusicGroup",
"name": "Jason Aldean"
}
Распространённые ошибки в JSON-LD разметке
Если ваша разметка не проходит валидацию в Google’s Structured Data Testing Tool, проверьте этот список типичных проблем.
1. Синтаксические ошибки
Кавычки: прямые vs. фигурные
- ✅ Правильно:
"" (прямые двойные кавычки).
- ❌ Ошибка:
“” (фигурные кавычки, которые могут появиться при копировании из Word/Excel).
Запятые
- Пропущенная запятая между свойствами → разметка не валидируется.
- Лишняя запятая после последнего элемента в объекте или массиве → ошибка.
- Как найти: В инструменте тестирования ищите красный крестик (
✗) слева — он часто указывает на проблему с запятой.
Пример:
// ❌ Ошибка (лишняя запятая)
"author": {
"@type": "Person",
"name": "Иван Иванов", // ← Запятая не нужна, это последнее свойство
}
// ✅ Исправлено
"author": {
"@type": "Person",
"name": "Иван Иванов"
}
2. Ошибки словаря Schema.org
- Использование свойств, недопустимых для данного
@type.
Пример: Свойство author не поддерживается для @type: Product.
- Пропуск обязательных свойств.
Пример: Для Offer обязательно указание price и priceCurrency.
Решение:
3. Нарушение правил Google
- Размеченные данные должны быть видны на странице.
Пример: Если в JSON-LD указан рейтинг 5.0, а на странице его нет — это нарушение.
- Запрещены манипулятивные практики.
Пример: Добавление ложных отзывов или несвязанных сущностей для обхода алгоритмов.
Что делать:
4. Проблемы при копировании из Microsoft Office
- Word/Excel автоматически заменяют кавычки на фигурные (
“”).
- Добавляют невидимые символы форматирования.
Решение:
- Используйте HTML-редактор (например, VS Code, Sublime Text).
- Вставляйте текст через «Вставить как обычный текст» (Ctrl+Shift+V).
Итоговый чек-лист
- Кавычки: Только прямые (
"").
- Запятые: Ни лишних, ни пропущенных.
- Словарь: Только разрешённые свойства для
@type.
- Контент: Разметка = содержимое страницы.
- Проверка: Всегда тестируйте в Google Rich Results Test.
💡 Совет: Для сложных типов (например, Product с Review) используйте пошаговую проверку — сначала базовые свойства, затем вложенные объекты.
Ошибка → Даже одна пропущенная кавычка или запятая может привести к тому, что Google проигнорирует всю разметку!
Процесс добавления JSON-LD на сайт
Создание JSON-LD разметки зависит от вашего уровня знакомства с синтаксисом JSON-LD и словарем Schema.org. Ниже приведен пошаговый процесс для новичков, который поможет вам разобраться в основах и создать эффективную разметку.
1. Определите цель разметки
📌 Вопросы, которые нужно задать себе:
- Что вы хотите разметить?
Убедитесь, что выбранный вами контент можно аннотировать с помощью Schema.org. Некоторые вещи могут казаться логичными, но не иметь подходящего типа в словаре.
- Зачем вам это нужно?
Определите, есть ли практическая польза (например, улучшение сниппетов в поиске) или вы просто экспериментируете. Разметка должна помогать поисковым системам лучше понимать ключевую информацию на странице.
2. Изучите документацию и примеры
- Проверьте, поддерживает ли Google ваш тип разметки.
Откройте официальную документацию Google и найдите примеры.
- Не изобретайте велосипед!
Используйте готовые примеры от Google или Schema.org, адаптируя их под свои нужды.
3. Откройте страницу типа данных на Schema.org
- Перейдите на Schema.org и найдите нужный
@type (например, Product, Article).
- Ознакомьтесь с:
- Описанием типа,
- Обязательными и рекомендуемыми свойствами,
- Примерами использования.
4. Скопируйте “неизменяемые” элементы
Начните с базовой структуры:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "ТипДанных"
}
</script>
- Не забывайте, что тег
<script> обязателен!
5. Определите свойства и их значения
- Выпишите свойства, которые хотите добавить (например, для
Product: name, description, image).
- Пока не думайте о синтаксисе — просто составьте список.
6. Добавьте синтаксис JSON-LD и вложенности
- Заполните свойства, соблюдая правила:
- Кавычки: только
"".
- Запятые: между свойствами, но не после последнего.
- Для вложенных объектов (например,
offers в Product) используйте фигурные скобки {} и указывайте @type.
Пример для товара:
{
"@context": "http://schema.org",
"@type": "Product",
"name": "Смартфон XYZ",
"image": "https://example.com/image.jpg",
"offers": {
"@type": "Offer",
"price": "299.99",
"priceCurrency": "USD"
}
}
7. Протестируйте разметку
8. Добавьте разметку на сайт
- Способ 1: Вставьте код в
<head> страницы.
- Способ 2: Для динамического контента согласуйте с разработчиками (например, генерация через CMS).
- Дополнительно: Используйте
itemID и itemRef для сложных структур (подробнее в статье Moz).
9. Делитесь опытом!
У вас есть вопросы или интересные кейсы по JSON-LD? Делитесь в комментариях!
Итог:
- Планируйте → Изучайте → Копируйте → Тестируйте → Внедряйте.
- Избегайте типичных ошибок: неправильные кавычки, запятые, нарушение правил Google.
- Используйте инструменты валидации на каждом этапе.
Теперь вы готовы создавать SEO-оптимизированную разметку!
Подробнее о JSON-LD смотри официальную документацию
2 - Документация RDF для универсальной микроразметки текстов для микропоиска
Синтаксис и правила обработки для встраивания RDF через атрибуты Рекомендация W3C от 17 марта 2015 года
RDFa Core 1.1 — Третье издание
Синтаксис и правила обработки для встраивания RDF через атрибуты
Рекомендация W3C от 17 марта 2015 года
Актуальная версия:
http://www.w3.org/TR/2015/REC-rdfa-core-20150317/
Последняя опубликованная версия:
http://www.w3.org/TR/rdfa-core/
Отчёт о внедрении:
http://www.w3.org/2010/02/rdfa/wiki/CR-ImplementationReport
Предыдущая версия:
http://www.w3.org/TR/2014/PER-rdfa-core-20141216/
Предыдущая рекомендация:
http://www.w3.org/TR/2013/REC-rdfa-core-20130822/
Редакторы:
Английская версия данной спецификации является единственной нормативной. Неофициальные переводы могут быть доступны.
Авторские права: © 2007–2015 W3C® (MIT, ERCIM, Кейо, Бэйхан). Применяются правила W3C об ответственности, товарных знаках и использовании документов.
Аннотация
Современный Интернет в основном состоит из огромного количества документов, созданных с использованием HTML. Эти документы содержат значительный объём структурированных данных, которые в большинстве случаев недоступны для инструментов и приложений. Если издатели смогут выражать эти данные более полно, а инструменты — считывать их, откроются новые возможности для пользователей: структурированные данные можно будет передавать между приложениями и веб-сайтами, а браузеры смогут улучшить пользовательский опыт. Например:
- событие на веб-странице можно будет напрямую импортировать в настольный календарь;
- лицензию на документ можно будет автоматически определить, чтобы информировать пользователей об их правах;
- информацию о создателе фотографии, настройках камеры, разрешении, местоположении и теме можно будет публиковать так же легко, как и саму фотографию, что позволит осуществлять структурированный поиск и обмен.
RDFa Core — это спецификация атрибутов для выражения структурированных данных в любом языке разметки. Встроенные данные, уже доступные в языке разметки (например, HTML), часто можно повторно использовать в RDFa, что избавляет издателей от необходимости дублировать информацию в содержимом документа.
Абстрактное представление данных основано на RDF (RDF11-PRIMER), что позволяет издателям создавать собственные словари, расширять чужие и развивать свою терминологию с максимальной совместимостью. Выраженная структура тесно связана с данными, поэтому визуализированную информацию можно копировать вместе с её структурой.
Правила интерпретации данных универсальны и не требуют отдельных инструкций для разных форматов. Это позволяет авторам и издателям данных определять собственные форматы без необходимости обновлять ПО, регистрировать их в централизованном органе или опасаться конфликтов между разными форматами.
RDFa разделяет некоторые цели с микроформатами (MICROFORMATS). Однако если микроформаты задают и синтаксис для встраивания структурированных данных в HTML, и конкретный словарь терминов для каждого микроформата, то RDFa определяет только синтаксис, полагаясь на независимые спецификации терминов (часто называемых словарями или таксономиями). RDFa позволяет свободно комбинировать термины из разных словарей и разработан так, что язык можно анализировать без знания конкретного используемого словаря.
Этот документ представляет собой детальное описание синтаксиса RDFa, предназначенное для:
- Разработчиков процессоров RDFa, которым необходимо точное описание правил разбора.
- Тех, кто хочет интегрировать RDFa в новый язык разметки.
- Организаций, желающих рекомендовать использование RDFa и создать руководства для пользователей.
- Всем, кто знаком с RDF и хочет понять, как работает процессор RDFa «под капотом».
Для тех, кто ищет введение в RDFa и практические примеры, рекомендуется ознакомиться с RDFA-PRIMER.
Как читать этот документ
-
Если вы не знакомы ни с RDFa, ни с RDF и просто хотите добавить RDFa в свои документы, то вам может быть полезнее ознакомиться с RDFa Primer, который даёт более простое введение.
-
Если вы уже знакомы с RDFa и хотите изучить правила обработки (например, для создания собственного процессора RDFa), то наиболее интересным для вас будет раздел «Модель обработки». В нём содержится обзор каждого этапа обработки, а затем более детальные подразделы с описанием отдельных правил.
-
Если вы не знакомы с RDFa, но знаете RDF, то перед изучением модели обработки полезно прочитать раздел «Обзор синтаксиса», где приведены примеры разметки с использованием RDFa. Примеры помогут легче понять правила обработки.
-
Если вы не знакомы с RDF, то перед активной работой с RDFa рекомендуется ознакомиться с разделом «Терминология RDF». Хотя RDFa разработан так, чтобы быть простым для авторов (и для его использования не обязательно глубоко разбираться в RDF), разработчикам приложений, обрабатывающих RDFa, понимание RDF необходимо. В интернете есть множество материалов по RDF, а также растущее число инструментов, поддерживающих RDFa. В этом документе содержится лишь минимальный необходимый контекст по RDF, чтобы прояснить цели RDFa.
Примечание
RDFa — это способ выражения отношений в стиле RDF с помощью простых атрибутов в существующих языках разметки, таких как HTML.
- RDF полностью интернационализирован и допускает использование Internationalized Resource Identifiers (IRI). В этой спецификации повсеместно используется термин IRI.
- Даже если вы не знакомы с термином IRI, вы, вероятно, встречали URI или URL. IRI — это расширение URI, позволяющее использовать символы за пределами ASCII.
- RDF поддерживает такие символы, как и RDFa. В этой спецификации сознательно используется термин IRI, чтобы подчеркнуть эту возможность.
Важное уточнение
Хотя в данной спецификации упоминаются исключительно IRI, язык-хост (Host Language) может ограничивать синтаксис своих атрибутов подмножеством IRI (например, атрибут @href в HTML5).
Однако, независимо от ограничений валидации в языке-хозяине, процессор RDFa способен обрабатывать полный диапазон IRI.
Статус данного документа
Данный раздел описывает статус документа на момент его публикации. Другие документы могут заменять текущую версию. Актуальный список публикаций W3C и последнюю редакцию данного технического отчёта можно найти в индексе технических отчётов W3C по адресу: http://www.w3.org/TR/.
Редакционные изменения
Настоящая версия представляет собой редакционную правку Рекомендации, опубликованной 22 августа 2013 года. Указанный документ являлся пересмотренной версией спецификации RDFa Syntax 1.0 [RDFA-SYNTAX]. Между текущей версией и версией 1.0 существует ряд существенных различий, включая:
- Удаление специальных правил для XHTML - теперь они определены в отдельном документе XHTML+RDFa [XHTML-RDFA].
- Расширение типов данных некоторых атрибутов RDFa для поддержки Terms (терминов), CURIES и Absolute IRIs.
- Разрешение языкам-хостам определять коллекции терминов по умолчанию, префиксные отображения и словарь по умолчанию.
- Возможность определения словаря по умолчанию для использования с неопределёнными терминами.
- Требование к регистронезависимому сравнению терминов.
- Расширенное поведение атрибута @property, которое во многих случаях может заменять атрибут @rel.
- Изменённая обработка @typeof для лучшего соответствия практическому использованию.
Более подробный список изменений доступен в разделе Changes (Изменения).
Тестирование
Доступен тестовый набор, который не является исчерпывающим, но может быть полезен как пример использования RDFa.
Участие и отзывы
Документ опубликован Рабочей группой RDFa в качестве Рекомендации. Все замечания и предложения можно направлять по адресу: public-rdfa@w3.org (подписка, архивы). Отзывы приветствуются.
С отчётом о внедрении рабочей группы можно ознакомиться здесь.
Статус рекомендации
Документ был рассмотрен членами W3C, разработчиками программного обеспечения, другими группами W3C и заинтересованными сторонами. Директор W3C утвердил его в качестве официальной Рекомендации. Это стабильный документ, который может использоваться в качестве справочного материала или цитироваться в других документах. Роль W3C заключается в привлечении внимания к спецификации и содействии её широкому внедрению, что способствует улучшению функциональности и совместимости веба.
Патентная политика
Документ разработан группой, действующей в соответствии с Патентной политикой W3C от 5 февраля 2004 года. W3C ведёт публичный список патентных заявлений, связанных с результатами работы группы. На этой странице также содержатся инструкции по подаче патентных заявлений. Лица, располагающие информацией о патентах, которые могут содержать существенные пункты (Essential Claims), обязаны раскрыть эту информацию в соответствии с разделом 6 Патентной политики W3C.
Процесс W3C
Документ регулируется Процессом W3C от 14 октября 2005 года.
1. Мотивация
(Данный раздел не является нормативным)
Проблемы RDF/XML
Спецификация RDF/XML [RDF-SYNTAX-GRAMMAR] обеспечивает достаточную гибкость для представления всех абстрактных концепций RDF. Однако у неё есть ряд недостатков:
-
Сложность валидации
- Документы, содержащие RDF/XML, крайне сложно (или невозможно) проверять с помощью XML-схем (XML Schemas) или DTD.
- Это затрудняет интеграцию RDF/XML в другие языки разметки.
- Новые языки схем, такие как RELAX NG [RELAXNG-SCHEMA], поддерживают валидацию произвольного RDF/XML, но их широкое внедрение займёт время.
-
Дублирование данных
- Даже если добавить RDF/XML напрямую в XML-диалект (например, XHTML), возникнет дублирование между визуальным содержимым и структурированными данными RDF.
- Идеальным решением было бы дополнять документ RDF-разметкой без повторения существующих данных.
- Пример: если имя автора указано в тексте (например, в подписи к новости), его не нужно дублировать в RDF — разметка должна позволять интерпретировать существующие данные как часть RDF-структуры.
Преимущества интеграции структуры и содержимого
-
Контекстная структуризация
- Совмещение визуальных и структурированных данных упрощает передачу информации между приложениями (включая не-веб-системы).
- Пример: пользователи могут получать дополнительную информацию о данных (например, через контекстное меню по клику).
-
Удобство для издателей
- Организациям, публикующим много контента (например, СМИ), проще встраивать семантические данные напрямую в разметку, чем поддерживать их отдельно.
Ограничения «жёстко заданных» атрибутов
- В традиционных языках разметки (например, XHTML 1.1 [XHTML11] или HTML [HTML401]) используются атрибуты с фиксированной семантикой, такие как
@cite для указания источника цитаты.
- Однако такие атрибуты:
- Требуют от процессоров RDFa знания каждого специфичного атрибута.
- Усложняют создание универсальных инструментов извлечения метаданных.
Решение через RDFa
-
Гибкость вместо «жёсткой» разметки
- RDFa предлагает универсальный набор атрибутов и правил разбора, позволяющий использовать свойства из любых RDF-словарей.
- В большинстве случаев значения этих свойств уже присутствуют в документе.
-
Снижение нагрузки на разработчиков языков
- RDFa устраняет необходимость предугадывать все возможные требования пользователей к структуре.
- Дизайнеры языков могут легко интегрировать RDFa, обеспечивая извлечение семантических данных любыми совместимыми процессорами.
Ключевые тезисы
- RDFa избегает дублирования данных, используя существующую разметку.
- Позволяет добавлять произвольные семантические свойства без привязки к конкретному словарю.
- Упрощает создание единого стандарта для извлечения метаданных из любых документов.
2.1 - Обзор синтаксиса
Следующие примеры помогут новичкам быстро понять принципы работы RDFa.
Для более глубокого изучения рекомендуется ознакомиться с RDFa Primer.
Сокращённые IRIs (CURIEs)
В RDF принято сокращать термины словарей с помощью префиксов и ссылок. Этот механизм подробно описан в разделе Compact URI Expressions. В примерах ниже используются следующие предопределённые префиксы словарей:
Примечание о локальных идентификаторах
В некоторых примерах используются IRI с фрагментными идентификаторами (например, about="#me"), которые ссылаются на сущности внутри текущего документа. Этот подход:
- Широко применяется в RDF/XML [RDF-SYNTAX-GRAMMAR] и других сериализациях RDF.
- Позволяет легко создавать новые IRIs для объектов, описываемых через RDFa, значительно расширяя выразительные возможности.
Точная семантика таких IRIs в RDF-графах определена в разделе 7 RDF-SYNTAX-GRAMMAR.
Важно
Для корректной интерпретации фрагментных идентификаторов регистрации MIME-типов языков разметки, поддерживающих RDFa, должны ссылаться на эту спецификацию (прямо или косвенно).
2.1 Атрибуты RDFa
RDFa использует ряд распространённых атрибутов, а также вводит несколько новых. Атрибуты, уже существующие в популярных языках разметки (например, HTML), сохраняют своё исходное значение, хотя в некоторых случаях их синтаксис был немного модифицирован. Например, в (X)HTML нет чёткого способа добавлять новые значения для атрибута @rel; RDFa явно решает эту проблему, разрешая использовать IRI в качестве значений. Также вводятся понятия терминов и “компактных выражений URI” (CURIEs), которые позволяют кратко выражать полные значения IRI. Полный список атрибутов RDFa и их синтаксис приведён в разделе “Атрибуты и синтаксис”.
2.2 Примеры
В (X)HTML авторы могут включать метаданные и отношения, касающиеся текущего документа, используя элементы meta и link (в этих примерах используется XHTML+RDFa [XHTML-RDFA]). Например, автор страницы вместе со ссылками на предыдущую и следующую страницы могут быть выражены следующим образом:
Пример 1
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Страница 7</title>
<meta name="author" content="Марк Бирбек" />
<link rel="prev" href="page6.html" />
<link rel="next" href="page8.html" />
</head>
<body>...</body>
</html>
RDFa использует эту концепцию, расширяя её возможностью работы с различными словарями через полные IRI:
Пример 2
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Моя домашняя страница</title>
<meta property="http://purl.org/dc/terms/creator" content="Марк Бирбек" />
<link rel="http://xmlns.com/foaf/0.1/topic" href="http://www.example.com/#us" />
</head>
<body>...</body>
</html>
Поскольку использование полных IRI, как в примере выше, может быть громоздким, RDFa также разрешает использовать компактные выражения URI (CURIEs), позволяя авторам применять сокращения для ссылок на термины из различных словарей:
Пример 3
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="foaf: http://xmlns.com/foaf/0.1/
dc: http://purl.org/dc/terms/"
>
<head>
<title>Моя домашняя страница</title>
<meta property="dc:creator" content="Марк Бирбек" />
<link rel="foaf:topic" href="http://www.example.com/#us" />
</head>
<body>...</body>
</html>
RDFa поддерживает использование @rel и @rev на любых элементах. Это становится ещё полезнее с добавлением поддержки различных словарей:
Пример 4
Этот документ распространяется по лицензии
<a prefix="cc: http://creativecommons.org/ns#"
rel="cc:license"
href="http://creativecommons.org/licenses/by-nc-nd/3.0/"
>Creative Commons By-NC-ND License</a>.
RDFa позволяет повторно использовать не только IRI в документе для предоставления метаданных, но и встроенный текст при использовании с @property:
Пример 5
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="dc: http://purl.org/dc/terms/"
>
<head><title>Моя домашняя страница</title></head>
<body>
<h1 property="dc:title">Моя домашняя страница</h1>
<p>Последнее изменение: 16 сентября 2015</p>
</body>
</html>
Когда отображаемый текст отличается от фактического значения, можно указать точное значение с помощью атрибута @content. Также можно явно указать тип данных через @datatype:
Пример 6
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="xsd: http://www.w3.org/2001/XMLSchema#
dc: http://purl.org/dc/terms/"
>
<head><title>Моя домашняя страница</title></head>
<body>
<h1 property="dc:title">Моя домашняя страница</h1>
<p>Последнее изменение:
<span property="dc:modified"
content="2015-09-16T16:00:00-05:00"
datatype="xsd:dateTime">16 сентября 2015</span>.
</p>
</body>
</html>
RDFa позволяет описывать метаданные не только для текущего документа, но и для других ресурсов:
Пример 7
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="bibo: http://purl.org/ontology/bibo/
dc: http://purl.org/dc/terms/"
>
<head>
<title>Книги Марко Пьера Уайта</title>
</head>
<body>
Я считаю, что книга Уайта
«<span about="urn:ISBN:0091808189"
property="dc:title">Кухня столовой</span>»
стоит того, чтобы её приобрести: хотя рецепты сложные,
автор объясняет их очень доступно. Вам также может понравиться
<span about="urn:ISBN:1596913614"
property="dc:description">автобиография Уайта</span>.
</body>
</html>
Для группировки свойств, относящихся к одному объекту, используется атрибут @typeof:
Пример 8
<html
xmlns="http://www.w3.org/1999/xhtml"
prefix="bibo: http://purl.org/ontology/bibo/
dc: http://purl.org/dc/terms/"
>
<head>
<title>Книги Марко Пьера Уайта</title>
</head>
<body>
Я считаю, что книга Уайта
«<span about="urn:ISBN:0091808189" typeof="bibo:Book"
property="dc:title">Кухня столовой</span>»
стоит того, чтобы её приобрести. Также рекомендую
<span about="urn:ISBN:1596913614"
typeof="bibo:Book"
property="dc:description"
>автобиографию Уайта</span>.
</body>
</html>
Для небольших фрагментов разметки иногда удобнее использовать полные IRI:
Пример 9
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Книги Марко Пьера Уайта</title>
</head>
<body>
Книга Уайта
«<span about="urn:ISBN:0091808189"
typeof="http://purl.org/ontology/bibo/Book"
property="http://purl.org/dc/terms/title"
>Кухня столовой</span>»
написана очень доступно. Также обратите внимание на
<span about="urn:ISBN:1596913614"
typeof="http://purl.org/ontology/bibo/Book"
property="http://purl.org/dc/terms/description"
>его автобиографию</span>.
</body>
</html>
Атрибут @vocab позволяет определить словарь по умолчанию для элементов:
Пример 10
<div vocab="http://xmlns.com/foaf/0.1/" about="#me">
Меня зовут <span property="name">Иван Иванов</span>, а мой блог —
<a rel="homepage" href="http://example.org/blog/">«Понимая семантику»</a>.
</div>
Приведённый выше пример (Пример 10) сгенерирует следующие триплеты в формате Turtle:
Пример 11
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<#me> foaf:name "John Doe" ;
foaf:homepage <http://example.org/blog/> .
В простых случаях атрибут @property может использоваться вместо @rel. Фактически, когда элемент не содержит атрибутов @rel, @datatype или @content, но имеет, например, атрибут @href, эффект от @property аналогичен @rel.
Тот же пример можно переписать следующим образом:
Пример 12
<div vocab="http://xmlns.com/foaf/0.1/" about="#me">
Меня зовут <span property="name">Иван Иванов</span>, а мой блог —
<a property="homepage" href="http://example.org/blog/">«Понимая семантику»</a>.
</div>
Особенности обработки:
- Когда используется только @property с элементом, содержащим @href, система интерпретирует это как отношение (аналогично @rel)
- Такой подход упрощает разметку в случаях, когда не требуется явное указание типа связи
Это демонстрирует гибкость RDFa в интерпретации различных вариантов разметки как семантически эквивалентных структур.
2.2 - Терминология RDF
Обзор терминологии RDF в различных примерах
3. Терминология RDF
Введение
Предыдущий раздел иллюстрировал типичную разметку RDFa. Хотя для создания RDFa-разметки глубокое понимание RDF не обязательно, разработчикам систем, обрабатывающих RDF-вывод, необходимо разбираться в концепциях RDF. Далее представлены базовые понятия. Для углублённого изучения обратитесь к:
3.1 Утверждения (Statements)
Структурированные данные в RDFa представляют собой коллекцию утверждений — минимальных единиц информации, оформленных по определённым правилам для упрощения обработки. Даже сложные метаданные можно обрабатывать, разбивая их на такие утверждения.
Пример неструктурированных данных:
Альберт родился 14 марта 1879 года в Германской империи. Его фото доступно
по адресу http://en.wikipedia.org/wiki/Image:Albert_Einstein_Head.jpg.
Для машины этот текст неинтерпретируем. В формате утверждений та же информация выглядит так:
Альберт родился 14 марта 1879 года
Альберт родился в Германской империи
Альберт имеет фото http://en.wikipedia.org/...
3.2 Триплеты (Triples)
RDF формализует утверждения как триплеты — структуры из трёх компонентов:
-
Субъект (Subject)
- Объект, о котором делается утверждение.
- В примерах: «Альберт».
-
Предикат (Predicate)
- Свойство субъекта.
- В примерах: «родился», «имеет фото».
-
Объект (Object)
- Значение свойства.
- В примерах: дата, место, URL фото.
Пример триплетов в RDF:
<Albert> <wasBornOn> "March 14, 1879" .
<Albert> <wasBornIn> <German_Empire> .
<Albert> <hasPhoto> <http://.../Albert_Einstein_Head.jpg> .
Особенности:
- RDFa поддерживает интернационализированные символы (Unicode) во всех компонентах триплета.
- Субъекты и предикаты обычно выражаются IRI, объекты — IRI или литералы (строки/числа).
3.3 Ссылки на IRI
Разбиение сложной информации на управляемые части помогает уточнить данные, но не исключает неоднозначности. Например, о каком именно “Альберте” идёт речь? Если другая система содержит дополнительные факты об “Альберте”, как определить, что они относятся к тому же человеку? Как сопоставить предикаты “родился в” и “место рождения” из разных систем? RDF решает эти проблемы, заменяя расплывчатые термины на ссылки IRI.
Уникальные идентификаторы
Хотя IRI чаще всего используются для идентификации веб-страниц, в RDF они служат уникальными идентификаторами концепций. Например, вместо неоднозначной строки “Альберт” можно использовать IRI из DBPedia:
Пример 15
<http://dbpedia.org/resource/Albert_Einstein>
имеет имя
"Альберт Эйнштейн".
<http://dbpedia.org/resource/Albert_Einstein>
родился
"14 марта 1879".
<http://dbpedia.org/resource/Albert_Einstein>
родился в
<http://dbpedia.org/resource/German_Empire>.
<http://dbpedia.org/resource/Albert_Einstein>
имеет фотографию
<http://.../Albert_Einstein_Head.jpg>.
Идентификация объектов
IRI также используются для однозначного определения объектов (третья часть триплета). Фотография уже имеет IRI, но можно аналогично идентифицировать и “Германскую империю”. Строковые значения (литералы) выделяются кавычками:
Пример 16
<http://dbpedia.org/resource/Albert_Einstein>
<http://xmlns.com/foaf/0.1/name>
"Альберт Эйнштейн".
<http://dbpedia.org/resource/Albert_Einstein>
<http://dbpedia.org/property/dateOfBirth>
"14 марта 1879".
Унификация предикатов
IRI устраняют неоднозначность предикатов, объединяя синонимы (“место рождения”, “birthplace”, “Lieu de naissance”) под одним идентификатором:
Пример 17
<http://dbpedia.org/resource/Albert_Einstein>
<http://dbpedia.org/property/birthPlace>
<http://dbpedia.org/resource/German_Empire>.
Ключевые преимущества:
- Устранение неоднозначностей — IRI точно идентифицируют сущности
- Межсистемная совместимость — разные источники могут ссылаться на одни и те же концепции
- Поддержка многоязычия — один IRI может представлять понятие на любом языке
Особенности реализации:
- Литералы (строки, числа) всегда заключаются в кавычки
- Веб-адреса (URL) и другие IRI обрамляются угловыми скобками
- Использование общепринятых словарей (FOAF, DBpedia) улучшает связанность данных
3.4 Простые литералы (Plain Literals)
Хотя для субъектов и предикатов всегда используются IRI-идентификаторы, объект в триплете может быть как IRI, так и литералом. В примерах имя Эйнштейна представлено простым литералом — строкой без указания типа или языка:
Пример 18
<http://dbpedia.org/resource/Albert_Einstein>
<http://xmlns.com/foaf/0.1/name> "Альберт Эйнштейн".
Литералы с указанием языка
Для текстов на естественных языках используется тег языка. Например, название Германской империи на разных языках:
Пример 19
<http://dbpedia.org/resource/German_Empire>
rdfs:label "German Empire"@en;
rdfs:label "Deutsches Kaiserreich"@de;
rdfs:label "Германская империя"@ru.
3.5 Типизированные литералы (Typed Literals)
Для специальных значений (даты, числа и т.д.) в RDF предусмотрен механизм указания типа литерала. Типизированный литерал формируется путём добавления IRI типа данных после литерала с использованием символов ^^. Обычно используются типы данных из спецификации XML Schema:
Пример 20
<http://dbpedia.org/resource/Albert_Einstein>
<http://dbpedia.org/property/dateOfBirth>
"1879-03-14"^^<http://www.w3.org/2001/XMLSchema#date>.
Ключевые особенности:
-
Строковые литералы
- Простые текстовые значения без дополнительной информации
- Могут включать указание языка (
@"ru")
-
Типизированные значения
- Числа:
"42"^^xsd:integer
- Даты:
"2023-05-15"^^xsd:date
- Логические значения:
"true"^^xsd:boolean
-
Стандартные типы данных
- Используются XSD-типы (
xsd:string, xsd:dateTime и др.)
- Позволяют однозначно интерпретировать значения
Практическое применение:
# Числовое значение
<http://example.org/product/123>
ex:weight "2.5"^^xsd:decimal.
# Дата и время
ex:event ex:startTime "2023-05-15T19:00:00"^^xsd:dateTime.
# Булево значение
ex:user ex:isActive "true"^^xsd:boolean.
3.6 Turtle (Синтаксис Turtle)
RDF не имеет единого обязательного формата представления триплетов, поскольку ключевыми концепциями являются сами триплеты и использование IRI, а не конкретный синтаксис. Однако существует несколько способов выражения триплетов, включая RDF/XML, Turtle и, конечно, RDFa. В документации часто используется синтаксис Turtle благодаря его компактности.
Пример с префиксами:
@prefix dbp: <http://dbpedia.org/property/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<http://dbpedia.org/resource/Albert_Einstein>
foaf:name "Альберт Эйнштейн" .
<http://dbpedia.org/resource/Albert_Einstein>
dbp:birthPlace <http://dbpedia.org/resource/German_Empire> .
Расширенный пример:
@prefix dbr: <http://dbpedia.org/resource/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
dbr:Albert_Einstein
foaf:name "Альберт Эйнштейн";
dbp:dateOfBirth "1879-03-14"^^xsd:date;
foaf:depiction <http://example.org/einstein.jpg> .
Специальные обозначения:
<> - обозначает текущий обрабатываемый документ- Префиксы используются только для удобства записи, в итоговых триплетах всегда полные IRI
3.7 Графы
Совокупность триплетов называется графом. Все триплеты, генерируемые согласно этой спецификации, содержатся в выходном графе, создаваемом процессором RDFa.
3.8 Компактные выражения URI (CURIEs)
Для сокращённой записи IRI в разметке RDFa использует механизм CURIEs. Подробное описание - в разделе “Обработка CURIE и IRI”.
Важно: CURIEs используются только в разметке и примерах, в итоговых триплетах всегда присутствуют полные IRI.
3.9 Фрагменты разметки и RDFa
При переносе фрагментов разметки между документами (например, через копирование или инструменты) следует учитывать:
- Обработка изолированных фрагментов вне контекста полного документа не определена
- Разработчикам инструментов следует предусматривать передачу необходимого контекста
- Авторам фрагментов нужно учитывать их поведение в составе полного документа
3.10 Описание RDFa в терминах RDF
Краткое соответствие между RDFa и RDF:
| Компонент RDF |
Эквивалент в RDFa |
| Субъект |
@about |
| Предикат |
@property, @rel, @rev |
| Объект (IRI) |
@resource, @href, @src |
| Объект (литерал) |
@content или содержимое элемента |
| Тип данных |
@datatype |
| Язык |
@xml:lang или аналоги |
Пример соответствия:
<div about="#albert"
property="foaf:name"
content="Альберт Эйнштейн"
datatype="xsd:string">
Генерируемый триплет:
<http://example.org/doc#albert>
<http://xmlns.com/foaf/0.1/name>
"Альберт Эйнштейн"^^xsd:string .
2.3 - Соответствие в RDF
Помимо разделов, помеченных как ненормативные, все рекомендации по разработке, диаграммы, примеры и примечания в этой спецификации не являются нормативными. Все остальное в этой спецификации является нормативным.
Ключевые слова MAY (может), MUST (должен), MUST NOT (не должен), RECOMMENDED (рекомендуется), SHOULD (следует) и SHOULD NOT (не следует) должны интерпретироваться в соответствии с [RFC2119].
4.1 Соответствие процессора RDFa
В данной спецификации термин выходной граф означает все триплеты, утвержденные документом в соответствии с разделом Модель обработки. Соответствующий требованиям процессор RDFa ДОЛЖЕН предоставить потребляющему приложению единый RDF-граф, содержащий все возможные триплеты, сгенерированные с использованием правил из раздела Модель обработки. Термин граф процессора используется для обозначения всех информационных, предупреждающих и ошибочных триплетов, которые МОГУТ быть сгенерированы процессором RDFa для отчета о своем состоянии. Выходной граф и граф процессора являются отдельными графами, и процессор RDFa НЕ ДОЛЖЕН хранить их в одном графе. Однако процессоры могут разрешать одновременное получение обоих графов; подробности см. в разделе 7.6.1.
Соответствующий требованиям процессор RDFa МОЖЕТ предоставлять дополнительные триплеты, сгенерированные с использованием правил, не описанных здесь, но эти триплеты НЕ ДОЛЖНЫ включаться в выходной граф. (Будут ли эти дополнительные триплеты доступны в одном или нескольких дополнительных RDF-графах, зависит от реализации и здесь не определяется.)
Соответствующий требованиям процессор RDFa ДОЛЖЕН сохранять пробельные символы как в простых литералах, так и в XML-литералах. Однако может случиться так, что архитектура, в которой работает процессор, изменила пробельные символы в документе до того, как он попал в процессор RDFa (например, процессоры [XMLSCHEMA11-1] могут «нормализовать» пробелы в значениях атрибутов — см. раздел 3.1.4). Чтобы обеспечить максимальную согласованность между средами обработки, авторам СЛЕДУЕТ удалять все избыточные пробелы в своих простых и XML-литералах.
Соответствующий требованиям процессор RDFa ДОЛЖЕН анализировать медиатип документа, который он обрабатывает, чтобы определить его язык-хост. Если процессор RDFa не может определить медиатип или не поддерживает его, он ДОЛЖЕН обрабатывать документ так, как если бы его медиатип был application/xml. См. Соответствие документов XML+RDFa. Язык-хост МОЖЕТ определять дополнительные механизмы объявления.
Примечание
Соответствующий требованиям процессор RDFa МОЖЕТ использовать дополнительные механизмы (например, DOCTYPE, расширение файла, корневой элемент, переопределяемый пользовательский параметр) для определения языка-хоста, если медиатип недоступен. Эти механизмы не регламентируются.
4.2 Соответствие языка-хоста RDFa
Языки-хосты, включающие RDFa, должны соответствовать следующим требованиям:
- Все функции, требуемые в данной спецификации, ДОЛЖНЫ быть включены в язык-хост.
- Обязательные атрибуты, определенные в данной спецификации, ДОЛЖНЫ быть включены в модель содержимого языка-хоста.
Примечание
Во избежание сомнений, нет требования, чтобы атрибуты, такие как @href и @src, использовались в соответствующем языке-хостe. Также нет требования, чтобы все обязательные атрибуты были включены в модель содержимого всех элементов. Рабочая группа рекомендует разработчикам языков-хостов обеспечивать включение обязательных атрибутов в модель содержимого элементов, которые часто используются в языке.
- Если язык-хост использует пространства имен XML [XML-NAMES], атрибуты из этой спецификации СЛЕДУЕТ определять «без пространства имен» (например, когда атрибуты используются на элементах в пространстве имен языка-хоста, они могут применяться без префикса:
<myml:myElement property="license">). Если язык-хост не использует атрибуты «без пространства имен», они ДОЛЖНЫ ссылаться на пространство имен XHTML (http://www.w3.org/1999/xhtml).
- Если язык-хост имеет собственное определение для любого атрибута, описанного в данной спецификации, это определение ДОЛЖНО обеспечивать возможность обработки, требуемой данной спецификацией, когда атрибут используется в соответствии с ее требованиями.
- Язык-хост МОЖЕТ определять начальный контекст (например, IRI-отображения и/или определение терминов или IRI словаря по умолчанию). Такой начальный контекст СЛЕДУЕТ определять с использованием соглашений, описанных в Начальные контексты RDFa.
4.3 Соответствие документов XML+RDFa
Данная спецификация не определяет самостоятельный тип документа. Атрибуты здесь предназначены для интеграции в другие языки-хосты (например, HTML+RDFa или XHTML+RDFa). Однако данная спецификация определяет правила обработки для общих XML-документов — то есть документов, доставляемых с медиатипами text/xml или application/xml. Такие документы должны соответствовать всем следующим критериям:
- Документ ДОЛЖЕН быть корректно сформированным, как определено в [XML10-4e].
- Документ СЛЕДУЕТ использовать атрибуты, определенные в данной спецификации, «без пространства имен» (например,
<myml:myElement property="license">).
Примечание
Возможно, что XML-грамматика будет иметь собственные атрибуты, конфликтующие с атрибутами из этой спецификации. Это может привести к тому, что процессор RDFa сгенерирует неожиданные триплеты.
При обработке документа XML+RDFa процессор RDFa использует следующий начальный контекст:
- Существуют термины по умолчанию (например,
describedby, license, role), определенные в http://www.w3.org/2011/rdfa-context/rdfa-1.1.
- Существуют префиксные отображения по умолчанию (например,
dc), определенные в http://www.w3.org/2011/rdfa-context/rdfa-1.1.
- Нет IRI словаря по умолчанию.
- База может быть установлена с помощью атрибута
@xml:base, как определено в [XML10-4e].
- Текущий язык может быть установлен с помощью атрибута
@xml:lang.
2.4 - Аттрибуты и синтаксис в RDF
Данная спецификация определяет ряд атрибутов и способ интерпретации их значений при генерации RDF-триплетов. В этом разделе описываются атрибуты и синтаксис их значений.
Атрибуты:
about
SafeCURIEorCURIEorIRI — указывает, о чем именно представлены данные («субъект» в терминологии RDF).content
CDATA-строка — предоставляет машиночитаемое содержимое для литерала («литеральный объект» в терминологии RDF).datatype
TERMorCURIEorAbsIRI — определяет тип данных литерала.href (опциональный)
Традиционно навигационный IRI — выражает связанный ресурс отношения («ресурсный объект» в терминологии RDF).inlist
Атрибут, указывающий, что объект, связанный с атрибутами rel или property на том же элементе, должен быть добавлен в список для данного предиката. Значение этого атрибута ДОЛЖНО игнорироваться. Наличие атрибута приводит к созданию списка, если он ещё не существует.prefix
Список пар «префикс : IRI», разделенных пробелами, в формате:
NCName ':' ' '+ xsd:anyURI
property
Список TERMorCURIEorAbsIRI, разделенных пробелами, — выражает отношения между субъектом и либо ресурсным объектом (если указан), либо текстовым литералом («предикат»).rel
Список TERMorCURIEorAbsIRI, разделенных пробелами, — выражает отношения между двумя ресурсами («предикаты» в терминологии RDF).resource
SafeCURIEorCURIEorIRI — выражает связанный ресурс отношения, не предназначенный для навигации (например, не «кликабельная» ссылка) («объект»).rev
Список TERMorCURIEorAbsIRI, разделенных пробелами, — выражает обратные отношения между двумя ресурсами («предикаты»).src (опциональный)
IRI — выражает связанный ресурс отношения, когда ресурс встроен («ресурсный объект»).typeof
Список TERMorCURIEorAbsIRI, разделенных пробелами, — указывает RDF-тип(ы), связываемые с субъектом.vocab
IRI — определяет отображение, используемое при ссылке на термин в значении атрибута. См. Общее использование терминов в атрибутах и раздел Расширение словаря.
Примечание
Во всех случаях возможно использование этих атрибутов без значения (например, @datatype="") или со значением, которое после обработки по правилам CURIE и IRI становится пустым (например, @datatype="[noprefix:foobar]").
5.1 Роли атрибутов
Атрибуты RDFa выполняют разные роли в семантически насыщенном документе. Вкратце:
- Синтаксические атрибуты:
@prefix, @vocab.
- Атрибуты субъекта:
@about.
- Атрибуты предиката:
@property, @rel, @rev.
- Атрибуты ресурса:
@resource, @href, @src.
- Атрибуты литерала:
@datatype, @content, @xml:lang или @lang.
- Макроатрибуты:
@typeof, @inlist.
5.2 Пробелы в значениях атрибутов
Многие атрибуты принимают список токенов, разделенных пробелами. В данной спецификации пробел определяется как:
whitespace ::= (#x20 | #x9 | #xD | #xA)+
Если атрибут принимает список токенов, разделенных пробелами, процессор RDFa ДОЛЖЕН игнорировать любые ведущие или завершающие пробелы.
Примечание
Это определение согласуется с определением из [XML10].
2.5 - Определение синтаксиса CURIE в RDF
Ключевым компонентом RDF является IRI, но такие идентификаторы обычно длинные и неудобные. Поэтому RDFa поддерживает механизм сокращения IRI, называемый компактными URI-выражениями (CURIE).
6. Определение синтаксиса CURIE
Примечание
Рабочая группа в настоящее время анализирует приведённые ниже правила формирования CURIE с учётом недавних замечаний от RDF Working Group и участников RDFa Working Group. Возможны незначительные изменения в правилах в ближайшем будущем, которые могут оказаться обратно несовместимыми. Однако любые такие несовместимости будут ограничены крайними случаями.
Основные положения
Ключевым компонентом RDF является IRI, но такие идентификаторы обычно длинные и неудобные. Поэтому RDFa поддерживает механизм сокращения IRI, называемый компактными URI-выражениями (CURIE).
При раскрытии CURIE ДОЛЖЕН получаться синтаксически корректный IRI ([RFC3987]). Подробнее см. Обработка CURIE и IRI. Лексическое пространство CURIE определяется правилом curie, приведённым ниже. Пространство значений — это множество IRI.
CURIE состоит из двух компонентов: префикса и ссылки. Префикс отделяется от ссылки двоеточием (:). В общем случае префикс можно опустить, создав CURIE, использующий отображение префикса по умолчанию. В RDFa отображение префикса по умолчанию — http://www.w3.org/1999/xhtml/vocab#. Также можно опустить и префикс, и двоеточие, создав CURIE, содержащий только ссылку, использующую отображение без префикса. Данная спецификация НЕ определяет отображение без префикса. Языки-хосты RDFa НЕ ДОЛЖНЫ определять отображение без префикса.
Примечание
Префикс по умолчанию в RDFa не следует путать с пространством имён по умолчанию, определённым в [XML-NAMES]. Процессор RDFa НЕ ДОЛЖЕН обрабатывать объявление пространства имён по умолчанию в XML-NAMES так, как если бы оно устанавливало префикс по умолчанию.
Общий синтаксис CURIE
Синтаксис CURIE можно описать следующим образом:
prefix ::= NCName
reference ::= ( ipath-absolute / ipath-rootless / ipath-empty )
[ "?" iquery ] [ "#" ifragment ] (как определено в [[!RFC3987]])
curie ::= [ [ prefix ] ':' ] reference
safe_curie ::= '[' [ [ prefix ] ':' ] reference ']'
Примечание
Правило safe_curie не является обязательным, даже в ситуациях, когда значение атрибута может быть CURIE или IRI: IRI, использующий схему, не соответствующую текущим отображениям, нельзя спутать с CURIE. Концепция safe_curie сохранена для обратной совместимости.
Примечание
Можно определить отображение префикса CURIE таким образом, что оно «перекроет» определённую схему IRI. Например, документ может сопоставить префикс mailto с http://www.example.com/addresses/. Тогда атрибут @resource со значением mailto:user@example.com может создать триплет с объектом http://www.example.com/addresses/user@example.com. Более того, возможно (хотя и маловероятно), что в будущем появятся схемы, конфликтующие с отображениями префиксов в документе (например, предлагаемая схема widget [WIDGETS-URI]). В обоих случаях такое «перекрытие» не изменит способ обработки IRI другими потребителями, но может привести к неверной интерпретации CURIE автора документа. Рабочая группа считает этот риск минимальным.
Контекст обработки CURIE
При обычной обработке CURIE требуется следующая контекстная информация:
- Набор отображений префиксов в IRI.
- Отображение для префикса по умолчанию (например,
:p).
- Отображение для случая без префикса (например,
p).
- Отображение для префикса
_, который используется для генерации уникальных идентификаторов (например, _:p).
В RDFa эти значения определяются следующим образом:
- Набор отображений префиксов в IRI предоставляется текущими активными объявлениями префиксов элемента во время разбора.
- Отображение для префикса по умолчанию — текущее отображение префикса по умолчанию.
- Отображение для случая без префикса НЕ определено.
- Отображение для префикса
_ не указано явно, но, поскольку он используется для генерации blank nodes, его реализация должна быть совместима с определением RDF и правилами из Ссылки на Blank Nodes. Документ НЕ ДОЛЖЕН определять отображение для префикса _. Соответствующий требованиям процессор RDFa ДОЛЖЕН игнорировать любые определения отображений для префикса _.
Правила преобразования CURIE в IRI
CURIE представляет собой полный IRI. Правила его определения:
- Если CURIE состоит из пустого префикса и ссылки, IRI получается путём конкатенации текущего отображения префикса по умолчанию и ссылки. Если отображение префикса по умолчанию отсутствует, CURIE считается невалидным и ДОЛЖЕН игнорироваться.
- Если CURIE состоит из непустого префикса и ссылки, и для префикса существует активное отображение (сравнение без учёта регистра), то IRI создаётся путём конкатенации этого отображения и ссылки.
- Если для префикса нет активного отображения, значение не является валидным CURIE.
Примечание
См. Общее использование терминов в атрибутах для случаев, когда элементы без двоеточия могут интерпретироваться процессорами RDFa в некоторых типах данных.
6.1 Почему CURIE, а не QNames?
(Этот раздел является не нормативным.)
Во многих случаях разработчики языков пытались использовать QNames в качестве механизма расширения [XMLSCHEMA11-2]. QNames действительно позволяют управлять коллекцией имён независимо и могут сопоставлять имена с ресурсами. Однако QNames в большинстве случаев не подходят, потому что:
- Использование QName в качестве идентификаторов в значениях атрибутов и содержимом элементов проблематично, как обсуждается в [QNAMES].
- Синтаксис QNames избыточно строг и не позволяет выразить все возможные IRI.
Пример проблемы: попытка определить коллекцию имён для книг. В QName часть после двоеточия должна быть валидным именем элемента, что делает следующий пример недопустимым:
Это невалидный QName, потому что 0321154991 не является допустимым именем элемента. Однако в данном случае нам и не нужно определять валидное имя элемента — цель использования QName заключалась в ссылке на элемент в частной области видимости (ISBN). Более того, мы хотим, чтобы имена в этой области видимости сопоставлялись с IRI, раскрывающим смысл ISBN. Как видно, определение QNames противоречит этому (довольно распространённому) сценарию.
Данная спецификация решает проблему, вводя CURIE. Синтаксически CURIE являются надмножеством QNames.
Важно
Эта спецификация предназначена для разработчиков языков, а не авторов документов. Любой разработчик языка, рассматривающий использование QNames для представления IRI или уникальных токенов, должен вместо этого рассмотреть CURIE:
- CURIE изначально разработаны для использования в значениях атрибутов. QNames предназначены для однозначного именования элементов и атрибутов.
- CURIE раскрываются в IRI, и любой IRI может быть представлен таким образом. QNames обрабатываются как пары значений, но даже если их объединить в строку, можно представить только подмножество IRI.
- CURIE можно использовать в не-XML грамматиках и даже в XML-языках, не поддерживающих XML Namespaces. QNames ограничены XML-приложениями с поддержкой XML Namespaces.