Введение в Opensearch
Введение в OpenSearch
Термин распределённая означает, что OpenSearch можно запускать на нескольких компьютерах. Поиск и аналитика подразумевают, что после загрузки данных в OpenSearch их можно искать и анализировать. Независимо от типа данных, их можно хранить и исследовать с помощью OpenSearch.
Документ
Документ — это единица хранения информации (текстовой или структурированной). В OpenSearch документы хранятся в формате JSON.
Документ можно представить несколькими способами:
- В базе данных студентов документ может представлять одного учащегося.
- При поиске информации OpenSearch возвращает документы, соответствующие запросу.
- Документ аналогичен строке в традиционной реляционной базе данных.
Например, в школьной базе данных документ может представлять студента и содержать следующие данные:
| ID | Имя | GPA | Год выпуска |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
Вот как этот документ выглядит в формате JSON:
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
Вы узнаете, как назначаются идентификаторы документов, в разделе Индексация документов.
Индекс
Индекс — это коллекция документов.
Индекс можно рассматривать несколькими способами:
- В базе данных студентов индекс представляет всех учащихся в базе.
- При поиске информации запрос выполняется к данным внутри индекса.
- Индекс соответствует таблице в традиционной реляционной базе данных.
Например, в школьной базе данных индекс может содержать всех студентов школы:
| ID | Имя | GPA | Год выпуска |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
| 2 | Jonathan Powers | 3.85 | 2025 |
| 3 | Jane Doe | 3.52 | 2024 |
| … | … | … | … |
Кластеры и узлы
OpenSearch разработан как распределённая поисковая система, что означает возможность работы на одном или нескольких узлах — серверах, хранящих данные и обрабатывающих поисковые запросы. Кластер OpenSearch — это совокупность таких узлов.
Вы можете запустить OpenSearch локально на ноутбуке (системные требования минимальны), но также можно масштабировать кластер до сотен мощных серверов в дата-центре.
В одноузловом кластере (например, развёрнутом на ноутбуке) одна машина выполняет все задачи:
- управляет состоянием кластера,
- индексирует данные и обрабатывает поисковые запросы,
- выполняет предварительную обработку данных перед индексацией.
Однако по мере роста кластера обязанности можно распределить:
- Узлы с быстрыми дисками и большим объёмом ОЗУ подходят для индексации и поиска.
- Узлы с мощными CPU, но малым дисковым пространством, могут управлять состоянием кластера.
В каждом кластере выбирается главный узел (cluster manager node), который координирует операции на уровне кластера (например, создание индекса). Узлы взаимодействуют между собой: если запрос направлен к одному узлу, он может запрашивать данные у других узлов, агрегировать их ответы и возвращать итоговый результат.
Подробнее о других типах узлов см. в разделе Формирование кластера.
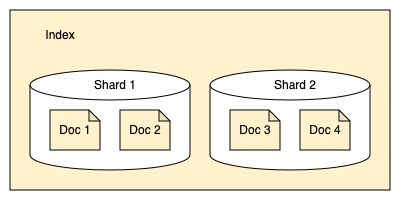
Шарды (Shards)
OpenSearch разделяет индексы на шарды. Каждый шард хранит подмножество всех документов индекса, как показано на следующей диаграмме:
Шарды используются для равномерного распределения данных между узлами кластера. Например:
- Индекс размером 400 ГБ может быть слишком большим для обработки на одном узле
- Если разделить его на 10 шардов по 40 ГБ каждый, OpenSearch сможет распределить их между 10 узлами
- Каждый шард будет обрабатываться независимо
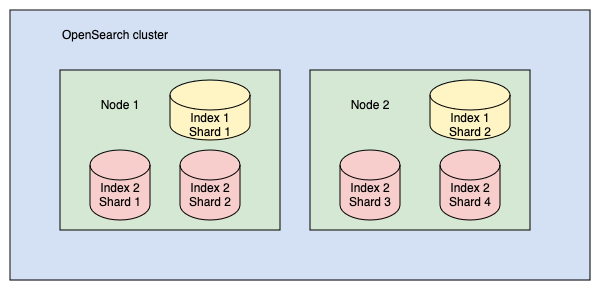
Рассмотрим кластер с двумя индексами:
- Индекс 1 разделён на 2 шарда
- Индекс 2 разделён на 4 шарда
Эти шарды распределены между двумя узлами, как показано на схеме:
Хотя каждый шард является частью индекса OpenSearch, технически он представляет собой полноценный индекс Lucene. Это важно учитывать, потому что:
- Каждый экземпляр Lucene - это отдельный процесс
- Каждый процесс потребляет ресурсы CPU и памяти
- Слишком большое количество шардов может перегрузить кластер
Рекомендации по работе с шардами:
- Не стоит разделять индекс на чрезмерное количество шардов
- Например, деление индекса 400 ГБ на 1000 шардов создаст ненужную нагрузку
- Оптимальный размер шарда - от 10 до 50 ГБ
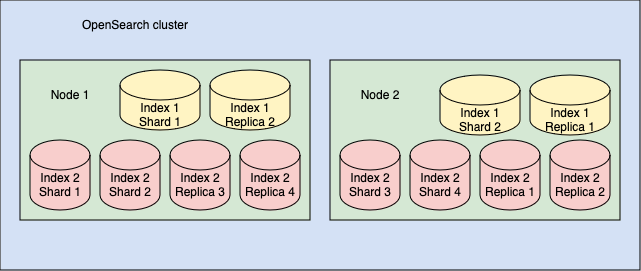
Первичные и реплицированные шарды
В OpenSearch шарды могут быть двух типов:
- Первичные (primary) - оригинальные шарды
- Реплики (replica) - копии шардов
По умолчанию OpenSearch создаёт по одной реплике для каждого первичного шарда. Таким образом:
- Если индекс разделён на 10 шардов, будет создано 10 реплик
- В примере из предыдущего раздела (2 индекса):
- Индекс 1: 2 шарда + 2 реплики
- Индекс 2: 4 шарда + 4 реплики
Функции реплик:
- Резервное копирование на случай сбоя узла
- Реплики размещаются на разных узлах от первичных шардов
- Ускорение обработки поисковых запросов
- Для нагрузок с интенсивным поиском можно создать несколько реплик
Инвертированный индекс
OpenSearch использует структуру данных под названием инвертированный индекс, которая:
- Сопоставляет слова с документами, где они встречаются
- Пример для двух документов:
- Документ 1: “Красота в глазах смотрящего”
- Документ 2: “Красавица и чудовище”
Инвертированный индекс будет выглядеть так:
| Слово | Документы |
|---|---|
| красота | 1 |
| в | 1 |
| глазах | 1 |
| смотрящего | 1 |
| красавица | 2 |
| и | 2 |
| чудовище | 2 |
Дополнительно OpenSearch хранит:
- Позиции слов в документах
- Это позволяет выполнять поиск по фразам
Релевантность
При поиске OpenSearch:
- Сопоставляет слова запроса с документами
- Присваивает каждому документу оценку релевантности
Факторы оценки:
- Частота термина (TF):
- Чем чаще слово встречается в документе, тем выше оценка
- Обратная частота документа (IDF):
- Редкие слова имеют больший вес (например, “аксолотль” vs “синий”)
- Нормализация по длине:
- Более короткие документы получают преимущество
OpenSearch использует алгоритм BM25 для расчёта релевантности и сортировки результатов.
Следующие шаги
Узнайте, как быстро установить OpenSearch, в разделе Быстрый старт установки.
